
最新刊期
卷 24 , 期 10 , 2019
-
 摘要:The visual simulation of crowd emergency evacuation is a method that uses agents to simulate individuals with autonomous perceptions, emotions, and behavioral abilities. With 3D visual means, it can visualize the emergency evacuation scenarios of the crowd. This study summarizes the research progress from the sources of crowd simulation data, the construction of the crowd navigation and behavior models, the crowd emotional contagion, and the crowd rendering. This study also discusses issues that must be studied from the perspective of the verifiability of the simulation model, the construction of the crowd evacuation navigation model and the physical model of humans and environments, the animal evacuation experiment and simulation, the social behavior of evacuation, and the visual calculation of crowd emotions. For the problems that must be studied in depth, results are as follows. The video surveillance analysis of emergency events and the user survey of virtual crowd scenarios can be used to improve the crowd simulation model. The analysis of animal evacuation experiments can improve the crowd navigation algorithm. The social behavior model can describe the diversity of the crowd evacuation behaviors in further details. The calculation method based on multichannel perceptions can describe the process of emotional contagion in further details. Visual simulation research on crowd emergency evacuation behaviors has important application prospects in the management of urban safety. However, numerous problems remain to be solved in this field. The comprehensive application of multidisciplinary knowledge and the improvement of experimental methods are the keys for future studies.关键词:crowd emergency evacuation;visual simulation;emotion contagion;crowd behavior;crowd navigation16|75|1更新时间:2024-05-07
摘要:The visual simulation of crowd emergency evacuation is a method that uses agents to simulate individuals with autonomous perceptions, emotions, and behavioral abilities. With 3D visual means, it can visualize the emergency evacuation scenarios of the crowd. This study summarizes the research progress from the sources of crowd simulation data, the construction of the crowd navigation and behavior models, the crowd emotional contagion, and the crowd rendering. This study also discusses issues that must be studied from the perspective of the verifiability of the simulation model, the construction of the crowd evacuation navigation model and the physical model of humans and environments, the animal evacuation experiment and simulation, the social behavior of evacuation, and the visual calculation of crowd emotions. For the problems that must be studied in depth, results are as follows. The video surveillance analysis of emergency events and the user survey of virtual crowd scenarios can be used to improve the crowd simulation model. The analysis of animal evacuation experiments can improve the crowd navigation algorithm. The social behavior model can describe the diversity of the crowd evacuation behaviors in further details. The calculation method based on multichannel perceptions can describe the process of emotional contagion in further details. Visual simulation research on crowd emergency evacuation behaviors has important application prospects in the management of urban safety. However, numerous problems remain to be solved in this field. The comprehensive application of multidisciplinary knowledge and the improvement of experimental methods are the keys for future studies.关键词:crowd emergency evacuation;visual simulation;emotion contagion;crowd behavior;crowd navigation16|75|1更新时间:2024-05-07
Scholar View

-
 摘要:Sensor-based smoke detection techniques have been widely used in industrial applications. With the development of artificial intelligence, especially the successful commercial application of deep learning, the number of cases in which computer vision-based techniques are applied to smoke detection for fire alarm has increased. Computer vision techniques have not been used as substitutes of sensors in smoke detection systems because of frequent false and missed alarm. By improving computer capability and storage devices, several shortcomings in traditional video smoke detection have been improved or even solved, but these improvements are accompanied with new challenges. To keep up with the development of and latest research on smoke recognition, detection, and segmentation, this study focuses on related domestic and international literature published from 2017 to 2019. From the perspective of tasks and based on years of studying smoke detection, we divide forest fire alarm relying on smoke into three categories, namely, smoke recognition, detection, and segmentation. The three categories of tasks are of different grains and called smoke surveillance tasks. This study grain-wisely presents the latest methods of achieving the above-mentioned surveillance tasks in different aspects ranging from traditional techniques to deep ones. Concretely, related studies on coarse-grained surveillance tasks based on traditional algorithms are introduced first, followed by those on fine-grained tasks implemented by deep learning frameworks. Among the three surveillance tasks, smoke recognition is adopted as the basis. Hence, regarding smoke recognition, detection, and segmentation as recognition-based tasks in coarse-to-fine grain is reasonable. For instance, smoke recognition is the coarsest-grained task and smoke segmentation is the finest-grained recognition task among the three surveillance tasks. Given that the latest literature focuses more on detection and segmentation than on recognition, this study follows this trend and introduces methods of smoke region rough extraction, which obtains a candidate smoke region, and region refinement, which obtains the final detection or segmentation results. Furthermore, according to research, the most distinguishing characteristics of smoke are dynamic features, such as motion and diffusion, and the most stable and robust characteristics of smoke are static features, such as texture. Therefore, during the introduction to smoke region extraction, the extraction and leveraging of static and motion features are explored in every step to gain discriminative capability and robustness for accurate smoke recognition and location. Meanwhile, because deep learning methods tend to present end-to-end solutions rather than individual steps for surveillance tasks, introducing deep learning-based surveillance tasks step-wisely is difficult. Consequently, deep learning-based methods for surveillance tasks are introduced in another section grain-wisely. The overall frameworks and inner concepts are involved rather than the algorithm steps of deep learning-based smoke surveillance. Lastly, the strengths and weaknesses in smoke surveillance tasks are determined, and widely used evaluation indicators and several available datasets are summarized to allow researchers to search for evaluators and annotated datasets. Future development trends are also predicted. Through a comprehensive literature review of surveillance tasks in coarse-to-fine grain, the key techniques, problems to be solved, and promising research directions are demonstrated. Thus, potential solutions can be provided to surveillance task-based forest fire alarm. Further research based on this review might promote the industrial application of smoke surveillance tasks.关键词:smoke recognition;smoke detection;smoke segmentation;deep learning;review79|154|10更新时间:2024-05-07
摘要:Sensor-based smoke detection techniques have been widely used in industrial applications. With the development of artificial intelligence, especially the successful commercial application of deep learning, the number of cases in which computer vision-based techniques are applied to smoke detection for fire alarm has increased. Computer vision techniques have not been used as substitutes of sensors in smoke detection systems because of frequent false and missed alarm. By improving computer capability and storage devices, several shortcomings in traditional video smoke detection have been improved or even solved, but these improvements are accompanied with new challenges. To keep up with the development of and latest research on smoke recognition, detection, and segmentation, this study focuses on related domestic and international literature published from 2017 to 2019. From the perspective of tasks and based on years of studying smoke detection, we divide forest fire alarm relying on smoke into three categories, namely, smoke recognition, detection, and segmentation. The three categories of tasks are of different grains and called smoke surveillance tasks. This study grain-wisely presents the latest methods of achieving the above-mentioned surveillance tasks in different aspects ranging from traditional techniques to deep ones. Concretely, related studies on coarse-grained surveillance tasks based on traditional algorithms are introduced first, followed by those on fine-grained tasks implemented by deep learning frameworks. Among the three surveillance tasks, smoke recognition is adopted as the basis. Hence, regarding smoke recognition, detection, and segmentation as recognition-based tasks in coarse-to-fine grain is reasonable. For instance, smoke recognition is the coarsest-grained task and smoke segmentation is the finest-grained recognition task among the three surveillance tasks. Given that the latest literature focuses more on detection and segmentation than on recognition, this study follows this trend and introduces methods of smoke region rough extraction, which obtains a candidate smoke region, and region refinement, which obtains the final detection or segmentation results. Furthermore, according to research, the most distinguishing characteristics of smoke are dynamic features, such as motion and diffusion, and the most stable and robust characteristics of smoke are static features, such as texture. Therefore, during the introduction to smoke region extraction, the extraction and leveraging of static and motion features are explored in every step to gain discriminative capability and robustness for accurate smoke recognition and location. Meanwhile, because deep learning methods tend to present end-to-end solutions rather than individual steps for surveillance tasks, introducing deep learning-based surveillance tasks step-wisely is difficult. Consequently, deep learning-based methods for surveillance tasks are introduced in another section grain-wisely. The overall frameworks and inner concepts are involved rather than the algorithm steps of deep learning-based smoke surveillance. Lastly, the strengths and weaknesses in smoke surveillance tasks are determined, and widely used evaluation indicators and several available datasets are summarized to allow researchers to search for evaluators and annotated datasets. Future development trends are also predicted. Through a comprehensive literature review of surveillance tasks in coarse-to-fine grain, the key techniques, problems to be solved, and promising research directions are demonstrated. Thus, potential solutions can be provided to surveillance task-based forest fire alarm. Further research based on this review might promote the industrial application of smoke surveillance tasks.关键词:smoke recognition;smoke detection;smoke segmentation;deep learning;review79|154|10更新时间:2024-05-07 -
 摘要:ObjectiveSmoke detection by surveillance cameras is reasonable to warn fire. This technology has many advantages compared with other traditional point detectors. Wide areas could be covered, rapid respondence could be available, and installation and maintenance requirements could be less. However, the current smoke detection algorithms are unsatisfying in terms of accuracy and sensitivity due to the varying colors, shapes, and textures of smoke. The traditional studies focus on designing handcrafted features that extract such static features as colors, shapes, and textures and dynamic ones, including shape deforming, drifting, and frequency shifting. This task is time consuming. Although the algorithm exhibits good characteristics, maintaining its robustness for all environments is difficult. The detection effectiveness often sharply descends when these methods are applied in different environments. The fashionable methods, such as convolution neural network (CNN), recurrent neural network (RNN), and other statistical methods, are based on deep learning. However, applying these methods is difficult because the surveillance platforms have limited resources. These networks are also unsatisfying in terms of accuracy and sensitivity.MethodThe proposed method utilizes trajectories in condensed images, which are summed in horizontal and vertical directions for all video pixels. Smoke trajectories in condensed images are always right-leaning, straightly linear, proportional, and streamline-like with low frequencies and fixed starting points. Accordingly, surveillance videos are summed into condensed images, sliced, and then fed into CNN to extract features to find the long-term relationship by RNN. Partitioning strategy is also adopted to improve sensitivity. Therefore, the method uses not only the trajectory shapes but also the short- and long-range relationships in the time domain to detect the existence of smoke in videos.ResultControlled experiments of CNN, C3D(3d convolutional networks), traj + SVM(support vector machine), traj + RNNs, and traj + CNN + RNNs are conducted. The CNN and C3D methods are typical deep learning networks that initially extract features and then make judgments. The traj + SVM method detects smoke trajectories by traditional SVM algorithm, the traj + RNNs method finds smoke trajectories by RNNs, and the traj + CNN + RNNs method recognizes smoke trajectories by combining CNN and RNNs, which is the proposed method. The accuracy of the traj + CNN + RNNs method is increased by 35.2% compared with that of traj + SVM, and the real negative rate is increased by 15.6%. However, the computing cost of the traj + CNN + RNNs method is relatively high. The frame rate, maximum memory consumption, and network weight are 49 frame/s, 2.31 GB, and 261 MB, respectively. By contrast, the frame rate of traj + SVM is 178 frame/s. The computing cost of deep learning networks is generally high. Nevertheless, the traj + CNN + RNNs method is the lightest and fastest among all deep learning networks. Some confusing data for many traditional methods are collected for the second experiment to further compare these methods. The methods based on trajectories, namely, traj + SVM, traj + RNNs, and traj + CNN + RNNs, remain at a good level, and the indexes of ACC(accaracy), TPR(trure positive rate), and TNR(true negative rate) and the sensitivity are 0.853, 0.847, 0.872, and 52/26(frame/s), respectively. However, the corresponding indexes of CNN and C3D considerably reduced. The accuracies of CNN and C3D are 0.585 and 0.716, respectively.ConclusionThe proposed method helps improve the accuracy and sensitivity of smoke detection. The smoke trajectories can be identified from the condensed images, even from those of early smoke, which are helpful for early fire warning.关键词:fire;smoke;summed trajectory;feature recognition;deep learning;recurrent neural network(RNN)22|43|3更新时间:2024-05-07
摘要:ObjectiveSmoke detection by surveillance cameras is reasonable to warn fire. This technology has many advantages compared with other traditional point detectors. Wide areas could be covered, rapid respondence could be available, and installation and maintenance requirements could be less. However, the current smoke detection algorithms are unsatisfying in terms of accuracy and sensitivity due to the varying colors, shapes, and textures of smoke. The traditional studies focus on designing handcrafted features that extract such static features as colors, shapes, and textures and dynamic ones, including shape deforming, drifting, and frequency shifting. This task is time consuming. Although the algorithm exhibits good characteristics, maintaining its robustness for all environments is difficult. The detection effectiveness often sharply descends when these methods are applied in different environments. The fashionable methods, such as convolution neural network (CNN), recurrent neural network (RNN), and other statistical methods, are based on deep learning. However, applying these methods is difficult because the surveillance platforms have limited resources. These networks are also unsatisfying in terms of accuracy and sensitivity.MethodThe proposed method utilizes trajectories in condensed images, which are summed in horizontal and vertical directions for all video pixels. Smoke trajectories in condensed images are always right-leaning, straightly linear, proportional, and streamline-like with low frequencies and fixed starting points. Accordingly, surveillance videos are summed into condensed images, sliced, and then fed into CNN to extract features to find the long-term relationship by RNN. Partitioning strategy is also adopted to improve sensitivity. Therefore, the method uses not only the trajectory shapes but also the short- and long-range relationships in the time domain to detect the existence of smoke in videos.ResultControlled experiments of CNN, C3D(3d convolutional networks), traj + SVM(support vector machine), traj + RNNs, and traj + CNN + RNNs are conducted. The CNN and C3D methods are typical deep learning networks that initially extract features and then make judgments. The traj + SVM method detects smoke trajectories by traditional SVM algorithm, the traj + RNNs method finds smoke trajectories by RNNs, and the traj + CNN + RNNs method recognizes smoke trajectories by combining CNN and RNNs, which is the proposed method. The accuracy of the traj + CNN + RNNs method is increased by 35.2% compared with that of traj + SVM, and the real negative rate is increased by 15.6%. However, the computing cost of the traj + CNN + RNNs method is relatively high. The frame rate, maximum memory consumption, and network weight are 49 frame/s, 2.31 GB, and 261 MB, respectively. By contrast, the frame rate of traj + SVM is 178 frame/s. The computing cost of deep learning networks is generally high. Nevertheless, the traj + CNN + RNNs method is the lightest and fastest among all deep learning networks. Some confusing data for many traditional methods are collected for the second experiment to further compare these methods. The methods based on trajectories, namely, traj + SVM, traj + RNNs, and traj + CNN + RNNs, remain at a good level, and the indexes of ACC(accaracy), TPR(trure positive rate), and TNR(true negative rate) and the sensitivity are 0.853, 0.847, 0.872, and 52/26(frame/s), respectively. However, the corresponding indexes of CNN and C3D considerably reduced. The accuracies of CNN and C3D are 0.585 and 0.716, respectively.ConclusionThe proposed method helps improve the accuracy and sensitivity of smoke detection. The smoke trajectories can be identified from the condensed images, even from those of early smoke, which are helpful for early fire warning.关键词:fire;smoke;summed trajectory;feature recognition;deep learning;recurrent neural network(RNN)22|43|3更新时间:2024-05-07 -
 摘要:ObjectiveVideo smoke detection plays an important role in real-time fire alarms by solving the limitation of applying sensors in large spaces, outdoors, and other types of environment with strong air turbulence. Current video-based methods mainly extract the static and dynamic features of smoke and process them with the same structured model, which may disregard its continuous information and unstructured feature properties. Graph convolutional networks (GCNs) and neural ordinary differential equations (ODEs) exhibit powerful strength on processing non-Euclidean structures and continuous timeline models. Therefore, these methods can ultimately be utilized in video smoke detection. On account of the success of these new methods, we propose a flow-based continuous graph model for video smoke detection.MethodIn this study, we constructed a continuous timeline model using a neural ODE network, while most methods in the video smoke detection domain remain focused on discrete spatial-temporal features in the Euclidean space. We considered video frames with fixed time spans as sample points on a continuous timeline. By simulating the latent space of hidden variables through the latent time series model, we could obtain the hidden information between frames, which may be disregarded in discrete models. When the model was established, the lost between-frames information and the short-term future frame can be predicted. Through this procedure, we could effectively advance fire alarms. For the detection functions, we used GCNs to extract the feature of the video frame (or block), which will be trained for classification by utilizing fully and weakly supervised methods. Considering the lack of smoke labels for bounding boxes or pixel-level ground truths in real smoke video datasets, we pretrained our model on a number of smoke images and used it to predict the label of sliding windows in a labeled video frame. This process was conducted to find the origin fire point or predict the motion information of smoke.ResultWe compare our model with seven state-of-the-art models of video smoke detection and five image-detection models, including the traditional approaches and deep-learning methods on two video and four image datasets. The video data are collected from KMU, Bilkent, USTC, and Yuan. The quantitative evaluation metrics contain detection rate (DR), accuracy rate (AR), false alarm rate, average true positive rate (ATPR), average false positive rate, average true negative rate, and F-measure (F2). We provide several latent models of each method for comparisons. Experimental results show that our model outperforms most of other methods in KMU and the Yuan datasets. The visualized detection samples show that our model can capture the dynamic motion feature of smoke and predict the origin fire point by combining these features. Comparative experiments demonstrate that the continuous model improves smoke detection accuracy. Compared with the 3D parallel convolutional network and other results in the KMU video dataset, ATPRs increase by 0.6%. Compared with DMCNN and other results in the Yuan image datasets, obtained ARs increase by 0.21% and 0.06% on image datasets, respectively. Although the results of the state-of-art models are over 98%, we also achieve DR increases by 0.54% and 0.28%. In addition, we conduct a series of experiments in the Bilkent video datasets to verify the effectiveness and robustness of our latent model on the prediction of smoke motion. As shown in the separated screenshots of the real smoke videos, we initially sample several frames randomly and slide the bounding box window to divide the image block and predict their labels using our continuous graph convolutional model. We use the pretrained model given that the real smoke videos do not have specific labels for bounding boxes or pixels. Thereafter, we feed the center point of these samples to our latent model and predict the labels of the bounding boxes in the current image. Through visualizing the smoke areas detected by our model, we find that our latent model correctly tracks the diffusion direction of smoke and updates its locations. By reversing the timeline fed to the latent model, we can obtain the trajectory of smoke fusion back to its origin point. Therefore, the effectiveness of our latent model to predict smoke motion and infer the origin fire point is demonstrated. However, a quantized verification has not been conducted yet.ConclusionIn this study, we propose a video-based continuous graph convolutional model that combines the strength of structured and unstructured models. We also capture the dynamic information of smoke and effectively predict the origin fire point. Experiment results show that our model outperforms several state-of-the-art approaches of video and image smoke detection.关键词:video smoke detection;smoke recognition;graph convolutional network(GCN);neural ordinary differential equations;metric learning;weakly supervised learning23|42|2更新时间:2024-05-07
摘要:ObjectiveVideo smoke detection plays an important role in real-time fire alarms by solving the limitation of applying sensors in large spaces, outdoors, and other types of environment with strong air turbulence. Current video-based methods mainly extract the static and dynamic features of smoke and process them with the same structured model, which may disregard its continuous information and unstructured feature properties. Graph convolutional networks (GCNs) and neural ordinary differential equations (ODEs) exhibit powerful strength on processing non-Euclidean structures and continuous timeline models. Therefore, these methods can ultimately be utilized in video smoke detection. On account of the success of these new methods, we propose a flow-based continuous graph model for video smoke detection.MethodIn this study, we constructed a continuous timeline model using a neural ODE network, while most methods in the video smoke detection domain remain focused on discrete spatial-temporal features in the Euclidean space. We considered video frames with fixed time spans as sample points on a continuous timeline. By simulating the latent space of hidden variables through the latent time series model, we could obtain the hidden information between frames, which may be disregarded in discrete models. When the model was established, the lost between-frames information and the short-term future frame can be predicted. Through this procedure, we could effectively advance fire alarms. For the detection functions, we used GCNs to extract the feature of the video frame (or block), which will be trained for classification by utilizing fully and weakly supervised methods. Considering the lack of smoke labels for bounding boxes or pixel-level ground truths in real smoke video datasets, we pretrained our model on a number of smoke images and used it to predict the label of sliding windows in a labeled video frame. This process was conducted to find the origin fire point or predict the motion information of smoke.ResultWe compare our model with seven state-of-the-art models of video smoke detection and five image-detection models, including the traditional approaches and deep-learning methods on two video and four image datasets. The video data are collected from KMU, Bilkent, USTC, and Yuan. The quantitative evaluation metrics contain detection rate (DR), accuracy rate (AR), false alarm rate, average true positive rate (ATPR), average false positive rate, average true negative rate, and F-measure (F2). We provide several latent models of each method for comparisons. Experimental results show that our model outperforms most of other methods in KMU and the Yuan datasets. The visualized detection samples show that our model can capture the dynamic motion feature of smoke and predict the origin fire point by combining these features. Comparative experiments demonstrate that the continuous model improves smoke detection accuracy. Compared with the 3D parallel convolutional network and other results in the KMU video dataset, ATPRs increase by 0.6%. Compared with DMCNN and other results in the Yuan image datasets, obtained ARs increase by 0.21% and 0.06% on image datasets, respectively. Although the results of the state-of-art models are over 98%, we also achieve DR increases by 0.54% and 0.28%. In addition, we conduct a series of experiments in the Bilkent video datasets to verify the effectiveness and robustness of our latent model on the prediction of smoke motion. As shown in the separated screenshots of the real smoke videos, we initially sample several frames randomly and slide the bounding box window to divide the image block and predict their labels using our continuous graph convolutional model. We use the pretrained model given that the real smoke videos do not have specific labels for bounding boxes or pixels. Thereafter, we feed the center point of these samples to our latent model and predict the labels of the bounding boxes in the current image. Through visualizing the smoke areas detected by our model, we find that our latent model correctly tracks the diffusion direction of smoke and updates its locations. By reversing the timeline fed to the latent model, we can obtain the trajectory of smoke fusion back to its origin point. Therefore, the effectiveness of our latent model to predict smoke motion and infer the origin fire point is demonstrated. However, a quantized verification has not been conducted yet.ConclusionIn this study, we propose a video-based continuous graph convolutional model that combines the strength of structured and unstructured models. We also capture the dynamic information of smoke and effectively predict the origin fire point. Experiment results show that our model outperforms several state-of-the-art approaches of video and image smoke detection.关键词:video smoke detection;smoke recognition;graph convolutional network(GCN);neural ordinary differential equations;metric learning;weakly supervised learning23|42|2更新时间:2024-05-07
Fire and Smoke Special Forum
-
 摘要:ObjectiveHeart rate is an important physiological parameter that reflects the cardiovascular condition and mental state of the human body. Traditional techniques for heart rate detection need pressure sensors or optical sensors attached with human skin. However, the contact between sensors and the human skin tends to result in inconvenience for subjects, especially for those with skin diseases. Accordingly, using traditional techniques in our daily lives is difficult. With the improvement of technology for bio-image information processing, a non-contact heart rate detection method based on imaging photoplethysmography has become an attractive research focus. The color of human epidermis changes in a subtle way with the rhythm of heart beat. These changes are invisible to human eyes and can be captured by a webcam for heart rate estimation. Current technologies for non-contact heart rate detection prioritize facial skin due to its dense capillary distribution and the significant improvement of face tracking technology. However, in realistic environments involving facial motions, the precision of heart rate detected fails to meet the requirements. In recent years, various methods, such as independent principal component analysis, adaptive filtering, and wavelet transform, have been proposed to address this problem. After obtaining initial chrominance signals from different channels of a video, the independent principal component analysis algorithm extracts mutually independent source signals from the initial signals. One of the source signals represents the pulsation of heart beat. However, the source signals obtained are still corrupted by abundant noise. The independent principal component analysis algorithm is complicated, which hinders their widespread application. Adaptive filtering is generally based on the least mean square algorithm. Noises mixed in the chrominance signal can be removed by adaptively adjusting the parameters of the filter, regardless of the noise characteristics. However, this method can merely filter out Gaussian white noise, rather than the sharp noise caused by motion interference in practice. Wavelet transformation method decomposes the original blood volume pulse signal into a series of frequency bands. The method then selects the signals limited in the heart rate band and integrates them into a desirable signal, from which heart rate can be estimated by later processes. Nevertheless, the power spectral density function of the sharp noise caused by motion interference overwhelms the entire heart rate band, which cannot be discarded thoroughly by wavelet transformation. Overall, existing non-contact heart rate detection technologies fail to effectively filter out the sharp noise caused by facial motions, and their results are inaccurate.MethodTo tackle above-mentioned problems, this work proposes a novel method for detection of facial motions. Discriminative response map fitting and Kanede-Lucas-Tomasi algorithm are used in video to detect and track the facial regions. Some facial areas (e.g., eyes) do not contain information about heart rate. Thus the face is divided into several sub-regions, and these sub-regions are then studied respectively, with the aim of mitigating the impact of uninteresting areas. Chrominance characteristics of each sub-region are extracted from the video to establish the raw blood volume pulse matrix. In theoretical aspect, the ideal blood volume pulse matrix should be low-rank. However, in practice, the expression change at a certain moment may make the blood volume pulse distorted abruptly in corresponding time. The rank of the blood volume pulse matrix increase as the result of the distortion of local elements. This work performs the adaptive signal recovery algorithm on the damaged blood volume pulse matrix to discard abnormal elements arising from facial motions and reconstruct the row-rank matrix. From the matrix, sub-regions rich in information about heart rate are selected to compose the desirable blood volume pulse signal. Heart rate can be calculated according to the power spectrum density of the desirable blood volume pulse signal.ResultAbout 211 videos from 30 subjects are recorded under natural ambient lighting condition. Three series of experiments are conducted on the proposed method to verify its validity:experiments focusing on heart rate accuracy in static scenarios and dynamic scenarios, experiments focusing on method stability with different video durations and frame rates, and a 10 minutes experiment for long-term heart rate monitoring. Results of the accuracy experiments show that the Pearson correlation coefficient between the estimated heart rate and the ground truth is 0.990 2 in static scenarios and 0.960 5 in dynamic scenarios. The heart rate estimated by the proposed method highly approximates to the ground truth. Compared with the newest method, our method decreases the error rates by 53.90% and increases the Pearson correlation coefficient by 7.46%. The stability experiments show that the proposed method performs well as long as the duration of videos is higher than 8 seconds or the frame rate is higher than 20 frames per second. The long-term heart rate monitoring shows that the heart rate measured by the proposed method has similar fluctuations with the ground truth.ConclusionThe proposed method, which is proved to be superior to state-of-the-art ones, can dispose of expression disturbances and increase the detection accuracy of heart rate. However, in cases involving sudden illumination changes, the accuracy of the proposed method fails to reach the high level, which is planned to be further improved in our future works.关键词:imaging photoplethysmography(IPPG);facial motions;heart rate detection;self-adaptive signal recovery(SSR);desirable blood volume pulse signal37|115|3更新时间:2024-05-07
摘要:ObjectiveHeart rate is an important physiological parameter that reflects the cardiovascular condition and mental state of the human body. Traditional techniques for heart rate detection need pressure sensors or optical sensors attached with human skin. However, the contact between sensors and the human skin tends to result in inconvenience for subjects, especially for those with skin diseases. Accordingly, using traditional techniques in our daily lives is difficult. With the improvement of technology for bio-image information processing, a non-contact heart rate detection method based on imaging photoplethysmography has become an attractive research focus. The color of human epidermis changes in a subtle way with the rhythm of heart beat. These changes are invisible to human eyes and can be captured by a webcam for heart rate estimation. Current technologies for non-contact heart rate detection prioritize facial skin due to its dense capillary distribution and the significant improvement of face tracking technology. However, in realistic environments involving facial motions, the precision of heart rate detected fails to meet the requirements. In recent years, various methods, such as independent principal component analysis, adaptive filtering, and wavelet transform, have been proposed to address this problem. After obtaining initial chrominance signals from different channels of a video, the independent principal component analysis algorithm extracts mutually independent source signals from the initial signals. One of the source signals represents the pulsation of heart beat. However, the source signals obtained are still corrupted by abundant noise. The independent principal component analysis algorithm is complicated, which hinders their widespread application. Adaptive filtering is generally based on the least mean square algorithm. Noises mixed in the chrominance signal can be removed by adaptively adjusting the parameters of the filter, regardless of the noise characteristics. However, this method can merely filter out Gaussian white noise, rather than the sharp noise caused by motion interference in practice. Wavelet transformation method decomposes the original blood volume pulse signal into a series of frequency bands. The method then selects the signals limited in the heart rate band and integrates them into a desirable signal, from which heart rate can be estimated by later processes. Nevertheless, the power spectral density function of the sharp noise caused by motion interference overwhelms the entire heart rate band, which cannot be discarded thoroughly by wavelet transformation. Overall, existing non-contact heart rate detection technologies fail to effectively filter out the sharp noise caused by facial motions, and their results are inaccurate.MethodTo tackle above-mentioned problems, this work proposes a novel method for detection of facial motions. Discriminative response map fitting and Kanede-Lucas-Tomasi algorithm are used in video to detect and track the facial regions. Some facial areas (e.g., eyes) do not contain information about heart rate. Thus the face is divided into several sub-regions, and these sub-regions are then studied respectively, with the aim of mitigating the impact of uninteresting areas. Chrominance characteristics of each sub-region are extracted from the video to establish the raw blood volume pulse matrix. In theoretical aspect, the ideal blood volume pulse matrix should be low-rank. However, in practice, the expression change at a certain moment may make the blood volume pulse distorted abruptly in corresponding time. The rank of the blood volume pulse matrix increase as the result of the distortion of local elements. This work performs the adaptive signal recovery algorithm on the damaged blood volume pulse matrix to discard abnormal elements arising from facial motions and reconstruct the row-rank matrix. From the matrix, sub-regions rich in information about heart rate are selected to compose the desirable blood volume pulse signal. Heart rate can be calculated according to the power spectrum density of the desirable blood volume pulse signal.ResultAbout 211 videos from 30 subjects are recorded under natural ambient lighting condition. Three series of experiments are conducted on the proposed method to verify its validity:experiments focusing on heart rate accuracy in static scenarios and dynamic scenarios, experiments focusing on method stability with different video durations and frame rates, and a 10 minutes experiment for long-term heart rate monitoring. Results of the accuracy experiments show that the Pearson correlation coefficient between the estimated heart rate and the ground truth is 0.990 2 in static scenarios and 0.960 5 in dynamic scenarios. The heart rate estimated by the proposed method highly approximates to the ground truth. Compared with the newest method, our method decreases the error rates by 53.90% and increases the Pearson correlation coefficient by 7.46%. The stability experiments show that the proposed method performs well as long as the duration of videos is higher than 8 seconds or the frame rate is higher than 20 frames per second. The long-term heart rate monitoring shows that the heart rate measured by the proposed method has similar fluctuations with the ground truth.ConclusionThe proposed method, which is proved to be superior to state-of-the-art ones, can dispose of expression disturbances and increase the detection accuracy of heart rate. However, in cases involving sudden illumination changes, the accuracy of the proposed method fails to reach the high level, which is planned to be further improved in our future works.关键词:imaging photoplethysmography(IPPG);facial motions;heart rate detection;self-adaptive signal recovery(SSR);desirable blood volume pulse signal37|115|3更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveHumans fully understand a picture, often classify different images, and understand all the information in each image, including the location and concept of the object. This task is called object detection and is one of the basic research areas in computer vision. Object detection consists of different subtasks, such as pedestrian detection and skeleton detection. Pedestrian detection is a key link in object detection and one of the difficult tasks. This study mainly investigates pedestrian detection in traffic scenes, which is one of the most valuable topics in the field of pedestrian detection. Pedestrian detection in traffic scenes has always been a key technology for intelligent video surveillance technology, unmanned technology, intelligent transportation, and other issues. In recent years, this topic has been the research focus in academic and industrial circles. With the upsurge of artificial intelligence technology development, a large number of computer vision technologies are widely used. Multi-scale pedestrian detection has great research value because the development and application of pedestrian detection has complex real scenes and different pedestrian scales. Pedestrian detection is widely used in the field of automatic driving and video surveillance and is a hot research topic. Current pedestrian detection algorithms based on deep learning have false detection and miss detection problems in the case of low resolution and small pedestrian scale. A multi-scale pedestrian detection algorithm based on multi-layer features is proposed. The proposed convolutional neural network exhibits improved accuracy of pedestrian detection by a level, and there has been no small progress in practical applications. The academic enthusiasm brought about by deep learning has enabled scholars to make great progress and breakthroughs in pedestrian detection in complex scenes. Deep learning in the future will be a major boost for pedestrian detection.MethodThe deep residual network is mainly used in the multi-objective classification field. After analyzing the network, only the feature maps of the three stages are used and the residual unit and the full connection layer of the last stage are deleted. The deep residual network is mainly used to extract the feature maps of the three stages. The feature map extracted by the last layer is doubled using the characteristics of the three feature maps and then added by the nearest neighbor sampling method. The features with rich high-level semantic information and the features with rich low-level detail information are combined to improve the detection effect. The merged three-layer features are encoded into the region proposal network, and the proposal frames with pedestrians are obtained through Softmax classification for pedestrian detection. In this work, four experiments are designed, three of which are used to verify the validity of the proposed method. Results are compared with the mainstream algorithm results. Comparative experiments indicate that simple stratification does not improve the effect and the effect of multi-layer fusion is unsatisfactory. Therefore, the method of adjacent layer fusion is selected, and the result of multi-scale pedestrian detection is directly compared with that of the deepest network. The effect of adjacent layer fusion is better than the result. All experimental results are compared, and the fusion results of the adjacent layers are the best. The rate of missed detection is lower than that of the mainstream algorithm. The network is fully convolved and consists end-to-end training through random downsampling and backpropagation. Each image contains a number of candidate boxes for positive and negative samples. However, directly taking the optimized sample will easily lead to loss bias to the negative sample because the number of negative samples is larger than that of positive samples. This study takes an image to select 256 anchors and calculates its loss. The ratio of the positive and negative samples is 1:1. This article will randomly initialize all new layers in the network, and the standard of initialization is from the zero mean standard deviation. The value set is 0.01, and the weight is taken from Gaussian distribution. The other layers are initialized by classifying the pre-trained model, and the entire training process iterates through two epochs.ResultOn the Caltech pedestrian detection dataset and under the condition that each image false alarm rate (FPPI) is 10%, the loss rate of the proposed algorithm is only 57.88%, which is decreased by 3.07% compared with the loss of one of the best models, namely, MS-CNN (multi-scale convolutional neural network) (60.95%). This work also adopts comparative experiment. The overall loss rate of Ped-RPN is 64.55%, which is worse than that of the proposed algorithm. The loss rate of the layered and then detected method (Ped-muti-RPN) is 77.15%, which is better than that of Ped-RPN method. Ped-fused-RPN is a detection algorithm that combines multiple layers. The result is 61.32%, and the effect is better than the proposed algorithm.ConclusionSmall-scale pedestrians have the disadvantage of blurred images, which make the detection effect extremely poor and affect the overall multi-scale detection. In order to solve the problem of the sharp decline of small-scale pedestrian detection, this paper proposes a method of integrating deep semantic information and shallow detail features so the features of all scales have rich semantic information. The deep features have high semantic information, and the receptive field is small. The shallow features have positional information, and the receptive field is more fused. The two features can enhance the deep features, which have rich target position information. The merged feature map has different levels of detail and semantic information and has a good effect on detecting pedestrians of different scales.关键词:target detection;pedestrian detection;feature fusion;multi-scale pedestrians;multi-layer features37|303|5更新时间:2024-05-07
摘要:ObjectiveHumans fully understand a picture, often classify different images, and understand all the information in each image, including the location and concept of the object. This task is called object detection and is one of the basic research areas in computer vision. Object detection consists of different subtasks, such as pedestrian detection and skeleton detection. Pedestrian detection is a key link in object detection and one of the difficult tasks. This study mainly investigates pedestrian detection in traffic scenes, which is one of the most valuable topics in the field of pedestrian detection. Pedestrian detection in traffic scenes has always been a key technology for intelligent video surveillance technology, unmanned technology, intelligent transportation, and other issues. In recent years, this topic has been the research focus in academic and industrial circles. With the upsurge of artificial intelligence technology development, a large number of computer vision technologies are widely used. Multi-scale pedestrian detection has great research value because the development and application of pedestrian detection has complex real scenes and different pedestrian scales. Pedestrian detection is widely used in the field of automatic driving and video surveillance and is a hot research topic. Current pedestrian detection algorithms based on deep learning have false detection and miss detection problems in the case of low resolution and small pedestrian scale. A multi-scale pedestrian detection algorithm based on multi-layer features is proposed. The proposed convolutional neural network exhibits improved accuracy of pedestrian detection by a level, and there has been no small progress in practical applications. The academic enthusiasm brought about by deep learning has enabled scholars to make great progress and breakthroughs in pedestrian detection in complex scenes. Deep learning in the future will be a major boost for pedestrian detection.MethodThe deep residual network is mainly used in the multi-objective classification field. After analyzing the network, only the feature maps of the three stages are used and the residual unit and the full connection layer of the last stage are deleted. The deep residual network is mainly used to extract the feature maps of the three stages. The feature map extracted by the last layer is doubled using the characteristics of the three feature maps and then added by the nearest neighbor sampling method. The features with rich high-level semantic information and the features with rich low-level detail information are combined to improve the detection effect. The merged three-layer features are encoded into the region proposal network, and the proposal frames with pedestrians are obtained through Softmax classification for pedestrian detection. In this work, four experiments are designed, three of which are used to verify the validity of the proposed method. Results are compared with the mainstream algorithm results. Comparative experiments indicate that simple stratification does not improve the effect and the effect of multi-layer fusion is unsatisfactory. Therefore, the method of adjacent layer fusion is selected, and the result of multi-scale pedestrian detection is directly compared with that of the deepest network. The effect of adjacent layer fusion is better than the result. All experimental results are compared, and the fusion results of the adjacent layers are the best. The rate of missed detection is lower than that of the mainstream algorithm. The network is fully convolved and consists end-to-end training through random downsampling and backpropagation. Each image contains a number of candidate boxes for positive and negative samples. However, directly taking the optimized sample will easily lead to loss bias to the negative sample because the number of negative samples is larger than that of positive samples. This study takes an image to select 256 anchors and calculates its loss. The ratio of the positive and negative samples is 1:1. This article will randomly initialize all new layers in the network, and the standard of initialization is from the zero mean standard deviation. The value set is 0.01, and the weight is taken from Gaussian distribution. The other layers are initialized by classifying the pre-trained model, and the entire training process iterates through two epochs.ResultOn the Caltech pedestrian detection dataset and under the condition that each image false alarm rate (FPPI) is 10%, the loss rate of the proposed algorithm is only 57.88%, which is decreased by 3.07% compared with the loss of one of the best models, namely, MS-CNN (multi-scale convolutional neural network) (60.95%). This work also adopts comparative experiment. The overall loss rate of Ped-RPN is 64.55%, which is worse than that of the proposed algorithm. The loss rate of the layered and then detected method (Ped-muti-RPN) is 77.15%, which is better than that of Ped-RPN method. Ped-fused-RPN is a detection algorithm that combines multiple layers. The result is 61.32%, and the effect is better than the proposed algorithm.ConclusionSmall-scale pedestrians have the disadvantage of blurred images, which make the detection effect extremely poor and affect the overall multi-scale detection. In order to solve the problem of the sharp decline of small-scale pedestrian detection, this paper proposes a method of integrating deep semantic information and shallow detail features so the features of all scales have rich semantic information. The deep features have high semantic information, and the receptive field is small. The shallow features have positional information, and the receptive field is more fused. The two features can enhance the deep features, which have rich target position information. The merged feature map has different levels of detail and semantic information and has a good effect on detecting pedestrians of different scales.关键词:target detection;pedestrian detection;feature fusion;multi-scale pedestrians;multi-layer features37|303|5更新时间:2024-05-07 -
 摘要:ObjectiveThe rapid development of modern network and computer technology has led people to gradually move toward the information and intelligent era. In human pose estimation, advanced semantic interpretation and judgment results are obtained through processing, analyzing, and comprehending the input image or image sequence with computer. Human pose estimation has a wide range of applications and development prospects in human-computer interaction, surveillance, image retrieval, motion analysis, virtual reality, perception interface, etc. Thus, human pose estimation based on image is an extremely important research topic in the field of computer vision. However, the problem of human pose estimation has always been a difficult and hot topic because of the influence of the diversity of human visual appearance, occlusion, and complex background. In this paper we consider the problem of human pose estimation from a single still image. Traditional 2D human pose estimation algorithms are based on the pictorial strictures (PS) models. Solving the problem with the following is difficult:human pose estimation algorithms based on the PS model need to detect human parts in images, but in real world, detecting a single member of the human body is very difficult because of the background noise and the wide variety of human appearance. In recent years, the development of deep learning has led to new methods for human pose estimation. Compared with traditional algorithms, deep models have deeper hierarchies and ability to learn more complex patterns. In this work, we mainly focus on the effect of initial features on human joint point positioning and propose cross-stage convolutional pose machines (CSCPM).MethodFirst, the VGG network is used to obtain the preliminary initial features of the image, which is the basis of the image joint point positioning. The VGG network inherits the frameworks of LeNet and AlexNet and adopts a 19-layer deep network. The VGG network is the preferred algorithm to extract convolutional neural network (CNN) features from the images. The initial features retain more original information because the VGG network directly processes the image. Learning parameters in the deep convolutional network is difficult due to the interference of self-occlusion and mixed background. Second, on the basis of initial features, a multistage model is constructed to study the structural features at different scales. The multistage model consists of a sequence of convolutional networks that repeatedly produce 2D belief maps for the location of each part. The initial features are concatenated in each subsequent stage feature to solve the problem of gradient disappearance in initial feature learning. The network is divided into six stages. The first and second stages use the original image as input, and the third to sixth stages use the feature maps produced by the second stage as input. Finally, the joint loss function of the multi-scale joint location is designed to learn parameters in the deep convolutional network. Each stage of the cross-stage convolutional pose machines (CSCPM) effectively enforces supervision in intermediate stages through the network. Intermediate supervision has the advantage that even though the full deep learning architecture can have many layers, it does not fall prey to the vanishing gradient problem as the intermediate loss functions replenish the gradients at each stage. We encourage the network to repeatedly arrive at such representation by defining a loss function at the output of each stage that minimizes the Euclidean distance between the predicted and ideal belief maps for each part.ResultWe evaluate the proposed method on two widely used benchmarks, namely, MPⅡ (MPⅡ human pose dataset) and extended LSP (leeds sport pose) dataset, and compare the method with other human pose estimation methods in the past three years in terms of qualitative and quantitative analyses. In the experiments, percentage of corrected keypoints (PCK) measure is used to evaluate the performance of human pose estimation methods, where a key-point location is considered correct if its distance to the ground truth location is no more than a certain threshold for the length of a portion of the body. The official benchmark on the MPⅡ dataset adopts PCKh (using portion of head length as reference) at 0.5, while the official benchmark on the LSP dataset adopts PCK at 0.2. In the MPⅡ dataset, the total detection rate of the model is 89.1%, which 0.7% points higher than that of the model with the second highest performance. In the LSP dataset, the total detection rate of the model is 91.0%, which is 0.5% points higher than that of the model with the second highest performance. The qualitative results fully show the benefits of the cross-stage structure. The detection results are improved in some scenes, such as occlusion and complex background, because the concatenated initial features retain the original information.ConclusionThe human pose estimation model CSCPM is designed aiming at the failure cases of the convolutional pose machines (CPM) in some complex, scenes such as self-occlusion, mixed background, and joints of nearby people. The model provides a sequential prediction framework for the task of human pose estimation, which introduces a cross-stage structure based on the CPM model. The experimental results show that the proposed model improves the accuracy of human pose estimation and further accurately locates the points of the joins. The effectiveness of the proposed initial features learning and the benefit in the cross-stage structure are evaluated on two widely used human pose estimation benchmarks. Our approach achieves state-of-the-art performance on both datasets. The initial feature learning can effectively judge the self-occlusion and mixed background interference of the joints. The CSCPM, a human pose estimation model with cross-stage structure, is superior to existing human pose estimation models.关键词:cross-stage structure;initial features;belief maps;human pose estimation;deep learning28|5|2更新时间:2024-05-07
摘要:ObjectiveThe rapid development of modern network and computer technology has led people to gradually move toward the information and intelligent era. In human pose estimation, advanced semantic interpretation and judgment results are obtained through processing, analyzing, and comprehending the input image or image sequence with computer. Human pose estimation has a wide range of applications and development prospects in human-computer interaction, surveillance, image retrieval, motion analysis, virtual reality, perception interface, etc. Thus, human pose estimation based on image is an extremely important research topic in the field of computer vision. However, the problem of human pose estimation has always been a difficult and hot topic because of the influence of the diversity of human visual appearance, occlusion, and complex background. In this paper we consider the problem of human pose estimation from a single still image. Traditional 2D human pose estimation algorithms are based on the pictorial strictures (PS) models. Solving the problem with the following is difficult:human pose estimation algorithms based on the PS model need to detect human parts in images, but in real world, detecting a single member of the human body is very difficult because of the background noise and the wide variety of human appearance. In recent years, the development of deep learning has led to new methods for human pose estimation. Compared with traditional algorithms, deep models have deeper hierarchies and ability to learn more complex patterns. In this work, we mainly focus on the effect of initial features on human joint point positioning and propose cross-stage convolutional pose machines (CSCPM).MethodFirst, the VGG network is used to obtain the preliminary initial features of the image, which is the basis of the image joint point positioning. The VGG network inherits the frameworks of LeNet and AlexNet and adopts a 19-layer deep network. The VGG network is the preferred algorithm to extract convolutional neural network (CNN) features from the images. The initial features retain more original information because the VGG network directly processes the image. Learning parameters in the deep convolutional network is difficult due to the interference of self-occlusion and mixed background. Second, on the basis of initial features, a multistage model is constructed to study the structural features at different scales. The multistage model consists of a sequence of convolutional networks that repeatedly produce 2D belief maps for the location of each part. The initial features are concatenated in each subsequent stage feature to solve the problem of gradient disappearance in initial feature learning. The network is divided into six stages. The first and second stages use the original image as input, and the third to sixth stages use the feature maps produced by the second stage as input. Finally, the joint loss function of the multi-scale joint location is designed to learn parameters in the deep convolutional network. Each stage of the cross-stage convolutional pose machines (CSCPM) effectively enforces supervision in intermediate stages through the network. Intermediate supervision has the advantage that even though the full deep learning architecture can have many layers, it does not fall prey to the vanishing gradient problem as the intermediate loss functions replenish the gradients at each stage. We encourage the network to repeatedly arrive at such representation by defining a loss function at the output of each stage that minimizes the Euclidean distance between the predicted and ideal belief maps for each part.ResultWe evaluate the proposed method on two widely used benchmarks, namely, MPⅡ (MPⅡ human pose dataset) and extended LSP (leeds sport pose) dataset, and compare the method with other human pose estimation methods in the past three years in terms of qualitative and quantitative analyses. In the experiments, percentage of corrected keypoints (PCK) measure is used to evaluate the performance of human pose estimation methods, where a key-point location is considered correct if its distance to the ground truth location is no more than a certain threshold for the length of a portion of the body. The official benchmark on the MPⅡ dataset adopts PCKh (using portion of head length as reference) at 0.5, while the official benchmark on the LSP dataset adopts PCK at 0.2. In the MPⅡ dataset, the total detection rate of the model is 89.1%, which 0.7% points higher than that of the model with the second highest performance. In the LSP dataset, the total detection rate of the model is 91.0%, which is 0.5% points higher than that of the model with the second highest performance. The qualitative results fully show the benefits of the cross-stage structure. The detection results are improved in some scenes, such as occlusion and complex background, because the concatenated initial features retain the original information.ConclusionThe human pose estimation model CSCPM is designed aiming at the failure cases of the convolutional pose machines (CPM) in some complex, scenes such as self-occlusion, mixed background, and joints of nearby people. The model provides a sequential prediction framework for the task of human pose estimation, which introduces a cross-stage structure based on the CPM model. The experimental results show that the proposed model improves the accuracy of human pose estimation and further accurately locates the points of the joins. The effectiveness of the proposed initial features learning and the benefit in the cross-stage structure are evaluated on two widely used human pose estimation benchmarks. Our approach achieves state-of-the-art performance on both datasets. The initial feature learning can effectively judge the self-occlusion and mixed background interference of the joints. The CSCPM, a human pose estimation model with cross-stage structure, is superior to existing human pose estimation models.关键词:cross-stage structure;initial features;belief maps;human pose estimation;deep learning28|5|2更新时间:2024-05-07 -
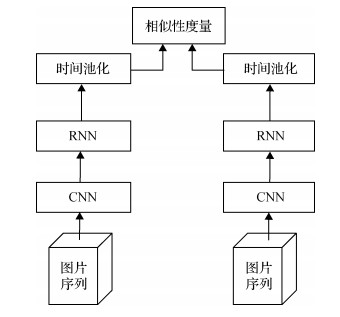 摘要:ObjectiveVideo person reidentification (re-ID) has attracted much attention due to the rapidly growing surveillance camera networks and the increasing demand of public safety. In recent years, the person reidentification task has become one of the core problems in intelligent surveillance and multimedia applications. This task aims to match the image sequences of pedestrians from non-overlapping cameras distributed at different physical locations. Given a tracklet taken from one camera, re-ID is the process of matching the person from tracklets of interest in another view. In practice, video re-ID faces several challenges. The image qualities of video frames tend to be rather low and pedestrians also exhibit a large range of pose variations because video acquisition is less constrained. Pedestrians in videos are usually moving, resulting in serious out-of-focus, blurring, and scale variations. Moreover, the same person in different videos may look different. When people move between cameras, the large appearance changes caused by environmental and geometric variations increases the difficulty of re-ID task. A lot of works has been proposed to deal with these issues. A typical video-based person re-id system first extracts the frame-wise features with deep convolutional neural networks (CNNs). The extracted features are fed into several recurrent neural networks (RNNs) to capture temporal structure information. Finally, the average or maximum temporal pooling procedure is conducted on the output RNNs to aggregate the features. However, the average pooling operation only considers the generic features of pedestrian sequences, and the specific features of samples in a sequence are neglected. While the maximum pooling operation concentrates on finding the local salient features, useful information may be abandoned. In this case, a video person re-id algorithm based on bi-directional long short-term memory (BiLSTM) and attention mechanism is proposed to make full use of temporal information and improve the robustness of person re-id systems for complex surveillance scenes.MethodFrom the input video sequence, the proposed algorithm breaks the long sequence into short snippets and randomly selects a constant number of frames for snippets. The snippets are fed into a pre-trained CNN network to extract the feature representation of each frame. In this method, the network can learn spatial appearance representation. Sequence representation is calculated by BiLSTM according to the temporal domain, which contains temporal motion information. BiLSTM in the network causes specific information to flow forward and backward in a flexible manner, allowing the underlying temporal information interaction to be fully exploited. After feature extraction, the frame-level and sequence-level features from the probe and gallery videos are fed into dot attention network independently. After calculating the correlation (the attention weight) between the sequence and its frames, the output sequence representation is reconstructed as a weighted sum of the frames at different spatial and temporal positions in the input sequence. In the attention mechanism, the network can alleviate sample noises and poor alignments in videos. Our network is implemented on the Pytorch platform and trained with a NVIDIA GTX 1080 GPU device. All training and testing images are rescaled to a fixed size of 256×128 pixels. The ResNet-50 with the pretrained parameters on ImageNet is considered the backbone network in our system. For network parameter training, we adopt stochastic gradient descent (SGD) with a momentum of 0.9. The learning rate is initially set as 0.001 and further divided by 10 after every 20 epochs. The batch size is set at 8 for training, and the total training process lasts for 40 epochs. The whole network is trained end-to-end with a joint identification and verification manner. During the test, the query and gallery videos are encoded to the feature vectors by using the aforementioned system. To compare the re-identification performance of the proposed method with the existing advanced methods, we adopt the cumulative matching characteristics (CMC) at rank-1, rank-5, rank-10, and rank-20 on all datasets.ResultThe proposed network is demonstrated on two public benchmark datasets including iLIDS-VID and PRID2011. For iLIDS-VID, the 600 video sequences of 300 persons are randomly split into 50% of persons for training and 50% of persons for testing. For PRID2011, we follow the experiment setup in previous methods and only use 400 video sequences of the first 200 persons, who appear in both cameras. The experiments on these two datasets are repeated 10 times with different test/train splits, and the results are averaged to ensure stable evaluation. Rank1 (represents the proportion of the queried people) results of the two datasets are 80.5% and 87.6% respectively. In the iLIDS-VID dataset, the Rank1 is increased by 4.5% compared with the second performance method. In the PRID2011 dataset, the Rank1 is increased by 3.9% compared with the second performance method. Extensive ablation studies verify the effectiveness of BiLSTM and attention mechanism. Compared with the results that only use LSTM in iLIDS-VID and PRID2011 datasets, the Rank1 (higher is better) is increased by 10.9% and 12.7%, respectively.ConclusionThis work proposes video person re-id method based on BiLSTM and attention mechanism. The proposed algorithm can effectively learn spatio-temporal features relevant for re-id task. Furthermore, the proposed BiLSTM allow temporal information not only to propagate from front to back but also in the reverse direction. The attention mechanism can adaptively select the discriminative information from the sequentially varying features. The proposed network significantly improves the recognition rate and has a practical application value. The proposed method shows improved robustness of video person re-id systems in complex scenes and outperforms several state-of-the-art approaches.关键词:computer vision;person re-identification;convolutional neural network (CNN);bi-directional long short-term memory(BiLSTM);attention mechanism15|4|4更新时间:2024-05-07
摘要:ObjectiveVideo person reidentification (re-ID) has attracted much attention due to the rapidly growing surveillance camera networks and the increasing demand of public safety. In recent years, the person reidentification task has become one of the core problems in intelligent surveillance and multimedia applications. This task aims to match the image sequences of pedestrians from non-overlapping cameras distributed at different physical locations. Given a tracklet taken from one camera, re-ID is the process of matching the person from tracklets of interest in another view. In practice, video re-ID faces several challenges. The image qualities of video frames tend to be rather low and pedestrians also exhibit a large range of pose variations because video acquisition is less constrained. Pedestrians in videos are usually moving, resulting in serious out-of-focus, blurring, and scale variations. Moreover, the same person in different videos may look different. When people move between cameras, the large appearance changes caused by environmental and geometric variations increases the difficulty of re-ID task. A lot of works has been proposed to deal with these issues. A typical video-based person re-id system first extracts the frame-wise features with deep convolutional neural networks (CNNs). The extracted features are fed into several recurrent neural networks (RNNs) to capture temporal structure information. Finally, the average or maximum temporal pooling procedure is conducted on the output RNNs to aggregate the features. However, the average pooling operation only considers the generic features of pedestrian sequences, and the specific features of samples in a sequence are neglected. While the maximum pooling operation concentrates on finding the local salient features, useful information may be abandoned. In this case, a video person re-id algorithm based on bi-directional long short-term memory (BiLSTM) and attention mechanism is proposed to make full use of temporal information and improve the robustness of person re-id systems for complex surveillance scenes.MethodFrom the input video sequence, the proposed algorithm breaks the long sequence into short snippets and randomly selects a constant number of frames for snippets. The snippets are fed into a pre-trained CNN network to extract the feature representation of each frame. In this method, the network can learn spatial appearance representation. Sequence representation is calculated by BiLSTM according to the temporal domain, which contains temporal motion information. BiLSTM in the network causes specific information to flow forward and backward in a flexible manner, allowing the underlying temporal information interaction to be fully exploited. After feature extraction, the frame-level and sequence-level features from the probe and gallery videos are fed into dot attention network independently. After calculating the correlation (the attention weight) between the sequence and its frames, the output sequence representation is reconstructed as a weighted sum of the frames at different spatial and temporal positions in the input sequence. In the attention mechanism, the network can alleviate sample noises and poor alignments in videos. Our network is implemented on the Pytorch platform and trained with a NVIDIA GTX 1080 GPU device. All training and testing images are rescaled to a fixed size of 256×128 pixels. The ResNet-50 with the pretrained parameters on ImageNet is considered the backbone network in our system. For network parameter training, we adopt stochastic gradient descent (SGD) with a momentum of 0.9. The learning rate is initially set as 0.001 and further divided by 10 after every 20 epochs. The batch size is set at 8 for training, and the total training process lasts for 40 epochs. The whole network is trained end-to-end with a joint identification and verification manner. During the test, the query and gallery videos are encoded to the feature vectors by using the aforementioned system. To compare the re-identification performance of the proposed method with the existing advanced methods, we adopt the cumulative matching characteristics (CMC) at rank-1, rank-5, rank-10, and rank-20 on all datasets.ResultThe proposed network is demonstrated on two public benchmark datasets including iLIDS-VID and PRID2011. For iLIDS-VID, the 600 video sequences of 300 persons are randomly split into 50% of persons for training and 50% of persons for testing. For PRID2011, we follow the experiment setup in previous methods and only use 400 video sequences of the first 200 persons, who appear in both cameras. The experiments on these two datasets are repeated 10 times with different test/train splits, and the results are averaged to ensure stable evaluation. Rank1 (represents the proportion of the queried people) results of the two datasets are 80.5% and 87.6% respectively. In the iLIDS-VID dataset, the Rank1 is increased by 4.5% compared with the second performance method. In the PRID2011 dataset, the Rank1 is increased by 3.9% compared with the second performance method. Extensive ablation studies verify the effectiveness of BiLSTM and attention mechanism. Compared with the results that only use LSTM in iLIDS-VID and PRID2011 datasets, the Rank1 (higher is better) is increased by 10.9% and 12.7%, respectively.ConclusionThis work proposes video person re-id method based on BiLSTM and attention mechanism. The proposed algorithm can effectively learn spatio-temporal features relevant for re-id task. Furthermore, the proposed BiLSTM allow temporal information not only to propagate from front to back but also in the reverse direction. The attention mechanism can adaptively select the discriminative information from the sequentially varying features. The proposed network significantly improves the recognition rate and has a practical application value. The proposed method shows improved robustness of video person re-id systems in complex scenes and outperforms several state-of-the-art approaches.关键词:computer vision;person re-identification;convolutional neural network (CNN);bi-directional long short-term memory(BiLSTM);attention mechanism15|4|4更新时间:2024-05-07 -
 摘要:ObjectiveThis study aims to improve the numerical stability of high-order moments and the ability of anti-noise and filtering for low-order moments, which are defined with orthogonal polynomial kernel-functions. A general semi-orthogonal moments with parameter-modulated is defined from frequency-response analysis, which is a generalization of the traditional orthogonal moments. This paper mainly attempts to study from the following three aspects:1) we take on the challenge of studying the influence of the performance of semi-orthogonal kernel-functions onto an image between orthogonal and non-orthogonal moments and design a general semi-orthogonal moment theory model for different orders; 2) we take on the challenge of trying to establish a theoretical analysis model of image moments in the frequency domain; by adjusting the bandwidth of the basis functions and the corresponding cut-off frequencies for various moments, we can analyze their effects on low-order moments, middle-order moments, and high-order moments and further study the advantages and disadvantages of reconstructed images by using different order moments (low-order and high-order); 3) to solve the traditional orthogonal moments that can only describe the characteristics of the image globally, we take on the challenge of constructing image local feature analysis method and establishing the local image moments of region of interest (ROI) feature extraction.MethodThe kernel functions of the traditional orthogonal moments are modified appropriately by using the modified kernel-functions (basis functions) to replace the original kernel-functions in the traditional orthogonal moments, making it a special case for modified moments. The modified basis functions can effectively eliminate the numerical instability of image moments. The low-order moments of an image can be quantitatively analyzed by time-domain analysis method, but the high-frequency of an image (corresponding high-order moments) cannot be described reasonably. Therefore, from the perspective of frequency domain, a time-frequency correspondence method is proposed to analyze and enhance the stability of different order moments. The main idea of this method is to treat the representation of the constructed image moments in the frequency domain as a filter (such as low-pass filtering). The bandwidth corresponding to the kernel functions will be wider when using low-order moments, and the cut-off frequency will be attenuated as much as possible. Meanwhile, the bandwidth corresponding to the high-order moments is narrow, and the cutoff frequency attenuates as fast as possible. In summary, various types of optimal-order moments can be established by slightly adjusting the band-width of the modified kernel function. Finally, the semi-orthogonal trigonometric function moments (SOTMs) are implemented to investigate the properties of the general semi-orthogonal moments. Compared with those of existing Zernike, pseudo-Zernike, orthogonal Fourier-Mellin moments, and Bessel-Fourier moments (the above image moments are composed of high-order polynomials), the image moments with triangular functions as basis have faster computational speed and lower computational complexity in image recognition due to their simple composition and the magnitude located in [-1, 1].ResultA semi-orthogonal triangular function moment is proposed to generalize the triangular functions, which can construct corresponding image moments in different coordinates space, and to improve the stability and accuracy of image reconstruction. Moments established by triangular functions are used as kernel functions, as verified by theoretical analysis and related simulation experiments.ConclusionTheoretical analysis and a series of simulation experiments for correlated images demonstrate that, the general semi-orthogonal moments outperform corresponding orthogonal moments (e.g., Zernike, pseudo-Zernike, orthogonal Fourier-Mellin moments, and Bessel-Fourier moments) in terms of the numerical stability, image-reconstruction, image ROI feature detection, noise robustness testing, and invariant recognition.关键词:semi-orthogonal;orthogonal moments;image reconstruction;numerical stability;invariant recognition11|4|0更新时间:2024-05-07
摘要:ObjectiveThis study aims to improve the numerical stability of high-order moments and the ability of anti-noise and filtering for low-order moments, which are defined with orthogonal polynomial kernel-functions. A general semi-orthogonal moments with parameter-modulated is defined from frequency-response analysis, which is a generalization of the traditional orthogonal moments. This paper mainly attempts to study from the following three aspects:1) we take on the challenge of studying the influence of the performance of semi-orthogonal kernel-functions onto an image between orthogonal and non-orthogonal moments and design a general semi-orthogonal moment theory model for different orders; 2) we take on the challenge of trying to establish a theoretical analysis model of image moments in the frequency domain; by adjusting the bandwidth of the basis functions and the corresponding cut-off frequencies for various moments, we can analyze their effects on low-order moments, middle-order moments, and high-order moments and further study the advantages and disadvantages of reconstructed images by using different order moments (low-order and high-order); 3) to solve the traditional orthogonal moments that can only describe the characteristics of the image globally, we take on the challenge of constructing image local feature analysis method and establishing the local image moments of region of interest (ROI) feature extraction.MethodThe kernel functions of the traditional orthogonal moments are modified appropriately by using the modified kernel-functions (basis functions) to replace the original kernel-functions in the traditional orthogonal moments, making it a special case for modified moments. The modified basis functions can effectively eliminate the numerical instability of image moments. The low-order moments of an image can be quantitatively analyzed by time-domain analysis method, but the high-frequency of an image (corresponding high-order moments) cannot be described reasonably. Therefore, from the perspective of frequency domain, a time-frequency correspondence method is proposed to analyze and enhance the stability of different order moments. The main idea of this method is to treat the representation of the constructed image moments in the frequency domain as a filter (such as low-pass filtering). The bandwidth corresponding to the kernel functions will be wider when using low-order moments, and the cut-off frequency will be attenuated as much as possible. Meanwhile, the bandwidth corresponding to the high-order moments is narrow, and the cutoff frequency attenuates as fast as possible. In summary, various types of optimal-order moments can be established by slightly adjusting the band-width of the modified kernel function. Finally, the semi-orthogonal trigonometric function moments (SOTMs) are implemented to investigate the properties of the general semi-orthogonal moments. Compared with those of existing Zernike, pseudo-Zernike, orthogonal Fourier-Mellin moments, and Bessel-Fourier moments (the above image moments are composed of high-order polynomials), the image moments with triangular functions as basis have faster computational speed and lower computational complexity in image recognition due to their simple composition and the magnitude located in [-1, 1].ResultA semi-orthogonal triangular function moment is proposed to generalize the triangular functions, which can construct corresponding image moments in different coordinates space, and to improve the stability and accuracy of image reconstruction. Moments established by triangular functions are used as kernel functions, as verified by theoretical analysis and related simulation experiments.ConclusionTheoretical analysis and a series of simulation experiments for correlated images demonstrate that, the general semi-orthogonal moments outperform corresponding orthogonal moments (e.g., Zernike, pseudo-Zernike, orthogonal Fourier-Mellin moments, and Bessel-Fourier moments) in terms of the numerical stability, image-reconstruction, image ROI feature detection, noise robustness testing, and invariant recognition.关键词:semi-orthogonal;orthogonal moments;image reconstruction;numerical stability;invariant recognition11|4|0更新时间:2024-05-07 -
 摘要:ObjectiveHuman action recognition, which is composed of single-person action and group activity recognition, has received considerable research attention. Group activity recognition is based on single-person action recognition and focuses on the group of people in the scene. This type of recognition has various applications, including video surveillance, sport analytics, and video retrieval. In group activity recognition, the hierarchical structure between the group and individuals is significant to recognition, and the main challenge is to build more discriminative representations of group activity based on the hierarchical structure. To overcome this difficulty, researchers have proposed numerous methods. Hierarchical framework is widely adopted to represent the relationships between individuals and their corresponding group and has achieved promising performance. In the early years, hand-crafted features are designed as the representations of individual and group-level activities. Recently, deep learning has been widely used in group activity recognition. Typically, hierarchical framework-based RNN (recurrent neural network) has been adopted to represent the relationships between individuals and their corresponding group and has achieved promising performance. Despite the promising performance, these methods ignore the relationships and interactions among individuals, thereby affecting the accuracy of recognition. Group activity is comprehensively defined by each individual action and the contextural information among individuals. Extracting individual features in isolation results in the loss of contextural information. To address this problem, we propose a novel model for group activity recognition based on the nonlocal network.MethodThe proposed model utilizes a bottom-up approach to represent and recognize individual actions and group activities in a hierarchical manner. First, tracklets of multi-person are constructed based on the detection and trajectories, and static features are extracted from these tracklets by nonlocal convolutional neural network (NCNN). Inside the NCNN module, the similarity of each individual is calculated to capture the nonlocal context within the individuals. The extracted features are then fed into the hierarchical temporal model (HTM), which is based on LSTM (long short term memory). HTM is composed of individual-level LSTM and group-level LSTM, which focuses on group dynamics in a hierarchical manner. Dynamic features of individuals are extracted, and features of group activities are generated by aggregating individual features in the HTM. Finally, the group activities and individual actions are classified by utilizing the output of HTM. The entire framework is easily implemented in with end-to-end training style.ResultWe evaluate our model on the widely-used The Volleyball Dataset in two different dataset settings, namely, fine-division and non-fine-division. Fine-division experimental settings refer to the group as combination of different subgroups, and a subgroup is composed of several individuals. In this setting, the structure of the group is "group-subgroup-individuals". We aggregate the individual features within the subgroup and then concatenate the features of subgroups. Non-fine-division experimental setting means the lack of involvement of subgroup. We aggregate all the individual features to generate the features of the group. Experimental results show that the proposed method can achieve 83.5% accuracy in fine-division manner and 77.6% accuracy in non-fine-division manner. Examples of recognition and relationships within the group are visualized.ConclusionThis study proposes a novel neural network for group activity recognition and constructs a unified framework based on the NCNN and hierarchical LSTM network. We address the motivation of taking the relationships among individuals into consideration with a nonlocal network and utilize the contextural information in the group. In extracting individual features, the method learns more discriminative features, which combine the impact of each individual. Thus, contextural information in nonlocal area is embedded into the extracted features. Experimental results confirm the effectiveness of our nonlocal model, indicating that the contextural information between individuals and the hierarchical structure of the group facilitate the group activity recognition.关键词:action recognition;group activity recognition;nonlocal network;feature representation;deep learning16|4|1更新时间:2024-05-07
摘要:ObjectiveHuman action recognition, which is composed of single-person action and group activity recognition, has received considerable research attention. Group activity recognition is based on single-person action recognition and focuses on the group of people in the scene. This type of recognition has various applications, including video surveillance, sport analytics, and video retrieval. In group activity recognition, the hierarchical structure between the group and individuals is significant to recognition, and the main challenge is to build more discriminative representations of group activity based on the hierarchical structure. To overcome this difficulty, researchers have proposed numerous methods. Hierarchical framework is widely adopted to represent the relationships between individuals and their corresponding group and has achieved promising performance. In the early years, hand-crafted features are designed as the representations of individual and group-level activities. Recently, deep learning has been widely used in group activity recognition. Typically, hierarchical framework-based RNN (recurrent neural network) has been adopted to represent the relationships between individuals and their corresponding group and has achieved promising performance. Despite the promising performance, these methods ignore the relationships and interactions among individuals, thereby affecting the accuracy of recognition. Group activity is comprehensively defined by each individual action and the contextural information among individuals. Extracting individual features in isolation results in the loss of contextural information. To address this problem, we propose a novel model for group activity recognition based on the nonlocal network.MethodThe proposed model utilizes a bottom-up approach to represent and recognize individual actions and group activities in a hierarchical manner. First, tracklets of multi-person are constructed based on the detection and trajectories, and static features are extracted from these tracklets by nonlocal convolutional neural network (NCNN). Inside the NCNN module, the similarity of each individual is calculated to capture the nonlocal context within the individuals. The extracted features are then fed into the hierarchical temporal model (HTM), which is based on LSTM (long short term memory). HTM is composed of individual-level LSTM and group-level LSTM, which focuses on group dynamics in a hierarchical manner. Dynamic features of individuals are extracted, and features of group activities are generated by aggregating individual features in the HTM. Finally, the group activities and individual actions are classified by utilizing the output of HTM. The entire framework is easily implemented in with end-to-end training style.ResultWe evaluate our model on the widely-used The Volleyball Dataset in two different dataset settings, namely, fine-division and non-fine-division. Fine-division experimental settings refer to the group as combination of different subgroups, and a subgroup is composed of several individuals. In this setting, the structure of the group is "group-subgroup-individuals". We aggregate the individual features within the subgroup and then concatenate the features of subgroups. Non-fine-division experimental setting means the lack of involvement of subgroup. We aggregate all the individual features to generate the features of the group. Experimental results show that the proposed method can achieve 83.5% accuracy in fine-division manner and 77.6% accuracy in non-fine-division manner. Examples of recognition and relationships within the group are visualized.ConclusionThis study proposes a novel neural network for group activity recognition and constructs a unified framework based on the NCNN and hierarchical LSTM network. We address the motivation of taking the relationships among individuals into consideration with a nonlocal network and utilize the contextural information in the group. In extracting individual features, the method learns more discriminative features, which combine the impact of each individual. Thus, contextural information in nonlocal area is embedded into the extracted features. Experimental results confirm the effectiveness of our nonlocal model, indicating that the contextural information between individuals and the hierarchical structure of the group facilitate the group activity recognition.关键词:action recognition;group activity recognition;nonlocal network;feature representation;deep learning16|4|1更新时间:2024-05-07 -
 摘要:ObjectiveWith the development of 3D scanning technology and virtual reality technology, the 3D recognition method for actual objects has become a major research topic. It is also one of the most challenging tasks in understanding natural scenes. Recognizing objects by taking photos on a smartphone has been widely used because 2D images are relatively easy to acquire and process. Recent advances in real-time SLAM and laser scanning technology have contributed to the availability of 3D models of actual objects. There is a great need for the effective methods to process 3D models and further recognize the corresponding 3D objects or 3D scenes. Some studies have attempted to use image-based methods to obtain 3D features through deep convolutional neural networks, and they have high memory efficiency. Other studies have used point-set methods or volume-based methods. The input forms of these methods are closer to the structure of the actual objects, and accordingly, the networks become more complicated and require huge computing resources. These studies have made some progress. However, the accuracy and real-time performance of 3D object recognition must still be improved. To deal with this problem, this study proposes a new 3D object recognition model that combines the perceptron residual network and the extreme learning machine (ELM).MethodThis model uses the proposed multi-layer perceptron residual network to learn the multi-view projection features of 3D objects on the basis of the framework of the extreme learning machine. The network model also uses a multi-channel integrated classifier composed of extreme learning machine, K-nearest neighbor (KNN), and support vector machine (SVM) to identify 3D objects. This study is not just stacking various classifiers, which has a huge risk of overfitting. After obtaining the prediction output vector of ELM, the difference
摘要:ObjectiveWith the development of 3D scanning technology and virtual reality technology, the 3D recognition method for actual objects has become a major research topic. It is also one of the most challenging tasks in understanding natural scenes. Recognizing objects by taking photos on a smartphone has been widely used because 2D images are relatively easy to acquire and process. Recent advances in real-time SLAM and laser scanning technology have contributed to the availability of 3D models of actual objects. There is a great need for the effective methods to process 3D models and further recognize the corresponding 3D objects or 3D scenes. Some studies have attempted to use image-based methods to obtain 3D features through deep convolutional neural networks, and they have high memory efficiency. Other studies have used point-set methods or volume-based methods. The input forms of these methods are closer to the structure of the actual objects, and accordingly, the networks become more complicated and require huge computing resources. These studies have made some progress. However, the accuracy and real-time performance of 3D object recognition must still be improved. To deal with this problem, this study proposes a new 3D object recognition model that combines the perceptron residual network and the extreme learning machine (ELM).MethodThis model uses the proposed multi-layer perceptron residual network to learn the multi-view projection features of 3D objects on the basis of the framework of the extreme learning machine. The network model also uses a multi-channel integrated classifier composed of extreme learning machine, K-nearest neighbor (KNN), and support vector machine (SVM) to identify 3D objects. This study is not just stacking various classifiers, which has a huge risk of overfitting. After obtaining the prediction output vector of ELM, the difference$e$ $e$ $T$ 关键词:multi-layer perceptron residual network;multi-channel classifier;extreme learning machine (ELM);3D object recognition;feature extraction15|19|0更新时间:2024-05-07 -
 摘要:ObjectiveThis study aims to introduce the global and local processing mechanism of visual information flow by constructing a visual information encoding and decoding model based on the correlation between visual nerve coding and contour perception and propose a contour perception method based on multi-path convolution neural network.MethodThe Gauss pyramid scale decomposition was used to obtain low-resolution molecular images to characterize the whole contour of visual information. Two-dimensional Gauss derivative was used to simulate the directional selectivity of classical receptive fields to obtain boundary response sub-graphs describing details. A multi-path convolution neural network was constructed, and a sparse encoding sub-network (Sparse-Net) was used to realize the fast processing of the whole contour detection. Redundancy enhanced coding (Redundancy-Net) was used to extract local details. The response of the multi-path convolution neural network was fused and coded to integrate global perception and local detection of contour responses and obtain the fine perception results of the contour.ResultWith the BSDS500 image database provided by Berkely Computer Vision Group as the experimental object, the detection speed of Sparse-Net in GTX1080Ti environment reached 42 frame/s, which was 35 times higher than that of HFL method (1.2 frame/s). The detection index data set of Sparse-Net and Redundancy-Net after fusion was the best in scale (ODS) and picture scale (OIS) and AP are 0.806, 0.824, and 0.846 respectively, which are better than the holistically-nested edge detection (HED) and richer convolution features for edge detection (RCF) methods, which are based on the analysis of the lateral output feature map, progressive encoding and decoding, and feature fusion from the shallow to the deep layer of the network, learning fine contour features and achieving end-to-end contour detection. The proposed method cannot only effectively highlight the main contour and suppress the texture background but also improve the detection efficiency of contour.ConclusionConvolution neural network can be explained by visual mechanism in some dimensions, such as convolution operation corresponding to the topological mapping of retinal visual information. Pooling operation is related to complex cells and simple cells in visual pathway. As such, convolution neural network is still a black box model which depends heavily on massive samples on the whole. Considering that the actual visual pathway is not simply a serial transmission of information but a fusion of the local and global characteristics of multi-channel visual information flow in the visual cortex, a Gauss pyramid decomposition model was constructed for sparse encoding of the spatial scale of visual information and obtaining low-resolution molecular maps representing the overall characteristics. Lateral suppression of non-classical receptive fields was used in the lateral geniculate region. A classical receptive field with directional selection characteristics was set up for isotropic suppression of background information and considering the ability of primary visual cortex for information processing in the visual radiation region. A two-dimensional Gauss derivative model was constructed to process the visual information by directional selection. The boundary response sub-graph representing local features was obtained. A multi-path convolution neural network was constructed considering the local details of external excitation and the layer-by-layer perception of overall information in the primary and advanced visual cortex. In the network, the fast detection path was composed of a sub-network Sparse-Net containing a pooling unit for sparse coding of the overall image contour. The detail detection path was composed of a sub-network Redundancy-Net containing a void convolution unit to realize image bureau. Redundancy enhanced the coding of part details. Finally, the feedback and fusion process of high-level visual cortex to visual information flow was simulated, and the above-mentioned multi-path convolution neural network response was fused and coded for overall perception and local detection fusion of the contour response. Finally, the fine perception results of the contour were obtained. Contour perception based on multi-path convolution neural network is helpful to further understand the mechanism of visual perception and is of great significance to weaken the black-box characteristics of the convolution neural network. Taking the natural scene image subject contour perception under complex texture background as an example, simulating the neural coding mechanism of multi-path cooperative work in primary visual pathway will help understand the intrinsic mechanism of visual system and its specific application in visual perception. This works provides a new idea for subsequent image understanding and analysis based on visual mechanism.关键词:contour detection;cavity convolution;convolution neural network (CNN);visual perception;feature fusion21|5|0更新时间:2024-05-07
摘要:ObjectiveThis study aims to introduce the global and local processing mechanism of visual information flow by constructing a visual information encoding and decoding model based on the correlation between visual nerve coding and contour perception and propose a contour perception method based on multi-path convolution neural network.MethodThe Gauss pyramid scale decomposition was used to obtain low-resolution molecular images to characterize the whole contour of visual information. Two-dimensional Gauss derivative was used to simulate the directional selectivity of classical receptive fields to obtain boundary response sub-graphs describing details. A multi-path convolution neural network was constructed, and a sparse encoding sub-network (Sparse-Net) was used to realize the fast processing of the whole contour detection. Redundancy enhanced coding (Redundancy-Net) was used to extract local details. The response of the multi-path convolution neural network was fused and coded to integrate global perception and local detection of contour responses and obtain the fine perception results of the contour.ResultWith the BSDS500 image database provided by Berkely Computer Vision Group as the experimental object, the detection speed of Sparse-Net in GTX1080Ti environment reached 42 frame/s, which was 35 times higher than that of HFL method (1.2 frame/s). The detection index data set of Sparse-Net and Redundancy-Net after fusion was the best in scale (ODS) and picture scale (OIS) and AP are 0.806, 0.824, and 0.846 respectively, which are better than the holistically-nested edge detection (HED) and richer convolution features for edge detection (RCF) methods, which are based on the analysis of the lateral output feature map, progressive encoding and decoding, and feature fusion from the shallow to the deep layer of the network, learning fine contour features and achieving end-to-end contour detection. The proposed method cannot only effectively highlight the main contour and suppress the texture background but also improve the detection efficiency of contour.ConclusionConvolution neural network can be explained by visual mechanism in some dimensions, such as convolution operation corresponding to the topological mapping of retinal visual information. Pooling operation is related to complex cells and simple cells in visual pathway. As such, convolution neural network is still a black box model which depends heavily on massive samples on the whole. Considering that the actual visual pathway is not simply a serial transmission of information but a fusion of the local and global characteristics of multi-channel visual information flow in the visual cortex, a Gauss pyramid decomposition model was constructed for sparse encoding of the spatial scale of visual information and obtaining low-resolution molecular maps representing the overall characteristics. Lateral suppression of non-classical receptive fields was used in the lateral geniculate region. A classical receptive field with directional selection characteristics was set up for isotropic suppression of background information and considering the ability of primary visual cortex for information processing in the visual radiation region. A two-dimensional Gauss derivative model was constructed to process the visual information by directional selection. The boundary response sub-graph representing local features was obtained. A multi-path convolution neural network was constructed considering the local details of external excitation and the layer-by-layer perception of overall information in the primary and advanced visual cortex. In the network, the fast detection path was composed of a sub-network Sparse-Net containing a pooling unit for sparse coding of the overall image contour. The detail detection path was composed of a sub-network Redundancy-Net containing a void convolution unit to realize image bureau. Redundancy enhanced the coding of part details. Finally, the feedback and fusion process of high-level visual cortex to visual information flow was simulated, and the above-mentioned multi-path convolution neural network response was fused and coded for overall perception and local detection fusion of the contour response. Finally, the fine perception results of the contour were obtained. Contour perception based on multi-path convolution neural network is helpful to further understand the mechanism of visual perception and is of great significance to weaken the black-box characteristics of the convolution neural network. Taking the natural scene image subject contour perception under complex texture background as an example, simulating the neural coding mechanism of multi-path cooperative work in primary visual pathway will help understand the intrinsic mechanism of visual system and its specific application in visual perception. This works provides a new idea for subsequent image understanding and analysis based on visual mechanism.关键词:contour detection;cavity convolution;convolution neural network (CNN);visual perception;feature fusion21|5|0更新时间:2024-05-07 -
 摘要:ObjectiveFace detection is a crucial step in various problems involving verification, identification, expression analysis. Although state-of-the-art convolutional neural network (CNN)-based face detectors exhibit improved detection accuracy, they are unsuitable to run on CPU devices because they are computationally prohibitive. Achieving high detection accuracy on CPUs and realizing real-time detection remain challenging. One of the reasons is that most back-bone networks in current face detection models are transferred from generic object detection networks. The models themselves are large and contain redundant information while modeling human faces. Moreover, the large search space of possible face locations and the variations of face sizes in one image require large computation for robust detection. Aiming at the fast and robust face detection problem under unconstrained conditions, this paper proposes a detection method based on a self-designed lightweight neural network.MethodThe instinct is to perform model compression and acceleration in deep networks without significantly decreasing the model performance. Efforts have been made to design compact networks.Resultsproved that changing the direction of convolution can save parameters in neural networks. In this study, depth-wise separable convolution, which was first introduced in MobileNets, is used for feature extraction. We then combine the idea of inception and residual connection to construct several feature extraction modules, which finally consist of our backbone network. Unlike standard convolutions, depth-wise separable convolution uses depth-wise convolution followed by 1×1 point-wise convolution to implement convolution operation. When the kernel size is 3×3, depth-wise separable convolution uses 8 to 9 times less computation than standard convolution. Given that the inception modules and residual connections have become essential in new networks, we also use them in our model to enrich receptive field. In our backbone network, depth-wise separable convolution is used to extract features; residual connection and inception modules are introduced to feature extraction module to enrich receptive fields. We design our own bottleneck modules (with different strides), inception modules, and residual inception modules based on depth-wise separable convolution in contrast to existing convolutional modules. The modules are then concatenated to form a complete network model. Inception modules, which are composed of bottleneck modules in parallel, aims at rapidly reducing the size of the input image. As the name suggests, residual inception modules are inception modules with residual connections and can decrease the sizes of feature maps and enrich receptive fields. Detection is carried out on multiple feature layers to increase the robustness to scale variants of faces in input images. While detecting faces, One-Stage detection strategy is applied for fast face detection. We conduct detection at three different levels of feature maps in a single feed forward manner, that is, we simultaneously classify and regress object areas at above-mentioned feature maps by using convolutions. When fine tuning the exact locations of the object areas, we need to set priori boxes, namely, default anchors, on the corresponding feature layers, and then use the bounding box regression algorithm to adjust the location and size of the anchors to make them closer to the locations of the ground truth. To reduce the number of default anchors and save model parameters, we set the default anchors according to the priori knowledge of face box ratio.ResultWe conduct and train our detection model based on TensorFlow deep learning library. Our model is trained on the WIDER FACE dataset with several data augmentation tricks. We test our model on the Face Detection Dataset and Benchmark and compare its mean average precision (mAP) and detection speed with several classical algorithms. The proposed method achieves real-time and high-precision detection on the CPU. Compared with typical deep learning methods, such as multitask cascaded convolutional networks (MTCNN), our method exhibits detection speed that increases to 25 frames per second on CPUs and mAP maintained at 0.892, which is higher than those obtained using most traditional methods and reaches a relatively high precision level.ConclusionFace detectors based on deep learning exhibit improved detection accuracy. However, the high computational complexity of these methods leads to their very slow detection speed on CPUs. This paper presents a fast and robust face detection method based on lightweight neural network. A simple and efficient convolution neural network is constructed by depth-wise separable convolution, and the ideas of inception and residual connection are also used to keep the model lightweight and powerful. The default anchors are set according to the characteristics of the face boxes while applying one-stage detection strategy. Experiments demonstrate that the proposed method can significantly reduce redundant operation in the detection process. With a detection speed of 25 frames/s on CPUs, the face detection method is robust and not only performs well in terms of accuracy but also shows fast detection speed with limited computing resources under unconstrained conditions.关键词:computer vision;face detection;convolutional neural network (CNN);compact model;One-Stage detection;default anchor12|4|5更新时间:2024-05-07
摘要:ObjectiveFace detection is a crucial step in various problems involving verification, identification, expression analysis. Although state-of-the-art convolutional neural network (CNN)-based face detectors exhibit improved detection accuracy, they are unsuitable to run on CPU devices because they are computationally prohibitive. Achieving high detection accuracy on CPUs and realizing real-time detection remain challenging. One of the reasons is that most back-bone networks in current face detection models are transferred from generic object detection networks. The models themselves are large and contain redundant information while modeling human faces. Moreover, the large search space of possible face locations and the variations of face sizes in one image require large computation for robust detection. Aiming at the fast and robust face detection problem under unconstrained conditions, this paper proposes a detection method based on a self-designed lightweight neural network.MethodThe instinct is to perform model compression and acceleration in deep networks without significantly decreasing the model performance. Efforts have been made to design compact networks.Resultsproved that changing the direction of convolution can save parameters in neural networks. In this study, depth-wise separable convolution, which was first introduced in MobileNets, is used for feature extraction. We then combine the idea of inception and residual connection to construct several feature extraction modules, which finally consist of our backbone network. Unlike standard convolutions, depth-wise separable convolution uses depth-wise convolution followed by 1×1 point-wise convolution to implement convolution operation. When the kernel size is 3×3, depth-wise separable convolution uses 8 to 9 times less computation than standard convolution. Given that the inception modules and residual connections have become essential in new networks, we also use them in our model to enrich receptive field. In our backbone network, depth-wise separable convolution is used to extract features; residual connection and inception modules are introduced to feature extraction module to enrich receptive fields. We design our own bottleneck modules (with different strides), inception modules, and residual inception modules based on depth-wise separable convolution in contrast to existing convolutional modules. The modules are then concatenated to form a complete network model. Inception modules, which are composed of bottleneck modules in parallel, aims at rapidly reducing the size of the input image. As the name suggests, residual inception modules are inception modules with residual connections and can decrease the sizes of feature maps and enrich receptive fields. Detection is carried out on multiple feature layers to increase the robustness to scale variants of faces in input images. While detecting faces, One-Stage detection strategy is applied for fast face detection. We conduct detection at three different levels of feature maps in a single feed forward manner, that is, we simultaneously classify and regress object areas at above-mentioned feature maps by using convolutions. When fine tuning the exact locations of the object areas, we need to set priori boxes, namely, default anchors, on the corresponding feature layers, and then use the bounding box regression algorithm to adjust the location and size of the anchors to make them closer to the locations of the ground truth. To reduce the number of default anchors and save model parameters, we set the default anchors according to the priori knowledge of face box ratio.ResultWe conduct and train our detection model based on TensorFlow deep learning library. Our model is trained on the WIDER FACE dataset with several data augmentation tricks. We test our model on the Face Detection Dataset and Benchmark and compare its mean average precision (mAP) and detection speed with several classical algorithms. The proposed method achieves real-time and high-precision detection on the CPU. Compared with typical deep learning methods, such as multitask cascaded convolutional networks (MTCNN), our method exhibits detection speed that increases to 25 frames per second on CPUs and mAP maintained at 0.892, which is higher than those obtained using most traditional methods and reaches a relatively high precision level.ConclusionFace detectors based on deep learning exhibit improved detection accuracy. However, the high computational complexity of these methods leads to their very slow detection speed on CPUs. This paper presents a fast and robust face detection method based on lightweight neural network. A simple and efficient convolution neural network is constructed by depth-wise separable convolution, and the ideas of inception and residual connection are also used to keep the model lightweight and powerful. The default anchors are set according to the characteristics of the face boxes while applying one-stage detection strategy. Experiments demonstrate that the proposed method can significantly reduce redundant operation in the detection process. With a detection speed of 25 frames/s on CPUs, the face detection method is robust and not only performs well in terms of accuracy but also shows fast detection speed with limited computing resources under unconstrained conditions.关键词:computer vision;face detection;convolutional neural network (CNN);compact model;One-Stage detection;default anchor12|4|5更新时间:2024-05-07 -
 摘要:ObjectiveMachine vision continues to innovate with the development of computer technology. Line structured light vision is a three-dimensional vision method and an important branch of machine vision technology. Line structured light vision has been widely used in industrial fields, such as industrial manufacturing, food processing, target tracking, defect detection, and robotics because the light stripe has obvious characteristics in images and is easy to extract and the light beam is actively controlled. Line structured light vision measurement is an active method that utilizes a controllable light source and a digital image. The method also uses the spatial position information of the light source and combines with the digital image and processing method of machine vision to obtain the three-dimensional coordinate information of the object. The information is obtained by extracting the center line of the line structured light stripe. The point coordinates on the center line of the light stripe are obtained so the center extraction of line structured light stripe is the key technology of the measurement. The center extraction directly affects the measurement accuracy of the line structured light vision system. In a vision measurement system based on line structured light, the light stripe often shows a phenomenon in which the width is not uniform, the brightness is not concentrated, and the discreteness is larger due to the influence of the quality of the light source and the surface characteristics of the object. In this regard, the precision of the center extracted by conventional methods is difficult to ensure. The increasing application of line structured light vision measurement has led scholars to focus on ensuring the accuracy and rapidity of center extraction. Because of the precision of traditional gray-gravity method is lower, an improved center extraction algorithm is proposed for accurate extraction of the center of the light stripe to rapidly obtain the sub-pixel center coordinates of the light stripe.MethodAn improved center extraction algorithm is proposed on the basis of the analysis of the gray-scale characteristics of the line structured light stripe to achieve accurate extraction of the center of the light stripe. This method is commonly used in the center extraction algorithm of light stripe. The method scans the stripe line by line or column by column, the gray center of gravity of each line or column is calculated, and the gray-gravity coordinates is used as the coordinates of the center of the light stripe. The traditional gray-gravity method calculates the gray center of gravity only in the lateral or longitudinal direction of the image without considering the normal direction of the light stripe. This work improves the traditional gray-gravity method. The direction template is used to obtain the normal direction of the light stripe, and the variable width is used to solve the problem of uneven distribution of width of the light stripe. An improved two-step extraction algorithm is proposed to extract the center of the light stripe. First, the effective line structured light stripe is separated from the original image by image difference method, where the background image is subtracted from the original image. The center of the light stripe is roughly extracted by the traditional gray-gravity method. The normal direction at the center point of the light stripe is finally centered by custom direction template. The direction template consists of four matrices representing directions, corresponding to the four directions of the light stripe at the pixel level, including horizontal and vertical and tilted to the left by 45ånd to the right by 45°. Finally, the center of the rough extraction is taken as the center. The pixel points participating in the calculation are determined according to the width of the light stripe in the normal direction. The gray center of gravity is used for secondary extraction along the normal direction. Finally, the center of the line structured light stripe is obtained.ResultA CCD camera, lens, line laser, and auxiliary mechanism are used to build a line structured light vision system. The structure of the laser and camera is that the former is perpendicular to the horizontal plane, and the latter is tilted relative to the laser. Line structured light is generated by the line laser, and the color CCD camera and the lens of fixed focus complete the collection of light stripe image. The line laser forms a straight light stripe, a discontinuous light stripe, and a curved light stripe by illuminating different objects. The proposed algorithm is used to extract the center of straight light stripe, discontinuous light stripe, and curved light stripe. Results of the center extraction are processed through MATLAB. In the center extraction experiment of the light stripe, the orientation of the acquired center line is approximately the same as that of the light stripe, which is in accordance with the expected center line of the light stripe. The proposed algorithm extracts the center of the light stripe closer to the center extracted by Steger method than that by traditional gray-gravity method. The running time of the algorithm is reduced by more than 3s than Steger method.ConclusionThis paper investigates the center extraction algorithm of line structured light stripe and proposes an improved center extraction algorithm of line structure light stripe on the basis of traditional gray-gravity method. The method can realize the sub-pixel level center extraction of straight light stripe, discontinuous light stripe, and curved light stripe. While maintaining less running time of program, the proposed method exhibits higher accuracy for center extraction of light stripe than traditional gray-gravity method.关键词:line structured light;sub-pixel level;gray-gravity method;center extraction algorithm of light stripe;direction template;normal direction13|4|5更新时间:2024-05-07
摘要:ObjectiveMachine vision continues to innovate with the development of computer technology. Line structured light vision is a three-dimensional vision method and an important branch of machine vision technology. Line structured light vision has been widely used in industrial fields, such as industrial manufacturing, food processing, target tracking, defect detection, and robotics because the light stripe has obvious characteristics in images and is easy to extract and the light beam is actively controlled. Line structured light vision measurement is an active method that utilizes a controllable light source and a digital image. The method also uses the spatial position information of the light source and combines with the digital image and processing method of machine vision to obtain the three-dimensional coordinate information of the object. The information is obtained by extracting the center line of the line structured light stripe. The point coordinates on the center line of the light stripe are obtained so the center extraction of line structured light stripe is the key technology of the measurement. The center extraction directly affects the measurement accuracy of the line structured light vision system. In a vision measurement system based on line structured light, the light stripe often shows a phenomenon in which the width is not uniform, the brightness is not concentrated, and the discreteness is larger due to the influence of the quality of the light source and the surface characteristics of the object. In this regard, the precision of the center extracted by conventional methods is difficult to ensure. The increasing application of line structured light vision measurement has led scholars to focus on ensuring the accuracy and rapidity of center extraction. Because of the precision of traditional gray-gravity method is lower, an improved center extraction algorithm is proposed for accurate extraction of the center of the light stripe to rapidly obtain the sub-pixel center coordinates of the light stripe.MethodAn improved center extraction algorithm is proposed on the basis of the analysis of the gray-scale characteristics of the line structured light stripe to achieve accurate extraction of the center of the light stripe. This method is commonly used in the center extraction algorithm of light stripe. The method scans the stripe line by line or column by column, the gray center of gravity of each line or column is calculated, and the gray-gravity coordinates is used as the coordinates of the center of the light stripe. The traditional gray-gravity method calculates the gray center of gravity only in the lateral or longitudinal direction of the image without considering the normal direction of the light stripe. This work improves the traditional gray-gravity method. The direction template is used to obtain the normal direction of the light stripe, and the variable width is used to solve the problem of uneven distribution of width of the light stripe. An improved two-step extraction algorithm is proposed to extract the center of the light stripe. First, the effective line structured light stripe is separated from the original image by image difference method, where the background image is subtracted from the original image. The center of the light stripe is roughly extracted by the traditional gray-gravity method. The normal direction at the center point of the light stripe is finally centered by custom direction template. The direction template consists of four matrices representing directions, corresponding to the four directions of the light stripe at the pixel level, including horizontal and vertical and tilted to the left by 45ånd to the right by 45°. Finally, the center of the rough extraction is taken as the center. The pixel points participating in the calculation are determined according to the width of the light stripe in the normal direction. The gray center of gravity is used for secondary extraction along the normal direction. Finally, the center of the line structured light stripe is obtained.ResultA CCD camera, lens, line laser, and auxiliary mechanism are used to build a line structured light vision system. The structure of the laser and camera is that the former is perpendicular to the horizontal plane, and the latter is tilted relative to the laser. Line structured light is generated by the line laser, and the color CCD camera and the lens of fixed focus complete the collection of light stripe image. The line laser forms a straight light stripe, a discontinuous light stripe, and a curved light stripe by illuminating different objects. The proposed algorithm is used to extract the center of straight light stripe, discontinuous light stripe, and curved light stripe. Results of the center extraction are processed through MATLAB. In the center extraction experiment of the light stripe, the orientation of the acquired center line is approximately the same as that of the light stripe, which is in accordance with the expected center line of the light stripe. The proposed algorithm extracts the center of the light stripe closer to the center extracted by Steger method than that by traditional gray-gravity method. The running time of the algorithm is reduced by more than 3s than Steger method.ConclusionThis paper investigates the center extraction algorithm of line structured light stripe and proposes an improved center extraction algorithm of line structure light stripe on the basis of traditional gray-gravity method. The method can realize the sub-pixel level center extraction of straight light stripe, discontinuous light stripe, and curved light stripe. While maintaining less running time of program, the proposed method exhibits higher accuracy for center extraction of light stripe than traditional gray-gravity method.关键词:line structured light;sub-pixel level;gray-gravity method;center extraction algorithm of light stripe;direction template;normal direction13|4|5更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveCloth simulation has a long history of research and is important in the fields of physical simulation, computer games, virtual reality, etc. With the continuous development of computer software and hardware technology, virtual simulation has become a research hotspot in the field of computer graphics. As a classic flexible object, cloth can be seen everywhere in people's lives. Effectively and realistically simulating the movement of fabrics (such as flags, curtains, tablecloths, etc.) on a computer remains challenging and needs to be solved. Realistic virtual human costume animation can bring a strong visual reality to virtual characters and has broad application prospects in cultural creative fields, such as animation, game entertainment, film and television. In addition, the method can be applied to the apparel industry for virtual clothing design and display. In recent years, with the emergence of applications, such as virtual reality and human-computer interaction, especially the rise of network virtual environments with high user-interaction characteristics, the demand for real-time virtual human costume animations, such as online games and distributed collaborative design environments, has increased. Neural network models are used to train the data and improve the simulation rate of fabrics for multi-precision cloth division threshold according to the degree of deformation of different regions, rather than manual threshold division, during the cloth simulation. However, the traditional physics-based method is still used to calculate the particle position in cloth simulation. Physics-based simulation methods are computationally complex, time consuming, and perform poorly in real time. Although considerable research has been conducted to improve physics-based methods, such as the recent alternating direction method of multipliers (ADMM) algorithm, further improvements can be made. This paper proposes a layered simulation of cloth based on the random forest model, instead of the physics-based simulation method.MethodWe present fabric layered modeling method based on random forest algorithm, and its working principle is as follows. The initial levels of fabric are simulated using traditional physics-based methods. Implicit integration method is used to calculate the initial position of each particle in the initial horizontal fabric. The index value of the triangle generated by the above steps is recorded as 0. High levels of fabric are then simulated using the random forest model. The random forest algorithm is applied to predict the position of each particle in the initial horizontal fabric in a higher level of fabric. One is added to the index value of the newly generated triangle in the above step. This article uses the
摘要:ObjectiveCloth simulation has a long history of research and is important in the fields of physical simulation, computer games, virtual reality, etc. With the continuous development of computer software and hardware technology, virtual simulation has become a research hotspot in the field of computer graphics. As a classic flexible object, cloth can be seen everywhere in people's lives. Effectively and realistically simulating the movement of fabrics (such as flags, curtains, tablecloths, etc.) on a computer remains challenging and needs to be solved. Realistic virtual human costume animation can bring a strong visual reality to virtual characters and has broad application prospects in cultural creative fields, such as animation, game entertainment, film and television. In addition, the method can be applied to the apparel industry for virtual clothing design and display. In recent years, with the emergence of applications, such as virtual reality and human-computer interaction, especially the rise of network virtual environments with high user-interaction characteristics, the demand for real-time virtual human costume animations, such as online games and distributed collaborative design environments, has increased. Neural network models are used to train the data and improve the simulation rate of fabrics for multi-precision cloth division threshold according to the degree of deformation of different regions, rather than manual threshold division, during the cloth simulation. However, the traditional physics-based method is still used to calculate the particle position in cloth simulation. Physics-based simulation methods are computationally complex, time consuming, and perform poorly in real time. Although considerable research has been conducted to improve physics-based methods, such as the recent alternating direction method of multipliers (ADMM) algorithm, further improvements can be made. This paper proposes a layered simulation of cloth based on the random forest model, instead of the physics-based simulation method.MethodWe present fabric layered modeling method based on random forest algorithm, and its working principle is as follows. The initial levels of fabric are simulated using traditional physics-based methods. Implicit integration method is used to calculate the initial position of each particle in the initial horizontal fabric. The index value of the triangle generated by the above steps is recorded as 0. High levels of fabric are then simulated using the random forest model. The random forest algorithm is applied to predict the position of each particle in the initial horizontal fabric in a higher level of fabric. One is added to the index value of the newly generated triangle in the above step. This article uses the$\sqrt 3 $ 关键词:cloth simulation;multi-resolution cloth;hierarchical cloth simulation;machine learning;random forest11|4|1更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveThe four components of a geometric-optical model, i.e., lit vegetation, lit soil, shaded vegetation, and shaded soil, could be observed by optical sensors in nature light condition. The four components are the important parameters of the geometric-optical model. Images obtained from a downward-looking canopy digital camera serve as an important source to derive the four components. A rapid and accurate method for extracting the four components for canopy parameter inversion, including the leaf area index and average leaf inclination angle, is proposed. However, most of the algorithms only distinguish the vegetation and soil (i.e., two-class task) pixels, and the classification error is large under the condition of complex natural light. The main error is produced by specular reflection pixels, which are nearly white in the image, and shadow-canopy pixels, which are nearly black in the image. With the rapid development of deep learning, the accuracy of image semantic segmentation, that is, the classification of pixels is improved significantly. Therefore, the error introduced by specular reflection pixels and shadow canopy pixels may be reduced.MethodSeveral two-class and four-component extraction algorithms are implemented on the basis of the convolutional neural network and threshold method. In the proposed methods, SHAR-LABFVC is a threshold method, and it is used to fulfill two-class classification. When an image is captured in a direct light condition, the V channel data from the HSV color model present a double-peak feature in histogram. Thus, on the basis of the result of SHAR-LABFVC, the Otsu method is applied to the V channel data to classify the four components. Thus, the two-stepwise procedure is referred to as the double-threshold algorithm. Another algorithm is the U-Net, which is a neural network-based method and is used to extract the two-class and four-component algorithms. We obtain two models based on U-Net. One is trained using RGB image data, which is referred as U-Net, and another is trained using RGB-V image data, which is referred to as U-Net-V. RGB-V data are images, which combine RGB and V channel data of HSV. Finally, to fully use the advantages of the supervised and unsupervised algorithms, a hybrid method, which combines U-Net and the threshold method, is proposed and used to classify the four components, similar to that done in the double-threshold algorithm. We use U-Net to obtain vegetation and soil pixels. Then, the Otsu algorithm is used to acquire four components.ResultThe validation experiment is conducted using 18 images (1 800 subgraphs), and the performance is evaluated using two metrics, i.e., root mean square error (RMSE) and Pearson's r (r). Results show that U-Net-V and hybrid are optimal and that they have close RMSE values (0.06 and 0.07) and r (0.95 and 0.94); U-Net and the double-threshold method have close RMSE values (0.09 and 0.08) and the same r (0.88). In the two-class experiment, the classification accuracy of U-Net is 91%, and that of SHAR-LABFVC is 85%. For the two-class experiment, we use F1 score to evaluate the result of U-Net and SHAR-LABFVC. The vegetation's F1 score of U-Net is 0.87, which is 0.07 higher than that of SHAR-LABFVC. The soil's F1 score of U-Net is 0.92, which is 0.03 higher than that of SHAR-LABFVC.ConclusionThe comparative experiments indicate that U-Net is superior to other methods in terms of dealing with digital images under complex natural light conditions in a two-class task. Compared with the SHAR-LABFVC method, U-Net can classify specular reflection pixels effectively and produce more stable and accurate classification results. The effective performance of U-Net in the two-class task is attributed to the convolution structure, which can utilize information from local image data and construct complex features by simple features. On the contrary, threshold methods only use one threshold to classify all pixels. The error will be high when some pixels disturb the distribution of the histogram. In the four-component extraction task, the hybrid algorithm has better result than U-Net and double-threshold method given the excellent performance of U-Net in the two-class task, whereas U-Net-V can produce the best results. U-Net can achieve an excellent performance by adding V channel data to raw RGB images. We summarize the RGB values of pixels and find that shadow leaf maybe close to sun lit leaf in a 3D space. Combined with the result of the confusion matrix, the shadow features are difficult to learn in our data set. Thus, we use RGB-V data to reduce the difficulty of learning shadow features and obtain the U-Net-V model. We suggest that the double-threshold method is the best candidate method to extract the four components under the condition that training samples are unavailable. For the case in which sufficient training samples are available, using the U-Net-V method to extract the four components is recommended.关键词:four component of geometric-optical model;convolutional neural network (CNN);threshold method;canopy image processing;semantic segmentation14|4|1更新时间:2024-05-07
摘要:ObjectiveThe four components of a geometric-optical model, i.e., lit vegetation, lit soil, shaded vegetation, and shaded soil, could be observed by optical sensors in nature light condition. The four components are the important parameters of the geometric-optical model. Images obtained from a downward-looking canopy digital camera serve as an important source to derive the four components. A rapid and accurate method for extracting the four components for canopy parameter inversion, including the leaf area index and average leaf inclination angle, is proposed. However, most of the algorithms only distinguish the vegetation and soil (i.e., two-class task) pixels, and the classification error is large under the condition of complex natural light. The main error is produced by specular reflection pixels, which are nearly white in the image, and shadow-canopy pixels, which are nearly black in the image. With the rapid development of deep learning, the accuracy of image semantic segmentation, that is, the classification of pixels is improved significantly. Therefore, the error introduced by specular reflection pixels and shadow canopy pixels may be reduced.MethodSeveral two-class and four-component extraction algorithms are implemented on the basis of the convolutional neural network and threshold method. In the proposed methods, SHAR-LABFVC is a threshold method, and it is used to fulfill two-class classification. When an image is captured in a direct light condition, the V channel data from the HSV color model present a double-peak feature in histogram. Thus, on the basis of the result of SHAR-LABFVC, the Otsu method is applied to the V channel data to classify the four components. Thus, the two-stepwise procedure is referred to as the double-threshold algorithm. Another algorithm is the U-Net, which is a neural network-based method and is used to extract the two-class and four-component algorithms. We obtain two models based on U-Net. One is trained using RGB image data, which is referred as U-Net, and another is trained using RGB-V image data, which is referred to as U-Net-V. RGB-V data are images, which combine RGB and V channel data of HSV. Finally, to fully use the advantages of the supervised and unsupervised algorithms, a hybrid method, which combines U-Net and the threshold method, is proposed and used to classify the four components, similar to that done in the double-threshold algorithm. We use U-Net to obtain vegetation and soil pixels. Then, the Otsu algorithm is used to acquire four components.ResultThe validation experiment is conducted using 18 images (1 800 subgraphs), and the performance is evaluated using two metrics, i.e., root mean square error (RMSE) and Pearson's r (r). Results show that U-Net-V and hybrid are optimal and that they have close RMSE values (0.06 and 0.07) and r (0.95 and 0.94); U-Net and the double-threshold method have close RMSE values (0.09 and 0.08) and the same r (0.88). In the two-class experiment, the classification accuracy of U-Net is 91%, and that of SHAR-LABFVC is 85%. For the two-class experiment, we use F1 score to evaluate the result of U-Net and SHAR-LABFVC. The vegetation's F1 score of U-Net is 0.87, which is 0.07 higher than that of SHAR-LABFVC. The soil's F1 score of U-Net is 0.92, which is 0.03 higher than that of SHAR-LABFVC.ConclusionThe comparative experiments indicate that U-Net is superior to other methods in terms of dealing with digital images under complex natural light conditions in a two-class task. Compared with the SHAR-LABFVC method, U-Net can classify specular reflection pixels effectively and produce more stable and accurate classification results. The effective performance of U-Net in the two-class task is attributed to the convolution structure, which can utilize information from local image data and construct complex features by simple features. On the contrary, threshold methods only use one threshold to classify all pixels. The error will be high when some pixels disturb the distribution of the histogram. In the four-component extraction task, the hybrid algorithm has better result than U-Net and double-threshold method given the excellent performance of U-Net in the two-class task, whereas U-Net-V can produce the best results. U-Net can achieve an excellent performance by adding V channel data to raw RGB images. We summarize the RGB values of pixels and find that shadow leaf maybe close to sun lit leaf in a 3D space. Combined with the result of the confusion matrix, the shadow features are difficult to learn in our data set. Thus, we use RGB-V data to reduce the difficulty of learning shadow features and obtain the U-Net-V model. We suggest that the double-threshold method is the best candidate method to extract the four components under the condition that training samples are unavailable. For the case in which sufficient training samples are available, using the U-Net-V method to extract the four components is recommended.关键词:four component of geometric-optical model;convolutional neural network (CNN);threshold method;canopy image processing;semantic segmentation14|4|1更新时间:2024-05-07 -
 摘要:ObjectiveHyperspectral remote sensing is a technique based on the principle of spectrometry to obtain some very narrow and continuous image data in the ultraviolet, visible, near-infrared and mid-infrared regions of the electromagnetic spectrum. Hyperspectral imaging technology combines the traditional two-dimensional image remote sensing technology and spectral technology to obtain the surface image and the spectral information at the same time. Hyperspectral images(HSI) can not only classify and recognize ground objects with high spectral diagnostic ability, but also contain rich information, which makes them widely used in many fields. The unique characteristics of hyperspectral images bring convenience and advantages to the acquisition of geographic information and the identification of ground objects. Unfortunately, there are also some difficulties in hyperspectral technology:the amount of data obtained by hyperspectral sensors is large, but it is often interfered by various factors during the acquisition process, such as environment and equipment, so that the data is polluted, which reduces the data availability and limits the subsequent application of hyperspectral sensors in various fields. Therefore, reducing noise pollution of data, obtaining more effective image information and increasing the utilization rate of image data are important links to ensure that hyperspectral images can play an important role in subsequent applications.MethodHundreds of continuous spectral bands image the target region at the same time, so that the hyperspectral image can provide spatial and spectral domain information. Moreover, the continuity of hyperspectral images in spatial domain and spectral domain makes the correlation between adjacent channels strong, that is a low-rank property. Based on this feature, spectral low-rank priors or spatial low-rank priors are considered to establish the restoration model for hyperspectral data restoration. Undoubtedly, the combination of the two models can achieve better recovery effect. But now, although the recovery method based on nuclear norm has a strong theory to ensure that excellent results can be obtained, due to the defects in the application, the second-best results can be obtained in the actual application. In the rank function, different eigenvalues contain different information of the observation data, among which the larger eigenvalues mainly contain the original data information, while the smaller eigenvalues mainly contain the noise information of the observation data. However, the restoration method based on nuclear norm minimization treats all the eigenvalues equally, and the corresponding model algorithm uses the same threshold to shrink the eigenvalues, thus losing a large amount of image information under the premise of false noise, which is an important defect of current mainstream denoising methods. In addition, some theoretical requirements of the nuclear norm are hardly satisfactory in practice. Considering truncated nuclear norm regularization is more robust and accurate than nuclear norm for the rank function's approximation, the application of truncated norm in hyperspectral denoising is still in the stage of using the low-rank priori information of hyperspectral spectrum for denoising, and the spatial low-rank priori information of hyperspectral is not used. The results of the existing methods are not satisfactory. We improve the current low rank based prior information in the spatial domain and based on the low rank based priori information in the spectral domain, a low rank representation model is proposed to depress the sparse noises. Based on the low rank based priori information in the spatial domain, the total variation regularization method is proposed to depress the density noises. Finally combined with the advantages of the two model we propose the model with truncated nuclear norm minimization and total variation regularization. This model not only retains the processing advantages of current mainstream models, but also makes full use of the truncated nuclear norm. As for the algorithm, alternating direction method of multipliers(ADMM) is a simple and effective method for distributed convex optimization. This method can decompose the original function and the amplification function, so as to optimize in parallel under more general assumptions. Therefore, the paper chooses ADMM method to solve the model. In order to verify the denoising effect of the model proposed in this paper, as well as the universality and generalization of the model, two truly collected hyperspectral sets were selected for the experiment. Gaussian noise, salt-pepper noise and dead line noise with different intensity are added to simulate noise pollution in real situation. In addition, different size images are selected for experiments to test the denoising effect of various methods.ResultThe restoration results of the proposed method are compared with the latest method, the peak signal to noise ratio (PSNR) index and the structure similarity (SSIM) index are improved 3.2 dB and 0.22. It can be seen from the experimental results that the gaussian white noise is still left after the traditional method is processed, while the image processed by the method in this paper effectively restrains the mixed noise. Not only the visual image shows that the de-noising result of the model proposed in this paper is more detailed than that recovered by total variation-regularized low-rank matrix factorization (LRTV) and other methods. PSNR and SSIM index of each channel also confirmed this result.In addition, the method proposed in this paper has stronger image restoration ability under higher noise, and no outliers appear. It can effectively improve the image quality, and get good recovery results for images containing various noises and images of different sizes, the peak signal to noise ratio is improved 1.33 dB, which shows that the model has good generalization and universality.ConclusionThe low rank based priori information in the spectral domain is more robust and the model in this paper relies on the low rank based priori knowledge in both spectral and spatial domain tightly so that it can efficiently depresses the sparse noise and the density noise in the degraded hyperspectral remote sensing images. Experiments show that truncated nuclear norm can better control noise error by using the sum of smaller eigenvalues, so as to better represent the characteristics of data. Experiments with different noises added to hyperspectral data of different sizes also show that this method has excellent denoising effect.关键词:hyperspectral remote sensing image;image restoration;low-rankprior;truncated nuclear norm regularization;total variation(TV);regularization method13|6|5更新时间:2024-05-07
摘要:ObjectiveHyperspectral remote sensing is a technique based on the principle of spectrometry to obtain some very narrow and continuous image data in the ultraviolet, visible, near-infrared and mid-infrared regions of the electromagnetic spectrum. Hyperspectral imaging technology combines the traditional two-dimensional image remote sensing technology and spectral technology to obtain the surface image and the spectral information at the same time. Hyperspectral images(HSI) can not only classify and recognize ground objects with high spectral diagnostic ability, but also contain rich information, which makes them widely used in many fields. The unique characteristics of hyperspectral images bring convenience and advantages to the acquisition of geographic information and the identification of ground objects. Unfortunately, there are also some difficulties in hyperspectral technology:the amount of data obtained by hyperspectral sensors is large, but it is often interfered by various factors during the acquisition process, such as environment and equipment, so that the data is polluted, which reduces the data availability and limits the subsequent application of hyperspectral sensors in various fields. Therefore, reducing noise pollution of data, obtaining more effective image information and increasing the utilization rate of image data are important links to ensure that hyperspectral images can play an important role in subsequent applications.MethodHundreds of continuous spectral bands image the target region at the same time, so that the hyperspectral image can provide spatial and spectral domain information. Moreover, the continuity of hyperspectral images in spatial domain and spectral domain makes the correlation between adjacent channels strong, that is a low-rank property. Based on this feature, spectral low-rank priors or spatial low-rank priors are considered to establish the restoration model for hyperspectral data restoration. Undoubtedly, the combination of the two models can achieve better recovery effect. But now, although the recovery method based on nuclear norm has a strong theory to ensure that excellent results can be obtained, due to the defects in the application, the second-best results can be obtained in the actual application. In the rank function, different eigenvalues contain different information of the observation data, among which the larger eigenvalues mainly contain the original data information, while the smaller eigenvalues mainly contain the noise information of the observation data. However, the restoration method based on nuclear norm minimization treats all the eigenvalues equally, and the corresponding model algorithm uses the same threshold to shrink the eigenvalues, thus losing a large amount of image information under the premise of false noise, which is an important defect of current mainstream denoising methods. In addition, some theoretical requirements of the nuclear norm are hardly satisfactory in practice. Considering truncated nuclear norm regularization is more robust and accurate than nuclear norm for the rank function's approximation, the application of truncated norm in hyperspectral denoising is still in the stage of using the low-rank priori information of hyperspectral spectrum for denoising, and the spatial low-rank priori information of hyperspectral is not used. The results of the existing methods are not satisfactory. We improve the current low rank based prior information in the spatial domain and based on the low rank based priori information in the spectral domain, a low rank representation model is proposed to depress the sparse noises. Based on the low rank based priori information in the spatial domain, the total variation regularization method is proposed to depress the density noises. Finally combined with the advantages of the two model we propose the model with truncated nuclear norm minimization and total variation regularization. This model not only retains the processing advantages of current mainstream models, but also makes full use of the truncated nuclear norm. As for the algorithm, alternating direction method of multipliers(ADMM) is a simple and effective method for distributed convex optimization. This method can decompose the original function and the amplification function, so as to optimize in parallel under more general assumptions. Therefore, the paper chooses ADMM method to solve the model. In order to verify the denoising effect of the model proposed in this paper, as well as the universality and generalization of the model, two truly collected hyperspectral sets were selected for the experiment. Gaussian noise, salt-pepper noise and dead line noise with different intensity are added to simulate noise pollution in real situation. In addition, different size images are selected for experiments to test the denoising effect of various methods.ResultThe restoration results of the proposed method are compared with the latest method, the peak signal to noise ratio (PSNR) index and the structure similarity (SSIM) index are improved 3.2 dB and 0.22. It can be seen from the experimental results that the gaussian white noise is still left after the traditional method is processed, while the image processed by the method in this paper effectively restrains the mixed noise. Not only the visual image shows that the de-noising result of the model proposed in this paper is more detailed than that recovered by total variation-regularized low-rank matrix factorization (LRTV) and other methods. PSNR and SSIM index of each channel also confirmed this result.In addition, the method proposed in this paper has stronger image restoration ability under higher noise, and no outliers appear. It can effectively improve the image quality, and get good recovery results for images containing various noises and images of different sizes, the peak signal to noise ratio is improved 1.33 dB, which shows that the model has good generalization and universality.ConclusionThe low rank based priori information in the spectral domain is more robust and the model in this paper relies on the low rank based priori knowledge in both spectral and spatial domain tightly so that it can efficiently depresses the sparse noise and the density noise in the degraded hyperspectral remote sensing images. Experiments show that truncated nuclear norm can better control noise error by using the sum of smaller eigenvalues, so as to better represent the characteristics of data. Experiments with different noises added to hyperspectral data of different sizes also show that this method has excellent denoising effect.关键词:hyperspectral remote sensing image;image restoration;low-rankprior;truncated nuclear norm regularization;total variation(TV);regularization method13|6|5更新时间:2024-05-07 -
 摘要:ObjectiveRemote sensing data have obvious big data characteristics owing to the continuous improvement in the spatial, temporal, spectral, and radiometric resolution for remote sensing data. The seamless integration and deployment of remote sensing image processing algorithms are becoming a big challenge in the era of remote sensing big data and cloud computing due to diverse and complex remote sensing image processing algorithms. Virtualization technology provides a feasible solution to the above problems. Docker is a new open source virtualization container technology. Compared with traditional virtualization technologies, such as KVM (kernel-based virtual machine), Docker container is a virtualizing operating system and has the advantages of lightweight and resource efficiency. In this paper, we propose a system framework for rapid integration of remote sensing algorithms on the basis of Docker container.MethodThe framework consists of an automated image encapsulation mechanism for remote sensing algorithms, a unified image distribution management, a containerized orchestration service for production of remote sensing information product, and a container scheduling scheme about daemons. We use the Dockerfile files to package automatically the base image, program dependencies, and remote sensing algorithm programs to build a new image layer by layer. A container is made up of a number of readable layers and a readable and writable layer. The Docker image is a read-only Docker container template that contains the file system structure, and its contents needed to start the Docker container. An image is the basis for starting a container. The Docker image is a static view of the Docker container, which is the running state of the Docker image. We upload the image to the repository such as "DockerHub" via the "Docker push" command. Users on other machines download the corresponding image to the local via the "Docker pull" command. The image arrangement refers to the serial connection of the associated containers in a logical sequence according to the production of the remote sensing information product. The image is represented by a compose file, which consists of three parts:version, services, and networks. The compose file is used to reproduce and share about the running process of flow. We design a container operation scheme based on the JAVA platform. First, the user sends an order task to the back end through the front-end interactive interface and backend parsing commands. The backend creates a specific compose.yaml file based on the template file. Finally, the running image of the remote sensing algorithm program is containerized. Production of NDVI and NDWI information products based on Landsat5 data is an example of prototype system and containerized production. In this experiment, remote sensing data are distributed storage using the distributed file system GlusterFS. The system consists of three server hosts and one client host. The server host is used to store data in a distributed manner. The client host reads the data of the server host by mounting. The client host is also the environment where the Docker container is integrated and running. In this experiment, Landsat5 DN value data are used as input data. The final output data are the binarized product data. The algorithm programs used include radiation correction programs written in C++, typical feature inversion index programs written in Python, and binarization programs written in MATLAB. We perform computational and deployment performance experiments, such as runtime, memory usage, and deployment efficiency in Docker virtualization environment, KVM virtual machine environment, and physical machine environment. Deployment efficiency refers to the configuration complexity required to deploy the same multiple applications in different environments. Run time is the time that takes to cycle through the same application in three environments. Memory usage refers to the number of memory usage of the same application running in parallel in the three environments.ResultAlmost no differences in performance are observed in system load metrics, such as operational efficiency and memory footprint, running applications in Docker container virtualization environments, and physical machine environments. The three environments are better than the KVM virtual machine environment. However, when installing and deploying a production environment on a new machine, the Docker container environment and the KVM virtual machine environment can reduce the amount of configuration and facilitate program migration and reuse compared with the physical machine environment.ConclusionThe containerized system integration method can solve effectively the problem of difficulty in the integration and deployment of remote sensing algorithm programs. The Docker container runs different remote sensing algorithm programs, which enable resource isolation and eliminate the problem of dependency conflicts among different programs. The deployment of applications using the Docker container enables one-click deployment and operation, which facilitates the reusability of remote sensing algorithm programs and facilitates software-level sharing. Our containerized framework is promising for improving the efficiency and seamlessness of system integration compared with physical and virtual machine environments.关键词:Docker container;algorithm integration;remote sensing product production;virtualization;reusability12|4|0更新时间:2024-05-07
摘要:ObjectiveRemote sensing data have obvious big data characteristics owing to the continuous improvement in the spatial, temporal, spectral, and radiometric resolution for remote sensing data. The seamless integration and deployment of remote sensing image processing algorithms are becoming a big challenge in the era of remote sensing big data and cloud computing due to diverse and complex remote sensing image processing algorithms. Virtualization technology provides a feasible solution to the above problems. Docker is a new open source virtualization container technology. Compared with traditional virtualization technologies, such as KVM (kernel-based virtual machine), Docker container is a virtualizing operating system and has the advantages of lightweight and resource efficiency. In this paper, we propose a system framework for rapid integration of remote sensing algorithms on the basis of Docker container.MethodThe framework consists of an automated image encapsulation mechanism for remote sensing algorithms, a unified image distribution management, a containerized orchestration service for production of remote sensing information product, and a container scheduling scheme about daemons. We use the Dockerfile files to package automatically the base image, program dependencies, and remote sensing algorithm programs to build a new image layer by layer. A container is made up of a number of readable layers and a readable and writable layer. The Docker image is a read-only Docker container template that contains the file system structure, and its contents needed to start the Docker container. An image is the basis for starting a container. The Docker image is a static view of the Docker container, which is the running state of the Docker image. We upload the image to the repository such as "DockerHub" via the "Docker push" command. Users on other machines download the corresponding image to the local via the "Docker pull" command. The image arrangement refers to the serial connection of the associated containers in a logical sequence according to the production of the remote sensing information product. The image is represented by a compose file, which consists of three parts:version, services, and networks. The compose file is used to reproduce and share about the running process of flow. We design a container operation scheme based on the JAVA platform. First, the user sends an order task to the back end through the front-end interactive interface and backend parsing commands. The backend creates a specific compose.yaml file based on the template file. Finally, the running image of the remote sensing algorithm program is containerized. Production of NDVI and NDWI information products based on Landsat5 data is an example of prototype system and containerized production. In this experiment, remote sensing data are distributed storage using the distributed file system GlusterFS. The system consists of three server hosts and one client host. The server host is used to store data in a distributed manner. The client host reads the data of the server host by mounting. The client host is also the environment where the Docker container is integrated and running. In this experiment, Landsat5 DN value data are used as input data. The final output data are the binarized product data. The algorithm programs used include radiation correction programs written in C++, typical feature inversion index programs written in Python, and binarization programs written in MATLAB. We perform computational and deployment performance experiments, such as runtime, memory usage, and deployment efficiency in Docker virtualization environment, KVM virtual machine environment, and physical machine environment. Deployment efficiency refers to the configuration complexity required to deploy the same multiple applications in different environments. Run time is the time that takes to cycle through the same application in three environments. Memory usage refers to the number of memory usage of the same application running in parallel in the three environments.ResultAlmost no differences in performance are observed in system load metrics, such as operational efficiency and memory footprint, running applications in Docker container virtualization environments, and physical machine environments. The three environments are better than the KVM virtual machine environment. However, when installing and deploying a production environment on a new machine, the Docker container environment and the KVM virtual machine environment can reduce the amount of configuration and facilitate program migration and reuse compared with the physical machine environment.ConclusionThe containerized system integration method can solve effectively the problem of difficulty in the integration and deployment of remote sensing algorithm programs. The Docker container runs different remote sensing algorithm programs, which enable resource isolation and eliminate the problem of dependency conflicts among different programs. The deployment of applications using the Docker container enables one-click deployment and operation, which facilitates the reusability of remote sensing algorithm programs and facilitates software-level sharing. Our containerized framework is promising for improving the efficiency and seamlessness of system integration compared with physical and virtual machine environments.关键词:Docker container;algorithm integration;remote sensing product production;virtualization;reusability12|4|0更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0