
最新刊期
2022 年 第 27 卷 第 7 期
-
 摘要:细粒度图像识别旨在对某一传统语义类别下细粒度级别的不同子类类别进行视觉识别,在智慧新经济和工业物联网等领域(如智慧城市、公共安全、生态保护、农业生产与安全保障)具有重要的科学意义和应用价值。细粒度图像识别在深度学习的助力下取得了长足进步,但其对大规模优质细粒度图像数据的依赖成为制约细粒度图像识别推广和普及的瓶颈。随着互联网和大数据的快速发展,网络监督图像数据作为免费的数据来源成为缓解深度学习对大数据依赖的可行解决方案,如何有效利用网络监督数据成为提升细粒度图像识别推广性和泛化性的热门课题。本文围绕细粒度图像识别主题,以网络监督数据下的细粒度识别为重点,先后对细粒度识别数据集、传统细粒度识别方法、网络监督下细粒度识别特点与方法进行介绍,并回顾了全球首届网络监督下的细粒度图像识别竞赛的相关情况及冠军解决方案。最后,在上述内容基础上总结和讨论了该领域的未来发展趋势。关键词:网络监督;细粒度图像识别;噪声数据;长尾分布;类间差异小;综述358|277|3更新时间:2024-05-07
摘要:细粒度图像识别旨在对某一传统语义类别下细粒度级别的不同子类类别进行视觉识别,在智慧新经济和工业物联网等领域(如智慧城市、公共安全、生态保护、农业生产与安全保障)具有重要的科学意义和应用价值。细粒度图像识别在深度学习的助力下取得了长足进步,但其对大规模优质细粒度图像数据的依赖成为制约细粒度图像识别推广和普及的瓶颈。随着互联网和大数据的快速发展,网络监督图像数据作为免费的数据来源成为缓解深度学习对大数据依赖的可行解决方案,如何有效利用网络监督数据成为提升细粒度图像识别推广性和泛化性的热门课题。本文围绕细粒度图像识别主题,以网络监督数据下的细粒度识别为重点,先后对细粒度识别数据集、传统细粒度识别方法、网络监督下细粒度识别特点与方法进行介绍,并回顾了全球首届网络监督下的细粒度图像识别竞赛的相关情况及冠军解决方案。最后,在上述内容基础上总结和讨论了该领域的未来发展趋势。关键词:网络监督;细粒度图像识别;噪声数据;长尾分布;类间差异小;综述358|277|3更新时间:2024-05-07
学者观点

-
 摘要:舰船目标检测是海域监控、港口流量统计、舰船身份识别以及行为分析与取证等智能海事应用的基石。随着我国海洋强国建设的推进,智慧航运和智慧海洋工程迅速发展,对通过海事监控视频开展有效的舰船目标检测识别以确保航运和海洋工程安全的需求日益紧迫。本文针对基于海事监控视频的舰船目标检测任务,回顾了舰船目标检测数据集及性能评价指标、基于传统机器学习和基于卷积神经网络的深度学习的目标检测方法等方面的国内外研究现状,分析了海洋环境中舰船目标检测任务面临的舰船目标尺度的多样性、舰船类别的多样性、海洋气象的复杂性、水面的动态性、相机的运动性和图像的低质量等技术难点,并通过实验验证,在多尺度特征融合、数据增广和能耗降低等方面提出了舰船目标检测的优化方法;同时,结合前人研究指出舰船目标检测数据集的发展应关注分类粒度的适宜性、标注的一致性和数据集的易扩充性,应加强对多尺度目标(尤其是小型目标)检测的模型结构的研究,为进一步提升舰船目标检测任务的综合性能,促进舰船目标检测技术的应用提供了新的思路。关键词:舰船目标检测;海事监控数据集;小目标检测;数据增广;卷积神经网络性能优化140|529|2更新时间:2024-05-07
摘要:舰船目标检测是海域监控、港口流量统计、舰船身份识别以及行为分析与取证等智能海事应用的基石。随着我国海洋强国建设的推进,智慧航运和智慧海洋工程迅速发展,对通过海事监控视频开展有效的舰船目标检测识别以确保航运和海洋工程安全的需求日益紧迫。本文针对基于海事监控视频的舰船目标检测任务,回顾了舰船目标检测数据集及性能评价指标、基于传统机器学习和基于卷积神经网络的深度学习的目标检测方法等方面的国内外研究现状,分析了海洋环境中舰船目标检测任务面临的舰船目标尺度的多样性、舰船类别的多样性、海洋气象的复杂性、水面的动态性、相机的运动性和图像的低质量等技术难点,并通过实验验证,在多尺度特征融合、数据增广和能耗降低等方面提出了舰船目标检测的优化方法;同时,结合前人研究指出舰船目标检测数据集的发展应关注分类粒度的适宜性、标注的一致性和数据集的易扩充性,应加强对多尺度目标(尤其是小型目标)检测的模型结构的研究,为进一步提升舰船目标检测任务的综合性能,促进舰船目标检测技术的应用提供了新的思路。关键词:舰船目标检测;海事监控数据集;小目标检测;数据增广;卷积神经网络性能优化140|529|2更新时间:2024-05-07 -
 摘要:行人检测技术在智能交通系统、智能安防监控和智能机器人等领域均表现出了极高的应用价值,已经成为计算机视觉领域的重要研究方向之一。得益于深度学习的飞速发展,基于深度卷积神经网络的通用目标检测模型不断拓展应用到行人检测领域,并取得了良好的性能。但是由于行人目标内在的特殊性和复杂性,特别是考虑到复杂场景下的行人遮挡和尺度变化等问题,基于深度学习的行人检测方法也面临着精度及效率的严峻挑战。本文针对上述问题,以基于深度学习的行人检测技术为研究对象,在充分调研文献的基础上,分别从基于锚点框、基于无锚点框以及通用技术改进(例如损失函数改进、非极大值抑制方法等)3个角度,对行人检测算法进行详细划分,并针对性地选取具有代表性的方法进行详细结合和对比分析。本文总结了当前行人检测领域的通用数据集,从数据构成角度分析各数据集应用场景。同时讨论了各类算法在不同数据集上的性能表现,对比分析各算法在不同数据集中的优劣。最后,对行人检测中待解决的问题与未来的研究方法做出预测和展望。如何缓解遮挡导致的特征缺失问题、如何应对单一视角下尺度变化问题、如何提高检测器效率以及如何有效利用多模态信息提高行人检测精度,均是值得进一步研究的方向。关键词:行人检测;深度学习;卷积神经网络(CNN);遮挡目标检测;小目标检测422|301|9更新时间:2024-05-07
摘要:行人检测技术在智能交通系统、智能安防监控和智能机器人等领域均表现出了极高的应用价值,已经成为计算机视觉领域的重要研究方向之一。得益于深度学习的飞速发展,基于深度卷积神经网络的通用目标检测模型不断拓展应用到行人检测领域,并取得了良好的性能。但是由于行人目标内在的特殊性和复杂性,特别是考虑到复杂场景下的行人遮挡和尺度变化等问题,基于深度学习的行人检测方法也面临着精度及效率的严峻挑战。本文针对上述问题,以基于深度学习的行人检测技术为研究对象,在充分调研文献的基础上,分别从基于锚点框、基于无锚点框以及通用技术改进(例如损失函数改进、非极大值抑制方法等)3个角度,对行人检测算法进行详细划分,并针对性地选取具有代表性的方法进行详细结合和对比分析。本文总结了当前行人检测领域的通用数据集,从数据构成角度分析各数据集应用场景。同时讨论了各类算法在不同数据集上的性能表现,对比分析各算法在不同数据集中的优劣。最后,对行人检测中待解决的问题与未来的研究方法做出预测和展望。如何缓解遮挡导致的特征缺失问题、如何应对单一视角下尺度变化问题、如何提高检测器效率以及如何有效利用多模态信息提高行人检测精度,均是值得进一步研究的方向。关键词:行人检测;深度学习;卷积神经网络(CNN);遮挡目标检测;小目标检测422|301|9更新时间:2024-05-07 -
 摘要:视觉显著性物体检测是对人类视觉和认知系统的模拟,而深度学习则是对人类大脑计算方式的模拟,将两者有机结合可以有效推动计算机视觉的发展。视觉显著性物体检测的任务是从图像中定位并提取具有明确轮廓的显著性物体实例。随着深度学习的发展,视觉显著性物体检测的精度和效率都得到巨大提升,但仍然面临改进主流算法性能、减少对像素级标注样本的依赖等主要挑战。针对上述挑战,本文从视觉显著性物体检测思想与深度学习方法融合策略的角度对相关论述进行分类总结。1)分析传统显著性物体检测方法带来的启示及其缺点,指出视觉显著性物体检测的核心思路为多层次特征的提取、融合与修整;2)从改进特征编码方式与信息传递结构、提升边缘定位精度、改善注意力机制、提升训练稳定性和控制噪声的角度对循环卷积神经网络、全卷积神经网络和生成对抗网络3种主流算法的性能提升进行分析,从优化弱监督样本处理模块的角度分析了减少对像素级标注样本依赖的方法;3)对协同显著性物体检测、多类别图像显著性物体检测以及未来的研究问题和方向进行介绍,并给出了可能的解决思路。关键词:显著性物体检测(SOD);深度学习;循环卷积神经网络(RCNN);全卷积网络(FCN);注意力机制;弱监督与多任务策略113|257|6更新时间:2024-05-07
摘要:视觉显著性物体检测是对人类视觉和认知系统的模拟,而深度学习则是对人类大脑计算方式的模拟,将两者有机结合可以有效推动计算机视觉的发展。视觉显著性物体检测的任务是从图像中定位并提取具有明确轮廓的显著性物体实例。随着深度学习的发展,视觉显著性物体检测的精度和效率都得到巨大提升,但仍然面临改进主流算法性能、减少对像素级标注样本的依赖等主要挑战。针对上述挑战,本文从视觉显著性物体检测思想与深度学习方法融合策略的角度对相关论述进行分类总结。1)分析传统显著性物体检测方法带来的启示及其缺点,指出视觉显著性物体检测的核心思路为多层次特征的提取、融合与修整;2)从改进特征编码方式与信息传递结构、提升边缘定位精度、改善注意力机制、提升训练稳定性和控制噪声的角度对循环卷积神经网络、全卷积神经网络和生成对抗网络3种主流算法的性能提升进行分析,从优化弱监督样本处理模块的角度分析了减少对像素级标注样本依赖的方法;3)对协同显著性物体检测、多类别图像显著性物体检测以及未来的研究问题和方向进行介绍,并给出了可能的解决思路。关键词:显著性物体检测(SOD);深度学习;循环卷积神经网络(RCNN);全卷积网络(FCN);注意力机制;弱监督与多任务策略113|257|6更新时间:2024-05-07
综述
-
 摘要:目的雾霾、雨雪天气和水下等非理想环境因素会引起图像退化,导致出现低质图像,从而影响人类主观视觉感受及机器视觉应用任务的性能,因此,低质图像被利用之前进行图像增强成为惯常的预处理过程。然而,图像增强能否提高图像机器视觉应用任务的性能及影响程度等问题鲜有系统性研究。针对上述问题,本文以图像显著性目标检测这一机器视觉应用为例,研究图像增强对显著性目标检测性能的影响。方法首先利用包括5种传统方法、6种深度学习方法等共11种典型图像增强方法对图像进行增强处理,然后利用8种典型的显著性目标检测方法对增强前后的图像分别进行显著性目标检测实验,并对比分析其结果。结果实验表明,图像增强对低质图像显著性目标检测方法性能的促进作用不明显,某些增强方法甚至表现出负面影响,也存在同一增强方法对不同的显著性目标检测方法作用不同的现象。结论图像增强对于显著性目标检测及其他的机器视觉应用的实际效果值得进一步研究,如何根据图像机器视觉应用的需求来选择和设计有效的增强方法需进一步探讨。关键词:水下图像;雾霾图像;图像增强;显著性目标检测;图像处理138|1106|4更新时间:2024-05-07
摘要:目的雾霾、雨雪天气和水下等非理想环境因素会引起图像退化,导致出现低质图像,从而影响人类主观视觉感受及机器视觉应用任务的性能,因此,低质图像被利用之前进行图像增强成为惯常的预处理过程。然而,图像增强能否提高图像机器视觉应用任务的性能及影响程度等问题鲜有系统性研究。针对上述问题,本文以图像显著性目标检测这一机器视觉应用为例,研究图像增强对显著性目标检测性能的影响。方法首先利用包括5种传统方法、6种深度学习方法等共11种典型图像增强方法对图像进行增强处理,然后利用8种典型的显著性目标检测方法对增强前后的图像分别进行显著性目标检测实验,并对比分析其结果。结果实验表明,图像增强对低质图像显著性目标检测方法性能的促进作用不明显,某些增强方法甚至表现出负面影响,也存在同一增强方法对不同的显著性目标检测方法作用不同的现象。结论图像增强对于显著性目标检测及其他的机器视觉应用的实际效果值得进一步研究,如何根据图像机器视觉应用的需求来选择和设计有效的增强方法需进一步探讨。关键词:水下图像;雾霾图像;图像增强;显著性目标检测;图像处理138|1106|4更新时间:2024-05-07 -
 摘要:目的经典的聚类算法在处理高维数据时存在维数灾难等问题,使得计算成本大幅增加并且效果不佳。以自编码或变分自编码网络构建的聚类网络改善了聚类效果,但是自编码器提取的特征往往比较差,变分自编码器存在后验崩塌等问题,影响了聚类的结果。为此,本文提出了一种基于混合高斯变分自编码器的聚类网络。方法使用混合高斯分布作为隐变量的先验分布构建变分自编码器,并以重建误差和隐变量先验与后验分布之间的KL散度(Kullback-Leibler divergence)构造自编码器的目标函数训练自编码网络;以训练获得的编码器对输入数据进行特征提取,结合聚类层构建聚类网络,以编码器隐层特征的软分配分布与软分配概率辅助目标分布之间的KL散度构建目标函数并训练聚类网络;变分自编码器采用卷积神经网络实现。结果为了验证本文算法的有效性,在基准数据集MNIST (Modified National Institute of Standards and Technology Database)和Fashion-MNIST上评估了该网络的性能,聚类精度(accuracy,ACC)和标准互信息(normalized mutual information,NMI)指标在MNIST数据集上分别为95.86%和91%,在Fashion-MNIST数据集上分别为61.34%和62.5%,与现有方法相比性能有了不同程度的提升。结论实验结果表明,本文网络取得了较好的聚类效果,且优于当前流行的多种聚类方法。关键词:聚类;混合高斯分布;变分自编码器(VAE);软分配;KL散度142|89|0更新时间:2024-05-07
摘要:目的经典的聚类算法在处理高维数据时存在维数灾难等问题,使得计算成本大幅增加并且效果不佳。以自编码或变分自编码网络构建的聚类网络改善了聚类效果,但是自编码器提取的特征往往比较差,变分自编码器存在后验崩塌等问题,影响了聚类的结果。为此,本文提出了一种基于混合高斯变分自编码器的聚类网络。方法使用混合高斯分布作为隐变量的先验分布构建变分自编码器,并以重建误差和隐变量先验与后验分布之间的KL散度(Kullback-Leibler divergence)构造自编码器的目标函数训练自编码网络;以训练获得的编码器对输入数据进行特征提取,结合聚类层构建聚类网络,以编码器隐层特征的软分配分布与软分配概率辅助目标分布之间的KL散度构建目标函数并训练聚类网络;变分自编码器采用卷积神经网络实现。结果为了验证本文算法的有效性,在基准数据集MNIST (Modified National Institute of Standards and Technology Database)和Fashion-MNIST上评估了该网络的性能,聚类精度(accuracy,ACC)和标准互信息(normalized mutual information,NMI)指标在MNIST数据集上分别为95.86%和91%,在Fashion-MNIST数据集上分别为61.34%和62.5%,与现有方法相比性能有了不同程度的提升。结论实验结果表明,本文网络取得了较好的聚类效果,且优于当前流行的多种聚类方法。关键词:聚类;混合高斯分布;变分自编码器(VAE);软分配;KL散度142|89|0更新时间:2024-05-07 -
 摘要:目的将半监督对抗学习应用于图像语义分割,可以有效减少训练过程中人工生成标记的数量。作为生成器的分割网络的卷积算子只具有局部感受域,因此对于图像不同区域之间的远程依赖关系只能通过多个卷积层或增加卷积核的大小进行建模,但这种做法也同时失去了使用局部卷积结构获得的计算效率。此外,生成对抗网络(generative adversarial network,GAN)中的另一个挑战是判别器的性能控制。在高维空间中,由判别器进行的密度比估计通常是不准确且不稳定的。为此,本文提出面向图像语义分割的半监督对抗学习方法。方法在生成对抗网络的分割网络中附加两层自注意模块,在空间维度上对语义依赖关系进行建模。自注意模块通过对所有位置的特征进行加权求和,有选择地在每个位置聚合特征。因而能够在像素级正确标记值数据的基础上有效处理输入图像中广泛分离的空间区域之间的关系。同时,为解决提出的半监督对抗学习方法的稳定性问题,在训练过程中将谱归一化应用到对抗网络的判别器中,这种加权归一化方法不仅可以稳定判别器网络的训练,并且不需要对唯一的超参数进行密集调整即可获得满意性能,且实现简单,计算量少,即使在缺乏互补的正则化技术的情况下,谱归一化也可以比权重归一化和梯度损失更好地改善生成图像的质量。结果实验在Cityscapes数据集及PASCAL VOC 2012(pattern analysis,statistical modeling and computational learning visual object classes)数据集上与9种方法进行比较。在Cityscapes数据集中,相比基线模型,性能提高了2.3%~3.2%。在PASCAL VOC 2012数据集中,性能比基线模型提高了1.4%~2.5%。同时,在PASCAL VOC 2012数据集上进行消融实验,可以看出本文方法的有效性。结论本文提出的半监督对抗学习的语义分割方法,通过引入的自注意力机制捕获特征图上各像素之间的依赖关系,应用谱归一化增强对抗生成网络的稳定性,表现出了较好的鲁棒性和有效性。关键词:半监督学习;卷积神经网络(CNN);图像语义分割;生成对抗网络(GAN);自注意机制;谱归一化133|196|1更新时间:2024-05-07
摘要:目的将半监督对抗学习应用于图像语义分割,可以有效减少训练过程中人工生成标记的数量。作为生成器的分割网络的卷积算子只具有局部感受域,因此对于图像不同区域之间的远程依赖关系只能通过多个卷积层或增加卷积核的大小进行建模,但这种做法也同时失去了使用局部卷积结构获得的计算效率。此外,生成对抗网络(generative adversarial network,GAN)中的另一个挑战是判别器的性能控制。在高维空间中,由判别器进行的密度比估计通常是不准确且不稳定的。为此,本文提出面向图像语义分割的半监督对抗学习方法。方法在生成对抗网络的分割网络中附加两层自注意模块,在空间维度上对语义依赖关系进行建模。自注意模块通过对所有位置的特征进行加权求和,有选择地在每个位置聚合特征。因而能够在像素级正确标记值数据的基础上有效处理输入图像中广泛分离的空间区域之间的关系。同时,为解决提出的半监督对抗学习方法的稳定性问题,在训练过程中将谱归一化应用到对抗网络的判别器中,这种加权归一化方法不仅可以稳定判别器网络的训练,并且不需要对唯一的超参数进行密集调整即可获得满意性能,且实现简单,计算量少,即使在缺乏互补的正则化技术的情况下,谱归一化也可以比权重归一化和梯度损失更好地改善生成图像的质量。结果实验在Cityscapes数据集及PASCAL VOC 2012(pattern analysis,statistical modeling and computational learning visual object classes)数据集上与9种方法进行比较。在Cityscapes数据集中,相比基线模型,性能提高了2.3%~3.2%。在PASCAL VOC 2012数据集中,性能比基线模型提高了1.4%~2.5%。同时,在PASCAL VOC 2012数据集上进行消融实验,可以看出本文方法的有效性。结论本文提出的半监督对抗学习的语义分割方法,通过引入的自注意力机制捕获特征图上各像素之间的依赖关系,应用谱归一化增强对抗生成网络的稳定性,表现出了较好的鲁棒性和有效性。关键词:半监督学习;卷积神经网络(CNN);图像语义分割;生成对抗网络(GAN);自注意机制;谱归一化133|196|1更新时间:2024-05-07 -
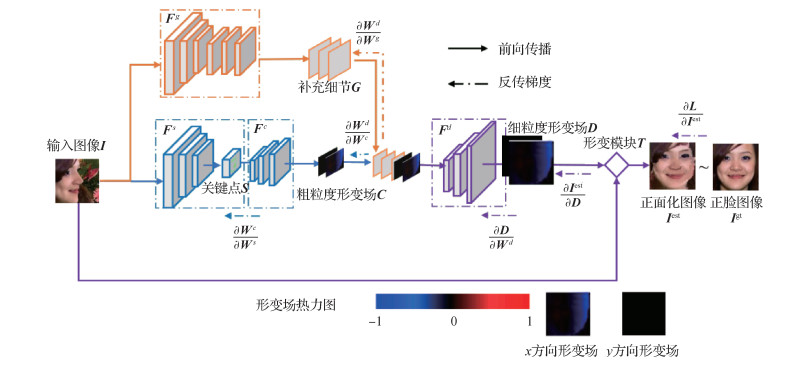 摘要:目的人脸识别已经得到了广泛应用,但大姿态人脸识别问题仍未完美解决。已有方法或提取姿态鲁棒特征,或进行人脸姿态的正面化。其中主流的人脸正面化方法包括2D回归生成和3D模型形变建模,前者能够生成相对自然真实的人脸,但会引入额外的噪声导致图像信息的扭曲;后者能够保持原始的人脸结构信息,但生成过程是基于物理模型的,不够自然灵活。为此,结合2D和3D方法的优势,本文提出了基于由粗到细形变场的人脸正面化方法。方法该形变场由深度网络以2D回归方式学得,反映的是不同视角人脸图像像素之间的语义级对应关系,可以类3D的方式实现非正面人脸图像的正面化,因此该方法兼具了2D正面化方法的灵活性与3D正面化方法的保真性,且借鉴分步渐进的思路,本文提出了由粗到细的形变场学习框架,以获得更加准确鲁棒的形变场。结果本文采用大姿态人脸识别实验来验证本文方法的有效性,在MultiPIE (multi pose,illumination,expressions)、LFW (labeled faces in the wild)、CFP (celebrities in frontal-profile in the wild)、IJB-A (intelligence advanced research projects activity Janus benchmark-A)等4个数据集上均取得了比已有方法更高的人脸识别精度。结论本文提出的基于由粗到细的形变场学习的人脸正面化方法,综合了2D和3D人脸正面化方法的优点,使人脸正面化结果的学习更加灵活、准确,保持了更多有利于识别的身份信息。关键词:大姿态人脸识别;人脸正面化;可学习形变场;由粗到细学习;全卷积网络124|88|2更新时间:2024-05-07
摘要:目的人脸识别已经得到了广泛应用,但大姿态人脸识别问题仍未完美解决。已有方法或提取姿态鲁棒特征,或进行人脸姿态的正面化。其中主流的人脸正面化方法包括2D回归生成和3D模型形变建模,前者能够生成相对自然真实的人脸,但会引入额外的噪声导致图像信息的扭曲;后者能够保持原始的人脸结构信息,但生成过程是基于物理模型的,不够自然灵活。为此,结合2D和3D方法的优势,本文提出了基于由粗到细形变场的人脸正面化方法。方法该形变场由深度网络以2D回归方式学得,反映的是不同视角人脸图像像素之间的语义级对应关系,可以类3D的方式实现非正面人脸图像的正面化,因此该方法兼具了2D正面化方法的灵活性与3D正面化方法的保真性,且借鉴分步渐进的思路,本文提出了由粗到细的形变场学习框架,以获得更加准确鲁棒的形变场。结果本文采用大姿态人脸识别实验来验证本文方法的有效性,在MultiPIE (multi pose,illumination,expressions)、LFW (labeled faces in the wild)、CFP (celebrities in frontal-profile in the wild)、IJB-A (intelligence advanced research projects activity Janus benchmark-A)等4个数据集上均取得了比已有方法更高的人脸识别精度。结论本文提出的基于由粗到细的形变场学习的人脸正面化方法,综合了2D和3D人脸正面化方法的优点,使人脸正面化结果的学习更加灵活、准确,保持了更多有利于识别的身份信息。关键词:大姿态人脸识别;人脸正面化;可学习形变场;由粗到细学习;全卷积网络124|88|2更新时间:2024-05-07 -
 摘要:目的人脸表情识别是计算机视觉的核心问题之一。一方面,表情的产生对应着面部肌肉的一个连续动态变化过程,另一方面,该运动过程中的表情峰值帧通常包含了能够识别该表情的完整信息。大部分已有的人脸表情识别算法要么基于表情视频序列,要么基于单幅表情峰值图像。为此,提出了一种融合时域和空域特征的深度神经网络来分析和理解视频序列中的表情信息,以提升表情识别的性能。方法该网络包含两个特征提取模块,分别用于学习单幅表情峰值图像中的表情静态“空域特征”和视频序列中的表情动态“时域特征”。首先,提出了一种基于三元组的深度度量融合技术,通过在三元组损失函数中采用不同的阈值,从单幅表情峰值图像中学习得到多个不同的表情特征表示,并将它们组合在一起形成一个鲁棒的且更具辩识能力的表情“空域特征”;其次,为了有效利用人脸关键组件的先验知识,准确提取人脸表情在时域上的运动特征,提出了基于人脸关键点轨迹的卷积神经网络,通过分析视频序列中的面部关键点轨迹,学习得到表情的动态“时域特征”;最后,提出了一种微调融合策略,取得了最优的时域特征和空域特征融合效果。结果该方法在3个基于视频序列的常用人脸表情数据集CK+(the extended Cohn-Kanade dataset)、MMI (the MMI facial expression database)和Oulu-CASIA (the Oulu-CASIA NIR&VIS facial expression database)上的识别准确率分别为98.46%、82.96%和87.12%,接近或超越了当前同类方法中的表情识别最高性能。结论提出的融合时空特征的人脸表情识别网络鲁棒地分析和理解了视频序列中的面部表情空域和时域信息,有效提升了人脸表情的识别性能。关键词:人脸表情识别(FER);深度学习;深度度量学习;三元组损失;特征融合138|93|2更新时间:2024-05-07
摘要:目的人脸表情识别是计算机视觉的核心问题之一。一方面,表情的产生对应着面部肌肉的一个连续动态变化过程,另一方面,该运动过程中的表情峰值帧通常包含了能够识别该表情的完整信息。大部分已有的人脸表情识别算法要么基于表情视频序列,要么基于单幅表情峰值图像。为此,提出了一种融合时域和空域特征的深度神经网络来分析和理解视频序列中的表情信息,以提升表情识别的性能。方法该网络包含两个特征提取模块,分别用于学习单幅表情峰值图像中的表情静态“空域特征”和视频序列中的表情动态“时域特征”。首先,提出了一种基于三元组的深度度量融合技术,通过在三元组损失函数中采用不同的阈值,从单幅表情峰值图像中学习得到多个不同的表情特征表示,并将它们组合在一起形成一个鲁棒的且更具辩识能力的表情“空域特征”;其次,为了有效利用人脸关键组件的先验知识,准确提取人脸表情在时域上的运动特征,提出了基于人脸关键点轨迹的卷积神经网络,通过分析视频序列中的面部关键点轨迹,学习得到表情的动态“时域特征”;最后,提出了一种微调融合策略,取得了最优的时域特征和空域特征融合效果。结果该方法在3个基于视频序列的常用人脸表情数据集CK+(the extended Cohn-Kanade dataset)、MMI (the MMI facial expression database)和Oulu-CASIA (the Oulu-CASIA NIR&VIS facial expression database)上的识别准确率分别为98.46%、82.96%和87.12%,接近或超越了当前同类方法中的表情识别最高性能。结论提出的融合时空特征的人脸表情识别网络鲁棒地分析和理解了视频序列中的面部表情空域和时域信息,有效提升了人脸表情的识别性能。关键词:人脸表情识别(FER);深度学习;深度度量学习;三元组损失;特征融合138|93|2更新时间:2024-05-07 -
 摘要:目的针对目前足迹检索中存在的采集设备种类多样化、有效的足迹特征难以提取等问题,本文以赤足足迹图像为研究对象,提出一种基于非局部(non-local)注意力双分支网络的跨模态赤足足迹检索算法。方法该网络由特征提取、特征嵌入以及双约束损失模块构成,其中特征提取模块采用双分支结构,各分支均以ResNet50作为基础网络分别提取光学和压力赤足图像的有效特征;同时在特征嵌入模块中通过参数共享学习一个多模态的共享空间,并引入非局部注意力机制快速捕获长范围依赖,获得更大感受野,专注足迹图像整体压力分布,在增强每个模态有用特征的同时突出了跨模态之间的共性特征;为了增大赤足足迹图像类间特征差异和减小类内特征差异,利用交叉熵损失LCE(cross-entropy loss)和三元组损失LTRI(triplet loss)对整个网络进行约束,以更好地学习跨模态共享特征,减小模态间的差异。结果本文将采集的138人的光学赤足图像和压力赤足图像作为实验数据集,并将本文算法与细粒度跨模态检索方法FGC(fine-grained cross-model)和跨模态行人重识别方法HC(hetero-center)进行了对比实验,本文算法在光学到压力检索模式下的mAP(mean average precision)值和rank1值分别为83.63%和98.29%,在压力到光学检索模式下的mAP值和rank1值分别为84.27%和94.71%,两种检索模式下的mAP均值和rank1均值分别为83.95%和96.5%,相较于FGC分别提高了40.01%和36.50%,相较于HC分别提高了26.07%和19.32%。同时本文算法在non-local注意力机制、损失函数、特征嵌入模块后采用的池化方式等方面进行了对比分析,其结果证实了本文算法的有效性。结论本文提出的跨模态赤足足迹检索算法取得了较高的精度,为现场足迹比对、鉴定等应用提供了研究基础。关键词:图像检索;跨模态足迹检索;非局部注意力机制;双分支网络;赤足足迹图像95|173|2更新时间:2024-05-07
摘要:目的针对目前足迹检索中存在的采集设备种类多样化、有效的足迹特征难以提取等问题,本文以赤足足迹图像为研究对象,提出一种基于非局部(non-local)注意力双分支网络的跨模态赤足足迹检索算法。方法该网络由特征提取、特征嵌入以及双约束损失模块构成,其中特征提取模块采用双分支结构,各分支均以ResNet50作为基础网络分别提取光学和压力赤足图像的有效特征;同时在特征嵌入模块中通过参数共享学习一个多模态的共享空间,并引入非局部注意力机制快速捕获长范围依赖,获得更大感受野,专注足迹图像整体压力分布,在增强每个模态有用特征的同时突出了跨模态之间的共性特征;为了增大赤足足迹图像类间特征差异和减小类内特征差异,利用交叉熵损失LCE(cross-entropy loss)和三元组损失LTRI(triplet loss)对整个网络进行约束,以更好地学习跨模态共享特征,减小模态间的差异。结果本文将采集的138人的光学赤足图像和压力赤足图像作为实验数据集,并将本文算法与细粒度跨模态检索方法FGC(fine-grained cross-model)和跨模态行人重识别方法HC(hetero-center)进行了对比实验,本文算法在光学到压力检索模式下的mAP(mean average precision)值和rank1值分别为83.63%和98.29%,在压力到光学检索模式下的mAP值和rank1值分别为84.27%和94.71%,两种检索模式下的mAP均值和rank1均值分别为83.95%和96.5%,相较于FGC分别提高了40.01%和36.50%,相较于HC分别提高了26.07%和19.32%。同时本文算法在non-local注意力机制、损失函数、特征嵌入模块后采用的池化方式等方面进行了对比分析,其结果证实了本文算法的有效性。结论本文提出的跨模态赤足足迹检索算法取得了较高的精度,为现场足迹比对、鉴定等应用提供了研究基础。关键词:图像检索;跨模态足迹检索;非局部注意力机制;双分支网络;赤足足迹图像95|173|2更新时间:2024-05-07 -
 摘要:目的场景图能够简洁且结构化地描述图像。现有场景图生成方法重点关注图像的视觉特征,忽视了数据集中丰富的语义信息。同时,受到数据集长尾分布的影响,大多数方法不能很好地对出现概率较小的三元组进行推理,而是趋于得到高频三元组。另外,现有大多数方法都采用相同的网络结构来推理目标和关系类别,不具有针对性。为了解决上述问题,本文提出一种提取全局语义信息的场景图生成算法。方法网络由语义编码、特征编码、目标推断以及关系推理等4个模块组成。语义编码模块从图像区域描述中提取语义信息并计算全局统计知识,融合得到鲁棒的全局语义信息来辅助不常见三元组的推理。目标编码模块提取图像的视觉特征。目标推断和关系推理模块采用不同的特征融合方法,分别利用门控图神经网络和门控循环单元进行特征学习。在此基础上,在全局统计知识的辅助下进行目标类别和关系类别推理。最后利用解析器构造场景图,进而结构化地描述图像。结果在公开的视觉基因组数据集上与其他10种方法进行比较,分别实现关系分类、场景图元素分类和场景图生成这3个任务,在限制和不限制每对目标只有一种关系的条件下,平均召回率分别达到了44.2%和55.3%。在可视化实验中,相比性能第2的方法,本文方法增强了不常见关系类别的推理能力,同时改善了目标类别与常见关系的推理能力。结论本文算法能够提高不常见三元组的推理能力,同时对于常见的三元组也具有较好的推理能力,能够有效地生成场景图。关键词:场景图;全局语义信息;目标推断;关系推理;图像理解104|250|0更新时间:2024-05-07
摘要:目的场景图能够简洁且结构化地描述图像。现有场景图生成方法重点关注图像的视觉特征,忽视了数据集中丰富的语义信息。同时,受到数据集长尾分布的影响,大多数方法不能很好地对出现概率较小的三元组进行推理,而是趋于得到高频三元组。另外,现有大多数方法都采用相同的网络结构来推理目标和关系类别,不具有针对性。为了解决上述问题,本文提出一种提取全局语义信息的场景图生成算法。方法网络由语义编码、特征编码、目标推断以及关系推理等4个模块组成。语义编码模块从图像区域描述中提取语义信息并计算全局统计知识,融合得到鲁棒的全局语义信息来辅助不常见三元组的推理。目标编码模块提取图像的视觉特征。目标推断和关系推理模块采用不同的特征融合方法,分别利用门控图神经网络和门控循环单元进行特征学习。在此基础上,在全局统计知识的辅助下进行目标类别和关系类别推理。最后利用解析器构造场景图,进而结构化地描述图像。结果在公开的视觉基因组数据集上与其他10种方法进行比较,分别实现关系分类、场景图元素分类和场景图生成这3个任务,在限制和不限制每对目标只有一种关系的条件下,平均召回率分别达到了44.2%和55.3%。在可视化实验中,相比性能第2的方法,本文方法增强了不常见关系类别的推理能力,同时改善了目标类别与常见关系的推理能力。结论本文算法能够提高不常见三元组的推理能力,同时对于常见的三元组也具有较好的推理能力,能够有效地生成场景图。关键词:场景图;全局语义信息;目标推断;关系推理;图像理解104|250|0更新时间:2024-05-07 -
 摘要:目的小样本学习旨在通过一幅或几幅图像来学习全新的类别。目前许多小样本学习方法基于图像的全局表征,可以很好地实现常规小样本图像分类任务。但是,细粒度图像分类需要依赖局部的图像特征,而基于全局表征的方法无法有效地获取图像的局部特征,导致很多小样本学习方法不能很好地处理细粒度小样本图像分类问题。为此,提出一种融合弱监督目标定位的细粒度小样本学习方法。方法在数据量有限的情况下,目标定位是一个有效的方法,能直接提供最具区分性的区域。受此启发,提出了一个基于自注意力的互补定位模块来实现弱监督目标定位,生成筛选掩膜进行特征描述子的筛选。基于筛选的特征描述子,设计了一种语义对齐距离来度量图像最具区分性区域的相关性,进而完成细粒度小样本图像分类。结果在miniImageNet数据集上,本文方法在1-shot和5-shot下的分类精度相较性能第2的方法高出0.56%和5.02%。在细粒度数据集Stanford Dogs和Stanford Cars数据集上,本文方法在1-shot和5-shot下的分类精度相较性能第2的方法分别提高了4.18%,7.49%和16.13,5.17%。在CUB 200-2011(Caltech-UCSD birds)数据集中,本文方法在5-shot下的分类精度相较性能第2的方法提升了1.82%。泛化性实验也显示出本文方法可以更好地同时处理常规小样本学习和细粒度小样本学习。此外,可视化结果显示出所提出的弱监督目标定位模块可以更完整地定位出目标。结论融合弱监督目标定位的细粒度小样本学习方法显著提高了细粒度小样本图像分类的性能,而且可以同时处理常规的和细粒度的小样本图像分类。关键词:弱监督目标定位(WSOL);小样本学习(FSL);细粒度图像分类;细粒度小样本学习;特征描述子176|1900|1更新时间:2024-05-07
摘要:目的小样本学习旨在通过一幅或几幅图像来学习全新的类别。目前许多小样本学习方法基于图像的全局表征,可以很好地实现常规小样本图像分类任务。但是,细粒度图像分类需要依赖局部的图像特征,而基于全局表征的方法无法有效地获取图像的局部特征,导致很多小样本学习方法不能很好地处理细粒度小样本图像分类问题。为此,提出一种融合弱监督目标定位的细粒度小样本学习方法。方法在数据量有限的情况下,目标定位是一个有效的方法,能直接提供最具区分性的区域。受此启发,提出了一个基于自注意力的互补定位模块来实现弱监督目标定位,生成筛选掩膜进行特征描述子的筛选。基于筛选的特征描述子,设计了一种语义对齐距离来度量图像最具区分性区域的相关性,进而完成细粒度小样本图像分类。结果在miniImageNet数据集上,本文方法在1-shot和5-shot下的分类精度相较性能第2的方法高出0.56%和5.02%。在细粒度数据集Stanford Dogs和Stanford Cars数据集上,本文方法在1-shot和5-shot下的分类精度相较性能第2的方法分别提高了4.18%,7.49%和16.13,5.17%。在CUB 200-2011(Caltech-UCSD birds)数据集中,本文方法在5-shot下的分类精度相较性能第2的方法提升了1.82%。泛化性实验也显示出本文方法可以更好地同时处理常规小样本学习和细粒度小样本学习。此外,可视化结果显示出所提出的弱监督目标定位模块可以更完整地定位出目标。结论融合弱监督目标定位的细粒度小样本学习方法显著提高了细粒度小样本图像分类的性能,而且可以同时处理常规的和细粒度的小样本图像分类。关键词:弱监督目标定位(WSOL);小样本学习(FSL);细粒度图像分类;细粒度小样本学习;特征描述子176|1900|1更新时间:2024-05-07 -
 摘要:目的道路裂缝检测旨在识别和定位裂缝对象,是保障道路安全的关键问题之一。为解决传统深度神经网络在检测背景较复杂、干扰较大的裂缝图像时精度较低的问题,设计了一种基于双注意力机制的深度学习道路裂缝检测网络。方法本文提出了在骨干网络中融入空洞卷积和两种注意力机制的方法,将其中的轻量型注意力机制与残差模块结合为残差注意力模块Res-A。对比研究了该模块“串联”和“并联”两种方式对于裂缝特征关系权重的影响并获得最佳连接。同时,引入Non-Local计算模式的注意力机制,通过挖掘特征图谱的关系权重以提高裂缝检测性能。结合两种注意力机制可以有效解决复杂背景下道路裂缝难检测的问题,提高了道路裂缝检测精度。结果在公开复杂道路裂缝数据集Crack500上进行对比实验与验证。为证明本文网络的有效性,将平均交并比(mean intersection over union,mIoU)、像素精确度(pixel accuracy,PA)和训练迭代时间作为评价指标,并进行了3组对比实验。第1组实验用于评价残差注意力模块中通道注意力机制和空间注意力机制之间不同组合方式的检测性能,结果表明这两种机制并联相加时的mIoU和PA分别为79.28%和93.88%,比其他两种组合方式分别提高了2.11%和2.08%、11.29%和0.23%。第2组实验用于评价残差注意力模块的有效性,结果表明添加残差注意力模块时的mIoU和PA分别比不添加时高出2.34%和3.01%。第3组实验用于对比本文网络和其他典型网络的检测性能。结果表明,本文网络的mIoU和PA分别比FCN(fully convolutional network)、PSPNet(pyramid scene parsing network)、ICNet(image cascade network)、PSANet(point-wise spatial attention network)和DenseASPP(dense atrous spatial pyramid pooling)高出7.67%和2.94%、1.54%和0.42%、6.51%和3.34%、7.76%和2.13%、7.70%和-1.59%。实验结果表明本文网络的mIoU和PA优于典型的深度神经网络。结论本文使用带空洞卷积的ResNet-101网络结合双注意力机制,在保持特征图分辨率并且提高感受野的同时,能够更好地适应背景复杂、干扰较多的裂缝对象。关键词:深度学习;残差网络;双注意力机制;道路裂缝检测;Crack500数据集222|281|5更新时间:2024-05-07
摘要:目的道路裂缝检测旨在识别和定位裂缝对象,是保障道路安全的关键问题之一。为解决传统深度神经网络在检测背景较复杂、干扰较大的裂缝图像时精度较低的问题,设计了一种基于双注意力机制的深度学习道路裂缝检测网络。方法本文提出了在骨干网络中融入空洞卷积和两种注意力机制的方法,将其中的轻量型注意力机制与残差模块结合为残差注意力模块Res-A。对比研究了该模块“串联”和“并联”两种方式对于裂缝特征关系权重的影响并获得最佳连接。同时,引入Non-Local计算模式的注意力机制,通过挖掘特征图谱的关系权重以提高裂缝检测性能。结合两种注意力机制可以有效解决复杂背景下道路裂缝难检测的问题,提高了道路裂缝检测精度。结果在公开复杂道路裂缝数据集Crack500上进行对比实验与验证。为证明本文网络的有效性,将平均交并比(mean intersection over union,mIoU)、像素精确度(pixel accuracy,PA)和训练迭代时间作为评价指标,并进行了3组对比实验。第1组实验用于评价残差注意力模块中通道注意力机制和空间注意力机制之间不同组合方式的检测性能,结果表明这两种机制并联相加时的mIoU和PA分别为79.28%和93.88%,比其他两种组合方式分别提高了2.11%和2.08%、11.29%和0.23%。第2组实验用于评价残差注意力模块的有效性,结果表明添加残差注意力模块时的mIoU和PA分别比不添加时高出2.34%和3.01%。第3组实验用于对比本文网络和其他典型网络的检测性能。结果表明,本文网络的mIoU和PA分别比FCN(fully convolutional network)、PSPNet(pyramid scene parsing network)、ICNet(image cascade network)、PSANet(point-wise spatial attention network)和DenseASPP(dense atrous spatial pyramid pooling)高出7.67%和2.94%、1.54%和0.42%、6.51%和3.34%、7.76%和2.13%、7.70%和-1.59%。实验结果表明本文网络的mIoU和PA优于典型的深度神经网络。结论本文使用带空洞卷积的ResNet-101网络结合双注意力机制,在保持特征图分辨率并且提高感受野的同时,能够更好地适应背景复杂、干扰较多的裂缝对象。关键词:深度学习;残差网络;双注意力机制;道路裂缝检测;Crack500数据集222|281|5更新时间:2024-05-07 -
 摘要:目的针对当前在虚拟环境中布料柔体碰撞检测效率慢和准确性低的问题,提出一种根节点双层包围盒树结构和融合OpenNN(open neural networks library)神经网络加速预测碰撞检测的算法。方法首先改进了碰撞检测常用的包围盒技术,提出根节点双层包围盒算法,减少包围盒的构造时间。其次使用神经网络优化碰撞检测技术,利用神经网络可以处理大量数据的优势,每次可以检测大量基本图元是否发生碰撞,解决了碰撞检测计算复杂性高的问题。最后准确地找到碰撞粒子并做出碰撞响应。结果在相同的复杂布料模型情况下,根节点双层包围盒算法在运行速度上比传统混合包围盒算法快,耗时缩减了5.51%~11.32%。基于OpenNN算法的总耗时比根节点双层包围盒缩减了11.70%,比融合DNN(deep neural network)的自碰撞检测算法减少了6.62%。随着碰撞检测难度的增大,当布料模型的精度增加84%时,传统物理碰撞检测方法用时增加96%,融合DNN的自碰撞检测算法用时增加90.11%,而本文基于神经网络的算法用时仅增加了68.37%,同时表现出更高的稳定性,满足使用者对实时性的要求。结论对于模拟场景中简单模型的碰撞,本文提出的根节点双层包围盒算法比传统的包围盒方法耗时短。对于复杂模型,基于OpenNN神经网络的碰撞检测算法在效率上优于传统的包围盒算法和融合DNN的自碰撞检查算法,而且模拟效果的准确性也得以保证,是一种高效的碰撞检测方法。关键词:碰撞检测;布料模拟;神经网络;轴对齐包围盒(AABB);双层包围盒71|215|1更新时间:2024-05-07
摘要:目的针对当前在虚拟环境中布料柔体碰撞检测效率慢和准确性低的问题,提出一种根节点双层包围盒树结构和融合OpenNN(open neural networks library)神经网络加速预测碰撞检测的算法。方法首先改进了碰撞检测常用的包围盒技术,提出根节点双层包围盒算法,减少包围盒的构造时间。其次使用神经网络优化碰撞检测技术,利用神经网络可以处理大量数据的优势,每次可以检测大量基本图元是否发生碰撞,解决了碰撞检测计算复杂性高的问题。最后准确地找到碰撞粒子并做出碰撞响应。结果在相同的复杂布料模型情况下,根节点双层包围盒算法在运行速度上比传统混合包围盒算法快,耗时缩减了5.51%~11.32%。基于OpenNN算法的总耗时比根节点双层包围盒缩减了11.70%,比融合DNN(deep neural network)的自碰撞检测算法减少了6.62%。随着碰撞检测难度的增大,当布料模型的精度增加84%时,传统物理碰撞检测方法用时增加96%,融合DNN的自碰撞检测算法用时增加90.11%,而本文基于神经网络的算法用时仅增加了68.37%,同时表现出更高的稳定性,满足使用者对实时性的要求。结论对于模拟场景中简单模型的碰撞,本文提出的根节点双层包围盒算法比传统的包围盒方法耗时短。对于复杂模型,基于OpenNN神经网络的碰撞检测算法在效率上优于传统的包围盒算法和融合DNN的自碰撞检查算法,而且模拟效果的准确性也得以保证,是一种高效的碰撞检测方法。关键词:碰撞检测;布料模拟;神经网络;轴对齐包围盒(AABB);双层包围盒71|215|1更新时间:2024-05-07 -
 摘要:目的在步态识别算法中,基于外观的方法准确率高且易于实施,但对外观变化敏感;基于模型的方法对外观变化更加鲁棒,但建模困难且准确率较低。为了使步态识别算法在获得高准确率的同时对外观变化具有更好的鲁棒性,提出了一种双分支网络融合外观特征和姿态特征,以结合两种方法的优点。方法双分支网络模型包含外观和姿态两条分支,外观分支采用GaitSet网络从轮廓图像中提取外观特征;姿态分支采用5层卷积网络从姿态骨架中提取姿态特征。在此基础上构建特征融合模块,融合外观特征和姿态特征,并引入通道注意力机制实现任意尺寸的特征融合,设计的模块结构使其能够在融合过程中抑制特征中的噪声。最后将融合后的步态特征应用于识别行人身份。结果实验在CASIA-B(Institute of Automation,Chinese Academy of Sciences,Gait Dataset B)数据集上通过跨视角和不同行走状态两种实验设置与目前主流的步态识别算法进行对比,并以Rank-1准确率作为评价指标。在跨视角实验设置的MT(medium-sample training)划分中,该算法在3种行走状态下的准确率分别为93.4%、84.8%和70.9%,相比性能第2的算法分别提升了1.4%、0.5%和8.4%;在不同行走状态实验设置中,该算法在两种行走状态下的准确率分别为94.9%和90.0%,获得了最佳性能。结论在能够同时获取外观数据和姿态数据的场景下,该算法能够有效地融合外观信息和姿态信息,在获得更丰富的步态特征的同时降低了外观变化对步态特征的影响,提高了步态识别的性能。关键词:生物特征识别;步态识别;特征融合;双分支网络;SE模块;人体姿态估计;步态轮廓图像179|179|5更新时间:2024-05-07
摘要:目的在步态识别算法中,基于外观的方法准确率高且易于实施,但对外观变化敏感;基于模型的方法对外观变化更加鲁棒,但建模困难且准确率较低。为了使步态识别算法在获得高准确率的同时对外观变化具有更好的鲁棒性,提出了一种双分支网络融合外观特征和姿态特征,以结合两种方法的优点。方法双分支网络模型包含外观和姿态两条分支,外观分支采用GaitSet网络从轮廓图像中提取外观特征;姿态分支采用5层卷积网络从姿态骨架中提取姿态特征。在此基础上构建特征融合模块,融合外观特征和姿态特征,并引入通道注意力机制实现任意尺寸的特征融合,设计的模块结构使其能够在融合过程中抑制特征中的噪声。最后将融合后的步态特征应用于识别行人身份。结果实验在CASIA-B(Institute of Automation,Chinese Academy of Sciences,Gait Dataset B)数据集上通过跨视角和不同行走状态两种实验设置与目前主流的步态识别算法进行对比,并以Rank-1准确率作为评价指标。在跨视角实验设置的MT(medium-sample training)划分中,该算法在3种行走状态下的准确率分别为93.4%、84.8%和70.9%,相比性能第2的算法分别提升了1.4%、0.5%和8.4%;在不同行走状态实验设置中,该算法在两种行走状态下的准确率分别为94.9%和90.0%,获得了最佳性能。结论在能够同时获取外观数据和姿态数据的场景下,该算法能够有效地融合外观信息和姿态信息,在获得更丰富的步态特征的同时降低了外观变化对步态特征的影响,提高了步态识别的性能。关键词:生物特征识别;步态识别;特征融合;双分支网络;SE模块;人体姿态估计;步态轮廓图像179|179|5更新时间:2024-05-07
图像分析和识别
-
 摘要:目的现有视觉问答模型的研究主要从注意力机制和多模态融合角度出发,未能对图像场景中对象之间的语义联系显式建模,且较少突出对象的空间位置关系,导致空间关系推理能力欠佳。对此,本文针对需要空间关系推理的视觉问答问题,提出利用视觉对象之间空间关系属性结构化建模图像,构建问题引导的空间关系图推理视觉问答模型。方法利用显著性注意力,用Faster R-CNN(region-based convolutional neural network)提取图像中显著的视觉对象和视觉特征;对图像中的视觉对象及其空间关系结构化建模为空间关系图;利用问题引导的聚焦式注意力进行基于问题的空间关系推理。聚焦式注意力分为节点注意力和边注意力,分别用于发现与问题相关的视觉对象和空间关系;利用节点注意力和边注意力权重构造门控图推理网络,通过门控图推理网络的信息传递机制和控制特征信息的聚合,获得节点的深度交互信息,学习得到具有空间感知的视觉特征表示,达到基于问题的空间关系推理;将具有空间关系感知的图像特征和问题特征进行多模态融合,预测出正确答案。结果模型在VQA(visual question answering)v2数据集上进行训练、验证和测试。实验结果表明,本文模型相比于Prior、Language only、MCB(multimodal compact bilinear)、ReasonNet和Bottom-Up等模型,在各项准确率方面有明显提升。相比于ReasonNet模型,本文模型总体的回答准确率提升2.73%,是否问题准确率提升4.41%,计数问题准确率提升5.37%,其他问题准确率提升0.65%。本文还进行了消融实验,验证了方法的有效性。结论提出的问题引导的空间关系图推理视觉问答模型能够较好地将问题文本信息和图像目标区域及对象关系进行匹配,特别是对于需要空间关系推理的问题,模型展现出较强的推理能力。关键词:视觉问答(VQA);图卷积神经网络(GCN);注意力机制;空间关系推理;多模态学习123|209|2更新时间:2024-05-07
摘要:目的现有视觉问答模型的研究主要从注意力机制和多模态融合角度出发,未能对图像场景中对象之间的语义联系显式建模,且较少突出对象的空间位置关系,导致空间关系推理能力欠佳。对此,本文针对需要空间关系推理的视觉问答问题,提出利用视觉对象之间空间关系属性结构化建模图像,构建问题引导的空间关系图推理视觉问答模型。方法利用显著性注意力,用Faster R-CNN(region-based convolutional neural network)提取图像中显著的视觉对象和视觉特征;对图像中的视觉对象及其空间关系结构化建模为空间关系图;利用问题引导的聚焦式注意力进行基于问题的空间关系推理。聚焦式注意力分为节点注意力和边注意力,分别用于发现与问题相关的视觉对象和空间关系;利用节点注意力和边注意力权重构造门控图推理网络,通过门控图推理网络的信息传递机制和控制特征信息的聚合,获得节点的深度交互信息,学习得到具有空间感知的视觉特征表示,达到基于问题的空间关系推理;将具有空间关系感知的图像特征和问题特征进行多模态融合,预测出正确答案。结果模型在VQA(visual question answering)v2数据集上进行训练、验证和测试。实验结果表明,本文模型相比于Prior、Language only、MCB(multimodal compact bilinear)、ReasonNet和Bottom-Up等模型,在各项准确率方面有明显提升。相比于ReasonNet模型,本文模型总体的回答准确率提升2.73%,是否问题准确率提升4.41%,计数问题准确率提升5.37%,其他问题准确率提升0.65%。本文还进行了消融实验,验证了方法的有效性。结论提出的问题引导的空间关系图推理视觉问答模型能够较好地将问题文本信息和图像目标区域及对象关系进行匹配,特别是对于需要空间关系推理的问题,模型展现出较强的推理能力。关键词:视觉问答(VQA);图卷积神经网络(GCN);注意力机制;空间关系推理;多模态学习123|209|2更新时间:2024-05-07 -
 摘要:目的对抗样本是指在原始数据中添加细微干扰使深度模型输出错误结果的合成数据。视觉感知性和攻击成功率是评价对抗样本的两个关键指标。当前大多数对抗样本研究侧重于提升算法的攻击成功率,对视觉感知性的关注较少。为此,本文提出了一种低感知性对抗样本生成算法,构造的对抗样本在保证较高攻击成功率的情况下具有更低的视觉感知性。方法提出在黑盒条件下通过约束对抗扰动的面积与空间分布以降低对抗样本视觉感知性的方法。利用卷积网络提取图像中对输出结果影响较大的关键区域作为约束,限定扰动的位置。之后结合带有自注意力机制的生成对抗网络在关键区域添加扰动,最终生成具有低感知性的对抗样本。结果在3种公开分类数据集上与多种典型攻击方法进行比较,包括7种白盒算法FGSM(fast gradient sign method)、BIM(basic iterative method)、DeepFool、PerC-C & W(perceptual color distance C & W)、JSMA(Jacobian-based saliency map attacks)、APGD(auto projected gradient descent)、AutoAttack和2种黑盒算法OnePixel、AdvGAN(adversarial generative adversarial network)。在攻击成功率(attack success rate,ASR)上,本文算法与对比算法处于同一水平。在客观视觉感知性对比中,本文算法较AdvGAN在低分辨率数据集上,均方误差(mean square error,MSE)值降低了42.1%,结构相似性值(structural similarity,SSIM)提升了8.4%;在中高分辨率数据集上,MSE值降低了72.7%,SSIM值提升了12.8%。与视觉感知性最好的对比算法DeepFool相比,在低分辨率数据集上,本文算法的MSE值降低了29.3%,SSIM值提升了0.8%。结论本文分析了当前算法在视觉感知性上存在的问题,提出了一种对抗样本生成方法,在攻击成功率近似的情况下显著降低了对抗样本的视觉感知性。关键词:对抗样本;视觉感知性;对抗扰动;生成对抗网络(GAN);黑盒攻击139|190|3更新时间:2024-05-07
摘要:目的对抗样本是指在原始数据中添加细微干扰使深度模型输出错误结果的合成数据。视觉感知性和攻击成功率是评价对抗样本的两个关键指标。当前大多数对抗样本研究侧重于提升算法的攻击成功率,对视觉感知性的关注较少。为此,本文提出了一种低感知性对抗样本生成算法,构造的对抗样本在保证较高攻击成功率的情况下具有更低的视觉感知性。方法提出在黑盒条件下通过约束对抗扰动的面积与空间分布以降低对抗样本视觉感知性的方法。利用卷积网络提取图像中对输出结果影响较大的关键区域作为约束,限定扰动的位置。之后结合带有自注意力机制的生成对抗网络在关键区域添加扰动,最终生成具有低感知性的对抗样本。结果在3种公开分类数据集上与多种典型攻击方法进行比较,包括7种白盒算法FGSM(fast gradient sign method)、BIM(basic iterative method)、DeepFool、PerC-C & W(perceptual color distance C & W)、JSMA(Jacobian-based saliency map attacks)、APGD(auto projected gradient descent)、AutoAttack和2种黑盒算法OnePixel、AdvGAN(adversarial generative adversarial network)。在攻击成功率(attack success rate,ASR)上,本文算法与对比算法处于同一水平。在客观视觉感知性对比中,本文算法较AdvGAN在低分辨率数据集上,均方误差(mean square error,MSE)值降低了42.1%,结构相似性值(structural similarity,SSIM)提升了8.4%;在中高分辨率数据集上,MSE值降低了72.7%,SSIM值提升了12.8%。与视觉感知性最好的对比算法DeepFool相比,在低分辨率数据集上,本文算法的MSE值降低了29.3%,SSIM值提升了0.8%。结论本文分析了当前算法在视觉感知性上存在的问题,提出了一种对抗样本生成方法,在攻击成功率近似的情况下显著降低了对抗样本的视觉感知性。关键词:对抗样本;视觉感知性;对抗扰动;生成对抗网络(GAN);黑盒攻击139|190|3更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的可回溯感是艺术欣赏和临摹时产生的一种审美感受,即在审美过程中想象地再现原作的创作行为,是书法艺术凸显的审美心理现象。在计算机书法的研究中,鲜有研究以动画效果增强书法可回溯感,且缺少关于可回溯感的量化评估方法。因此,本文结合心理感知实验提出可回溯感的测评方法,并探究动态墨迹效果对书法作品可回溯感的影响。方法首先将可回溯感分解为两种心理因素:顺序感和运动感。然后针对动态书法形式应用粒子动画制作7种不同墨迹效果,并设计心理感知实验对书法作品的可回溯感进行测量,即对选定标记点的运笔顺序进行排列以及对其运笔方向和相对速率进行估计。最后比较原作和动态书法可回溯感的差异,分析动态墨迹对书法作品可回溯感的影响。结果实验结果证明测评方法是可行的,并发现恰当运用动态墨迹效果,即沿笔迹流动的墨迹动画,可以改进作品的运动感、显著增强顺序感以及提升可回溯感,反之则不能。若混入逆向流动墨迹效果,会削弱其提升顺序感的效用,但减弱的程度与正逆向墨迹的比例并非线性关系。结论运笔顺序和笔触运动感知的评测方法可以有效量化视觉艺术品的可回溯感,为书法欣赏和临摹过程的研究提供实证方法。动态墨迹的设计也可用于增进书法的艺术化呈现,特别是增强其可回溯感。关键词:可回溯感;书法;实证美学;审美心理学;心理感知;动画特效104|376|0更新时间:2024-05-07
摘要:目的可回溯感是艺术欣赏和临摹时产生的一种审美感受,即在审美过程中想象地再现原作的创作行为,是书法艺术凸显的审美心理现象。在计算机书法的研究中,鲜有研究以动画效果增强书法可回溯感,且缺少关于可回溯感的量化评估方法。因此,本文结合心理感知实验提出可回溯感的测评方法,并探究动态墨迹效果对书法作品可回溯感的影响。方法首先将可回溯感分解为两种心理因素:顺序感和运动感。然后针对动态书法形式应用粒子动画制作7种不同墨迹效果,并设计心理感知实验对书法作品的可回溯感进行测量,即对选定标记点的运笔顺序进行排列以及对其运笔方向和相对速率进行估计。最后比较原作和动态书法可回溯感的差异,分析动态墨迹对书法作品可回溯感的影响。结果实验结果证明测评方法是可行的,并发现恰当运用动态墨迹效果,即沿笔迹流动的墨迹动画,可以改进作品的运动感、显著增强顺序感以及提升可回溯感,反之则不能。若混入逆向流动墨迹效果,会削弱其提升顺序感的效用,但减弱的程度与正逆向墨迹的比例并非线性关系。结论运笔顺序和笔触运动感知的评测方法可以有效量化视觉艺术品的可回溯感,为书法欣赏和临摹过程的研究提供实证方法。动态墨迹的设计也可用于增进书法的艺术化呈现,特别是增强其可回溯感。关键词:可回溯感;书法;实证美学;审美心理学;心理感知;动画特效104|376|0更新时间:2024-05-07
计算机图形学
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0