
最新刊期
2023 年 第 28 卷 第 8 期

-
 摘要:文档分析与识别(简称文档识别)技术将各种非结构化文档数据(图像、联机笔迹)转化为结构化数据,便于计算机处理和理解,应用场景十分广阔。20世纪60年代以来,文档识别方法研究与应用受到广泛关注并取得巨大进展。得益于深度学习技术的发展和应用,文档识别的性能快速提升,相关技术在文档数字化、票据处理、笔迹录入、智能交通、文档检索与信息抽取等领域得到广泛应用。首先介绍文档识别的背景和技术范畴,回顾该领域发展历史,然后重点对深度学习方法兴起以来的研究进行综述,分析当前技术存在的不足,并建议未来值得重视的研究方向。研究现状综述部分,按文档分析与识别的几个主要技术环节(文档图像预处理、版面分析、场景文本检测、文本识别、结构化符号和图形识别、文档检索与信息抽取)分别进行介绍,简述传统方法研究的代表性工作,重点介绍深度学习方法研究的新进展。总体上,当前研究对象向深度、广度扩展,处理方法全面转向深度神经网络模型和深度学习方法,识别性能大幅提升且应用场景不断扩展。在现状分析基础上,指出当前技术在识别精度和可靠性、可解释性、学习能力和自适应性等方面还有明显不足。最后从提升性能、应用扩展、提升学习能力几个角度提出一些研究方向。从提升性能角度,研究问题包括文本识别可靠性、可解释性、全要素识别、长尾问题、多语言、复杂版面分割与理解、变形文档分析与识别等。应用扩展包括新应用(如机器人流程自动化(robotic process automation, RPA)、文字信息抄录、考古)和新技术问题(语义信息抽取、跨模态融合、面向应用的推理决策等)两方面。从提升学习能力角度,相关问题包括小样本学习、迁移学习、多任务学习、领域自适应、结构化预测、弱监督学习、自监督学习、开放集学习和跨模态学习等。关键词:文档分析与识别;文档智能;版面分析;文本检测;文本识别;图形符号识别;语义信息抽取353|2383|4更新时间:2024-05-07
摘要:文档分析与识别(简称文档识别)技术将各种非结构化文档数据(图像、联机笔迹)转化为结构化数据,便于计算机处理和理解,应用场景十分广阔。20世纪60年代以来,文档识别方法研究与应用受到广泛关注并取得巨大进展。得益于深度学习技术的发展和应用,文档识别的性能快速提升,相关技术在文档数字化、票据处理、笔迹录入、智能交通、文档检索与信息抽取等领域得到广泛应用。首先介绍文档识别的背景和技术范畴,回顾该领域发展历史,然后重点对深度学习方法兴起以来的研究进行综述,分析当前技术存在的不足,并建议未来值得重视的研究方向。研究现状综述部分,按文档分析与识别的几个主要技术环节(文档图像预处理、版面分析、场景文本检测、文本识别、结构化符号和图形识别、文档检索与信息抽取)分别进行介绍,简述传统方法研究的代表性工作,重点介绍深度学习方法研究的新进展。总体上,当前研究对象向深度、广度扩展,处理方法全面转向深度神经网络模型和深度学习方法,识别性能大幅提升且应用场景不断扩展。在现状分析基础上,指出当前技术在识别精度和可靠性、可解释性、学习能力和自适应性等方面还有明显不足。最后从提升性能、应用扩展、提升学习能力几个角度提出一些研究方向。从提升性能角度,研究问题包括文本识别可靠性、可解释性、全要素识别、长尾问题、多语言、复杂版面分割与理解、变形文档分析与识别等。应用扩展包括新应用(如机器人流程自动化(robotic process automation, RPA)、文字信息抄录、考古)和新技术问题(语义信息抽取、跨模态融合、面向应用的推理决策等)两方面。从提升学习能力角度,相关问题包括小样本学习、迁移学习、多任务学习、领域自适应、结构化预测、弱监督学习、自监督学习、开放集学习和跨模态学习等。关键词:文档分析与识别;文档智能;版面分析;文本检测;文本识别;图形符号识别;语义信息抽取353|2383|4更新时间:2024-05-07 -
 摘要:文字广泛存在于各种文档图像和自然场景图像之中,蕴含着丰富且关键的语义信息。随着深度学习的发展,研究者不再满足于只获得图像中的文字内容,而更加关注图像中文字的理解,故以文字为中心的图像理解技术受到越来越多的关注。该技术旨在利用文字、视觉物体等多模态信息对文字图像进行充分理解,是计算机视觉和自然语言处理领域的一个交叉研究方向,具有十分重要的实际意义。本文主要对具有代表性的以文字为中心的图像理解任务进行综述,并按照理解认知程度,将以文字为中心的图像理解任务划分为两类,第1类仅要求模型具备抽取信息的能力,第2类不仅要求模型具备抽取信息的能力,而且要求模型具备一定的分析和推理能力。本文梳理了以文字为中心的图像理解任务所涉及的数据集、评价指标和经典方法,并进行对比分析,提出了相关工作中存在的问题和未来发展趋势,希望能够为后续相关研究提供参考。关键词:文字图像理解;视觉信息抽取;场景文字图像检索;文档视觉回答;场景文字视觉问答;场景文字图像描述198|513|1更新时间:2024-05-07
摘要:文字广泛存在于各种文档图像和自然场景图像之中,蕴含着丰富且关键的语义信息。随着深度学习的发展,研究者不再满足于只获得图像中的文字内容,而更加关注图像中文字的理解,故以文字为中心的图像理解技术受到越来越多的关注。该技术旨在利用文字、视觉物体等多模态信息对文字图像进行充分理解,是计算机视觉和自然语言处理领域的一个交叉研究方向,具有十分重要的实际意义。本文主要对具有代表性的以文字为中心的图像理解任务进行综述,并按照理解认知程度,将以文字为中心的图像理解任务划分为两类,第1类仅要求模型具备抽取信息的能力,第2类不仅要求模型具备抽取信息的能力,而且要求模型具备一定的分析和推理能力。本文梳理了以文字为中心的图像理解任务所涉及的数据集、评价指标和经典方法,并进行对比分析,提出了相关工作中存在的问题和未来发展趋势,希望能够为后续相关研究提供参考。关键词:文字图像理解;视觉信息抽取;场景文字图像检索;文档视觉回答;场景文字视觉问答;场景文字图像描述198|513|1更新时间:2024-05-07 -
 摘要:随着信息交互的日益频繁,大量的文档经数字化处理,以图像的格式保存和传播。实际生活工作中,票据识别理解、卡证识别、自动阅卷和文档匹配等诸多应用场景,都需要从文档图像中获取某一特定类别的文本内容,这一过程即为视觉信息抽取,旨在对视觉富文档图像中蕴含的指定类别的信息进行挖掘、分析和提取。随着深度学习技术的快速发展,基于该技术提出了诸多性能优异、流程高效的视觉信息抽取算法,在实际业务中得到了大规模应用,有效解决了以往人工操作速度慢、精度低的问题,极大提高了生产效率。本文调研了近年来提出的基于深度学习的信息抽取方法和公开数据集,并进行了整理、分类和总结。首先,介绍视觉信息抽取的研究背景,阐述了该领域的研究难点。其次,根据算法的主要特征,分别介绍隶属于不同类别的主要模型的算法流程和技术发展路线,同时总结它们各自的优缺点和适用场景。随后,介绍了主流公开数据集的内容、特点和一些常用的评价指标,对比了代表性模型方法在常用数据集上的性能。最后,总结了各类方法的特点和局限性,并对视觉信息抽取领域未来面临的挑战和发展趋势进行了探讨。关键词:视觉信息抽取(VIE);文档图像分析与理解;计算机视觉;自然语言处理;光学文字识别(OCR);深度学习;综述490|770|1更新时间:2024-05-07
摘要:随着信息交互的日益频繁,大量的文档经数字化处理,以图像的格式保存和传播。实际生活工作中,票据识别理解、卡证识别、自动阅卷和文档匹配等诸多应用场景,都需要从文档图像中获取某一特定类别的文本内容,这一过程即为视觉信息抽取,旨在对视觉富文档图像中蕴含的指定类别的信息进行挖掘、分析和提取。随着深度学习技术的快速发展,基于该技术提出了诸多性能优异、流程高效的视觉信息抽取算法,在实际业务中得到了大规模应用,有效解决了以往人工操作速度慢、精度低的问题,极大提高了生产效率。本文调研了近年来提出的基于深度学习的信息抽取方法和公开数据集,并进行了整理、分类和总结。首先,介绍视觉信息抽取的研究背景,阐述了该领域的研究难点。其次,根据算法的主要特征,分别介绍隶属于不同类别的主要模型的算法流程和技术发展路线,同时总结它们各自的优缺点和适用场景。随后,介绍了主流公开数据集的内容、特点和一些常用的评价指标,对比了代表性模型方法在常用数据集上的性能。最后,总结了各类方法的特点和局限性,并对视觉信息抽取领域未来面临的挑战和发展趋势进行了探讨。关键词:视觉信息抽取(VIE);文档图像分析与理解;计算机视觉;自然语言处理;光学文字识别(OCR);深度学习;综述490|770|1更新时间:2024-05-07 -
 摘要:目的视觉富文档信息抽取致力于将输入文档图像中的关键文字信息进行结构化提取,以解决实际业务问题,财务票据是其中一种常见的数据类型。解决该类问题通常需要应用光学字符识别(optical character recognition,OCR)和信息抽取等多个领域的技术。然而,目前公开的相关数据集的数量较少,且每个数据集中包含的图像数量也较少,这都成为了制约该领域技术发展的一个重要因素。为此,本文收集、标注并公开发布了一个真实中文扫描票据数据集SCID(scanned Chinese invoice dataset),包含6类常见财务票据,共40 716幅图像。方法该数据集提供了用于OCR任务和信息抽取的两种标签。针对该数据集,本文提出一个基于LayoutLM v2(layout language model v2)的基线方案,实现了从输入图像到最终结果的端到端推理。基于该数据集承办的CSIG(China Society of Image and Graphics)2022票据识别与分析挑战赛,吸引了大量科研人员参与,并提出了优秀的解决方案。结果在基线方案实验中,分别验证了使用OCR引擎推理、OCR模型精调和OCR真值3种设定的实验结果,F1值分别为0.768 7、0.857 0和0.985 7,一方面证明了LayoutLM v2模型的有效性;另一方面证明了该场景下OCR的挑战性。结论本文提出的扫描票据数据集SCID展示了真实OCR技术应用场景的多项挑战,可以为文档富视觉信息抽取相关技术领域研发和技术落地提供重要数据支持。该数据集下载网址:https://davar-lab.github.io/dataset/scid.html。关键词:数据集;财务票据;视觉富文档;信息抽取;光学字符识别(OCR);多模态信息296|1025|1更新时间:2024-05-07
摘要:目的视觉富文档信息抽取致力于将输入文档图像中的关键文字信息进行结构化提取,以解决实际业务问题,财务票据是其中一种常见的数据类型。解决该类问题通常需要应用光学字符识别(optical character recognition,OCR)和信息抽取等多个领域的技术。然而,目前公开的相关数据集的数量较少,且每个数据集中包含的图像数量也较少,这都成为了制约该领域技术发展的一个重要因素。为此,本文收集、标注并公开发布了一个真实中文扫描票据数据集SCID(scanned Chinese invoice dataset),包含6类常见财务票据,共40 716幅图像。方法该数据集提供了用于OCR任务和信息抽取的两种标签。针对该数据集,本文提出一个基于LayoutLM v2(layout language model v2)的基线方案,实现了从输入图像到最终结果的端到端推理。基于该数据集承办的CSIG(China Society of Image and Graphics)2022票据识别与分析挑战赛,吸引了大量科研人员参与,并提出了优秀的解决方案。结果在基线方案实验中,分别验证了使用OCR引擎推理、OCR模型精调和OCR真值3种设定的实验结果,F1值分别为0.768 7、0.857 0和0.985 7,一方面证明了LayoutLM v2模型的有效性;另一方面证明了该场景下OCR的挑战性。结论本文提出的扫描票据数据集SCID展示了真实OCR技术应用场景的多项挑战,可以为文档富视觉信息抽取相关技术领域研发和技术落地提供重要数据支持。该数据集下载网址:https://davar-lab.github.io/dataset/scid.html。关键词:数据集;财务票据;视觉富文档;信息抽取;光学字符识别(OCR);多模态信息296|1025|1更新时间:2024-05-07 -
 摘要:目的文档图形的几何校正是指通过图像处理的方法对图像采集过程中存在的扭曲、畸变和歪斜等几何干扰进行处理,以提升原始图像的视觉效果与光学字符识别(optical character recognition,OCR)精度。在深度学习普及以前,传统的图像处理方法需要使用激光扫描仪等辅助硬件或在多视角下对文档进行拍摄,且算法的鲁棒性欠佳。深度学习方法构建模型能规避传统算法的不足,但在现阶段这些模型还存在一定的局限性。针对现有算法的缺陷,提出了一种集成文档区域定位与校正的轻量化几何校正网络(asymmetric geometry correction network,AsymcNet),端到端地实现文档图像的几何校正。方法AsymcNet由用于文档区域定位的分割网络和用于校正网格回归的回归网络构成,两个子网络以级联的形式搭设。由于分割网络的存在,AsymcNet对于各种视野下的文档图像均能取得良好的校正效果。在回归网络部分,通过减小输出回归网格的分辨率来降低AsymcNet在训练及推理时的显存耗用和时长。结果在自制的测试数据集中与业内最新的4种方法进行了比较,使用AsymcNet可以将原始图像的多尺度结构相似度(multi-scale structural similarity,MS-SSIM)从0.318提升至0.467,局部畸变(local distortion,LD)从33.608降低至11.615,字符错误率(character error rate,CER)从0.570降低至0.273。相比于业内效果较好的DFE-FC(displacement flow estimation with fully convolutional network),AsymcNet的MS-SSIM提升了0.036,LD降低了2.193,CER降低了0.033,且AsymcNet处理单幅图像的平均耗时仅为DFE-FC的8.85%。结论实验验证了本文所提出AsymcNet的有效性与先进性。关键词:图像预处理;几何校正;全卷积网络(FCN);网格采样;端到端106|417|1更新时间:2024-05-07
摘要:目的文档图形的几何校正是指通过图像处理的方法对图像采集过程中存在的扭曲、畸变和歪斜等几何干扰进行处理,以提升原始图像的视觉效果与光学字符识别(optical character recognition,OCR)精度。在深度学习普及以前,传统的图像处理方法需要使用激光扫描仪等辅助硬件或在多视角下对文档进行拍摄,且算法的鲁棒性欠佳。深度学习方法构建模型能规避传统算法的不足,但在现阶段这些模型还存在一定的局限性。针对现有算法的缺陷,提出了一种集成文档区域定位与校正的轻量化几何校正网络(asymmetric geometry correction network,AsymcNet),端到端地实现文档图像的几何校正。方法AsymcNet由用于文档区域定位的分割网络和用于校正网格回归的回归网络构成,两个子网络以级联的形式搭设。由于分割网络的存在,AsymcNet对于各种视野下的文档图像均能取得良好的校正效果。在回归网络部分,通过减小输出回归网格的分辨率来降低AsymcNet在训练及推理时的显存耗用和时长。结果在自制的测试数据集中与业内最新的4种方法进行了比较,使用AsymcNet可以将原始图像的多尺度结构相似度(multi-scale structural similarity,MS-SSIM)从0.318提升至0.467,局部畸变(local distortion,LD)从33.608降低至11.615,字符错误率(character error rate,CER)从0.570降低至0.273。相比于业内效果较好的DFE-FC(displacement flow estimation with fully convolutional network),AsymcNet的MS-SSIM提升了0.036,LD降低了2.193,CER降低了0.033,且AsymcNet处理单幅图像的平均耗时仅为DFE-FC的8.85%。结论实验验证了本文所提出AsymcNet的有效性与先进性。关键词:图像预处理;几何校正;全卷积网络(FCN);网格采样;端到端106|417|1更新时间:2024-05-07 -
 摘要:目的敦煌遗书作为敦煌学研究的根基,是华夏多元民族弥足珍贵的文化遗产。现存的敦煌遗书大多为残片残卷,给整理和研究带来了极大的困难。而人工缀残可谓至难,费时费力,对研究者的要求极高。随着计算机技术和计算机图形学的发展,残片拼接技术也开始进入数字化时代。为此,本文提出基于分层模型的数字图像缀合方法。方法构建了一个古籍残片数据集。在流程设计上借鉴专家缀合的实践经验,融入专家知识,对碎片数字图像进行预处理。在碴口特征匹配的基础上,融合多种缀合线索,建立了包含物理层、结构层和语义层3层特征的分层模型,从低层次到高层次对匹配结果进行评估打分,完成两阶段的全自动缀合。结果为了验证提出方法的有效性,在由31张可拼接碎片(11组)和225张孤片组成的256张碎片数据集上进行实验。结果表明,本文方法能够完成其中8组碎片的完整缀合,2组不完整缀合,并找出218张孤片。通过计算,完整匹配准确率为95.76%,不完整匹配准确率为95.70%,缀合准确率都达到了95%。与现有类似任务的3种方法相比,准确率均有明显提升。结论本文提出的分层模型融合了多方面特征,能有效完成古籍残片缀合任务,提升研究人员的缀残效率。关键词:古籍残片;敦煌遗书;自动缀合;碴口特征;分层模型222|297|2更新时间:2024-05-07
摘要:目的敦煌遗书作为敦煌学研究的根基,是华夏多元民族弥足珍贵的文化遗产。现存的敦煌遗书大多为残片残卷,给整理和研究带来了极大的困难。而人工缀残可谓至难,费时费力,对研究者的要求极高。随着计算机技术和计算机图形学的发展,残片拼接技术也开始进入数字化时代。为此,本文提出基于分层模型的数字图像缀合方法。方法构建了一个古籍残片数据集。在流程设计上借鉴专家缀合的实践经验,融入专家知识,对碎片数字图像进行预处理。在碴口特征匹配的基础上,融合多种缀合线索,建立了包含物理层、结构层和语义层3层特征的分层模型,从低层次到高层次对匹配结果进行评估打分,完成两阶段的全自动缀合。结果为了验证提出方法的有效性,在由31张可拼接碎片(11组)和225张孤片组成的256张碎片数据集上进行实验。结果表明,本文方法能够完成其中8组碎片的完整缀合,2组不完整缀合,并找出218张孤片。通过计算,完整匹配准确率为95.76%,不完整匹配准确率为95.70%,缀合准确率都达到了95%。与现有类似任务的3种方法相比,准确率均有明显提升。结论本文提出的分层模型融合了多方面特征,能有效完成古籍残片缀合任务,提升研究人员的缀残效率。关键词:古籍残片;敦煌遗书;自动缀合;碴口特征;分层模型222|297|2更新时间:2024-05-07 -
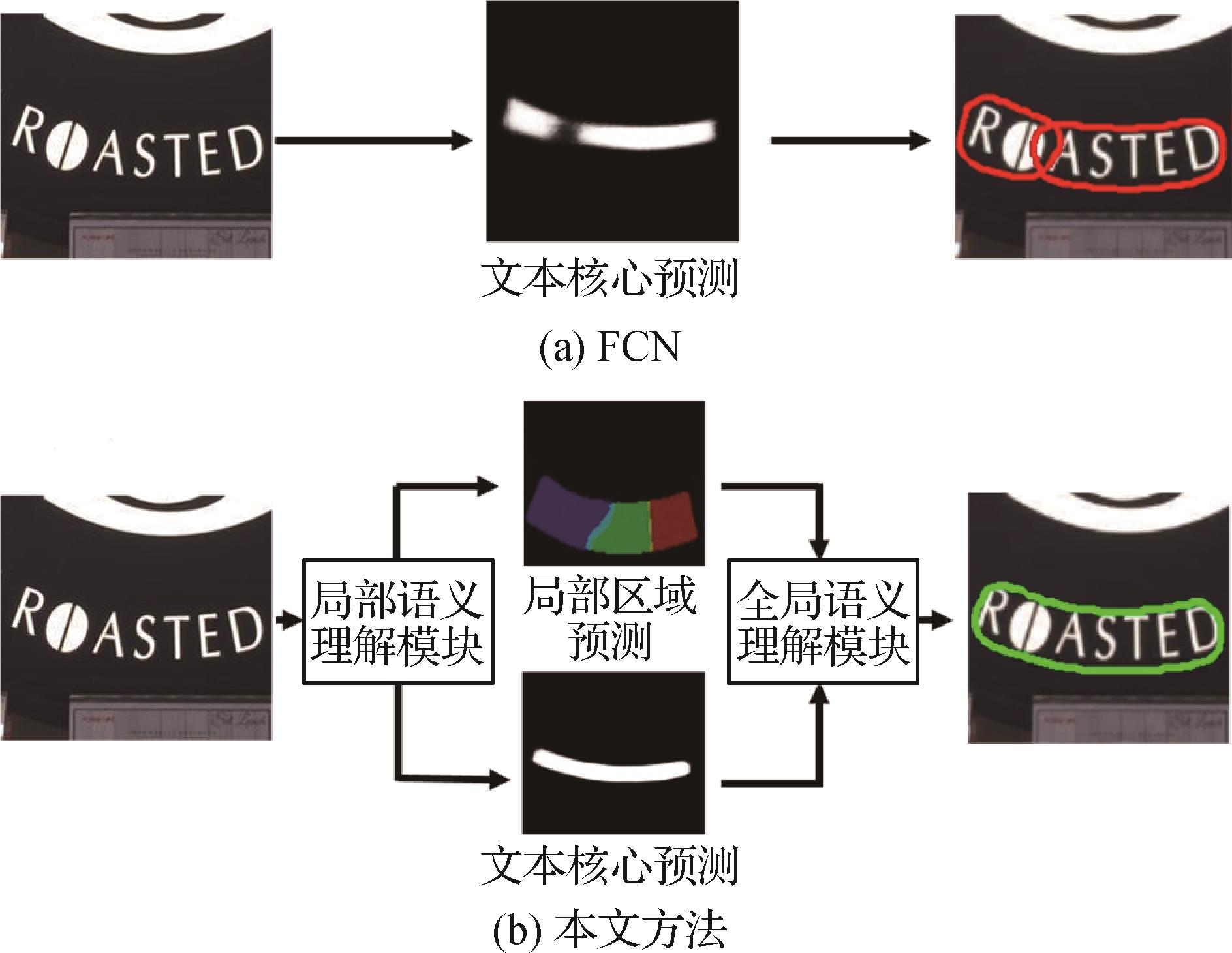 摘要:目的场景文本检测是场景理解和文字识别领域的重要任务之一,尽管基于深度学习的算法显著提升了检测精度,但现有的方法由于对文字局部语义和文字实例间的全局语义的提取能力不足,导致缺乏文字多层语义的建模,从而检测精度不理想。针对此问题,提出了一种层级语义融合的场景文本检测算法。方法该方法包括基于文本片段的局部语义理解模块和基于文本实例的全局语义理解模块,以分别引导网络关注文字局部和文字实例间的多层级语义信息。首先,基于文本片段的局部语义理解模块根据相对位置将文本划分为多个片段,在细粒度优化目标的监督下增强网络对局部语义的感知能力。然后,基于文本实例的全局语义理解模块利用文本片段粗分割结果过滤背景区域并提取可靠的文字区域特征,进而通过注意力机制自适应地捕获任意形状文本的全局语义信息并得到最终分割结果。此外,为了降低边界区域的预测噪声对层级语义信息聚合的干扰,提出边界感知损失函数以降低边界区域特征的歧义性。结果算法在3个常用的场景文字检测数据集上实验并与其他算法进行了比较,所提方法在性能上获得了显著提升,在Totoal-Text数据集上,F值为87.0%,相比其他模型提升了1.0%;在MSRA-TD500(MSRA text detection 500 database)数据集上,F值为88.2%,相比其他模型提升了1.0%;在ICDAR 2015(International Conference on Document Analysis and Recognition)数据集上,F值为87.0%。结论提出的模型通过分别构建不同层级下的语义上下文和对歧义特征额外的惩罚解决了层级语义提取不充分的问题,获得了更高的检测精度。关键词:场景文本;文字检测;全卷积网络(FCN);卷积神经网络(CNN);特征融合;注意力机制129|348|1更新时间:2024-05-07
摘要:目的场景文本检测是场景理解和文字识别领域的重要任务之一,尽管基于深度学习的算法显著提升了检测精度,但现有的方法由于对文字局部语义和文字实例间的全局语义的提取能力不足,导致缺乏文字多层语义的建模,从而检测精度不理想。针对此问题,提出了一种层级语义融合的场景文本检测算法。方法该方法包括基于文本片段的局部语义理解模块和基于文本实例的全局语义理解模块,以分别引导网络关注文字局部和文字实例间的多层级语义信息。首先,基于文本片段的局部语义理解模块根据相对位置将文本划分为多个片段,在细粒度优化目标的监督下增强网络对局部语义的感知能力。然后,基于文本实例的全局语义理解模块利用文本片段粗分割结果过滤背景区域并提取可靠的文字区域特征,进而通过注意力机制自适应地捕获任意形状文本的全局语义信息并得到最终分割结果。此外,为了降低边界区域的预测噪声对层级语义信息聚合的干扰,提出边界感知损失函数以降低边界区域特征的歧义性。结果算法在3个常用的场景文字检测数据集上实验并与其他算法进行了比较,所提方法在性能上获得了显著提升,在Totoal-Text数据集上,F值为87.0%,相比其他模型提升了1.0%;在MSRA-TD500(MSRA text detection 500 database)数据集上,F值为88.2%,相比其他模型提升了1.0%;在ICDAR 2015(International Conference on Document Analysis and Recognition)数据集上,F值为87.0%。结论提出的模型通过分别构建不同层级下的语义上下文和对歧义特征额外的惩罚解决了层级语义提取不充分的问题,获得了更高的检测精度。关键词:场景文本;文字检测;全卷积网络(FCN);卷积神经网络(CNN);特征融合;注意力机制129|348|1更新时间:2024-05-07 -
 摘要:目的在线公式识别是一种将在线输入手写轨迹点序列转换为公式文本的任务,其广泛应用在手机、平板等便携式设备上。众所周知,训练数据对于神经网络十分重要,但获取有标注的在线公式数据所需要的成本十分昂贵,在训练数据不足的情况下,深度神经网络在该任务上的泛化性和鲁棒性会受到影响。为此,提出了一个基于编码—解码模型的在线数据生成模型。方法该模型从给定的公式文本生成对应的在线轨迹点序列,从而灵活地扩充训练数据规模。生成模型在编码器端设计了结合树形表示的文本特征提取模块,并且引入了基于位置的注意力算法,使模型实现了输入文本序列与输出轨迹序列间的对齐。同时,解码器端融入了不同手写人风格特征,使模型可以生成多种手写人风格的样本。结果实验中,首先,将本文生成方法在不同类型输入文本和不同手写人风格上的结果可视化,并展示了模型在多数情况下的有效性。其次,生成模型合成的额外数据可作为训练集的增广,该数据被用于训练Transformer-TAP(track, attend, and parse)、TAP和DenseTAP-TD(DenseNet TAP with tree decoder)模型,并分析了3种模型在使用增广数据前后的性能变化。结果表明,引入增广数据分进行训练后,3个模型的绝对识别率分别提升了0.98%、1.55%和1.06%;相对识别率分别提升了9.9%、12.37%和9.81%。结论本文提出的在线生成模型可以更加灵活地实现对原有数据集的增广,并有效提升了在线识别模型的泛化性能。关键词:深度学习;手写公式识别;端到端;编解码模型;数据增广131|308|2更新时间:2024-05-07
摘要:目的在线公式识别是一种将在线输入手写轨迹点序列转换为公式文本的任务,其广泛应用在手机、平板等便携式设备上。众所周知,训练数据对于神经网络十分重要,但获取有标注的在线公式数据所需要的成本十分昂贵,在训练数据不足的情况下,深度神经网络在该任务上的泛化性和鲁棒性会受到影响。为此,提出了一个基于编码—解码模型的在线数据生成模型。方法该模型从给定的公式文本生成对应的在线轨迹点序列,从而灵活地扩充训练数据规模。生成模型在编码器端设计了结合树形表示的文本特征提取模块,并且引入了基于位置的注意力算法,使模型实现了输入文本序列与输出轨迹序列间的对齐。同时,解码器端融入了不同手写人风格特征,使模型可以生成多种手写人风格的样本。结果实验中,首先,将本文生成方法在不同类型输入文本和不同手写人风格上的结果可视化,并展示了模型在多数情况下的有效性。其次,生成模型合成的额外数据可作为训练集的增广,该数据被用于训练Transformer-TAP(track, attend, and parse)、TAP和DenseTAP-TD(DenseNet TAP with tree decoder)模型,并分析了3种模型在使用增广数据前后的性能变化。结果表明,引入增广数据分进行训练后,3个模型的绝对识别率分别提升了0.98%、1.55%和1.06%;相对识别率分别提升了9.9%、12.37%和9.81%。结论本文提出的在线生成模型可以更加灵活地实现对原有数据集的增广,并有效提升了在线识别模型的泛化性能。关键词:深度学习;手写公式识别;端到端;编解码模型;数据增广131|308|2更新时间:2024-05-07 -
 摘要:目的中国书法博大精深,是中国文化很重要的组成部分。书法字体与风格分类是书法领域的研究热点。目前书法字体和书法风格两个概念混淆,并且书法风格分类准确率不高,针对上述问题,本文将两个概念进行区分,并提出了一个融合多损失的孪生卷积神经网络,能同时解决中国书法字体以及风格分类问题。方法提出的网络包含两个共享权重的分支,每个分支用于提取输入图像的特征。为了获得不同尺度下的特征表示,将Haar小波分解嵌入到每个网络分支中。与传统孪生神经网络不同的是,将网络的每个分支扩展为一个分类网络。网络训练时融合了两类不同的损失,即对比损失和分类损失,进而从两个角度同时对网络训练进行监督。具体来说,为了使来自同一类的两幅输入图像特征之间的距离尽可能小、使来自不同类的两幅输入图像特征之间的距离尽可能大,网络采用对比损失作为损失函数。此外,为了充分利用每幅输入图像的类别信息,在网络每个分支上采用交叉熵作为分类损失。结果实验结果表明,本文方法在两个中国书法字体数据集和两个中国书法风格数据集上的分类准确率分别达到了99.90%、94.09% 、99.38%和93.28%,高于对比方法。两种损失起到了良好的互补作用,Haar小波分解的引入在4个数据集上均提升了分类准确率,在风格数据集的提升效果更为明显。结论本文方法在中国书法字体以及风格分类两个任务中取得了令人满意的效果,为书法领域研究工作提供了新思路。关键词:中国书法;风格分类;字体分类;多损失融合孪生卷积神经网络;对比损失;交叉熵损失149|754|0更新时间:2024-05-07
摘要:目的中国书法博大精深,是中国文化很重要的组成部分。书法字体与风格分类是书法领域的研究热点。目前书法字体和书法风格两个概念混淆,并且书法风格分类准确率不高,针对上述问题,本文将两个概念进行区分,并提出了一个融合多损失的孪生卷积神经网络,能同时解决中国书法字体以及风格分类问题。方法提出的网络包含两个共享权重的分支,每个分支用于提取输入图像的特征。为了获得不同尺度下的特征表示,将Haar小波分解嵌入到每个网络分支中。与传统孪生神经网络不同的是,将网络的每个分支扩展为一个分类网络。网络训练时融合了两类不同的损失,即对比损失和分类损失,进而从两个角度同时对网络训练进行监督。具体来说,为了使来自同一类的两幅输入图像特征之间的距离尽可能小、使来自不同类的两幅输入图像特征之间的距离尽可能大,网络采用对比损失作为损失函数。此外,为了充分利用每幅输入图像的类别信息,在网络每个分支上采用交叉熵作为分类损失。结果实验结果表明,本文方法在两个中国书法字体数据集和两个中国书法风格数据集上的分类准确率分别达到了99.90%、94.09% 、99.38%和93.28%,高于对比方法。两种损失起到了良好的互补作用,Haar小波分解的引入在4个数据集上均提升了分类准确率,在风格数据集的提升效果更为明显。结论本文方法在中国书法字体以及风格分类两个任务中取得了令人满意的效果,为书法领域研究工作提供了新思路。关键词:中国书法;风格分类;字体分类;多损失融合孪生卷积神经网络;对比损失;交叉熵损失149|754|0更新时间:2024-05-07 -
 摘要:目的手写汉字纠错(handwritten Chinese character error correction,HCCEC)任务具有两重性,即判断汉字正确性和对错字进行纠正,该任务在教育场景下应用广泛,可以帮助学生学习汉字、纠正书写错误。由于手写汉字具有复杂的空间结构、多样的书写风格以及巨大的数量,且错字与正确字之间具有高度的相似性,因此,手写汉字纠错的关键是如何精确地建模一个汉字。为此,提出一种层级部首网络(hierarchical radical network,HRN)。方法从部首字形的角度出发,挖掘部首形状结构上的相似性,通过注意力模块捕获包含部首信息的细粒度图像特征,增大相似字之间的区分性。另外,结合汉字本身的层级结构特性,采用基于概率解码的思路,对部首的层级位置进行建模。结果在手写汉字数据集上进行实验,与现有方案相比,HRN在正确字测试集与错字测试集上,精确率分别提升了0.5%和9.8%,修正率在错字测试集上提升了15.3%。此外,通过注意力机制的可视化分析,验证了HRN可以捕捉包含部首信息的细粒度图像特征。部首表征之间的欧氏距离证明了HRN学习到的部首表征向量中包含了部首的字形结构信息。结论本文提出的HRN能够更好地对相似部首进行区分,进而精确地区分正确字与错字,具有很强的鲁棒性和泛化性。关键词:手写汉字纠错(HCCEC);汉字识别;部首分析;广义零样本学习(GZSL);注意力机制;卷积神经网络(CNN)151|528|1更新时间:2024-05-07
摘要:目的手写汉字纠错(handwritten Chinese character error correction,HCCEC)任务具有两重性,即判断汉字正确性和对错字进行纠正,该任务在教育场景下应用广泛,可以帮助学生学习汉字、纠正书写错误。由于手写汉字具有复杂的空间结构、多样的书写风格以及巨大的数量,且错字与正确字之间具有高度的相似性,因此,手写汉字纠错的关键是如何精确地建模一个汉字。为此,提出一种层级部首网络(hierarchical radical network,HRN)。方法从部首字形的角度出发,挖掘部首形状结构上的相似性,通过注意力模块捕获包含部首信息的细粒度图像特征,增大相似字之间的区分性。另外,结合汉字本身的层级结构特性,采用基于概率解码的思路,对部首的层级位置进行建模。结果在手写汉字数据集上进行实验,与现有方案相比,HRN在正确字测试集与错字测试集上,精确率分别提升了0.5%和9.8%,修正率在错字测试集上提升了15.3%。此外,通过注意力机制的可视化分析,验证了HRN可以捕捉包含部首信息的细粒度图像特征。部首表征之间的欧氏距离证明了HRN学习到的部首表征向量中包含了部首的字形结构信息。结论本文提出的HRN能够更好地对相似部首进行区分,进而精确地区分正确字与错字,具有很强的鲁棒性和泛化性。关键词:手写汉字纠错(HCCEC);汉字识别;部首分析;广义零样本学习(GZSL);注意力机制;卷积神经网络(CNN)151|528|1更新时间:2024-05-07
文档图像智能处理与识别
-
 摘要:三维重建是指从单幅或多幅二维图像中重建出物体的三维模型并对三维模型进行纹理映射的过程。三维重建可获取从任意视角观测并具有色彩纹理的三维模型,是计算机视觉领域的一个重要研究方向。传统的三维重建方法通常需要输入大量图像,并进行相机参数估计、密集点云重建、表面重建和纹理映射等多个步骤。近年来,深度学习背景下的图像三维重建受到了广泛关注,并表现出了优越的性能和发展前景。本文对深度学习背景下的图像三维重建的技术方法、评测方法和数据集进行全面综述。首先对三维重建进行分类,根据三维模型的表示形式可将图像三维重建方法分类为基于体素的三维重建、基于点云的三维重建和基于网格的三维重建;根据输入图像的类型可将图像三维重建分类为单幅图像三维重建和多幅图像三维重建。随后介绍了不同类别的三维重建方法,从三维重建方法的输入、三维模型表示形式、模型纹理颜色、重建网络的基准值类型和特点等方面进行总结,归纳了深度学习背景下的图像三维重建方法的常用数据集和实验对比,最后总结了当前图像三维重建领域的待解决问题以及未来的研究方向。关键词:三维重建;深度学习;体素模型;点云模型;网格模型602|1072|5更新时间:2024-05-07
摘要:三维重建是指从单幅或多幅二维图像中重建出物体的三维模型并对三维模型进行纹理映射的过程。三维重建可获取从任意视角观测并具有色彩纹理的三维模型,是计算机视觉领域的一个重要研究方向。传统的三维重建方法通常需要输入大量图像,并进行相机参数估计、密集点云重建、表面重建和纹理映射等多个步骤。近年来,深度学习背景下的图像三维重建受到了广泛关注,并表现出了优越的性能和发展前景。本文对深度学习背景下的图像三维重建的技术方法、评测方法和数据集进行全面综述。首先对三维重建进行分类,根据三维模型的表示形式可将图像三维重建方法分类为基于体素的三维重建、基于点云的三维重建和基于网格的三维重建;根据输入图像的类型可将图像三维重建分类为单幅图像三维重建和多幅图像三维重建。随后介绍了不同类别的三维重建方法,从三维重建方法的输入、三维模型表示形式、模型纹理颜色、重建网络的基准值类型和特点等方面进行总结,归纳了深度学习背景下的图像三维重建方法的常用数据集和实验对比,最后总结了当前图像三维重建领域的待解决问题以及未来的研究方向。关键词:三维重建;深度学习;体素模型;点云模型;网格模型602|1072|5更新时间:2024-05-07
综述
-
 摘要:目的针对ASPP(atrous spatial pyramid pooling)在空洞率变大时空洞(atrous)卷积效果会变差的情况,以及图像分类经典模型ResNet(residual neural network)并不能有效地适用于细粒度图像分割任务的问题,提出一种基于改进ASPP和极化自注意力的自底向上全景分割方法。方法重新设计ASPP模块,将小空洞率卷积的输出与原始输入进行拼接(concat),将得到的结果作为新的输入传递给大空洞率卷积,然后将不同空洞率卷积的输出结果拼接,并将得到的结果与ASPP中的其他模块进行最后拼接,从而改善ASPP中因空洞率变大导致的空洞卷积效果变差的问题,达到既获得足够感受野的同时又能编码多尺度信息的目的;在主干网络的输出后引入改进的极化自注意力模块,实现对图像像素级的自我注意强化,使其得到的特征能直接适用于细粒度像素分割任务。结果本文在Cityscapes数据集的验证集上进行测试,与复现的基线网络Panoptic-DeepLab(58.26%)相比,改进ASPP模块后分割精度PQ(panoptic quality)(58.61%)提高了0.35%,运行时间从103 ms增加到124 ms,运行速度没有明显变化;通过进一步引入极化自注意力,PQ指标(58.86%)提高了0.25%,运行时间增加到187 ms;通过对该注意力模块进一步改进,PQ指标(59.36%)在58.86%基础上又提高了0.50%,运行时间增加到192 ms,速度略有下降,但实时性仍好于大多数方法。结论本文采用改进ASPP和极化自注意力模块,能够更有效地提取适合细粒度像素分割的特征,且在保证足够感受野的同时能编码多尺度信息,从而提升全景分割性能。关键词:全景分割;语义分割;实例分割;极化自注意力;ASPP73|139|2更新时间:2024-05-07
摘要:目的针对ASPP(atrous spatial pyramid pooling)在空洞率变大时空洞(atrous)卷积效果会变差的情况,以及图像分类经典模型ResNet(residual neural network)并不能有效地适用于细粒度图像分割任务的问题,提出一种基于改进ASPP和极化自注意力的自底向上全景分割方法。方法重新设计ASPP模块,将小空洞率卷积的输出与原始输入进行拼接(concat),将得到的结果作为新的输入传递给大空洞率卷积,然后将不同空洞率卷积的输出结果拼接,并将得到的结果与ASPP中的其他模块进行最后拼接,从而改善ASPP中因空洞率变大导致的空洞卷积效果变差的问题,达到既获得足够感受野的同时又能编码多尺度信息的目的;在主干网络的输出后引入改进的极化自注意力模块,实现对图像像素级的自我注意强化,使其得到的特征能直接适用于细粒度像素分割任务。结果本文在Cityscapes数据集的验证集上进行测试,与复现的基线网络Panoptic-DeepLab(58.26%)相比,改进ASPP模块后分割精度PQ(panoptic quality)(58.61%)提高了0.35%,运行时间从103 ms增加到124 ms,运行速度没有明显变化;通过进一步引入极化自注意力,PQ指标(58.86%)提高了0.25%,运行时间增加到187 ms;通过对该注意力模块进一步改进,PQ指标(59.36%)在58.86%基础上又提高了0.50%,运行时间增加到192 ms,速度略有下降,但实时性仍好于大多数方法。结论本文采用改进ASPP和极化自注意力模块,能够更有效地提取适合细粒度像素分割的特征,且在保证足够感受野的同时能编码多尺度信息,从而提升全景分割性能。关键词:全景分割;语义分割;实例分割;极化自注意力;ASPP73|139|2更新时间:2024-05-07 -
 摘要:目的基于Transformer架构的网络在图像分类中表现出优异的性能。然而,注意力机制往往只关注图像中的显著性特征,而忽略了其他区域的次级显著信息,基于自注意力机制的Transformer也是如此。为了获取更多的有效信息,从有区别的潜在性特征中学习到更多的可判别特征,提出了一种互补注意多样性特征融合网络(complementary attention diversity feature fusion network,CADF),通过关注次显特征和对通道与空间特征协同编码,以增强特征多样性的注意感知。方法CADF由潜在性特征模块(potential feature module,PFM)和多样性特征融合模块(diversity feature fusion module,DFFM)组成。PFM模块通过聚合空间与通道中感兴趣区域得到显著性特征,再对特征的显著性进行抑制,以强制网络挖掘潜在性特征,从而增强网络对微小判别特征的感知。DFFM模块探索特征间的相关性,对不同尺寸的特征交互建模,以得到更加丰富的互补信息,从而产生更强的细粒度特征。结果本文方法可以端到端地进行训练,不需要边界框和多阶段训练。在CUB-200-2011(Caltech-UCSD Birds-200-2011)、Stanford Dogs、Stanford Cars以及FGVC-Aircraft(fine-grained visual classification of aircraft) 4个基准数据集上验证所提方法,准确率分别达到了92.6%、94.5%、95.3%和93.5%。实验结果表明,本文方法的性能优于当前主流方法,并在多个数据集中表现出良好的性能。在消融研究中,验证了模型中各个模块的有效性。结论本文方法具有显著性能,通过注意互补有效提升了特征的多样性,以此尽可能地获取丰富的判别特征,使分类的结果更加精准。关键词:细粒度分类;多样性特征;潜在特征;特征融合;端到端学习115|249|3更新时间:2024-05-07
摘要:目的基于Transformer架构的网络在图像分类中表现出优异的性能。然而,注意力机制往往只关注图像中的显著性特征,而忽略了其他区域的次级显著信息,基于自注意力机制的Transformer也是如此。为了获取更多的有效信息,从有区别的潜在性特征中学习到更多的可判别特征,提出了一种互补注意多样性特征融合网络(complementary attention diversity feature fusion network,CADF),通过关注次显特征和对通道与空间特征协同编码,以增强特征多样性的注意感知。方法CADF由潜在性特征模块(potential feature module,PFM)和多样性特征融合模块(diversity feature fusion module,DFFM)组成。PFM模块通过聚合空间与通道中感兴趣区域得到显著性特征,再对特征的显著性进行抑制,以强制网络挖掘潜在性特征,从而增强网络对微小判别特征的感知。DFFM模块探索特征间的相关性,对不同尺寸的特征交互建模,以得到更加丰富的互补信息,从而产生更强的细粒度特征。结果本文方法可以端到端地进行训练,不需要边界框和多阶段训练。在CUB-200-2011(Caltech-UCSD Birds-200-2011)、Stanford Dogs、Stanford Cars以及FGVC-Aircraft(fine-grained visual classification of aircraft) 4个基准数据集上验证所提方法,准确率分别达到了92.6%、94.5%、95.3%和93.5%。实验结果表明,本文方法的性能优于当前主流方法,并在多个数据集中表现出良好的性能。在消融研究中,验证了模型中各个模块的有效性。结论本文方法具有显著性能,通过注意互补有效提升了特征的多样性,以此尽可能地获取丰富的判别特征,使分类的结果更加精准。关键词:细粒度分类;多样性特征;潜在特征;特征融合;端到端学习115|249|3更新时间:2024-05-07 -
 摘要:目的机器人在进行同时定位与地图构建(simultaneous localization and mapping,SLAM)时需要有效利用未知复杂环境的场景信息,针对现有SLAM算法对场景细节理解不够及建图细节信息缺失的问题,本文构造出一种将SLAM点云定位技术与语义分割网络相结合的未知环境地图构建方法,实现高精度三维地图重建。方法首先,利用场景的实时彩色信息进行相机的位姿估计,并构造融合空间多尺度稀疏及稠密特征的深度学习网络HieSemNet(hierarchical semantic network),对未知场景信息进行语义分割,得到场景的实时二维语义信息;其次,利用深度信息和相机位姿进行空间点云估计,并将二维语义分割信息与三维点云信息融合,使语义分割的结果对应到点云的相应空间位置,构建出具有语义信息的高精度点云地图,实现三维地图重建。结果为验证本文方法的有效性,分别针对所构造的HieSemNet网络和语义SLAM系统进行验证实验。实验结果表明,本文的网络在平均像素准确度和平均交并比上均取得了较好的精度,MPA(mean pixel accuracy)指标相较于其他网络分别提高了17.47%、11.67%、4.86%、2.90%和0.44%,MIoU(mean intersection over union)指标分别提高了13.94%、1.10%、6.28%、2.28%和0.62%。本文的SLAM算法可以获得更多的建图信息,构建的地图精度和准确度都更好。结论本文方法充分考虑了不同尺寸物体的分割效果,提出的HieSemNet网络能有效提高场景语义分割准确性,此外,与现有的前沿语义SLAM系统相比,本文方法能够明显提高建图的精度和准确度,获得更高质量的地图。关键词:同时定位与地图构建(SLAM);语义分割;语义三维地图;空间多尺度特征99|228|1更新时间:2024-05-07
摘要:目的机器人在进行同时定位与地图构建(simultaneous localization and mapping,SLAM)时需要有效利用未知复杂环境的场景信息,针对现有SLAM算法对场景细节理解不够及建图细节信息缺失的问题,本文构造出一种将SLAM点云定位技术与语义分割网络相结合的未知环境地图构建方法,实现高精度三维地图重建。方法首先,利用场景的实时彩色信息进行相机的位姿估计,并构造融合空间多尺度稀疏及稠密特征的深度学习网络HieSemNet(hierarchical semantic network),对未知场景信息进行语义分割,得到场景的实时二维语义信息;其次,利用深度信息和相机位姿进行空间点云估计,并将二维语义分割信息与三维点云信息融合,使语义分割的结果对应到点云的相应空间位置,构建出具有语义信息的高精度点云地图,实现三维地图重建。结果为验证本文方法的有效性,分别针对所构造的HieSemNet网络和语义SLAM系统进行验证实验。实验结果表明,本文的网络在平均像素准确度和平均交并比上均取得了较好的精度,MPA(mean pixel accuracy)指标相较于其他网络分别提高了17.47%、11.67%、4.86%、2.90%和0.44%,MIoU(mean intersection over union)指标分别提高了13.94%、1.10%、6.28%、2.28%和0.62%。本文的SLAM算法可以获得更多的建图信息,构建的地图精度和准确度都更好。结论本文方法充分考虑了不同尺寸物体的分割效果,提出的HieSemNet网络能有效提高场景语义分割准确性,此外,与现有的前沿语义SLAM系统相比,本文方法能够明显提高建图的精度和准确度,获得更高质量的地图。关键词:同时定位与地图构建(SLAM);语义分割;语义三维地图;空间多尺度特征99|228|1更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的针对固流交互中的固体破碎现象模拟研究较少、物理模型复杂、多求解器耦合性差、真实感与实时性难以兼顾等问题,提出一种适用于光滑粒子流体动力学(smoothed particle hydrodynamics,SPH)固流交互统一粒子框架的实时固体破碎模拟方法。方法首先,结合断裂力学理论与统一粒子框架下固体边界粒子的空间和物理特性,构建基于物理的能量分析模型。然后,通过实时分析固体与流体之间的能量转化和自身能量平衡,将满足条件的粒子作为破碎发生的启发点。最后,采用基于几何的碎块生成方法,将启发点集作为种子点构建Voronoi图,完成碎块的生成。为确保模拟系统实时性,将模拟系统进行并行优化并加载至图形处理器(graphics processing unit,GPU)并行执行。结果通过在不同复杂度和粒子规模的实验场景中进行模拟得到的结果表明,本文方法能够稳定地模拟固体受到流体冲击后发生的破碎现象,破碎细节真实感良好,在百万级粒子规模下能够满足实时性要求,可大规模并行执行且GPU加速效果显著,加速收益随场景规模增大而增大。结论与现有研究相比,本文方法充分结合物理与几何方法的优点,与SPH统一粒子框架具有更高的耦合性,能够稳定地模拟固流交互中的固体破碎现象,细节符合现实世界物理规律,真实感渲染效果良好,可应用于洪涝、海啸、溃坝和泥石流等自然灾害的交互式预演、电子游戏特效等领域。关键词:物理动画;流体模拟;光滑粒子流体动力学;固流交互;固体破碎119|355|0更新时间:2024-05-07
摘要:目的针对固流交互中的固体破碎现象模拟研究较少、物理模型复杂、多求解器耦合性差、真实感与实时性难以兼顾等问题,提出一种适用于光滑粒子流体动力学(smoothed particle hydrodynamics,SPH)固流交互统一粒子框架的实时固体破碎模拟方法。方法首先,结合断裂力学理论与统一粒子框架下固体边界粒子的空间和物理特性,构建基于物理的能量分析模型。然后,通过实时分析固体与流体之间的能量转化和自身能量平衡,将满足条件的粒子作为破碎发生的启发点。最后,采用基于几何的碎块生成方法,将启发点集作为种子点构建Voronoi图,完成碎块的生成。为确保模拟系统实时性,将模拟系统进行并行优化并加载至图形处理器(graphics processing unit,GPU)并行执行。结果通过在不同复杂度和粒子规模的实验场景中进行模拟得到的结果表明,本文方法能够稳定地模拟固体受到流体冲击后发生的破碎现象,破碎细节真实感良好,在百万级粒子规模下能够满足实时性要求,可大规模并行执行且GPU加速效果显著,加速收益随场景规模增大而增大。结论与现有研究相比,本文方法充分结合物理与几何方法的优点,与SPH统一粒子框架具有更高的耦合性,能够稳定地模拟固流交互中的固体破碎现象,细节符合现实世界物理规律,真实感渲染效果良好,可应用于洪涝、海啸、溃坝和泥石流等自然灾害的交互式预演、电子游戏特效等领域。关键词:物理动画;流体模拟;光滑粒子流体动力学;固流交互;固体破碎119|355|0更新时间:2024-05-07
计算机图形学
-
 摘要:目的早期肾癌可以通过肾肿瘤剜除术进行有效治疗,为了降低手术难度和减少手术并发症,需要对手术的难度进行合理有效的评估。本文将深度学习、医学影像组学和图像分析技术进行结合,提出一种基于CT(computed tomography)影像的肾肿瘤剜除术难度自动评估方法。方法首先建立一个级联的端到端分割模型对肾脏、肾肿瘤和腹壁同时进行分割,同时融入子像素卷积与注意力机制,保证了小体积肿瘤分割的精确性;然后使用影像组学特征对误判的肾肿瘤进行去除;最后依据分割结果,采用国际标准的梅奥肾周粘连概率(Mayo adhesive probability,MAP)评分和R.E.N.A.L评分对肾脏和肾肿瘤进行自动化的评估计算,并根据计算结果得出肾肿瘤剜除术难度。结果将实验的自动化评估结果与三甲医院泌尿科的3位医疗专家的结果进行对比,从预测的平均结果来看,超过两个专家,与最好的专家相差仅0.1%。平均预测时间,单个肿瘤约为244 ms,标准差只有8 ms,专家评估时间约为26 s,标准差在3 s左右,自动评估速度是人工的108倍左右。结论自动化评估结果整体上与专家评估水平基本一致,同时评估速度更加快速稳定,可以有效替代专家进行自动化评估,为术前准确诊断、手术方案个体化规划和手术入路选择提供准确可靠的决策支持,给手术难度诊断评估提供智能化的医疗解决方案。关键词:肾肿瘤剜除术;医学图像分割;影像组学;深度学习;手术评估136|298|0更新时间:2024-05-07
摘要:目的早期肾癌可以通过肾肿瘤剜除术进行有效治疗,为了降低手术难度和减少手术并发症,需要对手术的难度进行合理有效的评估。本文将深度学习、医学影像组学和图像分析技术进行结合,提出一种基于CT(computed tomography)影像的肾肿瘤剜除术难度自动评估方法。方法首先建立一个级联的端到端分割模型对肾脏、肾肿瘤和腹壁同时进行分割,同时融入子像素卷积与注意力机制,保证了小体积肿瘤分割的精确性;然后使用影像组学特征对误判的肾肿瘤进行去除;最后依据分割结果,采用国际标准的梅奥肾周粘连概率(Mayo adhesive probability,MAP)评分和R.E.N.A.L评分对肾脏和肾肿瘤进行自动化的评估计算,并根据计算结果得出肾肿瘤剜除术难度。结果将实验的自动化评估结果与三甲医院泌尿科的3位医疗专家的结果进行对比,从预测的平均结果来看,超过两个专家,与最好的专家相差仅0.1%。平均预测时间,单个肿瘤约为244 ms,标准差只有8 ms,专家评估时间约为26 s,标准差在3 s左右,自动评估速度是人工的108倍左右。结论自动化评估结果整体上与专家评估水平基本一致,同时评估速度更加快速稳定,可以有效替代专家进行自动化评估,为术前准确诊断、手术方案个体化规划和手术入路选择提供准确可靠的决策支持,给手术难度诊断评估提供智能化的医疗解决方案。关键词:肾肿瘤剜除术;医学图像分割;影像组学;深度学习;手术评估136|298|0更新时间:2024-05-07 -
 摘要:目的为解决基于深度学习算法在执行胎儿四腔心超声切面图像质量评测时无法准确反映心脏区域中瓣膜与房室间隔及心室心房区域的可见程度问题,提出一种目标检测与两级分割相结合的胎儿四腔心超声切面图像质量评测方法。方法首先利用自行构建的胎儿超声切面数据集训练主流的YOLOv5x(you only look once v5x)模型,实现四腔心区域与胸腔区域的有效定位。当检测到四腔心区域在胸腔区域内时,将其视为感兴趣区域送入训练好的U2-Net模型,进一步分割出包含心房室及瓣膜的部分。然后利用形态学算子去除其外围可能存在的少许心脏外膜区域得到四腔心内区域后,通过直方图修正与最大类间方差法(OTSU)相结合的方法分割出瓣膜连同房室间隔区域,并通过减法操作得到心室心房区域的分割图。最后通过联合胎儿四腔心超声切面图像中瓣膜连同房室间隔与心室心房区域的面积之比、瓣膜与房室间隔区域以及心室心房区域的平均灰度构建评分公式与评分标准,实现胎儿四腔心超声切面图像质量的有效评测。结果在胸腔和四腔心区域的检测任务上的mAP@0.5、mAP@0.5-0.95和召回率分别为99.5%、84.6%和99.9%;在四腔心内部区域分割任务上的灵敏度、特异度和准确度分别为95.0%、95.1%和94.9%;所提质量评测方法在所构建的A、B、C三类评测数据集上分别取得了93.7%、90.3%和99.1%的准确率。结论所提方法的评测结果与医生主观评测结果相近,具有较好的可解释性,拥有良好的实际应用价值。关键词:深度学习(DL);卷积神经网络(CNN);超声图像质量评测;目标检测;两级图像分割71|224|1更新时间:2024-05-07
摘要:目的为解决基于深度学习算法在执行胎儿四腔心超声切面图像质量评测时无法准确反映心脏区域中瓣膜与房室间隔及心室心房区域的可见程度问题,提出一种目标检测与两级分割相结合的胎儿四腔心超声切面图像质量评测方法。方法首先利用自行构建的胎儿超声切面数据集训练主流的YOLOv5x(you only look once v5x)模型,实现四腔心区域与胸腔区域的有效定位。当检测到四腔心区域在胸腔区域内时,将其视为感兴趣区域送入训练好的U2-Net模型,进一步分割出包含心房室及瓣膜的部分。然后利用形态学算子去除其外围可能存在的少许心脏外膜区域得到四腔心内区域后,通过直方图修正与最大类间方差法(OTSU)相结合的方法分割出瓣膜连同房室间隔区域,并通过减法操作得到心室心房区域的分割图。最后通过联合胎儿四腔心超声切面图像中瓣膜连同房室间隔与心室心房区域的面积之比、瓣膜与房室间隔区域以及心室心房区域的平均灰度构建评分公式与评分标准,实现胎儿四腔心超声切面图像质量的有效评测。结果在胸腔和四腔心区域的检测任务上的mAP@0.5、mAP@0.5-0.95和召回率分别为99.5%、84.6%和99.9%;在四腔心内部区域分割任务上的灵敏度、特异度和准确度分别为95.0%、95.1%和94.9%;所提质量评测方法在所构建的A、B、C三类评测数据集上分别取得了93.7%、90.3%和99.1%的准确率。结论所提方法的评测结果与医生主观评测结果相近,具有较好的可解释性,拥有良好的实际应用价值。关键词:深度学习(DL);卷积神经网络(CNN);超声图像质量评测;目标检测;两级图像分割71|224|1更新时间:2024-05-07 -
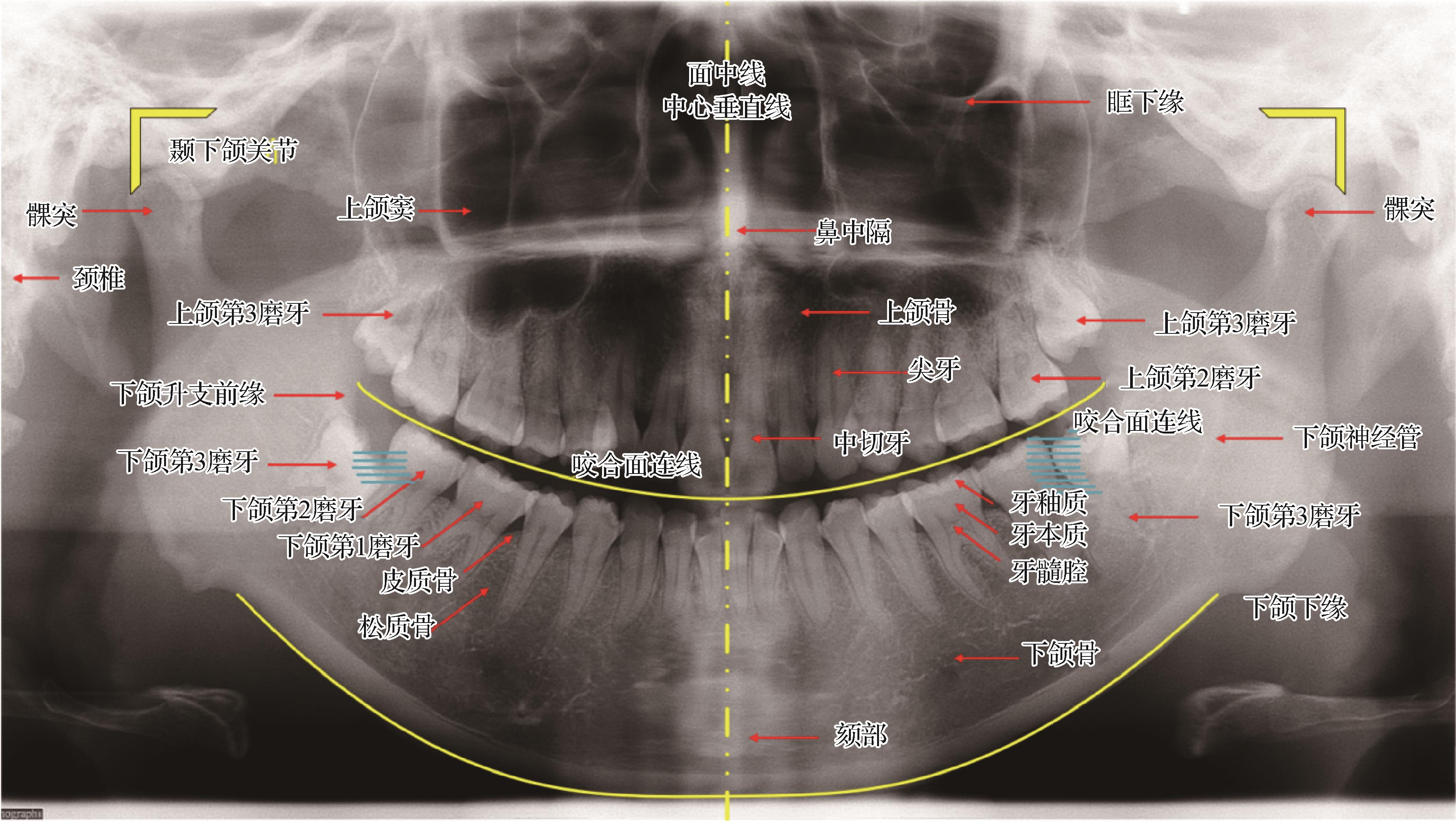 摘要:目的全口曲面断层片(全景片)需要病人的正确摆位辅以仪器的合理配置而取得合格的成像:以面中线为界,双侧上下颌骨等结构呈左右对称;牙齿的咬合面连线呈缓慢的微笑曲线,各牙齿在全景片上的生理位置是基本固定的。因此,以全景片为代表的口腔医学图像具备固定的前、背景关系和稳定的空间结构,但基于常规卷积的网络因其卷积的空间无关性而对上述空间域的结构信息并不敏感。虽然一些特殊的注意力模块能够引导模型关注特定信息并给予加权,但是它关注的信息常常背离人们的期望,反而降低模型性能;另一方面,注意力作为嵌入式的模块往往会提高计算量和参数量。针对口腔医学图像的结构特性,提出适用于全景智齿检测的基于内卷解耦的YOLO(you only look once)模型。方法在主干网络中,通过重塑跨阶段分部(cross stage partial,CSP)结构并引入一种具备空间特异性的内卷积方式,使模型优先关注空间域中信息量最大的视觉元素,以此强化模型对空间信息的建模能力;在检测头结构中,提出采用多支路解耦结构克服任务耦合的负面影响,解决内卷算子与YOLO模型的适配性问题,并对各支路的损失函数进行针对性优化。结果在全景片数据集上的智齿检测的实验结果表明,本文方法的检测性能和模型参数大幅优于近年优秀的单阶段目标检测模型,相较于本文的基线模型,参数量缩减了42.5%,平均精确率提升了6.3%,充分验证了本文模型结构的合理性及对于智齿检测任务的有效性。结论本文针对口腔医学图像的空间结构性质提出的基于内卷解耦的全景智齿检测方案,具有更强的空间信息建模能力,且降低了参数量成本。关键词:全景片;智齿;目标检测;YOLO;解耦;内卷92|297|0更新时间:2024-05-07
摘要:目的全口曲面断层片(全景片)需要病人的正确摆位辅以仪器的合理配置而取得合格的成像:以面中线为界,双侧上下颌骨等结构呈左右对称;牙齿的咬合面连线呈缓慢的微笑曲线,各牙齿在全景片上的生理位置是基本固定的。因此,以全景片为代表的口腔医学图像具备固定的前、背景关系和稳定的空间结构,但基于常规卷积的网络因其卷积的空间无关性而对上述空间域的结构信息并不敏感。虽然一些特殊的注意力模块能够引导模型关注特定信息并给予加权,但是它关注的信息常常背离人们的期望,反而降低模型性能;另一方面,注意力作为嵌入式的模块往往会提高计算量和参数量。针对口腔医学图像的结构特性,提出适用于全景智齿检测的基于内卷解耦的YOLO(you only look once)模型。方法在主干网络中,通过重塑跨阶段分部(cross stage partial,CSP)结构并引入一种具备空间特异性的内卷积方式,使模型优先关注空间域中信息量最大的视觉元素,以此强化模型对空间信息的建模能力;在检测头结构中,提出采用多支路解耦结构克服任务耦合的负面影响,解决内卷算子与YOLO模型的适配性问题,并对各支路的损失函数进行针对性优化。结果在全景片数据集上的智齿检测的实验结果表明,本文方法的检测性能和模型参数大幅优于近年优秀的单阶段目标检测模型,相较于本文的基线模型,参数量缩减了42.5%,平均精确率提升了6.3%,充分验证了本文模型结构的合理性及对于智齿检测任务的有效性。结论本文针对口腔医学图像的空间结构性质提出的基于内卷解耦的全景智齿检测方案,具有更强的空间信息建模能力,且降低了参数量成本。关键词:全景片;智齿;目标检测;YOLO;解耦;内卷92|297|0更新时间:2024-05-07
医学图像处理
-
 摘要:目的与标准RGB图像相比,高光谱图像(hyperspectral image,HSI)具有更为精细的光谱划分,这一特点可以为后续的图像分析处理带来更好的性能。然而在采集过程中,HSI可能会受到严重的噪声污染,比如高斯噪声、脉冲噪声、条纹噪声和死线噪声。受到污染的HSI在一定程度上会影响后续分析算法的性能,因此在进行图像分析处理之前,对采集到的HSI进行降噪是非常重要的。方法为了得到干净的HSI,本文提出了一种新的结构型张量分解算法,并将其应用于HSI降噪。该算法根据HSI的线性子空间模型,将干净的高光谱图像分解为矩阵向量外积的和,其中向量表示光谱的正交基,矩阵表示基对应的系数,即特征图像。考虑特征图像的低秩性,矩阵核范数算子被直接施加在特征图像上,这样既可以充分探索高光谱图像的全局信息,又可以避免对原始张量进行低秩约束所带来的计算负担。
摘要:目的与标准RGB图像相比,高光谱图像(hyperspectral image,HSI)具有更为精细的光谱划分,这一特点可以为后续的图像分析处理带来更好的性能。然而在采集过程中,HSI可能会受到严重的噪声污染,比如高斯噪声、脉冲噪声、条纹噪声和死线噪声。受到污染的HSI在一定程度上会影响后续分析算法的性能,因此在进行图像分析处理之前,对采集到的HSI进行降噪是非常重要的。方法为了得到干净的HSI,本文提出了一种新的结构型张量分解算法,并将其应用于HSI降噪。该算法根据HSI的线性子空间模型,将干净的高光谱图像分解为矩阵向量外积的和,其中向量表示光谱的正交基,矩阵表示基对应的系数,即特征图像。考虑特征图像的低秩性,矩阵核范数算子被直接施加在特征图像上,这样既可以充分探索高光谱图像的全局信息,又可以避免对原始张量进行低秩约束所带来的计算负担。 -
 摘要:目的精确估计热带气旋的强度有助于提升天气预报和预警的准确性。随着深度学习技术的不断发展,基于卷积神经网络(convolutional neural network,CNN)的方法已应用于强度估计任务中。然而,现有方法仍存在许多问题,例如无法充分利用不同波段的卫星图像信息、输入图像以热带气旋的定位为中心等限制,从而产生较大误差,影响实时估计的结果。针对以上问题,本文提出一种融合定位信息的强度估计网络IEFL(intensity estimation fusing location),提升强度估计的准确率。方法模型采用双分支结构,能有效融合不同波段的图像特征,同时可以同步优化两个任务,达到互相促进的效果。此外,模型对强度估计任务做了定位的特征融合,将得到的定位特征图与强度特征图进行拼接,共同输出最后的强度结果,通过利用定位信息达到提升强度估计精度的目的。结果本文在完成热带气旋强度估计的同时,可获取较好的热带气旋中心定位结果。收集了2015—2018年葵花-8卫星多通道图像用以训练模型,并在2019和2020年的数据上进行测试。结果表明,融合定位信息后模型的强度估计均方根误差为4.74 m/s,平均绝对误差为3.52 m/s。相比传统单一强度估计模型误差分别降低了7%和9%。结论IEFL模型在不依赖定位准确率的同时,能够有效提升强度估计的准确率。关键词:强度估计;热带气旋(TC);卷积神经网络(CNN);中心定位;葵花-892|226|0更新时间:2024-05-07
摘要:目的精确估计热带气旋的强度有助于提升天气预报和预警的准确性。随着深度学习技术的不断发展,基于卷积神经网络(convolutional neural network,CNN)的方法已应用于强度估计任务中。然而,现有方法仍存在许多问题,例如无法充分利用不同波段的卫星图像信息、输入图像以热带气旋的定位为中心等限制,从而产生较大误差,影响实时估计的结果。针对以上问题,本文提出一种融合定位信息的强度估计网络IEFL(intensity estimation fusing location),提升强度估计的准确率。方法模型采用双分支结构,能有效融合不同波段的图像特征,同时可以同步优化两个任务,达到互相促进的效果。此外,模型对强度估计任务做了定位的特征融合,将得到的定位特征图与强度特征图进行拼接,共同输出最后的强度结果,通过利用定位信息达到提升强度估计精度的目的。结果本文在完成热带气旋强度估计的同时,可获取较好的热带气旋中心定位结果。收集了2015—2018年葵花-8卫星多通道图像用以训练模型,并在2019和2020年的数据上进行测试。结果表明,融合定位信息后模型的强度估计均方根误差为4.74 m/s,平均绝对误差为3.52 m/s。相比传统单一强度估计模型误差分别降低了7%和9%。结论IEFL模型在不依赖定位准确率的同时,能够有效提升强度估计的准确率。关键词:强度估计;热带气旋(TC);卷积神经网络(CNN);中心定位;葵花-892|226|0更新时间:2024-05-07
遥感图像处理
-
 摘要:目的随着人工智能技术的大力发展,以无人船为代表的智能无人装备在海洋技术领域已开始实际应用。在大型海域巡逻任务中,相比传统的巡逻装备,多无人船协同执行区域覆盖任务具有运行时间短、效率高以及风险低等优势,但需要解决任务划分、能源补给等难点问题。针对上述问题,提出一套完整的解决大型海域巡逻任务的多无人船协同执行区域覆盖任务的解决方案,并进行面向实际海图的仿真实验。方法首先对多无人船海域巡逻任务进行了问题定义和建模,在构建栅格海域地图的基础上,提出了基于任务均衡的区域划分策略和多种评价指标;在分析比较多种传统遍历算法优劣的基础上,提出了无能源约束和有能源约束条件下的多无人船区域覆盖遍历算法,尤其在有能源约束条件下考虑了多种充电后路径规划策略。结果利用Python搭建仿真应用平台,对三沙市周边15 000多平方公里海域进行仿真实验,实验比较了不同遍历算法在无能源约束和有能源约束条件下的优劣,验证了所提出的区域划分策略和遍历算法的有效性和能源约束下无人船在充电后重新规划遍历路径策略的优越性,并对覆盖率和无人船电池里程等参数进行了消融实验。结论提出的方法和仿真分析结果为多无人船协同执行大型海域巡逻任务的实际应用提供了一定的借鉴作用。关键词:海域巡逻;无人船;区域覆盖路径规划;能源约束;仿真188|176|1更新时间:2024-05-07
摘要:目的随着人工智能技术的大力发展,以无人船为代表的智能无人装备在海洋技术领域已开始实际应用。在大型海域巡逻任务中,相比传统的巡逻装备,多无人船协同执行区域覆盖任务具有运行时间短、效率高以及风险低等优势,但需要解决任务划分、能源补给等难点问题。针对上述问题,提出一套完整的解决大型海域巡逻任务的多无人船协同执行区域覆盖任务的解决方案,并进行面向实际海图的仿真实验。方法首先对多无人船海域巡逻任务进行了问题定义和建模,在构建栅格海域地图的基础上,提出了基于任务均衡的区域划分策略和多种评价指标;在分析比较多种传统遍历算法优劣的基础上,提出了无能源约束和有能源约束条件下的多无人船区域覆盖遍历算法,尤其在有能源约束条件下考虑了多种充电后路径规划策略。结果利用Python搭建仿真应用平台,对三沙市周边15 000多平方公里海域进行仿真实验,实验比较了不同遍历算法在无能源约束和有能源约束条件下的优劣,验证了所提出的区域划分策略和遍历算法的有效性和能源约束下无人船在充电后重新规划遍历路径策略的优越性,并对覆盖率和无人船电池里程等参数进行了消融实验。结论提出的方法和仿真分析结果为多无人船协同执行大型海域巡逻任务的实际应用提供了一定的借鉴作用。关键词:海域巡逻;无人船;区域覆盖路径规划;能源约束;仿真188|176|1更新时间:2024-05-07 -
 摘要:目的鸟类跟踪技术的成熟发展使得鸟类专家可以轻松获得大量鸟类运动数据。然而,数据规模的增加使得传统方法难以有效完成数据检索和分析。研究如何辅助专家有效地分析这些数据,挖掘其中的有用信息,具有很强的实用价值。本文基于国家Ⅰ级重点保护物种朱鹮的卫星跟踪数据,从鸟类专家对数据分析的需求出发,提出了一种运动轨迹的可视分析方法。方法基于二维地图进行多视图协同展示的交互布局方式,以及聚类分析方法等对朱鹮运动轨迹进行可视分析,挖掘朱鹮的生活状态和习性。在以上工作的基础上,设计实现了一个朱鹮运动轨迹可视分析系统。结果本文提出的可视分析方法,允许用户从时空维度和时期(繁殖期、游荡期、越冬期)、状态(夜宿、觅食)等具有生态学意义的维度观察朱鹮运动轨迹,对运动数据进行统计分析,了解朱鹮运动行为。与现有朱鹮数据分析方法相比,本文提出的可视分析方法能够同时从多个不同维度对运动数据进行分析,针对朱鹮的生活状态和生活习性进行更深入的分析挖掘。结论案例分析表明,基于本文提出的方法,鸟类专家可以从多个角度对朱鹮运动轨迹数据进行综合分析,达到对鸟类习性和状态进行研究挖掘的目的,并能够为其他鸟类跟踪数据分析工作提供思路和方法。关键词:卫星跟踪;可视分析;多视图协同;聚类分析;时序数据插补136|244|0更新时间:2024-05-07
摘要:目的鸟类跟踪技术的成熟发展使得鸟类专家可以轻松获得大量鸟类运动数据。然而,数据规模的增加使得传统方法难以有效完成数据检索和分析。研究如何辅助专家有效地分析这些数据,挖掘其中的有用信息,具有很强的实用价值。本文基于国家Ⅰ级重点保护物种朱鹮的卫星跟踪数据,从鸟类专家对数据分析的需求出发,提出了一种运动轨迹的可视分析方法。方法基于二维地图进行多视图协同展示的交互布局方式,以及聚类分析方法等对朱鹮运动轨迹进行可视分析,挖掘朱鹮的生活状态和习性。在以上工作的基础上,设计实现了一个朱鹮运动轨迹可视分析系统。结果本文提出的可视分析方法,允许用户从时空维度和时期(繁殖期、游荡期、越冬期)、状态(夜宿、觅食)等具有生态学意义的维度观察朱鹮运动轨迹,对运动数据进行统计分析,了解朱鹮运动行为。与现有朱鹮数据分析方法相比,本文提出的可视分析方法能够同时从多个不同维度对运动数据进行分析,针对朱鹮的生活状态和生活习性进行更深入的分析挖掘。结论案例分析表明,基于本文提出的方法,鸟类专家可以从多个角度对朱鹮运动轨迹数据进行综合分析,达到对鸟类习性和状态进行研究挖掘的目的,并能够为其他鸟类跟踪数据分析工作提供思路和方法。关键词:卫星跟踪;可视分析;多视图协同;聚类分析;时序数据插补136|244|0更新时间:2024-05-07
地理信息技术
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0