
最新刊期
卷 23 , 期 10 , 2018
-
 摘要:ObjectiveThe appearance of generative adversarial networks (GANs) provides a new approach and a framework for the application of computer vision.GAN generates high-quality samples with unique zero-sum game and adversarial training concepts, and therefore more powerful in both feature learning and representation than traditional machine learning algorithms.Remarkable achievements have been realized in the field of computer vision, especially in sample generation, which is one of the popular topics in current research.MethodThe research and application of different GAN models based on computer vision are reviewed based on the extensive research and the latest achievements of relevant literature.The typical GAN network methods are introduced, categorized, and compared in experiments by using generation samples to present their performance and summarized the research status and development trends in computer vision fields, such as high-quality image generation, style transfer and image translation, text-image mutual generation, image inpainting, and restoration.Finally, existing major research problems are summarized and discussed, and potential future research directions are presented.ResultSince the emergence of GAN, many variations have been proposed for different fields, either structural improvement or development of theory or innovation in applications.Different GAN models have advantages and disadvantages in terms of generating examples, have significant achievements in many fields, especially the computer vision, and can generate examples such as the real ones.However, they also have unique problems, such as non-convergence, model collapse, and uncontrollability due to high degree-of-freedom.Priori hypotheses about the data in the original GAN, whose final goals are to realize infinite modeling power and fit for all distributions, hardly exits.In addition, the designs of GAN models are simple.A complex function model need not be pre-designed, and the generator and the discriminator can work normally with the back propagation algorithm.Moreover, GAN can use a machine to interact with other machines through continuous confrontation and learn the inherent laws in the real world with sufficient data training.Each aspect has two sides, and a series of problems are hidden behind the goal of infinite modeling.The generation process is extremely flexible that the stability and convergence of the training process cannot be guaranteed.Model collapse will likely occur and further training cannot be achieved.The original GAN has the following problems:disappearance of gradients, training difficulties, the losses of generator and discriminator cannot indicate the training process, the lack of diversities in the generated samples, and easy over-fitting.Discrete distributions are also difficult to generate due to the limitations of GAN.Many researchers have proposed new ways to address these problems, and several landmark models, such as DCGAN, CGAN, WGAN, WGAN-GP, EBGAN, BEGAN, InfoGAN, and LSGAN, have been introduced.DCGAN combines GAN with CNN and performs well in the field of computer vision.Furthermore, DCGAN sets a series of limitations for the CNN network so it can be trained stably and use the learned feature representation for sample generation and image classification.CGAN inputs the conditional variable (c) with the random variable (z) and the real data (x) to guide the data generation process.The conditional variable (c) can be category labels, texts, and generated targets.The straightforward improvement proves to be extremely effective and has been widely used in subsequent work.WGAN uses the Wasserstein distance to measure the distance between the real and generated samples instead of the JS divergence.The Wasserstein distance has the following advantages.It can measure distance even if the two distributions do not overlap, has excellent smoothing properties, and can solve the gradients disappearance problem to some degrees.In addition, WGAN solves the problems of instability in training, diversifies the generated examples, and does not require the careful balancing of the training of G and D.WGAN-GP replaces the weight pruning in WGAN to implement the Lipschitz constraint method.Experiments show that the quality of samples generated by WGAN-GP is higher than those of WGAN.It also provides stable training without hyperparameters and successfully trains various generating tasks.However, the convergence speed of WGAN-GP is slower, that is, it takes more time to converge under the same dataset.The EBGAN interprets GAN from the perspective of energy.It can learn the probability distributions of images with low convergence speed.The images BEGAN products are still disorganized, whereas other models have been able to express the outline of the objects roughly.However, the images generated by BEGAN have the sharpest edges and rich image diversities in the experiments.The discriminator of BEGAN draws lessons from EBGAN, and the loss of generator refers to the loss of WGAN.It also proposes a hyper parameter that can measure the diversity of generated samples to balance D and G and stabilize the training process.The internal texture of the generated images of InfoGAN is poor, and the shape of the generated objects is the same.As for the generator, in addition to the input noise (z), a controllable variable (c) is added, which contains interpretable information about the data to control the generative results, resulting in poor diversity.LSGAN can generate high quality examples because the object function of least squares loss replaces the cross-entropy loss, which partly solves the two shortcomings (i.e., low-quality and instability of training process).ConclusionGAN has significant theoretical and practical values as a new generative model.It provides a good solution to problems of insufficient sample, poor quality of generation, and difficulties in extracting features.GAN is an inclusive framework that can be combined with most deep learning algorithms to solve problems that traditional machine learning algorithms cannot solve.However, it has theoretical problems that must be solved urgently.How to generate high-quality examples and a realistic scene is worth studying.Further GAN developments are predicted in the following areas:breakthrough of theory, development of algorithm, system of evaluation, system of specialism, and combination of industry.关键词:generative adversarial networks;computer vision;image generation;style transfer;image inpainting14|18|26更新时间:2024-05-07
摘要:ObjectiveThe appearance of generative adversarial networks (GANs) provides a new approach and a framework for the application of computer vision.GAN generates high-quality samples with unique zero-sum game and adversarial training concepts, and therefore more powerful in both feature learning and representation than traditional machine learning algorithms.Remarkable achievements have been realized in the field of computer vision, especially in sample generation, which is one of the popular topics in current research.MethodThe research and application of different GAN models based on computer vision are reviewed based on the extensive research and the latest achievements of relevant literature.The typical GAN network methods are introduced, categorized, and compared in experiments by using generation samples to present their performance and summarized the research status and development trends in computer vision fields, such as high-quality image generation, style transfer and image translation, text-image mutual generation, image inpainting, and restoration.Finally, existing major research problems are summarized and discussed, and potential future research directions are presented.ResultSince the emergence of GAN, many variations have been proposed for different fields, either structural improvement or development of theory or innovation in applications.Different GAN models have advantages and disadvantages in terms of generating examples, have significant achievements in many fields, especially the computer vision, and can generate examples such as the real ones.However, they also have unique problems, such as non-convergence, model collapse, and uncontrollability due to high degree-of-freedom.Priori hypotheses about the data in the original GAN, whose final goals are to realize infinite modeling power and fit for all distributions, hardly exits.In addition, the designs of GAN models are simple.A complex function model need not be pre-designed, and the generator and the discriminator can work normally with the back propagation algorithm.Moreover, GAN can use a machine to interact with other machines through continuous confrontation and learn the inherent laws in the real world with sufficient data training.Each aspect has two sides, and a series of problems are hidden behind the goal of infinite modeling.The generation process is extremely flexible that the stability and convergence of the training process cannot be guaranteed.Model collapse will likely occur and further training cannot be achieved.The original GAN has the following problems:disappearance of gradients, training difficulties, the losses of generator and discriminator cannot indicate the training process, the lack of diversities in the generated samples, and easy over-fitting.Discrete distributions are also difficult to generate due to the limitations of GAN.Many researchers have proposed new ways to address these problems, and several landmark models, such as DCGAN, CGAN, WGAN, WGAN-GP, EBGAN, BEGAN, InfoGAN, and LSGAN, have been introduced.DCGAN combines GAN with CNN and performs well in the field of computer vision.Furthermore, DCGAN sets a series of limitations for the CNN network so it can be trained stably and use the learned feature representation for sample generation and image classification.CGAN inputs the conditional variable (c) with the random variable (z) and the real data (x) to guide the data generation process.The conditional variable (c) can be category labels, texts, and generated targets.The straightforward improvement proves to be extremely effective and has been widely used in subsequent work.WGAN uses the Wasserstein distance to measure the distance between the real and generated samples instead of the JS divergence.The Wasserstein distance has the following advantages.It can measure distance even if the two distributions do not overlap, has excellent smoothing properties, and can solve the gradients disappearance problem to some degrees.In addition, WGAN solves the problems of instability in training, diversifies the generated examples, and does not require the careful balancing of the training of G and D.WGAN-GP replaces the weight pruning in WGAN to implement the Lipschitz constraint method.Experiments show that the quality of samples generated by WGAN-GP is higher than those of WGAN.It also provides stable training without hyperparameters and successfully trains various generating tasks.However, the convergence speed of WGAN-GP is slower, that is, it takes more time to converge under the same dataset.The EBGAN interprets GAN from the perspective of energy.It can learn the probability distributions of images with low convergence speed.The images BEGAN products are still disorganized, whereas other models have been able to express the outline of the objects roughly.However, the images generated by BEGAN have the sharpest edges and rich image diversities in the experiments.The discriminator of BEGAN draws lessons from EBGAN, and the loss of generator refers to the loss of WGAN.It also proposes a hyper parameter that can measure the diversity of generated samples to balance D and G and stabilize the training process.The internal texture of the generated images of InfoGAN is poor, and the shape of the generated objects is the same.As for the generator, in addition to the input noise (z), a controllable variable (c) is added, which contains interpretable information about the data to control the generative results, resulting in poor diversity.LSGAN can generate high quality examples because the object function of least squares loss replaces the cross-entropy loss, which partly solves the two shortcomings (i.e., low-quality and instability of training process).ConclusionGAN has significant theoretical and practical values as a new generative model.It provides a good solution to problems of insufficient sample, poor quality of generation, and difficulties in extracting features.GAN is an inclusive framework that can be combined with most deep learning algorithms to solve problems that traditional machine learning algorithms cannot solve.However, it has theoretical problems that must be solved urgently.How to generate high-quality examples and a realistic scene is worth studying.Further GAN developments are predicted in the following areas:breakthrough of theory, development of algorithm, system of evaluation, system of specialism, and combination of industry.关键词:generative adversarial networks;computer vision;image generation;style transfer;image inpainting14|18|26更新时间:2024-05-07 -
 摘要:ObjectivePulmonary disorder has high morbidity and mortality world-wide according to the reports by the World Health Organization.Some common pulmonary disorders include lung nodule and cancer, interstitial lung disease, chronic obstructive pulmonary disease, bronchiectasis, and pulmonary embolism.The disorders are typically characterized by long-term poor breath quality, irregular blood supply, and obstructive airflow and circulation.Pulmonary disorders bring not only enormous societal financial burden but also physical and mental suffering to patients.Thus, the recognition and comprehension of the disorders are widely considered the most basic and crucial medical tasks.High-resolution multi-slice computed tomography (CT) has received significant attention from pulmonologists and radiologists due to its allowance of investigating pulmonary anatomic function, assessing physiological conditions, and detecting and diagnosing pulmonary disorders.Hundreds of isotropic thin slices that are reconstructed real time from a single spiral CT scan can realize objective, repeatable, and non-invasive clinical inspections unlike traditional tools, especially in the early disease stage.However, the manual delineation, measurement, and evaluation of volumetric scans are extremely time-consuming and entail intensively laborious work load for clinicians.Therefore, the biomedical engineering community aims to develop semi-automated and fully automated segmentations in CT images through voxel-by-voxel labeling by using computer software to separate sub-divided pulmonary anatomic structures from one another.In the presence of unique inter-and intra-anatomy relationships and the impact of imaging defects, abnormalities, or other interference factors, classical image processing methods suffer from performance limitations.The anatomic CT visibility is attenuated and the morphology is deformed spatially and pathologically, which affect the segmentation results negatively.Several studies, usually incorporating traditional work and carefully defined processing rules, that focus on thoracic CT images have been employed.MethodIn this paper, a systematic review of anatomic segmentation methods for pulmonary tissues, airways, vasculatures, fissures, and lobes is presented by tracking and summarizing the representative or up-to-date published literature.In addition, several attractive practices and extractions of sub-divided or related structures, derived from segmented anatomic results, are also attached to corresponding anatomic subsections.They include the segmentation of adhesive, pleura nodular, and interstitial diseased lungs; the centerline extraction of airways and vasculatures; airway wall quantification and segmentation; pulmonary artery and vein separation; and pulmonary segment approximation.Moreover, for all the referred segmentation methods, the full implementation pipeline, background image processing methodology, and key techniques are presented to elaborate the result performance.Analogous methods are further classified on the basis of their designed frameworks or mathematical theories, and the merits and demerits of each method type are analyzed at the end of the classification content.In general, evaluating segmentations and comparing with other work are tedious for researchers mainly because of the difficulty in obtaining the ground truth.LOLA11, EXACT09, and VESSEL12 are three of the public and authoritative MICCAI grand challenges in chest image analysis.They are introduced for result comparisons in the directions of pulmonary tissue and lobe, airway, and vasculature.The complete procedure renders it difficult for the owners to construct their reference repository and quantify the submission performance.The reported standard generation approaches to other anatomic-based applications are illuminated in parallel.The evaluated indices contain the anatomic boundary alignment and volume overlap and the trade-off between true and false positive detection.Subsequently, the experimental validation approaches are explained based on the reference standard and indices.The qualitative and quantitative results of different methods are shown specifically with the description of the test datasets.ResultOn the basis of the individual anatomic topic, the existing challenges of state-of-the-art studies are presented in detail, highlighting the accuracy performance in true positive detection and false positive removal and the robustness performance against the diversity of CT scanners, imaging protocols, and the appearance of various abnormalities.A set of practical problems, such as lesion location, qualitative and quantitative anatomic measurement, and sequential component segmentation, are also discussed in the paper.Besides deep learning algorithms, convolutional neural network-based algorithms have rapidly become a preference of medical imaging institutions.At present, two mature chest CT imaging fields exist, namely, nodule detection and malignancy prediction in lung cancer screening and interstitial lung disease type classification.The major deep learning-based efforts are surveyed in terms of their contribution to pulmonary tissue bounding box localization and pulmonary airway segmentation and leakage removal, most of which were proposed in the recent two years.The improvements are compared with previous methods.In terms of the frontier requirements from scientific groups, industrial units, and pulmonology domains, future work trends and open issues are listed pertinent to methodology and post-processing steps along with the applications, such as the identification of pulmonary lesion sites and the subsequent task of anatomic segmentation.The parameters of anatomic measurement are of vital importance in characterizing the progress and severity of pulmonary disorders.Thus, several possible innovative points to achieve these biomarkers are also recommended.ConclusionTheoretical studies and clinical practices will benefit from implementing accurate, fast, and robust pulmonary anatomic segmentation from large amounts of CT images.The transfer or modification of successful pulmonary segmentation methodologies will facilitate the segmentation of other tissues, organs, and multi-modality images.Inter-and intra-structure measurements and the relationship mapping information obtained, ranging from global to local analyses, can provide objective and effective evidence for computer-aided pulmonary disease detection and diagnosis.The 2D transversal or 3D visualization of these points can present intuitive, legible, and proportional views of the anatomic structures with the help of volume rendering techniques and grayscale Dicom slices overlaid by chromatic tissue marks.The contribution of these aspects reduces the labor requirement from pulmonologists and radiologists, thereby increasing their efficiency significantly.Although deep learning algorithms are relatively immature and require improvement in terms of segmentation time cost and refinement steps, they have considerable potential and are worth studying for pulmonary segmentation areas, which are predicted to dominate the field in the coming years.关键词:CT images;pulmonary segmentation;pulmonary airway segmentation;pulmonary vasculature segmentation;pulmonary lobe segmentation22|19|2更新时间:2024-05-07
摘要:ObjectivePulmonary disorder has high morbidity and mortality world-wide according to the reports by the World Health Organization.Some common pulmonary disorders include lung nodule and cancer, interstitial lung disease, chronic obstructive pulmonary disease, bronchiectasis, and pulmonary embolism.The disorders are typically characterized by long-term poor breath quality, irregular blood supply, and obstructive airflow and circulation.Pulmonary disorders bring not only enormous societal financial burden but also physical and mental suffering to patients.Thus, the recognition and comprehension of the disorders are widely considered the most basic and crucial medical tasks.High-resolution multi-slice computed tomography (CT) has received significant attention from pulmonologists and radiologists due to its allowance of investigating pulmonary anatomic function, assessing physiological conditions, and detecting and diagnosing pulmonary disorders.Hundreds of isotropic thin slices that are reconstructed real time from a single spiral CT scan can realize objective, repeatable, and non-invasive clinical inspections unlike traditional tools, especially in the early disease stage.However, the manual delineation, measurement, and evaluation of volumetric scans are extremely time-consuming and entail intensively laborious work load for clinicians.Therefore, the biomedical engineering community aims to develop semi-automated and fully automated segmentations in CT images through voxel-by-voxel labeling by using computer software to separate sub-divided pulmonary anatomic structures from one another.In the presence of unique inter-and intra-anatomy relationships and the impact of imaging defects, abnormalities, or other interference factors, classical image processing methods suffer from performance limitations.The anatomic CT visibility is attenuated and the morphology is deformed spatially and pathologically, which affect the segmentation results negatively.Several studies, usually incorporating traditional work and carefully defined processing rules, that focus on thoracic CT images have been employed.MethodIn this paper, a systematic review of anatomic segmentation methods for pulmonary tissues, airways, vasculatures, fissures, and lobes is presented by tracking and summarizing the representative or up-to-date published literature.In addition, several attractive practices and extractions of sub-divided or related structures, derived from segmented anatomic results, are also attached to corresponding anatomic subsections.They include the segmentation of adhesive, pleura nodular, and interstitial diseased lungs; the centerline extraction of airways and vasculatures; airway wall quantification and segmentation; pulmonary artery and vein separation; and pulmonary segment approximation.Moreover, for all the referred segmentation methods, the full implementation pipeline, background image processing methodology, and key techniques are presented to elaborate the result performance.Analogous methods are further classified on the basis of their designed frameworks or mathematical theories, and the merits and demerits of each method type are analyzed at the end of the classification content.In general, evaluating segmentations and comparing with other work are tedious for researchers mainly because of the difficulty in obtaining the ground truth.LOLA11, EXACT09, and VESSEL12 are three of the public and authoritative MICCAI grand challenges in chest image analysis.They are introduced for result comparisons in the directions of pulmonary tissue and lobe, airway, and vasculature.The complete procedure renders it difficult for the owners to construct their reference repository and quantify the submission performance.The reported standard generation approaches to other anatomic-based applications are illuminated in parallel.The evaluated indices contain the anatomic boundary alignment and volume overlap and the trade-off between true and false positive detection.Subsequently, the experimental validation approaches are explained based on the reference standard and indices.The qualitative and quantitative results of different methods are shown specifically with the description of the test datasets.ResultOn the basis of the individual anatomic topic, the existing challenges of state-of-the-art studies are presented in detail, highlighting the accuracy performance in true positive detection and false positive removal and the robustness performance against the diversity of CT scanners, imaging protocols, and the appearance of various abnormalities.A set of practical problems, such as lesion location, qualitative and quantitative anatomic measurement, and sequential component segmentation, are also discussed in the paper.Besides deep learning algorithms, convolutional neural network-based algorithms have rapidly become a preference of medical imaging institutions.At present, two mature chest CT imaging fields exist, namely, nodule detection and malignancy prediction in lung cancer screening and interstitial lung disease type classification.The major deep learning-based efforts are surveyed in terms of their contribution to pulmonary tissue bounding box localization and pulmonary airway segmentation and leakage removal, most of which were proposed in the recent two years.The improvements are compared with previous methods.In terms of the frontier requirements from scientific groups, industrial units, and pulmonology domains, future work trends and open issues are listed pertinent to methodology and post-processing steps along with the applications, such as the identification of pulmonary lesion sites and the subsequent task of anatomic segmentation.The parameters of anatomic measurement are of vital importance in characterizing the progress and severity of pulmonary disorders.Thus, several possible innovative points to achieve these biomarkers are also recommended.ConclusionTheoretical studies and clinical practices will benefit from implementing accurate, fast, and robust pulmonary anatomic segmentation from large amounts of CT images.The transfer or modification of successful pulmonary segmentation methodologies will facilitate the segmentation of other tissues, organs, and multi-modality images.Inter-and intra-structure measurements and the relationship mapping information obtained, ranging from global to local analyses, can provide objective and effective evidence for computer-aided pulmonary disease detection and diagnosis.The 2D transversal or 3D visualization of these points can present intuitive, legible, and proportional views of the anatomic structures with the help of volume rendering techniques and grayscale Dicom slices overlaid by chromatic tissue marks.The contribution of these aspects reduces the labor requirement from pulmonologists and radiologists, thereby increasing their efficiency significantly.Although deep learning algorithms are relatively immature and require improvement in terms of segmentation time cost and refinement steps, they have considerable potential and are worth studying for pulmonary segmentation areas, which are predicted to dominate the field in the coming years.关键词:CT images;pulmonary segmentation;pulmonary airway segmentation;pulmonary vasculature segmentation;pulmonary lobe segmentation22|19|2更新时间:2024-05-07
Review

-
 摘要:ObjectiveImage steganalysis is the opposite technology of steganography; it aims to detect, extract, restore, and destroy secret messages embedded in cover images.As an important technical tool for image information security, image steganalysis has become popular in multimedia information security to researchers all over the world.The basic concept of the current image steganalysis is to analyze the embedding mechanism and the statistical changes in image data caused by embedding secret messages.Images steganalysis overcomes the binary classification problem by using the cover and stego images of two image categories.The performance of steganalysis methods depends on feature extraction, and steganalysis features are expected to have small within-class scatter distances and big between-class scatter distances.However, embedded changes are not only correlated with steganography methods but also with image content and local statistical characteristics.The changes in steganalysis features caused by secret embedding are subtle, especially when the embedding ratio is low.The contents and statistical characteristics of images have a stronger impact on the distribution of steganalysis features than the embedding process.Thus, the steganalysis features of cover and stego images are inseparable, a scenario that can be attributed to the differences in image statistical characteristics.Consequently, image steganalysis becomes a classification problem with large within-class and small between-class scatter distances.To solve this problem, a new steganalysis framework for JPEG images, which aims to reduce the within-class scatter distances, is proposed.MethodThe secret messages after embedding will have different effects on the characteristics of images with different content complexities, while the steganalysis features of the images with the same content complexity are similar.This study on image steganalysis focuses on reducing the differences of image statistical characteristics caused by various contents and processing methods.The motivation of the new model is introduced by analyzing the Fisher linear discriminant analysis, which is the basis of the ensemble classifier, the most used one in steganalysis applications, and a new steganalysis model of JPEG images based on image classification and segmentation is proposed.We define a content complexity evaluation feature for each image, and the given images are first classified according to the content.Thus, the images classified to the same sub-class will have a closer content complexity.Then, each image is segmented to several sub-images according to the evaluated texture features and the complexity of each sub-block.During segmentation, we first categorize the image blocks according to texture complexity, and then amalgamate the adjacent block categories.After the combined classification and segmentation process, the content texture of the same class of image regions is more similar, and the steganalysis features are more centralized.The steganalysis features are extracted separately from each subset with the same or close texture complexity to build a classifier.When deciding which steganalysis feature set to extract, we mainly consider the performance.In our prior work, we found that when extracting a steganalysis feature set with low dimension, the performance of the method based on classification or segmentation can be obviously improved.However, when extracting high-dimensional steganalysis features, such as JPEG rich model (JRM), the performance is unsatisfactory because the rich model is based on the residual of the given image, and it can eliminate the effect of image content.The JRM feature set is sensitive to subtle image details, and the steganalysis result is good.However, we still extract the JRM feature set, which is the most representative high-dimensional feature set in the JPEG domain, to prove the validity of the proposed model.In the testing phase, the steganalysis features of each segmented sub-image in each sub-class are sent to the corresponding classifier.The final steganalysis result is obtained through the weighted fusing process.ResultIn the experiment, we compute two kinds of separability criteria of the tested steganalysis feature set, including the separability criterion based on the within-and between-class distances and the Bhattacharyya distances.The Bhattacharyya distance is one of the most used separability criteria on the basis of the probability density of classified samples.Both separability criteria of the proposed method are obviously improved, which means that the proposed classified and segmentation-based steganalysis features can be more easily categorized, thereby verifying the validity of the proposed steganalysis model.We also compare the classification performance of the proposed method and the prior work in various experimental circumstances, including the use of the same and different training and testing image databases.We compute the detection results for the original feature set, the features extracted from the classified image and the segmented image, and the image combined classification and segmentation.Experimental results show that in both circumstances, the combined classification and segmentation process can effectively improve the performance by up to 10%.The improvement considerably higher when the training and testing images have different statistical features, which implies that the proposed method is suitable for practical application on images from the Internet with considerable diversity in sources, processing methods, and contents.ConclusionIn this paper, a new steganalysis model for JPEG images is proposed.The differences in image statistical characteristics caused by various contents and processing methods are reduced by image classification and segmentation.The JRM feature set was extracted.The theoretical analysis of and the experimental results for several diverse image databases and circumstances demonstrate the validity of the framework.When a considerable diversity in image sources and contents exists, such as different training and testing images, the performance improvement of the proposed method is obvious, indicating that the performance of the proposed method does not depending highly on image content.Furthermore, the proposed steganalysis model is suitable for practical application in complex network environments.关键词:steganalysis;image statistical characteristics;image classification;image segmentation;weighted fusing23|91|2更新时间:2024-05-07
摘要:ObjectiveImage steganalysis is the opposite technology of steganography; it aims to detect, extract, restore, and destroy secret messages embedded in cover images.As an important technical tool for image information security, image steganalysis has become popular in multimedia information security to researchers all over the world.The basic concept of the current image steganalysis is to analyze the embedding mechanism and the statistical changes in image data caused by embedding secret messages.Images steganalysis overcomes the binary classification problem by using the cover and stego images of two image categories.The performance of steganalysis methods depends on feature extraction, and steganalysis features are expected to have small within-class scatter distances and big between-class scatter distances.However, embedded changes are not only correlated with steganography methods but also with image content and local statistical characteristics.The changes in steganalysis features caused by secret embedding are subtle, especially when the embedding ratio is low.The contents and statistical characteristics of images have a stronger impact on the distribution of steganalysis features than the embedding process.Thus, the steganalysis features of cover and stego images are inseparable, a scenario that can be attributed to the differences in image statistical characteristics.Consequently, image steganalysis becomes a classification problem with large within-class and small between-class scatter distances.To solve this problem, a new steganalysis framework for JPEG images, which aims to reduce the within-class scatter distances, is proposed.MethodThe secret messages after embedding will have different effects on the characteristics of images with different content complexities, while the steganalysis features of the images with the same content complexity are similar.This study on image steganalysis focuses on reducing the differences of image statistical characteristics caused by various contents and processing methods.The motivation of the new model is introduced by analyzing the Fisher linear discriminant analysis, which is the basis of the ensemble classifier, the most used one in steganalysis applications, and a new steganalysis model of JPEG images based on image classification and segmentation is proposed.We define a content complexity evaluation feature for each image, and the given images are first classified according to the content.Thus, the images classified to the same sub-class will have a closer content complexity.Then, each image is segmented to several sub-images according to the evaluated texture features and the complexity of each sub-block.During segmentation, we first categorize the image blocks according to texture complexity, and then amalgamate the adjacent block categories.After the combined classification and segmentation process, the content texture of the same class of image regions is more similar, and the steganalysis features are more centralized.The steganalysis features are extracted separately from each subset with the same or close texture complexity to build a classifier.When deciding which steganalysis feature set to extract, we mainly consider the performance.In our prior work, we found that when extracting a steganalysis feature set with low dimension, the performance of the method based on classification or segmentation can be obviously improved.However, when extracting high-dimensional steganalysis features, such as JPEG rich model (JRM), the performance is unsatisfactory because the rich model is based on the residual of the given image, and it can eliminate the effect of image content.The JRM feature set is sensitive to subtle image details, and the steganalysis result is good.However, we still extract the JRM feature set, which is the most representative high-dimensional feature set in the JPEG domain, to prove the validity of the proposed model.In the testing phase, the steganalysis features of each segmented sub-image in each sub-class are sent to the corresponding classifier.The final steganalysis result is obtained through the weighted fusing process.ResultIn the experiment, we compute two kinds of separability criteria of the tested steganalysis feature set, including the separability criterion based on the within-and between-class distances and the Bhattacharyya distances.The Bhattacharyya distance is one of the most used separability criteria on the basis of the probability density of classified samples.Both separability criteria of the proposed method are obviously improved, which means that the proposed classified and segmentation-based steganalysis features can be more easily categorized, thereby verifying the validity of the proposed steganalysis model.We also compare the classification performance of the proposed method and the prior work in various experimental circumstances, including the use of the same and different training and testing image databases.We compute the detection results for the original feature set, the features extracted from the classified image and the segmented image, and the image combined classification and segmentation.Experimental results show that in both circumstances, the combined classification and segmentation process can effectively improve the performance by up to 10%.The improvement considerably higher when the training and testing images have different statistical features, which implies that the proposed method is suitable for practical application on images from the Internet with considerable diversity in sources, processing methods, and contents.ConclusionIn this paper, a new steganalysis model for JPEG images is proposed.The differences in image statistical characteristics caused by various contents and processing methods are reduced by image classification and segmentation.The JRM feature set was extracted.The theoretical analysis of and the experimental results for several diverse image databases and circumstances demonstrate the validity of the framework.When a considerable diversity in image sources and contents exists, such as different training and testing images, the performance improvement of the proposed method is obvious, indicating that the performance of the proposed method does not depending highly on image content.Furthermore, the proposed steganalysis model is suitable for practical application in complex network environments.关键词:steganalysis;image statistical characteristics;image classification;image segmentation;weighted fusing23|91|2更新时间:2024-05-07 -
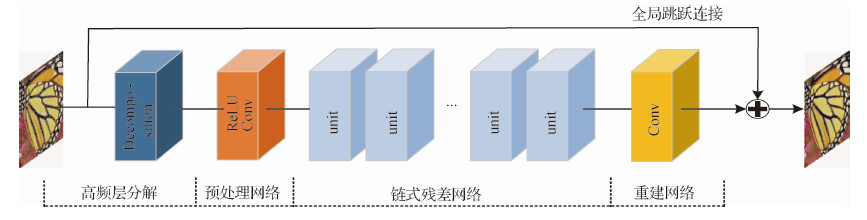 摘要:Objective Image denoising is a classical image reconstruction problem in low-level computer vision.It estimates the latent clean image from a noisy one.Digital images are often affected by the noise caused by imaging equipment and external environment in the process of digitization and transmission.Although several methods have achieved reasonable results in recent years, they rarely mentioned the over-smoothing effects and the loss of edge details.Thus, a novel image denoising method via residual learning based on edge enhancement is proposed.Method Recently, due to its powerful learning ability, very deep convolutional neural network has been widely used for image restoration.Inspired by ResNet, unlike other direct denoising networks, identity mappings are introduced to enable our residual network to increase the depth, and then slightly modify the architecture to adapt better to the denoising task.Pooling layers and batch normalization are removed to preserve details.Instead of these, high-frequency layer decomposition and global skip connection are used to prevent over-fitting.They change the input and output of the network to reduce the solution space.To speed up the training process, we select the rectified linear unit (ReLU) as the activation function and remove it before the convolution layer.Traditionally, image restoration work used the per-pixel loss between the ground truth and the restored image as the optimization target to obtain excellent quantitative scores.However, in recent research, minimizing pixel-wise errors only on the basis of low-level pixels has proven prone to loss of details and smoothens the results.Meanwhile, the perceptual loss function has shown that it can generate high-quality images with a better visual performance by capturing the difference between the high-level feature representations, but it sometimes fails to preserve color and local spatial information.To combine both benefits, we propose a new joint loss function that consists of a normal pixel-to-pixel loss and a perceptual loss with appropriate weights.In summary, the flow of our method is described as follows.First, the high-frequency layer of the noisy image is used as the input by removing the background information.Then, a residual mapping is trained to predict the difference between clean and noisy images as output instead of the final denoised image.The denoised result is improved further, and a joint loss function is defined as the weighted sum of the pixel-to-pixel Euclidean and perceptual losses.A well-trained convolutional neural network is connected to learn the semantic information, which we will likely measure in our perceptual loss.This setup encourages the train process to learn similar feature representations rather than match each low-level pixel, which can guide the front denoising network in reconstructing more edges and details.Unlike normal denoising models for only one specific noise level, our single model can deal with the noise of unknown levels (i.e., blind denoising).We employ CBSD400 as the training set and evaluate the quality in Set5, Set14, and CBSD100 with noise levels of 15, 25, and 50, respectively.To train the network for a specific noise level, we generate the noisy images by adding Gaussian noise with standard deviations of σ=15, 25, 50.Alternatively, we train a single blind network for the unknown noise range [1,50].Result To verify the effectiveness of the proposed network, we show the quantitative and qualitative results of our method in comparison to those of state-of-the-art methods, including BM3D, TNRD, and DnCNN.The performance of the algorithm is evaluated by the peak signal-to-noise ratio as the quantitative indicator.Results show that the proposed network training with MSE loss can solely produce the best index results.The proposed algorithm (MSE-S) is better by 0.63 dB、0.55 dB and 0.17 dB compared with BM3D, TNRD, and DnCNN, respectively.In the qualitative visual sense, the perceptual loss model proposed in this paper clearly achieves a clearer denoising result.Compared with the fuzzy regions generated by other methods, this method preserves more edge information and texture details.We perform another experiment to show the ability of blind denoising.The input is composed of noisy parts with three levels, 10, 30, and 50.Results indicate that our blind model can generate a satisfactory restored output without artifacts even when the input is corrupted by several levels of noise in different parts.Conclusion In this paper, we describe a deep residual denoising network of 26 weight layers where perceptual loss is adopted to enhance the information detail.Residual learning and high-frequency layer decomposition are used to reduce the solution space to speed up the training process without pooling layers and batch normalization.Unlike the normal denoising model for only one specific noise level, our new model can deal with blind denoising problems with different unknown noise levels.The experiments show that the proposed network achieves superior performances both in quantitative and qualitative results, and recovers majority of the missing details from low-quality observations.In the future, we will explore how to handle other kinds of noise, especially the complex real-world noise, and consider a single comprehensive network for more image restoration tasks.In addition, we will likely focus on researching more visually perceptible indicators in addition to PSNR.关键词:image denoising;residual learning;perceptual loss;hierarchical mode29|11|12更新时间:2024-05-07
摘要:Objective Image denoising is a classical image reconstruction problem in low-level computer vision.It estimates the latent clean image from a noisy one.Digital images are often affected by the noise caused by imaging equipment and external environment in the process of digitization and transmission.Although several methods have achieved reasonable results in recent years, they rarely mentioned the over-smoothing effects and the loss of edge details.Thus, a novel image denoising method via residual learning based on edge enhancement is proposed.Method Recently, due to its powerful learning ability, very deep convolutional neural network has been widely used for image restoration.Inspired by ResNet, unlike other direct denoising networks, identity mappings are introduced to enable our residual network to increase the depth, and then slightly modify the architecture to adapt better to the denoising task.Pooling layers and batch normalization are removed to preserve details.Instead of these, high-frequency layer decomposition and global skip connection are used to prevent over-fitting.They change the input and output of the network to reduce the solution space.To speed up the training process, we select the rectified linear unit (ReLU) as the activation function and remove it before the convolution layer.Traditionally, image restoration work used the per-pixel loss between the ground truth and the restored image as the optimization target to obtain excellent quantitative scores.However, in recent research, minimizing pixel-wise errors only on the basis of low-level pixels has proven prone to loss of details and smoothens the results.Meanwhile, the perceptual loss function has shown that it can generate high-quality images with a better visual performance by capturing the difference between the high-level feature representations, but it sometimes fails to preserve color and local spatial information.To combine both benefits, we propose a new joint loss function that consists of a normal pixel-to-pixel loss and a perceptual loss with appropriate weights.In summary, the flow of our method is described as follows.First, the high-frequency layer of the noisy image is used as the input by removing the background information.Then, a residual mapping is trained to predict the difference between clean and noisy images as output instead of the final denoised image.The denoised result is improved further, and a joint loss function is defined as the weighted sum of the pixel-to-pixel Euclidean and perceptual losses.A well-trained convolutional neural network is connected to learn the semantic information, which we will likely measure in our perceptual loss.This setup encourages the train process to learn similar feature representations rather than match each low-level pixel, which can guide the front denoising network in reconstructing more edges and details.Unlike normal denoising models for only one specific noise level, our single model can deal with the noise of unknown levels (i.e., blind denoising).We employ CBSD400 as the training set and evaluate the quality in Set5, Set14, and CBSD100 with noise levels of 15, 25, and 50, respectively.To train the network for a specific noise level, we generate the noisy images by adding Gaussian noise with standard deviations of σ=15, 25, 50.Alternatively, we train a single blind network for the unknown noise range [1,50].Result To verify the effectiveness of the proposed network, we show the quantitative and qualitative results of our method in comparison to those of state-of-the-art methods, including BM3D, TNRD, and DnCNN.The performance of the algorithm is evaluated by the peak signal-to-noise ratio as the quantitative indicator.Results show that the proposed network training with MSE loss can solely produce the best index results.The proposed algorithm (MSE-S) is better by 0.63 dB、0.55 dB and 0.17 dB compared with BM3D, TNRD, and DnCNN, respectively.In the qualitative visual sense, the perceptual loss model proposed in this paper clearly achieves a clearer denoising result.Compared with the fuzzy regions generated by other methods, this method preserves more edge information and texture details.We perform another experiment to show the ability of blind denoising.The input is composed of noisy parts with three levels, 10, 30, and 50.Results indicate that our blind model can generate a satisfactory restored output without artifacts even when the input is corrupted by several levels of noise in different parts.Conclusion In this paper, we describe a deep residual denoising network of 26 weight layers where perceptual loss is adopted to enhance the information detail.Residual learning and high-frequency layer decomposition are used to reduce the solution space to speed up the training process without pooling layers and batch normalization.Unlike the normal denoising model for only one specific noise level, our new model can deal with blind denoising problems with different unknown noise levels.The experiments show that the proposed network achieves superior performances both in quantitative and qualitative results, and recovers majority of the missing details from low-quality observations.In the future, we will explore how to handle other kinds of noise, especially the complex real-world noise, and consider a single comprehensive network for more image restoration tasks.In addition, we will likely focus on researching more visually perceptible indicators in addition to PSNR.关键词:image denoising;residual learning;perceptual loss;hierarchical mode29|11|12更新时间:2024-05-07 -
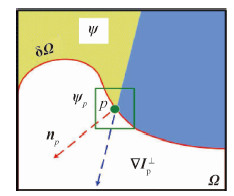 摘要:ObjectiveThe rapid development of multimedia information technology has led to images that have become the main carrier of information in people's lives.People communicate information through various means, such as voice, images, text, and video.Consequently, digital image inpainting technology has gradually attracted increasing attention, and its application fields are extensive.Digital image inpainting refers to the process of repairing or rebuilding missing information in damaged images by using a specific image inpainting algorithm, such that the observer cannot easily detect that the image has been repaired or damaged.Image inpainting technology has been used in many research areas, such as the restoration of old photos, the removal of image text, and the preservation of cultural relics.The traditional exemplar-based image inpainting algorithm only uses gradient information and the color information of the image to repair damaged areas, which can easily generate incorrect filling patches.In addition, the definition of the priority function is unreasonable, and thus causes the wrong filling order during inpainting, which affects the overall restoration effect.To solve these problems, an improved color image inpainting algorithm that is based on structure tensor is presented in this paper.Method Structure tensor is often used to analyze the local geometry of an image, which not only contains the intensity information of the local region, but also the main directions of the neighborhood gradient of a pixel and the degree of coherence of these directions.Its two eigenvalues can distinguish the edge, texture, and flat areas of an image.First, the proposed algorithm uses the structure tensor to define the data items to ensure that the structure information of the image can be transmitted accurately, and then uses the data items to form a new priority function for a more precise filling order.Second, different sizes of sample patches can be used to search for the best matching patch because an image has different structural features in different regions.Therefore, the size of the sample patch is adaptively selected according to the average coherence of the structure tensor.In other words, when the average coherence of the patch to be repaired is large, this patch is at the edge of the image and a small sample patch should be used; when the average coherence is small, it is in the flat region of the image and a large sample patch should be used.In this manner, when repairing complex damaged images, the continuity of the edge structure can be maintained; the flat area of the image can be effectively repaired.Finally, the traditional inpainting algorithm only uses the color information of the image to find the best matching patch, which renders the matching patch sub optimal.In this study, the eigenvalues of the structure tensor are added to the matching criteria to reduce the false matching rate.ResultExperimental results show that the improved algorithm is more effective in subjective vision than the other related algorithms.Moreover, the improved algorithm can achieve good results for different types of damaged images and effectively maintain the smoothness of the edge structure of the image.Compared with the traditional Criminisi algorithm, the power signal-to-noise ratio of the result has improved by approximately 1~3 dB and enhanced structure similarity.In addition, the proposed algorithm has a higher running time than other algorithms because in the inpainting process, the proposed algorithm uses the adaptive sample patch size to search for the best matching patch, and when analyzing the local structural features of the image, it needs to calculate the coherence factor of the pixels.These steps consequently increase the running time and reduce the efficiency of image inpainting.Conclusion When the traditional algorithm repairs the strong damaged area of the edge, the structural integrity and the good visual effect of the image are difficult to balance.In this study, we use the structure tensor of the color image to analyze the structure and texture area of the image.This paper discusses a color image inpainting algorithm based on the structure tensor.The proposed algorithm first uses the eigenvalue of the structure tensor instead of the isophote line in the traditional algorithm to improve the data items, which can spread the structure information of the image more accurately.Then, the average coherence factor of the structure tensor is used to analyze the texture and structural features of the image to repair the different image structural features.Finally, the matching rate used to select the best matching patch is improved with the addition of the constraint of the structural tensor to the traditional matching criteria.The proposed algorithm can obtain a better visual effect for damaged images with different structural features.The proposed algorithm can also effectively maintain the structural integrity of the image, and the complex texture area does not exhibit a wrong filled patch.Moreover, the large object and text removals by the proposed algorithm also have a good restoration effect.Compared with related Criminisi algorithms, the proposed algorithm has a better repair effect on complex linear structure and texture regions and effectively improves the overall quality of image restoration.关键词:color image restoration;structure tensor;adaptive patch size;matching criterion;the average coherence13|5|4更新时间:2024-05-07
摘要:ObjectiveThe rapid development of multimedia information technology has led to images that have become the main carrier of information in people's lives.People communicate information through various means, such as voice, images, text, and video.Consequently, digital image inpainting technology has gradually attracted increasing attention, and its application fields are extensive.Digital image inpainting refers to the process of repairing or rebuilding missing information in damaged images by using a specific image inpainting algorithm, such that the observer cannot easily detect that the image has been repaired or damaged.Image inpainting technology has been used in many research areas, such as the restoration of old photos, the removal of image text, and the preservation of cultural relics.The traditional exemplar-based image inpainting algorithm only uses gradient information and the color information of the image to repair damaged areas, which can easily generate incorrect filling patches.In addition, the definition of the priority function is unreasonable, and thus causes the wrong filling order during inpainting, which affects the overall restoration effect.To solve these problems, an improved color image inpainting algorithm that is based on structure tensor is presented in this paper.Method Structure tensor is often used to analyze the local geometry of an image, which not only contains the intensity information of the local region, but also the main directions of the neighborhood gradient of a pixel and the degree of coherence of these directions.Its two eigenvalues can distinguish the edge, texture, and flat areas of an image.First, the proposed algorithm uses the structure tensor to define the data items to ensure that the structure information of the image can be transmitted accurately, and then uses the data items to form a new priority function for a more precise filling order.Second, different sizes of sample patches can be used to search for the best matching patch because an image has different structural features in different regions.Therefore, the size of the sample patch is adaptively selected according to the average coherence of the structure tensor.In other words, when the average coherence of the patch to be repaired is large, this patch is at the edge of the image and a small sample patch should be used; when the average coherence is small, it is in the flat region of the image and a large sample patch should be used.In this manner, when repairing complex damaged images, the continuity of the edge structure can be maintained; the flat area of the image can be effectively repaired.Finally, the traditional inpainting algorithm only uses the color information of the image to find the best matching patch, which renders the matching patch sub optimal.In this study, the eigenvalues of the structure tensor are added to the matching criteria to reduce the false matching rate.ResultExperimental results show that the improved algorithm is more effective in subjective vision than the other related algorithms.Moreover, the improved algorithm can achieve good results for different types of damaged images and effectively maintain the smoothness of the edge structure of the image.Compared with the traditional Criminisi algorithm, the power signal-to-noise ratio of the result has improved by approximately 1~3 dB and enhanced structure similarity.In addition, the proposed algorithm has a higher running time than other algorithms because in the inpainting process, the proposed algorithm uses the adaptive sample patch size to search for the best matching patch, and when analyzing the local structural features of the image, it needs to calculate the coherence factor of the pixels.These steps consequently increase the running time and reduce the efficiency of image inpainting.Conclusion When the traditional algorithm repairs the strong damaged area of the edge, the structural integrity and the good visual effect of the image are difficult to balance.In this study, we use the structure tensor of the color image to analyze the structure and texture area of the image.This paper discusses a color image inpainting algorithm based on the structure tensor.The proposed algorithm first uses the eigenvalue of the structure tensor instead of the isophote line in the traditional algorithm to improve the data items, which can spread the structure information of the image more accurately.Then, the average coherence factor of the structure tensor is used to analyze the texture and structural features of the image to repair the different image structural features.Finally, the matching rate used to select the best matching patch is improved with the addition of the constraint of the structural tensor to the traditional matching criteria.The proposed algorithm can obtain a better visual effect for damaged images with different structural features.The proposed algorithm can also effectively maintain the structural integrity of the image, and the complex texture area does not exhibit a wrong filled patch.Moreover, the large object and text removals by the proposed algorithm also have a good restoration effect.Compared with related Criminisi algorithms, the proposed algorithm has a better repair effect on complex linear structure and texture regions and effectively improves the overall quality of image restoration.关键词:color image restoration;structure tensor;adaptive patch size;matching criterion;the average coherence13|5|4更新时间:2024-05-07 -
 摘要:Objective Depth map plays an increasingly important role in many computer vision applications, such as 3D reconstruction, augmented reality, and gesture recognition.A new generation of active 3D range sensors, such as Microsoft Kinect camera, enables the acquisition of a real-time and affordable depth map.Incidentally, unlike natural images captured by RGB sensors, the depth maps captured by range sensors typically have low resolution (LR) and inaccurate edges due to their intrinsic physical constraints.Given that an accurate and high-resolution (HR) depth map is required and preferable in many applications, excellent depth map super-resolution (SR) techniques are desirable.Depth map SR can be generally addressed by two different types of approaches that depend on the use of input data.For single depth map SR, the resolution of the input depth map can be enhanced based on the information learned with from a pre-collected training database.Meanwhile, depth map SR algorithms that use RGB-D data can be further classified into MRF and filtering-based approaches.MRF-based methods view depth map SR as an optimization problem.Filtering-based methods obtain the weighted average of local depth map pixels for SR purposes.These methods aim to obtain a smooth HR depth map for regions belonging to the same object.However, these methods have two main issues:1) the inaccurate edges of the depth map cannot be fully refined and 2) the edges of the HR depth map suffer from blurring.In this paper, a novel texture edge-guided depth reconstruction approach is proposed to address the issue of existing methods.We pay more attention to the depth edge refinement, which is usually ignored by existing methods.Method In the first stage, an initial HR depth map is obtained by general up-sampling methods, such as interpolation and filters.Then, initial depth edges are extracted from the initial HR depth map by using many edge detectors for edge detection, such as Sobel and Canny.The edges extracted directly from the initial HR depth map are not the true edges because the misalignment between the LR depth map edges and the texture edges and the up-sampling operation can cause further edge errors.Subsequently, the texture edges are extracted from the color image.Traditional approaches for edge detection do not consider the visually salient edges; the texture edges and illusory contours are all taken as image edges.Moreover, many edges of the color image do not correspond to depth edges, such as the edges inside the object.Inspired by the advanced positive result of the vision field, we propose a depth map edge detection method based on the structured forest.The edge map of the color image is initially extracted by using the recently structured learning approach.By incorporating the 3D space information provided by the initial HR depth map, the texture edges of the objects inside are removed.Then, we obtain a clear and true depth edge map.Finally, the depth values on each side of the depth edge are refined to align the depth edges and correct the depth errors in the initial HR depth map.We detect the incorrect depth regions between the initial depth edges and the corresponding true depth edges and then fill the incorrect regions until the depth edges are consistent with the corresponding color image.The incorrect regions of initial HR depth map are refined by the joint bilateral filter in an outside-inward refining order that is regularized by the detected true depth edges.Result We perform experiments on the NYU dataset, which offers real-world color-depth image pairs that were captured by a Kinect camera.To evaluate the performance of our proposed method, we compare our results with two method categories:1) state-of-the-art single depth image super resolution methods (ScSR, PB, and E.G.) and 2) state-of-the-art color-guided depth map super resolution approaches (JBU, GIU, MRF, WMF, and JTU).We implement most of these methods by using the same parameter settings as provided in the corresponding papers.We down-sample the original depth maps into LR ones and perform SR.We evaluate our proposed method with the recovered HR depth map and the reconstructed point clouds.The recovered HR depth maps indicate that our proposed methods generate more visually appealing results than the compared approaches.The boundaries in our results are generally sharper and smoother along the edge direction, whereas the compared methods suffer from blurred artifacts around the boundaries.To demonstrate further the effectiveness of our proposed approach, we provide the 3D point clouds constructed from the up-scaled depth map with different methods.Results indicate that our proposed method yields a relatively clear foreground and background, while the competing results suffer from obvious flying pixels and aliased planes.Conclusion We present a novel method for depth map SR for Kinect depth.Experimental results demonstrate that the proposed method provides sharp and clear edges for the Kinect depth, and the depth edges are aligned with the texture edges.The proposed framework synthesizes an HR depth map given its LR depth map and corresponding HR color image.Our proposed method first estimates the initial HR depth map via traditional up-sampling approaches, then extracts the true edges of the RGB-D data and the fake edges of the initial HR depth map to identify the incorrect regions between the two edges.The incorrect regions of the initial HR depth maps are further refined by joint bilateral filter in an outside-inward refining order to align the edges of color image and depth map.The key to our success is the use of RGB-D depth edge detection, which is inspired by the structured forests-based edge detection.Besides, unlike most depth enhancement methods that use raster-scan order to fill incorrect regions, our method can determine the filing order by considering the true edges.Thus, our HR depth map output exhibits better quality with clear and aligned depth edges compared with the existing depth map SR.However, texture-based guidance may result in incorrect depth value due to the smooth object surface with rich color texture.Thus, the suppression of texture copying artifacts may be our next research goal.关键词:depth map;Kinect;super-resolution reconstruction;edge detection;texture-guided46|6|4更新时间:2024-05-07
摘要:Objective Depth map plays an increasingly important role in many computer vision applications, such as 3D reconstruction, augmented reality, and gesture recognition.A new generation of active 3D range sensors, such as Microsoft Kinect camera, enables the acquisition of a real-time and affordable depth map.Incidentally, unlike natural images captured by RGB sensors, the depth maps captured by range sensors typically have low resolution (LR) and inaccurate edges due to their intrinsic physical constraints.Given that an accurate and high-resolution (HR) depth map is required and preferable in many applications, excellent depth map super-resolution (SR) techniques are desirable.Depth map SR can be generally addressed by two different types of approaches that depend on the use of input data.For single depth map SR, the resolution of the input depth map can be enhanced based on the information learned with from a pre-collected training database.Meanwhile, depth map SR algorithms that use RGB-D data can be further classified into MRF and filtering-based approaches.MRF-based methods view depth map SR as an optimization problem.Filtering-based methods obtain the weighted average of local depth map pixels for SR purposes.These methods aim to obtain a smooth HR depth map for regions belonging to the same object.However, these methods have two main issues:1) the inaccurate edges of the depth map cannot be fully refined and 2) the edges of the HR depth map suffer from blurring.In this paper, a novel texture edge-guided depth reconstruction approach is proposed to address the issue of existing methods.We pay more attention to the depth edge refinement, which is usually ignored by existing methods.Method In the first stage, an initial HR depth map is obtained by general up-sampling methods, such as interpolation and filters.Then, initial depth edges are extracted from the initial HR depth map by using many edge detectors for edge detection, such as Sobel and Canny.The edges extracted directly from the initial HR depth map are not the true edges because the misalignment between the LR depth map edges and the texture edges and the up-sampling operation can cause further edge errors.Subsequently, the texture edges are extracted from the color image.Traditional approaches for edge detection do not consider the visually salient edges; the texture edges and illusory contours are all taken as image edges.Moreover, many edges of the color image do not correspond to depth edges, such as the edges inside the object.Inspired by the advanced positive result of the vision field, we propose a depth map edge detection method based on the structured forest.The edge map of the color image is initially extracted by using the recently structured learning approach.By incorporating the 3D space information provided by the initial HR depth map, the texture edges of the objects inside are removed.Then, we obtain a clear and true depth edge map.Finally, the depth values on each side of the depth edge are refined to align the depth edges and correct the depth errors in the initial HR depth map.We detect the incorrect depth regions between the initial depth edges and the corresponding true depth edges and then fill the incorrect regions until the depth edges are consistent with the corresponding color image.The incorrect regions of initial HR depth map are refined by the joint bilateral filter in an outside-inward refining order that is regularized by the detected true depth edges.Result We perform experiments on the NYU dataset, which offers real-world color-depth image pairs that were captured by a Kinect camera.To evaluate the performance of our proposed method, we compare our results with two method categories:1) state-of-the-art single depth image super resolution methods (ScSR, PB, and E.G.) and 2) state-of-the-art color-guided depth map super resolution approaches (JBU, GIU, MRF, WMF, and JTU).We implement most of these methods by using the same parameter settings as provided in the corresponding papers.We down-sample the original depth maps into LR ones and perform SR.We evaluate our proposed method with the recovered HR depth map and the reconstructed point clouds.The recovered HR depth maps indicate that our proposed methods generate more visually appealing results than the compared approaches.The boundaries in our results are generally sharper and smoother along the edge direction, whereas the compared methods suffer from blurred artifacts around the boundaries.To demonstrate further the effectiveness of our proposed approach, we provide the 3D point clouds constructed from the up-scaled depth map with different methods.Results indicate that our proposed method yields a relatively clear foreground and background, while the competing results suffer from obvious flying pixels and aliased planes.Conclusion We present a novel method for depth map SR for Kinect depth.Experimental results demonstrate that the proposed method provides sharp and clear edges for the Kinect depth, and the depth edges are aligned with the texture edges.The proposed framework synthesizes an HR depth map given its LR depth map and corresponding HR color image.Our proposed method first estimates the initial HR depth map via traditional up-sampling approaches, then extracts the true edges of the RGB-D data and the fake edges of the initial HR depth map to identify the incorrect regions between the two edges.The incorrect regions of the initial HR depth maps are further refined by joint bilateral filter in an outside-inward refining order to align the edges of color image and depth map.The key to our success is the use of RGB-D depth edge detection, which is inspired by the structured forests-based edge detection.Besides, unlike most depth enhancement methods that use raster-scan order to fill incorrect regions, our method can determine the filing order by considering the true edges.Thus, our HR depth map output exhibits better quality with clear and aligned depth edges compared with the existing depth map SR.However, texture-based guidance may result in incorrect depth value due to the smooth object surface with rich color texture.Thus, the suppression of texture copying artifacts may be our next research goal.关键词:depth map;Kinect;super-resolution reconstruction;edge detection;texture-guided46|6|4更新时间:2024-05-07 -
 摘要:Objective Feature-based image matching is a fundamental research in the fields of computer vision and pattern recognition.Progress has been achieved in matching rigid objects.However, the fast and accurate registration of non-rigid deformation is often necessary in many practical matching problems to facilitate the subsequent processing and analysis.the existing non-rigid matching algorithms at home and abroad have difficulty in making perfect trade-offs between matching precision, speed, and robustness.Therefore, research on non-rigid matching algorithms that can achieve non-rigid deformation quickly and accurately and obtain nonlinear transformation parameters with an optimization algorithm should be conducted.Method Our method is based on the SIFT flow algorithm proposed by Ce Liu et al.for stereo matching.The SIFT flow algorithm uses fixed-scale SIFT descriptors densely for the entire image lattice, and thus, it cannot match the scenes containing non-rigid and spatially varying deformations well (e.g., the scale and rotation changes).Meanwhile, due to the complex construction process of SIFT feature operators, the algorithm has an unsatisfactory real-time performance.In this study, we introduce the DAISY descriptor to replace the SIFT operator.The descriptor not only improves the operator construction speed but also has a good rotation invariance because of its unique circular symmetric structure.This paper presents a non-rigid dense matching algorithm that is based on the DAISY feature descriptor and the constrained patch-match.First, the DAISY feature descriptor is generated for the reference and under-matched images.Second, the reference and under-matched images are segmented to form super-pixel block structures, which are adjacent but non-overlapping.These super-pixel block structures will be used as units for calculating the cost of the DAISY feature descriptor in each pixel at the initial position.Then, each pixel in the entire image undergoes propagation followed by a random search based on the patch-match algorithm.In the process of random search, the initialization window of the local label is localized, and the position tag of each pixel is updated in the space range based on the prior knowledge obtained by the pre-process and analysis.The new aggregation cost is calculated through the above processes, and the position tag with the smaller cost is retained.This process is repeated until the aggregate cost does not change or the maximum number of iterations is reached.Result A random search should be conducted for each pixel in the entire image to provide more matching possibilities due to the spatially varying deformations of the moving object in the traditional optical flow-based stereo matching method.In this paper, three types of images are selected:the standard test sets provided by the Middlebury visual website, the coupler buffer images taken with TFDS line array cameras, and the non-rigid images collected by frame cameras.These datasets contain non-rigid and a small range of deformations.In this experiment, we perform spatial constraints artificially on the initialization window in the random search of the patch-match algorithm, which avoids the mismatches caused by noise or a lack of texture, instead of randomly searching the entire image.All tests achieve improved match results.The experiments verify that the matching accuracy of our method is 86%, and the average matching error of mismatched points is approximately 5 pixels, which is half of that produced by the traditional SIFT flow matching method.The speed of the DAISY operator adopted in this paper is 1 to 2 times faster than that of the Dense SIFT in features extraction, which greatly improves the image matching efficiency.Conclusion Traditionally, the entire image should be searched for the best matching points to consider the matching accuracy of the points with large-scale changes, which can result in mismatches.To obtain non-rigid images with small-scale deformation, this paper proposes a non-rigid dense matching algorithm.To deal with the uncertainty of changes in non-rigid images, we use the optimization search algorithm based on dense features.Experiment results indicate that our method is adaptive to the image matching with non-rigid deformation and successfully achieves higher matching accuracy and better visual effects than other methods.关键词:computer vision;non-rigid matching;DAISY descriptor;super pixel segmentation;cost aggregation correction;Patch-Match11|4|1更新时间:2024-05-07
摘要:Objective Feature-based image matching is a fundamental research in the fields of computer vision and pattern recognition.Progress has been achieved in matching rigid objects.However, the fast and accurate registration of non-rigid deformation is often necessary in many practical matching problems to facilitate the subsequent processing and analysis.the existing non-rigid matching algorithms at home and abroad have difficulty in making perfect trade-offs between matching precision, speed, and robustness.Therefore, research on non-rigid matching algorithms that can achieve non-rigid deformation quickly and accurately and obtain nonlinear transformation parameters with an optimization algorithm should be conducted.Method Our method is based on the SIFT flow algorithm proposed by Ce Liu et al.for stereo matching.The SIFT flow algorithm uses fixed-scale SIFT descriptors densely for the entire image lattice, and thus, it cannot match the scenes containing non-rigid and spatially varying deformations well (e.g., the scale and rotation changes).Meanwhile, due to the complex construction process of SIFT feature operators, the algorithm has an unsatisfactory real-time performance.In this study, we introduce the DAISY descriptor to replace the SIFT operator.The descriptor not only improves the operator construction speed but also has a good rotation invariance because of its unique circular symmetric structure.This paper presents a non-rigid dense matching algorithm that is based on the DAISY feature descriptor and the constrained patch-match.First, the DAISY feature descriptor is generated for the reference and under-matched images.Second, the reference and under-matched images are segmented to form super-pixel block structures, which are adjacent but non-overlapping.These super-pixel block structures will be used as units for calculating the cost of the DAISY feature descriptor in each pixel at the initial position.Then, each pixel in the entire image undergoes propagation followed by a random search based on the patch-match algorithm.In the process of random search, the initialization window of the local label is localized, and the position tag of each pixel is updated in the space range based on the prior knowledge obtained by the pre-process and analysis.The new aggregation cost is calculated through the above processes, and the position tag with the smaller cost is retained.This process is repeated until the aggregate cost does not change or the maximum number of iterations is reached.Result A random search should be conducted for each pixel in the entire image to provide more matching possibilities due to the spatially varying deformations of the moving object in the traditional optical flow-based stereo matching method.In this paper, three types of images are selected:the standard test sets provided by the Middlebury visual website, the coupler buffer images taken with TFDS line array cameras, and the non-rigid images collected by frame cameras.These datasets contain non-rigid and a small range of deformations.In this experiment, we perform spatial constraints artificially on the initialization window in the random search of the patch-match algorithm, which avoids the mismatches caused by noise or a lack of texture, instead of randomly searching the entire image.All tests achieve improved match results.The experiments verify that the matching accuracy of our method is 86%, and the average matching error of mismatched points is approximately 5 pixels, which is half of that produced by the traditional SIFT flow matching method.The speed of the DAISY operator adopted in this paper is 1 to 2 times faster than that of the Dense SIFT in features extraction, which greatly improves the image matching efficiency.Conclusion Traditionally, the entire image should be searched for the best matching points to consider the matching accuracy of the points with large-scale changes, which can result in mismatches.To obtain non-rigid images with small-scale deformation, this paper proposes a non-rigid dense matching algorithm.To deal with the uncertainty of changes in non-rigid images, we use the optimization search algorithm based on dense features.Experiment results indicate that our method is adaptive to the image matching with non-rigid deformation and successfully achieves higher matching accuracy and better visual effects than other methods.关键词:computer vision;non-rigid matching;DAISY descriptor;super pixel segmentation;cost aggregation correction;Patch-Match11|4|1更新时间:2024-05-07
Image Processing and Coding
-
 摘要:Objective An affine shape matching method using a projection area calculated with a contour is proposed to improve the computation speed and the discrimination ability of a descriptor during shape matching.MethodThe algorithm can be divided into the coarse and fine matching stages.The coarse matching stage aims to select the shape and find consistent feature points.Area is an important affine invariant.In the coarse matching stage, we use CSS corner points as alternative feature points, and the statistics of the contour projection area as the feature point descriptor.Then, the ant colony algorithm is employed in matching the public feature point sequence in the two pictures.Finally, the target curve is divided by the public feature point sequence to obtain the corresponding contour curve.We use low-dimensional descriptors in the rough matching phase to increase the matching speed.Then, in the precise matching stage, Affine invariant descriptors constructed by wavelet coefficients are used to describe the target curve segment, match the 5% target with the minimum cost of the first step, obtain the matching cost of the second phase, and achieve the recognition of the affine target.ResultThe average retrieval rate of this algorithm is higher than that of the traditional shape projection distribution descriptor by 44.3%, The retrieval result in the MPEG-7 image library is 98.65%.The comprehensive evaluation index of precision and recall ratio on the MPEG-7 affine image library is higher than those of the traditional shape projection distribution descriptor and the shape context by 3.1% and 25%, respectively.Conclusion The main contribution of the algorithm lies in the shape projection distribution descriptor that is calculated quickly by using the contour and the wavelet affine invariant that matches the target contour sub-curve and compensates the shortcoming of the description based on the projection area distribution.Moreover, this study addresses the problems of slow calculation speed and insufficient description ability of affine descriptors, and the proposed method has a certain anti-noise ability, which can be used effectively in the field of affine shape matching and retrieval.The strict affine invariance of the QSPD descriptor ensures the applicability of this method to affine transformation shapes.However, the algorithm is not applicable for targets with large shape changes because the calculation of the QSPD is based on global shape information.关键词:shape matching;affine invariant descriptor;ant colony algorithm;wavelet transform;contour19|4|1更新时间:2024-05-07
摘要:Objective An affine shape matching method using a projection area calculated with a contour is proposed to improve the computation speed and the discrimination ability of a descriptor during shape matching.MethodThe algorithm can be divided into the coarse and fine matching stages.The coarse matching stage aims to select the shape and find consistent feature points.Area is an important affine invariant.In the coarse matching stage, we use CSS corner points as alternative feature points, and the statistics of the contour projection area as the feature point descriptor.Then, the ant colony algorithm is employed in matching the public feature point sequence in the two pictures.Finally, the target curve is divided by the public feature point sequence to obtain the corresponding contour curve.We use low-dimensional descriptors in the rough matching phase to increase the matching speed.Then, in the precise matching stage, Affine invariant descriptors constructed by wavelet coefficients are used to describe the target curve segment, match the 5% target with the minimum cost of the first step, obtain the matching cost of the second phase, and achieve the recognition of the affine target.ResultThe average retrieval rate of this algorithm is higher than that of the traditional shape projection distribution descriptor by 44.3%, The retrieval result in the MPEG-7 image library is 98.65%.The comprehensive evaluation index of precision and recall ratio on the MPEG-7 affine image library is higher than those of the traditional shape projection distribution descriptor and the shape context by 3.1% and 25%, respectively.Conclusion The main contribution of the algorithm lies in the shape projection distribution descriptor that is calculated quickly by using the contour and the wavelet affine invariant that matches the target contour sub-curve and compensates the shortcoming of the description based on the projection area distribution.Moreover, this study addresses the problems of slow calculation speed and insufficient description ability of affine descriptors, and the proposed method has a certain anti-noise ability, which can be used effectively in the field of affine shape matching and retrieval.The strict affine invariance of the QSPD descriptor ensures the applicability of this method to affine transformation shapes.However, the algorithm is not applicable for targets with large shape changes because the calculation of the QSPD is based on global shape information.关键词:shape matching;affine invariant descriptor;ant colony algorithm;wavelet transform;contour19|4|1更新时间:2024-05-07 -
 摘要:ObjectiveFacial image analysis has been an important and active subfield of computer vision and pattern recognition.Kinship verification refers to the tasks of training a machine based on features extracted from facial images to determine the existence, type, and degree of kinship of two or more people.Moreover, kinship verification has extensive and promising applications in many technical and social fields, such as family history research and photo management in social network services.In addition, the study on kinship verification is of great theoretical significance to related fields.Several commonalities can be observed among kinship verification algorithms, which are based on traditional machine learning.This paper proposes a new method for studying kinship verification based on face images through deep metric learning.MethodCurrently, deep learning algorithm can effectively understand a single face image, but the relationship between multiple subjects is still one of the challenging problems in the field of computer vision.This paper presents an approach to kinship verification between parents and children.First, a deep convolution neural network called "FaceCNN" is trained by using a dataset that contains more than 5 000 000 face images from which deep features are extracted.The training set of the deep convolutional neural network contains Internet-sourced datasets of thousands of people, including public kinship datasets, Microsoft face datasets, some films and television dramas, and public figures.Each dataset contains several face images.These face images have complex backgrounds, large differences in image quality, and various face postures, expressions, ages, and genders.Before training the deep network, the face images in the dataset must be preprocessed, including face filtering, face detection, and key point alignment.Then, all images are cut into 144×144 pixels.Then, we divide the father-mother-son and father-mother-daughter samples into father-son, mother-son, father-daughter, and mother-daughter samples.However, we cannot use the Mahalanobis distance to perform metric learning for kinship verification because the traditional Mahalanobis distance measurement learning method only seeks a linear transformation and cannot easily capture the non-linear manifold of the face image.A discriminative metric learning algorithm called DDML is adopted to render the kinship features as near as possible and vice versa.Hierarchical non-linear transformation is employed to achieve a more discriminative learning.Finally, we propose a kinship verification method for parents and children where the cosine similarity is calculated between parents and children.The children may be more similar to one of the parents, and thus we must calculate the similarity probability of the children with their father and mother.The final kinship score is the weighted average of the similarity between children and parents.ResultA nine-layer deep model is trained to determine whether the given images have a relationship.The effectiveness of features extraction by using FaceCNN combined with the deep metric learning for kinship verification is validated in the experiment in which the recognition accuracy between parents and son performed on the TSKinFace dataset is 87.71%, and that between parents and daughter is 89.18%, which indicates that the recognition rate of the model increased by 1.31% and 4.87%, respectively.Meanwhile, the proposed approach only requires 3.616 s for metric learning and parental similarity calculation, reducing the time consumed greatly compared with other algorithms.ConclusionThe proposed kinship verification takes full advantage of the characterization and learning ability of the deep neural network, and it does not only consume less time but also improves the recognition accuracy.关键词:kinship verification;convolution neural network;deep feature;deep learning;metric learning12|12|0更新时间:2024-05-07
摘要:ObjectiveFacial image analysis has been an important and active subfield of computer vision and pattern recognition.Kinship verification refers to the tasks of training a machine based on features extracted from facial images to determine the existence, type, and degree of kinship of two or more people.Moreover, kinship verification has extensive and promising applications in many technical and social fields, such as family history research and photo management in social network services.In addition, the study on kinship verification is of great theoretical significance to related fields.Several commonalities can be observed among kinship verification algorithms, which are based on traditional machine learning.This paper proposes a new method for studying kinship verification based on face images through deep metric learning.MethodCurrently, deep learning algorithm can effectively understand a single face image, but the relationship between multiple subjects is still one of the challenging problems in the field of computer vision.This paper presents an approach to kinship verification between parents and children.First, a deep convolution neural network called "FaceCNN" is trained by using a dataset that contains more than 5 000 000 face images from which deep features are extracted.The training set of the deep convolutional neural network contains Internet-sourced datasets of thousands of people, including public kinship datasets, Microsoft face datasets, some films and television dramas, and public figures.Each dataset contains several face images.These face images have complex backgrounds, large differences in image quality, and various face postures, expressions, ages, and genders.Before training the deep network, the face images in the dataset must be preprocessed, including face filtering, face detection, and key point alignment.Then, all images are cut into 144×144 pixels.Then, we divide the father-mother-son and father-mother-daughter samples into father-son, mother-son, father-daughter, and mother-daughter samples.However, we cannot use the Mahalanobis distance to perform metric learning for kinship verification because the traditional Mahalanobis distance measurement learning method only seeks a linear transformation and cannot easily capture the non-linear manifold of the face image.A discriminative metric learning algorithm called DDML is adopted to render the kinship features as near as possible and vice versa.Hierarchical non-linear transformation is employed to achieve a more discriminative learning.Finally, we propose a kinship verification method for parents and children where the cosine similarity is calculated between parents and children.The children may be more similar to one of the parents, and thus we must calculate the similarity probability of the children with their father and mother.The final kinship score is the weighted average of the similarity between children and parents.ResultA nine-layer deep model is trained to determine whether the given images have a relationship.The effectiveness of features extraction by using FaceCNN combined with the deep metric learning for kinship verification is validated in the experiment in which the recognition accuracy between parents and son performed on the TSKinFace dataset is 87.71%, and that between parents and daughter is 89.18%, which indicates that the recognition rate of the model increased by 1.31% and 4.87%, respectively.Meanwhile, the proposed approach only requires 3.616 s for metric learning and parental similarity calculation, reducing the time consumed greatly compared with other algorithms.ConclusionThe proposed kinship verification takes full advantage of the characterization and learning ability of the deep neural network, and it does not only consume less time but also improves the recognition accuracy.关键词:kinship verification;convolution neural network;deep feature;deep learning;metric learning12|12|0更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveCurrently, circular target is widely used in a multitude of vision measurement systems in which center positioning accuracy determines the accuracy of the measuring system.The projection of a circular feature is generally an ellipse and not a true circle because the main optical axis of a camera is not parallel with the feature surface.When the angle between the main optical axis of a camera and the feature surface is large, the eccentricity error will affect the accuracy of the measurement system extremely.Most of the research on eccentricity errors in the last two decades has examined quite a few methods and conducted experiments to derive the mechanism of eccentricity and attempted to correct the errors.Incidentally, the past studies used geometric parameters to calculate the eccentricity errors, which increased the complexity of the process.This paper introduces a new method for correcting the eccentricity error with the help of the three concentric circle targets.MethodMost algorithms for eccentricity errors usually involve several geometric parameters, and calibration and bundle adjustment are always required to obtain these parameters.These algorithms increase the computational complexity and reduce the rate of convergence.Our method designs three concentric circles as the target, which has common center coordinates in the object plane and different centers in the image plane, which are on a line.The moment invariants of Zernike moment are used for the edge detection of the pixel level to obtain the precise positioning of the sub-pixel level edge.The center of the ellipse is determined with the least-square ellipse fitting.To achieve better results, the images of the concentric circle targets should include at least 20 pixels to ensure sufficient effective edge points.The ellipse center is easily calculated with the sub-pixel level edge, then we can use the three groups of ellipse centers to calculate the eccentricity error model.The three concentric circles in the error equation have the same six parameters.Thus, the corresponding parameters can be set into blocks as new variables, which in turn can be reduced to three unknown parameters.The error equations can be sufficiently solved with the help of the three concentric circles.Through the formulas derived in this study, the eccentricity errors can be solved completely.Obtaining geometrical parameters should be avoided and the nonlinear model should be solved.ResultA possible solution for the correction of this systematic eccentricity error is proposed in this paper.The method can effectively improve the positioning accuracy of the circular target center.Simulation experiment results by using MATLAB show that the eccentricity errors can be compensated from the pixel level to the 10-11-pixel level when the targets are photos taken in different angles, distances, and sizes of the targets.This study designs a target that has three concentric circles and diameters of 6, 12, and 18 cm.To calculate the true center of the circles, a circle with a size of 2 mm is designed in the central area of the target.During image processing, we use the improved gray barycenter localization algorithm to calculate the center of the small circle.By comparison, its radius is extremely small, and the simulation experiment shows that its eccentric error is only 0.02 pixels, which can be ignored compared with the three concentric circles used in the experiment and regarded as the true value in the experiment.Experiment results show that the measurement errors can be controlled at 0.1 mm.Relative to the concentric circles method, the accuracy is two times than that of before and the eccentricity error is decreased by approximately 80%.ConclusionThis paper presents a new eccentricity compensation method for calculating eccentricity error by using three concentric circle targets to add constraint.Unlike in previous eccentricity error correction methods, additional parameters should be estimated to correct the eccentricity error.Consequently, the computation complexity increases and convergence speed decreases.Prior knowledge about the geometric parameters of the measurement system (target and camera) are not needed; rather, the proportional relationship of the circles and ellipse center coordinates are the only information required.The experiment results show the efficiency of the proposed method for eccentricity error compensation.The algorithm can improve the location efficiency of circular targets.Consequently, the algorithm can enhance the effect on depth image matching that is based on non-coding markers, the precision of the automatic camera calibration method that is based on circular markers, and the robustness of the navigation and positional system.关键词:eccentricity error;three concentric circles;ellipse fitting;image measurement errors;visual location17|5|3更新时间:2024-05-07
摘要:ObjectiveCurrently, circular target is widely used in a multitude of vision measurement systems in which center positioning accuracy determines the accuracy of the measuring system.The projection of a circular feature is generally an ellipse and not a true circle because the main optical axis of a camera is not parallel with the feature surface.When the angle between the main optical axis of a camera and the feature surface is large, the eccentricity error will affect the accuracy of the measurement system extremely.Most of the research on eccentricity errors in the last two decades has examined quite a few methods and conducted experiments to derive the mechanism of eccentricity and attempted to correct the errors.Incidentally, the past studies used geometric parameters to calculate the eccentricity errors, which increased the complexity of the process.This paper introduces a new method for correcting the eccentricity error with the help of the three concentric circle targets.MethodMost algorithms for eccentricity errors usually involve several geometric parameters, and calibration and bundle adjustment are always required to obtain these parameters.These algorithms increase the computational complexity and reduce the rate of convergence.Our method designs three concentric circles as the target, which has common center coordinates in the object plane and different centers in the image plane, which are on a line.The moment invariants of Zernike moment are used for the edge detection of the pixel level to obtain the precise positioning of the sub-pixel level edge.The center of the ellipse is determined with the least-square ellipse fitting.To achieve better results, the images of the concentric circle targets should include at least 20 pixels to ensure sufficient effective edge points.The ellipse center is easily calculated with the sub-pixel level edge, then we can use the three groups of ellipse centers to calculate the eccentricity error model.The three concentric circles in the error equation have the same six parameters.Thus, the corresponding parameters can be set into blocks as new variables, which in turn can be reduced to three unknown parameters.The error equations can be sufficiently solved with the help of the three concentric circles.Through the formulas derived in this study, the eccentricity errors can be solved completely.Obtaining geometrical parameters should be avoided and the nonlinear model should be solved.ResultA possible solution for the correction of this systematic eccentricity error is proposed in this paper.The method can effectively improve the positioning accuracy of the circular target center.Simulation experiment results by using MATLAB show that the eccentricity errors can be compensated from the pixel level to the 10-11-pixel level when the targets are photos taken in different angles, distances, and sizes of the targets.This study designs a target that has three concentric circles and diameters of 6, 12, and 18 cm.To calculate the true center of the circles, a circle with a size of 2 mm is designed in the central area of the target.During image processing, we use the improved gray barycenter localization algorithm to calculate the center of the small circle.By comparison, its radius is extremely small, and the simulation experiment shows that its eccentric error is only 0.02 pixels, which can be ignored compared with the three concentric circles used in the experiment and regarded as the true value in the experiment.Experiment results show that the measurement errors can be controlled at 0.1 mm.Relative to the concentric circles method, the accuracy is two times than that of before and the eccentricity error is decreased by approximately 80%.ConclusionThis paper presents a new eccentricity compensation method for calculating eccentricity error by using three concentric circle targets to add constraint.Unlike in previous eccentricity error correction methods, additional parameters should be estimated to correct the eccentricity error.Consequently, the computation complexity increases and convergence speed decreases.Prior knowledge about the geometric parameters of the measurement system (target and camera) are not needed; rather, the proportional relationship of the circles and ellipse center coordinates are the only information required.The experiment results show the efficiency of the proposed method for eccentricity error compensation.The algorithm can improve the location efficiency of circular targets.Consequently, the algorithm can enhance the effect on depth image matching that is based on non-coding markers, the precision of the automatic camera calibration method that is based on circular markers, and the robustness of the navigation and positional system.关键词:eccentricity error;three concentric circles;ellipse fitting;image measurement errors;visual location17|5|3更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveMRI uses the principle of nuclear magnetic resonance.In addition, MRI is safe to use and has a high soft tissue resolution.CT is being gradually replaced by MRI for checking bones and joints.The automated detection and segmentation of shoulder joint structures in MRI are extremely important for measuring and diagnosing bone injuries and diseases.In MRI, the internal bone region and the air, fat, and some soft tissue in it show similar gray and black features and a low image signal to noise ratio and partial volume effect.Thus, the automatic and accurate segmentation of the clinically valuable glenoid and humeral head in the shoulder joint is difficult.Common conventional bone segmentation algorithms, such as region growing or level set, cannot be implemented without prior knowledge, and their generality and accuracy are relatively low.Although various deep learning algorithms have been applied to the segmentation of medical images, such as MRI and CT, a successful segmentation is almost impossible with only one deep network without post-processing.To the best of our knowledge, few studies on the use of deep learning to segment bones in MRI have been conducted, and no study has been conducted about shoulder segmentation.Two deep learning networks, namely, patch-based and fully convolutional networks (PCNN and FCN), are employed for the automated detection and segmentation of the shoulder joint structure in MRI.MethodFirst, four segmentation models are built, including three U-Net based models (glenoid segmentation model, humeral head segmentation model, glenoid and humeral head segmentation model) and one patch-based AlexNet segmentation model.The network depth of U-Net is 3, and the number of features in the first layer is 16.Edge expansion is performed by mirroring to ensure that the resolution of the output segmentation map is consistent with the original image because the resolution of the input image is reduced after passing through U-Net.The traditional AlexNet has a three-channel RGB input, but MRI is a grayscale image, and thus the RGB channel values are the same.Three channels can be added to an image by using the three window-level mappings or three different resolutions.However, no performance improvement is observed relative to the channel test, and thus, we adjust the input to one channel.Then, the four segmentation models are used to obtain the candidate bone regions from which the correct glenoid and humeral head locations and regions are obtained by voting.However, false bone regions still exist.Given that the signal intensity of the bone is near the fat and some soft tissues, which are easily misjudged as glenoid and humeral head in partial shapes and positions, and due to the complex shape and wider variation range of the humeral head, the diversity of morphologies easily leads to the misinterpretation of noise or fat as a humeral head.These false bone regions are filtered by location information, and the missing bone objects are calculated by inter-frame prediction due to the continuity of MRI scanning in the time direction.Finally, the AlexNet model is used to segment the edge of the bone with accuracy at the pixel level.ResultThe experimental data are derived from eight groups of patients of Harvard Medical School/Massachusetts General Hospital of the United States.Each scan sequence includes approximately 100 images with marked bone edge labels.Five groups of patients are used for training and five-fold cross-validation, and three groups are used to test the actual segmentation results.The Dice coefficient, positive predicted value, and sensitivity average accuracy are 0.92±0.02, 0.96±0.03, and 0.94±0.02, respectively.Experimental results show that the segmentation accuracy is very high, which is basically consistent with the results of artificial segmentation.The segmentation accuracy also exceeds the average artificial annotation in a considerable part of the images from observation.In practical segmentation applications, training and segmentation are generally performed at the service end of the GPU device, and the segmentation result is displayed at the client end.For medical institutions, the operation is usually performed in a local area network.For a slice of a patient's MRI sequence, the overall time from the segmentation request of the client to the segmentation result from the server is approximately 1.2 seconds, meeting the real-time requirements of the application.In many cases, the scanned images of a group of patients are uniformly processed offline on the server side, and the segmentation results are saved.The segmentation results can be retrieved when the client loads the patient data.In this case, no real-time performance requirement exists, which is common in application modes.From the experimental dataset, our sample set is very limited, that is, 8 sets of patient use cases.This finding indicates that a highly effective predictive effect can be achieved if the methods for obtaining image blocks and data argument are appropriate.ConclusionThe model ensemble method obtained by voting is used to accurately locate the glenoid and humeral head bone in the shoulder joint.Four types of segmentation modeling are performed.The spatial consistency of the image sequence is used to predict the incorrectly deleted area.Then, PCNN segmentation is employed by the local perception and features in the located bone region of interest.Although the patients' datasets are quite small, accurate shoulder joint segmentation results are obtained.The proposed algorithm has been integrated into 3DQI, a medical image measurement and analysis platform we developed, which can demonstrate 3D segmentation of shoulder bones and provide clinical diagnosis and guidance to orthopedists.With the deepening cooperation with hospitals and the increasing number of MRI samples, we can test and analyze the three-dimensional segmentation based on deep learning and compare the segmentation results with the two-dimensional operation in future studies.关键词:deep learning;medical image segmentation;fully convolutional networks;magnetic resonance imaging;orthopedics diagnosis11|4|5更新时间:2024-05-07
摘要:ObjectiveMRI uses the principle of nuclear magnetic resonance.In addition, MRI is safe to use and has a high soft tissue resolution.CT is being gradually replaced by MRI for checking bones and joints.The automated detection and segmentation of shoulder joint structures in MRI are extremely important for measuring and diagnosing bone injuries and diseases.In MRI, the internal bone region and the air, fat, and some soft tissue in it show similar gray and black features and a low image signal to noise ratio and partial volume effect.Thus, the automatic and accurate segmentation of the clinically valuable glenoid and humeral head in the shoulder joint is difficult.Common conventional bone segmentation algorithms, such as region growing or level set, cannot be implemented without prior knowledge, and their generality and accuracy are relatively low.Although various deep learning algorithms have been applied to the segmentation of medical images, such as MRI and CT, a successful segmentation is almost impossible with only one deep network without post-processing.To the best of our knowledge, few studies on the use of deep learning to segment bones in MRI have been conducted, and no study has been conducted about shoulder segmentation.Two deep learning networks, namely, patch-based and fully convolutional networks (PCNN and FCN), are employed for the automated detection and segmentation of the shoulder joint structure in MRI.MethodFirst, four segmentation models are built, including three U-Net based models (glenoid segmentation model, humeral head segmentation model, glenoid and humeral head segmentation model) and one patch-based AlexNet segmentation model.The network depth of U-Net is 3, and the number of features in the first layer is 16.Edge expansion is performed by mirroring to ensure that the resolution of the output segmentation map is consistent with the original image because the resolution of the input image is reduced after passing through U-Net.The traditional AlexNet has a three-channel RGB input, but MRI is a grayscale image, and thus the RGB channel values are the same.Three channels can be added to an image by using the three window-level mappings or three different resolutions.However, no performance improvement is observed relative to the channel test, and thus, we adjust the input to one channel.Then, the four segmentation models are used to obtain the candidate bone regions from which the correct glenoid and humeral head locations and regions are obtained by voting.However, false bone regions still exist.Given that the signal intensity of the bone is near the fat and some soft tissues, which are easily misjudged as glenoid and humeral head in partial shapes and positions, and due to the complex shape and wider variation range of the humeral head, the diversity of morphologies easily leads to the misinterpretation of noise or fat as a humeral head.These false bone regions are filtered by location information, and the missing bone objects are calculated by inter-frame prediction due to the continuity of MRI scanning in the time direction.Finally, the AlexNet model is used to segment the edge of the bone with accuracy at the pixel level.ResultThe experimental data are derived from eight groups of patients of Harvard Medical School/Massachusetts General Hospital of the United States.Each scan sequence includes approximately 100 images with marked bone edge labels.Five groups of patients are used for training and five-fold cross-validation, and three groups are used to test the actual segmentation results.The Dice coefficient, positive predicted value, and sensitivity average accuracy are 0.92±0.02, 0.96±0.03, and 0.94±0.02, respectively.Experimental results show that the segmentation accuracy is very high, which is basically consistent with the results of artificial segmentation.The segmentation accuracy also exceeds the average artificial annotation in a considerable part of the images from observation.In practical segmentation applications, training and segmentation are generally performed at the service end of the GPU device, and the segmentation result is displayed at the client end.For medical institutions, the operation is usually performed in a local area network.For a slice of a patient's MRI sequence, the overall time from the segmentation request of the client to the segmentation result from the server is approximately 1.2 seconds, meeting the real-time requirements of the application.In many cases, the scanned images of a group of patients are uniformly processed offline on the server side, and the segmentation results are saved.The segmentation results can be retrieved when the client loads the patient data.In this case, no real-time performance requirement exists, which is common in application modes.From the experimental dataset, our sample set is very limited, that is, 8 sets of patient use cases.This finding indicates that a highly effective predictive effect can be achieved if the methods for obtaining image blocks and data argument are appropriate.ConclusionThe model ensemble method obtained by voting is used to accurately locate the glenoid and humeral head bone in the shoulder joint.Four types of segmentation modeling are performed.The spatial consistency of the image sequence is used to predict the incorrectly deleted area.Then, PCNN segmentation is employed by the local perception and features in the located bone region of interest.Although the patients' datasets are quite small, accurate shoulder joint segmentation results are obtained.The proposed algorithm has been integrated into 3DQI, a medical image measurement and analysis platform we developed, which can demonstrate 3D segmentation of shoulder bones and provide clinical diagnosis and guidance to orthopedists.With the deepening cooperation with hospitals and the increasing number of MRI samples, we can test and analyze the three-dimensional segmentation based on deep learning and compare the segmentation results with the two-dimensional operation in future studies.关键词:deep learning;medical image segmentation;fully convolutional networks;magnetic resonance imaging;orthopedics diagnosis11|4|5更新时间:2024-05-07 -
 摘要:ObjectiveThe tongue is difficult to segment accurately due to the blurred contours and the similar colors of the surrounding tissue.Current tongue segmentation methods, whether based on texture analysis, edge detection, or threshold segmentation, mostly extract the color features of the tongue image, i.e., they are pixel-based segmentation methods.Although color features are easy to extract, the position information of the target is difficult to express.The color between the tongue and the background is similar, and the color features of the tongue and the background may overlap.Therefore, tongue information is difficult to express by using the color features of the tongue image.The deep semantic information of the image should be extracted and more complete features must be obtained to achieve an accurate segmentation of the tongue body.A tongue segmentation method based on two-stage convolutional neural network is proposed in this paper.The cascade method is used to combine the networks, and the output of the previous stage is taken as the input of the next stage.MethodFirst, in the rough segmentation stage, the rough segmentation network (Rsnet) consists of the convolutional and fully connected layers.The problem of excessive interference information in the original tongue image needs to be solved.Thus, the region suggestion strategy is adopted to obtain tongue candidate boxes, and the regions of interest are extracted from the similar background, i.e., the tongue is located and a large amount of interference information are removed.Therefore, the influence of the tissue around the tongue during the segmentation of the tongue is weakened.Second, in the fine segmentation phase, the fine segmentation network (Fsnet) consists of the convolutional and deconvolutional layers.The regions of interest obtained in the previous stage are taken as the input to the Fsnet.The Softmax classifier is automatically trained and learned without manual intervention.With the trained Softmax classifier, each pixel of the image is classified to achieve fine segmentation and obtain a more accurate tongue image.Finally, the designed algorithm performs post-processing on the finely divided tongue image.The morphology-related algorithm is used to deal with the fine-segmented tongue image, and can further eliminate noise and edge roughness.Therefore, the segmentation result is further optimized.In addition, the training of deep convolutional neural network depends on many samples.The collection and labeling of medical images are difficult.Consequently, large-scale tongue image datasets are difficult to obtain.When a small-scale dataset is used for direct training, the network is not easy to converge; moreover, overfitting can occur easily.The desired results are difficult to achieve.In the training process, three aspects are considered, namely, training strategy, network structure, and dataset, to avoid the overfitting of models.ResultIn this study, a database of 2 764 tongue images is constructed, and the five-cross experiment is performed on this database.Experimental results show that the proposed algorithm can achieve better segmentation results and faster processing.Accuracy, recall rate, and F-measure are selected as the evaluation criteria.As opposed to the three common traditional segmentation methods, the proposed method can increase the comprehensive F-measure by 0.58, 0.34, and 0.12 and the efficiency by at least 6 times.Moreover, as opposed to the MNC algorithm based on deep learning, the F-measure can be increased by 0.17 while efficiency can be increased by 1.9 times.ConclusionThe method based on deep learning is applied to tongue segmentation to help realize accurate, robust, and rapid tongue segmentation.The tongue is positioned before segmentation, which helps reduce the division of the misclassification and leakage points further.The models are combined in a cascading manner, which is flexible and easily combines the model of the tongue positioning stage with other methods to assist in segmentation.Experimental results show that the accuracy of tongue segmentation is effectively improved, and a solid foundation is established for follow-up tongue automatic identification and analysis with the proposed algorithm.关键词:convolutional neural network;deep learning;tongue segmentation;two-stage semantic segmentation;morphology12|4|8更新时间:2024-05-07
摘要:ObjectiveThe tongue is difficult to segment accurately due to the blurred contours and the similar colors of the surrounding tissue.Current tongue segmentation methods, whether based on texture analysis, edge detection, or threshold segmentation, mostly extract the color features of the tongue image, i.e., they are pixel-based segmentation methods.Although color features are easy to extract, the position information of the target is difficult to express.The color between the tongue and the background is similar, and the color features of the tongue and the background may overlap.Therefore, tongue information is difficult to express by using the color features of the tongue image.The deep semantic information of the image should be extracted and more complete features must be obtained to achieve an accurate segmentation of the tongue body.A tongue segmentation method based on two-stage convolutional neural network is proposed in this paper.The cascade method is used to combine the networks, and the output of the previous stage is taken as the input of the next stage.MethodFirst, in the rough segmentation stage, the rough segmentation network (Rsnet) consists of the convolutional and fully connected layers.The problem of excessive interference information in the original tongue image needs to be solved.Thus, the region suggestion strategy is adopted to obtain tongue candidate boxes, and the regions of interest are extracted from the similar background, i.e., the tongue is located and a large amount of interference information are removed.Therefore, the influence of the tissue around the tongue during the segmentation of the tongue is weakened.Second, in the fine segmentation phase, the fine segmentation network (Fsnet) consists of the convolutional and deconvolutional layers.The regions of interest obtained in the previous stage are taken as the input to the Fsnet.The Softmax classifier is automatically trained and learned without manual intervention.With the trained Softmax classifier, each pixel of the image is classified to achieve fine segmentation and obtain a more accurate tongue image.Finally, the designed algorithm performs post-processing on the finely divided tongue image.The morphology-related algorithm is used to deal with the fine-segmented tongue image, and can further eliminate noise and edge roughness.Therefore, the segmentation result is further optimized.In addition, the training of deep convolutional neural network depends on many samples.The collection and labeling of medical images are difficult.Consequently, large-scale tongue image datasets are difficult to obtain.When a small-scale dataset is used for direct training, the network is not easy to converge; moreover, overfitting can occur easily.The desired results are difficult to achieve.In the training process, three aspects are considered, namely, training strategy, network structure, and dataset, to avoid the overfitting of models.ResultIn this study, a database of 2 764 tongue images is constructed, and the five-cross experiment is performed on this database.Experimental results show that the proposed algorithm can achieve better segmentation results and faster processing.Accuracy, recall rate, and F-measure are selected as the evaluation criteria.As opposed to the three common traditional segmentation methods, the proposed method can increase the comprehensive F-measure by 0.58, 0.34, and 0.12 and the efficiency by at least 6 times.Moreover, as opposed to the MNC algorithm based on deep learning, the F-measure can be increased by 0.17 while efficiency can be increased by 1.9 times.ConclusionThe method based on deep learning is applied to tongue segmentation to help realize accurate, robust, and rapid tongue segmentation.The tongue is positioned before segmentation, which helps reduce the division of the misclassification and leakage points further.The models are combined in a cascading manner, which is flexible and easily combines the model of the tongue positioning stage with other methods to assist in segmentation.Experimental results show that the accuracy of tongue segmentation is effectively improved, and a solid foundation is established for follow-up tongue automatic identification and analysis with the proposed algorithm.关键词:convolutional neural network;deep learning;tongue segmentation;two-stage semantic segmentation;morphology12|4|8更新时间:2024-05-07 -
 摘要:ObjectiveDetection and analysis of thyroid nodules play vital roles in diagnosing thyroid cancer.With the development of theories and technologies in medical imaging, most of the thyroid nodules can be incidentally detected in the early stage.However, the nature of nodule lacks accurate judgement, leading to that many patients with benign nodules still need Fine Needle Aspiration (FNA) biopsies or surgeries, increasing the physical pain and mental pressure of patients as well as unnecessary medical health care costs.Therefore, we present an image-based computer-aided diagnosis (CAD) system for classifying the thyroid nodules in ultrasound images in this paper, which novelly applies the image features fused by both high-level features from deep learning network and low-level features from texture descriptor.MethodOur proposed thyroid nodule classification method consists of four steps.Firstly, we pre-process the ultrasound image to enhance the image quality, including searching scale ticks, calibrating images so that the pixel-distance in each image represents the same real-world distance, removing the artifacts and restoring images so that the lesion regions in the images are not interrupted.Secondly, the enhanced images are augmented to enlarge the size of training data set and used to fine-tune the parameters of the pre-trained GoogLeNet convolutional neural network.Meanwhile the rotation invariant uniform local binary pattern (ULBP) features are extracted from each of the images as the low-level texture features.Thirdly, the high-level deep features extracted by the fine-tuned GoogLeNet neural network and the low-level ULBP features are normalized and cascaded as one fusion feature that can represent both the semantic context and the texture patterns distributed in the image.Finally, the fusion features of the images are sent to the Cost-sensitive Random Forest classifier to classify the images into "malignant" and "benign" cases.ResultThe proposed classification method is applied to a standard open access thyroid nodule database to evaluate the effectiveness, achieving excellent classification performance where the accuracy, sensitivity, specificity and area of the ROC curve are 99.15%, 99.73%, 95.85% and 0.9970 respectively.ConclusionExperimental results indicate that the high-level features extracted by the deep neural network from the medical ultrasound image can reflect the visual features of the lesion region, while the low-level texture features can describe the edges, direction and distribution of intensities.The combination of the two types of features can describe the differences between the lesion regions and other regions, and the differences between lesions regions of malignant and benign thyroid nodules.Therefore, the proposed method can classify the thyroid nodules accurately, and provides the superior performance over most of the state-of-the-art thyroid nodule classification approaches, especially in reducing the false positive rate of the diagnosis.关键词:ultrasound image classification;thyroid nodule;computer-aided diagnosis;deep learning;convolutional neural network;transfer learning24|4|11更新时间:2024-05-07
摘要:ObjectiveDetection and analysis of thyroid nodules play vital roles in diagnosing thyroid cancer.With the development of theories and technologies in medical imaging, most of the thyroid nodules can be incidentally detected in the early stage.However, the nature of nodule lacks accurate judgement, leading to that many patients with benign nodules still need Fine Needle Aspiration (FNA) biopsies or surgeries, increasing the physical pain and mental pressure of patients as well as unnecessary medical health care costs.Therefore, we present an image-based computer-aided diagnosis (CAD) system for classifying the thyroid nodules in ultrasound images in this paper, which novelly applies the image features fused by both high-level features from deep learning network and low-level features from texture descriptor.MethodOur proposed thyroid nodule classification method consists of four steps.Firstly, we pre-process the ultrasound image to enhance the image quality, including searching scale ticks, calibrating images so that the pixel-distance in each image represents the same real-world distance, removing the artifacts and restoring images so that the lesion regions in the images are not interrupted.Secondly, the enhanced images are augmented to enlarge the size of training data set and used to fine-tune the parameters of the pre-trained GoogLeNet convolutional neural network.Meanwhile the rotation invariant uniform local binary pattern (ULBP) features are extracted from each of the images as the low-level texture features.Thirdly, the high-level deep features extracted by the fine-tuned GoogLeNet neural network and the low-level ULBP features are normalized and cascaded as one fusion feature that can represent both the semantic context and the texture patterns distributed in the image.Finally, the fusion features of the images are sent to the Cost-sensitive Random Forest classifier to classify the images into "malignant" and "benign" cases.ResultThe proposed classification method is applied to a standard open access thyroid nodule database to evaluate the effectiveness, achieving excellent classification performance where the accuracy, sensitivity, specificity and area of the ROC curve are 99.15%, 99.73%, 95.85% and 0.9970 respectively.ConclusionExperimental results indicate that the high-level features extracted by the deep neural network from the medical ultrasound image can reflect the visual features of the lesion region, while the low-level texture features can describe the edges, direction and distribution of intensities.The combination of the two types of features can describe the differences between the lesion regions and other regions, and the differences between lesions regions of malignant and benign thyroid nodules.Therefore, the proposed method can classify the thyroid nodules accurately, and provides the superior performance over most of the state-of-the-art thyroid nodule classification approaches, especially in reducing the false positive rate of the diagnosis.关键词:ultrasound image classification;thyroid nodule;computer-aided diagnosis;deep learning;convolutional neural network;transfer learning24|4|11更新时间:2024-05-07 -
 摘要:ObjectiveDiabetic retinopathy(DR) is a serious eye disease that causes blindness.The retinal pathological image is an important criterion for diagnosing eye diseases, and the accurate classification of retinal images is a crucial step taken by doctors in developing personalized treatment plans.The automated classification of diabetic retinopathy images has significant clinical values.The traditional image classification methods based on manually extracted features have problems, including complex retinal image processing, discriminative features extraction difficulties, poor classification performance, time-consuming, and difficult objective and consistent diagnoses.In this paper, an improved deep convolutional neural network based on AlexNet and a deep classifier are proposed to realize automated diabetic retinopathy image classification.MethodFirst, training the retinal samples is insufficient because retinal images contain much noise, and the differences between retinal pathological images at adjacent stages are small.These prevent the application of convolutional neural networks in retinal images classification, and retinal images should be preprocessed before they are used as training samples.Preprocessing mainly includes retinal image denoising, enhancement, and normalization.The small number of retinal images and data imbalance at different stages are solved by data enhancement.Second, the feature extraction network is designed based on the network structure of AlexNet.The data distribution is changed during the training process.Hence, a batch normalization layer is introduced before every convolutional layer and fully connected layer of the AlexNet network to produce a new deep network, which we call the BNnet network.The introduction of a batch normalization layer can accelerate the convergence of the network, improve the classification accuracy of the obtained model, and reduce the need for a dropout layer.The BNnet network is a complex deep convolutional neural network, which not only serves as a feature extraction network for retinal images but also effectively suppresses data distribution changes in the training process.In this work, the BNnet network is pre-trained using the ILSVRC2012 dataset based on the transfer learning strategy, and the obtained model is migrated to the enhanced diabetic retinopathy dataset for further study to capture the distinguishing features.Finally, a classifier is designed based on the fully connected layer, which can map the learned deep features to the sample label space.The classifier is composed of the fully connected, ReLU, and dropout layers and is applied in learning to partition a diabetic retinopathy status to no DR, mild DR, moderate DR, severe DR, and proliferative DR.ResultWe designed four groups of comparative experiments to fully describe the effects of the different depths of neural network and the different training methods, the introduced batch normalized layer, and data preprocessing of the experimental results.The experimental results show that the more layers the network has, the more features are learned with sufficient training samples, and the classification performance of the pre-trained network is better than the traditional direct training method.Moreover, the proposed BNnet neural network and training method can capture the differences of various stages of diabetic retinopathy with a classification accuracy of up to 93%, outperforming other methods.The introduction of the batch normalization layer can control the data distribution changes during the training process and improve the recognition rate.In the case of insufficient retinal image samples, the adoption of transfer learning and data enhancement strategies is good for extracting deep discriminative features for classification.Hence, a deep classifier that is composed of fully connected layers can accurately distinguish the stage when a retinal image is located, indicating that the obtained deep features based on BNnet and transfer learning can provide suitable information for classifiers to accurately classify retinal images into five categories.ConclusionWe use deep learning methods to achieve the automatic classification of retinal images.We also present a new diabetic retinopathy classification framework that mainly benefits from three important components:the image preprocessing stage, the deep features extraction stage that is based on transfer learning strategies and BNnet neural networks, and the stable classification stage.Intensive dropout and ReLU are used to suppress the over-fitting problem of the deep learning algorithm when the training samples are insufficient.Experimental results show that deep features combined with the proposed methods can provide suitable information for the construction of the most accurate prediction mode, predict diabetic retinopathy status, and effectively avoid the limitations of manual feature extraction and image classification.This method has relatively better robustness and generalization, and it can be widely used for various image classification problems.In future studies, we will likely develop a real-time computer-aided diagnosis system for diabetic retina images based on the above mentioned approach.关键词:diabetic retinopathy image classification;convolution neural network;deep learning;transfer learning;deep features11|4|10更新时间:2024-05-07
摘要:ObjectiveDiabetic retinopathy(DR) is a serious eye disease that causes blindness.The retinal pathological image is an important criterion for diagnosing eye diseases, and the accurate classification of retinal images is a crucial step taken by doctors in developing personalized treatment plans.The automated classification of diabetic retinopathy images has significant clinical values.The traditional image classification methods based on manually extracted features have problems, including complex retinal image processing, discriminative features extraction difficulties, poor classification performance, time-consuming, and difficult objective and consistent diagnoses.In this paper, an improved deep convolutional neural network based on AlexNet and a deep classifier are proposed to realize automated diabetic retinopathy image classification.MethodFirst, training the retinal samples is insufficient because retinal images contain much noise, and the differences between retinal pathological images at adjacent stages are small.These prevent the application of convolutional neural networks in retinal images classification, and retinal images should be preprocessed before they are used as training samples.Preprocessing mainly includes retinal image denoising, enhancement, and normalization.The small number of retinal images and data imbalance at different stages are solved by data enhancement.Second, the feature extraction network is designed based on the network structure of AlexNet.The data distribution is changed during the training process.Hence, a batch normalization layer is introduced before every convolutional layer and fully connected layer of the AlexNet network to produce a new deep network, which we call the BNnet network.The introduction of a batch normalization layer can accelerate the convergence of the network, improve the classification accuracy of the obtained model, and reduce the need for a dropout layer.The BNnet network is a complex deep convolutional neural network, which not only serves as a feature extraction network for retinal images but also effectively suppresses data distribution changes in the training process.In this work, the BNnet network is pre-trained using the ILSVRC2012 dataset based on the transfer learning strategy, and the obtained model is migrated to the enhanced diabetic retinopathy dataset for further study to capture the distinguishing features.Finally, a classifier is designed based on the fully connected layer, which can map the learned deep features to the sample label space.The classifier is composed of the fully connected, ReLU, and dropout layers and is applied in learning to partition a diabetic retinopathy status to no DR, mild DR, moderate DR, severe DR, and proliferative DR.ResultWe designed four groups of comparative experiments to fully describe the effects of the different depths of neural network and the different training methods, the introduced batch normalized layer, and data preprocessing of the experimental results.The experimental results show that the more layers the network has, the more features are learned with sufficient training samples, and the classification performance of the pre-trained network is better than the traditional direct training method.Moreover, the proposed BNnet neural network and training method can capture the differences of various stages of diabetic retinopathy with a classification accuracy of up to 93%, outperforming other methods.The introduction of the batch normalization layer can control the data distribution changes during the training process and improve the recognition rate.In the case of insufficient retinal image samples, the adoption of transfer learning and data enhancement strategies is good for extracting deep discriminative features for classification.Hence, a deep classifier that is composed of fully connected layers can accurately distinguish the stage when a retinal image is located, indicating that the obtained deep features based on BNnet and transfer learning can provide suitable information for classifiers to accurately classify retinal images into five categories.ConclusionWe use deep learning methods to achieve the automatic classification of retinal images.We also present a new diabetic retinopathy classification framework that mainly benefits from three important components:the image preprocessing stage, the deep features extraction stage that is based on transfer learning strategies and BNnet neural networks, and the stable classification stage.Intensive dropout and ReLU are used to suppress the over-fitting problem of the deep learning algorithm when the training samples are insufficient.Experimental results show that deep features combined with the proposed methods can provide suitable information for the construction of the most accurate prediction mode, predict diabetic retinopathy status, and effectively avoid the limitations of manual feature extraction and image classification.This method has relatively better robustness and generalization, and it can be widely used for various image classification problems.In future studies, we will likely develop a real-time computer-aided diagnosis system for diabetic retina images based on the above mentioned approach.关键词:diabetic retinopathy image classification;convolution neural network;deep learning;transfer learning;deep features11|4|10更新时间:2024-05-07 -
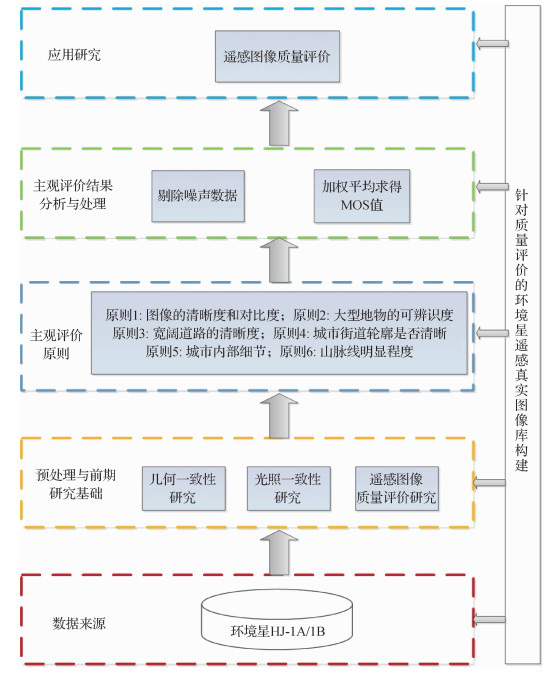 摘要:ObjectiveAdvances in space technology have resulted in the rapid increase of satellites in orbit and the ever-increasing scale of remote sensing image data.However, the ineffective utilization of remote sensing data has become a common issue.Remote sensing image quality assessment (RSIQA) not only selects valuable images for other image processing tasks, such as target recognition and object classification, but also monitors the service condition of satellite equipment according to the changing trend of remote sensing image quality.The choice on whether to adjust parameters or repair or replace satellite equipment depends on the assessment reports.RSIQA can be performed either subjectively or objectively.Subjective RSIQA is limited by time and cost considerations, and it can be easily influenced by experimental conditions.These limitations prohibit the extensive use of subjective quality assessment for remote sensing.According to the degree of assessment of a reference image, objective quality assessment can be classified as full, reduced, or no-reference methods.Most RSIQA methods separately model the different distortion types.Therefore, these methods may have not considered the interaction among different distortion types.Furthermore, most methods are based on simulated images because remote sensing data are difficult to obtain, but complex distortions are also difficult to simulate.Although the research on authentic remote sensing images has practical value, a public authentic remote sensing image database for quality assessment has still not been established in China.In other words, RSIQA may still lack a credible verification platform.MethodThis study builds an authentic remote sensing image database for quality assessment that refers to several existing databases, such as the LIVE simulated image database and usability-based remote sensing image database.Most remote sensing image data are either confidential or for sale, which renders it difficult to acquire resources.By contrast, resources from environmental satellites are public and free.For instance, images of a place taken at different times are easy to collect.Therefore, we choose environmental satellite HJ-1A/1B with a resolution of 30 m to obtain remote sensing image data with a per image size of 600×600.For database universality, we select different surface types, including farmland, river, city, airport, mountain, and port.After the light and geometric consistency corrections, 70 representative groups are selected for the database.Given the difficulty of distinguishing surface form in images with low resolution, subjective assessment cannot refer to traditional principles.Hence, we propose principles of quality grading from six aspects:contrast of the entire image, discernibility degree of large-scale surfaces, definition of wide roads, definition of city skyline, discernibility degree of city internal details, and definition of mountain lines.To ensure the objectivity and universality of the subjective quality scores, we choose personnel with two different knowledge backgrounds who will oversee the assessment.One is a non-professional staff whose expertise is image processing but not image quality assessment, and the other is a professional personnel with image quality assessment expertise.They label each remote sensing image according to the principles mentioned above and their own experience in image processing.The experimental equipment, assessment process, and experimental environment are also considered.For the convenience of subjective assessment, we construct the image quality grading system.We also analyze and screen the assessment scores.After the unreasonable scores are eliminated, we obtain the final subjective quality score, i.e., the mean opinion score.Thus, the database contains 350 authentic remote sensing images with corresponding subjective quality scores, including 70 groups of images.Each group contains 5 images of the same location at 5 different times.The distortion of an authentic remote sensing image is more complex than that of a simulated one.An image may contain several distortion types, and the effect of every distortion type of an image may interact with that of another image.Moreover, the features are difficult to extract in traditional machine learning metrics.Therefore, we verify the usability of the database with the RSIQA method based on the convolutional neural network because of its superior performance in feature extraction.The input of this network is a remote sensing image patch with a corresponding subjective quality score.The main architecture consists of fifty 7×7 convolutional kernels, one 26×26 max pooling, and two full connection layers with a size of 800.The output of the network is the predicted quality score.ResultIn the experiment, we compare the performance of the proposed metric and the four up-to-date no-reference image quality assessment metrics (FEDM, DⅡVINE, BRISQUE, and SSEQ) with that of the authentic remote sensing image database.The result indicates that the existing no-reference image quality assessment metrics for simulated images are unsuitable for this new remote sensing image database, which indicates a major difference between simulated images and authentic remote sensing images.The result of the method based on convolutional neural network demonstrates the usability of our new database.In addition, we analyze the relationship between the performance and the scale of the training and testing sets because the performance of a traditional machine learning algorithm depends on extracted features, Moreover, in convolutional neural networks, an important aspect is the scale of the training data.Therefore, the performances of traditional image quality assessment metrics are stable with the decreasing scale of training data.Despite the decline in the performance of the proposed convolutional neural network-based metric, it is still superior to traditional metrics a certain extent.ConclusionThis study proposes a database for RSIQA.Here, the database contains 350 images of 70 different places captured at different times.We verify the reasonability of our database through the metric based on convolutional neural network.The performance of the proposed metric demonstrates the ability of the database to provide a verification platform for RSIQA.Furthermore, the proposed metric can support the application of deep learning on remote sensing image processing.关键词:remote sensing image quality assessment;remote sensing image database;authentic image;environmental satellite;convolutional neural network12|6|0更新时间:2024-05-07
摘要:ObjectiveAdvances in space technology have resulted in the rapid increase of satellites in orbit and the ever-increasing scale of remote sensing image data.However, the ineffective utilization of remote sensing data has become a common issue.Remote sensing image quality assessment (RSIQA) not only selects valuable images for other image processing tasks, such as target recognition and object classification, but also monitors the service condition of satellite equipment according to the changing trend of remote sensing image quality.The choice on whether to adjust parameters or repair or replace satellite equipment depends on the assessment reports.RSIQA can be performed either subjectively or objectively.Subjective RSIQA is limited by time and cost considerations, and it can be easily influenced by experimental conditions.These limitations prohibit the extensive use of subjective quality assessment for remote sensing.According to the degree of assessment of a reference image, objective quality assessment can be classified as full, reduced, or no-reference methods.Most RSIQA methods separately model the different distortion types.Therefore, these methods may have not considered the interaction among different distortion types.Furthermore, most methods are based on simulated images because remote sensing data are difficult to obtain, but complex distortions are also difficult to simulate.Although the research on authentic remote sensing images has practical value, a public authentic remote sensing image database for quality assessment has still not been established in China.In other words, RSIQA may still lack a credible verification platform.MethodThis study builds an authentic remote sensing image database for quality assessment that refers to several existing databases, such as the LIVE simulated image database and usability-based remote sensing image database.Most remote sensing image data are either confidential or for sale, which renders it difficult to acquire resources.By contrast, resources from environmental satellites are public and free.For instance, images of a place taken at different times are easy to collect.Therefore, we choose environmental satellite HJ-1A/1B with a resolution of 30 m to obtain remote sensing image data with a per image size of 600×600.For database universality, we select different surface types, including farmland, river, city, airport, mountain, and port.After the light and geometric consistency corrections, 70 representative groups are selected for the database.Given the difficulty of distinguishing surface form in images with low resolution, subjective assessment cannot refer to traditional principles.Hence, we propose principles of quality grading from six aspects:contrast of the entire image, discernibility degree of large-scale surfaces, definition of wide roads, definition of city skyline, discernibility degree of city internal details, and definition of mountain lines.To ensure the objectivity and universality of the subjective quality scores, we choose personnel with two different knowledge backgrounds who will oversee the assessment.One is a non-professional staff whose expertise is image processing but not image quality assessment, and the other is a professional personnel with image quality assessment expertise.They label each remote sensing image according to the principles mentioned above and their own experience in image processing.The experimental equipment, assessment process, and experimental environment are also considered.For the convenience of subjective assessment, we construct the image quality grading system.We also analyze and screen the assessment scores.After the unreasonable scores are eliminated, we obtain the final subjective quality score, i.e., the mean opinion score.Thus, the database contains 350 authentic remote sensing images with corresponding subjective quality scores, including 70 groups of images.Each group contains 5 images of the same location at 5 different times.The distortion of an authentic remote sensing image is more complex than that of a simulated one.An image may contain several distortion types, and the effect of every distortion type of an image may interact with that of another image.Moreover, the features are difficult to extract in traditional machine learning metrics.Therefore, we verify the usability of the database with the RSIQA method based on the convolutional neural network because of its superior performance in feature extraction.The input of this network is a remote sensing image patch with a corresponding subjective quality score.The main architecture consists of fifty 7×7 convolutional kernels, one 26×26 max pooling, and two full connection layers with a size of 800.The output of the network is the predicted quality score.ResultIn the experiment, we compare the performance of the proposed metric and the four up-to-date no-reference image quality assessment metrics (FEDM, DⅡVINE, BRISQUE, and SSEQ) with that of the authentic remote sensing image database.The result indicates that the existing no-reference image quality assessment metrics for simulated images are unsuitable for this new remote sensing image database, which indicates a major difference between simulated images and authentic remote sensing images.The result of the method based on convolutional neural network demonstrates the usability of our new database.In addition, we analyze the relationship between the performance and the scale of the training and testing sets because the performance of a traditional machine learning algorithm depends on extracted features, Moreover, in convolutional neural networks, an important aspect is the scale of the training data.Therefore, the performances of traditional image quality assessment metrics are stable with the decreasing scale of training data.Despite the decline in the performance of the proposed convolutional neural network-based metric, it is still superior to traditional metrics a certain extent.ConclusionThis study proposes a database for RSIQA.Here, the database contains 350 images of 70 different places captured at different times.We verify the reasonability of our database through the metric based on convolutional neural network.The performance of the proposed metric demonstrates the ability of the database to provide a verification platform for RSIQA.Furthermore, the proposed metric can support the application of deep learning on remote sensing image processing.关键词:remote sensing image quality assessment;remote sensing image database;authentic image;environmental satellite;convolutional neural network12|6|0更新时间:2024-05-07
Medical Image Processing
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0