
最新刊期
卷 24 , 期 5 , 2019
-
 摘要:ObjectiveThis work is the 24rd annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for editors of journals and potential authors of papers.MethodConsidering the wide distribution of related publications in China, 747 references on image engineering research and technique are selected carefully from 2 863 research papers published in 148 issues of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have high quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (similar to the last 13 years). Analysis and discussions about the statistics of the results of classifications by journal and category are also presented.ResultAnalysis on the statistics in 2018 shows that image analysis is receiving the most attention, in which the focuses are on object detection and recognition, image segmentation and edge detection, and object feature extraction and analysis. The studies and applications of image technology in various areas, such as remote sensing, radar, and mapping, are continuously active.ConclusionThis work shows a general and up-to-date picture of the various progresses, either for depth or for width, of image engineering in China in 2018.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics160|183|0更新时间:2024-05-08
摘要:ObjectiveThis work is the 24rd annual survey series of bibliographies on image engineering in China. This statistic and analysis study aims to capture the up-to-date development of image engineering in China, provide a targeted means of literature searching facility for readers working in related areas, and supply a useful recommendation for editors of journals and potential authors of papers.MethodConsidering the wide distribution of related publications in China, 747 references on image engineering research and technique are selected carefully from 2 863 research papers published in 148 issues of 15 Chinese journals. These 15 journals are considered important, in which papers concerning image engineering have high quality and are relatively concentrated. The selected references are initially classified into five categories (image processing, image analysis, image understanding, technique application, and survey) and then into 23 specialized classes in accordance with their main contents (similar to the last 13 years). Analysis and discussions about the statistics of the results of classifications by journal and category are also presented.ResultAnalysis on the statistics in 2018 shows that image analysis is receiving the most attention, in which the focuses are on object detection and recognition, image segmentation and edge detection, and object feature extraction and analysis. The studies and applications of image technology in various areas, such as remote sensing, radar, and mapping, are continuously active.ConclusionThis work shows a general and up-to-date picture of the various progresses, either for depth or for width, of image engineering in China in 2018.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics160|183|0更新时间:2024-05-08 -
 摘要:ObjectiveImage matching, the core task of computer vision, is the key of subsequent advanced image processing, such as object recognition, image mosaic, 3D reconstruction, visual location, and scene depth calculation. Although many excellent methods have been proposed by domestic and foreign scholars in this field in recent years, no comprehensive summary of image matching methods has been reported. On this basis, this study reviews these methods from three aspects, namely, locally invariant feature points, straight lines, and regions.MethodLocally invariant feature point matching first appeared in image matching development, such as Harris corner detector, features from accelerated segment test, and scale-invariant feature transform. The classical algorithms in this type of method are only briefly described in this paper. New methods, especially deep learning-based matching methods, including temporally invariant learned detector, Quad-networks, discriminative learning of deep convolutional feature point descriptors, and learned invariant feature transform (LIFT), are mainly introduced in recent years. Other methods, including bilateral functions for global motion modeling, grid-based motion statistics, and vector field consensus, are also introduced because the outer point culling method is often used to improve the accuracy of local invariant feature matching. Lines contain more scene and object structure information and are more suitable for matching image pairs with repeated texture information than local invariant feature points. Research on line matching should overcome various problems, such as inaccurate endpoint position, inconspicuous line segment, and segment fragmentation. The methods for solving such problems are line band descriptor, two-view line matching algorithm based on context and appearance, line matching leveraged by point correspondences, and new coplanar line point projection invariant. This paper introduces such methods from the perspective of problem solving process. Region matching is introduced from two aspects of region feature extraction and matching and template matching. Typical regional feature extraction and matching methods include maximally stable extremal regions, tree-based morse regions, template matching (including fast affine template matching), fast affine template matching for color images, deformable diversity similarity, occlusion aware template matching, and deep learning methods, such as MatchNet, L2-Net, PN-Net, and DeepCD. Medical image matching is an important application in the image matching field, which is significant for clinically precise diagnosis and treatment. This work introduces this type of method from the point of view of practical applications, such as fractional total variation-L1 and feature matching with learned nonlinear descriptors.ResultIn the analysis and comparison of multiple image matching algorithms, the CPU with two cores at 3.4 GHz and with graphics card NVIDIA GTX TITAN X GPU are selected as the experimental environment of the computer. The test datasets are the Technical University of Denmark dataset and Oxford University dataset Graf. This paper summarizes and compares these methods from three aspects, namely, local invariant feature points, straight lines, and regions. The comparison results of influential factors in feature matching methods, mismatched point removal methods, between hand-crafted and learn-based descriptors, and matching objects and the implementation forms of semantic matching methods are also presented. The corresponding papers and downloaded code addresses of such methods are provided, and the future research directions of image matching algorithms are prospected.ConclusionImage matching is the basis for subsequent advanced processing in the computer vision field. This method is widely used in medical image analysis, satellite image processing, remote sensing image processing, and computer vision. At present, further research is required on wide baseline and real-time matching.关键词:image matching;local invariant feature matching;line matching;region matching;semantic matching;deep learning277|178|0更新时间:2024-05-08
摘要:ObjectiveImage matching, the core task of computer vision, is the key of subsequent advanced image processing, such as object recognition, image mosaic, 3D reconstruction, visual location, and scene depth calculation. Although many excellent methods have been proposed by domestic and foreign scholars in this field in recent years, no comprehensive summary of image matching methods has been reported. On this basis, this study reviews these methods from three aspects, namely, locally invariant feature points, straight lines, and regions.MethodLocally invariant feature point matching first appeared in image matching development, such as Harris corner detector, features from accelerated segment test, and scale-invariant feature transform. The classical algorithms in this type of method are only briefly described in this paper. New methods, especially deep learning-based matching methods, including temporally invariant learned detector, Quad-networks, discriminative learning of deep convolutional feature point descriptors, and learned invariant feature transform (LIFT), are mainly introduced in recent years. Other methods, including bilateral functions for global motion modeling, grid-based motion statistics, and vector field consensus, are also introduced because the outer point culling method is often used to improve the accuracy of local invariant feature matching. Lines contain more scene and object structure information and are more suitable for matching image pairs with repeated texture information than local invariant feature points. Research on line matching should overcome various problems, such as inaccurate endpoint position, inconspicuous line segment, and segment fragmentation. The methods for solving such problems are line band descriptor, two-view line matching algorithm based on context and appearance, line matching leveraged by point correspondences, and new coplanar line point projection invariant. This paper introduces such methods from the perspective of problem solving process. Region matching is introduced from two aspects of region feature extraction and matching and template matching. Typical regional feature extraction and matching methods include maximally stable extremal regions, tree-based morse regions, template matching (including fast affine template matching), fast affine template matching for color images, deformable diversity similarity, occlusion aware template matching, and deep learning methods, such as MatchNet, L2-Net, PN-Net, and DeepCD. Medical image matching is an important application in the image matching field, which is significant for clinically precise diagnosis and treatment. This work introduces this type of method from the point of view of practical applications, such as fractional total variation-L1 and feature matching with learned nonlinear descriptors.ResultIn the analysis and comparison of multiple image matching algorithms, the CPU with two cores at 3.4 GHz and with graphics card NVIDIA GTX TITAN X GPU are selected as the experimental environment of the computer. The test datasets are the Technical University of Denmark dataset and Oxford University dataset Graf. This paper summarizes and compares these methods from three aspects, namely, local invariant feature points, straight lines, and regions. The comparison results of influential factors in feature matching methods, mismatched point removal methods, between hand-crafted and learn-based descriptors, and matching objects and the implementation forms of semantic matching methods are also presented. The corresponding papers and downloaded code addresses of such methods are provided, and the future research directions of image matching algorithms are prospected.ConclusionImage matching is the basis for subsequent advanced processing in the computer vision field. This method is widely used in medical image analysis, satellite image processing, remote sensing image processing, and computer vision. At present, further research is required on wide baseline and real-time matching.关键词:image matching;local invariant feature matching;line matching;region matching;semantic matching;deep learning277|178|0更新时间:2024-05-08
Review

-
 摘要:ObjectiveAs a fundamental issue in the field of image processing, image inpainting has been widely studied in the past two decades. The goal of image inpainting is to reconstruct the original high-quality image from its corrupted observation. Notably, prior knowledge of images is important in image inpainting. Thus, designing an effective regularization to represent image priors is a critical task for image inpainting. The TV(total variation) model usually exploits local structures and high effectiveness to preserve image edges; thus, it has been found to be widely used in image inpainting. However, the regular term of the TV model is a first-order differential, which usually loses image details and tends to suffer from over-smooth effects owing to the piecewise constant assumption. Fortunately, fractional differential is capable of enhancing low-and intermediate-frequency signals and amplifying high-frequency signals moderately; thus, it is introduced into the TV model. However, the existing fractional TV model is limited with regard to its preservation of the information of images with texture and edge details. Furthermore, it does not fully use prior information such as known edges and textures.MethodTo address these problems, we propose a new fractional-order TV model that introduces texture structure information into a fractional TV model for image inpainting. A minimum value is used in the TV model to calculate the image gradient when solving the fractional model. Thus, the improved model is robust because it overcomes the problem of the model being non-differentiable at zero point. In this way, the weak texture information is effectively preserved. The improved model determines the texture direction of the region to be restored on the basis of the priors of the known region of the image and fully uses the texture information of the image to improve the accuracy of image inpainting.ResultThe Barbara and Lena images are selected as test images. The Barbara image presents a large weak texture area. By contrast, the Lena image includes few texture regions and a highly smooth area. Therefore, these two images are used for the experiment. To improve efficiency, we intercept the texture part of the original image and conduct many experiments by using differently sized templates and different orders of fractional differential. Then, the optimal parameters for different images, such as template size and order, can be obtained. The optimal parameters for the Barbara and Lena images are as follows. For the Barbara image, the optimal order is 0.1, and the optimal template size is 3×3 pixels; for the Lena image, the optimal order is 0.9, and the optimal template size is 5×5 pixels. The algorithm is compared with three algorithms with better restoration effects. Mean square error (MSE) and peak signal-to-noise ratio (PSNR) are introduced to evaluate the performance of the different methods. Experimental results indicate that the proposed algorithm achieves improved inpainting result. Unlike that in the TV model, the PSNR values after the restoration of the Barbara, Lena, and Rock images in the proposed method increase by 5.94%, 8.07%, and 3.85%, respectively; and the MSE values decrease by 48.66%, 65.89%, and 35%, respectively. Relative to the fractional TV model, the proposed method achieves PSNR values for the Barbara image, Lena image, and Rock image that increase by 4.17%, 8.59%, and 1.81%, respectively; its MSE values decrease by 37.90%, 68.00%, and 18.68%, respectively.ConclusionThe relationship between inpainting effect, template order, and template size is are demonstrated in experiments, thereby providing the basis for selecting optimal parameters. Although the optimal parameters of different types of images are different, the optimal inpainting order is generally between 0 and 1 because the smooth part of the image corresponds to the low-frequency part of the signal. The texture details of the image correspond to the intermediate-frequency part of the signal. Meanwhile, the TV algorithm is not ideal for the weak texture region. To enhance the gradient information of the region, we must improve the low-and intermediate-frequency parts. Therefore, choosing the order between 0 and 1 is recommended. Furthermore, although the optimal order varies with the type of the image, a weak texture region usually results in a small order. Theoretical analysis and experimental results show that the proposed model can effectively improve the accuracy of image restoration relative to the original TV model and fractional order TV model. The proposed model is suitable for inpainting images with weak texture and edge information. This model is an important extension of the TV model.关键词:image inpainting;fractional differential;weak texture;TV model;edge detail28|30|0更新时间:2024-05-08
摘要:ObjectiveAs a fundamental issue in the field of image processing, image inpainting has been widely studied in the past two decades. The goal of image inpainting is to reconstruct the original high-quality image from its corrupted observation. Notably, prior knowledge of images is important in image inpainting. Thus, designing an effective regularization to represent image priors is a critical task for image inpainting. The TV(total variation) model usually exploits local structures and high effectiveness to preserve image edges; thus, it has been found to be widely used in image inpainting. However, the regular term of the TV model is a first-order differential, which usually loses image details and tends to suffer from over-smooth effects owing to the piecewise constant assumption. Fortunately, fractional differential is capable of enhancing low-and intermediate-frequency signals and amplifying high-frequency signals moderately; thus, it is introduced into the TV model. However, the existing fractional TV model is limited with regard to its preservation of the information of images with texture and edge details. Furthermore, it does not fully use prior information such as known edges and textures.MethodTo address these problems, we propose a new fractional-order TV model that introduces texture structure information into a fractional TV model for image inpainting. A minimum value is used in the TV model to calculate the image gradient when solving the fractional model. Thus, the improved model is robust because it overcomes the problem of the model being non-differentiable at zero point. In this way, the weak texture information is effectively preserved. The improved model determines the texture direction of the region to be restored on the basis of the priors of the known region of the image and fully uses the texture information of the image to improve the accuracy of image inpainting.ResultThe Barbara and Lena images are selected as test images. The Barbara image presents a large weak texture area. By contrast, the Lena image includes few texture regions and a highly smooth area. Therefore, these two images are used for the experiment. To improve efficiency, we intercept the texture part of the original image and conduct many experiments by using differently sized templates and different orders of fractional differential. Then, the optimal parameters for different images, such as template size and order, can be obtained. The optimal parameters for the Barbara and Lena images are as follows. For the Barbara image, the optimal order is 0.1, and the optimal template size is 3×3 pixels; for the Lena image, the optimal order is 0.9, and the optimal template size is 5×5 pixels. The algorithm is compared with three algorithms with better restoration effects. Mean square error (MSE) and peak signal-to-noise ratio (PSNR) are introduced to evaluate the performance of the different methods. Experimental results indicate that the proposed algorithm achieves improved inpainting result. Unlike that in the TV model, the PSNR values after the restoration of the Barbara, Lena, and Rock images in the proposed method increase by 5.94%, 8.07%, and 3.85%, respectively; and the MSE values decrease by 48.66%, 65.89%, and 35%, respectively. Relative to the fractional TV model, the proposed method achieves PSNR values for the Barbara image, Lena image, and Rock image that increase by 4.17%, 8.59%, and 1.81%, respectively; its MSE values decrease by 37.90%, 68.00%, and 18.68%, respectively.ConclusionThe relationship between inpainting effect, template order, and template size is are demonstrated in experiments, thereby providing the basis for selecting optimal parameters. Although the optimal parameters of different types of images are different, the optimal inpainting order is generally between 0 and 1 because the smooth part of the image corresponds to the low-frequency part of the signal. The texture details of the image correspond to the intermediate-frequency part of the signal. Meanwhile, the TV algorithm is not ideal for the weak texture region. To enhance the gradient information of the region, we must improve the low-and intermediate-frequency parts. Therefore, choosing the order between 0 and 1 is recommended. Furthermore, although the optimal order varies with the type of the image, a weak texture region usually results in a small order. Theoretical analysis and experimental results show that the proposed model can effectively improve the accuracy of image restoration relative to the original TV model and fractional order TV model. The proposed model is suitable for inpainting images with weak texture and edge information. This model is an important extension of the TV model.关键词:image inpainting;fractional differential;weak texture;TV model;edge detail28|30|0更新时间:2024-05-08 -
 摘要:ObjectiveIn recent years, the technique of intelligent video analysis has become an important research area in computer vision. Moving object detection is aimed at catching moving foreground in all types of surveillance environment and is thus an essential foundation for following video processing, including target tracking and object segmentation. Traditional methods often model the background in a color feature space and single pixel. The traditional color feature is easily disturbed by light and shadow. A single pixel cannot reflect the region spatial relation between pixels. To detect the moving foreground precisely in complex video sequences, including the illumination and dynamic background in time, we propose a moving detection method on the basis of the background modeling technique via region spatiogram in the color name space. Color names are linguistic labels that humans attach to colors. The learning of color names is achieved by the PLSA model. In fact, it conducts mapping from the RGB space to the robust 11-dimension CN space. The modeling background in the color name space addresses the illumination variation. A histogram is a zeroth-order tool for feature description that is robust to scale variation and rotation variation, whereas a second-order spatiogram contains the spatial mean and covariance for each histogram bin. Thus, the spatiogram retains extensive information about the geometry of patches and captures the global positions of pixels rather than their pairwise relationships. Therefore, using spatiogram in the color name space for background modeling is necessary.MethodA novel method for moving detection was proposed. At first, we mapped the RGB color space to a lower-dimensional color name space that is more robust. Then, we established spatiograms in the pixel local region characterized by the color name feature and recorded the spatial information of pixels in every bin. The background models of every pixel comprised K spatiograms. The spatiograms were given different weights according to the matching rates. The color name feature by dimension reduction enhanced the robustness of the models and the detection of timeliness. The spatial information introduced by the spatiograms enhanced the accuracy of the background model. To enhance the adaptivity of the models, the approach controlled the update of the model spatiograms and their weights by learning rate αb and αω. We conducted experiments on all video sequences from the standard test data CDnet (changedetection.net), which included different challenges, such as illumination variation, moving shadow, multi-model background, and so on. The parameters such as model size K; threshold TB, Tp; and learning rates αb, αω in the algorithm were determined through the analysis of comprehensive performance F1 and averaged false negative curves.ResultThe quantitative and qualitative analyses indicates that the proposed method can achieve expected results. The method can obtain outstanding effects in certain scenes, including illumination and multi-model background. Compared with ViBe, LOBSTER(loeal binary similarity segmenter), and DECOLOR(detecting contiguous outliers in the low-rank representation), the method enhances 0.65%, 3.86%, and 3.9% of the average comprehensive performance F1 of all scenes, respectively. Modeling for every pixel in its local region is concurrent. Thus, real-time detection is achieved with GPU parallel acceleration to improve time efficiency.ConclusionRobust color name spaces effectively address illumination variation. Multiple spatiogram models effectively match multi-model background, such as waving tree, water, and fountain. Therefore, the algorithm can segment moving foreground in complex video environment more accurately than existing methods. The algorithm is a real-time and effective detection algorithm that has certain practical value in intelligent video analysis.关键词:computer vision;intelligent video analysis;moving detection;background model;color names;spatiogram21|25|0更新时间:2024-05-08
摘要:ObjectiveIn recent years, the technique of intelligent video analysis has become an important research area in computer vision. Moving object detection is aimed at catching moving foreground in all types of surveillance environment and is thus an essential foundation for following video processing, including target tracking and object segmentation. Traditional methods often model the background in a color feature space and single pixel. The traditional color feature is easily disturbed by light and shadow. A single pixel cannot reflect the region spatial relation between pixels. To detect the moving foreground precisely in complex video sequences, including the illumination and dynamic background in time, we propose a moving detection method on the basis of the background modeling technique via region spatiogram in the color name space. Color names are linguistic labels that humans attach to colors. The learning of color names is achieved by the PLSA model. In fact, it conducts mapping from the RGB space to the robust 11-dimension CN space. The modeling background in the color name space addresses the illumination variation. A histogram is a zeroth-order tool for feature description that is robust to scale variation and rotation variation, whereas a second-order spatiogram contains the spatial mean and covariance for each histogram bin. Thus, the spatiogram retains extensive information about the geometry of patches and captures the global positions of pixels rather than their pairwise relationships. Therefore, using spatiogram in the color name space for background modeling is necessary.MethodA novel method for moving detection was proposed. At first, we mapped the RGB color space to a lower-dimensional color name space that is more robust. Then, we established spatiograms in the pixel local region characterized by the color name feature and recorded the spatial information of pixels in every bin. The background models of every pixel comprised K spatiograms. The spatiograms were given different weights according to the matching rates. The color name feature by dimension reduction enhanced the robustness of the models and the detection of timeliness. The spatial information introduced by the spatiograms enhanced the accuracy of the background model. To enhance the adaptivity of the models, the approach controlled the update of the model spatiograms and their weights by learning rate αb and αω. We conducted experiments on all video sequences from the standard test data CDnet (changedetection.net), which included different challenges, such as illumination variation, moving shadow, multi-model background, and so on. The parameters such as model size K; threshold TB, Tp; and learning rates αb, αω in the algorithm were determined through the analysis of comprehensive performance F1 and averaged false negative curves.ResultThe quantitative and qualitative analyses indicates that the proposed method can achieve expected results. The method can obtain outstanding effects in certain scenes, including illumination and multi-model background. Compared with ViBe, LOBSTER(loeal binary similarity segmenter), and DECOLOR(detecting contiguous outliers in the low-rank representation), the method enhances 0.65%, 3.86%, and 3.9% of the average comprehensive performance F1 of all scenes, respectively. Modeling for every pixel in its local region is concurrent. Thus, real-time detection is achieved with GPU parallel acceleration to improve time efficiency.ConclusionRobust color name spaces effectively address illumination variation. Multiple spatiogram models effectively match multi-model background, such as waving tree, water, and fountain. Therefore, the algorithm can segment moving foreground in complex video environment more accurately than existing methods. The algorithm is a real-time and effective detection algorithm that has certain practical value in intelligent video analysis.关键词:computer vision;intelligent video analysis;moving detection;background model;color names;spatiogram21|25|0更新时间:2024-05-08 -
 摘要:ObjectiveGiven the development of digital video technology, especially the emergence of ultra-high definition (UHD) video technology, video compression faces enormous challenges. To solve the problem of voluminous data and to address the high-speed transmission requirements of UHD videos, the Joint Video Experts Team (JVET) is exploring future video coding (FVC) based on the high-efficiency video coding (HEVC) standard. FVC uses the hybrid coding framework of HEVC with new techniques. The compression efficiency of FVC is higher than that of HEVC; however, its coding complexity is extremely high. Therefore, reducing the complexity of FVC is of great significance. Among all the new techniques in FVC, the most effective but extremely time consuming one is the quad tree plus binary tree (QTBT) coding structure, which includes four partition modes, namely, quad tree split, vertical split, horizontal split, and no-split. The final split of coding units (CUs) is decided after trying all the partition modes and calculating the rate distortion cost. Thus, the complexity of the QTBT is extremely high. The existing HEVC-based fast coding method is no longer suitable for FVC because the QTBT coding structure and the recent work about low-complexity encoding methods are insufficient for FVC applications. To reduce the high complexity of FVC, the complexity of the QTBT structure should be considered. The traversal process of CU partition modes exhibits redundancy, and unnecessary attempts to achieve mode partition should be avoided. To optimize CUs' split process, we propose a random forest-based fast intra coding unit partition algorithm for FVC.MethodThe proposed algorithm is designed to optimize the QTBT structure in FVC. Compared with traditional statistical-based methods, the machine learning-based approach is more applicable because of the elaborate split modes of the QTBT structure. Among the methods of machine learning, random forest offers unique advantages. Random forest can handle the classification problem of multi-dimensional data and is strongly resistant to over-fitting and estimation. Furthermore, the approach performs well on classification issues and is suitable for CU splitting. Therefore, a fast algorithm based on random forest is proposed. The problem of distinguishing different split results of CUs is considered a classification problem, and random forest is used as the classifier. The image texture features and split results of the CU in the first frame of video sequences are first extracted. Image texture features have a strong correlation with split results and can thus be selected as the training data of the model. Various image texture features are used in the algorithm to achieve superior performance, and they are carefully selected by the calculation of feature importance. Specifically, the features finally used in the proposed algorithm are the width and height of the CU, Haar wavelet coefficients, angular second moment, entropy, contrast, inverse differential moment, and standard deviation. After the data collection process, four random forest models are established for different depths of CUs. CU depth can be represented as the joint depth of the quad tree and the binary tree, and this representative method is used to collect data in the algorithm. Then, the texture features and split results are set as multidimensional data, and they are separately trained online for each model. The training time is included in the entire encoding time and is relatively shorter than the encoding time. Finally, the trained models are used to predict the split results of the CUs of the remaining frames of the video sequences, thereby reducing the traversal of the partition modes and the time of rate distortion cost calculation. To ensure the algorithm's effectiveness, we test the accuracy of the models online by using different video sequences. The algorithm is implemented on the recently released JEM5.0 platform. A total of 22 test sequences of different contents and resolutions from class A1 to class E are tested under the common test condition, which is a full I-frame configuration mode with quantization parameters 22, 27, 32, and 37. The encoding performance of the algorithm is evaluated using the Bjontegaard delta bitrate (BDBR) and average amount of time saved between the proposed algorithm and the original platform.ResultExperimental results show that compared with the original platform's algorithm, the proposed algorithm can decrease the average encoding time by 44.1% with negligible coding performance loss, and the BDBR only increases by 2.6%. The approach can also save more than 20% of encoding time relative to state-of-the-art methods, with BDBR slightly increasing. This algorithm is suitable for various classes of video sequences with different resolutions and textures. Among all the sequences, the sequences with high resolution save more encoding time than other sequences do because of the online training time consumption. Furthermore, the coding performance of the proposed algorithm is stable, thereby proving the effectiveness of the models.ConclusionA random forest-based fast intra CU partition algorithm for FVC is proposed to reduce the complexity of the QTBT structure in FVC. By extracting the texture features of images, the algorithm establishes random forest models to predict the CU partitioning result while avoiding the unnecessary traversal of split modes to save encoding time. The proposed intra prediction coding algorithm can effectively reduce the complexity of FVC and maintain the encoding performance. The proposed algorithm is more suitable for video sequences with high resolution. Furthermore, the proposed algorithm should be optimized in the future to enhance time reduction and reduce coding performance loss. The possibilities of machine learning in FVC inter-prediction will also be explored in the future.关键词:video encoding;future video coding (FVC);fast intra prediction coding;machine learning;random forest20|70|0更新时间:2024-05-08
摘要:ObjectiveGiven the development of digital video technology, especially the emergence of ultra-high definition (UHD) video technology, video compression faces enormous challenges. To solve the problem of voluminous data and to address the high-speed transmission requirements of UHD videos, the Joint Video Experts Team (JVET) is exploring future video coding (FVC) based on the high-efficiency video coding (HEVC) standard. FVC uses the hybrid coding framework of HEVC with new techniques. The compression efficiency of FVC is higher than that of HEVC; however, its coding complexity is extremely high. Therefore, reducing the complexity of FVC is of great significance. Among all the new techniques in FVC, the most effective but extremely time consuming one is the quad tree plus binary tree (QTBT) coding structure, which includes four partition modes, namely, quad tree split, vertical split, horizontal split, and no-split. The final split of coding units (CUs) is decided after trying all the partition modes and calculating the rate distortion cost. Thus, the complexity of the QTBT is extremely high. The existing HEVC-based fast coding method is no longer suitable for FVC because the QTBT coding structure and the recent work about low-complexity encoding methods are insufficient for FVC applications. To reduce the high complexity of FVC, the complexity of the QTBT structure should be considered. The traversal process of CU partition modes exhibits redundancy, and unnecessary attempts to achieve mode partition should be avoided. To optimize CUs' split process, we propose a random forest-based fast intra coding unit partition algorithm for FVC.MethodThe proposed algorithm is designed to optimize the QTBT structure in FVC. Compared with traditional statistical-based methods, the machine learning-based approach is more applicable because of the elaborate split modes of the QTBT structure. Among the methods of machine learning, random forest offers unique advantages. Random forest can handle the classification problem of multi-dimensional data and is strongly resistant to over-fitting and estimation. Furthermore, the approach performs well on classification issues and is suitable for CU splitting. Therefore, a fast algorithm based on random forest is proposed. The problem of distinguishing different split results of CUs is considered a classification problem, and random forest is used as the classifier. The image texture features and split results of the CU in the first frame of video sequences are first extracted. Image texture features have a strong correlation with split results and can thus be selected as the training data of the model. Various image texture features are used in the algorithm to achieve superior performance, and they are carefully selected by the calculation of feature importance. Specifically, the features finally used in the proposed algorithm are the width and height of the CU, Haar wavelet coefficients, angular second moment, entropy, contrast, inverse differential moment, and standard deviation. After the data collection process, four random forest models are established for different depths of CUs. CU depth can be represented as the joint depth of the quad tree and the binary tree, and this representative method is used to collect data in the algorithm. Then, the texture features and split results are set as multidimensional data, and they are separately trained online for each model. The training time is included in the entire encoding time and is relatively shorter than the encoding time. Finally, the trained models are used to predict the split results of the CUs of the remaining frames of the video sequences, thereby reducing the traversal of the partition modes and the time of rate distortion cost calculation. To ensure the algorithm's effectiveness, we test the accuracy of the models online by using different video sequences. The algorithm is implemented on the recently released JEM5.0 platform. A total of 22 test sequences of different contents and resolutions from class A1 to class E are tested under the common test condition, which is a full I-frame configuration mode with quantization parameters 22, 27, 32, and 37. The encoding performance of the algorithm is evaluated using the Bjontegaard delta bitrate (BDBR) and average amount of time saved between the proposed algorithm and the original platform.ResultExperimental results show that compared with the original platform's algorithm, the proposed algorithm can decrease the average encoding time by 44.1% with negligible coding performance loss, and the BDBR only increases by 2.6%. The approach can also save more than 20% of encoding time relative to state-of-the-art methods, with BDBR slightly increasing. This algorithm is suitable for various classes of video sequences with different resolutions and textures. Among all the sequences, the sequences with high resolution save more encoding time than other sequences do because of the online training time consumption. Furthermore, the coding performance of the proposed algorithm is stable, thereby proving the effectiveness of the models.ConclusionA random forest-based fast intra CU partition algorithm for FVC is proposed to reduce the complexity of the QTBT structure in FVC. By extracting the texture features of images, the algorithm establishes random forest models to predict the CU partitioning result while avoiding the unnecessary traversal of split modes to save encoding time. The proposed intra prediction coding algorithm can effectively reduce the complexity of FVC and maintain the encoding performance. The proposed algorithm is more suitable for video sequences with high resolution. Furthermore, the proposed algorithm should be optimized in the future to enhance time reduction and reduce coding performance loss. The possibilities of machine learning in FVC inter-prediction will also be explored in the future.关键词:video encoding;future video coding (FVC);fast intra prediction coding;machine learning;random forest20|70|0更新时间:2024-05-08
Image Processing and Coding
-
 摘要:ObjectiveCollective motion detection is fundamentally important for analyzing crowd behavior and has attracted considerable attention in artificial intelligence. The recognition and segmentation of collective behavior are important branches of computer vision and graphics, which are significant for public safety, intelligent traffic, and architectural design. The main task of recognizing collective behavior is to mine the coherent patterns consisting of highly coherent tracklets according to the extracted features from crowd motion in videos. However, existing works mostly have limitations due to the insufficient utilization of crowd properties and the arbitrary processing of individuals. Collective behavior involves local and global motion patterns, in which varying densities and arbitrary shapes are salient characteristics. The global coherent motion with complex interaction requires an accurate measurement of local coherency and analysis of global continuity. A further study demonstrates that the motion descriptor and similarity measurement remain limited to finding the latent relativity among tracklet points under the circumstances of perspective distortion and large spatial gap. In view of these shortcomings, we propose the density-based manifold collective clustering approach for detecting groups in crowd scenes.MethodOur background modeling is based on the clustering strategy and aims to recognize arbitrarily shaped clusters in coherent motion. Motion features are detected with the generalized Kanade-Lucas-Tomasi feature point tracker, which jointly combines the detecting and tracking stages with efficient computation. The corresponding algorithms mainly include manifold collective density definition, density-based manifold collective clustering, and hierarchical collectiveness merging process. In the first process, a new manifold distance metric is presented to express the intrinsic characteristics of moving individuals. A collective density with novelty is defined based on this topological structure to describe the collectiveness between an individual and its neighbors. This collective density represents the local density efficiently, reflects the global consistency, and is highly adaptive to reveal the underlying patterns of varying densities in coherent motion. We propose a novel collective clustering to find a local topological relationship that can precisely recognize the collectiveness relationship between points and their surroundings. Similar to the core idea of fast search and density peak cluster method, the cluster peak centers of subgroups are assumed to be characterized by a higher collective density calculated by collectiveness than their neighbors. The density-based manifold collective clustering approach is proposed to detect local and global coherent motions with arbitrary shapes and varying densities. Three salient properties must not be ignored:1) the accurate identification of outliers and exploration of manifold structure, 2) the automatic decision of group number without involving any arbitrary threshold, and 3) the capability of dealing with crowd scenes with varying densities. Thus, in the proposed method, the center of collective subgroups is characterized by two criteria:one is a higher collective density than its neighbors, and the other is a relatively large distance and inconsistent orientation from points with a higher density. From this view, the clustering method can determine the cluster centers automatically. In the recognition of global consistency part, inspired by the main ideology of the BIRCH clustering method, a hierarchical collectiveness merging strategy is developed to combine local motions and recognize global consistency. In this process, the collectiveness is used to capture the intracorrelations of subgroups, and local clusters are successfully combined into global coherent groups by merging the highly consistent pairwise subgroups iteratively.ResultCollective Motion Database is employed to evaluate the experimental performance, and four state-of-the-art group detection techniques are used for comparison, namely, coherent filtering, collective transition, measuring crowd collectiveness, and collective density clustering. Results show that in complex scenes under different conditions, the experimental results of the algorithm remain highly effective and robust. Compared with the traditional clustering methods and state-of-the-art algorithms, average difference (AD) and variance (VAR) are used as criteria to evaluate the algorithm performance. The AD rate of our proposed method is controlled within 0.81, and the VAR rate is under 0.99, which is approximately 6% lower than those of classical clustering methods. Compared with such classical methods, our method exhibits great improvement. Accurate and effective recognition results can be obtained in crowd scenes with complex manifold structures and arbitrary density conditions, which solve the shortcomings of the classical methods in this special scenario.ConclusionThis study proposes a cluster aggregation clustering algorithm based on manifold density for multiple complex real-world videos based on the manifold description and analysis of existing methods for identifying the lack of accuracy and stability of collective behavioral flow in manifold structures. Experiments on various real-world videos and comparisons with previous works validate that our method yields substantial boosts over state-of-the-art competitors. Therefore, the proposed algorithm can have a preferable adaptive performance in complex scenes with varying densities and arbitrary shape situations.关键词:coherent motion detection;manifold density clustering;collective manifold;collectiveness;motion consistency22|10|0更新时间:2024-05-08
摘要:ObjectiveCollective motion detection is fundamentally important for analyzing crowd behavior and has attracted considerable attention in artificial intelligence. The recognition and segmentation of collective behavior are important branches of computer vision and graphics, which are significant for public safety, intelligent traffic, and architectural design. The main task of recognizing collective behavior is to mine the coherent patterns consisting of highly coherent tracklets according to the extracted features from crowd motion in videos. However, existing works mostly have limitations due to the insufficient utilization of crowd properties and the arbitrary processing of individuals. Collective behavior involves local and global motion patterns, in which varying densities and arbitrary shapes are salient characteristics. The global coherent motion with complex interaction requires an accurate measurement of local coherency and analysis of global continuity. A further study demonstrates that the motion descriptor and similarity measurement remain limited to finding the latent relativity among tracklet points under the circumstances of perspective distortion and large spatial gap. In view of these shortcomings, we propose the density-based manifold collective clustering approach for detecting groups in crowd scenes.MethodOur background modeling is based on the clustering strategy and aims to recognize arbitrarily shaped clusters in coherent motion. Motion features are detected with the generalized Kanade-Lucas-Tomasi feature point tracker, which jointly combines the detecting and tracking stages with efficient computation. The corresponding algorithms mainly include manifold collective density definition, density-based manifold collective clustering, and hierarchical collectiveness merging process. In the first process, a new manifold distance metric is presented to express the intrinsic characteristics of moving individuals. A collective density with novelty is defined based on this topological structure to describe the collectiveness between an individual and its neighbors. This collective density represents the local density efficiently, reflects the global consistency, and is highly adaptive to reveal the underlying patterns of varying densities in coherent motion. We propose a novel collective clustering to find a local topological relationship that can precisely recognize the collectiveness relationship between points and their surroundings. Similar to the core idea of fast search and density peak cluster method, the cluster peak centers of subgroups are assumed to be characterized by a higher collective density calculated by collectiveness than their neighbors. The density-based manifold collective clustering approach is proposed to detect local and global coherent motions with arbitrary shapes and varying densities. Three salient properties must not be ignored:1) the accurate identification of outliers and exploration of manifold structure, 2) the automatic decision of group number without involving any arbitrary threshold, and 3) the capability of dealing with crowd scenes with varying densities. Thus, in the proposed method, the center of collective subgroups is characterized by two criteria:one is a higher collective density than its neighbors, and the other is a relatively large distance and inconsistent orientation from points with a higher density. From this view, the clustering method can determine the cluster centers automatically. In the recognition of global consistency part, inspired by the main ideology of the BIRCH clustering method, a hierarchical collectiveness merging strategy is developed to combine local motions and recognize global consistency. In this process, the collectiveness is used to capture the intracorrelations of subgroups, and local clusters are successfully combined into global coherent groups by merging the highly consistent pairwise subgroups iteratively.ResultCollective Motion Database is employed to evaluate the experimental performance, and four state-of-the-art group detection techniques are used for comparison, namely, coherent filtering, collective transition, measuring crowd collectiveness, and collective density clustering. Results show that in complex scenes under different conditions, the experimental results of the algorithm remain highly effective and robust. Compared with the traditional clustering methods and state-of-the-art algorithms, average difference (AD) and variance (VAR) are used as criteria to evaluate the algorithm performance. The AD rate of our proposed method is controlled within 0.81, and the VAR rate is under 0.99, which is approximately 6% lower than those of classical clustering methods. Compared with such classical methods, our method exhibits great improvement. Accurate and effective recognition results can be obtained in crowd scenes with complex manifold structures and arbitrary density conditions, which solve the shortcomings of the classical methods in this special scenario.ConclusionThis study proposes a cluster aggregation clustering algorithm based on manifold density for multiple complex real-world videos based on the manifold description and analysis of existing methods for identifying the lack of accuracy and stability of collective behavioral flow in manifold structures. Experiments on various real-world videos and comparisons with previous works validate that our method yields substantial boosts over state-of-the-art competitors. Therefore, the proposed algorithm can have a preferable adaptive performance in complex scenes with varying densities and arbitrary shape situations.关键词:coherent motion detection;manifold density clustering;collective manifold;collectiveness;motion consistency22|10|0更新时间:2024-05-08 -
 摘要:ObjectiveThe development and popularization of face recognition authentication technology in recent years has made the storage of a large number of face photos in third-party servers highly common. Face recognition plays an important role in clothing, food, housing, and various industries, and moves from theoretical research to practical application of the "blowout period". However, faces are relatively open features compared to irises and fingerprints, and many people post selfies on various social platforms. Not only can you get face photos easily through the Internet, but you can also use a variety of image processing tools to fake faces. Thus, the protection of the privacy of face information has become prominent. At present, the research content in the field of face recognition focuses on directly recognizing face images, and there is a problem of privacy leakage; or the face image is encrypted and decrypted, but the encryption and decryption operation has the disadvantage of high computational complexity.MethodTo solve the problem of the unevenness of the face in a scrambled photo due to camera angles, this study preprocesses the face image as follows. First, we determine whether a given image contains a face. If a face does exist, then we find the border that contains the complete face. Next, we must locate the key points such as the nose and eyes, align the face images on the basis of these key point positions, and normalize them to the same size following the key mechanism of vision. That is, the human eye consistently sees the center of the photo first and then gradually moves to the last four corners. Then, the key parts of the face (eyes, ears, mouth, and nose) are scrambled and blocked by Arnold transform for a random number of times. Second, to achieve face privacy protection and image recognition after scrambling, this study proposes a deep convolutional neural network based on block random scrambling, which does not include an additional layer. The network structure of the model is composed of four convolutional layers, three pooling layers, one fully connected layer, and a softmax regression layer. The convolution kernel sizes of the four convolutional layers are 6×6, 3×3, 3×3, and 2×2. In the training phase, the preprocessed samples are divided into training sets and test sets. At the beginning of training, the convolution kernel parameters are randomly initialized to a small value, and small random numbers are used to ensure that the network does not enter a saturated state due to excessive weights. The training process is divided into the forward propagation and backward propagation phases. After the input passes by the multiple convolutional layers and pooling layers, it is transferred to the output layer. In the process, the input is actually multiplied by each layer of the weight matrix, and a calculation is performed to obtain the output result. The difference between the actual output and the ideal output is calculated in the backward propagation phase, and the weight is adjusted in reverse on the basis of the minimization error method. The server side directly verifies and recognizes the scrambled face image by the deep neural network model. Prior to transmission or storage on the server, the preprocessed and randomized scrambled images are encrypted, and the key is saved to further improve security. Then, the color histogram of the image will show a straight line. When identification is necessary and if a legal key is available, it can be correctly restored to the previous state to perform the identification operation.ResultThis algorithm enables the server to not store the original face template throughout the entire process, thereby achieving effective scrambling protection of the original face image. Using the block random scrambling proposed in this paper, a higher recognition rate can be obtained. Further considering the security problem, the image after random scrambling is twice encrypted and the key is saved before being transmitted or stored in the server. The experiment uses this deep convolutional neural network to identify the ORL face database, and the final recognition accuracy rate reaches 97.62%. Concurrently, the effectiveness of the proposed method is verified by multiple sets of comparative experiments. The face of the original image before processing has a strong correlation with adjacent pixels. After the pixel position is scrambled, the pixel points of the key positions of the face have a uniform distribution trend on the whole image, and the correlation is obviously weakened. Thus, the algorithm has a good effect on hiding the pixel points of the face.ConclusionCompared with other methods that are used to manually extract features and methods based on decision trees and random forest for training recognition in the literature, the proposed method reduces the workload of manually extracting features and retains a higher recognition rate. From the experimental results, the Arnold random parameter scrambling on the block image effectively reduces the correlation of the ciphertext image, and still maintains a high recognition rate for deep neural network recognition. This paper also uses the chaotic map encryption method for secondary encryption. The results show that the correlation of ciphertext images is further reduced, which not only enhances the protection of face privacy, but also has strong robustness to the image recognition after scrambling transformation.关键词:face recognition authentication;convolutional neural network;Arnold transform;face alignment;face privacy protection22|9|0更新时间:2024-05-08
摘要:ObjectiveThe development and popularization of face recognition authentication technology in recent years has made the storage of a large number of face photos in third-party servers highly common. Face recognition plays an important role in clothing, food, housing, and various industries, and moves from theoretical research to practical application of the "blowout period". However, faces are relatively open features compared to irises and fingerprints, and many people post selfies on various social platforms. Not only can you get face photos easily through the Internet, but you can also use a variety of image processing tools to fake faces. Thus, the protection of the privacy of face information has become prominent. At present, the research content in the field of face recognition focuses on directly recognizing face images, and there is a problem of privacy leakage; or the face image is encrypted and decrypted, but the encryption and decryption operation has the disadvantage of high computational complexity.MethodTo solve the problem of the unevenness of the face in a scrambled photo due to camera angles, this study preprocesses the face image as follows. First, we determine whether a given image contains a face. If a face does exist, then we find the border that contains the complete face. Next, we must locate the key points such as the nose and eyes, align the face images on the basis of these key point positions, and normalize them to the same size following the key mechanism of vision. That is, the human eye consistently sees the center of the photo first and then gradually moves to the last four corners. Then, the key parts of the face (eyes, ears, mouth, and nose) are scrambled and blocked by Arnold transform for a random number of times. Second, to achieve face privacy protection and image recognition after scrambling, this study proposes a deep convolutional neural network based on block random scrambling, which does not include an additional layer. The network structure of the model is composed of four convolutional layers, three pooling layers, one fully connected layer, and a softmax regression layer. The convolution kernel sizes of the four convolutional layers are 6×6, 3×3, 3×3, and 2×2. In the training phase, the preprocessed samples are divided into training sets and test sets. At the beginning of training, the convolution kernel parameters are randomly initialized to a small value, and small random numbers are used to ensure that the network does not enter a saturated state due to excessive weights. The training process is divided into the forward propagation and backward propagation phases. After the input passes by the multiple convolutional layers and pooling layers, it is transferred to the output layer. In the process, the input is actually multiplied by each layer of the weight matrix, and a calculation is performed to obtain the output result. The difference between the actual output and the ideal output is calculated in the backward propagation phase, and the weight is adjusted in reverse on the basis of the minimization error method. The server side directly verifies and recognizes the scrambled face image by the deep neural network model. Prior to transmission or storage on the server, the preprocessed and randomized scrambled images are encrypted, and the key is saved to further improve security. Then, the color histogram of the image will show a straight line. When identification is necessary and if a legal key is available, it can be correctly restored to the previous state to perform the identification operation.ResultThis algorithm enables the server to not store the original face template throughout the entire process, thereby achieving effective scrambling protection of the original face image. Using the block random scrambling proposed in this paper, a higher recognition rate can be obtained. Further considering the security problem, the image after random scrambling is twice encrypted and the key is saved before being transmitted or stored in the server. The experiment uses this deep convolutional neural network to identify the ORL face database, and the final recognition accuracy rate reaches 97.62%. Concurrently, the effectiveness of the proposed method is verified by multiple sets of comparative experiments. The face of the original image before processing has a strong correlation with adjacent pixels. After the pixel position is scrambled, the pixel points of the key positions of the face have a uniform distribution trend on the whole image, and the correlation is obviously weakened. Thus, the algorithm has a good effect on hiding the pixel points of the face.ConclusionCompared with other methods that are used to manually extract features and methods based on decision trees and random forest for training recognition in the literature, the proposed method reduces the workload of manually extracting features and retains a higher recognition rate. From the experimental results, the Arnold random parameter scrambling on the block image effectively reduces the correlation of the ciphertext image, and still maintains a high recognition rate for deep neural network recognition. This paper also uses the chaotic map encryption method for secondary encryption. The results show that the correlation of ciphertext images is further reduced, which not only enhances the protection of face privacy, but also has strong robustness to the image recognition after scrambling transformation.关键词:face recognition authentication;convolutional neural network;Arnold transform;face alignment;face privacy protection22|9|0更新时间:2024-05-08 -
 摘要:ObjectiveExpression is important in human-computer interaction. As a special expression, spontaneous expression features shorter duration and weaker intensity in comparison with traditional expressions. Spontaneous expressions can reveal a person's true emotions and present immense potential in detection, anti-detection, and medical diagnosis. Therefore, identifying the categories of spontaneous expression can make human-computer interaction smooth and fundamentally change the relationship between people and computers. Given that spontaneous expressions are difficult to be induced and collected, the scale of a spontaneous expression dataset is relatively small for training a new deep neural network. Only ten thousand spontaneous samples are present in each database. The convolutional neural network shows excellent performance and is thus widely used in a large number of scenes. For instance, the approach is better than the traditional feature extraction method in the aspect of improving the accuracy of discriminating the categories of spontaneous expression.MethodThis study proposes a method on the basis of different deep transfer network models for discriminating the categories of spontaneous expression. To preserve the characteristics of the original spontaneous expression, we do not use the technique of data enhancement to reduce the risk of convergence. At the same time, training samples, which comprise three-dimensional images that are composed of optical flow and grayscale images, are compared with the original RGB images. The three-dimensional image contains spatial information and temporal displacement information. In this study, we compare three network models with different samples. The first model is based on Alexnet that only changes the number of output layer neurons that is equal to the number of categories of spontaneous expression. Then, the network is fine-tuned to obtain the best training and testing results by fixing the parameters of different layers several times. The second model is based on InceptionV3. Two fully connected layers whose neuron numbers are equal to 512 and the number of spontaneous expression categories, respectively, are added to the output results. Thus, we only need to fine-tune the parameters of the two layers. Network depth increases with a reduction of the number of parameters due to the 3×3 convolution kernel replacing the 7×7 convolution kernel. The third model is based on Inception-ResNet-v2. Similar to the first model, we only change the number of output layer neurons. Finally, the isomorphic network model is proposed to identify the categories of spontaneous expression. The model is composed of two transfer learning networks of the same type that are trained by different samples and then takes the maximum as the final output. The isomorphic network makes decisions with high accuracy because the same output of the isomorphic network is infinitely close to the standard answer. From the perspective of probability, we take the maximum of different outputs as a prediction value.ResultExperimental results indicate that the proposed method exhibits excellent classification performance on different samples. The single network output clearly shows that the features extracted from RGB images are as effective as the features extracted from the three-dimensional images of optical flow. This result indicates that spatiotemporal features extracted by the optical flow method can be replaced by features that are extracted from the deep neural network. Simultaneously, the method shows that at a certain degree, features extracted from the neural network can replace the lost information and features, such as the temporal features of RGB images or color features of OF+ images. The high average accuracy of a single network indicates that it has good testing performance on each dataset. Networks with high complexity perform well because the samples of spontaneous expression can train the deep transfer learning network effectively. The proposed models achieve state-of-the-art performance and an average accuracy of over 96%. After analyzing the result of the isomorphic network model, we know that its expression is not better than that of a single network in some cases because a single network has a high confidence degree in discriminating the categories of spontaneous expression and thus, the isomorphic network cannot easily improve the average accuracy. The Titan Xp used for this research was donated by the NVIDIA Corporation.ConclusionCompared with traditional expression, spontaneous expression is able to change subtly and extract features in a difficult manner. In the study, different transfer learning networks are applied to discriminate the categories of spontaneous expression. Concurrently, the testing accuracies of different networks, which are trained by different kinds of samples, are compared. Experimental results show that in contrast to traditional methods, deep learning has obvious advantages in spontaneous expression feature extraction. The findings also prove that deep network can extract complete features from spontaneous expression and that it is robust on different databases because of its good testing results. In the future, we will extract spontaneous expressions directly from videos and identify the categories of spontaneous expression with high accuracy by removing distracting occurrences, such as blinking.关键词:spontaneous expression;transfer learning;classification;neural networks;isomorphic network15|9|0更新时间:2024-05-08
摘要:ObjectiveExpression is important in human-computer interaction. As a special expression, spontaneous expression features shorter duration and weaker intensity in comparison with traditional expressions. Spontaneous expressions can reveal a person's true emotions and present immense potential in detection, anti-detection, and medical diagnosis. Therefore, identifying the categories of spontaneous expression can make human-computer interaction smooth and fundamentally change the relationship between people and computers. Given that spontaneous expressions are difficult to be induced and collected, the scale of a spontaneous expression dataset is relatively small for training a new deep neural network. Only ten thousand spontaneous samples are present in each database. The convolutional neural network shows excellent performance and is thus widely used in a large number of scenes. For instance, the approach is better than the traditional feature extraction method in the aspect of improving the accuracy of discriminating the categories of spontaneous expression.MethodThis study proposes a method on the basis of different deep transfer network models for discriminating the categories of spontaneous expression. To preserve the characteristics of the original spontaneous expression, we do not use the technique of data enhancement to reduce the risk of convergence. At the same time, training samples, which comprise three-dimensional images that are composed of optical flow and grayscale images, are compared with the original RGB images. The three-dimensional image contains spatial information and temporal displacement information. In this study, we compare three network models with different samples. The first model is based on Alexnet that only changes the number of output layer neurons that is equal to the number of categories of spontaneous expression. Then, the network is fine-tuned to obtain the best training and testing results by fixing the parameters of different layers several times. The second model is based on InceptionV3. Two fully connected layers whose neuron numbers are equal to 512 and the number of spontaneous expression categories, respectively, are added to the output results. Thus, we only need to fine-tune the parameters of the two layers. Network depth increases with a reduction of the number of parameters due to the 3×3 convolution kernel replacing the 7×7 convolution kernel. The third model is based on Inception-ResNet-v2. Similar to the first model, we only change the number of output layer neurons. Finally, the isomorphic network model is proposed to identify the categories of spontaneous expression. The model is composed of two transfer learning networks of the same type that are trained by different samples and then takes the maximum as the final output. The isomorphic network makes decisions with high accuracy because the same output of the isomorphic network is infinitely close to the standard answer. From the perspective of probability, we take the maximum of different outputs as a prediction value.ResultExperimental results indicate that the proposed method exhibits excellent classification performance on different samples. The single network output clearly shows that the features extracted from RGB images are as effective as the features extracted from the three-dimensional images of optical flow. This result indicates that spatiotemporal features extracted by the optical flow method can be replaced by features that are extracted from the deep neural network. Simultaneously, the method shows that at a certain degree, features extracted from the neural network can replace the lost information and features, such as the temporal features of RGB images or color features of OF+ images. The high average accuracy of a single network indicates that it has good testing performance on each dataset. Networks with high complexity perform well because the samples of spontaneous expression can train the deep transfer learning network effectively. The proposed models achieve state-of-the-art performance and an average accuracy of over 96%. After analyzing the result of the isomorphic network model, we know that its expression is not better than that of a single network in some cases because a single network has a high confidence degree in discriminating the categories of spontaneous expression and thus, the isomorphic network cannot easily improve the average accuracy. The Titan Xp used for this research was donated by the NVIDIA Corporation.ConclusionCompared with traditional expression, spontaneous expression is able to change subtly and extract features in a difficult manner. In the study, different transfer learning networks are applied to discriminate the categories of spontaneous expression. Concurrently, the testing accuracies of different networks, which are trained by different kinds of samples, are compared. Experimental results show that in contrast to traditional methods, deep learning has obvious advantages in spontaneous expression feature extraction. The findings also prove that deep network can extract complete features from spontaneous expression and that it is robust on different databases because of its good testing results. In the future, we will extract spontaneous expressions directly from videos and identify the categories of spontaneous expression with high accuracy by removing distracting occurrences, such as blinking.关键词:spontaneous expression;transfer learning;classification;neural networks;isomorphic network15|9|0更新时间:2024-05-08 -
 摘要:ObjectiveFlower image classification is a fine-grained image classification. Its main challenges are large intra-class differences and inter-class similarities. Different types of flowers have high similarities in morphology, color, and other aspects, whereas flowers in the same category have great diversities in color, shape, and others. According to research and analysis, the current methods of flower image classification can be divided into two categories:methods based on handcrafted features and methods based on deep learning. The former usually obtains flower areas by image segmentation methods and then extracts or designs features manually. Finally, the extracted features are combined with a traditional machine learning algorithm to complete classification. These methods rely on the design experience of researchers. By contrast, methods based on deep learning utilize deep networks to learn the features of flowers automatically. Bounding boxes and part annotations are used to define accurate target positions, and then different convolution neural network models are fine-tuned to obtain the targets' features. Given that currently available flower image datasets lack annotation information, such as bounding box and part annotation, these strongly supervised methods are difficult to apply. Furthermore, tagging many flower images' bounding boxes and part annotations incurs high cost. To solve these problems, this study proposes an unsupervised flower image classification method on the basis of selective convolution descriptor aggregation.MethodA flower image classification network is constructed on the basis of selective deep convolution descriptor aggregation. The proposed method can be divided into four phases:flower image preprocessing, selection and aggregation of convolution features in the Pool5 layer, selection and aggregation of convolution features in the Relu5-2 layer, and multi-layer feature fusion and classification. In the first phase, flower images are preprocessed with the normalization method that retains the aspect ratio to make the size of all flower images equal; thus, the dimension of each flower feature generated by the deep convolutional neural network is consistent. The input image size is set to 224×224 pixels in this study. In the second phase, the features of the preprocessed flower images are learned by VGG-16, which is the deep convolutional neural network model pre-trained by ImageNet. Then, the saliency region is located according to the high response value in the feature map of the Pool5 layer. However, some background regions also have high response values. The area of the background region with a large response value is smaller than the target area. Thus, the flood filling algorithm is used to calculate the maximum connected region of the saliency region. On the basis of the location information of the saliency region, deep convolution features within the region are selected and aggregated to form a low-dimensional feature of flower images. In the third phase, deep convolution features in the Relu5-2 layer are selected and fused to form another low-dimensional feature of flowers. Multi-layer convolution features have been proven to help the network to learn features and then complete the classification task; thus, the deep convolution features in the Pool5 and Relu5-2 layers are chosen in this study. Similarly, a saliency region map from the Relu5-2 layer is obtained on the basis of the response value. The saliency map from the Relu5-2 layer more accurately locates the flower region relative to the saliency map from the Pool5 layer, in which numerous noise regions and few semantic information exist. Thus, the saliency region map from the Relu5-2 layer is combined with a maximum connected region map from the Pool5 layer to produce a true saliency region map with little noise. Finally, deep convolution features are selected and aggregated to form the low-dimensional feature of flower images from the Relu5-2 layer on the basis of the location information of the true saliency region map. In the final phase, the above two low-dimensional features are aggregated to form the final flower features, which are then entered into the softmax layer for classification.ResultTo explore the effects of the proposed selective convolution descriptor aggregation method, we perform the following experiment on Oxford 102 Flowers. The preprocessed flower images are entered into the AlexNet, VGG-16, and Xception models, all of which are pre-trained by ImageNet. Experimental results show that the classification accuracy of the proposed method is superior to that of other models. Experiments are also conducted to compare the proposed method and other current flower image classification methods in the literature. Results indicate that the classification accuracy of this method is higher than that of methods based on handcrafted features and other methods based on deep learning.ConclusionA method for classifying flower images using selective convolution descriptor aggregation was proposed. A flower image's features were learned by using the transfer learning technique on the basis of a pre-trained network. Effective deep convolution features were selected according to the response value distribution in the feature map. Then, multi-layer deep convolution features were fused. Finally, the softmax layer is used for classification. The advantages of this method include locating the conspicuous region in the flower image in an unsupervised manner and selecting deep convolution features in the located region to exclude other invalid parts, such as background and noise parts. Therefore, the accuracy of flower image classification can be improved by reducing the disturbing information from invalid parts.关键词:flower classification;deep learning;saliency region;features selection;features aggregation22|49|0更新时间:2024-05-08
摘要:ObjectiveFlower image classification is a fine-grained image classification. Its main challenges are large intra-class differences and inter-class similarities. Different types of flowers have high similarities in morphology, color, and other aspects, whereas flowers in the same category have great diversities in color, shape, and others. According to research and analysis, the current methods of flower image classification can be divided into two categories:methods based on handcrafted features and methods based on deep learning. The former usually obtains flower areas by image segmentation methods and then extracts or designs features manually. Finally, the extracted features are combined with a traditional machine learning algorithm to complete classification. These methods rely on the design experience of researchers. By contrast, methods based on deep learning utilize deep networks to learn the features of flowers automatically. Bounding boxes and part annotations are used to define accurate target positions, and then different convolution neural network models are fine-tuned to obtain the targets' features. Given that currently available flower image datasets lack annotation information, such as bounding box and part annotation, these strongly supervised methods are difficult to apply. Furthermore, tagging many flower images' bounding boxes and part annotations incurs high cost. To solve these problems, this study proposes an unsupervised flower image classification method on the basis of selective convolution descriptor aggregation.MethodA flower image classification network is constructed on the basis of selective deep convolution descriptor aggregation. The proposed method can be divided into four phases:flower image preprocessing, selection and aggregation of convolution features in the Pool5 layer, selection and aggregation of convolution features in the Relu5-2 layer, and multi-layer feature fusion and classification. In the first phase, flower images are preprocessed with the normalization method that retains the aspect ratio to make the size of all flower images equal; thus, the dimension of each flower feature generated by the deep convolutional neural network is consistent. The input image size is set to 224×224 pixels in this study. In the second phase, the features of the preprocessed flower images are learned by VGG-16, which is the deep convolutional neural network model pre-trained by ImageNet. Then, the saliency region is located according to the high response value in the feature map of the Pool5 layer. However, some background regions also have high response values. The area of the background region with a large response value is smaller than the target area. Thus, the flood filling algorithm is used to calculate the maximum connected region of the saliency region. On the basis of the location information of the saliency region, deep convolution features within the region are selected and aggregated to form a low-dimensional feature of flower images. In the third phase, deep convolution features in the Relu5-2 layer are selected and fused to form another low-dimensional feature of flowers. Multi-layer convolution features have been proven to help the network to learn features and then complete the classification task; thus, the deep convolution features in the Pool5 and Relu5-2 layers are chosen in this study. Similarly, a saliency region map from the Relu5-2 layer is obtained on the basis of the response value. The saliency map from the Relu5-2 layer more accurately locates the flower region relative to the saliency map from the Pool5 layer, in which numerous noise regions and few semantic information exist. Thus, the saliency region map from the Relu5-2 layer is combined with a maximum connected region map from the Pool5 layer to produce a true saliency region map with little noise. Finally, deep convolution features are selected and aggregated to form the low-dimensional feature of flower images from the Relu5-2 layer on the basis of the location information of the true saliency region map. In the final phase, the above two low-dimensional features are aggregated to form the final flower features, which are then entered into the softmax layer for classification.ResultTo explore the effects of the proposed selective convolution descriptor aggregation method, we perform the following experiment on Oxford 102 Flowers. The preprocessed flower images are entered into the AlexNet, VGG-16, and Xception models, all of which are pre-trained by ImageNet. Experimental results show that the classification accuracy of the proposed method is superior to that of other models. Experiments are also conducted to compare the proposed method and other current flower image classification methods in the literature. Results indicate that the classification accuracy of this method is higher than that of methods based on handcrafted features and other methods based on deep learning.ConclusionA method for classifying flower images using selective convolution descriptor aggregation was proposed. A flower image's features were learned by using the transfer learning technique on the basis of a pre-trained network. Effective deep convolution features were selected according to the response value distribution in the feature map. Then, multi-layer deep convolution features were fused. Finally, the softmax layer is used for classification. The advantages of this method include locating the conspicuous region in the flower image in an unsupervised manner and selecting deep convolution features in the located region to exclude other invalid parts, such as background and noise parts. Therefore, the accuracy of flower image classification can be improved by reducing the disturbing information from invalid parts.关键词:flower classification;deep learning;saliency region;features selection;features aggregation22|49|0更新时间:2024-05-08 -
 摘要:ObjectiveGiven the improvement of people's consumption, daily waste increases in quantity and type. Classifying waste correctly is important to protect human health and maintain a clean and safe environment. With the popularity of the internet and the development of information technology, retrieving waste by smartphones based on waste names is a popular waste classification method. However, this method usually works on some static data classifications. Hence, covering all waste with this method and extending the approach to include new types of waste are difficult. To address the problem, this study proposes a long-term waste classification method for domestic waste based on self-training.MethodThe proposed method, which fully uses the capability of machine learning, can update its corresponding training set and conduct self-training on the basis of users' inputs and feedback realized by waste image selection. Thus, a high user participation equates to the high classification accuracy of our method. Accordingly, the proposed method is mainly composed of two parts. 1) To make our method effective in classification, we adopt a new ensemble classifier that integrates K-nearest neighbor classifier (KNN)s and support vector machine (SVM)s (as basis classifiers) together by adopting bagging based on independent voting and weights. In this method, misclassification oversampling technology is combined with bagging to promote the accuracies of these basis classifiers. 2) A feedback mechanism based on image selection is used to automatically update our classifier's confidence and extend our waste training set, thereby upgrading its classification accuracy and self-training ability.ResultA corresponding domestic waste classifying prototype is developed to validate the effectiveness of the above method. Here, a training set that contains 233 waste samples is used to train our ensembled classifier, whereas a test set with 151 waste samples is used to evaluate the accuracy and robustness of our ensembled classifier. The experiments demonstrate that the average classification accuracy rate of the ensembled classifier (approximately 95%) is better than that of each basis classifier. Along with the gradual increase in the proportion of incorrect samples in the training set (≤ 30%), we correspondingly train the ensembled classifier on the data and then conduct a classification test by using the above test set. The corresponding average accuracy analyses illustrate that our ensembled classifier can maintain a relatively high and stable classification accuracy rate (≥ 93%), whereas the feedback mechanism can effectively help our method to alleviate the negative influence brought by incorrect samples.ConclusionClassifying waste is closely related to people's health and environmental protection. However, long-term methods to effectively implement the above work, along with the increasing number and types of waste, remain rare, especially in mobile platforms. Thus, a new long-term waste classification for domestic waste based on self-training is presented in this work. The method is characterized by an accurate and robust domestic waste classification ability and a self-learning ability. These abilities are verified by a novel ensembled classifier and feedback mechanism. However, the method still has some disadvantages that should be improved. 1) The waste image input is mainly used by our feedback mechanism, whereas its corresponding features are mainly described by text because the general and effective methods for extracting waste features from images remain rare. 2) The automatic feedback mechanism should be studied to improve the automation level of the entire method.关键词:waste classification;self-training;ensembled classifier;Bagging;long-term classification19|102|0更新时间:2024-05-08
摘要:ObjectiveGiven the improvement of people's consumption, daily waste increases in quantity and type. Classifying waste correctly is important to protect human health and maintain a clean and safe environment. With the popularity of the internet and the development of information technology, retrieving waste by smartphones based on waste names is a popular waste classification method. However, this method usually works on some static data classifications. Hence, covering all waste with this method and extending the approach to include new types of waste are difficult. To address the problem, this study proposes a long-term waste classification method for domestic waste based on self-training.MethodThe proposed method, which fully uses the capability of machine learning, can update its corresponding training set and conduct self-training on the basis of users' inputs and feedback realized by waste image selection. Thus, a high user participation equates to the high classification accuracy of our method. Accordingly, the proposed method is mainly composed of two parts. 1) To make our method effective in classification, we adopt a new ensemble classifier that integrates K-nearest neighbor classifier (KNN)s and support vector machine (SVM)s (as basis classifiers) together by adopting bagging based on independent voting and weights. In this method, misclassification oversampling technology is combined with bagging to promote the accuracies of these basis classifiers. 2) A feedback mechanism based on image selection is used to automatically update our classifier's confidence and extend our waste training set, thereby upgrading its classification accuracy and self-training ability.ResultA corresponding domestic waste classifying prototype is developed to validate the effectiveness of the above method. Here, a training set that contains 233 waste samples is used to train our ensembled classifier, whereas a test set with 151 waste samples is used to evaluate the accuracy and robustness of our ensembled classifier. The experiments demonstrate that the average classification accuracy rate of the ensembled classifier (approximately 95%) is better than that of each basis classifier. Along with the gradual increase in the proportion of incorrect samples in the training set (≤ 30%), we correspondingly train the ensembled classifier on the data and then conduct a classification test by using the above test set. The corresponding average accuracy analyses illustrate that our ensembled classifier can maintain a relatively high and stable classification accuracy rate (≥ 93%), whereas the feedback mechanism can effectively help our method to alleviate the negative influence brought by incorrect samples.ConclusionClassifying waste is closely related to people's health and environmental protection. However, long-term methods to effectively implement the above work, along with the increasing number and types of waste, remain rare, especially in mobile platforms. Thus, a new long-term waste classification for domestic waste based on self-training is presented in this work. The method is characterized by an accurate and robust domestic waste classification ability and a self-learning ability. These abilities are verified by a novel ensembled classifier and feedback mechanism. However, the method still has some disadvantages that should be improved. 1) The waste image input is mainly used by our feedback mechanism, whereas its corresponding features are mainly described by text because the general and effective methods for extracting waste features from images remain rare. 2) The automatic feedback mechanism should be studied to improve the automation level of the entire method.关键词:waste classification;self-training;ensembled classifier;Bagging;long-term classification19|102|0更新时间:2024-05-08 -
 摘要:ObjectiveAlthough 3D technology is increasingly used in film and television, the development of 3D display technology has been stagnant in recent years. The main reason is that image degradation occurs in the process of 3D information transmission, along with the decline of the depth perception of stereo images to a certain extent. These conditions affect users' immersion experience. Furthermore, the discomfort caused by 3D display limits the development of 3D technology. On the one hand, an effective stereo image quality evaluation technology can provide new ideas for image compression standards. On the other hand, the technology provides a reference for the rational improvement of the quality of 3D videos, thereby accelerating the development of 3D multimedia application technology. Providing content that conforms to users' viewing experience is of paramount importance for the further promotion of 3D multimedia technology. The stereoscopic image quality evaluation method that conforms to users' visual characteristics helps to accurately and objectively reflect the visual perception experience when users watch 3D images or videos. On the basis of different dimensions that affect the quality of stereoscopic image experience, four categories of image quality assessment algorithms are used:image quality evaluation based on distortion, quality of experience based on depth perception, quality of experience based on comfort, and comprehensive dimensions. The quality of experience (QoE) represents the quality of the stereoscopic visual experience of users. QoE is an objective result that takes users as the core and considers the multi-dimensional perception factors that comprehensively affect it. The stereo image quality is the result of the three perceptions of distortion, depth, and comfort of 3D images. Distortion quality indicates the degree of image degradation caused by image distortion. Depth quality indicates the depth and immersion feeling experienced when viewing 3D content. Visual comfort indicates the degree of visual fatigue experienced when viewing stereoscopic images. The existing research on the objective evaluation of 3D QoE only evaluates results beginning from one or two dimensions of image distortion, stereoscopic perception, and visual comfort. However, in an actual subjective experiment, we found that any change in dimensions leads to changes in the quality of the stereo image experience and that existing methods do not comprehensively consider the three factors of image distortion, depth perception, and comfort. To evaluate the visual perception experience of 3D images comprehensively and accurately, this study proposes a stereoscopic image experience quality evaluation method that is based on users multi-dimensional perception.MethodA distortion-free natural scene image has a certain regularity in distribution, and image distortion causes its distribution law to change; thus, image quality can be estimated from the extracted feature parameters. The left and right eye images are subtracted and added to obtain the difference image and fused image. Then, the difference image and fused image are fitted by the generalized Gaussian distribution function, and the fitting parameters are obtained as the distortion quality features. Distortion reduces the depth perception quality of stereo images. It exerts two main effects on depth perception. First, the relative depth information between objects is lost, and the position of the object consequently becomes blurred, thereby affecting depth perception. Second, distortion reduces the feature points at which the left and right viewpoint images are matched; thus, the binocular depth perception information is reduced, thereby diminishing the sense of depth. Then, the distortion-sensitive pixel map is obtained. For each distortion-sensitive pixel, the neighborhood brightness distribution is calculated. SIFT (scale invariant feature transform) key point matching is performed on the left and right views. The statistical result of the neighborhood brightness distribution and the key point matching quantity are used as the depth quality feature. When the parallax of the stereoscopic image exceeds a certain range, the human eye may generate a convergence conflict, thereby resulting in visual fatigue. The human eye is only sensitive to the comfort/discomfort characteristics of the significant area. Thus, we adopt the comfort evaluation model based on the visual important regions and extract the mean parallax value of the significant area. Finally, the three-dimensional features are combined as the experience quality feature vector, and the objective prediction model is constructed by support vector regression.ResultExperimental results on the LIVE database and Waterloo IVC database show that the proposed method correlates with people's subjective perception at values of 0.942 and 0.858, which are better than those of other methods.ConclusionThe method fully uses the characteristics of the stereo image, and the evaluation result is better than that of several classical algorithms. Therefore, the evaluation result of the constructed model shows improved consistency with the subjective experience of the user. In the future, we will combine the evaluation process with the stereo image quality optimization process and guide quality optimization to stereo images from various dimensions.关键词:Quality evaluation;distortion;depth perception;visual fatigue;user experience19|22|0更新时间:2024-05-08
摘要:ObjectiveAlthough 3D technology is increasingly used in film and television, the development of 3D display technology has been stagnant in recent years. The main reason is that image degradation occurs in the process of 3D information transmission, along with the decline of the depth perception of stereo images to a certain extent. These conditions affect users' immersion experience. Furthermore, the discomfort caused by 3D display limits the development of 3D technology. On the one hand, an effective stereo image quality evaluation technology can provide new ideas for image compression standards. On the other hand, the technology provides a reference for the rational improvement of the quality of 3D videos, thereby accelerating the development of 3D multimedia application technology. Providing content that conforms to users' viewing experience is of paramount importance for the further promotion of 3D multimedia technology. The stereoscopic image quality evaluation method that conforms to users' visual characteristics helps to accurately and objectively reflect the visual perception experience when users watch 3D images or videos. On the basis of different dimensions that affect the quality of stereoscopic image experience, four categories of image quality assessment algorithms are used:image quality evaluation based on distortion, quality of experience based on depth perception, quality of experience based on comfort, and comprehensive dimensions. The quality of experience (QoE) represents the quality of the stereoscopic visual experience of users. QoE is an objective result that takes users as the core and considers the multi-dimensional perception factors that comprehensively affect it. The stereo image quality is the result of the three perceptions of distortion, depth, and comfort of 3D images. Distortion quality indicates the degree of image degradation caused by image distortion. Depth quality indicates the depth and immersion feeling experienced when viewing 3D content. Visual comfort indicates the degree of visual fatigue experienced when viewing stereoscopic images. The existing research on the objective evaluation of 3D QoE only evaluates results beginning from one or two dimensions of image distortion, stereoscopic perception, and visual comfort. However, in an actual subjective experiment, we found that any change in dimensions leads to changes in the quality of the stereo image experience and that existing methods do not comprehensively consider the three factors of image distortion, depth perception, and comfort. To evaluate the visual perception experience of 3D images comprehensively and accurately, this study proposes a stereoscopic image experience quality evaluation method that is based on users multi-dimensional perception.MethodA distortion-free natural scene image has a certain regularity in distribution, and image distortion causes its distribution law to change; thus, image quality can be estimated from the extracted feature parameters. The left and right eye images are subtracted and added to obtain the difference image and fused image. Then, the difference image and fused image are fitted by the generalized Gaussian distribution function, and the fitting parameters are obtained as the distortion quality features. Distortion reduces the depth perception quality of stereo images. It exerts two main effects on depth perception. First, the relative depth information between objects is lost, and the position of the object consequently becomes blurred, thereby affecting depth perception. Second, distortion reduces the feature points at which the left and right viewpoint images are matched; thus, the binocular depth perception information is reduced, thereby diminishing the sense of depth. Then, the distortion-sensitive pixel map is obtained. For each distortion-sensitive pixel, the neighborhood brightness distribution is calculated. SIFT (scale invariant feature transform) key point matching is performed on the left and right views. The statistical result of the neighborhood brightness distribution and the key point matching quantity are used as the depth quality feature. When the parallax of the stereoscopic image exceeds a certain range, the human eye may generate a convergence conflict, thereby resulting in visual fatigue. The human eye is only sensitive to the comfort/discomfort characteristics of the significant area. Thus, we adopt the comfort evaluation model based on the visual important regions and extract the mean parallax value of the significant area. Finally, the three-dimensional features are combined as the experience quality feature vector, and the objective prediction model is constructed by support vector regression.ResultExperimental results on the LIVE database and Waterloo IVC database show that the proposed method correlates with people's subjective perception at values of 0.942 and 0.858, which are better than those of other methods.ConclusionThe method fully uses the characteristics of the stereo image, and the evaluation result is better than that of several classical algorithms. Therefore, the evaluation result of the constructed model shows improved consistency with the subjective experience of the user. In the future, we will combine the evaluation process with the stereo image quality optimization process and guide quality optimization to stereo images from various dimensions.关键词:Quality evaluation;distortion;depth perception;visual fatigue;user experience19|22|0更新时间:2024-05-08
Image Analysis and Recognition
-
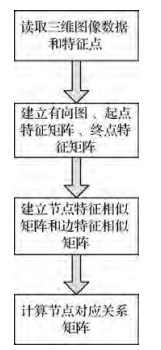 摘要:ObjectiveGraph matching involves establishing a one-to-one correspondence between the feature points of two images on the basis of graph theory. As a basic problem in computer vision, graph matching is closely related to many computer vision areas, such as object tracking, image classification, object recognition, contour matching, and so on. Existing graph matching algorithms are mostly applied to two-dimensional images, and many problems, such as low accuracy rate and slow calculation speed, remain in matching feature points from three-dimensional images. To solve these problems, this study generalized the factorized graph matching algorithm to three-dimensional images.MethodThe three-dimensional graph matching method comprises five main steps. In the first step, the feature points of the two three-dimensional images that must be matched are used as the node set of the graph. Then, the three-dimensional feature points are connected by the Delaunay triangulation algorithm, and the obtained edges are used as the edge sets of the graph to establish the directed graph. In the second step, the starting node matrix is computed on the basis of the structure of the directed graph, and each element with a value of 1 represents the starting node of the edge in the graph. The ending node matrix can be computed in the same manner. The starting node matrix and the ending node matrix can be combined to represent which node of each edge in the graph is initiated and which node is terminated. In the third step, we use the graph's degree and eccentricity as the node's feature to build node feature vectors. We also use the edge length and the angle between the edge and the plane XOY as the edge's feature to build edge feature vectors. The node feature adjacency matrix can be calculated according to the node feature vectors. The number of matrix rows is equal to the number of one graph's nodes. The number of matrix columns is equal to the number of the other graph's nodes. The value of each element in the matrix can be calculated on the basis of the Euclidean distance between corresponding nodes from the two graphs and represents the degree of similarity between two nodes in the graphs. Similarly, the edge feature adjacency matrix can be calculated on the basis of edge feature vectors. The node feature adjacency matrix and edge feature adjacency matrix can be used to delineate the degree of similarity between nodes and edges from two graphs. In the fourth step, using the starting node matrix, ending node matrix, node feature adjacency matrix, and edge feature adjacency matrix, we can build a special matrix K to transform the three-dimensional graph matching problem into a problem of solving a node matching matrix X to maximize an equation J. In the fifth step, the maximum value solution of equation J is a quadratic assignment Problem; therefore, we use the path following algorithm to obtain the optimal solution by splitting the equation J into a series of concave and convex expressions and then find the optimal solution X by iterative approximation. The solution matrix X is the node matching matrix and represents the feature point matching result from two three-dimensional images.ResultWe tested and validated our method in five experiments. In the first experiment, we manually picked 102 feature points from a three-dimensional image in the dataset that comprised nine three-dimensional car images and had a 97.56% average accuracy rate in feature point matching from the same three-dimensional images. In the second experiment, we achieved a 76.39% average accuracy rate from the feature point matching from different three-dimensional images from the dataset. In the third experiment, we rotated the three-dimensional images every 10° from 10° to 180° and matched all 102 manually selected feature points from the same three-dimensional images; the average accuracy rate of matching was 90%. In the fourth experiment, we randomly removed several feature points from the three-dimensional images. During the removal, the accuracy rate of matching decreased. Nevertheless, removing a maximum of 30 feature points still yielded an 80% accuracy rate of matching. In the first four experiments, we used the manually selected feature points from the three-dimensional images; furthermore, we validated our method on the feature points automatically obtained by the 3D scale-invariant feature transform (SIFT) algorithm and achieved a 98.78% average accuracy rate in the feature point matching of the three-dimensional images.ConclusionThe three-dimensional image feature point matching algorithm based on graph theory proposed in this work was tested and validated by five experiments. Results indicate that our method can achieve good matching results for manually selected feature points and automatically calculated feature points.关键词:graph matching;three-dimensional image processing;graph theory;path following algorithm;artificial intelligence25|54|0更新时间:2024-05-08
摘要:ObjectiveGraph matching involves establishing a one-to-one correspondence between the feature points of two images on the basis of graph theory. As a basic problem in computer vision, graph matching is closely related to many computer vision areas, such as object tracking, image classification, object recognition, contour matching, and so on. Existing graph matching algorithms are mostly applied to two-dimensional images, and many problems, such as low accuracy rate and slow calculation speed, remain in matching feature points from three-dimensional images. To solve these problems, this study generalized the factorized graph matching algorithm to three-dimensional images.MethodThe three-dimensional graph matching method comprises five main steps. In the first step, the feature points of the two three-dimensional images that must be matched are used as the node set of the graph. Then, the three-dimensional feature points are connected by the Delaunay triangulation algorithm, and the obtained edges are used as the edge sets of the graph to establish the directed graph. In the second step, the starting node matrix is computed on the basis of the structure of the directed graph, and each element with a value of 1 represents the starting node of the edge in the graph. The ending node matrix can be computed in the same manner. The starting node matrix and the ending node matrix can be combined to represent which node of each edge in the graph is initiated and which node is terminated. In the third step, we use the graph's degree and eccentricity as the node's feature to build node feature vectors. We also use the edge length and the angle between the edge and the plane XOY as the edge's feature to build edge feature vectors. The node feature adjacency matrix can be calculated according to the node feature vectors. The number of matrix rows is equal to the number of one graph's nodes. The number of matrix columns is equal to the number of the other graph's nodes. The value of each element in the matrix can be calculated on the basis of the Euclidean distance between corresponding nodes from the two graphs and represents the degree of similarity between two nodes in the graphs. Similarly, the edge feature adjacency matrix can be calculated on the basis of edge feature vectors. The node feature adjacency matrix and edge feature adjacency matrix can be used to delineate the degree of similarity between nodes and edges from two graphs. In the fourth step, using the starting node matrix, ending node matrix, node feature adjacency matrix, and edge feature adjacency matrix, we can build a special matrix K to transform the three-dimensional graph matching problem into a problem of solving a node matching matrix X to maximize an equation J. In the fifth step, the maximum value solution of equation J is a quadratic assignment Problem; therefore, we use the path following algorithm to obtain the optimal solution by splitting the equation J into a series of concave and convex expressions and then find the optimal solution X by iterative approximation. The solution matrix X is the node matching matrix and represents the feature point matching result from two three-dimensional images.ResultWe tested and validated our method in five experiments. In the first experiment, we manually picked 102 feature points from a three-dimensional image in the dataset that comprised nine three-dimensional car images and had a 97.56% average accuracy rate in feature point matching from the same three-dimensional images. In the second experiment, we achieved a 76.39% average accuracy rate from the feature point matching from different three-dimensional images from the dataset. In the third experiment, we rotated the three-dimensional images every 10° from 10° to 180° and matched all 102 manually selected feature points from the same three-dimensional images; the average accuracy rate of matching was 90%. In the fourth experiment, we randomly removed several feature points from the three-dimensional images. During the removal, the accuracy rate of matching decreased. Nevertheless, removing a maximum of 30 feature points still yielded an 80% accuracy rate of matching. In the first four experiments, we used the manually selected feature points from the three-dimensional images; furthermore, we validated our method on the feature points automatically obtained by the 3D scale-invariant feature transform (SIFT) algorithm and achieved a 98.78% average accuracy rate in the feature point matching of the three-dimensional images.ConclusionThe three-dimensional image feature point matching algorithm based on graph theory proposed in this work was tested and validated by five experiments. Results indicate that our method can achieve good matching results for manually selected feature points and automatically calculated feature points.关键词:graph matching;three-dimensional image processing;graph theory;path following algorithm;artificial intelligence25|54|0更新时间:2024-05-08 -
 摘要:ObjectiveThe effectiveness of contour detection in many applications has been well established and demonstrated widely. This operation is fundamental for numerous vision tasks, such as image analysis and scene understanding. The operation can be used for image segmentation, object detection, and occlusion and depth reasoning. Many studies on contour detection respond not only to foreground objects but also to background textures. In this study, a new method of "object-only" contour detection based on the primary visual pathway computation model is proposed according to the characteristics of visual information transmission and processing in the primary visual pathway. Obtaining the accurate boundaries of an object in the foreground is expected, and the noise and background textures in images are suppressed.MethodIn this study, we attempt to construct a primary visual pathway computation model to simulate the transmission and processing of visual information flows. First, in the retinal ganglion, a classical receptive field direction selection model that combines multi-scale features is constructed to obtain the primary contour response of image targets. Then, a spatiotemporal coding mechanism is used to streamline the redundant features in the primary contour response in the visual pathway of the retinal ganglion to the LGN (lateral geniculate nucleus). Furthermore, the synergistic effects of NSCT (non-subsampled contourlet transform) and Gabor transform are used to simulate the processing effects of the lateral suppression characteristics of NCRF (non-classical receptive field) on the texture background information. Finally, the feedforward mechanism of the visual pathway to the primary visual cortex is combined with the visual features of the multi-visual pathway to obtain the contour response.ResultThe experimental images are derived from RuG40. To verify the effectiveness of our proposed algorithm, we use and compare two methods (ISO and MCI) with the best contour detection results. After the non-maximum suppression and threshold processing, the binary contour map obtained is compared with the reference map. On the one hand, the qualitative analysis of the proposed algorithm shows that although the ISO method achieves a certain balance between false detection rate and missed detection rate in general, some parts present severely distorted contours, such as the image ganglions. Although the MCI method has an improved balance between false detection rate and missed detection rate, the actual detection effect is equally superior. However, its suppression of the image background must be improved in the processing effect of some complex background images, such as the Buffalo. The proposed detection model has the best detection performance under the premise of ensuring that the contour detection results are close to the manual detection results. On the other hand, the quantitative analysis of the proposed algorithm shows that the optimal average indicators for the entire data set and a single map of the RuG40 library are 0.49 and 0.56, respectively. For the average detection results of the optimal parameters of the entire library, the proposed detection model achieves an increase of 22.5% and 6.5% relative to the ISO and MCI models, respectively. For the mean values of the detection results of the optimal parameters for a single image, the proposed detection model achieves an increase of 19.1% and 7.7% relative to the ISO and MCI models, respectively.ConclusionThis study attempts to construct a primary visual pathway computation model to simulate the transmission and processing of biological visual information flows. Compared with the best methods for current contour detection by ISO and MCI, the proposed algorithm can suppress texture background information to a large extent while achieving complete extraction of contour information. Moreover, the proposed algorithm is close to the biological vision mechanism. The contour detection method put forward in this study provides a new research approach for the subsequent contour detection method based on the biological vision mechanism. Subsequent research can be based on the biological vision mechanism to explore how the proposed contour detection method affects advanced image understanding and perception tasks. At the same time, the proposed contour detection method can be used to provide a solid foundation for subsequent high-level visual perception technology.关键词:contour detection;visual mechanism;multi-scale feature fusion;lateral inhibitory properties;temporal and spatial coding19|10|0更新时间:2024-05-08
摘要:ObjectiveThe effectiveness of contour detection in many applications has been well established and demonstrated widely. This operation is fundamental for numerous vision tasks, such as image analysis and scene understanding. The operation can be used for image segmentation, object detection, and occlusion and depth reasoning. Many studies on contour detection respond not only to foreground objects but also to background textures. In this study, a new method of "object-only" contour detection based on the primary visual pathway computation model is proposed according to the characteristics of visual information transmission and processing in the primary visual pathway. Obtaining the accurate boundaries of an object in the foreground is expected, and the noise and background textures in images are suppressed.MethodIn this study, we attempt to construct a primary visual pathway computation model to simulate the transmission and processing of visual information flows. First, in the retinal ganglion, a classical receptive field direction selection model that combines multi-scale features is constructed to obtain the primary contour response of image targets. Then, a spatiotemporal coding mechanism is used to streamline the redundant features in the primary contour response in the visual pathway of the retinal ganglion to the LGN (lateral geniculate nucleus). Furthermore, the synergistic effects of NSCT (non-subsampled contourlet transform) and Gabor transform are used to simulate the processing effects of the lateral suppression characteristics of NCRF (non-classical receptive field) on the texture background information. Finally, the feedforward mechanism of the visual pathway to the primary visual cortex is combined with the visual features of the multi-visual pathway to obtain the contour response.ResultThe experimental images are derived from RuG40. To verify the effectiveness of our proposed algorithm, we use and compare two methods (ISO and MCI) with the best contour detection results. After the non-maximum suppression and threshold processing, the binary contour map obtained is compared with the reference map. On the one hand, the qualitative analysis of the proposed algorithm shows that although the ISO method achieves a certain balance between false detection rate and missed detection rate in general, some parts present severely distorted contours, such as the image ganglions. Although the MCI method has an improved balance between false detection rate and missed detection rate, the actual detection effect is equally superior. However, its suppression of the image background must be improved in the processing effect of some complex background images, such as the Buffalo. The proposed detection model has the best detection performance under the premise of ensuring that the contour detection results are close to the manual detection results. On the other hand, the quantitative analysis of the proposed algorithm shows that the optimal average indicators for the entire data set and a single map of the RuG40 library are 0.49 and 0.56, respectively. For the average detection results of the optimal parameters of the entire library, the proposed detection model achieves an increase of 22.5% and 6.5% relative to the ISO and MCI models, respectively. For the mean values of the detection results of the optimal parameters for a single image, the proposed detection model achieves an increase of 19.1% and 7.7% relative to the ISO and MCI models, respectively.ConclusionThis study attempts to construct a primary visual pathway computation model to simulate the transmission and processing of biological visual information flows. Compared with the best methods for current contour detection by ISO and MCI, the proposed algorithm can suppress texture background information to a large extent while achieving complete extraction of contour information. Moreover, the proposed algorithm is close to the biological vision mechanism. The contour detection method put forward in this study provides a new research approach for the subsequent contour detection method based on the biological vision mechanism. Subsequent research can be based on the biological vision mechanism to explore how the proposed contour detection method affects advanced image understanding and perception tasks. At the same time, the proposed contour detection method can be used to provide a solid foundation for subsequent high-level visual perception technology.关键词:contour detection;visual mechanism;multi-scale feature fusion;lateral inhibitory properties;temporal and spatial coding19|10|0更新时间:2024-05-08
Image Understanding and Computer Vision
-
 摘要:Objective As data collection methods mature and diversify, data sources such as personal smart devices, floating car GPS, internet of things, and social media are becoming increasingly abundant, and the amount of data have been accumulating in an explosive manner. Big data hold spatio-temporal information and high-dimensional features. Spatial and temporal features refer to attribute fields with spatial position and time tags. High dimensional features mean that the target data often contain other valuable attributes. Visual analysis is a highly important method for big data research as it can quickly and intuitively help researchers analyze and understand intrinsic values. However, because of its massive volume, spatio-temporal correlation, and high dimensions, big data visualization poses many challenges to current implementations, including large memory consumption, high rendering delay, and poor visual effects. Method In this study, we propose a generic multi-dimension aggregation pyramid (MAP) model on the basis of the well-known 2D tile pyramid model. This MAP model can support the hierarchical aggregation of time, space, and attributes simultaneously and transform the aggregated results into discrete key-value pairs for scalable storage and efficient retrieval. Then, we use the high-performance Spark cluster as a parallel preprocessing platform and the distributed HBase as final storage to store the generated MAP data. Finally, with the generated MAP datasets, we design and implement an open-source distributed visualization framework (MAP-Vis). Result The experiments use the open New York taxi data, which cover 30 months from January 2014 to June 2016. A single record contains trip-related information, including the location and time of the taxi origin/destination, trip duration, and distance. The visualization interface is implemented on the MAP-Vis framework, which uses HTML, CSS, and JavaScript. Leaflet and OpenStreetMap are used for road network display; the timeline and attribute histogram sections use the d3 library to support user interaction. Three efficiency metrics are collected to evaluate the performance of the MAP model and MAP-Vis system in terms of model validation, storage scalability, and system scalability. In the experiment of model validation, as the size of the raw data increases, the response time curve remains flat and does not show a significant linear increase; the values slightly fluctuate between 0.7 s and 1 s. This result indicates that the MAP model can scale well with the size of spatio-temporal data sets, guarantee a sub-second response, and achieve a smooth interactive visualization experience. In the experiment of storage scalability, as the number of clusters increases, the overall response time decreases dramatically from 3.2 s to 0.9 s, and the parallel efficiency is improved by approximately 2.4 times. This finding can be attributed to distributed storage. More storage nodes are used and the possibility of access to only one region and the access queue time are reduced. Therefore, by increasing the number of HBase storage regions, the proposed framework enhances query efficiency, fully exploits the parallelism of distributed clusters, and significantly improves the visual interactive experience. In the experiment of system scalability, the number of worker nodes in the Spark cluster is changed to measure how the pre-processing time changes (excluding the time of importing the HBase database). An increase in the number of nodes leads to the reduction of pre-processing time from 360 min to 160 min, and the efficiency is improved by approximately 1.3 times. Therefore, with computation nodes, the Spark cluster uses worker nodes and executor processes to share pre-processing tasks, thereby significantly improving the pre-processing efficiency.Conclusion Given its large size, space-time properties, high dimension, and other characteristics, spatial-temporal big data face various challenges such as large memory consumption, high rendering delay, and poor visual effect. To solve this problem, we first propose a spatio-temporal big data organization model, namely, the MAP, which integrates the tile pyramid model and the key-value matching method. The MAP model can consider the time and space dimensions, attribute information, and the three aggregate aggregations step by step, thereby adapting to the rapid and high visualization of time and space big data. On the basis of the MAP model, an open-source visualization framework, MAP-Vis, is implemented on a Linux cluster. The MAP-Vis system uses Spark as a pre-processing tool and HBase as a distributed storage platform. Experiments validate the efficiency of the proposed MAP model, and the undrerlying distributed platforms provide high scalability for visualization and processing. With the cluster, the MAP-Vis realizes sub-second data query and achieves good interactive visualization. Future work can be conducted in the following aspects. 1) This framework has strong support for point type data, but visual elements, including line type elements, polygon type elements, images, etc. should be considered compatible with other data types as much as possible. 2) A simple visual display cannot fully explore the law and value of big data. Hence, joining data analysis modules could be taken into consideration to make the MAP-Vis framework function complete.关键词:big data;multi-dimensional;hierarchical aggregation;distributed database;visual analysis25|12|0更新时间:2024-05-08
摘要:Objective As data collection methods mature and diversify, data sources such as personal smart devices, floating car GPS, internet of things, and social media are becoming increasingly abundant, and the amount of data have been accumulating in an explosive manner. Big data hold spatio-temporal information and high-dimensional features. Spatial and temporal features refer to attribute fields with spatial position and time tags. High dimensional features mean that the target data often contain other valuable attributes. Visual analysis is a highly important method for big data research as it can quickly and intuitively help researchers analyze and understand intrinsic values. However, because of its massive volume, spatio-temporal correlation, and high dimensions, big data visualization poses many challenges to current implementations, including large memory consumption, high rendering delay, and poor visual effects. Method In this study, we propose a generic multi-dimension aggregation pyramid (MAP) model on the basis of the well-known 2D tile pyramid model. This MAP model can support the hierarchical aggregation of time, space, and attributes simultaneously and transform the aggregated results into discrete key-value pairs for scalable storage and efficient retrieval. Then, we use the high-performance Spark cluster as a parallel preprocessing platform and the distributed HBase as final storage to store the generated MAP data. Finally, with the generated MAP datasets, we design and implement an open-source distributed visualization framework (MAP-Vis). Result The experiments use the open New York taxi data, which cover 30 months from January 2014 to June 2016. A single record contains trip-related information, including the location and time of the taxi origin/destination, trip duration, and distance. The visualization interface is implemented on the MAP-Vis framework, which uses HTML, CSS, and JavaScript. Leaflet and OpenStreetMap are used for road network display; the timeline and attribute histogram sections use the d3 library to support user interaction. Three efficiency metrics are collected to evaluate the performance of the MAP model and MAP-Vis system in terms of model validation, storage scalability, and system scalability. In the experiment of model validation, as the size of the raw data increases, the response time curve remains flat and does not show a significant linear increase; the values slightly fluctuate between 0.7 s and 1 s. This result indicates that the MAP model can scale well with the size of spatio-temporal data sets, guarantee a sub-second response, and achieve a smooth interactive visualization experience. In the experiment of storage scalability, as the number of clusters increases, the overall response time decreases dramatically from 3.2 s to 0.9 s, and the parallel efficiency is improved by approximately 2.4 times. This finding can be attributed to distributed storage. More storage nodes are used and the possibility of access to only one region and the access queue time are reduced. Therefore, by increasing the number of HBase storage regions, the proposed framework enhances query efficiency, fully exploits the parallelism of distributed clusters, and significantly improves the visual interactive experience. In the experiment of system scalability, the number of worker nodes in the Spark cluster is changed to measure how the pre-processing time changes (excluding the time of importing the HBase database). An increase in the number of nodes leads to the reduction of pre-processing time from 360 min to 160 min, and the efficiency is improved by approximately 1.3 times. Therefore, with computation nodes, the Spark cluster uses worker nodes and executor processes to share pre-processing tasks, thereby significantly improving the pre-processing efficiency.Conclusion Given its large size, space-time properties, high dimension, and other characteristics, spatial-temporal big data face various challenges such as large memory consumption, high rendering delay, and poor visual effect. To solve this problem, we first propose a spatio-temporal big data organization model, namely, the MAP, which integrates the tile pyramid model and the key-value matching method. The MAP model can consider the time and space dimensions, attribute information, and the three aggregate aggregations step by step, thereby adapting to the rapid and high visualization of time and space big data. On the basis of the MAP model, an open-source visualization framework, MAP-Vis, is implemented on a Linux cluster. The MAP-Vis system uses Spark as a pre-processing tool and HBase as a distributed storage platform. Experiments validate the efficiency of the proposed MAP model, and the undrerlying distributed platforms provide high scalability for visualization and processing. With the cluster, the MAP-Vis realizes sub-second data query and achieves good interactive visualization. Future work can be conducted in the following aspects. 1) This framework has strong support for point type data, but visual elements, including line type elements, polygon type elements, images, etc. should be considered compatible with other data types as much as possible. 2) A simple visual display cannot fully explore the law and value of big data. Hence, joining data analysis modules could be taken into consideration to make the MAP-Vis framework function complete.关键词:big data;multi-dimensional;hierarchical aggregation;distributed database;visual analysis25|12|0更新时间:2024-05-08
Computer Graphics
-
 摘要:ObjectiveOcular fundus image processing is one of the most popular research fields that combine medical science and computer science. Fundus images have the advantages of clear imaging, simple operation, and high efficiency, thereby enabling people to find various eye diseases as soon as possible. At present, deep learning methods provide state-of-the-art results on many tasks of image processing, including medical image segmentation and instance segmentation. A small number of objects are found in many cases of biomedical applications. Moreover, few datasets can be used. In most cases, fundus tests require a doctor to locate the optic disc and find its boundary. Therefore, retinal optic disc segmentation is an important problem in fundus image research. The success of the fully supervised learning algorithm relies on many high-quality manual comments/tags, which are often time consuming and costly to obtain. Different experts use different criteria, thereby resulting in some difficulties in medical image segmentation. If experiments with inaccurate data are conducted, not only will incorrect results be obtained but time will also be wasted. To save cost, this study proposes a constrained weakly supervised optic disc segmentation algorithm.MethodBy referring to the literature, we combine the convolution neural network (CNN) and the weak supervision method. A weak supervised learning method for sub-ocular image segmentation is proposed. First, the proposed visual CNN is pre-trained on a large auxiliary dataset, which contains approximately 1.2 million labeled training images of 1 000 classes. We can use this pre-training model to complete our own segmentation. Notably, we only use the parameters of the first five layers of the model to train our own models. Then, the top layer of the deep CNN is trained from RIM-ONE dataset. We fuse the conv3, conv4, and conv8 layers in our new model to improve the optic segmentation performance. Finally, we design a new constrained weak loss function to achieve an optimal output. The proposed loss function can optimize convolutional networks with arbitrary linear constraints on the structured output space of pixel labels. The key contribution of this study is to model a distribution over latent "pixel-wise" labels while keeping the network's output the same as the distribution. In this way, the output size is within a reasonable range. The weak loss function is used to constrain the foreground and background sizes of the target. The KL divergence and stochastic gradient descent methods are used to optimize the model.ResultThe proposed algorithm for constrained weakly supervised optic disc segmentation is evaluated with the RIM-ONE dataset. This method can effectively segment the contour of the video disc. The central part of the optic disc covered by blood vessels is well segmented. Our approach is evaluated in terms of mean accuracy, mean precision, and mean intersection over union. These three indexes are the common evaluation indexes in the field of image segmentation. We calculate the results prior to convolutional layer fusion and after convolutional layer fusion. Obviously, the latter results are better than the former ones. The latter results show that the mean accuracy in this work can reach 0.852, the mean precision can reach 0.831, and the mean intersection over union can reach 0.827; these findings are close to current state-of-the-art result. We only use image-level tags without any pixel-level mask. Overall, our algorithm for constrained weakly supervised optic disc segmentation achieves 90% of the performance of the fully supervised approach, which uses orders of magnitude without annotation. With the model trained on the server, each image takes only a few seconds to predict. This prediction is faster than that of the method in the same type of some weakly supervised segmentation articles.ConclusionA new method to segment optic discs is proposed, and an end-to-end framework under deep weak supervision for image-to-image segmentation for medical images is developed. To preferably learn video disc information, we develop deep weak supervision for our formulation. Size constraints are also introduced naturally to seek for additional weakly supervised information. This work is the first to use image-level tags to conduct optic disc segmentation. The proposed models obtain more competitive results than the fully supervised method does. Experiments demonstrate that our methods achieve state-of-the-art results on weakly supervised medical images. The results can be applied to a wide range of medical imaging and computer vision applications. The research area on weakly supervised medical image processing has a broad prospect. An increasing number of people are expected to prefer the weak supervision method over the fully supervised method; even unsupervised learning is likely to cause a boom among scholars. These options can improve work efficiency and reduce labor costs. Experimental results also prove the effectiveness of our weakly supervised optic disc segmentation method.关键词:weak supervised learning;optic disc segmentation;size constrained;convolutional neural network;fundus image21|10|0更新时间:2024-05-08
摘要:ObjectiveOcular fundus image processing is one of the most popular research fields that combine medical science and computer science. Fundus images have the advantages of clear imaging, simple operation, and high efficiency, thereby enabling people to find various eye diseases as soon as possible. At present, deep learning methods provide state-of-the-art results on many tasks of image processing, including medical image segmentation and instance segmentation. A small number of objects are found in many cases of biomedical applications. Moreover, few datasets can be used. In most cases, fundus tests require a doctor to locate the optic disc and find its boundary. Therefore, retinal optic disc segmentation is an important problem in fundus image research. The success of the fully supervised learning algorithm relies on many high-quality manual comments/tags, which are often time consuming and costly to obtain. Different experts use different criteria, thereby resulting in some difficulties in medical image segmentation. If experiments with inaccurate data are conducted, not only will incorrect results be obtained but time will also be wasted. To save cost, this study proposes a constrained weakly supervised optic disc segmentation algorithm.MethodBy referring to the literature, we combine the convolution neural network (CNN) and the weak supervision method. A weak supervised learning method for sub-ocular image segmentation is proposed. First, the proposed visual CNN is pre-trained on a large auxiliary dataset, which contains approximately 1.2 million labeled training images of 1 000 classes. We can use this pre-training model to complete our own segmentation. Notably, we only use the parameters of the first five layers of the model to train our own models. Then, the top layer of the deep CNN is trained from RIM-ONE dataset. We fuse the conv3, conv4, and conv8 layers in our new model to improve the optic segmentation performance. Finally, we design a new constrained weak loss function to achieve an optimal output. The proposed loss function can optimize convolutional networks with arbitrary linear constraints on the structured output space of pixel labels. The key contribution of this study is to model a distribution over latent "pixel-wise" labels while keeping the network's output the same as the distribution. In this way, the output size is within a reasonable range. The weak loss function is used to constrain the foreground and background sizes of the target. The KL divergence and stochastic gradient descent methods are used to optimize the model.ResultThe proposed algorithm for constrained weakly supervised optic disc segmentation is evaluated with the RIM-ONE dataset. This method can effectively segment the contour of the video disc. The central part of the optic disc covered by blood vessels is well segmented. Our approach is evaluated in terms of mean accuracy, mean precision, and mean intersection over union. These three indexes are the common evaluation indexes in the field of image segmentation. We calculate the results prior to convolutional layer fusion and after convolutional layer fusion. Obviously, the latter results are better than the former ones. The latter results show that the mean accuracy in this work can reach 0.852, the mean precision can reach 0.831, and the mean intersection over union can reach 0.827; these findings are close to current state-of-the-art result. We only use image-level tags without any pixel-level mask. Overall, our algorithm for constrained weakly supervised optic disc segmentation achieves 90% of the performance of the fully supervised approach, which uses orders of magnitude without annotation. With the model trained on the server, each image takes only a few seconds to predict. This prediction is faster than that of the method in the same type of some weakly supervised segmentation articles.ConclusionA new method to segment optic discs is proposed, and an end-to-end framework under deep weak supervision for image-to-image segmentation for medical images is developed. To preferably learn video disc information, we develop deep weak supervision for our formulation. Size constraints are also introduced naturally to seek for additional weakly supervised information. This work is the first to use image-level tags to conduct optic disc segmentation. The proposed models obtain more competitive results than the fully supervised method does. Experiments demonstrate that our methods achieve state-of-the-art results on weakly supervised medical images. The results can be applied to a wide range of medical imaging and computer vision applications. The research area on weakly supervised medical image processing has a broad prospect. An increasing number of people are expected to prefer the weak supervision method over the fully supervised method; even unsupervised learning is likely to cause a boom among scholars. These options can improve work efficiency and reduce labor costs. Experimental results also prove the effectiveness of our weakly supervised optic disc segmentation method.关键词:weak supervised learning;optic disc segmentation;size constrained;convolutional neural network;fundus image21|10|0更新时间:2024-05-08
Medical Image Processing
-
 摘要:ObjectiveClouds cover most of the Earth's space and play an important role in the Earth's water cycle, its energy balance, and radiation transmission. Concurrently, clouds are one of the most vital and active factors in weather and climate. They usually cover ground information, thereby causing many problems and difficulties in the processing of image registration and fusion. Thus, cloud detection is highly significant and necessary.MethodOn the basis of the Earth polychromatic image camera (EPIC) data from the deep space climate observatory (DSCOVR) satellite launched in 2015, we study the characteristics of EPIC data, including the hemisphere scale and the wide range of band spectra, including ultraviolet, visible, and infrared bands. Then, we propose a new cloud detection method for EPIC data with hemispherical scale on the basis of the normalized difference cloud index (NDCI). First, we analyze the different reflection characteristics of different bands, which are determined by the physical properties of objects. In particular, the ultraviolet bands of EPIC data are new. Combined with the applications of EPIC data bands, 340, 388, 680, and 780 nm are identified as the main research bands. Second, we analyze the reflection characteristics of clouds, including thin clouds and residual clouds. According to the above two aspects, we define the cloud index (CI) to detect clouds, thereby effectively reducing the influence of the underlying surface on cloud detection results. On the basis of the research bands, we design two CI indexes. CI (340) is the difference between the reflectivity of the 680 and 340 nm bands divided by the reflectivity of the 780 nm band. CI (388) is the difference between the reflectivity of the 680 nm band and the 388 nm band divided by the reflectivity of the 780 nm band. The method is analyzed in terms of the cloud amount and cloud distribution.ResultTo verify the effectiveness of the proposed cloud detection method, we compare three other cloud detection methods, namely, the visible light cloud detection method, support vector machine (SVM) cloud detection method, and traditional NDCI cloud detection method. The EPIC data that correspond to summer (July 3, 2017) and winter (January 3, 2017) are used to conduct the experiments. The comparison results consider cloud distribution and cloud amount. In the experimental cloud distribution results, the cloud distribution obtained by the proposed method is most consistent with the cloud distribution in the original EPIC image combined with RGB true color. The results of cloud distribution also show that the proposed method effectively detects thin clouds and residual clouds that are not detected by other methods, even in winter and in summer. The traditional NDCI cloud detection method misjudges a large amount of land as the cloud. Thus, the cloud amount of the traditional NDCI method is not included in the comparison. CI (388) is the optimal band combination for cloud detection in winter and summer. In July, the cloud amounts of the visible light cloud detection method, CI (340), CI (388), and SVM method are 21.07%, 26.90%, 31.40%, and 32.49%, respectively. Except for the visible light method, the maximum difference between the other methods is 5.59%. In January, the cloud amounts of four methods are 30.60%, 35.34%, 38.50%, and 31.34%, respectively. To validate the results of the cloud and cloud distribution, the results are verified using the EPIC L2 data, including the reflectivity product, CF340 product, and CF388 product. The mean cloud amount of the three products in July is 32.33%. In summer, the cloud distributions of various methods are consistent with the cloud distributions of products. The differences between the visible light method, CI (340), CI (388), and SVM method with the product mean are 11.26%, 5.43%, 0.93%, and 0.16%, respectively. The difference in the cloud amount between the SVM method and the product is the smallest, followed by that between CI (388) and the product. The mean cloud amount of products in winter is 37.34%. The difference in the cloud amount between the product and CI (388) is the smallest at 1.16%. Finally, the accuracy evaluation, including the correct detection ratio, missed detection ratio, false detection ratio, and kappa coefficient, is completed. Regardless of the season, the correct detection ratios of the four methods are more than 80%. In winter, the detection accuracy of the four methods is lower than that in summer. For the visible light method, the kappa coefficients in summer and winter are 0.84 and 0.79, respectively, which are the lowest of the four methods; the correct ratios are also the lowest at 84.40% and 80.07%, respectively. For the SVM method, the overall accuracy is up to 88.26%, and the lowest is 86.01%. The kappa coefficients for summer and winter are 0.88 and 0.86, respectively. The cloud distribution of the SVM method is closer to that of the EPIC product than to that of the visible light method. In the band combination of the CI method for summer, the correct ratios of CI (388) and CI (340) are 94.34% and 93.24%, respectively. The correct ratio of CI (388) in winter is as high as 92.96%. CI (388) has the largest Kappa coefficient with 0.94 in summer and 0.92 in winter. The correct ratio of our method is greater than 91%, and the Kappa coefficient is greater than 0.9. However, the correct ratios of the other methods are less than 89%, and the Kappa coefficients are at approximately 0.8. Therefore, in winter and summer, the CI (388) band combination obtains the best cloud distribution and cloud amount as the EPIC L2 product.ConclusionIn the cloud detection process for an EPIC image, our proposed cloud detection method is superior to the visible light cloud detection method and SVM method in terms of cloud distribution and cloud amount. The findings are valid and reliable according to the EPIC L2 product verification. Moreover, the proposed method can quickly obtain cloud distribution and cloud amount within the hemisphere, which is helpful for dynamic research and natural weather prediction of global clouds.关键词:hemisphere scale;DISCOVR EPIC;cloud detection;cloud index method;cloud amount;cloud distribution16|10|0更新时间:2024-05-08
摘要:ObjectiveClouds cover most of the Earth's space and play an important role in the Earth's water cycle, its energy balance, and radiation transmission. Concurrently, clouds are one of the most vital and active factors in weather and climate. They usually cover ground information, thereby causing many problems and difficulties in the processing of image registration and fusion. Thus, cloud detection is highly significant and necessary.MethodOn the basis of the Earth polychromatic image camera (EPIC) data from the deep space climate observatory (DSCOVR) satellite launched in 2015, we study the characteristics of EPIC data, including the hemisphere scale and the wide range of band spectra, including ultraviolet, visible, and infrared bands. Then, we propose a new cloud detection method for EPIC data with hemispherical scale on the basis of the normalized difference cloud index (NDCI). First, we analyze the different reflection characteristics of different bands, which are determined by the physical properties of objects. In particular, the ultraviolet bands of EPIC data are new. Combined with the applications of EPIC data bands, 340, 388, 680, and 780 nm are identified as the main research bands. Second, we analyze the reflection characteristics of clouds, including thin clouds and residual clouds. According to the above two aspects, we define the cloud index (CI) to detect clouds, thereby effectively reducing the influence of the underlying surface on cloud detection results. On the basis of the research bands, we design two CI indexes. CI (340) is the difference between the reflectivity of the 680 and 340 nm bands divided by the reflectivity of the 780 nm band. CI (388) is the difference between the reflectivity of the 680 nm band and the 388 nm band divided by the reflectivity of the 780 nm band. The method is analyzed in terms of the cloud amount and cloud distribution.ResultTo verify the effectiveness of the proposed cloud detection method, we compare three other cloud detection methods, namely, the visible light cloud detection method, support vector machine (SVM) cloud detection method, and traditional NDCI cloud detection method. The EPIC data that correspond to summer (July 3, 2017) and winter (January 3, 2017) are used to conduct the experiments. The comparison results consider cloud distribution and cloud amount. In the experimental cloud distribution results, the cloud distribution obtained by the proposed method is most consistent with the cloud distribution in the original EPIC image combined with RGB true color. The results of cloud distribution also show that the proposed method effectively detects thin clouds and residual clouds that are not detected by other methods, even in winter and in summer. The traditional NDCI cloud detection method misjudges a large amount of land as the cloud. Thus, the cloud amount of the traditional NDCI method is not included in the comparison. CI (388) is the optimal band combination for cloud detection in winter and summer. In July, the cloud amounts of the visible light cloud detection method, CI (340), CI (388), and SVM method are 21.07%, 26.90%, 31.40%, and 32.49%, respectively. Except for the visible light method, the maximum difference between the other methods is 5.59%. In January, the cloud amounts of four methods are 30.60%, 35.34%, 38.50%, and 31.34%, respectively. To validate the results of the cloud and cloud distribution, the results are verified using the EPIC L2 data, including the reflectivity product, CF340 product, and CF388 product. The mean cloud amount of the three products in July is 32.33%. In summer, the cloud distributions of various methods are consistent with the cloud distributions of products. The differences between the visible light method, CI (340), CI (388), and SVM method with the product mean are 11.26%, 5.43%, 0.93%, and 0.16%, respectively. The difference in the cloud amount between the SVM method and the product is the smallest, followed by that between CI (388) and the product. The mean cloud amount of products in winter is 37.34%. The difference in the cloud amount between the product and CI (388) is the smallest at 1.16%. Finally, the accuracy evaluation, including the correct detection ratio, missed detection ratio, false detection ratio, and kappa coefficient, is completed. Regardless of the season, the correct detection ratios of the four methods are more than 80%. In winter, the detection accuracy of the four methods is lower than that in summer. For the visible light method, the kappa coefficients in summer and winter are 0.84 and 0.79, respectively, which are the lowest of the four methods; the correct ratios are also the lowest at 84.40% and 80.07%, respectively. For the SVM method, the overall accuracy is up to 88.26%, and the lowest is 86.01%. The kappa coefficients for summer and winter are 0.88 and 0.86, respectively. The cloud distribution of the SVM method is closer to that of the EPIC product than to that of the visible light method. In the band combination of the CI method for summer, the correct ratios of CI (388) and CI (340) are 94.34% and 93.24%, respectively. The correct ratio of CI (388) in winter is as high as 92.96%. CI (388) has the largest Kappa coefficient with 0.94 in summer and 0.92 in winter. The correct ratio of our method is greater than 91%, and the Kappa coefficient is greater than 0.9. However, the correct ratios of the other methods are less than 89%, and the Kappa coefficients are at approximately 0.8. Therefore, in winter and summer, the CI (388) band combination obtains the best cloud distribution and cloud amount as the EPIC L2 product.ConclusionIn the cloud detection process for an EPIC image, our proposed cloud detection method is superior to the visible light cloud detection method and SVM method in terms of cloud distribution and cloud amount. The findings are valid and reliable according to the EPIC L2 product verification. Moreover, the proposed method can quickly obtain cloud distribution and cloud amount within the hemisphere, which is helpful for dynamic research and natural weather prediction of global clouds.关键词:hemisphere scale;DISCOVR EPIC;cloud detection;cloud index method;cloud amount;cloud distribution16|10|0更新时间:2024-05-08
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0