
最新刊期
卷 24 , 期 3 , 2019
-
 摘要:ObjectiveA new type of chaotic map is constructed that focuses on the comprehensive application of nonlinear methods, such as mapping, transformation, and operation in image encryption. The popularity of communication infrastructure and the rapid development of network technologies have made information exchange and sharing around the world more frequent and faster. In the meantime, security problems represented by information theft, leakage, and loss are more serious. As image is the main form of information carrier, image security is a major issue in information security. Under threats of multiple information risks, image encryption is an important means to ensure the security of image information. Image encryption is an important content of digital image processing and is also one of the basic research fields of applied cryptography. Research on image encryption algorithm is valuable to the practice of image encryption and an irreplaceable function in promoting the cross development of digital image-processing method and applied cryptography theory. Moreover, such research has achieved significant results, and remaining problems are expected to be solved. First, text encryption standards, such as DES (data encryption standard) and IDEA (international data encryption algorithm), need large storage space and have high computational complexity. Consequently, these methods cannot be used directly for image encryption. Second, several encryption algorithms are oriented to grayscale images. If these algorithms are applied on color images, corresponding algorithm transformation should be performed. Third, other encryption schemes, such as Arnold transform, can only be directly applied to square images. For rectangular image encryption, other technologies, such as image blocking, need to be used. These conditions invisibly increase algorithm complexity. Recently, image encryption methods, which are represented by chaotic encryption algorithms, have attracted extensive attention and achieved vital results. Unfortunately, most image encryption schemes based on common chaotic maps have been cracked. Therefore, research on new chaotic image encryption schemes is imminent. We constructed a generalized chaotic mapping based on Henon chaotic map, which is called Henon Sine (H-S) mapping, to improve the algorithm of image encryption and provide a feasible solution with effective properties for image encryption practice.MethodWith the use of H-S map, matrix nonlinear transformation and point operation, the inner random function of MATLAB, and rounding operation, an image hybrid encryption algorithm is proposed through sequence rearrangement and gray transformation. The encryption algorithm adopts the basic pattern of pixel scrambling and sequence transformation. The pattern comprises two stages. In the first stage, the first chaotic and the original pixel matrixes are combined and subjected to nonlinear transformation via matrix point operation. The scrambling encryption scheme of the original pixel matrix is given using random sorting of the transformation results. In the second stage, another nonlinear transformation with different parameters is implemented between the scrambled pixel and the second chaotic key matrixes, and a rounding operation is run to realize gray encryption. Accordingly, the decryption process is performed using the inverse operations and transformations in the contrary order. That is, the pixel sequence decryption is performed by applying the inverse operation of the pixel sequence encryption, and the inverse operation of the sequence rearrangement is applied to complete the scrambling decryption.ResultTo verify the security and effectiveness of the encryption algorithm, we carried out image encryption experiments for standard images with different sizes. The algorithm shows the feature of the one-time-pad and demonstrates perfect performance on anti-attacks due to the combination of chaotic keys, nonlinear operations, and random factors. Moreover, the algorithm has low computational complexity and is convenient for programming. Furthermore, the algorithm circumvents the reversibility requirement of the conventional chaotic encryption for mapping, and can be widely implemented on rectangular images of arbitrary size.ConclusionTo evaluate objectively the performance of hybrid encryption algorithms, multiple performance indicators were quantitatively analyzed. These indicators include encryption time, image gray surface, image information entropy, correlation, and similarity of encryption and decryption images, key sensitivity, and differential attack. The algorithm performs with high efficiency given the large enough key space to resist various attacks and is sensitive to keys and plain text. The security features and robustness of the proposed encryption scheme can be effectively guaranteed. Compared with other scrambling encryption algorithms, the superiority of the algorithm is displayed. The algorithm in this study provides a reference scheme for the encryption of rectangular gray images of any size. This scheme can be applied to rectangular color image encryption with appropriate adjustment.关键词:hybrid encryption;chaotic mapping;matrices point operation;nonlinear transformation;sequence rearrangement0|28|2更新时间:2024-05-07
摘要:ObjectiveA new type of chaotic map is constructed that focuses on the comprehensive application of nonlinear methods, such as mapping, transformation, and operation in image encryption. The popularity of communication infrastructure and the rapid development of network technologies have made information exchange and sharing around the world more frequent and faster. In the meantime, security problems represented by information theft, leakage, and loss are more serious. As image is the main form of information carrier, image security is a major issue in information security. Under threats of multiple information risks, image encryption is an important means to ensure the security of image information. Image encryption is an important content of digital image processing and is also one of the basic research fields of applied cryptography. Research on image encryption algorithm is valuable to the practice of image encryption and an irreplaceable function in promoting the cross development of digital image-processing method and applied cryptography theory. Moreover, such research has achieved significant results, and remaining problems are expected to be solved. First, text encryption standards, such as DES (data encryption standard) and IDEA (international data encryption algorithm), need large storage space and have high computational complexity. Consequently, these methods cannot be used directly for image encryption. Second, several encryption algorithms are oriented to grayscale images. If these algorithms are applied on color images, corresponding algorithm transformation should be performed. Third, other encryption schemes, such as Arnold transform, can only be directly applied to square images. For rectangular image encryption, other technologies, such as image blocking, need to be used. These conditions invisibly increase algorithm complexity. Recently, image encryption methods, which are represented by chaotic encryption algorithms, have attracted extensive attention and achieved vital results. Unfortunately, most image encryption schemes based on common chaotic maps have been cracked. Therefore, research on new chaotic image encryption schemes is imminent. We constructed a generalized chaotic mapping based on Henon chaotic map, which is called Henon Sine (H-S) mapping, to improve the algorithm of image encryption and provide a feasible solution with effective properties for image encryption practice.MethodWith the use of H-S map, matrix nonlinear transformation and point operation, the inner random function of MATLAB, and rounding operation, an image hybrid encryption algorithm is proposed through sequence rearrangement and gray transformation. The encryption algorithm adopts the basic pattern of pixel scrambling and sequence transformation. The pattern comprises two stages. In the first stage, the first chaotic and the original pixel matrixes are combined and subjected to nonlinear transformation via matrix point operation. The scrambling encryption scheme of the original pixel matrix is given using random sorting of the transformation results. In the second stage, another nonlinear transformation with different parameters is implemented between the scrambled pixel and the second chaotic key matrixes, and a rounding operation is run to realize gray encryption. Accordingly, the decryption process is performed using the inverse operations and transformations in the contrary order. That is, the pixel sequence decryption is performed by applying the inverse operation of the pixel sequence encryption, and the inverse operation of the sequence rearrangement is applied to complete the scrambling decryption.ResultTo verify the security and effectiveness of the encryption algorithm, we carried out image encryption experiments for standard images with different sizes. The algorithm shows the feature of the one-time-pad and demonstrates perfect performance on anti-attacks due to the combination of chaotic keys, nonlinear operations, and random factors. Moreover, the algorithm has low computational complexity and is convenient for programming. Furthermore, the algorithm circumvents the reversibility requirement of the conventional chaotic encryption for mapping, and can be widely implemented on rectangular images of arbitrary size.ConclusionTo evaluate objectively the performance of hybrid encryption algorithms, multiple performance indicators were quantitatively analyzed. These indicators include encryption time, image gray surface, image information entropy, correlation, and similarity of encryption and decryption images, key sensitivity, and differential attack. The algorithm performs with high efficiency given the large enough key space to resist various attacks and is sensitive to keys and plain text. The security features and robustness of the proposed encryption scheme can be effectively guaranteed. Compared with other scrambling encryption algorithms, the superiority of the algorithm is displayed. The algorithm in this study provides a reference scheme for the encryption of rectangular gray images of any size. This scheme can be applied to rectangular color image encryption with appropriate adjustment.关键词:hybrid encryption;chaotic mapping;matrices point operation;nonlinear transformation;sequence rearrangement0|28|2更新时间:2024-05-07 -
 摘要:ObjectiveImage enhancement techniques have received increasing attention along with the rapid development of digital photography in recent years. Image enhancement aims to improve the visual quality of an image through tone mapping, denoising, and recomposition. In image aesthetic assessment, the main factors that influence aesthetics, namely, object relationships and geometric structure, are considered in recomposition. As a research hotspot, image recomposition utilizes photographic composition rules, such as the rule of thirds, visual balance, diagonal dominance, and object size, to capture aesthetically pleasing content. Nonphotographic experts can also acquire photographic images that conform to image aesthetics using image recomposition technology. Stereoscopic technologies have undergone a tremendous boom in recent years. Various stereoscopic services and applications are currently available which present great demands for the availability of 3D contents. A growing demand for stereoscopic image layout adjustment has been observed due to the separation of stereoscopic content production and display. However, the content modification of 3D images is difficult compared with the conventional 2D image modification. The former requires additional care due to the additional depth dimension. The misalignment between left and right images may result in uncomfortable 3D viewing and cause eye strain and headache. In consideration of the above factors, starting from stereoscopic image layout adjustment, this study proposes a stereoscopic image recomposition method based on Delaunay mesh deformation and depth adaptation.MethodA pair of stereoscopic images to be recomposed is first recorded as source images, including left and right images, and a binary image used for rule determination is recorded as a reference image. Alpha matting is used to obtain a precise region with opacity value for each object in the left image and calculate the significance of stereoscopic images. We then detect feature points from the left image and use the Delaunay triangulation algorithm to generate meshes as follows. We employ an edge detection operator, such as Canny operator, and utilize a corner detection algorithm, such as Harris corner detection, to extract feature points in a target object. Hough transform is used to detect feature lines and select points in the left image to evenly sample feature points in the feature lines. Here, the location of the target object and the feature line are classified into three categories:intersect, above separate, and below separate. When intersecting with the feature line, the target object moves along with the feature line, and the rest of the situation can be considered separately. The left image boundary is evenly discretized to use all the points there as part of the feature points and sample the remaining area to gain feature points. The Delaunay triangulation mesh can be automatically generated based on the feature points. After the left image meshes are established, the meshes in the right image are mapped by disparity from the left image meshes, and the reference image meshes are also built similar to the operation of the left image. A template-matching operation is performed on the contents of the left and reference images to obtain the corresponding relationship between the source and reference images in the layout. In the optimization process, we construct energy terms from three aspects, namely, image quality, layout adjustment, and depth adaptation. Finally, the target object is moved and scaled based on the characteristics of mesh deformation, and the depth of the stereoscopic image is adaptively adjusted. The disparity change ratio of the target object is consistent with the size scaling.ResultThis study conducts an experimental design from two aspects of single object and multiple objects, which prove that the proposed method is applicable to all objects. When the movement of the target object or the adjustment of the feature line is involved, the disparity of the stereoscopic image is maintained. When the target object is scaled, the disparity of the target object in the stereoscopic image varies according to the scaling ratio, while the background disparity remains unchanged. Experimental results show that the stereoscopic image after recomposition is consistent with the layout of the reference image for the target object movement, scaling, and feature line adjustment and that the depth can be adjusted adaptively. The coefficients of different energy terms are also adjusted to prove that the new framework proposed in this study can achieve satisfactory stereoscopic content recomposition. Compared with the latest method, the optimization method used in this study has advantages in the segmentation accuracy of the target object and the preservation of image semantics.ConclusionIn this study, image quality, layout matching, and disparity adaptive energy terms are constructed based on the theory of mesh deformation, and content recomposition of the stereoscopic image is achieved according to energy term optimization. Unlike the existing recomposition method that needs to extract and paste the target object, the proposed method does not require high accuracy in the segmentation of the target object. Image-inpainting and -blending techniques are not needed. The stereoscopic image after recomposition has no artifacts and semantic errors. The user can guide the layout adjustment of the stereoscopic image by using the reference image to achieve the image enhancement desired by the user. In the future, mesh deformation and cropping technologies can be combined to enhance the efficiency and flexibility of stereoscopic image recomposition.关键词:stereoscopic image editing;stereoscopic image layout;Delaunay mesh deformation;depth adaptation;optimization12|4|1更新时间:2024-05-07
摘要:ObjectiveImage enhancement techniques have received increasing attention along with the rapid development of digital photography in recent years. Image enhancement aims to improve the visual quality of an image through tone mapping, denoising, and recomposition. In image aesthetic assessment, the main factors that influence aesthetics, namely, object relationships and geometric structure, are considered in recomposition. As a research hotspot, image recomposition utilizes photographic composition rules, such as the rule of thirds, visual balance, diagonal dominance, and object size, to capture aesthetically pleasing content. Nonphotographic experts can also acquire photographic images that conform to image aesthetics using image recomposition technology. Stereoscopic technologies have undergone a tremendous boom in recent years. Various stereoscopic services and applications are currently available which present great demands for the availability of 3D contents. A growing demand for stereoscopic image layout adjustment has been observed due to the separation of stereoscopic content production and display. However, the content modification of 3D images is difficult compared with the conventional 2D image modification. The former requires additional care due to the additional depth dimension. The misalignment between left and right images may result in uncomfortable 3D viewing and cause eye strain and headache. In consideration of the above factors, starting from stereoscopic image layout adjustment, this study proposes a stereoscopic image recomposition method based on Delaunay mesh deformation and depth adaptation.MethodA pair of stereoscopic images to be recomposed is first recorded as source images, including left and right images, and a binary image used for rule determination is recorded as a reference image. Alpha matting is used to obtain a precise region with opacity value for each object in the left image and calculate the significance of stereoscopic images. We then detect feature points from the left image and use the Delaunay triangulation algorithm to generate meshes as follows. We employ an edge detection operator, such as Canny operator, and utilize a corner detection algorithm, such as Harris corner detection, to extract feature points in a target object. Hough transform is used to detect feature lines and select points in the left image to evenly sample feature points in the feature lines. Here, the location of the target object and the feature line are classified into three categories:intersect, above separate, and below separate. When intersecting with the feature line, the target object moves along with the feature line, and the rest of the situation can be considered separately. The left image boundary is evenly discretized to use all the points there as part of the feature points and sample the remaining area to gain feature points. The Delaunay triangulation mesh can be automatically generated based on the feature points. After the left image meshes are established, the meshes in the right image are mapped by disparity from the left image meshes, and the reference image meshes are also built similar to the operation of the left image. A template-matching operation is performed on the contents of the left and reference images to obtain the corresponding relationship between the source and reference images in the layout. In the optimization process, we construct energy terms from three aspects, namely, image quality, layout adjustment, and depth adaptation. Finally, the target object is moved and scaled based on the characteristics of mesh deformation, and the depth of the stereoscopic image is adaptively adjusted. The disparity change ratio of the target object is consistent with the size scaling.ResultThis study conducts an experimental design from two aspects of single object and multiple objects, which prove that the proposed method is applicable to all objects. When the movement of the target object or the adjustment of the feature line is involved, the disparity of the stereoscopic image is maintained. When the target object is scaled, the disparity of the target object in the stereoscopic image varies according to the scaling ratio, while the background disparity remains unchanged. Experimental results show that the stereoscopic image after recomposition is consistent with the layout of the reference image for the target object movement, scaling, and feature line adjustment and that the depth can be adjusted adaptively. The coefficients of different energy terms are also adjusted to prove that the new framework proposed in this study can achieve satisfactory stereoscopic content recomposition. Compared with the latest method, the optimization method used in this study has advantages in the segmentation accuracy of the target object and the preservation of image semantics.ConclusionIn this study, image quality, layout matching, and disparity adaptive energy terms are constructed based on the theory of mesh deformation, and content recomposition of the stereoscopic image is achieved according to energy term optimization. Unlike the existing recomposition method that needs to extract and paste the target object, the proposed method does not require high accuracy in the segmentation of the target object. Image-inpainting and -blending techniques are not needed. The stereoscopic image after recomposition has no artifacts and semantic errors. The user can guide the layout adjustment of the stereoscopic image by using the reference image to achieve the image enhancement desired by the user. In the future, mesh deformation and cropping technologies can be combined to enhance the efficiency and flexibility of stereoscopic image recomposition.关键词:stereoscopic image editing;stereoscopic image layout;Delaunay mesh deformation;depth adaptation;optimization12|4|1更新时间:2024-05-07 -
 摘要:ObjectiveHarsh environments exist in the process of medical image acquisition and video surveillance. Such environments lead to poor image quality and many strong noise spots, which in turn affect the doctor's identification of lesions. When dealing with strong noise images, traditional variational model-based algorithms are computationally complex and have slow convergence because they need to calculate high-order partial differential equations. The curvature filtering model that implicitly uses image curvature information deals with strong noise images, and incomplete denoising defects occur. An improved curvature filtering algorithm is proposed in this study to overcome these deficiencies and achieve strong noise removal from images while maintaining the edge and detail features of the images and realizing a fast denoising process.MethodThis study proposes a novel algorithm for strong noise denoising based on improved curvature filters. The curvature is implicitly calculated, such that the proposed algorithm is as fast as the curvature filtering algorithm. The semi-window triangular tangent plane is combined with the minimum trigonometric tangent plane projection operator to replace the only minimum triangulation tangent plane projection operator for traditional curvature filtering, thereby enhancing the denoising capability of the algorithm aiming for strong noise images. According to the characteristics of strong noise spots in strong noise images, the regular energy function is modified, and the regular energy of local variance is added. These actions result in a reasonable constraint of regular terms and improves the denoising performance of the algorithm, thus enhancing the denoising capability and protecting the image edges.ResultAn improved curvature filtering algorithm is proposed to denoise strong noise images. Images are reconstructed based on the Gaussian curvature and local variance. Denoising performance is improved, particularly in processing images with high noise.The performance of the proposed algorithm is tested against mixed noise images of different intensities to verify its effect and texture-preserving capability. For instance, 0.1-density salt-and-pepper-mixed Gaussian noise with a standard deviation of 50 is added to the classic image of Lena and an emphysema CT lung image in the experiment. The noise reduction effects are compared with those of the traditional algorithms based on the denoising algorithm (Rudin-Osher-Fatemi model, ROF) and curvature filtering and denoising. Peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are used as objective evaluation indicators of the performance of the filtering algorithm. The proposed algorithm can effectively preserve the edge and detail features of images when denoising high-noise images and has good PSNR and SSIM. For the mixed salt-and-pepper noise density of 0.02 and Gaussian noise variance of 30 compared with the ROF model and the curvature filtering algorithm, the PSNR can be improved by 0.196 dB and 2.264 dB, respectively, and the SSIM can increase by 0.13 and 0.305, respectively. Especially in strong noise environments, such as mixed salt-and-pepper noise density of 0.1, Gaussian noise variance of 50, and superimposed Poisson noise, experimental results show that the PSNR obtained by the proposed algorithm increases by 2.196 dB more than the denoising image of the ROF model and by 3.194 dB more than the curvature filtering algorithm. The SSIM obtained by the proposed algorithm is 0.398 more than that of the ROF model and 0.403 more than that of the curvature filtering model. The traditional ROF model can achieve a good denoising image, but it requires 26 s of running time and thereby cannot achieve real-time denoising. Although curvature filtering can acquire denoising images in a relatively short time, its denoising capability is insufficient and noise cannot be removed efficiently. Implicitly calculated image curvature is adopted, and the processing speed of the algorithm is similar to that of the curvature filtering algorithm.ConclusionThe curvature filtering algorithm is optimized based on the noise characteristics of strong noise images. According to the enhanced denoising capability projection operator and the modified energy function regularization term, the curvature filtering model can be better applied to strong noise images than traditional methods. Experiments are performed on images with three mixed strong noise levels. The corresponding running time, PSNR, and SSIM are calculated for comparison. The PSNR, SSIM, and image visual effect of the proposed method are superior to those of the total variation(TV) and adaptive fidelity term total variation (AFTV) models, particularly for the images polluted by strong noise. The running time of the proposed algorithm is close to that of the curvature filtering algorithm and is significantly faster than that of the ROF model. Experimental results show that compared with the traditional variational method, the proposed algorithm has a significant effect on denoising strong noise images.关键词:image denoising;curvature filter;strong noise;Gaussian curvature;variational model18|5|4更新时间:2024-05-07
摘要:ObjectiveHarsh environments exist in the process of medical image acquisition and video surveillance. Such environments lead to poor image quality and many strong noise spots, which in turn affect the doctor's identification of lesions. When dealing with strong noise images, traditional variational model-based algorithms are computationally complex and have slow convergence because they need to calculate high-order partial differential equations. The curvature filtering model that implicitly uses image curvature information deals with strong noise images, and incomplete denoising defects occur. An improved curvature filtering algorithm is proposed in this study to overcome these deficiencies and achieve strong noise removal from images while maintaining the edge and detail features of the images and realizing a fast denoising process.MethodThis study proposes a novel algorithm for strong noise denoising based on improved curvature filters. The curvature is implicitly calculated, such that the proposed algorithm is as fast as the curvature filtering algorithm. The semi-window triangular tangent plane is combined with the minimum trigonometric tangent plane projection operator to replace the only minimum triangulation tangent plane projection operator for traditional curvature filtering, thereby enhancing the denoising capability of the algorithm aiming for strong noise images. According to the characteristics of strong noise spots in strong noise images, the regular energy function is modified, and the regular energy of local variance is added. These actions result in a reasonable constraint of regular terms and improves the denoising performance of the algorithm, thus enhancing the denoising capability and protecting the image edges.ResultAn improved curvature filtering algorithm is proposed to denoise strong noise images. Images are reconstructed based on the Gaussian curvature and local variance. Denoising performance is improved, particularly in processing images with high noise.The performance of the proposed algorithm is tested against mixed noise images of different intensities to verify its effect and texture-preserving capability. For instance, 0.1-density salt-and-pepper-mixed Gaussian noise with a standard deviation of 50 is added to the classic image of Lena and an emphysema CT lung image in the experiment. The noise reduction effects are compared with those of the traditional algorithms based on the denoising algorithm (Rudin-Osher-Fatemi model, ROF) and curvature filtering and denoising. Peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) are used as objective evaluation indicators of the performance of the filtering algorithm. The proposed algorithm can effectively preserve the edge and detail features of images when denoising high-noise images and has good PSNR and SSIM. For the mixed salt-and-pepper noise density of 0.02 and Gaussian noise variance of 30 compared with the ROF model and the curvature filtering algorithm, the PSNR can be improved by 0.196 dB and 2.264 dB, respectively, and the SSIM can increase by 0.13 and 0.305, respectively. Especially in strong noise environments, such as mixed salt-and-pepper noise density of 0.1, Gaussian noise variance of 50, and superimposed Poisson noise, experimental results show that the PSNR obtained by the proposed algorithm increases by 2.196 dB more than the denoising image of the ROF model and by 3.194 dB more than the curvature filtering algorithm. The SSIM obtained by the proposed algorithm is 0.398 more than that of the ROF model and 0.403 more than that of the curvature filtering model. The traditional ROF model can achieve a good denoising image, but it requires 26 s of running time and thereby cannot achieve real-time denoising. Although curvature filtering can acquire denoising images in a relatively short time, its denoising capability is insufficient and noise cannot be removed efficiently. Implicitly calculated image curvature is adopted, and the processing speed of the algorithm is similar to that of the curvature filtering algorithm.ConclusionThe curvature filtering algorithm is optimized based on the noise characteristics of strong noise images. According to the enhanced denoising capability projection operator and the modified energy function regularization term, the curvature filtering model can be better applied to strong noise images than traditional methods. Experiments are performed on images with three mixed strong noise levels. The corresponding running time, PSNR, and SSIM are calculated for comparison. The PSNR, SSIM, and image visual effect of the proposed method are superior to those of the total variation(TV) and adaptive fidelity term total variation (AFTV) models, particularly for the images polluted by strong noise. The running time of the proposed algorithm is close to that of the curvature filtering algorithm and is significantly faster than that of the ROF model. Experimental results show that compared with the traditional variational method, the proposed algorithm has a significant effect on denoising strong noise images.关键词:image denoising;curvature filter;strong noise;Gaussian curvature;variational model18|5|4更新时间:2024-05-07 -
 摘要:ObjectiveIn traditional video acquisition, a video signal is sampled based on Nyquist sampling theory with a sampling frequency greater than or equal to twice the maximum frequency of the signal. The spatial and temporal redundancy information in the video signal is removed by the conventional encoding method. As people's requirements on the quality of multimedia content are increasing, the burden on the video encoder is becoming heavier. However, the traditional video-coding method is unsuitable for the application environments with limits in power consumption, storage capacity, and computing power (e.g., wireless video surveillance). Compressed sensing (CS) conducts sampling and compression simultaneously, thereby saving enormous sampling resources while reducing the sampling complexity significantly. Thus, this technique is suitable for application scenarios with a resource-deprived sampling side. CS-based distributed video coding attracts considerable attention, in which utilizing the correlation among frames to reconstruct video efficiently has become a main research area. Multi-hypothesis (MH) prediction is a key technique in predicting residual reconstruction algorithm for compressed video sensing. In the existing MH prediction algorithm, the block size usually remains unchanged during the prediction process. The scheme accuracy depends on the similarity between the hypothetical and current blocks; hence, high similarity of the block group is assumed to lead to a good prediction result. Nevertheless, the content motion type is complicated for some image blocks in a video frame. The invariable-size block prediction scheme consequently leads to inconsiderably similar matching blocks and poor prediction results. Simulations indicate that the motion vectors of the image block in the motion gradual region are close, and therefore, searching the best match for each single block produces an unnecessary computing burden. The existing MH prediction algorithm generally has two disadvantages. First, the prediction accuracy for video frames with complex movement is poor. Second, for the smooth motion region or frames, the motion vectors of adjacent image blocks are highly similar, and searching the best matching block for each one separately leads to high algorithm complexity.MethodFor these problems, we propose a hierarchical MH prediction method (Hi-MH) that adopts different block-matching prediction methods for regions with different motion complexities and then introduce an implementation method. For the image block in smooth motion regions, the motion vector of the current block is predicted by that of the neighboring image block to decrease the motion estimation complexity (Motion estimation starts from a large block with a size four times of the observing block, and the motion estimation process from large block to small block is controlled by a suitable threshold to ensure the accuracy of each motion estimation until the block size is smaller than the observing block size, which means that this image block does not belong to a flat motion area).For the image blocks with complex movement, smaller blocks are used to find the best match and then adopt the MH prediction in pixel domain to obtain the prediction block. For the image blocks with a considerably complex movement, the autoregressive model is used to predict every individual pixel in the blocks. The reconstruction superiority of the regression model improves the prediction accuracy.ResultA comparison of the result of Hi-MH and that of an MH prediction scheme based on fast diamond search with two matching regions (MH-DS) shows that the prediction time for each frame decreases by 1.43 s and 1.73 s for the Foreman and Coastguard sequences, respectively. The reconstruction accuracy of Hi-MH is higher than those of 2sMHR (Gw_2sMHR, Fw_2sMHR) and MH-DS. At the sample rate from 0.1 to 0.5 for non-key frames, the average PSNR of Hi-MH is 1.3 dB better than that of Fw_2sMHR, 1.1 dB better than that of Gw_2sMHR, and 0.34 dB better than that of MH-DS. Compared with the PBCR algorithm which currently has the best reconstruction accuracy, the Hi-MH improves the reconstruction accuracy by 1 dB for some complex motion sequences.Conclusion1) The Hi-MH algorithm is improved based on the MH-DS algorithm. For some image blocks with complex motion, the hierarchical motion estimation scheme in Hi-MH can find more accurate matching regions and obtain high-quality hypothesis block groups to improve the prediction accuracy of those blocks. The block classification prediction scheme in Hi-MH improves the prediction accuracy for some severely deformed image blocks; therefore, the overall reconstruction quality is enhanced. 2) For fast-moving video sequences, the Hi-MH algorithm has a significant improvement in reconstruction result over the PBCR-DCVS algorithm which currently has the best reconstruction quality. Local correlation in the videos is fully utilized because the Hi-MH algorithm proposed in this study can obtain higher accuracy image block-matching regions through the fast diamond search method and hierarchical motion estimation. Thus, the video reconstruction result is better. For slow-moving video sequences, such as Mother-daughter and Coastguard, the Hi-MH algorithm remains superior to the PBCR-DCVS algorithm at low sampling rates. As the sampling rate increases, the advantage gradually disappears. The reason is that at low sampling rates, the PBCR-DCVS algorithm cannot find more high-quality hypothetical block groups but Hi-MH can better solve this problem, thereby greatly improving the reconstruction quality. As the sampling rate increases, numerous observations are transmitted to the decoder, and PBCR-DCVS can find a good matching block group that helps in high-quality reconstruction. However, the neighborhood motion vector prediction technique used in Hi-MH to reduce the motion estimation complexity decreases the quality of the matching block group and the reconstruction quality. In general, the Hi-MH algorithm reduces the computational complexity for video sequences or regions with simple movement and improves the prediction accuracy for video sequences or regions with complex motion patterns.关键词:compressed video sensing(CVS);multi-hypothesis prediction;block matching;motion estimation;auto regression53|49|0更新时间:2024-05-07
摘要:ObjectiveIn traditional video acquisition, a video signal is sampled based on Nyquist sampling theory with a sampling frequency greater than or equal to twice the maximum frequency of the signal. The spatial and temporal redundancy information in the video signal is removed by the conventional encoding method. As people's requirements on the quality of multimedia content are increasing, the burden on the video encoder is becoming heavier. However, the traditional video-coding method is unsuitable for the application environments with limits in power consumption, storage capacity, and computing power (e.g., wireless video surveillance). Compressed sensing (CS) conducts sampling and compression simultaneously, thereby saving enormous sampling resources while reducing the sampling complexity significantly. Thus, this technique is suitable for application scenarios with a resource-deprived sampling side. CS-based distributed video coding attracts considerable attention, in which utilizing the correlation among frames to reconstruct video efficiently has become a main research area. Multi-hypothesis (MH) prediction is a key technique in predicting residual reconstruction algorithm for compressed video sensing. In the existing MH prediction algorithm, the block size usually remains unchanged during the prediction process. The scheme accuracy depends on the similarity between the hypothetical and current blocks; hence, high similarity of the block group is assumed to lead to a good prediction result. Nevertheless, the content motion type is complicated for some image blocks in a video frame. The invariable-size block prediction scheme consequently leads to inconsiderably similar matching blocks and poor prediction results. Simulations indicate that the motion vectors of the image block in the motion gradual region are close, and therefore, searching the best match for each single block produces an unnecessary computing burden. The existing MH prediction algorithm generally has two disadvantages. First, the prediction accuracy for video frames with complex movement is poor. Second, for the smooth motion region or frames, the motion vectors of adjacent image blocks are highly similar, and searching the best matching block for each one separately leads to high algorithm complexity.MethodFor these problems, we propose a hierarchical MH prediction method (Hi-MH) that adopts different block-matching prediction methods for regions with different motion complexities and then introduce an implementation method. For the image block in smooth motion regions, the motion vector of the current block is predicted by that of the neighboring image block to decrease the motion estimation complexity (Motion estimation starts from a large block with a size four times of the observing block, and the motion estimation process from large block to small block is controlled by a suitable threshold to ensure the accuracy of each motion estimation until the block size is smaller than the observing block size, which means that this image block does not belong to a flat motion area).For the image blocks with complex movement, smaller blocks are used to find the best match and then adopt the MH prediction in pixel domain to obtain the prediction block. For the image blocks with a considerably complex movement, the autoregressive model is used to predict every individual pixel in the blocks. The reconstruction superiority of the regression model improves the prediction accuracy.ResultA comparison of the result of Hi-MH and that of an MH prediction scheme based on fast diamond search with two matching regions (MH-DS) shows that the prediction time for each frame decreases by 1.43 s and 1.73 s for the Foreman and Coastguard sequences, respectively. The reconstruction accuracy of Hi-MH is higher than those of 2sMHR (Gw_2sMHR, Fw_2sMHR) and MH-DS. At the sample rate from 0.1 to 0.5 for non-key frames, the average PSNR of Hi-MH is 1.3 dB better than that of Fw_2sMHR, 1.1 dB better than that of Gw_2sMHR, and 0.34 dB better than that of MH-DS. Compared with the PBCR algorithm which currently has the best reconstruction accuracy, the Hi-MH improves the reconstruction accuracy by 1 dB for some complex motion sequences.Conclusion1) The Hi-MH algorithm is improved based on the MH-DS algorithm. For some image blocks with complex motion, the hierarchical motion estimation scheme in Hi-MH can find more accurate matching regions and obtain high-quality hypothesis block groups to improve the prediction accuracy of those blocks. The block classification prediction scheme in Hi-MH improves the prediction accuracy for some severely deformed image blocks; therefore, the overall reconstruction quality is enhanced. 2) For fast-moving video sequences, the Hi-MH algorithm has a significant improvement in reconstruction result over the PBCR-DCVS algorithm which currently has the best reconstruction quality. Local correlation in the videos is fully utilized because the Hi-MH algorithm proposed in this study can obtain higher accuracy image block-matching regions through the fast diamond search method and hierarchical motion estimation. Thus, the video reconstruction result is better. For slow-moving video sequences, such as Mother-daughter and Coastguard, the Hi-MH algorithm remains superior to the PBCR-DCVS algorithm at low sampling rates. As the sampling rate increases, the advantage gradually disappears. The reason is that at low sampling rates, the PBCR-DCVS algorithm cannot find more high-quality hypothetical block groups but Hi-MH can better solve this problem, thereby greatly improving the reconstruction quality. As the sampling rate increases, numerous observations are transmitted to the decoder, and PBCR-DCVS can find a good matching block group that helps in high-quality reconstruction. However, the neighborhood motion vector prediction technique used in Hi-MH to reduce the motion estimation complexity decreases the quality of the matching block group and the reconstruction quality. In general, the Hi-MH algorithm reduces the computational complexity for video sequences or regions with simple movement and improves the prediction accuracy for video sequences or regions with complex motion patterns.关键词:compressed video sensing(CVS);multi-hypothesis prediction;block matching;motion estimation;auto regression53|49|0更新时间:2024-05-07
Image Processing and Coding

-
 摘要:ObjectiveAs a hotspot in computer vision, image co-segmentation is a research branch of the classic image segmentation problem that uses multiple images to separate foreground objects from background regions in an image. It has been widely used in many fields, such as image classification, object recognition, and 3D object reconstruction. Image co-segmentation has become an ill-conditioned and challenging problem due to many factors, such as viewpoint change and intraclass diversity of the foreground objects in the image. Most current image co-segmentation algorithms have limits in performance, which only work efficiently in images with dramatic background and minimal foreground changes.MethodThis study proposes a new unsupervised algorithm that optimizes foreground/background estimation progressively. Our proposed algorithm has three advantages:1) it is unsupervised and does not need sample learning, 2) it can be used to co-segment multiple images simultaneously or an image with multiple foreground objects, 3) it is more adaptable to dramatic intraclass variations than previous algorithms. The main steps of our algorithm are as follows. A classic hierarchical segmentation is first utilized to generate a multiscale superpixel set. Different Gaussian mixture models are then used to estimate the foreground and background distributions on the basis of classic color and texture descriptors at the superpixel level. A Markov random field (MRF) model is used to estimate the annotation of each superpixel by solving a traditional energy minimization problem. In our MRF model, each node represents a superpixel or pixel. The first two unary potentials denote the possibilities of a superpixel or pixel belonging to the foreground or background, and the last pairwise potential penalizes the annotation consistency among superpixels in different images. This energy minimization can be solved by a classic graph cut. Unlike most image co-segmentation algorithms, the foreground and background models are progressively estimated based on the initial superpixel annotation from the pre-learned object detector. These models use the annotation in the current step to update the superpixel annotation in the next step for foreground and background distribution updating until these distributions are no longer optimized significantly. Intra- and inter-image similarity correlations in different superpixel levels are integrated into our iterative-type framework to increase the robustness of foreground and background model estimation. Each image is divided into a series of segmentation levels by hierarchical segmentation, and three matrices are used to model the semantic correlations among different regions. An affinity matrix
摘要:ObjectiveAs a hotspot in computer vision, image co-segmentation is a research branch of the classic image segmentation problem that uses multiple images to separate foreground objects from background regions in an image. It has been widely used in many fields, such as image classification, object recognition, and 3D object reconstruction. Image co-segmentation has become an ill-conditioned and challenging problem due to many factors, such as viewpoint change and intraclass diversity of the foreground objects in the image. Most current image co-segmentation algorithms have limits in performance, which only work efficiently in images with dramatic background and minimal foreground changes.MethodThis study proposes a new unsupervised algorithm that optimizes foreground/background estimation progressively. Our proposed algorithm has three advantages:1) it is unsupervised and does not need sample learning, 2) it can be used to co-segment multiple images simultaneously or an image with multiple foreground objects, 3) it is more adaptable to dramatic intraclass variations than previous algorithms. The main steps of our algorithm are as follows. A classic hierarchical segmentation is first utilized to generate a multiscale superpixel set. Different Gaussian mixture models are then used to estimate the foreground and background distributions on the basis of classic color and texture descriptors at the superpixel level. A Markov random field (MRF) model is used to estimate the annotation of each superpixel by solving a traditional energy minimization problem. In our MRF model, each node represents a superpixel or pixel. The first two unary potentials denote the possibilities of a superpixel or pixel belonging to the foreground or background, and the last pairwise potential penalizes the annotation consistency among superpixels in different images. This energy minimization can be solved by a classic graph cut. Unlike most image co-segmentation algorithms, the foreground and background models are progressively estimated based on the initial superpixel annotation from the pre-learned object detector. These models use the annotation in the current step to update the superpixel annotation in the next step for foreground and background distribution updating until these distributions are no longer optimized significantly. Intra- and inter-image similarity correlations in different superpixel levels are integrated into our iterative-type framework to increase the robustness of foreground and background model estimation. Each image is divided into a series of segmentation levels by hierarchical segmentation, and three matrices are used to model the semantic correlations among different regions. An affinity matrix$\mathit{\boldsymbol{A}}$ $\mathit{\boldsymbol{C}}$ $\mathit{\boldsymbol{M}}$ $\mathit{\boldsymbol{P}}$ $\mathit{\boldsymbol{Q}}$ $\mathit{\boldsymbol{C}}$ $\mathit{\boldsymbol{P}}$ 关键词:image co-segmentation;hierarchical image segmentation;progressive foreground estimation;hierarchical region correlation;normalized cut13|4|0更新时间:2024-05-07 -
 摘要:ObjectiveLocal image descriptors have been successfully applied to computer vision research, such as image search, robot navigation, image classification, and video action recognition. Local image descriptors perform effectively in the large viewpoint change of cameras, photometric change, noise, and local occlusion.MethodA new local feature for image region description, namely, local intensity extremum pattern (LIEP), is proposed in this study. The same number of pixel points is uniformly sampled on two concentric circles with different radii from one pixel point. The angles between the sampling points and the center pixel on different concentric circles interpolate each another. The maximum and minimum intensity patterns of each concentric circle are calculated independently. Two-dimensional joint distributions of the minimum intensity pattern on the concentric circle with a small radius and the maximum intensity pattern on the concentric circle with a large radius are computed. Subsequently, an intensity extreme pattern is obtained. Two-dimensional joint distributions of the maximum intensity pattern on the concentric circle with a small radius and the minimum intensity pattern on the concentric circle with a large radius are computed, and another intensity extreme pattern is obtained. The two extreme patterns are cascaded to obtain LIEP. From the calculation process of LIEP, the two LIEP sub-patterns will not change because the position of the maximum intensity pixel on a concentric circle and the position of the minimum intensity pixel on the other concentric circle do not change. Local patterns related to LIEP include local binary and intensity order patterns. Local binary pattern calculates the symbol of intensity difference between multiple pairs of pixels at the same time. Change in the symbol of intensity differences between any pairs of pixels will change the local binary pattern. Local intensity order pattern calculates the ranking of intensity value of multiple pixels and the change of the ranking of intensity value of any pixel will subsequently change the local intensity order pattern. Under the condition of image patch with adding Gaussian noise, the statistical histogram crossover of the LIEP feature between the origin image patch and image patch with adding Gaussian noise is higher than that of the local binary and intensity order patterns. Compared with local intensity order and binary patterns, the LIEP is more stable and robust to noise and image changes, and has smaller probability of pattern errors. LIEP is calculated in the local rotation-invariant coordinate system. A new local image descriptor, namely, LIEP histogram (LIEPH), is obtained using multiple support regions and the space convergence method of global intensity order in an image patch. The LIEPH descriptor has monotonous illumination invariance and keeps the rotation invariance without calculating the main direction of the image patch.ResultsComparison experiments with other popular local descriptors were conducted out on the standard image matching database. Experiments show that MRRID and LIEPH are superior to SIFT, LIOP, CS-LBP, HRI-CSLTP, and EOD in all image distortion conditions. LIEPH is superior to MRRID under Boat 1-5 and Wall 1-5 image distortion; LIEPH is slightly superior under Graffiti 1-5, Boat 1-3, Wall 1-3, and UBC 1-5 image distortion. The matching performance of LIEPH is equivalent to that of MRRID under other image distortions. In other words, the matching performance of LIEPH is equal to, slightly, or much higher than that of MRRID under all image distortion conditions. Based on all above situations, LIEPH performs better than that of MRRID, and the matching performance of LIEPH is better in large image photometric and geometric distortions. Therefore, LIEPH has strong discrimination and robustness. The robustness in resisting large image geometric distortion of LIEPH is better than MRRID as well. In the quantitative analysis experiments of the descriptors, when 1-precision is 0.4, the recall value of the LIEPH descriptor is largest under all types of image distortion. In the experiments of adding Gauss and salt-and-pepper noise to the standard image matching databases, the matching performance of LIEPH is better than that of MRRID. The algorithm complexity of LIEPH is lower, which is close to half of that of MRRID.ConclusionLIEPH has high capability to describe texture statistics in local image regions. The superior performance in discriminative power, robustness, and anti-noise enable the application of LIEPH to image region description and matching occasions under complex conditions.关键词:local image descriptor;local intensity order pattern;local binary pattern;local intensity extremum pattern;image matching14|5|0更新时间:2024-05-07
摘要:ObjectiveLocal image descriptors have been successfully applied to computer vision research, such as image search, robot navigation, image classification, and video action recognition. Local image descriptors perform effectively in the large viewpoint change of cameras, photometric change, noise, and local occlusion.MethodA new local feature for image region description, namely, local intensity extremum pattern (LIEP), is proposed in this study. The same number of pixel points is uniformly sampled on two concentric circles with different radii from one pixel point. The angles between the sampling points and the center pixel on different concentric circles interpolate each another. The maximum and minimum intensity patterns of each concentric circle are calculated independently. Two-dimensional joint distributions of the minimum intensity pattern on the concentric circle with a small radius and the maximum intensity pattern on the concentric circle with a large radius are computed. Subsequently, an intensity extreme pattern is obtained. Two-dimensional joint distributions of the maximum intensity pattern on the concentric circle with a small radius and the minimum intensity pattern on the concentric circle with a large radius are computed, and another intensity extreme pattern is obtained. The two extreme patterns are cascaded to obtain LIEP. From the calculation process of LIEP, the two LIEP sub-patterns will not change because the position of the maximum intensity pixel on a concentric circle and the position of the minimum intensity pixel on the other concentric circle do not change. Local patterns related to LIEP include local binary and intensity order patterns. Local binary pattern calculates the symbol of intensity difference between multiple pairs of pixels at the same time. Change in the symbol of intensity differences between any pairs of pixels will change the local binary pattern. Local intensity order pattern calculates the ranking of intensity value of multiple pixels and the change of the ranking of intensity value of any pixel will subsequently change the local intensity order pattern. Under the condition of image patch with adding Gaussian noise, the statistical histogram crossover of the LIEP feature between the origin image patch and image patch with adding Gaussian noise is higher than that of the local binary and intensity order patterns. Compared with local intensity order and binary patterns, the LIEP is more stable and robust to noise and image changes, and has smaller probability of pattern errors. LIEP is calculated in the local rotation-invariant coordinate system. A new local image descriptor, namely, LIEP histogram (LIEPH), is obtained using multiple support regions and the space convergence method of global intensity order in an image patch. The LIEPH descriptor has monotonous illumination invariance and keeps the rotation invariance without calculating the main direction of the image patch.ResultsComparison experiments with other popular local descriptors were conducted out on the standard image matching database. Experiments show that MRRID and LIEPH are superior to SIFT, LIOP, CS-LBP, HRI-CSLTP, and EOD in all image distortion conditions. LIEPH is superior to MRRID under Boat 1-5 and Wall 1-5 image distortion; LIEPH is slightly superior under Graffiti 1-5, Boat 1-3, Wall 1-3, and UBC 1-5 image distortion. The matching performance of LIEPH is equivalent to that of MRRID under other image distortions. In other words, the matching performance of LIEPH is equal to, slightly, or much higher than that of MRRID under all image distortion conditions. Based on all above situations, LIEPH performs better than that of MRRID, and the matching performance of LIEPH is better in large image photometric and geometric distortions. Therefore, LIEPH has strong discrimination and robustness. The robustness in resisting large image geometric distortion of LIEPH is better than MRRID as well. In the quantitative analysis experiments of the descriptors, when 1-precision is 0.4, the recall value of the LIEPH descriptor is largest under all types of image distortion. In the experiments of adding Gauss and salt-and-pepper noise to the standard image matching databases, the matching performance of LIEPH is better than that of MRRID. The algorithm complexity of LIEPH is lower, which is close to half of that of MRRID.ConclusionLIEPH has high capability to describe texture statistics in local image regions. The superior performance in discriminative power, robustness, and anti-noise enable the application of LIEPH to image region description and matching occasions under complex conditions.关键词:local image descriptor;local intensity order pattern;local binary pattern;local intensity extremum pattern;image matching14|5|0更新时间:2024-05-07 -
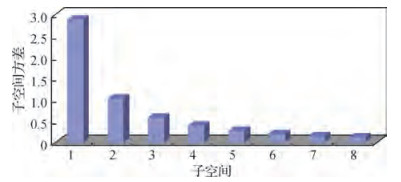 摘要:ObjectiveHashing method is one of the most popular approaches for content-based image retrieval. The main idea of this approach is to learn the same size of binary codes for each image and then use the Hamming distance to measure the similarity of images. Effective Hashing methods should include at least three properties. First, the learned codes should be short so that large amounts of images can be stored in a small memory. Second, the learned codes should transform images that are perceptually or semantically similar into binary strings with a small Hamming distance. Third, the method should be efficient to learn the parameters of the binary code and encode a new test image. Most Hashing approaches include two important steps to achieve binary coding, namely, projection and quantization. For projection, most Hashing approaches perform principal component analysis (PCA) to reduce the dimensionality of raw data. For quantization, different Hashing approaches may design different strategies. In the quantization stage, most traditional Hashing methods usually allocate the same number of bit to each data subspace for image retrieval. However, information quantities are different in each data subspace. Accordingly, a uniform quantization may result in inefficient codes and high quantization distortion problems, especially when the data have unbalanced information quantities. To address this problem, this study proposes an effective coding method based on product quantization, called Huffman coding.MethodSimilar to most Hashing approaches, the proposed method utilizes PCA to reduce the dimensionality of raw data in the projection stage. A vector quantization scheme is then carefully designed at the quantization stage. The proposed approach first utilizes product quantization to quantize data after dimensionality reduction to preserve data distribution in the original space. For each subspace, the variance can be directly calculated as the measure of its information quantity. For effectiveness, the subspace with high information quantity should be allocated with a large number of bit for binary coding and vice versa. To achieve this goal, the reciprocal value of the variance proportion can be used to build a Huffman tree, which can then be applied to generate Huffman codes. Accordingly, different bit and values of binary code can be assigned to each subspace. In other words, numerous bit will be allocated to encode subspaces with large variance and few for subspaces with small variance. The variance is easy to calculated, and therefore, the proposed approach is simple and efficient for binary coding. Experimental results illustrate that the Huffman coding method is effective for image retrieval.ResultDuring the experiment, the proposed approach is tested on three public datasets, namely, MNIST, NUS-WIDE, and 22K LabelMe. For each image, a 512D GIST descriptor can be extracted as the input of the Hashing approach. To verify its good performance, the proposed approach is compared with four related approaches:original product quantization method, PCA-based product quantization method, iterative quantization method, and transform coding (TC) method. The experimental results are reported in the form of quantization distortion, mean average precision, recall, and training time. Results show that the average quantization distortion of the proposed approach can be decreased by approximately 49%, and the mean average precision of the retrieval results is increased by approximately 19% compared with the existing method based on product quantization. The training time of the proposed approach is also compared with that of TC from 32 bit to 256 bit on MNIST. The proposed approach can reduce 22.5 s of the training time on average.ConclusionThis study proposes Huffman coding for image retrieval in the product quantization stage. According to information quantities, the Huffman-based product quantization scheme can allocate different numbers of bit to each data subspace, which can effectively increase coding efficiency and quantization accuracy. The proposed approach is tested on three public datasets and compared with four related approaches. Experimental results demonstrate that the proposed approach is superior to some state-of-the-art algorithms for image retrieval on mean average precision and recall. The proposed approach does not belong to precise coding methods; thus, our future work will focus on precise Hashing method for effective image retrieval.关键词:Hashing;image retrieval;approximate nearest neighbor search;product quantization;bit allocation;coding efficiency15|4|3更新时间:2024-05-07
摘要:ObjectiveHashing method is one of the most popular approaches for content-based image retrieval. The main idea of this approach is to learn the same size of binary codes for each image and then use the Hamming distance to measure the similarity of images. Effective Hashing methods should include at least three properties. First, the learned codes should be short so that large amounts of images can be stored in a small memory. Second, the learned codes should transform images that are perceptually or semantically similar into binary strings with a small Hamming distance. Third, the method should be efficient to learn the parameters of the binary code and encode a new test image. Most Hashing approaches include two important steps to achieve binary coding, namely, projection and quantization. For projection, most Hashing approaches perform principal component analysis (PCA) to reduce the dimensionality of raw data. For quantization, different Hashing approaches may design different strategies. In the quantization stage, most traditional Hashing methods usually allocate the same number of bit to each data subspace for image retrieval. However, information quantities are different in each data subspace. Accordingly, a uniform quantization may result in inefficient codes and high quantization distortion problems, especially when the data have unbalanced information quantities. To address this problem, this study proposes an effective coding method based on product quantization, called Huffman coding.MethodSimilar to most Hashing approaches, the proposed method utilizes PCA to reduce the dimensionality of raw data in the projection stage. A vector quantization scheme is then carefully designed at the quantization stage. The proposed approach first utilizes product quantization to quantize data after dimensionality reduction to preserve data distribution in the original space. For each subspace, the variance can be directly calculated as the measure of its information quantity. For effectiveness, the subspace with high information quantity should be allocated with a large number of bit for binary coding and vice versa. To achieve this goal, the reciprocal value of the variance proportion can be used to build a Huffman tree, which can then be applied to generate Huffman codes. Accordingly, different bit and values of binary code can be assigned to each subspace. In other words, numerous bit will be allocated to encode subspaces with large variance and few for subspaces with small variance. The variance is easy to calculated, and therefore, the proposed approach is simple and efficient for binary coding. Experimental results illustrate that the Huffman coding method is effective for image retrieval.ResultDuring the experiment, the proposed approach is tested on three public datasets, namely, MNIST, NUS-WIDE, and 22K LabelMe. For each image, a 512D GIST descriptor can be extracted as the input of the Hashing approach. To verify its good performance, the proposed approach is compared with four related approaches:original product quantization method, PCA-based product quantization method, iterative quantization method, and transform coding (TC) method. The experimental results are reported in the form of quantization distortion, mean average precision, recall, and training time. Results show that the average quantization distortion of the proposed approach can be decreased by approximately 49%, and the mean average precision of the retrieval results is increased by approximately 19% compared with the existing method based on product quantization. The training time of the proposed approach is also compared with that of TC from 32 bit to 256 bit on MNIST. The proposed approach can reduce 22.5 s of the training time on average.ConclusionThis study proposes Huffman coding for image retrieval in the product quantization stage. According to information quantities, the Huffman-based product quantization scheme can allocate different numbers of bit to each data subspace, which can effectively increase coding efficiency and quantization accuracy. The proposed approach is tested on three public datasets and compared with four related approaches. Experimental results demonstrate that the proposed approach is superior to some state-of-the-art algorithms for image retrieval on mean average precision and recall. The proposed approach does not belong to precise coding methods; thus, our future work will focus on precise Hashing method for effective image retrieval.关键词:Hashing;image retrieval;approximate nearest neighbor search;product quantization;bit allocation;coding efficiency15|4|3更新时间:2024-05-07 -
 摘要:ObjectiveAction recognition based on depth data is gradually performed due to the insensitivity to illumination of depth data. Two main methods are used; one refers to the point clouds converted from depth maps, and the other refers to the depth motion maps (DMMs) generated from depth map projection. Motion history point cloud (MHPC) is proposed to represent actions, but the large amount of points in the MHPC incur expensive computations when extracting features. DMMs are generated by stacking the motion energy of depth map sequence projected onto three orthogonal Cartesian planes. Projecting the depth maps onto a specific plane provides additional body shape and motion information. However, DMM contains inadequate motion information, which caps the human action recognition accuracy, although extracting features from DMMs is simple. In other words, an action is represented by DMMs from only three views; consequently, the action information from other perspectives is lacking. Multi-perspective DMMs for human action recognition are proposed to solve the above problems.MethodIn the algorithm, MHPC is first generated from a depth map sequence to represent actions. Motion information under different perspectives is supplemented through rotating the MHPC around axis
摘要:ObjectiveAction recognition based on depth data is gradually performed due to the insensitivity to illumination of depth data. Two main methods are used; one refers to the point clouds converted from depth maps, and the other refers to the depth motion maps (DMMs) generated from depth map projection. Motion history point cloud (MHPC) is proposed to represent actions, but the large amount of points in the MHPC incur expensive computations when extracting features. DMMs are generated by stacking the motion energy of depth map sequence projected onto three orthogonal Cartesian planes. Projecting the depth maps onto a specific plane provides additional body shape and motion information. However, DMM contains inadequate motion information, which caps the human action recognition accuracy, although extracting features from DMMs is simple. In other words, an action is represented by DMMs from only three views; consequently, the action information from other perspectives is lacking. Multi-perspective DMMs for human action recognition are proposed to solve the above problems.MethodIn the algorithm, MHPC is first generated from a depth map sequence to represent actions. Motion information under different perspectives is supplemented through rotating the MHPC around axis$Y$ $XOY$ $XOY$ $z$ $YOZ$ $XOZ$ $z$ $x$ $y$ $XOY$ $x, y, z$ $x$ $z$ $y$ 关键词:human action recognition;depth maps;depth motion maps;multi-perspective depth motion maps;motion history point cloud;histogram of oriented gradient;support vector machine36|91|2更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveSingle-image super-resolution aims to generate a visually pleasing high-resolution image from its degraded low-resolution measurement. Single-image super-resolution is used in various computer vision tasks, such as security and surveillance imaging, medical imaging, and image generation. However, image super-resolution is an ill-posed inverse problem because of a multitude of solutions for any low-resolution input. In recent years, a series of convolution neural networks model has been proposed for single-image super-resolution. The deep learning algorithms applied to single-image super-resolution reconstructions have used single-scale convolutional kernels to extract feature information of low-resolution images, thereby causing omissions of detailed information easily. Moreover, to obtain better image super-resolution reconstruction effects, the network model is constantly deepened, and the accompanying problems of gradients vanished, thereby resulting in longer training time and difficulty. A multi-scale dense residual network model based on GoogleNet, residual network, and intensive convolution network ideas is proposed to address these existing super-resolution reconstruction problems.MethodDifferent from the traditional single-scale feature extraction convolutional kernel, this study uses three different scales of convolution kernels 3×3, 5×5, and 7×7 to perform convolution processing on the input low-resolution images and collects the underlying features of different convolution kernels. Therefore, more detailed information on low-resolution images, which are beneficial to image restoration, are extracted. Then, the collected feature information is inputted into the residual block. Each residual block contains a number of feature extraction units consisting of convolutional and active layers. In addition, the output of each feature extraction unit is connected to the next feature extraction unit through a short path. Short-path connections can effectively alleviate the disappearance of gradients, enhance the propagation of features, and promote the reuse of features. Then, the feature information extracted by the three convolution kernels is merged, and the feature information extracted by the 3×3 pixels convolution kernel is added after dimensionality reduction processing to form a global residual learning. After a final reconstruction, a clear, high-resolution image is obtained. Throughout the training process, an input low-resolution image corresponds to a high-resolution image tag. This end-to-end learning method results in faster training. We use the mean squared error as the loss function. The loss is minimized using stochastic gradient descent with the standard backpropagation. We use a training data of 1 000 images from DIV2k, and the flipped and rotated versions of the training images are considered. We rotate the original images by 90° and 270°.ResultsThis study uses two objective evaluation criteria, namely, peak signal-to-noise ratio and structural similarity index to test the effect map of the experiment and compare it with other mainstream methods. The final results show that compared with interpolation method and SRCNN algorithm on Set5 dataset, the proposed algorithm improves approximately 3.4 dB and 1.1 dB at three times of magnification and 3.5 dB and 1.4 dB at four times of magnification, respectively.ConclusionWe propose a multi-scale dense residual network for single-image super-resolution. The experimental data and the effect graph confirm that the proposed algorithm can better recover the edge and texture information of low-resolution images. However, our networks have a large number of parameters because our algorithm uses three channels to recover image details. Therefore, our algorithm requires more convergence time. We will also reduce the number of weight parameters by decomposing the convolution kernel.关键词:single image super-resolution;multi-scale convolution kernel;residual network;dense convolutional network;feature extraction unit12|4|11更新时间:2024-05-07
摘要:ObjectiveSingle-image super-resolution aims to generate a visually pleasing high-resolution image from its degraded low-resolution measurement. Single-image super-resolution is used in various computer vision tasks, such as security and surveillance imaging, medical imaging, and image generation. However, image super-resolution is an ill-posed inverse problem because of a multitude of solutions for any low-resolution input. In recent years, a series of convolution neural networks model has been proposed for single-image super-resolution. The deep learning algorithms applied to single-image super-resolution reconstructions have used single-scale convolutional kernels to extract feature information of low-resolution images, thereby causing omissions of detailed information easily. Moreover, to obtain better image super-resolution reconstruction effects, the network model is constantly deepened, and the accompanying problems of gradients vanished, thereby resulting in longer training time and difficulty. A multi-scale dense residual network model based on GoogleNet, residual network, and intensive convolution network ideas is proposed to address these existing super-resolution reconstruction problems.MethodDifferent from the traditional single-scale feature extraction convolutional kernel, this study uses three different scales of convolution kernels 3×3, 5×5, and 7×7 to perform convolution processing on the input low-resolution images and collects the underlying features of different convolution kernels. Therefore, more detailed information on low-resolution images, which are beneficial to image restoration, are extracted. Then, the collected feature information is inputted into the residual block. Each residual block contains a number of feature extraction units consisting of convolutional and active layers. In addition, the output of each feature extraction unit is connected to the next feature extraction unit through a short path. Short-path connections can effectively alleviate the disappearance of gradients, enhance the propagation of features, and promote the reuse of features. Then, the feature information extracted by the three convolution kernels is merged, and the feature information extracted by the 3×3 pixels convolution kernel is added after dimensionality reduction processing to form a global residual learning. After a final reconstruction, a clear, high-resolution image is obtained. Throughout the training process, an input low-resolution image corresponds to a high-resolution image tag. This end-to-end learning method results in faster training. We use the mean squared error as the loss function. The loss is minimized using stochastic gradient descent with the standard backpropagation. We use a training data of 1 000 images from DIV2k, and the flipped and rotated versions of the training images are considered. We rotate the original images by 90° and 270°.ResultsThis study uses two objective evaluation criteria, namely, peak signal-to-noise ratio and structural similarity index to test the effect map of the experiment and compare it with other mainstream methods. The final results show that compared with interpolation method and SRCNN algorithm on Set5 dataset, the proposed algorithm improves approximately 3.4 dB and 1.1 dB at three times of magnification and 3.5 dB and 1.4 dB at four times of magnification, respectively.ConclusionWe propose a multi-scale dense residual network for single-image super-resolution. The experimental data and the effect graph confirm that the proposed algorithm can better recover the edge and texture information of low-resolution images. However, our networks have a large number of parameters because our algorithm uses three channels to recover image details. Therefore, our algorithm requires more convergence time. We will also reduce the number of weight parameters by decomposing the convolution kernel.关键词:single image super-resolution;multi-scale convolution kernel;residual network;dense convolutional network;feature extraction unit12|4|11更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveThe traditional content-based image retrieval method can only retrieve and analyze the features of low layers, such as color, texture, and shape, which exist in an image. Therefore, a low level of visual features exist in such method, which is inconsistent with the high-level semantic meaning of the user's understanding of the image. This inconsistency results in the "semantic gap" phenomenon, which leads to the low accuracy of image retrieval. Moreover, the traditional method cannot meet the user's demand for high-accuracy retrieval, while remote sensing images have rich information, complex content, and high dimensionality. Analyzing only the low-level features greatly reduces the accuracy of image retrieval. Therefore, selecting an appropriate image feature extraction is the key step to achieving high-accuracy retrieval. At the same time, the traditional classification method is insignificantly accurate in image classification. Determining how to select a high-accuracy image classification method is also essential. A remote sensing image retrieval method based on convolutional neural network and relevance feedback support vector machine (SVM) is proposed in this research.MethodThe proposed method can preprocess remote sensing images by contrasting the limited histogram equalization algorithm, limiting the noise magnification of the remote sensing images, and avoiding the influence of noise interference on the retrieval precision. On the basis of the GoogLeNet convolutional neural network model with good self-learning capability, a multilayer neural network of remote sensing images is supervised and studied, the rich features of the remote sensing images are extracted, and the problem of "semantic gap" in the content-based image retrieval method is solved. The original dataset is divided into training and test sets, and selecting the training set reasonably is the basis for the best classification. If too many samples exist in other categories in the training set, then determining the hyperplane classification will be greatly affected. A multi-distance combined top-k sorting method is proposed to rationally screen the original training set. The image closest to the query one will be used as the training set. On the one hand, the method saves considerable time for subsequent determination of the optimal hyperplane. On the other hand, most dissimilar images are filtered out to avoid the influences of more dissimilar images on the classification results. The SVM is used as the basic classifier, and the optimal hyperplane is trained according to the training set samples. The retrieval results are sorted according to the distance between the test sample data and the classified hyperplane. A feedback of the distance evaluation standard is proposed to update the retrieval results with the distance evaluation standard. The strategy readjusts the experimental results. The method uses a small-sample marking method to mark the counterexample images to avoid too many markers and lose the meaning of the retrieval. In addition, the optimal hyperplane of the SVM does not need to be retrained to avoid unnecessary time waste. Only multiple iterations are used to update the retrieval results, and one feedback can achieve the desired results.ResultThe image retrieval experiments are performed on the remote sensing image dataset of UC Merced Land-use dataset. Experimental results show that the mean average precision (mAP) of the proposed method is increased by 29.4% compared with that of the locality-sensitive Hashing method, is 37.2% higher than that of the density-sensitive Hashing method, which is 68.8% higher than the efficient manifold ranking, and is 3.5% higher than that of the SVM method without feedback and training set screening. The number of retrieved images is 100. For the average retrieval speed, this method is four times higher than the method with the highest mAP accuracy in the comparison method. For the average recall rate and the average precision rate, this method is also higher than the comparison method, which shows that this method can improve not only the retrieval accuracy but also the retrieval speed. For complex remote sensing image data, the retrieval effect of this method is better than those of other methods.ConclusionA new feedback strategy is proposed in this study to improve the retrieval accuracy. Small-sample markers are used for the poor retrieval results and the distance evaluation standard as the core to perform many iterations. One time feedback can achieve good retrieval results. In terms of speed increase, this study proposes a multi-distance combined Top-k sorting method, which reduces the time of SVMs to train the optimal hyperplane by rationally selecting the training sample set and then improving the retrieval speed. This method can be widely applied to face recognition, target tracking, and other fields, and it is significant to improving retrieval performance.关键词:remote sensing image retrieval;convolution neural network;feedback;support vector machine;contrast limited adaptive histogram equalization;Top-
摘要:ObjectiveThe traditional content-based image retrieval method can only retrieve and analyze the features of low layers, such as color, texture, and shape, which exist in an image. Therefore, a low level of visual features exist in such method, which is inconsistent with the high-level semantic meaning of the user's understanding of the image. This inconsistency results in the "semantic gap" phenomenon, which leads to the low accuracy of image retrieval. Moreover, the traditional method cannot meet the user's demand for high-accuracy retrieval, while remote sensing images have rich information, complex content, and high dimensionality. Analyzing only the low-level features greatly reduces the accuracy of image retrieval. Therefore, selecting an appropriate image feature extraction is the key step to achieving high-accuracy retrieval. At the same time, the traditional classification method is insignificantly accurate in image classification. Determining how to select a high-accuracy image classification method is also essential. A remote sensing image retrieval method based on convolutional neural network and relevance feedback support vector machine (SVM) is proposed in this research.MethodThe proposed method can preprocess remote sensing images by contrasting the limited histogram equalization algorithm, limiting the noise magnification of the remote sensing images, and avoiding the influence of noise interference on the retrieval precision. On the basis of the GoogLeNet convolutional neural network model with good self-learning capability, a multilayer neural network of remote sensing images is supervised and studied, the rich features of the remote sensing images are extracted, and the problem of "semantic gap" in the content-based image retrieval method is solved. The original dataset is divided into training and test sets, and selecting the training set reasonably is the basis for the best classification. If too many samples exist in other categories in the training set, then determining the hyperplane classification will be greatly affected. A multi-distance combined top-k sorting method is proposed to rationally screen the original training set. The image closest to the query one will be used as the training set. On the one hand, the method saves considerable time for subsequent determination of the optimal hyperplane. On the other hand, most dissimilar images are filtered out to avoid the influences of more dissimilar images on the classification results. The SVM is used as the basic classifier, and the optimal hyperplane is trained according to the training set samples. The retrieval results are sorted according to the distance between the test sample data and the classified hyperplane. A feedback of the distance evaluation standard is proposed to update the retrieval results with the distance evaluation standard. The strategy readjusts the experimental results. The method uses a small-sample marking method to mark the counterexample images to avoid too many markers and lose the meaning of the retrieval. In addition, the optimal hyperplane of the SVM does not need to be retrained to avoid unnecessary time waste. Only multiple iterations are used to update the retrieval results, and one feedback can achieve the desired results.ResultThe image retrieval experiments are performed on the remote sensing image dataset of UC Merced Land-use dataset. Experimental results show that the mean average precision (mAP) of the proposed method is increased by 29.4% compared with that of the locality-sensitive Hashing method, is 37.2% higher than that of the density-sensitive Hashing method, which is 68.8% higher than the efficient manifold ranking, and is 3.5% higher than that of the SVM method without feedback and training set screening. The number of retrieved images is 100. For the average retrieval speed, this method is four times higher than the method with the highest mAP accuracy in the comparison method. For the average recall rate and the average precision rate, this method is also higher than the comparison method, which shows that this method can improve not only the retrieval accuracy but also the retrieval speed. For complex remote sensing image data, the retrieval effect of this method is better than those of other methods.ConclusionA new feedback strategy is proposed in this study to improve the retrieval accuracy. Small-sample markers are used for the poor retrieval results and the distance evaluation standard as the core to perform many iterations. One time feedback can achieve good retrieval results. In terms of speed increase, this study proposes a multi-distance combined Top-k sorting method, which reduces the time of SVMs to train the optimal hyperplane by rationally selecting the training sample set and then improving the retrieval speed. This method can be widely applied to face recognition, target tracking, and other fields, and it is significant to improving retrieval performance.关键词:remote sensing image retrieval;convolution neural network;feedback;support vector machine;contrast limited adaptive histogram equalization;Top-$ k $ 15|34|4更新时间:2024-05-07 -
 摘要:ObjectiveVarious remote sensing sensors presently exist, and multisource remote sensing images, such as multispectral (MS) and panchromatic (PAN) images, can be acquired. MS images, which have rich spectral information and low spatial resolution, cannot meet the remote sensing application demand. Correspondingly, PAN images have more spatial details and higher spatial resolutions. The significance of MS and PAN image fusion is that it improves the spatial resolution of MS images while maintaining original spectral information. It also combines target shape and the structural characteristics of PAN images and the spectral information of MS images to provide great interpretation capability and reliable results, as well as enhances the classification and identification precision of objects. However, the spatial resolution enhancement of PAN images and the spectral information maintenance of MS images are usually contradictory. How to acquire a high fusion performance in the contradictions has always been a popular and difficult point in the research field of remote sensing image fusion and has an extensive prospect in research and application. In this study, a fusion method based on morphological filter and improved pulse-coupled neural network (PCNN) in a non-subsampled shearlet transform (NSST) domain is proposed to improve the fusion quality of MS and PAN images by combining spectral information with spatial details efficiently.MethodThe proposed method is conducted on MS and PAN images that have been accurately registered. First, the PAN and MS images are decomposed by NSST to obtain low- and high-frequency sub-band coefficients. Second, the low-frequency sub-bands, which are approximate sub-graphs of the original image and inherit the overall characteristics, still have some edges and detailed information. The fusion rule of low-frequency coefficients based on morphological filtering and high-pass modulation (HPM) scheme is proposed. The morphological half-gradient operator is used to extract the details of the low-frequency sub-bands of the PAN image owing to its preliminary encouraging fusion results on remote sensing images. The low-resolution PAN sub-band image can be obtained by morphological filtering, and the detailed PAN sub-band image is estimated by subtracting the low-resolution PAN sub-band image from the PAN sub-band image equalized with histogram on the basis of the MS sub-band image. The spatial details are then injected into the low-frequency sub-band of the MS image through the HPM scheme. For the fusion of high-frequency sub-bands, an improved PCNN is taken to enhance spatial detail information. Existing PCNN models usually adopt a hard-limiting function as output, and the firing output is 0 or 1, which cannot reflect the amplitude difference of the synchronous pulse excitation efficiently. At a point, a soft-limiting sigmoid function is adopted to calculate the firing output amplitude during the iterations, and the decision matrix for high-frequency coefficient selection can be achieved by summing up the firing output amplitude in the iterative process. Then, the fusion low- and high-frequency coefficients are reconstructed with the inverse NSST to obtain the final fusion image.ResultA series of simulation experiments is conducted to verify the superiority and validity of the proposed fusion method. Three groups of QuickBird remote sensing images are utilized to test the proposed method. The performance evaluation of the fusion methods includes the subjective visual effect and objective standard evaluation. Visual analysis is the most immediate detection method. Five objective evaluation indicators, namely, image clarity, information entropy, correlation coefficient, spatial frequency, and spectral distortion, are selected to evaluate the fusion results quantitatively and objectively. Experimental results show that the proposed method has obvious advantages in the fusion effect. The subjective visual effect of the proposed method is obviously better than those of the other five methods. Details such as image textures and edges are clear, and the spectral information is maintained efficiently. Compared with the other fusion methods, the proposed method also has great superiority on the objective evaluation indicators. The average values of the five indicators for three bands are calculated, four of which are the best among the comparison methods. The average value of three groups of images are also calculated. Compared with the best indicator of the other five methods, the image clarity and spatial frequency of our method are improved by 0.5% and 1.0%, respectively, compared with the NSCT-PCNN method. Our spectral distortion is 4.2% lower than that of the NSST-PCNN method. Our correlation coefficient is 1.4% higher than that of NSST-PCNN, and the information entropy is only 0.08% lower than the best value from NSST-PCNN. The results of the correlation coefficient and spectral distortion demonstrate that the proposed method maintains better spectral information than do the other five methods. Results of the image clarity and spatial frequency show that the proposed method has an excellent capability of detailed information injection, and only the image clarity of B band in group 2 is poor. The information entropy is approximate to the best result.ConclusionA fusion method of MS and PAN images based on morphological operator and improved PCNN in NSST domain is proposed. We present the fusion rules for different frequency bands according to the NSST decomposition of the original MS and PAN images. Low-frequency coefficient fusion rule based on morphological half-gradient filtering and the HPM scheme and high-frequency coefficient fusion rule based on the improved PCNN are designed. A real satellite dataset is employed for the performance evaluation of the proposed method. The analysis indicates that our method can improve the spatial resolution and maintain the spectral information of fusion results. In general, the proposed method is superior to the traditional methods and some current popular fusion methods from the overall effect of visual aspects and objective indicators.关键词:multispectral and panchromatic images fusion;non-subsampled shearlet transform;morphological filter;high-pass modulation;pulse coupled neural network14|24|13更新时间:2024-05-07
摘要:ObjectiveVarious remote sensing sensors presently exist, and multisource remote sensing images, such as multispectral (MS) and panchromatic (PAN) images, can be acquired. MS images, which have rich spectral information and low spatial resolution, cannot meet the remote sensing application demand. Correspondingly, PAN images have more spatial details and higher spatial resolutions. The significance of MS and PAN image fusion is that it improves the spatial resolution of MS images while maintaining original spectral information. It also combines target shape and the structural characteristics of PAN images and the spectral information of MS images to provide great interpretation capability and reliable results, as well as enhances the classification and identification precision of objects. However, the spatial resolution enhancement of PAN images and the spectral information maintenance of MS images are usually contradictory. How to acquire a high fusion performance in the contradictions has always been a popular and difficult point in the research field of remote sensing image fusion and has an extensive prospect in research and application. In this study, a fusion method based on morphological filter and improved pulse-coupled neural network (PCNN) in a non-subsampled shearlet transform (NSST) domain is proposed to improve the fusion quality of MS and PAN images by combining spectral information with spatial details efficiently.MethodThe proposed method is conducted on MS and PAN images that have been accurately registered. First, the PAN and MS images are decomposed by NSST to obtain low- and high-frequency sub-band coefficients. Second, the low-frequency sub-bands, which are approximate sub-graphs of the original image and inherit the overall characteristics, still have some edges and detailed information. The fusion rule of low-frequency coefficients based on morphological filtering and high-pass modulation (HPM) scheme is proposed. The morphological half-gradient operator is used to extract the details of the low-frequency sub-bands of the PAN image owing to its preliminary encouraging fusion results on remote sensing images. The low-resolution PAN sub-band image can be obtained by morphological filtering, and the detailed PAN sub-band image is estimated by subtracting the low-resolution PAN sub-band image from the PAN sub-band image equalized with histogram on the basis of the MS sub-band image. The spatial details are then injected into the low-frequency sub-band of the MS image through the HPM scheme. For the fusion of high-frequency sub-bands, an improved PCNN is taken to enhance spatial detail information. Existing PCNN models usually adopt a hard-limiting function as output, and the firing output is 0 or 1, which cannot reflect the amplitude difference of the synchronous pulse excitation efficiently. At a point, a soft-limiting sigmoid function is adopted to calculate the firing output amplitude during the iterations, and the decision matrix for high-frequency coefficient selection can be achieved by summing up the firing output amplitude in the iterative process. Then, the fusion low- and high-frequency coefficients are reconstructed with the inverse NSST to obtain the final fusion image.ResultA series of simulation experiments is conducted to verify the superiority and validity of the proposed fusion method. Three groups of QuickBird remote sensing images are utilized to test the proposed method. The performance evaluation of the fusion methods includes the subjective visual effect and objective standard evaluation. Visual analysis is the most immediate detection method. Five objective evaluation indicators, namely, image clarity, information entropy, correlation coefficient, spatial frequency, and spectral distortion, are selected to evaluate the fusion results quantitatively and objectively. Experimental results show that the proposed method has obvious advantages in the fusion effect. The subjective visual effect of the proposed method is obviously better than those of the other five methods. Details such as image textures and edges are clear, and the spectral information is maintained efficiently. Compared with the other fusion methods, the proposed method also has great superiority on the objective evaluation indicators. The average values of the five indicators for three bands are calculated, four of which are the best among the comparison methods. The average value of three groups of images are also calculated. Compared with the best indicator of the other five methods, the image clarity and spatial frequency of our method are improved by 0.5% and 1.0%, respectively, compared with the NSCT-PCNN method. Our spectral distortion is 4.2% lower than that of the NSST-PCNN method. Our correlation coefficient is 1.4% higher than that of NSST-PCNN, and the information entropy is only 0.08% lower than the best value from NSST-PCNN. The results of the correlation coefficient and spectral distortion demonstrate that the proposed method maintains better spectral information than do the other five methods. Results of the image clarity and spatial frequency show that the proposed method has an excellent capability of detailed information injection, and only the image clarity of B band in group 2 is poor. The information entropy is approximate to the best result.ConclusionA fusion method of MS and PAN images based on morphological operator and improved PCNN in NSST domain is proposed. We present the fusion rules for different frequency bands according to the NSST decomposition of the original MS and PAN images. Low-frequency coefficient fusion rule based on morphological half-gradient filtering and the HPM scheme and high-frequency coefficient fusion rule based on the improved PCNN are designed. A real satellite dataset is employed for the performance evaluation of the proposed method. The analysis indicates that our method can improve the spatial resolution and maintain the spectral information of fusion results. In general, the proposed method is superior to the traditional methods and some current popular fusion methods from the overall effect of visual aspects and objective indicators.关键词:multispectral and panchromatic images fusion;non-subsampled shearlet transform;morphological filter;high-pass modulation;pulse coupled neural network14|24|13更新时间:2024-05-07
Remote Sensing Image Processing
-
 摘要:ObjectiveInpainting is the process of reconstructing lost or deteriorated parts of images and videos. This reconstruction process is an important research area in the field of computer vision, and its purpose is to automatically repair lost content according to the known content of the images and videos. Inpainting has extensive application value in the fields of image editing, film and television special effect production, virtual reality, and digital cultural heritage protection. Deep learning has been widely studied in the academic and industrial fields in recent years. Its advantages in image semantic extraction, feature representation, and image generation have become increasingly prominent, leading to the increasing attention to and popularity of research on image inpainting based on deep learning. This study reviews the current research status of image inpainting based on deep learning to enable researchers to explore its theory and development.MethodThis paper first discusses the issue of image inpainting and summarizes the advantages and disadvantages of the commonly used methods by comparing their application results in image restoration in large areas. The theoretical basis of image inpainting based on deep learning is then analyzed, and the key technologies of image inpainting based on deep learning, which include the generation network based on auto encoder, the general training methods of deep network, and the training methods based on convolutional auto encoder network, are studied. This paper also summarizes some image inpainting methods based on deep learning that have been proposed in recent years and classifies these methods into three categories according to the architecture of their repairing network:image inpainting methods based on deep convolutional auto encoder architecture, image inpainting methods based on generative adversarial network (GAN) architecture, and image inpainting based on recurrent neural network (RNN) architecture. The basic structure of the generation network based on autoencoder is described, many improved networks and their loss functions are analyzed, and the experimental results based on different loss functions are provided. For the image inpainting methods based on GAN, the basic structure and process architecture of the GAN are described, and the experimental results based on some classical methods are presented. For the image inpainting methods based on RNN, the RNN model is analyzed, especially the methods based on the PixelRNN model, and the experimental results based on MNIST and CIFAR-10 datasets are provided.ResultThe design of deep learning networks and the selection of training loss functions are important in image inpainting based on deep learning methods. Each method has its merits, demerits, and application ranges. However, the main direction of the research is how to improve the rationality of semantics, the correctness of structure, and the detail of the repaired image. On the basis of this purpose, this paper summarizes and analyzes the characteristics, existing issues, requirements for training samples, application fields, and reference codes of these methods through experiments.ConclusionAlthough remarkable progress has been made in the field of image inpainting based on deep learning, the application of deep learning in image restoration remains in its infancy research focuses on using own image content information to restore images and still has demerits and own adaptation range. Consequently, image inpainting based on deep learning remains a challenging subject. How to improve the adaptability of the repairing network and the correctness of repairing results still requires further studies. This paper indicates the developing prospects from the following aspects:1) Further research may focus on how to design an adaptive network based on both semantic and texture networks. 2) The quality of inpainting images must be improved by studying the loss function of the repair network; the study of distance measurement based on different application purposes is especially critical. 3) Further research may focus on image inpainting methods of specific types, such as improving the generalization capability of the methods on small datasets through designing targeted training network structure and performing processes, such as fine tuning. 4) As processing power, such as GPUs, increases, the inpainting methods that train high-resolution images directly are also worth studying. 5) For some complex scenes, utilizing human-computer interaction strategies to repair images is still worth studying to promote their practical application and enrich digital image restoration technologies.关键词:image inpainting;deep learning;convolutional neural network;generative adversarial network;recurrent neural network;deep convolutional auto encoder network45|7|21更新时间:2024-05-07
摘要:ObjectiveInpainting is the process of reconstructing lost or deteriorated parts of images and videos. This reconstruction process is an important research area in the field of computer vision, and its purpose is to automatically repair lost content according to the known content of the images and videos. Inpainting has extensive application value in the fields of image editing, film and television special effect production, virtual reality, and digital cultural heritage protection. Deep learning has been widely studied in the academic and industrial fields in recent years. Its advantages in image semantic extraction, feature representation, and image generation have become increasingly prominent, leading to the increasing attention to and popularity of research on image inpainting based on deep learning. This study reviews the current research status of image inpainting based on deep learning to enable researchers to explore its theory and development.MethodThis paper first discusses the issue of image inpainting and summarizes the advantages and disadvantages of the commonly used methods by comparing their application results in image restoration in large areas. The theoretical basis of image inpainting based on deep learning is then analyzed, and the key technologies of image inpainting based on deep learning, which include the generation network based on auto encoder, the general training methods of deep network, and the training methods based on convolutional auto encoder network, are studied. This paper also summarizes some image inpainting methods based on deep learning that have been proposed in recent years and classifies these methods into three categories according to the architecture of their repairing network:image inpainting methods based on deep convolutional auto encoder architecture, image inpainting methods based on generative adversarial network (GAN) architecture, and image inpainting based on recurrent neural network (RNN) architecture. The basic structure of the generation network based on autoencoder is described, many improved networks and their loss functions are analyzed, and the experimental results based on different loss functions are provided. For the image inpainting methods based on GAN, the basic structure and process architecture of the GAN are described, and the experimental results based on some classical methods are presented. For the image inpainting methods based on RNN, the RNN model is analyzed, especially the methods based on the PixelRNN model, and the experimental results based on MNIST and CIFAR-10 datasets are provided.ResultThe design of deep learning networks and the selection of training loss functions are important in image inpainting based on deep learning methods. Each method has its merits, demerits, and application ranges. However, the main direction of the research is how to improve the rationality of semantics, the correctness of structure, and the detail of the repaired image. On the basis of this purpose, this paper summarizes and analyzes the characteristics, existing issues, requirements for training samples, application fields, and reference codes of these methods through experiments.ConclusionAlthough remarkable progress has been made in the field of image inpainting based on deep learning, the application of deep learning in image restoration remains in its infancy research focuses on using own image content information to restore images and still has demerits and own adaptation range. Consequently, image inpainting based on deep learning remains a challenging subject. How to improve the adaptability of the repairing network and the correctness of repairing results still requires further studies. This paper indicates the developing prospects from the following aspects:1) Further research may focus on how to design an adaptive network based on both semantic and texture networks. 2) The quality of inpainting images must be improved by studying the loss function of the repair network; the study of distance measurement based on different application purposes is especially critical. 3) Further research may focus on image inpainting methods of specific types, such as improving the generalization capability of the methods on small datasets through designing targeted training network structure and performing processes, such as fine tuning. 4) As processing power, such as GPUs, increases, the inpainting methods that train high-resolution images directly are also worth studying. 5) For some complex scenes, utilizing human-computer interaction strategies to repair images is still worth studying to promote their practical application and enrich digital image restoration technologies.关键词:image inpainting;deep learning;convolutional neural network;generative adversarial network;recurrent neural network;deep convolutional auto encoder network45|7|21更新时间:2024-05-07 -
 摘要:ObjectiveDeep convolutional neural networks have recently shown outstanding performances in object recognition and have also been the first choice for dense classification problems, such as semantic segmentation. Fully convolutional network based methods have become the main research direction in the field of image semantic segmentation. However, repeated downsampling operations in these methods, such as pooling or convolution striding, lead to a significant decrease in the initial image resolution, which results in poor object delineation, small target losing, and weak segmentation output. Although some studies have solved this problem in recent years, determining how to effectively handle this problem remains an open question and deserves further attention. This study proposes a feature map slice module for semantic segmentation to solve this problem.MethodThe proposed method mainly includes two parts:middle layer feature map segmentation and corresponding feature extraction network. The feature map slice module mainly focuses on the middle layer feature map. The feature map is sliced into several small cubes, and then each cube is upsampled to the corresponding resolution of the original feature map, which enlarges the small target in the local area. Each cube is equivalent to a subregion of the original feature map by the proposed feature map slice module. After upsampling these cubes, the objects in these subregions are enlarged. Thus, the small objects in these regions can be regarded as relatively large objects, which are difficult to detect through the entire feature map. Therefore, in the process of feature extraction, attention must be focused on the small target objects in these subregions, which are difficult to detect if we handle the entire feature map. A weight-shared feature extraction network is thus designed for sliced feature maps. The feature extraction network adopts multiple convolution operations (different kernel sizes) to extract different scale feature information. For each input of the network, the dimension is reduced to half to save memory and dilation convolution is adopted to enlarge the network's receptive field. We then concatenate a difficult feature map (obtained by different convolution operations) and add a channel-attention operation. The feature extraction network combines multi-scale convolution and attention mechanism; when subregions are passing through the feature extraction network, it can extract different semantic category information from corresponding subregions, as well as provide contextual and global information and discriminant information of each slice effectively. Accordingly, we can focus on small objects in local areas and improve the discriminability of small target objects. Each cube passes through the feature extraction network. The extracted feature in the corresponding position is assembled and the entire mosaic feature map is acquired. The network original output is upsampled and fused with the mosaic feature map by element-wise max operation. In this way, the middle-layer feature can be reused efficiently. To utilize the middlelayer feature information, this module is introduced at multiple scales, which enhances the capability of extracting small target characteristics and spatial information in local areas. It also utilizes the semantic information in different scales and exhibits an obvious improvement for extracting small target features, refining segmentation edge, and enhancing network discrimination.ResultThe proposed method is verified on two urban scene-understanding datasets, namely, CamVid and GATECH. Both datasets contain many common urban scene objects, such as building, car, and cyclist. Several ablation experiments are conducted on the two datasets and excellent performances are achieved. In particular, intersection-over-union scores of 66.3 and 52.6 are acquired on CamVid and GATECH, respectively.ConclusionThe proposed method utilizes the spatial distribution information of images, enhances the network capability to determine the semantic categories of different spatial locations, pays considerable attention to small target objects, and provides effective context and global information. The proposed method is expanded into different resolutions of the network considering that different resolutions can provide rich-scale information. Thus, we utilize middle layer feature information, improve the network capability to discriminate small target objects, and enhance the overall segmentation performance of the network.关键词:deep learning;fully convolutional neural networks;semantic segmentation;scene parsing;feature slice;multiple scales;feature reuse19|5|4更新时间:2024-05-07
摘要:ObjectiveDeep convolutional neural networks have recently shown outstanding performances in object recognition and have also been the first choice for dense classification problems, such as semantic segmentation. Fully convolutional network based methods have become the main research direction in the field of image semantic segmentation. However, repeated downsampling operations in these methods, such as pooling or convolution striding, lead to a significant decrease in the initial image resolution, which results in poor object delineation, small target losing, and weak segmentation output. Although some studies have solved this problem in recent years, determining how to effectively handle this problem remains an open question and deserves further attention. This study proposes a feature map slice module for semantic segmentation to solve this problem.MethodThe proposed method mainly includes two parts:middle layer feature map segmentation and corresponding feature extraction network. The feature map slice module mainly focuses on the middle layer feature map. The feature map is sliced into several small cubes, and then each cube is upsampled to the corresponding resolution of the original feature map, which enlarges the small target in the local area. Each cube is equivalent to a subregion of the original feature map by the proposed feature map slice module. After upsampling these cubes, the objects in these subregions are enlarged. Thus, the small objects in these regions can be regarded as relatively large objects, which are difficult to detect through the entire feature map. Therefore, in the process of feature extraction, attention must be focused on the small target objects in these subregions, which are difficult to detect if we handle the entire feature map. A weight-shared feature extraction network is thus designed for sliced feature maps. The feature extraction network adopts multiple convolution operations (different kernel sizes) to extract different scale feature information. For each input of the network, the dimension is reduced to half to save memory and dilation convolution is adopted to enlarge the network's receptive field. We then concatenate a difficult feature map (obtained by different convolution operations) and add a channel-attention operation. The feature extraction network combines multi-scale convolution and attention mechanism; when subregions are passing through the feature extraction network, it can extract different semantic category information from corresponding subregions, as well as provide contextual and global information and discriminant information of each slice effectively. Accordingly, we can focus on small objects in local areas and improve the discriminability of small target objects. Each cube passes through the feature extraction network. The extracted feature in the corresponding position is assembled and the entire mosaic feature map is acquired. The network original output is upsampled and fused with the mosaic feature map by element-wise max operation. In this way, the middle-layer feature can be reused efficiently. To utilize the middlelayer feature information, this module is introduced at multiple scales, which enhances the capability of extracting small target characteristics and spatial information in local areas. It also utilizes the semantic information in different scales and exhibits an obvious improvement for extracting small target features, refining segmentation edge, and enhancing network discrimination.ResultThe proposed method is verified on two urban scene-understanding datasets, namely, CamVid and GATECH. Both datasets contain many common urban scene objects, such as building, car, and cyclist. Several ablation experiments are conducted on the two datasets and excellent performances are achieved. In particular, intersection-over-union scores of 66.3 and 52.6 are acquired on CamVid and GATECH, respectively.ConclusionThe proposed method utilizes the spatial distribution information of images, enhances the network capability to determine the semantic categories of different spatial locations, pays considerable attention to small target objects, and provides effective context and global information. The proposed method is expanded into different resolutions of the network considering that different resolutions can provide rich-scale information. Thus, we utilize middle layer feature information, improve the network capability to discriminate small target objects, and enhance the overall segmentation performance of the network.关键词:deep learning;fully convolutional neural networks;semantic segmentation;scene parsing;feature slice;multiple scales;feature reuse19|5|4更新时间:2024-05-07 -
 摘要:ObjectiveThe mainstream object detection algorithm needs to delimit the default box in advance and then acquire the object box by filtering out the default box. Sufficiently dense and multi-scale default boxes must be preset to ensure a sufficient recall rate, which leads to repeated detection of various areas in an image and great computational waste. This study proposes a multi-task deep learning model (FCDN), which does not need to delimit the default boxes and can improve the detection speed while ensuring accuracy.MethodThe condition that the number of objects being detected is undetermined is the reason the current mainstream object detection algorithm needs to delineate the default box in advance. Deep learning object detection networks are developed by image classification models. Consequently, the number of objects to be detected is unpredictable, and the output of the detection model cannot be determined. Sufficiently dense and multiscale default boxes must be classified or recognized to ensure the recall rate. The object detection task requires object category information to realize the recognition of different objects and object boundary information to realize the positioning of each object. A semantic segmentation map extracts rich category information of objects, which can be used to recognize the categories of the objects. Object recognition and positioning can be completed by adopting the idea of semantic segmentation, designing a module to extract the boundary key points of the objects, and combining semantic segmentation map and the boundary key points of the objects. Object detection methods based on image classification have a rectangular receptive field that contains the information of other objects or background other than the object itself. Object detection methods based on semantic segmentation map and boundary key points are different; their receptive field is at the pixel level. Pixels of detected object can be removed from the semantic segmentation map and boundary key point distribution map, which does not affect the other object detection and can avoid the residual of small objects. According to the preceding analysis, we propose a new multi-task learning model, which increases the prediction layer of boundary key points on the basis of a semantic segmentation model, can complete the semantic segmentation and boundary key point prediction at the same time, and combines the semantic segmentation map and boundary key point distribution map to complete object detection. Boundary lines are obtained through boundary key points and object boxes according to the boundary lines.ResultAn object detection network that does not need to delimit the default boxes is proposed. This object detection algorithm is no longer based on image classification but uses the semantic segmentation idea to detect all object boundary key points at the pixel level. The ground truth box is obtained by combining the category information of the semantic segmentation result. The object detection method is trained based on semantic segmentation and then tested with PASCAL VOC 2007 test image data sets to verify its feasibility. The performance comparison results with the current mainstream object detection algorithm show that the semantic segmentation and object can be realized at the same time by using the new model trained with the same training sample. The detection precision of FCDN is superior to that of classic detection models. In terms of the running speed of the algorithm, compared with FCN, it is reduced by 8 ms, which is close to fast detection algorithms, such as YOLO.ConclusionThis study proposes an idea of object detection that is no longer based on image classification and it utilizes semantic segmentation to extract information from the image to be detected. Experimental results show that according to the semantic segmentation image and the boundary point to complete, the object detection method is feasible. This method can avoid repeated detection and reduced waste calculation by decreasing the pixels of semantic segmentation prediction to improve detection efficiency. The simplified semantic segmentation map will not affect the detection accuracy.关键词:deep learning;object detection;semantic segmentation;object boundary key points;multi-task learning;transfer learning;default boxes24|29|4更新时间:2024-05-07
摘要:ObjectiveThe mainstream object detection algorithm needs to delimit the default box in advance and then acquire the object box by filtering out the default box. Sufficiently dense and multi-scale default boxes must be preset to ensure a sufficient recall rate, which leads to repeated detection of various areas in an image and great computational waste. This study proposes a multi-task deep learning model (FCDN), which does not need to delimit the default boxes and can improve the detection speed while ensuring accuracy.MethodThe condition that the number of objects being detected is undetermined is the reason the current mainstream object detection algorithm needs to delineate the default box in advance. Deep learning object detection networks are developed by image classification models. Consequently, the number of objects to be detected is unpredictable, and the output of the detection model cannot be determined. Sufficiently dense and multiscale default boxes must be classified or recognized to ensure the recall rate. The object detection task requires object category information to realize the recognition of different objects and object boundary information to realize the positioning of each object. A semantic segmentation map extracts rich category information of objects, which can be used to recognize the categories of the objects. Object recognition and positioning can be completed by adopting the idea of semantic segmentation, designing a module to extract the boundary key points of the objects, and combining semantic segmentation map and the boundary key points of the objects. Object detection methods based on image classification have a rectangular receptive field that contains the information of other objects or background other than the object itself. Object detection methods based on semantic segmentation map and boundary key points are different; their receptive field is at the pixel level. Pixels of detected object can be removed from the semantic segmentation map and boundary key point distribution map, which does not affect the other object detection and can avoid the residual of small objects. According to the preceding analysis, we propose a new multi-task learning model, which increases the prediction layer of boundary key points on the basis of a semantic segmentation model, can complete the semantic segmentation and boundary key point prediction at the same time, and combines the semantic segmentation map and boundary key point distribution map to complete object detection. Boundary lines are obtained through boundary key points and object boxes according to the boundary lines.ResultAn object detection network that does not need to delimit the default boxes is proposed. This object detection algorithm is no longer based on image classification but uses the semantic segmentation idea to detect all object boundary key points at the pixel level. The ground truth box is obtained by combining the category information of the semantic segmentation result. The object detection method is trained based on semantic segmentation and then tested with PASCAL VOC 2007 test image data sets to verify its feasibility. The performance comparison results with the current mainstream object detection algorithm show that the semantic segmentation and object can be realized at the same time by using the new model trained with the same training sample. The detection precision of FCDN is superior to that of classic detection models. In terms of the running speed of the algorithm, compared with FCN, it is reduced by 8 ms, which is close to fast detection algorithms, such as YOLO.ConclusionThis study proposes an idea of object detection that is no longer based on image classification and it utilizes semantic segmentation to extract information from the image to be detected. Experimental results show that according to the semantic segmentation image and the boundary point to complete, the object detection method is feasible. This method can avoid repeated detection and reduced waste calculation by decreasing the pixels of semantic segmentation prediction to improve detection efficiency. The simplified semantic segmentation map will not affect the detection accuracy.关键词:deep learning;object detection;semantic segmentation;object boundary key points;multi-task learning;transfer learning;default boxes24|29|4更新时间:2024-05-07 -
 摘要:ObjectiveCrowd counting is a task that estimates the counting results and density distribution of a crowd by extracting and analyzing the crowd features. A common strategy extracts the crowd features of different scales through multiscale convolutional neural networks (CNNs) and then fuses them to yield the final density estimation results. However, crowd information will be lost due to the downsampling operation in CNNs and the model averaging effects in the multi-scale CNNs induced by the fusion method. The strategy does not necessarily acquire accurate estimation results. Accordingly, this study proposes a novel model named multi-scale crowd counting via adversarial dilated convolutions.MethodOur background modeling is based on a dilated convolution model proposed by solving the problem of image semantic segmentation. In the domain of image segmentation, the most common method is to use a CNN to solve the problem. We enter the images into the CNN, and the network performs the convolution operation to images and then the pooling operation. As a result, the image size is reduced, and the receptive field of the network is increased. However, the image segmentation is a pixel-wise problem, and the smaller image must be upsampled after pooling to the original image size for prediction (a deconvolution operation is generally used to realize upsampling). Therefore, two key points exist in image segmentation. One is that pooling reduces the image size and increases the receptive field, and the other is upsampling to enlarge the image size. Information may be lost in the processes of reducing and resizing. Dilated convolution, which can make the network scale consistent, is proposed to solve this issue. A specific principle is to remove the pooling layer in the network that reduces the resolution of the feature map. However, the model cannot learn the global vision of images. Increasing the convolution kernel scale will cause the computation to increase sharply and overload the memory. We can increase the original convolution kernel to a certain expansion coefficient and fill the empty position with 0 to enlarge the scale of the convolution kernel and increase the receptive field. In this way, the receptive field widens due to the expansion of the convolution kernel and the computation remains unchanged because the effective computation points in the convolution kernel remain unchanged. The scale of each feature is invariable, and thus the image information is also preserved. The proposed model is based on adversarial dilated convolutions. On the one hand, the dilated convolution can extract the features of input image without losing resolution and the module uses different dilated convolutions to aggregate multi-scale context information. On the other hand, the adversarial loss function improves the accuracy of estimation results in a collaborating manner to fuse different-scale information.ResultThe proposed method reduces the mean absolute error (MAE) and the mean squared error (MSE) to 60.5 and 109.7 on the Part_A of ShanghaiTech dataset and to 10.2 and 15.3 on the Part_B, respectively. Compared with existing methods, the proposed method shows improved MAEs by 7.7 and 0.4 in the two parts. A synthetic analysis of five sets of video sequences on the WorldExpo' 10 database demonstrates that the average prediction result increases by 0.66 compared with that of the classical algorithm. On the UCF_CC_50 dataset, MAE and MSE improve by 18.6 and 22.9, respectively, which proves that the estimation accuracy is enhanced because of the noticeable effect on the environment with a complex number of scenes. However, the MAE reduces to 1.02 on the UCSD database and the MSE does not improve. The adversarial loss function limits the robustness of crowd counting with a low-density environment.ConclusionA new learning strategy named multiscale crowd counting via adversarial dilated convolutions is proposed in this study. The network uses the dilated convolutions to save significant image information, and the dilated convolutions with dilated coefficients of different sizes aggregate multiscale contextual information, which solves the problem of counting the head of different scales in crowd scene images due to angle difference. The adversarial loss function utilizes the image feature extracted by the network to estimate crowd density. Experimental results show that the algorithm model constructed in the scene with large population distribution has good adaptability. The model can estimate the density distribution according to different scenes and count the population accurately.关键词:crowd counting;multi-scale;adversarial loss;dilated convolutions;computer vision;crowd safety13|4|1更新时间:2024-05-07
摘要:ObjectiveCrowd counting is a task that estimates the counting results and density distribution of a crowd by extracting and analyzing the crowd features. A common strategy extracts the crowd features of different scales through multiscale convolutional neural networks (CNNs) and then fuses them to yield the final density estimation results. However, crowd information will be lost due to the downsampling operation in CNNs and the model averaging effects in the multi-scale CNNs induced by the fusion method. The strategy does not necessarily acquire accurate estimation results. Accordingly, this study proposes a novel model named multi-scale crowd counting via adversarial dilated convolutions.MethodOur background modeling is based on a dilated convolution model proposed by solving the problem of image semantic segmentation. In the domain of image segmentation, the most common method is to use a CNN to solve the problem. We enter the images into the CNN, and the network performs the convolution operation to images and then the pooling operation. As a result, the image size is reduced, and the receptive field of the network is increased. However, the image segmentation is a pixel-wise problem, and the smaller image must be upsampled after pooling to the original image size for prediction (a deconvolution operation is generally used to realize upsampling). Therefore, two key points exist in image segmentation. One is that pooling reduces the image size and increases the receptive field, and the other is upsampling to enlarge the image size. Information may be lost in the processes of reducing and resizing. Dilated convolution, which can make the network scale consistent, is proposed to solve this issue. A specific principle is to remove the pooling layer in the network that reduces the resolution of the feature map. However, the model cannot learn the global vision of images. Increasing the convolution kernel scale will cause the computation to increase sharply and overload the memory. We can increase the original convolution kernel to a certain expansion coefficient and fill the empty position with 0 to enlarge the scale of the convolution kernel and increase the receptive field. In this way, the receptive field widens due to the expansion of the convolution kernel and the computation remains unchanged because the effective computation points in the convolution kernel remain unchanged. The scale of each feature is invariable, and thus the image information is also preserved. The proposed model is based on adversarial dilated convolutions. On the one hand, the dilated convolution can extract the features of input image without losing resolution and the module uses different dilated convolutions to aggregate multi-scale context information. On the other hand, the adversarial loss function improves the accuracy of estimation results in a collaborating manner to fuse different-scale information.ResultThe proposed method reduces the mean absolute error (MAE) and the mean squared error (MSE) to 60.5 and 109.7 on the Part_A of ShanghaiTech dataset and to 10.2 and 15.3 on the Part_B, respectively. Compared with existing methods, the proposed method shows improved MAEs by 7.7 and 0.4 in the two parts. A synthetic analysis of five sets of video sequences on the WorldExpo' 10 database demonstrates that the average prediction result increases by 0.66 compared with that of the classical algorithm. On the UCF_CC_50 dataset, MAE and MSE improve by 18.6 and 22.9, respectively, which proves that the estimation accuracy is enhanced because of the noticeable effect on the environment with a complex number of scenes. However, the MAE reduces to 1.02 on the UCSD database and the MSE does not improve. The adversarial loss function limits the robustness of crowd counting with a low-density environment.ConclusionA new learning strategy named multiscale crowd counting via adversarial dilated convolutions is proposed in this study. The network uses the dilated convolutions to save significant image information, and the dilated convolutions with dilated coefficients of different sizes aggregate multiscale contextual information, which solves the problem of counting the head of different scales in crowd scene images due to angle difference. The adversarial loss function utilizes the image feature extracted by the network to estimate crowd density. Experimental results show that the algorithm model constructed in the scene with large population distribution has good adaptability. The model can estimate the density distribution according to different scenes and count the population accurately.关键词:crowd counting;multi-scale;adversarial loss;dilated convolutions;computer vision;crowd safety13|4|1更新时间:2024-05-07
ChinaMM 2018
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0