
最新刊期
卷 24 , 期 2 , 2019
-
 摘要:ObjectiveClothing retrieval is a technology that combines clothing inspection, clothing classification, and feature learning, which plays an important role in clothing promotion and sales. Current clothing retrieval algorithms are mainly based on deep neural network. These algorithms initially learn the high-dimensional features of a clothing image through the network and compare the high-dimensional features between different images to determine clothing similarity. These clothing retrieval algorithms usually possess a semantic gap problem. They cannot connect the clothing features with semantic information, such as color, texture, and style, which results in their insufficient interpretability. Therefore, these algorithms cannot adapt another domain and usually fail in retrieving several clothing with new styles. The accuracy of clothing retrieval algorithm should be improved, especially for cross-domain multilabel clothing image. This study proposes a new cloth retrieval pipeline with deep multilabel parsing and hashing to increase the cross-domain clothing retrieval accuracy and reduce the high-dimensional output features of the deep neural network.MethodOn the basis of the semantic expression of street shot photos, we introduce and improve a fully convolutional network (FCN) structure to parse clothing in pixel level. To overcome the fragment label and noise problem, we employ conditional random fields (CRFs) to the FCN as a post process. In addition, a new image retrieval algorithm based on multi-task learning and Hashing is proposed to solve the semantic gap problem and dimension disaster in clothing retrieval. On the basis of extracted image features, a Hashing algorithm is used to map the high-dimensional feature vectors to low-dimensional Hamming space while maintaining their similarities. Hence, the dimension disaster problem in the clothing retrieval algorithm can be solved, and a real-time performance can be achieved. Moreover, we reorganize the Consumer-to-Shop database based on cross-scene clothing retrieval. The database is organized in accordance with shops and consumers' photos to ensure that the clothes under the same ID are similar. We also propose a clothing classification model and integrate this model on a traditional clothing similarity model to overcome the semantic drift problem. In summary, the proposed clothing retrieval model can be divided into two parts. The first part is a semantic segmentation network for street shot photos, which is used to identify the specific clothing target in the image. The second part is a Hashing model based on the multi-task network, which can map the high-dimensional network features to the low-latitude hash space.ResultWe modify the Clothing Co-Parsing dataset and establish the Consumer-to-Shop dataset. We conduct a clothing parsing experiment for the modified dataset. We find that the FCN might drop the detailed features of an image. The segmentation results show blurred edges and color blocking effect after several up-sampling operations. To overcome these limitations, CRFs are used in the method for subsequent correction. The experimental results show that many areas are recognized as correct labels, and fine color blocks are replaced by smooth segmentation results after the addition of CRFs as post-processing, which are easily recognized by human intuition. Then, we compare our method with three mainstream retrieval algorithms, and the results show that our method can achieve top-level accuracy with the usage of hash features. The top-5 accuracy is 1.31% higher than that of WTBI and 0.21% higher than that of DARN.ConclusionWe propose a deep multilabel parsing and hashing retrieval network to increase the efficiency and accuracy of clothing retrieval algorithm. For the clothing parsing task, the modified FCN-CRFs model shows the best subjective visual effects among other methods and achieves a superior time performance. For the clothing retrieval task, an approximate nearest neighbor search technique is employed and a hashing algorithm is used to simplify high-dimensional features. At the same time, the clothing classification and clothing similarity models are trained by using a multi-task learning network to solve the semantic drift phenomena during retrieval. In comparison with other clothing retrieval methods, our method shows several advantages in multi-label clothing retrieval scenarios. Our method achieves the highest score in top-10 accuracy, effectively reduces storage space, and improves retrieval efficiency.关键词:clothes retrieval;FCN;Hashing;multi-label parsing;multi-task learning20|61|3更新时间:2024-05-07
摘要:ObjectiveClothing retrieval is a technology that combines clothing inspection, clothing classification, and feature learning, which plays an important role in clothing promotion and sales. Current clothing retrieval algorithms are mainly based on deep neural network. These algorithms initially learn the high-dimensional features of a clothing image through the network and compare the high-dimensional features between different images to determine clothing similarity. These clothing retrieval algorithms usually possess a semantic gap problem. They cannot connect the clothing features with semantic information, such as color, texture, and style, which results in their insufficient interpretability. Therefore, these algorithms cannot adapt another domain and usually fail in retrieving several clothing with new styles. The accuracy of clothing retrieval algorithm should be improved, especially for cross-domain multilabel clothing image. This study proposes a new cloth retrieval pipeline with deep multilabel parsing and hashing to increase the cross-domain clothing retrieval accuracy and reduce the high-dimensional output features of the deep neural network.MethodOn the basis of the semantic expression of street shot photos, we introduce and improve a fully convolutional network (FCN) structure to parse clothing in pixel level. To overcome the fragment label and noise problem, we employ conditional random fields (CRFs) to the FCN as a post process. In addition, a new image retrieval algorithm based on multi-task learning and Hashing is proposed to solve the semantic gap problem and dimension disaster in clothing retrieval. On the basis of extracted image features, a Hashing algorithm is used to map the high-dimensional feature vectors to low-dimensional Hamming space while maintaining their similarities. Hence, the dimension disaster problem in the clothing retrieval algorithm can be solved, and a real-time performance can be achieved. Moreover, we reorganize the Consumer-to-Shop database based on cross-scene clothing retrieval. The database is organized in accordance with shops and consumers' photos to ensure that the clothes under the same ID are similar. We also propose a clothing classification model and integrate this model on a traditional clothing similarity model to overcome the semantic drift problem. In summary, the proposed clothing retrieval model can be divided into two parts. The first part is a semantic segmentation network for street shot photos, which is used to identify the specific clothing target in the image. The second part is a Hashing model based on the multi-task network, which can map the high-dimensional network features to the low-latitude hash space.ResultWe modify the Clothing Co-Parsing dataset and establish the Consumer-to-Shop dataset. We conduct a clothing parsing experiment for the modified dataset. We find that the FCN might drop the detailed features of an image. The segmentation results show blurred edges and color blocking effect after several up-sampling operations. To overcome these limitations, CRFs are used in the method for subsequent correction. The experimental results show that many areas are recognized as correct labels, and fine color blocks are replaced by smooth segmentation results after the addition of CRFs as post-processing, which are easily recognized by human intuition. Then, we compare our method with three mainstream retrieval algorithms, and the results show that our method can achieve top-level accuracy with the usage of hash features. The top-5 accuracy is 1.31% higher than that of WTBI and 0.21% higher than that of DARN.ConclusionWe propose a deep multilabel parsing and hashing retrieval network to increase the efficiency and accuracy of clothing retrieval algorithm. For the clothing parsing task, the modified FCN-CRFs model shows the best subjective visual effects among other methods and achieves a superior time performance. For the clothing retrieval task, an approximate nearest neighbor search technique is employed and a hashing algorithm is used to simplify high-dimensional features. At the same time, the clothing classification and clothing similarity models are trained by using a multi-task learning network to solve the semantic drift phenomena during retrieval. In comparison with other clothing retrieval methods, our method shows several advantages in multi-label clothing retrieval scenarios. Our method achieves the highest score in top-10 accuracy, effectively reduces storage space, and improves retrieval efficiency.关键词:clothes retrieval;FCN;Hashing;multi-label parsing;multi-task learning20|61|3更新时间:2024-05-07 -
 摘要:ObjectiveImage dehazing is a process of reducing the degradation effect of low-visibility imaging environment, such as fog, sputum, and sand, and improving the quality of image information acquisition. Image dehazing mainly solves the problems of image feature information blur, low contrast, gray-level concentration, and color distortion. At present, image dehazing methods are mainly divided into two categories, namely, image restoration and image enhancement. A dehazing algorithm based on image restoration is used to establish a physical model of image degradation in restoring the clear image in a targeted manner by analyzing the degradation mechanism of the image and by using prior knowledge or assumptions. The dehazing algorithm is more targeted compared with image enhancement algorithms. Deblurring is better and image information is complete, which should be investigated. Therefore, an image dehazing algorithm based on mixed prior and weighted guided filter (MPWGF) is proposed to eliminate the prior blind zone and improve the sharpness of the edge detail of haze-free images.MethodFirst, a new method of atmospheric light value estimation is proposed to reduce the limitation of atmospheric light value estimation and utilize the advantage of mixed prior conditions. Pixel positions of 0.1% before brightness in dark channel and depth maps are extracted, and coordinate points extracted from the two images are compared. The coordinate points are retained when two images are observed simultaneously; otherwise, the values with the highest brightness that correspond to the remaining coordinate points in the original image are eliminated. This method can eliminate outliers to some extent and improves the accuracy of atmospheric light estimation. Then, mixed prior theory is used to calculate the atmospheric transmission of the double-constraint region, which eliminates the prior blind zone to a certain extent. This theory improves the robustness of the dehazing algorithm. The dark channel prior (DCP) and color attenuation prior (CAP) have good recovery effects and can compensate for the existence of the prior blind zone. Therefore, an effective region segmentation method is proposed to segment the bright and foggy regions of blurred images. On the basis of regional characteristics, DCP and CAP are used to obtain atmospheric transmittance maps to solve the prior blind region problem in which a single prior estimation method affects the robustness of the restoration algorithm. Finally, an adaptive guided filter algorithm is used to optimize the transmission map, which improves the sharpness of the image edge details. The obtained coarse transmittance map should be refined to eliminate the halo and block artifacts that locally exist in the restored image. A traditional transmittance map optimization algorithm has poor edge retention capability and serious loss of details. Thus, this study proposes an adaptive weighted guidance filtering algorithm based on the traditional algorithm. The edge detail improvement of the fine transmittance map is achieved by adding an adaptive weighted factor.ResultIn this study, the general dehazing test image and foggy image captured by a small UAV are taken as experimental objects. The rationality of the improved methods and the superiority of the overall algorithm are verified by comparing and analyzing the restoration effects of the four combined step algorithms. Experimental results show that the mixed prior theory improves the distortion of the dark priori in the bright region and the deficiency of CAP in dense fog processing and achieves better visual effect. Weighted guided filtering improves the image edge blurring and makes the image edge details clear after restoration. In comparison with other comparison algorithms, the proposed method has better visual effects, and the edge details of haze-free images are more evident. The average increase of comprehensive evaluation index is large.ConclusionFor the restoration of hazy images, the superiority of the proposed improved model is demonstrated through theoretical analysis and experimental verification. The restoration of the proposed algorithm is better than that with the traditional algorithm. The main conclusions are summarized as follows. Mixed prior theory can improve the prior blind area problem in DCP and CAP theories to a certain extent, and the effect of image defogging is better. The adaptive guided filtering algorithm can optimize the transmittance image better and improve the edge sharpness of the defogging image. The image defogging effect can be improved by combining hybrid prior theory with the adaptive guided filtering algorithm. Under the same conditions, the proposed algorithm has better image restoration effect compared with the traditional fog removal algorithm. In this study, several limitations are observed in the parameter setting of regional segmentation, such as the adjustment of parameters through experience and insufficient certain theoretical basis. The parameter setting will be investigated in our future study. MPWGF has broad application prospects in image restoration, artificial intelligence, photogrammetry, and other fields.关键词:image dehazing;mixed prior;double constraint region;guided filter;atmospheric light22|5|6更新时间:2024-05-07
摘要:ObjectiveImage dehazing is a process of reducing the degradation effect of low-visibility imaging environment, such as fog, sputum, and sand, and improving the quality of image information acquisition. Image dehazing mainly solves the problems of image feature information blur, low contrast, gray-level concentration, and color distortion. At present, image dehazing methods are mainly divided into two categories, namely, image restoration and image enhancement. A dehazing algorithm based on image restoration is used to establish a physical model of image degradation in restoring the clear image in a targeted manner by analyzing the degradation mechanism of the image and by using prior knowledge or assumptions. The dehazing algorithm is more targeted compared with image enhancement algorithms. Deblurring is better and image information is complete, which should be investigated. Therefore, an image dehazing algorithm based on mixed prior and weighted guided filter (MPWGF) is proposed to eliminate the prior blind zone and improve the sharpness of the edge detail of haze-free images.MethodFirst, a new method of atmospheric light value estimation is proposed to reduce the limitation of atmospheric light value estimation and utilize the advantage of mixed prior conditions. Pixel positions of 0.1% before brightness in dark channel and depth maps are extracted, and coordinate points extracted from the two images are compared. The coordinate points are retained when two images are observed simultaneously; otherwise, the values with the highest brightness that correspond to the remaining coordinate points in the original image are eliminated. This method can eliminate outliers to some extent and improves the accuracy of atmospheric light estimation. Then, mixed prior theory is used to calculate the atmospheric transmission of the double-constraint region, which eliminates the prior blind zone to a certain extent. This theory improves the robustness of the dehazing algorithm. The dark channel prior (DCP) and color attenuation prior (CAP) have good recovery effects and can compensate for the existence of the prior blind zone. Therefore, an effective region segmentation method is proposed to segment the bright and foggy regions of blurred images. On the basis of regional characteristics, DCP and CAP are used to obtain atmospheric transmittance maps to solve the prior blind region problem in which a single prior estimation method affects the robustness of the restoration algorithm. Finally, an adaptive guided filter algorithm is used to optimize the transmission map, which improves the sharpness of the image edge details. The obtained coarse transmittance map should be refined to eliminate the halo and block artifacts that locally exist in the restored image. A traditional transmittance map optimization algorithm has poor edge retention capability and serious loss of details. Thus, this study proposes an adaptive weighted guidance filtering algorithm based on the traditional algorithm. The edge detail improvement of the fine transmittance map is achieved by adding an adaptive weighted factor.ResultIn this study, the general dehazing test image and foggy image captured by a small UAV are taken as experimental objects. The rationality of the improved methods and the superiority of the overall algorithm are verified by comparing and analyzing the restoration effects of the four combined step algorithms. Experimental results show that the mixed prior theory improves the distortion of the dark priori in the bright region and the deficiency of CAP in dense fog processing and achieves better visual effect. Weighted guided filtering improves the image edge blurring and makes the image edge details clear after restoration. In comparison with other comparison algorithms, the proposed method has better visual effects, and the edge details of haze-free images are more evident. The average increase of comprehensive evaluation index is large.ConclusionFor the restoration of hazy images, the superiority of the proposed improved model is demonstrated through theoretical analysis and experimental verification. The restoration of the proposed algorithm is better than that with the traditional algorithm. The main conclusions are summarized as follows. Mixed prior theory can improve the prior blind area problem in DCP and CAP theories to a certain extent, and the effect of image defogging is better. The adaptive guided filtering algorithm can optimize the transmittance image better and improve the edge sharpness of the defogging image. The image defogging effect can be improved by combining hybrid prior theory with the adaptive guided filtering algorithm. Under the same conditions, the proposed algorithm has better image restoration effect compared with the traditional fog removal algorithm. In this study, several limitations are observed in the parameter setting of regional segmentation, such as the adjustment of parameters through experience and insufficient certain theoretical basis. The parameter setting will be investigated in our future study. MPWGF has broad application prospects in image restoration, artificial intelligence, photogrammetry, and other fields.关键词:image dehazing;mixed prior;double constraint region;guided filter;atmospheric light22|5|6更新时间:2024-05-07 -
 摘要:ObjectiveNatural images generally consist of smooth regions with sharp edges, which lead to a heavy-tailed gradient distribution. The gradient priors of these images are commonly used for image deblurring. However, previous results show that existing parameter estimation methods cannot tightly fit the texture change of different image patches. This study presents an image deblurring algorithm that uses a local adaptive sparse gradient model that is based on a blocky stationary distribution characteristic of a natural image.MethodFirst, our method uses a generalized Gaussian distribution (GGD) to represent the image's heavy-tailed gradient statistics. Second, an adaptive sparse gradient model is established to estimate a clean image via the maximization of posterior probability. In the model, different patches have different gradient statistics distribution, even within a single image, rather than assigning a single image gradient prior to an entire image. Third, an alternating minimization algorithm based on a variable-splitting technique is employed to solve the optimization problem of the deblurring model. This optimization problem is divided into two sub-problems, namely, latent image
摘要:ObjectiveNatural images generally consist of smooth regions with sharp edges, which lead to a heavy-tailed gradient distribution. The gradient priors of these images are commonly used for image deblurring. However, previous results show that existing parameter estimation methods cannot tightly fit the texture change of different image patches. This study presents an image deblurring algorithm that uses a local adaptive sparse gradient model that is based on a blocky stationary distribution characteristic of a natural image.MethodFirst, our method uses a generalized Gaussian distribution (GGD) to represent the image's heavy-tailed gradient statistics. Second, an adaptive sparse gradient model is established to estimate a clean image via the maximization of posterior probability. In the model, different patches have different gradient statistics distribution, even within a single image, rather than assigning a single image gradient prior to an entire image. Third, an alternating minimization algorithm based on a variable-splitting technique is employed to solve the optimization problem of the deblurring model. This optimization problem is divided into two sub-problems, namely, latent image$\boldsymbol{u}$ $\boldsymbol{\omega }$ $\boldsymbol{\omega }$ $\boldsymbol{u}$ $\boldsymbol{u}$ $\boldsymbol{\omega }$ $\boldsymbol{g}$ $\boldsymbol{u}_0$ $\boldsymbol{u}_1$ $\boldsymbol{u}_1$ 关键词:image deblurring;adaptive sparse gradient;statistical prior;distribution parameter estimation;image deconvolution27|49|1更新时间:2024-05-07 -
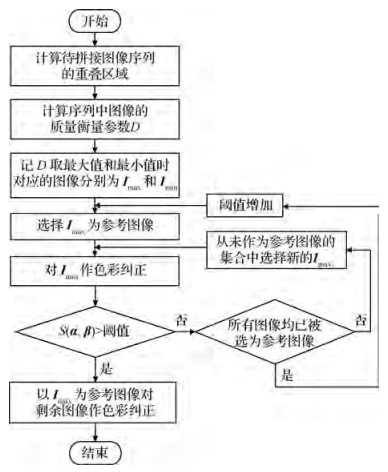 摘要:ObjectivePanorama scene reproduction, which is widely used in medicine, tourism, remote sensing, and photography, is a technique utilized to produce a large or wide-angle scene with multiple overlapping images. Color correction and image blending are the key issues in the generation of high-quality panoramas. The generation efficiency and quality are primarily determined by selecting a reference image for color correction and an image blending algorithm. To determine a reference image, state-of-the-art methods compare the similarity of all target images, which is computationally complex with poor real-time responsiveness. In addition, a contradiction exists between the quality and speed in image blending. Therefore, a high-quality panoramic image should be rapidly generated to reproduce panoramic scenes.MethodA key task for a panorama stitching technique is finding the optimal seams in the overlap region of the source image, merging them along the seam, and minimizing the seam artifact. This study presents an efficient method in selecting a reference image for color correction and a partition blending method that differentiates the overlapping area. The color and illumination of images are inconsistent due to the difference in camera equipment, shooting angle, and shooting time, which affect the visual quality of the panorama. Color correction is applied to reduce the color difference between images and accelerate the optimal seam search and image blending processes. Color correction uses a reference image to adjust the color style of other images. In other words, the reference image determines the quality of the final panorama. The panoramic image may suffer from blurriness, inappropriate brightness, and low contrast when the quality of the selected reference image is poor. The quality of an image is usually inversely proportional to the stability of an image; thus, a greedy strategy is adopted to determine the best reference image and reduce the computational complexity. The worst quality image is selected as the baseline, which is determined based on the relative standard deviation of the image pixels of adjacent images. The similarity between the original and corrected baselines is used to determine whether an input image is appropriate to be used as the reference image, such that the complexity for selecting a reference image is remarkably reduced while guaranteeing the need for color correction. An effective color correction method can achieve a smooth transition of the panoramic image. However, an unnatural transition along the seam is observed. Image blending is required to conceal the artifacts, in which Poisson and linear blending are usually used. Linear blending is simple and fast. However, the weakness of linear blending is that stitching artifacts may be visible after the blending. In comparison with linear blending, Poisson blending is more effective although it is more time-consuming than the former. Partition blending is proposed to solve the following problems. The overlapping region is divided into seam and non-seam regions, Poisson blending is performed in the seam region, and linear correction is conducted in the non-seam region to obtain a high-quality image. A simple point-light source is added to solve the light inconsistency generated by the aforementioned processes and improve the quality of the panorama.ResultSubjective and objective evaluations show interesting results for the proposed method. For the subjective evaluation, the methods can produce a panoramic scene with consistent color styles and can maintain the original details. For the objective evaluation, the structural similarity of the image after color correction is controlled between 0.85 and 0.99, the time complexity is reduced to O(
摘要:ObjectivePanorama scene reproduction, which is widely used in medicine, tourism, remote sensing, and photography, is a technique utilized to produce a large or wide-angle scene with multiple overlapping images. Color correction and image blending are the key issues in the generation of high-quality panoramas. The generation efficiency and quality are primarily determined by selecting a reference image for color correction and an image blending algorithm. To determine a reference image, state-of-the-art methods compare the similarity of all target images, which is computationally complex with poor real-time responsiveness. In addition, a contradiction exists between the quality and speed in image blending. Therefore, a high-quality panoramic image should be rapidly generated to reproduce panoramic scenes.MethodA key task for a panorama stitching technique is finding the optimal seams in the overlap region of the source image, merging them along the seam, and minimizing the seam artifact. This study presents an efficient method in selecting a reference image for color correction and a partition blending method that differentiates the overlapping area. The color and illumination of images are inconsistent due to the difference in camera equipment, shooting angle, and shooting time, which affect the visual quality of the panorama. Color correction is applied to reduce the color difference between images and accelerate the optimal seam search and image blending processes. Color correction uses a reference image to adjust the color style of other images. In other words, the reference image determines the quality of the final panorama. The panoramic image may suffer from blurriness, inappropriate brightness, and low contrast when the quality of the selected reference image is poor. The quality of an image is usually inversely proportional to the stability of an image; thus, a greedy strategy is adopted to determine the best reference image and reduce the computational complexity. The worst quality image is selected as the baseline, which is determined based on the relative standard deviation of the image pixels of adjacent images. The similarity between the original and corrected baselines is used to determine whether an input image is appropriate to be used as the reference image, such that the complexity for selecting a reference image is remarkably reduced while guaranteeing the need for color correction. An effective color correction method can achieve a smooth transition of the panoramic image. However, an unnatural transition along the seam is observed. Image blending is required to conceal the artifacts, in which Poisson and linear blending are usually used. Linear blending is simple and fast. However, the weakness of linear blending is that stitching artifacts may be visible after the blending. In comparison with linear blending, Poisson blending is more effective although it is more time-consuming than the former. Partition blending is proposed to solve the following problems. The overlapping region is divided into seam and non-seam regions, Poisson blending is performed in the seam region, and linear correction is conducted in the non-seam region to obtain a high-quality image. A simple point-light source is added to solve the light inconsistency generated by the aforementioned processes and improve the quality of the panorama.ResultSubjective and objective evaluations show interesting results for the proposed method. For the subjective evaluation, the methods can produce a panoramic scene with consistent color styles and can maintain the original details. For the objective evaluation, the structural similarity of the image after color correction is controlled between 0.85 and 0.99, the time complexity is reduced to O($n$ ${n^2}$ 关键词:panoramic scene reproduction;reference image;color correction;image blending;region division;local light11|6|0更新时间:2024-05-07
Image Processing and Coding

-
 摘要:ObjectiveAs an important part of face recognition, face detection has attracted considerable attention in computer vision and has been widely investigated. Face detection determines the location and size of human faces in an image. Traditional face detection methods are limited by face multi-pose changes and incomplete facial features, which lead to their poor detection effect. Modern face detectors can easily detect near-frontal faces. Recent research in this area has focused on the uncontrolled face detection problem, where a number of factors, such as multi-pose changes and incomplete facial features, can lead to large visual variations in face appearance and can severely degrade the robustness of the face detector. A convolutional neural network can automatically select facial features, rapidly delete a large number of non-face background information, and can achieve good face detection results. However, a single convolutional neural network should possess three functions, namely, facial feature extraction, reduction of feature dimensions to decrease the computational complexity, and feature classification, which result in complex network structure, limited detection speed, and overfitting of the network. To solve these problems, this study presents a face detection method of two-layer cascaded convolutional neural network (TC_CNN).MethodFirst, a two-layer convolutional neural network model is constructed. The first convolutional neural network model is used to extract the features of the face image, and a max pooling method is adopted to reduce the dimension of those features in which multiple suspected face windows are outputted. Second, the face windows are used as the inputs of the second convolutional neural network model for fine feature extraction, and a new feature map is obtained by pool operation. Finally, the best detection window is outputted through full connection layer discrimination. The face is successfully detected and the face window is returned when the result of discriminant classification is a face; otherwise, the non-face window is deleted. An optimal face detection window can be selected through non-maximum suppression, the size and position of the face in the input image are returned based on the location information of the optimal face detection window, and the entire process of face detection is completed. In the training of TC_CNN, we use 10 000 images with near-frontal faces, face multi-pose changes, and incomplete facial features from the labeled faces in the Wild dataset as positive training samples and 1 000 images as negative training samples. In the testing of the TC_CNN model, we utilize an authoritative dataset FDDB to evaluate, measure, and determine the validity of the model based on four indexes, namely, detection rate, false detection rate, missing detection rate, and detection time. The TC_CNN model is compared with excellent face detection algorithms, such as AdaBoost, fast LBP, NPD+AdaBoost, and SPP+CNN methods.ResultImages with face multi-pose changes and incomplete face feature information in the FDDB face detection dataset are selected for the test. Results show that the face detection rate by TC_CNN method is up to 96.39%, false detection rate is as low as 3.78%, and detection time is 0.451 s. For the detection rate, the TC_CNN method is 7.63% higher than the traditional AdaBoost method based on cascade idea, 3.57% higher than the fast LBP method, 0.50% higher than the NPD+AdaBoost method, and 6.04% higher than the SPP+CNN method. For the false detection rate, the TC_CNN method is 2.44% lower than the AdaBoost method, 4.47% lower than the fast LBP method, 0.59% lower than the NPD+AdaBoost method, and 5.09% lower than the SPP+CNN method. For the detection time, the TC_CNN method's detection efficiency is remarkably higher than the SPP+CNN method and slightly higher than the AdaBoost, fast LBP, and NPD+AdaBoost methods. In comparison with the current methods, the detection rate is increased while ensuring the efficiency of the algorithm. To verify the robustness of the TC_CNN model under the conditions of face multi-pose changes and incomplete facial features, representative images of two special cases are selected from the FDDB dataset in conducting four groups of comparative experiments under the multi-pose changes of a single face image, multi-pose changes of a multi face image, incomplete facial features of a single face image, and incomplete facial features of a multi face image. Experimental results show that the TC_CNN model shows good effectiveness and robustness compared with the four excellent algorithms or four groups of contrastive experiments under different interference conditions.ConclusionThe TC_CNN model for face detection can achieve accurate detection under face multi-pose changes and incomplete facial feature information. This model can obtain a high detection rate and effectively reduce false detection rate. The method has good robustness and generalization capability. The TC_CNN method overcomes the limitations of the excellent AdaBoost cascade concept on the face detection method (such as cascading two convolutional neural networks; effectively avoiding the complex network structure caused by the three functions of extraction, reduction, and classification of features simultaneously), which easily cause overfitting and other contradictions. However, the selection of the number and parameter of the cascaded convolutional neural network is difficult for the improvement of the model performance and detection effect. In future research, we will determine the number and parameter of cascaded convolution neural network to optimize the model and will attempt to detect the size and position of the face accurately.关键词:face detection;convolutional neural network;ten-fold cross validation;two-layer cascaded convolutional neural network;max pooling19|35|3更新时间:2024-05-07
摘要:ObjectiveAs an important part of face recognition, face detection has attracted considerable attention in computer vision and has been widely investigated. Face detection determines the location and size of human faces in an image. Traditional face detection methods are limited by face multi-pose changes and incomplete facial features, which lead to their poor detection effect. Modern face detectors can easily detect near-frontal faces. Recent research in this area has focused on the uncontrolled face detection problem, where a number of factors, such as multi-pose changes and incomplete facial features, can lead to large visual variations in face appearance and can severely degrade the robustness of the face detector. A convolutional neural network can automatically select facial features, rapidly delete a large number of non-face background information, and can achieve good face detection results. However, a single convolutional neural network should possess three functions, namely, facial feature extraction, reduction of feature dimensions to decrease the computational complexity, and feature classification, which result in complex network structure, limited detection speed, and overfitting of the network. To solve these problems, this study presents a face detection method of two-layer cascaded convolutional neural network (TC_CNN).MethodFirst, a two-layer convolutional neural network model is constructed. The first convolutional neural network model is used to extract the features of the face image, and a max pooling method is adopted to reduce the dimension of those features in which multiple suspected face windows are outputted. Second, the face windows are used as the inputs of the second convolutional neural network model for fine feature extraction, and a new feature map is obtained by pool operation. Finally, the best detection window is outputted through full connection layer discrimination. The face is successfully detected and the face window is returned when the result of discriminant classification is a face; otherwise, the non-face window is deleted. An optimal face detection window can be selected through non-maximum suppression, the size and position of the face in the input image are returned based on the location information of the optimal face detection window, and the entire process of face detection is completed. In the training of TC_CNN, we use 10 000 images with near-frontal faces, face multi-pose changes, and incomplete facial features from the labeled faces in the Wild dataset as positive training samples and 1 000 images as negative training samples. In the testing of the TC_CNN model, we utilize an authoritative dataset FDDB to evaluate, measure, and determine the validity of the model based on four indexes, namely, detection rate, false detection rate, missing detection rate, and detection time. The TC_CNN model is compared with excellent face detection algorithms, such as AdaBoost, fast LBP, NPD+AdaBoost, and SPP+CNN methods.ResultImages with face multi-pose changes and incomplete face feature information in the FDDB face detection dataset are selected for the test. Results show that the face detection rate by TC_CNN method is up to 96.39%, false detection rate is as low as 3.78%, and detection time is 0.451 s. For the detection rate, the TC_CNN method is 7.63% higher than the traditional AdaBoost method based on cascade idea, 3.57% higher than the fast LBP method, 0.50% higher than the NPD+AdaBoost method, and 6.04% higher than the SPP+CNN method. For the false detection rate, the TC_CNN method is 2.44% lower than the AdaBoost method, 4.47% lower than the fast LBP method, 0.59% lower than the NPD+AdaBoost method, and 5.09% lower than the SPP+CNN method. For the detection time, the TC_CNN method's detection efficiency is remarkably higher than the SPP+CNN method and slightly higher than the AdaBoost, fast LBP, and NPD+AdaBoost methods. In comparison with the current methods, the detection rate is increased while ensuring the efficiency of the algorithm. To verify the robustness of the TC_CNN model under the conditions of face multi-pose changes and incomplete facial features, representative images of two special cases are selected from the FDDB dataset in conducting four groups of comparative experiments under the multi-pose changes of a single face image, multi-pose changes of a multi face image, incomplete facial features of a single face image, and incomplete facial features of a multi face image. Experimental results show that the TC_CNN model shows good effectiveness and robustness compared with the four excellent algorithms or four groups of contrastive experiments under different interference conditions.ConclusionThe TC_CNN model for face detection can achieve accurate detection under face multi-pose changes and incomplete facial feature information. This model can obtain a high detection rate and effectively reduce false detection rate. The method has good robustness and generalization capability. The TC_CNN method overcomes the limitations of the excellent AdaBoost cascade concept on the face detection method (such as cascading two convolutional neural networks; effectively avoiding the complex network structure caused by the three functions of extraction, reduction, and classification of features simultaneously), which easily cause overfitting and other contradictions. However, the selection of the number and parameter of the cascaded convolutional neural network is difficult for the improvement of the model performance and detection effect. In future research, we will determine the number and parameter of cascaded convolution neural network to optimize the model and will attempt to detect the size and position of the face accurately.关键词:face detection;convolutional neural network;ten-fold cross validation;two-layer cascaded convolutional neural network;max pooling19|35|3更新时间:2024-05-07 -
 摘要:ObjectiveThe texture reflected by 2D facial image is different for a 3D face surface, and this 2D texture is considerably affected by the variations of illumination and make-up. These issues make the investigation on 3D local texture features important for face recognition tasks. The concept of 3D texture is completely different from 2D texture, which reflects the repeatable patterns of a 3D facial surface. Aside from the geometric information, 3D texture preserves the photometric information of the same individual due to the flexibility of 3D mesh. Therefore, two original 3D textures, namely, 3D geometric texture and 3D photometric texture, should be investigated.MethodIn this study, we investigate a novel framework called mesh-LBP in representing 3D facial texture in detail. Here, we mainly focus on the improvement and statistic of this operator rather than the comparisons on final face recognition rate with state-of-the-art methods. First, a set of general preprocessing operations, including face detection, outlier removal, and hole filling, are performed before feature extraction and classification because raw 3D facial data contain spikes and holes and a large background area. Specifically, a facial surface is initially cropped by using a common scheme, that is, the point sets of a raw face model located on a sphere that are constructed by nose tip and fixed radius, are extracted as the detected facial area. Then, we define the outlier of raw data as the point whose number of neighborhood points are lower than that of a threshold. A mean filter is used to smooth the facial surface when these outliers are detected. The outlier removal operation usually results in holes in 3D facial data. Thus, we adopt bicubic interpolation to solve this problem. Second, the construction procedure of original mesh-LBP operator and three improved operators based on thresholding scheme, which we called mesh-tLBP, mesh-MBP, and mesh-LTP, are developed. For the mesh-tLBP, a small threshold is added to the calculation process of the mesh-LBP. For the mesh-MBP, the value of a center facet on the mesh is replaced by the mean value of its neighborhood. For the mesh-LTP, an additional coding unit is added for the subtle capture of code changes of the mesh-LBP. The first two improvements are designed for the robustness of the mesh-LBP to noise or face changes, whereas the last one improves the power of the mesh-LBP in capturing facial details. Third, different statistical methods, including naïve holistic histogram, spatially enhanced histogram, and holistic coded image, are employed to form the final facial representation. For the naïve holistic histogram, we do not use any processing method and directly perform frequency statistics on the calculated LBP pattern. For the spatially enhanced histogram, we initially block a 3D facial surface, perform frequency statistics for each block, and concatenate them to form the entire description of the face. For the holistic coded image, we directly use the calculated LBP pattern. However, the number of patterns from different faces is different; thus, we initially normalize them to the same size. Finally, we employ 615 neutral scans under different illumination condition from CASIA3D face database as the training set and evaluate the recognition performance on 615 scans of expression variation and 1 230 scans of pose on the basis of a simple minimum distance classifier.ResultComparison of the texture features of facial surface and common object surface show that the facial texture is completely different from ordinary texture and is irregular and difficult to describe. In addition, the texture variations of 3D faces are smaller than that of 2D faces, and this finding shows the superiority of 3D data. Experiments on the two variants of mesh-LBP show that the mesh-LBP(
摘要:ObjectiveThe texture reflected by 2D facial image is different for a 3D face surface, and this 2D texture is considerably affected by the variations of illumination and make-up. These issues make the investigation on 3D local texture features important for face recognition tasks. The concept of 3D texture is completely different from 2D texture, which reflects the repeatable patterns of a 3D facial surface. Aside from the geometric information, 3D texture preserves the photometric information of the same individual due to the flexibility of 3D mesh. Therefore, two original 3D textures, namely, 3D geometric texture and 3D photometric texture, should be investigated.MethodIn this study, we investigate a novel framework called mesh-LBP in representing 3D facial texture in detail. Here, we mainly focus on the improvement and statistic of this operator rather than the comparisons on final face recognition rate with state-of-the-art methods. First, a set of general preprocessing operations, including face detection, outlier removal, and hole filling, are performed before feature extraction and classification because raw 3D facial data contain spikes and holes and a large background area. Specifically, a facial surface is initially cropped by using a common scheme, that is, the point sets of a raw face model located on a sphere that are constructed by nose tip and fixed radius, are extracted as the detected facial area. Then, we define the outlier of raw data as the point whose number of neighborhood points are lower than that of a threshold. A mean filter is used to smooth the facial surface when these outliers are detected. The outlier removal operation usually results in holes in 3D facial data. Thus, we adopt bicubic interpolation to solve this problem. Second, the construction procedure of original mesh-LBP operator and three improved operators based on thresholding scheme, which we called mesh-tLBP, mesh-MBP, and mesh-LTP, are developed. For the mesh-tLBP, a small threshold is added to the calculation process of the mesh-LBP. For the mesh-MBP, the value of a center facet on the mesh is replaced by the mean value of its neighborhood. For the mesh-LTP, an additional coding unit is added for the subtle capture of code changes of the mesh-LBP. The first two improvements are designed for the robustness of the mesh-LBP to noise or face changes, whereas the last one improves the power of the mesh-LBP in capturing facial details. Third, different statistical methods, including naïve holistic histogram, spatially enhanced histogram, and holistic coded image, are employed to form the final facial representation. For the naïve holistic histogram, we do not use any processing method and directly perform frequency statistics on the calculated LBP pattern. For the spatially enhanced histogram, we initially block a 3D facial surface, perform frequency statistics for each block, and concatenate them to form the entire description of the face. For the holistic coded image, we directly use the calculated LBP pattern. However, the number of patterns from different faces is different; thus, we initially normalize them to the same size. Finally, we employ 615 neutral scans under different illumination condition from CASIA3D face database as the training set and evaluate the recognition performance on 615 scans of expression variation and 1 230 scans of pose on the basis of a simple minimum distance classifier.ResultComparison of the texture features of facial surface and common object surface show that the facial texture is completely different from ordinary texture and is irregular and difficult to describe. In addition, the texture variations of 3D faces are smaller than that of 2D faces, and this finding shows the superiority of 3D data. Experiments on the two variants of mesh-LBP show that the mesh-LBP($α_1$ $α_2$ $α_2$ 关键词:three dimensional texture;mesh-LBP;threshold scheme;statistical method;three dimensional face recognition11|4|1更新时间:2024-05-07 -
 摘要:ObjectiveFace emotion recognition is widely applied in the fields of commercial, security, and medicine. Rapid and accurate identification of facial expressions are of great significance for their research and application. Several traditional machine learning methods, such as support vector machine (SVM), principal component analysis (PCA), and local binary pattern (LBP) are used to identify facial expressions. However, these traditional machine learning algorithms require manual feature extraction. In this process, some features are hidden or deliberately enlarged due to many human interventions, which affect accuracy. In recent years, convolutional neural networks (CNNs) have been used extensively in image recognition due to their good self-learning and generalization capabilities. However, several problems, such as difficulty in facial expression feature extraction and long training time of neural network, are still observed with neural network training. This study presents an expression recognition method based on parallel CNN to solve the aforementioned problems.MethodFirst, a series of preprocessing operations is performed on facial expression images. For example, an original image is detected by using an AdaBoost cascade classifier to remove the complex background and obtain the face part. Then, a face image is compensated by illumination, a histogram equalization method is used to stretch the image nonlinearly, and the pixel value of the image is reallocated. Finally, affine transformation is used to achieve face alignment. The preceding preprocessing can remove complex background effects, compensate lighting, and adjust the angle to obtain more accurate face parts than that of the original image. Then, a CNN with two parallel convolution and pooling structures, which can extract subtle expressions, is designed for facial expression images. This parallel unit is the core unit of the CNN and comprises a convolutional layer, a pooling layer, and an activation function ReLu. This parallel structure has three different channels, in which each channel has different number of convolutions, pooling layers, and ReLu to extract different image features and fuse the extracted features. The second parallel processing unit can perform convolution and pooling on the extracted features by the first parallel processing unit and reduce the dimension of the image and shorten the training time of CNN. Finally, the previously merged features are sent to the SoftMax layer for expression classification.ResultCK+ and FER2013 expression datasets that have undergone pre-processing and data enhancement are divided into 10 equal parts. Then, training and testing are performed on 10 parts, and the final accuracy is the average of the 10 results. Experimental results show that the accuracy increases and time decreases remarkably compared with traditional machine learning methods, such as SVM, PCA, and LBP or their combination and other classical CNNs, such as AlexNet and GoogLeNet. Finally, CK+ and FER2013 achieve 94.03% and 65.6% accuracy, and the iteration time reaches 0.185 s and 0.101 s, respectively.ConclusionThis study presents a new parallel CNN structure that extracts the features of facial expressions by using three different convolutional and pooling structures. The three paths have different combinations of convolutional and pooling layers, and they can extract different image features. The different extracted features are combined and sent to the next layer for processing. This study provides a new concept for the design of CNNs, which can extend the breadth of CNN and control the depth. The proposed CNN can extract many expressions that are ignored or difficult to extract. CK+ and FER2013 expression datasets have large difference in quantity, size, and resolution. The experiments of CK+ and FER2013 show that the model can extract the precise and subtle features of facial expression images in a relatively short time under the premise of ensuring the recognition rate.关键词:expression recognition;deep learning;convolutional neural network(CNN);parallel processing;image classification21|70|21更新时间:2024-05-07
摘要:ObjectiveFace emotion recognition is widely applied in the fields of commercial, security, and medicine. Rapid and accurate identification of facial expressions are of great significance for their research and application. Several traditional machine learning methods, such as support vector machine (SVM), principal component analysis (PCA), and local binary pattern (LBP) are used to identify facial expressions. However, these traditional machine learning algorithms require manual feature extraction. In this process, some features are hidden or deliberately enlarged due to many human interventions, which affect accuracy. In recent years, convolutional neural networks (CNNs) have been used extensively in image recognition due to their good self-learning and generalization capabilities. However, several problems, such as difficulty in facial expression feature extraction and long training time of neural network, are still observed with neural network training. This study presents an expression recognition method based on parallel CNN to solve the aforementioned problems.MethodFirst, a series of preprocessing operations is performed on facial expression images. For example, an original image is detected by using an AdaBoost cascade classifier to remove the complex background and obtain the face part. Then, a face image is compensated by illumination, a histogram equalization method is used to stretch the image nonlinearly, and the pixel value of the image is reallocated. Finally, affine transformation is used to achieve face alignment. The preceding preprocessing can remove complex background effects, compensate lighting, and adjust the angle to obtain more accurate face parts than that of the original image. Then, a CNN with two parallel convolution and pooling structures, which can extract subtle expressions, is designed for facial expression images. This parallel unit is the core unit of the CNN and comprises a convolutional layer, a pooling layer, and an activation function ReLu. This parallel structure has three different channels, in which each channel has different number of convolutions, pooling layers, and ReLu to extract different image features and fuse the extracted features. The second parallel processing unit can perform convolution and pooling on the extracted features by the first parallel processing unit and reduce the dimension of the image and shorten the training time of CNN. Finally, the previously merged features are sent to the SoftMax layer for expression classification.ResultCK+ and FER2013 expression datasets that have undergone pre-processing and data enhancement are divided into 10 equal parts. Then, training and testing are performed on 10 parts, and the final accuracy is the average of the 10 results. Experimental results show that the accuracy increases and time decreases remarkably compared with traditional machine learning methods, such as SVM, PCA, and LBP or their combination and other classical CNNs, such as AlexNet and GoogLeNet. Finally, CK+ and FER2013 achieve 94.03% and 65.6% accuracy, and the iteration time reaches 0.185 s and 0.101 s, respectively.ConclusionThis study presents a new parallel CNN structure that extracts the features of facial expressions by using three different convolutional and pooling structures. The three paths have different combinations of convolutional and pooling layers, and they can extract different image features. The different extracted features are combined and sent to the next layer for processing. This study provides a new concept for the design of CNNs, which can extend the breadth of CNN and control the depth. The proposed CNN can extract many expressions that are ignored or difficult to extract. CK+ and FER2013 expression datasets have large difference in quantity, size, and resolution. The experiments of CK+ and FER2013 show that the model can extract the precise and subtle features of facial expression images in a relatively short time under the premise of ensuring the recognition rate.关键词:expression recognition;deep learning;convolutional neural network(CNN);parallel processing;image classification21|70|21更新时间:2024-05-07 -
 摘要:ObjectiveA new straight-line matching algorithm for line band descriptors (LBDs) combined with multiple constraints is proposed to solve the typical problems in many straight-line matching algorithms that use descriptors. Such problems include insufficient information utilization between matching straight lines, which are effective geometric constraints, and vulnerability of matching straight lines to the influence of low texture and scale change of images during the matching process.MethodStraight line segments are extracted by using a line segment detector method as matching elements, and a corresponding triangulation network established by using SIFT matching points is then used as the constraint region to determine the candidate lines in the searched image. After the candidate lines are selected, a region for band descriptor construction is constructed. The construction method is described as follows. A rectangular support region, in which the target straight line segment is the central axis in the region, is established in the reference image. Then, the corresponding support region of the candidate straight line segment in the searched image is determined based on epipolar constraints, which is calculated by the endpoints of the target straight line segment and four corner points of its support region in the reference image. The support regions of the target and candidate straight line segments are constructed with the same size by utilizing affine transformation. After completing the support regions of straight line segments, the regions are divided into a set of bands, where each band has the same size and the length of the band equals the length of the straight line segment, and the LBDs of straight line segment are obtained by calculating the information of each band in the support region. The descriptors are calculated based on the gradient values of four directions of pixels, and each band weight coefficient that is along the vertical direction in the support region is controlled by using a Gaussian function. On the basis of the above methods, the matching descriptor construction of LBDs for the target and candidate straight line segments is completed in sequence. Furthermore, new LBDs combined with multiple constraints are normalized in obtaining a unit LBD to reduce the influence of nonlinear illumination changes, and the descriptor is a 40D vector. Euclidean distances are used as the similarity measure in our algorithm and are determined based on the calculated vectors between the target straight line segment and each candidate straight line segment descriptor. The candidate straight line segment, which satisfies the nearest neighbor distance ratio criterion of Euclidean distances, is the matching straight line. In this process, the minimum Euclidean distance and nearest neighbor distance ratio thresholds should be determined, which directly affect the matching performance of the algorithm. Thus, many experiments should be conducted to ensure the accuracy of multi-threshold. The angle constraint, which is between the corresponding straight line and its corresponding epipolar line, is used to evaluate the matching result and determine the final corresponding straight lines.ResultThree typical groups of close-range image pairs with angle, rotation, and scale transformation are used as the experimental dataset, which is used to complete the straight line segment matching experiments by the proposed algorithm. In comparison with other straight line segment matching algorithms, the matching results show that the proposed algorithm is more suitable in different typical close-range image pairs. The conclusions based on the result analysis are summarized as follows. The successful matches of the proposed algorithm have 1.06-1.41 times more lines compared with other straight-line matching algorithms, and the proposed algorithm can improve the accuracy of straight line matching by 2.4% to 11.6%. In terms of matching efficiency, although the proposed algorithm is time-consuming, it is robust and achieves accurate and reliable straight line matching results by synthesizing the relevant experiment results on the number of corresponding matching straight lines, matching accuracy, and running time. Moreover, a highly accurate and reliable matching result is obtained.ConclusionConstructed LBDs combined with multiple constraints are stable for line matching of close-range images with angles, rotation, and scale changes. The instability of other descriptors caused by numerous factors in line matching is improved.关键词:multiple constraints;line band descriptor;straight line matching;nearest neighbor distance ratio;angle constraint11|4|3更新时间:2024-05-07
摘要:ObjectiveA new straight-line matching algorithm for line band descriptors (LBDs) combined with multiple constraints is proposed to solve the typical problems in many straight-line matching algorithms that use descriptors. Such problems include insufficient information utilization between matching straight lines, which are effective geometric constraints, and vulnerability of matching straight lines to the influence of low texture and scale change of images during the matching process.MethodStraight line segments are extracted by using a line segment detector method as matching elements, and a corresponding triangulation network established by using SIFT matching points is then used as the constraint region to determine the candidate lines in the searched image. After the candidate lines are selected, a region for band descriptor construction is constructed. The construction method is described as follows. A rectangular support region, in which the target straight line segment is the central axis in the region, is established in the reference image. Then, the corresponding support region of the candidate straight line segment in the searched image is determined based on epipolar constraints, which is calculated by the endpoints of the target straight line segment and four corner points of its support region in the reference image. The support regions of the target and candidate straight line segments are constructed with the same size by utilizing affine transformation. After completing the support regions of straight line segments, the regions are divided into a set of bands, where each band has the same size and the length of the band equals the length of the straight line segment, and the LBDs of straight line segment are obtained by calculating the information of each band in the support region. The descriptors are calculated based on the gradient values of four directions of pixels, and each band weight coefficient that is along the vertical direction in the support region is controlled by using a Gaussian function. On the basis of the above methods, the matching descriptor construction of LBDs for the target and candidate straight line segments is completed in sequence. Furthermore, new LBDs combined with multiple constraints are normalized in obtaining a unit LBD to reduce the influence of nonlinear illumination changes, and the descriptor is a 40D vector. Euclidean distances are used as the similarity measure in our algorithm and are determined based on the calculated vectors between the target straight line segment and each candidate straight line segment descriptor. The candidate straight line segment, which satisfies the nearest neighbor distance ratio criterion of Euclidean distances, is the matching straight line. In this process, the minimum Euclidean distance and nearest neighbor distance ratio thresholds should be determined, which directly affect the matching performance of the algorithm. Thus, many experiments should be conducted to ensure the accuracy of multi-threshold. The angle constraint, which is between the corresponding straight line and its corresponding epipolar line, is used to evaluate the matching result and determine the final corresponding straight lines.ResultThree typical groups of close-range image pairs with angle, rotation, and scale transformation are used as the experimental dataset, which is used to complete the straight line segment matching experiments by the proposed algorithm. In comparison with other straight line segment matching algorithms, the matching results show that the proposed algorithm is more suitable in different typical close-range image pairs. The conclusions based on the result analysis are summarized as follows. The successful matches of the proposed algorithm have 1.06-1.41 times more lines compared with other straight-line matching algorithms, and the proposed algorithm can improve the accuracy of straight line matching by 2.4% to 11.6%. In terms of matching efficiency, although the proposed algorithm is time-consuming, it is robust and achieves accurate and reliable straight line matching results by synthesizing the relevant experiment results on the number of corresponding matching straight lines, matching accuracy, and running time. Moreover, a highly accurate and reliable matching result is obtained.ConclusionConstructed LBDs combined with multiple constraints are stable for line matching of close-range images with angles, rotation, and scale changes. The instability of other descriptors caused by numerous factors in line matching is improved.关键词:multiple constraints;line band descriptor;straight line matching;nearest neighbor distance ratio;angle constraint11|4|3更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveFrameworks for point cloud object recognition are generally composed by two stages. An offline stage constructs a model library, and an online stage recognizes objects by using nearest neighbor search. Traditional methods use global surfaces to construct a model library, which is sensitive to occlusion and inaccurate segmentation result. This study investigates the offline stage and presents a novel model library construction method.MethodThe proposed method simulates possible occlusions and adds point clouds with simulated occlusions to the model library to alleviate the influence of occlusion and inaccurate segmentation result. First, a CAD model is placed at the center of an icosahedron, and multiple virtual cameras are used to obtain the partial point clouds of the model. For each partial point cloud, a local coordinate system is constructed using principal component analysis, and the point cloud is aligned with the coordinate system. This process makes the proposed method invariant to rigid transformations. Second, several direction vectors are obtained based on the local coordinate system, and the partial point clouds are segmented into multiple subparts based on the length of the point cloud on each direction vector. Simulation of occlusion at different degrees is performed on these subparts, which contain the global and local surfaces of the partial point cloud. Third, a simple clustering method is used to obtain the largest cluster of the subparts, and outliner points are removed at this stage. The largest cluster will be added to the model library only if the cluster has sufficient points. This process reduces the memory requirements and decreases time consumption during the nearest searches. Redundant clusters with similar surface in the library are still observed after removing the clusters with few points. Finally, an iterative closest point(ICP) based algorithm is used to remove the point clouds with similar surfaces, thereby further decreasing the memory requirements. Subsequently, only dozens of subparts are used to describe each of the CAD model.ResultExperimental results on two public datasets show that the proposed method promotes recognition accuracy at different levels. For the UWAOR dataset, the recognition performance on five types of point cloud descriptor is remarkably improved. Particularly, the proposed method enhances the recognition performance by 0.208 on the GASD descriptor and 0.173 on the ROPS descriptor (
摘要:ObjectiveFrameworks for point cloud object recognition are generally composed by two stages. An offline stage constructs a model library, and an online stage recognizes objects by using nearest neighbor search. Traditional methods use global surfaces to construct a model library, which is sensitive to occlusion and inaccurate segmentation result. This study investigates the offline stage and presents a novel model library construction method.MethodThe proposed method simulates possible occlusions and adds point clouds with simulated occlusions to the model library to alleviate the influence of occlusion and inaccurate segmentation result. First, a CAD model is placed at the center of an icosahedron, and multiple virtual cameras are used to obtain the partial point clouds of the model. For each partial point cloud, a local coordinate system is constructed using principal component analysis, and the point cloud is aligned with the coordinate system. This process makes the proposed method invariant to rigid transformations. Second, several direction vectors are obtained based on the local coordinate system, and the partial point clouds are segmented into multiple subparts based on the length of the point cloud on each direction vector. Simulation of occlusion at different degrees is performed on these subparts, which contain the global and local surfaces of the partial point cloud. Third, a simple clustering method is used to obtain the largest cluster of the subparts, and outliner points are removed at this stage. The largest cluster will be added to the model library only if the cluster has sufficient points. This process reduces the memory requirements and decreases time consumption during the nearest searches. Redundant clusters with similar surface in the library are still observed after removing the clusters with few points. Finally, an iterative closest point(ICP) based algorithm is used to remove the point clouds with similar surfaces, thereby further decreasing the memory requirements. Subsequently, only dozens of subparts are used to describe each of the CAD model.ResultExperimental results on two public datasets show that the proposed method promotes recognition accuracy at different levels. For the UWAOR dataset, the recognition performance on five types of point cloud descriptor is remarkably improved. Particularly, the proposed method enhances the recognition performance by 0.208 on the GASD descriptor and 0.173 on the ROPS descriptor ($k$ $k$ 关键词:point cloud object recognition;offline stage;model library construction;point cloud feature extraction;global and local surfaces35|8|3更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveDeep learning has been widely used in the field of synthetic aperture radar (SAR) target recognition and most studies have been conducted for target recognition under the standard operating conditions (SOCs) of MSTAR datasets. Many challenges exist due to the small differences among the targets when applied to target recognition with variants, such as T72 subclasses. To preserve the input features of SAR images, a deep convolutional neural network (CNN) architecture for SAR target recognition with variants is designed in this study.MethodThe proposed network is composed of one multiscale feature extraction module and several dense blocks and transition layers proposed in DenseNet. The multiscale feature extraction module, which is placed at the bottom of the network, uses multiple convolution kernels with sizes of 1×1, 3×3, 5×5, 7×7, and 9×9 to extract rich spatial features. The convolution kernels with a size of 1×1 are adopted to preserve the detailed information from the input image, and convolution kernels with large sizes are used in multiscale feature extraction module to suppress the influence of speckle noise on extracted features because speckle noise is a main factor that affects recognition performance. To transfer the information from the input image effectively and utilize the feature learned from all layers, dense blocks and transition layers are adopted in designing the latter layers of the network. A full convolution layer is used behind three dense blocks and transition layers to transform the learned features to vectors, and a SoftMax layer is adopted to perform classification. Finally, training datasets are augmented by displacing and adding speckle noise to the original images, and the proposed model is implemented using TensorFlow and is trained by using these samples. The influences of input image resolution, target translation, and different noise levels on the recognition accuracy of the proposed network are determined after augmenting the training datasets, and performance comparisons with other deep learning models under SOCs.ResultExperimental results demonstrate that the input image resolution has a considerable influence on the recognition accuracy for eight types of T72 targets, and the accuracy improves considerably with the increase of input resolution. However, the input resolution has minimal effect on the recognition accuracy for SOC due to the large differences among the targets in SOC. The image resolution as the input of the proposed model is set to 88×88×1 because the target and shadow information during data enhancement should be preserved. To verify the performance of the proposed multiscale feature extraction module, tests are performed using different multiscale feature extraction strategies, and the proposed model obtains a classification accuracy of approximately 95.48% in the classification of eight subclasses of T72 target with variants. Aside from the recognition of test samples under SOC, the classification accuracies of the proposed model are investigated in terms of target translation and different noise levels. The proposed model can achieve a recognition accuracy higher than 90%, especially when the target is displaced 16 pixels away from the center of the original image. The proposed model still exhibits a good performance when the noise intensity is set to 0.5 or 1 but causes a remarkable decline in recognition accuracy when the noise intensity is greater than 1. The average classification accuracy can reach 94.61% and 86.36% in the case of object translation and different noise levels. Recognition accuracies of 99.38% (SOC1-10), 99.50% (SOC1-14), and 98.81% (SOC2) are achieved by using augmented training datasets in training the models for 10-class target recognition under SOC (without variants and with variants). Our model achieves comparable recognition performance with other deep models.ConclusionOur model utilizes the input information and features of each convolutional layer and captures the detailed difference among the targets from the images. Our model not only can be applied to target recognition task with variants but also achieve satisfactory recognition results under SOC.关键词:SAR target recognition;target variants;deep learning;multi-scale feature;DenseNet37|47|2更新时间:2024-05-07
摘要:ObjectiveDeep learning has been widely used in the field of synthetic aperture radar (SAR) target recognition and most studies have been conducted for target recognition under the standard operating conditions (SOCs) of MSTAR datasets. Many challenges exist due to the small differences among the targets when applied to target recognition with variants, such as T72 subclasses. To preserve the input features of SAR images, a deep convolutional neural network (CNN) architecture for SAR target recognition with variants is designed in this study.MethodThe proposed network is composed of one multiscale feature extraction module and several dense blocks and transition layers proposed in DenseNet. The multiscale feature extraction module, which is placed at the bottom of the network, uses multiple convolution kernels with sizes of 1×1, 3×3, 5×5, 7×7, and 9×9 to extract rich spatial features. The convolution kernels with a size of 1×1 are adopted to preserve the detailed information from the input image, and convolution kernels with large sizes are used in multiscale feature extraction module to suppress the influence of speckle noise on extracted features because speckle noise is a main factor that affects recognition performance. To transfer the information from the input image effectively and utilize the feature learned from all layers, dense blocks and transition layers are adopted in designing the latter layers of the network. A full convolution layer is used behind three dense blocks and transition layers to transform the learned features to vectors, and a SoftMax layer is adopted to perform classification. Finally, training datasets are augmented by displacing and adding speckle noise to the original images, and the proposed model is implemented using TensorFlow and is trained by using these samples. The influences of input image resolution, target translation, and different noise levels on the recognition accuracy of the proposed network are determined after augmenting the training datasets, and performance comparisons with other deep learning models under SOCs.ResultExperimental results demonstrate that the input image resolution has a considerable influence on the recognition accuracy for eight types of T72 targets, and the accuracy improves considerably with the increase of input resolution. However, the input resolution has minimal effect on the recognition accuracy for SOC due to the large differences among the targets in SOC. The image resolution as the input of the proposed model is set to 88×88×1 because the target and shadow information during data enhancement should be preserved. To verify the performance of the proposed multiscale feature extraction module, tests are performed using different multiscale feature extraction strategies, and the proposed model obtains a classification accuracy of approximately 95.48% in the classification of eight subclasses of T72 target with variants. Aside from the recognition of test samples under SOC, the classification accuracies of the proposed model are investigated in terms of target translation and different noise levels. The proposed model can achieve a recognition accuracy higher than 90%, especially when the target is displaced 16 pixels away from the center of the original image. The proposed model still exhibits a good performance when the noise intensity is set to 0.5 or 1 but causes a remarkable decline in recognition accuracy when the noise intensity is greater than 1. The average classification accuracy can reach 94.61% and 86.36% in the case of object translation and different noise levels. Recognition accuracies of 99.38% (SOC1-10), 99.50% (SOC1-14), and 98.81% (SOC2) are achieved by using augmented training datasets in training the models for 10-class target recognition under SOC (without variants and with variants). Our model achieves comparable recognition performance with other deep models.ConclusionOur model utilizes the input information and features of each convolutional layer and captures the detailed difference among the targets from the images. Our model not only can be applied to target recognition task with variants but also achieve satisfactory recognition results under SOC.关键词:SAR target recognition;target variants;deep learning;multi-scale feature;DenseNet37|47|2更新时间:2024-05-07
Remote Sensing Image Processing
-
 摘要:ObjectiveSmoke frequently occurs earlier than flames when fire breaks out. Thus, smoke detection provides earlier fire alarms than flame detection. The color, shape, and movement of smoke are susceptible to external environment. Thus, existing smoke features lack discriminative capability and robustness. These factors make image-based smoke recognition or detection a difficult task. To decrease the false alarm rates (FARs) and error rates (ERRs) of smoke recognition without dropping detection rates (DRs), we propose a Gabor-based hierarchy (termed GaborNet) in this study.MethodFirst, a Gabor convolutional unit, which consists of a set of learning-free convolutional kernels and condensing modules, is constructed. Gabor filters with fixed parameters generate a set of response maps from an original image as a multiscale and multi-orientation representation. In addition, a condensing module conducts max pooling across the channels of every response map to capture subtle scale- and orientation- invariant information, thereby generating a condensed response map. Then, condensed maps, that is, the outputs of the aforementioned Gabor convolution unit, are encoded within and across the channels. A local binary pattern encoding method is utilized to describe the texture distribution within every channel of a condensed map, and hash binary encoding is used to capture the relations across the map channels. The binarization during encoding enhances the robustness of representation to local changes. Subsequently, histogram calculation is applied to encoded maps to obtain statistical features, which are known as basic features. The aforementioned Gabor convolution unit, encoding module, and histogram calculation form a basic Gabor layer. In addition, this Gabor layer is provided with two extensive modules. The first module determines the invariance and global structures of texture distributions, and the second module enriches the pattern of response maps. The former restores and encodes the indices of max responses in the Gabor convolutional unit. The latter holistically learns a set of projection vectors from condensed response maps to construct a feature space. The texture representation not only becomes separable but also contains many patterns when it is projected in this feature space. Finally, the completed smoke features of a Gabor layer are generated by concatenating the basic and extensive features. The addition of extensive features enhances the robustness and discriminative capabilities of basic features because invariant texture structures, holistic information, and several patterns are characterized. A feedforward network termed GaborNet can be built by stacking several Gabor layers on top of one another. Consequently, the concatenation of features acquired from every Gabor layer constitutes multiscale, multi-orientation, and hierarchical features. The features become high level and slightly explicable with the deepening of the network. Thus, the extension, which explicitly improves the basic features, is conducted only on the first Gabor layer that possesses low-level features. In addition, holistic learning extension is not required in subsequent steps when the extension is implemented.ResultThis study conducted ablation experiments to gain insights on extensive features. Comparison experiments for smoke recognition were then conducted to present the performance of the proposed GaborNet. This algorithm utilizes texture representations to present smoke; thus, texture classification was conducted as a supplement to the experiment. Experimental results demonstrate that the proposed GaborNet achieves powerful generalization capability. Smoke features extracted by GaborNet decrease FARs and ERRs without dropping DRs, and the results of GaborNet rank first among state-of-the-art methods. The results of texture classification rank first and second in two standard texture datasets. In summary, the GaborNet provides better texture representation than most existing texture descriptors in smoke recognition and texture classification.ConclusionThe proposed GaborNet extracts multiscale, multi-orientation, and hierarchical representations for textures; improves the performance of smoke recognition; and increases the accuracy of texture classification. Future studies should focus on eliminating the redundancy of features to gain compactness and in investigating and utilizing the relations between features in different layers to enhance transform invariance. This method is expected to be widely applied in real-time video smoke recognition.关键词:smoke recognition;texture classification;feature extraction;Gabor filtering;hierarchy13|6|10更新时间:2024-05-07
摘要:ObjectiveSmoke frequently occurs earlier than flames when fire breaks out. Thus, smoke detection provides earlier fire alarms than flame detection. The color, shape, and movement of smoke are susceptible to external environment. Thus, existing smoke features lack discriminative capability and robustness. These factors make image-based smoke recognition or detection a difficult task. To decrease the false alarm rates (FARs) and error rates (ERRs) of smoke recognition without dropping detection rates (DRs), we propose a Gabor-based hierarchy (termed GaborNet) in this study.MethodFirst, a Gabor convolutional unit, which consists of a set of learning-free convolutional kernels and condensing modules, is constructed. Gabor filters with fixed parameters generate a set of response maps from an original image as a multiscale and multi-orientation representation. In addition, a condensing module conducts max pooling across the channels of every response map to capture subtle scale- and orientation- invariant information, thereby generating a condensed response map. Then, condensed maps, that is, the outputs of the aforementioned Gabor convolution unit, are encoded within and across the channels. A local binary pattern encoding method is utilized to describe the texture distribution within every channel of a condensed map, and hash binary encoding is used to capture the relations across the map channels. The binarization during encoding enhances the robustness of representation to local changes. Subsequently, histogram calculation is applied to encoded maps to obtain statistical features, which are known as basic features. The aforementioned Gabor convolution unit, encoding module, and histogram calculation form a basic Gabor layer. In addition, this Gabor layer is provided with two extensive modules. The first module determines the invariance and global structures of texture distributions, and the second module enriches the pattern of response maps. The former restores and encodes the indices of max responses in the Gabor convolutional unit. The latter holistically learns a set of projection vectors from condensed response maps to construct a feature space. The texture representation not only becomes separable but also contains many patterns when it is projected in this feature space. Finally, the completed smoke features of a Gabor layer are generated by concatenating the basic and extensive features. The addition of extensive features enhances the robustness and discriminative capabilities of basic features because invariant texture structures, holistic information, and several patterns are characterized. A feedforward network termed GaborNet can be built by stacking several Gabor layers on top of one another. Consequently, the concatenation of features acquired from every Gabor layer constitutes multiscale, multi-orientation, and hierarchical features. The features become high level and slightly explicable with the deepening of the network. Thus, the extension, which explicitly improves the basic features, is conducted only on the first Gabor layer that possesses low-level features. In addition, holistic learning extension is not required in subsequent steps when the extension is implemented.ResultThis study conducted ablation experiments to gain insights on extensive features. Comparison experiments for smoke recognition were then conducted to present the performance of the proposed GaborNet. This algorithm utilizes texture representations to present smoke; thus, texture classification was conducted as a supplement to the experiment. Experimental results demonstrate that the proposed GaborNet achieves powerful generalization capability. Smoke features extracted by GaborNet decrease FARs and ERRs without dropping DRs, and the results of GaborNet rank first among state-of-the-art methods. The results of texture classification rank first and second in two standard texture datasets. In summary, the GaborNet provides better texture representation than most existing texture descriptors in smoke recognition and texture classification.ConclusionThe proposed GaborNet extracts multiscale, multi-orientation, and hierarchical representations for textures; improves the performance of smoke recognition; and increases the accuracy of texture classification. Future studies should focus on eliminating the redundancy of features to gain compactness and in investigating and utilizing the relations between features in different layers to enhance transform invariance. This method is expected to be widely applied in real-time video smoke recognition.关键词:smoke recognition;texture classification;feature extraction;Gabor filtering;hierarchy13|6|10更新时间:2024-05-07 -
 摘要:ObjectiveThe mainstream methods of action recognition still experience two main challenges, that is the extraction of target features and the speed and real-time of the overall process of action recognition. At present, most of the state-of-the-art methods use CNN(convolutional neural network) to extract depth features. However, CNN has a large computational complexity, and most of the regions in the video stream are not target images. The feature extraction of an entire image is certainly expensive. Target detection algorithms, such as optical flow method, are not real-time; unstable; susceptible to external environmental conditions, such as illumination, camera angle, and distance; increase the amount of calculation; and reduce time efficiency. Therefore, a human action recognition algorithm called LC-YOLO(LSTM and CNN based on YOLO), which is based on YOLO(you only look once:unified, real-time object detection) combined with LSTM(long short-term memory) and CNN, is proposed to improve the accuracy and time efficiency of action recognition in intelligent surveillance scenarios.MethodThe LC-YOLO algorithm mainly consists of three parts, namely, target detection, feature extraction, and action recognition. YOLO target detection is added as an aid to the mainstream method system of CNN+LSTM. The fast and real-time nature of YOLO target detection is utilized; real-time detection of specific actions in surveillance video is conducted; target size, location, and other information are obtained; features are extracted; and noise data are efficiently removed from unrelated areas of the image. Combined with LSTM modeling and processing time series, the final action recognition is made for the sequence of actions in video surveillance. Generally, the proposed model is an end-to-end deep neural network that uses the input raw video action sequence as input and returns the action category. The specific process of the single action recognition of the LC-YOLO algorithm can be described as follows. 1) YOLO is used to extract the position and confidence information (x, y, w, h, c), which has a 45 frame/s speed, can realize real-time detection of surveillance video when a specific action frame is detected; Under the training of a large number of datasets, the accurate rate of YOLO action detection can reach more than 90%. 2) On the basis of target detection, the target range image content is acquired and retained, and the noise data interference of the remaining background parts is removed, which extracts complete and accurate target features. A 4 096-dimensional depth feature vector is extracted by using a VGGNet-16 model and is returned to the recognition module combined with the target size and position information (x, y, w, h, c) predicted by YOLO. 3) In comparison with a standard RNN, the LSTM architecture uses memory cells to store and output information by using the LSTM unit as the identification module, thereby determining the temporal relationship of multiple target actions. The action category of the entire sequence of actions is outputted. In comparison with the work conducted by predecessors, the contributions of the proposed algorithm are as follows. 1) Instead of motion foreground extraction, R-CNN, and other target detection methods, the YOLO algorithm which is faster and more efficient, is used in this study. 2) The target size and position information are obtained when the target area is locked, and the interference information of the unrelated area in the picture can be removed, thereby effectively utilizing CNN to extract the depth feature. Moreover, the accuracy of feature extraction and overall time efficiency of behavior recognition are improved.ResultExperiments in the public action recognition datasets KTH and MSR show that the average recognition rate of each action reaches 96.6%, the average recognition speed reaches 215 ms, and the proposed method has a good effect on the action recognition of intelligent monitoring.ConclusionThis study presents a human action recognition algorithm called LC-YOLO, which is based on YOLO combined with LSTM and CNN. The fast and real-time nature of YOLO target detection is utilized; real-time detection of specific actions in surveillance video is conducted; target size, location, and other information are obtained; features are extracted; and the noise data of unrelated regions in the image are efficiently removed, which reduces the computational complexity of feature extraction and time complexity of behavior recognition. Experimental results in the public action recognition datasets KTH and MSR show that they have better adaptability and broad application prospects in intelligent monitoring with high real-time requirements and complex scenes.关键词:action recognition;target detection;deep learning;convolutional neural network;recurrent neural network50|87|11更新时间:2024-05-07
摘要:ObjectiveThe mainstream methods of action recognition still experience two main challenges, that is the extraction of target features and the speed and real-time of the overall process of action recognition. At present, most of the state-of-the-art methods use CNN(convolutional neural network) to extract depth features. However, CNN has a large computational complexity, and most of the regions in the video stream are not target images. The feature extraction of an entire image is certainly expensive. Target detection algorithms, such as optical flow method, are not real-time; unstable; susceptible to external environmental conditions, such as illumination, camera angle, and distance; increase the amount of calculation; and reduce time efficiency. Therefore, a human action recognition algorithm called LC-YOLO(LSTM and CNN based on YOLO), which is based on YOLO(you only look once:unified, real-time object detection) combined with LSTM(long short-term memory) and CNN, is proposed to improve the accuracy and time efficiency of action recognition in intelligent surveillance scenarios.MethodThe LC-YOLO algorithm mainly consists of three parts, namely, target detection, feature extraction, and action recognition. YOLO target detection is added as an aid to the mainstream method system of CNN+LSTM. The fast and real-time nature of YOLO target detection is utilized; real-time detection of specific actions in surveillance video is conducted; target size, location, and other information are obtained; features are extracted; and noise data are efficiently removed from unrelated areas of the image. Combined with LSTM modeling and processing time series, the final action recognition is made for the sequence of actions in video surveillance. Generally, the proposed model is an end-to-end deep neural network that uses the input raw video action sequence as input and returns the action category. The specific process of the single action recognition of the LC-YOLO algorithm can be described as follows. 1) YOLO is used to extract the position and confidence information (x, y, w, h, c), which has a 45 frame/s speed, can realize real-time detection of surveillance video when a specific action frame is detected; Under the training of a large number of datasets, the accurate rate of YOLO action detection can reach more than 90%. 2) On the basis of target detection, the target range image content is acquired and retained, and the noise data interference of the remaining background parts is removed, which extracts complete and accurate target features. A 4 096-dimensional depth feature vector is extracted by using a VGGNet-16 model and is returned to the recognition module combined with the target size and position information (x, y, w, h, c) predicted by YOLO. 3) In comparison with a standard RNN, the LSTM architecture uses memory cells to store and output information by using the LSTM unit as the identification module, thereby determining the temporal relationship of multiple target actions. The action category of the entire sequence of actions is outputted. In comparison with the work conducted by predecessors, the contributions of the proposed algorithm are as follows. 1) Instead of motion foreground extraction, R-CNN, and other target detection methods, the YOLO algorithm which is faster and more efficient, is used in this study. 2) The target size and position information are obtained when the target area is locked, and the interference information of the unrelated area in the picture can be removed, thereby effectively utilizing CNN to extract the depth feature. Moreover, the accuracy of feature extraction and overall time efficiency of behavior recognition are improved.ResultExperiments in the public action recognition datasets KTH and MSR show that the average recognition rate of each action reaches 96.6%, the average recognition speed reaches 215 ms, and the proposed method has a good effect on the action recognition of intelligent monitoring.ConclusionThis study presents a human action recognition algorithm called LC-YOLO, which is based on YOLO combined with LSTM and CNN. The fast and real-time nature of YOLO target detection is utilized; real-time detection of specific actions in surveillance video is conducted; target size, location, and other information are obtained; features are extracted; and the noise data of unrelated regions in the image are efficiently removed, which reduces the computational complexity of feature extraction and time complexity of behavior recognition. Experimental results in the public action recognition datasets KTH and MSR show that they have better adaptability and broad application prospects in intelligent monitoring with high real-time requirements and complex scenes.关键词:action recognition;target detection;deep learning;convolutional neural network;recurrent neural network50|87|11更新时间:2024-05-07 -
 摘要:ObjectiveVisual tracking is an important research direction in the field of computer vision and is widely applied in intelligent transportation, human-computer interaction, and other areas. Correlation filter-based trackers (CFTs) have achieved excellent performance due to their efficiency and robustness in tracking field. However, the design of a robust tracking algorithm for complex dynamic scenes is challenging due to the influence of lighting, fast motion, background interference, target rotation, scale change, occlusion, and other factors. In addition, the selection and presentation of features are constantly used as the primary considerations in establishing a target appearance model during tracking. To improve the robustness of the appearance model, many trackers introduce gradient feature, color feature, or several other combined features rather than a single gray feature. However, they do not discuss the role of each feature and their relationships in the model.MethodThe research on correlation filter theory achieves remarkable improvements. On the basis of this research, the appearance model is used to represent the target and verify the observation. This process is the most important part of any tracking algorithm. Moreover, the features are fundamental and difficult in appearance representation. Therefore, this study mainly focuses on the selection and combination of features. Gradient feature, color feature, and raw pixel have been discussed in previous works. As a common descriptor of shape and edge, gradient feature is invariable in translation and light and performs well in the tracking scene of deformation, light change, and partial occlusion. However, the gradient feature of the target is not evident, and the description capability of the feature is weakened when considerable noise is encountered in the background, target rotation, and target blur. The color of the target and background can be distinguished although they are usually different. On this basis, a new tracking method called weighted multi-feature fusion (WMFF) tracker is proposed via the introduction of a weight vector to fuse multiple feature on the appearance model. The model is dominated by gradient features and is supplemented by color feature and original pixels, which can compensate the inadequacies of single-gradient feature and provide the utilization of the color features of color, thereby making features complementary to each other. In detail, this study constructs a three-variable linear equation on weights based on the calculation method of each feature. The proportional relationships in this equation are solved rather than their specific values. The gradient feature can transform the solutions of weight vector to determine the proportional coefficients of each feature by using it as a criterion. Therefore, the equation is a system of linear equations of two unknowns. In addition, the equation has a limited integer solution set, and the final proportion coefficient is determined by experimental verification on test sequence in terms of the dimension information of feature calculation. This method normalizes the proportion coefficient as weight vector and builds a new weighted feature-mixing model of target appearance to model. The WMFF tracker adopts a detection-based tracking framework, which includes feature extraction, model construction, filter training, target center detection, and model update.ResultA total of 100 video sequences from the object tracking benchmark datasets (herein, OTB-100 datasets) are adopted in the experiments to compare the performance with seven other state-of-the-art trackers, which include five CFTs. A total of 11 different attributes, such as illumination, occlusion, and scale variation, are annotated on video sequences. Comparisons and analyses are performed for these trackers by using precision, average center error, average Pascal VOC overlap ratio, and median frame per second as evaluation standards. Precision and success plots of different datasets are also presented, and the performance of different attributes are discussed. Experimental results on benchmark OTB-100 datasets demonstrate that our tracker can achieve real-time and better performance compared with other methods, especially on Basketball, DragonBaby, Panda, and Lemming sequences. The edge contours, especially the gradient information of the target, are unremarkable when the scene is subjected to motion blur due to occlusion or deformation, which causes the appearance model constructed by the gradient feature not being able to distinguish the target accurately and thus tracking failure easily occurs. Meanwhile, the WMFF tracker can utilize the color feature as a supplement to construct the appearance model in time to obtain a robust tracking effect when the gradient feature is invalid. The color feature has the same level of importance as the gradient feature and achieves an ideal feature combination effect. The performance of the proposed method outperforms other algorithms on multiple datasets, and the average results on OTB-100 datasets show that the precision is improved by 1.2% compared with a scale-adaptive kernel CFT with feature integration tracker.ConclusionIn this study, a weight vector is introduced to combine features in describing the appearance of the target, and a WMFF tracker is proposed based on a CFT framework. A new hybrid feature HCG is dominated by gradient feature and is supplemented by color and gray feature, which can be used to model the appearance of the target. This model can compensate the deficiency of single feature and enables the function of each feature. This model not only can make the features complement one another but also make the appearance model adapt to multiple complex scenes. The WMFF tracker makes the tracking length longer than other trackers in complex dynamic scenes and improves the robustness of the algorithm.关键词:correlation filter;appearance description;feature fusion;weighted feature;real-time tracking15|6|1更新时间:2024-05-07
摘要:ObjectiveVisual tracking is an important research direction in the field of computer vision and is widely applied in intelligent transportation, human-computer interaction, and other areas. Correlation filter-based trackers (CFTs) have achieved excellent performance due to their efficiency and robustness in tracking field. However, the design of a robust tracking algorithm for complex dynamic scenes is challenging due to the influence of lighting, fast motion, background interference, target rotation, scale change, occlusion, and other factors. In addition, the selection and presentation of features are constantly used as the primary considerations in establishing a target appearance model during tracking. To improve the robustness of the appearance model, many trackers introduce gradient feature, color feature, or several other combined features rather than a single gray feature. However, they do not discuss the role of each feature and their relationships in the model.MethodThe research on correlation filter theory achieves remarkable improvements. On the basis of this research, the appearance model is used to represent the target and verify the observation. This process is the most important part of any tracking algorithm. Moreover, the features are fundamental and difficult in appearance representation. Therefore, this study mainly focuses on the selection and combination of features. Gradient feature, color feature, and raw pixel have been discussed in previous works. As a common descriptor of shape and edge, gradient feature is invariable in translation and light and performs well in the tracking scene of deformation, light change, and partial occlusion. However, the gradient feature of the target is not evident, and the description capability of the feature is weakened when considerable noise is encountered in the background, target rotation, and target blur. The color of the target and background can be distinguished although they are usually different. On this basis, a new tracking method called weighted multi-feature fusion (WMFF) tracker is proposed via the introduction of a weight vector to fuse multiple feature on the appearance model. The model is dominated by gradient features and is supplemented by color feature and original pixels, which can compensate the inadequacies of single-gradient feature and provide the utilization of the color features of color, thereby making features complementary to each other. In detail, this study constructs a three-variable linear equation on weights based on the calculation method of each feature. The proportional relationships in this equation are solved rather than their specific values. The gradient feature can transform the solutions of weight vector to determine the proportional coefficients of each feature by using it as a criterion. Therefore, the equation is a system of linear equations of two unknowns. In addition, the equation has a limited integer solution set, and the final proportion coefficient is determined by experimental verification on test sequence in terms of the dimension information of feature calculation. This method normalizes the proportion coefficient as weight vector and builds a new weighted feature-mixing model of target appearance to model. The WMFF tracker adopts a detection-based tracking framework, which includes feature extraction, model construction, filter training, target center detection, and model update.ResultA total of 100 video sequences from the object tracking benchmark datasets (herein, OTB-100 datasets) are adopted in the experiments to compare the performance with seven other state-of-the-art trackers, which include five CFTs. A total of 11 different attributes, such as illumination, occlusion, and scale variation, are annotated on video sequences. Comparisons and analyses are performed for these trackers by using precision, average center error, average Pascal VOC overlap ratio, and median frame per second as evaluation standards. Precision and success plots of different datasets are also presented, and the performance of different attributes are discussed. Experimental results on benchmark OTB-100 datasets demonstrate that our tracker can achieve real-time and better performance compared with other methods, especially on Basketball, DragonBaby, Panda, and Lemming sequences. The edge contours, especially the gradient information of the target, are unremarkable when the scene is subjected to motion blur due to occlusion or deformation, which causes the appearance model constructed by the gradient feature not being able to distinguish the target accurately and thus tracking failure easily occurs. Meanwhile, the WMFF tracker can utilize the color feature as a supplement to construct the appearance model in time to obtain a robust tracking effect when the gradient feature is invalid. The color feature has the same level of importance as the gradient feature and achieves an ideal feature combination effect. The performance of the proposed method outperforms other algorithms on multiple datasets, and the average results on OTB-100 datasets show that the precision is improved by 1.2% compared with a scale-adaptive kernel CFT with feature integration tracker.ConclusionIn this study, a weight vector is introduced to combine features in describing the appearance of the target, and a WMFF tracker is proposed based on a CFT framework. A new hybrid feature HCG is dominated by gradient feature and is supplemented by color and gray feature, which can be used to model the appearance of the target. This model can compensate the deficiency of single feature and enables the function of each feature. This model not only can make the features complement one another but also make the appearance model adapt to multiple complex scenes. The WMFF tracker makes the tracking length longer than other trackers in complex dynamic scenes and improves the robustness of the algorithm.关键词:correlation filter;appearance description;feature fusion;weighted feature;real-time tracking15|6|1更新时间:2024-05-07 -
 摘要:ObjectiveThe recovery of a high-resolution (HR) image or video from its low-resolution (LR) counterpart, which is referred to as super resolution (SR), has attracted considerable attention in computer vision community. The SR problem is inherently ill-posed because the HR image or video actually does not exist. Several methods have been proposed to address this issue. Several typical methods, such as bilinear or bicubic interpolation, Lanczos resampling, and internal patch recurrence, have been used. Recently, learning-based methods, such as sparse coding, random forest, and convolutional neural networks (CNNs), have been utilized to create a mapping between LR and HR images. Particularly, the CNN-based scheme has achieved remarkable performance improvement. Different network models, such as SRCNN, VDSR, LapSRN, and DRRN, have been proposed. These models abstract and combine the features of LR image to establish an effective nonlinear mapping from LR input images to HR target images. In this process, low- and high-level features play an important role in determining the correlation between pixels and in improving the performance of restored HR images. However, the features of previous layer in the aforementioned typical SR network models are directly fed in the next layer, where multi-level features are incompletely utilized. Inspired by the recent DenseNet, we concatenate and fuse multi-level features from multilayers. Although multi-level features are utilized in this manner, the number of parameters is large, which costs long training time and large storage. Therefore, we employ a recursive network architecture for parameter sharing. The overall model develops an efficient CNN model that can utilize the multi-level features of CNN to improve the SR performance and can control the number of model parameters within an acceptable range.MethodWe propose an image SR model that utilizes multi-level features. The proposed multi-feature fusion recursive network (MFRN) is based on recursive neural network with the same units in series. The information of features is passed along the basic unit of MFRN, named as the multi-feature fusion unit (MFU). The parameters are shared among these basic units, and the required number of parameters is effectively reduced. The input status within each MFU is obtained from the previous unit with continuous memory mechanism. Then, the low-level to high-level features are concatenated and fused to obtain abundant features in describing the image. Valuable features are extracted and enhanced, which can accurately describe the mapping relationship between LR and HR. With regard to the training process, a residual learning strategy, which involves local residual learning inside each unit and global residual learning through the entire network, is adopted to accelerate the training speed. Specifically, a global residual learning strategy is employed in the training of the overall MFRN, and a local residual learning strategy is applied for MFU. The training difficulty is efficiently reduced, and typical phenomena, such as network degradation and vanishing gradient, can be avoided by combining the aforementioned strategies. In terms of the cost function, the averaged mean square error over the training set is minimized. We train a single model for multiple scales based on the proposed cost function and training methods.ResultWe use 291 pictures from public databases as the training set. In addition, data augmentation (rotation or flip) is applied. Images with different scales (×2, ×3, and ×4) are included in the training set. Therefore, only a single model is trained for all different scales. During the training process, we adopt an adaptive learning rate and an adjustable gradient clipping to accelerate the convergence rate while suppressing exploding gradients. We evaluate four network models with different numbers of MFUs, which correspond to 29, 37, 53, and 81 layers. The network with nine MFUs achieves the best performance by comparing the convergence rate and performance. Hence, we adopt nine MFUs in the final CNN model. Although the proposed network has 37 layers, it elegantly converges at 230 epochs and obtains remarkable gains. The dominant evaluation criteria of image quality, such as PSNR, SSIM, and IFC, are employed for the performance assessment of restored images. Experimental results show that the proposed model achieves average PSNR gains of 0.24, 0.23, and 0.19 dB compared with the very deep convolutional networks for super-resoluton(VDSR) with the general four test sets for ×2, ×3, and ×4 resolutions. Specifically, the proposed MFRN considerably improves the quality of restored images in the dataset Urban100 that contains rich details. In addition, the subjective quality of restored images is illustrated. The MFRN can produce relatively sharper edges than that of other methods.ConclusionA multilevel feature fusion image SR algorithm based on recursive neural network, referred to as MFRN, is proposed in this study. The MFRN consists of multiple MFUs. Several recursive units are stacked to learn the residual image between the HR and LR images. The parameters with the recursive learning scheme are shared among the units, thereby effectively reducing the number of network parameters. The features of different levels within each unit are concatenated and fused to provide intensive description of the images. In this way, the proposed MFRN can extract and adaptively enhance valuable features, which leads to accurate mapping between LR and HR images. During the training procedure, we adopt a local residual learning inside each unit and a global residual learning through the entire network. Thus, a single model is trained for different scales. Experimental results show that the proposed MFRN considerably improves the performance. Specifically, in the Urban100 dataset, MFRN achieves 0.4 dB PSNR gains compared with the classical VDSR model. In comparison with the basic recursive network DRRN, 0.14 dB PNSR improvement is obtained. With regard to the subjective quality, MFRN is focused on handling the details of images. The visual perception of images is remarkably improved.关键词:image super-resolution;convolutional neural network;feature fusion;recursive neural network;residual learning17|4|6更新时间:2024-05-07
摘要:ObjectiveThe recovery of a high-resolution (HR) image or video from its low-resolution (LR) counterpart, which is referred to as super resolution (SR), has attracted considerable attention in computer vision community. The SR problem is inherently ill-posed because the HR image or video actually does not exist. Several methods have been proposed to address this issue. Several typical methods, such as bilinear or bicubic interpolation, Lanczos resampling, and internal patch recurrence, have been used. Recently, learning-based methods, such as sparse coding, random forest, and convolutional neural networks (CNNs), have been utilized to create a mapping between LR and HR images. Particularly, the CNN-based scheme has achieved remarkable performance improvement. Different network models, such as SRCNN, VDSR, LapSRN, and DRRN, have been proposed. These models abstract and combine the features of LR image to establish an effective nonlinear mapping from LR input images to HR target images. In this process, low- and high-level features play an important role in determining the correlation between pixels and in improving the performance of restored HR images. However, the features of previous layer in the aforementioned typical SR network models are directly fed in the next layer, where multi-level features are incompletely utilized. Inspired by the recent DenseNet, we concatenate and fuse multi-level features from multilayers. Although multi-level features are utilized in this manner, the number of parameters is large, which costs long training time and large storage. Therefore, we employ a recursive network architecture for parameter sharing. The overall model develops an efficient CNN model that can utilize the multi-level features of CNN to improve the SR performance and can control the number of model parameters within an acceptable range.MethodWe propose an image SR model that utilizes multi-level features. The proposed multi-feature fusion recursive network (MFRN) is based on recursive neural network with the same units in series. The information of features is passed along the basic unit of MFRN, named as the multi-feature fusion unit (MFU). The parameters are shared among these basic units, and the required number of parameters is effectively reduced. The input status within each MFU is obtained from the previous unit with continuous memory mechanism. Then, the low-level to high-level features are concatenated and fused to obtain abundant features in describing the image. Valuable features are extracted and enhanced, which can accurately describe the mapping relationship between LR and HR. With regard to the training process, a residual learning strategy, which involves local residual learning inside each unit and global residual learning through the entire network, is adopted to accelerate the training speed. Specifically, a global residual learning strategy is employed in the training of the overall MFRN, and a local residual learning strategy is applied for MFU. The training difficulty is efficiently reduced, and typical phenomena, such as network degradation and vanishing gradient, can be avoided by combining the aforementioned strategies. In terms of the cost function, the averaged mean square error over the training set is minimized. We train a single model for multiple scales based on the proposed cost function and training methods.ResultWe use 291 pictures from public databases as the training set. In addition, data augmentation (rotation or flip) is applied. Images with different scales (×2, ×3, and ×4) are included in the training set. Therefore, only a single model is trained for all different scales. During the training process, we adopt an adaptive learning rate and an adjustable gradient clipping to accelerate the convergence rate while suppressing exploding gradients. We evaluate four network models with different numbers of MFUs, which correspond to 29, 37, 53, and 81 layers. The network with nine MFUs achieves the best performance by comparing the convergence rate and performance. Hence, we adopt nine MFUs in the final CNN model. Although the proposed network has 37 layers, it elegantly converges at 230 epochs and obtains remarkable gains. The dominant evaluation criteria of image quality, such as PSNR, SSIM, and IFC, are employed for the performance assessment of restored images. Experimental results show that the proposed model achieves average PSNR gains of 0.24, 0.23, and 0.19 dB compared with the very deep convolutional networks for super-resoluton(VDSR) with the general four test sets for ×2, ×3, and ×4 resolutions. Specifically, the proposed MFRN considerably improves the quality of restored images in the dataset Urban100 that contains rich details. In addition, the subjective quality of restored images is illustrated. The MFRN can produce relatively sharper edges than that of other methods.ConclusionA multilevel feature fusion image SR algorithm based on recursive neural network, referred to as MFRN, is proposed in this study. The MFRN consists of multiple MFUs. Several recursive units are stacked to learn the residual image between the HR and LR images. The parameters with the recursive learning scheme are shared among the units, thereby effectively reducing the number of network parameters. The features of different levels within each unit are concatenated and fused to provide intensive description of the images. In this way, the proposed MFRN can extract and adaptively enhance valuable features, which leads to accurate mapping between LR and HR images. During the training procedure, we adopt a local residual learning inside each unit and a global residual learning through the entire network. Thus, a single model is trained for different scales. Experimental results show that the proposed MFRN considerably improves the performance. Specifically, in the Urban100 dataset, MFRN achieves 0.4 dB PSNR gains compared with the classical VDSR model. In comparison with the basic recursive network DRRN, 0.14 dB PNSR improvement is obtained. With regard to the subjective quality, MFRN is focused on handling the details of images. The visual perception of images is remarkably improved.关键词:image super-resolution;convolutional neural network;feature fusion;recursive neural network;residual learning17|4|6更新时间:2024-05-07 -
Decision making simulation of autonomous driving combined with state machine and dynamic target path
 摘要:ObjectiveDriverless technology is an essential part of intelligent transportation systems, such as environmental information perception, intelligent planning, and multilevel auxiliary driving. This technology reduces driver's work intensification and prevents accidents. With the development of artificial intelligence, autonomous vehicles have attracted considerable attention in the industry and academia in recent years. In addition, a decision-making system is a core research of driverless technology. The reduction on the number of road accidents is of paramount societal importance, and increasing research efforts have been devoted to decision-making systems within the past few years. Conducting human-like decisions with other encountered vehicles in complex traffic scenarios causes great challenges to autonomous vehicles. The research on autonomous driving decision systems has important theoretical and practical values to improve the level of intelligent vehicles and intelligent transportation systems. However, the current decision-making system has several limitations, such as unreasonable logic, large computational complexity, and limited application scene, due to the uncertainty and randomness of the driving behavior of surrounding vehicles. To solve these problems, this study constructs a finite-state machine-based decision-making system for the safety driving of autonomous vehicles in dynamic urban traffic environments. This study mainly investigates the passage of vehicles through intersections and their changing of lanes, which are the core issues of decision-making systems.MethodThe driver's behavior at a certain period of time is determined based on the current traffic condition and risk perception. We define the primary state of the vehicle based on the driving range of the autonomous vehicle, such as driving at the intersection, driving in the driveway, and approaching the crossroads. Each primary state includes many secondary states. For example, a vehicle at crossroads may turn or keep straight. Combined with the original finite-state machine theory, a suitable traffic state machine (TSM) for intelligent systems is proposed. Considering the complexity and diversity of traffic environment, a dynamic target path (DTP) algorithm is proposed to improve the feasibility of the decision system. Combined with the TSM and DTP algorithm, we propose a DTP model based on finite-state machine for the decision system and analyze the importance of the model. For complex and diverse traffic environment, intelligent vehicles only focus on their own driving information and ignore the state of other vehicles, which cause considerable risks. Thus, we divide the awareness and conflict areas for each autonomous vehicle. The perceived range of autonomous vehicles at the crossroads is defined as the awareness area, and the reachable range of autonomous vehicles is called the conflict area. The perception area of vehicles in the driveway is defined as the consciousness area, and the range of interaction between autonomous and surrounding vehicles is defined as the conflict area. A reasonable decision can effectively reduce the probability of accidents in conflict areas. We use the DTP algorithm to calculate the risk of decision making in restricting vehicle behavior. A fixed follow-up distance cannot consider the influence of speed. Thus, this study proposes a dynamic critical follow-up distance, which reduces the collision with preceding vehicle while following the vehicle. Furthermore, a full velocity difference model is used to avoid collision with the front vehicle of the target lane during lane change under different scenarios.ResultsWe repeatedly perform experiments in different scenarios through the Unity 3D engine to verify the effectiveness of the model and algorithm. In the first experiment, we simulate a scene of an autonomous vehicle driven at a crossroad. The second experiment simulates the responses of autonomous vehicles to emergencies. The third experiment simulates the changing of lanes of autonomous vehicles in reaching their destinations. The fourth experiment simulates the changing of lanes of autonomous vehicles in increasing their speed. We simulate the lane changing behavior of autonomous vehicles during foggy days to verify that the experimental results are unaffected by poor weather conditions. Experiments show that autonomous vehicles not only can meet the driving expectation but also ensure driving safety during poor weather conditions. Experimental results show that the driving intentions of other vehicles can be obtained and autonomous vehicles can make correct decisions based on the potential risk of intersection and current traffic environment. Autonomous vehicles can change lanes based on their driving demand when driving on the driveway. In case of emergencies, the autonomous vehicle considers the special vehicle as a dynamic obstacle. After yielding the right-of-way to emergency vehicles, the autonomous vehicle returns to the original lane to continue driving. To prove that the proposed method can improve the traffic flow efficiency, the proposed model is compared with other models. Results demonstrate that the difference among the three models is uncertain when the vehicle density is small. However, the average speed of the model is increased at most by 32 km/h and 22 km/h when the vehicle density is greater than 0.2 and less than 0.5, respectively. The success rate of lane changing in this model is approximately increased at most by 37 percentage points and 25 percentage points when the density of vehicles is less than 0.65, respectively.ConclusionsThe proposed algorithm not only improves the safety and accuracy of decision making in dynamic urban traffic environment but also helps improve traffic flow saturation and reduces traffic flow. In addition, various traffic environments can be modeled by our simulation framework. Although the proposed model and algorithm are relatively simple, the assessment of potential risks can meet the planning time of autonomous driving. Our work provides the rules for the decision making in autonomous driving and several references for the development of intelligent transportation systems. However, the influence of vehicle types, trajectory, and road width on decision making are ignored. In the future, we will improve the current work and provide a complete and reasonable framework for automatic driving decision systems.关键词:risk factor;lane-changing behavior;collision avoidance;autonomous driving technology;full velocity difference model11|4|0更新时间:2024-05-07
摘要:ObjectiveDriverless technology is an essential part of intelligent transportation systems, such as environmental information perception, intelligent planning, and multilevel auxiliary driving. This technology reduces driver's work intensification and prevents accidents. With the development of artificial intelligence, autonomous vehicles have attracted considerable attention in the industry and academia in recent years. In addition, a decision-making system is a core research of driverless technology. The reduction on the number of road accidents is of paramount societal importance, and increasing research efforts have been devoted to decision-making systems within the past few years. Conducting human-like decisions with other encountered vehicles in complex traffic scenarios causes great challenges to autonomous vehicles. The research on autonomous driving decision systems has important theoretical and practical values to improve the level of intelligent vehicles and intelligent transportation systems. However, the current decision-making system has several limitations, such as unreasonable logic, large computational complexity, and limited application scene, due to the uncertainty and randomness of the driving behavior of surrounding vehicles. To solve these problems, this study constructs a finite-state machine-based decision-making system for the safety driving of autonomous vehicles in dynamic urban traffic environments. This study mainly investigates the passage of vehicles through intersections and their changing of lanes, which are the core issues of decision-making systems.MethodThe driver's behavior at a certain period of time is determined based on the current traffic condition and risk perception. We define the primary state of the vehicle based on the driving range of the autonomous vehicle, such as driving at the intersection, driving in the driveway, and approaching the crossroads. Each primary state includes many secondary states. For example, a vehicle at crossroads may turn or keep straight. Combined with the original finite-state machine theory, a suitable traffic state machine (TSM) for intelligent systems is proposed. Considering the complexity and diversity of traffic environment, a dynamic target path (DTP) algorithm is proposed to improve the feasibility of the decision system. Combined with the TSM and DTP algorithm, we propose a DTP model based on finite-state machine for the decision system and analyze the importance of the model. For complex and diverse traffic environment, intelligent vehicles only focus on their own driving information and ignore the state of other vehicles, which cause considerable risks. Thus, we divide the awareness and conflict areas for each autonomous vehicle. The perceived range of autonomous vehicles at the crossroads is defined as the awareness area, and the reachable range of autonomous vehicles is called the conflict area. The perception area of vehicles in the driveway is defined as the consciousness area, and the range of interaction between autonomous and surrounding vehicles is defined as the conflict area. A reasonable decision can effectively reduce the probability of accidents in conflict areas. We use the DTP algorithm to calculate the risk of decision making in restricting vehicle behavior. A fixed follow-up distance cannot consider the influence of speed. Thus, this study proposes a dynamic critical follow-up distance, which reduces the collision with preceding vehicle while following the vehicle. Furthermore, a full velocity difference model is used to avoid collision with the front vehicle of the target lane during lane change under different scenarios.ResultsWe repeatedly perform experiments in different scenarios through the Unity 3D engine to verify the effectiveness of the model and algorithm. In the first experiment, we simulate a scene of an autonomous vehicle driven at a crossroad. The second experiment simulates the responses of autonomous vehicles to emergencies. The third experiment simulates the changing of lanes of autonomous vehicles in reaching their destinations. The fourth experiment simulates the changing of lanes of autonomous vehicles in increasing their speed. We simulate the lane changing behavior of autonomous vehicles during foggy days to verify that the experimental results are unaffected by poor weather conditions. Experiments show that autonomous vehicles not only can meet the driving expectation but also ensure driving safety during poor weather conditions. Experimental results show that the driving intentions of other vehicles can be obtained and autonomous vehicles can make correct decisions based on the potential risk of intersection and current traffic environment. Autonomous vehicles can change lanes based on their driving demand when driving on the driveway. In case of emergencies, the autonomous vehicle considers the special vehicle as a dynamic obstacle. After yielding the right-of-way to emergency vehicles, the autonomous vehicle returns to the original lane to continue driving. To prove that the proposed method can improve the traffic flow efficiency, the proposed model is compared with other models. Results demonstrate that the difference among the three models is uncertain when the vehicle density is small. However, the average speed of the model is increased at most by 32 km/h and 22 km/h when the vehicle density is greater than 0.2 and less than 0.5, respectively. The success rate of lane changing in this model is approximately increased at most by 37 percentage points and 25 percentage points when the density of vehicles is less than 0.65, respectively.ConclusionsThe proposed algorithm not only improves the safety and accuracy of decision making in dynamic urban traffic environment but also helps improve traffic flow saturation and reduces traffic flow. In addition, various traffic environments can be modeled by our simulation framework. Although the proposed model and algorithm are relatively simple, the assessment of potential risks can meet the planning time of autonomous driving. Our work provides the rules for the decision making in autonomous driving and several references for the development of intelligent transportation systems. However, the influence of vehicle types, trajectory, and road width on decision making are ignored. In the future, we will improve the current work and provide a complete and reasonable framework for automatic driving decision systems.关键词:risk factor;lane-changing behavior;collision avoidance;autonomous driving technology;full velocity difference model11|4|0更新时间:2024-05-07
ChinaMM 2018
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0