
最新刊期
2022 年 第 27 卷 第 9 期

-
 摘要:过去10年中涌现出大量新兴的多媒体应用和服务,带来了很多可以用于多媒体前沿研究的多媒体数据。多媒体研究在图像/视频内容分析、多媒体搜索和推荐、流媒体服务和多媒体内容分发等方向均取得了重要进展。与此同时,由于在深度学习领域所取得的重大突破,人工智能(artificial intelligence,AI)在20世纪50年代被正式视为一门学科之后,迎来了一次“新”的发展浪潮。因此,一个问题就自然而然地出现了:当多媒体遇到人工智能时会带来什么?为了回答这个问题,本文通过研究多媒体和人工智能之间的相互影响引入了多媒体智能的概念。从两个方面探讨多媒体与人工智能之间的相互影响:一是多媒体促使人工智能向着更具可解释性的方向发展;二是人工智能反过来为多媒体研究注入了新的思维方式。这两个方面形成了一个良性循环,多媒体和人工智能在其中不断促进彼此发展。本文对相关研究及进展进行了讨论,并围绕值得进一步探索的研究方向分享见解。希望可以对多媒体智能的未来发展带来新的研究思路。关键词:多媒体技术;人工智能(AI);多媒体智能;多媒体推理;可解释人工智能225|291|1更新时间:2024-08-15
摘要:过去10年中涌现出大量新兴的多媒体应用和服务,带来了很多可以用于多媒体前沿研究的多媒体数据。多媒体研究在图像/视频内容分析、多媒体搜索和推荐、流媒体服务和多媒体内容分发等方向均取得了重要进展。与此同时,由于在深度学习领域所取得的重大突破,人工智能(artificial intelligence,AI)在20世纪50年代被正式视为一门学科之后,迎来了一次“新”的发展浪潮。因此,一个问题就自然而然地出现了:当多媒体遇到人工智能时会带来什么?为了回答这个问题,本文通过研究多媒体和人工智能之间的相互影响引入了多媒体智能的概念。从两个方面探讨多媒体与人工智能之间的相互影响:一是多媒体促使人工智能向着更具可解释性的方向发展;二是人工智能反过来为多媒体研究注入了新的思维方式。这两个方面形成了一个良性循环,多媒体和人工智能在其中不断促进彼此发展。本文对相关研究及进展进行了讨论,并围绕值得进一步探索的研究方向分享见解。希望可以对多媒体智能的未来发展带来新的研究思路。关键词:多媒体技术;人工智能(AI);多媒体智能;多媒体推理;可解释人工智能225|291|1更新时间:2024-08-15 -
 摘要:回顾跨媒体智能的发展历程,分析跨媒体智能的新趋势与现实瓶颈,展望跨媒体智能的未来前景。跨媒体智能旨在融合多来源、多模态数据,并试图利用不同媒体数据间的关系进行高层次语义理解与逻辑推理。现有跨媒体算法主要遵循了单媒体表达到多媒体融合的范式,其中特征学习与逻辑推理两个过程相对割裂,无法综合多源多层次的语义信息以获得统一特征,阻碍了推理和学习过程的相互促进和修正。这类范式缺乏显式知识积累与多级结构理解的过程,同时限制了模型可信度与鲁棒性。在这样的背景下,本文转向一种新的智能表达方式——视觉知识。以视觉知识驱动的跨媒体智能具有多层次建模和知识推理的特点,并易于进行视觉操作与重建。本文介绍了视觉知识的3个基本要素,即视觉概念、视觉关系和视觉推理,并对每个要素展开详细讨论与分析。视觉知识有助于实现数据与知识驱动的统一框架,学习可归因可溯源的结构化表达,推动跨媒体知识关联与智能推理。视觉知识具有强大的知识抽象表达能力和多重知识互补能力,为跨媒体智能进化提供了新的有力支点。关键词:跨媒体智能;视觉知识;视觉概念;视觉关系;视觉推理124|349|1更新时间:2024-08-15
摘要:回顾跨媒体智能的发展历程,分析跨媒体智能的新趋势与现实瓶颈,展望跨媒体智能的未来前景。跨媒体智能旨在融合多来源、多模态数据,并试图利用不同媒体数据间的关系进行高层次语义理解与逻辑推理。现有跨媒体算法主要遵循了单媒体表达到多媒体融合的范式,其中特征学习与逻辑推理两个过程相对割裂,无法综合多源多层次的语义信息以获得统一特征,阻碍了推理和学习过程的相互促进和修正。这类范式缺乏显式知识积累与多级结构理解的过程,同时限制了模型可信度与鲁棒性。在这样的背景下,本文转向一种新的智能表达方式——视觉知识。以视觉知识驱动的跨媒体智能具有多层次建模和知识推理的特点,并易于进行视觉操作与重建。本文介绍了视觉知识的3个基本要素,即视觉概念、视觉关系和视觉推理,并对每个要素展开详细讨论与分析。视觉知识有助于实现数据与知识驱动的统一框架,学习可归因可溯源的结构化表达,推动跨媒体知识关联与智能推理。视觉知识具有强大的知识抽象表达能力和多重知识互补能力,为跨媒体智能进化提供了新的有力支点。关键词:跨媒体智能;视觉知识;视觉概念;视觉关系;视觉推理124|349|1更新时间:2024-08-15 -
 摘要:海洋是高质量发展的要地,海洋科学大数据的发展为认知和经略海洋带来机遇的同时也引入了新的挑战。海洋科学大数据具有超多模态的显著特征,目前尚未形成面向海洋领域特色的多模态智能计算理论体系和技术框架。因此,本文首次从多模态数据技术的视角,系统性介绍面向海洋现象/过程的智能感知、认知和预知的交叉研究进展。首先,通过梳理海洋科学大数据全生命周期的阶段演进过程,明确海洋多模态智能计算的研究对象、科学问题和典型应用场景。其次,在海洋多模态大数据内容分析、推理预测和高性能计算3个典型应用场景中展开现有工作的系统性梳理和介绍。最后,针对海洋数据分布和计算模式的差异性,提出海洋多模态大数据表征建模、跨模态关联、推理预测以及高性能计算4个关键科学问题中的挑战,并提出未来展望。关键词:海洋大数据;多模态;海洋多媒体内容分析;海洋知识图谱;海洋大数据预测;海洋高性能计算;海洋目标重识别409|832|1更新时间:2024-08-15
摘要:海洋是高质量发展的要地,海洋科学大数据的发展为认知和经略海洋带来机遇的同时也引入了新的挑战。海洋科学大数据具有超多模态的显著特征,目前尚未形成面向海洋领域特色的多模态智能计算理论体系和技术框架。因此,本文首次从多模态数据技术的视角,系统性介绍面向海洋现象/过程的智能感知、认知和预知的交叉研究进展。首先,通过梳理海洋科学大数据全生命周期的阶段演进过程,明确海洋多模态智能计算的研究对象、科学问题和典型应用场景。其次,在海洋多模态大数据内容分析、推理预测和高性能计算3个典型应用场景中展开现有工作的系统性梳理和介绍。最后,针对海洋数据分布和计算模式的差异性,提出海洋多模态大数据表征建模、跨模态关联、推理预测以及高性能计算4个关键科学问题中的挑战,并提出未来展望。关键词:海洋大数据;多模态;海洋多媒体内容分析;海洋知识图谱;海洋大数据预测;海洋高性能计算;海洋目标重识别409|832|1更新时间:2024-08-15
学者观点
-
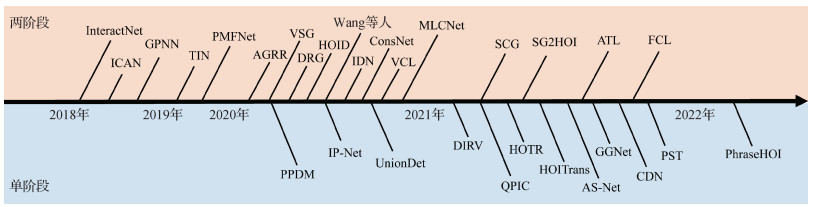 摘要:人—物交互关系检测旨在通过精细化定位图像或视频中产生特定动作行为的人,以及与其产生交互关系的物体,并识别人和物体之间的动作关系来理解和分析人体的行为。人—物交互关系检测是一个非常具有实际应用意义和前瞻性的研究方向,是高层视觉理解的关键基石。随着深度学习的发展,基于深度学习的研究方法引领了近期人—物交互关系检测研究的进步。本文一方面分析空域人—物交互关系检测任务,从数据内容场景、标注粒度两个方面总结和分析当下数据库和基准。然后从两阶段分段式方法和单阶段端到端式方法两个流派出发系统性地阐述当前检测方法的发展现状,分析两个流派方法的特性和优劣,厘清该领域方法的发展路线。其中,两阶段方法包括多流模型和图模型两种主要范式,而单阶段模型包括基于框的范式、基于关系点的范式和基于查询的范式。另一方面,对时空域人—物交互关系检测任务进行总结,分析现有时空域交互关系数据集构造与特性和现有基线算法的优劣。最后对未来的研究方向进行展望。关键词:人—物交互关系(HOI)检测;行为理解;深度学习;目标检测;关系检测161|565|2更新时间:2024-08-15
摘要:人—物交互关系检测旨在通过精细化定位图像或视频中产生特定动作行为的人,以及与其产生交互关系的物体,并识别人和物体之间的动作关系来理解和分析人体的行为。人—物交互关系检测是一个非常具有实际应用意义和前瞻性的研究方向,是高层视觉理解的关键基石。随着深度学习的发展,基于深度学习的研究方法引领了近期人—物交互关系检测研究的进步。本文一方面分析空域人—物交互关系检测任务,从数据内容场景、标注粒度两个方面总结和分析当下数据库和基准。然后从两阶段分段式方法和单阶段端到端式方法两个流派出发系统性地阐述当前检测方法的发展现状,分析两个流派方法的特性和优劣,厘清该领域方法的发展路线。其中,两阶段方法包括多流模型和图模型两种主要范式,而单阶段模型包括基于框的范式、基于关系点的范式和基于查询的范式。另一方面,对时空域人—物交互关系检测任务进行总结,分析现有时空域交互关系数据集构造与特性和现有基线算法的优劣。最后对未来的研究方向进行展望。关键词:人—物交互关系(HOI)检测;行为理解;深度学习;目标检测;关系检测161|565|2更新时间:2024-08-15 -
 摘要:随着计算机视觉领域图像生成研究的发展, 面部重演引起广泛关注, 这项技术旨在根据源人脸图像的身份以及驱动信息提供的嘴型、表情和姿态等信息合成新的说话人图像或视频。面部重演具有十分广泛的应用, 例如虚拟主播生成、线上授课、游戏形象定制、配音视频中的口型配准以及视频会议压缩等, 该项技术发展时间较短, 但是涌现了大量研究。然而目前国内外几乎没有重点关注面部重演的综述, 面部重演的研究概述只是在深度伪造检测综述中以深度伪造的内容出现。鉴于此, 本文对面部重演领域的发展进行梳理和总结。本文从面部重演模型入手, 对面部重演存在的问题、模型的分类以及驱动人脸特征表达进行阐述, 列举并介绍了训练面部重演模型常用的数据集及评估模型的评价指标, 对面部重演近年研究工作进行归纳、分析与比较, 最后对面部重演的演化趋势、当前挑战、未来发展方向、危害及应对策略进行了总结和展望。关键词:人工智能(AI);计算机视觉;深度学习;生成对抗网络(GAN);深度伪造;面部重演176|530|1更新时间:2024-08-15
摘要:随着计算机视觉领域图像生成研究的发展, 面部重演引起广泛关注, 这项技术旨在根据源人脸图像的身份以及驱动信息提供的嘴型、表情和姿态等信息合成新的说话人图像或视频。面部重演具有十分广泛的应用, 例如虚拟主播生成、线上授课、游戏形象定制、配音视频中的口型配准以及视频会议压缩等, 该项技术发展时间较短, 但是涌现了大量研究。然而目前国内外几乎没有重点关注面部重演的综述, 面部重演的研究概述只是在深度伪造检测综述中以深度伪造的内容出现。鉴于此, 本文对面部重演领域的发展进行梳理和总结。本文从面部重演模型入手, 对面部重演存在的问题、模型的分类以及驱动人脸特征表达进行阐述, 列举并介绍了训练面部重演模型常用的数据集及评估模型的评价指标, 对面部重演近年研究工作进行归纳、分析与比较, 最后对面部重演的演化趋势、当前挑战、未来发展方向、危害及应对策略进行了总结和展望。关键词:人工智能(AI);计算机视觉;深度学习;生成对抗网络(GAN);深度伪造;面部重演176|530|1更新时间:2024-08-15 -
 摘要:在多模态机器学习领域,为特定任务而制作的人工标注数据昂贵,且不同任务难以进行迁移,从而需要大量重新训练,导致训练多个任务时效率低下、资源浪费。预训练模型通过以自监督为代表的方式进行大规模数据训练,对数据集中不同模态的信息进行提取和融合,以学习其中蕴涵的通用知识表征,从而服务于广泛的相关下游视觉语言多模态任务,这一方法逐渐成为人工智能各领域的主流方法。依靠互联网所获取的大规模图文对与视频数据,以及以自监督学习为代表的预训练方法的进步,视觉语言多模态预训练模型在很大程度上打破了不同视觉语言任务之间的壁垒,提升了多个任务训练的效率并促进了具体任务的性能表现。本文总结视觉语言多模态预训练领域的进展,首先对常见的预训练数据集和预训练方法进行汇总,然后对目前最新方法以及经典方法进行系统概述,按输入来源分为图像—文本预训练模型和视频—文本多模态模型两大类,阐述了各方法之间的共性和差异,并将各模型在具体下游任务上的实验情况进行汇总。最后,总结了视觉语言预训练面临的挑战和未来发展趋势。关键词:多模态机器学习;视觉语言多模态;预训练;自监督学习;图像文本预训练;视频文本预训练281|1789|8更新时间:2024-08-15
摘要:在多模态机器学习领域,为特定任务而制作的人工标注数据昂贵,且不同任务难以进行迁移,从而需要大量重新训练,导致训练多个任务时效率低下、资源浪费。预训练模型通过以自监督为代表的方式进行大规模数据训练,对数据集中不同模态的信息进行提取和融合,以学习其中蕴涵的通用知识表征,从而服务于广泛的相关下游视觉语言多模态任务,这一方法逐渐成为人工智能各领域的主流方法。依靠互联网所获取的大规模图文对与视频数据,以及以自监督学习为代表的预训练方法的进步,视觉语言多模态预训练模型在很大程度上打破了不同视觉语言任务之间的壁垒,提升了多个任务训练的效率并促进了具体任务的性能表现。本文总结视觉语言多模态预训练领域的进展,首先对常见的预训练数据集和预训练方法进行汇总,然后对目前最新方法以及经典方法进行系统概述,按输入来源分为图像—文本预训练模型和视频—文本多模态模型两大类,阐述了各方法之间的共性和差异,并将各模型在具体下游任务上的实验情况进行汇总。最后,总结了视觉语言预训练面临的挑战和未来发展趋势。关键词:多模态机器学习;视觉语言多模态;预训练;自监督学习;图像文本预训练;视频文本预训练281|1789|8更新时间:2024-08-15 -
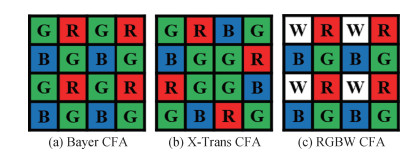 摘要:Bayer阵列图像去马赛克技术是对稀疏采样的Bayer阵列图像进行RGB信息重建,图像重建质量是成像设备评价的重要因素之一,同时也对其他计算机视觉任务(如图像分割、人脸识别)产生影响。随着深度学习方法的快速发展,图像去马赛克领域提出了多种高性能算法。为了便于研究者更全面了解图像去马赛克算法的原理和研究进展,本文对该领域的经典算法和深度学习算法进行综述。首先对Bayer采样阵列原理和图像去马赛克技术进行概述。然后将现有方法分为传统方法和基于深度学习方法两类进行总结,同时根据去马赛克任务是否具有独立性,将深度学习方法分为独立去马赛克任务和联合去马赛克任务两类,分析不同方法的原理和优缺点,重点阐述基于深度学习的去马赛克方法的网络结构和重建机理,介绍去马赛克领域常用的公共数据集和性能评价指标,并对图像去马赛克相关实验进行分析对比。最后,围绕网络深度、运算效率和实用性等方面分析了现阶段图像去马赛克技术面临的挑战及未来发展方向。目前,基于深度学习的图像去马赛克方法已成为主流发展方向,但仍然存在计算成本较高、实际应用性不强等问题。因此,如何开发出重建精度高、处理时间短以及实用性强的图像去马赛克方法,是该领域未来重要的研究方向。关键词:图像去马赛克;Bayer阵列图像;图像处理;深度学习;卷积神经网络(CNN);综述396|504|2更新时间:2024-08-15
摘要:Bayer阵列图像去马赛克技术是对稀疏采样的Bayer阵列图像进行RGB信息重建,图像重建质量是成像设备评价的重要因素之一,同时也对其他计算机视觉任务(如图像分割、人脸识别)产生影响。随着深度学习方法的快速发展,图像去马赛克领域提出了多种高性能算法。为了便于研究者更全面了解图像去马赛克算法的原理和研究进展,本文对该领域的经典算法和深度学习算法进行综述。首先对Bayer采样阵列原理和图像去马赛克技术进行概述。然后将现有方法分为传统方法和基于深度学习方法两类进行总结,同时根据去马赛克任务是否具有独立性,将深度学习方法分为独立去马赛克任务和联合去马赛克任务两类,分析不同方法的原理和优缺点,重点阐述基于深度学习的去马赛克方法的网络结构和重建机理,介绍去马赛克领域常用的公共数据集和性能评价指标,并对图像去马赛克相关实验进行分析对比。最后,围绕网络深度、运算效率和实用性等方面分析了现阶段图像去马赛克技术面临的挑战及未来发展方向。目前,基于深度学习的图像去马赛克方法已成为主流发展方向,但仍然存在计算成本较高、实际应用性不强等问题。因此,如何开发出重建精度高、处理时间短以及实用性强的图像去马赛克方法,是该领域未来重要的研究方向。关键词:图像去马赛克;Bayer阵列图像;图像处理;深度学习;卷积神经网络(CNN);综述396|504|2更新时间:2024-08-15
综述
-
 摘要:目的随着深度伪造技术的快速发展, 人脸伪造图像越来越难以鉴别, 对人们的日常生活和社会稳定造成了潜在的安全威胁。尽管当前很多方法在域内测试中取得了令人满意的性能表现, 但在检测未知伪造类型时效果不佳。鉴于伪造人脸图像的伪造区域和非伪造区域具有不一致的源域特征, 提出一种基于多级特征全局一致性的人脸深度伪造检测方法。方法使用人脸结构破除模块加强模型对局部细节和轻微异常信息的关注。采用多级特征融合模块使主干网络不同层级的特征进行交互学习, 充分挖掘每个层级特征蕴含的伪造信息。使用全局一致性模块引导模型更好地提取伪造区域的特征表示, 最终实现对人脸图像的精确分类。结果在两个数据集上进行实验。在域内实验中, 本文方法的各项指标均优于目前先进的检测方法, 在高质量和低质量FaceForensics++数据集上, AUC (area under the curve)分别达到99.02%和90.06%。在泛化实验中, 本文的多项评价指标相比目前主流的伪造检测方法均占优。此外, 消融实验进一步验证了模型的每个模块的有效性。结论本文方法可以较准确地对深度伪造人脸进行检测, 具有优越的泛化性能, 能够作为应对当前人脸伪造威胁的一种有效检测手段。关键词:人脸伪造检测;深度伪造;多级特征学习;全局一致性;注意力机制125|253|5更新时间:2024-08-15
摘要:目的随着深度伪造技术的快速发展, 人脸伪造图像越来越难以鉴别, 对人们的日常生活和社会稳定造成了潜在的安全威胁。尽管当前很多方法在域内测试中取得了令人满意的性能表现, 但在检测未知伪造类型时效果不佳。鉴于伪造人脸图像的伪造区域和非伪造区域具有不一致的源域特征, 提出一种基于多级特征全局一致性的人脸深度伪造检测方法。方法使用人脸结构破除模块加强模型对局部细节和轻微异常信息的关注。采用多级特征融合模块使主干网络不同层级的特征进行交互学习, 充分挖掘每个层级特征蕴含的伪造信息。使用全局一致性模块引导模型更好地提取伪造区域的特征表示, 最终实现对人脸图像的精确分类。结果在两个数据集上进行实验。在域内实验中, 本文方法的各项指标均优于目前先进的检测方法, 在高质量和低质量FaceForensics++数据集上, AUC (area under the curve)分别达到99.02%和90.06%。在泛化实验中, 本文的多项评价指标相比目前主流的伪造检测方法均占优。此外, 消融实验进一步验证了模型的每个模块的有效性。结论本文方法可以较准确地对深度伪造人脸进行检测, 具有优越的泛化性能, 能够作为应对当前人脸伪造威胁的一种有效检测手段。关键词:人脸伪造检测;深度伪造;多级特征学习;全局一致性;注意力机制125|253|5更新时间:2024-08-15 -
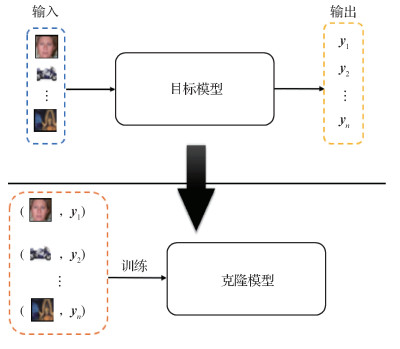 摘要:目的模型功能窃取攻击是人工智能安全领域的核心问题之一,目的是利用有限的与目标模型有关的信息训练出性能接近的克隆模型,从而实现模型的功能窃取。针对此类问题,一类经典的工作是基于生成模型的方法,这类方法利用生成器生成的图像作为查询数据,在同一查询数据下对两个模型预测结果的一致性进行约束,从而进行模型学习。然而此类方法生成器生成的数据常常是人眼不可辨识的图像,不含有任何语义信息,导致目标模型的输出缺乏有效指导性。针对上述问题,提出一种新的模型窃取攻击方法,实现对图像分类器的有效功能窃取。方法借助真实的图像数据,利用生成对抗网络(generative adversarial net,GAN)使生成器生成的数据接近真实图像,加强目标模型输出的物理意义。同时,为了提高克隆模型的性能,基于对比学习的思想,提出一种新的损失函数进行网络优化学习。结果在两个公开数据集CIFAR-10(Canadian Institute for Advanced Research-10)和SVHN(street view house numbers)的实验结果表明,本文方法能够取得良好的功能窃取效果。在CIFAR-10数据集上,相比目前较先进的方法,本文方法的窃取精度提高了5%。同时,在相同的查询代价下,本文方法能够取得更好的窃取效果,有效降低了查询目标模型的成本。结论本文提出的模型窃取攻击方法,从数据真实性的角度出发,有效提高了针对图像分类器的模型功能窃取攻击效果,在一定程度上降低了查询目标模型代价。关键词:模型功能窃取;生成模型;对比学习;对抗攻击;人工智能安全174|180|0更新时间:2024-08-15
摘要:目的模型功能窃取攻击是人工智能安全领域的核心问题之一,目的是利用有限的与目标模型有关的信息训练出性能接近的克隆模型,从而实现模型的功能窃取。针对此类问题,一类经典的工作是基于生成模型的方法,这类方法利用生成器生成的图像作为查询数据,在同一查询数据下对两个模型预测结果的一致性进行约束,从而进行模型学习。然而此类方法生成器生成的数据常常是人眼不可辨识的图像,不含有任何语义信息,导致目标模型的输出缺乏有效指导性。针对上述问题,提出一种新的模型窃取攻击方法,实现对图像分类器的有效功能窃取。方法借助真实的图像数据,利用生成对抗网络(generative adversarial net,GAN)使生成器生成的数据接近真实图像,加强目标模型输出的物理意义。同时,为了提高克隆模型的性能,基于对比学习的思想,提出一种新的损失函数进行网络优化学习。结果在两个公开数据集CIFAR-10(Canadian Institute for Advanced Research-10)和SVHN(street view house numbers)的实验结果表明,本文方法能够取得良好的功能窃取效果。在CIFAR-10数据集上,相比目前较先进的方法,本文方法的窃取精度提高了5%。同时,在相同的查询代价下,本文方法能够取得更好的窃取效果,有效降低了查询目标模型的成本。结论本文提出的模型窃取攻击方法,从数据真实性的角度出发,有效提高了针对图像分类器的模型功能窃取攻击效果,在一定程度上降低了查询目标模型代价。关键词:模型功能窃取;生成模型;对比学习;对抗攻击;人工智能安全174|180|0更新时间:2024-08-15
多媒体智能安全
-
 摘要:目的随着深度神经网络的出现,视觉跟踪快速发展,视觉跟踪任务中的视频时空特性,尤其是时序外观一致性(temporal appearance consistency)具有巨大探索空间。本文提出一种新颖简单实用的跟踪算法——时间感知网络(temporal-aware network, TAN),从视频角度出发,对序列的时间特征和空间特征同时编码。方法TAN内部嵌入了一个新的时间聚合模块(temporal aggregation module, TAM)用来交换和融合多个历史帧的信息,无需任何模型更新策略也能适应目标的外观变化,如形变、旋转等。为了构建简单实用的跟踪算法框架,设计了一种目标估计策略,通过检测目标的4个角点,由对角构成两组候选框,结合目标框选择策略确定最终目标位置,能够有效应对遮挡等困难。通过离线训练,在没有任何模型更新的情况下,本文提出的跟踪器TAN通过完全前向推理(fully feed-forward)实现跟踪。结果在OTB(online object tracking: a benchmark)50、OTB100、TrackingNet、LaSOT(a high-quality benchmark for large-scale single object tracking)和UAV(a benchmark and simulator for UAV tracking)123公开数据集上的效果达到了小网络模型的领先水平,并且同时保持高速处理速度(70帧/s)。与多个目前先进的跟踪器对比,TAN在性能和速度上达到了很好的平衡,即使部分跟踪器使用了复杂的模板更新策略或在线更新机制,TAN仍表现出优越的性能。消融实验进一步验证了提出的各个模块的有效性。结论本文提出的跟踪器完全离线训练,前向推理不需任何在线模型更新策略,能够适应目标的外观变化,相比其他轻量级的跟踪器,具有更优的性能。关键词:计算机视觉;目标跟踪;时空特征编码;任意目标跟踪;角点跟踪;时序外观一致性;高速跟踪84|231|2更新时间:2024-08-15
摘要:目的随着深度神经网络的出现,视觉跟踪快速发展,视觉跟踪任务中的视频时空特性,尤其是时序外观一致性(temporal appearance consistency)具有巨大探索空间。本文提出一种新颖简单实用的跟踪算法——时间感知网络(temporal-aware network, TAN),从视频角度出发,对序列的时间特征和空间特征同时编码。方法TAN内部嵌入了一个新的时间聚合模块(temporal aggregation module, TAM)用来交换和融合多个历史帧的信息,无需任何模型更新策略也能适应目标的外观变化,如形变、旋转等。为了构建简单实用的跟踪算法框架,设计了一种目标估计策略,通过检测目标的4个角点,由对角构成两组候选框,结合目标框选择策略确定最终目标位置,能够有效应对遮挡等困难。通过离线训练,在没有任何模型更新的情况下,本文提出的跟踪器TAN通过完全前向推理(fully feed-forward)实现跟踪。结果在OTB(online object tracking: a benchmark)50、OTB100、TrackingNet、LaSOT(a high-quality benchmark for large-scale single object tracking)和UAV(a benchmark and simulator for UAV tracking)123公开数据集上的效果达到了小网络模型的领先水平,并且同时保持高速处理速度(70帧/s)。与多个目前先进的跟踪器对比,TAN在性能和速度上达到了很好的平衡,即使部分跟踪器使用了复杂的模板更新策略或在线更新机制,TAN仍表现出优越的性能。消融实验进一步验证了提出的各个模块的有效性。结论本文提出的跟踪器完全离线训练,前向推理不需任何在线模型更新策略,能够适应目标的外观变化,相比其他轻量级的跟踪器,具有更优的性能。关键词:计算机视觉;目标跟踪;时空特征编码;任意目标跟踪;角点跟踪;时序外观一致性;高速跟踪84|231|2更新时间:2024-08-15 -
 摘要:目的视频多目标跟踪(multiple object tracking,MOT)是计算机视觉中的一项重要任务,现有研究分别针对目标检测和目标关联部分进行改进,均忽视了多目标跟踪中的不一致问题。不一致问题主要包括3方面,即目标检测框中心与身份特征中心不一致、帧间目标响应不一致以及训练测试过程中相似度度量方式不一致。为了解决上述不一致问题,本文提出一种基于时空一致性的多目标跟踪方法,以提升跟踪的准确度。方法从空间、时间以及特征维度对上述不一致性进行修正。对于目标检测框中心与身份特征中心不一致,针对每个目标检测框中心到特征中心之间的空间差异,在偏移后的位置上提取目标的ReID(re-identification)特征;对帧间响应不一致,使用空间相关计算相邻帧之间的运动偏移信息,基于该偏移信息对前一帧的目标响应进行变换后得到帧间一致性响应信息,然后对目标响应进行增强;对训练和测试过程中的相似度度量不一致,提出特征正交损失函数,在训练时考虑目标两两之间的相似关系。结果在3个数据集上与现有方法进行比较。在MOT17、MOT20和Hieve数据集中,MOTA(multiple object tracking accuracy)值分别为71.2%、60.2%和36.1%,相比改进前的FairMOT算法分别提高了1.6%、3.2%和1.1%。与大多数其他现有方法对比,本文方法的MT(mostly tracked)比例更高,ML(mostly lost)比例更低,跟踪的整体性能更好。同时,在MOT17数据集中进行对比实验验证融合算法的有效性,结果表明提出的方法显著改善了多目标跟踪中的不一致问题。结论本文提出的一致性跟踪方法,使特征在时间、空间以及训练测试中达成了更好的一致性,使多目标跟踪结果更加准确。关键词:多目标跟踪(MOT);一致性;特征提取位置偏移;特征正交损失;帧间增强206|253|1更新时间:2024-08-15
摘要:目的视频多目标跟踪(multiple object tracking,MOT)是计算机视觉中的一项重要任务,现有研究分别针对目标检测和目标关联部分进行改进,均忽视了多目标跟踪中的不一致问题。不一致问题主要包括3方面,即目标检测框中心与身份特征中心不一致、帧间目标响应不一致以及训练测试过程中相似度度量方式不一致。为了解决上述不一致问题,本文提出一种基于时空一致性的多目标跟踪方法,以提升跟踪的准确度。方法从空间、时间以及特征维度对上述不一致性进行修正。对于目标检测框中心与身份特征中心不一致,针对每个目标检测框中心到特征中心之间的空间差异,在偏移后的位置上提取目标的ReID(re-identification)特征;对帧间响应不一致,使用空间相关计算相邻帧之间的运动偏移信息,基于该偏移信息对前一帧的目标响应进行变换后得到帧间一致性响应信息,然后对目标响应进行增强;对训练和测试过程中的相似度度量不一致,提出特征正交损失函数,在训练时考虑目标两两之间的相似关系。结果在3个数据集上与现有方法进行比较。在MOT17、MOT20和Hieve数据集中,MOTA(multiple object tracking accuracy)值分别为71.2%、60.2%和36.1%,相比改进前的FairMOT算法分别提高了1.6%、3.2%和1.1%。与大多数其他现有方法对比,本文方法的MT(mostly tracked)比例更高,ML(mostly lost)比例更低,跟踪的整体性能更好。同时,在MOT17数据集中进行对比实验验证融合算法的有效性,结果表明提出的方法显著改善了多目标跟踪中的不一致问题。结论本文提出的一致性跟踪方法,使特征在时间、空间以及训练测试中达成了更好的一致性,使多目标跟踪结果更加准确。关键词:多目标跟踪(MOT);一致性;特征提取位置偏移;特征正交损失;帧间增强206|253|1更新时间:2024-08-15
目标智能检测
-
 摘要:目的现有视觉问答方法通常只关注图像中的视觉物体,忽略了对图像中关键文本内容的理解,从而限制了图像内容理解的深度和精度。鉴于图像中隐含的文本信息对理解图像的重要性,学者提出了针对图像中场景文本理解的“场景文本视觉问答”任务以量化模型对场景文字的理解能力,并构建相应的基准评测数据集TextVQA(text visual question answering)和ST-VQA(scene text visual question answering)。本文聚焦场景文本视觉问答任务,针对现有基于自注意力模型的方法存在过拟合风险导致的性能瓶颈问题,提出一种融合知识表征的多模态Transformer的场景文本视觉问答方法,有效提升了模型的稳健性和准确性。方法对现有基线模型M4C(multimodal multi-copy mesh)进行改进,针对视觉对象间的“空间关联”和文本单词间的“语义关联”这两种互补的先验知识进行建模,并在此基础上设计了一种通用的知识表征增强注意力模块以实现对两种关系的统一编码表达,得到知识表征增强的KR-M4C(knowledge-representation-enhanced M4C)方法。结果在TextVQA和ST-VQA两个场景文本视觉问答基准评测集上,将本文KR-M4C方法与最新方法进行比较。本文方法在TextVQA数据集中,相比于对比方法中最好的结果,在不增加额外训练数据的情况下,测试集准确率提升2.4%,在增加ST-VQA数据集作为训练数据的情况下,测试集准确率提升1.1%;在ST-VQA数据集中,相比于对比方法中最好的结果,测试集的平均归一化Levenshtein相似度提升5%。同时,在TextVQA数据集中进行对比实验以验证两种先验知识的有效性,结果表明提出的KR-M4C模型提高了预测答案的准确率。结论本文提出的KR-M4C方法的性能在TextVQA和ST-VQA两个场景文本视觉问答基准评测集上均有显著提升,获得了在该任务上的最好结果。关键词:场景文本视觉问答;知识表征;注意力机制;Transformer;多模态融合257|242|0更新时间:2024-08-15
摘要:目的现有视觉问答方法通常只关注图像中的视觉物体,忽略了对图像中关键文本内容的理解,从而限制了图像内容理解的深度和精度。鉴于图像中隐含的文本信息对理解图像的重要性,学者提出了针对图像中场景文本理解的“场景文本视觉问答”任务以量化模型对场景文字的理解能力,并构建相应的基准评测数据集TextVQA(text visual question answering)和ST-VQA(scene text visual question answering)。本文聚焦场景文本视觉问答任务,针对现有基于自注意力模型的方法存在过拟合风险导致的性能瓶颈问题,提出一种融合知识表征的多模态Transformer的场景文本视觉问答方法,有效提升了模型的稳健性和准确性。方法对现有基线模型M4C(multimodal multi-copy mesh)进行改进,针对视觉对象间的“空间关联”和文本单词间的“语义关联”这两种互补的先验知识进行建模,并在此基础上设计了一种通用的知识表征增强注意力模块以实现对两种关系的统一编码表达,得到知识表征增强的KR-M4C(knowledge-representation-enhanced M4C)方法。结果在TextVQA和ST-VQA两个场景文本视觉问答基准评测集上,将本文KR-M4C方法与最新方法进行比较。本文方法在TextVQA数据集中,相比于对比方法中最好的结果,在不增加额外训练数据的情况下,测试集准确率提升2.4%,在增加ST-VQA数据集作为训练数据的情况下,测试集准确率提升1.1%;在ST-VQA数据集中,相比于对比方法中最好的结果,测试集的平均归一化Levenshtein相似度提升5%。同时,在TextVQA数据集中进行对比实验以验证两种先验知识的有效性,结果表明提出的KR-M4C模型提高了预测答案的准确率。结论本文提出的KR-M4C方法的性能在TextVQA和ST-VQA两个场景文本视觉问答基准评测集上均有显著提升,获得了在该任务上的最好结果。关键词:场景文本视觉问答;知识表征;注意力机制;Transformer;多模态融合257|242|0更新时间:2024-08-15 -
 摘要:目的注意力机制是图像描述模型的常用方法,特点是自动关注图像的不同区域以动态生成描述图像的文本序列,但普遍存在不聚焦问题,即生成描述单词时,有时关注物体不重要区域,有时关注物体上下文,有时忽略图像重要目标,导致描述文本不够准确。针对上述问题,提出一种结合多层级解码器和动态融合机制的图像描述模型,以提高图像描述的准确性。方法对Transformer的结构进行扩展,整体模型由图像特征编码、多层级文本解码和自适应融合等3个模块构成。通过设计多层级文本解码结构,不断精化预测的文本信息,为注意力机制的聚焦提供可靠反馈,从而不断修正注意力机制以生成更加准确的图像描述。同时,设计文本融合模块,自适应地融合由粗到精的图像描述,使低层级解码器的输出直接参与文本预测,不仅可以缓解训练过程产生的梯度消失现象,同时保证输出的文本描述细节信息丰富且语法多样。结果在MS COCO(Microsoft common objects in context)和Flickr30K两个数据集上使用不同评估方法对模型进行验证,并与具有代表性的12种方法进行对比实验。结果表明,本文模型性能优于其他对比方法。其中,在MS COCO数据集中,相比于对比方法中性能最好的模型,BLEU-1(bilingual evaluation understudy)值提高了0.5,CIDEr(consensus-based image description evaluation)指标提高了1.0;在Flickr30K数据集中,相比于对比方法中性能最好的模型,BLEU-1值提高了0.1,CIDEr指标提高了0.6;同时,消融实验分别验证了级联结构和自适应模型的有效性。定性分析也表明本文方法能够生成更加准确的图像描述。结论本文方法在多种数据集的多项评价指标上取得最优性能,能够有效提高文本序列生成的准确性,最终形成对图像内容的准确描述。关键词:图像描述;注意力机制;Transformer;多层级解码;动态融合;门机制178|273|1更新时间:2024-08-15
摘要:目的注意力机制是图像描述模型的常用方法,特点是自动关注图像的不同区域以动态生成描述图像的文本序列,但普遍存在不聚焦问题,即生成描述单词时,有时关注物体不重要区域,有时关注物体上下文,有时忽略图像重要目标,导致描述文本不够准确。针对上述问题,提出一种结合多层级解码器和动态融合机制的图像描述模型,以提高图像描述的准确性。方法对Transformer的结构进行扩展,整体模型由图像特征编码、多层级文本解码和自适应融合等3个模块构成。通过设计多层级文本解码结构,不断精化预测的文本信息,为注意力机制的聚焦提供可靠反馈,从而不断修正注意力机制以生成更加准确的图像描述。同时,设计文本融合模块,自适应地融合由粗到精的图像描述,使低层级解码器的输出直接参与文本预测,不仅可以缓解训练过程产生的梯度消失现象,同时保证输出的文本描述细节信息丰富且语法多样。结果在MS COCO(Microsoft common objects in context)和Flickr30K两个数据集上使用不同评估方法对模型进行验证,并与具有代表性的12种方法进行对比实验。结果表明,本文模型性能优于其他对比方法。其中,在MS COCO数据集中,相比于对比方法中性能最好的模型,BLEU-1(bilingual evaluation understudy)值提高了0.5,CIDEr(consensus-based image description evaluation)指标提高了1.0;在Flickr30K数据集中,相比于对比方法中性能最好的模型,BLEU-1值提高了0.1,CIDEr指标提高了0.6;同时,消融实验分别验证了级联结构和自适应模型的有效性。定性分析也表明本文方法能够生成更加准确的图像描述。结论本文方法在多种数据集的多项评价指标上取得最优性能,能够有效提高文本序列生成的准确性,最终形成对图像内容的准确描述。关键词:图像描述;注意力机制;Transformer;多层级解码;动态融合;门机制178|273|1更新时间:2024-08-15 -
 摘要:目的人脸正面化重建是当前视觉领域的热点问题。现有方法对于模型的训练数据具有较高的需求,如精确的输入输出图像配准、完备的人脸先验信息等。但该类数据采集成本较高,可应用的数据集规模较小,直接将现有方法应用于真实的非受控场景中往往难以取得理想表现。针对上述问题,提出了一种无图像配准和先验信息依赖的任意视角人脸图像正面化重建方法。方法首先提出了一种具有双输入路径的人脸编码网络,分别用于学习输入人脸的视觉表征信息以及人脸的语义表征信息,两者联合构造出更加完备的人脸表征模型。随后建立了一种多类别表征融合的解码网络,通过以视觉表征为基础、以语义表征为引导的方式对两种表征信息进行融合,融合后的信息经过图像解码即可得到最终的正面化人脸图像重建结果。结果首先在Multi-PIE(multi-pose, illumination and expression)数据集上与8种较先进方法进行了性能评估。定量和定性的实验结果表明,所提方法在客观指标以及视觉质量方面均优于对比方法。此外,相较于当前性能先进的基于光流的特征翘曲模型(flow-based feature warping model,FFWM)方法,本文方法能够节省79%的参数量和42%的计算操作数。进一步基于CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences—WebFace)数据集对所提出方法在真实非受控场景中的表现进行了评估,识别精度超过现有方法10%以上。结论本文提出的双层级表征集成推理网络,能够挖掘并联合人脸图像的底层视觉特征以及高层语义特征,充分利用图像自身信息,不仅以更低的计算复杂度取得了更优的视觉质量和身份识别精度,而且在非受控的场景下同样展现出了出色的泛化性能。关键词:人脸正面化重建;任意姿态;双编码路径;视觉表征;语义表征;融合算法105|161|0更新时间:2024-08-15
摘要:目的人脸正面化重建是当前视觉领域的热点问题。现有方法对于模型的训练数据具有较高的需求,如精确的输入输出图像配准、完备的人脸先验信息等。但该类数据采集成本较高,可应用的数据集规模较小,直接将现有方法应用于真实的非受控场景中往往难以取得理想表现。针对上述问题,提出了一种无图像配准和先验信息依赖的任意视角人脸图像正面化重建方法。方法首先提出了一种具有双输入路径的人脸编码网络,分别用于学习输入人脸的视觉表征信息以及人脸的语义表征信息,两者联合构造出更加完备的人脸表征模型。随后建立了一种多类别表征融合的解码网络,通过以视觉表征为基础、以语义表征为引导的方式对两种表征信息进行融合,融合后的信息经过图像解码即可得到最终的正面化人脸图像重建结果。结果首先在Multi-PIE(multi-pose, illumination and expression)数据集上与8种较先进方法进行了性能评估。定量和定性的实验结果表明,所提方法在客观指标以及视觉质量方面均优于对比方法。此外,相较于当前性能先进的基于光流的特征翘曲模型(flow-based feature warping model,FFWM)方法,本文方法能够节省79%的参数量和42%的计算操作数。进一步基于CASIA-WebFace(Institute of Automation, Chinese Academy of Sciences—WebFace)数据集对所提出方法在真实非受控场景中的表现进行了评估,识别精度超过现有方法10%以上。结论本文提出的双层级表征集成推理网络,能够挖掘并联合人脸图像的底层视觉特征以及高层语义特征,充分利用图像自身信息,不仅以更低的计算复杂度取得了更优的视觉质量和身份识别精度,而且在非受控的场景下同样展现出了出色的泛化性能。关键词:人脸正面化重建;任意姿态;双编码路径;视觉表征;语义表征;融合算法105|161|0更新时间:2024-08-15
多媒体分析与理解
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0