
最新刊期
2022 年 第 27 卷 第 2 期

-
 摘要:场景的深度估计问题是计算机视觉领域中的经典问题之一,也是3维重建和图像合成等应用中的一个重要环节。基于深度学习的单目深度估计技术高速发展,各种网络结构相继提出。本文对基于深度学习的单目深度估计技术最新进展进行了综述,回顾了基于监督学习和基于无监督学习方法的发展历程。重点关注单目深度估计的优化思路及其在深度学习网络结构中的表现,将监督学习方法分为多尺度特征融合的方法、结合条件随机场(conditional random field,CRF)的方法、基于序数关系的方法、结合多元图像信息的方法和其他方法等5类;将无监督学习方法分为基于立体视觉的方法、基于运动恢复结构(structure from motion,SfM)的方法、结合对抗性网络的方法、基于序数关系的方法和结合不确定性的方法等5类。此外,还介绍了单目深度估计任务中常用的数据集和评价指标,并对目前基于深度学习的单目深度估计技术在精确度、泛化性、应用场景和无监督网络中不确定性研究等方面的现状和面临的挑战进行了讨论,为相关领域的研究人员提供一个比较全面的参考。关键词:深度学习;单目深度估计;监督学习;无监督学习;多尺度特征融合;序数关系;立体视觉775|1132|4更新时间:2024-05-07
摘要:场景的深度估计问题是计算机视觉领域中的经典问题之一,也是3维重建和图像合成等应用中的一个重要环节。基于深度学习的单目深度估计技术高速发展,各种网络结构相继提出。本文对基于深度学习的单目深度估计技术最新进展进行了综述,回顾了基于监督学习和基于无监督学习方法的发展历程。重点关注单目深度估计的优化思路及其在深度学习网络结构中的表现,将监督学习方法分为多尺度特征融合的方法、结合条件随机场(conditional random field,CRF)的方法、基于序数关系的方法、结合多元图像信息的方法和其他方法等5类;将无监督学习方法分为基于立体视觉的方法、基于运动恢复结构(structure from motion,SfM)的方法、结合对抗性网络的方法、基于序数关系的方法和结合不确定性的方法等5类。此外,还介绍了单目深度估计任务中常用的数据集和评价指标,并对目前基于深度学习的单目深度估计技术在精确度、泛化性、应用场景和无监督网络中不确定性研究等方面的现状和面临的挑战进行了讨论,为相关领域的研究人员提供一个比较全面的参考。关键词:深度学习;单目深度估计;监督学习;无监督学习;多尺度特征融合;序数关系;立体视觉775|1132|4更新时间:2024-05-07 -
 摘要:随着3维采集设备的日渐推广,点云配准在越来越多的领域得到应用。然而,传统方法在低重叠、大量噪声、多异常点和大场景等方面表现不佳,这限制了点云配准在真实场景中的应用。面对传统方法的局限性,结合深度学习技术的点云配准方法开始出现,本文将这种方法称为深度点云配准,并对深度点云配准方法研究进展予以综述。首先,根据有无对应关系对目前的深度学习点云配准方法进行区分,分为无对应关系配准和基于对应关系的点云配准。针对基于对应关系的配准,根据各类方法的主要功能进行详细的分类与总结,其中包括几何特征提取、关键点检测、点对离群值去除、姿态估计和端到端配准,并重点介绍了最新出现的一些方法;针对无对应配准方法,详细介绍了各类方法的特点并对无对应与有对应方法的特点进行了总结。在性能评估中,首先对现有主要的评价指标进行了详细的分类与总结,给出其适用场景。对于真实数据集,给出了特征匹配、点对离群值去除的对比数据,并进行了总结。在合成数据集中,给出了相关方法在部分重叠、实时性和全局配准场景下的对比数据。最后讨论了当前深度点云配准面临的挑战并给出对未来研究方向的展望。关键词:点云配准;深度学习;无对应配准;端到端配准;对应关系;几何特征提取;离群值去除;综述250|401|10更新时间:2024-05-07
摘要:随着3维采集设备的日渐推广,点云配准在越来越多的领域得到应用。然而,传统方法在低重叠、大量噪声、多异常点和大场景等方面表现不佳,这限制了点云配准在真实场景中的应用。面对传统方法的局限性,结合深度学习技术的点云配准方法开始出现,本文将这种方法称为深度点云配准,并对深度点云配准方法研究进展予以综述。首先,根据有无对应关系对目前的深度学习点云配准方法进行区分,分为无对应关系配准和基于对应关系的点云配准。针对基于对应关系的配准,根据各类方法的主要功能进行详细的分类与总结,其中包括几何特征提取、关键点检测、点对离群值去除、姿态估计和端到端配准,并重点介绍了最新出现的一些方法;针对无对应配准方法,详细介绍了各类方法的特点并对无对应与有对应方法的特点进行了总结。在性能评估中,首先对现有主要的评价指标进行了详细的分类与总结,给出其适用场景。对于真实数据集,给出了特征匹配、点对离群值去除的对比数据,并进行了总结。在合成数据集中,给出了相关方法在部分重叠、实时性和全局配准场景下的对比数据。最后讨论了当前深度点云配准面临的挑战并给出对未来研究方向的展望。关键词:点云配准;深度学习;无对应配准;端到端配准;对应关系;几何特征提取;离群值去除;综述250|401|10更新时间:2024-05-07 -
 摘要:点云是一种3维表示方式,在广泛应用的同时产生了对点云处理的诸多挑战。其中,点云配准是一项非常值得研究的工作。点云配准旨在将多个点云正确配准到同一个坐标系下,形成更完整的点云。点云配准要应对点云非结构化、不均匀和噪声等干扰,要以更短的时间消耗达到更高的精度,时间消耗和精度往往是矛盾的,但在一定程度上优化是有可能的。点云配准广泛应用于3维重建、参数评估、定位和姿态估计等领域,在自动驾驶、机器人和增强现实等新兴应用上也有点云配准技术的参与。为此,研究者开发了多样巧妙的点云配准方法。本文梳理了一些比较有代表性的点云配准方法并进行分类总结,对比相关工作,尽量覆盖点云配准的各种形式,并对一些方法的细节加以分析介绍。将现有方法归纳为非学习方法和基于学习的方法进行分析。非学习方法分为经典方法和基于特征的方法;基于学习的方法分为结合了非学习方法的部分学习方法和直接的端到端学习方法。本文分别介绍了各类方法的典型算法,并对比总结算法特性,展望了点云配准技术的未来研究方向。关键词:点云;配准;特征;深度学习;综述454|177|29更新时间:2024-05-07
摘要:点云是一种3维表示方式,在广泛应用的同时产生了对点云处理的诸多挑战。其中,点云配准是一项非常值得研究的工作。点云配准旨在将多个点云正确配准到同一个坐标系下,形成更完整的点云。点云配准要应对点云非结构化、不均匀和噪声等干扰,要以更短的时间消耗达到更高的精度,时间消耗和精度往往是矛盾的,但在一定程度上优化是有可能的。点云配准广泛应用于3维重建、参数评估、定位和姿态估计等领域,在自动驾驶、机器人和增强现实等新兴应用上也有点云配准技术的参与。为此,研究者开发了多样巧妙的点云配准方法。本文梳理了一些比较有代表性的点云配准方法并进行分类总结,对比相关工作,尽量覆盖点云配准的各种形式,并对一些方法的细节加以分析介绍。将现有方法归纳为非学习方法和基于学习的方法进行分析。非学习方法分为经典方法和基于特征的方法;基于学习的方法分为结合了非学习方法的部分学习方法和直接的端到端学习方法。本文分别介绍了各类方法的典型算法,并对比总结算法特性,展望了点云配准技术的未来研究方向。关键词:点云;配准;特征;深度学习;综述454|177|29更新时间:2024-05-07 -
 摘要:同时定位与地图构建(simultaneous localization and mapping,SLAM)技术在过去几十年中取得了惊人的进步,并在现实生活中实现了大规模的应用。由于精度和鲁棒性的不足,以及场景的复杂性,使用单一传感器(如相机、激光雷达)的SLAM系统往往无法适应目标需求,故研究者们逐步探索并改进多源融合的SLAM解决方案。本文从3个层面回顾总结该领域的现有方法:1)多传感器融合(由两种及以上传感器组成的混合系统,如相机、激光雷达和惯性测量单元,可分为松耦合、紧耦合);2)多特征基元融合(点、线、面、其他高维几何特征等与直接法相结合);3)多维度信息融合(几何、语义、物理信息和深度神经网络的推理信息等相融合)。惯性测量单元和视觉、激光雷达的融合可以解决视觉里程计的漂移和尺度丢失问题,提高系统在非结构化或退化场景中的鲁棒性。此外,不同几何特征基元的融合,可以大大减少有效约束的程度,并可为自主导航任务提供更多的有用信息。另外,数据驱动下的基于深度学习的策略为SLAM系统开辟了新的道路。监督学习、无监督学习和混合监督学习等逐渐应用于SLAM系统的各个模块,如相对姿势估计、地图表示、闭环检测和后端优化等。学习方法与传统方法的结合将是提升SLAM系统性能的有效途径。本文分别对上述多源融合SLAM方法进行分析归纳,并指出其面临的挑战及未来发展方向。关键词:同时定位与地图构建(SLAM);多源融合;多传感器融合;多特征基元融合;多维度信息融合517|689|13更新时间:2024-05-07
摘要:同时定位与地图构建(simultaneous localization and mapping,SLAM)技术在过去几十年中取得了惊人的进步,并在现实生活中实现了大规模的应用。由于精度和鲁棒性的不足,以及场景的复杂性,使用单一传感器(如相机、激光雷达)的SLAM系统往往无法适应目标需求,故研究者们逐步探索并改进多源融合的SLAM解决方案。本文从3个层面回顾总结该领域的现有方法:1)多传感器融合(由两种及以上传感器组成的混合系统,如相机、激光雷达和惯性测量单元,可分为松耦合、紧耦合);2)多特征基元融合(点、线、面、其他高维几何特征等与直接法相结合);3)多维度信息融合(几何、语义、物理信息和深度神经网络的推理信息等相融合)。惯性测量单元和视觉、激光雷达的融合可以解决视觉里程计的漂移和尺度丢失问题,提高系统在非结构化或退化场景中的鲁棒性。此外,不同几何特征基元的融合,可以大大减少有效约束的程度,并可为自主导航任务提供更多的有用信息。另外,数据驱动下的基于深度学习的策略为SLAM系统开辟了新的道路。监督学习、无监督学习和混合监督学习等逐渐应用于SLAM系统的各个模块,如相对姿势估计、地图表示、闭环检测和后端优化等。学习方法与传统方法的结合将是提升SLAM系统性能的有效途径。本文分别对上述多源融合SLAM方法进行分析归纳,并指出其面临的挑战及未来发展方向。关键词:同时定位与地图构建(SLAM);多源融合;多传感器融合;多特征基元融合;多维度信息融合517|689|13更新时间:2024-05-07 -
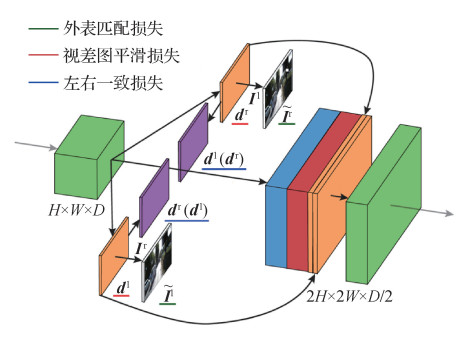 摘要:单目深度估计是从单幅图像中获取场景深度信息的重要技术,在智能汽车和机器人定位等领域应用广泛,具有重要的研究价值。随着深度学习技术的发展,涌现出许多基于深度学习的单目深度估计研究,单目深度估计性能也取得了很大进展。本文按照单目深度估计模型采用的训练数据的类型,从3个方面综述了近年来基于深度学习的单目深度估计方法:基于单图像训练的模型、基于多图像训练的模型和基于辅助信息优化训练的单目深度估计模型。同时,本文在综述了单目深度估计研究常用数据集和性能指标基础上,对经典的单目深度估计模型进行了性能比较分析。以单幅图像作为训练数据的模型具有网络结构简单的特点,但泛化性能较差。采用多图像训练的深度估计网络有更强的泛化性,但网络的参数量大、网络收敛速度慢、训练耗时长。引入辅助信息的深度估计网络的深度估计精度得到了进一步提升,但辅助信息的引入会造成网络结构复杂、收敛速度慢等问题。单目深度估计研究还存在许多的难题和挑战。利用多图像输入中包含的潜在信息和特定领域的约束信息,来提高单目深度估计的性能,逐渐成为了单目深度估计研究的趋势。关键词:单目视觉;场景感知;深度学习;3维重建;深度估计247|154|4更新时间:2024-05-07
摘要:单目深度估计是从单幅图像中获取场景深度信息的重要技术,在智能汽车和机器人定位等领域应用广泛,具有重要的研究价值。随着深度学习技术的发展,涌现出许多基于深度学习的单目深度估计研究,单目深度估计性能也取得了很大进展。本文按照单目深度估计模型采用的训练数据的类型,从3个方面综述了近年来基于深度学习的单目深度估计方法:基于单图像训练的模型、基于多图像训练的模型和基于辅助信息优化训练的单目深度估计模型。同时,本文在综述了单目深度估计研究常用数据集和性能指标基础上,对经典的单目深度估计模型进行了性能比较分析。以单幅图像作为训练数据的模型具有网络结构简单的特点,但泛化性能较差。采用多图像训练的深度估计网络有更强的泛化性,但网络的参数量大、网络收敛速度慢、训练耗时长。引入辅助信息的深度估计网络的深度估计精度得到了进一步提升,但辅助信息的引入会造成网络结构复杂、收敛速度慢等问题。单目深度估计研究还存在许多的难题和挑战。利用多图像输入中包含的潜在信息和特定领域的约束信息,来提高单目深度估计的性能,逐渐成为了单目深度估计研究的趋势。关键词:单目视觉;场景感知;深度学习;3维重建;深度估计247|154|4更新时间:2024-05-07
综述
-
 摘要:目的本征图像分解是计算视觉和图形学领域的一个基本问题,旨在将图像中场景的纹理和光照成分分离开来。基于深度学习的本征图像分解方法受限于现有的数据集,存在分解结果过度平滑、在真实数据泛化能力较差等问题。方法首先设计基于图卷积的模块,显式地考虑图像中的非局部信息。同时,为了使训练的网络可以处理更复杂的光照情况,渲染了高质量的合成数据集。此外,引入了一个基于神经网络的反照率图像优化模块,提升获得的反照率图像的局部平滑性。结果将不同方法在所提的数据集上训练,相比之前合成数据集CGIntrinsics进行训练的结果,在IIW(intrinsic images in the wild)测试数据集的平均WHDR(weighted human disagreement rate)降低了7.29%,在SAW(shading annotations in the wild)测试集的AP(average precision)指标上提升了2.74%。同时,所提出的基于图卷积的神经网络,在IIW、SAW数据集上均取得了较好的结果,在视觉结果上显著优于此前的方法。此外,利用本文算法得到的本征结果,在重光照、纹理编辑和光照编辑等图像编辑任务上,取得了更优的结果。结论所提出的数据集质量更高,有利于基于神经网络的本征分解模型的训练。同时,提出的本征分解模型由于显式地结合了非局部先验,得到了更优的本征分解结果,并通过一系列应用任务进一步验证了结果。关键词:图像处理;图像理解;本征图像分解;图卷积网络(GCN);合成数据集313|1076|1更新时间:2024-05-07
摘要:目的本征图像分解是计算视觉和图形学领域的一个基本问题,旨在将图像中场景的纹理和光照成分分离开来。基于深度学习的本征图像分解方法受限于现有的数据集,存在分解结果过度平滑、在真实数据泛化能力较差等问题。方法首先设计基于图卷积的模块,显式地考虑图像中的非局部信息。同时,为了使训练的网络可以处理更复杂的光照情况,渲染了高质量的合成数据集。此外,引入了一个基于神经网络的反照率图像优化模块,提升获得的反照率图像的局部平滑性。结果将不同方法在所提的数据集上训练,相比之前合成数据集CGIntrinsics进行训练的结果,在IIW(intrinsic images in the wild)测试数据集的平均WHDR(weighted human disagreement rate)降低了7.29%,在SAW(shading annotations in the wild)测试集的AP(average precision)指标上提升了2.74%。同时,所提出的基于图卷积的神经网络,在IIW、SAW数据集上均取得了较好的结果,在视觉结果上显著优于此前的方法。此外,利用本文算法得到的本征结果,在重光照、纹理编辑和光照编辑等图像编辑任务上,取得了更优的结果。结论所提出的数据集质量更高,有利于基于神经网络的本征分解模型的训练。同时,提出的本征分解模型由于显式地结合了非局部先验,得到了更优的本征分解结果,并通过一系列应用任务进一步验证了结果。关键词:图像处理;图像理解;本征图像分解;图卷积网络(GCN);合成数据集313|1076|1更新时间:2024-05-07
数据集论文
-
 摘要:目的结构化重建,即从离散点云或者原始三角网格中提取几何平面并将其拼接成紧凑的参数化3维模型,一直是计算机图形学领域中极具挑战性的问题。现有方法通常面临着两个挑战。一是传统的形状检测方法通常只考虑物体的局部特征,无法保证整体结果的准确性。二是现有的形状拼接算法往往受限于计算复杂度,从而只能处理由一百多个几何平面组成的物体,极大地限制了算法的应用场景。针对这些问题,提出了一种快速、鲁棒的结构化重建算法以自动地生成轻量的多边形网格。方法提出了一种多源区域增长算法,全局地从原始3维数据中提取特征平面。该策略保证了原始数据可以被正确地聚类到所属的平面区域。为了减轻几何平面分割3维空间带来的计算负担,采用了一种基于二叉空间分割树的结构将3维空间切分为凸多面体。提出了一种基于光线射击的马尔可夫能量方程以提取水密、无自相交的多边形网格。结果实验结果表明,本文方法可以在没有并行化方案的标准计算机上处理由上万个几何平面组成的物体。与传统的全相交分割相比,本文方法得到的多面体数目和运行时间都降低了至少两个数量级,总耗时可控制在5 s/万点以内。此外,模型化简前后的均方根误差平均控制在1%以内,面片化简比例控制在1.5%以内。结论本文方法在计算效率以及结果的准确性上均取得了较大的进步,能够恢复有部分缺陷的表面模型,保留重要结构细节,在复杂性和保真度之间提供了一种较好的方案。关键词:几何建模;表面重建;形状检测;二叉空间分割(BSP);马尔可夫随机场(MRF)191|301|2更新时间:2024-05-07
摘要:目的结构化重建,即从离散点云或者原始三角网格中提取几何平面并将其拼接成紧凑的参数化3维模型,一直是计算机图形学领域中极具挑战性的问题。现有方法通常面临着两个挑战。一是传统的形状检测方法通常只考虑物体的局部特征,无法保证整体结果的准确性。二是现有的形状拼接算法往往受限于计算复杂度,从而只能处理由一百多个几何平面组成的物体,极大地限制了算法的应用场景。针对这些问题,提出了一种快速、鲁棒的结构化重建算法以自动地生成轻量的多边形网格。方法提出了一种多源区域增长算法,全局地从原始3维数据中提取特征平面。该策略保证了原始数据可以被正确地聚类到所属的平面区域。为了减轻几何平面分割3维空间带来的计算负担,采用了一种基于二叉空间分割树的结构将3维空间切分为凸多面体。提出了一种基于光线射击的马尔可夫能量方程以提取水密、无自相交的多边形网格。结果实验结果表明,本文方法可以在没有并行化方案的标准计算机上处理由上万个几何平面组成的物体。与传统的全相交分割相比,本文方法得到的多面体数目和运行时间都降低了至少两个数量级,总耗时可控制在5 s/万点以内。此外,模型化简前后的均方根误差平均控制在1%以内,面片化简比例控制在1.5%以内。结论本文方法在计算效率以及结果的准确性上均取得了较大的进步,能够恢复有部分缺陷的表面模型,保留重要结构细节,在复杂性和保真度之间提供了一种较好的方案。关键词:几何建模;表面重建;形状检测;二叉空间分割(BSP);马尔可夫随机场(MRF)191|301|2更新时间:2024-05-07 -
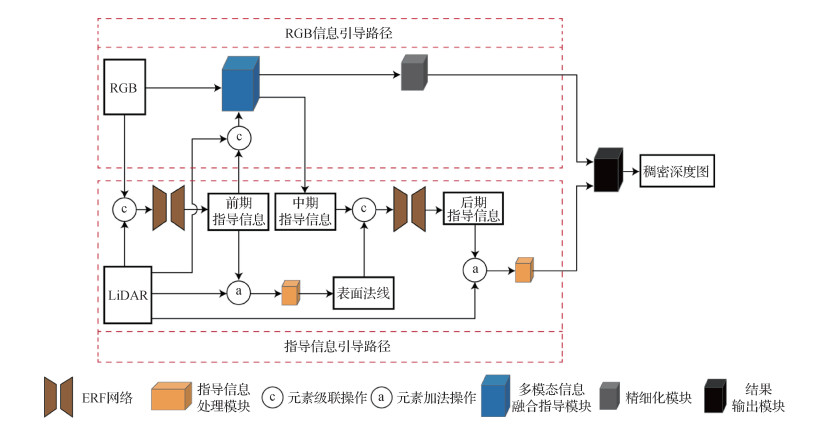 摘要:目的使用单幅RGB图像引导稀疏激光雷达(light detection and ranging,LiDAR)点云构建稠密深度图已逐渐成为研究热点,然而现有方法在构建场景深度信息时,目标边缘处的深度依然存在模糊的问题,影响3维重建与摄影测量的准确性。为此,本文提出一种基于多阶段指导网络的稠密深度图构建方法。方法多阶段指导网络由指导信息引导路径和RGB信息引导路径构成。在指导信息引导路径上,通过ERF(efficient residual factorized)网络融合稀疏激光雷达点云和RGB数据提取前期指导信息,采用指导信息处理模块融合稀疏深度和前期指导信息,并将融合后的信息通过双线性插值的方式构建出表面法线,将多模态信息融合指导模块提取的中期指导信息和表面法线信息输入到ERF网络中,提取可用于引导稀疏深度稠密化的后期指导信息,以此构建该路径上的稠密深度图;在RGB信息引导路径上,通过前期指导信息引导融合稀疏深度与RGB信息,通过多模态信息融合指导模块获得该路径上的稠密深度图,采用精细化模块减少该稠密深度图中的误差信息。融合上述两条路径得到的结果,获得最终稠密深度图。结果通过KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)深度估计数据集训练多阶段指导网络,将测试数据结果提交到KITTI官方评估服务器,评估指标中,均方根误差值和反演深度的均方根误差分别为768.35和2.40,均低于对比方法,且本文方法在物体边缘和细节处的构建精度更高。结论本文给出的多阶段指导网络可以更好地提高稠密深度图构建准确率,弥补激光雷达点云稀疏的缺陷,实验结果验证了本文方法的有效性。关键词:深度估计;深度学习;LiDAR;多模态数据融合;图像处理169|221|3更新时间:2024-05-07
摘要:目的使用单幅RGB图像引导稀疏激光雷达(light detection and ranging,LiDAR)点云构建稠密深度图已逐渐成为研究热点,然而现有方法在构建场景深度信息时,目标边缘处的深度依然存在模糊的问题,影响3维重建与摄影测量的准确性。为此,本文提出一种基于多阶段指导网络的稠密深度图构建方法。方法多阶段指导网络由指导信息引导路径和RGB信息引导路径构成。在指导信息引导路径上,通过ERF(efficient residual factorized)网络融合稀疏激光雷达点云和RGB数据提取前期指导信息,采用指导信息处理模块融合稀疏深度和前期指导信息,并将融合后的信息通过双线性插值的方式构建出表面法线,将多模态信息融合指导模块提取的中期指导信息和表面法线信息输入到ERF网络中,提取可用于引导稀疏深度稠密化的后期指导信息,以此构建该路径上的稠密深度图;在RGB信息引导路径上,通过前期指导信息引导融合稀疏深度与RGB信息,通过多模态信息融合指导模块获得该路径上的稠密深度图,采用精细化模块减少该稠密深度图中的误差信息。融合上述两条路径得到的结果,获得最终稠密深度图。结果通过KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)深度估计数据集训练多阶段指导网络,将测试数据结果提交到KITTI官方评估服务器,评估指标中,均方根误差值和反演深度的均方根误差分别为768.35和2.40,均低于对比方法,且本文方法在物体边缘和细节处的构建精度更高。结论本文给出的多阶段指导网络可以更好地提高稠密深度图构建准确率,弥补激光雷达点云稀疏的缺陷,实验结果验证了本文方法的有效性。关键词:深度估计;深度学习;LiDAR;多模态数据融合;图像处理169|221|3更新时间:2024-05-07 -
 摘要:目的双目视差估计可以实现稠密的深度估计,因而具有重要研究价值。而视差估计和光流估计两个任务之间具有相似性,在两种任务之间可以互相借鉴并启迪新算法。受光流估计高效算法RAFT(recurrent all-pairs field transforms)的启发,本文提出采用单、双边多尺度相似性迭代查找的方法实现高精度的双目视差估计。针对方法在不同区域估计精度和置信度不一致的问题,提出了左右图像视差估计一致性检测提取可靠估计区域的方法。方法采用金字塔池化模块、跳层连接和残差结构的特征网络提取具有强表征能力的表示向量,采用向量内积表示像素间的相似性,通过平均池化得到多尺度的相似量,第0次迭代集成初始视差量,根据初始视差单方向向左查找多尺度的相似性得到的大视野相似量和上下文3种信息,而其他次迭代集成更新的视差估计量,根据估计视差双向查找多尺度的相似性得到的大视野相似量和上下文3种信息,集成信息通过第0次更新的卷积循环神经网络和其他次更新共享的卷积循环神经网络迭代输出视差的更新量,多次迭代得到最终的视差估计值。之后,通过对输入左、右图像反序和左右翻转估计右图视差,对比左、右图匹配点视差差值的绝对值和给定阈值之差判断视差估计置信度,从而实现可靠区域提取。结果本文方法在Sceneflow数据集上得到了与先进方法相当的精度,平均误差只有0.84像素,并且推理时间有相对优势,可以和精度之间通过控制迭代次数灵活平衡。可靠区域提取后,Sceneflow数据集上误差进一步减小到了历史最佳值0.21像素,在KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)双目测试数据集上,估计区域评估指标最优。结论本文方法对于双目视差估计具有优越性能,可靠区域提取方法能高效提取高精度估计区域,极大地提升了估计区域的可靠性。关键词:双目视差估计;遮挡;卷积循环神经网络;深度学习;监督学习101|202|1更新时间:2024-05-07
摘要:目的双目视差估计可以实现稠密的深度估计,因而具有重要研究价值。而视差估计和光流估计两个任务之间具有相似性,在两种任务之间可以互相借鉴并启迪新算法。受光流估计高效算法RAFT(recurrent all-pairs field transforms)的启发,本文提出采用单、双边多尺度相似性迭代查找的方法实现高精度的双目视差估计。针对方法在不同区域估计精度和置信度不一致的问题,提出了左右图像视差估计一致性检测提取可靠估计区域的方法。方法采用金字塔池化模块、跳层连接和残差结构的特征网络提取具有强表征能力的表示向量,采用向量内积表示像素间的相似性,通过平均池化得到多尺度的相似量,第0次迭代集成初始视差量,根据初始视差单方向向左查找多尺度的相似性得到的大视野相似量和上下文3种信息,而其他次迭代集成更新的视差估计量,根据估计视差双向查找多尺度的相似性得到的大视野相似量和上下文3种信息,集成信息通过第0次更新的卷积循环神经网络和其他次更新共享的卷积循环神经网络迭代输出视差的更新量,多次迭代得到最终的视差估计值。之后,通过对输入左、右图像反序和左右翻转估计右图视差,对比左、右图匹配点视差差值的绝对值和给定阈值之差判断视差估计置信度,从而实现可靠区域提取。结果本文方法在Sceneflow数据集上得到了与先进方法相当的精度,平均误差只有0.84像素,并且推理时间有相对优势,可以和精度之间通过控制迭代次数灵活平衡。可靠区域提取后,Sceneflow数据集上误差进一步减小到了历史最佳值0.21像素,在KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)双目测试数据集上,估计区域评估指标最优。结论本文方法对于双目视差估计具有优越性能,可靠区域提取方法能高效提取高精度估计区域,极大地提升了估计区域的可靠性。关键词:双目视差估计;遮挡;卷积循环神经网络;深度学习;监督学习101|202|1更新时间:2024-05-07 -
 摘要:目的显微光学成像有景深小和易模糊等缺陷,很难根据几何光学中的点扩散函数准确评估图像的模糊程度,进而很难计算景物深度。同时,传统的使用边缘检测算子衡量图像模糊程度变化的方法缺少与景物深度之间的函数关系,影响深度计算的精度。为此,本文提出一种显微光学系统成像模糊程度与景物深度关系曲线的获取方法。方法从显微光学系统中的光学传递特性出发,建立光学传递函数中的光程差、高频能量参数和景物深度之间的数学关系,并通过归一化和曲线拟合得到显微光学系统的成像模糊程度与景物深度之间的解析函数。结果为了验证本文获取的图像模糊程度和景物深度之间的函数关系,首先使用纳米方形栅格的模糊图像进行深度计算,实验测得的深度平均误差为0.008 μm,即相对误差为0.8%,与通过清晰图像和模糊图像的逐个像素亮度值比较,根据最小二乘方法搜索两幅图像的亮度差最小时求得深度的方法相比,精度提高了约73%。然后基于深度测量结果进行模糊栅格图像的清晰重构,重构后的图像在平均梯度和拉普拉斯值两个方面都明显提高,且相对于传统基于高斯点扩散函数清晰重构方法,本文方法的重构精度更高,稳定性更强;最后通过多种不同形状和亮度特性的栅格模糊图像的深度计算,证明了本文的模糊程度—深度变化曲线对不同景物的通用性。结论本文建立的函数关系能够更加直观地反映系统参数对光学模糊成像过程的影响。使用高频能量参数表征图像的模糊特性,既可以准确测量图像模糊程度,也与景物深度具有直接的函数关系。固定光学系统参数后,建立的归一化系统成像模糊程度与景物深度之间的函数关系不会受到景物图像的纹理、亮度等特性差异的影响,鲁棒性强、更方便、更省时。关键词:光学显微系统;模糊程度;景物深度;解析函数;光学传递特性;高频能量参数78|2998|0更新时间:2024-05-07
摘要:目的显微光学成像有景深小和易模糊等缺陷,很难根据几何光学中的点扩散函数准确评估图像的模糊程度,进而很难计算景物深度。同时,传统的使用边缘检测算子衡量图像模糊程度变化的方法缺少与景物深度之间的函数关系,影响深度计算的精度。为此,本文提出一种显微光学系统成像模糊程度与景物深度关系曲线的获取方法。方法从显微光学系统中的光学传递特性出发,建立光学传递函数中的光程差、高频能量参数和景物深度之间的数学关系,并通过归一化和曲线拟合得到显微光学系统的成像模糊程度与景物深度之间的解析函数。结果为了验证本文获取的图像模糊程度和景物深度之间的函数关系,首先使用纳米方形栅格的模糊图像进行深度计算,实验测得的深度平均误差为0.008 μm,即相对误差为0.8%,与通过清晰图像和模糊图像的逐个像素亮度值比较,根据最小二乘方法搜索两幅图像的亮度差最小时求得深度的方法相比,精度提高了约73%。然后基于深度测量结果进行模糊栅格图像的清晰重构,重构后的图像在平均梯度和拉普拉斯值两个方面都明显提高,且相对于传统基于高斯点扩散函数清晰重构方法,本文方法的重构精度更高,稳定性更强;最后通过多种不同形状和亮度特性的栅格模糊图像的深度计算,证明了本文的模糊程度—深度变化曲线对不同景物的通用性。结论本文建立的函数关系能够更加直观地反映系统参数对光学模糊成像过程的影响。使用高频能量参数表征图像的模糊特性,既可以准确测量图像模糊程度,也与景物深度具有直接的函数关系。固定光学系统参数后,建立的归一化系统成像模糊程度与景物深度之间的函数关系不会受到景物图像的纹理、亮度等特性差异的影响,鲁棒性强、更方便、更省时。关键词:光学显微系统;模糊程度;景物深度;解析函数;光学传递特性;高频能量参数78|2998|0更新时间:2024-05-07 -
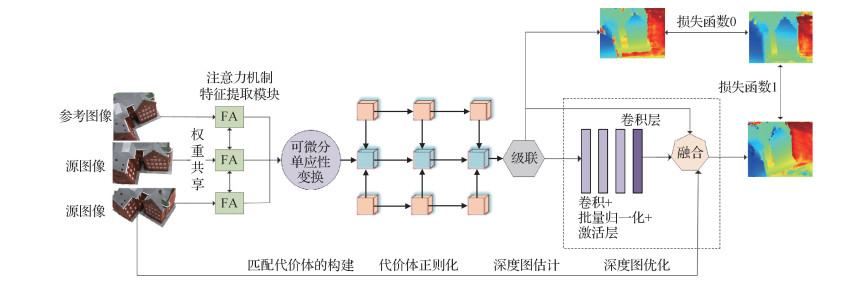 摘要:目的针对多视图立体(multi-view stereo,MVS)重建效果整体性不理想的问题,本文对MVS 3D重建中的特征提取模块和代价体正则化模块进行研究,提出一种基于注意力机制的端到端深度学习架构。方法首先从输入的源图像和参考图像中提取深度特征,在每一级特征提取模块中均加入注意力层,以捕获深度推理任务的远程依赖关系;然后通过可微分单应性变换构建参考视锥的特征量,并构建代价体;最后利用多层U-Net体系结构正则化代价体,并通过回归结合参考图像边缘信息生成最终的细化深度图。结果在DTU(Technical University of Denmark)数据集上进行测试,与现有的几种方法相比,本文方法相较于Colmap、Gipuma和Tola方法,整体性指标分别提高8.5%、13.1%和31.9%,完整性指标分别提高20.7%、41.6%和73.3%;相较于Camp、Furu和SurfaceNet方法,整体性指标分别提高24.8%、33%和29.8%,准确性指标分别提高39.8%、17.6%和1.3%,完整性指标分别提高9.7%、48.4%和58.3%;相较于PruMvsnet方法,整体性指标提高1.7%,准确性指标提高5.8%;相较于Mvsnet方法,整体性指标提高1.5%,完整性标提高7%。结论在DTU数据集上的测试结果表明,本文提出的网络架构在整体性指标上得到了目前最优的结果,完整性和准确性指标得到较大提升,3D重建质量更好。关键词:注意力机制;多层U-Net;可微分单应性变换;代价体正则化;多视图立体(MVS)141|171|4更新时间:2024-05-07
摘要:目的针对多视图立体(multi-view stereo,MVS)重建效果整体性不理想的问题,本文对MVS 3D重建中的特征提取模块和代价体正则化模块进行研究,提出一种基于注意力机制的端到端深度学习架构。方法首先从输入的源图像和参考图像中提取深度特征,在每一级特征提取模块中均加入注意力层,以捕获深度推理任务的远程依赖关系;然后通过可微分单应性变换构建参考视锥的特征量,并构建代价体;最后利用多层U-Net体系结构正则化代价体,并通过回归结合参考图像边缘信息生成最终的细化深度图。结果在DTU(Technical University of Denmark)数据集上进行测试,与现有的几种方法相比,本文方法相较于Colmap、Gipuma和Tola方法,整体性指标分别提高8.5%、13.1%和31.9%,完整性指标分别提高20.7%、41.6%和73.3%;相较于Camp、Furu和SurfaceNet方法,整体性指标分别提高24.8%、33%和29.8%,准确性指标分别提高39.8%、17.6%和1.3%,完整性指标分别提高9.7%、48.4%和58.3%;相较于PruMvsnet方法,整体性指标提高1.7%,准确性指标提高5.8%;相较于Mvsnet方法,整体性指标提高1.5%,完整性标提高7%。结论在DTU数据集上的测试结果表明,本文提出的网络架构在整体性指标上得到了目前最优的结果,完整性和准确性指标得到较大提升,3D重建质量更好。关键词:注意力机制;多层U-Net;可微分单应性变换;代价体正则化;多视图立体(MVS)141|171|4更新时间:2024-05-07 -
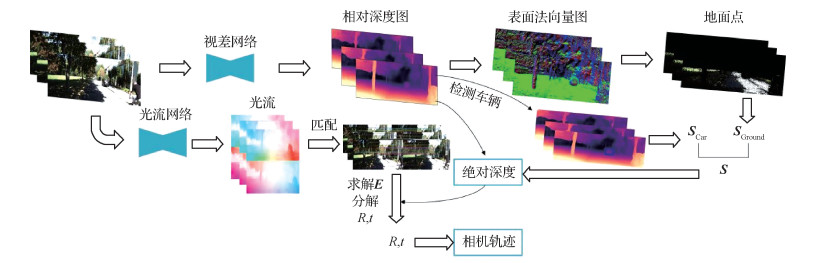 摘要:目的单目相机运动轨迹恢复由于输入只有单目视频序列而缺乏尺度信息,生成的轨迹存在严重漂移而无法进行高精度应用。为了能够运用单目相机普及度高、成本低的优势,提出一种基于场景几何的方法在自动驾驶领域进行真实尺度恢复。方法首先使用深度估计网络对连续图像进行相对深度估计,利用估计的深度值将像素点从2维平面投影到3维空间。然后对光流网络估计出的光流进行前后光流一致性计算得到有效匹配点,使用传统方法求解位姿,使相对深度与位姿尺度统一。再利用相对深度值计算表面法向量图求解地面点群,通过几何关系计算相同尺度的相机高度后引入相机先验高度得到初始尺度。最后为了减小图像噪声对尺度造成的偏差,由额外的车辆检测模块计算出的补偿尺度与初始尺度加权得到最终尺度。结果实验在KITTI(Karlsruhe Institute of Technology and Toyota Technological at Chicago)自动驾驶数据集上进行,相机运动轨迹和图像深度均在精度上得到提高。使用深度真实值尺度还原后的相对深度的绝对误差为0.114,使用本文方法进行尺度恢复后的绝对深度的绝对误差为0.116。对得到的相机运动轨迹在不同复杂路径中进行对比测试,使用尺度恢复的距离与真实距离误差为2.67%,恢复出的轨迹相比传统方法的ORB-SLAM2(oriented FAST and rotated BRIEF-simultaneous localization and mapping)更接近真实轨迹。结论本文仅以单目相机图像作为输入,在自动驾驶数据集中利用自监督学习方法,不需要真实深度标签进行训练,利用场景中的几何约束对真实尺度进行恢复,恢复出的绝对深度和真实轨迹均在精度上有所提高。相比于传统方法在加入真实尺度后偏移量误差更低,且计算速度快、鲁棒性高。关键词:自监督学习;自动驾驶;单目深度估计;位姿估计;尺度恢复155|232|0更新时间:2024-05-07
摘要:目的单目相机运动轨迹恢复由于输入只有单目视频序列而缺乏尺度信息,生成的轨迹存在严重漂移而无法进行高精度应用。为了能够运用单目相机普及度高、成本低的优势,提出一种基于场景几何的方法在自动驾驶领域进行真实尺度恢复。方法首先使用深度估计网络对连续图像进行相对深度估计,利用估计的深度值将像素点从2维平面投影到3维空间。然后对光流网络估计出的光流进行前后光流一致性计算得到有效匹配点,使用传统方法求解位姿,使相对深度与位姿尺度统一。再利用相对深度值计算表面法向量图求解地面点群,通过几何关系计算相同尺度的相机高度后引入相机先验高度得到初始尺度。最后为了减小图像噪声对尺度造成的偏差,由额外的车辆检测模块计算出的补偿尺度与初始尺度加权得到最终尺度。结果实验在KITTI(Karlsruhe Institute of Technology and Toyota Technological at Chicago)自动驾驶数据集上进行,相机运动轨迹和图像深度均在精度上得到提高。使用深度真实值尺度还原后的相对深度的绝对误差为0.114,使用本文方法进行尺度恢复后的绝对深度的绝对误差为0.116。对得到的相机运动轨迹在不同复杂路径中进行对比测试,使用尺度恢复的距离与真实距离误差为2.67%,恢复出的轨迹相比传统方法的ORB-SLAM2(oriented FAST and rotated BRIEF-simultaneous localization and mapping)更接近真实轨迹。结论本文仅以单目相机图像作为输入,在自动驾驶数据集中利用自监督学习方法,不需要真实深度标签进行训练,利用场景中的几何约束对真实尺度进行恢复,恢复出的绝对深度和真实轨迹均在精度上有所提高。相比于传统方法在加入真实尺度后偏移量误差更低,且计算速度快、鲁棒性高。关键词:自监督学习;自动驾驶;单目深度估计;位姿估计;尺度恢复155|232|0更新时间:2024-05-07
深度估计与三维重建
-
 摘要:目的传统针对对抗攻击的研究通常集中于2维图像领域,而对3维物体进行修改会直接影响该物体的3维特性,生成令人无法察觉的扰动是十分困难的,因此针对3维点云数据的对抗攻击研究并不多。点云对抗样本,如点云物体分类、点云物体分割等的深度神经网络通常容易受到攻击,致使网络做出错误判断。因此,提出一种基于显著性图的点云替换对抗攻击方法。方法由于现有点云分类网络通常需要获取点云模型中的关键点,该方法通过将点移动到点云中心计算点的显著性值,从而构建点云显著性图,选择具有最高显著性值的采样点集作为关键点集,以确保对网络分类结果造成更大的影响;利用Chamfer距离衡量点云模型之间的差异性,并选择与点云模型库中具有最近Chamfer距离的模型关键点集进行替换,从而实现最小化点云扰动并使得人眼难以察觉。结果使用ModelNet40数据集,分别在点云分类网络PointNet和PointNet++上进行对比实验。在PointNet网络上,对比FGSM(fast gradient sign method)、I-FGSM(iterative fast gradient sign method)和JSMA(Jacobian-based saliency map attack)方法,本文方法攻击成功率分别提高38.6%、7.3%和41%;若扰动100个采样点,本文方法将使网络准确率下降到6.2%。在PointNet++网络上,对比FGSM和JSMA,本文方法的攻击成功率分别提高58.6%和85.3%;若扰动100个采样点,本文方法将使网络准确率下降到12.8%。结论本文提出的点云对抗攻击方法,不仅考虑到对抗攻击的效率,而且考虑了对抗样本的不可察觉性,能够高效攻击主流的点云深度神经网络。关键词:点云对抗攻击;显著性图;Chamfer距离;PointNet;PointNet++87|112|3更新时间:2024-05-07
摘要:目的传统针对对抗攻击的研究通常集中于2维图像领域,而对3维物体进行修改会直接影响该物体的3维特性,生成令人无法察觉的扰动是十分困难的,因此针对3维点云数据的对抗攻击研究并不多。点云对抗样本,如点云物体分类、点云物体分割等的深度神经网络通常容易受到攻击,致使网络做出错误判断。因此,提出一种基于显著性图的点云替换对抗攻击方法。方法由于现有点云分类网络通常需要获取点云模型中的关键点,该方法通过将点移动到点云中心计算点的显著性值,从而构建点云显著性图,选择具有最高显著性值的采样点集作为关键点集,以确保对网络分类结果造成更大的影响;利用Chamfer距离衡量点云模型之间的差异性,并选择与点云模型库中具有最近Chamfer距离的模型关键点集进行替换,从而实现最小化点云扰动并使得人眼难以察觉。结果使用ModelNet40数据集,分别在点云分类网络PointNet和PointNet++上进行对比实验。在PointNet网络上,对比FGSM(fast gradient sign method)、I-FGSM(iterative fast gradient sign method)和JSMA(Jacobian-based saliency map attack)方法,本文方法攻击成功率分别提高38.6%、7.3%和41%;若扰动100个采样点,本文方法将使网络准确率下降到6.2%。在PointNet++网络上,对比FGSM和JSMA,本文方法的攻击成功率分别提高58.6%和85.3%;若扰动100个采样点,本文方法将使网络准确率下降到12.8%。结论本文提出的点云对抗攻击方法,不仅考虑到对抗攻击的效率,而且考虑了对抗样本的不可察觉性,能够高效攻击主流的点云深度神经网络。关键词:点云对抗攻击;显著性图;Chamfer距离;PointNet;PointNet++87|112|3更新时间:2024-05-07 -
 摘要:目的3D形状分析是计算机视觉和图形学的一个重要研究课题。虽然现有方法使用基于图的卷积将基于图像的深度学习推广到3维网格,但缺乏有效的池化操作限制了其网络的学习能力。针对具有相同连通性,但几何形状不同的网格模型数据集,本文利用网格简化的边收缩操作建立网格层次结构,提出了一种新的网格池化操作。方法本文改进了传统的网格简化方法,以避免生成高度不规则的三角形,利用改进的网格简化方法定义了新的网格池化操作。网格简化的边收缩操作建立的网格层次结构之间存在对应关系,有利于网格池化的定义。新定义的池化操作有效地编码了层次结构中较粗糙和较稠密网格之间的对应关系。最后提出了一种带有边收缩池化和图卷积的变分自编码器(variational auto-encoder,VAE)结构,以探索3D形状的隐空间并用于3D形状的生成。结果由于引入了新定义的池化操作和图卷积操作,提出的网络结构比原始MeshVAE需要的参数更少,因此可以处理更稠密的网格模型。结论实验表明提出的方法具有更好的泛化能力,并且在各种应用中更可靠,包括形状生成、形状插值和形状嵌入。关键词:网格生成;网格插值;变分自编码器(VAE);网格池化;边收缩68|415|0更新时间:2024-05-07
摘要:目的3D形状分析是计算机视觉和图形学的一个重要研究课题。虽然现有方法使用基于图的卷积将基于图像的深度学习推广到3维网格,但缺乏有效的池化操作限制了其网络的学习能力。针对具有相同连通性,但几何形状不同的网格模型数据集,本文利用网格简化的边收缩操作建立网格层次结构,提出了一种新的网格池化操作。方法本文改进了传统的网格简化方法,以避免生成高度不规则的三角形,利用改进的网格简化方法定义了新的网格池化操作。网格简化的边收缩操作建立的网格层次结构之间存在对应关系,有利于网格池化的定义。新定义的池化操作有效地编码了层次结构中较粗糙和较稠密网格之间的对应关系。最后提出了一种带有边收缩池化和图卷积的变分自编码器(variational auto-encoder,VAE)结构,以探索3D形状的隐空间并用于3D形状的生成。结果由于引入了新定义的池化操作和图卷积操作,提出的网络结构比原始MeshVAE需要的参数更少,因此可以处理更稠密的网格模型。结论实验表明提出的方法具有更好的泛化能力,并且在各种应用中更可靠,包括形状生成、形状插值和形状嵌入。关键词:网格生成;网格插值;变分自编码器(VAE);网格池化;边收缩68|415|0更新时间:2024-05-07 -
 摘要:目的体映射建立了两个3维体网格之间的对应关系,是计算机图形学中的重要研究方向。很多应用要求体映射是无翻转的,即其雅可比矩阵的行列式处处大于0。然而,现有的无翻转体映射生成算法经常无法完全消除翻转。挑战主要在于很难在保证满足位置约束的前提下消除映射的翻转。为此,提出一种新的无翻转体映射计算方法,核心是一种新的变形方法。方法首先放松位置约束,然后在变形过程中通过线搜索的方式保证不产生翻转,最后将网格无翻转地变形到满足位置约束。为实现这个变形过程,提出一种雅可比矩阵引导的变形算法。虽然现有的无翻转体映射方法不能完全消除翻转,但其雅可比矩阵可以作为本文变形算法的指导。此外,优化了位置能量,使得变形网格最终能够满足位置约束要求。为了满足体映射低扭曲的要求,算法最后在固定位置约束的前提下进一步优化了体映射的扭曲能量。结果对大量复杂网格进行实验,本文算法能够保证生成无翻转的体映射,并且通过多步优化最终结果均能满足给定的位置约束要求。结论通过与现有其他算法的优点和局限性对比,结果表明本文算法具有较好的鲁棒性。本文算法从一个全新的角度促进了无翻转体映射生成技术的进步与发展。关键词:体映射;无翻转;雅可比引导;变形优化;位置约束;低扭曲104|70|0更新时间:2024-05-07
摘要:目的体映射建立了两个3维体网格之间的对应关系,是计算机图形学中的重要研究方向。很多应用要求体映射是无翻转的,即其雅可比矩阵的行列式处处大于0。然而,现有的无翻转体映射生成算法经常无法完全消除翻转。挑战主要在于很难在保证满足位置约束的前提下消除映射的翻转。为此,提出一种新的无翻转体映射计算方法,核心是一种新的变形方法。方法首先放松位置约束,然后在变形过程中通过线搜索的方式保证不产生翻转,最后将网格无翻转地变形到满足位置约束。为实现这个变形过程,提出一种雅可比矩阵引导的变形算法。虽然现有的无翻转体映射方法不能完全消除翻转,但其雅可比矩阵可以作为本文变形算法的指导。此外,优化了位置能量,使得变形网格最终能够满足位置约束要求。为了满足体映射低扭曲的要求,算法最后在固定位置约束的前提下进一步优化了体映射的扭曲能量。结果对大量复杂网格进行实验,本文算法能够保证生成无翻转的体映射,并且通过多步优化最终结果均能满足给定的位置约束要求。结论通过与现有其他算法的优点和局限性对比,结果表明本文算法具有较好的鲁棒性。本文算法从一个全新的角度促进了无翻转体映射生成技术的进步与发展。关键词:体映射;无翻转;雅可比引导;变形优化;位置约束;低扭曲104|70|0更新时间:2024-05-07 -
 摘要:目的当前点云补全的深度学习算法多采用自编码器结构,然而编码器端常用的多层感知器(multilayer perceptron,MLP)网络往往只聚焦于点云整体形状,很难对物体的细节特征进行有效提取,使点云残缺结构的补全效果不佳。因此需要一种准确的点云局部特征提取算法,用于点云补全任务。方法为解决该问题,本文提出了嵌入注意力模块的多尺度点云补全算法。网络整体采用编码器—解码器结构,通过编码器端的特征嵌入层和Transformer层提取并融合3种不同分辨率的残缺点云特征信息,将其输入到全连接网络的解码器中,输出逐级补全的缺失点云。最后在解码器端添加注意力鉴别器,借鉴生成对抗网络(generative adversarial networks,GAN)的思想,优化网络补全性能。结果采用倒角距离(Chamfer distance,CD)作为评价标准,本文算法在2个数据集上与相关的4种方法进行了实验比较,在ShapeNet数据集上,相比于性能第2的PF-Net(point fractal network)模型,本文算法的类别平均CD值降低了3.73%;在ModelNet10数据集上,相比于PF-Net模型,本文算法的类别平均CD值降低了12.75%。不同算法的可视化补全效果图,验证了本文算法具有更精准的细节结构补全能力和面对类别中特殊样本的强泛化能力。结论本文所提出的基于Transformer结构的多尺度点云补全算法,更好地提取了残缺点云的局部特征信息,使得点云补全的结果更加准确。关键词:3维点云;点云补全;自编码器;注意力机制;生成对抗网络(GAN)182|253|9更新时间:2024-05-07
摘要:目的当前点云补全的深度学习算法多采用自编码器结构,然而编码器端常用的多层感知器(multilayer perceptron,MLP)网络往往只聚焦于点云整体形状,很难对物体的细节特征进行有效提取,使点云残缺结构的补全效果不佳。因此需要一种准确的点云局部特征提取算法,用于点云补全任务。方法为解决该问题,本文提出了嵌入注意力模块的多尺度点云补全算法。网络整体采用编码器—解码器结构,通过编码器端的特征嵌入层和Transformer层提取并融合3种不同分辨率的残缺点云特征信息,将其输入到全连接网络的解码器中,输出逐级补全的缺失点云。最后在解码器端添加注意力鉴别器,借鉴生成对抗网络(generative adversarial networks,GAN)的思想,优化网络补全性能。结果采用倒角距离(Chamfer distance,CD)作为评价标准,本文算法在2个数据集上与相关的4种方法进行了实验比较,在ShapeNet数据集上,相比于性能第2的PF-Net(point fractal network)模型,本文算法的类别平均CD值降低了3.73%;在ModelNet10数据集上,相比于PF-Net模型,本文算法的类别平均CD值降低了12.75%。不同算法的可视化补全效果图,验证了本文算法具有更精准的细节结构补全能力和面对类别中特殊样本的强泛化能力。结论本文所提出的基于Transformer结构的多尺度点云补全算法,更好地提取了残缺点云的局部特征信息,使得点云补全的结果更加准确。关键词:3维点云;点云补全;自编码器;注意力机制;生成对抗网络(GAN)182|253|9更新时间:2024-05-07
三维形状分析
-
 摘要:目的为建立3维模型语义部件之间的对应关系并实现模型自动分割,提出一种利用隐式解码器(implicit decoder,IM-decoder)的无监督3维模型簇协同分割网络。方法首先对3维点云模型进行体素化操作,进而由CNN-encoder(convolutional neural network encoder)提取体素化点云模型的特征,并将模型信息映射至特征空间。然后使用注意力模块聚合3维模型相邻点特征,将聚合特征与3维点坐标作为IM-decoder的输入来增强模型的空间感知能力,并输出采样点相对于模型部件的内外状态。最后使用max pooling聚合解码器生成的隐式场,以得到模型的协同分割结果。结果实验结果表明,本文算法在ShapeNet Part数据集上的mIoU(mean intersection-over-union)为62.1%,与目前已知的两类无监督3维点云模型分割方法相比,分别提高了22.5%和18.9%,分割性能得到了极大提升。与两种有监督方法相比,分别降低了19.3%和20.2%,但其在部件数较少的模型上可获得更优的分割效果。相比于使用交叉熵函数作为重构损失函数,本文使用均方差函数可获得更高的分割准确率,mIoU提高了26.3%。结论与当前主流的无监督分割算法相比,本文利用隐式解码器进行3维模型簇协同分割的无监督方法分割准确率更高。关键词:协同分割;模型簇;隐式解码器;注意力模块;无监督109|284|0更新时间:2024-05-07
摘要:目的为建立3维模型语义部件之间的对应关系并实现模型自动分割,提出一种利用隐式解码器(implicit decoder,IM-decoder)的无监督3维模型簇协同分割网络。方法首先对3维点云模型进行体素化操作,进而由CNN-encoder(convolutional neural network encoder)提取体素化点云模型的特征,并将模型信息映射至特征空间。然后使用注意力模块聚合3维模型相邻点特征,将聚合特征与3维点坐标作为IM-decoder的输入来增强模型的空间感知能力,并输出采样点相对于模型部件的内外状态。最后使用max pooling聚合解码器生成的隐式场,以得到模型的协同分割结果。结果实验结果表明,本文算法在ShapeNet Part数据集上的mIoU(mean intersection-over-union)为62.1%,与目前已知的两类无监督3维点云模型分割方法相比,分别提高了22.5%和18.9%,分割性能得到了极大提升。与两种有监督方法相比,分别降低了19.3%和20.2%,但其在部件数较少的模型上可获得更优的分割效果。相比于使用交叉熵函数作为重构损失函数,本文使用均方差函数可获得更高的分割准确率,mIoU提高了26.3%。结论与当前主流的无监督分割算法相比,本文利用隐式解码器进行3维模型簇协同分割的无监督方法分割准确率更高。关键词:协同分割;模型簇;隐式解码器;注意力模块;无监督109|284|0更新时间:2024-05-07 -
 摘要:目的3维点云是编码几何信息的主要数据结构,与2维视觉数据不同的是,点云中隐藏了3维物体中重要的形状特征。为更好地从无序的点云中挖掘形状特征,本文提出一种能够端到端且鲁棒地处理点云数据的多维度多层级神经网络(multi-dimensional multi-layer neural network,MM-Net)。方法多维度特征修正与融合(multi-dimensional feature correction and fusion module,MDCF)模块从多个维度自适应地修正局部特征和逐点特征,并将其整合至高维空间以获得丰富的区域形状。另一方面,多层级特征衔接(multi-layer feature articulation module,MLFA)模块利用多个层级间的远程依赖关系,推理得到网络所需的全局形状。此外设计了两种分别应用于点云分类与分割任务的网络结构MM-Net-C(multi-dimensional multi-layer feature classification network)和MM-Net-S(multi-dimensional multi-layer feature segmentation network)。结果在公开的ModelNet40数据集与ShapeNet数据集上进行测试,并与多种方法进行比较。在ModelNet40数据集中,MM-Net-C的分类精度较PointNet++和DGCNN(dynamic graph convolutional neural network)方法分别提高了2.2%和1.9%;在ShapeNet数据集中,MM-Net-S的分割精度较ELM(extreme learning machine)和A-CNN(annularly convolutional neural networks)方法分别提高了1.2%和0.4%。此外,在ModelNet40数据集中的消融实验验证了多维度多层级神经网络(MM-Net)架构的可靠性,消融实验的结果也表明了多维度特征修正与融合(MDCF)模块和多层级特征衔接(MLFA)模块设计的必要性。结论本文提出的多维度多层级神经网络(MM-Net)在分类与分割任务中取得了优秀的性能。关键词:3维点云;点云分类与分割;深度学习;形状特征;多维度特征;多层级特征81|84|0更新时间:2024-05-07
摘要:目的3维点云是编码几何信息的主要数据结构,与2维视觉数据不同的是,点云中隐藏了3维物体中重要的形状特征。为更好地从无序的点云中挖掘形状特征,本文提出一种能够端到端且鲁棒地处理点云数据的多维度多层级神经网络(multi-dimensional multi-layer neural network,MM-Net)。方法多维度特征修正与融合(multi-dimensional feature correction and fusion module,MDCF)模块从多个维度自适应地修正局部特征和逐点特征,并将其整合至高维空间以获得丰富的区域形状。另一方面,多层级特征衔接(multi-layer feature articulation module,MLFA)模块利用多个层级间的远程依赖关系,推理得到网络所需的全局形状。此外设计了两种分别应用于点云分类与分割任务的网络结构MM-Net-C(multi-dimensional multi-layer feature classification network)和MM-Net-S(multi-dimensional multi-layer feature segmentation network)。结果在公开的ModelNet40数据集与ShapeNet数据集上进行测试,并与多种方法进行比较。在ModelNet40数据集中,MM-Net-C的分类精度较PointNet++和DGCNN(dynamic graph convolutional neural network)方法分别提高了2.2%和1.9%;在ShapeNet数据集中,MM-Net-S的分割精度较ELM(extreme learning machine)和A-CNN(annularly convolutional neural networks)方法分别提高了1.2%和0.4%。此外,在ModelNet40数据集中的消融实验验证了多维度多层级神经网络(MM-Net)架构的可靠性,消融实验的结果也表明了多维度特征修正与融合(MDCF)模块和多层级特征衔接(MLFA)模块设计的必要性。结论本文提出的多维度多层级神经网络(MM-Net)在分类与分割任务中取得了优秀的性能。关键词:3维点云;点云分类与分割;深度学习;形状特征;多维度特征;多层级特征81|84|0更新时间:2024-05-07 -
 摘要:目的点云分类传统方法中大量依赖人工设计特征,缺乏深层次特征,难以进一步提高精度,基于深度学习的方法大部分利用结构化网络,转化为其他表征造成了3维空间结构信息的丢失,部分利用局部结构学习多层次特征的方法也因为忽略了机载数据的几何信息,难以实现精细分类。针对上述问题,本文提出了一种基于多特征融合几何卷积神经网络(multi-feature fusion and geometric convolutional neural network,MFFGCNN)的机载LiDAR(light detection and ranging)点云地物分类方法。方法提取并融合有效的浅层传统特征,并结合坐标尺度等预处理方法,称为APD模块(airporne laser scanning point cloud design module),在输入特征层面对典型地物有针对性地进行信息补充,来提高网络对大区域、低密度的机载LiDAR点云原始数据的适应能力和基础分类精度,基于多特征融合的几何卷积模块,称为FGC(multi-feature fusion and geometric convolution)算子,编码点的全局和局部空间几何结构,实现对大区域点云层次化几何结构的获取,最终与多尺度全局的逐点深度特征聚合提取高级语义特征,并基于空间上采样获得逐点的多尺度深度特征实现机载LiDAR点云的语义分割。结果在ISPRS(International Society for Photogrammetry and Remote Sensing)提供的3维标记基准数据集上进行模型训练与测试,由于面向建筑物、地面和植被3类典型地物,对ISPRS的9类数据集进行了类别划分。本文算法在全局准确率上取得了81.42%的较高精度,消融实验结果证明FGC模块可以提高8%的全局准确率,能够有效地提取局部几何特性,相较仅基于点的3维空间坐标方法,本文方法可提高15%的整体分类精度。结论提出的MFFCGNN网络综合了传统特征的优势和深度学习模型的优点,能够实现机载LiDAR点云的城市重要地物快速分类。关键词:点云分类;机载LiDAR;PointNet++;深度学习;多特征融合;几何卷积网络(GCN)111|212|4更新时间:2024-05-07
摘要:目的点云分类传统方法中大量依赖人工设计特征,缺乏深层次特征,难以进一步提高精度,基于深度学习的方法大部分利用结构化网络,转化为其他表征造成了3维空间结构信息的丢失,部分利用局部结构学习多层次特征的方法也因为忽略了机载数据的几何信息,难以实现精细分类。针对上述问题,本文提出了一种基于多特征融合几何卷积神经网络(multi-feature fusion and geometric convolutional neural network,MFFGCNN)的机载LiDAR(light detection and ranging)点云地物分类方法。方法提取并融合有效的浅层传统特征,并结合坐标尺度等预处理方法,称为APD模块(airporne laser scanning point cloud design module),在输入特征层面对典型地物有针对性地进行信息补充,来提高网络对大区域、低密度的机载LiDAR点云原始数据的适应能力和基础分类精度,基于多特征融合的几何卷积模块,称为FGC(multi-feature fusion and geometric convolution)算子,编码点的全局和局部空间几何结构,实现对大区域点云层次化几何结构的获取,最终与多尺度全局的逐点深度特征聚合提取高级语义特征,并基于空间上采样获得逐点的多尺度深度特征实现机载LiDAR点云的语义分割。结果在ISPRS(International Society for Photogrammetry and Remote Sensing)提供的3维标记基准数据集上进行模型训练与测试,由于面向建筑物、地面和植被3类典型地物,对ISPRS的9类数据集进行了类别划分。本文算法在全局准确率上取得了81.42%的较高精度,消融实验结果证明FGC模块可以提高8%的全局准确率,能够有效地提取局部几何特性,相较仅基于点的3维空间坐标方法,本文方法可提高15%的整体分类精度。结论提出的MFFCGNN网络综合了传统特征的优势和深度学习模型的优点,能够实现机载LiDAR点云的城市重要地物快速分类。关键词:点云分类;机载LiDAR;PointNet++;深度学习;多特征融合;几何卷积网络(GCN)111|212|4更新时间:2024-05-07
三维点云分割
-
 摘要:目的从图像中裁剪出构图更佳的区域是提升图像美感的有效手段之一,也是计算机视觉领域极具挑战性的问题。为提升自动裁图的视觉效果,本文提出了聚合细粒度特征的深度注意力自动裁图方法(deep attention guided image cropping network with fine-grained feature aggregation,DAIC-Net)。方法整体模型结构由通道校准的语义特征提取(semantic feature extraction with channel calibration,ECC)、细粒度特征聚合(fine-grained feature aggregation,FFA)和上下文注意力融合(contextual attention fusion,CAF)3个模块构成,采用端到端的训练方式,核心思想是多尺度逐级增强不同细粒度区域特征,融合全局和局部注意力特征,强化上下文语义信息表征。ECC模块在通用语义特征的通道维度上进行自适应校准,融合了通道注意力;FFA模块将多尺度区域特征级联互补,产生富含图像构成和空间位置信息的特征表示;CAF模块模拟人眼观看图像的规律,从不同方向、不同尺度显式编码图像空间不同像素块之间的记忆上下文关系;此外,定义了多项损失函数以指导模型训练,进行多任务监督学习。结果在3个数据集上与最新的6种方法进行对比实验,本文方法优于现有的自动裁图方法,在最新裁图数据集GAICD(grid anchor based image cropping database)上,斯皮尔曼相关性和皮尔森相关性指标分别提升了2.0%和1.9%,其他最佳回报率指标最高提升了4.1%。在ICDB(image cropping database)和FCDB(flickr cropping database)上的跨数据集测试结果进一步表明了本文提出的DAIC-Net的泛化性能。此外,消融实验验证了各模块的有效性,用户主观实验及定性分析也表明DAIC-Net能裁剪出视觉效果更佳的裁图结果。结论本文提出的DAIC-Net在GAICD数据集上多种评价指标均取得最优的预测结果,在ICDB和FCDB测试集上展现出较强的泛化能力,能有效提升裁图效果。关键词:自动裁图;图像美学评价(IAA);感兴趣区域(RoI);空间金字塔池化(SPP);注意力机制;多任务学习96|468|1更新时间:2024-05-07
摘要:目的从图像中裁剪出构图更佳的区域是提升图像美感的有效手段之一,也是计算机视觉领域极具挑战性的问题。为提升自动裁图的视觉效果,本文提出了聚合细粒度特征的深度注意力自动裁图方法(deep attention guided image cropping network with fine-grained feature aggregation,DAIC-Net)。方法整体模型结构由通道校准的语义特征提取(semantic feature extraction with channel calibration,ECC)、细粒度特征聚合(fine-grained feature aggregation,FFA)和上下文注意力融合(contextual attention fusion,CAF)3个模块构成,采用端到端的训练方式,核心思想是多尺度逐级增强不同细粒度区域特征,融合全局和局部注意力特征,强化上下文语义信息表征。ECC模块在通用语义特征的通道维度上进行自适应校准,融合了通道注意力;FFA模块将多尺度区域特征级联互补,产生富含图像构成和空间位置信息的特征表示;CAF模块模拟人眼观看图像的规律,从不同方向、不同尺度显式编码图像空间不同像素块之间的记忆上下文关系;此外,定义了多项损失函数以指导模型训练,进行多任务监督学习。结果在3个数据集上与最新的6种方法进行对比实验,本文方法优于现有的自动裁图方法,在最新裁图数据集GAICD(grid anchor based image cropping database)上,斯皮尔曼相关性和皮尔森相关性指标分别提升了2.0%和1.9%,其他最佳回报率指标最高提升了4.1%。在ICDB(image cropping database)和FCDB(flickr cropping database)上的跨数据集测试结果进一步表明了本文提出的DAIC-Net的泛化性能。此外,消融实验验证了各模块的有效性,用户主观实验及定性分析也表明DAIC-Net能裁剪出视觉效果更佳的裁图结果。结论本文提出的DAIC-Net在GAICD数据集上多种评价指标均取得最优的预测结果,在ICDB和FCDB测试集上展现出较强的泛化能力,能有效提升裁图效果。关键词:自动裁图;图像美学评价(IAA);感兴趣区域(RoI);空间金字塔池化(SPP);注意力机制;多任务学习96|468|1更新时间:2024-05-07 -
 摘要:目的针对从单幅人脸图像中恢复面部纹理图时获得的信息不完整、纹理细节不够真实等问题,提出一种基于生成对抗网络的人脸全景纹理图生成方法。方法将2维人脸图像与3维人脸模型之间的特征关系转换为编码器中的条件参数,从图像数据与人脸条件参数的多元高斯分布中得到隐层数据的概率分布,用于在生成器中学习人物的头面部纹理特征。在新创建的人脸纹理图数据集上训练一个全景纹理图生成模型,利用不同属性的鉴别器对输出结果进行评估反馈,提升生成纹理图的完整性和真实性。结果实验与当前最新方法进行了比较,在CelebA-HQ和LFW(labled faces in the wild)数据集中随机选取单幅正面人脸测试图像,经生成结果的可视化对比及3维映射显示效果对比,纹理图的完整度和显示效果均优于其他方法。通过全局和面部区域的像素量化指标进行数据比较,相比于UVGAN,全局峰值信噪比(peak signal to noise ratio,PSNR)和全局结构相似性(structural similarity index,SSIM)分别提高了7.9 dB和0.088,局部PSNR和局部SSIM分别提高了2.8 dB和0.053;相比于OSTeC,全局PSNR和全局SSIM分别提高了5.45 dB和0.043,局部PSNR和局部SSIM分别提高了0.4 dB和0.044;相比于MVF-Net(multi-view 3D face network),局部PSNR和局部SSIM分别提高了0.6和0.119。实验结果证明,提出的人脸全景纹理图生成方法解决了从单幅人脸图像中重建面部纹理不完整的问题,改善了生成纹理图的显示细节。结论本文提出的人脸全景纹理图生成方法,利用人脸参数和网络模型的特性,使生成的人脸纹理图更完整,尤其是对原图不可见区域,像素恢复自然连贯,纹理细节更真实。关键词:人脸图像;人脸纹理图;生成对抗网络(GAN);纹理映射;3维可变人脸模型(3DMM)99|228|3更新时间:2024-05-07
摘要:目的针对从单幅人脸图像中恢复面部纹理图时获得的信息不完整、纹理细节不够真实等问题,提出一种基于生成对抗网络的人脸全景纹理图生成方法。方法将2维人脸图像与3维人脸模型之间的特征关系转换为编码器中的条件参数,从图像数据与人脸条件参数的多元高斯分布中得到隐层数据的概率分布,用于在生成器中学习人物的头面部纹理特征。在新创建的人脸纹理图数据集上训练一个全景纹理图生成模型,利用不同属性的鉴别器对输出结果进行评估反馈,提升生成纹理图的完整性和真实性。结果实验与当前最新方法进行了比较,在CelebA-HQ和LFW(labled faces in the wild)数据集中随机选取单幅正面人脸测试图像,经生成结果的可视化对比及3维映射显示效果对比,纹理图的完整度和显示效果均优于其他方法。通过全局和面部区域的像素量化指标进行数据比较,相比于UVGAN,全局峰值信噪比(peak signal to noise ratio,PSNR)和全局结构相似性(structural similarity index,SSIM)分别提高了7.9 dB和0.088,局部PSNR和局部SSIM分别提高了2.8 dB和0.053;相比于OSTeC,全局PSNR和全局SSIM分别提高了5.45 dB和0.043,局部PSNR和局部SSIM分别提高了0.4 dB和0.044;相比于MVF-Net(multi-view 3D face network),局部PSNR和局部SSIM分别提高了0.6和0.119。实验结果证明,提出的人脸全景纹理图生成方法解决了从单幅人脸图像中重建面部纹理不完整的问题,改善了生成纹理图的显示细节。结论本文提出的人脸全景纹理图生成方法,利用人脸参数和网络模型的特性,使生成的人脸纹理图更完整,尤其是对原图不可见区域,像素恢复自然连贯,纹理细节更真实。关键词:人脸图像;人脸纹理图;生成对抗网络(GAN);纹理映射;3维可变人脸模型(3DMM)99|228|3更新时间:2024-05-07 -
 摘要:目的智能适配显示的图像/视频重定向技术近年受到广泛关注。与图像重定向以及2D视频重定向相比,3D视频重定向需要同时考虑视差保持和时域保持。现有的3D视频重定向方法虽然考虑了视差保持却忽略了对视差舒适度的调整,针对因视差过大和视差突变造成视觉不舒适度这一问题,提出了一种基于时空联合视差优化的立体视频重定向方法,将视频视差范围控制在舒适区间。方法在原始视频上建立均匀网格,并提取显著信息和视差,进而得到每个网格的平均显著值;根据相似性变化原理构建形状保持能量项,利用目标轨迹以及原始视频的视差变化构建时域保持能量项,并结合人眼辐辏调节原理构建视差舒适度调整能量项;结合各个网格的显著性,联合求解所有能量项得到优化后的网格顶点坐标,将其用于确定网格形变,从而生成指定宽高比的视频。结果实验结果表明,与基于细缝裁剪的立体视频重定向方法对比,本文方法在形状保持、时域保持及视差舒适度方面均具有更好的性能。另外,使用现有的客观质量评价方法对重定向结果进行评价,本文方法客观质量评价指标性能优于均匀缩放和细缝裁剪的视频重定向方法,时间复杂度较低,每帧的时间复杂度至少比细缝裁剪方法降低了98%。结论提出的时空联合的视差优化方法同时在时域和舒适度上对视差进行优化,并考虑了时域保持,具有良好的视差优化与时域保持效果,展现了较高的稳定性和鲁棒性。本文方法能够用于3D视频的重定向,在保持立体视觉舒适性的同时适配不同尺寸的3D显示屏幕。关键词:立体视频重定向;网格形变;时空视差优化;视频时间一致性;立体视觉舒适度;立体显著50|200|0更新时间:2024-05-07
摘要:目的智能适配显示的图像/视频重定向技术近年受到广泛关注。与图像重定向以及2D视频重定向相比,3D视频重定向需要同时考虑视差保持和时域保持。现有的3D视频重定向方法虽然考虑了视差保持却忽略了对视差舒适度的调整,针对因视差过大和视差突变造成视觉不舒适度这一问题,提出了一种基于时空联合视差优化的立体视频重定向方法,将视频视差范围控制在舒适区间。方法在原始视频上建立均匀网格,并提取显著信息和视差,进而得到每个网格的平均显著值;根据相似性变化原理构建形状保持能量项,利用目标轨迹以及原始视频的视差变化构建时域保持能量项,并结合人眼辐辏调节原理构建视差舒适度调整能量项;结合各个网格的显著性,联合求解所有能量项得到优化后的网格顶点坐标,将其用于确定网格形变,从而生成指定宽高比的视频。结果实验结果表明,与基于细缝裁剪的立体视频重定向方法对比,本文方法在形状保持、时域保持及视差舒适度方面均具有更好的性能。另外,使用现有的客观质量评价方法对重定向结果进行评价,本文方法客观质量评价指标性能优于均匀缩放和细缝裁剪的视频重定向方法,时间复杂度较低,每帧的时间复杂度至少比细缝裁剪方法降低了98%。结论提出的时空联合的视差优化方法同时在时域和舒适度上对视差进行优化,并考虑了时域保持,具有良好的视差优化与时域保持效果,展现了较高的稳定性和鲁棒性。本文方法能够用于3D视频的重定向,在保持立体视觉舒适性的同时适配不同尺寸的3D显示屏幕。关键词:立体视频重定向;网格形变;时空视差优化;视频时间一致性;立体视觉舒适度;立体显著50|200|0更新时间:2024-05-07 -
 摘要:目的视觉目标的形状特征表示和识别是图像领域中的重要问题。在实际应用中,视角、形变、遮挡和噪声等干扰因素造成识别精度较低,且大数据场景需要算法具有较高的学习效率。针对这些问题,本文提出一种全尺度可视化形状表示方法。方法在尺度空间的所有尺度上对形状轮廓提取形状的不变量特征,获得形状的全尺度特征。将获得的全部特征紧凑地表示为单幅彩色图像,得到形状特征的可视化表示。将表示形状特征的彩色图像输入双路卷积网络模型,完成形状分类和检索任务。结果通过对原始形状加入旋转、遮挡和噪声等不同干扰的定性实验,验证了本文方法具有旋转和缩放不变性,以及对铰接变换、遮挡和噪声等干扰的鲁棒性。在通用数据集上进行形状分类和形状检索的定量实验,所得准确率在不同数据集上均超过对比算法。在MPEG-7数据集上精度达到99.57%,对比算法的最好结果为98.84%。在铰接和射影变换数据集上皆达到100%的识别精度,而对比算法的最好结果分别为89.75%和95%。结论本文提出的全尺度可视化形状表示方法,通过一幅彩色图像紧凑地表达了全部形状信息。通过卷积模型既学习了轮廓点间的形状特征关系,又学习了不同尺度间的形状特征关系。本文方法在视角变化、局部遮挡、铰接变形和噪声等干扰下能保持较高的识别正确率,可应用于图像采集干扰较多以及红外或深度图像的目标识别,并适用于大数据场景下的识别任务。关键词:形状表示;尺度空间;不变量;形状识别;目标识别;目标检索56|167|2更新时间:2024-05-07
摘要:目的视觉目标的形状特征表示和识别是图像领域中的重要问题。在实际应用中,视角、形变、遮挡和噪声等干扰因素造成识别精度较低,且大数据场景需要算法具有较高的学习效率。针对这些问题,本文提出一种全尺度可视化形状表示方法。方法在尺度空间的所有尺度上对形状轮廓提取形状的不变量特征,获得形状的全尺度特征。将获得的全部特征紧凑地表示为单幅彩色图像,得到形状特征的可视化表示。将表示形状特征的彩色图像输入双路卷积网络模型,完成形状分类和检索任务。结果通过对原始形状加入旋转、遮挡和噪声等不同干扰的定性实验,验证了本文方法具有旋转和缩放不变性,以及对铰接变换、遮挡和噪声等干扰的鲁棒性。在通用数据集上进行形状分类和形状检索的定量实验,所得准确率在不同数据集上均超过对比算法。在MPEG-7数据集上精度达到99.57%,对比算法的最好结果为98.84%。在铰接和射影变换数据集上皆达到100%的识别精度,而对比算法的最好结果分别为89.75%和95%。结论本文提出的全尺度可视化形状表示方法,通过一幅彩色图像紧凑地表达了全部形状信息。通过卷积模型既学习了轮廓点间的形状特征关系,又学习了不同尺度间的形状特征关系。本文方法在视角变化、局部遮挡、铰接变形和噪声等干扰下能保持较高的识别正确率,可应用于图像采集干扰较多以及红外或深度图像的目标识别,并适用于大数据场景下的识别任务。关键词:形状表示;尺度空间;不变量;形状识别;目标识别;目标检索56|167|2更新时间:2024-05-07 -
 摘要:目的6D姿态估计是3D目标识别及重建中的一个重要问题。由于很多物体表面光滑、无纹理,特征难以提取,导致检测难度大。很多算法依赖后处理过程提高姿态估计精度,导致算法速度降低。针对以上问题,本文提出一种基于热力图的6D物体姿态估计算法。方法首先,采用分割掩码避免遮挡造成的热力图污染导致的特征点预测准确率下降问题。其次,基于漏斗网络架构,无需后处理过程,保证算法具有高效性能。在物体检测阶段,采用一个分割网络结构,使用速度较快的YOLOv3(you only look once v3)作为网络骨架,目的在于预测目标物体掩码分割图,从而减少其他不相关物体通过遮挡带来的影响。为了提高掩码的准确度,增加反卷积层提高特征层的分辨率并对它们进行融合。然后,针对关键点采用漏斗网络进行特征点预测,避免残差网络模块由于局部特征丢失导致的关键点检测准确率下降问题。最后,对检测得到的关键点进行位姿计算,通过P
摘要:目的6D姿态估计是3D目标识别及重建中的一个重要问题。由于很多物体表面光滑、无纹理,特征难以提取,导致检测难度大。很多算法依赖后处理过程提高姿态估计精度,导致算法速度降低。针对以上问题,本文提出一种基于热力图的6D物体姿态估计算法。方法首先,采用分割掩码避免遮挡造成的热力图污染导致的特征点预测准确率下降问题。其次,基于漏斗网络架构,无需后处理过程,保证算法具有高效性能。在物体检测阶段,采用一个分割网络结构,使用速度较快的YOLOv3(you only look once v3)作为网络骨架,目的在于预测目标物体掩码分割图,从而减少其他不相关物体通过遮挡带来的影响。为了提高掩码的准确度,增加反卷积层提高特征层的分辨率并对它们进行融合。然后,针对关键点采用漏斗网络进行特征点预测,避免残差网络模块由于局部特征丢失导致的关键点检测准确率下降问题。最后,对检测得到的关键点进行位姿计算,通过P$n$ $n$ 关键词:姿态估计;目标分割;关键点定位;漏斗网络;特征融合136|197|3更新时间:2024-05-07
图像视频分析
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0