
最新刊期
卷 23 , 期 6 , 2018
-
 摘要:ObjectiveDigital video regional tampering is a technology that can overwrite or replace a critical area of a video frame. After image inpainting, the modified traces of the critical area cannot be directly identified by human eyes. The critical region of the video frame carries the key semantic information of the video sequence. If the video regional tampering is a malicious behavior of the attacker, then it will have a serious impact. Therefore, detection and localization of video regional tampering have significant research value and application prospects.MethodThe detection of digital image copy-move tampering has been successful and many methods have been proposed. However, the detection and localization of digital video regional tampering cannot directly use tampering detection algorithms of digital images. Video tampering detection and localization are new research topics in digital video passive forensics. In recent years, numerous scholars have focused on the research on video tampering detection. However, no systematic theoretical framework or universal algorithm for regional tampering detection and location of digital videos is available at present. The concept and importance of digital video regional tampering forensics are first introduced based on extensive studies and achievements reported on the existing literature. Then, the current passive forensic algorithms for video regional tampering are divided into the following four categories: based on pattern noise, based on pixel correlation, based on video codec features, and based on statistical features. These passive forensic algorithms are discussed and compared, and video regional tampering tools and video forensic data sets are introduced. Finally, we summarize the problems and challenges and propose possible future research trends in video regional tampering detection and location.ResultIn this study, we select 18 algorithms in 20 works to introduce the methods of each algorithm and compare the algorithms individually. Most of the algorithms claim that they can detect and locate tampering region, but the accuracy and computational complexity of detection and localization are different. Among these methods, the algorithm based on pixel spatial-temporal coherence analysis has achieved good detection and localization performance in moving background video sequences. The algorithm based on the optical flow smoothing anomaly and the algorithm based on the moving object detection have obtained good detection performance on the public video forgery dataset. The ensemble classification algorithm based on steganalysis feature extraction is a tampering localization method in the temporal domain based on machine learning and steganalysis feature extraction. Although this method cannot achieve spatial tampering localization, it develops a new research direction based on machine learning for large-scale video tampering detection.ConclusionVideo regional tampering detection and localization are challenging research topics due to the noise introduced by video compression and the improvement of video tampering software tools. In the next several years, the video regional tampering detection and localization algorithm based on video content feature and abstract statistical characteristics may be further studied and developed in combination with deep learning networks. Furthermore, theoretical framework, system model, and evaluation standard will be gradually improved.关键词:video passive forensic;tampering detection and localization;pixel correlation;video codec features;statistical features29|114|3更新时间:2024-05-07
摘要:ObjectiveDigital video regional tampering is a technology that can overwrite or replace a critical area of a video frame. After image inpainting, the modified traces of the critical area cannot be directly identified by human eyes. The critical region of the video frame carries the key semantic information of the video sequence. If the video regional tampering is a malicious behavior of the attacker, then it will have a serious impact. Therefore, detection and localization of video regional tampering have significant research value and application prospects.MethodThe detection of digital image copy-move tampering has been successful and many methods have been proposed. However, the detection and localization of digital video regional tampering cannot directly use tampering detection algorithms of digital images. Video tampering detection and localization are new research topics in digital video passive forensics. In recent years, numerous scholars have focused on the research on video tampering detection. However, no systematic theoretical framework or universal algorithm for regional tampering detection and location of digital videos is available at present. The concept and importance of digital video regional tampering forensics are first introduced based on extensive studies and achievements reported on the existing literature. Then, the current passive forensic algorithms for video regional tampering are divided into the following four categories: based on pattern noise, based on pixel correlation, based on video codec features, and based on statistical features. These passive forensic algorithms are discussed and compared, and video regional tampering tools and video forensic data sets are introduced. Finally, we summarize the problems and challenges and propose possible future research trends in video regional tampering detection and location.ResultIn this study, we select 18 algorithms in 20 works to introduce the methods of each algorithm and compare the algorithms individually. Most of the algorithms claim that they can detect and locate tampering region, but the accuracy and computational complexity of detection and localization are different. Among these methods, the algorithm based on pixel spatial-temporal coherence analysis has achieved good detection and localization performance in moving background video sequences. The algorithm based on the optical flow smoothing anomaly and the algorithm based on the moving object detection have obtained good detection performance on the public video forgery dataset. The ensemble classification algorithm based on steganalysis feature extraction is a tampering localization method in the temporal domain based on machine learning and steganalysis feature extraction. Although this method cannot achieve spatial tampering localization, it develops a new research direction based on machine learning for large-scale video tampering detection.ConclusionVideo regional tampering detection and localization are challenging research topics due to the noise introduced by video compression and the improvement of video tampering software tools. In the next several years, the video regional tampering detection and localization algorithm based on video content feature and abstract statistical characteristics may be further studied and developed in combination with deep learning networks. Furthermore, theoretical framework, system model, and evaluation standard will be gradually improved.关键词:video passive forensic;tampering detection and localization;pixel correlation;video codec features;statistical features29|114|3更新时间:2024-05-07 -
 摘要:ObjectiveAn accurate phase map is crucial for magnetic resonance imaging (MRI)-based clinical applications, such as two-point and three-point Dixon techniques, susceptibility-weighted imaging, and human-brain phase imaging. However, the phase calculated from the complex MR signal is commonly wrapped back into the range of (-π, π] for the arctangent operation. Phase unwrapping is required to recover the underlying actual phase. A certain number of phase unwrapping methods have been proposed under the assumption that the underlying actual phase difference between adjacent pixels should not be larger than π. If the wrapped phase map contains severe noise, rapid phase change, or even disconnected regions in the interesting region, then the underlying actual phase difference between adjacent pixels may be larger than π; thus, this assumption becomes invalid. A new phase-unwrapping method is proposed; this method is based on phase partition and local polynomial surface fitting, which works robustly under the situation of severe noise, rapid phase changes, and disconnected regions.MethodThe proposed method first exploits the phase partition method to split the acquired phase map into the connected blocks. The phase inside each block remains within a given interval, and the wrapped phase difference between adjacent pixels is less than π. Therefore, no phase wrap exists inside each block. To reduce the affection of noise, the blocks with pixel number of less than a given threshold (such as 50) are clustered into residual pixels. Then, the proposed method sequentially performs inter-block phase unwrapping and residual-pixel phase unwrapping by a region-growing local polynomial surface fitting approach. Three simulated datasets were separately generated with signal-to-noise ratios (SNRs) varying from 6.5 to 0.5, phase height changing from 100 rad to 200 rad, and disconnected regions to test the performance of the proposed method on the data under the situation of severe noise, different phase change levels and disconnected regions. The three-point Dixon knee and ankle data of five healthy adult human volunteers were acquired on a 0.35 T permanent magnet MR scanner to test the performance of the proposed method on the in vivo MR data (XGY-OPER, Ningbo Xingaoyi, Ningbo, China). In addition, the two-point Dixon knee data of one healthy volunteer were acquired on a 3.0 T MR scanner (Philips, Achieva, Netherlands). The simulation and in vivo two-point and three-point water-fat Dixon data were used to evaluate the proposed method and compared with phase-region expanding labeler for unwrapping discrete estimates (PRELUDE). The unwrapped error ratio was calculated as the number of inaccurate unwrapped pixels divided by the total number of pixels to quantitatively evaluate the performance of the proposed method. Each simulation was repeated 20 times, and the corresponding means and standard deviations (SDs) of unwrapped error ratio (%) were calculated. The unwrapped results were implemented via Dixon technique to produce water and fat images to evaluate the performance of the proposed method on in vivo data. If the phase-unwrapping method does not acquire an accurate phase map, then the water and fat images will contain swaps. The water-fat separation results of every slice were evaluated by a blinded board-certified radiologist according to the following four-point scale: 1) many swaps (slices), 2) few swaps (slices), 3) total swap slices, and 4) error ratio.Result1) In the simulation experiment of different signal-to-noise ratio (SNR) levels, the phase map unwrapped by PRELUDE contains evident wrapping residues in low SNR regions. However, the unwrapped error is substantively reduced in the results generated by the proposed method. The proposed method consistently produced a substantially lower mean and SD of unwrapped error ratio than those of PRELUDE when SNR is below 2.5. 2) In the simulation experiment of different phase change levels, the unwrapped results produced by PRELUDE contain evident wraps when the phase height increased to 200 rad. On the contrary, the proposed method consistently produced accurate unwrapped results for different phase heights. 3) In the simulation experiment of existing discontented regions, PRELUDE generated results with serious wrapping residues, and the mean and SD of the unwrapped error ratio was 12.79±0.67 (%). The proposed method produced an accurate unwrapped phase with the mean and SD of unwrapped error ratio of 0.10±0.05 (%). 4) In the in vivo 0.35 T datasets of five volunteers and the 3.0 T dataset of one volunteer (a total of 100 slices, consisting of 75 sagittal knees and 25 sagittal ankles) water-fat separation experiments, the results generated by PRELUDE had nine times many swaps and 33 times few swaps out of 100 outputs. Meanwhile, the proposed method only produced six times few swaps. The total error ratio of PRELUDE was 42% and that of the proposed method was only 6%.ConclusionA new phase-unwrapping method, which first splits the acquired phase map into connected blocks by exploiting the phase partition method, is presented. The blocks with the pixel number of less than a given threshold are clustered into the residual pixels. Then, the proposed method sequentially performs inter-block phase unwrapping and residual-pixel phase unwrapping by using a region-growing local polynomial surface fitting approach. The simulation results demonstrate that the proposed method can achieve robust and accurate phase unwrapping even under serious noise, rapid phase changes, and disconnected regions. The application on two-point and three-point water-fat Dixon MRI data shows that the proposed method can successfully separate water and fat with few swaps. Therefore, the proposed method is beneficial to phase-related MRI applications, such as two-point and three-point Dixon techniques, susceptibility-weighted imaging, and human-brain phase imaging.关键词:magnetic resonance imaging;phase unwrapping;phase partition;local polynomial surface fitting;water-fat separation12|5|1更新时间:2024-05-07
摘要:ObjectiveAn accurate phase map is crucial for magnetic resonance imaging (MRI)-based clinical applications, such as two-point and three-point Dixon techniques, susceptibility-weighted imaging, and human-brain phase imaging. However, the phase calculated from the complex MR signal is commonly wrapped back into the range of (-π, π] for the arctangent operation. Phase unwrapping is required to recover the underlying actual phase. A certain number of phase unwrapping methods have been proposed under the assumption that the underlying actual phase difference between adjacent pixels should not be larger than π. If the wrapped phase map contains severe noise, rapid phase change, or even disconnected regions in the interesting region, then the underlying actual phase difference between adjacent pixels may be larger than π; thus, this assumption becomes invalid. A new phase-unwrapping method is proposed; this method is based on phase partition and local polynomial surface fitting, which works robustly under the situation of severe noise, rapid phase changes, and disconnected regions.MethodThe proposed method first exploits the phase partition method to split the acquired phase map into the connected blocks. The phase inside each block remains within a given interval, and the wrapped phase difference between adjacent pixels is less than π. Therefore, no phase wrap exists inside each block. To reduce the affection of noise, the blocks with pixel number of less than a given threshold (such as 50) are clustered into residual pixels. Then, the proposed method sequentially performs inter-block phase unwrapping and residual-pixel phase unwrapping by a region-growing local polynomial surface fitting approach. Three simulated datasets were separately generated with signal-to-noise ratios (SNRs) varying from 6.5 to 0.5, phase height changing from 100 rad to 200 rad, and disconnected regions to test the performance of the proposed method on the data under the situation of severe noise, different phase change levels and disconnected regions. The three-point Dixon knee and ankle data of five healthy adult human volunteers were acquired on a 0.35 T permanent magnet MR scanner to test the performance of the proposed method on the in vivo MR data (XGY-OPER, Ningbo Xingaoyi, Ningbo, China). In addition, the two-point Dixon knee data of one healthy volunteer were acquired on a 3.0 T MR scanner (Philips, Achieva, Netherlands). The simulation and in vivo two-point and three-point water-fat Dixon data were used to evaluate the proposed method and compared with phase-region expanding labeler for unwrapping discrete estimates (PRELUDE). The unwrapped error ratio was calculated as the number of inaccurate unwrapped pixels divided by the total number of pixels to quantitatively evaluate the performance of the proposed method. Each simulation was repeated 20 times, and the corresponding means and standard deviations (SDs) of unwrapped error ratio (%) were calculated. The unwrapped results were implemented via Dixon technique to produce water and fat images to evaluate the performance of the proposed method on in vivo data. If the phase-unwrapping method does not acquire an accurate phase map, then the water and fat images will contain swaps. The water-fat separation results of every slice were evaluated by a blinded board-certified radiologist according to the following four-point scale: 1) many swaps (slices), 2) few swaps (slices), 3) total swap slices, and 4) error ratio.Result1) In the simulation experiment of different signal-to-noise ratio (SNR) levels, the phase map unwrapped by PRELUDE contains evident wrapping residues in low SNR regions. However, the unwrapped error is substantively reduced in the results generated by the proposed method. The proposed method consistently produced a substantially lower mean and SD of unwrapped error ratio than those of PRELUDE when SNR is below 2.5. 2) In the simulation experiment of different phase change levels, the unwrapped results produced by PRELUDE contain evident wraps when the phase height increased to 200 rad. On the contrary, the proposed method consistently produced accurate unwrapped results for different phase heights. 3) In the simulation experiment of existing discontented regions, PRELUDE generated results with serious wrapping residues, and the mean and SD of the unwrapped error ratio was 12.79±0.67 (%). The proposed method produced an accurate unwrapped phase with the mean and SD of unwrapped error ratio of 0.10±0.05 (%). 4) In the in vivo 0.35 T datasets of five volunteers and the 3.0 T dataset of one volunteer (a total of 100 slices, consisting of 75 sagittal knees and 25 sagittal ankles) water-fat separation experiments, the results generated by PRELUDE had nine times many swaps and 33 times few swaps out of 100 outputs. Meanwhile, the proposed method only produced six times few swaps. The total error ratio of PRELUDE was 42% and that of the proposed method was only 6%.ConclusionA new phase-unwrapping method, which first splits the acquired phase map into connected blocks by exploiting the phase partition method, is presented. The blocks with the pixel number of less than a given threshold are clustered into the residual pixels. Then, the proposed method sequentially performs inter-block phase unwrapping and residual-pixel phase unwrapping by using a region-growing local polynomial surface fitting approach. The simulation results demonstrate that the proposed method can achieve robust and accurate phase unwrapping even under serious noise, rapid phase changes, and disconnected regions. The application on two-point and three-point water-fat Dixon MRI data shows that the proposed method can successfully separate water and fat with few swaps. Therefore, the proposed method is beneficial to phase-related MRI applications, such as two-point and three-point Dixon techniques, susceptibility-weighted imaging, and human-brain phase imaging.关键词:magnetic resonance imaging;phase unwrapping;phase partition;local polynomial surface fitting;water-fat separation12|5|1更新时间:2024-05-07 -
 摘要:ObjectiveThe amount of biomedical literature in electronic format has increased considerably with the development of the Internet. PubMed comprises more than 27 million citations for biomedical literature linking to full-text content from PubMed Central and publisher web sites. The figures in these biomedical studies can be retrieved through tools along with the full text. However, the lack of associated metadata, apart from the captions, hinders the fulfillment of richer information requirements of biomedical researchers and educators. The modality of a figure is an extremely useful type of metadata. Therefore, biomedical modality classification is an important primary step that can aid users to access required biomedical images and further improve the performance of the literature retrieval system. Many images in the biomedical literature (more than 40%) are compound figures including several subfigures with various biomedical modalities, such as computerized tomography, X-ray, or generic biomedical illustrations. The subfigures in one compound figure may describe one medical problem in several views and have strong semantic correlation with each other. Thus, these figures are valuable to biomedical research and education. The standard approach to modality recognition from biomedical compound figure first detects whether the figure is compound or not. If it is compound, then a figure separation algorithm is first invoked to split it into its constituent subfigures. Then, another multi-class classifier is used to predict the modality of each subfigure. Nevertheless, the figure separation algorithms are not perfect, and the errors in figure separation propagate to the multi-class model for modality classification. Recently, some multi-label learning models use pre-trained convolutional neural networks to extract high-level features to recognize the image modalities from the compound figures. These deep learning methods learn more expressive representations of image data. However, convolutional neural networks may be hindered to disentangle the factors of variation by the limited samples with high variability and the imbalanced label distribution of training data. A new cross-modal multi-label classification model using convolutional neural networks based on hybrid transfer learning is presented to learn biomedical modality information from the compound figure without separating it into subfigures.MethodAn end-to-end training and multi-label classification method, which does not require additional classifiers, is proposed. Building two convolutional neural networks enables to learn the components of an image without learning from single separated subfigure that represents the image modalities, but from labeled compound figures and their captions. The proposed cross-modal model learns general domain features from large-scale nature images and more special biomedical domain features from the simple figures and their captions in biomedical literature, leveraging techniques of heterogeneous and homogeneous transfer learning. Specifically, the proposed visual convolutional neural network (CNN) is pre-trained on a large auxiliary dataset, which contains approximately 1.2 million labeled training images of 1000 classes. Then, the top layer of the deep CNN is trained from scratch on single-label simple biomedical figures to achieve homogeneous transfer learning. The key point of such transfer learning is fine-tuning the pre-trained deep visual models on the current multi-label compound figure dataset. The architecture of the deep visual models should be changed slightly and then they could be fine-tuned on the current dataset. On the other hand, the weights of the embedding layer are initialized by the word vectors, which are pre-trained on captions extracted from 300 000 biomedical articles in PubMed, and are updated while training the networks. Similar to the homogeneous transfer learning strategy of visual model, the proposed textual convolutional neural networks are first pre-trained on the captions of the simple biomedical figures. Then, the pre-trained textual model is fine-tuned on current multi-label compound figures to capture more biomedical features. Finally, cross-modal multi-label learning model combines outputs of the visual and textual models to predict labels using multi-stage fusion strategy.ResultThe proposed cross-modal multi-label classification model based on hybrid transfer learning is evaluated on the dataset of the multi-label classification task in ImageCLEF2016. Our approach is evaluated based on multi-label classification Hamming Loss and Macro F1 Score, according to the evaluation criterion of the benchmark. The two comparative models learn multi-label information only from visual content. They pre-train AlexNet on large-scale nature images. Then, the DeCAF features are extracted from the pre-trained AlexNet and fed into the SVM classifier with a linear kernel. One comparative model predicts modalities by the highest score of SVM and the other model predicts by the highest posterior probability. The visual model achieves 33.9% lower Hamming Loss and 100.3% higher Macro F1 Score by introducing homogeneous transfer learning technique, and the textual model efficiently improves the performance in the two metrics. Thus, the proposed cross-modal model can achieve similar Hamming Loss of 0.0157 with the state-of-the-art model and obtain 52.5% higher Macro F1 Score, which is increased from 0.320 to 0.488.ConclusionA new method to extract biomedical modalities from the compound figures is proposed. The proposed models obtain more competitive results than the other reported methods in the literature. The proposed cross-modal model exhibits acceptable generalization capability and could achieve higher performance. The results imply that the homogeneous transfer learning method can aid deep convolutional neural networks (DCNNs) to capture a larger number of biomedical domain features and improve the performance of multi-label classification. The proposed cross-modal model addresses the problems of overfitting and imbalanced dataset and effectively recognizes modalities from biomedical compound figures based on visual content and textual information. In the future, building DCNNs and training networks with new techniques could further improve the proposed method.关键词:multi-label learning;convolutional neural network;transfer learning;medical image;deep learning25|81|6更新时间:2024-05-07
摘要:ObjectiveThe amount of biomedical literature in electronic format has increased considerably with the development of the Internet. PubMed comprises more than 27 million citations for biomedical literature linking to full-text content from PubMed Central and publisher web sites. The figures in these biomedical studies can be retrieved through tools along with the full text. However, the lack of associated metadata, apart from the captions, hinders the fulfillment of richer information requirements of biomedical researchers and educators. The modality of a figure is an extremely useful type of metadata. Therefore, biomedical modality classification is an important primary step that can aid users to access required biomedical images and further improve the performance of the literature retrieval system. Many images in the biomedical literature (more than 40%) are compound figures including several subfigures with various biomedical modalities, such as computerized tomography, X-ray, or generic biomedical illustrations. The subfigures in one compound figure may describe one medical problem in several views and have strong semantic correlation with each other. Thus, these figures are valuable to biomedical research and education. The standard approach to modality recognition from biomedical compound figure first detects whether the figure is compound or not. If it is compound, then a figure separation algorithm is first invoked to split it into its constituent subfigures. Then, another multi-class classifier is used to predict the modality of each subfigure. Nevertheless, the figure separation algorithms are not perfect, and the errors in figure separation propagate to the multi-class model for modality classification. Recently, some multi-label learning models use pre-trained convolutional neural networks to extract high-level features to recognize the image modalities from the compound figures. These deep learning methods learn more expressive representations of image data. However, convolutional neural networks may be hindered to disentangle the factors of variation by the limited samples with high variability and the imbalanced label distribution of training data. A new cross-modal multi-label classification model using convolutional neural networks based on hybrid transfer learning is presented to learn biomedical modality information from the compound figure without separating it into subfigures.MethodAn end-to-end training and multi-label classification method, which does not require additional classifiers, is proposed. Building two convolutional neural networks enables to learn the components of an image without learning from single separated subfigure that represents the image modalities, but from labeled compound figures and their captions. The proposed cross-modal model learns general domain features from large-scale nature images and more special biomedical domain features from the simple figures and their captions in biomedical literature, leveraging techniques of heterogeneous and homogeneous transfer learning. Specifically, the proposed visual convolutional neural network (CNN) is pre-trained on a large auxiliary dataset, which contains approximately 1.2 million labeled training images of 1000 classes. Then, the top layer of the deep CNN is trained from scratch on single-label simple biomedical figures to achieve homogeneous transfer learning. The key point of such transfer learning is fine-tuning the pre-trained deep visual models on the current multi-label compound figure dataset. The architecture of the deep visual models should be changed slightly and then they could be fine-tuned on the current dataset. On the other hand, the weights of the embedding layer are initialized by the word vectors, which are pre-trained on captions extracted from 300 000 biomedical articles in PubMed, and are updated while training the networks. Similar to the homogeneous transfer learning strategy of visual model, the proposed textual convolutional neural networks are first pre-trained on the captions of the simple biomedical figures. Then, the pre-trained textual model is fine-tuned on current multi-label compound figures to capture more biomedical features. Finally, cross-modal multi-label learning model combines outputs of the visual and textual models to predict labels using multi-stage fusion strategy.ResultThe proposed cross-modal multi-label classification model based on hybrid transfer learning is evaluated on the dataset of the multi-label classification task in ImageCLEF2016. Our approach is evaluated based on multi-label classification Hamming Loss and Macro F1 Score, according to the evaluation criterion of the benchmark. The two comparative models learn multi-label information only from visual content. They pre-train AlexNet on large-scale nature images. Then, the DeCAF features are extracted from the pre-trained AlexNet and fed into the SVM classifier with a linear kernel. One comparative model predicts modalities by the highest score of SVM and the other model predicts by the highest posterior probability. The visual model achieves 33.9% lower Hamming Loss and 100.3% higher Macro F1 Score by introducing homogeneous transfer learning technique, and the textual model efficiently improves the performance in the two metrics. Thus, the proposed cross-modal model can achieve similar Hamming Loss of 0.0157 with the state-of-the-art model and obtain 52.5% higher Macro F1 Score, which is increased from 0.320 to 0.488.ConclusionA new method to extract biomedical modalities from the compound figures is proposed. The proposed models obtain more competitive results than the other reported methods in the literature. The proposed cross-modal model exhibits acceptable generalization capability and could achieve higher performance. The results imply that the homogeneous transfer learning method can aid deep convolutional neural networks (DCNNs) to capture a larger number of biomedical domain features and improve the performance of multi-label classification. The proposed cross-modal model addresses the problems of overfitting and imbalanced dataset and effectively recognizes modalities from biomedical compound figures based on visual content and textual information. In the future, building DCNNs and training networks with new techniques could further improve the proposed method.关键词:multi-label learning;convolutional neural network;transfer learning;medical image;deep learning25|81|6更新时间:2024-05-07
Medical Image Processing

-
 摘要:ObjectiveFace super-resolution reconstruction is a technique based on an observed low-quality, low-resolution face image. Combined with prior knowledge, which is acquired from learning high- and low-resolution training sample pairs, face super-resolution reconstruction can estimate clear high-resolution face images and increase the resolution of the image to effectively improve the image visual effects. The existing face super-resolution reconstruction algorithm mainly adopts the method of neighborhood embedding, but the traditional reconstruction algorithm based on neighborhood embedding has drawbacks. For example, the algorithm only utilizes the geometric structure of the low-resolution image manifold space while ignoring the manifold geometry of the original high-resolution image, so it cannot effectively reflect the relationship between the high- and low-resolution image manifold geometry. This situation also causes a significant loss in available information of the original high-resolution images and eventually leads to a reconstructed face image with incomplete local details, image blur, and other issues. In addition, the method is based on the image super-resolution reconstruction, where a fixed number of nearest neighborhood image blocks are selected for different image blocks in the same image. Both methods are based on the assumption that the high- and low-resolution image block manifolds have a consistent geometric structure. However, a "one-to-many" correspondence exists between the high-and low-resolution images, and the assumptions of the proposed manifold geometry consistency do not conform to the actual situation. The neighborhood relationship of the low-resolution image obtained after the original image is degraded and cannot truly reflect the neighborhood relationship of the original image, resulting in a decline in the quality of reconstruction. To fully utilize the geometric structure information of the original high-resolution image space, this work proposes a neighborhood embedded face super-resolution reconstruction algorithm based on joint local constraints and adaptive neighborhood selection.MethodTo solve the problem caused by the algorithm presented, this work proposes a face super-resolution reconstruction method based on joint local constraint neighbor embedding. The algorithm mainly includes two parts, namely, sample library and match reconstruction. Establishing the sample library mainly involves construction on high-and low-resolution image blocks. When matching the reconstruction process, to better characterize the neighborhood relation of the original image block, this study introduces the following constraints: the distance between the input low-resolution image and the low-resolution sample is taken as one of the constraints, and the distance between the initial high-resolution image obtained by the input low-resolution image interpolation and the high-resolution sample is assumed as another constraint. The neighborhood of the low-resolution image block in the low-resolution image block sample and the initial high-resolution image block in the high-resolution image block sample are used as local constraints to solve the optimal reconstruction weight coefficients. The two constraints are combined to effectively maintain the geometric structure of the image, forming a reconstructed weight coefficient that constrains the low-resolution image block. For each image block obtained from the input low-resolution face image, the optimal reconstruction weight is solved by minimizing the reconstruction error. After determining the optimal weight, the reconstructed high-resolution image block can be obtained by weighted summing and using the weight and the corresponding high-resolution image sample block. Then, the high-resolution face image is estimated by using the reconstructed weight. At the same time, the method of adaptive neighborhood selection is introduced.ResultIn this study, the experiment is conducted on the CAS-PEAL-R1 face database, and the proposed reconstruction algorithm is compared with the relatively advanced face super-resolution reconstruction algorithm to verify the effectiveness of the algorithm. Furthermore, the subjective image of the experimental results is given, and the image quality of the reconstructed results of different methods is evaluated by the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). The experimental results show that, compared with the traditional face super-resolution reconstruction method based on neighborhood embedding, the subject image obtained by the proposed algorithm has more details on facial features and is more similar to the original high-resolution face image. Moreover, the contrast of the objective indicators, which were raised to 0.39 and 0.02 dB in the PSNR and SSIM, respectively, shows the superiority of the algorithm. Compared with the indicators for the LSR reconstruction method, the PSNR and SSIM were improved by 0.63 dB and 0.01, respectively. Compared with the indicators for the LCR reconstruction method, the PSNR and SSIM were improved by 0.36 dB and 0.003 2, respectively. Compared with the indicators for the TRNR reconstruction method, the PSNR and SSIM were improved by 0.33 dB and 0.001 1, respectively.ConclusionThe reconstruction method described in this study is conducted on the existing face database. The facial image is unified and segmented through the experiment to determine the optimal experimental parameters, while ignoring the location information of the facial features. Compared with the indicators of other algorithms, the subjective visual and objective evaluation indicators of the proposed algorithm achieved good results, which can be further applied to a real surveillance video with high-resolution image reconstruction. Combined with the location information of facial features and a reasonable segmentation of human face images, the full use of the prior structure of face images for super-resolution reconstruction is a future research direction.关键词:manifold space;joint local constraint;adaptive neighborhood selection;neighbor embedding;face super resolution reconstruction11|4|2更新时间:2024-05-07
摘要:ObjectiveFace super-resolution reconstruction is a technique based on an observed low-quality, low-resolution face image. Combined with prior knowledge, which is acquired from learning high- and low-resolution training sample pairs, face super-resolution reconstruction can estimate clear high-resolution face images and increase the resolution of the image to effectively improve the image visual effects. The existing face super-resolution reconstruction algorithm mainly adopts the method of neighborhood embedding, but the traditional reconstruction algorithm based on neighborhood embedding has drawbacks. For example, the algorithm only utilizes the geometric structure of the low-resolution image manifold space while ignoring the manifold geometry of the original high-resolution image, so it cannot effectively reflect the relationship between the high- and low-resolution image manifold geometry. This situation also causes a significant loss in available information of the original high-resolution images and eventually leads to a reconstructed face image with incomplete local details, image blur, and other issues. In addition, the method is based on the image super-resolution reconstruction, where a fixed number of nearest neighborhood image blocks are selected for different image blocks in the same image. Both methods are based on the assumption that the high- and low-resolution image block manifolds have a consistent geometric structure. However, a "one-to-many" correspondence exists between the high-and low-resolution images, and the assumptions of the proposed manifold geometry consistency do not conform to the actual situation. The neighborhood relationship of the low-resolution image obtained after the original image is degraded and cannot truly reflect the neighborhood relationship of the original image, resulting in a decline in the quality of reconstruction. To fully utilize the geometric structure information of the original high-resolution image space, this work proposes a neighborhood embedded face super-resolution reconstruction algorithm based on joint local constraints and adaptive neighborhood selection.MethodTo solve the problem caused by the algorithm presented, this work proposes a face super-resolution reconstruction method based on joint local constraint neighbor embedding. The algorithm mainly includes two parts, namely, sample library and match reconstruction. Establishing the sample library mainly involves construction on high-and low-resolution image blocks. When matching the reconstruction process, to better characterize the neighborhood relation of the original image block, this study introduces the following constraints: the distance between the input low-resolution image and the low-resolution sample is taken as one of the constraints, and the distance between the initial high-resolution image obtained by the input low-resolution image interpolation and the high-resolution sample is assumed as another constraint. The neighborhood of the low-resolution image block in the low-resolution image block sample and the initial high-resolution image block in the high-resolution image block sample are used as local constraints to solve the optimal reconstruction weight coefficients. The two constraints are combined to effectively maintain the geometric structure of the image, forming a reconstructed weight coefficient that constrains the low-resolution image block. For each image block obtained from the input low-resolution face image, the optimal reconstruction weight is solved by minimizing the reconstruction error. After determining the optimal weight, the reconstructed high-resolution image block can be obtained by weighted summing and using the weight and the corresponding high-resolution image sample block. Then, the high-resolution face image is estimated by using the reconstructed weight. At the same time, the method of adaptive neighborhood selection is introduced.ResultIn this study, the experiment is conducted on the CAS-PEAL-R1 face database, and the proposed reconstruction algorithm is compared with the relatively advanced face super-resolution reconstruction algorithm to verify the effectiveness of the algorithm. Furthermore, the subjective image of the experimental results is given, and the image quality of the reconstructed results of different methods is evaluated by the peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). The experimental results show that, compared with the traditional face super-resolution reconstruction method based on neighborhood embedding, the subject image obtained by the proposed algorithm has more details on facial features and is more similar to the original high-resolution face image. Moreover, the contrast of the objective indicators, which were raised to 0.39 and 0.02 dB in the PSNR and SSIM, respectively, shows the superiority of the algorithm. Compared with the indicators for the LSR reconstruction method, the PSNR and SSIM were improved by 0.63 dB and 0.01, respectively. Compared with the indicators for the LCR reconstruction method, the PSNR and SSIM were improved by 0.36 dB and 0.003 2, respectively. Compared with the indicators for the TRNR reconstruction method, the PSNR and SSIM were improved by 0.33 dB and 0.001 1, respectively.ConclusionThe reconstruction method described in this study is conducted on the existing face database. The facial image is unified and segmented through the experiment to determine the optimal experimental parameters, while ignoring the location information of the facial features. Compared with the indicators of other algorithms, the subjective visual and objective evaluation indicators of the proposed algorithm achieved good results, which can be further applied to a real surveillance video with high-resolution image reconstruction. Combined with the location information of facial features and a reasonable segmentation of human face images, the full use of the prior structure of face images for super-resolution reconstruction is a future research direction.关键词:manifold space;joint local constraint;adaptive neighborhood selection;neighbor embedding;face super resolution reconstruction11|4|2更新时间:2024-05-07 -
 摘要:ObjectiveLicense plate images captured by monitoring systems often have relatively low spatial resolution and are thus difficult to identify due to the large distances between vehicles and cameras, the low resolution of the imaging devices used for video images, and factors such as atmospheric disturbances, lighting conditions, and motion blur. The high-resolution reconstruction of low-resolution license plate images is crucial in enhancing license plate image resolution and thus increasing the accuracy of license plate recognition. Multiframe super-resolution techniques are particularly well suited for this application because they facilitate recovery of valid results from low-quality images by gathering information not only from the image itself but also from the constraints that must be satisfied. In this work, a super-resolution reconstruction algorithm based on intensity-gradient prior combinations is proposed to improve the quality and detectability of license plate images.MethodThe proposed algorithm includes three steps. First, the motion displacement between the multiframe images is estimated with a novel optical flow estimation method under a robust data function. The data fidelity model that adds gradient constancy constraints to the color constancy constraint is more accurate in terms of modeling the confidence of pixel correspondence than that using only one out of the two terms, which is not appropriate because the color constancy constraint is often violated when illumination or exposure changes. In the optical flow estimation model, the selective combination of the color and gradient constraints in defining the data term enables the recovery of many motion details that are robust to outliers. The blur function of the reference license plate image is then estimated with a blind deblurring method that is based on regularized intensity and gradient prior in the second step of the algorithm. The proposed intensity and gradient prior, which is based on distinctive properties such that text and background regions usually have nearly uniform intensity values in clear images without blurs, is effective for cases with rich text, which can be modeled by two-tone distributions. We can reliably estimate the blur kernel with an efficient optimization algorithm. By combining the advantages of intensity and gradient constraints fully combined, we can realize the high accurate estimation of accurately estimate the motion displacement and the blur function. Meanwhile, an intensity-gradient image prior combination model based on the characterization of license plate images is also further utilized in the super-resolution algorithm to suppress the noise and artifacts in the reconstructed images.ResultTo verify the effectiveness of the proposed algorithm, experiments with simulated and real license plate images are implemented. The proposed algorithm is utilized to reconstruct a low-quality license plate image and compare its results with those obtained by bicubic, traditional maximum a posterior, nonlinear diffusion regularization, and adaptive norm regularized methods, which are used as benchmarks. Qualitative and quantitative analyses are conducted to evaluate the proposed algorithm. Experimental results show that the proposed technique can remove image noise and blur and produce the best reconstructed image among all compared methods. The peak signal-to-noise ratio (PSNR) and structure similarity image measure (SSIM) value of the proposed method are higher than those of the four other algorithms. The PSNR and SSIM values obtained by the proposed method without Gaussian noise in the simulated license plate image experiments are 35.326 dB and 0.958, respectively. The proposed method can also effectively enhance the detailed information of license plate images and obtain superior visual effect in the real experiments. In addition, the license plate recognition accuracy of the proposed algorithm is higher than that of the three other algorithms.ConclusionThe proposed method can effectively eliminate artifacts and compensate for the texture information of low-quality license plate images. The effectiveness of the proposed method is validated by simulation and real image reconstruction experiments. The results of these experiments demonstrate that the proposed method can significantly reduce the error of motion and blur estimation, effectively decrease image blur and noise, and achieve promising PSNRs. Notably, the proposed method performs better than existing methods in terms of accuracy and visual improvement results, which are natural and consistent with those of the human visual system. The accuracy of the license plate image detection results shows that the super-resolution reconstruction method proposed in this study significantly improves the identification of license plate characters. Consequently, this method can also enhance license plate image resolution and effectively increase the accuracy of license plate recognition. The proposed method can be widely applied to the super-resolution reconstruction of license plate images, which are seriously affected by illumination variation and motion blur.关键词:super-resolution reconstruction;combined constraints;maximum a posterior;optical flow estimation;blur estimation;image prior16|4|6更新时间:2024-05-07
摘要:ObjectiveLicense plate images captured by monitoring systems often have relatively low spatial resolution and are thus difficult to identify due to the large distances between vehicles and cameras, the low resolution of the imaging devices used for video images, and factors such as atmospheric disturbances, lighting conditions, and motion blur. The high-resolution reconstruction of low-resolution license plate images is crucial in enhancing license plate image resolution and thus increasing the accuracy of license plate recognition. Multiframe super-resolution techniques are particularly well suited for this application because they facilitate recovery of valid results from low-quality images by gathering information not only from the image itself but also from the constraints that must be satisfied. In this work, a super-resolution reconstruction algorithm based on intensity-gradient prior combinations is proposed to improve the quality and detectability of license plate images.MethodThe proposed algorithm includes three steps. First, the motion displacement between the multiframe images is estimated with a novel optical flow estimation method under a robust data function. The data fidelity model that adds gradient constancy constraints to the color constancy constraint is more accurate in terms of modeling the confidence of pixel correspondence than that using only one out of the two terms, which is not appropriate because the color constancy constraint is often violated when illumination or exposure changes. In the optical flow estimation model, the selective combination of the color and gradient constraints in defining the data term enables the recovery of many motion details that are robust to outliers. The blur function of the reference license plate image is then estimated with a blind deblurring method that is based on regularized intensity and gradient prior in the second step of the algorithm. The proposed intensity and gradient prior, which is based on distinctive properties such that text and background regions usually have nearly uniform intensity values in clear images without blurs, is effective for cases with rich text, which can be modeled by two-tone distributions. We can reliably estimate the blur kernel with an efficient optimization algorithm. By combining the advantages of intensity and gradient constraints fully combined, we can realize the high accurate estimation of accurately estimate the motion displacement and the blur function. Meanwhile, an intensity-gradient image prior combination model based on the characterization of license plate images is also further utilized in the super-resolution algorithm to suppress the noise and artifacts in the reconstructed images.ResultTo verify the effectiveness of the proposed algorithm, experiments with simulated and real license plate images are implemented. The proposed algorithm is utilized to reconstruct a low-quality license plate image and compare its results with those obtained by bicubic, traditional maximum a posterior, nonlinear diffusion regularization, and adaptive norm regularized methods, which are used as benchmarks. Qualitative and quantitative analyses are conducted to evaluate the proposed algorithm. Experimental results show that the proposed technique can remove image noise and blur and produce the best reconstructed image among all compared methods. The peak signal-to-noise ratio (PSNR) and structure similarity image measure (SSIM) value of the proposed method are higher than those of the four other algorithms. The PSNR and SSIM values obtained by the proposed method without Gaussian noise in the simulated license plate image experiments are 35.326 dB and 0.958, respectively. The proposed method can also effectively enhance the detailed information of license plate images and obtain superior visual effect in the real experiments. In addition, the license plate recognition accuracy of the proposed algorithm is higher than that of the three other algorithms.ConclusionThe proposed method can effectively eliminate artifacts and compensate for the texture information of low-quality license plate images. The effectiveness of the proposed method is validated by simulation and real image reconstruction experiments. The results of these experiments demonstrate that the proposed method can significantly reduce the error of motion and blur estimation, effectively decrease image blur and noise, and achieve promising PSNRs. Notably, the proposed method performs better than existing methods in terms of accuracy and visual improvement results, which are natural and consistent with those of the human visual system. The accuracy of the license plate image detection results shows that the super-resolution reconstruction method proposed in this study significantly improves the identification of license plate characters. Consequently, this method can also enhance license plate image resolution and effectively increase the accuracy of license plate recognition. The proposed method can be widely applied to the super-resolution reconstruction of license plate images, which are seriously affected by illumination variation and motion blur.关键词:super-resolution reconstruction;combined constraints;maximum a posterior;optical flow estimation;blur estimation;image prior16|4|6更新时间:2024-05-07 -
 摘要:ObjectiveWith the rapid development and popularity of the Internet and information technologies, computers and mobile phones have become an important part of the daily lives of people. Through these electronic devices, a large number of pictures that may contain private information are transmitted and stored. Image information security is becoming increasingly important. However, the use of traditional encryption algorithms (e.g., data encryption standard, advanced encryption standard, and international data encryption algorithm) to encrypt images will result in low efficiency and poor security because of the data size and high redundancy among the pixels of digital images. An effective approach to deal with this issue is to develop secure and effective digital image encryption algorithms. The existing image algorithms can be categorized into pixel-permutation-based, chaotic-system-based, and bitplane-based methods. The image encryption algorithms of the pixel-permutation-based method change the pixel position to destroy adjacent pixel dependencies by performing the permutation operation on the pixel matrix, thereby generating noise-like and meaningless cipher images. However, only the encryption algorithms that use pixel permutation have weak resistance to statistical attacks and poor security. The image encryption algorithms of the chaotic-system-based method take advantage of the excellent intrinsic properties of a chaotic sequence, such as ergodicity, pseudorandomness, and sensitivity to initial conditional and control parameters, to enable diffusion and confusion encryption. These methods have a large key space, strong keystream adaptivity, and high security and often combine with other encryption methods to achieve effective image encryption. The image encryption algorithms of the bitplane-based method decompose the pixels into bit levels, implementing the permutation and diffusion operations on the bitplanes. Bitplane matrix transformation, selective encryption based on bitplane information distribution, and integrating bit-level encryption with pixel-level encryption are the typical bitplane encryption algorithms. The bitplane encryption operation can enhance the sensitivity of the algorithm to small changes in the original image, thus improving the capability to resist differential attack. Moreover, the bitplane permutation operation can change the position and value of a pixel simultaneously, thereby reducing the computational complexity of the image encryption algorithm. Most bitplane encryption algorithms have desirable encryption performance with only one round. Therefore, a novel image encryption algorithm with the bit-level synchronous permutation diffusion and pixel-level annular diffusion (called BSPDPAD) was proposed in this study to improve image encryption efficiency and security to solve the security problem of the selective encryption algorithms with the bitplane information distribution, the statistical attack problem of pixel permutation encryption algorithms, and the problem of sequential diffusion producing stop point mechanism and nonuniform plaintext sensitivity effectively.MethodBSPDPAD uses the chaotic sequence generated by the piecewise linear chaotic map (PWLCM) to construct bit-level and pixel-level keystreams and simultaneously encrypts the image at the bit and pixel levels. At the bit-level encryption stage, BSPDPAD first generates two sets of chaotic sequences by iteratively executing the PWLCM. One set is used to block an image randomly, and the other set is decomposed into bitplanes to obtain the binary keystream sequences. For the four lower bitplanes that contain few information, only the circular shift operation is performed on them. However, for the four higher bitplanes that contain abundant information, exclusive disjunction of the binary elements of the four higher bitplanes with the binary elements of the four lower bitplanes and bit-level keystream is necessary in addition to the cyclic shift operation. Thus, BSPDPAD synchronously permutes and diffuses the four higher bitplanes with the binary keystream sequences and permutes the four lower bitplanes to achieve intra-block and inter-block diffusion. At the pixel-level encryption stage, BSPDPAD iterates the PWLCM again to generate a new keystream. We use the new keystream to perform horizontal sequential diffusion and vertical inversion diffusion of the intermediate encryption image, which completely underwent the bit-level encryption operation, thereby avoiding the problem of stop point mechanism and nonuniform plaintext sensitivity. In addition, the initial value of the PWLCM is modified according to the plain image information at the bit-level and pixel-level encryption stages to enhance the adaptation and the plaintext sensitivity of BSPDPAD.ResultSimulation experiments on several gray-scale images and color images show that the key space of BSPDPAD is more than 2100, indicating that the BSPDPAD algorithm can effectively resist the exhaustive attack. The histogram of the cipher image tends to be evenly distributed, which can cover the distribution of image pixels well and ensure that the algorithm is effective against statistical attack and known cipher attack. The absolute value of the adjacent pixel correlation coefficient of the cipher image encrypted by the BSPDPAD is lower than that of the plaintext image and that of similar encryption algorithms. The entropy of the BSPDPAD ciphering image is close to the theoretical value of 8. Therefore, BSPDPAD has a strong capability to resist entropy attack. The key sensitivity analysis shows that BSPDPAD has satisfactory key sensitivity in the encryption and decryption phases. BSPDPAD also has high NPCR and UACI values, thereby indicating that BSPDPAD has strong plaintext sensitivity and high capability to resist differential attack. Moreover, color image encryption experiments show that BSPDPAD is also suitable for color image encryption, and its encryption performance is excellent. In summary, BSPDPAD is superior to other state-of-the-art encryption algorithms in terms of correlation, information entropy, key space, sensitivity, and capacity to resist multiple attacks. In addition, BSPDPAD has a better diffusion effect, which can obtain excellent encryption performance with only one round of encryption.ConclusionBy integrating bit-level selective encryption and pixel-level annular diffusion, BSPDPAD can effectively resist various attacks and exhibit high security. Therefore, BSPDPAD is suitable for all kinds of grayscale and color images and has a large potential application value in the image encryption field.关键词:bit-level;synchronous permutation-diffusion;annular diffusion;blocking;image encryption61|299|6更新时间:2024-05-07
摘要:ObjectiveWith the rapid development and popularity of the Internet and information technologies, computers and mobile phones have become an important part of the daily lives of people. Through these electronic devices, a large number of pictures that may contain private information are transmitted and stored. Image information security is becoming increasingly important. However, the use of traditional encryption algorithms (e.g., data encryption standard, advanced encryption standard, and international data encryption algorithm) to encrypt images will result in low efficiency and poor security because of the data size and high redundancy among the pixels of digital images. An effective approach to deal with this issue is to develop secure and effective digital image encryption algorithms. The existing image algorithms can be categorized into pixel-permutation-based, chaotic-system-based, and bitplane-based methods. The image encryption algorithms of the pixel-permutation-based method change the pixel position to destroy adjacent pixel dependencies by performing the permutation operation on the pixel matrix, thereby generating noise-like and meaningless cipher images. However, only the encryption algorithms that use pixel permutation have weak resistance to statistical attacks and poor security. The image encryption algorithms of the chaotic-system-based method take advantage of the excellent intrinsic properties of a chaotic sequence, such as ergodicity, pseudorandomness, and sensitivity to initial conditional and control parameters, to enable diffusion and confusion encryption. These methods have a large key space, strong keystream adaptivity, and high security and often combine with other encryption methods to achieve effective image encryption. The image encryption algorithms of the bitplane-based method decompose the pixels into bit levels, implementing the permutation and diffusion operations on the bitplanes. Bitplane matrix transformation, selective encryption based on bitplane information distribution, and integrating bit-level encryption with pixel-level encryption are the typical bitplane encryption algorithms. The bitplane encryption operation can enhance the sensitivity of the algorithm to small changes in the original image, thus improving the capability to resist differential attack. Moreover, the bitplane permutation operation can change the position and value of a pixel simultaneously, thereby reducing the computational complexity of the image encryption algorithm. Most bitplane encryption algorithms have desirable encryption performance with only one round. Therefore, a novel image encryption algorithm with the bit-level synchronous permutation diffusion and pixel-level annular diffusion (called BSPDPAD) was proposed in this study to improve image encryption efficiency and security to solve the security problem of the selective encryption algorithms with the bitplane information distribution, the statistical attack problem of pixel permutation encryption algorithms, and the problem of sequential diffusion producing stop point mechanism and nonuniform plaintext sensitivity effectively.MethodBSPDPAD uses the chaotic sequence generated by the piecewise linear chaotic map (PWLCM) to construct bit-level and pixel-level keystreams and simultaneously encrypts the image at the bit and pixel levels. At the bit-level encryption stage, BSPDPAD first generates two sets of chaotic sequences by iteratively executing the PWLCM. One set is used to block an image randomly, and the other set is decomposed into bitplanes to obtain the binary keystream sequences. For the four lower bitplanes that contain few information, only the circular shift operation is performed on them. However, for the four higher bitplanes that contain abundant information, exclusive disjunction of the binary elements of the four higher bitplanes with the binary elements of the four lower bitplanes and bit-level keystream is necessary in addition to the cyclic shift operation. Thus, BSPDPAD synchronously permutes and diffuses the four higher bitplanes with the binary keystream sequences and permutes the four lower bitplanes to achieve intra-block and inter-block diffusion. At the pixel-level encryption stage, BSPDPAD iterates the PWLCM again to generate a new keystream. We use the new keystream to perform horizontal sequential diffusion and vertical inversion diffusion of the intermediate encryption image, which completely underwent the bit-level encryption operation, thereby avoiding the problem of stop point mechanism and nonuniform plaintext sensitivity. In addition, the initial value of the PWLCM is modified according to the plain image information at the bit-level and pixel-level encryption stages to enhance the adaptation and the plaintext sensitivity of BSPDPAD.ResultSimulation experiments on several gray-scale images and color images show that the key space of BSPDPAD is more than 2100, indicating that the BSPDPAD algorithm can effectively resist the exhaustive attack. The histogram of the cipher image tends to be evenly distributed, which can cover the distribution of image pixels well and ensure that the algorithm is effective against statistical attack and known cipher attack. The absolute value of the adjacent pixel correlation coefficient of the cipher image encrypted by the BSPDPAD is lower than that of the plaintext image and that of similar encryption algorithms. The entropy of the BSPDPAD ciphering image is close to the theoretical value of 8. Therefore, BSPDPAD has a strong capability to resist entropy attack. The key sensitivity analysis shows that BSPDPAD has satisfactory key sensitivity in the encryption and decryption phases. BSPDPAD also has high NPCR and UACI values, thereby indicating that BSPDPAD has strong plaintext sensitivity and high capability to resist differential attack. Moreover, color image encryption experiments show that BSPDPAD is also suitable for color image encryption, and its encryption performance is excellent. In summary, BSPDPAD is superior to other state-of-the-art encryption algorithms in terms of correlation, information entropy, key space, sensitivity, and capacity to resist multiple attacks. In addition, BSPDPAD has a better diffusion effect, which can obtain excellent encryption performance with only one round of encryption.ConclusionBy integrating bit-level selective encryption and pixel-level annular diffusion, BSPDPAD can effectively resist various attacks and exhibit high security. Therefore, BSPDPAD is suitable for all kinds of grayscale and color images and has a large potential application value in the image encryption field.关键词:bit-level;synchronous permutation-diffusion;annular diffusion;blocking;image encryption61|299|6更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectivePerson re-identification is an extremely challenging problem and has practical application value. It plays an important role in video surveillance systems because it can reduce human efforts in searching for a target from a large number of videos. This topic has gained increasing interest in computer vision. Nowadays, person re-identification algorithms have been applied in criminal investigation, where the interference of passers-by can be eliminated to help the police find final suspects. However, differences in color, illumination, posture, imaging quality, as well as low-resolution of the captured frames cause large appearance variance across multiple cameras; thus, person re-identification remains a significant problem. An algorithm for person re-identification, which is based on multi-feature fusion and alternating direction method of multipliers, is proposed to improve the accuracy of person re-identification.MethodFirst, the original images are processed by the image enhancement algorithm to reduce the impact of illumination changes. This enhancement algorithm is committed to provide an image that is close to human visual characteristics. Then, the method of non-uniform segmentation that processes images is used. The method uses a sub-window size of 10-by-10 pixels with 5-pixel overlapping steps to obtain the local information of the pedestrian image. Meanwhile, the method uses the specific region mean method to divide the pedestrian image into five blocks. Specifically, depending on the difference of the expression ability of the legs and torso, these parts are divided into three blocks and two blocks, respectively. Then, the second and third blocks take the maximum operation, whereas the other blocks perform the mean operation because the second and third blocks are less affected by ambient noise compared with the other blocks. We also extract the HSV and LAB color features of the processed images, a texture feature of scale-invariant local ternary pattern and a shape feature of histogram of oriented gradient. The existing pedestrian re-identification algorithms generally consider the matching between local regions to eliminate the gap information between blocks. The combination of the global and local methods can effectively solve this problem. The proposed algorithm uses the multi-feature fusion method to combine the global and local information, which combines the global and local similarity measurement function of the related person, to obtain the final similarity function. Finally, the optimal distance measurement matrix is updated by the alternating direction method of multipliers, and the final similarities between each pair are obtained to conduct the re-identification.ResultThe proposed method is demonstrated on four public benchmark datasets including VIPeR, CUHK01, CUHK03, and GRID. Each dataset has its own characteristics. The proposed method achieves a 51.5% rank 1 (represents the accurately matched pair) on VIPeR benchmark and 48.7% and 21.4% on CUHK01 and GRID benchmarks, respectively. Rank 5 (represents the expectation of the matches at rank 5) is more than 80% on the VIPeR datasets and more than 70% on the CUHK01 datasets. The proposed method achieved 62.40% and 55.05% rank 1 identification rates with the labeled bounding boxes and automatically detected bounding boxes, respectively, thereby indicating that the method outperforms that of local maximal occurrence with an improvement of 10.2% for the labeled setting and 8.8% for the detected setting. The proposed method significantly improves the recognition rate and has a practical application value.ConclusionThe experimental results show that the proposed method can express the image information of pedestrians effectively. Furthermore, the effectiveness of our algorithm stems from the non-uniform segmentation and the specific mean method, which reduces the influence of ambient noise, increases robustness to occlusion, and is more flexible in handling pose variation. The updated distance measure matrix can express the information of the distance between pedestrians and improve the recognition rate effectively. This method is applicable to person re-identification in most scenarios, especially for static image-based person re-identification in complex scenes. This method can maintain high recognition accuracy even in the presence of local occlusion, illumination difference, and pose or viewpoint difference.关键词:person re-identification;multi-feature fusion;non-uniform segmentation;HOG feature;specific region mean method;alternating direction method of multipliers11|4|6更新时间:2024-05-07
摘要:ObjectivePerson re-identification is an extremely challenging problem and has practical application value. It plays an important role in video surveillance systems because it can reduce human efforts in searching for a target from a large number of videos. This topic has gained increasing interest in computer vision. Nowadays, person re-identification algorithms have been applied in criminal investigation, where the interference of passers-by can be eliminated to help the police find final suspects. However, differences in color, illumination, posture, imaging quality, as well as low-resolution of the captured frames cause large appearance variance across multiple cameras; thus, person re-identification remains a significant problem. An algorithm for person re-identification, which is based on multi-feature fusion and alternating direction method of multipliers, is proposed to improve the accuracy of person re-identification.MethodFirst, the original images are processed by the image enhancement algorithm to reduce the impact of illumination changes. This enhancement algorithm is committed to provide an image that is close to human visual characteristics. Then, the method of non-uniform segmentation that processes images is used. The method uses a sub-window size of 10-by-10 pixels with 5-pixel overlapping steps to obtain the local information of the pedestrian image. Meanwhile, the method uses the specific region mean method to divide the pedestrian image into five blocks. Specifically, depending on the difference of the expression ability of the legs and torso, these parts are divided into three blocks and two blocks, respectively. Then, the second and third blocks take the maximum operation, whereas the other blocks perform the mean operation because the second and third blocks are less affected by ambient noise compared with the other blocks. We also extract the HSV and LAB color features of the processed images, a texture feature of scale-invariant local ternary pattern and a shape feature of histogram of oriented gradient. The existing pedestrian re-identification algorithms generally consider the matching between local regions to eliminate the gap information between blocks. The combination of the global and local methods can effectively solve this problem. The proposed algorithm uses the multi-feature fusion method to combine the global and local information, which combines the global and local similarity measurement function of the related person, to obtain the final similarity function. Finally, the optimal distance measurement matrix is updated by the alternating direction method of multipliers, and the final similarities between each pair are obtained to conduct the re-identification.ResultThe proposed method is demonstrated on four public benchmark datasets including VIPeR, CUHK01, CUHK03, and GRID. Each dataset has its own characteristics. The proposed method achieves a 51.5% rank 1 (represents the accurately matched pair) on VIPeR benchmark and 48.7% and 21.4% on CUHK01 and GRID benchmarks, respectively. Rank 5 (represents the expectation of the matches at rank 5) is more than 80% on the VIPeR datasets and more than 70% on the CUHK01 datasets. The proposed method achieved 62.40% and 55.05% rank 1 identification rates with the labeled bounding boxes and automatically detected bounding boxes, respectively, thereby indicating that the method outperforms that of local maximal occurrence with an improvement of 10.2% for the labeled setting and 8.8% for the detected setting. The proposed method significantly improves the recognition rate and has a practical application value.ConclusionThe experimental results show that the proposed method can express the image information of pedestrians effectively. Furthermore, the effectiveness of our algorithm stems from the non-uniform segmentation and the specific mean method, which reduces the influence of ambient noise, increases robustness to occlusion, and is more flexible in handling pose variation. The updated distance measure matrix can express the information of the distance between pedestrians and improve the recognition rate effectively. This method is applicable to person re-identification in most scenarios, especially for static image-based person re-identification in complex scenes. This method can maintain high recognition accuracy even in the presence of local occlusion, illumination difference, and pose or viewpoint difference.关键词:person re-identification;multi-feature fusion;non-uniform segmentation;HOG feature;specific region mean method;alternating direction method of multipliers11|4|6更新时间:2024-05-07 -
 摘要:ObjectiveOver the past few decades, studies on visual object recognition have mostly focused on the category level, such as ImageNet Large-scale Visual Recognition Challenge and PASCAL VOC challenge. With the powerful feature extraction of convolutional neural networks (CNNs), many studies have begun to focus on challenging visual tasks aimed at the subtle classification of subcategories, which is called fine-grained visual pattern recognition. Fine-grained car model recognition is designed to recognize the exact make, model, and year of a car from an arbitrary viewpoint, which is essential in intelligent transportation, public security, and other fields. Research on this field mainly includes three aspects: finding and extracting features of discriminative parts, using the alignment algorithm or 3D object representations to eliminate the effects of posture and angle, and looking for powerful feature extractors such as CNN features. The three methods presented have various degrees of defect, the bottleneck of most part-based models is accurate part localization, and methods generally report adequate part localization only when a known bounding box at test time is given. 3D object representations and many other alignment algorithms need complex preprocessing or post-processing of training samples, such as co-segmentation and 3D geometry estimation. Currently, methods based on CNNs significantly outperform those of previous works, which rely on handcrafted features for fine-grained classification, but the location of objects is essential even at test time due to the subtle difference between categories. These methods are difficult to apply in real intelligent transportation because a video frame in a real traffic monitoring scenario typically shows multiple cars in which each car object and parts cannot be assigned with a bounding box. To solve these problems, the present study proposes a fine-grained car recognition method based on deep fully CNNs called region proposal network (RPN), which automatically proposes regions of discriminative parts and car objects. Our method can be trained in an end-to-end manner and without requiring a bounding box at test time.MethodRPN is a type of fully CNN that simultaneously predicts object bounding box and scores at each position, which has made remarkable achievements in the field of object detection. We improve RPN with an outstanding deep CNN called deep residual network (ResNet). First, the deep convolution feature of the image is extracted by the ResNet pipeline. Then, we slide a small network over the convolutional feature map and each sliding window is mapped to a low-dimensional vector. The vector is fed into a box-regression layer and box-classification layer; the former outputs the probability of a region, which includes an object, whereas the latter outputs the coordinates of the region by bounding-box regression. Finally, these object regional candidates obtain the specific category and corrected object position through the object detection network and the final recognition result through the non-maximal suppression algorithm. To quickly optimize the model parameters, we use the ImageNet pre-training model to initialize the RPN and object detection network and then share convolutional features between them through joint optimization.ResultFirst, we verify the performance of the proposed method on several public fine-grained car datasets. Stanford BMW-10 dataset has 512 pictures, including 10 BMW serials. However, most CNNs suffered from over-fitting and thus obtained poor results due to the limit of training samples. The Stanford Cars-196 dataset is currently the most widely used dataset for fine-grained car recognition, with 16185 images of 196 fine-grained car models covering SUVs, coupes, convertibles, pickup trucks, and trucks, to name a few. Second, apart from using the public dataset, we conduct the recognition experiment under a real traffic monitoring video. Finally, we carefully analyze the misrecognized samples of our models to explore the improved room of fine-grained methods. Recognition accuracy could be significantly improved by training data augmentation, and all our experiments only use image horizontal flip as data augmentation to compare with other methods with the same standard. The recognition accuracy of this method is 76.38% in the Stanford BMW-10 dataset and 91.48% in the Stanford Cars-196 dataset. The method also achieves excellent recognition effect in a traffic monitoring video. In particular, our method is trained in an end-to-end manner and requires no knowledge of object or part bounding box at test time. The RPN provides not only an object detection network with the specific location of the car object but also the distinguishable region, which contributes to the classification. The misrecognized samples are mostly at the same makes, which have tiny visual difference. Methods based on handcrafted global feature templates, such as HOG, achieve 28.3% recognition accuracy on the Stanford BMW-10 dataset. The most valuable 3D object representations, which trains from 59040 synthetic images, achieves 76.0% less accuracy than that of our methods. The state-of-the-art method of the Stanford Car-196 dataset without bounding-box annotation is recurrent attention CNN, which is published on CVPR2017 and achieved 92.5% recognition accuracy by combining features at three scales via a fully connected layer. Experiments show that our method not only outperforms significantly traditional methods based on handcrafted feature but is also comparable with the current state-of-the-art methods.ConclusionWe introduce a new deep learning method, which is used in fine-grained car recognition, that overcomes the dependence of the traditional object recognition on the object location and can realize the recognition of cars under complex scenes, such as multiple vehicles and dense vehicles with high accuracy. The findings of this study can provide new ideas for fine-grained object recognition. Compared with traditional methods, the proposed model is better in terms of robustness and practicability.关键词:deep learning;convolutional neural networks;car recognition;fine-grained recognition;image classification16|4|3更新时间:2024-05-07
摘要:ObjectiveOver the past few decades, studies on visual object recognition have mostly focused on the category level, such as ImageNet Large-scale Visual Recognition Challenge and PASCAL VOC challenge. With the powerful feature extraction of convolutional neural networks (CNNs), many studies have begun to focus on challenging visual tasks aimed at the subtle classification of subcategories, which is called fine-grained visual pattern recognition. Fine-grained car model recognition is designed to recognize the exact make, model, and year of a car from an arbitrary viewpoint, which is essential in intelligent transportation, public security, and other fields. Research on this field mainly includes three aspects: finding and extracting features of discriminative parts, using the alignment algorithm or 3D object representations to eliminate the effects of posture and angle, and looking for powerful feature extractors such as CNN features. The three methods presented have various degrees of defect, the bottleneck of most part-based models is accurate part localization, and methods generally report adequate part localization only when a known bounding box at test time is given. 3D object representations and many other alignment algorithms need complex preprocessing or post-processing of training samples, such as co-segmentation and 3D geometry estimation. Currently, methods based on CNNs significantly outperform those of previous works, which rely on handcrafted features for fine-grained classification, but the location of objects is essential even at test time due to the subtle difference between categories. These methods are difficult to apply in real intelligent transportation because a video frame in a real traffic monitoring scenario typically shows multiple cars in which each car object and parts cannot be assigned with a bounding box. To solve these problems, the present study proposes a fine-grained car recognition method based on deep fully CNNs called region proposal network (RPN), which automatically proposes regions of discriminative parts and car objects. Our method can be trained in an end-to-end manner and without requiring a bounding box at test time.MethodRPN is a type of fully CNN that simultaneously predicts object bounding box and scores at each position, which has made remarkable achievements in the field of object detection. We improve RPN with an outstanding deep CNN called deep residual network (ResNet). First, the deep convolution feature of the image is extracted by the ResNet pipeline. Then, we slide a small network over the convolutional feature map and each sliding window is mapped to a low-dimensional vector. The vector is fed into a box-regression layer and box-classification layer; the former outputs the probability of a region, which includes an object, whereas the latter outputs the coordinates of the region by bounding-box regression. Finally, these object regional candidates obtain the specific category and corrected object position through the object detection network and the final recognition result through the non-maximal suppression algorithm. To quickly optimize the model parameters, we use the ImageNet pre-training model to initialize the RPN and object detection network and then share convolutional features between them through joint optimization.ResultFirst, we verify the performance of the proposed method on several public fine-grained car datasets. Stanford BMW-10 dataset has 512 pictures, including 10 BMW serials. However, most CNNs suffered from over-fitting and thus obtained poor results due to the limit of training samples. The Stanford Cars-196 dataset is currently the most widely used dataset for fine-grained car recognition, with 16185 images of 196 fine-grained car models covering SUVs, coupes, convertibles, pickup trucks, and trucks, to name a few. Second, apart from using the public dataset, we conduct the recognition experiment under a real traffic monitoring video. Finally, we carefully analyze the misrecognized samples of our models to explore the improved room of fine-grained methods. Recognition accuracy could be significantly improved by training data augmentation, and all our experiments only use image horizontal flip as data augmentation to compare with other methods with the same standard. The recognition accuracy of this method is 76.38% in the Stanford BMW-10 dataset and 91.48% in the Stanford Cars-196 dataset. The method also achieves excellent recognition effect in a traffic monitoring video. In particular, our method is trained in an end-to-end manner and requires no knowledge of object or part bounding box at test time. The RPN provides not only an object detection network with the specific location of the car object but also the distinguishable region, which contributes to the classification. The misrecognized samples are mostly at the same makes, which have tiny visual difference. Methods based on handcrafted global feature templates, such as HOG, achieve 28.3% recognition accuracy on the Stanford BMW-10 dataset. The most valuable 3D object representations, which trains from 59040 synthetic images, achieves 76.0% less accuracy than that of our methods. The state-of-the-art method of the Stanford Car-196 dataset without bounding-box annotation is recurrent attention CNN, which is published on CVPR2017 and achieved 92.5% recognition accuracy by combining features at three scales via a fully connected layer. Experiments show that our method not only outperforms significantly traditional methods based on handcrafted feature but is also comparable with the current state-of-the-art methods.ConclusionWe introduce a new deep learning method, which is used in fine-grained car recognition, that overcomes the dependence of the traditional object recognition on the object location and can realize the recognition of cars under complex scenes, such as multiple vehicles and dense vehicles with high accuracy. The findings of this study can provide new ideas for fine-grained object recognition. Compared with traditional methods, the proposed model is better in terms of robustness and practicability.关键词:deep learning;convolutional neural networks;car recognition;fine-grained recognition;image classification16|4|3更新时间:2024-05-07 -
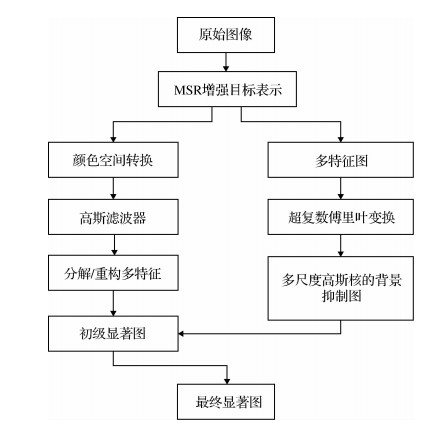 摘要:ObjectiveSaliency object detection with development of human visual attention mechanism has been widely studied by computer vision researchers. Visual significance is an important mechanism of human visual system. It simulates the human visual attention mechanism, extracts the most interesting areas of the scene quickly and accurately, and ignores redundant information. Saliency object detection has been widely used in image compression, segmentation, redirection, video coding, target detection, recognition, and many other tasks. Although numerous significant target detection methods are available, problems remain. For example, the detection results look well when the background is simple, but when the background is complex, the results may have some uncertainty as regards the environment, cluttered background in the area around the target, or influence of selection on the significant target detection method. The problem of cluttered background and inaccurate detection area often occurs when the salient object detection method generates significant graphs. To solve these problems, saliency object detection method is proposed based on complex domain. The complex domain combines frequency, spatial, and wavelet domains; takes advantage of the complex domain to combine the advantages on three domains; and suppresses the background to obtain an accurate and clear salient target area.MethodEnvironmental conditions are one of the key factors that influence saliency object detection; for example, weak light or foggy days can cause unclear images and lead to poor results of significant target detection. Multi-scale retinex is an image enhancement algorithm based on color theory. By introducing multi-scale retinex algorithm, the image restoration is realized by linear weighting in the process of dynamically scaling a picture. First, multi-scale retinex enhancement algorithm is used to preliminarily process the original image in spatial domain and exclude environmental impacts. After image processing, the brightness becomes more appropriate to the real scene brightness, and the foreground and background contrast is also significantly improved. In addition to the environmental impact, the background areas of the non-significant target often occupy most of the image space in the saliency object detection images. These background areas increase the error detection problem and reduce the accuracy rate. Experiments found that most background areas are the sky, trees, grasslands, and buildings, which are beyond the scope of this study. The characteristics of the background areas with repeatability can be suppressed by hyper-complex Fourier transform. Then, undirected graph is established and node features on the images are extracted preliminarily. The hyper-complex Fourier transform in the frequency domain is reconstructed to acquire the smoothing amplitude spectrum, phase spectrum, and Euler spectrum. Then, background suppression graphs are obtained through the smoothness of multi-scale Gaussian kernel. At the same time, the multi-level feature of wavelet transform in the wavelet domain is utilized to extract multiple features in terms of images, and the saliency graph of multiple features is calculated. The saliency graph effectively preserves the details of the image because of the unique localization characteristics of the wavelet domain. Finally, the proposed adaptive threshold selection method is used to fuse the background suppression diagram with the saliency graph of multiple features and the final saliency graph is selected and obtained. The final saliency figure suppresses the background while preserving the details of the image.ResultTo make the experimental effect persuasive, saliency object detection experiments in the standard test dataset images MSRA10K and THUR15k are conducted. MSRA10K datasets consist of 10 000 images of hand-annotated and accurate to pixel-level salient target annotations, including images of natural scenery, biology, architecture, and transportation. THUR15K datasets consist of 15 000 web images with five keywords, namely, butterflies, airplanes, giraffes, cups, and dogs, representing significant targets with pixel precision as the former datasets. The two datasets are public standard image databases and are widely used in salient target detection and image segmentation. A total of 300 background-complex pictures are selected from each dataset, under the same experimental conditions, and compared with six popular significant target detection methods. Results show that the problems presented by our method had a good solution. Even in a complex environment, the accuracy and recall rate of the algorithm are higher than those of state-of-the-art contrast algorithms. In MSRA10k datasets, the mean absolute error (MAE) value is 0.106; in THUR15K datasets, the mean absolute error value was reduced to 0.068, and the average structure (s) measure value was 0.844 9. The result of the MAE evaluation reflects the advantage of a saliency object detection method based on complex domain in terms of overall performance, and the s-measure indicates that the detected target is highly similar to the structure of the target of the ground truth graph.ConclusionSaliency object detection is a promising preprocessing operation in image processing and analysis. In this study, a new saliency object detection method based on complex domain is proposed. Multi-scale retinex algorithm in spatial domain can be used for pretreatment of images; it enhances contrast and prevents images from being affected by environmental factors. Hyper-complex Fourier transform in the frequency domain can suppress complex repetitive background regions, and the significant target detection method in the wavelet domain can completely describe the details of the target. Moreover, the proposed algorithm integrates the advantages of multiple domains and improves the accuracy while suppressing background clutter. Thus, the proposed algorithm is suitable for detecting significant target images, such as natural scenery, biology, architecture, and transportation. To improve the algorithm speed, our next research project aims to reduce the complexity of the algorithm by using the influence of wavelet transform function on time complexity.关键词:salient objects detection;multi-scale Retinex enhancement algorithm;hyper complex Fourier transformation;wavelet transform;adaptive threshold selection method21|13|1更新时间:2024-05-07
摘要:ObjectiveSaliency object detection with development of human visual attention mechanism has been widely studied by computer vision researchers. Visual significance is an important mechanism of human visual system. It simulates the human visual attention mechanism, extracts the most interesting areas of the scene quickly and accurately, and ignores redundant information. Saliency object detection has been widely used in image compression, segmentation, redirection, video coding, target detection, recognition, and many other tasks. Although numerous significant target detection methods are available, problems remain. For example, the detection results look well when the background is simple, but when the background is complex, the results may have some uncertainty as regards the environment, cluttered background in the area around the target, or influence of selection on the significant target detection method. The problem of cluttered background and inaccurate detection area often occurs when the salient object detection method generates significant graphs. To solve these problems, saliency object detection method is proposed based on complex domain. The complex domain combines frequency, spatial, and wavelet domains; takes advantage of the complex domain to combine the advantages on three domains; and suppresses the background to obtain an accurate and clear salient target area.MethodEnvironmental conditions are one of the key factors that influence saliency object detection; for example, weak light or foggy days can cause unclear images and lead to poor results of significant target detection. Multi-scale retinex is an image enhancement algorithm based on color theory. By introducing multi-scale retinex algorithm, the image restoration is realized by linear weighting in the process of dynamically scaling a picture. First, multi-scale retinex enhancement algorithm is used to preliminarily process the original image in spatial domain and exclude environmental impacts. After image processing, the brightness becomes more appropriate to the real scene brightness, and the foreground and background contrast is also significantly improved. In addition to the environmental impact, the background areas of the non-significant target often occupy most of the image space in the saliency object detection images. These background areas increase the error detection problem and reduce the accuracy rate. Experiments found that most background areas are the sky, trees, grasslands, and buildings, which are beyond the scope of this study. The characteristics of the background areas with repeatability can be suppressed by hyper-complex Fourier transform. Then, undirected graph is established and node features on the images are extracted preliminarily. The hyper-complex Fourier transform in the frequency domain is reconstructed to acquire the smoothing amplitude spectrum, phase spectrum, and Euler spectrum. Then, background suppression graphs are obtained through the smoothness of multi-scale Gaussian kernel. At the same time, the multi-level feature of wavelet transform in the wavelet domain is utilized to extract multiple features in terms of images, and the saliency graph of multiple features is calculated. The saliency graph effectively preserves the details of the image because of the unique localization characteristics of the wavelet domain. Finally, the proposed adaptive threshold selection method is used to fuse the background suppression diagram with the saliency graph of multiple features and the final saliency graph is selected and obtained. The final saliency figure suppresses the background while preserving the details of the image.ResultTo make the experimental effect persuasive, saliency object detection experiments in the standard test dataset images MSRA10K and THUR15k are conducted. MSRA10K datasets consist of 10 000 images of hand-annotated and accurate to pixel-level salient target annotations, including images of natural scenery, biology, architecture, and transportation. THUR15K datasets consist of 15 000 web images with five keywords, namely, butterflies, airplanes, giraffes, cups, and dogs, representing significant targets with pixel precision as the former datasets. The two datasets are public standard image databases and are widely used in salient target detection and image segmentation. A total of 300 background-complex pictures are selected from each dataset, under the same experimental conditions, and compared with six popular significant target detection methods. Results show that the problems presented by our method had a good solution. Even in a complex environment, the accuracy and recall rate of the algorithm are higher than those of state-of-the-art contrast algorithms. In MSRA10k datasets, the mean absolute error (MAE) value is 0.106; in THUR15K datasets, the mean absolute error value was reduced to 0.068, and the average structure (s) measure value was 0.844 9. The result of the MAE evaluation reflects the advantage of a saliency object detection method based on complex domain in terms of overall performance, and the s-measure indicates that the detected target is highly similar to the structure of the target of the ground truth graph.ConclusionSaliency object detection is a promising preprocessing operation in image processing and analysis. In this study, a new saliency object detection method based on complex domain is proposed. Multi-scale retinex algorithm in spatial domain can be used for pretreatment of images; it enhances contrast and prevents images from being affected by environmental factors. Hyper-complex Fourier transform in the frequency domain can suppress complex repetitive background regions, and the significant target detection method in the wavelet domain can completely describe the details of the target. Moreover, the proposed algorithm integrates the advantages of multiple domains and improves the accuracy while suppressing background clutter. Thus, the proposed algorithm is suitable for detecting significant target images, such as natural scenery, biology, architecture, and transportation. To improve the algorithm speed, our next research project aims to reduce the complexity of the algorithm by using the influence of wavelet transform function on time complexity.关键词:salient objects detection;multi-scale Retinex enhancement algorithm;hyper complex Fourier transformation;wavelet transform;adaptive threshold selection method21|13|1更新时间:2024-05-07 -
 摘要:ObjectiveThe method of saliency detection via absorbing Markov chain uses simple linear iterative cluster (SLIC) method to obtain superpixels as graph nodes. Then, a k-regular graph is constructed, and the edge weight is calculated by the difference of two nodes on CIELAB value. The superpixels are duplicated on boundary as absorbing nodes. Then, the absorbed time of transient nodes on the Markov chain is calculated. If the absorbed time is small, then the transient node is similar to the absorbing node, which is possibly a background node. On the contrary, the transient node is dissimilar to the absorbing node when the absorbed time is large. Then, the node is a salient node. Actually, the number of superpixels obtained by using the SLIC method influences the results of the saliency maps. If the size of the superpixel is extremely large, then the detailed information is ignored. On the contrary, if the size of the superpixel is extremely small, then the global cue is missed. The saliency objects usually occupy one or two boundaries of images, especially for portraits and sculptures. The final saliency results are influenced when four boundary nodes are duplicated as absorbing nodes. Considering these drawbacks, we propose an improved method based on background nodes as absorbing nodes on absorbing Markov chain. Multilayer image fusion is used to restrain the influence of the uncertain number of superpixels through the SLIC method.MethodFirst, we confirm the edge selection. We separately obtain the four boundaries of the image nodes by SLIC method, duplicate them as absorbing nodes, and obtain four types of saliency maps. Then, we calculate the difference values of two saliency maps. The largest value of one saliency map is computed and compared with those of the other three maps. Then, we remove the most different edge and continue to use the remaining three boundary nodes to be duplicated as absorbing nodes. Then, the initial saliency map can be obtained by calculating the absorbed time of the transient nodes to absorbing nodes at the absorbing Markov chain. Second, to further optimize the algorithm, the number of absorbing nodes should be increased. In addition, the background may be a part of the boundary nodes. We add other nodes that are probably background nodes, which are selected from the initial saliency map by a threshold. If the initial saliency value of the node is lower than the threshold, then the node is considered a background node. The selected boundary and background nodes are duplicated as absorbing nodes, by which the absorbed time of the transient nodes are calculated. The pixel saliency value can be obtained from the saliency value of the superpixels. Finally, we fuse the multiple pixel saliency maps and calculate the average values as the final results. The multiple saliency values are obtained via different numbers of superpixels by using the SLIC method.ResultWe evaluate the effectiveness of our method on the following three benchmark datasets: ASD, DUT-OMRON, and SED. We compare our method with 12 recent state-of-art saliency detection methods, namely, MC, CA, FT, SEG, BM, SWD, SF, GCHC, LMLC, PCA, MS, and MST. ASD contains 1 000 simple images. DUT-OMRONS contains 5 168 complex images. SED includes 200 images, in which 100 images have one salient object, and the other 100 images have two salient objects. The experimental results show that the improved algorithm is efficient and better than the 12 state-of-the-art methods in precision recall curves (PR-curve) and F-measure. The precision is calculated as the ratio of actual saliency results assigned to all predicted saliency pixels. Recall is defined as the ratio of the total saliency captured pixels to the ground-truth number. F-measure is an overall performance measurement. Some visual comparative examples selected from three datasets are shown intuitively. The F-measure values of the three benchmark databases are 0.775 6, 0.903, and 0.544 7. These values are higher than that of the other 12 methods.ConclusionThe image can be segmented into complex background, and the partition of human eyes is interesting. The visual image saliency detection extracts the portion of interest through the computer simulation as a human visual system. We propose an improved model, which is based on the background nodes and image fusion, to obtain the final results given the drawbacks of using four image boundaries to be duplicated as absorbing nodes and the uncertain number of superpixels through the SLIC method. The experiments show that the method is efficient and can be applicable to the bottom-up image saliency detection, especially for images such as portraits or sculptures. It can also be applied to many fields, such as image retrieval, object recognition, image segmentation, and image compression.关键词:object detection;SLIC method;saliency detection;Markov chain;absorbing node12|4|0更新时间:2024-05-07
摘要:ObjectiveThe method of saliency detection via absorbing Markov chain uses simple linear iterative cluster (SLIC) method to obtain superpixels as graph nodes. Then, a k-regular graph is constructed, and the edge weight is calculated by the difference of two nodes on CIELAB value. The superpixels are duplicated on boundary as absorbing nodes. Then, the absorbed time of transient nodes on the Markov chain is calculated. If the absorbed time is small, then the transient node is similar to the absorbing node, which is possibly a background node. On the contrary, the transient node is dissimilar to the absorbing node when the absorbed time is large. Then, the node is a salient node. Actually, the number of superpixels obtained by using the SLIC method influences the results of the saliency maps. If the size of the superpixel is extremely large, then the detailed information is ignored. On the contrary, if the size of the superpixel is extremely small, then the global cue is missed. The saliency objects usually occupy one or two boundaries of images, especially for portraits and sculptures. The final saliency results are influenced when four boundary nodes are duplicated as absorbing nodes. Considering these drawbacks, we propose an improved method based on background nodes as absorbing nodes on absorbing Markov chain. Multilayer image fusion is used to restrain the influence of the uncertain number of superpixels through the SLIC method.MethodFirst, we confirm the edge selection. We separately obtain the four boundaries of the image nodes by SLIC method, duplicate them as absorbing nodes, and obtain four types of saliency maps. Then, we calculate the difference values of two saliency maps. The largest value of one saliency map is computed and compared with those of the other three maps. Then, we remove the most different edge and continue to use the remaining three boundary nodes to be duplicated as absorbing nodes. Then, the initial saliency map can be obtained by calculating the absorbed time of the transient nodes to absorbing nodes at the absorbing Markov chain. Second, to further optimize the algorithm, the number of absorbing nodes should be increased. In addition, the background may be a part of the boundary nodes. We add other nodes that are probably background nodes, which are selected from the initial saliency map by a threshold. If the initial saliency value of the node is lower than the threshold, then the node is considered a background node. The selected boundary and background nodes are duplicated as absorbing nodes, by which the absorbed time of the transient nodes are calculated. The pixel saliency value can be obtained from the saliency value of the superpixels. Finally, we fuse the multiple pixel saliency maps and calculate the average values as the final results. The multiple saliency values are obtained via different numbers of superpixels by using the SLIC method.ResultWe evaluate the effectiveness of our method on the following three benchmark datasets: ASD, DUT-OMRON, and SED. We compare our method with 12 recent state-of-art saliency detection methods, namely, MC, CA, FT, SEG, BM, SWD, SF, GCHC, LMLC, PCA, MS, and MST. ASD contains 1 000 simple images. DUT-OMRONS contains 5 168 complex images. SED includes 200 images, in which 100 images have one salient object, and the other 100 images have two salient objects. The experimental results show that the improved algorithm is efficient and better than the 12 state-of-the-art methods in precision recall curves (PR-curve) and F-measure. The precision is calculated as the ratio of actual saliency results assigned to all predicted saliency pixels. Recall is defined as the ratio of the total saliency captured pixels to the ground-truth number. F-measure is an overall performance measurement. Some visual comparative examples selected from three datasets are shown intuitively. The F-measure values of the three benchmark databases are 0.775 6, 0.903, and 0.544 7. These values are higher than that of the other 12 methods.ConclusionThe image can be segmented into complex background, and the partition of human eyes is interesting. The visual image saliency detection extracts the portion of interest through the computer simulation as a human visual system. We propose an improved model, which is based on the background nodes and image fusion, to obtain the final results given the drawbacks of using four image boundaries to be duplicated as absorbing nodes and the uncertain number of superpixels through the SLIC method. The experiments show that the method is efficient and can be applicable to the bottom-up image saliency detection, especially for images such as portraits or sculptures. It can also be applied to many fields, such as image retrieval, object recognition, image segmentation, and image compression.关键词:object detection;SLIC method;saliency detection;Markov chain;absorbing node12|4|0更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveThe extrinsic parameter of the RGB-D camera can be used to convert point cloud in camera coordinate to that in world coordinate. This parameter can be applied to 3D reconstruction, 3D measurement, robot gesture estimation, and target detection, among others. The RGB-D camera (e.g., Kinect, PrimeSense, and RealSense) consists of two sensors: RGB sensor and depth sensor. The former sensor retrieves the RGB image, whereas the latter retrieves depth image from the scene. To translate the 3D point cloud in the camera coordinate to the world coordinate, the extrinsic parameters of depth sensor have to be calibrated. The general calibration methods use calibration objects (such as chessboard) to obtain the extrinsic parameter of the RGB-D color sensor, which is regarded as the extrinsic parameter of the depth sensor approximately. These methods do not make full use of depth information, thereby causing difficulty in simplifying the calibration process. Moreover, lack of knowledge on the difference between the depth sensor and color sensor can cause large errors. Thus, to accurately estimate the extrinsic parameter of the depth sensor in the RGB-D camera, some methods have been proposed by using the extrinsic parameters of depth sensor relative to the color sensor. However, these methods complicate the calibration process. To simplify the calibration process of the extrinsic parameter of the depth sensor, the depth information should be fully utilized. Results of the methods are based on the color image with the parameter of the color sensor. However, the majority of applications on the RGB-D camera are based on the depth sensor. Moreover, parameters of the depth sensor should be directly calibrated.MethodWe build the spatial constraint relation between the ground plane and the camera, which can be used to select the ground plane from planes detected in the 3D point cloud. The ground plane should satisfy the following conditions: 1) The angle between the z axis of the camera and the ground plane is less than the specified threshold. 2) The z value of the ground plane in the world coordinate is larger than that of the other points, which are not in the ground plane. Moreover, we create the world coordinate based on the detected ground planes automatically. The origin point of the world coordinate is the projection of the origin point of the camera coordinate to the plane and the y axis of the world coordinate is the projection of the z axis of the camera coordinate to the plane. In addition, the direction of the z axis of the world coordinate is toward the origin point of the world coordinate from the origin point of the camera coordinate. We calibrate the extrinsic parameter of the RGB-D camera in the following steps. First, we reconstruct the 3D point cloud from the depth image retrieved from the depth sensor of the RGB-D camera. The reconstructed 3D point cloud is in the camera coordinate, whose subset forms a large number of planes. Second, planes in the 3D point cloud are detected by the MELSAC method. At most, one ground plane exists in the detected planes. Third, the spatial constraint rule between the ground plane and camera is built. The detected planes are filtered by the spatial constraint rule until the ground plane is found or all the planes are iterated. The process stops when a ground plane cannot be found. Finally, by using the relation between the ground plane and the camera, point sets are selected to calculate the extrinsic parameters.ResultIn the experiment, the benchmark is the result of checkerboard extrinsic calibration method only processing the RGB image of RGB-D information which is retrieved from the PrimeSense camera. We record an 89.4 s video and use it in the experiment. The videos contain two sub-videos: RGB video whose channel is 3 and depth video whose channel is 1. A 7x7 checkerboard is found in every frame of the RGB video, which is processed by the checkerboard-based method. The input of our proposed method is the frame of the depth video. The result shows that the average tilt angle error is -1.14°, the average pitch angle error is 4.57°, and the average camera height error is 3.96 cm. An experiment to test the robustness of the noise is also performed. The variance of the Gaussian noise in the depth frame is increased, and the result of each variance Gaussian noise is obtained. The stability of calibration decreases with the increase in the variance of Gaussian noise. The result shows that our method performs effectively when the variance of the Gaussian noise is below 0.01.ConclusionOur proposed method fully utilizes the depth information of the RGB-D camera, and simplifies the process of extrinsic calibration of the depth sensor. Thus, our method can be used in actual application. For convenience, the source code is also published. This method can automatically detect the ground plane and does not require other calibration objects. Therefore, the proposed method can calibrate each frame of the recorded video accurately, and it is not sensitive to the noise in the depth image. In addition, the algorithm has high parallelism. The process of estimating planes in the 3D point cloud and filtering these planes can be implemented in a parallel manner. The proposed method will have real-time performance based on this parallel implementation.关键词:RGB-D camera;automatic extrinsic calibration;3D point cloud;plane detection;depth map14|4|1更新时间:2024-05-07
摘要:ObjectiveThe extrinsic parameter of the RGB-D camera can be used to convert point cloud in camera coordinate to that in world coordinate. This parameter can be applied to 3D reconstruction, 3D measurement, robot gesture estimation, and target detection, among others. The RGB-D camera (e.g., Kinect, PrimeSense, and RealSense) consists of two sensors: RGB sensor and depth sensor. The former sensor retrieves the RGB image, whereas the latter retrieves depth image from the scene. To translate the 3D point cloud in the camera coordinate to the world coordinate, the extrinsic parameters of depth sensor have to be calibrated. The general calibration methods use calibration objects (such as chessboard) to obtain the extrinsic parameter of the RGB-D color sensor, which is regarded as the extrinsic parameter of the depth sensor approximately. These methods do not make full use of depth information, thereby causing difficulty in simplifying the calibration process. Moreover, lack of knowledge on the difference between the depth sensor and color sensor can cause large errors. Thus, to accurately estimate the extrinsic parameter of the depth sensor in the RGB-D camera, some methods have been proposed by using the extrinsic parameters of depth sensor relative to the color sensor. However, these methods complicate the calibration process. To simplify the calibration process of the extrinsic parameter of the depth sensor, the depth information should be fully utilized. Results of the methods are based on the color image with the parameter of the color sensor. However, the majority of applications on the RGB-D camera are based on the depth sensor. Moreover, parameters of the depth sensor should be directly calibrated.MethodWe build the spatial constraint relation between the ground plane and the camera, which can be used to select the ground plane from planes detected in the 3D point cloud. The ground plane should satisfy the following conditions: 1) The angle between the z axis of the camera and the ground plane is less than the specified threshold. 2) The z value of the ground plane in the world coordinate is larger than that of the other points, which are not in the ground plane. Moreover, we create the world coordinate based on the detected ground planes automatically. The origin point of the world coordinate is the projection of the origin point of the camera coordinate to the plane and the y axis of the world coordinate is the projection of the z axis of the camera coordinate to the plane. In addition, the direction of the z axis of the world coordinate is toward the origin point of the world coordinate from the origin point of the camera coordinate. We calibrate the extrinsic parameter of the RGB-D camera in the following steps. First, we reconstruct the 3D point cloud from the depth image retrieved from the depth sensor of the RGB-D camera. The reconstructed 3D point cloud is in the camera coordinate, whose subset forms a large number of planes. Second, planes in the 3D point cloud are detected by the MELSAC method. At most, one ground plane exists in the detected planes. Third, the spatial constraint rule between the ground plane and camera is built. The detected planes are filtered by the spatial constraint rule until the ground plane is found or all the planes are iterated. The process stops when a ground plane cannot be found. Finally, by using the relation between the ground plane and the camera, point sets are selected to calculate the extrinsic parameters.ResultIn the experiment, the benchmark is the result of checkerboard extrinsic calibration method only processing the RGB image of RGB-D information which is retrieved from the PrimeSense camera. We record an 89.4 s video and use it in the experiment. The videos contain two sub-videos: RGB video whose channel is 3 and depth video whose channel is 1. A 7x7 checkerboard is found in every frame of the RGB video, which is processed by the checkerboard-based method. The input of our proposed method is the frame of the depth video. The result shows that the average tilt angle error is -1.14°, the average pitch angle error is 4.57°, and the average camera height error is 3.96 cm. An experiment to test the robustness of the noise is also performed. The variance of the Gaussian noise in the depth frame is increased, and the result of each variance Gaussian noise is obtained. The stability of calibration decreases with the increase in the variance of Gaussian noise. The result shows that our method performs effectively when the variance of the Gaussian noise is below 0.01.ConclusionOur proposed method fully utilizes the depth information of the RGB-D camera, and simplifies the process of extrinsic calibration of the depth sensor. Thus, our method can be used in actual application. For convenience, the source code is also published. This method can automatically detect the ground plane and does not require other calibration objects. Therefore, the proposed method can calibrate each frame of the recorded video accurately, and it is not sensitive to the noise in the depth image. In addition, the algorithm has high parallelism. The process of estimating planes in the 3D point cloud and filtering these planes can be implemented in a parallel manner. The proposed method will have real-time performance based on this parallel implementation.关键词:RGB-D camera;automatic extrinsic calibration;3D point cloud;plane detection;depth map14|4|1更新时间:2024-05-07 -
 摘要:ObjectiveIn unmanned aerial vehicle systems, estimation of scene information in real time is a key issue in conducting automatic obstacle avoidance and navigation. A binocular stereo vision system is an effective means to obtain scene information; this system simulates the working principle of the human eyes by using two cameras to capture the same sense at the same time and generates a disparity map by using a stereo matching algorithm. In this work, we propose ADCC-TSGM, a novel texture-optimized semi-global stereo matching algorithm based on the fusion of absolute difference (AD) feature and center average census feature. Efforts are made to speed up the algorithm through CUDA parallel acceleration.MethodFirst, a one-dimensional difference method is used to calculate the texture information along the epipolar line, the center average census feature and AD feature are exploited to conduct the cost computation, and the global stereo matching algorithm is texture-optimized to aggregate the cost and obtain the initial disparity. Second, left-right consistency check is used to detect unstable pixels and occlusion pixels, and linear interpolation and median filter method are used to fill the holes of the disparity map. Lastly, to improve the running speed, we optimize the code of GPU acceleration for each step of the stereo matching. The time consumption of memory access is considered in the feature calculation of types, such that center average census is much higher than that of computation, and a large number of data-intensive computing tasks are conducted between adjacent threads. Consequently, we divide the dataset of the entire thread block into four regions, copy them into a shared memory, and use the shared memory for computation to reduce the overhead of memory accessing. A single thread can simultaneously handle two consecutive disparity calculations by using SIMD instructions. When the GPU is processing, the CPU is basically idle. Therefore, a hybrid pipeline is designed to fully utilize the computing resources of the embedded platform.ResultTo demonstrate the effectiveness of the proposed algorithm, we use NVIDIA Jetson TK1 developer kit, which has a quad-core ARM Cortex-A15 CPU, a Kepler GPU with 192 CUDA cores, and 2 GB memory, as the embedded computing platform to conduct experiments on Middlebury stereo datasets that have been resized to QVGA resolution. With the actual application scenarios and resolution of images, the maximum disparity for each algorithm is set to 64, and the block matching window size of SGBM and BM is set to 9×9. The texture penalty coefficients ε1 and ε2 in the proposed algorithm are set to 0.25 and 0.125, respectively. Experimental results show that the total bad-pixel rate and the average error rate of the proposed algorithm are significantly lower than those of BM, SGBM, and SGM, respectively. The total bad-pixel rate of the ADCC-TSGM algorithm is 73.9% lower than that of BM algorithm, 36.1% lower than that of SGBM algorithm, and 28.3% lower than that of SGM algorithm. The average error rate of the proposed algorithm is 83.2% lower than that of the BM algorithm, 44.5% lower than that of the SGBM algorithm, and 49.9% lower than that of the SGM algorithm. In particular, the use of center average census in feature matching can reduce the bad-pixel and error rates. The texture-based optimization can adaptively increase the penalty coefficient in low-texture regions and reduce the average error rate from 6.62 to 4.84. The post-processing method, including disparity consistency check and hole filling, can reduce the total bad-pixel rate from 14.46 to 7.12. Through GPU parallel acceleration, the CUDA implementation of the proposed algorithm becomes hundreds of times faster than that of pure CPU implementation without any loss in the quality of disparity map. Compared with SGBM, which has been optimized by using SIMD and multi-core parallel method, our proposed algorithm has a running time that is reduced by 85%. For QVGA resolution, the frame processing rate is as high as 31.8 FPS.ConclusionThe proposed algorithm outperforms existing algorithms, such as BM, SGM, and SGBM, which have been used in industries. The CUDA-accelerated implementation of the proposed algorithm provides an effective and feasible method to obtain high-quality disparity information and can be used as a basic means of environmental perception, visual positioning, and map construction for real-time embedded applications, such as micro-aircraft systems.关键词:stereo vision;census feature;semi-global matching;CUDA acceleration;parallel computing15|4|6更新时间:2024-05-07
摘要:ObjectiveIn unmanned aerial vehicle systems, estimation of scene information in real time is a key issue in conducting automatic obstacle avoidance and navigation. A binocular stereo vision system is an effective means to obtain scene information; this system simulates the working principle of the human eyes by using two cameras to capture the same sense at the same time and generates a disparity map by using a stereo matching algorithm. In this work, we propose ADCC-TSGM, a novel texture-optimized semi-global stereo matching algorithm based on the fusion of absolute difference (AD) feature and center average census feature. Efforts are made to speed up the algorithm through CUDA parallel acceleration.MethodFirst, a one-dimensional difference method is used to calculate the texture information along the epipolar line, the center average census feature and AD feature are exploited to conduct the cost computation, and the global stereo matching algorithm is texture-optimized to aggregate the cost and obtain the initial disparity. Second, left-right consistency check is used to detect unstable pixels and occlusion pixels, and linear interpolation and median filter method are used to fill the holes of the disparity map. Lastly, to improve the running speed, we optimize the code of GPU acceleration for each step of the stereo matching. The time consumption of memory access is considered in the feature calculation of types, such that center average census is much higher than that of computation, and a large number of data-intensive computing tasks are conducted between adjacent threads. Consequently, we divide the dataset of the entire thread block into four regions, copy them into a shared memory, and use the shared memory for computation to reduce the overhead of memory accessing. A single thread can simultaneously handle two consecutive disparity calculations by using SIMD instructions. When the GPU is processing, the CPU is basically idle. Therefore, a hybrid pipeline is designed to fully utilize the computing resources of the embedded platform.ResultTo demonstrate the effectiveness of the proposed algorithm, we use NVIDIA Jetson TK1 developer kit, which has a quad-core ARM Cortex-A15 CPU, a Kepler GPU with 192 CUDA cores, and 2 GB memory, as the embedded computing platform to conduct experiments on Middlebury stereo datasets that have been resized to QVGA resolution. With the actual application scenarios and resolution of images, the maximum disparity for each algorithm is set to 64, and the block matching window size of SGBM and BM is set to 9×9. The texture penalty coefficients ε1 and ε2 in the proposed algorithm are set to 0.25 and 0.125, respectively. Experimental results show that the total bad-pixel rate and the average error rate of the proposed algorithm are significantly lower than those of BM, SGBM, and SGM, respectively. The total bad-pixel rate of the ADCC-TSGM algorithm is 73.9% lower than that of BM algorithm, 36.1% lower than that of SGBM algorithm, and 28.3% lower than that of SGM algorithm. The average error rate of the proposed algorithm is 83.2% lower than that of the BM algorithm, 44.5% lower than that of the SGBM algorithm, and 49.9% lower than that of the SGM algorithm. In particular, the use of center average census in feature matching can reduce the bad-pixel and error rates. The texture-based optimization can adaptively increase the penalty coefficient in low-texture regions and reduce the average error rate from 6.62 to 4.84. The post-processing method, including disparity consistency check and hole filling, can reduce the total bad-pixel rate from 14.46 to 7.12. Through GPU parallel acceleration, the CUDA implementation of the proposed algorithm becomes hundreds of times faster than that of pure CPU implementation without any loss in the quality of disparity map. Compared with SGBM, which has been optimized by using SIMD and multi-core parallel method, our proposed algorithm has a running time that is reduced by 85%. For QVGA resolution, the frame processing rate is as high as 31.8 FPS.ConclusionThe proposed algorithm outperforms existing algorithms, such as BM, SGM, and SGBM, which have been used in industries. The CUDA-accelerated implementation of the proposed algorithm provides an effective and feasible method to obtain high-quality disparity information and can be used as a basic means of environmental perception, visual positioning, and map construction for real-time embedded applications, such as micro-aircraft systems.关键词:stereo vision;census feature;semi-global matching;CUDA acceleration;parallel computing15|4|6更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveShape segmentation is a fundamental problem in shape analysis. Automatic shape segmentation contributes to various shape processing and 3D modeling applications, such as shape retrieval, partial matching, reverse engineering, and medical imaging. Although shape segmentation has been an active research area in the past decade, problems remain, such as excessive parameters that are manually set in the existing 3D shape segmentation. A segmentation approach for 3D shape based on topological persistence and heat kernel affinity matrix is presented to solve this problem. This approach requires setting the number of segments without the need to alter other parameters.MethodFirst, Laplace-Beltrami operators of the 3D model are calculated to obtain the first 30 eigenvalues and the corresponding eigenvectors, which are used to compute heat kernel feature and signature. Heat kernel feature and heat kernel signature inherit the invariance under isometric deformations of the Laplace-Beltrami operator. Thus, it could beused to analyze shapes that undergo isometric deformations. Heat kernel feature is the amount of heat that transfers between two vertexes on the model in a given diffusion time; one of the vertexes is the given unit heat source. As heat tends to diffuse slowly at the vertex with positive curvature and faster with negative curvature, the heat kernel signature of a vertex is directly related to the Gaussian curvature of the surface at the vertex for a short diffusion time. Then, a hierarchy of components is obtained after the heat kernel signature of the 3D model is processed through topological persistence. The lifespan of the components is calculated, and the vertex that corresponds to the maximum of the heat kernel signature in the component is the feature point that inherits the hierarchical relationship and lifespan of the component, where it is located. Then, K longest lifespan feature points are selected as critical points of the segmented parts of the model, and K is also the number of segmented parts. The value of heat kernel signature on the torso of the model is generally low; thus, its critical point could not be obtained by topological persistence. The vertex with the minimum of the heat kernel signature is the critical point of the torso of the model. Thus, the initial clustering centers of the 3D models are obtained. The heat kernel affinity matrix is established by the heat kernel feature, and k-means clustering is performed by using the heat kernel affinity matrix that corresponds to different diffusion time periods and the initial clustering centers. Then, the heat kernel signature of the segmentation parts is calculated, and the vertex in the parts whose heat kernel signature value is close to the average value of all vertexes in this part are selected as the second cluster center to perform k-means clustering. Thus, the boundary is optimized in the second clustering. Finally, the clustering results are screened in accordance with the offset distance of the clustering centers and edge value, and the segmentation results of the 3D model are obtained. These screened rules are summarized by various experiments as follows: (1) When the offset distance of the clustering centers is less, the results of model segmentation improve. (2) Within the diffusion time, the values of all vertexes on the edge monotonously decrease first, and then monotonously increase, thereby resulting in a minimum edge value. Thus, the segmentation results are visually accurate with a relatively appropriate boundary after the minimum edge value is achieved.ResultHuman models are selected to verify the proposed algorithm and compare it with other algorithms. The experimental results show that the computing time of the heat kernel affinity matrix is less than the geodesic distance and exponential kernel, which are typically used for k-means clustering. The computing speed of the heat kernel affinity is 16.25 times that of the exponential kernel and 44.42 times that of the geodesic distance. Compared with the clustering methods based on topological persistence and geodesic distance, the proposed method could obtain accurate segmentation parts and appropriate segmentation boundaries. The clustering method based on topological persistence could not segment the torso of the human model, and the clustering method based on geodesic distance could not obtain an appropriate segmentation boundary. For non-rigid 3D shapes with various postures, the proposed approach could obtain consistent critical points and segmentation results. When the approach is applied to the common quadruped models, it could also achieve acceptable segmentation results. In addition, it is robust to model surface noise. The vertexes of the model are corrupted with different levels of Gaussian noise. When 10% Gaussian noise is added, our approach still obtains appropriate segmentation boundary, and when the Gaussian noise is raised to 20%, the relatively appropriate segmentation parts are still obtained.ConclusionCompared with the existing algorithms, the approach based on topological persistence and heat kernel affinity matrix could automatically select the clustering center under the premise of providing the number of segments. Moreover, the proposed approach exhibits strong robustness to the model surface noise. The computing time of the heat kernel affinity matrix is evidently less than the geodesic distance and exponential kernel. It could also be used extensively for the segmentation of other animal models.关键词:3D Shape;segmentation;topological persistence;heat kernel affinity matrix;k-means clustering;heat kernel signature19|6|2更新时间:2024-05-07
摘要:ObjectiveShape segmentation is a fundamental problem in shape analysis. Automatic shape segmentation contributes to various shape processing and 3D modeling applications, such as shape retrieval, partial matching, reverse engineering, and medical imaging. Although shape segmentation has been an active research area in the past decade, problems remain, such as excessive parameters that are manually set in the existing 3D shape segmentation. A segmentation approach for 3D shape based on topological persistence and heat kernel affinity matrix is presented to solve this problem. This approach requires setting the number of segments without the need to alter other parameters.MethodFirst, Laplace-Beltrami operators of the 3D model are calculated to obtain the first 30 eigenvalues and the corresponding eigenvectors, which are used to compute heat kernel feature and signature. Heat kernel feature and heat kernel signature inherit the invariance under isometric deformations of the Laplace-Beltrami operator. Thus, it could beused to analyze shapes that undergo isometric deformations. Heat kernel feature is the amount of heat that transfers between two vertexes on the model in a given diffusion time; one of the vertexes is the given unit heat source. As heat tends to diffuse slowly at the vertex with positive curvature and faster with negative curvature, the heat kernel signature of a vertex is directly related to the Gaussian curvature of the surface at the vertex for a short diffusion time. Then, a hierarchy of components is obtained after the heat kernel signature of the 3D model is processed through topological persistence. The lifespan of the components is calculated, and the vertex that corresponds to the maximum of the heat kernel signature in the component is the feature point that inherits the hierarchical relationship and lifespan of the component, where it is located. Then, K longest lifespan feature points are selected as critical points of the segmented parts of the model, and K is also the number of segmented parts. The value of heat kernel signature on the torso of the model is generally low; thus, its critical point could not be obtained by topological persistence. The vertex with the minimum of the heat kernel signature is the critical point of the torso of the model. Thus, the initial clustering centers of the 3D models are obtained. The heat kernel affinity matrix is established by the heat kernel feature, and k-means clustering is performed by using the heat kernel affinity matrix that corresponds to different diffusion time periods and the initial clustering centers. Then, the heat kernel signature of the segmentation parts is calculated, and the vertex in the parts whose heat kernel signature value is close to the average value of all vertexes in this part are selected as the second cluster center to perform k-means clustering. Thus, the boundary is optimized in the second clustering. Finally, the clustering results are screened in accordance with the offset distance of the clustering centers and edge value, and the segmentation results of the 3D model are obtained. These screened rules are summarized by various experiments as follows: (1) When the offset distance of the clustering centers is less, the results of model segmentation improve. (2) Within the diffusion time, the values of all vertexes on the edge monotonously decrease first, and then monotonously increase, thereby resulting in a minimum edge value. Thus, the segmentation results are visually accurate with a relatively appropriate boundary after the minimum edge value is achieved.ResultHuman models are selected to verify the proposed algorithm and compare it with other algorithms. The experimental results show that the computing time of the heat kernel affinity matrix is less than the geodesic distance and exponential kernel, which are typically used for k-means clustering. The computing speed of the heat kernel affinity is 16.25 times that of the exponential kernel and 44.42 times that of the geodesic distance. Compared with the clustering methods based on topological persistence and geodesic distance, the proposed method could obtain accurate segmentation parts and appropriate segmentation boundaries. The clustering method based on topological persistence could not segment the torso of the human model, and the clustering method based on geodesic distance could not obtain an appropriate segmentation boundary. For non-rigid 3D shapes with various postures, the proposed approach could obtain consistent critical points and segmentation results. When the approach is applied to the common quadruped models, it could also achieve acceptable segmentation results. In addition, it is robust to model surface noise. The vertexes of the model are corrupted with different levels of Gaussian noise. When 10% Gaussian noise is added, our approach still obtains appropriate segmentation boundary, and when the Gaussian noise is raised to 20%, the relatively appropriate segmentation parts are still obtained.ConclusionCompared with the existing algorithms, the approach based on topological persistence and heat kernel affinity matrix could automatically select the clustering center under the premise of providing the number of segments. Moreover, the proposed approach exhibits strong robustness to the model surface noise. The computing time of the heat kernel affinity matrix is evidently less than the geodesic distance and exponential kernel. It could also be used extensively for the segmentation of other animal models.关键词:3D Shape;segmentation;topological persistence;heat kernel affinity matrix;k-means clustering;heat kernel signature19|6|2更新时间:2024-05-07 -
 摘要:ObjectiveThe Ball curve has excellent geometric properties. However, its shape cannot be adjusted when the control points remain unchanged. This condition undoubtedly limits its application in geometrical modeling. A simple method for constructing the Ball curve of the same degree with a parameter is presented to enable the Ball curve with arbitrary degree to obtain shape adjustment capability under fixed control points.MethodThe cubic Ball basis, referred to as cubic α-Ball basis, is constructed by extending the definition interval of the traditional cubic Ball basis from [0, 1] to [0, α]. Then, the corresponding cubic α-Ball curve is defined base on the cubic α-Ball basis. The splicing of the curves, the influence of the parameter on the curve, and the three selection schemes for the parameter are discussed. Finally, the α-Ball basis and α-Ball curve with arbitrary degree are established by the recursion of the transitional high-degree Ball basis, and the properties of the α-Ball basis and α-Ball curve with arbitrary degree are provided.ResultExamples show that the proposed α-Ball curve is an extension of the same degree to the traditional Ball curve. The curve not only preserves the properties of the traditional Ball curve, such as convex hull, symmetry, geometric invariance, variance reduction, and convexity, but also has better performance because of the parameter α. The α-Ball curve can be constructed to satisfy the requirements by using the three selection schemes for the parameter, including the scheme for the curve with the shortest arc length, the curve with minimum energy, and the curve with the shortest arc length and minimum energy.ConclusionThe α-Ball curve overcomes the disadvantage of the traditional Ball curve in shape adjustment, which is an effective method for constructing the shape-adjustable Ball curve with arbitrary degree.关键词:Ball basis;Ball curve;arbitrary degree extension of the same degree;shape adjustment;parameter selection17|70|2更新时间:2024-05-07
摘要:ObjectiveThe Ball curve has excellent geometric properties. However, its shape cannot be adjusted when the control points remain unchanged. This condition undoubtedly limits its application in geometrical modeling. A simple method for constructing the Ball curve of the same degree with a parameter is presented to enable the Ball curve with arbitrary degree to obtain shape adjustment capability under fixed control points.MethodThe cubic Ball basis, referred to as cubic α-Ball basis, is constructed by extending the definition interval of the traditional cubic Ball basis from [0, 1] to [0, α]. Then, the corresponding cubic α-Ball curve is defined base on the cubic α-Ball basis. The splicing of the curves, the influence of the parameter on the curve, and the three selection schemes for the parameter are discussed. Finally, the α-Ball basis and α-Ball curve with arbitrary degree are established by the recursion of the transitional high-degree Ball basis, and the properties of the α-Ball basis and α-Ball curve with arbitrary degree are provided.ResultExamples show that the proposed α-Ball curve is an extension of the same degree to the traditional Ball curve. The curve not only preserves the properties of the traditional Ball curve, such as convex hull, symmetry, geometric invariance, variance reduction, and convexity, but also has better performance because of the parameter α. The α-Ball curve can be constructed to satisfy the requirements by using the three selection schemes for the parameter, including the scheme for the curve with the shortest arc length, the curve with minimum energy, and the curve with the shortest arc length and minimum energy.ConclusionThe α-Ball curve overcomes the disadvantage of the traditional Ball curve in shape adjustment, which is an effective method for constructing the shape-adjustable Ball curve with arbitrary degree.关键词:Ball basis;Ball curve;arbitrary degree extension of the same degree;shape adjustment;parameter selection17|70|2更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveTo solve issues in the optimization design of deep convolutional neural network (DCNN) model architecture for synthetic aperture radar (SAR) target recognition, a DCNN model architecture for SAR target recognition is presented based on the analysis of the influence of convolution kernel size on classification performance.MethodFirst, two-dimensional random convolution features and extreme learning machines (ELMs), which are a single-hidden-layer neural network, are used to analyze the influence of convolution kernel size on SAR target recognition performance. Experimental results show that recognition performance increases as the kernel size increases although convolution kernels generate randomly and the convolution kernel with size 3×3 is unsuitable for SAR image recognition. Second, a DCNN architecture for SAR target recognition, in which the pixel resolution of input image is set to 88×88, is presented based on directed acyclic graph architecture. Multiple convolution kernels with different sizes, which are set as 5×5, 7×7, 9×9, and 11×11, are first adopted in the spatial-feature-extraction convolutional layer of DCNN to extract multi-scale local features from input images, and convolution kernels with large size, including 7×7, 5×5, and 6×6, are then used in the last convolutional layers to extract semantic features. A fully connected layer is used as the classifier to recognize various types of targets and softmax loss function is used to train the parameters of the convolutional layers. The dropout strategy, which can improve regularization performance, is used between the fully connected layer and the output layer. Rectified linear units following behind each convolutional layer are used as activation functions, and pooling operations with width 3 and stride 2 are used to perform downsampling behind each activation function layer. Finally, MSTAR database, where the training samples are randomly augmented through sampling and adding speckle noises, is used to train the parameters of the proposed model architecture after setting proper training hyperparameters, and the recognition performances are tested in standard operating conditions, where target configurations with non-deformable and deformable conditions are considered.ResultThe MatConvNet toolbox is used to implement the proposed DCNN model architecture. In this task, 90% of the augmented training samples are used to train the parameters of each convolutional layer, and other training samples are used to verify the trained parameters. The dropout rate is set as 0.1. The training procedure stops after 28 epochs, and the trained parameters are used to test recognition performance. The experimental results demonstrate that superior performance can be achieved for SAR image recognition because large-size kernels are used to extract spatial features from input image to overcome the influence of high-level speckle noise. This result is different from that of natural scene classification scenario using visible images, where small kernel sizes, such as 3×3, 3×1, and 1×3, are used to achieve high recognition performance. The classification results based on the proposed architecture for 10 classes (including non-deformable and deformable target configurations) are compared with two DCNN models. The experimental results show that it can achieve comparable or better results than that of state-of-the-art deep model architectures, where the overall recognition performances reach 98.39% and 97.69%, respectively, for the two scenarios. The deep model using 3×3 convolutional layers can only achieve 93.16% recognition rate, which confirms our analysis on the influence of convolution kernel size on SAR image recognition performance. The recognition performance using the proposed DCNN model architecture is also better than that using random convolution features and ELM. This finding demonstrates that the DCNN model architecture can achieve satisfactory performance when deep architecture is carefully designed and more training samples are used to train these parameters.ConclusionA large convolution kernel size should be used to extract spatial features for SAR target recognition due to different imaging mechanisms compared with visible images, and better performance can be achieved through the optimization design of deep model architecture with augmented training samples.关键词:SAR target recognition;deep convolution neural network;architecture design;random weight;extreme learning machines12|4|3更新时间:2024-05-07
摘要:ObjectiveTo solve issues in the optimization design of deep convolutional neural network (DCNN) model architecture for synthetic aperture radar (SAR) target recognition, a DCNN model architecture for SAR target recognition is presented based on the analysis of the influence of convolution kernel size on classification performance.MethodFirst, two-dimensional random convolution features and extreme learning machines (ELMs), which are a single-hidden-layer neural network, are used to analyze the influence of convolution kernel size on SAR target recognition performance. Experimental results show that recognition performance increases as the kernel size increases although convolution kernels generate randomly and the convolution kernel with size 3×3 is unsuitable for SAR image recognition. Second, a DCNN architecture for SAR target recognition, in which the pixel resolution of input image is set to 88×88, is presented based on directed acyclic graph architecture. Multiple convolution kernels with different sizes, which are set as 5×5, 7×7, 9×9, and 11×11, are first adopted in the spatial-feature-extraction convolutional layer of DCNN to extract multi-scale local features from input images, and convolution kernels with large size, including 7×7, 5×5, and 6×6, are then used in the last convolutional layers to extract semantic features. A fully connected layer is used as the classifier to recognize various types of targets and softmax loss function is used to train the parameters of the convolutional layers. The dropout strategy, which can improve regularization performance, is used between the fully connected layer and the output layer. Rectified linear units following behind each convolutional layer are used as activation functions, and pooling operations with width 3 and stride 2 are used to perform downsampling behind each activation function layer. Finally, MSTAR database, where the training samples are randomly augmented through sampling and adding speckle noises, is used to train the parameters of the proposed model architecture after setting proper training hyperparameters, and the recognition performances are tested in standard operating conditions, where target configurations with non-deformable and deformable conditions are considered.ResultThe MatConvNet toolbox is used to implement the proposed DCNN model architecture. In this task, 90% of the augmented training samples are used to train the parameters of each convolutional layer, and other training samples are used to verify the trained parameters. The dropout rate is set as 0.1. The training procedure stops after 28 epochs, and the trained parameters are used to test recognition performance. The experimental results demonstrate that superior performance can be achieved for SAR image recognition because large-size kernels are used to extract spatial features from input image to overcome the influence of high-level speckle noise. This result is different from that of natural scene classification scenario using visible images, where small kernel sizes, such as 3×3, 3×1, and 1×3, are used to achieve high recognition performance. The classification results based on the proposed architecture for 10 classes (including non-deformable and deformable target configurations) are compared with two DCNN models. The experimental results show that it can achieve comparable or better results than that of state-of-the-art deep model architectures, where the overall recognition performances reach 98.39% and 97.69%, respectively, for the two scenarios. The deep model using 3×3 convolutional layers can only achieve 93.16% recognition rate, which confirms our analysis on the influence of convolution kernel size on SAR image recognition performance. The recognition performance using the proposed DCNN model architecture is also better than that using random convolution features and ELM. This finding demonstrates that the DCNN model architecture can achieve satisfactory performance when deep architecture is carefully designed and more training samples are used to train these parameters.ConclusionA large convolution kernel size should be used to extract spatial features for SAR target recognition due to different imaging mechanisms compared with visible images, and better performance can be achieved through the optimization design of deep model architecture with augmented training samples.关键词:SAR target recognition;deep convolution neural network;architecture design;random weight;extreme learning machines12|4|3更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0