
最新刊期
2023 年 第 28 卷 第 10 期
-
 摘要:Transformer模型在自然语言处理领域取得了很好的效果,同时因其能够更好地连接视觉和语言,也激发了计算机视觉界的极大兴趣。本文总结了视觉Transformer处理多种识别任务的百余种代表性方法,并对比分析了不同任务内的模型表现,在此基础上总结了每类任务模型的优点、不足以及面临的挑战。根据识别粒度的不同,分别着眼于诸如图像分类、视频分类的基于全局识别的方法,以及目标检测、视觉分割的基于局部识别的方法。考虑到现有方法在3种具体识别任务的广泛流行,总结了在人脸识别、动作识别和姿态估计中的方法。同时,也总结了可用于多种视觉任务或领域无关的通用方法的研究现状。基于Transformer的模型实现了许多端到端的方法,并不断追求准确率与计算成本的平衡。全局识别任务下的Transformer模型对补丁序列切分和标记特征表示进行了探索,局部识别任务下的Transformer模型因能够更好地捕获全局信息而取得了较好的表现。在人脸识别和动作识别方面,注意力机制减少了特征表示的误差,可以处理丰富多样的特征。Transformer可以解决姿态估计中特征错位的问题,有利于改善基于回归的方法性能,还减少了三维估计时深度映射所产生的歧义。大量探索表明视觉Transformer在识别任务中的有效性,并且在特征表示或网络结构等方面的改进有利于提升性能。关键词:视觉Transformer(ViT);自注意力;视觉识别;深度学习;图像处理;视频理解307|2498|7更新时间:2024-05-07
摘要:Transformer模型在自然语言处理领域取得了很好的效果,同时因其能够更好地连接视觉和语言,也激发了计算机视觉界的极大兴趣。本文总结了视觉Transformer处理多种识别任务的百余种代表性方法,并对比分析了不同任务内的模型表现,在此基础上总结了每类任务模型的优点、不足以及面临的挑战。根据识别粒度的不同,分别着眼于诸如图像分类、视频分类的基于全局识别的方法,以及目标检测、视觉分割的基于局部识别的方法。考虑到现有方法在3种具体识别任务的广泛流行,总结了在人脸识别、动作识别和姿态估计中的方法。同时,也总结了可用于多种视觉任务或领域无关的通用方法的研究现状。基于Transformer的模型实现了许多端到端的方法,并不断追求准确率与计算成本的平衡。全局识别任务下的Transformer模型对补丁序列切分和标记特征表示进行了探索,局部识别任务下的Transformer模型因能够更好地捕获全局信息而取得了较好的表现。在人脸识别和动作识别方面,注意力机制减少了特征表示的误差,可以处理丰富多样的特征。Transformer可以解决姿态估计中特征错位的问题,有利于改善基于回归的方法性能,还减少了三维估计时深度映射所产生的歧义。大量探索表明视觉Transformer在识别任务中的有效性,并且在特征表示或网络结构等方面的改进有利于提升性能。关键词:视觉Transformer(ViT);自注意力;视觉识别;深度学习;图像处理;视频理解307|2498|7更新时间:2024-05-07 -
 摘要:年龄信息作为人类生物特征识别的重要组成部分,在社会保障和数字娱乐等领域具有广泛的应用前景。人脸年龄合成技术由于其广泛的应用价值,受到了越来越多学者的重视,已经成为计算机视觉领域的重要研究方向之一。随着深度学习的快速发展,基于生成对抗网络的人脸年龄合成技术已成为研究热点。尽管基于生成对抗网络的人脸年龄合成方法取得了不错的成果,但生成的人脸年龄图像仍存在图像质量较差、真实感较低、年龄转换效果和多样性不足等问题。主要因为当前人脸年龄合成研究仍存在以下困难:1)现有人脸年龄合成数据集的限制;2)引入人脸年龄合成的先验知识不足;3)人脸年龄图像的细粒度性被忽视;4)高分辨率下的人脸年龄合成问题;5)目前人脸年龄合成方法的评价标准不规范。本文对目前人脸年龄合成技术进行全面综述,以人脸年龄合成方法为研究对象,阐述其研究现状。通过调研文献,对人脸年龄合成方法进行分类,重点介绍了基于生成对抗网络的人脸年龄合成方法。此外,本文还讨论了常用的人脸年龄合成数据集及评价指标,分析了各种人脸年龄合成方法的基本思想、特点及其局限性,对比了部分代表方法的性能,指出了该领域目前存在的挑战并提供了一些具有潜力的研究方向,为研究者们解决存在的问题提供便利。关键词:人脸年龄合成;图像生成;人脸图像数据集;人脸老化;深度生成方法;生成对抗网络(GAN)217|650|1更新时间:2024-05-07
摘要:年龄信息作为人类生物特征识别的重要组成部分,在社会保障和数字娱乐等领域具有广泛的应用前景。人脸年龄合成技术由于其广泛的应用价值,受到了越来越多学者的重视,已经成为计算机视觉领域的重要研究方向之一。随着深度学习的快速发展,基于生成对抗网络的人脸年龄合成技术已成为研究热点。尽管基于生成对抗网络的人脸年龄合成方法取得了不错的成果,但生成的人脸年龄图像仍存在图像质量较差、真实感较低、年龄转换效果和多样性不足等问题。主要因为当前人脸年龄合成研究仍存在以下困难:1)现有人脸年龄合成数据集的限制;2)引入人脸年龄合成的先验知识不足;3)人脸年龄图像的细粒度性被忽视;4)高分辨率下的人脸年龄合成问题;5)目前人脸年龄合成方法的评价标准不规范。本文对目前人脸年龄合成技术进行全面综述,以人脸年龄合成方法为研究对象,阐述其研究现状。通过调研文献,对人脸年龄合成方法进行分类,重点介绍了基于生成对抗网络的人脸年龄合成方法。此外,本文还讨论了常用的人脸年龄合成数据集及评价指标,分析了各种人脸年龄合成方法的基本思想、特点及其局限性,对比了部分代表方法的性能,指出了该领域目前存在的挑战并提供了一些具有潜力的研究方向,为研究者们解决存在的问题提供便利。关键词:人脸年龄合成;图像生成;人脸图像数据集;人脸老化;深度生成方法;生成对抗网络(GAN)217|650|1更新时间:2024-05-07 -
 摘要:随着各大电力公司对无人机(unmanned aerial vehicle,UAV)巡检的大力推广,“机巡为主,人巡为辅”已成为我国电力巡检的主要运维模式。电力线检测作为电力巡检的关键技术,在无人机自主导航、低空避障飞行以及输电线路安全稳定运行等方面发挥着重要作用。众多研究者将输电线路的无人机航拍图像用于线路设备识别与故障诊断,利用机器视觉的方法在电力线检测技术研究中占据主导地位,也是未来的主要发展方向。本文综述了近10年来无人机航拍图像中电力线检测方法的研究进展。首先简述了电力线特征,阐明了电力线检测的传统处理方法的一般流程及所面临的挑战;然后重点阐述了使用传统图像处理方法及深度学习方法的电力线检测原理,前者包括基于Hough变换的方法、基于Radon变换的方法、基于LSD(line segment detector)的方法、基于扫描标记的方法及其他检测方法,后者根据深度卷积神经网络(deep convolutional neural network,DCNN)的结构不同分为基于DCNN的分类方法及基于DCNN的语义分割方法,评述各类方法的优缺点并进行分析与比较,与传统图像处理方法相比,深度学习方法能更有效地实现航拍图像中的电力线检测,并指出基于DCNN的语义分割方法在电力线目标智能识别与分析中发挥着重要作用;随后介绍了电力线检测的常用数据集及性能评价指标;最后针对电力线检测方法目前存在的问题,对下一步的研究方向进行展望。关键词:机器视觉;电力线检测;无人机巡检;图像处理;深度学习;语义分割306|1495|1更新时间:2024-05-07
摘要:随着各大电力公司对无人机(unmanned aerial vehicle,UAV)巡检的大力推广,“机巡为主,人巡为辅”已成为我国电力巡检的主要运维模式。电力线检测作为电力巡检的关键技术,在无人机自主导航、低空避障飞行以及输电线路安全稳定运行等方面发挥着重要作用。众多研究者将输电线路的无人机航拍图像用于线路设备识别与故障诊断,利用机器视觉的方法在电力线检测技术研究中占据主导地位,也是未来的主要发展方向。本文综述了近10年来无人机航拍图像中电力线检测方法的研究进展。首先简述了电力线特征,阐明了电力线检测的传统处理方法的一般流程及所面临的挑战;然后重点阐述了使用传统图像处理方法及深度学习方法的电力线检测原理,前者包括基于Hough变换的方法、基于Radon变换的方法、基于LSD(line segment detector)的方法、基于扫描标记的方法及其他检测方法,后者根据深度卷积神经网络(deep convolutional neural network,DCNN)的结构不同分为基于DCNN的分类方法及基于DCNN的语义分割方法,评述各类方法的优缺点并进行分析与比较,与传统图像处理方法相比,深度学习方法能更有效地实现航拍图像中的电力线检测,并指出基于DCNN的语义分割方法在电力线目标智能识别与分析中发挥着重要作用;随后介绍了电力线检测的常用数据集及性能评价指标;最后针对电力线检测方法目前存在的问题,对下一步的研究方向进行展望。关键词:机器视觉;电力线检测;无人机巡检;图像处理;深度学习;语义分割306|1495|1更新时间:2024-05-07
综述

-
 摘要:目的现有方法存在特征提取时间过长、非对称失真图像预测准确性不高的问题,同时少有工作对非对称失真与对称失真立体图像的分类进行研究,为此提出了基于双目竞争的非对称失真立体图像质量评价方法。方法依据双目竞争的视觉现象,利用非对称失真立体图像两个视点的图像质量衰减程度的不同,生成单目图像特征的融合系数,融合从左右视点图像中提取的灰度空间特征与HSV(hue-saturation-value)彩色空间特征。同时,量化两个视点图像在结构、信息量和质量衰减程度等多方面的差异,获得双目差异特征。并且将双目融合特征与双目差异特征级联为一个描述能力更强的立体图像质量感知特征向量,训练基于支持向量回归的特征—质量映射模型。此外,还利用双目差异特征训练基于支持向量分类模型的对称失真与非对称失真立体图像分类模型。结果本文提出的质量预测模型在4个数据库上的SROCC(Spearman rank order correlation coefficient)和PLCC(Pearson linear correlation coefficient)均达到0.95以上,在3个非对称失真数据库上的均方根误差(root of mean square error,RMSE)取值均优于对比算法。在LIVE-II(LIVE 3D image quality database phase II)、IVC-I(Waterloo-IVC 3D image quality assessment database phase I)和IVC-II(Waterloo-IVC 3D image quality assessment database phase II)这3个非对称失真立体图像测试数据库上的失真类型分类测试中,对称失真立体图像的分类准确率分别为89.91%、94.76%和98.97%,非对称失真立体图像的分类准确率分别为95.46%,92.64%和96.22%。结论本文方法依据双目竞争的视觉现象融合左右视点图像的质量感知特征用于立体图像质量预测,能够提升非对称失真立体图像的评价准确性和鲁棒性。所提取双目差异性特征还能够用于将对称失真与非对称失真立体图像进行有效分类,分类准确性高。关键词:立体图像质量评价(SIQA);非对称失真;双目竞争;图像质量衰减系数;双目差异特征95|216|1更新时间:2024-05-07
摘要:目的现有方法存在特征提取时间过长、非对称失真图像预测准确性不高的问题,同时少有工作对非对称失真与对称失真立体图像的分类进行研究,为此提出了基于双目竞争的非对称失真立体图像质量评价方法。方法依据双目竞争的视觉现象,利用非对称失真立体图像两个视点的图像质量衰减程度的不同,生成单目图像特征的融合系数,融合从左右视点图像中提取的灰度空间特征与HSV(hue-saturation-value)彩色空间特征。同时,量化两个视点图像在结构、信息量和质量衰减程度等多方面的差异,获得双目差异特征。并且将双目融合特征与双目差异特征级联为一个描述能力更强的立体图像质量感知特征向量,训练基于支持向量回归的特征—质量映射模型。此外,还利用双目差异特征训练基于支持向量分类模型的对称失真与非对称失真立体图像分类模型。结果本文提出的质量预测模型在4个数据库上的SROCC(Spearman rank order correlation coefficient)和PLCC(Pearson linear correlation coefficient)均达到0.95以上,在3个非对称失真数据库上的均方根误差(root of mean square error,RMSE)取值均优于对比算法。在LIVE-II(LIVE 3D image quality database phase II)、IVC-I(Waterloo-IVC 3D image quality assessment database phase I)和IVC-II(Waterloo-IVC 3D image quality assessment database phase II)这3个非对称失真立体图像测试数据库上的失真类型分类测试中,对称失真立体图像的分类准确率分别为89.91%、94.76%和98.97%,非对称失真立体图像的分类准确率分别为95.46%,92.64%和96.22%。结论本文方法依据双目竞争的视觉现象融合左右视点图像的质量感知特征用于立体图像质量预测,能够提升非对称失真立体图像的评价准确性和鲁棒性。所提取双目差异性特征还能够用于将对称失真与非对称失真立体图像进行有效分类,分类准确性高。关键词:立体图像质量评价(SIQA);非对称失真;双目竞争;图像质量衰减系数;双目差异特征95|216|1更新时间:2024-05-07
图像处理和编码
-
 摘要:目的输电线路金具种类繁多、用处多样,与导线和杆塔安全密切相关。评估金具运行状态并实现故障诊断,需对输电线路金具目标进行精确定位和识别,然而随着无人机巡检采集的数据逐渐增多,将全部数据进行人工标注愈发困难。针对无标注数据无法有效利用的问题,提出一种基于自监督E-Swin Transformer(efficient shifted windows Transformer)的输电线路金具检测模型,充分利用无标注数据提高检测精度。方法首先,为了减少自注意力的计算量、提高模型计算效率,对Swin Transformer自注意力计算进行优化,提出一种高效的主干网络E-Swin。然后,为了利用无标注金具数据加强特征提取效果,针对E-Swin设计轻量化的自监督方法,并进行预训练。最后,为了提高检测定位精度,采用一种添加额外分支的检测头,并结合预训练之后的主干网络构建检测模型,利用少量有标注的数据进行微调训练,得到最终检测结果。结果实验结果表明,在输电线路金具数据集上, 本文模型的各目标平均检测精确度(AP50)为88.6%,相比传统检测模型提高了10%左右。结论本文改进主干网络的自注意力计算,并采用自监督学习,使模型高效提取特征,实现无标注数据的有效利用,构建的金具检测模型为解决输电线路金具检测的数据利用问题提供了新思路。关键词:深度学习;目标检测;输电线路金具;自监督学习;E-Swin Transformer模型;一阶段检测器188|170|1更新时间:2024-05-07
摘要:目的输电线路金具种类繁多、用处多样,与导线和杆塔安全密切相关。评估金具运行状态并实现故障诊断,需对输电线路金具目标进行精确定位和识别,然而随着无人机巡检采集的数据逐渐增多,将全部数据进行人工标注愈发困难。针对无标注数据无法有效利用的问题,提出一种基于自监督E-Swin Transformer(efficient shifted windows Transformer)的输电线路金具检测模型,充分利用无标注数据提高检测精度。方法首先,为了减少自注意力的计算量、提高模型计算效率,对Swin Transformer自注意力计算进行优化,提出一种高效的主干网络E-Swin。然后,为了利用无标注金具数据加强特征提取效果,针对E-Swin设计轻量化的自监督方法,并进行预训练。最后,为了提高检测定位精度,采用一种添加额外分支的检测头,并结合预训练之后的主干网络构建检测模型,利用少量有标注的数据进行微调训练,得到最终检测结果。结果实验结果表明,在输电线路金具数据集上, 本文模型的各目标平均检测精确度(AP50)为88.6%,相比传统检测模型提高了10%左右。结论本文改进主干网络的自注意力计算,并采用自监督学习,使模型高效提取特征,实现无标注数据的有效利用,构建的金具检测模型为解决输电线路金具检测的数据利用问题提供了新思路。关键词:深度学习;目标检测;输电线路金具;自监督学习;E-Swin Transformer模型;一阶段检测器188|170|1更新时间:2024-05-07 -
 摘要:目的视频描述定位是视频理解领域一个重要且具有挑战性的任务,该任务需要根据一个自然语言描述的查询,从一段未修剪的视频中定位出文本描述的视频片段。由于语言模态与视频模态之间存在巨大的特征表示差异,因此如何构建出合适的视频—文本多模态特征表示,并准确高效地定位目标片段成为该任务的关键点和难点。针对上述问题,本文聚焦于构建视频—文本多模态特征的优化表示,提出使用视频中的运动信息去激励多模态特征表示中的运动语义信息,并以无候选框的方式实现视频描述定位。方法基于自注意力的方法提取自然语言描述中的多个短语特征,并与视频特征进行跨模态融合,得到多个关注不同语义短语的多模态特征。为了优化多模态特征表示,分别从时序维度及特征通道两个方面进行建模:1)在时序维度上使用跳连卷积,即一维时序卷积对运动信息的局部上下文进行建模,在时序维度上对齐语义短语与视频片段;2)在特征通道上使用运动激励,通过计算时序相邻的多模态特征向量之间的差异,构建出响应运动信息的通道权重分布,从而激励多模态特征中表示运动信息的通道。本文关注不同语义短语的多模态特征融合,采用非局部神经网络(non-local neural network)建模不同语义短语之间的依赖关系,并采用时序注意力池化模块将多模态特征融合为一个特征向量,回归得到目标片段的开始与结束时刻。结果在多个数据集上验证了本文方法的有效性。在Charades-STA数据集和ActivityNet Captions数据集上,模型的平均交并比(mean intersection over union,mIoU)分别达到了52.36%和42.97%,模型在两个数据集上的召回率R@1(Recall@1)分别在交并比阈值为0.3、0.5和0.7时达到了73.79%、61.16%和52.36%以及60.54%、43.68%和25.43%。与LGI(local-global video-text interactions)和CPNet(contextual pyramid network)等方法相比,本文方法在性能上均有明显的提升。结论本文在视频描述定位任务上提出了使用运动特征激励优化视频—文本多模态特征表示的方法,在多个数据集上的实验结果证明了运动激励下的特征能够更好地表征视频片段和语言查询的匹配信息。关键词:视频描述定位;运动激励;多模态特征表示;无候选框;计算机视觉;视频理解109|454|0更新时间:2024-05-07
摘要:目的视频描述定位是视频理解领域一个重要且具有挑战性的任务,该任务需要根据一个自然语言描述的查询,从一段未修剪的视频中定位出文本描述的视频片段。由于语言模态与视频模态之间存在巨大的特征表示差异,因此如何构建出合适的视频—文本多模态特征表示,并准确高效地定位目标片段成为该任务的关键点和难点。针对上述问题,本文聚焦于构建视频—文本多模态特征的优化表示,提出使用视频中的运动信息去激励多模态特征表示中的运动语义信息,并以无候选框的方式实现视频描述定位。方法基于自注意力的方法提取自然语言描述中的多个短语特征,并与视频特征进行跨模态融合,得到多个关注不同语义短语的多模态特征。为了优化多模态特征表示,分别从时序维度及特征通道两个方面进行建模:1)在时序维度上使用跳连卷积,即一维时序卷积对运动信息的局部上下文进行建模,在时序维度上对齐语义短语与视频片段;2)在特征通道上使用运动激励,通过计算时序相邻的多模态特征向量之间的差异,构建出响应运动信息的通道权重分布,从而激励多模态特征中表示运动信息的通道。本文关注不同语义短语的多模态特征融合,采用非局部神经网络(non-local neural network)建模不同语义短语之间的依赖关系,并采用时序注意力池化模块将多模态特征融合为一个特征向量,回归得到目标片段的开始与结束时刻。结果在多个数据集上验证了本文方法的有效性。在Charades-STA数据集和ActivityNet Captions数据集上,模型的平均交并比(mean intersection over union,mIoU)分别达到了52.36%和42.97%,模型在两个数据集上的召回率R@1(Recall@1)分别在交并比阈值为0.3、0.5和0.7时达到了73.79%、61.16%和52.36%以及60.54%、43.68%和25.43%。与LGI(local-global video-text interactions)和CPNet(contextual pyramid network)等方法相比,本文方法在性能上均有明显的提升。结论本文在视频描述定位任务上提出了使用运动特征激励优化视频—文本多模态特征表示的方法,在多个数据集上的实验结果证明了运动激励下的特征能够更好地表征视频片段和语言查询的匹配信息。关键词:视频描述定位;运动激励;多模态特征表示;无候选框;计算机视觉;视频理解109|454|0更新时间:2024-05-07 -
 摘要:目的由于相关滤波(correlation filter,CF)跟踪算法使用循环移位操作增加训练样本,不可避免会引起边界效应问题。研究者大多采用余弦窗来抑制边界效应,但余弦窗的引入会导致样本污染,降低了算法的性能。为解决该问题,提出了嵌入高斯形状掩膜的相关滤波跟踪算法。方法在空间正则化相关滤波跟踪框架中嵌入高斯形状掩膜,对靠近目标中心和搜索区域边缘的样本重新分配权重,提高中心样本的重要性,同时降低远离中心的边缘样本的重要性,增加中心样本的响应,从而降低样本污染的影响,增强滤波器的判别能力。建立了高斯掩膜相关滤波跟踪算法的目标公式,然后使用交替方向乘子法(alternating direction of multiplier method,ADMM)求解滤波器及空间权重的闭合解。结果为评估所提算法的跟踪性能,在OTB2013(online tracking benchmark)、TC128(temple color)、UAV123(unmmaned aerial vehicle)及Got-10k(general object tracking)等多个基准数据集上进行了大量实验,并与多个先进的相关滤波跟踪算法对比。结果表明,在OTB2013数据集上精度和成功率分别为90.2%和65.2%,其中精度比基准算法提高0.5%;在TC128数据集上精度和成功率分别为77.9%和57.7%,其中成功率提高0.4%; UAV123数据集上的两个指标数据分别为74.1%和50.8%,精度提高0.3%;在Got-10k数据集上成功率提高了0.2%。结论与其他相关滤波跟踪算法相比,本文算法在各数据集上的精度和成功率表现出较强的竞争力,显著提高了基准算法的跟踪性能。关键词:目标跟踪;相关滤波(CF);边界效应;样本污染;高斯形状掩膜119|378|1更新时间:2024-05-07
摘要:目的由于相关滤波(correlation filter,CF)跟踪算法使用循环移位操作增加训练样本,不可避免会引起边界效应问题。研究者大多采用余弦窗来抑制边界效应,但余弦窗的引入会导致样本污染,降低了算法的性能。为解决该问题,提出了嵌入高斯形状掩膜的相关滤波跟踪算法。方法在空间正则化相关滤波跟踪框架中嵌入高斯形状掩膜,对靠近目标中心和搜索区域边缘的样本重新分配权重,提高中心样本的重要性,同时降低远离中心的边缘样本的重要性,增加中心样本的响应,从而降低样本污染的影响,增强滤波器的判别能力。建立了高斯掩膜相关滤波跟踪算法的目标公式,然后使用交替方向乘子法(alternating direction of multiplier method,ADMM)求解滤波器及空间权重的闭合解。结果为评估所提算法的跟踪性能,在OTB2013(online tracking benchmark)、TC128(temple color)、UAV123(unmmaned aerial vehicle)及Got-10k(general object tracking)等多个基准数据集上进行了大量实验,并与多个先进的相关滤波跟踪算法对比。结果表明,在OTB2013数据集上精度和成功率分别为90.2%和65.2%,其中精度比基准算法提高0.5%;在TC128数据集上精度和成功率分别为77.9%和57.7%,其中成功率提高0.4%; UAV123数据集上的两个指标数据分别为74.1%和50.8%,精度提高0.3%;在Got-10k数据集上成功率提高了0.2%。结论与其他相关滤波跟踪算法相比,本文算法在各数据集上的精度和成功率表现出较强的竞争力,显著提高了基准算法的跟踪性能。关键词:目标跟踪;相关滤波(CF);边界效应;样本污染;高斯形状掩膜119|378|1更新时间:2024-05-07 -
 摘要:目的车辆多目标跟踪是智能交通领域关键技术,其性能对车辆轨迹分析和异常行为鉴别有显著影响。然而,车辆多目标跟踪常受外部光照、道路环境因素影响,车辆远近尺度变化以及相互遮挡等干扰,导致远处车辆漏检或车辆身份切换(ID switch, IDs)问题。本文提出短时记忆与CenterTrack的车辆多目标跟踪,提升车辆多目标跟踪准确度(multiple object tracking accuracy, MOTA),改善算法的适应性。方法利用小样本扩增增加远处小目标车辆训练样本数;通过增加的样本重新训练CenterTrack确定车辆位置及车辆在相邻帧之间的中心位移量;当待关联轨迹与检测目标匹配失败时通过轨迹运动信息预测将来的位置;利用短时记忆将待关联轨迹按丢失时间长短分级与待匹配检测关联以减少跟踪车辆IDs。结果在交通监控车辆多目标跟踪数据集UA-DETRAC(University at Albany detection and tracking)构建的5个测试序列数据中,本文方法在维持CenterTrack优势的同时,对其表现不佳的场景获得近30%的提升,与YOLOv4-DeepSort(you only look once—simple online and realtime tracking with deep association metric)相比,4种场景均获得近10%的提升,效果显著。Sherbrooke数据集的测试结果,本文方法同样获得了性能提升。结论本文扩增了远处小目标车辆训练样本,缓解了远处小目标与近处大目标存在的样本不均衡,提高了算法对远处小目标车辆的检测能力,同时短时记忆维持关联失败的轨迹运动信息并分级匹配检测目标,降低了算法对跟踪车辆的IDs,综合提高了MOTA。关键词:多目标跟踪;目标检测;轨迹记忆;样本扩增;轨迹关联157|422|0更新时间:2024-05-07
摘要:目的车辆多目标跟踪是智能交通领域关键技术,其性能对车辆轨迹分析和异常行为鉴别有显著影响。然而,车辆多目标跟踪常受外部光照、道路环境因素影响,车辆远近尺度变化以及相互遮挡等干扰,导致远处车辆漏检或车辆身份切换(ID switch, IDs)问题。本文提出短时记忆与CenterTrack的车辆多目标跟踪,提升车辆多目标跟踪准确度(multiple object tracking accuracy, MOTA),改善算法的适应性。方法利用小样本扩增增加远处小目标车辆训练样本数;通过增加的样本重新训练CenterTrack确定车辆位置及车辆在相邻帧之间的中心位移量;当待关联轨迹与检测目标匹配失败时通过轨迹运动信息预测将来的位置;利用短时记忆将待关联轨迹按丢失时间长短分级与待匹配检测关联以减少跟踪车辆IDs。结果在交通监控车辆多目标跟踪数据集UA-DETRAC(University at Albany detection and tracking)构建的5个测试序列数据中,本文方法在维持CenterTrack优势的同时,对其表现不佳的场景获得近30%的提升,与YOLOv4-DeepSort(you only look once—simple online and realtime tracking with deep association metric)相比,4种场景均获得近10%的提升,效果显著。Sherbrooke数据集的测试结果,本文方法同样获得了性能提升。结论本文扩增了远处小目标车辆训练样本,缓解了远处小目标与近处大目标存在的样本不均衡,提高了算法对远处小目标车辆的检测能力,同时短时记忆维持关联失败的轨迹运动信息并分级匹配检测目标,降低了算法对跟踪车辆的IDs,综合提高了MOTA。关键词:多目标跟踪;目标检测;轨迹记忆;样本扩增;轨迹关联157|422|0更新时间:2024-05-07 -
 摘要:目的油画区别于其他绘画形式的重要特征之一是其颜料图层存在厚度变化。因此,油画相似度鉴别不仅关注油画的纹理色彩细节,也需考虑其表面颜料厚度的差异。针对颜料厚度的细微变化,提出一种油画相似度的表面光场特征点分布鉴别方法。采用光场成像技术观测由于油画表面厚度起伏导致的不同角度成像的差异,以量化计算油画表面光场的相似性。方法该方法采用一块微透镜阵列板对油画表面的角度域变化进行光场编码,利用光场相机采集编码后的油画表面光场。在此基础上,选取油画表面光场中角度域差异大的特征点集合,采用K-Means方法对该特征点集合的二维分布进行多边形向量化描述。进而提出计算关键点连接线的欧氏距离与线段夹角,以度量表面光场特征点分布多边形的相似性。结果采用Illum光场相机拍摄了多组真实油画的表面光场实验数据,实验结果表明本文方法可对存在细微颜料厚度差别的油画相似度进行鉴别。在对油画表面光场的识别区分度以及检测精度方面,本文方法显著优于现有图像特征匹配鉴别方法。结论实验分析表明,相比于经典交并比及相似度系数,所提出油画相似性度量具有更优的相似性度量精度。通过调整编码板与测试油画表面距离的反复实验,验证所提方法能够有效检测0.5 mm以上厚度变化的表面光场差异。关键词:表面光场;油画鉴别;光场特征;相似度计算;特征点提取121|222|1更新时间:2024-05-07
摘要:目的油画区别于其他绘画形式的重要特征之一是其颜料图层存在厚度变化。因此,油画相似度鉴别不仅关注油画的纹理色彩细节,也需考虑其表面颜料厚度的差异。针对颜料厚度的细微变化,提出一种油画相似度的表面光场特征点分布鉴别方法。采用光场成像技术观测由于油画表面厚度起伏导致的不同角度成像的差异,以量化计算油画表面光场的相似性。方法该方法采用一块微透镜阵列板对油画表面的角度域变化进行光场编码,利用光场相机采集编码后的油画表面光场。在此基础上,选取油画表面光场中角度域差异大的特征点集合,采用K-Means方法对该特征点集合的二维分布进行多边形向量化描述。进而提出计算关键点连接线的欧氏距离与线段夹角,以度量表面光场特征点分布多边形的相似性。结果采用Illum光场相机拍摄了多组真实油画的表面光场实验数据,实验结果表明本文方法可对存在细微颜料厚度差别的油画相似度进行鉴别。在对油画表面光场的识别区分度以及检测精度方面,本文方法显著优于现有图像特征匹配鉴别方法。结论实验分析表明,相比于经典交并比及相似度系数,所提出油画相似性度量具有更优的相似性度量精度。通过调整编码板与测试油画表面距离的反复实验,验证所提方法能够有效检测0.5 mm以上厚度变化的表面光场差异。关键词:表面光场;油画鉴别;光场特征;相似度计算;特征点提取121|222|1更新时间:2024-05-07 -
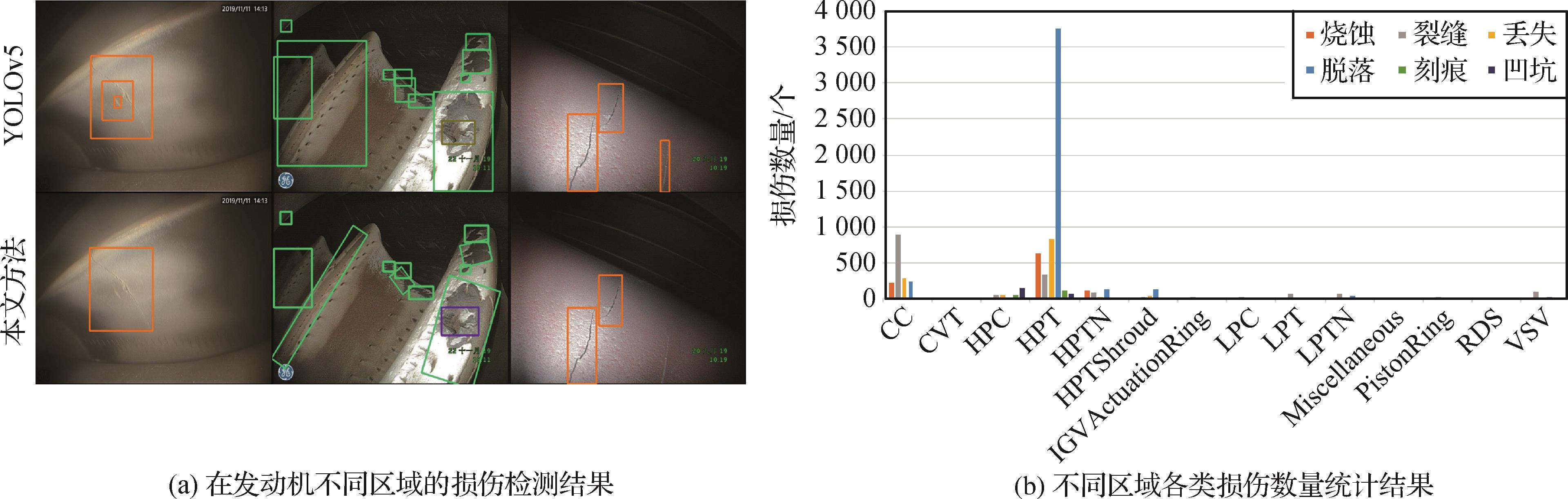 摘要:目的航空发动机孔探图像的损伤检测关系到航空发动机是否要非例行更换,直接影响飞机的飞行安全和利用率。现有的孔探图像损伤检测方法直接使用目标检测方法训练一个多类别损伤检测器,使用相同的参数在不同位置检测损伤。由于没有考虑同类型损伤在发动机不同区域发生概率的不同,导致现有方法的检测准确率较低。为了提高损伤检测的准确率,提出了一种自适应参数的航空发动机孔探图像损伤检测方法。方法通过识别孔探图像所属的发动机区域,针对不同区域孔探图像设置不同的参数用于检测发动机损伤。同时为了避免单检测器上不同类型损伤之间相互干扰,采用独立检测器检测单一类型的损伤,并对误检率高的损伤进行真假识别。通过合并检测到的不同类型的损伤,得到最终的损伤检测结果。此外,为了改进水平的矩形检测框,使用分割结果产生旋转的检测框,有效地减少了框中的背景区域。结果在13个航空发动机区域的2 654幅孔探图像上针对烧蚀、裂缝、材料丢失、涂层脱落、刻痕和凹坑等6种典型的发动机损伤进行检测实验。提出的损伤检测方法在准确率和召回率两方面分别达到了90.4%和90.7%,相较于目标检测方法YOLOv5(you only look once version 5)的准确率和召回率高24.8%和25.1%。实验结果表明,本文方法在航空发动机损伤检测方面优于其他对比方法。结论本文所提出的自适应参数的航空发动机损伤检测模型通过识别发动机图像所属的部位,针对同种类型的损伤检测器设定不同的参数,有效地提高了检测器的检测性能。同时,针对容易误检的裂缝、刻痕和凹坑增加了真假损伤判别器,有效地减少了误检的情况。关键词:航空发动机;损伤检测;目标检测;孔探图像;自适应参数115|325|0更新时间:2024-05-07
摘要:目的航空发动机孔探图像的损伤检测关系到航空发动机是否要非例行更换,直接影响飞机的飞行安全和利用率。现有的孔探图像损伤检测方法直接使用目标检测方法训练一个多类别损伤检测器,使用相同的参数在不同位置检测损伤。由于没有考虑同类型损伤在发动机不同区域发生概率的不同,导致现有方法的检测准确率较低。为了提高损伤检测的准确率,提出了一种自适应参数的航空发动机孔探图像损伤检测方法。方法通过识别孔探图像所属的发动机区域,针对不同区域孔探图像设置不同的参数用于检测发动机损伤。同时为了避免单检测器上不同类型损伤之间相互干扰,采用独立检测器检测单一类型的损伤,并对误检率高的损伤进行真假识别。通过合并检测到的不同类型的损伤,得到最终的损伤检测结果。此外,为了改进水平的矩形检测框,使用分割结果产生旋转的检测框,有效地减少了框中的背景区域。结果在13个航空发动机区域的2 654幅孔探图像上针对烧蚀、裂缝、材料丢失、涂层脱落、刻痕和凹坑等6种典型的发动机损伤进行检测实验。提出的损伤检测方法在准确率和召回率两方面分别达到了90.4%和90.7%,相较于目标检测方法YOLOv5(you only look once version 5)的准确率和召回率高24.8%和25.1%。实验结果表明,本文方法在航空发动机损伤检测方面优于其他对比方法。结论本文所提出的自适应参数的航空发动机损伤检测模型通过识别发动机图像所属的部位,针对同种类型的损伤检测器设定不同的参数,有效地提高了检测器的检测性能。同时,针对容易误检的裂缝、刻痕和凹坑增加了真假损伤判别器,有效地减少了误检的情况。关键词:航空发动机;损伤检测;目标检测;孔探图像;自适应参数115|325|0更新时间:2024-05-07
图像分析和识别
-
 摘要:目的由于室内点云场景中物体的密集性、复杂性以及多遮挡等带来的数据不完整和多噪声问题,极大地限制了室内点云场景的重建工作,无法保证场景重建的准确度。为了更好地从无序点云中恢复出完整的场景,提出了一种基于语义分割的室内场景重建方法。方法通过体素滤波对原始数据进行下采样,计算场景三维尺度不变特征变换(3D scale-invariant feature transform,3D SIFT)特征点,融合下采样结果与场景特征点从而获得优化的场景下采样结果;利用随机抽样一致算法(random sample consensus,RANSAC)对融合采样后的场景提取平面特征,将该特征输入PointNet网络中进行训练,确保共面的点具有相同的局部特征,从而得到每个点在数据集中各个类别的置信度,在此基础上,提出了一种基于投影的区域生长优化方法,聚合语义分割结果中同一物体的点,获得更精细的分割结果;将场景物体的分割结果划分为内环境元素或外环境元素,分别采用模型匹配的方法、平面拟合的方法从而实现场景的重建。结果在S3DIS(Stanford large-scale 3D indoor space dataset)数据集上进行实验,本文融合采样算法对后续方法的效率和效果有着不同程度的提高,采样后平面提取算法的运行时间仅为采样前的15%;而语义分割方法在全局准确率(overall accuracy,OA)和平均交并比(mean intersection over union,mIoU)两个方面比PointNet网络分别提高了2.3%和4.2%。结论本文方法能够在保留关键点的同时提高计算效率,在分割准确率方面也有着明显提升,同时可以得到高质量的重建结果。关键词:点云;室内场景;语义分割;实例分割;三维重建187|758|2更新时间:2024-05-07
摘要:目的由于室内点云场景中物体的密集性、复杂性以及多遮挡等带来的数据不完整和多噪声问题,极大地限制了室内点云场景的重建工作,无法保证场景重建的准确度。为了更好地从无序点云中恢复出完整的场景,提出了一种基于语义分割的室内场景重建方法。方法通过体素滤波对原始数据进行下采样,计算场景三维尺度不变特征变换(3D scale-invariant feature transform,3D SIFT)特征点,融合下采样结果与场景特征点从而获得优化的场景下采样结果;利用随机抽样一致算法(random sample consensus,RANSAC)对融合采样后的场景提取平面特征,将该特征输入PointNet网络中进行训练,确保共面的点具有相同的局部特征,从而得到每个点在数据集中各个类别的置信度,在此基础上,提出了一种基于投影的区域生长优化方法,聚合语义分割结果中同一物体的点,获得更精细的分割结果;将场景物体的分割结果划分为内环境元素或外环境元素,分别采用模型匹配的方法、平面拟合的方法从而实现场景的重建。结果在S3DIS(Stanford large-scale 3D indoor space dataset)数据集上进行实验,本文融合采样算法对后续方法的效率和效果有着不同程度的提高,采样后平面提取算法的运行时间仅为采样前的15%;而语义分割方法在全局准确率(overall accuracy,OA)和平均交并比(mean intersection over union,mIoU)两个方面比PointNet网络分别提高了2.3%和4.2%。结论本文方法能够在保留关键点的同时提高计算效率,在分割准确率方面也有着明显提升,同时可以得到高质量的重建结果。关键词:点云;室内场景;语义分割;实例分割;三维重建187|758|2更新时间:2024-05-07 -
 摘要:目的针对行人轨迹预测问题,已有的几种结合场景信息的方法基于合并操作通过神经网络隐式学习场景与行人运动的关联,无法直观地解释场景对单个行人运动的调节作用。除此之外,基于图注意力机制的时空图神经网络旨在学习全局模式下行人之间的社会交互,在人群拥挤场景下精度不佳。鉴于此,本文提出一种场景限制时空图卷积神经网络(scene-constrained spatial-temporal graph convolutional neural network,Scene-STGCNN)。方法Scene-STGCNN由运动模块、基于场景的微调模块、时空卷积和时空外推卷积组成。运动模块以时空图卷积提取局部行人时空特征,避免了时空图神经网络在全局模式下学习交互的局限性。基于场景的微调模块将场景信息嵌入为掩模矩阵,用来调节运动模块生成的中间运动特征,具备实际场景下的物理解释性。通过最小化核密度估计下真实轨迹的负对数似然,增强Scene-STGCNN输出的多模态性,减少预测误差。结果实验在公开数据集ETH(包含ETH和HOTEL)和UCY(包含UNIV、ZARA1和ZARA2)上与其他7种主流方法进行比较,就平均值而言,相对于性能第2的模型,平均位移误差(average displacement error,ADE)值减少了12%,最终位移误差(final displacement error,FDE)值减少了9%。在同样的数据集上进行了消融实验以验证基于场景的微调模块的有效性,结果表明基于场景的微调模块能有效建模场景对行人轨迹的调节作用,从而减小算法的预测误差。结论本文提出的场景限制时空图卷积网络能有效融合场景和行人运动,在学习局部模式下行人交互的同时基于场景特征对轨迹特征做实时性调节,相比于其他主流方法,具有更优的性能。关键词:行人轨迹预测;场景空间限制;时空特征提取;时空卷积;核密度估计164|525|2更新时间:2024-05-07
摘要:目的针对行人轨迹预测问题,已有的几种结合场景信息的方法基于合并操作通过神经网络隐式学习场景与行人运动的关联,无法直观地解释场景对单个行人运动的调节作用。除此之外,基于图注意力机制的时空图神经网络旨在学习全局模式下行人之间的社会交互,在人群拥挤场景下精度不佳。鉴于此,本文提出一种场景限制时空图卷积神经网络(scene-constrained spatial-temporal graph convolutional neural network,Scene-STGCNN)。方法Scene-STGCNN由运动模块、基于场景的微调模块、时空卷积和时空外推卷积组成。运动模块以时空图卷积提取局部行人时空特征,避免了时空图神经网络在全局模式下学习交互的局限性。基于场景的微调模块将场景信息嵌入为掩模矩阵,用来调节运动模块生成的中间运动特征,具备实际场景下的物理解释性。通过最小化核密度估计下真实轨迹的负对数似然,增强Scene-STGCNN输出的多模态性,减少预测误差。结果实验在公开数据集ETH(包含ETH和HOTEL)和UCY(包含UNIV、ZARA1和ZARA2)上与其他7种主流方法进行比较,就平均值而言,相对于性能第2的模型,平均位移误差(average displacement error,ADE)值减少了12%,最终位移误差(final displacement error,FDE)值减少了9%。在同样的数据集上进行了消融实验以验证基于场景的微调模块的有效性,结果表明基于场景的微调模块能有效建模场景对行人轨迹的调节作用,从而减小算法的预测误差。结论本文提出的场景限制时空图卷积网络能有效融合场景和行人运动,在学习局部模式下行人交互的同时基于场景特征对轨迹特征做实时性调节,相比于其他主流方法,具有更优的性能。关键词:行人轨迹预测;场景空间限制;时空特征提取;时空卷积;核密度估计164|525|2更新时间:2024-05-07
图像理解和计算机视觉
-
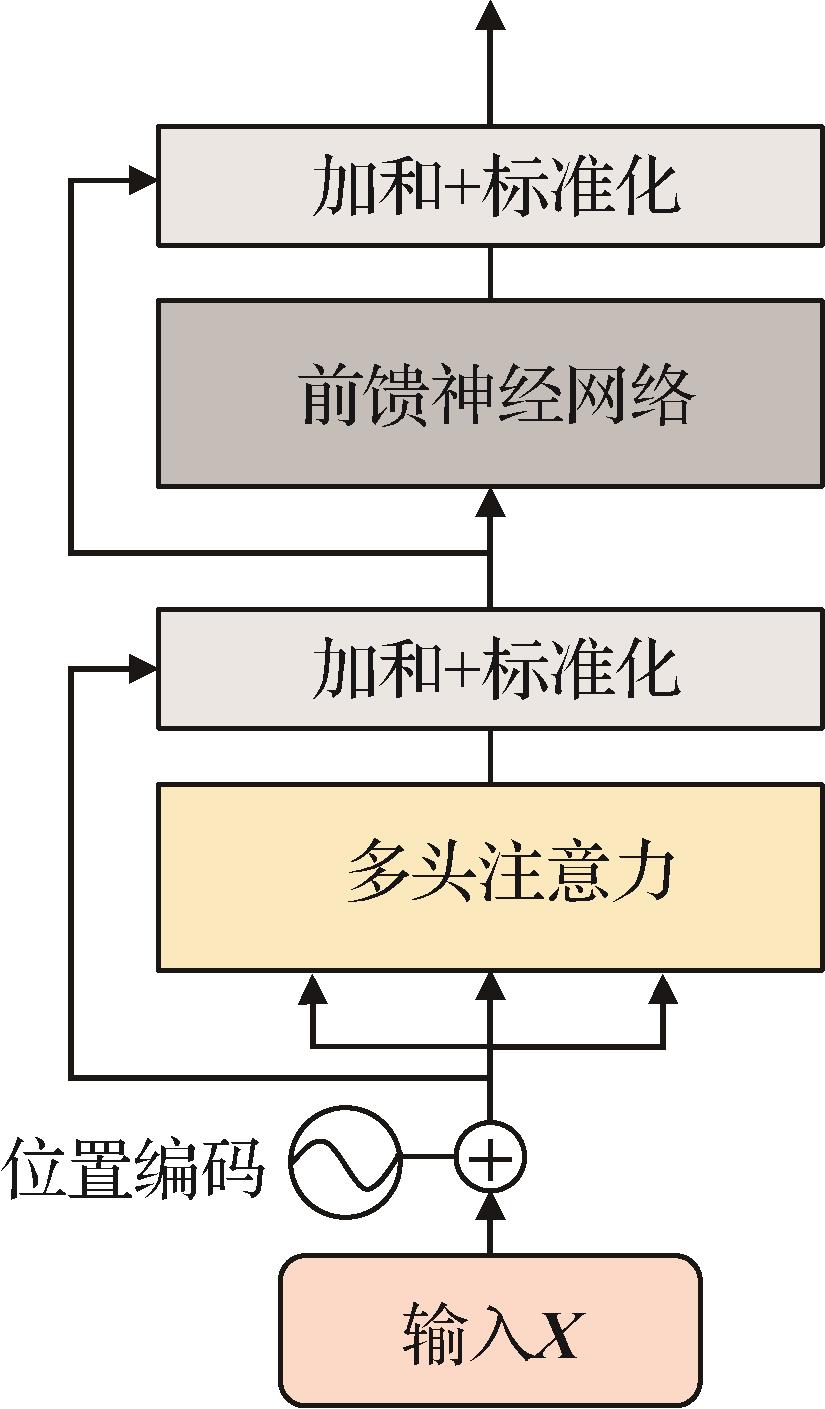 摘要:目的基于深度模型的跟踪算法往往需要大规模的高质量标注训练数据集,而人工逐帧标注视频数据会耗费大量的人力及时间成本。本文提出一个基于Transformer模型的轻量化视频标注算法(Transformer-based label network,TLNet),实现对大规模稀疏标注视频数据集的高效逐帧标注。方法该算法通过Transformer模型来处理时序的目标外观和运动信息,并融合前反向的跟踪结果。其中质量评估子网络用于筛选跟踪失败帧,进行人工标注;回归子网络则对剩余帧的初始标注进行优化,输出更精确的目标框标注。该算法具有强泛化性,能够与具体跟踪算法解耦,应用现有的任意轻量化跟踪算法,实现高效的视频自动标注。结果在2个大规模跟踪数据集上生成标注。对于LaSOT(large-scale single object tracking)数据集,自动标注过程仅需约43 h,与真实标注的平均重叠率(mean intersection over union,mIoU)由0.824提升至0.871。对于TrackingNet数据集,本文使用自动标注重新训练3种跟踪算法,并在3个数据集上测试跟踪性能,使用本文标注训练的模型在跟踪性能上超过使用TrackingNet原始标注训练的模型。结论本文算法TLNet能够挖掘时序的目标外观和运动信息,对前反向跟踪结果进行帧级的质量评估并进一步优化目标框。该方法与具体跟踪算法解耦,具有强泛化性,并能节省超过90%的人工标注成本,高效地生成高质量的视频标注。关键词:视频目标标注;单目标视觉跟踪;Transformer模型;互相关操作;时序信息融合167|418|2更新时间:2024-05-07
摘要:目的基于深度模型的跟踪算法往往需要大规模的高质量标注训练数据集,而人工逐帧标注视频数据会耗费大量的人力及时间成本。本文提出一个基于Transformer模型的轻量化视频标注算法(Transformer-based label network,TLNet),实现对大规模稀疏标注视频数据集的高效逐帧标注。方法该算法通过Transformer模型来处理时序的目标外观和运动信息,并融合前反向的跟踪结果。其中质量评估子网络用于筛选跟踪失败帧,进行人工标注;回归子网络则对剩余帧的初始标注进行优化,输出更精确的目标框标注。该算法具有强泛化性,能够与具体跟踪算法解耦,应用现有的任意轻量化跟踪算法,实现高效的视频自动标注。结果在2个大规模跟踪数据集上生成标注。对于LaSOT(large-scale single object tracking)数据集,自动标注过程仅需约43 h,与真实标注的平均重叠率(mean intersection over union,mIoU)由0.824提升至0.871。对于TrackingNet数据集,本文使用自动标注重新训练3种跟踪算法,并在3个数据集上测试跟踪性能,使用本文标注训练的模型在跟踪性能上超过使用TrackingNet原始标注训练的模型。结论本文算法TLNet能够挖掘时序的目标外观和运动信息,对前反向跟踪结果进行帧级的质量评估并进一步优化目标框。该方法与具体跟踪算法解耦,具有强泛化性,并能节省超过90%的人工标注成本,高效地生成高质量的视频标注。关键词:视频目标标注;单目标视觉跟踪;Transformer模型;互相关操作;时序信息融合167|418|2更新时间:2024-05-07 -
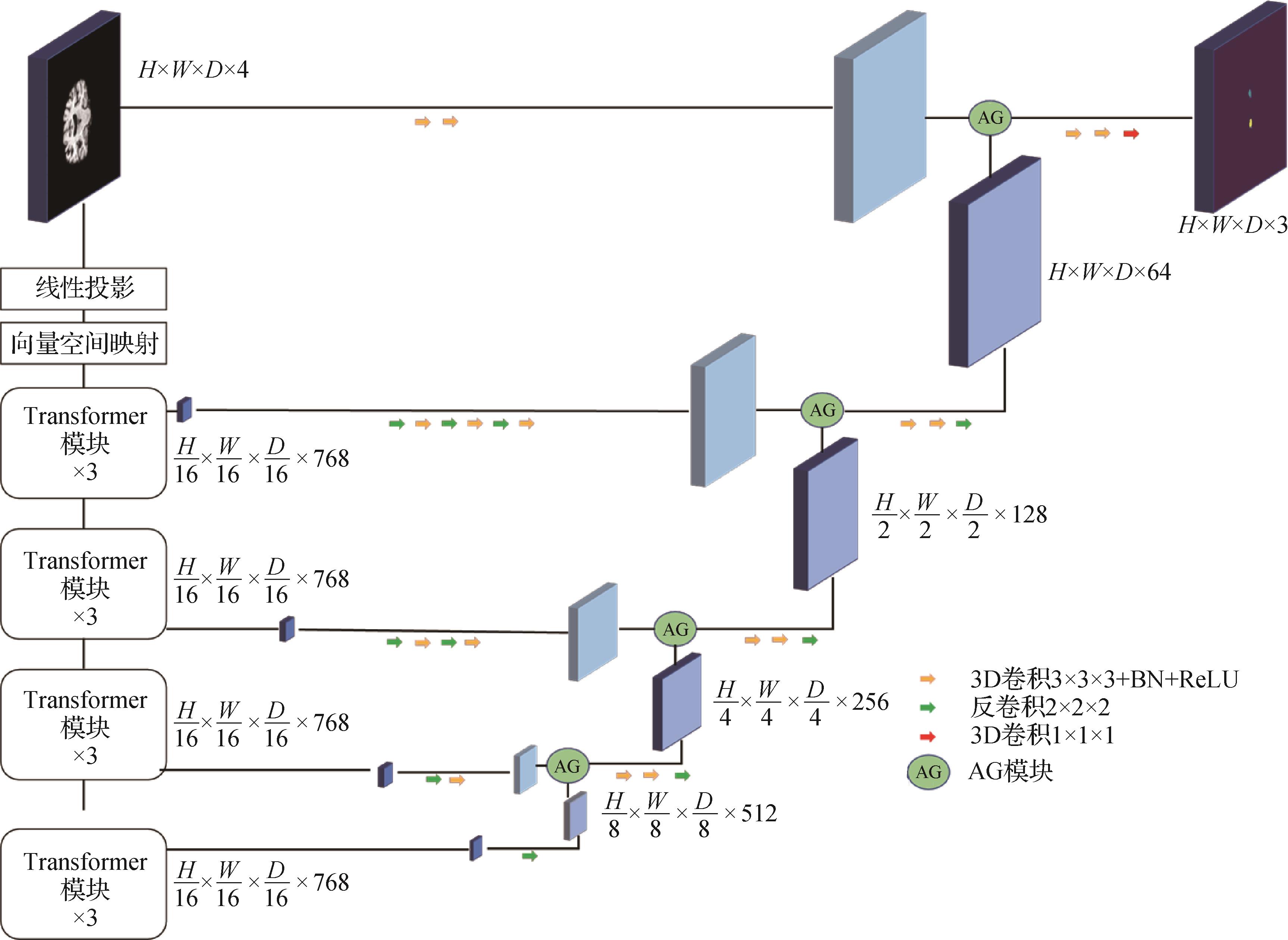 摘要:目的海马体内嗅皮层的像素体积较小,这些特征给医学影像的分割任务带来很大挑战。综合海马体的形态特点以及医生的分割流程,提出一种新的海马体分割方法,以实现在临床医学影像处理中对海马体的精确分割,辅助阿尔兹海默症的早期诊断。方法提出一个基于自注意力机制与空间注意力机制的U型网络模型SA-TF-UNet(hippocampus segmentation network based on Transformer and spatial attention mechanisms)。该网络为端到端的预测网络,输入任意大小的3维MRI(magnetic resonance imaging)影像,输出类别标签。SA-TF-UNet采用编码器—解码器结构,编码器采用纯Transformer模块,不包含卷积模块。多头自注意力机制为Transformer模块中的特征提取器,自注意力模块基于全局信息建模,并提取特征。因此,使用Transformer提取特征符合医生分割海马体的基本思路。解码器采用简单的卷积模块进行上采样。使用AG(attention gate)模块作为跳跃连接的方式,自动增加前景的权重,代替了传统网络中的直接连接。为了验证AG的有效性,分别做了只在单层加入AG的实验,与在4层网络中全部加入AG的实验结果进行对比。为了进一步探讨AG模块中门控信号的来源,设计了两个SA-TF-UNet的变体,它们的网络结构中AG门控信号分别为比AG中的特征图深两层的Transformer模块输出和深3层的Transformer模块输出。结果为了验证SA-TF-UNet在临床数据集中分割海马体的有效性,在由阿尔兹海默症患者的MRI影像组成的脑MRI数据集上进行实验。4层网络全部加入AG,且AG的门控信号是由比AG特征图更深一层的Transformer模块输出的SA-TF-UNet模型分割效果最好。SA-TF-UNet对于左海马体、右海马体的分割Dice系数分别为0.900 1与0.909 1,相较于对比的语义分割网络有显著提升,Dice系数提升分别为2.82%与3.43%。结论加入空间注意力机制的以纯Transformer模块为编码器的分割网络有效提升了脑部MRI海马体的分割精度。关键词:海马体;医学图像处理;Transformer;空间注意力机制;语义分割186|397|0更新时间:2024-05-07
摘要:目的海马体内嗅皮层的像素体积较小,这些特征给医学影像的分割任务带来很大挑战。综合海马体的形态特点以及医生的分割流程,提出一种新的海马体分割方法,以实现在临床医学影像处理中对海马体的精确分割,辅助阿尔兹海默症的早期诊断。方法提出一个基于自注意力机制与空间注意力机制的U型网络模型SA-TF-UNet(hippocampus segmentation network based on Transformer and spatial attention mechanisms)。该网络为端到端的预测网络,输入任意大小的3维MRI(magnetic resonance imaging)影像,输出类别标签。SA-TF-UNet采用编码器—解码器结构,编码器采用纯Transformer模块,不包含卷积模块。多头自注意力机制为Transformer模块中的特征提取器,自注意力模块基于全局信息建模,并提取特征。因此,使用Transformer提取特征符合医生分割海马体的基本思路。解码器采用简单的卷积模块进行上采样。使用AG(attention gate)模块作为跳跃连接的方式,自动增加前景的权重,代替了传统网络中的直接连接。为了验证AG的有效性,分别做了只在单层加入AG的实验,与在4层网络中全部加入AG的实验结果进行对比。为了进一步探讨AG模块中门控信号的来源,设计了两个SA-TF-UNet的变体,它们的网络结构中AG门控信号分别为比AG中的特征图深两层的Transformer模块输出和深3层的Transformer模块输出。结果为了验证SA-TF-UNet在临床数据集中分割海马体的有效性,在由阿尔兹海默症患者的MRI影像组成的脑MRI数据集上进行实验。4层网络全部加入AG,且AG的门控信号是由比AG特征图更深一层的Transformer模块输出的SA-TF-UNet模型分割效果最好。SA-TF-UNet对于左海马体、右海马体的分割Dice系数分别为0.900 1与0.909 1,相较于对比的语义分割网络有显著提升,Dice系数提升分别为2.82%与3.43%。结论加入空间注意力机制的以纯Transformer模块为编码器的分割网络有效提升了脑部MRI海马体的分割精度。关键词:海马体;医学图像处理;Transformer;空间注意力机制;语义分割186|397|0更新时间:2024-05-07 -
 摘要:目的COVID-19(corona virus disease 2019)患者肺部CT(computed tomography)图像病变呈多尺度特性,且形状不规则。由于卷积层缺乏长距离依赖性,基于卷积神经网络(convolutional neural network,CNN)的语义分割方法对病变的假阴性关注度不够,存在灵敏度低、特异度高的问题。针对COVID-19病变的多尺度问题,利用Transformer强大的全局上下文信息捕获能力,提出了一种COVID-19患者肺部CT图像分割的Transformer网络:COVID-TransNet。方法该网络以Swin Transformer为主干,在编码器部分提出了一个具有残差连接和层归一化(layer normalization,LN)的线性前馈模块,用于特征图通道维度的调整,并用轴向注意力模块(axial attention)替换跳跃连接,提升网络对全局信息的关注度。在解码器部分引入了一种新的特征融合模块,在上采样的过程中逐级细化局部信息,并采用多级预测的方法进行深度监督,最后利用Swin Transformer模块对解码器各级特征图进行解码。结果在COVID-19 CT segmentation数据集上实现了0.789的Dice系数、0.807的灵敏度、0.960的特异度和0.055的平均绝对误差,较Semi-Inf-Net分别提升了5%、8.2%、0.9%,平均绝对误差下降了0.9%,取得了先进水平。结论基于Transformer的COVID-19 CT图像分割网络,提高了COVID-19病变的分割精度,有效解决了CNN方法低灵敏度、高特异度的问题。关键词:COVID-19;CT图像分割;Swin Transformer;轴向注意力;多级预测240|381|1更新时间:2024-05-07
摘要:目的COVID-19(corona virus disease 2019)患者肺部CT(computed tomography)图像病变呈多尺度特性,且形状不规则。由于卷积层缺乏长距离依赖性,基于卷积神经网络(convolutional neural network,CNN)的语义分割方法对病变的假阴性关注度不够,存在灵敏度低、特异度高的问题。针对COVID-19病变的多尺度问题,利用Transformer强大的全局上下文信息捕获能力,提出了一种COVID-19患者肺部CT图像分割的Transformer网络:COVID-TransNet。方法该网络以Swin Transformer为主干,在编码器部分提出了一个具有残差连接和层归一化(layer normalization,LN)的线性前馈模块,用于特征图通道维度的调整,并用轴向注意力模块(axial attention)替换跳跃连接,提升网络对全局信息的关注度。在解码器部分引入了一种新的特征融合模块,在上采样的过程中逐级细化局部信息,并采用多级预测的方法进行深度监督,最后利用Swin Transformer模块对解码器各级特征图进行解码。结果在COVID-19 CT segmentation数据集上实现了0.789的Dice系数、0.807的灵敏度、0.960的特异度和0.055的平均绝对误差,较Semi-Inf-Net分别提升了5%、8.2%、0.9%,平均绝对误差下降了0.9%,取得了先进水平。结论基于Transformer的COVID-19 CT图像分割网络,提高了COVID-19病变的分割精度,有效解决了CNN方法低灵敏度、高特异度的问题。关键词:COVID-19;CT图像分割;Swin Transformer;轴向注意力;多级预测240|381|1更新时间:2024-05-07 -
 摘要:目的手术器械分割是外科手术机器人精准操作的关键环节之一,然而,受复杂因素的影响,精准的手术器械分割目前仍然面临着一定的挑战,如低对比度手术器械、复杂的手术环境、镜面反射以及手术器械的尺度和形状变化等,造成分割结果存在模糊边界和细节错分的问题,影响手术器械分割的精度。针对以上挑战,提出了一种新的手术器械分割网络,实现内窥镜图像中手术器械的准确分割。方法为了实现内窥镜图像的准确表征以获取有效的特征图,提出了基于卷积神经网络(convolutional neural network,CNN)和Transformer融合的双编码器结构,实现分割网络对细节特征和全局上下文语义信息的提取。为了实现局部特征图的特征增强,引入空洞卷积,设计了多尺度注意融合模块,以获取多尺度注意力特征图。针对手术器械分割面临的类不均衡问题,引入全局注意力模块,提高分割网络对手术器械区域的关注度,并减少对于无关特征的关注。结果为了有效验证本文模型的性能,使用两个公共手术器械分割数据集进行性能分析和测试。基于定性分析和定量分析通过消融实验和对比实验,验证了本文算法的有效性和优越性。实验结果表明:在Kvasir-instrument数据集上,本文算法的Dice分数和mIOU(mean intersection over union)值分别为96.46%和94.12%;在Endovis2017(2017 Endoscopic Vision Challenge)数据集上,本文算法的Dice分数和mIOU值分别为96.27%和92.55%。相较于对比的先进分割网络,本文算法实现了分割精度的有效提升。同时,消融研究也证明了本文算法方案设计的合理性,缺失任何一个子模块都会造成不同程度的精度损失。结论本文所提出的分割模型有效地融合了CNN和Transformer的优点,同时实现了细节特征和全局上下文信息的充分提取,可以实现手术器械准确、稳定分割。关键词:深度学习;手术器械分割;卷积神经网络(CNN);Transformer;双编码;特征注意机制190|307|0更新时间:2024-05-07
摘要:目的手术器械分割是外科手术机器人精准操作的关键环节之一,然而,受复杂因素的影响,精准的手术器械分割目前仍然面临着一定的挑战,如低对比度手术器械、复杂的手术环境、镜面反射以及手术器械的尺度和形状变化等,造成分割结果存在模糊边界和细节错分的问题,影响手术器械分割的精度。针对以上挑战,提出了一种新的手术器械分割网络,实现内窥镜图像中手术器械的准确分割。方法为了实现内窥镜图像的准确表征以获取有效的特征图,提出了基于卷积神经网络(convolutional neural network,CNN)和Transformer融合的双编码器结构,实现分割网络对细节特征和全局上下文语义信息的提取。为了实现局部特征图的特征增强,引入空洞卷积,设计了多尺度注意融合模块,以获取多尺度注意力特征图。针对手术器械分割面临的类不均衡问题,引入全局注意力模块,提高分割网络对手术器械区域的关注度,并减少对于无关特征的关注。结果为了有效验证本文模型的性能,使用两个公共手术器械分割数据集进行性能分析和测试。基于定性分析和定量分析通过消融实验和对比实验,验证了本文算法的有效性和优越性。实验结果表明:在Kvasir-instrument数据集上,本文算法的Dice分数和mIOU(mean intersection over union)值分别为96.46%和94.12%;在Endovis2017(2017 Endoscopic Vision Challenge)数据集上,本文算法的Dice分数和mIOU值分别为96.27%和92.55%。相较于对比的先进分割网络,本文算法实现了分割精度的有效提升。同时,消融研究也证明了本文算法方案设计的合理性,缺失任何一个子模块都会造成不同程度的精度损失。结论本文所提出的分割模型有效地融合了CNN和Transformer的优点,同时实现了细节特征和全局上下文信息的充分提取,可以实现手术器械准确、稳定分割。关键词:深度学习;手术器械分割;卷积神经网络(CNN);Transformer;双编码;特征注意机制190|307|0更新时间:2024-05-07 -
 摘要:目的卷积神经网络结合U-Net架构的深度学习方法广泛应用于各种医学图像处理中,取得了良好的效果,特别是在局部特征提取上表现出色,但由于卷积操作本身固有的局部性,导致其在全局信息获取上表现不佳。而基于Transformer的方法具有较好的全局建模能力,但在局部特征提取方面不如卷积神经网络。为充分融合两种方法各自的优点,提出一种基于分组注意力的医学图像分割模型(medical image segmentation module based on group attention,GAU-Net)。方法利用注意力机制,设计了一个同时集成了Swin Transformer和卷积神经网络的分组注意力模块,并嵌入网络编码器中,使网络能够高效地对图像的全局和局部重要特征进行提取和融合;在注意力计算方式上,通过特征分组的方式,在同一尺度特征内,同时进行不同的注意力计算,进一步提高网络提取语义信息的多样性;将提取的特征通过上采样恢复到原图尺寸,进行像素分类,得到最终的分割结果。结果在Synapse多器官分割数据集和ACDC(automated cardiac diagnosis challenge)数据集上进行了相关实验验证。在Synapse数据集中,Dice值为82.93%,HD(Hausdorff distance)值为12.32%,相较于排名第2的方法,Dice值提高了0.97%,HD值降低了5.88%;在ACDC数据集中,Dice值为91.34%,相较于排名第2的方法提高了0.48%。结论本文提出的医学图像分割模型有效地融合了Transformer和卷积神经网络各自的优势,提高了医学图像分割结果的精确度。关键词:深度学习;卷积神经网络(CNN);医学图像分割;U-Net;分组注意力;Swin Transformer295|439|3更新时间:2024-05-07
摘要:目的卷积神经网络结合U-Net架构的深度学习方法广泛应用于各种医学图像处理中,取得了良好的效果,特别是在局部特征提取上表现出色,但由于卷积操作本身固有的局部性,导致其在全局信息获取上表现不佳。而基于Transformer的方法具有较好的全局建模能力,但在局部特征提取方面不如卷积神经网络。为充分融合两种方法各自的优点,提出一种基于分组注意力的医学图像分割模型(medical image segmentation module based on group attention,GAU-Net)。方法利用注意力机制,设计了一个同时集成了Swin Transformer和卷积神经网络的分组注意力模块,并嵌入网络编码器中,使网络能够高效地对图像的全局和局部重要特征进行提取和融合;在注意力计算方式上,通过特征分组的方式,在同一尺度特征内,同时进行不同的注意力计算,进一步提高网络提取语义信息的多样性;将提取的特征通过上采样恢复到原图尺寸,进行像素分类,得到最终的分割结果。结果在Synapse多器官分割数据集和ACDC(automated cardiac diagnosis challenge)数据集上进行了相关实验验证。在Synapse数据集中,Dice值为82.93%,HD(Hausdorff distance)值为12.32%,相较于排名第2的方法,Dice值提高了0.97%,HD值降低了5.88%;在ACDC数据集中,Dice值为91.34%,相较于排名第2的方法提高了0.48%。结论本文提出的医学图像分割模型有效地融合了Transformer和卷积神经网络各自的优势,提高了医学图像分割结果的精确度。关键词:深度学习;卷积神经网络(CNN);医学图像分割;U-Net;分组注意力;Swin Transformer295|439|3更新时间:2024-05-07 -
 摘要:目的胸腔积液肿瘤细胞团块的分割对肺癌的筛查有着积极作用。胸腔积液肿瘤细胞团块显微图像存在细胞聚集、对比度低和边界模糊等问题,现有网络模型进行细胞分割时无法达到较高精度。提出一种基于UNet网络框架,融合过参数卷积与注意力机制的端到端语义分割模型DOCUNet(depthwise over-parameterized CBAM UNet)。方法将UNet网络中的卷积层替换为过参数卷积层。过参数卷积层结合了深度卷积和传统卷积两种卷积,保证网络深度不变的同时,提高模型对图像特征的提取能力。在网络底端的过渡区域,引入结合了通道注意力与空间注意力机制的注意力模块CBAM(convolutional block attention module),对编码器提取的特征权重进行再分配,增强模型的分割能力。结果在包含117幅显微图像的胸腔积液肿瘤细胞团块数据集上进行5折交叉实验。平均IoU(intersection over union)、Dice系数、精确率、召回率和豪斯多夫距离分别为0.858 0、0.920 4、0.928 2、0.920 3和18.17。并且与UNet等多种已存在的分割网络模型进行对比,IoU、Dice系数和精确率、召回率相较于UNet提高了2.80%、1.65%、1.47%和1.36%,豪斯多夫距离下降了41.16%。通过消融实验与类激活热力图,证明加入CBAM注意力机制与过参数卷积后能够提高网络分割精度,并能使网络更加专注于细胞的内部特征。结论本文提出的DOCUNet将过参数卷积和注意力机制与UNet相融合,实现了胸水肿瘤细胞团块的有效分割。经过对比实验证明所提方法提高了细胞分割的精度。关键词:胸腔积液肿瘤细胞团块;UNet;注意力机制;细胞分割;过参数卷积123|303|0更新时间:2024-05-07
摘要:目的胸腔积液肿瘤细胞团块的分割对肺癌的筛查有着积极作用。胸腔积液肿瘤细胞团块显微图像存在细胞聚集、对比度低和边界模糊等问题,现有网络模型进行细胞分割时无法达到较高精度。提出一种基于UNet网络框架,融合过参数卷积与注意力机制的端到端语义分割模型DOCUNet(depthwise over-parameterized CBAM UNet)。方法将UNet网络中的卷积层替换为过参数卷积层。过参数卷积层结合了深度卷积和传统卷积两种卷积,保证网络深度不变的同时,提高模型对图像特征的提取能力。在网络底端的过渡区域,引入结合了通道注意力与空间注意力机制的注意力模块CBAM(convolutional block attention module),对编码器提取的特征权重进行再分配,增强模型的分割能力。结果在包含117幅显微图像的胸腔积液肿瘤细胞团块数据集上进行5折交叉实验。平均IoU(intersection over union)、Dice系数、精确率、召回率和豪斯多夫距离分别为0.858 0、0.920 4、0.928 2、0.920 3和18.17。并且与UNet等多种已存在的分割网络模型进行对比,IoU、Dice系数和精确率、召回率相较于UNet提高了2.80%、1.65%、1.47%和1.36%,豪斯多夫距离下降了41.16%。通过消融实验与类激活热力图,证明加入CBAM注意力机制与过参数卷积后能够提高网络分割精度,并能使网络更加专注于细胞的内部特征。结论本文提出的DOCUNet将过参数卷积和注意力机制与UNet相融合,实现了胸水肿瘤细胞团块的有效分割。经过对比实验证明所提方法提高了细胞分割的精度。关键词:胸腔积液肿瘤细胞团块;UNet;注意力机制;细胞分割;过参数卷积123|303|0更新时间:2024-05-07
医学图像处理
-
 摘要:目的近年来,深度网络成功应用于高光谱图像分类。然而,难以获取充足的标记数据大大限制了深度网络的充分训练,进而导致网络对高光谱图像的分类能力下降。为解决以上困难,提出一种关联子域对齐网络的高光谱图像迁移分类方法。方法基于深度迁移学习方法,通过对两域分布进行多角度、全面领域适应的同时将两域分类器进行差异适配。一方面,利用关联对齐从整体上对齐了两域的二阶统计量信息,适配了两域的全局分布;另一方面,利用局部最大均值差异对齐了相关子域的一阶统计量信息,适配了两域的局部分布。另外,构造一种分类器适配模块并将其加入所提网络中,通过对两域分类器差异进行适配,进一步增强网络的领域适应效果。结果从4组真实高光谱数据集上的实验结果可看出:在分别采集于不同区域的高光谱图像数据对上,所提方法的精度比排名第2的分类方法高出1.01%、0.42%、0.73%和0.64%。本文方法的Kappa系数也取得最优结果。结论与现有主流算法相比较,所提网络能够在整体和局部、一阶和二阶统计量上分别对两域进行有效对齐,进而充分利用在源域上训练好的分类器完成对目标域高光谱数据的跨域分类。关键词:高光谱图像(HSI);分类;迁移学习;深度学习;跨域156|195|1更新时间:2024-05-07
摘要:目的近年来,深度网络成功应用于高光谱图像分类。然而,难以获取充足的标记数据大大限制了深度网络的充分训练,进而导致网络对高光谱图像的分类能力下降。为解决以上困难,提出一种关联子域对齐网络的高光谱图像迁移分类方法。方法基于深度迁移学习方法,通过对两域分布进行多角度、全面领域适应的同时将两域分类器进行差异适配。一方面,利用关联对齐从整体上对齐了两域的二阶统计量信息,适配了两域的全局分布;另一方面,利用局部最大均值差异对齐了相关子域的一阶统计量信息,适配了两域的局部分布。另外,构造一种分类器适配模块并将其加入所提网络中,通过对两域分类器差异进行适配,进一步增强网络的领域适应效果。结果从4组真实高光谱数据集上的实验结果可看出:在分别采集于不同区域的高光谱图像数据对上,所提方法的精度比排名第2的分类方法高出1.01%、0.42%、0.73%和0.64%。本文方法的Kappa系数也取得最优结果。结论与现有主流算法相比较,所提网络能够在整体和局部、一阶和二阶统计量上分别对两域进行有效对齐,进而充分利用在源域上训练好的分类器完成对目标域高光谱数据的跨域分类。关键词:高光谱图像(HSI);分类;迁移学习;深度学习;跨域156|195|1更新时间:2024-05-07 -
 摘要:目的针对极化合成孔径雷达(polarimetric synthetic aperture radar,PolSAR)小样本分类问题,基于充分挖掘有限样本的极化、空间特征考虑,提出一种由高阶条件随机场(conditional random field,CRF)引导的多分支分类网络模型。方法利用Yamaguchi非相干目标分解方法,构建每个像素的极化特征向量。设计了由高阶CRF能量函数引导的多卷积分支特征提取网络,将像素点极化特征向量作为输入,分别提取像素点的像素特征、邻域特征和位置特征信息。将以上特征进行加和融合,并输入到 softmax 分类器中得到预分类结果。利用超像素方法对预分类结果图进行进一步修正和调优,平滑相邻像素之间的特异性和相似性。结果采用1%的采样率对两组真实的极化SAR数据进行测试。同时,为了更好地模拟实际应用中训练样本位置分布不均匀的情况,考虑了空间不相交采样方法作为对比实验。综合两种采样策略的实验结果表明,相较于只利用像素级特征或简单利用空间特征的方法,本文方法总分类精度平均提升7%~10%,不同地物类别的分类精准度均在90%以上,运行速度相比于支持向量机(support vector machine,SVM)提高了2.5倍以上。结论通过构建高阶CRF引导的卷积神经网络,将像素特征信息、同质区域特征和地理位置信息进行融合,有效建立了像素级和对象级数据之间的尺度关联,进一步扩充了像素点之间的空间依赖性,提取到了更强大更准确的表征特征,显著提高了标记样本数量较少情况下的卷积网络模型的分类性能,进一步保证了地物目标散射机制表征的全面性和可靠性。关键词:SAR图像分类;卷积神经网络(CNN);条件随机场(CRF);超像素分割;采样策略;Yamaguchi分解244|291|1更新时间:2024-05-07
摘要:目的针对极化合成孔径雷达(polarimetric synthetic aperture radar,PolSAR)小样本分类问题,基于充分挖掘有限样本的极化、空间特征考虑,提出一种由高阶条件随机场(conditional random field,CRF)引导的多分支分类网络模型。方法利用Yamaguchi非相干目标分解方法,构建每个像素的极化特征向量。设计了由高阶CRF能量函数引导的多卷积分支特征提取网络,将像素点极化特征向量作为输入,分别提取像素点的像素特征、邻域特征和位置特征信息。将以上特征进行加和融合,并输入到 softmax 分类器中得到预分类结果。利用超像素方法对预分类结果图进行进一步修正和调优,平滑相邻像素之间的特异性和相似性。结果采用1%的采样率对两组真实的极化SAR数据进行测试。同时,为了更好地模拟实际应用中训练样本位置分布不均匀的情况,考虑了空间不相交采样方法作为对比实验。综合两种采样策略的实验结果表明,相较于只利用像素级特征或简单利用空间特征的方法,本文方法总分类精度平均提升7%~10%,不同地物类别的分类精准度均在90%以上,运行速度相比于支持向量机(support vector machine,SVM)提高了2.5倍以上。结论通过构建高阶CRF引导的卷积神经网络,将像素特征信息、同质区域特征和地理位置信息进行融合,有效建立了像素级和对象级数据之间的尺度关联,进一步扩充了像素点之间的空间依赖性,提取到了更强大更准确的表征特征,显著提高了标记样本数量较少情况下的卷积网络模型的分类性能,进一步保证了地物目标散射机制表征的全面性和可靠性。关键词:SAR图像分类;卷积神经网络(CNN);条件随机场(CRF);超像素分割;采样策略;Yamaguchi分解244|291|1更新时间:2024-05-07
遥感图像处理
-
 摘要:目的现有的地图智能生成技术没有考虑到地图生成任务存在的地理要素类内差异性和地理要素域间差异性,这使得生成的地图质量难以满足实际需要。针对地理要素类内差异性和地理要素域间差异性,提出了一种Transformer特征引导的双阶段地图智能生成方法。方法首先基于最新的Transformer网络,设计了一个基于该网络的特征提取模块,该模块提取遥感图像中的地理要素特征用于引导地图生成,解决了地理要素类内差异性导致的地图生成困难的问题。然后设计双阶段生成框架,该框架具备两个生成对抗网络,第1个生成对抗网络为初步生成对抗网络,利用遥感图像和Transformer特征得到初步的地图图像;第2个生成对抗网络为精修生成对抗网络利用初步地图图像生成高质量的精修地图图像,缓解了地理要素域间差异性导致的地图地理要素生成不准确问题。结果在AIDOMG (aerial image dataset for online map generation)数据集上的9个区域进行了实验,与10种经典的和最新方法进行了比较,提出方法取得了最优的结果。其中,在海口区域,相比于Creative GAN方法,FID(Frechet inception distance)值降低了16.0%,WD(Wasserstein distance)降低了4.2%,1-NN(1-nearest neighbor)降低了5.9%;在巴黎区域,相比于Creative GAN方法,FID值降低了2.9%,WD降低了1.0%,1-NN降低了2.1%。结论提出的Transformer特征引导的双阶段地图智能生成方法通过高质量的Transformer特征引导和双阶段生成框架解决了地理要素类内差异性和地理要素域间差异性所带来的地图生成质量较差的问题。关键词:Transformer特征;遥感图像;地图图像;地图智能生成;生成对抗网络(GAN)125|315|0更新时间:2024-05-07
摘要:目的现有的地图智能生成技术没有考虑到地图生成任务存在的地理要素类内差异性和地理要素域间差异性,这使得生成的地图质量难以满足实际需要。针对地理要素类内差异性和地理要素域间差异性,提出了一种Transformer特征引导的双阶段地图智能生成方法。方法首先基于最新的Transformer网络,设计了一个基于该网络的特征提取模块,该模块提取遥感图像中的地理要素特征用于引导地图生成,解决了地理要素类内差异性导致的地图生成困难的问题。然后设计双阶段生成框架,该框架具备两个生成对抗网络,第1个生成对抗网络为初步生成对抗网络,利用遥感图像和Transformer特征得到初步的地图图像;第2个生成对抗网络为精修生成对抗网络利用初步地图图像生成高质量的精修地图图像,缓解了地理要素域间差异性导致的地图地理要素生成不准确问题。结果在AIDOMG (aerial image dataset for online map generation)数据集上的9个区域进行了实验,与10种经典的和最新方法进行了比较,提出方法取得了最优的结果。其中,在海口区域,相比于Creative GAN方法,FID(Frechet inception distance)值降低了16.0%,WD(Wasserstein distance)降低了4.2%,1-NN(1-nearest neighbor)降低了5.9%;在巴黎区域,相比于Creative GAN方法,FID值降低了2.9%,WD降低了1.0%,1-NN降低了2.1%。结论提出的Transformer特征引导的双阶段地图智能生成方法通过高质量的Transformer特征引导和双阶段生成框架解决了地理要素类内差异性和地理要素域间差异性所带来的地图生成质量较差的问题。关键词:Transformer特征;遥感图像;地图图像;地图智能生成;生成对抗网络(GAN)125|315|0更新时间:2024-05-07
地理信息技术
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0