
最新刊期
卷 23 , 期 12 , 2018
-
 摘要:ObjectiveThe use of image super-resolution reconstruction technology implies the utilization of a set of low-quality low-resolution images (or motion sequences) to produce the corresponding high-quality and high-resolution ones.This technology has a wide range of applications in many fields, such as military, medicine, public safety, and computer vision.In the field of computer vision, image super-resolution reconstruction enables the image to transform from the detection level to the recognition level, and even advance to the identification level.In other words, image super-resolution reconstruction can enhance image recognition capability and identification accuracy.In addition, image super-resolution reconstruction involves a dedicated analysis of a target.In this analytic scheme, a comparatively high spatial resolution image of the region of interest is obtained instead of directly calculating the configuration of a high spatial resolution image by using large amounts of data.The conventional approaches of super-resolution reconstruction generally include example-based model, bi-cubic interpolation model, and sparse coding methods, among others.Deep learning has been considered for many associative subjects since the advent of artificial intelligence in recent years, and substantial research achievements have been realized in this field alongside the research on super-resolution reconstruction.Convolutional neural networks (CNNs) and generative adversarial networks (GANs) have resulted in numerous breakthroughs and achievements in the domain of image super-resolution reconstruction.Examples include super-resolution reconstruction with CNN (SRCNN), super-resolution reconstruction with very-deep convolutional networks (VDSR), and super-resolution reconstruction with generative adversarial network (SRGAN).Particularly in SRGAN modeling, the single-image super-resolution technology has achieved remarkable progress, especially when the perceptual loss function instead of the traditional loss function based on the mean square error (MSE) is the optimization goal.The common problems during modeling can be effectively solved using the original loss function, and a relatively high peak signal-to-noise ratio (PSNR) can be obtained to resolve the fuzziness in the reconstruction results.However, even if super-resolution reconstruction can remarkably ameliorate image quality, a common problem is knowing how to comprehensively highlight the feature representation of reconstructed images, which then can improve the reconstruction quality of generated images.By itself, the method of super-resolution reconstruction causes an ill-posed problem; that is, images lose a certain amount of information during the down-sampling process.Therefore, the reconstruction of a high-resolution image may include the lost parts or characteristic of the corresponding low-resolution image, and this scenario inevitably leads to generative deviation.In addition, given that SRGAN does not add auxiliary trademark information into the loss function (i.e., the model should have been explicitly instructed to generate the corresponding features), the model may fail to accurately match the specific dimensions and semantic features of the data.Moreover, controllability will likely constrain the model from sufficiently representing the feature information of generated images, which then limits the model from improving the quality of reconstructed images.Such constraints pose difficulties to the subsequent identification and processing of the image.Aiming to solve the above problems, on the basis of the advantages of the SRGAN method, a super-resolution model based on the class-information generative adversarial network (class-info SRGAN) is proposed.Class-info SRGAN can be designed for the utilization of additional information variables to restrict the solution space scope of super-resolution reconstruction.Furthermore, class-info SRGAN can be used to assist the model to accurately fulfil the reconstruction task, particularly those referring to data semantic features.MethodThe original SRGAN model involves the adding of a class classifier and integrating the class-loss item into the generative network loss.Then, back-propagation is employed during the training process to update the parameter weights of the network and provide feature class-information for the model.Finally, the reconstructed images are produced and possessed with the corresponding features.In contrast to the original objective function, the proposed model is innovative given its merits of having to introduce feature class-information and improving the optimization objective of the super-resolution model.Sequentially, it optimizes the network training process, and it then renders the feature representation of the reconstruction results to become more prominent.ResultAccording to the CelebA experiments, the class-loss item enables the SRGAN model to make minor changes and improve the output.A comparison of the SRGAN model with other models with gender-class information was conducted, and the differences were inconclusive, i.e., it is hard to conclude whether the model has a significant effect even if improvements were achieved to some extent.The overall gender recognition rate of the generated images from the class-info SRGAN model ranges from 58% to 97%, which is higher than the rate of those from SRGAN (8% to 98%).However, with glasses-class information, the capability of the model to learn how to form better-shaped glasses increased.The results for the Fashion-mnist dataset and Cifar-10 dataset also show that the model has a significant effect even if the final results with the Cifar-10 dataset were not highly prominent as the previous experiments.In summary, the outcomes show that the reconstruction quality of the generated images from the class-info SRGAN model are better than those of the original SRGAN model.Conclusion Class-information operates well in cases where the attributes are clear and the model has learned as much as possible.The experimental results verify the superiority and effectiveness of the proposed model in the super-resolution reconstruction task.On the basis of some concrete and simple feature attributes, class-info SRGAN will likely become a promising super-resolution model.However, to advance its application, the goals must be definite, e.g., how to develop a general class-info SRGAN that can be used for various super-resolution reconstruction tasks, how to successfully conduct class-info SRGAN with multiple attributes simultaneously, and how to integrate auxiliary class-information into the architectures of class-info SRGAN efficiently and conveniently.These assumptions can provide references and conditions for acquiring better performing super-resolution reconstruction in the future.关键词:super-resolution based on generative adversarial network (SRGAN);perceptual loss function;Mean Square Error (MSE);class-info;class-info SRGAN19|62|6更新时间:2024-05-07
摘要:ObjectiveThe use of image super-resolution reconstruction technology implies the utilization of a set of low-quality low-resolution images (or motion sequences) to produce the corresponding high-quality and high-resolution ones.This technology has a wide range of applications in many fields, such as military, medicine, public safety, and computer vision.In the field of computer vision, image super-resolution reconstruction enables the image to transform from the detection level to the recognition level, and even advance to the identification level.In other words, image super-resolution reconstruction can enhance image recognition capability and identification accuracy.In addition, image super-resolution reconstruction involves a dedicated analysis of a target.In this analytic scheme, a comparatively high spatial resolution image of the region of interest is obtained instead of directly calculating the configuration of a high spatial resolution image by using large amounts of data.The conventional approaches of super-resolution reconstruction generally include example-based model, bi-cubic interpolation model, and sparse coding methods, among others.Deep learning has been considered for many associative subjects since the advent of artificial intelligence in recent years, and substantial research achievements have been realized in this field alongside the research on super-resolution reconstruction.Convolutional neural networks (CNNs) and generative adversarial networks (GANs) have resulted in numerous breakthroughs and achievements in the domain of image super-resolution reconstruction.Examples include super-resolution reconstruction with CNN (SRCNN), super-resolution reconstruction with very-deep convolutional networks (VDSR), and super-resolution reconstruction with generative adversarial network (SRGAN).Particularly in SRGAN modeling, the single-image super-resolution technology has achieved remarkable progress, especially when the perceptual loss function instead of the traditional loss function based on the mean square error (MSE) is the optimization goal.The common problems during modeling can be effectively solved using the original loss function, and a relatively high peak signal-to-noise ratio (PSNR) can be obtained to resolve the fuzziness in the reconstruction results.However, even if super-resolution reconstruction can remarkably ameliorate image quality, a common problem is knowing how to comprehensively highlight the feature representation of reconstructed images, which then can improve the reconstruction quality of generated images.By itself, the method of super-resolution reconstruction causes an ill-posed problem; that is, images lose a certain amount of information during the down-sampling process.Therefore, the reconstruction of a high-resolution image may include the lost parts or characteristic of the corresponding low-resolution image, and this scenario inevitably leads to generative deviation.In addition, given that SRGAN does not add auxiliary trademark information into the loss function (i.e., the model should have been explicitly instructed to generate the corresponding features), the model may fail to accurately match the specific dimensions and semantic features of the data.Moreover, controllability will likely constrain the model from sufficiently representing the feature information of generated images, which then limits the model from improving the quality of reconstructed images.Such constraints pose difficulties to the subsequent identification and processing of the image.Aiming to solve the above problems, on the basis of the advantages of the SRGAN method, a super-resolution model based on the class-information generative adversarial network (class-info SRGAN) is proposed.Class-info SRGAN can be designed for the utilization of additional information variables to restrict the solution space scope of super-resolution reconstruction.Furthermore, class-info SRGAN can be used to assist the model to accurately fulfil the reconstruction task, particularly those referring to data semantic features.MethodThe original SRGAN model involves the adding of a class classifier and integrating the class-loss item into the generative network loss.Then, back-propagation is employed during the training process to update the parameter weights of the network and provide feature class-information for the model.Finally, the reconstructed images are produced and possessed with the corresponding features.In contrast to the original objective function, the proposed model is innovative given its merits of having to introduce feature class-information and improving the optimization objective of the super-resolution model.Sequentially, it optimizes the network training process, and it then renders the feature representation of the reconstruction results to become more prominent.ResultAccording to the CelebA experiments, the class-loss item enables the SRGAN model to make minor changes and improve the output.A comparison of the SRGAN model with other models with gender-class information was conducted, and the differences were inconclusive, i.e., it is hard to conclude whether the model has a significant effect even if improvements were achieved to some extent.The overall gender recognition rate of the generated images from the class-info SRGAN model ranges from 58% to 97%, which is higher than the rate of those from SRGAN (8% to 98%).However, with glasses-class information, the capability of the model to learn how to form better-shaped glasses increased.The results for the Fashion-mnist dataset and Cifar-10 dataset also show that the model has a significant effect even if the final results with the Cifar-10 dataset were not highly prominent as the previous experiments.In summary, the outcomes show that the reconstruction quality of the generated images from the class-info SRGAN model are better than those of the original SRGAN model.Conclusion Class-information operates well in cases where the attributes are clear and the model has learned as much as possible.The experimental results verify the superiority and effectiveness of the proposed model in the super-resolution reconstruction task.On the basis of some concrete and simple feature attributes, class-info SRGAN will likely become a promising super-resolution model.However, to advance its application, the goals must be definite, e.g., how to develop a general class-info SRGAN that can be used for various super-resolution reconstruction tasks, how to successfully conduct class-info SRGAN with multiple attributes simultaneously, and how to integrate auxiliary class-information into the architectures of class-info SRGAN efficiently and conveniently.These assumptions can provide references and conditions for acquiring better performing super-resolution reconstruction in the future.关键词:super-resolution based on generative adversarial network (SRGAN);perceptual loss function;Mean Square Error (MSE);class-info;class-info SRGAN19|62|6更新时间:2024-05-07
Image Processing and Coding

-
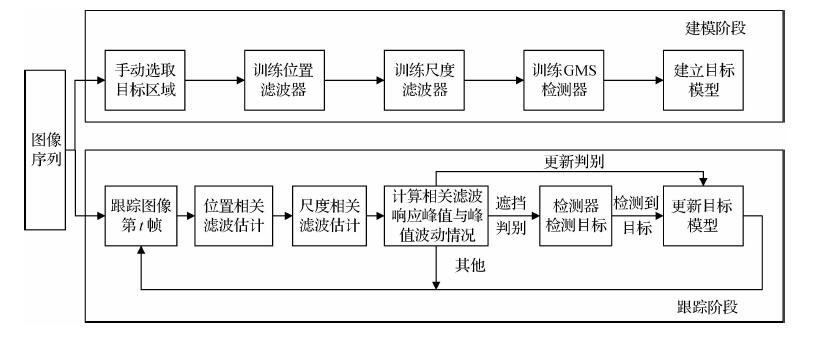 摘要:ObjectiveVisual target tracking has become a popular research topic locally and globally in the field of artificial intelligence, which is widely used in national defense security, industry, and people's daily life, such as military recognition, security monitoring, pilotless automobile, and human-computer interaction. Although great progress has been realized in the past decade, model-free tracking remains a tough problem due to illumination changes, geometric deformation, partial occlusion, fast motions, and background clutters. The traditional methods of target tracking generally track the target through visual features. In the case of the simple environment, these trackers can perform well for specific targets. Recently, visual object tracking has been widely applied to object tracking field due to its efficiency and robustness of correlation filter theory. A series of new advances of target tracking have been introduced and much attention has been achieved. A novel approach to predictive tracking, which is based on occlusion discriminant multi-scale correlation filter tracking algorithm, is proposed to overcome the problems of low accuracy caused by occlusion, which are scale changes in the tracking processin complex environments.MethodOn the basis of the basic framework of DSST (discriminated scale space tracker), a multi-scale correlation filter tracking algorithm is proposed. Reliability discrimination for the results of the correlation filter response, which contributes to long-term stable tracking, refers to occlusion and update discrimination by the peak and multiple peak fluctuation of the response map. The proposed algorithm in this paper can be summarized as two main points:1) Two types of calculation models were designed for the maximum and multiple peak fluctuation. By evaluating the tracking results according to the two abovementioned models, we can determine the occlusion of the target, and whether the target should be updated. 2) Redetect the missing target using the detector based on GMS (grid-based motion statistics). When the target is occluded, the GMS detector has been trained start to detect the target and locate it again. Concrete tracking is conducted as follows:First, the foreground area of the first frame image is selected, and the target position and scale filters and GMS detector are trained. Then, the target location is estimated by the translation filter, and the target scale is calculated by the scale filter. Performing a correlation between the candidate samples that are obtained using different scales center on the new position, and the scale correlation filter derives the primary target area. The maximum response scale is the current frame image scale. Finally, the primary target area is evaluated by the correlation filter response, and occlusion and update conditions are determined by the peak and multiple peak fluctuation of the correlation filter response values. The mutation of the peak and multiple peak fluctuation indicated that the target is occluded at the moment. The greater the mutation, the greater the degree of occlusion. In this case, update should be avoided to prevent tracking drift. If the target is occluded, then the detector detects the target position and updates the target model after detecting the target location. When the peak value of the correlation filter response is greater than the historical value, and the peak fluctuation does not mutate, then the target information at the moment is complete than that at time t-1, and the correlation filter should be updated. If the target is updated, then this update should focus on the location and scale filters and the GMS detector to complete tracking.ResultThe multi-scale correlation filtering method is used as the basic framework in our algorithm, which displays good adaptability to the target tracking of scale transformation. At the same time, the target model updating mechanism and GMS detector are used to retrieve the target and effectively solve the target loss problem in the occlusion. This paper selected nine challenging video sequences namely, Box, Bird1, Lemming, Panda, Basketball, DragonBaby, CarScale, Bird2, Girl2 from the public dataset OTB-2013 and OTB-2015, and video data car_Xvid, to conduct the experiments. The test results from using the public datasets show that the algorithm has a lower average center error of 5.58 and has a better tracking accuracy of 0.942 and tracking speed of 27.5 frames per second, compared with state-of-the-art tracking algorithms DSST, KCF (kernel correlation filter), LCT (long-term correlation tracking), Staple, GOTUTN (generic object tracking by using regression networks), and FCNT (fully convolutional networks tracking). Thus, the algorithm shows improved tracking performance with higher tracking speed and accuracy.ConclusionBased on DSST correlation filtering tracking, a multi-scale correlation filtering method based on occlusion discrimination is proposed. The results show that the algorithm solved the problems of losing goals due to occlusion and error accumulation because of the continuously and effectively updated strategy and achieved stable tracking under occlusion and multi-scale changes. Compared with current popular tracking algorithms, this algorithm has the following remarkable advantages:Solves the problem of losing goals due to occlusion in DSST algorithm and detects occlusion and determines whether updates can mitigate the tracking drift problem via frame update. Doing so can not only reduce unnecessary update time, but also substantially improve the tracking speed and accuracy. This paper presents a new multi-scale correlation filtering tracking algorithm based on occlusion discrimination. Experiments show that the proposed algorithm can track the target rapidly and accurately under conditions of varying scale transformation and occlusion, and it has enhanced tracking accuracy and robustness.关键词:target tracking;security monitoring;occlusion discrimination;scale transformation;correlation filter13|4|4更新时间:2024-05-07
摘要:ObjectiveVisual target tracking has become a popular research topic locally and globally in the field of artificial intelligence, which is widely used in national defense security, industry, and people's daily life, such as military recognition, security monitoring, pilotless automobile, and human-computer interaction. Although great progress has been realized in the past decade, model-free tracking remains a tough problem due to illumination changes, geometric deformation, partial occlusion, fast motions, and background clutters. The traditional methods of target tracking generally track the target through visual features. In the case of the simple environment, these trackers can perform well for specific targets. Recently, visual object tracking has been widely applied to object tracking field due to its efficiency and robustness of correlation filter theory. A series of new advances of target tracking have been introduced and much attention has been achieved. A novel approach to predictive tracking, which is based on occlusion discriminant multi-scale correlation filter tracking algorithm, is proposed to overcome the problems of low accuracy caused by occlusion, which are scale changes in the tracking processin complex environments.MethodOn the basis of the basic framework of DSST (discriminated scale space tracker), a multi-scale correlation filter tracking algorithm is proposed. Reliability discrimination for the results of the correlation filter response, which contributes to long-term stable tracking, refers to occlusion and update discrimination by the peak and multiple peak fluctuation of the response map. The proposed algorithm in this paper can be summarized as two main points:1) Two types of calculation models were designed for the maximum and multiple peak fluctuation. By evaluating the tracking results according to the two abovementioned models, we can determine the occlusion of the target, and whether the target should be updated. 2) Redetect the missing target using the detector based on GMS (grid-based motion statistics). When the target is occluded, the GMS detector has been trained start to detect the target and locate it again. Concrete tracking is conducted as follows:First, the foreground area of the first frame image is selected, and the target position and scale filters and GMS detector are trained. Then, the target location is estimated by the translation filter, and the target scale is calculated by the scale filter. Performing a correlation between the candidate samples that are obtained using different scales center on the new position, and the scale correlation filter derives the primary target area. The maximum response scale is the current frame image scale. Finally, the primary target area is evaluated by the correlation filter response, and occlusion and update conditions are determined by the peak and multiple peak fluctuation of the correlation filter response values. The mutation of the peak and multiple peak fluctuation indicated that the target is occluded at the moment. The greater the mutation, the greater the degree of occlusion. In this case, update should be avoided to prevent tracking drift. If the target is occluded, then the detector detects the target position and updates the target model after detecting the target location. When the peak value of the correlation filter response is greater than the historical value, and the peak fluctuation does not mutate, then the target information at the moment is complete than that at time t-1, and the correlation filter should be updated. If the target is updated, then this update should focus on the location and scale filters and the GMS detector to complete tracking.ResultThe multi-scale correlation filtering method is used as the basic framework in our algorithm, which displays good adaptability to the target tracking of scale transformation. At the same time, the target model updating mechanism and GMS detector are used to retrieve the target and effectively solve the target loss problem in the occlusion. This paper selected nine challenging video sequences namely, Box, Bird1, Lemming, Panda, Basketball, DragonBaby, CarScale, Bird2, Girl2 from the public dataset OTB-2013 and OTB-2015, and video data car_Xvid, to conduct the experiments. The test results from using the public datasets show that the algorithm has a lower average center error of 5.58 and has a better tracking accuracy of 0.942 and tracking speed of 27.5 frames per second, compared with state-of-the-art tracking algorithms DSST, KCF (kernel correlation filter), LCT (long-term correlation tracking), Staple, GOTUTN (generic object tracking by using regression networks), and FCNT (fully convolutional networks tracking). Thus, the algorithm shows improved tracking performance with higher tracking speed and accuracy.ConclusionBased on DSST correlation filtering tracking, a multi-scale correlation filtering method based on occlusion discrimination is proposed. The results show that the algorithm solved the problems of losing goals due to occlusion and error accumulation because of the continuously and effectively updated strategy and achieved stable tracking under occlusion and multi-scale changes. Compared with current popular tracking algorithms, this algorithm has the following remarkable advantages:Solves the problem of losing goals due to occlusion in DSST algorithm and detects occlusion and determines whether updates can mitigate the tracking drift problem via frame update. Doing so can not only reduce unnecessary update time, but also substantially improve the tracking speed and accuracy. This paper presents a new multi-scale correlation filtering tracking algorithm based on occlusion discrimination. Experiments show that the proposed algorithm can track the target rapidly and accurately under conditions of varying scale transformation and occlusion, and it has enhanced tracking accuracy and robustness.关键词:target tracking;security monitoring;occlusion discrimination;scale transformation;correlation filter13|4|4更新时间:2024-05-07 -
 摘要:ObjectiveLarge-scale image monitoring and video data have continuously increased in the field of public safety. Intelligent transportation has constantly evolved. Vehicle retrieval has extremely important application value. Existing vehicle retrieval techniques have low automation and intelligence level. Accurate search results are difficult to obtain. These retrieval techniques consume a large amount of storage space. To solve these problems, this study proposes a multi-task segmented compact feature vehicle retrieval method. The method can effectively use the correlation between detection and identification tasks. To achieve real-time retrieval, the method completely utilizes the diversity of information of vehicle attributes. Vehicle retrieval technology based on appearance features can overcome the limitation of traditional license plate recognition methods. This technology has broad application prospects in illegal inspections and search and seize of suspected criminal vehicles.MethodThis study constructs a multi-tasking deep convolutional network to investigate the hash code. This learning technique combines the image semantics with image representation. The technique uses the connection between the related tasks to improve the retrieval accuracy and to refine the image features. The hash code learning method uses the minimum image coding to ensure robustness of the learned vehicle features. Then, we use a feature pyramid network to extract the instance characteristics of the vehicle image. In the retrieval process, the extracted features are sorted using a local sensitive hash reordering method. A vehicle image cannot be obtained for several vehicle searches. For example, the night vision of a camera is blurred. This study proposes that a cross-modal-assisted retrieval can meet the actual requirements of different environments.ResultTwo datasets are used to verify the recognition of multitasking networks. The two datasets contain large-scale images of different vehicles. The BIT-Vehicle database is a commonly used database for vehicle identification. This database contains pictures of 9 850 bayonet vehicles. The pictures of these vehicles are divided into 12 categories. The categories are mainly divided into two tasks, namely, color and model. To verify the accuracy of fine-grained vehicle classification and multi-tasking network identification, we use the CompCars dataset that is more subdivided than the BIT-Vehicle dataset. The CompCars dataset contains two parts, namely, a network collection image and a bayonet capture image. We select the bayonet image part of the dataset and organized it, including the 30 000 positive bayonet capture images. The pictures of these vehicles are divided into 11 body color labels, 69 vehicle brands, 281 vehicle models, and 3 vehicle models. Therefore, this dataset is suitable for the verification of multitask convolutional neural network recognition performance. In addition, the general adaptability of the proposed vehicle retrieval method is verified. Experimental vehicle retrieval experiments are conducted on the VehicleID dataset. The VehicleID dataset contains approximately 200 000 images of 26 000 vehicles captured from surveillance cameras in real-world scenarios in different environments. The VehicleID dataset contains 250 models and 7 colors. The proposed search method outperforms the current mainstream search methods on all three public datasets. Among the datasets, the search accuracy on the CompCars dataset reaches 0.966. The search precision of the VehicleID dataset increases to 0.862. Compared with the existing methods, the retrieval accuracy of the proposed method is remarkably improved.ConclusionThis study focused on the reality of public safety scenarios and the improvement of retrieval accuracy of massive video data. We designed a multitask neural network learning method that is suitable for identification and retrieval. The method unifies multiple feature extraction in the same model and uses end-to-end training. The proposed multi-task segmented compact feature vehicle retrieval method can achieve the minimum image coding and image feature. The method can also perform cross-modal retrieval when the target retrieval image information cannot be obtained. The effectiveness of the method is verified based on the comparison of experiments.关键词:depth hash algorithm;vehicle retrieval;multitasking;cross modal retrieval;convolutional neural network15|4|0更新时间:2024-05-07
摘要:ObjectiveLarge-scale image monitoring and video data have continuously increased in the field of public safety. Intelligent transportation has constantly evolved. Vehicle retrieval has extremely important application value. Existing vehicle retrieval techniques have low automation and intelligence level. Accurate search results are difficult to obtain. These retrieval techniques consume a large amount of storage space. To solve these problems, this study proposes a multi-task segmented compact feature vehicle retrieval method. The method can effectively use the correlation between detection and identification tasks. To achieve real-time retrieval, the method completely utilizes the diversity of information of vehicle attributes. Vehicle retrieval technology based on appearance features can overcome the limitation of traditional license plate recognition methods. This technology has broad application prospects in illegal inspections and search and seize of suspected criminal vehicles.MethodThis study constructs a multi-tasking deep convolutional network to investigate the hash code. This learning technique combines the image semantics with image representation. The technique uses the connection between the related tasks to improve the retrieval accuracy and to refine the image features. The hash code learning method uses the minimum image coding to ensure robustness of the learned vehicle features. Then, we use a feature pyramid network to extract the instance characteristics of the vehicle image. In the retrieval process, the extracted features are sorted using a local sensitive hash reordering method. A vehicle image cannot be obtained for several vehicle searches. For example, the night vision of a camera is blurred. This study proposes that a cross-modal-assisted retrieval can meet the actual requirements of different environments.ResultTwo datasets are used to verify the recognition of multitasking networks. The two datasets contain large-scale images of different vehicles. The BIT-Vehicle database is a commonly used database for vehicle identification. This database contains pictures of 9 850 bayonet vehicles. The pictures of these vehicles are divided into 12 categories. The categories are mainly divided into two tasks, namely, color and model. To verify the accuracy of fine-grained vehicle classification and multi-tasking network identification, we use the CompCars dataset that is more subdivided than the BIT-Vehicle dataset. The CompCars dataset contains two parts, namely, a network collection image and a bayonet capture image. We select the bayonet image part of the dataset and organized it, including the 30 000 positive bayonet capture images. The pictures of these vehicles are divided into 11 body color labels, 69 vehicle brands, 281 vehicle models, and 3 vehicle models. Therefore, this dataset is suitable for the verification of multitask convolutional neural network recognition performance. In addition, the general adaptability of the proposed vehicle retrieval method is verified. Experimental vehicle retrieval experiments are conducted on the VehicleID dataset. The VehicleID dataset contains approximately 200 000 images of 26 000 vehicles captured from surveillance cameras in real-world scenarios in different environments. The VehicleID dataset contains 250 models and 7 colors. The proposed search method outperforms the current mainstream search methods on all three public datasets. Among the datasets, the search accuracy on the CompCars dataset reaches 0.966. The search precision of the VehicleID dataset increases to 0.862. Compared with the existing methods, the retrieval accuracy of the proposed method is remarkably improved.ConclusionThis study focused on the reality of public safety scenarios and the improvement of retrieval accuracy of massive video data. We designed a multitask neural network learning method that is suitable for identification and retrieval. The method unifies multiple feature extraction in the same model and uses end-to-end training. The proposed multi-task segmented compact feature vehicle retrieval method can achieve the minimum image coding and image feature. The method can also perform cross-modal retrieval when the target retrieval image information cannot be obtained. The effectiveness of the method is verified based on the comparison of experiments.关键词:depth hash algorithm;vehicle retrieval;multitasking;cross modal retrieval;convolutional neural network15|4|0更新时间:2024-05-07 -
 摘要:ObjectiveEffective detection of moving objects is a prerequisite in real-time tracking, behavior analysis, and behavioral judgment. Detection of moving objects has been widely applied in the fields of security, intelligent transportation, military, medical, and aerospace. Detection of moving objects is a key issue in the field of computer vision. The common methods used in the detection of moving objects include the optical flow, frame difference, and background subtraction methods. The optical flow method detects the moving region in the image sequence by using the vector feature of moving objects. This method performs well in the case of background motion. However, the computation of this method is complex and time consuming. The frame difference method uses the absolute value of difference between two adjacent frames to detect moving objects. The algorithm is simple and has good robustness. However, the detection results of this algorithm are easily affected by noises and is easy to produce "void". The background subtraction method is the most commonly used method in the detection of moving objects, in which the moving region is detected based on the difference between the current frame and background. The background subtraction method is simple, easy to implement, and can completely extract the object. The ViBe algorithm is a commonly used background subtraction method. This algorithm is mainly composed of background model initialization, foreground detection, and background model update, in which its concept is simple and easy to implement with high efficiency. However, a "ghost" phenomenon occurs in the ViBe algorithm when the initial frame contains moving objects and has the poor adaptability to noise, illumination, and dynamic environment. At the same time, the ViBe algorithm conducts foreground detection on each frame pixel-by-pixel, which has a large room for improvement regarding computational complexity. Thus, in this study, we improve the ViBe algorithm and propose the ViBeImp algorithm.MethodIn the ViBe algorithm, the construction of the background sample in the first frame of the video that contains the moving objects leads to the appearance of "ghost". Three solutions are used to solve this problem, where the first solution is by changing the manner of background model initialization, the second solution is by accelerating the elimination of the "ghost", and the third solution is by combining with other methods to detect the "ghost" areas and deal with them. The acceleration of elimination of the "ghost" does not fundamentally eliminate the "ghost" and still leads to false detection in the initial part of the "ghost". The combination with other methods in detecting the "ghost" increases the complexity and the amount of calculation of the algorithm. Therefore, we modify the initialization of the background model to eliminate the "ghost". In the ViBeImp algorithm, the initial background used for the initial background sampling model is given by a multi-frame average method, which can eliminate the "ghost" to some extent. Different calculation methods of radius threshold directly affect the performance of foreground detection. A suitable radius threshold can be used to adapt to the changes in light and dynamic scenes in the video, which can effectively reduce the occurrence of missed detection and false detection. Thus, in the process of foreground detection, a self-adaptive calculation method of radius threshold is given by combining the background subtraction method, frame difference method, and OTSU algorithm. At the same time, foreground detection and model update are conducted only in the motion area, which are obtained based on the background difference method to reduce the computational complexity of the algorithm.ResultFirst, the detection results of the ViBeImp algorithm, ViBe algorithm, ViBeDiff2 algorithm, and ViBeIniR algorithm in 25 different scenes that are selected from several public datasets, such as MOTChallenge, CDNET, and ViSOR, are provided with their corresponding precision, recall, and F1 values. Second, the improved detection results and effectiveness of the ViBeImp algorithm in the initialization background, adaptive radius threshold, and computational complexity are given. The ViBeImp algorithm improves the precision, recall, and F1 value of the ViBe algorithm by 13.73%, 3.15%, and 9.44%, respectively, when the background initialization method differs from the ViBe algorithm. The ViBeImp algorithm improves the precision, recall, and F1 value of the ViBe algorithm by 11.14%, 10.09%, and 12.35%, respectively, when the radius threshold calculation method differs from the ViBe algorithm. In terms of computational complexity, the average processing times per frame of the four methods are given, and 19 videos' average processing time per frame of the ViBeImp algorithm is lower than the ViBe algorithm in the 25 videos, which shows the effectiveness of our improvement in computational complexity. Finally, the comparison among the ViBeImp algorithm, Surendra algorithm, and Gaussian mixture model, which are commonly used in the detection of moving objects, is given. The experimental results show that the ViBeImp algorithm is robust to noise, illumination, and dynamic environment with complete detection results and better performance in real-time compared with the ViBe algorithm, ViBeDiff2 algorithm, ViBeIniR algorithm, Surendra algorithm, and Gaussian Mixture Model. Simultaneously, the ViBeImp algorithm improves the precision, recall and F1 of the ViBe algorithm by 17.98%, 11.40%, and 15.96%, respectively.ConclusionThe ViBeImp algorithm uses the multi-frame average method to construct the initial background that can effectively eliminate the "ghost". A self-adaptive calculation method of radius threshold is given, which enables the ViBe algorithm to rapidly adapt to the change of video environment and to accurately and completely detect the moving objects. The ViBe algorithm is a kind of algorithm with low false alarm and missed detection rates. The method overcomes the dependence of the ViBe algorithm on the initial background and video environment and reduces the computational complexity to a great extent with good robustness and applicability.关键词:intelligent transportation;moving object detection;ViBe algorithm;self-adaptive radius threshold;background subtraction method;frame difference method20|68|11更新时间:2024-05-07
摘要:ObjectiveEffective detection of moving objects is a prerequisite in real-time tracking, behavior analysis, and behavioral judgment. Detection of moving objects has been widely applied in the fields of security, intelligent transportation, military, medical, and aerospace. Detection of moving objects is a key issue in the field of computer vision. The common methods used in the detection of moving objects include the optical flow, frame difference, and background subtraction methods. The optical flow method detects the moving region in the image sequence by using the vector feature of moving objects. This method performs well in the case of background motion. However, the computation of this method is complex and time consuming. The frame difference method uses the absolute value of difference between two adjacent frames to detect moving objects. The algorithm is simple and has good robustness. However, the detection results of this algorithm are easily affected by noises and is easy to produce "void". The background subtraction method is the most commonly used method in the detection of moving objects, in which the moving region is detected based on the difference between the current frame and background. The background subtraction method is simple, easy to implement, and can completely extract the object. The ViBe algorithm is a commonly used background subtraction method. This algorithm is mainly composed of background model initialization, foreground detection, and background model update, in which its concept is simple and easy to implement with high efficiency. However, a "ghost" phenomenon occurs in the ViBe algorithm when the initial frame contains moving objects and has the poor adaptability to noise, illumination, and dynamic environment. At the same time, the ViBe algorithm conducts foreground detection on each frame pixel-by-pixel, which has a large room for improvement regarding computational complexity. Thus, in this study, we improve the ViBe algorithm and propose the ViBeImp algorithm.MethodIn the ViBe algorithm, the construction of the background sample in the first frame of the video that contains the moving objects leads to the appearance of "ghost". Three solutions are used to solve this problem, where the first solution is by changing the manner of background model initialization, the second solution is by accelerating the elimination of the "ghost", and the third solution is by combining with other methods to detect the "ghost" areas and deal with them. The acceleration of elimination of the "ghost" does not fundamentally eliminate the "ghost" and still leads to false detection in the initial part of the "ghost". The combination with other methods in detecting the "ghost" increases the complexity and the amount of calculation of the algorithm. Therefore, we modify the initialization of the background model to eliminate the "ghost". In the ViBeImp algorithm, the initial background used for the initial background sampling model is given by a multi-frame average method, which can eliminate the "ghost" to some extent. Different calculation methods of radius threshold directly affect the performance of foreground detection. A suitable radius threshold can be used to adapt to the changes in light and dynamic scenes in the video, which can effectively reduce the occurrence of missed detection and false detection. Thus, in the process of foreground detection, a self-adaptive calculation method of radius threshold is given by combining the background subtraction method, frame difference method, and OTSU algorithm. At the same time, foreground detection and model update are conducted only in the motion area, which are obtained based on the background difference method to reduce the computational complexity of the algorithm.ResultFirst, the detection results of the ViBeImp algorithm, ViBe algorithm, ViBeDiff2 algorithm, and ViBeIniR algorithm in 25 different scenes that are selected from several public datasets, such as MOTChallenge, CDNET, and ViSOR, are provided with their corresponding precision, recall, and F1 values. Second, the improved detection results and effectiveness of the ViBeImp algorithm in the initialization background, adaptive radius threshold, and computational complexity are given. The ViBeImp algorithm improves the precision, recall, and F1 value of the ViBe algorithm by 13.73%, 3.15%, and 9.44%, respectively, when the background initialization method differs from the ViBe algorithm. The ViBeImp algorithm improves the precision, recall, and F1 value of the ViBe algorithm by 11.14%, 10.09%, and 12.35%, respectively, when the radius threshold calculation method differs from the ViBe algorithm. In terms of computational complexity, the average processing times per frame of the four methods are given, and 19 videos' average processing time per frame of the ViBeImp algorithm is lower than the ViBe algorithm in the 25 videos, which shows the effectiveness of our improvement in computational complexity. Finally, the comparison among the ViBeImp algorithm, Surendra algorithm, and Gaussian mixture model, which are commonly used in the detection of moving objects, is given. The experimental results show that the ViBeImp algorithm is robust to noise, illumination, and dynamic environment with complete detection results and better performance in real-time compared with the ViBe algorithm, ViBeDiff2 algorithm, ViBeIniR algorithm, Surendra algorithm, and Gaussian Mixture Model. Simultaneously, the ViBeImp algorithm improves the precision, recall and F1 of the ViBe algorithm by 17.98%, 11.40%, and 15.96%, respectively.ConclusionThe ViBeImp algorithm uses the multi-frame average method to construct the initial background that can effectively eliminate the "ghost". A self-adaptive calculation method of radius threshold is given, which enables the ViBe algorithm to rapidly adapt to the change of video environment and to accurately and completely detect the moving objects. The ViBe algorithm is a kind of algorithm with low false alarm and missed detection rates. The method overcomes the dependence of the ViBe algorithm on the initial background and video environment and reduces the computational complexity to a great extent with good robustness and applicability.关键词:intelligent transportation;moving object detection;ViBe algorithm;self-adaptive radius threshold;background subtraction method;frame difference method20|68|11更新时间:2024-05-07 -
 摘要:ObjectivePedestrian detection in complex thermal infrared surveillance is an important research topic in the field of computer vision. Pedestrian detection is a crucial task to be conducted in several practical applications, such as public security management, disaster relief, and intelligent surveillance. Existing thermal infrared-based pedestrian detection algorithms are generally composed of two steps. In the first step, several regions of interest (ROI) in thermal infrared imageries that are suspected to be containing human targets are generated. Subsequently, the second step verifies whether the ROI is a human target. The verification can be conducted by processing with a classifier after the extraction of features from the ROIs, and the classification task can be combined with the feature extraction task by adopting a deep learning method. However, most of the existing thermal infrared-based pedestrian detection algorithms remarkably rely on the assumption that the gray value of the human target in the image is higher than the environment in their first step, which renders the algorithms ineffective in dealing with high ambient temperature. The gray value inversion occurs with the increase of ambient temperature, that is, the environmental gray value in the thermal infrared imagery becomes higher than the human target gray value, which reduces the accuracy of the pedestrian detection algorithm. On this basis, a fully convolutional network pedestrian detection algorithm based on frequency domain saliency detection is proposed, which aims to improve the robustness of pedestrian detection systems for thermal infrared surveillance scenes and to achieve better accuracy in pedestrian detection.MethodIn the algorithm, a frequency domain-based saliency detection is first employed to generate the saliency map that can cover all pedestrian targets in the original thermal infrared imagery. The difference of the saliency detection-based method from existing methods is that its detection is related to the saliency of human targets rather than the effect of their gray value. Therefore, the generation of the following ROI map in the saliency detection-based method is not limited to the assumption that the gray value of the human target is high, which avoids the inaccuracies in detection caused by the failure of the assumption when ambient temperature is high. In addition, one full-size saliency map is generated in this algorithm rather than several sub-regions. Then, a fully convolutional network is constructed, where the ROI map generated by the saliency map and thermal infrared original imagery is defined as the network input, and the pedestrian target probability map is defined as the network output. The constructed fully convolutional network consists of two parts. The first part mainly refers to AlexNet and VGG network structures, which can be regarded as feature extraction module. The second part is the probability generation module that consists of three deconvolution layers with two size kernels. A sigmoid activation function is used in the last layer to generate the probability map of pedestrian targets, and the remaining layers use the ReLU activation function. The proposed thermal infrared pedestrian detection algorithm is trained to obtain the pedestrian probability map and achieve the detection of pedestrian target.ResultThe Ohio State University (OSU) thermal infrared pedestrian database in the infrared video dataset of OTCBVS, which has also been established by OSU, is employed to verify the algorithm, and a comparison between the proposed algorithm and five existing mature algorithms is conducted. A total of 10 sequences are captured from single viewpoint surveillance in the database that covers several weathers, such as sunny, cloudy, and rainy days, which enables the conduct of a comprehensive test on the efficiency of pedestrian detection algorithms. Apart from the methods that are not based on convolutional neural network, the performance of region-based convolutional neural network is plotted. The results show that the proposed algorithm can accurately detect pedestrian targets in various environmental conditions. Furthermore, the several sample results of different pedestrian detections are shown. Taking the miss rate-false positive indicator as a basis for comparison, the proposed algorithm achieves an average miss rate of 7% and performs better than the existing thermal infrared-based pedestrian detection methods and basic deep learning-based object detection methods. The proposed algorithm achieves a high detection rate and shows better robustness in dealing with gray value inversion in thermal infrared imageries. In the detection process, the proposed algorithm can remove the non-pedestrian targets and detect the most pedestrians in thermal imageries, especially when the environment scene is complex, such as the existence of other heat sources (street lights) or at day time.ConclusionA fully convolutional network pedestrian detection algorithm based on frequency domain saliency detection for thermal infrared surveillance scenes is proposed in this study. In the first step, a saliency detection method, which is robust to gray value inversion when the ambient temperature is high, such as in hot summer or at day time, is employed to generate a full-size ROI map. Subsequently, a fully convolutional network is used to output the probability map of pedestrian targets. The proposed algorithm can be trained and avoids the generation of many sub-regions, which renders it efficient without the requirement of redundant computing and storage space. Experiments are conducted, and the results show that the proposed method achieves an improvement in the robustness of pedestrian detection systems in various complex scenes and obtains a high pedestrian detection rate. The experimental results also verify the capability of the proposed method to enhance the detection of pedestrian targets in thermal infrared surveillance systems.关键词:computer vision;thermal infrared surveillance;pedestrian detection;saliency detection;fully convolutional network (FCN)16|5|7更新时间:2024-05-07
摘要:ObjectivePedestrian detection in complex thermal infrared surveillance is an important research topic in the field of computer vision. Pedestrian detection is a crucial task to be conducted in several practical applications, such as public security management, disaster relief, and intelligent surveillance. Existing thermal infrared-based pedestrian detection algorithms are generally composed of two steps. In the first step, several regions of interest (ROI) in thermal infrared imageries that are suspected to be containing human targets are generated. Subsequently, the second step verifies whether the ROI is a human target. The verification can be conducted by processing with a classifier after the extraction of features from the ROIs, and the classification task can be combined with the feature extraction task by adopting a deep learning method. However, most of the existing thermal infrared-based pedestrian detection algorithms remarkably rely on the assumption that the gray value of the human target in the image is higher than the environment in their first step, which renders the algorithms ineffective in dealing with high ambient temperature. The gray value inversion occurs with the increase of ambient temperature, that is, the environmental gray value in the thermal infrared imagery becomes higher than the human target gray value, which reduces the accuracy of the pedestrian detection algorithm. On this basis, a fully convolutional network pedestrian detection algorithm based on frequency domain saliency detection is proposed, which aims to improve the robustness of pedestrian detection systems for thermal infrared surveillance scenes and to achieve better accuracy in pedestrian detection.MethodIn the algorithm, a frequency domain-based saliency detection is first employed to generate the saliency map that can cover all pedestrian targets in the original thermal infrared imagery. The difference of the saliency detection-based method from existing methods is that its detection is related to the saliency of human targets rather than the effect of their gray value. Therefore, the generation of the following ROI map in the saliency detection-based method is not limited to the assumption that the gray value of the human target is high, which avoids the inaccuracies in detection caused by the failure of the assumption when ambient temperature is high. In addition, one full-size saliency map is generated in this algorithm rather than several sub-regions. Then, a fully convolutional network is constructed, where the ROI map generated by the saliency map and thermal infrared original imagery is defined as the network input, and the pedestrian target probability map is defined as the network output. The constructed fully convolutional network consists of two parts. The first part mainly refers to AlexNet and VGG network structures, which can be regarded as feature extraction module. The second part is the probability generation module that consists of three deconvolution layers with two size kernels. A sigmoid activation function is used in the last layer to generate the probability map of pedestrian targets, and the remaining layers use the ReLU activation function. The proposed thermal infrared pedestrian detection algorithm is trained to obtain the pedestrian probability map and achieve the detection of pedestrian target.ResultThe Ohio State University (OSU) thermal infrared pedestrian database in the infrared video dataset of OTCBVS, which has also been established by OSU, is employed to verify the algorithm, and a comparison between the proposed algorithm and five existing mature algorithms is conducted. A total of 10 sequences are captured from single viewpoint surveillance in the database that covers several weathers, such as sunny, cloudy, and rainy days, which enables the conduct of a comprehensive test on the efficiency of pedestrian detection algorithms. Apart from the methods that are not based on convolutional neural network, the performance of region-based convolutional neural network is plotted. The results show that the proposed algorithm can accurately detect pedestrian targets in various environmental conditions. Furthermore, the several sample results of different pedestrian detections are shown. Taking the miss rate-false positive indicator as a basis for comparison, the proposed algorithm achieves an average miss rate of 7% and performs better than the existing thermal infrared-based pedestrian detection methods and basic deep learning-based object detection methods. The proposed algorithm achieves a high detection rate and shows better robustness in dealing with gray value inversion in thermal infrared imageries. In the detection process, the proposed algorithm can remove the non-pedestrian targets and detect the most pedestrians in thermal imageries, especially when the environment scene is complex, such as the existence of other heat sources (street lights) or at day time.ConclusionA fully convolutional network pedestrian detection algorithm based on frequency domain saliency detection for thermal infrared surveillance scenes is proposed in this study. In the first step, a saliency detection method, which is robust to gray value inversion when the ambient temperature is high, such as in hot summer or at day time, is employed to generate a full-size ROI map. Subsequently, a fully convolutional network is used to output the probability map of pedestrian targets. The proposed algorithm can be trained and avoids the generation of many sub-regions, which renders it efficient without the requirement of redundant computing and storage space. Experiments are conducted, and the results show that the proposed method achieves an improvement in the robustness of pedestrian detection systems in various complex scenes and obtains a high pedestrian detection rate. The experimental results also verify the capability of the proposed method to enhance the detection of pedestrian targets in thermal infrared surveillance systems.关键词:computer vision;thermal infrared surveillance;pedestrian detection;saliency detection;fully convolutional network (FCN)16|5|7更新时间:2024-05-07 -
 摘要:ObjectiveIn existing image segmentation theories and methods, the fuzzy clustering segmentation method has been widely studied and applied in image segmentation and object detection in images with intrinsic fuzziness and uncertainty. Fuzzy C-means clustering and its related improvement is a typical unsupervised clustering learning method, which has become an important tool in solving problems in image processing, machine vision, and remote sensing image interpretation. Many relevant scholars, local and abroad, have paid high attention to this research field for a long time. The classical fuzzy C-means clustering applied in image segmentation has only considered the clustering problem of pixels and cannot overcome the influence of noise on image segmentation results and thus cannot meet the requirements for target extraction, recognition, and interpretation of industrial, medical, and high-resolution remote sensing images. Hence, a robust fuzzy C-means clustering segmentation algorithm that is embedded in pixel spatial neighborhood or local information is a popular topic in image segmentation theory in recent years. The existing robust kernel-based fuzzy C-means clustering segmentation algorithms cannot meet the requirement of fast and robust segmentation of large images with strong interferences, such as Gaussian, salt-and-pepper, and mixed noise due to the large time cost and weak ability to suppress the aforementioned noise. Hence, a fast robust kernel-based fuzzy C-means clustering segmentation algorithm, which is based on a two-dimensional histogram, is proposed in view of pixel clustering accumulation.MethodThe linear weighted filtering image is first obtained by combining the gray and spatial location information of neighboring pixels with other related information in the segmenting gray image. The weighted filtering image is segmented by the existing robust kernel-based fuzzy C-means clustering to obtain positive segmentation quality and strong robustness against Gaussian, salt-and-pepper, and mixed noise. Second, to improve the operational efficiency of the robust fuzzy clustering segmentation algorithm in further segmenting large images, the two-dimensional histogram between the current clustered pixel and mean value of its neighborhood pixels is introduced into the existing robust kernel-based fuzzy C-means clustering method with spatial information. The two-dimensional histogram-based fuzzy clustering optimization mathematical model of the robust kernel-based fuzzy C-means clustering method is constructed in view of pixel clustering accumulation. In summary, the iterative expression of the gray level robust fuzzy clustering segmentation algorithm to segment image is rapidly deduced by the Lagrange multiplier method to solute the new optimization model of the robust kernel-based fuzzy clustering segmentation method embedded in the two-dimensional histogram of the weighted filtered image. Meanwhile, a fast robust kernel-based fuzzy C-means clustering segmentation in the two-dimensional histogram is designed to implement image segmentation.ResultSegmentation results of the noiseless standard medical and large remote sensing images that are interrupted by Gaussian, salt-and-pepper, and mixed noise, show that the proposed fast algorithm in the two-dimensional histogram can obtain better segmentation performance than those of the existing robust kernel-based fuzzy C-means and other kernel-based fuzzy clustering segmentation algorithms. In detail, the proposed fast robust kernel-based fuzzy clustering segmentation algorithm has increased the peak signal-to-noise ratio by nearly 1.5 dB, reduced at least 5% of the misclassification rate, and increased approximately 10% of the partition coefficient compared with the existing robust kernel-based fuzzy clustering segmentation algorithms with spatial neighborhood information. In the meantime, the method can reduce the computational complexity to a considerable extent, and the running speed of the proposed robust kernel-based fuzzy clustering segmentation algorithm is similar to that of the classical kernel-based fuzzy C-means clustering segmentation method based on a one-dimensional histogram. Furthermore, the result of the proposed fast robust kernel-based fuzzy C-means clustering segmentation algorithm has better segmentation effects than those of the existing kernel-based fuzzy C-means clustering segmentation algorithms from the perspective of human visual perception.ConclusionCompared with the existing robust kernel-based fuzzy clustering segmentation algorithm, which is based on spatial constraints of neighborhood information, the kernel-based fuzzy C-means and classical fuzzy clustering segmentation algorithms and the proposed algorithm with spatial neighborhood formation not only have stronger ability against noise but has also improved segmentation performance and real time. Meanwhile, it has a positive effect on rapid interpretation of images, such as large high resolution remote sensing and medical images. The proposed algorithm can meet the requirements of large remote sensing and medical image segmentation with high real-time demands.关键词:image segmentation;Kernel function;fuzzy clustering;linear weighted image;two-dimension histogram;robustness;clustering validity17|4|2更新时间:2024-05-07
摘要:ObjectiveIn existing image segmentation theories and methods, the fuzzy clustering segmentation method has been widely studied and applied in image segmentation and object detection in images with intrinsic fuzziness and uncertainty. Fuzzy C-means clustering and its related improvement is a typical unsupervised clustering learning method, which has become an important tool in solving problems in image processing, machine vision, and remote sensing image interpretation. Many relevant scholars, local and abroad, have paid high attention to this research field for a long time. The classical fuzzy C-means clustering applied in image segmentation has only considered the clustering problem of pixels and cannot overcome the influence of noise on image segmentation results and thus cannot meet the requirements for target extraction, recognition, and interpretation of industrial, medical, and high-resolution remote sensing images. Hence, a robust fuzzy C-means clustering segmentation algorithm that is embedded in pixel spatial neighborhood or local information is a popular topic in image segmentation theory in recent years. The existing robust kernel-based fuzzy C-means clustering segmentation algorithms cannot meet the requirement of fast and robust segmentation of large images with strong interferences, such as Gaussian, salt-and-pepper, and mixed noise due to the large time cost and weak ability to suppress the aforementioned noise. Hence, a fast robust kernel-based fuzzy C-means clustering segmentation algorithm, which is based on a two-dimensional histogram, is proposed in view of pixel clustering accumulation.MethodThe linear weighted filtering image is first obtained by combining the gray and spatial location information of neighboring pixels with other related information in the segmenting gray image. The weighted filtering image is segmented by the existing robust kernel-based fuzzy C-means clustering to obtain positive segmentation quality and strong robustness against Gaussian, salt-and-pepper, and mixed noise. Second, to improve the operational efficiency of the robust fuzzy clustering segmentation algorithm in further segmenting large images, the two-dimensional histogram between the current clustered pixel and mean value of its neighborhood pixels is introduced into the existing robust kernel-based fuzzy C-means clustering method with spatial information. The two-dimensional histogram-based fuzzy clustering optimization mathematical model of the robust kernel-based fuzzy C-means clustering method is constructed in view of pixel clustering accumulation. In summary, the iterative expression of the gray level robust fuzzy clustering segmentation algorithm to segment image is rapidly deduced by the Lagrange multiplier method to solute the new optimization model of the robust kernel-based fuzzy clustering segmentation method embedded in the two-dimensional histogram of the weighted filtered image. Meanwhile, a fast robust kernel-based fuzzy C-means clustering segmentation in the two-dimensional histogram is designed to implement image segmentation.ResultSegmentation results of the noiseless standard medical and large remote sensing images that are interrupted by Gaussian, salt-and-pepper, and mixed noise, show that the proposed fast algorithm in the two-dimensional histogram can obtain better segmentation performance than those of the existing robust kernel-based fuzzy C-means and other kernel-based fuzzy clustering segmentation algorithms. In detail, the proposed fast robust kernel-based fuzzy clustering segmentation algorithm has increased the peak signal-to-noise ratio by nearly 1.5 dB, reduced at least 5% of the misclassification rate, and increased approximately 10% of the partition coefficient compared with the existing robust kernel-based fuzzy clustering segmentation algorithms with spatial neighborhood information. In the meantime, the method can reduce the computational complexity to a considerable extent, and the running speed of the proposed robust kernel-based fuzzy clustering segmentation algorithm is similar to that of the classical kernel-based fuzzy C-means clustering segmentation method based on a one-dimensional histogram. Furthermore, the result of the proposed fast robust kernel-based fuzzy C-means clustering segmentation algorithm has better segmentation effects than those of the existing kernel-based fuzzy C-means clustering segmentation algorithms from the perspective of human visual perception.ConclusionCompared with the existing robust kernel-based fuzzy clustering segmentation algorithm, which is based on spatial constraints of neighborhood information, the kernel-based fuzzy C-means and classical fuzzy clustering segmentation algorithms and the proposed algorithm with spatial neighborhood formation not only have stronger ability against noise but has also improved segmentation performance and real time. Meanwhile, it has a positive effect on rapid interpretation of images, such as large high resolution remote sensing and medical images. The proposed algorithm can meet the requirements of large remote sensing and medical image segmentation with high real-time demands.关键词:image segmentation;Kernel function;fuzzy clustering;linear weighted image;two-dimension histogram;robustness;clustering validity17|4|2更新时间:2024-05-07 -
 摘要:ObjectiveThe Markov random field (MRF) model for variational optical flow computing is a robust one. The MRF variational energy function includes the data and smooth terms. Brief propagation (BP) is a highly effective global method that minimizes the MRF energy function by iteratively transmitting messages from one pixel to the next in four directions. However, its computational cost remains high. The computational complexity of the BP method with a 3-level data pyramid is O(
摘要:ObjectiveThe Markov random field (MRF) model for variational optical flow computing is a robust one. The MRF variational energy function includes the data and smooth terms. Brief propagation (BP) is a highly effective global method that minimizes the MRF energy function by iteratively transmitting messages from one pixel to the next in four directions. However, its computational cost remains high. The computational complexity of the BP method with a 3-level data pyramid is O($ N$ $ L$ $T$ $ N$ $ T$ $ L$ $ L$ $L $ $L $ $ L$ $ L$ $ N$ $L $ $ T$ $L $ $ L$ $T $ $ N$ $L $ $ L$ $ L$ $ T$ 关键词:optical flow;Markov random field;parallel computing on CUDA;brief propagation method;non-squared penalty function12|4|0更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveSaliency detection is a fundamental problem in computer vision and image processing, which aims to identify the most conspicuous objects or regions in an image. Saliency detection has been widely used in several visual applications, including object retargeting, scene classification, visual tracking, image retrieval, and semantic segmentation. In most traditional approaches, salient objects are derived based on the extracted features from pixels or regions. Final saliency maps consist of these regions with their saliency scores. The performance of these models rely on the segmentation methods and the selection of features. These approaches cannot produce satisfactory results when images with multiple salient objects or low-contrast contents are encountered. Traditional approaches preserve the boundaries well but with insufficient confidence of salient objects, which yield low recall rates. Convolution neural networks (CNNs) have been introduced in pixel-wise prediction problems, such as saliency detection, due to their outstanding performance in image classification tasks. CNNs redefine the saliency problem as a labeling problem where the feature selection between salient and non-salient objects is automatically performed through gradient descent. A CNN cannot be directly used to train a saliency model, and a CNN can be utilized in saliency detection by extracting a square patch around each pixel and by using the patch to predict the center pixel's class. Patches are frequently obtained from different resolutions of the input image to capture global information. Another method is the addition of up-sampled layers in the CNN. A modified CNN is called fully connected network (FCN), which is first proposed for semantic segmentation. Most saliency detection CNN models use FCN to capture considerable global and local information. FCN is a popular model that modifies the CNN to fit dense prediction problem, which replaces the SoftMax and fully connected layers in the CNN into convolution and deconvolution layers. Compared with traditional methods, FCNs can accurately locate salient objects and yield their high confidence. However, the boundaries of salient objects are coarse and their precision rates are lower than the traditional approaches due to the down-sampling structure in FCNs. To deal with the limitations of the 2 kinds of saliency models, we proposed a novel composite saliency model that combines the advantages and restrains the drawbacks of two saliency models.MethodIn this study, a new FCN based on dense convolutional network (DenseNet) is built. For saliency detection, we replace the fully connected layer and final pooling layer into a 1×1 kernel size convolution layer and a deconvolution layer. A sigmoid layer is applied to obtain the saliency maps. In the training process, the saliency network end with a squared Euclidean loss layer for saliency regression. We fine-tune the pre-trained DenseNet-161 to train our saliency model. Our training set consists of 3 900 images that are randomly selected from 5 saliency public dataset, namely, ECSSD, SOD, HKU-IS, MSRA, and ICOSEG. Our saliency network is implemented in Caffe toolbox. The input images and ground-truth maps are resized to 500×500 for training, the momentum parameter is set to 0.99, the learning rate is set to 10-10, and the weight decay is 0.000 5. The SGD learning procedure is accelerated using a NVIDIA GTX TITAN X GPU device, which takes approximately one day in 200 000 iterations. Then, we use a traditional saliency model. The selected model adopts multi-level segmentation to produce several segmentations of an image, where each superpixel is represented by a feature vector that contains different kinds of image features. A random forest is trained by those feature vectors to derive saliency maps. On the basis of the 2 models, we propose a fusion algorithm that combines the advantages of traditional approaches and deep learning methods. For an image, 15 segmentations of the image are produced, and the saliency maps of all segmentations are derived by the random forest. Then, we use FCN to produce another type of saliency map of the image. The fusion algorithm applies the Hadamard product on the 2 types of saliency maps, and the initial fusion result is obtained by averaging the Hadamard product results. Then, an adaptive threshold is used to fuse the initial fusion and FCN results by using a pixel-to-pixel map to obtain the final fusion result.ResultWe compared our model with 10 state-of-the-art saliency models, including the traditional approaches and deep learning methods on 4 public datasets, namely, DUT-OMRON, ECSSD, HKU-IS, and MSRA. The quantitative evaluation metrics contained F-measure, mean square error (MAE), and PR curves, and we provided several saliency maps of each method for comparison. The experiment results show that our model outperforms all other methods in HKU-IS, MSRA, and DUT-OMRON datasets. The saliency maps showed that our model can produce refined results. We compared the performance of random forest, FCN, and final fusion results in verify the effectiveness of our fusion algorithm. Comparative experiments demonstrated that the fusion algorithm improves saliency detection. Compared with the random forest results in ECSSD, HKU-IS, MSRA, and DUT-OMRON, the F-measure (higher is better) increased by 6.2%, 15.6%, 5.7%, and 16.6% and MAE (i.e., less is better) decreased by 17.4%, 43.9%, 33.3%, and 24.5% respectively. Compared with the FCN results in ECSSD, HKU-IS, MSRA, and DUT-OMRON, the F-measure increased by 2.2%, 4.1%, 5.7%, and 11.3%, respectively, and MAE decreased by 0.6%, 10.7%, and 18.4% in ECSSD, MSRA, and DUT-OMRON, respectively. In addition, we conducted a series of comparative experiments in MSRA to clearly show the effectiveness of different steps of the fusion algorithm.ConclusionIn this study, we proposed a composite saliency model that contains an FCN and a traditional model and a fusion algorithm to fuse 2 kinds of saliency maps. The experiment results show that our model outperforms several state-of-the-art saliency approaches and the fusion algorithm improves the performance.关键词:saliency detection;dense convolutional network;fully convolutional network;fusion algorithm;Hadamardproduct66|4|3更新时间:2024-05-07
摘要:ObjectiveSaliency detection is a fundamental problem in computer vision and image processing, which aims to identify the most conspicuous objects or regions in an image. Saliency detection has been widely used in several visual applications, including object retargeting, scene classification, visual tracking, image retrieval, and semantic segmentation. In most traditional approaches, salient objects are derived based on the extracted features from pixels or regions. Final saliency maps consist of these regions with their saliency scores. The performance of these models rely on the segmentation methods and the selection of features. These approaches cannot produce satisfactory results when images with multiple salient objects or low-contrast contents are encountered. Traditional approaches preserve the boundaries well but with insufficient confidence of salient objects, which yield low recall rates. Convolution neural networks (CNNs) have been introduced in pixel-wise prediction problems, such as saliency detection, due to their outstanding performance in image classification tasks. CNNs redefine the saliency problem as a labeling problem where the feature selection between salient and non-salient objects is automatically performed through gradient descent. A CNN cannot be directly used to train a saliency model, and a CNN can be utilized in saliency detection by extracting a square patch around each pixel and by using the patch to predict the center pixel's class. Patches are frequently obtained from different resolutions of the input image to capture global information. Another method is the addition of up-sampled layers in the CNN. A modified CNN is called fully connected network (FCN), which is first proposed for semantic segmentation. Most saliency detection CNN models use FCN to capture considerable global and local information. FCN is a popular model that modifies the CNN to fit dense prediction problem, which replaces the SoftMax and fully connected layers in the CNN into convolution and deconvolution layers. Compared with traditional methods, FCNs can accurately locate salient objects and yield their high confidence. However, the boundaries of salient objects are coarse and their precision rates are lower than the traditional approaches due to the down-sampling structure in FCNs. To deal with the limitations of the 2 kinds of saliency models, we proposed a novel composite saliency model that combines the advantages and restrains the drawbacks of two saliency models.MethodIn this study, a new FCN based on dense convolutional network (DenseNet) is built. For saliency detection, we replace the fully connected layer and final pooling layer into a 1×1 kernel size convolution layer and a deconvolution layer. A sigmoid layer is applied to obtain the saliency maps. In the training process, the saliency network end with a squared Euclidean loss layer for saliency regression. We fine-tune the pre-trained DenseNet-161 to train our saliency model. Our training set consists of 3 900 images that are randomly selected from 5 saliency public dataset, namely, ECSSD, SOD, HKU-IS, MSRA, and ICOSEG. Our saliency network is implemented in Caffe toolbox. The input images and ground-truth maps are resized to 500×500 for training, the momentum parameter is set to 0.99, the learning rate is set to 10-10, and the weight decay is 0.000 5. The SGD learning procedure is accelerated using a NVIDIA GTX TITAN X GPU device, which takes approximately one day in 200 000 iterations. Then, we use a traditional saliency model. The selected model adopts multi-level segmentation to produce several segmentations of an image, where each superpixel is represented by a feature vector that contains different kinds of image features. A random forest is trained by those feature vectors to derive saliency maps. On the basis of the 2 models, we propose a fusion algorithm that combines the advantages of traditional approaches and deep learning methods. For an image, 15 segmentations of the image are produced, and the saliency maps of all segmentations are derived by the random forest. Then, we use FCN to produce another type of saliency map of the image. The fusion algorithm applies the Hadamard product on the 2 types of saliency maps, and the initial fusion result is obtained by averaging the Hadamard product results. Then, an adaptive threshold is used to fuse the initial fusion and FCN results by using a pixel-to-pixel map to obtain the final fusion result.ResultWe compared our model with 10 state-of-the-art saliency models, including the traditional approaches and deep learning methods on 4 public datasets, namely, DUT-OMRON, ECSSD, HKU-IS, and MSRA. The quantitative evaluation metrics contained F-measure, mean square error (MAE), and PR curves, and we provided several saliency maps of each method for comparison. The experiment results show that our model outperforms all other methods in HKU-IS, MSRA, and DUT-OMRON datasets. The saliency maps showed that our model can produce refined results. We compared the performance of random forest, FCN, and final fusion results in verify the effectiveness of our fusion algorithm. Comparative experiments demonstrated that the fusion algorithm improves saliency detection. Compared with the random forest results in ECSSD, HKU-IS, MSRA, and DUT-OMRON, the F-measure (higher is better) increased by 6.2%, 15.6%, 5.7%, and 16.6% and MAE (i.e., less is better) decreased by 17.4%, 43.9%, 33.3%, and 24.5% respectively. Compared with the FCN results in ECSSD, HKU-IS, MSRA, and DUT-OMRON, the F-measure increased by 2.2%, 4.1%, 5.7%, and 11.3%, respectively, and MAE decreased by 0.6%, 10.7%, and 18.4% in ECSSD, MSRA, and DUT-OMRON, respectively. In addition, we conducted a series of comparative experiments in MSRA to clearly show the effectiveness of different steps of the fusion algorithm.ConclusionIn this study, we proposed a composite saliency model that contains an FCN and a traditional model and a fusion algorithm to fuse 2 kinds of saliency maps. The experiment results show that our model outperforms several state-of-the-art saliency approaches and the fusion algorithm improves the performance.关键词:saliency detection;dense convolutional network;fully convolutional network;fusion algorithm;Hadamardproduct66|4|3更新时间:2024-05-07 -
 摘要:ObjectiveFor the traditional image search retrieval problem based on the bag-of-words model, the enhancement of the recognition capability of local features of images has attracted considerable attention. Although the image results obtained by image search retrieval are similar to the query image in the detail part, the image results differ from the semantic perspective. In addition, an image search retrieval method based on global descriptors is used, which focuses on global features but loses several valuable information in the detail. Thus, the images that have similar layout but are not related are considered as related images. To solve this problem, this study uses deep convolution features to construct a dynamic matching kernel function.MethodThe proposed dynamic match kernel algorithm stimulates the feature matches between near-duplicate images and filters the matches between irrelevant images. This study extracts the features from the last fully connected layer in a convolutional neural network as the input for dynamic match kernel. Then, an adaptive threshold is constructed to match the local features. The threshold for relevant images should be large to enable the inclusion of positive matches. Conversely, for uncorrelated images, this dynamic matching kernel function reduces the matching score and local feature matching.ResultIn this study, we initially proposed two criteria to evaluate the effect of the dynamic match kernel algorithm and two indicators to quantify the performance of the dynamic matching kernel function. Then, on the basis of the two indicators, this study analyzed the intermediate results and verified the superiority of the dynamic matching kernel function through a comparison with the static matching kernel function. Finally, this study conducted a large number of experiments on five public datasets (Holidays, UKBench, Paris6K, Oxford5K, and DupImages), including the experiments with dynamic matching kernel function methods with other methods and experiments with dynamic matching kernel functions versus mainstream deep learning methods. The range of average accuracy is from 85.11% to 98.08% using our method, which indicates that the dynamic kernel method is compatible with other methods.ConclusionThe dynamic kernel method can be used as a portable component of image retrieval to improve the experimental results of image search retrieval. In the contrast deep learning method, the experimental results of our dynamic matching method with other methods outperform the method based on deep learning features, which indicate that the proposed method is effective and its performance is better than the current work in this field.关键词:image retrieval;bag-of-word model;match kernel;deep learning;convolutional neural network;AlexNet13|4|1更新时间:2024-05-07
摘要:ObjectiveFor the traditional image search retrieval problem based on the bag-of-words model, the enhancement of the recognition capability of local features of images has attracted considerable attention. Although the image results obtained by image search retrieval are similar to the query image in the detail part, the image results differ from the semantic perspective. In addition, an image search retrieval method based on global descriptors is used, which focuses on global features but loses several valuable information in the detail. Thus, the images that have similar layout but are not related are considered as related images. To solve this problem, this study uses deep convolution features to construct a dynamic matching kernel function.MethodThe proposed dynamic match kernel algorithm stimulates the feature matches between near-duplicate images and filters the matches between irrelevant images. This study extracts the features from the last fully connected layer in a convolutional neural network as the input for dynamic match kernel. Then, an adaptive threshold is constructed to match the local features. The threshold for relevant images should be large to enable the inclusion of positive matches. Conversely, for uncorrelated images, this dynamic matching kernel function reduces the matching score and local feature matching.ResultIn this study, we initially proposed two criteria to evaluate the effect of the dynamic match kernel algorithm and two indicators to quantify the performance of the dynamic matching kernel function. Then, on the basis of the two indicators, this study analyzed the intermediate results and verified the superiority of the dynamic matching kernel function through a comparison with the static matching kernel function. Finally, this study conducted a large number of experiments on five public datasets (Holidays, UKBench, Paris6K, Oxford5K, and DupImages), including the experiments with dynamic matching kernel function methods with other methods and experiments with dynamic matching kernel functions versus mainstream deep learning methods. The range of average accuracy is from 85.11% to 98.08% using our method, which indicates that the dynamic kernel method is compatible with other methods.ConclusionThe dynamic kernel method can be used as a portable component of image retrieval to improve the experimental results of image search retrieval. In the contrast deep learning method, the experimental results of our dynamic matching method with other methods outperform the method based on deep learning features, which indicate that the proposed method is effective and its performance is better than the current work in this field.关键词:image retrieval;bag-of-word model;match kernel;deep learning;convolutional neural network;AlexNet13|4|1更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveA physical-based animation synthesis can generate a human physical motion, which satisfies physical laws. Human physical motion is generated by responding to the environment in real-time and is not mechanically repetitive. Therefore, the human physical motion has been an interesting topic in the computer graphics and virtual reality fields in recent years. However, the human physical motion is difficult to generate given the high dimensionality, nonlinearity, and strong coupling of joints in human physical model. In addition, a feedback controller is frequently used to control human physical motion, especially in the diverse environment or under external forces. Multiple objective functions are typically designed during the process of solving the feedback controllers. Researchers apply optimization methods to solve the feedback controller. Multiple objective functions are frequently converted to a single objective function by utilizing the weighted sum method. However, inaccurate weights can easily result in failure of convergence considering the local traps. Therefore, the setting of weights is crucial to the direction of optimization, convergence time, and result. Thus, experiments become difficult, and these systems require dedicated technical developers. Owing to these problems, a multi-objective solving method is proposed for a feedback motion controller.MethodWe preprocess motion data and extract key frames to construct the initial controller. Furthermore, an improved feedback control mechanism is designed to reduce the difficulty of the constraint-solving problem. The parents of the population generate children after variation. However, many failure individuals do not satisfy the constraints in the children population. We utilize a forbidden region pre-filtering strategy to solve the abovementioned problem. This strategy adopts the support vector machine (SVM) with a radial basis kernel function (RBF) to remove these failure individuals. We replenish new children by re-sampling to supplement these removed individuals. We set several objective functions, including root, pose, and energy cost functions to measure the quality of every individual. Then, every individual controller is inputted to the physical simulation system, and multi-objective fitness values are obtained after simulations are completed. The regional density multi-layer optimization algorithm is adopted to select the excellent individuals, which show a uniform distribution to construct the next generation of parent individuals. Simultaneously, the SVM with kernel RBF is updated. We prune several individual controllers, which merely generate short physical motion, to obtain stable controllers, which can generate an extensive physical motion. Then, we decide whether to proceed to the next stage of optimization through multi-stage physical solving algorithm based on pruning. The optimized physical controller is obtained after many iterations. Finally, the optimal controller is applied to generate a human physical motion with feedback.ResultThe experiments are conducted on multiple test functions and physical motions on the basis of the proposed method. In the test function experiment, the classical test functions, including
摘要:ObjectiveA physical-based animation synthesis can generate a human physical motion, which satisfies physical laws. Human physical motion is generated by responding to the environment in real-time and is not mechanically repetitive. Therefore, the human physical motion has been an interesting topic in the computer graphics and virtual reality fields in recent years. However, the human physical motion is difficult to generate given the high dimensionality, nonlinearity, and strong coupling of joints in human physical model. In addition, a feedback controller is frequently used to control human physical motion, especially in the diverse environment or under external forces. Multiple objective functions are typically designed during the process of solving the feedback controllers. Researchers apply optimization methods to solve the feedback controller. Multiple objective functions are frequently converted to a single objective function by utilizing the weighted sum method. However, inaccurate weights can easily result in failure of convergence considering the local traps. Therefore, the setting of weights is crucial to the direction of optimization, convergence time, and result. Thus, experiments become difficult, and these systems require dedicated technical developers. Owing to these problems, a multi-objective solving method is proposed for a feedback motion controller.MethodWe preprocess motion data and extract key frames to construct the initial controller. Furthermore, an improved feedback control mechanism is designed to reduce the difficulty of the constraint-solving problem. The parents of the population generate children after variation. However, many failure individuals do not satisfy the constraints in the children population. We utilize a forbidden region pre-filtering strategy to solve the abovementioned problem. This strategy adopts the support vector machine (SVM) with a radial basis kernel function (RBF) to remove these failure individuals. We replenish new children by re-sampling to supplement these removed individuals. We set several objective functions, including root, pose, and energy cost functions to measure the quality of every individual. Then, every individual controller is inputted to the physical simulation system, and multi-objective fitness values are obtained after simulations are completed. The regional density multi-layer optimization algorithm is adopted to select the excellent individuals, which show a uniform distribution to construct the next generation of parent individuals. Simultaneously, the SVM with kernel RBF is updated. We prune several individual controllers, which merely generate short physical motion, to obtain stable controllers, which can generate an extensive physical motion. Then, we decide whether to proceed to the next stage of optimization through multi-stage physical solving algorithm based on pruning. The optimized physical controller is obtained after many iterations. Finally, the optimal controller is applied to generate a human physical motion with feedback.ResultThe experiments are conducted on multiple test functions and physical motions on the basis of the proposed method. In the test function experiment, the classical test functions, including${\rm{LZ}}1$ ${\rm{ZDT}}2$ ${\rm{DTLZ4}}$ 关键词:physics-based animation;motion control;multi-objective evolution;feedback;nonlinear constrained optimization;motion synthesis11|4|0更新时间:2024-05-07 -
 摘要:Objective 3D reconstruction has attracted considerable attention in the editing operation of 3D models. Various applications, such as 3D model registration, classification and retrieval, segmentation, reconstruction and modeling, guiding model editing, and automatic model synthesis, can benefit from 3D reconstruction. Mesh model is a mainstream 3D model. The editing and transforming of existing 3D models are an important method used to improve the model and to rapidly acquire new models. The technology of mesh mosaic fusion is a commonly used method in acquiring a new model. The fusion and splicing of the mesh can also be called the technology of mesh reconstruction. Graphs and images have widely appeared in daily life with the development of the society. The rapid and easy acquisition of new image models, the rapid reconstruction of existing models, and other issues play a dominant role in the field of graphic processing with the development of corresponding hardware technologies. Spline interpolation is an interpolation method that is commonly used in the industry to obtain a smooth curve. B-spline interpolation is a widely applied method. B-spline interpolation possesses powerful functions in representing and designing curves and surfaces, and is a mainstream method used in mathematical shape description. Therefore, in this study, we utilize the advantage of B-spline interpolation in dealing with boundary curves and surfaces and apply it to the mesh model splicing and interpolate model boundary to achieve the high integrity of grid models with various boundary conditions. In addition, the splicing transition can be sufficient to achieve the high integrity of the new model. The existing 3D model splicing fusion methods, which pursue several certain splicing results, may cause problems, such as large calculation amount, low splicing precision, and program redundancy. To improve the visual appearance of a synthetic model in terms of its continuity and flexibility, the splicing result at the joint is smoothened and the precision and efficiency of the spliced surface between the 3D models are improved. In this study, a mesh fusion method based on three uniform B-spline curves and surfaces is proposed.Method First, the region of interest is selected on the source model, the fusion region is selected on the target model by using the co-variation analysis and data-driven method, and the size and direction of the model to be merged are determined. Second, on the basis of the selected 3D mesh model, the boundary and adjacent curve of the area to be spliced between the source model and target model are determined, respectively. The points of the boundary and adjacent curve are also identified and recorded. In the set, a cubic B-spline is used to interpolate the boundary point and adjacent curve point sets of the source and target models. Subsequently, four cubic B-spline interpolation curves are obtained. Third, the boundary surface curve is interpolated by bi-cubic B-spline surfaces to obtain the continuous surface of the stitched area, which is used as the transition surface when the two models are spliced. Finally, the spliced area is resampled and triangulated by using a Laplacian smoothing algorithm to smooth the spliced regions to achieve seamless smooth splicing and fusion of mesh models.Results To verify the effectiveness of proposed method for the 3D model splicing, four different models were selected for the experiments, and the splicing result of the first two models were selected for comparison. The proposed fusion splicing method was used on the selected models. The experimental results showed that the proposed method can achieve remarkable results. The splicing effect can maintain the detailed features of the other parts of the source model, the spliced model shows good integrity, and a good result of smooth processing of the transition region of the spliced portion can be obtained. Compared with the data-driven modeling method, the proposed method can process at least 2 000 nodes and 5 000 patches within 0.05 s.Conclusion The proposed B-spline curve interpolation model is suitable with any boundary conditions and does not require to deal with the boundary of the model. Thus, considerable attention can be paid on the splicing of the model. The splicing area is resampled using the control points that generate and mesh the cubic B-spline surface. This method can improve the efficiency and reduce the computational complexity. Meanwhile, the proposed method can obtain the smooth splicing area. The shape, size, and topology requirements are low in selecting models. Therefore, the algorithm can be applied to medicine, commercial advertising, animation and entertainment, teaching models, geometric modeling, and manufacturing. This algorithm has a good effect on grid fusion and can be used for the rapid construction of new models.关键词:3D restruction;mesh splicing;mesh merging;cubic B-spline;curve and surface12|4|1更新时间:2024-05-07
摘要:Objective 3D reconstruction has attracted considerable attention in the editing operation of 3D models. Various applications, such as 3D model registration, classification and retrieval, segmentation, reconstruction and modeling, guiding model editing, and automatic model synthesis, can benefit from 3D reconstruction. Mesh model is a mainstream 3D model. The editing and transforming of existing 3D models are an important method used to improve the model and to rapidly acquire new models. The technology of mesh mosaic fusion is a commonly used method in acquiring a new model. The fusion and splicing of the mesh can also be called the technology of mesh reconstruction. Graphs and images have widely appeared in daily life with the development of the society. The rapid and easy acquisition of new image models, the rapid reconstruction of existing models, and other issues play a dominant role in the field of graphic processing with the development of corresponding hardware technologies. Spline interpolation is an interpolation method that is commonly used in the industry to obtain a smooth curve. B-spline interpolation is a widely applied method. B-spline interpolation possesses powerful functions in representing and designing curves and surfaces, and is a mainstream method used in mathematical shape description. Therefore, in this study, we utilize the advantage of B-spline interpolation in dealing with boundary curves and surfaces and apply it to the mesh model splicing and interpolate model boundary to achieve the high integrity of grid models with various boundary conditions. In addition, the splicing transition can be sufficient to achieve the high integrity of the new model. The existing 3D model splicing fusion methods, which pursue several certain splicing results, may cause problems, such as large calculation amount, low splicing precision, and program redundancy. To improve the visual appearance of a synthetic model in terms of its continuity and flexibility, the splicing result at the joint is smoothened and the precision and efficiency of the spliced surface between the 3D models are improved. In this study, a mesh fusion method based on three uniform B-spline curves and surfaces is proposed.Method First, the region of interest is selected on the source model, the fusion region is selected on the target model by using the co-variation analysis and data-driven method, and the size and direction of the model to be merged are determined. Second, on the basis of the selected 3D mesh model, the boundary and adjacent curve of the area to be spliced between the source model and target model are determined, respectively. The points of the boundary and adjacent curve are also identified and recorded. In the set, a cubic B-spline is used to interpolate the boundary point and adjacent curve point sets of the source and target models. Subsequently, four cubic B-spline interpolation curves are obtained. Third, the boundary surface curve is interpolated by bi-cubic B-spline surfaces to obtain the continuous surface of the stitched area, which is used as the transition surface when the two models are spliced. Finally, the spliced area is resampled and triangulated by using a Laplacian smoothing algorithm to smooth the spliced regions to achieve seamless smooth splicing and fusion of mesh models.Results To verify the effectiveness of proposed method for the 3D model splicing, four different models were selected for the experiments, and the splicing result of the first two models were selected for comparison. The proposed fusion splicing method was used on the selected models. The experimental results showed that the proposed method can achieve remarkable results. The splicing effect can maintain the detailed features of the other parts of the source model, the spliced model shows good integrity, and a good result of smooth processing of the transition region of the spliced portion can be obtained. Compared with the data-driven modeling method, the proposed method can process at least 2 000 nodes and 5 000 patches within 0.05 s.Conclusion The proposed B-spline curve interpolation model is suitable with any boundary conditions and does not require to deal with the boundary of the model. Thus, considerable attention can be paid on the splicing of the model. The splicing area is resampled using the control points that generate and mesh the cubic B-spline surface. This method can improve the efficiency and reduce the computational complexity. Meanwhile, the proposed method can obtain the smooth splicing area. The shape, size, and topology requirements are low in selecting models. Therefore, the algorithm can be applied to medicine, commercial advertising, animation and entertainment, teaching models, geometric modeling, and manufacturing. This algorithm has a good effect on grid fusion and can be used for the rapid construction of new models.关键词:3D restruction;mesh splicing;mesh merging;cubic B-spline;curve and surface12|4|1更新时间:2024-05-07 -
 摘要:Objective The Bézier and B-spline curves play an important role in traditional geometric design. With the development of the geometric industry over the recent years, the traditional Bézier and B-spline curves cannot meet people's needs due to defects. At the same time, many rational forms of Bézier curves are proposed, which solve the problems faced by traditional methods. However, rational methods have not only progressive problems, but also employ the improper use of weight factors, which can be destructived to the curve and surface design. In view of the abovementioned problems, a large number of Bernstein-like and B-spline-like basis functions with shape parameters are proposed. These methods are mainly constructed in trigonometric, hyperbolic and exponential function spaces, a combination of said spaces, and polynomial space. Although many improved methods are available, these methods are rarely applied in solving practical problems. In the final analysis, these methods increase the flexibility of the curve by adding shape parameters, compared with the traditional Bézier and B-spline methods. However, the method itself does not have the ability to replace the traditional method. Several aspects still need improvement. For example, the majority of these methods only discuss basic properties, such as non-negativity, partition of unity, symmetry, and linear independence. Shape preservation, total positivity, and variation diminishing are often overlooked, which are important properties for curve design. However, the basis function, which has total positivity, will ensure that the related curve contains variation diminishing and shape preservation. Therefore, possessing total positivity is highly important for basis function. In addition, constructing cubic curves and surfaces remains the main method among the improved methods. In general, these improved methods have
摘要:Objective The Bézier and B-spline curves play an important role in traditional geometric design. With the development of the geometric industry over the recent years, the traditional Bézier and B-spline curves cannot meet people's needs due to defects. At the same time, many rational forms of Bézier curves are proposed, which solve the problems faced by traditional methods. However, rational methods have not only progressive problems, but also employ the improper use of weight factors, which can be destructived to the curve and surface design. In view of the abovementioned problems, a large number of Bernstein-like and B-spline-like basis functions with shape parameters are proposed. These methods are mainly constructed in trigonometric, hyperbolic and exponential function spaces, a combination of said spaces, and polynomial space. Although many improved methods are available, these methods are rarely applied in solving practical problems. In the final analysis, these methods increase the flexibility of the curve by adding shape parameters, compared with the traditional Bézier and B-spline methods. However, the method itself does not have the ability to replace the traditional method. Several aspects still need improvement. For example, the majority of these methods only discuss basic properties, such as non-negativity, partition of unity, symmetry, and linear independence. Shape preservation, total positivity, and variation diminishing are often overlooked, which are important properties for curve design. However, the basis function, which has total positivity, will ensure that the related curve contains variation diminishing and shape preservation. Therefore, possessing total positivity is highly important for basis function. In addition, constructing cubic curves and surfaces remains the main method among the improved methods. In general, these improved methods have${{\rm{C}}^2}$ ${{\rm{C}}^2}$ 关键词:quasi extended Chebyshev space;optimal normalized totally positive basis;totally positivity;high-order continuity;shape preserving12|4|3更新时间:2024-05-07
Computer Graphics
-
 摘要:Objective Collision detection is a key technique applied in virtual reality, especially in virtual assembly. A collision detection algorithm based on an object space uses three-dimensional geometric features of the object for expansion and calculation. This phenomenon is evaluated by two methods, namely, a space division method and a bounding box method. The collision detection algorithm based on the bounding box method has attracted considerable attention and is widely used globally. The testing between the bounding boxes increases the possibility of collision detection errors. This condition can be explained by the use of an algorithm based on the axis-aligned bounding box (AABB) hierarchy binary tree that has many testing nodes but lowers detection efficiency in several cases. The space division method divides the entire virtual space into a sequence of equally sized cells and only detects objects in the same cell. The space division method is suitable for consistently distributed and sparse objects. The cells are divided into small sizes for cases with many objects and irregular distribution. The intersection tests between the collections of cells reduce the collision detection speed and require considerable storage space. To solve the problems of traditional collision detection algorithms, this study proposes a collision detection algorithm based on AABB bounding box and space division.Method The proposed algorithm utilizes a step-by-step detection method. In the pre-detection phase of the algorithm, a bounding box is generated for each object in the scene. This method determines the intersection area of the two bounding boxes based on the AABB algorithm. Subsequently, the method divides the areas of intersections to conduct cross-tests on each planned area. The algorithm combines the direction and movement trend of the model to create a space division. The intersection of space-time related parts is evaluated based on the corresponding correlation of collision detection. In this algorithm, the spatial correlation of the object is used to reduce the detection range, which improves the efficiency of the algorithm. The transfer of bounding box into triangle surfaces and points is used to reduce detection errors. The algorithm refines the interference detection between the triangle plane and points. This process directly restores the collision detection between various models. In addition, the algorithm uses a rapid detection method to determine whether a set of points passes through a triangle or not. The detection method conducted in two steps obviously improves the efficiency of the collision detection algorithm.Result In the experiment, five typical experimental environments are established to compare the AABB hierarchical bounding box binary tree algorithm,
摘要:Objective Collision detection is a key technique applied in virtual reality, especially in virtual assembly. A collision detection algorithm based on an object space uses three-dimensional geometric features of the object for expansion and calculation. This phenomenon is evaluated by two methods, namely, a space division method and a bounding box method. The collision detection algorithm based on the bounding box method has attracted considerable attention and is widely used globally. The testing between the bounding boxes increases the possibility of collision detection errors. This condition can be explained by the use of an algorithm based on the axis-aligned bounding box (AABB) hierarchy binary tree that has many testing nodes but lowers detection efficiency in several cases. The space division method divides the entire virtual space into a sequence of equally sized cells and only detects objects in the same cell. The space division method is suitable for consistently distributed and sparse objects. The cells are divided into small sizes for cases with many objects and irregular distribution. The intersection tests between the collections of cells reduce the collision detection speed and require considerable storage space. To solve the problems of traditional collision detection algorithms, this study proposes a collision detection algorithm based on AABB bounding box and space division.Method The proposed algorithm utilizes a step-by-step detection method. In the pre-detection phase of the algorithm, a bounding box is generated for each object in the scene. This method determines the intersection area of the two bounding boxes based on the AABB algorithm. Subsequently, the method divides the areas of intersections to conduct cross-tests on each planned area. The algorithm combines the direction and movement trend of the model to create a space division. The intersection of space-time related parts is evaluated based on the corresponding correlation of collision detection. In this algorithm, the spatial correlation of the object is used to reduce the detection range, which improves the efficiency of the algorithm. The transfer of bounding box into triangle surfaces and points is used to reduce detection errors. The algorithm refines the interference detection between the triangle plane and points. This process directly restores the collision detection between various models. In addition, the algorithm uses a rapid detection method to determine whether a set of points passes through a triangle or not. The detection method conducted in two steps obviously improves the efficiency of the collision detection algorithm.Result In the experiment, five typical experimental environments are established to compare the AABB hierarchical bounding box binary tree algorithm,$k$ $k$ $k$ 关键词:virtual assembly;AABB bounding boxes;space division;collision detection;the step detection;space-time correlation;triangle faces17|4|12更新时间:2024-05-07
Virtual Reality and Augmented Reality
-
 摘要:Objective With the increasing resolution of airborne SAR (synthetic aperture radar) images and large swath width, the conventional radar display and control system directly store the entire image in memory for sampling and displaying. The problems of conventional methods are resource-intensive and time-consuming, among others. The image pyramid method can effectively allocate and use memory when displaying large images. Previous studies required an entire image as input for display, which cannot meet the requirement of real-time display in application. Develop real-time display software for airborne SAR images with little memory consumption and independent of image size. When the received image size is larger than one tile, the image will be displayed to the user in real time, and will zoom to the original resolution.Methods The real-time display techniques proposed in this study include dynamic pyramid construction and display techniques. The processes of dynamic pyramid construction in detail are as follows:outputting the 0th-level pyramid tiles when receiving tile data; then, six cases are used to generate higher-level tiles. With the increasing numbers of received data, the pyramid file is gradually completed. The dynamic pyramid display technology uses a recursive algorithm to read low-level tiles and synthesizes and displays the current display hierarchy images when the tile data is incomplete. These two technologies run in two threads, interact with hard disk files (tiles) as interfaces, and work together.Result In the real-time display software, we add a separate thread to read 64 MB (8 192×8 192 pixels), 256 MB (16 384×16 384 pixels), and 1 GB (32 768×32 768 pixels) test image files and send a data block of 256×256 pixels to the pyramid module. The time intervals for data transfer vary from 10 ms to 1 ms. The display software runs on solid state hard (SSD) and mechanical disks. The time delay of displaying the first tile and the complete frame of the image is counted. the SAR image real-time display software occupies only 30 MB of memory and is independent of image size. The results show that the use of the SAR image real-time display technology results in a time delay of less than 1 s for displaying the first SAR image tile. Compared with the traditional display control system, the transmission delay of one frame image can be reduced. The delay of an entire frame image display varies greatly due to the access rate of the storage media. The time delay of SSDs is relatively stable, which is related to the size of the image. The larger the image, the greater the delay and the larger the difference between the delay and transmission delay (delay difference). The display delay differences for 64 MB, 256 MB, and 1 GB images are 0.76 s, 3.06 s, and 12.55 s, respectively. The delay of the mechanical disk is divided into two cases:at a sending interval of less than 6 ms, the time delay is relatively stable due to the limitation of hard disks' read/write speed, which is the time required to construct the pyramid for the entire image. The building pyramid time of the 64 MB, 256 MB and 1 GB images is approximately 5.779 s, 23.55 s, and 104.202 s, respectively. At the time interval of more than 6 ms for sending images, the time delay of displaying a frame of image is increased and accompanied by a decrease in transmission rate. Thus, the size of the delay is positively correlated with the size of the image. The delay differences for the 64 MB, 256 MB, and 1 GB images are approximately 0.01 s, 0.15 s, and 1.47 s, respectively.Conclusion The technique developed in this study can present received SAR images to users in real time, improve the display time effectiveness of airborne SAR images, reduce the memory requirements of the airborne radar display and control terminals, and improve user experience in terms of airborne radar display and control terminals.关键词:remote sensing;image pyramid;airborne SAR image;real-time display;recursive algorithm13|4|0更新时间:2024-05-07
摘要:Objective With the increasing resolution of airborne SAR (synthetic aperture radar) images and large swath width, the conventional radar display and control system directly store the entire image in memory for sampling and displaying. The problems of conventional methods are resource-intensive and time-consuming, among others. The image pyramid method can effectively allocate and use memory when displaying large images. Previous studies required an entire image as input for display, which cannot meet the requirement of real-time display in application. Develop real-time display software for airborne SAR images with little memory consumption and independent of image size. When the received image size is larger than one tile, the image will be displayed to the user in real time, and will zoom to the original resolution.Methods The real-time display techniques proposed in this study include dynamic pyramid construction and display techniques. The processes of dynamic pyramid construction in detail are as follows:outputting the 0th-level pyramid tiles when receiving tile data; then, six cases are used to generate higher-level tiles. With the increasing numbers of received data, the pyramid file is gradually completed. The dynamic pyramid display technology uses a recursive algorithm to read low-level tiles and synthesizes and displays the current display hierarchy images when the tile data is incomplete. These two technologies run in two threads, interact with hard disk files (tiles) as interfaces, and work together.Result In the real-time display software, we add a separate thread to read 64 MB (8 192×8 192 pixels), 256 MB (16 384×16 384 pixels), and 1 GB (32 768×32 768 pixels) test image files and send a data block of 256×256 pixels to the pyramid module. The time intervals for data transfer vary from 10 ms to 1 ms. The display software runs on solid state hard (SSD) and mechanical disks. The time delay of displaying the first tile and the complete frame of the image is counted. the SAR image real-time display software occupies only 30 MB of memory and is independent of image size. The results show that the use of the SAR image real-time display technology results in a time delay of less than 1 s for displaying the first SAR image tile. Compared with the traditional display control system, the transmission delay of one frame image can be reduced. The delay of an entire frame image display varies greatly due to the access rate of the storage media. The time delay of SSDs is relatively stable, which is related to the size of the image. The larger the image, the greater the delay and the larger the difference between the delay and transmission delay (delay difference). The display delay differences for 64 MB, 256 MB, and 1 GB images are 0.76 s, 3.06 s, and 12.55 s, respectively. The delay of the mechanical disk is divided into two cases:at a sending interval of less than 6 ms, the time delay is relatively stable due to the limitation of hard disks' read/write speed, which is the time required to construct the pyramid for the entire image. The building pyramid time of the 64 MB, 256 MB and 1 GB images is approximately 5.779 s, 23.55 s, and 104.202 s, respectively. At the time interval of more than 6 ms for sending images, the time delay of displaying a frame of image is increased and accompanied by a decrease in transmission rate. Thus, the size of the delay is positively correlated with the size of the image. The delay differences for the 64 MB, 256 MB, and 1 GB images are approximately 0.01 s, 0.15 s, and 1.47 s, respectively.Conclusion The technique developed in this study can present received SAR images to users in real time, improve the display time effectiveness of airborne SAR images, reduce the memory requirements of the airborne radar display and control terminals, and improve user experience in terms of airborne radar display and control terminals.关键词:remote sensing;image pyramid;airborne SAR image;real-time display;recursive algorithm13|4|0更新时间:2024-05-07 -
 摘要:Objective Ships and warships are important sea-based transportation carriers and military targets. Thus, detecting and recognizing these targets in high resolution remote sensing images are of substantial practical significance to. However, satellite imaging can be affected by weather, illumination, cloud, and atmosphere scattering. In addition, the targets in the image can be disturbed by sea clutters and other objects, which render the ship detection and recognition increasingly difficult. The majority of ship recognition algorithms typically adopt low-level features, such as shape, invariant moment, and histogram of gradient (HOG), which are simple but not robust to disturbances, such as waves, clouds, and islands. In general, handcraft features can only be used to distinguish ships from other interferences on the sea surface and have weak ability to differentiate various types of ship. In view of the above mentioned problems, this study proposes a new method that combines salient features and a convolutional neural network to recognize ships in remote sensing images.Method The proposed method consists of three parts, namely, image pre-processing, ship pre-detection, and ship recognition. First, the image can be enhanced by a homomorphic filter to improve the texture clarity and contrast in the pre-processing phase, which is helpful for the detection and recognition of the subsequent phase. In the ship detection stage, the saliency map of images can be calculated by phase spectrum of Fourier transform (PFT), which is a technique based on the analysis of the frequency domain. To take account of different resolutions, the multi-scale saliency maps are fused. The PFT method can effectively suppress the interference of cloud and sea wave, but the distinction between background and ship is barely notable. To solve this problem, logarithmic transformation is utilized to enhance the saliency map. Then, the gray morphological operation of close is adapted to eliminate the noise areas and fill holes, and the image segmentation algorithm of Otsu is used to extract all salient areas as areas of interest. In the stage of recognition, a deep convolutional neural network (CNN) can be well trained with a small number of ship samples based on the concept of transfer learning. All areas of interest can be finally classified and recognized by the CNN.Result To verify the effectiveness of the proposed algorithm, experiments were conducted on remote sensing images with varying backgrounds. The experiments were conducted in three aspects, namely, visual saliency detection, ship detection, and ship recognition. Three kinds of indicators, namely, detection, false alarm, and recognition rates were used to quantify experimental results. The qualitative results indicate that saliency detection based on PFT can effectively restrain the disturbance of sea surface and clutter, in which logarithmic transformation substantially improves the integrity of the ships' contour. Quantitative analysis shows that the three indexes of the proposed method are 93.63%, 3.01%, and 90.09%, respectively, which are extensively better than the compared algorithms.Conclusion Visual saliency detection is one of the commonly used and effective methods for ship detection. This paper combined the advantages of visual salient features and convolutional neural network for ship recognition in remote sensing images. The method can realize the rapid detection of ship targets with high accuracy of classification in complex backgrounds.关键词:ship detection;remote sensing image;visual saliency detection on frequency domain;convolutional neural network;transfer learning18|4|7更新时间:2024-05-07
摘要:Objective Ships and warships are important sea-based transportation carriers and military targets. Thus, detecting and recognizing these targets in high resolution remote sensing images are of substantial practical significance to. However, satellite imaging can be affected by weather, illumination, cloud, and atmosphere scattering. In addition, the targets in the image can be disturbed by sea clutters and other objects, which render the ship detection and recognition increasingly difficult. The majority of ship recognition algorithms typically adopt low-level features, such as shape, invariant moment, and histogram of gradient (HOG), which are simple but not robust to disturbances, such as waves, clouds, and islands. In general, handcraft features can only be used to distinguish ships from other interferences on the sea surface and have weak ability to differentiate various types of ship. In view of the above mentioned problems, this study proposes a new method that combines salient features and a convolutional neural network to recognize ships in remote sensing images.Method The proposed method consists of three parts, namely, image pre-processing, ship pre-detection, and ship recognition. First, the image can be enhanced by a homomorphic filter to improve the texture clarity and contrast in the pre-processing phase, which is helpful for the detection and recognition of the subsequent phase. In the ship detection stage, the saliency map of images can be calculated by phase spectrum of Fourier transform (PFT), which is a technique based on the analysis of the frequency domain. To take account of different resolutions, the multi-scale saliency maps are fused. The PFT method can effectively suppress the interference of cloud and sea wave, but the distinction between background and ship is barely notable. To solve this problem, logarithmic transformation is utilized to enhance the saliency map. Then, the gray morphological operation of close is adapted to eliminate the noise areas and fill holes, and the image segmentation algorithm of Otsu is used to extract all salient areas as areas of interest. In the stage of recognition, a deep convolutional neural network (CNN) can be well trained with a small number of ship samples based on the concept of transfer learning. All areas of interest can be finally classified and recognized by the CNN.Result To verify the effectiveness of the proposed algorithm, experiments were conducted on remote sensing images with varying backgrounds. The experiments were conducted in three aspects, namely, visual saliency detection, ship detection, and ship recognition. Three kinds of indicators, namely, detection, false alarm, and recognition rates were used to quantify experimental results. The qualitative results indicate that saliency detection based on PFT can effectively restrain the disturbance of sea surface and clutter, in which logarithmic transformation substantially improves the integrity of the ships' contour. Quantitative analysis shows that the three indexes of the proposed method are 93.63%, 3.01%, and 90.09%, respectively, which are extensively better than the compared algorithms.Conclusion Visual saliency detection is one of the commonly used and effective methods for ship detection. This paper combined the advantages of visual salient features and convolutional neural network for ship recognition in remote sensing images. The method can realize the rapid detection of ship targets with high accuracy of classification in complex backgrounds.关键词:ship detection;remote sensing image;visual saliency detection on frequency domain;convolutional neural network;transfer learning18|4|7更新时间:2024-05-07
Remote Sensing Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0