
最新刊期
卷 23 , 期 11 , 2018
-
 摘要:ObjectiveThe human brain that has evolved over a million years is perhaps the most complex and sophisticated machine in the world, carrying all the intelligent activities of human beings, such as attention, learning, memory, intuition, insight and decision making. The core of the human brain consists of billions of neurons and synapses. Each neuron "receives" information from some neurons through synapses, and then passes the processed information to other neurons through the synapse. In this way, external sensory information (i.e., visual, auditory, olfactory, taste, touch) is analyzed and processed in the brain in a complex way to form perception and cognition. Attention and memory play an important role in the cognitive process of human understanding. The development of artificial intelligence based on the memory mechanism of the brain is an advanced aspect of research. Given that "end-to-end" deep learning enables an excellent performance in tasks, such as recognition and classification, introducing attention mechanism and external memory in the deep learning model to mine information of interest in data and effectively use auxiliary information is a popular research area in artificial intelligence.MethodThis report focuses on the external memory and attention mechanism of the brain. Firstly, three representative works, namely, neural turing machine, memory networks, and differentiable neural computer, are introduced. Neural turing machine is analogous to a Turing Machine or Von Neumann architecture but is differentiable end-to-end, allowing it to be efficiently trained with gradient descent. Memory networks can reason with inference components combined with a long-term memory component and they learn how to use these components jointly. Differentiable neural computer, which consists of a neural network that can read from and write to an external memory matrix, analogous to the random-access memory in a conventional computer. Secondly, several specific applications, such as knowledge memory network for question answering, memory-driven movie question answering, and memory-driven creativity (text-to-image), are presented. For answering the factoid questions, this report present the temporality-enhanced knowledge memory network (TE-KMN), which encodes not only the content of questions and answers, but also the temporal cues in a sequence of ordered sentences that gradually remark the answer. Moreover, TE-KMN collaboratively uses external knowledge for a better understanding of a given question. For answering questions about movies, the layered memory network (LMN) that represents frame-level and clip-level movie content by the static word memory module and the dynamic subtitle memory module respectively, is introduced. To generate images depending on their corresponding narrative sentences, this report presents the visual-memory Creative Adversarial Network (vmCAN), which appropriately leverages an external visual knowledge memory in both multi-modal fusion and image synthesis. Finally, research progress of memory networks at home and abroad is compared.ResultResearch results show that 1) introducing attention mechanism and external memory structure in the deep learning model is a current hotspot in artificial intelligence research. 2) Research that focuses on memory networks at home and abroad has been intensified, and literature related to machine learning and artificial intelligence has been published at top conferences and has been increasing annually. 3) Research on memory networks is gaining popularity. An increasing number of papers have been published yearly, and this trend has been constantly growing. Thus far, 9, 4, 9, and 14 articles have been published from 2015 to 2018, respectively. 4) Memory-driven methods and approaches are general, and memory networks have been successfully used in areas, such as question answering, visual question answering, object detection, reinforcement learning, and text-to-images.ConclusionThis report shows a future work on media learning and creativity. The next generation of artificial intelligence should be never-ending learning from data, experience, and automatic reasoning. In the future, artificial intelligence should be integrated organically with human knowledge through methods such as attention mechanism, memory network, transfer learning, and reinforcement learning, so as to achieve from shallow computing to deep reasoning, from simple data-driven to data-driven combined with logic rules, from vertical domain intelligence to more general artificial intelligence.关键词:multimedia;memory network;memory augmented;knowledge augmented;media learning;media creativity14|18|1更新时间:2024-05-07
摘要:ObjectiveThe human brain that has evolved over a million years is perhaps the most complex and sophisticated machine in the world, carrying all the intelligent activities of human beings, such as attention, learning, memory, intuition, insight and decision making. The core of the human brain consists of billions of neurons and synapses. Each neuron "receives" information from some neurons through synapses, and then passes the processed information to other neurons through the synapse. In this way, external sensory information (i.e., visual, auditory, olfactory, taste, touch) is analyzed and processed in the brain in a complex way to form perception and cognition. Attention and memory play an important role in the cognitive process of human understanding. The development of artificial intelligence based on the memory mechanism of the brain is an advanced aspect of research. Given that "end-to-end" deep learning enables an excellent performance in tasks, such as recognition and classification, introducing attention mechanism and external memory in the deep learning model to mine information of interest in data and effectively use auxiliary information is a popular research area in artificial intelligence.MethodThis report focuses on the external memory and attention mechanism of the brain. Firstly, three representative works, namely, neural turing machine, memory networks, and differentiable neural computer, are introduced. Neural turing machine is analogous to a Turing Machine or Von Neumann architecture but is differentiable end-to-end, allowing it to be efficiently trained with gradient descent. Memory networks can reason with inference components combined with a long-term memory component and they learn how to use these components jointly. Differentiable neural computer, which consists of a neural network that can read from and write to an external memory matrix, analogous to the random-access memory in a conventional computer. Secondly, several specific applications, such as knowledge memory network for question answering, memory-driven movie question answering, and memory-driven creativity (text-to-image), are presented. For answering the factoid questions, this report present the temporality-enhanced knowledge memory network (TE-KMN), which encodes not only the content of questions and answers, but also the temporal cues in a sequence of ordered sentences that gradually remark the answer. Moreover, TE-KMN collaboratively uses external knowledge for a better understanding of a given question. For answering questions about movies, the layered memory network (LMN) that represents frame-level and clip-level movie content by the static word memory module and the dynamic subtitle memory module respectively, is introduced. To generate images depending on their corresponding narrative sentences, this report presents the visual-memory Creative Adversarial Network (vmCAN), which appropriately leverages an external visual knowledge memory in both multi-modal fusion and image synthesis. Finally, research progress of memory networks at home and abroad is compared.ResultResearch results show that 1) introducing attention mechanism and external memory structure in the deep learning model is a current hotspot in artificial intelligence research. 2) Research that focuses on memory networks at home and abroad has been intensified, and literature related to machine learning and artificial intelligence has been published at top conferences and has been increasing annually. 3) Research on memory networks is gaining popularity. An increasing number of papers have been published yearly, and this trend has been constantly growing. Thus far, 9, 4, 9, and 14 articles have been published from 2015 to 2018, respectively. 4) Memory-driven methods and approaches are general, and memory networks have been successfully used in areas, such as question answering, visual question answering, object detection, reinforcement learning, and text-to-images.ConclusionThis report shows a future work on media learning and creativity. The next generation of artificial intelligence should be never-ending learning from data, experience, and automatic reasoning. In the future, artificial intelligence should be integrated organically with human knowledge through methods such as attention mechanism, memory network, transfer learning, and reinforcement learning, so as to achieve from shallow computing to deep reasoning, from simple data-driven to data-driven combined with logic rules, from vertical domain intelligence to more general artificial intelligence.关键词:multimedia;memory network;memory augmented;knowledge augmented;media learning;media creativity14|18|1更新时间:2024-05-07 -
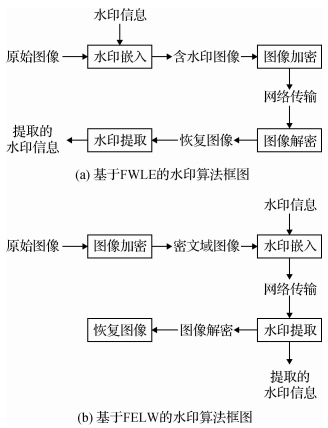 摘要:ObjectiveThe rapid evolution of cloud technology has provided users with convenience but still has security risks. Users' privacy (e.g., personal photos, corporate user information, and electronic notes) will be exposed once the cloud data are inaccessible or corrupted. Owing to the existence of security vulnerabilities or internal staff illicit activity, data may be tampered, replaced, or distributed illegally. In such a case, protecting the user' privacy is crucial. Currently and in practice, protecting the users' privacy is achieved by watermarking technology, especially reversible watermarking technology. Reversible watermarking can not only extract data correctly but also completely restore the original carrier. This technique is used in the medical, military, and other fields. Therefore, reversible watermarking technology plays an important role in the privacy protection field. Most of the existing reversible watermarking algorithms are based on the plaintext domain, such that they can be easily pirated or tampered. Thus, we proposed a reversible watermarking scheme in the homomorphic encrypted domain on the basis of Gray code for piracy tracing to enhance security and protect privacy. The proposed scheme provides support for a direct operation in the homomorphic encrypted domain. The ultimate goal of the new proposed scheme in the encrypted domain is to protect the users' privacy.MethodFirst, the "homomorphic encryption system based on Gray code" (HESGC) is proposed to encrypt the original carrier image. Gray code encryption converts the grayscale values of the original carrier image into binary values. Second, in accordance with integer homomorphic encryption, the binary values are converted into different decimal grayscale values. Subsequently, region division and classification can be reasonably performed in accordance with the "integer wavelet transform" and "human visual system" characteristics. Region division is used to avoid conflicts between watermarking and tracing proofs, and region classification fits well with human visual characteristics. Humans are sensitive to smooth regions and minimally sensitive to the textured regions. Moreover, neighboring quadratic optimization approach is presented to improve the concentration of the same regions and enhance the accuracy and reasonability of region classification. Third, we implement the proposed embedding, reversible recovery, and extraction operations. Finally, we present "joint watermarking and tracing" (JWT) strategy and utilize it to achieve piracy tracing. The JWT strategy can trace piracy and the first unauthorized person who illegally copies or distributes the image. This study uses the nonrepudiation of tracing proofs.ResultExperiments on the commonly used image database (i.e., USC-SIPI) are conducted. Six classical images from the USC-SIPI image database are selected for this experiment. The proposed algorithm has higher peak signal-to-noise ratio (PSNR) values than the existing reversible watermarking algorithms, and the PSNR value can reach 50 dB. In addition, the structural similarity index metric values of the original carrier, restored, original watermarking, and extracted watermarking images are all equal to 1. The proposed scheme achieves a reversible recovery. Furthermore, the proposed HESGC expands the original carrier image by eight times, thus increasing the capacity. Theoretically, the maximum capacity of the algorithm proposed in this study is 3.75 bit/pixel. Currently, the maximum capacity of most existing reversible watermarking algorithms is less than 1 bit/pixel. Moreover, the proposed scheme can not only achieve piracy tracing but also resist several common attacks, such as random noise, median filter, image smoothing, JPEG-coded, LZW-coded, and convolutional fuzzy attacks. We calculate the similarity value of the extracted and generated tracing proofs by the image copyright owner and determine who has the maximum similarity value to identify the piracy origin. If the similarity value is approximately 1, then it is a pirate. For other non-pirates, the similarity value is less than 1, most of which are approximately 0.6. Experimental results confirm the efficiency of the proposed scheme.ConclusionIn this study, we present the HESGC and JWT for the first time to achieve piracy tracing and reversible watermarking in an encrypted image. Most of the existing reversible watermarking algorithms directly use a binary sequence as the watermark. Alternatively, the gray image in this scheme serves as the watermark image directly; the restrictions when the binary image is used as the watermark image are removed, or the gray image is binarized as the watermark image. Moreover, cascade chaotic technology is adopted to encrypt the gray watermark image to enhance its security. We also successfully eliminate the smooth/textured islands in the textured/smooth regions, such that the block classification results are accurate and reasonable. In particular, security is an important measurement indicator for privacy protection, where only a secure watermarking system is meaningful. This study examines a triple security protection mechanism, which has the strongest security performance. The experimental results indicate that this scheme not only achieves privacy protection and piracy tracing but also has the characteristics of high security, large capacity, and high restoration quality. Moreover, this scheme can resist several common attacks, which are suitable for protecting users' privacy. The proposed algorithm focuses on the reversible watermarking technology in an encrypted image and is widely applied to digital images, such as military images, medical images, electronic invoice, and legal documents, that require high confidentiality, security, and fidelity.关键词:privacy protection;reversible watermarking;piracy tracing;HESGC(homomorphic encryption system based on gray code);JWT(joint watermarking and tracing);high capacity;high security17|4|1更新时间:2024-05-07
摘要:ObjectiveThe rapid evolution of cloud technology has provided users with convenience but still has security risks. Users' privacy (e.g., personal photos, corporate user information, and electronic notes) will be exposed once the cloud data are inaccessible or corrupted. Owing to the existence of security vulnerabilities or internal staff illicit activity, data may be tampered, replaced, or distributed illegally. In such a case, protecting the user' privacy is crucial. Currently and in practice, protecting the users' privacy is achieved by watermarking technology, especially reversible watermarking technology. Reversible watermarking can not only extract data correctly but also completely restore the original carrier. This technique is used in the medical, military, and other fields. Therefore, reversible watermarking technology plays an important role in the privacy protection field. Most of the existing reversible watermarking algorithms are based on the plaintext domain, such that they can be easily pirated or tampered. Thus, we proposed a reversible watermarking scheme in the homomorphic encrypted domain on the basis of Gray code for piracy tracing to enhance security and protect privacy. The proposed scheme provides support for a direct operation in the homomorphic encrypted domain. The ultimate goal of the new proposed scheme in the encrypted domain is to protect the users' privacy.MethodFirst, the "homomorphic encryption system based on Gray code" (HESGC) is proposed to encrypt the original carrier image. Gray code encryption converts the grayscale values of the original carrier image into binary values. Second, in accordance with integer homomorphic encryption, the binary values are converted into different decimal grayscale values. Subsequently, region division and classification can be reasonably performed in accordance with the "integer wavelet transform" and "human visual system" characteristics. Region division is used to avoid conflicts between watermarking and tracing proofs, and region classification fits well with human visual characteristics. Humans are sensitive to smooth regions and minimally sensitive to the textured regions. Moreover, neighboring quadratic optimization approach is presented to improve the concentration of the same regions and enhance the accuracy and reasonability of region classification. Third, we implement the proposed embedding, reversible recovery, and extraction operations. Finally, we present "joint watermarking and tracing" (JWT) strategy and utilize it to achieve piracy tracing. The JWT strategy can trace piracy and the first unauthorized person who illegally copies or distributes the image. This study uses the nonrepudiation of tracing proofs.ResultExperiments on the commonly used image database (i.e., USC-SIPI) are conducted. Six classical images from the USC-SIPI image database are selected for this experiment. The proposed algorithm has higher peak signal-to-noise ratio (PSNR) values than the existing reversible watermarking algorithms, and the PSNR value can reach 50 dB. In addition, the structural similarity index metric values of the original carrier, restored, original watermarking, and extracted watermarking images are all equal to 1. The proposed scheme achieves a reversible recovery. Furthermore, the proposed HESGC expands the original carrier image by eight times, thus increasing the capacity. Theoretically, the maximum capacity of the algorithm proposed in this study is 3.75 bit/pixel. Currently, the maximum capacity of most existing reversible watermarking algorithms is less than 1 bit/pixel. Moreover, the proposed scheme can not only achieve piracy tracing but also resist several common attacks, such as random noise, median filter, image smoothing, JPEG-coded, LZW-coded, and convolutional fuzzy attacks. We calculate the similarity value of the extracted and generated tracing proofs by the image copyright owner and determine who has the maximum similarity value to identify the piracy origin. If the similarity value is approximately 1, then it is a pirate. For other non-pirates, the similarity value is less than 1, most of which are approximately 0.6. Experimental results confirm the efficiency of the proposed scheme.ConclusionIn this study, we present the HESGC and JWT for the first time to achieve piracy tracing and reversible watermarking in an encrypted image. Most of the existing reversible watermarking algorithms directly use a binary sequence as the watermark. Alternatively, the gray image in this scheme serves as the watermark image directly; the restrictions when the binary image is used as the watermark image are removed, or the gray image is binarized as the watermark image. Moreover, cascade chaotic technology is adopted to encrypt the gray watermark image to enhance its security. We also successfully eliminate the smooth/textured islands in the textured/smooth regions, such that the block classification results are accurate and reasonable. In particular, security is an important measurement indicator for privacy protection, where only a secure watermarking system is meaningful. This study examines a triple security protection mechanism, which has the strongest security performance. The experimental results indicate that this scheme not only achieves privacy protection and piracy tracing but also has the characteristics of high security, large capacity, and high restoration quality. Moreover, this scheme can resist several common attacks, which are suitable for protecting users' privacy. The proposed algorithm focuses on the reversible watermarking technology in an encrypted image and is widely applied to digital images, such as military images, medical images, electronic invoice, and legal documents, that require high confidentiality, security, and fidelity.关键词:privacy protection;reversible watermarking;piracy tracing;HESGC(homomorphic encryption system based on gray code);JWT(joint watermarking and tracing);high capacity;high security17|4|1更新时间:2024-05-07 -
 摘要:ObjectiveMost traditional methods used to merge sequential multi-exposure low dynamic range (LDR) images into a high dynamic range (HDR) image are sensitive to certain problems, such as noise and object motion, and must address large-scale data, which hinder the application and further development of HDR image acquisition technology. Low-rank matrix recovery can extract an aligned low-rank image with linear correlation from a sparse noise-corrupted data matrix. A new method that exploits the abovementioned feature based on the low-rank matrix recovery is proposed to merge sequential multi-exposure LDR images into an HDR image and improve the anti-noise and de-artifact performances in capturing HDR images.MethodFirst, the sequential multi-exposure LDR images are inputted and mapped to the linear luminance space by a calibrated camera response function (CRF). Second, a partial sum of singular values (PSSV) is used as an optimization objective function to build a low-rank matrix mathematical model for HDR image fusion method, which is used to merge the captured sequential multi-exposure LDR images. With the help of the proposed method, the data matrix is decomposed into low-rank and sparse matrices through the exact augmented Lagrange multiplier method, where the PSSV is the objective function. This algorithm is optimized given the motivation for an alternating direction multiplier method. An adaptive penalty factor is set to address different singular values. If a singular value tends to 0, then the algorithm will update the low-rank and sparse matrices with a new partial singular value thresholding (PSVT); otherwise, the algorithm will update the low-rank and sparse matrices with the classical PSVT. Moreover, the augmented Lagrange multiplier and penalty factor are updated simultaneously. The algorithm will terminate when the optimal solution concentrates within the space of the maximum singular value as much as possible after a finite number of iteration steps. Thus, a low-rank matrix with the light information of an entire scene, where the noises and artifacts are eliminated, is obtained. This obtained low-rank matrix is also the final merged HDR image from the captured sequential multi-exposure LDR images.ResultThe convergence and anti-noise performance are first evaluated. The proposed method and two other comparison methods are applied to the randomly generated data matrices with a size of 10 000 ×50 pixels and rank from 1 to 4. Simultaneously, a sparse noise is added to each data matrix with a ratio from 0.1 to 0.4. The comparison methods refer to robust principal component analysis (RPCA) and the PSSV. Simulation results indicate that the proposed method has better convergence and anti-noise performance than the two other comparison methods. The experimental results of various matrices with different ranks and sparse noise ratios show that the proposed method achieves low normalized mean square and solution errors. Furthermore, the proposed algorithm guarantees that the rank of the result is sufficiently lower than the original matrix. Thus, the singular value of the main information will not be considerably attenuated. This finding indicates that the new method can obtain low-rank results even when the reconstruction error is low. The performance of HDR image fusion is evaluated by analyzing the values of peak signal-to-noise ratio (PSNR) and structural similarity index metric based on perceptually uniform mapping. The experiments run with the classical sequential multi-exposure LDR images, such as memorial church and arch, to acquire the HDR images. The experimental results show that the expectation is achieved. The proposed method can eliminate the artifacts in dynamic scenes with sparse noise and improve the quality of the fused HDR images compared with the recovering high dynamic range radiance maps from photographs (RHDRRMP), RPCA, and PSSV algorithms. The RHDRRMP method cannot suppress the sparse noise and artifacts and produces poor brightness and contrast. The RPCA method cannot suppress artifacts well, and missing details and even inaccurate results have emerged. The PSSV method can obtain better results but fewer details than the proposed method. The index metrics of the PSNR and SSIM of the results obtained through the proposed method from the objective indicators are higher than those of the comparison algorithms. For the memorial church sequence without noise, the PSNR and SSIM of the RPCA method are 28.117 dB and 0.935, respectively; those of the PSSV method are 30.557 dB and 0.959, correspondingly; and those of our method are 32.550 dB and 0.968, respectively. The PSNR and SSIM of the RPCA method are 28.115 dB and 0.935, correspondingly; those of the PSSV method are 30.579 dB and 0.959, respectively; and those of the proposed method are 32.562 dB and 0.967, correspondingly. The proposed algorithm can recover the low-rank matrix to obtain the HDR image, even with few images in the multi-exposure image sequence. In this situation, the RPCA method cannot obtain the optimal solution to the low-rank matrix. The PSSV method only ensures that the variance of the singular value vectors in the data, rather than the low-rank data, is not the largest and cannot guarantee that the low-rank data have the maximum variance on the singular value vector. Overall, the results show that the proposed algorithm has better robustness than the traditional fusion methods.ConclusionIn this study, a new method based on low-rank matrix recovery optimization theory is proposed. The proposed method can merge sequential multi-exposure LDR images into an HDR image. With the help of the proposed method, the HDR image can be obtained with a low reconstruction error in the case of few datasets, and the interference of the noise and artifacts can be removed in a dynamic scene. Thus, the proposed method has better robustness than the traditional experimental methods. The demand for high-quality images can be satisfied by improving HDR images. However, the proposed method depends on the CRF, that is, an accurate CRF indicates an improved quality of the result of image fusion. The proposed method also requires the aligned sequential multi-exposure LDR images to further eliminate the serious problems of image displacement or high-speed moving objects in a scene. Otherwise, the ghost and blur phenomena will affect the fused HDR image.关键词:image fusion;high dynamic range image;low-rank matrix recovery;de-ghosting;Lagrange multiplier55|225|2更新时间:2024-05-07
摘要:ObjectiveMost traditional methods used to merge sequential multi-exposure low dynamic range (LDR) images into a high dynamic range (HDR) image are sensitive to certain problems, such as noise and object motion, and must address large-scale data, which hinder the application and further development of HDR image acquisition technology. Low-rank matrix recovery can extract an aligned low-rank image with linear correlation from a sparse noise-corrupted data matrix. A new method that exploits the abovementioned feature based on the low-rank matrix recovery is proposed to merge sequential multi-exposure LDR images into an HDR image and improve the anti-noise and de-artifact performances in capturing HDR images.MethodFirst, the sequential multi-exposure LDR images are inputted and mapped to the linear luminance space by a calibrated camera response function (CRF). Second, a partial sum of singular values (PSSV) is used as an optimization objective function to build a low-rank matrix mathematical model for HDR image fusion method, which is used to merge the captured sequential multi-exposure LDR images. With the help of the proposed method, the data matrix is decomposed into low-rank and sparse matrices through the exact augmented Lagrange multiplier method, where the PSSV is the objective function. This algorithm is optimized given the motivation for an alternating direction multiplier method. An adaptive penalty factor is set to address different singular values. If a singular value tends to 0, then the algorithm will update the low-rank and sparse matrices with a new partial singular value thresholding (PSVT); otherwise, the algorithm will update the low-rank and sparse matrices with the classical PSVT. Moreover, the augmented Lagrange multiplier and penalty factor are updated simultaneously. The algorithm will terminate when the optimal solution concentrates within the space of the maximum singular value as much as possible after a finite number of iteration steps. Thus, a low-rank matrix with the light information of an entire scene, where the noises and artifacts are eliminated, is obtained. This obtained low-rank matrix is also the final merged HDR image from the captured sequential multi-exposure LDR images.ResultThe convergence and anti-noise performance are first evaluated. The proposed method and two other comparison methods are applied to the randomly generated data matrices with a size of 10 000 ×50 pixels and rank from 1 to 4. Simultaneously, a sparse noise is added to each data matrix with a ratio from 0.1 to 0.4. The comparison methods refer to robust principal component analysis (RPCA) and the PSSV. Simulation results indicate that the proposed method has better convergence and anti-noise performance than the two other comparison methods. The experimental results of various matrices with different ranks and sparse noise ratios show that the proposed method achieves low normalized mean square and solution errors. Furthermore, the proposed algorithm guarantees that the rank of the result is sufficiently lower than the original matrix. Thus, the singular value of the main information will not be considerably attenuated. This finding indicates that the new method can obtain low-rank results even when the reconstruction error is low. The performance of HDR image fusion is evaluated by analyzing the values of peak signal-to-noise ratio (PSNR) and structural similarity index metric based on perceptually uniform mapping. The experiments run with the classical sequential multi-exposure LDR images, such as memorial church and arch, to acquire the HDR images. The experimental results show that the expectation is achieved. The proposed method can eliminate the artifacts in dynamic scenes with sparse noise and improve the quality of the fused HDR images compared with the recovering high dynamic range radiance maps from photographs (RHDRRMP), RPCA, and PSSV algorithms. The RHDRRMP method cannot suppress the sparse noise and artifacts and produces poor brightness and contrast. The RPCA method cannot suppress artifacts well, and missing details and even inaccurate results have emerged. The PSSV method can obtain better results but fewer details than the proposed method. The index metrics of the PSNR and SSIM of the results obtained through the proposed method from the objective indicators are higher than those of the comparison algorithms. For the memorial church sequence without noise, the PSNR and SSIM of the RPCA method are 28.117 dB and 0.935, respectively; those of the PSSV method are 30.557 dB and 0.959, correspondingly; and those of our method are 32.550 dB and 0.968, respectively. The PSNR and SSIM of the RPCA method are 28.115 dB and 0.935, correspondingly; those of the PSSV method are 30.579 dB and 0.959, respectively; and those of the proposed method are 32.562 dB and 0.967, correspondingly. The proposed algorithm can recover the low-rank matrix to obtain the HDR image, even with few images in the multi-exposure image sequence. In this situation, the RPCA method cannot obtain the optimal solution to the low-rank matrix. The PSSV method only ensures that the variance of the singular value vectors in the data, rather than the low-rank data, is not the largest and cannot guarantee that the low-rank data have the maximum variance on the singular value vector. Overall, the results show that the proposed algorithm has better robustness than the traditional fusion methods.ConclusionIn this study, a new method based on low-rank matrix recovery optimization theory is proposed. The proposed method can merge sequential multi-exposure LDR images into an HDR image. With the help of the proposed method, the HDR image can be obtained with a low reconstruction error in the case of few datasets, and the interference of the noise and artifacts can be removed in a dynamic scene. Thus, the proposed method has better robustness than the traditional experimental methods. The demand for high-quality images can be satisfied by improving HDR images. However, the proposed method depends on the CRF, that is, an accurate CRF indicates an improved quality of the result of image fusion. The proposed method also requires the aligned sequential multi-exposure LDR images to further eliminate the serious problems of image displacement or high-speed moving objects in a scene. Otherwise, the ghost and blur phenomena will affect the fused HDR image.关键词:image fusion;high dynamic range image;low-rank matrix recovery;de-ghosting;Lagrange multiplier55|225|2更新时间:2024-05-07 -
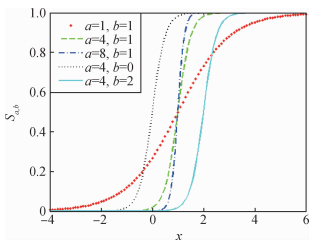
 摘要:ObjectiveTexture is a repetitive pattern with high pixel values. Many natural images and works of art include textures such as cross-stitch and mosaic. In many cases, the visual system of individuals ignores the texture pattern and focuses on the main structure of an image. Texture filtering is a basic tool in the computer graphics and image processing fields; the goal of which is to suppress unnecessary texture details and maintain the salient structure in the image. In recent years, various texture filtering methods, which are mainly divided into global-and local-based filtering methods, have been proposed. Most of the existing texture filtering methods handle the small gradient texture images. However, handling the strong gradient texture and losing part of the structure is difficult. To solve this problem, we propose a texture filtering method by using texture gradient suppression and
摘要:ObjectiveTexture is a repetitive pattern with high pixel values. Many natural images and works of art include textures such as cross-stitch and mosaic. In many cases, the visual system of individuals ignores the texture pattern and focuses on the main structure of an image. Texture filtering is a basic tool in the computer graphics and image processing fields; the goal of which is to suppress unnecessary texture details and maintain the salient structure in the image. In recent years, various texture filtering methods, which are mainly divided into global-and local-based filtering methods, have been proposed. Most of the existing texture filtering methods handle the small gradient texture images. However, handling the strong gradient texture and losing part of the structure is difficult. To solve this problem, we propose a texture filtering method by using texture gradient suppression and${L_0}$ ${L_0}$ ${L_0}$ $\lambda $ $\lambda $ ${L_0}$ $\lambda $ $\lambda $ ${L_0}$ ${L_0}$ 关键词:texture filtering;${L_0}$ 15|5|1更新时间:2024-05-07
Image Processing and Cording

-
 摘要:Objective Object detection has been a popular research topic in the field of computer vision and is an essential component for security video surveillance system and other computer vision applications. Image recognition, which is based on convolutional neural network, has fulfilled remarkable achievements. Many current object detection pipelines due to the deep learning can be divided into three stages as follows:1) extracts region proposals, 2) classifies and refines each region proposal, and 3) removes extra detection boxes that might belong to the same object. Non-maximum suppression (NMS) algorithm is frequently used in Stage 3 as an essential part of object detection and obtains impressive effect. Numerous studies have focused on feature design, classifier design, and object proposals, although the NMS algorithm is a core part of object detection. Few studies on the NMS algorithms exist. The NMS algorithm is used as a post-processing step of object detection to remove the redundant detection boxes. However, this algorithm suppresses all detection boxes with higher intersection-over-union (IoU) overlap than the threshold with pre-selected detection box. NMS algorithm may remove the positive detection box if the positive detection box is adjacent to the pre-selected with a high IoU value. It may also preserve the negative detection box because this box with the pre-selected detection box has a low IoU value. Mean average precision (mAP) decreases as a result of the missing and false positives; thus, the traditional NMS can also be called GreedyNMS. GreedyNMS easily causes missed and false detections.Method To overcome these shortages, an improved NMS algorithm is proposed in accordance with the different IoU values to assign a proportional penalty coefficient to reduce detection scores. The improved NMS algorithm includes the piecewise and the continuous proportional penalty factor NMS algorithms. The piecewise proportional penalty factor NMS algorithm reduces the scores of detection boxes and has a higher IoU than threshold T. The detection boxes with IoU, which is less than the threshold T, maintains its original score. The detection boxes whose scores are lower than another threshold σ are removed after many iterations. The performance of this algorithm remains limited by the threshold T. The continuous proportional penalty factor NMS algorithm no longer uses threshold T but directly reduces all detection boxes, except those with the maximum score in each iteration. In the continuous proportional penalty factor NMS algorithm, the threshold slightly affects the performance of the algorithm. The improved NMS algorithm initially calculates the proportional penalty factors the correspond to the detection boxes in accordance with the IoU value of the pre-selection detection box. The improved NMS algorithm multiplies the confidence scores of the detection boxes by the proportional penalty factors and reduces the detection box scores through the proportional penalty factor after many iterations. Moreover, the improved NMS algorithm removes the detection boxes with a score below the threshold after many iterations. The piecewise and the continuous proportional penalty factor NMS algorithms are used in each iteration in a post-processing step of object detection rather than in a region proposal network. The threshold in the continuous proportional penalty factor is less sensitive to the performance of the algorithm than the influence of the threshold in GreedyNMS. In addition, the computational complexity of the improved NMS algorithm is O(n2), which is the same as that of GreedyNMS, where
摘要:Objective Object detection has been a popular research topic in the field of computer vision and is an essential component for security video surveillance system and other computer vision applications. Image recognition, which is based on convolutional neural network, has fulfilled remarkable achievements. Many current object detection pipelines due to the deep learning can be divided into three stages as follows:1) extracts region proposals, 2) classifies and refines each region proposal, and 3) removes extra detection boxes that might belong to the same object. Non-maximum suppression (NMS) algorithm is frequently used in Stage 3 as an essential part of object detection and obtains impressive effect. Numerous studies have focused on feature design, classifier design, and object proposals, although the NMS algorithm is a core part of object detection. Few studies on the NMS algorithms exist. The NMS algorithm is used as a post-processing step of object detection to remove the redundant detection boxes. However, this algorithm suppresses all detection boxes with higher intersection-over-union (IoU) overlap than the threshold with pre-selected detection box. NMS algorithm may remove the positive detection box if the positive detection box is adjacent to the pre-selected with a high IoU value. It may also preserve the negative detection box because this box with the pre-selected detection box has a low IoU value. Mean average precision (mAP) decreases as a result of the missing and false positives; thus, the traditional NMS can also be called GreedyNMS. GreedyNMS easily causes missed and false detections.Method To overcome these shortages, an improved NMS algorithm is proposed in accordance with the different IoU values to assign a proportional penalty coefficient to reduce detection scores. The improved NMS algorithm includes the piecewise and the continuous proportional penalty factor NMS algorithms. The piecewise proportional penalty factor NMS algorithm reduces the scores of detection boxes and has a higher IoU than threshold T. The detection boxes with IoU, which is less than the threshold T, maintains its original score. The detection boxes whose scores are lower than another threshold σ are removed after many iterations. The performance of this algorithm remains limited by the threshold T. The continuous proportional penalty factor NMS algorithm no longer uses threshold T but directly reduces all detection boxes, except those with the maximum score in each iteration. In the continuous proportional penalty factor NMS algorithm, the threshold slightly affects the performance of the algorithm. The improved NMS algorithm initially calculates the proportional penalty factors the correspond to the detection boxes in accordance with the IoU value of the pre-selection detection box. The improved NMS algorithm multiplies the confidence scores of the detection boxes by the proportional penalty factors and reduces the detection box scores through the proportional penalty factor after many iterations. Moreover, the improved NMS algorithm removes the detection boxes with a score below the threshold after many iterations. The piecewise and the continuous proportional penalty factor NMS algorithms are used in each iteration in a post-processing step of object detection rather than in a region proposal network. The threshold in the continuous proportional penalty factor is less sensitive to the performance of the algorithm than the influence of the threshold in GreedyNMS. In addition, the computational complexity of the improved NMS algorithm is O(n2), which is the same as that of GreedyNMS, where$ n$ 关键词:object detection;non-maximum suppression algorithm;detection boxes;scale factor;false positives18|41|19更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:Objective Visual tracking is widely applied in fields, such as video surveillance, human-computer interaction, and intelligent transportation, at present. In recent years, domestic and foreign researchers have proposed numerous tracking algorithms for this purpose. When applied to practical use, these algorithms are required to track a target extensively. However, continuously tracking a target is difficult for most algorithms given the complexity of the tracking scenario. Therefore, conducting rapid and robust tracking of a target is a key issue that must be solved when applying visual target tracking technology to practical use. TLD algorithm provides an effective solution to this issue. This study improves two aspects of the TLD algorithm to improve its tracking performance.Method First, a scale adaptive kernel correlation filter (KCF) is used as a tracker in the tracking module. The KCF algorithm cannot adapt to the scale change of the target because the size of the filter template is fixed. However, the detection module of the TLD algorithm has a certain scale adaptability. Therefore, the proposed algorithm utilizes the scale adaptive capabilities of the detection module to measure the scale of the region of interest of the KCF tracker. Moreover, the scale adjustments can enable the KCF tracker to achieve an improved tracking precision. The algorithm uses the detection module to assess the accuracy of the results of the tracking, module and selectively updates the KCF filter template in accordance with the assessed result because the tracking and detection modules are independent of each other. Second, an optical flow method in the detection module is used to preliminarily predict a target position. The optical flow method is used to estimate the target movement between two adjacent frames without any prior knowledge. The target detection area is set in accordance with the predicted position, and the size of the detection area is proportional to the target size. A three-layer cascade classifier is used to locate the target accurately after dynamically adjusting the target detection area. An anti-interference capability of the algorithm to similar objects in the scene is enhanced since the target motion information is introduced.ResultTwo sets of experiments are conducted to verify the superiority of the proposed algorithm. The first set of experiments is conducted on the OTB2013 and Temple Color 128 data platforms. The OTB2013 data platform has 50 sets of video sequences, and the Temple Color 128 data platform has 128 sets of video sequences. Results show that the tracking accuracy and success rate of the algorithm on the OTB2013 data platform are 0.761 and 0.559, respectively, and the tracking accuracy and success rate of the algorithm on the Temple Color 128 data platform are 0.678 and 0.481, correspondingly. The proposed algorithm is compared with six state-of-the art algorithms, namely, DSST, KCF, CNT, Struck, TLD, and DLT. Among all the algorithms, the proposed algorithm exhibits the optimum performance on the two data platforms, Besides, the. The average tracking speed of all test videos reaches 27.92 frame/s, thereby indicating a favorable real-time performance. In another set of experiments, the proposed algorithm and three other improved algorithms are tested and compared with the randomly selected eight sets of video sequences. The experimental results show that the proposed algorithm has the smallest center position error of 14.01, the largest overlap rate of 72.2%, and the fastest tracking speed of 26.23 frame/s, thus denoting that the proposed algorithm achieves the optimum tracking performance among all of the improved algorithms.Conclusion The proposed algorithm uses the KCF tracker to improve the capability of the algorithm to adapt to different scenes, such as occlusion, illumination change, and motion blur. Furthermore, the proposed algorithm uses the optical flow method to narrow the detection area. Consequently, the tracking speed of the algorithm is improved. The experimental results show that the proposed algorithm exhibits better tracking performance than the reference algorithm in most cases and achieves favorable tracking robustness in an extensive tracking process.关键词:visual tracking;TLD(tracking-learning-detection);kernel correlation;optical flow method;detection area adjustment12|4|3更新时间:2024-05-07
摘要:Objective Visual tracking is widely applied in fields, such as video surveillance, human-computer interaction, and intelligent transportation, at present. In recent years, domestic and foreign researchers have proposed numerous tracking algorithms for this purpose. When applied to practical use, these algorithms are required to track a target extensively. However, continuously tracking a target is difficult for most algorithms given the complexity of the tracking scenario. Therefore, conducting rapid and robust tracking of a target is a key issue that must be solved when applying visual target tracking technology to practical use. TLD algorithm provides an effective solution to this issue. This study improves two aspects of the TLD algorithm to improve its tracking performance.Method First, a scale adaptive kernel correlation filter (KCF) is used as a tracker in the tracking module. The KCF algorithm cannot adapt to the scale change of the target because the size of the filter template is fixed. However, the detection module of the TLD algorithm has a certain scale adaptability. Therefore, the proposed algorithm utilizes the scale adaptive capabilities of the detection module to measure the scale of the region of interest of the KCF tracker. Moreover, the scale adjustments can enable the KCF tracker to achieve an improved tracking precision. The algorithm uses the detection module to assess the accuracy of the results of the tracking, module and selectively updates the KCF filter template in accordance with the assessed result because the tracking and detection modules are independent of each other. Second, an optical flow method in the detection module is used to preliminarily predict a target position. The optical flow method is used to estimate the target movement between two adjacent frames without any prior knowledge. The target detection area is set in accordance with the predicted position, and the size of the detection area is proportional to the target size. A three-layer cascade classifier is used to locate the target accurately after dynamically adjusting the target detection area. An anti-interference capability of the algorithm to similar objects in the scene is enhanced since the target motion information is introduced.ResultTwo sets of experiments are conducted to verify the superiority of the proposed algorithm. The first set of experiments is conducted on the OTB2013 and Temple Color 128 data platforms. The OTB2013 data platform has 50 sets of video sequences, and the Temple Color 128 data platform has 128 sets of video sequences. Results show that the tracking accuracy and success rate of the algorithm on the OTB2013 data platform are 0.761 and 0.559, respectively, and the tracking accuracy and success rate of the algorithm on the Temple Color 128 data platform are 0.678 and 0.481, correspondingly. The proposed algorithm is compared with six state-of-the art algorithms, namely, DSST, KCF, CNT, Struck, TLD, and DLT. Among all the algorithms, the proposed algorithm exhibits the optimum performance on the two data platforms, Besides, the. The average tracking speed of all test videos reaches 27.92 frame/s, thereby indicating a favorable real-time performance. In another set of experiments, the proposed algorithm and three other improved algorithms are tested and compared with the randomly selected eight sets of video sequences. The experimental results show that the proposed algorithm has the smallest center position error of 14.01, the largest overlap rate of 72.2%, and the fastest tracking speed of 26.23 frame/s, thus denoting that the proposed algorithm achieves the optimum tracking performance among all of the improved algorithms.Conclusion The proposed algorithm uses the KCF tracker to improve the capability of the algorithm to adapt to different scenes, such as occlusion, illumination change, and motion blur. Furthermore, the proposed algorithm uses the optical flow method to narrow the detection area. Consequently, the tracking speed of the algorithm is improved. The experimental results show that the proposed algorithm exhibits better tracking performance than the reference algorithm in most cases and achieves favorable tracking robustness in an extensive tracking process.关键词:visual tracking;TLD(tracking-learning-detection);kernel correlation;optical flow method;detection area adjustment12|4|3更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:Objective Freeform deformation techniques of curves and surfaces have received considerable attention recently with the rapid development of geometric modeling and computer animation. A new local deformation algorithm for curves based on progressive iterative approximation (PIA) and dominant point methods is proposed in this study to acquire interesting and lifelike deformation effects. The new deformation method not only produces various deformation effects but also possesses desirable properties, such as flexibility and convergence, given the PIA method.Method First, the initial deformation curves are obtained using the PIA or least squares PIA method. Second, the dominant points, which include the maximum local curvature points, and two end points are selected from the initial control points by calculating and comparing the curvatures that correspond to the control points. In this phase, we detect the maximum local curvature points using the rule that the curvature of a point must be larger than the curvatures of its neighboring points. Thus, the maximum local curvature points can be selected as the dominant points. Then, an extension rule is constructed on the region expected to be deformed. That is, we extend this region along the curve until it satisfies the two closest dominant points after selecting the region for deformation in accordance with real requirements. Thus, we can obtain a segment that is bounded by two dominant points. We classify the situation into two categories using the abovementioned extension rule on the basis of the number of dominant points in the obtained segment. The control points, which will be adjusted subsequently, are selected in accordance with the dominant points and the shape information of the curves. If the region that is prepared for deformation contains a dominant point, then three dominant points in the segment will be obtained after applying such extension rule. The dominant point in the middle is selected for subsequent adjustment. If the region that is prepared for deformation does not contain any dominant point, then only two dominant points in the segment will be obtained after extension. We select a control point in accordance with the shape information of the curve, which is useful in handling several complex deformation problems. In this situation, we first calculate the shape parameter for each control point in the obtained segment. The shape parameter represents the complexity of the curve and indicates the difference between two adjacent segments. Second, the control point that has the smallest shape parameter is selected for subsequent adjustment after comparing these parameters. We call this procedure the dominant point method. Moreover, if more than one dominant point in the region is expected to be deformed, then we can split the segment in accordance with the distribution of dominant points to ensure that each segment contains less than one dominant point. Then, we can use the abovementioned dominant point method to select the control points. Finally, local progressive iterative approximation (LPIA) method is adopted to generate the final curves after local deformation.Result The proposed deformation method selects the control points on the basis of the complexity of the shapes of the curves. The deformation method is convergent, can be executed flexibly, and can highlight the features of the deformed regions through local iteration because we use the LPIA method to fit the data set after adjustment. Numerical examples, such as teapot, face contour, and hand, show that the proposed method can obtain favorable deformation effects through the B-spline basis, which is the most commonly used basis in geometric design and exhibits excellent local properties. Specifically, the teapot mouth is stretched by adjusting the selected control point. The lips, eyebrows, and earlobes of the face contour are deformed by using the deformation algorithm to generate a fascinating face. The fingers are also stretched to make the hand natural. We also demonstrate the distortion, which occurs when we do not use the deformation method proposed in this study, as illustrated in the teapot example. We can clearly observe that, if we do not adjust the control points generated by the algorithm, then the curve after deformation will be distorted and lack reality. Furthermore, this algorithm can be used repeatedly to generate the global, local, periodic, and elastic deformation effects.Conclusion This study mainly focuses on applying the PIA method to the local curve deformations. First, we discuss the PIA method, which presents an intuitive and straightforward approach to fitting data points and provides flexibility for shape control in data fitting. Second, we introduce the notion of dominant points into the curve deformations. Finally, we propose a new deformation method on the basis of the PIA and dominant point methods by combining the two techniques. The algorithm not only possesses the properties of convergence and stability through the PIA method but also produces various positive deformation effects by selecting dominant points. A user must only select the regions expected to be deformed during the implementation of the deformation method and determine the deformation scales in accordance with his/her requirements, thus guaranteeing the interactivity of this algorithm. In summary, the proposed method significantly enriches the deformation effects of curves.关键词:progressive iterative approximation;curve deformation;local curvature;deformation effect;computer aided design12|4|0更新时间:2024-05-07
摘要:Objective Freeform deformation techniques of curves and surfaces have received considerable attention recently with the rapid development of geometric modeling and computer animation. A new local deformation algorithm for curves based on progressive iterative approximation (PIA) and dominant point methods is proposed in this study to acquire interesting and lifelike deformation effects. The new deformation method not only produces various deformation effects but also possesses desirable properties, such as flexibility and convergence, given the PIA method.Method First, the initial deformation curves are obtained using the PIA or least squares PIA method. Second, the dominant points, which include the maximum local curvature points, and two end points are selected from the initial control points by calculating and comparing the curvatures that correspond to the control points. In this phase, we detect the maximum local curvature points using the rule that the curvature of a point must be larger than the curvatures of its neighboring points. Thus, the maximum local curvature points can be selected as the dominant points. Then, an extension rule is constructed on the region expected to be deformed. That is, we extend this region along the curve until it satisfies the two closest dominant points after selecting the region for deformation in accordance with real requirements. Thus, we can obtain a segment that is bounded by two dominant points. We classify the situation into two categories using the abovementioned extension rule on the basis of the number of dominant points in the obtained segment. The control points, which will be adjusted subsequently, are selected in accordance with the dominant points and the shape information of the curves. If the region that is prepared for deformation contains a dominant point, then three dominant points in the segment will be obtained after applying such extension rule. The dominant point in the middle is selected for subsequent adjustment. If the region that is prepared for deformation does not contain any dominant point, then only two dominant points in the segment will be obtained after extension. We select a control point in accordance with the shape information of the curve, which is useful in handling several complex deformation problems. In this situation, we first calculate the shape parameter for each control point in the obtained segment. The shape parameter represents the complexity of the curve and indicates the difference between two adjacent segments. Second, the control point that has the smallest shape parameter is selected for subsequent adjustment after comparing these parameters. We call this procedure the dominant point method. Moreover, if more than one dominant point in the region is expected to be deformed, then we can split the segment in accordance with the distribution of dominant points to ensure that each segment contains less than one dominant point. Then, we can use the abovementioned dominant point method to select the control points. Finally, local progressive iterative approximation (LPIA) method is adopted to generate the final curves after local deformation.Result The proposed deformation method selects the control points on the basis of the complexity of the shapes of the curves. The deformation method is convergent, can be executed flexibly, and can highlight the features of the deformed regions through local iteration because we use the LPIA method to fit the data set after adjustment. Numerical examples, such as teapot, face contour, and hand, show that the proposed method can obtain favorable deformation effects through the B-spline basis, which is the most commonly used basis in geometric design and exhibits excellent local properties. Specifically, the teapot mouth is stretched by adjusting the selected control point. The lips, eyebrows, and earlobes of the face contour are deformed by using the deformation algorithm to generate a fascinating face. The fingers are also stretched to make the hand natural. We also demonstrate the distortion, which occurs when we do not use the deformation method proposed in this study, as illustrated in the teapot example. We can clearly observe that, if we do not adjust the control points generated by the algorithm, then the curve after deformation will be distorted and lack reality. Furthermore, this algorithm can be used repeatedly to generate the global, local, periodic, and elastic deformation effects.Conclusion This study mainly focuses on applying the PIA method to the local curve deformations. First, we discuss the PIA method, which presents an intuitive and straightforward approach to fitting data points and provides flexibility for shape control in data fitting. Second, we introduce the notion of dominant points into the curve deformations. Finally, we propose a new deformation method on the basis of the PIA and dominant point methods by combining the two techniques. The algorithm not only possesses the properties of convergence and stability through the PIA method but also produces various positive deformation effects by selecting dominant points. A user must only select the regions expected to be deformed during the implementation of the deformation method and determine the deformation scales in accordance with his/her requirements, thus guaranteeing the interactivity of this algorithm. In summary, the proposed method significantly enriches the deformation effects of curves.关键词:progressive iterative approximation;curve deformation;local curvature;deformation effect;computer aided design12|4|0更新时间:2024-05-07 -
 摘要:Objective An importance sampling method based on bidirectional reflectance distribution function (BRDF) has excellent fidelity when rendering the surface of an object. However, this sampling method has a complicated form and can lead to heavy hardware storage cost, which can cause many problems when applied to practical use. These problems include high implementation complexity, low execution efficiency, and high debugging difficulty. Owing to these problems, this study provides a new method for computing the reflection direction of a light path. The new method uses weight generation technique and vector linear interpolation. This method not only reduces the complexity of the algorithm but also reduces the computational complexity of many previous sampling algorithms. The new method is also easy to implement.Method The algorithm initially calculates the direction of reflected light and subsequently combines the features of cosine and exponential functions given the direction of incident light and surface normal. This algorithm generates a weight value that has a certain distribution characteristic. The algorithm defines a parameter called ε to enable the distribution characteristic to be controllable. The surface tends to exhibit a diffuse reflection for each incoming light ray when ε is relatively small. Otherwise, the surface tends to exhibit an ideal mirror reflection. The new algorithm performs a linear interpolation between a mirror and diffuse reflection directions to obtain a new vector after the weight generation process, and the weight that was generated previously was used in this process. Finally, the algorithm obtains the desired reflection direction of a light ray by normalizing the new vector. This method efficiently simulates glossy surfaces, which exist vastly in real life.Result This study conducts a full implementation of the path tracing algorithm. The new algorithm is based on the new sampling method described previously. Nine kinds of common surface materials are selected for the rendering test through this algorithm. Experimental results are compared with the actual results obtained by the original BRDF sampling algorithm. The original data size for the BRDF parameter of each actual surface is approximately 34 MB. Notably, storing the raw BRDF data when the scene contains various material surfaces is infeasible. The rendering speed can be increased by 1.521.99 times using the fast sampling algorithm, and the relative error caused by approximation can be controlled within 8%. Moreover, the original 34 MB data used to describe the surface of the object can be replaced by only storing few floating-point numbers, which can apparently reduce hardware storage overhead considerably. This sampling method has a low hardware storage cost, and its rendered picture can still retain a high degree of realism. These features are favorable for modern hardware that is specifically designed for solving high computational complexity problems but limited to memory bandwidth. The object being rendered can achieve a smooth transition from an ideal diffuse to specular reflection and ideal mirror reflection because a smoothness parameter changes continuously. Moreover, the new algorithm unifies the sampling method used in many path tracing renderers. These renderers frequently use different sampling models when rendering various types of material surfaces to improve rendering quality. This improvement will inevitably increase thread divergence when rendering and considerably reduce the operating efficiency of the rendering program. These drawbacks are particularly evident on parallel hardware, such as GPUs, and must be avoided to a feasible extent. Thus, this algorithm condenses different rendering models used by various types of renderers and obtains a unified sampling method, even when the material properties of the surface are relatively complex to render correctly. The algorithm can also be appropriately extended and approximated by a multilayer fitting technique to simulate the material properties of the rendered surface. The algorithm has favorable scalability and practicality.Conclusion This study uses a simplified algorithm to compute the exit direction of light to replace the traditional method used in path tracing renderers without sacrificing the authenticity of the rendered image. This study also fully implements the path tracing algorithm to enable its practical application. This algorithm can effectively simulate mirror, diffuse, and glossy reflection, has extensive applications when rendering various kinds of objects that exist in real life, and can be used as an alternative approach to replace existing sampling methods. This algorithm has a low storage overhead, which is an advantage when rendering complex scenes that contain various materials without consuming numerous memory resources. This algorithm also exhibits excellent performance when rendering common isotropic materials, such as rough or diffuse surfaces, porcelain, and metals.关键词:computer graphics;path tracing;bidirectional reflectance distribution function;bidirectional reflectance distribution function(BRDF);fast sampling;GPU25|4|0更新时间:2024-05-07
摘要:Objective An importance sampling method based on bidirectional reflectance distribution function (BRDF) has excellent fidelity when rendering the surface of an object. However, this sampling method has a complicated form and can lead to heavy hardware storage cost, which can cause many problems when applied to practical use. These problems include high implementation complexity, low execution efficiency, and high debugging difficulty. Owing to these problems, this study provides a new method for computing the reflection direction of a light path. The new method uses weight generation technique and vector linear interpolation. This method not only reduces the complexity of the algorithm but also reduces the computational complexity of many previous sampling algorithms. The new method is also easy to implement.Method The algorithm initially calculates the direction of reflected light and subsequently combines the features of cosine and exponential functions given the direction of incident light and surface normal. This algorithm generates a weight value that has a certain distribution characteristic. The algorithm defines a parameter called ε to enable the distribution characteristic to be controllable. The surface tends to exhibit a diffuse reflection for each incoming light ray when ε is relatively small. Otherwise, the surface tends to exhibit an ideal mirror reflection. The new algorithm performs a linear interpolation between a mirror and diffuse reflection directions to obtain a new vector after the weight generation process, and the weight that was generated previously was used in this process. Finally, the algorithm obtains the desired reflection direction of a light ray by normalizing the new vector. This method efficiently simulates glossy surfaces, which exist vastly in real life.Result This study conducts a full implementation of the path tracing algorithm. The new algorithm is based on the new sampling method described previously. Nine kinds of common surface materials are selected for the rendering test through this algorithm. Experimental results are compared with the actual results obtained by the original BRDF sampling algorithm. The original data size for the BRDF parameter of each actual surface is approximately 34 MB. Notably, storing the raw BRDF data when the scene contains various material surfaces is infeasible. The rendering speed can be increased by 1.521.99 times using the fast sampling algorithm, and the relative error caused by approximation can be controlled within 8%. Moreover, the original 34 MB data used to describe the surface of the object can be replaced by only storing few floating-point numbers, which can apparently reduce hardware storage overhead considerably. This sampling method has a low hardware storage cost, and its rendered picture can still retain a high degree of realism. These features are favorable for modern hardware that is specifically designed for solving high computational complexity problems but limited to memory bandwidth. The object being rendered can achieve a smooth transition from an ideal diffuse to specular reflection and ideal mirror reflection because a smoothness parameter changes continuously. Moreover, the new algorithm unifies the sampling method used in many path tracing renderers. These renderers frequently use different sampling models when rendering various types of material surfaces to improve rendering quality. This improvement will inevitably increase thread divergence when rendering and considerably reduce the operating efficiency of the rendering program. These drawbacks are particularly evident on parallel hardware, such as GPUs, and must be avoided to a feasible extent. Thus, this algorithm condenses different rendering models used by various types of renderers and obtains a unified sampling method, even when the material properties of the surface are relatively complex to render correctly. The algorithm can also be appropriately extended and approximated by a multilayer fitting technique to simulate the material properties of the rendered surface. The algorithm has favorable scalability and practicality.Conclusion This study uses a simplified algorithm to compute the exit direction of light to replace the traditional method used in path tracing renderers without sacrificing the authenticity of the rendered image. This study also fully implements the path tracing algorithm to enable its practical application. This algorithm can effectively simulate mirror, diffuse, and glossy reflection, has extensive applications when rendering various kinds of objects that exist in real life, and can be used as an alternative approach to replace existing sampling methods. This algorithm has a low storage overhead, which is an advantage when rendering complex scenes that contain various materials without consuming numerous memory resources. This algorithm also exhibits excellent performance when rendering common isotropic materials, such as rough or diffuse surfaces, porcelain, and metals.关键词:computer graphics;path tracing;bidirectional reflectance distribution function;bidirectional reflectance distribution function(BRDF);fast sampling;GPU25|4|0更新时间:2024-05-07
Computer Graphics
-
 摘要:Objective The classification of sea ice is an important task in sea ice monitoring. Synthetic aperture radar (SAR), as an active microwave sensor, has all-weather, day-and-night, multi-view, and penetration imaging capabilities. SAR has been widely used for sea ice monitoring. Existing methods of automatic sea ice classification using SAR data are divided into two categories as follows:1) Classification based on the physical characteristics of sea ice and imaging characteristics of SAR imagery, such as the relationship between sea ice types and incidence angle, polarization mode, and backscatter coefficient of SAR image; SAR imagery requires professional background. 2) Traditional image classification methods with SAR imagery, such as support vector machine (SVM) and artificial neural network, must design features in advance and thus are limited by prior knowledge. In recent years, deep learning has achieved considerable success in image classification and object recognition. Image classification based on deep learning can automatically learn high-level features of sample data beyond low-level texture and color features, thus achieving a high accuracy of classification results without constraints of human prior knowledge. However, SAR images have different imaging mechanisms from optical imaging of ordinary camera, and sea ice shows lower identifiable characteristics on the SAR imagery than general ground objects with specific shape, texture, and other distinctive features. The effectiveness of deep learning models for sea ice classification remains unclear. We aim to use deep learning models, such as a convolutional neural network (CNN) and a deep belief network (DBN), to classify sea ice and water in SAR imagery and evaluate the performance and influence factors of the two models to improve the accuracy and speed of sea ice classification.Method The entire process of sea ice-water classification experiment mainly includes four steps. First, the study area and the corresponding SAR images must be determined. Hudson Bay was selected, and 16 SAR images of the area were obtained from Sentinel-1 satellite. Second, an experimental data set must be constructed in accordance with the ice chart published by the Canadian Ice Service (CIS), including image cutting, normalization, and labeling. A total of 2 000 training and 400 validation samples were prepared for each sample size, although the sample size varied from 16×16 pixels to 64×64 pixels. Eight regions were used for testing. Third, the structures of the CNN and DBN must be designed, and the influence of different network hyperparameters on classification performance must be discussed. Finally, the classification performance of models influenced by train patch size, data set size, layers of the models, sea ice proportion in the test image, and image filter size must be evaluated. The evaluation was based on the indices of precision ratio, recall ratio, F1 score, and kappa coefficient.Result The CNN and DBN models reached more than 93% overall accuracy and 0.8 kappa coefficient given the pixel-level ground truth generated by SVM and manual correction. Regional concentration values computed by the classification results were close to the concentration data provided in the CIS ice chart with a mean squared error of 0.001 for CNN and 0.016 for DBN. The train patch size of sea ice significantly influenced the classification performance of the models, whereas the data set size and layers of the models only slightly influenced the classification performance of the models. Additional ice and water would be misclassified when the size of the training samples was large. Therefore, the sample size of the CNN and DBN should not be very large. Under our experimental conditions, the optimal train patch size of CNN and DBN was 16×16 pixels and 32×32 pixels, correspondingly. In addition, the sea ice-water ratio of the test samples affected the precision and recall ratios. The ice and water in terms of F1 score and the kappa coefficient stabilized when the sea ice-water ratio was at 0.5. The precision and recall of the DBN were relatively sensitive to the sea ice-water ratio of the test samples.Conclusion We evaluated the performance of the sea ice-water classification in SAR imagery with CNN and DBN. Notably, deep learning demonstrates considerable potential in the sea ice classification. The sea ice classification of SAR images based on deep learning without designing features in advance can be robustly applied to different SAR data products over several traditional classification methods, such as SVM. The classification method based on deep learning models can provide more convenient and more detailed sea ice interpretations than the complex production process of the CIS ice chart and the rough range of sea ice-type tagging information. Owing to the different resolutions of SAR images, the patch size of the optimal classification sample will be different. In this study, errors in the ground truth are inevitable considering the limitations of current sea ice observation methods; these limitations have been discussed. The main contributions of this study are as follows:1) In the sea ice-water classification using SAR images, two typical deep learning networks with different mechanisms have been used. The convolution operation of the CNN is suitable for exploring the local spatial correlation of images and has a robust application in the image recognition field. The restricted Boltzmann machine, as an important component of the DBN, is better at exploring probabilistic relationships among different elements and is more suitable for incremental learning than the CNN. The CNN showed better performance than the DBN in the classification of sea ice-water with SAR imagery. 2) A complete experimental procedure for sea ice classification of SAR images through deep learning methods, which can help guide related research, is summarized. 3) A new idea of using the deep learning method for sea ice classification is proposed. This method can shorten the existing process of creating a sea ice interpretation map and provide accurate geographic distribution information of a sea ice type. In our future work, we will compare the classification performance of different SAR data sources.关键词:sea ice-water classification;SAR imagery;deep learning;convolution neural network;deep belief network;sea ice interpretation map15|4|9更新时间:2024-05-07
摘要:Objective The classification of sea ice is an important task in sea ice monitoring. Synthetic aperture radar (SAR), as an active microwave sensor, has all-weather, day-and-night, multi-view, and penetration imaging capabilities. SAR has been widely used for sea ice monitoring. Existing methods of automatic sea ice classification using SAR data are divided into two categories as follows:1) Classification based on the physical characteristics of sea ice and imaging characteristics of SAR imagery, such as the relationship between sea ice types and incidence angle, polarization mode, and backscatter coefficient of SAR image; SAR imagery requires professional background. 2) Traditional image classification methods with SAR imagery, such as support vector machine (SVM) and artificial neural network, must design features in advance and thus are limited by prior knowledge. In recent years, deep learning has achieved considerable success in image classification and object recognition. Image classification based on deep learning can automatically learn high-level features of sample data beyond low-level texture and color features, thus achieving a high accuracy of classification results without constraints of human prior knowledge. However, SAR images have different imaging mechanisms from optical imaging of ordinary camera, and sea ice shows lower identifiable characteristics on the SAR imagery than general ground objects with specific shape, texture, and other distinctive features. The effectiveness of deep learning models for sea ice classification remains unclear. We aim to use deep learning models, such as a convolutional neural network (CNN) and a deep belief network (DBN), to classify sea ice and water in SAR imagery and evaluate the performance and influence factors of the two models to improve the accuracy and speed of sea ice classification.Method The entire process of sea ice-water classification experiment mainly includes four steps. First, the study area and the corresponding SAR images must be determined. Hudson Bay was selected, and 16 SAR images of the area were obtained from Sentinel-1 satellite. Second, an experimental data set must be constructed in accordance with the ice chart published by the Canadian Ice Service (CIS), including image cutting, normalization, and labeling. A total of 2 000 training and 400 validation samples were prepared for each sample size, although the sample size varied from 16×16 pixels to 64×64 pixels. Eight regions were used for testing. Third, the structures of the CNN and DBN must be designed, and the influence of different network hyperparameters on classification performance must be discussed. Finally, the classification performance of models influenced by train patch size, data set size, layers of the models, sea ice proportion in the test image, and image filter size must be evaluated. The evaluation was based on the indices of precision ratio, recall ratio, F1 score, and kappa coefficient.Result The CNN and DBN models reached more than 93% overall accuracy and 0.8 kappa coefficient given the pixel-level ground truth generated by SVM and manual correction. Regional concentration values computed by the classification results were close to the concentration data provided in the CIS ice chart with a mean squared error of 0.001 for CNN and 0.016 for DBN. The train patch size of sea ice significantly influenced the classification performance of the models, whereas the data set size and layers of the models only slightly influenced the classification performance of the models. Additional ice and water would be misclassified when the size of the training samples was large. Therefore, the sample size of the CNN and DBN should not be very large. Under our experimental conditions, the optimal train patch size of CNN and DBN was 16×16 pixels and 32×32 pixels, correspondingly. In addition, the sea ice-water ratio of the test samples affected the precision and recall ratios. The ice and water in terms of F1 score and the kappa coefficient stabilized when the sea ice-water ratio was at 0.5. The precision and recall of the DBN were relatively sensitive to the sea ice-water ratio of the test samples.Conclusion We evaluated the performance of the sea ice-water classification in SAR imagery with CNN and DBN. Notably, deep learning demonstrates considerable potential in the sea ice classification. The sea ice classification of SAR images based on deep learning without designing features in advance can be robustly applied to different SAR data products over several traditional classification methods, such as SVM. The classification method based on deep learning models can provide more convenient and more detailed sea ice interpretations than the complex production process of the CIS ice chart and the rough range of sea ice-type tagging information. Owing to the different resolutions of SAR images, the patch size of the optimal classification sample will be different. In this study, errors in the ground truth are inevitable considering the limitations of current sea ice observation methods; these limitations have been discussed. The main contributions of this study are as follows:1) In the sea ice-water classification using SAR images, two typical deep learning networks with different mechanisms have been used. The convolution operation of the CNN is suitable for exploring the local spatial correlation of images and has a robust application in the image recognition field. The restricted Boltzmann machine, as an important component of the DBN, is better at exploring probabilistic relationships among different elements and is more suitable for incremental learning than the CNN. The CNN showed better performance than the DBN in the classification of sea ice-water with SAR imagery. 2) A complete experimental procedure for sea ice classification of SAR images through deep learning methods, which can help guide related research, is summarized. 3) A new idea of using the deep learning method for sea ice classification is proposed. This method can shorten the existing process of creating a sea ice interpretation map and provide accurate geographic distribution information of a sea ice type. In our future work, we will compare the classification performance of different SAR data sources.关键词:sea ice-water classification;SAR imagery;deep learning;convolution neural network;deep belief network;sea ice interpretation map15|4|9更新时间:2024-05-07 -
 摘要:ObjectiveSynthetic aperture radar (SAR) is an important means of earth observation considering its all-weather, day-and-night, and penetrating imaging capabilities. SAR has been extensively used in battlefield detection and intelligence acquisition. SAR is a kind of electromagnetic wave coherent imaging system. A SAR image not only has variability but also has a strong speckle noise, which leads to considerable difficulties in target recognition of a SAR image. A manual interpretation of numerous SAR image data is difficult given the diversity of SAR image acquisition methods. A SAR automatic target recognition can effectively improve the utilization efficiency of SAR image data. However, the current SAR image target recognition algorithm has two main problems. First, the characteristics of target recognition, such as edge, corner, contour, texture, and other low-level features, are not representative. Second, in the traditional SAR image target recognition method, an effective filtering algorithm is crucial, but the filtering process is time-consuming. A convolutional neural network model is presented in this study to solve the problems of time-consuming filtering process and low recognition accuracy in the SAR target recognition.MethodFirst, a network structure of the feature extraction part was specifically designed for the characteristics of SAR images, which are slightly different from optical images. We must design a reasonable network structure for the characteristics of SAR images. First, a SAR image that reflects a target radar echo intensity is a gray image because the feature information is less in a SAR image than in an optical image. Second, speckle noise inevitably exists in the SAR image. Third, the pixel size of the target is small because of the resolution limitation of the SAR image. Owing to the characteristics of SAR images, the convolutional neural network applied to SAR image target recognition must use a small convolution kernel and an appropriate convolution layer number. The feature extraction part of the proposed convolutional neural network model consists of four convolutional layers, four nonlinear layers, and two pooling layers. Second, an L2 norm was introduced to the cost function to improve the anti-noise and generalization performances of the model. Theoretical deduction shows the means by which the L2 norm enhances the noise immunity and generalization performance of the model. Third, Dropout reduced the computational complexity of the network and improved the generalization performance of the model. Dropout is a regularization technique for the reduction of overfitting in neural networks by preventing complex co-adaptations in training data. Dropout is an efficient technique for conducting model averaging with neural networks. Finally, the influence of filtering on the convergence speed and accuracy of the network was investigated. In the traditional SAR image target recognition method, the effective filtering algorithm is crucial, but the filtering process is time-consuming.ResultExperimental data were obtained from the United States Moving and Stationary Target Acquisition and Recognition database. Experimental results of 10 types of target recognition showed that the overall recognition rate (including the variant) of the improved convolutional neural network increased from 93.76% to 98.10%. The improved feature extraction network structure extracts effective target features, thus improving the accuracy of the model. The accuracy of target variant recognition in SAR images had also been considerably improved. Notably, L2 regularization and Dropout enhanced the generalization performance of the model. Different sets of comparative experiments were set up to illustrate the effectiveness of improving and optimizing the network structure. The accuracy rate decreased from 98.10% to 97.06% when the first layer uses a 9×9 convolution kernel instead of two cascaded 5×5 convolution kernels. The accuracy of network identification increases from 94.91% to 96.19% when using L2 regularization, thereby indicating that L2 regularization can effectively improve the accuracy of network identification. Dropout increases the fluctuation range of the recognition rate, thus increasing the recognition accuracy to the highest level. Noise suppression experiments on the convolutional neural network were conducted to analyze the effects of three filtering methods, namely, Lee, bilateral, and Gamma MAP (Maximum A Posteriori), on the training process and results of the model. The experiments verified that the feature extraction process of the convolutional neural network can suppress the speckle noise of the SAR image and can save time during the filtering process. The filtering process consumes additional time, does not improve the convergence speed of convolutional neural network training, and decreases the recognition accuracy because it may filter out effective target recognition features, such as target texture, thus resulting in a decrease in recognition accuracy.ConclusionThe convolutional neural network model proposed in this study improves the accuracy and generalization of the network, does not require a time-consuming filtering process, and is an effective method for target recognition of SAR images.关键词:synthetic aperture radar (SAR);automatic target recognition (ATR);convolutional neural network (CNN);regularization;Dropout14|8|4更新时间:2024-05-07
摘要:ObjectiveSynthetic aperture radar (SAR) is an important means of earth observation considering its all-weather, day-and-night, and penetrating imaging capabilities. SAR has been extensively used in battlefield detection and intelligence acquisition. SAR is a kind of electromagnetic wave coherent imaging system. A SAR image not only has variability but also has a strong speckle noise, which leads to considerable difficulties in target recognition of a SAR image. A manual interpretation of numerous SAR image data is difficult given the diversity of SAR image acquisition methods. A SAR automatic target recognition can effectively improve the utilization efficiency of SAR image data. However, the current SAR image target recognition algorithm has two main problems. First, the characteristics of target recognition, such as edge, corner, contour, texture, and other low-level features, are not representative. Second, in the traditional SAR image target recognition method, an effective filtering algorithm is crucial, but the filtering process is time-consuming. A convolutional neural network model is presented in this study to solve the problems of time-consuming filtering process and low recognition accuracy in the SAR target recognition.MethodFirst, a network structure of the feature extraction part was specifically designed for the characteristics of SAR images, which are slightly different from optical images. We must design a reasonable network structure for the characteristics of SAR images. First, a SAR image that reflects a target radar echo intensity is a gray image because the feature information is less in a SAR image than in an optical image. Second, speckle noise inevitably exists in the SAR image. Third, the pixel size of the target is small because of the resolution limitation of the SAR image. Owing to the characteristics of SAR images, the convolutional neural network applied to SAR image target recognition must use a small convolution kernel and an appropriate convolution layer number. The feature extraction part of the proposed convolutional neural network model consists of four convolutional layers, four nonlinear layers, and two pooling layers. Second, an L2 norm was introduced to the cost function to improve the anti-noise and generalization performances of the model. Theoretical deduction shows the means by which the L2 norm enhances the noise immunity and generalization performance of the model. Third, Dropout reduced the computational complexity of the network and improved the generalization performance of the model. Dropout is a regularization technique for the reduction of overfitting in neural networks by preventing complex co-adaptations in training data. Dropout is an efficient technique for conducting model averaging with neural networks. Finally, the influence of filtering on the convergence speed and accuracy of the network was investigated. In the traditional SAR image target recognition method, the effective filtering algorithm is crucial, but the filtering process is time-consuming.ResultExperimental data were obtained from the United States Moving and Stationary Target Acquisition and Recognition database. Experimental results of 10 types of target recognition showed that the overall recognition rate (including the variant) of the improved convolutional neural network increased from 93.76% to 98.10%. The improved feature extraction network structure extracts effective target features, thus improving the accuracy of the model. The accuracy of target variant recognition in SAR images had also been considerably improved. Notably, L2 regularization and Dropout enhanced the generalization performance of the model. Different sets of comparative experiments were set up to illustrate the effectiveness of improving and optimizing the network structure. The accuracy rate decreased from 98.10% to 97.06% when the first layer uses a 9×9 convolution kernel instead of two cascaded 5×5 convolution kernels. The accuracy of network identification increases from 94.91% to 96.19% when using L2 regularization, thereby indicating that L2 regularization can effectively improve the accuracy of network identification. Dropout increases the fluctuation range of the recognition rate, thus increasing the recognition accuracy to the highest level. Noise suppression experiments on the convolutional neural network were conducted to analyze the effects of three filtering methods, namely, Lee, bilateral, and Gamma MAP (Maximum A Posteriori), on the training process and results of the model. The experiments verified that the feature extraction process of the convolutional neural network can suppress the speckle noise of the SAR image and can save time during the filtering process. The filtering process consumes additional time, does not improve the convergence speed of convolutional neural network training, and decreases the recognition accuracy because it may filter out effective target recognition features, such as target texture, thus resulting in a decrease in recognition accuracy.ConclusionThe convolutional neural network model proposed in this study improves the accuracy and generalization of the network, does not require a time-consuming filtering process, and is an effective method for target recognition of SAR images.关键词:synthetic aperture radar (SAR);automatic target recognition (ATR);convolutional neural network (CNN);regularization;Dropout14|8|4更新时间:2024-05-07
Remote Sensing Image Processing
-
 摘要:ObjectiveIn the field of object tracking, the most serious difficulty is that the object may have a motion in different degrees in each video frame. Different types of movements will cause complex scenes of the object's own non-rigid deformation, background clusters, occlusion, fast motion and so on, thereby making object tracking more difficult. The balance between high speed and high accuracy remains a challenging task, although considerable progress in enhancing the accuracy and speed of tracking has been achieved. Recently, discriminative correlation filter methods have been successfully and widely applied to the visual tracking field. The standard correlation filter method can obtain numerous training samples through a cyclic shift and can train the filters through fast Fourier transform algorithm, which can ensure real-time favorable performance and robustness. However, the tracking accuracy of the correlation filter tracking algorithms based on traditional manual features must be improved given the limitations of traditional manual features. Therefore, correlation filter tracking algorithms based on convolutional features have been proposed and developed. The correlation filter tracking algorithms based on deep convolutional features can lead to a low tracking speed considering multiple feature dimensions and tracking failure problems when the object is subjected to deformation or occlusion despite a high accuracy of such algorithms. Thus, a real-time tracking algorithm based on adaptive convolutional feature selection is proposed to solve these problems.MethodFirst, the proposed method analyzes the characteristics of convolution features extracted from the convolutional network model trained on the classification data set and selects the multilayer convolution features suitable for object tracking. The method also analyzes the characteristics of localization prediction of correlation filter trackers based on deep convolutional features. Analysis results show that a large average feature ratio between object and search regions indicates an improved convolution operator. Thus, this study proposed the average feature ratio between object and search regions to evaluate the convolution operator of each channel of every convolution layer. Then, the feature selection strategy is applied to select the convolution layer with the most convolution channels whose feature mean ratio is larger than the threshold for each preselected convolution layer. This strategy can effectively reduce the number of layers with convolution features. Simultaneously, the strategy can reduce the dimensions of the selected convolution layer by removing the convolution features that are not larger than the threshold. Then, the correlation filter classifier is trained by extracting the remaining effective convolutional features from the selected layer. The trained classifier is used to predict the position of the object. Finally, a sparse model updating strategy is adopted to prevent overfitting of the correlation filter classifier and improve the tracking speed.ResultThe proposed approach is evaluated on 100 sequences of Object Tracker Benchmark (OTB-100), which mainly contains 11 challenges (e.g., variation, background blusters, low resolution and so on) that may be encountered in object tracking, and compared with 9 other state-of-the-art tracking methods. The selected benchmark, namely, center location error, distance precision, overlap precision, and one-pass evaluation is applied to evaluate the tracking algorithm. The experiments are divided into two parts. The first part analyzes the tracking results of the different pre-selected convolutional layers. This part includes the results of no dimension reduction method, dimension reduction using principal component analysis, and our adaptive feature selection method using the feature mean ratio. The average distance accuracy of our adaptive feature selection method is 86.4%, which is higher than that of other methods. Experimental results show that the method can effectively improve the tracking speed and that it is better than the current trackers which use principal component analysis in reducing feature dimensions. The second part presents the comparison of our method and the existing mainstream object tracking method. These algorithms include the original hierarchical convolutional filter tracking algorithm and other correlation filter tracking algorithms that use convolutional features or traditional manual features. The average distance accuracy of our algorithm is 86.4%, which is 2.7 percent points higher than the original hierarchical convolutional features for visual tracking algorithm. The average success rate in the proposed approach is 68.4%, which is 2.9 percent points higher than the original hierarchical convolutional filter tracking algorithm. The average tracking speed is 29.9 frame/s, which is approximately three times faster than the previous performance. The experimental results show that the adaptive feature selection method can effectively improve the tracking speed while ensuring the tracking accuracy. The overall performance is superior to the nine other state-of-the-art tracking methods in the experiment.ConclusionThe feature mean ratio of the object and search regions is used to evaluate the convolution operator. The convolutional layer with the largest number of convolutional channels that satisfy the feature mean ratio threshold is selected, and the convolutional effective features of the selected convolutional layer are extracted to train the correlation filter classifier. The method not only effectively reduces the number of convolutional layers and the dimensions of the feature but also reduces the complexity of the model to improve the tracking speed by adaptively selecting convolutional channels and layers. In addition, a sparse model update strategy is utilized to further enhance the tracking speed and prevent model drifting. The proposed algorithm has excellent robustness and adaptability under complex scenes, such as occlusion, illumination change, and fast motion.关键词:machine vision;object tracking;deep learning;channel pruning;correlation filter;sparse updating104|0|1更新时间:2024-05-07
摘要:ObjectiveIn the field of object tracking, the most serious difficulty is that the object may have a motion in different degrees in each video frame. Different types of movements will cause complex scenes of the object's own non-rigid deformation, background clusters, occlusion, fast motion and so on, thereby making object tracking more difficult. The balance between high speed and high accuracy remains a challenging task, although considerable progress in enhancing the accuracy and speed of tracking has been achieved. Recently, discriminative correlation filter methods have been successfully and widely applied to the visual tracking field. The standard correlation filter method can obtain numerous training samples through a cyclic shift and can train the filters through fast Fourier transform algorithm, which can ensure real-time favorable performance and robustness. However, the tracking accuracy of the correlation filter tracking algorithms based on traditional manual features must be improved given the limitations of traditional manual features. Therefore, correlation filter tracking algorithms based on convolutional features have been proposed and developed. The correlation filter tracking algorithms based on deep convolutional features can lead to a low tracking speed considering multiple feature dimensions and tracking failure problems when the object is subjected to deformation or occlusion despite a high accuracy of such algorithms. Thus, a real-time tracking algorithm based on adaptive convolutional feature selection is proposed to solve these problems.MethodFirst, the proposed method analyzes the characteristics of convolution features extracted from the convolutional network model trained on the classification data set and selects the multilayer convolution features suitable for object tracking. The method also analyzes the characteristics of localization prediction of correlation filter trackers based on deep convolutional features. Analysis results show that a large average feature ratio between object and search regions indicates an improved convolution operator. Thus, this study proposed the average feature ratio between object and search regions to evaluate the convolution operator of each channel of every convolution layer. Then, the feature selection strategy is applied to select the convolution layer with the most convolution channels whose feature mean ratio is larger than the threshold for each preselected convolution layer. This strategy can effectively reduce the number of layers with convolution features. Simultaneously, the strategy can reduce the dimensions of the selected convolution layer by removing the convolution features that are not larger than the threshold. Then, the correlation filter classifier is trained by extracting the remaining effective convolutional features from the selected layer. The trained classifier is used to predict the position of the object. Finally, a sparse model updating strategy is adopted to prevent overfitting of the correlation filter classifier and improve the tracking speed.ResultThe proposed approach is evaluated on 100 sequences of Object Tracker Benchmark (OTB-100), which mainly contains 11 challenges (e.g., variation, background blusters, low resolution and so on) that may be encountered in object tracking, and compared with 9 other state-of-the-art tracking methods. The selected benchmark, namely, center location error, distance precision, overlap precision, and one-pass evaluation is applied to evaluate the tracking algorithm. The experiments are divided into two parts. The first part analyzes the tracking results of the different pre-selected convolutional layers. This part includes the results of no dimension reduction method, dimension reduction using principal component analysis, and our adaptive feature selection method using the feature mean ratio. The average distance accuracy of our adaptive feature selection method is 86.4%, which is higher than that of other methods. Experimental results show that the method can effectively improve the tracking speed and that it is better than the current trackers which use principal component analysis in reducing feature dimensions. The second part presents the comparison of our method and the existing mainstream object tracking method. These algorithms include the original hierarchical convolutional filter tracking algorithm and other correlation filter tracking algorithms that use convolutional features or traditional manual features. The average distance accuracy of our algorithm is 86.4%, which is 2.7 percent points higher than the original hierarchical convolutional features for visual tracking algorithm. The average success rate in the proposed approach is 68.4%, which is 2.9 percent points higher than the original hierarchical convolutional filter tracking algorithm. The average tracking speed is 29.9 frame/s, which is approximately three times faster than the previous performance. The experimental results show that the adaptive feature selection method can effectively improve the tracking speed while ensuring the tracking accuracy. The overall performance is superior to the nine other state-of-the-art tracking methods in the experiment.ConclusionThe feature mean ratio of the object and search regions is used to evaluate the convolution operator. The convolutional layer with the largest number of convolutional channels that satisfy the feature mean ratio threshold is selected, and the convolutional effective features of the selected convolutional layer are extracted to train the correlation filter classifier. The method not only effectively reduces the number of convolutional layers and the dimensions of the feature but also reduces the complexity of the model to improve the tracking speed by adaptively selecting convolutional channels and layers. In addition, a sparse model update strategy is utilized to further enhance the tracking speed and prevent model drifting. The proposed algorithm has excellent robustness and adaptability under complex scenes, such as occlusion, illumination change, and fast motion.关键词:machine vision;object tracking;deep learning;channel pruning;correlation filter;sparse updating104|0|1更新时间:2024-05-07 -
 摘要:ObjectiveCross-media retrieval aims to retrieve the data of different media types by a query, which can provide flexible and useful retrieval experience with numerous user demands at present. However, a "heterogeneity gap" leads to inconsistent representations of different media types, thus resulting in a challenging construction of correlation and realizing cross-media retrieval between them. However, data from different media types naturally have a semantic consistency, and their patches contain abundant fine-grained information, which provides key clues for cross-media correlation learning. Existing methods mostly consider a pairwise correlation of various media types with the same semantics, but they ignore the context information among the fine-grained patches, which cannot fully capture the cross-media correlation. To address this problem, a cross-media hierarchical recurrent attention network (CHRAN) is proposed to fully consider the intra-and inter-media fine-grained context information.MethodFirst, we propose to construct a hierarchical recurrent network to fully exploit the cross-media fine-grained context information. Specifically, the hierarchical recurrent network consists of two levels, which are implemented by a long short-term memory network. We extract features from the fine-grained patches of different media types and organize them into sequences, which are considered the inputs of the hierarchical network. The bottom level aims to model the intra-media fine-grained context information, whereas the top level adopts a weight-sharing constraint to fully exploit inter-media context correlation, which aims to share the knowledge learned from different media types. Thus, the hierarchical recurrent network can provide intra-and inter-media fine-grained hints for boosting cross-media correlation learning. Second, we propose an attention-based cross-media joint embedding loss to learn a cross-media correlation. We utilize an attention mechanism to allow the models to focus on the necessary fine-grained patches within various media types, thereby allowing the inter-media co-attention to be explored. Furthermore, we jointly consider the matched and mismatched cross-media pairs to preserve the relative similarity ranking information. We also adopt a semantic constraint to preserve the semantically discriminative capability during the correlation learning process. Therefore, a precise fine-grained cross-media correlation can be captured to improve retrieval accuracy.ResultWe conduct experiments on two widely-used cross-media datasets, including Wikipedia and Pascal Sentence datasets, which consider 10 state-of-the-art methods for comprehensive comparisons to verify the effectiveness of our proposed CHRAN approach. We perform a cross-media retrieval with two types of retrieval tasks, that is, retrieving text by image and retrieving the image by text, and then we adopt mean average precision (MAP) score as the evaluation metric. We also conduct baseline experiments to verify the contribution of a weight-sharing constraint and cross-media attention modeling. The experimental results show that our proposed approach achieves the optimal MAP scores of 0.469 and 0.575 on two datasets and outperforms the state-of-the-art methods.ConclusionThe proposed approach can effectively learn a fine-grained cross-media correlation precisely. Compared with the existing methods that mainly model the pairwise correlation and ignore the fine-grained context information, our proposed hierarchical recurrent network can fully capture the intra-and inter-media fine-grained context information with a cross-media co-attention mechanism that can further promote the accuracy of cross-media retrieval.关键词:cross-media retrieval;attention mechanism;recurrent network;correlation learning;semantic discrimination12|0|1更新时间:2024-05-07
摘要:ObjectiveCross-media retrieval aims to retrieve the data of different media types by a query, which can provide flexible and useful retrieval experience with numerous user demands at present. However, a "heterogeneity gap" leads to inconsistent representations of different media types, thus resulting in a challenging construction of correlation and realizing cross-media retrieval between them. However, data from different media types naturally have a semantic consistency, and their patches contain abundant fine-grained information, which provides key clues for cross-media correlation learning. Existing methods mostly consider a pairwise correlation of various media types with the same semantics, but they ignore the context information among the fine-grained patches, which cannot fully capture the cross-media correlation. To address this problem, a cross-media hierarchical recurrent attention network (CHRAN) is proposed to fully consider the intra-and inter-media fine-grained context information.MethodFirst, we propose to construct a hierarchical recurrent network to fully exploit the cross-media fine-grained context information. Specifically, the hierarchical recurrent network consists of two levels, which are implemented by a long short-term memory network. We extract features from the fine-grained patches of different media types and organize them into sequences, which are considered the inputs of the hierarchical network. The bottom level aims to model the intra-media fine-grained context information, whereas the top level adopts a weight-sharing constraint to fully exploit inter-media context correlation, which aims to share the knowledge learned from different media types. Thus, the hierarchical recurrent network can provide intra-and inter-media fine-grained hints for boosting cross-media correlation learning. Second, we propose an attention-based cross-media joint embedding loss to learn a cross-media correlation. We utilize an attention mechanism to allow the models to focus on the necessary fine-grained patches within various media types, thereby allowing the inter-media co-attention to be explored. Furthermore, we jointly consider the matched and mismatched cross-media pairs to preserve the relative similarity ranking information. We also adopt a semantic constraint to preserve the semantically discriminative capability during the correlation learning process. Therefore, a precise fine-grained cross-media correlation can be captured to improve retrieval accuracy.ResultWe conduct experiments on two widely-used cross-media datasets, including Wikipedia and Pascal Sentence datasets, which consider 10 state-of-the-art methods for comprehensive comparisons to verify the effectiveness of our proposed CHRAN approach. We perform a cross-media retrieval with two types of retrieval tasks, that is, retrieving text by image and retrieving the image by text, and then we adopt mean average precision (MAP) score as the evaluation metric. We also conduct baseline experiments to verify the contribution of a weight-sharing constraint and cross-media attention modeling. The experimental results show that our proposed approach achieves the optimal MAP scores of 0.469 and 0.575 on two datasets and outperforms the state-of-the-art methods.ConclusionThe proposed approach can effectively learn a fine-grained cross-media correlation precisely. Compared with the existing methods that mainly model the pairwise correlation and ignore the fine-grained context information, our proposed hierarchical recurrent network can fully capture the intra-and inter-media fine-grained context information with a cross-media co-attention mechanism that can further promote the accuracy of cross-media retrieval.关键词:cross-media retrieval;attention mechanism;recurrent network;correlation learning;semantic discrimination12|0|1更新时间:2024-05-07 -
 摘要:ObjectiveAn increasing number of underwater image enhancement methods have been put into practical applications because underwater images typically have quality degradation problems, such as blurring, distortion, and low visibility. At present, each quality evaluation criterion mainly focuses on the single image. Existing methods adopt the average quality score of a quality evaluation criterion as an indicator, and the enhancement algorithm is evaluated by the average score. However, the non-consistent average quality score changes with the image set and produces large fluctuations. If an enhancement algorithm cannot consistently improve the image quality score in a small-scale image set, then the average quality score has certain limitations and large error when the enhancement algorithm is applied to a large-scale image set. To solve the abovementioned problems, a universal underwater image quality assessment method, namely, consistent enhancement quality assessment (CEQA) for an underwater image set, is proposed.MethodThe proposed method can judge the consistency of the enhancement algorithm by comparing the difference of the quality score before and after image enhancement and by changing the weight proportion of the selected quality score difference, unifying the fractional system, and calculating the CEQA fraction of the enhanced image set. The concrete steps of this proposed method are as follows:1) An image set ({
摘要:ObjectiveAn increasing number of underwater image enhancement methods have been put into practical applications because underwater images typically have quality degradation problems, such as blurring, distortion, and low visibility. At present, each quality evaluation criterion mainly focuses on the single image. Existing methods adopt the average quality score of a quality evaluation criterion as an indicator, and the enhancement algorithm is evaluated by the average score. However, the non-consistent average quality score changes with the image set and produces large fluctuations. If an enhancement algorithm cannot consistently improve the image quality score in a small-scale image set, then the average quality score has certain limitations and large error when the enhancement algorithm is applied to a large-scale image set. To solve the abovementioned problems, a universal underwater image quality assessment method, namely, consistent enhancement quality assessment (CEQA) for an underwater image set, is proposed.MethodThe proposed method can judge the consistency of the enhancement algorithm by comparing the difference of the quality score before and after image enhancement and by changing the weight proportion of the selected quality score difference, unifying the fractional system, and calculating the CEQA fraction of the enhanced image set. The concrete steps of this proposed method are as follows:1) An image set ({$ {{I}_{1}},\; {{I}_{2}}, \;{{I}_{3}}, \;\cdots , \;{{I}_{n}}$ $ n$ $ I_1$ $ {{\alpha }_{1}}$ $ I_1$ $ I_1$ $ {{{{I}'}}_{1}}$ $ {{{{I}'}}_{1}}$ $ {{\beta }_{1}}$ $ {{\beta }_{1}}$ $ {{\alpha }_{1}}$ $ Q_1$ $ I_2$ $ I_3$ $ I_n$ $ {{Q}_{2}},\; {{Q}_{3}},\; \cdots ,\; {{Q}_{n}}$ $ {{Q}_{1}},\; {{Q}_{2}},\; \cdots , \;{{Q}_{n}}$ $ {{Q}_{1}}, \;{{Q}_{2}}, \;\cdots , \;{{Q}_{n}}$ $ Q_{\rm max}$ $ Q_{\rm min}$ $ {{Q}_{1}},\; {{Q}_{2}}, \;\cdots , \;{{Q}_{n}}$ $ Q_{\rm ave}$ $ C_{\rm eff}$ $ Q_{\rm ave}$ $ Q_{\rm min}$ $ {{{\rm A}}_{1}},\; {{{\rm A}}_{2}},\; \cdots ,\; {{{\rm A}}_{m}}$ $ m$ $ Q_{\rm ave}$ $ C_{\rm eff}$ $ Q_{\rm ave}$ $ C_{\rm eff}$ 关键词:image set;consistent enhancement;image quality;image enhancement;quality assessment17|0|0更新时间:2024-05-07 -
 摘要:ObjectiveInfrared dim and small target detection is a research interest in the field of infrared image processing, which is difficult but practical. It plays a crucial role in reconnaissance and warning, aircraft tracking, and missile guidance systems. The process of detecting infrared small targets in natural scenes is characterized by the fact that the target area can frequently be expressed as a small, uniform, compact area with a significant discontinuity or contrast compared with the surrounding background. The detection of a small target in an infrared image is affected by many factors, such as the small number of target pixels, low contrast between a target and a background, dim edges of the targets, complex image background, and lack of texture information of the small targets, thereby resulting in the difficulty of infrared small target detections. The existing methods have achieved effective results in detecting small targets in infrared images; however, drawbacks, such as low adaptability to complex background, low detection rate, and high false alarm rate, still remain. In addition, methods related to sparse representation have the following shortcomings:the construction of a dictionary directly from the original images ignores the feature extraction of the target, or does not establish the target and the background dictionaries simultaneously, thus resulting in a weak representation capability of the entire dictionary. Thus, an infrared small target detection algorithm that combines facet directional derivative features with sparse representation is proposed.MethodA dictionary must initially be constructed. A background dictionary is constructed by intercepting 1 000 small blocks and then obtaining their derivatives in a certain direction. K-SVD algorithm is used to train the blocks after merging them into column vectors. A background dictionary with 500 atoms is achieved. The construction method of the target dictionary is as follows:325 small blocks containing small targets are generated in accordance with the characteristics of the small target. The first-order derivative in one direction is calculated for these small blocks containing small targets, and then the columns are converted into column vectors. The target dictionary containing 325 atoms is obtained in that direction after normalizing. We combine the target and the background dictionaries into one large dictionary with 825 atoms, which will be used in the subsequent sparse solution section. The facet model is utilized to extract the first-order derivative features of the original infrared image in four directions, that is 0°, 90°, 45°, and -45°. Then, the blocks separated from the image are processed from top to bottom and left to right on the basis of the directional derivative information through the sparse representation method. The detection result map is constructed using the sparse coefficients and reconstruction residuals of the derivative image blocks. Finally, a threshold is calculated from the detection result map to separate the target from the background.ResultThe classical max-mean and max-median algorithms are selected as the algorithms for comparison. Comparative results show that the max-mean and max-median algorithms are sensitive to the edges in the infrared image. The traditional algorithms perform ineffectively in removing these clusters when the infrared image has clusters due to distance, atmospheric refraction, lens aberration, and optical defocus. A 3D image of the detection result shows that our method has better performance, is insensitive to noise, and can achieve an excellent target detection effect. Therefore, our algorithm has certain advantages over the traditional algorithms. Receiver operating characteristic (ROC) curves of detection and false alarm rates are plotted through experimental verification of four infrared image sequences. The results evidently show that the proposed algorithm has a higher detection rate and lower false alarm rate in a small target detection than other algorithms.ConclusionOur algorithm extracts image directional derivative information through the facet model, combines the directional derivative features of infrared imagery with sparse representation theory, analyzes the characteristics of the small target in a single direction in detail, and extends it to feature information presented in multiple directions. The difference between the target and the background is discussed. The final test results of the small target are obtained using sparse representation theory as a medium. Experiments show that the proposed algorithm has a high detection accuracy and strong anti-noise capability. The proposed algorithm has certain advantages, improves detection rate, and reduces false alarm rate over the traditional detection algorithms. Another important advantage of our algorithm is that it can generate different background dictionaries in accordance with a certain background under different conditions to obtain improved detection results and perform an effective pertinence in practical applications.关键词:infrared image;object detection;small target;directional derivative;sparse representation22|0|3更新时间:2024-05-07
摘要:ObjectiveInfrared dim and small target detection is a research interest in the field of infrared image processing, which is difficult but practical. It plays a crucial role in reconnaissance and warning, aircraft tracking, and missile guidance systems. The process of detecting infrared small targets in natural scenes is characterized by the fact that the target area can frequently be expressed as a small, uniform, compact area with a significant discontinuity or contrast compared with the surrounding background. The detection of a small target in an infrared image is affected by many factors, such as the small number of target pixels, low contrast between a target and a background, dim edges of the targets, complex image background, and lack of texture information of the small targets, thereby resulting in the difficulty of infrared small target detections. The existing methods have achieved effective results in detecting small targets in infrared images; however, drawbacks, such as low adaptability to complex background, low detection rate, and high false alarm rate, still remain. In addition, methods related to sparse representation have the following shortcomings:the construction of a dictionary directly from the original images ignores the feature extraction of the target, or does not establish the target and the background dictionaries simultaneously, thus resulting in a weak representation capability of the entire dictionary. Thus, an infrared small target detection algorithm that combines facet directional derivative features with sparse representation is proposed.MethodA dictionary must initially be constructed. A background dictionary is constructed by intercepting 1 000 small blocks and then obtaining their derivatives in a certain direction. K-SVD algorithm is used to train the blocks after merging them into column vectors. A background dictionary with 500 atoms is achieved. The construction method of the target dictionary is as follows:325 small blocks containing small targets are generated in accordance with the characteristics of the small target. The first-order derivative in one direction is calculated for these small blocks containing small targets, and then the columns are converted into column vectors. The target dictionary containing 325 atoms is obtained in that direction after normalizing. We combine the target and the background dictionaries into one large dictionary with 825 atoms, which will be used in the subsequent sparse solution section. The facet model is utilized to extract the first-order derivative features of the original infrared image in four directions, that is 0°, 90°, 45°, and -45°. Then, the blocks separated from the image are processed from top to bottom and left to right on the basis of the directional derivative information through the sparse representation method. The detection result map is constructed using the sparse coefficients and reconstruction residuals of the derivative image blocks. Finally, a threshold is calculated from the detection result map to separate the target from the background.ResultThe classical max-mean and max-median algorithms are selected as the algorithms for comparison. Comparative results show that the max-mean and max-median algorithms are sensitive to the edges in the infrared image. The traditional algorithms perform ineffectively in removing these clusters when the infrared image has clusters due to distance, atmospheric refraction, lens aberration, and optical defocus. A 3D image of the detection result shows that our method has better performance, is insensitive to noise, and can achieve an excellent target detection effect. Therefore, our algorithm has certain advantages over the traditional algorithms. Receiver operating characteristic (ROC) curves of detection and false alarm rates are plotted through experimental verification of four infrared image sequences. The results evidently show that the proposed algorithm has a higher detection rate and lower false alarm rate in a small target detection than other algorithms.ConclusionOur algorithm extracts image directional derivative information through the facet model, combines the directional derivative features of infrared imagery with sparse representation theory, analyzes the characteristics of the small target in a single direction in detail, and extends it to feature information presented in multiple directions. The difference between the target and the background is discussed. The final test results of the small target are obtained using sparse representation theory as a medium. Experiments show that the proposed algorithm has a high detection accuracy and strong anti-noise capability. The proposed algorithm has certain advantages, improves detection rate, and reduces false alarm rate over the traditional detection algorithms. Another important advantage of our algorithm is that it can generate different background dictionaries in accordance with a certain background under different conditions to obtain improved detection results and perform an effective pertinence in practical applications.关键词:infrared image;object detection;small target;directional derivative;sparse representation22|0|3更新时间:2024-05-07
Column of NCIG'2018
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0