
最新刊期
2022 年 第 27 卷 第 5 期

-
 摘要:水下光学图像可以提供直观丰富的海洋信息,近年来在海洋资源开发、环境保护和海洋工程等诸多领域发挥越来越重要的作用。但是受恶劣复杂的水下成像环境影响,水下光学图像普遍存在对比度低、图像模糊以及颜色失真等质量退化问题,严重制约水下智能处理系统的性能和应用。如何清晰地重建水下光学图像是国内外广泛关注的、具有挑战性的难点问题。随着深度学习技术的蓬勃发展,利用深度学习来提升水下图像质量成为当前的研究热点。鉴于目前国内在水下光学图像重建方面的研究综述较少,本文全面综述其研究进展。分析了水下图像退化机理,总结了现有水下成像模型以及水下图像重建的挑战;梳理了水下光学图像重建方法的发展历程,根据是否采用深度学习以及是否基于成像模型,将现有方法分为4大类,并按照研究发展顺序,依次介绍4类方法的基本思想,分析其优缺点;归纳了目前公开的水下图像数据集以及常用的水下图像质量评价方法,并对8种典型的水下图像重建方法进行了性能评测和对比分析;总结了该领域目前仍存在的问题,展望了后续研究方向,以便于相关研究人员了解该领域的研究现状,促进该领域的技术发展。关键词:水下图像退化;深度学习;图像增强;图像复原;水下数据集;水下图像质量评价345|511|3更新时间:2024-05-07
摘要:水下光学图像可以提供直观丰富的海洋信息,近年来在海洋资源开发、环境保护和海洋工程等诸多领域发挥越来越重要的作用。但是受恶劣复杂的水下成像环境影响,水下光学图像普遍存在对比度低、图像模糊以及颜色失真等质量退化问题,严重制约水下智能处理系统的性能和应用。如何清晰地重建水下光学图像是国内外广泛关注的、具有挑战性的难点问题。随着深度学习技术的蓬勃发展,利用深度学习来提升水下图像质量成为当前的研究热点。鉴于目前国内在水下光学图像重建方面的研究综述较少,本文全面综述其研究进展。分析了水下图像退化机理,总结了现有水下成像模型以及水下图像重建的挑战;梳理了水下光学图像重建方法的发展历程,根据是否采用深度学习以及是否基于成像模型,将现有方法分为4大类,并按照研究发展顺序,依次介绍4类方法的基本思想,分析其优缺点;归纳了目前公开的水下图像数据集以及常用的水下图像质量评价方法,并对8种典型的水下图像重建方法进行了性能评测和对比分析;总结了该领域目前仍存在的问题,展望了后续研究方向,以便于相关研究人员了解该领域的研究现状,促进该领域的技术发展。关键词:水下图像退化;深度学习;图像增强;图像复原;水下数据集;水下图像质量评价345|511|3更新时间:2024-05-07 -
 摘要:雨天会影响室外图像捕捉的质量,进而引起户外视觉任务性能下降。基于深度学习的单幅图像去雨研究因算法性能优越而引起了大家的关注,并且聚焦点集中在数据集的质量、图像去雨方法、单幅图像去雨后续高层任务的研究和性能评价指标等方面。为了方便研究者快速全面了解该领域,本文从上述4个方面综述了基于深度学习的单幅图像去雨的主流文献。依据数据集的构建方式将雨图数据集分为4类:基于背景雨层简单加和、背景雨层复杂融合、生成对抗网络(generative adversarial network,GAN)数据驱动合成的数据集,以及半自动化采集的真实数据集。依据任务场景、采取的学习机制以及网络设计对主流算法分类总结。综述了面向单任务和联合任务的去雨算法,单任务即雨滴、雨纹、雨雾和暴雨的去除;联合任务即雨滴和雨纹、所有噪声去除。综述了学习机制和网络构建方式(比如: 卷积神经网络(convolutional neural network,CNN)结构多分支组合,GAN的生成结构,循环和多阶段结构,多尺度结构,编解码结构,基于注意力,基于Transformer)以及数据模型双驱动的构建方式。综述了单幅图像去雨后续高层任务的研究文献和图像去雨算法性能的评价指标。通过合成数据集和真实数据集上的综合实验对比,证实了领域知识隐式引导网络构建可以有效提升算法性能,领域知识显式引导正则化网络的学习有潜力进一步提升算法的泛化性。最后,指出单幅图像去雨工作目前面临的挑战和未来的研究方向。关键词:单幅图像去雨;深度神经网络;雨图数据集;雨图合成;模型数据双驱动;后续高层任务;性能评价指标255|814|2更新时间:2024-05-07
摘要:雨天会影响室外图像捕捉的质量,进而引起户外视觉任务性能下降。基于深度学习的单幅图像去雨研究因算法性能优越而引起了大家的关注,并且聚焦点集中在数据集的质量、图像去雨方法、单幅图像去雨后续高层任务的研究和性能评价指标等方面。为了方便研究者快速全面了解该领域,本文从上述4个方面综述了基于深度学习的单幅图像去雨的主流文献。依据数据集的构建方式将雨图数据集分为4类:基于背景雨层简单加和、背景雨层复杂融合、生成对抗网络(generative adversarial network,GAN)数据驱动合成的数据集,以及半自动化采集的真实数据集。依据任务场景、采取的学习机制以及网络设计对主流算法分类总结。综述了面向单任务和联合任务的去雨算法,单任务即雨滴、雨纹、雨雾和暴雨的去除;联合任务即雨滴和雨纹、所有噪声去除。综述了学习机制和网络构建方式(比如: 卷积神经网络(convolutional neural network,CNN)结构多分支组合,GAN的生成结构,循环和多阶段结构,多尺度结构,编解码结构,基于注意力,基于Transformer)以及数据模型双驱动的构建方式。综述了单幅图像去雨后续高层任务的研究文献和图像去雨算法性能的评价指标。通过合成数据集和真实数据集上的综合实验对比,证实了领域知识隐式引导网络构建可以有效提升算法性能,领域知识显式引导正则化网络的学习有潜力进一步提升算法的泛化性。最后,指出单幅图像去雨工作目前面临的挑战和未来的研究方向。关键词:单幅图像去雨;深度神经网络;雨图数据集;雨图合成;模型数据双驱动;后续高层任务;性能评价指标255|814|2更新时间:2024-05-07 -
 摘要:低光照图像增强旨在提高光照不足场景下捕获数据的视觉感知质量以获取更多信息,逐渐成为图像处理领域中的研究热点,在自动驾驶、安防等人工智能相关行业中具有十分广阔的应用前景。传统的低光照图像增强技术往往需要高深的数学技巧以及严格的数学推导,且导出的迭代过程普遍流程复杂,不利于实际应用。随着大规模数据集的相继诞生,基于深度学习的低光照图像增强已经成为当前的主流技术,然而此类技术受限于数据分布,存在性能不稳定、应用场景单一等问题。此外,在低光照环境下的高层视觉任务(如目标检测)对于低光照图像增强技术的发展带来了新的机遇与挑战。本文从3个方面系统地综述了低光照图像增强技术的研究现状。介绍了现有低光照图像数据集,详述了低光照图像增强技术的发展脉络,通过对比低光照图像增强质量与夜间人脸检测精度,进一步对现有低光照增强技术进行了全面评估与分析。基于对上述现状的探讨,结合实际应用,本文指出当前技术的局限性,并对其发展趋势进行预测。关键词:低光照图像增强;Retinex理论;光照估计;深度学习;低光照人脸检测688|997|16更新时间:2024-05-07
摘要:低光照图像增强旨在提高光照不足场景下捕获数据的视觉感知质量以获取更多信息,逐渐成为图像处理领域中的研究热点,在自动驾驶、安防等人工智能相关行业中具有十分广阔的应用前景。传统的低光照图像增强技术往往需要高深的数学技巧以及严格的数学推导,且导出的迭代过程普遍流程复杂,不利于实际应用。随着大规模数据集的相继诞生,基于深度学习的低光照图像增强已经成为当前的主流技术,然而此类技术受限于数据分布,存在性能不稳定、应用场景单一等问题。此外,在低光照环境下的高层视觉任务(如目标检测)对于低光照图像增强技术的发展带来了新的机遇与挑战。本文从3个方面系统地综述了低光照图像增强技术的研究现状。介绍了现有低光照图像数据集,详述了低光照图像增强技术的发展脉络,通过对比低光照图像增强质量与夜间人脸检测精度,进一步对现有低光照增强技术进行了全面评估与分析。基于对上述现状的探讨,结合实际应用,本文指出当前技术的局限性,并对其发展趋势进行预测。关键词:低光照图像增强;Retinex理论;光照估计;深度学习;低光照人脸检测688|997|16更新时间:2024-05-07 -
 摘要:图像/视频的获取及传输过程中,由于物理环境及算法性能的限制,其质量难免会出现无法预估的衰减,导致其在实际场景中的应用受到限制,并对人的视觉体验造成显著影响。因此,作为计算机视觉领域的一项重要任务,图像/视频质量评价应运而生。其目的在于通过构建计算机数学模型来衡量图像/视频中的失真信息以判断其质量的好坏,达到自动预测质量的效果。在城市生活、交通监控以及多媒体直播等多个场景中具有广泛的应用前景。图像/视频质量评价研究取得了长足的发展,为计算机视觉领域中其他任务提供了一定的便利。本文在广泛调研前人研究的基础上,回顾了整个图像/视频质量评价领域的发展历程,分别列举了传统方法和深度学习方法中一些具有里程碑意义的算法和影响力较大的算法,然后从全参考、半参考和无参考3个方面分别对图像/视频质量评价领域的一些文献进行了综述,具体涉及的方法包含基于结构信息、基于人类视觉系统和基于自然图像统计的方法等;在LIVE(laboratory for image & video engineering)、CSIQ(categorical subjective image quality database)、TID2013等公开数据集的基础上,基于SROCC(Spearman rank order correlation coefficient)、PLCC(Pearson linear correlation coefficient)等评价指标,对一些具有代表性算法的性能进行了分析;最后总结当前质量评价领域仍存在的一些挑战与问题,并对其进行了展望。本文旨在为质量评价领域的研究人员提供一个较全面的参考。关键词:图像/视频质量评价(I/VQA);结构信息;人类视觉系统(HVS);自然图像统计(NSS);深度学习290|323|4更新时间:2024-05-07
摘要:图像/视频的获取及传输过程中,由于物理环境及算法性能的限制,其质量难免会出现无法预估的衰减,导致其在实际场景中的应用受到限制,并对人的视觉体验造成显著影响。因此,作为计算机视觉领域的一项重要任务,图像/视频质量评价应运而生。其目的在于通过构建计算机数学模型来衡量图像/视频中的失真信息以判断其质量的好坏,达到自动预测质量的效果。在城市生活、交通监控以及多媒体直播等多个场景中具有广泛的应用前景。图像/视频质量评价研究取得了长足的发展,为计算机视觉领域中其他任务提供了一定的便利。本文在广泛调研前人研究的基础上,回顾了整个图像/视频质量评价领域的发展历程,分别列举了传统方法和深度学习方法中一些具有里程碑意义的算法和影响力较大的算法,然后从全参考、半参考和无参考3个方面分别对图像/视频质量评价领域的一些文献进行了综述,具体涉及的方法包含基于结构信息、基于人类视觉系统和基于自然图像统计的方法等;在LIVE(laboratory for image & video engineering)、CSIQ(categorical subjective image quality database)、TID2013等公开数据集的基础上,基于SROCC(Spearman rank order correlation coefficient)、PLCC(Pearson linear correlation coefficient)等评价指标,对一些具有代表性算法的性能进行了分析;最后总结当前质量评价领域仍存在的一些挑战与问题,并对其进行了展望。本文旨在为质量评价领域的研究人员提供一个较全面的参考。关键词:图像/视频质量评价(I/VQA);结构信息;人类视觉系统(HVS);自然图像统计(NSS);深度学习290|323|4更新时间:2024-05-07 -
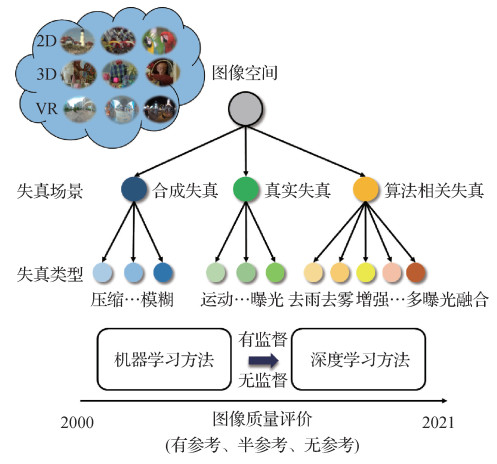 摘要:随着多媒体技术的快速发展及广泛应用,图像质量评价因其在多媒体处理中的重要作用得到越来越多的关注,其作用包括图像数据筛选、算法参数选择与优化等。根据图像质量评价应用时是否需要参考信息,它可分为全参考图像质量评价、半参考图像质量评价和无参考图像质量评价,前两类分别需要全部参考信息和部分参考信息,而第3类不需要参考信息。无论是全参考、半参考还是无参考图像质量评价,图像失真对图像质量评价的影响均较大,主要体现在图像质量评价数据库构建和图像质量评价模型设计两方面。本文从图像失真的角度,主要概述2011—2021年国内外公开发表的图像质量评价模型,涵盖全参考、半参考和无参考模型。根据图像的失真类型,将图像质量评价模型分为针对合成失真的图像质量评价模型、针对真实失真的图像质量评价模型和针对算法相关失真的图像质量评价模型。其中,合成失真是指人工添加噪声,如高斯噪声和模糊失真,通常呈现均匀分布;真实失真是指在图像的获取中,由于环境、拍摄设备或拍摄操作不当等因素所引入的失真类型。相对合成失真,真实失真更为复杂,可能包括一种或多种失真,数据收集难度更大;算法相关失真是指图像处理算法或计算机视觉算法在处理图像时,由于算法本身的缺陷或性能不足等原因而出现在结果图像中的降质,相对合成失真和真实失真,算法相关失真的显著特点是该类型失真呈现非均匀分布。本文介绍现有的图像质量评价数据库,包括图像数据来源和数据库构建细节等;然后重点介绍图像质量评价模型的设计思想。最后总结了介绍的图像质量评价模型,并指出未来可能的发展方向。关键词:图像质量评价(IQA);图像处理;视觉感知;计算机视觉;机器学习;深度学习535|1176|7更新时间:2024-05-07
摘要:随着多媒体技术的快速发展及广泛应用,图像质量评价因其在多媒体处理中的重要作用得到越来越多的关注,其作用包括图像数据筛选、算法参数选择与优化等。根据图像质量评价应用时是否需要参考信息,它可分为全参考图像质量评价、半参考图像质量评价和无参考图像质量评价,前两类分别需要全部参考信息和部分参考信息,而第3类不需要参考信息。无论是全参考、半参考还是无参考图像质量评价,图像失真对图像质量评价的影响均较大,主要体现在图像质量评价数据库构建和图像质量评价模型设计两方面。本文从图像失真的角度,主要概述2011—2021年国内外公开发表的图像质量评价模型,涵盖全参考、半参考和无参考模型。根据图像的失真类型,将图像质量评价模型分为针对合成失真的图像质量评价模型、针对真实失真的图像质量评价模型和针对算法相关失真的图像质量评价模型。其中,合成失真是指人工添加噪声,如高斯噪声和模糊失真,通常呈现均匀分布;真实失真是指在图像的获取中,由于环境、拍摄设备或拍摄操作不当等因素所引入的失真类型。相对合成失真,真实失真更为复杂,可能包括一种或多种失真,数据收集难度更大;算法相关失真是指图像处理算法或计算机视觉算法在处理图像时,由于算法本身的缺陷或性能不足等原因而出现在结果图像中的降质,相对合成失真和真实失真,算法相关失真的显著特点是该类型失真呈现非均匀分布。本文介绍现有的图像质量评价数据库,包括图像数据来源和数据库构建细节等;然后重点介绍图像质量评价模型的设计思想。最后总结了介绍的图像质量评价模型,并指出未来可能的发展方向。关键词:图像质量评价(IQA);图像处理;视觉感知;计算机视觉;机器学习;深度学习535|1176|7更新时间:2024-05-07
综述
-
 摘要:目的由于光在水中的衰减/散射以及微生物对光的吸收/反射等影响,水下图像通常存在色偏、模糊、光照不均匀以及对比度过低等诸多质量问题。研究人员对此提出了许多不同的水下图像增强算法。为了探究目前已有的水下图像增强算法的性能和图像质量客观评价方法是否适用于评估水下图像,本文开展大规模主观实验来对比不同水下图像增强算法在真实水下图像数据集上的性能,并对现有图像质量评价方法用于评估水下图像的准确性进行测试。方法构建了一个真实的水下图像数据集,其中包含100幅原始水下图像以及对应的1 000幅由10种主流水下图像增强方法增强后的图像。基于成对比较的策略开展水下图像主观质量评价,进一步对主观评价得到的结果进行分析,包括一致性分析、收敛性分析以及显著性检验。最后将10种现有主流的无参考图像质量评价在本文数据集上进行测试,检验其在真实水下图像数据集上的评价性能。结果一致性分析中,该数据集包含的主观评分有较高的肯德尔一致性系数,其值为0.41;收敛性分析中,所收集的投票数量与图像数量足够得到稳定的主观评分;表明本文构建的数据集具有良好的有效性与可靠性。此外,目前对比自然图像的无参考图像质量评价方法并不适用于水下图像数据集,验证了水下图像与自然图像的巨大差异。结论本文构建的真实水下图像数据集为未来水下图像质量客观评价方法以及水下图像增强算法的研究提供了参考与支持。所涉及的图像以及所有收集的用户数据,都在项目主页(https://github.com/yia-yuese/RealUWIQ-dataset)上公开。关键词:图像质量评价;水下图像增强;主观质量评价;数据集;成对比较(PC)469|459|1更新时间:2024-05-07
摘要:目的由于光在水中的衰减/散射以及微生物对光的吸收/反射等影响,水下图像通常存在色偏、模糊、光照不均匀以及对比度过低等诸多质量问题。研究人员对此提出了许多不同的水下图像增强算法。为了探究目前已有的水下图像增强算法的性能和图像质量客观评价方法是否适用于评估水下图像,本文开展大规模主观实验来对比不同水下图像增强算法在真实水下图像数据集上的性能,并对现有图像质量评价方法用于评估水下图像的准确性进行测试。方法构建了一个真实的水下图像数据集,其中包含100幅原始水下图像以及对应的1 000幅由10种主流水下图像增强方法增强后的图像。基于成对比较的策略开展水下图像主观质量评价,进一步对主观评价得到的结果进行分析,包括一致性分析、收敛性分析以及显著性检验。最后将10种现有主流的无参考图像质量评价在本文数据集上进行测试,检验其在真实水下图像数据集上的评价性能。结果一致性分析中,该数据集包含的主观评分有较高的肯德尔一致性系数,其值为0.41;收敛性分析中,所收集的投票数量与图像数量足够得到稳定的主观评分;表明本文构建的数据集具有良好的有效性与可靠性。此外,目前对比自然图像的无参考图像质量评价方法并不适用于水下图像数据集,验证了水下图像与自然图像的巨大差异。结论本文构建的真实水下图像数据集为未来水下图像质量客观评价方法以及水下图像增强算法的研究提供了参考与支持。所涉及的图像以及所有收集的用户数据,都在项目主页(https://github.com/yia-yuese/RealUWIQ-dataset)上公开。关键词:图像质量评价;水下图像增强;主观质量评价;数据集;成对比较(PC)469|459|1更新时间:2024-05-07
数据集论文
-
 摘要:目的室外监控在雾霾天气所采集图像的成像清晰度和目标显著程度均会降低,当在雾霾图像提取与人眼视觉质量相关的自然场景统计特征和与目标检测精度相关的目标类别语义特征时,这些特征与从清晰图像提取的特征存在明显差别。为了提升图像质量并且在缺乏雾霾天气目标检测标注数据的情况下提升跨域目标检测效果,本文综合利用传统方法和深度学习方法,提出了一种无监督先验混合图像特征级增强网络。方法利用本文提出的传统先验构成雾气先验模块;其后连接一个特征级增强网络模块,将去散射图像视为输入图像,利用像素域和特征域的损失实现场景统计特征和目标类别语义相关表观特征的增强。该混合网络突破了传统像素级增强方法难以表征抽象特征的制约,同时克服了对抗迁移网络难以准确衡量无重合图像域在特征空间分布差异的弱点,也减弱了识别算法对于低能见度天候采集图像标注数据的依赖,可以同时提高雾霾图像整体视觉感知质量以及局部目标可识别表现。结果实验在两个真实雾霾图像数据集、真实图像任务驱动的测试数据集(real-world task-driven testing set, RTTS)和自动驾驶雾天数据集(foggy driving dense)上与最新的5种散射去除方法进行了比较,相比于各指标中性能第2的算法,本文方法结果中梯度比指标R值平均提高了50.83%,属于感知质量指标的集成自然图像质量评价指标(integrated local natural image quality evaluator, IL-NIQE)值平均提高了6.33%,属于跨域目标检测指标的平均精准率(mean average precision, MAP)值平均提高了6.40%,平均查全率Recall值平均提高了7.79%。实验结果表明,本文方法结果在视觉质量和目标可识别层面都优于对比方法,并且本文方法对于高清视频的处理速度达50帧/s,且无需标注数据,因而在监控系统具有更高的实用价值。结论本文方法可以同时满足雾霾天候下对采集视频进行人眼观看和使用识别算法进行跨域目标检测的需求,具有较强的应用意义。关键词:图像去雾;特征增强;先验混合网络;无监督学习;图像域转换174|462|2更新时间:2024-05-07
摘要:目的室外监控在雾霾天气所采集图像的成像清晰度和目标显著程度均会降低,当在雾霾图像提取与人眼视觉质量相关的自然场景统计特征和与目标检测精度相关的目标类别语义特征时,这些特征与从清晰图像提取的特征存在明显差别。为了提升图像质量并且在缺乏雾霾天气目标检测标注数据的情况下提升跨域目标检测效果,本文综合利用传统方法和深度学习方法,提出了一种无监督先验混合图像特征级增强网络。方法利用本文提出的传统先验构成雾气先验模块;其后连接一个特征级增强网络模块,将去散射图像视为输入图像,利用像素域和特征域的损失实现场景统计特征和目标类别语义相关表观特征的增强。该混合网络突破了传统像素级增强方法难以表征抽象特征的制约,同时克服了对抗迁移网络难以准确衡量无重合图像域在特征空间分布差异的弱点,也减弱了识别算法对于低能见度天候采集图像标注数据的依赖,可以同时提高雾霾图像整体视觉感知质量以及局部目标可识别表现。结果实验在两个真实雾霾图像数据集、真实图像任务驱动的测试数据集(real-world task-driven testing set, RTTS)和自动驾驶雾天数据集(foggy driving dense)上与最新的5种散射去除方法进行了比较,相比于各指标中性能第2的算法,本文方法结果中梯度比指标R值平均提高了50.83%,属于感知质量指标的集成自然图像质量评价指标(integrated local natural image quality evaluator, IL-NIQE)值平均提高了6.33%,属于跨域目标检测指标的平均精准率(mean average precision, MAP)值平均提高了6.40%,平均查全率Recall值平均提高了7.79%。实验结果表明,本文方法结果在视觉质量和目标可识别层面都优于对比方法,并且本文方法对于高清视频的处理速度达50帧/s,且无需标注数据,因而在监控系统具有更高的实用价值。结论本文方法可以同时满足雾霾天候下对采集视频进行人眼观看和使用识别算法进行跨域目标检测的需求,具有较强的应用意义。关键词:图像去雾;特征增强;先验混合网络;无监督学习;图像域转换174|462|2更新时间:2024-05-07 -
 摘要:目的在沙尘天气条件下,由于大气中悬浮微粒对入射光线的吸收和散射,户外计算机视觉系统所采集图像通常存在颜色偏黄失真和低对比度等问题,严重影响户外计算机视觉系统的性能。为此,提出一种带色彩恢复的沙尘图像卷积神经网络增强方法,由一个色彩恢复子网和一个去尘增强子网组成。方法采用提出的色彩恢复子网(sand dust color correction, SDCC)校正沙尘图像的偏色,将颜色校正后的图像作为条件,输入到由自适应实例归一化残差块组成的去尘增强子网中,对沙尘图像进行增强处理。本文还提出一种基于物理光学模型的沙尘图像合成方法,并采用该方法构建了大规模的配对沙尘图像数据集。结果对大量沙尘图像的实验结果表明,所提出的沙尘图像增强方法能很好地去除图像中的偏色和沙尘,获得正常的视觉颜色和细节清晰的图像。进一步的对比实验表明,该方法能取得优于对比方法的增强图像。结论本文所提出的沙尘图像增强方法能很好地消除整体的黄色色调和尘霾现象,获得正常的视觉色彩和细节清晰的图像。关键词:沙尘图像;沙尘图像增强;颜色校正;自适应实例归一化残差块;合成沙尘图像数据集245|446|1更新时间:2024-05-07
摘要:目的在沙尘天气条件下,由于大气中悬浮微粒对入射光线的吸收和散射,户外计算机视觉系统所采集图像通常存在颜色偏黄失真和低对比度等问题,严重影响户外计算机视觉系统的性能。为此,提出一种带色彩恢复的沙尘图像卷积神经网络增强方法,由一个色彩恢复子网和一个去尘增强子网组成。方法采用提出的色彩恢复子网(sand dust color correction, SDCC)校正沙尘图像的偏色,将颜色校正后的图像作为条件,输入到由自适应实例归一化残差块组成的去尘增强子网中,对沙尘图像进行增强处理。本文还提出一种基于物理光学模型的沙尘图像合成方法,并采用该方法构建了大规模的配对沙尘图像数据集。结果对大量沙尘图像的实验结果表明,所提出的沙尘图像增强方法能很好地去除图像中的偏色和沙尘,获得正常的视觉颜色和细节清晰的图像。进一步的对比实验表明,该方法能取得优于对比方法的增强图像。结论本文所提出的沙尘图像增强方法能很好地消除整体的黄色色调和尘霾现象,获得正常的视觉色彩和细节清晰的图像。关键词:沙尘图像;沙尘图像增强;颜色校正;自适应实例归一化残差块;合成沙尘图像数据集245|446|1更新时间:2024-05-07 -
 摘要:目的因为有雨图像中雨线存在方向、密度和大小等各方面的差异,单幅图像去雨依旧是一个充满挑战的研究问题。现有算法在某些复杂图像上仍存在过度去雨或去雨不足等问题,部分复杂图像的边缘高频信息在去雨过程中被抹除,或图像中残留雨成分。针对上述问题,本文提出三维注意力和Transformer去雨网络(three-dimension attention and Transformer deraining network,TDATDN)。方法将三维注意力机制与残差密集块结构相结合,以解决残差密集块通道高维度特征融合问题;使用Transformer计算特征全局关联性;针对去雨过程中图像高频信息被破坏和结构信息被抹除的问题,将多尺度结构相似性损失与常用图像去雨损失函数结合参与去雨网络训练。结果本文将提出的TDATDN网络在Rain12000雨线数据集上进行实验。其中,峰值信噪比(peak signal to noise ratio,PSNR)达到33.01 dB,结构相似性(structural similarity,SSIM)达到0.927 8。实验结果表明,本文算法对比以往基于深度学习的神经网络去雨算法,显著改善了单幅图像去雨效果。结论本文提出的TDATDN图像去雨网络结合了3D注意力机制、Transformer和编码器—解码器架构的优点,可较好地完成单幅图像去雨工作。关键词:单幅图像去雨;卷积神经网络(CNN);Transformer;3D注意力;U-Net175|280|4更新时间:2024-05-07
摘要:目的因为有雨图像中雨线存在方向、密度和大小等各方面的差异,单幅图像去雨依旧是一个充满挑战的研究问题。现有算法在某些复杂图像上仍存在过度去雨或去雨不足等问题,部分复杂图像的边缘高频信息在去雨过程中被抹除,或图像中残留雨成分。针对上述问题,本文提出三维注意力和Transformer去雨网络(three-dimension attention and Transformer deraining network,TDATDN)。方法将三维注意力机制与残差密集块结构相结合,以解决残差密集块通道高维度特征融合问题;使用Transformer计算特征全局关联性;针对去雨过程中图像高频信息被破坏和结构信息被抹除的问题,将多尺度结构相似性损失与常用图像去雨损失函数结合参与去雨网络训练。结果本文将提出的TDATDN网络在Rain12000雨线数据集上进行实验。其中,峰值信噪比(peak signal to noise ratio,PSNR)达到33.01 dB,结构相似性(structural similarity,SSIM)达到0.927 8。实验结果表明,本文算法对比以往基于深度学习的神经网络去雨算法,显著改善了单幅图像去雨效果。结论本文提出的TDATDN图像去雨网络结合了3D注意力机制、Transformer和编码器—解码器架构的优点,可较好地完成单幅图像去雨工作。关键词:单幅图像去雨;卷积神经网络(CNN);Transformer;3D注意力;U-Net175|280|4更新时间:2024-05-07 -
 摘要:目的图像去雨技术是对雨天拍摄图像中雨纹信息进行检测和去除,恢复目标场景的细节信息,从而获得清晰的无雨图像。针对现有方法对雨纹信息检测不完全、去除不彻底的问题,提出一种联合自适应形态学滤波和多尺度卷积稀疏编码(multi-scale convolution sparse coding, MS-CSC)的单幅图像去雨方法。方法考虑雨纹信息的形状结构特点,构造一种自适应形态学滤波器来滤除有雨图像中的雨纹信息,获得包含图像自身纹理的低频成分;利用全变分模型正则化方法来增强低频成分的纹理信息,并利用有雨图像减去低频成分获得包含雨纹信息的高频成分;针对高频成分,根据雨纹的方向性提出一种基于方向梯度正则化的MS-CSC方法来重构高频成分,并通过迭代求解获得包含精确雨纹的高频成分,即雨层;利用有雨图像减去雨层得到最终的去雨图像。结果为验证本文方法的有效性,与一些主流的去雨方法进行实验比较。实验结果表明,本文方法在模拟数据集上的平均峰值信噪比(peak signal-to-noise ratio, PSNR)和平均结构相似度(structural similarity, SSIM)指标分别提高了0.95和0.005 2,能得到较好的主观视觉效果和客观评价,特别是在真实数据集上具有明显优势。结论本文方法可有效去除雨纹,同时可保留更多的原始图像纹理信息,经证明是一种有效的去雨算法。关键词:图像去雨;自适应形态学滤波;全变分模型;方向梯度正则化;多尺度卷积稀疏编码(MS-CSC)115|125|0更新时间:2024-05-07
摘要:目的图像去雨技术是对雨天拍摄图像中雨纹信息进行检测和去除,恢复目标场景的细节信息,从而获得清晰的无雨图像。针对现有方法对雨纹信息检测不完全、去除不彻底的问题,提出一种联合自适应形态学滤波和多尺度卷积稀疏编码(multi-scale convolution sparse coding, MS-CSC)的单幅图像去雨方法。方法考虑雨纹信息的形状结构特点,构造一种自适应形态学滤波器来滤除有雨图像中的雨纹信息,获得包含图像自身纹理的低频成分;利用全变分模型正则化方法来增强低频成分的纹理信息,并利用有雨图像减去低频成分获得包含雨纹信息的高频成分;针对高频成分,根据雨纹的方向性提出一种基于方向梯度正则化的MS-CSC方法来重构高频成分,并通过迭代求解获得包含精确雨纹的高频成分,即雨层;利用有雨图像减去雨层得到最终的去雨图像。结果为验证本文方法的有效性,与一些主流的去雨方法进行实验比较。实验结果表明,本文方法在模拟数据集上的平均峰值信噪比(peak signal-to-noise ratio, PSNR)和平均结构相似度(structural similarity, SSIM)指标分别提高了0.95和0.005 2,能得到较好的主观视觉效果和客观评价,特别是在真实数据集上具有明显优势。结论本文方法可有效去除雨纹,同时可保留更多的原始图像纹理信息,经证明是一种有效的去雨算法。关键词:图像去雨;自适应形态学滤波;全变分模型;方向梯度正则化;多尺度卷积稀疏编码(MS-CSC)115|125|0更新时间:2024-05-07 -
 摘要:目的现有的去雨方法存在去雨不彻底和去雨后图像结构信息丢失等问题。针对这些问题, 提出多尺度渐进式残差网络(multi scale progressive residual network, MSPRNet)的单幅图像去雨方法。方法提出的多尺度渐进式残差网络通过3个不同感受野的子网络进行逐步去雨。将有雨图像通过具有较大感受野的初步去雨子网络去除图像中的大尺度雨痕。通过残留雨痕去除子网络进一步去除残留的雨痕。将中间去雨结果输入图像恢复子网络, 通过这种渐进式网络逐步恢复去雨过程中损失的图像结构信息。为了充分利用残差网络的残差分支上包含的重要信息, 提出了一种改进残差网络模块, 并在每个子网络中引入注意力机制来指导改进残差网络模块去雨。结果在5个数据集上与最新的8种方法进行对比实验,相较于其他方法中性能第1的模型, 本文算法在5个数据集上分别获得了0.018、0.028、0.012、0.007和0.07的结构相似度(structural similarity, SSIM)增益。同时在Rain100L数据集上进行了消融实验,实验结果表明,每个子网络的缺失都会造成去雨性能的下降, 提出的多尺度渐进式网络算法能够有效去除各种雨痕。结论提出的算法能够获得最高的客观评价指标值和最优的视觉效果。在有效解决雨痕重叠问题的同时能够更好地保持图像的细节信息。关键词:单幅图像去雨;深度学习;卷积神经网络(CNN);残差网络;注意力机制126|173|4更新时间:2024-05-07
摘要:目的现有的去雨方法存在去雨不彻底和去雨后图像结构信息丢失等问题。针对这些问题, 提出多尺度渐进式残差网络(multi scale progressive residual network, MSPRNet)的单幅图像去雨方法。方法提出的多尺度渐进式残差网络通过3个不同感受野的子网络进行逐步去雨。将有雨图像通过具有较大感受野的初步去雨子网络去除图像中的大尺度雨痕。通过残留雨痕去除子网络进一步去除残留的雨痕。将中间去雨结果输入图像恢复子网络, 通过这种渐进式网络逐步恢复去雨过程中损失的图像结构信息。为了充分利用残差网络的残差分支上包含的重要信息, 提出了一种改进残差网络模块, 并在每个子网络中引入注意力机制来指导改进残差网络模块去雨。结果在5个数据集上与最新的8种方法进行对比实验,相较于其他方法中性能第1的模型, 本文算法在5个数据集上分别获得了0.018、0.028、0.012、0.007和0.07的结构相似度(structural similarity, SSIM)增益。同时在Rain100L数据集上进行了消融实验,实验结果表明,每个子网络的缺失都会造成去雨性能的下降, 提出的多尺度渐进式网络算法能够有效去除各种雨痕。结论提出的算法能够获得最高的客观评价指标值和最优的视觉效果。在有效解决雨痕重叠问题的同时能够更好地保持图像的细节信息。关键词:单幅图像去雨;深度学习;卷积神经网络(CNN);残差网络;注意力机制126|173|4更新时间:2024-05-07
图像去雾去雨
-
 摘要:目的针对传统的逆光图像增强算法存在的曝光正常区域与逆光区域间阈值计算复杂、分割精度不足、过度曝光以及增强不足等问题,提出一种改进融合策略下透明度引导的逆光图像增强算法。方法对逆光图像在HSV(hue, saturation, value)空间中的亮度分量进行亮度提升和对比度增强,然后通过金字塔融合策略对改进的亮度分量进行分解和重构,恢复逆光区域的细节和颜色信息。此外,利用深度抠图网络计算透明度蒙版,对增强的逆光区域与源图像进行融合处理,维持非逆光区域亮度不变。通过改进融合策略增强的图像在透明度引导下既有效恢复了逆光区域又避免了曝光过度的问题。结果实验在多幅逆光图像上与直方图均衡算法、MSR (multi-scale Retinex)、Zero-DEC (zero-reference deep curve estimation)、AGLLNet (attention guided low-light image enhancement)和LBR (learning-based restoration) 5种方法进行了比较,在信息熵(information entropy, IE)和盲图像质量指标(blind image quality indicators, BIQI)上,比AGLLNet分别提高了1.9%和10.2%;在自然图像质量评价(natural image quality evaluation, NIQE)方面,比Zero-DCE(zero-reference deep curve estimation)提高了3.5%。从主观评估上看,本文算法增强的图像在亮度、对比度、颜色及细节上恢复得更加自然,达到了较好的视觉效果。结论本文方法通过结合金字塔融合技术与抠图技术,解决了其他方法存在的色彩失真和曝光过度问题,具有更好的增强效果。关键词:图像处理;逆光图像增强;深度抠图;灰度拉伸;金字塔融合198|269|4更新时间:2024-05-07
摘要:目的针对传统的逆光图像增强算法存在的曝光正常区域与逆光区域间阈值计算复杂、分割精度不足、过度曝光以及增强不足等问题,提出一种改进融合策略下透明度引导的逆光图像增强算法。方法对逆光图像在HSV(hue, saturation, value)空间中的亮度分量进行亮度提升和对比度增强,然后通过金字塔融合策略对改进的亮度分量进行分解和重构,恢复逆光区域的细节和颜色信息。此外,利用深度抠图网络计算透明度蒙版,对增强的逆光区域与源图像进行融合处理,维持非逆光区域亮度不变。通过改进融合策略增强的图像在透明度引导下既有效恢复了逆光区域又避免了曝光过度的问题。结果实验在多幅逆光图像上与直方图均衡算法、MSR (multi-scale Retinex)、Zero-DEC (zero-reference deep curve estimation)、AGLLNet (attention guided low-light image enhancement)和LBR (learning-based restoration) 5种方法进行了比较,在信息熵(information entropy, IE)和盲图像质量指标(blind image quality indicators, BIQI)上,比AGLLNet分别提高了1.9%和10.2%;在自然图像质量评价(natural image quality evaluation, NIQE)方面,比Zero-DCE(zero-reference deep curve estimation)提高了3.5%。从主观评估上看,本文算法增强的图像在亮度、对比度、颜色及细节上恢复得更加自然,达到了较好的视觉效果。结论本文方法通过结合金字塔融合技术与抠图技术,解决了其他方法存在的色彩失真和曝光过度问题,具有更好的增强效果。关键词:图像处理;逆光图像增强;深度抠图;灰度拉伸;金字塔融合198|269|4更新时间:2024-05-07 -
 摘要:目的微光图像存在低对比度、噪声伪影和颜色失真等退化问题,造成图像的视觉感受质量较差,同时也导致后续图像识别、分类和检测等任务的精度降低。针对以上问题,提出一种融合注意力机制和上下文信息的微光图像增强方法。方法为提高运算精度,以U型结构网络为基础构建了一种端到端的微光图像增强网络框架,主要由注意力机制编/解码模块、跨尺度上下文模块和融合模块等组成。由混合注意力块(包括空间注意力和通道注意力)引导主干网络学习,其空间注意力模块用于计算空间位置的权重以学习不同区域的噪声特征,而通道注意力模块根据不同通道的颜色信息计算通道权重,以提升网络的颜色信息重建能力。此外,跨尺度上下文模块用于聚合各阶段网络中的深层和浅层特征,借助融合机制来提高网络的亮度和颜色增强效果。结果本文方法与现有主流方法进行定量和定性对比实验,结果显示本文方法显著提升了微光图像亮度,并且较好保持了图像颜色一致性,原微光图像较暗区域的噪点显著去除,重建图像的纹理细节清晰。在峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity,SSIM)和图像感知相似度(perceptual image patch similarity,LPIPS)等客观指标上,本文方法较其他方法的最优值分别提高了0.74 dB、0.153和0.172。结论本文方法能有效解决微光图像存在的曝光不足、噪声干扰和颜色不一致等问题,具有一定应用价值。关键词:图像处理;微光图像增强;深度学习;注意力机制;上下文信息92|336|5更新时间:2024-05-07
摘要:目的微光图像存在低对比度、噪声伪影和颜色失真等退化问题,造成图像的视觉感受质量较差,同时也导致后续图像识别、分类和检测等任务的精度降低。针对以上问题,提出一种融合注意力机制和上下文信息的微光图像增强方法。方法为提高运算精度,以U型结构网络为基础构建了一种端到端的微光图像增强网络框架,主要由注意力机制编/解码模块、跨尺度上下文模块和融合模块等组成。由混合注意力块(包括空间注意力和通道注意力)引导主干网络学习,其空间注意力模块用于计算空间位置的权重以学习不同区域的噪声特征,而通道注意力模块根据不同通道的颜色信息计算通道权重,以提升网络的颜色信息重建能力。此外,跨尺度上下文模块用于聚合各阶段网络中的深层和浅层特征,借助融合机制来提高网络的亮度和颜色增强效果。结果本文方法与现有主流方法进行定量和定性对比实验,结果显示本文方法显著提升了微光图像亮度,并且较好保持了图像颜色一致性,原微光图像较暗区域的噪点显著去除,重建图像的纹理细节清晰。在峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性(structural similarity,SSIM)和图像感知相似度(perceptual image patch similarity,LPIPS)等客观指标上,本文方法较其他方法的最优值分别提高了0.74 dB、0.153和0.172。结论本文方法能有效解决微光图像存在的曝光不足、噪声干扰和颜色不一致等问题,具有一定应用价值。关键词:图像处理;微光图像增强;深度学习;注意力机制;上下文信息92|336|5更新时间:2024-05-07 -
 摘要:目的由于海水中悬浮的颗粒会吸收和散射光,并且不同波长的光在海水中的衰减程度也不同,使得水下机器人拍摄的图像呈现出对比度低、颜色失真等问题。为解决上述问题以呈现出自然清晰的水下图像,本文提出了基于神经网络的多残差联合学习的方法来对水下图像进行增强。方法该方法包括3个模块:预处理、特征提取和特征融合。首先,采用Sigmoid校正方法对原始图像的对比度进行预处理,增强失真图像的对比度,得到校正后的图像;然后,采用双分支网络对特征进行提取,将原始图像送入分支1——残差通道注意分支网络,将校正后的图像与原始图像级联送入分支2——残差卷积增强分支网络。其中,通道注意分支在残差密集块中嵌入了通道注意力模型,通过对不同通道的特征重新进行加权分配,以加强有用特征;卷积增强分支通过密集级联和残差学习,提取校正图像中边缘等高频信息以保持原始结构与边缘。最后,在特征融合部分,将以上双分支网络的特征级联后,通过残差学习进一步增强;增强后的特征与分支1的输出、分支1与分支2的输出分别经过自适应掩膜进行再次融合。选取通用UIEB(underwater image benchmark dataset)数据集中的800幅水下图像作为训练集进行训练,设计了结合图像内容感知、均方误差、梯度和结构相似性的联合损失函数对网络进行端到端训练。结果在通用UIEB数据集上选取非训练集中有参考图像的90幅图像与当前10种方法进行测试。结果显示,本文方法增强后的水下图像的PSNR(peak signal-to-noise ratio)指标平均达到了20.739 4 dB,SSIM(structural similarity)为0.876 8,UIQM(underwater image quality measure)为3.183 3,均高于对比方法。结论本文方法不仅在客观质量上超越了对比方法,且在主观质量上也显著提高了对比度,能够产生颜色丰富并且清晰度较高的增强图像。尤其是对于深水场景中偏蓝的水下图像,本文方法获得显著的质量提升。关键词:卷积神经网络(CNN);密集级联网络;水下图像增强;特征提取;通道注意80|190|0更新时间:2024-05-07
摘要:目的由于海水中悬浮的颗粒会吸收和散射光,并且不同波长的光在海水中的衰减程度也不同,使得水下机器人拍摄的图像呈现出对比度低、颜色失真等问题。为解决上述问题以呈现出自然清晰的水下图像,本文提出了基于神经网络的多残差联合学习的方法来对水下图像进行增强。方法该方法包括3个模块:预处理、特征提取和特征融合。首先,采用Sigmoid校正方法对原始图像的对比度进行预处理,增强失真图像的对比度,得到校正后的图像;然后,采用双分支网络对特征进行提取,将原始图像送入分支1——残差通道注意分支网络,将校正后的图像与原始图像级联送入分支2——残差卷积增强分支网络。其中,通道注意分支在残差密集块中嵌入了通道注意力模型,通过对不同通道的特征重新进行加权分配,以加强有用特征;卷积增强分支通过密集级联和残差学习,提取校正图像中边缘等高频信息以保持原始结构与边缘。最后,在特征融合部分,将以上双分支网络的特征级联后,通过残差学习进一步增强;增强后的特征与分支1的输出、分支1与分支2的输出分别经过自适应掩膜进行再次融合。选取通用UIEB(underwater image benchmark dataset)数据集中的800幅水下图像作为训练集进行训练,设计了结合图像内容感知、均方误差、梯度和结构相似性的联合损失函数对网络进行端到端训练。结果在通用UIEB数据集上选取非训练集中有参考图像的90幅图像与当前10种方法进行测试。结果显示,本文方法增强后的水下图像的PSNR(peak signal-to-noise ratio)指标平均达到了20.739 4 dB,SSIM(structural similarity)为0.876 8,UIQM(underwater image quality measure)为3.183 3,均高于对比方法。结论本文方法不仅在客观质量上超越了对比方法,且在主观质量上也显著提高了对比度,能够产生颜色丰富并且清晰度较高的增强图像。尤其是对于深水场景中偏蓝的水下图像,本文方法获得显著的质量提升。关键词:卷积神经网络(CNN);密集级联网络;水下图像增强;特征提取;通道注意80|190|0更新时间:2024-05-07 -
 摘要:目的随着数码设备的普及,拍照成为记录生活的一种主流方式。但是周围环境的不可控因素会导致用户获取到逆光图像。传统的图像增强方法大多是全局增强,通常存在增强过度或增强程度不够的问题。而基于深度学习的图像增强方法大多是针对低照度图像增强任务,此类方法无法同时兼顾逆光图像中欠曝光区域和过曝光区域的增强问题,且在网络训练时需要成对的数据集。方法提出一个基于注意力机制的逆光图像增强网络ABIEN(attention-based backlight image enhancement network),该网络学习逆光图像与增强图像之间像素级的映射参数, 解决无参考图像的问题,同时使用注意力机制使网络关注欠曝光区域和过曝光区域的增强。为了解决无法获取成对图像数据集的问题,所设计的网络学习逆光图像与恢复图像之间的映射参数,并借助该参数进行迭代映射以实现图像增强;为了在增强欠曝光区域的同时还能抑制过曝光区域增强过度的问题,通过引入注意力机制帮助网络关注这两个不同区域的增强过程;为了解决大多数图像恢复中都会出现的光晕、伪影等问题,采用原始分辨率保留策略,在不改变图像大小的情况下将主网络各个深度的特征信息充分利用,以削弱该类问题对增强图像的影响。结果通过将本文方法与MSRCR(multi-scale retinex with color restoration)、Fusion-based(fusion-based method)、Learnning-based(learning-based restoration)、NPEA(naturalness preserved enhancement algorithm)和ExCNet(exposure correction network)等方法进行对比,本文方法得到的增强图像从主观上看曝光度更好、颜色保留更真实、伪影更少;从客观指标来看,本文方法在LOE(lightness order error)上取得了最好的效果,在VLD(visibility level descriptor)和CDIQA(contrast-distorted image quality assessment)上表现也很好;从处理时间上来看,本文方法的处理时间相对较短,可以满足在现实场景中的实时应用。结论提出的逆光图像增强方法通过结合注意力机制和原始分辨率保留策略,可以帮助网络学习各个层次的特征信息,充分挖掘图像内容信息,在矫正图像亮度的同时,还能更好地恢复图像细节。关键词:逆光图像;图像增强;卷积神经网络(CNN);注意力机制;零参考样本235|581|4更新时间:2024-05-07
摘要:目的随着数码设备的普及,拍照成为记录生活的一种主流方式。但是周围环境的不可控因素会导致用户获取到逆光图像。传统的图像增强方法大多是全局增强,通常存在增强过度或增强程度不够的问题。而基于深度学习的图像增强方法大多是针对低照度图像增强任务,此类方法无法同时兼顾逆光图像中欠曝光区域和过曝光区域的增强问题,且在网络训练时需要成对的数据集。方法提出一个基于注意力机制的逆光图像增强网络ABIEN(attention-based backlight image enhancement network),该网络学习逆光图像与增强图像之间像素级的映射参数, 解决无参考图像的问题,同时使用注意力机制使网络关注欠曝光区域和过曝光区域的增强。为了解决无法获取成对图像数据集的问题,所设计的网络学习逆光图像与恢复图像之间的映射参数,并借助该参数进行迭代映射以实现图像增强;为了在增强欠曝光区域的同时还能抑制过曝光区域增强过度的问题,通过引入注意力机制帮助网络关注这两个不同区域的增强过程;为了解决大多数图像恢复中都会出现的光晕、伪影等问题,采用原始分辨率保留策略,在不改变图像大小的情况下将主网络各个深度的特征信息充分利用,以削弱该类问题对增强图像的影响。结果通过将本文方法与MSRCR(multi-scale retinex with color restoration)、Fusion-based(fusion-based method)、Learnning-based(learning-based restoration)、NPEA(naturalness preserved enhancement algorithm)和ExCNet(exposure correction network)等方法进行对比,本文方法得到的增强图像从主观上看曝光度更好、颜色保留更真实、伪影更少;从客观指标来看,本文方法在LOE(lightness order error)上取得了最好的效果,在VLD(visibility level descriptor)和CDIQA(contrast-distorted image quality assessment)上表现也很好;从处理时间上来看,本文方法的处理时间相对较短,可以满足在现实场景中的实时应用。结论提出的逆光图像增强方法通过结合注意力机制和原始分辨率保留策略,可以帮助网络学习各个层次的特征信息,充分挖掘图像内容信息,在矫正图像亮度的同时,还能更好地恢复图像细节。关键词:逆光图像;图像增强;卷积神经网络(CNN);注意力机制;零参考样本235|581|4更新时间:2024-05-07
低照图像增强
-
 摘要:目的虽然深度学习技术已大幅提高了图像超分辨率的性能,但是现有方法大多仅考虑了特定的整数比例因子,不能灵活地实现连续比例因子的超分辨率。现有方法通常为每个比例因子训练一次模型,导致耗费很长的训练时间和占用过多的模型存储空间。针对以上问题,本文提出了一种基于跨尺度耦合网络的连续比例因子超分辨率方法。方法提出一个用于替代传统上采样层的跨尺度耦合上采样模块,用于实现连续比例因子上采样。其次,提出一个跨尺度卷积层,可以在多个尺度上并行提取特征,通过动态地激活和聚合不同尺度的特征来挖掘跨尺度上下文信息,有效提升连续比例因子超分辨率任务的性能。结果在3个数据集上与最新的超分辨率方法进行比较,在连续比例因子任务中,相比于性能第2的对比算法Meta-SR(meta super-resolution),峰值信噪比提升达0.13 dB,而参数量减少了73%。在整数比例因子任务中,相比于参数量相近的轻量网络SRFBN(super-resolution feedback network),峰值信噪比提升达0.24 dB。同时,提出的算法能够生成视觉效果更加逼真、纹理更加清晰的结果。消融实验证明了所提算法中各个模块的有效性。结论本文提出的连续比例因子超分辨率模型,仅需要一次训练,就可以在任意比例因子上获得优秀的超分辨率结果。此外,跨尺度耦合上采样模块可以用于替代常用的亚像素层或反卷积层,在实现连续比例因子上采样的同时,保持模型性能。关键词:深度学习;单幅图像超分辨率(SISR);连续比例因子;跨尺度耦合;跨尺度卷积66|142|2更新时间:2024-05-07
摘要:目的虽然深度学习技术已大幅提高了图像超分辨率的性能,但是现有方法大多仅考虑了特定的整数比例因子,不能灵活地实现连续比例因子的超分辨率。现有方法通常为每个比例因子训练一次模型,导致耗费很长的训练时间和占用过多的模型存储空间。针对以上问题,本文提出了一种基于跨尺度耦合网络的连续比例因子超分辨率方法。方法提出一个用于替代传统上采样层的跨尺度耦合上采样模块,用于实现连续比例因子上采样。其次,提出一个跨尺度卷积层,可以在多个尺度上并行提取特征,通过动态地激活和聚合不同尺度的特征来挖掘跨尺度上下文信息,有效提升连续比例因子超分辨率任务的性能。结果在3个数据集上与最新的超分辨率方法进行比较,在连续比例因子任务中,相比于性能第2的对比算法Meta-SR(meta super-resolution),峰值信噪比提升达0.13 dB,而参数量减少了73%。在整数比例因子任务中,相比于参数量相近的轻量网络SRFBN(super-resolution feedback network),峰值信噪比提升达0.24 dB。同时,提出的算法能够生成视觉效果更加逼真、纹理更加清晰的结果。消融实验证明了所提算法中各个模块的有效性。结论本文提出的连续比例因子超分辨率模型,仅需要一次训练,就可以在任意比例因子上获得优秀的超分辨率结果。此外,跨尺度耦合上采样模块可以用于替代常用的亚像素层或反卷积层,在实现连续比例因子上采样的同时,保持模型性能。关键词:深度学习;单幅图像超分辨率(SISR);连续比例因子;跨尺度耦合;跨尺度卷积66|142|2更新时间:2024-05-07 -
 摘要:目的以卷积神经网络为代表的深度学习方法已经在单帧图像超分辨领域取得了丰硕成果,这些方法大多假设低分辨图像不存在模糊效应。然而,由于相机抖动、物体运动等原因,真实场景下的低分辨率图像通常会伴随着模糊现象。因此,为了解决模糊图像的超分辨问题,提出了一种新颖的Transformer融合网络。方法首先使用去模糊模块和细节纹理特征提取模块分别提取清晰边缘轮廓特征和细节纹理特征。然后,通过多头自注意力机制计算特征图任一局部信息对于全局信息的响应,从而使Transformer融合模块对边缘特征和纹理特征进行全局语义级的特征融合。最后,通过一个高清图像重建模块将融合特征恢复成高分辨率图像。结果实验在2个公开数据集上与最新的9种方法进行了比较,在GOPRO数据集上进行2倍、4倍、8倍超分辨重建,相比于性能第2的模型GFN(gated fusion network), 峰值信噪比(peak signal-to-noive ratio, PSNR)分别提高了0.12 dB、0.18 dB、0.07 dB;在Kohler数据集上进行2倍、4倍、8倍超分辨重建,相比于性能第2的模型GFN,PSNR值分别提高了0.17 dB、0.28 dB、0.16 dB。同时也在GOPRO数据集上进行了对比实验以验证Transformer融合网络的有效性。对比实验结果表明,提出的网络明显提升了对模糊图像超分辨重建的效果。结论本文所提出的用于模糊图像超分辨的Transformer融合网络,具有优异的长程依赖关系和全局信息捕捉能力,其通过多头自注意力层计算特征图任一局部信息在全局信息上的响应,实现了对去模糊特征和细节纹理特征在全局语义层次的深度融合,从而提升了对模糊图像进行超分辨重建的效果。关键词:超分辨;单帧图像超分辨;模糊图像;融合网络;Transformer163|245|5更新时间:2024-05-07
摘要:目的以卷积神经网络为代表的深度学习方法已经在单帧图像超分辨领域取得了丰硕成果,这些方法大多假设低分辨图像不存在模糊效应。然而,由于相机抖动、物体运动等原因,真实场景下的低分辨率图像通常会伴随着模糊现象。因此,为了解决模糊图像的超分辨问题,提出了一种新颖的Transformer融合网络。方法首先使用去模糊模块和细节纹理特征提取模块分别提取清晰边缘轮廓特征和细节纹理特征。然后,通过多头自注意力机制计算特征图任一局部信息对于全局信息的响应,从而使Transformer融合模块对边缘特征和纹理特征进行全局语义级的特征融合。最后,通过一个高清图像重建模块将融合特征恢复成高分辨率图像。结果实验在2个公开数据集上与最新的9种方法进行了比较,在GOPRO数据集上进行2倍、4倍、8倍超分辨重建,相比于性能第2的模型GFN(gated fusion network), 峰值信噪比(peak signal-to-noive ratio, PSNR)分别提高了0.12 dB、0.18 dB、0.07 dB;在Kohler数据集上进行2倍、4倍、8倍超分辨重建,相比于性能第2的模型GFN,PSNR值分别提高了0.17 dB、0.28 dB、0.16 dB。同时也在GOPRO数据集上进行了对比实验以验证Transformer融合网络的有效性。对比实验结果表明,提出的网络明显提升了对模糊图像超分辨重建的效果。结论本文所提出的用于模糊图像超分辨的Transformer融合网络,具有优异的长程依赖关系和全局信息捕捉能力,其通过多头自注意力层计算特征图任一局部信息在全局信息上的响应,实现了对去模糊特征和细节纹理特征在全局语义层次的深度融合,从而提升了对模糊图像进行超分辨重建的效果。关键词:超分辨;单帧图像超分辨;模糊图像;融合网络;Transformer163|245|5更新时间:2024-05-07
图像超分辨
-
 摘要:目的曝光融合算法,即将多幅不同曝光时间的图像融合得到一幅曝光度良好的图像,可能在最终的输出图像中引入光晕伪影、边缘模糊和细节丢失等问题。针对曝光融合过程中存在的上述问题,本文从细节增强原理出发提出了一种全细节增强的曝光融合算法。方法在分析了光晕现象产生原因的基础上,从聚合的新角度对经典引导滤波进行改进,明显改善引导滤波器的保边特性,从而有效去除或减小光晕;用该改进引导滤波器提取不同曝光图像的细节信息,并依据曝光良好度将多幅细节图融合得到拍摄场景的全细节信息;将提取、融合得到的全细节信息整合到由经典曝光融合算法得到的初步融合图像上,最终输出一幅全细节增强后的融合图像。结果实验选取17组多曝光高质量图像作为输入图像序列,本文算法相较于其他算法得到的融合图像边缘保持较好,融合自然;从客观指标看,本文算法在信息熵、互信息与平均梯度等指标上都较其他融合算法有所提升。以本文17组图像的平均结果来看,本文算法相较于经典的拉普拉斯金字塔融合算法在信息熵上提升了14.13%,在互信息熵上提升了0.03%,在平均梯度上提升了16.45%。结论提出的全细节增强的曝光融合算法将加权聚合引导滤波用于计算多曝光序列图像的细节信息,并将该细节信息融合到经典曝光融合算法所得到的一幅中间图像之上,从而得到最终的融合图像。本文的处理方法使最终融合图像包含更多细节,降低或避免了光晕及梯度翻转等现象,且最终输出图像的视觉效果更加优秀。关键词:多曝光图像融合;细节提取;引导滤波(GIF);加权聚合;光晕效应113|525|2更新时间:2024-05-07
摘要:目的曝光融合算法,即将多幅不同曝光时间的图像融合得到一幅曝光度良好的图像,可能在最终的输出图像中引入光晕伪影、边缘模糊和细节丢失等问题。针对曝光融合过程中存在的上述问题,本文从细节增强原理出发提出了一种全细节增强的曝光融合算法。方法在分析了光晕现象产生原因的基础上,从聚合的新角度对经典引导滤波进行改进,明显改善引导滤波器的保边特性,从而有效去除或减小光晕;用该改进引导滤波器提取不同曝光图像的细节信息,并依据曝光良好度将多幅细节图融合得到拍摄场景的全细节信息;将提取、融合得到的全细节信息整合到由经典曝光融合算法得到的初步融合图像上,最终输出一幅全细节增强后的融合图像。结果实验选取17组多曝光高质量图像作为输入图像序列,本文算法相较于其他算法得到的融合图像边缘保持较好,融合自然;从客观指标看,本文算法在信息熵、互信息与平均梯度等指标上都较其他融合算法有所提升。以本文17组图像的平均结果来看,本文算法相较于经典的拉普拉斯金字塔融合算法在信息熵上提升了14.13%,在互信息熵上提升了0.03%,在平均梯度上提升了16.45%。结论提出的全细节增强的曝光融合算法将加权聚合引导滤波用于计算多曝光序列图像的细节信息,并将该细节信息融合到经典曝光融合算法所得到的一幅中间图像之上,从而得到最终的融合图像。本文的处理方法使最终融合图像包含更多细节,降低或避免了光晕及梯度翻转等现象,且最终输出图像的视觉效果更加优秀。关键词:多曝光图像融合;细节提取;引导滤波(GIF);加权聚合;光晕效应113|525|2更新时间:2024-05-07 -
 摘要:目的破损图像修复是一项具有挑战性的任务,其目的是根据破损图像中已知内容对破损区域进行填充。许多基于深度学习的破损图像修复方法对大面积破损的图像修复效果欠佳,且对高分辨率破损图像修复的研究也较少。对此,本文提出基于卷积自编码生成式对抗网络(convolutional auto-encoder generative adversarial network,CAE-GAN)的修复方法。方法通过训练生成器学习从高斯噪声到低维特征矩阵的映射关系,再将生成器生成的特征矩阵升维成高分辨率图像,搜索与待修复图像完好部分相似的生成图像,并将对应部分覆盖到破损图像上,实现高分辨率破损图像的修复。结果通过将学习难度较大的映射关系进行拆分,降低了单个映射关系的学习难度,提升了模型训练效果,在4个数据集上对不同破损程度的512×512×3高分辨率破损图像进行修复,结果表明,本文方法成功预测了大面积缺失区域的信息。与CE(context-encoders)方法相比,本文方法在破损面积大的图像上的修复效果提升显著,峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)值最高分别提升了31.6%和18.0%,与DCGAN(deep convolutional generative adversarial network)方法相比,本文方法修复的图像内容符合度更高,破损区域修复结果更加清晰,PSNR和SSIM值最高分别提升了24.4%和50.0%。结论本文方法更适用于大面积破损图像与高分辨率图像的修复工作。关键词:破损图像修复;高分辨率;生成式对抗网络(GAN);大面积破损;深度学习118|170|2更新时间:2024-05-07
摘要:目的破损图像修复是一项具有挑战性的任务,其目的是根据破损图像中已知内容对破损区域进行填充。许多基于深度学习的破损图像修复方法对大面积破损的图像修复效果欠佳,且对高分辨率破损图像修复的研究也较少。对此,本文提出基于卷积自编码生成式对抗网络(convolutional auto-encoder generative adversarial network,CAE-GAN)的修复方法。方法通过训练生成器学习从高斯噪声到低维特征矩阵的映射关系,再将生成器生成的特征矩阵升维成高分辨率图像,搜索与待修复图像完好部分相似的生成图像,并将对应部分覆盖到破损图像上,实现高分辨率破损图像的修复。结果通过将学习难度较大的映射关系进行拆分,降低了单个映射关系的学习难度,提升了模型训练效果,在4个数据集上对不同破损程度的512×512×3高分辨率破损图像进行修复,结果表明,本文方法成功预测了大面积缺失区域的信息。与CE(context-encoders)方法相比,本文方法在破损面积大的图像上的修复效果提升显著,峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)值最高分别提升了31.6%和18.0%,与DCGAN(deep convolutional generative adversarial network)方法相比,本文方法修复的图像内容符合度更高,破损区域修复结果更加清晰,PSNR和SSIM值最高分别提升了24.4%和50.0%。结论本文方法更适用于大面积破损图像与高分辨率图像的修复工作。关键词:破损图像修复;高分辨率;生成式对抗网络(GAN);大面积破损;深度学习118|170|2更新时间:2024-05-07 -
 摘要:目的修复老照片具有重要的实用价值,但老照片包含多种未知复杂的退化,传统的修复方法组合不同的数字图像处理技术进行修复,通常产生不连贯或不自然的修复结果。基于深度学习的修复方法虽然被提出,但大多集中于对单一或有限的退化进行修复。针对上述问题,本文提出一种融合参考先验与生成先验的生成对抗网络来修复老照片。方法对提取的老照片和参考图像的浅层特征进行编码获得深层语义特征与潜在编码,对获得的潜在编码进一步融合获得深度语义编码,深度语义编码通过生成先验网络获得生成先验特征,并且深度语义编码引导条件空间多特征变换条件注意力块进行参考语义特征、生成先验特征与待修复特征的空间融合变换,最后通过解码网络重建修复图像。结果实验与6种图像修复方法进行了定量与定性评估。比较了4种评估指标,本文算法的所有指标评估结果均优于其他算法,PSNR (peak signal-to-noise ratio)为23.69 dB,SSIM (structural similarity index)为0.828 3,FID (Fréchet inception distance)为71.53,LPIPS (learned perceptual image patch similarity)为0.309),相比指标排名第2的算法,分别提高了0.75 dB, 0.019 7, 13.69%, 19.86%。定性结果中,本文算法具有更好的复杂退化修复能力,修复的细节更加丰富。此外,本文算法相比对比算法更加轻量,推断速度更快,以43.44 M的参数量完成256×256像素分辨率图像推断仅需248 ms。结论本文提出了融合参考先验与生成先验的老照片修复方法,充分利用了参考先验的语义信息与生成模型封装的人像先验,在主观与客观上均取得了先进的修复性能。关键词:深度学习;生成对抗网络(GAN);老照片修复;参考先验;生成先验;空间特征变换;编解码网络;多尺度感知144|216|1更新时间:2024-05-07
摘要:目的修复老照片具有重要的实用价值,但老照片包含多种未知复杂的退化,传统的修复方法组合不同的数字图像处理技术进行修复,通常产生不连贯或不自然的修复结果。基于深度学习的修复方法虽然被提出,但大多集中于对单一或有限的退化进行修复。针对上述问题,本文提出一种融合参考先验与生成先验的生成对抗网络来修复老照片。方法对提取的老照片和参考图像的浅层特征进行编码获得深层语义特征与潜在编码,对获得的潜在编码进一步融合获得深度语义编码,深度语义编码通过生成先验网络获得生成先验特征,并且深度语义编码引导条件空间多特征变换条件注意力块进行参考语义特征、生成先验特征与待修复特征的空间融合变换,最后通过解码网络重建修复图像。结果实验与6种图像修复方法进行了定量与定性评估。比较了4种评估指标,本文算法的所有指标评估结果均优于其他算法,PSNR (peak signal-to-noise ratio)为23.69 dB,SSIM (structural similarity index)为0.828 3,FID (Fréchet inception distance)为71.53,LPIPS (learned perceptual image patch similarity)为0.309),相比指标排名第2的算法,分别提高了0.75 dB, 0.019 7, 13.69%, 19.86%。定性结果中,本文算法具有更好的复杂退化修复能力,修复的细节更加丰富。此外,本文算法相比对比算法更加轻量,推断速度更快,以43.44 M的参数量完成256×256像素分辨率图像推断仅需248 ms。结论本文提出了融合参考先验与生成先验的老照片修复方法,充分利用了参考先验的语义信息与生成模型封装的人像先验,在主观与客观上均取得了先进的修复性能。关键词:深度学习;生成对抗网络(GAN);老照片修复;参考先验;生成先验;空间特征变换;编解码网络;多尺度感知144|216|1更新时间:2024-05-07 -
 摘要:目的虹膜识别是一种稳定可靠的生物识别技术,但虹膜图像的采集过程会受到多种干扰造成图像中虹膜被遮挡,比如光斑遮挡、上下眼皮遮挡等。这些遮挡的存在,一方面会导致虹膜信息缺失,直接影响虹膜识别的准确性,另一方面会影响预处理(如定位、分割)的准确性,间接影响虹膜识别的准确性。为解决上述问题,本文提出区域注意力机制引导的双路虹膜补全网络,通过遮挡区域的像素补齐,可以显著减少被遮挡区域对虹膜图像预处理和识别的影响,进而提升识别性能。方法使用基于Transformer的编码器和基于卷积神经网络(convolutional neural network, CNN)的编码器提取虹膜特征,通过融合模块将两种不同编码器提取的特征进行交互结合,并利用区域注意力机制分别处理低层和高层特征,最后利用解码器对处理后的特征进行上采样,恢复遮挡区域,生成完整图像。结果在CASIA(Institute of Automation,Chinese Academy of Sciences)虹膜数据集上对本文方法进行测试。在虹膜识别性能方面,本文方法在固定遮挡大小为64×64像素的情况下,遮挡补全结果的TAR(true accept rate)(0.1%FAR(false accept rate))为63%,而带有遮挡的图像仅为19.2%,提高了43.8%。结论本文所提出的区域注意力机制引导的双路虹膜补全网络,有效结合Transformer的全局建模能力和CNN的局部建模能力,并使用针对遮挡的区域注意力机制,实现了虹膜遮挡区域补全,进一步提高了虹膜识别的性能。关键词:虹膜补全;虹膜识别;虹膜分割;Transformer;卷积神经网络(CNN);注意力117|218|2更新时间:2024-05-07
摘要:目的虹膜识别是一种稳定可靠的生物识别技术,但虹膜图像的采集过程会受到多种干扰造成图像中虹膜被遮挡,比如光斑遮挡、上下眼皮遮挡等。这些遮挡的存在,一方面会导致虹膜信息缺失,直接影响虹膜识别的准确性,另一方面会影响预处理(如定位、分割)的准确性,间接影响虹膜识别的准确性。为解决上述问题,本文提出区域注意力机制引导的双路虹膜补全网络,通过遮挡区域的像素补齐,可以显著减少被遮挡区域对虹膜图像预处理和识别的影响,进而提升识别性能。方法使用基于Transformer的编码器和基于卷积神经网络(convolutional neural network, CNN)的编码器提取虹膜特征,通过融合模块将两种不同编码器提取的特征进行交互结合,并利用区域注意力机制分别处理低层和高层特征,最后利用解码器对处理后的特征进行上采样,恢复遮挡区域,生成完整图像。结果在CASIA(Institute of Automation,Chinese Academy of Sciences)虹膜数据集上对本文方法进行测试。在虹膜识别性能方面,本文方法在固定遮挡大小为64×64像素的情况下,遮挡补全结果的TAR(true accept rate)(0.1%FAR(false accept rate))为63%,而带有遮挡的图像仅为19.2%,提高了43.8%。结论本文所提出的区域注意力机制引导的双路虹膜补全网络,有效结合Transformer的全局建模能力和CNN的局部建模能力,并使用针对遮挡的区域注意力机制,实现了虹膜遮挡区域补全,进一步提高了虹膜识别的性能。关键词:虹膜补全;虹膜识别;虹膜分割;Transformer;卷积神经网络(CNN);注意力117|218|2更新时间:2024-05-07 -
 摘要:目的去模糊任务通常难以进行对图像纹理细节的学习,所复原图像的细节信息不丰富,图像边缘不够清晰,并且需要耗费大量时间。本文通过对图像去模糊方法进行分析,同时结合深度学习和对抗学习的方法,提出一种新型的基于生成对抗网络(generative adversarial network, GAN)的模糊图像多尺度复原方法。方法使用多尺度级联网络结构,采用由粗到细的策略对模糊图像进行复原,增强去模糊图像的纹理细节;同时采用改进的残差卷积结构,在不增加计算量的同时,加入并行空洞卷积模块,增加了感受野,获得更大范围的特征信息;并且加入通道注意力模块,通过对通道之间的相关性进行建模,加强有效特征权重,并抑制无效特征;在损失函数方面,结合感知损失(perceptual loss)以及最小均方差(mean squared error, MSE)损失,保证生成图像和清晰图像内容一致性。结果通过全参考图像质量评价指标峰值信噪比(peak signal to noise ratio, PSNR)、结构相似性(structural similarity, SSIM)以及复原时间来评价算法优劣。与其他方法的对比结果表明,本文方法生成的去模糊图像PSNR指标提升至少3.8%,复原图像的边缘也更加清晰。将去模糊后的图像应用于YOLO-v4(you only look once)目标检测网络,发现去模糊后的图像可以检测到更小的物体,识别物体的数量有所增加,所识别物体的置信度也有一定的提升。结论采用由粗到细的策略对模糊图像进行复原,在残差网络中注入通道注意力模块以及并行空洞卷积模块改进网络的性能,并进一步简化网络结构,有效提升了复原速度。同时,复原图像有着更清晰的边缘和更丰富的细节信息。关键词:注意力机制;图像修复;深度学习;生成对抗网络(GAN);多尺度141|283|3更新时间:2024-05-07
摘要:目的去模糊任务通常难以进行对图像纹理细节的学习,所复原图像的细节信息不丰富,图像边缘不够清晰,并且需要耗费大量时间。本文通过对图像去模糊方法进行分析,同时结合深度学习和对抗学习的方法,提出一种新型的基于生成对抗网络(generative adversarial network, GAN)的模糊图像多尺度复原方法。方法使用多尺度级联网络结构,采用由粗到细的策略对模糊图像进行复原,增强去模糊图像的纹理细节;同时采用改进的残差卷积结构,在不增加计算量的同时,加入并行空洞卷积模块,增加了感受野,获得更大范围的特征信息;并且加入通道注意力模块,通过对通道之间的相关性进行建模,加强有效特征权重,并抑制无效特征;在损失函数方面,结合感知损失(perceptual loss)以及最小均方差(mean squared error, MSE)损失,保证生成图像和清晰图像内容一致性。结果通过全参考图像质量评价指标峰值信噪比(peak signal to noise ratio, PSNR)、结构相似性(structural similarity, SSIM)以及复原时间来评价算法优劣。与其他方法的对比结果表明,本文方法生成的去模糊图像PSNR指标提升至少3.8%,复原图像的边缘也更加清晰。将去模糊后的图像应用于YOLO-v4(you only look once)目标检测网络,发现去模糊后的图像可以检测到更小的物体,识别物体的数量有所增加,所识别物体的置信度也有一定的提升。结论采用由粗到细的策略对模糊图像进行复原,在残差网络中注入通道注意力模块以及并行空洞卷积模块改进网络的性能,并进一步简化网络结构,有效提升了复原速度。同时,复原图像有着更清晰的边缘和更丰富的细节信息。关键词:注意力机制;图像修复;深度学习;生成对抗网络(GAN);多尺度141|283|3更新时间:2024-05-07
图像修复
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0