
最新刊期
2023 年 第 28 卷 第 5 期

-
 摘要:小股人群重识别旨在将非重叠视域的摄像头网络下具有相同成员的群组图像进行正确的关联。小股人群重识别是传统行人重识别任务的一个重要拓展,在安防监控场景下有着重要的研究意义和应用前景。小股人群重识别所面临的独特挑战在于如何针对群内成员的数量变化和布局变化进行建模,并提取稳定、鲁棒的特征表达。近年来,小股人群重识别引发了研究人员的广泛关注,并获得了快速的发展。本文对小股人群重识别技术的研究进展进行了全面的梳理回顾。首先简要介绍本领域的研究背景,对基本概念、数据集和相关技术进行了简要总结。在此基础上,对多种小股人群重识别算法进行了详细的介绍,并在多个数据集上对前沿算法进行性能对比。最后,对该任务进行展望。整体而言,与行人重识别相比,小股人群重识别的现有方法在具体场景下的特定挑战性能表现欠佳,还需要从数据收集和方法设计两方面进一步探讨。此外,现有的小股人群重识别研究与其他视觉任务的关联性不够紧密,如何协同多任务作业以解决更多业界需求、加速产业落地,需要学术界和工业界共同思考和推动。关键词:小股人群重识别(GReID);行人重识别;虚拟数据;深度学习;特征学习;度量学习;Transformer238|359|1更新时间:2024-05-07
摘要:小股人群重识别旨在将非重叠视域的摄像头网络下具有相同成员的群组图像进行正确的关联。小股人群重识别是传统行人重识别任务的一个重要拓展,在安防监控场景下有着重要的研究意义和应用前景。小股人群重识别所面临的独特挑战在于如何针对群内成员的数量变化和布局变化进行建模,并提取稳定、鲁棒的特征表达。近年来,小股人群重识别引发了研究人员的广泛关注,并获得了快速的发展。本文对小股人群重识别技术的研究进展进行了全面的梳理回顾。首先简要介绍本领域的研究背景,对基本概念、数据集和相关技术进行了简要总结。在此基础上,对多种小股人群重识别算法进行了详细的介绍,并在多个数据集上对前沿算法进行性能对比。最后,对该任务进行展望。整体而言,与行人重识别相比,小股人群重识别的现有方法在具体场景下的特定挑战性能表现欠佳,还需要从数据收集和方法设计两方面进一步探讨。此外,现有的小股人群重识别研究与其他视觉任务的关联性不够紧密,如何协同多任务作业以解决更多业界需求、加速产业落地,需要学术界和工业界共同思考和推动。关键词:小股人群重识别(GReID);行人重识别;虚拟数据;深度学习;特征学习;度量学习;Transformer238|359|1更新时间:2024-05-07 -
 摘要:行人重识别旨在建立目标行人在多个无交叉覆盖监控区域间的身份联系,在智慧城市、司法侦查和监控安全等领域具有重要应用价值。传统行人重识别方法针对短时间跨度场景,依赖行人外观特征的稳定不变性,旨在克服光照差异、视角变化和物体遮挡等挑战。与之不同,换装行人重识别针对长时间跨度场景,除受限于上述挑战还面临换装带来的外观变化问题,是近几年的一个研究难点和热点。围绕换装行人重识别,本文从数据集和解决方法两个方面综述国内外研究进展,探讨面临的挑战和难点。首先,梳理并比较了当前针对换装行人重识别的数据集,从采集方式、行人及样本数量等方面分析其挑战性和面临的局限性。然后,在简单回顾换装行人重识别发展历史的基础上,将其归纳为基于非视觉传感器的方法和基于视觉相机的方法两类。针对基于非视觉传感器的方法,介绍了深度传感器、射频信号等在换装行人重识别中的应用。针对基于视觉相机的方法,详细阐述了基于显式特征设计与提取的方法、基于特征解耦的方法和基于隐式数据驱动自适应学习的方法。在此基础上,探讨了当前换装行人重识别面临的问题并展望未来的发展趋势,旨在为相关研究提供参考。关键词:视频监控;换装行人重识别;深度学习;特征学习与表示;生物特征;特征解耦;数据驱动学习331|610|2更新时间:2024-05-07
摘要:行人重识别旨在建立目标行人在多个无交叉覆盖监控区域间的身份联系,在智慧城市、司法侦查和监控安全等领域具有重要应用价值。传统行人重识别方法针对短时间跨度场景,依赖行人外观特征的稳定不变性,旨在克服光照差异、视角变化和物体遮挡等挑战。与之不同,换装行人重识别针对长时间跨度场景,除受限于上述挑战还面临换装带来的外观变化问题,是近几年的一个研究难点和热点。围绕换装行人重识别,本文从数据集和解决方法两个方面综述国内外研究进展,探讨面临的挑战和难点。首先,梳理并比较了当前针对换装行人重识别的数据集,从采集方式、行人及样本数量等方面分析其挑战性和面临的局限性。然后,在简单回顾换装行人重识别发展历史的基础上,将其归纳为基于非视觉传感器的方法和基于视觉相机的方法两类。针对基于非视觉传感器的方法,介绍了深度传感器、射频信号等在换装行人重识别中的应用。针对基于视觉相机的方法,详细阐述了基于显式特征设计与提取的方法、基于特征解耦的方法和基于隐式数据驱动自适应学习的方法。在此基础上,探讨了当前换装行人重识别面临的问题并展望未来的发展趋势,旨在为相关研究提供参考。关键词:视频监控;换装行人重识别;深度学习;特征学习与表示;生物特征;特征解耦;数据驱动学习331|610|2更新时间:2024-05-07 -
 摘要:步态识别具有对图像分辨率要求低、可远距离识别、无需受试者合作、难以隐藏或伪装等优势,在安防监控和调查取证等领域有着广阔的应用前景。然而在实际应用中,步态识别的性能常受到视角、着装、携物和遮挡等协变量的影响,其中视角变化最为普遍,并且会使行人的外观发生显著改变。因此,提高步态识别对视角的鲁棒性一直是该领域的研究热点。为了全面认识现有的跨视角步态识别方法,本文对相关研究工作进行了梳理和综述。首先,从基本概念、数据采集方式和发展历程等角度简要介绍了该领域的研究背景,在此基础上,整理并分析了基于视频的主流跨视角步态数据库;然后,从基于3维步态信息的识别方法、基于视角转换模型的识别方法、基于视角不变特征的识别方法和基于深度学习的识别方法4个方面详细介绍了跨视角步态识别方法。最后,在CASIA-B(CASIA gait database, dataset B)、OU-ISIR LP(OU-ISIR gait database, large population dataset)和OU-MVLP(OU-ISIR gait database, multi-view large population dataset)3个数据库上对该领域代表性方法的性能进行了对比分析,并指出跨视角步态识别的未来研究方向。关键词:计算机视觉;生物特征识别;步态识别;跨视角;机器学习;深度学习;神经网络252|2172|8更新时间:2024-05-07
摘要:步态识别具有对图像分辨率要求低、可远距离识别、无需受试者合作、难以隐藏或伪装等优势,在安防监控和调查取证等领域有着广阔的应用前景。然而在实际应用中,步态识别的性能常受到视角、着装、携物和遮挡等协变量的影响,其中视角变化最为普遍,并且会使行人的外观发生显著改变。因此,提高步态识别对视角的鲁棒性一直是该领域的研究热点。为了全面认识现有的跨视角步态识别方法,本文对相关研究工作进行了梳理和综述。首先,从基本概念、数据采集方式和发展历程等角度简要介绍了该领域的研究背景,在此基础上,整理并分析了基于视频的主流跨视角步态数据库;然后,从基于3维步态信息的识别方法、基于视角转换模型的识别方法、基于视角不变特征的识别方法和基于深度学习的识别方法4个方面详细介绍了跨视角步态识别方法。最后,在CASIA-B(CASIA gait database, dataset B)、OU-ISIR LP(OU-ISIR gait database, large population dataset)和OU-MVLP(OU-ISIR gait database, multi-view large population dataset)3个数据库上对该领域代表性方法的性能进行了对比分析,并指出跨视角步态识别的未来研究方向。关键词:计算机视觉;生物特征识别;步态识别;跨视角;机器学习;深度学习;神经网络252|2172|8更新时间:2024-05-07 -
 摘要:可见光图像在光照充足的条件下可以提供一系列辅助检测行人的信息,如颜色和纹理等信息,但在低照度场景下表现并不理想。红外图像虽然不能提供颜色和纹理信息,但红外图像根据热辐射差异成像而不依赖于光照条件这一特性,使其可以在低照度场景下有效区分行人区域与背景区域并提供清晰的行人轮廓信息。由于红外和可见光两种模态之间直观的互补性,同时使用红外和可见光图像的行人检测任务被认为是一个很有前景的研究方向,受到了广泛关注,大幅促进了在安防(如安全监控和自动驾驶)和疫情防控等领域应用的发展。本文对红外—可见光跨模态的行人检测工作进行全面梳理,并对未来方向进行深入思考。首先,该课题具有独特性质。可见光图像对应三通道的颜色信息而红外图像对应单通道的温差信息,如何在两种模态存在本质差异的前提下,充分利用二者的互补性是红外—可见光跨模态行人检测领域的核心挑战和主要任务。其次,近几年红外—可见光跨模态行人检测研究针对的问题可分为两类,即模态差异大和实际应用难。针对模态差异大的问题,可分为图像未对准和融合不充分两类问题。针对实际应用难的问题,又分为标注成本、实时检测和硬件成本3类问题。本文依次对跨模态行人检测的主要研究方向展开细致且全面的描述并进行相应的总结。然后,详细地介绍与跨模态行人检测相关的数据集和评价指标,并以不同的评价指标对相关方法在不同层面上进行比较。最后,对跨模态行人检测领域存在的且尚未解决的问题进行讨论,并提出对未来相关工作方向的一些思考。关键词:跨模态行人检测;可见光图像;红外图像;深度学习;行人检测222|259|4更新时间:2024-05-07
摘要:可见光图像在光照充足的条件下可以提供一系列辅助检测行人的信息,如颜色和纹理等信息,但在低照度场景下表现并不理想。红外图像虽然不能提供颜色和纹理信息,但红外图像根据热辐射差异成像而不依赖于光照条件这一特性,使其可以在低照度场景下有效区分行人区域与背景区域并提供清晰的行人轮廓信息。由于红外和可见光两种模态之间直观的互补性,同时使用红外和可见光图像的行人检测任务被认为是一个很有前景的研究方向,受到了广泛关注,大幅促进了在安防(如安全监控和自动驾驶)和疫情防控等领域应用的发展。本文对红外—可见光跨模态的行人检测工作进行全面梳理,并对未来方向进行深入思考。首先,该课题具有独特性质。可见光图像对应三通道的颜色信息而红外图像对应单通道的温差信息,如何在两种模态存在本质差异的前提下,充分利用二者的互补性是红外—可见光跨模态行人检测领域的核心挑战和主要任务。其次,近几年红外—可见光跨模态行人检测研究针对的问题可分为两类,即模态差异大和实际应用难。针对模态差异大的问题,可分为图像未对准和融合不充分两类问题。针对实际应用难的问题,又分为标注成本、实时检测和硬件成本3类问题。本文依次对跨模态行人检测的主要研究方向展开细致且全面的描述并进行相应的总结。然后,详细地介绍与跨模态行人检测相关的数据集和评价指标,并以不同的评价指标对相关方法在不同层面上进行比较。最后,对跨模态行人检测领域存在的且尚未解决的问题进行讨论,并提出对未来相关工作方向的一些思考。关键词:跨模态行人检测;可见光图像;红外图像;深度学习;行人检测222|259|4更新时间:2024-05-07 -
 摘要:指代表达理解(referring expression comprehension,REC)作为视觉—语言相结合的多模态任务,旨在理解输入指代表达式的内容并在图像中定位其所描述的目标对象,受到计算机视觉和自然语言处理两个领域的关注。REC任务建立了人类语言与物理世界的视觉内容之间的桥梁,可以广泛应用于视觉理解系统和对话系统等人工智能设备中。解决该任务的关键在于对复杂的指代表达式进行充分的语义理解;然后利用语义信息对包含多个对象的图像进行关系推理以及对象筛选,最终在图像中唯一地定位目标对象。本文从计算机视觉的视角出发对REC任务进行了综述,首先介绍该任务的通用处理流程。然后,重点对REC领域现有方法进行分类总结,根据视觉数据表征粒度的不同,划分为基于区域卷积粒度视觉表征、基于网格卷积粒度视觉表征以及基于图像块粒度视觉表征的方法;并进一步按照视觉—文本特征融合模块的建模方式进行了更细粒度的归类。此外,本文还介绍了该任务的主流数据集和评估指标。最后,从模型的推理速度、模型的可解释性以及模型对表达式的推理能力3个方面揭示了现有方法面临的挑战,并对REC的发展进行了全面展望。本文希望通过对REC任务现有研究以及未来趋势的总结为相关领域研究人员提供一个全面的参考以及探索的方向。关键词:视觉定位(VG);指代表达理解(REC);视觉与语言;视觉表征粒度;多模态特征融合340|1293|2更新时间:2024-05-07
摘要:指代表达理解(referring expression comprehension,REC)作为视觉—语言相结合的多模态任务,旨在理解输入指代表达式的内容并在图像中定位其所描述的目标对象,受到计算机视觉和自然语言处理两个领域的关注。REC任务建立了人类语言与物理世界的视觉内容之间的桥梁,可以广泛应用于视觉理解系统和对话系统等人工智能设备中。解决该任务的关键在于对复杂的指代表达式进行充分的语义理解;然后利用语义信息对包含多个对象的图像进行关系推理以及对象筛选,最终在图像中唯一地定位目标对象。本文从计算机视觉的视角出发对REC任务进行了综述,首先介绍该任务的通用处理流程。然后,重点对REC领域现有方法进行分类总结,根据视觉数据表征粒度的不同,划分为基于区域卷积粒度视觉表征、基于网格卷积粒度视觉表征以及基于图像块粒度视觉表征的方法;并进一步按照视觉—文本特征融合模块的建模方式进行了更细粒度的归类。此外,本文还介绍了该任务的主流数据集和评估指标。最后,从模型的推理速度、模型的可解释性以及模型对表达式的推理能力3个方面揭示了现有方法面临的挑战,并对REC的发展进行了全面展望。本文希望通过对REC任务现有研究以及未来趋势的总结为相关领域研究人员提供一个全面的参考以及探索的方向。关键词:视觉定位(VG);指代表达理解(REC);视觉与语言;视觉表征粒度;多模态特征融合340|1293|2更新时间:2024-05-07
综述
-
 摘要:行人再识别(person re-identification,Person ReID)指利用计算机视觉技术对在一个摄像头的视频图像中出现的某个确定行人在其他时间、不同位置的摄像头中再次出现时能够辨识出来,或在图像或视频库中检索特定行人。行人再识别研究具有强烈的实际需求,在公共安全、新零售以及人机交互领域具有潜在应用,具备显著的机器学习和计算机视觉领域的理论研究价值。行人成像存在复杂的姿态、视角、光照和成像质量等变化,同时也有一定范围的遮挡等难点,因此行人再识别面临着非常大的技术挑战。近年来,学术界和产业界投入了巨大的人力和资源研究该问题,并取得了一定进展,在多个数据集上的平均准确率均值(mean average precision,mAP)有了较大提升,并部分开始实际应用。尽管如此,当前行人再识别研究主要还是侧重于服装表观的特征,缺乏对行人表观显式的多视角观测和描述,这与人类观测的机理不尽相符。本文旨在打破现有行人再识别任务的设定,形成对行人综合性观测描述。为推进行人再识别研究的进展,本文在前期行人再识别研究的基础上提出了人像态势计算的概念(ReID2.0)。人像态势计算以像态、形态、神态和意态这4态对人像的静态属性和似动状态进行多视角观测和描述。构建了一个新的基准数据集Portrait250K,包含250 000幅人像和对应8个子任务的手动标记的8种标签,并提出一个新的评价指标。提出的人像态势计算从多视角表观信息对行人形成综合性的观测描述,为行人再识别2.0以及类人智能体的进一步研究提供了参考。关键词:行人再识别;人像态势计算;ReID2.0;表征学习;计算机视觉180|228|1更新时间:2024-05-07
摘要:行人再识别(person re-identification,Person ReID)指利用计算机视觉技术对在一个摄像头的视频图像中出现的某个确定行人在其他时间、不同位置的摄像头中再次出现时能够辨识出来,或在图像或视频库中检索特定行人。行人再识别研究具有强烈的实际需求,在公共安全、新零售以及人机交互领域具有潜在应用,具备显著的机器学习和计算机视觉领域的理论研究价值。行人成像存在复杂的姿态、视角、光照和成像质量等变化,同时也有一定范围的遮挡等难点,因此行人再识别面临着非常大的技术挑战。近年来,学术界和产业界投入了巨大的人力和资源研究该问题,并取得了一定进展,在多个数据集上的平均准确率均值(mean average precision,mAP)有了较大提升,并部分开始实际应用。尽管如此,当前行人再识别研究主要还是侧重于服装表观的特征,缺乏对行人表观显式的多视角观测和描述,这与人类观测的机理不尽相符。本文旨在打破现有行人再识别任务的设定,形成对行人综合性观测描述。为推进行人再识别研究的进展,本文在前期行人再识别研究的基础上提出了人像态势计算的概念(ReID2.0)。人像态势计算以像态、形态、神态和意态这4态对人像的静态属性和似动状态进行多视角观测和描述。构建了一个新的基准数据集Portrait250K,包含250 000幅人像和对应8个子任务的手动标记的8种标签,并提出一个新的评价指标。提出的人像态势计算从多视角表观信息对行人形成综合性的观测描述,为行人再识别2.0以及类人智能体的进一步研究提供了参考。关键词:行人再识别;人像态势计算;ReID2.0;表征学习;计算机视觉180|228|1更新时间:2024-05-07
前沿进展
-
 摘要:目的行人重识别旨在解决多个非重叠摄像头下行人的查询和识别问题。在很多实际的应用场景中,监控摄像头获取的是低分辨率行人图像,而现有的许多行人重识别方法很少关注真实场景中低分辨率行人相互匹配的问题。为研究该问题,本文收集并标注了一个新的基于枪球摄像头的行人重识别数据集,并基于此设计了一种低分辨率行人重识别模型来提升低分辨率行人匹配性能。方法该数据集由部署在3个不同位置的枪机摄像头和球机摄像头收集裁剪得到,最终形成包含200个有身份标签的行人和320个无身份标签的行人重识别数据集。与同类其他数据集不同,该数据集为每个行人同时提供高分辨率和低分辨率图像。针对低分辨率下的行人匹配难题,本文提出的基准模型考虑了图像超分、行人特征学习以及判别3个方面因素,并设计了相应的超分模块、特征学习模块和特征判别器模块,分别完成低分辨率图像超分、行人特征学习以及行人特征判断。结果提出的基准模型在枪球行人重识别数据集上的实验表明,对比于经典的行人重识别模型,新基准模型在平均精度均值(mean average precision,mAP)和Rank-1指标上分别提高了3.1%和6.1%。结论本文构建了典型的低分辨率行人重识别数据集,为研究低分辨率行人重识别问题提供了重要的数据来源,并基于该数据集研究了低分辨率下行人重识别基础方法。研究表明,提出的基准方法能够有效地解决低分辨行人匹配问题。关键词:行人重识别;基准数据集;低分辨率(LR);超分辨率(SR);判别器229|340|1更新时间:2024-05-07
摘要:目的行人重识别旨在解决多个非重叠摄像头下行人的查询和识别问题。在很多实际的应用场景中,监控摄像头获取的是低分辨率行人图像,而现有的许多行人重识别方法很少关注真实场景中低分辨率行人相互匹配的问题。为研究该问题,本文收集并标注了一个新的基于枪球摄像头的行人重识别数据集,并基于此设计了一种低分辨率行人重识别模型来提升低分辨率行人匹配性能。方法该数据集由部署在3个不同位置的枪机摄像头和球机摄像头收集裁剪得到,最终形成包含200个有身份标签的行人和320个无身份标签的行人重识别数据集。与同类其他数据集不同,该数据集为每个行人同时提供高分辨率和低分辨率图像。针对低分辨率下的行人匹配难题,本文提出的基准模型考虑了图像超分、行人特征学习以及判别3个方面因素,并设计了相应的超分模块、特征学习模块和特征判别器模块,分别完成低分辨率图像超分、行人特征学习以及行人特征判断。结果提出的基准模型在枪球行人重识别数据集上的实验表明,对比于经典的行人重识别模型,新基准模型在平均精度均值(mean average precision,mAP)和Rank-1指标上分别提高了3.1%和6.1%。结论本文构建了典型的低分辨率行人重识别数据集,为研究低分辨率行人重识别问题提供了重要的数据来源,并基于该数据集研究了低分辨率下行人重识别基础方法。研究表明,提出的基准方法能够有效地解决低分辨行人匹配问题。关键词:行人重识别;基准数据集;低分辨率(LR);超分辨率(SR);判别器229|340|1更新时间:2024-05-07
数据集
-
 摘要:目的行人重识别任务中,同一行人在不同图像中的背景差异会导致识别准确率下降,出现误识别的现象。针对此问题,提出了一种结合前景分割的多特征融合行人重识别方法。方法首先构建前景分割模块,提取图像的前景,并通过前景分割损失,保持前景图像的平滑性和完整性;然后提出了注意力共享策略和多尺度非局部运算方法,将图像中的全局特征与局部特征、高维特征与低维特征结合,实现不同特征之间的优势互补;最后通过多损失函数对网络模型进行训练优化。结果在3个公开数据集Market-1501、DukeMTMC-reID(Duke multi-tracking multi-camera re-identification)和MSMT17(multi-scene multi-time person ReID dataset)上进行了消融实验和对比实验,并以首位命中率(rank-1 accuracy,Rank-1)和平均精度均值(mean average precision,mAP)作为评价指标。实验结果显示,在引入前景分割和多特征融合方法时,网络的识别准确率均有一定提升。本文方法在Market-1501、DukeMTMC-reID和MSMT17数据集上Rank-1和mAP分别为96.8%和91.5%、91.5%和82.3%以及83.9%和63.8%,相比于对比算法,本文方法具有较大优势。结论本文提出的结合前景分割的多特征融合方法,在提取前景的同时,综合了不同尺度和不同粒度图像特征,相较于已有模型,提高了识别准确率。同时,前景分割模块消除了无用背景,缓解了背景差异导致的误识别现象,使行人重识别模型的实用性得到加强,在面对实际背景情况时,也能有较好的识别效果。关键词:前景分割;语义分割;行人重识别(ReID);特征融合;注意力机制136|216|1更新时间:2024-05-07
摘要:目的行人重识别任务中,同一行人在不同图像中的背景差异会导致识别准确率下降,出现误识别的现象。针对此问题,提出了一种结合前景分割的多特征融合行人重识别方法。方法首先构建前景分割模块,提取图像的前景,并通过前景分割损失,保持前景图像的平滑性和完整性;然后提出了注意力共享策略和多尺度非局部运算方法,将图像中的全局特征与局部特征、高维特征与低维特征结合,实现不同特征之间的优势互补;最后通过多损失函数对网络模型进行训练优化。结果在3个公开数据集Market-1501、DukeMTMC-reID(Duke multi-tracking multi-camera re-identification)和MSMT17(multi-scene multi-time person ReID dataset)上进行了消融实验和对比实验,并以首位命中率(rank-1 accuracy,Rank-1)和平均精度均值(mean average precision,mAP)作为评价指标。实验结果显示,在引入前景分割和多特征融合方法时,网络的识别准确率均有一定提升。本文方法在Market-1501、DukeMTMC-reID和MSMT17数据集上Rank-1和mAP分别为96.8%和91.5%、91.5%和82.3%以及83.9%和63.8%,相比于对比算法,本文方法具有较大优势。结论本文提出的结合前景分割的多特征融合方法,在提取前景的同时,综合了不同尺度和不同粒度图像特征,相较于已有模型,提高了识别准确率。同时,前景分割模块消除了无用背景,缓解了背景差异导致的误识别现象,使行人重识别模型的实用性得到加强,在面对实际背景情况时,也能有较好的识别效果。关键词:前景分割;语义分割;行人重识别(ReID);特征融合;注意力机制136|216|1更新时间:2024-05-07 -
 摘要:目的无监督域适应行人重识别(unsupervised domain adaptive pedestrians’ re-identification,UDA Re-ID)旨在通过已有标记的应用场景(即源域)数据和新的无标记应用场景(即目标域)数据,训练一个可以在目标域泛化性能好的行人重识别模型。现有方法没有考虑实例特征在训练过程中的不稳定问题,也没有显式考虑由于相机变化所导致的行人类内距离变大、类间距离变小的问题,以及无标注目标域数据聚类误差带来的伪标签噪声问题。针对这些问题,提出了一种具有一致性约束和标签优化的方法。方法首先提出了实例一致性以约束同一实例在不同增广下的特征距离,提升行人实例特征稳定性;然后提出相机一致性以约束跨相机正实例特征对之间的距离,提升对相机变化的鲁棒性;最后提出了基于标签集成的标签优化,将one-hot编码的伪标签转换为更可靠的软标签,提升了监督信号的鲁棒性。结果本文方法在Duke→Market,Market→Duke,Duke→MSMT,Market→MSMT等常用的UDA Re-ID任务上的平均精度均值(mean average precision,mAP)分别为85.0%,73.5%,41.3%, 39.3%;Rank-1分别为94.0%,85.6%,71.6%,69.5%。通过消融实验验证了本文提出的3个模块的有效性。结论提出的实例一致性约束和相机一致性约束可以使模型学习到更鲁棒的行人特征表达,提升行人特征的稳定性,提出的基于标签集成的标签优化可以减少伪标签噪声的过拟合风险。关键词:计算机视觉;行人重识别(Re-ID);无监督域适应(UDA);一致性约束;标签优化117|432|1更新时间:2024-05-07
摘要:目的无监督域适应行人重识别(unsupervised domain adaptive pedestrians’ re-identification,UDA Re-ID)旨在通过已有标记的应用场景(即源域)数据和新的无标记应用场景(即目标域)数据,训练一个可以在目标域泛化性能好的行人重识别模型。现有方法没有考虑实例特征在训练过程中的不稳定问题,也没有显式考虑由于相机变化所导致的行人类内距离变大、类间距离变小的问题,以及无标注目标域数据聚类误差带来的伪标签噪声问题。针对这些问题,提出了一种具有一致性约束和标签优化的方法。方法首先提出了实例一致性以约束同一实例在不同增广下的特征距离,提升行人实例特征稳定性;然后提出相机一致性以约束跨相机正实例特征对之间的距离,提升对相机变化的鲁棒性;最后提出了基于标签集成的标签优化,将one-hot编码的伪标签转换为更可靠的软标签,提升了监督信号的鲁棒性。结果本文方法在Duke→Market,Market→Duke,Duke→MSMT,Market→MSMT等常用的UDA Re-ID任务上的平均精度均值(mean average precision,mAP)分别为85.0%,73.5%,41.3%, 39.3%;Rank-1分别为94.0%,85.6%,71.6%,69.5%。通过消融实验验证了本文提出的3个模块的有效性。结论提出的实例一致性约束和相机一致性约束可以使模型学习到更鲁棒的行人特征表达,提升行人特征的稳定性,提出的基于标签集成的标签优化可以减少伪标签噪声的过拟合风险。关键词:计算机视觉;行人重识别(Re-ID);无监督域适应(UDA);一致性约束;标签优化117|432|1更新时间:2024-05-07 -
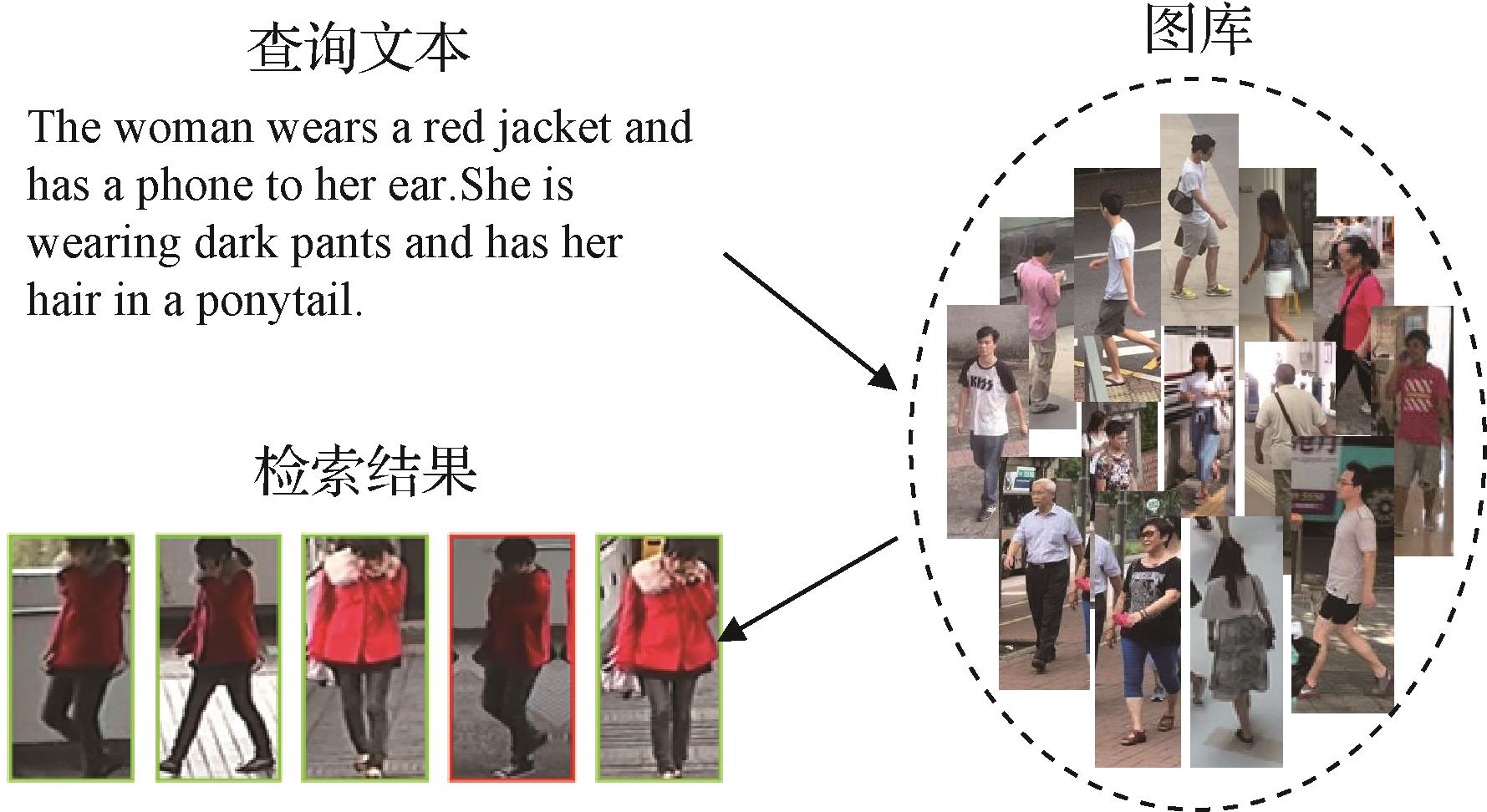 摘要:目的文本到图像的行人重识别是一个图像文本跨模态检索的子任务,现有方法大都采用在全局特征匹配的基础上加入多个局部特征进行跨模态匹配。这些局部特征匹配的方法都过分复杂且在检索时会大幅减慢速度,因此需要一种更简洁有效的方法提升文本到图像的行人重识别模型的跨模态对齐能力。对此,本文基于通用图像文本对大规模数据集预训练模型,对比语言—图像预训练(contrastive language-image pretraining,CLIP),提出了一种温度投影匹配结合CLIP的文本到图像行人重识别方法。方法借助CLIP预训练模型的跨模态图像文本对齐的能力,本文模型仅使用全局特征进行细粒度的图像文本语义特征对齐。此外,本文提出了温度缩放跨模态投影匹配(temperature-scaled cross modal projection matching,TCMPM)损失函数来进行图像文本跨模态特征匹配。结果在本领域的两个数据集上与最新的文本到图像行人重识别方法进行实验对比,在CUHK-PEDES(CUHK person description)和ICFG-PEDES(identity-centric and fine-grained person description)数据集中,相比于现有性能较好的局部匹配模型,本文方法Rank-1值分别提高了5.92%和1.21%。结论本文提出的基于双流Transformer的文本到图像行人重识别方法可以直接迁移CLIP的跨模态匹配知识,无须冻结模型参数训练或接入其他小模型辅助训练。结合提出的TCMPM损失函数,本文方法仅使用全局特征匹配就在检索性能上大幅超过了现有局部特征方法。关键词:跨模态检索;行人重识别;行人搜索;Transformer;图文检索511|411|2更新时间:2024-05-07
摘要:目的文本到图像的行人重识别是一个图像文本跨模态检索的子任务,现有方法大都采用在全局特征匹配的基础上加入多个局部特征进行跨模态匹配。这些局部特征匹配的方法都过分复杂且在检索时会大幅减慢速度,因此需要一种更简洁有效的方法提升文本到图像的行人重识别模型的跨模态对齐能力。对此,本文基于通用图像文本对大规模数据集预训练模型,对比语言—图像预训练(contrastive language-image pretraining,CLIP),提出了一种温度投影匹配结合CLIP的文本到图像行人重识别方法。方法借助CLIP预训练模型的跨模态图像文本对齐的能力,本文模型仅使用全局特征进行细粒度的图像文本语义特征对齐。此外,本文提出了温度缩放跨模态投影匹配(temperature-scaled cross modal projection matching,TCMPM)损失函数来进行图像文本跨模态特征匹配。结果在本领域的两个数据集上与最新的文本到图像行人重识别方法进行实验对比,在CUHK-PEDES(CUHK person description)和ICFG-PEDES(identity-centric and fine-grained person description)数据集中,相比于现有性能较好的局部匹配模型,本文方法Rank-1值分别提高了5.92%和1.21%。结论本文提出的基于双流Transformer的文本到图像行人重识别方法可以直接迁移CLIP的跨模态匹配知识,无须冻结模型参数训练或接入其他小模型辅助训练。结合提出的TCMPM损失函数,本文方法仅使用全局特征匹配就在检索性能上大幅超过了现有局部特征方法。关键词:跨模态检索;行人重识别;行人搜索;Transformer;图文检索511|411|2更新时间:2024-05-07 -
 摘要:目的传统行人重识别方法提取到的特征中包含大量的衣物信息,在换装行人重识别问题中,依靠衣物相关的信息难以准确判别行人身份,使模型性能显著下降;虽然一些方法从轮廓图像中提取行人的体型信息以增强行人特征,但轮廓图像的质量参差不齐,鲁棒性差。针对这些问题,本文提出一种素描图像指导的换装行人重识别方法。方法首先,本文认为相对于轮廓图像,素描图像能够提供更鲁棒、更精准的行人体型信息,因此本文使用素描图像提取行人的体型信息,并将其融入表观特征以获取完备的行人特征。然后,提出一个基于素描图像的衣物无关权重指导模块,进一步使用素描图像中的衣物位置信息指导表观特征的提取过程,从而减少表观特征中的衣物信息,增强表观特征的判别力。结果在LTCC(long-term cloth changing)和PRCC(person re-identification under moderate clothing change)两个常用换装行人数据集上,本文方法与最先进的方法进行了对比。相较于先进方法,在LTCC和PRCC数据集上,本文方法在Rank-1性能指标上分别提高了6.5%和3.9%。实验结果表明,素描图像在鲁棒性和准确性上均优于轮廓图像,能够更好地获取行人体型信息,并且能够为表观特征提供更多体型互补信息。结论提出的衣物无关权重指导模块能有效减少行人表观特征中衣物信息的含量;提出的素描图像指导的换装行人重识别方法有效获取了包含衣物无关表观特征和体型特征在内的完备行人特征。关键词:计算机视觉;换装行人重识别;素描图像;表观特征;体型特征;双流网络137|327|0更新时间:2024-05-07
摘要:目的传统行人重识别方法提取到的特征中包含大量的衣物信息,在换装行人重识别问题中,依靠衣物相关的信息难以准确判别行人身份,使模型性能显著下降;虽然一些方法从轮廓图像中提取行人的体型信息以增强行人特征,但轮廓图像的质量参差不齐,鲁棒性差。针对这些问题,本文提出一种素描图像指导的换装行人重识别方法。方法首先,本文认为相对于轮廓图像,素描图像能够提供更鲁棒、更精准的行人体型信息,因此本文使用素描图像提取行人的体型信息,并将其融入表观特征以获取完备的行人特征。然后,提出一个基于素描图像的衣物无关权重指导模块,进一步使用素描图像中的衣物位置信息指导表观特征的提取过程,从而减少表观特征中的衣物信息,增强表观特征的判别力。结果在LTCC(long-term cloth changing)和PRCC(person re-identification under moderate clothing change)两个常用换装行人数据集上,本文方法与最先进的方法进行了对比。相较于先进方法,在LTCC和PRCC数据集上,本文方法在Rank-1性能指标上分别提高了6.5%和3.9%。实验结果表明,素描图像在鲁棒性和准确性上均优于轮廓图像,能够更好地获取行人体型信息,并且能够为表观特征提供更多体型互补信息。结论提出的衣物无关权重指导模块能有效减少行人表观特征中衣物信息的含量;提出的素描图像指导的换装行人重识别方法有效获取了包含衣物无关表观特征和体型特征在内的完备行人特征。关键词:计算机视觉;换装行人重识别;素描图像;表观特征;体型特征;双流网络137|327|0更新时间:2024-05-07 -
 摘要:目的在真实行人识别场景中,获得准确的标注需要耗费大量人力,因此无监督领域自适应成为行人重识别具有潜力的研究方向,这类方法通常需要聚类生成伪标签,往往会存在噪音。此外,在行人搜索过程中,好的排序算法也是取得更好识别性能的关键,但寻常的Re-Ranking排序优化由于巨大的性能消耗,限制了在真实场景下的应用。针对这两个问题,本文提出了一个联合多网络、分摄像头训练的框架,利用时空信息对排序进行优化。方法对源域数据使用有监督进行预训练,利用未标记的目标域样本进行多个网络模型的深度互学习无监督训练,提高网络的泛化能力,同时在训练过程中进行分摄像头处理,减小跨摄像头的影响,提升伪标签的质量。在排序匹配阶段利用时空信息对排序进行优化,进一步提升匹配性能。结果实验在2个跨域实验数据集上进行测试比较,在源域为DukeMTMC-ReID(Duke multi-tracking multi-camera re-identification)数据集,目标域为Market-1501数据集的实验中,本文方法的平均精度均值(mean average precision,mAP)和Rank1分别为82.5%和95.3%;在源域为Market-1501,目标域为DukeMTMC-ReID数据集的实验中,mAP和Rank1分别为75.3%和90.2%。结论提出的结合时空距离排序的分摄像头网络互学习模型,提升了伪标签的精度,并优化了匹配排序,相比于其他优化算法大幅减少了计算量,进一步提升了行人重识别性能。关键词:行人重识别;互学习;分摄像头;跨域;时空距离89|226|0更新时间:2024-05-07
摘要:目的在真实行人识别场景中,获得准确的标注需要耗费大量人力,因此无监督领域自适应成为行人重识别具有潜力的研究方向,这类方法通常需要聚类生成伪标签,往往会存在噪音。此外,在行人搜索过程中,好的排序算法也是取得更好识别性能的关键,但寻常的Re-Ranking排序优化由于巨大的性能消耗,限制了在真实场景下的应用。针对这两个问题,本文提出了一个联合多网络、分摄像头训练的框架,利用时空信息对排序进行优化。方法对源域数据使用有监督进行预训练,利用未标记的目标域样本进行多个网络模型的深度互学习无监督训练,提高网络的泛化能力,同时在训练过程中进行分摄像头处理,减小跨摄像头的影响,提升伪标签的质量。在排序匹配阶段利用时空信息对排序进行优化,进一步提升匹配性能。结果实验在2个跨域实验数据集上进行测试比较,在源域为DukeMTMC-ReID(Duke multi-tracking multi-camera re-identification)数据集,目标域为Market-1501数据集的实验中,本文方法的平均精度均值(mean average precision,mAP)和Rank1分别为82.5%和95.3%;在源域为Market-1501,目标域为DukeMTMC-ReID数据集的实验中,mAP和Rank1分别为75.3%和90.2%。结论提出的结合时空距离排序的分摄像头网络互学习模型,提升了伪标签的精度,并优化了匹配排序,相比于其他优化算法大幅减少了计算量,进一步提升了行人重识别性能。关键词:行人重识别;互学习;分摄像头;跨域;时空距离89|226|0更新时间:2024-05-07 -
 摘要:目的可见光—红外跨模态行人再识别旨在匹配具有相同行人身份的可见光图像和红外图像。现有方法主要采用模态共享特征学习或模态转换来缩小模态间的差异,前者通常只关注全局或局部特征表示,后者则存在生成模态不可靠的问题。事实上,轮廓具有一定的跨模态不变性,同时也是一种相对可靠的行人识别线索。为了有效利用轮廓信息减少模态间差异,本文将轮廓作为辅助模态,提出了一种轮廓引导的双粒度特征融合网络,用于跨模态行人再识别。方法在全局粒度上,通过行人图像到轮廓图像的融合,用于增强轮廓的全局特征表达,得到轮廓增广特征。在局部粒度上,通过轮廓增广特征和基于部件的局部特征的融合,用于联合全局特征和局部特征,得到融合后的图像表达。结果在可见光—红外跨模态行人再识别的两个公开数据集对模型进行评估,结果优于一些代表性方法。在SYSU-MM01(Sun Yat-sen University multiple modality 01)数据集上,本文方法rank-1准确率和平均精度均值(mean average precision,mAP)分别为62.42%和58.14%。在RegDB(Dongguk body-based person recognition database)数据集上,本文方法rank-1和mAP分别为84.42%和77.82%。结论本文将轮廓信息引入跨模态行人再识别,提出一种轮廓引导的双粒度特征融合网络,在全局粒度和局部粒度上进行特征融合,从而学习具有判别性的特征,性能超过了近年来一些具有代表性的方法,验证了轮廓线索及其使用方法的有效性。关键词:行人再识别;跨模态;特征融合;轮廓;特征学习151|211|0更新时间:2024-05-07
摘要:目的可见光—红外跨模态行人再识别旨在匹配具有相同行人身份的可见光图像和红外图像。现有方法主要采用模态共享特征学习或模态转换来缩小模态间的差异,前者通常只关注全局或局部特征表示,后者则存在生成模态不可靠的问题。事实上,轮廓具有一定的跨模态不变性,同时也是一种相对可靠的行人识别线索。为了有效利用轮廓信息减少模态间差异,本文将轮廓作为辅助模态,提出了一种轮廓引导的双粒度特征融合网络,用于跨模态行人再识别。方法在全局粒度上,通过行人图像到轮廓图像的融合,用于增强轮廓的全局特征表达,得到轮廓增广特征。在局部粒度上,通过轮廓增广特征和基于部件的局部特征的融合,用于联合全局特征和局部特征,得到融合后的图像表达。结果在可见光—红外跨模态行人再识别的两个公开数据集对模型进行评估,结果优于一些代表性方法。在SYSU-MM01(Sun Yat-sen University multiple modality 01)数据集上,本文方法rank-1准确率和平均精度均值(mean average precision,mAP)分别为62.42%和58.14%。在RegDB(Dongguk body-based person recognition database)数据集上,本文方法rank-1和mAP分别为84.42%和77.82%。结论本文将轮廓信息引入跨模态行人再识别,提出一种轮廓引导的双粒度特征融合网络,在全局粒度和局部粒度上进行特征融合,从而学习具有判别性的特征,性能超过了近年来一些具有代表性的方法,验证了轮廓线索及其使用方法的有效性。关键词:行人再识别;跨模态;特征融合;轮廓;特征学习151|211|0更新时间:2024-05-07
行人重识别
-
 摘要:目的低质量3维人脸识别是近年来模式识别领域的热点问题;区别于传统高质量3维人脸识别,低质量、高噪声是低质量3维人脸识别面对的主要问题。围绕低质量3维人脸数据噪声大、依赖单张有限深度数据提取有效特征困难的问题,提出了一种联合软阈值去噪和视频数据融合的低质量3维人脸识别方法。方法首先,针对低质量3维人脸中存在的噪声问题,提出了一个即插即用的软阈值去噪模块,在网络提取特征的过程中对特征进行去噪处理。为了使网络提取的特征更具有判别性,结合softmax和Arcface(additive angular margin loss for deep face recognition)提出的联合渐变损失函数使网络提取更具有判别性特征。为了更好地利用多帧低质量视频数据实现人脸数据质量提升,提出了基于门控循环单元的视频数据融合模块,实现了视频帧数据间互补信息的有效融合,进一步提高了低质量3维人脸识别准确率。结果实验在两个公开数据集上与较新方法进行比较,在Lock3DFace(low-cost kinect 3D faces)开、闭集评估协议上,相比于性能第2的方法,平均识别率分别提高了0.28%和3.13%;在Extended-Multi-Dim开集评估协议上,相比于性能第2的方法,平均识别率提高了1.03%。结论提出的低质量3维人脸识别方法,不仅能有效缓解低质量噪声带来的影响,还有效融合了多帧视频数据的互补信息,大幅提高了低质量3维人脸识别准确率。关键词:3维人脸识别;低质量3维人脸;软阈值去噪;联合渐变损失函数;视频数据融合104|258|1更新时间:2024-05-07
摘要:目的低质量3维人脸识别是近年来模式识别领域的热点问题;区别于传统高质量3维人脸识别,低质量、高噪声是低质量3维人脸识别面对的主要问题。围绕低质量3维人脸数据噪声大、依赖单张有限深度数据提取有效特征困难的问题,提出了一种联合软阈值去噪和视频数据融合的低质量3维人脸识别方法。方法首先,针对低质量3维人脸中存在的噪声问题,提出了一个即插即用的软阈值去噪模块,在网络提取特征的过程中对特征进行去噪处理。为了使网络提取的特征更具有判别性,结合softmax和Arcface(additive angular margin loss for deep face recognition)提出的联合渐变损失函数使网络提取更具有判别性特征。为了更好地利用多帧低质量视频数据实现人脸数据质量提升,提出了基于门控循环单元的视频数据融合模块,实现了视频帧数据间互补信息的有效融合,进一步提高了低质量3维人脸识别准确率。结果实验在两个公开数据集上与较新方法进行比较,在Lock3DFace(low-cost kinect 3D faces)开、闭集评估协议上,相比于性能第2的方法,平均识别率分别提高了0.28%和3.13%;在Extended-Multi-Dim开集评估协议上,相比于性能第2的方法,平均识别率提高了1.03%。结论提出的低质量3维人脸识别方法,不仅能有效缓解低质量噪声带来的影响,还有效融合了多帧视频数据的互补信息,大幅提高了低质量3维人脸识别准确率。关键词:3维人脸识别;低质量3维人脸;软阈值去噪;联合渐变损失函数;视频数据融合104|258|1更新时间:2024-05-07 -
 摘要:目的光流估计是计算机视觉研究中的一个重要方向,尽管光流估计方法不断改进,但光照变化条件下光流计算精度的提高仍然是一个尚待解决的挑战。人脸反欺诈方法对于确保人脸识别系统的安全性十分重要,光照鲁棒的脸部运动光流特征能为人脸活体检测提供有关运动和结构的可靠信息。为了获得对含光照变化视频中物体运动的理解能力并应用于人脸活体检测,提高系统性能,提出了一种基于结构纹理感知视网膜模型的鲁棒光流估计方法。方法基于Retinex理论,通过结构纹理感知方式将图像中的反射分量与光照分量充分解耦。由于反射分量具有丰富的纹理信息且光照分量中包含部分有用的结构信息,因此对所提取的光照分量进行滤波操作后再与反射分量一起融合到光流模型中,有效提高了光流估计的鲁棒性。为使模型所获光流具有更好的边缘保持性,采用光滑—稀疏正则化约束方式进行最小化求解。本文给出了求解优化问题的数值方法。结果采用MPI Sintel数据集图像序列,与PWC-Net、DCFlow+KF和FDFlowNet(fast deep flownet)等主流算法进行对比实验,本文方法在Clean和Final数据集中均得到最低的平均终点误差(end-point error,EPE),分别为2.473和4.807,在3个公开数据集上进行的评测进一步验证了本文方法的鲁棒性。最后,将所提取的脸部运动光流特征在人脸反欺诈数据集上进行了活体检测对比实验,对比实验结果验证了提出的光流估计算法更具鲁棒性,改善了人脸活体检测的效果。结论提出的光流计算模型,在不同光照变化条件下具有良好的鲁棒性,更适合于人脸活体检测应用。本项目代码链接为https://github.com/Xiaoxin-Liao/STARFlow。关键词:Retinex模型;结构纹理感知;光照变化;L0范数正则化;光流;人脸反欺诈141|383|0更新时间:2024-05-07
摘要:目的光流估计是计算机视觉研究中的一个重要方向,尽管光流估计方法不断改进,但光照变化条件下光流计算精度的提高仍然是一个尚待解决的挑战。人脸反欺诈方法对于确保人脸识别系统的安全性十分重要,光照鲁棒的脸部运动光流特征能为人脸活体检测提供有关运动和结构的可靠信息。为了获得对含光照变化视频中物体运动的理解能力并应用于人脸活体检测,提高系统性能,提出了一种基于结构纹理感知视网膜模型的鲁棒光流估计方法。方法基于Retinex理论,通过结构纹理感知方式将图像中的反射分量与光照分量充分解耦。由于反射分量具有丰富的纹理信息且光照分量中包含部分有用的结构信息,因此对所提取的光照分量进行滤波操作后再与反射分量一起融合到光流模型中,有效提高了光流估计的鲁棒性。为使模型所获光流具有更好的边缘保持性,采用光滑—稀疏正则化约束方式进行最小化求解。本文给出了求解优化问题的数值方法。结果采用MPI Sintel数据集图像序列,与PWC-Net、DCFlow+KF和FDFlowNet(fast deep flownet)等主流算法进行对比实验,本文方法在Clean和Final数据集中均得到最低的平均终点误差(end-point error,EPE),分别为2.473和4.807,在3个公开数据集上进行的评测进一步验证了本文方法的鲁棒性。最后,将所提取的脸部运动光流特征在人脸反欺诈数据集上进行了活体检测对比实验,对比实验结果验证了提出的光流估计算法更具鲁棒性,改善了人脸活体检测的效果。结论提出的光流计算模型,在不同光照变化条件下具有良好的鲁棒性,更适合于人脸活体检测应用。本项目代码链接为https://github.com/Xiaoxin-Liao/STARFlow。关键词:Retinex模型;结构纹理感知;光照变化;L0范数正则化;光流;人脸反欺诈141|383|0更新时间:2024-05-07 -
 摘要:目的虹膜识别是具有发展前景的生物特征认证方式,然而现有的一些方法无法在远距离、非协作状态下捕获的低质量图像中表现出较好的性能,极大阻碍了虹膜识别在实际中的应用部署。为此,提出一种基于卷积神经网络的网络模型,使用眼周和虹膜进行有效融合,克服单一模态生物特征的局限性,增强生物特征身份认证方式的可靠性和安全性。方法为了能够提取鲁棒性更强的辨别特征,将空间注意力机制和特征重用方法进行结合,有效减轻了在前向传播过程中梯度消失的问题。同时,引入中间融合表达层,根据不同模态低、中、高层特征信息对融合策略产生的贡献值自适应地学习相对应的权重,并通过加权组合的方式有效地融合生成鲁棒性更强的辨别特征,极大提升了虹膜识别在远距离、非协作状态下的识别性能。结果在3个公开数据集ND-IRIS-0405(notre dame)、CASIA(Institute of Automation,Chinese Academy of Sciences)-Iris-M1-S3以及CASIA-Iris-Distance上进行测试,本文方法EER(equal error rate)值分别为0.19%,0.48%,1.33%,优于对比方法,表明了本文方法的优越性。结论本文提出的中间融合表达层融合方法能够有效融合眼周和虹膜在不同阶段的语义信息,生成判别性更强的特征模板,提升了远距离、非协作状态下虹膜识别的性能。关键词:虹膜识别;眼周识别;中间融合表达层;自适应加权;生物特征融合;远距离和非协作113|244|1更新时间:2024-05-07
摘要:目的虹膜识别是具有发展前景的生物特征认证方式,然而现有的一些方法无法在远距离、非协作状态下捕获的低质量图像中表现出较好的性能,极大阻碍了虹膜识别在实际中的应用部署。为此,提出一种基于卷积神经网络的网络模型,使用眼周和虹膜进行有效融合,克服单一模态生物特征的局限性,增强生物特征身份认证方式的可靠性和安全性。方法为了能够提取鲁棒性更强的辨别特征,将空间注意力机制和特征重用方法进行结合,有效减轻了在前向传播过程中梯度消失的问题。同时,引入中间融合表达层,根据不同模态低、中、高层特征信息对融合策略产生的贡献值自适应地学习相对应的权重,并通过加权组合的方式有效地融合生成鲁棒性更强的辨别特征,极大提升了虹膜识别在远距离、非协作状态下的识别性能。结果在3个公开数据集ND-IRIS-0405(notre dame)、CASIA(Institute of Automation,Chinese Academy of Sciences)-Iris-M1-S3以及CASIA-Iris-Distance上进行测试,本文方法EER(equal error rate)值分别为0.19%,0.48%,1.33%,优于对比方法,表明了本文方法的优越性。结论本文提出的中间融合表达层融合方法能够有效融合眼周和虹膜在不同阶段的语义信息,生成判别性更强的特征模板,提升了远距离、非协作状态下虹膜识别的性能。关键词:虹膜识别;眼周识别;中间融合表达层;自适应加权;生物特征融合;远距离和非协作113|244|1更新时间:2024-05-07 -
 摘要:目的基于步态剪影的方法取得了很大的性能提升,其中通过水平划分骨干网络的输出从而学习多身体部位特征的机制起到了重要作用。然而在这些方法对不同部位的特征都是以相对独立的方式进行提取,不同部位之间缺乏交互,有碍于识别准确率的进一步提高。针对这一问题,本文提出了一个新模块用于增强步态识别中的多部位特征学习。方法本文将“分离—共享”机制引入到步态识别的多部位特征学习过程中。分离机制允许每个部位学习自身独有的特征,主要通过区域池化和独立权重的全连接层进行实现。共享机制允许不同部位的特征进行交互,由特征归一化和特征重映射两部分组成。在共享机制中,特征归一化不包含任何参数,目的是使不同部位的特征具有相似的统计特性以便进行权值共享;特征重映射则是通过全连接层或逐项乘积进行实现,并且在不同部位之间共享权重。结果实验在步态识别领域应用最广泛的数据集CASIA-B(Institute of Automation, Chinese Academy of Sciences)和OUMVLP上进行,分别以GaitSet和GaitPart作为基线方法。实验结果表明,本文设计的模块能够带来稳定的性能提升。在CASIA-B背包条件下,本文提出的模块相对于GaitSet和GaitPart分别将rank-1的识别准确率提升了1.62%和1.17%。结论本文设计了一个新的模块用于增强步态识别的多部位特征学习过程,能够在不显著增加计算代价的条件下带来稳定的性能提升。关键词:步态识别;剪影序列;多部位特征;分离机制;共享机制193|129|0更新时间:2024-05-07
摘要:目的基于步态剪影的方法取得了很大的性能提升,其中通过水平划分骨干网络的输出从而学习多身体部位特征的机制起到了重要作用。然而在这些方法对不同部位的特征都是以相对独立的方式进行提取,不同部位之间缺乏交互,有碍于识别准确率的进一步提高。针对这一问题,本文提出了一个新模块用于增强步态识别中的多部位特征学习。方法本文将“分离—共享”机制引入到步态识别的多部位特征学习过程中。分离机制允许每个部位学习自身独有的特征,主要通过区域池化和独立权重的全连接层进行实现。共享机制允许不同部位的特征进行交互,由特征归一化和特征重映射两部分组成。在共享机制中,特征归一化不包含任何参数,目的是使不同部位的特征具有相似的统计特性以便进行权值共享;特征重映射则是通过全连接层或逐项乘积进行实现,并且在不同部位之间共享权重。结果实验在步态识别领域应用最广泛的数据集CASIA-B(Institute of Automation, Chinese Academy of Sciences)和OUMVLP上进行,分别以GaitSet和GaitPart作为基线方法。实验结果表明,本文设计的模块能够带来稳定的性能提升。在CASIA-B背包条件下,本文提出的模块相对于GaitSet和GaitPart分别将rank-1的识别准确率提升了1.62%和1.17%。结论本文设计了一个新的模块用于增强步态识别的多部位特征学习过程,能够在不显著增加计算代价的条件下带来稳定的性能提升。关键词:步态识别;剪影序列;多部位特征;分离机制;共享机制193|129|0更新时间:2024-05-07
人脸、虹膜、步态等身份识别
-
 摘要:目的现阶段行人属性识别任务存在的主要问题在于某些属性类别的样本分布严重不均衡,为了解决上述问题,提出了一种基于渐进式迭代优化的行人属性识别方法。方法首先针对不均衡类别,采用马赛克自编码器进行数据增广,构建基于属性平衡化的数据生成模型(balanced attributes-data generation model,BA-DGM),实现从通用大模型到专用小任务的迁移学习和知识增强;然后针对新生成的样本数据,采用判别模型进行一致性筛选,在与生成模型的相互对抗中实现启发式的注意力机制,从而构建基于特征注意力的数据判别模型(attention features-data discrimination model,AF-DDM);最后通过数据生成与数据判别相互交替的循环迭代,实现行人属性识别模型和数据的渐进式优化,并针对均衡后的样本数据,采用知识蒸馏框架对不同轮次的判别模型进行融合,实现基于渐进式迭代的蒸馏融合模型(progressive iterations-distillation fusion model,PI-DFM),进一步提高模型的泛化能力。结果实验结果表明,所提出的渐进式优化方法在4个当前主流的评测数据集上均能有效提升模型准确率。在RAPv2(richly annotated pedestrian v2)数据集上,在模型复杂度不变的情况下,与已公开的最优行人属性识别模型相比,平均准确率(mean accuracy,mA)和平均F1分数分别提升了约5.0%和约1.7%;同时,经过多轮循环迭代后,原始数据中不均衡类别的个数减少为0,从而实现了数据集的渐进式优化。结论本文提出的渐进式迭代优化策略与现有的改进方法之间具有良好的互补性,并有助于进一步提升模型的准确性指标。关键词:行人属性识别;样本不均衡;渐进式迭代;马赛克自编码器;迁移学习;一致性筛选;知识蒸馏69|147|0更新时间:2024-05-07
摘要:目的现阶段行人属性识别任务存在的主要问题在于某些属性类别的样本分布严重不均衡,为了解决上述问题,提出了一种基于渐进式迭代优化的行人属性识别方法。方法首先针对不均衡类别,采用马赛克自编码器进行数据增广,构建基于属性平衡化的数据生成模型(balanced attributes-data generation model,BA-DGM),实现从通用大模型到专用小任务的迁移学习和知识增强;然后针对新生成的样本数据,采用判别模型进行一致性筛选,在与生成模型的相互对抗中实现启发式的注意力机制,从而构建基于特征注意力的数据判别模型(attention features-data discrimination model,AF-DDM);最后通过数据生成与数据判别相互交替的循环迭代,实现行人属性识别模型和数据的渐进式优化,并针对均衡后的样本数据,采用知识蒸馏框架对不同轮次的判别模型进行融合,实现基于渐进式迭代的蒸馏融合模型(progressive iterations-distillation fusion model,PI-DFM),进一步提高模型的泛化能力。结果实验结果表明,所提出的渐进式优化方法在4个当前主流的评测数据集上均能有效提升模型准确率。在RAPv2(richly annotated pedestrian v2)数据集上,在模型复杂度不变的情况下,与已公开的最优行人属性识别模型相比,平均准确率(mean accuracy,mA)和平均F1分数分别提升了约5.0%和约1.7%;同时,经过多轮循环迭代后,原始数据中不均衡类别的个数减少为0,从而实现了数据集的渐进式优化。结论本文提出的渐进式迭代优化策略与现有的改进方法之间具有良好的互补性,并有助于进一步提升模型的准确性指标。关键词:行人属性识别;样本不均衡;渐进式迭代;马赛克自编码器;迁移学习;一致性筛选;知识蒸馏69|147|0更新时间:2024-05-07
行人属性识别
-
 摘要:目的视频动作检测旨在检测出视频中所有人员的空间位置,并确定其对应的动作类别。现实场景中的视频动作检测主要面临两大问题,一是不同动作执行者之间可能存在交互作用,仅根据本身的区域特征进行动作识别是不准确的;二是一个动作执行者在同一时刻可能有多个动作标签,单独预测每个动作类忽视了它们的内在关联。为此,本文提出了一种建模交互关系和类别依赖的视频动作检测方法。方法首先,特征提取部分提取出关键帧中每个动作执行者的区域特征;然后,长短期交互部分设计短期交互模块(short-term interaction module,STIM)和长期交互模块(long-term interaction module,LTIM),分别建模动作执行者之间的短期时空交互和长期时序依赖,特别地,基于空间维度和时间维度的异质性,STIM采用解耦机制针对性地处理空间交互和短期时间交互;最后,为了解决多标签问题,分类器部分设计类别关系模块(class relationship module,CRM)计算类别之间的依赖关系以增强表征,并利用不同模块对分数预测结果的互补性,提出一种双阶段分数融合(two-stage score fusion,TSSF)策略更新最终的概率得分。结果在公开数据集AVA v2.1(atomic visual actions version 2.1)上进行定量和定性分析。定量分析中,以阈值取0.5时的平均精度均值mAP@IoU 0.5(mean average precision @ intersection over union 0.5)作为主要评价指标,本文方法在所有测试子类、Human Pose大类、Human-Object Interaction大类和Human-Human Interaction大类上的结果分别为31.0%,50.8%,22.3%,32.5%。与基准模型相比,分别提高了2.8%,2.0%,2.6%,3.6%。与其他主流算法相比,在所有子类上的指标相较于次好算法提高了0.8%;定性分析中,可视化结果一方面表明了本文模型能精准捕捉动作执行者之间的交互关系,另一方面体现了本文在类别依赖建模上的合理性和可靠性。此外,消融实验证明了各个模块的有效性。结论本文提出的建模交互关系和类别依赖的视频动作检测方法能够提升交互类动作的识别效果,并在一定程度上解决了多标签分类问题。关键词:视频动作检测;多标签分类;交互关系建模;双阶段融合;深度学习;注意力机制159|334|1更新时间:2024-05-07
摘要:目的视频动作检测旨在检测出视频中所有人员的空间位置,并确定其对应的动作类别。现实场景中的视频动作检测主要面临两大问题,一是不同动作执行者之间可能存在交互作用,仅根据本身的区域特征进行动作识别是不准确的;二是一个动作执行者在同一时刻可能有多个动作标签,单独预测每个动作类忽视了它们的内在关联。为此,本文提出了一种建模交互关系和类别依赖的视频动作检测方法。方法首先,特征提取部分提取出关键帧中每个动作执行者的区域特征;然后,长短期交互部分设计短期交互模块(short-term interaction module,STIM)和长期交互模块(long-term interaction module,LTIM),分别建模动作执行者之间的短期时空交互和长期时序依赖,特别地,基于空间维度和时间维度的异质性,STIM采用解耦机制针对性地处理空间交互和短期时间交互;最后,为了解决多标签问题,分类器部分设计类别关系模块(class relationship module,CRM)计算类别之间的依赖关系以增强表征,并利用不同模块对分数预测结果的互补性,提出一种双阶段分数融合(two-stage score fusion,TSSF)策略更新最终的概率得分。结果在公开数据集AVA v2.1(atomic visual actions version 2.1)上进行定量和定性分析。定量分析中,以阈值取0.5时的平均精度均值mAP@IoU 0.5(mean average precision @ intersection over union 0.5)作为主要评价指标,本文方法在所有测试子类、Human Pose大类、Human-Object Interaction大类和Human-Human Interaction大类上的结果分别为31.0%,50.8%,22.3%,32.5%。与基准模型相比,分别提高了2.8%,2.0%,2.6%,3.6%。与其他主流算法相比,在所有子类上的指标相较于次好算法提高了0.8%;定性分析中,可视化结果一方面表明了本文模型能精准捕捉动作执行者之间的交互关系,另一方面体现了本文在类别依赖建模上的合理性和可靠性。此外,消融实验证明了各个模块的有效性。结论本文提出的建模交互关系和类别依赖的视频动作检测方法能够提升交互类动作的识别效果,并在一定程度上解决了多标签分类问题。关键词:视频动作检测;多标签分类;交互关系建模;双阶段融合;深度学习;注意力机制159|334|1更新时间:2024-05-07
视频动作检测
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0