
最新刊期
2023 年 第 28 卷 第 1 期

-
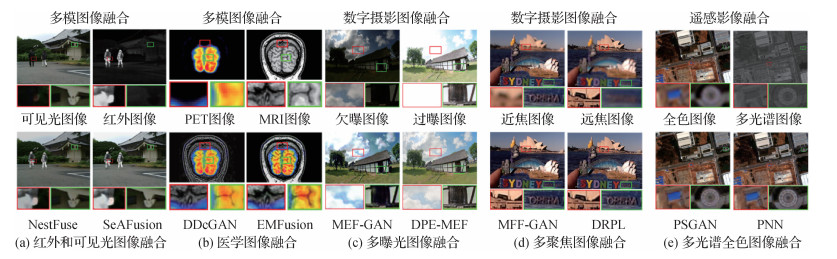 摘要:图像融合技术旨在将不同源图像中的互补信息整合到单幅融合图像中以全面表征成像场景,并促进后续的视觉任务。随着深度学习的兴起,基于深度学习的图像融合算法如雨后春笋般涌现,特别是自编码器、生成对抗网络以及Transformer等技术的出现使图像融合性能产生了质的飞跃。本文对不同融合任务场景下的前沿深度融合算法进行全面论述和分析。首先,介绍图像融合的基本概念以及不同融合场景的定义。针对多模图像融合、数字摄影图像融合以及遥感影像融合等不同的融合场景,从网络架构和监督范式等角度全面阐述各类方法的基本思想,并讨论各类方法的特点。其次,总结各类算法的局限性,并给出进一步的改进方向。再次,简要介绍不同融合场景中常用的数据集,并给出各种评估指标的具体定义。对于每一种融合任务,从定性评估、定量评估和运行效率等多角度全面比较其中代表性算法的性能。本文提及的算法、数据集和评估指标已汇总至https://github.com/Linfeng-Tang/Image-Fusion。最后,给出了本文结论以及图像融合研究中存在的一些严峻挑战,并对未来可能的研究方向进行了展望。关键词:图像融合;深度学习;多模图像;数字摄影;遥感影像6357|7342|21更新时间:2024-05-08
摘要:图像融合技术旨在将不同源图像中的互补信息整合到单幅融合图像中以全面表征成像场景,并促进后续的视觉任务。随着深度学习的兴起,基于深度学习的图像融合算法如雨后春笋般涌现,特别是自编码器、生成对抗网络以及Transformer等技术的出现使图像融合性能产生了质的飞跃。本文对不同融合任务场景下的前沿深度融合算法进行全面论述和分析。首先,介绍图像融合的基本概念以及不同融合场景的定义。针对多模图像融合、数字摄影图像融合以及遥感影像融合等不同的融合场景,从网络架构和监督范式等角度全面阐述各类方法的基本思想,并讨论各类方法的特点。其次,总结各类算法的局限性,并给出进一步的改进方向。再次,简要介绍不同融合场景中常用的数据集,并给出各种评估指标的具体定义。对于每一种融合任务,从定性评估、定量评估和运行效率等多角度全面比较其中代表性算法的性能。本文提及的算法、数据集和评估指标已汇总至https://github.com/Linfeng-Tang/Image-Fusion。最后,给出了本文结论以及图像融合研究中存在的一些严峻挑战,并对未来可能的研究方向进行了展望。关键词:图像融合;深度学习;多模图像;数字摄影;遥感影像6357|7342|21更新时间:2024-05-08 -
 摘要:目标跟踪是计算机视觉研究中的前沿和热点问题,在安全监控、无人驾驶等领域中有着重要的应用价值。然而,目前基于可见光数据的视觉跟踪方法,在光照变化、恶劣天气下因数据质量受限难以实现鲁棒跟踪。因此,一些研究者提出了多模态视觉跟踪任务,通过引入其他模态数据,包括红外模态、深度模态、事件模态以及文本模态,在一定程度上弥补了可见光模态在恶劣天气、遮挡、快速运动和外观歧义等条件下的不足。多模态视觉跟踪旨在挖掘可见光和其他模态数据的互补优势,在视频中实现鲁棒的目标定位,对全天时全天候感知有着重要的价值和意义,受到越来越多的研究和关注。由于主流的多模态视觉跟踪方法针对可见光—红外跟踪展开,因此,本文以阐述可见光—红外跟踪方法为主,从信息融合的角度将现有方法划分为结合式融合和判别式融合,分别进行了详细介绍和分析,并对不同类方法的优缺点进行了分析和比较。然后,本文对其他多模态视觉跟踪任务的研究工作进行了介绍,并对不同多模态视觉跟踪任务的优缺点进行了分析和比较。最后,本文对多模态视觉跟踪方法进行了总结并对未来发展进行展望。关键词:信息融合;视觉跟踪;多模态;结合式融合;判别式融合439|404|7更新时间:2024-05-08
摘要:目标跟踪是计算机视觉研究中的前沿和热点问题,在安全监控、无人驾驶等领域中有着重要的应用价值。然而,目前基于可见光数据的视觉跟踪方法,在光照变化、恶劣天气下因数据质量受限难以实现鲁棒跟踪。因此,一些研究者提出了多模态视觉跟踪任务,通过引入其他模态数据,包括红外模态、深度模态、事件模态以及文本模态,在一定程度上弥补了可见光模态在恶劣天气、遮挡、快速运动和外观歧义等条件下的不足。多模态视觉跟踪旨在挖掘可见光和其他模态数据的互补优势,在视频中实现鲁棒的目标定位,对全天时全天候感知有着重要的价值和意义,受到越来越多的研究和关注。由于主流的多模态视觉跟踪方法针对可见光—红外跟踪展开,因此,本文以阐述可见光—红外跟踪方法为主,从信息融合的角度将现有方法划分为结合式融合和判别式融合,分别进行了详细介绍和分析,并对不同类方法的优缺点进行了分析和比较。然后,本文对其他多模态视觉跟踪任务的研究工作进行了介绍,并对不同多模态视觉跟踪任务的优缺点进行了分析和比较。最后,本文对多模态视觉跟踪方法进行了总结并对未来发展进行展望。关键词:信息融合;视觉跟踪;多模态;结合式融合;判别式融合439|404|7更新时间:2024-05-08 -
 摘要:随着计算机科学、遥感科学和大数据科学等领域的迅速发展,基于卷积神经网络的方法在图像处理、计算机视觉等任务上发挥着越来越重要的作用。而在遥感图像全色锐化领域,卷积神经网络由于其优秀的融合效果,已得到研究学者的广泛关注并有大量的研究成果产生。尽管如此,依然有一些亟待解决的问题,例如缺乏全色锐化数据集的仿真细节描述、公平公开的训练—测试数据集、简单易懂的统一代码编写框架等。对此,本文主要从以下几方面回顾当前遥感图像全色锐化问题在卷积神经网络方面的一些进展,并针对前述问题发布相关数据集和代码编写框架。1)详细介绍7种典型的基于卷积神经网络的全色锐化方法,并在统一数据集上进行公平比较(包括与典型传统方法的比较);2)详细介绍训练—测试数据集的仿真细节,并发布相关卫星(如WorldView-3,QuickBird,GaoFen2,WorldView-2)的全色锐化训练—测试数据集;3)针对本文介绍的7种基于卷积神经网络的方法,发布基于Pytorch深度学习库的Python代码统一编写框架,便于后来初学者入门、开展研究以及公平比较;4)发布统一的全色锐化传统—深度学习方法MATLAB测试软件包,便于后来学者进行公平的实验测试对比;5)对本领域的未来研究方向进行讨论和展望。本文的相关数据集和代码详见课题主页:https://liangjiandeng.github.io/PanCollection.html。关键词:全色锐化;卷积神经网络(CNN);典型卷积神经网络方法比较;数据集发布;代码框架发布;全色锐化综述532|746|2更新时间:2024-05-08
摘要:随着计算机科学、遥感科学和大数据科学等领域的迅速发展,基于卷积神经网络的方法在图像处理、计算机视觉等任务上发挥着越来越重要的作用。而在遥感图像全色锐化领域,卷积神经网络由于其优秀的融合效果,已得到研究学者的广泛关注并有大量的研究成果产生。尽管如此,依然有一些亟待解决的问题,例如缺乏全色锐化数据集的仿真细节描述、公平公开的训练—测试数据集、简单易懂的统一代码编写框架等。对此,本文主要从以下几方面回顾当前遥感图像全色锐化问题在卷积神经网络方面的一些进展,并针对前述问题发布相关数据集和代码编写框架。1)详细介绍7种典型的基于卷积神经网络的全色锐化方法,并在统一数据集上进行公平比较(包括与典型传统方法的比较);2)详细介绍训练—测试数据集的仿真细节,并发布相关卫星(如WorldView-3,QuickBird,GaoFen2,WorldView-2)的全色锐化训练—测试数据集;3)针对本文介绍的7种基于卷积神经网络的方法,发布基于Pytorch深度学习库的Python代码统一编写框架,便于后来初学者入门、开展研究以及公平比较;4)发布统一的全色锐化传统—深度学习方法MATLAB测试软件包,便于后来学者进行公平的实验测试对比;5)对本领域的未来研究方向进行讨论和展望。本文的相关数据集和代码详见课题主页:https://liangjiandeng.github.io/PanCollection.html。关键词:全色锐化;卷积神经网络(CNN);典型卷积神经网络方法比较;数据集发布;代码框架发布;全色锐化综述532|746|2更新时间:2024-05-08 -
 摘要:多聚焦图像融合是一种以软件方式有效扩展光学镜头景深的技术,该技术通过综合同一场景下多幅部分聚焦图像包含的互补信息,生成一幅更加适合人类观察或计算机处理的全聚焦融合图像,在数码摄影、显微成像等领域具有广泛的应用价值。传统的多聚焦图像融合方法往往需要人工设计图像的变换模型、活跃程度度量及融合规则,无法全面充分地提取和融合图像特征。深度学习由于强大的特征学习能力被引入多聚焦图像融合问题研究,并迅速发展为该问题的主流研究方向,多种多样的方法不断提出。鉴于国内鲜有多聚焦图像融合方面的研究综述,本文对基于深度学习的多聚焦图像融合方法进行系统综述,将现有方法分为基于深度分类模型和基于深度回归模型两大类,对每一类中的代表性方法进行介绍;然后基于3个多聚焦图像融合数据集和8个常用的客观质量评价指标,对25种代表性融合方法进行了性能评估和对比分析;最后总结了该研究方向存在的一些挑战性问题,并对后续研究进行展望。本文旨在帮助相关研究人员了解多聚焦图像融合领域的研究现状,促进该领域的进一步发展。关键词:多聚焦图像融合(MFIF);图像融合;深度学习;卷积神经网络(CNN);生成对抗网络(GAN)503|872|0更新时间:2024-05-08
摘要:多聚焦图像融合是一种以软件方式有效扩展光学镜头景深的技术,该技术通过综合同一场景下多幅部分聚焦图像包含的互补信息,生成一幅更加适合人类观察或计算机处理的全聚焦融合图像,在数码摄影、显微成像等领域具有广泛的应用价值。传统的多聚焦图像融合方法往往需要人工设计图像的变换模型、活跃程度度量及融合规则,无法全面充分地提取和融合图像特征。深度学习由于强大的特征学习能力被引入多聚焦图像融合问题研究,并迅速发展为该问题的主流研究方向,多种多样的方法不断提出。鉴于国内鲜有多聚焦图像融合方面的研究综述,本文对基于深度学习的多聚焦图像融合方法进行系统综述,将现有方法分为基于深度分类模型和基于深度回归模型两大类,对每一类中的代表性方法进行介绍;然后基于3个多聚焦图像融合数据集和8个常用的客观质量评价指标,对25种代表性融合方法进行了性能评估和对比分析;最后总结了该研究方向存在的一些挑战性问题,并对后续研究进行展望。本文旨在帮助相关研究人员了解多聚焦图像融合领域的研究现状,促进该领域的进一步发展。关键词:多聚焦图像融合(MFIF);图像融合;深度学习;卷积神经网络(CNN);生成对抗网络(GAN)503|872|0更新时间:2024-05-08 -
 摘要:为提升真实场景视觉信号的采集质量,往往需要通过多种融合方式获取相应的图像,例如,多聚焦、多曝光、多光谱和多模态等。针对视觉信号采集的以上特性,图像融合技术旨在利用同一场景不同视觉信号的优势,生成单图像信息描述,提升视觉低、中、高级任务的性能。目前,依托端对端学习强大的特征提取、表征及重构能力,深度学习已成为图像融合研究的主流技术。与传统图像融合技术相比,基于深度学习的图像融合模型性能显著提高。随着深度学习研究的深入,一些新颖的理论和方法也促进了图像融合技术的发展,如生成对抗网络、注意力机制、视觉Transformer和感知损失函数等。为厘清基于深度学习技术的图像融合研究进展,本文首先介绍了图像融合问题建模,并从传统方法视角逐渐向深度学习视角过渡。具体地,从数据集生成、神经网络构造、损失函数设计、模型优化和性能评估等方面总结了基于深度学习的图像融合研究现状。此外,还讨论了选择性图像融合这类衍生问题建模(如基于高分辨率纹理图融合的深度图增强),回顾了一些基于图像融合实现其他视觉任务的代表性工作。最后,根据现有技术的缺陷,提出目前图像融合技术存在的挑战,并对未来发展趋势给出了展望。关键词:图像融合;深度神经网络;随机梯度优化(SGD);图像质量评价;深度学习407|539|2更新时间:2024-05-08
摘要:为提升真实场景视觉信号的采集质量,往往需要通过多种融合方式获取相应的图像,例如,多聚焦、多曝光、多光谱和多模态等。针对视觉信号采集的以上特性,图像融合技术旨在利用同一场景不同视觉信号的优势,生成单图像信息描述,提升视觉低、中、高级任务的性能。目前,依托端对端学习强大的特征提取、表征及重构能力,深度学习已成为图像融合研究的主流技术。与传统图像融合技术相比,基于深度学习的图像融合模型性能显著提高。随着深度学习研究的深入,一些新颖的理论和方法也促进了图像融合技术的发展,如生成对抗网络、注意力机制、视觉Transformer和感知损失函数等。为厘清基于深度学习技术的图像融合研究进展,本文首先介绍了图像融合问题建模,并从传统方法视角逐渐向深度学习视角过渡。具体地,从数据集生成、神经网络构造、损失函数设计、模型优化和性能评估等方面总结了基于深度学习的图像融合研究现状。此外,还讨论了选择性图像融合这类衍生问题建模(如基于高分辨率纹理图融合的深度图增强),回顾了一些基于图像融合实现其他视觉任务的代表性工作。最后,根据现有技术的缺陷,提出目前图像融合技术存在的挑战,并对未来发展趋势给出了展望。关键词:图像融合;深度神经网络;随机梯度优化(SGD);图像质量评价;深度学习407|539|2更新时间:2024-05-08 -
 摘要:多模态医学图像能够为医疗诊断、治疗规划和手术导航等临床应用提供更为全面和准确的医学图像描述。由于疾病的类型多样且复杂,无法通过单一模态的医学图像进行疾病类型诊断和病灶定位,而多模态医学图像融合方法可以解决这一问题。融合方法获得的融合图像具有更丰富全面的信息,可以辅助医学影像更好地服务于临床应用。为了对医学图像融合方法的现状进行全面研究,本文对近年国内外发表的相关文献进行综述。对医学图像融合技术进行分类,将融合方法分为传统方法和深度学习方法两类并总结其优缺点。结合多模态医学图像成像原理和各类疾病的图像表征,分析不同部位、不同疾病的融合方法的相关技术并进行定性比较。总结现有多模态医学图像数据库,并按分类对25项常见的医学图像融合质量评价指标进行概述。总结22种基于传统方法和深度学习领域的多模态医学图像融合算法。此外,本文进行实验,比较基于深度学习与传统的医学图像融合方法的性能,通过对3组多模态医学图像融合结果的定性和定量分析,总结各技术领域医学图像融合算法的优缺点。最后,对医学图像融合技术的现状、重难点和未来展望进行讨论。关键词:多模态医学图像;医学图像融合;深度学习;医学图像数据库;质量评价指标873|1380|3更新时间:2024-05-08
摘要:多模态医学图像能够为医疗诊断、治疗规划和手术导航等临床应用提供更为全面和准确的医学图像描述。由于疾病的类型多样且复杂,无法通过单一模态的医学图像进行疾病类型诊断和病灶定位,而多模态医学图像融合方法可以解决这一问题。融合方法获得的融合图像具有更丰富全面的信息,可以辅助医学影像更好地服务于临床应用。为了对医学图像融合方法的现状进行全面研究,本文对近年国内外发表的相关文献进行综述。对医学图像融合技术进行分类,将融合方法分为传统方法和深度学习方法两类并总结其优缺点。结合多模态医学图像成像原理和各类疾病的图像表征,分析不同部位、不同疾病的融合方法的相关技术并进行定性比较。总结现有多模态医学图像数据库,并按分类对25项常见的医学图像融合质量评价指标进行概述。总结22种基于传统方法和深度学习领域的多模态医学图像融合算法。此外,本文进行实验,比较基于深度学习与传统的医学图像融合方法的性能,通过对3组多模态医学图像融合结果的定性和定量分析,总结各技术领域医学图像融合算法的优缺点。最后,对医学图像融合技术的现状、重难点和未来展望进行讨论。关键词:多模态医学图像;医学图像融合;深度学习;医学图像数据库;质量评价指标873|1380|3更新时间:2024-05-08
综述
-
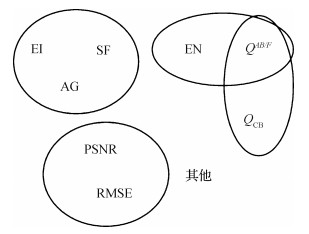 摘要:目的客观评价作为图像融合的重要研究领域,是评价融合算法性能的有力工具。目前,已有几十种不同类型的评价指标,但各应用领域包括可见光与红外图像融合,仍缺少统一的选择依据。为了方便比较不同融合算法性能,提出一种客观评价指标的通用分析方法并应用于可见光与红外图像融合。方法将可见光与红外图像基准数据集中的客观评价指标分为两类,分别是基于融合图像的评价指标与基于源图像和融合图像的评价指标。采用Kendall相关系数分析融合指标间的相关性,聚类得到指标分组;采用Borda计数排序法统计算法的综合排序,分析单一指标排序和综合排序的相关性,得到一致性较高的指标集合;采用离散系数分析指标均值随不同算法的波动程度,选择充分体现不同算法间差异的指标;综合相关性分析、一致性分析及离散系数分析,总结具有代表性的建议指标集合。结果在13对彩色可见光与红外和8对灰度可见光与红外两组图像源中,分别统计分析不同图像融合算法的客观评价数据,得到可见光与红外图像融合的建议指标集(标准差、边缘保持度),作为融合算法性能评估的重要参考。相较于现有方法,实验覆盖20种融合算法和13种客观评价指标,并且不依赖主观评价结果。结论针对可见光与红外图像融合,提出了一种基于统计分析的客观评价指标分析方法,该方法可以推广至更多的图像融合应用,指导选择具有代表性的客观评价指标。关键词:图像融合;客观评价指标;相关性分析;一致性分析;离散系数897|471|9更新时间:2024-05-08
摘要:目的客观评价作为图像融合的重要研究领域,是评价融合算法性能的有力工具。目前,已有几十种不同类型的评价指标,但各应用领域包括可见光与红外图像融合,仍缺少统一的选择依据。为了方便比较不同融合算法性能,提出一种客观评价指标的通用分析方法并应用于可见光与红外图像融合。方法将可见光与红外图像基准数据集中的客观评价指标分为两类,分别是基于融合图像的评价指标与基于源图像和融合图像的评价指标。采用Kendall相关系数分析融合指标间的相关性,聚类得到指标分组;采用Borda计数排序法统计算法的综合排序,分析单一指标排序和综合排序的相关性,得到一致性较高的指标集合;采用离散系数分析指标均值随不同算法的波动程度,选择充分体现不同算法间差异的指标;综合相关性分析、一致性分析及离散系数分析,总结具有代表性的建议指标集合。结果在13对彩色可见光与红外和8对灰度可见光与红外两组图像源中,分别统计分析不同图像融合算法的客观评价数据,得到可见光与红外图像融合的建议指标集(标准差、边缘保持度),作为融合算法性能评估的重要参考。相较于现有方法,实验覆盖20种融合算法和13种客观评价指标,并且不依赖主观评价结果。结论针对可见光与红外图像融合,提出了一种基于统计分析的客观评价指标分析方法,该方法可以推广至更多的图像融合应用,指导选择具有代表性的客观评价指标。关键词:图像融合;客观评价指标;相关性分析;一致性分析;离散系数897|471|9更新时间:2024-05-08 -
 摘要:目的红外与可见光图像融合的目标是获得具有完整场景表达能力的高质量融合图像。由于深度特征具有良好的泛化性、鲁棒性和发展潜力,很多基于深度学习的融合方法被提出,在深度特征空间进行图像融合,并取得了良好的效果。此外,受传统基于多尺度分解的融合方法的启发,不同尺度的特征有利于保留源图像的更多信息。基于此,提出了一种新颖的渐进式红外与可见光图像融合框架(progressive fusion, ProFuse)。方法该框架以U-Net为骨干提取多尺度特征,然后逐渐融合多尺度特征,既对包含全局信息的高层特征和包含更多细节的低层特征进行融合,也在原始尺寸特征(保持更多细节)和其他更小尺寸特征(保持语义信息)上进行融合,最终逐层重建融合图像。结果实验在TNO(Toegepast Natuurwetenschappelijk Onderzoek)和INO(Institut National D’optique)数据集上与其他6种方法进行比较,在选择的6项客观指标上,本文方法在互信息(mutual Information,MI)上相比FusionGAN(generative adversarial network for infrared and visible image fusion)方法提升了115.64%,在标准差(standard deviation,STD)上相比于GANMcC(generative adversarial network with multiclassification constraints for infrared and visible image fusion)方法提升了19.93%,在边缘保存度Qabf上相比DWT(discrete wavelet transform)方法提升了1.91%,在信息熵(entopy,EN)上相比GANMcC方法提升了1.30%。主观结果方面,本文方法得到的融合结果具有更高的对比度、更多的细节和更清晰的目标。结论大量实验表明了本文方法的有效性和泛化性。与其他先进的方法相比,本文方法在主观和客观评估上都显示出更好的结果。关键词:图像融合;深度学习;无监督学习;红外图像;可见光图像401|1|1更新时间:2024-05-08
摘要:目的红外与可见光图像融合的目标是获得具有完整场景表达能力的高质量融合图像。由于深度特征具有良好的泛化性、鲁棒性和发展潜力,很多基于深度学习的融合方法被提出,在深度特征空间进行图像融合,并取得了良好的效果。此外,受传统基于多尺度分解的融合方法的启发,不同尺度的特征有利于保留源图像的更多信息。基于此,提出了一种新颖的渐进式红外与可见光图像融合框架(progressive fusion, ProFuse)。方法该框架以U-Net为骨干提取多尺度特征,然后逐渐融合多尺度特征,既对包含全局信息的高层特征和包含更多细节的低层特征进行融合,也在原始尺寸特征(保持更多细节)和其他更小尺寸特征(保持语义信息)上进行融合,最终逐层重建融合图像。结果实验在TNO(Toegepast Natuurwetenschappelijk Onderzoek)和INO(Institut National D’optique)数据集上与其他6种方法进行比较,在选择的6项客观指标上,本文方法在互信息(mutual Information,MI)上相比FusionGAN(generative adversarial network for infrared and visible image fusion)方法提升了115.64%,在标准差(standard deviation,STD)上相比于GANMcC(generative adversarial network with multiclassification constraints for infrared and visible image fusion)方法提升了19.93%,在边缘保存度Qabf上相比DWT(discrete wavelet transform)方法提升了1.91%,在信息熵(entopy,EN)上相比GANMcC方法提升了1.30%。主观结果方面,本文方法得到的融合结果具有更高的对比度、更多的细节和更清晰的目标。结论大量实验表明了本文方法的有效性和泛化性。与其他先进的方法相比,本文方法在主观和客观评估上都显示出更好的结果。关键词:图像融合;深度学习;无监督学习;红外图像;可见光图像401|1|1更新时间:2024-05-08 -
 摘要:目的针对传统红外与可见光图像融合方法中人工设计特征提取和特征融合的局限性,以及基于卷积神经网络(convolutional neural networks,CNN)的方法无法有效提取图像中的全局上下文信息和特征融合过程中融合不充分的问题,本文提出了基于视觉Transformer和分组渐进式融合策略的端到端无监督图像融合网络。方法首先,将在通道维度上进行自注意力计算的多头转置注意力模块和通道注意力模块组合成视觉Transformer,多头转置注意力模块解决了自注意力计算量随像素大小呈次方增大的问题,通道注意力可以强化突出特征。其次,将CNN和设计的视觉Transformer并联组成局部—全局特征提取模块,用来提取源图像中的局部细节信息和全局上下文信息,使提取的特征既具有通用性又具有全局性。此外,为了避免融合过程中信息丢失,通过将特征分组和构造渐进残差结构的方式进行特征融合。最后,通过解码融合特征得到最终的融合图像。结果实验在TNO数据集和RoadScene数据集上与6种方法进行比较。主观上看,本文方法能够有效融合红外图像和可见光图像中的互补信息,得到优质的融合图像。从客观定量分析来说,在TNO数据集中,本文方法相比于性能第2的方法,在归一化互信息、非线性相关信息熵、平均梯度和标准差指标上分别提高了30.90%、0.58%、11.72%和11.82%;在RoadScene数据集中,本文方法在以上4个指标上依然取得了最好成绩。结论由于有效特征的提取和融合的复杂性以及融合过程中噪声的干扰,现有的融合方法都存在一定的局限性,或者融合效果质量不理想。相比之下,本文提出的基于视觉Transformer的图像融合方法在融合质量上取得了巨大提升,能够有效突出红外显著目标,并且将源图像中的背景信息和细节纹理有效保留在融合图像中,在对比度和清晰度方面也具有优越性。关键词:红外图像;可见光图像;图像融合;视觉Transformer;卷积神经网络(CNN)220|801|5更新时间:2024-05-08
摘要:目的针对传统红外与可见光图像融合方法中人工设计特征提取和特征融合的局限性,以及基于卷积神经网络(convolutional neural networks,CNN)的方法无法有效提取图像中的全局上下文信息和特征融合过程中融合不充分的问题,本文提出了基于视觉Transformer和分组渐进式融合策略的端到端无监督图像融合网络。方法首先,将在通道维度上进行自注意力计算的多头转置注意力模块和通道注意力模块组合成视觉Transformer,多头转置注意力模块解决了自注意力计算量随像素大小呈次方增大的问题,通道注意力可以强化突出特征。其次,将CNN和设计的视觉Transformer并联组成局部—全局特征提取模块,用来提取源图像中的局部细节信息和全局上下文信息,使提取的特征既具有通用性又具有全局性。此外,为了避免融合过程中信息丢失,通过将特征分组和构造渐进残差结构的方式进行特征融合。最后,通过解码融合特征得到最终的融合图像。结果实验在TNO数据集和RoadScene数据集上与6种方法进行比较。主观上看,本文方法能够有效融合红外图像和可见光图像中的互补信息,得到优质的融合图像。从客观定量分析来说,在TNO数据集中,本文方法相比于性能第2的方法,在归一化互信息、非线性相关信息熵、平均梯度和标准差指标上分别提高了30.90%、0.58%、11.72%和11.82%;在RoadScene数据集中,本文方法在以上4个指标上依然取得了最好成绩。结论由于有效特征的提取和融合的复杂性以及融合过程中噪声的干扰,现有的融合方法都存在一定的局限性,或者融合效果质量不理想。相比之下,本文提出的基于视觉Transformer的图像融合方法在融合质量上取得了巨大提升,能够有效突出红外显著目标,并且将源图像中的背景信息和细节纹理有效保留在融合图像中,在对比度和清晰度方面也具有优越性。关键词:红外图像;可见光图像;图像融合;视觉Transformer;卷积神经网络(CNN)220|801|5更新时间:2024-05-08 -
 摘要:目的在基于深度学习的红外与可见光图像融合方法中,多尺度分解是一种提取不同尺度特征的重要方式。针对传统多尺度分解方法里尺度设置粗糙的问题,提出了一种基于八度(octave)卷积的改进图像融合算法。方法融合方法由4部分组成:编码器、特征增强、融合策略和解码器。首先,使用改进后的编码器获取源图像的多尺度上的低频、次低频和高频特征。这些特征会被从顶层到底层进行强化。其次,将这些特征按照对应的融合策略进行融合。最后,融合后的深度特征由本文设计的解码器重构为信息丰富的融合图像。结果实验在TNO和RoadScene数据集上与9种图像融合算法进行比较。主观评价方面,所提算法可以充分保留源图像中的有效信息,融合结果也符合人的视觉感知;客观指标方面,在TNO数据集上所提算法在信息熵、标准差、视觉信息保真度、互信息和基于小波变换提取局部特征的特征互信息5个指标上均有最优表现,相较于9种对比方法中最优值分别提升了0.54%,4.14%,5.01%,0.55%,0.68%。在RoadScene数据集上所提算法在信息熵、标准差、视觉信息保真度和互信息4个指标上取得了最优值,相较9种对比方法的最优值分别提升了0.45%,6.13%,7.43%,0.45%,基于小波变换提取局部特征的特征互信息与最优值仅相差0.002 05。结论所提融合方法在主观和客观评估中都取得了优秀的结果,可以有效完成图像融合任务。关键词:图像处理;图像融合;八度卷积;红外图像;可见光图像109|224|1更新时间:2024-05-08
摘要:目的在基于深度学习的红外与可见光图像融合方法中,多尺度分解是一种提取不同尺度特征的重要方式。针对传统多尺度分解方法里尺度设置粗糙的问题,提出了一种基于八度(octave)卷积的改进图像融合算法。方法融合方法由4部分组成:编码器、特征增强、融合策略和解码器。首先,使用改进后的编码器获取源图像的多尺度上的低频、次低频和高频特征。这些特征会被从顶层到底层进行强化。其次,将这些特征按照对应的融合策略进行融合。最后,融合后的深度特征由本文设计的解码器重构为信息丰富的融合图像。结果实验在TNO和RoadScene数据集上与9种图像融合算法进行比较。主观评价方面,所提算法可以充分保留源图像中的有效信息,融合结果也符合人的视觉感知;客观指标方面,在TNO数据集上所提算法在信息熵、标准差、视觉信息保真度、互信息和基于小波变换提取局部特征的特征互信息5个指标上均有最优表现,相较于9种对比方法中最优值分别提升了0.54%,4.14%,5.01%,0.55%,0.68%。在RoadScene数据集上所提算法在信息熵、标准差、视觉信息保真度和互信息4个指标上取得了最优值,相较9种对比方法的最优值分别提升了0.45%,6.13%,7.43%,0.45%,基于小波变换提取局部特征的特征互信息与最优值仅相差0.002 05。结论所提融合方法在主观和客观评估中都取得了优秀的结果,可以有效完成图像融合任务。关键词:图像处理;图像融合;八度卷积;红外图像;可见光图像109|224|1更新时间:2024-05-08 -
 摘要:目的红外图像在工业中发挥着重要的作用。但是由于技术原因,红外图像的分辨率一般较低,限制了其普遍适用性。许多低分辨率红外传感器都和高分辨率可见光传感器搭配使用,一种可行的思路是利用可见光传感器捕获的高分辨率图像,辅助红外图像进行超分辨率重建。方法本文提出了一种使用高分辨率可见光图像引导红外图像进行超分辨率的神经网络模型,包含两个模块:引导Transformer模块和超分辨率重建模块。考虑到红外和可见光图像对一般存在一定的视差,两者之间是不完全对齐的,本文使用基于引导Transformer的信息引导与融合方法,从高分辨率可见光图像中搜索相关纹理信息,并将这些相关纹理信息与低分辨率红外图像的信息融合得到合成特征。然后这个合成特征经过后面的超分辨率重建子网络,得到最终的超分辨率红外图像。在超分辨率重建模块,本文使用通道拆分策略来消除深度模型中的冗余特征,减少计算量,提高模型性能。结果本文方法在FLIR-aligned数据集上与其他代表性图像超分辨率方法进行对比。实验结果表明,本文方法可以取得优于对比方法的超分辨率性能。客观结果上,本文方法比其他红外图像引导超分辨率方法在峰值信噪比(peak signal to noise ratio, PSNR)上高0.75 dB; 主观结果上,本文方法能够生成视觉效果更加逼真、纹理更加清晰的超分辨率图像。消融实验证明了所提算法各个模块的有效性。结论本文提出的引导超分辨率算法能够充分利用红外图像和可见光图像之间的关联信息,同时获得红外图像的高质量超分辨率重建结果。关键词:图像超分辨率;图像融合;红外图像;Transformer;深度学习455|447|6更新时间:2024-05-08
摘要:目的红外图像在工业中发挥着重要的作用。但是由于技术原因,红外图像的分辨率一般较低,限制了其普遍适用性。许多低分辨率红外传感器都和高分辨率可见光传感器搭配使用,一种可行的思路是利用可见光传感器捕获的高分辨率图像,辅助红外图像进行超分辨率重建。方法本文提出了一种使用高分辨率可见光图像引导红外图像进行超分辨率的神经网络模型,包含两个模块:引导Transformer模块和超分辨率重建模块。考虑到红外和可见光图像对一般存在一定的视差,两者之间是不完全对齐的,本文使用基于引导Transformer的信息引导与融合方法,从高分辨率可见光图像中搜索相关纹理信息,并将这些相关纹理信息与低分辨率红外图像的信息融合得到合成特征。然后这个合成特征经过后面的超分辨率重建子网络,得到最终的超分辨率红外图像。在超分辨率重建模块,本文使用通道拆分策略来消除深度模型中的冗余特征,减少计算量,提高模型性能。结果本文方法在FLIR-aligned数据集上与其他代表性图像超分辨率方法进行对比。实验结果表明,本文方法可以取得优于对比方法的超分辨率性能。客观结果上,本文方法比其他红外图像引导超分辨率方法在峰值信噪比(peak signal to noise ratio, PSNR)上高0.75 dB; 主观结果上,本文方法能够生成视觉效果更加逼真、纹理更加清晰的超分辨率图像。消融实验证明了所提算法各个模块的有效性。结论本文提出的引导超分辨率算法能够充分利用红外图像和可见光图像之间的关联信息,同时获得红外图像的高质量超分辨率重建结果。关键词:图像超分辨率;图像融合;红外图像;Transformer;深度学习455|447|6更新时间:2024-05-08 -
 摘要:目的以卷积神经网络为基础的深度学习技术在图像融合方面表现出优越的性能。在各类图像融合领域,红外与可见光的图像融合应用十分广泛,这两种图像各自的特性十分鲜明,二者信息交互融合得到的融合图像具有显著的价值和意义。为了提高红外与可见光图像的融合质量,本文提出了一种多级特征引导网络的融合框架。方法本文框架中编码器用于提取源图像的特征,并将多级特征引导至解码器中对融合结果进行重建。为了有效地训练网络,设计了一种混合损失函数。其中,加权保真项约束融合结果与源图像的像素相似度,而结构张量损失鼓励融合图像从源图像中提取更多的结构特征,为了有效进行多尺度信息交互,不同于普通的编解码结构,本文方法在编码器每一层的每一部分均进行特征引导,在编码部分采用池化对尺寸进行缩小,解码采用上采样将尺寸放大,实现多尺度融合与重建,有效弥补了训练过程中卷积层数的堆叠导致的信息的丢失,在编码部分适时地对特征进行引导,及时地与解码层进行融合,在网络结构构建完成后,提出一种损失融合算法,从红外图像和可见光图像各自特点出发,分别设计基于视觉显著性权值估计的2范数损失和基于结构张量的F范数损失。结果为了说明融合方法的可行性,在TNO数据集与RoadScene数据集上进行实验,与传统以及深度学习融合方法进行了视觉对比和客观对比,在信息保真度准则、基于梯度的融合性能边缘信息保持度、非线性相关熵以及基于结构相似度的图像质量测量指标等关键图像评价指标上达到了理想的结果。同时,为了验证提出的网络结构以及损失函数的有效性,使得提出的网络模型完备性得到保证。结论提出的融合模型综合了传统模型和深度学习模型的优点,得到了高质量的融合图像,取得了良好的融合效果。关键词:图像融合;多级特征引导;混合损失;结构张量;显著性检测;深度学习188|582|0更新时间:2024-05-08
摘要:目的以卷积神经网络为基础的深度学习技术在图像融合方面表现出优越的性能。在各类图像融合领域,红外与可见光的图像融合应用十分广泛,这两种图像各自的特性十分鲜明,二者信息交互融合得到的融合图像具有显著的价值和意义。为了提高红外与可见光图像的融合质量,本文提出了一种多级特征引导网络的融合框架。方法本文框架中编码器用于提取源图像的特征,并将多级特征引导至解码器中对融合结果进行重建。为了有效地训练网络,设计了一种混合损失函数。其中,加权保真项约束融合结果与源图像的像素相似度,而结构张量损失鼓励融合图像从源图像中提取更多的结构特征,为了有效进行多尺度信息交互,不同于普通的编解码结构,本文方法在编码器每一层的每一部分均进行特征引导,在编码部分采用池化对尺寸进行缩小,解码采用上采样将尺寸放大,实现多尺度融合与重建,有效弥补了训练过程中卷积层数的堆叠导致的信息的丢失,在编码部分适时地对特征进行引导,及时地与解码层进行融合,在网络结构构建完成后,提出一种损失融合算法,从红外图像和可见光图像各自特点出发,分别设计基于视觉显著性权值估计的2范数损失和基于结构张量的F范数损失。结果为了说明融合方法的可行性,在TNO数据集与RoadScene数据集上进行实验,与传统以及深度学习融合方法进行了视觉对比和客观对比,在信息保真度准则、基于梯度的融合性能边缘信息保持度、非线性相关熵以及基于结构相似度的图像质量测量指标等关键图像评价指标上达到了理想的结果。同时,为了验证提出的网络结构以及损失函数的有效性,使得提出的网络模型完备性得到保证。结论提出的融合模型综合了传统模型和深度学习模型的优点,得到了高质量的融合图像,取得了良好的融合效果。关键词:图像融合;多级特征引导;混合损失;结构张量;显著性检测;深度学习188|582|0更新时间:2024-05-08
红外与可见光图像融合
-
 摘要:目的跨模态像素级医学图像融合是精准医疗领域的研究热点。针对传统的像素级图像融合算法存在融合图像对比度不高和边缘细节不能较好保留等问题,本文提出并行分解图像自适应融合模型。方法首先,使用NSCT(non-subsampled contourlet transform)提取原图像的细节方向信息,将原图像分为低频子带和高频子带,同时使用潜在低秩表示方法(latent low-rank representation, LatLRR)提取原图像的显著能量信息,得到低秩部分、显著部分和噪声部分。然后,在低频子带融合方面,NSCT分解后得到的低频子带包含原图像的主要能量,在融合过程中存在多对一的模糊映射关系,因此低频子带融合规则采用基于模糊逻辑的自适应方法,使用高斯隶属函数表示图像模糊关系;在高频子带融合方面,NSCT分解后得到高频子带系数间有较强的结构相似性,高频子带包含图像的轮廓边缘信息,因此高频子带采用基于Piella框架的自适应融合方法,引入平均结构相似性作为匹配测度,区域方差作为活性测度,设计自适应加权决策因子对高频子带进行融合。结果在5组CT(computed tomography)肺窗/PET(positron emission tomography)和5组CT纵膈窗/PET进行测试,与对比方法相比,本文方法融合图像的平均梯度提升了66.6%,边缘强度提升了64.4%,边缘保持度提升了52.7%,空间频率提升了47.3%。结论本文方法生成的融合图像在主客观评价指标中均取得了较好的结果,有助于辅助医生进行更快速和更精准的诊疗。关键词:图像融合;Piella框架;NSCT;低秩表示方法(LatLRR);PET/CT152|130|1更新时间:2024-05-08
摘要:目的跨模态像素级医学图像融合是精准医疗领域的研究热点。针对传统的像素级图像融合算法存在融合图像对比度不高和边缘细节不能较好保留等问题,本文提出并行分解图像自适应融合模型。方法首先,使用NSCT(non-subsampled contourlet transform)提取原图像的细节方向信息,将原图像分为低频子带和高频子带,同时使用潜在低秩表示方法(latent low-rank representation, LatLRR)提取原图像的显著能量信息,得到低秩部分、显著部分和噪声部分。然后,在低频子带融合方面,NSCT分解后得到的低频子带包含原图像的主要能量,在融合过程中存在多对一的模糊映射关系,因此低频子带融合规则采用基于模糊逻辑的自适应方法,使用高斯隶属函数表示图像模糊关系;在高频子带融合方面,NSCT分解后得到高频子带系数间有较强的结构相似性,高频子带包含图像的轮廓边缘信息,因此高频子带采用基于Piella框架的自适应融合方法,引入平均结构相似性作为匹配测度,区域方差作为活性测度,设计自适应加权决策因子对高频子带进行融合。结果在5组CT(computed tomography)肺窗/PET(positron emission tomography)和5组CT纵膈窗/PET进行测试,与对比方法相比,本文方法融合图像的平均梯度提升了66.6%,边缘强度提升了64.4%,边缘保持度提升了52.7%,空间频率提升了47.3%。结论本文方法生成的融合图像在主客观评价指标中均取得了较好的结果,有助于辅助医生进行更快速和更精准的诊疗。关键词:图像融合;Piella框架;NSCT;低秩表示方法(LatLRR);PET/CT152|130|1更新时间:2024-05-08 -
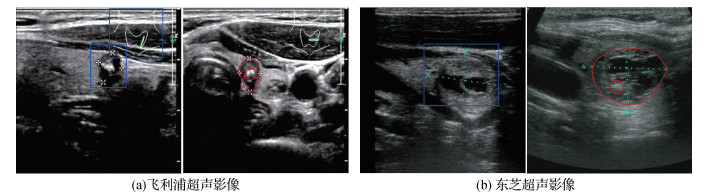 摘要:目的计算机辅助诊断是临床诊断中一种重要的辅助手段。然而在多机型超声影像的应用现状中,单一深度卷积神经网络面临难以从不同数据源中提取样本特征的问题,导致模型在区分多源数据方面性能欠佳。为提升单一深度模型在多源数据的泛化能力,本文提出一种无监督域自适应网络。方法将深度对抗域适应方法应用于多源甲状腺超声影像分类任务,通过生成对抗思想提取源域图像与目标域图像的域不变特征,提出一种多级对抗域自适应网络(multi-level adversarial domain adaptation network,MADAN)。将元优化(meta-optimized)策略引入对抗域适应的学习中,将域对齐目标和样本分类目标以协调的方式联合优化,提升了模型对无标记目标域数据的分类性能。结果在包含4种域的甲状腺超声影像数据集上实验,与7种经典域自适应方法比较。实验结果表明,MADAN在全部迁移任务中取得90.141%的目标域样本平均分类准确率,优于残差分类网络和多种经典域自适应分类网络。融合元优化训练策略后的MADAN在目标域的测试平均准确率提升约1.67%。结论本文提出的元优化多级对抗域适应网络一方面通过多级对抗学习进行图像域不变特征的提取,另一方面使用元优化方式改进模型训练过程的优化策略,将带有人工标记的源域信息有效迁移至目标域,提升了单一模型对于不同域数据的泛化性能。关键词:计算机辅助诊断(CAD);多机型甲状腺超声影像;域自适应;元优化;生成对抗网络(GAN)146|272|1更新时间:2024-05-08
摘要:目的计算机辅助诊断是临床诊断中一种重要的辅助手段。然而在多机型超声影像的应用现状中,单一深度卷积神经网络面临难以从不同数据源中提取样本特征的问题,导致模型在区分多源数据方面性能欠佳。为提升单一深度模型在多源数据的泛化能力,本文提出一种无监督域自适应网络。方法将深度对抗域适应方法应用于多源甲状腺超声影像分类任务,通过生成对抗思想提取源域图像与目标域图像的域不变特征,提出一种多级对抗域自适应网络(multi-level adversarial domain adaptation network,MADAN)。将元优化(meta-optimized)策略引入对抗域适应的学习中,将域对齐目标和样本分类目标以协调的方式联合优化,提升了模型对无标记目标域数据的分类性能。结果在包含4种域的甲状腺超声影像数据集上实验,与7种经典域自适应方法比较。实验结果表明,MADAN在全部迁移任务中取得90.141%的目标域样本平均分类准确率,优于残差分类网络和多种经典域自适应分类网络。融合元优化训练策略后的MADAN在目标域的测试平均准确率提升约1.67%。结论本文提出的元优化多级对抗域适应网络一方面通过多级对抗学习进行图像域不变特征的提取,另一方面使用元优化方式改进模型训练过程的优化策略,将带有人工标记的源域信息有效迁移至目标域,提升了单一模型对于不同域数据的泛化性能。关键词:计算机辅助诊断(CAD);多机型甲状腺超声影像;域自适应;元优化;生成对抗网络(GAN)146|272|1更新时间:2024-05-08 -
 摘要:目的现有医学图像超分辨率方法主要针对单一模态图像进行设计,然而在磁共振成像(magnetic resonance imaging,MRI)技术的诸多应用场合,往往需要采集不同成像参数下的多模态图像。针对单一模态的方法无法利用不同模态图像之间的关联信息,很大程度上限制了重建性能。目前超分辨率网络模型参数量往往较大,导致计算和存储代价较高。为此,本文提出了一个轻量级残差密集注意力网络,以一个统一的网络模型同时实现多模态MR图像的超分辨率重建。方法首先将不同模态的MR图像堆叠后输入网络,在低分辨率空间中提取共有特征,之后采用设计的残差密集注意力模块进一步精炼特征,再通过一个亚像素卷积层上采样到高分辨率空间,最终分别重建出不同模态的高分辨率图像。结果本文采用MICCAI (medical image computing and computer assisted intervention) BraTS (brain tumor segmentation) 2019数据集中的T1和T2加权MR图像对网络进行训练和测试,并与8种代表性超分辨率方法进行对比。实验结果表明,本文方法可以取得优于对比方法的重建性能。相对于对比方法中性能最优的方法,本文方法在参数量低于对比模型的10%的情况下,当放大因子为2时,T1和T2加权模态的峰值信噪比(peak signal to noise ratio,PSNR)分别提高了0.109 8 dB和0.415 5 dB;当放大因子为3时,T2加权模态的PSNR提高了0.295 9 dB,T1加权模态下降了0.064 6 dB;当放大因子为4时,T1和T2加权模态的PSNR分别提高了0.269 3 dB和0.042 9 dB。结论本文提出的轻量级超分辨率网络能够充分利用不同模态MR图像之间的关联信息,同时获得各输入模态图像高质量的超分辨率重建结果。关键词:图像超分辨率;多模态MR图像;卷积神经网络(CNN);残差学习;密集连接;注意力机制;多模态信息融合242|260|1更新时间:2024-05-08
摘要:目的现有医学图像超分辨率方法主要针对单一模态图像进行设计,然而在磁共振成像(magnetic resonance imaging,MRI)技术的诸多应用场合,往往需要采集不同成像参数下的多模态图像。针对单一模态的方法无法利用不同模态图像之间的关联信息,很大程度上限制了重建性能。目前超分辨率网络模型参数量往往较大,导致计算和存储代价较高。为此,本文提出了一个轻量级残差密集注意力网络,以一个统一的网络模型同时实现多模态MR图像的超分辨率重建。方法首先将不同模态的MR图像堆叠后输入网络,在低分辨率空间中提取共有特征,之后采用设计的残差密集注意力模块进一步精炼特征,再通过一个亚像素卷积层上采样到高分辨率空间,最终分别重建出不同模态的高分辨率图像。结果本文采用MICCAI (medical image computing and computer assisted intervention) BraTS (brain tumor segmentation) 2019数据集中的T1和T2加权MR图像对网络进行训练和测试,并与8种代表性超分辨率方法进行对比。实验结果表明,本文方法可以取得优于对比方法的重建性能。相对于对比方法中性能最优的方法,本文方法在参数量低于对比模型的10%的情况下,当放大因子为2时,T1和T2加权模态的峰值信噪比(peak signal to noise ratio,PSNR)分别提高了0.109 8 dB和0.415 5 dB;当放大因子为3时,T2加权模态的PSNR提高了0.295 9 dB,T1加权模态下降了0.064 6 dB;当放大因子为4时,T1和T2加权模态的PSNR分别提高了0.269 3 dB和0.042 9 dB。结论本文提出的轻量级超分辨率网络能够充分利用不同模态MR图像之间的关联信息,同时获得各输入模态图像高质量的超分辨率重建结果。关键词:图像超分辨率;多模态MR图像;卷积神经网络(CNN);残差学习;密集连接;注意力机制;多模态信息融合242|260|1更新时间:2024-05-08 -
 摘要:目的针对肝脏肿瘤检测方法对小尺寸肿瘤的检测能力较差和检测网络参数量过大的问题,在改进EfficientDet的基础上,提出用于肝脏肿瘤检测的多尺度自适应融合网络MAEfficientDet-D0(multiscale adaptive fusion network-D0)和MAEfficientDet-D1。方法首先,利用高效倒置瓶颈块替换EfficientDet骨干网络的移动倒置瓶颈块,在保证计算效率的同时,有效解决移动倒置瓶颈块的挤压激励网络维度和参数量较大的问题;其次,在特征融合网络前添加多尺度块,以扩大网络有效感受野,提高体积偏小病灶的检测能力;最后,提出多通路自适应加权特征融合块,以解决低层病灶特征图的语义偏弱和高层病灶特征图的细节感知能力较差的问题,提高了特征的利用率和增强模型对小尺寸肝脏肿瘤的检测能力。结果实验表明,高效倒置瓶颈层在少量增加网络复杂性的同时,可以有效提高网络对模糊图像的检测精度;多通路自适应加权特征融合模块可以有效融合含有上下文信息的深层特征和含有细节信息的浅层特征,进一步提高了模型对病灶特征的表达能力;多尺度自适应融合网络对肝脏肿瘤检测的效果明显优于对比模型。在LiTS(liver tumor segmentation)数据集上,MAEfficientDet-D0和MAEfficientDet-D1的mAP(mean average precision)分别为86.30%和87.39%;在3D-IRCADb(3D image reconstruction for comparison of algorithm database)数据集上,MAEfficientDet-D0和MAEfficientDet-D1的mAP分别为85.62%和86.46%。结论本文提出的MAEfficientDet系列网络提高了特征的利用率和小病灶的检测能力。相比主流检测网络,本文算法具有较好的检测精度和更少的参数量、计算量和运行时间,对肝脏肿瘤检测模型部署于嵌入式设备和移动终端设备具有重要参考价值。关键词:MAEfficientDet;高效倒置瓶颈块;多尺度块;多通路;特征融合;自适应加权116|182|0更新时间:2024-05-08
摘要:目的针对肝脏肿瘤检测方法对小尺寸肿瘤的检测能力较差和检测网络参数量过大的问题,在改进EfficientDet的基础上,提出用于肝脏肿瘤检测的多尺度自适应融合网络MAEfficientDet-D0(multiscale adaptive fusion network-D0)和MAEfficientDet-D1。方法首先,利用高效倒置瓶颈块替换EfficientDet骨干网络的移动倒置瓶颈块,在保证计算效率的同时,有效解决移动倒置瓶颈块的挤压激励网络维度和参数量较大的问题;其次,在特征融合网络前添加多尺度块,以扩大网络有效感受野,提高体积偏小病灶的检测能力;最后,提出多通路自适应加权特征融合块,以解决低层病灶特征图的语义偏弱和高层病灶特征图的细节感知能力较差的问题,提高了特征的利用率和增强模型对小尺寸肝脏肿瘤的检测能力。结果实验表明,高效倒置瓶颈层在少量增加网络复杂性的同时,可以有效提高网络对模糊图像的检测精度;多通路自适应加权特征融合模块可以有效融合含有上下文信息的深层特征和含有细节信息的浅层特征,进一步提高了模型对病灶特征的表达能力;多尺度自适应融合网络对肝脏肿瘤检测的效果明显优于对比模型。在LiTS(liver tumor segmentation)数据集上,MAEfficientDet-D0和MAEfficientDet-D1的mAP(mean average precision)分别为86.30%和87.39%;在3D-IRCADb(3D image reconstruction for comparison of algorithm database)数据集上,MAEfficientDet-D0和MAEfficientDet-D1的mAP分别为85.62%和86.46%。结论本文提出的MAEfficientDet系列网络提高了特征的利用率和小病灶的检测能力。相比主流检测网络,本文算法具有较好的检测精度和更少的参数量、计算量和运行时间,对肝脏肿瘤检测模型部署于嵌入式设备和移动终端设备具有重要参考价值。关键词:MAEfficientDet;高效倒置瓶颈块;多尺度块;多通路;特征融合;自适应加权116|182|0更新时间:2024-05-08
医学图像处理
-
 摘要:目的在高光谱和多光谱融合领域,光谱字典学习是一种常用的方法,但是这种算法获得的融合结果不可避免地会损失一部分空间信息。针对这一问题,本文提出了一种面向误差补偿的高光谱和多光谱融合框架,即先利用低分辨率图像构建出误差,再将构建的误差对字典学习所得初步结果进行补偿,从而捕获更多的空间信息和光谱信息。方法设计了一种基于局部区域的注入系数,使得到的系数能够根据局部区域的光谱特性自适应地调整误差信息的注入权重,从而避免注入过多或者过少的空间信息而导致光谱失真。为了保证融合结果在提升空间分辨率的同时不发生光谱畸变,在梯度域提取多光谱图像的空间结构,构造变分模型,并将光谱字典学习得到的初步结果与计算出的系数相结合构成优化项并将该优化项与变分模型结合,构建出一个新的模型,通过迭代更新,逐步提升补偿系数的精度和融合结果的质量。结果分别在两个公开数据集上与其他算法进行对比,实验结果表明,本文算法在评价指标和视觉效果上都取得明显提升。从主观分析来看,本文方法可以得到融合质量高、视觉效果自然清晰的目标图像。从客观评价指标来看,在Pavia University数据集上的实验结果在ERGAS(relative dimensionless global error in synthesis)、SAM(spectral angle mapper)、RMSE(root mean square error)指标上与次优方法相比,分别提升了4.2%、4.1%和2.2%;在AVIRIS(airborne visible infrared imaging spectrometer)数据集上分别提升了2.0%,4.0%和3.5%。结论本文算法在有效提升融合结果空间分辨率的同时, 很好地保持了光谱信息。且在不同数据集上取得了较优的表现,具有一定的鲁棒性。关键词:遥感;高光谱与多光谱图像融合;字典学习;误差补偿;超像素分割150|337|2更新时间:2024-05-08
摘要:目的在高光谱和多光谱融合领域,光谱字典学习是一种常用的方法,但是这种算法获得的融合结果不可避免地会损失一部分空间信息。针对这一问题,本文提出了一种面向误差补偿的高光谱和多光谱融合框架,即先利用低分辨率图像构建出误差,再将构建的误差对字典学习所得初步结果进行补偿,从而捕获更多的空间信息和光谱信息。方法设计了一种基于局部区域的注入系数,使得到的系数能够根据局部区域的光谱特性自适应地调整误差信息的注入权重,从而避免注入过多或者过少的空间信息而导致光谱失真。为了保证融合结果在提升空间分辨率的同时不发生光谱畸变,在梯度域提取多光谱图像的空间结构,构造变分模型,并将光谱字典学习得到的初步结果与计算出的系数相结合构成优化项并将该优化项与变分模型结合,构建出一个新的模型,通过迭代更新,逐步提升补偿系数的精度和融合结果的质量。结果分别在两个公开数据集上与其他算法进行对比,实验结果表明,本文算法在评价指标和视觉效果上都取得明显提升。从主观分析来看,本文方法可以得到融合质量高、视觉效果自然清晰的目标图像。从客观评价指标来看,在Pavia University数据集上的实验结果在ERGAS(relative dimensionless global error in synthesis)、SAM(spectral angle mapper)、RMSE(root mean square error)指标上与次优方法相比,分别提升了4.2%、4.1%和2.2%;在AVIRIS(airborne visible infrared imaging spectrometer)数据集上分别提升了2.0%,4.0%和3.5%。结论本文算法在有效提升融合结果空间分辨率的同时, 很好地保持了光谱信息。且在不同数据集上取得了较优的表现,具有一定的鲁棒性。关键词:遥感;高光谱与多光谱图像融合;字典学习;误差补偿;超像素分割150|337|2更新时间:2024-05-08 -
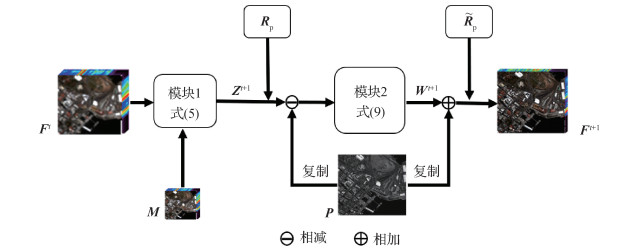 摘要:目的多光谱图像融合是遥感领域中的重要研究问题,变分模型方法和深度学习方法是目前的研究热点,但变分模型方法通常采用线性先验构建融合模型,难以描述自然场景复杂非线性关系,导致成像模型准确性较低,同时存在手动调参的难题;而主流深度学习方法将融合过程当做一个黑盒,忽视了真实物理成像机理,因此,现有融合方法的性能依然有待提升。为了解决上述问题,提出了一种基于可解译深度网络的多光谱图像融合方法。方法首先构建深度学习先验描述融合图像与全色图像之间的关系,基于多光谱图像是融合图像下采样结果这一认知构建数据保真项,结合深度学习先验和数据保真项建立一种新的多光谱图像融合模型,提升融合模型准确性。采用近端梯度下降法对融合模型进行求解,进一步将求解步骤映射为具有明确物理成像机理的可解译深度网络架构。结果分别在Gaofen-2和GeoEye-1遥感卫星仿真数据集,以及QuickBird遥感卫星真实数据集上进行了主客观对比实验。相对于经典方法,本文方法的主观视觉效果有了显著提升。在Gaofen-2和GeoEye-1遥感卫星仿真数据集,相对于性能第2的方法,本文方法的客观评价指标全局相对无量纲误差(relative dimensionless global error in synthesis,ERGAS)有效减小了7.58%和4.61%。结论本文提出的可解译深度网络,综合了变分模型方法和深度学习方法的优点,在有效保持光谱信息的同时较好地增强融合图像空间细节信息。关键词:遥感(RS);多光谱图像(MSI);图像融合;深度学习(DL);可解译网络;近端梯度下降法(PGD)273|223|1更新时间:2024-05-08
摘要:目的多光谱图像融合是遥感领域中的重要研究问题,变分模型方法和深度学习方法是目前的研究热点,但变分模型方法通常采用线性先验构建融合模型,难以描述自然场景复杂非线性关系,导致成像模型准确性较低,同时存在手动调参的难题;而主流深度学习方法将融合过程当做一个黑盒,忽视了真实物理成像机理,因此,现有融合方法的性能依然有待提升。为了解决上述问题,提出了一种基于可解译深度网络的多光谱图像融合方法。方法首先构建深度学习先验描述融合图像与全色图像之间的关系,基于多光谱图像是融合图像下采样结果这一认知构建数据保真项,结合深度学习先验和数据保真项建立一种新的多光谱图像融合模型,提升融合模型准确性。采用近端梯度下降法对融合模型进行求解,进一步将求解步骤映射为具有明确物理成像机理的可解译深度网络架构。结果分别在Gaofen-2和GeoEye-1遥感卫星仿真数据集,以及QuickBird遥感卫星真实数据集上进行了主客观对比实验。相对于经典方法,本文方法的主观视觉效果有了显著提升。在Gaofen-2和GeoEye-1遥感卫星仿真数据集,相对于性能第2的方法,本文方法的客观评价指标全局相对无量纲误差(relative dimensionless global error in synthesis,ERGAS)有效减小了7.58%和4.61%。结论本文提出的可解译深度网络,综合了变分模型方法和深度学习方法的优点,在有效保持光谱信息的同时较好地增强融合图像空间细节信息。关键词:遥感(RS);多光谱图像(MSI);图像融合;深度学习(DL);可解译网络;近端梯度下降法(PGD)273|223|1更新时间:2024-05-08 -
 摘要:目的遥感图像融合的目的是将低空间分辨率的多光谱图像和对应的高空间分辨率全色图像融合为高空间分辨率的多光谱图像。为了解决上采样多光谱图像带来的图像质量下降和空间细节不连续问题,本文提出了渐进式增强策略,同时为了更好地融合两种图像互补的信息,提出在通道维度上进行融合的策略。方法构建了一种端到端的网络,网络分为两个阶段:渐进尺度细节增强阶段和通道融合阶段。考虑到上采样低空间分辨率多光谱图像导致的细节模糊问题,在第1阶段将不同尺度的全色图像作为额外的信息,通过两个细节增强模块逐步增强多光谱图像;在第2阶段,全色图像在多光谱图像的每个通道上都通过结构保持模块进行融合,更好地利用两种图像的互补信息,获得高空间分辨率的多光谱图像。结果实验在GaoFen-2和QuickBird数据集上与表现优异的8种方法进行了比较,本文算法在有参考指标峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似度(structural similarity,SSIM)、相关系数(correlation coefficient,CC)和总体相对误差(erreur relative globale adimensionnelle de synthese,ERGAS)等评价指标上均取得最优值。在GaoFen-2数据集上PSNR、CC和ERGAS分别平均提高了0.872 dB、0.01和0.109,在QuickBird数据集上分别平均提高了0.755 dB、0.011和0.099。结论本文算法在空间分辨率和光谱保持方面都取得了良好的效果,生成了质量更高的融合结果。关键词:全色锐化;渐进增强;通道融合;深度学习;多光谱图像180|297|1更新时间:2024-05-08
摘要:目的遥感图像融合的目的是将低空间分辨率的多光谱图像和对应的高空间分辨率全色图像融合为高空间分辨率的多光谱图像。为了解决上采样多光谱图像带来的图像质量下降和空间细节不连续问题,本文提出了渐进式增强策略,同时为了更好地融合两种图像互补的信息,提出在通道维度上进行融合的策略。方法构建了一种端到端的网络,网络分为两个阶段:渐进尺度细节增强阶段和通道融合阶段。考虑到上采样低空间分辨率多光谱图像导致的细节模糊问题,在第1阶段将不同尺度的全色图像作为额外的信息,通过两个细节增强模块逐步增强多光谱图像;在第2阶段,全色图像在多光谱图像的每个通道上都通过结构保持模块进行融合,更好地利用两种图像的互补信息,获得高空间分辨率的多光谱图像。结果实验在GaoFen-2和QuickBird数据集上与表现优异的8种方法进行了比较,本文算法在有参考指标峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似度(structural similarity,SSIM)、相关系数(correlation coefficient,CC)和总体相对误差(erreur relative globale adimensionnelle de synthese,ERGAS)等评价指标上均取得最优值。在GaoFen-2数据集上PSNR、CC和ERGAS分别平均提高了0.872 dB、0.01和0.109,在QuickBird数据集上分别平均提高了0.755 dB、0.011和0.099。结论本文算法在空间分辨率和光谱保持方面都取得了良好的效果,生成了质量更高的融合结果。关键词:全色锐化;渐进增强;通道融合;深度学习;多光谱图像180|297|1更新时间:2024-05-08
遥感图像处理
-
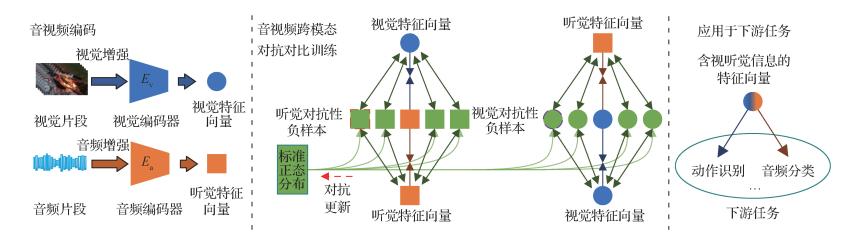 摘要:目的同一视频中的视觉与听觉是两个共生模态,二者相辅相成,同时发生,从而形成一种自监督模式。随着对比学习在视觉领域取得很好的效果,将对比学习这一自监督表示学习范式应用于音视频多模态领域引起了研究人员的极大兴趣。本文专注于构建一个高效的音视频负样本空间,提高对比学习的音视频特征融合能力。方法提出了面向多模态自监督特征融合的音视频对抗对比学习方法:1)创新性地引入了视觉、听觉对抗性负样本集合来构建音视频负样本空间;2)在模态间与模态内进行对抗对比学习,使得音视频负样本空间中的视觉和听觉对抗性负样本可以不断跟踪难以区分的视听觉样本,有效地促进了音视频自监督特征融合。在上述两点基础上,进一步简化了音视频对抗对比学习框架。结果本文方法在Kinetics-400数据集的子集上进行训练,得到音视频特征。这一音视频特征用于指导动作识别和音频分类任务,取得了很好的效果。具体来说,在动作识别数据集UCF-101和HMDB-51(human metabolome database)上,本文方法相较于Cross-AVID(cross-audio visual instance discrimination)模型,视频级别的TOP1准确率分别高出了0.35%和0.83%;在环境声音数据集ECS-50上,本文方法相较于Cross-AVID模型,音频级别的TOP1准确率高出了2.88%。结论音视频对抗对比学习方法创新性地引入了视觉和听觉对抗性负样本集合,该方法可以很好地融合视觉特征和听觉特征,得到包含视听觉信息的音视频特征,得到的特征可以提高动作识别、音频分类任务的准确率。关键词:自监督特征融合;对抗对比学习;音视频多模态;视听觉对抗性负样本;预训练168|197|1更新时间:2024-05-08
摘要:目的同一视频中的视觉与听觉是两个共生模态,二者相辅相成,同时发生,从而形成一种自监督模式。随着对比学习在视觉领域取得很好的效果,将对比学习这一自监督表示学习范式应用于音视频多模态领域引起了研究人员的极大兴趣。本文专注于构建一个高效的音视频负样本空间,提高对比学习的音视频特征融合能力。方法提出了面向多模态自监督特征融合的音视频对抗对比学习方法:1)创新性地引入了视觉、听觉对抗性负样本集合来构建音视频负样本空间;2)在模态间与模态内进行对抗对比学习,使得音视频负样本空间中的视觉和听觉对抗性负样本可以不断跟踪难以区分的视听觉样本,有效地促进了音视频自监督特征融合。在上述两点基础上,进一步简化了音视频对抗对比学习框架。结果本文方法在Kinetics-400数据集的子集上进行训练,得到音视频特征。这一音视频特征用于指导动作识别和音频分类任务,取得了很好的效果。具体来说,在动作识别数据集UCF-101和HMDB-51(human metabolome database)上,本文方法相较于Cross-AVID(cross-audio visual instance discrimination)模型,视频级别的TOP1准确率分别高出了0.35%和0.83%;在环境声音数据集ECS-50上,本文方法相较于Cross-AVID模型,音频级别的TOP1准确率高出了2.88%。结论音视频对抗对比学习方法创新性地引入了视觉和听觉对抗性负样本集合,该方法可以很好地融合视觉特征和听觉特征,得到包含视听觉信息的音视频特征,得到的特征可以提高动作识别、音频分类任务的准确率。关键词:自监督特征融合;对抗对比学习;音视频多模态;视听觉对抗性负样本;预训练168|197|1更新时间:2024-05-08
多模态信息融合
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0