
最新刊期
2022 年 第 27 卷 第 8 期
-
 摘要:随着科学技术的发展,虚拟现实(virtual reality, VR)技术逐渐渗透到医疗、教育、军事和娱乐等众多领域,并凭借在各个领域广阔的应用前景而受到广泛关注。鉴于视觉质量是决定VR技术能否成功应用的关键,且图像是VR应用最基础和最重要的视觉信息载体,VR图像质量评价已经成为质量评价领域的重要前沿性研究方向。与传统图像质量评价类似,VR图像质量评价可以分为主观质量评价和客观质量评价。由于客观质量评价相比主观质量评价具有成本低、稳定性高和应用范围广等优点,对VR图像客观质量评价的研究受到了国内外学者的高度重视。目前,关于VR图像客观质量评价的研究已经取得了一定进展,但是文献中缺少对该方向相关研究方法的综述。基于此,本文针对VR图像客观质量评价的研究进行概述。首先,对VR图像质量评价的研究现状进行分析。然后,重点对现有的VR图像客观质量评价模型进行综述。具体地,根据模型是否需要使用原始无失真图像信息作为参考,将现有的VR图像客观质量评价模型划分为全参考型和无参考型两大类。其中,全参考型方法进一步划分为基于峰值信噪比/结构相似度的方法和基于传统机器学习的方法。根据特征表达空间的不同,无参考型VR图像质量评价模型划分为3类:基于等矩形投影表达空间的方法、基于其他投影表达空间的方法和基于实际观看空间的方法。介绍完各类模型后,分别对其相应的优缺点进行分析。此外,本文对VR图像客观质量评价模型的性能评价指标和现有VR图像质量评价数据库进行了归纳。最后对VR图像客观质量评价模型的应用进行了介绍,并指出了未来的研究可能的发展方向。关键词:图像质量评价;客观评价;虚拟现实(VR);球面图像;等矩形投影(ERP)125|410|1更新时间:2024-08-15
摘要:随着科学技术的发展,虚拟现实(virtual reality, VR)技术逐渐渗透到医疗、教育、军事和娱乐等众多领域,并凭借在各个领域广阔的应用前景而受到广泛关注。鉴于视觉质量是决定VR技术能否成功应用的关键,且图像是VR应用最基础和最重要的视觉信息载体,VR图像质量评价已经成为质量评价领域的重要前沿性研究方向。与传统图像质量评价类似,VR图像质量评价可以分为主观质量评价和客观质量评价。由于客观质量评价相比主观质量评价具有成本低、稳定性高和应用范围广等优点,对VR图像客观质量评价的研究受到了国内外学者的高度重视。目前,关于VR图像客观质量评价的研究已经取得了一定进展,但是文献中缺少对该方向相关研究方法的综述。基于此,本文针对VR图像客观质量评价的研究进行概述。首先,对VR图像质量评价的研究现状进行分析。然后,重点对现有的VR图像客观质量评价模型进行综述。具体地,根据模型是否需要使用原始无失真图像信息作为参考,将现有的VR图像客观质量评价模型划分为全参考型和无参考型两大类。其中,全参考型方法进一步划分为基于峰值信噪比/结构相似度的方法和基于传统机器学习的方法。根据特征表达空间的不同,无参考型VR图像质量评价模型划分为3类:基于等矩形投影表达空间的方法、基于其他投影表达空间的方法和基于实际观看空间的方法。介绍完各类模型后,分别对其相应的优缺点进行分析。此外,本文对VR图像客观质量评价模型的性能评价指标和现有VR图像质量评价数据库进行了归纳。最后对VR图像客观质量评价模型的应用进行了介绍,并指出了未来的研究可能的发展方向。关键词:图像质量评价;客观评价;虚拟现实(VR);球面图像;等矩形投影(ERP)125|410|1更新时间:2024-08-15
综述

-
 摘要:目的眼部状态的变化可以作为反映用户真实心理状态及情感变化的依据。由于眼部区域面积较小,瞳孔与虹膜颜色接近,在自然光下利用普通摄像头捕捉瞳孔大小以及位置的变化信息是当前一项具有较大挑战的任务。同时,与现实应用环境类似的具有精细定位和分割信息的眼部结构数据集的欠缺也是制约该领域研究发展的原因之一。针对以上问题,本文利用在普通摄像头场景下采集眼部图像数据,捕捉瞳孔的变化信息并建立了一个眼部图像分割及特征点定位数据集(eye segment and landmark detection dataset, ESLD)。方法收集、标注并公开发布一个包含多种眼部类型的图像数据集ESLD。采用3种方式采集图像:1)采集用户使用电脑时的面部图像;2)收集已经公开的数据集中满足在自然光下使用普通摄像机条件时采集到的面部图像;3)基于公开软件UnityEye合成的眼部图像。3种采集方式可分别得到1 386幅、804幅和1 600幅眼部图像。得到原始图像后,在原始图像中分割出眼部区域,将不同尺寸的眼部图像归一化为256×128像素。最后对眼部图像的特征点进行人工标记和眼部结构分割。结果ESLD数据集包含多种类型的眼部图像,可满足研究人员的不同需求。因为实际采集和从公开数据集中获取真实眼部图像十分困难,所以本文利用UnityEye生成眼部图像以改善训练数据量少的问题。实验结果表明,合成的眼部图像可以有效地弥补数据量缺少的问题,
摘要:目的眼部状态的变化可以作为反映用户真实心理状态及情感变化的依据。由于眼部区域面积较小,瞳孔与虹膜颜色接近,在自然光下利用普通摄像头捕捉瞳孔大小以及位置的变化信息是当前一项具有较大挑战的任务。同时,与现实应用环境类似的具有精细定位和分割信息的眼部结构数据集的欠缺也是制约该领域研究发展的原因之一。针对以上问题,本文利用在普通摄像头场景下采集眼部图像数据,捕捉瞳孔的变化信息并建立了一个眼部图像分割及特征点定位数据集(eye segment and landmark detection dataset, ESLD)。方法收集、标注并公开发布一个包含多种眼部类型的图像数据集ESLD。采用3种方式采集图像:1)采集用户使用电脑时的面部图像;2)收集已经公开的数据集中满足在自然光下使用普通摄像机条件时采集到的面部图像;3)基于公开软件UnityEye合成的眼部图像。3种采集方式可分别得到1 386幅、804幅和1 600幅眼部图像。得到原始图像后,在原始图像中分割出眼部区域,将不同尺寸的眼部图像归一化为256×128像素。最后对眼部图像的特征点进行人工标记和眼部结构分割。结果ESLD数据集包含多种类型的眼部图像,可满足研究人员的不同需求。因为实际采集和从公开数据集中获取真实眼部图像十分困难,所以本文利用UnityEye生成眼部图像以改善训练数据量少的问题。实验结果表明,合成的眼部图像可以有效地弥补数据量缺少的问题,$ {\rm{F1}}$ 关键词:真实环境;瞳孔分割;特征点检测;身份识别;在线教育;数据集190|205|0更新时间:2024-08-15
数据集论文
-
 摘要:目的深度图像作为一种重要的视觉感知数据,其质量对于3维视觉系统至关重要。由于传统方法获取的深度图像大多有使用场景的限制,容易受到噪声和环境影响,导致深度图像缺失部分深度信息,使得修复深度图像仍然是一个值得研究并有待解决的问题。对此,本文提出一种用于深度图像修复的双尺度顺序填充框架。方法首先,提出基于条件熵快速逼近的填充优先级估计算法。其次,采用最大似然估计实现缺失深度值的最优预测。最后,在像素和超像素两个尺度上对修复结果进行整合,准确实现了深度图像孔洞填充。结果本文方法在主流数据集MB(Middlebury)上与7种方法进行比较,平均峰值信噪比(peak signal-to-noise ratio,PSNR)和平均结构相似性指数(structural similarity index,SSIM)分别为47.955 dB和0.998 2;在手工填充的数据集MB+中,本文方法的PSNR平均值为34.697 dB,SSIM平均值为0.978 5,对比其他算法,本文深度修复效果有较大优势。在时间效率对比实验中,本文方法也表现优异,具有较高的效率。在消融实验部分,对本文提出的填充优先级估计、深度值预测和双尺度改进分别进行评估,验证了本文创新点的有效性。结论实验结果表明,本文方法在鲁棒性、精确度和效率方面相较于现有方法具有比较明显的优势。关键词:深度图像修复;顺序填充;条件熵快速逼近;深度最优预测;超像素126|190|0更新时间:2024-08-15
摘要:目的深度图像作为一种重要的视觉感知数据,其质量对于3维视觉系统至关重要。由于传统方法获取的深度图像大多有使用场景的限制,容易受到噪声和环境影响,导致深度图像缺失部分深度信息,使得修复深度图像仍然是一个值得研究并有待解决的问题。对此,本文提出一种用于深度图像修复的双尺度顺序填充框架。方法首先,提出基于条件熵快速逼近的填充优先级估计算法。其次,采用最大似然估计实现缺失深度值的最优预测。最后,在像素和超像素两个尺度上对修复结果进行整合,准确实现了深度图像孔洞填充。结果本文方法在主流数据集MB(Middlebury)上与7种方法进行比较,平均峰值信噪比(peak signal-to-noise ratio,PSNR)和平均结构相似性指数(structural similarity index,SSIM)分别为47.955 dB和0.998 2;在手工填充的数据集MB+中,本文方法的PSNR平均值为34.697 dB,SSIM平均值为0.978 5,对比其他算法,本文深度修复效果有较大优势。在时间效率对比实验中,本文方法也表现优异,具有较高的效率。在消融实验部分,对本文提出的填充优先级估计、深度值预测和双尺度改进分别进行评估,验证了本文创新点的有效性。结论实验结果表明,本文方法在鲁棒性、精确度和效率方面相较于现有方法具有比较明显的优势。关键词:深度图像修复;顺序填充;条件熵快速逼近;深度最优预测;超像素126|190|0更新时间:2024-08-15 -
 摘要:目的快速响应矩阵码(quick response code,QR code)简称二维码,是一种由深色和浅色模块组成的正方形符号。给定输入数据,不同编码算法可能输出不同的位流。位流长度决定了二维码的版本,进而决定了二维码每条边上的模块数量。减小二维码的版本能够在不减小模块大小的前提下节省面积,或者在不改变面积的前提下增大模块大小。为了减小二维码面积、提高二维码识读率,本文提出了位流长度最小化算法。方法首先,根据二维码位流可以分段切换编码模式的特点,归纳了6种编码状态;然后,根据二维码位流编码标准推导了状态转移关系,从而将位流长度最小化问题转换成动态规划问题;最后,通过求解动态规划问题,计算出最短位流。针对统一资源定位符(uniform resource locator,URL)类型数据,利用其部分字段对大小写不敏感、部分字段可以转义的性质,提出了统一资源定位符的最短位流计算算法,进一步缩短位流。结果本文构建了一个测试集,包含603个编码了非URL数据的二维码,以及1 679个编码了URL数据的二维码。实验结果表明,本文算法与二维码标准相比,对于非URL测试集,位流长度减小的二维码占比9.1%,版本减小的二维码占比1.2%;对于URL测试集,位流长度减小的二维码占比98.4%,版本减小的二维码占比31.7%。结论二维码位流长度最小化算法输出的位流长度最短,输出的二维码版本最小,能在兼容标准二维码解码器且不影响纠错能力的前提下提升二维码的数据容量。同时,本文算法运行速度快,易于使用,没有需要调节的参数。关键词:二维码;快速响应矩阵码;二维码编码;动态规划;统一资源定位符(URL)98|167|0更新时间:2024-08-15
摘要:目的快速响应矩阵码(quick response code,QR code)简称二维码,是一种由深色和浅色模块组成的正方形符号。给定输入数据,不同编码算法可能输出不同的位流。位流长度决定了二维码的版本,进而决定了二维码每条边上的模块数量。减小二维码的版本能够在不减小模块大小的前提下节省面积,或者在不改变面积的前提下增大模块大小。为了减小二维码面积、提高二维码识读率,本文提出了位流长度最小化算法。方法首先,根据二维码位流可以分段切换编码模式的特点,归纳了6种编码状态;然后,根据二维码位流编码标准推导了状态转移关系,从而将位流长度最小化问题转换成动态规划问题;最后,通过求解动态规划问题,计算出最短位流。针对统一资源定位符(uniform resource locator,URL)类型数据,利用其部分字段对大小写不敏感、部分字段可以转义的性质,提出了统一资源定位符的最短位流计算算法,进一步缩短位流。结果本文构建了一个测试集,包含603个编码了非URL数据的二维码,以及1 679个编码了URL数据的二维码。实验结果表明,本文算法与二维码标准相比,对于非URL测试集,位流长度减小的二维码占比9.1%,版本减小的二维码占比1.2%;对于URL测试集,位流长度减小的二维码占比98.4%,版本减小的二维码占比31.7%。结论二维码位流长度最小化算法输出的位流长度最短,输出的二维码版本最小,能在兼容标准二维码解码器且不影响纠错能力的前提下提升二维码的数据容量。同时,本文算法运行速度快,易于使用,没有需要调节的参数。关键词:二维码;快速响应矩阵码;二维码编码;动态规划;统一资源定位符(URL)98|167|0更新时间:2024-08-15
图像处理和编码
-
 摘要:目的在自动化、智能化的现代生产制造过程中,行为识别技术扮演着越来越重要的角色,但实际生产制造环境的复杂性,使其成为一项具有挑战性的任务。目前,基于3D卷积网络结合光流的方法在行为识别方面表现出良好的性能,但还是不能很好地解决人体被遮挡的问题,而且光流的计算成本很高,无法在实时场景中应用。针对实际工业装箱场景中存在的人体被遮挡问题和光流计算成本问题,本文提出一种结合双视图3D卷积网络的装箱行为识别方法。方法首先,通过使用堆叠的差分图像(residual frames,RF)作为模型的输入来更好地提取运动特征,替代实时场景中无法使用的光流。原始RGB图像和差分图像分别输入到两个并行的3D ResNeXt101中。其次,采用双视图结构来解决人体被遮挡的问题,将3D ResNeXt101优化为双视图模型,使用一个可学习权重的双视图池化层对不同角度的视图做特征融合,然后使用该双视图3DResNeXt101模型进行行为识别。最后,为进一步提高检测结果的真负率(true negative rate,TNR),本文在模型中加入降噪自编码器和two-class支持向量机(support vector machine,SVM)。结果本文在实际生产环境下装箱场景进行了实验,采用准确率和真负率两个指标进行评估,得到的装箱行为识别准确率为94.2%、真负率为98.9%。同时在公共数据集UCF(University of Central Florida)101上进行了评估,以准确率为评估指标,得到的装箱行为识别准确率为97.9%。进一步验证了本文方法的有效性和准确性。结论本文提出的人体行为识别方法能够有效利用多个视图中的人体行为信息,结合传统模型和深度学习模型,显著提高了行为识别准确率和真负率。关键词:行为识别;双视图;三维卷积神经网络;降噪自编码器;支持向量机(SVM)115|207|1更新时间:2024-08-15
摘要:目的在自动化、智能化的现代生产制造过程中,行为识别技术扮演着越来越重要的角色,但实际生产制造环境的复杂性,使其成为一项具有挑战性的任务。目前,基于3D卷积网络结合光流的方法在行为识别方面表现出良好的性能,但还是不能很好地解决人体被遮挡的问题,而且光流的计算成本很高,无法在实时场景中应用。针对实际工业装箱场景中存在的人体被遮挡问题和光流计算成本问题,本文提出一种结合双视图3D卷积网络的装箱行为识别方法。方法首先,通过使用堆叠的差分图像(residual frames,RF)作为模型的输入来更好地提取运动特征,替代实时场景中无法使用的光流。原始RGB图像和差分图像分别输入到两个并行的3D ResNeXt101中。其次,采用双视图结构来解决人体被遮挡的问题,将3D ResNeXt101优化为双视图模型,使用一个可学习权重的双视图池化层对不同角度的视图做特征融合,然后使用该双视图3DResNeXt101模型进行行为识别。最后,为进一步提高检测结果的真负率(true negative rate,TNR),本文在模型中加入降噪自编码器和two-class支持向量机(support vector machine,SVM)。结果本文在实际生产环境下装箱场景进行了实验,采用准确率和真负率两个指标进行评估,得到的装箱行为识别准确率为94.2%、真负率为98.9%。同时在公共数据集UCF(University of Central Florida)101上进行了评估,以准确率为评估指标,得到的装箱行为识别准确率为97.9%。进一步验证了本文方法的有效性和准确性。结论本文提出的人体行为识别方法能够有效利用多个视图中的人体行为信息,结合传统模型和深度学习模型,显著提高了行为识别准确率和真负率。关键词:行为识别;双视图;三维卷积神经网络;降噪自编码器;支持向量机(SVM)115|207|1更新时间:2024-08-15 -
 摘要:目的利用无人机(unmanned aerial vehicle, UAV)巡检识别航拍图像中的工程车辆对于减少电力安全事故的发生具有重要意义。采用人工提取特征的经典模式识别方法或YOLOv5(you only look once v5)等深度学习算法识别无人机电力巡检航拍图像中的工程车辆,存在识别准确率低、模型参数规模大等问题。针对上述问题,提出一种改进的胶囊网络识别航拍图像中的工程车辆。方法采用多层密集连接型方法改进原始胶囊网络结构,以提取图像中工程车辆更多的特征;改进了胶囊网络的动态路由方法,以提高胶囊网络的抗干扰能力;探索了网络层数和动态路由算法中关键参数对识别准确率的影响,以找到识别准确率最高时的参数。结果实验结果表明:1)在所采用的算法模型中,本文方法的平均识别率(mean average precision, mAP)达到94.56%,明显高于其他方法。2)网络层数对识别准确率有很大影响,但二者之间并非单调线性关系。在本文的应用场景中,5层胶囊网络的识别准确率最高;此外,动态路由算法改进与否并不会影响识别准确率跟随网络层数的变化趋势。3)胶囊网络层数增加会降低识别效率,但是并不会明显增加参数规模,且参数规模与mAP无明显关联。结论本文方法在获得较高识别准确率的同时具有参数规模较小的特点,为无人机在机载端识别目标物奠定了基础。关键词:无人机航拍图像;工程车辆识别;胶囊网络;动态路由算法;密集连接型网络90|94|1更新时间:2024-08-15
摘要:目的利用无人机(unmanned aerial vehicle, UAV)巡检识别航拍图像中的工程车辆对于减少电力安全事故的发生具有重要意义。采用人工提取特征的经典模式识别方法或YOLOv5(you only look once v5)等深度学习算法识别无人机电力巡检航拍图像中的工程车辆,存在识别准确率低、模型参数规模大等问题。针对上述问题,提出一种改进的胶囊网络识别航拍图像中的工程车辆。方法采用多层密集连接型方法改进原始胶囊网络结构,以提取图像中工程车辆更多的特征;改进了胶囊网络的动态路由方法,以提高胶囊网络的抗干扰能力;探索了网络层数和动态路由算法中关键参数对识别准确率的影响,以找到识别准确率最高时的参数。结果实验结果表明:1)在所采用的算法模型中,本文方法的平均识别率(mean average precision, mAP)达到94.56%,明显高于其他方法。2)网络层数对识别准确率有很大影响,但二者之间并非单调线性关系。在本文的应用场景中,5层胶囊网络的识别准确率最高;此外,动态路由算法改进与否并不会影响识别准确率跟随网络层数的变化趋势。3)胶囊网络层数增加会降低识别效率,但是并不会明显增加参数规模,且参数规模与mAP无明显关联。结论本文方法在获得较高识别准确率的同时具有参数规模较小的特点,为无人机在机载端识别目标物奠定了基础。关键词:无人机航拍图像;工程车辆识别;胶囊网络;动态路由算法;密集连接型网络90|94|1更新时间:2024-08-15 -
 摘要:目的在行为识别任务中,妥善利用时空建模与通道之间的相关性对于捕获丰富的动作信息至关重要。尽管图卷积网络在基于骨架信息的行为识别方面取得了稳步进展,但以往的注意力机制应用于图卷积网络时,其分类效果并未获得明显提升。基于兼顾时空交互与通道依赖关系的重要性,提出了多维特征嵌合注意力机制(multi-dimensional feature fusion attention mechanism,M2FA)。方法不同于现今广泛应用的行为识别框架研究理念,如卷积块注意力模块(convolutional block attention module,CBAM)、双流自适应图卷积网络(two-stream adaptive graph convolutional network,2s-AGCN)等,M2FA通过嵌入在注意力机制框架中的特征融合模块显式地获取综合依赖信息。对于给定的特征图,M2FA沿着空间、时间和通道维度使用全局平均池化操作推断相应维度的特征描述符。特征图使用多维特征描述符的融合结果进行过滤学习以达到细化自适应特征的目的,并通过压缩全局动态信息的全局特征分支与仅使用逐点卷积层的局部特征分支相互嵌合获取多尺度动态信息。结果实验在骨架行为识别数据集NTU-RGBD和Kinetics-Skeleton中进行,分析了M2FA与其基线方法2s-AGCN及最新提出的图卷积模型之间的识别准确率对比结果。在Kinetics-Skeleton验证集中,相比于基线方法2s-AGCN,M2FA分类准确率提高了1.8%;在NTU-RGBD的两个不同基准分支中,M2FA的分类准确率比基线方法2s-AGCN分别提高了1.6%和1.0%。同时,消融实验验证了多维特征嵌合机制的有效性。实验结果表明,提出的M2FA改善了图卷积骨架行为识别方法的分类效果。结论通过与基线方法2s-AGCN及目前主流图卷积模型比较,多维特征嵌合注意力机制获得了最高的识别精度,可以集成至基于骨架信息的体系结构中进行端到端的训练,使分类结果更加准确。关键词:行为识别;骨架信息;图卷积网络(GCN);注意力机制;时空交互;通道依赖性;多维特征嵌合113|164|4更新时间:2024-08-15
摘要:目的在行为识别任务中,妥善利用时空建模与通道之间的相关性对于捕获丰富的动作信息至关重要。尽管图卷积网络在基于骨架信息的行为识别方面取得了稳步进展,但以往的注意力机制应用于图卷积网络时,其分类效果并未获得明显提升。基于兼顾时空交互与通道依赖关系的重要性,提出了多维特征嵌合注意力机制(multi-dimensional feature fusion attention mechanism,M2FA)。方法不同于现今广泛应用的行为识别框架研究理念,如卷积块注意力模块(convolutional block attention module,CBAM)、双流自适应图卷积网络(two-stream adaptive graph convolutional network,2s-AGCN)等,M2FA通过嵌入在注意力机制框架中的特征融合模块显式地获取综合依赖信息。对于给定的特征图,M2FA沿着空间、时间和通道维度使用全局平均池化操作推断相应维度的特征描述符。特征图使用多维特征描述符的融合结果进行过滤学习以达到细化自适应特征的目的,并通过压缩全局动态信息的全局特征分支与仅使用逐点卷积层的局部特征分支相互嵌合获取多尺度动态信息。结果实验在骨架行为识别数据集NTU-RGBD和Kinetics-Skeleton中进行,分析了M2FA与其基线方法2s-AGCN及最新提出的图卷积模型之间的识别准确率对比结果。在Kinetics-Skeleton验证集中,相比于基线方法2s-AGCN,M2FA分类准确率提高了1.8%;在NTU-RGBD的两个不同基准分支中,M2FA的分类准确率比基线方法2s-AGCN分别提高了1.6%和1.0%。同时,消融实验验证了多维特征嵌合机制的有效性。实验结果表明,提出的M2FA改善了图卷积骨架行为识别方法的分类效果。结论通过与基线方法2s-AGCN及目前主流图卷积模型比较,多维特征嵌合注意力机制获得了最高的识别精度,可以集成至基于骨架信息的体系结构中进行端到端的训练,使分类结果更加准确。关键词:行为识别;骨架信息;图卷积网络(GCN);注意力机制;时空交互;通道依赖性;多维特征嵌合113|164|4更新时间:2024-08-15 -
 摘要:目的行为识别在人体交互、行为分析和监控等实际场景中具有广泛的应用。大部分基于骨架的行为识别方法利用空间和时间两个维度的信息才能获得好的效果。GCN(graph convolutional network)能够将空间和时间信息有效地结合起来,然而基于GCN的方法具有较高的计算复杂度,结合注意力模块和多流融合策略使整个训练过程具有更低的效率。目前大多数研究都专注于算法的性能,如何在保证精度的基础上减少算法的计算量是行为识别需要解决的关键性问题。对此,本文在轻量级Shift-GCN(shift graph convolutional network)的基础上,提出了整数倍稀疏网络IntSparse-GCN(integer sparse graph convolutional network)。方法首先提出奇数列向上移动,偶数列向下移动,并将移出部分用0替代新的稀疏移位操作,并在此基础上,提出将网络每层的输入输出设置成关节点的整数倍,即整数倍稀疏网络IntSparse-GCN。然后对Shift-GCN中的mask掩膜函数进行研究分析,通过自动化遍历方式得到精度最高的优化参数。结果消融实验表明,每次算法改进都能提高算法整体性能。在NTU RGB + D数据集的子集X-sub和X-view上,4流IntSparse-GCN + M-Sparse的Top-1精度分别为90.72%和96.57%。在Northwestern-UCLA数据集上,4流IntSparse-GCN + M-Sparse的Top-1精度达到96.77%,较原模型提高2.17%。相比代表性的其他算法,在不同数据集及4个流上的准确率均有提升,尤其在Northwestern-UCLA数据集上提升非常明显。结论本文针对shift稀疏特征提出整数倍IntSparse-GCN网络,对Shift-GCN中的mask掩膜函数进行研究分析,并设计自动化遍历方式得到精度最高的优化参数,不但提高了精度,也为进一步的剪枝及量化提供了依据。关键词:行为识别;轻量级;稀疏特征矩阵;整数倍稀疏网络(IntSparse-GCN);mask掩膜函数108|175|2更新时间:2024-08-15
摘要:目的行为识别在人体交互、行为分析和监控等实际场景中具有广泛的应用。大部分基于骨架的行为识别方法利用空间和时间两个维度的信息才能获得好的效果。GCN(graph convolutional network)能够将空间和时间信息有效地结合起来,然而基于GCN的方法具有较高的计算复杂度,结合注意力模块和多流融合策略使整个训练过程具有更低的效率。目前大多数研究都专注于算法的性能,如何在保证精度的基础上减少算法的计算量是行为识别需要解决的关键性问题。对此,本文在轻量级Shift-GCN(shift graph convolutional network)的基础上,提出了整数倍稀疏网络IntSparse-GCN(integer sparse graph convolutional network)。方法首先提出奇数列向上移动,偶数列向下移动,并将移出部分用0替代新的稀疏移位操作,并在此基础上,提出将网络每层的输入输出设置成关节点的整数倍,即整数倍稀疏网络IntSparse-GCN。然后对Shift-GCN中的mask掩膜函数进行研究分析,通过自动化遍历方式得到精度最高的优化参数。结果消融实验表明,每次算法改进都能提高算法整体性能。在NTU RGB + D数据集的子集X-sub和X-view上,4流IntSparse-GCN + M-Sparse的Top-1精度分别为90.72%和96.57%。在Northwestern-UCLA数据集上,4流IntSparse-GCN + M-Sparse的Top-1精度达到96.77%,较原模型提高2.17%。相比代表性的其他算法,在不同数据集及4个流上的准确率均有提升,尤其在Northwestern-UCLA数据集上提升非常明显。结论本文针对shift稀疏特征提出整数倍IntSparse-GCN网络,对Shift-GCN中的mask掩膜函数进行研究分析,并设计自动化遍历方式得到精度最高的优化参数,不但提高了精度,也为进一步的剪枝及量化提供了依据。关键词:行为识别;轻量级;稀疏特征矩阵;整数倍稀疏网络(IntSparse-GCN);mask掩膜函数108|175|2更新时间:2024-08-15 -
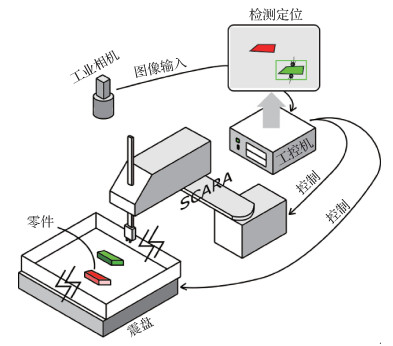 摘要:目的随着工业领域智能分拣业务的兴起,目标检测引起越来越多的关注。然而为了适应工业现场快速部署和应用的需求,算法只能在获得少量目标样本的情况下调整参数;另外工控机运算资源有限,工业零件表面光滑、缺乏显著的纹理信息,都不利于基于深度学习的目标检测方法。目前普遍认为Line2D可以很好地用于小样本情况的低纹理目标快速匹配,但Line2D不能正确匹配形状相同而颜色不同的两个零件。对此,提出一种更为鲁棒的低纹理目标快速匹配框架CL2D(color Line2D)。方法首先使用梯度方向特征作为物体形状的描述在输入图像快速匹配,获取粗匹配结果;然后通过非极大值抑制和颜色直方图比对完成精细匹配。最后根据工业分拣的特点,由坐标变换完成对目标的抓取点定位。结果为了对算法性能进行测试,本文根据工业分拣的实际环境,提出了YNU-BBD 2020(YNU-building blocks datasets 2020)数据集。在YNU-BBD 2020数据集上的测试结果表明,CL2D可以在CPU平台上以平均2.15 s/幅的速度处理高分辨率图像,在精度上相比于经典算法和深度学习算法,mAP(mean average precision)分别提升了10%和7%。结论本文针对工业零件分拣系统的特点,提出了一种快速低纹理目标检测方法,能够在CPU平台上高效完成目标检测任务,并且相较于现有方法具有显著优势。关键词:模板匹配;低纹理目标检测;颜色直方图;智能制造;随机分拣123|294|3更新时间:2024-08-15
摘要:目的随着工业领域智能分拣业务的兴起,目标检测引起越来越多的关注。然而为了适应工业现场快速部署和应用的需求,算法只能在获得少量目标样本的情况下调整参数;另外工控机运算资源有限,工业零件表面光滑、缺乏显著的纹理信息,都不利于基于深度学习的目标检测方法。目前普遍认为Line2D可以很好地用于小样本情况的低纹理目标快速匹配,但Line2D不能正确匹配形状相同而颜色不同的两个零件。对此,提出一种更为鲁棒的低纹理目标快速匹配框架CL2D(color Line2D)。方法首先使用梯度方向特征作为物体形状的描述在输入图像快速匹配,获取粗匹配结果;然后通过非极大值抑制和颜色直方图比对完成精细匹配。最后根据工业分拣的特点,由坐标变换完成对目标的抓取点定位。结果为了对算法性能进行测试,本文根据工业分拣的实际环境,提出了YNU-BBD 2020(YNU-building blocks datasets 2020)数据集。在YNU-BBD 2020数据集上的测试结果表明,CL2D可以在CPU平台上以平均2.15 s/幅的速度处理高分辨率图像,在精度上相比于经典算法和深度学习算法,mAP(mean average precision)分别提升了10%和7%。结论本文针对工业零件分拣系统的特点,提出了一种快速低纹理目标检测方法,能够在CPU平台上高效完成目标检测任务,并且相较于现有方法具有显著优势。关键词:模板匹配;低纹理目标检测;颜色直方图;智能制造;随机分拣123|294|3更新时间:2024-08-15 -
 摘要:目的特征融合是改善模糊图像、小目标以及受遮挡物体等目标检测困难的有效手段之一,为了更有效地利用特征融合来整合不同网络层次的特征信息,显著表达其中的重要特征,本文提出一种基于融合策略优选和双注意力机制的单阶段目标检测算法FDA-SSD(fusion double attention single shot multibox detector)。方法设计融合策略优化选择方法,结合特征金字塔(feature pyramid network,FPN)来确定最优的多层特征图组合及融合过程,之后连接双注意力模块,通过对各个通道和空间特征的权重再分配,提升模型对通道特征和空间信息的敏感性,最终产生包含丰富语义信息和凸显重要特征的特征图组。结果本文在公开数据集PASCAL VOC2007(pattern analysis, statistical modelling and computational learning visual object classes)和TGRS-HRRSD-Dataset(high resolution remote sensing detection)上进行对比实验,结果表明,在输入为300×300像素的PASCAL VOC2007测试集上,FDA-SSD模型的精度达到79.8%,比SSD(single shot multibox detector)、RSSD(rainbow SSD)、DSSD(de-convolution SSD)、FSSD(feature fusion SSD)模型分别高了2.6%、1.3%、1.2%、1.0%,在Titan X上的检测速度为47帧/s(frame per second,FPS),与SSD算法相当,分别高于RSSD和DSSD模型12 FPS和37.5 FPS。在输入像素为300×300的TGRS-HRRSD-Dataset测试集上的精度为84.2%,在Tesla V100上的检测速度高于SSD模型10%的情况下,准确率提高了1.5%。结论通过在单阶段目标检测模型中引入融合策略选择和双注意力机制,使得预测的速度和准确率同时得到提升,并且对于小目标、受遮挡以及模糊图像等难目标的检测能力也得到较大提升。关键词:单阶段目标检测;SSD算法;特征金字塔(FPN);特征融合;注意力机制121|303|4更新时间:2024-08-15
摘要:目的特征融合是改善模糊图像、小目标以及受遮挡物体等目标检测困难的有效手段之一,为了更有效地利用特征融合来整合不同网络层次的特征信息,显著表达其中的重要特征,本文提出一种基于融合策略优选和双注意力机制的单阶段目标检测算法FDA-SSD(fusion double attention single shot multibox detector)。方法设计融合策略优化选择方法,结合特征金字塔(feature pyramid network,FPN)来确定最优的多层特征图组合及融合过程,之后连接双注意力模块,通过对各个通道和空间特征的权重再分配,提升模型对通道特征和空间信息的敏感性,最终产生包含丰富语义信息和凸显重要特征的特征图组。结果本文在公开数据集PASCAL VOC2007(pattern analysis, statistical modelling and computational learning visual object classes)和TGRS-HRRSD-Dataset(high resolution remote sensing detection)上进行对比实验,结果表明,在输入为300×300像素的PASCAL VOC2007测试集上,FDA-SSD模型的精度达到79.8%,比SSD(single shot multibox detector)、RSSD(rainbow SSD)、DSSD(de-convolution SSD)、FSSD(feature fusion SSD)模型分别高了2.6%、1.3%、1.2%、1.0%,在Titan X上的检测速度为47帧/s(frame per second,FPS),与SSD算法相当,分别高于RSSD和DSSD模型12 FPS和37.5 FPS。在输入像素为300×300的TGRS-HRRSD-Dataset测试集上的精度为84.2%,在Tesla V100上的检测速度高于SSD模型10%的情况下,准确率提高了1.5%。结论通过在单阶段目标检测模型中引入融合策略选择和双注意力机制,使得预测的速度和准确率同时得到提升,并且对于小目标、受遮挡以及模糊图像等难目标的检测能力也得到较大提升。关键词:单阶段目标检测;SSD算法;特征金字塔(FPN);特征融合;注意力机制121|303|4更新时间:2024-08-15 -
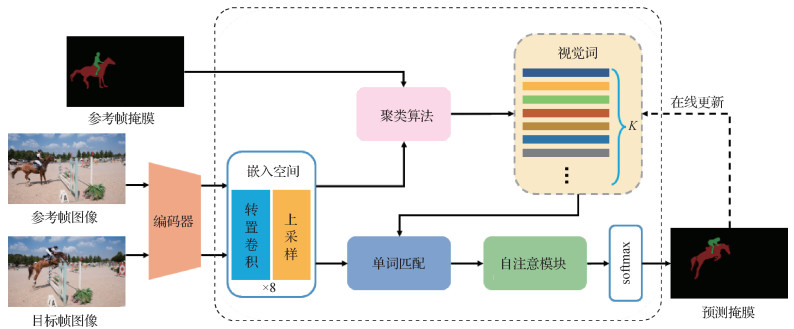 摘要:目的视频目标分割(video object segmentation, VOS)是在给定初始帧的目标掩码条件下,实现对整个视频序列中感兴趣对象的分割,但是视频中往往会出现目标形状不规则、背景中存在干扰信息和运动速度过快等情况,影响视频目标分割质量。对此,本文提出一种融合视觉词和自注意力机制的视频目标分割算法。方法对于参考帧,首先将其图像输入编码器中,提取分辨率为原图像1/8的像素特征。然后将该特征输入由若干卷积核构成的嵌入空间中,并将其结果上采样至原始尺寸。最后结合参考帧的目标掩码信息,通过聚类算法对嵌入空间中的像素进行聚类分簇,形成用于表示目标对象的视觉词。对于目标帧,首先将其图像通过编码器并输入嵌入空间中,通过单词匹配操作用参考帧生成的视觉词来表示嵌入空间中的像素,并获得多个相似图。然后,对相似图应用自注意力机制捕获全局依赖关系,最后取通道方向上的最大值作为预测结果。为了解决目标对象的外观变化和视觉词失配的问题,提出在线更新机制和全局校正机制以进一步提高准确率。结果实验结果表明,本文方法在视频目标分割数据集DAVIS(densely annotated video segmentation)2016和DAVIS 2017上取得了有竞争力的结果,区域相似度与轮廓精度之间的平均值J&F-mean(Jaccard and F-score mean)分别为83.2%和72.3%。结论本文提出的算法可以有效地处理由遮挡、变形和视点变化等带来的干扰问题,实现高质量的视频目标分割。关键词:视频目标分割(VOS);聚类算法;视觉词;自注意力机制;在线更新机制;全局校正机制77|172|1更新时间:2024-08-15
摘要:目的视频目标分割(video object segmentation, VOS)是在给定初始帧的目标掩码条件下,实现对整个视频序列中感兴趣对象的分割,但是视频中往往会出现目标形状不规则、背景中存在干扰信息和运动速度过快等情况,影响视频目标分割质量。对此,本文提出一种融合视觉词和自注意力机制的视频目标分割算法。方法对于参考帧,首先将其图像输入编码器中,提取分辨率为原图像1/8的像素特征。然后将该特征输入由若干卷积核构成的嵌入空间中,并将其结果上采样至原始尺寸。最后结合参考帧的目标掩码信息,通过聚类算法对嵌入空间中的像素进行聚类分簇,形成用于表示目标对象的视觉词。对于目标帧,首先将其图像通过编码器并输入嵌入空间中,通过单词匹配操作用参考帧生成的视觉词来表示嵌入空间中的像素,并获得多个相似图。然后,对相似图应用自注意力机制捕获全局依赖关系,最后取通道方向上的最大值作为预测结果。为了解决目标对象的外观变化和视觉词失配的问题,提出在线更新机制和全局校正机制以进一步提高准确率。结果实验结果表明,本文方法在视频目标分割数据集DAVIS(densely annotated video segmentation)2016和DAVIS 2017上取得了有竞争力的结果,区域相似度与轮廓精度之间的平均值J&F-mean(Jaccard and F-score mean)分别为83.2%和72.3%。结论本文提出的算法可以有效地处理由遮挡、变形和视点变化等带来的干扰问题,实现高质量的视频目标分割。关键词:视频目标分割(VOS);聚类算法;视觉词;自注意力机制;在线更新机制;全局校正机制77|172|1更新时间:2024-08-15 -
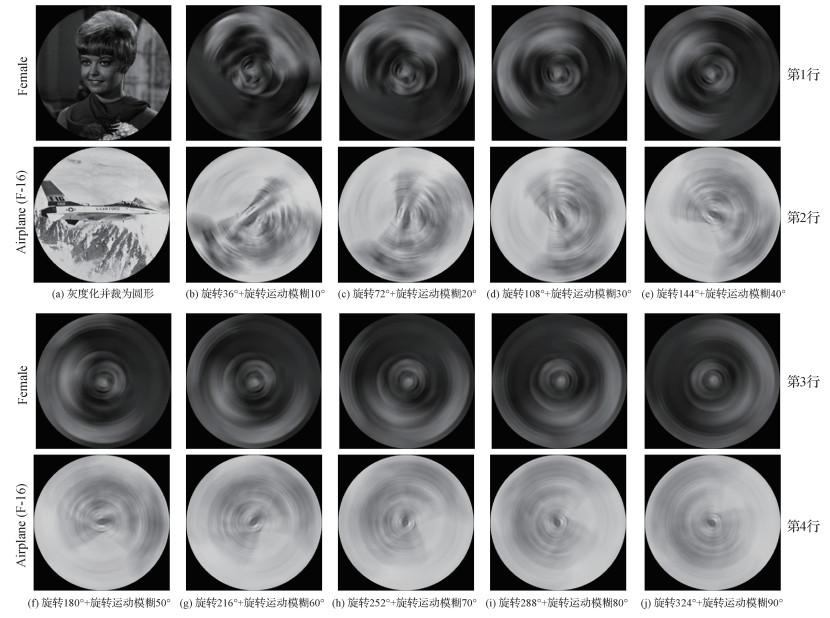 摘要:目的模糊图像的分析与识别是图像分析与识别领域的重要方向。有些图像形成过程中成像系统与物体之间存在相对旋转运动,如因导弹高速自旋转造成的制导图像的旋转运动模糊。大多数对于这类图像的识别都需要先对模糊图像进行“去模糊”的预处理,且该类方法存在计算时间复杂度较高及不适定的问题。对此,提出一种直接提取旋转运动模糊图像中的不变特征,用于旋转运动模糊图像目标检索和识别。方法本文以旋转运动模糊的退化模型为出发点,提出了旋转运动模糊Gaussian-Hermite(GH)矩,构造了一组由5个对旋转变换和旋转运动模糊保持不变性的GH矩不变量组成的特征向量(rotational motion blur Gaussian-Hermite moment invariants,RMB_GHMI-5),可从旋转变换和旋转运动模糊的图像中直接进行目标检索和识别,无需前置复杂的“去模糊”预处理过程。结果在USC-SIPI(University of Southern California — Signal and Image Processing Institute)数据集上进行不变性实验,对原图进行不同程度的旋转变换叠加旋转运动模糊处理,证明RMB_GHMI-5对于旋转变换和旋转运动模糊具有良好的稳定性和不变性。在两个数据集上与同类4种方法进行图像检索实验比较,在80%召回率下,本文方法维数更少,相比性能第2的特征向量,在Flavia数据集中,高斯噪声、椒盐噪声、泊松噪声和乘性噪声干扰下的准确率分别提高25.89%、39.95%、22.79%和35.80%;在Butterfly Image数据集中,高斯噪声、椒盐噪声、泊松噪声和乘性噪声干扰下的准确率分别提高4.79、7.63%、5.65%和18.31%。同时,在上述8个测试数据集中进行对比实验以验证融合算法的有效性,结果表明本文提出的GH矩和几何矩相融合算法显著改善了图像检索效果。结论本文提出的RMB_GHMI-5特征向量在旋转变换和旋转运动模糊下具有良好的不变性与稳定性,在图像检索抗噪性能方面表现优异。相比同类方法,本文方法更具实际应用价值。关键词:图像检索;图像不变特征;旋转运动模糊;Gaussian-Hermite矩;不变量109|160|1更新时间:2024-08-15
摘要:目的模糊图像的分析与识别是图像分析与识别领域的重要方向。有些图像形成过程中成像系统与物体之间存在相对旋转运动,如因导弹高速自旋转造成的制导图像的旋转运动模糊。大多数对于这类图像的识别都需要先对模糊图像进行“去模糊”的预处理,且该类方法存在计算时间复杂度较高及不适定的问题。对此,提出一种直接提取旋转运动模糊图像中的不变特征,用于旋转运动模糊图像目标检索和识别。方法本文以旋转运动模糊的退化模型为出发点,提出了旋转运动模糊Gaussian-Hermite(GH)矩,构造了一组由5个对旋转变换和旋转运动模糊保持不变性的GH矩不变量组成的特征向量(rotational motion blur Gaussian-Hermite moment invariants,RMB_GHMI-5),可从旋转变换和旋转运动模糊的图像中直接进行目标检索和识别,无需前置复杂的“去模糊”预处理过程。结果在USC-SIPI(University of Southern California — Signal and Image Processing Institute)数据集上进行不变性实验,对原图进行不同程度的旋转变换叠加旋转运动模糊处理,证明RMB_GHMI-5对于旋转变换和旋转运动模糊具有良好的稳定性和不变性。在两个数据集上与同类4种方法进行图像检索实验比较,在80%召回率下,本文方法维数更少,相比性能第2的特征向量,在Flavia数据集中,高斯噪声、椒盐噪声、泊松噪声和乘性噪声干扰下的准确率分别提高25.89%、39.95%、22.79%和35.80%;在Butterfly Image数据集中,高斯噪声、椒盐噪声、泊松噪声和乘性噪声干扰下的准确率分别提高4.79、7.63%、5.65%和18.31%。同时,在上述8个测试数据集中进行对比实验以验证融合算法的有效性,结果表明本文提出的GH矩和几何矩相融合算法显著改善了图像检索效果。结论本文提出的RMB_GHMI-5特征向量在旋转变换和旋转运动模糊下具有良好的不变性与稳定性,在图像检索抗噪性能方面表现优异。相比同类方法,本文方法更具实际应用价值。关键词:图像检索;图像不变特征;旋转运动模糊;Gaussian-Hermite矩;不变量109|160|1更新时间:2024-08-15
图像分析和识别
-
 摘要:目的在室内场景语义分割任务中,深度信息会在一定程度上提高分割精度。但是如何更有效地利用深度信息仍是一个开放性问题。当前方法大都引入全部深度信息,然而将全部深度信息和视觉特征组合在一起可能对模型产生干扰,原因是仅依靠视觉特征网络模型就能区分的不同物体,在引入深度信息后可能产生错误判断。此外,卷积核固有的几何结构限制了卷积神经网络的建模能力,可变形卷积(deformable convolution,DC)在一定程度上缓解了这个问题。但是可变形卷积中产生位置偏移的视觉特征空间深度信息相对不足,限制了进一步发展。基于上述问题,本文提出一种深度信息引导的特征提取(depth guided feature extraction,DFE)模块。方法深度信息引导的特征提取模块包括深度信息引导的特征选择模块(depth guided feature selection,DFS)和深度信息嵌入的可变形卷积模块(depth embedded deformable convolution,DDC)。DFS可以筛选出关键的深度信息,自适应地调整深度信息引入视觉特征的比例,在网络模型需要时将深度信息嵌入视觉特征。DDC在额外深度信息的引入下,增强了可变形卷积的特征提取能力,可以根据物体形状提取更相关的特征。结果为了验证方法的有效性,在NYUv2(New York University Depth Dataset V2)数据集上进行一系列消融实验并与当前最好的方法进行比较,使用平均交并比(mean intersection over union,mIoU)和平均像素准确率(pixel accuracy,PA)作为度量标准。结果显示,在NYUv2数据集上,本文方法的mIoU和PA分别为51.9%和77.6%,实现了较好的分割效果。结论本文提出的深度信息引导的特征提取模块,可以自适应地调整深度信息嵌入视觉特征的程度,更加合理地利用深度信息,且在深度信息的作用下提高可变形卷积的特征提取能力。此外,本文提出的深度信息引导的特征提取模块可以比较方便地嵌入当下流行的特征提取网络中,提高网络的建模能力。关键词:语义分割;RGB-D;深度信息引导的特征选择(DFS);深度信息嵌入的可变形卷积(DDC);深度信息引导的特征提取(DFE)109|151|1更新时间:2024-08-15
摘要:目的在室内场景语义分割任务中,深度信息会在一定程度上提高分割精度。但是如何更有效地利用深度信息仍是一个开放性问题。当前方法大都引入全部深度信息,然而将全部深度信息和视觉特征组合在一起可能对模型产生干扰,原因是仅依靠视觉特征网络模型就能区分的不同物体,在引入深度信息后可能产生错误判断。此外,卷积核固有的几何结构限制了卷积神经网络的建模能力,可变形卷积(deformable convolution,DC)在一定程度上缓解了这个问题。但是可变形卷积中产生位置偏移的视觉特征空间深度信息相对不足,限制了进一步发展。基于上述问题,本文提出一种深度信息引导的特征提取(depth guided feature extraction,DFE)模块。方法深度信息引导的特征提取模块包括深度信息引导的特征选择模块(depth guided feature selection,DFS)和深度信息嵌入的可变形卷积模块(depth embedded deformable convolution,DDC)。DFS可以筛选出关键的深度信息,自适应地调整深度信息引入视觉特征的比例,在网络模型需要时将深度信息嵌入视觉特征。DDC在额外深度信息的引入下,增强了可变形卷积的特征提取能力,可以根据物体形状提取更相关的特征。结果为了验证方法的有效性,在NYUv2(New York University Depth Dataset V2)数据集上进行一系列消融实验并与当前最好的方法进行比较,使用平均交并比(mean intersection over union,mIoU)和平均像素准确率(pixel accuracy,PA)作为度量标准。结果显示,在NYUv2数据集上,本文方法的mIoU和PA分别为51.9%和77.6%,实现了较好的分割效果。结论本文提出的深度信息引导的特征提取模块,可以自适应地调整深度信息嵌入视觉特征的程度,更加合理地利用深度信息,且在深度信息的作用下提高可变形卷积的特征提取能力。此外,本文提出的深度信息引导的特征提取模块可以比较方便地嵌入当下流行的特征提取网络中,提高网络的建模能力。关键词:语义分割;RGB-D;深度信息引导的特征选择(DFS);深度信息嵌入的可变形卷积(DDC);深度信息引导的特征提取(DFE)109|151|1更新时间:2024-08-15 -
 摘要:目的人脸美丽预测是研究如何使计算机具有与人类相似的人脸美丽判断或预测能力,然而利用深度神经网络进行人脸美丽预测存在过度拟合噪声标签样本问题,从而影响深度神经网络的泛化性。因此,本文提出一种自纠正噪声标签方法用于人脸美丽预测。方法该方法包括自训练教师模型机制和重标签再训练机制。自训练教师模型机制以自训练的方式获得教师模型,帮助学生模型进行干净样本选择和训练,直至学生模型泛化能力超过教师模型并成为新的教师模型,并不断重复该过程;重标签再训练机制通过比较最大预测概率和标签对应预测概率,从而纠正噪声标签。同时,利用纠正后的数据反复执行自训练教师模型机制。结果在大规模人脸美丽数据库LSFBD(large scale facial beauty database)和SCUT-FBP5500数据库上进行实验。结果表明,本文方法在人工合成噪声标签的条件下可降低噪声标签的负面影响,同时在原始LSFBD数据库和SCUT-FBP5500数据库上分别取得60.8%和75.5%的准确率,高于常规方法。结论在人工合成噪声标签条件下的LSFBD和SCUT-FBP5500数据库以及原始LSFBD和SCUT-FBP5500数据库上的实验表明,所提自纠正噪声标签方法具有选择干净样本学习、充分利用全部数据的特点,可降低噪声标签的负面影响,能在一定程度上降低人脸美丽预测中噪声标签的负面影响,提高预测准确率。关键词:深度学习;噪声标签;人脸美丽预测;特征分类;深度神经网络83|139|0更新时间:2024-08-15
摘要:目的人脸美丽预测是研究如何使计算机具有与人类相似的人脸美丽判断或预测能力,然而利用深度神经网络进行人脸美丽预测存在过度拟合噪声标签样本问题,从而影响深度神经网络的泛化性。因此,本文提出一种自纠正噪声标签方法用于人脸美丽预测。方法该方法包括自训练教师模型机制和重标签再训练机制。自训练教师模型机制以自训练的方式获得教师模型,帮助学生模型进行干净样本选择和训练,直至学生模型泛化能力超过教师模型并成为新的教师模型,并不断重复该过程;重标签再训练机制通过比较最大预测概率和标签对应预测概率,从而纠正噪声标签。同时,利用纠正后的数据反复执行自训练教师模型机制。结果在大规模人脸美丽数据库LSFBD(large scale facial beauty database)和SCUT-FBP5500数据库上进行实验。结果表明,本文方法在人工合成噪声标签的条件下可降低噪声标签的负面影响,同时在原始LSFBD数据库和SCUT-FBP5500数据库上分别取得60.8%和75.5%的准确率,高于常规方法。结论在人工合成噪声标签条件下的LSFBD和SCUT-FBP5500数据库以及原始LSFBD和SCUT-FBP5500数据库上的实验表明,所提自纠正噪声标签方法具有选择干净样本学习、充分利用全部数据的特点,可降低噪声标签的负面影响,能在一定程度上降低人脸美丽预测中噪声标签的负面影响,提高预测准确率。关键词:深度学习;噪声标签;人脸美丽预测;特征分类;深度神经网络83|139|0更新时间:2024-08-15 -
 摘要:目的太赫兹由于穿透性强、对人体无害等特性在安检领域中得到了广泛关注。太赫兹图像中目标尺寸较小、特征有限,且图像分辨率低,目标边缘信息模糊,目标信息容易和背景信息混淆,为太赫兹图像检测带来了一定困难。方法本文在YOLO(you only look once)算法的基础上提出了一种融合非对称特征注意力和特征融合的目标检测网络AFA-YOLO(asymmetric feature attention-YOLO)。在特征提取网络CSPDarkNet53(cross stage paritial DarkNet53)中设计了非对称特征注意力模块。该模块在浅层网络中采用非对称卷积强化了网络的特征提取能力,帮助网络模型在目标特征有限的太赫兹图像中提取到更有效的目标信息;使用通道注意力和空间注意力机制使网络更加关注图像中目标的重要信息,抑制与目标无关的背景信息;AFA-YOLO通过增加网络中低层到高层的信息传输路径对高层特征进行特征融合,充分利用到低层高分辨率特征进行小目标的检测。结果本文在太赫兹数据集上进行了相关实验,相比原YOLOv4算法,AFA-YOLO对phone的检测精度为81.15%,提升了4.12%,knife的检测精度为83.06%,提升了3.72%。模型平均精度均值(mean average precision, mAP)为82.36%,提升了3.92%,漏警率(missing alarm, MA)为12.78%,降低了2.65%,帧率为32.26帧/s,降低了4.06帧/s。同时,本文在太赫兹数据集上对比了不同的检测算法,综合检测速度、检测精度和漏警率,AFA-YOLO优于其他目标检测算法。结论本文提出的AFA-YOLO算法在保证实时性检测的同时有效提升了太赫兹图像中目标的检测精度并降低了漏警率。关键词:太赫兹图像;小尺度目标检测;YOLOv4;非对称卷积;注意力机制;特征融合85|212|2更新时间:2024-08-15
摘要:目的太赫兹由于穿透性强、对人体无害等特性在安检领域中得到了广泛关注。太赫兹图像中目标尺寸较小、特征有限,且图像分辨率低,目标边缘信息模糊,目标信息容易和背景信息混淆,为太赫兹图像检测带来了一定困难。方法本文在YOLO(you only look once)算法的基础上提出了一种融合非对称特征注意力和特征融合的目标检测网络AFA-YOLO(asymmetric feature attention-YOLO)。在特征提取网络CSPDarkNet53(cross stage paritial DarkNet53)中设计了非对称特征注意力模块。该模块在浅层网络中采用非对称卷积强化了网络的特征提取能力,帮助网络模型在目标特征有限的太赫兹图像中提取到更有效的目标信息;使用通道注意力和空间注意力机制使网络更加关注图像中目标的重要信息,抑制与目标无关的背景信息;AFA-YOLO通过增加网络中低层到高层的信息传输路径对高层特征进行特征融合,充分利用到低层高分辨率特征进行小目标的检测。结果本文在太赫兹数据集上进行了相关实验,相比原YOLOv4算法,AFA-YOLO对phone的检测精度为81.15%,提升了4.12%,knife的检测精度为83.06%,提升了3.72%。模型平均精度均值(mean average precision, mAP)为82.36%,提升了3.92%,漏警率(missing alarm, MA)为12.78%,降低了2.65%,帧率为32.26帧/s,降低了4.06帧/s。同时,本文在太赫兹数据集上对比了不同的检测算法,综合检测速度、检测精度和漏警率,AFA-YOLO优于其他目标检测算法。结论本文提出的AFA-YOLO算法在保证实时性检测的同时有效提升了太赫兹图像中目标的检测精度并降低了漏警率。关键词:太赫兹图像;小尺度目标检测;YOLOv4;非对称卷积;注意力机制;特征融合85|212|2更新时间:2024-08-15 -
 摘要:目的传统图像处理的纹理滤波方法难以区分梯度较强的纹理与物体的结构,而深度学习方法使用的训练集生成方式不够合理,且模型表示方式比较粗糙,为此本文设计了一种面向纹理平滑的方向性滤波尺度预测模型,并生成了含有标签的新的纹理滤波数据集。方法在现有结构图像中逐连通区域填充多种纹理图,生成有利于模型训练的纹理滤波数据集。设计了方向性滤波尺度预测模型,该模型包含尺度感知子网络和图像平滑子网络。前者预测得到的滤波尺度图不但体现了该像素与周围像素是否为同一纹理,而且还隐含了该像素是否为结构像素的信息。后者以滤波尺度图和原图的堆叠作为输入,凭借少量的卷积层快速得出纹理滤波的结果。结果在本文的纹理滤波数据集上与7个算法进行比较,峰值信噪比(peak signal to noise ratio,PSNR)与结构相似度(structural similarity,SSIM)分别高于第2名2.79 dB、0.0133,均方误差(mean squared error,MSE)低于第2名6.863 8,运算速度快于第2名0.002 s。在其他数据集上的实验对比也显示出本文算法更好地保持结构与平滑纹理。通过比较不同数据集上训练的同一网络模型,证实了本文的纹理滤波数据集有助于增强模型对于强梯度纹理与物体结构的区分能力。结论本文制作的纹理滤波数据集使模型更好地区分强梯度纹理与物体结构并增强模型的泛化能力。本文设计的方向性滤波尺度预测模型在性能上超越了已有的大多数纹理平滑方法,尤其在强梯度纹理的抑制和弱梯度结构的保持两个方面表现优异。关键词:深度学习;图像平滑;纹理滤波;数据集生成;U型网络(U-Net)87|168|1更新时间:2024-08-15
摘要:目的传统图像处理的纹理滤波方法难以区分梯度较强的纹理与物体的结构,而深度学习方法使用的训练集生成方式不够合理,且模型表示方式比较粗糙,为此本文设计了一种面向纹理平滑的方向性滤波尺度预测模型,并生成了含有标签的新的纹理滤波数据集。方法在现有结构图像中逐连通区域填充多种纹理图,生成有利于模型训练的纹理滤波数据集。设计了方向性滤波尺度预测模型,该模型包含尺度感知子网络和图像平滑子网络。前者预测得到的滤波尺度图不但体现了该像素与周围像素是否为同一纹理,而且还隐含了该像素是否为结构像素的信息。后者以滤波尺度图和原图的堆叠作为输入,凭借少量的卷积层快速得出纹理滤波的结果。结果在本文的纹理滤波数据集上与7个算法进行比较,峰值信噪比(peak signal to noise ratio,PSNR)与结构相似度(structural similarity,SSIM)分别高于第2名2.79 dB、0.0133,均方误差(mean squared error,MSE)低于第2名6.863 8,运算速度快于第2名0.002 s。在其他数据集上的实验对比也显示出本文算法更好地保持结构与平滑纹理。通过比较不同数据集上训练的同一网络模型,证实了本文的纹理滤波数据集有助于增强模型对于强梯度纹理与物体结构的区分能力。结论本文制作的纹理滤波数据集使模型更好地区分强梯度纹理与物体结构并增强模型的泛化能力。本文设计的方向性滤波尺度预测模型在性能上超越了已有的大多数纹理平滑方法,尤其在强梯度纹理的抑制和弱梯度结构的保持两个方面表现优异。关键词:深度学习;图像平滑;纹理滤波;数据集生成;U型网络(U-Net)87|168|1更新时间:2024-08-15
图像理解和计算机视觉
-
 摘要:目的在高分辨率遥感影像语义分割任务中,仅利用可见光图像很难区分光谱特征相似的区域(如草坪和树、道路和建筑物),高程信息的引入可以显著改善分类结果。然而,可见光图像与高程数据的特征分布差异较大,简单的级联或相加的融合方式不能有效处理两种模态融合时的噪声,使得融合效果不佳。因此如何有效地融合多模态特征成为遥感语义分割的关键问题。针对这一问题,本文提出了一个多源特征自适应融合模型。方法通过像素的目标类别以及上下文信息动态融合模态特征,减弱融合噪声影响,有效利用多模态数据的互补信息。该模型主要包含3个部分:双编码器负责提取光谱和高程模态的特征;模态自适应融合模块协同处理多模态特征,依据像素的目标类别以及上下文信息动态地利用高程信息强化光谱特征,使得网络可以针对特定的对象类别或者特定的空间位置来选择特定模态网络的特征信息;全局上下文聚合模块,从空间和通道角度进行全局上下文建模以获得更丰富的特征表示。结果对实验结果进行定性、定量相结合的评价。定性结果中,本文算法获取的分割结果更加精细化。定量结果中,在ISPRS(International Society for Photogrammetry and Remote Sensing)Vaihingen和GID(Gaofen Image Dataset)数据集上对本文模型进行评估,分别达到了90.77%、82.1%的总体精度。与DeepLab V3+、PSPNet(pyramid scene parsing network)等算法相比,本文算法明显更优。结论实验结果表明,本文提出的多源特征自适应融合网络可以有效地进行模态特征融合,更加高效地建模全局上下文关系,可以广泛应用于遥感领域。关键词:语义分割;遥感影像;多模态;模态自适应融合;全局上下文聚合227|192|7更新时间:2024-08-15
摘要:目的在高分辨率遥感影像语义分割任务中,仅利用可见光图像很难区分光谱特征相似的区域(如草坪和树、道路和建筑物),高程信息的引入可以显著改善分类结果。然而,可见光图像与高程数据的特征分布差异较大,简单的级联或相加的融合方式不能有效处理两种模态融合时的噪声,使得融合效果不佳。因此如何有效地融合多模态特征成为遥感语义分割的关键问题。针对这一问题,本文提出了一个多源特征自适应融合模型。方法通过像素的目标类别以及上下文信息动态融合模态特征,减弱融合噪声影响,有效利用多模态数据的互补信息。该模型主要包含3个部分:双编码器负责提取光谱和高程模态的特征;模态自适应融合模块协同处理多模态特征,依据像素的目标类别以及上下文信息动态地利用高程信息强化光谱特征,使得网络可以针对特定的对象类别或者特定的空间位置来选择特定模态网络的特征信息;全局上下文聚合模块,从空间和通道角度进行全局上下文建模以获得更丰富的特征表示。结果对实验结果进行定性、定量相结合的评价。定性结果中,本文算法获取的分割结果更加精细化。定量结果中,在ISPRS(International Society for Photogrammetry and Remote Sensing)Vaihingen和GID(Gaofen Image Dataset)数据集上对本文模型进行评估,分别达到了90.77%、82.1%的总体精度。与DeepLab V3+、PSPNet(pyramid scene parsing network)等算法相比,本文算法明显更优。结论实验结果表明,本文提出的多源特征自适应融合网络可以有效地进行模态特征融合,更加高效地建模全局上下文关系,可以广泛应用于遥感领域。关键词:语义分割;遥感影像;多模态;模态自适应融合;全局上下文聚合227|192|7更新时间:2024-08-15 -
 摘要:目的图像分割的中心任务是寻找更强大的特征表示,而合成孔径雷达(synthetic aperture radar,SAR)图像中斑点噪声阻碍特征提取。为加强对SAR图像特征的提取以及对特征充分利用,提出一种改进的全卷积分割网络。方法该网络遵循编码器—解码器结构,主要包括上下文编码模块和特征融合模块两部分。上下文编码模块(contextual encoder module,CEM)通过捕获局部上下文和通道上下文信息增强对图像的特征提取;特征融合模块(feature fusion module,FFM)提取高层特征中的全局上下文信息,将其嵌入低层特征,然后将增强的低层特征并入解码网络,提升特征图分辨率恢复的准确性。结果在两幅真实SAR图像上,采用5种基于全卷积神经网络的分割算法作为对比,并对CEM与CEM-FFM分别进行实验。结果显示,该网络分割结果的总体精度(overall accuracy,OA)、平均精度(average accuracy,AA)与Kappa系数比5种先进算法均有显著提升。其中,网络在OA上表现最好,CEM在两幅SAR图像上OA分别为91.082%和90.903%,较对比算法中性能最优者分别提高了0.948%和0.941%,证实了CEM的有效性。而CEM-FFM在CEM基础上又将结果分别提高了2.149%和2.390%,验证了FFM的有效性。结论本文提出的分割网络较其他方法对图像具有更强大的特征提取能力,且能更好地将低层特征中的空间信息与高层特征中的语义信息融合为一体,使得网络对特征的表征能力更强、图像分割结果更准确。关键词:图像分割;全卷积神经网络(FCN);特征融合;上下文信息;合成孔径雷达(SAR)54|162|0更新时间:2024-08-15
摘要:目的图像分割的中心任务是寻找更强大的特征表示,而合成孔径雷达(synthetic aperture radar,SAR)图像中斑点噪声阻碍特征提取。为加强对SAR图像特征的提取以及对特征充分利用,提出一种改进的全卷积分割网络。方法该网络遵循编码器—解码器结构,主要包括上下文编码模块和特征融合模块两部分。上下文编码模块(contextual encoder module,CEM)通过捕获局部上下文和通道上下文信息增强对图像的特征提取;特征融合模块(feature fusion module,FFM)提取高层特征中的全局上下文信息,将其嵌入低层特征,然后将增强的低层特征并入解码网络,提升特征图分辨率恢复的准确性。结果在两幅真实SAR图像上,采用5种基于全卷积神经网络的分割算法作为对比,并对CEM与CEM-FFM分别进行实验。结果显示,该网络分割结果的总体精度(overall accuracy,OA)、平均精度(average accuracy,AA)与Kappa系数比5种先进算法均有显著提升。其中,网络在OA上表现最好,CEM在两幅SAR图像上OA分别为91.082%和90.903%,较对比算法中性能最优者分别提高了0.948%和0.941%,证实了CEM的有效性。而CEM-FFM在CEM基础上又将结果分别提高了2.149%和2.390%,验证了FFM的有效性。结论本文提出的分割网络较其他方法对图像具有更强大的特征提取能力,且能更好地将低层特征中的空间信息与高层特征中的语义信息融合为一体,使得网络对特征的表征能力更强、图像分割结果更准确。关键词:图像分割;全卷积神经网络(FCN);特征融合;上下文信息;合成孔径雷达(SAR)54|162|0更新时间:2024-08-15 -
 摘要:目的主流深度学习的目标检测技术对自然影像的识别精度依赖于锚框设置的好坏,并使用平行于坐标轴的正框表示物体位置,而遥感影像中地物目标具有尺寸多变、分布密集、长宽比悬殊且朝向不定的特点,更宜通过与物体朝向一致的斜框表示其位置。本文试图结合无锚框和斜框检测技术,在遥感影像上实现高精度目标识别。方法使用斜框标注能够更为紧密地贴合目标边缘,有效减少识别干扰因素。本文基于单阶段无锚框目标检测算法:一阶全卷积目标检测网络(fully convolutional one-stage object detector, FCOS),通过引入滑动点结构,在遥感影像上实现高效率、高精度的斜框目标检测。与FCOS的不同之处在于,本文改进的检测算法增加了用于斜框检测的两个分支,通过在正框的两邻边上回归滑动顶点比率产生斜框,并预测斜框与正框的面积比以减少极端情况下的检测误差。结果在当前最大、最复杂的斜框遥感目标检测数据集DOTA(object detection in aerial images)上对本文方法进行评测,使用ResNet50作为骨干网络,平均精确率(mean average precision, mAP)达到74.84%,相比原始正框FCOS算法精度提升了33.02%,相比于YOLOv3(you only look once)效率提升了38.82%,比斜框检测算法R3Det(refined rotation RetinaNet)精度提升了1.53%。结论实验结果说明改进的FCOS算法能够很好地适应高分辨率遥感倾斜目标识别场景。关键词:深度学习;遥感影像;无锚框;特征提取;多尺度特征融合;倾斜目标检测196|219|0更新时间:2024-08-15
摘要:目的主流深度学习的目标检测技术对自然影像的识别精度依赖于锚框设置的好坏,并使用平行于坐标轴的正框表示物体位置,而遥感影像中地物目标具有尺寸多变、分布密集、长宽比悬殊且朝向不定的特点,更宜通过与物体朝向一致的斜框表示其位置。本文试图结合无锚框和斜框检测技术,在遥感影像上实现高精度目标识别。方法使用斜框标注能够更为紧密地贴合目标边缘,有效减少识别干扰因素。本文基于单阶段无锚框目标检测算法:一阶全卷积目标检测网络(fully convolutional one-stage object detector, FCOS),通过引入滑动点结构,在遥感影像上实现高效率、高精度的斜框目标检测。与FCOS的不同之处在于,本文改进的检测算法增加了用于斜框检测的两个分支,通过在正框的两邻边上回归滑动顶点比率产生斜框,并预测斜框与正框的面积比以减少极端情况下的检测误差。结果在当前最大、最复杂的斜框遥感目标检测数据集DOTA(object detection in aerial images)上对本文方法进行评测,使用ResNet50作为骨干网络,平均精确率(mean average precision, mAP)达到74.84%,相比原始正框FCOS算法精度提升了33.02%,相比于YOLOv3(you only look once)效率提升了38.82%,比斜框检测算法R3Det(refined rotation RetinaNet)精度提升了1.53%。结论实验结果说明改进的FCOS算法能够很好地适应高分辨率遥感倾斜目标识别场景。关键词:深度学习;遥感影像;无锚框;特征提取;多尺度特征融合;倾斜目标检测196|219|0更新时间:2024-08-15
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0