
最新刊期
2023 年 第 28 卷 第 4 期
-
 摘要:本文是关于中国图像工程的年度文献综述系列之二十八。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,本文对2022年度发表的图像工程相关文献进行了统计和分析。具体从国内15种有关图像工程重要中文期刊在2022年发行的所有154期上所发表的学术研究和技术应用文献(共3 096篇)中,选取出所有属于图像工程领域的文献(共908篇),并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前17年相同),并在此基础上分别进行了各期刊及各类文献的统计和分析。根据对2022年统计数据的分析可以看出:图像分析方向当前得到了最多的关注,其中目标检测和识别、图像分割和基元检测等都是研究的焦点。此外,遥感、雷达、声呐、测绘以及生物、医学等领域的图像技术开发和应用最为活跃。另外,图像工程技术正在不断拓展新的应用领域,未来新的应用小类有可能还会增加。总的来说,中国图像工程在2022年的研究深度和广度还在继续提高和扩大,仍保持了快速发展的势头。综合28年的统计数据还为读者提供了更全面和更可信的各个研究方向发展趋势的信息。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学96|226|1更新时间:2024-05-07
摘要:本文是关于中国图像工程的年度文献综述系列之二十八。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,本文对2022年度发表的图像工程相关文献进行了统计和分析。具体从国内15种有关图像工程重要中文期刊在2022年发行的所有154期上所发表的学术研究和技术应用文献(共3 096篇)中,选取出所有属于图像工程领域的文献(共908篇),并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前17年相同),并在此基础上分别进行了各期刊及各类文献的统计和分析。根据对2022年统计数据的分析可以看出:图像分析方向当前得到了最多的关注,其中目标检测和识别、图像分割和基元检测等都是研究的焦点。此外,遥感、雷达、声呐、测绘以及生物、医学等领域的图像技术开发和应用最为活跃。另外,图像工程技术正在不断拓展新的应用领域,未来新的应用小类有可能还会增加。总的来说,中国图像工程在2022年的研究深度和广度还在继续提高和扩大,仍保持了快速发展的势头。综合28年的统计数据还为读者提供了更全面和更可信的各个研究方向发展趋势的信息。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学96|226|1更新时间:2024-05-07 -
 摘要:近年来,人工智能技术接连取得突破,尤其是在强化学习、大规模语言模型和人工智能生成内容技术等方面,正逐步成为各个行业的创新驱动力。OpenAI于2022年11月30日发布的ChatGPT由于具有惊人的自然语言理解和生成能力,引起全社会大范围的关注,成为全球热议的话题,并被广泛应用于各个行业。仅两个月后,ChatGPT的月活跃用户数便达1亿,成为史上用户数增长最快的消费者应用。鉴于ChatGPT目前造成的影响,对其进行全面的分析较为必要。本文从历史沿革、应用现状和前景展望这3个角度对ChatGPT进行剖析,探究其对社会的影响、技术的原理和挑战以及未来发展的可能性,并从模型能力的角度简要介绍GPT-4相对于ChatGPT的改进。作为一个现象级技术产品,从技术角度而言ChatGPT对相关领域具有里程碑式的重要意义,从应用角度而言其可能会给人类社会带来巨大的影响。ChatGPT有潜力成为计算机领域最伟大的成就之一。但就目前而言,ChatGPT仍然存在一些局限,尚未达到强人工智能的水平。在当前阶段,研究人员需要对人工智能技术持有自信和谦虚学习的态度,继续发展相关的技术研究和应用。关键词:人工智能(AI);深度学习;自然语言处理;生成式人工智能技术(AIGC);ChatGPT239|195|3更新时间:2024-05-07
摘要:近年来,人工智能技术接连取得突破,尤其是在强化学习、大规模语言模型和人工智能生成内容技术等方面,正逐步成为各个行业的创新驱动力。OpenAI于2022年11月30日发布的ChatGPT由于具有惊人的自然语言理解和生成能力,引起全社会大范围的关注,成为全球热议的话题,并被广泛应用于各个行业。仅两个月后,ChatGPT的月活跃用户数便达1亿,成为史上用户数增长最快的消费者应用。鉴于ChatGPT目前造成的影响,对其进行全面的分析较为必要。本文从历史沿革、应用现状和前景展望这3个角度对ChatGPT进行剖析,探究其对社会的影响、技术的原理和挑战以及未来发展的可能性,并从模型能力的角度简要介绍GPT-4相对于ChatGPT的改进。作为一个现象级技术产品,从技术角度而言ChatGPT对相关领域具有里程碑式的重要意义,从应用角度而言其可能会给人类社会带来巨大的影响。ChatGPT有潜力成为计算机领域最伟大的成就之一。但就目前而言,ChatGPT仍然存在一些局限,尚未达到强人工智能的水平。在当前阶段,研究人员需要对人工智能技术持有自信和谦虚学习的态度,继续发展相关的技术研究和应用。关键词:人工智能(AI);深度学习;自然语言处理;生成式人工智能技术(AIGC);ChatGPT239|195|3更新时间:2024-05-07 -
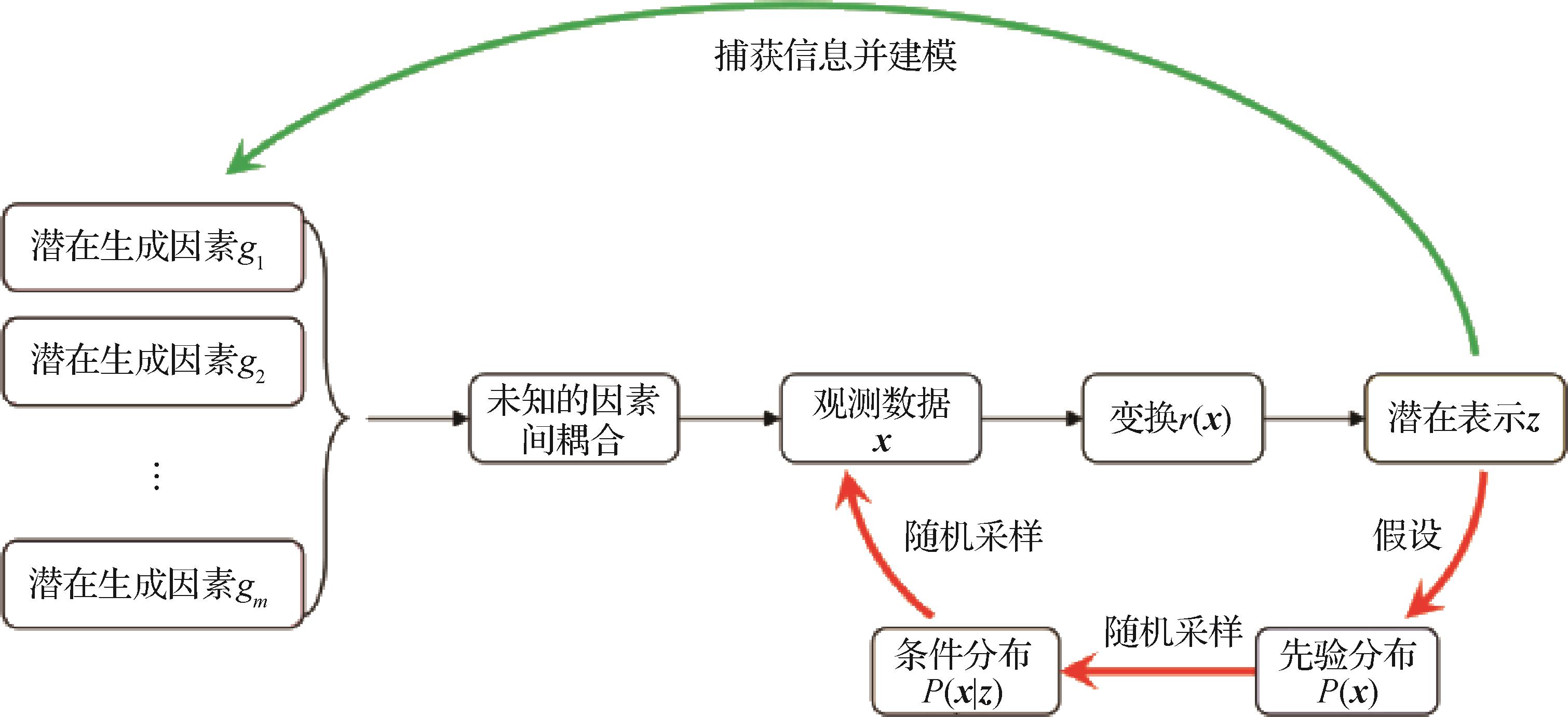 摘要:表示学习是机器学习研究的核心问题之一。机器学习算法的输入表征从过去主流的手工特征过渡到现在面向多媒体数据的潜在表示,使算法性能获得了巨大提升。然而,视觉数据的表示通常是高度耦合的,即输入数据的所有信息成分被编码进同一个特征空间,从而互相影响且难以区分,使得表示的可解释性不高。解耦表示学习旨在学习一种低维的可解释性抽象表示,可以识别并分离出隐藏在高维观测数据中的不同潜在变化因素。通过解耦表示学习,可以捕获到单个变化因素信息并通过相对应的潜在子空间进行控制,因此解耦表示更具有可解释性。解耦表征可用于提高样本效率和对无关干扰因素的容忍度,为数据中的复杂变化提供一种鲁棒性表示,提取的语义信息对识别分类、域适应等人工智能下游任务具有重要意义。本文首先介绍并分析解耦表示的研究现状及其因果机制,总结解耦表示的3个重要性质。然后,将解耦表示学习算法分为4类,并从数学描述、类型特点及适用范围3个方面进行归纳及对比。随后,分类总结了现有解耦表示工作中常用的损失函数、数据集及客观评估指标。最后,总结了解耦表示学习在实际问题中的各类应用,并对其未来发展进行了探讨。关键词:解耦表示学习;视觉数据;潜在表征;变化因素;潜空间189|252|1更新时间:2024-05-07
摘要:表示学习是机器学习研究的核心问题之一。机器学习算法的输入表征从过去主流的手工特征过渡到现在面向多媒体数据的潜在表示,使算法性能获得了巨大提升。然而,视觉数据的表示通常是高度耦合的,即输入数据的所有信息成分被编码进同一个特征空间,从而互相影响且难以区分,使得表示的可解释性不高。解耦表示学习旨在学习一种低维的可解释性抽象表示,可以识别并分离出隐藏在高维观测数据中的不同潜在变化因素。通过解耦表示学习,可以捕获到单个变化因素信息并通过相对应的潜在子空间进行控制,因此解耦表示更具有可解释性。解耦表征可用于提高样本效率和对无关干扰因素的容忍度,为数据中的复杂变化提供一种鲁棒性表示,提取的语义信息对识别分类、域适应等人工智能下游任务具有重要意义。本文首先介绍并分析解耦表示的研究现状及其因果机制,总结解耦表示的3个重要性质。然后,将解耦表示学习算法分为4类,并从数学描述、类型特点及适用范围3个方面进行归纳及对比。随后,分类总结了现有解耦表示工作中常用的损失函数、数据集及客观评估指标。最后,总结了解耦表示学习在实际问题中的各类应用,并对其未来发展进行了探讨。关键词:解耦表示学习;视觉数据;潜在表征;变化因素;潜空间189|252|1更新时间:2024-05-07 -
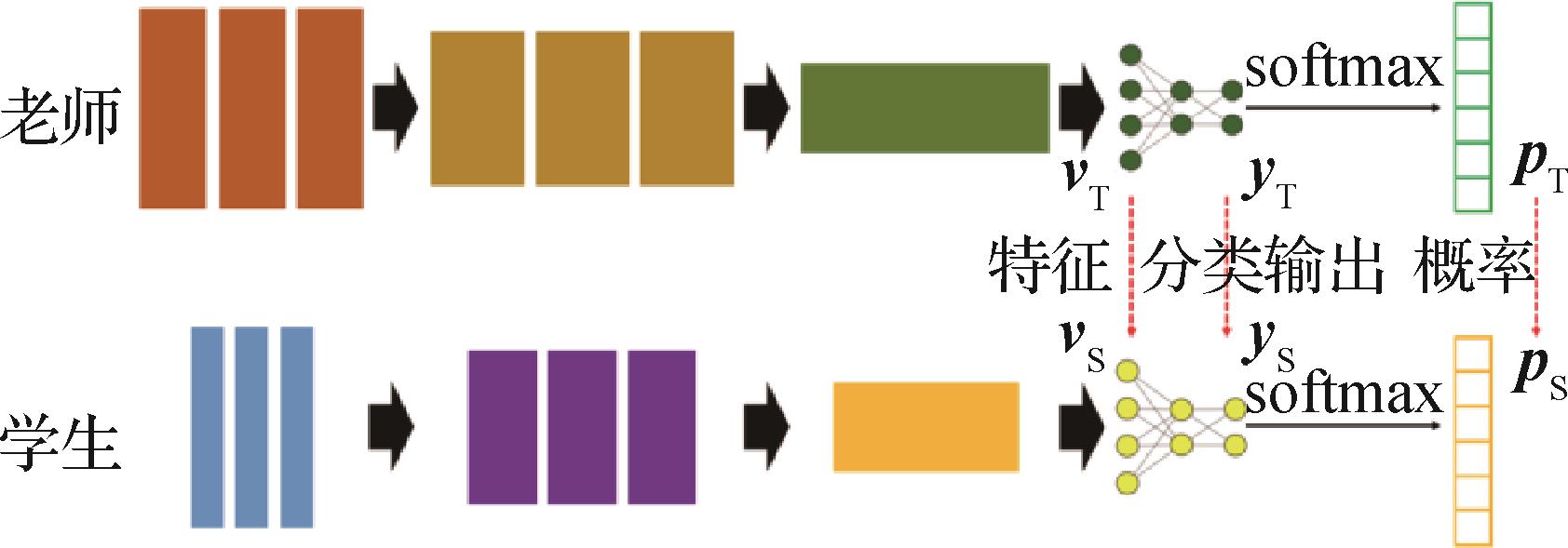 摘要:计算机视觉的任务目标是建立接近人类视觉系统的计算模型。随着深度神经网络(deep neural network,DNN)的发展,对计算机视觉中高层语义的分析与理解成为研究重点。计算机视觉的高层语义通常为人类可理解、可表述的用于表达图像、视频等媒体信号内容的描述子(descriptor),典型的高层语义分析任务包含图像分类、目标检测、实例分割、语义分割与视频场景识别、目标跟踪等。基于深度神经网络的算法使计算机视觉任务获得逐步提升的性能,但是网络模型的体量增大与计算效率的降低随之而来。模型蒸馏是一种基于迁移学习进行模型压缩的方案。此类方案通常利用一个预训练模型作为教师,提取其有效的表示,如模型输出、隐藏层特征或特征间相似度等,并将上述表示作为另一个规模较小、推断速度较快的学生模型的额外监督信号,对该学生模型进行训练,以达到提升小模型性能从而取代大模型的目的。模型蒸馏对模型性能与计算复杂度有着良好权衡,因此愈来愈多地用于基于深度学习的高层语义分析中。自2014年模型蒸馏概念提出以来,研究人员开发了大量应用于高层语义分析的模型蒸馏方法,在图像分类、目标检测与语义分割任务中的应用最为广泛。本文对上述典型任务中具有代表性的模型蒸馏方案进行调研和汇总,依照不同的视觉任务进行介绍。首先,从最成熟、应用最广泛的分类任务模型蒸馏方法开始,介绍其不同的设计思路与应用场景,展示部分实验性能的对比,指出在分类任务上与在检测、分割任务上应用模型蒸馏的条件差异性。接着,对几种经特殊设计而应用于目标检测、语义分割的典型模型蒸馏方法进行介绍,结合模型结构对设计目的与思路进行说明,提供部分实验结果的对比与分析。最后,对当前高层语义分析中模型蒸馏方法的现状进行了总结分析,并指出存在的困难及不足,设想未来可能的探索思路与发展方向。关键词:模型蒸馏;深度学习;图像分类;目标检测;语义分割;迁移学习188|450|1更新时间:2024-05-07
摘要:计算机视觉的任务目标是建立接近人类视觉系统的计算模型。随着深度神经网络(deep neural network,DNN)的发展,对计算机视觉中高层语义的分析与理解成为研究重点。计算机视觉的高层语义通常为人类可理解、可表述的用于表达图像、视频等媒体信号内容的描述子(descriptor),典型的高层语义分析任务包含图像分类、目标检测、实例分割、语义分割与视频场景识别、目标跟踪等。基于深度神经网络的算法使计算机视觉任务获得逐步提升的性能,但是网络模型的体量增大与计算效率的降低随之而来。模型蒸馏是一种基于迁移学习进行模型压缩的方案。此类方案通常利用一个预训练模型作为教师,提取其有效的表示,如模型输出、隐藏层特征或特征间相似度等,并将上述表示作为另一个规模较小、推断速度较快的学生模型的额外监督信号,对该学生模型进行训练,以达到提升小模型性能从而取代大模型的目的。模型蒸馏对模型性能与计算复杂度有着良好权衡,因此愈来愈多地用于基于深度学习的高层语义分析中。自2014年模型蒸馏概念提出以来,研究人员开发了大量应用于高层语义分析的模型蒸馏方法,在图像分类、目标检测与语义分割任务中的应用最为广泛。本文对上述典型任务中具有代表性的模型蒸馏方案进行调研和汇总,依照不同的视觉任务进行介绍。首先,从最成熟、应用最广泛的分类任务模型蒸馏方法开始,介绍其不同的设计思路与应用场景,展示部分实验性能的对比,指出在分类任务上与在检测、分割任务上应用模型蒸馏的条件差异性。接着,对几种经特殊设计而应用于目标检测、语义分割的典型模型蒸馏方法进行介绍,结合模型结构对设计目的与思路进行说明,提供部分实验结果的对比与分析。最后,对当前高层语义分析中模型蒸馏方法的现状进行了总结分析,并指出存在的困难及不足,设想未来可能的探索思路与发展方向。关键词:模型蒸馏;深度学习;图像分类;目标检测;语义分割;迁移学习188|450|1更新时间:2024-05-07 -
 摘要:随着大数据的普及和算力的提升,深度学习已成为一个热门研究领域,但其强大的性能过分依赖网络结构和参数设置。 因此,如何在提高模型性能的同时降低模型的复杂度,关键在于模型优化。为了更加精简地描述优化问题,本文以有监督深度学习作为切入点,对其提升拟合能力和泛化能力的优化方法进行归纳分析。给出优化的基本公式并阐述其核心;其次,从拟合能力的角度将优化问题分解为3个优化方向,即收敛性、收敛速度和全局质量问题,并总结分析这3个优化方向中的具体方法与研究成果;从提升模型泛化能力的角度出发,分为数据预处理和模型参数限制两类对正则化方法的研究现状进行梳理;结合上述理论基础,以生成对抗网络(generative adversarial network,GAN)变体模型的发展历程为主线,回顾各种优化方法在该领域的应用,并基于实验结果对优化效果进行比较和分析,进一步给出几种在GAN领域效果较好的优化策略。现阶段,各种优化方法已普遍应用于深度学习模型,能够较好地提升模型的拟合能力,同时通过正则化缓解模型过拟合问题来提高模型的鲁棒性。尽管深度学习的优化领域已得到广泛研究,但仍缺少成熟的系统性理论来指导优化方法的使用,且存在几个优化问题有待进一步研究,包括无法保证全局梯度的Lipschitz限制、在GAN中找寻稳定的全局最优解,以及优化方法的可解释性缺乏严格的理论证明。关键词:机器学习;深度学习;深度学习优化;正则化;生成对抗网络(GAN)225|389|1更新时间:2024-05-07
摘要:随着大数据的普及和算力的提升,深度学习已成为一个热门研究领域,但其强大的性能过分依赖网络结构和参数设置。 因此,如何在提高模型性能的同时降低模型的复杂度,关键在于模型优化。为了更加精简地描述优化问题,本文以有监督深度学习作为切入点,对其提升拟合能力和泛化能力的优化方法进行归纳分析。给出优化的基本公式并阐述其核心;其次,从拟合能力的角度将优化问题分解为3个优化方向,即收敛性、收敛速度和全局质量问题,并总结分析这3个优化方向中的具体方法与研究成果;从提升模型泛化能力的角度出发,分为数据预处理和模型参数限制两类对正则化方法的研究现状进行梳理;结合上述理论基础,以生成对抗网络(generative adversarial network,GAN)变体模型的发展历程为主线,回顾各种优化方法在该领域的应用,并基于实验结果对优化效果进行比较和分析,进一步给出几种在GAN领域效果较好的优化策略。现阶段,各种优化方法已普遍应用于深度学习模型,能够较好地提升模型的拟合能力,同时通过正则化缓解模型过拟合问题来提高模型的鲁棒性。尽管深度学习的优化领域已得到广泛研究,但仍缺少成熟的系统性理论来指导优化方法的使用,且存在几个优化问题有待进一步研究,包括无法保证全局梯度的Lipschitz限制、在GAN中找寻稳定的全局最优解,以及优化方法的可解释性缺乏严格的理论证明。关键词:机器学习;深度学习;深度学习优化;正则化;生成对抗网络(GAN)225|389|1更新时间:2024-05-07
综述

-
 摘要:目的舰船舷号检测识别是海面态势感知的关键技术,精准的舷号检测识别对海洋权益保护具有重要意义。但目前没有公开数据提供支持。为此,本文先构建了一个真实场景下的稀疏舰船舷号数据集(sparse ship hull number dataset in real scene,SSHN-RS),包含3 004幅舰船图像,共计11 328个舷号字符,覆盖了多国、各类、水平、倾斜、背景简单、背景复杂、光线不佳和被遮挡的舰船舷号样本,是一个具有挑战性的数据集。基于SSHN-RS,开展舰船舷号检测识别研究,其主要难点在于:1)样本稀疏,模型容易过拟合;2)舷号字符分布密集,网络难以充分提取各字符特征;3)部分字符存在嵌套区域和相似区域,网络会识别出大量冗余结果。针对上述难点,提出了一种基于多视角渐进式上下文解耦的舰船舷号检测识别算法。方法首先,引入一个固定中心和最大化面积的随机透视变换技术,在不增加样本数量的前提下扩充舷号姿态,实现了数据增广,提升了模型的泛化能力;其次,提出了一个渐进式上下文解耦技术,先通过依次擦除舷号各字符生成一系列新样本,再利用特征提取网络提取和融合各样本的多尺度特征,不仅减少字符上下文信息对特征学习的干扰,而且再次增广了数据;最后,在测试阶段,提出了一个掩码间扰动抑制技术,先根据预测结果采用与渐进式上下文解耦技术类似的方法生成新样本并重新进行预测,再引入一个1维非极大值抑制技术去除预测结果中错误的冗余字符,输出最佳检测识别结果,进一步优化网络性能。结果在SSHN-RS上采用主流实例分割算法进行定性和定量评估。在定量评估上,本文算法舷号的检测精确率、召回率、F值和识别率分别可达0.985 4,0.957 6,0.971 3,0.901 8,均优于其他算法。相比指标排名第2的算法,分别提高了4.51%,3.45%,3.97%,8.83%;在定性评估上,本文算法更适合舰船舷号检测识别任务,检测识别性能更高。此外,本文算法可以泛化到其他实例分割算法中,以经典算法Mask RCNN(mask region based convolutional neural network)为例,加入本文算法各模块后,各指标分别提升了9.82%,6.04%,7.80%,6.73%。结论本文算法可以解决舷号检测识别任务中因样本稀疏、舷号分布密集、部分字符存在嵌套和相似性带来的问题,在主观和客观上均取得了最先进的性能,并且具有通用性。SSHN-RS可通过https://github.com/Bingchuan897/SSHN-RS获取。关键词:稀疏样本;公开数据集;舰船舷号检测与识别;实例分割;数据增广;渐进式上下文解耦336|1931|1更新时间:2024-05-07
摘要:目的舰船舷号检测识别是海面态势感知的关键技术,精准的舷号检测识别对海洋权益保护具有重要意义。但目前没有公开数据提供支持。为此,本文先构建了一个真实场景下的稀疏舰船舷号数据集(sparse ship hull number dataset in real scene,SSHN-RS),包含3 004幅舰船图像,共计11 328个舷号字符,覆盖了多国、各类、水平、倾斜、背景简单、背景复杂、光线不佳和被遮挡的舰船舷号样本,是一个具有挑战性的数据集。基于SSHN-RS,开展舰船舷号检测识别研究,其主要难点在于:1)样本稀疏,模型容易过拟合;2)舷号字符分布密集,网络难以充分提取各字符特征;3)部分字符存在嵌套区域和相似区域,网络会识别出大量冗余结果。针对上述难点,提出了一种基于多视角渐进式上下文解耦的舰船舷号检测识别算法。方法首先,引入一个固定中心和最大化面积的随机透视变换技术,在不增加样本数量的前提下扩充舷号姿态,实现了数据增广,提升了模型的泛化能力;其次,提出了一个渐进式上下文解耦技术,先通过依次擦除舷号各字符生成一系列新样本,再利用特征提取网络提取和融合各样本的多尺度特征,不仅减少字符上下文信息对特征学习的干扰,而且再次增广了数据;最后,在测试阶段,提出了一个掩码间扰动抑制技术,先根据预测结果采用与渐进式上下文解耦技术类似的方法生成新样本并重新进行预测,再引入一个1维非极大值抑制技术去除预测结果中错误的冗余字符,输出最佳检测识别结果,进一步优化网络性能。结果在SSHN-RS上采用主流实例分割算法进行定性和定量评估。在定量评估上,本文算法舷号的检测精确率、召回率、F值和识别率分别可达0.985 4,0.957 6,0.971 3,0.901 8,均优于其他算法。相比指标排名第2的算法,分别提高了4.51%,3.45%,3.97%,8.83%;在定性评估上,本文算法更适合舰船舷号检测识别任务,检测识别性能更高。此外,本文算法可以泛化到其他实例分割算法中,以经典算法Mask RCNN(mask region based convolutional neural network)为例,加入本文算法各模块后,各指标分别提升了9.82%,6.04%,7.80%,6.73%。结论本文算法可以解决舷号检测识别任务中因样本稀疏、舷号分布密集、部分字符存在嵌套和相似性带来的问题,在主观和客观上均取得了最先进的性能,并且具有通用性。SSHN-RS可通过https://github.com/Bingchuan897/SSHN-RS获取。关键词:稀疏样本;公开数据集;舰船舷号检测与识别;实例分割;数据增广;渐进式上下文解耦336|1931|1更新时间:2024-05-07 -
 摘要:目的轻量级目标检测方法旨在保证检测精度,并减少神经网络的计算成本和存储成本。针对MobileNetv3网络瓶颈层bneck之间特征连接弱和深度可分离卷积在低维度下易出现参数为0的问题,提出一种融合跨阶段连接与倒残差的NAS-FPNLite(neural architecture search-feature pyramid networks lite)目标检测方法。方法提出一种跨阶段连接(cross stage connection,CSC)结构,将同一级网络块的初始输入与最终输出做通道融合,获取差异最大的梯度组合,得到一种改进的CSCMobileNetv3网络模型。在NAS-FPNLite的检测器结构中特征金字塔(feature pyramid networks,FPN)部分融合倒残差结构,将不同特征层之间逐元素相加的特征融合方式替换为通道叠加的方式,使得进行深度可分离卷积时保持更高的通道数,并将输入的特征层与最终的输出层做跳跃连接,进行充分特征融合,得到一种融合倒残差的NAS-FPNLite目标检测方法。结果实验数据表明,在CIFAR(Canadian Institute for Advanced Research)-100数据集上,当缩放系数为0.5、0.75和1.0时,CSCMobileNetv3网络准确率相比MobileNetv3均有0.71%~1.04%的上升,尤其在CSCMobileNetv3缩放系数为0.75时,相比于MobileNetv3缩放系数为1.0,准确率有0.19%的提升,而参数量却降低了30%,浮点数运算量降低了20%。在ImageNet 1000数据集上,相比于MobileNetv3准确率有0.7%的提升,且相较于其他轻量级网络准确率均有一定的提升。在COCO(common objects in context)数据集上,CSCMobileNetv3+倒残差NAS-FPNLite轻量级目标检测方法与其他轻量级目标检测方法相比,在运算量相当的情况下,检测精度均有0.7%~4%的提高。结论本文提出的CSCMobileNetv3可以有效获取差异梯度信息,在只少量增加运算量的情况下,获得了更高的准确率;融合倒残差的NAS-FPNLite目标检测方法可以有效避免参数变为0的情况,提升了检测精度,在运算量与检测精度达到了更好的平衡。关键词:轻量级目标检测;图像分类;深度可分离卷积;多尺度特征融合139|267|1更新时间:2024-05-07
摘要:目的轻量级目标检测方法旨在保证检测精度,并减少神经网络的计算成本和存储成本。针对MobileNetv3网络瓶颈层bneck之间特征连接弱和深度可分离卷积在低维度下易出现参数为0的问题,提出一种融合跨阶段连接与倒残差的NAS-FPNLite(neural architecture search-feature pyramid networks lite)目标检测方法。方法提出一种跨阶段连接(cross stage connection,CSC)结构,将同一级网络块的初始输入与最终输出做通道融合,获取差异最大的梯度组合,得到一种改进的CSCMobileNetv3网络模型。在NAS-FPNLite的检测器结构中特征金字塔(feature pyramid networks,FPN)部分融合倒残差结构,将不同特征层之间逐元素相加的特征融合方式替换为通道叠加的方式,使得进行深度可分离卷积时保持更高的通道数,并将输入的特征层与最终的输出层做跳跃连接,进行充分特征融合,得到一种融合倒残差的NAS-FPNLite目标检测方法。结果实验数据表明,在CIFAR(Canadian Institute for Advanced Research)-100数据集上,当缩放系数为0.5、0.75和1.0时,CSCMobileNetv3网络准确率相比MobileNetv3均有0.71%~1.04%的上升,尤其在CSCMobileNetv3缩放系数为0.75时,相比于MobileNetv3缩放系数为1.0,准确率有0.19%的提升,而参数量却降低了30%,浮点数运算量降低了20%。在ImageNet 1000数据集上,相比于MobileNetv3准确率有0.7%的提升,且相较于其他轻量级网络准确率均有一定的提升。在COCO(common objects in context)数据集上,CSCMobileNetv3+倒残差NAS-FPNLite轻量级目标检测方法与其他轻量级目标检测方法相比,在运算量相当的情况下,检测精度均有0.7%~4%的提高。结论本文提出的CSCMobileNetv3可以有效获取差异梯度信息,在只少量增加运算量的情况下,获得了更高的准确率;融合倒残差的NAS-FPNLite目标检测方法可以有效避免参数变为0的情况,提升了检测精度,在运算量与检测精度达到了更好的平衡。关键词:轻量级目标检测;图像分类;深度可分离卷积;多尺度特征融合139|267|1更新时间:2024-05-07 -
 摘要:目的道路裂缝是路面病害的早期征兆。定期监测路面状况、及时准确地发现路面裂缝对于交通养护机构降低成本、保证路面结构的可靠性和耐久性以及提高驾驶安全性、舒适性有重要意义。目前基于卷积神经网络的深度学习模型在长距离依赖建模方面存在不足,模型精度难以满足真实路面环境下的裂缝检测任务。一些模型通过引入空间/通道注意力机制进行长距离依赖建模,但是会导致计算量和计算复杂程度增加,无法实现实时检测。鉴于此,本文提出一种基于Transformer编码—解码结构的深度神经网络道路裂缝检测模型CTNet(crack transformer network)。方法该模型主要由Transformer注意力模块、多尺度局部特征增强模块、上采样模块和跨越连接4部分构成。采用Transformer注意力机制能更有效提取全局和长距离依赖关系,克服传统卷积神经网络表征输入信息的短距离相关缺陷。同时,为适应裂缝尺寸变化多样性,将Transformer与多尺度局部特征增强模块相结合,从而有效整合不同尺度局部信息,克服Transformer局部特征建模不足。结果通过与DeepCrack模型在不同裂缝检测数据集中的比较表明,本文提出的多尺度局部特征增强Transformer网络能快速、准确地分割路面裂缝,且效率更优。定量研究结果表明,CTNet在更有挑战性的CrackLS315 数据集中的精度、召回率和F1值达到91.38%、80.38%和85.53%,明显优于对比方法。在CrackWH100数据集中,精度、召回率和F1值进一步提升,分别达到92.70%、90.52%和91.60%。此外,CTNet的训练速率提升至DeepCrack模型的6.78倍。结论CTNet可以实现强噪声背景下的道路裂缝检测,检测效果优于目前最优方法,且参数量小,易于训练和部署。关键词:道路工程;道路裂缝检测;深度学习;语义分割;自注意力;Transformer249|540|4更新时间:2024-05-07
摘要:目的道路裂缝是路面病害的早期征兆。定期监测路面状况、及时准确地发现路面裂缝对于交通养护机构降低成本、保证路面结构的可靠性和耐久性以及提高驾驶安全性、舒适性有重要意义。目前基于卷积神经网络的深度学习模型在长距离依赖建模方面存在不足,模型精度难以满足真实路面环境下的裂缝检测任务。一些模型通过引入空间/通道注意力机制进行长距离依赖建模,但是会导致计算量和计算复杂程度增加,无法实现实时检测。鉴于此,本文提出一种基于Transformer编码—解码结构的深度神经网络道路裂缝检测模型CTNet(crack transformer network)。方法该模型主要由Transformer注意力模块、多尺度局部特征增强模块、上采样模块和跨越连接4部分构成。采用Transformer注意力机制能更有效提取全局和长距离依赖关系,克服传统卷积神经网络表征输入信息的短距离相关缺陷。同时,为适应裂缝尺寸变化多样性,将Transformer与多尺度局部特征增强模块相结合,从而有效整合不同尺度局部信息,克服Transformer局部特征建模不足。结果通过与DeepCrack模型在不同裂缝检测数据集中的比较表明,本文提出的多尺度局部特征增强Transformer网络能快速、准确地分割路面裂缝,且效率更优。定量研究结果表明,CTNet在更有挑战性的CrackLS315 数据集中的精度、召回率和F1值达到91.38%、80.38%和85.53%,明显优于对比方法。在CrackWH100数据集中,精度、召回率和F1值进一步提升,分别达到92.70%、90.52%和91.60%。此外,CTNet的训练速率提升至DeepCrack模型的6.78倍。结论CTNet可以实现强噪声背景下的道路裂缝检测,检测效果优于目前最优方法,且参数量小,易于训练和部署。关键词:道路工程;道路裂缝检测;深度学习;语义分割;自注意力;Transformer249|540|4更新时间:2024-05-07 -
 摘要:目的视频异常检测通过挖掘正常事件样本的模式来检测不符合正常模式的异常事件。基于自编码器的模型广泛用于视频异常检测领域,由于自监督学习的特征提取具有一定盲目性,使得网络的特征表达能力有限。为了提升模型对正常模式的学习能力,提出一种基于Transformer和U-Net的视频异常检测方法。方法首先,编码器对输入的连续帧进行下采样提取低层特征,并将最后一层特征图输入Transformer编码全局信息,学习特征像素之间的相关信息。然后解码器对编码特征进行上采样,通过跳跃连接与编码器中相同分辨率的低层特征融合,将全局空间信息与局部细节信息结合从而实现异常定位。针对近景康复动作的异常反馈需求,本文基于周期性动作收集了一个室内近景数据集,并进一步引入动态图约束引导网络关注近景周期性运动区域。结果实验在4个室外公开数据集和1个室内近景数据集上与同类方法比较。在室外数据集CUHK(Chinese University of Hong Kong)Avenue,UCSD Ped1(University of California, San Diego, pedestrian1),UCSD Ped2,LV(live videos)中,本文算法的帧级AUC(area under curve)值分别提高了1%,0.4%,1.1%,6.8%。在室内数据集中,本文算法相比同类算法提升了1.6%以上。消融实验结果分别验证了Transformer 模块以及动态图约束的有效性。结论本文将U-Net网络与基于自注意力机制的Transformer网络结合,能够提升模型对正常模式的学习能力,从而有效检测视频中的异常事件。关键词:异常检测;卷积神经网络(CNN);Transformer编码器;自注意力机制;自监督学习316|437|3更新时间:2024-05-07
摘要:目的视频异常检测通过挖掘正常事件样本的模式来检测不符合正常模式的异常事件。基于自编码器的模型广泛用于视频异常检测领域,由于自监督学习的特征提取具有一定盲目性,使得网络的特征表达能力有限。为了提升模型对正常模式的学习能力,提出一种基于Transformer和U-Net的视频异常检测方法。方法首先,编码器对输入的连续帧进行下采样提取低层特征,并将最后一层特征图输入Transformer编码全局信息,学习特征像素之间的相关信息。然后解码器对编码特征进行上采样,通过跳跃连接与编码器中相同分辨率的低层特征融合,将全局空间信息与局部细节信息结合从而实现异常定位。针对近景康复动作的异常反馈需求,本文基于周期性动作收集了一个室内近景数据集,并进一步引入动态图约束引导网络关注近景周期性运动区域。结果实验在4个室外公开数据集和1个室内近景数据集上与同类方法比较。在室外数据集CUHK(Chinese University of Hong Kong)Avenue,UCSD Ped1(University of California, San Diego, pedestrian1),UCSD Ped2,LV(live videos)中,本文算法的帧级AUC(area under curve)值分别提高了1%,0.4%,1.1%,6.8%。在室内数据集中,本文算法相比同类算法提升了1.6%以上。消融实验结果分别验证了Transformer 模块以及动态图约束的有效性。结论本文将U-Net网络与基于自注意力机制的Transformer网络结合,能够提升模型对正常模式的学习能力,从而有效检测视频中的异常事件。关键词:异常检测;卷积神经网络(CNN);Transformer编码器;自注意力机制;自监督学习316|437|3更新时间:2024-05-07 -
 摘要:目的在人体行为识别研究中,利用多模态方法将深度数据与骨骼数据相融合,可有效提高动作的识别率。针对深度图像信息数据量大、冗余度高等问题,提出一种通过获取关键时程信息动作帧序列降低冗余的算法,即质心运动路径松弛算法,并根据不同模态数据的特点,提出一种新的时空特征表示方法。方法质心运动路径松弛算法根据质心在相邻帧之间的运动距离,计算图像差分后获得的活跃部分的相似系数,然后剔除掉相似度高的帧,获得足以表达行为的关键时程信息。根据图像动态部分的变化特性、人体各部分在运动中的协同性和局部显著性特征构建一种新的时空特征表示方法。结果在MSR-Action3D数据集上对本文方法的效果进行验证。在3个子集中进行交叉验证的平均分类识别率为95.743 2%,分别比Multi-fused,CovP3DJ,D3D-LSTM(densely connected 3D-CNN and long short-term memory),Joint Subset Selection方法高2.443 2%,4.763 2%,0.343 2%,0.213 2%。本文方法在使用完整数据集的扩展实验中进行交叉验证的分类识别率为93.040 3%,具有很好的鲁棒性。结论实验结果表明,本文提出的去冗余算法在降低冗余后提升了识别效果,提取的特征之间具有相关性低的特点,在组合识别中具有良好的互补性,有效提高了分类识别的精确度。关键词:行为识别;质心运动;关键时程信息;时空特征表示;多模态融合186|460|4更新时间:2024-05-07
摘要:目的在人体行为识别研究中,利用多模态方法将深度数据与骨骼数据相融合,可有效提高动作的识别率。针对深度图像信息数据量大、冗余度高等问题,提出一种通过获取关键时程信息动作帧序列降低冗余的算法,即质心运动路径松弛算法,并根据不同模态数据的特点,提出一种新的时空特征表示方法。方法质心运动路径松弛算法根据质心在相邻帧之间的运动距离,计算图像差分后获得的活跃部分的相似系数,然后剔除掉相似度高的帧,获得足以表达行为的关键时程信息。根据图像动态部分的变化特性、人体各部分在运动中的协同性和局部显著性特征构建一种新的时空特征表示方法。结果在MSR-Action3D数据集上对本文方法的效果进行验证。在3个子集中进行交叉验证的平均分类识别率为95.743 2%,分别比Multi-fused,CovP3DJ,D3D-LSTM(densely connected 3D-CNN and long short-term memory),Joint Subset Selection方法高2.443 2%,4.763 2%,0.343 2%,0.213 2%。本文方法在使用完整数据集的扩展实验中进行交叉验证的分类识别率为93.040 3%,具有很好的鲁棒性。结论实验结果表明,本文提出的去冗余算法在降低冗余后提升了识别效果,提取的特征之间具有相关性低的特点,在组合识别中具有良好的互补性,有效提高了分类识别的精确度。关键词:行为识别;质心运动;关键时程信息;时空特征表示;多模态融合186|460|4更新时间:2024-05-07
图像分析和识别
-
 摘要:目的在图像分类领域,小样本学习旨在利用从大规模数据集中训练到的知识来处理仅包含少量有标记训练样本的下游分类任务。通常情况下,下游任务只涉及新类样本,由于元训练阶段会构造大量任务随机抽取训练集中不同类别的样本且训练集与测试集类别间存在领域间隙,因此模型训练周期长且可能对训练集过拟合,以致元知识无法迁移到测试集,进而导致模型泛化性差。针对以上问题,提出一种多层自适应聚合的自监督小样本图像分类模型。方法首先使用分组卷积对残差块进行改进,减少神经网络参数量,降低训练难度,缩短训练时间;然后采用多层自适应聚合的方法改进骨干网络,对网络各层语义信息加以提炼聚合,自适应分配各层权重,将聚合后的特征图作为后续分类的依据;最后加入自监督对比学习结合有监督学习挖掘样本自身潜在的信息,从而提升样本特征表达能力。结果在mini-ImageNet 数据集和CUB(Caltech-UCSD birds-200-2011)数据集上与当前主流模型进行分类效果对比实验,与baseline相比,所提模型的准确率在mini-ImageNet数据集的5-way 1-shot与5-way 5-shot实验上分别提升了6.31%和6.04%,在CUB数据集的5-way 1-shot与5-way 5-shot实验上分别提升了8.95%和8.77%。结论本文模型能在一定程度上缩短训练时间、增强样本特征表达能力和优化数据分布,并缓解领域间隙所带来的问题,从而提高模型泛化性与分类效果。关键词:小样本学习;图像分类;自适应聚合;自监督学习;对比学习197|339|2更新时间:2024-05-07
摘要:目的在图像分类领域,小样本学习旨在利用从大规模数据集中训练到的知识来处理仅包含少量有标记训练样本的下游分类任务。通常情况下,下游任务只涉及新类样本,由于元训练阶段会构造大量任务随机抽取训练集中不同类别的样本且训练集与测试集类别间存在领域间隙,因此模型训练周期长且可能对训练集过拟合,以致元知识无法迁移到测试集,进而导致模型泛化性差。针对以上问题,提出一种多层自适应聚合的自监督小样本图像分类模型。方法首先使用分组卷积对残差块进行改进,减少神经网络参数量,降低训练难度,缩短训练时间;然后采用多层自适应聚合的方法改进骨干网络,对网络各层语义信息加以提炼聚合,自适应分配各层权重,将聚合后的特征图作为后续分类的依据;最后加入自监督对比学习结合有监督学习挖掘样本自身潜在的信息,从而提升样本特征表达能力。结果在mini-ImageNet 数据集和CUB(Caltech-UCSD birds-200-2011)数据集上与当前主流模型进行分类效果对比实验,与baseline相比,所提模型的准确率在mini-ImageNet数据集的5-way 1-shot与5-way 5-shot实验上分别提升了6.31%和6.04%,在CUB数据集的5-way 1-shot与5-way 5-shot实验上分别提升了8.95%和8.77%。结论本文模型能在一定程度上缩短训练时间、增强样本特征表达能力和优化数据分布,并缓解领域间隙所带来的问题,从而提高模型泛化性与分类效果。关键词:小样本学习;图像分类;自适应聚合;自监督学习;对比学习197|339|2更新时间:2024-05-07 -
 摘要:目的随着实际应用场景中海量数据采集技术的发展和数据标注成本的不断增加,自监督学习成为海量数据分析的一个重要策略。然而,如何从海量数据中抽取有用的监督信息,并该监督信息下开展有效的学习仍然是制约该方向发展的研究难点。为此,提出了一个基于共识图学习的自监督集成聚类框架。方法框架主要包括3个功能模块。首先,利用集成学习中多个基学习器构建共识图;其次,利用图神经网络分析共识图,捕获节点优化表示和节点的聚类结构,并从聚类中挑选高置信度的节点子集及对应的类标签生成监督信息;再次,在此标签监督下,联合其他无标注样本更新集成成员基学习器。交替迭代上述功能块,最终提高无监督聚类的性能。结果为验证该框架的有效性,在标准数据集(包括图像和文本数据)上设计了一系列实验。实验结果表明,所提方法在性能上一致优于现有聚类方法。尤其是在MNIST-Test(modified national institute of standards and technology database)上,本文方法实现了97.78%的准确率,比已有最佳方法高出3.85%。结论该方法旨在利用图表示学习提升自监督学习中监督信息捕获的能力,监督信息的有效获取进一步强化了集成学习中成员构建的能力,最终提升了无监督海量数据本质结构的挖掘性能。关键词:集成聚类;自监督聚类;图表示学习;共识图;伪标签置信度126|141|0更新时间:2024-05-07
摘要:目的随着实际应用场景中海量数据采集技术的发展和数据标注成本的不断增加,自监督学习成为海量数据分析的一个重要策略。然而,如何从海量数据中抽取有用的监督信息,并该监督信息下开展有效的学习仍然是制约该方向发展的研究难点。为此,提出了一个基于共识图学习的自监督集成聚类框架。方法框架主要包括3个功能模块。首先,利用集成学习中多个基学习器构建共识图;其次,利用图神经网络分析共识图,捕获节点优化表示和节点的聚类结构,并从聚类中挑选高置信度的节点子集及对应的类标签生成监督信息;再次,在此标签监督下,联合其他无标注样本更新集成成员基学习器。交替迭代上述功能块,最终提高无监督聚类的性能。结果为验证该框架的有效性,在标准数据集(包括图像和文本数据)上设计了一系列实验。实验结果表明,所提方法在性能上一致优于现有聚类方法。尤其是在MNIST-Test(modified national institute of standards and technology database)上,本文方法实现了97.78%的准确率,比已有最佳方法高出3.85%。结论该方法旨在利用图表示学习提升自监督学习中监督信息捕获的能力,监督信息的有效获取进一步强化了集成学习中成员构建的能力,最终提升了无监督海量数据本质结构的挖掘性能。关键词:集成聚类;自监督聚类;图表示学习;共识图;伪标签置信度126|141|0更新时间:2024-05-07 -
 摘要:目的随着深度卷积神经网络广泛应用于双目立体图像超分辨率重建任务,双目图像之间的信息融合成为近年来的研究热点。针对目前的双目图像超分辨重建算法对单幅图像的内部信息学习较少的问题,提出多层次融合注意力网络的双目图像超分辨率重建算法,在立体匹配的基础上学习图像内部的丰富信息。方法首先,利用特征提取模块从不同尺度和深度来获取左图和右图的低频特征。然后,将低频特征作为混合注意力模块的输入,此注意力模块先利用二阶通道非局部注意力模块学习每个图像内部的通道和空间特征,再采用视差注意力模块对左右特征图进行立体匹配。接着采用多层融合模块获取不同深度特征之间的相关信息,进一步指导产生高质量图像重建效果。再利用亚像素卷积对特征图进行上采样,并和低分辨率左图的放大特征相加得到重建特征。最后使用1层卷积得到重建后的高分辨率图像。结果本文算法采用Flickr1024数据集的800幅图像和60幅经过2倍下采样的Middlebury图像作为训练集,以峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity,SSIM)作为指标。实验在3个基准测试集Middlebury、KITTI2012和KITTI2015上进行定量和定性评估。实验结果显示,本文算法获得了最清晰的图像效果。当放大因子为2时,在3个数据集上的指标与PASSRnet(learning parallax attention for stereo image super-resolution)相比,本文算法的峰值信噪比提升了0.56 dB、0.31 dB和0.26 dB,结构相似性均提升了0.005。结论本文提出的网络模型充分学习图像内部的丰富信息,有效指导左右特征图的立体匹配。同时,能够不断进行高低频信息融合,取得了较好的重建效果。关键词:卷积神经网络(CNN);双目图像超分辨率;注意力机制;立体匹配;信息融合137|287|3更新时间:2024-05-07
摘要:目的随着深度卷积神经网络广泛应用于双目立体图像超分辨率重建任务,双目图像之间的信息融合成为近年来的研究热点。针对目前的双目图像超分辨重建算法对单幅图像的内部信息学习较少的问题,提出多层次融合注意力网络的双目图像超分辨率重建算法,在立体匹配的基础上学习图像内部的丰富信息。方法首先,利用特征提取模块从不同尺度和深度来获取左图和右图的低频特征。然后,将低频特征作为混合注意力模块的输入,此注意力模块先利用二阶通道非局部注意力模块学习每个图像内部的通道和空间特征,再采用视差注意力模块对左右特征图进行立体匹配。接着采用多层融合模块获取不同深度特征之间的相关信息,进一步指导产生高质量图像重建效果。再利用亚像素卷积对特征图进行上采样,并和低分辨率左图的放大特征相加得到重建特征。最后使用1层卷积得到重建后的高分辨率图像。结果本文算法采用Flickr1024数据集的800幅图像和60幅经过2倍下采样的Middlebury图像作为训练集,以峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity,SSIM)作为指标。实验在3个基准测试集Middlebury、KITTI2012和KITTI2015上进行定量和定性评估。实验结果显示,本文算法获得了最清晰的图像效果。当放大因子为2时,在3个数据集上的指标与PASSRnet(learning parallax attention for stereo image super-resolution)相比,本文算法的峰值信噪比提升了0.56 dB、0.31 dB和0.26 dB,结构相似性均提升了0.005。结论本文提出的网络模型充分学习图像内部的丰富信息,有效指导左右特征图的立体匹配。同时,能够不断进行高低频信息融合,取得了较好的重建效果。关键词:卷积神经网络(CNN);双目图像超分辨率;注意力机制;立体匹配;信息融合137|287|3更新时间:2024-05-07 -
 摘要:目的3维目标分类是视觉领域的一个基本问题,3维目标的旋转变化给分类带来极大挑战。同时不规则3维网格模型难以运用传统2维卷积网络提取特征。针对这两个问题,提出一种基于矢量型球面卷积网络的分类方法,用于识别未知旋转的3维网格模型。方法使用矢量型神经元作为网络的基础神经元,并提出一种新型矢量层间的卷积方式。首先,将3维模型规范化并映射到单位球上,获取球面的信号表示;然后,使用矢量型分类网络和重建网络学习等变的3维模型特征;最后,使用分类网络完成3维模型分类。结果经过消融实验对比,使用本文提出的球面卷积模块和矢量卷积层,并在训练时加入重建模块。对原本未旋转(no rotation,NR)数据集进行任意旋转(arbitrary rotation,AR),并设定NR/AR,AR/AR,NR/NR共3种训练/测试策略的分类任务,其中NR/AR任务衡量模型识别未知旋转的能力。在刚性数据集ModelNet40上,相比基于球面卷积网络(spherical convolutional neural network, SCNN)的分类方法,在3种任务上分别提高了7.7%,1.8%,3.1%。为验证本文方法在识别非刚性3维网格目标的优越性,在非刚性数据集SHREC15(shape retrieval contest 2015)上,相比SCNN,本文方法在3种任务上分别提高了8.8%,4.5%,5.0%。结论本文提出一种将矢量型网络运用在3维目标分类的思路,使用光线投射法获得分布在球面空间的特征,便于使用统一的球面卷积算子进行处理;设计一种球面残差模块避免梯度消失;使用矢量型神经元并设计矢量层之间的卷积方式以保证网络的等变性,使得识别任意旋转的3维模型时更加准确。关键词:3维目标分类;矢量型网络;胶囊网络;球面卷积网络(SCNN);旋转等变网络100|175|0更新时间:2024-05-07
摘要:目的3维目标分类是视觉领域的一个基本问题,3维目标的旋转变化给分类带来极大挑战。同时不规则3维网格模型难以运用传统2维卷积网络提取特征。针对这两个问题,提出一种基于矢量型球面卷积网络的分类方法,用于识别未知旋转的3维网格模型。方法使用矢量型神经元作为网络的基础神经元,并提出一种新型矢量层间的卷积方式。首先,将3维模型规范化并映射到单位球上,获取球面的信号表示;然后,使用矢量型分类网络和重建网络学习等变的3维模型特征;最后,使用分类网络完成3维模型分类。结果经过消融实验对比,使用本文提出的球面卷积模块和矢量卷积层,并在训练时加入重建模块。对原本未旋转(no rotation,NR)数据集进行任意旋转(arbitrary rotation,AR),并设定NR/AR,AR/AR,NR/NR共3种训练/测试策略的分类任务,其中NR/AR任务衡量模型识别未知旋转的能力。在刚性数据集ModelNet40上,相比基于球面卷积网络(spherical convolutional neural network, SCNN)的分类方法,在3种任务上分别提高了7.7%,1.8%,3.1%。为验证本文方法在识别非刚性3维网格目标的优越性,在非刚性数据集SHREC15(shape retrieval contest 2015)上,相比SCNN,本文方法在3种任务上分别提高了8.8%,4.5%,5.0%。结论本文提出一种将矢量型网络运用在3维目标分类的思路,使用光线投射法获得分布在球面空间的特征,便于使用统一的球面卷积算子进行处理;设计一种球面残差模块避免梯度消失;使用矢量型神经元并设计矢量层之间的卷积方式以保证网络的等变性,使得识别任意旋转的3维模型时更加准确。关键词:3维目标分类;矢量型网络;胶囊网络;球面卷积网络(SCNN);旋转等变网络100|175|0更新时间:2024-05-07 -
 摘要:目的由于现有时尚服饰搭配方法缺乏服饰图像局部细节的有效特征表示,难以对不同服饰间的局部兼容性进行建模,限制了服饰兼容性学习的完备性,导致时尚服饰搭配的准确率较低。因此,提出一种全局—局部特征优化的时尚服饰搭配方法。方法首先,利用不同卷积网络提取时尚服饰的图像和文本特征作为全局特征,同时在卷积网络基础上构建局部特征提取网络,提取时尚服饰图像的局部特征;然后,基于图网络和自注意力机制构建全局—局部兼容性学习模块,通过学习不同时尚服饰全局特征间和局部特征间的交互关系,并定义不同时尚服饰的权重,进行服饰全局和局部兼容性建模;最后,构建服饰搭配优化模型,通过融合套装中所有服饰的全局和局部兼容性优化服饰搭配,并计算搭配得分,输出正确的服饰搭配结果。结果在公开数据集Polyvore上将本文方法与其他方法进行对比。实验结果表明,利用局部特征提取网络提取的时尚服饰图像局部特征能有效地表示服饰局部信息;构建的全局—局部兼容性学习模块对时尚服饰的全局兼容性和局部兼容性进行了完整建模;构建的时尚服饰搭配优化模型实现了全局和局部兼容性的优化组合,使时尚服饰搭配准确率(fill in the blank,FITB)提高至86.89%。结论本文提出的全局—局部特征优化的时尚服饰搭配方法,能够有效提高时尚服饰搭配的准确率,较好地满足日常时尚搭配的需求。关键词:时尚服饰搭配;兼容性建模;全局特征;局部特征;特征优化111|234|0更新时间:2024-05-07
摘要:目的由于现有时尚服饰搭配方法缺乏服饰图像局部细节的有效特征表示,难以对不同服饰间的局部兼容性进行建模,限制了服饰兼容性学习的完备性,导致时尚服饰搭配的准确率较低。因此,提出一种全局—局部特征优化的时尚服饰搭配方法。方法首先,利用不同卷积网络提取时尚服饰的图像和文本特征作为全局特征,同时在卷积网络基础上构建局部特征提取网络,提取时尚服饰图像的局部特征;然后,基于图网络和自注意力机制构建全局—局部兼容性学习模块,通过学习不同时尚服饰全局特征间和局部特征间的交互关系,并定义不同时尚服饰的权重,进行服饰全局和局部兼容性建模;最后,构建服饰搭配优化模型,通过融合套装中所有服饰的全局和局部兼容性优化服饰搭配,并计算搭配得分,输出正确的服饰搭配结果。结果在公开数据集Polyvore上将本文方法与其他方法进行对比。实验结果表明,利用局部特征提取网络提取的时尚服饰图像局部特征能有效地表示服饰局部信息;构建的全局—局部兼容性学习模块对时尚服饰的全局兼容性和局部兼容性进行了完整建模;构建的时尚服饰搭配优化模型实现了全局和局部兼容性的优化组合,使时尚服饰搭配准确率(fill in the blank,FITB)提高至86.89%。结论本文提出的全局—局部特征优化的时尚服饰搭配方法,能够有效提高时尚服饰搭配的准确率,较好地满足日常时尚搭配的需求。关键词:时尚服饰搭配;兼容性建模;全局特征;局部特征;特征优化111|234|0更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的Ki67分数是乳腺癌预后评估的重要指标,计算该分数的关键步骤是检测阴性与阳性癌细胞核。人工检测面临疲劳与主观差异的问题。卷积神经网络有望实现高质量、自动化的细胞核检测,然而需要病理专家为其标注细胞核。为了减轻标注的工作量,不少研究者提出以中心点标注训练卷积神经网络。然而这些方法采用过于复杂的卷积神经网络和后处理流程,未能充分提高易用性和效率、发挥卷积神经网络的质量。对此,提出CentroidNet模型,旨在提高中心点检测的质量、效率和易用性。方法CentroidNet模型在图像上放置均匀排布的锚点,为每个锚点预测一个候选点,一部分候选点通过基于阈值的筛选策略成为预测点。本文提出最近锚点匹配策略用于生成训练标签,既保证了端到端推理,又规避了其他一对一标签匹配算法所具有的标签抖动问题。本文建议锚点间距应尽可能接近训练集答案点间最短距离的第一百分位数,并指出这样的锚点间距能够在前景标签数、坐标回归难度与效率之间取得良好的平衡。本文在设计卷积神经网络的结构时,没有采纳广为使用的U-Net或特征金字塔(feature pyramid network, FPN)中的多级上采样与旁路连接,反而提高了质量和效率。结果本文在BCData数据集上评估CentroidNet模型的质量与效率。BCData是目前规模最大的、公开的乳腺癌Ki67癌细胞核中心点检测数据集。在质量方面,CentroidNet取得的综合F1分数为0.879 1,媲美当前的最高质量。在效率方面,CentroidNet的推理速度为12.96 ms/幅、显存占用为138.8 MB/幅,达到了当前最高的效率,远低于若干主流或最新的模型。结论CentroidNet具有高质量、高效率和高易用性;与现有同类模型相比,进一步提高了乳腺癌Ki67细胞核中心点检测的可行性。关键词:乳腺癌;Ki67分数;中心点检测;一对一标签匹配;锚点62|188|1更新时间:2024-05-07
摘要:目的Ki67分数是乳腺癌预后评估的重要指标,计算该分数的关键步骤是检测阴性与阳性癌细胞核。人工检测面临疲劳与主观差异的问题。卷积神经网络有望实现高质量、自动化的细胞核检测,然而需要病理专家为其标注细胞核。为了减轻标注的工作量,不少研究者提出以中心点标注训练卷积神经网络。然而这些方法采用过于复杂的卷积神经网络和后处理流程,未能充分提高易用性和效率、发挥卷积神经网络的质量。对此,提出CentroidNet模型,旨在提高中心点检测的质量、效率和易用性。方法CentroidNet模型在图像上放置均匀排布的锚点,为每个锚点预测一个候选点,一部分候选点通过基于阈值的筛选策略成为预测点。本文提出最近锚点匹配策略用于生成训练标签,既保证了端到端推理,又规避了其他一对一标签匹配算法所具有的标签抖动问题。本文建议锚点间距应尽可能接近训练集答案点间最短距离的第一百分位数,并指出这样的锚点间距能够在前景标签数、坐标回归难度与效率之间取得良好的平衡。本文在设计卷积神经网络的结构时,没有采纳广为使用的U-Net或特征金字塔(feature pyramid network, FPN)中的多级上采样与旁路连接,反而提高了质量和效率。结果本文在BCData数据集上评估CentroidNet模型的质量与效率。BCData是目前规模最大的、公开的乳腺癌Ki67癌细胞核中心点检测数据集。在质量方面,CentroidNet取得的综合F1分数为0.879 1,媲美当前的最高质量。在效率方面,CentroidNet的推理速度为12.96 ms/幅、显存占用为138.8 MB/幅,达到了当前最高的效率,远低于若干主流或最新的模型。结论CentroidNet具有高质量、高效率和高易用性;与现有同类模型相比,进一步提高了乳腺癌Ki67细胞核中心点检测的可行性。关键词:乳腺癌;Ki67分数;中心点检测;一对一标签匹配;锚点62|188|1更新时间:2024-05-07 -
 摘要:目的病理学检查是明确乳腺癌诊断及肿瘤类型的金标准。深度神经网络广泛应用于乳腺病理全切片的诊断工作并取得了明显进展,但是现有大多数工作只是将全切片切割成小图像块,对每个图像块进行单独处理,没有考虑它们之间的空间信息。为此,提出了一种融合空间相关性特征的乳腺组织病理全切片分类方法。方法首先基于卷积神经网络对病理图像块进行预测,并提取每个图像块有代表性的深层特征,然后利用特征融合将图像块及其周围图像的特征进行聚合,以形成具有空间相关性的块描述符,最后将全切片图像中最可疑的块描述符传递给循环神经网络,以预测最终的全切片级别的分类。结果本文构建了一个经过详细标注的乳腺病理全切片数据集,并在此数据集上进行良性/恶性二分类实验。在自建的数据集中与3种全切片分类方法进行了比较。结果表明,本文方法的分类精度达到96.3%,比未考虑空间相关性的方法高出了1.9%,与基于热力图特征和基于空间性和随机森林的方法相比,分类精度分别高出8.8%和1.3%。结论本文提出的乳腺组织病理全切片识别方法将空间相关性特征融合和RNN分类集成到一个统一模型,有助于提高图像识别准确率,为病理图像诊断工作提供了高效的辅助诊断工具。关键词:乳腺癌;病理组织全切片;分类;卷积神经网络(CNN);特征融合;循环神经网络(RNN)131|283|1更新时间:2024-05-07
摘要:目的病理学检查是明确乳腺癌诊断及肿瘤类型的金标准。深度神经网络广泛应用于乳腺病理全切片的诊断工作并取得了明显进展,但是现有大多数工作只是将全切片切割成小图像块,对每个图像块进行单独处理,没有考虑它们之间的空间信息。为此,提出了一种融合空间相关性特征的乳腺组织病理全切片分类方法。方法首先基于卷积神经网络对病理图像块进行预测,并提取每个图像块有代表性的深层特征,然后利用特征融合将图像块及其周围图像的特征进行聚合,以形成具有空间相关性的块描述符,最后将全切片图像中最可疑的块描述符传递给循环神经网络,以预测最终的全切片级别的分类。结果本文构建了一个经过详细标注的乳腺病理全切片数据集,并在此数据集上进行良性/恶性二分类实验。在自建的数据集中与3种全切片分类方法进行了比较。结果表明,本文方法的分类精度达到96.3%,比未考虑空间相关性的方法高出了1.9%,与基于热力图特征和基于空间性和随机森林的方法相比,分类精度分别高出8.8%和1.3%。结论本文提出的乳腺组织病理全切片识别方法将空间相关性特征融合和RNN分类集成到一个统一模型,有助于提高图像识别准确率,为病理图像诊断工作提供了高效的辅助诊断工具。关键词:乳腺癌;病理组织全切片;分类;卷积神经网络(CNN);特征融合;循环神经网络(RNN)131|283|1更新时间:2024-05-07 -
 摘要:目的阿尔兹海默症疾病的发展是一个缓慢的过程,患者在出现明显症状之后才开始用药,而这时患者的脑损伤已经过于严重难以恢复,阿尔兹海默症的早期预测能够尽早干预这一过程。目前2D及3D的卷积方法大多基于单次检测的磁共振成像(magnetic resonance imaging,MRI)影像进行特征提取,但是病程的发展预测更应该关注时序的特征。考虑到病例在疾病发展过程中的MRI检查时序能够为诊断提供疾病发展的影像变化的有效信息,本文建立CTISS(ConvLSTM based on temporal images series slice)模型,提取病程发展不同阶段的变化特征,实现阿尔兹海默症病病程的早期预测。方法与现有算法通过一阶段MRI影像提取特征不同,该模型采用两阶段脑影像建立了一种分层时序卷积的网络结构,采用自适应学习率方法RMSprop(root mean square prop)训练模型。参数优化实验结果显示,2层卷积时序含注意力机制,1层长短时记忆含注意力机制的模型结构性能最好。算法采用时序卷积双向长短时记忆模型(bi-directional long short-term memory,Bi-ConvLSTM)及注意力机制,在大脑影像的分层切面上进行时序特征提取。结果CTISS模型与现有的5种算法在4个分类任务进行对比。结果显示,CTISS 模型在长序列阿尔兹海默症病程预测中取得很好的预测性能。CTISS模型能够捕捉与疾病发展过程相关的长时序影像特征,并获得更好的算法性能,特别在3分类任务中AUC(area under curve)较其他算法提升12%的精度。同时,CTISS 模型其他深度模型所提取的全脑萎缩空腔增大、大脑白质区域纤维化的影像变化特征与阿尔兹海默症的病理解剖所获得的结论一致。结论与其他算法相比,CTISS 模型的AUC在3分类中取得较2分类更好的算法性能提升,因此CTISS 模型在长期跟踪数据集上具有较其他算法更好的表现。关键词:阿尔兹海默症(AD);预测;时序;磁共振成像(MRI);特征提取;长短时记忆(LSTM)120|300|0更新时间:2024-05-07
摘要:目的阿尔兹海默症疾病的发展是一个缓慢的过程,患者在出现明显症状之后才开始用药,而这时患者的脑损伤已经过于严重难以恢复,阿尔兹海默症的早期预测能够尽早干预这一过程。目前2D及3D的卷积方法大多基于单次检测的磁共振成像(magnetic resonance imaging,MRI)影像进行特征提取,但是病程的发展预测更应该关注时序的特征。考虑到病例在疾病发展过程中的MRI检查时序能够为诊断提供疾病发展的影像变化的有效信息,本文建立CTISS(ConvLSTM based on temporal images series slice)模型,提取病程发展不同阶段的变化特征,实现阿尔兹海默症病病程的早期预测。方法与现有算法通过一阶段MRI影像提取特征不同,该模型采用两阶段脑影像建立了一种分层时序卷积的网络结构,采用自适应学习率方法RMSprop(root mean square prop)训练模型。参数优化实验结果显示,2层卷积时序含注意力机制,1层长短时记忆含注意力机制的模型结构性能最好。算法采用时序卷积双向长短时记忆模型(bi-directional long short-term memory,Bi-ConvLSTM)及注意力机制,在大脑影像的分层切面上进行时序特征提取。结果CTISS模型与现有的5种算法在4个分类任务进行对比。结果显示,CTISS 模型在长序列阿尔兹海默症病程预测中取得很好的预测性能。CTISS模型能够捕捉与疾病发展过程相关的长时序影像特征,并获得更好的算法性能,特别在3分类任务中AUC(area under curve)较其他算法提升12%的精度。同时,CTISS 模型其他深度模型所提取的全脑萎缩空腔增大、大脑白质区域纤维化的影像变化特征与阿尔兹海默症的病理解剖所获得的结论一致。结论与其他算法相比,CTISS 模型的AUC在3分类中取得较2分类更好的算法性能提升,因此CTISS 模型在长期跟踪数据集上具有较其他算法更好的表现。关键词:阿尔兹海默症(AD);预测;时序;磁共振成像(MRI);特征提取;长短时记忆(LSTM)120|300|0更新时间:2024-05-07 -
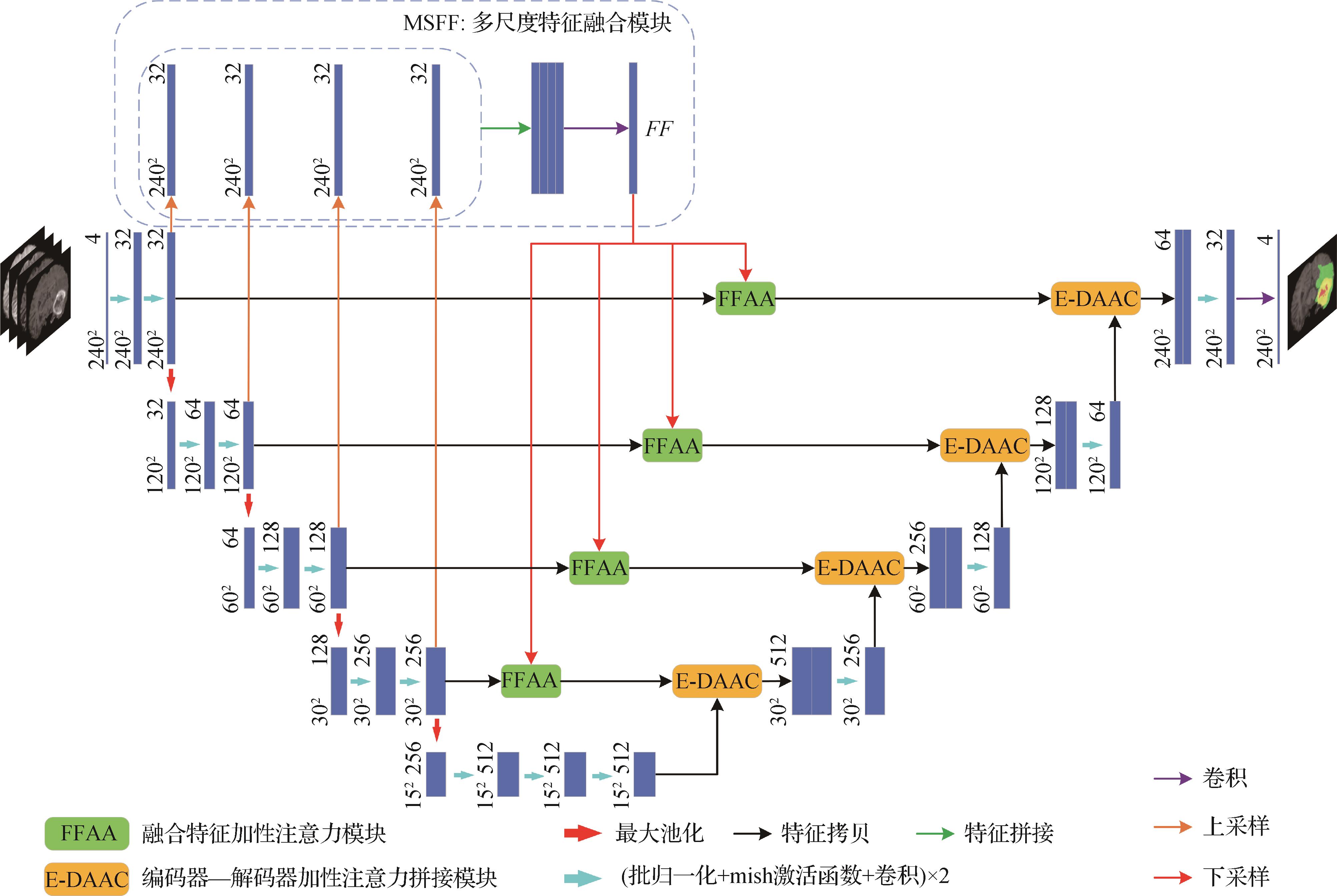 摘要:目的U-Net是医学图像分割领域中应用最为广泛的基础分割网络,然而U-Net及其各种增强网络在跳跃连接时仅利用相同尺度特征,忽略了具有互补信息的多尺度特征对当前尺度特征的指导作用。同时,跳跃连接时编码器特征和解码器特征所处的网络深度不同,二者直接串联会产生语义特征差距。针对这两个问题,提出了一种新型分割网络,以改进现有网络存在的不足。方法首先,将编码器不同层级具有不同尺度感受野的特征进行融合,并在融合特征与编码器各层级特征间引入加性注意力对编码器特征进行指导,以增强编码器特征的判别性;其次,在编码器特征和解码器特征间采用加性注意力来自适应地学习跳跃连接特征中的重要特征信息,以降低二者间的语义特征差距。结果在多模态脑肿瘤数据集BraTS2020(multimodal brain tumor segmentation challenge 2020)上评估了所提出的网络模型,并进行了消融实验和对比实验。实验结果表明,所提出的网络在BraTS2020验证数据集上关于整个肿瘤、肿瘤核心和增强肿瘤的平均Dice分别为0.887 5、0.719 4和0.706 4,优于2D网络DR-Unet104(deep residual Unet with 104 convolutional layers)的分割结果,其中肿瘤核心和增强肿瘤的分割结果分别高出后者4.73%和3.08%。结论所提出的分割网络模型,通过将编码器中具有互补信息的多尺度特征进行融合,然后对当前尺度特征进行加性注意力指导,同时在编码器和解码器特征间采用加性注意力机制来降低跳跃连接时二者间的语义特征差距,能更精准地分割MR(magnetic resonance)图像中脑肿瘤子区域。关键词:医学图像分割;脑肿瘤;磁共振(MR)图像;U-Net;多尺度特征融合;加性注意力196|443|1更新时间:2024-05-07
摘要:目的U-Net是医学图像分割领域中应用最为广泛的基础分割网络,然而U-Net及其各种增强网络在跳跃连接时仅利用相同尺度特征,忽略了具有互补信息的多尺度特征对当前尺度特征的指导作用。同时,跳跃连接时编码器特征和解码器特征所处的网络深度不同,二者直接串联会产生语义特征差距。针对这两个问题,提出了一种新型分割网络,以改进现有网络存在的不足。方法首先,将编码器不同层级具有不同尺度感受野的特征进行融合,并在融合特征与编码器各层级特征间引入加性注意力对编码器特征进行指导,以增强编码器特征的判别性;其次,在编码器特征和解码器特征间采用加性注意力来自适应地学习跳跃连接特征中的重要特征信息,以降低二者间的语义特征差距。结果在多模态脑肿瘤数据集BraTS2020(multimodal brain tumor segmentation challenge 2020)上评估了所提出的网络模型,并进行了消融实验和对比实验。实验结果表明,所提出的网络在BraTS2020验证数据集上关于整个肿瘤、肿瘤核心和增强肿瘤的平均Dice分别为0.887 5、0.719 4和0.706 4,优于2D网络DR-Unet104(deep residual Unet with 104 convolutional layers)的分割结果,其中肿瘤核心和增强肿瘤的分割结果分别高出后者4.73%和3.08%。结论所提出的分割网络模型,通过将编码器中具有互补信息的多尺度特征进行融合,然后对当前尺度特征进行加性注意力指导,同时在编码器和解码器特征间采用加性注意力机制来降低跳跃连接时二者间的语义特征差距,能更精准地分割MR(magnetic resonance)图像中脑肿瘤子区域。关键词:医学图像分割;脑肿瘤;磁共振(MR)图像;U-Net;多尺度特征融合;加性注意力196|443|1更新时间:2024-05-07 -
 摘要:目的胆囊癌作为胆道系统中一种恶性程度极高的肿瘤,早期诊断困难、预后极差,因此准确鉴别胆囊病变对早期发现胆囊癌具有重要意义。目前胆囊癌的诊断主要依赖于超声、CT(computed tomography)等传统影像学方法,但准确性较低。显微高光谱能够在获取生物组织图像信息的同时从生化角度对生物组织进行分析,从而实现对胆囊癌的早期诊断,相比于传统医学图像更具优势。因此,本文基于胆囊癌显微高光谱图像设计了一种基于多尺度融合注意力机制的网络模型,以提高分类准确率。方法提出多尺度融合注意力模块(multiscale squeeze-and-excitation-residual, MSE-Res)。MSE-Res模块引入改进的多尺度特征提取模块实现通道维上特征的融合,用一个最大池化层和一个上采样层代替1 × 1的卷积层来提取图像的显著特征。为了弥补池化层丢失的局部信息,在跳跃连接中加入一个1 × 1的卷积层。在多尺度特征提取模块后,引入注意力机制来学习不同通道间特征的相关性,实现通道间特征的融合,并通过残差连接使网络在提取图像深层特征的同时避免出现过拟合现象。结果在胆囊癌高光谱数据集上进行实验,本文模型的总体分类精度、平均分类精度和Kappa系数分别为99.599%、99.546%和0.990,性能优于SE-ResNet(squeeze-and-excitation-residual network)和Inception-SE-ResNet(inception-squeeze-and-excitation-residual network)。结论本文提出的MSE-ResNet能够有效利用高光谱图像的空间信息和光谱信息,提高胆囊癌分类准确率,在对胆囊癌的医学诊断方面具有一定的研究价值和现实意义。关键词:胆囊癌高光谱图像;多尺度特征融合;残差网络;图像分类;SE模块187|286|6更新时间:2024-05-07
摘要:目的胆囊癌作为胆道系统中一种恶性程度极高的肿瘤,早期诊断困难、预后极差,因此准确鉴别胆囊病变对早期发现胆囊癌具有重要意义。目前胆囊癌的诊断主要依赖于超声、CT(computed tomography)等传统影像学方法,但准确性较低。显微高光谱能够在获取生物组织图像信息的同时从生化角度对生物组织进行分析,从而实现对胆囊癌的早期诊断,相比于传统医学图像更具优势。因此,本文基于胆囊癌显微高光谱图像设计了一种基于多尺度融合注意力机制的网络模型,以提高分类准确率。方法提出多尺度融合注意力模块(multiscale squeeze-and-excitation-residual, MSE-Res)。MSE-Res模块引入改进的多尺度特征提取模块实现通道维上特征的融合,用一个最大池化层和一个上采样层代替1 × 1的卷积层来提取图像的显著特征。为了弥补池化层丢失的局部信息,在跳跃连接中加入一个1 × 1的卷积层。在多尺度特征提取模块后,引入注意力机制来学习不同通道间特征的相关性,实现通道间特征的融合,并通过残差连接使网络在提取图像深层特征的同时避免出现过拟合现象。结果在胆囊癌高光谱数据集上进行实验,本文模型的总体分类精度、平均分类精度和Kappa系数分别为99.599%、99.546%和0.990,性能优于SE-ResNet(squeeze-and-excitation-residual network)和Inception-SE-ResNet(inception-squeeze-and-excitation-residual network)。结论本文提出的MSE-ResNet能够有效利用高光谱图像的空间信息和光谱信息,提高胆囊癌分类准确率,在对胆囊癌的医学诊断方面具有一定的研究价值和现实意义。关键词:胆囊癌高光谱图像;多尺度特征融合;残差网络;图像分类;SE模块187|286|6更新时间:2024-05-07 -
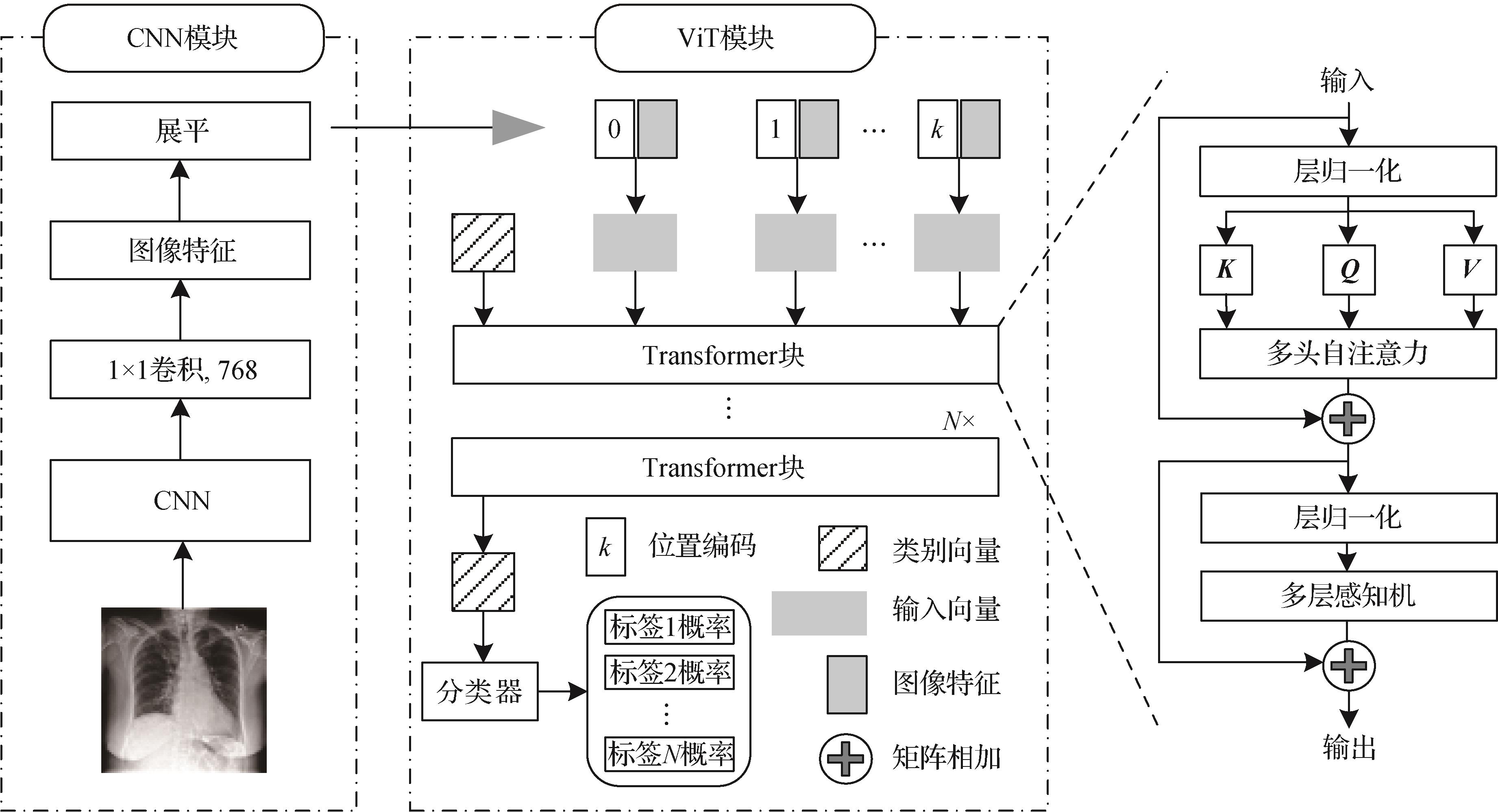 摘要:目的基于计算机的胸腔X线影像疾病检测和分类目前存在误诊率高,准确率低的问题。本文在视觉Transformer(vision Transformer,ViT)预训练模型的基础上,通过迁移学习方法,实现胸腔X线影像辅助诊断,提高诊断准确率和效率。方法选用带有卷积神经网络(convolutional neural network,CNN)的ViT模型,其在超大规模自然图像数据集中进行了预训练;通过微调模型结构,使用预训练的ViT模型参数初始化主干网络,并迁移至胸腔X线影像数据集中再次训练,实现疾病多标签分类。结果在IU X-Ray数据集中对ViT迁移学习前、后模型平均AUC(area under ROC curve)得分进行对比分析实验。结果表明,预训练ViT模型平均AUC得分为0.774,与不使用迁移学习相比提升了0.208。并针对模型结构和数据预处理进行了消融实验,对ViT中的注意力机制进行可视化,进一步验证了模型有效性。最后使用Chest X-Ray14和CheXpert数据集训练微调后的ViT模型,平均AUC得分为0.839和0.806,与对比方法相比分别有0.014~0.031的提升。结论与其他方法相比,ViT模型胸腔X线影像的多标签分类精确度更高,且迁移学习可以在降低训练成本的同时提升ViT模型的分类性能和泛化性。消融实验与模型可视化表明,包含CNN结构的ViT模型能重点关注有意义的区域,高效获取胸腔X线影像的视觉特征。关键词:胸腔X线影像;多标签分类;卷积神经网络(CNN);视觉Transformer(ViT);迁移学习263|443|1更新时间:2024-05-07
摘要:目的基于计算机的胸腔X线影像疾病检测和分类目前存在误诊率高,准确率低的问题。本文在视觉Transformer(vision Transformer,ViT)预训练模型的基础上,通过迁移学习方法,实现胸腔X线影像辅助诊断,提高诊断准确率和效率。方法选用带有卷积神经网络(convolutional neural network,CNN)的ViT模型,其在超大规模自然图像数据集中进行了预训练;通过微调模型结构,使用预训练的ViT模型参数初始化主干网络,并迁移至胸腔X线影像数据集中再次训练,实现疾病多标签分类。结果在IU X-Ray数据集中对ViT迁移学习前、后模型平均AUC(area under ROC curve)得分进行对比分析实验。结果表明,预训练ViT模型平均AUC得分为0.774,与不使用迁移学习相比提升了0.208。并针对模型结构和数据预处理进行了消融实验,对ViT中的注意力机制进行可视化,进一步验证了模型有效性。最后使用Chest X-Ray14和CheXpert数据集训练微调后的ViT模型,平均AUC得分为0.839和0.806,与对比方法相比分别有0.014~0.031的提升。结论与其他方法相比,ViT模型胸腔X线影像的多标签分类精确度更高,且迁移学习可以在降低训练成本的同时提升ViT模型的分类性能和泛化性。消融实验与模型可视化表明,包含CNN结构的ViT模型能重点关注有意义的区域,高效获取胸腔X线影像的视觉特征。关键词:胸腔X线影像;多标签分类;卷积神经网络(CNN);视觉Transformer(ViT);迁移学习263|443|1更新时间:2024-05-07 -
 摘要:目的针对人体组织器官及病灶区域的3维图像分割是计算机辅助医疗诊断的重要前提,是医学影像3维可视化的重要技术基础。深度学习方法在医学图像分割任务中的成功通常取决于大量有标注数据。半监督学习利用未标注数据容易获取的优点,在模型训练过程中使用少量标注数据和大量未标注数据进行学习,缓解了数据标注昂贵耗时的问题,在医学图像分割中受到了广泛关注。为更好地利用无标注数据,提升医学图像分割效果,提出一种新的一致性正则方法用于半监督3维医学图像分割。方法模型以V-Net为基础架构,通过扩展网络结构,在均带有分割任务及回归任务属性的双任务主副解码器之间添加了用于正则化约束的交叉损失,构建了具有形状感知的基于双任务的交叉一致性正则网络SACC-Net(shape-aware cross-consistency regular network based on dual tasks),实现将数据层面和模型层面的扰动融合进多任务机制的一致性正则方法,使模型能够更好地利用未标注数据的有效先验信息,并且具有更好的泛化性能。结果在MICCAI 2018(Medical Image Computing and Computer Assisted Intervention Society)心房分割挑战赛公布的数据集中的3维左心房核磁共振成像上验证本文算法,在仅使用训练集中10% 的有标注数据的实验组中,Dice系数、Jaccard指数、HD(Hausdorff distance)距离和平均对称表面距离分别为88.01%、78.89%、8.19和2.09。在另一组仅使用20%的有标注数据的实验中Dice系数、Jaccard指数、HD距离和平均对称表面距离分别达到90.11%、82.11%、6.57和1.78。结论本文提出的半监督分割模型性能显著,综合了数据、模型和任务层面的一致性正则约束,与其他半监督方法相比分割效果更好且具有更佳的泛化性能。关键词:医学影像;半监督学习;3维图像分割;一致性正则;核磁共振图像(MRI)128|315|1更新时间:2024-05-07
摘要:目的针对人体组织器官及病灶区域的3维图像分割是计算机辅助医疗诊断的重要前提,是医学影像3维可视化的重要技术基础。深度学习方法在医学图像分割任务中的成功通常取决于大量有标注数据。半监督学习利用未标注数据容易获取的优点,在模型训练过程中使用少量标注数据和大量未标注数据进行学习,缓解了数据标注昂贵耗时的问题,在医学图像分割中受到了广泛关注。为更好地利用无标注数据,提升医学图像分割效果,提出一种新的一致性正则方法用于半监督3维医学图像分割。方法模型以V-Net为基础架构,通过扩展网络结构,在均带有分割任务及回归任务属性的双任务主副解码器之间添加了用于正则化约束的交叉损失,构建了具有形状感知的基于双任务的交叉一致性正则网络SACC-Net(shape-aware cross-consistency regular network based on dual tasks),实现将数据层面和模型层面的扰动融合进多任务机制的一致性正则方法,使模型能够更好地利用未标注数据的有效先验信息,并且具有更好的泛化性能。结果在MICCAI 2018(Medical Image Computing and Computer Assisted Intervention Society)心房分割挑战赛公布的数据集中的3维左心房核磁共振成像上验证本文算法,在仅使用训练集中10% 的有标注数据的实验组中,Dice系数、Jaccard指数、HD(Hausdorff distance)距离和平均对称表面距离分别为88.01%、78.89%、8.19和2.09。在另一组仅使用20%的有标注数据的实验中Dice系数、Jaccard指数、HD距离和平均对称表面距离分别达到90.11%、82.11%、6.57和1.78。结论本文提出的半监督分割模型性能显著,综合了数据、模型和任务层面的一致性正则约束,与其他半监督方法相比分割效果更好且具有更佳的泛化性能。关键词:医学影像;半监督学习;3维图像分割;一致性正则;核磁共振图像(MRI)128|315|1更新时间:2024-05-07 -
 摘要:目的当前数字重建放射影像(digitally reconstructed radiograph,DRR)生成算法难以同时保证影像生成效率和质量。为此,提出一种基于循环一致性生成对抗网络(generative adversarial network, GAN)的新型DRR生成算法(cycle-GAN-DRR, CG-DRR),在保证生成效率的同时,兼顾生成影像与真实X射线影像的灰度和结构一致性。方法CG-DRR算法包含数据预处理、网络训练和网络应用3个阶段。数据预处理阶段准备后续网络训练需要的图像数据;网络训练阶段使用预处理后的数据训练循环一致性生成对抗网络;在应用阶段,训练后网络输入光线跟踪法生成的DRR图像实现DRR图像灰度校正。结果使用4个常用图像相似性指标和2个梯度相似性指标分别评估原始DRR图像与灰度校正后的DRR图像的灰度和几何结构一致性。与传统光线跟踪法相比,盆腔和胸腔数据平均峰值信噪比分别提高18.22 dB和8.82 dB,平均绝对误差分别减少0.18和0.07,归一化均方根误差分别减少0.23和0.10,结构相似度指数分别提高23.5%和13.5%,与当前最新RealDRR算法结果指标相差无几。与RealDRR算法结果相比,CG-DRR算法在DRR图像灰度校正前后人体组织结构保持更好的一致性,盆腔和胸腔数据图像特征相似性指数分别提高0.02和0.03,梯度相似性偏差分别减少0.18和0.03。CG-DRR算法生成一幅DRR图像平均耗时0.31 s。结论本文创新性地将循环一致性生成对抗机制应用于DRR生成,所提算法可以很好地应对实际临床中DRR图像与X光影像存在结构偏差的问题,可在保证生成效率的前提下兼顾灰度相似性及结构一致性,相比于现有算法更具优势。关键词:数字重建放射影像(DRR);灰度校正;深度学习;循环一致性对抗网络;梯度惩罚265|223|0更新时间:2024-05-07
摘要:目的当前数字重建放射影像(digitally reconstructed radiograph,DRR)生成算法难以同时保证影像生成效率和质量。为此,提出一种基于循环一致性生成对抗网络(generative adversarial network, GAN)的新型DRR生成算法(cycle-GAN-DRR, CG-DRR),在保证生成效率的同时,兼顾生成影像与真实X射线影像的灰度和结构一致性。方法CG-DRR算法包含数据预处理、网络训练和网络应用3个阶段。数据预处理阶段准备后续网络训练需要的图像数据;网络训练阶段使用预处理后的数据训练循环一致性生成对抗网络;在应用阶段,训练后网络输入光线跟踪法生成的DRR图像实现DRR图像灰度校正。结果使用4个常用图像相似性指标和2个梯度相似性指标分别评估原始DRR图像与灰度校正后的DRR图像的灰度和几何结构一致性。与传统光线跟踪法相比,盆腔和胸腔数据平均峰值信噪比分别提高18.22 dB和8.82 dB,平均绝对误差分别减少0.18和0.07,归一化均方根误差分别减少0.23和0.10,结构相似度指数分别提高23.5%和13.5%,与当前最新RealDRR算法结果指标相差无几。与RealDRR算法结果相比,CG-DRR算法在DRR图像灰度校正前后人体组织结构保持更好的一致性,盆腔和胸腔数据图像特征相似性指数分别提高0.02和0.03,梯度相似性偏差分别减少0.18和0.03。CG-DRR算法生成一幅DRR图像平均耗时0.31 s。结论本文创新性地将循环一致性生成对抗机制应用于DRR生成,所提算法可以很好地应对实际临床中DRR图像与X光影像存在结构偏差的问题,可在保证生成效率的前提下兼顾灰度相似性及结构一致性,相比于现有算法更具优势。关键词:数字重建放射影像(DRR);灰度校正;深度学习;循环一致性对抗网络;梯度惩罚265|223|0更新时间:2024-05-07
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0