
最新刊期
卷 24 , 期 12 , 2019
-
 摘要:Object tracking is a fundamental problem in computer vision, which uses context information in a video or image sequence to predict and locate a target(s). It is widely used in smart video monitoring systems, intelligent human interaction, intelligent transportation, visual navigation systems, and many other areas. With the advent of the big data era and the emergence of deep learning methods, tracking performance has substantially improved. In this paper, we introduce the basic research framework of object tracking and review the history of object tracking from the perspective of the observation model. We indicate that deep learning allows for a more robust observation model to be obtained. We review the deep learning methods that are suitable for object tracking from the aspects of deep discriminative model and deep generative model. We also classify and analyze the existing deep object tracking methods from the perspectives of network structure, network function, and network training. In addition, we introduce several other deep object tracking methods, including deep object tracking based on the fusion of classification and regression, on reinforcement learning, on ensemble learning, and on meta-learning. We show the current commonly used databases for object tracking based on deep learning and their evaluation methods. We likewise analyze and summarize the latest specific application scenarios in object tracking from the perspectives of mobile tracking system, detection, and tracking-based system. Finally, we analyze the problems of object tracking, including insufficient training data, real-time tracking, and long-term tracking and specify further research directions for deep object tracking.关键词:visual object tracking;deep neural network;correlation filter;deep Siamese network;reinforcement learning;generative adversarial network395|311|58更新时间:2024-05-07
摘要:Object tracking is a fundamental problem in computer vision, which uses context information in a video or image sequence to predict and locate a target(s). It is widely used in smart video monitoring systems, intelligent human interaction, intelligent transportation, visual navigation systems, and many other areas. With the advent of the big data era and the emergence of deep learning methods, tracking performance has substantially improved. In this paper, we introduce the basic research framework of object tracking and review the history of object tracking from the perspective of the observation model. We indicate that deep learning allows for a more robust observation model to be obtained. We review the deep learning methods that are suitable for object tracking from the aspects of deep discriminative model and deep generative model. We also classify and analyze the existing deep object tracking methods from the perspectives of network structure, network function, and network training. In addition, we introduce several other deep object tracking methods, including deep object tracking based on the fusion of classification and regression, on reinforcement learning, on ensemble learning, and on meta-learning. We show the current commonly used databases for object tracking based on deep learning and their evaluation methods. We likewise analyze and summarize the latest specific application scenarios in object tracking from the perspectives of mobile tracking system, detection, and tracking-based system. Finally, we analyze the problems of object tracking, including insufficient training data, real-time tracking, and long-term tracking and specify further research directions for deep object tracking.关键词:visual object tracking;deep neural network;correlation filter;deep Siamese network;reinforcement learning;generative adversarial network395|311|58更新时间:2024-05-07 -
 摘要:Depth estimation from a single image, a classical problem in computer vision, is important for scene reconstruction, occlusion, and illumination processing in augmented reality. In this paper, the recent related literature of single-image depth estimation are reviewed, and the commonly used datasets and methods are introduced. According to different types of scenes, the datasets can be divided into indoor, outdoor, and virtual scenes. In consideration of the different mathematical models, monocular depth estimation methods can be divided into traditional machine learning-based methods and deep learning-based methods. Traditional machine learning-based methods use a Markov random field or conditional random field to model the depth relationships of pixels in an image. In the framework of maximum a posteriori probability, the depth can be obtained by minimizing the energy function. According to whether the model contains parameters, traditional machine learning-based methods can be further divided into parameter and non-parameter learning methods. The former assumes that the model contains unknown parameters, and the training process obtains these unknown parameters. The latter uses existing datasets for similarity retrieval to infer depth, and no parameters need to be solved. In recent years, deep learning has promoted the development of computer vision in many fields. The current research situations of deep learning-based monocular depth estimation methods in China abroad are analyzed with their advantages and disadvantages. These methods are classified hierarchically in a bottom-up paradigm with reference to different classification criteria. The depth and semantics of images are closely related, and several works focus on multi-task joint learning. In the first level, single-depth estimation methods are segregated into single-task methods that predict only depth and multi-task methods that simultaneously predict depth and semantics. The second level contains absolute depth prediction methods and relative depth prediction methods. Absolute depth refers to the actual distance between the object in the scene and the camera, while relative depth focuses on the relative distance of the object in the picture. Given arbitrary images, people are often better at judging the relative distances of objects in the scene. The third level consists of supervised regression method, supervised classification method, and unsupervised method. For single-image depth estimation task, most works focus on the prediction of absolute depth, and most of the early methods use a supervised regression model. In this manner, the model regression on continuous depth values and the training data should contain depth labels. On the basis of the characteristics of the scene from far to near, several studies were conducted to solve the problem of depth estimation with classification methods. Supervised learning methods require each RGB image to have a corresponding depth label, whose acquisition usually requires a depth camera or radar. However, the depth camera is limited in scope, and the radar is expensive. Furthermore, the original depth collected by the depth camera is usually sparse and cannot precisely match the original image. Therefore, the unsupervised depth estimation methods that do not need a depth label have been the research trends in recent years. The basic idea is to combine the polar geometry based on left-right consistency with an automatic coding machine to obtain depth.关键词:machine learning;depth estimation;3D reconstruction;deep learning110|374|15更新时间:2024-05-07
摘要:Depth estimation from a single image, a classical problem in computer vision, is important for scene reconstruction, occlusion, and illumination processing in augmented reality. In this paper, the recent related literature of single-image depth estimation are reviewed, and the commonly used datasets and methods are introduced. According to different types of scenes, the datasets can be divided into indoor, outdoor, and virtual scenes. In consideration of the different mathematical models, monocular depth estimation methods can be divided into traditional machine learning-based methods and deep learning-based methods. Traditional machine learning-based methods use a Markov random field or conditional random field to model the depth relationships of pixels in an image. In the framework of maximum a posteriori probability, the depth can be obtained by minimizing the energy function. According to whether the model contains parameters, traditional machine learning-based methods can be further divided into parameter and non-parameter learning methods. The former assumes that the model contains unknown parameters, and the training process obtains these unknown parameters. The latter uses existing datasets for similarity retrieval to infer depth, and no parameters need to be solved. In recent years, deep learning has promoted the development of computer vision in many fields. The current research situations of deep learning-based monocular depth estimation methods in China abroad are analyzed with their advantages and disadvantages. These methods are classified hierarchically in a bottom-up paradigm with reference to different classification criteria. The depth and semantics of images are closely related, and several works focus on multi-task joint learning. In the first level, single-depth estimation methods are segregated into single-task methods that predict only depth and multi-task methods that simultaneously predict depth and semantics. The second level contains absolute depth prediction methods and relative depth prediction methods. Absolute depth refers to the actual distance between the object in the scene and the camera, while relative depth focuses on the relative distance of the object in the picture. Given arbitrary images, people are often better at judging the relative distances of objects in the scene. The third level consists of supervised regression method, supervised classification method, and unsupervised method. For single-image depth estimation task, most works focus on the prediction of absolute depth, and most of the early methods use a supervised regression model. In this manner, the model regression on continuous depth values and the training data should contain depth labels. On the basis of the characteristics of the scene from far to near, several studies were conducted to solve the problem of depth estimation with classification methods. Supervised learning methods require each RGB image to have a corresponding depth label, whose acquisition usually requires a depth camera or radar. However, the depth camera is limited in scope, and the radar is expensive. Furthermore, the original depth collected by the depth camera is usually sparse and cannot precisely match the original image. Therefore, the unsupervised depth estimation methods that do not need a depth label have been the research trends in recent years. The basic idea is to combine the polar geometry based on left-right consistency with an automatic coding machine to obtain depth.关键词:machine learning;depth estimation;3D reconstruction;deep learning110|374|15更新时间:2024-05-07 - 摘要:Aerospace science and technology (S&T) is a direct indicator of comprehensive national power and S&T strength. Satellite remote sensing is one of the most immediate and realistic productivities transformed from aerospace S&T, which is composed of two broad procedures:remote sensing data acquisition and dissemination and data processing and information extraction. On the one hand, given the steady promotion of China's Civil Space Infrastructure, the capacity for satellite image acquisition has been enhanced largely in terms of quality and quantity. On the other hand, an image processing platform is a considerable infrastructure for satellite remote sensing application. Platform development is increasingly becoming an important factor restricting the application of satellite remote sensing and the development of spatial information-related business. This paper reviews state-of-the-art status and analyzes the future trend of acquisition capacity and processing platform of satellite remote sensing image.In terms of data acquisition and dissemination, international open remote sensing satellites and sensors, such as Terro/Aqua-MODIS, Landsat, and Sentinel, have largely broadened and deepened applications of satellite remote sensing imagery. Data sharing policy and regularized senior image product enable the use of these commonweal data to analyze a long-term geographical phenomenon in a large region. Large commercial satellites, such as WorldView, Pleiades, and Radarsat, are operated by sizeable commercial remote sensing firms. The imagery obtained by big satellites helps promote the commercial value of satellite imagery in traditional industry applications, whereas small commercial satellite constellations, such as Flock, SkySat, and BlackSky, lower the barrier for more generalized and common applications. With the steady promotion of China's Civil Space Infrastructure, China's 27 civil remote sensing satellites in orbit can be broadly categorized into land, ocean, and atmosphere observation satellites. Land observation satellites are composed of GaoFen, HuanJing, and ZiYuan series, and sensors onboard can acquire high-resolution visible-near infrared, hyperspectral, thermal, and synthetic aperture radar (SAR) imagery. Over 30 small commercial satellites in orbit include BeiJing, GaoJing, JiLin, and ZhuHai series. Despite the substantial progress of China's capacity for remote sensing data acquisition and dissemination, distinct generation gaps remain, especially in terms of new type sensors such as polarization and electromagnetic monitoring sensors. Policy barrier, data regularity, and quality as well as data sharing model in big data era are the main challenges encountered in data sharing. Several efforts, including project on big earth data science engineering, have been made to accelerate the development of satellite remote sensing data sharing.In terms of satellite remote sensing processing platforms, well-known platforms such as ERDAS IMAGINE, ENVI, and PCI Geomatic lead the development worldwide. The leadership can be characterized by four advantages. First, platform expandability is reflected by flexible deployment environment, powerful secondary development capability, and seamless integration with GIS platforms. Second, these platforms support the processing of multi-source and multi-format remote sensing data. Multi-source data refer to optical, SAR, LiDAR, and hyperspectral data, while multi-format data refer to image, point cloud, and video data. Third, ERDAS IMAGINE and ENVI start to develop modules based on deep learning algorithms, such as Faster RCNN. The introduction of deep learning is based on its overwhelming accuracy compared with traditional machine learning algorithms, such as SVM. Finally, algorithms and hardware, such as GPU, DSP, and FPGA, are integrated more tightly to continue promoting data processing efficiency. In China, common platforms such as IRSA, ImageInfo, Titan Image, and PIE pay more attention to satellite optical imagery processing despite limited support for multi-source data. Specialized software, including HypEYE and CAESAR, are developed to fulfil the demands of hyperspectral and SAR image processing. In the last 10 years, cloud computing technology has been introduced into remote sensing imagery processing platforms because of its advantage of providing one-step geospatial service by integrating remote sensing data, information product, application software, and computing and storage resources. Google Earth Engine, Data Cube, ENVI Service Engine, and ERDAS APOLLO are some of the successful platforms, and several similar platforms are available in China. China's self-developed remote sensing imagery processing platforms are not competitive with their international counterparts owing to backwardness caused by a lack of independent innovation and steady profit model.Four evident trends are observed in satellite remote sensing in the era of big data and artificial intelligence. First, small satellite constellations accelerate the industrialization and popularization of satellite remote sensing, while the improvement of geometric and radial accuracy remains the bottleneck. Second, autonomous and intelligent satellites with capabilities of adaptive optimization of imaging parameters, onboard thorough perception of object, and environment are future directions of remote sensing. The intelligent satellite will be an essential component of collaborative unmanned systems. Third, the transformation from meaningless DN value to semantic object information based on artificial intelligence techniques will certainly improve the information provided by satellite remote sensing in terms of quantity and quality. Finally, the integration of position and navigation, time, remote sensing, and communication platforms and signals will magnify remote sensing capability by providing application-oriented solutions.关键词:satellite remote sensing;image processing;cloud computing;remote sensing application89|148|20更新时间:2024-05-07
Review

-
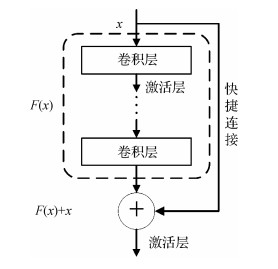 摘要:ObjectiveColor constancy refers to the human ability that allows the brain to recognize an object as having a consistent color under varying illuminants. Color constancy has become an important prerequisite of high-level tasks, such as recognition, segmentation, and 3D vision. In the computer vision community, the goal of computational color constancy is to remove illuminant color casts and obtain accurate color representations for images. Therefore, illuminant estimation is an important means to achieve computational color constancy, which is a difficult and underdetermined problem because the observed image color is influenced by unknown factors, such as scene illuminants and object reflections. Illuminant estimation methods can be categorized into two classes:statistics-based (or static) and learning-based methods. Statistics-based methods estimate the illuminant based on the statistical properties (e.g., reflectance distributions) of the image. Learning-based methods learn a model from training images then estimate the illuminant using the model. Convolutional neural networks (CNNs) are very powerful methods of estimating illuminants, and many competitive results have been obtained with CNN-based methods. We propose a CNN-based illuminant estimation algorithm in this study. We use deep residual learning to improve network accuracy and a patch-selecting network to overcome the color ambiguity issue of local patches.MethodWe uniformly sample local patches from the image, estimate the local illuminant of each patch individually, and generate a global illuminant estimation of the entire image by combining the local illuminants. We use a 64×64 patch size in the patch sampling to guarantee the estimation accuracy of the local illuminant and provide sufficient training inputs without data augmentation. The proposed approach includes two residual networks, namely, illuminant estimation net (IEN) and patch selection net (PSN). IEN estimates the local illuminant of image patches. To improve the estimation accuracy of IEN, we increase the feature extraction hierarchy by adding network depth and use the residual structure to ensure gradient propagation and facilitate the training of the deep network. IEN is based on the residual structure, which consists of many stacked 3×3 and 1×1 convolutional layers, batch normalization layers, and rectified linear unit layers. The remaining part is composed of one global average pooling layer and one full connection layer. We use Euclidean loss and stochastic gradient descent (SGD) to optimize IEN. PSN shares a similar architecture with IEN, except that PSN has an additional Softmax layer that serves as the classifier at the end of the network. PSN is proposed to classify image patches according to their illuminant estimation errors. We use cross entropy loss and SGD to optimize PSN. According to the results of PSN, patches with a large estimation error are removed from the entire image, thus improving the performance of global illuminant estimation. Additionally, we preprocess the input image by using the log-chrominance algorithm, which converts a three-channel RGB image into a two-channel log-chrominance image; this reduces the influence of image luminance and improves the computational efficiency by decreasing the amount of data by 1/3.ResultWe implement the proposed IEN and PSN on the Caffe library. To evaluate the performance of our approach, we use two standard single-illuminant datasets, namely, the NUS-8 dataset and the reprocessed ColorChecker dataset. Both datasets include indoor and outdoor images, and a Macbeth ColorChecker is placed in each image to calculate the ground truth illuminant. The NUS-8 dataset contains 1 736 images captured from 8 different cameras, and the reprocessed ColorChecker dataset consists of 568 images from 2 cameras. Following the configurations of previous studies, we report the following metrics:the mean, the median, the tri-mean, and the mean of the lowest 25% and the highest 25% of angular errors. We also report the additional metric of the 95th percentile for the reprocessed ColorChecker dataset. We divide the NUS-8 dataset into eight subsets, apply three-fold cross-validation on the eight subsets individually, and report the geometric mean of the proposed metrics for all eight subsets. We directly apply three-fold cross-validation on the reprocessed ColorChecker dataset. Experimental results show that the proposed approach is competitive with state-of-the-art methods. For the NUS-8 dataset, the proposed IEN achieves the best results among all compared methods, and the proposed PSN can further increase the precision of the IEN results. For the reprocessed ColorChecker dataset, our results are comparable with those of other advanced methods. In addition, we conduct ablation studies to evaluate the model components of the proposed approach. We compare the proposed IEN with several shallower CNNs. Experimental results show that deep residual learning is effective in improving illuminant estimation accuracy. Moreover, compared with the estimated illuminant on the original image, log-chrominance preprocessing can reduce the illuminant estimation error by 10% to 15%. The proposed PSN can further decrease the global illuminant estimation error by 5% compared with the method that uses IEN alone. Finally, we evaluate the time cost of our method on a PC with an Intel i5 2.7 GHz CPU, 16GB of memory, and an NVIDIA GeForce GTX 1080Ti GPU. Our code takes less than 1.4 s to estimate a 2 K image, which has a typical resolution of 2 048×1 080 pixels.ConclusionExperiments on the two single-illuminant datasets show that the proposed approach, which includes log-chrominance preprocessing, deep residual learning-based network structure, and patch selection for global illuminant estimation, is reasonable and effective. The proposed approach has high precision and robustness and can be widely used in image processing and computer vision systems that require color calibrations.关键词:visual optics;color constancy;illuminant estimation;deep residual learning;log-chrominance35|35|3更新时间:2024-05-07
摘要:ObjectiveColor constancy refers to the human ability that allows the brain to recognize an object as having a consistent color under varying illuminants. Color constancy has become an important prerequisite of high-level tasks, such as recognition, segmentation, and 3D vision. In the computer vision community, the goal of computational color constancy is to remove illuminant color casts and obtain accurate color representations for images. Therefore, illuminant estimation is an important means to achieve computational color constancy, which is a difficult and underdetermined problem because the observed image color is influenced by unknown factors, such as scene illuminants and object reflections. Illuminant estimation methods can be categorized into two classes:statistics-based (or static) and learning-based methods. Statistics-based methods estimate the illuminant based on the statistical properties (e.g., reflectance distributions) of the image. Learning-based methods learn a model from training images then estimate the illuminant using the model. Convolutional neural networks (CNNs) are very powerful methods of estimating illuminants, and many competitive results have been obtained with CNN-based methods. We propose a CNN-based illuminant estimation algorithm in this study. We use deep residual learning to improve network accuracy and a patch-selecting network to overcome the color ambiguity issue of local patches.MethodWe uniformly sample local patches from the image, estimate the local illuminant of each patch individually, and generate a global illuminant estimation of the entire image by combining the local illuminants. We use a 64×64 patch size in the patch sampling to guarantee the estimation accuracy of the local illuminant and provide sufficient training inputs without data augmentation. The proposed approach includes two residual networks, namely, illuminant estimation net (IEN) and patch selection net (PSN). IEN estimates the local illuminant of image patches. To improve the estimation accuracy of IEN, we increase the feature extraction hierarchy by adding network depth and use the residual structure to ensure gradient propagation and facilitate the training of the deep network. IEN is based on the residual structure, which consists of many stacked 3×3 and 1×1 convolutional layers, batch normalization layers, and rectified linear unit layers. The remaining part is composed of one global average pooling layer and one full connection layer. We use Euclidean loss and stochastic gradient descent (SGD) to optimize IEN. PSN shares a similar architecture with IEN, except that PSN has an additional Softmax layer that serves as the classifier at the end of the network. PSN is proposed to classify image patches according to their illuminant estimation errors. We use cross entropy loss and SGD to optimize PSN. According to the results of PSN, patches with a large estimation error are removed from the entire image, thus improving the performance of global illuminant estimation. Additionally, we preprocess the input image by using the log-chrominance algorithm, which converts a three-channel RGB image into a two-channel log-chrominance image; this reduces the influence of image luminance and improves the computational efficiency by decreasing the amount of data by 1/3.ResultWe implement the proposed IEN and PSN on the Caffe library. To evaluate the performance of our approach, we use two standard single-illuminant datasets, namely, the NUS-8 dataset and the reprocessed ColorChecker dataset. Both datasets include indoor and outdoor images, and a Macbeth ColorChecker is placed in each image to calculate the ground truth illuminant. The NUS-8 dataset contains 1 736 images captured from 8 different cameras, and the reprocessed ColorChecker dataset consists of 568 images from 2 cameras. Following the configurations of previous studies, we report the following metrics:the mean, the median, the tri-mean, and the mean of the lowest 25% and the highest 25% of angular errors. We also report the additional metric of the 95th percentile for the reprocessed ColorChecker dataset. We divide the NUS-8 dataset into eight subsets, apply three-fold cross-validation on the eight subsets individually, and report the geometric mean of the proposed metrics for all eight subsets. We directly apply three-fold cross-validation on the reprocessed ColorChecker dataset. Experimental results show that the proposed approach is competitive with state-of-the-art methods. For the NUS-8 dataset, the proposed IEN achieves the best results among all compared methods, and the proposed PSN can further increase the precision of the IEN results. For the reprocessed ColorChecker dataset, our results are comparable with those of other advanced methods. In addition, we conduct ablation studies to evaluate the model components of the proposed approach. We compare the proposed IEN with several shallower CNNs. Experimental results show that deep residual learning is effective in improving illuminant estimation accuracy. Moreover, compared with the estimated illuminant on the original image, log-chrominance preprocessing can reduce the illuminant estimation error by 10% to 15%. The proposed PSN can further decrease the global illuminant estimation error by 5% compared with the method that uses IEN alone. Finally, we evaluate the time cost of our method on a PC with an Intel i5 2.7 GHz CPU, 16GB of memory, and an NVIDIA GeForce GTX 1080Ti GPU. Our code takes less than 1.4 s to estimate a 2 K image, which has a typical resolution of 2 048×1 080 pixels.ConclusionExperiments on the two single-illuminant datasets show that the proposed approach, which includes log-chrominance preprocessing, deep residual learning-based network structure, and patch selection for global illuminant estimation, is reasonable and effective. The proposed approach has high precision and robustness and can be widely used in image processing and computer vision systems that require color calibrations.关键词:visual optics;color constancy;illuminant estimation;deep residual learning;log-chrominance35|35|3更新时间:2024-05-07 -
 摘要:ObjectiveTwo typical methods of coverless information hiding are currently available. One is search-based coverless information hiding, which transmits secret information by querying a text or image containing secret information from a database, and the other is texture generation-based information hiding, which relays secret information by generating a stego texture similar to a given image texture. Search-based information hiding has a small embedding capacity and a large search space and involves the intensive transmission of numerous carriers. Although every isolated text or image in this method is a normal text or image without modification, the method is still suspicious because of the dense transmission of carriers. Texture generation-based information hiding can be further divided into texture construction and texture synthesis-based information hiding. Generating a real natural texture directly is challenging. In texture synthesis-based information hiding, apparent distinguishing features between coded and non-coded blocks and a fixed mapping relationship between secret information and coded blocks exist. The method has low security and disregards the difference degree among various coded blocks and category errors during attacks. To address these problems, this work proposes a generation information hiding method that combines difference clustering and minimum error texture synthesis.MethodFirst, in the embedding process, sample blocks are randomly captured in the sample texture image by a key. Then, the mean square errors of the kernel regions between the sample blocks and the random key template are calculated. These errors are divided into several categories through a difference mean clustering strategy, in which the sample block closest to the cluster center position is selected as the coded sample block in each category. Second, a multiple mapping relationship is established to obtain the coded sample block number through secret information decimal numbers, the MD5 (message-digest algorithm 5) value of the secret information, random coordinates, and the coded sample blocks. Finally, the coded sample blocks that represent the secret information decimal numbers are placed randomly in a blank image. The nearest sample blocks are selected to cover the secret information and generate a stego texture image through minimum error priority stitching, where the splicing order is determined by the minimum difference among adjacent blocks. This strategy always selects the least difference error line for minimum difference splicing. In the extraction process, all stego blocks are truncated in the stego texture image by the key, and the same coded sample blocks are obtained by difference mean clustering through the given sample image. All of the closest coded block numbers corresponding to the truncated stego blocks are identified via a similarity comparison and used to recover the binary secret information by combining these block numbers with the secret information's MD5 value and random coordinates.ResultThe proposed method is tightly bound to the plaintext attribute of the secret information's MD5 value and the key. The method completely depends on the key, MD5 value, and sample texture image. Only the correct key, MD5 value, and sample texture image can completely recover secret information. Any change or changes in individual or multiple key variables and the texture sample image will result in errors. For example, the EBR (error bit rate) of the extracted secret information could approach 0.5, and half of the extracted secret information bits cannot be fetched with the maximum uncertainty. Through the minimum error priority, the proposed method has a smaller pixel cumulative difference on the minimum error line compared with existing methods, and the generated stego texture image has better visual quality and is extremely sensitive to the key. The visual quality of stego texture maps decreases whether in salt-and-pepper noise, graffiti, or JPEG compression. However, during high-intensity salt-and-pepper noise and large-scale graffiti attacks, most of the bits embedded into the secret information can be accurately extracted or even completely fetched. In the given experiment samples, the quality factors are set from 50 to 70 for JPEG compression attacks, the EBR of the recovered secret information is always 0, and the entire secret information is completely restored. For 5% to 15% salt-and-pepper noise attacks, the EBR of the recovered secret information is still 0, and the secret information can be completely fetched. Even under 25% to 40% high-intensity salt-and-pepper noise attacks, the EBR of the extracted secret information remains very low, that is, less than 7%. Thus, the proposed method has a strong attack tolerance to high-intensity salt-and-pepper noise and large-scale graffiti attacks. The method can also resist low-quality JPEG compression attacks.ConclusionThe proposed method does not require many samples to build a large database. It avoids the retrieval of big data, and its computation cost is small. The proposed method only involves single carrier embedding, and its embedding capacity is high. It can produce high-quality texture to cover secret information. The introduced random key template and the established multiple mapping relationship between random coordinates and coded sample blocks avoid the fixed mapping relationship between secret information and coded sample blocks. The coded sample blocks have the largest inter-class difference because of sample difference mean clustering. Therefore, the proposed method has a robust recovery process that is entirely dependent on the key, and its security is high. The splicing order is determined according to the minimum difference among adjacent blocks, and the least difference error line that can cover the secret information with high quality is selected for splicing. Moreover, difference minimum error line splicing that can cover secret information with high quality is selected.关键词:difference mean clustering;texture generation;information hiding;minimum error;image stitching;sample texture synthesis28|148|2更新时间:2024-05-07
摘要:ObjectiveTwo typical methods of coverless information hiding are currently available. One is search-based coverless information hiding, which transmits secret information by querying a text or image containing secret information from a database, and the other is texture generation-based information hiding, which relays secret information by generating a stego texture similar to a given image texture. Search-based information hiding has a small embedding capacity and a large search space and involves the intensive transmission of numerous carriers. Although every isolated text or image in this method is a normal text or image without modification, the method is still suspicious because of the dense transmission of carriers. Texture generation-based information hiding can be further divided into texture construction and texture synthesis-based information hiding. Generating a real natural texture directly is challenging. In texture synthesis-based information hiding, apparent distinguishing features between coded and non-coded blocks and a fixed mapping relationship between secret information and coded blocks exist. The method has low security and disregards the difference degree among various coded blocks and category errors during attacks. To address these problems, this work proposes a generation information hiding method that combines difference clustering and minimum error texture synthesis.MethodFirst, in the embedding process, sample blocks are randomly captured in the sample texture image by a key. Then, the mean square errors of the kernel regions between the sample blocks and the random key template are calculated. These errors are divided into several categories through a difference mean clustering strategy, in which the sample block closest to the cluster center position is selected as the coded sample block in each category. Second, a multiple mapping relationship is established to obtain the coded sample block number through secret information decimal numbers, the MD5 (message-digest algorithm 5) value of the secret information, random coordinates, and the coded sample blocks. Finally, the coded sample blocks that represent the secret information decimal numbers are placed randomly in a blank image. The nearest sample blocks are selected to cover the secret information and generate a stego texture image through minimum error priority stitching, where the splicing order is determined by the minimum difference among adjacent blocks. This strategy always selects the least difference error line for minimum difference splicing. In the extraction process, all stego blocks are truncated in the stego texture image by the key, and the same coded sample blocks are obtained by difference mean clustering through the given sample image. All of the closest coded block numbers corresponding to the truncated stego blocks are identified via a similarity comparison and used to recover the binary secret information by combining these block numbers with the secret information's MD5 value and random coordinates.ResultThe proposed method is tightly bound to the plaintext attribute of the secret information's MD5 value and the key. The method completely depends on the key, MD5 value, and sample texture image. Only the correct key, MD5 value, and sample texture image can completely recover secret information. Any change or changes in individual or multiple key variables and the texture sample image will result in errors. For example, the EBR (error bit rate) of the extracted secret information could approach 0.5, and half of the extracted secret information bits cannot be fetched with the maximum uncertainty. Through the minimum error priority, the proposed method has a smaller pixel cumulative difference on the minimum error line compared with existing methods, and the generated stego texture image has better visual quality and is extremely sensitive to the key. The visual quality of stego texture maps decreases whether in salt-and-pepper noise, graffiti, or JPEG compression. However, during high-intensity salt-and-pepper noise and large-scale graffiti attacks, most of the bits embedded into the secret information can be accurately extracted or even completely fetched. In the given experiment samples, the quality factors are set from 50 to 70 for JPEG compression attacks, the EBR of the recovered secret information is always 0, and the entire secret information is completely restored. For 5% to 15% salt-and-pepper noise attacks, the EBR of the recovered secret information is still 0, and the secret information can be completely fetched. Even under 25% to 40% high-intensity salt-and-pepper noise attacks, the EBR of the extracted secret information remains very low, that is, less than 7%. Thus, the proposed method has a strong attack tolerance to high-intensity salt-and-pepper noise and large-scale graffiti attacks. The method can also resist low-quality JPEG compression attacks.ConclusionThe proposed method does not require many samples to build a large database. It avoids the retrieval of big data, and its computation cost is small. The proposed method only involves single carrier embedding, and its embedding capacity is high. It can produce high-quality texture to cover secret information. The introduced random key template and the established multiple mapping relationship between random coordinates and coded sample blocks avoid the fixed mapping relationship between secret information and coded sample blocks. The coded sample blocks have the largest inter-class difference because of sample difference mean clustering. Therefore, the proposed method has a robust recovery process that is entirely dependent on the key, and its security is high. The splicing order is determined according to the minimum difference among adjacent blocks, and the least difference error line that can cover the secret information with high quality is selected for splicing. Moreover, difference minimum error line splicing that can cover secret information with high quality is selected.关键词:difference mean clustering;texture generation;information hiding;minimum error;image stitching;sample texture synthesis28|148|2更新时间:2024-05-07 -
 摘要:ObjectiveLow-illumination images are easily produced when taking pictures because of weak lighting conditions or devices with poor filling flash. Low-illumination images are difficult to recognize. Thus, the quality of low-illumination images needs to be improved. In the past, low-illumination image enhancement was dominated by histogram equalization (HE) and Retinex, but these methods cannot easily generate the desired results. Their results often entail problems, such as color distortion and blurred edges. A conditional generative adversarial network (CGAN)-based method is proposed to solve this poor visual perception problem. CGAN is an extension of the generative adversarial network (GAN). At present, it is widely used in data generation, including image de-raining, image resolution enhancement, and speech denoising. Unlike traditional low-illumination image enhancement methods that work on single image adjustment, this method achieves data-driven enhancement.MethodThis study proposes an encode-decode convolutional neural network (CNN) model as the generative model and a CNN model with a classification function as the discriminative model. The two models constitute a GAN. The model processes input images end to end and without adjusting the parameters manually. Instead of using synthetic image datasets, real-shot low-illumination images from the multi-exposure image dataset are used for training and testing. This image dataset contains multi-exposure sequential images, including under-and over-exposure images. The exposure of images is shifted by the exposure value (EV) of cameras or phones. Moreover, this dataset offers high-quality reference light images. During training, by offering reference light images from datasets as conditions to GAN, both models optimize their parameters according to the light images. As a result, the entire model is transformed into CGAN. The coding path of the generative model samples low-illumination images and processes the images at different scales. After coding, the encoding path restores the image size and shortens the distance between the outputs and conditional light images. The low-illumination images are denoised and restored by a different convolution processing of the generative model, and enhanced images are obtained. The discriminative model distinguishes the enhanced and reference light images by comparing their differences. The enhanced images are regarded as false, and the reference light images are regarded as true. Then, the discriminative model provides the result to the generative model. According to the feedback, the generative model optimizes the parameters to obtain an improved enhancement capability, and the discriminative model obtains an improved distinguishing capability by optimizing its own parameters. After training thousands of pairs of images, the parameters of both models are optimized. By using the discriminative model to supervise the generative model and by combining the interrelation between the two models, an improved image enhancement effect is achieved. When the proposed model is used to enhance low-illumination images, the discriminative model is no longer involved in the work, and the result is obtained directly from the generative model. Furthermore, skip connection and batch normalization are integrated into the proposed model. Skip connection transmits the gradient from shallow to deep layers. It has a transitional effect on the shallow and deep features. Batch normalization can effectively avoid gradient vanishing and explosion. Both approaches enhance the processing capability of the model.ResultIn this study, the entire network model and the single generative model are compared; the two sets of models represent CGAN and CNN methods, respectively.Resultsshow that the entire network model has a better processing effect than the single generative model. This finding proves that the discriminative model improves the effect of the generative model during training. Afterward, eight existing methods are applied for comparison with the proposed method. By subjectively comparing the results of these methods, we find that our method achieves a better effect in terms of brightness, clarity, and color restoration. By using the peak signal-to-noise ratio (PSNR), histogram similarity (HS), and structural similarity (SSIM) as the objectives of comparison, our method exhibits improvements of 0.7 dB, 3.9%, and 8.2%, respectively. Meanwhile, the processing time of each method is compared. By using a graphics processing unit (GPU) for acceleration, the proposed method becomes much faster than the other methods, especially traditional central processing unit (CPU)-based methods. The proposed method can meet the requirement of real-time applications. Furthermore, for several low-illumination images with bright parts, our method does not enhance these parts, whereas other existing methods always over-enhance the bright parts.ConclusionA conditional generative adversarial network-based method for low-illumination image enhancement is proposed. Experimental results show that the method proposed is more effective than existing methods not only in perception but also in speed.关键词:image processing;low-illumination image enhancement;convolutional neural network (CNN);conditional generative adversarial network (CGAN);deep learning37|134|10更新时间:2024-05-07
摘要:ObjectiveLow-illumination images are easily produced when taking pictures because of weak lighting conditions or devices with poor filling flash. Low-illumination images are difficult to recognize. Thus, the quality of low-illumination images needs to be improved. In the past, low-illumination image enhancement was dominated by histogram equalization (HE) and Retinex, but these methods cannot easily generate the desired results. Their results often entail problems, such as color distortion and blurred edges. A conditional generative adversarial network (CGAN)-based method is proposed to solve this poor visual perception problem. CGAN is an extension of the generative adversarial network (GAN). At present, it is widely used in data generation, including image de-raining, image resolution enhancement, and speech denoising. Unlike traditional low-illumination image enhancement methods that work on single image adjustment, this method achieves data-driven enhancement.MethodThis study proposes an encode-decode convolutional neural network (CNN) model as the generative model and a CNN model with a classification function as the discriminative model. The two models constitute a GAN. The model processes input images end to end and without adjusting the parameters manually. Instead of using synthetic image datasets, real-shot low-illumination images from the multi-exposure image dataset are used for training and testing. This image dataset contains multi-exposure sequential images, including under-and over-exposure images. The exposure of images is shifted by the exposure value (EV) of cameras or phones. Moreover, this dataset offers high-quality reference light images. During training, by offering reference light images from datasets as conditions to GAN, both models optimize their parameters according to the light images. As a result, the entire model is transformed into CGAN. The coding path of the generative model samples low-illumination images and processes the images at different scales. After coding, the encoding path restores the image size and shortens the distance between the outputs and conditional light images. The low-illumination images are denoised and restored by a different convolution processing of the generative model, and enhanced images are obtained. The discriminative model distinguishes the enhanced and reference light images by comparing their differences. The enhanced images are regarded as false, and the reference light images are regarded as true. Then, the discriminative model provides the result to the generative model. According to the feedback, the generative model optimizes the parameters to obtain an improved enhancement capability, and the discriminative model obtains an improved distinguishing capability by optimizing its own parameters. After training thousands of pairs of images, the parameters of both models are optimized. By using the discriminative model to supervise the generative model and by combining the interrelation between the two models, an improved image enhancement effect is achieved. When the proposed model is used to enhance low-illumination images, the discriminative model is no longer involved in the work, and the result is obtained directly from the generative model. Furthermore, skip connection and batch normalization are integrated into the proposed model. Skip connection transmits the gradient from shallow to deep layers. It has a transitional effect on the shallow and deep features. Batch normalization can effectively avoid gradient vanishing and explosion. Both approaches enhance the processing capability of the model.ResultIn this study, the entire network model and the single generative model are compared; the two sets of models represent CGAN and CNN methods, respectively.Resultsshow that the entire network model has a better processing effect than the single generative model. This finding proves that the discriminative model improves the effect of the generative model during training. Afterward, eight existing methods are applied for comparison with the proposed method. By subjectively comparing the results of these methods, we find that our method achieves a better effect in terms of brightness, clarity, and color restoration. By using the peak signal-to-noise ratio (PSNR), histogram similarity (HS), and structural similarity (SSIM) as the objectives of comparison, our method exhibits improvements of 0.7 dB, 3.9%, and 8.2%, respectively. Meanwhile, the processing time of each method is compared. By using a graphics processing unit (GPU) for acceleration, the proposed method becomes much faster than the other methods, especially traditional central processing unit (CPU)-based methods. The proposed method can meet the requirement of real-time applications. Furthermore, for several low-illumination images with bright parts, our method does not enhance these parts, whereas other existing methods always over-enhance the bright parts.ConclusionA conditional generative adversarial network-based method for low-illumination image enhancement is proposed. Experimental results show that the method proposed is more effective than existing methods not only in perception but also in speed.关键词:image processing;low-illumination image enhancement;convolutional neural network (CNN);conditional generative adversarial network (CGAN);deep learning37|134|10更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveInfrared small-target detection is a key technology in precision guidance. It is crucial in aircraft infrared search and tracking systems, infrared imaging and guidance systems, and early warning systems for military installations. However, infrared small-target detection in complex backgrounds still encounters challenges. First, due to the long imaging distance, the target is usually very dim and small and lacks a concrete structure and texture information. Second, when strong background clutter and noise exist, such targets are often buried in the background with a low signal-to-clutter ratio. Hence, the issue remains difficult and challenging. Meanwhile, utilizing the existing low rank constraint and sparse representation joint model directly has disadvantages of low accuracy, high false alarm rate, and slow detection. To solve these problems, a small-target detection method based on the multiscale infrared superpixel-image model is proposed.MethodThe method of constructing an infrared-patch image in prior literature involves setting the sliding window to slide from up to down and left to right of the image at a certain step size. The gray value of each pixel in the sliding window is rearranged into a column vector when it slides to each position. The matrix composed of these column vectors is called the patch image. However, in the process of constructing such a patch image in this manner, the proportion of overlapping area between sliding windows is large, resulting in a high degree of information redundancy. In addition, the constructed patch image has high dimensionality, which leads to a large amount of calculation. To overcome these deficiencies, the superpixel method is adopted to segment the original infrared image and obtain superpixel images with no overlapping area. The method makes full use of the local spatial correlation of the infrared image and avoids the computational burden caused by redundant information. Moreover, introducing multiscale theory then merging the target images detected at different scales can further improve the robustness of the algorithm for detecting targets of different sizes.ResultFirst, experiments are conducted on many infrared small target images with varying situations and levels of noise. Experimental results demonstrate that from the perspective of subjective visual evaluation, the proposed method is robust to different scenes and noise. Experiments are also conducted to verify two aspects, namely, background suppression effect and detection speed. The signal-to-clutter ratio gain and background suppression factor are selected as quantitative evaluation indicators for the background suppression effect. Experimental results reveal that compared with the Top-Hat, Max-Median, two-dimensional least mean square, local saliency map, infrared patch-image, and weighted infrared patch-image methods, the proposed method can effectively eliminate various interferences, exerts a superior effect on background suppression, and can accurately detect infrared small targets in complex backgrounds simultaneously. The background suppression factor of the proposed method is several tens of times that of other methods, and the infrared superpixel-image model reduces the detection time by at least 78.2% compared with similar methods.ConclusionIn this study, superpixel image segmentation and multiscale theory are introduced into the low rank constraint and sparse representation joint model. The model can achieve an advantageous background suppression effect and good adaptability to the target size when applied to infrared small-target detection in complex backgrounds. In addition, the proposed method of infrared small-target detection at different scales can be further transformed into parallel processing, which is beneficial for accelerating the detection process of the method. Our future work will focus on reducing the algorithm's complexity and designing a more flexible method for constructing an infrared-patch image.关键词:small target detection;infrared image;low rank constraint;sparse representation;superpixel;multiscale56|88|2更新时间:2024-05-07
摘要:ObjectiveInfrared small-target detection is a key technology in precision guidance. It is crucial in aircraft infrared search and tracking systems, infrared imaging and guidance systems, and early warning systems for military installations. However, infrared small-target detection in complex backgrounds still encounters challenges. First, due to the long imaging distance, the target is usually very dim and small and lacks a concrete structure and texture information. Second, when strong background clutter and noise exist, such targets are often buried in the background with a low signal-to-clutter ratio. Hence, the issue remains difficult and challenging. Meanwhile, utilizing the existing low rank constraint and sparse representation joint model directly has disadvantages of low accuracy, high false alarm rate, and slow detection. To solve these problems, a small-target detection method based on the multiscale infrared superpixel-image model is proposed.MethodThe method of constructing an infrared-patch image in prior literature involves setting the sliding window to slide from up to down and left to right of the image at a certain step size. The gray value of each pixel in the sliding window is rearranged into a column vector when it slides to each position. The matrix composed of these column vectors is called the patch image. However, in the process of constructing such a patch image in this manner, the proportion of overlapping area between sliding windows is large, resulting in a high degree of information redundancy. In addition, the constructed patch image has high dimensionality, which leads to a large amount of calculation. To overcome these deficiencies, the superpixel method is adopted to segment the original infrared image and obtain superpixel images with no overlapping area. The method makes full use of the local spatial correlation of the infrared image and avoids the computational burden caused by redundant information. Moreover, introducing multiscale theory then merging the target images detected at different scales can further improve the robustness of the algorithm for detecting targets of different sizes.ResultFirst, experiments are conducted on many infrared small target images with varying situations and levels of noise. Experimental results demonstrate that from the perspective of subjective visual evaluation, the proposed method is robust to different scenes and noise. Experiments are also conducted to verify two aspects, namely, background suppression effect and detection speed. The signal-to-clutter ratio gain and background suppression factor are selected as quantitative evaluation indicators for the background suppression effect. Experimental results reveal that compared with the Top-Hat, Max-Median, two-dimensional least mean square, local saliency map, infrared patch-image, and weighted infrared patch-image methods, the proposed method can effectively eliminate various interferences, exerts a superior effect on background suppression, and can accurately detect infrared small targets in complex backgrounds simultaneously. The background suppression factor of the proposed method is several tens of times that of other methods, and the infrared superpixel-image model reduces the detection time by at least 78.2% compared with similar methods.ConclusionIn this study, superpixel image segmentation and multiscale theory are introduced into the low rank constraint and sparse representation joint model. The model can achieve an advantageous background suppression effect and good adaptability to the target size when applied to infrared small-target detection in complex backgrounds. In addition, the proposed method of infrared small-target detection at different scales can be further transformed into parallel processing, which is beneficial for accelerating the detection process of the method. Our future work will focus on reducing the algorithm's complexity and designing a more flexible method for constructing an infrared-patch image.关键词:small target detection;infrared image;low rank constraint;sparse representation;superpixel;multiscale56|88|2更新时间:2024-05-07 -
 摘要:ObjectiveThe shoreline is not only the basis of analysis in video surveillance in the water industry but also the key to autonomous navigation of unmanned surface boats. Many scholars have proposed shoreline detection methods. However, many existing shoreline detection algorithms utilize traditional image recognition methods for image segmentation using several features of the water surface and the ground. When dealing with different scenes, the parameters must be adjusted, but this is unsuitable for complex scenes. Traditional detection methods cannot overcome the influence of various factors, such as water surface ripple and reflection, and are unadaptable because they cannot be applied to the simultaneous analysis of multiple shoreline scenes. In this study, the Deeplab v3+ network for shoreline segmentation is trained by applying several complex shoreline scene images provided by the Chengdu River Chief's Office and self-photographed images. We simplify the Deeplab v3+ network to improve the performance and speed of segmentation. Then, on the basis of the improved Deeplab v3+, we segment the water surface image and propose a method to extract the shoreline by using the segmented image to achieve automatic shoreline extraction.MethodFirst, images of different waterfront scenes are collected for training and verification sets. To further improve the generalization capability of the network, we use the gamma function to process 10 photos captured in different complex scenes and simulate different lighting situations in the same scene. We add 20 processed images to the verification set to expand the sample. After performing comparative experiments on various semantic segmentation networks, the Deeplab v3 + network is selected for modification, and the Xception structure is fine-tuned to reduce the number of network layers and increase the speed. Meanwhile, a low-level feature is added to the decoder to increase the feature information. Consequently, the time consumption is reduced without affecting the accuracy of the algorithm. Comparison of the modified network with the original network indicates that the modified network improves computational efficiency when the accuracy is basically unchanged. Then, according to the image information, we set the loss weight coefficient and visualization parameters to train data under the improved Deeplab v3+. Second, using the Linux operating system with the C++ interface of TensorFlow, the test image is segmented under the trained PB model. Finally, the waterfront line is detected by the edge detection operator on the basis of the extracted water surface region. The extracted water shoreline is expanded and superimposed on the original image for convenient observation.Result Waterfront detection experiments are performed on the collection of water surface images with different illumination intensities, degrees of corrugation, and shadows. Representative waterfront images are selected and compared using waterfront algorithms proposed by scholars, such as Iwahash et al., Bao et al., and Peng et al.. Experimental results show that only the proposed algorithm can completely process complex scenes on land and water surfaces and accurately detect clear and complete waterfront lines in different waterfront images. Furthermore, the real-time performance of the algorithm can reach 8 frame/s. Compared with the speed of other algorithms, the speed of the proposed algorithm is increased by nearly five times, and its accuracy is 93.98%, indicating an improvement of nearly 20%.ConclusionThe algorithm can overcome the following situations:severely irregular waterfront edges, large difference in waterfront scenes, and interference of light, ripple, reflection, and other factors in complex waterfront scenes. In practical application, the algorithm achieves automatic shoreline extraction without artificial configuration and tuning. In addition, the accuracy and efficiency of waterfront image segmentation are improved, and a clear and complete waterfront line is detected for intelligent monitoring and analysis in the water conservancy industry. The algorithm requires a very large number of samples. However, the current sample is far from being sufficient. In the future, the number of samples in different scenarios must be increased to enhance the generalization capability of the network and the applicability of the algorithm. The application of this method in Windows and the improvement of the algorithm's practicability are other future research directions.关键词:water video surveillance;Deeplab v3+;waterfront image segmentation;edge detection;shoreline detection15|5|2更新时间:2024-05-07
摘要:ObjectiveThe shoreline is not only the basis of analysis in video surveillance in the water industry but also the key to autonomous navigation of unmanned surface boats. Many scholars have proposed shoreline detection methods. However, many existing shoreline detection algorithms utilize traditional image recognition methods for image segmentation using several features of the water surface and the ground. When dealing with different scenes, the parameters must be adjusted, but this is unsuitable for complex scenes. Traditional detection methods cannot overcome the influence of various factors, such as water surface ripple and reflection, and are unadaptable because they cannot be applied to the simultaneous analysis of multiple shoreline scenes. In this study, the Deeplab v3+ network for shoreline segmentation is trained by applying several complex shoreline scene images provided by the Chengdu River Chief's Office and self-photographed images. We simplify the Deeplab v3+ network to improve the performance and speed of segmentation. Then, on the basis of the improved Deeplab v3+, we segment the water surface image and propose a method to extract the shoreline by using the segmented image to achieve automatic shoreline extraction.MethodFirst, images of different waterfront scenes are collected for training and verification sets. To further improve the generalization capability of the network, we use the gamma function to process 10 photos captured in different complex scenes and simulate different lighting situations in the same scene. We add 20 processed images to the verification set to expand the sample. After performing comparative experiments on various semantic segmentation networks, the Deeplab v3 + network is selected for modification, and the Xception structure is fine-tuned to reduce the number of network layers and increase the speed. Meanwhile, a low-level feature is added to the decoder to increase the feature information. Consequently, the time consumption is reduced without affecting the accuracy of the algorithm. Comparison of the modified network with the original network indicates that the modified network improves computational efficiency when the accuracy is basically unchanged. Then, according to the image information, we set the loss weight coefficient and visualization parameters to train data under the improved Deeplab v3+. Second, using the Linux operating system with the C++ interface of TensorFlow, the test image is segmented under the trained PB model. Finally, the waterfront line is detected by the edge detection operator on the basis of the extracted water surface region. The extracted water shoreline is expanded and superimposed on the original image for convenient observation.Result Waterfront detection experiments are performed on the collection of water surface images with different illumination intensities, degrees of corrugation, and shadows. Representative waterfront images are selected and compared using waterfront algorithms proposed by scholars, such as Iwahash et al., Bao et al., and Peng et al.. Experimental results show that only the proposed algorithm can completely process complex scenes on land and water surfaces and accurately detect clear and complete waterfront lines in different waterfront images. Furthermore, the real-time performance of the algorithm can reach 8 frame/s. Compared with the speed of other algorithms, the speed of the proposed algorithm is increased by nearly five times, and its accuracy is 93.98%, indicating an improvement of nearly 20%.ConclusionThe algorithm can overcome the following situations:severely irregular waterfront edges, large difference in waterfront scenes, and interference of light, ripple, reflection, and other factors in complex waterfront scenes. In practical application, the algorithm achieves automatic shoreline extraction without artificial configuration and tuning. In addition, the accuracy and efficiency of waterfront image segmentation are improved, and a clear and complete waterfront line is detected for intelligent monitoring and analysis in the water conservancy industry. The algorithm requires a very large number of samples. However, the current sample is far from being sufficient. In the future, the number of samples in different scenarios must be increased to enhance the generalization capability of the network and the applicability of the algorithm. The application of this method in Windows and the improvement of the algorithm's practicability are other future research directions.关键词:water video surveillance;Deeplab v3+;waterfront image segmentation;edge detection;shoreline detection15|5|2更新时间:2024-05-07 -
 摘要:ObjectiveThe target tracking algorithm that is based on deep learning and uses deep convolution features is highly accurate,but it cannot be tracked in real time nor applied to actual situations. The deep convolutional features of convolutional neural networks (CNNs) contain advanced semantic information. Even when the target appearance model has serious interference,such as illumination variation,deformation,and other interference factors,the deep convolution features still exhibit an accurate discriminative performance in the target. Although the tracking algorithm based on correlation filtering is fast (up to several hundred frame/s),it is inaccurate. The algorithm uses the histogram of oriented gradient (HOG),color name (CN),and color histogram as statistical features to calculate the correlation of two image blocks. The position with the highest correlation is the predicted position. To balance the real-time tracking capability and accuracy of the target tracking algorithm,this study proposes a dual-model kernel correlation filtering algorithm based on the combination of the accuracy of the deep convolution feature algorithm and the speed of the correlation filtering algorithm.MethodAn adaptive dual-feature model selection mechanism is proposed. The dual model consists of main-and auxiliary-feature models. The main-feature model adopts a shallow texture feature. The dimension of the HOG feature is relatively low. Thus,it has a high calculation speed. The main-feature model is used for the real-time tracking of video sequences with clear texture contour features,and the kernel correlation function of the correlation filter of the main-feature model uses the Gaussian kernel function. The auxiliary-feature model employs CNN features containing deep semantic information. When serious interference factors,such as illumination variation,occlusion,and deformation,occur in video sequences,the auxiliary-feature model with deep CNN features is used to determine and correct the target position because such factors lead to low-confidence responses of the main-feature model. The linear kernel function is utilized by the kernel correlation function of the auxiliary feature model's correlation filter. The main-and auxiliary-feature models correspond to individual model update and synergistically cooperate to generate a stable correlation filter and improve the computational efficiency of the algorithm. The auxiliary-feature model adopts deep CNN features. The dimension of deep CNN features is too high,resulting in low calculation speed. To optimize the calculation speed and ensure the real-time performance of the algorithm,we use principal component analysis (PCA) to reduce the dimensionality of high-dimensional deep convolution features. Under the premise of saving as much effective information of the original features as possible,the dimension of the CNN features is reduced,and the computing speed is improved. This work also improves the accuracy of the tracking algorithm by optimizing the scale and the solution method.ResultWhen the appearance model of the target changes seriously,the confidence response value of the main-feature model becomes too low. In this case,the dual-feature model discriminating mechanism promptly calls the auxiliary-feature model to correct the target positioning in real time. Experiments show that adopting the adaptive dual-feature model recognition mechanism is effective. We compare our algorithm with current advanced tracking algorithms with real-time speed,such as SiamFC(fully-convolutional Siamese networks),MEM(multiple experts using entropy minimization),SAMF(scale adaptive muttiple features),DSST(discriminative scale space tracking),KCF(kernel correlation filter) Struck,and TLD(tracking learning detection). The OPEresult of the public dataset OTB-2013 shows that the proposed algorithm ranks first in terms of distance precision rate. Compared with the KCF algorithm,the distance precision and overlap success rates of the proposed algorithm are improved by 25.2% and 25.6%,respectively,and the average speed of the proposed algorithm can reach 38 frame/s. To demonstrate the performance of the proposed tracking algorithm more concretely,we also compare it with the most advanced tracking algorithms based on deep convolution characteristics,such as VITAL,SANet,and CCOT. However,these algorithms cannot meet the real-time performance requirement and cannot be applied in actual situations.ConclusionA new tracking model mechanism is proposed in this study. An auxiliary-feature model is added to the main-feature model. The auxiliary-feature model adjusts the optimal position of the target in real time according to the change in the confidence response of the main-feature model and prevents the main-feature model from drifting. PCA is introduced to reduce the dimensionality of the deep convolution feature and optimize the speed of the algorithm. However,the proposed algorithm still has problems. First,a change in the environment would lead to uncertainty of the auxiliary model's threshold. Setting the threshold of the mobilization auxiliary model to a fixed value would reduce the adaptability of the tracking algorithm. Second,the stability of the main-feature model's correlation filter directly affects the accuracy of the algorithm. The correlation filtering algorithm expands the sample set by introducing a sample period hypothesis,but the period hypothesis also introduces the boundary effect,which considerably reduces the accuracy of the filter. To improve the accuracy of the algorithm,methods to eliminate the boundary effect should be introduced. Examples of such methods include adding a spatial regularization term in the ridge regression solution or adding a mask matrix image to highlight the target position. The results of the OTB-2013 public dataset show that the performance of the proposed target tracking algorithm is better than that of current tracking algorithms in terms of tracking accuracy and real-time tracking. The proposed tracking algorithm has good adaptability under 10 different interference factors,such as motion blur,scale variation,and rotation.关键词:target tracking;adaptive feature;convolutional neural network (CNN);correlation filter;principal component analysis (PCA)12|4|2更新时间:2024-05-07
摘要:ObjectiveThe target tracking algorithm that is based on deep learning and uses deep convolution features is highly accurate,but it cannot be tracked in real time nor applied to actual situations. The deep convolutional features of convolutional neural networks (CNNs) contain advanced semantic information. Even when the target appearance model has serious interference,such as illumination variation,deformation,and other interference factors,the deep convolution features still exhibit an accurate discriminative performance in the target. Although the tracking algorithm based on correlation filtering is fast (up to several hundred frame/s),it is inaccurate. The algorithm uses the histogram of oriented gradient (HOG),color name (CN),and color histogram as statistical features to calculate the correlation of two image blocks. The position with the highest correlation is the predicted position. To balance the real-time tracking capability and accuracy of the target tracking algorithm,this study proposes a dual-model kernel correlation filtering algorithm based on the combination of the accuracy of the deep convolution feature algorithm and the speed of the correlation filtering algorithm.MethodAn adaptive dual-feature model selection mechanism is proposed. The dual model consists of main-and auxiliary-feature models. The main-feature model adopts a shallow texture feature. The dimension of the HOG feature is relatively low. Thus,it has a high calculation speed. The main-feature model is used for the real-time tracking of video sequences with clear texture contour features,and the kernel correlation function of the correlation filter of the main-feature model uses the Gaussian kernel function. The auxiliary-feature model employs CNN features containing deep semantic information. When serious interference factors,such as illumination variation,occlusion,and deformation,occur in video sequences,the auxiliary-feature model with deep CNN features is used to determine and correct the target position because such factors lead to low-confidence responses of the main-feature model. The linear kernel function is utilized by the kernel correlation function of the auxiliary feature model's correlation filter. The main-and auxiliary-feature models correspond to individual model update and synergistically cooperate to generate a stable correlation filter and improve the computational efficiency of the algorithm. The auxiliary-feature model adopts deep CNN features. The dimension of deep CNN features is too high,resulting in low calculation speed. To optimize the calculation speed and ensure the real-time performance of the algorithm,we use principal component analysis (PCA) to reduce the dimensionality of high-dimensional deep convolution features. Under the premise of saving as much effective information of the original features as possible,the dimension of the CNN features is reduced,and the computing speed is improved. This work also improves the accuracy of the tracking algorithm by optimizing the scale and the solution method.ResultWhen the appearance model of the target changes seriously,the confidence response value of the main-feature model becomes too low. In this case,the dual-feature model discriminating mechanism promptly calls the auxiliary-feature model to correct the target positioning in real time. Experiments show that adopting the adaptive dual-feature model recognition mechanism is effective. We compare our algorithm with current advanced tracking algorithms with real-time speed,such as SiamFC(fully-convolutional Siamese networks),MEM(multiple experts using entropy minimization),SAMF(scale adaptive muttiple features),DSST(discriminative scale space tracking),KCF(kernel correlation filter) Struck,and TLD(tracking learning detection). The OPEresult of the public dataset OTB-2013 shows that the proposed algorithm ranks first in terms of distance precision rate. Compared with the KCF algorithm,the distance precision and overlap success rates of the proposed algorithm are improved by 25.2% and 25.6%,respectively,and the average speed of the proposed algorithm can reach 38 frame/s. To demonstrate the performance of the proposed tracking algorithm more concretely,we also compare it with the most advanced tracking algorithms based on deep convolution characteristics,such as VITAL,SANet,and CCOT. However,these algorithms cannot meet the real-time performance requirement and cannot be applied in actual situations.ConclusionA new tracking model mechanism is proposed in this study. An auxiliary-feature model is added to the main-feature model. The auxiliary-feature model adjusts the optimal position of the target in real time according to the change in the confidence response of the main-feature model and prevents the main-feature model from drifting. PCA is introduced to reduce the dimensionality of the deep convolution feature and optimize the speed of the algorithm. However,the proposed algorithm still has problems. First,a change in the environment would lead to uncertainty of the auxiliary model's threshold. Setting the threshold of the mobilization auxiliary model to a fixed value would reduce the adaptability of the tracking algorithm. Second,the stability of the main-feature model's correlation filter directly affects the accuracy of the algorithm. The correlation filtering algorithm expands the sample set by introducing a sample period hypothesis,but the period hypothesis also introduces the boundary effect,which considerably reduces the accuracy of the filter. To improve the accuracy of the algorithm,methods to eliminate the boundary effect should be introduced. Examples of such methods include adding a spatial regularization term in the ridge regression solution or adding a mask matrix image to highlight the target position. The results of the OTB-2013 public dataset show that the performance of the proposed target tracking algorithm is better than that of current tracking algorithms in terms of tracking accuracy and real-time tracking. The proposed tracking algorithm has good adaptability under 10 different interference factors,such as motion blur,scale variation,and rotation.关键词:target tracking;adaptive feature;convolutional neural network (CNN);correlation filter;principal component analysis (PCA)12|4|2更新时间:2024-05-07 -
 摘要:ObjectiveSemantic segmentation plays an increasingly important role in visual analysis. It combines image classification,object detection,and image segmentation and classifies the pixels in an image through certain methods. Semantic segmentation divides an image into regions with certain semantic meanings and identifies the semantic categories of each region block. The semantic inference process from low to high levels is realized,and a segmented image with pixel-by-pixel semantic annotation is obtained. The semantic segmentation method based on candidate regions extracts free-form regions from the image,describes their features,classifies them based on regions,and converts the region-based prediction into pixel-level prediction. Although the candidate region-based model contributes to the development of semantic segmentation,it needs to generate many candidate regions. The process of generating candidate regions requires a huge amount of time and memory space. In addition,the quality of the candidate regions extracted by different algorithms and the lack of spatial information on the candidate areas,especially the loss of information on small objects,directly affect the final semantic segmentation. To solve the problem of rough semantic segmentation results and low accuracy ofregion-based semantic segmentation methods caused by the lack of detailed information,a semantic segmentation method that fuses the context and multiple layer features of convolutional neural networks is proposed in this study.MethodFirst,candidate regions of different scales are generated from an image by using a selection method.The candidate area includes three parts,namely,square bounding box,foreground mask,and foreground size. The foreground mask is a binary mask that covers the foreground of the area over the candidate area. Multiplying the square region features on each channel with the corresponding foreground mask yields the foreground features of the region. Selective search uses graph-based image segmentation to generate several sub-regions,iteratively merges regions according to the similarity between sub-regions (i.e.,color,texture,size,and spatial overlap),and outputs all possible regions of the target.Second,a convolutional neural network is used to extract the features of each region,and the high-and low-level features are fused in parallel. Parallel fusion combines the features of the same data set according to a certain rule,and the dimensions of the features must be the same before the combination.The features obtained by each convolutional layer are reduced using the linear discriminant analysis (LDA) method because of the different sizes of feature maps extracted from different layers. By selecting a projection hyperplane in the multi-dimensional space,the projection distance of the same category on the hyperplane is probably closer than the projection distance of different categories. The dimension reduction of LDA is only related to the number of categories because it is independent of the dimension of the data. The image dataset used in this work contains 33 categories. The LDA dimension reduction method is utilized to reduce the feature dimensions to 32,and this reduction decreases the size of the network's parameters. Moreover,LDA as a supervised algorithm can use prior knowledge on the class very well. Experimental results show that dimension reduction may lose some feature information but does not affect the segmentation result. After feature dimension reduction,the distance between different categories may increase,and the distance between the same categories may decrease,which can make the classification task easy. The RefineNet model is used to fuse feature maps with different resolutions. In this work,five feature map resolutions are used for fusion.The RefineNet network consists of three main components,namely,adaptive convolution,multi-resolution fusion,and chain residual pooling. The multi-resolution fusion part of the structure is utilized to adapt the input feature maps with a convolution layer,conduct upsampling,and perform pixel-level addition. The main task is to perform multi-resolution fusion to solve the problem of information loss caused by the downsampling operation and allow the image features extracted by each layer to be added to the final segmentation network. Finally,the regional feature mask and the fused feature map are inputted into the free-form pool of interest regions,and the pixel-level classification label of the image is obtained through the softmax classification layer.ResultContext and convolutional neural network (CNN) multi-layer features are used for semantic segmentation,which exhibits good performance.The experimental content mainly includes CNN multi-layer feature fusion,combination of background information and fusion features,and the influence of dropout values on the experimental results.The training model is tested on the Siftflow dataset with a pixel accuracy of 82.3% and an average accuracy of 63.1%. Compared with the current region-based,end-to-end semantic segmentation model,the pixel accuracy is increased by 10.6% and the average accuracy is increased by 0.6%.ConclusionA semantic segmentation algorithm that combines context features with CNN multi-layer features is proposed in this study. The foreground and context information of the region are combined in the proposed method to utilize the context information of the region. The abstention principle is employed to reduce the parameter quantity of the network and avoid over-fitting,and the RefineNet network model is used to fuse the multi-layer features of CNN. By effectively using the multi-layer detail information of the image for segmentation,the model's capability to discriminate between small and medium-sized objects in the region is enhanced,and the segmentation effect is improved for images with occlusion and complex backgrounds. The experimental results show that the proposed method has a better segmentation effect,better segmentation performance,and higher robustness than several state-of-the-art methods.关键词:semantic segmentation;convolutional neural network (CNN);feature fusion;selection search;RefineNet model13|4|2更新时间:2024-05-07
摘要:ObjectiveSemantic segmentation plays an increasingly important role in visual analysis. It combines image classification,object detection,and image segmentation and classifies the pixels in an image through certain methods. Semantic segmentation divides an image into regions with certain semantic meanings and identifies the semantic categories of each region block. The semantic inference process from low to high levels is realized,and a segmented image with pixel-by-pixel semantic annotation is obtained. The semantic segmentation method based on candidate regions extracts free-form regions from the image,describes their features,classifies them based on regions,and converts the region-based prediction into pixel-level prediction. Although the candidate region-based model contributes to the development of semantic segmentation,it needs to generate many candidate regions. The process of generating candidate regions requires a huge amount of time and memory space. In addition,the quality of the candidate regions extracted by different algorithms and the lack of spatial information on the candidate areas,especially the loss of information on small objects,directly affect the final semantic segmentation. To solve the problem of rough semantic segmentation results and low accuracy ofregion-based semantic segmentation methods caused by the lack of detailed information,a semantic segmentation method that fuses the context and multiple layer features of convolutional neural networks is proposed in this study.MethodFirst,candidate regions of different scales are generated from an image by using a selection method.The candidate area includes three parts,namely,square bounding box,foreground mask,and foreground size. The foreground mask is a binary mask that covers the foreground of the area over the candidate area. Multiplying the square region features on each channel with the corresponding foreground mask yields the foreground features of the region. Selective search uses graph-based image segmentation to generate several sub-regions,iteratively merges regions according to the similarity between sub-regions (i.e.,color,texture,size,and spatial overlap),and outputs all possible regions of the target.Second,a convolutional neural network is used to extract the features of each region,and the high-and low-level features are fused in parallel. Parallel fusion combines the features of the same data set according to a certain rule,and the dimensions of the features must be the same before the combination.The features obtained by each convolutional layer are reduced using the linear discriminant analysis (LDA) method because of the different sizes of feature maps extracted from different layers. By selecting a projection hyperplane in the multi-dimensional space,the projection distance of the same category on the hyperplane is probably closer than the projection distance of different categories. The dimension reduction of LDA is only related to the number of categories because it is independent of the dimension of the data. The image dataset used in this work contains 33 categories. The LDA dimension reduction method is utilized to reduce the feature dimensions to 32,and this reduction decreases the size of the network's parameters. Moreover,LDA as a supervised algorithm can use prior knowledge on the class very well. Experimental results show that dimension reduction may lose some feature information but does not affect the segmentation result. After feature dimension reduction,the distance between different categories may increase,and the distance between the same categories may decrease,which can make the classification task easy. The RefineNet model is used to fuse feature maps with different resolutions. In this work,five feature map resolutions are used for fusion.The RefineNet network consists of three main components,namely,adaptive convolution,multi-resolution fusion,and chain residual pooling. The multi-resolution fusion part of the structure is utilized to adapt the input feature maps with a convolution layer,conduct upsampling,and perform pixel-level addition. The main task is to perform multi-resolution fusion to solve the problem of information loss caused by the downsampling operation and allow the image features extracted by each layer to be added to the final segmentation network. Finally,the regional feature mask and the fused feature map are inputted into the free-form pool of interest regions,and the pixel-level classification label of the image is obtained through the softmax classification layer.ResultContext and convolutional neural network (CNN) multi-layer features are used for semantic segmentation,which exhibits good performance.The experimental content mainly includes CNN multi-layer feature fusion,combination of background information and fusion features,and the influence of dropout values on the experimental results.The training model is tested on the Siftflow dataset with a pixel accuracy of 82.3% and an average accuracy of 63.1%. Compared with the current region-based,end-to-end semantic segmentation model,the pixel accuracy is increased by 10.6% and the average accuracy is increased by 0.6%.ConclusionA semantic segmentation algorithm that combines context features with CNN multi-layer features is proposed in this study. The foreground and context information of the region are combined in the proposed method to utilize the context information of the region. The abstention principle is employed to reduce the parameter quantity of the network and avoid over-fitting,and the RefineNet network model is used to fuse the multi-layer features of CNN. By effectively using the multi-layer detail information of the image for segmentation,the model's capability to discriminate between small and medium-sized objects in the region is enhanced,and the segmentation effect is improved for images with occlusion and complex backgrounds. The experimental results show that the proposed method has a better segmentation effect,better segmentation performance,and higher robustness than several state-of-the-art methods.关键词:semantic segmentation;convolutional neural network (CNN);feature fusion;selection search;RefineNet model13|4|2更新时间:2024-05-07 -
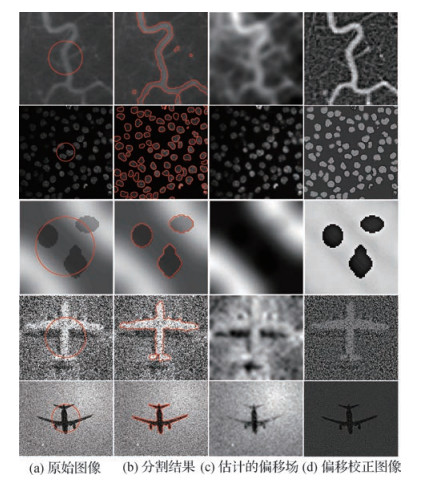 摘要:ObjectiveImage segmentation is important in computer vision and image processing. The level-set method has been widely used for image segmentation because it can handle complex topological changes. Intensity inhomogeneity,which is usually caused by a defect in the imaging device or illumination variation,is a common phenomenon in real-world images. Images with intensity inhomogeneity are difficult to segment due to the overlap of the intensity distributions between different object regions. Meanwhile,noise severely reduces the segmentation accuracy. Therefore,the traditional level-set method cannot robustly,accurately,and quickly segment images with intensity inhomogeneity and noise. To address this problem,a fast level-set method based on local region information is proposed for segmenting images in the presence of intensity inhomogeneity and noise.MethodAn intensity inhomogeneous image is usually described as a piecewise constant image multiplied by a slowly varying bias field. The bias field can be estimated by a multi-scale mean filter because it varies slowly over the entire image domain. However,the traditional multi-scale mean filter utilizes a fixed number of scales to estimate the bias field; hence,it may not correctly estimate the bias field for a small-sized image with severe intensity inhomogeneity. Therefore,a fine-tuned multi-scale mean filter is utilized to roughly estimate the bias field and preprocess the image to mitigate image intensity inhomogeneity. Then,the processed image is used to construct a bias correction-based pressure function,with which the image with weak intensity inhomogeneity can be quickly segmented and the bias field can be estimated simultaneously. The original image is also utilized to design a local region-based pressure function that can provide accurate segmentation for the region near the object boundaries. In addition,image entropy is integrated into the local region-based pressure function to extract additional local intensity information from the boundary region. The two pressure functions proposed are then embedded into the level-set framework to build two energy terms. A weight function is also constructed to balance the two energy terms by using the coefficient of joint variation that estimates the degree of overlap of the intensity distributions between the image regions inside and outside the contour of the evolution curve. The weight function can adaptively adjust the weights of the two energy terms according to the overlap of the intensity distributions between different image segmentation regions,thereby improving the efficiency and accuracy of the model in segmenting intensity inhomogeneity images. Subsequently,the total variance-based regularization function is utilized to regularize the evolution of the level-set function,thus enhancing the stability of numerical calculation and reducing the impact of noise. The two proposed energy terms and the regularization term are used to construct the final energy function. By minimizing the final energy function,the proposed method can segment the image and estimate the bias field simultaneously. In the numerical implementation,the additive operator splitting (AOS) scheme is employed to decompose the level-set evolution equation into linear and nonlinear differential equations. The linear differential equation can be quickly solved by the explicit iterative scheme,and the nonlinear differential equation can be solved quickly by the implicit iterative scheme and fast Fourier transform. Moreover,a Gaussian filter with a small-scale parameter is utilized to smooth the level-set function and reduce the impact of noise.ResultTo demonstrate the proposed method 's performance,the method is applied to several synthetic,infrared,and medical images with intensity inhomogeneity and noise and compared with traditional level-set-based segmentation models. The proposed method is applied on five images with intensity inhomogeneity or noise to qualitatively analyze its effectiveness.Resultsshow that the images are correctly segmented,and the bias fields can be accurately estimated simultaneously. Then,the proposed method is applied to three inhomogeneous images with different initial contours to demonstrate its robustness to the initial contour. The method is also utilized to segment two types of images with different degrees of intensity inhomogeneity and quantitatively compared with several level-set-based segmentation methods to demonstrate the proposed method 's robustness to the degree of intensity inhomogeneity. In addition,the proposed method is applied to homogenous and inhomogeneous images with different kinds of noise and compared with several level-set-segmentation methods to demonstrate its robustness to noise. The effectiveness of the proposed weight function is also analyzed. Finally,the proposed method is quantitatively analyzed on several images with intensity inhomogeneity and noise. Compared with traditional level-set methods,the proposed method obtains the highest segmentation accuracy of 94.5%,and it requires the least number of iterations and the second least amount of computation time. The segmentation accuracy is at least 20.6% higher than that of traditional level-set methods,and the segmentation efficiency is nine times higher than that of the LIC model. Experimental results demonstrate that compared with traditional level-set methods,the proposed method is not only robust to the position of the initial contour and various noises but also has higher segmentation accuracy and efficiency for images with noise and different degrees of intensity inhomogeneity.ConclusionThis study proposes a fast level-set image segmentation method based on local region information to segment images in the presence of noise and intensity inhomogeneity. The fine-tuned multi-scale mean filter can roughly estimate the bias field. The two proposed pressure functions can provide appropriate local information to segment images with different degrees of intensity inhomogeneity. The regularization term makes the proposed method robust to noise,and the AOS scheme accelerates the convergence of the proposed method. Experimental results show that the proposed method can effectively,robustly,accurately,and efficiently segment images with intensity inhomogeneity and noise. The proposed method can be applied to the segmentation of medical,infrared,and natural images with intensity inhomogeneity and noise.关键词:image segmentation;fast level set method;intensity inhomogeneity;multi-scale mean filter;local region information11|4|0更新时间:2024-05-07
摘要:ObjectiveImage segmentation is important in computer vision and image processing. The level-set method has been widely used for image segmentation because it can handle complex topological changes. Intensity inhomogeneity,which is usually caused by a defect in the imaging device or illumination variation,is a common phenomenon in real-world images. Images with intensity inhomogeneity are difficult to segment due to the overlap of the intensity distributions between different object regions. Meanwhile,noise severely reduces the segmentation accuracy. Therefore,the traditional level-set method cannot robustly,accurately,and quickly segment images with intensity inhomogeneity and noise. To address this problem,a fast level-set method based on local region information is proposed for segmenting images in the presence of intensity inhomogeneity and noise.MethodAn intensity inhomogeneous image is usually described as a piecewise constant image multiplied by a slowly varying bias field. The bias field can be estimated by a multi-scale mean filter because it varies slowly over the entire image domain. However,the traditional multi-scale mean filter utilizes a fixed number of scales to estimate the bias field; hence,it may not correctly estimate the bias field for a small-sized image with severe intensity inhomogeneity. Therefore,a fine-tuned multi-scale mean filter is utilized to roughly estimate the bias field and preprocess the image to mitigate image intensity inhomogeneity. Then,the processed image is used to construct a bias correction-based pressure function,with which the image with weak intensity inhomogeneity can be quickly segmented and the bias field can be estimated simultaneously. The original image is also utilized to design a local region-based pressure function that can provide accurate segmentation for the region near the object boundaries. In addition,image entropy is integrated into the local region-based pressure function to extract additional local intensity information from the boundary region. The two pressure functions proposed are then embedded into the level-set framework to build two energy terms. A weight function is also constructed to balance the two energy terms by using the coefficient of joint variation that estimates the degree of overlap of the intensity distributions between the image regions inside and outside the contour of the evolution curve. The weight function can adaptively adjust the weights of the two energy terms according to the overlap of the intensity distributions between different image segmentation regions,thereby improving the efficiency and accuracy of the model in segmenting intensity inhomogeneity images. Subsequently,the total variance-based regularization function is utilized to regularize the evolution of the level-set function,thus enhancing the stability of numerical calculation and reducing the impact of noise. The two proposed energy terms and the regularization term are used to construct the final energy function. By minimizing the final energy function,the proposed method can segment the image and estimate the bias field simultaneously. In the numerical implementation,the additive operator splitting (AOS) scheme is employed to decompose the level-set evolution equation into linear and nonlinear differential equations. The linear differential equation can be quickly solved by the explicit iterative scheme,and the nonlinear differential equation can be solved quickly by the implicit iterative scheme and fast Fourier transform. Moreover,a Gaussian filter with a small-scale parameter is utilized to smooth the level-set function and reduce the impact of noise.ResultTo demonstrate the proposed method 's performance,the method is applied to several synthetic,infrared,and medical images with intensity inhomogeneity and noise and compared with traditional level-set-based segmentation models. The proposed method is applied on five images with intensity inhomogeneity or noise to qualitatively analyze its effectiveness.Resultsshow that the images are correctly segmented,and the bias fields can be accurately estimated simultaneously. Then,the proposed method is applied to three inhomogeneous images with different initial contours to demonstrate its robustness to the initial contour. The method is also utilized to segment two types of images with different degrees of intensity inhomogeneity and quantitatively compared with several level-set-based segmentation methods to demonstrate the proposed method 's robustness to the degree of intensity inhomogeneity. In addition,the proposed method is applied to homogenous and inhomogeneous images with different kinds of noise and compared with several level-set-segmentation methods to demonstrate its robustness to noise. The effectiveness of the proposed weight function is also analyzed. Finally,the proposed method is quantitatively analyzed on several images with intensity inhomogeneity and noise. Compared with traditional level-set methods,the proposed method obtains the highest segmentation accuracy of 94.5%,and it requires the least number of iterations and the second least amount of computation time. The segmentation accuracy is at least 20.6% higher than that of traditional level-set methods,and the segmentation efficiency is nine times higher than that of the LIC model. Experimental results demonstrate that compared with traditional level-set methods,the proposed method is not only robust to the position of the initial contour and various noises but also has higher segmentation accuracy and efficiency for images with noise and different degrees of intensity inhomogeneity.ConclusionThis study proposes a fast level-set image segmentation method based on local region information to segment images in the presence of noise and intensity inhomogeneity. The fine-tuned multi-scale mean filter can roughly estimate the bias field. The two proposed pressure functions can provide appropriate local information to segment images with different degrees of intensity inhomogeneity. The regularization term makes the proposed method robust to noise,and the AOS scheme accelerates the convergence of the proposed method. Experimental results show that the proposed method can effectively,robustly,accurately,and efficiently segment images with intensity inhomogeneity and noise. The proposed method can be applied to the segmentation of medical,infrared,and natural images with intensity inhomogeneity and noise.关键词:image segmentation;fast level set method;intensity inhomogeneity;multi-scale mean filter;local region information11|4|0更新时间:2024-05-07 -
 摘要:ObjectiveIn the process of analyzing brain tumor images,accurate segmentation of brain tumors is crucial to the diagnosis and treatment of computer-aided brain tumor diseases. Magnetic resonance imaging (MRI) is the primary method of brain structure imaging in clinical applications,and imaging specialists commonly outline tumor tissues from MRI images manually to segment brain tumors. However,manual segmentation is laborious,especially when the brain image has a complex structure and the boundary is blurred. The brain tumor area in the image might have bright or dark blocks that are marked in magenta. These areas may cause holes in the result or excessive shrinkage of the contour. Moreover,due to the limitation of the imaging principle and the complexity of the human tissue structure,this technique usually encounters problems,such as uneven intensity distribution and overlapping of tissues. The segmentation effect of traditional methods based on thresholds,geometric constraints,or statistics is poor and adds challenges to tumor image segmentation. To overcome these difficulties and realize improved segmentation,the common characteristics of the brain tumor's shape are studied to construct a sparse representation-based model and propose a brain tumor image segmentation algorithm based on prior sparse shapes.MethodThe Fourier-Melli method is utilized to implement image registration,and the shape description of brain tumor images is studied. A prior sparse shape constraint model of brain tumors is proposed to weaken the influence of light and dark areas inside the tumor on the segmentation results. The K-means method is used to cluster the data in the mapping matrix into several classes and calculate the average of each group separately to be used as a predefined sparse dictionary,and the sparse coefficients are updated through the orthogonal matching method. Then,the prior sparse shape constraint model is combined with the regional energy to construct the energy function. The following steps are implemented to initialize the contour. First,the fast bounding box (FBB) algorithm is used to obtain the initial rectangular contour region of the brain tumor,and the region centroid is adopted as the seed of the region growing method. The initial value of the level set function is then generated. The optimization and iteration details of the energy function utilizing the relationship between the high-level sparse constraint and the underlying energy function are also provided in this paper.ResultTo verify the feasibility of the proposed algorithm,this study uses the multimodal glioma dataset from the MICCAI BraTS2017 challenge,which contains brain MRI images of patients suffering from brain glioma,to test the algorithm. The dice similarity coefficient,sensitivity,and positive predictive positivity value (PPV) are selected as technical indicators to further evaluate the accuracy of the brain tumor segmentation results. We compare the algorithm with other image segmentation algorithms. The algorithm proposed by Joshi et al. uses wavelet transform to preprocess an MRI image,roughly segments the image through a contour-based level set method,and filters the shape and size of the results from the previous step by utilizing the soft threshold method. The algorithm proposed by Zabir et al. uses the K-means method to determine the initial tumor location points and calculates the initial value of the DRLSE level set by utilizing the region grown method. The algorithm proposed by Kermi et al. uses FBB to determine the approximate location of the brain tumor then utilizes the region growing method and geodesic active contour model for brain tumor segmentation. The algorithm proposed by Mojtabavi et al. outlines the initial contours of brain tumors artificially. It defines a level set function combined with region-and edge-based approaches then iteratively optimizes the energy function using the fast-marching method. In addition,to further verify the influence of the shape constraint terms on the segmentation results,the shape constraint terms are shielded during the testing of the algorithm for comparison. Experimental results show that the proposed algorithm can accurately and stably extract brain tumors from images. The average similarity between the segmentation result and the real data of the algorithm,the sensitivity,and the positive prediction rate reach 93.97%,91.3%,and 95.9%,respectively. The proposed algorithm is more accurate and has a lower false positive rate and stronger robustness than other algorithms of the same type.ConclusionA novel image segmentation algorithm based on sparse shape priori is proposed to describe the shape of brain tumors and construct the sparse shape constraint model of brain tumors. Then,the energy function is constructed by combining the level set constraint method,and the relationship between the high-level sparse constraint and the low-level energy function is used to derive the target contour. The difficulty in this work is selecting the appropriate variational level set model according to the image features and the appropriate shape priori model for dealing with the complex and changeable shape of brain tumors to ensure that the complexity of the algorithm is reduced while retaining a significant amount of shape details. Compared with other algorithms,the proposed algorithm combines the advantages of the level set method in topological structure description and the sparse expression method in complex shape expression. The algorithm has good robustness and can accurately segment brain tumors. In our future work,we will further study the problem of multi-modal brain tumor segmentation to make better use of information from MRI data.关键词:brain tumor;image segmentation;sparse constraint;prior shapes;level set31|51|2更新时间:2024-05-07
摘要:ObjectiveIn the process of analyzing brain tumor images,accurate segmentation of brain tumors is crucial to the diagnosis and treatment of computer-aided brain tumor diseases. Magnetic resonance imaging (MRI) is the primary method of brain structure imaging in clinical applications,and imaging specialists commonly outline tumor tissues from MRI images manually to segment brain tumors. However,manual segmentation is laborious,especially when the brain image has a complex structure and the boundary is blurred. The brain tumor area in the image might have bright or dark blocks that are marked in magenta. These areas may cause holes in the result or excessive shrinkage of the contour. Moreover,due to the limitation of the imaging principle and the complexity of the human tissue structure,this technique usually encounters problems,such as uneven intensity distribution and overlapping of tissues. The segmentation effect of traditional methods based on thresholds,geometric constraints,or statistics is poor and adds challenges to tumor image segmentation. To overcome these difficulties and realize improved segmentation,the common characteristics of the brain tumor's shape are studied to construct a sparse representation-based model and propose a brain tumor image segmentation algorithm based on prior sparse shapes.MethodThe Fourier-Melli method is utilized to implement image registration,and the shape description of brain tumor images is studied. A prior sparse shape constraint model of brain tumors is proposed to weaken the influence of light and dark areas inside the tumor on the segmentation results. The K-means method is used to cluster the data in the mapping matrix into several classes and calculate the average of each group separately to be used as a predefined sparse dictionary,and the sparse coefficients are updated through the orthogonal matching method. Then,the prior sparse shape constraint model is combined with the regional energy to construct the energy function. The following steps are implemented to initialize the contour. First,the fast bounding box (FBB) algorithm is used to obtain the initial rectangular contour region of the brain tumor,and the region centroid is adopted as the seed of the region growing method. The initial value of the level set function is then generated. The optimization and iteration details of the energy function utilizing the relationship between the high-level sparse constraint and the underlying energy function are also provided in this paper.ResultTo verify the feasibility of the proposed algorithm,this study uses the multimodal glioma dataset from the MICCAI BraTS2017 challenge,which contains brain MRI images of patients suffering from brain glioma,to test the algorithm. The dice similarity coefficient,sensitivity,and positive predictive positivity value (PPV) are selected as technical indicators to further evaluate the accuracy of the brain tumor segmentation results. We compare the algorithm with other image segmentation algorithms. The algorithm proposed by Joshi et al. uses wavelet transform to preprocess an MRI image,roughly segments the image through a contour-based level set method,and filters the shape and size of the results from the previous step by utilizing the soft threshold method. The algorithm proposed by Zabir et al. uses the K-means method to determine the initial tumor location points and calculates the initial value of the DRLSE level set by utilizing the region grown method. The algorithm proposed by Kermi et al. uses FBB to determine the approximate location of the brain tumor then utilizes the region growing method and geodesic active contour model for brain tumor segmentation. The algorithm proposed by Mojtabavi et al. outlines the initial contours of brain tumors artificially. It defines a level set function combined with region-and edge-based approaches then iteratively optimizes the energy function using the fast-marching method. In addition,to further verify the influence of the shape constraint terms on the segmentation results,the shape constraint terms are shielded during the testing of the algorithm for comparison. Experimental results show that the proposed algorithm can accurately and stably extract brain tumors from images. The average similarity between the segmentation result and the real data of the algorithm,the sensitivity,and the positive prediction rate reach 93.97%,91.3%,and 95.9%,respectively. The proposed algorithm is more accurate and has a lower false positive rate and stronger robustness than other algorithms of the same type.ConclusionA novel image segmentation algorithm based on sparse shape priori is proposed to describe the shape of brain tumors and construct the sparse shape constraint model of brain tumors. Then,the energy function is constructed by combining the level set constraint method,and the relationship between the high-level sparse constraint and the low-level energy function is used to derive the target contour. The difficulty in this work is selecting the appropriate variational level set model according to the image features and the appropriate shape priori model for dealing with the complex and changeable shape of brain tumors to ensure that the complexity of the algorithm is reduced while retaining a significant amount of shape details. Compared with other algorithms,the proposed algorithm combines the advantages of the level set method in topological structure description and the sparse expression method in complex shape expression. The algorithm has good robustness and can accurately segment brain tumors. In our future work,we will further study the problem of multi-modal brain tumor segmentation to make better use of information from MRI data.关键词:brain tumor;image segmentation;sparse constraint;prior shapes;level set31|51|2更新时间:2024-05-07 -
 摘要:ObjectiveUnder the background of "machine substitution" robotic visual intelligence is crucial to the industrial upgrading of the manufacturing industry. Algorithm-guided industrial robots with a visual perception function are also receiving increasing attention in industrial production.One of the most critical difficulties in the automatic picking of industrial robots is the identification of the target area.This problem is particularly prominent in the picking process of metal parts. Unstructured factors, such as reflective surface and mutual occlusion during random placement, pose great challenges to the identification of the picking area.To solve these problems, this study proposes a picking region recognition method based on deep learning and support vector machine (SVM).These two models are combined to exploit their individual advantages and further improve their accuracy.MethodThe proposed approach is used to construct a new model that combines regions with a convolutional neural network feature (Mask R-CNN) and SVM.Our methods include feature extraction, multi-feature fusion, SVM classifier training, neural network training, the combination of SVM and deep neural network.First, the local binary pattern(LBP) and histogram of oriented gradient(HOG) features of the picking areaare extracted.The presence of interference areas poses a huge challenge to the identification of the picking area.The interference area is relative to the identification areaand is easily misidentified and obtained through long-term practice on the assembly line.The dimension of the feature matrix generated by directly merging these two features is too large.Thus, we mustutilize principal component analysis to reduce the dimensions of the feature matrix and train the SVM classifier through the trained feature matrix.The size of the matrix after the direct fusion of the two features is 7 000×2 692. Hence, we select a cumulative contribution rate of 94%, at which the recognition accuracy rate is up to 97.25%.The size of the feature matrix is reduced to 7 000×231after dimension reduction.After that, we cancomplete the initial segmentation of the picking area by training the Mask R-CNN, which may contain interference areas inside.Mask R-CNN is roughly composed of the following parts:feature extraction, area suggestion network (RPN), ROIAlign, and final result.The feature extraction part is the backbone of the entire network. Its function is to extract several important features of different targets from numerous training photos.We use an already trained residual network (ResNet101)as the feature extraction network.The RPN network uses the feature map to obtain the candidate frame of the object in the original image, which is currently implemented by anchor technology.In this study, nine candidate regions are selected for each anchor on the feature graph according to different scales (i.e., 128, 256, and 512 pixels) and different aspect ratios (i.e., 1:1, 0.5:1, and 1:0.5).By using the ROIAlign network, the corresponding area in the feature map is pooled to a fixed size according to the position coordinates of the candidate frame.The final classification and regression results are generated by the fully connected layer, and the mask division of the object is generated by the deconvolution operation.Then, quadratic segmentation of the results after initial segmentation by the SVM algorithm basically completes the elimination of the interference area.The final instance segmentation is completed by mask calculation of the picking area.ResultMulti-feature fusion SVM, Mask R-CNN, and the proposed algorithm are used to detect the picking area of 500 metal parts.Experimental results show that the algorithm can adapt to the recognition of the picking region. The correct rate of algorithm identification in this work is 89.40%, the missed detection rate is 7.80%, and the false detection rate is 2.80%.The correct rate of algorithm identification is 7.00% and 25.00% higher than those of Mask R-CNN and SVM, respectively.The error detection rate of the algorithm is 7.80% and 18.40% lower than those of Mask R-CNN and SVM, respectively. The missed detection rate of the algorithm is 6.60% lower than that of SVM.ConclusionThe SVM classifier with multi-feature fusion is used to classify the recognition results of Mask R-CNN, and the rejection of the interference region is completed. Accurate recognition of the picking region is completed by the calculation of the mask.In the construction of the image training set, the effects of illumination and occlusion between parts are fully considered, and the illumination and occlusion conditions are effectively divided and investigated; hence, the approach exhibits a certain robustness in practical applications.Compared with the sliding window frame method used in traditional target recognition, this work accurately identifies the shape of the target area through mask calculation and has a high recognition accuracy.Moreover, this work compensates for the limitations of the single-network framework by constructing a multi-feature fusion SVM classifier, which effectively reduces the false detection rate.关键词:target recognition;multi-feature fusion;support vector machine(SVM);deep learning;instance segmentation22|6|4更新时间:2024-05-07
摘要:ObjectiveUnder the background of "machine substitution" robotic visual intelligence is crucial to the industrial upgrading of the manufacturing industry. Algorithm-guided industrial robots with a visual perception function are also receiving increasing attention in industrial production.One of the most critical difficulties in the automatic picking of industrial robots is the identification of the target area.This problem is particularly prominent in the picking process of metal parts. Unstructured factors, such as reflective surface and mutual occlusion during random placement, pose great challenges to the identification of the picking area.To solve these problems, this study proposes a picking region recognition method based on deep learning and support vector machine (SVM).These two models are combined to exploit their individual advantages and further improve their accuracy.MethodThe proposed approach is used to construct a new model that combines regions with a convolutional neural network feature (Mask R-CNN) and SVM.Our methods include feature extraction, multi-feature fusion, SVM classifier training, neural network training, the combination of SVM and deep neural network.First, the local binary pattern(LBP) and histogram of oriented gradient(HOG) features of the picking areaare extracted.The presence of interference areas poses a huge challenge to the identification of the picking area.The interference area is relative to the identification areaand is easily misidentified and obtained through long-term practice on the assembly line.The dimension of the feature matrix generated by directly merging these two features is too large.Thus, we mustutilize principal component analysis to reduce the dimensions of the feature matrix and train the SVM classifier through the trained feature matrix.The size of the matrix after the direct fusion of the two features is 7 000×2 692. Hence, we select a cumulative contribution rate of 94%, at which the recognition accuracy rate is up to 97.25%.The size of the feature matrix is reduced to 7 000×231after dimension reduction.After that, we cancomplete the initial segmentation of the picking area by training the Mask R-CNN, which may contain interference areas inside.Mask R-CNN is roughly composed of the following parts:feature extraction, area suggestion network (RPN), ROIAlign, and final result.The feature extraction part is the backbone of the entire network. Its function is to extract several important features of different targets from numerous training photos.We use an already trained residual network (ResNet101)as the feature extraction network.The RPN network uses the feature map to obtain the candidate frame of the object in the original image, which is currently implemented by anchor technology.In this study, nine candidate regions are selected for each anchor on the feature graph according to different scales (i.e., 128, 256, and 512 pixels) and different aspect ratios (i.e., 1:1, 0.5:1, and 1:0.5).By using the ROIAlign network, the corresponding area in the feature map is pooled to a fixed size according to the position coordinates of the candidate frame.The final classification and regression results are generated by the fully connected layer, and the mask division of the object is generated by the deconvolution operation.Then, quadratic segmentation of the results after initial segmentation by the SVM algorithm basically completes the elimination of the interference area.The final instance segmentation is completed by mask calculation of the picking area.ResultMulti-feature fusion SVM, Mask R-CNN, and the proposed algorithm are used to detect the picking area of 500 metal parts.Experimental results show that the algorithm can adapt to the recognition of the picking region. The correct rate of algorithm identification in this work is 89.40%, the missed detection rate is 7.80%, and the false detection rate is 2.80%.The correct rate of algorithm identification is 7.00% and 25.00% higher than those of Mask R-CNN and SVM, respectively.The error detection rate of the algorithm is 7.80% and 18.40% lower than those of Mask R-CNN and SVM, respectively. The missed detection rate of the algorithm is 6.60% lower than that of SVM.ConclusionThe SVM classifier with multi-feature fusion is used to classify the recognition results of Mask R-CNN, and the rejection of the interference region is completed. Accurate recognition of the picking region is completed by the calculation of the mask.In the construction of the image training set, the effects of illumination and occlusion between parts are fully considered, and the illumination and occlusion conditions are effectively divided and investigated; hence, the approach exhibits a certain robustness in practical applications.Compared with the sliding window frame method used in traditional target recognition, this work accurately identifies the shape of the target area through mask calculation and has a high recognition accuracy.Moreover, this work compensates for the limitations of the single-network framework by constructing a multi-feature fusion SVM classifier, which effectively reduces the false detection rate.关键词:target recognition;multi-feature fusion;support vector machine(SVM);deep learning;instance segmentation22|6|4更新时间:2024-05-07 -
 摘要:ObjectiveFeature extraction can be completed automatically by using a nonlinear network structure for deep learning.Thus, multi-dimensional features can be obtained through the distributed expression of features. Deep convolutional neural networks are supported by a large volume of valid data. However, obtaining a large volume of effective labeled data is often labor-intensive and time-consuming. Hence, achieving deep learning on a large volume of labeled datasets is still a challenge. Presently, deep convolutional neural networks on few-shot datasets have become a popular research topic in deep learning, and deep learning with transfer learning is the latest approach to solve the problem of data poverty. In this paper, two-stream deep transfer learning with multi-source domain confusion is proposed to address the limited adaptionissue of the source model's general features extracted on the target data.MethodThe proposed deep transfer learning network is based on the confusion domain deep transfer learning model. First, amulti-source domain transfer strategy is used to increase the coverage of target domain transfer features from the source domain. Second, a two-stage adaptive learning method is proposed to achieve domain-invariant deep feature representations and similar recognition results of the inter-domain classifier. Third, a data fusion strategy of natural light images with two-dimensional features and depth images with three-dimensional features is proposed to enrich the features dimension of few-shot datasets and suppress the influence of a complex background. Finally, the composite loss function is presented with the softmax and center loss functions to improve the recognition performance of the classifier in few-shot deep learning, and intra-and inter-class distances are shortened and expanded, respectively. The proposed method increases the recognition rate by improving the feature extraction and loss function of the deep convolutional neural network. Regarding feature extraction, the efficiency of feature transfer is enhanced, and the feature parameters of few-shot datasets are enriched by multi-source deep transfer features and feature fusion. The efficiency of multi-source domain feature transfer is improved with three kinds of loss functions. The inter-and intra-class feature distances are adjusted by introducing the center loss function. To extract the deep adaptation features, the difference loss of domain-invariant deep feature representation is calculated, and the inter-domain features are aligned with oneanother. In addition, the mutual adaptation of different domain classifiers is designed with the difference loss function. A two-stream deep transfer learning model with multi-source domain confusion is developed by combining the above methods. The model enhances the characterization of targets in complex contexts while improving the applicability of transfer features. Gesture recognition experiments are conducted on public datasets to verify the validity of the proposed model. Quantitative analysis of comparative experiments shows that the performance of the proposed model is superior to that of other classical gesture recognition models.ResultThe two-stream deep transfer learning model with multi-source domain confusiondemonstratesa more effective gesture recognition performance on few-shot datasets than previous models. In the model with the DenseNet-169 pre-training network, theproposed network achieves 97.17% accuracy. Compared with other classic gesture recognition and transfer learning models, the two-stream deep transfer learning model with multi-source domain confusion has 2.34% higher accuracy.The recognition performance of the proposed model in a small gesture sample dataset is evaluated through comparison as follows. First, compared with other transfer learning models, the proposed framework of the two-stream fusion model with multi-source domain confusion transfer learning can effectively complete the transfer of features. Second, the performance of the proposed fusion model is superior to that of the traditional two-stream information fusion model, which verifies that the proposed fusion model can improve recognition efficiency while effectively combining natural light and depth image features.ConclusionA deep transfer learning method with multi-source domain confusion is proposed. By studying the principle and mechanism of deep learning and transfer learning, a multi-source domain transfer method that covers the characteristics of the target domain is proposed. First, an adaptable featureis introduced to enhance the description capability of the transfer feature. Second, a two-stage adaptive learning method is proposed to represent the deep features of the invariant domain and reduce the prediction differences of inter-domain classifiers. Third, combined with the three-dimensional feature information of the depth image, a two-stream convolution fusion strategy that can realize the full use of scene information is proposed. Through the fusion of natural light imaging and depth information, the capability to segment the foreground and background in the image is improved, and the data fusion strategy realizes the recombination of the twotypes of modal information. Finally, the efficiency of multi-source domain feature transfer is improved by three kinds of loss functions. To improve the recognition performance of the classifier in few-shot datasets, the penalty performance of classifiers on inter-and intra-class features is adjusted by introducing center loss to softmax loss. The inter-domain features are adapted to oneanother by calculating the loss of the domain-invariant deep feature. The mutual adaptation of different domain classifiers is designed with the difference loss function of inter-domain classifiers. The two-stream deep transfer learning model with multi-source domain confusion is generated through two-stage adaptive learning, which can facilitate the feature transfer from the source domain to the target domain. The model structure of the two-stream deep transfer learning with multi-source domain confusion is designed by combining the proposed deep transfer learning method and data fusion strategy with multi-source domain confusion. On the public gesture dataset, the superior performance of the proposed model is verified through the contrast of multiple angles.Experimental results prove that the proposed method can increase the matching rate of the source and target domains, enrich the feature dimension, and enhance the penalty supervision capability of the loss function. The proposed method can improve the recognition accuracy of the deep transfer network on few-shot datasets.关键词:few-shot datasets;transfer learning;multi-source domain;two-stream convolution fusion;domain confusion12|4|0更新时间:2024-05-07
摘要:ObjectiveFeature extraction can be completed automatically by using a nonlinear network structure for deep learning.Thus, multi-dimensional features can be obtained through the distributed expression of features. Deep convolutional neural networks are supported by a large volume of valid data. However, obtaining a large volume of effective labeled data is often labor-intensive and time-consuming. Hence, achieving deep learning on a large volume of labeled datasets is still a challenge. Presently, deep convolutional neural networks on few-shot datasets have become a popular research topic in deep learning, and deep learning with transfer learning is the latest approach to solve the problem of data poverty. In this paper, two-stream deep transfer learning with multi-source domain confusion is proposed to address the limited adaptionissue of the source model's general features extracted on the target data.MethodThe proposed deep transfer learning network is based on the confusion domain deep transfer learning model. First, amulti-source domain transfer strategy is used to increase the coverage of target domain transfer features from the source domain. Second, a two-stage adaptive learning method is proposed to achieve domain-invariant deep feature representations and similar recognition results of the inter-domain classifier. Third, a data fusion strategy of natural light images with two-dimensional features and depth images with three-dimensional features is proposed to enrich the features dimension of few-shot datasets and suppress the influence of a complex background. Finally, the composite loss function is presented with the softmax and center loss functions to improve the recognition performance of the classifier in few-shot deep learning, and intra-and inter-class distances are shortened and expanded, respectively. The proposed method increases the recognition rate by improving the feature extraction and loss function of the deep convolutional neural network. Regarding feature extraction, the efficiency of feature transfer is enhanced, and the feature parameters of few-shot datasets are enriched by multi-source deep transfer features and feature fusion. The efficiency of multi-source domain feature transfer is improved with three kinds of loss functions. The inter-and intra-class feature distances are adjusted by introducing the center loss function. To extract the deep adaptation features, the difference loss of domain-invariant deep feature representation is calculated, and the inter-domain features are aligned with oneanother. In addition, the mutual adaptation of different domain classifiers is designed with the difference loss function. A two-stream deep transfer learning model with multi-source domain confusion is developed by combining the above methods. The model enhances the characterization of targets in complex contexts while improving the applicability of transfer features. Gesture recognition experiments are conducted on public datasets to verify the validity of the proposed model. Quantitative analysis of comparative experiments shows that the performance of the proposed model is superior to that of other classical gesture recognition models.ResultThe two-stream deep transfer learning model with multi-source domain confusiondemonstratesa more effective gesture recognition performance on few-shot datasets than previous models. In the model with the DenseNet-169 pre-training network, theproposed network achieves 97.17% accuracy. Compared with other classic gesture recognition and transfer learning models, the two-stream deep transfer learning model with multi-source domain confusion has 2.34% higher accuracy.The recognition performance of the proposed model in a small gesture sample dataset is evaluated through comparison as follows. First, compared with other transfer learning models, the proposed framework of the two-stream fusion model with multi-source domain confusion transfer learning can effectively complete the transfer of features. Second, the performance of the proposed fusion model is superior to that of the traditional two-stream information fusion model, which verifies that the proposed fusion model can improve recognition efficiency while effectively combining natural light and depth image features.ConclusionA deep transfer learning method with multi-source domain confusion is proposed. By studying the principle and mechanism of deep learning and transfer learning, a multi-source domain transfer method that covers the characteristics of the target domain is proposed. First, an adaptable featureis introduced to enhance the description capability of the transfer feature. Second, a two-stage adaptive learning method is proposed to represent the deep features of the invariant domain and reduce the prediction differences of inter-domain classifiers. Third, combined with the three-dimensional feature information of the depth image, a two-stream convolution fusion strategy that can realize the full use of scene information is proposed. Through the fusion of natural light imaging and depth information, the capability to segment the foreground and background in the image is improved, and the data fusion strategy realizes the recombination of the twotypes of modal information. Finally, the efficiency of multi-source domain feature transfer is improved by three kinds of loss functions. To improve the recognition performance of the classifier in few-shot datasets, the penalty performance of classifiers on inter-and intra-class features is adjusted by introducing center loss to softmax loss. The inter-domain features are adapted to oneanother by calculating the loss of the domain-invariant deep feature. The mutual adaptation of different domain classifiers is designed with the difference loss function of inter-domain classifiers. The two-stream deep transfer learning model with multi-source domain confusion is generated through two-stage adaptive learning, which can facilitate the feature transfer from the source domain to the target domain. The model structure of the two-stream deep transfer learning with multi-source domain confusion is designed by combining the proposed deep transfer learning method and data fusion strategy with multi-source domain confusion. On the public gesture dataset, the superior performance of the proposed model is verified through the contrast of multiple angles.Experimental results prove that the proposed method can increase the matching rate of the source and target domains, enrich the feature dimension, and enhance the penalty supervision capability of the loss function. The proposed method can improve the recognition accuracy of the deep transfer network on few-shot datasets.关键词:few-shot datasets;transfer learning;multi-source domain;two-stream convolution fusion;domain confusion12|4|0更新时间:2024-05-07 -
 摘要:ObjectivePlants are one of the common natural landscapes in our daily lives, and they are an important part of natural scene modeling. Different plants have different morphological characteristics. Consequently, measuring the similarity among plants is a key problem to be resolved in the fields of plant classification, variety identification, storage, and retrieval of 3D plant models. The similarity of plant morphology is studied in this work to distinguish plant species effectively. The current method only considers the similarity of geometrical shapes, such as plant topology or edge contour. Plant topology describes the similarity between their structure and the distribution of organs, while edge contour describes the similarity of the edge contour of the plants. However, these methods do not consider intuitive factors, such as the color of the leaves, dense state of the canopy, and loose state of the plant type. This limitation results in a lack of accuracy because geometry and color are the main basis for distinguishing plant species. Therefore, this work proposes a method to calculate plant morphology similarity based on image features, particularly the shape and color characteristics of plant images.MethodFirst, the shape features of an image, which include contour and regional features, are obtained. The contour features are expressed by the looseness of the plant shoots, which include the aspect ratio of the plant, the boundary quadrilateral, and the height of the lowest primary branch. The plant's aspect ratio describes the ratio of overall height to width of a plant. The boundary quadrilateral describes the border of the furthest point of a plant and constrains the plant's morphological distribution. The height of the lowest primary branch describes the starting position of the branch of a plant and claims the position of the canopy. The basic peripheral contour features of a plant can be described with the combination of these factors. The method will calculate the ratio of the height to width of the plant and the four internal angles of the boundary quadrilateral using the boundary points of the plant outline. The lowest primary branch of the plant will then be found, and the proportion of the height of the branch to the height of the entire plant will be calculated. The regional features are reflected in the density of the leaves, and the proportion of the surrounding rectangles of the leaves is calculated. Second, the color features of the images are obtained, in which the color histograms based on the HSV and YUV color spaces are used. The color spaces are divided into seven levels according to hue. Each level is subdivided into five levels according to the gray level. The proportion of each color section of the image is calculated to construct a 2D color matrix. Finally, appropriate weight-setting strategies are needed because the proportion of the various features in the overall similarity is different and the empirical knowledge is lacking. A high degree of data dispersion leads to a large difference among species. Specifically, obvious discrimination of the attribute value results in a considerable influence of the factor on the comprehensive evaluation result and a large corresponding weight. Otherwise, a small corresponding weight will be obtained. The degree of dispersion of the data reflects the uncertainty in the data. In information theory, entropy is used to measure uncertainty. Therefore, information entropy is used to identify the weight of each separate, and the weighting is used to obtain the overall similarity.ResultAn experiment is conducted on a manually collected data set. After the experiment, the weights of the looseness, density, and color are set to 0.62, 0.17, and 0.21, respectively. In common plant species, the similarity calculation results are in line with reality, which can effectively distinguish plant species and measure the similarity among plants. The proposed algorithm is also applied to image retrieval. The precision of the algorithm is above 0.747 7. Under the same precision level, the recall rate is higher than the results of five ordinary methods. Especially when the similarity threshold is larger than 0.8, the precision can reach 0.910 8 or more, and the recall rate remains higher than that of other methods at the same precision level. The proposed algorithm is insensitive to plant image scaling, and the similarity of similar plants remains close to 1.ConclusionA plant morphology similarity algorithm that combines shape and color features is proposed in this work. The results of plant morphology similarity are in line with those of human visual perception. Compared with other methods, the proposed algorithm can distinguish plant species more effectively. The algorithm is mainly applied to a single plant image with a plain background, which can provide a new idea for studying the similarity of plant morphology.关键词:plant morphology;image similarity;visual features;weight setting;information entropy17|4|3更新时间:2024-05-07
摘要:ObjectivePlants are one of the common natural landscapes in our daily lives, and they are an important part of natural scene modeling. Different plants have different morphological characteristics. Consequently, measuring the similarity among plants is a key problem to be resolved in the fields of plant classification, variety identification, storage, and retrieval of 3D plant models. The similarity of plant morphology is studied in this work to distinguish plant species effectively. The current method only considers the similarity of geometrical shapes, such as plant topology or edge contour. Plant topology describes the similarity between their structure and the distribution of organs, while edge contour describes the similarity of the edge contour of the plants. However, these methods do not consider intuitive factors, such as the color of the leaves, dense state of the canopy, and loose state of the plant type. This limitation results in a lack of accuracy because geometry and color are the main basis for distinguishing plant species. Therefore, this work proposes a method to calculate plant morphology similarity based on image features, particularly the shape and color characteristics of plant images.MethodFirst, the shape features of an image, which include contour and regional features, are obtained. The contour features are expressed by the looseness of the plant shoots, which include the aspect ratio of the plant, the boundary quadrilateral, and the height of the lowest primary branch. The plant's aspect ratio describes the ratio of overall height to width of a plant. The boundary quadrilateral describes the border of the furthest point of a plant and constrains the plant's morphological distribution. The height of the lowest primary branch describes the starting position of the branch of a plant and claims the position of the canopy. The basic peripheral contour features of a plant can be described with the combination of these factors. The method will calculate the ratio of the height to width of the plant and the four internal angles of the boundary quadrilateral using the boundary points of the plant outline. The lowest primary branch of the plant will then be found, and the proportion of the height of the branch to the height of the entire plant will be calculated. The regional features are reflected in the density of the leaves, and the proportion of the surrounding rectangles of the leaves is calculated. Second, the color features of the images are obtained, in which the color histograms based on the HSV and YUV color spaces are used. The color spaces are divided into seven levels according to hue. Each level is subdivided into five levels according to the gray level. The proportion of each color section of the image is calculated to construct a 2D color matrix. Finally, appropriate weight-setting strategies are needed because the proportion of the various features in the overall similarity is different and the empirical knowledge is lacking. A high degree of data dispersion leads to a large difference among species. Specifically, obvious discrimination of the attribute value results in a considerable influence of the factor on the comprehensive evaluation result and a large corresponding weight. Otherwise, a small corresponding weight will be obtained. The degree of dispersion of the data reflects the uncertainty in the data. In information theory, entropy is used to measure uncertainty. Therefore, information entropy is used to identify the weight of each separate, and the weighting is used to obtain the overall similarity.ResultAn experiment is conducted on a manually collected data set. After the experiment, the weights of the looseness, density, and color are set to 0.62, 0.17, and 0.21, respectively. In common plant species, the similarity calculation results are in line with reality, which can effectively distinguish plant species and measure the similarity among plants. The proposed algorithm is also applied to image retrieval. The precision of the algorithm is above 0.747 7. Under the same precision level, the recall rate is higher than the results of five ordinary methods. Especially when the similarity threshold is larger than 0.8, the precision can reach 0.910 8 or more, and the recall rate remains higher than that of other methods at the same precision level. The proposed algorithm is insensitive to plant image scaling, and the similarity of similar plants remains close to 1.ConclusionA plant morphology similarity algorithm that combines shape and color features is proposed in this work. The results of plant morphology similarity are in line with those of human visual perception. Compared with other methods, the proposed algorithm can distinguish plant species more effectively. The algorithm is mainly applied to a single plant image with a plain background, which can provide a new idea for studying the similarity of plant morphology.关键词:plant morphology;image similarity;visual features;weight setting;information entropy17|4|3更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveArtificial intelligence has been a popular issue in recent years. Therefore, quantitative analysis of human perception, such as affective computing based on picture or music materials, has elicited much concern. One of the most important events in image aesthetic research is the introduction of experimental psychology methods to establish the relationship between the subjective affective state and objective artworks. Recent developments inempirical aesthetics in the general cultural background have heightened the need for parallel research on single cultural background. Traditional Chinese art is part and parcel of the world culture. Central to conducting quantification research on the art perception and affective computing of Chinese paintings and enriching the database of general aesthetics and emotion is building an image database for aesthetic and emotion analyses of traditional Chinese paintings. To this end, we introduce a new image aesthetic database for aesthetic and emotion analyses of Chinese paintings. The database contains over 500 images of Chinese paintings in five semantic aesthetic categories and quantitative annotations of the three-dimensional emotion score and aesthetic quality of each image.MethodTo accumulate basic data, 511 traditional Chinese paintings are collected and filtered as digital images from multiple sources(e.g., www.artsjk.com), and 350 adjectives are gathered through extensive provenance(e.g., Historical Dictionary of Aesthetics and classical documents in psycho-aesthetics, art aesthetics, and philosophical aesthetics). Two methods are used in annotating Chinese paintings:the discrete emotion model and the pleasure-arousal-dominance (PAD) scale. Discrete emotion theory claims that a small number of core emotions exists. In the PAD emotional state model, the pleasure-displeasure scale measures how pleasant or unpleasant one feels about something, the arousal-non-arousal scale measures how energized or soporific one feels, and the dominance-submissiveness scale represents how controlling and dominant versus controlled or submissive one feels. The major differences between the two models pertain to the low resolution of the discrete model in discriminating affectively vague examples and the difficulty in understanding part subjects in the PAD scale. Therefore, the combination of the two approaches is necessary. First, to build the basic concepts of our subjective annotation, a questionnaire survey is conducted to select favorable adjectives for describing affective feelings when appreciating Chinese paintings. Participants are asked to answer if they think the adjective is applicable for representing aesthetic feelings when appreciating a Chinese painting (yes or no), and from the adjectives selected, more than 50% are chosen as meaningful. Second, subjective assessment and factor analysis are adopted to conduct a pilot study of the principle factors of aesthetics in Chinese paintings based on the adjectives collected previously. Responses are received from 40 participants who rated each item with regard to how frequently they use it to describe their emotional reaction in Chinese painting appreciation (1 never; 5 very frequently). Two groups of participants, namely, experts (50%) and amateurs (50%), are investigated. With the factor analysis method, 5 aesthetic semantic categories and 25 secondary aesthetic concepts of the principle factors are obtained for annotation in the discrete adjective method. Third, the aesthetic style and affective response of the collected paintings are annotated. The participants are asked to make a judgement of the aesthetic category and rate the aesthetic quality and PAD value of a painting. Fourth, statistical analysis is performed to calculate the distributions of aesthetics and emotions in the annotating experiment. Two parameters, namely, aesthetic membership vector and aesthetic average intensity, are designed to measure the ratings and frequencies of different aesthetics and calculate the distribution of aesthetic judgements. In addition, the distribution of mean values and the standard deviations of PAD scores are computed. Then, an analysis between aesthetic feelings and emotional responses is performed to determine the effects of emotion distribution on aesthetic classification. Finally, to identify the utility of the database, emotion and aesthetic pattern classification is conducted using various methods. Regression analysis using various models is performed between the image feature and PAD value, and pattern classification of five aesthetic categories based on different classifiers is conducted.ResultThe following five aesthetic categories of traditional Chinese paintings are identified:Qishi(mighty, magnificent, glorious, grandeur, vigorous and firm, precipitous, powerful in strength and impetus, towering, tremendous, boundless, bold and unconstrained, and extremely attractive and impressive), Qingyou(quiet and beautiful, ethereal, distant, solemn, flexible and elusive, tranquil, and extremely delicate and light), Shengji(full of life, vivid, full of vitality, smart, spirited, and characterized by spirit and animation), Yazhi(elegant, refined, pure and classic, layered, and designed well), and Xiaose(bleak, empty and without people, and makes people feel sad or frightened).The test-retest reliability and Cronbach's alpha of the PAD ratings verify the credibility of the database. The distribution of aesthetic categories and PAD emotional ratings shows a selection bias in the perception of Chinese paintings with positive and dynamic feelings. The mean classification accuracy of emotion is 0.68, and the highest classification of aesthetics is 0.77.ConclusionThis study identifies five semantic categories of aesthetics of Chinese paintings. Experiments confirm that these categories can cover most paintings in Chinese painting appreciation. A database is established based on the five categories, and the emotional responses and aesthetic style and quality of the collected paintings are confirmed in the subjective assessment. The database shows great diversity in artistic style and emotional expression. By pattern classification of emotion polarity and aesthetic label, the effectiveness of the extra-trees classifier through uneven data is tested and proven. The accuracy of emotion and aesthetic classification illustrates that the regression and classification methods presented in this paper are effective. We believe that this database can be used forthe quantitative study of visual beauty, computer vision, affective computing, and experimental aesthetics. Our future work will include expanding the data of rare aesthetics (e.g., Qingyou and Xiaose) and conducting multi-label aesthetic classification based on the PAD affective model of images in the database.关键词:emotion;aesthetics;database;Chinese painting31|11|3更新时间:2024-05-07
摘要:ObjectiveArtificial intelligence has been a popular issue in recent years. Therefore, quantitative analysis of human perception, such as affective computing based on picture or music materials, has elicited much concern. One of the most important events in image aesthetic research is the introduction of experimental psychology methods to establish the relationship between the subjective affective state and objective artworks. Recent developments inempirical aesthetics in the general cultural background have heightened the need for parallel research on single cultural background. Traditional Chinese art is part and parcel of the world culture. Central to conducting quantification research on the art perception and affective computing of Chinese paintings and enriching the database of general aesthetics and emotion is building an image database for aesthetic and emotion analyses of traditional Chinese paintings. To this end, we introduce a new image aesthetic database for aesthetic and emotion analyses of Chinese paintings. The database contains over 500 images of Chinese paintings in five semantic aesthetic categories and quantitative annotations of the three-dimensional emotion score and aesthetic quality of each image.MethodTo accumulate basic data, 511 traditional Chinese paintings are collected and filtered as digital images from multiple sources(e.g., www.artsjk.com), and 350 adjectives are gathered through extensive provenance(e.g., Historical Dictionary of Aesthetics and classical documents in psycho-aesthetics, art aesthetics, and philosophical aesthetics). Two methods are used in annotating Chinese paintings:the discrete emotion model and the pleasure-arousal-dominance (PAD) scale. Discrete emotion theory claims that a small number of core emotions exists. In the PAD emotional state model, the pleasure-displeasure scale measures how pleasant or unpleasant one feels about something, the arousal-non-arousal scale measures how energized or soporific one feels, and the dominance-submissiveness scale represents how controlling and dominant versus controlled or submissive one feels. The major differences between the two models pertain to the low resolution of the discrete model in discriminating affectively vague examples and the difficulty in understanding part subjects in the PAD scale. Therefore, the combination of the two approaches is necessary. First, to build the basic concepts of our subjective annotation, a questionnaire survey is conducted to select favorable adjectives for describing affective feelings when appreciating Chinese paintings. Participants are asked to answer if they think the adjective is applicable for representing aesthetic feelings when appreciating a Chinese painting (yes or no), and from the adjectives selected, more than 50% are chosen as meaningful. Second, subjective assessment and factor analysis are adopted to conduct a pilot study of the principle factors of aesthetics in Chinese paintings based on the adjectives collected previously. Responses are received from 40 participants who rated each item with regard to how frequently they use it to describe their emotional reaction in Chinese painting appreciation (1 never; 5 very frequently). Two groups of participants, namely, experts (50%) and amateurs (50%), are investigated. With the factor analysis method, 5 aesthetic semantic categories and 25 secondary aesthetic concepts of the principle factors are obtained for annotation in the discrete adjective method. Third, the aesthetic style and affective response of the collected paintings are annotated. The participants are asked to make a judgement of the aesthetic category and rate the aesthetic quality and PAD value of a painting. Fourth, statistical analysis is performed to calculate the distributions of aesthetics and emotions in the annotating experiment. Two parameters, namely, aesthetic membership vector and aesthetic average intensity, are designed to measure the ratings and frequencies of different aesthetics and calculate the distribution of aesthetic judgements. In addition, the distribution of mean values and the standard deviations of PAD scores are computed. Then, an analysis between aesthetic feelings and emotional responses is performed to determine the effects of emotion distribution on aesthetic classification. Finally, to identify the utility of the database, emotion and aesthetic pattern classification is conducted using various methods. Regression analysis using various models is performed between the image feature and PAD value, and pattern classification of five aesthetic categories based on different classifiers is conducted.ResultThe following five aesthetic categories of traditional Chinese paintings are identified:Qishi(mighty, magnificent, glorious, grandeur, vigorous and firm, precipitous, powerful in strength and impetus, towering, tremendous, boundless, bold and unconstrained, and extremely attractive and impressive), Qingyou(quiet and beautiful, ethereal, distant, solemn, flexible and elusive, tranquil, and extremely delicate and light), Shengji(full of life, vivid, full of vitality, smart, spirited, and characterized by spirit and animation), Yazhi(elegant, refined, pure and classic, layered, and designed well), and Xiaose(bleak, empty and without people, and makes people feel sad or frightened).The test-retest reliability and Cronbach's alpha of the PAD ratings verify the credibility of the database. The distribution of aesthetic categories and PAD emotional ratings shows a selection bias in the perception of Chinese paintings with positive and dynamic feelings. The mean classification accuracy of emotion is 0.68, and the highest classification of aesthetics is 0.77.ConclusionThis study identifies five semantic categories of aesthetics of Chinese paintings. Experiments confirm that these categories can cover most paintings in Chinese painting appreciation. A database is established based on the five categories, and the emotional responses and aesthetic style and quality of the collected paintings are confirmed in the subjective assessment. The database shows great diversity in artistic style and emotional expression. By pattern classification of emotion polarity and aesthetic label, the effectiveness of the extra-trees classifier through uneven data is tested and proven. The accuracy of emotion and aesthetic classification illustrates that the regression and classification methods presented in this paper are effective. We believe that this database can be used forthe quantitative study of visual beauty, computer vision, affective computing, and experimental aesthetics. Our future work will include expanding the data of rare aesthetics (e.g., Qingyou and Xiaose) and conducting multi-label aesthetic classification based on the PAD affective model of images in the database.关键词:emotion;aesthetics;database;Chinese painting31|11|3更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveWith the recent development of smart cities, urban big data are increasingly becoming available, including traffic accident data. Big traffic accident data may contain spatial patterns of traffic accidents and are valuable for traffic accident prevention and management by mining spatial patterns from traffic accident data. Although traffic accident position is currently available, its spatial-semantic information is missing, which is adverse for its spatial pattern analysis. This study presents a method to enhance the spatial semantics of traffic accident data and designs a visual analytic system to analyze spatial patterns from spatial semantic-enhanced traffic accident data.MethodPoint of interest (POI) is used to enhance the spatial semantics of traffic accidents. First, all POIs around a traffic accident are collected to form a POI collection, and a feature vector is defined according to the number of POIs, type of POIs, and distance between POIs and traffic accident. The feature vector is named the spatial-semantic feature vector because it encodes spatial semantic information. This vector is associated with traffic accident data to enhance the traffic accident data's spatial semantics. Second, self-organizing map (SOM) clustering algorithm is applied to analyze spatial semantic-enhanced traffic accident data according to the spatial-semantic feature vector, and several clusters are obtained for further analysis. Each resulting cluster implies some spatial semantic information because the spatial-semantic feature vector is used for clustering. Finally, a visual analytic system with linked views is designed and implemented to analyze the spatial semantic-enhanced traffic accident data and the resulting clusters. Map view using heat map and glyphs is applied to visualize the distribution of traffic accident data. Histogram view and parallel coordinate view are used to visualize clusters and spatial-semantic feature vectors, respectively. Several interaction methods are provided to help users filter data of interest for the traffic accidents' spatial pattern.ResultThrough cooperation with two traffic policemen from Hefei Traffic Police Division, the authors analyze the traffic accidents in Hefei City using the presented visual analytic system and obtain nine clusters via SOM clustering. The spatial-semantic features of the nine clusters are analyzed and interpreted, and several possible causes of traffic accidents are found and validated by the traffic police. For example, the largest cluster's "financial" feature is prominent, which means the traffic accidents contained in this cluster are related to banks or other financial institutions. The policemen interpret that many people park their car temporarily when visiting financial institutions, and such parking tends to cause collision accidents.ConclusionPOI has spatial-semantic information, and this study utilizes POI to enhance the spatial semantics of traffic accident data. A spatial semantic-enhanced method is presented, and the corresponding visual analytic system is designed and implemented. Analysis of 2018 Hefei traffic accident data reveals several interesting results that are confirmed by traffic policemen. The presented method is useful for discovering the spatial pattern of traffic accidents and beneficial for traffic accident prevention and management. In the future, additional attributes, such as time and density, could be considered, and more sophisticated visual encoding and interaction methods should be studied and applied.关键词:visual analytics;traffic accident;spatial semantic;point of interest (POI);self-organized map13|23|1更新时间:2024-05-07
摘要:ObjectiveWith the recent development of smart cities, urban big data are increasingly becoming available, including traffic accident data. Big traffic accident data may contain spatial patterns of traffic accidents and are valuable for traffic accident prevention and management by mining spatial patterns from traffic accident data. Although traffic accident position is currently available, its spatial-semantic information is missing, which is adverse for its spatial pattern analysis. This study presents a method to enhance the spatial semantics of traffic accident data and designs a visual analytic system to analyze spatial patterns from spatial semantic-enhanced traffic accident data.MethodPoint of interest (POI) is used to enhance the spatial semantics of traffic accidents. First, all POIs around a traffic accident are collected to form a POI collection, and a feature vector is defined according to the number of POIs, type of POIs, and distance between POIs and traffic accident. The feature vector is named the spatial-semantic feature vector because it encodes spatial semantic information. This vector is associated with traffic accident data to enhance the traffic accident data's spatial semantics. Second, self-organizing map (SOM) clustering algorithm is applied to analyze spatial semantic-enhanced traffic accident data according to the spatial-semantic feature vector, and several clusters are obtained for further analysis. Each resulting cluster implies some spatial semantic information because the spatial-semantic feature vector is used for clustering. Finally, a visual analytic system with linked views is designed and implemented to analyze the spatial semantic-enhanced traffic accident data and the resulting clusters. Map view using heat map and glyphs is applied to visualize the distribution of traffic accident data. Histogram view and parallel coordinate view are used to visualize clusters and spatial-semantic feature vectors, respectively. Several interaction methods are provided to help users filter data of interest for the traffic accidents' spatial pattern.ResultThrough cooperation with two traffic policemen from Hefei Traffic Police Division, the authors analyze the traffic accidents in Hefei City using the presented visual analytic system and obtain nine clusters via SOM clustering. The spatial-semantic features of the nine clusters are analyzed and interpreted, and several possible causes of traffic accidents are found and validated by the traffic police. For example, the largest cluster's "financial" feature is prominent, which means the traffic accidents contained in this cluster are related to banks or other financial institutions. The policemen interpret that many people park their car temporarily when visiting financial institutions, and such parking tends to cause collision accidents.ConclusionPOI has spatial-semantic information, and this study utilizes POI to enhance the spatial semantics of traffic accident data. A spatial semantic-enhanced method is presented, and the corresponding visual analytic system is designed and implemented. Analysis of 2018 Hefei traffic accident data reveals several interesting results that are confirmed by traffic policemen. The presented method is useful for discovering the spatial pattern of traffic accidents and beneficial for traffic accident prevention and management. In the future, additional attributes, such as time and density, could be considered, and more sophisticated visual encoding and interaction methods should be studied and applied.关键词:visual analytics;traffic accident;spatial semantic;point of interest (POI);self-organized map13|23|1更新时间:2024-05-07
Computer Graphics
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0