
最新刊期
卷 23 , 期 3 , 2018
-
 摘要:ObjectiveVideo smoke detection methods can guarantee real-time fire alarms because these methods respond quickly to fire and have strong robustness to the environment, suitability for various scenes, and low-cost application. Many state-of-the-art video smoke detection methods have been proposed recently. The detection rates of these methods have been greatly improved by recent efforts, but these methods still suffer from the problem of high false and missing alarms. We provide an up-to-date critical survey of research on video smoke detection methods to keep up with the latest research progress, research focus, and development trends in video smoke detection. We focused on domestic and international research on video smoke detection published from 2014 to 2017. These publications include feature extraction, smoke recognition, and detection based on images and videos.MethodWe review papers on video smoke detection and summarize a general research framework for video smoke detection. The general framework of video smoke detection indicates that the general procedure of these methods is divided into several processing steps, namely, video preprocessing, detection of candidate smoke regions, feature extraction of smoke regions, video smoke classification, and other processing techniques. We discuss these methods in detail according to the general processing steps. Aside from describing traditional smoke detection methods based on handcrafted features, we also discuss and analyze deep learning-based smoke detection methods that were recently proposed given that deep learning is a hot area in machine learning research.ResultOn the basis of the general processing steps, we analyze these video preprocessing methods and divide the relevant literature into three major categories. These video preprocessing methods include preprocessing methods for color, preprocessing techniques for noise interference, and preprocessing approaches to image segmentation. Candidate smoke regions are detected in two ways. One way is to simply divide the image into a set of blocks, and each image block is tested. Some blocks may be classified as a candidate smoke region. Another way is to extract complete candidate smoke regions. The extraction methods of complete candidate smoke regions are sorted according to smoke motion and static characteristics. The information of smoke motion features can be obtained through object detection based on background modeling technology and object detection based on the simple differences of adjacent frames.Some static characteristics of smoke can be summed up as traditional features, such as color and shape. Other static characteristics are extracted by methods of a novel perspective. Statistical measures, transformation domain, and local features are classified into seven categories of features:color, shape, gradient, orientation, textures, frequency, and motion. Classification methods for video smoke detection are first reviewed and then categorized into two types, namely, rule-based methods and learning-based ones. Deep learning-based methods are reviewed independently because they are different from traditional smoke recognition methods. On the basis of the above analysis of these methods, we detail the advantages of existing video smoke detection methods. State-of-the-art methods with high detection rates and low false alarm rates have been proposed in recent years. Some novel methods exist. Some methods attempt to explore classification methods. Some datasets have been created and widely used to facilitate the training and testing of methods. We also elaborate the shortcomings of existing video smoke detection methods. The false alarm rates and error rates of detection methods remain high. Most algorithms are dependent on scenes and are easily disturbed by noise. Smoke features are simply combined without rules in some methods. Moreover, no publicly available video datasets exist with labeled smoke regions and standard evaluation criteria for video smoke detection. Finally, we suggest possible promising directions for future research. First, a set of video datasets is manually labeled, and standard evaluation criteria must be established. Second, researchers must explore essential features of smoke. Third, an effective fusing method for multiple smoke features extracted by different methods is needed. Fourth, smoke features must be automatically learned by machine learning methods instead of handcrafted designed ones. Finally, we refer to a new detection framework, such as deep learning-based frameworks, which are completely different from the basic framework.ConclusionVideo smoke detection methods are one of the most important and popular research topics nowadays. Our review and analysis of existing methods may provide researchers with powerful support for their work on early fire alarms, promote the advancement of video smoke detection, and further push industrial applications for video smoke detection.关键词:video smoke detection;smoke recognition;feature extraction;motion feature;static feature;local feature15|20|19更新时间:2024-05-07
摘要:ObjectiveVideo smoke detection methods can guarantee real-time fire alarms because these methods respond quickly to fire and have strong robustness to the environment, suitability for various scenes, and low-cost application. Many state-of-the-art video smoke detection methods have been proposed recently. The detection rates of these methods have been greatly improved by recent efforts, but these methods still suffer from the problem of high false and missing alarms. We provide an up-to-date critical survey of research on video smoke detection methods to keep up with the latest research progress, research focus, and development trends in video smoke detection. We focused on domestic and international research on video smoke detection published from 2014 to 2017. These publications include feature extraction, smoke recognition, and detection based on images and videos.MethodWe review papers on video smoke detection and summarize a general research framework for video smoke detection. The general framework of video smoke detection indicates that the general procedure of these methods is divided into several processing steps, namely, video preprocessing, detection of candidate smoke regions, feature extraction of smoke regions, video smoke classification, and other processing techniques. We discuss these methods in detail according to the general processing steps. Aside from describing traditional smoke detection methods based on handcrafted features, we also discuss and analyze deep learning-based smoke detection methods that were recently proposed given that deep learning is a hot area in machine learning research.ResultOn the basis of the general processing steps, we analyze these video preprocessing methods and divide the relevant literature into three major categories. These video preprocessing methods include preprocessing methods for color, preprocessing techniques for noise interference, and preprocessing approaches to image segmentation. Candidate smoke regions are detected in two ways. One way is to simply divide the image into a set of blocks, and each image block is tested. Some blocks may be classified as a candidate smoke region. Another way is to extract complete candidate smoke regions. The extraction methods of complete candidate smoke regions are sorted according to smoke motion and static characteristics. The information of smoke motion features can be obtained through object detection based on background modeling technology and object detection based on the simple differences of adjacent frames.Some static characteristics of smoke can be summed up as traditional features, such as color and shape. Other static characteristics are extracted by methods of a novel perspective. Statistical measures, transformation domain, and local features are classified into seven categories of features:color, shape, gradient, orientation, textures, frequency, and motion. Classification methods for video smoke detection are first reviewed and then categorized into two types, namely, rule-based methods and learning-based ones. Deep learning-based methods are reviewed independently because they are different from traditional smoke recognition methods. On the basis of the above analysis of these methods, we detail the advantages of existing video smoke detection methods. State-of-the-art methods with high detection rates and low false alarm rates have been proposed in recent years. Some novel methods exist. Some methods attempt to explore classification methods. Some datasets have been created and widely used to facilitate the training and testing of methods. We also elaborate the shortcomings of existing video smoke detection methods. The false alarm rates and error rates of detection methods remain high. Most algorithms are dependent on scenes and are easily disturbed by noise. Smoke features are simply combined without rules in some methods. Moreover, no publicly available video datasets exist with labeled smoke regions and standard evaluation criteria for video smoke detection. Finally, we suggest possible promising directions for future research. First, a set of video datasets is manually labeled, and standard evaluation criteria must be established. Second, researchers must explore essential features of smoke. Third, an effective fusing method for multiple smoke features extracted by different methods is needed. Fourth, smoke features must be automatically learned by machine learning methods instead of handcrafted designed ones. Finally, we refer to a new detection framework, such as deep learning-based frameworks, which are completely different from the basic framework.ConclusionVideo smoke detection methods are one of the most important and popular research topics nowadays. Our review and analysis of existing methods may provide researchers with powerful support for their work on early fire alarms, promote the advancement of video smoke detection, and further push industrial applications for video smoke detection.关键词:video smoke detection;smoke recognition;feature extraction;motion feature;static feature;local feature15|20|19更新时间:2024-05-07
Review

-
 摘要:ObjectiveImage stitching technology can be used to combine multiple narrow-angle images with overlapping regions into a one wide-angle image and has a wide range of applications. Image registration is the core method of image mosaic technology. The traditional registration method requires shooting a picture to meet the ideal condition in which the photographing device is located in a fixed point in a three-dimensional space. However, the ideal condition is often hard to achieve, which results in a certain parallax between images. Image registration with a large parallax is highly difficult, which affects the quality of image mosaic. This paper proposes a novel dominant sub-plane automatic registration algorithm to achieve a large parallax image registration for image stitching.MethodWe propose the hypothesis that large parallax images contain multiple dominant sub-planes and that feature points contained in each plane are densely distributed. To prove the hypothesis, we register the images after clustering feature points. Experimental result shows that the hypothesis is applicable to large parallax images. The proposed algorithm based on the distribution of feature points performs the local registration on the sub-plane segmented by clustering. First, feature points of the input images are extracted by scale-invariant feature transform, and the nearest neighbor principle is used to pre-match the feature points. The random sample consensus algorithm is used to remove the mismatched feature points, and the overlapping area of the image is delimited by feature points. A canvas that is the same as the overlap region is initialized, and all correctly matched feature points are mapped to the canvas. The hierarchical clustering algorithm is used to group the matched feature points. The grouping number is determined by the stitching error designed in this study. The overlapping regions are re-clustered by taking the clustering centers of each group feature point as new clustering centers to obtain the dominant sub-plane. The projection parameters of each sub-plane are solved through their feature points, and the projection matrix of the non-overlapping region is assigned by the nearest neighbor principle. The proposed algorithm needs to project the image multiple times for different regions. Thus, the use of traditional bilinear interpolation in the projection process has a significant boundary effect, and the nearest neighbor interpolation method can effectively overcome this problem. Visual effects are improved significantly.ResultThe algorithm is tested on public datasets and compared with two commercial software, auto-stitching and Microsoft Image Composite Editor (ICE), and two common methods, namely, baseline and as-projective-as-possible algorithm (APAP). Root mean square error (RMSE) was used as anobjectivecriterion for registration accuracy. Experimental results show that, compared with the baseline algorithm, the average RMSE of the proposed algorithm is reduced by approximately 55%. Many misaligned areas are aligned. Compared with the APAP algorithm, the accuracy is close, and the visual effect of registration is the same. The method in this paper can realize automatic registration without adjusting complex parameters. Compared with auto-stitching and Microsoft ICE, the method can effectively register the local area and eliminate the ghosting and dislocation caused by misalignment when stitching large parallax images.ConclusionThe proposed dominant sub-plane automatic registration algorithm achieves local registration by segmenting sub-planes contained in the image. Using the sub-plane local registration method can effectively overcome the global registration error. The area prone to ghosting and other issues can often be separated as a separate plane registration area that improves the accuracy of the local registration. This method has high registration accuracy for large parallax images and is better than some commercial software and advanced algorithms. The method can be applied to the registration of large parallax images in image mosaic. The proposed method is based on plane approximation and allocates the projection matrix of the non-overlapping region using the proximity principle. Thus, some accumulative distortion may be observed in the non-overlapping region of the images because of projection transformation, which affects the mosaic of multiple images. This paper combines some excellent image transformation methods to address projection distortion in non-overlapping regions and apply the algorithm in a panoramic image mosaic.关键词:image stitching;image registration;large parallax image;clustering;dominant sub-plane30|32|4更新时间:2024-05-07
摘要:ObjectiveImage stitching technology can be used to combine multiple narrow-angle images with overlapping regions into a one wide-angle image and has a wide range of applications. Image registration is the core method of image mosaic technology. The traditional registration method requires shooting a picture to meet the ideal condition in which the photographing device is located in a fixed point in a three-dimensional space. However, the ideal condition is often hard to achieve, which results in a certain parallax between images. Image registration with a large parallax is highly difficult, which affects the quality of image mosaic. This paper proposes a novel dominant sub-plane automatic registration algorithm to achieve a large parallax image registration for image stitching.MethodWe propose the hypothesis that large parallax images contain multiple dominant sub-planes and that feature points contained in each plane are densely distributed. To prove the hypothesis, we register the images after clustering feature points. Experimental result shows that the hypothesis is applicable to large parallax images. The proposed algorithm based on the distribution of feature points performs the local registration on the sub-plane segmented by clustering. First, feature points of the input images are extracted by scale-invariant feature transform, and the nearest neighbor principle is used to pre-match the feature points. The random sample consensus algorithm is used to remove the mismatched feature points, and the overlapping area of the image is delimited by feature points. A canvas that is the same as the overlap region is initialized, and all correctly matched feature points are mapped to the canvas. The hierarchical clustering algorithm is used to group the matched feature points. The grouping number is determined by the stitching error designed in this study. The overlapping regions are re-clustered by taking the clustering centers of each group feature point as new clustering centers to obtain the dominant sub-plane. The projection parameters of each sub-plane are solved through their feature points, and the projection matrix of the non-overlapping region is assigned by the nearest neighbor principle. The proposed algorithm needs to project the image multiple times for different regions. Thus, the use of traditional bilinear interpolation in the projection process has a significant boundary effect, and the nearest neighbor interpolation method can effectively overcome this problem. Visual effects are improved significantly.ResultThe algorithm is tested on public datasets and compared with two commercial software, auto-stitching and Microsoft Image Composite Editor (ICE), and two common methods, namely, baseline and as-projective-as-possible algorithm (APAP). Root mean square error (RMSE) was used as anobjectivecriterion for registration accuracy. Experimental results show that, compared with the baseline algorithm, the average RMSE of the proposed algorithm is reduced by approximately 55%. Many misaligned areas are aligned. Compared with the APAP algorithm, the accuracy is close, and the visual effect of registration is the same. The method in this paper can realize automatic registration without adjusting complex parameters. Compared with auto-stitching and Microsoft ICE, the method can effectively register the local area and eliminate the ghosting and dislocation caused by misalignment when stitching large parallax images.ConclusionThe proposed dominant sub-plane automatic registration algorithm achieves local registration by segmenting sub-planes contained in the image. Using the sub-plane local registration method can effectively overcome the global registration error. The area prone to ghosting and other issues can often be separated as a separate plane registration area that improves the accuracy of the local registration. This method has high registration accuracy for large parallax images and is better than some commercial software and advanced algorithms. The method can be applied to the registration of large parallax images in image mosaic. The proposed method is based on plane approximation and allocates the projection matrix of the non-overlapping region using the proximity principle. Thus, some accumulative distortion may be observed in the non-overlapping region of the images because of projection transformation, which affects the mosaic of multiple images. This paper combines some excellent image transformation methods to address projection distortion in non-overlapping regions and apply the algorithm in a panoramic image mosaic.关键词:image stitching;image registration;large parallax image;clustering;dominant sub-plane30|32|4更新时间:2024-05-07 -
 摘要:ObjectiveReconstructing defective images accurately and efficiently has become increasingly important nowadays. With the development of image analysis and recognition, many reconstructed images have been used for feature extraction, and few algorithms can realize accurate and efficient reconstruction effect. This study reconstructs local image regions based on the directional derivative of a field and proposes a stable field model of image local texture to achieve accuracy and reconstruction efficiency. The point source effect function is chosen as the transfer function of the pixel information relationship between the known region and the defect region. However, the designed point source effect function only considered the function of the gradient in the process of energy transfer. The energy transfer value of pixels in the defective region is calculated. The weighted summation is realized by average filtering. Experimental data show that the reconstruction of the edge of the geometry is not fine enough to greatly improve the accuracy of the actual image reconstruction. Given the problem of the accuracy and efficiency of the two-dimensional image reconstruction (or inpainting), this study designed the transfer function as the core function, proposed a new relative reconstruction algorithm, and mainly introduced the transfer function because this function involved energy transformation.MethodStationary images can be regarded as a stable energy field because of the stable result of the interaction between the surface and structure of object and light. Several studies have reconstructed defect images based on a stable field and have proven that the reconstruction effects can achieve the desired visual effect and high accuracy rate. Thus, the stable field model is used in this paper to describe the image local region. The energy value of the defect points is almost the same as that of the points in the nearest neighborhood. Thus, considering the value of these points is of great importance. In view of each pixel in the defect region, a reconstruction model considers the pixels in the known region as transmitting energy to each known pixel. During the reconstruction process, the energy is first transmitted into the nearest neighborhood, the transfer function is then constructed, and second-order Taylor expansion is introduced to achieve this process. Finally, the reconstruction is completed by interpolation according to the energy value in the nearest neighbor domain.ResultThis study reconstructed defect typical geometric graphs, gray images, and color images by using an algorithm that contains the transfer function and different interpolation methods. The interpolation methods include nearest neighbor interpolation, bilinear interpolation, and cubic convolution interpolation. Reconstruction results obtained by different interpolation methods are different. Compared with studies on reconstructing image local regions based on the directional derivative of a field, the typical curvature-driven diffusion, Bertalmio-Sapiro-Caselles-Ballester method, and total variation reconstruction algorithms, the reconstruction accuracy increased by approximately 6%, 10%, 15%, and 13% respectively, and the peak signal-to-noise ratio (PSNR) increased by approximately 2, 1, 3, and 2.5 dB, respectively. The reconstruction of the damaged edges and texture is clearer than that of the relative reconstruction models. Results improved considerably compared with traditional models because the proposed algorithm differs from traditional algorithms in certain aspects. For traditional algorithms, the main research idea is to use the information around the image defect area to transfer the inside of the region through several iterations. Once an iteration is performed, the value of the transfer function is updated to satisfy the visual effect of human visual observation. However, our algorithm does not involve iterations and transfers the energy value only once.ConclusionAn improved algorithm based on the foundation of the image local region's stable field model and the inpainting algorithms based on the stable field is proposed in this study, which investigates the transfer function of two-dimensional image reconstruction and the related reconstruction algorithms and shows the reconstruction of image edge and texture details. To maintain a good visual effect, the proposed method greatly improved reconstruction accuracy and PSNR, especially in the image defect region edge, and performs well in reconstructing texture details. Experimental results show that the proposed algorithm obtains good effects and has universal applicability to different types of images with varying degrees of defect.关键词:accurate reconstruction of 2-D image;stable field;transfer function;the nearest neighborhood;the second-order Taylor expansion12|4|1更新时间:2024-05-07
摘要:ObjectiveReconstructing defective images accurately and efficiently has become increasingly important nowadays. With the development of image analysis and recognition, many reconstructed images have been used for feature extraction, and few algorithms can realize accurate and efficient reconstruction effect. This study reconstructs local image regions based on the directional derivative of a field and proposes a stable field model of image local texture to achieve accuracy and reconstruction efficiency. The point source effect function is chosen as the transfer function of the pixel information relationship between the known region and the defect region. However, the designed point source effect function only considered the function of the gradient in the process of energy transfer. The energy transfer value of pixels in the defective region is calculated. The weighted summation is realized by average filtering. Experimental data show that the reconstruction of the edge of the geometry is not fine enough to greatly improve the accuracy of the actual image reconstruction. Given the problem of the accuracy and efficiency of the two-dimensional image reconstruction (or inpainting), this study designed the transfer function as the core function, proposed a new relative reconstruction algorithm, and mainly introduced the transfer function because this function involved energy transformation.MethodStationary images can be regarded as a stable energy field because of the stable result of the interaction between the surface and structure of object and light. Several studies have reconstructed defect images based on a stable field and have proven that the reconstruction effects can achieve the desired visual effect and high accuracy rate. Thus, the stable field model is used in this paper to describe the image local region. The energy value of the defect points is almost the same as that of the points in the nearest neighborhood. Thus, considering the value of these points is of great importance. In view of each pixel in the defect region, a reconstruction model considers the pixels in the known region as transmitting energy to each known pixel. During the reconstruction process, the energy is first transmitted into the nearest neighborhood, the transfer function is then constructed, and second-order Taylor expansion is introduced to achieve this process. Finally, the reconstruction is completed by interpolation according to the energy value in the nearest neighbor domain.ResultThis study reconstructed defect typical geometric graphs, gray images, and color images by using an algorithm that contains the transfer function and different interpolation methods. The interpolation methods include nearest neighbor interpolation, bilinear interpolation, and cubic convolution interpolation. Reconstruction results obtained by different interpolation methods are different. Compared with studies on reconstructing image local regions based on the directional derivative of a field, the typical curvature-driven diffusion, Bertalmio-Sapiro-Caselles-Ballester method, and total variation reconstruction algorithms, the reconstruction accuracy increased by approximately 6%, 10%, 15%, and 13% respectively, and the peak signal-to-noise ratio (PSNR) increased by approximately 2, 1, 3, and 2.5 dB, respectively. The reconstruction of the damaged edges and texture is clearer than that of the relative reconstruction models. Results improved considerably compared with traditional models because the proposed algorithm differs from traditional algorithms in certain aspects. For traditional algorithms, the main research idea is to use the information around the image defect area to transfer the inside of the region through several iterations. Once an iteration is performed, the value of the transfer function is updated to satisfy the visual effect of human visual observation. However, our algorithm does not involve iterations and transfers the energy value only once.ConclusionAn improved algorithm based on the foundation of the image local region's stable field model and the inpainting algorithms based on the stable field is proposed in this study, which investigates the transfer function of two-dimensional image reconstruction and the related reconstruction algorithms and shows the reconstruction of image edge and texture details. To maintain a good visual effect, the proposed method greatly improved reconstruction accuracy and PSNR, especially in the image defect region edge, and performs well in reconstructing texture details. Experimental results show that the proposed algorithm obtains good effects and has universal applicability to different types of images with varying degrees of defect.关键词:accurate reconstruction of 2-D image;stable field;transfer function;the nearest neighborhood;the second-order Taylor expansion12|4|1更新时间:2024-05-07 -
 摘要:ObjectiveSeveral commonalities can be observed among all image encryption algorithms, which are based on a chaotic system. Most secret key generating sources are for the single chaos system, but they lack high randomicity and uniformity. Scramblings only use pixel rank swap, Arnold transform, Baker transform, sequences structure substitution table, and other common methods. The entire encryption process involves one-pixel position scrambling and pixel replacement. This paper proposes a highly secure image encryption algorithm, that is, a dynamic self-feedback chaotic system image encryption algorithm that integrates a neural network scrambling image.MethodThe algorithm constructs a dynamic self-feedback chaotic system as the secret key generation source. The specific practice is to obtain output using the one-dimensional Logistic chaotic system and the Chebyshev chaotic system through a custom m(
摘要:ObjectiveSeveral commonalities can be observed among all image encryption algorithms, which are based on a chaotic system. Most secret key generating sources are for the single chaos system, but they lack high randomicity and uniformity. Scramblings only use pixel rank swap, Arnold transform, Baker transform, sequences structure substitution table, and other common methods. The entire encryption process involves one-pixel position scrambling and pixel replacement. This paper proposes a highly secure image encryption algorithm, that is, a dynamic self-feedback chaotic system image encryption algorithm that integrates a neural network scrambling image.MethodThe algorithm constructs a dynamic self-feedback chaotic system as the secret key generation source. The specific practice is to obtain output using the one-dimensional Logistic chaotic system and the Chebyshev chaotic system through a custom m($x$ 关键词:dynamic self-feedback chaotic system;neural network;randomness;double scrambling;image encryption11|4|1更新时间:2024-05-07
Image Processing and Coding
-
 摘要:ObjectiveIn recent years, 3D television (3DTV) and virtual reality technology have developed rapidly, but the shortage of 3D resources has become the bottleneck of this technology development. Existing 2D videos must be converted to 3D videos to provide more 3D resources quickly. Depth estimation is the key step of 2D to 3D technology. Hardware implementation is one of the effective methods to meet the requirements of real-time conversion process. Most depth estimation algorithms make hardware implementation highly complex. Considering the depth estimation effect and easy implementation, this study proposes a hardware implementation scheme based on relative height and depth cue method to realize high-speed processing and hardware resource saving.MethodFor the algorithm level, a color image is first converted to grayscale, and the edge graph is obtained by Sobel edge detection of a grayscale image. Line trace is obtained by a line tracing algorithm, and the depth map is obtained by the depth assignment of the line trajectory.In hardware implementation, Sobel edge detection uses a five-stage pipeline design and parallel trajectory calculation to maximize the parallelism of hardware design to improve system efficiency. In the depth estimation, energy function is simplified by equivalent processing. Thus, a large number of multiplication, division, and exponential operations are replaced by addition, subtraction, and comparison operations. More than 2 300 multiplication and division operations and more than 780 exponential operations are reduced, thereby reducing hardware resource cost. Given that linear tracking and depth assignment are performed in columns, edge graph informationneeds to be converted from rows to columns. In this design, SDRAM burst characteristics are used to complete row-column conversion and save system hardware resources. The hardware implementation scheme is designed with VERILOG-HDL, a hardware description language.ResultThe study selects two typical images, including buildings and people, and verifies the algorithm based on the Altera DE2-115 FPGA platform to verify the feasibility of the hardware implementation method. The verification method is as follows:First, the design with VERILOG-HDL is simulated with QUARTUS-Ⅱ.A grayscale picture with a size of 1 024×768 pixels is downloaded to FPGA through the serial port, and the depth map is estimated by FPGA. The data are later sent to the PC terminal through a serial port, and the depth map is drawn by MATLAB. Simulation and verification results show that the proposed hardware implementation method can extract the depth of 2D images correctly, and the estimated frame rate is up to 33.18 fps at 100 MHz clock frequency.Finally, the hardware processing effect is compared with the software processing effect of this method and the typical motion estimation algorithm, and the peak signal-to-noise ratio(PSNR) after image processing is calculated. Experimental results show that the PSNR of the three methods for the building picture is 13.147, 13.028, and 13.208 4 and that the PSNR of the three methods for the character image is 11.072 8, 10.94, and 10.980 4. Thus, the proposed algorithm is more effective than the motion estimation method, and the hardware processing method can achieve the depth of 2D image extraction, which is consistent with the software processing.ConclusionThe proposed hardware implementation can complete the depth information extraction of an image. The estimated frame rate is larger than the real-time requirements in 3D video applications, such as 24 fram/s in 3DTV, and has good real-time performance and portability, thereby establishing a foundation for video information processing. However, similar to methods based on other typical algorithms such as motion estimation, the edge of the extracted depth map in this study remains sharp with burr. Future works can consider the use of a digital filter to smooth the depth map and improve quality.关键词:relative height depth clue;Sobel;linear tracing;five-stage pipeline;depth map11|4|1更新时间:2024-05-07
摘要:ObjectiveIn recent years, 3D television (3DTV) and virtual reality technology have developed rapidly, but the shortage of 3D resources has become the bottleneck of this technology development. Existing 2D videos must be converted to 3D videos to provide more 3D resources quickly. Depth estimation is the key step of 2D to 3D technology. Hardware implementation is one of the effective methods to meet the requirements of real-time conversion process. Most depth estimation algorithms make hardware implementation highly complex. Considering the depth estimation effect and easy implementation, this study proposes a hardware implementation scheme based on relative height and depth cue method to realize high-speed processing and hardware resource saving.MethodFor the algorithm level, a color image is first converted to grayscale, and the edge graph is obtained by Sobel edge detection of a grayscale image. Line trace is obtained by a line tracing algorithm, and the depth map is obtained by the depth assignment of the line trajectory.In hardware implementation, Sobel edge detection uses a five-stage pipeline design and parallel trajectory calculation to maximize the parallelism of hardware design to improve system efficiency. In the depth estimation, energy function is simplified by equivalent processing. Thus, a large number of multiplication, division, and exponential operations are replaced by addition, subtraction, and comparison operations. More than 2 300 multiplication and division operations and more than 780 exponential operations are reduced, thereby reducing hardware resource cost. Given that linear tracking and depth assignment are performed in columns, edge graph informationneeds to be converted from rows to columns. In this design, SDRAM burst characteristics are used to complete row-column conversion and save system hardware resources. The hardware implementation scheme is designed with VERILOG-HDL, a hardware description language.ResultThe study selects two typical images, including buildings and people, and verifies the algorithm based on the Altera DE2-115 FPGA platform to verify the feasibility of the hardware implementation method. The verification method is as follows:First, the design with VERILOG-HDL is simulated with QUARTUS-Ⅱ.A grayscale picture with a size of 1 024×768 pixels is downloaded to FPGA through the serial port, and the depth map is estimated by FPGA. The data are later sent to the PC terminal through a serial port, and the depth map is drawn by MATLAB. Simulation and verification results show that the proposed hardware implementation method can extract the depth of 2D images correctly, and the estimated frame rate is up to 33.18 fps at 100 MHz clock frequency.Finally, the hardware processing effect is compared with the software processing effect of this method and the typical motion estimation algorithm, and the peak signal-to-noise ratio(PSNR) after image processing is calculated. Experimental results show that the PSNR of the three methods for the building picture is 13.147, 13.028, and 13.208 4 and that the PSNR of the three methods for the character image is 11.072 8, 10.94, and 10.980 4. Thus, the proposed algorithm is more effective than the motion estimation method, and the hardware processing method can achieve the depth of 2D image extraction, which is consistent with the software processing.ConclusionThe proposed hardware implementation can complete the depth information extraction of an image. The estimated frame rate is larger than the real-time requirements in 3D video applications, such as 24 fram/s in 3DTV, and has good real-time performance and portability, thereby establishing a foundation for video information processing. However, similar to methods based on other typical algorithms such as motion estimation, the edge of the extracted depth map in this study remains sharp with burr. Future works can consider the use of a digital filter to smooth the depth map and improve quality.关键词:relative height depth clue;Sobel;linear tracing;five-stage pipeline;depth map11|4|1更新时间:2024-05-07 -
 摘要:ObjectiveThe traditional SLAM system requires a camera to return to the position where tracking is lost to restart location and mapping, thereby greatly limiting the application of monocular SLAM scenarios. Thus, a new and highly adaptive recovery strategy is required. In a traditional keyframe-based SLAM system, relocalization is achieved by finding the keyframes (a reference camera pose and image) that match the current frame to estimate the camera pose. Localization only to previously visited places where keyframes were added to the map is possible. In practical application, relocalization is not a user-friendly solution because users prefer to walk into previous unseen areas where no associated keyframes exist. Moreover, finding matches between the two frames is difficult when the scene changes considerably. Tracking resumption can even be difficult when the camera arrives at the place from where it has been. The motion and map message during lost time cannot be recovered, which leads to an imperfect map. Thus, this study proposes a strategy of monocular vision combined with inertial measurement unit (IMU) to recover a lost map based on map fusion.MethodThe ORB_SLAM system incorporates three threads that run in parallel:tracking, local mapping, and loop closing. Our algorithm improved on the basis of ORB_SLAM. When tracking fails in conditions with motion blur or occlusions, our system immediately restarts a new map. The first map created before tracking lost is saved, and relocalization is achieved by fusing the two maps. A new map is created by re-initializing. Compared with relocalization, initialization is achievable, whereas the scale of the camera trajectory computed by ORB_SLAM is arbitrary. The inconsistent scale must be solved first to fuse the two maps. The absolute scale of the map is calculated by combining monocular vision with IMU. The IMU sensor can recover the metric scale for monocular vision and is affected by the limitation of vision. The position of the camera is calculated by IMU data before the initialization is completed. The pose information during lost time can be used as a bridge to fuse the two maps when the new map is initialized. The process of map fusion consists of three steps:1) Coordinate transformation. The coordinate system of the new map has changed after re-initialization. The transformation between the new map and the lost map can be computed by IMU during the lost time, which is applied to the lost map to move the lost map onto the new map. 2) Matching strategy. The data measured by IMU contains various errors unavoidably affect the result of the map fusion. Thus, vision information is considered to eliminate errors. A jumping matching search strategy is proposed according to the covisibility relationship between keyframes to reduce matching time. We match keyframes selected from the two maps according to a certain condition instead of matching them individually. Thus, a considerable amount of matching time can be reduced. 3) Estimating the error between the two maps. After a set of matching map points is obtained, motion estimation between the matching points is solved by nonlinear optimization, which is applied to the two maps to reduce errors. Finally, the new map points in the matching map points are erased, and the two maps are merged. The relationship of the keyframes and the map points between the old and new maps is established, which are used to jointly optimize the pose of the camera and the position of the map points in subsequent tracking and mapping.ResultThe algorithm is tested on an open dataset (visual-inertial datasets collected onboard a micro aerial vehicle). Results show that our method can effectively solve the system's inability to keep the map and location when SLAM system tracking fails. The experiment includes map accuracy and map completeness. When referring to accuracy, the trajectory of the fusion map achieves a typical precision of 8 cm for a 30 m2 room environment and a 300 m2 industrial environment compared with the ground truth. We compare fusion trajectory with the trajectory without loss and find that the precision can reach 4 cm. In case the camera moves violently, the map recovered by our algorithm is more complete than that by the ORB_SLAM relocalization algorithm. The result of our algorithm contains 30% more keyframes than the ORB_SLAM algorithm.ConclusionThe proposed algorithm can retrieve tracking by merging maps if tracking is lost and recover the trajectory during the lost time. Compared with the traditional SLAM system, our relocalization strategy does not need the camera to return to the previous place visited but only requires one to observe part of the place before the loss. Our algorithm is more adaptive than the ORB_SLAM algorithm in case the tracking fails soon after initialization.关键词:simultaneous localization and mapping;inertial measurement unit;relocalization;map merging;coordinate transformation11|4|2更新时间:2024-05-07
摘要:ObjectiveThe traditional SLAM system requires a camera to return to the position where tracking is lost to restart location and mapping, thereby greatly limiting the application of monocular SLAM scenarios. Thus, a new and highly adaptive recovery strategy is required. In a traditional keyframe-based SLAM system, relocalization is achieved by finding the keyframes (a reference camera pose and image) that match the current frame to estimate the camera pose. Localization only to previously visited places where keyframes were added to the map is possible. In practical application, relocalization is not a user-friendly solution because users prefer to walk into previous unseen areas where no associated keyframes exist. Moreover, finding matches between the two frames is difficult when the scene changes considerably. Tracking resumption can even be difficult when the camera arrives at the place from where it has been. The motion and map message during lost time cannot be recovered, which leads to an imperfect map. Thus, this study proposes a strategy of monocular vision combined with inertial measurement unit (IMU) to recover a lost map based on map fusion.MethodThe ORB_SLAM system incorporates three threads that run in parallel:tracking, local mapping, and loop closing. Our algorithm improved on the basis of ORB_SLAM. When tracking fails in conditions with motion blur or occlusions, our system immediately restarts a new map. The first map created before tracking lost is saved, and relocalization is achieved by fusing the two maps. A new map is created by re-initializing. Compared with relocalization, initialization is achievable, whereas the scale of the camera trajectory computed by ORB_SLAM is arbitrary. The inconsistent scale must be solved first to fuse the two maps. The absolute scale of the map is calculated by combining monocular vision with IMU. The IMU sensor can recover the metric scale for monocular vision and is affected by the limitation of vision. The position of the camera is calculated by IMU data before the initialization is completed. The pose information during lost time can be used as a bridge to fuse the two maps when the new map is initialized. The process of map fusion consists of three steps:1) Coordinate transformation. The coordinate system of the new map has changed after re-initialization. The transformation between the new map and the lost map can be computed by IMU during the lost time, which is applied to the lost map to move the lost map onto the new map. 2) Matching strategy. The data measured by IMU contains various errors unavoidably affect the result of the map fusion. Thus, vision information is considered to eliminate errors. A jumping matching search strategy is proposed according to the covisibility relationship between keyframes to reduce matching time. We match keyframes selected from the two maps according to a certain condition instead of matching them individually. Thus, a considerable amount of matching time can be reduced. 3) Estimating the error between the two maps. After a set of matching map points is obtained, motion estimation between the matching points is solved by nonlinear optimization, which is applied to the two maps to reduce errors. Finally, the new map points in the matching map points are erased, and the two maps are merged. The relationship of the keyframes and the map points between the old and new maps is established, which are used to jointly optimize the pose of the camera and the position of the map points in subsequent tracking and mapping.ResultThe algorithm is tested on an open dataset (visual-inertial datasets collected onboard a micro aerial vehicle). Results show that our method can effectively solve the system's inability to keep the map and location when SLAM system tracking fails. The experiment includes map accuracy and map completeness. When referring to accuracy, the trajectory of the fusion map achieves a typical precision of 8 cm for a 30 m2 room environment and a 300 m2 industrial environment compared with the ground truth. We compare fusion trajectory with the trajectory without loss and find that the precision can reach 4 cm. In case the camera moves violently, the map recovered by our algorithm is more complete than that by the ORB_SLAM relocalization algorithm. The result of our algorithm contains 30% more keyframes than the ORB_SLAM algorithm.ConclusionThe proposed algorithm can retrieve tracking by merging maps if tracking is lost and recover the trajectory during the lost time. Compared with the traditional SLAM system, our relocalization strategy does not need the camera to return to the previous place visited but only requires one to observe part of the place before the loss. Our algorithm is more adaptive than the ORB_SLAM algorithm in case the tracking fails soon after initialization.关键词:simultaneous localization and mapping;inertial measurement unit;relocalization;map merging;coordinate transformation11|4|2更新时间:2024-05-07 -
 摘要:ObjectiveA target tracking algorithm is proposed to address violent deformation of the target during the tracking process, especially a dramatic scale change, which leads to tracking failure. This algorithm is considered by fusing invariant scalable key points matching and image saliency.MethodFirst, the target template and its feature point set are determined using the initial frame of a video sequence. Feature points are extracted from the initial frame by the improved BRISK feature point detection algorithm. The feature points of the current frame are extracted and matched with the target template feature points by using the FLANN method to obtain a subset of matching feature points. Second, the matching feature points and the light flow feature points are fused to determine the set of reliable feature points. Third, on the basis of the set of reliable feature points and the target template feature points, a homography transformation matrix is calculated to determine the target tracking box. The target tracking box is located based on image saliency, which is calculated by using the LC method. Finally, the target tracking box is adaptively determined by fusing image saliency and reliability feature points. In response to a highly severe non-rigid deformation, the target template and the target template feature point set are updated when the target in three consecutive frames is drastically deformed.ResultA total of 2 214 frames of images with intense deformation of eight video sequences were selected from OTB2013 dataset as experimental datasets to verify the performance of the proposed algorithm. In a coincidence degree experiment, the algorithm in this paper can achieve an average coincidence degree of 0.567 1, which is better than the current advanced tracking algorithm. In the experiment of coincidence degree success rate, the proposed algorithm also has a better tracking effect than the current advanced tracking algorithm. Vega Prime is used to simulate UAV aerial video sequences, in which the object undergoes dramatic deformation. The maximum deformation of the target in the sequence exceeds 14, and the maximum deformation between frames reaches 1.72. Experiments show that the proposed algorithm has an improved tracking effect on this video sequence.ConclusionExperimental results show that the proposed algorithm can track the target of violent deformation, especially the target of violent scale change. The proposed algorithm has good real-time performance and an average frame rate of 48.6 frames/second.关键词:object tracking;deformation;scale change;image saliency;keypoints matching11|4|3更新时间:2024-05-07
摘要:ObjectiveA target tracking algorithm is proposed to address violent deformation of the target during the tracking process, especially a dramatic scale change, which leads to tracking failure. This algorithm is considered by fusing invariant scalable key points matching and image saliency.MethodFirst, the target template and its feature point set are determined using the initial frame of a video sequence. Feature points are extracted from the initial frame by the improved BRISK feature point detection algorithm. The feature points of the current frame are extracted and matched with the target template feature points by using the FLANN method to obtain a subset of matching feature points. Second, the matching feature points and the light flow feature points are fused to determine the set of reliable feature points. Third, on the basis of the set of reliable feature points and the target template feature points, a homography transformation matrix is calculated to determine the target tracking box. The target tracking box is located based on image saliency, which is calculated by using the LC method. Finally, the target tracking box is adaptively determined by fusing image saliency and reliability feature points. In response to a highly severe non-rigid deformation, the target template and the target template feature point set are updated when the target in three consecutive frames is drastically deformed.ResultA total of 2 214 frames of images with intense deformation of eight video sequences were selected from OTB2013 dataset as experimental datasets to verify the performance of the proposed algorithm. In a coincidence degree experiment, the algorithm in this paper can achieve an average coincidence degree of 0.567 1, which is better than the current advanced tracking algorithm. In the experiment of coincidence degree success rate, the proposed algorithm also has a better tracking effect than the current advanced tracking algorithm. Vega Prime is used to simulate UAV aerial video sequences, in which the object undergoes dramatic deformation. The maximum deformation of the target in the sequence exceeds 14, and the maximum deformation between frames reaches 1.72. Experiments show that the proposed algorithm has an improved tracking effect on this video sequence.ConclusionExperimental results show that the proposed algorithm can track the target of violent deformation, especially the target of violent scale change. The proposed algorithm has good real-time performance and an average frame rate of 48.6 frames/second.关键词:object tracking;deformation;scale change;image saliency;keypoints matching11|4|3更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveFace recognition has an important role in our daily life. Applications are increasingly using face recognition as a useful interactive function. Real-life environments often introduce complex effects on data collection. Thus, face recognition always encounters challenges from several variations and occlusions. Face images collected from the real-world environment are usually accompanied with factors, such as occlusion, illumination, and expression changes, that interfere with recognition results. The number of collected training samples cannot be guaranteed in many special circumstances. Sometimes, the number of training samples is much smaller than the number of test samples. This paper aims to address difficult face recognition problems, such as eliminating complex environmental changes, undersampled training sets, and other recognition factors.MethodThis paper proposes an efficient face recognition algorithm under occlusion and the expressed variable, which is based on low rank approximation decomposition and auxiliary dictionary learning. It utilizes non-convex rank approximation norm and nuclear norm to perform matrix decomposition twice. The algorithm efficiently eliminates gross sparse errors on occlusion and other factors. First, we obtain the initial low-rank dictionary without illumination and occluded variation based on the non-convex robust principal component analysis algorithm to increase the convergence efficiency of the algorithm. Second, we perform the second low-rank decomposition based on a nuclear norm to obtain discriminant and incoherent low-rank dictionary and eliminate the influence of common facial parts through different classes. Finally, we choose the auxiliary data from the same database as an auxiliary dictionary that can simulate possible interference to overcome the problem of insufficient training samples and the large number of occlusion samples. The testing samples can be classified by minimizing the reconstruction error. This study considered the variation of noise, occlusion, illumination, and expression in the natural environment. The proposed efficient algorithm extracts low-complexity components that correspond to facial attributes, which are mutually incoherent among different classes (e.g., identity and expression) from training data, even in the presence of gross sparse errors. The lack of training data, joint low-rank dictionary, and auxiliary dictionary is addressed, and the weighted reconstruction model is established to complete the classification.ResultWe test our algorithm with the AR and CK+ databases. Experiments on both databases show that the proposed algorithm can achieve outstanding recognition accuracy. We divided the experiments on the AR database into three different training scales. We choose different numbers of images occluded by a scarf or sunglasses with an occlusion percent of 20%-40%. The number of occluded images that contain a scarf or sunglasses increased from one to three, and the unoccluded images decreased from six to four. The training set on each person consists of seven images. With one or three occluded images in the training set, the uncovered images consist of natural images with no extra interface factors, such as expression and illumination. However, when the proportion of the covered images is two in seven, the other five uncovered images contain expression and illumination variables. Experimental results demonstrate that the proposed algorithm has a higher recognition rate in a variety of experimental cases. According to the cover types, such as scarves and sunglasses, the recognition rates are 97.75%, 92%, 95.25%, 97.75%, 90%, and 95.25%. Compared with the recognition accuracy of recent algorithms, such as sparse representation classification, robust principal component analysis (RPCA), and non-convex RPCA, the recognition accuracy of the proposed method improved by 3% to 5%. The recognition results are 96.75%-98% when the amount of selected external data increased from 10 to 40. The recognition rates of the proposed method's recognition rates are 2%-3% higher than those of the compared algorithms.ConclusionThe algorithm proposed in this paper can overcome the complex environmental variation and insufficient training sample problems effectively and robustly. We obtained state-of-the-art performance after testing on different databases. This study attempts to deal with data with multiple occlusions. The proposed algorithm aims to adapt to complex interference factors and achieves high recognition accuracy. However, this algorithm does not effectively deal with joint expression and face recognition. Thus, further research is needed to understand figure joint expression and face recognition.关键词:face recognition;low-rank decomposition;dictionary learning;structure incoherent11|4|4更新时间:2024-05-07
摘要:ObjectiveFace recognition has an important role in our daily life. Applications are increasingly using face recognition as a useful interactive function. Real-life environments often introduce complex effects on data collection. Thus, face recognition always encounters challenges from several variations and occlusions. Face images collected from the real-world environment are usually accompanied with factors, such as occlusion, illumination, and expression changes, that interfere with recognition results. The number of collected training samples cannot be guaranteed in many special circumstances. Sometimes, the number of training samples is much smaller than the number of test samples. This paper aims to address difficult face recognition problems, such as eliminating complex environmental changes, undersampled training sets, and other recognition factors.MethodThis paper proposes an efficient face recognition algorithm under occlusion and the expressed variable, which is based on low rank approximation decomposition and auxiliary dictionary learning. It utilizes non-convex rank approximation norm and nuclear norm to perform matrix decomposition twice. The algorithm efficiently eliminates gross sparse errors on occlusion and other factors. First, we obtain the initial low-rank dictionary without illumination and occluded variation based on the non-convex robust principal component analysis algorithm to increase the convergence efficiency of the algorithm. Second, we perform the second low-rank decomposition based on a nuclear norm to obtain discriminant and incoherent low-rank dictionary and eliminate the influence of common facial parts through different classes. Finally, we choose the auxiliary data from the same database as an auxiliary dictionary that can simulate possible interference to overcome the problem of insufficient training samples and the large number of occlusion samples. The testing samples can be classified by minimizing the reconstruction error. This study considered the variation of noise, occlusion, illumination, and expression in the natural environment. The proposed efficient algorithm extracts low-complexity components that correspond to facial attributes, which are mutually incoherent among different classes (e.g., identity and expression) from training data, even in the presence of gross sparse errors. The lack of training data, joint low-rank dictionary, and auxiliary dictionary is addressed, and the weighted reconstruction model is established to complete the classification.ResultWe test our algorithm with the AR and CK+ databases. Experiments on both databases show that the proposed algorithm can achieve outstanding recognition accuracy. We divided the experiments on the AR database into three different training scales. We choose different numbers of images occluded by a scarf or sunglasses with an occlusion percent of 20%-40%. The number of occluded images that contain a scarf or sunglasses increased from one to three, and the unoccluded images decreased from six to four. The training set on each person consists of seven images. With one or three occluded images in the training set, the uncovered images consist of natural images with no extra interface factors, such as expression and illumination. However, when the proportion of the covered images is two in seven, the other five uncovered images contain expression and illumination variables. Experimental results demonstrate that the proposed algorithm has a higher recognition rate in a variety of experimental cases. According to the cover types, such as scarves and sunglasses, the recognition rates are 97.75%, 92%, 95.25%, 97.75%, 90%, and 95.25%. Compared with the recognition accuracy of recent algorithms, such as sparse representation classification, robust principal component analysis (RPCA), and non-convex RPCA, the recognition accuracy of the proposed method improved by 3% to 5%. The recognition results are 96.75%-98% when the amount of selected external data increased from 10 to 40. The recognition rates of the proposed method's recognition rates are 2%-3% higher than those of the compared algorithms.ConclusionThe algorithm proposed in this paper can overcome the complex environmental variation and insufficient training sample problems effectively and robustly. We obtained state-of-the-art performance after testing on different databases. This study attempts to deal with data with multiple occlusions. The proposed algorithm aims to adapt to complex interference factors and achieves high recognition accuracy. However, this algorithm does not effectively deal with joint expression and face recognition. Thus, further research is needed to understand figure joint expression and face recognition.关键词:face recognition;low-rank decomposition;dictionary learning;structure incoherent11|4|4更新时间:2024-05-07 -
 摘要:ObjectiveThe recognition of Chinese characters has a broad application prospect in Chinese automatic processing and intelligent input. It is an important subject in the field of pattern recognition. With the emergence of the new technology of deep learning in recent years, the recognition of Chinese characters based on a deep convolutional neural network has made a breakthrough in theoretical method and actual performance. However, many problems still exist, such as the need for a large sample size, long training time, and great difficulty in parameter tuning. Thus, achieving the best identification result for Chinese characters, which belong to numerous categories, is difficult.MethodAn end-to-end deep convolutional neural network model was proposed for processing unscreened images with printed and handwritten Chinese characters. Regardless of the additional layers, such as batch normalization and dropout layers, the network mainly consisted of three convolutional layers, two pooling layers, one fully connected layer, and a softmax regression layer. This paper proposed the data augmentation method, which comprehensively adopted a wave distortion, translation, rotation, and zooming, to solve the problem of a small sample size. The translation and zooming scale, the rotation angles, and a large number of pseudo-samples were randomly generated by controlling the amplitude and period of the sine function that caused the wave distortion. The overall structure of the characters could not be changed, and the number of the trainset samples could be increased to infinity. Advanced strategies, such as batch normalization and fine-tuning the model by combining two optimizers, namely, stochastic gradient descent (SGD) and adaptive moment estimation (Adam), were used to reduce the difficulty of parameter adjustment and the long model training duration. Batch normalization refers to normalizing the input data for each training mini-batch in the process of stochastic gradient descent. Thus, the probability distribution in each dimension becomes a stable probability distribution with mean 0 and standard deviation 1. We define internal covariate shift as the change in the distribution of network activations due to the change in network parameters during training. The network should learn to adapt to different distributions at each iteration, which will greatly reduce the training speed of the network. Batch normalization is an effective way to solve this problem. In the proposed network, the batch normalization layer was placed in front of the activation function layer. In the classic convolutional neural network, the mini-batch stochastic gradient descent method is usually adopted during the training process. However, selecting suitable hyper-parameters is difficult. Parameter selection, such as learning rate and initial weight, greatly affects training speed and classification results. Adam is an algorithm for first-order gradient-based optimization of stochastic objective functions based on adaptive estimates of lower-order moments. The method computes individual adaptive learning rates for different parameters from estimates of the first and second moments of the gradients. The greatest advantage of the method is that the magnitudes of parameter updates are invariant to the rescaling of the gradient and that the training speed can be accelerated tremendously. However, the single use of this method cannot ensure state-of-the-art results. Therefore, this paper presents a new training method that combines the novel optimization method, Adam, and the traditional method, SGD. We divided the training process into two steps. First, we adopted Adam to adjust the parameter, such as learning rate, to avoid manual adjustment and make the network coverage immediately. This process lasted for 200 iterations, and the best model was saved after the first training step. Second, SGD was used to further fine-tune the trained model with a minimal learning rate to achieve the best classification result. The initial learning rate was set to 0.0001 in this step and exponentially decayed. Through these methods, the network performed well in terms of training speed and generalization ability.ResultA seven-layer deep model was trained to categorize 3, 755 Chinese characters, and the recognition accuracy rate reached 98.336%. The contribution of each proposed method to improve the final effect of the model was verified by several sets of comparative experiments.The recognition rate of the model increased by 8.0%, 0.3%, and 1.4% by using data augmentation, combining the two kinds of optimizers, and using batch normalization, respectively.The training time of the model was 483 and 43 minutes less than when SGD was used and batch normalization was not used, respectively.ConclusionThe workload of extracting features is manually reduced compared with traditional recognition methods that use handcrafted features in combination with convolutional neural networks in the reference paper. Our proposed method achieves superior performance because it has a higher recognition rate, stronger extraction ability, and shorter training time compared with the classic convolutional neural network.关键词:recognition of Chinese characters;convolutional neural network;deep learning;data augmentation;batch normalization17|7|6更新时间:2024-05-07
摘要:ObjectiveThe recognition of Chinese characters has a broad application prospect in Chinese automatic processing and intelligent input. It is an important subject in the field of pattern recognition. With the emergence of the new technology of deep learning in recent years, the recognition of Chinese characters based on a deep convolutional neural network has made a breakthrough in theoretical method and actual performance. However, many problems still exist, such as the need for a large sample size, long training time, and great difficulty in parameter tuning. Thus, achieving the best identification result for Chinese characters, which belong to numerous categories, is difficult.MethodAn end-to-end deep convolutional neural network model was proposed for processing unscreened images with printed and handwritten Chinese characters. Regardless of the additional layers, such as batch normalization and dropout layers, the network mainly consisted of three convolutional layers, two pooling layers, one fully connected layer, and a softmax regression layer. This paper proposed the data augmentation method, which comprehensively adopted a wave distortion, translation, rotation, and zooming, to solve the problem of a small sample size. The translation and zooming scale, the rotation angles, and a large number of pseudo-samples were randomly generated by controlling the amplitude and period of the sine function that caused the wave distortion. The overall structure of the characters could not be changed, and the number of the trainset samples could be increased to infinity. Advanced strategies, such as batch normalization and fine-tuning the model by combining two optimizers, namely, stochastic gradient descent (SGD) and adaptive moment estimation (Adam), were used to reduce the difficulty of parameter adjustment and the long model training duration. Batch normalization refers to normalizing the input data for each training mini-batch in the process of stochastic gradient descent. Thus, the probability distribution in each dimension becomes a stable probability distribution with mean 0 and standard deviation 1. We define internal covariate shift as the change in the distribution of network activations due to the change in network parameters during training. The network should learn to adapt to different distributions at each iteration, which will greatly reduce the training speed of the network. Batch normalization is an effective way to solve this problem. In the proposed network, the batch normalization layer was placed in front of the activation function layer. In the classic convolutional neural network, the mini-batch stochastic gradient descent method is usually adopted during the training process. However, selecting suitable hyper-parameters is difficult. Parameter selection, such as learning rate and initial weight, greatly affects training speed and classification results. Adam is an algorithm for first-order gradient-based optimization of stochastic objective functions based on adaptive estimates of lower-order moments. The method computes individual adaptive learning rates for different parameters from estimates of the first and second moments of the gradients. The greatest advantage of the method is that the magnitudes of parameter updates are invariant to the rescaling of the gradient and that the training speed can be accelerated tremendously. However, the single use of this method cannot ensure state-of-the-art results. Therefore, this paper presents a new training method that combines the novel optimization method, Adam, and the traditional method, SGD. We divided the training process into two steps. First, we adopted Adam to adjust the parameter, such as learning rate, to avoid manual adjustment and make the network coverage immediately. This process lasted for 200 iterations, and the best model was saved after the first training step. Second, SGD was used to further fine-tune the trained model with a minimal learning rate to achieve the best classification result. The initial learning rate was set to 0.0001 in this step and exponentially decayed. Through these methods, the network performed well in terms of training speed and generalization ability.ResultA seven-layer deep model was trained to categorize 3, 755 Chinese characters, and the recognition accuracy rate reached 98.336%. The contribution of each proposed method to improve the final effect of the model was verified by several sets of comparative experiments.The recognition rate of the model increased by 8.0%, 0.3%, and 1.4% by using data augmentation, combining the two kinds of optimizers, and using batch normalization, respectively.The training time of the model was 483 and 43 minutes less than when SGD was used and batch normalization was not used, respectively.ConclusionThe workload of extracting features is manually reduced compared with traditional recognition methods that use handcrafted features in combination with convolutional neural networks in the reference paper. Our proposed method achieves superior performance because it has a higher recognition rate, stronger extraction ability, and shorter training time compared with the classic convolutional neural network.关键词:recognition of Chinese characters;convolutional neural network;deep learning;data augmentation;batch normalization17|7|6更新时间:2024-05-07 -
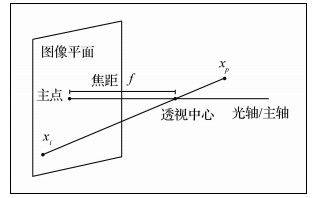 摘要:ObjectiveWheel-rail attack angle is a key index in the evaluation of locomotive operation safety. Strong vibration occurs during the train operation process, and many disadvantages in the attack angle measurement methods exist based on the strain gauge transducer and sensor in the contact measurement, such as loss, damage, and other problems. The attack angle, as an important parameter in safety evaluation and the evaluation of the running stability of trains, has great significance. A new method forimage detection of wheel-rail attack angle is proposed to avoid issues in contact detection, such as the loss and damage of sensors and detection difficulty due to the minimal value of the attack angle.MethodThis method uses a charge-coupled devicesensor installed on the train bogie to form a visual inspection system. The single mapping relationship between the geometry of the target image and the object deflects the attack angle of the wheel-rail. Thus, the parameter of the attackangle φ measurement of locomotive inspection into the detection of elliptic geometry includes the characteristic of the minor axis and the major axis. This parameter reduces the difficulty of wheel-rail attack angle detection and increases the feasibility of the measuring method, thereby ensuring easy image detection of the locomotive attack angle. Simulation results of the attack angle are given to prove measurement accuracy and availability.ResultExperimental results show that the average error between the value of the attack angle measured by a measuring apparatus and theangle used by the proposed method is 0.024°. For the experimental data, the maximum error is 0.084°, and the simulation model of attack angle is established. The changes before the locking mechanism and after locking the radial angle are compared. The angle value is large when the locking mechanism is locked. The single frame image detection time is approximately 400ms, which is related to the velocity of the train; the result is highly accurate.ConclusionThe proposed method detects the wheel-rail attack angle quickly and achieves a highly accurate result. Thus, this study establishes a foundation for the stability and safety evaluation of trains.关键词:serpentine movement;attack angle;ellipse detection;safety evaluation11|4|0更新时间:2024-05-07
摘要:ObjectiveWheel-rail attack angle is a key index in the evaluation of locomotive operation safety. Strong vibration occurs during the train operation process, and many disadvantages in the attack angle measurement methods exist based on the strain gauge transducer and sensor in the contact measurement, such as loss, damage, and other problems. The attack angle, as an important parameter in safety evaluation and the evaluation of the running stability of trains, has great significance. A new method forimage detection of wheel-rail attack angle is proposed to avoid issues in contact detection, such as the loss and damage of sensors and detection difficulty due to the minimal value of the attack angle.MethodThis method uses a charge-coupled devicesensor installed on the train bogie to form a visual inspection system. The single mapping relationship between the geometry of the target image and the object deflects the attack angle of the wheel-rail. Thus, the parameter of the attackangle φ measurement of locomotive inspection into the detection of elliptic geometry includes the characteristic of the minor axis and the major axis. This parameter reduces the difficulty of wheel-rail attack angle detection and increases the feasibility of the measuring method, thereby ensuring easy image detection of the locomotive attack angle. Simulation results of the attack angle are given to prove measurement accuracy and availability.ResultExperimental results show that the average error between the value of the attack angle measured by a measuring apparatus and theangle used by the proposed method is 0.024°. For the experimental data, the maximum error is 0.084°, and the simulation model of attack angle is established. The changes before the locking mechanism and after locking the radial angle are compared. The angle value is large when the locking mechanism is locked. The single frame image detection time is approximately 400ms, which is related to the velocity of the train; the result is highly accurate.ConclusionThe proposed method detects the wheel-rail attack angle quickly and achieves a highly accurate result. Thus, this study establishes a foundation for the stability and safety evaluation of trains.关键词:serpentine movement;attack angle;ellipse detection;safety evaluation11|4|0更新时间:2024-05-07 -
 摘要:ObjectiveObject segmentation from a single image is a fundamental step in many computer vision and digital image processing applications, such as image semantic recognition, medical image analysis, traffic control, weather forecasting, image searching, geological exploration, and scene understanding. Traditional image segmentation methods mainly use low-level semantic information of an image, which includes the color, texture, and shape of image pixels. This method is not ideal because it easily causes oversegmentation and overmerging in the actual segmentation of a complex scene. Obtaining semantic segmentation results is difficult. A novel approach that combines graph-based algorithm and t junction cues is proposed to improve the oversegmentation and merging of a single image object segmentation algorithm.MethodOn the basis of the Graph-based algorithm, t junction cues are introduced, which can guarantee accurate segmentation results to avoid the influence of color information on segmentation. First, L0 gradient minimization is applied to smooth the target image and eliminate artifacts caused by noise and texture detail. The L0 gradient minimization algorithm uses the number of non-zero gradients in the image to retain useful edge details in the image and removes useless edge parts. Thus, image smoothing is achieved. The L0 gradient minimization algorithm achieves edge-preserving smoothing without changing the artwork structure. The initial oversegmentation result of the smoothing image uses the Graph-based algorithm. The Graph-based algorithm considers the similarity between regions and the differences between regions and maintains image boundaries better. However, it cannot control the number of image blocks and the compact program. A region merging algorithm is applied to optimize the error segmentations by t junction cues.ResultThe proposed algorithms are compared with the Grabcut algorithm and the Graph-based algorithm under different scene types. Experimental results show that the Grabcut algorithm of artificial boundary and positioning is only a single object segmentation. The proposed algorithm has advantages in terms of robustness, time consumption, and boundary location accuracy over the Grabcut algorithm. The Graph-based method considers the similarities between and differences among regions. The image boundaries can be maintained well by segmenting the vertices in the graph. However, the defects of the Graph-based algorithm are obvious, such as class difference. Moreover, the number and the compactness of the image blocks are not controlled, and the segmentation effect depends strongly on the selected threshold. Oversegmentation and overmerging occur easily. The average rate of segmentation accuracy for several groups of different types of images reaches 91.16% given other algorithms. The image size of 800×600 pixels and the average time of 3.5 s increased slightly compared with other algorithms. The proposed algorithm is more time consuming than the Graph-based algorithm, but segmentation accuracy is greatly improved. The proposed algorithmcan generate concise and smooth segmentation boundaries and obtain segmentation results with some semantics.ConclusionThis study proposes the object segmentation algorithm of a single image on the basis of t junction cues. A comparison of the proposed algorithm and the traditional graph-based and improved Grabcut algorithms shows the effectiveness of the proposed algorithm. Moreover, the proposed algorithm can effectively solve the problem of oversegmentation and overmerging, and semantic object segmentation results can be achieved. Experimental results show the effectiveness of the proposed algorithm.关键词:image segmentation;T junction;L0 gradient minimization;Graph-based algorithm;image segementation evaluation12|5|1更新时间:2024-05-07
摘要:ObjectiveObject segmentation from a single image is a fundamental step in many computer vision and digital image processing applications, such as image semantic recognition, medical image analysis, traffic control, weather forecasting, image searching, geological exploration, and scene understanding. Traditional image segmentation methods mainly use low-level semantic information of an image, which includes the color, texture, and shape of image pixels. This method is not ideal because it easily causes oversegmentation and overmerging in the actual segmentation of a complex scene. Obtaining semantic segmentation results is difficult. A novel approach that combines graph-based algorithm and t junction cues is proposed to improve the oversegmentation and merging of a single image object segmentation algorithm.MethodOn the basis of the Graph-based algorithm, t junction cues are introduced, which can guarantee accurate segmentation results to avoid the influence of color information on segmentation. First, L0 gradient minimization is applied to smooth the target image and eliminate artifacts caused by noise and texture detail. The L0 gradient minimization algorithm uses the number of non-zero gradients in the image to retain useful edge details in the image and removes useless edge parts. Thus, image smoothing is achieved. The L0 gradient minimization algorithm achieves edge-preserving smoothing without changing the artwork structure. The initial oversegmentation result of the smoothing image uses the Graph-based algorithm. The Graph-based algorithm considers the similarity between regions and the differences between regions and maintains image boundaries better. However, it cannot control the number of image blocks and the compact program. A region merging algorithm is applied to optimize the error segmentations by t junction cues.ResultThe proposed algorithms are compared with the Grabcut algorithm and the Graph-based algorithm under different scene types. Experimental results show that the Grabcut algorithm of artificial boundary and positioning is only a single object segmentation. The proposed algorithm has advantages in terms of robustness, time consumption, and boundary location accuracy over the Grabcut algorithm. The Graph-based method considers the similarities between and differences among regions. The image boundaries can be maintained well by segmenting the vertices in the graph. However, the defects of the Graph-based algorithm are obvious, such as class difference. Moreover, the number and the compactness of the image blocks are not controlled, and the segmentation effect depends strongly on the selected threshold. Oversegmentation and overmerging occur easily. The average rate of segmentation accuracy for several groups of different types of images reaches 91.16% given other algorithms. The image size of 800×600 pixels and the average time of 3.5 s increased slightly compared with other algorithms. The proposed algorithm is more time consuming than the Graph-based algorithm, but segmentation accuracy is greatly improved. The proposed algorithmcan generate concise and smooth segmentation boundaries and obtain segmentation results with some semantics.ConclusionThis study proposes the object segmentation algorithm of a single image on the basis of t junction cues. A comparison of the proposed algorithm and the traditional graph-based and improved Grabcut algorithms shows the effectiveness of the proposed algorithm. Moreover, the proposed algorithm can effectively solve the problem of oversegmentation and overmerging, and semantic object segmentation results can be achieved. Experimental results show the effectiveness of the proposed algorithm.关键词:image segmentation;T junction;L0 gradient minimization;Graph-based algorithm;image segementation evaluation12|5|1更新时间:2024-05-07 -
 摘要:ObjectiveMedical image segmentation results can help doctors predict, diagnose, and make a treatment plan. Medical images are affected by many factors in the process of collection in that the same tissue has different gray levels and is usually corrupted by strong noise. Existing medical images segmentation methods are undesirable because the description of the intensity distribution of the image is insufficient and the robustness to noise is poor. An active contour model with high accuracy and strong robustness to noise is proposed to obtain precise segmentation of medical images.MethodFirst, entropy of an image is introduced with the local mean and the variance as the descriptor to represent the intensity distribution of the image. The entropy can reflect the richness of image information and measure the degree of heterogeneity of the image within segmentation regions. Great homogeneity of the partition corresponds to high entropy. The local entropy with mean and variance as the local image descriptors can obtain a high fitting degree for image intensity distribution. The value of the local entropy is not sensitive to a single noise pixel because it is determined by several pixels in a continuous domain. Therefore, local entropy has a certain filtering effect. Moreover, the normalization of intensity probability can smooth the noise, which can guarantee the robustness to noise of the proposed method especially when dealing with brain MR images with serious noises. Second, the bias field factor is introduced in the Bayesian framework to establish the energy function of the active contour model. The proposed method adopts the commonly used model to describe images with intensity inhomogeneity. The introduced bias field factor is spatially variant. The introduction of the bias factor can describe the inhomogeneous intensity well when model energy function is established. In the minimization of energy function, the bias factor is involved in the calculation, and the bias correction process is incorporated into the segmentation process to help improve segmentation accuracy. The evolution equation of the level set is obtained using the gradient descent method. At the end of evolution, the bias field correction is realized at the same time of the segmentation. We obtain the image segmentation result by minimizing this energy. Energy minimization is achieved by an iterative process. We minimize the energy with respect to each of its variables in each iteration given that the other three variables are updated in the previous iteration.ResultSynthetic images and medical images, such as the heart, blood vessel, and brain, are used to perform simulation experiments. Experiment 1 verifies the effectiveness of the proposed algorithm. The MDAC model is used to segment intensity inhomogeneous images with noise, and results show that the bias-corrected image is achieved with accurate segmentation. Moreover, the gray histogram of the images before and after bias correction is calculated. The gray histogram of the image before bias correction has three peaks due to inhomogeneous intensity, and the boundaries are unclear. After bias correction, the gray histogram of the image has only two peaks because of the removal of the intensity inhomogeneity and the boundary is clear. In Experiment 2, the accuracy of the MDAC model and other two classic models, namely, LIC and LGDF models, is compared. The MDAC model has the best visual effects and quantitative analysis.ConclusionExperimental results show that the algorithm accuracy is guaranteed by mean, variance and local entropy to describe image intensity distribution. The introduction of local entropy ensures the accuracy of the algorithm and improves the robustness to the algorithm noise. In the energy function, the bias factor is embedded, which ensures that the algorithm performs bias correction at the same time of segmentation and further improves the accuracy of the algorithm. This method is extended to multiphase medical image segmentation. We attempt to employ partition entropy as data fitting energy to improve segmentation accuracy.关键词:medical image segmentation;active contour model;local entropy;intensity inhomogeneity;bias field13|5|6更新时间:2024-05-07
摘要:ObjectiveMedical image segmentation results can help doctors predict, diagnose, and make a treatment plan. Medical images are affected by many factors in the process of collection in that the same tissue has different gray levels and is usually corrupted by strong noise. Existing medical images segmentation methods are undesirable because the description of the intensity distribution of the image is insufficient and the robustness to noise is poor. An active contour model with high accuracy and strong robustness to noise is proposed to obtain precise segmentation of medical images.MethodFirst, entropy of an image is introduced with the local mean and the variance as the descriptor to represent the intensity distribution of the image. The entropy can reflect the richness of image information and measure the degree of heterogeneity of the image within segmentation regions. Great homogeneity of the partition corresponds to high entropy. The local entropy with mean and variance as the local image descriptors can obtain a high fitting degree for image intensity distribution. The value of the local entropy is not sensitive to a single noise pixel because it is determined by several pixels in a continuous domain. Therefore, local entropy has a certain filtering effect. Moreover, the normalization of intensity probability can smooth the noise, which can guarantee the robustness to noise of the proposed method especially when dealing with brain MR images with serious noises. Second, the bias field factor is introduced in the Bayesian framework to establish the energy function of the active contour model. The proposed method adopts the commonly used model to describe images with intensity inhomogeneity. The introduced bias field factor is spatially variant. The introduction of the bias factor can describe the inhomogeneous intensity well when model energy function is established. In the minimization of energy function, the bias factor is involved in the calculation, and the bias correction process is incorporated into the segmentation process to help improve segmentation accuracy. The evolution equation of the level set is obtained using the gradient descent method. At the end of evolution, the bias field correction is realized at the same time of the segmentation. We obtain the image segmentation result by minimizing this energy. Energy minimization is achieved by an iterative process. We minimize the energy with respect to each of its variables in each iteration given that the other three variables are updated in the previous iteration.ResultSynthetic images and medical images, such as the heart, blood vessel, and brain, are used to perform simulation experiments. Experiment 1 verifies the effectiveness of the proposed algorithm. The MDAC model is used to segment intensity inhomogeneous images with noise, and results show that the bias-corrected image is achieved with accurate segmentation. Moreover, the gray histogram of the images before and after bias correction is calculated. The gray histogram of the image before bias correction has three peaks due to inhomogeneous intensity, and the boundaries are unclear. After bias correction, the gray histogram of the image has only two peaks because of the removal of the intensity inhomogeneity and the boundary is clear. In Experiment 2, the accuracy of the MDAC model and other two classic models, namely, LIC and LGDF models, is compared. The MDAC model has the best visual effects and quantitative analysis.ConclusionExperimental results show that the algorithm accuracy is guaranteed by mean, variance and local entropy to describe image intensity distribution. The introduction of local entropy ensures the accuracy of the algorithm and improves the robustness to the algorithm noise. In the energy function, the bias factor is embedded, which ensures that the algorithm performs bias correction at the same time of segmentation and further improves the accuracy of the algorithm. This method is extended to multiphase medical image segmentation. We attempt to employ partition entropy as data fitting energy to improve segmentation accuracy.关键词:medical image segmentation;active contour model;local entropy;intensity inhomogeneity;bias field13|5|6更新时间:2024-05-07 -
 摘要:ObjectiveThe macula in the retinal fundus is an oval-shaped pigmented area near the center of the retina and is responsible for detailed central vision, which is needed in activities such as reading and driving. The fovea is located at the center of the macula, which is the site of the sharpest center vision. Any abnormal changes in the macula may cause vision loss. The distance between the lesions and fovea has clinical relevance to the extent of damage. Therefore, accurate localization of the fovea has an important significance in computer-aided diagnosis of diabetic retinopathy. However, fovea detection faces challenges that vary illumination, computational load, and abnormal images. This study develops a novel fovea detection approach by using blood vessels projection and mathematical morphology to achieve accurate and effective fovea detection. A series of techniques has been proposed for fovea detection using color retinal images, which can be divided into anatomical-based and visual-based features. The former criterion involves techniques to determine the region of interest (ROI) that contains fovea by using the geometrical relationship between the fovea and the optic disc diameter. The fovea can be located at a distance that is approximately two and a half disc diameters from the optic disc center. The latter criterion includes techniques of searching the fovea together with visual features of the fovea, such as a round-shaped dark area in the neighborhood of the optic disc.MethodOur proposed fovea detection approach consists of four steps. First, we use a series of mathematical morphology techniques that contain open, erosion, and reconstruction operations for automatic blood vessel detection. The center of the optic disc is then determined using the primary distribution of blood vessels within the optic disc (vertical vessel is aggregated, and few blood vessels are present above or below the optic disc). The anatomical prior information between the optic disc and the macula indicates that the fovea can be located approximately two and a half disc diameters from the optic disc center. Thus, an ROI that contains the fovea is extracted. Finally, we conduct fovea localization on the green channel of the corresponding ROI image that contains the fovea. Brightness adjustment is first applied to improve the contrast of the fovea within the ROI to make the fovea region highly visible. Morphological erosion reconstruction operation is used to remove the lesions, which have a similar color as the fovea. The macula has low luminance. Thus, we invert the reconstructed image and extract the binary image using region maximum and Ostu threshold techniques. Dilatation operation is used to smooth the extracted candidate regions. A series of features of candidate regions is extracted to determine the fovea.ResultTwo standard diabetic retinopathy databases, DIARETDB0 and DIARETDB1, are used to evaluate the effectiveness of the proposed approach. The proposed approach achieves 96.92% and 96.63% success rates on DIARETDB0 and DIARETDB1, respectively, with a total success rate of 96.35%, thereby outperforming state-of-the-art fovea detection approaches. Experimental results indicate that the locations of the macula fovea detected by using our proposed method are close to the corresponding reference positions marked by specialists. Moreover, the average execution time on DIARETDB0 and DIARETDB1 is 8.236 s and 8.912 s, respectively.ConclusionExperimental results indicate that the proposed approach can locate macula fovea quickly and accurately, and performs better than existing macula fovea detection approaches.关键词:computer aided diagnosis;retinal fundus image;optic disc;macula fovea;mathematical morphology;projection13|4|1更新时间:2024-05-07
摘要:ObjectiveThe macula in the retinal fundus is an oval-shaped pigmented area near the center of the retina and is responsible for detailed central vision, which is needed in activities such as reading and driving. The fovea is located at the center of the macula, which is the site of the sharpest center vision. Any abnormal changes in the macula may cause vision loss. The distance between the lesions and fovea has clinical relevance to the extent of damage. Therefore, accurate localization of the fovea has an important significance in computer-aided diagnosis of diabetic retinopathy. However, fovea detection faces challenges that vary illumination, computational load, and abnormal images. This study develops a novel fovea detection approach by using blood vessels projection and mathematical morphology to achieve accurate and effective fovea detection. A series of techniques has been proposed for fovea detection using color retinal images, which can be divided into anatomical-based and visual-based features. The former criterion involves techniques to determine the region of interest (ROI) that contains fovea by using the geometrical relationship between the fovea and the optic disc diameter. The fovea can be located at a distance that is approximately two and a half disc diameters from the optic disc center. The latter criterion includes techniques of searching the fovea together with visual features of the fovea, such as a round-shaped dark area in the neighborhood of the optic disc.MethodOur proposed fovea detection approach consists of four steps. First, we use a series of mathematical morphology techniques that contain open, erosion, and reconstruction operations for automatic blood vessel detection. The center of the optic disc is then determined using the primary distribution of blood vessels within the optic disc (vertical vessel is aggregated, and few blood vessels are present above or below the optic disc). The anatomical prior information between the optic disc and the macula indicates that the fovea can be located approximately two and a half disc diameters from the optic disc center. Thus, an ROI that contains the fovea is extracted. Finally, we conduct fovea localization on the green channel of the corresponding ROI image that contains the fovea. Brightness adjustment is first applied to improve the contrast of the fovea within the ROI to make the fovea region highly visible. Morphological erosion reconstruction operation is used to remove the lesions, which have a similar color as the fovea. The macula has low luminance. Thus, we invert the reconstructed image and extract the binary image using region maximum and Ostu threshold techniques. Dilatation operation is used to smooth the extracted candidate regions. A series of features of candidate regions is extracted to determine the fovea.ResultTwo standard diabetic retinopathy databases, DIARETDB0 and DIARETDB1, are used to evaluate the effectiveness of the proposed approach. The proposed approach achieves 96.92% and 96.63% success rates on DIARETDB0 and DIARETDB1, respectively, with a total success rate of 96.35%, thereby outperforming state-of-the-art fovea detection approaches. Experimental results indicate that the locations of the macula fovea detected by using our proposed method are close to the corresponding reference positions marked by specialists. Moreover, the average execution time on DIARETDB0 and DIARETDB1 is 8.236 s and 8.912 s, respectively.ConclusionExperimental results indicate that the proposed approach can locate macula fovea quickly and accurately, and performs better than existing macula fovea detection approaches.关键词:computer aided diagnosis;retinal fundus image;optic disc;macula fovea;mathematical morphology;projection13|4|1更新时间:2024-05-07 -
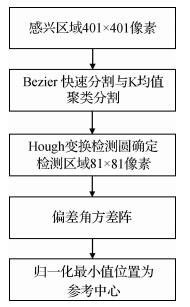 摘要:ObjectiveA tropical cyclone (TC) is a strong weather system generated in tropical or subtropical surfaces. In the analysis and forecasting of TC, accurately determining the real-time location of its center accurately is important. The precise location of TC is an important parameter of TC strength estimation. This paper presents a new method for locating the center of TC with deviation angle variance.MethodFirst, an area of interest is selected from an infrared satellite cloud image. On the basis of this image, the Bezier histogram segmentation method is employed to obtain the binary image of the TC core region. The core region of the TC can be extracted from the satellite infrared cloud image by the binary image of the TC core region. The influence of the small cloud block on the locating result can be removed using the extracted image. K-means clustering segmentation is used to deal with the cloud region with violent changes in infrared bright temperature. The TC edge region and the large gradient region of the TC core region, the spiral cloud band, and the discrete cloud blocks that form a circular flow can be extracted from the satellite infrared cloud image by using the binary image of the cloud region, in which infrared bright temperature changes violently. These regions are the main basis for the positioning of the TC center. The two binary images are combined to obtain a new binary image. The discrete cloud blocks were removed from the TC. The TC edge region and the large gradient region of the TC core region and spiral cloud band can be extracted from the satellite infrared cloud image using the new binary image. The resulting binary image is detected by the Hough transform approach to reduce the search range of the center position of the TC. Finally, the deviation angle matrix is calculated from each pixel in the detection area as the reference center. The variance matrix is obtained by calculating the variance of the deviation angle matrix and filling it in the corresponding reference center pixel point of the detection area. The minimum value position of the variance matrix is taken as the corresponding TC center position. The TC can be described in circles except in a few special cases. The TC is described as spiral most of the time. However, exact identification of the appropriate number degrees of the spiral. The variance of the deviation angle matrix can be used to measure whether these cloud bands and edges are concentrated or not. A small variance corresponds to a concentrated deviation, that is, a small variance corresponds to a high concentration of bias of the TC toward a definite spiral angle.ResultIn contrast to the center position issued by China Meteorological Administration (CMA), the Japan Meteorological Agency (JMA), and the US Typhoon Warning Center (JTWC), the average location deviation of the eyed (no-eye) TC determined by the new method is approximately 27 km (45 km). Specific to CMA, JMA, and JTWC, the location deviation of the eyed (no-eye) TC determined by the new method is 26.82 (45.84), 26.05 (44.84), and 27.84 km (47.15 km), respectively.ConclusionThe location deviation of JTWC is greater than that of CMA and JMA. In the case of TCs in the northwest Pacific, the positioning accuracy of CMA and JMA is slightly higher than that of JTWC, which is consistent with cognition. This finding proves that this method has high credibility. In this regard, the new method should be valuable for future operational TC center positioning.关键词:deviation angle variance;Bezier histogram;K-means clustering;Hough transfer11|4|3更新时间:2024-05-07
摘要:ObjectiveA tropical cyclone (TC) is a strong weather system generated in tropical or subtropical surfaces. In the analysis and forecasting of TC, accurately determining the real-time location of its center accurately is important. The precise location of TC is an important parameter of TC strength estimation. This paper presents a new method for locating the center of TC with deviation angle variance.MethodFirst, an area of interest is selected from an infrared satellite cloud image. On the basis of this image, the Bezier histogram segmentation method is employed to obtain the binary image of the TC core region. The core region of the TC can be extracted from the satellite infrared cloud image by the binary image of the TC core region. The influence of the small cloud block on the locating result can be removed using the extracted image. K-means clustering segmentation is used to deal with the cloud region with violent changes in infrared bright temperature. The TC edge region and the large gradient region of the TC core region, the spiral cloud band, and the discrete cloud blocks that form a circular flow can be extracted from the satellite infrared cloud image by using the binary image of the cloud region, in which infrared bright temperature changes violently. These regions are the main basis for the positioning of the TC center. The two binary images are combined to obtain a new binary image. The discrete cloud blocks were removed from the TC. The TC edge region and the large gradient region of the TC core region and spiral cloud band can be extracted from the satellite infrared cloud image using the new binary image. The resulting binary image is detected by the Hough transform approach to reduce the search range of the center position of the TC. Finally, the deviation angle matrix is calculated from each pixel in the detection area as the reference center. The variance matrix is obtained by calculating the variance of the deviation angle matrix and filling it in the corresponding reference center pixel point of the detection area. The minimum value position of the variance matrix is taken as the corresponding TC center position. The TC can be described in circles except in a few special cases. The TC is described as spiral most of the time. However, exact identification of the appropriate number degrees of the spiral. The variance of the deviation angle matrix can be used to measure whether these cloud bands and edges are concentrated or not. A small variance corresponds to a concentrated deviation, that is, a small variance corresponds to a high concentration of bias of the TC toward a definite spiral angle.ResultIn contrast to the center position issued by China Meteorological Administration (CMA), the Japan Meteorological Agency (JMA), and the US Typhoon Warning Center (JTWC), the average location deviation of the eyed (no-eye) TC determined by the new method is approximately 27 km (45 km). Specific to CMA, JMA, and JTWC, the location deviation of the eyed (no-eye) TC determined by the new method is 26.82 (45.84), 26.05 (44.84), and 27.84 km (47.15 km), respectively.ConclusionThe location deviation of JTWC is greater than that of CMA and JMA. In the case of TCs in the northwest Pacific, the positioning accuracy of CMA and JMA is slightly higher than that of JTWC, which is consistent with cognition. This finding proves that this method has high credibility. In this regard, the new method should be valuable for future operational TC center positioning.关键词:deviation angle variance;Bezier histogram;K-means clustering;Hough transfer11|4|3更新时间:2024-05-07 -
 摘要:ObjectiveInfrared digital TDI(time delay integration) first converts analog signals into digital ones and accumulates time delay integration signals unlike traditional infrared analog TDI. Its exposure method is highly flexible and could improve system detection sensitivity and the signal-to-noise ratio of the target. Thus, infrared digital TDI is widely used in aerospace remote sensing applications. An infrared digital TDI image system usually works through scanning, along with the characteristic of gaze because the system could be regarded as a small area array detector. For information processing, infrared digital TDI imaging non-uniformity is the key factor in limiting image quality. Reducing the non-uniformity of the output image is of great significance to the research and application of target detector and identification.MethodThis study establishes an imaging input and output model by analyzing every part of the imaging system and discusses the influence of the parameters on the non-uniformity of imaging. This study also identifies the way to optimize the non-uniformity of the system. The non-uniformity correction of images includes blind element compensation and non-uniformity correction of an effective pixel. The compensating rate of the blind pixel is improved by iterating the compensated blind pixel with field pixel substitution and field pixel average. The response characteristics of all pixels are analyzed, and the nonlinearity between the grayscale output and the input energy is corrected by the optimized target calibration curve. The non-uniformity in the non-scanning direction is further corrected by introducing the correction factor.ResultBlackbody calibration was performed by using a domestic 640×8 medium-wave infrared TDI detector. The two-point method, multi-point method, and our method were used for image non-uniformity correction. The blackbody temperature of radiation calibration ranged from 30℃ to 56℃, and the pixel response tended to saturate higher than 56℃. The integration time of the detector is fixed at the typical time for imaging of 0.4 ms. The two-point method takes 30℃ and 56℃ pixel response data as original data to estimate the pixel response value between them and the multi-point method takes the data from 30℃ to 56℃ every 2℃ interval. An observation of the response curve of the sampled pixels shows good linearity of the pixel response curve from 30℃ to 50℃; the curve from 50℃ to 56℃ indicates nonlinearity. Correction result shows that non-uniformity of 7.45% and 7.31% at 35℃ and 45℃ is better than that of 8.26% at 53℃ with the two-point method because the two-point data that estimate pixel value needs the pixel signal to fit a straight line between points. Unlike the two-point method, the multi-point method could take the two nearest points to compute the pixel value and consider the linearity between the two nearest points only. The non-uniformity result at a different temperature is approximately 5% better than the result of the two-point method. On the basis of the multi-point data correction, the distributions of all the pixel response curves are considered, and a reasonable target curve is chosen as the correction curve. Therefore, nonlinear fitting is added between the multi-point data, and the non-uniformity value is reduced to approximately 4% at each temperature, which indicates that the method is effective. An imaging experiment was conducted in the real-world environment, and a few pictures were processed according to the radiation calibration data. The horizontal stripes on the obtained infrared TDI images are reduced and weakened after correction with the proposed methods.ConclusionAn analysis of the whole link for the target scene from the optical signal to the electrical signal clearly identifies the specific parameters that affect image non-uniformity. This finding has reference significance for the design of infrared digital TDI imaging systems. Blind pixel compensation and non-uniformity correction of the infrared digital TDI imaging system were performed by using the proposed method. The non-uniformity of the image was greatly decreased, and the effectiveness of the method was verified.关键词:infrared;imaging;model;blind pixel;non-uniformity correction26|5|1更新时间:2024-05-07
摘要:ObjectiveInfrared digital TDI(time delay integration) first converts analog signals into digital ones and accumulates time delay integration signals unlike traditional infrared analog TDI. Its exposure method is highly flexible and could improve system detection sensitivity and the signal-to-noise ratio of the target. Thus, infrared digital TDI is widely used in aerospace remote sensing applications. An infrared digital TDI image system usually works through scanning, along with the characteristic of gaze because the system could be regarded as a small area array detector. For information processing, infrared digital TDI imaging non-uniformity is the key factor in limiting image quality. Reducing the non-uniformity of the output image is of great significance to the research and application of target detector and identification.MethodThis study establishes an imaging input and output model by analyzing every part of the imaging system and discusses the influence of the parameters on the non-uniformity of imaging. This study also identifies the way to optimize the non-uniformity of the system. The non-uniformity correction of images includes blind element compensation and non-uniformity correction of an effective pixel. The compensating rate of the blind pixel is improved by iterating the compensated blind pixel with field pixel substitution and field pixel average. The response characteristics of all pixels are analyzed, and the nonlinearity between the grayscale output and the input energy is corrected by the optimized target calibration curve. The non-uniformity in the non-scanning direction is further corrected by introducing the correction factor.ResultBlackbody calibration was performed by using a domestic 640×8 medium-wave infrared TDI detector. The two-point method, multi-point method, and our method were used for image non-uniformity correction. The blackbody temperature of radiation calibration ranged from 30℃ to 56℃, and the pixel response tended to saturate higher than 56℃. The integration time of the detector is fixed at the typical time for imaging of 0.4 ms. The two-point method takes 30℃ and 56℃ pixel response data as original data to estimate the pixel response value between them and the multi-point method takes the data from 30℃ to 56℃ every 2℃ interval. An observation of the response curve of the sampled pixels shows good linearity of the pixel response curve from 30℃ to 50℃; the curve from 50℃ to 56℃ indicates nonlinearity. Correction result shows that non-uniformity of 7.45% and 7.31% at 35℃ and 45℃ is better than that of 8.26% at 53℃ with the two-point method because the two-point data that estimate pixel value needs the pixel signal to fit a straight line between points. Unlike the two-point method, the multi-point method could take the two nearest points to compute the pixel value and consider the linearity between the two nearest points only. The non-uniformity result at a different temperature is approximately 5% better than the result of the two-point method. On the basis of the multi-point data correction, the distributions of all the pixel response curves are considered, and a reasonable target curve is chosen as the correction curve. Therefore, nonlinear fitting is added between the multi-point data, and the non-uniformity value is reduced to approximately 4% at each temperature, which indicates that the method is effective. An imaging experiment was conducted in the real-world environment, and a few pictures were processed according to the radiation calibration data. The horizontal stripes on the obtained infrared TDI images are reduced and weakened after correction with the proposed methods.ConclusionAn analysis of the whole link for the target scene from the optical signal to the electrical signal clearly identifies the specific parameters that affect image non-uniformity. This finding has reference significance for the design of infrared digital TDI imaging systems. Blind pixel compensation and non-uniformity correction of the infrared digital TDI imaging system were performed by using the proposed method. The non-uniformity of the image was greatly decreased, and the effectiveness of the method was verified.关键词:infrared;imaging;model;blind pixel;non-uniformity correction26|5|1更新时间:2024-05-07
Column of CACIS 2017
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0