
最新刊期
卷 23 , 期 5 , 2018
-
 摘要:ObjectiveThis is the twenty-third one in the annual survey series of the yearly important bibliographies on image engineering in China. The purpose of this statistic and analysis work is mainly to capture the up-to-date development of image engineering in China, to provide a targeted means of literature searching facility for readers working in related areas, and to supply a useful recommendation for the editors of journals and potential authors of papers.MethodConsidering the wide distribution of related publications in China, 771 references on image engineering research and technique are selected carefully from 2 932 research papers published in 148 issues of a set of 15 Chinese journals. These 15 journals are considered as important journals in which papers concerning image engineering have higher quality and are relatively concentrated. Those selected references are classified first into 5 categories (image processing, image analysis, image understanding, technique application and survey), and then into 23 specialized classes according to their main contents (same as the last 12 years). Some analysis and discussions about the statistics made on the results of classifications by journal and by category are also presented, respectively.ResultAccording to the analysis on the statistics in 2017, it seems that image analysis is getting the most attention, in which the focuses are mainly on object detection and recognition, image segmentation and edge detection, and object feature extraction and analysis. The researches and applications of image technology in the areas of remote sensing, radar and mapping are continuously very active.ConclusionThis work shows a general and off-the-shelf picture of the various progresses, either for depth or for width, of image engineering in China in 2017.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics12|5|7更新时间:2024-05-07
摘要:ObjectiveThis is the twenty-third one in the annual survey series of the yearly important bibliographies on image engineering in China. The purpose of this statistic and analysis work is mainly to capture the up-to-date development of image engineering in China, to provide a targeted means of literature searching facility for readers working in related areas, and to supply a useful recommendation for the editors of journals and potential authors of papers.MethodConsidering the wide distribution of related publications in China, 771 references on image engineering research and technique are selected carefully from 2 932 research papers published in 148 issues of a set of 15 Chinese journals. These 15 journals are considered as important journals in which papers concerning image engineering have higher quality and are relatively concentrated. Those selected references are classified first into 5 categories (image processing, image analysis, image understanding, technique application and survey), and then into 23 specialized classes according to their main contents (same as the last 12 years). Some analysis and discussions about the statistics made on the results of classifications by journal and by category are also presented, respectively.ResultAccording to the analysis on the statistics in 2017, it seems that image analysis is getting the most attention, in which the focuses are mainly on object detection and recognition, image segmentation and edge detection, and object feature extraction and analysis. The researches and applications of image technology in the areas of remote sensing, radar and mapping are continuously very active.ConclusionThis work shows a general and off-the-shelf picture of the various progresses, either for depth or for width, of image engineering in China in 2017.关键词:image engineering;image processing;image analysis;image understanding;technique application;literature survey;literature statistics;literature classification;bibliometrics12|5|7更新时间:2024-05-07
Medical Image Processing

-
 摘要:ObjectiveSteganography is an active and attractive topic in the field of information hiding where a secret message is embedded into carriers, such as images and audios. Security, payload, and image quality are the most important metrics of image steganography. A good steganography indicates high security, large payload, and imperceptibility, and all characteristics should be robust to all the images and secret information to be embedded. High security prevents the stego-images from being discovered by visual and statistical attack methods. However, maintaining the balance between these three metrics remains a challenging problem. In addition, existing algorithms embed secret information into images in sequence without considering the visual quality of the stego-images. Therefore, steganography should be adaptive to the content of the image, the secret messages to be embedded, and the image regions to prevent the attacker from doubting the stego-images. The human visual system should be considered to improve the capacity of steganography. The human visual system is more sensitive to the smooth regions of images than to the complex regions of images. Thus, different considerations are taken into account when secret information is hidden in different image regions, that is, more secret messages should be embedded into the complex regions of an image than in the smooth regions of an image. With regard to imperceptibility, different limitations should be exerted on different regions. Therefore, adaptive steganography can effectively avoid large modifications to sensitive regions of the carrier. To address the essential problem of adaptive steganography, this study proposes adaptive steganography in the spatial domain based on quadtree segmentation for improving security and increasing steganography capacity indirectly. The proposed scheme employs a specially designed function to measure the texture complexity of image blocks and uses quadtree segmentation technology to segment the cover image into blocks with different sizes.MethodFirst, the texture complexity of image blocks is used as the consistency measure to segment the image, and the image block size in the segmented image is considered the discriminant criterion for image segmentation. According to the principle of quadtree segmentation, the small image block belongs to the complex region and the large image block belongs to the smooth region, in which the image is divided into three regions, i.e., high-, normal-, and low-complexity regions. The proposed algorithm embeds less data into smooth regions to enhance the cover image quality and embeds more data into complex regions to improve the steganographic capacity. Therefore, the proposed algorithm can ensure imperceptibility and increase the payload of secret data. Second, adaptive pixel pair matching (APPM) is utilized as the embedding method. According to the capacity of the secret message and the content of the cover image, the proposed scheme can select the appropriate basis for embedding secret messages. Finally, small image blocks are selected to embed high-capacity secret messages, whereas smooth regions are selected to embed low-capacity secret messages to improve the security and steganography capacity of the proposed algorithm. That is, the high-complexity regions of the cover image are selected for embedding secret messages in n-ary more than B-ary, the normal-complexity regions are selected for embedding secret messages in B-ary, and the low-complexity regions are selected for embedding secret messages in n-ary less than B-ary.ResultEight classical images from the USC-SIPI image database are selected for this experiment. The proposed algorithm has higher peak signal-to-noise ratio (PSNR) values than the existing pixel value differencing-based steganographic algorithms and diamond encoding (DE) with the same embedding rate, and the PSNR value can reach 48 dB with the embedding rate of 1.92 bit/pixel. In addition, when the embedding rate is 2.5 bit/pixel, the average Kullback-Leibler (KL) divergence of the proposed algorithm is reduced by 25.37% compared with that of the traditional APPM algorithm. The average value of the first-order Markov security index is reduced by 12.11% compared with that of the traditional APPM algorithm, and the corresponding average PSNR value is improved by 0.43% compared with that of the traditional APPM algorithm. When the embedding rate is 1.5 bit/pixel, the average KL value of the proposed algorithm is reduced by 37.84% compared with that of the traditional APPM algorithm. The average value of the first-order Markov security index is reduced by 26.61% compared with that of the traditional APPM algorithm, and the corresponding average PSNR value is improved by 1.56% compared with that of the traditional APPM algorithm. In addition, 1 000 images from the RSP standard gallery are selected randomly as datasets. The minimum mean error rate of the combination of SPAM features and SVM classifier is higher than several least significant bit (LSB)-based and APPM-based classical algorithms when the embedding rates are 0.5, 0.6, 0.7, 0.8, 0.9, and 1.0 bit/pixel.Conclusion1) Given the different sensitivities of the human visual system to different regions of the image, quadtree segmentation as a preprocessing measure can ensure that the algorithm can improve the steganography capacity with a certain security. The proposed scheme is superior to the traditional DE-based and LSB-based classical algorithms in terms of anti-spam characteristic detection and imperceptibility. 2) A strategy to adjust the texture complexity of the pixel block is adopted for different conditions before and after quadtree segmentation, which guarantees that the secret information can be correctly and completely extracted. 3) Through the large capacity of the APPM algorithm, secret information can be embedded with embedding rates higher than 1 bpp, which is suitable for large-capacity secret steganography. Moreover, the secret message can be embedded into any base inside the cover image to minimize the embedding distortion. In addition, the proposed algorithm performs quadtree segmentation as a preprocessing measure and is superior to the traditional APPM algorithm in terms of security.关键词:quad-tree segmentation;adaptive pixel pair matching;steganography;texture complexity;human visual system;security;steganography capacity15|4|1更新时间:2024-05-07
摘要:ObjectiveSteganography is an active and attractive topic in the field of information hiding where a secret message is embedded into carriers, such as images and audios. Security, payload, and image quality are the most important metrics of image steganography. A good steganography indicates high security, large payload, and imperceptibility, and all characteristics should be robust to all the images and secret information to be embedded. High security prevents the stego-images from being discovered by visual and statistical attack methods. However, maintaining the balance between these three metrics remains a challenging problem. In addition, existing algorithms embed secret information into images in sequence without considering the visual quality of the stego-images. Therefore, steganography should be adaptive to the content of the image, the secret messages to be embedded, and the image regions to prevent the attacker from doubting the stego-images. The human visual system should be considered to improve the capacity of steganography. The human visual system is more sensitive to the smooth regions of images than to the complex regions of images. Thus, different considerations are taken into account when secret information is hidden in different image regions, that is, more secret messages should be embedded into the complex regions of an image than in the smooth regions of an image. With regard to imperceptibility, different limitations should be exerted on different regions. Therefore, adaptive steganography can effectively avoid large modifications to sensitive regions of the carrier. To address the essential problem of adaptive steganography, this study proposes adaptive steganography in the spatial domain based on quadtree segmentation for improving security and increasing steganography capacity indirectly. The proposed scheme employs a specially designed function to measure the texture complexity of image blocks and uses quadtree segmentation technology to segment the cover image into blocks with different sizes.MethodFirst, the texture complexity of image blocks is used as the consistency measure to segment the image, and the image block size in the segmented image is considered the discriminant criterion for image segmentation. According to the principle of quadtree segmentation, the small image block belongs to the complex region and the large image block belongs to the smooth region, in which the image is divided into three regions, i.e., high-, normal-, and low-complexity regions. The proposed algorithm embeds less data into smooth regions to enhance the cover image quality and embeds more data into complex regions to improve the steganographic capacity. Therefore, the proposed algorithm can ensure imperceptibility and increase the payload of secret data. Second, adaptive pixel pair matching (APPM) is utilized as the embedding method. According to the capacity of the secret message and the content of the cover image, the proposed scheme can select the appropriate basis for embedding secret messages. Finally, small image blocks are selected to embed high-capacity secret messages, whereas smooth regions are selected to embed low-capacity secret messages to improve the security and steganography capacity of the proposed algorithm. That is, the high-complexity regions of the cover image are selected for embedding secret messages in n-ary more than B-ary, the normal-complexity regions are selected for embedding secret messages in B-ary, and the low-complexity regions are selected for embedding secret messages in n-ary less than B-ary.ResultEight classical images from the USC-SIPI image database are selected for this experiment. The proposed algorithm has higher peak signal-to-noise ratio (PSNR) values than the existing pixel value differencing-based steganographic algorithms and diamond encoding (DE) with the same embedding rate, and the PSNR value can reach 48 dB with the embedding rate of 1.92 bit/pixel. In addition, when the embedding rate is 2.5 bit/pixel, the average Kullback-Leibler (KL) divergence of the proposed algorithm is reduced by 25.37% compared with that of the traditional APPM algorithm. The average value of the first-order Markov security index is reduced by 12.11% compared with that of the traditional APPM algorithm, and the corresponding average PSNR value is improved by 0.43% compared with that of the traditional APPM algorithm. When the embedding rate is 1.5 bit/pixel, the average KL value of the proposed algorithm is reduced by 37.84% compared with that of the traditional APPM algorithm. The average value of the first-order Markov security index is reduced by 26.61% compared with that of the traditional APPM algorithm, and the corresponding average PSNR value is improved by 1.56% compared with that of the traditional APPM algorithm. In addition, 1 000 images from the RSP standard gallery are selected randomly as datasets. The minimum mean error rate of the combination of SPAM features and SVM classifier is higher than several least significant bit (LSB)-based and APPM-based classical algorithms when the embedding rates are 0.5, 0.6, 0.7, 0.8, 0.9, and 1.0 bit/pixel.Conclusion1) Given the different sensitivities of the human visual system to different regions of the image, quadtree segmentation as a preprocessing measure can ensure that the algorithm can improve the steganography capacity with a certain security. The proposed scheme is superior to the traditional DE-based and LSB-based classical algorithms in terms of anti-spam characteristic detection and imperceptibility. 2) A strategy to adjust the texture complexity of the pixel block is adopted for different conditions before and after quadtree segmentation, which guarantees that the secret information can be correctly and completely extracted. 3) Through the large capacity of the APPM algorithm, secret information can be embedded with embedding rates higher than 1 bpp, which is suitable for large-capacity secret steganography. Moreover, the secret message can be embedded into any base inside the cover image to minimize the embedding distortion. In addition, the proposed algorithm performs quadtree segmentation as a preprocessing measure and is superior to the traditional APPM algorithm in terms of security.关键词:quad-tree segmentation;adaptive pixel pair matching;steganography;texture complexity;human visual system;security;steganography capacity15|4|1更新时间:2024-05-07 -
 摘要:ObjectiveUnderwater image is an important carrier of ocean information, and clear images obtained underwater play a critical role in ocean engineering, such as underwater device inspection and marine biological recognition. However, compared with images captured in terrestrial environment, underwater images often exhibit color shift, low contrast, and poor visibility because the light is absorbed, scattered, and reflected by the water medium when traveling from an object to a camera in the complicated underwater environment. Existing methods cannot be effective and suitable for different types of underwater images. To address these problems, we propose a simple underwater image enhancement method using adaptive histogram stretching in different color models, which can improve the contrast and brightness of the underwater image, reduce the introduction of noise, and generate a relatively natural image.MethodGiven that images are rarely color balanced in the underwater situation, we first preprocess the underwater image with color equalization in the red, green, and blue (RGB) color model based on gray world assumption theory. Color equalization is employed only on the green and blue channels of the input image to avoid the inappropriate compensation for the red channel in the water, which is often achieved by simple color balancing. Then, we analyze the distribution characteristics of the RGB channels, which are focused on the regular range. Meanwhile, we determine the rule of selective attenuation in three channels of the underwater image, in which the red color is seriously affected and the wavelength of the red color is the longest, leading to most underwater images having a blue-green tone. On the basis of the results and analysis, we propose an adaptive histogram stretching approach in the RGB color model to adapt to different underwater images. Given that underwater images are disturbed by various factors, the stretching range is limited to the range[0.5%, 99.5%] and is obtained based on the inherent characteristics similar to the variation of Rayleigh distribution to reduce the effect of several extreme pixels on the process of adaptive histogram stretching. The desired range of each channel is acquired according to Rayleigh distribution theory, the image formation model, and the residual energy ratios of different color channels underwater. These dynamic stretching ranges have considered the characteristics of histogram distribution in hazed image and in the expected output image simultaneously. Finally, four possible situations of histogram stretching on the basis of the desired range are introduced to preserve the enhanced underwater images from over-stretching or under-stretching. Although the smart method based on adaptive histogram stretching will not introduce obvious noise to the output image, the guided filter is employed to eliminate the effect of noise to improve the contrast and capture relevant details of the image. Then, in the CIE-Lab color model, the "L" luminance component, which is equivalent to image luminance, is applied with linear normalization in the stretch range[0.1%, 99.9%], and the brightness of the entire image is significantly improved. The "a" and "b" color components are modified to acquire the appropriate color correction using the exponential model curve function. Ultimately, a color-equalized, contrast-enhanced, and brightness-corrected underwater image can be produced as the perceivable output image.ResultOur proposed method is evaluated by comparing it with two effective nonphysical methods and two state-of-the-art physical methods qualitatively and quantitatively. The integrated color model and the unsupervised color correction model, as typical nonphysical methods, are most similar to the proposed method in terms of histogram modification. The blind global histogram stretching usually tends to produce output images that contain under-enhanced or over-enhanced and undersaturated or oversaturated areas and high noise. The dark channel prior-based and underwater dark channel prior-based underwater image restoration are imposed to estimate the background light and transmission map (TM) to restore underwater images based on the optical physical model. Physical methods are appropriate only for the enhancement and restoration of certain underwater images under specific circumstances and are time consuming for estimating the TM. Experimental results of different types of underwater images, such as brown coral, underwater fishes, and stones with different color tones, show that our proposed method can achieve better enhanced quality. Our method obtains the highest average subjective quality score among the underwater image enhancement and restoration methods, further proving that our method exhibits the best visual effects. The proposed method is not only simple and effective but also improves the contrast, details, and colors of the input images. In quantitative assessment, the maximum value of UCIQE represents the balance of the chroma, saturation, and contrast of the enhanced image in all methods; the highest value of ENTROPY means that our method preserves the richest information and details; the lowest value of Q-MOS indicates better perceptual quality; and the lowest value of MSE and the highest value of the peak signal-to-noise ratio can reduce the introduction of noise when the original image is enhanced based on adaptive histogram stretching. In summary, the final results have shown that our method can recover natural underwater images, enhance the visibility of hazed images, and produce high-quality underwater images.ConclusionThe proposed method consists of two parts, i.e., color correction and contrast enhancement in the RGB color model and modification of the brightness and hue in the CIE-Lab color model. In the RGB color model, adaptive histogram stretching is proposed with reasonable consideration of the distribution characteristics of the underwater image and the physical model of underwater image degradation. In the CIE-Lab color model, the stretching and S-model curve functions are adopted to modify the luminance and colors. The proposed method can be of low complexity, can be appropriate for different underwater images under complicated scenarios, and can effectively enhance visibility according to the best perceptual quality, high contrast, and most information and details. Our method achieves impressive results for applicability and robustness compared with the representative underwater image enhancement and restoration methods. Despite its satisfactory performance, our method still needs some improvements:1) the influences of the distance from the object to the water surface and artificial light on the results of restoration and enhancement are all ignored to some extent; 2) the noise due to histogram stretching cannot be entirely removed based on the guided filter; 3) in deep ocean, the radiation of natural light spreading from the water surface to the object fades away and the artificial light becomes the main light source for underwater imaging. These limitations will be investigated, and the proposed method will be refined in future work.关键词:underwater image enhancement;histogram distribution;adaptive histogram stretching;color model;stretching function;exponential-model curve function15|5|18更新时间:2024-05-07
摘要:ObjectiveUnderwater image is an important carrier of ocean information, and clear images obtained underwater play a critical role in ocean engineering, such as underwater device inspection and marine biological recognition. However, compared with images captured in terrestrial environment, underwater images often exhibit color shift, low contrast, and poor visibility because the light is absorbed, scattered, and reflected by the water medium when traveling from an object to a camera in the complicated underwater environment. Existing methods cannot be effective and suitable for different types of underwater images. To address these problems, we propose a simple underwater image enhancement method using adaptive histogram stretching in different color models, which can improve the contrast and brightness of the underwater image, reduce the introduction of noise, and generate a relatively natural image.MethodGiven that images are rarely color balanced in the underwater situation, we first preprocess the underwater image with color equalization in the red, green, and blue (RGB) color model based on gray world assumption theory. Color equalization is employed only on the green and blue channels of the input image to avoid the inappropriate compensation for the red channel in the water, which is often achieved by simple color balancing. Then, we analyze the distribution characteristics of the RGB channels, which are focused on the regular range. Meanwhile, we determine the rule of selective attenuation in three channels of the underwater image, in which the red color is seriously affected and the wavelength of the red color is the longest, leading to most underwater images having a blue-green tone. On the basis of the results and analysis, we propose an adaptive histogram stretching approach in the RGB color model to adapt to different underwater images. Given that underwater images are disturbed by various factors, the stretching range is limited to the range[0.5%, 99.5%] and is obtained based on the inherent characteristics similar to the variation of Rayleigh distribution to reduce the effect of several extreme pixels on the process of adaptive histogram stretching. The desired range of each channel is acquired according to Rayleigh distribution theory, the image formation model, and the residual energy ratios of different color channels underwater. These dynamic stretching ranges have considered the characteristics of histogram distribution in hazed image and in the expected output image simultaneously. Finally, four possible situations of histogram stretching on the basis of the desired range are introduced to preserve the enhanced underwater images from over-stretching or under-stretching. Although the smart method based on adaptive histogram stretching will not introduce obvious noise to the output image, the guided filter is employed to eliminate the effect of noise to improve the contrast and capture relevant details of the image. Then, in the CIE-Lab color model, the "L" luminance component, which is equivalent to image luminance, is applied with linear normalization in the stretch range[0.1%, 99.9%], and the brightness of the entire image is significantly improved. The "a" and "b" color components are modified to acquire the appropriate color correction using the exponential model curve function. Ultimately, a color-equalized, contrast-enhanced, and brightness-corrected underwater image can be produced as the perceivable output image.ResultOur proposed method is evaluated by comparing it with two effective nonphysical methods and two state-of-the-art physical methods qualitatively and quantitatively. The integrated color model and the unsupervised color correction model, as typical nonphysical methods, are most similar to the proposed method in terms of histogram modification. The blind global histogram stretching usually tends to produce output images that contain under-enhanced or over-enhanced and undersaturated or oversaturated areas and high noise. The dark channel prior-based and underwater dark channel prior-based underwater image restoration are imposed to estimate the background light and transmission map (TM) to restore underwater images based on the optical physical model. Physical methods are appropriate only for the enhancement and restoration of certain underwater images under specific circumstances and are time consuming for estimating the TM. Experimental results of different types of underwater images, such as brown coral, underwater fishes, and stones with different color tones, show that our proposed method can achieve better enhanced quality. Our method obtains the highest average subjective quality score among the underwater image enhancement and restoration methods, further proving that our method exhibits the best visual effects. The proposed method is not only simple and effective but also improves the contrast, details, and colors of the input images. In quantitative assessment, the maximum value of UCIQE represents the balance of the chroma, saturation, and contrast of the enhanced image in all methods; the highest value of ENTROPY means that our method preserves the richest information and details; the lowest value of Q-MOS indicates better perceptual quality; and the lowest value of MSE and the highest value of the peak signal-to-noise ratio can reduce the introduction of noise when the original image is enhanced based on adaptive histogram stretching. In summary, the final results have shown that our method can recover natural underwater images, enhance the visibility of hazed images, and produce high-quality underwater images.ConclusionThe proposed method consists of two parts, i.e., color correction and contrast enhancement in the RGB color model and modification of the brightness and hue in the CIE-Lab color model. In the RGB color model, adaptive histogram stretching is proposed with reasonable consideration of the distribution characteristics of the underwater image and the physical model of underwater image degradation. In the CIE-Lab color model, the stretching and S-model curve functions are adopted to modify the luminance and colors. The proposed method can be of low complexity, can be appropriate for different underwater images under complicated scenarios, and can effectively enhance visibility according to the best perceptual quality, high contrast, and most information and details. Our method achieves impressive results for applicability and robustness compared with the representative underwater image enhancement and restoration methods. Despite its satisfactory performance, our method still needs some improvements:1) the influences of the distance from the object to the water surface and artificial light on the results of restoration and enhancement are all ignored to some extent; 2) the noise due to histogram stretching cannot be entirely removed based on the guided filter; 3) in deep ocean, the radiation of natural light spreading from the water surface to the object fades away and the artificial light becomes the main light source for underwater imaging. These limitations will be investigated, and the proposed method will be refined in future work.关键词:underwater image enhancement;histogram distribution;adaptive histogram stretching;color model;stretching function;exponential-model curve function15|5|18更新时间:2024-05-07 -
 摘要:ObjectiveAs the amount of image data produced every day increases, large-scale image retrieval technology is one of the hot topics in the field of computer vision. The basic idea is to extract features from all the images in the database and define the similarity measure to perform nearest neighbor search. The key of massive image retrieval is to design a nearest neighbor search algorithm that can meet efficiency and storage needs. An approximate nearest neighbor search based on multi-index additive quantization method is presented to improve the approximate representation accuracy and reduce the storage space requirements of image visual features.MethodIf each image is described by a set of local descriptors, then an exhaustive search is prohibitive as we need to index billions of descriptors and perform multiple queries. The image descriptors should be stored in memory to ensure real-time retrieval; however, this approach creates a storage problem. Artificial neural network (ANN) algorithms, which mainly include index structure and quantization methods, are typically compared based on the trade-off between search quality and efficiency. On the basis of the superiority of nonlinear search, we employ an inverted multi-index structure to avoid an exhaustive search. The multi-index structure divides the original data space into multiple subspaces. Each subspace that uses an inverted index stores the list of vectors that lie in the proximity of each codeword as each entry of the multi-index table corresponds to a part of the original vector space and contains a list of points that fall within that part. The purpose of a multi-index structure is to generate a list of data vectors that lie close to any query vector efficiently by only searching in a small dataset in which the near neighbors of the query vector most likely lie, thus ensuring a substantial speed-up over the exhaustive search. As a solution to the storage problem, compact code representations of descriptors are used. Vector quantization is an effective and efficient ANN search method. These methods quantize data by using codewords to reduce the cardinality of the data space. Among the vector quantization methods, additive quantization that approximates the vectors using sums of M codewords from M different codebooks generalizes product quantization and further improves product quantization accuracy while retaining its computational efficiency to a large degree. In this study, we use the additive quantization encoding method to encode the residual data produced by the multi-index structure, which further reduces the quantitative loss of original space. We regard the method mentioned previously as a two-stage quantizer that approximates the residual vector of the preceding stage using one of the centroids in the stage codebook and generates a new residual vector for the succeeding quantization stage. The multi-index structure is used as the first-order quantizer to approximate the vectors, and the additive quantization method is utilized as the second-order quantizer to approximate the residual. The non-exhaustive search strategy retrieves only the near neighbors in a few inverted lists, which can significantly reduce the retrieval time cost. With the use of the additive quantization method in the retrieval process, the original data need not be stored in memory and only the index of the codeword in the codebook should be stored, the sum of which is nearest the data item, significantly reducing memory consumption.ResultExperiments on three datasets, i.e., SIFT1M, GIST1M, and MNIST, were conducted to verify the effectiveness of the proposed algorithm. The recall rate of the proposed algorithm is approximately 4% to 15% higher and its average precision is approximately 12% higher than that of existing algorithms. The search time of the proposed algorithm is the same as that of the fastest algorithm.ConclusionAn approximate nearest neighbor search based on the multi-index additive quantization method proposed in this study can effectively improve the approximate representation accuracy and reduce the storage space requirements of image visual features. The proposed method also improves retrieval accuracy and recall in large-scale datasets. The proposed algorithm focuses on the nearest neighbor search, which is suitable for large-scale images and other multimedia data.关键词:multi-index;compact encoding;additive quantization;approximate nearest neighbor search;vector quantization19|47|0更新时间:2024-05-07
摘要:ObjectiveAs the amount of image data produced every day increases, large-scale image retrieval technology is one of the hot topics in the field of computer vision. The basic idea is to extract features from all the images in the database and define the similarity measure to perform nearest neighbor search. The key of massive image retrieval is to design a nearest neighbor search algorithm that can meet efficiency and storage needs. An approximate nearest neighbor search based on multi-index additive quantization method is presented to improve the approximate representation accuracy and reduce the storage space requirements of image visual features.MethodIf each image is described by a set of local descriptors, then an exhaustive search is prohibitive as we need to index billions of descriptors and perform multiple queries. The image descriptors should be stored in memory to ensure real-time retrieval; however, this approach creates a storage problem. Artificial neural network (ANN) algorithms, which mainly include index structure and quantization methods, are typically compared based on the trade-off between search quality and efficiency. On the basis of the superiority of nonlinear search, we employ an inverted multi-index structure to avoid an exhaustive search. The multi-index structure divides the original data space into multiple subspaces. Each subspace that uses an inverted index stores the list of vectors that lie in the proximity of each codeword as each entry of the multi-index table corresponds to a part of the original vector space and contains a list of points that fall within that part. The purpose of a multi-index structure is to generate a list of data vectors that lie close to any query vector efficiently by only searching in a small dataset in which the near neighbors of the query vector most likely lie, thus ensuring a substantial speed-up over the exhaustive search. As a solution to the storage problem, compact code representations of descriptors are used. Vector quantization is an effective and efficient ANN search method. These methods quantize data by using codewords to reduce the cardinality of the data space. Among the vector quantization methods, additive quantization that approximates the vectors using sums of M codewords from M different codebooks generalizes product quantization and further improves product quantization accuracy while retaining its computational efficiency to a large degree. In this study, we use the additive quantization encoding method to encode the residual data produced by the multi-index structure, which further reduces the quantitative loss of original space. We regard the method mentioned previously as a two-stage quantizer that approximates the residual vector of the preceding stage using one of the centroids in the stage codebook and generates a new residual vector for the succeeding quantization stage. The multi-index structure is used as the first-order quantizer to approximate the vectors, and the additive quantization method is utilized as the second-order quantizer to approximate the residual. The non-exhaustive search strategy retrieves only the near neighbors in a few inverted lists, which can significantly reduce the retrieval time cost. With the use of the additive quantization method in the retrieval process, the original data need not be stored in memory and only the index of the codeword in the codebook should be stored, the sum of which is nearest the data item, significantly reducing memory consumption.ResultExperiments on three datasets, i.e., SIFT1M, GIST1M, and MNIST, were conducted to verify the effectiveness of the proposed algorithm. The recall rate of the proposed algorithm is approximately 4% to 15% higher and its average precision is approximately 12% higher than that of existing algorithms. The search time of the proposed algorithm is the same as that of the fastest algorithm.ConclusionAn approximate nearest neighbor search based on the multi-index additive quantization method proposed in this study can effectively improve the approximate representation accuracy and reduce the storage space requirements of image visual features. The proposed method also improves retrieval accuracy and recall in large-scale datasets. The proposed algorithm focuses on the nearest neighbor search, which is suitable for large-scale images and other multimedia data.关键词:multi-index;compact encoding;additive quantization;approximate nearest neighbor search;vector quantization19|47|0更新时间:2024-05-07 -
 摘要:ObjectiveA robust correlation filtering-based visual tracking algorithm based on multifeature hierarchical fusion is proposed to improve the robustness of target tracking after summarizing the main multifeature fusion strategies to solve the multifeature fusion problem in correlation filtering-based tracking.MethodThree features, including histogram of oriented gradient (HOG), color name (CN), and color histogram, are extracted from the target area and its surroundings to depict the appearances of the target and background when the multichannel correlation filtering algorithm is used to track the target. Two fusion layers are used in the proposed hierarchical fusion scheme to combine the response maps of the three features. The HOG and CN features, which describe the gradient and color information of the target, respectively, have a strong discrimination capability and are a pair of complementary features. Given that the saliency of the HOG and CN features is different under different tracking scenarios, the adaptive weighted fusion strategy, which can adaptively adjust fusion weights according to scene change, can be used to combine the responses of the HOG and CN features. Therefore, the adaptive weighted fusion strategy is used to combine the response maps of the HOG and CN features at the first fusion layer, where fusion weights are computed by calculating the smooth constraint and peak-to-sidelobe ratio of the feature response maps. Color histogram is a global statistical feature, and it can handle the case of deformation because the position information is discarded during computation of the color histogram. However, the tracking algorithm has a low accuracy when using the color histogram only because it is susceptible to the interference of similar-colored backgrounds. Thus, the color histogram feature is used as an additional feature in the proposed algorithm. The fixed-coefficient fusion strategy is adopted to combine the feature response maps of the first fusion layer and the feature response maps of the second fusion layer based on the color histogram. Finally, the position of the target is estimated based on the final response map, and the maximum of the final response map corresponds to the target position. The scale estimation algorithm, which uses a 1D scale-dependent filter to estimate the target scale rapidly, is adopted to obtain an accurate bounding box of the target. The model update procedure using a fixed learning factor at each frame is performed to adapt to appearance changes.ResultThe performance of the proposed tracking algorithm is verified using two public datasets, i.e., OTB-2013 and VOT-2014, for the evaluation of the visual tracking algorithm. The OTB-2013 dataset contains 51 test sequences, of which 35 are color video sequences. The distance precision and success rate curves are selected as performance metrics for the OTB-2013 dataset, and the one-pass evaluation assessment method is used to compute these metrics. The VOT-2014 dataset contains 25 color test sequences, and the accuracy and robustness metrics are used to analyze the performance for the VOT-2014 dataset. The experiments are divided into two parts, i.e., performance analysis of different parameters on the proposed algorithm and comparison with five mainstream correlation-filtering-based tracking algorithms, to analyze the performance of the proposed algorithm fully. The parameters of the proposed multifeature hierarchical fusion scheme, including fusion methods, target features, and fusion parameters, are analyzed using 35 sequences of the OTB-2013 dataset. Experimental results indicate that the proposed adaptive weighted fusion strategy is better than multiplicative fusion strategy, and the HOG, CN, color histogram features can improve the performance of the tracking algorithm. Second, the performance of our algorithm and five mainstream tracking algorithms are compared and analyzed. The six tracking algorithms are initially tested on all sequences and subsequently tested on 10 different individual attribute sequences. Experimental results indicate that the tracking performance is improved, where the precision score of the proposed algorithm is higher than that of the Staple algorithm by 5.9% (0.840 vs 0.781). Meanwhile, the robustness of the proposed algorithm is superior to that of other algorithms in most scenarios because of the effective integration of the CN, HOG, and color histogram features, and the highest success rate is achieved on out-of-plane rotation, occlusion, and fast motion sequences.ConclusionThe robustness of the proposed multifeature hierarchical fusion tracking algorithm is superior to that of other algorithms based on correlation filtering under the premise of ensuring the tracking accuracy. The proposed hierarchical fusion strategy can be used and expanded when different types of features are adopted in the correlation filtering-based tracking algorithm.关键词:target tracking;correlation filter;multi-feature fusion;hierarchical fusion;feature response map23|34|1更新时间:2024-05-07
摘要:ObjectiveA robust correlation filtering-based visual tracking algorithm based on multifeature hierarchical fusion is proposed to improve the robustness of target tracking after summarizing the main multifeature fusion strategies to solve the multifeature fusion problem in correlation filtering-based tracking.MethodThree features, including histogram of oriented gradient (HOG), color name (CN), and color histogram, are extracted from the target area and its surroundings to depict the appearances of the target and background when the multichannel correlation filtering algorithm is used to track the target. Two fusion layers are used in the proposed hierarchical fusion scheme to combine the response maps of the three features. The HOG and CN features, which describe the gradient and color information of the target, respectively, have a strong discrimination capability and are a pair of complementary features. Given that the saliency of the HOG and CN features is different under different tracking scenarios, the adaptive weighted fusion strategy, which can adaptively adjust fusion weights according to scene change, can be used to combine the responses of the HOG and CN features. Therefore, the adaptive weighted fusion strategy is used to combine the response maps of the HOG and CN features at the first fusion layer, where fusion weights are computed by calculating the smooth constraint and peak-to-sidelobe ratio of the feature response maps. Color histogram is a global statistical feature, and it can handle the case of deformation because the position information is discarded during computation of the color histogram. However, the tracking algorithm has a low accuracy when using the color histogram only because it is susceptible to the interference of similar-colored backgrounds. Thus, the color histogram feature is used as an additional feature in the proposed algorithm. The fixed-coefficient fusion strategy is adopted to combine the feature response maps of the first fusion layer and the feature response maps of the second fusion layer based on the color histogram. Finally, the position of the target is estimated based on the final response map, and the maximum of the final response map corresponds to the target position. The scale estimation algorithm, which uses a 1D scale-dependent filter to estimate the target scale rapidly, is adopted to obtain an accurate bounding box of the target. The model update procedure using a fixed learning factor at each frame is performed to adapt to appearance changes.ResultThe performance of the proposed tracking algorithm is verified using two public datasets, i.e., OTB-2013 and VOT-2014, for the evaluation of the visual tracking algorithm. The OTB-2013 dataset contains 51 test sequences, of which 35 are color video sequences. The distance precision and success rate curves are selected as performance metrics for the OTB-2013 dataset, and the one-pass evaluation assessment method is used to compute these metrics. The VOT-2014 dataset contains 25 color test sequences, and the accuracy and robustness metrics are used to analyze the performance for the VOT-2014 dataset. The experiments are divided into two parts, i.e., performance analysis of different parameters on the proposed algorithm and comparison with five mainstream correlation-filtering-based tracking algorithms, to analyze the performance of the proposed algorithm fully. The parameters of the proposed multifeature hierarchical fusion scheme, including fusion methods, target features, and fusion parameters, are analyzed using 35 sequences of the OTB-2013 dataset. Experimental results indicate that the proposed adaptive weighted fusion strategy is better than multiplicative fusion strategy, and the HOG, CN, color histogram features can improve the performance of the tracking algorithm. Second, the performance of our algorithm and five mainstream tracking algorithms are compared and analyzed. The six tracking algorithms are initially tested on all sequences and subsequently tested on 10 different individual attribute sequences. Experimental results indicate that the tracking performance is improved, where the precision score of the proposed algorithm is higher than that of the Staple algorithm by 5.9% (0.840 vs 0.781). Meanwhile, the robustness of the proposed algorithm is superior to that of other algorithms in most scenarios because of the effective integration of the CN, HOG, and color histogram features, and the highest success rate is achieved on out-of-plane rotation, occlusion, and fast motion sequences.ConclusionThe robustness of the proposed multifeature hierarchical fusion tracking algorithm is superior to that of other algorithms based on correlation filtering under the premise of ensuring the tracking accuracy. The proposed hierarchical fusion strategy can be used and expanded when different types of features are adopted in the correlation filtering-based tracking algorithm.关键词:target tracking;correlation filter;multi-feature fusion;hierarchical fusion;feature response map23|34|1更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveVisual object tracking is a significant computer vision task that can be applied to many domains, such as military, robotics, intelligent visual surveillance, human-computer interaction, and medical diagnosis. A large variety of trackers that have been proposed in the literature in the past decades have delivered satisfactory performances. Despite the success of researching on this topic, visual object tracking still suffers from difficulties in handling complex object appearance changes caused by factors such as illumination, partial occlusion, shape deformation, background clutter, low contrast, specularities, camera motion, and at least seven more aspects. Generally, visual tracking is a search (or classification) problem that continuously infers the state of a target in video sequences, aims to identify the candidate while it matches to the target template accurately, and returns it as a tracking result. Constructing an effective and high-performance tracker has two core issues. The first is the issue of representative feature learning and high-level modeling. The second is the problem of filtering and efficient searching. Given that the target states in every video frame are represented using several online learned feature templates, the modeling capability of the tracker will significantly depend on the generalizability of template data and accurate model representation with error estimation precision because of the complex interference factors caused by the target itself or the scene conditions. In addition, the relationship between each data pixel is significantly damaged while its original data structures are being changed because the sample data are intentionally forced into vector form in most existing algorithms. Moreover, the computational complexity with high data dimensionality must be increased. Therefore, designing an effective model representation mechanism of the 2D appearance of moving objects with the appropriate data expression is the key issue for the success of a visual tracker.MethodIn this study, the appearance model representation problem of generative-model-based visual object tracking algorithm is investigated in depth. In a prior work, we formulated the observation model via tensor (3D array) nuclear norm regularization. The tracker is called tensor nuclear norm regression-based tracker (TNRT) and has achieved favorable results in many tracking environments. However, the TNRT requires high hardware conditions and graphics processing unit computing demands, which will lead to slow tracking speeds if some practical uses require low hardware conditions. Therefore, we redesign a novel matrix low-rank representation-based observation model and its corresponding likelihood measurement function, as well as maintain several good properties of the TNRT algorithm, such as multitask joint learning, nuclear norm regularization-based model representation, and original data structures of sample signals. In the proposed tracking framework, several critical feature templates (dictionary or subspace) are learned from online data using the incremental principal component analysis algorithm. Then, in accordance with the appearance information of an incoming video frame, the proposed appearance modeling mechanism will use the feature templates to represent the target candidate linearly with independent and identically distributed Gaussian-Laplacian mixture noise by adopting the multitask joint learning strategy. Subsequently, the matrix nuclear norm and weighted
摘要:ObjectiveVisual object tracking is a significant computer vision task that can be applied to many domains, such as military, robotics, intelligent visual surveillance, human-computer interaction, and medical diagnosis. A large variety of trackers that have been proposed in the literature in the past decades have delivered satisfactory performances. Despite the success of researching on this topic, visual object tracking still suffers from difficulties in handling complex object appearance changes caused by factors such as illumination, partial occlusion, shape deformation, background clutter, low contrast, specularities, camera motion, and at least seven more aspects. Generally, visual tracking is a search (or classification) problem that continuously infers the state of a target in video sequences, aims to identify the candidate while it matches to the target template accurately, and returns it as a tracking result. Constructing an effective and high-performance tracker has two core issues. The first is the issue of representative feature learning and high-level modeling. The second is the problem of filtering and efficient searching. Given that the target states in every video frame are represented using several online learned feature templates, the modeling capability of the tracker will significantly depend on the generalizability of template data and accurate model representation with error estimation precision because of the complex interference factors caused by the target itself or the scene conditions. In addition, the relationship between each data pixel is significantly damaged while its original data structures are being changed because the sample data are intentionally forced into vector form in most existing algorithms. Moreover, the computational complexity with high data dimensionality must be increased. Therefore, designing an effective model representation mechanism of the 2D appearance of moving objects with the appropriate data expression is the key issue for the success of a visual tracker.MethodIn this study, the appearance model representation problem of generative-model-based visual object tracking algorithm is investigated in depth. In a prior work, we formulated the observation model via tensor (3D array) nuclear norm regularization. The tracker is called tensor nuclear norm regression-based tracker (TNRT) and has achieved favorable results in many tracking environments. However, the TNRT requires high hardware conditions and graphics processing unit computing demands, which will lead to slow tracking speeds if some practical uses require low hardware conditions. Therefore, we redesign a novel matrix low-rank representation-based observation model and its corresponding likelihood measurement function, as well as maintain several good properties of the TNRT algorithm, such as multitask joint learning, nuclear norm regularization-based model representation, and original data structures of sample signals. In the proposed tracking framework, several critical feature templates (dictionary or subspace) are learned from online data using the incremental principal component analysis algorithm. Then, in accordance with the appearance information of an incoming video frame, the proposed appearance modeling mechanism will use the feature templates to represent the target candidate linearly with independent and identically distributed Gaussian-Laplacian mixture noise by adopting the multitask joint learning strategy. Subsequently, the matrix nuclear norm and weighted$ {\rm L}_1$ $ {\rm L}_1$ $ {\rm L}_2$ $ {\rm L}_1$ $ {\rm L}_2$ 关键词:data prototypes;matrix low-rank representation;multi-task;observation modeling;likelihood estimation;object tracking11|5|0更新时间:2024-05-07 -
 摘要:ObjectiveWith the continuous development of artificial intelligence, researchers and scholars from other fields have become increasingly interested in providing computers with the capability to understand the emotions conveyed by(human beings and naturally interact with them. Therefore, emotion recognition has gradually become one of the key points of research to achieve harmonious human-computer interaction. The performance of video emotion recognition algorithms critically depends on the quality of the extracted emotion information. Previous research showed that facial expression is the most direct method to convey emotional information. Thus, current works usually rely on facial expressions only to complete emotion recognition. Feature extraction methods based on facial expression images are mostly based on gray images. However, during the conversion of color images into gray images, the latent physiological signals in the color information and the hidden physiological signals contained in facial videos that have discriminant information for emotion recognition are lost. In this study, a novel dual-modality video emotion recognition method for fusion decision, which combines facial expressions and blood volume pulse (BVP) physiological signals that can be extracted from facial videos, is introduced to overcome this problem.MethodFirst, the video is preprocessed (including face detection and normalization) to acquire a sequence of video frames that contain only the face image. The LBP-TOP feature is an effective local texture descriptor, whereas the HOG-TOP feature is a gradient-based local shape descriptor that can compensate for the lack of LBP-TOP feature extraction in image edge and direction information. Thus, in this study, we extract the LBP-TOP and HOG-TOP features from the video frames and fuse the two facial expression features. We use video color amplification technology to process the original video and extract the BVP physiological signal from the processed video. Then, the emotional feature of physiological signals can be extracted from the BVP physiological signal. Afterward, the two features are inputted into the BP classifier to train the classification models. Finally, the fuzzy integral is used to fuse the posterior probability information obtained by the two classifiers to obtain the final emotion recognition result.ResultConsidering that the current commonly used video emotion databases cannot satisfy the requirements for extracting the BVP signal, we conduct experimental verification by using the self-built facial expression video database. Each group of experiments was cross-validated, and the final results were averaged to increase the credibility of the experiment. The average recognition rates of single modality, i.e., facial expression or physiological signal, are 80% and 63.75%, respectively, whereas the emotion recognition result of the fusion of the two modalities is up to 83.33%, which is higher than that of each single modality before fusion. This finding indicates that the fusion decision algorithm with facial expression and BVP physiological signal is effective for emotion recognition. The experimental results of other fusion methods, namely, the D-S evidence theory and the maximum value rule, are 71% and 80%, respectively, which are lower than that of the fuzzy integral method. In addition, the recognition rate of our method is 2% and 2.5% higher than the results of the two existing video emotion recognition methods.ConclusionThe dual-modality space-time feature fusion method proposed in this study characterizes the emotion information contained in the facial videos from two aspects, i.e., the facial expression and the physiological signals, to make full use of the emotional information of the video. The experimental results show that this algorithm can make full use of the emotion information of the video and effectively improve the classification performance of video emotion recognition. The effectiveness of our proposed method in comparison to that of similar video emotion recognition algorithms is verified. In addition, the fuzzy integral is used to fuse two different modalities at the decision level. The reliability of different classifiers in the fusion process is considered and compared with that of D-S evidence theory and the maximum value rule. The influence of unreliable decision-making information on the fusion decision is effectively reduced. Finally, a high recognition accuracy is obtained by the proposed fusion method. The contrast experiment with other fusion methods also proves the superiority of the proposed fusion method.关键词:facial expression;physiological signal;video color amplification technology;fuzzy integral;dual-modality12|37|5更新时间:2024-05-07
摘要:ObjectiveWith the continuous development of artificial intelligence, researchers and scholars from other fields have become increasingly interested in providing computers with the capability to understand the emotions conveyed by(human beings and naturally interact with them. Therefore, emotion recognition has gradually become one of the key points of research to achieve harmonious human-computer interaction. The performance of video emotion recognition algorithms critically depends on the quality of the extracted emotion information. Previous research showed that facial expression is the most direct method to convey emotional information. Thus, current works usually rely on facial expressions only to complete emotion recognition. Feature extraction methods based on facial expression images are mostly based on gray images. However, during the conversion of color images into gray images, the latent physiological signals in the color information and the hidden physiological signals contained in facial videos that have discriminant information for emotion recognition are lost. In this study, a novel dual-modality video emotion recognition method for fusion decision, which combines facial expressions and blood volume pulse (BVP) physiological signals that can be extracted from facial videos, is introduced to overcome this problem.MethodFirst, the video is preprocessed (including face detection and normalization) to acquire a sequence of video frames that contain only the face image. The LBP-TOP feature is an effective local texture descriptor, whereas the HOG-TOP feature is a gradient-based local shape descriptor that can compensate for the lack of LBP-TOP feature extraction in image edge and direction information. Thus, in this study, we extract the LBP-TOP and HOG-TOP features from the video frames and fuse the two facial expression features. We use video color amplification technology to process the original video and extract the BVP physiological signal from the processed video. Then, the emotional feature of physiological signals can be extracted from the BVP physiological signal. Afterward, the two features are inputted into the BP classifier to train the classification models. Finally, the fuzzy integral is used to fuse the posterior probability information obtained by the two classifiers to obtain the final emotion recognition result.ResultConsidering that the current commonly used video emotion databases cannot satisfy the requirements for extracting the BVP signal, we conduct experimental verification by using the self-built facial expression video database. Each group of experiments was cross-validated, and the final results were averaged to increase the credibility of the experiment. The average recognition rates of single modality, i.e., facial expression or physiological signal, are 80% and 63.75%, respectively, whereas the emotion recognition result of the fusion of the two modalities is up to 83.33%, which is higher than that of each single modality before fusion. This finding indicates that the fusion decision algorithm with facial expression and BVP physiological signal is effective for emotion recognition. The experimental results of other fusion methods, namely, the D-S evidence theory and the maximum value rule, are 71% and 80%, respectively, which are lower than that of the fuzzy integral method. In addition, the recognition rate of our method is 2% and 2.5% higher than the results of the two existing video emotion recognition methods.ConclusionThe dual-modality space-time feature fusion method proposed in this study characterizes the emotion information contained in the facial videos from two aspects, i.e., the facial expression and the physiological signals, to make full use of the emotional information of the video. The experimental results show that this algorithm can make full use of the emotion information of the video and effectively improve the classification performance of video emotion recognition. The effectiveness of our proposed method in comparison to that of similar video emotion recognition algorithms is verified. In addition, the fuzzy integral is used to fuse two different modalities at the decision level. The reliability of different classifiers in the fusion process is considered and compared with that of D-S evidence theory and the maximum value rule. The influence of unreliable decision-making information on the fusion decision is effectively reduced. Finally, a high recognition accuracy is obtained by the proposed fusion method. The contrast experiment with other fusion methods also proves the superiority of the proposed fusion method.关键词:facial expression;physiological signal;video color amplification technology;fuzzy integral;dual-modality12|37|5更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveIn the research field of feature extraction and feature matching in large-scale 2D image retrieval, 3D model retrieval, and image stitching, we determined that the large number of redundant feature descriptors in an image and the high dimensionality of these feature descriptors have caused an intractable problem for large-scale image databases in terms of feature matching speed and retrieval efficiency and have resulted in the poor performance scalability of these feature descriptors. In this study, for the previously mentioned problems, we present a feature descriptor selection algorithm based on dictionary learning and entropy spatial constraints to reduce and even remove the redundant feature descriptors to the maximum extent. That is, in our algorithm, we aim to preserve only the most representative subset of feature descriptors and to ensure that the selected feature descriptors in our algorithm can have a consistent spatial distribution with the original feature descriptors set.MethodFirst, during our experiments, we observed the inner relativity between feature descriptor selection and dictionary learning problems in terms of the feature descriptor sparse representations. That is, based on the conception of sparse coding in dictionary learning, we determined that feature descriptor selection and dictionary learning are transferable between each other. Thus, we turn our feature descriptor selection problem into the research field of dictionary reconstruction. In the field of feature descriptor selection, we need to reduce the repeated feature descriptor points and save a small set of the most representative feature descriptors. After the transformation of the feature descriptor selection problems into dictionary learning tasks, we only need to identify the best key feature descriptors to reconstruct the original feature descriptor set under some conditions, such as the sparse and representative conditions, which we called dictionary reconstruction. After the transformation of the feature selection problem into the dictionary reconstruction task, we turn the feature descriptor selection problem into the research field of dictionary optimization. Second, after the transformation of our feature descriptor selection problem into a dictionary learning task, for the new dictionary of the original feature set, we design a new dictionary learning model to keep the robustness of our selected feature descriptors. In the field of dictionary learning, we take the entire original feature descriptor set as a dictionary and take the best representative feature descriptors as the keywords in our dictionary learning model. We derive the object functions of our dictionary reconstruction model, but our dictionary learning model is different from that of other situations because, in our dictionary learning model, we must ensure that the bases of our dictionary are unchangeable and the coefficients of the corresponding base are non-negative. On the basis of these limitations, we employ the simulated annealing algorithm to solve our object function and obtain the optimal solutions, which we finally take as the selected feature descriptors. Finally, during the process of dictionary learning, we add the entropy sparse constraint to save the spatial distribution characteristic of the original feature descriptor points to the largest extent, that is, we use entropy theory to limit dictionary learning. If the distribution of our final selected feature descriptor points is consistent with the original feature descriptor points, then the entropy value is low; otherwise, the entropy value is high. Thus, in this manner, we force our dictionary learning model to select the representative feature descriptor points with low value during the learning process, that is, our dictionary learning model tends to preserve the representative feature descriptor points whose spatial distribution is in accordance with the original feature descriptor points. Thus, we can finally obtain a small set of representative feature descriptors with good spatial distribution.ResultWe test our selected feature descriptors on two research fields to verify our feature descriptor selection algorithm. On the one hand, we implement our experiments on a large-scale image retrieval dataset, i.e., holiday image retrieval dataset, by comparing our algorithm with the existing feature descriptor selection methods. The experiments showed that our algorithm can considerably save memory space, increase the time efficiency of feature matching and image retrieval (30% to 50%), and improve the retrieval accuracy by approximately 8% to 14.1%. On the other hand, we test our feature descriptor selection algorithm on the standard image stitching dataset, i.e., IPM image stitching dataset. We verified our feature descriptor selection method on the aspects of feature extraction and feature matching in the research field of image stitching. The experiments on the IPM image stitching dataset proved that our feature descriptor selection algorithm achieved the best time saving (50% to 70%) with a low range of accuracy degradation.ConclusionCompared with the existing methods, our feature descriptor selection algorithm neither relies on the database nor loses important spatial structure and texture information, that is, our feature descriptor selection algorithm has a stable performance and strong scalability in different situations, many datasets, and various tasks, such as video retrieval, image search, picture retrieval, and image matching, which require feature extraction, feature selection, and feature matching operations. The experimental results indicated that our model has a stable adaptive performance to different datasets and various scenes. The image retrieval and image stitching experiments illustrated that our feature descriptor selection algorithm can be adapted to different situations and achieve a good performance, which surpasses that of other feature selection approaches. By contrast, with the advent of Big Data, the demand for the most valuable feature descriptors in our large number of image datasets is urgent, and our feature selection approach can be further adopted to reduce the redundant descriptors. According to our feature descriptor selection algorithm, we can achieve 50% to 70% reduction of noise feature descriptors and the main advantage of our approach in improving the efficiency and accuracy of feature matching in many mainstream tasks, such as the research fields of large-scale image retrieval, image stitching, and 3D model retrieval.关键词:feature selection;dictionary reconstruction;entropy spatial constrains;large-scale image retrieval;image stitching12|4|0更新时间:2024-05-07
摘要:ObjectiveIn the research field of feature extraction and feature matching in large-scale 2D image retrieval, 3D model retrieval, and image stitching, we determined that the large number of redundant feature descriptors in an image and the high dimensionality of these feature descriptors have caused an intractable problem for large-scale image databases in terms of feature matching speed and retrieval efficiency and have resulted in the poor performance scalability of these feature descriptors. In this study, for the previously mentioned problems, we present a feature descriptor selection algorithm based on dictionary learning and entropy spatial constraints to reduce and even remove the redundant feature descriptors to the maximum extent. That is, in our algorithm, we aim to preserve only the most representative subset of feature descriptors and to ensure that the selected feature descriptors in our algorithm can have a consistent spatial distribution with the original feature descriptors set.MethodFirst, during our experiments, we observed the inner relativity between feature descriptor selection and dictionary learning problems in terms of the feature descriptor sparse representations. That is, based on the conception of sparse coding in dictionary learning, we determined that feature descriptor selection and dictionary learning are transferable between each other. Thus, we turn our feature descriptor selection problem into the research field of dictionary reconstruction. In the field of feature descriptor selection, we need to reduce the repeated feature descriptor points and save a small set of the most representative feature descriptors. After the transformation of the feature descriptor selection problems into dictionary learning tasks, we only need to identify the best key feature descriptors to reconstruct the original feature descriptor set under some conditions, such as the sparse and representative conditions, which we called dictionary reconstruction. After the transformation of the feature selection problem into the dictionary reconstruction task, we turn the feature descriptor selection problem into the research field of dictionary optimization. Second, after the transformation of our feature descriptor selection problem into a dictionary learning task, for the new dictionary of the original feature set, we design a new dictionary learning model to keep the robustness of our selected feature descriptors. In the field of dictionary learning, we take the entire original feature descriptor set as a dictionary and take the best representative feature descriptors as the keywords in our dictionary learning model. We derive the object functions of our dictionary reconstruction model, but our dictionary learning model is different from that of other situations because, in our dictionary learning model, we must ensure that the bases of our dictionary are unchangeable and the coefficients of the corresponding base are non-negative. On the basis of these limitations, we employ the simulated annealing algorithm to solve our object function and obtain the optimal solutions, which we finally take as the selected feature descriptors. Finally, during the process of dictionary learning, we add the entropy sparse constraint to save the spatial distribution characteristic of the original feature descriptor points to the largest extent, that is, we use entropy theory to limit dictionary learning. If the distribution of our final selected feature descriptor points is consistent with the original feature descriptor points, then the entropy value is low; otherwise, the entropy value is high. Thus, in this manner, we force our dictionary learning model to select the representative feature descriptor points with low value during the learning process, that is, our dictionary learning model tends to preserve the representative feature descriptor points whose spatial distribution is in accordance with the original feature descriptor points. Thus, we can finally obtain a small set of representative feature descriptors with good spatial distribution.ResultWe test our selected feature descriptors on two research fields to verify our feature descriptor selection algorithm. On the one hand, we implement our experiments on a large-scale image retrieval dataset, i.e., holiday image retrieval dataset, by comparing our algorithm with the existing feature descriptor selection methods. The experiments showed that our algorithm can considerably save memory space, increase the time efficiency of feature matching and image retrieval (30% to 50%), and improve the retrieval accuracy by approximately 8% to 14.1%. On the other hand, we test our feature descriptor selection algorithm on the standard image stitching dataset, i.e., IPM image stitching dataset. We verified our feature descriptor selection method on the aspects of feature extraction and feature matching in the research field of image stitching. The experiments on the IPM image stitching dataset proved that our feature descriptor selection algorithm achieved the best time saving (50% to 70%) with a low range of accuracy degradation.ConclusionCompared with the existing methods, our feature descriptor selection algorithm neither relies on the database nor loses important spatial structure and texture information, that is, our feature descriptor selection algorithm has a stable performance and strong scalability in different situations, many datasets, and various tasks, such as video retrieval, image search, picture retrieval, and image matching, which require feature extraction, feature selection, and feature matching operations. The experimental results indicated that our model has a stable adaptive performance to different datasets and various scenes. The image retrieval and image stitching experiments illustrated that our feature descriptor selection algorithm can be adapted to different situations and achieve a good performance, which surpasses that of other feature selection approaches. By contrast, with the advent of Big Data, the demand for the most valuable feature descriptors in our large number of image datasets is urgent, and our feature selection approach can be further adopted to reduce the redundant descriptors. According to our feature descriptor selection algorithm, we can achieve 50% to 70% reduction of noise feature descriptors and the main advantage of our approach in improving the efficiency and accuracy of feature matching in many mainstream tasks, such as the research fields of large-scale image retrieval, image stitching, and 3D model retrieval.关键词:feature selection;dictionary reconstruction;entropy spatial constrains;large-scale image retrieval;image stitching12|4|0更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveGiven the rapid growth of remote sensing techniques, multispectral remote sensing images exhibit increasing potential for more applications. However, a multispectral image can be easily tampered with or forged during transmission and processing because of the widespread use of sophisticated image editing tools, which threatens the integrity of its content and reduces its value. Therefore, ensuring the content credibility and authenticity of multispectral imaged is a major issue before such images are used. However, existing authentication technologies cannot meet requirements because they are sensitive to each bit of the input data. Perceptual hashing, also known as robustness hash, is able to solve the problems of multispectral image content authentication. Perceptual hash has been developed as a frontier research topic in the field of digital media content security and can be applied to image content authentication, image retrieval, image registration, and digital watermarking. Similar to cryptographic hash functions, perceptual hash compresses the representation of the perceptual features of an image to generate a compact feature vector called perceptual hash value, which is a short summary of the perceptual content of an image. Although perceptual hash for the authentication of normal images has been extensively investigated, research on perceptual hashing for multispectral image authentication is limited. The bands of the MS remote sensing image obtain information from the visible and near-infrared spectra of reflected light, which have clear physical meanings. A multispectral image is composed of a set of monochrome images of the same scene, whereas a normal color image is composed of only three monochrome images and grayscale image that has only one channel. The existing perceptual hash algorithm essentially does not take this into account and cannot perceive the content of each band. In light of the data characteristics of the multispectral remote sensing image, a perceptual hash algorithm based on band feature fusion for multispectral image authentication is proposed in this study.MethodThe algorithm consists of four main stages, i.e., preprocessing, band fusion, feature extraction, and hash value generation. First, taking the large amount of data of multispectral image into consideration, the bands of the multispectral image are partitioned into grids. Given that the tamper location capability is built on the resolution of grid division, the choice of the grid division resolution presents the trade-off between cost and tamper location capability. Second, the grids with the same geographic location are decomposed and fused by two-level discrete wavelet transform, in which different fusion rules are used by low-frequency, intermediate-frequency, and high-frequency components to keep as many fringe features as possible. For intermediate-frequency components, the fusion rule of "maximum first" is selected; for low-frequency and high-frequency components, the adaptive weighted fusion is selected. This stage is intended for encoding the grids of the source bands into a single grid that contains the best aspects of the original grids, which could be suitable for hashing computation. Third, the edge features of the fusion result are extracted based on the Canny operator to construct the edge feature matrix. Given that the hash value has to be as compact and robust as possible to preserve content, the significant singular values are selected as the perceptual features of the fusion result after singular value decomposition on the matrix. Then, the selected singular value is normalized by the hash function to generate the perceptual hash value of the multispectral image. The number of singular values selected depends on the robustness requirement of the algorithm, and the security of the perceptual hash value depends on the selected hash function. The authentication process is implemented through a precise comparison between reconstructed and original perceptual hash values, and the tamper location can be determined if necessary.ResultThe experiments indicate that the proposed algorithm can achieve content integrity authentication for multispectral remote sensing images with only 32 bytes of authentication information and has good sensitivity to detect local detailed tampering of the multispectral image, such as removing an object, appending an object, and changing an object. The comparison of the hash values of each grid can be used to identify the tamper location and the corresponding geographic region, and the location granularity depends on the resolution of the grid division. By contrast, the proposed algorithm has approximately 100% robustness to lossless compression, has the least significant bit watermark embedding, and has relatively good robustness to lossy compression. In addition, the computational efficiency of the proposed algorithm is doubled that of the existing algorithm. The robustness of the algorithm can be adjusted by setting the number of selected singular values of the feature matrix.ConclusionThe experiments and discussions show that the proposed algorithm is sensitive to malicious tampering and is robust to content-preserving operations on multispectral images, whereas the hash value is relatively compact and the computational efficiency is relatively high. The algorithm can meet the requirement of integrity authentication for multispectral remote sensing image.关键词:multi-spectral remote sensing images;perceptual hashing;band fusion;integrity authentication;edge features;discrete wavelet transform (DWT)21|4|2更新时间:2024-05-07
摘要:ObjectiveGiven the rapid growth of remote sensing techniques, multispectral remote sensing images exhibit increasing potential for more applications. However, a multispectral image can be easily tampered with or forged during transmission and processing because of the widespread use of sophisticated image editing tools, which threatens the integrity of its content and reduces its value. Therefore, ensuring the content credibility and authenticity of multispectral imaged is a major issue before such images are used. However, existing authentication technologies cannot meet requirements because they are sensitive to each bit of the input data. Perceptual hashing, also known as robustness hash, is able to solve the problems of multispectral image content authentication. Perceptual hash has been developed as a frontier research topic in the field of digital media content security and can be applied to image content authentication, image retrieval, image registration, and digital watermarking. Similar to cryptographic hash functions, perceptual hash compresses the representation of the perceptual features of an image to generate a compact feature vector called perceptual hash value, which is a short summary of the perceptual content of an image. Although perceptual hash for the authentication of normal images has been extensively investigated, research on perceptual hashing for multispectral image authentication is limited. The bands of the MS remote sensing image obtain information from the visible and near-infrared spectra of reflected light, which have clear physical meanings. A multispectral image is composed of a set of monochrome images of the same scene, whereas a normal color image is composed of only three monochrome images and grayscale image that has only one channel. The existing perceptual hash algorithm essentially does not take this into account and cannot perceive the content of each band. In light of the data characteristics of the multispectral remote sensing image, a perceptual hash algorithm based on band feature fusion for multispectral image authentication is proposed in this study.MethodThe algorithm consists of four main stages, i.e., preprocessing, band fusion, feature extraction, and hash value generation. First, taking the large amount of data of multispectral image into consideration, the bands of the multispectral image are partitioned into grids. Given that the tamper location capability is built on the resolution of grid division, the choice of the grid division resolution presents the trade-off between cost and tamper location capability. Second, the grids with the same geographic location are decomposed and fused by two-level discrete wavelet transform, in which different fusion rules are used by low-frequency, intermediate-frequency, and high-frequency components to keep as many fringe features as possible. For intermediate-frequency components, the fusion rule of "maximum first" is selected; for low-frequency and high-frequency components, the adaptive weighted fusion is selected. This stage is intended for encoding the grids of the source bands into a single grid that contains the best aspects of the original grids, which could be suitable for hashing computation. Third, the edge features of the fusion result are extracted based on the Canny operator to construct the edge feature matrix. Given that the hash value has to be as compact and robust as possible to preserve content, the significant singular values are selected as the perceptual features of the fusion result after singular value decomposition on the matrix. Then, the selected singular value is normalized by the hash function to generate the perceptual hash value of the multispectral image. The number of singular values selected depends on the robustness requirement of the algorithm, and the security of the perceptual hash value depends on the selected hash function. The authentication process is implemented through a precise comparison between reconstructed and original perceptual hash values, and the tamper location can be determined if necessary.ResultThe experiments indicate that the proposed algorithm can achieve content integrity authentication for multispectral remote sensing images with only 32 bytes of authentication information and has good sensitivity to detect local detailed tampering of the multispectral image, such as removing an object, appending an object, and changing an object. The comparison of the hash values of each grid can be used to identify the tamper location and the corresponding geographic region, and the location granularity depends on the resolution of the grid division. By contrast, the proposed algorithm has approximately 100% robustness to lossless compression, has the least significant bit watermark embedding, and has relatively good robustness to lossy compression. In addition, the computational efficiency of the proposed algorithm is doubled that of the existing algorithm. The robustness of the algorithm can be adjusted by setting the number of selected singular values of the feature matrix.ConclusionThe experiments and discussions show that the proposed algorithm is sensitive to malicious tampering and is robust to content-preserving operations on multispectral images, whereas the hash value is relatively compact and the computational efficiency is relatively high. The algorithm can meet the requirement of integrity authentication for multispectral remote sensing image.关键词:multi-spectral remote sensing images;perceptual hashing;band fusion;integrity authentication;edge features;discrete wavelet transform (DWT)21|4|2更新时间:2024-05-07 -
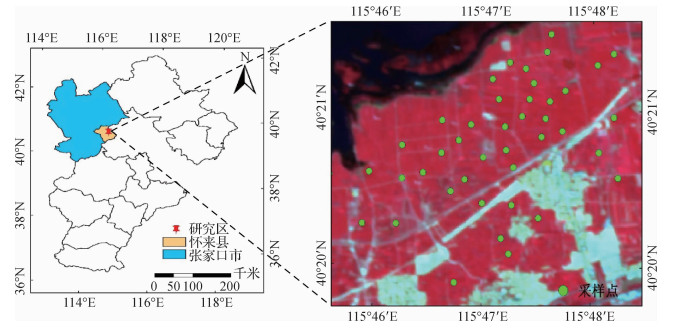 摘要:ObjectiveLeaf area index (LAI) is an important biological and physical parameter of vegetation, and it plays an important role in predicting crop growth and yield. A number of LAI estimation methods have been developed from remotely sensed data, each of which presents unique advantages and limitations. The empirical regression and physical models are the most widely used among these methods. The empirical regression model can reduce the effect of background noise on the spectral reflectance of plant canopies, and the physical model simulates the radiative transfer process in vegetation and describes the canopy spectral variation as a function of canopy, leaf, and soil background characteristics. However, the efficiency and accuracy of the two methods are limited. In recent years, machine learning algorithms have been widely used in remote sensing monitoring, and they can describe nonlinear data fitting and fuse more auxiliary information. This study evaluates the applicability of machine learning algorithms in maize LAI remote sensing estimation.MethodIn this study, the east garden of Huailai County in Hebei Province was used as the study area. Eight kinds of vegetation indices based on the GF1 WFV satellite images were calculated, and the correlation between the same-period measured LAI and the vegetation index was analyzed. Then, all the in situ measured corn LAI and corresponding eight vegetation indices were randomly divided into a training dataset and an independent model validation dataset (65% and 35% of the data, respectively). These datasets were randomly divided into three groups repeated three times. The training dataset was used to establish models to predict corn LAI, and the validation dataset was employed to test the quality of each prediction model. Finally, utilizing random forest, backpropagation (BP) neural network algorithm, and the traditional empirical model, the LAI inverting model was established based on previous work. This study compared the estimation accuracy of the three models for each sample group on the basis of the coefficient of determination (
摘要:ObjectiveLeaf area index (LAI) is an important biological and physical parameter of vegetation, and it plays an important role in predicting crop growth and yield. A number of LAI estimation methods have been developed from remotely sensed data, each of which presents unique advantages and limitations. The empirical regression and physical models are the most widely used among these methods. The empirical regression model can reduce the effect of background noise on the spectral reflectance of plant canopies, and the physical model simulates the radiative transfer process in vegetation and describes the canopy spectral variation as a function of canopy, leaf, and soil background characteristics. However, the efficiency and accuracy of the two methods are limited. In recent years, machine learning algorithms have been widely used in remote sensing monitoring, and they can describe nonlinear data fitting and fuse more auxiliary information. This study evaluates the applicability of machine learning algorithms in maize LAI remote sensing estimation.MethodIn this study, the east garden of Huailai County in Hebei Province was used as the study area. Eight kinds of vegetation indices based on the GF1 WFV satellite images were calculated, and the correlation between the same-period measured LAI and the vegetation index was analyzed. Then, all the in situ measured corn LAI and corresponding eight vegetation indices were randomly divided into a training dataset and an independent model validation dataset (65% and 35% of the data, respectively). These datasets were randomly divided into three groups repeated three times. The training dataset was used to establish models to predict corn LAI, and the validation dataset was employed to test the quality of each prediction model. Finally, utilizing random forest, backpropagation (BP) neural network algorithm, and the traditional empirical model, the LAI inverting model was established based on previous work. This study compared the estimation accuracy of the three models for each sample group on the basis of the coefficient of determination ($ R^2$ $ P$ $ R^2$ $ R^2$ $ R^2$ 关键词:random forest;back propagation neural network;leaf area index;machine learing;vegetation index;agricultural remote sensing monitoring11|5|5更新时间:2024-05-07
Remote Sensing Image Processing
-
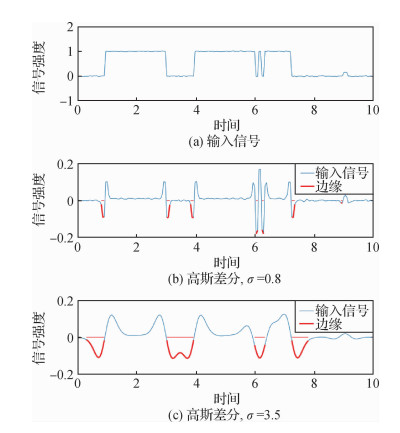 摘要:ObjectiveGenerating line drawings based on reference images is the most common application of non-photorealistic rendering, which is widely used in creative arts, scientific graphing, animation, video games, and print advertisement. During the creation of a line drawing, artists outline the contours of objects. The artists emphasize the main structure with long and thick lines and present the simple details with short and thin lines. Meanwhile, the artists barely use any ink for those unimportant regions on visual observation. A good line drawing successfully balances density and thickness features, thereby providing a sense of layering.MethodA line-drawing-simulating algorithm initially analyzes the features and visual importance of an input image and subsequently detects the edges to generate a contour line and form a line drawing with a certain flavor. Given its simplicity, difference of Gaussians (DoG) may be calculated as a simple approximation of the Marr operator, which is widely used for edge detection. A flow-based anisotropic filtering framework is produced to improve the continuity of edges. The new filtering framework initially forms an edge tangent field and subsequently applies a flow-based difference of Gaussians (FDoG) on the intermediate results. Finally, the hyperbolic tangent function in the framework will soften the calculated result and link the detected edge points to form a line drawing. Different spatial parameters of DoG can only detect the edge of different scales in the image. DoG with small-scale parameter finds thin edges, but most probably takes noise as an edge. By contrast, DoG with large-scale parameter finds thick edges and is capable of ignoring some noise, but most probably takes neighboring edges as noise. Thus, selecting the appropriate parameters of DoG is important. For images with multiple edge scales, the FDoG method based on fixed parameters is not adapted to detect the edges, which leads to unsatisfactory line drawings. This study presents an adaptive non-photorealistic rendering technique for stylizing a photograph in the line drawing style. Generating the final line drawing has three main steps. 1) We segment the reference image into different regions. In each region, we calculate the intensity variance and minimum distance to the region boundary of all of its pixels. We define the ratio of the intensity variance to the region boundary as its complexity. 2) We use the preprocessed results to construct a smooth and direction-enhanced edge flow field to indicate the visual significance of the region. 3) We use the flow field to guide the line drawing process with anisotropy Gaussian filter, in which the parameters are adaptively determined. Finally, the hyperbolic tangent function in the framework will soften the calculated result and link the detected edge points to form a line drawing. Several improvements have been made on the three steps. During the procedure acquiring the edge flow field, the tangential vector of each pixel is the weighted mean of the tangential vector of its neighbor. The tangent vectors from the same category have a similar direction, whereas the tangent vectors from different categories may behave differently. We introduce a new weight item to balance the weight of these vectors. If the pixel of the neighbor and the reference pixel are located in the same segmented region, then the weight is strong. During the DoG filtering process, the scale parameter of each pixel is based on the regional complexity of the pixel and the precomputed minimum distance between the pixel and the region boundary. If a pixel is in a detailed area or near the region boundary, then a small-scale parameter is set and weak and thin lines are highlighted. By applying this strategy, we prevent the formation of thick curves from thin curves. During Gaussian filtering of the DoG flow, if a pixel is in a detailed area or near the region boundary, then the scale parameter is small and short and thin lines are observed in complex areas. Thus, we have an improved chance of decreasing the possibility of incorrectly highlighting long and thick lines.ResultExperimental results show that the thickness and shade of the line produced by our approach change with the complexity of the image. Therefore, our approach can produce attractive and impressive line illustrations with a variety of photographs.ConclusionCompared with the fixed-parameter line drawing algorithm, our line drawing algorithm is more adaptive and has better results.关键词:non-photorealistic rendering;line drawing;edge tangent flow;image segmentation12|5|2更新时间:2024-05-07
摘要:ObjectiveGenerating line drawings based on reference images is the most common application of non-photorealistic rendering, which is widely used in creative arts, scientific graphing, animation, video games, and print advertisement. During the creation of a line drawing, artists outline the contours of objects. The artists emphasize the main structure with long and thick lines and present the simple details with short and thin lines. Meanwhile, the artists barely use any ink for those unimportant regions on visual observation. A good line drawing successfully balances density and thickness features, thereby providing a sense of layering.MethodA line-drawing-simulating algorithm initially analyzes the features and visual importance of an input image and subsequently detects the edges to generate a contour line and form a line drawing with a certain flavor. Given its simplicity, difference of Gaussians (DoG) may be calculated as a simple approximation of the Marr operator, which is widely used for edge detection. A flow-based anisotropic filtering framework is produced to improve the continuity of edges. The new filtering framework initially forms an edge tangent field and subsequently applies a flow-based difference of Gaussians (FDoG) on the intermediate results. Finally, the hyperbolic tangent function in the framework will soften the calculated result and link the detected edge points to form a line drawing. Different spatial parameters of DoG can only detect the edge of different scales in the image. DoG with small-scale parameter finds thin edges, but most probably takes noise as an edge. By contrast, DoG with large-scale parameter finds thick edges and is capable of ignoring some noise, but most probably takes neighboring edges as noise. Thus, selecting the appropriate parameters of DoG is important. For images with multiple edge scales, the FDoG method based on fixed parameters is not adapted to detect the edges, which leads to unsatisfactory line drawings. This study presents an adaptive non-photorealistic rendering technique for stylizing a photograph in the line drawing style. Generating the final line drawing has three main steps. 1) We segment the reference image into different regions. In each region, we calculate the intensity variance and minimum distance to the region boundary of all of its pixels. We define the ratio of the intensity variance to the region boundary as its complexity. 2) We use the preprocessed results to construct a smooth and direction-enhanced edge flow field to indicate the visual significance of the region. 3) We use the flow field to guide the line drawing process with anisotropy Gaussian filter, in which the parameters are adaptively determined. Finally, the hyperbolic tangent function in the framework will soften the calculated result and link the detected edge points to form a line drawing. Several improvements have been made on the three steps. During the procedure acquiring the edge flow field, the tangential vector of each pixel is the weighted mean of the tangential vector of its neighbor. The tangent vectors from the same category have a similar direction, whereas the tangent vectors from different categories may behave differently. We introduce a new weight item to balance the weight of these vectors. If the pixel of the neighbor and the reference pixel are located in the same segmented region, then the weight is strong. During the DoG filtering process, the scale parameter of each pixel is based on the regional complexity of the pixel and the precomputed minimum distance between the pixel and the region boundary. If a pixel is in a detailed area or near the region boundary, then a small-scale parameter is set and weak and thin lines are highlighted. By applying this strategy, we prevent the formation of thick curves from thin curves. During Gaussian filtering of the DoG flow, if a pixel is in a detailed area or near the region boundary, then the scale parameter is small and short and thin lines are observed in complex areas. Thus, we have an improved chance of decreasing the possibility of incorrectly highlighting long and thick lines.ResultExperimental results show that the thickness and shade of the line produced by our approach change with the complexity of the image. Therefore, our approach can produce attractive and impressive line illustrations with a variety of photographs.ConclusionCompared with the fixed-parameter line drawing algorithm, our line drawing algorithm is more adaptive and has better results.关键词:non-photorealistic rendering;line drawing;edge tangent flow;image segmentation12|5|2更新时间:2024-05-07 -
 摘要:ObjectiveBronzes are one of China's cultural treasures. However, most unearthed bronzes are broken and deformed, and restoration is needed to protect them. Recently, digital restoration technologies for cultural relics have attracted considerable attention with the development of 3D laser scanning technologies and the research progress in digital geometry processing. Patterns of the adjacent pieces of a broken bronze should be aligned during restoration to ensure the continuity of the patterns and guarantee high restoration quality. Consequently, the extraction of bronze patterns is a significant step in the restoration process.MethodGenerally, bronze patterns have apparent sharp edges, which distinguish decoration feature parts from non-decoration feature parts. Therefore, an algorithm for enhancing and extracting the sharp features of bronzes, which aims to extract pattern features, is proposed and implemented in this study. No interactive parameter setting is needed in the proposed algorithm, and the feature points are extracted automatically. First, a weighted projection distance is proposed to eliminate the adverse effect of the nonuniformity of the mesh on feature extraction. The projection distance of a vertex is the absolute value of the dot product between the normal at the vertex and the vector from the vertex to the center point of its one-ring neighborhood vertices. The projection distance of a vertex on sharp edges is always larger than that on non-sharp edges for a uniform triangular mesh model. Thus, it is easy to distinguish the feature point in this case. However, it is difficult to distinguish the feature point for the nonuniform mesh, which is more general in application. Therefore, the weighted projection distance, which means that all edges in the one-ring neighborhood of a vertex should be normalized first before calculating the projection distance, is more adaptive than the traditional projection distance for the triangular meshes in general. Then, reverse bilateral filtering is proposed and utilized to generate an anti-sharpening mask to enhance the weighted projection distance because the feature points are not obvious in the reconstructed mesh model of a real bronze as a result of the digital nature of the scanning process. The anti-sharpening mask is a three-step image enhancement process. First, the original image is filtered and subtracted from the smoothed image to obtain the weight. Second, the mask is added to the original image. Finally, the details of the image are enhanced. Reverse bilateral filtering is developed to filter all weighted projection distances with the intention to smooth all weighted projection distances of the feature points to the maximum extent instead of preserving features in bilateral filtering. The enhanced weighted projection distance is obtained by performing the three-step anti-sharpening mask in image enhancement. Consequently, a large weighted projection distance becomes even larger and a small weighted projection distance becomes even smaller. Finally, Otsu's method is applied to the histogram of the enhanced weighted projection distance to determine the optimal threshold automatically, and the vertices of the mesh model are classified into feature and non-feature point sets with the threshold.ResultWe compare the extraction results of our algorithm with those of Tran's algorithm with the scanned bronze models, including before and after weighted projection distance enhancement. All experiments show that better extraction results can be achieved with the proposed algorithm than the existing algorithms, and the identified feature points of the proposed algorithm are more continuous than those of the existing algorithms. The time consumed by all of the three models with vertex numbers between 6 000 and 800 000 is less than 10 s. Therefore, the proposed algorithm is effective, and its results are beneficial for the succeeding process.ConclusionThe decoration features of bronzes can be extracted automatically and efficiently with the proposed algorithm.关键词:bronze restoration;feature extraction;feature enhancement;automatic segmentation57|76|2更新时间:2024-05-07
摘要:ObjectiveBronzes are one of China's cultural treasures. However, most unearthed bronzes are broken and deformed, and restoration is needed to protect them. Recently, digital restoration technologies for cultural relics have attracted considerable attention with the development of 3D laser scanning technologies and the research progress in digital geometry processing. Patterns of the adjacent pieces of a broken bronze should be aligned during restoration to ensure the continuity of the patterns and guarantee high restoration quality. Consequently, the extraction of bronze patterns is a significant step in the restoration process.MethodGenerally, bronze patterns have apparent sharp edges, which distinguish decoration feature parts from non-decoration feature parts. Therefore, an algorithm for enhancing and extracting the sharp features of bronzes, which aims to extract pattern features, is proposed and implemented in this study. No interactive parameter setting is needed in the proposed algorithm, and the feature points are extracted automatically. First, a weighted projection distance is proposed to eliminate the adverse effect of the nonuniformity of the mesh on feature extraction. The projection distance of a vertex is the absolute value of the dot product between the normal at the vertex and the vector from the vertex to the center point of its one-ring neighborhood vertices. The projection distance of a vertex on sharp edges is always larger than that on non-sharp edges for a uniform triangular mesh model. Thus, it is easy to distinguish the feature point in this case. However, it is difficult to distinguish the feature point for the nonuniform mesh, which is more general in application. Therefore, the weighted projection distance, which means that all edges in the one-ring neighborhood of a vertex should be normalized first before calculating the projection distance, is more adaptive than the traditional projection distance for the triangular meshes in general. Then, reverse bilateral filtering is proposed and utilized to generate an anti-sharpening mask to enhance the weighted projection distance because the feature points are not obvious in the reconstructed mesh model of a real bronze as a result of the digital nature of the scanning process. The anti-sharpening mask is a three-step image enhancement process. First, the original image is filtered and subtracted from the smoothed image to obtain the weight. Second, the mask is added to the original image. Finally, the details of the image are enhanced. Reverse bilateral filtering is developed to filter all weighted projection distances with the intention to smooth all weighted projection distances of the feature points to the maximum extent instead of preserving features in bilateral filtering. The enhanced weighted projection distance is obtained by performing the three-step anti-sharpening mask in image enhancement. Consequently, a large weighted projection distance becomes even larger and a small weighted projection distance becomes even smaller. Finally, Otsu's method is applied to the histogram of the enhanced weighted projection distance to determine the optimal threshold automatically, and the vertices of the mesh model are classified into feature and non-feature point sets with the threshold.ResultWe compare the extraction results of our algorithm with those of Tran's algorithm with the scanned bronze models, including before and after weighted projection distance enhancement. All experiments show that better extraction results can be achieved with the proposed algorithm than the existing algorithms, and the identified feature points of the proposed algorithm are more continuous than those of the existing algorithms. The time consumed by all of the three models with vertex numbers between 6 000 and 800 000 is less than 10 s. Therefore, the proposed algorithm is effective, and its results are beneficial for the succeeding process.ConclusionThe decoration features of bronzes can be extracted automatically and efficiently with the proposed algorithm.关键词:bronze restoration;feature extraction;feature enhancement;automatic segmentation57|76|2更新时间:2024-05-07 -
 摘要:ObjectiveVideo highlight extraction is of interest in video summary, organization, browsing, and indexing. Current research mainly focuses on extraction by optimizing the low-level feature diversity or representativeness of video frames, ignoring the interests of users, which leads to extraction results that are inconsistent with the expectation of users. However, collecting a large number of required labeled videos to model different user interest concepts for different videos is time consuming and labor intensive.MethodWe propose to learn models for user interest concepts on different videos by leveraging numerous Web images that which cover many roughly annotated concepts and are often captured in a maximally informative manner to alleviate the labeling process. However, knowledge from the Web is noisy and diverse such that brute force knowledge transfer may adversely affect the highlight extraction performance. In this study, we propose a novel user-oriented keyframe extraction framework for online videos by leveraging a large number of Web images queried by synonyms from image search engines. Our work is based on the observation that users may have different interests in different frames when browsing the same video. By using user interest-related words as keywords, we can easily collect weakly labeled image data for interest concept model training. Given that different users may have different descriptions of the same interest concept, we denote different descriptions with similar semantic meanings as synonyms. When querying images from the Web, we use synonyms as keywords to avoid semantic one-sidedness. An image set returned by a synonym is considered a synonym group. Different synonym groups are weighted according to their relevance to the video frames. Moreover, the group weights and classifiers are simultaneously learned by a joint synonym group optimization problem to make them mutually beneficial and reciprocal. We also exploit the unlabeled online videos to optimize the group weights and classifiers for building the target classifier. Specifically, new data-dependent regularizers are introduced to enhance the generalization capability and adaptiveness of the target classifier.ResultOur method's mAP achieved 46.54 in average and boosted 21.6% compare to the stat-of-the-art without take much longer time. Experimental results several challenging video datasets that using grouped knowledge obtained from Web images for video highlight extraction is effective and provides comprehensive results.ConclusionWe presented a new framework for video highlight extraction by leveraging a large number of loosely labeled Web images. Specifically, we exploited synonym groups to learn more sophisticated representations of source domain Web images. The group classifiers and weights are jointly learned in a unified optimization algorithm to build the target domain classifiers. We also introduced two new data-dependent regularizers based on the unlabeled target domain consumer videos to enhance the generalization capability of the target classifier.关键词:video retrieval;highlights extraction;video analysis;knowledge transfer12|4|0更新时间:2024-05-07
摘要:ObjectiveVideo highlight extraction is of interest in video summary, organization, browsing, and indexing. Current research mainly focuses on extraction by optimizing the low-level feature diversity or representativeness of video frames, ignoring the interests of users, which leads to extraction results that are inconsistent with the expectation of users. However, collecting a large number of required labeled videos to model different user interest concepts for different videos is time consuming and labor intensive.MethodWe propose to learn models for user interest concepts on different videos by leveraging numerous Web images that which cover many roughly annotated concepts and are often captured in a maximally informative manner to alleviate the labeling process. However, knowledge from the Web is noisy and diverse such that brute force knowledge transfer may adversely affect the highlight extraction performance. In this study, we propose a novel user-oriented keyframe extraction framework for online videos by leveraging a large number of Web images queried by synonyms from image search engines. Our work is based on the observation that users may have different interests in different frames when browsing the same video. By using user interest-related words as keywords, we can easily collect weakly labeled image data for interest concept model training. Given that different users may have different descriptions of the same interest concept, we denote different descriptions with similar semantic meanings as synonyms. When querying images from the Web, we use synonyms as keywords to avoid semantic one-sidedness. An image set returned by a synonym is considered a synonym group. Different synonym groups are weighted according to their relevance to the video frames. Moreover, the group weights and classifiers are simultaneously learned by a joint synonym group optimization problem to make them mutually beneficial and reciprocal. We also exploit the unlabeled online videos to optimize the group weights and classifiers for building the target classifier. Specifically, new data-dependent regularizers are introduced to enhance the generalization capability and adaptiveness of the target classifier.ResultOur method's mAP achieved 46.54 in average and boosted 21.6% compare to the stat-of-the-art without take much longer time. Experimental results several challenging video datasets that using grouped knowledge obtained from Web images for video highlight extraction is effective and provides comprehensive results.ConclusionWe presented a new framework for video highlight extraction by leveraging a large number of loosely labeled Web images. Specifically, we exploited synonym groups to learn more sophisticated representations of source domain Web images. The group classifiers and weights are jointly learned in a unified optimization algorithm to build the target domain classifiers. We also introduced two new data-dependent regularizers based on the unlabeled target domain consumer videos to enhance the generalization capability of the target classifier.关键词:video retrieval;highlights extraction;video analysis;knowledge transfer12|4|0更新时间:2024-05-07 -
 摘要:ObjectiveWith the emergence of a large number of diverse and versatile display devices, the size of images must be adjusted appropriately with different resolutions and aspect ratios before displaying them on the devices. Content-aware image scaling technology has gradually become the focus of new research in the field of image processing, which resizes an image such that the prominent feature of the image is intact and the homogenous content is distorted as little as possible. This study proposes a novel content-aware image scaling method based on spring analogy to achieve image scaling effectively and have better capability to prevent the distortion of significant objects and feature lines.MethodWe resize an image by representing an image as a triangular mesh in 2D space and viewing each triangle edge as a spring. By deforming the spring system, we can implicitly retarget the image to its new size. First, for the input image, we use the saliency detection algorithm to generate the saliency of each pixel and employ the Hough transformation to detect the feature lines. Second, Delaunay triangulation of the sampling nodes of the image is employed to build a 2D triangular mesh on the input image to build a spring system for the image. A spring system on the mesh is constructed. Each edge of the mesh is considered a segment of an elastic spring, and the length of the edge is used as the initial equilibrium length of the spring. Once the boundary locations are changed by an external force, the interior will expand or contract to reach a new balance of the spring system, leading to a deformed mesh. Then, the image zoom is implemented through optimized deformation of the spring system. Furthermore, we assign a stiffness value to each spring segment to constrain its deformation in the balance of the spring system. Obviously, a high saliency of the image area is corresponds to great stiffness of the segments in the area and small distortion of the segments. Thus, we propose a new measure for spring stiffness, which uses image saliency to compute the elastic coefficient. The coefficient can effectively avoid the main content of inhomogeneous deformation. Finally, the objective function for constraining the deformation of the spring system is constructed by keeping the image linear features as constraints. We map the input image onto the deformed mesh to obtain the final resized image by using the trilinear interpolation method.ResultExtensive experiments and comparisons with other state-of-the-art methods (i.e., seam carving, quadratic programming, object size adjustment, shape-preserving approach, and methods based on spring analogy) show that our algorithm can better maintain the main region of the image and the feature line, and the scaled image has a better visual effect as a whole. The calculation time of the proposed method is less than 0.19 s, which is approximately the same as that of the existing method.ConclusionAn image scaling method based on spring analogy is proposed to achieve image zooming. Extensive experiments show that, compared with the existing content-aware image scaling approaches, our method has better visual effects and better ability to prevent the distortion of significant objects and feature lines关键词:content aware;image scaling;spring analogy;feature-preserving;important region21|60|2更新时间:2024-05-07
摘要:ObjectiveWith the emergence of a large number of diverse and versatile display devices, the size of images must be adjusted appropriately with different resolutions and aspect ratios before displaying them on the devices. Content-aware image scaling technology has gradually become the focus of new research in the field of image processing, which resizes an image such that the prominent feature of the image is intact and the homogenous content is distorted as little as possible. This study proposes a novel content-aware image scaling method based on spring analogy to achieve image scaling effectively and have better capability to prevent the distortion of significant objects and feature lines.MethodWe resize an image by representing an image as a triangular mesh in 2D space and viewing each triangle edge as a spring. By deforming the spring system, we can implicitly retarget the image to its new size. First, for the input image, we use the saliency detection algorithm to generate the saliency of each pixel and employ the Hough transformation to detect the feature lines. Second, Delaunay triangulation of the sampling nodes of the image is employed to build a 2D triangular mesh on the input image to build a spring system for the image. A spring system on the mesh is constructed. Each edge of the mesh is considered a segment of an elastic spring, and the length of the edge is used as the initial equilibrium length of the spring. Once the boundary locations are changed by an external force, the interior will expand or contract to reach a new balance of the spring system, leading to a deformed mesh. Then, the image zoom is implemented through optimized deformation of the spring system. Furthermore, we assign a stiffness value to each spring segment to constrain its deformation in the balance of the spring system. Obviously, a high saliency of the image area is corresponds to great stiffness of the segments in the area and small distortion of the segments. Thus, we propose a new measure for spring stiffness, which uses image saliency to compute the elastic coefficient. The coefficient can effectively avoid the main content of inhomogeneous deformation. Finally, the objective function for constraining the deformation of the spring system is constructed by keeping the image linear features as constraints. We map the input image onto the deformed mesh to obtain the final resized image by using the trilinear interpolation method.ResultExtensive experiments and comparisons with other state-of-the-art methods (i.e., seam carving, quadratic programming, object size adjustment, shape-preserving approach, and methods based on spring analogy) show that our algorithm can better maintain the main region of the image and the feature line, and the scaled image has a better visual effect as a whole. The calculation time of the proposed method is less than 0.19 s, which is approximately the same as that of the existing method.ConclusionAn image scaling method based on spring analogy is proposed to achieve image zooming. Extensive experiments show that, compared with the existing content-aware image scaling approaches, our method has better visual effects and better ability to prevent the distortion of significant objects and feature lines关键词:content aware;image scaling;spring analogy;feature-preserving;important region21|60|2更新时间:2024-05-07 -
 摘要:ObjectiveImage interpolation has become an active area of research in image processing, which can be easily extended to diverse applications ranging from medical imaging, remote sensing, aviation, animation production, and multimedia entertainment industries. A large number of image interpolation methods have been proposed by researchers. Generally, the interpolation methods can be divided into discrete and continuous methods. The adaptive interpolation methods based on discrete ideas can preserve the image structure of the edge. However, its performance in maintaining image details is less than satisfactory. The image cannot be amplified at any multiple by using discrete methods. And such methods are considerably time consuming. The interpolation methods based on continuous ideas can obtain rich image detail information but cannot maintain the image edge structure well. A new method of rational function image interpolation based on gradient optimization that has the advantages of the discrete and continuous methods is proposed.MethodFirst, a novel bivariate rational interpolation function is constructed. With varying shape parameters, the function has different forms of expression, i.e., an organic unity of polynomial and rational models. The constructed
摘要:ObjectiveImage interpolation has become an active area of research in image processing, which can be easily extended to diverse applications ranging from medical imaging, remote sensing, aviation, animation production, and multimedia entertainment industries. A large number of image interpolation methods have been proposed by researchers. Generally, the interpolation methods can be divided into discrete and continuous methods. The adaptive interpolation methods based on discrete ideas can preserve the image structure of the edge. However, its performance in maintaining image details is less than satisfactory. The image cannot be amplified at any multiple by using discrete methods. And such methods are considerably time consuming. The interpolation methods based on continuous ideas can obtain rich image detail information but cannot maintain the image edge structure well. A new method of rational function image interpolation based on gradient optimization that has the advantages of the discrete and continuous methods is proposed.MethodFirst, a novel bivariate rational interpolation function is constructed. With varying shape parameters, the function has different forms of expression, i.e., an organic unity of polynomial and rational models. The constructed${{\rm{C}}^2}$ 关键词:image interpolation;rational function;gradient optimization;regional division;isoline method12|4|2更新时间:2024-05-07
Column of GDC 2017
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0