
最新刊期
卷 23 , 期 9 , 2018
-
 摘要:ObjectiveRelief art is a type of sculpture that can be categorized into high, bas, and sunken reliefs in accordance with space structure and application. High relief is characterized by height above 50% of the original mesh depth. Bas relief has a height below 50% of the original mesh depth. Sunken relief is always obtained by carving an object into a background plane. In modern industrial production, relief has a broad application in producing nameplates, coins, architectural decorations, and others. Currently, two main methods are available to generate digital reliefs:2D image-based and 3D mesh-based methods. Most 2D image-based methods usually generate digital relief by feature extraction and 3D reconstruction technologies. However, 2D images cannot convey the depth of 3D mesh. 3D mesh-based methods always obtain digital relief by compression and detail preservation technologies. Digital relief generation based on 3D mesh is a recently emerging research topic with the development of digital technology and 3D printing. This method has become one of the hot topics to generate digital reliefs from 3D models in computer graphic fields. Therefore, this paper presents a literature review to support scholars in gaining further insights into the frontier development of the topic.MethodThree types of digital relief generation techniques were systematically analyzed, and the key technologies, problems, and solutions in the process of digital bas-relief generation were examined and compared. Although digital high-relief and bas-relief generation has been widely investigated, spaces remain to be explored for the sunken relief. Currently, some drawbacks are present in generating sunken reliefs with a complex model:detailed information is missing, the line type has not achieved a good embodied form, the transition between the lines and the body was not achieved, and the generated sunken relief is not vivid and natural. This paper provides a solution for generating digital sunken reliefs from 3D complex models. To investigate the technology of optimal relief generation, this paper starts from the character animation sequence and calculates the optimal action and perspective of the scene with the information entropy theory aiming to recover the creation process of artists. The investigation work aims to provide a feasible solution for user customization and 3D printing relief production services.ResultThis process is one of the main methods to generate a piece of relief from 3D models. Considering high and bas reliefs, numerous researchers have studied several methods, which we categorize into two classes. One is based on human visual information and relief is generated by compressing the 3D model. Although this algorithm is simple, most relief details are lost during compression. The other class is based on several geometrical operations. This algorithm is good in preserving details but always needs to solve the Poisson equation, which requires several calculations and has low efficiency. Furthermore, this algorithm can easily generate local deformation, and sometimes, human interactions, such as adjusting parameters, are necessary to achieve the desired effect. At present, the process of how to obtain a vivid effect through compression and detail preservation has been a hot topic. Sunken relief always conveys information by lines. However, existing methods have not considered the manifestations of three types of lines, namely, main, inner, and fine shadow lines. A simple line arrangement could not show a complete sunken relief. Moreover, transition between the lines is necessary to generate a vivid and natural sunken relief. For these problems, some research is consequential, such as investigating different embodied forms of various types of lines and setting different engraving depths and locations for various types of lines for a smooth transition between the lines and the body. On the basis of relief generation, two important studies exist, that is, the selections of best attitude and perspective. In addition, the process of how to achieve an optimal relief through intelligent algorithms is worth discussing. This case will reduce the difficulty encountered by artists and sculptors in the process of carving. Selecting the best posture from an animation sequence is similar to the problem of key frame extraction. Furthermore, the best perspective can provide more important information than other perspectives. Thus, using the information entropy theory is a feasible scheme for optimal relief generation from an animation sequence. In addition, current digital relief generation methods cannot composite models considering the spatial structure and importance of characters. Combination model relief should not be generated by simply compositing several models together.ConclusionGenerating a digital relief from 3D models is an effective method. However, the processes of obtaining additional details and line types, creating the transition between lines, and intelligently generating the 3D bas relief automatically from the 3D animation sequence also pose certain problems.关键词:bas relief;sunken relief;details reservation;non-linear compression;the best perspectives;the best attitude;3D printing13|19|2更新时间:2024-05-07
摘要:ObjectiveRelief art is a type of sculpture that can be categorized into high, bas, and sunken reliefs in accordance with space structure and application. High relief is characterized by height above 50% of the original mesh depth. Bas relief has a height below 50% of the original mesh depth. Sunken relief is always obtained by carving an object into a background plane. In modern industrial production, relief has a broad application in producing nameplates, coins, architectural decorations, and others. Currently, two main methods are available to generate digital reliefs:2D image-based and 3D mesh-based methods. Most 2D image-based methods usually generate digital relief by feature extraction and 3D reconstruction technologies. However, 2D images cannot convey the depth of 3D mesh. 3D mesh-based methods always obtain digital relief by compression and detail preservation technologies. Digital relief generation based on 3D mesh is a recently emerging research topic with the development of digital technology and 3D printing. This method has become one of the hot topics to generate digital reliefs from 3D models in computer graphic fields. Therefore, this paper presents a literature review to support scholars in gaining further insights into the frontier development of the topic.MethodThree types of digital relief generation techniques were systematically analyzed, and the key technologies, problems, and solutions in the process of digital bas-relief generation were examined and compared. Although digital high-relief and bas-relief generation has been widely investigated, spaces remain to be explored for the sunken relief. Currently, some drawbacks are present in generating sunken reliefs with a complex model:detailed information is missing, the line type has not achieved a good embodied form, the transition between the lines and the body was not achieved, and the generated sunken relief is not vivid and natural. This paper provides a solution for generating digital sunken reliefs from 3D complex models. To investigate the technology of optimal relief generation, this paper starts from the character animation sequence and calculates the optimal action and perspective of the scene with the information entropy theory aiming to recover the creation process of artists. The investigation work aims to provide a feasible solution for user customization and 3D printing relief production services.ResultThis process is one of the main methods to generate a piece of relief from 3D models. Considering high and bas reliefs, numerous researchers have studied several methods, which we categorize into two classes. One is based on human visual information and relief is generated by compressing the 3D model. Although this algorithm is simple, most relief details are lost during compression. The other class is based on several geometrical operations. This algorithm is good in preserving details but always needs to solve the Poisson equation, which requires several calculations and has low efficiency. Furthermore, this algorithm can easily generate local deformation, and sometimes, human interactions, such as adjusting parameters, are necessary to achieve the desired effect. At present, the process of how to obtain a vivid effect through compression and detail preservation has been a hot topic. Sunken relief always conveys information by lines. However, existing methods have not considered the manifestations of three types of lines, namely, main, inner, and fine shadow lines. A simple line arrangement could not show a complete sunken relief. Moreover, transition between the lines is necessary to generate a vivid and natural sunken relief. For these problems, some research is consequential, such as investigating different embodied forms of various types of lines and setting different engraving depths and locations for various types of lines for a smooth transition between the lines and the body. On the basis of relief generation, two important studies exist, that is, the selections of best attitude and perspective. In addition, the process of how to achieve an optimal relief through intelligent algorithms is worth discussing. This case will reduce the difficulty encountered by artists and sculptors in the process of carving. Selecting the best posture from an animation sequence is similar to the problem of key frame extraction. Furthermore, the best perspective can provide more important information than other perspectives. Thus, using the information entropy theory is a feasible scheme for optimal relief generation from an animation sequence. In addition, current digital relief generation methods cannot composite models considering the spatial structure and importance of characters. Combination model relief should not be generated by simply compositing several models together.ConclusionGenerating a digital relief from 3D models is an effective method. However, the processes of obtaining additional details and line types, creating the transition between lines, and intelligently generating the 3D bas relief automatically from the 3D animation sequence also pose certain problems.关键词:bas relief;sunken relief;details reservation;non-linear compression;the best perspectives;the best attitude;3D printing13|19|2更新时间:2024-05-07
Review

-
 摘要:ObjectiveTo overcome the low efficiency of dictionary atom screening and the poor effect of image reconstruction results in some super-resolution methods based on sparse representation, which are mostly unconsidered in atom screening, this paper proposes a super-resolution reconstruction algorithm. This algorithm is based on a combination of kernel method and dictionary atomic correlation, which fully uses the correlation between the dictionary and image, and selects the atoms, which significantly contributes to the reconstruction results and improves the efficiency and effect of the reconstruction.MethodFirst, a set of low-and high-resolution samples are obtained by pre-processing applied on the high-resolution images. Low-and high-resolution dictionaries are learned by using a dictionary learning algorithm. Second, the dictionary atom is uncorrelated to improve the ability of the dictionary atom to express. Third, by using the low-resolution dictionary, the kernel method and dictionary atom screening method are used for sparse representation, to set thresholds to screen for highly correlated atoms, eliminate low-correlation atoms, and then use the normal atoms for normalized processing. The resulting high-and low-resolution dictionary atoms are incoherent, thereby eliminating the similarity between dictionary atoms, enhancing the expressive power of dictionary atoms, and helping to select the next dictionary atoms. In the process of solving the representation coefficient, selecting the appropriate atoms from the low-resolution dictionary to the support set, which is the largest part of the computation, is necessary. When updating the support set, the dictionary of low-resolution images is trained from other images, which leads to the large contribution of some atoms to the samples. The atoms with low correlation often do not contribute during the iteration process, but each iteration has considerable computation costs. At the same time, for the image blocks that need to be restored, a number of highly correlated atomic pairs have a major contribution to reconstruction. To reduce the computational complexity and improve the reconstruction effect, this paper improves the traditional method by using the correlation of the residual and atom to conduct efficient dictionary selection. Finally, the sparse representation problem is solved to obtain sparse coefficients, and the super-resolution image is recovered by using these coefficients. High-resolution image blocks are obtained by using high-resolution dictionary and coefficient representation coefficients, and then, high-resolution images are synthesized by utilizing image blocks.ResultThe performance of algorithm reconstruction is measured by PSNR, structural similarity, and time and compared with Yang, MSDSC, and SDCKR algorithms. In the experiment, the following test chart is analyzed in detail, and the ImageNet standard image database is trained to obtain additional detailed experimental results. The experimental results show that, compared with the contrast method, the image reconstruction time is increased by 22.2%, the image structure similarity is increased by 9.06%, and the PSNR is increased by 2.30 dB. The original method based on dictionary learning for dictionary selection has a certain blindness. The atom and reconstruction image correlation degree is low, and the reconstruction effect is poor. This method can reduce the dictionary sparse representation of time consumption and improve the accuracy of sparse representation. In the super-resolution reconstruction of the classical image reconstruction algorithm, the effect is not ideal and the reconstruction time is too long. The main reason is that the dictionary selection efficiency is low, aiming at the abovementioned problem. For the improvement of dictionary learning algorithm in solving the sparse coefficient method in the process of nuclear innovation and the introduction of machine learning and new atom selection method, this paper presents a test with the commissioning of a large number of practical engineering images. The experimental results show that this method can improve the reconstruction effect and reduce the time required for reconstruction.ConclusionCompared with the same algorithm of dictionary learning, the reconstruction time of this algorithm is also less. Experiments have proven that in this method, the reconstruction time of image sparse representation process is significantly reduced. The reconstruction effect is also improved, with good reconstruction efficiency and effectiveness under the condition of few training samples, which is suitable for practical use.关键词:sparse representation;super-resolution reconstruction;kernel method;atomic correlation;unrelated processing11|4|1更新时间:2024-05-07
摘要:ObjectiveTo overcome the low efficiency of dictionary atom screening and the poor effect of image reconstruction results in some super-resolution methods based on sparse representation, which are mostly unconsidered in atom screening, this paper proposes a super-resolution reconstruction algorithm. This algorithm is based on a combination of kernel method and dictionary atomic correlation, which fully uses the correlation between the dictionary and image, and selects the atoms, which significantly contributes to the reconstruction results and improves the efficiency and effect of the reconstruction.MethodFirst, a set of low-and high-resolution samples are obtained by pre-processing applied on the high-resolution images. Low-and high-resolution dictionaries are learned by using a dictionary learning algorithm. Second, the dictionary atom is uncorrelated to improve the ability of the dictionary atom to express. Third, by using the low-resolution dictionary, the kernel method and dictionary atom screening method are used for sparse representation, to set thresholds to screen for highly correlated atoms, eliminate low-correlation atoms, and then use the normal atoms for normalized processing. The resulting high-and low-resolution dictionary atoms are incoherent, thereby eliminating the similarity between dictionary atoms, enhancing the expressive power of dictionary atoms, and helping to select the next dictionary atoms. In the process of solving the representation coefficient, selecting the appropriate atoms from the low-resolution dictionary to the support set, which is the largest part of the computation, is necessary. When updating the support set, the dictionary of low-resolution images is trained from other images, which leads to the large contribution of some atoms to the samples. The atoms with low correlation often do not contribute during the iteration process, but each iteration has considerable computation costs. At the same time, for the image blocks that need to be restored, a number of highly correlated atomic pairs have a major contribution to reconstruction. To reduce the computational complexity and improve the reconstruction effect, this paper improves the traditional method by using the correlation of the residual and atom to conduct efficient dictionary selection. Finally, the sparse representation problem is solved to obtain sparse coefficients, and the super-resolution image is recovered by using these coefficients. High-resolution image blocks are obtained by using high-resolution dictionary and coefficient representation coefficients, and then, high-resolution images are synthesized by utilizing image blocks.ResultThe performance of algorithm reconstruction is measured by PSNR, structural similarity, and time and compared with Yang, MSDSC, and SDCKR algorithms. In the experiment, the following test chart is analyzed in detail, and the ImageNet standard image database is trained to obtain additional detailed experimental results. The experimental results show that, compared with the contrast method, the image reconstruction time is increased by 22.2%, the image structure similarity is increased by 9.06%, and the PSNR is increased by 2.30 dB. The original method based on dictionary learning for dictionary selection has a certain blindness. The atom and reconstruction image correlation degree is low, and the reconstruction effect is poor. This method can reduce the dictionary sparse representation of time consumption and improve the accuracy of sparse representation. In the super-resolution reconstruction of the classical image reconstruction algorithm, the effect is not ideal and the reconstruction time is too long. The main reason is that the dictionary selection efficiency is low, aiming at the abovementioned problem. For the improvement of dictionary learning algorithm in solving the sparse coefficient method in the process of nuclear innovation and the introduction of machine learning and new atom selection method, this paper presents a test with the commissioning of a large number of practical engineering images. The experimental results show that this method can improve the reconstruction effect and reduce the time required for reconstruction.ConclusionCompared with the same algorithm of dictionary learning, the reconstruction time of this algorithm is also less. Experiments have proven that in this method, the reconstruction time of image sparse representation process is significantly reduced. The reconstruction effect is also improved, with good reconstruction efficiency and effectiveness under the condition of few training samples, which is suitable for practical use.关键词:sparse representation;super-resolution reconstruction;kernel method;atomic correlation;unrelated processing11|4|1更新时间:2024-05-07 -
 摘要:ObjectiveThe highlight and difficult point of the current research in terms of image completion is to complete the image of a large damaged region with complex structure and rich texture information. Traditional exemplar-based completion algorithms mainly adapt the regular sample and matching patches to complete the damaged region. During the completion process, the irregular information, especially the local irregular information, of the image structure and texture cannot be fully used. This condition affects the accuracy and efficiency of the algorithm. To solve this problem, an image completion method with irregular patch is proposed in this paper.MethodIn our approach, the structure sparsity is used to distinguish the structure information and texture information of the input image first. Thus, a patch with a structure sparsity higher than a threshold is marked as a structural patch, and a patch with a structure sparsity lower than a threshold is regarded as a texture patch. Moreover, the patch priority of pixels on the boundary of the damaged region is calculated on the basis of the structure sparsity and confidence terms. Then, the pixel of the highest priority is selected as the center of the sample patch. If the neighborhood of a sample patch, which is in the complex structure area of the image, contains the known structure information, then this regular patch is dilated to construct its corresponding irregular sample patch by using structure information in its neighborhood. Then, the matching patch is being searched in the known part of the image. If the neighborhood of this matching patch contains a valid structure information, then the matching patch is dilated, and the structure information in its neighborhood is supplemented to construct its corresponding irregular matching patch. Finally, this irregular matching patch is used to complete its corresponding damaged region. The steps of constructing irregular patches specifically include transforming the inspection patch into the grayscale patch, using Gaussian blurring to denoise, extracting the structural information by using the Canny operator, integrating the structural information and original image patch to form an irregular mask, and picking the mask into the source image to obtain the irregular patch. In terms of the problem of visual disconnectivity, which is caused by seams during the completion process, the texture information of the image is used for modification in the proposed algorithm. The specific method aims to map the overlapping region of the texture patches into a network, and then, the graph cut algorithm is used to cut the network to generate a new optimal seam.ResultOur approach and four other completion algorithms, three of which are based on the regular patch and one is based on sensitive hash, are used to complete eight classic image benchmarks. The efforts of these algorithms are evaluated by objective and subjective evaluation, which are the peak signal-to-noise ratio (PSNR) and visual connectivity. In comparison with these four completion algorithms, the results show that the proposed algorithm can achieve a better result in the fineness of the completion as well as the visual connectivity. Moreover, the PSNR of the proposed algorithm is improved by 0 dB to 4 dB.ConclusionThe proposed algorithm improves the traditional exemplar-based completion algorithms, which cannot fully use the image irregularity information, and enhances the accuracy. Simultaneously, the texture information of the image is used to modify the visual disconnectivity so the visual effect of the image is improved. The proposed algorithm has a good application in the restoration of damaged natural images and cultural relics with both geometric structure and rich texture as well as the removal of target objects. Thus, the proposed algorithm is generalizable.关键词:image completion;structure sparsity;irregular patch;seam rectify;local consistency;adaptivity18|38|0更新时间:2024-05-07
摘要:ObjectiveThe highlight and difficult point of the current research in terms of image completion is to complete the image of a large damaged region with complex structure and rich texture information. Traditional exemplar-based completion algorithms mainly adapt the regular sample and matching patches to complete the damaged region. During the completion process, the irregular information, especially the local irregular information, of the image structure and texture cannot be fully used. This condition affects the accuracy and efficiency of the algorithm. To solve this problem, an image completion method with irregular patch is proposed in this paper.MethodIn our approach, the structure sparsity is used to distinguish the structure information and texture information of the input image first. Thus, a patch with a structure sparsity higher than a threshold is marked as a structural patch, and a patch with a structure sparsity lower than a threshold is regarded as a texture patch. Moreover, the patch priority of pixels on the boundary of the damaged region is calculated on the basis of the structure sparsity and confidence terms. Then, the pixel of the highest priority is selected as the center of the sample patch. If the neighborhood of a sample patch, which is in the complex structure area of the image, contains the known structure information, then this regular patch is dilated to construct its corresponding irregular sample patch by using structure information in its neighborhood. Then, the matching patch is being searched in the known part of the image. If the neighborhood of this matching patch contains a valid structure information, then the matching patch is dilated, and the structure information in its neighborhood is supplemented to construct its corresponding irregular matching patch. Finally, this irregular matching patch is used to complete its corresponding damaged region. The steps of constructing irregular patches specifically include transforming the inspection patch into the grayscale patch, using Gaussian blurring to denoise, extracting the structural information by using the Canny operator, integrating the structural information and original image patch to form an irregular mask, and picking the mask into the source image to obtain the irregular patch. In terms of the problem of visual disconnectivity, which is caused by seams during the completion process, the texture information of the image is used for modification in the proposed algorithm. The specific method aims to map the overlapping region of the texture patches into a network, and then, the graph cut algorithm is used to cut the network to generate a new optimal seam.ResultOur approach and four other completion algorithms, three of which are based on the regular patch and one is based on sensitive hash, are used to complete eight classic image benchmarks. The efforts of these algorithms are evaluated by objective and subjective evaluation, which are the peak signal-to-noise ratio (PSNR) and visual connectivity. In comparison with these four completion algorithms, the results show that the proposed algorithm can achieve a better result in the fineness of the completion as well as the visual connectivity. Moreover, the PSNR of the proposed algorithm is improved by 0 dB to 4 dB.ConclusionThe proposed algorithm improves the traditional exemplar-based completion algorithms, which cannot fully use the image irregularity information, and enhances the accuracy. Simultaneously, the texture information of the image is used to modify the visual disconnectivity so the visual effect of the image is improved. The proposed algorithm has a good application in the restoration of damaged natural images and cultural relics with both geometric structure and rich texture as well as the removal of target objects. Thus, the proposed algorithm is generalizable.关键词:image completion;structure sparsity;irregular patch;seam rectify;local consistency;adaptivity18|38|0更新时间:2024-05-07 -
 摘要:ObjectiveFacial image publication (FIP) in a direct way may lead to privacy leakage of individuals because facial images are inherently sensitive. To protect the private information in facial images, this paper proposes an efficient publishing algorithm called FIP that is based on Fourier transform combined with differential privacy, which is the state-of-the-art model to address privacy concerns.MethodFirst, this algorithm uses the real-valued matrix to model the facial image, in which each cell corresponds to each pixel point of the image. Then, on the basis of the matrix, this algorithm relies on the Fourier transform technique to extract the Fourier coefficients (e.g., a pre-defined limit
摘要:ObjectiveFacial image publication (FIP) in a direct way may lead to privacy leakage of individuals because facial images are inherently sensitive. To protect the private information in facial images, this paper proposes an efficient publishing algorithm called FIP that is based on Fourier transform combined with differential privacy, which is the state-of-the-art model to address privacy concerns.MethodFirst, this algorithm uses the real-valued matrix to model the facial image, in which each cell corresponds to each pixel point of the image. Then, on the basis of the matrix, this algorithm relies on the Fourier transform technique to extract the Fourier coefficients (e.g., a pre-defined limit$k$ $k$ $k$ $ $ $k$ $ $ $k$ $k$ $k$ $k$ $k$ $k$ $k$ $\varepsilon $ $k$ $k$ $\varepsilon $ $\varepsilon $ $\varepsilon $ 关键词:facial image processing;privacy protection;differential privacy;Fourier transform76|110|2更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveWith the widespread use of high-dimensional data, dimensionality reduction has become an important research direction in both machine learning and data mining. High-dimensional data require additional storage space, cause high complexity in calculating, and are time consuming. Given that the large number of redundant features indicates a minimal effect on data analysis, the sparse preserving project method is proposed, and this method maintains the sparse reconstruction relations of data by minimizing an objective function including
摘要:ObjectiveWith the widespread use of high-dimensional data, dimensionality reduction has become an important research direction in both machine learning and data mining. High-dimensional data require additional storage space, cause high complexity in calculating, and are time consuming. Given that the large number of redundant features indicates a minimal effect on data analysis, the sparse preserving project method is proposed, and this method maintains the sparse reconstruction relations of data by minimizing an objective function including$l$ $\alpha $ 关键词:feature selection;semi-supervised learning;low rank representation;sparse representation;structural embedding;image classification11|4|3更新时间:2024-05-07 -
 摘要:Objective Image segmentation is a process of dividing an image into different regions such that each region is homogeneous but the union of any two adjacent regions is not. As the first step in image analysis and pattern recognition, image segmentation serves as a fundamental step in numerous computer vision applications, such as object detection, content-based image retrieval, and medical image analysis. Threshold-based methods, which subdivide the image into several homogenous regions on the basis of pixel intensities, are popular segmentation techniques. Numerous algorithms have been proposed in this direction, which include gray-level thresholding and interactive pixel classification. Among these algorithms, the frequently used maximum fuzzy correlations are widely adopted to measure the appropriateness of fuzzy two partitions for the image segmentation purpose due to the unavoidable ambiguities, fuzziness, and uncertainty of the image information. However, this method has some limitations, i.e., the partition number needs to be preset, the results have isolated noise, and maximum fuzzy correlation approach cannot be extended to color image segmentation.MethodMost existing gray-level image segmentation techniques could be extended to color image. They can be directly applied to each component of a color space, and then, the result can be combined in a certain way to obtain the final segmentation result. However, one of the problems is how to use the color information as a whole for each pixel and how to select the color representation for segmentation because each color representation has advantages and disadvantages. To address these problems, an unsupervised hierarchical color image segmentation through maximum fuzzy correlation and graph cut is proposed. First, we oversegment the color image into superpixels to improve the efficiency of hierarchical image segmentation. Then, we combine the fast fuzzy correlation with graph cut to form a bi-level segmentation operator, which can suppress the isolated noise caused by the single threshold-based approach and enforce the spatial coherence in the thresholding segmentation approach. Here, an iterative calculation scheme is presented to reduce redundant computations in fuzzy correlation evaluation. Finally, a top-down hierarchical segmentation approach has been designed. By iteratively performing this bi-level segmentation operator, multilevel image segmentation is achieved in a hierarchical manner. Starting from the input color image, our algorithm first selects the color channel that can best segment the image into two labels and then iteratively selects channels to further split each label until convergence. In practice, we partition the 3D color space and adopt the idea of k-d tree to record the segmentation process.Result The presented hierarchical segmentation is implemented in Matlab 7.0. Quantitative and qualitative evaluations are performed to compare with those from the state-of-the-art methods. To test the effectiveness of graph cut on the basis of two fuzzy correlation partitions, we compare our method with maximum fuzzy correlation. The experiment shows that our method can overcome the isolated noise and obtain satisfactory results. To demonstrate the segmentation performance of our algorithm on the color images, the Berkeley segmentation database is used, which consists of 300 natural images of diverse scene categories. We quantitatively compare the performance of our method with existing SAS, Ncut, and JSEG methods. Among these methods, SAS and Ncut are semi-supervised hierarchical superpixel-based color image segmentation methods. However, JSEG is an unsupervised color image segmentation method. By utilizing four widely used metrics, we can find that our method outperforms the Ncut and JSEG methods in terms of precision, and the running time is improved by 20%. Compared with SAS, our method obtains subpar results because it uses only pixel color information and is fully unsupervised. In comparison, the SAS approach uses high-level features, such as texture, edges, and color for segmentation.ConclusionAn unsupervised hierarchical image segmentation approach is presented in this paper. The algorithm uses superpixels as segmentation primitives and iteratively partitions all superpixels using a bi-level segmentation operator, which combines fuzzy correlation and graph cut. By using this scheme, the proposed method can effectively handle color images and provide an important reference for the application of the maximum fuzzy correlation algorithm in the field of unsupervised color image segmentation. The limitation of the proposed approach is that it only segments images by using color information, which leads to suboptimal results when the objects and background have similar colors. Utilizing high-level cues in the proposed hierarchical segmentation framework while maintaining it as an unsupervised approach is a non-trivial task. We plan to study this issue as part of our future work.关键词:color image segmentation;unsupervised segmentation;superpixel;fuzzy correlation;graph cut21|5|2更新时间:2024-05-07
摘要:Objective Image segmentation is a process of dividing an image into different regions such that each region is homogeneous but the union of any two adjacent regions is not. As the first step in image analysis and pattern recognition, image segmentation serves as a fundamental step in numerous computer vision applications, such as object detection, content-based image retrieval, and medical image analysis. Threshold-based methods, which subdivide the image into several homogenous regions on the basis of pixel intensities, are popular segmentation techniques. Numerous algorithms have been proposed in this direction, which include gray-level thresholding and interactive pixel classification. Among these algorithms, the frequently used maximum fuzzy correlations are widely adopted to measure the appropriateness of fuzzy two partitions for the image segmentation purpose due to the unavoidable ambiguities, fuzziness, and uncertainty of the image information. However, this method has some limitations, i.e., the partition number needs to be preset, the results have isolated noise, and maximum fuzzy correlation approach cannot be extended to color image segmentation.MethodMost existing gray-level image segmentation techniques could be extended to color image. They can be directly applied to each component of a color space, and then, the result can be combined in a certain way to obtain the final segmentation result. However, one of the problems is how to use the color information as a whole for each pixel and how to select the color representation for segmentation because each color representation has advantages and disadvantages. To address these problems, an unsupervised hierarchical color image segmentation through maximum fuzzy correlation and graph cut is proposed. First, we oversegment the color image into superpixels to improve the efficiency of hierarchical image segmentation. Then, we combine the fast fuzzy correlation with graph cut to form a bi-level segmentation operator, which can suppress the isolated noise caused by the single threshold-based approach and enforce the spatial coherence in the thresholding segmentation approach. Here, an iterative calculation scheme is presented to reduce redundant computations in fuzzy correlation evaluation. Finally, a top-down hierarchical segmentation approach has been designed. By iteratively performing this bi-level segmentation operator, multilevel image segmentation is achieved in a hierarchical manner. Starting from the input color image, our algorithm first selects the color channel that can best segment the image into two labels and then iteratively selects channels to further split each label until convergence. In practice, we partition the 3D color space and adopt the idea of k-d tree to record the segmentation process.Result The presented hierarchical segmentation is implemented in Matlab 7.0. Quantitative and qualitative evaluations are performed to compare with those from the state-of-the-art methods. To test the effectiveness of graph cut on the basis of two fuzzy correlation partitions, we compare our method with maximum fuzzy correlation. The experiment shows that our method can overcome the isolated noise and obtain satisfactory results. To demonstrate the segmentation performance of our algorithm on the color images, the Berkeley segmentation database is used, which consists of 300 natural images of diverse scene categories. We quantitatively compare the performance of our method with existing SAS, Ncut, and JSEG methods. Among these methods, SAS and Ncut are semi-supervised hierarchical superpixel-based color image segmentation methods. However, JSEG is an unsupervised color image segmentation method. By utilizing four widely used metrics, we can find that our method outperforms the Ncut and JSEG methods in terms of precision, and the running time is improved by 20%. Compared with SAS, our method obtains subpar results because it uses only pixel color information and is fully unsupervised. In comparison, the SAS approach uses high-level features, such as texture, edges, and color for segmentation.ConclusionAn unsupervised hierarchical image segmentation approach is presented in this paper. The algorithm uses superpixels as segmentation primitives and iteratively partitions all superpixels using a bi-level segmentation operator, which combines fuzzy correlation and graph cut. By using this scheme, the proposed method can effectively handle color images and provide an important reference for the application of the maximum fuzzy correlation algorithm in the field of unsupervised color image segmentation. The limitation of the proposed approach is that it only segments images by using color information, which leads to suboptimal results when the objects and background have similar colors. Utilizing high-level cues in the proposed hierarchical segmentation framework while maintaining it as an unsupervised approach is a non-trivial task. We plan to study this issue as part of our future work.关键词:color image segmentation;unsupervised segmentation;superpixel;fuzzy correlation;graph cut21|5|2更新时间:2024-05-07 -
 摘要:ObjectiveThe delineation of lumen and media-adventitia (MA) borders in intravascular ultrasound (IVUS) images is necessary for quantitative assessment of coronary atherosclerosis and vulnerable plaques. Automatic segmentation for detecting these important borders represents a difficult task due to ultrasonic speckle, various artifacts and atherosclerotic plaques. In this paper, we present a simple yet effective fully automated methodology for the detection of lumen and MA borders in 20 MHz ECG-gated intravascular ultrasound frames.Method The delineation of lumen and MA borders in IVUS images was solved by two major stages:region segmentation and border refinement in proposed method, or key point detection and curve fitting in previous approaches. Different from the second class solution, the first class solution was more adopted because borders from most IVUS images to be analyzed are able to be observed. Most of automatic detection algorithms for lumen and media-adventitia border from IVUS images is lack of consideration of professional clinicians observing IVUS images, identifying borders of interest and delineating the outline of organs or tissues. However, computer algorithms based on machine learning, computer vision and other emerging intelligent technologies extract hierarchical and discriminative deep features by learning given training dataset, simulate how clinicians recognize lumen and media-adventitia border, therefore often obtain better segmentation results. In view of problems of the existing automatic algorithms for detecting lumen and media-adventitia border, this work simulates the process of clinicians identifying the lumen and media-adventitia border, and proposes an automatic algorithm combining a priori shape information of coronary artery and deep convolutional networks. First the proposed approach uses deep fully convolutional networks (DFCN) to directly learn mappings between raw IVUS images and their corresponding manual segmentations in order to predict an object or background probability map across the whole image. Then, on basis of the above coarse segmentation and the prior information of vessel appearance we employed mathematical morphological post-processing open or close operator and some simple image processing steps to smooth the extracted lumen and MA borders from the output of DFCN. The border refinement stage is to eliminate misclassified pixels or regions in the stage of medical image semantic segmentation.Result Our method is evaluated on a publicly available dataset that consists of 435 IVUS images in vivo acquired from ten patients in different hospital or medical center using linear regression, Bland-Altman analysis and several measure metrics such as Jaccard Measure (
摘要:ObjectiveThe delineation of lumen and media-adventitia (MA) borders in intravascular ultrasound (IVUS) images is necessary for quantitative assessment of coronary atherosclerosis and vulnerable plaques. Automatic segmentation for detecting these important borders represents a difficult task due to ultrasonic speckle, various artifacts and atherosclerotic plaques. In this paper, we present a simple yet effective fully automated methodology for the detection of lumen and MA borders in 20 MHz ECG-gated intravascular ultrasound frames.Method The delineation of lumen and MA borders in IVUS images was solved by two major stages:region segmentation and border refinement in proposed method, or key point detection and curve fitting in previous approaches. Different from the second class solution, the first class solution was more adopted because borders from most IVUS images to be analyzed are able to be observed. Most of automatic detection algorithms for lumen and media-adventitia border from IVUS images is lack of consideration of professional clinicians observing IVUS images, identifying borders of interest and delineating the outline of organs or tissues. However, computer algorithms based on machine learning, computer vision and other emerging intelligent technologies extract hierarchical and discriminative deep features by learning given training dataset, simulate how clinicians recognize lumen and media-adventitia border, therefore often obtain better segmentation results. In view of problems of the existing automatic algorithms for detecting lumen and media-adventitia border, this work simulates the process of clinicians identifying the lumen and media-adventitia border, and proposes an automatic algorithm combining a priori shape information of coronary artery and deep convolutional networks. First the proposed approach uses deep fully convolutional networks (DFCN) to directly learn mappings between raw IVUS images and their corresponding manual segmentations in order to predict an object or background probability map across the whole image. Then, on basis of the above coarse segmentation and the prior information of vessel appearance we employed mathematical morphological post-processing open or close operator and some simple image processing steps to smooth the extracted lumen and MA borders from the output of DFCN. The border refinement stage is to eliminate misclassified pixels or regions in the stage of medical image semantic segmentation.Result Our method is evaluated on a publicly available dataset that consists of 435 IVUS images in vivo acquired from ten patients in different hospital or medical center using linear regression, Bland-Altman analysis and several measure metrics such as Jaccard Measure ($JM $ $PAD $ $ HD$ $AD $ $JM$ $PAD$ 关键词:medical image analysis;deep learning;deep fully convolutional networks;prior shape information;intravascular ultrasound;lumen border detection;media-adventitia border detection11|4|2更新时间:2024-05-07 -
 摘要:ObjectiveIn recent years, due to the availability of low-cost scanners and high-performance computing devices, three-dimensional object recognition has become an active research area in computer vision tasks. Local feature descriptors can effectively overcome the interference of noise, different point cloud resolution, local occlusion, scattered cloud point distribution, and other issues in 3D object recognition tasks. However, difficulties occur in balancing the performance and efficiency of the 3D descriptor. Therefore, a local multi-view projection correlation encoding (LoVPE) feature descriptor is proposed for 3D object recognition in complex scenes.Method The sub-construction process of the descriptor is divided into three steps. First, a local reference frame of the key point is constructed and the local surface in the world coordinate system is transformed to it. The local reference frame provides spatial information such that the descriptor indicates invariance to translation and rotation and is robust to noise and clutter. Then, the K angles are rotated around each coordinate axis of the local reference coordinate system to obtain the multi-view local surface. In each coordinate plane of the local reference frame, the projection plane is divided into NxN blocks, to which the points on the local surface are projected, and the scatter information of the projection points in each block is calculated to generate the feature description vector. Multi-view projection provides descriptive information that makes the descriptor descriptive, robust to noise, and possess different rates of grid resolution, clutter, and occlusion. Finally, view-pair of each view feature description vector is used to construct the correlative encoding to obtain the low-dimension feature description vector, using zero component analysis whitening to reduce the correlation between its dimensions to obtain the LoVPE descriptor. The view-pair correlative encoding effectively avoids the dimension explosion problem caused by the simple combination of the viewpoint feature description vectors in the past. At the same time, the encoding provides a more invariant spatial relationship, is more robust to interference, and highlights the key information of the object.Result For descriptive ability, robustness and recognition capability in complex scenes, the proposed descriptor and other descriptors were compared some public datasets. The robustness of the descriptors to noise and different grid resolutions are validated on Bologna datasets. The robustness of the descriptors to occlusion and clutter are validated on Queen's lidar and SHOTDataset5 datasets. The results show that, compared with other descriptors, with increasing the standard deviation of the Gaussian noise, the proposed descriptor still maintains good performance. As the descending sampling rate increases, the advantages of the proposed descriptor are gradually reflected and maintains a good performance. The proposed descriptor is superior to others in terms of descriptive ability and robustness, as well as maintains lower feature dimensions and higher computational efficiency.Conclusion A new 3D local feature descriptor is proposed, which has strong descriptive ability, strong robustness against noise, different grid resolution, occlusion and clutter, less memory consumption, and high computational efficiency. The descriptor is suitable for model point cloud and real point cloud data and can be used for 3D target recognition in complex scenes.关键词:3D local feature descriptor;local reference frame;multi-view projection;correlation encoding;3D object recognition13|6|1更新时间:2024-05-07
摘要:ObjectiveIn recent years, due to the availability of low-cost scanners and high-performance computing devices, three-dimensional object recognition has become an active research area in computer vision tasks. Local feature descriptors can effectively overcome the interference of noise, different point cloud resolution, local occlusion, scattered cloud point distribution, and other issues in 3D object recognition tasks. However, difficulties occur in balancing the performance and efficiency of the 3D descriptor. Therefore, a local multi-view projection correlation encoding (LoVPE) feature descriptor is proposed for 3D object recognition in complex scenes.Method The sub-construction process of the descriptor is divided into three steps. First, a local reference frame of the key point is constructed and the local surface in the world coordinate system is transformed to it. The local reference frame provides spatial information such that the descriptor indicates invariance to translation and rotation and is robust to noise and clutter. Then, the K angles are rotated around each coordinate axis of the local reference coordinate system to obtain the multi-view local surface. In each coordinate plane of the local reference frame, the projection plane is divided into NxN blocks, to which the points on the local surface are projected, and the scatter information of the projection points in each block is calculated to generate the feature description vector. Multi-view projection provides descriptive information that makes the descriptor descriptive, robust to noise, and possess different rates of grid resolution, clutter, and occlusion. Finally, view-pair of each view feature description vector is used to construct the correlative encoding to obtain the low-dimension feature description vector, using zero component analysis whitening to reduce the correlation between its dimensions to obtain the LoVPE descriptor. The view-pair correlative encoding effectively avoids the dimension explosion problem caused by the simple combination of the viewpoint feature description vectors in the past. At the same time, the encoding provides a more invariant spatial relationship, is more robust to interference, and highlights the key information of the object.Result For descriptive ability, robustness and recognition capability in complex scenes, the proposed descriptor and other descriptors were compared some public datasets. The robustness of the descriptors to noise and different grid resolutions are validated on Bologna datasets. The robustness of the descriptors to occlusion and clutter are validated on Queen's lidar and SHOTDataset5 datasets. The results show that, compared with other descriptors, with increasing the standard deviation of the Gaussian noise, the proposed descriptor still maintains good performance. As the descending sampling rate increases, the advantages of the proposed descriptor are gradually reflected and maintains a good performance. The proposed descriptor is superior to others in terms of descriptive ability and robustness, as well as maintains lower feature dimensions and higher computational efficiency.Conclusion A new 3D local feature descriptor is proposed, which has strong descriptive ability, strong robustness against noise, different grid resolution, occlusion and clutter, less memory consumption, and high computational efficiency. The descriptor is suitable for model point cloud and real point cloud data and can be used for 3D target recognition in complex scenes.关键词:3D local feature descriptor;local reference frame;multi-view projection;correlation encoding;3D object recognition13|6|1更新时间:2024-05-07 -
 摘要:ObjectiveA face recognition approach of generalized parallel two-dimensional (2D) complex discriminant analysis was proposed to tackle such problems that 2D linear discriminant analysis demonstrated poor stability when extracting facial feature vectors, the covariance information of different rows or columns which was conducive to discriminant analysis was very likely to get lost when only features in rows or columns were being extracted, and the dimensions where features existed were relatively high.Method Firstly, generalized parallel 2D linear discriminant analysis was conducted on facial images, and the feature vectors are selected according to the feature value contribution rate to form the orthogonal projection matrix, then the projection of horizontal and vertical direction is completed; secondly, the two types of feature matrices obtained after processing were added together in forms of real part and imaginary part of complex numbers, and the complex feature matrices were obtained by conducting generalized 2D complex discriminant analysis on feature matrices having been fused; then, the recognition performance of feature matrix components was measured based on feature values of complex feature matrices, the feature matrix components were re-ranked, and the most discriminative components were selected to form the final features characterizing human faces; and at last, maximum similarity classifier was used to classify and recognize features of human face images by comparing the similarity between the test samples and the training sample features.Result Yale, ORL, FERET, CMU-PIE and LFW face databases were experimented, from which the optimal recognition rates obtained by using this method were respectively 100%, 100%, 98.98%, 99.76%, and 98.67%, with the feature dimensions ranging from 85 to 90, which indicated that this method delivered relatively high face recognition precision and low space occupancy in complex conditions.Conclusion This method could effectively overcome drawbacks such as poor feature extraction stability of 2D linear discriminant analysis, overlap of features in feature space, excessive storage coefficients, and high dimension of features, manifesting high robustness, great precision, and low space complexity.关键词:face recognition;generalized parallel two-dimensional complex discriminant analysis;complex feature matrices;maximum similarity classification12|5|1更新时间:2024-05-07
摘要:ObjectiveA face recognition approach of generalized parallel two-dimensional (2D) complex discriminant analysis was proposed to tackle such problems that 2D linear discriminant analysis demonstrated poor stability when extracting facial feature vectors, the covariance information of different rows or columns which was conducive to discriminant analysis was very likely to get lost when only features in rows or columns were being extracted, and the dimensions where features existed were relatively high.Method Firstly, generalized parallel 2D linear discriminant analysis was conducted on facial images, and the feature vectors are selected according to the feature value contribution rate to form the orthogonal projection matrix, then the projection of horizontal and vertical direction is completed; secondly, the two types of feature matrices obtained after processing were added together in forms of real part and imaginary part of complex numbers, and the complex feature matrices were obtained by conducting generalized 2D complex discriminant analysis on feature matrices having been fused; then, the recognition performance of feature matrix components was measured based on feature values of complex feature matrices, the feature matrix components were re-ranked, and the most discriminative components were selected to form the final features characterizing human faces; and at last, maximum similarity classifier was used to classify and recognize features of human face images by comparing the similarity between the test samples and the training sample features.Result Yale, ORL, FERET, CMU-PIE and LFW face databases were experimented, from which the optimal recognition rates obtained by using this method were respectively 100%, 100%, 98.98%, 99.76%, and 98.67%, with the feature dimensions ranging from 85 to 90, which indicated that this method delivered relatively high face recognition precision and low space occupancy in complex conditions.Conclusion This method could effectively overcome drawbacks such as poor feature extraction stability of 2D linear discriminant analysis, overlap of features in feature space, excessive storage coefficients, and high dimension of features, manifesting high robustness, great precision, and low space complexity.关键词:face recognition;generalized parallel two-dimensional complex discriminant analysis;complex feature matrices;maximum similarity classification12|5|1更新时间:2024-05-07 -
 摘要:Objective With the development of urban management, a growing number of cities are implementing coding projects for streetlight poles. In such projects, the coordinates of streetlamps are obtained and serial numbers are assigned to them. The coordinates can be obtained in many ways, such as RTK and laser measurements. A quick and easy approach to obtain the data is required because tens of thousands of streetlamps are present in a city. In consideration of the cost, mobile panorama measurement is preferred. However, most current panorama measurements are conducted by means of human-computer interaction, in which homologous image points are selected to perform forward intersection to obtain the coordinates. This approach consumes substantial energy and time. Therefore, in this paper, we propose an automatic method to obtain the coordinates of streetlamps by combining object detection with panoramic measurement.Method The method combines deep learning and panoramic measurement to automatically obtain the coordinates of streetlight poles. No feature points are obvious on the poles because of their rod-shaped features, and the top of the streetlamp is different because of the different design. The distortion of panoramic images strongly influences the detection of the top of a streetlamp. Thus, the bottom of the poles is used as the detection target in this paper. The pole bottoms are detected by faster R-CNN. Meanwhile, the coordinate file that contains the upper-left and lower-right corners of the detection frames are output and compared with the detection results obtained by the combination of histogram of oriented gradient (HOG) and support vector machine (SVM). Then, the diagonal intersection of the detection box is regarded as the foot of the streetlight pole, and an epipolar line is used to find homologous image points in two panoramic images because multiple streetlight poles can be present in a panoramic image. Based on the matching results, the space coordinates of the streetlight poles are obtained by forward intersection of the panoramas, thereby confirming the potential of this preliminary work for the coding projects.Result The aforementioned two methods were used to detect the streetlights of 100 panoramic images, which include 162 streetlights. A total of 1826 detection results were obtained based on HOG features, of which the correct bottom of streetlamps is 142. A total of 149 detection results are based on the faster R-CNN, of which 137 are correct. We can conclude that the faster R-CNN has obvious advantages. Thus, in this study, we use the faster R-CNN combined with panoramic measurement to automatically obtain the streetlight coordinates. The distance from the bottom of the streetlamp to the two imaging centers and the intersection angle formed by the three points significantly affect the accuracy of coordinate measurement. To filter out the coordinates that are less affected by the aforementioned two factors, we compare measurement results, which are the distances of approximately 7, 11, and 18m; the intersection angles are 0° to 180°. We have verified that when the intersection angles are from 30° to 150°, the influence on the measurement accuracy is smaller because the distance is closer. Based on the preceding rules, 120 coordinates of streetlamps are selected to determine the statistical distribution of the intersection angle and distance. Points with a distance of less than 20 m and intersection angle greater than 30° and less than 150° are selected for the coordinate error analysis, and 102 points meet the requirements for accuracy verification. The deviation of space coordinate measurement is less than 0.3 m and the maximum is not more than 0.6 m, thereby satisfying the requirement that the accuracy of the coordinates is within 1 m.ConclusionThis paper presents a method of automatically obtaining the coordinates of streetlamps. The method of target detection based on deep learning is applied to the panorama measurement. The method avoids the manual selection of the homologous image points for measurement, which saves considerable labor and material resources. We conclude that this method exhibits practical significance because it is suitable for road sections or periods with low traffic volume in the city, thereby preventing excessive obstruction caused by vehicles. However, for panoramas with seriously obstructed streetlights, this method has certain limitations.关键词:faster region convolutional neural network (Faster R-CNN);deep learning;street light pole detection;panorama;forward intersection;epipolar geometry13|4|3更新时间:2024-05-07
摘要:Objective With the development of urban management, a growing number of cities are implementing coding projects for streetlight poles. In such projects, the coordinates of streetlamps are obtained and serial numbers are assigned to them. The coordinates can be obtained in many ways, such as RTK and laser measurements. A quick and easy approach to obtain the data is required because tens of thousands of streetlamps are present in a city. In consideration of the cost, mobile panorama measurement is preferred. However, most current panorama measurements are conducted by means of human-computer interaction, in which homologous image points are selected to perform forward intersection to obtain the coordinates. This approach consumes substantial energy and time. Therefore, in this paper, we propose an automatic method to obtain the coordinates of streetlamps by combining object detection with panoramic measurement.Method The method combines deep learning and panoramic measurement to automatically obtain the coordinates of streetlight poles. No feature points are obvious on the poles because of their rod-shaped features, and the top of the streetlamp is different because of the different design. The distortion of panoramic images strongly influences the detection of the top of a streetlamp. Thus, the bottom of the poles is used as the detection target in this paper. The pole bottoms are detected by faster R-CNN. Meanwhile, the coordinate file that contains the upper-left and lower-right corners of the detection frames are output and compared with the detection results obtained by the combination of histogram of oriented gradient (HOG) and support vector machine (SVM). Then, the diagonal intersection of the detection box is regarded as the foot of the streetlight pole, and an epipolar line is used to find homologous image points in two panoramic images because multiple streetlight poles can be present in a panoramic image. Based on the matching results, the space coordinates of the streetlight poles are obtained by forward intersection of the panoramas, thereby confirming the potential of this preliminary work for the coding projects.Result The aforementioned two methods were used to detect the streetlights of 100 panoramic images, which include 162 streetlights. A total of 1826 detection results were obtained based on HOG features, of which the correct bottom of streetlamps is 142. A total of 149 detection results are based on the faster R-CNN, of which 137 are correct. We can conclude that the faster R-CNN has obvious advantages. Thus, in this study, we use the faster R-CNN combined with panoramic measurement to automatically obtain the streetlight coordinates. The distance from the bottom of the streetlamp to the two imaging centers and the intersection angle formed by the three points significantly affect the accuracy of coordinate measurement. To filter out the coordinates that are less affected by the aforementioned two factors, we compare measurement results, which are the distances of approximately 7, 11, and 18m; the intersection angles are 0° to 180°. We have verified that when the intersection angles are from 30° to 150°, the influence on the measurement accuracy is smaller because the distance is closer. Based on the preceding rules, 120 coordinates of streetlamps are selected to determine the statistical distribution of the intersection angle and distance. Points with a distance of less than 20 m and intersection angle greater than 30° and less than 150° are selected for the coordinate error analysis, and 102 points meet the requirements for accuracy verification. The deviation of space coordinate measurement is less than 0.3 m and the maximum is not more than 0.6 m, thereby satisfying the requirement that the accuracy of the coordinates is within 1 m.ConclusionThis paper presents a method of automatically obtaining the coordinates of streetlamps. The method of target detection based on deep learning is applied to the panorama measurement. The method avoids the manual selection of the homologous image points for measurement, which saves considerable labor and material resources. We conclude that this method exhibits practical significance because it is suitable for road sections or periods with low traffic volume in the city, thereby preventing excessive obstruction caused by vehicles. However, for panoramas with seriously obstructed streetlights, this method has certain limitations.关键词:faster region convolutional neural network (Faster R-CNN);deep learning;street light pole detection;panorama;forward intersection;epipolar geometry13|4|3更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:Objective2D to 3D technology can quickly and effectively transfer the existing rich resource of 2D images into 3D images. However, existing methods only consider depth estimation on the entire object of a tree in the process of depth map generation. In this way, the tree in the final 3D images generated would normally lack a sense of depth and look like a piece of paper stuck on the background. The depth map generated by these methods cannot show the natural three-dimensional structural features of trees and has no sufficient rich stereoscopic levels to show the layering on the trees. To this end, this paper presents a 3D tree image construction method on the basis of depth template.MethodIn our proposed method, we first utilize the color difference of pixels under the laboratory color model to divide the 2D tree image into trunk and canopy areas and then divide the canopy area again into several small areas by using multiscale spectral-based image segmentation method. Then, considering the assumption of depth gradient hypothesis, we create various types of basic depth templates. In addition to the six commonly used basic depth templates, two new basic depth templates are added on the basis of the structural features of the trees. In accordance with the complexity of the morphology of trees, this paper divides the tree objects into two major categories:typical and atypical trees. The typical trees are those with regular shapes and can basically belong to the four typical tree models of spherical, conical, cylindrical, and wide spread shapes. The atypical trees are inconsistent with the basic characteristics of the existing four tree models. The initial depth maps of typical tree objects are constructed by combining the basic depth template and the area information of canopy. For the atypical tree object, we first select some basic depth templates to generate a personal depth temple, and then a personalized initial depth map is constructed through the combination of the personal depth temple and the tree's canopy area information. Finally, the tree depth information is adjusted and optimized adaptively in accordance with the application scene. 3D images of trees are adaptively adjusted in accordance with the depth information of the corresponding position of the background to obtain a depth map consistent with the background depth information. In addition, different objects in the scene are located at different depths, so when the tree images are synthesized into the background image, the occlusion between the objects in the scene needs to be adjusted. After the abovementioned process, the tree image is synthesized into the background image and the 3D image is constructed.ResultTo verify the effectiveness and practicability of our method, we used different background and tree image materials to create 3D image pairs. We show the five generated 3D images from the experiment in this paper. The experimental results show that all the tree images of different sizes, namely, typical and atypical, can produce layered depth images and can be adaptively synthesized into different 3D background images. The operating efficiency of the system is stable, and the time required to construct the stereoscopic image is linearly related to the size of the original tree image, which means that the run-time growth would not be explosively increased due to the increase in tree image size. In the subjective evaluation test on the stereoscopic image quality, we conducted tests and statistics on three aspects:3D image pair quality, depth map quality, and 3D comfort situation. Five different ratings are available for each aspect, covering all aspects related to the quality of the 3D image. In accordance with the statistics of each item, we obtain the total score under the percentile and then divide the total score into five grades:excellent, good, medium, normal, and poor. In the test, the ratings for these images all reach good levels, and some of them even achieve excellent levels.ConclusionTo naturally blend 3D trees and 3D background images and enhance the 3D display of trees, by using the morphological characteristics of trees, this paper presents a 3D tree image construction method on the basis of depth template. The method takes full advantage of the morphological characteristics of trees and can be applied to both typical and atypical trees. The constructed 3D trees have a high image quality and comfortable stereoscopic effect. The depth template used in this paper presents a greater improvement in the depth sense of trees in 3D images than the existing methods.关键词:tree image;3D image;image synthesis;depth template;tree structure11|4|3更新时间:2024-05-07
摘要:Objective2D to 3D technology can quickly and effectively transfer the existing rich resource of 2D images into 3D images. However, existing methods only consider depth estimation on the entire object of a tree in the process of depth map generation. In this way, the tree in the final 3D images generated would normally lack a sense of depth and look like a piece of paper stuck on the background. The depth map generated by these methods cannot show the natural three-dimensional structural features of trees and has no sufficient rich stereoscopic levels to show the layering on the trees. To this end, this paper presents a 3D tree image construction method on the basis of depth template.MethodIn our proposed method, we first utilize the color difference of pixels under the laboratory color model to divide the 2D tree image into trunk and canopy areas and then divide the canopy area again into several small areas by using multiscale spectral-based image segmentation method. Then, considering the assumption of depth gradient hypothesis, we create various types of basic depth templates. In addition to the six commonly used basic depth templates, two new basic depth templates are added on the basis of the structural features of the trees. In accordance with the complexity of the morphology of trees, this paper divides the tree objects into two major categories:typical and atypical trees. The typical trees are those with regular shapes and can basically belong to the four typical tree models of spherical, conical, cylindrical, and wide spread shapes. The atypical trees are inconsistent with the basic characteristics of the existing four tree models. The initial depth maps of typical tree objects are constructed by combining the basic depth template and the area information of canopy. For the atypical tree object, we first select some basic depth templates to generate a personal depth temple, and then a personalized initial depth map is constructed through the combination of the personal depth temple and the tree's canopy area information. Finally, the tree depth information is adjusted and optimized adaptively in accordance with the application scene. 3D images of trees are adaptively adjusted in accordance with the depth information of the corresponding position of the background to obtain a depth map consistent with the background depth information. In addition, different objects in the scene are located at different depths, so when the tree images are synthesized into the background image, the occlusion between the objects in the scene needs to be adjusted. After the abovementioned process, the tree image is synthesized into the background image and the 3D image is constructed.ResultTo verify the effectiveness and practicability of our method, we used different background and tree image materials to create 3D image pairs. We show the five generated 3D images from the experiment in this paper. The experimental results show that all the tree images of different sizes, namely, typical and atypical, can produce layered depth images and can be adaptively synthesized into different 3D background images. The operating efficiency of the system is stable, and the time required to construct the stereoscopic image is linearly related to the size of the original tree image, which means that the run-time growth would not be explosively increased due to the increase in tree image size. In the subjective evaluation test on the stereoscopic image quality, we conducted tests and statistics on three aspects:3D image pair quality, depth map quality, and 3D comfort situation. Five different ratings are available for each aspect, covering all aspects related to the quality of the 3D image. In accordance with the statistics of each item, we obtain the total score under the percentile and then divide the total score into five grades:excellent, good, medium, normal, and poor. In the test, the ratings for these images all reach good levels, and some of them even achieve excellent levels.ConclusionTo naturally blend 3D trees and 3D background images and enhance the 3D display of trees, by using the morphological characteristics of trees, this paper presents a 3D tree image construction method on the basis of depth template. The method takes full advantage of the morphological characteristics of trees and can be applied to both typical and atypical trees. The constructed 3D trees have a high image quality and comfortable stereoscopic effect. The depth template used in this paper presents a greater improvement in the depth sense of trees in 3D images than the existing methods.关键词:tree image;3D image;image synthesis;depth template;tree structure11|4|3更新时间:2024-05-07 -
 摘要:ObjectiveIn the field of moving object detection, detecting fixed cameras has gradually matured. In numerous practical applications, camera motion, such as rotating scan, is required to increase the monitoring range and achieve gaze monitoring. In comparison with moving object detection under fixed camera conditions, the camera motion causes further difficulty in moving object detection. Image compensation is needed to eliminate the effect of image transformation caused by the camera motion. However, the traditional linear model cannot solve the nonlinear transform generated by the rotating scan movement of cameras. Under the condition of camera rotating scan, the key step of image compensation is to find an accurate motion model to describe image transformations between image frames, including rotation, translation, and scaling. The existing methods are not able to meet simultaneously the application requirements in terms of calculation time and accuracy. To solve this problem, a robust image compensation method under the condition of camera rotating scan is proposed, which can simultaneously achieve background motion and image nonlinear transform compensations.MethodOur method includes four steps to achieve the goal of image compensation for camera rotating scan. First, corresponding point pairs are obtained through image matching. Feature points in the current frame are extracted through Features from Accelerated Segment Test (FAST) corner detection method and then matched with those in the previous frame. Subsequently, the global displacement of the background is computed through the matching points. On this basis, the Kalman filter updates its state and predicts the global displacement of the next frame and the positions of the current feature points appearing on the next image. Consequently, the feature points in the next frame matched with the current feature point are searched in the estimated image area. As the matched image area is reduced, feature matching accuracy can be improved. Second, a global transformation model between adjacent frames is established. In accordance with the analysis of the camera imaging mechanism for rotating scan, a nonlinear motion model is proposed. On the basis of the nonlinear motion model, a camera equation is established, which is further transformed into a linear problem by parameter space conversion. Third, Hough transform is utilized to estimate the parameters of the global motion model by using the matched point pairs. The global motion model is then mapped into the image to obtain the coordinate transformation relationship between adjacent images. Through the coordinate transformation relationship, the image is normalized to a unified coordinate system. This step leads to the implementation of background motion and nonlinear transform compensations. Finally, foreground objects are segmented from the image. The block-based inter-frame difference method is used to detect moving objects. To extract the foreground objects completely, the mathematical morphological opening is operated to eliminate isolated pixel points and small line segments. Then, a closing operation is performed to fill the holes in the object regions to maintain the completeness of the object.ResultTo prove the validity of the proposed method, different experiments are tested on several videos, including grass, traffic section, and indoor and other real scenes. All the experiments run on the Windows platform and the algorithm is implemented in C++. The adopted camera is Hikvision's DS-2DF230IW-A with resolution of 1 280×720. To evaluate the performance of this method, we compare it with other global motion models, including affine transformation and local linear models. The experimental results can be summarized as follows. When the frame interval is small, the affine transformation model produces a large error. The local model and method presented in this paper can achieve improved results. As the rotation angle of the camera increases, nonlinear transformation becomes increasingly significant. The compensation result generates isolated pixels and small segments due to the occurrence of edge effect for the local linear model method. However, the method proposed in this paper can remove 90% of the isolated pixels and small segments, which can solve the problem of nonlinear transformation for camera rotating scan. In addition, the proposed method can be quickly solved by camera equations and Hough transform with processing speed of 50 frames per second (fps), which can meets real-time requirements. This method also has limitations in that it is only suitable for a low-pitch angle of the camera. The influence of pitch angle on the results of our method requires further analysis and research.ConclusionDetecting moving objects on a rotating scan camera is a difficult issue because the motion of the camera leads to the movement of the background and deformation of the image. Image compensation is required to remove background motion and image deformation. The quality of the image compensation method directly affects the final result of moving object detection. For traditional methods, nonlinear transformation is not considered thoroughly. The camera imaging mechanism under the condition of camera rotating scan is analyzed in this paper. Then, a nonlinear transformation model and the corresponding calculation method are presented. Results prove that compared with existing methods, our proposed method can achieve real-time performance and smaller compensation errors under the condition of camera rotating scan. On the basis of this method, the object detection problem in the dynamic background is converted into the object detection problem in the static background. Then, the reliable detection of the moving object can be achieved by using frame difference. As pan-tilt-zoom monitoring technology is increasingly widely used for scanning and monitoring large-scale scenes, the proposed method has practical values for object detection.关键词:rotating-scan;nonlinear transform;Hough transform;frame difference;image compensation13|4|0更新时间:2024-05-07
摘要:ObjectiveIn the field of moving object detection, detecting fixed cameras has gradually matured. In numerous practical applications, camera motion, such as rotating scan, is required to increase the monitoring range and achieve gaze monitoring. In comparison with moving object detection under fixed camera conditions, the camera motion causes further difficulty in moving object detection. Image compensation is needed to eliminate the effect of image transformation caused by the camera motion. However, the traditional linear model cannot solve the nonlinear transform generated by the rotating scan movement of cameras. Under the condition of camera rotating scan, the key step of image compensation is to find an accurate motion model to describe image transformations between image frames, including rotation, translation, and scaling. The existing methods are not able to meet simultaneously the application requirements in terms of calculation time and accuracy. To solve this problem, a robust image compensation method under the condition of camera rotating scan is proposed, which can simultaneously achieve background motion and image nonlinear transform compensations.MethodOur method includes four steps to achieve the goal of image compensation for camera rotating scan. First, corresponding point pairs are obtained through image matching. Feature points in the current frame are extracted through Features from Accelerated Segment Test (FAST) corner detection method and then matched with those in the previous frame. Subsequently, the global displacement of the background is computed through the matching points. On this basis, the Kalman filter updates its state and predicts the global displacement of the next frame and the positions of the current feature points appearing on the next image. Consequently, the feature points in the next frame matched with the current feature point are searched in the estimated image area. As the matched image area is reduced, feature matching accuracy can be improved. Second, a global transformation model between adjacent frames is established. In accordance with the analysis of the camera imaging mechanism for rotating scan, a nonlinear motion model is proposed. On the basis of the nonlinear motion model, a camera equation is established, which is further transformed into a linear problem by parameter space conversion. Third, Hough transform is utilized to estimate the parameters of the global motion model by using the matched point pairs. The global motion model is then mapped into the image to obtain the coordinate transformation relationship between adjacent images. Through the coordinate transformation relationship, the image is normalized to a unified coordinate system. This step leads to the implementation of background motion and nonlinear transform compensations. Finally, foreground objects are segmented from the image. The block-based inter-frame difference method is used to detect moving objects. To extract the foreground objects completely, the mathematical morphological opening is operated to eliminate isolated pixel points and small line segments. Then, a closing operation is performed to fill the holes in the object regions to maintain the completeness of the object.ResultTo prove the validity of the proposed method, different experiments are tested on several videos, including grass, traffic section, and indoor and other real scenes. All the experiments run on the Windows platform and the algorithm is implemented in C++. The adopted camera is Hikvision's DS-2DF230IW-A with resolution of 1 280×720. To evaluate the performance of this method, we compare it with other global motion models, including affine transformation and local linear models. The experimental results can be summarized as follows. When the frame interval is small, the affine transformation model produces a large error. The local model and method presented in this paper can achieve improved results. As the rotation angle of the camera increases, nonlinear transformation becomes increasingly significant. The compensation result generates isolated pixels and small segments due to the occurrence of edge effect for the local linear model method. However, the method proposed in this paper can remove 90% of the isolated pixels and small segments, which can solve the problem of nonlinear transformation for camera rotating scan. In addition, the proposed method can be quickly solved by camera equations and Hough transform with processing speed of 50 frames per second (fps), which can meets real-time requirements. This method also has limitations in that it is only suitable for a low-pitch angle of the camera. The influence of pitch angle on the results of our method requires further analysis and research.ConclusionDetecting moving objects on a rotating scan camera is a difficult issue because the motion of the camera leads to the movement of the background and deformation of the image. Image compensation is required to remove background motion and image deformation. The quality of the image compensation method directly affects the final result of moving object detection. For traditional methods, nonlinear transformation is not considered thoroughly. The camera imaging mechanism under the condition of camera rotating scan is analyzed in this paper. Then, a nonlinear transformation model and the corresponding calculation method are presented. Results prove that compared with existing methods, our proposed method can achieve real-time performance and smaller compensation errors under the condition of camera rotating scan. On the basis of this method, the object detection problem in the dynamic background is converted into the object detection problem in the static background. Then, the reliable detection of the moving object can be achieved by using frame difference. As pan-tilt-zoom monitoring technology is increasingly widely used for scanning and monitoring large-scale scenes, the proposed method has practical values for object detection.关键词:rotating-scan;nonlinear transform;Hough transform;frame difference;image compensation13|4|0更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveFracturing has been widely applied in video games, films, and other industries. Fracturing simulation has attracted increasing attention in the field of computer graphics. Particularly, with the rapid development of virtual reality over the past few years, considerable demands have been placed on the diversity of fracturing results and real-time fracturing in a virtual scene. An improved fracturing result could significantly strengthen the realistic experience of players. In physics-based simulation method, the work of rigid body fracture simulation has been gradually conducted from the early inelastic deformation model to simulate the inelastic behavior to the mass-spring model and then to the fracture mechanism based on the tetrahedral model. To improve the realistic sense of fracturing effect as much as possible, numerous scholars have focused on enriching the detail expression of cracks during fracturing. During the continuous exploration of the simulation of physical phenomena in the real world, several physics engines have appeared in succession to simulate fragmentation and explosion in the real world. In recent years, significant progress has also been achieved in simulating the fragmentation of thin-plate type materials, such as paper, which renders the real-life fracturing phenomenon further varied on a computer. In the non-physical method of rigid body fracturing, the Voronoi diagram-based fracturing method plays a main role. However, the rigid body fracturing method has several disadvantages. First, the method based on physical force analysis does not work well in the situation where real-time is highly demanded, and the instant fracturing effect produced by the fracturing simulation based on non-physical method lacks diversity. Second, in most games, models often have been pre-fractured during their authoring time. When fracturing occurs, the original models are simply replaced by the pre-fractured one. This type of method significantly increases the authoring time of the designer and reduces the diversity. Most of the early works in film use the miniature model to simulate the crushing of large-scale scenes, such as the collapse of high-rise buildings. This type of method also lacks realism. To obtain real-time fracturing and diversified effects in fracturing simulation, a method applicable to diversified types is proposed, namely, a real-time rigid body fracturing method.MethodDuring the fracturing simulation, the type of seed generation (three types of seed generation are available:completely random, evenly distributed with disturbance, and radiation) should be selected first. Then, sweep plane algorithm is used to generate the Voronoi diagram, based on which space partition is conducted on the model. During this process, to avoid the situation in which the seed points concentrated in a local area are too much or worse in the global area, sparse processing has been introduced:when multiple seed points are separated from each other by a certain threshold, the average value of the position of these seed points is selected as one seed point. Then, by means of a simulation pattern of fracture behavior (two types of simulation pattern:explosion and collapse), the external force when rigid-body fracturing is simulated and collision detection, following the impact process of the broken fragments, is also simulated. Finally, rendering and display follows.ResultThrough a combination of different seed point-generating types and simulation patterns of fracture behavior, the diversified effect of fracturing are simulated. The real-time requirement can be satisfied. In a single rigid-body model fracturing simulation, the frame rate can reach 75 fram/s with 200 broken fragments. In further complex scenarios (e.g., a building) where approximately 150 fracturing objectives with three types of materials are available, the frame rate can also reach 50 fram/s to cause the fracturing effect in this complex situation, not only to meet the diversity of fracturing effect but also to meet the real-time requirements, in the fracturing of different building components using different fracturing simulation types, through the combination of different types of seed point generation and fracture behavior simulation. A number of less affected parts from each other are broken at the same time. After comparison with some existing methods, the method used in this article achieves a better balance between computational efficiency (compared with the physics-based method) and diversity of fracturing effects (compared with the Voronoi-based method).ConclusionA real-time rigid-body fracturing method applicable to multi-fracturing effect is proposed in this paper. On the one hand, this method possesses a real-time feature, and on the other hand, it also contributes to enhancing the diversity of rigid body fracturing. By combining different seed point-generating types and simulation patterns of fracture behavior, diversified fracturing effects can be achieved. In our future work, this method will be further improved and optimized to be applied to highly complex fracturing simulation.关键词:computer simulation;virtual reality;rigid body fracturing simulation;Voronoi diagram;diversified fracturing;collision effect28|7|1更新时间:2024-05-07
摘要:ObjectiveFracturing has been widely applied in video games, films, and other industries. Fracturing simulation has attracted increasing attention in the field of computer graphics. Particularly, with the rapid development of virtual reality over the past few years, considerable demands have been placed on the diversity of fracturing results and real-time fracturing in a virtual scene. An improved fracturing result could significantly strengthen the realistic experience of players. In physics-based simulation method, the work of rigid body fracture simulation has been gradually conducted from the early inelastic deformation model to simulate the inelastic behavior to the mass-spring model and then to the fracture mechanism based on the tetrahedral model. To improve the realistic sense of fracturing effect as much as possible, numerous scholars have focused on enriching the detail expression of cracks during fracturing. During the continuous exploration of the simulation of physical phenomena in the real world, several physics engines have appeared in succession to simulate fragmentation and explosion in the real world. In recent years, significant progress has also been achieved in simulating the fragmentation of thin-plate type materials, such as paper, which renders the real-life fracturing phenomenon further varied on a computer. In the non-physical method of rigid body fracturing, the Voronoi diagram-based fracturing method plays a main role. However, the rigid body fracturing method has several disadvantages. First, the method based on physical force analysis does not work well in the situation where real-time is highly demanded, and the instant fracturing effect produced by the fracturing simulation based on non-physical method lacks diversity. Second, in most games, models often have been pre-fractured during their authoring time. When fracturing occurs, the original models are simply replaced by the pre-fractured one. This type of method significantly increases the authoring time of the designer and reduces the diversity. Most of the early works in film use the miniature model to simulate the crushing of large-scale scenes, such as the collapse of high-rise buildings. This type of method also lacks realism. To obtain real-time fracturing and diversified effects in fracturing simulation, a method applicable to diversified types is proposed, namely, a real-time rigid body fracturing method.MethodDuring the fracturing simulation, the type of seed generation (three types of seed generation are available:completely random, evenly distributed with disturbance, and radiation) should be selected first. Then, sweep plane algorithm is used to generate the Voronoi diagram, based on which space partition is conducted on the model. During this process, to avoid the situation in which the seed points concentrated in a local area are too much or worse in the global area, sparse processing has been introduced:when multiple seed points are separated from each other by a certain threshold, the average value of the position of these seed points is selected as one seed point. Then, by means of a simulation pattern of fracture behavior (two types of simulation pattern:explosion and collapse), the external force when rigid-body fracturing is simulated and collision detection, following the impact process of the broken fragments, is also simulated. Finally, rendering and display follows.ResultThrough a combination of different seed point-generating types and simulation patterns of fracture behavior, the diversified effect of fracturing are simulated. The real-time requirement can be satisfied. In a single rigid-body model fracturing simulation, the frame rate can reach 75 fram/s with 200 broken fragments. In further complex scenarios (e.g., a building) where approximately 150 fracturing objectives with three types of materials are available, the frame rate can also reach 50 fram/s to cause the fracturing effect in this complex situation, not only to meet the diversity of fracturing effect but also to meet the real-time requirements, in the fracturing of different building components using different fracturing simulation types, through the combination of different types of seed point generation and fracture behavior simulation. A number of less affected parts from each other are broken at the same time. After comparison with some existing methods, the method used in this article achieves a better balance between computational efficiency (compared with the physics-based method) and diversity of fracturing effects (compared with the Voronoi-based method).ConclusionA real-time rigid-body fracturing method applicable to multi-fracturing effect is proposed in this paper. On the one hand, this method possesses a real-time feature, and on the other hand, it also contributes to enhancing the diversity of rigid body fracturing. By combining different seed point-generating types and simulation patterns of fracture behavior, diversified fracturing effects can be achieved. In our future work, this method will be further improved and optimized to be applied to highly complex fracturing simulation.关键词:computer simulation;virtual reality;rigid body fracturing simulation;Voronoi diagram;diversified fracturing;collision effect28|7|1更新时间:2024-05-07 -
 摘要:ObjectiveThe purpose of this paper is to construct a type of Bézier curve with a shape parameter. We require the curves defined in algebraic polynomial space. The degree of the basis functions should be the same as the Bernstein basis functions, which needed the same number of control points. The calculation of the basis functions and corresponding curves should be as simple as possible. The selection scheme under common design requirements of the shape parameter in the curves should be provided.MethodWith the cubic Bézier curve as the initial research object and in accordance with the idea of defining a shape-adjustable curve by using adjustable control points, we introduce a parameter into the two inner control points. Let the control points with the parameter have a linear combination with the Bernstein basis functions to generate the shape adjustable curves. By rewriting the expression of the curves as the linear combination of the fixed control points and the blending functions with the parameter, we obtain the extended basis with the parameter of the cubic Bernstein basis functions. By using the recursive formula, we obtain the extended basis with the parameter of a high degree. Then, we observe the rule of the basis function expression and provide the uniform explicit expression of all extended basis functions with parameters. The properties of the extended basis functions are analyzed, and the corresponding curves with parameters are defined. The properties of the curves are analyzed. The geometric drawing method and smooth joining conditions of the curves are also provided. The calculation formula of the parameter, which causes the stretch, strain, and jerk energies of the curves to be approximately minimum, is deduced. The difference of the curves determined by different energy targets is compared and analyzed by using the graph of the curves and their curvatures.ResultThe method provides the Bézier curve shape adjustability without increasing the calculation amount due to the fact that the extended basis functions have the same degree as the Bernstein basis functions and have a uniform explicit expression. Determining the shape parameter that conforms to the design requirements when using this method is easy because the calculation formula of the shape parameter can be used directly. The numerical examples intuitively show the correctness and validity of the proposed curve modeling method and the shape parameter selection scheme in the curve. The illustration also shows the superiority of the method provided in this paper over similar methods presented in the literature.ConclusionThe method of constructing an extended basis with the parameter and selection method of the shape parameter are general. This method can be extended to construct a triangular Bézier surface with parameter.关键词:curve modeling;Bezier curve;shape parameter;energy minimization;parameter selection32|115|2更新时间:2024-05-07
摘要:ObjectiveThe purpose of this paper is to construct a type of Bézier curve with a shape parameter. We require the curves defined in algebraic polynomial space. The degree of the basis functions should be the same as the Bernstein basis functions, which needed the same number of control points. The calculation of the basis functions and corresponding curves should be as simple as possible. The selection scheme under common design requirements of the shape parameter in the curves should be provided.MethodWith the cubic Bézier curve as the initial research object and in accordance with the idea of defining a shape-adjustable curve by using adjustable control points, we introduce a parameter into the two inner control points. Let the control points with the parameter have a linear combination with the Bernstein basis functions to generate the shape adjustable curves. By rewriting the expression of the curves as the linear combination of the fixed control points and the blending functions with the parameter, we obtain the extended basis with the parameter of the cubic Bernstein basis functions. By using the recursive formula, we obtain the extended basis with the parameter of a high degree. Then, we observe the rule of the basis function expression and provide the uniform explicit expression of all extended basis functions with parameters. The properties of the extended basis functions are analyzed, and the corresponding curves with parameters are defined. The properties of the curves are analyzed. The geometric drawing method and smooth joining conditions of the curves are also provided. The calculation formula of the parameter, which causes the stretch, strain, and jerk energies of the curves to be approximately minimum, is deduced. The difference of the curves determined by different energy targets is compared and analyzed by using the graph of the curves and their curvatures.ResultThe method provides the Bézier curve shape adjustability without increasing the calculation amount due to the fact that the extended basis functions have the same degree as the Bernstein basis functions and have a uniform explicit expression. Determining the shape parameter that conforms to the design requirements when using this method is easy because the calculation formula of the shape parameter can be used directly. The numerical examples intuitively show the correctness and validity of the proposed curve modeling method and the shape parameter selection scheme in the curve. The illustration also shows the superiority of the method provided in this paper over similar methods presented in the literature.ConclusionThe method of constructing an extended basis with the parameter and selection method of the shape parameter are general. This method can be extended to construct a triangular Bézier surface with parameter.关键词:curve modeling;Bezier curve;shape parameter;energy minimization;parameter selection32|115|2更新时间:2024-05-07
Computer Graphics
-
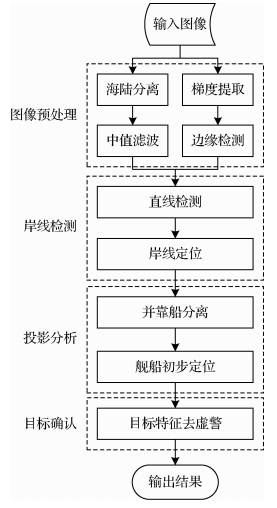 摘要:ObjectiveIn high-resolution remote sensing images, inshore ship detection has broad application prospects, such as ocean surveillance, fisheries management, and military reconnaissance. However, unlike the ship detection under pure sea background, inshore ship detection is much more challenging, considering the complex background of the port. The main difficulty of inshore ship detection is that the ship and the dock are adjacent in space and similar in color and texture features, thereby introducing difficulties in distinguishing them. Effective methods for this task are scarce. The existing methods can be mainly into three types. The first is based on template matching but prior geographical information of the port is needed, which is often difficult to obtain. The second type is based on the ship contour method, in which the robustness is low and detecting side-by-side ships is difficult. The third type is based on local features of the ship, which often assume that the ship has a V-shaped bow and is powerless to other ships. Other than the existing methods, a method for inshore ship detection using projection analysis is proposed in this paper. Our method is based on the observation that the shoreline of a dock is typically straight and inshore ships are usually anchored along the ship's rail.MethodFirst, the original image is preprocessed by two sibling approaches:one that segments the sea and land and another that extracts edges. For sea-land segmentation, the K-means clustering algorithm and region-growing algorithm are combined to improve the segmentation quality, which is significant for our method. Meanwhile, the original image is processed to a gradient image by Sobel operator, and then the gradient image is segmented to an edge image with the Otsu algorithm. Second, an improved Hough transform is conducted on the edge image to extract the straight lines, among which are dock shorelines. To remove interference lines, we assume that all extracted lines of dock shorelines should only lie on the border of water. Then, we start to search for ships on both sides of the located dock shorelines. Taking one dock shoreline as an example, we project the sea-land segmentation image perpendicular to the dock shoreline direction and obtain a projection curve. If a ship is anchored along the dock shoreline, the projection curve shape is convex. Otherwise, the curve shape is flat. Furthermore, we can locate the ship with a bounding box by analyzing the curve shape conveniently. To separate side-by-side ships, we conduct another projection in the dock shoreline direction and separate these ships by analyzing the peak and valley of the projection curve. Finally, we remove false alarms using features of ship size, aspect ratio, and duty ratio.ResultWe have randomly chosen 292 high-resolution remote sensing images of 15 different scenes on Google Earth to test our method. The test images have a total of 962 ships, comprising 139 aircraft carriers, 794 destroyers, and 29 civilian ships. The resolution of the images ranges from 1 m to 5.5 m. Thus, the ships on these images are variant in scale, orientation, and even brightness. Our method has correctly detected 822 of the 962 ships, comprising 134 aircraft carriers, 666 destroyers, and 22 civilian ships. These results represent 85.4% of the total detection rate, 96.4% of the aircraft carrier detection rate, and 83.9% destroyer detection rate. Meanwhile, we have 171 false alarm targets, thereby representing a false alarm rate of 17.2%. Results show that if the resolution is limited from 2 m to 4 m, the total detection rate grows up to 93.5% and the false alarm rate decreases to 5.3%. However, our method is sensitive to the quality of sea-land segmentation, which is essential to extracting the straight line features of the dock shorelines. Thus, the detection rate is compromised on very complex backgrounds, as shown in this paper.ConclusionOur method is simple and effective for inshore ship detection tasks. No prior information on the harbors is needed. The method is suitable for detection of inshore ships in variable resolutions and directions. It is robust to ship shapes and side-by-side ships can be detected as well. Given that our method is sensitive to the quality of sea-land segmentation, more powerful segmentation algorithms, which is our future research direction, may be effective.关键词:inshore ship detection;dock shoreline detection;projection analysis;high resolution remote sensing image;side-by-side ships detection12|4|4更新时间:2024-05-07
摘要:ObjectiveIn high-resolution remote sensing images, inshore ship detection has broad application prospects, such as ocean surveillance, fisheries management, and military reconnaissance. However, unlike the ship detection under pure sea background, inshore ship detection is much more challenging, considering the complex background of the port. The main difficulty of inshore ship detection is that the ship and the dock are adjacent in space and similar in color and texture features, thereby introducing difficulties in distinguishing them. Effective methods for this task are scarce. The existing methods can be mainly into three types. The first is based on template matching but prior geographical information of the port is needed, which is often difficult to obtain. The second type is based on the ship contour method, in which the robustness is low and detecting side-by-side ships is difficult. The third type is based on local features of the ship, which often assume that the ship has a V-shaped bow and is powerless to other ships. Other than the existing methods, a method for inshore ship detection using projection analysis is proposed in this paper. Our method is based on the observation that the shoreline of a dock is typically straight and inshore ships are usually anchored along the ship's rail.MethodFirst, the original image is preprocessed by two sibling approaches:one that segments the sea and land and another that extracts edges. For sea-land segmentation, the K-means clustering algorithm and region-growing algorithm are combined to improve the segmentation quality, which is significant for our method. Meanwhile, the original image is processed to a gradient image by Sobel operator, and then the gradient image is segmented to an edge image with the Otsu algorithm. Second, an improved Hough transform is conducted on the edge image to extract the straight lines, among which are dock shorelines. To remove interference lines, we assume that all extracted lines of dock shorelines should only lie on the border of water. Then, we start to search for ships on both sides of the located dock shorelines. Taking one dock shoreline as an example, we project the sea-land segmentation image perpendicular to the dock shoreline direction and obtain a projection curve. If a ship is anchored along the dock shoreline, the projection curve shape is convex. Otherwise, the curve shape is flat. Furthermore, we can locate the ship with a bounding box by analyzing the curve shape conveniently. To separate side-by-side ships, we conduct another projection in the dock shoreline direction and separate these ships by analyzing the peak and valley of the projection curve. Finally, we remove false alarms using features of ship size, aspect ratio, and duty ratio.ResultWe have randomly chosen 292 high-resolution remote sensing images of 15 different scenes on Google Earth to test our method. The test images have a total of 962 ships, comprising 139 aircraft carriers, 794 destroyers, and 29 civilian ships. The resolution of the images ranges from 1 m to 5.5 m. Thus, the ships on these images are variant in scale, orientation, and even brightness. Our method has correctly detected 822 of the 962 ships, comprising 134 aircraft carriers, 666 destroyers, and 22 civilian ships. These results represent 85.4% of the total detection rate, 96.4% of the aircraft carrier detection rate, and 83.9% destroyer detection rate. Meanwhile, we have 171 false alarm targets, thereby representing a false alarm rate of 17.2%. Results show that if the resolution is limited from 2 m to 4 m, the total detection rate grows up to 93.5% and the false alarm rate decreases to 5.3%. However, our method is sensitive to the quality of sea-land segmentation, which is essential to extracting the straight line features of the dock shorelines. Thus, the detection rate is compromised on very complex backgrounds, as shown in this paper.ConclusionOur method is simple and effective for inshore ship detection tasks. No prior information on the harbors is needed. The method is suitable for detection of inshore ships in variable resolutions and directions. It is robust to ship shapes and side-by-side ships can be detected as well. Given that our method is sensitive to the quality of sea-land segmentation, more powerful segmentation algorithms, which is our future research direction, may be effective.关键词:inshore ship detection;dock shoreline detection;projection analysis;high resolution remote sensing image;side-by-side ships detection12|4|4更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0