
最新刊期
2022 年 第 27 卷 第 11 期
-
 摘要:行为识别是当前计算机视觉方向中视频理解领域的重要研究课题。从视频中准确提取人体动作的特征并识别动作,能为医疗、安防等领域提供重要的信息,是一个十分具有前景的方向。本文从数据驱动的角度出发,全面介绍了行为识别技术的研究发展,对具有代表性的行为识别方法或模型进行了系统阐述。行为识别的数据分为RGB模态数据、深度模态数据、骨骼模态数据以及融合模态数据。首先介绍了行为识别的主要过程和人类行为识别领域不同数据模态的公开数据集;然后根据数据模态分类,回顾了RGB模态、深度模态和骨骼模态下基于传统手工特征和深度学习的行为识别方法,以及多模态融合分类下RGB模态与深度模态融合的方法和其他模态融合的方法。传统手工特征法包括基于时空体积和时空兴趣点的方法(RGB模态)、基于运动变化和外观的方法(深度模态)以及基于骨骼特征的方法(骨骼模态)等;深度学习方法主要涉及卷积网络、图卷积网络和混合网络,重点介绍了其改进点、特点以及模型的创新点。基于不同模态的数据集分类进行不同行为识别技术的对比分析。通过类别内部和类别之间两个角度对比分析后,得出不同模态的优缺点与适用场景、手工特征法与深度学习法的区别和融合多模态的优势。最后,总结了行为识别技术当前面临的问题和挑战,并基于数据模态的角度提出了未来可行的研究方向和研究重点。关键词:计算机视觉;行为识别;深度学习;神经网络;多模态;模态融合357|235|2更新时间:2024-05-07
摘要:行为识别是当前计算机视觉方向中视频理解领域的重要研究课题。从视频中准确提取人体动作的特征并识别动作,能为医疗、安防等领域提供重要的信息,是一个十分具有前景的方向。本文从数据驱动的角度出发,全面介绍了行为识别技术的研究发展,对具有代表性的行为识别方法或模型进行了系统阐述。行为识别的数据分为RGB模态数据、深度模态数据、骨骼模态数据以及融合模态数据。首先介绍了行为识别的主要过程和人类行为识别领域不同数据模态的公开数据集;然后根据数据模态分类,回顾了RGB模态、深度模态和骨骼模态下基于传统手工特征和深度学习的行为识别方法,以及多模态融合分类下RGB模态与深度模态融合的方法和其他模态融合的方法。传统手工特征法包括基于时空体积和时空兴趣点的方法(RGB模态)、基于运动变化和外观的方法(深度模态)以及基于骨骼特征的方法(骨骼模态)等;深度学习方法主要涉及卷积网络、图卷积网络和混合网络,重点介绍了其改进点、特点以及模型的创新点。基于不同模态的数据集分类进行不同行为识别技术的对比分析。通过类别内部和类别之间两个角度对比分析后,得出不同模态的优缺点与适用场景、手工特征法与深度学习法的区别和融合多模态的优势。最后,总结了行为识别技术当前面临的问题和挑战,并基于数据模态的角度提出了未来可行的研究方向和研究重点。关键词:计算机视觉;行为识别;深度学习;神经网络;多模态;模态融合357|235|2更新时间:2024-05-07 -
 摘要:研究表明在明确驱动基因后进行特异性靶向治疗,肺癌患者的中位生存期显著延长。而除高通量测序技术和荧光原位杂交等分子生物学技术外,影像基因组学的出现,也为肺腺癌分子分型预测提供了一种无创的新方法。本文对肺腺癌计算机断层扫描(computed tomography,CT)影像分子分型的研究进展进行综述。首先,介绍肺腺癌分子分型的研究背景及肺腺癌主要的基因突变类型;然后,重点介绍两种主要的研究方法,即CT语义特征与肺腺癌分子亚型的相关性分析和基于机器学习的肺腺癌分子分型预测模型;最后,总结了该领域现阶段面临的主要问题,并对未来的研究方向做出展望。肺腺癌CT影像分子分型研究已经取得了一定成果,但仍存在很多问题。相关性分析与基于影像组学的预测模型研究由于样本各异且受过多人为干预,导致研究结果差异大,甚至有部分文献得到的结论截然相反。而基于深度学习的预测模型研究采用端到端的神经网络模型,人为参与极少,降低了研究难度,但尚处于起步阶段,构建的模型大多相对简单,远不能达到临床应用标准。今后的研究应聚焦于结合多种医学图像构建肺腺癌分子分型的大样本深度学习预测模型,同时结合临床信息、语义特征及影像组学特征,实现肺腺癌分子分型的无创、精准预测。关键词:非小细胞肺癌;腺癌;分子分型;影像基因组学;计算机断层扫描(CT)78|71|0更新时间:2024-05-07
摘要:研究表明在明确驱动基因后进行特异性靶向治疗,肺癌患者的中位生存期显著延长。而除高通量测序技术和荧光原位杂交等分子生物学技术外,影像基因组学的出现,也为肺腺癌分子分型预测提供了一种无创的新方法。本文对肺腺癌计算机断层扫描(computed tomography,CT)影像分子分型的研究进展进行综述。首先,介绍肺腺癌分子分型的研究背景及肺腺癌主要的基因突变类型;然后,重点介绍两种主要的研究方法,即CT语义特征与肺腺癌分子亚型的相关性分析和基于机器学习的肺腺癌分子分型预测模型;最后,总结了该领域现阶段面临的主要问题,并对未来的研究方向做出展望。肺腺癌CT影像分子分型研究已经取得了一定成果,但仍存在很多问题。相关性分析与基于影像组学的预测模型研究由于样本各异且受过多人为干预,导致研究结果差异大,甚至有部分文献得到的结论截然相反。而基于深度学习的预测模型研究采用端到端的神经网络模型,人为参与极少,降低了研究难度,但尚处于起步阶段,构建的模型大多相对简单,远不能达到临床应用标准。今后的研究应聚焦于结合多种医学图像构建肺腺癌分子分型的大样本深度学习预测模型,同时结合临床信息、语义特征及影像组学特征,实现肺腺癌分子分型的无创、精准预测。关键词:非小细胞肺癌;腺癌;分子分型;影像基因组学;计算机断层扫描(CT)78|71|0更新时间:2024-05-07
综述

-
 摘要:目的随着存在大量低性能电子设备的物联网系统迅速发展和普及,人们对低精度计算环境下安全高效的图像加密技术有着越来越迫切的需求。现有以混沌系统为代表的图像加密方法不仅加密速度普遍较低,而且在低精度计算环境下存在严重的安全缺陷,难以满足实际需求。针对上述问题,本文提出了一种基于素数模乘线性同余产生器的批图像加密方法,用以提升低精度环境下图像加密的效率和安全性。方法该方法的核心是构建一个能在低精度环境下有效运行的素数模乘线性同余产生器;将图像集均分为3组,并借助异或运算生成3幅组合图像;接着引入图像集的哈希值更新上述第3组图像;将更新后的组合图像作为上述产生器的输入,进而生成一个加密序列矩阵;基于加密序列矩阵对明文图像进行置乱和扩散,并使用异或运算生成密文图像;使用具有较高安全性的改进版2D-SCL(a new 2D hypher chaotic map based on the sine map,the chebysher map and a linear function)加密方法对加密序列矩阵进行加密。结果仿真结果表明,本文提出的批图像加密方法在计算精度为2-8的情况下不仅能抵御各类攻击,而且加密速度相较于对比加密方法有所提升。而对比加密方法在上述计算精度环境下存在不能抵御相应攻击的情况。结论本文提出的基于素数模乘线性同余产生器的批图像加密方法,不仅有效地解决了低计算精度环境下图像加密安全性低的问题,而且还大幅提升了图像的加密速度,为后续高效安全图像加密方法的研究提供了一个新的思路。关键词:批图像加密;低精度;安全性;加密速度;素数模乘线性同余产生器(PMMLCG)101|137|0更新时间:2024-05-07
摘要:目的随着存在大量低性能电子设备的物联网系统迅速发展和普及,人们对低精度计算环境下安全高效的图像加密技术有着越来越迫切的需求。现有以混沌系统为代表的图像加密方法不仅加密速度普遍较低,而且在低精度计算环境下存在严重的安全缺陷,难以满足实际需求。针对上述问题,本文提出了一种基于素数模乘线性同余产生器的批图像加密方法,用以提升低精度环境下图像加密的效率和安全性。方法该方法的核心是构建一个能在低精度环境下有效运行的素数模乘线性同余产生器;将图像集均分为3组,并借助异或运算生成3幅组合图像;接着引入图像集的哈希值更新上述第3组图像;将更新后的组合图像作为上述产生器的输入,进而生成一个加密序列矩阵;基于加密序列矩阵对明文图像进行置乱和扩散,并使用异或运算生成密文图像;使用具有较高安全性的改进版2D-SCL(a new 2D hypher chaotic map based on the sine map,the chebysher map and a linear function)加密方法对加密序列矩阵进行加密。结果仿真结果表明,本文提出的批图像加密方法在计算精度为2-8的情况下不仅能抵御各类攻击,而且加密速度相较于对比加密方法有所提升。而对比加密方法在上述计算精度环境下存在不能抵御相应攻击的情况。结论本文提出的基于素数模乘线性同余产生器的批图像加密方法,不仅有效地解决了低计算精度环境下图像加密安全性低的问题,而且还大幅提升了图像的加密速度,为后续高效安全图像加密方法的研究提供了一个新的思路。关键词:批图像加密;低精度;安全性;加密速度;素数模乘线性同余产生器(PMMLCG)101|137|0更新时间:2024-05-07 -
 摘要:目的基于清晰图像训练的深度神经网络检测模型因为成像差异导致的域偏移问题使其难以直接泛化到水下场景。为了有效解决清晰图像和水下图像的特征偏移问题,提出一种即插即用的特征增强模块(feature de-drifting module Unet,FDM-Unet)。方法首先提出一种基于成像模型的水下图像合成方法,从真实水下图像中估计色偏颜色和亮度,从清晰图像估计得到场景深度信息,根据改进的光照散射模型将清晰图像合成为具有真实感的水下图像。然后,借鉴U-Net结构,设计了一个轻量的特征增强模块FDM-Unet。在清晰图像和对应的合成水下图像对上,采用常见的清晰图像上预训练的检测器,提取它们对应的浅层特征,将水下图像对应的退化浅层特征输入FDM-Unet进行增强,并将增强之后的特征与清晰图像对应的特征计算均方误差(mean-square error,MSE)损失,从而监督FDM-Unet进行训练。最后,将训练好的FDM-Unet直接插入上述预训练的检测器的浅层位置,不需要对网络进行重新训练或微调,即可以直接处理水下图像目标检测。结果实验结果表明,FDM-Unet在PASCAL VOC 2007(pattern analysis,statistical modeling and computational learning visual object classes 2007)合成水下图像测试集上,针对YOLO v3(you only look once v3)和SSD(single shot multibox detector)预训练检测器,检测精度mAP(mean average precision)分别提高了8.58%和7.71%;在真实水下数据集URPC19(underwater robot professional contest 19)上,使用不同比例的数据进行微调,相比YOLO v3和SSD,mAP分别提高了4.4%~10.6%和3.9%~10.7%。结论本文提出的特征增强模块FDM-Unet以增加极小的参数量和计算量为代价,不仅能直接提升预训练检测器在合成水下图像的检测精度,也能在提升在真实水下图像上微调后的检测精度。关键词:卷积神经网络(CNN);目标检测;特征增强;成像模型;图像合成261|192|2更新时间:2024-05-07
摘要:目的基于清晰图像训练的深度神经网络检测模型因为成像差异导致的域偏移问题使其难以直接泛化到水下场景。为了有效解决清晰图像和水下图像的特征偏移问题,提出一种即插即用的特征增强模块(feature de-drifting module Unet,FDM-Unet)。方法首先提出一种基于成像模型的水下图像合成方法,从真实水下图像中估计色偏颜色和亮度,从清晰图像估计得到场景深度信息,根据改进的光照散射模型将清晰图像合成为具有真实感的水下图像。然后,借鉴U-Net结构,设计了一个轻量的特征增强模块FDM-Unet。在清晰图像和对应的合成水下图像对上,采用常见的清晰图像上预训练的检测器,提取它们对应的浅层特征,将水下图像对应的退化浅层特征输入FDM-Unet进行增强,并将增强之后的特征与清晰图像对应的特征计算均方误差(mean-square error,MSE)损失,从而监督FDM-Unet进行训练。最后,将训练好的FDM-Unet直接插入上述预训练的检测器的浅层位置,不需要对网络进行重新训练或微调,即可以直接处理水下图像目标检测。结果实验结果表明,FDM-Unet在PASCAL VOC 2007(pattern analysis,statistical modeling and computational learning visual object classes 2007)合成水下图像测试集上,针对YOLO v3(you only look once v3)和SSD(single shot multibox detector)预训练检测器,检测精度mAP(mean average precision)分别提高了8.58%和7.71%;在真实水下数据集URPC19(underwater robot professional contest 19)上,使用不同比例的数据进行微调,相比YOLO v3和SSD,mAP分别提高了4.4%~10.6%和3.9%~10.7%。结论本文提出的特征增强模块FDM-Unet以增加极小的参数量和计算量为代价,不仅能直接提升预训练检测器在合成水下图像的检测精度,也能在提升在真实水下图像上微调后的检测精度。关键词:卷积神经网络(CNN);目标检测;特征增强;成像模型;图像合成261|192|2更新时间:2024-05-07
图像处理和编码
-
 摘要:目的图像美学属性评价可以提供丰富的美学要素,极大地增强图像美学的可解释性。然而现有的图像美学属性评价方法并没有考虑到图像场景类别的多样性,导致评价任务的性能不够理想。为此,本文提出一种深度多任务卷积神经网络(multi task convolutional neural network,MTCNN)模型,利用场景信息辅助图像的美学属性预测。方法本文模型由双流深度残差网络组成,其中一支网络基于场景预测任务进行训练,以提取图像的场景特征;另一支网络提取图像的美学特征。然后融合这两种特征,通过多任务学习的方式进行训练,以预测图像的美学属性和整体美学分数。结果为了验证模型的有效性,在图像美学属性数据集(aesthetics and attributes database,AADB)上进行实验验证。结果显示,在斯皮尔曼相关系数(Spearman rank-order correlation coefficient,SRCC)指标上,本文方法各美学属性预测的结果较其他方法的最优值平均提升了6.1%,本文方法整体美学分数预测的结果较其他方法的最优值提升了6.2%。结论提出的图像美学属性预测方法,挖掘了图像中的场景语义与美学属性的耦合关系,有效地提高了图像美学属性及美学分数预测的准确率。关键词:图像美学评价;美学属性;深度卷积网络;多任务学习;场景分类167|441|0更新时间:2024-05-07
摘要:目的图像美学属性评价可以提供丰富的美学要素,极大地增强图像美学的可解释性。然而现有的图像美学属性评价方法并没有考虑到图像场景类别的多样性,导致评价任务的性能不够理想。为此,本文提出一种深度多任务卷积神经网络(multi task convolutional neural network,MTCNN)模型,利用场景信息辅助图像的美学属性预测。方法本文模型由双流深度残差网络组成,其中一支网络基于场景预测任务进行训练,以提取图像的场景特征;另一支网络提取图像的美学特征。然后融合这两种特征,通过多任务学习的方式进行训练,以预测图像的美学属性和整体美学分数。结果为了验证模型的有效性,在图像美学属性数据集(aesthetics and attributes database,AADB)上进行实验验证。结果显示,在斯皮尔曼相关系数(Spearman rank-order correlation coefficient,SRCC)指标上,本文方法各美学属性预测的结果较其他方法的最优值平均提升了6.1%,本文方法整体美学分数预测的结果较其他方法的最优值提升了6.2%。结论提出的图像美学属性预测方法,挖掘了图像中的场景语义与美学属性的耦合关系,有效地提高了图像美学属性及美学分数预测的准确率。关键词:图像美学评价;美学属性;深度卷积网络;多任务学习;场景分类167|441|0更新时间:2024-05-07 -
 摘要:目的视频异常行为检测是当前智能监控技术的研究热点之一,在社会安防领域具有重要应用。如何通过有效地对视频空间维度信息和时间维度信息建模来提高异常检测的精度仍是目前研究的难点。由于结构优势,生成对抗网络目前广泛应用于视频异常检测任务。针对传统生成对抗网络时空特征利用率低和检测效果差等问题,本文提出一种融合门控自注意力机制的生成对抗网络进行视频异常行为检测。方法在生成对抗网络的生成网络U-net部分引入门控自注意力机制,逐层对采样过程中的特征图进行权重分配,融合U-net网络和门控自注意力机制的性能优势,抑制输入视频帧中与异常检测任务不相关背景区域的特征表达,突出任务中不同目标对象的相关特征表达,更有效地针对时空维度信息进行建模。采用LiteFlownet网络对视频流中的运动信息进行提取,以保证视频序列之间的连续性。同时,加入强度损失函数、梯度损失函数和运动损失函数加强模型检测的稳定性,以实现对视频异常行为的检测。结果在CUHK(Chinese University of Hong Kong)Avenue、UCSD(University of California,San Diego)Ped1和UCSD Ped2等视频异常事件数据集上进行实验。在CUHK Avenue数据集中,本文方法的AUC(area under curve)为87.2%,比同类方法高2.3%;在UCSD Ped1和UCSD Ped2数据集中,本文方法的AUC值均高于同类其他方法。同时,设计了4个消融实验并对实验结果进行对比分析,本文方法具有更高的AUC值。结论实验结果表明,本文方法更适合视频异常检测任务,有效提高了异常行为检测任务模型的稳定性和准确率,且采用视频序列帧间运动信息能够显著提升异常行为检测性能。关键词:视频异常检测;生成对抗网络(GAN);U-Net;门控自注意力机制;光流网络178|1337|2更新时间:2024-05-07
摘要:目的视频异常行为检测是当前智能监控技术的研究热点之一,在社会安防领域具有重要应用。如何通过有效地对视频空间维度信息和时间维度信息建模来提高异常检测的精度仍是目前研究的难点。由于结构优势,生成对抗网络目前广泛应用于视频异常检测任务。针对传统生成对抗网络时空特征利用率低和检测效果差等问题,本文提出一种融合门控自注意力机制的生成对抗网络进行视频异常行为检测。方法在生成对抗网络的生成网络U-net部分引入门控自注意力机制,逐层对采样过程中的特征图进行权重分配,融合U-net网络和门控自注意力机制的性能优势,抑制输入视频帧中与异常检测任务不相关背景区域的特征表达,突出任务中不同目标对象的相关特征表达,更有效地针对时空维度信息进行建模。采用LiteFlownet网络对视频流中的运动信息进行提取,以保证视频序列之间的连续性。同时,加入强度损失函数、梯度损失函数和运动损失函数加强模型检测的稳定性,以实现对视频异常行为的检测。结果在CUHK(Chinese University of Hong Kong)Avenue、UCSD(University of California,San Diego)Ped1和UCSD Ped2等视频异常事件数据集上进行实验。在CUHK Avenue数据集中,本文方法的AUC(area under curve)为87.2%,比同类方法高2.3%;在UCSD Ped1和UCSD Ped2数据集中,本文方法的AUC值均高于同类其他方法。同时,设计了4个消融实验并对实验结果进行对比分析,本文方法具有更高的AUC值。结论实验结果表明,本文方法更适合视频异常检测任务,有效提高了异常行为检测任务模型的稳定性和准确率,且采用视频序列帧间运动信息能够显著提升异常行为检测性能。关键词:视频异常检测;生成对抗网络(GAN);U-Net;门控自注意力机制;光流网络178|1337|2更新时间:2024-05-07 -
 摘要:目的螺栓销钉是输电线路中至关重要的连接部件,螺栓的销钉缺失会导致输电线路中关键部件解体,甚至造成大规模停电事故。螺栓缺销检测属于小目标检测问题,由于其尺寸较小且背景复杂,现有的目标检测算法针对螺栓缺销的检测效果较差。为了提升输电线路中螺栓缺销的检测效果,本文以SSD(single shot multibox detector)算法为基础,提出了基于隔级交叉自适应特征融合的输电线路螺栓缺销检测方法。方法在建立了螺栓缺销故障检测数据集后,首先在SSD网络中加入隔级交叉特征金字塔结构,增强特征图的视觉信息和语义信息;其次,引入自适应特征融合机制进行特征图二次融合,不同尺度的特征图以自适应学习到的权重进行加权特征融合,有效提升螺栓缺销的检测效果;最后,对原始的SSD网络中的先验框尺寸进行调整,使其大小和长宽比更加适合螺栓目标。结果实验结果表明,本文方法在正常螺栓类的检测精度达到87.93%,螺栓缺销类的检测精度达到89.15%。与原始的SSD网络相比,检测精度分别提升了2.71%和3.99%。结论本文方法针对螺栓缺销故障的检测精度较高,较原始SSD网络的检测精度有明显提升,与其他方法相比也有一定优势。为后续进一步提升螺栓缺销的检测精度以及对输电线路中其他部件的识别检测工作奠定了良好的基础。关键词:螺栓;缺销;单阶段框检测(SSD);隔级交叉特征金字塔;自适应特征融合;先验框优化95|168|1更新时间:2024-05-07
摘要:目的螺栓销钉是输电线路中至关重要的连接部件,螺栓的销钉缺失会导致输电线路中关键部件解体,甚至造成大规模停电事故。螺栓缺销检测属于小目标检测问题,由于其尺寸较小且背景复杂,现有的目标检测算法针对螺栓缺销的检测效果较差。为了提升输电线路中螺栓缺销的检测效果,本文以SSD(single shot multibox detector)算法为基础,提出了基于隔级交叉自适应特征融合的输电线路螺栓缺销检测方法。方法在建立了螺栓缺销故障检测数据集后,首先在SSD网络中加入隔级交叉特征金字塔结构,增强特征图的视觉信息和语义信息;其次,引入自适应特征融合机制进行特征图二次融合,不同尺度的特征图以自适应学习到的权重进行加权特征融合,有效提升螺栓缺销的检测效果;最后,对原始的SSD网络中的先验框尺寸进行调整,使其大小和长宽比更加适合螺栓目标。结果实验结果表明,本文方法在正常螺栓类的检测精度达到87.93%,螺栓缺销类的检测精度达到89.15%。与原始的SSD网络相比,检测精度分别提升了2.71%和3.99%。结论本文方法针对螺栓缺销故障的检测精度较高,较原始SSD网络的检测精度有明显提升,与其他方法相比也有一定优势。为后续进一步提升螺栓缺销的检测精度以及对输电线路中其他部件的识别检测工作奠定了良好的基础。关键词:螺栓;缺销;单阶段框检测(SSD);隔级交叉特征金字塔;自适应特征融合;先验框优化95|168|1更新时间:2024-05-07 -
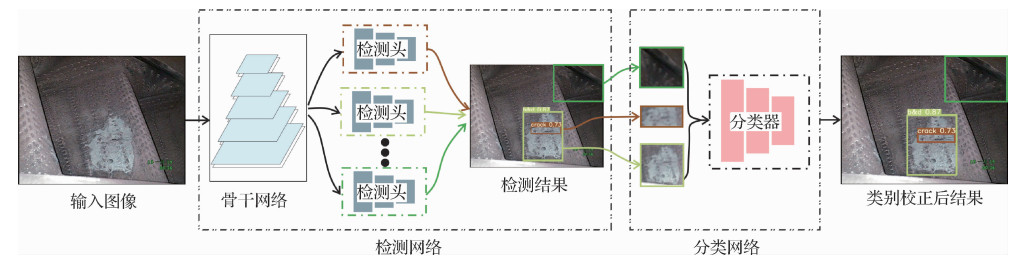 摘要:目的基于深度学习的飞机发动机损伤检测是计算机视觉中的一个新问题。当前的目标检测方法没有考虑飞机发动机损伤检测问题的特殊性,将其直接用于发动机损伤检测的效果较差,无法满足实际使用的要求。为了提高损伤检测的精度,提出检测器和分类器级联的发动机损伤检测方法:Cascade-YOLO(cascade-you only look once)。方法首先,将损伤区域作为正例、正常区域作为负例,训练损伤检测网络,初始化特征提取网络的网络参数;其次,固定特征提取网络,使用多个检测头分别检测不同类型的发动机损伤,每个检测头独立进行检测,从而提高单类别损伤的检测召回率;最后,对于置信度在一定范围内的损伤,训练一个多分类判别器,用于校正检测头输出的损伤类别。基于检测结果,利用语义分割分支可以准确分割出损伤区域。结果构建了一个具有1 305幅且包含9种损伤类型的孔探图像数据集,并在该数据集上量化、对比了6个先进的目标检测方法。本文方法的平均精确率(mean average precision,MAP)、准确率、召回率相比单阶段检测器YOLO v5分别提高了2.49%、12.59%和12.46%。结论本文提出的检测器和分类器级联的发动机损伤检测模型通过对每类缺陷针对性地训练单独的检测头,充分考虑了不同缺陷间的分布差异,在提高召回率的同时提升了检测精度。同时该模型易于扩展类别,并可以快速应用于分割任务,符合实际的应用需求。关键词:损伤检测;孔探图像;级联检测;飞机发动机;YOLO(you only look once)89|119|2更新时间:2024-05-07
摘要:目的基于深度学习的飞机发动机损伤检测是计算机视觉中的一个新问题。当前的目标检测方法没有考虑飞机发动机损伤检测问题的特殊性,将其直接用于发动机损伤检测的效果较差,无法满足实际使用的要求。为了提高损伤检测的精度,提出检测器和分类器级联的发动机损伤检测方法:Cascade-YOLO(cascade-you only look once)。方法首先,将损伤区域作为正例、正常区域作为负例,训练损伤检测网络,初始化特征提取网络的网络参数;其次,固定特征提取网络,使用多个检测头分别检测不同类型的发动机损伤,每个检测头独立进行检测,从而提高单类别损伤的检测召回率;最后,对于置信度在一定范围内的损伤,训练一个多分类判别器,用于校正检测头输出的损伤类别。基于检测结果,利用语义分割分支可以准确分割出损伤区域。结果构建了一个具有1 305幅且包含9种损伤类型的孔探图像数据集,并在该数据集上量化、对比了6个先进的目标检测方法。本文方法的平均精确率(mean average precision,MAP)、准确率、召回率相比单阶段检测器YOLO v5分别提高了2.49%、12.59%和12.46%。结论本文提出的检测器和分类器级联的发动机损伤检测模型通过对每类缺陷针对性地训练单独的检测头,充分考虑了不同缺陷间的分布差异,在提高召回率的同时提升了检测精度。同时该模型易于扩展类别,并可以快速应用于分割任务,符合实际的应用需求。关键词:损伤检测;孔探图像;级联检测;飞机发动机;YOLO(you only look once)89|119|2更新时间:2024-05-07 -
 摘要:目的现有的显著对象检测模型能够很好地定位显著对象,但是在获得完整均匀的对象和保留清晰边缘的任务上存在不足。为了得到整体均匀和边缘清晰的显著对象,本文提出了结合语义辅助和边缘特征的显著对象检测模型。方法模型利用设计的语义辅助特征融合模块优化骨干网的侧向输出特征,每层特征通过语义辅助选择性融合相邻的低层特征,获得足够的结构信息并增强显著区域的特征强度,进而检测出整体均匀的显著对象。通过设计的边缘分支网络以及显著对象特征得到精确的边缘特征,将边缘特征融合到显著对象特征中,加强特征中显著对象边缘区域的可区分性,以便检测出清晰的边缘。同时,本文设计了一个双向多尺度模块来提取网络中的多尺度信息。结果在4种常用的数据集ECSSD(extended complex scene saliency dataset)、DUT-O(Dalian University of Technology and OMRON Corporation)、HKU-IS和DUTS上与12种较流行的显著模型进行比较,本文模型的最大F值度量(max F-measure,MaxF)和平均绝对误差(mean absolution error,MAE)分别是0.940、0.795、0.929、0.870和0.041、0.057、0.034、0.043。从实验结果看,本文方法得到的显著图更接近真值图,在MaxF和MAE上取得最佳性能的次数多于其他12种方法。结论本文提出的结合语义辅助和边缘特征的显著对象检测模型十分有效。语义辅助特征融合和边缘特征的引入使检测出的显著对象更为完整均匀,对象的边缘区分性也更强,多尺度特征提取进一步改善了显著对象的检测效果。关键词:显著对象检测;全卷积神经网络;语义辅助;边缘特征融合;多尺度提取71|106|0更新时间:2024-05-07
摘要:目的现有的显著对象检测模型能够很好地定位显著对象,但是在获得完整均匀的对象和保留清晰边缘的任务上存在不足。为了得到整体均匀和边缘清晰的显著对象,本文提出了结合语义辅助和边缘特征的显著对象检测模型。方法模型利用设计的语义辅助特征融合模块优化骨干网的侧向输出特征,每层特征通过语义辅助选择性融合相邻的低层特征,获得足够的结构信息并增强显著区域的特征强度,进而检测出整体均匀的显著对象。通过设计的边缘分支网络以及显著对象特征得到精确的边缘特征,将边缘特征融合到显著对象特征中,加强特征中显著对象边缘区域的可区分性,以便检测出清晰的边缘。同时,本文设计了一个双向多尺度模块来提取网络中的多尺度信息。结果在4种常用的数据集ECSSD(extended complex scene saliency dataset)、DUT-O(Dalian University of Technology and OMRON Corporation)、HKU-IS和DUTS上与12种较流行的显著模型进行比较,本文模型的最大F值度量(max F-measure,MaxF)和平均绝对误差(mean absolution error,MAE)分别是0.940、0.795、0.929、0.870和0.041、0.057、0.034、0.043。从实验结果看,本文方法得到的显著图更接近真值图,在MaxF和MAE上取得最佳性能的次数多于其他12种方法。结论本文提出的结合语义辅助和边缘特征的显著对象检测模型十分有效。语义辅助特征融合和边缘特征的引入使检测出的显著对象更为完整均匀,对象的边缘区分性也更强,多尺度特征提取进一步改善了显著对象的检测效果。关键词:显著对象检测;全卷积神经网络;语义辅助;边缘特征融合;多尺度提取71|106|0更新时间:2024-05-07 -
 摘要:目的多目标跟踪与分割是计算机视觉领域一个重要的研究方向。现有方法多是借鉴多目标跟踪领域先检测然后进行跟踪与分割的思路,这类方法对重要特征信息的关注不足,难以处理目标遮挡等问题。为了解决上述问题,本文提出一种基于时空特征融合的多目标跟踪与分割模型,利用空间三坐标注意力模块和时间压缩自注意力模块选择出显著特征,以此达到优异的多目标跟踪与分割性能。方法本文网络由2D编码器和3D解码器构成,首先将多幅连续帧图像输入到2D编码层,提取出不同分辨率的图像特征,然后从低分辨率的特征开始通过空间三坐标注意力模块得到重要的空间特征,通过时间压缩自注意力模块获得含有关键帧信息的时间特征,再将两者与原始特征融合,然后与较高分辨率的特征共同输入3D卷积层,反复聚合不同层次的特征,以此得到融合多次的既有关键时间信息又有重要空间信息的特征,最后得到跟踪和分割结果。结果实验在YouTube-VIS(YouTube video instance segmentation)和KITTI MOTS(multi-object tracking and segmentation)两个数据集上进行定量评估。在YouTube-VIS数据集中,相比于性能第2的CompFeat模型,本文方法的AP(average precision)值提高了0.2%。在KITTI MOTS数据集中,相比于性能第2的STEm-Seg模型,在汽车类上,本文方法的ID switch指标减少了9;在行人类上,本文方法的sMOTSA(soft multi-object tracking and segmentation accuracy)、MOTSA(multi-object tracking and segmentation accuracy)和MOTSP(multi-object tracking and segmentation precision)分别提高了0.7%、0.6%和0.9%,ID switch指标减少了1。在KITTI MOTS数据集中进行消融实验,验证空间三坐标注意力模块和时间压缩自注意力模块的有效性,消融实验结果表明提出的算法改善了多目标跟踪与分割的效果。结论提出的多目标跟踪与分割模型充分挖掘多帧图像之间的特征信息,使多目标跟踪与分割的结果更加精准。关键词:深度学习;多目标跟踪与分割(MOTS);3D卷积神经网络;特征融合;注意力机制100|181|1更新时间:2024-05-07
摘要:目的多目标跟踪与分割是计算机视觉领域一个重要的研究方向。现有方法多是借鉴多目标跟踪领域先检测然后进行跟踪与分割的思路,这类方法对重要特征信息的关注不足,难以处理目标遮挡等问题。为了解决上述问题,本文提出一种基于时空特征融合的多目标跟踪与分割模型,利用空间三坐标注意力模块和时间压缩自注意力模块选择出显著特征,以此达到优异的多目标跟踪与分割性能。方法本文网络由2D编码器和3D解码器构成,首先将多幅连续帧图像输入到2D编码层,提取出不同分辨率的图像特征,然后从低分辨率的特征开始通过空间三坐标注意力模块得到重要的空间特征,通过时间压缩自注意力模块获得含有关键帧信息的时间特征,再将两者与原始特征融合,然后与较高分辨率的特征共同输入3D卷积层,反复聚合不同层次的特征,以此得到融合多次的既有关键时间信息又有重要空间信息的特征,最后得到跟踪和分割结果。结果实验在YouTube-VIS(YouTube video instance segmentation)和KITTI MOTS(multi-object tracking and segmentation)两个数据集上进行定量评估。在YouTube-VIS数据集中,相比于性能第2的CompFeat模型,本文方法的AP(average precision)值提高了0.2%。在KITTI MOTS数据集中,相比于性能第2的STEm-Seg模型,在汽车类上,本文方法的ID switch指标减少了9;在行人类上,本文方法的sMOTSA(soft multi-object tracking and segmentation accuracy)、MOTSA(multi-object tracking and segmentation accuracy)和MOTSP(multi-object tracking and segmentation precision)分别提高了0.7%、0.6%和0.9%,ID switch指标减少了1。在KITTI MOTS数据集中进行消融实验,验证空间三坐标注意力模块和时间压缩自注意力模块的有效性,消融实验结果表明提出的算法改善了多目标跟踪与分割的效果。结论提出的多目标跟踪与分割模型充分挖掘多帧图像之间的特征信息,使多目标跟踪与分割的结果更加精准。关键词:深度学习;多目标跟踪与分割(MOTS);3D卷积神经网络;特征融合;注意力机制100|181|1更新时间:2024-05-07 -
 摘要:目的高精度图像分割是生物医学图像处理中的一个重要问题。在磁共振成像过程中,噪声和强度不均匀很大程度影响图像分割的精度。因此,提出了一种基于相异性准则熵率超像素的多模态高精度图像分割网络。方法采用熵率超像素分割算法对多模态图像进行预分割得到超像素块,提出新的融合算法对其重新编号,建立超像素图,该图中的每一个超像素块构成无向图的一个结点;利用每个结点的灰度值提取特征向量,通过相异性权重判断结点间的相关性,构建相邻结点的特征序列;将特征序列作为双向长短期记忆模型(bi-directional long short-term memory,BiLSTM)的输入,经过训练和测试,得到最终的分割结果。结果本文方法在BrainWeb、MRBrainS和BraTS2017数据集上与主流算法进行了对比。在BrainWeb数据集上,本文方法的像素精度(pixel accuracy,PA)和骰子相似系数(Dice similarity coefficient,DSC)分别为98.93%、97.71%,比LSTM-MA(LSTM method with multi-modality and adjacency constraint)提升了1.28%、2.8%。在MRBrainS数据集上,本文方法的PA为92.46%,DSC为84.74%,比LSTM-MA提升了0.63%、1.44%。在BraTS2017数据集上,本文方法的PA和DSC上分别为98.80%,99.47%,也取得了满意的分割结果。结论提出的分割网络在多模态图像分割应用中,获得了较好的分割结果,对图像强度不均匀和噪声有较好的鲁棒性。关键词:图像分割;多模态;超像素;双向长短期记忆模型(BiLSTM);噪声鲁棒性107|113|0更新时间:2024-05-07
摘要:目的高精度图像分割是生物医学图像处理中的一个重要问题。在磁共振成像过程中,噪声和强度不均匀很大程度影响图像分割的精度。因此,提出了一种基于相异性准则熵率超像素的多模态高精度图像分割网络。方法采用熵率超像素分割算法对多模态图像进行预分割得到超像素块,提出新的融合算法对其重新编号,建立超像素图,该图中的每一个超像素块构成无向图的一个结点;利用每个结点的灰度值提取特征向量,通过相异性权重判断结点间的相关性,构建相邻结点的特征序列;将特征序列作为双向长短期记忆模型(bi-directional long short-term memory,BiLSTM)的输入,经过训练和测试,得到最终的分割结果。结果本文方法在BrainWeb、MRBrainS和BraTS2017数据集上与主流算法进行了对比。在BrainWeb数据集上,本文方法的像素精度(pixel accuracy,PA)和骰子相似系数(Dice similarity coefficient,DSC)分别为98.93%、97.71%,比LSTM-MA(LSTM method with multi-modality and adjacency constraint)提升了1.28%、2.8%。在MRBrainS数据集上,本文方法的PA为92.46%,DSC为84.74%,比LSTM-MA提升了0.63%、1.44%。在BraTS2017数据集上,本文方法的PA和DSC上分别为98.80%,99.47%,也取得了满意的分割结果。结论提出的分割网络在多模态图像分割应用中,获得了较好的分割结果,对图像强度不均匀和噪声有较好的鲁棒性。关键词:图像分割;多模态;超像素;双向长短期记忆模型(BiLSTM);噪声鲁棒性107|113|0更新时间:2024-05-07 -
 摘要:目的为了满足羽毛球教练针对球员单打视频中的动作进行辅助分析,以及用户欣赏每种击球动作的视频集锦等多元化需求,提出一种在提取的羽毛球视频片段中对控球球员动作进行时域定位和分类的方法。方法在羽毛球视频片段上基于姿态估计方法检测球员执拍手臂,并根据手臂的挥动幅度变化特点定位击球动作时域,根据定位结果生成元视频。将通道—空间注意力机制引入时序分段网络,并通过网络训练实现对羽毛球动作的分类,分类结果包括正手击球、反手击球、头顶击球和挑球4种常见类型,同时基于图像形态学处理方法将头顶击球判别为高远球或杀球。结果实验结果表明,本文对羽毛球视频片段中动作时域定位的交并比(intersection over union,IoU)值为82.6%,对羽毛球每种动作类别预测的AUC(area under curve)值均在0.98以上,平均召回率与平均查准率分别为91.2%和91.6%,能够有效针对羽毛球视频片段中的击球动作进行定位与分类,较好地实现对羽毛球动作的识别。结论本文提出的基于羽毛球视频片段的动作识别方法,兼顾了羽毛球动作时域定位和动作分类,使羽毛球动作识别过程更为智能,对体育视频分析提供了重要的应用价值。关键词:姿态估计;元视频;羽毛球动作定位;注意力机制-时序分段网络(CBAM-TSN);形态学处理;羽毛球动作识别352|790|2更新时间:2024-05-07
摘要:目的为了满足羽毛球教练针对球员单打视频中的动作进行辅助分析,以及用户欣赏每种击球动作的视频集锦等多元化需求,提出一种在提取的羽毛球视频片段中对控球球员动作进行时域定位和分类的方法。方法在羽毛球视频片段上基于姿态估计方法检测球员执拍手臂,并根据手臂的挥动幅度变化特点定位击球动作时域,根据定位结果生成元视频。将通道—空间注意力机制引入时序分段网络,并通过网络训练实现对羽毛球动作的分类,分类结果包括正手击球、反手击球、头顶击球和挑球4种常见类型,同时基于图像形态学处理方法将头顶击球判别为高远球或杀球。结果实验结果表明,本文对羽毛球视频片段中动作时域定位的交并比(intersection over union,IoU)值为82.6%,对羽毛球每种动作类别预测的AUC(area under curve)值均在0.98以上,平均召回率与平均查准率分别为91.2%和91.6%,能够有效针对羽毛球视频片段中的击球动作进行定位与分类,较好地实现对羽毛球动作的识别。结论本文提出的基于羽毛球视频片段的动作识别方法,兼顾了羽毛球动作时域定位和动作分类,使羽毛球动作识别过程更为智能,对体育视频分析提供了重要的应用价值。关键词:姿态估计;元视频;羽毛球动作定位;注意力机制-时序分段网络(CBAM-TSN);形态学处理;羽毛球动作识别352|790|2更新时间:2024-05-07 -
 摘要:目的抑郁症是一种常见的情感性精神障碍,会带来诸多情绪和身体问题。在实践中,临床医生主要通过面对面访谈并结合自身经验评估抑郁症的严重程度。这种诊断方式具有较强的主观性,整个过程比较耗时,且易造成误诊、漏诊。为了客观便捷地评估抑郁症的严重程度,本文围绕面部图像研究深度特征提取及其在抑郁症自动识别中的应用,基于人脸图像的全局和局部特征,构建一种融合通道层注意力机制的多支路卷积网络模型,进行抑郁症严重程度的自动识别。方法首先从原始视频提取图像,使用多任务级联卷积神经网络检测人脸关键点。在对齐后分别裁剪出整幅人脸图像和眼睛、嘴部区域图像,然后将它们分别送入与通道层注意力机制结合的深度卷积神经网络以提取全局特征和局部特征。在训练时,将训练图像进行标准化预处理,并通过翻转、裁剪等操作增强数据。在特征融合层将3个支路网络提取的特征拼接在一起,最后输出抑郁症严重程度的分值。结果在AVEC 2013(The Continuous Audio/Visual Emotion and Depression Recognition Challenge)抑郁症数据库上平均绝对误差为6.74、均方根误差为8.70,相较于Baseline分别降低4.14和4.91;在AVEC2014抑郁症数据库上平均绝对误差和均方根误差分别为6.56和8.56,相较于Baseline分别降低2.30和2.30。同时,相较于其他抑郁症识别方法,本文方法取得了最低的平均绝对误差和均方根误差。结论本文方法能够以端到端的形式实现抑郁症的自动识别,将特征提取和抑郁症严重程度识别在统一框架下进行和调优,学习到的多种视觉特征更加具有鉴别性,实验结果表明了该算法的有效性和可行性。关键词:抑郁症识别;通道层注意力机制;深度卷积神经网络;特征融合;空间权重120|180|2更新时间:2024-05-07
摘要:目的抑郁症是一种常见的情感性精神障碍,会带来诸多情绪和身体问题。在实践中,临床医生主要通过面对面访谈并结合自身经验评估抑郁症的严重程度。这种诊断方式具有较强的主观性,整个过程比较耗时,且易造成误诊、漏诊。为了客观便捷地评估抑郁症的严重程度,本文围绕面部图像研究深度特征提取及其在抑郁症自动识别中的应用,基于人脸图像的全局和局部特征,构建一种融合通道层注意力机制的多支路卷积网络模型,进行抑郁症严重程度的自动识别。方法首先从原始视频提取图像,使用多任务级联卷积神经网络检测人脸关键点。在对齐后分别裁剪出整幅人脸图像和眼睛、嘴部区域图像,然后将它们分别送入与通道层注意力机制结合的深度卷积神经网络以提取全局特征和局部特征。在训练时,将训练图像进行标准化预处理,并通过翻转、裁剪等操作增强数据。在特征融合层将3个支路网络提取的特征拼接在一起,最后输出抑郁症严重程度的分值。结果在AVEC 2013(The Continuous Audio/Visual Emotion and Depression Recognition Challenge)抑郁症数据库上平均绝对误差为6.74、均方根误差为8.70,相较于Baseline分别降低4.14和4.91;在AVEC2014抑郁症数据库上平均绝对误差和均方根误差分别为6.56和8.56,相较于Baseline分别降低2.30和2.30。同时,相较于其他抑郁症识别方法,本文方法取得了最低的平均绝对误差和均方根误差。结论本文方法能够以端到端的形式实现抑郁症的自动识别,将特征提取和抑郁症严重程度识别在统一框架下进行和调优,学习到的多种视觉特征更加具有鉴别性,实验结果表明了该算法的有效性和可行性。关键词:抑郁症识别;通道层注意力机制;深度卷积神经网络;特征融合;空间权重120|180|2更新时间:2024-05-07 -
 摘要:目的图像的临界差异(just noticeable difference,JND)阈值估计对提升图像压缩比以及信息隐藏效率具有重要意义。亮度适应性和空域掩蔽效应是决定JND阈值大小的两大核心因素。现有的空域掩蔽模型主要考虑对比度掩蔽和纹理掩蔽两方面。然而,当前采用的纹理掩蔽模型不能有效地描述与纹理粗糙度相关的掩蔽效应对图像JND阈值的影响。对此,本文提出一种基于分形理论的JND阈值估计模型。方法首先,考虑到人眼视觉系统对具有粗糙表面的图像内容变化具有较低的分辨能力,通过经典的分形理论来计算图像局部区域的分形维数,并以此作为对纹理粗糙度的度量,并在此基础上提出一种新的基于纹理粗糙度的纹理掩蔽模型。然后,将提出的纹理掩蔽模型与传统的亮度适应性相结合估计得到初步的JND阈值。最后,考虑到人眼的视觉注意机制,进一步考虑图像内容的视觉显著性,对JND阈值进行感知一致性修正,估计得到最终的JND阈值。结果选取4种相关方法进行对比,结果表明,在注入相同甚至更多噪声的情况下,相较于对比方法中的最优结果,本文方法的平均VSI(visual saliency-induced index)和平均MOS(mean opinion score)在LIVE(Laboratory for Image & Video Engineering)图像库上分别提高了0.001 7和50%,在TID 2013(tampere image database 2013)图像库上分别提高了0.001 9和40%,在CSIQ(categorical subjective image quality)图像库上分别提高了0.001 3和9.1%,在基于VVC(versatile video coding)的JND图像库上分别提高了0.000 3和54.5%。此外,作为另一典型应用,开展了感知冗余去除实验。实验结果表明,在保持视觉质量的前提下,经过本文JND模型平滑处理后的图像,其JPEG压缩图像相比于原图直接JPEG压缩得到的图像能节省12.5%的字节数。结论本文提出的基于分形维数的纹理粗糙度能够有效刻画纹理掩蔽效应,构建的纹理掩蔽效应与传统的空域掩蔽效应相结合能够大幅提升图像JND阈值估计的准确性和可靠性。关键词:临界差异(JND);分形维数;纹理粗糙度;空域掩蔽;纹理掩蔽94|124|3更新时间:2024-05-07
摘要:目的图像的临界差异(just noticeable difference,JND)阈值估计对提升图像压缩比以及信息隐藏效率具有重要意义。亮度适应性和空域掩蔽效应是决定JND阈值大小的两大核心因素。现有的空域掩蔽模型主要考虑对比度掩蔽和纹理掩蔽两方面。然而,当前采用的纹理掩蔽模型不能有效地描述与纹理粗糙度相关的掩蔽效应对图像JND阈值的影响。对此,本文提出一种基于分形理论的JND阈值估计模型。方法首先,考虑到人眼视觉系统对具有粗糙表面的图像内容变化具有较低的分辨能力,通过经典的分形理论来计算图像局部区域的分形维数,并以此作为对纹理粗糙度的度量,并在此基础上提出一种新的基于纹理粗糙度的纹理掩蔽模型。然后,将提出的纹理掩蔽模型与传统的亮度适应性相结合估计得到初步的JND阈值。最后,考虑到人眼的视觉注意机制,进一步考虑图像内容的视觉显著性,对JND阈值进行感知一致性修正,估计得到最终的JND阈值。结果选取4种相关方法进行对比,结果表明,在注入相同甚至更多噪声的情况下,相较于对比方法中的最优结果,本文方法的平均VSI(visual saliency-induced index)和平均MOS(mean opinion score)在LIVE(Laboratory for Image & Video Engineering)图像库上分别提高了0.001 7和50%,在TID 2013(tampere image database 2013)图像库上分别提高了0.001 9和40%,在CSIQ(categorical subjective image quality)图像库上分别提高了0.001 3和9.1%,在基于VVC(versatile video coding)的JND图像库上分别提高了0.000 3和54.5%。此外,作为另一典型应用,开展了感知冗余去除实验。实验结果表明,在保持视觉质量的前提下,经过本文JND模型平滑处理后的图像,其JPEG压缩图像相比于原图直接JPEG压缩得到的图像能节省12.5%的字节数。结论本文提出的基于分形维数的纹理粗糙度能够有效刻画纹理掩蔽效应,构建的纹理掩蔽效应与传统的空域掩蔽效应相结合能够大幅提升图像JND阈值估计的准确性和可靠性。关键词:临界差异(JND);分形维数;纹理粗糙度;空域掩蔽;纹理掩蔽94|124|3更新时间:2024-05-07
图像分析和识别
-
 摘要:目的红外与可见光图像融合的目标是将红外图像与可见光图像的互补信息进行融合,增强源图像中的细节场景信息。然而现有的深度学习方法通常人为定义源图像中需要保留的特征,降低了热目标在融合图像中的显著性。此外,特征的多样性和难解释性限制了融合规则的发展,现有的融合规则难以对源图像的特征进行充分保留。针对这两个问题,本文提出了一种基于特有信息分离和质量引导的红外与可见光图像融合算法。方法本文提出了基于特有信息分离和质量引导融合策略的红外与可见光图像融合算法。设计基于神经网络的特有信息分离以将源图像客观地分解为共有信息和特有信息,对分解出的两部分分别使用特定的融合策略;设计权重编码器以学习质量引导的融合策略,将衡量融合图像质量的指标应用于提升融合策略的性能,权重编码器依据提取的特有信息生成对应权重。结果实验在公开数据集RoadScene上与6种领先的红外与可见光图像融合算法进行了对比。此外,基于质量引导的融合策略也与4种常见的融合策略进行了比较。定性结果表明,本文算法使融合图像具备更显著的热目标、更丰富的场景信息和更多的信息量。在熵、标准差、差异相关和、互信息及相关系数等指标上,相较于对比算法中的最优结果分别提升了0.508%、7.347%、14.849%、9.927%和1.281%。结论与具有领先水平的红外与可见光算法以及现有的融合策略相比,本文融合算法基于特有信息分离和质量引导,融合结果具有更丰富的场景信息、更强的对比度,视觉效果更符合人眼的视觉特征。关键词:图像融合;特有信息分离;质量引导;红外与可见光图像;深度学习123|2229|1更新时间:2024-05-07
摘要:目的红外与可见光图像融合的目标是将红外图像与可见光图像的互补信息进行融合,增强源图像中的细节场景信息。然而现有的深度学习方法通常人为定义源图像中需要保留的特征,降低了热目标在融合图像中的显著性。此外,特征的多样性和难解释性限制了融合规则的发展,现有的融合规则难以对源图像的特征进行充分保留。针对这两个问题,本文提出了一种基于特有信息分离和质量引导的红外与可见光图像融合算法。方法本文提出了基于特有信息分离和质量引导融合策略的红外与可见光图像融合算法。设计基于神经网络的特有信息分离以将源图像客观地分解为共有信息和特有信息,对分解出的两部分分别使用特定的融合策略;设计权重编码器以学习质量引导的融合策略,将衡量融合图像质量的指标应用于提升融合策略的性能,权重编码器依据提取的特有信息生成对应权重。结果实验在公开数据集RoadScene上与6种领先的红外与可见光图像融合算法进行了对比。此外,基于质量引导的融合策略也与4种常见的融合策略进行了比较。定性结果表明,本文算法使融合图像具备更显著的热目标、更丰富的场景信息和更多的信息量。在熵、标准差、差异相关和、互信息及相关系数等指标上,相较于对比算法中的最优结果分别提升了0.508%、7.347%、14.849%、9.927%和1.281%。结论与具有领先水平的红外与可见光算法以及现有的融合策略相比,本文融合算法基于特有信息分离和质量引导,融合结果具有更丰富的场景信息、更强的对比度,视觉效果更符合人眼的视觉特征。关键词:图像融合;特有信息分离;质量引导;红外与可见光图像;深度学习123|2229|1更新时间:2024-05-07 -
 摘要:目的多视角立体重建方法是3维视觉技术中的重要部分。相较于传统方法,基于深度学习的方法大幅减少重建所需时间,同时在重建完整性上也有所提升。然而,现有方法的特征提取效果一般和代价体之间的关联性较差,使得重建结果仍有可以提升的空间。针对以上问题,本文提出了一种双U-Net特征提取的多尺度代价体信息共享的多视角立体重建网络模型。方法为了获得输入图像更加完整和准确的特征信息,设计了一个双U-Net特征提取模块,同时按照3个不同尺度构成由粗到细的级联结构输出特征;在代价体正则化阶段,设计了一个多尺度代价体信息共享的预处理模块,对小尺度代价体内的信息进行分离并传给下层代价体进行融合,由粗到细地进行深度图估计,使重建精度和完整度有大幅提升。结果实验在DTU(Technical University of Denmark)数据集上与CasMVSNet相比,在准确度误差、完整度误差和整体性误差3个主要指标上分别提升约16.2%,6.5%和11.5%,相较于其他基于深度学习的方法更是有大幅度提升,并且在其他几个次要指标上也均有不同程度的提升。结论提出的双U-Net提取多尺度代价体信息共享的多视角立体重建网络在特征提取和代价体正则化阶段均取得了效果,在重建精度上相比于原模型和其他方法都有一定的提升,验证了该方法的真实有效。关键词:3维重建;深度学习;多视角立体网络;双U-Net网络;特征提取;代价体信息共享123|2332|3更新时间:2024-05-07
摘要:目的多视角立体重建方法是3维视觉技术中的重要部分。相较于传统方法,基于深度学习的方法大幅减少重建所需时间,同时在重建完整性上也有所提升。然而,现有方法的特征提取效果一般和代价体之间的关联性较差,使得重建结果仍有可以提升的空间。针对以上问题,本文提出了一种双U-Net特征提取的多尺度代价体信息共享的多视角立体重建网络模型。方法为了获得输入图像更加完整和准确的特征信息,设计了一个双U-Net特征提取模块,同时按照3个不同尺度构成由粗到细的级联结构输出特征;在代价体正则化阶段,设计了一个多尺度代价体信息共享的预处理模块,对小尺度代价体内的信息进行分离并传给下层代价体进行融合,由粗到细地进行深度图估计,使重建精度和完整度有大幅提升。结果实验在DTU(Technical University of Denmark)数据集上与CasMVSNet相比,在准确度误差、完整度误差和整体性误差3个主要指标上分别提升约16.2%,6.5%和11.5%,相较于其他基于深度学习的方法更是有大幅度提升,并且在其他几个次要指标上也均有不同程度的提升。结论提出的双U-Net提取多尺度代价体信息共享的多视角立体重建网络在特征提取和代价体正则化阶段均取得了效果,在重建精度上相比于原模型和其他方法都有一定的提升,验证了该方法的真实有效。关键词:3维重建;深度学习;多视角立体网络;双U-Net网络;特征提取;代价体信息共享123|2332|3更新时间:2024-05-07 -
 摘要:目的由于缺乏图像与目标语言域的成对数据,现有的跨语言描述方法都是基于轴(源)语言转化为目标语言,由于转化过程中的语义噪音干扰,生成的句子存在不够流畅以及与图像视觉内容关联弱等问题,为此,本文提出了一种引入语义匹配和语言评价的跨语言图像描述模型。方法首先,选择基于编码器—解码器的图像描述基准网络框架。其次,为了兼顾图像及其轴语言所包含的语义知识,构建了一个源域语义匹配模块;为了学习目标语言域的语言习惯,还构建了一个目标语言域评价模块。基于上述两个模块,对图像描述模型进行语义匹配约束和语言指导:1)图像&轴语言域语义匹配模块通过将图像、轴语言描述以及目标语言描述映射到公共嵌入空间来衡量各自模态特征表示的语义一致性。2)目标语言域评价模块依据目标语言风格,对所生成的描述句子进行语言评分。结果针对跨语言的英文图像描述任务,本文在MS COCO(Microsoft common objects in context)数据集上进行了测试。与性能较好的方法相比,本文方法在BLEU(bilingual evaluation understudy)-2、BLEU-3、BLEU-4和METEOR(metric for evaluation of translation with explicit ordering)等4个评价指标上的得分分别提升了1.4%,1.0%,0.7%和1.3%。针对跨语言的中文图像描述任务,本文在AIC-ICC(image Chinese captioning from artificial intelligence challenge)数据集上进行了测试。与性能较好的方法相比,本文方法在BLEU-1、BLEU-2、BLEU-3、BLEU-4、METEOR和CIDEr(consensus-based image description evaluation)等6个评价指标上的评分分别提升了5.7%,2.0%,1.6%,1.3%,1.2%和3.4%。结论本文模型中图像&轴语言域语义匹配模块引导模型学习了更丰富的语义知识,目标语言域评价模块约束模型生成更加流畅的句子,本文模型适用于跨语言图像描述生成任务。关键词:跨语言;图像描述;强化学习;神经网络;轴语言434|267|0更新时间:2024-05-07
摘要:目的由于缺乏图像与目标语言域的成对数据,现有的跨语言描述方法都是基于轴(源)语言转化为目标语言,由于转化过程中的语义噪音干扰,生成的句子存在不够流畅以及与图像视觉内容关联弱等问题,为此,本文提出了一种引入语义匹配和语言评价的跨语言图像描述模型。方法首先,选择基于编码器—解码器的图像描述基准网络框架。其次,为了兼顾图像及其轴语言所包含的语义知识,构建了一个源域语义匹配模块;为了学习目标语言域的语言习惯,还构建了一个目标语言域评价模块。基于上述两个模块,对图像描述模型进行语义匹配约束和语言指导:1)图像&轴语言域语义匹配模块通过将图像、轴语言描述以及目标语言描述映射到公共嵌入空间来衡量各自模态特征表示的语义一致性。2)目标语言域评价模块依据目标语言风格,对所生成的描述句子进行语言评分。结果针对跨语言的英文图像描述任务,本文在MS COCO(Microsoft common objects in context)数据集上进行了测试。与性能较好的方法相比,本文方法在BLEU(bilingual evaluation understudy)-2、BLEU-3、BLEU-4和METEOR(metric for evaluation of translation with explicit ordering)等4个评价指标上的得分分别提升了1.4%,1.0%,0.7%和1.3%。针对跨语言的中文图像描述任务,本文在AIC-ICC(image Chinese captioning from artificial intelligence challenge)数据集上进行了测试。与性能较好的方法相比,本文方法在BLEU-1、BLEU-2、BLEU-3、BLEU-4、METEOR和CIDEr(consensus-based image description evaluation)等6个评价指标上的评分分别提升了5.7%,2.0%,1.6%,1.3%,1.2%和3.4%。结论本文模型中图像&轴语言域语义匹配模块引导模型学习了更丰富的语义知识,目标语言域评价模块约束模型生成更加流畅的句子,本文模型适用于跨语言图像描述生成任务。关键词:跨语言;图像描述;强化学习;神经网络;轴语言434|267|0更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的传统的糖尿病视网膜病变(糖网)(diabetic retinopathy,DR)依赖于早期病理特征的精确检测,但由于数据集缺乏病灶标记区域导致无法有效地建立监督性分类模型,引入其他辅助数据集又会出现跨域数据异质性问题;另外,现有的糖网诊断方法大多无法直观地从语义上解释医学模型预测的结果。基于此,本文提出一种端到端式结合域适应学习的糖网自动多分类方法,该方法协同注意力机制和弱监督学习加强优化。方法首先,利用已标记病灶区域的辅助数据训练病灶检测模型,再将目标域数据集的糖网诊断转化为弱监督学习问题,依靠多分类预测结果指导深度跨域生成对抗网络模型,提升跨域的样本图像质量,用于微调病灶检测模型,进而过滤目标域中一些无关的病灶样本,提升多分类分级诊断性能。最后,在整体模型中融合注意力机制,从医学病理诊断角度提供可解释性支持其分类决策。结果在公开数据集Messidor上进行糖网多分类评估实验,本文方法获得了71.2%的平均准确率和80.8%的AUC(area under curve)值,相比于其他多种方法具有很大优势,可以辅助医生进行临床眼底筛查。结论结合域适应学习的糖网分类方法在没有提供像素级病灶标注数据的情况下,只需要图像级监督信息就可以高效自动地对眼底图像实现分级诊断,从而避免医学图像中手工提取病灶特征的局限性和因疲劳可能造成漏诊或误诊问题,另外,为医生提供了与病理学相关的分类依据,获得了较好的分类效果。关键词:糖尿病视网膜病变(DR);眼底图像;注意力机制;深度学习;弱监督学习;域适应292|1090|1更新时间:2024-05-07
摘要:目的传统的糖尿病视网膜病变(糖网)(diabetic retinopathy,DR)依赖于早期病理特征的精确检测,但由于数据集缺乏病灶标记区域导致无法有效地建立监督性分类模型,引入其他辅助数据集又会出现跨域数据异质性问题;另外,现有的糖网诊断方法大多无法直观地从语义上解释医学模型预测的结果。基于此,本文提出一种端到端式结合域适应学习的糖网自动多分类方法,该方法协同注意力机制和弱监督学习加强优化。方法首先,利用已标记病灶区域的辅助数据训练病灶检测模型,再将目标域数据集的糖网诊断转化为弱监督学习问题,依靠多分类预测结果指导深度跨域生成对抗网络模型,提升跨域的样本图像质量,用于微调病灶检测模型,进而过滤目标域中一些无关的病灶样本,提升多分类分级诊断性能。最后,在整体模型中融合注意力机制,从医学病理诊断角度提供可解释性支持其分类决策。结果在公开数据集Messidor上进行糖网多分类评估实验,本文方法获得了71.2%的平均准确率和80.8%的AUC(area under curve)值,相比于其他多种方法具有很大优势,可以辅助医生进行临床眼底筛查。结论结合域适应学习的糖网分类方法在没有提供像素级病灶标注数据的情况下,只需要图像级监督信息就可以高效自动地对眼底图像实现分级诊断,从而避免医学图像中手工提取病灶特征的局限性和因疲劳可能造成漏诊或误诊问题,另外,为医生提供了与病理学相关的分类依据,获得了较好的分类效果。关键词:糖尿病视网膜病变(DR);眼底图像;注意力机制;深度学习;弱监督学习;域适应292|1090|1更新时间:2024-05-07
医学图像处理
-
 摘要:目的卷积神经网络(convolutional neural network,CNN)在遥感场景图像分类中广泛应用,但缺乏训练数据依然是不容忽视的问题。小样本遥感场景分类是指模型只需利用少量样本训练即可完成遥感场景图像分类任务。虽然现有基于元学习的小样本遥感场景图像分类方法可以摆脱大数据训练的依赖,但模型的泛化能力依然较弱。为了解决这一问题,本文提出一种基于自监督学习的小样本遥感场景图像分类方法来增加模型的泛化能力。方法本文方法分为两个阶段。首先,使用元学习训练老师网络直到收敛;然后,双学生网络和老师网络对同一个输入进行预测。老师网络的预测结果会通过蒸馏损失指导双学生网络的训练。另外,在图像特征进入分类器之前,自监督对比学习通过度量同类样本的类中心距离,使模型学习到更明确的类间边界。两种自监督机制能够使模型学习到更丰富的类间关系,从而提高模型的泛化能力。结果本文在NWPU-RESISC45(North Western Polytechnical University-remote sensing image scene classification)、AID(aerial image dataset)和UCMerced LandUse(UC merced land use dataset)3个数据集上进行实验。在5-way 1-shot条件下,本文方法的精度在3个数据集上分别达到了72.72%±0.15%、68.62%±0.76%和68.21%±0.65%,比Relation Net*模型分别提高了4.43%、1.93%和0.68%。随着可用标签的增加,本文方法的提升作用依然能够保持,在5-way 5-shot条件下,本文方法的精度比Relation Net*分别提高3.89%、2.99%和1.25%。结论本文方法可以使模型学习到更丰富的类内类间关系,有效提升小样本遥感场景图像分类模型的泛化能力。关键词:小样本学习;遥感场景分类;自监督学习;蒸馏学习;对比学习1808|4120|7更新时间:2024-05-07
摘要:目的卷积神经网络(convolutional neural network,CNN)在遥感场景图像分类中广泛应用,但缺乏训练数据依然是不容忽视的问题。小样本遥感场景分类是指模型只需利用少量样本训练即可完成遥感场景图像分类任务。虽然现有基于元学习的小样本遥感场景图像分类方法可以摆脱大数据训练的依赖,但模型的泛化能力依然较弱。为了解决这一问题,本文提出一种基于自监督学习的小样本遥感场景图像分类方法来增加模型的泛化能力。方法本文方法分为两个阶段。首先,使用元学习训练老师网络直到收敛;然后,双学生网络和老师网络对同一个输入进行预测。老师网络的预测结果会通过蒸馏损失指导双学生网络的训练。另外,在图像特征进入分类器之前,自监督对比学习通过度量同类样本的类中心距离,使模型学习到更明确的类间边界。两种自监督机制能够使模型学习到更丰富的类间关系,从而提高模型的泛化能力。结果本文在NWPU-RESISC45(North Western Polytechnical University-remote sensing image scene classification)、AID(aerial image dataset)和UCMerced LandUse(UC merced land use dataset)3个数据集上进行实验。在5-way 1-shot条件下,本文方法的精度在3个数据集上分别达到了72.72%±0.15%、68.62%±0.76%和68.21%±0.65%,比Relation Net*模型分别提高了4.43%、1.93%和0.68%。随着可用标签的增加,本文方法的提升作用依然能够保持,在5-way 5-shot条件下,本文方法的精度比Relation Net*分别提高3.89%、2.99%和1.25%。结论本文方法可以使模型学习到更丰富的类内类间关系,有效提升小样本遥感场景图像分类模型的泛化能力。关键词:小样本学习;遥感场景分类;自监督学习;蒸馏学习;对比学习1808|4120|7更新时间:2024-05-07 -
 摘要:目的遥感图像处理技术在农作物规划、植被检测以及农用地监测等方面具有重要的作用。然而农作物遥感图像上存在类别不平衡的问题,部分样本中农作物类间相似度高、类内差异性大,使得农作物遥感图像的语义分割更具挑战性。为了解决这些问题,提出一种融合不同尺度类别关系的农作物遥感图像语义分割网络CRNet(class relation network)。方法该网络将ResNet-34作为编码器的主干网络提取图像特征,并采用特征金字塔结构融合高阶语义特征和低阶空间信息,增强网络对图像细节的处理能力。引入类别关系模块获取不同尺度的类别关系,利用一种新的类别特征加强注意力机制(class feature enhancement,CFE)结合通道注意力和加强位置信息的空间注意力,使得农作物类间的语义差异和农作物类内的相关性增大。在解码器中,将不同尺度的类别关系融合,增强了网络对不同尺度农作物特征的识别能力,从而提高了对农作物边界分割的精度。通过数据预处理、数据增强和类别平衡损失函数(class-balanced loss,CB loss)进一步缓解了农作物遥感图像中类别不平衡的问题。结果在Barley Remote Sensing数据集上进行的实验表明,CRNet网络的平均交并比(mean intersection over union,MIoU)和总体分类精度(overall accuracy,OA)分别达到68.89%和82.59%,性能在评价指标和可视化效果上均优于PSPNet(pyramid scene parsing network)、FPN(feature pyramid network)、LinkNet、DeepLabv3+、FarSeg(foreground-aware relation network)以及STLNet(statistical texture learning network)。结论CRNet网络通过类别关系模块,在遥感图像复杂的地物背景中更加精准地区分相似的不同农作物,识别特征差异大的同种农作物,并融合多级特征使得提取出的目标边界更加清晰完整,提高了分割精度。关键词:农作物遥感图像;语义分割;类别关系模块;注意力机制;类别平衡损失函数(CB loss);Barley Remote Sensing数据集175|186|2更新时间:2024-05-07
摘要:目的遥感图像处理技术在农作物规划、植被检测以及农用地监测等方面具有重要的作用。然而农作物遥感图像上存在类别不平衡的问题,部分样本中农作物类间相似度高、类内差异性大,使得农作物遥感图像的语义分割更具挑战性。为了解决这些问题,提出一种融合不同尺度类别关系的农作物遥感图像语义分割网络CRNet(class relation network)。方法该网络将ResNet-34作为编码器的主干网络提取图像特征,并采用特征金字塔结构融合高阶语义特征和低阶空间信息,增强网络对图像细节的处理能力。引入类别关系模块获取不同尺度的类别关系,利用一种新的类别特征加强注意力机制(class feature enhancement,CFE)结合通道注意力和加强位置信息的空间注意力,使得农作物类间的语义差异和农作物类内的相关性增大。在解码器中,将不同尺度的类别关系融合,增强了网络对不同尺度农作物特征的识别能力,从而提高了对农作物边界分割的精度。通过数据预处理、数据增强和类别平衡损失函数(class-balanced loss,CB loss)进一步缓解了农作物遥感图像中类别不平衡的问题。结果在Barley Remote Sensing数据集上进行的实验表明,CRNet网络的平均交并比(mean intersection over union,MIoU)和总体分类精度(overall accuracy,OA)分别达到68.89%和82.59%,性能在评价指标和可视化效果上均优于PSPNet(pyramid scene parsing network)、FPN(feature pyramid network)、LinkNet、DeepLabv3+、FarSeg(foreground-aware relation network)以及STLNet(statistical texture learning network)。结论CRNet网络通过类别关系模块,在遥感图像复杂的地物背景中更加精准地区分相似的不同农作物,识别特征差异大的同种农作物,并融合多级特征使得提取出的目标边界更加清晰完整,提高了分割精度。关键词:农作物遥感图像;语义分割;类别关系模块;注意力机制;类别平衡损失函数(CB loss);Barley Remote Sensing数据集175|186|2更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0