
最新刊期
卷 23 , 期 2 , 2018
-
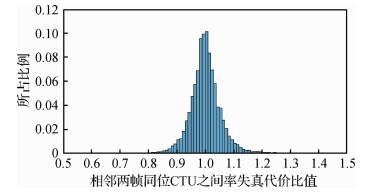 摘要:ObjectiveThe coding rate of high efficiency video coding (HEVC) can be reduced by approximately 50% compared with H.264/AVS, with nearly the same video coding quality. However, the coding complexity of HEVC increases exponentially at the same time. In particular, high resolution and high frame rate videos require additional coding time for HEVC. The coding time of HEVC must be reduced to satisfy the requirements of real-time coding and transmission for high-resolution and high frame rate videos. Statistics show that intra-coding unit (CU) segmentation comprises approximately 99% of the total coding time in HEVC, and the efficiency of the CU segmentation has a decisive impact on the efficiency of HEVC. The real-time coding of HEVC can be promoted significantly by optimizing the CU segmentation method used in HEVC. Many methods, such as reducing the traversal range of the depth of the CU, decreasing the rate-distortion cost calculation, and skipping the intra prediction of large CU, have been used in optimizing the CU segmentation method used in HEVC.MethodA robust spatial and temporal correlation exists among consecutive frames in video data. Coding tree unit (CTU) exhibits a strong correlation with the CTU of the same position in the consecutive frames and the surrounding CTUs in the same frame in HEVC. According to statistics, approximately 71.5% of CTUs of the same position in the current and consecutive frames provide the same depth, and the correlation between the consecutive frames in the gentle video is stronger than in the dramatic video. Therefore, the CTU of the current frame can be estimated based on the CTUs of its previous frame. The rate-distortion cost ratio between the CTUs of the same position in the consecutive frames is mostly between 0.8 and 1.2. Statistics denotes that the rate-distortion cost ratio is near 1.0 for gentle videos and far from 1.0 for dramatic videos. The rate-distortion value of the current CTU can be estimated based on the rate-distortion value of the CTUs of the same position in the previous frames, which can be used to accelerate CU segmentation. According to the above characteristics, a fast intra CU splitting algorithm is proposed in this paper. In this algorithm, the CTU is determined preliminarily based on the CTU of the same position in the previous frame and its adjacent CTUs. The CTU is finally determined based on the average depth of the CTU of the same position in the previous frame, weighted average depth of its adjacent CTUs, standard deviation of the brightness of CU, and corresponding rate-distortion cost value. All parameters used in the algorithm are obtained according to the actual video. The proposed method can significantly reduce the intra CU splitting time. The selected refresh frame adopts the standard CU partition method used in HM16.7 to avoid errors caused by the cumulative effects in this fast CU splitting algorithm at the interval-specified frames in the video. All the codes of the proposed algorithm were written in C++ based on the HM16.7, which is a popular framework for HEVC.ResultThe proposed method was used in many different resolution and frame rate videos to verify the feasibility and reliability of the method. Experimental results show that this algorithm can maintain the video quality and save approximately 40% encoding time with only nearly 1.4% increase in video coding rate, approximately 2.93% increase in the BDBR (bjøntegaard delta bitrate) of a video, and approximately 0.17 dB decrease in the BD-PSNR (bjøntegaard delta peak signal-to-noise rate) compared with HM16.7. The statistical results indicate that the absolute values of BDBR and BD-PSNR have a decreasing trend with the increase in video resolution, and the increment in video coding rate for high-resolution, high frame rate videos is generally smaller than that for low-resolution, low-frame rate videos.ConclusionThe analysis of the experimental results shows that the proposed algorithm based on HEVC framework HM16.7 can reduce the video coding time by using the spatial and temporal correlation in video data to decrease the time used for intra-CU splitting. The algorithm skips the rate-distortion calculation of the CU with zero depth and uses the similarity of the CTUs in consecutive frames to determine the CTUs of the current frame in advance. The method is feasible, reliable, and can improve the real-time performance of HEVC significantly, especially for the highresolution, high frame rate videos. The proposed algorithm is more suitable for high-resolution and high frame rate videos and has a better effect for all I-frame encoding schemes than for low-latency and random-access encoding schemes. The proposed algorithm should be continuously optimized to achieve minimal coding time, reduced coding rate, and enhanced coding quality not only for low-resolution and lowframe rate videos but also for different HEVC coding modes.关键词:intra coding unit;fast segmentation;spatial-temporal correlation;high efficiency video coding16|96|3更新时间:2024-05-07
摘要:ObjectiveThe coding rate of high efficiency video coding (HEVC) can be reduced by approximately 50% compared with H.264/AVS, with nearly the same video coding quality. However, the coding complexity of HEVC increases exponentially at the same time. In particular, high resolution and high frame rate videos require additional coding time for HEVC. The coding time of HEVC must be reduced to satisfy the requirements of real-time coding and transmission for high-resolution and high frame rate videos. Statistics show that intra-coding unit (CU) segmentation comprises approximately 99% of the total coding time in HEVC, and the efficiency of the CU segmentation has a decisive impact on the efficiency of HEVC. The real-time coding of HEVC can be promoted significantly by optimizing the CU segmentation method used in HEVC. Many methods, such as reducing the traversal range of the depth of the CU, decreasing the rate-distortion cost calculation, and skipping the intra prediction of large CU, have been used in optimizing the CU segmentation method used in HEVC.MethodA robust spatial and temporal correlation exists among consecutive frames in video data. Coding tree unit (CTU) exhibits a strong correlation with the CTU of the same position in the consecutive frames and the surrounding CTUs in the same frame in HEVC. According to statistics, approximately 71.5% of CTUs of the same position in the current and consecutive frames provide the same depth, and the correlation between the consecutive frames in the gentle video is stronger than in the dramatic video. Therefore, the CTU of the current frame can be estimated based on the CTUs of its previous frame. The rate-distortion cost ratio between the CTUs of the same position in the consecutive frames is mostly between 0.8 and 1.2. Statistics denotes that the rate-distortion cost ratio is near 1.0 for gentle videos and far from 1.0 for dramatic videos. The rate-distortion value of the current CTU can be estimated based on the rate-distortion value of the CTUs of the same position in the previous frames, which can be used to accelerate CU segmentation. According to the above characteristics, a fast intra CU splitting algorithm is proposed in this paper. In this algorithm, the CTU is determined preliminarily based on the CTU of the same position in the previous frame and its adjacent CTUs. The CTU is finally determined based on the average depth of the CTU of the same position in the previous frame, weighted average depth of its adjacent CTUs, standard deviation of the brightness of CU, and corresponding rate-distortion cost value. All parameters used in the algorithm are obtained according to the actual video. The proposed method can significantly reduce the intra CU splitting time. The selected refresh frame adopts the standard CU partition method used in HM16.7 to avoid errors caused by the cumulative effects in this fast CU splitting algorithm at the interval-specified frames in the video. All the codes of the proposed algorithm were written in C++ based on the HM16.7, which is a popular framework for HEVC.ResultThe proposed method was used in many different resolution and frame rate videos to verify the feasibility and reliability of the method. Experimental results show that this algorithm can maintain the video quality and save approximately 40% encoding time with only nearly 1.4% increase in video coding rate, approximately 2.93% increase in the BDBR (bjøntegaard delta bitrate) of a video, and approximately 0.17 dB decrease in the BD-PSNR (bjøntegaard delta peak signal-to-noise rate) compared with HM16.7. The statistical results indicate that the absolute values of BDBR and BD-PSNR have a decreasing trend with the increase in video resolution, and the increment in video coding rate for high-resolution, high frame rate videos is generally smaller than that for low-resolution, low-frame rate videos.ConclusionThe analysis of the experimental results shows that the proposed algorithm based on HEVC framework HM16.7 can reduce the video coding time by using the spatial and temporal correlation in video data to decrease the time used for intra-CU splitting. The algorithm skips the rate-distortion calculation of the CU with zero depth and uses the similarity of the CTUs in consecutive frames to determine the CTUs of the current frame in advance. The method is feasible, reliable, and can improve the real-time performance of HEVC significantly, especially for the highresolution, high frame rate videos. The proposed algorithm is more suitable for high-resolution and high frame rate videos and has a better effect for all I-frame encoding schemes than for low-latency and random-access encoding schemes. The proposed algorithm should be continuously optimized to achieve minimal coding time, reduced coding rate, and enhanced coding quality not only for low-resolution and lowframe rate videos but also for different HEVC coding modes.关键词:intra coding unit;fast segmentation;spatial-temporal correlation;high efficiency video coding16|96|3更新时间:2024-05-07 -
 摘要:ObjectiveNumerous video encoding standards commonly acquire encoding data through intra-and inter-frame predictions, which use encoded information to predict the data to be encoded. Thus, the temporal-spatial correlation between data is a common phenomenon between the motion vectors (MV) of adjacent macroblocks in the same frame or the macroblocks in the same position of the adjacent frames. Steganography algorithms that are based on MV typically change the value of MV selectively to embed confidential information. The change may damage the correlation between the MVs of adjacent macroblocks in the same frame or the macroblocks in the same position of the adjacent frames. Consequently, these algorithms could be easily detected by steganalysis algorithms based on MV temporal-spatial correlations. A video steganography algorithm that can resist the steganalysis algorithms based on the temporal-spatial correlations of MVs is proposed with the video-encoding standard guideline of H.264/AVC to solve the abovementioned problem.MethodThis paper deduces the correlation between MV difference (MVD) and temporal-spatial correlations of MVs to verify that maintaining the statistical features of the MVD is helpful for maintaining the temporal-spatial correlations of the video MVs by analyzing the calculation theorems of the MVD and temporal-spatial correlations of MVs. The proposed method develops an embedding rule, which could retain the features of the histogram related to the MVD because the statistical histogram of MVD is consistent with the Laplace distribution. This rule uses four counters and a queue to record the change in features caused by the modifying carriers, while compensation operations are conducted to recover statistical features to embed the secret messages into the MVDs before the entropy coding in the video compression process. To further decrease the modification of carriers related to embedding confidential information, matrix coding with variable length is applied according to various macroblock partitions to embed multiple bits of confidential information with only one bit of carriers that are modified.ResultThree experiments were conducted in this study. First, the confidential information embedding and extraction experiment were conducted. Experimental results show that the steganography algorithm can effectively and correctly complete the embedding and extraction of confidential information, and the accurate rate of multi-group experiments are all 100%. Then, the experiment for determining the influence of the algorithm on the statistics characteristics of video sequences was conducted. In this experiment, the proposed and other previous algorithms were used to embed confidential information in the case of full load embedding. Experimental results also show that the proposed steganography algorithm has visual invisibility and has a modification of less than 0.5% on the peak signal-to-noise ratio (PSNR) and the bit rate of the videos after embedding information. Finally, the resisting steganalysis algorithm experiment was conducted. The proposed and other previous algorithms were used to embed confidential information with various embedding rates, and then extract feature values from the video sequences. The steganalysis algorithms based on the temporal-spatial correlations of motion vectors were used to detect the feature values. Compared with previous steganography algorithms based on MVs, the proposed algorithms can maintain the histogram feature of MVDs before and after secret information is embedded. The use of matrix coding with variable length leads to a considerable decrease in the influence of steganography on the video sequence features, and the detection accuracy of steganalysis algorithms based on the temporal-spatial correlations of MVs on the proposed algorithm in this paper is only approximately 70%.ConclusionOur algorithm uses the MVD as the carrier of steganography while using the embedding rule, which could retain the statistics histogram features. Moreover, matrix coding with variable length is used to decrease the modification of steganography on carriers. Overall, the proposed algorithm can effectively and accurately complete the embedding and extraction of confidential information, minimally modify the PSNR and bit rate of videos, and significantly produce favorable performance when facing steganography algorithms based on MV temporal-spatial correlations.关键词:information hiding;video steganography;H.264;motion vector;motion vector difference;matrix encoding;temporal-spatial correlation37|39|2更新时间:2024-05-07
摘要:ObjectiveNumerous video encoding standards commonly acquire encoding data through intra-and inter-frame predictions, which use encoded information to predict the data to be encoded. Thus, the temporal-spatial correlation between data is a common phenomenon between the motion vectors (MV) of adjacent macroblocks in the same frame or the macroblocks in the same position of the adjacent frames. Steganography algorithms that are based on MV typically change the value of MV selectively to embed confidential information. The change may damage the correlation between the MVs of adjacent macroblocks in the same frame or the macroblocks in the same position of the adjacent frames. Consequently, these algorithms could be easily detected by steganalysis algorithms based on MV temporal-spatial correlations. A video steganography algorithm that can resist the steganalysis algorithms based on the temporal-spatial correlations of MVs is proposed with the video-encoding standard guideline of H.264/AVC to solve the abovementioned problem.MethodThis paper deduces the correlation between MV difference (MVD) and temporal-spatial correlations of MVs to verify that maintaining the statistical features of the MVD is helpful for maintaining the temporal-spatial correlations of the video MVs by analyzing the calculation theorems of the MVD and temporal-spatial correlations of MVs. The proposed method develops an embedding rule, which could retain the features of the histogram related to the MVD because the statistical histogram of MVD is consistent with the Laplace distribution. This rule uses four counters and a queue to record the change in features caused by the modifying carriers, while compensation operations are conducted to recover statistical features to embed the secret messages into the MVDs before the entropy coding in the video compression process. To further decrease the modification of carriers related to embedding confidential information, matrix coding with variable length is applied according to various macroblock partitions to embed multiple bits of confidential information with only one bit of carriers that are modified.ResultThree experiments were conducted in this study. First, the confidential information embedding and extraction experiment were conducted. Experimental results show that the steganography algorithm can effectively and correctly complete the embedding and extraction of confidential information, and the accurate rate of multi-group experiments are all 100%. Then, the experiment for determining the influence of the algorithm on the statistics characteristics of video sequences was conducted. In this experiment, the proposed and other previous algorithms were used to embed confidential information in the case of full load embedding. Experimental results also show that the proposed steganography algorithm has visual invisibility and has a modification of less than 0.5% on the peak signal-to-noise ratio (PSNR) and the bit rate of the videos after embedding information. Finally, the resisting steganalysis algorithm experiment was conducted. The proposed and other previous algorithms were used to embed confidential information with various embedding rates, and then extract feature values from the video sequences. The steganalysis algorithms based on the temporal-spatial correlations of motion vectors were used to detect the feature values. Compared with previous steganography algorithms based on MVs, the proposed algorithms can maintain the histogram feature of MVDs before and after secret information is embedded. The use of matrix coding with variable length leads to a considerable decrease in the influence of steganography on the video sequence features, and the detection accuracy of steganalysis algorithms based on the temporal-spatial correlations of MVs on the proposed algorithm in this paper is only approximately 70%.ConclusionOur algorithm uses the MVD as the carrier of steganography while using the embedding rule, which could retain the statistics histogram features. Moreover, matrix coding with variable length is used to decrease the modification of steganography on carriers. Overall, the proposed algorithm can effectively and accurately complete the embedding and extraction of confidential information, minimally modify the PSNR and bit rate of videos, and significantly produce favorable performance when facing steganography algorithms based on MV temporal-spatial correlations.关键词:information hiding;video steganography;H.264;motion vector;motion vector difference;matrix encoding;temporal-spatial correlation37|39|2更新时间:2024-05-07
Image Processing and Coding

-
 摘要:ObjectiveSigned distance functions are the nearest distances between pixels and points on the closed curve in an image, with a negative sign in the curve and a positive sign outside the curve. The signed distance function has important applications in image processing, such as level set-based segmentation, 3D visual feature extraction, and pattern recognition in computer vision. The computational complexity of the signed distance function is O(N×M), where N is the number of pixels in an image, and M is the number of points on a closed curve. The high computational complexity of the signed distance function directly affects the computational efficiency of image processing with the increase in image resolution. For real-time processing of an image with high resolution, an improved real-time computing method for the signed distance function based on the dimension reduction method was proposed to improve the computational efficiency.MethodDimension reduction method transforms the 2D signed distance function into two independent 1D signed distance functions for each row (or column) of the image and uses lower parabola envelope-based method for calculating the 1D distance. The low-er parabola envelope-based method sequentially computes the lower envelope of the first q parabolas, where the parabolas are ordered according to the horizontal locations of their vertices. The computational complexity of the dimension reduction method is O(2N) and is one of the fastest methods for calculating the signed distance function. This paper first proposes a parallel dimension reduction method according to the computational independence of the signed distance function among the rows (or columns) in an image to reduce the computational time of the dimension reduction method. The parallel dimension reduction method calculates the signed distance functions of the different rows (or columns) in an image simultaneously by allowing each thread to correspond to a row (or column) in the image. Thus, the computational complexity of the proposed parallel dimension reduction method is reduced to O(2W+2H), where W and H are the width and height of the image, respectively. Second, this paper proposes an improved parallel dimension reduction method by running the lower parabola envelope-based method in a parallel manner to improve the computational efficiency further. The improved parallel dimension reduction method uses multi-threads in calculating the lower parabola envelope in different segments to perform the dimension reduction method by finding the intersection points between two neighboring parabolas in a segment simultaneously. All parallel processing steps were completed on CUDA platform for general parallel computing on GPU. The first step is calculating the sign by assigning H threads, and each thread should correspond to a row in the image. The second step is calculating the 1D distance by assigning W×H threads. Each thread should correspond to a pixel in the image and should scan from left to right of the image to touch the closed curve and set the scanning distance as the 1D distance of each pixel. The last step is calculating the 2D distance by assigning W×H threads. Each thread should correspond to a pixel in the image and should scan from top to bottom of the image to obtain the final distance using the proposed parallel lower parabola envelope-based method. The entire computational complexity of distance in this method is O(2W+kS), where k is the iterative times, and S is the length of the segment.ResultNine images with different image sizes (256×256, 1 280×1 280, and 2 560×2 560) and curve shapes were tested in our experiments. The computational time of three generating methods for signed distance function (the regular serial, the proposed parallel, and the improved parallel dimension reduction methods) was compared with the case in which the maximal error was below 1. The computational time of the parallel method was less than 0.06 s for all testing images and more than 10 times faster than that of the regular serial dimension reduction method. The computational time of the improved parallel method was less than 0.03 s for all testing images and approximately 20 times faster than that of the regular serial dimension reduction method.ConclusionThe proposed parallel method for the signed distance function can generate the signed distance in tens of milliseconds. Thus, the proposed parallel method is sufficiently fast for real-time image processing, especially for high-resolution images.关键词:signed distance function;parallel computing;dimension reduction method;lower parabola envelope based method;level set11|4|1更新时间:2024-05-07
摘要:ObjectiveSigned distance functions are the nearest distances between pixels and points on the closed curve in an image, with a negative sign in the curve and a positive sign outside the curve. The signed distance function has important applications in image processing, such as level set-based segmentation, 3D visual feature extraction, and pattern recognition in computer vision. The computational complexity of the signed distance function is O(N×M), where N is the number of pixels in an image, and M is the number of points on a closed curve. The high computational complexity of the signed distance function directly affects the computational efficiency of image processing with the increase in image resolution. For real-time processing of an image with high resolution, an improved real-time computing method for the signed distance function based on the dimension reduction method was proposed to improve the computational efficiency.MethodDimension reduction method transforms the 2D signed distance function into two independent 1D signed distance functions for each row (or column) of the image and uses lower parabola envelope-based method for calculating the 1D distance. The low-er parabola envelope-based method sequentially computes the lower envelope of the first q parabolas, where the parabolas are ordered according to the horizontal locations of their vertices. The computational complexity of the dimension reduction method is O(2N) and is one of the fastest methods for calculating the signed distance function. This paper first proposes a parallel dimension reduction method according to the computational independence of the signed distance function among the rows (or columns) in an image to reduce the computational time of the dimension reduction method. The parallel dimension reduction method calculates the signed distance functions of the different rows (or columns) in an image simultaneously by allowing each thread to correspond to a row (or column) in the image. Thus, the computational complexity of the proposed parallel dimension reduction method is reduced to O(2W+2H), where W and H are the width and height of the image, respectively. Second, this paper proposes an improved parallel dimension reduction method by running the lower parabola envelope-based method in a parallel manner to improve the computational efficiency further. The improved parallel dimension reduction method uses multi-threads in calculating the lower parabola envelope in different segments to perform the dimension reduction method by finding the intersection points between two neighboring parabolas in a segment simultaneously. All parallel processing steps were completed on CUDA platform for general parallel computing on GPU. The first step is calculating the sign by assigning H threads, and each thread should correspond to a row in the image. The second step is calculating the 1D distance by assigning W×H threads. Each thread should correspond to a pixel in the image and should scan from left to right of the image to touch the closed curve and set the scanning distance as the 1D distance of each pixel. The last step is calculating the 2D distance by assigning W×H threads. Each thread should correspond to a pixel in the image and should scan from top to bottom of the image to obtain the final distance using the proposed parallel lower parabola envelope-based method. The entire computational complexity of distance in this method is O(2W+kS), where k is the iterative times, and S is the length of the segment.ResultNine images with different image sizes (256×256, 1 280×1 280, and 2 560×2 560) and curve shapes were tested in our experiments. The computational time of three generating methods for signed distance function (the regular serial, the proposed parallel, and the improved parallel dimension reduction methods) was compared with the case in which the maximal error was below 1. The computational time of the parallel method was less than 0.06 s for all testing images and more than 10 times faster than that of the regular serial dimension reduction method. The computational time of the improved parallel method was less than 0.03 s for all testing images and approximately 20 times faster than that of the regular serial dimension reduction method.ConclusionThe proposed parallel method for the signed distance function can generate the signed distance in tens of milliseconds. Thus, the proposed parallel method is sufficiently fast for real-time image processing, especially for high-resolution images.关键词:signed distance function;parallel computing;dimension reduction method;lower parabola envelope based method;level set11|4|1更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveVisual information is the main source of human perception of outside information. The visual system of the human brain, as the most important means of obtaining information from the outside world, has a near-perfect information processing capability, which is far superior to existing computer vision systems in all aspects. The model description of the visual information processing mechanism can provide a novel way of solving engineering application problems, such as image analysis and understanding. Therefore, the study of the visual information processing mechanism has become an important direction in brain and cognitive science research. The complexity of the visual system lies in the complexity of information transmission between neurons; multiple information paths exist, and high cortical information demonstrates feedback regulation. Visual computing is an important means of studying visual information processing mechanisms and promoting the development of computer vision-related applications. Researchers can study the coding and processing of visual information from different ranges, such as microcosmic to macroscopic and molecular to behavioral, with the continuous improvement of the technical means of visual mechanism research. However, only the experimental data, which are organized organically from different levels and angles, can help determine the laws and mechanisms of nature. Contour detection is crucial to understanding the function and application of a high cortex visual perception.MethodThis study considers the process of visual information transmission by taking the entire visual paths as the object in studying the visual response characteristics of different mechanisms in the paths and constructing the visual fusion model of multiple visual pathways. The response model of the antagonistic mechanism of ganglion cells in the pathway is improved, the negative value of the primary contour response is preserved, and several features of the non-classical receptive field of the lateral geniculate nucleus are enhanced. We designed and implemented a multi-oriented simple cell receptive field model based on the DOG negative effect and constructed a visual fusion model of the complex cells of the primary visual cortex to suppress texture and enhance contours through the visual information differences among various visual pathways. We simulated the transmission and processing of visual information in the visual pathway. First, we realized the rapid extraction of primary contour information according to the antagonistic mechanism of ganglion cells. Then, the difference between the Gaussian function and the DOG function was constructed to simulate the modulation of the non-classical receptive field of the LGN, which could suppress the background texture. A multi-oriented receptive field model of a simple cell in the V1 region was constructed, and an improved evaluation model that considers the negative effect of DOG was proposed. A visual response fusion method based on parallel processing was provided to enhance target contour given the capability of the complex cells in the V1 region to represent advanced visual features.ResultVisual test and quantitative calculation results show that the method has an enhanced contour detection capability in a natural image with complex background and can detect certain weak contour edge information in the image. The miss rate of the DG method is low, but the error rate is high. The CORF method reduces the error rate but increases the miss rate. The mistake rate of the CORF method is improved compared with the DG method, but the miss rate is increased. The overall performance of the CORF method remains low, although the overall performance is higher in the CORF method than in the DG method. The SSC method strengthens the texture suppression while retaining the main contour and achieving improved detection results. However, the SSC method produces additional burrs at the periphery of the main contour, thereby resulting in insufficiently smooth contour lines. The proposed method has clear background and contours, thereby effectively suppressing the background of the texture and enhancing the contour of the subject. The method achieves a certain balance between the error and miss rates, thus improving the overall performance. In addition, the method can effectively suppress the texture background of the adjacent area of the subject contour, in which the extracted contour lines are smooth, and the burr phenomenon in the SSC method is removed. This study selected 40 natural scene graphs from the RuG contour detection database for contour detection experiments and compared them using three typical methods of natural image contour detection, namely, DG, CORF, and SSC, to verify the effectiveness of the proposed method in the contour detection of natural scene images. Results show that the main contours detected by the method proposed in this paper are complete, and the image purity is high. Overall, results reflect the biological intelligence of the proposed contour detection method. The average P index of the proposed method is 0.45, which indicates a better contour detection performance than the contrast methods.ConclusionIn this paper, we improved the classical receptive field responses of ganglion cells in the visual pathway. We studied the enhancement effect of the LGN cells in the visual pathway by considering the visual pathway the main body of the non-classical receptive field regulation mechanism. We focused on the negative effects of the DOG produced by the antagonistic mechanism of ganglion cells and designed a multi-oriented simple cell receptive field model. We introduced a parallel mechanism in multiple visual pathways for visual information processing, and the visual pathway was divided into the main and vice paths. We proposed a method that uses the visual information difference of the different visual pathways for suppressing the texture and enhancing the contours. The proposed method has enhanced natural contour detection and extraction capabilities, especially in detecting several weak contour edges in images. The new model constructed in this study will help in elucidating the function and internal mechanisms of the visual pathway and provide a new approach for image analysis and understanding based on visual mechanism.关键词:contour detection;multiple receptive fields;negative value effect of DOG;multiple visual pathways;visual mechanism11|4|1更新时间:2024-05-07
摘要:ObjectiveVisual information is the main source of human perception of outside information. The visual system of the human brain, as the most important means of obtaining information from the outside world, has a near-perfect information processing capability, which is far superior to existing computer vision systems in all aspects. The model description of the visual information processing mechanism can provide a novel way of solving engineering application problems, such as image analysis and understanding. Therefore, the study of the visual information processing mechanism has become an important direction in brain and cognitive science research. The complexity of the visual system lies in the complexity of information transmission between neurons; multiple information paths exist, and high cortical information demonstrates feedback regulation. Visual computing is an important means of studying visual information processing mechanisms and promoting the development of computer vision-related applications. Researchers can study the coding and processing of visual information from different ranges, such as microcosmic to macroscopic and molecular to behavioral, with the continuous improvement of the technical means of visual mechanism research. However, only the experimental data, which are organized organically from different levels and angles, can help determine the laws and mechanisms of nature. Contour detection is crucial to understanding the function and application of a high cortex visual perception.MethodThis study considers the process of visual information transmission by taking the entire visual paths as the object in studying the visual response characteristics of different mechanisms in the paths and constructing the visual fusion model of multiple visual pathways. The response model of the antagonistic mechanism of ganglion cells in the pathway is improved, the negative value of the primary contour response is preserved, and several features of the non-classical receptive field of the lateral geniculate nucleus are enhanced. We designed and implemented a multi-oriented simple cell receptive field model based on the DOG negative effect and constructed a visual fusion model of the complex cells of the primary visual cortex to suppress texture and enhance contours through the visual information differences among various visual pathways. We simulated the transmission and processing of visual information in the visual pathway. First, we realized the rapid extraction of primary contour information according to the antagonistic mechanism of ganglion cells. Then, the difference between the Gaussian function and the DOG function was constructed to simulate the modulation of the non-classical receptive field of the LGN, which could suppress the background texture. A multi-oriented receptive field model of a simple cell in the V1 region was constructed, and an improved evaluation model that considers the negative effect of DOG was proposed. A visual response fusion method based on parallel processing was provided to enhance target contour given the capability of the complex cells in the V1 region to represent advanced visual features.ResultVisual test and quantitative calculation results show that the method has an enhanced contour detection capability in a natural image with complex background and can detect certain weak contour edge information in the image. The miss rate of the DG method is low, but the error rate is high. The CORF method reduces the error rate but increases the miss rate. The mistake rate of the CORF method is improved compared with the DG method, but the miss rate is increased. The overall performance of the CORF method remains low, although the overall performance is higher in the CORF method than in the DG method. The SSC method strengthens the texture suppression while retaining the main contour and achieving improved detection results. However, the SSC method produces additional burrs at the periphery of the main contour, thereby resulting in insufficiently smooth contour lines. The proposed method has clear background and contours, thereby effectively suppressing the background of the texture and enhancing the contour of the subject. The method achieves a certain balance between the error and miss rates, thus improving the overall performance. In addition, the method can effectively suppress the texture background of the adjacent area of the subject contour, in which the extracted contour lines are smooth, and the burr phenomenon in the SSC method is removed. This study selected 40 natural scene graphs from the RuG contour detection database for contour detection experiments and compared them using three typical methods of natural image contour detection, namely, DG, CORF, and SSC, to verify the effectiveness of the proposed method in the contour detection of natural scene images. Results show that the main contours detected by the method proposed in this paper are complete, and the image purity is high. Overall, results reflect the biological intelligence of the proposed contour detection method. The average P index of the proposed method is 0.45, which indicates a better contour detection performance than the contrast methods.ConclusionIn this paper, we improved the classical receptive field responses of ganglion cells in the visual pathway. We studied the enhancement effect of the LGN cells in the visual pathway by considering the visual pathway the main body of the non-classical receptive field regulation mechanism. We focused on the negative effects of the DOG produced by the antagonistic mechanism of ganglion cells and designed a multi-oriented simple cell receptive field model. We introduced a parallel mechanism in multiple visual pathways for visual information processing, and the visual pathway was divided into the main and vice paths. We proposed a method that uses the visual information difference of the different visual pathways for suppressing the texture and enhancing the contours. The proposed method has enhanced natural contour detection and extraction capabilities, especially in detecting several weak contour edges in images. The new model constructed in this study will help in elucidating the function and internal mechanisms of the visual pathway and provide a new approach for image analysis and understanding based on visual mechanism.关键词:contour detection;multiple receptive fields;negative value effect of DOG;multiple visual pathways;visual mechanism11|4|1更新时间:2024-05-07
Image Understanding and Computer Vision
-
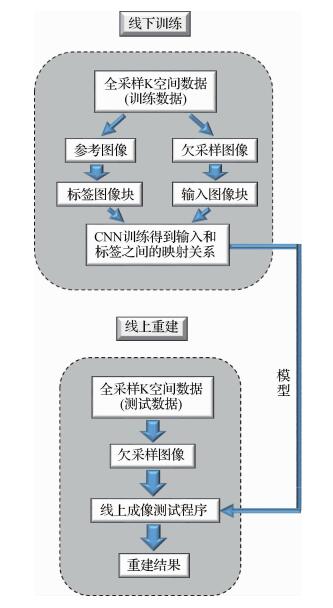 摘要:ObjectiveMagnetic resonance imaging (MRI) with non-ionizing and non-radiating nature is capable of providing rich anatomical and functional information and is an indispensable tool for medical diagnosis, disease staging, and clinical research.However, many advanced applications, such as cardiovascular imaging, magnetic resonance (MR) spectroscopy, and functional MRI, have not been widely used in clinical practice given the extended scanning time of MRI. Thus, fast imaging has been constantly one of the emphases in the MRI technology. The existing multi-coil parallel imaging and partial k-space data reconstruction techniques decrease acquisition times by reducing the amount of phase encoding required. The parallel imaging based on utilizing the spatial sensitivity of multiple coils with gradient encoding has been an essential technique for accelerating MRI scan. In addition to exploring the physical properties of multiple coils, an increasing number of researchers have been using signal processing in MR image reconstruction. Specifically, diverse prior information as regularizations is incorporated into the reconstruction equation inside. One of the representative efforts focuses on compressed sensing, which utilizes image sparsity and incoherent undersampling for fast MRI. The benefit of the combination compared with the individual techniques is the significantly increased scanning rate. However, serious aliasing artifacts may still occur in case of a high acceleration factor. Therefore, a means of accelerating the imaging rate while ensuring imaging accuracy should be devised.MethodThe wide application of convolutional neural network (CNN) has revealed its powerful capability incorrelation exploration, automatic feature extraction, and nonlinear correlation description. Therefore, we apply CNN to medical MR image reconstruction and design a multi-coil CNN to exploit the local correlation in multi-channel images. The proposed MRI based on the convolutional neural network (CNN-MRI) method utilizes prior knowledge from numerous existing fully-sampled multi-coil data. The proposed method designs and trains an off-line deep CNN to describe the mapping relationship between zero-filled and fully sampled MR images. The trained network is then used for the online prediction of images from the undersampled multi-channel data. The entire research contents include two main parts as follows:off-line training and online imaging. The two important components in the off-line training are the preprocessing of big datasets for training samples and the network design. We directly predict images online with the trained network parameter model in the online imaging. This paper discusses the undersampling methods for MRI based on deep learning. Unlike the popular parallel imaging or compressed sensing technique, which exploits sensitivity and sparsity for fast MRI, CNN-MRI learns the end-to-end mapping between the MR images reconstructed from the undersampled and fully-sampled k-space data from huge offline acquisitions, and then aids in exacting online fast imaging with the learned mapping prior. Therefore, conventional sampling methods may not be the optimal undersampling trajectory for CNN-MRI, in which uniform and incoherent undersampling are required for parallel and compressed sensing MRI, respectively. Furthermore, three 1D undersampling patterns, namely, 1D random undersampling with variable density, 1D uniform undersampling, and 1D low frequency, have been investigated with the proposed CNN-MRI framework.Specifically, we proposed a new trajectory scheme, namely, hamming filtered asymmetrical 1D partial Fourier sampling. The reconstruction results were quantitatively evaluated in terms of peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and root-mean-square error (RMSE) to determine the performance of the proposed scheme.ResultExperimental results show that the proposed undersampling pattern performs better than the traditional sampling trajectory. The PSNR improved by 1 dB to 2 dB, the SSIM ratio improved by approximately 0.1, and the RMSE decreased by approximately 0.02~0.04. In addition, we compared the proposed method to the classical parallel imaging methods, GRAPPA, SPIRiT, and SAKE, at an acceleration factor of 4. GRAPPA, SPIRiT, and SAKE has used their typical uniform undersampling patterns with autocalibration lines and parameter settings. For CNN-MRI, we adopted the hamming filtered 1D low-frequency trajectory, with a shifting distance of 18. For a quantitative comparison, four MRI images were tested with the different methods, which mean index values in PSNR, SSIM, and RMSE are summarized. The images reconstructed through the proposed method were closer to the ground truth image, while aliasing artifacts were observed in the images reconstructed using GRAPPA/SPIRiT/SAKE. The mean PSNR of the proposed method improved by 0.5~4 dB, the mean SSIM ratio improved by 0.15~0.27, and the mean RMSE decreased by approximately 0.01~0.07. Synthetically, the mean quantitative and visual comparisons show that the proposed method produces superior quality with the least time, with a reconstruction rate of faster than five times.ConclusionDeep learning can learn valuable prior knowledge from big off-line datasets, and then perform high-quality online image reconstruction from undersampled MR data with a low computational cost. The hamming filtered 1D low-frequency undersampling pattern was developed to improve the performance of the proposed CNN. Future work will further optimize the undersampling trajectories, which can also be extended to non-Cartesian sampling design, and include additional big data in the proposed framework to extract further valuable prior information for fast MRI.关键词:fast MR imaging;prior knowledge;deep learning;convolutional neural network;undersampling trajectory13|4|1更新时间:2024-05-07
摘要:ObjectiveMagnetic resonance imaging (MRI) with non-ionizing and non-radiating nature is capable of providing rich anatomical and functional information and is an indispensable tool for medical diagnosis, disease staging, and clinical research.However, many advanced applications, such as cardiovascular imaging, magnetic resonance (MR) spectroscopy, and functional MRI, have not been widely used in clinical practice given the extended scanning time of MRI. Thus, fast imaging has been constantly one of the emphases in the MRI technology. The existing multi-coil parallel imaging and partial k-space data reconstruction techniques decrease acquisition times by reducing the amount of phase encoding required. The parallel imaging based on utilizing the spatial sensitivity of multiple coils with gradient encoding has been an essential technique for accelerating MRI scan. In addition to exploring the physical properties of multiple coils, an increasing number of researchers have been using signal processing in MR image reconstruction. Specifically, diverse prior information as regularizations is incorporated into the reconstruction equation inside. One of the representative efforts focuses on compressed sensing, which utilizes image sparsity and incoherent undersampling for fast MRI. The benefit of the combination compared with the individual techniques is the significantly increased scanning rate. However, serious aliasing artifacts may still occur in case of a high acceleration factor. Therefore, a means of accelerating the imaging rate while ensuring imaging accuracy should be devised.MethodThe wide application of convolutional neural network (CNN) has revealed its powerful capability incorrelation exploration, automatic feature extraction, and nonlinear correlation description. Therefore, we apply CNN to medical MR image reconstruction and design a multi-coil CNN to exploit the local correlation in multi-channel images. The proposed MRI based on the convolutional neural network (CNN-MRI) method utilizes prior knowledge from numerous existing fully-sampled multi-coil data. The proposed method designs and trains an off-line deep CNN to describe the mapping relationship between zero-filled and fully sampled MR images. The trained network is then used for the online prediction of images from the undersampled multi-channel data. The entire research contents include two main parts as follows:off-line training and online imaging. The two important components in the off-line training are the preprocessing of big datasets for training samples and the network design. We directly predict images online with the trained network parameter model in the online imaging. This paper discusses the undersampling methods for MRI based on deep learning. Unlike the popular parallel imaging or compressed sensing technique, which exploits sensitivity and sparsity for fast MRI, CNN-MRI learns the end-to-end mapping between the MR images reconstructed from the undersampled and fully-sampled k-space data from huge offline acquisitions, and then aids in exacting online fast imaging with the learned mapping prior. Therefore, conventional sampling methods may not be the optimal undersampling trajectory for CNN-MRI, in which uniform and incoherent undersampling are required for parallel and compressed sensing MRI, respectively. Furthermore, three 1D undersampling patterns, namely, 1D random undersampling with variable density, 1D uniform undersampling, and 1D low frequency, have been investigated with the proposed CNN-MRI framework.Specifically, we proposed a new trajectory scheme, namely, hamming filtered asymmetrical 1D partial Fourier sampling. The reconstruction results were quantitatively evaluated in terms of peak signal-to-noise ratio (PSNR), structural similarity (SSIM), and root-mean-square error (RMSE) to determine the performance of the proposed scheme.ResultExperimental results show that the proposed undersampling pattern performs better than the traditional sampling trajectory. The PSNR improved by 1 dB to 2 dB, the SSIM ratio improved by approximately 0.1, and the RMSE decreased by approximately 0.02~0.04. In addition, we compared the proposed method to the classical parallel imaging methods, GRAPPA, SPIRiT, and SAKE, at an acceleration factor of 4. GRAPPA, SPIRiT, and SAKE has used their typical uniform undersampling patterns with autocalibration lines and parameter settings. For CNN-MRI, we adopted the hamming filtered 1D low-frequency trajectory, with a shifting distance of 18. For a quantitative comparison, four MRI images were tested with the different methods, which mean index values in PSNR, SSIM, and RMSE are summarized. The images reconstructed through the proposed method were closer to the ground truth image, while aliasing artifacts were observed in the images reconstructed using GRAPPA/SPIRiT/SAKE. The mean PSNR of the proposed method improved by 0.5~4 dB, the mean SSIM ratio improved by 0.15~0.27, and the mean RMSE decreased by approximately 0.01~0.07. Synthetically, the mean quantitative and visual comparisons show that the proposed method produces superior quality with the least time, with a reconstruction rate of faster than five times.ConclusionDeep learning can learn valuable prior knowledge from big off-line datasets, and then perform high-quality online image reconstruction from undersampled MR data with a low computational cost. The hamming filtered 1D low-frequency undersampling pattern was developed to improve the performance of the proposed CNN. Future work will further optimize the undersampling trajectories, which can also be extended to non-Cartesian sampling design, and include additional big data in the proposed framework to extract further valuable prior information for fast MRI.关键词:fast MR imaging;prior knowledge;deep learning;convolutional neural network;undersampling trajectory13|4|1更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveSuper-resolution (SR), which restores a high-resolution (HR) image from single or sequential low-resolution (LR) images, is a widely applied technology in image processing, especially in the remote sensing field. HR remote sensing images are increasingly sought with the rapid advancement of remote sensing technology in agriculture and forestry monitoring, urban planning, and military reconnaissance. However, traditional interpolation-based methods cannot achieve a satisfying effect, while reconstruction-based methods require pre-registration and are constrained by the lack of sequential images. In several modern learning-based methods, complicated network, considerable training time, and neglect of chrominance space still require improvement. To solve these problems, a novel SR method combined with deep learning is proposed in this paper to achieve high-quality SR reconstruction of single remote sensing image, thereby overcoming traditional drawbacks, such as dependence on image sequences or registration. The proposed method also aims to improve the efficiency and reduce the overfitting risk during training and provide a reference for the weakening block effect of chrominance interpolation.MethodThe proposed SR reconstruction process is conducted from the luminance and chrominance spaces of single remote sensing image. First, a network model named PL-CNN that is based on a four-layer convolutional neural network (CNN) is optimized with parametric rectified linear unit (PReLU) and local response normalization (LRN) layers considering the autocorrelation and texture richness of remote sensing images. In the PL-CNN, the first to the fourth convolutional layers can successively achieve feature extraction, enhancement, nonlinear mapping, and reconstruction. The deployment of PReLU can accelerate the training speed and retain the image features simultaneously. The LRN layers are used to avoid overfitting, thereby enhancing the final SR effect further. Then, the proposed PL-CNN with an iteration of 2.5 million is trained with an upscaling factor to obtain the SR model by taking the mean square error as the loss function. The training data from the UC Merced land use dataset, with a 0.3 m resolution, thereby covering 21 categories of remote sensing scenes. The training inputs are used to simulate the LR remote sensing image patches, and the outputs correspond to the original HR remote sensing images. For multiband images, the model is utilized to obtain a reconstructed result in the luminance space. Then, a joint bilateral filtering with a pixel scope of 3×3 under the guidance of the result is introduced to improve the edge details of the chrominance space after bicubic interpolation. A single-band image could be considered a special case of multiband image in which its reconstruction excludes the chrominance part.ResultA series of simulation experiments is conducted to verify the validity and applicability of the proposed SR method, and a dataset (RS5) that includes five remote sensing images with different sizes and resolutions is established to serve as the experimental images. Full-and no-reference evaluations are applied to value the quality of the SR reconstructed images objectively and fairly. Full-reference evaluation indexes include peak signal-to-noise ratio (PSNR) and structure similarity index (SSIM), while the no-reference evaluation indexes include spatial and spectral entropies (SSEQ) and clarity. Results show that the proposed reconstruction of RS5 is superior to others at no-reference evaluation indexes with upscaling factors of 2, 3, and 4. The SSEQ is enhanced, and the mean clarity value improves by 2.5 standard units. The proposed method's results also display advantageous PSNR and efficiency, thereby achieving 2 dB better in PSNR than in bicubic interpolation algorithm and limiting the average training time to one-third or less than the other learning-based methods. The visualization of the first-layer filters is rich in textures, and the typical feature maps are gradually enhanced along with the layers. The capability of joint bilateral filtering to remove the block effect and sharpen the edges is easily verified by observing the images of the chrominance space before and after filtering. Furthermore, the PSNR result continuously improves with the increase in iteration, thereby indicating a potential ameliorated orientation. A Landsat-8 image of Tangshan, China is selected for reconstruction through the PL-CNN method and decomposition into red, green, and blue bands to verify the band applicability of the proposed method. The PSNR result for each band is more than 28 dB, and the average SSIM is approximately 98.5%. The mean value and standard deviation of the original and reconstructed images in the three bands are near, thus manifesting that the proposed method is unrestricted to band factors and has a robust applicability.ConclusionA SR reconstruction method of single remote sensing image combined with deep learning is proposed. The optimized network, namely, PL-CNN, on the basis the CNN extracts additional features and performs well in terms of anti-overfitting. Moreover, the PReLU structure can effectively accelerate the training process. Experimental results suggest that the proposed method is unrestricted to the image sequence or band, thereby aiming for a single remote sensing image and considering the chrominance space, and the reconstruction quality under several upscaling factors provides evident advantages over the traditional SR reconstruction methods. Owing to the natural and clear visual effect of images reconstructed with PL-CNN, the method has broad prospects, especially in the remote sensing field. Future studies may be conducted using additional samples, appropriately increasing the iterations, and focusing on high upscaling factors.关键词:remote sensing image;super resolution;deep learning;convolutional neural networks(CNN);joint bilateral filtering41|45|13更新时间:2024-05-07
摘要:ObjectiveSuper-resolution (SR), which restores a high-resolution (HR) image from single or sequential low-resolution (LR) images, is a widely applied technology in image processing, especially in the remote sensing field. HR remote sensing images are increasingly sought with the rapid advancement of remote sensing technology in agriculture and forestry monitoring, urban planning, and military reconnaissance. However, traditional interpolation-based methods cannot achieve a satisfying effect, while reconstruction-based methods require pre-registration and are constrained by the lack of sequential images. In several modern learning-based methods, complicated network, considerable training time, and neglect of chrominance space still require improvement. To solve these problems, a novel SR method combined with deep learning is proposed in this paper to achieve high-quality SR reconstruction of single remote sensing image, thereby overcoming traditional drawbacks, such as dependence on image sequences or registration. The proposed method also aims to improve the efficiency and reduce the overfitting risk during training and provide a reference for the weakening block effect of chrominance interpolation.MethodThe proposed SR reconstruction process is conducted from the luminance and chrominance spaces of single remote sensing image. First, a network model named PL-CNN that is based on a four-layer convolutional neural network (CNN) is optimized with parametric rectified linear unit (PReLU) and local response normalization (LRN) layers considering the autocorrelation and texture richness of remote sensing images. In the PL-CNN, the first to the fourth convolutional layers can successively achieve feature extraction, enhancement, nonlinear mapping, and reconstruction. The deployment of PReLU can accelerate the training speed and retain the image features simultaneously. The LRN layers are used to avoid overfitting, thereby enhancing the final SR effect further. Then, the proposed PL-CNN with an iteration of 2.5 million is trained with an upscaling factor to obtain the SR model by taking the mean square error as the loss function. The training data from the UC Merced land use dataset, with a 0.3 m resolution, thereby covering 21 categories of remote sensing scenes. The training inputs are used to simulate the LR remote sensing image patches, and the outputs correspond to the original HR remote sensing images. For multiband images, the model is utilized to obtain a reconstructed result in the luminance space. Then, a joint bilateral filtering with a pixel scope of 3×3 under the guidance of the result is introduced to improve the edge details of the chrominance space after bicubic interpolation. A single-band image could be considered a special case of multiband image in which its reconstruction excludes the chrominance part.ResultA series of simulation experiments is conducted to verify the validity and applicability of the proposed SR method, and a dataset (RS5) that includes five remote sensing images with different sizes and resolutions is established to serve as the experimental images. Full-and no-reference evaluations are applied to value the quality of the SR reconstructed images objectively and fairly. Full-reference evaluation indexes include peak signal-to-noise ratio (PSNR) and structure similarity index (SSIM), while the no-reference evaluation indexes include spatial and spectral entropies (SSEQ) and clarity. Results show that the proposed reconstruction of RS5 is superior to others at no-reference evaluation indexes with upscaling factors of 2, 3, and 4. The SSEQ is enhanced, and the mean clarity value improves by 2.5 standard units. The proposed method's results also display advantageous PSNR and efficiency, thereby achieving 2 dB better in PSNR than in bicubic interpolation algorithm and limiting the average training time to one-third or less than the other learning-based methods. The visualization of the first-layer filters is rich in textures, and the typical feature maps are gradually enhanced along with the layers. The capability of joint bilateral filtering to remove the block effect and sharpen the edges is easily verified by observing the images of the chrominance space before and after filtering. Furthermore, the PSNR result continuously improves with the increase in iteration, thereby indicating a potential ameliorated orientation. A Landsat-8 image of Tangshan, China is selected for reconstruction through the PL-CNN method and decomposition into red, green, and blue bands to verify the band applicability of the proposed method. The PSNR result for each band is more than 28 dB, and the average SSIM is approximately 98.5%. The mean value and standard deviation of the original and reconstructed images in the three bands are near, thus manifesting that the proposed method is unrestricted to band factors and has a robust applicability.ConclusionA SR reconstruction method of single remote sensing image combined with deep learning is proposed. The optimized network, namely, PL-CNN, on the basis the CNN extracts additional features and performs well in terms of anti-overfitting. Moreover, the PReLU structure can effectively accelerate the training process. Experimental results suggest that the proposed method is unrestricted to the image sequence or band, thereby aiming for a single remote sensing image and considering the chrominance space, and the reconstruction quality under several upscaling factors provides evident advantages over the traditional SR reconstruction methods. Owing to the natural and clear visual effect of images reconstructed with PL-CNN, the method has broad prospects, especially in the remote sensing field. Future studies may be conducted using additional samples, appropriately increasing the iterations, and focusing on high upscaling factors.关键词:remote sensing image;super resolution;deep learning;convolutional neural networks(CNN);joint bilateral filtering41|45|13更新时间:2024-05-07 -
 摘要:ObjectiveAnomalies typically refer to pixels that evidently reflect different spectral features in a homogeneous background. The regions of the background refer to the pixels that occupy a larger proportion in an image than anomalies. The anomaly detection of hyperspectral remote sensing aims to find the pixels that exhibit distinct spectral features compared with its surrounding pixels. Traditional anomaly detection methods mainly distinguish anomalies by describing the spectral characteristic with a background statistic model, and numerous anomaly detection algorithms are proposed to obtain the uncontaminated statistic model for hyperspectral imagery (HSI). However, the different proportions of ground objects and complex spectrum features of hyperspectral imagery constantly induce a poor representation of the background statistic model. The difference between anomaly and non-anomaly will be weakened, and the final discrimination results will be inaccurate given the existing anomalies in the background statistic model. The spectral character of small background clusters will be covered by large clusters because of the different scales of ground objects and difference in spectral character. The background statistic model cannot be described accurately by extracting all the background pixels simultaneously considering the diversity of the background objects. This paper proposes a novel algorithm for extracting the background model based on the maximum relative density analysis to obtain an accurate background statistic model. An iterative clustering method is applied to address the abovementioned problem and avoid contamination in the background statistic model.MethodIterative screening is applied to extract background objects gradually to obtain small-scale background clusters without interference from the complex spatial distribution and texture feature of ground objects. The relative similarity density for each pixel is defined by the total number of pixels that have similar spectral features under the concept of relative density analysis. Pixels with the largest relative density will be selected as the cluster center under the current scale, driven by the similarity distribution density. One of the background objects will be extracted adaptively on the basis of the cluster center. In each iteration, we only add the cluster with the largest population to the background statistic model. The background pixels will be extracted when the iteration process is terminated, and the background can be modeled by the spectral features of the obtained clusters. The details of the proposed algorithm are as follows. First, the Euclidean distance between pixels is selected as similarity features. Second, the density and central degree of a pixel can be obtained on the basis of the distance from other pixels in the dataset. We select the pixels with high density and central degree as the center of clusters, and then classify the entire hyperspectral data. Finally, classical Mahalanobis distance is used to measure the anomaly salience of the detection results. The pixels with large Mahalanobis distances according to the value of anomaly salience are likely to be anomalies. Simulation experiments were conducted with two sets of hyperspectral imagery, namely, HyMap, and HYDICE; these sets of hyperspectral imagery are commonly used for experiment. The algorithm was compared with classical algorithms, such as CBAD, LRX, and 2DCAD, in the experiments. The detection results were analyzed using ROC and AUC as the evaluation criteria.ResultThe experimental data indicate that the ROC is generally better in the proposed algorithms than in other algorithms; the AUC tested in two hyperspectral data is higher by at least 5.6% and 13.6% than similar algorithms. The comparison of the computational costs between the proposed and the other algorithms is also presented. The computational cost of the proposed algorithm is not superior, but the comprehensive performance of our method is generally optimal. The proposed and the previous methods differ in two points. The proposed method classifies the pixels according to the degree of difference by the data characteristics, and the result obtained by the proposed method is unaffected by various complex scenes. Furthermore, the proposed method considers the scale of the ground object. Thus, the iterative strategy is applied to focus on the pixels with strongest background feathers in the current iteration and avoid the interference caused by existing different scale backgrounds. The proposed algorithm is stable under two complex scenes. Results show the robustness and effectiveness of the proposed method.ConclusionThe pixels with a high degree of anomaly salience are obtained according to the characteristics of the data without constructing the classification surface and setting the number of categories prior. Experimental results also verify that the proposed method improves the effectiveness of the background statistic model and obtains an accurate detection result. The algorithms that can characterize the clutter background accurately will achieve favorable results in anomaly detection. Therefore, the precise estimation of background statistic model is a current research direction. This study provides a novel means of obtaining the model. The novel clustering algorithm combined with the iteration process can extract an efficient uncontaminated model. The proposed method can certainly be improved. The largest population cluster obtained in each iteration step is gathered as the final statistic model. We can also consider clusters independently and analyze the background features under each category. The parameters in this study are determined by experience and experiments. The experiments show that all parameters result in local optimum. Thus, we must develop methods for establishing models for finding global optimal parameters. Furthermore, time consumption requires improvement. The algorithm steps can be further optimized to reduce the time consumption. These steps will be our next research direction.关键词:hyperspectral data;anomaly detection;background statistic model;iterative screening;largest relative density11|4|4更新时间:2024-05-07
摘要:ObjectiveAnomalies typically refer to pixels that evidently reflect different spectral features in a homogeneous background. The regions of the background refer to the pixels that occupy a larger proportion in an image than anomalies. The anomaly detection of hyperspectral remote sensing aims to find the pixels that exhibit distinct spectral features compared with its surrounding pixels. Traditional anomaly detection methods mainly distinguish anomalies by describing the spectral characteristic with a background statistic model, and numerous anomaly detection algorithms are proposed to obtain the uncontaminated statistic model for hyperspectral imagery (HSI). However, the different proportions of ground objects and complex spectrum features of hyperspectral imagery constantly induce a poor representation of the background statistic model. The difference between anomaly and non-anomaly will be weakened, and the final discrimination results will be inaccurate given the existing anomalies in the background statistic model. The spectral character of small background clusters will be covered by large clusters because of the different scales of ground objects and difference in spectral character. The background statistic model cannot be described accurately by extracting all the background pixels simultaneously considering the diversity of the background objects. This paper proposes a novel algorithm for extracting the background model based on the maximum relative density analysis to obtain an accurate background statistic model. An iterative clustering method is applied to address the abovementioned problem and avoid contamination in the background statistic model.MethodIterative screening is applied to extract background objects gradually to obtain small-scale background clusters without interference from the complex spatial distribution and texture feature of ground objects. The relative similarity density for each pixel is defined by the total number of pixels that have similar spectral features under the concept of relative density analysis. Pixels with the largest relative density will be selected as the cluster center under the current scale, driven by the similarity distribution density. One of the background objects will be extracted adaptively on the basis of the cluster center. In each iteration, we only add the cluster with the largest population to the background statistic model. The background pixels will be extracted when the iteration process is terminated, and the background can be modeled by the spectral features of the obtained clusters. The details of the proposed algorithm are as follows. First, the Euclidean distance between pixels is selected as similarity features. Second, the density and central degree of a pixel can be obtained on the basis of the distance from other pixels in the dataset. We select the pixels with high density and central degree as the center of clusters, and then classify the entire hyperspectral data. Finally, classical Mahalanobis distance is used to measure the anomaly salience of the detection results. The pixels with large Mahalanobis distances according to the value of anomaly salience are likely to be anomalies. Simulation experiments were conducted with two sets of hyperspectral imagery, namely, HyMap, and HYDICE; these sets of hyperspectral imagery are commonly used for experiment. The algorithm was compared with classical algorithms, such as CBAD, LRX, and 2DCAD, in the experiments. The detection results were analyzed using ROC and AUC as the evaluation criteria.ResultThe experimental data indicate that the ROC is generally better in the proposed algorithms than in other algorithms; the AUC tested in two hyperspectral data is higher by at least 5.6% and 13.6% than similar algorithms. The comparison of the computational costs between the proposed and the other algorithms is also presented. The computational cost of the proposed algorithm is not superior, but the comprehensive performance of our method is generally optimal. The proposed and the previous methods differ in two points. The proposed method classifies the pixels according to the degree of difference by the data characteristics, and the result obtained by the proposed method is unaffected by various complex scenes. Furthermore, the proposed method considers the scale of the ground object. Thus, the iterative strategy is applied to focus on the pixels with strongest background feathers in the current iteration and avoid the interference caused by existing different scale backgrounds. The proposed algorithm is stable under two complex scenes. Results show the robustness and effectiveness of the proposed method.ConclusionThe pixels with a high degree of anomaly salience are obtained according to the characteristics of the data without constructing the classification surface and setting the number of categories prior. Experimental results also verify that the proposed method improves the effectiveness of the background statistic model and obtains an accurate detection result. The algorithms that can characterize the clutter background accurately will achieve favorable results in anomaly detection. Therefore, the precise estimation of background statistic model is a current research direction. This study provides a novel means of obtaining the model. The novel clustering algorithm combined with the iteration process can extract an efficient uncontaminated model. The proposed method can certainly be improved. The largest population cluster obtained in each iteration step is gathered as the final statistic model. We can also consider clusters independently and analyze the background features under each category. The parameters in this study are determined by experience and experiments. The experiments show that all parameters result in local optimum. Thus, we must develop methods for establishing models for finding global optimal parameters. Furthermore, time consumption requires improvement. The algorithm steps can be further optimized to reduce the time consumption. These steps will be our next research direction.关键词:hyperspectral data;anomaly detection;background statistic model;iterative screening;largest relative density11|4|4更新时间:2024-05-07
Remote Sensing Image Processing
-
 摘要:ObjectiveMoving target detection is an important research content of image analysis technology. The purpose of it is to remove the background interference through a series of operations to extract and detect moving targets. It can be applied to video surveillance, image retrieval and motion analysis etc. The classical methods of moving object detection are mainly realized by extracting motion information of inter frames, detecting optical flow changes, or background modeling. But in dynamic scenarios, such as the scenarios which are affected by static noise (background is similar to moving target) and dynamic noise (noise which is caused by the branches, ripple and camera jitter), accuracy and robustness of moving target detection is greatly reduced. For this reason, many improved methods have been put forward. Some achievements have been made in static background noise scene or dynamic background noise scene. However, it is a pity that few methods achieve perfect results in both two situations. Aiming to solve the problems of false detection caused by static noise(background is similar to moving target) and dynamic noise (background changes or camera shaking etc.), this paper proposes a moving object detection method by using the motion saliency probability map and compares it with 9 moving object detection methods in 3 typical dynamic scenes.MethodThe motion saliency probability map enhances the saliency of the moving targets at the current frame by using the motion information in a long time and weakens the saliency of background and moving targets in historical frames. Therefore, the maximum of the probability value corresponds to the motion saliency of the current frame. The dynamic noise in the image (such as background branches, ripple and camera jitter) often causes a large number of mistakes in detection results. These pixels are not only gathered together, but also partially salient in movement, and can not be eliminated by morphological or noise filtering methods. However, the correlation between adjacent pixels can provide a high level of detection accuracy in dynamic background scenes, and can effectively suppress dynamic noise. In this method, the paper firstly constructs a set of time series including short-term motion information and long-term motion information on a time scale. Then the saliency value is calculated by the TFT method. Based on this, the conditional motion saliency probability map is obtained. Next, the motion saliency probability map is given under the guidance of the full probability formula, which can eliminate static noise, small dynamic noise and the influence of historical frame on moving targets. By segmenting the motion saliency probability map, the saliency of the moving target is highlighted, and the saliency of the background is suppressed. Finally, the spatial information of the pixel is modeled based on the motion saliency probability map to optimize the result, which can eliminate significant dynamic noise. The process of modeling is divided into two steps, including the calculation of shift probability map and component shift probability map. Foreground target can be extracted by binaryzating the component shift probability map. Generally speaking, the main innovation of this paper lies in:a saliency probability model is proposed. The paper combines the saliency value with the probability of occurrence of the moving targets. Besides, it fuses saliency detection model and probability model to construct a saliency probability model creatively.ResultIn this paper, the proposed method is compared with 9 moving object detection methods in 3 typical dynamic scenes, including static background noise scene, dynamic background noise scene caused by camera shake and dynamic background noise scene caused by water ripple. The experimental results show that in the static noise scene,
摘要:ObjectiveMoving target detection is an important research content of image analysis technology. The purpose of it is to remove the background interference through a series of operations to extract and detect moving targets. It can be applied to video surveillance, image retrieval and motion analysis etc. The classical methods of moving object detection are mainly realized by extracting motion information of inter frames, detecting optical flow changes, or background modeling. But in dynamic scenarios, such as the scenarios which are affected by static noise (background is similar to moving target) and dynamic noise (noise which is caused by the branches, ripple and camera jitter), accuracy and robustness of moving target detection is greatly reduced. For this reason, many improved methods have been put forward. Some achievements have been made in static background noise scene or dynamic background noise scene. However, it is a pity that few methods achieve perfect results in both two situations. Aiming to solve the problems of false detection caused by static noise(background is similar to moving target) and dynamic noise (background changes or camera shaking etc.), this paper proposes a moving object detection method by using the motion saliency probability map and compares it with 9 moving object detection methods in 3 typical dynamic scenes.MethodThe motion saliency probability map enhances the saliency of the moving targets at the current frame by using the motion information in a long time and weakens the saliency of background and moving targets in historical frames. Therefore, the maximum of the probability value corresponds to the motion saliency of the current frame. The dynamic noise in the image (such as background branches, ripple and camera jitter) often causes a large number of mistakes in detection results. These pixels are not only gathered together, but also partially salient in movement, and can not be eliminated by morphological or noise filtering methods. However, the correlation between adjacent pixels can provide a high level of detection accuracy in dynamic background scenes, and can effectively suppress dynamic noise. In this method, the paper firstly constructs a set of time series including short-term motion information and long-term motion information on a time scale. Then the saliency value is calculated by the TFT method. Based on this, the conditional motion saliency probability map is obtained. Next, the motion saliency probability map is given under the guidance of the full probability formula, which can eliminate static noise, small dynamic noise and the influence of historical frame on moving targets. By segmenting the motion saliency probability map, the saliency of the moving target is highlighted, and the saliency of the background is suppressed. Finally, the spatial information of the pixel is modeled based on the motion saliency probability map to optimize the result, which can eliminate significant dynamic noise. The process of modeling is divided into two steps, including the calculation of shift probability map and component shift probability map. Foreground target can be extracted by binaryzating the component shift probability map. Generally speaking, the main innovation of this paper lies in:a saliency probability model is proposed. The paper combines the saliency value with the probability of occurrence of the moving targets. Besides, it fuses saliency detection model and probability model to construct a saliency probability model creatively.ResultIn this paper, the proposed method is compared with 9 moving object detection methods in 3 typical dynamic scenes, including static background noise scene, dynamic background noise scene caused by camera shake and dynamic background noise scene caused by water ripple. The experimental results show that in the static noise scene,$ {\mathit{F}_{{\rm{score}}}}$ $ {\mathit{F}_{{\rm{score}}}}$ 关键词:moving object detection;time series group;motion saliency;motion saliency probability map;spatial information modeling;noise removal11|4|0更新时间:2024-05-07 -
 摘要:ObjectiveSaliency detection is widely used in computer vision. When dealing with simple images, the bottom-up low-level features can achieve good detection results. As for images with complex background, the existing methods do not perform well and many regions of background could also be detected, and since the low-level features of saliency detection are not so reliable. At the same time, a single feature is also difficult to get high-quality saliency map. Hence, more salient factors are need to be integrated to solve it. This paper proposes a method to achieve saliency detection by increasing the diversity of features.MethodA new consistency method base on the standard structure of the cognitive vision model. On the basis of high-level prior knowledge, the background prior characteristics and the center prior characteristics are redefined. By combining the theory of boundary prior and merging the spatial and color information get background prior saliency map. Then, according to the mechanism of human visual attention, taking the center of the background prior map as the central position of the salient region, and then apply the center prior, get the center prior saliency map. And consider the human eye vision to pay more attention to the warm color, while the warm tone has an effect on the image saliency, thus adding color prior. The local contrast method is better for the detailed texture of the image, but the integrity is not enough, the saliency map is generally dark. The contrast between the salient region and the background region is not enough, and it does not highlight the overall sense of the saliency objects. Global contrast can better show a large saliency target, but the details of the edge of the image is not good enough, at the same time there are still many unrelated interference pixels in the background region. Therefore, the more popular global contrast and local contrast characteristics are used in the low-level feature of the image, considering the overall degree of difference and the edge and contour information of the object, the global contrast saliency map and the local contrast saliency map are obtained. Finally, a new fusion strategy with linear and nonlinear are adopted to different situations in the feature fusion, to obtain high quality saliency map.ResultThe method of saliency detection based on multiple priorities and comprehensive contrast are conducted on MSRA-1000 and DUT-OMRON benchmark datasets. Experimental results show that compared with 10 state-of-the-art methods, the proposed method reaches higher precision, recall, and F-measure, which compared with RBD algorithm are improved by more than 1.5% and the comprehensive performance is better than any of the compared methods.ConclusionIn contrast to the method based on the low-level features and a single prior, the proposed method based on Multiple Priorities and Comprehensive Contrast can extract more minute features of the input image.The saliency maps not only show global contrast but also have highly detailed information.The proposed method can uniformly highlight the salient region and effectively suppress the complex background area. The result is more in line with visual perception.关键词:complex background region;low-level features;high-level prior;background prior;center prior;human eye vision11|4|6更新时间:2024-05-07
摘要:ObjectiveSaliency detection is widely used in computer vision. When dealing with simple images, the bottom-up low-level features can achieve good detection results. As for images with complex background, the existing methods do not perform well and many regions of background could also be detected, and since the low-level features of saliency detection are not so reliable. At the same time, a single feature is also difficult to get high-quality saliency map. Hence, more salient factors are need to be integrated to solve it. This paper proposes a method to achieve saliency detection by increasing the diversity of features.MethodA new consistency method base on the standard structure of the cognitive vision model. On the basis of high-level prior knowledge, the background prior characteristics and the center prior characteristics are redefined. By combining the theory of boundary prior and merging the spatial and color information get background prior saliency map. Then, according to the mechanism of human visual attention, taking the center of the background prior map as the central position of the salient region, and then apply the center prior, get the center prior saliency map. And consider the human eye vision to pay more attention to the warm color, while the warm tone has an effect on the image saliency, thus adding color prior. The local contrast method is better for the detailed texture of the image, but the integrity is not enough, the saliency map is generally dark. The contrast between the salient region and the background region is not enough, and it does not highlight the overall sense of the saliency objects. Global contrast can better show a large saliency target, but the details of the edge of the image is not good enough, at the same time there are still many unrelated interference pixels in the background region. Therefore, the more popular global contrast and local contrast characteristics are used in the low-level feature of the image, considering the overall degree of difference and the edge and contour information of the object, the global contrast saliency map and the local contrast saliency map are obtained. Finally, a new fusion strategy with linear and nonlinear are adopted to different situations in the feature fusion, to obtain high quality saliency map.ResultThe method of saliency detection based on multiple priorities and comprehensive contrast are conducted on MSRA-1000 and DUT-OMRON benchmark datasets. Experimental results show that compared with 10 state-of-the-art methods, the proposed method reaches higher precision, recall, and F-measure, which compared with RBD algorithm are improved by more than 1.5% and the comprehensive performance is better than any of the compared methods.ConclusionIn contrast to the method based on the low-level features and a single prior, the proposed method based on Multiple Priorities and Comprehensive Contrast can extract more minute features of the input image.The saliency maps not only show global contrast but also have highly detailed information.The proposed method can uniformly highlight the salient region and effectively suppress the complex background area. The result is more in line with visual perception.关键词:complex background region;low-level features;high-level prior;background prior;center prior;human eye vision11|4|6更新时间:2024-05-07 -
 摘要:ObjectiveBlind image deblurring is one of the main phases in most media analysis tasks, which has better research value and broad application. Such as image feature extraction, classification and retrieval. In fact, the shake of camera, out of focus or noise in circumstances, both of them can result in blurred image. It has been a long history to design algorithms to address blind deconvolution task. So far, there exists two general categories for image deblurring:One is by simultaneously estimate the latent image and the blur kernel under a commonly used framework maximum a posteriori (MAP), which has been appeared on many existing works. Many efforts have been made to improve the performance of MAP. Both estimate kernel on gradient domain and regularizer on latent iamge are designed to enhance the effective of deblurring. The most widely used form is norms. However, it has been demonstrated that such joint estimation strategies may lead to the undesired trivial solution since of the priors or initial value is not reasonable, and always bring blurred result. The other is Variational Bayesian (VB), which often marginalizes the edge probability of the blind kernel from all possible sharp latent images. The solution is always stable, but the higher requirement of strong edges for latent images is difficult. It becomes hard to achieve since of the complexity and computation. Based on the advantages and disadvantages of them, we proposed a new algorithm for blind image deconvolution based on learnable higher-order differential equation.MethodIn this paper, we absorb the advantages of traditional differential equation iterations method and learnable networks method, then joint the features (including strong edge image, convolutional filter and sparsity measure) learned from networks into the processing of the iterations of differential equation. Finally, we propose a learnable higher-order differential equation processing to formulate the image propagation. Specially, we first learn a rough sharp guidance, then use the convolutional filter and sparsity measure together on the current latent image. By combining them, we can obtain a better gradient direction as one step in the propagation of the higher-order differential equation. The blur kernel estimation can be efficiently controlled by both cues and training data, it also can bring a better blind deconvolution result.ResultWe first verify our higher-order differential equation propagation on non-blind image deconvolution, the comparisons with other methods show that our propagation is feasible. For blind deconvolution, the quantitative results with some state-of-the-art methods on two benchmarks indicate that our method has better performance on the indexes:PSNR, SSIM and ER. Specifically, the average PSNR, SSIM and ER on Levin et al.'s dataset are 30.30, 0.91 and 1.24, which are the best compared with other methods. For time consumption, our proposed system isn't the fastest, but is already far faster than the method, which has the second performance on the three quantitative metrics. We also test our method on special images, such as facial image, text image and nature blurry image. No matter whole image or detail restorations, our method has better performance than others on visualization.ConclusionOur method based on the propagation of the higher-order differential equation can estimate blur kernel effectively, which is better for restoring clear image. It's flexible and adaptive to deblur in all kinds of blurred scene.关键词:blind image deblurring;higher-order differential equation;blur kernel;strong edge image;learnable11|5|0更新时间:2024-05-07
摘要:ObjectiveBlind image deblurring is one of the main phases in most media analysis tasks, which has better research value and broad application. Such as image feature extraction, classification and retrieval. In fact, the shake of camera, out of focus or noise in circumstances, both of them can result in blurred image. It has been a long history to design algorithms to address blind deconvolution task. So far, there exists two general categories for image deblurring:One is by simultaneously estimate the latent image and the blur kernel under a commonly used framework maximum a posteriori (MAP), which has been appeared on many existing works. Many efforts have been made to improve the performance of MAP. Both estimate kernel on gradient domain and regularizer on latent iamge are designed to enhance the effective of deblurring. The most widely used form is norms. However, it has been demonstrated that such joint estimation strategies may lead to the undesired trivial solution since of the priors or initial value is not reasonable, and always bring blurred result. The other is Variational Bayesian (VB), which often marginalizes the edge probability of the blind kernel from all possible sharp latent images. The solution is always stable, but the higher requirement of strong edges for latent images is difficult. It becomes hard to achieve since of the complexity and computation. Based on the advantages and disadvantages of them, we proposed a new algorithm for blind image deconvolution based on learnable higher-order differential equation.MethodIn this paper, we absorb the advantages of traditional differential equation iterations method and learnable networks method, then joint the features (including strong edge image, convolutional filter and sparsity measure) learned from networks into the processing of the iterations of differential equation. Finally, we propose a learnable higher-order differential equation processing to formulate the image propagation. Specially, we first learn a rough sharp guidance, then use the convolutional filter and sparsity measure together on the current latent image. By combining them, we can obtain a better gradient direction as one step in the propagation of the higher-order differential equation. The blur kernel estimation can be efficiently controlled by both cues and training data, it also can bring a better blind deconvolution result.ResultWe first verify our higher-order differential equation propagation on non-blind image deconvolution, the comparisons with other methods show that our propagation is feasible. For blind deconvolution, the quantitative results with some state-of-the-art methods on two benchmarks indicate that our method has better performance on the indexes:PSNR, SSIM and ER. Specifically, the average PSNR, SSIM and ER on Levin et al.'s dataset are 30.30, 0.91 and 1.24, which are the best compared with other methods. For time consumption, our proposed system isn't the fastest, but is already far faster than the method, which has the second performance on the three quantitative metrics. We also test our method on special images, such as facial image, text image and nature blurry image. No matter whole image or detail restorations, our method has better performance than others on visualization.ConclusionOur method based on the propagation of the higher-order differential equation can estimate blur kernel effectively, which is better for restoring clear image. It's flexible and adaptive to deblur in all kinds of blurred scene.关键词:blind image deblurring;higher-order differential equation;blur kernel;strong edge image;learnable11|5|0更新时间:2024-05-07 -
 摘要:ObjectiveThe active contour model is a widely used method in image segmentation. The basic idea of the traditional parametric active contour model is to define an initial curve composed of control points, and make the curve as close to the target as possible, by defining the energy function and finding the minimum value to obtain the edge contour of the target object, because of its sensitivity to initialization, small capture range and can not converge to the concave area and other shortcomings, so that the initial contour must be set close to the edge of the target object in order to get a better segmentation results, or can not effectively extract the target edge contour or extract the results are not accurate. Some scholars have made improvements on this basis and proposed various active contour models based on vector fields, such as classical gradient vector flow (GVF), vector field convolution (VFC), adaptive diffusion flow (ADF) model and other models, these vector-based active contour models use the new external force field instead of the original Gaussian force field. Although the shortcomings of the traditional parametric active contour model are solved, the initial contour is insensitive, and the capturing range is extended, for some simple images with concave regions, the boundary can be extracted accurately, but there is still a problem of premature convergence for image of containing complex concave. For the vector contour model based on the vector field, the vector field often appears at the equilibrium point when extracting the concave object, resulting in premature convergence, it can not be better convergence to the depression area, especially deep and narrow concave and complex depression area. An active contour model integrating concave point detection and affine transformation is proposed to solve the above problems.MethodBecause VFC model is not sensitive to initialization, can enter a part of the concave area, and the calculation is simple, so this paper chooses the VFC model based on the fusion concave point detection and affine transformation method. First, the VFC active contour model based on vector field is used to simulate the curve. The coordinates of the points on the contour curve are obtained, and the normal direction of each point is obtained. And then use the method of concave point detection to judge the concavity and convexity of each point, concave points are extracted separately, the concave point that does not converge to the target boundary is detected by the gradient method; Second, the affine transformation of these concave points is extended to the normal direction, and the maximum distance can be obtained without approaching and not crossing the target boundary, a new contour curve is formed by replacing the original points with the transformed points, and the transformed points cross the area of equilibrium point, have the force to continue converging to the concave area; Finally, in order to ensure the accuracy of the extraction boundary, the new contour curve will be transformed once again, and finally converge to the target boundary, the complete object is extracted.ResultThe GVF model, VFC model, ADF model and the proposed model were tested and compared respectively in the data sets of the composite images with concave regions, single/multi-target real images and noise images. By dividing the synthetic image with the concave area, it shows that the proposed model is superior to the concave area segmentation, and can accurately enter the concave area and the calculation is simple, on the basis of this, the average JS value of the model segmentation is 95.51%. Compared with the current advanced active contour model based on vector field:GVF model, VFC model and ADF model, the similarity of model segmentation results is improved 15.08%, 12.09% and 10.70% respectively, the overall effect is superior to the mention of these advanced models, which not only solves the problem of edge contour extraction of target objects in concave area, but also improves the accuracy of segmentation. Then, segmentation of single/multi-target images and noise images, the experimental results show that the proposed model can improve the robustness of the segmentation performance on the basis of maintaining the good segmentation effect of the original model.ConclusionThe model proposed by the fusion concave points detection and affine transformation effectively avoids the problem of the equilibrium point which is often found in the concave area of the active contour model based on the vector field. It not only achieves the effective segmentation of the deep concave and the complex concave image, but also improves the segmentation accuracy so that the extracted edge contour is closer to the real boundary of the target object. In addition, although this paper is a fusion of concave point detection and affine transform based on the VFC model, but the fusion of concave point detection and affine transform in active contour model is introduced to solve the equilibrium problem can be applied to any vector field based on active contour model, and has wide universality. This paper mainly solves the problem that the active contour model based on vector field appears the equilibrium point in the process of evolution of concave area, the problem of premature convergence leads to the in correctly edge contour, and there is not too much consideration of multi-objective image segmentation, background and noise effects, although the proposed model to maintain the excellent segmentation characteristics of original model to solve these problems, but also need a lot of experiments to test, verify. So this problem can be used as the next step to improve the direction of the model, continue in-depth study.关键词:image segmentation;vector field;active contour models;concave point detection;affine transformation11|4|0更新时间:2024-05-07
摘要:ObjectiveThe active contour model is a widely used method in image segmentation. The basic idea of the traditional parametric active contour model is to define an initial curve composed of control points, and make the curve as close to the target as possible, by defining the energy function and finding the minimum value to obtain the edge contour of the target object, because of its sensitivity to initialization, small capture range and can not converge to the concave area and other shortcomings, so that the initial contour must be set close to the edge of the target object in order to get a better segmentation results, or can not effectively extract the target edge contour or extract the results are not accurate. Some scholars have made improvements on this basis and proposed various active contour models based on vector fields, such as classical gradient vector flow (GVF), vector field convolution (VFC), adaptive diffusion flow (ADF) model and other models, these vector-based active contour models use the new external force field instead of the original Gaussian force field. Although the shortcomings of the traditional parametric active contour model are solved, the initial contour is insensitive, and the capturing range is extended, for some simple images with concave regions, the boundary can be extracted accurately, but there is still a problem of premature convergence for image of containing complex concave. For the vector contour model based on the vector field, the vector field often appears at the equilibrium point when extracting the concave object, resulting in premature convergence, it can not be better convergence to the depression area, especially deep and narrow concave and complex depression area. An active contour model integrating concave point detection and affine transformation is proposed to solve the above problems.MethodBecause VFC model is not sensitive to initialization, can enter a part of the concave area, and the calculation is simple, so this paper chooses the VFC model based on the fusion concave point detection and affine transformation method. First, the VFC active contour model based on vector field is used to simulate the curve. The coordinates of the points on the contour curve are obtained, and the normal direction of each point is obtained. And then use the method of concave point detection to judge the concavity and convexity of each point, concave points are extracted separately, the concave point that does not converge to the target boundary is detected by the gradient method; Second, the affine transformation of these concave points is extended to the normal direction, and the maximum distance can be obtained without approaching and not crossing the target boundary, a new contour curve is formed by replacing the original points with the transformed points, and the transformed points cross the area of equilibrium point, have the force to continue converging to the concave area; Finally, in order to ensure the accuracy of the extraction boundary, the new contour curve will be transformed once again, and finally converge to the target boundary, the complete object is extracted.ResultThe GVF model, VFC model, ADF model and the proposed model were tested and compared respectively in the data sets of the composite images with concave regions, single/multi-target real images and noise images. By dividing the synthetic image with the concave area, it shows that the proposed model is superior to the concave area segmentation, and can accurately enter the concave area and the calculation is simple, on the basis of this, the average JS value of the model segmentation is 95.51%. Compared with the current advanced active contour model based on vector field:GVF model, VFC model and ADF model, the similarity of model segmentation results is improved 15.08%, 12.09% and 10.70% respectively, the overall effect is superior to the mention of these advanced models, which not only solves the problem of edge contour extraction of target objects in concave area, but also improves the accuracy of segmentation. Then, segmentation of single/multi-target images and noise images, the experimental results show that the proposed model can improve the robustness of the segmentation performance on the basis of maintaining the good segmentation effect of the original model.ConclusionThe model proposed by the fusion concave points detection and affine transformation effectively avoids the problem of the equilibrium point which is often found in the concave area of the active contour model based on the vector field. It not only achieves the effective segmentation of the deep concave and the complex concave image, but also improves the segmentation accuracy so that the extracted edge contour is closer to the real boundary of the target object. In addition, although this paper is a fusion of concave point detection and affine transform based on the VFC model, but the fusion of concave point detection and affine transform in active contour model is introduced to solve the equilibrium problem can be applied to any vector field based on active contour model, and has wide universality. This paper mainly solves the problem that the active contour model based on vector field appears the equilibrium point in the process of evolution of concave area, the problem of premature convergence leads to the in correctly edge contour, and there is not too much consideration of multi-objective image segmentation, background and noise effects, although the proposed model to maintain the excellent segmentation characteristics of original model to solve these problems, but also need a lot of experiments to test, verify. So this problem can be used as the next step to improve the direction of the model, continue in-depth study.关键词:image segmentation;vector field;active contour models;concave point detection;affine transformation11|4|0更新时间:2024-05-07 -
 摘要:ObjectiveDue to pose variation of the target, occlusion and background clutter in complex scene, visual object tracking is still a challenging task. Recently, discriminative correlation filter methods have been successfully and widely applied to visual tracking problem. The standard correlation filter method obtains a number of training samples by cyclic shift, and solves the filters by fast Fourier transform algorithm, which makes it have good real-time and robustness. However, the negative training samples caused by the boundary shift reduce the tracking effect. Spatially regularized correlation filters based tracker enhances the effect of target area by introducing a spatial weight function, which makes the difference between positive and negative samples more obvious. The target search area is increased while the computation time is also increased. In addition, for those complex scene, in which, target deformation is irregular or background is similar, the background filters are also enhanced which result in failure of tracking.MethodIn order to address the above problems, an adaptive fusion of multiple correlation filters method is proposed in this paper. The unconstrained correlation filter tracking problem is transformed into two sub problems with constraints via an alternating direction multiplier optimization method. And two sub problems are solved by different correlation filter methods. Firstly, standard correlation filters are used to locate target coarsely, and then the relocation is done via spatially regularized correlation filters, which adjusts the target position to improve the tracking effect.ResultIn the experiment, the algorithm is evaluated on 100 videos of OTB-2015 benchmark dataset and compared with other state-of-the-art trackers, and the central coordinate error and the overlap rate of target frame are used as evaluation criteria. And the algorithm can handle variation in position, scale, and occlusion and shows the best results in CarScale, Freeman4, Girl and other videos. The average center position error of 100 videos is 28.55 pixels and the average overlap rate of target frame is 61%. Compared with the methods which utilize artificial features, our algorithm is better than those other algorithms. Compared with the correlation filter method using deep feature such as CNN feature, the average center position error of our algorithm is 6 pixels higher, but the average overlap rate of target frame improves 4%.ConclusionExtensive experimental results show that our algorithm has better accuracy and robustness under appearance changes such as variation in position and scale.关键词:visual tracking;spatially regularized;correlation filter;alternating direction multiplier;robustness11|4|3更新时间:2024-05-07
摘要:ObjectiveDue to pose variation of the target, occlusion and background clutter in complex scene, visual object tracking is still a challenging task. Recently, discriminative correlation filter methods have been successfully and widely applied to visual tracking problem. The standard correlation filter method obtains a number of training samples by cyclic shift, and solves the filters by fast Fourier transform algorithm, which makes it have good real-time and robustness. However, the negative training samples caused by the boundary shift reduce the tracking effect. Spatially regularized correlation filters based tracker enhances the effect of target area by introducing a spatial weight function, which makes the difference between positive and negative samples more obvious. The target search area is increased while the computation time is also increased. In addition, for those complex scene, in which, target deformation is irregular or background is similar, the background filters are also enhanced which result in failure of tracking.MethodIn order to address the above problems, an adaptive fusion of multiple correlation filters method is proposed in this paper. The unconstrained correlation filter tracking problem is transformed into two sub problems with constraints via an alternating direction multiplier optimization method. And two sub problems are solved by different correlation filter methods. Firstly, standard correlation filters are used to locate target coarsely, and then the relocation is done via spatially regularized correlation filters, which adjusts the target position to improve the tracking effect.ResultIn the experiment, the algorithm is evaluated on 100 videos of OTB-2015 benchmark dataset and compared with other state-of-the-art trackers, and the central coordinate error and the overlap rate of target frame are used as evaluation criteria. And the algorithm can handle variation in position, scale, and occlusion and shows the best results in CarScale, Freeman4, Girl and other videos. The average center position error of 100 videos is 28.55 pixels and the average overlap rate of target frame is 61%. Compared with the methods which utilize artificial features, our algorithm is better than those other algorithms. Compared with the correlation filter method using deep feature such as CNN feature, the average center position error of our algorithm is 6 pixels higher, but the average overlap rate of target frame improves 4%.ConclusionExtensive experimental results show that our algorithm has better accuracy and robustness under appearance changes such as variation in position and scale.关键词:visual tracking;spatially regularized;correlation filter;alternating direction multiplier;robustness11|4|3更新时间:2024-05-07 -
 摘要:ObjectiveIn recent years, artificial intelligence has become the emerging area and attract the attention of many research institutions. Computer vision is the force at the core of the development in the area of artificial intelligence. Image restoration remains an active research topic in low-level computer vision. Because the distribution of the rain streaks is irregular and the problem is ill-posed, rain removal for the single image is one of the difficult problems to be solved. So far, the basic idea to solve the problem is building the rational rain image generative model, and find the solution by different measures. There are two representative ways. One is by describing the priors of rain streaks and background with conventional models and then solve it by the optimization algorithm, but the shortcoming is due to the interdependent connection between rain streaks and the background, it is hard to balance the relationship between the performance of rain removal and the clarity of background. The other is deep neural network based framework to build the network structure and loss function, then learning the network with large amounts of data, but the shortcoming is the difficulty of generalization because of test results are subject to the training data which is hard to cover the rain in the different scene.MethodFor the shortcomings mentioned above, inspired by general image restoration, this paper combines the network by data-driven with the empirical model, and the process displays the advantages of the network and empirical model, then learnable mixture MAP network is proposed so that image deraining problem can be solved effectively. The specific process is to build the energy model which contains the implicit prior item based on maximum a posterior (MAP) framework, then transfer the model to two parts that is estimating background and estimating rain streaks by the optimization algorithm, and that reduce the dependency of background and rain streaks. For the first part, it can be solved by the residual network for denoising by analysis the model and the optimization objective and in this way, the estimated image is more clearly. For the second part, the rain streaks prior to the input image can be described real-time by gaussian mixture model to improve the accuracy of estimating rain streaks.ResultIn the end, compared with the three empirical model-based algorithms and two deep learning-based algorithms, the experiments on the synthetic dataset and real-world image demonstrate the good performance of our model on removing rain streaks meanwhile reducing the information loss of the background, in addition, the SSIM value reaches to 0.92 on the synthetic dataset.ConclusionThis paper proposes to combine model-based method with deep network-based method, assimilates the advantages from each other. Not only can the majority of visible rain streaks be removed, but also remains detail information of background. Achieving a harmonious of the two aspects and standing out from state-of-the-art methods. At the same time, this paper makes a verification, which is the effective way to solve the image restoration problem by combining the conventional model and deep network.关键词:image deraining;learnable hybrid MAP network;maximum a posteriori estimate;Gaussian mixture model;residual network14|7|3更新时间:2024-05-07
摘要:ObjectiveIn recent years, artificial intelligence has become the emerging area and attract the attention of many research institutions. Computer vision is the force at the core of the development in the area of artificial intelligence. Image restoration remains an active research topic in low-level computer vision. Because the distribution of the rain streaks is irregular and the problem is ill-posed, rain removal for the single image is one of the difficult problems to be solved. So far, the basic idea to solve the problem is building the rational rain image generative model, and find the solution by different measures. There are two representative ways. One is by describing the priors of rain streaks and background with conventional models and then solve it by the optimization algorithm, but the shortcoming is due to the interdependent connection between rain streaks and the background, it is hard to balance the relationship between the performance of rain removal and the clarity of background. The other is deep neural network based framework to build the network structure and loss function, then learning the network with large amounts of data, but the shortcoming is the difficulty of generalization because of test results are subject to the training data which is hard to cover the rain in the different scene.MethodFor the shortcomings mentioned above, inspired by general image restoration, this paper combines the network by data-driven with the empirical model, and the process displays the advantages of the network and empirical model, then learnable mixture MAP network is proposed so that image deraining problem can be solved effectively. The specific process is to build the energy model which contains the implicit prior item based on maximum a posterior (MAP) framework, then transfer the model to two parts that is estimating background and estimating rain streaks by the optimization algorithm, and that reduce the dependency of background and rain streaks. For the first part, it can be solved by the residual network for denoising by analysis the model and the optimization objective and in this way, the estimated image is more clearly. For the second part, the rain streaks prior to the input image can be described real-time by gaussian mixture model to improve the accuracy of estimating rain streaks.ResultIn the end, compared with the three empirical model-based algorithms and two deep learning-based algorithms, the experiments on the synthetic dataset and real-world image demonstrate the good performance of our model on removing rain streaks meanwhile reducing the information loss of the background, in addition, the SSIM value reaches to 0.92 on the synthetic dataset.ConclusionThis paper proposes to combine model-based method with deep network-based method, assimilates the advantages from each other. Not only can the majority of visible rain streaks be removed, but also remains detail information of background. Achieving a harmonious of the two aspects and standing out from state-of-the-art methods. At the same time, this paper makes a verification, which is the effective way to solve the image restoration problem by combining the conventional model and deep network.关键词:image deraining;learnable hybrid MAP network;maximum a posteriori estimate;Gaussian mixture model;residual network14|7|3更新时间:2024-05-07 -
 摘要:ObjectiveNowadays, dynamic adaptive streaming over HTTP (DASH) has been widely adopted for providing continuous video delivery service under various network conditions and heterogeneous devices, and bitrate adaptation algorithm is the most important feature of the DASH service. State-of-the-art bitrate adaptation algorithms are classified as two types:throughput-based methods and buffer-based methods. The throughput-based adaptive video streaming often estimates the current bandwidth on the smoothed throughputs collected in a time window and chooses the best suitable presentation for streaming to the client. While the buffer-based adaptive video streaming needs not to estimate the real-time bandwidth, and directly selects the best quality representation according to the current network status through the mapping function from the buffer occupancy to the bit-rate. However, this conventional buffer-based adaptation algorithm without considering the content features based rate selection for different motion video content, sudden rate fluctuations on high motion content would severally harm the user quality of experience (QoE) in an unstable wireless network. A motion-aware buffer-based adaption (MA-BBA) is proposed to determine the bit-rate mapping function based on motion rank from buffer occupancy for each segment.MethodCommonly, high motion content in a streaming means the most import part to attract viewer's interest, and which should be streamed in a high quality version to obtain high QoE, while the high motion content needs more resource than slow motion content at the same quality. To reduce the quality fluctuations and assure better average quality best effort, the bit rate of high motion content should be mapped to higher bit-rate version than the slow motion content according to the current bandwidth. The MA-BBA assumes different bit-rate mapping policies for different motion content. It maps higher bit-rate for high motion segment, and while maps the more conservative bit-rate for those slower motion segments, which also results increasing the buffer resources to prevent rebuffering. Even though the mapped bit-rate for high motion segment exceeds current bandwidth sometimes, MA-BBA would consume a certain proportion of available pre-buffering occupancy above the safe boundary to assure high motion content streaming on higher bitrate than current bandwidth.ResultWe have implemented three adaptation algorithms including the proposed MA-BBA, throughput-based adaptation (TBA) and buffer-based adaptation (BBA) on a set of public online wireless traces, among which the QoE metrics and network performance have been evaluated. Compared with the conventional TBA and BBA, the proposed MA-BBA performs better average quality on high motion content respectively, which has been proved 1.7% higher than TBA and 1.2% higher than BBA, and MA-BBA also results less quality fluctuations than the other algorithms. Furthermore, the average utilization rate of buffer occupancy in MA-BBA has been reported up to 72%, which is greatly higher than 45.9% of TBA and 45.4% of BBA.ConclusionComparing with TBA and BBA, MA-BBA improves the utilization of buffer resource, and improves average streaming quality of high motion content in constrained resource environment. MA-BBA also reduces the amplitude and frequency of bit-rate switching, and then the overall QoE of video service has been improved. MA-BBA have implied future direction on adaptive streaming that important content as well as semantic content should be optimized to better QoE than those ordinary content, thus a novel solution on content adaptation could be introduced to the emerging wireless applications such as smart helmet, unmanned aerial vehicle, remote medical technology in resource limited environment.关键词:adaptive video streaming;buffer management;semantic-aware;quality of experience11|4|0更新时间:2024-05-07
摘要:ObjectiveNowadays, dynamic adaptive streaming over HTTP (DASH) has been widely adopted for providing continuous video delivery service under various network conditions and heterogeneous devices, and bitrate adaptation algorithm is the most important feature of the DASH service. State-of-the-art bitrate adaptation algorithms are classified as two types:throughput-based methods and buffer-based methods. The throughput-based adaptive video streaming often estimates the current bandwidth on the smoothed throughputs collected in a time window and chooses the best suitable presentation for streaming to the client. While the buffer-based adaptive video streaming needs not to estimate the real-time bandwidth, and directly selects the best quality representation according to the current network status through the mapping function from the buffer occupancy to the bit-rate. However, this conventional buffer-based adaptation algorithm without considering the content features based rate selection for different motion video content, sudden rate fluctuations on high motion content would severally harm the user quality of experience (QoE) in an unstable wireless network. A motion-aware buffer-based adaption (MA-BBA) is proposed to determine the bit-rate mapping function based on motion rank from buffer occupancy for each segment.MethodCommonly, high motion content in a streaming means the most import part to attract viewer's interest, and which should be streamed in a high quality version to obtain high QoE, while the high motion content needs more resource than slow motion content at the same quality. To reduce the quality fluctuations and assure better average quality best effort, the bit rate of high motion content should be mapped to higher bit-rate version than the slow motion content according to the current bandwidth. The MA-BBA assumes different bit-rate mapping policies for different motion content. It maps higher bit-rate for high motion segment, and while maps the more conservative bit-rate for those slower motion segments, which also results increasing the buffer resources to prevent rebuffering. Even though the mapped bit-rate for high motion segment exceeds current bandwidth sometimes, MA-BBA would consume a certain proportion of available pre-buffering occupancy above the safe boundary to assure high motion content streaming on higher bitrate than current bandwidth.ResultWe have implemented three adaptation algorithms including the proposed MA-BBA, throughput-based adaptation (TBA) and buffer-based adaptation (BBA) on a set of public online wireless traces, among which the QoE metrics and network performance have been evaluated. Compared with the conventional TBA and BBA, the proposed MA-BBA performs better average quality on high motion content respectively, which has been proved 1.7% higher than TBA and 1.2% higher than BBA, and MA-BBA also results less quality fluctuations than the other algorithms. Furthermore, the average utilization rate of buffer occupancy in MA-BBA has been reported up to 72%, which is greatly higher than 45.9% of TBA and 45.4% of BBA.ConclusionComparing with TBA and BBA, MA-BBA improves the utilization of buffer resource, and improves average streaming quality of high motion content in constrained resource environment. MA-BBA also reduces the amplitude and frequency of bit-rate switching, and then the overall QoE of video service has been improved. MA-BBA have implied future direction on adaptive streaming that important content as well as semantic content should be optimized to better QoE than those ordinary content, thus a novel solution on content adaptation could be introduced to the emerging wireless applications such as smart helmet, unmanned aerial vehicle, remote medical technology in resource limited environment.关键词:adaptive video streaming;buffer management;semantic-aware;quality of experience11|4|0更新时间:2024-05-07 -
 摘要:ObjectiveA video captured with a hand-held device (e.g., cell-phone or tablet computer) often appears remarkably shaky. It has a great negative impact to people's visual perception and is difficult for the following processings of the video. Therefore, video stabilization has always been one of the focuses in the field of image and video processing for a long time. Many of the previous methods focused primarily on the stability of the final results, while paying little attention to the processing delays. These methods spend too much time and they can only stabilize videos after obtaining most of the video frames. These methods are difficult to handle the scenario that requires low latency processing. To solve this problem, a video stabilization method based on the on-the-fly total variation optimization is proposed.MethodThe first step is motion estimation. In order to meet the requirements of low latency. The algorithm first gets the feature points by detecting FAST features that are very fast. It is observed that a point is considered as a feature point when the difference of the pixel value between this point and other points in the neighborhood is large enough. Then it tracks the feature points by KLT to the adjacent frame. After that, it calculates the inter frame homography matrix through the feature points. Homography matrix can accurately describe the translation, rotation and other transformations between the video frames. And then we can get the camera path of the shaky video. The second step is motion smoothing. This is usually the time-consuming step of traditional methods. In this step, we should not only remove the shake of the camera path, but also need to try to avoid that the clipping and distortion rate of video is too high. In order to obtain the better effect of video stabilization and meet the requirements of low latency, the on-the-fly total variation minimization method is used to smooth the shaky path so as to obtain a stable path. This method greatly improves the computation speed. And it has a regularization parameter, so we can control the smoothness of the camera path by adjusting it. It can help us get better results. If we want a smoother camera path, we can increase this regularization parameter. However, this may make the optimization path more different from the original path, and results in excessive loss of image information. The visual result is that the video shows larger black edges. When the parameter is reduced, the smoothing effect may not be obvious and the shake may not be removed effectively. So we need to set the parameter according to the size of the camera path. After that, we can compute the motion compensation matrix through the stable camera path and shaky video. The shaky frames are then deformed according to the transformation matrix. Finally, a stable video can be generated.ResultTo test the effectiveness of this algorithm, a public dataset containing multiple categories of videos is used. This algorithm is compared with several video stabilization algorithms and commercial softwares that can provide good video stabilization results. Among these methods, there are three offline methods. They are the bundled camera paths method (BCP), the deformation stabilizer of Adobe After Effects CC 2015 (AE), and the online video stabilizer provided by YouTube. The two low latency video stabilization methods are video stabilization method based on Kalman filtering and the MeshFlow method. We compare these methods in two ways and implement these methods on the same computer. First, we count the average consumption time per frame of different methods. At the same time, we count the delay time and the number of delay frames in processing the video. Second, we calculate the video distortion rate and cropping rate of different methods. These two rates are derived from the inter-frame affine transformation of videos that are processed by these methods. In addition, we invite 50 non-professional volunteers to make subjective judgments about the stability of these methods. The eventual experimental results show that, different from these offline methods that need to get all or most of the video frames, our algorithm can obtain the stable video with only one frame latency. This result is similar to the Kalman filtering method. Compared with the MeshFlow method, there are about 15% speed improvements. In terms of distortion, this algorithm is only a little worse than the Kalman filtering method, better than any other methods. Similarly, our algorithm is only a little worse than the BCP method in cropping. But it is better than the others. Generally, our algorithm can produce comparable quality with these offline approaches that are recognized generally as the best ones of all the algorithms in stability. This result is similar to the MeshFlow method and almost completely better than the Kalman filtering method.ConclusionA video stabilization method based on the on-the-fly total variation optimization is proposed, which can get the stable videos with only one frame latency. The results show that the proposed algorithm can generate pleasing results both in delay performance and stability. Compared with the traditional methods, our algorithm is more suitable for the scenario that needs to get the stabilization results with low latency. However, our algorithm estimate inter-frame motion by detecting and matching feature points, it may fail to obtain good stabilization results for those videos that have minor feature points.关键词:video stabilization;low-latency;on-the-fly;total variation minimization;camera path14|5|0更新时间:2024-05-07
摘要:ObjectiveA video captured with a hand-held device (e.g., cell-phone or tablet computer) often appears remarkably shaky. It has a great negative impact to people's visual perception and is difficult for the following processings of the video. Therefore, video stabilization has always been one of the focuses in the field of image and video processing for a long time. Many of the previous methods focused primarily on the stability of the final results, while paying little attention to the processing delays. These methods spend too much time and they can only stabilize videos after obtaining most of the video frames. These methods are difficult to handle the scenario that requires low latency processing. To solve this problem, a video stabilization method based on the on-the-fly total variation optimization is proposed.MethodThe first step is motion estimation. In order to meet the requirements of low latency. The algorithm first gets the feature points by detecting FAST features that are very fast. It is observed that a point is considered as a feature point when the difference of the pixel value between this point and other points in the neighborhood is large enough. Then it tracks the feature points by KLT to the adjacent frame. After that, it calculates the inter frame homography matrix through the feature points. Homography matrix can accurately describe the translation, rotation and other transformations between the video frames. And then we can get the camera path of the shaky video. The second step is motion smoothing. This is usually the time-consuming step of traditional methods. In this step, we should not only remove the shake of the camera path, but also need to try to avoid that the clipping and distortion rate of video is too high. In order to obtain the better effect of video stabilization and meet the requirements of low latency, the on-the-fly total variation minimization method is used to smooth the shaky path so as to obtain a stable path. This method greatly improves the computation speed. And it has a regularization parameter, so we can control the smoothness of the camera path by adjusting it. It can help us get better results. If we want a smoother camera path, we can increase this regularization parameter. However, this may make the optimization path more different from the original path, and results in excessive loss of image information. The visual result is that the video shows larger black edges. When the parameter is reduced, the smoothing effect may not be obvious and the shake may not be removed effectively. So we need to set the parameter according to the size of the camera path. After that, we can compute the motion compensation matrix through the stable camera path and shaky video. The shaky frames are then deformed according to the transformation matrix. Finally, a stable video can be generated.ResultTo test the effectiveness of this algorithm, a public dataset containing multiple categories of videos is used. This algorithm is compared with several video stabilization algorithms and commercial softwares that can provide good video stabilization results. Among these methods, there are three offline methods. They are the bundled camera paths method (BCP), the deformation stabilizer of Adobe After Effects CC 2015 (AE), and the online video stabilizer provided by YouTube. The two low latency video stabilization methods are video stabilization method based on Kalman filtering and the MeshFlow method. We compare these methods in two ways and implement these methods on the same computer. First, we count the average consumption time per frame of different methods. At the same time, we count the delay time and the number of delay frames in processing the video. Second, we calculate the video distortion rate and cropping rate of different methods. These two rates are derived from the inter-frame affine transformation of videos that are processed by these methods. In addition, we invite 50 non-professional volunteers to make subjective judgments about the stability of these methods. The eventual experimental results show that, different from these offline methods that need to get all or most of the video frames, our algorithm can obtain the stable video with only one frame latency. This result is similar to the Kalman filtering method. Compared with the MeshFlow method, there are about 15% speed improvements. In terms of distortion, this algorithm is only a little worse than the Kalman filtering method, better than any other methods. Similarly, our algorithm is only a little worse than the BCP method in cropping. But it is better than the others. Generally, our algorithm can produce comparable quality with these offline approaches that are recognized generally as the best ones of all the algorithms in stability. This result is similar to the MeshFlow method and almost completely better than the Kalman filtering method.ConclusionA video stabilization method based on the on-the-fly total variation optimization is proposed, which can get the stable videos with only one frame latency. The results show that the proposed algorithm can generate pleasing results both in delay performance and stability. Compared with the traditional methods, our algorithm is more suitable for the scenario that needs to get the stabilization results with low latency. However, our algorithm estimate inter-frame motion by detecting and matching feature points, it may fail to obtain good stabilization results for those videos that have minor feature points.关键词:video stabilization;low-latency;on-the-fly;total variation minimization;camera path14|5|0更新时间:2024-05-07
Column of China MM 2017
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0