
最新刊期
2024 年 第 29 卷 第 9 期
数字人建模、生成与渲染技术
-
-
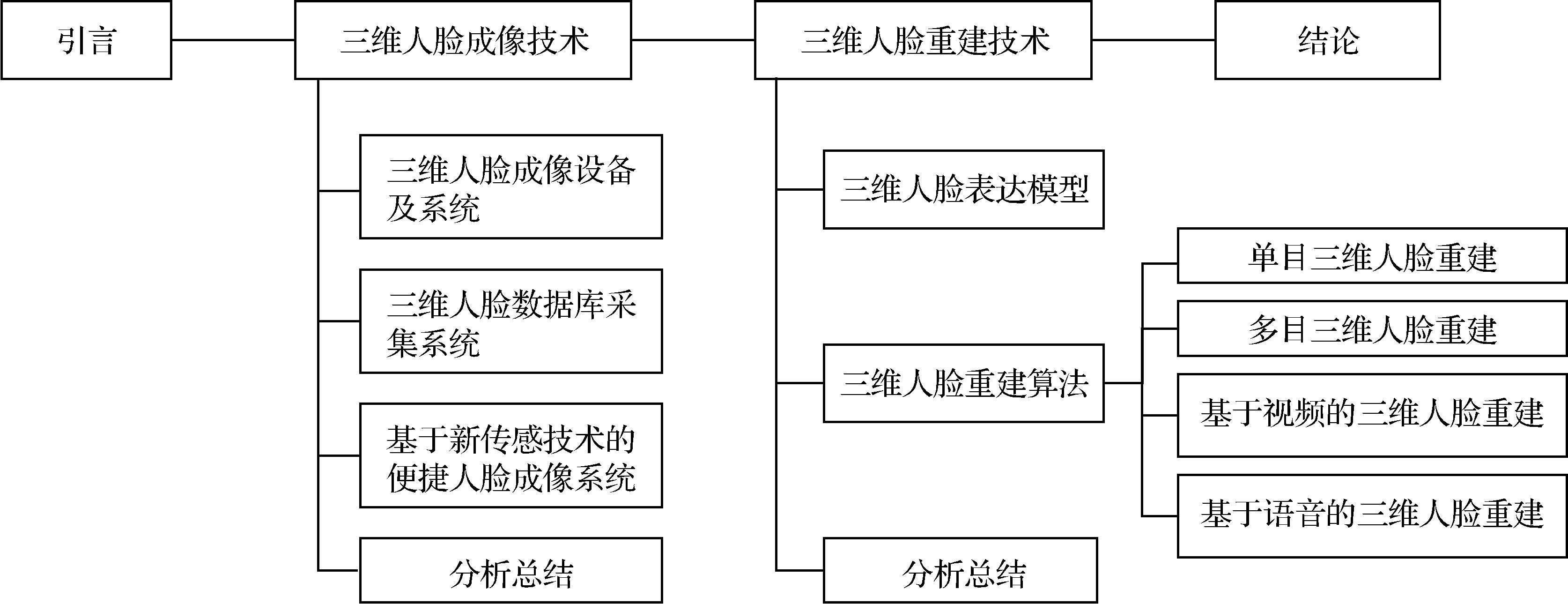 摘要:得益于新型三维视觉测量技术及深度学习模型的飞速发展,三维视觉成为人工智能、虚拟现实等领域的重要支撑技术,三维人脸成像及重建技术取得了突破性进展,不仅能够更好地应对光照、遮挡、表情和姿态等变化,同时增大了伪造攻击难度,大大推动了真实感“虚拟数字人”的重建与渲染,有效提升了人脸系统的安全性。本文对三维人脸成像技术和重建模型进行了全面综述,尤其对基于深度学习的三维人脸重建进行系统深入地分析。首先,对三维人脸成像设备及采集系统进行详细梳理及对比归纳,并介绍了基于新传感技术的人脸成像系统;然后,对基于深度学习的三维人脸重建模型进行系统分析,从输入数据源角度分为基于单目图像、基于多目图像、基于视频和基于语音的三维人脸重建算法4类。通过深入分析,总结三维人脸成像的研究现状及面临的难点与挑战,对未来发展方向及应用进行积极探讨与展望。本文涵盖了近5年经典的三维人脸成像及重建相关的技术与研究,为人脸研究、发展和应用提供了很好的参考。关键词:三维人脸成像;三维人脸重建;深度学习 (DL);生成对抗网络 (GAN);隐式神经表示 (INR)907|1010|0更新时间:2024-09-18
摘要:得益于新型三维视觉测量技术及深度学习模型的飞速发展,三维视觉成为人工智能、虚拟现实等领域的重要支撑技术,三维人脸成像及重建技术取得了突破性进展,不仅能够更好地应对光照、遮挡、表情和姿态等变化,同时增大了伪造攻击难度,大大推动了真实感“虚拟数字人”的重建与渲染,有效提升了人脸系统的安全性。本文对三维人脸成像技术和重建模型进行了全面综述,尤其对基于深度学习的三维人脸重建进行系统深入地分析。首先,对三维人脸成像设备及采集系统进行详细梳理及对比归纳,并介绍了基于新传感技术的人脸成像系统;然后,对基于深度学习的三维人脸重建模型进行系统分析,从输入数据源角度分为基于单目图像、基于多目图像、基于视频和基于语音的三维人脸重建算法4类。通过深入分析,总结三维人脸成像的研究现状及面临的难点与挑战,对未来发展方向及应用进行积极探讨与展望。本文涵盖了近5年经典的三维人脸成像及重建相关的技术与研究,为人脸研究、发展和应用提供了很好的参考。关键词:三维人脸成像;三维人脸重建;深度学习 (DL);生成对抗网络 (GAN);隐式神经表示 (INR)907|1010|0更新时间:2024-09-18 -
 摘要:在计算机图形学发展过程中,数字三维场景长期对于学术界和工业界都起着至关重要的作用。其作用体现在展示渲染效果、支持应用环境以及充当交互载体等多个方面。然而,三维场景本身作为一种数据形式,其结构复杂且没有统一的数据结构,故难以像诸如图像、文本数据集一样被大量获取与应用。已有一些工作尝试让计算机自动构建场景或是让计算机辅助构建场景。而在众多场景之中,室内场景尤为重要。本文总结归纳了这些数字室内三维场景构建工作。提出从3个方面调研和总结场景构建的主要工作:场景自动构建、基于用户交互的场景辅助构建以及基于多通道与丰富输入的场景构建。自动构建在于让计算机直接基于当前三维内容给出场景构建结果;交互构建在于让用户控制计算机并辅助构建场景;多通道构建在于让构建的场景参考输入的图像、文本和点云。最后,本文总结了科研工作的应用场景和关键技术,并介绍了一些其他应用情景与未来面对的诸多挑战。数字室内三维场景构建的发展前景十分广阔,随着新算法的不断提出以及三维场景数据集日益完善,数字室内三维场景构建领域也将持续发展。关键词:室内场景;三维场景构建;三维场景交互;三维场景智能编辑;计算机图形学602|1160|0更新时间:2024-09-18
摘要:在计算机图形学发展过程中,数字三维场景长期对于学术界和工业界都起着至关重要的作用。其作用体现在展示渲染效果、支持应用环境以及充当交互载体等多个方面。然而,三维场景本身作为一种数据形式,其结构复杂且没有统一的数据结构,故难以像诸如图像、文本数据集一样被大量获取与应用。已有一些工作尝试让计算机自动构建场景或是让计算机辅助构建场景。而在众多场景之中,室内场景尤为重要。本文总结归纳了这些数字室内三维场景构建工作。提出从3个方面调研和总结场景构建的主要工作:场景自动构建、基于用户交互的场景辅助构建以及基于多通道与丰富输入的场景构建。自动构建在于让计算机直接基于当前三维内容给出场景构建结果;交互构建在于让用户控制计算机并辅助构建场景;多通道构建在于让构建的场景参考输入的图像、文本和点云。最后,本文总结了科研工作的应用场景和关键技术,并介绍了一些其他应用情景与未来面对的诸多挑战。数字室内三维场景构建的发展前景十分广阔,随着新算法的不断提出以及三维场景数据集日益完善,数字室内三维场景构建领域也将持续发展。关键词:室内场景;三维场景构建;三维场景交互;三维场景智能编辑;计算机图形学602|1160|0更新时间:2024-09-18 -
 摘要:多模态数字人是指具备多模态认知与交互能力,且有类人的思维和行为逻辑的真实自然虚拟人。近年来随着计算机视觉与自然语言处理等领域的交叉融合以及蓬勃发展,相关技术取得显著进步。本文讨论在图形学和视觉领域比较重要的多模态人头动画、多模态人体动画以及多模态数字人形象构建3个主题,介绍其方法论和代表工作。在多模态人头动画主题下介绍语音驱动人头和表情驱动人头两个问题的相关工作。在多模态人体动画主题下介绍基于循环神经网络(recurrent neural networks,RNN)的、基于Transformer的和基于降噪扩散模型的人体动画生成。在多模态数字人形象构建主题下介绍视觉语言相似性引导的虚拟形象构建、基于多模态降噪扩散模型引导的虚拟形象构建以及三维多模态虚拟人生成模型。本文将相关方向的代表性工作进行介绍和归类,对已有方法进行总结,并展望未来可能的研究方向。关键词:虚拟数字人建模;多模态角色动画;多模态生成与编辑;神经渲染;生成模型;神经隐式表示1014|2480|0更新时间:2024-09-18
摘要:多模态数字人是指具备多模态认知与交互能力,且有类人的思维和行为逻辑的真实自然虚拟人。近年来随着计算机视觉与自然语言处理等领域的交叉融合以及蓬勃发展,相关技术取得显著进步。本文讨论在图形学和视觉领域比较重要的多模态人头动画、多模态人体动画以及多模态数字人形象构建3个主题,介绍其方法论和代表工作。在多模态人头动画主题下介绍语音驱动人头和表情驱动人头两个问题的相关工作。在多模态人体动画主题下介绍基于循环神经网络(recurrent neural networks,RNN)的、基于Transformer的和基于降噪扩散模型的人体动画生成。在多模态数字人形象构建主题下介绍视觉语言相似性引导的虚拟形象构建、基于多模态降噪扩散模型引导的虚拟形象构建以及三维多模态虚拟人生成模型。本文将相关方向的代表性工作进行介绍和归类,对已有方法进行总结,并展望未来可能的研究方向。关键词:虚拟数字人建模;多模态角色动画;多模态生成与编辑;神经渲染;生成模型;神经隐式表示1014|2480|0更新时间:2024-09-18 -
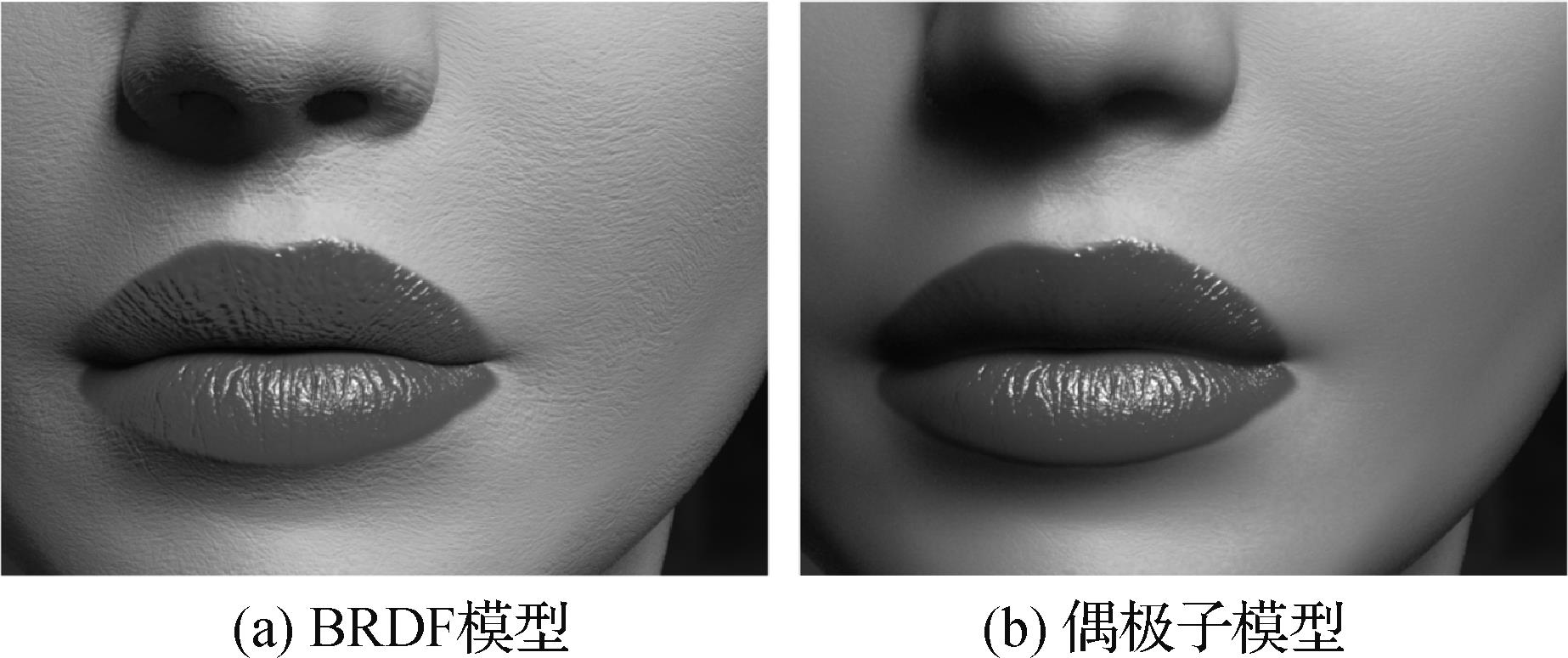 摘要:数字人技术引起了数字孪生、元宇宙等领域的广泛关注,其中人脸作为数字人的重要构成部分,其数字化生成和呈现成为人们关注的焦点,且相关技术已经在电影、游戏等领域得到了广阔应用。人们对实现逼真的人脸效果以及精确恢复人脸的需求日益增长,但由于人脸的多层材质结构、复杂的半透明皮肤效果以及毛孔、褶皱等微观特征的综合影响,实现高保真的、高效的人脸渲染一直是领域内的难题。此外,通过采集设备对人脸的几何和外观进行恢复是构建人脸数据的重要方式,然而对人脸的高品质恢复也同样受限于高成本的采集设备和相关数据集的不足。本文对数字人脸的渲染与恢复的相关方法进行综述。首先介绍了真实感人脸的渲染方法,根据其不同的渲染原理,将它们分为基于扩散近似的渲染方法和基于蒙特卡洛采样的渲染方法,并着重分析了基于近似扩散渲染方法的发展现状及面临的问题。进一步,将人脸恢复工作分类为基于专业采集设备的高精度恢复和基于深度学习的低精度恢复。针对高精度人脸恢复,从主动照明和被动捕获两个分支,对相应的工作进行了总结。针对结合深度学习的低精度人脸恢复方法,将其分类为几何细节的恢复、纹理贴图的恢复以及人脸材质信息的恢复3个方面进行介绍。本文系统地论述了各类方法的核心思路,并进行了横向对比和分析。最后,对未来人脸渲染及恢复方法的发展趋势进行了展望。希望本文可以为人脸渲染和外观恢复的初学者提供一些背景知识和思路启发。关键词:人脸真实感渲染;次表面散射;人脸逆向恢复;主动照明;被动捕获;深度学习501|1074|1更新时间:2024-09-18
摘要:数字人技术引起了数字孪生、元宇宙等领域的广泛关注,其中人脸作为数字人的重要构成部分,其数字化生成和呈现成为人们关注的焦点,且相关技术已经在电影、游戏等领域得到了广阔应用。人们对实现逼真的人脸效果以及精确恢复人脸的需求日益增长,但由于人脸的多层材质结构、复杂的半透明皮肤效果以及毛孔、褶皱等微观特征的综合影响,实现高保真的、高效的人脸渲染一直是领域内的难题。此外,通过采集设备对人脸的几何和外观进行恢复是构建人脸数据的重要方式,然而对人脸的高品质恢复也同样受限于高成本的采集设备和相关数据集的不足。本文对数字人脸的渲染与恢复的相关方法进行综述。首先介绍了真实感人脸的渲染方法,根据其不同的渲染原理,将它们分为基于扩散近似的渲染方法和基于蒙特卡洛采样的渲染方法,并着重分析了基于近似扩散渲染方法的发展现状及面临的问题。进一步,将人脸恢复工作分类为基于专业采集设备的高精度恢复和基于深度学习的低精度恢复。针对高精度人脸恢复,从主动照明和被动捕获两个分支,对相应的工作进行了总结。针对结合深度学习的低精度人脸恢复方法,将其分类为几何细节的恢复、纹理贴图的恢复以及人脸材质信息的恢复3个方面进行介绍。本文系统地论述了各类方法的核心思路,并进行了横向对比和分析。最后,对未来人脸渲染及恢复方法的发展趋势进行了展望。希望本文可以为人脸渲染和外观恢复的初学者提供一些背景知识和思路启发。关键词:人脸真实感渲染;次表面散射;人脸逆向恢复;主动照明;被动捕获;深度学习501|1074|1更新时间:2024-09-18 -
 摘要:基于多模态信息的三维数字人运动生成技术旨在通过文本、音频、图像和视频等数据实现特定输入条件下的人体运动生成。这项技术在电影、动画、游戏制作和元宇宙等领域具有重要的应用价值和广泛的经济社会效益,是近年来计算机图形学和计算机视觉等领域研究的热点问题之一。然而,基于多模态信息的三维数字人运动生成面临着诸多挑战,包括跨模态信息的表征和融合困难、高质量数据集缺乏、生成的运动质量较差(如抖动、穿模和脚部滑动等)以及生成效率低等问题。虽然近年来研究者们提出了各式各样的解决方案来应对上述挑战,但如何根据不同模态数据的特点实现高效、高质量的三维数字人运动生成仍然是一个开放性问题。本文以数字人运动生成所采用的模型架构为分类标准,将现有的主流方法分为基于生成对抗网络(generative adversarial network,GAN)的方法、基于自编码器(autoencoder,AE)的方法、基于变分自编码器(variational autoencoder,VAE)的方法以及基于扩散模型的方法,总结并形成了一种数字人运动生成通用框架。本文还介绍了该领域常见的参数化人体模型、数据集以及评估指标。对于一些具有代表性的工作,本文在一些常用数据集上进行了对比实验,评估这些方法的性能表现。最后综合现有的数据集、算法和代表性研究,总结了该领域的问题和挑战,探讨了完善数据集、优化运动质量和多样性、融合跨模态信息和提高生成效率等潜在的研究方向。关键词:三维数字人;运动生成;多模态信息;参数化人体模型;生成对抗网络 (GAN);自编码器 (AE);变分自编码器 (VAE);扩散模型776|1293|1更新时间:2024-09-18
摘要:基于多模态信息的三维数字人运动生成技术旨在通过文本、音频、图像和视频等数据实现特定输入条件下的人体运动生成。这项技术在电影、动画、游戏制作和元宇宙等领域具有重要的应用价值和广泛的经济社会效益,是近年来计算机图形学和计算机视觉等领域研究的热点问题之一。然而,基于多模态信息的三维数字人运动生成面临着诸多挑战,包括跨模态信息的表征和融合困难、高质量数据集缺乏、生成的运动质量较差(如抖动、穿模和脚部滑动等)以及生成效率低等问题。虽然近年来研究者们提出了各式各样的解决方案来应对上述挑战,但如何根据不同模态数据的特点实现高效、高质量的三维数字人运动生成仍然是一个开放性问题。本文以数字人运动生成所采用的模型架构为分类标准,将现有的主流方法分为基于生成对抗网络(generative adversarial network,GAN)的方法、基于自编码器(autoencoder,AE)的方法、基于变分自编码器(variational autoencoder,VAE)的方法以及基于扩散模型的方法,总结并形成了一种数字人运动生成通用框架。本文还介绍了该领域常见的参数化人体模型、数据集以及评估指标。对于一些具有代表性的工作,本文在一些常用数据集上进行了对比实验,评估这些方法的性能表现。最后综合现有的数据集、算法和代表性研究,总结了该领域的问题和挑战,探讨了完善数据集、优化运动质量和多样性、融合跨模态信息和提高生成效率等潜在的研究方向。关键词:三维数字人;运动生成;多模态信息;参数化人体模型;生成对抗网络 (GAN);自编码器 (AE);变分自编码器 (VAE);扩散模型776|1293|1更新时间:2024-09-18 -
 摘要:三维穿衣人体重建,在计算机图形学和三维视觉领域占有重要地位,广泛应用于多个方向。人体穿衣的多样性和动作的复杂性使得穿衣人体的高保真重建变得极其困难。深度学习技术优化了数据特征提取、隐式几何表示和神经渲染等关键环节,也推动了高保真穿衣人体重建技术的革命性进步。本文综述了人体重建的基本流程和组成模块,如各类输入数据、人体几何与动作表示、参数化模型以及三维到二维的渲染技术。同时,介绍了公开的穿衣人体数据集,简要回顾了近10年来人体重建算法的快速发展。本文详细探讨了几种主要的重建方法:稠密视角重建、非刚性运动重建(non-rigid structure from motion, NRSFM)、基于像素对齐的隐式几何重建以及生成模型方法。特别是,稠密视角重建能够生成高质量的人体几何,而NRSFM方法减少了对多视角的需求。基于像素对齐的方法重建细节丰富的人体几何,而生成模型方法利用多模态输入信息实现重建。最后总结了现有方法,并展望了未来研究方向,包括实现低成本高保真重建、加速重建过程和增强重建结果的可编辑性,以及在自然环境下进行重建的可能性。本文总结了近年来穿衣人体重建技术的进步,同时指出了未来研究可能集中的方向。关键词:三维人体重建;深度学习;参数化模型;隐式几何表示;非刚性运动重建方法;生成模型451|1523|0更新时间:2024-09-18
摘要:三维穿衣人体重建,在计算机图形学和三维视觉领域占有重要地位,广泛应用于多个方向。人体穿衣的多样性和动作的复杂性使得穿衣人体的高保真重建变得极其困难。深度学习技术优化了数据特征提取、隐式几何表示和神经渲染等关键环节,也推动了高保真穿衣人体重建技术的革命性进步。本文综述了人体重建的基本流程和组成模块,如各类输入数据、人体几何与动作表示、参数化模型以及三维到二维的渲染技术。同时,介绍了公开的穿衣人体数据集,简要回顾了近10年来人体重建算法的快速发展。本文详细探讨了几种主要的重建方法:稠密视角重建、非刚性运动重建(non-rigid structure from motion, NRSFM)、基于像素对齐的隐式几何重建以及生成模型方法。特别是,稠密视角重建能够生成高质量的人体几何,而NRSFM方法减少了对多视角的需求。基于像素对齐的方法重建细节丰富的人体几何,而生成模型方法利用多模态输入信息实现重建。最后总结了现有方法,并展望了未来研究方向,包括实现低成本高保真重建、加速重建过程和增强重建结果的可编辑性,以及在自然环境下进行重建的可能性。本文总结了近年来穿衣人体重建技术的进步,同时指出了未来研究可能集中的方向。关键词:三维人体重建;深度学习;参数化模型;隐式几何表示;非刚性运动重建方法;生成模型451|1523|0更新时间:2024-09-18 -
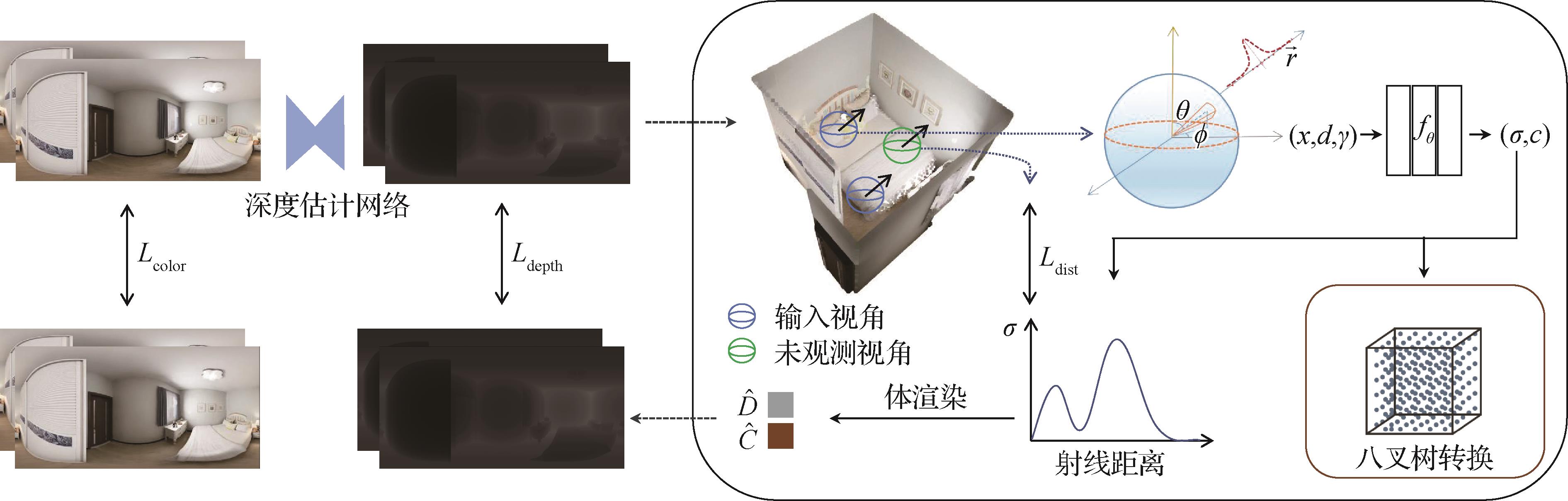 摘要:目的神经辐射场(NeRF)可以为数字人、交互游戏等虚拟现实应用提供沉浸式环境。然而,现有神经辐射场算法往往依赖大量位置的全景图进行大规模室内场景重建,在稀疏全景图条件下的重建效果不佳。为此,提出了一种用于室内稀疏全景图的神经辐射场重建算法,以实现低开销、高质量的室内新视角合成。方法针对稀疏输入问题,本文首先设计了深度监督策略,以分配更多的采样点在物体表面,从而获取更精细的几何重建结构。然后,引入了未观测视角下的射线形变损失来增强射线约束,从而有效提升了稀疏输入下的室内场景重建质量。结果本文算法在多个室内全景数据集上与较新的神经辐射场重建算法进行了比较。在两幅Replica数据集全景图输入条件下,本文算法在峰值信噪比(peak signal-to-noise ratio,PSNR)指标上比基准算法提升了6%。即使在单幅PNVS数据集全景图输入条件下,本文算法在PSNR指标上也比基准算法提升了11%。结论实验结果表明,本文提出的神经辐射场重建算法能够从稀疏室内全景图中重建高质量场景,实现高真实感的新视角合成。关键词:神经辐射场(NeRF)重建;稀疏输入;全景图;新视角合成;虚拟现实;数字人266|212|0更新时间:2024-09-18
摘要:目的神经辐射场(NeRF)可以为数字人、交互游戏等虚拟现实应用提供沉浸式环境。然而,现有神经辐射场算法往往依赖大量位置的全景图进行大规模室内场景重建,在稀疏全景图条件下的重建效果不佳。为此,提出了一种用于室内稀疏全景图的神经辐射场重建算法,以实现低开销、高质量的室内新视角合成。方法针对稀疏输入问题,本文首先设计了深度监督策略,以分配更多的采样点在物体表面,从而获取更精细的几何重建结构。然后,引入了未观测视角下的射线形变损失来增强射线约束,从而有效提升了稀疏输入下的室内场景重建质量。结果本文算法在多个室内全景数据集上与较新的神经辐射场重建算法进行了比较。在两幅Replica数据集全景图输入条件下,本文算法在峰值信噪比(peak signal-to-noise ratio,PSNR)指标上比基准算法提升了6%。即使在单幅PNVS数据集全景图输入条件下,本文算法在PSNR指标上也比基准算法提升了11%。结论实验结果表明,本文提出的神经辐射场重建算法能够从稀疏室内全景图中重建高质量场景,实现高真实感的新视角合成。关键词:神经辐射场(NeRF)重建;稀疏输入;全景图;新视角合成;虚拟现实;数字人266|212|0更新时间:2024-09-18 -
 摘要:目的由于单视角着装人体重建中存在肢体遮挡、着装姿态复杂,且现有方法仅能精确提取和表示着装人体图像中的视觉特征,未考虑复杂的着装姿态引起的动态细节表达,较难生成具有动态褶皱的着装人体模型。因此,提出一种单视角三维人体重建的着装特征学习方法。方法首先对着装人体图像集中的单视角图像进行肢体特征表示,通过二维关节点预测与姿态特征深度回归,提取人体的着装姿态特征;再基于着装姿态特征,定义以柔性变形关节点为中心的着装褶皱采样空间和柔性变形损失函数,通过引入服装模板对输入的着装人体真值模型学习着装柔性变形,获得着装褶皱特征;然后,结合姿态参数回归、特征图采样特征和编解码器,构建联合着装人体像素和体素的人体形状特征学习模块,得到着装人体形状特征;最后结合褶皱特征、着装人体形状特征和计算的三维采样空间,通过定义有向距离场进行三维人体重建,输出最终的着装人体模型。结果为了验证方法的有效性,在公开的THuman2.0数据集进行对比实验。结果显示,构建姿态特征学习模块有助于重建完整的肢体与正确的姿态,以褶皱特征学习对形状特征进行优化,可以获得高精度的重建结果。与当前先进的单视角三维人体重建方法比较,相比于性能第2的模型,本文方法重建结果的点到面距离与倒角距离分别降低了4.4%和2.6%。结论本文提出的单视角三维人体重建的着装特征学习方法,能有效学习单视角三维人体重建的着装特征,生成具有复杂姿态和动态褶皱的着装人体模型。关键词:单视角三维人体重建;着装特征学习;采样空间;柔性变形;有向距离场275|889|1更新时间:2024-09-18
摘要:目的由于单视角着装人体重建中存在肢体遮挡、着装姿态复杂,且现有方法仅能精确提取和表示着装人体图像中的视觉特征,未考虑复杂的着装姿态引起的动态细节表达,较难生成具有动态褶皱的着装人体模型。因此,提出一种单视角三维人体重建的着装特征学习方法。方法首先对着装人体图像集中的单视角图像进行肢体特征表示,通过二维关节点预测与姿态特征深度回归,提取人体的着装姿态特征;再基于着装姿态特征,定义以柔性变形关节点为中心的着装褶皱采样空间和柔性变形损失函数,通过引入服装模板对输入的着装人体真值模型学习着装柔性变形,获得着装褶皱特征;然后,结合姿态参数回归、特征图采样特征和编解码器,构建联合着装人体像素和体素的人体形状特征学习模块,得到着装人体形状特征;最后结合褶皱特征、着装人体形状特征和计算的三维采样空间,通过定义有向距离场进行三维人体重建,输出最终的着装人体模型。结果为了验证方法的有效性,在公开的THuman2.0数据集进行对比实验。结果显示,构建姿态特征学习模块有助于重建完整的肢体与正确的姿态,以褶皱特征学习对形状特征进行优化,可以获得高精度的重建结果。与当前先进的单视角三维人体重建方法比较,相比于性能第2的模型,本文方法重建结果的点到面距离与倒角距离分别降低了4.4%和2.6%。结论本文提出的单视角三维人体重建的着装特征学习方法,能有效学习单视角三维人体重建的着装特征,生成具有复杂姿态和动态褶皱的着装人体模型。关键词:单视角三维人体重建;着装特征学习;采样空间;柔性变形;有向距离场275|889|1更新时间:2024-09-18
数字人建模、生成与渲染技术

-
 摘要:在复杂背景和噪声干扰下,如何利用红外探测系统快速且准确发现特征少、强度低、尺度变化以及运动状态未知的非合作小目标是一项具有挑战性的任务,备受学者关注。为了让读者全面了解该领域的研究现状,本综述将从算法原理、文献、数据集、评价指标、实验和发展方向等方面进行总结概括。首先,解释了以“红外多尺度小目标(点源和小面源)”为对象进行研究的原因并分析了红外多尺度小目标及背景的成像特性;其次,分别讨论了基于经典算法和深度学习算法的原理、设计策略和相关文献,并对比分析了这两类算法的优缺点;然后,总结了现有的红外小目标公开数据集和算法评价指标;最后,分别选取7种经典算法和15种深度学习算法进行定性和定量的对比分析。通过对单帧红外图像多尺度小目标检测技术的全面回顾,对该领域下一步的研究方向给出了9条具体建议。本综述不仅可以帮助初学者快速了解该领域的研究现状和发展趋势,也可作为其他研究的参考资料。此外,在本领域研究过程中,还将现有的20种经典算法、15种深度学习算法和9种评价指标集成在人机交互系统中,相关系统的视频介绍发布可由以下链接得到:https://github.com/kourenke/GUI-system-for-infrared-small-target-detection。关键词:红外图像;多尺度小目标;目标检测;经典算法;深度学习算法1588|981|2更新时间:2024-09-18
摘要:在复杂背景和噪声干扰下,如何利用红外探测系统快速且准确发现特征少、强度低、尺度变化以及运动状态未知的非合作小目标是一项具有挑战性的任务,备受学者关注。为了让读者全面了解该领域的研究现状,本综述将从算法原理、文献、数据集、评价指标、实验和发展方向等方面进行总结概括。首先,解释了以“红外多尺度小目标(点源和小面源)”为对象进行研究的原因并分析了红外多尺度小目标及背景的成像特性;其次,分别讨论了基于经典算法和深度学习算法的原理、设计策略和相关文献,并对比分析了这两类算法的优缺点;然后,总结了现有的红外小目标公开数据集和算法评价指标;最后,分别选取7种经典算法和15种深度学习算法进行定性和定量的对比分析。通过对单帧红外图像多尺度小目标检测技术的全面回顾,对该领域下一步的研究方向给出了9条具体建议。本综述不仅可以帮助初学者快速了解该领域的研究现状和发展趋势,也可作为其他研究的参考资料。此外,在本领域研究过程中,还将现有的20种经典算法、15种深度学习算法和9种评价指标集成在人机交互系统中,相关系统的视频介绍发布可由以下链接得到:https://github.com/kourenke/GUI-system-for-infrared-small-target-detection。关键词:红外图像;多尺度小目标;目标检测;经典算法;深度学习算法1588|981|2更新时间:2024-09-18 -
 摘要:在智能交通系统中,车辆作为最普及的交通工具,常被不法分子利用,使其成为一种安全隐患,因此,实现监控设备下的车辆身份识别一直是一个研究热点。车辆标志(简称车标)是车辆的特殊身份,包含着车辆品牌制造商的基本信息,相比车牌、车型和车色,车标具有相对独立和可靠的特性。车辆标志识别能够快速、精准地缩小车辆查询范围,为案件侦破、交通自动化管理等有效降低搜索成本,因此车辆标志识别在车辆身份识别中尤其重要。本文对近十年内的主流车标识别方法进行了系统概述,为车标识别领域的后续研究者提供参考。1)简要阐述了在智能交通系统中车标识别技术的研究背景和重要性。2)根据车标识别过程中是否依赖手工提取特征,将目前国际主流的车标识别方法归纳为传统的车标识别方法和基于深度学习的车标识别方法,并分别总结了这两类方法的优劣。随后,分类、梳理和评价了这两类方法中现有的各种算法。3)针对车标数据集稀少导致难以评价各类算法性能、影响车标识别研究进展的问题,详细介绍了3种公开车标数据集:XMU(Xiamen University Vehicle Logo Dataset)、HFUT-VL(Vehicle Logo Dataset from Hefei University of Technology)和VLD-45(Vehicle Logo Dataset-45),并给出下载地址,可供研究者进行实验和测试。4)描述了4种常用的评价指标,并在公开数据集上基于这些评价指标对车标识别方法开展实验,并对实验结果进行比较和分析。5)综述现有车标识别技术中存在的一些问题与挑战,对未来车标识别的研究方向做出预测和展望。关键词:智能交通系统 (ITSs);车标识别;特征提取;图像分类;深度学习;综述489|288|0更新时间:2024-09-18
摘要:在智能交通系统中,车辆作为最普及的交通工具,常被不法分子利用,使其成为一种安全隐患,因此,实现监控设备下的车辆身份识别一直是一个研究热点。车辆标志(简称车标)是车辆的特殊身份,包含着车辆品牌制造商的基本信息,相比车牌、车型和车色,车标具有相对独立和可靠的特性。车辆标志识别能够快速、精准地缩小车辆查询范围,为案件侦破、交通自动化管理等有效降低搜索成本,因此车辆标志识别在车辆身份识别中尤其重要。本文对近十年内的主流车标识别方法进行了系统概述,为车标识别领域的后续研究者提供参考。1)简要阐述了在智能交通系统中车标识别技术的研究背景和重要性。2)根据车标识别过程中是否依赖手工提取特征,将目前国际主流的车标识别方法归纳为传统的车标识别方法和基于深度学习的车标识别方法,并分别总结了这两类方法的优劣。随后,分类、梳理和评价了这两类方法中现有的各种算法。3)针对车标数据集稀少导致难以评价各类算法性能、影响车标识别研究进展的问题,详细介绍了3种公开车标数据集:XMU(Xiamen University Vehicle Logo Dataset)、HFUT-VL(Vehicle Logo Dataset from Hefei University of Technology)和VLD-45(Vehicle Logo Dataset-45),并给出下载地址,可供研究者进行实验和测试。4)描述了4种常用的评价指标,并在公开数据集上基于这些评价指标对车标识别方法开展实验,并对实验结果进行比较和分析。5)综述现有车标识别技术中存在的一些问题与挑战,对未来车标识别的研究方向做出预测和展望。关键词:智能交通系统 (ITSs);车标识别;特征提取;图像分类;深度学习;综述489|288|0更新时间:2024-09-18 -
 摘要:文本识别技术可以分为光学字符识别(optical character recognition, OCR)和场景文本识别(scene text recognition,STR),其中STR是在OCR基础上针对日益复杂的应用场景衍生出来的。依托深度学习,OCR技术近年来取得了长足进步并大规模商业落地,但深度学习面临的对抗样本攻击问题也给OCR带来了安全威胁。目前大多数OCR模型均存在识别自然扰动和防御对抗样本攻击能力差的问题,如OCR模型在噪声、水印和梯度等攻击算法下的识别准确率大大降低。相比图像领域,文本识别领域的对抗样本攻击研究还远远不够。文本识别通常被视为一个序列到序列的问题,其中输入(如图像中的像素)和输出(像素对应的字符)都是序列,这使得对抗样本的生成更具挑战性。本文对文本识别的对抗样本攻击和防御方法进行研究综述,梳理了近年来文本识别领域的对抗样本攻击方法并进行对比分析,根据攻击类型、应用场景和模型可知性,对攻击方式进行了系统分类。具体来说,按照攻击类型,可分为基于梯度的攻击、基于优化的攻击和基于生成模型的攻击;按照应用场景,可以分为OCR攻击和STR攻击;按照模型可知性,可分为白盒攻击和黑盒攻击。除了回顾文本识别对抗样本攻击方法,还简要介绍了防御技术,具体分为数据预处理、文本篡改检测和传统对抗防御技术。通过这些技术的应用,可以有效地提升文本识别模型的安全性和鲁棒性。最后,总结了文本识别领域对抗样本攻击及防御面临的挑战,并对未来发展方向做出展望。关键词:光学字符识别(OCR);场景文本识别(STR);对抗样本;生成对抗网络 (GAN);深度学习;序列模型494|287|1更新时间:2024-09-18
摘要:文本识别技术可以分为光学字符识别(optical character recognition, OCR)和场景文本识别(scene text recognition,STR),其中STR是在OCR基础上针对日益复杂的应用场景衍生出来的。依托深度学习,OCR技术近年来取得了长足进步并大规模商业落地,但深度学习面临的对抗样本攻击问题也给OCR带来了安全威胁。目前大多数OCR模型均存在识别自然扰动和防御对抗样本攻击能力差的问题,如OCR模型在噪声、水印和梯度等攻击算法下的识别准确率大大降低。相比图像领域,文本识别领域的对抗样本攻击研究还远远不够。文本识别通常被视为一个序列到序列的问题,其中输入(如图像中的像素)和输出(像素对应的字符)都是序列,这使得对抗样本的生成更具挑战性。本文对文本识别的对抗样本攻击和防御方法进行研究综述,梳理了近年来文本识别领域的对抗样本攻击方法并进行对比分析,根据攻击类型、应用场景和模型可知性,对攻击方式进行了系统分类。具体来说,按照攻击类型,可分为基于梯度的攻击、基于优化的攻击和基于生成模型的攻击;按照应用场景,可以分为OCR攻击和STR攻击;按照模型可知性,可分为白盒攻击和黑盒攻击。除了回顾文本识别对抗样本攻击方法,还简要介绍了防御技术,具体分为数据预处理、文本篡改检测和传统对抗防御技术。通过这些技术的应用,可以有效地提升文本识别模型的安全性和鲁棒性。最后,总结了文本识别领域对抗样本攻击及防御面临的挑战,并对未来发展方向做出展望。关键词:光学字符识别(OCR);场景文本识别(STR);对抗样本;生成对抗网络 (GAN);深度学习;序列模型494|287|1更新时间:2024-09-18 -
 摘要:医学影像分析中,血管和气道分割是备受关注的研究。通过对血管和气道异常的评估,例如动脉壁增厚和硬化、脑血管破裂导致的出血以及肺部或气道内的肿瘤等,可以实现此类疾病的早期诊断和临床治疗指导。随着医学成像技术的发展,影像分割技术在评估和诊断这些结构异常方面变得越来越重要。然而,由于其复杂的结构和病理变化,血管和气道的准确分割仍然是一项具有挑战性的任务。许多研究都集中在特定类型的血管或气道分割上,对多种类型的血管和气道分割方法的综合回顾相对缺乏。对各类血管和气道的综合回顾可以为医学专家和研究人员提供更全面的临床参考价值。此外,不同类型的血管和气道具有形态上的相似性,一些算法和技术可以同时应用于它们的分割中,综合回顾也增强了讨论的广泛性。因此,本文对近20年来具有代表性的视网膜血管分割、脑血管分割、冠状动脉分割和气道分割4类研究工作进行了归纳,分别从传统方法、机器学习方法和深度学习方法3个方面对每类研究进行综述,同时总结了各种方法的优缺点,为后续研究提供了理论参考。此外,本文还介绍了适用于医学影像血管和气道分割的损失函数、评价指标,并收集了目前公开的各类血管和气道分割数据集。最后,本文讨论了目前医学影像血管和气道分割方法的局限性以及未来研究的方向。关键词:深度学习;医学影像分割;视网膜血管分割;脑血管分割;冠状动脉分割;气道分割;图像处理595|1393|0更新时间:2024-09-18
摘要:医学影像分析中,血管和气道分割是备受关注的研究。通过对血管和气道异常的评估,例如动脉壁增厚和硬化、脑血管破裂导致的出血以及肺部或气道内的肿瘤等,可以实现此类疾病的早期诊断和临床治疗指导。随着医学成像技术的发展,影像分割技术在评估和诊断这些结构异常方面变得越来越重要。然而,由于其复杂的结构和病理变化,血管和气道的准确分割仍然是一项具有挑战性的任务。许多研究都集中在特定类型的血管或气道分割上,对多种类型的血管和气道分割方法的综合回顾相对缺乏。对各类血管和气道的综合回顾可以为医学专家和研究人员提供更全面的临床参考价值。此外,不同类型的血管和气道具有形态上的相似性,一些算法和技术可以同时应用于它们的分割中,综合回顾也增强了讨论的广泛性。因此,本文对近20年来具有代表性的视网膜血管分割、脑血管分割、冠状动脉分割和气道分割4类研究工作进行了归纳,分别从传统方法、机器学习方法和深度学习方法3个方面对每类研究进行综述,同时总结了各种方法的优缺点,为后续研究提供了理论参考。此外,本文还介绍了适用于医学影像血管和气道分割的损失函数、评价指标,并收集了目前公开的各类血管和气道分割数据集。最后,本文讨论了目前医学影像血管和气道分割方法的局限性以及未来研究的方向。关键词:深度学习;医学影像分割;视网膜血管分割;脑血管分割;冠状动脉分割;气道分割;图像处理595|1393|0更新时间:2024-09-18 -
 摘要:跨视角图像地理定位旨在通过图像匹配和地理坐标估计实现不同视角图像之间的准确对应和地理定位,广泛应用于机器人导航、自动驾驶和三维重建等领域。传统的单一视角图像地理定位方法通常受限于数据集质量和规模等因素,定位精度较低。为克服这些局限,近年来研究人员提出了一系列跨视角图像地理定位方法,同时利用多个视角的图像数据,通过视角比较和匹配提高定位精度。跨视角图像匹配方法呈现多元的分类体系。根据面向的跨视角图像类型的不同,可将其分为面向地面—卫星图像的方法与面向无人机—卫星图像的方法两类。根据图像特征提取与表达方式的不同,又可将其分为基于人工设计特征的方法与基于深度神经网络自学习特征的方法两类,对于后者,还可根据是否采用视角对齐方法以及所采用对齐方法的不同将其细分为无视角对齐处理的跨视角图像地理定位、基于传统图像变换的跨视角图像地理定位和基于图像生成的跨视角图像地理定位等3类。本综述对以上方法进行了介绍并比较了它们的优缺点;此外,还总结了常用于跨视角图像地理定位的数据集和评价方法;最后,展望了跨视角图像地理定位的应用领域和未来发展方向。尽管跨视角地理定位方法已取得突破和进展,但仍面临一些问题和挑战。因此,本综述提出了可能的解决方向和未来研究的重点,以期推动该领域的发展和创新。关键词:图像地理定位;跨视角;图像匹配;深度学习;表征学习;视角转换627|1233|0更新时间:2024-09-18
摘要:跨视角图像地理定位旨在通过图像匹配和地理坐标估计实现不同视角图像之间的准确对应和地理定位,广泛应用于机器人导航、自动驾驶和三维重建等领域。传统的单一视角图像地理定位方法通常受限于数据集质量和规模等因素,定位精度较低。为克服这些局限,近年来研究人员提出了一系列跨视角图像地理定位方法,同时利用多个视角的图像数据,通过视角比较和匹配提高定位精度。跨视角图像匹配方法呈现多元的分类体系。根据面向的跨视角图像类型的不同,可将其分为面向地面—卫星图像的方法与面向无人机—卫星图像的方法两类。根据图像特征提取与表达方式的不同,又可将其分为基于人工设计特征的方法与基于深度神经网络自学习特征的方法两类,对于后者,还可根据是否采用视角对齐方法以及所采用对齐方法的不同将其细分为无视角对齐处理的跨视角图像地理定位、基于传统图像变换的跨视角图像地理定位和基于图像生成的跨视角图像地理定位等3类。本综述对以上方法进行了介绍并比较了它们的优缺点;此外,还总结了常用于跨视角图像地理定位的数据集和评价方法;最后,展望了跨视角图像地理定位的应用领域和未来发展方向。尽管跨视角地理定位方法已取得突破和进展,但仍面临一些问题和挑战。因此,本综述提出了可能的解决方向和未来研究的重点,以期推动该领域的发展和创新。关键词:图像地理定位;跨视角;图像匹配;深度学习;表征学习;视角转换627|1233|0更新时间:2024-09-18
综述
-
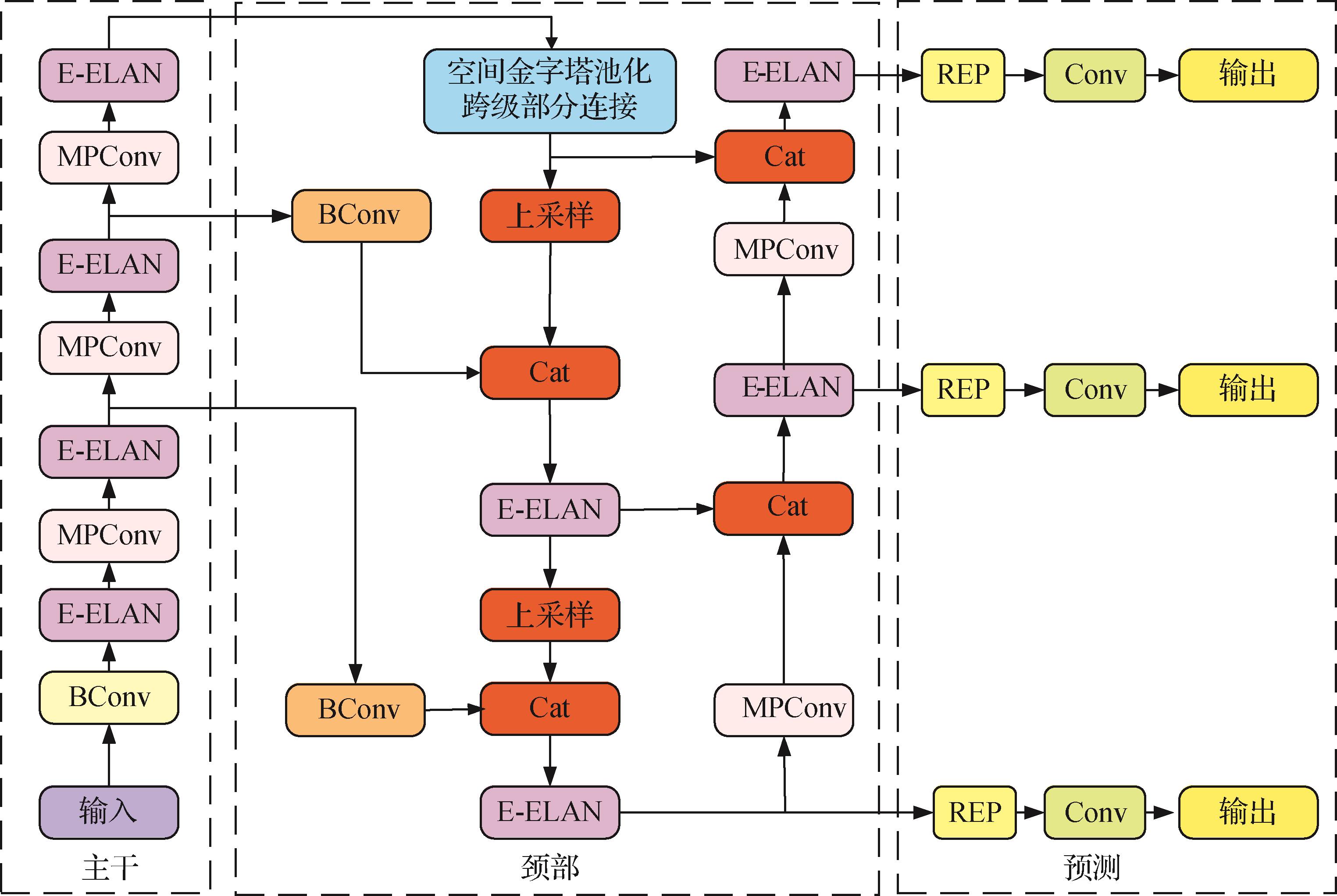 摘要:目的随着自动驾驶和辅助驾驶的快速发展,交通标志识别研究变得越来越重要。但是现阶段交通标志识别算法对交通标志识别的精度较低,尤其在面对目标背景较为复杂、光照不足和小目标交通标志的场景时,更加容易出现错检和漏检情况。针对以上问题,提出了一种改进YOLOv7(you only look once version 7)的交通标志识别模型。方法首先,采用空间金字塔池化快速跨级部分连接(spatial pyramid pooling fast cross stage partial concat,SPPFCSPC)方法,替换YOLOv7算法使用的空间金字塔池化跨级部分连接(spatial pyramid pooling cross stage partial concat,SPPCSPC)方法,提高算法的特征提取能力。其次,采用加权双向特征金字塔网络(bi-directional feature pyramid network,BiFPN),增强算法的多尺度特征融合能力。接着,采用一种新的框间距离度量的归一化Wasserstein距离(normalized Wasserstein distance,NWD)方法,解决传统的IoU(intersection over union)度量对小目标交通标志检测过于敏感的问题。最后,使用特征内容的感知重组(content-aware reassembly of feature,CARAFE)算子,通过输入的特征,自适应生成上采样内核,有效地增加模型的感受域,更好地利用目标周边的信息,减少交通标志错检和漏检情况。结果实验结果表明,在减少算法参数量的基础上,改进算法在TT100K交通标志数据集上的mAP@0.5和mAP@0.5∶0.9值分别达到了92.50%和72.21%,较原始的YOLOv7算法分别提高了3.24%和1.83%。同时,在具有小目标特性的CCTSDB交通标志数据集和整理的国外交通标志数据集上验证了模型改进的有效性。结论通过实验验证和主客观评价,证明了本文改进算法的可行性,能够有效地对多种环境下的小目标交通标志进行识别,并在降低算法参数量的前提下,进一步提高了YOLOv7算法对交通标志识别的平均精度。关键词:交通标志识别;空间金字塔池化快速跨级部分连接(SPPFCSPC);加权双向特征金字塔网络(BiFPN);归一化Wasserstein距离(NWD);特征内容的感知重组(CARAFE);小目标561|712|1更新时间:2024-09-18
摘要:目的随着自动驾驶和辅助驾驶的快速发展,交通标志识别研究变得越来越重要。但是现阶段交通标志识别算法对交通标志识别的精度较低,尤其在面对目标背景较为复杂、光照不足和小目标交通标志的场景时,更加容易出现错检和漏检情况。针对以上问题,提出了一种改进YOLOv7(you only look once version 7)的交通标志识别模型。方法首先,采用空间金字塔池化快速跨级部分连接(spatial pyramid pooling fast cross stage partial concat,SPPFCSPC)方法,替换YOLOv7算法使用的空间金字塔池化跨级部分连接(spatial pyramid pooling cross stage partial concat,SPPCSPC)方法,提高算法的特征提取能力。其次,采用加权双向特征金字塔网络(bi-directional feature pyramid network,BiFPN),增强算法的多尺度特征融合能力。接着,采用一种新的框间距离度量的归一化Wasserstein距离(normalized Wasserstein distance,NWD)方法,解决传统的IoU(intersection over union)度量对小目标交通标志检测过于敏感的问题。最后,使用特征内容的感知重组(content-aware reassembly of feature,CARAFE)算子,通过输入的特征,自适应生成上采样内核,有效地增加模型的感受域,更好地利用目标周边的信息,减少交通标志错检和漏检情况。结果实验结果表明,在减少算法参数量的基础上,改进算法在TT100K交通标志数据集上的mAP@0.5和mAP@0.5∶0.9值分别达到了92.50%和72.21%,较原始的YOLOv7算法分别提高了3.24%和1.83%。同时,在具有小目标特性的CCTSDB交通标志数据集和整理的国外交通标志数据集上验证了模型改进的有效性。结论通过实验验证和主客观评价,证明了本文改进算法的可行性,能够有效地对多种环境下的小目标交通标志进行识别,并在降低算法参数量的前提下,进一步提高了YOLOv7算法对交通标志识别的平均精度。关键词:交通标志识别;空间金字塔池化快速跨级部分连接(SPPFCSPC);加权双向特征金字塔网络(BiFPN);归一化Wasserstein距离(NWD);特征内容的感知重组(CARAFE);小目标561|712|1更新时间:2024-09-18 -
 摘要:目的基于手掌静脉的身份识别需要在近红外光下采集手掌血管图像,安全性高。开放环境下的非接触式采集,相对于传统的将手掌放到采集箱体内固定栓上的采集方式更受用户欢迎。但开放环境带来的可见光干扰和非接触拍摄带来的图像旋转、平移、比例缩放、光照改变使得识别具有挑战性。针对以上两个难点,研究了一种基于非监督卷积神经网络的方法。方法在卷积层中结合主成分分析(principal component analysis,PCA)滤波器提取主元信息,减少由于可见光引起的噪声影响;以固定尺寸Gabor滤波器为多尺度自适应Gabor滤波器提供先验知识,克服图像因几何与光照改变对识别产生的干扰,用以增强掌脉稳定特征,提升识别性能,再以二值化方式降低数据量,最后使用自适应K近邻(K-nearest neighbors,KNN)的变体分类器进行分类识别。结果采用自建图库、同济图库和PolyU-NIR图库进行实验分析,在3个图库中的等误率分别为0.289 9%、0.211 3%和0.158 6%,误拒率和误识率分别为0.002 7和2.318 8、0.002 3和1.282 1、0.000 0和1.596 2。结论与传统方法以及经典网络方法相比,该方法能有效提高识别准确率,适用于对安全性要求较高的场合进行身份识别,具有实用价值。关键词:生物特征识别;手掌静脉识别;非接触;近红外光图像;卷积神经网络(CNN)159|272|0更新时间:2024-09-18
摘要:目的基于手掌静脉的身份识别需要在近红外光下采集手掌血管图像,安全性高。开放环境下的非接触式采集,相对于传统的将手掌放到采集箱体内固定栓上的采集方式更受用户欢迎。但开放环境带来的可见光干扰和非接触拍摄带来的图像旋转、平移、比例缩放、光照改变使得识别具有挑战性。针对以上两个难点,研究了一种基于非监督卷积神经网络的方法。方法在卷积层中结合主成分分析(principal component analysis,PCA)滤波器提取主元信息,减少由于可见光引起的噪声影响;以固定尺寸Gabor滤波器为多尺度自适应Gabor滤波器提供先验知识,克服图像因几何与光照改变对识别产生的干扰,用以增强掌脉稳定特征,提升识别性能,再以二值化方式降低数据量,最后使用自适应K近邻(K-nearest neighbors,KNN)的变体分类器进行分类识别。结果采用自建图库、同济图库和PolyU-NIR图库进行实验分析,在3个图库中的等误率分别为0.289 9%、0.211 3%和0.158 6%,误拒率和误识率分别为0.002 7和2.318 8、0.002 3和1.282 1、0.000 0和1.596 2。结论与传统方法以及经典网络方法相比,该方法能有效提高识别准确率,适用于对安全性要求较高的场合进行身份识别,具有实用价值。关键词:生物特征识别;手掌静脉识别;非接触;近红外光图像;卷积神经网络(CNN)159|272|0更新时间:2024-09-18 -
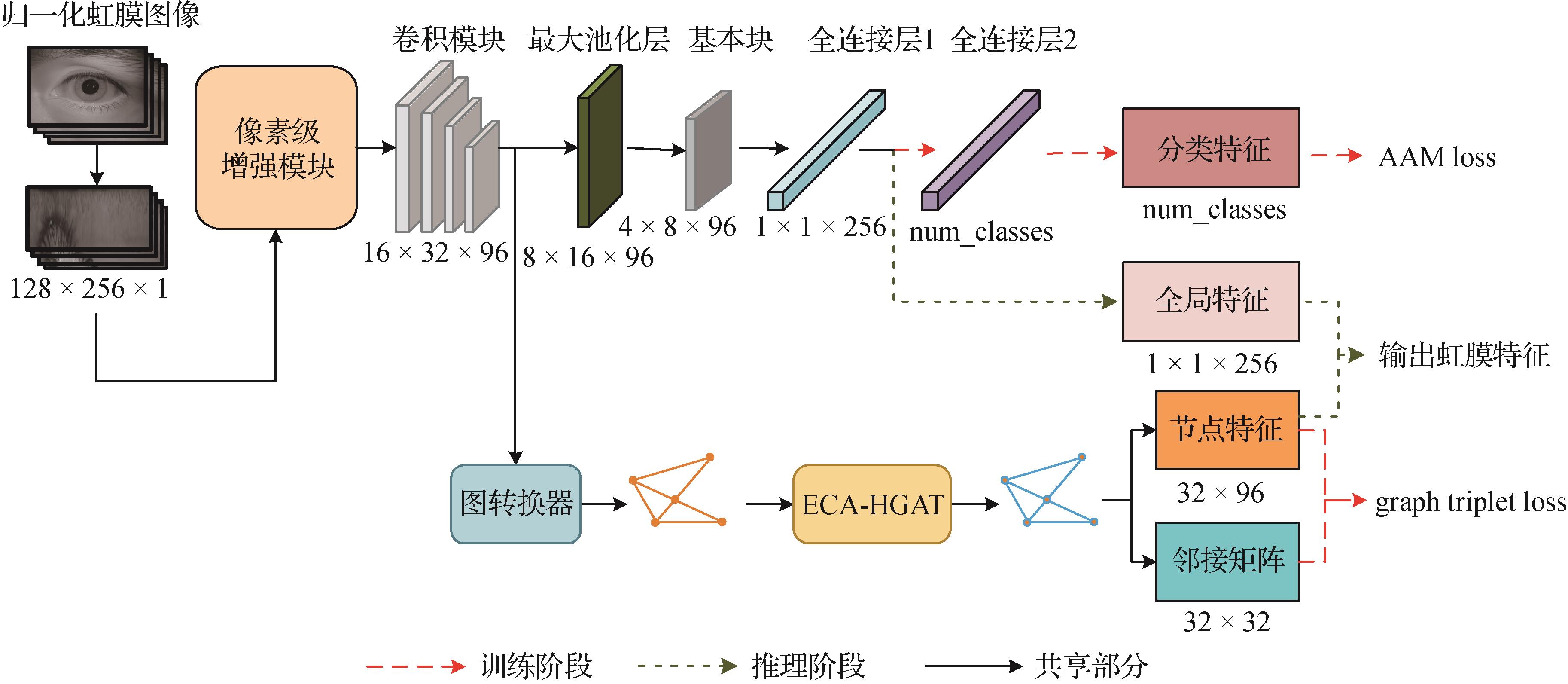 摘要:目的更具可解释性的虹膜特征编码方法一直是虹膜识别中的一个关键问题,且低质量虹膜样本识别比较困难,图神经网络的发展为此类虹膜图像特征编码带来了新思路。本文提出了一种图神经网络与卷积神经网络融合的虹膜特征编码网络IrisFusionNet。方法在骨干网络前添加一个像素级增强模块以消除输入图像不确定性,并使用双分支骨干网络提取虹膜微观与宏观融合特征。训练阶段使用一个独特的联合损失函数对网络参数进行优化;推理阶段使用融合特征匹配策略进行特征匹配。结果实验结果表明:使用IrisFusionNet训练得到的特征提取器在多个公开低质量虹膜数据集上进行测试分别得到了EER(equal error rate)和FAR@FRR = 0.01%的最佳值0.27%与0.84%,并且将分离度DI(discriminating index)提升30%以上,识别准确性以及类聚性均远远领先于基于卷积神经网络和其他使用图神经网络模型的虹膜识别优秀算法。结论本文提出的IrisFusionNet应用于虹膜识别任务具有极高的可行性和优越性。关键词:虹膜特征编码;图神经网络 (GNN);硬图注意力算子;特征融合;联合损失函数203|447|0更新时间:2024-09-18
摘要:目的更具可解释性的虹膜特征编码方法一直是虹膜识别中的一个关键问题,且低质量虹膜样本识别比较困难,图神经网络的发展为此类虹膜图像特征编码带来了新思路。本文提出了一种图神经网络与卷积神经网络融合的虹膜特征编码网络IrisFusionNet。方法在骨干网络前添加一个像素级增强模块以消除输入图像不确定性,并使用双分支骨干网络提取虹膜微观与宏观融合特征。训练阶段使用一个独特的联合损失函数对网络参数进行优化;推理阶段使用融合特征匹配策略进行特征匹配。结果实验结果表明:使用IrisFusionNet训练得到的特征提取器在多个公开低质量虹膜数据集上进行测试分别得到了EER(equal error rate)和FAR@FRR = 0.01%的最佳值0.27%与0.84%,并且将分离度DI(discriminating index)提升30%以上,识别准确性以及类聚性均远远领先于基于卷积神经网络和其他使用图神经网络模型的虹膜识别优秀算法。结论本文提出的IrisFusionNet应用于虹膜识别任务具有极高的可行性和优越性。关键词:虹膜特征编码;图神经网络 (GNN);硬图注意力算子;特征融合;联合损失函数203|447|0更新时间:2024-09-18 -
 摘要:目的指纹识别技术已大规模应用于人们的日常生活中,如身份鉴定、指纹支付与考勤等。然而,最新研究表明这些系统极易遭受伪造指纹的欺骗攻击,因此在使用指纹认证用户身份前,鉴别待测指纹的真伪至关重要。伪造指纹的制作材料具有多样性,现有工作忽视了不同材料伪造指纹之间数据分布的关联性,致使跨材料检测泛化性普遍较低。因此,本文通过分析不同材料伪造指纹数据间的分布关联性,挖掘不同伪造指纹间的材料域不变伪造特征,提出了一种基于共性特征学习的高泛化伪造指纹检测方法。方法首先,为了表征和学习不同材料伪造指纹间的特征,设计了一种多尺度伪造特征提取器(multi-scale spoofing feature extractor, MSFE),包含一个多尺度空间通道(multi-scale spatial-channel, MSC)注意力模块,以学习真假指纹类间的细粒度差异特征。然后,为了进一步分析不同材料伪造指纹数据间的分布关联性,又构造了一种共性伪造特征提取器(common spoofing feature extractor, CSFE),在MSFE先验知识的引导下进行多任务的材料域不变伪造特征学习。最后,设计一个材料鉴别器对学习到的共性伪造特征进行约束,同时构建一个自适应联合优化损失模块来平衡多个模块在训练过程中的损失权重,以进一步提高面对未知材料伪造指纹检测时的泛化性。结果在两个公开的指纹数据集(LivDet(liveness detection competition)2017和LivDet2019)上进行了跨材料测试,实验结果表明所提算法相较对比工作,ACE(average classification error)降低了1.34%,TDR(true detection rate)提高了1.43%,表现出较高的泛化性。结论本文算法在ACE和TDR方面均取得优异性能。此外,当面对未知材料的伪造指纹检测时,同样表现出较强的泛化性。关键词:伪造指纹检测;材料域不变伪造特征;注意力;共性特征学习;泛化性356|191|0更新时间:2024-09-18
摘要:目的指纹识别技术已大规模应用于人们的日常生活中,如身份鉴定、指纹支付与考勤等。然而,最新研究表明这些系统极易遭受伪造指纹的欺骗攻击,因此在使用指纹认证用户身份前,鉴别待测指纹的真伪至关重要。伪造指纹的制作材料具有多样性,现有工作忽视了不同材料伪造指纹之间数据分布的关联性,致使跨材料检测泛化性普遍较低。因此,本文通过分析不同材料伪造指纹数据间的分布关联性,挖掘不同伪造指纹间的材料域不变伪造特征,提出了一种基于共性特征学习的高泛化伪造指纹检测方法。方法首先,为了表征和学习不同材料伪造指纹间的特征,设计了一种多尺度伪造特征提取器(multi-scale spoofing feature extractor, MSFE),包含一个多尺度空间通道(multi-scale spatial-channel, MSC)注意力模块,以学习真假指纹类间的细粒度差异特征。然后,为了进一步分析不同材料伪造指纹数据间的分布关联性,又构造了一种共性伪造特征提取器(common spoofing feature extractor, CSFE),在MSFE先验知识的引导下进行多任务的材料域不变伪造特征学习。最后,设计一个材料鉴别器对学习到的共性伪造特征进行约束,同时构建一个自适应联合优化损失模块来平衡多个模块在训练过程中的损失权重,以进一步提高面对未知材料伪造指纹检测时的泛化性。结果在两个公开的指纹数据集(LivDet(liveness detection competition)2017和LivDet2019)上进行了跨材料测试,实验结果表明所提算法相较对比工作,ACE(average classification error)降低了1.34%,TDR(true detection rate)提高了1.43%,表现出较高的泛化性。结论本文算法在ACE和TDR方面均取得优异性能。此外,当面对未知材料的伪造指纹检测时,同样表现出较强的泛化性。关键词:伪造指纹检测;材料域不变伪造特征;注意力;共性特征学习;泛化性356|191|0更新时间:2024-09-18 -
 摘要:目的新兴视频服务的功能参数设置将会直接影响到用户的认知状态,进一步影响用户体验质量,称为功能性用户体验质量(functional quality of experience, fQoE)。脑电信号蕴含丰富的大脑活动信息,能够揭示复杂脑活动中的脑网络模式,为fQoE提供可靠的评估依据。为此,本文首次提出了一个基于脑电的脑网络构建方法以评估fQoE,并研究fQoE背后的神经机制。方法首先,通过改变功能参数诱发不同水平的fQoE,并同步收集脑电数据;然后,从脑电数据中提取单电极和多电极特征并以图结构进行融合,用以全面表征用户使用视频服务时的大脑状态;最后,使用基于自注意力图池化的脑网络构建模型来识别对fQoE敏感的脑网络,为fQoE提供可解释性,并进行分类以完成fQoE评估。结果本文以弹幕视频服务的弹幕覆盖率这一功能参数为例验证了方法的科学性和可行性。实验表明,提出的评估方法在多种视频类型的fQoE评估中均达到了满意的效果,最佳识别准确率分别为86%(鬼畜类)、81%(科技类)、80%(舞蹈类)、82%(影视类)和84%(音乐类)。结论来自fQoE相关的脑网络分析结果表明,额极、额中回、顶叶和颞叶的脑连接数量减少预示着观看弹幕视频的fQoE更高,即观看体验更好,同时也证明了功能参数通过影响人的脑状态进一步导致了fQoE的改变。本文的评估方法为fQoE的精确评估和视频服务功能参数的优化提供了来自神经生理学的定量工具和理论依据。关键词:新兴视频服务;功能性用户体验质量(fQoE);脑电信号(EEG);脑网络构建171|315|0更新时间:2024-09-18
摘要:目的新兴视频服务的功能参数设置将会直接影响到用户的认知状态,进一步影响用户体验质量,称为功能性用户体验质量(functional quality of experience, fQoE)。脑电信号蕴含丰富的大脑活动信息,能够揭示复杂脑活动中的脑网络模式,为fQoE提供可靠的评估依据。为此,本文首次提出了一个基于脑电的脑网络构建方法以评估fQoE,并研究fQoE背后的神经机制。方法首先,通过改变功能参数诱发不同水平的fQoE,并同步收集脑电数据;然后,从脑电数据中提取单电极和多电极特征并以图结构进行融合,用以全面表征用户使用视频服务时的大脑状态;最后,使用基于自注意力图池化的脑网络构建模型来识别对fQoE敏感的脑网络,为fQoE提供可解释性,并进行分类以完成fQoE评估。结果本文以弹幕视频服务的弹幕覆盖率这一功能参数为例验证了方法的科学性和可行性。实验表明,提出的评估方法在多种视频类型的fQoE评估中均达到了满意的效果,最佳识别准确率分别为86%(鬼畜类)、81%(科技类)、80%(舞蹈类)、82%(影视类)和84%(音乐类)。结论来自fQoE相关的脑网络分析结果表明,额极、额中回、顶叶和颞叶的脑连接数量减少预示着观看弹幕视频的fQoE更高,即观看体验更好,同时也证明了功能参数通过影响人的脑状态进一步导致了fQoE的改变。本文的评估方法为fQoE的精确评估和视频服务功能参数的优化提供了来自神经生理学的定量工具和理论依据。关键词:新兴视频服务;功能性用户体验质量(fQoE);脑电信号(EEG);脑网络构建171|315|0更新时间:2024-09-18
图像分析和识别
-
 摘要:目的染色体核型分析从细胞分裂中期图像中分离和分类染色体,是遗传疾病诊断广泛采用的方法,其中形态多样的重叠染色体簇的分割,依赖于准确的边界等细节特征。为此,本文融合目标的上下文信息,构建了一种两阶段的重叠染色体分割模型SC-Net(skip connection network)。方法首先,在语义分割基线模型U-Net++中增加混合池化模块捕获重叠染色体的局部上下文信息,在解码器网络中并联上下文融合模块和上下文先验辅助分支,增强通道和空间上的全局上下文信息。其次,利用已标注样本的类别先验信息生成真实亲和矩阵,加入训练过程以有效区分重叠染色体图像中易混淆的空间信息。最后,通过染色体实例重建算法对重叠与非重叠区域的元素迭代进行配对,拼接形成单条染色体。结果在公开的ChromSeg(chromosome segmentation)数据集上进行实验,结果表明SC-Net分割出的重叠染色体区域交并比值为83.5%,与对比算法中的较优算法相比性能提升2.7%。结论本文构建的重叠染色体分割模型通过融合上下文信息,能更有效地解决形态多样的重叠染色体簇的分割问题,相比对比方法可以得到更精细和准确的结果。关键词:重叠染色体分割;混合池化模块 (HPM);上下文融合模块 (CFM);上下文先验辅助分支 (CPAB);真实亲和矩阵142|423|0更新时间:2024-09-18
摘要:目的染色体核型分析从细胞分裂中期图像中分离和分类染色体,是遗传疾病诊断广泛采用的方法,其中形态多样的重叠染色体簇的分割,依赖于准确的边界等细节特征。为此,本文融合目标的上下文信息,构建了一种两阶段的重叠染色体分割模型SC-Net(skip connection network)。方法首先,在语义分割基线模型U-Net++中增加混合池化模块捕获重叠染色体的局部上下文信息,在解码器网络中并联上下文融合模块和上下文先验辅助分支,增强通道和空间上的全局上下文信息。其次,利用已标注样本的类别先验信息生成真实亲和矩阵,加入训练过程以有效区分重叠染色体图像中易混淆的空间信息。最后,通过染色体实例重建算法对重叠与非重叠区域的元素迭代进行配对,拼接形成单条染色体。结果在公开的ChromSeg(chromosome segmentation)数据集上进行实验,结果表明SC-Net分割出的重叠染色体区域交并比值为83.5%,与对比算法中的较优算法相比性能提升2.7%。结论本文构建的重叠染色体分割模型通过融合上下文信息,能更有效地解决形态多样的重叠染色体簇的分割问题,相比对比方法可以得到更精细和准确的结果。关键词:重叠染色体分割;混合池化模块 (HPM);上下文融合模块 (CFM);上下文先验辅助分支 (CPAB);真实亲和矩阵142|423|0更新时间:2024-09-18 -
 摘要:目的自监督与弱监督学习是解决乳腺癌全切片病理图像分类标注困难的有效方式。然而,由于组织病理图像的复杂性与多样性,仅依靠自监督学习生成的伪标签可能无法准确反映图像真实类别信息;同时,单一弱监督学习方法又存在标签信息匮乏等问题,在病理图像学习过程中易受干扰而导致预测结果不稳定。为此,提出了一种混合监督学习的乳腺癌全切片病理图像分类方法。方法首先,使用基于MoBY自监督框架进行训练,通过对比学习方式深入挖掘乳腺癌病理图像内在结构信息;然后,采用弱监督多示例学习方法进一步优化自监督模型,来获得更精准的判别示例;最后,从每幅全切片中筛选出具有代表性的乳腺癌病理图像关键示例,并借助Transformer编码器实现关键示例的特征融合以增强不同病理图像块之间的关联性,从而实现乳腺癌全切片病理图像的高精度分类。结果在公开的Camelyon-16乳腺癌病理图像数据集上进行实验评估,相比于该数据集上既有最优弱监督和自监督方法,本文方法的曲线下面积值分别可提升2.34%和2.74%,验证了所提出混合监督学习方法的有效性。此外,在MSK(Memorial Sloan-Kettering)腺癌病理外部验证数据集上较有监督方法取得了6.26%的性能提升,表明了本文方法的良好泛化能力。结论提出了混合监督学习的乳腺癌全切片病理图像分类方法,通过集成MoBY自监督对比学习与Transformer弱监督多示例学习,实现了乳腺癌全切片病理图像的更准确分类。关键词:乳腺癌全切片病理图像;分类;混合监督学习;特征融合;Transformer324|779|0更新时间:2024-09-18
摘要:目的自监督与弱监督学习是解决乳腺癌全切片病理图像分类标注困难的有效方式。然而,由于组织病理图像的复杂性与多样性,仅依靠自监督学习生成的伪标签可能无法准确反映图像真实类别信息;同时,单一弱监督学习方法又存在标签信息匮乏等问题,在病理图像学习过程中易受干扰而导致预测结果不稳定。为此,提出了一种混合监督学习的乳腺癌全切片病理图像分类方法。方法首先,使用基于MoBY自监督框架进行训练,通过对比学习方式深入挖掘乳腺癌病理图像内在结构信息;然后,采用弱监督多示例学习方法进一步优化自监督模型,来获得更精准的判别示例;最后,从每幅全切片中筛选出具有代表性的乳腺癌病理图像关键示例,并借助Transformer编码器实现关键示例的特征融合以增强不同病理图像块之间的关联性,从而实现乳腺癌全切片病理图像的高精度分类。结果在公开的Camelyon-16乳腺癌病理图像数据集上进行实验评估,相比于该数据集上既有最优弱监督和自监督方法,本文方法的曲线下面积值分别可提升2.34%和2.74%,验证了所提出混合监督学习方法的有效性。此外,在MSK(Memorial Sloan-Kettering)腺癌病理外部验证数据集上较有监督方法取得了6.26%的性能提升,表明了本文方法的良好泛化能力。结论提出了混合监督学习的乳腺癌全切片病理图像分类方法,通过集成MoBY自监督对比学习与Transformer弱监督多示例学习,实现了乳腺癌全切片病理图像的更准确分类。关键词:乳腺癌全切片病理图像;分类;混合监督学习;特征融合;Transformer324|779|0更新时间:2024-09-18
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0