
最新刊期
卷 23 , 期 1 , 2018
-
 摘要:ObjectiveData hiding is a well-known method used to protect secret information or provide authentication. Thus, we can embed secret data into carriers, such as images and videos. After the embedding, the carriers can still perform as they were. Data hiding has many advantages over traditional encryption methods. Encryption algorithm can be regarded as a function used to transform secret data into cipher texts, and secret data and keys are parameters. However, making cipher texts understandable remains a challenge. If cipher texts are captured by an attacker, the attacker can easily notice that the texts must be processed, although he plain texts cannot be generated immediately. This situation may cause security issues. Such issues cannot happen in data hiding because the data-hiding process does not influence carrier readability. Humans also hardly notice the difference between cover and stego carriers. As a way of reversible data hiding, pixel permutation has a good ability of anti-gray histogram steganalysis but with low payload capacity. An adaptive reversible data-hiding algorithm based on pixel permutation is accordingly proposed.MethodFirst, a more efficient embedding unit structure than the conventional 2×2 pixel block structure is proposed. A cover image can be densely segmented, which provides a condition for improving payload capacity. For every embedded bit, the proposed triangular embedded pixel pair consists of 3 pixels. The specific shape and position of all embeddable pixel pairs (EPPs) are determined by the keys shared between sender and receiver. Second, EPPs are screened from all pixel pairs to avoid embedding secret bits in the pixel pairs that may cause a significant decline in image quality. Adaptive precoding is conducted according to the characteristic of gray trend of EPPs, such that the 0, 1 distribution in the binary sequence that represents all EPPs is as asymmetrical as possible. This adaptive precoding process effectively improves Huffman coding compression ratio to enhance payload capacity. Huffman coding is a method of compressing a sequence using the frequencies of different arrays. This method spends a minimal storage on arrays with a high frequency and adopts long code words to represent arrays that seldom occur. Finally, data are embedded into the cover image by permuting the two end pixels of the corresponding EPP bit by bit. Data extraction is the inverse process of data embedding. Receivers can obtain all correct EPPs according to the keys and two pixel pair embedding conditions, and secret data can be easily extracted by using a location map. Eight different gray-scale images are randomly selected from a standard gray-scale test image data set for the experiments. A key is created by a pseudo random number generator. For every cover image, we test the payload capacity and PSNR of a full-load stego image. The histograms of cover and stego images are shown to prove the histogram robustness of the proposed scheme.ResultsExperimental results demonstrate that the PSNR of the proposed scheme is improved by approximately 32% and its payload capacity is increased by more than 95% compared with those of a non-adaptive data-hiding algorithm with a 2×2 pixel block structure. The proposed scheme also keeps the robustness of gray-scale histograms before and after the data-hiding process. Notably, adaptability plays a decisive role in capacity improvement.ConclusionThis study presents a reversible information-hiding algorithm with high embedding capacity and a capability of anti-gray-scale histogram steganalysis. We construct an efficient embedding unit and differentiate embeddable regions for the characteristics of different cover images. The confidentiality of all embedding units is guaranteed by a key. The experimental results show that the proposed algorithm greatly improves payload capacity by adaptive precoding process and a special triangular pixel structure. Moreover, imperceptibility is kept in a high level by using appropriate EPP-filtering criteria. The proposed scheme considers the visual and statistical invisibilities of the data-hiding process. Consequently, the scheme provides a high security level for secret information when providing large embedding capacity of cover images. For practical applications, the proposed scheme can be utilized in secret information transmission, storage, and privacy protection. Although the payload capacity of the proposed scheme has been greatly enhanced compared with that of the same type of reversible data hiding methods, it remains lower than that of the methods without providing histogram robustness. Therefore, improving capacity while keeping confidentiality in a high level is worth of further research.关键词:reversible data hiding;pixel permutation;adaptivity;compress coding;embeddable pixel pair;grayscale histogram13|19|3更新时间:2024-05-07
摘要:ObjectiveData hiding is a well-known method used to protect secret information or provide authentication. Thus, we can embed secret data into carriers, such as images and videos. After the embedding, the carriers can still perform as they were. Data hiding has many advantages over traditional encryption methods. Encryption algorithm can be regarded as a function used to transform secret data into cipher texts, and secret data and keys are parameters. However, making cipher texts understandable remains a challenge. If cipher texts are captured by an attacker, the attacker can easily notice that the texts must be processed, although he plain texts cannot be generated immediately. This situation may cause security issues. Such issues cannot happen in data hiding because the data-hiding process does not influence carrier readability. Humans also hardly notice the difference between cover and stego carriers. As a way of reversible data hiding, pixel permutation has a good ability of anti-gray histogram steganalysis but with low payload capacity. An adaptive reversible data-hiding algorithm based on pixel permutation is accordingly proposed.MethodFirst, a more efficient embedding unit structure than the conventional 2×2 pixel block structure is proposed. A cover image can be densely segmented, which provides a condition for improving payload capacity. For every embedded bit, the proposed triangular embedded pixel pair consists of 3 pixels. The specific shape and position of all embeddable pixel pairs (EPPs) are determined by the keys shared between sender and receiver. Second, EPPs are screened from all pixel pairs to avoid embedding secret bits in the pixel pairs that may cause a significant decline in image quality. Adaptive precoding is conducted according to the characteristic of gray trend of EPPs, such that the 0, 1 distribution in the binary sequence that represents all EPPs is as asymmetrical as possible. This adaptive precoding process effectively improves Huffman coding compression ratio to enhance payload capacity. Huffman coding is a method of compressing a sequence using the frequencies of different arrays. This method spends a minimal storage on arrays with a high frequency and adopts long code words to represent arrays that seldom occur. Finally, data are embedded into the cover image by permuting the two end pixels of the corresponding EPP bit by bit. Data extraction is the inverse process of data embedding. Receivers can obtain all correct EPPs according to the keys and two pixel pair embedding conditions, and secret data can be easily extracted by using a location map. Eight different gray-scale images are randomly selected from a standard gray-scale test image data set for the experiments. A key is created by a pseudo random number generator. For every cover image, we test the payload capacity and PSNR of a full-load stego image. The histograms of cover and stego images are shown to prove the histogram robustness of the proposed scheme.ResultsExperimental results demonstrate that the PSNR of the proposed scheme is improved by approximately 32% and its payload capacity is increased by more than 95% compared with those of a non-adaptive data-hiding algorithm with a 2×2 pixel block structure. The proposed scheme also keeps the robustness of gray-scale histograms before and after the data-hiding process. Notably, adaptability plays a decisive role in capacity improvement.ConclusionThis study presents a reversible information-hiding algorithm with high embedding capacity and a capability of anti-gray-scale histogram steganalysis. We construct an efficient embedding unit and differentiate embeddable regions for the characteristics of different cover images. The confidentiality of all embedding units is guaranteed by a key. The experimental results show that the proposed algorithm greatly improves payload capacity by adaptive precoding process and a special triangular pixel structure. Moreover, imperceptibility is kept in a high level by using appropriate EPP-filtering criteria. The proposed scheme considers the visual and statistical invisibilities of the data-hiding process. Consequently, the scheme provides a high security level for secret information when providing large embedding capacity of cover images. For practical applications, the proposed scheme can be utilized in secret information transmission, storage, and privacy protection. Although the payload capacity of the proposed scheme has been greatly enhanced compared with that of the same type of reversible data hiding methods, it remains lower than that of the methods without providing histogram robustness. Therefore, improving capacity while keeping confidentiality in a high level is worth of further research.关键词:reversible data hiding;pixel permutation;adaptivity;compress coding;embeddable pixel pair;grayscale histogram13|19|3更新时间:2024-05-07 -
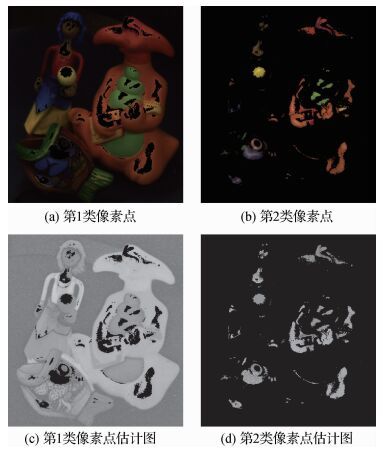 摘要:ObjectiveVarious inhomogeneous materials, including plastic, wood, ceramic, and other opaque nonconductors with uniform pigmentation, usually present some blocks of reflection areas due to nonuniform illumination conditions. However, these blocks of reflection areas often exert some negative effects on visual quality and degrade the performances of vision algorithms, such as color constancy, image segmentation, visual tracking, and object detection. For simplification, specular components are usually disregarded as outliers by methods based on diffuse component analysis. When we use traditional methods to remove the highlight of a simple image, they cannot completely separate the specular components of the image. For example, the colors and edges of images were always missed, parts of the result image exhibited color distortion, caused artifacts for noisy and highly textured surfaces, the method was inapplicable to natural images. In view of these shortcomings, an improved method of removing highlights based on bilateral filtering is proposed.MethodTo solve the shortcomings of the traditional methods, we raise an improved bilateral filtering method. The method comprises three stages. First, we can determine the relationship between the diffuse component and the maximum diffuse chromaticity of pixels in an image according to the dichromatic reflection model and by assuming that illumination chromaticity can be measured (with a white reference). If we want to separate the diffuse component from an image, then we must estimate the maximum diffuse chromaticity value for every pixel. An estimation of the maximum diffuse chromaticity, which is the key to separating specular and diffuse components, is thus necessary. Second, we use an appropriate threshold to divide the input image into two categories. The first class of pixels contains only a diffuse component, whereas the second class of pixels includes specular and diffuse components. We then implement our proposed method (two different algorithms) to estimate the maximum diffuse chromaticity of the two categories. We adopt a compensation function in the second class of pixels. This compensation function can exert a positive effect on pixels with similar RGB channels, as well as avoid the negative effect of the specular component of the second class of pixels. Third, we use the approximated maximum diffuse chromaticity in the second step to guide the smoothing and iteratively apply joint low-pass filter (bilateral filter) to update the maximum diffuse chromaticity estimation. This stage is based on a key observation that the maximum diffuse chromaticity in local patches in colorful images generally changes smoothly. We update the maximum diffuse chromaticity after every iteration. The maximum diffuse chromaticity values can be gradually propagated from diffuse pixels to specular pixels. Our algorithm does not stop until an insignificant difference (set at 0.02 in our experiments) exists between the updated and filtered maximum diffuse chromaticity values. In practice, our method generally converges after two to four iterations. As a result, our method can remove highlights more efficiently than previous methods.ResultsIn this study, we use classic images with highlights as processing objects and yield a new maximum diffuse chromaticity estimation of pixels that contain specular and diffuse reflections. We also yield a new maximum diffuse chromaticity estimation of remaining pixels that contain only diffuse reflection. With the maximum diffuse chromaticity image as a bilateral filtering guide map, we can remove the specular reflection component, as well as effectively preserve the image edge information. We remove the specular component of the pictures, and the color degradation of pixels with similar values in RGB channels is reduced. In the experiment, the proposed algorithm is compared with the methods of Yang et al. and Shen et al. We compare the peak-signal-to-noise ratios of 50 pictures and determine that our result images increase by 4.17% and 8.40% in average. The processing effect of the proposed algorithm is in line with the human eye vision. The experimental results on synthetic and real images show that our method performs better than the state-of-the-art methods in separating specular reflection.ConclusionWe propose a new estimation of maximum diffuse chromaticity in the highlight removal field. The use of a low-pass filter guarantees the estimated diffuse reflections. With a single color image, the highlight removal problem is formulated as an iterative bilateral filtering process that normally converges in two to four iterations. The experimental evaluation indicates that the proposed method can effectively remove the specular reflection components from images. We also provide an effective theoretical basis for indoor and outdoor images with specular reflection. Our future works involve solving the limitations of our method and practically applying it.关键词:dichromatic reflection model;specular reflection component;the maximum diffuse chromaticity estimation;range;bilateral filtering85|51|5更新时间:2024-05-07
摘要:ObjectiveVarious inhomogeneous materials, including plastic, wood, ceramic, and other opaque nonconductors with uniform pigmentation, usually present some blocks of reflection areas due to nonuniform illumination conditions. However, these blocks of reflection areas often exert some negative effects on visual quality and degrade the performances of vision algorithms, such as color constancy, image segmentation, visual tracking, and object detection. For simplification, specular components are usually disregarded as outliers by methods based on diffuse component analysis. When we use traditional methods to remove the highlight of a simple image, they cannot completely separate the specular components of the image. For example, the colors and edges of images were always missed, parts of the result image exhibited color distortion, caused artifacts for noisy and highly textured surfaces, the method was inapplicable to natural images. In view of these shortcomings, an improved method of removing highlights based on bilateral filtering is proposed.MethodTo solve the shortcomings of the traditional methods, we raise an improved bilateral filtering method. The method comprises three stages. First, we can determine the relationship between the diffuse component and the maximum diffuse chromaticity of pixels in an image according to the dichromatic reflection model and by assuming that illumination chromaticity can be measured (with a white reference). If we want to separate the diffuse component from an image, then we must estimate the maximum diffuse chromaticity value for every pixel. An estimation of the maximum diffuse chromaticity, which is the key to separating specular and diffuse components, is thus necessary. Second, we use an appropriate threshold to divide the input image into two categories. The first class of pixels contains only a diffuse component, whereas the second class of pixels includes specular and diffuse components. We then implement our proposed method (two different algorithms) to estimate the maximum diffuse chromaticity of the two categories. We adopt a compensation function in the second class of pixels. This compensation function can exert a positive effect on pixels with similar RGB channels, as well as avoid the negative effect of the specular component of the second class of pixels. Third, we use the approximated maximum diffuse chromaticity in the second step to guide the smoothing and iteratively apply joint low-pass filter (bilateral filter) to update the maximum diffuse chromaticity estimation. This stage is based on a key observation that the maximum diffuse chromaticity in local patches in colorful images generally changes smoothly. We update the maximum diffuse chromaticity after every iteration. The maximum diffuse chromaticity values can be gradually propagated from diffuse pixels to specular pixels. Our algorithm does not stop until an insignificant difference (set at 0.02 in our experiments) exists between the updated and filtered maximum diffuse chromaticity values. In practice, our method generally converges after two to four iterations. As a result, our method can remove highlights more efficiently than previous methods.ResultsIn this study, we use classic images with highlights as processing objects and yield a new maximum diffuse chromaticity estimation of pixels that contain specular and diffuse reflections. We also yield a new maximum diffuse chromaticity estimation of remaining pixels that contain only diffuse reflection. With the maximum diffuse chromaticity image as a bilateral filtering guide map, we can remove the specular reflection component, as well as effectively preserve the image edge information. We remove the specular component of the pictures, and the color degradation of pixels with similar values in RGB channels is reduced. In the experiment, the proposed algorithm is compared with the methods of Yang et al. and Shen et al. We compare the peak-signal-to-noise ratios of 50 pictures and determine that our result images increase by 4.17% and 8.40% in average. The processing effect of the proposed algorithm is in line with the human eye vision. The experimental results on synthetic and real images show that our method performs better than the state-of-the-art methods in separating specular reflection.ConclusionWe propose a new estimation of maximum diffuse chromaticity in the highlight removal field. The use of a low-pass filter guarantees the estimated diffuse reflections. With a single color image, the highlight removal problem is formulated as an iterative bilateral filtering process that normally converges in two to four iterations. The experimental evaluation indicates that the proposed method can effectively remove the specular reflection components from images. We also provide an effective theoretical basis for indoor and outdoor images with specular reflection. Our future works involve solving the limitations of our method and practically applying it.关键词:dichromatic reflection model;specular reflection component;the maximum diffuse chromaticity estimation;range;bilateral filtering85|51|5更新时间:2024-05-07 -
 摘要:ObjectiveThe multi-view video plus depth (MVD) format is gradually becoming one of the main representations for 3D videos. The 3D high-efficiency video coding (3D-HEVC) is the latest coding standard for compressing the MVD format. The 3D-HEVC inherits the coding structure of HEVC. Consequently, the splitting process of coding units (CUs) and the intra mode search process in depth map intra coding have great computational complexity. New techniques for depth map intra coding, such as depth modeling mode and simplified depth coding, have been introduced in recent years to preserve the sharp edges of depth maps. These techniques play an important role in the coding of depth maps. However, the adoption of these techniques further increases the computational complexity in 3D-HEVC encoder. A fast algorithm for depth map intra coding is proposed in this study to reduce the computational complexity of depth map intra coding.MethodThere are a lot of large smooth regions which are separated by sharp edges in depth maps. The CU splitting process and the rough mode decision (RMD) process are improved by the proposed algorithm by using the unique characteristics of depth maps. An algorithm based on the concept of texture primitive is proposed for the hierarchical quad-tree coding structure to early terminate the CU splitting process. First, the gradient matrix of the current CU can be calculated by using the texture analysis algorithm based on texture primitive. On the basis of statistical analysis, a strong correlation between the optimal size and sum of gradient values in gradient matrix is considered for each CU. If the sum of gradient values in gradient matrix is small, then the optimal size of current CU will be large. By contrast, if the sum of gradient values in gradient matrix is large, then the optimal size of current CU will be small. Therefore, if the sum of gradient values in gradient matrix is smaller than a given threshold, then the CU splitting process should be terminated. For the RMD process, the texture features and the smallest
摘要:ObjectiveThe multi-view video plus depth (MVD) format is gradually becoming one of the main representations for 3D videos. The 3D high-efficiency video coding (3D-HEVC) is the latest coding standard for compressing the MVD format. The 3D-HEVC inherits the coding structure of HEVC. Consequently, the splitting process of coding units (CUs) and the intra mode search process in depth map intra coding have great computational complexity. New techniques for depth map intra coding, such as depth modeling mode and simplified depth coding, have been introduced in recent years to preserve the sharp edges of depth maps. These techniques play an important role in the coding of depth maps. However, the adoption of these techniques further increases the computational complexity in 3D-HEVC encoder. A fast algorithm for depth map intra coding is proposed in this study to reduce the computational complexity of depth map intra coding.MethodThere are a lot of large smooth regions which are separated by sharp edges in depth maps. The CU splitting process and the rough mode decision (RMD) process are improved by the proposed algorithm by using the unique characteristics of depth maps. An algorithm based on the concept of texture primitive is proposed for the hierarchical quad-tree coding structure to early terminate the CU splitting process. First, the gradient matrix of the current CU can be calculated by using the texture analysis algorithm based on texture primitive. On the basis of statistical analysis, a strong correlation between the optimal size and sum of gradient values in gradient matrix is considered for each CU. If the sum of gradient values in gradient matrix is small, then the optimal size of current CU will be large. By contrast, if the sum of gradient values in gradient matrix is large, then the optimal size of current CU will be small. Therefore, if the sum of gradient values in gradient matrix is smaller than a given threshold, then the CU splitting process should be terminated. For the RMD process, the texture features and the smallest$LCRD_{\rm cost}$ $LCRD_{\rm cost}$ 关键词:3D-HEVC;computational complexity;depth map;intra coding;coding unit (CU);gradient matrix15|4|1更新时间:2024-05-07
Image Processing and Coding

-
 摘要:ObjectiveIris is the annular part between the pupil and white sclera of human eyes and possesses rich texture information. The iris texture is highly discriminative and stable, which makes iris an important part of the human body for biometric identification. Iris recognition aims to assign a unique identity label to each iris image based on automatic preprocessing, feature analysis, and feature matching. As a reliable method for personal identification, iris recognition has numerous important applications in public and personal security areas. The rapid development of iris recognition in commercial applications has dramatically increased the sizes of iris databases, thereby resulting in large database sizes and slow system responses. Race classification is a key method in solving large-scale iris classification problems. Iris is initially classified according to race, and a rough classification result is obtained. Iris is then matched with the subclass where it belongs. In this way, the runtime for iris recognition can be reduced effectively. Several applications can be adopted for race classification. In the era of information, if a computer can automatically detect the race information of a user, then it can match the computer language with the user language and provide a personalized login interface. Existing approaches to iris-based race classification mainly focus on Asian and non-Asian iris image classification, and the features used for classification are manually designed. Sub-ethnic classification, such as the classification of Koreans, Japanese, and Chinese, has also emerged in recent years. However, no sub-ethnic classification based on iris images has been conducted. No significant difference in iris texture exists among subspecies compared with the iris of the basic race, and manually designed features for basic race are not suited to sub-ethnic classification. These problems pose a great challenge to sub-ethnic classification on iris images. This study proposes a novel race classification method based on deep features and Fisher vectors of iris texture. The study focuses on basic race classification of Asian and non-Asian iris images and sub-ethnic classification of Han and Tibetan iris images.MethodThe original iris image contains not only the annular iris but also the pupil, eyelids, eyelashes, and other eye areas, as well as some light reflection of the formation of light spots. Therefore, the iris image should be preprocessed before features are extracted. The iris image preprocessing mainly includes iris detection, localization, segmentation, and normalization. Normalized unwrapped iris images are obtained. Our method feeds the preprocessed iris images to a convolutional neural network to extract deep features as low-level features. We use a Gaussian mixture model to cluster the features to obtain iris texture textons, and the model is then used with Fisher vector to extract high-level features. A support vector machine is used for classification.ResultsWe evaluate our proposed method on two iris image databases, namely, CASIA multi-race iris race database and Han-Tibetan iris race database, for basic race and sub-ethnic classifications, respectively. Thus far, no iris database dedicated to sub-ethnic classification has been developed. We establish a Han-Tibetan sub-ethnic classification database to further study race classification. We perform an evaluation in two different dataset settings, namely non-person-disjoint and person disjoint. Non-person-disjoint experimental setting refers to the random selection of certain iris images as the training set and the remaining iris images are the test set. In this way, the iris image of the same person can appear in the training and testing sets. Person-disjoint experimental setting means we randomly select iris images of some people as the training set and the iris images of remaining people as the testing set. This method can ensure that the iris images of the same person do not appear in the training and testing sets simultaneously. When we design the experiment, we compare the two methods on the two databases. Experimental results show that the proposed method can achieve 99.93% accuracy in non-person-disjoint approach and 91.94% in person-disjoint manner on the Asian and non-Asian dataset. For the Han-Tibetan dataset, the proposed method can obtain 99.69% accuracy in non-person-disjoint approach and 82.25% accuracy in person-disjoint manner.ConclusionThis study proposes a race classification method based on deep features and Fisher vector of iris texture. The method learns low-level visual features highly suitable for iris race classification from training data to solve the problem of traditional methods, in which a strong prior knowledge is required to design discriminating features. In a data-driven manner, the proposed method can learn features significantly suitable for basic race classification and sub-ethnic classification, which improves the accuracy of race classification. Fisher vector is used to encode low-level visual features. The obtained features can describe the global texture features of iris images, as well as retain local texture features, which is favorable to race classification. We use iris images to solve the sub-ethnic classification of Han and Tibetan for the first time and prove the feasibility and validity of sub-ethnic classification based on iris images. A new iris image database, which is suitable for sub-ethnic classification based on iris images is also established. The experimental results show that the differences in sub-ethnic iris images are insignificant and that the classification is challenging.关键词:race classification;Fisher vector;Gaussian mixture model;feature representation;deep learning15|4|2更新时间:2024-05-07
摘要:ObjectiveIris is the annular part between the pupil and white sclera of human eyes and possesses rich texture information. The iris texture is highly discriminative and stable, which makes iris an important part of the human body for biometric identification. Iris recognition aims to assign a unique identity label to each iris image based on automatic preprocessing, feature analysis, and feature matching. As a reliable method for personal identification, iris recognition has numerous important applications in public and personal security areas. The rapid development of iris recognition in commercial applications has dramatically increased the sizes of iris databases, thereby resulting in large database sizes and slow system responses. Race classification is a key method in solving large-scale iris classification problems. Iris is initially classified according to race, and a rough classification result is obtained. Iris is then matched with the subclass where it belongs. In this way, the runtime for iris recognition can be reduced effectively. Several applications can be adopted for race classification. In the era of information, if a computer can automatically detect the race information of a user, then it can match the computer language with the user language and provide a personalized login interface. Existing approaches to iris-based race classification mainly focus on Asian and non-Asian iris image classification, and the features used for classification are manually designed. Sub-ethnic classification, such as the classification of Koreans, Japanese, and Chinese, has also emerged in recent years. However, no sub-ethnic classification based on iris images has been conducted. No significant difference in iris texture exists among subspecies compared with the iris of the basic race, and manually designed features for basic race are not suited to sub-ethnic classification. These problems pose a great challenge to sub-ethnic classification on iris images. This study proposes a novel race classification method based on deep features and Fisher vectors of iris texture. The study focuses on basic race classification of Asian and non-Asian iris images and sub-ethnic classification of Han and Tibetan iris images.MethodThe original iris image contains not only the annular iris but also the pupil, eyelids, eyelashes, and other eye areas, as well as some light reflection of the formation of light spots. Therefore, the iris image should be preprocessed before features are extracted. The iris image preprocessing mainly includes iris detection, localization, segmentation, and normalization. Normalized unwrapped iris images are obtained. Our method feeds the preprocessed iris images to a convolutional neural network to extract deep features as low-level features. We use a Gaussian mixture model to cluster the features to obtain iris texture textons, and the model is then used with Fisher vector to extract high-level features. A support vector machine is used for classification.ResultsWe evaluate our proposed method on two iris image databases, namely, CASIA multi-race iris race database and Han-Tibetan iris race database, for basic race and sub-ethnic classifications, respectively. Thus far, no iris database dedicated to sub-ethnic classification has been developed. We establish a Han-Tibetan sub-ethnic classification database to further study race classification. We perform an evaluation in two different dataset settings, namely non-person-disjoint and person disjoint. Non-person-disjoint experimental setting refers to the random selection of certain iris images as the training set and the remaining iris images are the test set. In this way, the iris image of the same person can appear in the training and testing sets. Person-disjoint experimental setting means we randomly select iris images of some people as the training set and the iris images of remaining people as the testing set. This method can ensure that the iris images of the same person do not appear in the training and testing sets simultaneously. When we design the experiment, we compare the two methods on the two databases. Experimental results show that the proposed method can achieve 99.93% accuracy in non-person-disjoint approach and 91.94% in person-disjoint manner on the Asian and non-Asian dataset. For the Han-Tibetan dataset, the proposed method can obtain 99.69% accuracy in non-person-disjoint approach and 82.25% accuracy in person-disjoint manner.ConclusionThis study proposes a race classification method based on deep features and Fisher vector of iris texture. The method learns low-level visual features highly suitable for iris race classification from training data to solve the problem of traditional methods, in which a strong prior knowledge is required to design discriminating features. In a data-driven manner, the proposed method can learn features significantly suitable for basic race classification and sub-ethnic classification, which improves the accuracy of race classification. Fisher vector is used to encode low-level visual features. The obtained features can describe the global texture features of iris images, as well as retain local texture features, which is favorable to race classification. We use iris images to solve the sub-ethnic classification of Han and Tibetan for the first time and prove the feasibility and validity of sub-ethnic classification based on iris images. A new iris image database, which is suitable for sub-ethnic classification based on iris images is also established. The experimental results show that the differences in sub-ethnic iris images are insignificant and that the classification is challenging.关键词:race classification;Fisher vector;Gaussian mixture model;feature representation;deep learning15|4|2更新时间:2024-05-07
Image Analysis and Recognition
-
 摘要:ObjectiveDescription, matching, similarity measurement, and retrieval of shapes are basic tasks in computer vision, image recognition, and machine intelligence, and they remain as open issues. Except for the methods of geometry complex transform and shape contour-based Fourier descriptor, all other methods are not information preserving, which means that the original shapes cannot be reconstructed from their descriptors. Consequently, the descriptors cannot be guaranteed to fully represent the characteristics of original shapes. Although geometry complex transform and shape contour-based Fourier descriptor are information preserving, they are only applicable to simple closed shapes or some other special types of shapes, which limits their applications. We propose a generic shape descriptor, which is named inside-circle distance transform (ICD). The ICD method can be used for matching, similarity measurement, and retrieval of any shape with obvious contours, and it is information preserving.MethodIn the ICD method, we initially calculate the minimum circumscribed circle of a shape. Then, we draw a set of equidistant parallel lines that are perpendicular to x-axes, calculate the intersections of each line and shape contour, and compute the distance vector for each line. We finally form a distance matrix with all distance vectors. We yield another distance matrix by rotating the shape anticlockwise around the center of its minimum circumscribed circle by $θ$ degree and repeating the aforementioned process. A set of distance matrices is generated by repeating the process for[360/$θ$] times. With all distance matrices of the shape in hand, we construct the feature matrix of the shape. The feature matrix of a shape is a representation of the original shape with rich information, which can be used to describe the original shape, to measure the similarity of two shapes and reconstruct the original shape. Therefore, ICD is an information-preserving method. This capability of ICD to reconstruct original shapes is useful. We can thoroughly understand the intrinsic of shapes using the ICD method. Feature matrix is a powerful tool for shape representation and shape matching. We prove that ICD is scaling, rotation, and translation invariant, which is an important property in shape description, matching, and retrieval.ResultsWe construct 40 shapes to verify the capability and test the effectiveness of the ICD method. The shapes are categorized into eight classes, with five shapes in each class. In each of these eight classes, one basic shape exists, and the others are deformations of the basic shape through modifications, such as twisting the contour or adding noise. We further expand the set of shapes by performing affine transformation with random scale factor, random rotation angle, and random translation of position to generate two new shapes for each of the 40 shapes. This expansion results in a total of 120 shapes. We initially perform a similarity measurement between each of the eight basic shapes and each of 12 randomly selected shapes. Experimental result shows that in similarity measurement of shapes, the ICD method generates the same vision results as those of human vision. If two shapes are determined to be similar, then the ICD method can calculate their scaling factor and orientation differences. We also test the effectiveness of retrieval through the well-known method of "Bullseye score." Results show that 38 out of 40 subclasses achieve a score of 100, which is extremely satisfactory. We compare the ICD method with three other classic shape description and matching methods, namely, shape context method, histogram of Radon transform, and generic Fourier descriptor, on the basis of the widely used shape database of MPEG-7. This database consists of 70 classes, with 20 shapes in each class and hence a total of 1400 shapes. The Bullseye score method is adopted. Results indicate that all the methods under evaluation have their own advantages and disadvantages with respect to different shape classes. Moreover, on average, the test score of the ICD method is approximately 20 points higher than those of the other three classic methods. ICD shows significant effects outperforming those of the other methods in all experiments. In the reconstruction experiments, we randomly select four shapes from the MPEG-7 database and reconstruct them by using the ICD method with varying parameters $k$ and $θ$, where $k$=30, 50, 150 and $θ$=1, 6. Experiment results show that the reconstructed shapes become accurate with the increase of parameter $k$ and decrease of parameter $θ$. The reconstruction experiments also imply that shape reconstruction is more sensitive to parameter $k$ than to parameter $θ$. In application scenarios in which the rotational angle is insignificant, $θ$=3 is an optimal recommendation by our experiments.ConclusionThe ICD method and its corresponding feature matrix can be used to represent, match, and retrieve shapes effectively. This method has the prominent feature of being information preserving, thereby assuring that it represents a shape without losing information. When this method is used to compute similarity of shapes, it can generate the same result as that of human vision. For two similar shapes, the ICD method can compute their scale factor and rotation differences. Theoretical analysis, mathematical proofs, and experiments show that ICD is effective, useful, and information preserving, and it outperforms several important classic methods.关键词:shape;shape descriptor;similarity measurement;shape matching;shape retrieval11|4|2更新时间:2024-05-07
摘要:ObjectiveDescription, matching, similarity measurement, and retrieval of shapes are basic tasks in computer vision, image recognition, and machine intelligence, and they remain as open issues. Except for the methods of geometry complex transform and shape contour-based Fourier descriptor, all other methods are not information preserving, which means that the original shapes cannot be reconstructed from their descriptors. Consequently, the descriptors cannot be guaranteed to fully represent the characteristics of original shapes. Although geometry complex transform and shape contour-based Fourier descriptor are information preserving, they are only applicable to simple closed shapes or some other special types of shapes, which limits their applications. We propose a generic shape descriptor, which is named inside-circle distance transform (ICD). The ICD method can be used for matching, similarity measurement, and retrieval of any shape with obvious contours, and it is information preserving.MethodIn the ICD method, we initially calculate the minimum circumscribed circle of a shape. Then, we draw a set of equidistant parallel lines that are perpendicular to x-axes, calculate the intersections of each line and shape contour, and compute the distance vector for each line. We finally form a distance matrix with all distance vectors. We yield another distance matrix by rotating the shape anticlockwise around the center of its minimum circumscribed circle by $θ$ degree and repeating the aforementioned process. A set of distance matrices is generated by repeating the process for[360/$θ$] times. With all distance matrices of the shape in hand, we construct the feature matrix of the shape. The feature matrix of a shape is a representation of the original shape with rich information, which can be used to describe the original shape, to measure the similarity of two shapes and reconstruct the original shape. Therefore, ICD is an information-preserving method. This capability of ICD to reconstruct original shapes is useful. We can thoroughly understand the intrinsic of shapes using the ICD method. Feature matrix is a powerful tool for shape representation and shape matching. We prove that ICD is scaling, rotation, and translation invariant, which is an important property in shape description, matching, and retrieval.ResultsWe construct 40 shapes to verify the capability and test the effectiveness of the ICD method. The shapes are categorized into eight classes, with five shapes in each class. In each of these eight classes, one basic shape exists, and the others are deformations of the basic shape through modifications, such as twisting the contour or adding noise. We further expand the set of shapes by performing affine transformation with random scale factor, random rotation angle, and random translation of position to generate two new shapes for each of the 40 shapes. This expansion results in a total of 120 shapes. We initially perform a similarity measurement between each of the eight basic shapes and each of 12 randomly selected shapes. Experimental result shows that in similarity measurement of shapes, the ICD method generates the same vision results as those of human vision. If two shapes are determined to be similar, then the ICD method can calculate their scaling factor and orientation differences. We also test the effectiveness of retrieval through the well-known method of "Bullseye score." Results show that 38 out of 40 subclasses achieve a score of 100, which is extremely satisfactory. We compare the ICD method with three other classic shape description and matching methods, namely, shape context method, histogram of Radon transform, and generic Fourier descriptor, on the basis of the widely used shape database of MPEG-7. This database consists of 70 classes, with 20 shapes in each class and hence a total of 1400 shapes. The Bullseye score method is adopted. Results indicate that all the methods under evaluation have their own advantages and disadvantages with respect to different shape classes. Moreover, on average, the test score of the ICD method is approximately 20 points higher than those of the other three classic methods. ICD shows significant effects outperforming those of the other methods in all experiments. In the reconstruction experiments, we randomly select four shapes from the MPEG-7 database and reconstruct them by using the ICD method with varying parameters $k$ and $θ$, where $k$=30, 50, 150 and $θ$=1, 6. Experiment results show that the reconstructed shapes become accurate with the increase of parameter $k$ and decrease of parameter $θ$. The reconstruction experiments also imply that shape reconstruction is more sensitive to parameter $k$ than to parameter $θ$. In application scenarios in which the rotational angle is insignificant, $θ$=3 is an optimal recommendation by our experiments.ConclusionThe ICD method and its corresponding feature matrix can be used to represent, match, and retrieve shapes effectively. This method has the prominent feature of being information preserving, thereby assuring that it represents a shape without losing information. When this method is used to compute similarity of shapes, it can generate the same result as that of human vision. For two similar shapes, the ICD method can compute their scale factor and rotation differences. Theoretical analysis, mathematical proofs, and experiments show that ICD is effective, useful, and information preserving, and it outperforms several important classic methods.关键词:shape;shape descriptor;similarity measurement;shape matching;shape retrieval11|4|2更新时间:2024-05-07 -
 摘要:ObjectiveThe development of science and technology has reduced the cost of data collection, increased data in geometric series, and caused data dimension reduction technology to be an important part of machine learning. Manifold learning method is a nonlinear dimensionality reduction technique that is widely used in the visualization, feature extraction, and solving of the computational complexity of high-dimensional data. Locally linear embedding (LLE) algorithm is a classical manifold learning algorithm in machine learning and data mining. The basic idea of the LLE algorithm is that any sampling point and its neighbors form a locally linear plane. Each nearest neighbor corresponds to a weight, and the sampling point can be linearly represented by the principle of minimizing the reconstruction error of the nearest neighbor. An improved reconstruction weight-based LLE (IRWLLE) algorithm is proposed to overcome the problem of the LLE algorithm, including noise, large curvature, and sparse sampling data.MethodGeodesic distance is used to describe the structure and reconstruct weights and define the reconstruction weights in the LLE to overcome the shortcomings of the original LLE algorithm, which considers only distance factors and ignores structural factors. Structural and distance weights are added. Any sample is selected as the center point, and the nearest-neighbor point (sample) from the center point is selected as the local neighborhood according to Euclidean distance. In this neighborhood, the ratio of the geodesic distance to the Euclidean distance between the center and neighboring points is defined as the structural weight, and the ratio of the geodesic distance to the median geodesic distance between the center and neighboring points is defined as the distance weight. The product of structural and distance weights is defined as the reconstruction weight; thus, the structure and distance information of the manifold are organically combined. Geometric distance calculation method using the classic Dijkstra algorithm is commonly used in Isomap algorithm. For the distance weight, the median distance of the geodesic distance in a local neighborhood is fixed. A farther distance from the center sample point of a neighboring point indicates a smaller distance weight corresponding to this neighbor point, which is in line with the idea that "a greater distance from the neighborhood center means a smaller contribution to the reconstruction center." The geodesic distance divided by its value reduces the noise effect on the weight to a certain extent. In the structural weight part, the ratio of Euclidean distance to geodesic distance is selected to measure the linearity of the local neighborhood. A greater distance from the linear plane of a neighboring point indicates a smaller contribution to the reconstruction center point and a smaller structural weight of the adjacent point. This notion further emphasizes the importance of structure to weight and enhances noise immunity.ResultClassical artificial data, such as Swiss roll, S-curve, and Helix, are experimented, and noise is added to the data. Sparse sampling is used to generate a data set. The proposed algorithm is compared with the original LLE algorithm and Hessian LLE (HLLE) algorithm. Results show that the IRWLLE algorithm is better than the LLE and HLLE algorithms by maintaining the neighbor relation of the manifold and improving the manifold. In particular, IRWLLE exhibits stronger robustness for the large curvature data set Helix. A face recognition experiment on ORL and Yale face databases is conducted by using a nearest-neighbor classifier, and the recognition result of the IRWLLE algorithm is compared with that of the LLE algorithm. For the ORL dataset, the recognition rate of the IRWLLE algorithm is 90%, whereas that of the original LLE algorithm is 85.5%. For the Yale dataset, the recognition rate of the IRWLLE algorithm is 88%, whereas that of the original LLE algorithm is 75%. Therefore, the face recognition rate of IRWLLE is also greatly improved.ConclusionThe proposed IRWLLE algorithm is based on the original LLE algorithm. This proposed algorithm not only introduces manifold distance information into reconstruction weight but also adds structural information, thereby effectively reducing the interference from noise and data outside the manifold. The IRWLLE algorithm has high robustness to noise data and can manage sparse sampling and large curvature data. The face recognition rate of the IRWLLE algorithm is also enhanced.关键词:Manifold learning;locally linear embedding;reconstruction weight;dimensionality reduction;robustness11|4|2更新时间:2024-05-07
摘要:ObjectiveThe development of science and technology has reduced the cost of data collection, increased data in geometric series, and caused data dimension reduction technology to be an important part of machine learning. Manifold learning method is a nonlinear dimensionality reduction technique that is widely used in the visualization, feature extraction, and solving of the computational complexity of high-dimensional data. Locally linear embedding (LLE) algorithm is a classical manifold learning algorithm in machine learning and data mining. The basic idea of the LLE algorithm is that any sampling point and its neighbors form a locally linear plane. Each nearest neighbor corresponds to a weight, and the sampling point can be linearly represented by the principle of minimizing the reconstruction error of the nearest neighbor. An improved reconstruction weight-based LLE (IRWLLE) algorithm is proposed to overcome the problem of the LLE algorithm, including noise, large curvature, and sparse sampling data.MethodGeodesic distance is used to describe the structure and reconstruct weights and define the reconstruction weights in the LLE to overcome the shortcomings of the original LLE algorithm, which considers only distance factors and ignores structural factors. Structural and distance weights are added. Any sample is selected as the center point, and the nearest-neighbor point (sample) from the center point is selected as the local neighborhood according to Euclidean distance. In this neighborhood, the ratio of the geodesic distance to the Euclidean distance between the center and neighboring points is defined as the structural weight, and the ratio of the geodesic distance to the median geodesic distance between the center and neighboring points is defined as the distance weight. The product of structural and distance weights is defined as the reconstruction weight; thus, the structure and distance information of the manifold are organically combined. Geometric distance calculation method using the classic Dijkstra algorithm is commonly used in Isomap algorithm. For the distance weight, the median distance of the geodesic distance in a local neighborhood is fixed. A farther distance from the center sample point of a neighboring point indicates a smaller distance weight corresponding to this neighbor point, which is in line with the idea that "a greater distance from the neighborhood center means a smaller contribution to the reconstruction center." The geodesic distance divided by its value reduces the noise effect on the weight to a certain extent. In the structural weight part, the ratio of Euclidean distance to geodesic distance is selected to measure the linearity of the local neighborhood. A greater distance from the linear plane of a neighboring point indicates a smaller contribution to the reconstruction center point and a smaller structural weight of the adjacent point. This notion further emphasizes the importance of structure to weight and enhances noise immunity.ResultClassical artificial data, such as Swiss roll, S-curve, and Helix, are experimented, and noise is added to the data. Sparse sampling is used to generate a data set. The proposed algorithm is compared with the original LLE algorithm and Hessian LLE (HLLE) algorithm. Results show that the IRWLLE algorithm is better than the LLE and HLLE algorithms by maintaining the neighbor relation of the manifold and improving the manifold. In particular, IRWLLE exhibits stronger robustness for the large curvature data set Helix. A face recognition experiment on ORL and Yale face databases is conducted by using a nearest-neighbor classifier, and the recognition result of the IRWLLE algorithm is compared with that of the LLE algorithm. For the ORL dataset, the recognition rate of the IRWLLE algorithm is 90%, whereas that of the original LLE algorithm is 85.5%. For the Yale dataset, the recognition rate of the IRWLLE algorithm is 88%, whereas that of the original LLE algorithm is 75%. Therefore, the face recognition rate of IRWLLE is also greatly improved.ConclusionThe proposed IRWLLE algorithm is based on the original LLE algorithm. This proposed algorithm not only introduces manifold distance information into reconstruction weight but also adds structural information, thereby effectively reducing the interference from noise and data outside the manifold. The IRWLLE algorithm has high robustness to noise data and can manage sparse sampling and large curvature data. The face recognition rate of the IRWLLE algorithm is also enhanced.关键词:Manifold learning;locally linear embedding;reconstruction weight;dimensionality reduction;robustness11|4|2更新时间:2024-05-07
Image Understanding and Computer Vision
-
 摘要:ObjectiveThe rapid development of advanced and intelligent manufacturing has caused the seamless data integration of geometric design and simulation to be a key problem in computer-aided design (CAD) and computer-aided engineering (CAE). In the product simulation and analysis stage for the classical finite element analysis method and the emerging iso-geometric analysis method, the meshing quality of computational domain is an important factor that affects the accuracy and computing efficiency of simulation results. Mesh generation has become an important research direction in the field of CAE. Research on high-quality quadrilateral meshing has particularly attracted significant attention because it is an important and challenging problem in the fields of CAD, iso-geometric analysis, and computer graphics. The main quad mesh generation methods currently used in commercial software include triangular mesh conversion, paving, template, and medial axis methods. The triangular mesh conversion method is usually limited by the vertex distribution of the triangular mesh and the connectivity among the vertices, and it hardly generates a high-quality quadrilateral mesh with few singular vertices. The quadrilateral mesh generation method based on medial axis decomposition is sensitive to boundary changes, which is insufficiently robust and is difficult to be implemented automatically. For complex planar regions, the paving method can generate high-quality quadrilateral meshes; however, the elements paving in different directions may lead to self-intersections, in which the validity of the generated meshes cannot be guaranteed. For complex boundaries, the paving method generates many singular vertices. To overcome the above limitations of the quadrilateral meshing methods for planar domain, we propose a new framework for high-quality quadrilateral mesh generation by using boundary simplification and multi-objective optimization technique, considering the urgent requirement for data seamless integration in CAD/CAE.MethodFirst, a new method is proposed to transfer a multiply-connected domain to a simply-connected domain with a high-quality and uniform-boundary insertion. Second, boundary simplification is used in decreasing the number of initial boundary vertex to reduce computing costs. Two threshold concepts, namely simplification angle and simplification area ratio, are proposed to simplify the given boundary into a rough polygon from the vertex angle and the area of vertex triangle. Third, subdomain decomposition method is performed on the rough polygon obtained by boundary simplification, and high-quality domain decomposition can be obtained by uniform vertex insertion. After n-sided domain decomposition is obtained, the optimal quadrilateral mesh is selected from the existing catalog of meshes by high-quality patterns. The vertex connectivity information for each subdomain is determined by meshing rules with few singularities. The main idea of this method is to use integer-programming techniques, such that the resulting topological connectivity template has the smallest number of singularities. Finally, the geometric position of interior mesh vertices is obtained by multi-objective optimization technique, an extended Laplacian operator is proposed for quad mesh, and a uniformity objective function is derived from the concept of variance in statistics and probability theory to obtain a quadrilateral mesh with a uniform element size; that is, if the variance of the quadrilateral element area in the generated grid is zero, then the mesh has a uniform element size. Furthermore, a unified formula for the objective function related to the orthogonality around the vertex with arbitrary valence is proposed. The geometric position of the vertex in the quad mesh is determined by the multi-objective nonlinear optimization technique to minimize the objective functions for the smoothness, uniformity and orthogonality measurements, which are solved by a quasi-Newton nonlinear optimization algorithm.ResultFrom the same discrete boundary, the quadrilateral mesh generated by our method has smaller numbers of mesh vertices and elements than those of previous methods. The number of extraordinary vertices can also be reduced by 70%~80%. The metrics for the evaluation of mesh quality, such as scaled Jacobian, are also improved. The corresponding computing time for each method in terms of computational efficiency is listed. In terms of algorithm complexity, the proposed method is similar to three classical quadrilateral mesh generation methods, and the time complexity of the proposed method is related to the number of vertices for a given discrete boundary.ConclusionCompared with previous approaches, the proposed method can generate high-quality quad meshes with fewer extraordinary vertices and higher mesh qualities, such as smoothness, uniformity, and orthogonality, as exhibited by the presented mesh generation examples.关键词:quadrilateral mesh generation;boundary simplification;sub-domain decomposition;multi-objective optimization;iso-geometric analysis11|5|1更新时间:2024-05-07
摘要:ObjectiveThe rapid development of advanced and intelligent manufacturing has caused the seamless data integration of geometric design and simulation to be a key problem in computer-aided design (CAD) and computer-aided engineering (CAE). In the product simulation and analysis stage for the classical finite element analysis method and the emerging iso-geometric analysis method, the meshing quality of computational domain is an important factor that affects the accuracy and computing efficiency of simulation results. Mesh generation has become an important research direction in the field of CAE. Research on high-quality quadrilateral meshing has particularly attracted significant attention because it is an important and challenging problem in the fields of CAD, iso-geometric analysis, and computer graphics. The main quad mesh generation methods currently used in commercial software include triangular mesh conversion, paving, template, and medial axis methods. The triangular mesh conversion method is usually limited by the vertex distribution of the triangular mesh and the connectivity among the vertices, and it hardly generates a high-quality quadrilateral mesh with few singular vertices. The quadrilateral mesh generation method based on medial axis decomposition is sensitive to boundary changes, which is insufficiently robust and is difficult to be implemented automatically. For complex planar regions, the paving method can generate high-quality quadrilateral meshes; however, the elements paving in different directions may lead to self-intersections, in which the validity of the generated meshes cannot be guaranteed. For complex boundaries, the paving method generates many singular vertices. To overcome the above limitations of the quadrilateral meshing methods for planar domain, we propose a new framework for high-quality quadrilateral mesh generation by using boundary simplification and multi-objective optimization technique, considering the urgent requirement for data seamless integration in CAD/CAE.MethodFirst, a new method is proposed to transfer a multiply-connected domain to a simply-connected domain with a high-quality and uniform-boundary insertion. Second, boundary simplification is used in decreasing the number of initial boundary vertex to reduce computing costs. Two threshold concepts, namely simplification angle and simplification area ratio, are proposed to simplify the given boundary into a rough polygon from the vertex angle and the area of vertex triangle. Third, subdomain decomposition method is performed on the rough polygon obtained by boundary simplification, and high-quality domain decomposition can be obtained by uniform vertex insertion. After n-sided domain decomposition is obtained, the optimal quadrilateral mesh is selected from the existing catalog of meshes by high-quality patterns. The vertex connectivity information for each subdomain is determined by meshing rules with few singularities. The main idea of this method is to use integer-programming techniques, such that the resulting topological connectivity template has the smallest number of singularities. Finally, the geometric position of interior mesh vertices is obtained by multi-objective optimization technique, an extended Laplacian operator is proposed for quad mesh, and a uniformity objective function is derived from the concept of variance in statistics and probability theory to obtain a quadrilateral mesh with a uniform element size; that is, if the variance of the quadrilateral element area in the generated grid is zero, then the mesh has a uniform element size. Furthermore, a unified formula for the objective function related to the orthogonality around the vertex with arbitrary valence is proposed. The geometric position of the vertex in the quad mesh is determined by the multi-objective nonlinear optimization technique to minimize the objective functions for the smoothness, uniformity and orthogonality measurements, which are solved by a quasi-Newton nonlinear optimization algorithm.ResultFrom the same discrete boundary, the quadrilateral mesh generated by our method has smaller numbers of mesh vertices and elements than those of previous methods. The number of extraordinary vertices can also be reduced by 70%~80%. The metrics for the evaluation of mesh quality, such as scaled Jacobian, are also improved. The corresponding computing time for each method in terms of computational efficiency is listed. In terms of algorithm complexity, the proposed method is similar to three classical quadrilateral mesh generation methods, and the time complexity of the proposed method is related to the number of vertices for a given discrete boundary.ConclusionCompared with previous approaches, the proposed method can generate high-quality quad meshes with fewer extraordinary vertices and higher mesh qualities, such as smoothness, uniformity, and orthogonality, as exhibited by the presented mesh generation examples.关键词:quadrilateral mesh generation;boundary simplification;sub-domain decomposition;multi-objective optimization;iso-geometric analysis11|5|1更新时间:2024-05-07
Computer Graphics
-
 摘要:ObjectiveHippocampus is a structure in the brain in memory consolidation and can be divided into nine subfields. Hippocampus atrophy has been mostly studied in various neurological diseases, such as Alzheimer's disease and mild cognitive impairment. Accurate hippocampus subfield segmentation in magnetic resonance (MR) images plays a crucial role in the diagnosis, prevention, and treatment of neurological diseases. However, the segmentation is a challenging task due to small size, relatively low contrast, complex shape, and indistinct boundaries of hippocampus subfields. Numerous scholars have been engaged in hippocampus subfield segmentation. Multi-atlas-based methods can obtain accurate segmentation results by fusing propagated labels of multiple atlases in a target image space. However, the performance of multi-atlas significantly relies on the effectiveness of the label fusion method. Deep learning algorithms have emerged as promising machine-learning tools in general imaging and computer vision domains, such as medical image segmentation. However, Cornu Ammonis (CA)2 and CA3 are limited by MR resolution and are thus significantly smaller than other subfields in hippocampus MR images. Most deep learning algorithms with identical network models and uniform patches present poor segmentation accuracy regardless of the considerable differences in the volume of different subfields.MethodThis study proposes a combined multi-scale patch and cascaded convolutional neural network (CNN)-based classification algorithm for segmenting the hippocampus into nine subfields to address the aforementioned deficiencies. In comparison with traditional label fusion method, the proposed method does not rely on explicit features but learns to extract important features for classification. Two different CNNs are designed considering the significant volume differences among different subfields. Network 1, which considers large patches as inputs, is trained to segment large subfields accurately. Network 2, which includes two patch types with small sizes that form a two-pathway network, is trained to obtain high segmentation accuracy on small subfields. Each network is trained using datasets from multiple atlases. The same number of patches is randomly extracted from different subfields that comprise a balanced training set to manage imbalanced datasets, in which the training patches of CA2 and CA3 are less than those of other subfields. The segmentation is performed slice by slice along the coronal direction, and a two-phase cascaded segmentation procedure is designed. First, the preliminary segmentation is performed using Network 1. Second, the voxels in small subfields are further classified using Network 2. The prior structural knowledge is used to recognize and correct mislabeling voxels to further improve the segmentation accuracy.ResultAll experiments are validated on CIND dataset, which contains 32 subjects with manually labeled ROIs. After the preprocessing, three separate training sets, which consist of patches with three different sizes, are extracted from multiple atlases. The training data of different classes are numerically balanced. We investigate the influence of using different sizes of input patches and kernels at the first convolutional layer of Network 1 to select the most appropriate parameters. We evaluate the different segmentation performances on small subfields by using the two different networks. The Dice similarity coefficient is selected as the evaluation metric. Several approaches in recent literature are implemented to compare with the proposed algorithm. Quantitative and qualitative comparisons demonstrate that the proposed method outperforms the traditional label fusion method on most subfields. The accuracies on tail, SUB, and PHG subfields are 0.865, 0.81, and 0.773, respectively. On the two small subfields, CA2 and CA3, the proposed method exhibits better performances with accuracies of 60% and 64%, surpassing the traditional method by 6% and 9%, respectively.ConclusionIn this paper, we propose a combined multi-scale patch and cascaded CNN-based method for hippocampus subfield segmentation. Two different networks are developed to solve the problems related to significant volume differences among different subfields. Three different sizes are used as inputs of two networks to capture considerable contextual information. A balanced training set is established to avoid incorrect training of the networks. We describe a cascaded segmentation procedure using the proposed networks. This cascaded procedure integrates two different networks for accurate segmentation on different subfields. The experiments show that the two CNNs with nonuniform patches outperform an identical network with a uniform patch. The significant improvement compared with traditional method shows that the feature extracted by the proposed network is considerably more effective and distinctive. Therefore, the proposed algorithm can label with high accuracy and is highly appropriate for hippocampus subfield segmentation.关键词:segmentation of hippocampus subfields;multi-scale;convolutional neural network;cascaded segmentation;multi-atlas11|4|3更新时间:2024-05-07
摘要:ObjectiveHippocampus is a structure in the brain in memory consolidation and can be divided into nine subfields. Hippocampus atrophy has been mostly studied in various neurological diseases, such as Alzheimer's disease and mild cognitive impairment. Accurate hippocampus subfield segmentation in magnetic resonance (MR) images plays a crucial role in the diagnosis, prevention, and treatment of neurological diseases. However, the segmentation is a challenging task due to small size, relatively low contrast, complex shape, and indistinct boundaries of hippocampus subfields. Numerous scholars have been engaged in hippocampus subfield segmentation. Multi-atlas-based methods can obtain accurate segmentation results by fusing propagated labels of multiple atlases in a target image space. However, the performance of multi-atlas significantly relies on the effectiveness of the label fusion method. Deep learning algorithms have emerged as promising machine-learning tools in general imaging and computer vision domains, such as medical image segmentation. However, Cornu Ammonis (CA)2 and CA3 are limited by MR resolution and are thus significantly smaller than other subfields in hippocampus MR images. Most deep learning algorithms with identical network models and uniform patches present poor segmentation accuracy regardless of the considerable differences in the volume of different subfields.MethodThis study proposes a combined multi-scale patch and cascaded convolutional neural network (CNN)-based classification algorithm for segmenting the hippocampus into nine subfields to address the aforementioned deficiencies. In comparison with traditional label fusion method, the proposed method does not rely on explicit features but learns to extract important features for classification. Two different CNNs are designed considering the significant volume differences among different subfields. Network 1, which considers large patches as inputs, is trained to segment large subfields accurately. Network 2, which includes two patch types with small sizes that form a two-pathway network, is trained to obtain high segmentation accuracy on small subfields. Each network is trained using datasets from multiple atlases. The same number of patches is randomly extracted from different subfields that comprise a balanced training set to manage imbalanced datasets, in which the training patches of CA2 and CA3 are less than those of other subfields. The segmentation is performed slice by slice along the coronal direction, and a two-phase cascaded segmentation procedure is designed. First, the preliminary segmentation is performed using Network 1. Second, the voxels in small subfields are further classified using Network 2. The prior structural knowledge is used to recognize and correct mislabeling voxels to further improve the segmentation accuracy.ResultAll experiments are validated on CIND dataset, which contains 32 subjects with manually labeled ROIs. After the preprocessing, three separate training sets, which consist of patches with three different sizes, are extracted from multiple atlases. The training data of different classes are numerically balanced. We investigate the influence of using different sizes of input patches and kernels at the first convolutional layer of Network 1 to select the most appropriate parameters. We evaluate the different segmentation performances on small subfields by using the two different networks. The Dice similarity coefficient is selected as the evaluation metric. Several approaches in recent literature are implemented to compare with the proposed algorithm. Quantitative and qualitative comparisons demonstrate that the proposed method outperforms the traditional label fusion method on most subfields. The accuracies on tail, SUB, and PHG subfields are 0.865, 0.81, and 0.773, respectively. On the two small subfields, CA2 and CA3, the proposed method exhibits better performances with accuracies of 60% and 64%, surpassing the traditional method by 6% and 9%, respectively.ConclusionIn this paper, we propose a combined multi-scale patch and cascaded CNN-based method for hippocampus subfield segmentation. Two different networks are developed to solve the problems related to significant volume differences among different subfields. Three different sizes are used as inputs of two networks to capture considerable contextual information. A balanced training set is established to avoid incorrect training of the networks. We describe a cascaded segmentation procedure using the proposed networks. This cascaded procedure integrates two different networks for accurate segmentation on different subfields. The experiments show that the two CNNs with nonuniform patches outperform an identical network with a uniform patch. The significant improvement compared with traditional method shows that the feature extracted by the proposed network is considerably more effective and distinctive. Therefore, the proposed algorithm can label with high accuracy and is highly appropriate for hippocampus subfield segmentation.关键词:segmentation of hippocampus subfields;multi-scale;convolutional neural network;cascaded segmentation;multi-atlas11|4|3更新时间:2024-05-07 -
 摘要:ObjectiveSegmentation of individual tooth from 3D dental meshes is an important process in computer-aided orthodontic system. However, gingival margin and tooth interstices usually overlap or fuse due to limited measuring resolution and mesh-triangulating precision, which causes the automatic segmentation of teeth directly from 3D dental models into individual tooth objects to be extraordinarily difficult, especially when dealing with models with severe malocclusion problems. Traditional approaches easily lead to boundary breaks, branch interferences, and manual interactions. Therefore, a novel and automatic tooth segmentation method based on path planning is proposed in this study. As path-planning method can provide mathematically piecewise optimal boundaries while greatly reducing sensitivity to local noise and intervening structures, such as tooth interstices and fossae; it can reduce user interaction and repair time to a great extent.MethodThe proposed strategy avoids the limitations of previous methods by initially searching gingiva-teeth boundary paths and then tooth-tooth interstitial boundary paths to avoid interference between gingiva and interstice in the course of detecting boundaries. Dental differential characteristics, image morphology, and B-spline-fitting technology are also employed to ensure stability and accuracy. The feature region of interest between gingiva and teeth is firstly extracted using a discrete curvature analysis. The optimal gingiva-teeth boundary paths are detected based on this feature region by using a novel double-path-planning algorithm. The algorithm initially searches the gingiva-teeth paths on the basis of the vertex distance information of the feature region to ensure that the paths avoid the branching points at tooth interstices. Accurate gingiva-teeth paths are then searched by formulating the neighborhood set of initial gingiva-teeth paths, their vertex distance and curvature information to ensure that the paths adhere to the high-curvature locations between gingiva and teeth. Afterward, the searched gingiva-teeth paths are projected on the occlusal plane to form a gingiva-teeth path binary image, and the dental arch curve is automatically constructed using image morphology and a B-spline-extended-fitting technology. The interstitial concave corners on the gingiva-teeth paths are detected and deleted by combining the normal vectors and curvature characteristics of the gingiva-teeth boundary paths and the ones of the dental arch curve to demarcate the gingival boundary of each individual tooth. The tooth-tooth interstitial boundary paths are then obtained by searching the optimal paths from the endpoints on the lingual side of the gingival boundary of each tooth to their corresponding ones on the buccal side. The tooth-tooth interstitial paths and the gingiva-teeth paths constitute the closed boundary of each individual tooth. These path boundaries can be further refined by using a simple yet efficient method based on bipartition and path searching.ResultExperiments on numerous dental models of patients with different levels of crowding problems are conducted to verify the efficiency and accuracy of the proposed method. The segmentation performance, time consumption, and user interaction of the proposed method are analyzed and compared with those of other published approaches. Results demonstrate that although some models include considerable noise and intervened branches, such as tooth fossae and grooves, the proposed method can easily remove these interference structures and produce good segmentation results even for severely deformed teeth and complex tooth arrangements. Besides, the proposed method involves fewer user interactions and parameter adjustments. And the procedures are automatic, except from setting the default curvature threshold for some models. In special cases where the tooth boundary is ambiguous, additional interactions are needed to repair undetected regions within this system interface manually. However, all these interactions are simple and time saving. The time consumption in manually repairing few missing or unwanted boundaries is generally less than 10 s. The key procedures (i.e., the gingiva-teeth path planning and the tooth-tooth interstitial path planning) only take less than 1 s, which greatly reduce the searching time compared with that of other methods. The most time-consuming operations are feature region extraction (5~6 s) and path refining (4~5 s). Along with the entire program execution time, the entire execution in each segmentation experiment can be finished in less than 20 s.ConclusionThis study proposes a novel automated approach for segmenting individual tooth from dental meshes based on path planning. The approach utilizes the strong anti-interference and anti-fracture capabilities of path planning to avoid local noise, intervening structures, and boundary breaks. The proposed method can effectively overcome the interferences of interstice and fossa and the difficulty of path walking around tooth interstice branches by combining multiple-path planning, image morphology, and B-spline-fitting technology. Therefore, good results can be obtained even in the presence of distorted tooth shapes and complex tooth arrangements. Furthermore, the method is fast and effective and involves fewer user interactions and parameter adjustments compared with published approaches. The experimental results demonstrate that the proposed approach can address different levels of crowding problems. Therefore, this approach can be applied to clinical orthodontic planning treatments to improve their accuracy and efficiency. The limitation of the approach is that in cases where the convex and concave features of the gingival boundary is not distinct, the method may require user interactions to guarantee accurate results. However, all required interactions are simple and time saving. In the future, additional prior knowledge and artificial intelligence will be fused into the proposed framework to further enhance its efficiency and robustness.关键词:tooth segmentation;path planning;discrete curvature;B-spline fitting;orthodontics;3D dental meshes14|4|4更新时间:2024-05-07
摘要:ObjectiveSegmentation of individual tooth from 3D dental meshes is an important process in computer-aided orthodontic system. However, gingival margin and tooth interstices usually overlap or fuse due to limited measuring resolution and mesh-triangulating precision, which causes the automatic segmentation of teeth directly from 3D dental models into individual tooth objects to be extraordinarily difficult, especially when dealing with models with severe malocclusion problems. Traditional approaches easily lead to boundary breaks, branch interferences, and manual interactions. Therefore, a novel and automatic tooth segmentation method based on path planning is proposed in this study. As path-planning method can provide mathematically piecewise optimal boundaries while greatly reducing sensitivity to local noise and intervening structures, such as tooth interstices and fossae; it can reduce user interaction and repair time to a great extent.MethodThe proposed strategy avoids the limitations of previous methods by initially searching gingiva-teeth boundary paths and then tooth-tooth interstitial boundary paths to avoid interference between gingiva and interstice in the course of detecting boundaries. Dental differential characteristics, image morphology, and B-spline-fitting technology are also employed to ensure stability and accuracy. The feature region of interest between gingiva and teeth is firstly extracted using a discrete curvature analysis. The optimal gingiva-teeth boundary paths are detected based on this feature region by using a novel double-path-planning algorithm. The algorithm initially searches the gingiva-teeth paths on the basis of the vertex distance information of the feature region to ensure that the paths avoid the branching points at tooth interstices. Accurate gingiva-teeth paths are then searched by formulating the neighborhood set of initial gingiva-teeth paths, their vertex distance and curvature information to ensure that the paths adhere to the high-curvature locations between gingiva and teeth. Afterward, the searched gingiva-teeth paths are projected on the occlusal plane to form a gingiva-teeth path binary image, and the dental arch curve is automatically constructed using image morphology and a B-spline-extended-fitting technology. The interstitial concave corners on the gingiva-teeth paths are detected and deleted by combining the normal vectors and curvature characteristics of the gingiva-teeth boundary paths and the ones of the dental arch curve to demarcate the gingival boundary of each individual tooth. The tooth-tooth interstitial boundary paths are then obtained by searching the optimal paths from the endpoints on the lingual side of the gingival boundary of each tooth to their corresponding ones on the buccal side. The tooth-tooth interstitial paths and the gingiva-teeth paths constitute the closed boundary of each individual tooth. These path boundaries can be further refined by using a simple yet efficient method based on bipartition and path searching.ResultExperiments on numerous dental models of patients with different levels of crowding problems are conducted to verify the efficiency and accuracy of the proposed method. The segmentation performance, time consumption, and user interaction of the proposed method are analyzed and compared with those of other published approaches. Results demonstrate that although some models include considerable noise and intervened branches, such as tooth fossae and grooves, the proposed method can easily remove these interference structures and produce good segmentation results even for severely deformed teeth and complex tooth arrangements. Besides, the proposed method involves fewer user interactions and parameter adjustments. And the procedures are automatic, except from setting the default curvature threshold for some models. In special cases where the tooth boundary is ambiguous, additional interactions are needed to repair undetected regions within this system interface manually. However, all these interactions are simple and time saving. The time consumption in manually repairing few missing or unwanted boundaries is generally less than 10 s. The key procedures (i.e., the gingiva-teeth path planning and the tooth-tooth interstitial path planning) only take less than 1 s, which greatly reduce the searching time compared with that of other methods. The most time-consuming operations are feature region extraction (5~6 s) and path refining (4~5 s). Along with the entire program execution time, the entire execution in each segmentation experiment can be finished in less than 20 s.ConclusionThis study proposes a novel automated approach for segmenting individual tooth from dental meshes based on path planning. The approach utilizes the strong anti-interference and anti-fracture capabilities of path planning to avoid local noise, intervening structures, and boundary breaks. The proposed method can effectively overcome the interferences of interstice and fossa and the difficulty of path walking around tooth interstice branches by combining multiple-path planning, image morphology, and B-spline-fitting technology. Therefore, good results can be obtained even in the presence of distorted tooth shapes and complex tooth arrangements. Furthermore, the method is fast and effective and involves fewer user interactions and parameter adjustments compared with published approaches. The experimental results demonstrate that the proposed approach can address different levels of crowding problems. Therefore, this approach can be applied to clinical orthodontic planning treatments to improve their accuracy and efficiency. The limitation of the approach is that in cases where the convex and concave features of the gingival boundary is not distinct, the method may require user interactions to guarantee accurate results. However, all required interactions are simple and time saving. In the future, additional prior knowledge and artificial intelligence will be fused into the proposed framework to further enhance its efficiency and robustness.关键词:tooth segmentation;path planning;discrete curvature;B-spline fitting;orthodontics;3D dental meshes14|4|4更新时间:2024-05-07
Medical Image Processing
-
 摘要:ObjectiveHyperspectral image contains abundant spatial, spectral, and radiant information and can be used for precise earth object classification. The imbalance between high-dimensional data and limited samples should be solved to obtain accurate classification results of ground objects. The influence of "same object with different spectra" caused by noise and mixing pixels should also be reduced. To solve the aforementioned problems effectively, this study proposes a superpixel and subspace projection-based support vector machine (SVM) method (SP-SVMsub) for hyperspectral image classification.MethodThe framework foundation is the object-based image classification (OBIC), which is a widely used classification method that includes spatial information. OBIC performs classification after segmentation, and each segment can be regarded as the smallest element in the classification process. The result of over-segmentation can be referred to as a superpixel, which represents the local neighborhood information in an adaptive domain. This study proposes to integrate superpixel segmentation with subspace-based SVM (SVMsub) for hyperspectral image classification. The proposed method can be implemented in three steps. First, simple linear iterative clustering is used to segment a hyperspectral image into several nonoverlapping homogeneous regions, and each region can be considered a superpixel. Second, subspace projection is adopted as a dimensionality reduction method for the image composed of superpixels and the original image. Third, SVM is implemented for classification with the obtained low-dimensional feature space. Innovation:A new spectral-spatial hyperspectral image classification approach is presented in this study. In spatial domain, the original hyperspectral image can be integrated with a segmentation map by applying a feature fusion process such that a pixel-level image is represented by superpixel-level data sets. In spectral domain, SVMsub is adopted to obtain final classification maps. vResultIn the experiments with data sets collected by using an Airborne Visible/Infrared Imaging Spectrometer over the Indian Pines region in America and a Reflective Optics Spectrographic Imaging System over the University of Pavia in Italy, the accuracies of algorithms with subspace projection are higher than those without subjection projection, and remarkable improvements are shown in cases with few samples. Algorithms that integrate spatial information, either by using Markov random field or superpixel, can acquire higher classification accuracy than those without spatial information. In the case in which less than 1% training samples of two data sets are used, SP-SVMsub obtains the highest classification accuracy. The overall accuracy of SP-SVMsub is approximately 4% higher than that of other related methods.ConclusionSuperpixel can be used to integrate spatial information and effectively reduce the influence of "same object with different spectra" on classification results. Subspace projection can transform hyperspectral data to a low-dimensional space and can achieve high classification accuracy with limited samples. SP-SVMsub can achieve high classification accuracy for hyperspectral images.关键词:hyperspectral image;image classification;subspace projection;superpixel;support vector machine (SVM)13|4|12更新时间:2024-05-07
摘要:ObjectiveHyperspectral image contains abundant spatial, spectral, and radiant information and can be used for precise earth object classification. The imbalance between high-dimensional data and limited samples should be solved to obtain accurate classification results of ground objects. The influence of "same object with different spectra" caused by noise and mixing pixels should also be reduced. To solve the aforementioned problems effectively, this study proposes a superpixel and subspace projection-based support vector machine (SVM) method (SP-SVMsub) for hyperspectral image classification.MethodThe framework foundation is the object-based image classification (OBIC), which is a widely used classification method that includes spatial information. OBIC performs classification after segmentation, and each segment can be regarded as the smallest element in the classification process. The result of over-segmentation can be referred to as a superpixel, which represents the local neighborhood information in an adaptive domain. This study proposes to integrate superpixel segmentation with subspace-based SVM (SVMsub) for hyperspectral image classification. The proposed method can be implemented in three steps. First, simple linear iterative clustering is used to segment a hyperspectral image into several nonoverlapping homogeneous regions, and each region can be considered a superpixel. Second, subspace projection is adopted as a dimensionality reduction method for the image composed of superpixels and the original image. Third, SVM is implemented for classification with the obtained low-dimensional feature space. Innovation:A new spectral-spatial hyperspectral image classification approach is presented in this study. In spatial domain, the original hyperspectral image can be integrated with a segmentation map by applying a feature fusion process such that a pixel-level image is represented by superpixel-level data sets. In spectral domain, SVMsub is adopted to obtain final classification maps. vResultIn the experiments with data sets collected by using an Airborne Visible/Infrared Imaging Spectrometer over the Indian Pines region in America and a Reflective Optics Spectrographic Imaging System over the University of Pavia in Italy, the accuracies of algorithms with subspace projection are higher than those without subjection projection, and remarkable improvements are shown in cases with few samples. Algorithms that integrate spatial information, either by using Markov random field or superpixel, can acquire higher classification accuracy than those without spatial information. In the case in which less than 1% training samples of two data sets are used, SP-SVMsub obtains the highest classification accuracy. The overall accuracy of SP-SVMsub is approximately 4% higher than that of other related methods.ConclusionSuperpixel can be used to integrate spatial information and effectively reduce the influence of "same object with different spectra" on classification results. Subspace projection can transform hyperspectral data to a low-dimensional space and can achieve high classification accuracy with limited samples. SP-SVMsub can achieve high classification accuracy for hyperspectral images.关键词:hyperspectral image;image classification;subspace projection;superpixel;support vector machine (SVM)13|4|12更新时间:2024-05-07
Remote Sensing Image Processing
-
 摘要:ObjectiveCAD(Computer Aided Design) is widely applied in many areas; however, rapidly rendering a large-scale CAD model on a commodity personal computer remains a challenge. Many researchers have been working on general-purpose rendering methods for large-scale models, and some have evaluated special-purpose rendering methods by utilizing the features of target models. The presented method belongs to special-purpose rendering methods. The method is designed to render a large-scale repeated-structure model, which is constructed by arranging several basic objects according to certain rules.MethodTree is often used to represent hierarchical CAD models. Two special nodes are defined to represent repeated-structure CAD models. One is used to represent basic objects, and the other is used for the "arrangement rule" of basic objects. A large-scale repeated-structure CAD model can thus be represented with a small-scale tree. CAD models cannot usually be rendered directly; they are to be converted into facets for rendering. However, the corresponding facet models for large-scale CAD models are extremely large to be stored and processed, which is a significant problem for large CAD model rendering. Repeated-structure CAD models are constructed by arranging few basic objects according to some rules. Therefore, the presented method solves the problem by generating and storing only the facets of basic objects, and the facets of all other objects are generated during the rendering process according to arrangement rules. Basic objects are less than the total objects in CAD models, and facets of basic objects are thus easy to generate and store. The running time of the view-frustum culling algorithm is proportional to facet number. For a large number of facets involved in large-scale CAD model rendering, the efficiency of the view-frustum culling algorithm is necessary to improve. Instead of processing facets directly, the presented method culls objects layer by layer by utilizing the hierarchical structure of repeated-structure CAD models. Accordingly, most objects can be processed in a high level, and only small part of objects is left to be processed in the facet level. The presented view-frustum culling algorithm is implemented by combining hierarchical structure features of the repeated structure CAD model and the render-to-texture functions of a modern GPU. The algorithm can select target objects rapidly, which is another contribution to rapid rendering.ResultThe presented method is implemented on the basis of ACIS, OpenGL, and HOOPS in Visual Studio 2010, and all testing is performed on a computer equipped with 3.20 GHz CPU, 4.0 GB RAM, NIVIDIA GeForce GT740 GPU, and Windows 7 operating system. The presented method is integrated into SuperMC (Multi-physics Coupling Analysis Modeling program), which is a self-developed nuclear simulation program. SuperMC is often used in processing full reactor core models, which are typical repeated-structure CAD models. Thus, three full reactor core CAD models, namely, HM, ADS, and DCA, are selected for testing, which consist of 1 114 384, 113 952, and 20 808 entities, respectively. For the three full reactor core models, the presented method performs best on the HM model and performs worst on the DCA model. HM is considerably larger than DCA. The presented method is designed for large-scale models. In comparison with the traditional rendering method, the presented method exhibits better performances on all the three models, it can achieve about three times rendering speed increase for far-view rendering. Although the presented method and the traditional method can achieve similar rendering qualities, the presented method can achieve a higher rendering rate, especially for far-view rendering. The test result demonstrates the effectiveness of the presented method.ConclusionThe development of general-purpose rendering methods for large-scale CAD models remains a challenge. This paper presents a special-purpose rapid rendering method, which can render a large repeated-structure CAD model, according to the features of repeated-structure CAD models. The developed method is integrated into self-developed software SuperMC for application. Three full reactor core models based on SuperMC are used for testing. The presented method can achieve a good rendering quality and a high rendering rate than those of the traditional rendering method, which demonstrates the effectiveness of the presented method. Only "array-arrangement rule" is currently supported by the presented method; thus, to support more "arrangement rules" is our future work.关键词:large scale CAD model;rapid rendering;repeated structure;frustum culling15|6|1更新时间:2024-05-07
摘要:ObjectiveCAD(Computer Aided Design) is widely applied in many areas; however, rapidly rendering a large-scale CAD model on a commodity personal computer remains a challenge. Many researchers have been working on general-purpose rendering methods for large-scale models, and some have evaluated special-purpose rendering methods by utilizing the features of target models. The presented method belongs to special-purpose rendering methods. The method is designed to render a large-scale repeated-structure model, which is constructed by arranging several basic objects according to certain rules.MethodTree is often used to represent hierarchical CAD models. Two special nodes are defined to represent repeated-structure CAD models. One is used to represent basic objects, and the other is used for the "arrangement rule" of basic objects. A large-scale repeated-structure CAD model can thus be represented with a small-scale tree. CAD models cannot usually be rendered directly; they are to be converted into facets for rendering. However, the corresponding facet models for large-scale CAD models are extremely large to be stored and processed, which is a significant problem for large CAD model rendering. Repeated-structure CAD models are constructed by arranging few basic objects according to some rules. Therefore, the presented method solves the problem by generating and storing only the facets of basic objects, and the facets of all other objects are generated during the rendering process according to arrangement rules. Basic objects are less than the total objects in CAD models, and facets of basic objects are thus easy to generate and store. The running time of the view-frustum culling algorithm is proportional to facet number. For a large number of facets involved in large-scale CAD model rendering, the efficiency of the view-frustum culling algorithm is necessary to improve. Instead of processing facets directly, the presented method culls objects layer by layer by utilizing the hierarchical structure of repeated-structure CAD models. Accordingly, most objects can be processed in a high level, and only small part of objects is left to be processed in the facet level. The presented view-frustum culling algorithm is implemented by combining hierarchical structure features of the repeated structure CAD model and the render-to-texture functions of a modern GPU. The algorithm can select target objects rapidly, which is another contribution to rapid rendering.ResultThe presented method is implemented on the basis of ACIS, OpenGL, and HOOPS in Visual Studio 2010, and all testing is performed on a computer equipped with 3.20 GHz CPU, 4.0 GB RAM, NIVIDIA GeForce GT740 GPU, and Windows 7 operating system. The presented method is integrated into SuperMC (Multi-physics Coupling Analysis Modeling program), which is a self-developed nuclear simulation program. SuperMC is often used in processing full reactor core models, which are typical repeated-structure CAD models. Thus, three full reactor core CAD models, namely, HM, ADS, and DCA, are selected for testing, which consist of 1 114 384, 113 952, and 20 808 entities, respectively. For the three full reactor core models, the presented method performs best on the HM model and performs worst on the DCA model. HM is considerably larger than DCA. The presented method is designed for large-scale models. In comparison with the traditional rendering method, the presented method exhibits better performances on all the three models, it can achieve about three times rendering speed increase for far-view rendering. Although the presented method and the traditional method can achieve similar rendering qualities, the presented method can achieve a higher rendering rate, especially for far-view rendering. The test result demonstrates the effectiveness of the presented method.ConclusionThe development of general-purpose rendering methods for large-scale CAD models remains a challenge. This paper presents a special-purpose rapid rendering method, which can render a large repeated-structure CAD model, according to the features of repeated-structure CAD models. The developed method is integrated into self-developed software SuperMC for application. Three full reactor core models based on SuperMC are used for testing. The presented method can achieve a good rendering quality and a high rendering rate than those of the traditional rendering method, which demonstrates the effectiveness of the presented method. Only "array-arrangement rule" is currently supported by the presented method; thus, to support more "arrangement rules" is our future work.关键词:large scale CAD model;rapid rendering;repeated structure;frustum culling15|6|1更新时间:2024-05-07 -
 摘要:ObjectiveImage super-resolution reconstruction is a branch of image restoration, which concerns with the problem of generating a plausible and visually pleasing high-resolution output image from a low-resolution input image. This approach has many practical applications, ranging from video surveillance imaging to medical imaging and satellite remote-sensing image processing. Although some methods have achieved reasonable results in recent years, they have mainly focused on visual artifacts, while the loss of edge information has been rarely mentioned. To address these weaknesses, a novel image super-resolution reconstruction method via deep network based on edge enhancement is proposed in this study.MethodGiven that deep learning has demonstrated excellent performance in computer vision problems, some scholars have utilized convolutional neural networks to design deep architecture for image super resolution. Dong et al successfully introduced deep learning into a super-resolution-based method; they demonstrated that convolutional neural networks could be used to learn mapping from a low-resolution image to a high-resolution image in an end-to-end way and achieved state-of-the-art results. Besides, Inspired by semantic segmentation based on deconvolution network, we introduce a deconvolution network to reconstruct edge information. The proposed model considers an interpolated low-resolution image (to the desired size) as input. The preprocessed network is utilized to extract low-level features of the input image, which are imported into the mixture network. The mixture network consists of two roads. One road is used to obtain high-level features by cascading the convolutional layer many times, and the other road realizes the reconstruction of the image edge by cascading between the convolutional network and its mirror network-deconvolution network. The convolutional and deconvolution layers in stacked style can retain the feature map size by adding pad wise-pixel. We can obtain the final reconstruction result through a convolutional layer by fusing the two road results via bypass connection. We select the rectified linear unit as activation function in our model to accelerate the training process and avoid the vanishing gradient. We employ 91 images as the training set and observe their performance changes in Set5, Set14, and B100 with scaling factors of 2, 3, and 4 respectively. The training set is further augmented by rotating the original image by 90°, 180°, and 270° and flipping them upside down to prevent overfitting in deep network. Notably, we initially convert the color images of RGB space into YCbCr space, considering that human vision is more sensitive to details in intensity than in color. We then apply the proposed algorithm to the luminance Y channel, and the Cb, Cr channels are upscaled by bicubic interpolation.ResultAll experiments are implemented on the Caffe package. The proposed algorithm considers peak-signal-to-noise ratio and structural similarity index as evaluation metrics. The experimental results on Set5 for the scale factor of 3 are 33.24 dB/0.915 6, 30.60 dB/0.852 1, and 27.99 dB/0.784 8. Compared with bicubic, ScSR, A+, SelfEx, SRCNN, and CSCN, the proposed algorithm shows improved performances by 2.85 dB/4.74, 1.9 dB/2.87, 0.66 dB/0.68, 0.66 dB/0.63, 0.49 dB/0.66, and 0.14 dB/0.12 respectively. The running time of GPU version on Set5 for scale factor of 3 only takes 0.62 s, which is obviously superior to those of the other methods.ConclusionConvolutional neural networks have been increasingly popular in image super-resolution reconstruction. This study employs a deep network that contains convolution, deconvolution, and unpooling, which is used for reconstructing image edge information. The experimental results demonstrate that the proposed method based on edge enhancement model achieves better quantitative and qualitative reconstruction performances than those of the other methods.关键词:super-resolution reconstructions;convolutional neural networks;deconvolution;unpooling;edge enhancement11|4|3更新时间:2024-05-07
摘要:ObjectiveImage super-resolution reconstruction is a branch of image restoration, which concerns with the problem of generating a plausible and visually pleasing high-resolution output image from a low-resolution input image. This approach has many practical applications, ranging from video surveillance imaging to medical imaging and satellite remote-sensing image processing. Although some methods have achieved reasonable results in recent years, they have mainly focused on visual artifacts, while the loss of edge information has been rarely mentioned. To address these weaknesses, a novel image super-resolution reconstruction method via deep network based on edge enhancement is proposed in this study.MethodGiven that deep learning has demonstrated excellent performance in computer vision problems, some scholars have utilized convolutional neural networks to design deep architecture for image super resolution. Dong et al successfully introduced deep learning into a super-resolution-based method; they demonstrated that convolutional neural networks could be used to learn mapping from a low-resolution image to a high-resolution image in an end-to-end way and achieved state-of-the-art results. Besides, Inspired by semantic segmentation based on deconvolution network, we introduce a deconvolution network to reconstruct edge information. The proposed model considers an interpolated low-resolution image (to the desired size) as input. The preprocessed network is utilized to extract low-level features of the input image, which are imported into the mixture network. The mixture network consists of two roads. One road is used to obtain high-level features by cascading the convolutional layer many times, and the other road realizes the reconstruction of the image edge by cascading between the convolutional network and its mirror network-deconvolution network. The convolutional and deconvolution layers in stacked style can retain the feature map size by adding pad wise-pixel. We can obtain the final reconstruction result through a convolutional layer by fusing the two road results via bypass connection. We select the rectified linear unit as activation function in our model to accelerate the training process and avoid the vanishing gradient. We employ 91 images as the training set and observe their performance changes in Set5, Set14, and B100 with scaling factors of 2, 3, and 4 respectively. The training set is further augmented by rotating the original image by 90°, 180°, and 270° and flipping them upside down to prevent overfitting in deep network. Notably, we initially convert the color images of RGB space into YCbCr space, considering that human vision is more sensitive to details in intensity than in color. We then apply the proposed algorithm to the luminance Y channel, and the Cb, Cr channels are upscaled by bicubic interpolation.ResultAll experiments are implemented on the Caffe package. The proposed algorithm considers peak-signal-to-noise ratio and structural similarity index as evaluation metrics. The experimental results on Set5 for the scale factor of 3 are 33.24 dB/0.915 6, 30.60 dB/0.852 1, and 27.99 dB/0.784 8. Compared with bicubic, ScSR, A+, SelfEx, SRCNN, and CSCN, the proposed algorithm shows improved performances by 2.85 dB/4.74, 1.9 dB/2.87, 0.66 dB/0.68, 0.66 dB/0.63, 0.49 dB/0.66, and 0.14 dB/0.12 respectively. The running time of GPU version on Set5 for scale factor of 3 only takes 0.62 s, which is obviously superior to those of the other methods.ConclusionConvolutional neural networks have been increasingly popular in image super-resolution reconstruction. This study employs a deep network that contains convolution, deconvolution, and unpooling, which is used for reconstructing image edge information. The experimental results demonstrate that the proposed method based on edge enhancement model achieves better quantitative and qualitative reconstruction performances than those of the other methods.关键词:super-resolution reconstructions;convolutional neural networks;deconvolution;unpooling;edge enhancement11|4|3更新时间:2024-05-07 -
 摘要:ObjectiveRaster map data (hereinafter referred to as raster map) refer to a paper topographic map of various scales and a digital product of numerous professionally used color maps. A raster data file is formed according to existing papers, films, and other topographic maps by scanning, geometric correction, and color correction. Such file is consistent with a topographic map in content, geometric precision, and color and has the characteristics of a digital image and a large amount of data. Security protection technologies that are commonly used for raster maps include the image encryption technology based on chaos theory, digital image scrambling technology, and image information-hiding technology. These technologies have a common shortcoming, that is, a single carrier in the transmission is generally through a channel to achieve. When the channel has a failure or damage, the receiver cannot correctly receive the original image information. These technologies do not apply to the loss of tolerance, simple decryption, exchangeable share orders, permission control, and other applications. Image sharing technology can be adopted to the above occasions. The basic principle is to encrypt secret image information into multiple shared copies of the image and distribute it to multiple participants. In this process, only the authorized participant subset can decrypt (restore) the secret image, whereas the non-authorized subset cannot. The image sharing technology has the characteristic of loss of tolerance; that is, when part of the shared image is lost, the secret image can still be decrypted. Research on image sharing technology has mainly focused on the two aspects of image sharing technology based on polynomials and visual cryptography. The former mainly shares a secret image to multiple shadow images by using Shamir's polynomial sharing algorithm and then uses interpolation principle to yield the exact recovery of the secret image. However, the method has a high computational complexity. The latter has an advantage of simple recovery process of the secret image. The image recovery information can be obtained by using human visual system or with a simple computing device. Nevertheless, large pixel expansion and limited color of the secret image are yielded. To solve this problem, this study defines and constructs a probabilistic (
摘要:ObjectiveRaster map data (hereinafter referred to as raster map) refer to a paper topographic map of various scales and a digital product of numerous professionally used color maps. A raster data file is formed according to existing papers, films, and other topographic maps by scanning, geometric correction, and color correction. Such file is consistent with a topographic map in content, geometric precision, and color and has the characteristics of a digital image and a large amount of data. Security protection technologies that are commonly used for raster maps include the image encryption technology based on chaos theory, digital image scrambling technology, and image information-hiding technology. These technologies have a common shortcoming, that is, a single carrier in the transmission is generally through a channel to achieve. When the channel has a failure or damage, the receiver cannot correctly receive the original image information. These technologies do not apply to the loss of tolerance, simple decryption, exchangeable share orders, permission control, and other applications. Image sharing technology can be adopted to the above occasions. The basic principle is to encrypt secret image information into multiple shared copies of the image and distribute it to multiple participants. In this process, only the authorized participant subset can decrypt (restore) the secret image, whereas the non-authorized subset cannot. The image sharing technology has the characteristic of loss of tolerance; that is, when part of the shared image is lost, the secret image can still be decrypted. Research on image sharing technology has mainly focused on the two aspects of image sharing technology based on polynomials and visual cryptography. The former mainly shares a secret image to multiple shadow images by using Shamir's polynomial sharing algorithm and then uses interpolation principle to yield the exact recovery of the secret image. However, the method has a high computational complexity. The latter has an advantage of simple recovery process of the secret image. The image recovery information can be obtained by using human visual system or with a simple computing device. Nevertheless, large pixel expansion and limited color of the secret image are yielded. To solve this problem, this study defines and constructs a probabilistic ($k, n$ $k, n$ $k, n$ $k, n$ $k, k$ $k$ $n$ $f$ $k, n$ $k, n$ 关键词:raster map sharing;color visual cryptography;probabilistic;exclusive OR(XOR) operation;no pixel expansion12|4|1更新时间:2024-05-07 -
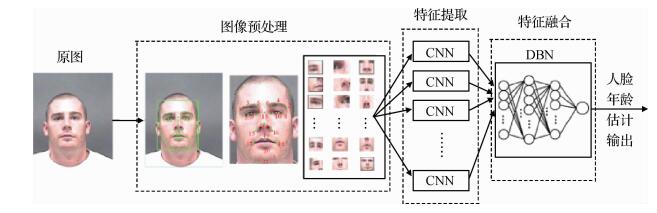 摘要:ObjectiveIn this study, we propose a facial age estimation (FAE) method based on end-to-end trainable deep neural network called deep fusion network (DFN), which adopts the idea of stacking multiple CNNs (Convolutional Neural Networks) and a DBN (Deep Belief Network) extract and fuse facial features for age estimation.MethodDFN-based method for FAE comprises image preprocessing, feature extraction, feature fusion, and age estimation. In image preprocessing, the faces are cropped from images by a face detector. Face alignment is utilized to deform the face image to a fixed size and position based on landmark points, which reduce the adverse effects on the subsequent process due to various face poses and noises. Several multiscale local patches are cropped from the aligned face image based on facial landmark points. We employ CNN as the feature extraction module (FEM), which extracts deep features from the local face patches obtained by image preprocessing. The number of FEM is 37, which is the same as that of face patches. One FEM corresponds to one local face patch. Thirty-seven parallel FEMs can simultaneously extract global and local facial features from the face patches. After feature extraction from local patches by multiple FEMs, we obtain 37 CNN features with a size of 160. These 37 deep features are concatenated to form a feature vector. We use a DBN model to fuse these deep features. Two challenges exist in DFN training. The first challenge is implementing the end-to-end training of DFN, which comprises multiple parallel CNNs and one stacked DBN. The other challenge is training large-scale deep neural networks on limited local face patches. To address these issues, a scheme of iterative net-wise training (INWT) is proposed to train the DFN. The term "net-wise" means that all neural networks, including multiple CNNs and one DBN, in the DFN are pre-trained network by network, and the entire DFN then undergoes a globally end-to-end fine-tuning. The term "iterative" means that we use a scheme of multiple iterative transfer learning to train the network of FEM on limited local face patches. CNNs corresponding to patches that contain a small portion of the face are gradually fine-tuned on the basis of multiple iterative transfer learning to reduce overfitting. After all CNNs and DBN are pretrained, the DFN is globally fine-tuned to perform a regression of face age estimation.ResultWe conduct extensive experiments to evaluate the proposed FAE method. The experiments are performed on two well-known benchmarks, namely, FG-NET database and MORPH Ⅱ databases. First, we evaluate the performance of the proposed method in the case of using different iterations of transfer learning. Results show that the proposed multiple iterative transfer learning can significantly improve the accuracy of age estimation. Second, we evaluate the performance of the proposed method with different patch combinations. Results show that various scales of local patches provide complementary information for FAE and that they all contribute to the decrease of MAE. Third, we evaluate the proposed method with four fusion methods. In comparison with LR, SVR, and RA, DBN-based method can achieve the best MAE in all experiments. Finally, the proposed method is compared with state-of-the-art methods. Experimental results on the two databases show that the proposed DFN-based method is an effective deep architecture for FAE and achieves a competitive performance (MAE=3.42 and 4.14) compared with state-of-the-art methods.ConclusionWe propose a deep neural network called DFN for FAE. Multiple CNNs are trained to extract deep facial age features, and one DBN is stacked for feature fusion, which makes the DFN a globally trainable end-to-end deep learning model that enlarges the scale of neural network for better age estimation performance. Then, INWT scheme is developed to train the DFN on limited multiscale local face patches. Experimental results on MORPH Ⅱ and FG-NET databases show that DFN is an effective deep learning model for FAE and can achieve a competitive result compared with state-of-the-art methods.关键词:facial age estimation;deep fusion network;hierarchical training principle;gradually fine-tuning13|4|2更新时间:2024-05-07
摘要:ObjectiveIn this study, we propose a facial age estimation (FAE) method based on end-to-end trainable deep neural network called deep fusion network (DFN), which adopts the idea of stacking multiple CNNs (Convolutional Neural Networks) and a DBN (Deep Belief Network) extract and fuse facial features for age estimation.MethodDFN-based method for FAE comprises image preprocessing, feature extraction, feature fusion, and age estimation. In image preprocessing, the faces are cropped from images by a face detector. Face alignment is utilized to deform the face image to a fixed size and position based on landmark points, which reduce the adverse effects on the subsequent process due to various face poses and noises. Several multiscale local patches are cropped from the aligned face image based on facial landmark points. We employ CNN as the feature extraction module (FEM), which extracts deep features from the local face patches obtained by image preprocessing. The number of FEM is 37, which is the same as that of face patches. One FEM corresponds to one local face patch. Thirty-seven parallel FEMs can simultaneously extract global and local facial features from the face patches. After feature extraction from local patches by multiple FEMs, we obtain 37 CNN features with a size of 160. These 37 deep features are concatenated to form a feature vector. We use a DBN model to fuse these deep features. Two challenges exist in DFN training. The first challenge is implementing the end-to-end training of DFN, which comprises multiple parallel CNNs and one stacked DBN. The other challenge is training large-scale deep neural networks on limited local face patches. To address these issues, a scheme of iterative net-wise training (INWT) is proposed to train the DFN. The term "net-wise" means that all neural networks, including multiple CNNs and one DBN, in the DFN are pre-trained network by network, and the entire DFN then undergoes a globally end-to-end fine-tuning. The term "iterative" means that we use a scheme of multiple iterative transfer learning to train the network of FEM on limited local face patches. CNNs corresponding to patches that contain a small portion of the face are gradually fine-tuned on the basis of multiple iterative transfer learning to reduce overfitting. After all CNNs and DBN are pretrained, the DFN is globally fine-tuned to perform a regression of face age estimation.ResultWe conduct extensive experiments to evaluate the proposed FAE method. The experiments are performed on two well-known benchmarks, namely, FG-NET database and MORPH Ⅱ databases. First, we evaluate the performance of the proposed method in the case of using different iterations of transfer learning. Results show that the proposed multiple iterative transfer learning can significantly improve the accuracy of age estimation. Second, we evaluate the performance of the proposed method with different patch combinations. Results show that various scales of local patches provide complementary information for FAE and that they all contribute to the decrease of MAE. Third, we evaluate the proposed method with four fusion methods. In comparison with LR, SVR, and RA, DBN-based method can achieve the best MAE in all experiments. Finally, the proposed method is compared with state-of-the-art methods. Experimental results on the two databases show that the proposed DFN-based method is an effective deep architecture for FAE and achieves a competitive performance (MAE=3.42 and 4.14) compared with state-of-the-art methods.ConclusionWe propose a deep neural network called DFN for FAE. Multiple CNNs are trained to extract deep facial age features, and one DBN is stacked for feature fusion, which makes the DFN a globally trainable end-to-end deep learning model that enlarges the scale of neural network for better age estimation performance. Then, INWT scheme is developed to train the DFN on limited multiscale local face patches. Experimental results on MORPH Ⅱ and FG-NET databases show that DFN is an effective deep learning model for FAE and can achieve a competitive result compared with state-of-the-art methods.关键词:facial age estimation;deep fusion network;hierarchical training principle;gradually fine-tuning13|4|2更新时间:2024-05-07 -
 摘要:ObjectiveRespiratory rate is a sensitive indicator that can directly reflect the health of the human body for related respiratory diseases, such as Biot's respiration, Cheyne-Stokes respiration, and sleep-related breathing disorders. Video-based respiratory detection, which has the features of low cost and few restrictions, has been an advanced research interest in recent years. Given that normal cameras cannot capture videos and present high noise at night, existing methods cannot handle night environment, which could lead to deviations in respiratory estimation and even to errors. To solve these problems, a respiratory detection method was proposed in this study. The proposed method is appropriate for day and night conditions and has a good anti-noise performance.MethodThe method was mainly composed of three parts. First, the main face region in videos was confirmed using a Viola-Jones face detector, and the chest region was located by body geometry. We improved the face detection box algorithm to repair the problem that the Viola-Jones algorithm might have a high detection error at night. Second, the chest video was obtained by using a phase-based video motion-processing method, which was combined with spatial scale and phase difference to amplify respiratory movement. We decomposed the original video frames to multiple spatial-scale orientations of phase video sequences. Respiratory signal was extracted by applying average luminance signal operation. Finally, we applied the maximum likelihood (ML) criterion to estimate the respiratory rate by using the signal generated in the second step. The result from the ML criterion could present minimal deviation because breathing waves extracted from the average luminance signal were coarse, which presented the respiratory characteristic unsatisfactorily. Therefore, we used the first estimated respiratory rate as a reference and broadened the frequency band to process the original breathing wave by smoothing filter. Accurate respiratory rate was estimated by peak detection from the smoothed respiratory wave. We solved the problem that normal cameras cannot work efficiently at night by using an active infrared camera. Our method benefited from the extraction of phase information and could thus yield a better performance than those of traditional methods that extract based on luminance information.ResultWe collected videos under day and night conditions and conducted a quantitative analysis of the result of respiratory detection. Significant robustness improvements were obtained. The average errors were 0.54 times/min in the day and 0.62 times/min in the night compared with those of the traditional respiratory rate estimation method proposed by Alinovi and Zhang. A stability test was performed to verify the best working environment of our method in different video durations and thickness of clothes.ConclusionWe propose a respiratory rate estimation method that is appropriate for day and night conditions and exhibits good anti-noise performance. We used an active infrared camera to collect videos at night. The breathing region was highlighted by applying a Viola-Jones face detector. The robustness of respiratory rate estimation was improved by effectively selecting breathing region and restraining noise amplification through the phase-based video motion method, which decomposed video frames into different spatial scales and phase orientations.关键词:extraction of breathing wave;chest location;video motion magnification;maximum likelihood estimation;respiratory rate estimation11|4|2更新时间:2024-05-07
摘要:ObjectiveRespiratory rate is a sensitive indicator that can directly reflect the health of the human body for related respiratory diseases, such as Biot's respiration, Cheyne-Stokes respiration, and sleep-related breathing disorders. Video-based respiratory detection, which has the features of low cost and few restrictions, has been an advanced research interest in recent years. Given that normal cameras cannot capture videos and present high noise at night, existing methods cannot handle night environment, which could lead to deviations in respiratory estimation and even to errors. To solve these problems, a respiratory detection method was proposed in this study. The proposed method is appropriate for day and night conditions and has a good anti-noise performance.MethodThe method was mainly composed of three parts. First, the main face region in videos was confirmed using a Viola-Jones face detector, and the chest region was located by body geometry. We improved the face detection box algorithm to repair the problem that the Viola-Jones algorithm might have a high detection error at night. Second, the chest video was obtained by using a phase-based video motion-processing method, which was combined with spatial scale and phase difference to amplify respiratory movement. We decomposed the original video frames to multiple spatial-scale orientations of phase video sequences. Respiratory signal was extracted by applying average luminance signal operation. Finally, we applied the maximum likelihood (ML) criterion to estimate the respiratory rate by using the signal generated in the second step. The result from the ML criterion could present minimal deviation because breathing waves extracted from the average luminance signal were coarse, which presented the respiratory characteristic unsatisfactorily. Therefore, we used the first estimated respiratory rate as a reference and broadened the frequency band to process the original breathing wave by smoothing filter. Accurate respiratory rate was estimated by peak detection from the smoothed respiratory wave. We solved the problem that normal cameras cannot work efficiently at night by using an active infrared camera. Our method benefited from the extraction of phase information and could thus yield a better performance than those of traditional methods that extract based on luminance information.ResultWe collected videos under day and night conditions and conducted a quantitative analysis of the result of respiratory detection. Significant robustness improvements were obtained. The average errors were 0.54 times/min in the day and 0.62 times/min in the night compared with those of the traditional respiratory rate estimation method proposed by Alinovi and Zhang. A stability test was performed to verify the best working environment of our method in different video durations and thickness of clothes.ConclusionWe propose a respiratory rate estimation method that is appropriate for day and night conditions and exhibits good anti-noise performance. We used an active infrared camera to collect videos at night. The breathing region was highlighted by applying a Viola-Jones face detector. The robustness of respiratory rate estimation was improved by effectively selecting breathing region and restraining noise amplification through the phase-based video motion method, which decomposed video frames into different spatial scales and phase orientations.关键词:extraction of breathing wave;chest location;video motion magnification;maximum likelihood estimation;respiratory rate estimation11|4|2更新时间:2024-05-07
Column of CACIS 2017
- Postal code:100190
- Tel:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- Technical support is provided by Beijing Founder electronics co., LTD 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - It is recommended to read the content of this site in Chrome&IE9+. Please switch to extreme mode in browser 360.
- Cookies We use cookies to help provide and enhance our service and tailor content. By continuing, you agree to the use of cookies.

0