
最新刊期
卷 23 , 期 8 , 2018
-
 摘要:ObjectiveWith the development of military reconnaissance mission equipment, infrared and visible light target reconnaissance techniques have already become the main means of reconnaissance among military equipment. Research on infrared and visible light object tracking technology is important for the improvement of intelligence equipment related to battlefield acquisition and precision strike in military missions, such as all-weather target reconnaissance, object tracking, and target location. Presently, with the rise of computer vision technology, visual object tracking technology has gradually become the focus and challenge of research, and the methods and kinds of object tracking techniques are increasing. In this study, four kinds of visual object tracking methods, which are extensively used at present, are reviewed. This work serves as basis for follow-up research on the theory and development of object tracking.MethodBy analyzing the difficult problems of infrared and visible object tracking technology, the visual object tracking method is divided into generative and discriminative model methods, the different modeling methods of object tracking. The mean shift and particle filter object tracking in generative model algorithm and the correlation filtering and deep learning object tracking in discriminative model algorithm are reviewed in this paper. First, the basic principles of the three standard object tracking algorithms, namely, mean shift object tracking and particle filter object tracking methods and correlation filters for object tracking method, are comprehensively analyzed. Then, the limitations of the basic principles of the three tracking algorithms are listed, and the corresponding difficulties in object tracking that need to be solved are presented. By analyzing the difficult problems in object tracking, the mainstream improvement scheme of the corresponding object tracking algorithm is given. According to the characteristics of infrared image and the difficult problem of infrared object tracking, the improved algorithm of infrared correlation filter for object tracking is presented. We analyzed the methods of object tracking using deep learning and divided them into two categories. One is to take the neural network feature as the target feature extraction method. We analyzed its feature extraction principles and characteristics and feature extraction strategy in object tracking. Moreover, the corresponding improvement scheme is also provided according to the characteristics of infrared object tracking. The other one is the neural network framework. We summarized its principles and characteristics and analyzed its various architecture advantages and disadvantages in object tracking. To address the problem of infrared object tracking, an improvement scheme is proposed. Finally, we summarized the present situation and discussed the practical application and future development trend of object tracking technology.ResultPresently, the visual object tracking technology has a reliable performance under short-term object tracking condition. However, in long-term tracking required in practical application is difficult because the application scene is complex, making the difficult problem of object tracking prominent. Given the key and difficult problems in object tracking, such as target occlusion and target out of view, the robustness and precision of object tracking technology are required to be high in practical application, and corresponding solutions to the problem of long-time object tracking should be put forward. In view of the progress in the research on technology related to visual object tracking, along with the demand of unmanned aerial vehicle reconnaissance mission and the high maneuverability of unmanned aerial vehicles, this study analyzes the key problems, gives the current solutions of the existing weaknesses and explores the development direction.ConclusionThus far, the visual object tracking technology has performed remarkable progress, and its accuracy and success rate have been significantly improved. Visual object tracking technology is becoming widely used in the reconnaissance missions of military equipment. However, the technology of object tracking remains challenging. The related theories of object tracking need to be further tested and improved, especially in view of the characteristics of infrared object tracking. To improve the object tracking effect in infrared image, the corresponding object tracking method and improved scheme should be further studied. The object tracking is challenging because the application scene is complex. The robustness and accuracy of the object tracking algorithm should be high to avoid failure, and its real-time performance and tracking speed should meet real-time requirements. Considering the application characteristics and application scope of different military equipment, finding a visual object tracking algorithm is important. The algorithm must be relatively accurate and robust and meets real-time requirements to enhance the equipment's all-weather reconnaissance ability and target battlefield information acquisition capability.关键词:object tracking;Mean-shift;particle filter;correlation filter;deep learning32|257|38更新时间:2024-08-15
摘要:ObjectiveWith the development of military reconnaissance mission equipment, infrared and visible light target reconnaissance techniques have already become the main means of reconnaissance among military equipment. Research on infrared and visible light object tracking technology is important for the improvement of intelligence equipment related to battlefield acquisition and precision strike in military missions, such as all-weather target reconnaissance, object tracking, and target location. Presently, with the rise of computer vision technology, visual object tracking technology has gradually become the focus and challenge of research, and the methods and kinds of object tracking techniques are increasing. In this study, four kinds of visual object tracking methods, which are extensively used at present, are reviewed. This work serves as basis for follow-up research on the theory and development of object tracking.MethodBy analyzing the difficult problems of infrared and visible object tracking technology, the visual object tracking method is divided into generative and discriminative model methods, the different modeling methods of object tracking. The mean shift and particle filter object tracking in generative model algorithm and the correlation filtering and deep learning object tracking in discriminative model algorithm are reviewed in this paper. First, the basic principles of the three standard object tracking algorithms, namely, mean shift object tracking and particle filter object tracking methods and correlation filters for object tracking method, are comprehensively analyzed. Then, the limitations of the basic principles of the three tracking algorithms are listed, and the corresponding difficulties in object tracking that need to be solved are presented. By analyzing the difficult problems in object tracking, the mainstream improvement scheme of the corresponding object tracking algorithm is given. According to the characteristics of infrared image and the difficult problem of infrared object tracking, the improved algorithm of infrared correlation filter for object tracking is presented. We analyzed the methods of object tracking using deep learning and divided them into two categories. One is to take the neural network feature as the target feature extraction method. We analyzed its feature extraction principles and characteristics and feature extraction strategy in object tracking. Moreover, the corresponding improvement scheme is also provided according to the characteristics of infrared object tracking. The other one is the neural network framework. We summarized its principles and characteristics and analyzed its various architecture advantages and disadvantages in object tracking. To address the problem of infrared object tracking, an improvement scheme is proposed. Finally, we summarized the present situation and discussed the practical application and future development trend of object tracking technology.ResultPresently, the visual object tracking technology has a reliable performance under short-term object tracking condition. However, in long-term tracking required in practical application is difficult because the application scene is complex, making the difficult problem of object tracking prominent. Given the key and difficult problems in object tracking, such as target occlusion and target out of view, the robustness and precision of object tracking technology are required to be high in practical application, and corresponding solutions to the problem of long-time object tracking should be put forward. In view of the progress in the research on technology related to visual object tracking, along with the demand of unmanned aerial vehicle reconnaissance mission and the high maneuverability of unmanned aerial vehicles, this study analyzes the key problems, gives the current solutions of the existing weaknesses and explores the development direction.ConclusionThus far, the visual object tracking technology has performed remarkable progress, and its accuracy and success rate have been significantly improved. Visual object tracking technology is becoming widely used in the reconnaissance missions of military equipment. However, the technology of object tracking remains challenging. The related theories of object tracking need to be further tested and improved, especially in view of the characteristics of infrared object tracking. To improve the object tracking effect in infrared image, the corresponding object tracking method and improved scheme should be further studied. The object tracking is challenging because the application scene is complex. The robustness and accuracy of the object tracking algorithm should be high to avoid failure, and its real-time performance and tracking speed should meet real-time requirements. Considering the application characteristics and application scope of different military equipment, finding a visual object tracking algorithm is important. The algorithm must be relatively accurate and robust and meets real-time requirements to enhance the equipment's all-weather reconnaissance ability and target battlefield information acquisition capability.关键词:object tracking;Mean-shift;particle filter;correlation filter;deep learning32|257|38更新时间:2024-08-15
Review

-
 摘要:ObjectiveConventional multi-carrier secret image sharing scheme based on error diffusion and recovery function can be used to hide secret image in multiple same size carriers. In these carriers, the error diffusion method leads to low visual quality and the recovery function is only designed for specific gray scale images, such as 1-bit binary images or 8-bit gray scale images. This scheme can only provide limited security by using simple Arnold scrambling or XOR encryption in which Arnold mapping is usually employed for special resolution images, such as square images. However, the security of Arnold mapping is poor due to its dependence on iteration numbers, and its scrambling coefficients are only 1, 1, 1, 2. In addition, Arnold mapping cannot change its mapping type and form by multiple iterations. To address these problems and further improve the visual qualities of carriers and security, a multi-carrier secret image sharing scheme with EMD-cl embedding is proposed in this study.MethodIn sharing phase, the double hash function values (MD5 and SHA-1 values) are first used to randomly generate scrambling. Iteration variables of secret images and related user keys are used to change every carrier pixel position by 2D bi-scale rectangular mapping. Vectors composed of same position pixels in scrambled carriers are then randomly allocated to the weights of EMD-cl basis vector using extended Josephus mapping where the start position and count termination value, count gap, and count direction sequences are added to increase the number of permutations and the kinds of variations in Josephus mapping. Afterward, EMD-cl embedding strategy is used to embed secret image pixels into multiple carriers to verify the high visual qualities of stego carriers. Finally, both user keys and the double hash function values of secret image are distributed to N participant sharing information by Lagrange (N, N) under module p, where each participant sharing information is kept by one participant and the MD5 and SHA-1 values of each participant sharing information are known to the third trust party to guarantee that every participant sharing information cannot be faked. In recovering phase, all participant sharing information is verified by checking their MD5 and SHA-1 values known to the third trust party. This information is used to recover the related variables, such as the MD5 and SHA-1 values of secret image and the user keys by Lagrange (N, N) under module p. These related variables are used to generate groups of scrambling and iteration variables of a 2D bi-scale rectangular mapping and variables of extended Josephus mapping. Scrambling and iteration variables are used to find the mapping relationships between each secret pixel and N carrier pixels. Extended Josephus mapping variables are used to find the weights of EMD-cl, and EMD-cl is adopted to embed the secret image pixels. In recovering phase, if all participant sharing information passes the third trust party checking and the related variables are the same as those of the sharing phase, then the secret image can be recovered correctly.ResultUnlike in conventional methods, the visual qualities of all stego carriers are enhanced because EMD-cl only makes slight modifications, and the most modification for any non-overflow pixel is only
摘要:ObjectiveConventional multi-carrier secret image sharing scheme based on error diffusion and recovery function can be used to hide secret image in multiple same size carriers. In these carriers, the error diffusion method leads to low visual quality and the recovery function is only designed for specific gray scale images, such as 1-bit binary images or 8-bit gray scale images. This scheme can only provide limited security by using simple Arnold scrambling or XOR encryption in which Arnold mapping is usually employed for special resolution images, such as square images. However, the security of Arnold mapping is poor due to its dependence on iteration numbers, and its scrambling coefficients are only 1, 1, 1, 2. In addition, Arnold mapping cannot change its mapping type and form by multiple iterations. To address these problems and further improve the visual qualities of carriers and security, a multi-carrier secret image sharing scheme with EMD-cl embedding is proposed in this study.MethodIn sharing phase, the double hash function values (MD5 and SHA-1 values) are first used to randomly generate scrambling. Iteration variables of secret images and related user keys are used to change every carrier pixel position by 2D bi-scale rectangular mapping. Vectors composed of same position pixels in scrambled carriers are then randomly allocated to the weights of EMD-cl basis vector using extended Josephus mapping where the start position and count termination value, count gap, and count direction sequences are added to increase the number of permutations and the kinds of variations in Josephus mapping. Afterward, EMD-cl embedding strategy is used to embed secret image pixels into multiple carriers to verify the high visual qualities of stego carriers. Finally, both user keys and the double hash function values of secret image are distributed to N participant sharing information by Lagrange (N, N) under module p, where each participant sharing information is kept by one participant and the MD5 and SHA-1 values of each participant sharing information are known to the third trust party to guarantee that every participant sharing information cannot be faked. In recovering phase, all participant sharing information is verified by checking their MD5 and SHA-1 values known to the third trust party. This information is used to recover the related variables, such as the MD5 and SHA-1 values of secret image and the user keys by Lagrange (N, N) under module p. These related variables are used to generate groups of scrambling and iteration variables of a 2D bi-scale rectangular mapping and variables of extended Josephus mapping. Scrambling and iteration variables are used to find the mapping relationships between each secret pixel and N carrier pixels. Extended Josephus mapping variables are used to find the weights of EMD-cl, and EMD-cl is adopted to embed the secret image pixels. In recovering phase, if all participant sharing information passes the third trust party checking and the related variables are the same as those of the sharing phase, then the secret image can be recovered correctly.ResultUnlike in conventional methods, the visual qualities of all stego carriers are enhanced because EMD-cl only makes slight modifications, and the most modification for any non-overflow pixel is only$ \pm \left\lfloor {c/2} \right\rfloor $ 关键词:exploiting modification direction;multi-carrier;image sharing;2D bi-scale rectangular mapping;Josephus mapping;hash function;error diffusion;recovery function11|5|1更新时间:2024-08-15
Image Processing and Coding
-
 摘要:ObjectivePresently, the segmentation of intensity inhomogeneous images, weak edges, and weak texture images remains a challenge. The CV model alone is not ideal for the segmentation of intensity inhomogeneous image due to using the global information of the image. In the segmentation of weak edges and weak texture images, optimization easily falls into the local optimum, leading to the low efficiency of segmentation and the sensitive selection of the initial position.MethodTo address these problems, a new CV model combining fractional differential and image local information is proposed for image segmentation. the algorithm first integrates fractional gradient information into the local information of the image, replacing the integer order global information of the CV model. An adaptive fractional mathematical model is then constructed according to the gradient modulus and the information entropy of the image. Using the mathematical model as basis, the optimal fractional order can be obtained adaptively. Finally, the symbol distance constraint item is added to the model.ResultThe CV model is an active contour model based on global information, and it works well in segmenting images with homogeneous intensity. However, the CV model is not ideal for the segmentation of intensity inhomogeneous images because it only uses the global information of the image. The local information in the LBF model can be used to replace the global information in the CV model, thereby solving the segmentation of intensity inhomogeneous images. We then use local information instead of the global information, handling the limitation of the CV model in segmenting images with inhomogeneous intensity to a certain extent. In addition, by integrating G-L fractional gradient information into local information, when the fractional order is between 0 and 1, the algorithm increases the gradient information in these regions of inhomogeneous intensity, weak edge, and weak texture. Doing so increasing the driving force of evolution to prevent evolutionary curve from falling into the local optimum and effectively solving the little driving force of the image for the evolvement curve due to the small change of intensity. Furthermore, when the fractional order is between 0 and 1, the fractional differential enhancement of high-frequency signals is less than that of integer-order differential pairs of high-frequency signals. Therefore, fractional differential relatively suppresses noise and has a certain anti-noise ability. Our model can solve the selection of the initial contour position and the sensitivity of the model to noise to an extent. To address the time-consuming and labor-intensive selection of the optimal fractional order, a mathematical model for calculating the optimal order is established according to the gradient modulus and the information entropy of the image, and the adaptive fractional order model is applied to the algorithm to adaptively determine the optimal fraction order. To correct the deviation of the level set function and symbol distance function and avoid the re-initialization of the model, the symbol distance constraint term is added to the model so as to improve the evolution efficiency of the curve.ConclusionTheoretical analysis and experimental results show that the proposed algorithm can segment images with inhomogeneous intensity, weak edge, and weak texture regions, improving the segmentation accuracy and efficiency. Moreover, the optimal order of fraction order derivative can be adjusted adaptively, solving the time-consuming and labor-intensive selection of the optimal fractional orders. The use of fraction order derivative can enhance the weak edge and texture regions without substantially increasing the noise signal. To verify the robustness to the initial selection of evolution curve of the algorithm, five different initial contour positions were selected for the two images, and four different noise images were tested to verify the anti-noise performance of the algorithm. Experimental results demonstrate that our model can correct segment the target contour and has good stability to noise. Our model is robust to the initial selection of evolution curve and noise.关键词:image segmentation;fraction order derivative;local information;CV model;adaptive;intensity inhomogeneous41|43|1更新时间:2024-08-15
摘要:ObjectivePresently, the segmentation of intensity inhomogeneous images, weak edges, and weak texture images remains a challenge. The CV model alone is not ideal for the segmentation of intensity inhomogeneous image due to using the global information of the image. In the segmentation of weak edges and weak texture images, optimization easily falls into the local optimum, leading to the low efficiency of segmentation and the sensitive selection of the initial position.MethodTo address these problems, a new CV model combining fractional differential and image local information is proposed for image segmentation. the algorithm first integrates fractional gradient information into the local information of the image, replacing the integer order global information of the CV model. An adaptive fractional mathematical model is then constructed according to the gradient modulus and the information entropy of the image. Using the mathematical model as basis, the optimal fractional order can be obtained adaptively. Finally, the symbol distance constraint item is added to the model.ResultThe CV model is an active contour model based on global information, and it works well in segmenting images with homogeneous intensity. However, the CV model is not ideal for the segmentation of intensity inhomogeneous images because it only uses the global information of the image. The local information in the LBF model can be used to replace the global information in the CV model, thereby solving the segmentation of intensity inhomogeneous images. We then use local information instead of the global information, handling the limitation of the CV model in segmenting images with inhomogeneous intensity to a certain extent. In addition, by integrating G-L fractional gradient information into local information, when the fractional order is between 0 and 1, the algorithm increases the gradient information in these regions of inhomogeneous intensity, weak edge, and weak texture. Doing so increasing the driving force of evolution to prevent evolutionary curve from falling into the local optimum and effectively solving the little driving force of the image for the evolvement curve due to the small change of intensity. Furthermore, when the fractional order is between 0 and 1, the fractional differential enhancement of high-frequency signals is less than that of integer-order differential pairs of high-frequency signals. Therefore, fractional differential relatively suppresses noise and has a certain anti-noise ability. Our model can solve the selection of the initial contour position and the sensitivity of the model to noise to an extent. To address the time-consuming and labor-intensive selection of the optimal fractional order, a mathematical model for calculating the optimal order is established according to the gradient modulus and the information entropy of the image, and the adaptive fractional order model is applied to the algorithm to adaptively determine the optimal fraction order. To correct the deviation of the level set function and symbol distance function and avoid the re-initialization of the model, the symbol distance constraint term is added to the model so as to improve the evolution efficiency of the curve.ConclusionTheoretical analysis and experimental results show that the proposed algorithm can segment images with inhomogeneous intensity, weak edge, and weak texture regions, improving the segmentation accuracy and efficiency. Moreover, the optimal order of fraction order derivative can be adjusted adaptively, solving the time-consuming and labor-intensive selection of the optimal fractional orders. The use of fraction order derivative can enhance the weak edge and texture regions without substantially increasing the noise signal. To verify the robustness to the initial selection of evolution curve of the algorithm, five different initial contour positions were selected for the two images, and four different noise images were tested to verify the anti-noise performance of the algorithm. Experimental results demonstrate that our model can correct segment the target contour and has good stability to noise. Our model is robust to the initial selection of evolution curve and noise.关键词:image segmentation;fraction order derivative;local information;CV model;adaptive;intensity inhomogeneous41|43|1更新时间:2024-08-15 -
 摘要:ObjectiveFacial expression is an effective means of communicating inner feelings and intentions. With the rapid development of artificial intelligence, facial expression recognition has become a critical part of human-computer interaction today. Research on human facial expression recognition technology bears important theoretical significance and practical application value. A video sequence contains more emotional information than a static expression image. In recent years, facial expression recognition based on video sequences has gradually become a field of interest in computer vision because expressing emotions is a dynamic process. Information obtained from a single-frame image is not as rich as that from a video sequence, and the accuracy of the former is low compared with the latter. Presently, two mainstream solutions for video facial expression recognition are available. The advantage of motion or movement direction of the face unit to analyze facial expressions is that it does not require selection of video frames. Rather, this method directly extracts the dynamic feature of the video for processing. However, the recognition process is complex, and the recognition rate is low. Another method is basing on the image of facial expressions to identify the expression category. Despite its high recognition rate, this method requires processing the original video sequence in advance. In a complete sequence of expressions, obvious expression plays a key role in feature extraction and recognition, but a video sequence also presents a neutral expression, which may interfere training of the model parameters and affect the output. Therefore, we need to manually select noticeable features of the expression sequence from the original video sequence. However, this operation generates extra work and affects the accuracy of experiment. This study proposes a new modified method of dynamic time warping, which is called the sliding window dynamic time warping (SWDTW), to automatically select the distinct facial expressions in a video sequence. The method can reduce redundant input information and improve adaptability during experiment. Moreover, noise in feature extraction and expression recognition is lessened. In video facial expression recognition, identification results are greatly influenced by environmental lights, and traditional feature extraction requires excessive manual intervention. Therefore, this study proposes a facial expression recognition method based on deep convolution neural network, which is a new type of neural network. This network combines traditional artificial neural network with deep learning technology, and it has achieved considerable success in the area of image processing. Convolution neural network has two main characteristics. The first is its strategy in establishing local connection between neurons, and the second is the sharing of neurons in the same layer. These characteristics reduce the complexity of the model and the number of parameters to be trained. This network structure can achieve several degrees of invariance, such as translation, scale, and deformation.MethodFirst, this method uses an algorithm to intercept front face frame in an expression sequence after a series of normalized processing by indicating the gradient direction histogram feature to calculate cost matrix and adding the sliding window mechanism to the cost matrix. Second, the average distances of all sliding windows are calculated, and the global optimal selection of the expression sequence is obtained by intercepting the sequence corresponding to the minimum distance. Finally, theoretical analysis and experimental verification are performed to determine the structure and parameters of the convolution neural network. In this work, the Alexnet network is selected as a reference because it won in the image classification competition of ImageNet Large Scale Visual Recognition Challenge (ⅡSVRC) in 2012. In view of the feature of facial expression images, this study makes certain adjustments on the original AlexNet network to better meet facial expression recognition and improves the network's utilization of overall information by reducing two convolution layers and adding a pooling layer. During convolution, the ReLU activation function is used to replace the traditional sigmoid and tanh activation function, increase the training speed of the model, and solve gradient disappearance. Dropout technology to address network over-fitting problem is also introduced. Finally, this study uses two fully connected layers to classify facial expression. Regularized facial expression video sequence is used for unsupervised learning and facial expression classification through deep convolution neural network. Images in video sequence undergo classification probability to determine which belong to each expression category, and the final identification results of the video sequence are obtained.ResultFive cross-validation experiments are conducted on CK+ and MMI database. This method performs better than the randomly selected video sequence and manual feature extraction methods in terms of recognition and generalization. In CK+ and MMI database, the average recognition accuracies are 92.54% and 74.67%, respectively, which are 19.86% and 22.24% higher than those of randomly selected video sequences. In addition, in comparison with other methods, SWDTW achieves better recognition performance.ConclusionThe proposed method exhibits good performance and adaptability during preprocessing, feature extraction, and recognition of facial expression system. SWDTW effectively achieves the selection of expression sequence, and the designed convolution neural network improves the robustness of facial expression classification based on video.关键词:facial expression recognition;video sequence selection;sliding window dynamic time regularization;feature extraction;convolution neural network13|4|6更新时间:2024-08-15
摘要:ObjectiveFacial expression is an effective means of communicating inner feelings and intentions. With the rapid development of artificial intelligence, facial expression recognition has become a critical part of human-computer interaction today. Research on human facial expression recognition technology bears important theoretical significance and practical application value. A video sequence contains more emotional information than a static expression image. In recent years, facial expression recognition based on video sequences has gradually become a field of interest in computer vision because expressing emotions is a dynamic process. Information obtained from a single-frame image is not as rich as that from a video sequence, and the accuracy of the former is low compared with the latter. Presently, two mainstream solutions for video facial expression recognition are available. The advantage of motion or movement direction of the face unit to analyze facial expressions is that it does not require selection of video frames. Rather, this method directly extracts the dynamic feature of the video for processing. However, the recognition process is complex, and the recognition rate is low. Another method is basing on the image of facial expressions to identify the expression category. Despite its high recognition rate, this method requires processing the original video sequence in advance. In a complete sequence of expressions, obvious expression plays a key role in feature extraction and recognition, but a video sequence also presents a neutral expression, which may interfere training of the model parameters and affect the output. Therefore, we need to manually select noticeable features of the expression sequence from the original video sequence. However, this operation generates extra work and affects the accuracy of experiment. This study proposes a new modified method of dynamic time warping, which is called the sliding window dynamic time warping (SWDTW), to automatically select the distinct facial expressions in a video sequence. The method can reduce redundant input information and improve adaptability during experiment. Moreover, noise in feature extraction and expression recognition is lessened. In video facial expression recognition, identification results are greatly influenced by environmental lights, and traditional feature extraction requires excessive manual intervention. Therefore, this study proposes a facial expression recognition method based on deep convolution neural network, which is a new type of neural network. This network combines traditional artificial neural network with deep learning technology, and it has achieved considerable success in the area of image processing. Convolution neural network has two main characteristics. The first is its strategy in establishing local connection between neurons, and the second is the sharing of neurons in the same layer. These characteristics reduce the complexity of the model and the number of parameters to be trained. This network structure can achieve several degrees of invariance, such as translation, scale, and deformation.MethodFirst, this method uses an algorithm to intercept front face frame in an expression sequence after a series of normalized processing by indicating the gradient direction histogram feature to calculate cost matrix and adding the sliding window mechanism to the cost matrix. Second, the average distances of all sliding windows are calculated, and the global optimal selection of the expression sequence is obtained by intercepting the sequence corresponding to the minimum distance. Finally, theoretical analysis and experimental verification are performed to determine the structure and parameters of the convolution neural network. In this work, the Alexnet network is selected as a reference because it won in the image classification competition of ImageNet Large Scale Visual Recognition Challenge (ⅡSVRC) in 2012. In view of the feature of facial expression images, this study makes certain adjustments on the original AlexNet network to better meet facial expression recognition and improves the network's utilization of overall information by reducing two convolution layers and adding a pooling layer. During convolution, the ReLU activation function is used to replace the traditional sigmoid and tanh activation function, increase the training speed of the model, and solve gradient disappearance. Dropout technology to address network over-fitting problem is also introduced. Finally, this study uses two fully connected layers to classify facial expression. Regularized facial expression video sequence is used for unsupervised learning and facial expression classification through deep convolution neural network. Images in video sequence undergo classification probability to determine which belong to each expression category, and the final identification results of the video sequence are obtained.ResultFive cross-validation experiments are conducted on CK+ and MMI database. This method performs better than the randomly selected video sequence and manual feature extraction methods in terms of recognition and generalization. In CK+ and MMI database, the average recognition accuracies are 92.54% and 74.67%, respectively, which are 19.86% and 22.24% higher than those of randomly selected video sequences. In addition, in comparison with other methods, SWDTW achieves better recognition performance.ConclusionThe proposed method exhibits good performance and adaptability during preprocessing, feature extraction, and recognition of facial expression system. SWDTW effectively achieves the selection of expression sequence, and the designed convolution neural network improves the robustness of facial expression classification based on video.关键词:facial expression recognition;video sequence selection;sliding window dynamic time regularization;feature extraction;convolution neural network13|4|6更新时间:2024-08-15 -
 摘要:ObjectiveFace images collected from real people are usually influenced by environmental factors, such as illumination and occlusion. In this situation, face images from the same class have varying degrees of otherness, and face images from different classes have distinct degrees of similarity, which can greatly affect the accuracy of face recognition. To address these problems, a face recognition algorithm for discerning structured low-rank dictionary learning is put forward and it is based on the theory of low-rank matrix recovery.MethodThe proposed algorithm adds low-rank regularization and structured sparse to discern dictionary learning based on the label information of training samples. During dictionary learning, the proposed algorithm first adopts the reconstruction error of training samples to constrain the relationships between training samples and the dictionary. The algorithm then applies Fisher discrimination criterion to the coding coefficients of dictionary learning for the coding coefficients to maintain discrimination. The proposed algorithm also applies low-rank regularization to the dictionary on the basis of the theory of low-rank matrix recovery because the noise in the training samples can influence the discrimination of the dictionary. During dictionary learning, structured sparse is imposed to avoid losing structure information and guarantee optimal classification of samples. Finally, test samples can be classified on the basis of reconstruction error.ResultExperiments regarding the proposed algorithm are performed on the AR and ORL face databases. In the AR face database, to analyze the effects of experimental results from the different dimensions of samples, training samples include six images in the first session, that is, one scarf occlusion image, two sunglasses occlusion images, and three facial expression change and illumination change images per person. Test samples are the same as training samples. Face recognition is higher as face image dimension is higher in any method. Comparing the face recognition rate of sparse representation based on classification (SRC) algorithm with that of discriminative KSVD (DKSVD) algorithm, DKSVD algorithm reduces the effects of recognition results from uncertain factors in training samples by dictionary learning. Comparing the face recognition rate of discriminative low-rank dictionary learning for sparse representation(DLRD_SR) algorithm with that of Fisher discriminative dictionary learning (FDDL) algorithm, the low-rank regularization of dictionary can improve the face recognition rate by at least 5.8% when images show noise information such as occlusion. Comparing the face recognition rate of the proposed algorithm with that of DLRD_SR algorithm, face recognition rate can be improved noticeably when Fisher discrimination criterion is imposed to dictionary learning, and the ideal sparse values guarantee the optimal classification of test samples. The face recognition rate of images of 500 dimensions, in which a part of images is occluded with scarf or sunglasses, is 85.2%. In the AR face database, the occlusion degrees using sunglasses and scarf can be regarded as 20% and 40% of the face image, respectively. To verify the validity of the proposed algorithm in different facial expression and illumination changes and with scarf and sunglasses occlusion, experiments are performed according to specific image combinations of training samples. In any image combination, the proposed algorithm exhibits prominent superiority in face recognition when the face images are occluded. In training samples of images containing only facial expression and illumination changes and sunglasses occlusion, the recognition rate of the proposed algorithm is higher than that of other algorithms by at least 2.7%. In training samples of images with only facial expression and illumination changes and scarf occlusion, the recognition rate of the proposed algorithm is higher than that of other algorithms by at least 3.6%. In training samples of images showing facial expression and illumination changes and sunglasses and scarf occlusions, the recognition rate of the proposed algorithm is higher than that of other algorithms by at least 1.9%.In the ORL face database, the face recognition rate of images without occlusion is 95.2%, which is slightly lower than the recognition rate of FDDL algorithm. When the degree of random block occlusion of face images increases up to 20%, the face recognition rate of the proposed algorithm is higher than SRC, DKSVD, FDDL, and DLRD_SR algorithms. When the degree of random block occlusion of face images increases up to 50%, the face recognition rates of the aforementioned algorithms are all low, whereas that of the proposed algorithm remains the highest.ConclusionThe proposed algorithm features certain robustness when face images are influenced by different factors, such as occlusion. Results also show that the proposed algorithm possesses feasibility for face recognition.关键词:face recognition;low-rank regularization;label information;structured sparse;Fisher discrimination criterion;dictionary learning12|4|1更新时间:2024-08-15
摘要:ObjectiveFace images collected from real people are usually influenced by environmental factors, such as illumination and occlusion. In this situation, face images from the same class have varying degrees of otherness, and face images from different classes have distinct degrees of similarity, which can greatly affect the accuracy of face recognition. To address these problems, a face recognition algorithm for discerning structured low-rank dictionary learning is put forward and it is based on the theory of low-rank matrix recovery.MethodThe proposed algorithm adds low-rank regularization and structured sparse to discern dictionary learning based on the label information of training samples. During dictionary learning, the proposed algorithm first adopts the reconstruction error of training samples to constrain the relationships between training samples and the dictionary. The algorithm then applies Fisher discrimination criterion to the coding coefficients of dictionary learning for the coding coefficients to maintain discrimination. The proposed algorithm also applies low-rank regularization to the dictionary on the basis of the theory of low-rank matrix recovery because the noise in the training samples can influence the discrimination of the dictionary. During dictionary learning, structured sparse is imposed to avoid losing structure information and guarantee optimal classification of samples. Finally, test samples can be classified on the basis of reconstruction error.ResultExperiments regarding the proposed algorithm are performed on the AR and ORL face databases. In the AR face database, to analyze the effects of experimental results from the different dimensions of samples, training samples include six images in the first session, that is, one scarf occlusion image, two sunglasses occlusion images, and three facial expression change and illumination change images per person. Test samples are the same as training samples. Face recognition is higher as face image dimension is higher in any method. Comparing the face recognition rate of sparse representation based on classification (SRC) algorithm with that of discriminative KSVD (DKSVD) algorithm, DKSVD algorithm reduces the effects of recognition results from uncertain factors in training samples by dictionary learning. Comparing the face recognition rate of discriminative low-rank dictionary learning for sparse representation(DLRD_SR) algorithm with that of Fisher discriminative dictionary learning (FDDL) algorithm, the low-rank regularization of dictionary can improve the face recognition rate by at least 5.8% when images show noise information such as occlusion. Comparing the face recognition rate of the proposed algorithm with that of DLRD_SR algorithm, face recognition rate can be improved noticeably when Fisher discrimination criterion is imposed to dictionary learning, and the ideal sparse values guarantee the optimal classification of test samples. The face recognition rate of images of 500 dimensions, in which a part of images is occluded with scarf or sunglasses, is 85.2%. In the AR face database, the occlusion degrees using sunglasses and scarf can be regarded as 20% and 40% of the face image, respectively. To verify the validity of the proposed algorithm in different facial expression and illumination changes and with scarf and sunglasses occlusion, experiments are performed according to specific image combinations of training samples. In any image combination, the proposed algorithm exhibits prominent superiority in face recognition when the face images are occluded. In training samples of images containing only facial expression and illumination changes and sunglasses occlusion, the recognition rate of the proposed algorithm is higher than that of other algorithms by at least 2.7%. In training samples of images with only facial expression and illumination changes and scarf occlusion, the recognition rate of the proposed algorithm is higher than that of other algorithms by at least 3.6%. In training samples of images showing facial expression and illumination changes and sunglasses and scarf occlusions, the recognition rate of the proposed algorithm is higher than that of other algorithms by at least 1.9%.In the ORL face database, the face recognition rate of images without occlusion is 95.2%, which is slightly lower than the recognition rate of FDDL algorithm. When the degree of random block occlusion of face images increases up to 20%, the face recognition rate of the proposed algorithm is higher than SRC, DKSVD, FDDL, and DLRD_SR algorithms. When the degree of random block occlusion of face images increases up to 50%, the face recognition rates of the aforementioned algorithms are all low, whereas that of the proposed algorithm remains the highest.ConclusionThe proposed algorithm features certain robustness when face images are influenced by different factors, such as occlusion. Results also show that the proposed algorithm possesses feasibility for face recognition.关键词:face recognition;low-rank regularization;label information;structured sparse;Fisher discrimination criterion;dictionary learning12|4|1更新时间:2024-08-15 -
 摘要:ObjectiveFace recognition technology has extensive applications in many fields because of its user-friendly and intuitive nature. According to input data, face recognition can be divided into 2D and 3D. Traditional 2D face recognition technology is based on image or video information. Although 2D face recognition technology has achieved a great success, its limitations, which are mostly caused by illumination, posture, and makeup, remain difficult to address. Unlike traditional 2D face recognition, 3D face recognition is based on the 3D data of human face, such as 3D point cloud and mesh. Although 3D face recognition technology is less affected by illumination, pose, and makeup, partial occlusion in 3D face is an important factor that affects its accuracy rate. The problem is that collected face data are always occluded by external objects, such as hands, hair, and glasses. Therefore, 3D face recognition with partial occlusions becomes an important research subject. To reduce the influence of partial occlusions in 3D face recognition, a novel 3D face recognition algorithm based on radial strings and local feature is proposed.MethodThis 3D face recognition algorithm includes four main parts. First, the nasal tip on 3D face data using shape index is located, the radial strings are extracted, and then the uniform sampling on every radial strings is produced. To fully use the neighbor information of radial strings, a radial string representation that encoded radial strings into local feature is proposed. In this algorithm, we extract three local features, namely, the center of every two adjacent sample points, the area of local region, and the histogram of slant angle. Local feature descriptors with these local features to represent local region are then constructed. Second, sparse cloud points lead to nonuniform sample points and subsequently to large errors in the matching result. To address this problem, an operator that merges adjacent local regions is adopted. Third, cost function of the local feature on the corresponding local region and similarity vectors of the corresponding radial strings with this cost function are constructed. Finally, the corresponding radial strings according to these similarity vectors are matched, and the 3D face by the result of all radial strings are recognized.ResultThe experiments are conducted on the basis of the FRGC v2.0 and Bosphorus databases. FRGC v2.0 is a large-scale public 3D face database, which is composed of 466 subjects and 4007 3D point cloud. Bosphorus database is a new 3D face database, which is composed of 105 subjects and 4666 3D point cloud, and this database consists of partial occlusions at different levels. We select 300 subjects with neutral and not occluded 3D face point cloud to test the recognition rate of different local features. Consequently, the rank one recognition rate is 95.2%, 0.9%, and 2.4% higher than the other two local features, because FRGC v2.0 database is standard and at a high level. Although one local feature is only 0.9% higher than the second local feature, those local features promote the convenience of merging adjacent local regions. We then choose 300 3D face point cloud from Bosphorus database to perform the experiments of recognition rate and time with partial occlusions 3D face. The rank one recognition rate is 92.0%, 2.7%, 3.0%, and 0.4% higher than the other three recognition methods. The experiment is performed within 8.17 s, which is lower than that of the other recognition methods, and is 2.05 s, 0.18 s, and 34.43 s less than the other three methods, respectively. In those experiments, our methods receive the best result based on its recognition rate and recognition time.ConclusionThe proposed method of 3D face recognition based on radial strings and local feature extracts the adjacent information of radial strings effectively, thereby constructing cost function of corresponding local regions with the adjacent information to achieve region matching. The similarity vector that is constructed using the cost function of the local feature reduces the influence of partial occlusions effectively. This result demonstrates that the proposed algorithm achieves high recognition rates and is robust to partial occlusions. This 3D face recognition method is suitable in recognizing faces with partial occlusions. However, this method is inapplicable when the nasal tip is occluded because this method must locate the position of nasal tip.关键词:three dimensional face recognition;facial partial occlusions;local feature;radial strings;region merging11|4|2更新时间:2024-08-15
摘要:ObjectiveFace recognition technology has extensive applications in many fields because of its user-friendly and intuitive nature. According to input data, face recognition can be divided into 2D and 3D. Traditional 2D face recognition technology is based on image or video information. Although 2D face recognition technology has achieved a great success, its limitations, which are mostly caused by illumination, posture, and makeup, remain difficult to address. Unlike traditional 2D face recognition, 3D face recognition is based on the 3D data of human face, such as 3D point cloud and mesh. Although 3D face recognition technology is less affected by illumination, pose, and makeup, partial occlusion in 3D face is an important factor that affects its accuracy rate. The problem is that collected face data are always occluded by external objects, such as hands, hair, and glasses. Therefore, 3D face recognition with partial occlusions becomes an important research subject. To reduce the influence of partial occlusions in 3D face recognition, a novel 3D face recognition algorithm based on radial strings and local feature is proposed.MethodThis 3D face recognition algorithm includes four main parts. First, the nasal tip on 3D face data using shape index is located, the radial strings are extracted, and then the uniform sampling on every radial strings is produced. To fully use the neighbor information of radial strings, a radial string representation that encoded radial strings into local feature is proposed. In this algorithm, we extract three local features, namely, the center of every two adjacent sample points, the area of local region, and the histogram of slant angle. Local feature descriptors with these local features to represent local region are then constructed. Second, sparse cloud points lead to nonuniform sample points and subsequently to large errors in the matching result. To address this problem, an operator that merges adjacent local regions is adopted. Third, cost function of the local feature on the corresponding local region and similarity vectors of the corresponding radial strings with this cost function are constructed. Finally, the corresponding radial strings according to these similarity vectors are matched, and the 3D face by the result of all radial strings are recognized.ResultThe experiments are conducted on the basis of the FRGC v2.0 and Bosphorus databases. FRGC v2.0 is a large-scale public 3D face database, which is composed of 466 subjects and 4007 3D point cloud. Bosphorus database is a new 3D face database, which is composed of 105 subjects and 4666 3D point cloud, and this database consists of partial occlusions at different levels. We select 300 subjects with neutral and not occluded 3D face point cloud to test the recognition rate of different local features. Consequently, the rank one recognition rate is 95.2%, 0.9%, and 2.4% higher than the other two local features, because FRGC v2.0 database is standard and at a high level. Although one local feature is only 0.9% higher than the second local feature, those local features promote the convenience of merging adjacent local regions. We then choose 300 3D face point cloud from Bosphorus database to perform the experiments of recognition rate and time with partial occlusions 3D face. The rank one recognition rate is 92.0%, 2.7%, 3.0%, and 0.4% higher than the other three recognition methods. The experiment is performed within 8.17 s, which is lower than that of the other recognition methods, and is 2.05 s, 0.18 s, and 34.43 s less than the other three methods, respectively. In those experiments, our methods receive the best result based on its recognition rate and recognition time.ConclusionThe proposed method of 3D face recognition based on radial strings and local feature extracts the adjacent information of radial strings effectively, thereby constructing cost function of corresponding local regions with the adjacent information to achieve region matching. The similarity vector that is constructed using the cost function of the local feature reduces the influence of partial occlusions effectively. This result demonstrates that the proposed algorithm achieves high recognition rates and is robust to partial occlusions. This 3D face recognition method is suitable in recognizing faces with partial occlusions. However, this method is inapplicable when the nasal tip is occluded because this method must locate the position of nasal tip.关键词:three dimensional face recognition;facial partial occlusions;local feature;radial strings;region merging11|4|2更新时间:2024-08-15 -
 摘要:ObjectiveWith the growing attention paid to public safety and security, video surveillance systems become increasingly important. Pedestrian detection is the first step in video surveillance systems when analyzing behaviors of pedestrians, so it plays a critical role in computer vision research area. Although pedestrian detection has realized several achievements in recent years, speed and accuracy continue to show rooms for improvement. On the one hand, pedestrian detection is time consuming as it requires extensive calculation and high dimension of features. On the other hand, the detection results are easily influenced by different environmental factors, such as the changes of illumination and background, different postures of pedestrians, and occlusion among pedestrians. As detection results depend on the performances of the feature set and classifier, the features should be adequately representative to distinguish a pedestrian from other objects and background. This study proposes an algorithm for pedestrian detection based on improved feature and graphic processing unit (GPU) acceleration to reduce detection time and improve detection rate.MethodFirst, Canny operator is used to process the original images and obtain images with enhanced edge information. Second, the images are processed in three scales to reduce the interference of background and deformation effect of unified standardized. Third, the images are divided into six regions to address the occlusion problem among pedestrians. These regions are head, left arm, upper body, right arm, left leg, and right leg, which are divided according to the characteristics of pedestrian action. Thereafter, the scale invariant local ternary pattern (SILTP) feature is used instead of the local binary pattern (LBP) feature to improve the pixel of low resolution and varied illuminations of images. The SILTP feature in parallel is extracted as the texture feature in GPU space to reduce the time of calculation. At the same time, the gradient and amplitude information of the six regions is calculated in the GPU space, and the value of the gradient is weighed with the value of the distribution characteristics. Therefore, the improved histogram of oriented gradient (HOG) features with 180 dimensions are obtained. The dimensions are much lower compared with traditional HOG feature and the calculation time is reduced. Finally, the features extracted in the three scales is concatenated, including HOG and SILTP feature. All features are outputted to central processing unit (CPU) space from GPU space, achieving pedestrian detection by the linear support vector machine (SVM) classifier.ResultThe proposed algorithm is demonstrated on two datasets, namely, INRIA and NICTA. The INRIA dataset is presently the most widely used static pedestrian dataset. The backgrounds, pedestrians' postures, and occlusions among pedestrians in this dataset are complex. By contrast, the NICTA dataset contains a large number of pedestrian images in different sizes. Therefore, the detection results of INRIA and NICTA datasets are representative. The INRIA dataset contains 2 416 positive training and 1 218 negative training samples and 1 126 positive detecting and 453 negative detecting samples. The NICTA dataset contains 142 598 positive training and 90 605 negative training samples and 34 416 positive detecting and 42800 negative detecting samples. The proposed method achieves a detection rate of 99.80% and 99.91% on INRIA dataset and NICTA dataset, respectively. On the INRIA dataset, the acceleration ratio is 12.19 compared with the algorithm based on traditional HOG and LBP, and the acceleration ratio of feature extraction is more than 8.19. On the NICTA dataset, the acceleration ratio is 13.49 compared with the algorithm based on traditional HOG and LBP. Therefore, the proposed algorithm based on improved feature and GPU acceleration enhances the detection rate and reduces the detection time.ConclusionExperiment results show that the proposed algorithm based on improved feature and GPU acceleration perform better than other algorithms in terms of accuracy and speed. The improved feature exhibits strong robustness to the changes of illumination and environment and performs well despite the occlusion among pedestrians. Apart from its lower dimension which improves the speed of pedestrian detection, the algorithm provides accurate information on pedestrians. The proposed algorithm is suitable for most situations involving pedestrian detection, especially for images or videos in an environment with different illuminations and occlusions. Its speed also performs well, especially with large amount of calculation and high repeatability. The proposed algorithm based on improved feature and GPU acceleration can achieve effective and fast pedestrian detection and has practical value.关键词:pedestrian detection;graphic processing unit(GPU) acceleration;scale invariant local ternary pattern (SILTP)feature;histogram of oriented gradient(HOG) feature;support vector machine(SVM) classifier13|5|2更新时间:2024-08-15
摘要:ObjectiveWith the growing attention paid to public safety and security, video surveillance systems become increasingly important. Pedestrian detection is the first step in video surveillance systems when analyzing behaviors of pedestrians, so it plays a critical role in computer vision research area. Although pedestrian detection has realized several achievements in recent years, speed and accuracy continue to show rooms for improvement. On the one hand, pedestrian detection is time consuming as it requires extensive calculation and high dimension of features. On the other hand, the detection results are easily influenced by different environmental factors, such as the changes of illumination and background, different postures of pedestrians, and occlusion among pedestrians. As detection results depend on the performances of the feature set and classifier, the features should be adequately representative to distinguish a pedestrian from other objects and background. This study proposes an algorithm for pedestrian detection based on improved feature and graphic processing unit (GPU) acceleration to reduce detection time and improve detection rate.MethodFirst, Canny operator is used to process the original images and obtain images with enhanced edge information. Second, the images are processed in three scales to reduce the interference of background and deformation effect of unified standardized. Third, the images are divided into six regions to address the occlusion problem among pedestrians. These regions are head, left arm, upper body, right arm, left leg, and right leg, which are divided according to the characteristics of pedestrian action. Thereafter, the scale invariant local ternary pattern (SILTP) feature is used instead of the local binary pattern (LBP) feature to improve the pixel of low resolution and varied illuminations of images. The SILTP feature in parallel is extracted as the texture feature in GPU space to reduce the time of calculation. At the same time, the gradient and amplitude information of the six regions is calculated in the GPU space, and the value of the gradient is weighed with the value of the distribution characteristics. Therefore, the improved histogram of oriented gradient (HOG) features with 180 dimensions are obtained. The dimensions are much lower compared with traditional HOG feature and the calculation time is reduced. Finally, the features extracted in the three scales is concatenated, including HOG and SILTP feature. All features are outputted to central processing unit (CPU) space from GPU space, achieving pedestrian detection by the linear support vector machine (SVM) classifier.ResultThe proposed algorithm is demonstrated on two datasets, namely, INRIA and NICTA. The INRIA dataset is presently the most widely used static pedestrian dataset. The backgrounds, pedestrians' postures, and occlusions among pedestrians in this dataset are complex. By contrast, the NICTA dataset contains a large number of pedestrian images in different sizes. Therefore, the detection results of INRIA and NICTA datasets are representative. The INRIA dataset contains 2 416 positive training and 1 218 negative training samples and 1 126 positive detecting and 453 negative detecting samples. The NICTA dataset contains 142 598 positive training and 90 605 negative training samples and 34 416 positive detecting and 42800 negative detecting samples. The proposed method achieves a detection rate of 99.80% and 99.91% on INRIA dataset and NICTA dataset, respectively. On the INRIA dataset, the acceleration ratio is 12.19 compared with the algorithm based on traditional HOG and LBP, and the acceleration ratio of feature extraction is more than 8.19. On the NICTA dataset, the acceleration ratio is 13.49 compared with the algorithm based on traditional HOG and LBP. Therefore, the proposed algorithm based on improved feature and GPU acceleration enhances the detection rate and reduces the detection time.ConclusionExperiment results show that the proposed algorithm based on improved feature and GPU acceleration perform better than other algorithms in terms of accuracy and speed. The improved feature exhibits strong robustness to the changes of illumination and environment and performs well despite the occlusion among pedestrians. Apart from its lower dimension which improves the speed of pedestrian detection, the algorithm provides accurate information on pedestrians. The proposed algorithm is suitable for most situations involving pedestrian detection, especially for images or videos in an environment with different illuminations and occlusions. Its speed also performs well, especially with large amount of calculation and high repeatability. The proposed algorithm based on improved feature and GPU acceleration can achieve effective and fast pedestrian detection and has practical value.关键词:pedestrian detection;graphic processing unit(GPU) acceleration;scale invariant local ternary pattern (SILTP)feature;histogram of oriented gradient(HOG) feature;support vector machine(SVM) classifier13|5|2更新时间:2024-08-15 -
 摘要:ObjectiveWith the noticeable growth in population, large-scale collective activities have become increasingly frequent. In recent years, a series of social problems have become progressively prominent due to crowding of crowds. In particular, frequent accidents occur in densely populated areas, such as scenic spots, railway stations, and shopping malls. Crowd analysis has become an important research topic of intelligent video surveillance. Crowd density estimation has also become the focus of crowd safety control and management research. Crowd density estimation can help the staff to optimize the management of the statistics of the crowd in the current situation. Preventing overcrowding and detecting potential safety issues are important contributions of such a process. However, several of the available technologies are only applicable to a small number of people, and the environment is relatively static scene. Aiming at the visual detection of crowd density, uneven distribution, and occlusion crowd density, this study proposes a crowd density estimation method based on multi-level feature fusion network.MethodFirst, we generate the feature map of each level using the convolutional pooling of the network. After five out of eight convolution layers are generated, a feature map that is 1/32 of the original size and 128 dimensions is generated and then perform three deconvolution operations. Thereafter, the convolutional layer features of the previous stage are fused together. Finally, the convolution layer is convoluted using a 1×1 volumetric kernel to form a density feature map of 1/4 of the original size. For the image, each convolution operation is an abstraction of the image features of the previous layer, and its different depths correspond to different levels of semantic features. Moreover, if convolution' shallow network resolution is high, the additional image details are found. However, if its deep network resolution is low, then deep semantic and some key features should be learned. Low-level features can be suitably used to extract small target features, whereas high-level features can be used to extract large target features. We solve the problem of inconsistent image scales by combining the feature information of different layers. Second, we use the public dataset to generate the corresponding density label map using our artificial calibration and then train the network to independently predict the density map of the test image. Finally, by integrating the density map, on the basis of the generated density map, we propose a quantitative method of crowd extent, and the crowd crowding is calculated through the reduction and combination of crowd spatial information on density map.ResultThe proposed method reduces the MAE to 2.35 on the mall dataset and reduces the MAE to 20.73 and 104.86 on the ShanghaiTech dataset. Compared with the existing methods, the crowd density estimation accuracy is improved, having a noticeable effect on the environment with complex number of scenes. In addition, the experimental results of different network structures show an improvement of the test results after adding the deconvolution layer compared with pure convolutional networks. Under the complex scene of ShanghaiTech dataset, after the feature fusion network, the performance has further improved, especially the integration of 1, 2 features, which generates a more prominent effect. When the integration of the characteristics of the three layer basically does not improve the effect, the main reason is the level is too high and contains additional details. Moreover, several redundant information affects the generalization of the network capacity. The effect of network improvements is also not noticeable for the mall dataset with the standard scenario. However, when we use a pure convolutional network, the result is noticeable.ConclusionThis study proposes a crowd density estimation method based on multi-level feature fusion network. Through the extraction and fusion of the features of different semantic layers, the network can extract the features of people in different scales and sizes, which effectively improves the robustness of the algorithm. Using the complete picture as the input better preserves the overall picture information, the feature space location information is considered in network training. This algorithm is more scientific and efficient when using the density map generated by forecasting in combination with the spatial information in the estimation of the number of people and the degree of congestion. The algorithm also has the advantages in small scene constraints, high crowd estimation accuracy, and simple and reliable crowd congestion assessment. The effectiveness of the proposed multi-level feature fusion network and crowd congestion evaluation method is verified through experiments.关键词:crowd density estimation;crowded degree assessment;hierarchical feature fusion;convolutional neural network(CNN);deep learning;intelligent video analysis12|5|1更新时间:2024-08-15
摘要:ObjectiveWith the noticeable growth in population, large-scale collective activities have become increasingly frequent. In recent years, a series of social problems have become progressively prominent due to crowding of crowds. In particular, frequent accidents occur in densely populated areas, such as scenic spots, railway stations, and shopping malls. Crowd analysis has become an important research topic of intelligent video surveillance. Crowd density estimation has also become the focus of crowd safety control and management research. Crowd density estimation can help the staff to optimize the management of the statistics of the crowd in the current situation. Preventing overcrowding and detecting potential safety issues are important contributions of such a process. However, several of the available technologies are only applicable to a small number of people, and the environment is relatively static scene. Aiming at the visual detection of crowd density, uneven distribution, and occlusion crowd density, this study proposes a crowd density estimation method based on multi-level feature fusion network.MethodFirst, we generate the feature map of each level using the convolutional pooling of the network. After five out of eight convolution layers are generated, a feature map that is 1/32 of the original size and 128 dimensions is generated and then perform three deconvolution operations. Thereafter, the convolutional layer features of the previous stage are fused together. Finally, the convolution layer is convoluted using a 1×1 volumetric kernel to form a density feature map of 1/4 of the original size. For the image, each convolution operation is an abstraction of the image features of the previous layer, and its different depths correspond to different levels of semantic features. Moreover, if convolution' shallow network resolution is high, the additional image details are found. However, if its deep network resolution is low, then deep semantic and some key features should be learned. Low-level features can be suitably used to extract small target features, whereas high-level features can be used to extract large target features. We solve the problem of inconsistent image scales by combining the feature information of different layers. Second, we use the public dataset to generate the corresponding density label map using our artificial calibration and then train the network to independently predict the density map of the test image. Finally, by integrating the density map, on the basis of the generated density map, we propose a quantitative method of crowd extent, and the crowd crowding is calculated through the reduction and combination of crowd spatial information on density map.ResultThe proposed method reduces the MAE to 2.35 on the mall dataset and reduces the MAE to 20.73 and 104.86 on the ShanghaiTech dataset. Compared with the existing methods, the crowd density estimation accuracy is improved, having a noticeable effect on the environment with complex number of scenes. In addition, the experimental results of different network structures show an improvement of the test results after adding the deconvolution layer compared with pure convolutional networks. Under the complex scene of ShanghaiTech dataset, after the feature fusion network, the performance has further improved, especially the integration of 1, 2 features, which generates a more prominent effect. When the integration of the characteristics of the three layer basically does not improve the effect, the main reason is the level is too high and contains additional details. Moreover, several redundant information affects the generalization of the network capacity. The effect of network improvements is also not noticeable for the mall dataset with the standard scenario. However, when we use a pure convolutional network, the result is noticeable.ConclusionThis study proposes a crowd density estimation method based on multi-level feature fusion network. Through the extraction and fusion of the features of different semantic layers, the network can extract the features of people in different scales and sizes, which effectively improves the robustness of the algorithm. Using the complete picture as the input better preserves the overall picture information, the feature space location information is considered in network training. This algorithm is more scientific and efficient when using the density map generated by forecasting in combination with the spatial information in the estimation of the number of people and the degree of congestion. The algorithm also has the advantages in small scene constraints, high crowd estimation accuracy, and simple and reliable crowd congestion assessment. The effectiveness of the proposed multi-level feature fusion network and crowd congestion evaluation method is verified through experiments.关键词:crowd density estimation;crowded degree assessment;hierarchical feature fusion;convolutional neural network(CNN);deep learning;intelligent video analysis12|5|1更新时间:2024-08-15 -
 摘要:ObjectivePresently, existing research on art classification is primarily based on feature extraction and hence feature-based classification. Although such feature-based methods reported in the literature achieve a certain level of success, a major weakness lies in the considerable dependence of classification performances on the effectiveness of the features in describing the content of Chinese paintings. Given that traditional Chinese artists tend to rely on popular objects, such as figures, trees, flowers, birds, mountains, horses, and houses to express their artistic feelings and emotions, we explore a new concept of artistic object-based approach to classify traditional Chinese paintings in this study. In this way, automated classification can be integrated with perception, understanding, and interpretation of artistic expressions and emotions via the segmented artistic objects. Such an approach also possibly enables our proposed methods to be further developed into an interactive object-based classification approach for other forms of paintings. In comparison with the existing state of the arts, one advantage of our proposed approach over those based on features or content is that objects provide direct and integrated art expressions inside paintings.MethodOur proposed method includes three stages of processing and analytics for traditional Chinese paintings, that is, 1) interactive art object segmentation; 2) description and characterization of art objects via convolution neural network (CNN), the most popular deep learning unit; and 3) SVM-based classification and fusion across all art objects. Specifically, via an iterative linear clustering algorithm, super-pixels are constructed to detect the difference between the color and position of each individual pixel. By maximizing the similarity within the neighborhood of those super-pixels, a sequence of objects can be segmented, and an interactive scheme can be designed, allowing users to add, revise, and interact with the content of paintings to achieve the best possible balance between subjective demand and objective art description. Afterward, a CNN-based deep learning unit is added to describe those objects, so its classification can be carried out with regard to the individual art object. Finally, an SVM unit is adopted to achieve the final fusion of all these classifications via consideration of each individual object within the given window, which is influenced and initialized through the training process.ResultExtensive experiments are carried out, which are in four phases, each of which considers one impact factor, such as consideration of the number of artists, comparison with the existing state of the arts, consideration of benchmarking via content-based classifications, and assessment of contributions from CNN alone. Experimental results show that our proposed algorithm:1) outperforms several existing representative approaches, including MHMM and fusion-based method, 2) achieves effective fusion of all different object classifications, including CNN and SVM units, 3) captures the artistic emotions through those segmented art objects, and 4) shows potential for interactive classification of Chinese paintings via segmentation of artistic objects.ConclusionThis study proposes the computerized classification and recognition of art styles based on artistic objects in paintings rather than the whole paintings. Experimental results reveal that the proposed algorithm outperforms the existing representative benchmarks, providing potential for developing effective digital tools for computerized management of Chinese paintings. In addition, this method can be used to formulate an important tool for computerized management of Chinese traditional paintings, providing a range of techniques for effective and efficient digitization, manipulation, understanding, perception, and interpretation of Chinese traditional arts as well as its legacy.关键词:artistic object segmentation;classification of Chinese paintings;convolutional neural network;fusion algorithm;deep learning;superpixel segmentation28|11|10更新时间:2024-08-15
摘要:ObjectivePresently, existing research on art classification is primarily based on feature extraction and hence feature-based classification. Although such feature-based methods reported in the literature achieve a certain level of success, a major weakness lies in the considerable dependence of classification performances on the effectiveness of the features in describing the content of Chinese paintings. Given that traditional Chinese artists tend to rely on popular objects, such as figures, trees, flowers, birds, mountains, horses, and houses to express their artistic feelings and emotions, we explore a new concept of artistic object-based approach to classify traditional Chinese paintings in this study. In this way, automated classification can be integrated with perception, understanding, and interpretation of artistic expressions and emotions via the segmented artistic objects. Such an approach also possibly enables our proposed methods to be further developed into an interactive object-based classification approach for other forms of paintings. In comparison with the existing state of the arts, one advantage of our proposed approach over those based on features or content is that objects provide direct and integrated art expressions inside paintings.MethodOur proposed method includes three stages of processing and analytics for traditional Chinese paintings, that is, 1) interactive art object segmentation; 2) description and characterization of art objects via convolution neural network (CNN), the most popular deep learning unit; and 3) SVM-based classification and fusion across all art objects. Specifically, via an iterative linear clustering algorithm, super-pixels are constructed to detect the difference between the color and position of each individual pixel. By maximizing the similarity within the neighborhood of those super-pixels, a sequence of objects can be segmented, and an interactive scheme can be designed, allowing users to add, revise, and interact with the content of paintings to achieve the best possible balance between subjective demand and objective art description. Afterward, a CNN-based deep learning unit is added to describe those objects, so its classification can be carried out with regard to the individual art object. Finally, an SVM unit is adopted to achieve the final fusion of all these classifications via consideration of each individual object within the given window, which is influenced and initialized through the training process.ResultExtensive experiments are carried out, which are in four phases, each of which considers one impact factor, such as consideration of the number of artists, comparison with the existing state of the arts, consideration of benchmarking via content-based classifications, and assessment of contributions from CNN alone. Experimental results show that our proposed algorithm:1) outperforms several existing representative approaches, including MHMM and fusion-based method, 2) achieves effective fusion of all different object classifications, including CNN and SVM units, 3) captures the artistic emotions through those segmented art objects, and 4) shows potential for interactive classification of Chinese paintings via segmentation of artistic objects.ConclusionThis study proposes the computerized classification and recognition of art styles based on artistic objects in paintings rather than the whole paintings. Experimental results reveal that the proposed algorithm outperforms the existing representative benchmarks, providing potential for developing effective digital tools for computerized management of Chinese paintings. In addition, this method can be used to formulate an important tool for computerized management of Chinese traditional paintings, providing a range of techniques for effective and efficient digitization, manipulation, understanding, perception, and interpretation of Chinese traditional arts as well as its legacy.关键词:artistic object segmentation;classification of Chinese paintings;convolutional neural network;fusion algorithm;deep learning;superpixel segmentation28|11|10更新时间:2024-08-15 -
 摘要:ObjectiveHandwritten text line extraction is fundamental in document image processing. The text lines may suffer from tilting curving crossing and adhesion because of unconstrained paper layout and free writing style. Traditional text line segmentation or clustering method cannot guarantee the classification accuracy of the pixels between text lines. In this study, a text line regression-clustering joint framework for handwritten text line extraction is proposed.MethodFirst, the anisotropic Gaussian filter bank is used to filter the handwritten document image in multiple scales and directions. The main body area (MBA) of text line is first extracted by smearing, andthe text line regression model is then obtained by extracting the skeleton structure of the MBA. Second, the super-pixel representation is constructed with connected component as the basic image element. For super-pixel classification and clustering, an approach based on associative hierarchical random fields is presented. A higher-order energy model is established by constructing a hierarchical network of pixel-connected component text lines. On the basis of the model, an energy function is built whose minimization yields the text line labels of the connected components. With the achieved instance labels of connected components as basis, the sticky characters that share the same label are detected. Third, the pixels of the sticky characters are re-clustered with k-means algorithm under the constraint of the text line regression model. With the instance labels of text lines, the manipulation of the text lines can be achieved by label switch. Therefore, the geometric segmentation of the document image is no longer needed, and the bounding box can be used to extract text line directly.ResultExperiments were performed on HIT-MW document level dataset. The proposed framework achieved an overall detection rate of 99.83% and recognition accuracy of 99.92% which reach to the state-of-the-art performance for Chinese handwritten text line extraction.ConclusionExperimental results show that the proposed text line regression-clustering joint framework improves the segmentation accuracy in pixel levels and makes the edge of the text line more controllable than traditional algorithms, such as piecewise projection, minimum spanning tree-based clustering, and seam carving. The proposed system exhibits high performance on Chinese handwritten text line extraction together with enhanced robustness and accuracy without interference of adjacent text lines.关键词:handwritten text line extraction;superpixel;image segmentation;regression;clustering15|10|0更新时间:2024-08-15
摘要:ObjectiveHandwritten text line extraction is fundamental in document image processing. The text lines may suffer from tilting curving crossing and adhesion because of unconstrained paper layout and free writing style. Traditional text line segmentation or clustering method cannot guarantee the classification accuracy of the pixels between text lines. In this study, a text line regression-clustering joint framework for handwritten text line extraction is proposed.MethodFirst, the anisotropic Gaussian filter bank is used to filter the handwritten document image in multiple scales and directions. The main body area (MBA) of text line is first extracted by smearing, andthe text line regression model is then obtained by extracting the skeleton structure of the MBA. Second, the super-pixel representation is constructed with connected component as the basic image element. For super-pixel classification and clustering, an approach based on associative hierarchical random fields is presented. A higher-order energy model is established by constructing a hierarchical network of pixel-connected component text lines. On the basis of the model, an energy function is built whose minimization yields the text line labels of the connected components. With the achieved instance labels of connected components as basis, the sticky characters that share the same label are detected. Third, the pixels of the sticky characters are re-clustered with k-means algorithm under the constraint of the text line regression model. With the instance labels of text lines, the manipulation of the text lines can be achieved by label switch. Therefore, the geometric segmentation of the document image is no longer needed, and the bounding box can be used to extract text line directly.ResultExperiments were performed on HIT-MW document level dataset. The proposed framework achieved an overall detection rate of 99.83% and recognition accuracy of 99.92% which reach to the state-of-the-art performance for Chinese handwritten text line extraction.ConclusionExperimental results show that the proposed text line regression-clustering joint framework improves the segmentation accuracy in pixel levels and makes the edge of the text line more controllable than traditional algorithms, such as piecewise projection, minimum spanning tree-based clustering, and seam carving. The proposed system exhibits high performance on Chinese handwritten text line extraction together with enhanced robustness and accuracy without interference of adjacent text lines.关键词:handwritten text line extraction;superpixel;image segmentation;regression;clustering15|10|0更新时间:2024-08-15 -
 摘要:ObjectiveCultural heritage is a powerful witness to the cultural inheritance and development of a country or region. In view of the current trend in which cultural relics extend from traditional physical relics to virtual exhibitions and digital relics, providing a multi-mode presentation method of digital cultural relics is necessary. By introducing computer haptics into the field of cultural relic exhibitions, we propose an algorithm framework for interactive presentation based on the multi-mode perception of 3D artifacts. The proposed framework is based on multi-channel analysis of tactual, auditory, and visual characteristics of cultural relics. Considering the contact states between users and these digital 3D models of relics, the multi-channel information is identified, calculated, integrated, and processed. Eventually, information is passed to the visual, audio, and haptic devices to complete the multi-mode perception.MethodIn this study, the impedance control mode is used as the basic driving mechanism of the haptic computing rendering. The basic idea is that a user inputs the position and direction information, and the force and torque are then calculated and fed back to the user. The calculation and rendering for different characteristics of these artifacts, such as contour shapes, physical materials, and surface textures, are also implemented in stages. For the contour shape of these artifacts, the spring system based on the embedding depth is constructed to simulate the contact process, and the stiffness coefficient of the spring is related with the cultural object. To reflect these material characteristics of the surface friction, the friction during the contact of cultural relics is simulated by introducing the dynamic and static friction factors. With the movement of the operation proxy on the surface of cultural relics, the finite state machine is alternately updated between static and dynamic friction. Although discrete triangular patch groups can identify the complex form, deviations remain because the existing models are usually represented by triangular patches. To address this problem, the normal mapping is used to perform the haptic processing of the surface texture. Compared with the traditional 2D interaction, 3D space provides more freedom and more abundant interactive tasks. At this time, through the comparison or abstraction of certain mechanisms existing in the real world, the behaviors and states of users' operation can be mapped to a proxy in a virtual environment. Through the operation proxy, we further build unified "rotation" and "select-move-release" interaction models to realize user intention. The "rotation" operation allows users to freely change their perspective according to their own needs, providing multi-view observation and appreciation of cultural relic models. During 3D interaction, the "select-move-release" operation helps users to freely manipulate the artifact model in a virtual environment. This method can also enhance the overall cognition of the artifact model. Finally, to further enhance the realistic characteristics of the virtual environment, ODE physics engine is introduced to cultural relic interaction. The reasonable introduction of physics engine integrates the basic motion law of objects into the virtual environment to enhance the realism of physical movement and scene interaction.ResultWith Phantom Omni haptic device as basis, multi-mode perceptual experimental systems for cultural artifacts are built, and 15 volunteers (eight males and seven females) are selected to evaluate the system. Experimental results show that the method can enable human operators to perceive the overall and detailed information of digital relics through multiple channels of vision, hearing, and touch. In addition, the entire interaction is simple, natural, and effective. On the basis of the user experience theory of Rolls-Royce, we evaluate the experiential effects from three dimensions, namely, usability, sensory experience, and emotional experience. Among these dimensions, usability and emotional experience scores are higher, whereas the sensory experience score is relatively lower. With regard to these set problems, users' acceptance and satisfaction degree are relatively high, satisfying the curiosity of people and the attraction of the presentation manner. However, users' ratings in realistic details of cultural models and the naturalness of interaction between the human and artifacts are relatively low. In general, the interactive mode proposed in this study is more natural than the mouse interaction, but it still maintains a certain distance from the human-object interaction under the real environment.ConclusionThis study presents an interactive presentation method of digital artifacts based on multi-modal perception that can effectively achieve the multi-modal reproduction of various types of digital heritage, especially 3D artifacts. While ensuring high real-time performance, the method has good usability and emotional experience. In our future work, we will continue to explore the new surface haptic-rendering algorithm of the cultural relics. The method of haptic interaction for multi-point grasping of virtual artifacts needs to be further studied. Multi-point interaction can provide higher fidelity and richer operation experience than the existing interaction between single point and digital relics.关键词:virtual reality;haptic rendering;digital cultural relics;multi-mode integration;human computer interaction38|122|1更新时间:2024-08-15
摘要:ObjectiveCultural heritage is a powerful witness to the cultural inheritance and development of a country or region. In view of the current trend in which cultural relics extend from traditional physical relics to virtual exhibitions and digital relics, providing a multi-mode presentation method of digital cultural relics is necessary. By introducing computer haptics into the field of cultural relic exhibitions, we propose an algorithm framework for interactive presentation based on the multi-mode perception of 3D artifacts. The proposed framework is based on multi-channel analysis of tactual, auditory, and visual characteristics of cultural relics. Considering the contact states between users and these digital 3D models of relics, the multi-channel information is identified, calculated, integrated, and processed. Eventually, information is passed to the visual, audio, and haptic devices to complete the multi-mode perception.MethodIn this study, the impedance control mode is used as the basic driving mechanism of the haptic computing rendering. The basic idea is that a user inputs the position and direction information, and the force and torque are then calculated and fed back to the user. The calculation and rendering for different characteristics of these artifacts, such as contour shapes, physical materials, and surface textures, are also implemented in stages. For the contour shape of these artifacts, the spring system based on the embedding depth is constructed to simulate the contact process, and the stiffness coefficient of the spring is related with the cultural object. To reflect these material characteristics of the surface friction, the friction during the contact of cultural relics is simulated by introducing the dynamic and static friction factors. With the movement of the operation proxy on the surface of cultural relics, the finite state machine is alternately updated between static and dynamic friction. Although discrete triangular patch groups can identify the complex form, deviations remain because the existing models are usually represented by triangular patches. To address this problem, the normal mapping is used to perform the haptic processing of the surface texture. Compared with the traditional 2D interaction, 3D space provides more freedom and more abundant interactive tasks. At this time, through the comparison or abstraction of certain mechanisms existing in the real world, the behaviors and states of users' operation can be mapped to a proxy in a virtual environment. Through the operation proxy, we further build unified "rotation" and "select-move-release" interaction models to realize user intention. The "rotation" operation allows users to freely change their perspective according to their own needs, providing multi-view observation and appreciation of cultural relic models. During 3D interaction, the "select-move-release" operation helps users to freely manipulate the artifact model in a virtual environment. This method can also enhance the overall cognition of the artifact model. Finally, to further enhance the realistic characteristics of the virtual environment, ODE physics engine is introduced to cultural relic interaction. The reasonable introduction of physics engine integrates the basic motion law of objects into the virtual environment to enhance the realism of physical movement and scene interaction.ResultWith Phantom Omni haptic device as basis, multi-mode perceptual experimental systems for cultural artifacts are built, and 15 volunteers (eight males and seven females) are selected to evaluate the system. Experimental results show that the method can enable human operators to perceive the overall and detailed information of digital relics through multiple channels of vision, hearing, and touch. In addition, the entire interaction is simple, natural, and effective. On the basis of the user experience theory of Rolls-Royce, we evaluate the experiential effects from three dimensions, namely, usability, sensory experience, and emotional experience. Among these dimensions, usability and emotional experience scores are higher, whereas the sensory experience score is relatively lower. With regard to these set problems, users' acceptance and satisfaction degree are relatively high, satisfying the curiosity of people and the attraction of the presentation manner. However, users' ratings in realistic details of cultural models and the naturalness of interaction between the human and artifacts are relatively low. In general, the interactive mode proposed in this study is more natural than the mouse interaction, but it still maintains a certain distance from the human-object interaction under the real environment.ConclusionThis study presents an interactive presentation method of digital artifacts based on multi-modal perception that can effectively achieve the multi-modal reproduction of various types of digital heritage, especially 3D artifacts. While ensuring high real-time performance, the method has good usability and emotional experience. In our future work, we will continue to explore the new surface haptic-rendering algorithm of the cultural relics. The method of haptic interaction for multi-point grasping of virtual artifacts needs to be further studied. Multi-point interaction can provide higher fidelity and richer operation experience than the existing interaction between single point and digital relics.关键词:virtual reality;haptic rendering;digital cultural relics;multi-mode integration;human computer interaction38|122|1更新时间:2024-08-15 -
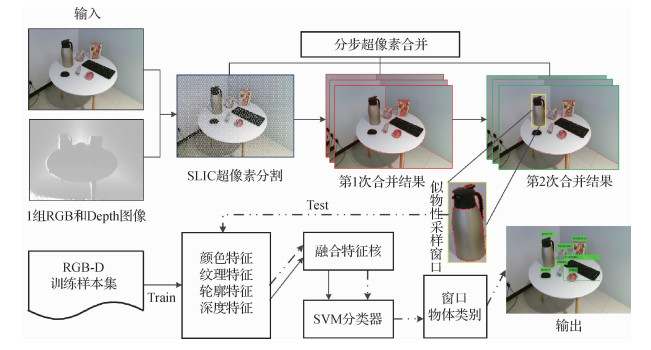 摘要:ObjectiveWith the development of artificial intelligence, a growing number of scholars begin to study object detection in the field of computer vision, and they are no longer content with the recent research on RGB images. The object detection methods based on the depth of images have attracted attention. However, the accuracy and real-time performance of indoor multi-class object detection is susceptible to illumination change, shooting angle, the number of objects, and object size. To improve detection accuracy, several studies have begun to employ deep learning methods. Although deep learning can effectively extract the underlying characteristics of objects at different levels, large samples and long learning time make the immediate and wide application of these methods impossible. With regard to improving detection efficiency, many scholars wanted to find all possible areas that contain objects based on the edge information of objects, thus reducing the number of detection windows. Several researchers used deep learning method to preselect it. To address these problems, this study proposes two methods by stages, which adopt RGB-D graphs. The first method is object proposal with super-pixel merging by steps, and the other is object classification adopting the technology of multi-modal data fusion.MethodIn the stage of object proposal, the method first segments images into super-pixels and merges them by steps adopting the method of self-adaptive multi-threshold scale on the basis of the color and depth information, according to the theory of eyes observing the color information first and then the depth information of an object. The method proposes to segment the graph with simple linear iterative clustering and merges the super-pixel in two steps, calculating the area similarity with respect to color and depth information. In this way, the detection windows with similar color and depth information are extracted to decrease the window number through filtering them by area and adopting non-maximal suppression to detection results with the overlapping region. At the end of the process, the number of detected windows becomes far less than that when using a sliding window scan, and each area may contain an object or part of an object. In the object recognition stage, the proposed method fuses the multi-modal features, including color, texture, contour, and depth, which are extracted from RGB-D images, employing multi-kernel learning. In general, objects are unclear when identified simply with one feature because of the multiplicity of objects. For example, distinguishing an apple from one painted in a picture is difficult. Multi-modal data fusion can cover several object characteristics in RGB-D images relative to single feature or simple fusion with two features. Finally, the fusing feature kernel is inputted into the SVM classifier, and the procedure of object detection is complete.ResultBy setting different threshold segmentation interval parameters and multi-kernel learning gauss kernel parameters, the study compares the proposed method and the current mainstream algorithm. The textual method has a certain advantage in object detection. The detection rate of the method is better by 4.7% than the state-of-art method via the comparative experiment based on the standard RGB-D databases from the University of Washington and real-scene databases obtained by Kinect sensor. The method of sub-step merging of super-pixel is superior to the present mainstream object proposal methods in object location, and the amounts of sampling windows are approximately fourfold less than the other algorithms in the situation of same recall rate. Moreover, by comparing the individual feature and the fusion feature recognition accuracy, multi-feature fusion method is much higher than the individual characteristics. The characteristics of the two fusions in the overall detection accuracy also have outstanding performance on object categories with different gestures.ConclusionExperimental results show that the proposed method can take full use of the color and depth information in object location and classification and is important in achieving high accuracy and enhanced real-time performance. The sub-step merging of super-pixel can also be used in the field of object detection based on deep learning.关键词:three-dimension object detection;sub-step merging of super-pixel;multi-modal data fusion;depth image;object proposal;machine learning15|6|4更新时间:2024-08-15
摘要:ObjectiveWith the development of artificial intelligence, a growing number of scholars begin to study object detection in the field of computer vision, and they are no longer content with the recent research on RGB images. The object detection methods based on the depth of images have attracted attention. However, the accuracy and real-time performance of indoor multi-class object detection is susceptible to illumination change, shooting angle, the number of objects, and object size. To improve detection accuracy, several studies have begun to employ deep learning methods. Although deep learning can effectively extract the underlying characteristics of objects at different levels, large samples and long learning time make the immediate and wide application of these methods impossible. With regard to improving detection efficiency, many scholars wanted to find all possible areas that contain objects based on the edge information of objects, thus reducing the number of detection windows. Several researchers used deep learning method to preselect it. To address these problems, this study proposes two methods by stages, which adopt RGB-D graphs. The first method is object proposal with super-pixel merging by steps, and the other is object classification adopting the technology of multi-modal data fusion.MethodIn the stage of object proposal, the method first segments images into super-pixels and merges them by steps adopting the method of self-adaptive multi-threshold scale on the basis of the color and depth information, according to the theory of eyes observing the color information first and then the depth information of an object. The method proposes to segment the graph with simple linear iterative clustering and merges the super-pixel in two steps, calculating the area similarity with respect to color and depth information. In this way, the detection windows with similar color and depth information are extracted to decrease the window number through filtering them by area and adopting non-maximal suppression to detection results with the overlapping region. At the end of the process, the number of detected windows becomes far less than that when using a sliding window scan, and each area may contain an object or part of an object. In the object recognition stage, the proposed method fuses the multi-modal features, including color, texture, contour, and depth, which are extracted from RGB-D images, employing multi-kernel learning. In general, objects are unclear when identified simply with one feature because of the multiplicity of objects. For example, distinguishing an apple from one painted in a picture is difficult. Multi-modal data fusion can cover several object characteristics in RGB-D images relative to single feature or simple fusion with two features. Finally, the fusing feature kernel is inputted into the SVM classifier, and the procedure of object detection is complete.ResultBy setting different threshold segmentation interval parameters and multi-kernel learning gauss kernel parameters, the study compares the proposed method and the current mainstream algorithm. The textual method has a certain advantage in object detection. The detection rate of the method is better by 4.7% than the state-of-art method via the comparative experiment based on the standard RGB-D databases from the University of Washington and real-scene databases obtained by Kinect sensor. The method of sub-step merging of super-pixel is superior to the present mainstream object proposal methods in object location, and the amounts of sampling windows are approximately fourfold less than the other algorithms in the situation of same recall rate. Moreover, by comparing the individual feature and the fusion feature recognition accuracy, multi-feature fusion method is much higher than the individual characteristics. The characteristics of the two fusions in the overall detection accuracy also have outstanding performance on object categories with different gestures.ConclusionExperimental results show that the proposed method can take full use of the color and depth information in object location and classification and is important in achieving high accuracy and enhanced real-time performance. The sub-step merging of super-pixel can also be used in the field of object detection based on deep learning.关键词:three-dimension object detection;sub-step merging of super-pixel;multi-modal data fusion;depth image;object proposal;machine learning15|6|4更新时间:2024-08-15
Image Analysis and Recognition
-
 摘要:ObjectiveShape representation and shape matching are the basic tasks in computer vision and pattern recognition. Among all the region-based methods, several classic methods are already available, including Hu moment invariants (Hu method), angular radial transform (ART method), generic Fourier descriptor (GFD method), histogram of Radon transform (HRT method), and multi-scale integral invariant (MSⅡ method). Given the long time spans between all these proposed methods and the fact that only one factor (i.e., retrieval accuracy) is always compared in the past studies, we need a comprehensive comparative study of all these methods to help in application engineering and in future studies.MethodTo compare the different aspects of the five shape descriptors, we utilize three shape databases. The first shape database, which is a group of simple geometry and one that we modified, includes ten seed shapes. From each of these ten seed shapes, we construct three more shapes through non-rigid deformation, with increasing deformation from the first one to the third one, that is, 40 basic shapes constructed in total. Finally, for each of these 40 basic shapes, we obtain another three more similar shapes by random scale, random rotation, and random translation. Consequently, 160 shapes in the first shape database are constructed. In the retrieval test of the first database, we define a new rule of test scoring, which not only count the retrieval score but also considered the retrieval result order. Therefore, this new test score rule can inspect the intrinsic representation and retrieval ability of the shape descriptor. The second shape database we used in our comparative experiments is the MPEG-7, which consists of 70 different shape categories with each category consisting of 20 shapes of the same category modulo with various rigid and non-rigid deformations and is the standard shape database for shape descriptor and shape retrieval. The experiments are performed on 1400 shape images. Test score for MPEG-7 shape database is based on bullseye score, which counts the number of shapes in the same category (20 shapes in this case) within 40 best matching shapes. The third shape database we used in our experiments is the collection of vehicle trademark shapes. We collect 100 common vehicle flags, such as from Bents, BMW, and Toyota. For each of these 100 vehicle flag shapes, we construct three additional shapes by random scale, random rotation, and random translation and another three shapes using the random perspective parameters. Thus, we obtain a total of 700 vehicle flag shapes. The test score we used for this third database is also based on bullseye score, which counts the number of shapes in the same category (seven shapes in this case) within 14 best matching shapes. In all retrieval experiments for all the three shape databases, we not only compute the test scores but also the retrieval stability using the standard deviations of retrieval scores. We analyze and verified the computation complexity of the compared shape descriptors. After obtaining the test scores, retrieval stability, and computation complexity, a weighted formula, which considers all the three factors, is also defined to measure their comprehensive performances.ResultIn the retrieval experiments of the first simple geometry shape database, the HRT method achieves the best test score and lowest standard deviation, with the GFD method following, which indicates that HRT is not sensitive to noise in comparison with the other methods. In the retrieval experiments of the second shape database, ART and GFD methods obtain almost the same retrieval scores. In the retrieval experiments of the third shape database, GFD, ART, and HRT methods almost achieve the same retrieval score. In all of the retrieval experiments, the five compared methods are all invariant to scale, rotation, and translation, which are the fundamental requirements for a shape descriptor. We analyze and verify the computation complexity of the 5 methods and find that in the stage of feature creation, Hu method has the lowest computation complexity, and in the stage of feature matching, except for HRT method, all the other four methods have low matching computation complexity. The comprehensive performances of these five methods are measured by a weighted formula, and the GFD method has the best performance with ART as the next. HRT method can degrade with large number of shapes, because HRT method has higher complexity in matching phase than the other methods. The performances of Hu and MSⅡ methods are not satisfactory in all our experiments. The visual features of a shape can also be captured practically by the method of projecting shape onto a basis of orthogonal base functions. In this study, we suppose that the visual features of an image can also be captured practically by the same projection method.ConclusionAmong all the evaluated region-based methods, GFD and ART methods have the best performance, and we suppose that they can be employed in engineering applications. Finding new basis of orthogonal base functions may be a fruitful research direction in shape visual feature extraction, as well as in image visual feature extraction, because projecting a shape onto the orthogonal base functions can capture its intrinsic vision features.关键词:computer vision;pattern recognition;shape projection;shape descriptor;shape matching11|4|2更新时间:2024-08-15
摘要:ObjectiveShape representation and shape matching are the basic tasks in computer vision and pattern recognition. Among all the region-based methods, several classic methods are already available, including Hu moment invariants (Hu method), angular radial transform (ART method), generic Fourier descriptor (GFD method), histogram of Radon transform (HRT method), and multi-scale integral invariant (MSⅡ method). Given the long time spans between all these proposed methods and the fact that only one factor (i.e., retrieval accuracy) is always compared in the past studies, we need a comprehensive comparative study of all these methods to help in application engineering and in future studies.MethodTo compare the different aspects of the five shape descriptors, we utilize three shape databases. The first shape database, which is a group of simple geometry and one that we modified, includes ten seed shapes. From each of these ten seed shapes, we construct three more shapes through non-rigid deformation, with increasing deformation from the first one to the third one, that is, 40 basic shapes constructed in total. Finally, for each of these 40 basic shapes, we obtain another three more similar shapes by random scale, random rotation, and random translation. Consequently, 160 shapes in the first shape database are constructed. In the retrieval test of the first database, we define a new rule of test scoring, which not only count the retrieval score but also considered the retrieval result order. Therefore, this new test score rule can inspect the intrinsic representation and retrieval ability of the shape descriptor. The second shape database we used in our comparative experiments is the MPEG-7, which consists of 70 different shape categories with each category consisting of 20 shapes of the same category modulo with various rigid and non-rigid deformations and is the standard shape database for shape descriptor and shape retrieval. The experiments are performed on 1400 shape images. Test score for MPEG-7 shape database is based on bullseye score, which counts the number of shapes in the same category (20 shapes in this case) within 40 best matching shapes. The third shape database we used in our experiments is the collection of vehicle trademark shapes. We collect 100 common vehicle flags, such as from Bents, BMW, and Toyota. For each of these 100 vehicle flag shapes, we construct three additional shapes by random scale, random rotation, and random translation and another three shapes using the random perspective parameters. Thus, we obtain a total of 700 vehicle flag shapes. The test score we used for this third database is also based on bullseye score, which counts the number of shapes in the same category (seven shapes in this case) within 14 best matching shapes. In all retrieval experiments for all the three shape databases, we not only compute the test scores but also the retrieval stability using the standard deviations of retrieval scores. We analyze and verified the computation complexity of the compared shape descriptors. After obtaining the test scores, retrieval stability, and computation complexity, a weighted formula, which considers all the three factors, is also defined to measure their comprehensive performances.ResultIn the retrieval experiments of the first simple geometry shape database, the HRT method achieves the best test score and lowest standard deviation, with the GFD method following, which indicates that HRT is not sensitive to noise in comparison with the other methods. In the retrieval experiments of the second shape database, ART and GFD methods obtain almost the same retrieval scores. In the retrieval experiments of the third shape database, GFD, ART, and HRT methods almost achieve the same retrieval score. In all of the retrieval experiments, the five compared methods are all invariant to scale, rotation, and translation, which are the fundamental requirements for a shape descriptor. We analyze and verify the computation complexity of the 5 methods and find that in the stage of feature creation, Hu method has the lowest computation complexity, and in the stage of feature matching, except for HRT method, all the other four methods have low matching computation complexity. The comprehensive performances of these five methods are measured by a weighted formula, and the GFD method has the best performance with ART as the next. HRT method can degrade with large number of shapes, because HRT method has higher complexity in matching phase than the other methods. The performances of Hu and MSⅡ methods are not satisfactory in all our experiments. The visual features of a shape can also be captured practically by the method of projecting shape onto a basis of orthogonal base functions. In this study, we suppose that the visual features of an image can also be captured practically by the same projection method.ConclusionAmong all the evaluated region-based methods, GFD and ART methods have the best performance, and we suppose that they can be employed in engineering applications. Finding new basis of orthogonal base functions may be a fruitful research direction in shape visual feature extraction, as well as in image visual feature extraction, because projecting a shape onto the orthogonal base functions can capture its intrinsic vision features.关键词:computer vision;pattern recognition;shape projection;shape descriptor;shape matching11|4|2更新时间:2024-08-15
Image Understanding and Computer Vision
-
 摘要:ObjectivePrecise liver segmentation is necessary in the computer-aided diagnosis and surgical planning of liver disease. However, liver segmentation remains challenging in medical image processing task due to the complexity of the liver anatomy and low contrast and morbidity of neighboring organs. To solve the problem of the fuzzy boundary of abdominal image organs and low accuracy of traditional U-Net model in end-to-end segmentation, this study presents an enhanced CT liver segmentation method based on improved U-Net and Morphsnakes algorithm.MethodFirst, we proposed a method for medical image preprocessing. Medical image is different from natural image. The CT images we obtained from a hospital cannot be used directly because the original format of CT images is not rectangular. Pixel padding value (0028, 0120) is used to pad grayscale images (those with a photometric interpretation of MONOCHROME1 or MONOCHROME2) to rectangular format. The first step of image preprocessing is to set the pixel padding value to 0. The second step is converting pixel values to CT values. We then used the processed images to create a dataset. Thereafter, IU-Net is trained with the constructed dataset. IU-Net is a U-Net-like convolution neural network that can achieve end-to-end segmentation. IU-Net contains two paths:downsample path to extract features from images and upsample path to resume image resolution. Between these two paths, the skip connections that can provide additional features for upsample path are available. IU-Net is deeper than U-Net but with less skip connections. While training segmentation neural network, only seeing the loss is insufficient. Often, the loss has good performance, but the segmentation accuracy is low. Therefore, IU-Net has an additional dice layer to evaluate segmentation accuracy during the training epoch. When training loss is stable at low levels, and dice accuracy is stable at high levels, training ends. Finally, OpenCV and Morphsnakes are used to refine the segmentation results generated by IU-Net. OpenCV is used to fill the hole and remove the redundant part of the segmented liver. Morphsnakes is a morphological approach to contour evolution on the basis of a new curvature morphological operator valid for surfaces of any dimension. Morphsnakes approximates the numerical solution of the curve evolution PDE by the successive application of a set of morphological operators defined on a binary level set and with equivalent infinitesimal behavior. The binary segmentation mask optimized by OpenCV also serves as the binary level set. Through the processing of Morphsnakes, we obtained the final segmentation mask and liver contour. In this study, we trained IU-Net, U-Net, and FCN-8s, and all of them were trained in two kinds of processed data. One kind of data is Hounsfield windows, which we used to set the CT value to[-100, 400]. The other one has nothing to do with CT value. IU-Net and U-Net were both trained from scratch. FCN-8s was trained using a fine-tuning strategy, because this strategy did not merge when we trained FCN-8s from scratch. We also compared the performance of rectified linear units and parametric rectified linear units on IU-Net.ResultThe experimental data include 200 sets of enhanced CT, 160 sets for training, and 40 sets for testing. The segmentation accuracy of our proposed method is 94.8%, which is better than that of the U-Net and FCN-8s models. Fine-tuning can make neural network training easy because it takes an already learned model and adapts the architecture. When building a neural network model completely different from a previous one, fine-tuning is no longer useful.ConclusionOur proposed method can accurately segment liver from enhanced CT images in various shapes and provide a reliable basis for clinical diagnosis.关键词:fully convolutional neural network;liver segmentation;deep learning;active contouring;Morphsnakes14|4|10更新时间:2024-08-15
摘要:ObjectivePrecise liver segmentation is necessary in the computer-aided diagnosis and surgical planning of liver disease. However, liver segmentation remains challenging in medical image processing task due to the complexity of the liver anatomy and low contrast and morbidity of neighboring organs. To solve the problem of the fuzzy boundary of abdominal image organs and low accuracy of traditional U-Net model in end-to-end segmentation, this study presents an enhanced CT liver segmentation method based on improved U-Net and Morphsnakes algorithm.MethodFirst, we proposed a method for medical image preprocessing. Medical image is different from natural image. The CT images we obtained from a hospital cannot be used directly because the original format of CT images is not rectangular. Pixel padding value (0028, 0120) is used to pad grayscale images (those with a photometric interpretation of MONOCHROME1 or MONOCHROME2) to rectangular format. The first step of image preprocessing is to set the pixel padding value to 0. The second step is converting pixel values to CT values. We then used the processed images to create a dataset. Thereafter, IU-Net is trained with the constructed dataset. IU-Net is a U-Net-like convolution neural network that can achieve end-to-end segmentation. IU-Net contains two paths:downsample path to extract features from images and upsample path to resume image resolution. Between these two paths, the skip connections that can provide additional features for upsample path are available. IU-Net is deeper than U-Net but with less skip connections. While training segmentation neural network, only seeing the loss is insufficient. Often, the loss has good performance, but the segmentation accuracy is low. Therefore, IU-Net has an additional dice layer to evaluate segmentation accuracy during the training epoch. When training loss is stable at low levels, and dice accuracy is stable at high levels, training ends. Finally, OpenCV and Morphsnakes are used to refine the segmentation results generated by IU-Net. OpenCV is used to fill the hole and remove the redundant part of the segmented liver. Morphsnakes is a morphological approach to contour evolution on the basis of a new curvature morphological operator valid for surfaces of any dimension. Morphsnakes approximates the numerical solution of the curve evolution PDE by the successive application of a set of morphological operators defined on a binary level set and with equivalent infinitesimal behavior. The binary segmentation mask optimized by OpenCV also serves as the binary level set. Through the processing of Morphsnakes, we obtained the final segmentation mask and liver contour. In this study, we trained IU-Net, U-Net, and FCN-8s, and all of them were trained in two kinds of processed data. One kind of data is Hounsfield windows, which we used to set the CT value to[-100, 400]. The other one has nothing to do with CT value. IU-Net and U-Net were both trained from scratch. FCN-8s was trained using a fine-tuning strategy, because this strategy did not merge when we trained FCN-8s from scratch. We also compared the performance of rectified linear units and parametric rectified linear units on IU-Net.ResultThe experimental data include 200 sets of enhanced CT, 160 sets for training, and 40 sets for testing. The segmentation accuracy of our proposed method is 94.8%, which is better than that of the U-Net and FCN-8s models. Fine-tuning can make neural network training easy because it takes an already learned model and adapts the architecture. When building a neural network model completely different from a previous one, fine-tuning is no longer useful.ConclusionOur proposed method can accurately segment liver from enhanced CT images in various shapes and provide a reliable basis for clinical diagnosis.关键词:fully convolutional neural network;liver segmentation;deep learning;active contouring;Morphsnakes14|4|10更新时间:2024-08-15
Medical Image Processing
-
 摘要:ObjectiveIn high-resolution remote sensing imagery, tall objects, such as buildings and trees, often cause interference with part of the light, resulting in the absence of corresponding spectral information and forming the shadow. Therefore, effective and accurate detection of shadow is helpful to recognize the shape of certain objects, relative position, surface properties, height, and other information. On the one hand, considering the common phenomenon of "same object with different spectra and same spectrum with different objects" and rich details in high-resolution remote-sensing imagery, traditional pixel level methods are often affected by noise when detecting shadow, but the imagery segmentation can allow spatially adjacent and spectrally similar pixels to be merged into the whole to avoid noise interference. On the other hand, morphology operation has certain recognition ability to the prominent region of the spectrum, and the spectral characteristics of shadow are often dark. With this analysis, a method based on multi-scale segmentation and morphology operation is proposed.MethodThe proposed method is based on objected-oriented idea. First, imagery segmentation objects are generated by mean shift algorithm, and object-based shadow index is obtained by object morphology dilation and erosion operation. Then, shadow index vector and brightness mean are constructed by setting different sizes of color space and coordinating space kernel function bandwidth. Finally, the shadow index vector and brightness mean are designated with high and low thresholds, and the shadow detection is accomplished.ResultGF-2 imagery from Guangzhou and Google earth imageries from Ohio are used in verifying the validity of the proposed method. The proposed method is compared with principal component analysis + HSV transformation + histogram segmentation algorithm and morphological shadow index algorithm by using error, miss, and total error rates. In the shadow quantitative detection experiment, although the error rate of the proposed method is relatively high, the miss rate decreases by 7.31%. In the building shadow detection experiment, the miss rate of the proposed method also dropped by 4.5 percentage points. In the multi-scale effect fusion analysis, the accuracy of the proposed method is ideal under the different combinations of multiple scales. In the capped ground shadow detection experiment, the error rate of the three methods are roughly the same, but the miss rate of the proposed method is significantly lower than that of the comparative methods, and the extent of its decrease reaches an average of 19.29 percentage points.ConclusionThis study presents a shadow detection method that combines morphology operation and multi-scale segmentation. Objected-oriented idea is used in the proposed method, which effectively solves the salt and pepper phenomenon. First, on the basis of imagery segmentation, the morphology operation is used to extract the dark area of spectral information. Then, shadow detection result is further determined by the brightness mean. In addition, in view of the difficulty of determining the optimal segmentation scale, the shadow index vector is constructed by multi-scale segmentation. Thus, this vector is helpful to effectively combine the advantages of each scale, enhance the applicability of the proposed method, and reduce the dependence on the segmentation scale. From the detection results, the proposed method achieves ideal results for different types of high-resolution remote-sensing imageries and exerts good detection effect on the capped ground shadow, showing strong robustness and universality. However, the proposed method needs to be improved. For example, if the spectral features are close to the shadows and the shapes of the areas are not much different, then the method needs further exploration. Moreover, how to remove several non-building shadows is challenging, especially when building shadows are adjacent to non-building shadows.关键词:high resolution remote sensing imagery;shadow detection;morphology operation;multi-scale segmentation;shadow index15|5|4更新时间:2024-08-15
摘要:ObjectiveIn high-resolution remote sensing imagery, tall objects, such as buildings and trees, often cause interference with part of the light, resulting in the absence of corresponding spectral information and forming the shadow. Therefore, effective and accurate detection of shadow is helpful to recognize the shape of certain objects, relative position, surface properties, height, and other information. On the one hand, considering the common phenomenon of "same object with different spectra and same spectrum with different objects" and rich details in high-resolution remote-sensing imagery, traditional pixel level methods are often affected by noise when detecting shadow, but the imagery segmentation can allow spatially adjacent and spectrally similar pixels to be merged into the whole to avoid noise interference. On the other hand, morphology operation has certain recognition ability to the prominent region of the spectrum, and the spectral characteristics of shadow are often dark. With this analysis, a method based on multi-scale segmentation and morphology operation is proposed.MethodThe proposed method is based on objected-oriented idea. First, imagery segmentation objects are generated by mean shift algorithm, and object-based shadow index is obtained by object morphology dilation and erosion operation. Then, shadow index vector and brightness mean are constructed by setting different sizes of color space and coordinating space kernel function bandwidth. Finally, the shadow index vector and brightness mean are designated with high and low thresholds, and the shadow detection is accomplished.ResultGF-2 imagery from Guangzhou and Google earth imageries from Ohio are used in verifying the validity of the proposed method. The proposed method is compared with principal component analysis + HSV transformation + histogram segmentation algorithm and morphological shadow index algorithm by using error, miss, and total error rates. In the shadow quantitative detection experiment, although the error rate of the proposed method is relatively high, the miss rate decreases by 7.31%. In the building shadow detection experiment, the miss rate of the proposed method also dropped by 4.5 percentage points. In the multi-scale effect fusion analysis, the accuracy of the proposed method is ideal under the different combinations of multiple scales. In the capped ground shadow detection experiment, the error rate of the three methods are roughly the same, but the miss rate of the proposed method is significantly lower than that of the comparative methods, and the extent of its decrease reaches an average of 19.29 percentage points.ConclusionThis study presents a shadow detection method that combines morphology operation and multi-scale segmentation. Objected-oriented idea is used in the proposed method, which effectively solves the salt and pepper phenomenon. First, on the basis of imagery segmentation, the morphology operation is used to extract the dark area of spectral information. Then, shadow detection result is further determined by the brightness mean. In addition, in view of the difficulty of determining the optimal segmentation scale, the shadow index vector is constructed by multi-scale segmentation. Thus, this vector is helpful to effectively combine the advantages of each scale, enhance the applicability of the proposed method, and reduce the dependence on the segmentation scale. From the detection results, the proposed method achieves ideal results for different types of high-resolution remote-sensing imageries and exerts good detection effect on the capped ground shadow, showing strong robustness and universality. However, the proposed method needs to be improved. For example, if the spectral features are close to the shadows and the shapes of the areas are not much different, then the method needs further exploration. Moreover, how to remove several non-building shadows is challenging, especially when building shadows are adjacent to non-building shadows.关键词:high resolution remote sensing imagery;shadow detection;morphology operation;multi-scale segmentation;shadow index15|5|4更新时间:2024-08-15
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0