
最新刊期
卷 24 , 期 4 , 2019
-
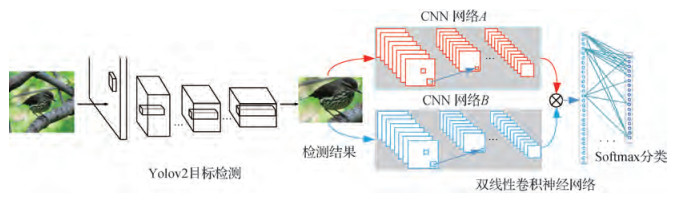 摘要:ObjectiveIn recent years, with the rapid progress of science and technology as well as the increasing demand of human life, people's research has shifted from the coarse-grained image classification to the fine-grained image classification. Fine-grained image classification is a hot research topic in the field of computer vision research in recent years. Its purpose is to provide a detailed subdivision of a large category, such as the distinction of bird species, car brand style, and dog breed. Nowadays, the fine-grained image classification has great application requirements. For example, in the field of ecological protection, the identification of different species of organisms is the key to ecological research. And in the field of botany, because of the variety and quantity of flowers as well as the similarity between different flowers which make the fine-grained image classification tasks more difficult. With the help of computer vision technology, we can realize low-cost fine-grained image classification tasks. However, the fine-grained classification often has smaller differences between classes and larger differences within classes. Thus, in comparison with the ordinary image classification, the task of the fine-grained image classification is more challenging. Moreover, the fine-grained image classification has much irrelevant information and background interference. Those problems would influence the network model to learn the actual discriminative characteristics and result in inferior classification performance in fine-grained image classification. Therefore, finding discriminative regions in the image is important for the improvement of fine-grained image classification performance. To solve this problem, a joint deep learning framework of focus and recognition is constructed for fine-grained image classification. This framework can remove the background in the image, highlight the target to be identified, and then automatically locate the discriminative area in the image. Thus, the deep convolutional neural networks can extract more useful and discriminative features, and the classification rate of fine-grained images can be improved naturally.MethodFirstly, the Yolov2 (you only look once v2) target detection algorithm can detect object in the image rapidly and eliminate the influence of background interference and unrelated information, and then the datasets, which include the detected target objects, are used to train the bilinear convolutional neural network. Finally, the final model can be used for fine-grained image classification. The Yolov2 algorithm is a further improvement of the Yolov1 target detection algorithm, and it is more precise for small object localization. It can automatically find the target in the picture to filter out most of the regions that do not contribute to image classification. Bilinear convolutional neural network is a special network for fine-grained image classification. Its characteristic is that it uses the two convolutional neural networks to extract the features of the same picture simultaneously, and the bilinear feature vector is obtained by the approaches of bilinear pooling. Finally, the bilinear feature vector is fed into the softmax network layer and the classification task is completed, we can get the final classification results. In addition, the advantage of the bilinear convolutional neural network is that it is not dependent on additional manual annotation information and it is an entire system which can complete end-to-end training. It only relies on the class label information. Therefore, it greatly reduces the difficulty and complexity of fine-grained image classification.ResultWe perform verification experiments on open standard fine-grained image library CUB-200-2011, Cars196, and Aircrafts100. We use the pre-trained target detection model of Yolov2 algorithm to detect these three datasets respectively, therefore, we can get the discriminative regions in the image for each datasets. Then, the bilinear convolutional neural network is trained by the processed datasets. Finally, our proposed bilinear convolutional neural network model can be used for the fine-grained image classification and achieves classification accuracy of 84.5%, 92%, and 88.4% on these three datasets. In comparison with the highest classification accuracy obtained by the same classification algorithm without discriminant information extraction, the classification accuracy of the three databases is improved by 0.4%, 0.7%, and 3.9%. Moreover, the recognition rate is also increased by 0.5%, 1.4%, and 4.5% compared with the same classification algorithm, which extracts features from two identical D(dence)-Net networks. We also compared with other fine-grained image classification algorithms, such as the Spatial Transformer Networks, which has a fine classification performance in fine-grained image classification and it is also an entire system and is only dependent on label information. For all that, the classification accuracy rate of ours is still 0.4 percentage points higher than the method of Spatial Transformer Networks on bird dataset.ConclusionIn this paper, an innovative method based on focused recognition network architecture is proposed to improve the recognition rate of the fine-grained image classification. And the experiment results show that our method positively affects the fine-grained image classification results, which uses the network architecture of focus and recognition to detect discriminative region in the image. It can filter out most of the area in the image which does not contribute to the classification of fine-grained images, thereby reducing the influence of background interference to the classification results. Thus, the bilinear convolutional neural network can learn more useful features, which are beneficial to the classification of fine-grained images. Finally, the recognition rate of the model of the fine-grained image classification can be improved effectively. Of course, we also compare with other fine-grained image classification algorithms on several datasets, which also strongly proves the effectiveness of our algorithm.关键词:fine-grained image classification;target detection;bilinear convolutional neural network;framework of focus and recognition;discrimination59|81|4更新时间:2024-05-07
摘要:ObjectiveIn recent years, with the rapid progress of science and technology as well as the increasing demand of human life, people's research has shifted from the coarse-grained image classification to the fine-grained image classification. Fine-grained image classification is a hot research topic in the field of computer vision research in recent years. Its purpose is to provide a detailed subdivision of a large category, such as the distinction of bird species, car brand style, and dog breed. Nowadays, the fine-grained image classification has great application requirements. For example, in the field of ecological protection, the identification of different species of organisms is the key to ecological research. And in the field of botany, because of the variety and quantity of flowers as well as the similarity between different flowers which make the fine-grained image classification tasks more difficult. With the help of computer vision technology, we can realize low-cost fine-grained image classification tasks. However, the fine-grained classification often has smaller differences between classes and larger differences within classes. Thus, in comparison with the ordinary image classification, the task of the fine-grained image classification is more challenging. Moreover, the fine-grained image classification has much irrelevant information and background interference. Those problems would influence the network model to learn the actual discriminative characteristics and result in inferior classification performance in fine-grained image classification. Therefore, finding discriminative regions in the image is important for the improvement of fine-grained image classification performance. To solve this problem, a joint deep learning framework of focus and recognition is constructed for fine-grained image classification. This framework can remove the background in the image, highlight the target to be identified, and then automatically locate the discriminative area in the image. Thus, the deep convolutional neural networks can extract more useful and discriminative features, and the classification rate of fine-grained images can be improved naturally.MethodFirstly, the Yolov2 (you only look once v2) target detection algorithm can detect object in the image rapidly and eliminate the influence of background interference and unrelated information, and then the datasets, which include the detected target objects, are used to train the bilinear convolutional neural network. Finally, the final model can be used for fine-grained image classification. The Yolov2 algorithm is a further improvement of the Yolov1 target detection algorithm, and it is more precise for small object localization. It can automatically find the target in the picture to filter out most of the regions that do not contribute to image classification. Bilinear convolutional neural network is a special network for fine-grained image classification. Its characteristic is that it uses the two convolutional neural networks to extract the features of the same picture simultaneously, and the bilinear feature vector is obtained by the approaches of bilinear pooling. Finally, the bilinear feature vector is fed into the softmax network layer and the classification task is completed, we can get the final classification results. In addition, the advantage of the bilinear convolutional neural network is that it is not dependent on additional manual annotation information and it is an entire system which can complete end-to-end training. It only relies on the class label information. Therefore, it greatly reduces the difficulty and complexity of fine-grained image classification.ResultWe perform verification experiments on open standard fine-grained image library CUB-200-2011, Cars196, and Aircrafts100. We use the pre-trained target detection model of Yolov2 algorithm to detect these three datasets respectively, therefore, we can get the discriminative regions in the image for each datasets. Then, the bilinear convolutional neural network is trained by the processed datasets. Finally, our proposed bilinear convolutional neural network model can be used for the fine-grained image classification and achieves classification accuracy of 84.5%, 92%, and 88.4% on these three datasets. In comparison with the highest classification accuracy obtained by the same classification algorithm without discriminant information extraction, the classification accuracy of the three databases is improved by 0.4%, 0.7%, and 3.9%. Moreover, the recognition rate is also increased by 0.5%, 1.4%, and 4.5% compared with the same classification algorithm, which extracts features from two identical D(dence)-Net networks. We also compared with other fine-grained image classification algorithms, such as the Spatial Transformer Networks, which has a fine classification performance in fine-grained image classification and it is also an entire system and is only dependent on label information. For all that, the classification accuracy rate of ours is still 0.4 percentage points higher than the method of Spatial Transformer Networks on bird dataset.ConclusionIn this paper, an innovative method based on focused recognition network architecture is proposed to improve the recognition rate of the fine-grained image classification. And the experiment results show that our method positively affects the fine-grained image classification results, which uses the network architecture of focus and recognition to detect discriminative region in the image. It can filter out most of the area in the image which does not contribute to the classification of fine-grained images, thereby reducing the influence of background interference to the classification results. Thus, the bilinear convolutional neural network can learn more useful features, which are beneficial to the classification of fine-grained images. Finally, the recognition rate of the model of the fine-grained image classification can be improved effectively. Of course, we also compare with other fine-grained image classification algorithms on several datasets, which also strongly proves the effectiveness of our algorithm.关键词:fine-grained image classification;target detection;bilinear convolutional neural network;framework of focus and recognition;discrimination59|81|4更新时间:2024-05-07 -
 摘要:ObjectiveTraditional sparse representation classification methods have drawn extensive attention due to the improved sparse classification capacity by means of high-dimensional data. However, they ignore the information redundancy between the gallery and query sets, thereby leading to the uncertainty of final recognized results. To address this issue, we propose a novel method by jointly using a convolutional neural network (CNN) and a PCA(principal component analysis)-constrained optimization model to perform sparse representation-based classification (EPCNN-SRC).Method In this study, we present a new sparse learning strategy based on CNN and PCA-constrained optimization model to perform sparse classification. The two critical contributions of this work are as follows. First, we utilize LDA (linear discriminant analysis) to enhance further the discriminative capacity of the collaborative representation classification. Second, we obtain robust face features by using a deep CNN. Specifically, for designing a classification method, we reconstruct PCA coefficients of training samples, which are achieved via PCA-constrained optimization. The objective of the proposed classification method is to use PCA plus LDA hybrid constrained model to enhance the discriminatory capacity of SRC. In the first phase, the proposed method seeks to achieve a compressive linear representation of the test samples. Our design achieves an accurate reconstruction of the test sample using sample space and principle coefficient space. The second phase further improves the discriminative capability of the PCA coefficient in representing a test sample, thereby obtaining a competitive optimization model for face classification. Assuming that a given dataset with multiple images per subject exists, the samples in each subject are stacked as vectors. Hence, an interclass variant dictionary can be constructed by subtracting the natural image from other images of the same class for training data augmentation. Many different approaches have been proposed by researchers to construct a variation dictionary. However, the idea of setting a variation dictionary can be the same, that is, to augment the training set. The constructed interclass dictionary contains all types of important difference information, such as illumination, expression, and other differences that the error cannot represent. To improve the optimization efficiency, we project the training samples into the PCA space, in which a new sparse representation model with PCA-constrained optimization is designed. The formula is described in this study. The strength of the proposed strategies lies in successfully constructing some optimization solutions using quadratic optimization in downsized coefficient subspace, thereby enhancing the collaborative and discriminative capacity of the dictionary to reconstruct the input images. Most existing sparse or collaborative representation methods focus on the training data augmentation for effective optimization to alleviate the adverse effect of the small sample size problem. However, the original dictionary is commonly built on a high-dimensional subspace. A typical example is found in some famous collaborative representation-based methods, such as ESRC(extended sparse representation-based classifier). The abundant hybrid training atoms with high dimensionality may lead to time-consuming and uncertainty in the dataset. In our method, original and within-class variations of one subject can be approximated by a collaborative linear combination of the other subjects, thereby integrating the dimensionality reduction of the training samples and the hybrid optimization process. With the PCA-constrained model, the ESRC decomposes the original face structure of the training set into the orthogonal components known as eigenfaces, and the transformed axes can be established as a set of biases, which represent the variations among the different subjects. Thus, our method can remarkably reduce the computational complexity. Meanwhile, CNNs have been successfully used in a wide range of computer vision and pattern recognition applications and become the mainstream in face biometrics. A CNN trained on a large number of face images can extract robust textural features for face recognition across a variety of appearance variations, such as pose, expression, illumination, and occlusion. To further improve the accuracy of the proposed system, we apply state-of-the-art deep CNN features to our model to improve the accuracy. Here, the proposed classification method is based on CNN features, which are different from widely used nearest neighbor classifiers with cosine and Euclidean distances. In the data processing phase, we use the pretrained VGG16 model for feature extraction. The extracted features from the original input face image can obtain better performance than the traditional sparse representation method, which uses the raw pixel intensities for classification. Therefore, the robust sample features in the process of classification perform a crucial role.Result The designed method has achieved better performance than the traditional sparse representation methods. We repeat each experiment 20 times in every dataset and compute the average value as the final recognition rate. We design an experiment in four different face datasets to evaluate the robustness of the proposed method. Each face dataset contains different styles and numbers in express and pose change. Results are compared with some traditional related classification methods, such as ESRC, NN_CNN(nearest neighbor convolutional neural networks), CIRLRC (conventional and inverse representation-based linear regression classification), TPTSR(two-phase test sample sparse representation), SRICE (sparse representation using iterative class elimination), SRC(sparse representation-based classifier), CRC(collaborative representation based classification), and LRC(linear representation classification). All the methods are operated under the same experimental condition. To confirm the capability of the method to alleviate the adverse effect of the small sample size problem, some experiments are performed in a single sample. The results obtained from the AR, FERET, FRGC, and LFW datasets show that when each subject has only one sample, the proposed EPCNN-SRC achieves 96.92%, 96.15%, 86.94%, and 42.44% recognition rates, respectively, which are higher than that of other traditional methods. This finding has fully provided the effectiveness of the proposed method. In addition, when the test environment contains complex changes, the algorithm still shows good recognition, particularly in terms of time complexity, which is considerably lower than that of the traditional representation classification algorithm, and achieves the expected results.ConclusionIn this study, we propose EPCNN-SRC. Experiments in many datasets show that this algorithm, which applies iterative optimization strategy in feature space, not only effectively extracts the robust information features of the original samples but also combines norm and norm minimization to reduce the time cost of the representation classification algorithm. The key innovation of the proposed work is to accomplish face recognition using a novel dimensionality reduction optimization model, thereby resulting in robust SRC under appearance variations. The strength of the technique lies in successfully constructing a quadratic optimization in downsized coefficient solution subspace, thereby enhancing the discriminatory capacity of the dictionary to reconstruct input signals effectively. We believe that our promising results can encourage future works on synthesizing additional informative optimization structures and can improve this study for better SRC solutions.关键词:sparse representation;convolutional neural network;dimensionality reduction of features;PCA-constrained optimization;face recognition38|125|0更新时间:2024-05-07
摘要:ObjectiveTraditional sparse representation classification methods have drawn extensive attention due to the improved sparse classification capacity by means of high-dimensional data. However, they ignore the information redundancy between the gallery and query sets, thereby leading to the uncertainty of final recognized results. To address this issue, we propose a novel method by jointly using a convolutional neural network (CNN) and a PCA(principal component analysis)-constrained optimization model to perform sparse representation-based classification (EPCNN-SRC).Method In this study, we present a new sparse learning strategy based on CNN and PCA-constrained optimization model to perform sparse classification. The two critical contributions of this work are as follows. First, we utilize LDA (linear discriminant analysis) to enhance further the discriminative capacity of the collaborative representation classification. Second, we obtain robust face features by using a deep CNN. Specifically, for designing a classification method, we reconstruct PCA coefficients of training samples, which are achieved via PCA-constrained optimization. The objective of the proposed classification method is to use PCA plus LDA hybrid constrained model to enhance the discriminatory capacity of SRC. In the first phase, the proposed method seeks to achieve a compressive linear representation of the test samples. Our design achieves an accurate reconstruction of the test sample using sample space and principle coefficient space. The second phase further improves the discriminative capability of the PCA coefficient in representing a test sample, thereby obtaining a competitive optimization model for face classification. Assuming that a given dataset with multiple images per subject exists, the samples in each subject are stacked as vectors. Hence, an interclass variant dictionary can be constructed by subtracting the natural image from other images of the same class for training data augmentation. Many different approaches have been proposed by researchers to construct a variation dictionary. However, the idea of setting a variation dictionary can be the same, that is, to augment the training set. The constructed interclass dictionary contains all types of important difference information, such as illumination, expression, and other differences that the error cannot represent. To improve the optimization efficiency, we project the training samples into the PCA space, in which a new sparse representation model with PCA-constrained optimization is designed. The formula is described in this study. The strength of the proposed strategies lies in successfully constructing some optimization solutions using quadratic optimization in downsized coefficient subspace, thereby enhancing the collaborative and discriminative capacity of the dictionary to reconstruct the input images. Most existing sparse or collaborative representation methods focus on the training data augmentation for effective optimization to alleviate the adverse effect of the small sample size problem. However, the original dictionary is commonly built on a high-dimensional subspace. A typical example is found in some famous collaborative representation-based methods, such as ESRC(extended sparse representation-based classifier). The abundant hybrid training atoms with high dimensionality may lead to time-consuming and uncertainty in the dataset. In our method, original and within-class variations of one subject can be approximated by a collaborative linear combination of the other subjects, thereby integrating the dimensionality reduction of the training samples and the hybrid optimization process. With the PCA-constrained model, the ESRC decomposes the original face structure of the training set into the orthogonal components known as eigenfaces, and the transformed axes can be established as a set of biases, which represent the variations among the different subjects. Thus, our method can remarkably reduce the computational complexity. Meanwhile, CNNs have been successfully used in a wide range of computer vision and pattern recognition applications and become the mainstream in face biometrics. A CNN trained on a large number of face images can extract robust textural features for face recognition across a variety of appearance variations, such as pose, expression, illumination, and occlusion. To further improve the accuracy of the proposed system, we apply state-of-the-art deep CNN features to our model to improve the accuracy. Here, the proposed classification method is based on CNN features, which are different from widely used nearest neighbor classifiers with cosine and Euclidean distances. In the data processing phase, we use the pretrained VGG16 model for feature extraction. The extracted features from the original input face image can obtain better performance than the traditional sparse representation method, which uses the raw pixel intensities for classification. Therefore, the robust sample features in the process of classification perform a crucial role.Result The designed method has achieved better performance than the traditional sparse representation methods. We repeat each experiment 20 times in every dataset and compute the average value as the final recognition rate. We design an experiment in four different face datasets to evaluate the robustness of the proposed method. Each face dataset contains different styles and numbers in express and pose change. Results are compared with some traditional related classification methods, such as ESRC, NN_CNN(nearest neighbor convolutional neural networks), CIRLRC (conventional and inverse representation-based linear regression classification), TPTSR(two-phase test sample sparse representation), SRICE (sparse representation using iterative class elimination), SRC(sparse representation-based classifier), CRC(collaborative representation based classification), and LRC(linear representation classification). All the methods are operated under the same experimental condition. To confirm the capability of the method to alleviate the adverse effect of the small sample size problem, some experiments are performed in a single sample. The results obtained from the AR, FERET, FRGC, and LFW datasets show that when each subject has only one sample, the proposed EPCNN-SRC achieves 96.92%, 96.15%, 86.94%, and 42.44% recognition rates, respectively, which are higher than that of other traditional methods. This finding has fully provided the effectiveness of the proposed method. In addition, when the test environment contains complex changes, the algorithm still shows good recognition, particularly in terms of time complexity, which is considerably lower than that of the traditional representation classification algorithm, and achieves the expected results.ConclusionIn this study, we propose EPCNN-SRC. Experiments in many datasets show that this algorithm, which applies iterative optimization strategy in feature space, not only effectively extracts the robust information features of the original samples but also combines norm and norm minimization to reduce the time cost of the representation classification algorithm. The key innovation of the proposed work is to accomplish face recognition using a novel dimensionality reduction optimization model, thereby resulting in robust SRC under appearance variations. The strength of the technique lies in successfully constructing a quadratic optimization in downsized coefficient solution subspace, thereby enhancing the discriminatory capacity of the dictionary to reconstruct input signals effectively. We believe that our promising results can encourage future works on synthesizing additional informative optimization structures and can improve this study for better SRC solutions.关键词:sparse representation;convolutional neural network;dimensionality reduction of features;PCA-constrained optimization;face recognition38|125|0更新时间:2024-05-07 -
 摘要:ObjectiveThe person re-identification task is of great value in multi-target tracking and the target retrieval of multi-cameras. Thus, it has received increasing attention in the field of computer vision and widespread interest among researchers at home and abroad in recent years. The differences in camera viewing angles and imaging quality lead to variations in pedestrian posture, image resolution, and illumination. These variations make the appearance of the same pedestrian in various surveillance videos considerably different. This difference, in turn, causes severe interference in person re-identification. To improve the recognition rate of person re-identification and solve the posture changing problem, this study proposes a person re-identification algorithm with region block segmentation and fusion on the basis of human body structure information.Method First, according to the distribution of the human body structure, a pedestrian image is divided into three local regions:the head part (the H region), the shoulder-knee part (the SK region), and the leg part (the L region). These local regions are enlarged to the original image size using a bilinear interpolation method, which can enhance the expression of the regions and fully use the region information. Second, according to the different roles of each local region in the recognition process, the Gaussian of Gaussian (GOG) feature is extracted from the H and the L regions. The GOG feature, the local maximal occurrence (LOMO) feature, and the kernel canonical correlation analysis (KCCA) feature are extracted from the SK region because the SK region contains the most abundant information of pedestrian images. Extracting numerous features in the SK region can increase the diversity of the region information and strengthen the role of the region in the re-identification process. Third, the interference block removal (IBR) algorithm is used to eliminate the invalid blocks in the image and fuse the similarities of the effective blocks. Given the differences in posture and viewpoint, some objects might appear in one image and be absent in another image of the same person captured by another camera. Such objects may cause large changes in the color and texture information of the pedestrian's corresponding body regions. These changes result in disturbances to the recognition process. The regions in which such objects are located are called interference blocks in this study. By observing the location of the interference blocks, we find that the interference blocks are distributed from the shoulder to the knee of pedestrians. Therefore, the IBR algorithm uses the image of the SK region. According to the human body structure distribution, the IBR algorithm horizontally divides the SK region into the chest part (h1 block), the lumbar part (h2 block), and the leg part (h3 block); and vertically divides the region into the left-arm part (v1 block), the torso part (v2 block), and the right-arm part (v3 block). Then, the GOG feature, LOMO feature, and KCCA feature are extracted from each block. The three features of each block are fed to the similarity measure function to obtain the three similarities between the corresponding blocks. The three similarities of the same block are merged to form the final similarity of the block. When the final similarities of the six block (h1, h2, h3, v1, v2, v3) pairs are calculated, the similarities of the three horizontal block (h1, h2, h3) pairs are compared to find the block with the smallest similarity, which is the interference block in the horizontal direction. The interference block in the vertical direction is found in the same manner. When the two interference blocks are removed, the influence of the interference block on the overall pedestrian similarity can be eliminated. After the interference blocks are removed, the similarities of the remaining four blocks are fused as the similarity of the SK region. Finally, the global similarity of the pedestrian image pair and the similarities of the three local regions (H, L, and SK) are combined to realize person re-identification.Result Many experiments are conducted on four benchmark datasets, namely, VIPeR, GRID, PRID450S, and CUHK01. The results of rank 1 (represents the proportion of queried people) for the four datasets are 62.85%, 30.56%, 71.82%, and 79.03%. The results of rank 5 are 86.17%, 51.20%, 91.16%, and 93.60%. The experimental results show the considerable improvement of recognition rates for the small and large datasets. Thus, the proposed algorithm offers practical application value.ConclusionExperimental results show that the proposed method can effectively express the image information of pedestrians. Furthermore, the proposed region block segmentation and fusion algorithm can remove useless and interference information in images as much as possible under the guidance of human body structure information. It can also preserve the effective information of pedestrians and use it effectively. This method can solve the differences in pedestrian appearance caused by changes in pedestrian posture to a certain extent and greatly improve recognition rates.关键词:person re-identification;human structure information;region block segmentation;interference block removal;region block fusion20|49|2更新时间:2024-05-07
摘要:ObjectiveThe person re-identification task is of great value in multi-target tracking and the target retrieval of multi-cameras. Thus, it has received increasing attention in the field of computer vision and widespread interest among researchers at home and abroad in recent years. The differences in camera viewing angles and imaging quality lead to variations in pedestrian posture, image resolution, and illumination. These variations make the appearance of the same pedestrian in various surveillance videos considerably different. This difference, in turn, causes severe interference in person re-identification. To improve the recognition rate of person re-identification and solve the posture changing problem, this study proposes a person re-identification algorithm with region block segmentation and fusion on the basis of human body structure information.Method First, according to the distribution of the human body structure, a pedestrian image is divided into three local regions:the head part (the H region), the shoulder-knee part (the SK region), and the leg part (the L region). These local regions are enlarged to the original image size using a bilinear interpolation method, which can enhance the expression of the regions and fully use the region information. Second, according to the different roles of each local region in the recognition process, the Gaussian of Gaussian (GOG) feature is extracted from the H and the L regions. The GOG feature, the local maximal occurrence (LOMO) feature, and the kernel canonical correlation analysis (KCCA) feature are extracted from the SK region because the SK region contains the most abundant information of pedestrian images. Extracting numerous features in the SK region can increase the diversity of the region information and strengthen the role of the region in the re-identification process. Third, the interference block removal (IBR) algorithm is used to eliminate the invalid blocks in the image and fuse the similarities of the effective blocks. Given the differences in posture and viewpoint, some objects might appear in one image and be absent in another image of the same person captured by another camera. Such objects may cause large changes in the color and texture information of the pedestrian's corresponding body regions. These changes result in disturbances to the recognition process. The regions in which such objects are located are called interference blocks in this study. By observing the location of the interference blocks, we find that the interference blocks are distributed from the shoulder to the knee of pedestrians. Therefore, the IBR algorithm uses the image of the SK region. According to the human body structure distribution, the IBR algorithm horizontally divides the SK region into the chest part (h1 block), the lumbar part (h2 block), and the leg part (h3 block); and vertically divides the region into the left-arm part (v1 block), the torso part (v2 block), and the right-arm part (v3 block). Then, the GOG feature, LOMO feature, and KCCA feature are extracted from each block. The three features of each block are fed to the similarity measure function to obtain the three similarities between the corresponding blocks. The three similarities of the same block are merged to form the final similarity of the block. When the final similarities of the six block (h1, h2, h3, v1, v2, v3) pairs are calculated, the similarities of the three horizontal block (h1, h2, h3) pairs are compared to find the block with the smallest similarity, which is the interference block in the horizontal direction. The interference block in the vertical direction is found in the same manner. When the two interference blocks are removed, the influence of the interference block on the overall pedestrian similarity can be eliminated. After the interference blocks are removed, the similarities of the remaining four blocks are fused as the similarity of the SK region. Finally, the global similarity of the pedestrian image pair and the similarities of the three local regions (H, L, and SK) are combined to realize person re-identification.Result Many experiments are conducted on four benchmark datasets, namely, VIPeR, GRID, PRID450S, and CUHK01. The results of rank 1 (represents the proportion of queried people) for the four datasets are 62.85%, 30.56%, 71.82%, and 79.03%. The results of rank 5 are 86.17%, 51.20%, 91.16%, and 93.60%. The experimental results show the considerable improvement of recognition rates for the small and large datasets. Thus, the proposed algorithm offers practical application value.ConclusionExperimental results show that the proposed method can effectively express the image information of pedestrians. Furthermore, the proposed region block segmentation and fusion algorithm can remove useless and interference information in images as much as possible under the guidance of human body structure information. It can also preserve the effective information of pedestrians and use it effectively. This method can solve the differences in pedestrian appearance caused by changes in pedestrian posture to a certain extent and greatly improve recognition rates.关键词:person re-identification;human structure information;region block segmentation;interference block removal;region block fusion20|49|2更新时间:2024-05-07 -
 摘要:ObjectiveHuman body detection is a key subject of computer vision and has important research relevance in areas, such as intelligent video surveillance, unmanned driving, and intelligent robots. Head-shoulder detection is often used in embedded systems due to its strong anti-masking capabilities, attitude adaptability, and low computational requirements. Commonly used embedded head-shoulder detection methods mainly include motion detection and matching; however, these two methods have low detection accuracy and poor adaptability to different postures and human appearances. To improve the head-shoulder detection accuracy, an embedded real-time human head-shoulder detection method based on aggregated channel features (ACFs) is proposed.MethodA variety of pedestrian detection and human pose datasets, namely, Caltech Pedestrian dataset, INRIA Pedestrian dataset, and MPⅡ Human Pose dataset, are analyzed to generate human head-shoulder sample. Suitable samples in MPⅡ Human Pose dataset are filtered. Then, head-shoulder areas are clipped accurately on the basis of the positions of head and neck joints, and a human head-shoulder dataset with varied head-shoulder poses and perspectives, named MPⅡ-HS, is generated. The MPⅡ-HS dataset is used as positive training samples. Images from Caltech and INRIA Pedestrian datasets, which do not contain humans are used as negative training samples. AdaBoost algorithm with multiple stages, which consist of one channel of gradient amplitude, six channels of gradient direction, and three channels in YUV color space, is used to train a head-shoulder classifier for a 40×40 pixels image based on ACFs. The trained classifier is an enhanced decision tree composed of 4 096 binary decision trees with a maximum depth of five. The final score of the classifier is the sum of the scores of every binary decision tree. The classification will end early if the score sum reaches a lower threshold to speed up detection. Image feature pyramid is calculated based on fast feature pyramid algorithm. For the Linux ARM platform, multi-core parallel techniques and single-instruction multiple-data instruction set are used to accelerate the calculation of image feature pyramid. Finally, sliding-window detection is applied in multiple threads where each thread handles one row of detection windows. The trained head-shoulder image classifier identifies candidate head-shoulder targets in every detection window, and candidate detection results are merged via non-maximum suppression algorithm.ResultTo estimate the accuracy of the proposed head-shoulder detector, head-shoulder targets in the validation set of INRIA Pedestrian dataset are re-labeled and named as INRIA-HS. The trained head-shoulder image classifier is applied. The detection results are evaluated by miss rate (MR) and false positive per picture (FPPI) in the receiver operating characteristic curve. The log-average MS for head-shoulder targets with a height of ≥ 50 pixels in INRIA-HS dataset is 16.61%, that of MR is lower than 20%, whereas the FPPI is 0.1. In addition, the head-shoulder images of various poses and perspectives in different scenes are collected in actual scenes to verify the adaptability of the proposed classifier. Results show that the proposed classifier can detect multi-pose, multi-perspective, and occluded head-shoulder target under different illumination conditions. However, the receptive field of the proposed classifier is limited to the head-shoulder area; thus, some image areas similar to that of the head-shoulder but not similar to the human body may be misclassified as positive. Thus, the FPPI of the proposed head-shoulder detection is slightly higher than that of the ACF classifier trained for all human body detection. However, the proposed head-shoulder classifier is suitable for occluded human in indoor and crowded scenes. In the embedded platform with quad-core ARM Cortex-A53 with 1.4 GHz Raspberry Pi 3B, the proposed optimized head-shoulder detection program takes approximately 178 ms for a 640×480 pixels image. For a single detection window containing positive samples, the classification takes approximately 2 ms. The overall detection speed can satisfy the demands of real-time detection of video streams.ConclusionHuman head-shoulders are detected based on ACF. The generated head-shoulder dataset MPⅡ-HS has rich and varied head-shoulder samples with accurate annotations. The AdaBoost algorithm is used to learn the ACF of head-shoulder images. The trained head-shoulder image classifier has strong adaptability to different human poses or appearances. It benefits from the struct of classifier, and its hardware performance requirement is low. These advantages allow human head-shoulder detection accuracy possible on an embedded platform in a wide range.关键词:pedestrian detection;head-shoulder detection;embedded system;aggregated channel features;AdaBoost;machine learning27|56|0更新时间:2024-05-07
摘要:ObjectiveHuman body detection is a key subject of computer vision and has important research relevance in areas, such as intelligent video surveillance, unmanned driving, and intelligent robots. Head-shoulder detection is often used in embedded systems due to its strong anti-masking capabilities, attitude adaptability, and low computational requirements. Commonly used embedded head-shoulder detection methods mainly include motion detection and matching; however, these two methods have low detection accuracy and poor adaptability to different postures and human appearances. To improve the head-shoulder detection accuracy, an embedded real-time human head-shoulder detection method based on aggregated channel features (ACFs) is proposed.MethodA variety of pedestrian detection and human pose datasets, namely, Caltech Pedestrian dataset, INRIA Pedestrian dataset, and MPⅡ Human Pose dataset, are analyzed to generate human head-shoulder sample. Suitable samples in MPⅡ Human Pose dataset are filtered. Then, head-shoulder areas are clipped accurately on the basis of the positions of head and neck joints, and a human head-shoulder dataset with varied head-shoulder poses and perspectives, named MPⅡ-HS, is generated. The MPⅡ-HS dataset is used as positive training samples. Images from Caltech and INRIA Pedestrian datasets, which do not contain humans are used as negative training samples. AdaBoost algorithm with multiple stages, which consist of one channel of gradient amplitude, six channels of gradient direction, and three channels in YUV color space, is used to train a head-shoulder classifier for a 40×40 pixels image based on ACFs. The trained classifier is an enhanced decision tree composed of 4 096 binary decision trees with a maximum depth of five. The final score of the classifier is the sum of the scores of every binary decision tree. The classification will end early if the score sum reaches a lower threshold to speed up detection. Image feature pyramid is calculated based on fast feature pyramid algorithm. For the Linux ARM platform, multi-core parallel techniques and single-instruction multiple-data instruction set are used to accelerate the calculation of image feature pyramid. Finally, sliding-window detection is applied in multiple threads where each thread handles one row of detection windows. The trained head-shoulder image classifier identifies candidate head-shoulder targets in every detection window, and candidate detection results are merged via non-maximum suppression algorithm.ResultTo estimate the accuracy of the proposed head-shoulder detector, head-shoulder targets in the validation set of INRIA Pedestrian dataset are re-labeled and named as INRIA-HS. The trained head-shoulder image classifier is applied. The detection results are evaluated by miss rate (MR) and false positive per picture (FPPI) in the receiver operating characteristic curve. The log-average MS for head-shoulder targets with a height of ≥ 50 pixels in INRIA-HS dataset is 16.61%, that of MR is lower than 20%, whereas the FPPI is 0.1. In addition, the head-shoulder images of various poses and perspectives in different scenes are collected in actual scenes to verify the adaptability of the proposed classifier. Results show that the proposed classifier can detect multi-pose, multi-perspective, and occluded head-shoulder target under different illumination conditions. However, the receptive field of the proposed classifier is limited to the head-shoulder area; thus, some image areas similar to that of the head-shoulder but not similar to the human body may be misclassified as positive. Thus, the FPPI of the proposed head-shoulder detection is slightly higher than that of the ACF classifier trained for all human body detection. However, the proposed head-shoulder classifier is suitable for occluded human in indoor and crowded scenes. In the embedded platform with quad-core ARM Cortex-A53 with 1.4 GHz Raspberry Pi 3B, the proposed optimized head-shoulder detection program takes approximately 178 ms for a 640×480 pixels image. For a single detection window containing positive samples, the classification takes approximately 2 ms. The overall detection speed can satisfy the demands of real-time detection of video streams.ConclusionHuman head-shoulders are detected based on ACF. The generated head-shoulder dataset MPⅡ-HS has rich and varied head-shoulder samples with accurate annotations. The AdaBoost algorithm is used to learn the ACF of head-shoulder images. The trained head-shoulder image classifier has strong adaptability to different human poses or appearances. It benefits from the struct of classifier, and its hardware performance requirement is low. These advantages allow human head-shoulder detection accuracy possible on an embedded platform in a wide range.关键词:pedestrian detection;head-shoulder detection;embedded system;aggregated channel features;AdaBoost;machine learning27|56|0更新时间:2024-05-07 -
 摘要:ObjectiveVisual tracking is a classical computer vision problem with many applications. In generic visual tracking, the task is to estimate the trajectory of a target in an image sequence, given only its initial location. Recently, traditional discriminative correlation filter-based approaches have been successfully applied to tracking problems. These methods learn a discriminative correlation filter from a set of training samples, which adopt a circular shift operator on the tracking target object (the only accurate positive sample) to obtain the training negative samples. These shifted patches are implicitly generated through the circulatory property of correlation in frequency domain and are used as negative examples for training the filter. All shifted patches are plagued by circular boundary effects and are not truly representative of negative patches in real-word scenes. Thus, the actual background information is not modeled during the total learning process and when the target object is similar to the background information, thereby leading to a drift. To improve the performance, a large number of training samples are collected, which results in the increase of computational complexity. Moreover, preferring the background is easy due to the online model update strategy, which causes drift. To resolve this problem, we construct a discriminative correlation filter-based target function with equation-constrained condition on the background-aware correlation filtering (BACF) visual object tracking algorithm, which is termed as the background-temporal-aware correlation filter (BTCF) visual object tracking. Our algorithm obtains the actual negative sample with the same size as the target object on the training set by multiplying the filter with a binary mask to suppress the background region. Moreover, it can learn a strong correlation filter-based discriminative classifier by only using the current frame information without online updating of the model.MethodIn this paper, the proposed BTCF model is convex and can be minimized to obtain the globally optimal solution. In order to further reduce the computational burden, we propose a new equation-constrained discriminative correlation filter-based objective function. This objective function satisfies the Eckstein-Bertsekas condition, therefore, it can be transformed into an unconstrained augmented Lagrange multiplier formula to converge to the global optimum solution. Then, two sub-problems with closed-form solution are gained by using the alternating direction multiplier method (ADMM). Every sub-problem is a smooth and convex function and is very easy to obtain the solution, therefore, each iteration of the sub-problem has a closed-form solution and is the global optimal solution of each sub-problem. Because of the convolution calculation in sub-problem two, it is difficult to solve the optimization problem, consequently, according to Parseval's theorem, we transform sub-problem two into Fourier domain to reduce computational complexity. The efficient ADMM based approach for learning our filter on multi-channel features, with computational cost of
摘要:ObjectiveVisual tracking is a classical computer vision problem with many applications. In generic visual tracking, the task is to estimate the trajectory of a target in an image sequence, given only its initial location. Recently, traditional discriminative correlation filter-based approaches have been successfully applied to tracking problems. These methods learn a discriminative correlation filter from a set of training samples, which adopt a circular shift operator on the tracking target object (the only accurate positive sample) to obtain the training negative samples. These shifted patches are implicitly generated through the circulatory property of correlation in frequency domain and are used as negative examples for training the filter. All shifted patches are plagued by circular boundary effects and are not truly representative of negative patches in real-word scenes. Thus, the actual background information is not modeled during the total learning process and when the target object is similar to the background information, thereby leading to a drift. To improve the performance, a large number of training samples are collected, which results in the increase of computational complexity. Moreover, preferring the background is easy due to the online model update strategy, which causes drift. To resolve this problem, we construct a discriminative correlation filter-based target function with equation-constrained condition on the background-aware correlation filtering (BACF) visual object tracking algorithm, which is termed as the background-temporal-aware correlation filter (BTCF) visual object tracking. Our algorithm obtains the actual negative sample with the same size as the target object on the training set by multiplying the filter with a binary mask to suppress the background region. Moreover, it can learn a strong correlation filter-based discriminative classifier by only using the current frame information without online updating of the model.MethodIn this paper, the proposed BTCF model is convex and can be minimized to obtain the globally optimal solution. In order to further reduce the computational burden, we propose a new equation-constrained discriminative correlation filter-based objective function. This objective function satisfies the Eckstein-Bertsekas condition, therefore, it can be transformed into an unconstrained augmented Lagrange multiplier formula to converge to the global optimum solution. Then, two sub-problems with closed-form solution are gained by using the alternating direction multiplier method (ADMM). Every sub-problem is a smooth and convex function and is very easy to obtain the solution, therefore, each iteration of the sub-problem has a closed-form solution and is the global optimal solution of each sub-problem. Because of the convolution calculation in sub-problem two, it is difficult to solve the optimization problem, consequently, according to Parseval's theorem, we transform sub-problem two into Fourier domain to reduce computational complexity. The efficient ADMM based approach for learning our filter on multi-channel features, with computational cost of${\rm{O}}\left({LKT\lg \left(T \right)} \right)$ $T$ $K$ $L$ 关键词:visual tracking;correlation filter;background-aware;temporal-aware;regularization;alternating direction multiplier method17|6|7更新时间:2024-05-07 -
 摘要:ObjectiveThe problem of environmental pollution in China has become increasingly serious with the rapid development of society and economy. Creating a beautiful ecological environment is becoming an important issue in the current national planning. Environmental pollution problems affect the sustainable development of the country and society. As an important source of pollution, cement plants must be effectively counted and monitored. With the development of satellite remote sensing, high-resolution and good quality images become available. At the same time, deep learning has made great progress in the field of target detection, and many excellent deep convolutional network models, such as Faster R-CNN, YOLO, SSD, and Mask R-CNN, have been proposed recently. In the object detection task on satellite images, huge differences lie in the plant area scales, the structures of equipment composition, and the orientations of each cement plant. Thus, various cement plants are presented with various appearances due to the complex natural geographical surroundings. Overcoming the problem of cement plant target detection and recognition using traditional artificial image feature methods is difficult. However, deep learning has achieved excellent performance in the field of image target recognition. The application of the deep convolutional network may be a brilliant method to locate cement plants on satellite images.MethodA method of detecting and locating cement plant position using high-resolution satellite images was proposed based on the convolutional neural network of Faster R-CNN framework for image target detection. First, we used GoogleMap API to download Google Earth satellite images. We developed this high-resolution satellite image dataset of cement factory target using GoogleMap web API, which contains 464 cement plant locations, according to the Beijing-Tianjin-Hebei cement dataset given by the Satellite Environment Center, Ministry of Environmental protection. Through the training and testing datasets of the cement plant in Beijing-Tianjin-Hebei with three different feature extracting modules (namely, VGG(visual geometry group network), ZF, and ResNet), we compared the testing results among the three CNN models. Three methods, which include image haze removal using dark channel prior, data augmentation, and adding negative training samples, were introduced to solve the problems of overfitting and reduce high false positive rate because of insufficient amount of training data. We also verified the influence of different numbers of negative training samples on model training. We used these features to assist cement plant target detection, considering the characteristics of cement buildings with evident cylindrical cement tanks and heating reaction tower buildings.ResultThe visualized images of the convolutional feature map show that the identification of the deep convolution network for cement plant target detection is mainly based on special buildings in the plant area, such as cylindrical cement tanks, heating towers, and rectangular plants. The experimental results on the test set reveal that the ResNet achieves the best performance with the average accuracy rate of 74%. An optimization method by three methods is proposed to further enhance the detection of accurate rate and suppress the false positive rate. The precision of the promoted CNN model reached 94% in the augmented testing dataset, and the false positive rate was reduced to 14%. The true positive detection rate in the global cement plant dataset reached 96%, and the number of false detection of 10 000 random satellite images was reduced to 30 (0.3%). The actual cement plant target scan detection of the satellite images in the entire Shanghai area was conducted. To avoid dividing the cement plant into two image parts, we used the overlapping detection method, which also detected adjacent areas between satellite images. As a result, 11 out of 16 registered cement plants, and 17 unregistered cement plants are detected.ConclusionThe cement plant has special buildings of different shapes and background, even varying over time, thereby resulting in relatively difficult detection task. However, the method of cement plant detection on satellite images based on deep convolutional networks can automatically learn to extract effective features and can identify the position of the target in the image. In addition, some optimization methods, including image preprocessing, data augmentation, and adding negative samples to promote the performance of the model, are adopted to improve the model detection accuracy and solve the problem of few training data. The geographic latitude and longitude coordinates of cement targets are easy to obtain based on the result of the image object detection and its position information because the satellite image is geocoded. We can also estimate the cement plant area using information of detected boxes. In the model generalization capability test experiment, the proposed method achieves good performance in the detection and location tasks in the global cement dataset. The scanning results of the entire satellite image set in Shanghai indicate that the deep convolution network target detection method not only can detect most registered cement plants but also multiple unregistered cement plants. The method provides a reliable reference for monitoring environmental pollution sources. Furthermore, this model can be easily converted to detect other architectural targets using transfer learning techniques.关键词:high-resolution satellite image;target detection;convolutional neural network;deep learning;model optimization25|4|4更新时间:2024-05-07
摘要:ObjectiveThe problem of environmental pollution in China has become increasingly serious with the rapid development of society and economy. Creating a beautiful ecological environment is becoming an important issue in the current national planning. Environmental pollution problems affect the sustainable development of the country and society. As an important source of pollution, cement plants must be effectively counted and monitored. With the development of satellite remote sensing, high-resolution and good quality images become available. At the same time, deep learning has made great progress in the field of target detection, and many excellent deep convolutional network models, such as Faster R-CNN, YOLO, SSD, and Mask R-CNN, have been proposed recently. In the object detection task on satellite images, huge differences lie in the plant area scales, the structures of equipment composition, and the orientations of each cement plant. Thus, various cement plants are presented with various appearances due to the complex natural geographical surroundings. Overcoming the problem of cement plant target detection and recognition using traditional artificial image feature methods is difficult. However, deep learning has achieved excellent performance in the field of image target recognition. The application of the deep convolutional network may be a brilliant method to locate cement plants on satellite images.MethodA method of detecting and locating cement plant position using high-resolution satellite images was proposed based on the convolutional neural network of Faster R-CNN framework for image target detection. First, we used GoogleMap API to download Google Earth satellite images. We developed this high-resolution satellite image dataset of cement factory target using GoogleMap web API, which contains 464 cement plant locations, according to the Beijing-Tianjin-Hebei cement dataset given by the Satellite Environment Center, Ministry of Environmental protection. Through the training and testing datasets of the cement plant in Beijing-Tianjin-Hebei with three different feature extracting modules (namely, VGG(visual geometry group network), ZF, and ResNet), we compared the testing results among the three CNN models. Three methods, which include image haze removal using dark channel prior, data augmentation, and adding negative training samples, were introduced to solve the problems of overfitting and reduce high false positive rate because of insufficient amount of training data. We also verified the influence of different numbers of negative training samples on model training. We used these features to assist cement plant target detection, considering the characteristics of cement buildings with evident cylindrical cement tanks and heating reaction tower buildings.ResultThe visualized images of the convolutional feature map show that the identification of the deep convolution network for cement plant target detection is mainly based on special buildings in the plant area, such as cylindrical cement tanks, heating towers, and rectangular plants. The experimental results on the test set reveal that the ResNet achieves the best performance with the average accuracy rate of 74%. An optimization method by three methods is proposed to further enhance the detection of accurate rate and suppress the false positive rate. The precision of the promoted CNN model reached 94% in the augmented testing dataset, and the false positive rate was reduced to 14%. The true positive detection rate in the global cement plant dataset reached 96%, and the number of false detection of 10 000 random satellite images was reduced to 30 (0.3%). The actual cement plant target scan detection of the satellite images in the entire Shanghai area was conducted. To avoid dividing the cement plant into two image parts, we used the overlapping detection method, which also detected adjacent areas between satellite images. As a result, 11 out of 16 registered cement plants, and 17 unregistered cement plants are detected.ConclusionThe cement plant has special buildings of different shapes and background, even varying over time, thereby resulting in relatively difficult detection task. However, the method of cement plant detection on satellite images based on deep convolutional networks can automatically learn to extract effective features and can identify the position of the target in the image. In addition, some optimization methods, including image preprocessing, data augmentation, and adding negative samples to promote the performance of the model, are adopted to improve the model detection accuracy and solve the problem of few training data. The geographic latitude and longitude coordinates of cement targets are easy to obtain based on the result of the image object detection and its position information because the satellite image is geocoded. We can also estimate the cement plant area using information of detected boxes. In the model generalization capability test experiment, the proposed method achieves good performance in the detection and location tasks in the global cement dataset. The scanning results of the entire satellite image set in Shanghai indicate that the deep convolution network target detection method not only can detect most registered cement plants but also multiple unregistered cement plants. The method provides a reliable reference for monitoring environmental pollution sources. Furthermore, this model can be easily converted to detect other architectural targets using transfer learning techniques.关键词:high-resolution satellite image;target detection;convolutional neural network;deep learning;model optimization25|4|4更新时间:2024-05-07 -
 摘要:ObjectiveIn view of the increasing number and diversity of minority clothing in the domains of multimedia, digital clothing, graphics, and images, understanding and recognizing minority clothing images automatically is essential. However, most previous works have used low-level features directly for classification and recognition, there by lacking local feature analysis and semantic annotation of clothing. The diversity of clothing colors and styles results in low recognition accuracy of minority clothing. Therefore, a minority clothing recognition method based on human detection and multitask learning was proposed for Yunnan minority clothing.MethodThe main idea of this work is to propose the
摘要:ObjectiveIn view of the increasing number and diversity of minority clothing in the domains of multimedia, digital clothing, graphics, and images, understanding and recognizing minority clothing images automatically is essential. However, most previous works have used low-level features directly for classification and recognition, there by lacking local feature analysis and semantic annotation of clothing. The diversity of clothing colors and styles results in low recognition accuracy of minority clothing. Therefore, a minority clothing recognition method based on human detection and multitask learning was proposed for Yunnan minority clothing.MethodThe main idea of this work is to propose the$k$ $k$ 关键词:minority clothing;image recognition;human detection;semantic attributes;multi-task learning13|4|8更新时间:2024-05-07 -
 摘要:ObjectiveRapid and convenient product retrieval is the key for excellent user experience in online shopping. The application of keyword-based retrieval in commodity retrieval is ineffective because of problems, such as standardization of the description of goods and the differences in the understanding of the attributes of the goods by the users. In recent years, "search by image" has been increasingly used in e-commerce platforms. Retrieval technology is constantly improving, from text-based image retrieval to content-based image retrieval, and then to utilizing deep learning to achieve image retrieval. However, retrieval results are often unsatisfactory. These methods cannot rapidly and accurately retrieve results that satisfy people's expectations, thereby lacking excellent user experience. Therefore, a new method of commodity retrieval is proposed. From the features of the commodity design, the image feature is obtained using the complete picture information as well as the human cognition of the goods, which is introduced into the retrieval process of the commodity picture to obtain the desired results.MethodHuman cognition of commodities is a type of subconsciousness formed by human experience, which corresponds to the designers' norms. We can obtain results that are consistent with human cognitive retrieval results by studying the commodity design specifications and designing commodity features and then using these features for commodity retrieval. We select fashionable women's bags as the research object. Women's bags are a necessity and favorable to women; thus, bags have practical relevance to the study. Moreover, the design elements of women's bags are relatively independent and flexible. Thus, using traditional image retrieval methods is difficult to satisfy user's retrieval intentions. Therefore, studying similar searches of women's bags is necessary. The design features are decomposed into shape, color, and design element features based on the designers' specifications (such as tassel, chain, and zipper). A deep convolution neural network is used to construct classification models for the three features. The features of each picture are then extracted, and three feature sets are established for similarity comparison in retrieval. The shape, color, and design element picture sets are established to construct the feature models that correspond to shape, color, and local design elements, respectively. Each picture set must be marked in advance. The shape picture set is marked by 14 categories, including shell, Boston, and platinum bags. The color picture set is marked by 13 categories, including red, orange, and yellow. The design element picture set is marked by 11 categories, including strip closure, zipper decoration, and diamond grille. Adding a Hashing layer into the deep convolution neural network and extracting Hashing layer data as image features can provide feature binarization and simplify the calculation. At the same time, in the retrieval process, using the proposed Top3 within-class retrieval algorithm can reduce the algorithm complexity. Searching can be according to the classification features, namely, shape, color, and design elements, selected by users in real time. Thus, the retrieval results reflect the users' intention of commodity search. Given a picture of a fashion woman bag image to be retrieved, the corresponding classification model is called after the user selects the classification features. First, the classification of the image under a feature is recognized, and the image feature is then extracted. Subsequently, the Euclidean distance is calculated with all the images in Top3. Finally, the retrieval results are returned in order of similarity.ResultThe dataset is currently the only one dedicated to the search of fashionable women's bags. Notably, the design element picture set contains not only the overall picture of bags but also the segmented design element picture. The dataset and feature models are used for classification recognition and image retrieval experiments. Results show that the recognition accuracy of each model of the Top1 algorithm is less than 95%, whereas the recognition accuracy of the Top3 is more than 98.5%. Using Top3 within-class retrieval algorithm can speed up the retrieval and ensure the accuracy of the retrieval results as much as possible. At the same time, the use of Hashing method and Top3 within-class retrieval algorithm results in nearly 3.5 times faster retrieval speed and greatly improves the retrieval efficiency. When multiple features for commodity retrieval are used, the corresponding weights of color, shape, and design elements are 0.6, 0.2, and 0.2 respectively. These weights can be defined by the users in real time to reflect the changes of users' attention to different features during the retrieval process.ConclusionA method of commodity retrieval that is based on the commodity appearance design criterion and is combined with people's cognitive model, is proposed. In comparison with image-based retrieval tools, such as Taobao and Baidu, the retrieval results are more similar to the original image and more in line with people's expectations. At the same time, according to the user's preference, the proposed method can synthetically query according to single and multiple features, and the retrieval results are diversified. In addition, we use the global features of shape and color and the local feature of design elements to conduct a survey of online users' retrieval satisfaction. The survey results show that the user satisfaction of Taobao and Baidu pictures is similar. However, the user satisfaction of women's bag retrieval results obtained by the proposed method is remarkably higher than those of Taobao and Baidu pictures, which is more consistent with human cognition. The proposed method is suitable for the retrieval of fashionable women's bags and can be used for reference in the research of image-based retrieval methods for other goods. At present, for a given bag picture, the design elements are obtained by interactive manual segmentation in the process of similar bag retrieval. In future works, we can study the method of identifying the design elements of women's package to realize the automatic identification and segmentation of design elements, thereby improving the automation of women's package retrieval and the practical value of the proposed method.关键词:cognitive;design specification;online shopping;image retrieval;deep convolution neural network (DCNN);Hashing method13|4|0更新时间:2024-05-07
摘要:ObjectiveRapid and convenient product retrieval is the key for excellent user experience in online shopping. The application of keyword-based retrieval in commodity retrieval is ineffective because of problems, such as standardization of the description of goods and the differences in the understanding of the attributes of the goods by the users. In recent years, "search by image" has been increasingly used in e-commerce platforms. Retrieval technology is constantly improving, from text-based image retrieval to content-based image retrieval, and then to utilizing deep learning to achieve image retrieval. However, retrieval results are often unsatisfactory. These methods cannot rapidly and accurately retrieve results that satisfy people's expectations, thereby lacking excellent user experience. Therefore, a new method of commodity retrieval is proposed. From the features of the commodity design, the image feature is obtained using the complete picture information as well as the human cognition of the goods, which is introduced into the retrieval process of the commodity picture to obtain the desired results.MethodHuman cognition of commodities is a type of subconsciousness formed by human experience, which corresponds to the designers' norms. We can obtain results that are consistent with human cognitive retrieval results by studying the commodity design specifications and designing commodity features and then using these features for commodity retrieval. We select fashionable women's bags as the research object. Women's bags are a necessity and favorable to women; thus, bags have practical relevance to the study. Moreover, the design elements of women's bags are relatively independent and flexible. Thus, using traditional image retrieval methods is difficult to satisfy user's retrieval intentions. Therefore, studying similar searches of women's bags is necessary. The design features are decomposed into shape, color, and design element features based on the designers' specifications (such as tassel, chain, and zipper). A deep convolution neural network is used to construct classification models for the three features. The features of each picture are then extracted, and three feature sets are established for similarity comparison in retrieval. The shape, color, and design element picture sets are established to construct the feature models that correspond to shape, color, and local design elements, respectively. Each picture set must be marked in advance. The shape picture set is marked by 14 categories, including shell, Boston, and platinum bags. The color picture set is marked by 13 categories, including red, orange, and yellow. The design element picture set is marked by 11 categories, including strip closure, zipper decoration, and diamond grille. Adding a Hashing layer into the deep convolution neural network and extracting Hashing layer data as image features can provide feature binarization and simplify the calculation. At the same time, in the retrieval process, using the proposed Top3 within-class retrieval algorithm can reduce the algorithm complexity. Searching can be according to the classification features, namely, shape, color, and design elements, selected by users in real time. Thus, the retrieval results reflect the users' intention of commodity search. Given a picture of a fashion woman bag image to be retrieved, the corresponding classification model is called after the user selects the classification features. First, the classification of the image under a feature is recognized, and the image feature is then extracted. Subsequently, the Euclidean distance is calculated with all the images in Top3. Finally, the retrieval results are returned in order of similarity.ResultThe dataset is currently the only one dedicated to the search of fashionable women's bags. Notably, the design element picture set contains not only the overall picture of bags but also the segmented design element picture. The dataset and feature models are used for classification recognition and image retrieval experiments. Results show that the recognition accuracy of each model of the Top1 algorithm is less than 95%, whereas the recognition accuracy of the Top3 is more than 98.5%. Using Top3 within-class retrieval algorithm can speed up the retrieval and ensure the accuracy of the retrieval results as much as possible. At the same time, the use of Hashing method and Top3 within-class retrieval algorithm results in nearly 3.5 times faster retrieval speed and greatly improves the retrieval efficiency. When multiple features for commodity retrieval are used, the corresponding weights of color, shape, and design elements are 0.6, 0.2, and 0.2 respectively. These weights can be defined by the users in real time to reflect the changes of users' attention to different features during the retrieval process.ConclusionA method of commodity retrieval that is based on the commodity appearance design criterion and is combined with people's cognitive model, is proposed. In comparison with image-based retrieval tools, such as Taobao and Baidu, the retrieval results are more similar to the original image and more in line with people's expectations. At the same time, according to the user's preference, the proposed method can synthetically query according to single and multiple features, and the retrieval results are diversified. In addition, we use the global features of shape and color and the local feature of design elements to conduct a survey of online users' retrieval satisfaction. The survey results show that the user satisfaction of Taobao and Baidu pictures is similar. However, the user satisfaction of women's bag retrieval results obtained by the proposed method is remarkably higher than those of Taobao and Baidu pictures, which is more consistent with human cognition. The proposed method is suitable for the retrieval of fashionable women's bags and can be used for reference in the research of image-based retrieval methods for other goods. At present, for a given bag picture, the design elements are obtained by interactive manual segmentation in the process of similar bag retrieval. In future works, we can study the method of identifying the design elements of women's package to realize the automatic identification and segmentation of design elements, thereby improving the automation of women's package retrieval and the practical value of the proposed method.关键词:cognitive;design specification;online shopping;image retrieval;deep convolution neural network (DCNN);Hashing method13|4|0更新时间:2024-05-07
Image Analysis and Recognition

-
 摘要:ObjectiveThe advent of driverless cars has become a hot topic in today's society. Driverless aims to achieve a high degree of autonomous driving behavior through environmental awareness, such as in starting, braking, lane line tracking, lane changing, collision avoidance, and parking. Image segmentation of road scenes plays an important role in this technology. Studying the manner in which complex scenes and high-efficiency scene segmentation images in the environment of severe noise interference are achieved is essential. Traditional road segmentation generally uses a binocular stereo vision map and a motion indicator-based approach. For example, some researchers proposed a pedestrian detection based on binocular stereo vision and SVM(support vector machine) algorithm and used threshold segmentation to determine the coordinate position of a moving target. For the diversity of motion indicators, other researchers used the projection surface direction and object. Multiple motion indicators, such as altitude and feature tracking density, segment the road. However, these methods have high requirements on computing resources. For the current unmanned practicality requirements, a concise and resource-intensive method is required. Since 2012, deep learning has been gradually introduced into road scene segmentation. A scholar proposed a smart car steering study based on end-to-end depth learning and obtained good road feature coding through pretraining self-encoding. In recent years, AI technology has suddenly caught the interest of scholars. Computer GPU parallel operation, computational acceleration, storage space compression, and other technologies are studied and developed. Large amount of data and calculation are no longer restricted. Convolutional neural network (CNN) has become a research hotspot and has been widely used. Some researchers studied the deep learning algorithm of CNN to learn high-order features in a scene to achieve road scene segmentation. However, to some extent, although the computational strength is reduced, some problems of over-segmentation of complex scenes. Other researchers proposed the feature automatic extraction capability of deep structure using deep CNN for complex scene problems; it is a method of feature self-encoder versus feature similarity metric in source-target scenarios. However, these algorithms do not achieve the desired results for road marking, vehicle, and pedestrian segmentation accuracy. During rainy days, snowy days, and high-temperature weather, road surface often appears to be divided. With the continuous introduction of autonomous driving technology, the study of road scene segmentation algorithms in machine vision has become crucial. Most researchers in the traditional methods use machine learning to segment thresholds. The introduction of deep learning in recent years has caused the wide usage of neural network in this field.MethodA road scene combining KSW(key seat wiper) and full CNN (FCNN) is proposed to address the problem of the traditional threshold segmentation method in terms of difficulty in extracting the road image threshold under multiple scenes and the training of data directly by deep neural network causing over-segmentation. The segmentation method, which combines the KSW entropy method and genetic algorithm, uses depth learning to extract features in different scenarios and applies it to the road segmentation of unmanned technology. First, the original test image of the road scene is converted into gray image, and the filtering effect is achieved by KSW genetic algorithm two-dimensional threshold segmentation; thus, the road water, road standard line, trees, and other scenes are clear in the image, and the preprocessing training set is obtained. Import pre-trained datasets into the FCNN framework After tens of thousands of training iterations, it learns and amends the weights, thereby resulting in an effective training model. Finally, the training model can be used to implement any road scene graph segmentation.ResultExperimental results show that the segmentation accuracy of the sky and trees reached 91.3% and 94.3% in the KITTI dataset, respectively, and the segmentation progress of roads, vehicles, and pedestrians increased by approximately 2%. In comparison with the previous super parsing and boosting algorithms, the proposed algorithm can distinguish road segmentation lines and increase the segmentation accuracy of trees, vehicles, and pedestrians by approximately 20%. Comparing with the result of SegNet and ResNet depth networks, in the environment of roads and trees. The segmentation accuracy of road segmentation lines is relatively improved by approximately 5%. In comparison with the original image, the KSW two-dimensional threshold and genetic algorithm filter out the excessively bright part of the sun on the road and the overly bright part of the sky to prevent over-segmentation of the segmented image.ConclusionSegmentation result shows that the over-segmentation of water accumulation and mud on the road has been remarkably improved. In comparison with the traditional machine learning road scene segmentation method, the proposed method improves the segmentation accuracy to a certain extent. In comparison with the depth learning method, the proposed method is directly applied to the road scene segmentation. This method avoids the over-segmentation phenomenon to some extent and improves the model robustness. In summary, the proposed road scene segmentation algorithm combined with KSW and FCNN has broad research prospects and is expected to be applied to the processing of medical and remote sensing images.关键词:image segmentation;road segmentation;full convolution neural network;deep learning;genetic algorithm30|39|1更新时间:2024-05-07
摘要:ObjectiveThe advent of driverless cars has become a hot topic in today's society. Driverless aims to achieve a high degree of autonomous driving behavior through environmental awareness, such as in starting, braking, lane line tracking, lane changing, collision avoidance, and parking. Image segmentation of road scenes plays an important role in this technology. Studying the manner in which complex scenes and high-efficiency scene segmentation images in the environment of severe noise interference are achieved is essential. Traditional road segmentation generally uses a binocular stereo vision map and a motion indicator-based approach. For example, some researchers proposed a pedestrian detection based on binocular stereo vision and SVM(support vector machine) algorithm and used threshold segmentation to determine the coordinate position of a moving target. For the diversity of motion indicators, other researchers used the projection surface direction and object. Multiple motion indicators, such as altitude and feature tracking density, segment the road. However, these methods have high requirements on computing resources. For the current unmanned practicality requirements, a concise and resource-intensive method is required. Since 2012, deep learning has been gradually introduced into road scene segmentation. A scholar proposed a smart car steering study based on end-to-end depth learning and obtained good road feature coding through pretraining self-encoding. In recent years, AI technology has suddenly caught the interest of scholars. Computer GPU parallel operation, computational acceleration, storage space compression, and other technologies are studied and developed. Large amount of data and calculation are no longer restricted. Convolutional neural network (CNN) has become a research hotspot and has been widely used. Some researchers studied the deep learning algorithm of CNN to learn high-order features in a scene to achieve road scene segmentation. However, to some extent, although the computational strength is reduced, some problems of over-segmentation of complex scenes. Other researchers proposed the feature automatic extraction capability of deep structure using deep CNN for complex scene problems; it is a method of feature self-encoder versus feature similarity metric in source-target scenarios. However, these algorithms do not achieve the desired results for road marking, vehicle, and pedestrian segmentation accuracy. During rainy days, snowy days, and high-temperature weather, road surface often appears to be divided. With the continuous introduction of autonomous driving technology, the study of road scene segmentation algorithms in machine vision has become crucial. Most researchers in the traditional methods use machine learning to segment thresholds. The introduction of deep learning in recent years has caused the wide usage of neural network in this field.MethodA road scene combining KSW(key seat wiper) and full CNN (FCNN) is proposed to address the problem of the traditional threshold segmentation method in terms of difficulty in extracting the road image threshold under multiple scenes and the training of data directly by deep neural network causing over-segmentation. The segmentation method, which combines the KSW entropy method and genetic algorithm, uses depth learning to extract features in different scenarios and applies it to the road segmentation of unmanned technology. First, the original test image of the road scene is converted into gray image, and the filtering effect is achieved by KSW genetic algorithm two-dimensional threshold segmentation; thus, the road water, road standard line, trees, and other scenes are clear in the image, and the preprocessing training set is obtained. Import pre-trained datasets into the FCNN framework After tens of thousands of training iterations, it learns and amends the weights, thereby resulting in an effective training model. Finally, the training model can be used to implement any road scene graph segmentation.ResultExperimental results show that the segmentation accuracy of the sky and trees reached 91.3% and 94.3% in the KITTI dataset, respectively, and the segmentation progress of roads, vehicles, and pedestrians increased by approximately 2%. In comparison with the previous super parsing and boosting algorithms, the proposed algorithm can distinguish road segmentation lines and increase the segmentation accuracy of trees, vehicles, and pedestrians by approximately 20%. Comparing with the result of SegNet and ResNet depth networks, in the environment of roads and trees. The segmentation accuracy of road segmentation lines is relatively improved by approximately 5%. In comparison with the original image, the KSW two-dimensional threshold and genetic algorithm filter out the excessively bright part of the sun on the road and the overly bright part of the sky to prevent over-segmentation of the segmented image.ConclusionSegmentation result shows that the over-segmentation of water accumulation and mud on the road has been remarkably improved. In comparison with the traditional machine learning road scene segmentation method, the proposed method improves the segmentation accuracy to a certain extent. In comparison with the depth learning method, the proposed method is directly applied to the road scene segmentation. This method avoids the over-segmentation phenomenon to some extent and improves the model robustness. In summary, the proposed road scene segmentation algorithm combined with KSW and FCNN has broad research prospects and is expected to be applied to the processing of medical and remote sensing images.关键词:image segmentation;road segmentation;full convolution neural network;deep learning;genetic algorithm30|39|1更新时间:2024-05-07
Image Anaiysis and Recognition
-
 摘要:ObjectiveFace aging/processing aims to render face information with or without the age information but still preserve personalized features of the face. It has considerable influence to a wide range of applications, such as face prediction of wanted/missing person, age-invariant verification, and entertainment. Our background modeling is based on the conditional adversarial autoencoder (CAAE) model proposed by Zhang et al. In the CAAE network, the face is initially mapped to a latent vector through a convolutional encoder, and the vector is then projected to the face manifold condition on age through a deconvolutional generator. The latent vector preserves personalized face features, and the age condition controls aging/processing. The generated images from CAAE networks is more believable than the those from traditional face aging/processing approaches, and the CAAE model reduces the demand of data for training. However, face aging/processing still has many challenges, such as low resolution and artificial ghost. Therefore, we proposed a high-quality image generation model (HQGM) for face aging/processing to enrich the texture and face feature information. MethodHQGM is based on CAAE model, where two generative adversarial networks (GANs) are imposed on the encoder and generator. HQGM only adds a GAN on the generator and replaces the GAN with the boundary equilibrium GAN (BEGAN). BEGAN is one of the best face generation models, and its discriminator is an autoencoder. Two loss functions are imposed on the encoder and generator, that is, the image gradient loss function and the face feature loss function using the VGG-FACE model. The VGG-FACE model is used as a face feature extractor. The image gradient loss function aims to reduce the image gradient difference between the input and generated images. The face feature loss function aims to reduce the difference between the face feature information of the input images and that of the generated images. We place the input and generated images into the VGG-FACE model to obtain the face feature information. HQGM has one encoder, one decoder (generator), and one discriminator. An encoder E maps the input face to a vector z. Concatenating the label l (age) to z, the new latent vector[z, l] is fed to a generator G. The encoder and generator are updated based on the L2, image gradient, face feature, and BEGAN losses. The discriminator forces the output face to become photorealistic and plausible for a given age label. The generator and discriminator are trained alternatingly until the loss imposed on the generator has good convergence. In practice, only the encoder and generator are used to generate the target age face. ResultUTKface, FGnet, and Morph datasets are used in the experiment. Approximately 21 000 faces and corresponding labels are used to train the network. During testing, four groups of contrast experiments include image gradient loss/no image gradient loss, face feature loss/no face feature loss, BEGAN loss/no BEGAN loss, and HQGM/CAAE model. The comparison tests use two methods; one is to contrast the effect of the generated images by observing with the naked eye, and the other is to contrast the quality of the generated images by the assessment criteria. PSNR and SSIM are adopted as the assessment criteria. The comparative result shows that the BEGAN, image gradient, and face feature losses can generate higher-quality images. Moreover, the generated images show that using the face feature loss function can reduce the noise, which causes twisted organs. When comparing the HQGM network with the CAAE network, the numerical value of the PSNR computed by the generated images of HQGM is greater than that computed by the generated images of the CAAE network at approximately 3.2; the numerical value of SSIM computed by the generated images of HQGM is greater than that computed by the generated image of the CAAE network at approximately 0.06; and the generated images from HQGM that removed the artificial ghost become more believable than that from the CAAE network. Experimental results demonstrate the appealing performance and flexibility of the proposed framework by comparing with some state-of-the-art works. ConclusionIn comparison with GAN, the generated images from BEGAN have more texture information and better visual effect. The generated images have more high-frequency information, such as profile information using the image gradient loss function. The generated images have more texture information and more face feature information using the face feature loss function. More face feature information can reduce the artificial ghost of the generated images. In summary, the generated images from our HQGM have more texture information and more face feature information. In the future work, the proposed method will be improved and optimized by using the new structure of network or some new loss functions.关键词:face aging/processing;deep learning;boundary equilibrium generative adversarial network;face feature;texture;VGG-FACE network27|202|4更新时间:2024-05-07
摘要:ObjectiveFace aging/processing aims to render face information with or without the age information but still preserve personalized features of the face. It has considerable influence to a wide range of applications, such as face prediction of wanted/missing person, age-invariant verification, and entertainment. Our background modeling is based on the conditional adversarial autoencoder (CAAE) model proposed by Zhang et al. In the CAAE network, the face is initially mapped to a latent vector through a convolutional encoder, and the vector is then projected to the face manifold condition on age through a deconvolutional generator. The latent vector preserves personalized face features, and the age condition controls aging/processing. The generated images from CAAE networks is more believable than the those from traditional face aging/processing approaches, and the CAAE model reduces the demand of data for training. However, face aging/processing still has many challenges, such as low resolution and artificial ghost. Therefore, we proposed a high-quality image generation model (HQGM) for face aging/processing to enrich the texture and face feature information. MethodHQGM is based on CAAE model, where two generative adversarial networks (GANs) are imposed on the encoder and generator. HQGM only adds a GAN on the generator and replaces the GAN with the boundary equilibrium GAN (BEGAN). BEGAN is one of the best face generation models, and its discriminator is an autoencoder. Two loss functions are imposed on the encoder and generator, that is, the image gradient loss function and the face feature loss function using the VGG-FACE model. The VGG-FACE model is used as a face feature extractor. The image gradient loss function aims to reduce the image gradient difference between the input and generated images. The face feature loss function aims to reduce the difference between the face feature information of the input images and that of the generated images. We place the input and generated images into the VGG-FACE model to obtain the face feature information. HQGM has one encoder, one decoder (generator), and one discriminator. An encoder E maps the input face to a vector z. Concatenating the label l (age) to z, the new latent vector[z, l] is fed to a generator G. The encoder and generator are updated based on the L2, image gradient, face feature, and BEGAN losses. The discriminator forces the output face to become photorealistic and plausible for a given age label. The generator and discriminator are trained alternatingly until the loss imposed on the generator has good convergence. In practice, only the encoder and generator are used to generate the target age face. ResultUTKface, FGnet, and Morph datasets are used in the experiment. Approximately 21 000 faces and corresponding labels are used to train the network. During testing, four groups of contrast experiments include image gradient loss/no image gradient loss, face feature loss/no face feature loss, BEGAN loss/no BEGAN loss, and HQGM/CAAE model. The comparison tests use two methods; one is to contrast the effect of the generated images by observing with the naked eye, and the other is to contrast the quality of the generated images by the assessment criteria. PSNR and SSIM are adopted as the assessment criteria. The comparative result shows that the BEGAN, image gradient, and face feature losses can generate higher-quality images. Moreover, the generated images show that using the face feature loss function can reduce the noise, which causes twisted organs. When comparing the HQGM network with the CAAE network, the numerical value of the PSNR computed by the generated images of HQGM is greater than that computed by the generated images of the CAAE network at approximately 3.2; the numerical value of SSIM computed by the generated images of HQGM is greater than that computed by the generated image of the CAAE network at approximately 0.06; and the generated images from HQGM that removed the artificial ghost become more believable than that from the CAAE network. Experimental results demonstrate the appealing performance and flexibility of the proposed framework by comparing with some state-of-the-art works. ConclusionIn comparison with GAN, the generated images from BEGAN have more texture information and better visual effect. The generated images have more high-frequency information, such as profile information using the image gradient loss function. The generated images have more texture information and more face feature information using the face feature loss function. More face feature information can reduce the artificial ghost of the generated images. In summary, the generated images from our HQGM have more texture information and more face feature information. In the future work, the proposed method will be improved and optimized by using the new structure of network or some new loss functions.关键词:face aging/processing;deep learning;boundary equilibrium generative adversarial network;face feature;texture;VGG-FACE network27|202|4更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveAs a research hotspot in computer vision, 3D scene reconstruction technique has been widely used in many fields, such as unmanned driving, digital entertainment, aeronautics, and astronautics. Traditional scene reconstruction methods iteratively estimate the camera pose and 3D scene models sparsely or densely on the basis of image sequences from multiple views by structure from motion. However, the large motion between cameras usually leads to occlusion and geometric deformation, which often appears in actual applications and will significantly increase the difficulty of image matching. Most previous works, including sparse and dense reconstructions, are only effective in narrow baseline environments, and wide-baseline 3D reconstruction is a considerably more difficult problem. This problem often exists in many applications, such robot navigation, aerial map building, and augmented reality, and is valuable for research. In recent years, several semantic fusion-based solutions have been proposed and have become the developing trends because these methods are more consistent with human cognition of the scene.MethodA novel wide-baseline dense 3D scene reconstruction algorithm, which integrates the attribute of an outdoor structural scene and high-level semantic prior, is proposed. Our algorithm has the following characteristics. 1) Superpixel, which is larger than the pixel in the area, is used as a geometric primitive for image representation with the following advantages. First, it increases the robustness of region correlation in weak-texture environments. Second, it describes the actual boundary of the objects in the scene and the discontinuity of the depth. Third, it reduces the number of graph nodes in Markov random field (MRF) model, thereby resulting in remarkable reduction of computational complexity when solving an energy minimization problem. 2) An MRF model is utilized to estimate the 3D position and orientation of each superpixel in different view images on the basis of multiple low-level features. In our MRF energy function, the unary potential models the planar parameter of each superpixel and uses the relational error of estimated and ground truth depths for penalty. The pairwise potential models three geometric relations, namely, co-linearity, connectivity, and co-planarity between adjacent superpixels. In addition, a new potential is added to model the relational error between the triangulated and estimated depths. 3) The depth and 3D model of the scene are progressively optimized through superpixel merging with similar depths according to high-level semantic priors in our iterative type framework. When the adjacent superpixels have similar depths, they are merged, and a larger superpixel is generated, thereby reducing the possibility of depth discontinuity further. The segmentation image after superpixel merging is used in the next iteration for MRF-based depth estimation. The MAP inference of our MRF model can be efficiently solved by the classic linear programming.ResultWe use several classic wide-baseline image sequences, such as "Stanford Ⅰ, Ⅱ, Ⅲ, and Ⅳ", "Merton College Ⅲ", "University Library", and "Wadham College" to evaluate the performance of our wide-baseline 3D scene reconstruction algorithm. Experimental results demonstrate that our algorithm can estimate the large camera motion more accurately than the classic method and can recover more robust and accurate depth estimation and 3D scene models. Our algorithm can work effectively in the narrow- and wide-baseline environments and are especially suitable for large-scale scene reconstruction.ConclusionThis study shows how to recover an accurate 3D scene model based on multiple image features and triangulated geometric features in wide-baseline environments. We use an MRF model to estimate the planar parameter of superpixel in different views, and high-level semantic prior is integrated to guide the superpixel merging with similar depths. Furthermore, an iterative framework is proposed to optimize the depth of the scene and the 3D scene model progressively. Experimental results show that our proposed algorithm can achieve more accurate 3D scene model than the classic algorithm in different wide-baseline image datasets.关键词:wide-baseline matching;dense 3D scene reconstruction;high-level semantic prior;superpixel merging;progressive optimization13|4|2更新时间:2024-05-07
摘要:ObjectiveAs a research hotspot in computer vision, 3D scene reconstruction technique has been widely used in many fields, such as unmanned driving, digital entertainment, aeronautics, and astronautics. Traditional scene reconstruction methods iteratively estimate the camera pose and 3D scene models sparsely or densely on the basis of image sequences from multiple views by structure from motion. However, the large motion between cameras usually leads to occlusion and geometric deformation, which often appears in actual applications and will significantly increase the difficulty of image matching. Most previous works, including sparse and dense reconstructions, are only effective in narrow baseline environments, and wide-baseline 3D reconstruction is a considerably more difficult problem. This problem often exists in many applications, such robot navigation, aerial map building, and augmented reality, and is valuable for research. In recent years, several semantic fusion-based solutions have been proposed and have become the developing trends because these methods are more consistent with human cognition of the scene.MethodA novel wide-baseline dense 3D scene reconstruction algorithm, which integrates the attribute of an outdoor structural scene and high-level semantic prior, is proposed. Our algorithm has the following characteristics. 1) Superpixel, which is larger than the pixel in the area, is used as a geometric primitive for image representation with the following advantages. First, it increases the robustness of region correlation in weak-texture environments. Second, it describes the actual boundary of the objects in the scene and the discontinuity of the depth. Third, it reduces the number of graph nodes in Markov random field (MRF) model, thereby resulting in remarkable reduction of computational complexity when solving an energy minimization problem. 2) An MRF model is utilized to estimate the 3D position and orientation of each superpixel in different view images on the basis of multiple low-level features. In our MRF energy function, the unary potential models the planar parameter of each superpixel and uses the relational error of estimated and ground truth depths for penalty. The pairwise potential models three geometric relations, namely, co-linearity, connectivity, and co-planarity between adjacent superpixels. In addition, a new potential is added to model the relational error between the triangulated and estimated depths. 3) The depth and 3D model of the scene are progressively optimized through superpixel merging with similar depths according to high-level semantic priors in our iterative type framework. When the adjacent superpixels have similar depths, they are merged, and a larger superpixel is generated, thereby reducing the possibility of depth discontinuity further. The segmentation image after superpixel merging is used in the next iteration for MRF-based depth estimation. The MAP inference of our MRF model can be efficiently solved by the classic linear programming.ResultWe use several classic wide-baseline image sequences, such as "Stanford Ⅰ, Ⅱ, Ⅲ, and Ⅳ", "Merton College Ⅲ", "University Library", and "Wadham College" to evaluate the performance of our wide-baseline 3D scene reconstruction algorithm. Experimental results demonstrate that our algorithm can estimate the large camera motion more accurately than the classic method and can recover more robust and accurate depth estimation and 3D scene models. Our algorithm can work effectively in the narrow- and wide-baseline environments and are especially suitable for large-scale scene reconstruction.ConclusionThis study shows how to recover an accurate 3D scene model based on multiple image features and triangulated geometric features in wide-baseline environments. We use an MRF model to estimate the planar parameter of superpixel in different views, and high-level semantic prior is integrated to guide the superpixel merging with similar depths. Furthermore, an iterative framework is proposed to optimize the depth of the scene and the 3D scene model progressively. Experimental results show that our proposed algorithm can achieve more accurate 3D scene model than the classic algorithm in different wide-baseline image datasets.关键词:wide-baseline matching;dense 3D scene reconstruction;high-level semantic prior;superpixel merging;progressive optimization13|4|2更新时间:2024-05-07 -
 摘要:ObjectiveThe construction of basis functions has consistently been a difficult point of computer-aided geometric design (CAGD). The construction of a class of practical basis functions often plays a decisive role in the development of the geometric industry. The traditional Bézier curves and B-splines have been widely used in CAGD. However, when the control points are determined, the generated curve is relatively fixed with respect to the control points and has a certain rigidity. Although the proposed rational B-spline curve can adjust the curve by adjusting the weight factor, the rational methods have difficulty in predicting the influence of the weight factor on the curve due to its own shortcomings. Researchers have exerted efforts in the past two decades to solve this problem. However, most of the improved methods have the basic properties of the traditional Bézier method and the B-spline method, such as affine invariance, convex hull, non-negativity, geometric invariance and flexible shape adjustability. Moreover, the proposed curve can accurately represent special curves used in engineering, such as conic and hyperbolic curves. However, most of the literature does not discuss the variation diminishing the generated curve. The curve with vanishing variation must have convexity. The curve with the total positivity must have diminishing variation. Therefore, the total positivity of the basis functions indicates that these functions are suitable for geometric design. We can easily obtain rectangular patches with shape parameters through these new curves. However, the Bernstein-Bézier patch over the triangular domain is not a tensor product patch exactly. Therefore, we cannot obtain triangular surfaces with an adjustable shape using the method of tensor product. Surface modeling over triangular domain is important for many applications. Thus, the practical methods for generating surfaces over a triangular domain must be explored. The blossom property in quasi extended Chebyshev space is used to construct a group of optimal normalized entirely positive basis for curve and surface construction. This method enables the extended curve and surface, thereby maintaining the good nature of the traditional Bézier and B-spline methods while preserving shape, shape adjustability, and practicability.MethodA class of cubic trigonometric quasi Bernstein basis functions with total positivity is constructed under the framework of the extended Chebyshev space, and the properties of the basis functions are provided. The corresponding curve is presented based on this basis function. The properties of the curve are analyzed. The cutting algorithm of the curve and the smooth connecting conditions are obtained. A trigonometric quasi Bernstein operator for estimating the degree of the control polygon is also proposed. Then, based on the cubic trigonometric quasi Bernstein basis function, a class of trigonometric polynomial basis functions with three shape parameters over the triangular domain is proposed. A type of triangular polynomial patch over the triangular domain is proposed based on this basis functions. This patch can be used to construct patches whose boundaries are elliptical arcs, parabolic arcs, and arcs. A practical de-Casteljau-type algorithm is proposed to calculate the proposed triangular polynomial surface efficiently and stably. In addition, G1 continuous conditions for joining two triangular polynomial patches are provided.ResultExperimental results show that the proposed total positivity patch in the frame of Chebyshev space not only can adjust the shape flexibly but also has shape preservation and good approximation.ConclusionWe construct a class of basis functions with total positivity under the framework of the extended Chebysh ev space, and construct the curve and surface with this basis function. Experimental results show that the curve constructed in this study has all the excellent properties of a traditional cubic Bézier curve and has flexible shape adjustability. As the parameters increase, the generated curve can be closer to the control polygon, thereby simulating its behavior. In addition, the surface constructed on the triangular domain can generate the surface whose boundaries are elliptical arcs. A de Casteljau-type algorithm for calculating the surface is also provided. In summary, the proposed basis function satisfies the requirements of the geometric industry and is a practical method.关键词:quasi extended Chebyshev space;totally positivity;corner cutting algorithm;triangular patch;de-Casteljau-type algorithm13|4|1更新时间:2024-05-07
摘要:ObjectiveThe construction of basis functions has consistently been a difficult point of computer-aided geometric design (CAGD). The construction of a class of practical basis functions often plays a decisive role in the development of the geometric industry. The traditional Bézier curves and B-splines have been widely used in CAGD. However, when the control points are determined, the generated curve is relatively fixed with respect to the control points and has a certain rigidity. Although the proposed rational B-spline curve can adjust the curve by adjusting the weight factor, the rational methods have difficulty in predicting the influence of the weight factor on the curve due to its own shortcomings. Researchers have exerted efforts in the past two decades to solve this problem. However, most of the improved methods have the basic properties of the traditional Bézier method and the B-spline method, such as affine invariance, convex hull, non-negativity, geometric invariance and flexible shape adjustability. Moreover, the proposed curve can accurately represent special curves used in engineering, such as conic and hyperbolic curves. However, most of the literature does not discuss the variation diminishing the generated curve. The curve with vanishing variation must have convexity. The curve with the total positivity must have diminishing variation. Therefore, the total positivity of the basis functions indicates that these functions are suitable for geometric design. We can easily obtain rectangular patches with shape parameters through these new curves. However, the Bernstein-Bézier patch over the triangular domain is not a tensor product patch exactly. Therefore, we cannot obtain triangular surfaces with an adjustable shape using the method of tensor product. Surface modeling over triangular domain is important for many applications. Thus, the practical methods for generating surfaces over a triangular domain must be explored. The blossom property in quasi extended Chebyshev space is used to construct a group of optimal normalized entirely positive basis for curve and surface construction. This method enables the extended curve and surface, thereby maintaining the good nature of the traditional Bézier and B-spline methods while preserving shape, shape adjustability, and practicability.MethodA class of cubic trigonometric quasi Bernstein basis functions with total positivity is constructed under the framework of the extended Chebyshev space, and the properties of the basis functions are provided. The corresponding curve is presented based on this basis function. The properties of the curve are analyzed. The cutting algorithm of the curve and the smooth connecting conditions are obtained. A trigonometric quasi Bernstein operator for estimating the degree of the control polygon is also proposed. Then, based on the cubic trigonometric quasi Bernstein basis function, a class of trigonometric polynomial basis functions with three shape parameters over the triangular domain is proposed. A type of triangular polynomial patch over the triangular domain is proposed based on this basis functions. This patch can be used to construct patches whose boundaries are elliptical arcs, parabolic arcs, and arcs. A practical de-Casteljau-type algorithm is proposed to calculate the proposed triangular polynomial surface efficiently and stably. In addition, G1 continuous conditions for joining two triangular polynomial patches are provided.ResultExperimental results show that the proposed total positivity patch in the frame of Chebyshev space not only can adjust the shape flexibly but also has shape preservation and good approximation.ConclusionWe construct a class of basis functions with total positivity under the framework of the extended Chebysh ev space, and construct the curve and surface with this basis function. Experimental results show that the curve constructed in this study has all the excellent properties of a traditional cubic Bézier curve and has flexible shape adjustability. As the parameters increase, the generated curve can be closer to the control polygon, thereby simulating its behavior. In addition, the surface constructed on the triangular domain can generate the surface whose boundaries are elliptical arcs. A de Casteljau-type algorithm for calculating the surface is also provided. In summary, the proposed basis function satisfies the requirements of the geometric industry and is a practical method.关键词:quasi extended Chebyshev space;totally positivity;corner cutting algorithm;triangular patch;de-Casteljau-type algorithm13|4|1更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveHyperspectral remote sensing has become a promising research field and is applied to various aspects. Thus, hyperspectral image classification has become the key part of hyperspectral image processing. The important trait of hyperspectral images is the excessive number of bands, which results in the phenomenon of "the curse of the dimension" in their interpretation and classification. Utilizing this band information fully in the classification of hyperspectral images is difficult. K-means algorithm is the most classical clustering algorithm, which is widely used for image classification. The general idea of K-means algorithm is to treat every feature as equally important. However, when the K-means algorithm is used for the classification of hyperspectral images, every band is regarded as a feature, which leads to the difficulty in feature utilization and poor classification results. To solve this problem, the idea of feature weighting is introduced. Therefore, this study proposes a hyperspectral image classification algorithm based on entropy weighted K-means by considering global information.MethodThe proposed hyperspectral image classification method is based on the K-means clustering algorithm and considers them to indicate the importance of every band to different clusters and the inter-cluster information. Feature weighting is used to distinguish the importance of every band to different clusters, as described by the band weight. In statistics, entropy represents the degree of uncertainty of information. Thus, entropy information measurement is defined to express the weight distribution. In hyperspectral image classification, the distance between classes greatly influences the clustering results. The distance measurement of inter-cluster information is introduced to realize the global optimal clustering to avoid the local optimal clustering and obtain more accurate results. These two types of measurements are introduced into the K-means clustering objective function, and the optimal classification results are obtained by minimizing the objective function.ResultClassification experiments are conducted using the proposed algorithm and K-means algorithm on Salinas and Pavia University hyperspectral images, respectively, to verify the proposed hyperspectral image classification method effectively. The ground objects in the standard images of Salinas and Pavia University are merged on the basis of the difference in the degree of spectral reflectance, and the combined standard images are considered the standard classification information. The classification results demonstrate that the proposed algorithm can effectively obtain better results than K-means algorithm. The overall accuracy and Kappa coefficient are calculated from a confusion matrix and compared with K-means algorithm to evaluate the proposed algorithm quantitatively. The overall accuracy of the algorithm is 92.20% and 82.96%, indicating 8.81% and 15.9% improvement compared with the K-means algorithm. The accuracy values demonstrate that the proposed algorithm can achieve more precise classification results than K-means algorithm.ConclusionThis study proposes a hyperspectral image classification method that connects the traditional K-means algorithm with the idea of feature weighting and the inter-cluster information. Experimental results show that this approach is promising and effective and can achieve excellent classification results for all types of ground objects in hyperspectral images with large spectral reflectance differences. In future research, the similarity between features and the spatial information must be improved.关键词:feature weighting;entropy information;inter-cluster information;K-means;hyperspectral image;classification13|5|6更新时间:2024-05-07
摘要:ObjectiveHyperspectral remote sensing has become a promising research field and is applied to various aspects. Thus, hyperspectral image classification has become the key part of hyperspectral image processing. The important trait of hyperspectral images is the excessive number of bands, which results in the phenomenon of "the curse of the dimension" in their interpretation and classification. Utilizing this band information fully in the classification of hyperspectral images is difficult. K-means algorithm is the most classical clustering algorithm, which is widely used for image classification. The general idea of K-means algorithm is to treat every feature as equally important. However, when the K-means algorithm is used for the classification of hyperspectral images, every band is regarded as a feature, which leads to the difficulty in feature utilization and poor classification results. To solve this problem, the idea of feature weighting is introduced. Therefore, this study proposes a hyperspectral image classification algorithm based on entropy weighted K-means by considering global information.MethodThe proposed hyperspectral image classification method is based on the K-means clustering algorithm and considers them to indicate the importance of every band to different clusters and the inter-cluster information. Feature weighting is used to distinguish the importance of every band to different clusters, as described by the band weight. In statistics, entropy represents the degree of uncertainty of information. Thus, entropy information measurement is defined to express the weight distribution. In hyperspectral image classification, the distance between classes greatly influences the clustering results. The distance measurement of inter-cluster information is introduced to realize the global optimal clustering to avoid the local optimal clustering and obtain more accurate results. These two types of measurements are introduced into the K-means clustering objective function, and the optimal classification results are obtained by minimizing the objective function.ResultClassification experiments are conducted using the proposed algorithm and K-means algorithm on Salinas and Pavia University hyperspectral images, respectively, to verify the proposed hyperspectral image classification method effectively. The ground objects in the standard images of Salinas and Pavia University are merged on the basis of the difference in the degree of spectral reflectance, and the combined standard images are considered the standard classification information. The classification results demonstrate that the proposed algorithm can effectively obtain better results than K-means algorithm. The overall accuracy and Kappa coefficient are calculated from a confusion matrix and compared with K-means algorithm to evaluate the proposed algorithm quantitatively. The overall accuracy of the algorithm is 92.20% and 82.96%, indicating 8.81% and 15.9% improvement compared with the K-means algorithm. The accuracy values demonstrate that the proposed algorithm can achieve more precise classification results than K-means algorithm.ConclusionThis study proposes a hyperspectral image classification method that connects the traditional K-means algorithm with the idea of feature weighting and the inter-cluster information. Experimental results show that this approach is promising and effective and can achieve excellent classification results for all types of ground objects in hyperspectral images with large spectral reflectance differences. In future research, the similarity between features and the spatial information must be improved.关键词:feature weighting;entropy information;inter-cluster information;K-means;hyperspectral image;classification13|5|6更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral remote sensing image data are rich in spatial and spectral information. Continuous spectral segment information enhances the capability to distinguish between ground objects. This information has been widely used in the fields of image classification, target detection, agricultural monitoring, and environmental management. However, the data structure of hyperspectral remote sensing image is highly nonlinear due to the high-dimensional characteristics of the signal, information redundancy, and multiple uncertainties. Some classification models based on statistical patterns are difficult to classify and recognize original hyperspectral data directly. Training samples for supervised learning are extremely limited. A Hughes phenomenon occurs for a limited number of training samples, that is, the classification accuracy decreases as feature dimension increases. The traditional pixel-level hyperspectral remote sensing image classification method mostly adopts the framework of feature extraction and classifier. In the feature extraction, a series of spectral feature dimension reduction methods is proposed for the high spectral characteristics of hyperspectral data. However, these methods cannot solve the nonlinear problem of hyperspectral data. Some methods only use spectral information, which will greatly neglect the rich spatial structural information of high-resolution images. Classification results often have many discrete isolated points, and the classification accuracy is greatly reduced. Therefore, introducing spatial information is necessary. In recent years, image classification based on deep learning has become a research hotspot. In comparison with the traditional artificial design features, it can automatically extract the abstract features from the bottom to the high-level semantics and convert the images into easily recognizable advanced features. At present, mainstream methods include the use of image input 2D-CNN(2D convolutional neural network) after PCA(principal component analysis) dimensionality reduction and fusion with spectral information in the subsequent stage, to achieve the extraction of spatial spectrum information. However, these methods require separate extraction of spatial and spectral information, do not take advantage of the combined spatial-spectral information, and require complex preprocessing. Moreover, 3D-CNN is used to extract spatial-spectral information simultaneously. The 3D-CNN simultaneously acquires the spectral and spatial information of hyperspectral remote sensing images and utilizes the characteristics of hyperspectral remote sensing image data cubes to achieve full fusion of spectral and spatial information. It extracts important discriminative features from the classification and effectively solves the problem of spatial homogeneity and heterogeneity. Therefore, the use of 3D-CNN for spatial and spectral information extraction of hyperspectral remote sensing images has become the development trend of image classification. However, such methods use only simply stacked CNNs, do not fully consider the excellent features of 3D-CNN, and has low model scalability. This study proposes a 3D-CNN model based on a doubleconvpool structure.MethodDoubleconvpool structure includes two convolution layers, two BN(batch normalization) layers, and one pooling layer. It not only considers the lack of label data in hyperspectral images but also the balance between the high-dimensional characteristics of hyperspectral images and model depth. Contrary to the use of only spatial or spectral information, the model fully uses the semantic information provided by the spatial-spectral information, thereby facilitating the feature extraction of hyperspectral images with small samples and high-dimensional characteristics. In a 3D-CNN based on doubleconvpool structure, the 3D remote sensing image without feature engineering is used as input data, and the deep learning model is trained in an end-to-end approach without complicated preprocessing. Moreover, the model uses regularization strategies, such as BN and Dropout, to avoid overfitting. We use the dual convolution pooling structure as a standard component of the network, and its number is used as an important hyperparameter of the network. For images with different data characteristics, acceptable classification results are achieved by rationally designing the number of doubleconvpool structures. The proposed method avoids the hyperparameter setting for the network when applied on different datasets and must greatly modify the network parameters. It also enhances the scalability of the network.ResultThe experiment compares SVM(support vector machine), SAE(stack autoencoder), and the current mainstream CNN method. The model has achieved 99.65% and 99.82% of the overall classification accuracy on the Indian Pines and Pavia University datasets, respectively. It effectively improves the classification accuracy of hyperspectral remote sensing images. We analyze and discuss the number of doubleconvpool structures, the regularization strategy, the spectral sampling stride of the first-layer convolution, the size of the convolution kernel, the size of neighboring pixel blocks, and the learning rate to provide a reasonable model under different constraints, such as training time and computational cost.ConclusionThe doubleconvpool structure can be combined and multiplexed according to the characteristics of datasets. In comparison with other deep learning models, it requires less parameters and has higher computational efficiency. It further illustrates the deep learning, particularly the application potential of 3D-CNN on hyperspectral images.关键词:3D-CNN;doubleconvpool structure;spatial-spectral information;hyperspectral image classification;regularization strategy17|4|13更新时间:2024-05-07
摘要:ObjectiveHyperspectral remote sensing image data are rich in spatial and spectral information. Continuous spectral segment information enhances the capability to distinguish between ground objects. This information has been widely used in the fields of image classification, target detection, agricultural monitoring, and environmental management. However, the data structure of hyperspectral remote sensing image is highly nonlinear due to the high-dimensional characteristics of the signal, information redundancy, and multiple uncertainties. Some classification models based on statistical patterns are difficult to classify and recognize original hyperspectral data directly. Training samples for supervised learning are extremely limited. A Hughes phenomenon occurs for a limited number of training samples, that is, the classification accuracy decreases as feature dimension increases. The traditional pixel-level hyperspectral remote sensing image classification method mostly adopts the framework of feature extraction and classifier. In the feature extraction, a series of spectral feature dimension reduction methods is proposed for the high spectral characteristics of hyperspectral data. However, these methods cannot solve the nonlinear problem of hyperspectral data. Some methods only use spectral information, which will greatly neglect the rich spatial structural information of high-resolution images. Classification results often have many discrete isolated points, and the classification accuracy is greatly reduced. Therefore, introducing spatial information is necessary. In recent years, image classification based on deep learning has become a research hotspot. In comparison with the traditional artificial design features, it can automatically extract the abstract features from the bottom to the high-level semantics and convert the images into easily recognizable advanced features. At present, mainstream methods include the use of image input 2D-CNN(2D convolutional neural network) after PCA(principal component analysis) dimensionality reduction and fusion with spectral information in the subsequent stage, to achieve the extraction of spatial spectrum information. However, these methods require separate extraction of spatial and spectral information, do not take advantage of the combined spatial-spectral information, and require complex preprocessing. Moreover, 3D-CNN is used to extract spatial-spectral information simultaneously. The 3D-CNN simultaneously acquires the spectral and spatial information of hyperspectral remote sensing images and utilizes the characteristics of hyperspectral remote sensing image data cubes to achieve full fusion of spectral and spatial information. It extracts important discriminative features from the classification and effectively solves the problem of spatial homogeneity and heterogeneity. Therefore, the use of 3D-CNN for spatial and spectral information extraction of hyperspectral remote sensing images has become the development trend of image classification. However, such methods use only simply stacked CNNs, do not fully consider the excellent features of 3D-CNN, and has low model scalability. This study proposes a 3D-CNN model based on a doubleconvpool structure.MethodDoubleconvpool structure includes two convolution layers, two BN(batch normalization) layers, and one pooling layer. It not only considers the lack of label data in hyperspectral images but also the balance between the high-dimensional characteristics of hyperspectral images and model depth. Contrary to the use of only spatial or spectral information, the model fully uses the semantic information provided by the spatial-spectral information, thereby facilitating the feature extraction of hyperspectral images with small samples and high-dimensional characteristics. In a 3D-CNN based on doubleconvpool structure, the 3D remote sensing image without feature engineering is used as input data, and the deep learning model is trained in an end-to-end approach without complicated preprocessing. Moreover, the model uses regularization strategies, such as BN and Dropout, to avoid overfitting. We use the dual convolution pooling structure as a standard component of the network, and its number is used as an important hyperparameter of the network. For images with different data characteristics, acceptable classification results are achieved by rationally designing the number of doubleconvpool structures. The proposed method avoids the hyperparameter setting for the network when applied on different datasets and must greatly modify the network parameters. It also enhances the scalability of the network.ResultThe experiment compares SVM(support vector machine), SAE(stack autoencoder), and the current mainstream CNN method. The model has achieved 99.65% and 99.82% of the overall classification accuracy on the Indian Pines and Pavia University datasets, respectively. It effectively improves the classification accuracy of hyperspectral remote sensing images. We analyze and discuss the number of doubleconvpool structures, the regularization strategy, the spectral sampling stride of the first-layer convolution, the size of the convolution kernel, the size of neighboring pixel blocks, and the learning rate to provide a reasonable model under different constraints, such as training time and computational cost.ConclusionThe doubleconvpool structure can be combined and multiplexed according to the characteristics of datasets. In comparison with other deep learning models, it requires less parameters and has higher computational efficiency. It further illustrates the deep learning, particularly the application potential of 3D-CNN on hyperspectral images.关键词:3D-CNN;doubleconvpool structure;spatial-spectral information;hyperspectral image classification;regularization strategy17|4|13更新时间:2024-05-07 -
 摘要:ObjectiveHashing methods, which aim at mapping the high-dimensional data to compact binary Hashing codes in Hamming space and rapidly calculate the Hamming distance by bit operation and XOR operation, can effectively achieve search and retrieval with remaining similarity for big data. However, a massive number of remote sensing images are associated with semantic information. Traditional methods of extracting image features and generating Hash codes cannot effectively use semantic information, thereby limiting the accuracy of remote sensing image retrieval. This study proposes an image retrieval method based on DSH(deep semantic Hashing) for mining semantic information of remote sensing images with tags or other semantic annotations. The contribution of this study includes introducing Hashing methods for RS images which encode the high-dimensional image feature vector to binary bits by using a limited number of labeled (annotated) images. Furthermore, DSH directly learns the discrete Hashing codes without relaxation thereby deteriorating the accuracy of the learned Hashing codes. Hence, DSH provides highly time-efficient (in terms of storage and speed) and accurate search capability within huge data archives. MethodThe DSH model performs simultaneous feature learning and Hashing codes learning in an end-to-end framework, which is organized into two main parts, namely feature learning and Hashing learning. In feature learning, we use two deep neural networks for images and semantic annotations. The deep neural network for image is a convolutional neural network (CNN) adapted from vgg_net. Particularly, feature learning has seven layers of vgg_16 network pretrained on ImageNet. We replace the eighth layer as a fully-connected layer with the output of the learned image features. The first seven layers use the rectified linear unit (ReLU) as the activation function, and the eighth layer uses identity function as the activation function. For semantic annotations, we use semantic vectors as the input to a deep neural network with two fully-connected layers. Moreover, we use ReLU and identity function for two fully-connected layers as activation function. In Hashing learning, we assume that f(xi; θx) represents the learned feature for image xi, which corresponds to the output of the CNN for images. Furthermore, let g(yj; θy) denote the learned feature for semantic yi, which corresponds to the output of the deep neural network for semantic vectors. Here, θx is the network parameter of the CNN for images, and θy is the network parameter of the deep neural network for semantic vectors. For binary codes, B={bi}i=1n, Then, we define the similarities with the likelihood and optimization function and learn the parameters of the CNN through an alternating learning strategy, which learns one parameter while fixing the other parameters. Result We have conducted experiments on three archives. The first archive consists of 2 000 images acquired from GF-2 satellite and Google Earth. Each image in the archive is a section of 224×224 pixels and is associated with several textual tags. In our experiments, we consider several tags, which are similar to one semantic annotation. We use CIFAR-10 dataset as the second archive, which is a single-label dataset consisting 60 000 color images with a size of 32×32 pixels. Each image belongs to one of the ten classes. The third archive is the FLICKR-25K dataset, which consists of 25 000 images associated with several textual tags. We consider several tags that are similar to one semantic annotation such as the first archive. Each image in the archive is a section of 224×224 pixels. On GF-2 satellite and Google Earth remote sensing image dataset, when the Hashing bit is 64, the mean average precision (mAP) value can be improved by approximately 2% contrary to DPSH(deep supervised Hashing with pairwise labels). On the CIFAR-10 dataset, the proposed method attains an improvement by 6%7% compared with DPSH for the mAP evaluation when the Hashing bit is 64. On the FLICKR-25K dataset, the proposed method attains improvement by approximately 0.6% compared with DPSH for the mAP evaluation when the Hashing bit is 64. ConclusionIn this study, we propose an end-to-end deep learning framework, which considers image visual and semantic features based on deep learning and generates Hashing functions for Hashing codes by utilizing the semantic information, thereby providing high accuracy for RS image retrieval. Experimental results show our proposed method greatly improves the detection accuracy of image retrieval. Notably, the archives used in the experiments are benchmarks, which are composed of a moderate number of images, whereas in many actual applications, the search is expected to be applied to considerably larger archives.关键词:Hashing;image retrieval;deep learning;semantic mining;remote sensing22|5|0更新时间:2024-05-07
摘要:ObjectiveHashing methods, which aim at mapping the high-dimensional data to compact binary Hashing codes in Hamming space and rapidly calculate the Hamming distance by bit operation and XOR operation, can effectively achieve search and retrieval with remaining similarity for big data. However, a massive number of remote sensing images are associated with semantic information. Traditional methods of extracting image features and generating Hash codes cannot effectively use semantic information, thereby limiting the accuracy of remote sensing image retrieval. This study proposes an image retrieval method based on DSH(deep semantic Hashing) for mining semantic information of remote sensing images with tags or other semantic annotations. The contribution of this study includes introducing Hashing methods for RS images which encode the high-dimensional image feature vector to binary bits by using a limited number of labeled (annotated) images. Furthermore, DSH directly learns the discrete Hashing codes without relaxation thereby deteriorating the accuracy of the learned Hashing codes. Hence, DSH provides highly time-efficient (in terms of storage and speed) and accurate search capability within huge data archives. MethodThe DSH model performs simultaneous feature learning and Hashing codes learning in an end-to-end framework, which is organized into two main parts, namely feature learning and Hashing learning. In feature learning, we use two deep neural networks for images and semantic annotations. The deep neural network for image is a convolutional neural network (CNN) adapted from vgg_net. Particularly, feature learning has seven layers of vgg_16 network pretrained on ImageNet. We replace the eighth layer as a fully-connected layer with the output of the learned image features. The first seven layers use the rectified linear unit (ReLU) as the activation function, and the eighth layer uses identity function as the activation function. For semantic annotations, we use semantic vectors as the input to a deep neural network with two fully-connected layers. Moreover, we use ReLU and identity function for two fully-connected layers as activation function. In Hashing learning, we assume that f(xi; θx) represents the learned feature for image xi, which corresponds to the output of the CNN for images. Furthermore, let g(yj; θy) denote the learned feature for semantic yi, which corresponds to the output of the deep neural network for semantic vectors. Here, θx is the network parameter of the CNN for images, and θy is the network parameter of the deep neural network for semantic vectors. For binary codes, B={bi}i=1n, Then, we define the similarities with the likelihood and optimization function and learn the parameters of the CNN through an alternating learning strategy, which learns one parameter while fixing the other parameters. Result We have conducted experiments on three archives. The first archive consists of 2 000 images acquired from GF-2 satellite and Google Earth. Each image in the archive is a section of 224×224 pixels and is associated with several textual tags. In our experiments, we consider several tags, which are similar to one semantic annotation. We use CIFAR-10 dataset as the second archive, which is a single-label dataset consisting 60 000 color images with a size of 32×32 pixels. Each image belongs to one of the ten classes. The third archive is the FLICKR-25K dataset, which consists of 25 000 images associated with several textual tags. We consider several tags that are similar to one semantic annotation such as the first archive. Each image in the archive is a section of 224×224 pixels. On GF-2 satellite and Google Earth remote sensing image dataset, when the Hashing bit is 64, the mean average precision (mAP) value can be improved by approximately 2% contrary to DPSH(deep supervised Hashing with pairwise labels). On the CIFAR-10 dataset, the proposed method attains an improvement by 6%7% compared with DPSH for the mAP evaluation when the Hashing bit is 64. On the FLICKR-25K dataset, the proposed method attains improvement by approximately 0.6% compared with DPSH for the mAP evaluation when the Hashing bit is 64. ConclusionIn this study, we propose an end-to-end deep learning framework, which considers image visual and semantic features based on deep learning and generates Hashing functions for Hashing codes by utilizing the semantic information, thereby providing high accuracy for RS image retrieval. Experimental results show our proposed method greatly improves the detection accuracy of image retrieval. Notably, the archives used in the experiments are benchmarks, which are composed of a moderate number of images, whereas in many actual applications, the search is expected to be applied to considerably larger archives.关键词:Hashing;image retrieval;deep learning;semantic mining;remote sensing22|5|0更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0