
最新刊期
2023 年 第 28 卷 第 12 期
-
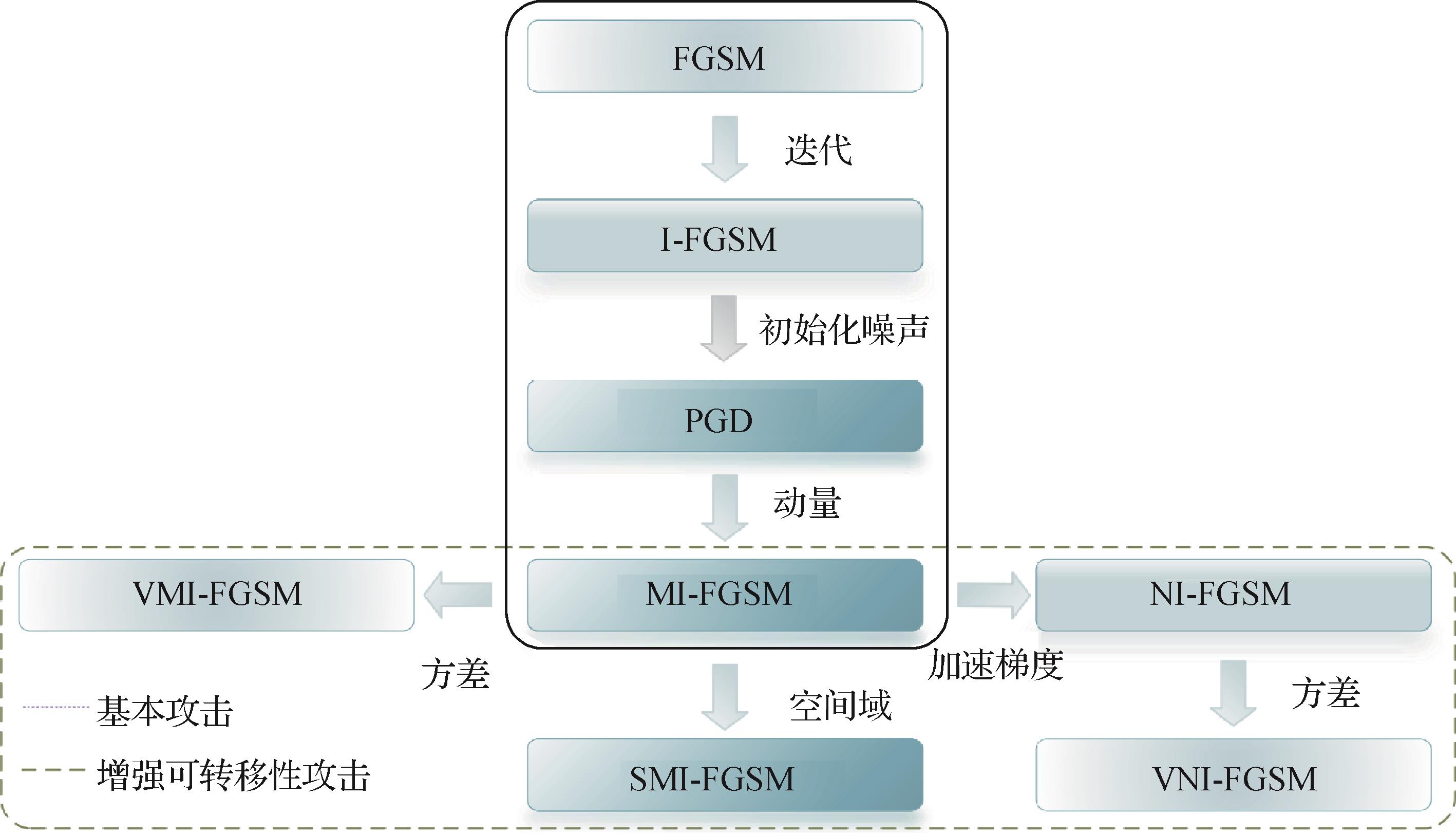 摘要:深度学习在众多领域取得了巨大成功。然而,其强大的数据拟合能力隐藏着不可解释的“捷径学习”现象,从而引发深度模型脆弱、易受攻击的安全隐患。众多研究表明,攻击者向正常数据中添加人类无法察觉的微小扰动,便可能造成模型产生灾难性的错误输出,这严重限制了深度学习在安全敏感领域的应用。对此,研究者提出了各种对抗性防御方法。其中,对抗训练是典型的启发式防御方法。它将对抗攻击与对抗防御注入一个框架,一方面通过攻击已有模型学习生成对抗样本,另一方面利用对抗样本进一步开展模型训练,从而提升模型的鲁棒性。为此,本文围绕对抗训练,首先,阐述了对抗训练的基本框架;其次,对对抗训练框架下的对抗样本生成、对抗模型防御性训练等方法与关键技术进行分类梳理;然后,对评估对抗训练鲁棒性的数据集及攻击方式进行总结;最后,通过对当前对抗训练所面临挑战的分析,本文给出了其未来的几个发展方向。关键词:深度学习;对抗攻击;对抗防御;对抗训练;鲁棒性596|568|1更新时间:2023-12-19
摘要:深度学习在众多领域取得了巨大成功。然而,其强大的数据拟合能力隐藏着不可解释的“捷径学习”现象,从而引发深度模型脆弱、易受攻击的安全隐患。众多研究表明,攻击者向正常数据中添加人类无法察觉的微小扰动,便可能造成模型产生灾难性的错误输出,这严重限制了深度学习在安全敏感领域的应用。对此,研究者提出了各种对抗性防御方法。其中,对抗训练是典型的启发式防御方法。它将对抗攻击与对抗防御注入一个框架,一方面通过攻击已有模型学习生成对抗样本,另一方面利用对抗样本进一步开展模型训练,从而提升模型的鲁棒性。为此,本文围绕对抗训练,首先,阐述了对抗训练的基本框架;其次,对对抗训练框架下的对抗样本生成、对抗模型防御性训练等方法与关键技术进行分类梳理;然后,对评估对抗训练鲁棒性的数据集及攻击方式进行总结;最后,通过对当前对抗训练所面临挑战的分析,本文给出了其未来的几个发展方向。关键词:深度学习;对抗攻击;对抗防御;对抗训练;鲁棒性596|568|1更新时间:2023-12-19 -
 摘要:基于骨骼信息的人体行为识别旨在从输入的包含一个或多个行为的骨骼序列中,正确地分析出行为的种类,是计算机视觉领域的研究热点之一。与基于图像的人体行为识别方法相比,基于骨骼信息的人体行为识别方法不受背景、人体外观等干扰因素的影响,具有更高的准确性、鲁棒性和计算效率。针对基于骨骼信息的人体行为识别方法的重要性和前沿性,对其进行全面和系统的总结分析具有十分重要的意义。本文首先回顾了9个广泛应用的骨骼行为识别数据集,按照数据收集视角的差异将它们分为单视角数据集和多视角数据集,并着重探讨了不同数据集的特点和用法。其次,根据算法所使用的基础网络,将基于骨骼信息的行为识别方法分为基于手工制作特征的方法、基于循环神经网络的方法、基于卷积神经网络的方法、基于图卷积网络的方法以及基于Transformer的方法,重点阐述分析了这些方法的原理及优缺点。其中,图卷积方法因其强大的空间关系捕捉能力而成为目前应用最为广泛的方法。采用了全新的归纳方法,对图卷积方法进行了全面综述,旨在为研究人员提供更多的思路和方法。最后,从8个方面总结现有方法存在的问题,并针对性地提出工作展望。关键词:行为识别;骨骼信息;数据集;深度学习;图卷积网络(GCN)320|604|0更新时间:2023-12-19
摘要:基于骨骼信息的人体行为识别旨在从输入的包含一个或多个行为的骨骼序列中,正确地分析出行为的种类,是计算机视觉领域的研究热点之一。与基于图像的人体行为识别方法相比,基于骨骼信息的人体行为识别方法不受背景、人体外观等干扰因素的影响,具有更高的准确性、鲁棒性和计算效率。针对基于骨骼信息的人体行为识别方法的重要性和前沿性,对其进行全面和系统的总结分析具有十分重要的意义。本文首先回顾了9个广泛应用的骨骼行为识别数据集,按照数据收集视角的差异将它们分为单视角数据集和多视角数据集,并着重探讨了不同数据集的特点和用法。其次,根据算法所使用的基础网络,将基于骨骼信息的行为识别方法分为基于手工制作特征的方法、基于循环神经网络的方法、基于卷积神经网络的方法、基于图卷积网络的方法以及基于Transformer的方法,重点阐述分析了这些方法的原理及优缺点。其中,图卷积方法因其强大的空间关系捕捉能力而成为目前应用最为广泛的方法。采用了全新的归纳方法,对图卷积方法进行了全面综述,旨在为研究人员提供更多的思路和方法。最后,从8个方面总结现有方法存在的问题,并针对性地提出工作展望。关键词:行为识别;骨骼信息;数据集;深度学习;图卷积网络(GCN)320|604|0更新时间:2023-12-19 -
 摘要:图像合成一直是图像处理领域的研究热点,具有广泛的应用前景。从原图中精确提取出前景目标对象并将其与新背景合成,构造尽量接近真实的图像是图像合成的基本目标。为推动基于深度学习的图像合成技术研究与发展,本文论述了当前图像合成任务中面临的主要问题:1)前景对象适应性问题,包括前景对象相对于背景图像的大小、位置、几何角度等几何一致性问题,以及前后景互相遮挡、前景对象边缘细节模糊的外观一致性问题;2)视觉和谐问题,包括前后景色彩、对比度、饱和度等不统一的色调一致性问题,及前景对象丢失对应阴影的阴影缺失问题;3)生境适应性问题,表现为前景对象与背景图像的逻辑合理性。总结了目前为解决不同问题主要使用的深度学习方法,同时对不同问题中的合成图像结果进行质量评估,总结了相应的评价指标,并介绍了为解决不同问题所使用的公开数据集,同时进行了深度学习方法的对比,描述了图像合成技术的主要应用场景,最后分析了基于深度学习的图像合成技术中仍然存在的不足,同时提出可行的研究意见,并对未来图像合成技术发展方向提出展望。关键词:深度学习;图像合成;前景对象适应性;图像和谐化;生境适应性208|1406|0更新时间:2023-12-19
摘要:图像合成一直是图像处理领域的研究热点,具有广泛的应用前景。从原图中精确提取出前景目标对象并将其与新背景合成,构造尽量接近真实的图像是图像合成的基本目标。为推动基于深度学习的图像合成技术研究与发展,本文论述了当前图像合成任务中面临的主要问题:1)前景对象适应性问题,包括前景对象相对于背景图像的大小、位置、几何角度等几何一致性问题,以及前后景互相遮挡、前景对象边缘细节模糊的外观一致性问题;2)视觉和谐问题,包括前后景色彩、对比度、饱和度等不统一的色调一致性问题,及前景对象丢失对应阴影的阴影缺失问题;3)生境适应性问题,表现为前景对象与背景图像的逻辑合理性。总结了目前为解决不同问题主要使用的深度学习方法,同时对不同问题中的合成图像结果进行质量评估,总结了相应的评价指标,并介绍了为解决不同问题所使用的公开数据集,同时进行了深度学习方法的对比,描述了图像合成技术的主要应用场景,最后分析了基于深度学习的图像合成技术中仍然存在的不足,同时提出可行的研究意见,并对未来图像合成技术发展方向提出展望。关键词:深度学习;图像合成;前景对象适应性;图像和谐化;生境适应性208|1406|0更新时间:2023-12-19
综述

-
 摘要:目的图像修复是根据图像中已知内容来自动恢复丢失内容的过程。目前基于深度学习的图像修复模型在自然图像和人脸图像修复上取得了一定效果,但是鲜有对文本图像修复的研究,其中保证结构连贯和纹理一致的方法也没有关注文字本身的修复。针对这一问题,提出了一种结构先验指导的文本图像修复模型。方法首先以Transformer为基础,构建一个结构先验重建网络,捕捉全局依赖关系重建文本骨架和边缘结构先验图像,然后提出一种新的静态到动态残差模块(static-to-dynamic residual block,StDRB),将静态特征转换到动态文本图像序列特征,并将其融合到编码器—解码器结构的修复网络中,在结构先验指导和梯度先验损失等联合损失的监督下,使修复后的文本笔划连贯,内容真实自然,达到有利于下游文本检测和识别任务的目的。结果实验在藏文和英文两种语言的合成数据集上,与4种图像修复模型进行了比较。结果表明,本文模型在主观视觉感受上达到了较好的效果,在藏文和英文数据集上的峰值信噪比和结构相似度分别达到了42.31 dB,98.10%和39.23 dB,98.55%,使用 Tesseract OCR(optical character recognition)识别修复后藏文图像中的文字的准确率达到了62.83%,使用Tesseract OCR、CRNN(convolutional recurrent neural network)以及ASTER(attentional scene text recognizer)识别修复后英文图像中的文字的准确率分别达到了85.13%,86.04%和76.71%,均优于对比模型。结论本文提出的文本图像修复模型借鉴了图像修复方法的思想,利用文本图像中文字本身的特性,取得了更加准确的文本图像修复结果。关键词:图像修复;文本图像修复;结构先验;静态到动态残差模块(StDRB);联合损失312|492|0更新时间:2023-12-19
摘要:目的图像修复是根据图像中已知内容来自动恢复丢失内容的过程。目前基于深度学习的图像修复模型在自然图像和人脸图像修复上取得了一定效果,但是鲜有对文本图像修复的研究,其中保证结构连贯和纹理一致的方法也没有关注文字本身的修复。针对这一问题,提出了一种结构先验指导的文本图像修复模型。方法首先以Transformer为基础,构建一个结构先验重建网络,捕捉全局依赖关系重建文本骨架和边缘结构先验图像,然后提出一种新的静态到动态残差模块(static-to-dynamic residual block,StDRB),将静态特征转换到动态文本图像序列特征,并将其融合到编码器—解码器结构的修复网络中,在结构先验指导和梯度先验损失等联合损失的监督下,使修复后的文本笔划连贯,内容真实自然,达到有利于下游文本检测和识别任务的目的。结果实验在藏文和英文两种语言的合成数据集上,与4种图像修复模型进行了比较。结果表明,本文模型在主观视觉感受上达到了较好的效果,在藏文和英文数据集上的峰值信噪比和结构相似度分别达到了42.31 dB,98.10%和39.23 dB,98.55%,使用 Tesseract OCR(optical character recognition)识别修复后藏文图像中的文字的准确率达到了62.83%,使用Tesseract OCR、CRNN(convolutional recurrent neural network)以及ASTER(attentional scene text recognizer)识别修复后英文图像中的文字的准确率分别达到了85.13%,86.04%和76.71%,均优于对比模型。结论本文提出的文本图像修复模型借鉴了图像修复方法的思想,利用文本图像中文字本身的特性,取得了更加准确的文本图像修复结果。关键词:图像修复;文本图像修复;结构先验;静态到动态残差模块(StDRB);联合损失312|492|0更新时间:2023-12-19 -
 摘要:目的在抗屏摄鲁棒图像水印算法的研究中,如何在保证含水印图像视觉质量的同时提高算法的鲁棒性是存在的主要挑战。为此,提出一种基于深度学习的端到端网络框架以用于鲁棒水印的嵌入与提取。方法在该网络框架中,本文设计了包含摩尔纹在内的噪声层用以模拟真实屏摄噪声造成的失真,并通过网络训练来学习到抵抗屏摄噪声的能力,增强网络生成的含水印图像的鲁棒性;同时引入了最小可察觉失真(just noticeable distortion,JND)损失函数,旨在通过监督图像的JND系数图与含有水印信息的残差图之间的感知差异来自适应控制鲁棒水印的嵌入强度,以提高生成的含水印图像的视觉质量。此外,还提出了两种图像区域自动定位方法,分别用于解决:拍摄图像中前景与背景分割即含水印图像区域的定位矫正问题,以及含水印图像经过数字裁剪攻击后的解码问题。结果实验结果表明,引入JND损失函数后嵌入水印图像的视觉质量得到了提高,平均的峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity,SSIM)可分别达到30.937 1 dB和0.942 4。加入摩尔纹的噪声模拟层后,所提算法的误码率可下降1%~3%,具有抵抗屏摄噪声的能力。另外,将图像的R通道嵌入用于抗裁剪的模板,使得算法可有效抵抗较大程度的数字裁剪攻击。本文算法的计算复杂度较低,对单幅图像进行嵌入时,定位与提取操作的总耗时小于0.1 s,可满足实际应用场景的实时性需求。结论本文算法的嵌入容量和生成的含水印图像视觉质量较为理想,且在不同拍摄距离、角度以及不同拍摄和显示设备条件下的鲁棒性优于已报道的主流算法。关键词:鲁棒水印;屏幕拍摄;视觉质量;端到端网络;自动定位373|694|0更新时间:2023-12-19
摘要:目的在抗屏摄鲁棒图像水印算法的研究中,如何在保证含水印图像视觉质量的同时提高算法的鲁棒性是存在的主要挑战。为此,提出一种基于深度学习的端到端网络框架以用于鲁棒水印的嵌入与提取。方法在该网络框架中,本文设计了包含摩尔纹在内的噪声层用以模拟真实屏摄噪声造成的失真,并通过网络训练来学习到抵抗屏摄噪声的能力,增强网络生成的含水印图像的鲁棒性;同时引入了最小可察觉失真(just noticeable distortion,JND)损失函数,旨在通过监督图像的JND系数图与含有水印信息的残差图之间的感知差异来自适应控制鲁棒水印的嵌入强度,以提高生成的含水印图像的视觉质量。此外,还提出了两种图像区域自动定位方法,分别用于解决:拍摄图像中前景与背景分割即含水印图像区域的定位矫正问题,以及含水印图像经过数字裁剪攻击后的解码问题。结果实验结果表明,引入JND损失函数后嵌入水印图像的视觉质量得到了提高,平均的峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity,SSIM)可分别达到30.937 1 dB和0.942 4。加入摩尔纹的噪声模拟层后,所提算法的误码率可下降1%~3%,具有抵抗屏摄噪声的能力。另外,将图像的R通道嵌入用于抗裁剪的模板,使得算法可有效抵抗较大程度的数字裁剪攻击。本文算法的计算复杂度较低,对单幅图像进行嵌入时,定位与提取操作的总耗时小于0.1 s,可满足实际应用场景的实时性需求。结论本文算法的嵌入容量和生成的含水印图像视觉质量较为理想,且在不同拍摄距离、角度以及不同拍摄和显示设备条件下的鲁棒性优于已报道的主流算法。关键词:鲁棒水印;屏幕拍摄;视觉质量;端到端网络;自动定位373|694|0更新时间:2023-12-19 -
 摘要:目的拍摄运动物体时,图像易出现运动模糊,这将影响计算机视觉任务的完成。为提升运动图像去模糊的质量,提出了基于深度特征融合注意力的双尺度去运动模糊网络。方法首先,设计了双尺度网络,在网络结构上设计高低尺度通路,在低尺度上增加对模糊区域的注意力,在高尺度上提升网络的高频细节恢复能力,增强了模型去模糊效果。其次,设计了深度特征融合注意力模块,通过融合全尺度特征、构建通道注意力,将编码的全尺度特征与解码的同级特征进行拼接融合,进一步增强了网络的去模糊性能和细节恢复能力。最后,在双尺度的基础上,引入多尺度损失,使模型更加关注高频细节的恢复。结果在3个数据集上,与12种去模糊方法进行了对比实验。在GoPro数据集上得到了最优结果,相比SRN(scale-recurrent network)方法,平均峰值信噪比提升了2.29 dB,能够恢复出更多的细节信息。在Kohler数据集上,得到了最高的峰值信噪比(29.91 dB)。在Lai数据集上,视觉上有最好的去模糊效果。结论实验结果表明,本文方法可以有效去除运动模糊并恢复细节。关键词:深度特征融合注意力;双尺度网络;运动图像去模糊;全尺度特征融合;多尺度损失160|368|2更新时间:2023-12-19
摘要:目的拍摄运动物体时,图像易出现运动模糊,这将影响计算机视觉任务的完成。为提升运动图像去模糊的质量,提出了基于深度特征融合注意力的双尺度去运动模糊网络。方法首先,设计了双尺度网络,在网络结构上设计高低尺度通路,在低尺度上增加对模糊区域的注意力,在高尺度上提升网络的高频细节恢复能力,增强了模型去模糊效果。其次,设计了深度特征融合注意力模块,通过融合全尺度特征、构建通道注意力,将编码的全尺度特征与解码的同级特征进行拼接融合,进一步增强了网络的去模糊性能和细节恢复能力。最后,在双尺度的基础上,引入多尺度损失,使模型更加关注高频细节的恢复。结果在3个数据集上,与12种去模糊方法进行了对比实验。在GoPro数据集上得到了最优结果,相比SRN(scale-recurrent network)方法,平均峰值信噪比提升了2.29 dB,能够恢复出更多的细节信息。在Kohler数据集上,得到了最高的峰值信噪比(29.91 dB)。在Lai数据集上,视觉上有最好的去模糊效果。结论实验结果表明,本文方法可以有效去除运动模糊并恢复细节。关键词:深度特征融合注意力;双尺度网络;运动图像去模糊;全尺度特征融合;多尺度损失160|368|2更新时间:2023-12-19 -
 摘要:目的基于深度学习的图像超分辨率重构研究取得了重大进展,如何在更好提升重构性能的同时,有效降低重构模型的复杂度,以满足低成本及实时应用的需要,是该领域研究关注的重要问题。为此,提出了一种基于通道注意力(channel attention,CA)嵌入的Transformer图像超分辨率深度重构方法(image super-resolution with channel-attention-embedded Transformer,CAET)。方法提出将通道注意力自适应地嵌入Transformer变换特征及卷积运算特征,不仅可充分利用卷积运算与Transformer变换在图像特征提取的各自优势,而且将对应特征进行自适应增强与融合,有效改进网络的学习能力及超分辨率性能。结果基于5个开源测试数据集,与6种代表性方法进行了实验比较,结果显示本文方法在不同放大倍数情形下均有最佳表现。具体在4倍放大因子时,比较先进的SwinIR(image restoration using swin Transformer)方法,峰值信噪比指标在Urban100数据集上得到了0.09 dB的提升,在Manga109数据集提升了0.30 dB,具有主观视觉质量的明显改善。结论提出的通道注意力嵌入的Transformer图像超分辨率方法,通过融合卷积特征与Transformer特征,并自适应嵌入通道注意力特征增强,可以在较好地平衡网络模型轻量化同时,得到图像超分辨率性能的有效提升,在多个公共实验数据集的测试结果验证了本文方法的有效性。关键词:超分辨率(SR);Transformer;卷积神经网络(CNN);通道注意力(CA);深度学习266|411|1更新时间:2023-12-19
摘要:目的基于深度学习的图像超分辨率重构研究取得了重大进展,如何在更好提升重构性能的同时,有效降低重构模型的复杂度,以满足低成本及实时应用的需要,是该领域研究关注的重要问题。为此,提出了一种基于通道注意力(channel attention,CA)嵌入的Transformer图像超分辨率深度重构方法(image super-resolution with channel-attention-embedded Transformer,CAET)。方法提出将通道注意力自适应地嵌入Transformer变换特征及卷积运算特征,不仅可充分利用卷积运算与Transformer变换在图像特征提取的各自优势,而且将对应特征进行自适应增强与融合,有效改进网络的学习能力及超分辨率性能。结果基于5个开源测试数据集,与6种代表性方法进行了实验比较,结果显示本文方法在不同放大倍数情形下均有最佳表现。具体在4倍放大因子时,比较先进的SwinIR(image restoration using swin Transformer)方法,峰值信噪比指标在Urban100数据集上得到了0.09 dB的提升,在Manga109数据集提升了0.30 dB,具有主观视觉质量的明显改善。结论提出的通道注意力嵌入的Transformer图像超分辨率方法,通过融合卷积特征与Transformer特征,并自适应嵌入通道注意力特征增强,可以在较好地平衡网络模型轻量化同时,得到图像超分辨率性能的有效提升,在多个公共实验数据集的测试结果验证了本文方法的有效性。关键词:超分辨率(SR);Transformer;卷积神经网络(CNN);通道注意力(CA);深度学习266|411|1更新时间:2023-12-19
图像处理和编码
-
 摘要:目的现有图像级标注的弱监督分割方法大多利用卷积神经网络获取伪标签,其覆盖的目标区域往往过小。基于Transformer的方法通常采用自注意力对类激活图进行扩张,然而受其深层注意力不准确性的影响,优化之后得到的伪标签中背景噪声比较多。为了利用该两类特征提取网络的优点,同时结合Transformer不同层级的注意力特性,构建了一种结合卷积特征和Transformer特征的自注意力融合调制网络进行弱监督语义分割。方法采用卷积增强的Transformer(Conformer)作为特征提取网络,其能够对图像进行更加全面的编码,得到初始的类激活图。设计了一种自注意力层级自适应融合模块,根据自注意力值和层级重要性生成融合权重,融合之后的自注意力能够较好地抑制背景噪声。提出了一种自注意力调制模块,利用像素对之间的注意力关系,设计调制函数,增大前景像素的激活响应。使用调制后的注意力对初始类激活图进行优化,使其覆盖较多的目标区域,同时有效抑制背景噪声。结果在最常用的PASCAL VOC 2012(pattern analysis, statistical modeling and computational learning visual object classes 2012)数据集和COCO 2014(common objectes in context 2014)数据集上利用获得的伪标签进行分割网络的训练,在对比实验中本文算法均取得最优结果,在PASCAL VOC验证集上,平均交并比(mean intersection over union,mIoU)达到了70.2%,测试集上mIoU值为70.5%,相比对比算法中最优的Transformer模型,其性能在验证集和测试集上均提升了0.9%,相比于卷积神经网络最优方法,验证集上mIoU提升了0.7%,测试集上mIoU值提升了0.8%。在COCO 2014验证集上结果为40.1%,与对比算法中最优方法相比分割精度提高了0.5%。结论本文提出的弱监督语义分割模型,结合了卷积神经网络和Transformer的优点,通过对Transformer自注意力进行自适应融合调制,得到了图像级标签下目前最优的语义分割结果,该方法可应用于三维重建、机器人场景理解等应用领域。此外,所构建的自注意力自适应融合模块和自注意力调制模块均可嵌入到Transformer结构中,为具体视觉任务获取更鲁棒、更具鉴别性的特征。关键词:语义分割;弱监督学习;Transformer;卷积神经网络(CNN);自注意力调制;自注意力融合;类激活图158|284|0更新时间:2023-12-19
摘要:目的现有图像级标注的弱监督分割方法大多利用卷积神经网络获取伪标签,其覆盖的目标区域往往过小。基于Transformer的方法通常采用自注意力对类激活图进行扩张,然而受其深层注意力不准确性的影响,优化之后得到的伪标签中背景噪声比较多。为了利用该两类特征提取网络的优点,同时结合Transformer不同层级的注意力特性,构建了一种结合卷积特征和Transformer特征的自注意力融合调制网络进行弱监督语义分割。方法采用卷积增强的Transformer(Conformer)作为特征提取网络,其能够对图像进行更加全面的编码,得到初始的类激活图。设计了一种自注意力层级自适应融合模块,根据自注意力值和层级重要性生成融合权重,融合之后的自注意力能够较好地抑制背景噪声。提出了一种自注意力调制模块,利用像素对之间的注意力关系,设计调制函数,增大前景像素的激活响应。使用调制后的注意力对初始类激活图进行优化,使其覆盖较多的目标区域,同时有效抑制背景噪声。结果在最常用的PASCAL VOC 2012(pattern analysis, statistical modeling and computational learning visual object classes 2012)数据集和COCO 2014(common objectes in context 2014)数据集上利用获得的伪标签进行分割网络的训练,在对比实验中本文算法均取得最优结果,在PASCAL VOC验证集上,平均交并比(mean intersection over union,mIoU)达到了70.2%,测试集上mIoU值为70.5%,相比对比算法中最优的Transformer模型,其性能在验证集和测试集上均提升了0.9%,相比于卷积神经网络最优方法,验证集上mIoU提升了0.7%,测试集上mIoU值提升了0.8%。在COCO 2014验证集上结果为40.1%,与对比算法中最优方法相比分割精度提高了0.5%。结论本文提出的弱监督语义分割模型,结合了卷积神经网络和Transformer的优点,通过对Transformer自注意力进行自适应融合调制,得到了图像级标签下目前最优的语义分割结果,该方法可应用于三维重建、机器人场景理解等应用领域。此外,所构建的自注意力自适应融合模块和自注意力调制模块均可嵌入到Transformer结构中,为具体视觉任务获取更鲁棒、更具鉴别性的特征。关键词:语义分割;弱监督学习;Transformer;卷积神经网络(CNN);自注意力调制;自注意力融合;类激活图158|284|0更新时间:2023-12-19 -
 摘要:目的针对现有视频目标分割(video object segmentation,VOS)算法不能自适应进行样本权重更新,以及使用过多的冗余特征信息导致不必要的空间与时间消耗等问题,提出一种自适应权重更新的轻量级视频目标分割算法。方法首先,为建立一个具有较强目标判别性的算法模型,所提算法根据提取特征的表征质量,自适应地赋予特征相应的权重;其次,为了去除冗余信息,提高算法的运行速度,通过优化信息存储策略,构建了一个轻量级的记忆模块。结果实验结果表明,在公开数据集DAVIS2016(densely annotated video segmentation)和DAVIS2017上,本文算法的区域相似度与轮廓准确度的均值
摘要:目的针对现有视频目标分割(video object segmentation,VOS)算法不能自适应进行样本权重更新,以及使用过多的冗余特征信息导致不必要的空间与时间消耗等问题,提出一种自适应权重更新的轻量级视频目标分割算法。方法首先,为建立一个具有较强目标判别性的算法模型,所提算法根据提取特征的表征质量,自适应地赋予特征相应的权重;其次,为了去除冗余信息,提高算法的运行速度,通过优化信息存储策略,构建了一个轻量级的记忆模块。结果实验结果表明,在公开数据集DAVIS2016(densely annotated video segmentation)和DAVIS2017上,本文算法的区域相似度与轮廓准确度的均值 -
 摘要:目的针对人脸风格迁移算法StarGAN(star generative adversarial network)、MSGAN(mode seeking generative adversarial network)等存在细节风格学习不佳、迁移效果单一和生成图像失真等缺点,提出一种能够降低失真并生成不同风格强度图像的人脸风格迁移算法MStarGAN(multilayer StarGAN)。方法首先,通过特征金字塔网络(feature pyramid network,FPN)构建前置编码器,生成蕴含有图像细节特征的多层特征向量,增强生成图像在风格传输时能学习到的风格图像的细节风格;其次,使用前置编码器对原图像及风格图像各生成一个风格向量并进行组合,利用组合后的风格向量进行风格传输,使生成图像具有不同的风格迁移强度;最后,采用权重解调算法作为生成器中的风格传输模块,通过对卷积权重的操作代替在特征图上的归一化操作,消除特征图中的特征伪影,减少生成图像中的失真。结果在Celeba_HQ数据集上进行实验,与MSGAN、StarGAN v2等对比算法相比,在参考引导合成实验中,MStarGAN的FID(Frechét inception distance score)指标分别降低了18.9和3.1,LPIPS(learned perceptual image patch similarity)指标分别提升了0.094和0.018。在潜在引导合成实验中,MStarGAN的FID指标分别降低了20.2和0.8,LPIPS指标分别提升了0.155和0.92,并能够生成具有不同风格强度的结果图像。结论提出的算法能够传输图像的细节风格,生成具有不同强度的输出图像,并减少生成图像的失真。关键词:人脸风格迁移网络;StarGAN;风格强度;特征金字塔网络(FPN);权重解调185|361|2更新时间:2023-12-19
摘要:目的针对人脸风格迁移算法StarGAN(star generative adversarial network)、MSGAN(mode seeking generative adversarial network)等存在细节风格学习不佳、迁移效果单一和生成图像失真等缺点,提出一种能够降低失真并生成不同风格强度图像的人脸风格迁移算法MStarGAN(multilayer StarGAN)。方法首先,通过特征金字塔网络(feature pyramid network,FPN)构建前置编码器,生成蕴含有图像细节特征的多层特征向量,增强生成图像在风格传输时能学习到的风格图像的细节风格;其次,使用前置编码器对原图像及风格图像各生成一个风格向量并进行组合,利用组合后的风格向量进行风格传输,使生成图像具有不同的风格迁移强度;最后,采用权重解调算法作为生成器中的风格传输模块,通过对卷积权重的操作代替在特征图上的归一化操作,消除特征图中的特征伪影,减少生成图像中的失真。结果在Celeba_HQ数据集上进行实验,与MSGAN、StarGAN v2等对比算法相比,在参考引导合成实验中,MStarGAN的FID(Frechét inception distance score)指标分别降低了18.9和3.1,LPIPS(learned perceptual image patch similarity)指标分别提升了0.094和0.018。在潜在引导合成实验中,MStarGAN的FID指标分别降低了20.2和0.8,LPIPS指标分别提升了0.155和0.92,并能够生成具有不同风格强度的结果图像。结论提出的算法能够传输图像的细节风格,生成具有不同强度的输出图像,并减少生成图像的失真。关键词:人脸风格迁移网络;StarGAN;风格强度;特征金字塔网络(FPN);权重解调185|361|2更新时间:2023-12-19 -
 摘要:目的基于深度卷积神经网络的目标检测模型易受复杂环境(遮挡、光照、远距离、小目标等)影响导致漏检、误检和目标轮廓特征模糊的问题,现有模型难以直接泛化到航拍场景下的小目标检测任务。为有效解决上述问题,提出一种融合非临近跳连与多尺度残差结构的小目标车辆检测算法(non-adjacent hop network you only look once version 5s multi-scale residual edge contour feature extraction strategy,NHN-YOLOv5s-MREFE)。方法首先,设计4种不同尺度的检测层,根据自身感受野大小,针对性地负责不同尺寸车辆的检测。其次,借鉴DenseNet密集跳连的思想,构建一种非临近跳连特征金字塔结构(non-adjacent hop network,NHN),通过跳连相加策略,在强化非临近层次信息交互的同时融合更多未被影响的原始信息,解决位置信息在传递过程中被逐渐稀释的问题,有效降低了模型的误检率。然后,以减少特征丢失为前提,引入反卷积和并行策略,通过参数学习实现像素填充和突破每1维度信息量的方式扩充小目标细节信息。接着,设计一种多尺度残差边缘轮廓特征提取策略(multi-scale residual edge contour feature extraction strategy,MREFE),遵循特征逐渐细化的原则,构建多尺度残差结构,采用双分支并行的方法捕获不同层级的多尺度信息,通过多尺度下的高语义信息与初始浅层信息的逐像素作差实现图像边缘特征提取,进而辅助网络模型完成目标分类。最后,采用K-Means++算法使聚类中心分散化,促使结果达到全局最优,加速模型收敛。结果实验结果表明,非临近跳连的特征金字塔与多尺度残差结构的多模态融合策略,在提升模型运行效率,降低模型计算资源消耗的同时,有效提升了小目标检测的准确性和鲁棒性。通过多场景、多时段、多角度的样本数据增强,强化了模型在不同场景下的泛化能力。最后,在十字路口、沿途车道双场景下包含多种车辆类型的航拍图像数据集上,对比分析4种主流的目标检测方法,本文算法的综合性能最优。相较于基准模型(YOLOv5s),精确率、召回率和平均精度均值分别提升了13.7%、1.6%和8.1%。结论本文算法可以较好地平衡检测速度与精度,以增加极小的参数量为代价,显著地提升了检测精度, 并能够自适应复杂的交通环境,满足航拍场景下小目标车辆检测的实时性需求,在交通流量、密度等参数的测量和统计,车辆定位与跟踪等场景下有较高的应用价值。关键词:智能交通;目标检测;深度学习;非临近跳连;多尺度残差结构209|301|1更新时间:2023-12-19
摘要:目的基于深度卷积神经网络的目标检测模型易受复杂环境(遮挡、光照、远距离、小目标等)影响导致漏检、误检和目标轮廓特征模糊的问题,现有模型难以直接泛化到航拍场景下的小目标检测任务。为有效解决上述问题,提出一种融合非临近跳连与多尺度残差结构的小目标车辆检测算法(non-adjacent hop network you only look once version 5s multi-scale residual edge contour feature extraction strategy,NHN-YOLOv5s-MREFE)。方法首先,设计4种不同尺度的检测层,根据自身感受野大小,针对性地负责不同尺寸车辆的检测。其次,借鉴DenseNet密集跳连的思想,构建一种非临近跳连特征金字塔结构(non-adjacent hop network,NHN),通过跳连相加策略,在强化非临近层次信息交互的同时融合更多未被影响的原始信息,解决位置信息在传递过程中被逐渐稀释的问题,有效降低了模型的误检率。然后,以减少特征丢失为前提,引入反卷积和并行策略,通过参数学习实现像素填充和突破每1维度信息量的方式扩充小目标细节信息。接着,设计一种多尺度残差边缘轮廓特征提取策略(multi-scale residual edge contour feature extraction strategy,MREFE),遵循特征逐渐细化的原则,构建多尺度残差结构,采用双分支并行的方法捕获不同层级的多尺度信息,通过多尺度下的高语义信息与初始浅层信息的逐像素作差实现图像边缘特征提取,进而辅助网络模型完成目标分类。最后,采用K-Means++算法使聚类中心分散化,促使结果达到全局最优,加速模型收敛。结果实验结果表明,非临近跳连的特征金字塔与多尺度残差结构的多模态融合策略,在提升模型运行效率,降低模型计算资源消耗的同时,有效提升了小目标检测的准确性和鲁棒性。通过多场景、多时段、多角度的样本数据增强,强化了模型在不同场景下的泛化能力。最后,在十字路口、沿途车道双场景下包含多种车辆类型的航拍图像数据集上,对比分析4种主流的目标检测方法,本文算法的综合性能最优。相较于基准模型(YOLOv5s),精确率、召回率和平均精度均值分别提升了13.7%、1.6%和8.1%。结论本文算法可以较好地平衡检测速度与精度,以增加极小的参数量为代价,显著地提升了检测精度, 并能够自适应复杂的交通环境,满足航拍场景下小目标车辆检测的实时性需求,在交通流量、密度等参数的测量和统计,车辆定位与跟踪等场景下有较高的应用价值。关键词:智能交通;目标检测;深度学习;非临近跳连;多尺度残差结构209|301|1更新时间:2023-12-19
图像分析和识别
-
 摘要:目的视频动作质量评估旨在评估视频中特定动作的执行情况和完成质量。自动化的动作质量评估能够有效地减少人力资源的损耗,可以更加精准、公正地对视频内容进行评估。传统动作质量评估方法主要存在以下问题:1)视频中动作主体的多尺度时空特征问题;2)认知差异导致的标记内在模糊性问题;3)多头自注意力机制的注意力头冗余问题。针对以上问题,提出了一种能够感知视频序列中不同时空位置、生成细粒度标记的动作质量评估模型SALDL(self-attention and label distribution learning)。方法SALDL提出Attention-Inc(attention-inception)结构,该结构通过Embedding、多头自注意力以及多层感知机将自注意力机制渐进式融入Inception结构,使模型能够获得不同尺度卷积特征之间的上下文信息。提出一种正负时间注意力模块PNTA(pos-neg temporal attention),通过PNTA损失挖掘时间注意力特征,从而减少自注意力头冗余并提取不同片段的注意力特征。SALDL模型通过标记增强及标记分布学习生成细粒度的动作质量标记。结果提出的SALDL模型在MTL-AQA(multitask learning-action quality assessment)和JIGSAWS(JHU-ISI gesture and skill assessment working set)等数据集上进行了大量对比及消融实验,斯皮尔曼等级相关系数分别为0.941 6和0.818 3。结论SALDL模型通过充分挖掘不同尺度的时空特征解决了多尺度时空特征问题,并引入符合标记分布的先验知识进行标记增强,达到了解决标记的内在模糊性问题以及注意力头的冗余问题。关键词:动作质量评估(AQA);Inception模块;自注意力机制;标记分布学习;斯皮尔曼等级相关系数100|343|0更新时间:2023-12-19
摘要:目的视频动作质量评估旨在评估视频中特定动作的执行情况和完成质量。自动化的动作质量评估能够有效地减少人力资源的损耗,可以更加精准、公正地对视频内容进行评估。传统动作质量评估方法主要存在以下问题:1)视频中动作主体的多尺度时空特征问题;2)认知差异导致的标记内在模糊性问题;3)多头自注意力机制的注意力头冗余问题。针对以上问题,提出了一种能够感知视频序列中不同时空位置、生成细粒度标记的动作质量评估模型SALDL(self-attention and label distribution learning)。方法SALDL提出Attention-Inc(attention-inception)结构,该结构通过Embedding、多头自注意力以及多层感知机将自注意力机制渐进式融入Inception结构,使模型能够获得不同尺度卷积特征之间的上下文信息。提出一种正负时间注意力模块PNTA(pos-neg temporal attention),通过PNTA损失挖掘时间注意力特征,从而减少自注意力头冗余并提取不同片段的注意力特征。SALDL模型通过标记增强及标记分布学习生成细粒度的动作质量标记。结果提出的SALDL模型在MTL-AQA(multitask learning-action quality assessment)和JIGSAWS(JHU-ISI gesture and skill assessment working set)等数据集上进行了大量对比及消融实验,斯皮尔曼等级相关系数分别为0.941 6和0.818 3。结论SALDL模型通过充分挖掘不同尺度的时空特征解决了多尺度时空特征问题,并引入符合标记分布的先验知识进行标记增强,达到了解决标记的内在模糊性问题以及注意力头的冗余问题。关键词:动作质量评估(AQA);Inception模块;自注意力机制;标记分布学习;斯皮尔曼等级相关系数100|343|0更新时间:2023-12-19 -
 摘要:目的针对GANILLA、Paint Transformer、StrokeNet等已有的风格迁移算法存在生成图像笔触丢失、线条灵活度低以及训练时间长等问题,提出一种基于曲线笔触渲染的图像风格迁移算法。方法首先按照自定义的超像素数量将图像前景分割为小区域的子图像,保留更多图像细节,背景分割为较大区域的子图像,再对分割后的每个子区域选取控制点,采用Bezier方程对控制点进行多尺度笔触生成,最后采用风格迁移算法将渲染后的图像与风格图像进行风格迁移。结果与AST(arbitrary style transfer)方法相比,本文方法在欺骗率指标上提升了0.13,测试者欺骗率提升了0.13。与Paint Transformer等基于笔触渲染的算法对比,本文能够在纹理丰富的前景区域生成细粒度笔触,在背景区域生成粗粒度笔触,保存更多的图像细节。结论与GANILLA、AdaIN(adaptive instance normalization)等风格迁移算法相比,本文采用图像分割算法取点生成笔触参数,无需训练,不仅提高了算法效率,而且生成的多风格图像保留风格化图像的笔触绘制痕迹,图像色彩鲜明。关键词:非真实感渲染;风格迁移;笔触渲染(SBR);Bezier曲线;超像素分割151|397|0更新时间:2023-12-19
摘要:目的针对GANILLA、Paint Transformer、StrokeNet等已有的风格迁移算法存在生成图像笔触丢失、线条灵活度低以及训练时间长等问题,提出一种基于曲线笔触渲染的图像风格迁移算法。方法首先按照自定义的超像素数量将图像前景分割为小区域的子图像,保留更多图像细节,背景分割为较大区域的子图像,再对分割后的每个子区域选取控制点,采用Bezier方程对控制点进行多尺度笔触生成,最后采用风格迁移算法将渲染后的图像与风格图像进行风格迁移。结果与AST(arbitrary style transfer)方法相比,本文方法在欺骗率指标上提升了0.13,测试者欺骗率提升了0.13。与Paint Transformer等基于笔触渲染的算法对比,本文能够在纹理丰富的前景区域生成细粒度笔触,在背景区域生成粗粒度笔触,保存更多的图像细节。结论与GANILLA、AdaIN(adaptive instance normalization)等风格迁移算法相比,本文采用图像分割算法取点生成笔触参数,无需训练,不仅提高了算法效率,而且生成的多风格图像保留风格化图像的笔触绘制痕迹,图像色彩鲜明。关键词:非真实感渲染;风格迁移;笔触渲染(SBR);Bezier曲线;超像素分割151|397|0更新时间:2023-12-19 -
 摘要:目的方面级多模态情感分析日益受到关注,其目的是预测多模态数据中所提及的特定方面的情感极性。然而目前的相关方法大都对方面词在上下文建模、模态间细粒度对齐的指向性作用考虑不够,限制了方面级多模态情感分析的性能。为了解决上述问题,提出一个方面级多模态协同注意图卷积情感分析模型(aspect-level multimodal co-attention graph convolutional sentiment analysis model,AMCGC)来同时建模方面指向的模态内上下文语义关联和跨模态的细粒度对齐,以提升情感分析性能。方法AMCGC为了获得方面导向的模态内的局部语义相关性,利用正交约束的自注意力机制生成各个模态的语义图。然后,通过图卷积获得含有方面词的文本语义图表示和融入方面词的视觉语义图表示,并设计两个不同方向的门控局部跨模态交互机制递进地实现文本语义图表示和视觉语义图表示的细粒度跨模态关联互对齐,从而降低模态间的异构鸿沟。最后,设计方面掩码来选用各模态图表示中方面节点特征作为情感表征,并引入跨模态损失降低异质方面特征的差异。结果在两个多模态数据集上与9种方法进行对比,在Twitter-2015数据集中,相比于性能第2的模型,准确率提高了1.76%;在Twitter-2017数据集中,相比于性能第2的模型,准确率提高了1.19%。在消融实验部分则从正交约束、跨模态损失、交叉协同多模态融合分别进行评估,验证了AMCGC模型各部分的合理性。结论本文提出的AMCGC模型能更好地捕捉模态内的局部语义相关性和模态之间的细粒度对齐,提升方面级多模态情感分析的准确性。关键词:多模态情感分析;方面级情感分析;图卷积;正交约束的自注意力机制;跨模态协同注意;方面掩码242|210|0更新时间:2023-12-19
摘要:目的方面级多模态情感分析日益受到关注,其目的是预测多模态数据中所提及的特定方面的情感极性。然而目前的相关方法大都对方面词在上下文建模、模态间细粒度对齐的指向性作用考虑不够,限制了方面级多模态情感分析的性能。为了解决上述问题,提出一个方面级多模态协同注意图卷积情感分析模型(aspect-level multimodal co-attention graph convolutional sentiment analysis model,AMCGC)来同时建模方面指向的模态内上下文语义关联和跨模态的细粒度对齐,以提升情感分析性能。方法AMCGC为了获得方面导向的模态内的局部语义相关性,利用正交约束的自注意力机制生成各个模态的语义图。然后,通过图卷积获得含有方面词的文本语义图表示和融入方面词的视觉语义图表示,并设计两个不同方向的门控局部跨模态交互机制递进地实现文本语义图表示和视觉语义图表示的细粒度跨模态关联互对齐,从而降低模态间的异构鸿沟。最后,设计方面掩码来选用各模态图表示中方面节点特征作为情感表征,并引入跨模态损失降低异质方面特征的差异。结果在两个多模态数据集上与9种方法进行对比,在Twitter-2015数据集中,相比于性能第2的模型,准确率提高了1.76%;在Twitter-2017数据集中,相比于性能第2的模型,准确率提高了1.19%。在消融实验部分则从正交约束、跨模态损失、交叉协同多模态融合分别进行评估,验证了AMCGC模型各部分的合理性。结论本文提出的AMCGC模型能更好地捕捉模态内的局部语义相关性和模态之间的细粒度对齐,提升方面级多模态情感分析的准确性。关键词:多模态情感分析;方面级情感分析;图卷积;正交约束的自注意力机制;跨模态协同注意;方面掩码242|210|0更新时间:2023-12-19 -
 摘要:目的场景文本识别(scene text recognition,STR)是计算机视觉中的一个热门研究领域。最近,基于多头自注意力机制的视觉Transformer(vision Transformer,ViT)模型被提出用于STR,以实现精度、速度和计算负载的平衡。然而,没有机制可以保证不同的自注意力头确实捕捉到多样性的特征,这将导致使用多头自注意力机制的ViT模型在多样性极强的场景文本识别任务中表现不佳。针对这个问题,提出了一种新颖的正交约束来显式增强多个自注意力头之间的多样性,提高多头自注意力对不同子空间信息的捕获能力,在保证速度和计算效率的同时进一步提高网络的精度。方法首先提出了针对不同自注意力头上Q(query)、K(key)和V(value)特征的正交约束,这可以使不同的自注意力头能够关注到不同的查询子空间、键子空间、值子空间的特征,关注不同子空间的特征可以显式地使不同的自注意力头捕捉到更具差异的特征。还提出了针对不同自注意力头上Q、K和V特征线性变换权重的正交约束,这将为Q、K和V特征的学习提供正交权重空间的解决方案,并在网络训练中带来隐式正则化的效果。结果实验在7个数据集上与基准方法进行比较,在规则数据集Street View Text(SVT)上精度提高了0.5%;在不规则数据集CUTE80(CT)上精度提高了1.1%;在7个公共数据集上的整体精度提升了0.5%。结论提出的即插即用的正交约束能够提高多头自注意力机制在STR任务中的特征捕获能力,使ViT模型在STR任务上的识别精度得到提高。本文代码已公开:https://github.com/lexiaoyuan/XViTSTR。关键词:场景文本识别(STR);视觉Transformer(ViT);多头自注意力;正交约束;计算机视觉82|162|0更新时间:2023-12-19
摘要:目的场景文本识别(scene text recognition,STR)是计算机视觉中的一个热门研究领域。最近,基于多头自注意力机制的视觉Transformer(vision Transformer,ViT)模型被提出用于STR,以实现精度、速度和计算负载的平衡。然而,没有机制可以保证不同的自注意力头确实捕捉到多样性的特征,这将导致使用多头自注意力机制的ViT模型在多样性极强的场景文本识别任务中表现不佳。针对这个问题,提出了一种新颖的正交约束来显式增强多个自注意力头之间的多样性,提高多头自注意力对不同子空间信息的捕获能力,在保证速度和计算效率的同时进一步提高网络的精度。方法首先提出了针对不同自注意力头上Q(query)、K(key)和V(value)特征的正交约束,这可以使不同的自注意力头能够关注到不同的查询子空间、键子空间、值子空间的特征,关注不同子空间的特征可以显式地使不同的自注意力头捕捉到更具差异的特征。还提出了针对不同自注意力头上Q、K和V特征线性变换权重的正交约束,这将为Q、K和V特征的学习提供正交权重空间的解决方案,并在网络训练中带来隐式正则化的效果。结果实验在7个数据集上与基准方法进行比较,在规则数据集Street View Text(SVT)上精度提高了0.5%;在不规则数据集CUTE80(CT)上精度提高了1.1%;在7个公共数据集上的整体精度提升了0.5%。结论提出的即插即用的正交约束能够提高多头自注意力机制在STR任务中的特征捕获能力,使ViT模型在STR任务上的识别精度得到提高。本文代码已公开:https://github.com/lexiaoyuan/XViTSTR。关键词:场景文本识别(STR);视觉Transformer(ViT);多头自注意力;正交约束;计算机视觉82|162|0更新时间:2023-12-19 -
 摘要:目的人脸年龄合成旨在合成指定年龄人脸图像的同时保持高可信度的人脸,是计算机视觉领域的热门研究方向之一。然而目前主流人脸年龄合成模型过于关注纹理信息,忽视了与人脸相关的多尺度特征,此外网络存在对身份信息筛选不佳的问题。针对以上问题,提出一种融合通道位置注意力机制和并行空洞卷积的人脸年龄合成网络(generative adversarial network(GAN)composed of the parallel dilated convolution and channel-coordinate attention mechanism,PDA-GAN)。方法PDA-GAN 基于生成对抗网络提出了并行三通道空洞卷积残差块和通道—位置注意力机制。并行三通道空洞卷积残差块将3种膨胀系数空洞卷积提取的不同尺度人脸特征融合,提升了特征尺度上的多样性和总量上的丰富度;通道—位置注意力机制通过对人脸特征的长度、宽度和深度显著性计算,定位图像中与年龄高度相关的通道和空间位置区域,增强了网络对通道和空间位置上敏感特征的表达能力,解决了特征冗余问题。结果实验在Flickr高清人脸数据集(Flickr-faces-high-quality,FFHQ)上训练,在名人人脸属性高清数据集(large-scale celebfaces attributes dataset-high quality, Celeba-HQ)上测试,将本文提出的 PDA-GAN 与最新的3种人脸年龄图像合成网络进行定性和定量比较,以验证本文方法的有效性。实验结果表明,PDA-GAN 显著提升了人脸年龄合成的身份置信度和年龄估计准确度,具有良好的身份信息保留和年龄操控能力。结论本文方法能够合成具有较高真实度和准确性的目标年龄人脸图像。关键词:图像合成;人脸年龄;生成对抗网络(GAN);空洞卷积;注意力机制87|333|0更新时间:2023-12-19
摘要:目的人脸年龄合成旨在合成指定年龄人脸图像的同时保持高可信度的人脸,是计算机视觉领域的热门研究方向之一。然而目前主流人脸年龄合成模型过于关注纹理信息,忽视了与人脸相关的多尺度特征,此外网络存在对身份信息筛选不佳的问题。针对以上问题,提出一种融合通道位置注意力机制和并行空洞卷积的人脸年龄合成网络(generative adversarial network(GAN)composed of the parallel dilated convolution and channel-coordinate attention mechanism,PDA-GAN)。方法PDA-GAN 基于生成对抗网络提出了并行三通道空洞卷积残差块和通道—位置注意力机制。并行三通道空洞卷积残差块将3种膨胀系数空洞卷积提取的不同尺度人脸特征融合,提升了特征尺度上的多样性和总量上的丰富度;通道—位置注意力机制通过对人脸特征的长度、宽度和深度显著性计算,定位图像中与年龄高度相关的通道和空间位置区域,增强了网络对通道和空间位置上敏感特征的表达能力,解决了特征冗余问题。结果实验在Flickr高清人脸数据集(Flickr-faces-high-quality,FFHQ)上训练,在名人人脸属性高清数据集(large-scale celebfaces attributes dataset-high quality, Celeba-HQ)上测试,将本文提出的 PDA-GAN 与最新的3种人脸年龄图像合成网络进行定性和定量比较,以验证本文方法的有效性。实验结果表明,PDA-GAN 显著提升了人脸年龄合成的身份置信度和年龄估计准确度,具有良好的身份信息保留和年龄操控能力。结论本文方法能够合成具有较高真实度和准确性的目标年龄人脸图像。关键词:图像合成;人脸年龄;生成对抗网络(GAN);空洞卷积;注意力机制87|333|0更新时间:2023-12-19 -
 摘要:目的针对点云分割需要大量监督信息所造成的时间成本高、计算效率低的问题,采用融合原型对齐的小样本元学习算法对点云进行语义分割,使模型能够在监督信息很少的情况下完成分割任务。方法首先,为了避免小样本训练时易导致的过拟合问题,采用2个边缘卷积层(edge convolution layer,EdgeConv)与6个MLP(multilayer perceptron)交叉构造DGCNN(dynamic graph convolutional neural network),同时还保证了能充分学习到点云信息;然后,以N-way K-shot的形式将数据集输入上述网络学习支持集与查询集的特征,通过average pooling feature获取类别原型并融合原型对齐算法得到更为鲁棒的支持集原型;最后,通过计算查询集点云特征与支持集原型的欧氏距离实现点云分割。结果在S3DIS(Stanford large-scale 3D indoor spaces dataset)、ScanNet和闽南古建筑数据集上进行点云语义分割实验,与原型网络和匹配网络在S3DIS数据集上进行比较。分割1-way时,平均交并比(mean intersection over union,mIoU)相比原型网络和匹配网络分别提高了0.06和0.33,最高类别的mIoU达到0.95;分割2-way时,mIoU相比原型网络提高了0.04;将DGCNN网络与PointNet++做特征提取器的对比时,分割ceiling和floor的mIoU分别提高了0.05和0.30。方法应用在ScanNet数据集和闽南古建筑数据集上的分割mIoU分别为0.63和0.51。结论提出的方法可以在少量标记数据的情况下取得良好的点云分割效果。相比于此前需用大量标记数据所训练的模型而言,只需要很少的监督信息,便能够分割出该新类,提高了模型的泛化能力。当面临样本的标记数据难以获得的情况时,提出的方法更能够发挥关键作用。关键词:点云分割;小样本学习(FSL);元学习;原型对齐;闽南古建筑145|409|1更新时间:2023-12-19
摘要:目的针对点云分割需要大量监督信息所造成的时间成本高、计算效率低的问题,采用融合原型对齐的小样本元学习算法对点云进行语义分割,使模型能够在监督信息很少的情况下完成分割任务。方法首先,为了避免小样本训练时易导致的过拟合问题,采用2个边缘卷积层(edge convolution layer,EdgeConv)与6个MLP(multilayer perceptron)交叉构造DGCNN(dynamic graph convolutional neural network),同时还保证了能充分学习到点云信息;然后,以N-way K-shot的形式将数据集输入上述网络学习支持集与查询集的特征,通过average pooling feature获取类别原型并融合原型对齐算法得到更为鲁棒的支持集原型;最后,通过计算查询集点云特征与支持集原型的欧氏距离实现点云分割。结果在S3DIS(Stanford large-scale 3D indoor spaces dataset)、ScanNet和闽南古建筑数据集上进行点云语义分割实验,与原型网络和匹配网络在S3DIS数据集上进行比较。分割1-way时,平均交并比(mean intersection over union,mIoU)相比原型网络和匹配网络分别提高了0.06和0.33,最高类别的mIoU达到0.95;分割2-way时,mIoU相比原型网络提高了0.04;将DGCNN网络与PointNet++做特征提取器的对比时,分割ceiling和floor的mIoU分别提高了0.05和0.30。方法应用在ScanNet数据集和闽南古建筑数据集上的分割mIoU分别为0.63和0.51。结论提出的方法可以在少量标记数据的情况下取得良好的点云分割效果。相比于此前需用大量标记数据所训练的模型而言,只需要很少的监督信息,便能够分割出该新类,提高了模型的泛化能力。当面临样本的标记数据难以获得的情况时,提出的方法更能够发挥关键作用。关键词:点云分割;小样本学习(FSL);元学习;原型对齐;闽南古建筑145|409|1更新时间:2023-12-19
图像理解和计算机视觉
-
 摘要:目的结直肠息肉检测可以有效预防癌变,然而人工诊断往往存在较高漏检率,使用深度学习技术可以提供有助于诊断的细粒度信息,辅助医生进行筛查。实际场景中,息肉形态各异和息肉边缘模糊的特点会严重影响算法的准确性。针对这一问题,提出了一种边缘概率分布模型引导的结直肠息肉分割网络(edge distribution guided high-resolution network,HRNetED)。方法本文所提的HRNetED网络使用HRNet结构作为网络主干,设计了一种堆叠残差卷积模块,显著降低模型参数量的同时提高模型性能;此外,本文使用边缘概率分布模型来描述息肉边缘,提高模型对边缘检测的稳定性;最后,本文在多尺度解码器中引入边缘检测任务,以加强模型对息肉边缘的感知。结果本文在Kvasir-Seg(Kvasir segmentation dataset)、ETIS(ETIS larib polyp database)、CVC-ColonDB(colonoscopy videos challenge colon database)、CVC-ClinicDB(colonoscopy videos challenge clinic database)和CVC-300(colonoscopy videos challenge 300)5个数据集上进行测试。最终,HRNetED在CVC-ClinicDB和CVC-300数据集上的Dice系数(Dice similarity coefficient)和平均交并比(mean intersection over union,mIoU)指标均优于对比算法,且在CVC-ClinicDB数据集上相较于对比最优模型分别获得了1.25%和1.37%的提升;在ETIS数据集上,Dice系数表现优于对比最优算法;在CVC-ColonDB数据集上,Dice和mIoU处于较优水平。此外,HRNetED在Kvasir-Seg、ETIS、CVC-ColonDB数据集上的HD95距离相较于对比最优算法分别降低了0.315%、29.19%和2.95%,在CVC-ClinicDB和CVC-300数据集上表现为次优,同样具有良好的性能。结论本文提出的HRNetED网络在多个数据集中表现稳定,对于小目标、模糊息肉有较好的感知能力,对息肉轮廓检测能力更强。关键词:医学图像处理;息肉分割;深度学习;高分辨率网络;边缘检测99|269|1更新时间:2023-12-19
摘要:目的结直肠息肉检测可以有效预防癌变,然而人工诊断往往存在较高漏检率,使用深度学习技术可以提供有助于诊断的细粒度信息,辅助医生进行筛查。实际场景中,息肉形态各异和息肉边缘模糊的特点会严重影响算法的准确性。针对这一问题,提出了一种边缘概率分布模型引导的结直肠息肉分割网络(edge distribution guided high-resolution network,HRNetED)。方法本文所提的HRNetED网络使用HRNet结构作为网络主干,设计了一种堆叠残差卷积模块,显著降低模型参数量的同时提高模型性能;此外,本文使用边缘概率分布模型来描述息肉边缘,提高模型对边缘检测的稳定性;最后,本文在多尺度解码器中引入边缘检测任务,以加强模型对息肉边缘的感知。结果本文在Kvasir-Seg(Kvasir segmentation dataset)、ETIS(ETIS larib polyp database)、CVC-ColonDB(colonoscopy videos challenge colon database)、CVC-ClinicDB(colonoscopy videos challenge clinic database)和CVC-300(colonoscopy videos challenge 300)5个数据集上进行测试。最终,HRNetED在CVC-ClinicDB和CVC-300数据集上的Dice系数(Dice similarity coefficient)和平均交并比(mean intersection over union,mIoU)指标均优于对比算法,且在CVC-ClinicDB数据集上相较于对比最优模型分别获得了1.25%和1.37%的提升;在ETIS数据集上,Dice系数表现优于对比最优算法;在CVC-ColonDB数据集上,Dice和mIoU处于较优水平。此外,HRNetED在Kvasir-Seg、ETIS、CVC-ColonDB数据集上的HD95距离相较于对比最优算法分别降低了0.315%、29.19%和2.95%,在CVC-ClinicDB和CVC-300数据集上表现为次优,同样具有良好的性能。结论本文提出的HRNetED网络在多个数据集中表现稳定,对于小目标、模糊息肉有较好的感知能力,对息肉轮廓检测能力更强。关键词:医学图像处理;息肉分割;深度学习;高分辨率网络;边缘检测99|269|1更新时间:2023-12-19
医学图像处理
-
 摘要:目的赤潮是一种常见的海洋生态灾害,严重威胁海洋生态系统安全。及时准确获取赤潮的发生和分布信息可以为赤潮的预警和防治提供有力支撑。然而,受混合像元和水环境要素影响,赤潮分布精细探测仍是挑战。针对赤潮边缘探测的难点,结合赤潮边缘高频特征学习与位置语义,提出了一种计算量小、精度高的网络模型RTDNet(red tide detection network)。方法针对赤潮边缘探测不准确的问题,设计了基于RIR(residual-in-residual)结构的网络,以提取赤潮边缘水体的高频特征;利用多感受野结构和坐标注意力机制捕获赤潮水体的位置语义信息,增强赤潮边缘水体的细节信息并抑制无用的特征。结果在GF1-WFV(Gaofen1 wide field of view)赤潮数据集上的实验结果表明,所提出的RTDNet模型赤潮探测效果不仅优于支持向量机(support vector machine,SVM)、U-Net、DeepLabv3+及HRNet(high-resolution network)等通用机器学习和深度学习模型,而且也优于赤潮指数法GF1_RI(Gaofen1 red tide index )以及赤潮探测专用深度学习模型RDU-Net(red tide detection U-Net),赤潮误提取、漏提取现象明显减少,F1分数在两幅测试图像上分别达到了0.905和0.898,相较于性能第2的模型DeepLabv3+提升了2%以上。而且,所提出的模型参数量小,仅有2.65 MB,约为DeepLabv3+的13%。结论面向赤潮探测提出一种基于RIR结构的赤潮深度学习探测模型,通过融合多感受野结构和注意力机制提升了赤潮边缘探测的精度和稳定性,同时有效降低了计算量。本文方法展现了较好的应用效果,可适用于不同高分辨率卫星影像的赤潮探测。关键词:赤潮探测;GF-1 WFV遥感影像;语义分割;残差网络;注意力机制182|275|0更新时间:2023-12-19
摘要:目的赤潮是一种常见的海洋生态灾害,严重威胁海洋生态系统安全。及时准确获取赤潮的发生和分布信息可以为赤潮的预警和防治提供有力支撑。然而,受混合像元和水环境要素影响,赤潮分布精细探测仍是挑战。针对赤潮边缘探测的难点,结合赤潮边缘高频特征学习与位置语义,提出了一种计算量小、精度高的网络模型RTDNet(red tide detection network)。方法针对赤潮边缘探测不准确的问题,设计了基于RIR(residual-in-residual)结构的网络,以提取赤潮边缘水体的高频特征;利用多感受野结构和坐标注意力机制捕获赤潮水体的位置语义信息,增强赤潮边缘水体的细节信息并抑制无用的特征。结果在GF1-WFV(Gaofen1 wide field of view)赤潮数据集上的实验结果表明,所提出的RTDNet模型赤潮探测效果不仅优于支持向量机(support vector machine,SVM)、U-Net、DeepLabv3+及HRNet(high-resolution network)等通用机器学习和深度学习模型,而且也优于赤潮指数法GF1_RI(Gaofen1 red tide index )以及赤潮探测专用深度学习模型RDU-Net(red tide detection U-Net),赤潮误提取、漏提取现象明显减少,F1分数在两幅测试图像上分别达到了0.905和0.898,相较于性能第2的模型DeepLabv3+提升了2%以上。而且,所提出的模型参数量小,仅有2.65 MB,约为DeepLabv3+的13%。结论面向赤潮探测提出一种基于RIR结构的赤潮深度学习探测模型,通过融合多感受野结构和注意力机制提升了赤潮边缘探测的精度和稳定性,同时有效降低了计算量。本文方法展现了较好的应用效果,可适用于不同高分辨率卫星影像的赤潮探测。关键词:赤潮探测;GF-1 WFV遥感影像;语义分割;残差网络;注意力机制182|275|0更新时间:2023-12-19 -
 摘要:目的将高光谱图像和多光谱图像进行融合,可以获得具有高空间分辨率和高光谱分辨率的光谱图像,提升光谱图像的质量。现有的基于深度学习的融合方法虽然表现良好,但缺乏对多源图像特征中光谱和空间长距离依赖关系的联合探索。为有效利用图像的光谱相关性和空间相似性,提出一种联合自注意力的Transformer网络来实现多光谱和高光谱图像融合超分辨。方法首先利用联合自注意力模块,通过光谱注意力机制提取高光谱图像的光谱相关性特征,通过空间注意力机制提取多光谱图像的空间相似性特征,将获得的联合相似性特征用于指导高光谱图像和多光谱图像的融合;随后,将得到的融合特征输入到基于滑动窗口的残差Transformer深度网络中,探索融合特征的长距离依赖信息,学习深度先验融合知识;最后,特征通过卷积层映射为高空间分辨率的高光谱图像。结果在CAVE和Harvard光谱数据集上分别进行了不同采样倍率下的实验,实验结果表明,与对比方法相比,本文方法从定量指标和视觉效果上,都取得了更好的效果。本文方法相较于性能第二的方法EDBIN(enhanced deep blind iterative network),在CAVE数据集上峰值信噪比提高了0.5 dB,在Harvard数据集上峰值信噪比提高了0.6 dB。结论本文方法能够更好地融合光谱信息和空间信息,显著提升高光谱融合超分图像的质量。关键词:超分辨率;高光谱图像;多光谱图像;联合自注意力;Transformer;融合算法325|439|1更新时间:2023-12-19
摘要:目的将高光谱图像和多光谱图像进行融合,可以获得具有高空间分辨率和高光谱分辨率的光谱图像,提升光谱图像的质量。现有的基于深度学习的融合方法虽然表现良好,但缺乏对多源图像特征中光谱和空间长距离依赖关系的联合探索。为有效利用图像的光谱相关性和空间相似性,提出一种联合自注意力的Transformer网络来实现多光谱和高光谱图像融合超分辨。方法首先利用联合自注意力模块,通过光谱注意力机制提取高光谱图像的光谱相关性特征,通过空间注意力机制提取多光谱图像的空间相似性特征,将获得的联合相似性特征用于指导高光谱图像和多光谱图像的融合;随后,将得到的融合特征输入到基于滑动窗口的残差Transformer深度网络中,探索融合特征的长距离依赖信息,学习深度先验融合知识;最后,特征通过卷积层映射为高空间分辨率的高光谱图像。结果在CAVE和Harvard光谱数据集上分别进行了不同采样倍率下的实验,实验结果表明,与对比方法相比,本文方法从定量指标和视觉效果上,都取得了更好的效果。本文方法相较于性能第二的方法EDBIN(enhanced deep blind iterative network),在CAVE数据集上峰值信噪比提高了0.5 dB,在Harvard数据集上峰值信噪比提高了0.6 dB。结论本文方法能够更好地融合光谱信息和空间信息,显著提升高光谱融合超分图像的质量。关键词:超分辨率;高光谱图像;多光谱图像;联合自注意力;Transformer;融合算法325|439|1更新时间:2023-12-19
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0