
最新刊期
2023 年 第 28 卷 第 2 期
-
-
 摘要:生物视觉系统的研究一直是计算机视觉算法的重要灵感来源。有许多计算机视觉算法与生物视觉研究具有不同程度的对应关系,包括从纯粹的功能启发到用于解释生物观察的物理模型的方法。从视觉神经科学向计算机视觉界传达的经典观点是视觉皮层分层层次处理的结构。而人工神经网络设计的灵感来源正是视觉系统中的分层结构设计。深度神经网络在计算机视觉和机器学习等领域都占据主导地位。许多神经科学领域的学者也开始将深度神经网络应用在生物视觉系统的计算建模中。深度神经网络多层的结构设计加上误差的反向传播训练,使得它可以拟合绝大多数函数。因此,深度神经网络在学习视觉刺激与神经元响应的映射关系并取得目前性能最好的模型同时,网络内部的单元甚至学习出生物视觉系统子单元的表达。本文将从视网膜等初级视觉皮层和高级视觉皮层(如,视觉皮层第4区(visual area 4,V4)和下颞叶皮层(inferior temporal,IT))分别介绍基于神经网络的视觉系统编码模型。主要内容包括:1)有关视觉系统模型的概念与定义;2)初级视觉系统的神经网络预测模型;3)任务驱动的高级视觉皮层编码模型。最后本文还将介绍最新有关无监督学习的神经编码模型,并展望基于神经网络的视觉系统编码模型的技术挑战与可能的发展方向。关键词:生物视觉系统;分层结构设计;深度神经网络;视觉皮层编码模型;无监督学习230|105|1更新时间:2024-05-07
摘要:生物视觉系统的研究一直是计算机视觉算法的重要灵感来源。有许多计算机视觉算法与生物视觉研究具有不同程度的对应关系,包括从纯粹的功能启发到用于解释生物观察的物理模型的方法。从视觉神经科学向计算机视觉界传达的经典观点是视觉皮层分层层次处理的结构。而人工神经网络设计的灵感来源正是视觉系统中的分层结构设计。深度神经网络在计算机视觉和机器学习等领域都占据主导地位。许多神经科学领域的学者也开始将深度神经网络应用在生物视觉系统的计算建模中。深度神经网络多层的结构设计加上误差的反向传播训练,使得它可以拟合绝大多数函数。因此,深度神经网络在学习视觉刺激与神经元响应的映射关系并取得目前性能最好的模型同时,网络内部的单元甚至学习出生物视觉系统子单元的表达。本文将从视网膜等初级视觉皮层和高级视觉皮层(如,视觉皮层第4区(visual area 4,V4)和下颞叶皮层(inferior temporal,IT))分别介绍基于神经网络的视觉系统编码模型。主要内容包括:1)有关视觉系统模型的概念与定义;2)初级视觉系统的神经网络预测模型;3)任务驱动的高级视觉皮层编码模型。最后本文还将介绍最新有关无监督学习的神经编码模型,并展望基于神经网络的视觉系统编码模型的技术挑战与可能的发展方向。关键词:生物视觉系统;分层结构设计;深度神经网络;视觉皮层编码模型;无监督学习230|105|1更新时间:2024-05-07 -
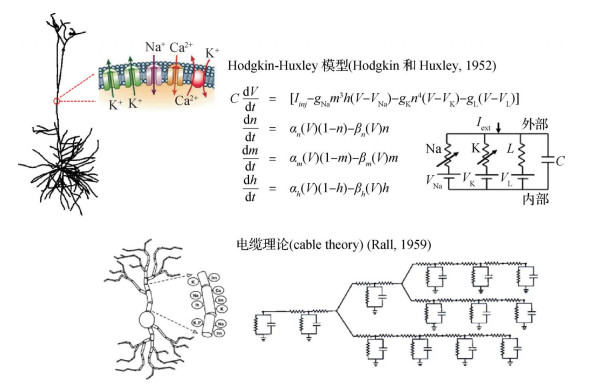 摘要:树突对大脑神经元实现不同的信息处理功能有着重要作用。精细神经元模型是一种对神经元树突以及离子通道的信息处理过程进行精细建模的模型,可以帮助科学家在实验条件的限制之外探索树突信息处理的特性。由精细神经元组成的精细神经网络模型可通过仿真对大脑的信息处理过程进行模拟,对于理解树突的信息处理机制、大脑神经网络功能背后的计算机理具有重要作用。然而,精细神经网络仿真需要进行大量计算,如何对精细神经网络进行高效仿真是一个具有挑战的研究问题。本文对精细神经网络仿真方法进行梳理,介绍了现有主流仿真平台与核心仿真算法,以及可进一步提升仿真效率的高效仿真方法。将具有代表性的高效仿真方法按照发展历程以及核心思路分为网络尺度并行方法、神经元尺度并行方法以及基于GPU(graphics processing unit)的并行仿真方法3类。对各类方法的核心思路进行总结,并对各类方法中代表性工作的细节进行分析介绍。随后对各类方法所具有的优劣势进行分析对比,对一些经典方法进行总结。最后根据高效仿真方法的发展趋势,对未来研究工作进行展望。关键词:神经形态计算;大脑仿真;树突计算;精细神经元模型;精细神经网络仿真130|175|0更新时间:2024-05-07
摘要:树突对大脑神经元实现不同的信息处理功能有着重要作用。精细神经元模型是一种对神经元树突以及离子通道的信息处理过程进行精细建模的模型,可以帮助科学家在实验条件的限制之外探索树突信息处理的特性。由精细神经元组成的精细神经网络模型可通过仿真对大脑的信息处理过程进行模拟,对于理解树突的信息处理机制、大脑神经网络功能背后的计算机理具有重要作用。然而,精细神经网络仿真需要进行大量计算,如何对精细神经网络进行高效仿真是一个具有挑战的研究问题。本文对精细神经网络仿真方法进行梳理,介绍了现有主流仿真平台与核心仿真算法,以及可进一步提升仿真效率的高效仿真方法。将具有代表性的高效仿真方法按照发展历程以及核心思路分为网络尺度并行方法、神经元尺度并行方法以及基于GPU(graphics processing unit)的并行仿真方法3类。对各类方法的核心思路进行总结,并对各类方法中代表性工作的细节进行分析介绍。随后对各类方法所具有的优劣势进行分析对比,对一些经典方法进行总结。最后根据高效仿真方法的发展趋势,对未来研究工作进行展望。关键词:神经形态计算;大脑仿真;树突计算;精细神经元模型;精细神经网络仿真130|175|0更新时间:2024-05-07 -
 摘要:视觉神经信息编解码旨在利用功能磁共振成像(functional magnetic resonance imaging,fMRI)等神经影像数据研究视觉刺激与大脑神经活动之间的关系。编码研究可以对神经活动模式进行建模和预测,有助于脑科学与类脑智能的发展;解码研究可以对人的视知觉状态进行解译,能够促进脑机接口领域的发展。因此,基于fMRI的视觉神经信息编解码方法研究具有重要的科学意义和工程价值。本文在总结基于fMRI的视觉神经信息编解码关键技术与研究进展的基础上,分析现有视觉神经信息编解码方法的局限。在视觉神经信息编码方面,详细介绍了基于群体感受野估计方法的发展过程;在视觉神经信息解码方面,首先,按照任务类型将其划分为语义分类、图像辨识和图像重建3个部分,并深入阐述了每个部分的代表性研究工作和所用的方法。特别地,在图像重建部分着重介绍了基于深度生成模型(主要包括变分自编码器和生成对抗网络)的简单图像、人脸图像和复杂自然图像的重建技术。其次,统计整理了该领域常用的10个开源数据集,并对数据集的样本规模、被试个数、刺激类型、研究用途及下载地址进行了详细归纳。最后,详细介绍了视觉神经信息编解码模型常用的度量指标,分析了当前视觉神经信息编码和解码方法的不足,提出可行的改进意见,并对未来发展方向进行展望。关键词:神经编码;神经解码;图像重建;视觉认知计算;深度学习;脑机接口(BCI)298|370|0更新时间:2024-05-07
摘要:视觉神经信息编解码旨在利用功能磁共振成像(functional magnetic resonance imaging,fMRI)等神经影像数据研究视觉刺激与大脑神经活动之间的关系。编码研究可以对神经活动模式进行建模和预测,有助于脑科学与类脑智能的发展;解码研究可以对人的视知觉状态进行解译,能够促进脑机接口领域的发展。因此,基于fMRI的视觉神经信息编解码方法研究具有重要的科学意义和工程价值。本文在总结基于fMRI的视觉神经信息编解码关键技术与研究进展的基础上,分析现有视觉神经信息编解码方法的局限。在视觉神经信息编码方面,详细介绍了基于群体感受野估计方法的发展过程;在视觉神经信息解码方面,首先,按照任务类型将其划分为语义分类、图像辨识和图像重建3个部分,并深入阐述了每个部分的代表性研究工作和所用的方法。特别地,在图像重建部分着重介绍了基于深度生成模型(主要包括变分自编码器和生成对抗网络)的简单图像、人脸图像和复杂自然图像的重建技术。其次,统计整理了该领域常用的10个开源数据集,并对数据集的样本规模、被试个数、刺激类型、研究用途及下载地址进行了详细归纳。最后,详细介绍了视觉神经信息编解码模型常用的度量指标,分析了当前视觉神经信息编码和解码方法的不足,提出可行的改进意见,并对未来发展方向进行展望。关键词:神经编码;神经解码;图像重建;视觉认知计算;深度学习;脑机接口(BCI)298|370|0更新时间:2024-05-07 -
 摘要:相较于第1代和第2代神经网络,第3代神经网络的脉冲神经网络是一种更加接近于生物神经网络的模型,因此更具有生物可解释性和低功耗性。基于脉冲神经元模型,脉冲神经网络可以通过脉冲信号的形式模拟生物信号在神经网络中的传播,通过脉冲神经元的膜电位变化来发放脉冲序列,脉冲序列通过时空联合表达不仅传递了空间信息还传递了时间信息。当前面向模式识别任务的脉冲神经网络模型性能还不及深度学习,其中一个重要原因在于脉冲神经网络的学习方法不成熟,深度学习中神经网络的人工神经元是基于实数形式的输出,这使得其可以使用全局性的反向传播算法对深度神经网络的参数进行训练,脉冲序列是二值性的离散输出,这直接导致对脉冲神经网络的训练存在一定困难,如何对脉冲神经网络进行高效训练是一个具有挑战的研究问题。本文首先总结了脉冲神经网络研究领域中的相关学习算法,然后对其中主要的方法:直接监督学习、无监督学习的算法以及ANN2SNN的转换算法进行分析介绍,并对其中代表性的工作进行对比分析,最后基于对当前主流方法的总结,对未来更高效、更仿生的脉冲神经网络参数学习方法进行展望。关键词:脉冲神经网络(SNN);学习算法;无监督学习;监督学习;脉冲神经元模型;图像识别259|508|2更新时间:2024-05-07
摘要:相较于第1代和第2代神经网络,第3代神经网络的脉冲神经网络是一种更加接近于生物神经网络的模型,因此更具有生物可解释性和低功耗性。基于脉冲神经元模型,脉冲神经网络可以通过脉冲信号的形式模拟生物信号在神经网络中的传播,通过脉冲神经元的膜电位变化来发放脉冲序列,脉冲序列通过时空联合表达不仅传递了空间信息还传递了时间信息。当前面向模式识别任务的脉冲神经网络模型性能还不及深度学习,其中一个重要原因在于脉冲神经网络的学习方法不成熟,深度学习中神经网络的人工神经元是基于实数形式的输出,这使得其可以使用全局性的反向传播算法对深度神经网络的参数进行训练,脉冲序列是二值性的离散输出,这直接导致对脉冲神经网络的训练存在一定困难,如何对脉冲神经网络进行高效训练是一个具有挑战的研究问题。本文首先总结了脉冲神经网络研究领域中的相关学习算法,然后对其中主要的方法:直接监督学习、无监督学习的算法以及ANN2SNN的转换算法进行分析介绍,并对其中代表性的工作进行对比分析,最后基于对当前主流方法的总结,对未来更高效、更仿生的脉冲神经网络参数学习方法进行展望。关键词:脉冲神经网络(SNN);学习算法;无监督学习;监督学习;脉冲神经元模型;图像识别259|508|2更新时间:2024-05-07 -
 摘要:随着深度学习在训练成本、泛化能力、可解释性以及可靠性等方面的不足日益突出,类脑计算已成为下一代人工智能的研究热点。脉冲神经网络能更好地模拟生物神经元的信息传递方式,且具有计算能力强、功耗低等特点,在模拟人脑学习、记忆、推理、判断和决策等复杂信息方面具有重要的潜力。本文对脉冲神经网络从以下几个方面进行总结:首先阐述脉冲神经网络的基本结构和工作原理;在结构优化方面,从脉冲神经网络的编码方式、脉冲神经元改进、拓扑结构、训练算法以及结合其他算法这5个方面进行总结;在训练算法方面,从基于反向传播方法、基于脉冲时序依赖可塑性规则方法、人工神经网络转脉冲神经网络和其他学习算法这4个方面进行总结;针对脉冲神经网络的不足与发展,从监督学习和无监督学习两方面剖析;最后,将脉冲神经网络应用到类脑计算和仿生任务中。本文对脉冲神经网络的基本原理、编码方式、网络结构和训练算法进行了系统归纳,对脉冲神经网络的研究发展具有一定的积极意义。关键词:类脑计算;脉冲神经网络(SNN);深度学习;网络结构;训练算法241|1629|1更新时间:2024-05-07
摘要:随着深度学习在训练成本、泛化能力、可解释性以及可靠性等方面的不足日益突出,类脑计算已成为下一代人工智能的研究热点。脉冲神经网络能更好地模拟生物神经元的信息传递方式,且具有计算能力强、功耗低等特点,在模拟人脑学习、记忆、推理、判断和决策等复杂信息方面具有重要的潜力。本文对脉冲神经网络从以下几个方面进行总结:首先阐述脉冲神经网络的基本结构和工作原理;在结构优化方面,从脉冲神经网络的编码方式、脉冲神经元改进、拓扑结构、训练算法以及结合其他算法这5个方面进行总结;在训练算法方面,从基于反向传播方法、基于脉冲时序依赖可塑性规则方法、人工神经网络转脉冲神经网络和其他学习算法这4个方面进行总结;针对脉冲神经网络的不足与发展,从监督学习和无监督学习两方面剖析;最后,将脉冲神经网络应用到类脑计算和仿生任务中。本文对脉冲神经网络的基本原理、编码方式、网络结构和训练算法进行了系统归纳,对脉冲神经网络的研究发展具有一定的积极意义。关键词:类脑计算;脉冲神经网络(SNN);深度学习;网络结构;训练算法241|1629|1更新时间:2024-05-07
类脑视觉

-
 摘要:目的准确快速的火焰检测技术在早期火灾预警中具有重要的实际应用价值。为了降低伪火类物体引起的误警率以及早期小火焰的漏检率,本文设计了一种结合感受野(receptive field,RF)模块与并联区域建议网络(parallel region proposal network,PRPN)的卷积神经网络(receptive field and parallel region proposal convolutional neural network,R-PRPNet)用于火焰检测。方法R-PRPNet主要由特征提取模块、并联区域建议网络和分类器3部分组成。特征提取模块在MobileNet卷积层的基础上,通过嵌入感受野RF模块扩大感受野捕获更丰富的上下文信息,从而提取更具鉴别性的火焰特征,降低伪火类物体引起的误警率;并联区域建议网络与特征提取模块后端的多尺度采样层连接,使用3×3和5×5的全卷积进一步拓宽多尺度锚点的感受野宽度,提升PRPN对不同尺度火焰的检测能力,解决火灾发生初期的小火焰漏检问题;分类器由softmax和smooth L1分别实现分类与回归。在R-PRPNet训练过程中,将伪火类物体作为负样本进行负样本微调,以更好区分伪火类物体。结果在包括室内、建筑物、森林和夜晚等场景火焰数据以及包括灯光、晚霞、火烧云和阳光等伪火类数据的自建数据集上对所提方法进行测试,在火焰检测任务中,准确度为98.07%,误警率为4.2%,漏检率为1.4%。消融实验结果表明,R-PRPNet较基线网络在漏检率和误警率上分别降低了4.9%和21.72%。与传统火焰检测方法相比,R-PRPNet在各项指标上均优于边缘梯度信息和聚类等方法。性能较几种目标检测算法有所提升,其中相较于YOLOX-L,误警率和漏检率分别降低了22.2%和5.2%。此外,本文在不同场景火焰下进行测试,都有较稳定的表现。结论本文方法有效降低了火焰检测中的误警率和漏检率,并可以满足火焰检测的实时性和准确性需求。关键词:火焰检测;深度学习;感受野(RF);并联区域建议网络(PRPN);负样本微调83|234|0更新时间:2024-05-07
摘要:目的准确快速的火焰检测技术在早期火灾预警中具有重要的实际应用价值。为了降低伪火类物体引起的误警率以及早期小火焰的漏检率,本文设计了一种结合感受野(receptive field,RF)模块与并联区域建议网络(parallel region proposal network,PRPN)的卷积神经网络(receptive field and parallel region proposal convolutional neural network,R-PRPNet)用于火焰检测。方法R-PRPNet主要由特征提取模块、并联区域建议网络和分类器3部分组成。特征提取模块在MobileNet卷积层的基础上,通过嵌入感受野RF模块扩大感受野捕获更丰富的上下文信息,从而提取更具鉴别性的火焰特征,降低伪火类物体引起的误警率;并联区域建议网络与特征提取模块后端的多尺度采样层连接,使用3×3和5×5的全卷积进一步拓宽多尺度锚点的感受野宽度,提升PRPN对不同尺度火焰的检测能力,解决火灾发生初期的小火焰漏检问题;分类器由softmax和smooth L1分别实现分类与回归。在R-PRPNet训练过程中,将伪火类物体作为负样本进行负样本微调,以更好区分伪火类物体。结果在包括室内、建筑物、森林和夜晚等场景火焰数据以及包括灯光、晚霞、火烧云和阳光等伪火类数据的自建数据集上对所提方法进行测试,在火焰检测任务中,准确度为98.07%,误警率为4.2%,漏检率为1.4%。消融实验结果表明,R-PRPNet较基线网络在漏检率和误警率上分别降低了4.9%和21.72%。与传统火焰检测方法相比,R-PRPNet在各项指标上均优于边缘梯度信息和聚类等方法。性能较几种目标检测算法有所提升,其中相较于YOLOX-L,误警率和漏检率分别降低了22.2%和5.2%。此外,本文在不同场景火焰下进行测试,都有较稳定的表现。结论本文方法有效降低了火焰检测中的误警率和漏检率,并可以满足火焰检测的实时性和准确性需求。关键词:火焰检测;深度学习;感受野(RF);并联区域建议网络(PRPN);负样本微调83|234|0更新时间:2024-05-07 -
 摘要:目的对旅客行李进行安全检查是维护公共安全的措施之一,安检智能化是未来的发展方向。基于X光图像的安检因不同的安检机成像方式不同,同一类违禁品在不同设备上的X光图像在颜色分布上有很大差异,导致安检图像智能识别算法在训练与测试数据分布不同时,识别性能明显降低,同时X光行李图像中物品的混乱复杂增加了违禁品识别的难度。针对上述问题,本文提出一种区域增强和多特征融合模型。方法首先,通过注意力机制的思想提取一种区域增强特征,消除颜色分布不同的影响,保留图像整体结构并增强违禁品区域信息。然后,采用多特征融合策略丰富特征信息,使模型适用于图像中物品混乱复杂情况。最后,提出一种三元损失函数优化特征融合。结果在公开数据集SIXray数据集上进行整体识别性能和泛化性能的实验分析,即测试本文方法在相同和不同颜色分布样本上的性能。在整体识别性能方面,本文方法在平均精度均值(mean average precision,mAP)上相较于基础模型ResNet18和ResNet34分别提升了4.09%和2.26%,并优于一些其他识别方法。对于单类违禁品,本文方法在枪支和钳子类违禁品上的平均识别精度为94.25%和90.89%,相较于对比方法有明显优势。在泛化性能方面,本文方法在SIXray_last101子数据集上可正确识别26张含违禁品样本,是基础模型能够正确识别数量的4.3倍,表明本文方法在颜色分布不同样本上的有效性。结论本文方法根据X光安检图像颜色差异的特点设计出一种区域增强特征,并与彩色和边缘特征融合,以获取多元化信息,在枪支、刀具、钳子等违禁品的识别任务中表现出较好效果,有效缓解了图像颜色分布差异导致的性能下降问题。关键词:X光安检图像;违禁品识别;区域增强;注意力机制;多特征融合107|151|0更新时间:2024-05-07
摘要:目的对旅客行李进行安全检查是维护公共安全的措施之一,安检智能化是未来的发展方向。基于X光图像的安检因不同的安检机成像方式不同,同一类违禁品在不同设备上的X光图像在颜色分布上有很大差异,导致安检图像智能识别算法在训练与测试数据分布不同时,识别性能明显降低,同时X光行李图像中物品的混乱复杂增加了违禁品识别的难度。针对上述问题,本文提出一种区域增强和多特征融合模型。方法首先,通过注意力机制的思想提取一种区域增强特征,消除颜色分布不同的影响,保留图像整体结构并增强违禁品区域信息。然后,采用多特征融合策略丰富特征信息,使模型适用于图像中物品混乱复杂情况。最后,提出一种三元损失函数优化特征融合。结果在公开数据集SIXray数据集上进行整体识别性能和泛化性能的实验分析,即测试本文方法在相同和不同颜色分布样本上的性能。在整体识别性能方面,本文方法在平均精度均值(mean average precision,mAP)上相较于基础模型ResNet18和ResNet34分别提升了4.09%和2.26%,并优于一些其他识别方法。对于单类违禁品,本文方法在枪支和钳子类违禁品上的平均识别精度为94.25%和90.89%,相较于对比方法有明显优势。在泛化性能方面,本文方法在SIXray_last101子数据集上可正确识别26张含违禁品样本,是基础模型能够正确识别数量的4.3倍,表明本文方法在颜色分布不同样本上的有效性。结论本文方法根据X光安检图像颜色差异的特点设计出一种区域增强特征,并与彩色和边缘特征融合,以获取多元化信息,在枪支、刀具、钳子等违禁品的识别任务中表现出较好效果,有效缓解了图像颜色分布差异导致的性能下降问题。关键词:X光安检图像;违禁品识别;区域增强;注意力机制;多特征融合107|151|0更新时间:2024-05-07 -
 摘要:目的针对低视点多目标跟踪场景的遮挡问题,提出一种能够遮挡自适应感知的多目标跟踪算法。方法首先根据每帧图像的全局遮挡状态,提出了“自适应抗遮挡特征”,增强目标特征对遮挡的感知和调整能力。同时,采用“级联筛查机制”,减少由遮挡带来的目标特征剧烈变化而认定为“虚新入目标”的错误跟踪现象。最后,考虑到历史模板库中存在遮挡的模板对跟踪性能的影响,根据每一帧中目标的局部遮挡状态,提出自适应干扰模板更新机制,进一步提高对遮挡的应变和适应能力。结果实验结果表明,本文算法在MOTA(multiple object tracking accuracy)、MOTP(multiple object tracking precision)、FN(false negatives)、Rcll(recall)、ML(mostly lost tracklets)等指标上明显优于STAM(spatial-temporal attention mechanism)、ATAF(aggregate tracklet appearance features)、STRN(spatial-temporal relation network)、BLSTM_MTP_O(bilinear long short-term memory with multi-track pooling)、IADMR(instance-aware tracker and dynamic model refreshment)等典型算法。消融实验表明,自适应抗遮挡特征在MOTA指标上,相比混合特征、外观特征和运动特征分别提升了1.9%、1.8%和13.6%。去干扰模板更新策略在MOTA指标上,相比带权更新策略和常规更新策略分别提升了10.7%和17.7%。结论本文算法在低视点跟踪场景下,能够减弱部分遮挡、短时全遮挡和长时全遮挡对跟踪性能的影响,跟踪鲁棒性得到了提升。关键词:多目标跟踪;低视点;遮挡;抗遮挡特征;数据关联;模板更新122|422|3更新时间:2024-05-07
摘要:目的针对低视点多目标跟踪场景的遮挡问题,提出一种能够遮挡自适应感知的多目标跟踪算法。方法首先根据每帧图像的全局遮挡状态,提出了“自适应抗遮挡特征”,增强目标特征对遮挡的感知和调整能力。同时,采用“级联筛查机制”,减少由遮挡带来的目标特征剧烈变化而认定为“虚新入目标”的错误跟踪现象。最后,考虑到历史模板库中存在遮挡的模板对跟踪性能的影响,根据每一帧中目标的局部遮挡状态,提出自适应干扰模板更新机制,进一步提高对遮挡的应变和适应能力。结果实验结果表明,本文算法在MOTA(multiple object tracking accuracy)、MOTP(multiple object tracking precision)、FN(false negatives)、Rcll(recall)、ML(mostly lost tracklets)等指标上明显优于STAM(spatial-temporal attention mechanism)、ATAF(aggregate tracklet appearance features)、STRN(spatial-temporal relation network)、BLSTM_MTP_O(bilinear long short-term memory with multi-track pooling)、IADMR(instance-aware tracker and dynamic model refreshment)等典型算法。消融实验表明,自适应抗遮挡特征在MOTA指标上,相比混合特征、外观特征和运动特征分别提升了1.9%、1.8%和13.6%。去干扰模板更新策略在MOTA指标上,相比带权更新策略和常规更新策略分别提升了10.7%和17.7%。结论本文算法在低视点跟踪场景下,能够减弱部分遮挡、短时全遮挡和长时全遮挡对跟踪性能的影响,跟踪鲁棒性得到了提升。关键词:多目标跟踪;低视点;遮挡;抗遮挡特征;数据关联;模板更新122|422|3更新时间:2024-05-07 -
 摘要:目的基于相关滤波的跟踪算法在无人机(unmanned aerial vehicle,UAV)视觉跟踪领域表现出卓越的性能。现有的相关滤波类跟踪算法从样本区域的所有特征中学习滤波器,然而某些来自遮挡或形变的特征可能会污染滤波器,降低模型判别能力。针对此问题,提出一种稀疏约束的时空正则相关滤波跟踪算法。方法在相关滤波目标函数上施加空间弹性网络约束以自适应地抑制跟踪过程中的干扰特征,同时集成空间—时间正则相关滤波算法(spatial-temporal regularized correlation filter,STRCF)中的时间正则项以增强滤波器抑制畸变的能力。采用交替方向乘子法(alternating direction method of multipliers,ADMM)将带有约束项的目标函数转化为两个具有闭式解的子问题迭代求局部最优解。此外,提出一种相关滤波框架通用的加速策略,根据当前帧的目标位移量,对检测定位阶段的特征矩阵进行等距离的循环移位,将其作为在线学习阶段的特征矩阵,每帧可节省一次训练样本的特征提取操作,提高跟踪速度。结果在3个UAV数据集上与14种主流跟踪算法进行对比实验,在DTB70(drone tracking benchmark)数据集中,平均精确率与平均成功率分别为0.707和0.477,在所有对比算法中位列第1,相比较STRCF分别提高了5.8%和4%;在UAVDT(the unmanned aerial vehicle benchmark:object detection and tracking)数据集中,平均精确率与平均成功率相比较STRCF分别提高了8.4%和3.8%;在UAV123_10 fps数据集中,平均精确率与平均成功率相比较STRCF分别提高了4%和3.3%。同时,消融实验结果表明,加速策略在不显著影响跟踪精度(±0.1%)的前提下,可提高跟踪速度约25%,在单个CPU上的跟踪速度为50帧/s。结论本文算法结合了稀疏约束与时间—空间正则化的优势,与对比算法相比,在遮挡、形变等复杂情况下跟踪效果更加鲁棒。关键词:无人机跟踪;相关滤波(CF);稀疏约束;时间—空间正则化;弹性网络;交替方向乘子法(ADMM);循环移位89|241|1更新时间:2024-05-07
摘要:目的基于相关滤波的跟踪算法在无人机(unmanned aerial vehicle,UAV)视觉跟踪领域表现出卓越的性能。现有的相关滤波类跟踪算法从样本区域的所有特征中学习滤波器,然而某些来自遮挡或形变的特征可能会污染滤波器,降低模型判别能力。针对此问题,提出一种稀疏约束的时空正则相关滤波跟踪算法。方法在相关滤波目标函数上施加空间弹性网络约束以自适应地抑制跟踪过程中的干扰特征,同时集成空间—时间正则相关滤波算法(spatial-temporal regularized correlation filter,STRCF)中的时间正则项以增强滤波器抑制畸变的能力。采用交替方向乘子法(alternating direction method of multipliers,ADMM)将带有约束项的目标函数转化为两个具有闭式解的子问题迭代求局部最优解。此外,提出一种相关滤波框架通用的加速策略,根据当前帧的目标位移量,对检测定位阶段的特征矩阵进行等距离的循环移位,将其作为在线学习阶段的特征矩阵,每帧可节省一次训练样本的特征提取操作,提高跟踪速度。结果在3个UAV数据集上与14种主流跟踪算法进行对比实验,在DTB70(drone tracking benchmark)数据集中,平均精确率与平均成功率分别为0.707和0.477,在所有对比算法中位列第1,相比较STRCF分别提高了5.8%和4%;在UAVDT(the unmanned aerial vehicle benchmark:object detection and tracking)数据集中,平均精确率与平均成功率相比较STRCF分别提高了8.4%和3.8%;在UAV123_10 fps数据集中,平均精确率与平均成功率相比较STRCF分别提高了4%和3.3%。同时,消融实验结果表明,加速策略在不显著影响跟踪精度(±0.1%)的前提下,可提高跟踪速度约25%,在单个CPU上的跟踪速度为50帧/s。结论本文算法结合了稀疏约束与时间—空间正则化的优势,与对比算法相比,在遮挡、形变等复杂情况下跟踪效果更加鲁棒。关键词:无人机跟踪;相关滤波(CF);稀疏约束;时间—空间正则化;弹性网络;交替方向乘子法(ADMM);循环移位89|241|1更新时间:2024-05-07 -
 摘要:目的车辆重识别指判断不同摄像设备拍摄的车辆图像是否属于同一辆车的检索问题。现有车辆重识别算法使用车辆的全局特征或额外的标注信息,忽略了对多尺度上下文信息的有效抽取。对此,本文提出了一种融合全局与空间多尺度上下文信息的车辆重识别模型。方法首先,设计一个全局上下文特征选择模块,提取车辆的细粒度判别信息,并且进一步设计了一个多尺度空间上下文特征选择模块,利用多尺度下采样的方式,从全局上下文特征选择模块输出的判别特征中获得其对应的多尺度特征。然后,选择性地集成来自多级特征的空间上下文信息,生成车辆图像的前景特征响应图,以此提升模型对于车辆空间位置特征的感知能力。最后,模型组合了标签平滑的交叉熵损失函数和三元组损失函数,以提升模型对强判别车辆特征的整体学习能力。结果在VeRi-776(vehicle re-idendification-776)数据集上,与模型PNVR(part-regularized near-duplicate vehicle re-identification)相比,本文模型的mAP(mean average precision)和rank-1(cumulative matching curve at rank 1)评价指标分别提升了2.3%和2.0%。在该数据集上的消融实验验证了各模块的有效性。在Vehicle ID数据集的大规模测试子集上,就rank-1和rank-5(cumulative matching curve at rank 5)而言,本文模型的mAP比PNVR分别提升了0.8%和4.5%。结论本文算法利用全局上下文特征和多尺度空间特征,提升了拍摄视角变化、遮挡等情况下车辆重识别的准确率,实验结果充分表明了所提模型的有效性与可行性。关键词:车辆重识别;深度学习;局部可区分性特征;特征选择;多尺度空间特征238|219|3更新时间:2024-05-07
摘要:目的车辆重识别指判断不同摄像设备拍摄的车辆图像是否属于同一辆车的检索问题。现有车辆重识别算法使用车辆的全局特征或额外的标注信息,忽略了对多尺度上下文信息的有效抽取。对此,本文提出了一种融合全局与空间多尺度上下文信息的车辆重识别模型。方法首先,设计一个全局上下文特征选择模块,提取车辆的细粒度判别信息,并且进一步设计了一个多尺度空间上下文特征选择模块,利用多尺度下采样的方式,从全局上下文特征选择模块输出的判别特征中获得其对应的多尺度特征。然后,选择性地集成来自多级特征的空间上下文信息,生成车辆图像的前景特征响应图,以此提升模型对于车辆空间位置特征的感知能力。最后,模型组合了标签平滑的交叉熵损失函数和三元组损失函数,以提升模型对强判别车辆特征的整体学习能力。结果在VeRi-776(vehicle re-idendification-776)数据集上,与模型PNVR(part-regularized near-duplicate vehicle re-identification)相比,本文模型的mAP(mean average precision)和rank-1(cumulative matching curve at rank 1)评价指标分别提升了2.3%和2.0%。在该数据集上的消融实验验证了各模块的有效性。在Vehicle ID数据集的大规模测试子集上,就rank-1和rank-5(cumulative matching curve at rank 5)而言,本文模型的mAP比PNVR分别提升了0.8%和4.5%。结论本文算法利用全局上下文特征和多尺度空间特征,提升了拍摄视角变化、遮挡等情况下车辆重识别的准确率,实验结果充分表明了所提模型的有效性与可行性。关键词:车辆重识别;深度学习;局部可区分性特征;特征选择;多尺度空间特征238|219|3更新时间:2024-05-07
图像分析和识别
-
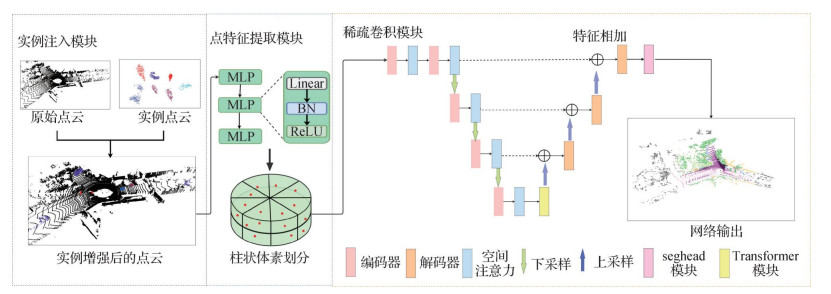 摘要:目的雷达点云语义分割是3维环境感知的重要环节,准确分割雷达点云对象对无人驾驶汽车和自主移动机器人等应用具有重要意义。由于雷达点云数据具有非结构化特征,为提取有效的语义信息,通常将不规则的点云数据投影成结构化的2维图像,但会造成点云数据中几何信息丢失,不能得到高精度分割效果。此外,真实数据集中存在数据分布不均匀问题,导致小样本物体分割效果较差。为解决这些问题,本文提出一种基于稀疏注意力和实例增强的雷达点云分割方法,有效提高了激光雷达点云语义分割精度。方法针对数据集中数据分布不平衡问题,采用实例注入方式增强点云数据。首先,通过提取数据集中的点云实例数据,并在训练中将实例数据注入到每一帧点云中,实现实例增强的效果。由于稀疏卷积网络不能获得较大的感受野,提出Transformer模块扩大网络的感受野。为了提取特征图的关键信息,使用基于稀疏卷积的空间注意力机制,显著提高了网络性能。另外,对不同类别点云对象的边缘,提出新的TVloss用于增强网络的监督能力。结果本文提出的模型在SemanticKITTI和nuScenes数据集上进行测试。在SemanticKITTI数据集上,本文方法在线单帧精度在平均交并比(mean intersection over union,mIoU)指标上为64.6%,在nuScenes数据集上为75.6%。消融实验表明,本文方法的精度在baseline的基础上提高了3.1%。结论实验结果表明,本文提出的基于稀疏注意力和实例增强的雷达点云分割方法在SemanticKITTI和nuScenes数据集上都取得了较好表现,提高了网络对点云细节的分割能力,使点云分割结果更加准确。关键词:激光雷达(LiDAR);语义分割;空间注意力机制;Transformer;深度学习(DL);实例增强195|346|2更新时间:2024-05-07
摘要:目的雷达点云语义分割是3维环境感知的重要环节,准确分割雷达点云对象对无人驾驶汽车和自主移动机器人等应用具有重要意义。由于雷达点云数据具有非结构化特征,为提取有效的语义信息,通常将不规则的点云数据投影成结构化的2维图像,但会造成点云数据中几何信息丢失,不能得到高精度分割效果。此外,真实数据集中存在数据分布不均匀问题,导致小样本物体分割效果较差。为解决这些问题,本文提出一种基于稀疏注意力和实例增强的雷达点云分割方法,有效提高了激光雷达点云语义分割精度。方法针对数据集中数据分布不平衡问题,采用实例注入方式增强点云数据。首先,通过提取数据集中的点云实例数据,并在训练中将实例数据注入到每一帧点云中,实现实例增强的效果。由于稀疏卷积网络不能获得较大的感受野,提出Transformer模块扩大网络的感受野。为了提取特征图的关键信息,使用基于稀疏卷积的空间注意力机制,显著提高了网络性能。另外,对不同类别点云对象的边缘,提出新的TVloss用于增强网络的监督能力。结果本文提出的模型在SemanticKITTI和nuScenes数据集上进行测试。在SemanticKITTI数据集上,本文方法在线单帧精度在平均交并比(mean intersection over union,mIoU)指标上为64.6%,在nuScenes数据集上为75.6%。消融实验表明,本文方法的精度在baseline的基础上提高了3.1%。结论实验结果表明,本文提出的基于稀疏注意力和实例增强的雷达点云分割方法在SemanticKITTI和nuScenes数据集上都取得了较好表现,提高了网络对点云细节的分割能力,使点云分割结果更加准确。关键词:激光雷达(LiDAR);语义分割;空间注意力机制;Transformer;深度学习(DL);实例增强195|346|2更新时间:2024-05-07 -
 摘要:目的实例分割通过像素级实例掩膜对图像中不同目标进行分类和定位。然而不同目标在图像中往往存在尺度差异,目标多尺度变化容易错检和漏检,导致实例分割精度提高受限。现有方法主要通过特征金字塔网络(feature pyramid network,FPN)提取多尺度信息,但是FPN采用插值和元素相加进行邻层特征融合的方式未能充分挖掘不同尺度特征的语义信息。因此,本文在Mask R-CNN(mask region-based convolutional neural network)的基础上,提出注意力引导的特征金字塔网络,并充分融合多尺度上下文信息进行实例分割。方法首先,设计邻层特征自适应融合模块优化FPN邻层特征融合,通过内容感知重组对特征上采样,并在融合相邻特征前引入通道注意力机制对通道加权增强语义一致性,缓解邻层不同尺度目标间的语义混叠;其次,利用多尺度通道注意力设计注意力特征融合模块和全局上下文模块,对感兴趣区域(region of interest,RoI)特征和多尺度上下文信息进行融合,增强分类回归和掩膜预测分支的多尺度特征表示,进而提高对不同尺度目标的掩膜预测质量。结果在MS COCO 2017(Microsoft common objects in context 2017)和Cityscapes数据集上进行综合实验。在MS COCO 2017数据集上,本文算法相较于Mask R-CNN在主干网络为ResNet50/101时分别提高了1.7%和2.5%;在Cityscapes数据集上,以ResNet50为主干网络,在验证集和测试集上进行评估,比Mask R-CNN分别提高了2.1%和2.3%。可视化结果显示,所提方法对不同尺度目标定位更精准,在相互遮挡和不同目标分界处的分割效果显著改善。结论本文算法有效提高了网络对不同尺度目标检测和分割的准确率。关键词:实例分割;Mask R-CNN;特征金字塔网络(FPN);多尺度上下文信息;多尺度通道注意力(MSCA)116|205|1更新时间:2024-05-07
摘要:目的实例分割通过像素级实例掩膜对图像中不同目标进行分类和定位。然而不同目标在图像中往往存在尺度差异,目标多尺度变化容易错检和漏检,导致实例分割精度提高受限。现有方法主要通过特征金字塔网络(feature pyramid network,FPN)提取多尺度信息,但是FPN采用插值和元素相加进行邻层特征融合的方式未能充分挖掘不同尺度特征的语义信息。因此,本文在Mask R-CNN(mask region-based convolutional neural network)的基础上,提出注意力引导的特征金字塔网络,并充分融合多尺度上下文信息进行实例分割。方法首先,设计邻层特征自适应融合模块优化FPN邻层特征融合,通过内容感知重组对特征上采样,并在融合相邻特征前引入通道注意力机制对通道加权增强语义一致性,缓解邻层不同尺度目标间的语义混叠;其次,利用多尺度通道注意力设计注意力特征融合模块和全局上下文模块,对感兴趣区域(region of interest,RoI)特征和多尺度上下文信息进行融合,增强分类回归和掩膜预测分支的多尺度特征表示,进而提高对不同尺度目标的掩膜预测质量。结果在MS COCO 2017(Microsoft common objects in context 2017)和Cityscapes数据集上进行综合实验。在MS COCO 2017数据集上,本文算法相较于Mask R-CNN在主干网络为ResNet50/101时分别提高了1.7%和2.5%;在Cityscapes数据集上,以ResNet50为主干网络,在验证集和测试集上进行评估,比Mask R-CNN分别提高了2.1%和2.3%。可视化结果显示,所提方法对不同尺度目标定位更精准,在相互遮挡和不同目标分界处的分割效果显著改善。结论本文算法有效提高了网络对不同尺度目标检测和分割的准确率。关键词:实例分割;Mask R-CNN;特征金字塔网络(FPN);多尺度上下文信息;多尺度通道注意力(MSCA)116|205|1更新时间:2024-05-07 -
 摘要:目的图表问答是计算机视觉多模态学习的一项重要研究任务,传统关系网络(relation network,RN)模型简单的两两配对方法可以包含所有像素之间的关系,因此取得了不错的结果,但此方法不仅包含冗余信息,而且平方式增长的关系配对的特征数量会给后续的推理网络在计算量和参数量上带来很大的负担。针对这个问题,提出了一种基于融合语义特征提取的引导性权重驱动的重定位关系网络模型来改善不足。方法首先通过融合场景任务的低级和高级图像特征来提取更丰富的统计图语义信息,同时提出了一种基于注意力机制的文本编码器,实现融合语义的特征提取,然后对引导性权重进行排序进一步重构图像的位置,从而构建了重定位的关系网络模型。结果在2个数据集上进行实验比较,在FigureQA(an annotated figure dataset for visual reasoning)数据集中,相较于IMG+QUES(image+questions)、RN和ARN(appearance and relation networks),本文方法的整体准确率分别提升了26.4%,8.1%,0.46%,在单一验证集上,相较于LEAF-Net(locate,encode and attend for figure network)和FigureNet,本文方法的准确率提升了2.3%,2.0%;在DVQA(understanding data visualization via question answering)数据集上,对于不使用OCR(optical character recognition)方法,相较于SANDY(san with dynamic encoding model)、ARN和RN,整体准确率分别提升了8.6%,0.12%,2.13%;对于有Oracle版本,相较于SANDY、LEAF-Net和RN,整体准确率分别提升了23.3%,7.09%,4.8%。结论本文算法围绕图表问答任务,在DVQA和FigureQA两个开源数据集上分别提升了准确率。关键词:计算机视觉;图表问答(FQA);多模态融合;注意力机制;关系网络(RN);深度学习87|252|2更新时间:2024-05-07
摘要:目的图表问答是计算机视觉多模态学习的一项重要研究任务,传统关系网络(relation network,RN)模型简单的两两配对方法可以包含所有像素之间的关系,因此取得了不错的结果,但此方法不仅包含冗余信息,而且平方式增长的关系配对的特征数量会给后续的推理网络在计算量和参数量上带来很大的负担。针对这个问题,提出了一种基于融合语义特征提取的引导性权重驱动的重定位关系网络模型来改善不足。方法首先通过融合场景任务的低级和高级图像特征来提取更丰富的统计图语义信息,同时提出了一种基于注意力机制的文本编码器,实现融合语义的特征提取,然后对引导性权重进行排序进一步重构图像的位置,从而构建了重定位的关系网络模型。结果在2个数据集上进行实验比较,在FigureQA(an annotated figure dataset for visual reasoning)数据集中,相较于IMG+QUES(image+questions)、RN和ARN(appearance and relation networks),本文方法的整体准确率分别提升了26.4%,8.1%,0.46%,在单一验证集上,相较于LEAF-Net(locate,encode and attend for figure network)和FigureNet,本文方法的准确率提升了2.3%,2.0%;在DVQA(understanding data visualization via question answering)数据集上,对于不使用OCR(optical character recognition)方法,相较于SANDY(san with dynamic encoding model)、ARN和RN,整体准确率分别提升了8.6%,0.12%,2.13%;对于有Oracle版本,相较于SANDY、LEAF-Net和RN,整体准确率分别提升了23.3%,7.09%,4.8%。结论本文算法围绕图表问答任务,在DVQA和FigureQA两个开源数据集上分别提升了准确率。关键词:计算机视觉;图表问答(FQA);多模态融合;注意力机制;关系网络(RN);深度学习87|252|2更新时间:2024-05-07 -
 摘要:目的视觉定位旨在利用易于获取的RGB图像对运动物体进行目标定位及姿态估计。室内场景中普遍存在的物体遮挡、弱纹理区域等干扰极易造成目标关键点的错误估计,严重影响了视觉定位的精度。针对这一问题,本文提出一种主被动融合的室内定位系统,结合固定视角和移动视角的方案优势,实现室内场景中运动目标的精准定位。方法提出一种基于平面先验的物体位姿估计方法,在关键点检测的单目定位框架基础上,使用平面约束进行3自由度姿态优化,提升固定视角下室内平面中运动目标的定位稳定性。基于无损卡尔曼滤波算法设计了一套数据融合定位系统,将从固定视角得到的被动式定位结果与从移动视角得到的主动式定位结果进行融合,提升了运动目标的位姿估计结果的可靠性。结果本文提出的主被动融合室内视觉定位系统在iGibson仿真数据集上的平均定位精度为2~3 cm,定位误差在10 cm内的准确率为99%;在真实场景中平均定位精度为3~4 cm,定位误差在10 cm内的准确率在90%以上,实现了cm级的定位精度。结论提出的室内视觉定位系统融合了被动式和主动式定位方法的优势,能够以较低设备成本实现室内场景中高精度的目标定位结果,并在遮挡、目标丢失等复杂环境因素干扰下展示出鲁棒的定位性能。关键词:视觉定位;数据融合;关键点检测;3维重建;PnP算法;卡尔曼滤波255|765|0更新时间:2024-05-07
摘要:目的视觉定位旨在利用易于获取的RGB图像对运动物体进行目标定位及姿态估计。室内场景中普遍存在的物体遮挡、弱纹理区域等干扰极易造成目标关键点的错误估计,严重影响了视觉定位的精度。针对这一问题,本文提出一种主被动融合的室内定位系统,结合固定视角和移动视角的方案优势,实现室内场景中运动目标的精准定位。方法提出一种基于平面先验的物体位姿估计方法,在关键点检测的单目定位框架基础上,使用平面约束进行3自由度姿态优化,提升固定视角下室内平面中运动目标的定位稳定性。基于无损卡尔曼滤波算法设计了一套数据融合定位系统,将从固定视角得到的被动式定位结果与从移动视角得到的主动式定位结果进行融合,提升了运动目标的位姿估计结果的可靠性。结果本文提出的主被动融合室内视觉定位系统在iGibson仿真数据集上的平均定位精度为2~3 cm,定位误差在10 cm内的准确率为99%;在真实场景中平均定位精度为3~4 cm,定位误差在10 cm内的准确率在90%以上,实现了cm级的定位精度。结论提出的室内视觉定位系统融合了被动式和主动式定位方法的优势,能够以较低设备成本实现室内场景中高精度的目标定位结果,并在遮挡、目标丢失等复杂环境因素干扰下展示出鲁棒的定位性能。关键词:视觉定位;数据融合;关键点检测;3维重建;PnP算法;卡尔曼滤波255|765|0更新时间:2024-05-07 -
 摘要:目的图像检索是计算机视觉领域的一项基础任务,大多采用卷积神经网络和对称式学习策略,导致所需训练数据量大、模型训练时间长、监督信息利用不充分。针对上述问题,本文提出一种Transformer与非对称学习策略相结合的图像检索方法。方法对于查询图像,使用Transformer生成图像的哈希表示,利用哈希损失学习哈希函数,使图像的哈希表示更加真实。对于待检索图像,采用非对称式学习策略,直接得到图像的哈希表示,并将哈希损失与分类损失相结合,充分利用监督信息,提高训练速度。在哈希空间通过计算汉明距离实现相似图像的快速检索。结果在CIFAR-10和NUS-WIDE两个数据集上,将本文方法与主流的5种对称式方法和性能最优的两种非对称式方法进行比较,本文方法的mAP(mean average precision)比当前最优方法分别提升了5.06%和4.17%。结论本文方法利用Transformer提取图像特征,并将哈希损失与分类损失相结合,在不增加训练数据量的前提下,减少了模型训练时间。所提方法性能优于当前同类方法,能够有效完成图像检索任务。关键词:图像检索;Transformer;哈希函数;非对称式学习;哈希损失;分类损失83|132|0更新时间:2024-05-07
摘要:目的图像检索是计算机视觉领域的一项基础任务,大多采用卷积神经网络和对称式学习策略,导致所需训练数据量大、模型训练时间长、监督信息利用不充分。针对上述问题,本文提出一种Transformer与非对称学习策略相结合的图像检索方法。方法对于查询图像,使用Transformer生成图像的哈希表示,利用哈希损失学习哈希函数,使图像的哈希表示更加真实。对于待检索图像,采用非对称式学习策略,直接得到图像的哈希表示,并将哈希损失与分类损失相结合,充分利用监督信息,提高训练速度。在哈希空间通过计算汉明距离实现相似图像的快速检索。结果在CIFAR-10和NUS-WIDE两个数据集上,将本文方法与主流的5种对称式方法和性能最优的两种非对称式方法进行比较,本文方法的mAP(mean average precision)比当前最优方法分别提升了5.06%和4.17%。结论本文方法利用Transformer提取图像特征,并将哈希损失与分类损失相结合,在不增加训练数据量的前提下,减少了模型训练时间。所提方法性能优于当前同类方法,能够有效完成图像检索任务。关键词:图像检索;Transformer;哈希函数;非对称式学习;哈希损失;分类损失83|132|0更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的在实时渲染领域中,立即辐射度算法是用于实时模拟间接光泽反射效果的算法之一。基于立即辐射度的GGX SLC(stochastic light culling)算法中使用符合真实物理定律的GGX BRDF(bidirectional reflectance distribution function)光照模型计算间接光泽反射,计算复杂度很高,并且其计算开销会随着虚拟点光源的数量呈明显的线性增长。为解决上述问题,提出一种更高效的实时间接光泽反射渲染算法。方法基于数学方法中的线性变换球面分布,将计算复杂度很高的GGX BRDF球面分布近似为一种计算复杂度较低的球面分布,并基于该球面分布提出了在单点光源以及多点光源环境下的基于物理的快速光照模型。该光照模型相比GGX BRDF光照模型具有更低的计算开销。然后基于该光照模型,提出实时间接光泽反射渲染算法,计算虚拟点光源对着色点的辐射强度,结合多点光源光照模型对着色点着色,高效地渲染间接光泽反射效果。结果实验结果表明,改进后的实时间接光泽反射算法能够以更高的渲染效率实现与GGX SLC算法相似的渲染效果,渲染效率提升了20%~40%,并且场景中虚拟点光源数量越多,所提算法的效率提升越大。结论基于线性变换球面分布的实时间接光泽反射算法,相比于GGX SLC算法,能够在不降低渲染效果的基础上,大幅提升间接光泽反射的渲染效率。关键词:实时渲染;立即辐射度;间接光泽反射(IGR);双向反射分布函数(BRDF);线性变换球面分布108|179|0更新时间:2024-05-07
摘要:目的在实时渲染领域中,立即辐射度算法是用于实时模拟间接光泽反射效果的算法之一。基于立即辐射度的GGX SLC(stochastic light culling)算法中使用符合真实物理定律的GGX BRDF(bidirectional reflectance distribution function)光照模型计算间接光泽反射,计算复杂度很高,并且其计算开销会随着虚拟点光源的数量呈明显的线性增长。为解决上述问题,提出一种更高效的实时间接光泽反射渲染算法。方法基于数学方法中的线性变换球面分布,将计算复杂度很高的GGX BRDF球面分布近似为一种计算复杂度较低的球面分布,并基于该球面分布提出了在单点光源以及多点光源环境下的基于物理的快速光照模型。该光照模型相比GGX BRDF光照模型具有更低的计算开销。然后基于该光照模型,提出实时间接光泽反射渲染算法,计算虚拟点光源对着色点的辐射强度,结合多点光源光照模型对着色点着色,高效地渲染间接光泽反射效果。结果实验结果表明,改进后的实时间接光泽反射算法能够以更高的渲染效率实现与GGX SLC算法相似的渲染效果,渲染效率提升了20%~40%,并且场景中虚拟点光源数量越多,所提算法的效率提升越大。结论基于线性变换球面分布的实时间接光泽反射算法,相比于GGX SLC算法,能够在不降低渲染效果的基础上,大幅提升间接光泽反射的渲染效率。关键词:实时渲染;立即辐射度;间接光泽反射(IGR);双向反射分布函数(BRDF);线性变换球面分布108|179|0更新时间:2024-05-07 -
 摘要:目的对采样设备获取的测量数据进行拟合,可实现原模型的重建及功能恢复。但有些情况下,获取的数据点不仅包含位置信息,还包含法向量信息。针对这一问题,本文提出了基于圆平均的双参数4点binary非线性细分法与单参数3点ternary插值非线性细分法。方法首先将线性细分法改写为点的重复binary线性平均,然后用圆平均代替相应的线性平均,最后用加权测地线平均计算的法向量作为新插入顶点的法向量。基于圆平均的双参数4点binary细分法的每一次细分过程可分为偏移步与张力步。基于圆平均的单参数3点ternary细分法的每一次细分过程可分为左插步、插值步与右插步。结果对于本文方法的收敛性与C1连续性条件给出了理论证明;数值实验表明,与相应的线性细分相比,本文方法生成的曲线更光滑且具有圆的再生力,可以较好地实现3个封闭曲线重建。结论本文方法可以在带法向量的初始控制顶点较少的情况下,较好地实现带法向约束的离散点集的曲线重建问题。关键词:非线性细分法;圆平均;加权测地线平均;点—法向量对;法向约束74|62|0更新时间:2024-05-07
摘要:目的对采样设备获取的测量数据进行拟合,可实现原模型的重建及功能恢复。但有些情况下,获取的数据点不仅包含位置信息,还包含法向量信息。针对这一问题,本文提出了基于圆平均的双参数4点binary非线性细分法与单参数3点ternary插值非线性细分法。方法首先将线性细分法改写为点的重复binary线性平均,然后用圆平均代替相应的线性平均,最后用加权测地线平均计算的法向量作为新插入顶点的法向量。基于圆平均的双参数4点binary细分法的每一次细分过程可分为偏移步与张力步。基于圆平均的单参数3点ternary细分法的每一次细分过程可分为左插步、插值步与右插步。结果对于本文方法的收敛性与C1连续性条件给出了理论证明;数值实验表明,与相应的线性细分相比,本文方法生成的曲线更光滑且具有圆的再生力,可以较好地实现3个封闭曲线重建。结论本文方法可以在带法向量的初始控制顶点较少的情况下,较好地实现带法向约束的离散点集的曲线重建问题。关键词:非线性细分法;圆平均;加权测地线平均;点—法向量对;法向约束74|62|0更新时间:2024-05-07
计算机图形学
-
 摘要:目的染色体分类是医学影像处理的具体任务之一,最终结果可为医生提供重要的临床诊断信息,在产前诊断中起着重要作用。深度学习由于强大的特征表达能力在医学影像领域得到了广泛应用,但是基于深度学习的大部分染色体分类算法都是在轻量化私有数据库上得到的不同水准的分类结果,难以客观评估不同算法间的优劣,导致缺乏对算法的临床筛选标准,因此迫切需要在大规模数据库上对不同算法开展基于同样数据级的性能评估,以获取具有客观可对比性的性能数据,这对于科研成果的转化具有重要意义。方法本文基于广东省妇幼保健院提供的染色体数据,构建了包含126 453条染色体的临床数据库,精选6个主流染色体分类模型在该数据库上展开对比实验与性能评估。结果在本文构建的大规模染色体临床数据库上,实验和分析发现,参评模型分类准确率均达到92%以上,其中MixNet模型提升后分类效果最好,为98.92%。即使分类性能落后的模型在本数据集上训练也得到明显改善,准确率从86.7%提升至92.09%,相比早期报告的性能提升了5.39%。结论开展实证研究实验发现,数据库规模大小是影响染色体分类算法能否取得理想分类效果的重要因素之一。对于染色体分类任务而言,残差神经网络是比较合适的网络结构,但结果方面缺乏可解释性等原因,导致与高精度临床应用要求还存在差距。基于深度学习技术的染色体分类研究还需要进一步深入开展。关键词:医学影像处理;深度学习;染色体分类;残差神经网络;分类评估113|94|1更新时间:2024-05-07
摘要:目的染色体分类是医学影像处理的具体任务之一,最终结果可为医生提供重要的临床诊断信息,在产前诊断中起着重要作用。深度学习由于强大的特征表达能力在医学影像领域得到了广泛应用,但是基于深度学习的大部分染色体分类算法都是在轻量化私有数据库上得到的不同水准的分类结果,难以客观评估不同算法间的优劣,导致缺乏对算法的临床筛选标准,因此迫切需要在大规模数据库上对不同算法开展基于同样数据级的性能评估,以获取具有客观可对比性的性能数据,这对于科研成果的转化具有重要意义。方法本文基于广东省妇幼保健院提供的染色体数据,构建了包含126 453条染色体的临床数据库,精选6个主流染色体分类模型在该数据库上展开对比实验与性能评估。结果在本文构建的大规模染色体临床数据库上,实验和分析发现,参评模型分类准确率均达到92%以上,其中MixNet模型提升后分类效果最好,为98.92%。即使分类性能落后的模型在本数据集上训练也得到明显改善,准确率从86.7%提升至92.09%,相比早期报告的性能提升了5.39%。结论开展实证研究实验发现,数据库规模大小是影响染色体分类算法能否取得理想分类效果的重要因素之一。对于染色体分类任务而言,残差神经网络是比较合适的网络结构,但结果方面缺乏可解释性等原因,导致与高精度临床应用要求还存在差距。基于深度学习技术的染色体分类研究还需要进一步深入开展。关键词:医学影像处理;深度学习;染色体分类;残差神经网络;分类评估113|94|1更新时间:2024-05-07 -
 摘要:目的在脑科学领域,已有研究借助脑功能核磁共振影像数据(functional magnetic resonance imaging,fMRI)探索和区分人类大脑在不同运动任务下的状态,然而传统方法没有充分利用fMRI数据的时序特性。对此,本文提出基于fMRI数据计算的全脑脑区时间信号(time course,TC)的门控循环单元(gated recurrent unit,GRU)方法(TC-GRU)进行运动任务分类。方法基于HCP(human connectome project)数据集中的100个健康被试者在5种运动任务中分两轮采集的1 000条fMRI数据,对每种运动任务计算每个被试者在各脑区(共360个脑区)的时间信号;使用10折交叉验证方案基于训练集和验证集训练TC-GRU模型,并用构建好的模型对测试集进行测试,考察其对5种运动任务的分类能力,其中TC-GRU在各时刻的输入特征为全脑脑区在对应时刻的TC信号幅值,通过这样的方式提取全脑脑区在整个时间段的时序特征。同时,为了展示使用TC-GRU模型可挖掘fMRI数据中更丰富的信息,设计了多个对比实验进行比较,利用长短期记忆网络(long short-term memory,LSTM)、图卷积网络(graph convolutional network,GCN)和多层感知器(multi-layer perceptron,MLP)基于全脑脑区时间信号进行运动任务分类,以及利用MLP基于由fMRI数据估计的脑功能连接进行运动任务分类。此外,考察了先验的特征选择对分类效果的效应。结果基于全脑脑区时间信号的TC-GRU模型在运动任务中的分类准确率最高,为94.51%±2.4%,其次是基于全脑脑区时间信号的LSTM模型,准确率为93.73%±2.67%。基于全脑脑区时间信号利用MLP进行分类,有先验和无先验的特征选择准确率分别为92.75%±2.59%和92.04%±7.15%,比基于全脑脑区时间信号的GCN(准确率为87.14%±3.73%)和基于脑功能连接利用MLP进行分类(有先验和无先验的特征选择准确率分别为72.47%±4.47%和61.49%±9.97%)表现更好。结论TC-GRU模型可挖掘脑fMRI数据中丰富的时序信息,非常有效地对不同的运动任务进行分类。关键词:脑功能核磁共振成像;全脑脑区时间信号;功能连接;门控循环单元(GRU);多层感知器(MLP);运动任务分类82|1|0更新时间:2024-05-07
摘要:目的在脑科学领域,已有研究借助脑功能核磁共振影像数据(functional magnetic resonance imaging,fMRI)探索和区分人类大脑在不同运动任务下的状态,然而传统方法没有充分利用fMRI数据的时序特性。对此,本文提出基于fMRI数据计算的全脑脑区时间信号(time course,TC)的门控循环单元(gated recurrent unit,GRU)方法(TC-GRU)进行运动任务分类。方法基于HCP(human connectome project)数据集中的100个健康被试者在5种运动任务中分两轮采集的1 000条fMRI数据,对每种运动任务计算每个被试者在各脑区(共360个脑区)的时间信号;使用10折交叉验证方案基于训练集和验证集训练TC-GRU模型,并用构建好的模型对测试集进行测试,考察其对5种运动任务的分类能力,其中TC-GRU在各时刻的输入特征为全脑脑区在对应时刻的TC信号幅值,通过这样的方式提取全脑脑区在整个时间段的时序特征。同时,为了展示使用TC-GRU模型可挖掘fMRI数据中更丰富的信息,设计了多个对比实验进行比较,利用长短期记忆网络(long short-term memory,LSTM)、图卷积网络(graph convolutional network,GCN)和多层感知器(multi-layer perceptron,MLP)基于全脑脑区时间信号进行运动任务分类,以及利用MLP基于由fMRI数据估计的脑功能连接进行运动任务分类。此外,考察了先验的特征选择对分类效果的效应。结果基于全脑脑区时间信号的TC-GRU模型在运动任务中的分类准确率最高,为94.51%±2.4%,其次是基于全脑脑区时间信号的LSTM模型,准确率为93.73%±2.67%。基于全脑脑区时间信号利用MLP进行分类,有先验和无先验的特征选择准确率分别为92.75%±2.59%和92.04%±7.15%,比基于全脑脑区时间信号的GCN(准确率为87.14%±3.73%)和基于脑功能连接利用MLP进行分类(有先验和无先验的特征选择准确率分别为72.47%±4.47%和61.49%±9.97%)表现更好。结论TC-GRU模型可挖掘脑fMRI数据中丰富的时序信息,非常有效地对不同的运动任务进行分类。关键词:脑功能核磁共振成像;全脑脑区时间信号;功能连接;门控循环单元(GRU);多层感知器(MLP);运动任务分类82|1|0更新时间:2024-05-07 -
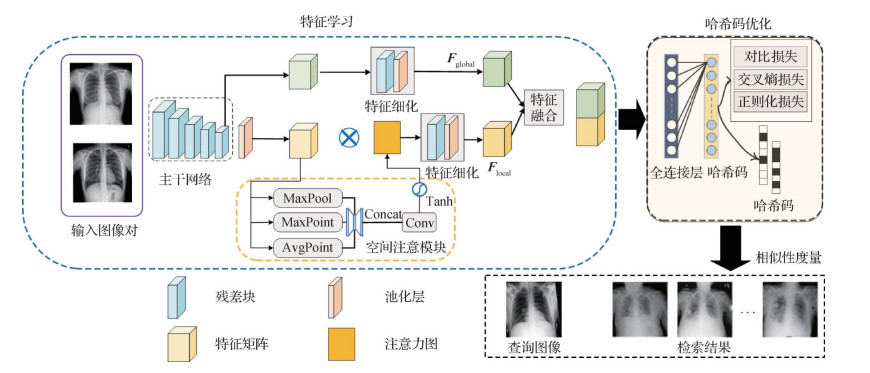 摘要:目的医学图像检索在疾病诊断、医疗教学和辅助症状参考中发挥了重要作用,但由于医学图像类间相似度高、病灶易遗漏以及数据量较大等问题,使得现有哈希方法对病灶区域特征的关注较少,图像检索准确率较低。对此,本文以胸部X-ray图像为例,提出一种面向大规模胸片图像的深度哈希检索网络。方法在特征学习部分,首先采用ResNet-50作为主干网络对输入图像进行特征提取得到初步特征,将该特征进行细化后获得全局特征;同时将初步特征输入构建的空间注意模块,该注意模块结合了3个描述符用于聚焦胸片图像中的显著区域,将该模块的输出进行细化得到局部特征;最后融合全局特征与局部特征用于后续哈希码优化。在哈希码优化部分,使用定义的二值交叉熵损失、对比损失和正则化损失的联合函数进行优化学习,生成高质量的哈希码用于图像检索。结果为了验证方法的有效性,在公开的ChestX-ray8和CheXpert数据集上进行对比实验。结果显示,构建空间注意模块有助于关注病灶区域,定义特征融合模块有效避免了信息的遗漏,联合3个损失函数进行优化可以获得高质量哈希码。与当前先进的医学图像检索方法比较,本文方法能够有效提高医学图像检索的准确率,在两个数据集上的检索平均精度分别提高了约6%和5%。结论在大规模胸片图像检索中,本文提出的深度哈希检索方法能够有效关注病灶区域,提高胸片图像检索的准确率。关键词:医学图像检索;注意力机制;特征融合;深度哈希(DH)105|86|0更新时间:2024-05-07
摘要:目的医学图像检索在疾病诊断、医疗教学和辅助症状参考中发挥了重要作用,但由于医学图像类间相似度高、病灶易遗漏以及数据量较大等问题,使得现有哈希方法对病灶区域特征的关注较少,图像检索准确率较低。对此,本文以胸部X-ray图像为例,提出一种面向大规模胸片图像的深度哈希检索网络。方法在特征学习部分,首先采用ResNet-50作为主干网络对输入图像进行特征提取得到初步特征,将该特征进行细化后获得全局特征;同时将初步特征输入构建的空间注意模块,该注意模块结合了3个描述符用于聚焦胸片图像中的显著区域,将该模块的输出进行细化得到局部特征;最后融合全局特征与局部特征用于后续哈希码优化。在哈希码优化部分,使用定义的二值交叉熵损失、对比损失和正则化损失的联合函数进行优化学习,生成高质量的哈希码用于图像检索。结果为了验证方法的有效性,在公开的ChestX-ray8和CheXpert数据集上进行对比实验。结果显示,构建空间注意模块有助于关注病灶区域,定义特征融合模块有效避免了信息的遗漏,联合3个损失函数进行优化可以获得高质量哈希码。与当前先进的医学图像检索方法比较,本文方法能够有效提高医学图像检索的准确率,在两个数据集上的检索平均精度分别提高了约6%和5%。结论在大规模胸片图像检索中,本文提出的深度哈希检索方法能够有效关注病灶区域,提高胸片图像检索的准确率。关键词:医学图像检索;注意力机制;特征融合;深度哈希(DH)105|86|0更新时间:2024-05-07
医学图像处理
-
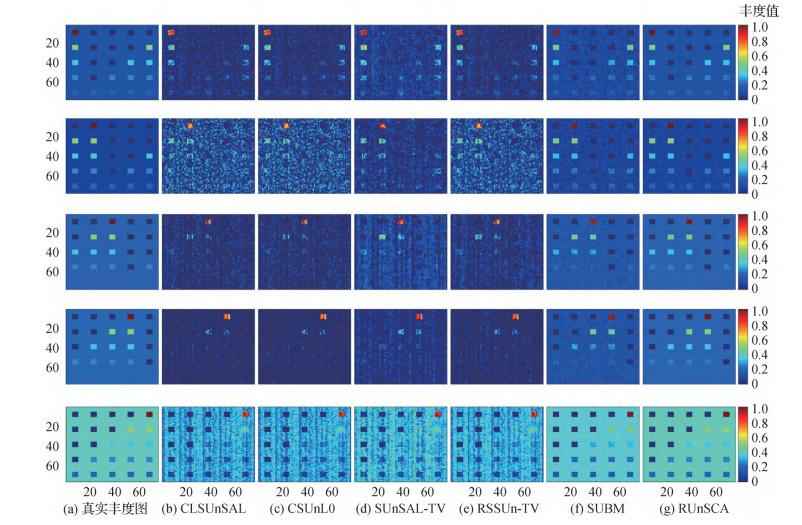 摘要:目的高光谱解混是高光谱遥感数据分析中的热点问题,其难点在于信息不充分导致的问题病态性。基于光谱库的稀疏性解混方法是目前的代表性方法,但是在实际情况中,高光谱数据通常包含高斯、脉冲和死线等噪声,且各波段噪声的强度往往不同,因此常用的稀疏解混方法鲁棒性不够,解混精度有待提高。针对该问题,本文对高光谱图像进行非负稀疏分量分解建模,提出了一种基于非负稀疏分量分析的鲁棒解混方法。方法首先综合考虑真实高光谱数据的混合噪声及其各波段噪声强度不同的统计特性,在最大后验概率框架下建立非负矩阵稀疏分量分解模型,然后采用
摘要:目的高光谱解混是高光谱遥感数据分析中的热点问题,其难点在于信息不充分导致的问题病态性。基于光谱库的稀疏性解混方法是目前的代表性方法,但是在实际情况中,高光谱数据通常包含高斯、脉冲和死线等噪声,且各波段噪声的强度往往不同,因此常用的稀疏解混方法鲁棒性不够,解混精度有待提高。针对该问题,本文对高光谱图像进行非负稀疏分量分解建模,提出了一种基于非负稀疏分量分析的鲁棒解混方法。方法首先综合考虑真实高光谱数据的混合噪声及其各波段噪声强度不同的统计特性,在最大后验概率框架下建立非负矩阵稀疏分量分解模型,然后采用$\ell_\text{1, 1}$ $\ell_\text{2, 0}$ 关键词:高光谱遥感;线性高光谱解混;稀疏解混;全变分(TV);交替方向乘子法(ADMM)123|223|2更新时间:2024-05-07 -
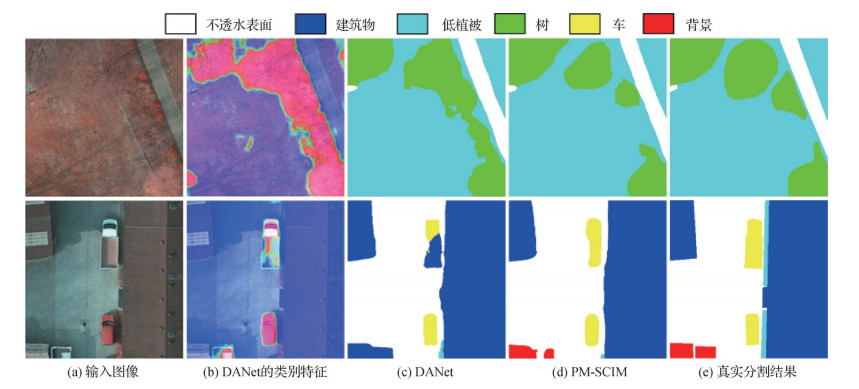 摘要:目的航拍图像分割为遥感领域中许多实际应用提供支撑。与传统方法相比,深度学习方法能够自适应地学习与任务相关的特征,极大提升了分割精度,但忽略了数据集中的偏置问题。由偏置引起的混杂因子干扰使分割方法容易获得模糊的物体边缘,并且难以区分易混淆物体。针对这个问题,提出了一种基于渐进式多尺度因果干预的模型。方法首先,使用深度卷积神经网络提取航拍图像的卷积特征。然后,解混杂模块引入类别隐特征,近似表示混杂因子特征。同时,使用混杂因子特征以因果干预的方式将卷积特征分解成对应每一种混杂因子下的特征表示,抑制特定混杂因子的干扰。最后,由深层解混杂特征得到的分割结果,经过融合模块指导浅层解混杂特征生成分割结果,以此得到每个尺度的分割结果,并以加权求和的方式得到最终分割结果。结果实验在公开的航拍图像数据集Potsdam和Vaihingen上进行,与6种先进的深度学习分割方法和7种公开的基准方法进行对比。本文方法在Potsdam和Vaihingen数据集中的总体准确率分别为90.3%和90.8%,相比性能第2的深度学习方法分别提高了0.6%和0.8%。与性能第2的基准方法相比,本文方法在Potsdam和Vaihingen数据集上的总体准确率分别提升了1.3%和0.5%。结论本文提出的分割模型能够有效缓解数据集中的偏置问题,提升了航拍图像分割性能。关键词:航拍图像;语义分割;卷积神经网络(CNN);因果干预;解混杂234|209|0更新时间:2024-05-07
摘要:目的航拍图像分割为遥感领域中许多实际应用提供支撑。与传统方法相比,深度学习方法能够自适应地学习与任务相关的特征,极大提升了分割精度,但忽略了数据集中的偏置问题。由偏置引起的混杂因子干扰使分割方法容易获得模糊的物体边缘,并且难以区分易混淆物体。针对这个问题,提出了一种基于渐进式多尺度因果干预的模型。方法首先,使用深度卷积神经网络提取航拍图像的卷积特征。然后,解混杂模块引入类别隐特征,近似表示混杂因子特征。同时,使用混杂因子特征以因果干预的方式将卷积特征分解成对应每一种混杂因子下的特征表示,抑制特定混杂因子的干扰。最后,由深层解混杂特征得到的分割结果,经过融合模块指导浅层解混杂特征生成分割结果,以此得到每个尺度的分割结果,并以加权求和的方式得到最终分割结果。结果实验在公开的航拍图像数据集Potsdam和Vaihingen上进行,与6种先进的深度学习分割方法和7种公开的基准方法进行对比。本文方法在Potsdam和Vaihingen数据集中的总体准确率分别为90.3%和90.8%,相比性能第2的深度学习方法分别提高了0.6%和0.8%。与性能第2的基准方法相比,本文方法在Potsdam和Vaihingen数据集上的总体准确率分别提升了1.3%和0.5%。结论本文提出的分割模型能够有效缓解数据集中的偏置问题,提升了航拍图像分割性能。关键词:航拍图像;语义分割;卷积神经网络(CNN);因果干预;解混杂234|209|0更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0