
最新刊期
卷 24 , 期 11 , 2019
-
 摘要:Remote sensing image, which is an important data source in spatial analysis, records both spectral and spatial information of the scene. Therefore, it is widely utilized in areas such as terrain classification, change detection and object identification etc.. Classification is the most primary problem of remote sensing applications while the issues of large date redundancy and small training set are still the barrier of its widespread application and development. Deep learning is one kind of representational learning, which has led to significant advances in imaging technology. Traditional pattern recognition algorithm always be the thought of a strategy of "divide and conquer", which tends to be divided into feature extraction and feature selection, classifier design processes. Although this solution idea can decompose the problem into several controllable subproblems, at the same time, the optimum solution of these subproblems cannot converge to the global optimum, and even the best feature extraction methods cannot make sure the classification of boundary is prefect. Comparing with the hand-crafted feature extraction methods, the end-to-end optimization pattern of deep learning has brought a superior performance for the remote sensing classification. Unfortunately, deep learning usually requires big data, with respect to both volume and variety, while most remote sensing applications only have limited training data, of which a small subset is labeled. Herein, we provide the most comprehensive survey of state-of-the-art approaches in deep learning to combat this challenge over recent one or two years, and to enable researchers to explore its theory and development. This paper summarizes three kinds of methods to train the deep model under limited training data. The first topic is deep generative model, in which we explore the applications of the generative adversarial networks (GAN), variation autoencoders (VAE) and their derived structures in remote sensing classification and change detection, and the application fields, applicable data and characteristics of the generated model are summarized. The next is transfer learning, in which we review the approaches that network structures or the data features are transferred from one domain to anther domain. Although transfer learning provides a possible solution to make full use of the existing tag data, the ability of transfer learning is also limited. When the task and data distribution between two domains are very different, negative migration is easy to occur. Therefore, the mobility measurement standards in the field of remote sensing technology should be further studied. The last is the novel deep neural networks which is trained with semi-supervised learning or active learning strategies towards remote sensing classification. At the same time, the author enumerates some attempts made by scholars based on novel network structures in recent years. There are two main solutions to handle the full training of deep learning under the limited training data. One is to enhance the prior knowledge. Before the deep generative model appears, data enhancement often relies on simple image transformation and data augmentation. For multispectral data, simple data transformations, such as translation, rotation, scaling, shearing, or any combination of these, were carried out to expand the training samples. For hyperspectral data, data simulation based on physical models, such as spectrum simulation under different illumination of the same ground scene, label propagation driven by data or additional Gaussian white noise is adopted. These solutions rely heavily on the data itself or the assumptions of the physical environment. Different from traditional methods, deep generative methods and transfer learning have strong capability in the learning of prior knowledges. And in the most case, the combination of these two kinds approaches are used.The other is to extract the more effective time-spatio-spectral features towards classification using novel deep neural networks on the limited labelled data. Such methods build or select advanced network structures, which perform well in computer vision fields, and the training process combine such training strategies as semi-supervised learning, ensemble learning and active learning strategies. In the practical applications, these mentioned solutions are jointed to obtain the optimum performance. Due to the exploration of various models, deep learning has shown its superiority in remote sensing technology and the performance exceeds the shallow model in general. Nonetheless, the physics-based deep learning approach and high-powered practicality are still worth studying.关键词:remote sensing classification;deep learning;deep generative model;semi-supervised learning;transfer learning61|93|15更新时间:2024-05-07
摘要:Remote sensing image, which is an important data source in spatial analysis, records both spectral and spatial information of the scene. Therefore, it is widely utilized in areas such as terrain classification, change detection and object identification etc.. Classification is the most primary problem of remote sensing applications while the issues of large date redundancy and small training set are still the barrier of its widespread application and development. Deep learning is one kind of representational learning, which has led to significant advances in imaging technology. Traditional pattern recognition algorithm always be the thought of a strategy of "divide and conquer", which tends to be divided into feature extraction and feature selection, classifier design processes. Although this solution idea can decompose the problem into several controllable subproblems, at the same time, the optimum solution of these subproblems cannot converge to the global optimum, and even the best feature extraction methods cannot make sure the classification of boundary is prefect. Comparing with the hand-crafted feature extraction methods, the end-to-end optimization pattern of deep learning has brought a superior performance for the remote sensing classification. Unfortunately, deep learning usually requires big data, with respect to both volume and variety, while most remote sensing applications only have limited training data, of which a small subset is labeled. Herein, we provide the most comprehensive survey of state-of-the-art approaches in deep learning to combat this challenge over recent one or two years, and to enable researchers to explore its theory and development. This paper summarizes three kinds of methods to train the deep model under limited training data. The first topic is deep generative model, in which we explore the applications of the generative adversarial networks (GAN), variation autoencoders (VAE) and their derived structures in remote sensing classification and change detection, and the application fields, applicable data and characteristics of the generated model are summarized. The next is transfer learning, in which we review the approaches that network structures or the data features are transferred from one domain to anther domain. Although transfer learning provides a possible solution to make full use of the existing tag data, the ability of transfer learning is also limited. When the task and data distribution between two domains are very different, negative migration is easy to occur. Therefore, the mobility measurement standards in the field of remote sensing technology should be further studied. The last is the novel deep neural networks which is trained with semi-supervised learning or active learning strategies towards remote sensing classification. At the same time, the author enumerates some attempts made by scholars based on novel network structures in recent years. There are two main solutions to handle the full training of deep learning under the limited training data. One is to enhance the prior knowledge. Before the deep generative model appears, data enhancement often relies on simple image transformation and data augmentation. For multispectral data, simple data transformations, such as translation, rotation, scaling, shearing, or any combination of these, were carried out to expand the training samples. For hyperspectral data, data simulation based on physical models, such as spectrum simulation under different illumination of the same ground scene, label propagation driven by data or additional Gaussian white noise is adopted. These solutions rely heavily on the data itself or the assumptions of the physical environment. Different from traditional methods, deep generative methods and transfer learning have strong capability in the learning of prior knowledges. And in the most case, the combination of these two kinds approaches are used.The other is to extract the more effective time-spatio-spectral features towards classification using novel deep neural networks on the limited labelled data. Such methods build or select advanced network structures, which perform well in computer vision fields, and the training process combine such training strategies as semi-supervised learning, ensemble learning and active learning strategies. In the practical applications, these mentioned solutions are jointed to obtain the optimum performance. Due to the exploration of various models, deep learning has shown its superiority in remote sensing technology and the performance exceeds the shallow model in general. Nonetheless, the physics-based deep learning approach and high-powered practicality are still worth studying.关键词:remote sensing classification;deep learning;deep generative model;semi-supervised learning;transfer learning61|93|15更新时间:2024-05-07
Scholar View

-
 摘要:Light field imaging is an attractive technique for 3D visualization, especially in virtual and augmented reality application scenarios. This technique has also been applied to computer vision areas, such as depth estimation, 3D reconstruction, and object detection. However, light field data have put great pressure on cost-effective storage and transmission owing to the large data volume. The data format of light field is also relatively different from that of conventional images or videos. This difference has resulted in the inefficient compression of light field data by current coding tools designed for traditional images or videos. Thus, light field compression methods must be developed, especially from the perspective of cost-effective storage and transmission bandwidth. With the advancement of light field compression, various light field compression methods have been proposed. This study conducts a survey of related works on light field compression to provide a research foundation for later researchers who will focus on this topic. First, this study briefly introduces the fundamentals of light field and the four types of light field-capturing devices. The advantages and drawbacks of different types of capturing devices are presented accordingly. The influence of different capturing devices on light field data format is also described. Second, this work discusses the recent advances in JPEG Pleno, which is a standard framework for representing and signaling plenoptic modalities. JPEG Pleno was started in 2015 by the Joint Photographic Experts Group Committee. The term "pleno" is an abbreviation of "plenoptic, " which is a mathematical formulation to represent the information of a beam of light passing through an arbitrary point within a scene. JPEG Pleno proposes a light field-coding framework for the light field data acquired by a plenoptic camera or a high-density array of cameras. The JPEG Pleno light field encoder consists of three parts, with each part illustrated in detail. Lastly, on the basis of extensive literature research, the proposed light field compression methods are divided into three categories according to the characteristics of the coding algorithms, namely, transform, pseudo-sequence-based, and predictive coding approaches. We analyze and discuss the coding methods in each category. As for transform coding approaches, the coding performance is not better than those of the other two methods because transform coding approaches do not contain the prediction process. Although several transform methods can achieve good performance in terms of energy compaction, the decorrelation efficiency of transform methods is not as good as that of the hybrid coding framework that consists of prediction and transformation. As for pseudo-sequence-based coding approaches, the correlation in spatial or view domain is converted into temporal domain. Temporal correlation can be removed by inter-prediction techniques with the use of a well-developed video encoder, such as HEVC (high efficiency video coding) codec. The coding performance can be further improved because the disparity information is not used in the video encoder. As for the predictive coding approaches, they can be further divided into two methods: self-similarity-based coding methods, which were proposed in the last two years, and disparity prediction-based coding approaches. Self-similarity-based coding methods directly encode light field images by applying template-matching-based coding methods. However, the coding performance of this method is insufficient compared with that of disparity prediction-based coding approaches. The latter can achieve the best coding performance compared with other coding methods. JPEG Pleno applies such method to encode light field data. The advantages and shortcomings of existing light field-coding methods are elucidated on the basis of the preceding analysis, and possible promising directions for future research are suggested. First, light field video data sets to explore light field video coding are lacking. Second, the JPEG Pleno light field coding framework should be studied, and coding methods should be developed on the basis of this framework. Lastly, a few coding tools, such as depth estimation and view synthesis, should be improved. Light field compression is a popular research topic, and related research achievements, including standardization advances on JPEG Pleno, will attract increasing attention. Efficient compression of light field data remains a great challenge. Although many compression approaches are available for light field data, the coding performance still needs to be improved.关键词:light field;light field compression;light field imaging;JPEG Pleno;transform;pseudo-sequence53|62|2更新时间:2024-05-07
摘要:Light field imaging is an attractive technique for 3D visualization, especially in virtual and augmented reality application scenarios. This technique has also been applied to computer vision areas, such as depth estimation, 3D reconstruction, and object detection. However, light field data have put great pressure on cost-effective storage and transmission owing to the large data volume. The data format of light field is also relatively different from that of conventional images or videos. This difference has resulted in the inefficient compression of light field data by current coding tools designed for traditional images or videos. Thus, light field compression methods must be developed, especially from the perspective of cost-effective storage and transmission bandwidth. With the advancement of light field compression, various light field compression methods have been proposed. This study conducts a survey of related works on light field compression to provide a research foundation for later researchers who will focus on this topic. First, this study briefly introduces the fundamentals of light field and the four types of light field-capturing devices. The advantages and drawbacks of different types of capturing devices are presented accordingly. The influence of different capturing devices on light field data format is also described. Second, this work discusses the recent advances in JPEG Pleno, which is a standard framework for representing and signaling plenoptic modalities. JPEG Pleno was started in 2015 by the Joint Photographic Experts Group Committee. The term "pleno" is an abbreviation of "plenoptic, " which is a mathematical formulation to represent the information of a beam of light passing through an arbitrary point within a scene. JPEG Pleno proposes a light field-coding framework for the light field data acquired by a plenoptic camera or a high-density array of cameras. The JPEG Pleno light field encoder consists of three parts, with each part illustrated in detail. Lastly, on the basis of extensive literature research, the proposed light field compression methods are divided into three categories according to the characteristics of the coding algorithms, namely, transform, pseudo-sequence-based, and predictive coding approaches. We analyze and discuss the coding methods in each category. As for transform coding approaches, the coding performance is not better than those of the other two methods because transform coding approaches do not contain the prediction process. Although several transform methods can achieve good performance in terms of energy compaction, the decorrelation efficiency of transform methods is not as good as that of the hybrid coding framework that consists of prediction and transformation. As for pseudo-sequence-based coding approaches, the correlation in spatial or view domain is converted into temporal domain. Temporal correlation can be removed by inter-prediction techniques with the use of a well-developed video encoder, such as HEVC (high efficiency video coding) codec. The coding performance can be further improved because the disparity information is not used in the video encoder. As for the predictive coding approaches, they can be further divided into two methods: self-similarity-based coding methods, which were proposed in the last two years, and disparity prediction-based coding approaches. Self-similarity-based coding methods directly encode light field images by applying template-matching-based coding methods. However, the coding performance of this method is insufficient compared with that of disparity prediction-based coding approaches. The latter can achieve the best coding performance compared with other coding methods. JPEG Pleno applies such method to encode light field data. The advantages and shortcomings of existing light field-coding methods are elucidated on the basis of the preceding analysis, and possible promising directions for future research are suggested. First, light field video data sets to explore light field video coding are lacking. Second, the JPEG Pleno light field coding framework should be studied, and coding methods should be developed on the basis of this framework. Lastly, a few coding tools, such as depth estimation and view synthesis, should be improved. Light field compression is a popular research topic, and related research achievements, including standardization advances on JPEG Pleno, will attract increasing attention. Efficient compression of light field data remains a great challenge. Although many compression approaches are available for light field data, the coding performance still needs to be improved.关键词:light field;light field compression;light field imaging;JPEG Pleno;transform;pseudo-sequence53|62|2更新时间:2024-05-07 -
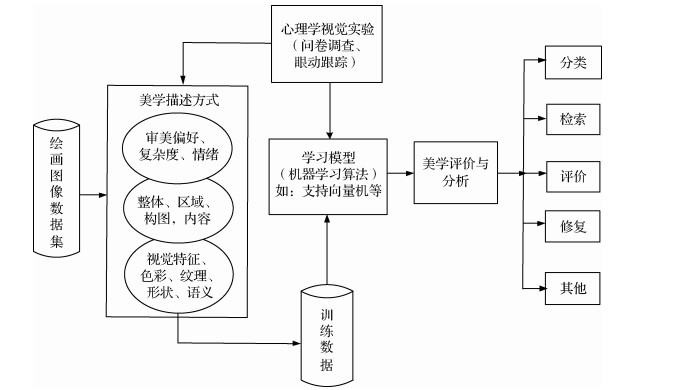 摘要:Aesthetics has been the subject of long-standing debates by philosophers and psychologists. In psychology, aesthetic experience is due to the interaction among perception, cognition, and emotion. This triad has been experimentally studied in the field of experimental aesthetics to obtain understanding of how aesthetic experience is related to the fundamental principles of human visual perception and brain processes. Recently, researchers in computer vision have gained interest in the topic, giving rise to the field of computational aesthetics. With computing hardware and methodology developing at a high pace, the modeling of perceptually relevant aspect of aesthetic stimuli has a huge potential. In the field of aesthetics, the image aesthetics is a popular issue in recent years. Image processing with computer scientists have, for a long time, attempted to solve image quality assessment and image semantics inference. The former deals primarily with the quantification of low-level perceptual degradation of an image, and the latter attempts to infer the content of an image and associate high level semantics to it in part or in whole. More recently, researchers have drawn ideas from the aforementioned methods to address more challenging problems such as associating pictures with aesthetics and emotions that they arouse in humans, with low-level image composition. Painting image is a kind of artistic work with emotion and aesthetics. By understanding the theme, the painter expresses his inner feelings in painting and passes them on to others. However, the artist's emotional communication is also affected and restricted by the audience's aesthetic ability. People's aesthetic and appreciation ability have a direct impact on the evaluation of painting. With the development and wide application of digital technology and network, people can obtain a large number of digital painting images through the Internet. Therefore, the aesthetic characteristics of painting images have become a research hotspot. At present, advanced image processing technology provides a theoretical basis and an effective method for aesthetic study of digital painting images and plays important roles in painting study and art protection. To better research the aesthetic characteristics of painting images, this study provides a comprehensive survey and analysis focusing on domestic and international research about painting aesthetics at present. Based on extensive literature research, this study first shows the different representation modes of Chinese and western paintings and analyzes the reason for such differences. This study also summarizes two methods of painting aesthetics, namely, experimental and computational aesthetics, and analyzes the correlation between the two methods. Experimental aesthetics provide abundant knowledge for computational aesthetics and also gains some quantitative information from computational aesthetics. Experimental aesthetics mainly study the specific attributes of works of art and can help us understand how aesthetic perception is related to human vision and how humans perceive the world. In the study of experimental aesthetics of painting images, researchers need to design aesthetic experiments for quantitative evaluation. The experiment mainly includes three steps: 1) preparing the sample set of painting images; 2) observing and evaluating the painting images by subjects; and 3) analyzing and studying the experimental results. The results of experimental aesthetics are mainly statistical data, such as the score of subjects to the painting image, the number and time of gaze, etc. These experimental data can be analyzed by statistical analytical methods, including variance analysis, correlation analysis, and principal component analysis, etc. Comparing with the subjective analysis in experimental aesthetics, the computational aesthetics of painting images are essentially objective, can avoid the influence of subjective will, and analyze detail features in the painting images. The purpose of the computational aesthetics research is to endow computer with the ability to assess the aesthetics value of images as human beings do. They mainly focus on the evaluation of image complexity (complex/uncomplicated), quality (high/low quality), visual preference (beautiful/not beautiful), and author or artistic style of the painting. Researchers can analyze a large number of painting images automatically by computational aesthetics. In the image classification model of computational aesthetics, data sets are generally divided into training and test data. Different capacities of data sets adopt different evaluation methods. Leave-One-Out is often used when the capacity is small, and K-fold cross-validation is used conversely. The evaluation indicators include precision, accuracy rate, recall rate, P-R (precision-recall) curve, F-measure, confusion matrix, and ROC (receiver operating characteristic) curve. This study sums up the painting database commonly used and briefly describes the sources, quantities, and characteristics of different databases. Based on the number of painting samples, the number of subjects, the quantification of aesthetic grade, and the eye movement indices, this study summarizes the status and development of experimental aesthetic research methods of Chinese and western painting. Based on classification category, features, number of painting samples, classification algorithm, and accuracy, this study presents several commonly machine learning algorithms of painting classification (including emotion, complexity, author and style etc.), and summarizes the research status and development of computational aesthetic research methods of Chinese and western painting.in detail. This study briefly reviews the commonly used evaluation methods in analyzing painting image aesthetics and evaluation indices. Finally, this study highlights the existing problems and challenges in the study of painting classification and affective analysis and discusses prospective solutions. Painting image aesthetics is an innovative and challenging research topic, which can be widely applied in the fields of classification of painting images, aesthetic evaluation of painting images, reconstruction and restoration of painting images, and historical and cultural research. Painting is a result of human creativity and pioneering civilization, so many excellent research ideas and methods have emerged. Through the comprehensive and systematic analysis of existing research, this article provides theoretical basis and exploration thoughts for future research on painting.关键词:Chinese and western paintings;experimental aesthetics;computational aesthetics;machine learning;evaluation method76|575|8更新时间:2024-05-07
摘要:Aesthetics has been the subject of long-standing debates by philosophers and psychologists. In psychology, aesthetic experience is due to the interaction among perception, cognition, and emotion. This triad has been experimentally studied in the field of experimental aesthetics to obtain understanding of how aesthetic experience is related to the fundamental principles of human visual perception and brain processes. Recently, researchers in computer vision have gained interest in the topic, giving rise to the field of computational aesthetics. With computing hardware and methodology developing at a high pace, the modeling of perceptually relevant aspect of aesthetic stimuli has a huge potential. In the field of aesthetics, the image aesthetics is a popular issue in recent years. Image processing with computer scientists have, for a long time, attempted to solve image quality assessment and image semantics inference. The former deals primarily with the quantification of low-level perceptual degradation of an image, and the latter attempts to infer the content of an image and associate high level semantics to it in part or in whole. More recently, researchers have drawn ideas from the aforementioned methods to address more challenging problems such as associating pictures with aesthetics and emotions that they arouse in humans, with low-level image composition. Painting image is a kind of artistic work with emotion and aesthetics. By understanding the theme, the painter expresses his inner feelings in painting and passes them on to others. However, the artist's emotional communication is also affected and restricted by the audience's aesthetic ability. People's aesthetic and appreciation ability have a direct impact on the evaluation of painting. With the development and wide application of digital technology and network, people can obtain a large number of digital painting images through the Internet. Therefore, the aesthetic characteristics of painting images have become a research hotspot. At present, advanced image processing technology provides a theoretical basis and an effective method for aesthetic study of digital painting images and plays important roles in painting study and art protection. To better research the aesthetic characteristics of painting images, this study provides a comprehensive survey and analysis focusing on domestic and international research about painting aesthetics at present. Based on extensive literature research, this study first shows the different representation modes of Chinese and western paintings and analyzes the reason for such differences. This study also summarizes two methods of painting aesthetics, namely, experimental and computational aesthetics, and analyzes the correlation between the two methods. Experimental aesthetics provide abundant knowledge for computational aesthetics and also gains some quantitative information from computational aesthetics. Experimental aesthetics mainly study the specific attributes of works of art and can help us understand how aesthetic perception is related to human vision and how humans perceive the world. In the study of experimental aesthetics of painting images, researchers need to design aesthetic experiments for quantitative evaluation. The experiment mainly includes three steps: 1) preparing the sample set of painting images; 2) observing and evaluating the painting images by subjects; and 3) analyzing and studying the experimental results. The results of experimental aesthetics are mainly statistical data, such as the score of subjects to the painting image, the number and time of gaze, etc. These experimental data can be analyzed by statistical analytical methods, including variance analysis, correlation analysis, and principal component analysis, etc. Comparing with the subjective analysis in experimental aesthetics, the computational aesthetics of painting images are essentially objective, can avoid the influence of subjective will, and analyze detail features in the painting images. The purpose of the computational aesthetics research is to endow computer with the ability to assess the aesthetics value of images as human beings do. They mainly focus on the evaluation of image complexity (complex/uncomplicated), quality (high/low quality), visual preference (beautiful/not beautiful), and author or artistic style of the painting. Researchers can analyze a large number of painting images automatically by computational aesthetics. In the image classification model of computational aesthetics, data sets are generally divided into training and test data. Different capacities of data sets adopt different evaluation methods. Leave-One-Out is often used when the capacity is small, and K-fold cross-validation is used conversely. The evaluation indicators include precision, accuracy rate, recall rate, P-R (precision-recall) curve, F-measure, confusion matrix, and ROC (receiver operating characteristic) curve. This study sums up the painting database commonly used and briefly describes the sources, quantities, and characteristics of different databases. Based on the number of painting samples, the number of subjects, the quantification of aesthetic grade, and the eye movement indices, this study summarizes the status and development of experimental aesthetic research methods of Chinese and western painting. Based on classification category, features, number of painting samples, classification algorithm, and accuracy, this study presents several commonly machine learning algorithms of painting classification (including emotion, complexity, author and style etc.), and summarizes the research status and development of computational aesthetic research methods of Chinese and western painting.in detail. This study briefly reviews the commonly used evaluation methods in analyzing painting image aesthetics and evaluation indices. Finally, this study highlights the existing problems and challenges in the study of painting classification and affective analysis and discusses prospective solutions. Painting image aesthetics is an innovative and challenging research topic, which can be widely applied in the fields of classification of painting images, aesthetic evaluation of painting images, reconstruction and restoration of painting images, and historical and cultural research. Painting is a result of human creativity and pioneering civilization, so many excellent research ideas and methods have emerged. Through the comprehensive and systematic analysis of existing research, this article provides theoretical basis and exploration thoughts for future research on painting.关键词:Chinese and western paintings;experimental aesthetics;computational aesthetics;machine learning;evaluation method76|575|8更新时间:2024-05-07
Review
-
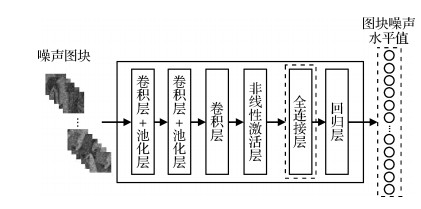 摘要:ObjectiveImage denoising is a fundamental but challenging problem in low-level vision and image processing. Most existing image-denoising methods can be classified as so-called non-blind approaches, which are assumed to work under the premise of the availability of noise level. Thus, their denoising performance highly depends on the accuracy of the noise level fed into them. In practice, however, noise level is always unknown beforehand. As a result, fast and accurate noise level estimation (NLE) is often necessary for blind image denoising. To date, training-based NLE methods using handcrafted features that reflect the distortion level of a noisy image, i.e., noise level-aware features (NLAFs), still suffer from the weak ability of feature description and the low accuracy of nonlinear mapping in NLAF extraction and noise level-mapping modules, respectively. To this end, an NLE algorithm that automatically extracts NLAFs with a convolutional neural network (CNN) and directly maps the NLAFs to their corresponding noise level using AdaBoost backpropagation (BP) neural network was proposed.MethodSubstantially clean images were first corrupted with Gaussian noise at different noise levels to form a set of noisy images. The noisy patches extracted from the noisy images and their corresponding noise levels were then fed into a CNN to train a CNN-based NLE model. However, the CNN-based NLE model directly used to obtain the noise level of a noisy image had poor estimation accuracy. The major reasons were as follows: 1) no strong correlation between most of the output values of the fully connected layer of the CNN-based NLE model and the noise levels, and 2) an inadequate nonlinear mapping ability of the regression layer used to predict noise level in the CNN-based NLE model. Therefore, the correlation between the output values of the fully connected layer and the ground truths was analyzed and then several outputs that had higher correlation coefficient with the ground-truth noise levels were selected as the NLAFs in the form of feature vector. With the support of the AdaBoost technique, multiple BP neural networks with relative weak mapping ability were combined to build a strong nonlinear mapping prediction model, i.e., enhanced BP network, and the obtained prediction model was used to map the extracted NLAFs to their corresponding noise level directly. In the prediction phase, given a noisy image to be denoised, several patches were first randomly extracted and then fed into the trained CNN-based NLE model. Next, several NLAFs were extracted from the fully connected layer of the CNN-based model. The extracted NLAFs were subsequently approximated to corresponding estimated noise levels via the enhanced BP neural network. Finally, the median value of the patch noise levels was taken as the final estimate of the entire image, which could effectively solve the over and underestimation problems and greatly improve the execution efficiency.ResultComparison experiments were conducted to test the validity of the proposed method from three aspects, namely, estimation accuracy, denoising effect, and execution efficiency. The proposed method was compared with several state-of-the-art NLE methods to demonstrate the estimation accuracy. The CNN-based NLE model used to automatically extract NLAFs in this work was also compared. These competing NLE methods were performed on two test image sets, namely, 1) 10 commonly used images, including Cameraman, House, Pepper, Monarch, Plane, Lena, Barbara, Couple, Man, and Boat; and 2) 50 textured images borrowed from the BSD database (different from training). For a fair comparison, all methods were implemented in the environment of MATLAB 2017b, which ran on Inter (R) Core (TM) i7-3770 CPU @ 3.4 GHz RAM 8 GB. For noisy images with different noise levels and texture structures, the estimation error between the noise levels estimated by the proposed method and the ground truths was less than 0.5, and the root mean square error between the noise levels estimated by the proposed method and the ground truths was less than 0.9 across different noise levels (i.e., 5, 15, 35, 55, 75, and 95). These results indicated satisfactory and robust estimation accuracy. In denoising comparison, noise levels different from ones used in the training phase, i.e., 7.5, 17.5, 37.5, 57.5, 77.5, and 97.5, were added to 10 commonly used clean images. The classic benchmark denoising algorithm, block matching and 3D filtering (BM3D), was adopted to restore noisy images of the test set. The peak signal-to-noise ratio results obtained by the BM3D algorithm fed into ground truths and estimated noise levels were nearly equal. The proposed NLE algorithm also had high execution efficiency and took only 13.9 ms to estimate the noise level for an image 512×512 pixels in size.ConclusionExperimental results demonstrate that the proposed NLE algorithm competes efficiently with the reference counterparts across different noise levels and image contents in terms of estimation accuracy and computational complexity. Unlike the previous training-based NLE algorithm with respect to NLAF extraction, the proposed algorithm is purely data-driven and does not rely on handcrafted features or other types of prior domain knowledge. These advantages make the proposed algorithm a preferable candidate for practical denoising. After the proposed NLE method is used as a preprocessing module, non-blind denoising algorithms can obtain good denoising performance when the noise level is required as the key parameter.关键词:noise level estimation (NLE);training-based approach;patch level;noise level-aware feature (NLAF);noise level mapping;median estimation scheme39|55|1更新时间:2024-05-07
摘要:ObjectiveImage denoising is a fundamental but challenging problem in low-level vision and image processing. Most existing image-denoising methods can be classified as so-called non-blind approaches, which are assumed to work under the premise of the availability of noise level. Thus, their denoising performance highly depends on the accuracy of the noise level fed into them. In practice, however, noise level is always unknown beforehand. As a result, fast and accurate noise level estimation (NLE) is often necessary for blind image denoising. To date, training-based NLE methods using handcrafted features that reflect the distortion level of a noisy image, i.e., noise level-aware features (NLAFs), still suffer from the weak ability of feature description and the low accuracy of nonlinear mapping in NLAF extraction and noise level-mapping modules, respectively. To this end, an NLE algorithm that automatically extracts NLAFs with a convolutional neural network (CNN) and directly maps the NLAFs to their corresponding noise level using AdaBoost backpropagation (BP) neural network was proposed.MethodSubstantially clean images were first corrupted with Gaussian noise at different noise levels to form a set of noisy images. The noisy patches extracted from the noisy images and their corresponding noise levels were then fed into a CNN to train a CNN-based NLE model. However, the CNN-based NLE model directly used to obtain the noise level of a noisy image had poor estimation accuracy. The major reasons were as follows: 1) no strong correlation between most of the output values of the fully connected layer of the CNN-based NLE model and the noise levels, and 2) an inadequate nonlinear mapping ability of the regression layer used to predict noise level in the CNN-based NLE model. Therefore, the correlation between the output values of the fully connected layer and the ground truths was analyzed and then several outputs that had higher correlation coefficient with the ground-truth noise levels were selected as the NLAFs in the form of feature vector. With the support of the AdaBoost technique, multiple BP neural networks with relative weak mapping ability were combined to build a strong nonlinear mapping prediction model, i.e., enhanced BP network, and the obtained prediction model was used to map the extracted NLAFs to their corresponding noise level directly. In the prediction phase, given a noisy image to be denoised, several patches were first randomly extracted and then fed into the trained CNN-based NLE model. Next, several NLAFs were extracted from the fully connected layer of the CNN-based model. The extracted NLAFs were subsequently approximated to corresponding estimated noise levels via the enhanced BP neural network. Finally, the median value of the patch noise levels was taken as the final estimate of the entire image, which could effectively solve the over and underestimation problems and greatly improve the execution efficiency.ResultComparison experiments were conducted to test the validity of the proposed method from three aspects, namely, estimation accuracy, denoising effect, and execution efficiency. The proposed method was compared with several state-of-the-art NLE methods to demonstrate the estimation accuracy. The CNN-based NLE model used to automatically extract NLAFs in this work was also compared. These competing NLE methods were performed on two test image sets, namely, 1) 10 commonly used images, including Cameraman, House, Pepper, Monarch, Plane, Lena, Barbara, Couple, Man, and Boat; and 2) 50 textured images borrowed from the BSD database (different from training). For a fair comparison, all methods were implemented in the environment of MATLAB 2017b, which ran on Inter (R) Core (TM) i7-3770 CPU @ 3.4 GHz RAM 8 GB. For noisy images with different noise levels and texture structures, the estimation error between the noise levels estimated by the proposed method and the ground truths was less than 0.5, and the root mean square error between the noise levels estimated by the proposed method and the ground truths was less than 0.9 across different noise levels (i.e., 5, 15, 35, 55, 75, and 95). These results indicated satisfactory and robust estimation accuracy. In denoising comparison, noise levels different from ones used in the training phase, i.e., 7.5, 17.5, 37.5, 57.5, 77.5, and 97.5, were added to 10 commonly used clean images. The classic benchmark denoising algorithm, block matching and 3D filtering (BM3D), was adopted to restore noisy images of the test set. The peak signal-to-noise ratio results obtained by the BM3D algorithm fed into ground truths and estimated noise levels were nearly equal. The proposed NLE algorithm also had high execution efficiency and took only 13.9 ms to estimate the noise level for an image 512×512 pixels in size.ConclusionExperimental results demonstrate that the proposed NLE algorithm competes efficiently with the reference counterparts across different noise levels and image contents in terms of estimation accuracy and computational complexity. Unlike the previous training-based NLE algorithm with respect to NLAF extraction, the proposed algorithm is purely data-driven and does not rely on handcrafted features or other types of prior domain knowledge. These advantages make the proposed algorithm a preferable candidate for practical denoising. After the proposed NLE method is used as a preprocessing module, non-blind denoising algorithms can obtain good denoising performance when the noise level is required as the key parameter.关键词:noise level estimation (NLE);training-based approach;patch level;noise level-aware feature (NLAF);noise level mapping;median estimation scheme39|55|1更新时间:2024-05-07 -
 摘要:ObjectiveWith the development of high-density industrial economy, the air quality gradually declines and haze occurs frequently. Haze is an aerosol system formed by the interaction of human daily life and special climate. Large particles in the air could scatter and absorb light, resulting in image collected degradation, which seriously affects image post-analysis. In general, two kinds of algorithms, namely, physical model image defogging and image enhancement defogging, have been adopted to improve the effect of weather factors on image quality. The former is to construct atmospheric scattering model to compensate distortion and obtain a clear image. The common de-fogging algorithms based on the physical model of atmospheric scattering are dark channel prior de-fogging algorithm and polarization imaging de-fogging algorithm and so on. In the last few years, based on the atmospheric scattering model, experts from all over the world have studied the dark channel priori de-fogging. Based on the dark channel priori principle of image de-fogging, on the one hand, the algorithm cannot keep the edge information of the image in the region where the depth of field changes greatly, and a halo phenomenon occurs in the fog-free image; on the other hand, when the global atmospheric light value is close to the pixel luminance component of the foggy image, the color distortion will occur in the restored image. The latter is achieved by improving the quality of image details according to the characteristics of human vision. The representative algorithms include de-fogging algorithm based on histogram equalization, homomorphic filtering, wavelet transform, Retinex theory, and atmospheric modulation transfer function. The basic idea of histogram equalization-based de-fogging algorithm is to obtain uniform distribution of histogram and increase the contrast of the image. The homomorphic filtering based de-fogging algorithm divides the image into irradiating component and reflection component in the frequency domain and increases the contrast of the image by enhancing the high-frequency information of the image. The fog algorithm based on wavelet transform in time domain and frequency domain transformation locally can effectively extract information from the signal. The de-fogging algorithm based on Retinex theory describes color invariance because it has good effect on dynamic range compression, detail enhancement, color fidelity, and so on. The de-fogging algorithm based on the atmospheric modulation transfer function predicts the corresponding upflow transfer function and aerosol transfer function through the formula, obtains the atmospheric modulation transfer function from the product of the two, and then recovers the degraded image in the frequency domain. The attenuation caused by the atmospheric modulation function is compensated. The MSRCR algorithm considers the ratio between the trichromatic channels of the image, so the color distortion should be eliminated to enhance the local detail to a certainextent.However, the time complexity of the algorithm is high, and the operation is complex. However, the following problems persist: the high light region and the thick foggy areas of the images acquired under the fog condition, the inaccurate transmittance calculation often results in detail loss of restored image, halo phenomenon, and contrast and color that cannot meet human visual characteristics. This paper proposes an image defogging algorithm combining GF-MSRCR with dark channel prior.MethodWeighted quad tree method is adopted to fast search the minimum channel graph to obtain the global atmospheric light value. The GF-MSRCR algorithm is used to preliminarily estimate the transmittance for the image enhancement. According to the dark channel prior theory, the minimum channel graph is estimated again. The pixel fusion is operated on the two above results with a certain proportion to determine the transmittance estimation value, which is further modified by variation function and by median filtering to acquire the precise transmittance value. Finally, the atmospheric scattering model is used to restore the foggy image and obtain haze-removed image with complete contour and clear details after contrast and color correction.ResultA computer with a lab platform of Intel (R) Core (TM) i5-7300HQ CPU @ 2.50 GHz 8 GB RAM is used, and the lab environment is MATLAB R2015b under Windows 10. Four types of fog sky images including close-range, small part sky area, large sky area and white object scene are defogged. Theoretical and experimental results show that on one hand, more edge information and local details in the image could be preserved by the proposed algorithm; moreover, color could be restored with high fidelity. With the aid of modification of variation function on scene transmittance and the smooth and optimization of median filtering, the algorithm could accurately process bright areas, such as sky, and retain more edge details. After the restoration and adjustment of the close-range image, the contrast and hue are well restored. After the image restoration and adjustment in the small sky area, the visual effect is better. After image restoration and adjustment, the contrast and color of sky region are more natural. After the white object image is restored and adjusted, the clarity and color can satisfy the visual characteristics of the human eye. When the proposed algorithm is applied to an image, the subjective visual effect of fog removal becomes evident. Five evaluation indicators, namely, information entropy, contrast, structural similarity, average gradient, and running time, are used to compare the image defogging quality of different algorithms. In particular, the running time obviously decreases by 53.22% with increases in the information entropy by 7.87%, contrast by 21.95%, average gradient by 47.73%, and structural similarity by 15.58%. The algorithm shows good restoration results for scene images containing fog close shot, a small sky area, a large sky area, or white objects.ConclusionThe image dehazing algorithm fusing GF-MSRCR and dark channel prior could quickly and effectively retain image details, eliminate halo, and satisfy human visual characteristics. The algorithm possesses certain practicability and universality. Future research would capture fog images in more complex scenes and restore foggy images.关键词:weighted quad tree;GF-MSRCR;dark channel prior;image fusion;variation function;median filtering145|156|6更新时间:2024-05-07
摘要:ObjectiveWith the development of high-density industrial economy, the air quality gradually declines and haze occurs frequently. Haze is an aerosol system formed by the interaction of human daily life and special climate. Large particles in the air could scatter and absorb light, resulting in image collected degradation, which seriously affects image post-analysis. In general, two kinds of algorithms, namely, physical model image defogging and image enhancement defogging, have been adopted to improve the effect of weather factors on image quality. The former is to construct atmospheric scattering model to compensate distortion and obtain a clear image. The common de-fogging algorithms based on the physical model of atmospheric scattering are dark channel prior de-fogging algorithm and polarization imaging de-fogging algorithm and so on. In the last few years, based on the atmospheric scattering model, experts from all over the world have studied the dark channel priori de-fogging. Based on the dark channel priori principle of image de-fogging, on the one hand, the algorithm cannot keep the edge information of the image in the region where the depth of field changes greatly, and a halo phenomenon occurs in the fog-free image; on the other hand, when the global atmospheric light value is close to the pixel luminance component of the foggy image, the color distortion will occur in the restored image. The latter is achieved by improving the quality of image details according to the characteristics of human vision. The representative algorithms include de-fogging algorithm based on histogram equalization, homomorphic filtering, wavelet transform, Retinex theory, and atmospheric modulation transfer function. The basic idea of histogram equalization-based de-fogging algorithm is to obtain uniform distribution of histogram and increase the contrast of the image. The homomorphic filtering based de-fogging algorithm divides the image into irradiating component and reflection component in the frequency domain and increases the contrast of the image by enhancing the high-frequency information of the image. The fog algorithm based on wavelet transform in time domain and frequency domain transformation locally can effectively extract information from the signal. The de-fogging algorithm based on Retinex theory describes color invariance because it has good effect on dynamic range compression, detail enhancement, color fidelity, and so on. The de-fogging algorithm based on the atmospheric modulation transfer function predicts the corresponding upflow transfer function and aerosol transfer function through the formula, obtains the atmospheric modulation transfer function from the product of the two, and then recovers the degraded image in the frequency domain. The attenuation caused by the atmospheric modulation function is compensated. The MSRCR algorithm considers the ratio between the trichromatic channels of the image, so the color distortion should be eliminated to enhance the local detail to a certainextent.However, the time complexity of the algorithm is high, and the operation is complex. However, the following problems persist: the high light region and the thick foggy areas of the images acquired under the fog condition, the inaccurate transmittance calculation often results in detail loss of restored image, halo phenomenon, and contrast and color that cannot meet human visual characteristics. This paper proposes an image defogging algorithm combining GF-MSRCR with dark channel prior.MethodWeighted quad tree method is adopted to fast search the minimum channel graph to obtain the global atmospheric light value. The GF-MSRCR algorithm is used to preliminarily estimate the transmittance for the image enhancement. According to the dark channel prior theory, the minimum channel graph is estimated again. The pixel fusion is operated on the two above results with a certain proportion to determine the transmittance estimation value, which is further modified by variation function and by median filtering to acquire the precise transmittance value. Finally, the atmospheric scattering model is used to restore the foggy image and obtain haze-removed image with complete contour and clear details after contrast and color correction.ResultA computer with a lab platform of Intel (R) Core (TM) i5-7300HQ CPU @ 2.50 GHz 8 GB RAM is used, and the lab environment is MATLAB R2015b under Windows 10. Four types of fog sky images including close-range, small part sky area, large sky area and white object scene are defogged. Theoretical and experimental results show that on one hand, more edge information and local details in the image could be preserved by the proposed algorithm; moreover, color could be restored with high fidelity. With the aid of modification of variation function on scene transmittance and the smooth and optimization of median filtering, the algorithm could accurately process bright areas, such as sky, and retain more edge details. After the restoration and adjustment of the close-range image, the contrast and hue are well restored. After the image restoration and adjustment in the small sky area, the visual effect is better. After image restoration and adjustment, the contrast and color of sky region are more natural. After the white object image is restored and adjusted, the clarity and color can satisfy the visual characteristics of the human eye. When the proposed algorithm is applied to an image, the subjective visual effect of fog removal becomes evident. Five evaluation indicators, namely, information entropy, contrast, structural similarity, average gradient, and running time, are used to compare the image defogging quality of different algorithms. In particular, the running time obviously decreases by 53.22% with increases in the information entropy by 7.87%, contrast by 21.95%, average gradient by 47.73%, and structural similarity by 15.58%. The algorithm shows good restoration results for scene images containing fog close shot, a small sky area, a large sky area, or white objects.ConclusionThe image dehazing algorithm fusing GF-MSRCR and dark channel prior could quickly and effectively retain image details, eliminate halo, and satisfy human visual characteristics. The algorithm possesses certain practicability and universality. Future research would capture fog images in more complex scenes and restore foggy images.关键词:weighted quad tree;GF-MSRCR;dark channel prior;image fusion;variation function;median filtering145|156|6更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveVisual target tracking is an important issue in machine vision. Its core tasks are to locate the target in a continuous video sequence and estimate the target's motion trajectory. This method has been widely used in many fields, such as human-computer interaction, security monitoring, automatic driving, navigation, and positioning. Through extensive research by domestic and foreign experts in recent years, visual target-tracking technology has gradually matured. However, tracking targets accurately in complex scenes, such as intense illumination change, occlusion, deformation, scale change, and background clutter, remains a challenging task. Visual target-tracking algorithms can be divided into two categories, namely, generative and discriminative tracking methods. Generative tracking converts the tracking problem into the nearest neighbor search task of the target model, constructs the target model by using a template or sparse representation in the subspace, and achieves target tracking by searching for the most similar region in the target model. Discriminant tracking treats the tracking problem as a binary classification problem.The target is separated from the background by training the classifier to achieve target tracking. Given that the generated visual target-tracking algorithm needs to construct a complex target appearance model, its computational complexity is high, and its algorithm has poor real-time performance. Discriminant tracking algorithm uses samples of the target and surrounding background to train a classifier online and achieves target tracking by detecting and tracking. Its classifier obtains considerable background information during training. Thus, this method can distinguish foreground and background better and its performance is generally better than that of the generative tracking method. Correlation-filtering algorithm is an algorithm with better performance than discriminant tracking algorithm. The traditional correlation-filtering algorithm introduces the concept of dense sampling and uses cyclically shifted samples of the base samples as training samples, which greatly improve the classification ability of the filter. The introduction of kernel strategy maps the linear regression problem of the ridge to the nonlinear space and uses the discrete Fourier transform to transform the time-domain calculation into the frequency-domain calculation, which greatly reduces algorithm complexity. Although traditional correlation-filtering algorithm has many advantages, it also has shortcomings.MethodFirst, this algorithm uses false negative samples generated by the cyclic shift to train a classifier, which limits the classifier's classification ability. Second, several incorrect samples (predicted target images) caused by occlusion are used to update the classifier when the target is seriously occluded. With an increase in occlusion time, the classifier will contain considerable noise information and gradually lose discrimination, which causes tracking failure.Aiming to address the above problems, this study proposes a long-term target-tracking algorithm based on a perceptual model. The algorithm introduces the background perceptual strategy to solve the problem of traditional correlation filtering lacking real negative samples and the occlusion-sensing strategy to effectively track the occluded target. The proposed algorithm first increases the number of training samples by enlarging the sampling area. A cropping matrix is then introduced into the algorithm to crop shifted samples and obtain complete and valid samples.This method overcomes the boundary effect problem caused by cyclically shifted samples. A classification pool is subsequently constructed by using the corresponding classifiers of a certain number of frames in the case of no occlusion. In the case of severe occlusion, the optimal classifier is finally selected from the classification pool by minimizing the energy function for redetection to achieve long-term target tracking.ResultThe performance of the proposed algorithm is evaluated by using a public data set. The proposed algorithm has a success rate of 0.990 and an accuracy of 0.988. These values are respectively 2.7% and 2.5% higher than those of the background-aware correlation filter algorithm. The overall success rate and accuracy of the proposed algorithm are considerably higher than those of other algorithms because of the introduction of background and occlusion perception strategies. The tracking accuracy for a single sequence is also higher. However, other algorithms have certain advantages in specific scenarios, and the proposed algorithm does not rank first in the accuracy and success rate of each sequence. The time complexity of the algorithm is slightly higher and the real-time performance is insufficient because of the introduction of perception module.ConclusionExperiments show that the proposed algorithm can accurately track a target under complex conditions, such as severe occlusion, scale change, and target deformation and has certain research value.关键词:target tracking;circular convolution;background perception;heavy occlusion;classification pool17|21|1更新时间:2024-05-07
摘要:ObjectiveVisual target tracking is an important issue in machine vision. Its core tasks are to locate the target in a continuous video sequence and estimate the target's motion trajectory. This method has been widely used in many fields, such as human-computer interaction, security monitoring, automatic driving, navigation, and positioning. Through extensive research by domestic and foreign experts in recent years, visual target-tracking technology has gradually matured. However, tracking targets accurately in complex scenes, such as intense illumination change, occlusion, deformation, scale change, and background clutter, remains a challenging task. Visual target-tracking algorithms can be divided into two categories, namely, generative and discriminative tracking methods. Generative tracking converts the tracking problem into the nearest neighbor search task of the target model, constructs the target model by using a template or sparse representation in the subspace, and achieves target tracking by searching for the most similar region in the target model. Discriminant tracking treats the tracking problem as a binary classification problem.The target is separated from the background by training the classifier to achieve target tracking. Given that the generated visual target-tracking algorithm needs to construct a complex target appearance model, its computational complexity is high, and its algorithm has poor real-time performance. Discriminant tracking algorithm uses samples of the target and surrounding background to train a classifier online and achieves target tracking by detecting and tracking. Its classifier obtains considerable background information during training. Thus, this method can distinguish foreground and background better and its performance is generally better than that of the generative tracking method. Correlation-filtering algorithm is an algorithm with better performance than discriminant tracking algorithm. The traditional correlation-filtering algorithm introduces the concept of dense sampling and uses cyclically shifted samples of the base samples as training samples, which greatly improve the classification ability of the filter. The introduction of kernel strategy maps the linear regression problem of the ridge to the nonlinear space and uses the discrete Fourier transform to transform the time-domain calculation into the frequency-domain calculation, which greatly reduces algorithm complexity. Although traditional correlation-filtering algorithm has many advantages, it also has shortcomings.MethodFirst, this algorithm uses false negative samples generated by the cyclic shift to train a classifier, which limits the classifier's classification ability. Second, several incorrect samples (predicted target images) caused by occlusion are used to update the classifier when the target is seriously occluded. With an increase in occlusion time, the classifier will contain considerable noise information and gradually lose discrimination, which causes tracking failure.Aiming to address the above problems, this study proposes a long-term target-tracking algorithm based on a perceptual model. The algorithm introduces the background perceptual strategy to solve the problem of traditional correlation filtering lacking real negative samples and the occlusion-sensing strategy to effectively track the occluded target. The proposed algorithm first increases the number of training samples by enlarging the sampling area. A cropping matrix is then introduced into the algorithm to crop shifted samples and obtain complete and valid samples.This method overcomes the boundary effect problem caused by cyclically shifted samples. A classification pool is subsequently constructed by using the corresponding classifiers of a certain number of frames in the case of no occlusion. In the case of severe occlusion, the optimal classifier is finally selected from the classification pool by minimizing the energy function for redetection to achieve long-term target tracking.ResultThe performance of the proposed algorithm is evaluated by using a public data set. The proposed algorithm has a success rate of 0.990 and an accuracy of 0.988. These values are respectively 2.7% and 2.5% higher than those of the background-aware correlation filter algorithm. The overall success rate and accuracy of the proposed algorithm are considerably higher than those of other algorithms because of the introduction of background and occlusion perception strategies. The tracking accuracy for a single sequence is also higher. However, other algorithms have certain advantages in specific scenarios, and the proposed algorithm does not rank first in the accuracy and success rate of each sequence. The time complexity of the algorithm is slightly higher and the real-time performance is insufficient because of the introduction of perception module.ConclusionExperiments show that the proposed algorithm can accurately track a target under complex conditions, such as severe occlusion, scale change, and target deformation and has certain research value.关键词:target tracking;circular convolution;background perception;heavy occlusion;classification pool17|21|1更新时间:2024-05-07 -
 摘要:ObjectiveThe development and progress of science and technology have made it possible to obtain numerous images from imaging equipment, the Internet, or image databases and have increased people's requirements for image processing. Consequently, image-processing technology has been deeply, widely, and rapidly developed. Target detection is an important research content in the field of computer vision. Rapid and accurate positioning and recognition of specific targets in uncontrolled natural scenes are vital functional bases of many artificial intelligence application scenes. However, several major difficulties presently exist in the field of target detection. First, many small objects are widely distributed in visual scenes. The existence of these small objects challenges the agility and reliability of detection algorithms. Second, detection accuracy and speed are linked, and many technical bottle necks must be overcome to consider the performance of these two factors. Finally, large-scale model parameters are an important reason restricting the loading of deep network chips. The compression of model size while ensuring detection accuracy is a meaningful and urgent problem. Targets with simple background, sufficient illumination, and no occlusion are relatively easy to detect, whereas targets with mixed background and target, occlusion near the target, excessively weak illumination intensity, or diverse target posture are difficult to detect. In natural scene images, the quality of feature extraction is the key factor to determine the performance of target detection. Decades of research have resulted in a more robust detection algorithm. Deep learning technology in the field of computer vision has also achieved great breakthroughs in recent years. Target detection framework based on deep learning has become the mainstream, and two main branches of target detection algorithms based on candidate regions and regression have been derived. Most of the current detection algorithms use the powerful learning ability of convolutional neural networks (CNNs) to obtain the prior knowledge of the target and perform target detection according to such knowledge. The low-level features of convolutional neural networks are characterized by high resolution ratio, low abstract semantics, limited position information, and lack of representation of features. High-level features are characterized by high identification, low resolution ratio, and a weak ability to detect small-scale targets. Therefore, in this study, the semantic information of context is transmitted by combining high- and low-level feature graphs to make the semantic information complete and evenly distributed.MethodWhile balancing detection speed and accuracy, the multiscale feature graph fusion target detection algorithm in this study takes a single-shot multibox detector (SSD) network structure as the basic network and adds a feature fusion module to obtain feature graphs with rich semantic information and uniform distribution. The speech information of feature graphs on different levels is transmitted from top to bottom by feature fusion structure to reduce the semantic difference among feature graphs at different levels. The original SSD network is first used to extract a feature graph, which is then unified into 256 channels through a 1×1 convolution layer. The spatial resolution of the top-down feature maps is subsequently increased by deconvolution. Hence, the feature graph coming from two directions has the same spatial resolution. Feature graphs in both directions are then fused to obtain feature graphs with complete semantic information and uniform distribution by adding corresponding elements. The fused feature graph is convolved with a 3×3 convolution kernel to reduce the aliasing effect of the fused feature graph. A feature graph with strong semantic information is constructed according to the abovementioned steps, and the details of the original feature graph are retained. Lastly, the predicted bounding boxes are aggregated and non maximum suppression is used to achieve the final detection results.ResultKey problems in the practical application of target detection algorithms and difficult problems in related target detection are analyzed according to the research progress and task requirements of visual target detection-related technology. Current solutions are also given. The target detection algorithm based on multiscale feature graph fusion in this study can achieve good results when dealing with weak targets, multiple targets, messy background, occlusion, and other detection difficulties. Experimental tests are performed on PASCAL VOC 2007 and 2012 data sets. The mean average precision values of the proposed model are 78.9% and 76.7%, which are 1.4 and 0.9 percentage points higher than those of the classical SSD algorithm, respectively. In addition, the method in this paper improves by 8.3% mAP compared with the classical SSD model when detecting small-scale targets. Compared with the classical SSD model, the method proposed in this study significantly improves the detection effect when detecting small-scale targets.ConclusionThe multiscale feature graph fusion target detection algorithm proposed in this study uses convolutional neural network to extract convolutional features instead of the traditional manual feature extraction process, thereby expanding semantic information in a top-down manner and constructing a high-strength semantic feature graph. The model can be used to detect new scene images with strong visual task. In combination with the idea of deep learning convolutional neural network, the convolution feature is used to replace the traditional manual feature, thus avoiding the problem of feature selection in the traditional detection problem. The deep convolution feature has improved expressive ability. The target detection model of multiscale feature map fusion is finally obtained through repeated iteration training on the basis of the SSD network. The detection model has good detection effect for small-scale target detection tasks. While realizing end-to-end training of detection algorithm, the model also improves its robustness to various complex scenes and the accuracy of target detection. Therefore, accurate target detection is achieved. This study provides a general and concise way to solve the problem of small-scale target detection.关键词:computer vision;deep learning;convolutional neural network(CNN);target detection;multiscale characteristic map44|78|9更新时间:2024-05-07
摘要:ObjectiveThe development and progress of science and technology have made it possible to obtain numerous images from imaging equipment, the Internet, or image databases and have increased people's requirements for image processing. Consequently, image-processing technology has been deeply, widely, and rapidly developed. Target detection is an important research content in the field of computer vision. Rapid and accurate positioning and recognition of specific targets in uncontrolled natural scenes are vital functional bases of many artificial intelligence application scenes. However, several major difficulties presently exist in the field of target detection. First, many small objects are widely distributed in visual scenes. The existence of these small objects challenges the agility and reliability of detection algorithms. Second, detection accuracy and speed are linked, and many technical bottle necks must be overcome to consider the performance of these two factors. Finally, large-scale model parameters are an important reason restricting the loading of deep network chips. The compression of model size while ensuring detection accuracy is a meaningful and urgent problem. Targets with simple background, sufficient illumination, and no occlusion are relatively easy to detect, whereas targets with mixed background and target, occlusion near the target, excessively weak illumination intensity, or diverse target posture are difficult to detect. In natural scene images, the quality of feature extraction is the key factor to determine the performance of target detection. Decades of research have resulted in a more robust detection algorithm. Deep learning technology in the field of computer vision has also achieved great breakthroughs in recent years. Target detection framework based on deep learning has become the mainstream, and two main branches of target detection algorithms based on candidate regions and regression have been derived. Most of the current detection algorithms use the powerful learning ability of convolutional neural networks (CNNs) to obtain the prior knowledge of the target and perform target detection according to such knowledge. The low-level features of convolutional neural networks are characterized by high resolution ratio, low abstract semantics, limited position information, and lack of representation of features. High-level features are characterized by high identification, low resolution ratio, and a weak ability to detect small-scale targets. Therefore, in this study, the semantic information of context is transmitted by combining high- and low-level feature graphs to make the semantic information complete and evenly distributed.MethodWhile balancing detection speed and accuracy, the multiscale feature graph fusion target detection algorithm in this study takes a single-shot multibox detector (SSD) network structure as the basic network and adds a feature fusion module to obtain feature graphs with rich semantic information and uniform distribution. The speech information of feature graphs on different levels is transmitted from top to bottom by feature fusion structure to reduce the semantic difference among feature graphs at different levels. The original SSD network is first used to extract a feature graph, which is then unified into 256 channels through a 1×1 convolution layer. The spatial resolution of the top-down feature maps is subsequently increased by deconvolution. Hence, the feature graph coming from two directions has the same spatial resolution. Feature graphs in both directions are then fused to obtain feature graphs with complete semantic information and uniform distribution by adding corresponding elements. The fused feature graph is convolved with a 3×3 convolution kernel to reduce the aliasing effect of the fused feature graph. A feature graph with strong semantic information is constructed according to the abovementioned steps, and the details of the original feature graph are retained. Lastly, the predicted bounding boxes are aggregated and non maximum suppression is used to achieve the final detection results.ResultKey problems in the practical application of target detection algorithms and difficult problems in related target detection are analyzed according to the research progress and task requirements of visual target detection-related technology. Current solutions are also given. The target detection algorithm based on multiscale feature graph fusion in this study can achieve good results when dealing with weak targets, multiple targets, messy background, occlusion, and other detection difficulties. Experimental tests are performed on PASCAL VOC 2007 and 2012 data sets. The mean average precision values of the proposed model are 78.9% and 76.7%, which are 1.4 and 0.9 percentage points higher than those of the classical SSD algorithm, respectively. In addition, the method in this paper improves by 8.3% mAP compared with the classical SSD model when detecting small-scale targets. Compared with the classical SSD model, the method proposed in this study significantly improves the detection effect when detecting small-scale targets.ConclusionThe multiscale feature graph fusion target detection algorithm proposed in this study uses convolutional neural network to extract convolutional features instead of the traditional manual feature extraction process, thereby expanding semantic information in a top-down manner and constructing a high-strength semantic feature graph. The model can be used to detect new scene images with strong visual task. In combination with the idea of deep learning convolutional neural network, the convolution feature is used to replace the traditional manual feature, thus avoiding the problem of feature selection in the traditional detection problem. The deep convolution feature has improved expressive ability. The target detection model of multiscale feature map fusion is finally obtained through repeated iteration training on the basis of the SSD network. The detection model has good detection effect for small-scale target detection tasks. While realizing end-to-end training of detection algorithm, the model also improves its robustness to various complex scenes and the accuracy of target detection. Therefore, accurate target detection is achieved. This study provides a general and concise way to solve the problem of small-scale target detection.关键词:computer vision;deep learning;convolutional neural network(CNN);target detection;multiscale characteristic map44|78|9更新时间:2024-05-07 -
 摘要:ObjectivePerson re-identification (ReID) aims to associate the same pedestrian across multiple cameras. It has attracted rapidly increasing attention in the computer vision community because of its importance for many potential applications, such as video surveillance analysis and content-based image/video retrieval. Person ReID is a challenging task. First, when a single person is captured by different cameras, the illumination conditions, background clutter, occlusion, observable human body parts, and perceived posture of the person can be dramatically different. Second, even within a single camera, the aforementioned conditions can vary through time as the person moves and engages in different actions (e.g., suddenly taking something out of a bag while walking). Third, a gallery itself usually consists of diverse images of a single person from multiple cameras, which, given the above factors, generate high intraclass variation that impedes the generalization of learned representations. Fourth, compared with images in problems such as object recognition or detection, images in person ReID benchmarks are usually of lower resolution, making it difficult to extract distinctive attributes to distinguish one identity from another. The success of deep convolutional networks has introduced powerful representations with high discrimination and robustness for pedestrian images and enhanced the performance of ReID. The combination of global and local features has been an essential solution to improve discriminative performances in person ReID tasks. Previous methods based on local features focused on locating regions with specific predefined semantics, which increased the learning difficulty and did not have robustness for different scenarios. In this study, a multishape part network (MSPN) that has horizontal and vertical strip features as local features is designed. This network can train from end to end.MethodWe carefully design the MSPN, which is a multibranch deep network architecture consisting of one branch for global feature representations and three branches for local feature representations. MSPN no longer learns to locate regions with specific semantics. Instead, the features extracted from images are divided into horizontal and vertical ones. The shape and partition of different branches are different. Local feature information with different granularities is finally obtained. Our network can be compatible with the horizontal and vertical dislocation of different image features of the same pedestrian because of the different directions of partition.ResultComprehensive experiments implemented on mainstream evaluation data sets, including Market-1501, DukeMTMC-ReID, and CUHK03, indicate that our method robustly achieves state-of-the-art performances.ConclusionA pedestrian recognition method based on MSPN, which can obtain a high discriminative representation of different pedestrians, is proposed in this study. The performance of person ReID is improved effectively.关键词:public security;surveillance;person re-identification;convolutional neural network(CNN);deep learning;part local feature15|12|2更新时间:2024-05-07
摘要:ObjectivePerson re-identification (ReID) aims to associate the same pedestrian across multiple cameras. It has attracted rapidly increasing attention in the computer vision community because of its importance for many potential applications, such as video surveillance analysis and content-based image/video retrieval. Person ReID is a challenging task. First, when a single person is captured by different cameras, the illumination conditions, background clutter, occlusion, observable human body parts, and perceived posture of the person can be dramatically different. Second, even within a single camera, the aforementioned conditions can vary through time as the person moves and engages in different actions (e.g., suddenly taking something out of a bag while walking). Third, a gallery itself usually consists of diverse images of a single person from multiple cameras, which, given the above factors, generate high intraclass variation that impedes the generalization of learned representations. Fourth, compared with images in problems such as object recognition or detection, images in person ReID benchmarks are usually of lower resolution, making it difficult to extract distinctive attributes to distinguish one identity from another. The success of deep convolutional networks has introduced powerful representations with high discrimination and robustness for pedestrian images and enhanced the performance of ReID. The combination of global and local features has been an essential solution to improve discriminative performances in person ReID tasks. Previous methods based on local features focused on locating regions with specific predefined semantics, which increased the learning difficulty and did not have robustness for different scenarios. In this study, a multishape part network (MSPN) that has horizontal and vertical strip features as local features is designed. This network can train from end to end.MethodWe carefully design the MSPN, which is a multibranch deep network architecture consisting of one branch for global feature representations and three branches for local feature representations. MSPN no longer learns to locate regions with specific semantics. Instead, the features extracted from images are divided into horizontal and vertical ones. The shape and partition of different branches are different. Local feature information with different granularities is finally obtained. Our network can be compatible with the horizontal and vertical dislocation of different image features of the same pedestrian because of the different directions of partition.ResultComprehensive experiments implemented on mainstream evaluation data sets, including Market-1501, DukeMTMC-ReID, and CUHK03, indicate that our method robustly achieves state-of-the-art performances.ConclusionA pedestrian recognition method based on MSPN, which can obtain a high discriminative representation of different pedestrians, is proposed in this study. The performance of person ReID is improved effectively.关键词:public security;surveillance;person re-identification;convolutional neural network(CNN);deep learning;part local feature15|12|2更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveThe accurate visualization of vocal organs and their movement patterns during pronunciation is crucial for the understanding of pronunciation mechanism, diagnosis and treatment of speech diseases, and human-computer interaction research. As an important vocal organ, the tongue is not completely visible and moves rapidly and flexibly during speaking; therefore, it is difficult to visualize. Advancements in medical imaging technique in recent years have made it possible to capture clear tongue images, thus promoting the development of modeling strategies. Among these strategies, the three most common methods are parametric modeling, physiological modeling, and statistical modeling. Statistical modeling has the advantages of simple calculation, minimal control parameters, fast simulation speed, and strong interpretability and it is suitable for developing a real-time speech training system. However, few studies have applied this method to tongue modeling for Chinese Mandarin pronunciation, and existing statistical models have drawbacks in precision and simulation capabilities. Therefore, this study proposes an improved 3D dynamic control model of the tongue based on statistical modeling for Mandarin vowel-consonant pronunciation.MethodThe control parameters were extracted using statistical modeling based on linear principal component analysis. The model was based on the assumption that the tongue motion and control parameters are linear. First, a representative corpus was established on the basis of tongue shape variation during Mandarin vowel-consonant pronunciation. The corpus included a set of 49 artificially sustained articulations designed to cover the maximal range of Mandarin allophones, namely, 8 vowels, 40 consonants in consonant vowel(CV) sequences, and a rest position. On the basis of the corpus, sagittal volume images of the tongue from one speaker were acquired by magnetic resonance imaging (MRI), and supplementary images of the hard palate, jaw, and teeth were acquired by computed tomography (CT). The images were preprocessed and then the upper and lower jaws in the CT images were filled manually into the MRI. The 3D tongue model composed of the sagittal MRI was segmented horizontally to obtain the corresponding axial slices. According to the distribution of the tongue muscles, a tongue contour-marking method was designed on the basis of a semi-polar grid proposed for the research on tongue. Afterward, the contours of the tongue were manually edited in sagittal and transverse MRI using the designed method to build models described as triangular meshes, which were combined to build full 3D models of the tongue. The 3D surface mesh model of the resting tongue was selected as the reference articulation and then fitted by elastic deformation to each of the 3D sets of planar contours to meet the LCA (linear principal compoment analysis) requirement for the vertices' correspondence in each observation. The vertices of the geometric model were taken as variables, the control parameters were extracted from the midsagittal contours of the models using a statistical method, and the simulation error of these parameters and their contribution to control the overall 3D shape of the tongue were evaluated.ResultA triangular surface mesh tongue model consisting of more than 2 000 vertices was established for Mandarin vowel-consonant pronunciation, and its movement was controlled by six parameters. One parameter affects the tongue rotation around a point of the tongue back, another two respectively control the front-back and flattening-bunching movements of the tongue, and the last three respectively control the upper-lower, front-back, and upper curved movements of the tongue tip. The six parameters were combined, and the 3D tongue model was restructured. The parameters could explain 87.4% of the variance in the tongue, only 2% below the optimal result from a raw principal component analysis with the same number of components. The vertices of the whole 3D model had a reconstruction error of 0.149 cm. The absolute values of the control parameters were compared from the vowel and consonant perspectives. The tongue body has a larger movement for vowel pronunciation, whereas the tip moves more flexibly during consonant pronunciation. The effects of the separameters can be introduced from a biomechanical perspective by analyzing the tongue's motions caused by its various muscles. Compared with the control parameters of a French tongue modeling, a parameter for controlling the tongue tip movement was added to our model, and a parameter for controlling the tongue root was removed to meet the strong dependence of Mandarin pronunciation on the tongue tip. The difference in contribution rate of each control parameter between the two language models was consistent with the characteristics of the tongue movement in each pronunciation.ConclusionThis work produced a number of valuable results. First, a database of 3D geometrical descriptions of the tongue was established for a speaker sustaining a set of 49 Chinese allophones covering the speech possibilities of the subject. Second, LCA of these data revealed that six components could account for approximately 87.4% of the total variance in the tongue shape, the highest value reached compared with those of other languages' statistical models. The method to extract parameters provides the biomechanical interpretation meaning of the parameters. The statistical model is suitable for Chinese tongue modeling, but the steps for parameter extraction must be adjusted according to the pronunciation characteristics of each language to achieve the ideal simulation effect. The method of contrasting the tongue shape change from the perspective of vowels and consonants and from Mandarin and French pronunciations based on control parameter values provides a new way of studying Mandarin pronunciation and comparing different languages.关键词:pronunciation organ visualization;tongue;magnetic resonance imaging (MRI);statistical model;Chinese Mandarin11|4|1更新时间:2024-05-07
摘要:ObjectiveThe accurate visualization of vocal organs and their movement patterns during pronunciation is crucial for the understanding of pronunciation mechanism, diagnosis and treatment of speech diseases, and human-computer interaction research. As an important vocal organ, the tongue is not completely visible and moves rapidly and flexibly during speaking; therefore, it is difficult to visualize. Advancements in medical imaging technique in recent years have made it possible to capture clear tongue images, thus promoting the development of modeling strategies. Among these strategies, the three most common methods are parametric modeling, physiological modeling, and statistical modeling. Statistical modeling has the advantages of simple calculation, minimal control parameters, fast simulation speed, and strong interpretability and it is suitable for developing a real-time speech training system. However, few studies have applied this method to tongue modeling for Chinese Mandarin pronunciation, and existing statistical models have drawbacks in precision and simulation capabilities. Therefore, this study proposes an improved 3D dynamic control model of the tongue based on statistical modeling for Mandarin vowel-consonant pronunciation.MethodThe control parameters were extracted using statistical modeling based on linear principal component analysis. The model was based on the assumption that the tongue motion and control parameters are linear. First, a representative corpus was established on the basis of tongue shape variation during Mandarin vowel-consonant pronunciation. The corpus included a set of 49 artificially sustained articulations designed to cover the maximal range of Mandarin allophones, namely, 8 vowels, 40 consonants in consonant vowel(CV) sequences, and a rest position. On the basis of the corpus, sagittal volume images of the tongue from one speaker were acquired by magnetic resonance imaging (MRI), and supplementary images of the hard palate, jaw, and teeth were acquired by computed tomography (CT). The images were preprocessed and then the upper and lower jaws in the CT images were filled manually into the MRI. The 3D tongue model composed of the sagittal MRI was segmented horizontally to obtain the corresponding axial slices. According to the distribution of the tongue muscles, a tongue contour-marking method was designed on the basis of a semi-polar grid proposed for the research on tongue. Afterward, the contours of the tongue were manually edited in sagittal and transverse MRI using the designed method to build models described as triangular meshes, which were combined to build full 3D models of the tongue. The 3D surface mesh model of the resting tongue was selected as the reference articulation and then fitted by elastic deformation to each of the 3D sets of planar contours to meet the LCA (linear principal compoment analysis) requirement for the vertices' correspondence in each observation. The vertices of the geometric model were taken as variables, the control parameters were extracted from the midsagittal contours of the models using a statistical method, and the simulation error of these parameters and their contribution to control the overall 3D shape of the tongue were evaluated.ResultA triangular surface mesh tongue model consisting of more than 2 000 vertices was established for Mandarin vowel-consonant pronunciation, and its movement was controlled by six parameters. One parameter affects the tongue rotation around a point of the tongue back, another two respectively control the front-back and flattening-bunching movements of the tongue, and the last three respectively control the upper-lower, front-back, and upper curved movements of the tongue tip. The six parameters were combined, and the 3D tongue model was restructured. The parameters could explain 87.4% of the variance in the tongue, only 2% below the optimal result from a raw principal component analysis with the same number of components. The vertices of the whole 3D model had a reconstruction error of 0.149 cm. The absolute values of the control parameters were compared from the vowel and consonant perspectives. The tongue body has a larger movement for vowel pronunciation, whereas the tip moves more flexibly during consonant pronunciation. The effects of the separameters can be introduced from a biomechanical perspective by analyzing the tongue's motions caused by its various muscles. Compared with the control parameters of a French tongue modeling, a parameter for controlling the tongue tip movement was added to our model, and a parameter for controlling the tongue root was removed to meet the strong dependence of Mandarin pronunciation on the tongue tip. The difference in contribution rate of each control parameter between the two language models was consistent with the characteristics of the tongue movement in each pronunciation.ConclusionThis work produced a number of valuable results. First, a database of 3D geometrical descriptions of the tongue was established for a speaker sustaining a set of 49 Chinese allophones covering the speech possibilities of the subject. Second, LCA of these data revealed that six components could account for approximately 87.4% of the total variance in the tongue shape, the highest value reached compared with those of other languages' statistical models. The method to extract parameters provides the biomechanical interpretation meaning of the parameters. The statistical model is suitable for Chinese tongue modeling, but the steps for parameter extraction must be adjusted according to the pronunciation characteristics of each language to achieve the ideal simulation effect. The method of contrasting the tongue shape change from the perspective of vowels and consonants and from Mandarin and French pronunciations based on control parameter values provides a new way of studying Mandarin pronunciation and comparing different languages.关键词:pronunciation organ visualization;tongue;magnetic resonance imaging (MRI);statistical model;Chinese Mandarin11|4|1更新时间:2024-05-07 -
 摘要:ObjectiveWith the fast development of virtual reality technology, determining how to establish virtual scenes rapidly and realistically becomes a bottleneck that restricts the popularization and promotion of virtual reality technology. As an important technical means to solve this problem, 3D reconstruction technology has been applied in many fields, such as ancient building protection and restoration, medical treatment, and tourism. Such technology has been developing continuously in recent years, and its application scenarios have been extended greatly. The scale of data to be processed has also increased substantially, and the accuracy requirements for reconstruction results have continuously increased. In these cases, many problems existing in the traditional methods are exposed. For instance, problems such as poor robustness of initial image pair selection process, inefficient incremental solving process, redundant calculation of bundle adjustment, and errors that remain after model correction are found in the traditional incremental structure from motion algorithm. Accordingly, this study proposes a new incremental structure from motion algorithm (named SFM-Y) based on the foundation called image sequence-based 3D reconstruction.MethodFirst, an improved adaptive outlier-filtering method is proposed to enhance the robustness of the initial image selection in this study. Next, an adaptive threshold estimation model is introduced into our algorithm, and constraints and filter conditions are added to improve the robustness of initial image selection and initial reconstruction to resolve the robustness problem caused by the threshold, which is set manually, used in the RANSAC (random sample consensus) filter process. The constraints include four-point method inspection, wide baseline constraint, and revised five-point outlier culling method. In this way, the initial image pair that is used to perform initial reconstruction is selected with strong robustness. Second, the proposed method processes incremental iterative reconstruction to enrich the point cloud model. In this process, the improved efficient perspective-$n$-point solution method is proposed to improve the computational efficiency and accuracy of the incremental addition process. The solution method combines the idea of weighted refinement and the method of how to reduce a linear system’s algebraic error. We try to give this method a rigorous derivation process to prove that it is an efficient solution to the question of how to accelerate the incremental solution process of the incremental structure from motion algorithm. Finally, an optimized bundling adjustment strategy is used to modify the model, solve the model drift, and revise the re-projection error. In this stage, the integration of graphics is checked by introducing a minimum triangulation angle and performing re-triangulation on the tracks among different projection points. Then, once or twice iterative optimization (including global bundle adjustment, filtering, and re-triangulation process) is executed to ameliorate the result of our algorithm. All the methods mentioned above that we performed or revised work together to complete a common goal, reducing solution time and improving reconstruction quality. ResultAmong all the experiments mentioned in this paper, we select data sets in different data scales first. A comparison and test are then performed among the methods involved in this study to comprehensively and objectively analyze the algorithm performance and acquire a convincing result. Experimental results show that the SFM-Y algorithm improves the computational efficiency and quality of results compared with the traditional incremental motion structure recovery algorithm. The performance analysis and comparison results indicate that the proposed method is more efficient than the traditional method. The reconstruction accuracy yields 10% improvement compared with that of the traditional algorithm referred to in this study.ConclusionAfter a series of analyses, arguments, and experiments, the following conclusions are drawn. Experiments in many databases show that the new incremental motion structure restoration algorithm (SFM-Y) proposed in this study can efficiently and accurately achieve the goal of 3D reconstruction based on image sequences. This algorithm provides a new way of thinking in the field of incremental structure from motion algorithm, which certainly has a positive promoting effect on the development of 3D reconstruction research and has great meaning for the following research and exploration. The proposed algorithm is better than traditional methods and has the advantages of high computational efficiency, strong initial reconstruction robustness, and high quality of the generated model.关键词:incremental structure from motion algorithm;3D reconstruction;image sequence;PNP (perspective-$n$-point) problem;bundle adjustment13|5|0更新时间:2024-05-07
摘要:ObjectiveWith the fast development of virtual reality technology, determining how to establish virtual scenes rapidly and realistically becomes a bottleneck that restricts the popularization and promotion of virtual reality technology. As an important technical means to solve this problem, 3D reconstruction technology has been applied in many fields, such as ancient building protection and restoration, medical treatment, and tourism. Such technology has been developing continuously in recent years, and its application scenarios have been extended greatly. The scale of data to be processed has also increased substantially, and the accuracy requirements for reconstruction results have continuously increased. In these cases, many problems existing in the traditional methods are exposed. For instance, problems such as poor robustness of initial image pair selection process, inefficient incremental solving process, redundant calculation of bundle adjustment, and errors that remain after model correction are found in the traditional incremental structure from motion algorithm. Accordingly, this study proposes a new incremental structure from motion algorithm (named SFM-Y) based on the foundation called image sequence-based 3D reconstruction.MethodFirst, an improved adaptive outlier-filtering method is proposed to enhance the robustness of the initial image selection in this study. Next, an adaptive threshold estimation model is introduced into our algorithm, and constraints and filter conditions are added to improve the robustness of initial image selection and initial reconstruction to resolve the robustness problem caused by the threshold, which is set manually, used in the RANSAC (random sample consensus) filter process. The constraints include four-point method inspection, wide baseline constraint, and revised five-point outlier culling method. In this way, the initial image pair that is used to perform initial reconstruction is selected with strong robustness. Second, the proposed method processes incremental iterative reconstruction to enrich the point cloud model. In this process, the improved efficient perspective-$n$-point solution method is proposed to improve the computational efficiency and accuracy of the incremental addition process. The solution method combines the idea of weighted refinement and the method of how to reduce a linear system’s algebraic error. We try to give this method a rigorous derivation process to prove that it is an efficient solution to the question of how to accelerate the incremental solution process of the incremental structure from motion algorithm. Finally, an optimized bundling adjustment strategy is used to modify the model, solve the model drift, and revise the re-projection error. In this stage, the integration of graphics is checked by introducing a minimum triangulation angle and performing re-triangulation on the tracks among different projection points. Then, once or twice iterative optimization (including global bundle adjustment, filtering, and re-triangulation process) is executed to ameliorate the result of our algorithm. All the methods mentioned above that we performed or revised work together to complete a common goal, reducing solution time and improving reconstruction quality. ResultAmong all the experiments mentioned in this paper, we select data sets in different data scales first. A comparison and test are then performed among the methods involved in this study to comprehensively and objectively analyze the algorithm performance and acquire a convincing result. Experimental results show that the SFM-Y algorithm improves the computational efficiency and quality of results compared with the traditional incremental motion structure recovery algorithm. The performance analysis and comparison results indicate that the proposed method is more efficient than the traditional method. The reconstruction accuracy yields 10% improvement compared with that of the traditional algorithm referred to in this study.ConclusionAfter a series of analyses, arguments, and experiments, the following conclusions are drawn. Experiments in many databases show that the new incremental motion structure restoration algorithm (SFM-Y) proposed in this study can efficiently and accurately achieve the goal of 3D reconstruction based on image sequences. This algorithm provides a new way of thinking in the field of incremental structure from motion algorithm, which certainly has a positive promoting effect on the development of 3D reconstruction research and has great meaning for the following research and exploration. The proposed algorithm is better than traditional methods and has the advantages of high computational efficiency, strong initial reconstruction robustness, and high quality of the generated model.关键词:incremental structure from motion algorithm;3D reconstruction;image sequence;PNP (perspective-$n$-point) problem;bundle adjustment13|5|0更新时间:2024-05-07 -
 摘要:ObjectiveThe dense matching of image pairs is the basis of advanced image-processing technologies, such as vision localization, image fusion, and super-resolution reconstruction. Efficient dense matching results are difficult to obtain because image pairs may be affected by various photographic conditions. Therefore, this study proposes a dense matching method combining density-clustering, smoothing constraint and triangulation.MethodFirst, ORB (oriented FAST and rotated BRIEF) algorithm is used to obtain the sparse matching point set and corresponding point set rapidly. The number of feature points directly arrived at by density in the neighborhood centered on the feature point is screened out by using integral graph. Connection distance, position information, and Euclidean distance are used to perform density estimation clustering, and the feature point pairs in the cluster are expanded by smoothing constraints. The inner point set is thus rapidly obtained. Second, the equal proportion property of triangulation under affine transformation, which plays a key role in the subsequent matching process, is proven. The triangulation is constructed on the basis of the interior point set. The positions of equal proportion points corresponding to the interior of the triangulation in two images to be matched are calculated by using this property, and the similarity of the two triangular regions is checked by the color information of these equal proportion points to purify the interior point set. Finally, the positions of dense matching points are calculated by using the refined interior point set as the final dense matching result.ResultThree pairs of images with large photographic baseline in Mikoalyciz data set were selected for feature point-matching process and fast dense matching algorithm experiments. These groups of images were pairs of images with scaling, repeated texture, and rotation. All experiments were conducted in CPU and 8 GB memory with the main frequency of 3.3 GHz. In the environment of Windows compiler, MATLAB was selected as the development tool. Experimental results showed that the proposed method had the ability to resist rotation, scale change, and repeated texture by analyzing the matching accuracy and efficiency and could estimate local consistency and achieve dense matching of image pairs. The proposed method could also avoid the inaccurate estimation of affine transformation matrix caused by several local outliers and then affect the accuracy of global plane dense matching. The experimental parameters of grid-based motion statistics (GMS) and DeepMatching algorithm were the default values. The empirical values of the density-clustering-smoothing constraint purification interior point algorithm were obtained through considerable experimental experience. The GMS used the mesh-smoothing motion constraint method, although it could complete the local invariant point feature matching while eliminating the outliers, to ensure matching accuracy and improve processing speed. However, this method was restricted by the grid parameters and boundary conditions, which reduced the number of sparse matching points obtained by this method and affected the subsequent dense matching work. The number of sparse matching points was obviously more than that of the GMS matching points. The advantage of DeepMatching algorithm was that it did not depend strongly on continuity constraints and monotonicity. Nevertheless, its time complexity was high and operation time was long because the dense results obtained by each layer were checked step by step by using pyramid architecture. The density of the experimental results was higher than that of DeepMatching matching results, and the interior point purity was higher after smoothing constraints and equal proportional triangulation constraints. Obvious outliers existed in the DeepMatching matching results. The dense matching range of the proposed method was not as wide as that of DeepMatching. Methods with high sparse matching performance (e.g., affine scale-invariant feature transform) can effectively solve this problem owing to the distribution of sparse matching points. The memory and time requirements of the proposed algorithm increased linearly with an increase in image size. The matching time of this method increased slowly. The difference between the processing times of this algorithm and of DeepMatching was increasingly obvious. The accuracy gap between the proposed algorithm and DeepMatching algorithm was also obvious and stable. With the increase in image size to 512, the accuracy of the proposed algorithm reached 0.9 (error 10 pixels). This algorithm was superior to DeepMatching in time efficiency and accuracy. Particularly when dealing with large-scale images, it could guarantee high accuracy and greatly shorten the processing time of dense matching. Therefore, the proposed method not only improved the number of sparse matching points but also enhanced the execution speed, accuracy, and efficiency in processing large-scale images.ConclusionThe experimental results verified the efficiency and practicability of the proposed method. In the future, this method will be integrated into advanced image processing, such as 3D reconstruction and super-resolution reconstruction.关键词:local consistency estimation;dense matching;equal proportion triangulation;affine transformation;smooth constraint13|4|0更新时间:2024-05-07
摘要:ObjectiveThe dense matching of image pairs is the basis of advanced image-processing technologies, such as vision localization, image fusion, and super-resolution reconstruction. Efficient dense matching results are difficult to obtain because image pairs may be affected by various photographic conditions. Therefore, this study proposes a dense matching method combining density-clustering, smoothing constraint and triangulation.MethodFirst, ORB (oriented FAST and rotated BRIEF) algorithm is used to obtain the sparse matching point set and corresponding point set rapidly. The number of feature points directly arrived at by density in the neighborhood centered on the feature point is screened out by using integral graph. Connection distance, position information, and Euclidean distance are used to perform density estimation clustering, and the feature point pairs in the cluster are expanded by smoothing constraints. The inner point set is thus rapidly obtained. Second, the equal proportion property of triangulation under affine transformation, which plays a key role in the subsequent matching process, is proven. The triangulation is constructed on the basis of the interior point set. The positions of equal proportion points corresponding to the interior of the triangulation in two images to be matched are calculated by using this property, and the similarity of the two triangular regions is checked by the color information of these equal proportion points to purify the interior point set. Finally, the positions of dense matching points are calculated by using the refined interior point set as the final dense matching result.ResultThree pairs of images with large photographic baseline in Mikoalyciz data set were selected for feature point-matching process and fast dense matching algorithm experiments. These groups of images were pairs of images with scaling, repeated texture, and rotation. All experiments were conducted in CPU and 8 GB memory with the main frequency of 3.3 GHz. In the environment of Windows compiler, MATLAB was selected as the development tool. Experimental results showed that the proposed method had the ability to resist rotation, scale change, and repeated texture by analyzing the matching accuracy and efficiency and could estimate local consistency and achieve dense matching of image pairs. The proposed method could also avoid the inaccurate estimation of affine transformation matrix caused by several local outliers and then affect the accuracy of global plane dense matching. The experimental parameters of grid-based motion statistics (GMS) and DeepMatching algorithm were the default values. The empirical values of the density-clustering-smoothing constraint purification interior point algorithm were obtained through considerable experimental experience. The GMS used the mesh-smoothing motion constraint method, although it could complete the local invariant point feature matching while eliminating the outliers, to ensure matching accuracy and improve processing speed. However, this method was restricted by the grid parameters and boundary conditions, which reduced the number of sparse matching points obtained by this method and affected the subsequent dense matching work. The number of sparse matching points was obviously more than that of the GMS matching points. The advantage of DeepMatching algorithm was that it did not depend strongly on continuity constraints and monotonicity. Nevertheless, its time complexity was high and operation time was long because the dense results obtained by each layer were checked step by step by using pyramid architecture. The density of the experimental results was higher than that of DeepMatching matching results, and the interior point purity was higher after smoothing constraints and equal proportional triangulation constraints. Obvious outliers existed in the DeepMatching matching results. The dense matching range of the proposed method was not as wide as that of DeepMatching. Methods with high sparse matching performance (e.g., affine scale-invariant feature transform) can effectively solve this problem owing to the distribution of sparse matching points. The memory and time requirements of the proposed algorithm increased linearly with an increase in image size. The matching time of this method increased slowly. The difference between the processing times of this algorithm and of DeepMatching was increasingly obvious. The accuracy gap between the proposed algorithm and DeepMatching algorithm was also obvious and stable. With the increase in image size to 512, the accuracy of the proposed algorithm reached 0.9 (error 10 pixels). This algorithm was superior to DeepMatching in time efficiency and accuracy. Particularly when dealing with large-scale images, it could guarantee high accuracy and greatly shorten the processing time of dense matching. Therefore, the proposed method not only improved the number of sparse matching points but also enhanced the execution speed, accuracy, and efficiency in processing large-scale images.ConclusionThe experimental results verified the efficiency and practicability of the proposed method. In the future, this method will be integrated into advanced image processing, such as 3D reconstruction and super-resolution reconstruction.关键词:local consistency estimation;dense matching;equal proportion triangulation;affine transformation;smooth constraint13|4|0更新时间:2024-05-07 -
 摘要:ObjectiveFish-eye lens is an ideal optical sensor to develop light and small omnidirectional vision systems. Due to the characteristics of large field of view and low cost, it is widely used in various places such as security monitoring. Based on a large number of original fisheye video materials, it has the potential for in-depth research and full exploitation. Therefore, the calibration of fisheye cameras needs to obtain the internal parameters of the images. How to improve the indoor and outdoor aspects of the city is imperative. The calibration efficiency of model fisheye camera is a valuable and challenging research work. However, due to the limitation of short focal length, large field of view and special optical principle, fish-eye images will produce serious barrel distortion, which is not conducive to the subsequent development and application of video images. Constraints of optical principle it is expected to be transformed into plane perspective projection, which conforms to human visual habits, by a set of high-precision parameters associated with the optical imaging model of the fish-eye lens. To this end, a high-precision and flexible method for calibrating the internal parameters of fish-eye lens is proposed in this study.MethodThe calibration is achieved through the following steps: Firstly, we need to obtain the initial internal parameters of fisheye image. According to the principle that the spatial line is imaged as an elliptic curve on the image, we extract the image elliptic curve. The specific methods are as follows: a) obtain the coordinates of the curve points on the image by image segmentation, b) obtain the general curve equation of the ellipse by curve fitting, than decompose the general equation into the ellipse long and short axis length and image principal point used as initial value. Secondly, ideal projection ellipse constraints (IPECs) for any space line on the horizontal plane under spherical perspective projection are mathematically set. The constraints are as follows: a) the half length of the long axis of projection ellipse of different space straight lines is constantly equal to the radius of the projection sphere; and b) the length ratio of long axis to short axis of the projection ellipse is constant for any one space line when the radius of the projection sphere is changed. Thirdly, a nonlinear function is built on the basis of the proposed IPECs and the strict geometric properties of ellipses to conduct an iterative least square estimation for the uncalibrated fish-eye lens parameters, namely, focal length f, aspect ratio
摘要:ObjectiveFish-eye lens is an ideal optical sensor to develop light and small omnidirectional vision systems. Due to the characteristics of large field of view and low cost, it is widely used in various places such as security monitoring. Based on a large number of original fisheye video materials, it has the potential for in-depth research and full exploitation. Therefore, the calibration of fisheye cameras needs to obtain the internal parameters of the images. How to improve the indoor and outdoor aspects of the city is imperative. The calibration efficiency of model fisheye camera is a valuable and challenging research work. However, due to the limitation of short focal length, large field of view and special optical principle, fish-eye images will produce serious barrel distortion, which is not conducive to the subsequent development and application of video images. Constraints of optical principle it is expected to be transformed into plane perspective projection, which conforms to human visual habits, by a set of high-precision parameters associated with the optical imaging model of the fish-eye lens. To this end, a high-precision and flexible method for calibrating the internal parameters of fish-eye lens is proposed in this study.MethodThe calibration is achieved through the following steps: Firstly, we need to obtain the initial internal parameters of fisheye image. According to the principle that the spatial line is imaged as an elliptic curve on the image, we extract the image elliptic curve. The specific methods are as follows: a) obtain the coordinates of the curve points on the image by image segmentation, b) obtain the general curve equation of the ellipse by curve fitting, than decompose the general equation into the ellipse long and short axis length and image principal point used as initial value. Secondly, ideal projection ellipse constraints (IPECs) for any space line on the horizontal plane under spherical perspective projection are mathematically set. The constraints are as follows: a) the half length of the long axis of projection ellipse of different space straight lines is constantly equal to the radius of the projection sphere; and b) the length ratio of long axis to short axis of the projection ellipse is constant for any one space line when the radius of the projection sphere is changed. Thirdly, a nonlinear function is built on the basis of the proposed IPECs and the strict geometric properties of ellipses to conduct an iterative least square estimation for the uncalibrated fish-eye lens parameters, namely, focal length f, aspect ratio$A$ $k$ $k$ $k$ $k$ 关键词:fish-eye lens calibration;fish-eye camera calibration;fish-eye image correction;spherical perspective projection;ideal projection ellipse constraint11|4|1更新时间:2024-05-07 -
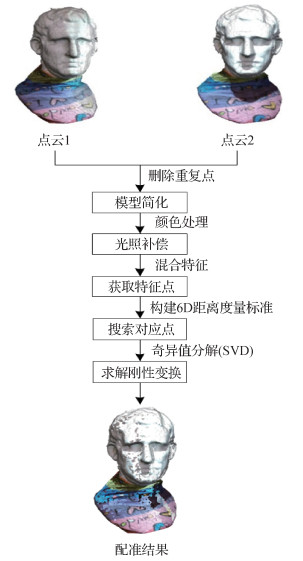 摘要:ObjectiveDigital restoration of historical cultural relics, simulation of medical equipment and human organs, and virtual teaching reflect that 3D reconstruction technology plays an extremely important role in the development level of human society. However, in 3Dreconstruction, geometric data in the RGB-D (RGB Depth) data collected by a depth camera have low quality and high noise. In 3D point cloud registration, the features of geometric data obtained from such low-quality and high-noise data are the only means to obtain an accurate registration result of the point cloud. However, the point cloud registration effect is not particularly obvious. Given that point cloud noise interference is relatively large and geometric information is unclear, which has a non-negligible effect on the registration accuracy. Color information is introduced to increase the feature information of the model. However, when the model data are collected by as canning device, the color is greatly affected by a change in illumination, and the model surface is affected by changes in illumination intensity and angle of view. These effects lead to an obvious color change and inevitable interference. In this study, an RGB-D point cloud registration method based on illumination compensation is proposed that considers 3D point cloud color information as susceptible to illumination conditions.MethodThe color data of the model surface consist of the product of illumination and reflection components. The illuminance component varies with spatial position and displays low-frequency information, where as the reflected component has various texture details visible to the human eye and expresses high-frequency information. The brightness of low-frequency information of color is suppressed when combined with homomorphic filtering, the amount of high-frequency information is enhanced, the influence of color changes by illumination is eliminated, and the consistency of color information is improved. RGB-D data acquired by a Kinect device must be sorted to form a linear point sequence. The color and geometric features of the model are acquired and weighted into a mixed feature to define the feature points of the source point cloud, and the K-nearest neighbor algorithm is used to search for the corresponding points. The singular value decomposition algorithm is used to obtain a rigid transformation matrix.ResultThrough experiments, data are collected from four models at different light intensities using Kinect scanning equipment. The experimental categories comprise three sets, namely, strong light and low light, left light and right light, and strong light and side light. Our method is compared with the traditional iterative closest point (ICP), super four-point congruent set(Super 4PCS), 4D ICP (hue + ICP) combined with hue and geometry information, and blending of geometric and color information. In the course of the experiments, the iteration running time, number of iterations, and average distance error of scale-invariant feature transform (SIFT) feature points are used as the evaluation criteria for the registration experiment results. The effects of different light intensity models after registration by each algorithm are also shown for comparison. Results according to the traditional ICP algorithm, the combination of depth information and hue, and the model registration experiment of different light intensity combinations on the David model with uniform mesh surface show that the times are relatively flat; the average running times are 8.920 s, 8.796 s, and 5.191 s; and the average errors of feature point matching are 3.677, 3.102, and 1.029, respectively. Registration time and average error of feature point matching are improved by approximately 50%. On the Archimedes model with inconsistent mesh surface irregularities, the number of iterations is undistinguishable. The average running times of the registration are 6.926 s, 3.955 s and 3.853 s, and the average errors of feature point matching are 26.718, 27.653, and 28.843, respectively. On the barrel model with smooth mesh surface, the average running times of registration are 0.509 s, 1.937 s and 0.691 s, and the average errors of feature point matching are 23.830, 22.820, and 3.931, respectively. On the barrel model with smooth mesh surface and the Archimedes model with inconsistent mesh surface irregularities, the average error of feature point matching is reduced to one-sixth and one-eighth of the comparison method. This study also compares the Super 4PCS and color point cloud registration algorithms under different combined illumination intensities. Of the four mesh structure models, the average distance error of SIFT feature points of the proposed algorithm is the lowest. The full-distance reduction is reduced to one-fifth of the comparison method, which proves that the proposed algorithm has stability in the model registration of different illumination intensities. This study further conducts correlation experiments on the missing point cloud model and proves that the algorithm can deal with the problem of point cloud registration with missing points. When the overlap rate of two point clouds is approximately 40%, the algorithm registration in this study can achieve better results.ConclusionHomomorphic filtering algorithm is used to suppress the influence of illumination changes, and the consistency of color information is improved. The interference of uneven illumination intensity on 3D point cloud registration accuracy is eliminated. The registration method is verified by comparing it with other correlation registration algorithms. The method has obvious advantages in algorithm stability and registration accuracy.关键词:RGB-D data;light compensation;HSV space;homomorphic filtering;mixed characteristics;point cloud registration15|7|4更新时间:2024-05-07
摘要:ObjectiveDigital restoration of historical cultural relics, simulation of medical equipment and human organs, and virtual teaching reflect that 3D reconstruction technology plays an extremely important role in the development level of human society. However, in 3Dreconstruction, geometric data in the RGB-D (RGB Depth) data collected by a depth camera have low quality and high noise. In 3D point cloud registration, the features of geometric data obtained from such low-quality and high-noise data are the only means to obtain an accurate registration result of the point cloud. However, the point cloud registration effect is not particularly obvious. Given that point cloud noise interference is relatively large and geometric information is unclear, which has a non-negligible effect on the registration accuracy. Color information is introduced to increase the feature information of the model. However, when the model data are collected by as canning device, the color is greatly affected by a change in illumination, and the model surface is affected by changes in illumination intensity and angle of view. These effects lead to an obvious color change and inevitable interference. In this study, an RGB-D point cloud registration method based on illumination compensation is proposed that considers 3D point cloud color information as susceptible to illumination conditions.MethodThe color data of the model surface consist of the product of illumination and reflection components. The illuminance component varies with spatial position and displays low-frequency information, where as the reflected component has various texture details visible to the human eye and expresses high-frequency information. The brightness of low-frequency information of color is suppressed when combined with homomorphic filtering, the amount of high-frequency information is enhanced, the influence of color changes by illumination is eliminated, and the consistency of color information is improved. RGB-D data acquired by a Kinect device must be sorted to form a linear point sequence. The color and geometric features of the model are acquired and weighted into a mixed feature to define the feature points of the source point cloud, and the K-nearest neighbor algorithm is used to search for the corresponding points. The singular value decomposition algorithm is used to obtain a rigid transformation matrix.ResultThrough experiments, data are collected from four models at different light intensities using Kinect scanning equipment. The experimental categories comprise three sets, namely, strong light and low light, left light and right light, and strong light and side light. Our method is compared with the traditional iterative closest point (ICP), super four-point congruent set(Super 4PCS), 4D ICP (hue + ICP) combined with hue and geometry information, and blending of geometric and color information. In the course of the experiments, the iteration running time, number of iterations, and average distance error of scale-invariant feature transform (SIFT) feature points are used as the evaluation criteria for the registration experiment results. The effects of different light intensity models after registration by each algorithm are also shown for comparison. Results according to the traditional ICP algorithm, the combination of depth information and hue, and the model registration experiment of different light intensity combinations on the David model with uniform mesh surface show that the times are relatively flat; the average running times are 8.920 s, 8.796 s, and 5.191 s; and the average errors of feature point matching are 3.677, 3.102, and 1.029, respectively. Registration time and average error of feature point matching are improved by approximately 50%. On the Archimedes model with inconsistent mesh surface irregularities, the number of iterations is undistinguishable. The average running times of the registration are 6.926 s, 3.955 s and 3.853 s, and the average errors of feature point matching are 26.718, 27.653, and 28.843, respectively. On the barrel model with smooth mesh surface, the average running times of registration are 0.509 s, 1.937 s and 0.691 s, and the average errors of feature point matching are 23.830, 22.820, and 3.931, respectively. On the barrel model with smooth mesh surface and the Archimedes model with inconsistent mesh surface irregularities, the average error of feature point matching is reduced to one-sixth and one-eighth of the comparison method. This study also compares the Super 4PCS and color point cloud registration algorithms under different combined illumination intensities. Of the four mesh structure models, the average distance error of SIFT feature points of the proposed algorithm is the lowest. The full-distance reduction is reduced to one-fifth of the comparison method, which proves that the proposed algorithm has stability in the model registration of different illumination intensities. This study further conducts correlation experiments on the missing point cloud model and proves that the algorithm can deal with the problem of point cloud registration with missing points. When the overlap rate of two point clouds is approximately 40%, the algorithm registration in this study can achieve better results.ConclusionHomomorphic filtering algorithm is used to suppress the influence of illumination changes, and the consistency of color information is improved. The interference of uneven illumination intensity on 3D point cloud registration accuracy is eliminated. The registration method is verified by comparing it with other correlation registration algorithms. The method has obvious advantages in algorithm stability and registration accuracy.关键词:RGB-D data;light compensation;HSV space;homomorphic filtering;mixed characteristics;point cloud registration15|7|4更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveSurface modeling is an important research content of computer-aided geometric design, architectural geometry, and computer graphics. The diagonal curve of the tensor product surface is an important tool to measure surface properties. In the aspect of modeling design, people have various requirements for the diagonal curves and boundary curves of a surface. People want to optimize the boundary of the entire surface through the special boundary curves and determine the overall shape of the surface by designing one or two diagonal curves. Therefore, constructing a surface based on the boundary and diagonal curves given by the user is important. The diagonal curve of the Bézier surface is related to its geometry. The method of surface design based on the input diagonal curve will have certain value in practical applications. Bézier surface modeling based on diagonal curve has been rarely published.MethodIn this paper, the Bézier surface construction method is investigated for given diagonal and boundary curves. The method is mainly divided into the case of a diagonal curve and the case of two diagonal curves. The information of the curves needs to be corrected to achieve an ideal shape. The Lagrange multiplier method is mainly used in the correction. In the case of a given diagonal curve, first, the users input the diagonal and boundary curves of the surface according to their personal requirement. The sum of the distances of the control points is taken as the objective function to ensure the minimum deviation between the modified diagonal curve and the boundary curves and the curves given by the user. The relationship between the diagonal curve and the boundary curve is used as the constraint condition, and the geometric information of the diagonal curve and the boundary curve input by the user is corrected. We then use the modified curve as the diagonal and boundary curves in subsequent surface construction. The internal control points to be determined are set as the independent variable by using Lagrangian multiplier method. The three internal energy functions of the surface (bending energy function, quasi-harmonic energy function and Dirichlet energy function) are taken as the objective function. The linear relationship between the control points of the diagonal curve and the surface is taken as the constraint condition. We convert a conditionally restricted extreme value problem to an extreme value problem without conditions. According to the modified diagonal and boundary curves, we determine the extremum of the internal energy function and find the relationship that the internal control points should satisfy and solve the internal control points. Finally, the surface is constructed from the modified boundary curves, the modified diagonal curves, and the obtained internal control points. In the case of two given diagonal curves, they must have an intersection. According to this condition, the correction of the control points of the diagonal curve is added. The sum of the distances of the control points is taken as the objective function to ensure that the deviation between the modified diagonal curve and the user-defined diagonal curve is minimized. We correct the diagonal curve given by the user. In a similar way as the previous case, we correct the geometric information of the two diagonal and boundary curves.ResultWe design three- and four-order surface modeling examples to satisfy the requirements of different minimal internal energy and verify the effectiveness of the surface construction method. By giving a diagonal curve or two diagonal curves, we design modeling examples to verify the practicality of the method. The examples of surface modeling with the same boundary and different degrees are also designed. These examples show that the higher the order of the surface is, the closer the corrected boundary and diagonal curves are to the boundary and diagonal curves given by the user and the smaller the deviation will be. Compared with other surface modeling methods, the proposed method considers the constraint condition of the diagonal curve of the surface, which satisfies the requirements of the user on the diagonal curve, and is closer to the user's design intention. The proposed method can be widely used in practical engineering.ConclusionThe surface constructed not only interpolates the modified diagonal curves and boundary curves but also has minimal internal energy. The proposed surface construction method is simple and practical and satisfies the relevant requirements of surface modeling.关键词:surface modeling;diagonal curve;Lagrangian multiplier method;bending energy;quasi-harmonic energy;Dirichlet energy16|49|0更新时间:2024-05-07
摘要:ObjectiveSurface modeling is an important research content of computer-aided geometric design, architectural geometry, and computer graphics. The diagonal curve of the tensor product surface is an important tool to measure surface properties. In the aspect of modeling design, people have various requirements for the diagonal curves and boundary curves of a surface. People want to optimize the boundary of the entire surface through the special boundary curves and determine the overall shape of the surface by designing one or two diagonal curves. Therefore, constructing a surface based on the boundary and diagonal curves given by the user is important. The diagonal curve of the Bézier surface is related to its geometry. The method of surface design based on the input diagonal curve will have certain value in practical applications. Bézier surface modeling based on diagonal curve has been rarely published.MethodIn this paper, the Bézier surface construction method is investigated for given diagonal and boundary curves. The method is mainly divided into the case of a diagonal curve and the case of two diagonal curves. The information of the curves needs to be corrected to achieve an ideal shape. The Lagrange multiplier method is mainly used in the correction. In the case of a given diagonal curve, first, the users input the diagonal and boundary curves of the surface according to their personal requirement. The sum of the distances of the control points is taken as the objective function to ensure the minimum deviation between the modified diagonal curve and the boundary curves and the curves given by the user. The relationship between the diagonal curve and the boundary curve is used as the constraint condition, and the geometric information of the diagonal curve and the boundary curve input by the user is corrected. We then use the modified curve as the diagonal and boundary curves in subsequent surface construction. The internal control points to be determined are set as the independent variable by using Lagrangian multiplier method. The three internal energy functions of the surface (bending energy function, quasi-harmonic energy function and Dirichlet energy function) are taken as the objective function. The linear relationship between the control points of the diagonal curve and the surface is taken as the constraint condition. We convert a conditionally restricted extreme value problem to an extreme value problem without conditions. According to the modified diagonal and boundary curves, we determine the extremum of the internal energy function and find the relationship that the internal control points should satisfy and solve the internal control points. Finally, the surface is constructed from the modified boundary curves, the modified diagonal curves, and the obtained internal control points. In the case of two given diagonal curves, they must have an intersection. According to this condition, the correction of the control points of the diagonal curve is added. The sum of the distances of the control points is taken as the objective function to ensure that the deviation between the modified diagonal curve and the user-defined diagonal curve is minimized. We correct the diagonal curve given by the user. In a similar way as the previous case, we correct the geometric information of the two diagonal and boundary curves.ResultWe design three- and four-order surface modeling examples to satisfy the requirements of different minimal internal energy and verify the effectiveness of the surface construction method. By giving a diagonal curve or two diagonal curves, we design modeling examples to verify the practicality of the method. The examples of surface modeling with the same boundary and different degrees are also designed. These examples show that the higher the order of the surface is, the closer the corrected boundary and diagonal curves are to the boundary and diagonal curves given by the user and the smaller the deviation will be. Compared with other surface modeling methods, the proposed method considers the constraint condition of the diagonal curve of the surface, which satisfies the requirements of the user on the diagonal curve, and is closer to the user's design intention. The proposed method can be widely used in practical engineering.ConclusionThe surface constructed not only interpolates the modified diagonal curves and boundary curves but also has minimal internal energy. The proposed surface construction method is simple and practical and satisfies the relevant requirements of surface modeling.关键词:surface modeling;diagonal curve;Lagrangian multiplier method;bending energy;quasi-harmonic energy;Dirichlet energy16|49|0更新时间:2024-05-07
Computer Graphics
-
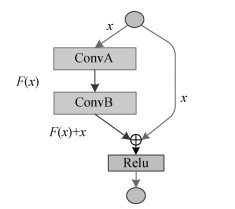 摘要:ObjectiveCNN (convolution neural network) shows excellent performance in the field of brain magnetic resonance image segmentation because of its ability to extract the deep information features of the image. However, the majority of deep learning methods have the problems of too many parameters and inaccurate result of edge segmentation. To overcome these problems, this study proposes a multi-channel fusion separable convolution neural network (MFSCNN).MethodFirst, the weight of the brain structure and its edge pixels are increased in the training set to make the network acquire numerous features of the brain structure and its edge in training. The network is also forced to learn how to segment the edge part of the brain structure to improve the accuracy of the entire brain structure segmentation. Second, the residual unit is introduced to allow the network to transfer the derivative back to the network by jumping connections between the layers of the residual network. While deepening the network, the gradient dispersion can be avoided, which makes up for the lack of information loss in information transmission. The deep separable convolution is used to replace the original convolution layer, and the depth is used to replace the width. Without changing the number of characteristic channels in each stage of the network, the number of network parameters, the number of network training parameters, the training cost, and the training time of the network are reduced. Finally, the feature information of different stages is merged, and the channel is shuffled to obtain the enhanced information features containing deep and shallow information. The features are then placed into the network for training. The input feature information of each stage is richer, the learning feature is faster, and the convergence is faster; so the performance of the brain image segmentation based on the network is obviously improved. Content of main experiment and result For IBSR data sets, the results of MFSCNN are compared with those of ordinary convolutional neural network model (CNN), neural network model with residual unit (ResCNN), and neural network model with local full connection (DenseCNN). The network structure is divided into four stages, and each stage is a specific unit. In training and testing, 75% of the samples are selected as training set and 25% as test set. Dice and IOU (intersection cver union) values are used to measure the accuracy of image segmentation. Dice value can measure the similarity between the segmentation and gold standard results. IOU value reflects the coincidence degree between the segmentation and gold standard results. The results of MFSCNN are significantly higher than those of CNN. In the complex part of the edge, the performance of segmentation is improved obviously. The Dice and IOU are increased by 0.9%6.6% and 1.3%9.7% respectively. In the edge smoothing part, MFSCNN is better than the deep network ResCNN and DenseCNN in terms of the segmentation effect. Moreover, the parameters of MFSCNN are only 50% of ResCNN and 28% of DenseCNN, which not only improves the segmentation performance but also reduces the computational complexity and training time. Comparisons with reviewed research. In the performance on the IBSR, Hammer67n20, and LPBA40, the segmentation results of MFSCNN are better than those of other existing methods. MFSCNN is more prominent in the segmentation of the hippocampus. Compared with commonly used segmentation software FIRST and FreeSurfer, the average Dice values of the putamen and caudate nucleus are increased by 3.4% and 8%, respectively. For the popular methods, the values of Brainsegnet and MSCNN+LC (label consistenay) are increased by 1.6%4.4% and 2.6%2.7%, respectively.ConclusionThe proposed MFSCNN method can form a friendly initialization training set for brain structure segmentation by increasing the weight of the interested brain structure and its edge pixels in the training set. When training the network, the deep separable convolution structure is used instead of the original convolution layer, thereby reducing the amount of network training parameters. The feature maps of each stage are merged, and the channels are shuffled to obtain enhanced information features containing deep and shallow information, thereby improving the accuracy of network model segmentation. MFSCNN not only solves the problem of inaccurate segmentation of complex edges of the brain structure by traditional CNN but also improves the inaccurate segmentation of the lateral edges of the brain structure by ResCNN and DenseCNN. In addition, for different data sets, accurate segmentation results of MR brain images can be obtained. Meanings: The regional contrast of MR image is low, and the gray value of each structure is similar. Therefore, fusion information can be extracted directly from MR image by the proposed MFSCNN method and further applied to other MR image segmentation. Although MFSCNN achieves good results for deep brain structure segmentation, the accuracy of segmentation for the discontinuous part of the brain structure still needs to be improved mainly because of the complex and discontinuous types of pixels on the edges of these parts. Therefore, how to extract features that can segment complex edge contours by using deep convolution network is a problem that needs to be studied in the future.关键词:subcortical brain MR image segmentation;convolution neural network(CNN);depthwise separable convolution;multi-channel fusion;channel shuffle17|54|3更新时间:2024-05-07
摘要:ObjectiveCNN (convolution neural network) shows excellent performance in the field of brain magnetic resonance image segmentation because of its ability to extract the deep information features of the image. However, the majority of deep learning methods have the problems of too many parameters and inaccurate result of edge segmentation. To overcome these problems, this study proposes a multi-channel fusion separable convolution neural network (MFSCNN).MethodFirst, the weight of the brain structure and its edge pixels are increased in the training set to make the network acquire numerous features of the brain structure and its edge in training. The network is also forced to learn how to segment the edge part of the brain structure to improve the accuracy of the entire brain structure segmentation. Second, the residual unit is introduced to allow the network to transfer the derivative back to the network by jumping connections between the layers of the residual network. While deepening the network, the gradient dispersion can be avoided, which makes up for the lack of information loss in information transmission. The deep separable convolution is used to replace the original convolution layer, and the depth is used to replace the width. Without changing the number of characteristic channels in each stage of the network, the number of network parameters, the number of network training parameters, the training cost, and the training time of the network are reduced. Finally, the feature information of different stages is merged, and the channel is shuffled to obtain the enhanced information features containing deep and shallow information. The features are then placed into the network for training. The input feature information of each stage is richer, the learning feature is faster, and the convergence is faster; so the performance of the brain image segmentation based on the network is obviously improved. Content of main experiment and result For IBSR data sets, the results of MFSCNN are compared with those of ordinary convolutional neural network model (CNN), neural network model with residual unit (ResCNN), and neural network model with local full connection (DenseCNN). The network structure is divided into four stages, and each stage is a specific unit. In training and testing, 75% of the samples are selected as training set and 25% as test set. Dice and IOU (intersection cver union) values are used to measure the accuracy of image segmentation. Dice value can measure the similarity between the segmentation and gold standard results. IOU value reflects the coincidence degree between the segmentation and gold standard results. The results of MFSCNN are significantly higher than those of CNN. In the complex part of the edge, the performance of segmentation is improved obviously. The Dice and IOU are increased by 0.9%6.6% and 1.3%9.7% respectively. In the edge smoothing part, MFSCNN is better than the deep network ResCNN and DenseCNN in terms of the segmentation effect. Moreover, the parameters of MFSCNN are only 50% of ResCNN and 28% of DenseCNN, which not only improves the segmentation performance but also reduces the computational complexity and training time. Comparisons with reviewed research. In the performance on the IBSR, Hammer67n20, and LPBA40, the segmentation results of MFSCNN are better than those of other existing methods. MFSCNN is more prominent in the segmentation of the hippocampus. Compared with commonly used segmentation software FIRST and FreeSurfer, the average Dice values of the putamen and caudate nucleus are increased by 3.4% and 8%, respectively. For the popular methods, the values of Brainsegnet and MSCNN+LC (label consistenay) are increased by 1.6%4.4% and 2.6%2.7%, respectively.ConclusionThe proposed MFSCNN method can form a friendly initialization training set for brain structure segmentation by increasing the weight of the interested brain structure and its edge pixels in the training set. When training the network, the deep separable convolution structure is used instead of the original convolution layer, thereby reducing the amount of network training parameters. The feature maps of each stage are merged, and the channels are shuffled to obtain enhanced information features containing deep and shallow information, thereby improving the accuracy of network model segmentation. MFSCNN not only solves the problem of inaccurate segmentation of complex edges of the brain structure by traditional CNN but also improves the inaccurate segmentation of the lateral edges of the brain structure by ResCNN and DenseCNN. In addition, for different data sets, accurate segmentation results of MR brain images can be obtained. Meanings: The regional contrast of MR image is low, and the gray value of each structure is similar. Therefore, fusion information can be extracted directly from MR image by the proposed MFSCNN method and further applied to other MR image segmentation. Although MFSCNN achieves good results for deep brain structure segmentation, the accuracy of segmentation for the discontinuous part of the brain structure still needs to be improved mainly because of the complex and discontinuous types of pixels on the edges of these parts. Therefore, how to extract features that can segment complex edge contours by using deep convolution network is a problem that needs to be studied in the future.关键词:subcortical brain MR image segmentation;convolution neural network(CNN);depthwise separable convolution;multi-channel fusion;channel shuffle17|54|3更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveUnlike conventional remote sensing images, hyperspectral images are composed of hundreds of spectral channels with extremely high spectral resolution, and each spectral channel holds an image of a specific spectral range. These spectral channels provide rich spectral information that distinguishes object species. The information provides effective technical feasibility for the analysis and processing of imaging targets, thereby enabling hyperspectral images in military, environment, mapping, agriculture, and disaster prevention. The field of hyperspectral image processing has a wide range of applications. Among them, hyperspectral image classification is one of the key tasks in the field. Hyperspectral images have numerous bands, narrow bandwidths, wide spectral response range, and high resolution. Moreover, these images provide spatial domain information, spectral domain information (i.e., spectral image integration), and large amounts of data but redundant information. Noise and the distribution of various types of ground objects are uneven. The deep learning method based on neural networks has become a popular trend of machine learning, and it is also the same in the classification of features of hyperspectral images. However, problems, such as the training needs of neural networks remain in the deep learning method based on neural networks. The amount of data is large, the training process requires a graphics processing unit acceleration card, neural network-based models are sensitive to hyperparameter setting, and the mobility of the models is poor. Noise in the spectral channels and imbalanced sample distribution of various ground objects usually cause many problems when classifying hyperspectral images. For example, classification accuracy and training efficiency are usually unbalanced, and the classification accuracy of small-sized samples is relatively low. To address the problems mentioned above, this study proposes a novel classification method for hyperspectral images based on cascade multiple classifiers.MethodFirst, highly correlated high-dimensional features are converted into independent low-dimensional features by principal component analysis, which will accelerate Gabor filters for texture feature extraction in the next step. Then, Gabor filters are used to extract image texture information in multiple scales and directions. Each Gabor filter generates one feature map. In the feature map, a
摘要:ObjectiveUnlike conventional remote sensing images, hyperspectral images are composed of hundreds of spectral channels with extremely high spectral resolution, and each spectral channel holds an image of a specific spectral range. These spectral channels provide rich spectral information that distinguishes object species. The information provides effective technical feasibility for the analysis and processing of imaging targets, thereby enabling hyperspectral images in military, environment, mapping, agriculture, and disaster prevention. The field of hyperspectral image processing has a wide range of applications. Among them, hyperspectral image classification is one of the key tasks in the field. Hyperspectral images have numerous bands, narrow bandwidths, wide spectral response range, and high resolution. Moreover, these images provide spatial domain information, spectral domain information (i.e., spectral image integration), and large amounts of data but redundant information. Noise and the distribution of various types of ground objects are uneven. The deep learning method based on neural networks has become a popular trend of machine learning, and it is also the same in the classification of features of hyperspectral images. However, problems, such as the training needs of neural networks remain in the deep learning method based on neural networks. The amount of data is large, the training process requires a graphics processing unit acceleration card, neural network-based models are sensitive to hyperparameter setting, and the mobility of the models is poor. Noise in the spectral channels and imbalanced sample distribution of various ground objects usually cause many problems when classifying hyperspectral images. For example, classification accuracy and training efficiency are usually unbalanced, and the classification accuracy of small-sized samples is relatively low. To address the problems mentioned above, this study proposes a novel classification method for hyperspectral images based on cascade multiple classifiers.MethodFirst, highly correlated high-dimensional features are converted into independent low-dimensional features by principal component analysis, which will accelerate Gabor filters for texture feature extraction in the next step. Then, Gabor filters are used to extract image texture information in multiple scales and directions. Each Gabor filter generates one feature map. In the feature map, a$ d $ $ d $ 关键词:hyperspectral image;Gabor filter;cascaded multi-classifier;principal component analysis(PCA);spectral-spatial joint feature;small samples23|18|1更新时间:2024-05-07 -
 摘要:ObjectiveWith the growing national economy and the increasing demand for the quantity and quality of fruits, satisfying the degree of mastery of fruit farmers' information on large-scale orchards has been difficult for traditional field research methods. Hence, determining how to accurately obtain the same fruit types in different fruit types and different mature states in high-resolution remote sensing orchard images by using remote sensing methods and image-processing methods to obtain orchard distribution and fruit growth information in a timely and rapid manner has become a research focus. Improving the classification accuracy rate effectively is conducive to the dynamic monitoring of large-scale orchard, which has far-reaching significance for promoting the sustainable development of the Chinese fruit industry. In recent years, combining artificial intelligence collection and analysis of high-resolution crop remote sensing images to analyze crop distribution, growth, and parameters has become an important field of agricultural technology development. Sample collection, image data preprocessing, image classification, and sample analysis from crop land data are cumbersome data-mining processes. Traditional machine-learning algorithms are widely used in data-preprocessing stages and image classification. Using traditional threshold segmentation algorithms can effectively classify different fruit types, and wavelet algorithm, support vector machine algorithm, and random forest algorithm as good classifiers can greatly improve the classification accuracy. When neural networks are once again valued and deeply explored, a series of networks, such as convolutional neural networks, deep confidence networks, and adversarial networks, is applied in image classification, segmentation, and recognition. The depth-mining ability of image feature information can be used to obtain a complete feature space effectively. Data with complete feature space and label are easy to be learned by computers to obtain training models, which greatly improve classification accuracy. High-resolution remote sensing image recognition technology, which focuses on crop planting, mechanization, and manorization, has been widely used in crop classification. Using superior depth-learning algorithms to mine high-resolution crop image information is beneficial for the efficient analysis of crop growth and parameter prediction.MethodAtrous convolution is more advantageous than other convolutional networks. It can mine detailed underlying feature information, but can easily cause overfitting and feature redundancy because substantial information space needs to be considered. Popular learning algorithms can effectively perform features. Preliminary classification extracts the feature space that is most conducive to deep learning classification. The depth-separable network and the porous space pyramid can be regarded as feature-encoding processes, and the upsampling process constitutes the backend decoding process. In this study, an improved deep neural network (DeepLab) high-resolution orchard remote sensing image segmentation algorithm is proposed. First, the polarization characteristics of the original data, the features based on coherent decomposition, and the features based on incoherent decomposition are used to form a high-dimensional feature space. Then, the popular learning dimension reduction method is used to obtain the optimal three-channel feature vector to form a pseudo-color map, and a depth separable network (xception), a cavity convolution network (atrous convolution), atrous spatial pyramid pooling (ASPP), and upsample are adopted to build the encoder-decoder of DeepLab. Finally, the pseudo-color training set and the label are imported into the constructed DeepLab to train and save the model, which can be used to effectively classify the target data.ResultThe proposed algorithm can be used to classify five types of fruits, namely, mango, phase Ⅱ mango, phase Ⅲ mango, betel nut, and longan, in a certain area of Hainan, China. The error rate of the same fruit classification for different periods decreases by approximately 8% according to the high-resolution image feature information-learning process of mango, betel nut, and longan. Compared with the traditional orchard classification algorithm, the proposed algorithm presents increased kappa coefficient by approximately 0.1 and improved overall classification accuracy to some extent. The proposed algorithm not only has considerable effects on different types of fruit classification but also a more accurate sample division effect in different periods of the same fruit.ConclusionThe algorithm improves the classification accuracy of the same type of fruit in different periods on the basis of preserving the classification accuracy of different types of fruits. The accuracy of crop growth analysis is improved to a certain extent, and the reliability of high-resolution orchard data analysis is ensured. The DeepLab network is advancing to high-resolution data classification. This network can be feasibly applied to determine the status of rice development in different periods in the future because of its superiority in the analysis of different maturity states of the same species. The health of large areas of rice can be monitored.关键词:high resolution;atrous convolution;deep learning;porous space pyramid;depth separable network14|4|0更新时间:2024-05-07
摘要:ObjectiveWith the growing national economy and the increasing demand for the quantity and quality of fruits, satisfying the degree of mastery of fruit farmers' information on large-scale orchards has been difficult for traditional field research methods. Hence, determining how to accurately obtain the same fruit types in different fruit types and different mature states in high-resolution remote sensing orchard images by using remote sensing methods and image-processing methods to obtain orchard distribution and fruit growth information in a timely and rapid manner has become a research focus. Improving the classification accuracy rate effectively is conducive to the dynamic monitoring of large-scale orchard, which has far-reaching significance for promoting the sustainable development of the Chinese fruit industry. In recent years, combining artificial intelligence collection and analysis of high-resolution crop remote sensing images to analyze crop distribution, growth, and parameters has become an important field of agricultural technology development. Sample collection, image data preprocessing, image classification, and sample analysis from crop land data are cumbersome data-mining processes. Traditional machine-learning algorithms are widely used in data-preprocessing stages and image classification. Using traditional threshold segmentation algorithms can effectively classify different fruit types, and wavelet algorithm, support vector machine algorithm, and random forest algorithm as good classifiers can greatly improve the classification accuracy. When neural networks are once again valued and deeply explored, a series of networks, such as convolutional neural networks, deep confidence networks, and adversarial networks, is applied in image classification, segmentation, and recognition. The depth-mining ability of image feature information can be used to obtain a complete feature space effectively. Data with complete feature space and label are easy to be learned by computers to obtain training models, which greatly improve classification accuracy. High-resolution remote sensing image recognition technology, which focuses on crop planting, mechanization, and manorization, has been widely used in crop classification. Using superior depth-learning algorithms to mine high-resolution crop image information is beneficial for the efficient analysis of crop growth and parameter prediction.MethodAtrous convolution is more advantageous than other convolutional networks. It can mine detailed underlying feature information, but can easily cause overfitting and feature redundancy because substantial information space needs to be considered. Popular learning algorithms can effectively perform features. Preliminary classification extracts the feature space that is most conducive to deep learning classification. The depth-separable network and the porous space pyramid can be regarded as feature-encoding processes, and the upsampling process constitutes the backend decoding process. In this study, an improved deep neural network (DeepLab) high-resolution orchard remote sensing image segmentation algorithm is proposed. First, the polarization characteristics of the original data, the features based on coherent decomposition, and the features based on incoherent decomposition are used to form a high-dimensional feature space. Then, the popular learning dimension reduction method is used to obtain the optimal three-channel feature vector to form a pseudo-color map, and a depth separable network (xception), a cavity convolution network (atrous convolution), atrous spatial pyramid pooling (ASPP), and upsample are adopted to build the encoder-decoder of DeepLab. Finally, the pseudo-color training set and the label are imported into the constructed DeepLab to train and save the model, which can be used to effectively classify the target data.ResultThe proposed algorithm can be used to classify five types of fruits, namely, mango, phase Ⅱ mango, phase Ⅲ mango, betel nut, and longan, in a certain area of Hainan, China. The error rate of the same fruit classification for different periods decreases by approximately 8% according to the high-resolution image feature information-learning process of mango, betel nut, and longan. Compared with the traditional orchard classification algorithm, the proposed algorithm presents increased kappa coefficient by approximately 0.1 and improved overall classification accuracy to some extent. The proposed algorithm not only has considerable effects on different types of fruit classification but also a more accurate sample division effect in different periods of the same fruit.ConclusionThe algorithm improves the classification accuracy of the same type of fruit in different periods on the basis of preserving the classification accuracy of different types of fruits. The accuracy of crop growth analysis is improved to a certain extent, and the reliability of high-resolution orchard data analysis is ensured. The DeepLab network is advancing to high-resolution data classification. This network can be feasibly applied to determine the status of rice development in different periods in the future because of its superiority in the analysis of different maturity states of the same species. The health of large areas of rice can be monitored.关键词:high resolution;atrous convolution;deep learning;porous space pyramid;depth separable network14|4|0更新时间:2024-05-07 -
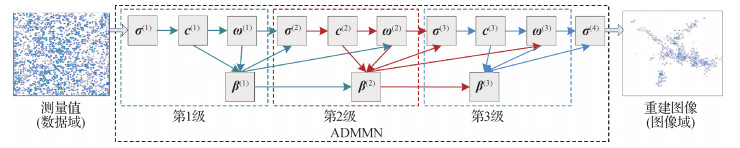 摘要:ObjectiveTraditional inverse synthetic aperture radar (ISAR) imaging uses the range-Doppler (RD) method. Compressive sensing (CS)-based ISAR imaging method that appeared in the last decade can obtain imaging results with high image contrast (IC) and minimal sidelobe interference using few undersampled data. However, the imaging quality and application of the CS ISAR imaging method are limited by the performance of the sparse representation of the target scene and the time-consuming iteration reconstruction. An alternating direction method of multipliers network (ADMMN)-based ISAR imaging method is proposed in this study to improve the image reconstruction quality and efficiency of CS ISAR imaging.MethodADMMN is a model-driven deep neural network (MDDNN) constructed by mapping the iterative steps of the alternating direction method of multipliers (ADMM) algorithm into the architecture of MDDNN. This network architecture can be explicitly expressed in terms of polynomials, which facilitate the generation of an accurate imaging network. The convex optimizing iterative solution process is mapped to a multi-level deep neural network (DNN) according to the strategy of splitting variables adopted by the ADMM algorithm to solve a CS ISAR imaging model under sparse assumption and construct the ADMMN. The network consists of four hidden layers, namely, reconstruction layer, transformation dictionary layer, nonlinear transformation layer, and multiplier update layer. The reconstruction layer is used for ISAR image reconstruction, the transformation dictionary layer is used to extract the sparse representation of the ISAR image, the nonlinear transformation layer is used to obtain the nonlinear characteristics of the ISAR image, and the multiplier update layer is used to update the Lagrange multiplier. ADMMN is trained to learn the mapping relationship between undersampled ISAR measurements and high-quality target images to realize ISAR undersampled data imaging. The target image is the well-focused ISAR image obtained by performing the RD algorithm on ISAR echo data matrix, and the measured data are obtained by 2D random down-sampling in range and cross-range dimensions after pulse compression and motion compensation on ISAR echo data. We use two types of metrics to provide a quantitative evaluation of the imaging performance of the proposed imaging method. One type of metrics is the "true-value"-based metrics, and the other is the conventional metrics for evaluating image quality, in which a high-quality image reconstructed is used via a conventional RD method on full data as the "true-value" image. The metrics used in "true-value"-based evaluation are as follows: false alarm (FA), missed detection (MD), and relative root mean square error (RRMSE). FA denotes the number of scatterers that are reconstructed in the image but are not present in the reference image. MD denotes the number of scatterers that are not reconstructed in the newly generated image but are reconstructed in the reference image. RRMSE measures the reconstruction error of the amplitude of the scatterers. The conventional metrics for evaluating the image quality are target-to-clutter ratio, entropy of the image, and IC.ResultSimulation satellite data and measured aircraft data are adopted in the experiment. The sampling rates of the two data are 25% and 10%, respectively. Experimental results show that compared with the traditional CS ISAR reconstruction algorithms of orthogonal matching pursuit (OMP) and greedy Kalman filtering (GKF), the ADMMN imaging method can more accurately reconstruct scattering points in the target area, with clearer target contour and fewer false scattering points in the background. The ADMMN imaging method is also better than the OMP and GKF imaging methods in terms of imaging quality evaluation metrics. In simulation satellite data-imaging experiments, compared with OMP and GKF, ADMMN decreases FA by 8.9% and 5%, MD by 61.7% and 59.4%, and RRMSE by 49.8% and 26.5%, respectively. In measured aircraft data-imaging experiments, compared with OMP and GKF, ADMMN decreases FA by 81.1% and 88.9%, MD by 34.3% and 31.6%, and RRMSE by 68.7% and 74.9%, respectively. This study further uses simulation satellite data to train ADMMN and applies the trained ADMMN to the measured aircraft data imaging to verify whether ADMMN strongly depends on prior information, that is, whether training and imaging data are required to be the same type of target data. Satellite and aircraft data are sampled at a rate of 10%. Experimental results show that the ADMMN trained by satellite training data and the ADMMN trained by aircraft training data can image 10% of the aircraft target measurement data; in other words, the wing and fuselage parts of the aircraft can be reconstructed efficiently.ConclusionIn this study, a new ADMMN is constructed, and an ISAR imaging method based on ADMMN is proposed. ADMMN utilizes the ability of the ADMM algorithm to solve sparse imaging problems and DNN's powerful learning ability. After learning, ADMMN can construct the best mapping between undersampled measurement data and high-quality images. Experimental results show that the proposed ISAR imaging method based on ADMMN can obtain good imaging results when using 10% of random undersampled data, and the network training does not depend strongly on the prior information of the same type of target. Compared with the traditional CS reconstruction algorithms of OMP and GKF, the ADMMN imaging method has a more complete target contour and more accurate scatter location reconstruction. In addition, the proposed imaging method has high computational efficiency and can meet the requirements of real-time processing, though it requires a certain number of training samples for pretraining. The next steps to analyze the influence of training data on the imaging network thoroughly and enhance the stability of the method are to simulate the electromagnetic scattering of the main ISAR targets, construct abundant simulation training samples for ADMMN training, and verify the performance of ADMMN with the measured data to optimize the ADMMN.关键词:imaging;compressive sensing (CS);inverse synthetic aperture radar (ISAR);convex optimization;deep neural network (DNN);deep alternating direction method of multipliers network (ADMMN)12|4|0更新时间:2024-05-07
摘要:ObjectiveTraditional inverse synthetic aperture radar (ISAR) imaging uses the range-Doppler (RD) method. Compressive sensing (CS)-based ISAR imaging method that appeared in the last decade can obtain imaging results with high image contrast (IC) and minimal sidelobe interference using few undersampled data. However, the imaging quality and application of the CS ISAR imaging method are limited by the performance of the sparse representation of the target scene and the time-consuming iteration reconstruction. An alternating direction method of multipliers network (ADMMN)-based ISAR imaging method is proposed in this study to improve the image reconstruction quality and efficiency of CS ISAR imaging.MethodADMMN is a model-driven deep neural network (MDDNN) constructed by mapping the iterative steps of the alternating direction method of multipliers (ADMM) algorithm into the architecture of MDDNN. This network architecture can be explicitly expressed in terms of polynomials, which facilitate the generation of an accurate imaging network. The convex optimizing iterative solution process is mapped to a multi-level deep neural network (DNN) according to the strategy of splitting variables adopted by the ADMM algorithm to solve a CS ISAR imaging model under sparse assumption and construct the ADMMN. The network consists of four hidden layers, namely, reconstruction layer, transformation dictionary layer, nonlinear transformation layer, and multiplier update layer. The reconstruction layer is used for ISAR image reconstruction, the transformation dictionary layer is used to extract the sparse representation of the ISAR image, the nonlinear transformation layer is used to obtain the nonlinear characteristics of the ISAR image, and the multiplier update layer is used to update the Lagrange multiplier. ADMMN is trained to learn the mapping relationship between undersampled ISAR measurements and high-quality target images to realize ISAR undersampled data imaging. The target image is the well-focused ISAR image obtained by performing the RD algorithm on ISAR echo data matrix, and the measured data are obtained by 2D random down-sampling in range and cross-range dimensions after pulse compression and motion compensation on ISAR echo data. We use two types of metrics to provide a quantitative evaluation of the imaging performance of the proposed imaging method. One type of metrics is the "true-value"-based metrics, and the other is the conventional metrics for evaluating image quality, in which a high-quality image reconstructed is used via a conventional RD method on full data as the "true-value" image. The metrics used in "true-value"-based evaluation are as follows: false alarm (FA), missed detection (MD), and relative root mean square error (RRMSE). FA denotes the number of scatterers that are reconstructed in the image but are not present in the reference image. MD denotes the number of scatterers that are not reconstructed in the newly generated image but are reconstructed in the reference image. RRMSE measures the reconstruction error of the amplitude of the scatterers. The conventional metrics for evaluating the image quality are target-to-clutter ratio, entropy of the image, and IC.ResultSimulation satellite data and measured aircraft data are adopted in the experiment. The sampling rates of the two data are 25% and 10%, respectively. Experimental results show that compared with the traditional CS ISAR reconstruction algorithms of orthogonal matching pursuit (OMP) and greedy Kalman filtering (GKF), the ADMMN imaging method can more accurately reconstruct scattering points in the target area, with clearer target contour and fewer false scattering points in the background. The ADMMN imaging method is also better than the OMP and GKF imaging methods in terms of imaging quality evaluation metrics. In simulation satellite data-imaging experiments, compared with OMP and GKF, ADMMN decreases FA by 8.9% and 5%, MD by 61.7% and 59.4%, and RRMSE by 49.8% and 26.5%, respectively. In measured aircraft data-imaging experiments, compared with OMP and GKF, ADMMN decreases FA by 81.1% and 88.9%, MD by 34.3% and 31.6%, and RRMSE by 68.7% and 74.9%, respectively. This study further uses simulation satellite data to train ADMMN and applies the trained ADMMN to the measured aircraft data imaging to verify whether ADMMN strongly depends on prior information, that is, whether training and imaging data are required to be the same type of target data. Satellite and aircraft data are sampled at a rate of 10%. Experimental results show that the ADMMN trained by satellite training data and the ADMMN trained by aircraft training data can image 10% of the aircraft target measurement data; in other words, the wing and fuselage parts of the aircraft can be reconstructed efficiently.ConclusionIn this study, a new ADMMN is constructed, and an ISAR imaging method based on ADMMN is proposed. ADMMN utilizes the ability of the ADMM algorithm to solve sparse imaging problems and DNN's powerful learning ability. After learning, ADMMN can construct the best mapping between undersampled measurement data and high-quality images. Experimental results show that the proposed ISAR imaging method based on ADMMN can obtain good imaging results when using 10% of random undersampled data, and the network training does not depend strongly on the prior information of the same type of target. Compared with the traditional CS reconstruction algorithms of OMP and GKF, the ADMMN imaging method has a more complete target contour and more accurate scatter location reconstruction. In addition, the proposed imaging method has high computational efficiency and can meet the requirements of real-time processing, though it requires a certain number of training samples for pretraining. The next steps to analyze the influence of training data on the imaging network thoroughly and enhance the stability of the method are to simulate the electromagnetic scattering of the main ISAR targets, construct abundant simulation training samples for ADMMN training, and verify the performance of ADMMN with the measured data to optimize the ADMMN.关键词:imaging;compressive sensing (CS);inverse synthetic aperture radar (ISAR);convex optimization;deep neural network (DNN);deep alternating direction method of multipliers network (ADMMN)12|4|0更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0