
最新刊期
2022 年 第 27 卷 第 12 期
-
 摘要:全像素双核(dual-pixel, DP)自动对焦(dual-pixel CMOS auto focus, DP CMOS AF)采用混合检测自动对焦,其在每个像素配备两个光电二极管, 使每个像素既参与对焦又参与成像,克服了传统相位检测自动对焦和反差检测自动对焦技术的缺点。根据离焦视差估计图像合焦镜头所需移动的距离,DP自动对焦具有更快的对焦速度和更高的对焦精度,因此广泛应用在手持设备中(如手机相机、单反相机等)。由于全像素双核传感器将每个像素分成两半,该传感器一次拍摄即可得到两幅图像。这两幅图像(全像素双核图像对)可以看做一个具有相同曝光时间和严格校正的小基线立体图像对。该图像对的视差与图像模糊程度相对应,只在离焦区域存在视差。全像素双核传感器不仅用于自动对焦,而且可以用于深度估计、散焦去模糊和反射去除等方面。本文系统地综述了全像素双核传感器的自动对焦、成像原理及研究现状,并进一步展望其未来发展。1)对自动对焦技术进行介绍,对比了传统对焦与全像素双核对焦;2)详细分析了全像素双核传感器的成像原理、成像模型及特点;3)系统地介绍了全像素双核在计算机视觉领域应用的最新进展,从深度估计、反射去除和离焦模糊去除等方面进行全面阐述及分析;4)适当的数据集是基于深度学习方法的基础,对目前的全像素双核数据集进行了介绍;5)分析了全像素双核在计算机视觉领域面临的挑战与机遇,对未来的全像素双核应用方向进行了讨论与展望。关键词:全像素双核(DP);自动对焦;深度学习;相机成像;反射去除;深度估计289|2308|0更新时间:2024-05-07
摘要:全像素双核(dual-pixel, DP)自动对焦(dual-pixel CMOS auto focus, DP CMOS AF)采用混合检测自动对焦,其在每个像素配备两个光电二极管, 使每个像素既参与对焦又参与成像,克服了传统相位检测自动对焦和反差检测自动对焦技术的缺点。根据离焦视差估计图像合焦镜头所需移动的距离,DP自动对焦具有更快的对焦速度和更高的对焦精度,因此广泛应用在手持设备中(如手机相机、单反相机等)。由于全像素双核传感器将每个像素分成两半,该传感器一次拍摄即可得到两幅图像。这两幅图像(全像素双核图像对)可以看做一个具有相同曝光时间和严格校正的小基线立体图像对。该图像对的视差与图像模糊程度相对应,只在离焦区域存在视差。全像素双核传感器不仅用于自动对焦,而且可以用于深度估计、散焦去模糊和反射去除等方面。本文系统地综述了全像素双核传感器的自动对焦、成像原理及研究现状,并进一步展望其未来发展。1)对自动对焦技术进行介绍,对比了传统对焦与全像素双核对焦;2)详细分析了全像素双核传感器的成像原理、成像模型及特点;3)系统地介绍了全像素双核在计算机视觉领域应用的最新进展,从深度估计、反射去除和离焦模糊去除等方面进行全面阐述及分析;4)适当的数据集是基于深度学习方法的基础,对目前的全像素双核数据集进行了介绍;5)分析了全像素双核在计算机视觉领域面临的挑战与机遇,对未来的全像素双核应用方向进行了讨论与展望。关键词:全像素双核(DP);自动对焦;深度学习;相机成像;反射去除;深度估计289|2308|0更新时间:2024-05-07 -
 摘要:汉字字体风格迁移旨在保证在语义内容不变的同时对汉字的字形作相应的转换。由于深度学习在图像风格迁移任务中表现出色,因此汉字生成可以从汉字图像入手,利用此技术实现汉字字体的转换,减少字体设计的人工干预,减轻字体设计的工作负担。然而,如何提高生成图像的质量仍是一个亟待解决的问题。本文首先系统梳理了当前汉字字体风格迁移的相关工作,将其分为3类,即基于卷积神经网络(convolutional neural network,CNN)、自编码器(auto-encoder,AE)和生成对抗网络(generative adversarial network,GAN)的汉字字体风格迁移方法。然后,对比分析了22种汉字字体风格迁移方法在数据集规模方面的需求和对不同字体类别转换的适用能力,并归纳了这些方法的特点,包括细化汉字图像特征、依赖预训练模型提取有效特征、支持去风格化等。同时,按照汉字部首检字表构造包含多种汉字字体的简繁体汉字图像数据集,并选取代表性的汉字字体风格迁移方法进行对比实验,实现源字体(仿宋)到目标字体(印刷体和手写体)的转换,展示并分析Rewrite2、zi2zi、TET-GAN(texture effects transfer GAN)和Unet-GAN等4种代表性汉字字体风格迁移方法的生成效果。最后,对该领域的现状和挑战进行总结,展望该领域未来发展方向。由于汉字具有数量庞大和风格多样的特性,因此基于深度学习的汉字生成与字体风格迁移技术还不够成熟。未来该领域将从融合汉字的风格化与去风格化为一体、有效提取汉字特征等方面进一步探索,使字体设计工作向更灵活、个性化的方向发展。关键词:汉字字体风格迁移;图像生成;卷积神经网络(CNN);自编码器(AE);生成对抗网络(GAN)296|853|2更新时间:2024-05-07
摘要:汉字字体风格迁移旨在保证在语义内容不变的同时对汉字的字形作相应的转换。由于深度学习在图像风格迁移任务中表现出色,因此汉字生成可以从汉字图像入手,利用此技术实现汉字字体的转换,减少字体设计的人工干预,减轻字体设计的工作负担。然而,如何提高生成图像的质量仍是一个亟待解决的问题。本文首先系统梳理了当前汉字字体风格迁移的相关工作,将其分为3类,即基于卷积神经网络(convolutional neural network,CNN)、自编码器(auto-encoder,AE)和生成对抗网络(generative adversarial network,GAN)的汉字字体风格迁移方法。然后,对比分析了22种汉字字体风格迁移方法在数据集规模方面的需求和对不同字体类别转换的适用能力,并归纳了这些方法的特点,包括细化汉字图像特征、依赖预训练模型提取有效特征、支持去风格化等。同时,按照汉字部首检字表构造包含多种汉字字体的简繁体汉字图像数据集,并选取代表性的汉字字体风格迁移方法进行对比实验,实现源字体(仿宋)到目标字体(印刷体和手写体)的转换,展示并分析Rewrite2、zi2zi、TET-GAN(texture effects transfer GAN)和Unet-GAN等4种代表性汉字字体风格迁移方法的生成效果。最后,对该领域的现状和挑战进行总结,展望该领域未来发展方向。由于汉字具有数量庞大和风格多样的特性,因此基于深度学习的汉字生成与字体风格迁移技术还不够成熟。未来该领域将从融合汉字的风格化与去风格化为一体、有效提取汉字特征等方面进一步探索,使字体设计工作向更灵活、个性化的方向发展。关键词:汉字字体风格迁移;图像生成;卷积神经网络(CNN);自编码器(AE);生成对抗网络(GAN)296|853|2更新时间:2024-05-07 -
 摘要:房颤是一种起源于心房的心脏疾病。据估计全球有超过3 000万人受其影响,虽然通过治疗可以降低患病风险,但房颤通常是隐匿的,很难及时诊断和干预。房颤的诊断方法主要有心脏触诊、光学体积描记术、血压监测振动法、心电图和基于影像的方法。房颤类型主要为阵发性房颤,前4种诊断方法不一定能捕捉到房颤发作,而且诊断周期长、成本高、准确率低及容易受医生的影响。左心房的解剖结构为房颤病理和研究进展提供了重要信息,基于医学影像的房颤分析需要准确分割左心房,通过分割结果计算房颤的临床指标,例如,射血分数、左心房体积、左心房应变及应变率,然后对左心房功能进行定量评估。采用影像的方法得出的诊断结果不易受人为干扰且具有处理大批量患者数据的能力,辅助医生及早发现房颤,对患者进行干预治疗,提高对房颤症状和临床诊断的认识,在临床实践中具有重大意义。本文将已有的分割方法归纳为传统方法、基于深度学习的方法以及传统与深度学习结合的方法。这些方法得到的结果为后续房颤分析提供了依据,但目前的分割方法许多都是半自动的,分割结果不够精确,训练数据集较小且依赖手工标注。本文总结了各种方法的优缺点,归纳了目前已有的公开数据集和房颤分析的临床应用,并展望了未来的发展趋势。关键词:房颤(AF);医学图像;深度学习(DL);左心房分割;左心房功能146|407|1更新时间:2024-05-07
摘要:房颤是一种起源于心房的心脏疾病。据估计全球有超过3 000万人受其影响,虽然通过治疗可以降低患病风险,但房颤通常是隐匿的,很难及时诊断和干预。房颤的诊断方法主要有心脏触诊、光学体积描记术、血压监测振动法、心电图和基于影像的方法。房颤类型主要为阵发性房颤,前4种诊断方法不一定能捕捉到房颤发作,而且诊断周期长、成本高、准确率低及容易受医生的影响。左心房的解剖结构为房颤病理和研究进展提供了重要信息,基于医学影像的房颤分析需要准确分割左心房,通过分割结果计算房颤的临床指标,例如,射血分数、左心房体积、左心房应变及应变率,然后对左心房功能进行定量评估。采用影像的方法得出的诊断结果不易受人为干扰且具有处理大批量患者数据的能力,辅助医生及早发现房颤,对患者进行干预治疗,提高对房颤症状和临床诊断的认识,在临床实践中具有重大意义。本文将已有的分割方法归纳为传统方法、基于深度学习的方法以及传统与深度学习结合的方法。这些方法得到的结果为后续房颤分析提供了依据,但目前的分割方法许多都是半自动的,分割结果不够精确,训练数据集较小且依赖手工标注。本文总结了各种方法的优缺点,归纳了目前已有的公开数据集和房颤分析的临床应用,并展望了未来的发展趋势。关键词:房颤(AF);医学图像;深度学习(DL);左心房分割;左心房功能146|407|1更新时间:2024-05-07
综述

-
 摘要:目的许多彩色图像去噪算法未充分利用图像局部和非局部的相似性信息,并且忽略了真实噪声在彩色图像不同区域内分布的差异,对不同图像块和不同颜色通道都进行同等处理,导致去噪图像中同时出现过平滑和欠平滑现象。针对这些问题,本文提出一种自适应非局部3维全变分去噪算法。方法利用一个非局部3维全变分正则项获取彩色图像块内和块间的相似性信息,同时在优化模型的保真项内嵌入一个自适应权重矩阵,该权重矩阵可以根据每次迭代得到的中间去噪结果的剩余噪声来调整算法在每个图像块、每个颜色分量以及每次迭代中的去噪强度。结果通过不同的高斯噪声添加方式得到两个彩色噪声图像数据集。将本文算法与其他6个基于全变分的算法进行比较,采用峰值信噪比(peak signal-to-noise ratio, PSNR)和结构相似性(structural similarity, SSIM)作为客观评价指标。相比于对比算法,本文算法在两个噪声图像数据集上的平均PSNR和SSIM分别提高了0.16~1.76 dB和0.12%~6.13%,并获得了更好的图像视觉效果。结论本文去噪算法不仅更好地兼顾了去噪与保边功能,而且提升了稳定性和鲁棒性,显示了在实际图像去噪中的应用潜力。关键词:彩色图像去噪;高斯噪声;非局部相似性;3维全变分;自适应权重109|464|2更新时间:2024-05-07
摘要:目的许多彩色图像去噪算法未充分利用图像局部和非局部的相似性信息,并且忽略了真实噪声在彩色图像不同区域内分布的差异,对不同图像块和不同颜色通道都进行同等处理,导致去噪图像中同时出现过平滑和欠平滑现象。针对这些问题,本文提出一种自适应非局部3维全变分去噪算法。方法利用一个非局部3维全变分正则项获取彩色图像块内和块间的相似性信息,同时在优化模型的保真项内嵌入一个自适应权重矩阵,该权重矩阵可以根据每次迭代得到的中间去噪结果的剩余噪声来调整算法在每个图像块、每个颜色分量以及每次迭代中的去噪强度。结果通过不同的高斯噪声添加方式得到两个彩色噪声图像数据集。将本文算法与其他6个基于全变分的算法进行比较,采用峰值信噪比(peak signal-to-noise ratio, PSNR)和结构相似性(structural similarity, SSIM)作为客观评价指标。相比于对比算法,本文算法在两个噪声图像数据集上的平均PSNR和SSIM分别提高了0.16~1.76 dB和0.12%~6.13%,并获得了更好的图像视觉效果。结论本文去噪算法不仅更好地兼顾了去噪与保边功能,而且提升了稳定性和鲁棒性,显示了在实际图像去噪中的应用潜力。关键词:彩色图像去噪;高斯噪声;非局部相似性;3维全变分;自适应权重109|464|2更新时间:2024-05-07 -
 摘要:目的基于语音增强和丢包补偿等技术的互联网低比特率编解码器(internet low bit rate codec, iLBC)在丢包率较高的网络环境下仍具有很好的语音质量。如何在隐写容量、不可感知性和抗检测性之间达到理想均衡是iLBC音频隐写面临的难点。为此,本文提出一种基于分层的iLBC语音大容量隐写方法。方法首先分析iLBC的编码比特流结构。然后基于主观语音质量评估指标PESQ-MOS(perceptual evaluation of speech quality-mean opinion score)和客观语音质量评估指标MCD(mel cepstral distortion)分析在线性频谱频率系数矢量量化过程、动态码本搜索过程和增益量化过程进行隐写对语音质量的影响,提出一种隐写位置分层方法,在增益量化过程和动态码本搜索过程按照嵌入容量和层次的优先级依次进行隐写,尽可能降低失真;对不能嵌满的层,提出一种基于Logistic混沌映射的嵌入位置选择方法,提升隐写的随机性和安全性。最后采用量化索引调制方法进行秘密信息嵌入,进一步提升隐写的安全性。结果在中英文语音数据集SSD(steganalysis-speech-dataset)上的对比实验结果表明,本文提出的分层隐写方法在隐写容量上提升了1倍,且保持了较好的不可感知性,没有因为写入额外秘密信息而导致音频过度失真。此外,本文方法在30 ms音频帧上嵌入量小于等于18 bit、在20 ms音频帧上嵌入量小于等于12 bit时可以很好地抵抗基于深度学习的音频隐写分析器的检测。结论本文方法可以充分挖掘iLBC语音的隐写潜能,在提升隐写容量的前提下,仍能保证良好的不可感知性和抗检测性。关键词:互联网低比特率编解码器(iLBC);量化索引调制;分层隐写;嵌入位置;大容量66|315|0更新时间:2024-05-07
摘要:目的基于语音增强和丢包补偿等技术的互联网低比特率编解码器(internet low bit rate codec, iLBC)在丢包率较高的网络环境下仍具有很好的语音质量。如何在隐写容量、不可感知性和抗检测性之间达到理想均衡是iLBC音频隐写面临的难点。为此,本文提出一种基于分层的iLBC语音大容量隐写方法。方法首先分析iLBC的编码比特流结构。然后基于主观语音质量评估指标PESQ-MOS(perceptual evaluation of speech quality-mean opinion score)和客观语音质量评估指标MCD(mel cepstral distortion)分析在线性频谱频率系数矢量量化过程、动态码本搜索过程和增益量化过程进行隐写对语音质量的影响,提出一种隐写位置分层方法,在增益量化过程和动态码本搜索过程按照嵌入容量和层次的优先级依次进行隐写,尽可能降低失真;对不能嵌满的层,提出一种基于Logistic混沌映射的嵌入位置选择方法,提升隐写的随机性和安全性。最后采用量化索引调制方法进行秘密信息嵌入,进一步提升隐写的安全性。结果在中英文语音数据集SSD(steganalysis-speech-dataset)上的对比实验结果表明,本文提出的分层隐写方法在隐写容量上提升了1倍,且保持了较好的不可感知性,没有因为写入额外秘密信息而导致音频过度失真。此外,本文方法在30 ms音频帧上嵌入量小于等于18 bit、在20 ms音频帧上嵌入量小于等于12 bit时可以很好地抵抗基于深度学习的音频隐写分析器的检测。结论本文方法可以充分挖掘iLBC语音的隐写潜能,在提升隐写容量的前提下,仍能保证良好的不可感知性和抗检测性。关键词:互联网低比特率编解码器(iLBC);量化索引调制;分层隐写;嵌入位置;大容量66|315|0更新时间:2024-05-07
图像处理和编码
-
 摘要:目的人脸识别技术已经在众多领域中得到广泛应用,然而现有识别方法对于人脸图像的质量要求普遍较高,低质量图像会严重影响系统的识别性能,产生误判。人脸图像质量评价方法可用于高质量图像的筛选,对改善人脸识别系统的性能有重要作用。不同于传统的图像质量评价,人脸图像质量评价是一种可用性评价,目前对其研究较少。人们在进行人脸识别时往往主要通过眼睛、鼻子、嘴等关键区域;基于此,本文提出了一种基于掩膜的人脸图像质量无参考评价方法,通过挖掘脸部关键区域对人脸识别算法的影响计算人脸图像质量。方法人脸识别方法通常需要比较输入人脸图像和高质量基准图像之间的特征相似度;本文从另一个角度出发,在输入人脸图像的基础上构造低可用性图像作为伪参考,并通过计算输入人脸图像和伪参考图像间的相似性获得输入人脸图像的质量评价分数。具体地,对一幅输入的人脸图像,首先对其关键区域添加掩膜获得低可用性质量的掩膜人脸图像,然后将输入图像和掩膜图像输入特征提取网络以获得人脸特征,最后计算特征间的距离获得输入人脸图像的质量分数。结果用AOC(错误拒绝曲线围成的区域面积)作为评估指标,在5个数据集上将本文方法与其他主流的人脸质量评价方法进行了充分比较,在LFW(labeled faces in the wild)数据集中比性能第2的模型提升了14.8%,在CelebA(celebFaces attribute)数据集中提升了0.1%,在DDFace(diversified distortion face)数据集中提升了2.9%,在VGGFace2(Visual Geometry Group Face2)数据集中提升了3.7%,在CASIA-WebFace(Institute of Automation,Chinese Academy of Science-Website Face)数据集中提升了4.9%。结论本文提出的基于掩膜的人脸图像质量评价方法,充分利用了人脸识别的关键性区域,将人脸识别的特点融入到人脸图像质量评价算法的设计中,能够在不需要参考图像的条件下准确预测出不同失真程度下的人脸图像质量分数,并且性能优于目前的主流方法。关键词:人脸识别;图像质量评价;人脸图像可用性质量;无参考;掩膜;伪参考105|199|1更新时间:2024-05-07
摘要:目的人脸识别技术已经在众多领域中得到广泛应用,然而现有识别方法对于人脸图像的质量要求普遍较高,低质量图像会严重影响系统的识别性能,产生误判。人脸图像质量评价方法可用于高质量图像的筛选,对改善人脸识别系统的性能有重要作用。不同于传统的图像质量评价,人脸图像质量评价是一种可用性评价,目前对其研究较少。人们在进行人脸识别时往往主要通过眼睛、鼻子、嘴等关键区域;基于此,本文提出了一种基于掩膜的人脸图像质量无参考评价方法,通过挖掘脸部关键区域对人脸识别算法的影响计算人脸图像质量。方法人脸识别方法通常需要比较输入人脸图像和高质量基准图像之间的特征相似度;本文从另一个角度出发,在输入人脸图像的基础上构造低可用性图像作为伪参考,并通过计算输入人脸图像和伪参考图像间的相似性获得输入人脸图像的质量评价分数。具体地,对一幅输入的人脸图像,首先对其关键区域添加掩膜获得低可用性质量的掩膜人脸图像,然后将输入图像和掩膜图像输入特征提取网络以获得人脸特征,最后计算特征间的距离获得输入人脸图像的质量分数。结果用AOC(错误拒绝曲线围成的区域面积)作为评估指标,在5个数据集上将本文方法与其他主流的人脸质量评价方法进行了充分比较,在LFW(labeled faces in the wild)数据集中比性能第2的模型提升了14.8%,在CelebA(celebFaces attribute)数据集中提升了0.1%,在DDFace(diversified distortion face)数据集中提升了2.9%,在VGGFace2(Visual Geometry Group Face2)数据集中提升了3.7%,在CASIA-WebFace(Institute of Automation,Chinese Academy of Science-Website Face)数据集中提升了4.9%。结论本文提出的基于掩膜的人脸图像质量评价方法,充分利用了人脸识别的关键性区域,将人脸识别的特点融入到人脸图像质量评价算法的设计中,能够在不需要参考图像的条件下准确预测出不同失真程度下的人脸图像质量分数,并且性能优于目前的主流方法。关键词:人脸识别;图像质量评价;人脸图像可用性质量;无参考;掩膜;伪参考105|199|1更新时间:2024-05-07 -
 摘要:目的表情是人机交互过程中重要的信息传递方式,因此表情识别具有重要的研究意义。针对目前表情识别方法存在背景干扰大、网络模型参数复杂、泛化性差等问题,本文提出了一种结合改进卷积神经网络(convolutional neural network,CNN)与通道加权的轻量级表情识别方法。方法首先,采用标准卷积和深度可分离卷积组合神经网络结构,再利用全局平均池化层作为输出层,简化网络的复杂程度,有效降低网络参数;其次,网络引入SE(squeeze-and-excitation)模块进行通道加权,通过在不同卷积层后设置不同的压缩率增强表情特征提取能力,提升网络模型精度;最后,用softmax分类函数实现各类表情的准确分类。结果本文网络参数量为6 108 519,相较于识别性能较好的Xception神经网络参数减少了63%,并且通过对网络模型的实时性测试,平均识别速度可达128帧/s。在5个公开的表情数据集上验证网络模型对7种表情的识别效果,与7种卷积神经网络方法相比,在FER2013 (Facial Expression Recognition 2013)、CK+ (the extended Cohn-Kanade)和JAFFE (Japanses Female Facial Expression) 3个表情数据集的识别精确度提高了5.72%、0.51%和0.28%,在RAF-DB (Real-world Affective Faces Database)、AffectNet这两个in-the-wild表情数据库的识别精确度分别提高了2.04%和0.68%。结论本文提出的轻量级表情识别方法在不同通道具有不同的加权能力,获取更多表情关键特征信息,提高了模型的泛化性。实验结果表明,本文方法在简化网络的复杂程度、减少计算量的同时能够准确识别人脸表情,能够有效提升网络的识别能力。关键词:表情识别;图像处理;卷积神经网络(CNN);深度可分离卷积;全局平均池化;SE模块84|198|1更新时间:2024-05-07
摘要:目的表情是人机交互过程中重要的信息传递方式,因此表情识别具有重要的研究意义。针对目前表情识别方法存在背景干扰大、网络模型参数复杂、泛化性差等问题,本文提出了一种结合改进卷积神经网络(convolutional neural network,CNN)与通道加权的轻量级表情识别方法。方法首先,采用标准卷积和深度可分离卷积组合神经网络结构,再利用全局平均池化层作为输出层,简化网络的复杂程度,有效降低网络参数;其次,网络引入SE(squeeze-and-excitation)模块进行通道加权,通过在不同卷积层后设置不同的压缩率增强表情特征提取能力,提升网络模型精度;最后,用softmax分类函数实现各类表情的准确分类。结果本文网络参数量为6 108 519,相较于识别性能较好的Xception神经网络参数减少了63%,并且通过对网络模型的实时性测试,平均识别速度可达128帧/s。在5个公开的表情数据集上验证网络模型对7种表情的识别效果,与7种卷积神经网络方法相比,在FER2013 (Facial Expression Recognition 2013)、CK+ (the extended Cohn-Kanade)和JAFFE (Japanses Female Facial Expression) 3个表情数据集的识别精确度提高了5.72%、0.51%和0.28%,在RAF-DB (Real-world Affective Faces Database)、AffectNet这两个in-the-wild表情数据库的识别精确度分别提高了2.04%和0.68%。结论本文提出的轻量级表情识别方法在不同通道具有不同的加权能力,获取更多表情关键特征信息,提高了模型的泛化性。实验结果表明,本文方法在简化网络的复杂程度、减少计算量的同时能够准确识别人脸表情,能够有效提升网络的识别能力。关键词:表情识别;图像处理;卷积神经网络(CNN);深度可分离卷积;全局平均池化;SE模块84|198|1更新时间:2024-05-07 -
 摘要:目的经典的人眼注视点预测模型通常采用跳跃连接的方式融合高、低层次特征,容易导致不同层级之间特征的重要性难以权衡,且没有考虑人眼在观察图像时偏向中心区域的问题。对此,本文提出一种融合注意力机制的图像特征提取方法,并利用高斯学习模块对提取的特征进行优化,提高了人眼注视点预测的精度。方法提出一种新的基于多重注意力机制(multiple attention mechanism,MAM)的人眼注视点预测模型,综合利用3种不同的注意力机制,对添加空洞卷积的ResNet-50模型提取的特征信息分别在空间、通道和层级上进行加权。该网络主要由特征提取模块、多重注意力模块和高斯学习优化模块组成。其中,空洞卷积能够有效获取不同大小的感受野信息,保证特征图分辨率大小的不变性;多重注意力模块旨在自动优化获得的低层丰富的细节信息和高层的全局语义信息,并充分提取特征图通道和空间信息,防止过度依赖模型中的高层特征;高斯学习模块用来自动选择合适的高斯模糊核来模糊显著性图像,解决人眼观察图像时的中心偏置问题。结果在公开数据集SALICON(saliency in context)上的实验表明,提出的方法相较于同结构的SAM-Res(saliency attention modal)模型以及DINet(dilated inception network)模型在相对熵(Kullback-Leibler divergence,KLD)、sAUC(shuffled area under ROC curve)和信息增益(information gain,IG)评价标准上分别提高了33%、0.3%和6%;53%、0.5%和192%。结论实验结果表明,提出的人眼注视点预测模型能通过加权的方式分别提取空间、通道、层之间的特征, 在多数人眼注视点预测指标上超过了主流模型。关键词:人眼注视点预测;多重注意力;层注意力;通道注意力;空间注意力;高斯学习121|212|0更新时间:2024-05-07
摘要:目的经典的人眼注视点预测模型通常采用跳跃连接的方式融合高、低层次特征,容易导致不同层级之间特征的重要性难以权衡,且没有考虑人眼在观察图像时偏向中心区域的问题。对此,本文提出一种融合注意力机制的图像特征提取方法,并利用高斯学习模块对提取的特征进行优化,提高了人眼注视点预测的精度。方法提出一种新的基于多重注意力机制(multiple attention mechanism,MAM)的人眼注视点预测模型,综合利用3种不同的注意力机制,对添加空洞卷积的ResNet-50模型提取的特征信息分别在空间、通道和层级上进行加权。该网络主要由特征提取模块、多重注意力模块和高斯学习优化模块组成。其中,空洞卷积能够有效获取不同大小的感受野信息,保证特征图分辨率大小的不变性;多重注意力模块旨在自动优化获得的低层丰富的细节信息和高层的全局语义信息,并充分提取特征图通道和空间信息,防止过度依赖模型中的高层特征;高斯学习模块用来自动选择合适的高斯模糊核来模糊显著性图像,解决人眼观察图像时的中心偏置问题。结果在公开数据集SALICON(saliency in context)上的实验表明,提出的方法相较于同结构的SAM-Res(saliency attention modal)模型以及DINet(dilated inception network)模型在相对熵(Kullback-Leibler divergence,KLD)、sAUC(shuffled area under ROC curve)和信息增益(information gain,IG)评价标准上分别提高了33%、0.3%和6%;53%、0.5%和192%。结论实验结果表明,提出的人眼注视点预测模型能通过加权的方式分别提取空间、通道、层之间的特征, 在多数人眼注视点预测指标上超过了主流模型。关键词:人眼注视点预测;多重注意力;层注意力;通道注意力;空间注意力;高斯学习121|212|0更新时间:2024-05-07 -
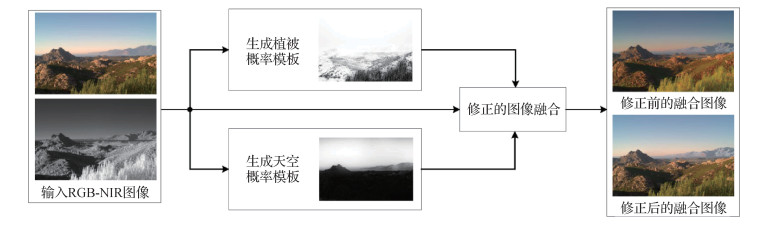 摘要:目的近红外(near-infrared,NIR)图像在夜视和去雾等方面发挥着重要作用,RGB-NIR图像融合是一种常见且有效的处理方式。在实际图像处理过程中,图像的不同对象区域因特性不同需要进行差异化处理,但是现有图像融合算法在植被和天空图像区域存在明显不足。对此,提出RGB-NIR联合图像的植被和天空区域概率模板生成算法。方法以植被为感兴趣区域,基于RGB图像各通道比值和扩展归一化植被指数(normalized difference vegetation index,NDVI)两种特征,提出RGB-NIR联合图像的植被区域概率模板生成算法。以天空为感兴趣区域,基于透射率图引导的局部熵和扩展NDVI两种特征,结合像素高度信息,提出RGB-NIR联合图像的天空区域概率模板生成算法。两种算法生成的植被和天空的概率模板在RGB-NIR图像融合过程中利用概率模板对权重矩阵进行修正,可明显改善融合效果。结果检测植被的模板生成算法与传统NDVI进行比较,在对比度和鲁棒性方面有更大优势;与语义分割进行比较,在准确度和纹理细节上有更好表现。检测天空的模板生成算法与当前的概率模板天空检测算法相比,准确率更高,边缘过渡更平滑;与当前的二值模板天空检测算法相比,在检测效果相当的情况下能保留更多细节信息,并且对小物体的划分更为准确。以本文检测算法修正后的图像融合结果在保持细节增强效果的同时,视觉感观更为自然,在定量指标上也更占优势。结论本文提出的概率模板生成算法结果准确、性能鲁棒,能有效提升RGB-NIR图像融合的效果,特别是在涉及权重的图像融合中能更好地结合与应用。关键词:植被检测;天空检测;概率模板;图像融合;视觉增强53|70|0更新时间:2024-05-07
摘要:目的近红外(near-infrared,NIR)图像在夜视和去雾等方面发挥着重要作用,RGB-NIR图像融合是一种常见且有效的处理方式。在实际图像处理过程中,图像的不同对象区域因特性不同需要进行差异化处理,但是现有图像融合算法在植被和天空图像区域存在明显不足。对此,提出RGB-NIR联合图像的植被和天空区域概率模板生成算法。方法以植被为感兴趣区域,基于RGB图像各通道比值和扩展归一化植被指数(normalized difference vegetation index,NDVI)两种特征,提出RGB-NIR联合图像的植被区域概率模板生成算法。以天空为感兴趣区域,基于透射率图引导的局部熵和扩展NDVI两种特征,结合像素高度信息,提出RGB-NIR联合图像的天空区域概率模板生成算法。两种算法生成的植被和天空的概率模板在RGB-NIR图像融合过程中利用概率模板对权重矩阵进行修正,可明显改善融合效果。结果检测植被的模板生成算法与传统NDVI进行比较,在对比度和鲁棒性方面有更大优势;与语义分割进行比较,在准确度和纹理细节上有更好表现。检测天空的模板生成算法与当前的概率模板天空检测算法相比,准确率更高,边缘过渡更平滑;与当前的二值模板天空检测算法相比,在检测效果相当的情况下能保留更多细节信息,并且对小物体的划分更为准确。以本文检测算法修正后的图像融合结果在保持细节增强效果的同时,视觉感观更为自然,在定量指标上也更占优势。结论本文提出的概率模板生成算法结果准确、性能鲁棒,能有效提升RGB-NIR图像融合的效果,特别是在涉及权重的图像融合中能更好地结合与应用。关键词:植被检测;天空检测;概率模板;图像融合;视觉增强53|70|0更新时间:2024-05-07
图像分析和识别
-
 摘要:目的针对自然场景下图像语义分割易受物体自身形状多样性、距离和光照等因素影响的问题,本文提出一种新的基于条形池化与通道注意力机制的双分支语义分割网络(strip pooling and channel attention net,SPCANet)。方法SPCANet从空间与内容两方面对图像特征进行抽取。首先,空间感知子网引入1维膨胀卷积与多尺度思想对条形池化技术进行优化改进,进一步在编码阶段增大水平与竖直方向上的感受野;其次,为了提升模型的内容感知能力,将在ImageNet数据集上预训练好的VGG16(Visual Geometry Group 16-layer network)作为内容感知子网,以辅助空间感知子网优化语义分割的嵌入特征,改善空间感知子网造成的图像细节信息缺失问题。此外,使用二阶通道注意力进一步优化网络中间层与高层的特征选择,并在一定程度上缓解光照产生的色差对分割结果的影响。结果使用Cityscapes作为实验数据,将本文方法与其他基于深度神经网络的分割方法进行对比,并从可视化效果和评测指标两方面进行分析。SPCANet在目标分割指标mIoU(mean intersection over union)上提升了1.2%。结论提出的双分支语义分割网络利用改进的条形池化技术、内容感知辅助网络和通道注意力机制对图像语义分割进行优化,对实验结果的提升起到了积极作用。关键词:图像分割;注意力;条形池化;膨胀卷积;感受野130|268|2更新时间:2024-05-07
摘要:目的针对自然场景下图像语义分割易受物体自身形状多样性、距离和光照等因素影响的问题,本文提出一种新的基于条形池化与通道注意力机制的双分支语义分割网络(strip pooling and channel attention net,SPCANet)。方法SPCANet从空间与内容两方面对图像特征进行抽取。首先,空间感知子网引入1维膨胀卷积与多尺度思想对条形池化技术进行优化改进,进一步在编码阶段增大水平与竖直方向上的感受野;其次,为了提升模型的内容感知能力,将在ImageNet数据集上预训练好的VGG16(Visual Geometry Group 16-layer network)作为内容感知子网,以辅助空间感知子网优化语义分割的嵌入特征,改善空间感知子网造成的图像细节信息缺失问题。此外,使用二阶通道注意力进一步优化网络中间层与高层的特征选择,并在一定程度上缓解光照产生的色差对分割结果的影响。结果使用Cityscapes作为实验数据,将本文方法与其他基于深度神经网络的分割方法进行对比,并从可视化效果和评测指标两方面进行分析。SPCANet在目标分割指标mIoU(mean intersection over union)上提升了1.2%。结论提出的双分支语义分割网络利用改进的条形池化技术、内容感知辅助网络和通道注意力机制对图像语义分割进行优化,对实验结果的提升起到了积极作用。关键词:图像分割;注意力;条形池化;膨胀卷积;感受野130|268|2更新时间:2024-05-07 -
 摘要:目的为有效解决半监督及弱监督语义分割模型中上下文信息缺失问题,在充分考虑模型推理效率的基础上,提出基于流形正则化的交叉一致性语义分割算法。方法首先,以交叉一致性训练模型作为骨架网络,通过骨架网络获得预测分割图像。其次,对输入域图像和输出域图像进行子图像块划分,以获取具有相同几何结构的数据对。再次,通过原始图像和分割图像的子图像块,计算输入数据与预测结果所处流形曲面上的潜在几何约束关系,并根据不同的训练方式分别设计半监督及弱监督的正则化算法。最后,利用流形约束的结果进一步优化图像分割网络中的参数,并通过反复迭代使半监督或弱监督的语义分割模型达到最优。结果通过加入流形正则化约束,捕获了图像中上下文信息,降低了网络前向计算过程中造成的本征结构的损失,在不改变网络结构的前提下提高了算法精度。为验证算法的有效性,实验分别在半监督和弱监督两种不同类型的语义分割中进行了对比,在PASCAL VOC 2012(pattern analysis, statistical modeling and computational learning visual object classes 2012)数据集上,对半监督语义分割任务,本文算法比原始网络提高了3.7%,对弱监督语义分割任务,本文算法比原始网络提高了1.1%。结论本文算法在不改变原有网络结构的基础上,提升了半监督及弱监督图像语义分割模型的精度,尤其对图像中几何特征明显的目标与区域,精度提升更加明显。关键词:深度学习;语义分割;半监督语义分割;弱监督语义分割;交叉一致性训练;流形正则化167|211|2更新时间:2024-05-07
摘要:目的为有效解决半监督及弱监督语义分割模型中上下文信息缺失问题,在充分考虑模型推理效率的基础上,提出基于流形正则化的交叉一致性语义分割算法。方法首先,以交叉一致性训练模型作为骨架网络,通过骨架网络获得预测分割图像。其次,对输入域图像和输出域图像进行子图像块划分,以获取具有相同几何结构的数据对。再次,通过原始图像和分割图像的子图像块,计算输入数据与预测结果所处流形曲面上的潜在几何约束关系,并根据不同的训练方式分别设计半监督及弱监督的正则化算法。最后,利用流形约束的结果进一步优化图像分割网络中的参数,并通过反复迭代使半监督或弱监督的语义分割模型达到最优。结果通过加入流形正则化约束,捕获了图像中上下文信息,降低了网络前向计算过程中造成的本征结构的损失,在不改变网络结构的前提下提高了算法精度。为验证算法的有效性,实验分别在半监督和弱监督两种不同类型的语义分割中进行了对比,在PASCAL VOC 2012(pattern analysis, statistical modeling and computational learning visual object classes 2012)数据集上,对半监督语义分割任务,本文算法比原始网络提高了3.7%,对弱监督语义分割任务,本文算法比原始网络提高了1.1%。结论本文算法在不改变原有网络结构的基础上,提升了半监督及弱监督图像语义分割模型的精度,尤其对图像中几何特征明显的目标与区域,精度提升更加明显。关键词:深度学习;语义分割;半监督语义分割;弱监督语义分割;交叉一致性训练;流形正则化167|211|2更新时间:2024-05-07 -
 摘要:目的传统图像修复方法缺乏对图像高级语义的理解,只能应对结构纹理简单的小面积受损。现有的端到端深度学习图像修复方法在大量训练图像的支持下克服了上述局限性,但由于这些方法试图在约束不足的情况下恢复整个目标,修复的图像往往存在边界模糊和结构扭曲问题。对此,本文提出一种语义分割结构与边缘结构联合指导的深度学习图像修复方法。方法该方法将图像修复任务分解为语义分割重建、边缘重建和内容补全3个阶段。首先重建缺失区域的语义分割结构,然后利用重建的语义分割结构指导缺失区域边缘结构的重建,最后利用重建的语义分割结构与边缘结构联合指导图像缺失区域内容的补全。结果在CelebAMask-HQ(celebfaces attributes mask high quality)人脸数据集和Cityscapes城市景观数据集上,将本文方法与其他先进的图像修复方法进行对比实验。在掩膜比例为50%~60%的情况下,与性能第2的方法相比,本文方法在Celebamask-HQ数据集上的平均绝对误差降低了4.5%,峰值信噪比提高了1.6%,结构相似性提高了1.7%;在Cityscapes数据集上平均绝对误差降低了4.2%,峰值信噪比提高了1.5%,结构相似性提高了1.9%。结果表明,本文方法在平均绝对误差、峰值信噪比和结构相似性3个指标上均优于对比方法,且生成的图像边界清晰,视觉上更加合理。结论本文提出的3阶段图像修复方法在语义分割结构与边缘结构的联合指导下,有效减少了结构重建错误。当修复涉及大面积缺失时,该方法比现有方法具有更高的修复质量。关键词:图像修复;生成对抗网络(GAN);语义分割;边缘检测;深度学习225|476|2更新时间:2024-05-07
摘要:目的传统图像修复方法缺乏对图像高级语义的理解,只能应对结构纹理简单的小面积受损。现有的端到端深度学习图像修复方法在大量训练图像的支持下克服了上述局限性,但由于这些方法试图在约束不足的情况下恢复整个目标,修复的图像往往存在边界模糊和结构扭曲问题。对此,本文提出一种语义分割结构与边缘结构联合指导的深度学习图像修复方法。方法该方法将图像修复任务分解为语义分割重建、边缘重建和内容补全3个阶段。首先重建缺失区域的语义分割结构,然后利用重建的语义分割结构指导缺失区域边缘结构的重建,最后利用重建的语义分割结构与边缘结构联合指导图像缺失区域内容的补全。结果在CelebAMask-HQ(celebfaces attributes mask high quality)人脸数据集和Cityscapes城市景观数据集上,将本文方法与其他先进的图像修复方法进行对比实验。在掩膜比例为50%~60%的情况下,与性能第2的方法相比,本文方法在Celebamask-HQ数据集上的平均绝对误差降低了4.5%,峰值信噪比提高了1.6%,结构相似性提高了1.7%;在Cityscapes数据集上平均绝对误差降低了4.2%,峰值信噪比提高了1.5%,结构相似性提高了1.9%。结果表明,本文方法在平均绝对误差、峰值信噪比和结构相似性3个指标上均优于对比方法,且生成的图像边界清晰,视觉上更加合理。结论本文提出的3阶段图像修复方法在语义分割结构与边缘结构的联合指导下,有效减少了结构重建错误。当修复涉及大面积缺失时,该方法比现有方法具有更高的修复质量。关键词:图像修复;生成对抗网络(GAN);语义分割;边缘检测;深度学习225|476|2更新时间:2024-05-07 -
 摘要:目的视频动作检测是视频理解领域的重要问题,该任务旨在定位视频中动作片段的起止时刻并预测动作类别。动作检测的关键环节包括动作模式的识别和视频内部时序关联的建立。目前主流方法往往试图设计一种普适的检测算法以定位所有类别的动作,忽略了不同类别间动作模式的巨大差异,限制了检测精度。此外,视频内部时序关联的建立对于检测精度至关重要,图卷积常用于全局时序建模,但其计算量较大。针对当前方法的不足,本文提出动作片段的逐类检测方法,并借助门控循环单元以较低的计算代价有效建立了视频内部的全局时序关联。方法动作模式识别方面,首先对视频动作进行粗略分类,然后借助多分支的逐类检测机制对每类动作进行针对性检测,通过识别视频局部特征的边界模式来定位动作边界,通过识别动作模式来评估锚框包含完整动作的概率;时序建模方面,构建了一个简洁有效的时序关联模块,利用门控循环单元建立了当前时刻与过去、未来时刻间的全局时序关联。上述创新点整合为类别敏感的全局时序关联视频动作检测方法。结果为验证本文方法的有效性,使用多种视频特征在两个公开数据集上进行实验,并与其他先进方法进行比较。在ActivityNet-1.3数据集中,该方法在双流特征下的平均mAP(mean average precision)达到35.58%,优于其他现有方法;在THUMOS-14数据集中,该方法在多种特征下的指标均取得了最佳性能。实验结果表明,类别敏感的逐类检测思路和借助门控循环单元的时序建模方法有效提升了视频动作检测精度。此外,提出的时序关联模块计算量低于使用图卷积建模的其他主流模型,且具备一定的泛化能力。结论提出了类别敏感的全局时序关联视频动作检测模型,实现了更为细化的逐类动作检测,同时借助门控循环单元设计了时序关联模块,提升了视频动作检测的精度。关键词:视频动作理解;视频动作提名;视频动作检测;卷积神经网络(CNN);门控循环单元(GRU)82|197|1更新时间:2024-05-07
摘要:目的视频动作检测是视频理解领域的重要问题,该任务旨在定位视频中动作片段的起止时刻并预测动作类别。动作检测的关键环节包括动作模式的识别和视频内部时序关联的建立。目前主流方法往往试图设计一种普适的检测算法以定位所有类别的动作,忽略了不同类别间动作模式的巨大差异,限制了检测精度。此外,视频内部时序关联的建立对于检测精度至关重要,图卷积常用于全局时序建模,但其计算量较大。针对当前方法的不足,本文提出动作片段的逐类检测方法,并借助门控循环单元以较低的计算代价有效建立了视频内部的全局时序关联。方法动作模式识别方面,首先对视频动作进行粗略分类,然后借助多分支的逐类检测机制对每类动作进行针对性检测,通过识别视频局部特征的边界模式来定位动作边界,通过识别动作模式来评估锚框包含完整动作的概率;时序建模方面,构建了一个简洁有效的时序关联模块,利用门控循环单元建立了当前时刻与过去、未来时刻间的全局时序关联。上述创新点整合为类别敏感的全局时序关联视频动作检测方法。结果为验证本文方法的有效性,使用多种视频特征在两个公开数据集上进行实验,并与其他先进方法进行比较。在ActivityNet-1.3数据集中,该方法在双流特征下的平均mAP(mean average precision)达到35.58%,优于其他现有方法;在THUMOS-14数据集中,该方法在多种特征下的指标均取得了最佳性能。实验结果表明,类别敏感的逐类检测思路和借助门控循环单元的时序建模方法有效提升了视频动作检测精度。此外,提出的时序关联模块计算量低于使用图卷积建模的其他主流模型,且具备一定的泛化能力。结论提出了类别敏感的全局时序关联视频动作检测模型,实现了更为细化的逐类动作检测,同时借助门控循环单元设计了时序关联模块,提升了视频动作检测的精度。关键词:视频动作理解;视频动作提名;视频动作检测;卷积神经网络(CNN);门控循环单元(GRU)82|197|1更新时间:2024-05-07 -
 摘要:目的通过融合一组不同曝光程度的低动态范围(low dynamic range, LDR)图像,可以有效重建出高动态范围(high dynamic range, HDR)图像。但LDR图像之间存在背景偏移和拍摄对象运动的现象,会导致重建的HDR图像中引入鬼影。基于注意力机制的HDR重建方法虽然有一定效果,但由于没有充分挖掘特征空间维度和通道维度的相互关系,只在物体出现轻微运动时取得比较好的效果。当场景中物体出现大幅运动时,这些方法的效果仍然存在提升空间。为此,本文提出了空间感知通道注意力引导的多尺度HDR图像重建网络来实现鬼影抑制和细节恢复。方法本文提出了一种全新的空间感知通道注意力机制(spatial aware channel attention mechanism, SACAM),该机制在挖掘通道上下文关系的过程中,通过提取特征通道维度的全局信息和显著信息,来进一步强化特征的空间关系。这有助于突出特征空间维度与通道维度有益信息的重要性,实现鬼影抑制和特征中有效信息增强。此外,本文还设计了一个多尺度信息重建模块(multiscale information reconstruction module, MIM)。该模块有助于增大网络感受野,强化特征空间维度的显著信息,还能充分利用不同尺度特征的上下文语义信息,来重构最终的HDR图像。结果在Kalantari测试集上,本文方法的PSNR-L(peak signal to noise ratio-linear domain)和SSIM-L(structural similarity-linear domain)分别为41.101 3、0.986 5。PSNR-μ(peak signal to noise ratio-tonemapped domain)和SSIM-μ(structural similarity-tonemapped domain)分别为43.413 6、0.990 2。在Sen和Tursun数据集上,本文方法较为真实地重构了场景的结构,并清晰地恢复出图像细节,有效避免了鬼影的产生。结论本文提出的空间感知通道注意力引导的多尺度HDR图像重建网络,有效挖掘了特征中对重构图像有益的信息,提升了网络恢复细节信息的能力。并在多个数据集上取得了较为理想的HDR重建效果。关键词:多曝光图像融合;高动态范围(HDR);注意力;多尺度;鬼影抑制128|198|1更新时间:2024-05-07
摘要:目的通过融合一组不同曝光程度的低动态范围(low dynamic range, LDR)图像,可以有效重建出高动态范围(high dynamic range, HDR)图像。但LDR图像之间存在背景偏移和拍摄对象运动的现象,会导致重建的HDR图像中引入鬼影。基于注意力机制的HDR重建方法虽然有一定效果,但由于没有充分挖掘特征空间维度和通道维度的相互关系,只在物体出现轻微运动时取得比较好的效果。当场景中物体出现大幅运动时,这些方法的效果仍然存在提升空间。为此,本文提出了空间感知通道注意力引导的多尺度HDR图像重建网络来实现鬼影抑制和细节恢复。方法本文提出了一种全新的空间感知通道注意力机制(spatial aware channel attention mechanism, SACAM),该机制在挖掘通道上下文关系的过程中,通过提取特征通道维度的全局信息和显著信息,来进一步强化特征的空间关系。这有助于突出特征空间维度与通道维度有益信息的重要性,实现鬼影抑制和特征中有效信息增强。此外,本文还设计了一个多尺度信息重建模块(multiscale information reconstruction module, MIM)。该模块有助于增大网络感受野,强化特征空间维度的显著信息,还能充分利用不同尺度特征的上下文语义信息,来重构最终的HDR图像。结果在Kalantari测试集上,本文方法的PSNR-L(peak signal to noise ratio-linear domain)和SSIM-L(structural similarity-linear domain)分别为41.101 3、0.986 5。PSNR-μ(peak signal to noise ratio-tonemapped domain)和SSIM-μ(structural similarity-tonemapped domain)分别为43.413 6、0.990 2。在Sen和Tursun数据集上,本文方法较为真实地重构了场景的结构,并清晰地恢复出图像细节,有效避免了鬼影的产生。结论本文提出的空间感知通道注意力引导的多尺度HDR图像重建网络,有效挖掘了特征中对重构图像有益的信息,提升了网络恢复细节信息的能力。并在多个数据集上取得了较为理想的HDR重建效果。关键词:多曝光图像融合;高动态范围(HDR);注意力;多尺度;鬼影抑制128|198|1更新时间:2024-05-07 -
 摘要:目的基于卷积神经网络的单阶段目标检测网络具有高实时性与高检测精度,但其通常存在两个问题:1)模型中存在大量冗余的卷积计算;2)多尺度特征融合结构导致额外的计算开销。这导致单阶段检测器需要大量的计算资源,难以在计算资源不足的设备上应用。针对上述问题,本文在YOLOv5(you only look once version 5)的结构基础上,提出一种轻量化单阶段目标检测网络架构,称为E-YOLO(efficient-YOLO)。方法利用E-YOLO架构构建了E-YOLOm(efficient-YOLO medium)与E-YOLOs(efficient-YOLO small)两种不同大小的模型。首先,设计了多种更加高效的特征提取模块以减少冗余的卷积计算,对模型中开销较大的特征图通过下采样、特征提取、通道升降维与金字塔池化进行了轻量化设计。其次,为解决多尺度特征融合带来的冗余开销,提出了一种高效多尺度特征融合结构,使用多尺度特征加权融合方案减少通道降维开销,设计中层特征长跳连接缓解特征流失。结果实验表明,E-YOLOm、E-YOLOs与YOLOv5m、YOLOv5s相比,参数量分别下降了71.5%和61.6%,运算量下降了67.3%和49.7%。在VOC(visual object classes)数据集上的平均精度(average precision, AP),E-YOLOm比YOLOv5m仅下降了2.3%,E-YOLOs比YOLOv5s提升了3.4%。同时,E-YOLOm的参数量和运算量相比YOLOv5s分别低15.5%与1.7%,mAP@0.5和AP比其高3.9%和11.1%,具有更小的计算开销与更高的检测效率。结论本文提出的E-YOLO架构显著降低了单阶段目标检测网络中冗余的卷积计算与多尺度融合开销,且具有良好的鲁棒性,并优于对比网络轻量化方案,在低运算性能的环境中具有重要的实用意义。关键词:卷积神经网络(CNN);目标检测;模型轻量化;注意力模块;多尺度融合91|240|1更新时间:2024-05-07
摘要:目的基于卷积神经网络的单阶段目标检测网络具有高实时性与高检测精度,但其通常存在两个问题:1)模型中存在大量冗余的卷积计算;2)多尺度特征融合结构导致额外的计算开销。这导致单阶段检测器需要大量的计算资源,难以在计算资源不足的设备上应用。针对上述问题,本文在YOLOv5(you only look once version 5)的结构基础上,提出一种轻量化单阶段目标检测网络架构,称为E-YOLO(efficient-YOLO)。方法利用E-YOLO架构构建了E-YOLOm(efficient-YOLO medium)与E-YOLOs(efficient-YOLO small)两种不同大小的模型。首先,设计了多种更加高效的特征提取模块以减少冗余的卷积计算,对模型中开销较大的特征图通过下采样、特征提取、通道升降维与金字塔池化进行了轻量化设计。其次,为解决多尺度特征融合带来的冗余开销,提出了一种高效多尺度特征融合结构,使用多尺度特征加权融合方案减少通道降维开销,设计中层特征长跳连接缓解特征流失。结果实验表明,E-YOLOm、E-YOLOs与YOLOv5m、YOLOv5s相比,参数量分别下降了71.5%和61.6%,运算量下降了67.3%和49.7%。在VOC(visual object classes)数据集上的平均精度(average precision, AP),E-YOLOm比YOLOv5m仅下降了2.3%,E-YOLOs比YOLOv5s提升了3.4%。同时,E-YOLOm的参数量和运算量相比YOLOv5s分别低15.5%与1.7%,mAP@0.5和AP比其高3.9%和11.1%,具有更小的计算开销与更高的检测效率。结论本文提出的E-YOLO架构显著降低了单阶段目标检测网络中冗余的卷积计算与多尺度融合开销,且具有良好的鲁棒性,并优于对比网络轻量化方案,在低运算性能的环境中具有重要的实用意义。关键词:卷积神经网络(CNN);目标检测;模型轻量化;注意力模块;多尺度融合91|240|1更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的3维人体姿态估计传统方法通常采用单帧点云作为输入,可能会忽略人体运动平滑度的固有先验知识,导致产生抖动伪影。目前,获取2维人体姿态标注的真实图像数据集相对容易,而采集大规模的具有高质量3维人体姿态标注的真实图像数据集进行完全监督训练有一定难度。对此,本文提出了一种新的点云序列3维人体姿态估计方法。方法首先从深度图像序列估计姿态相关点云,然后利用时序信息构建神经网络,对姿态相关点云序列的时空特征进行编码。选用弱监督深度学习,以利用大量的更容易获得的带2维人体姿态标注的数据集。最后采用多任务网络对人体姿态估计和人体运动预测进行联合训练,提高优化效果。结果在两个数据集上对本文算法进行评估。在ITOP(invariant-top view dataset)数据集上,本文方法的平均精度均值(mean average precision,mAP)比对比方法分别高0.99%、13.18%和17.96%。在NTU-RGBD数据集上,本文方法的mAP值比最先进的WSM(weakly supervised adversarial learning methods)方法高7.03%。同时,在ITOP数据集上对模型进行消融实验,验证了算法各个不同组成部分的有效性。与单任务模型训练相比,多任务网络联合进行人体姿态估计和运动预测的mAP可以提高2%以上。结论本文提出的点云序列3维人体姿态估计方法能充分利用人体运动连续性的先验知识,获得更平滑的人体姿态估计结果,在ITOP和NTU-RGBD数据集上都能获得很好的效果。采用多任务网络联合优化策略,人体姿态估计和运动预测两个任务联合优化求解,有互相促进的作用。关键词:人体运动;人体姿态估计;人体运动预测;点云序列;弱监督学习266|230|1更新时间:2024-05-07
摘要:目的3维人体姿态估计传统方法通常采用单帧点云作为输入,可能会忽略人体运动平滑度的固有先验知识,导致产生抖动伪影。目前,获取2维人体姿态标注的真实图像数据集相对容易,而采集大规模的具有高质量3维人体姿态标注的真实图像数据集进行完全监督训练有一定难度。对此,本文提出了一种新的点云序列3维人体姿态估计方法。方法首先从深度图像序列估计姿态相关点云,然后利用时序信息构建神经网络,对姿态相关点云序列的时空特征进行编码。选用弱监督深度学习,以利用大量的更容易获得的带2维人体姿态标注的数据集。最后采用多任务网络对人体姿态估计和人体运动预测进行联合训练,提高优化效果。结果在两个数据集上对本文算法进行评估。在ITOP(invariant-top view dataset)数据集上,本文方法的平均精度均值(mean average precision,mAP)比对比方法分别高0.99%、13.18%和17.96%。在NTU-RGBD数据集上,本文方法的mAP值比最先进的WSM(weakly supervised adversarial learning methods)方法高7.03%。同时,在ITOP数据集上对模型进行消融实验,验证了算法各个不同组成部分的有效性。与单任务模型训练相比,多任务网络联合进行人体姿态估计和运动预测的mAP可以提高2%以上。结论本文提出的点云序列3维人体姿态估计方法能充分利用人体运动连续性的先验知识,获得更平滑的人体姿态估计结果,在ITOP和NTU-RGBD数据集上都能获得很好的效果。采用多任务网络联合优化策略,人体姿态估计和运动预测两个任务联合优化求解,有互相促进的作用。关键词:人体运动;人体姿态估计;人体运动预测;点云序列;弱监督学习266|230|1更新时间:2024-05-07
计算机图形学
-
 摘要:目的针对目前多模态医学图像融合方法深层特征提取能力不足,部分模态特征被忽略的问题,提出了基于U-Net3+与跨模态注意力块的双鉴别器生成对抗网络医学图像融合算法(U-Net3+ and cross-modal attention block dual-discriminator generative adversal network,UC-DDGAN)。方法结合U-Net3+可用很少的参数提取深层特征、跨模态注意力块可提取两模态特征的特点,构建UC-DDGAN网络框架。UC-DDGAN包含一个生成器和两个鉴别器,生成器包括特征提取和特征融合。特征提取部分将跨模态注意力块嵌入到U-Net3+下采样提取图像深层特征的路径上,提取跨模态特征与提取深层特征交替进行,得到各层复合特征图,将其进行通道叠加、降维后上采样,输出包含两模态全尺度深层特征的特征图。特征融合部分通过将特征图在通道上进行拼接得到融合图像。双鉴别器分别对不同分布的源图像进行针对性鉴别。损失函数引入梯度损失,将其与像素损失加权优化生成器。结果将UC-DDGAN与5种经典的图像融合方法在美国哈佛医学院公开的脑部疾病图像数据集上进行实验对比,其融合图像在空间频率(spatial frequency, SF)、结构相似性(structural similarity, SSIM)、边缘信息传递因子(degree of edge information,
摘要:目的针对目前多模态医学图像融合方法深层特征提取能力不足,部分模态特征被忽略的问题,提出了基于U-Net3+与跨模态注意力块的双鉴别器生成对抗网络医学图像融合算法(U-Net3+ and cross-modal attention block dual-discriminator generative adversal network,UC-DDGAN)。方法结合U-Net3+可用很少的参数提取深层特征、跨模态注意力块可提取两模态特征的特点,构建UC-DDGAN网络框架。UC-DDGAN包含一个生成器和两个鉴别器,生成器包括特征提取和特征融合。特征提取部分将跨模态注意力块嵌入到U-Net3+下采样提取图像深层特征的路径上,提取跨模态特征与提取深层特征交替进行,得到各层复合特征图,将其进行通道叠加、降维后上采样,输出包含两模态全尺度深层特征的特征图。特征融合部分通过将特征图在通道上进行拼接得到融合图像。双鉴别器分别对不同分布的源图像进行针对性鉴别。损失函数引入梯度损失,将其与像素损失加权优化生成器。结果将UC-DDGAN与5种经典的图像融合方法在美国哈佛医学院公开的脑部疾病图像数据集上进行实验对比,其融合图像在空间频率(spatial frequency, SF)、结构相似性(structural similarity, SSIM)、边缘信息传递因子(degree of edge information,$ {\rm{Q}}^{{\rm{A B / F}}}$ $ {\rm{Q}}^{{\rm{A B / F}}}$ 关键词:U-Net3+;跨模态注意力块;双鉴别器生成对抗网络;梯度损失;多模态医学图像融合87|634|2更新时间:2024-05-07 -
 摘要:目的肠胃镜诊断一直被认为是检测及预防结直肠癌的金标准,但当前的临床检查中仍存在一定的漏诊概率,基于深度学习的肠胃内窥镜分割方法可以帮助医生准确评估癌前病变,对诊断和干预治疗都有积极作用。然而提高目标分割的准确性仍然是一项具有挑战性的工作,针对这一问题,本文提出一种基于双层编—解码结构的算法。方法本文算法由上、下游网络构成,创新性地利用上游网络训练产生注意力权重图,对下游网络解码过程中的特征图产生注意力引导,使分割模型更加注重目标区域;提出子空间通道注意力结构,在跨越连接中提取多分辨率下的跨通道信息,可以有效细化分割边缘;最终输出添加残差结构防止网络退化。结果在公共数据集CVC-ClinicDB(Colonoscopy Videos Challenge-ClinicDataBase)和Kvasir-Capsule上进行测试,采用Dice相似系数(Dice similariy coefficient,DSC)、均交并比(mean intersection over union,mIoU)、精确率(precision)以及召回率(recall)为评价指标,在两个数据集上的DSC分别达到了94.22%和96.02%。进一步将两个数据集混合,测试了算法在跨设备图像上的鲁棒性,其中DSC提升分别达到17%—20%,在没有后处理的情况下,相较其他先进模型(state-of-the-art,SOTA),如U-Net在DSC、mIoU以及recall上分别取得了1.64%、1.41%和2.54%的提升,与ResUNet++的对比中,在DSC以及recall指标上分别取得了2.23%和9.87%的提升,与SFA (selective feature aggregation network)、PraNet和TransFuse等算法相比,在上述评价指标上也均有显著提升。结论本文算法可以有效提高医学图像分割效果,并且对小目标分割、边缘分割具有更高的准确率。关键词:息肉分割;结肠镜检查;深度学习;语义分割;注意力机制;医学图像处理137|170|1更新时间:2024-05-07
摘要:目的肠胃镜诊断一直被认为是检测及预防结直肠癌的金标准,但当前的临床检查中仍存在一定的漏诊概率,基于深度学习的肠胃内窥镜分割方法可以帮助医生准确评估癌前病变,对诊断和干预治疗都有积极作用。然而提高目标分割的准确性仍然是一项具有挑战性的工作,针对这一问题,本文提出一种基于双层编—解码结构的算法。方法本文算法由上、下游网络构成,创新性地利用上游网络训练产生注意力权重图,对下游网络解码过程中的特征图产生注意力引导,使分割模型更加注重目标区域;提出子空间通道注意力结构,在跨越连接中提取多分辨率下的跨通道信息,可以有效细化分割边缘;最终输出添加残差结构防止网络退化。结果在公共数据集CVC-ClinicDB(Colonoscopy Videos Challenge-ClinicDataBase)和Kvasir-Capsule上进行测试,采用Dice相似系数(Dice similariy coefficient,DSC)、均交并比(mean intersection over union,mIoU)、精确率(precision)以及召回率(recall)为评价指标,在两个数据集上的DSC分别达到了94.22%和96.02%。进一步将两个数据集混合,测试了算法在跨设备图像上的鲁棒性,其中DSC提升分别达到17%—20%,在没有后处理的情况下,相较其他先进模型(state-of-the-art,SOTA),如U-Net在DSC、mIoU以及recall上分别取得了1.64%、1.41%和2.54%的提升,与ResUNet++的对比中,在DSC以及recall指标上分别取得了2.23%和9.87%的提升,与SFA (selective feature aggregation network)、PraNet和TransFuse等算法相比,在上述评价指标上也均有显著提升。结论本文算法可以有效提高医学图像分割效果,并且对小目标分割、边缘分割具有更高的准确率。关键词:息肉分割;结肠镜检查;深度学习;语义分割;注意力机制;医学图像处理137|170|1更新时间:2024-05-07 -
 摘要:目的新冠肺炎疫情席卷全球,为快速诊断肺炎患者,确认患者肺部感染区域,大量检测网络相继提出,但现有网络大多只能处理一种任务,即诊断或分割。本文提出了一种融合多头注意力机制的联合诊断与分割网络,能同时完成X线胸片的肺炎诊断分类和新冠感染区分割。方法整个网络由3部分组成,双路嵌入层通过两种不同的图像嵌入方式分别提取X线胸片的浅层直观特征和深层抽象特征;Transformer模块综合考虑提取到的浅层直观与深层抽象特征;分割解码器扩大特征图以输出分割区域。为响应联合训练,本文使用了一种混合损失函数以动态平衡分类与分割的训练。分类损失定义为分类对比损失与交叉熵损失的和;分割损失是二分类的交叉熵损失。结果基于6个公开数据集的合并数据实验结果表明,所提网络取得了95.37%的精度、96.28%的召回率、95.95%的F1指标和93.88%的kappa系数,诊断分类性能超过了主流的ResNet50、VGG16(Visual Geometry Group)和Inception_v3等网络;在新冠病灶分割表现上,相比流行的U-Net及其改进网络,取得最高的精度(95.96%),优异的敏感度(78.89%)、最好的Dice系数(76.68%)和AUC(area under ROC curve)指标(98.55%);效率上,每0.56 s可输出一次诊断分割结果。结论联合网络模型使用Transformer架构,通过自注意力机制关注全局特征,通过交叉注意力综合考虑深层抽象特征与浅层高级特征,具有优异的分类与分割性能。关键词:新冠肺炎(COVID-19);自动诊断;肺部区域分割;多头注意力机制;混合损失173|555|2更新时间:2024-05-07
摘要:目的新冠肺炎疫情席卷全球,为快速诊断肺炎患者,确认患者肺部感染区域,大量检测网络相继提出,但现有网络大多只能处理一种任务,即诊断或分割。本文提出了一种融合多头注意力机制的联合诊断与分割网络,能同时完成X线胸片的肺炎诊断分类和新冠感染区分割。方法整个网络由3部分组成,双路嵌入层通过两种不同的图像嵌入方式分别提取X线胸片的浅层直观特征和深层抽象特征;Transformer模块综合考虑提取到的浅层直观与深层抽象特征;分割解码器扩大特征图以输出分割区域。为响应联合训练,本文使用了一种混合损失函数以动态平衡分类与分割的训练。分类损失定义为分类对比损失与交叉熵损失的和;分割损失是二分类的交叉熵损失。结果基于6个公开数据集的合并数据实验结果表明,所提网络取得了95.37%的精度、96.28%的召回率、95.95%的F1指标和93.88%的kappa系数,诊断分类性能超过了主流的ResNet50、VGG16(Visual Geometry Group)和Inception_v3等网络;在新冠病灶分割表现上,相比流行的U-Net及其改进网络,取得最高的精度(95.96%),优异的敏感度(78.89%)、最好的Dice系数(76.68%)和AUC(area under ROC curve)指标(98.55%);效率上,每0.56 s可输出一次诊断分割结果。结论联合网络模型使用Transformer架构,通过自注意力机制关注全局特征,通过交叉注意力综合考虑深层抽象特征与浅层高级特征,具有优异的分类与分割性能。关键词:新冠肺炎(COVID-19);自动诊断;肺部区域分割;多头注意力机制;混合损失173|555|2更新时间:2024-05-07
医学图像处理
-
 摘要:目的在近岸合成孔径雷达(synthetic aperture radar,SAR)图像舰船检测中,由于陆地建筑及岛屿等复杂背景的影响,小型舰船与周边相似建筑及岛屿容易混淆。现有方法通常使用固定大小的方形卷积核提取图像特征。但是小型舰船在图像中占比较小,且呈长条形倾斜分布。固定大小的方形卷积核引入了过多背景信息,对分类造成干扰。为此,本文针对SAR图像舰船目标提出一种基于可变形空洞卷积的骨干网络。方法首先用可变形空洞卷积核代替传统卷积核,使提取特征位置更贴合目标形状,强化对舰船目标本身区域和边缘特征的提取能力,减少背景信息提取。然后提出3通道混合注意力机制来加强局部细节信息提取,突出小型舰船与暗礁、岛屿等的差异性,提高模型细分类效果。结果在SAR图像舰船数据集HRSID(high-resolution SAR images dataset)上的实验结果表明,本文方法应用在Cascade-RCNN(cascade region convolutional neural network)、YOLOv4(you only look once v4)和BorderDet(border detection)3种检测模型上,与原模型相比,对小型舰船的检测精度分别提高了3.5%、2.6%和2.9%,总体精度达到89.9%。在SSDD(SAR ship detection dataset)数据集上的总体精度达到95.9%,优于现有方法。结论本文通过改进骨干网络,使模型能够改变卷积核形状和大小,集中获取目标信息,抑制背景信息干扰,有效降低了SAR图像近岸复杂背景下小型舰船的误检漏检情况。关键词:舰船检测;合成孔径雷达(SAR)图像;可变形卷积;视觉注意力机制;空洞卷积149|211|7更新时间:2024-05-07
摘要:目的在近岸合成孔径雷达(synthetic aperture radar,SAR)图像舰船检测中,由于陆地建筑及岛屿等复杂背景的影响,小型舰船与周边相似建筑及岛屿容易混淆。现有方法通常使用固定大小的方形卷积核提取图像特征。但是小型舰船在图像中占比较小,且呈长条形倾斜分布。固定大小的方形卷积核引入了过多背景信息,对分类造成干扰。为此,本文针对SAR图像舰船目标提出一种基于可变形空洞卷积的骨干网络。方法首先用可变形空洞卷积核代替传统卷积核,使提取特征位置更贴合目标形状,强化对舰船目标本身区域和边缘特征的提取能力,减少背景信息提取。然后提出3通道混合注意力机制来加强局部细节信息提取,突出小型舰船与暗礁、岛屿等的差异性,提高模型细分类效果。结果在SAR图像舰船数据集HRSID(high-resolution SAR images dataset)上的实验结果表明,本文方法应用在Cascade-RCNN(cascade region convolutional neural network)、YOLOv4(you only look once v4)和BorderDet(border detection)3种检测模型上,与原模型相比,对小型舰船的检测精度分别提高了3.5%、2.6%和2.9%,总体精度达到89.9%。在SSDD(SAR ship detection dataset)数据集上的总体精度达到95.9%,优于现有方法。结论本文通过改进骨干网络,使模型能够改变卷积核形状和大小,集中获取目标信息,抑制背景信息干扰,有效降低了SAR图像近岸复杂背景下小型舰船的误检漏检情况。关键词:舰船检测;合成孔径雷达(SAR)图像;可变形卷积;视觉注意力机制;空洞卷积149|211|7更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0