
最新刊期
2021 年 第 26 卷 第 7 期
-
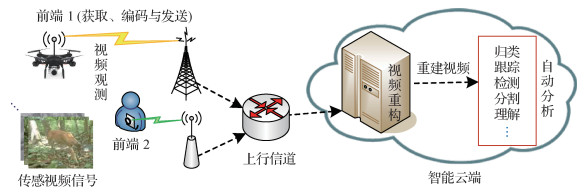 摘要:上行流媒体在军民融合领域展现出日益重要的新兴战略价值,压缩感知视频流技术体系在上行流媒体应用中具有前端功耗低、容错性好、适用信号广等独特优势,已成为当前可视通信研究的前沿与热点之一。本文从阐述上行流媒体的应用特征出发,从性能指标、并行分块计算成像、低复杂度视频编码、视频重构和语义质量评价等方面,分析了当前针对压缩感知视频流的基础理论与关键技术,对国内外相关的研究进展进行了探究与比较。面向上行流媒体的压缩感知视频流面临着观测效率难控、码流适配困难和重建质量较低等技术挑战。对压缩感知视频流的技术发展趋势进行展望,未来将通过前端与智能云端的分工协作,突破高效率的视频观测与语义质量导引视频重构等关键技术,进一步开拓压缩感知视频流在上行流媒体应用中的定量优势与演进途径。关键词:视频流;观测效率;码流适配;语义质量;视频重构;综述81|282|1更新时间:2024-05-07
摘要:上行流媒体在军民融合领域展现出日益重要的新兴战略价值,压缩感知视频流技术体系在上行流媒体应用中具有前端功耗低、容错性好、适用信号广等独特优势,已成为当前可视通信研究的前沿与热点之一。本文从阐述上行流媒体的应用特征出发,从性能指标、并行分块计算成像、低复杂度视频编码、视频重构和语义质量评价等方面,分析了当前针对压缩感知视频流的基础理论与关键技术,对国内外相关的研究进展进行了探究与比较。面向上行流媒体的压缩感知视频流面临着观测效率难控、码流适配困难和重建质量较低等技术挑战。对压缩感知视频流的技术发展趋势进行展望,未来将通过前端与智能云端的分工协作,突破高效率的视频观测与语义质量导引视频重构等关键技术,进一步开拓压缩感知视频流在上行流媒体应用中的定量优势与演进途径。关键词:视频流;观测效率;码流适配;语义质量;视频重构;综述81|282|1更新时间:2024-05-07
综述

-
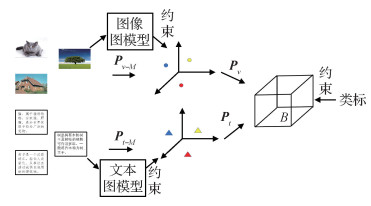 摘要:目的基于哈希的跨模态检索方法因其检索速度快、消耗存储空间小等优势受到了广泛关注。但是由于这类算法大都将不同模态数据直接映射至共同的汉明空间,因此难以克服不同模态数据的特征表示及特征维度的较大差异性,也很难在汉明空间中同时保持原有数据的结构信息。针对上述问题,本文提出了耦合保持投影哈希跨模态检索算法。方法为了解决跨模态数据间的异构性,先将不同模态的数据投影至各自子空间来减少模态“鸿沟”,并在子空间学习中引入图模型来保持数据间的结构一致性;为了构建不同模态之间的语义关联,再将子空间特征映射至汉明空间以得到一致的哈希码;最后引入类标约束来提升哈希码的判别性。结果实验在3个数据集上与主流的方法进行了比较,在Wikipedia数据集中,相比于性能第2的算法,在任务图像检索文本(I to T)和任务文本检索图像(T to I)上的平均检索精度(mean average precision,mAP)值分别提升了6%和3%左右;在MIRFlickr数据集中,相比于性能第2的算法,优势分别为2%和5%左右;在Pascal Sentence数据集中,优势分别为10%和7%左右。结论本文方法可适用于两个模态数据之间的相互检索任务,由于引入了耦合投影和图模型模块,有效提升了跨模态检索的精度。关键词:跨模态检索;哈希;结构保持;图模型;耦合投影;子空间学习95|165|0更新时间:2024-05-07
摘要:目的基于哈希的跨模态检索方法因其检索速度快、消耗存储空间小等优势受到了广泛关注。但是由于这类算法大都将不同模态数据直接映射至共同的汉明空间,因此难以克服不同模态数据的特征表示及特征维度的较大差异性,也很难在汉明空间中同时保持原有数据的结构信息。针对上述问题,本文提出了耦合保持投影哈希跨模态检索算法。方法为了解决跨模态数据间的异构性,先将不同模态的数据投影至各自子空间来减少模态“鸿沟”,并在子空间学习中引入图模型来保持数据间的结构一致性;为了构建不同模态之间的语义关联,再将子空间特征映射至汉明空间以得到一致的哈希码;最后引入类标约束来提升哈希码的判别性。结果实验在3个数据集上与主流的方法进行了比较,在Wikipedia数据集中,相比于性能第2的算法,在任务图像检索文本(I to T)和任务文本检索图像(T to I)上的平均检索精度(mean average precision,mAP)值分别提升了6%和3%左右;在MIRFlickr数据集中,相比于性能第2的算法,优势分别为2%和5%左右;在Pascal Sentence数据集中,优势分别为10%和7%左右。结论本文方法可适用于两个模态数据之间的相互检索任务,由于引入了耦合投影和图模型模块,有效提升了跨模态检索的精度。关键词:跨模态检索;哈希;结构保持;图模型;耦合投影;子空间学习95|165|0更新时间:2024-05-07 -
 摘要:目的视觉检索需要准确、高效地从大型图像或者视频数据集中检索出最相关的视觉内容,但是由于数据集中图像数据量大、特征维度高的特点,现有方法很难同时保证快速的检索速度和较好的检索效果。方法对于面向图像视频数据的高维数据视觉检索任务,提出加权语义局部敏感哈希算法(weighted semantic locality-sensitive hashing,WSLSH)。该算法利用两层视觉词典对参考特征空间进行二次空间划分,在每个子空间里使用加权语义局部敏感哈希对特征进行精确索引。其次,设计动态变长哈希码,在保证检索性能的基础上减少哈希表数量。此外,针对局部敏感哈希(locality sensitive hashing,LSH)的随机不稳定性,在LSH函数中加入反映参考特征空间语义的统计性数据,设计了一个简单投影语义哈希函数以确保算法检索性能的稳定性。结果在Holidays、Oxford5k和DataSetB数据集上的实验表明,WSLSH在DataSetB上取得最短平均检索时间0.034 25 s;在编码长度为64位的情况下,WSLSH算法在3个数据集上的平均精确度均值(mean average precision,mAP)分别提高了1.2%32.6%、1.7%19.1%和2.6%28.6%,与几种较新的无监督哈希方法相比有一定的优势。结论通过进行二次空间划分、对参考特征的哈希索引次数进行加权、动态使用变长哈希码以及提出简单投影语义哈希函数来对LSH算法进行改进。由此提出的加权语义局部敏感哈希(WSLSH)算法相比现有工作有更快的检索速度,同时,在长编码的情况下,取得了更为优异的性能。关键词:特征空间划分;局部敏感哈希(LSH);动态变长哈希码;视觉搜索;最近邻搜索77|163|1更新时间:2024-05-07
摘要:目的视觉检索需要准确、高效地从大型图像或者视频数据集中检索出最相关的视觉内容,但是由于数据集中图像数据量大、特征维度高的特点,现有方法很难同时保证快速的检索速度和较好的检索效果。方法对于面向图像视频数据的高维数据视觉检索任务,提出加权语义局部敏感哈希算法(weighted semantic locality-sensitive hashing,WSLSH)。该算法利用两层视觉词典对参考特征空间进行二次空间划分,在每个子空间里使用加权语义局部敏感哈希对特征进行精确索引。其次,设计动态变长哈希码,在保证检索性能的基础上减少哈希表数量。此外,针对局部敏感哈希(locality sensitive hashing,LSH)的随机不稳定性,在LSH函数中加入反映参考特征空间语义的统计性数据,设计了一个简单投影语义哈希函数以确保算法检索性能的稳定性。结果在Holidays、Oxford5k和DataSetB数据集上的实验表明,WSLSH在DataSetB上取得最短平均检索时间0.034 25 s;在编码长度为64位的情况下,WSLSH算法在3个数据集上的平均精确度均值(mean average precision,mAP)分别提高了1.2%32.6%、1.7%19.1%和2.6%28.6%,与几种较新的无监督哈希方法相比有一定的优势。结论通过进行二次空间划分、对参考特征的哈希索引次数进行加权、动态使用变长哈希码以及提出简单投影语义哈希函数来对LSH算法进行改进。由此提出的加权语义局部敏感哈希(WSLSH)算法相比现有工作有更快的检索速度,同时,在长编码的情况下,取得了更为优异的性能。关键词:特征空间划分;局部敏感哈希(LSH);动态变长哈希码;视觉搜索;最近邻搜索77|163|1更新时间:2024-05-07
图像处理和编码
-
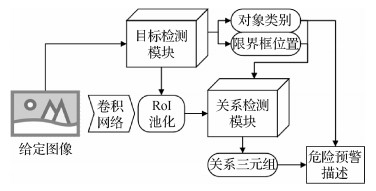 摘要:目的借助深度学习强大的识别与检测能力,辅助人工进行电力场景下的危险描述与作业预警是一种较为经济和高效的电力安全监管手段。然而,目前主流的以目标检测技术为基础的预警系统只能给出部分危险目标的信息,忽视了电力设备的单目危险关系和成对对象间潜在的二元危险关系。不同于以往的方法,为了拓展危险预警模块的识别能力与功能范畴,本文提出了一种在电力场景下基于视觉关系检测的自动危险预警描述生成方法。方法对给定的待检测图像,通过目标检测模块得到图中对象的类别名称和限界框位置;分别对图像进行语义特征、视觉特征和空间位置特征的抽取,将融合后的总特征送入关系检测模块,输出单个对象的一元关系和成对对象间的关系三元组;根据检测出的对象类别和关系信息,进行危险预测并给出警示描述。结果本文自主搜集了多场景下的电力生产作业图像并进行标注,同时进行大量消融实验。实验显示,结合了语义特征、空间特征和视觉特征的关系检测器在前5召回率Recall@5和前10召回率Recall@10上的精度分别达到86.80%和93.93%,比仅使用视觉特征的关系检测器的性能提高约15%。结论本文提出的融合多模态特征输入的视觉关系检测网络能够较好地给出谓词关系的最佳匹配,并减少不合理的关系预测,且具有一定零样本学习(zero-shot learning)能力。相关可视化结果表明,整体系统能够较好地完成电力场景下的危险预警描述任务。关键词:危险预警;目标检测;视觉关系检测;多模态特征融合;多标签余量损失66|206|2更新时间:2024-05-07
摘要:目的借助深度学习强大的识别与检测能力,辅助人工进行电力场景下的危险描述与作业预警是一种较为经济和高效的电力安全监管手段。然而,目前主流的以目标检测技术为基础的预警系统只能给出部分危险目标的信息,忽视了电力设备的单目危险关系和成对对象间潜在的二元危险关系。不同于以往的方法,为了拓展危险预警模块的识别能力与功能范畴,本文提出了一种在电力场景下基于视觉关系检测的自动危险预警描述生成方法。方法对给定的待检测图像,通过目标检测模块得到图中对象的类别名称和限界框位置;分别对图像进行语义特征、视觉特征和空间位置特征的抽取,将融合后的总特征送入关系检测模块,输出单个对象的一元关系和成对对象间的关系三元组;根据检测出的对象类别和关系信息,进行危险预测并给出警示描述。结果本文自主搜集了多场景下的电力生产作业图像并进行标注,同时进行大量消融实验。实验显示,结合了语义特征、空间特征和视觉特征的关系检测器在前5召回率Recall@5和前10召回率Recall@10上的精度分别达到86.80%和93.93%,比仅使用视觉特征的关系检测器的性能提高约15%。结论本文提出的融合多模态特征输入的视觉关系检测网络能够较好地给出谓词关系的最佳匹配,并减少不合理的关系预测,且具有一定零样本学习(zero-shot learning)能力。相关可视化结果表明,整体系统能够较好地完成电力场景下的危险预警描述任务。关键词:危险预警;目标检测;视觉关系检测;多模态特征融合;多标签余量损失66|206|2更新时间:2024-05-07 -
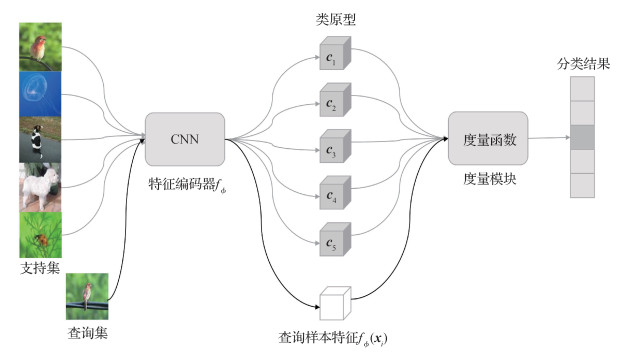 摘要:目的现有的深度学习模型往往需要大规模的训练数据,而小样本分类旨在识别只有少量带标签样本的目标类别。作为目前小样本学习的主流方法,基于度量的元学习方法在训练阶段大多没有使用小样本目标类的样本,导致这些模型的特征表示不能很好地泛化到目标类。为了提高基于元学习的小样本图像识别方法的泛化能力,本文提出了基于类别语义相似性监督的小样本图像识别方法。方法采用经典的词嵌入模型GloVe(global vectors for word representation)学习得到图像数据集每个类别英文名称的词嵌入向量,利用类别词嵌入向量之间的余弦距离表示类别语义相似度。通过把类别之间的语义相关性作为先验知识进行整合,在模型训练阶段引入类别之间的语义相似性度量作为额外的监督信息,训练一个更具类别样本特征约束能力和泛化能力的特征表示。结果在miniImageNet和tieredImageNet两个小样本学习基准数据集上进行了大量实验,验证提出方法的有效性。结果显示在miniImageNet数据集5-way 1-shot和5-way 5-shot设置上,提出的方法相比原型网络(prototypical networks)分类准确率分别提高1.9%和0.32%;在tieredImageNet数据集5-way 1-shot设置上,分类准确率相比原型网络提高0.33%。结论提出基于类别语义相似性监督的小样本图像识别模型,提高小样本学习方法的泛化能力,提高小样本图像识别的准确率。关键词:小样本学习;图像识别;特征表示;类别语义相似性监督;泛化能力103|111|5更新时间:2024-05-07
摘要:目的现有的深度学习模型往往需要大规模的训练数据,而小样本分类旨在识别只有少量带标签样本的目标类别。作为目前小样本学习的主流方法,基于度量的元学习方法在训练阶段大多没有使用小样本目标类的样本,导致这些模型的特征表示不能很好地泛化到目标类。为了提高基于元学习的小样本图像识别方法的泛化能力,本文提出了基于类别语义相似性监督的小样本图像识别方法。方法采用经典的词嵌入模型GloVe(global vectors for word representation)学习得到图像数据集每个类别英文名称的词嵌入向量,利用类别词嵌入向量之间的余弦距离表示类别语义相似度。通过把类别之间的语义相关性作为先验知识进行整合,在模型训练阶段引入类别之间的语义相似性度量作为额外的监督信息,训练一个更具类别样本特征约束能力和泛化能力的特征表示。结果在miniImageNet和tieredImageNet两个小样本学习基准数据集上进行了大量实验,验证提出方法的有效性。结果显示在miniImageNet数据集5-way 1-shot和5-way 5-shot设置上,提出的方法相比原型网络(prototypical networks)分类准确率分别提高1.9%和0.32%;在tieredImageNet数据集5-way 1-shot设置上,分类准确率相比原型网络提高0.33%。结论提出基于类别语义相似性监督的小样本图像识别模型,提高小样本学习方法的泛化能力,提高小样本图像识别的准确率。关键词:小样本学习;图像识别;特征表示;类别语义相似性监督;泛化能力103|111|5更新时间:2024-05-07 -
 摘要:目的双目视觉是目标距离估计问题的一个很好的解决方案。现有的双目目标距离估计方法存在估计精度较低或数据准备较繁琐的问题,为此需要一个可以兼顾精度和数据准备便利性的双目目标距离估计算法。方法提出一个基于R-CNN(region convolutional neural network)结构的网络,该网络可以实现同时进行目标检测与目标距离估计。双目图像输入网络后,通过主干网络提取特征,通过双目候选框提取网络以同时得到左右图像中相同目标的包围框,将成对的目标框内的局部特征输入目标视差估计分支以估计目标的距离。为了同时得到左右图像中相同目标的包围框,使用双目候选框提取网络代替原有的候选框提取网络,并提出了双目包围框分支以同时进行双目包围框的回归;为了提升视差估计的精度,借鉴双目视差图估计网络的结构,提出了一个基于组相关和3维卷积的视差估计分支。结果在KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute)数据集上进行验证实验,与同类算法比较,本文算法平均相对误差值约为3.2%,远小于基于双目视差图估计算法(11.3%),与基于3维目标检测的算法接近(约为3.9%)。另外,提出的视差估计分支改进对精度有明显的提升效果,平均相对误差值从5.1%下降到3.2%。通过在另外采集并标注的行人监控数据集上进行类似实验,实验结果平均相对误差值约为4.6%,表明本文方法可以有效应用于监控场景。结论提出的双目目标距离估计网络结合了目标检测与双目视差估计的优势,具有较高的精度。该网络可以有效运用于车载相机及监控场景,并有希望运用于其他安装有双目相机的场景。关键词:双目视觉;目标距离估计;视差估计;深度神经网络;3维卷积;监控场景115|177|3更新时间:2024-05-07
摘要:目的双目视觉是目标距离估计问题的一个很好的解决方案。现有的双目目标距离估计方法存在估计精度较低或数据准备较繁琐的问题,为此需要一个可以兼顾精度和数据准备便利性的双目目标距离估计算法。方法提出一个基于R-CNN(region convolutional neural network)结构的网络,该网络可以实现同时进行目标检测与目标距离估计。双目图像输入网络后,通过主干网络提取特征,通过双目候选框提取网络以同时得到左右图像中相同目标的包围框,将成对的目标框内的局部特征输入目标视差估计分支以估计目标的距离。为了同时得到左右图像中相同目标的包围框,使用双目候选框提取网络代替原有的候选框提取网络,并提出了双目包围框分支以同时进行双目包围框的回归;为了提升视差估计的精度,借鉴双目视差图估计网络的结构,提出了一个基于组相关和3维卷积的视差估计分支。结果在KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute)数据集上进行验证实验,与同类算法比较,本文算法平均相对误差值约为3.2%,远小于基于双目视差图估计算法(11.3%),与基于3维目标检测的算法接近(约为3.9%)。另外,提出的视差估计分支改进对精度有明显的提升效果,平均相对误差值从5.1%下降到3.2%。通过在另外采集并标注的行人监控数据集上进行类似实验,实验结果平均相对误差值约为4.6%,表明本文方法可以有效应用于监控场景。结论提出的双目目标距离估计网络结合了目标检测与双目视差估计的优势,具有较高的精度。该网络可以有效运用于车载相机及监控场景,并有希望运用于其他安装有双目相机的场景。关键词:双目视觉;目标距离估计;视差估计;深度神经网络;3维卷积;监控场景115|177|3更新时间:2024-05-07 -
 摘要:目的获取场景图像中的文本信息对理解场景内容具有重要意义,而文本检测是文本识别、理解的基础。为了解决场景文本识别中文字定位不准确的问题,本文提出了一种高效的任意形状文本检测器:非局部像素聚合网络。方法该方法使用特征金字塔增强模块和特征融合模块进行轻量级特征提取,保证了速度优势;同时引入非局部操作以增强骨干网络的特征提取能力,使其检测准确性得以提高。非局部操作是一种注意力机制,能捕捉到文本像素之间的内在关系。此外,本文设计了一种特征向量融合模块,用于融合不同尺度的特征图,使尺度多变的场景文本实例的特征表达得到增强。结果本文方法在3个场景文本数据集上与其他方法进行了比较,在速度和准确度上均表现突出。在ICDAR(International Conference on Document Analysis and Recognition)2015数据集上,本文方法比最优方法的F值提高了0.9%,检测速度达到了23.1帧/s;在CTW(Curve Text in the Wild)1500数据集上,本文方法比最优方法的F值提高了1.2%,检测速度达到了71.8帧/s;在Total-Text数据集上,本文方法比最优方法的F值提高了1.3%,检测速度达到了34.3帧/s,远远超出其他方法。结论本文方法兼顾了准确性和实时性,在准确度和速度上均达到较高水平。关键词:目标检测;场景文本检测;神经网络;非局部模块;像素聚合;实时检测;任意形状62|47|4更新时间:2024-05-07
摘要:目的获取场景图像中的文本信息对理解场景内容具有重要意义,而文本检测是文本识别、理解的基础。为了解决场景文本识别中文字定位不准确的问题,本文提出了一种高效的任意形状文本检测器:非局部像素聚合网络。方法该方法使用特征金字塔增强模块和特征融合模块进行轻量级特征提取,保证了速度优势;同时引入非局部操作以增强骨干网络的特征提取能力,使其检测准确性得以提高。非局部操作是一种注意力机制,能捕捉到文本像素之间的内在关系。此外,本文设计了一种特征向量融合模块,用于融合不同尺度的特征图,使尺度多变的场景文本实例的特征表达得到增强。结果本文方法在3个场景文本数据集上与其他方法进行了比较,在速度和准确度上均表现突出。在ICDAR(International Conference on Document Analysis and Recognition)2015数据集上,本文方法比最优方法的F值提高了0.9%,检测速度达到了23.1帧/s;在CTW(Curve Text in the Wild)1500数据集上,本文方法比最优方法的F值提高了1.2%,检测速度达到了71.8帧/s;在Total-Text数据集上,本文方法比最优方法的F值提高了1.3%,检测速度达到了34.3帧/s,远远超出其他方法。结论本文方法兼顾了准确性和实时性,在准确度和速度上均达到较高水平。关键词:目标检测;场景文本检测;神经网络;非局部模块;像素聚合;实时检测;任意形状62|47|4更新时间:2024-05-07 -
 摘要:目的全景图像的质量评价和传输、处理过程并不是在同一个空间进行的,传统的评价算法无法准确地反映用户在观察球面场景时产生的真实感受,针对观察空间与处理空间不一致的问题,本文提出一种基于相位一致性的全参考全景图像质量评价模型。方法将平面图像进行全景加权,使得平面上的特征能准确反映球面空间质量畸变。采用相位一致性互信息的相似度获取参考图像和失真图像的结构相似度。接着,利用相位一致性局部熵的相似度反映参考图像和失真图像的纹理相似度。将两部分相似度融合可得全景图像的客观质量分数。结果实验在全景质量评价数据集OIQA(omnidirectional image quality assessment)上进行,在原始图像中引入4种不同类型的失真,将提出的算法与6种主流算法进行性能对比,比较了基于相位信息的一致性互信息和一致性局部熵,以及评价标准依据4项指标。实验结果表明,相比于现有的6种全景图像质量评估算法,该算法在PLCC(Pearson linear correlation coefficient)和SRCC(Spearman rank order correlation coefficient)指标上比WS-SSIM(weighted-to-spherically-uniform structural similarity)算法高出0.4左右,并且在RMSE(root of mean square error)上低0.9左右,4项指标最优,能够获得更好的拟合效果。结论本文算法解决了观察空间和映射空间不一致的问题,并且融合了基于人眼感知的多尺度互信息相似度和局部熵相似度,获得与人眼感知更为一致的客观分数,评价效果更为准确,更加符合人眼视觉特征。关键词:全景图像/视频;质量评价;人类视觉系统;相位一致性;结构相似度(SSIM);纹理相似度51|47|1更新时间:2024-05-07
摘要:目的全景图像的质量评价和传输、处理过程并不是在同一个空间进行的,传统的评价算法无法准确地反映用户在观察球面场景时产生的真实感受,针对观察空间与处理空间不一致的问题,本文提出一种基于相位一致性的全参考全景图像质量评价模型。方法将平面图像进行全景加权,使得平面上的特征能准确反映球面空间质量畸变。采用相位一致性互信息的相似度获取参考图像和失真图像的结构相似度。接着,利用相位一致性局部熵的相似度反映参考图像和失真图像的纹理相似度。将两部分相似度融合可得全景图像的客观质量分数。结果实验在全景质量评价数据集OIQA(omnidirectional image quality assessment)上进行,在原始图像中引入4种不同类型的失真,将提出的算法与6种主流算法进行性能对比,比较了基于相位信息的一致性互信息和一致性局部熵,以及评价标准依据4项指标。实验结果表明,相比于现有的6种全景图像质量评估算法,该算法在PLCC(Pearson linear correlation coefficient)和SRCC(Spearman rank order correlation coefficient)指标上比WS-SSIM(weighted-to-spherically-uniform structural similarity)算法高出0.4左右,并且在RMSE(root of mean square error)上低0.9左右,4项指标最优,能够获得更好的拟合效果。结论本文算法解决了观察空间和映射空间不一致的问题,并且融合了基于人眼感知的多尺度互信息相似度和局部熵相似度,获得与人眼感知更为一致的客观分数,评价效果更为准确,更加符合人眼视觉特征。关键词:全景图像/视频;质量评价;人类视觉系统;相位一致性;结构相似度(SSIM);纹理相似度51|47|1更新时间:2024-05-07
图像分析和识别
-
 摘要:目的时序行为识别是视频理解中最重要的任务之一,该任务需要对一段视频中的行为片段同时进行分类和回归,而视频中往往包含不同时间长度的行为片段,对持续时间较短的行为片段进行检测尤其困难。针对持续时间较短的行为片段检测问题,文中构建了3维特征金字塔层次结构以增强网络检测不同持续时长的行为片段的能力,提出了一种提案网络后接分类器的两阶段新型网络。方法网络以RGB连续帧作为输入,经过特征金字塔结构产生不同分辨率和抽象程度的特征图,这些不同级别的特征图主要在网络的后两个阶段发挥作用:1)在提案阶段结合锚方法,使得不同时间长度的锚段具有与之对应的不同大小的感受野,锚段的初次预测将更加准确;2)在感兴趣区域池化阶段,不同的提案片段映射给对应级别特征图进行预测,平衡了分类和回归对特征图抽象度和分辨率的需求。结果在THUMOS Challenge 2014数据集上对模型进行测试,在与没有使用光流特征的其他典型方法进行比较时,本文模型在不同交并比阈值上超过了对比方法3%以上,按类别比较时,对持续时间较短的行为片段检测准确率则普遍得到提升。消融性实验中,在交并比阈值为0.5时,带特征金字塔结构的网络则超过使用普通特征提取网络的模型1.8%。结论本文提出的基于3维特征金字塔特征提取结构的双阶段时序行为模型能有效提升对持续时间较短的行为片段的检测准确率。关键词:时序行为识别;特征金字塔;深度学习;计算机视觉;视频理解100|136|2更新时间:2024-05-07
摘要:目的时序行为识别是视频理解中最重要的任务之一,该任务需要对一段视频中的行为片段同时进行分类和回归,而视频中往往包含不同时间长度的行为片段,对持续时间较短的行为片段进行检测尤其困难。针对持续时间较短的行为片段检测问题,文中构建了3维特征金字塔层次结构以增强网络检测不同持续时长的行为片段的能力,提出了一种提案网络后接分类器的两阶段新型网络。方法网络以RGB连续帧作为输入,经过特征金字塔结构产生不同分辨率和抽象程度的特征图,这些不同级别的特征图主要在网络的后两个阶段发挥作用:1)在提案阶段结合锚方法,使得不同时间长度的锚段具有与之对应的不同大小的感受野,锚段的初次预测将更加准确;2)在感兴趣区域池化阶段,不同的提案片段映射给对应级别特征图进行预测,平衡了分类和回归对特征图抽象度和分辨率的需求。结果在THUMOS Challenge 2014数据集上对模型进行测试,在与没有使用光流特征的其他典型方法进行比较时,本文模型在不同交并比阈值上超过了对比方法3%以上,按类别比较时,对持续时间较短的行为片段检测准确率则普遍得到提升。消融性实验中,在交并比阈值为0.5时,带特征金字塔结构的网络则超过使用普通特征提取网络的模型1.8%。结论本文提出的基于3维特征金字塔特征提取结构的双阶段时序行为模型能有效提升对持续时间较短的行为片段的检测准确率。关键词:时序行为识别;特征金字塔;深度学习;计算机视觉;视频理解100|136|2更新时间:2024-05-07 -
 摘要:目的自动检测谣言至关重要,目前已有多种谣言检测方法,但存在以下两点局限:1)只考虑文本内容,忽略了可用于判断谣言的辅助多模态信息;2)只关注时间序列模型捕捉谣言事件的时间特征,没有很好地研究事件的局部信息和全局信息。为了克服这些局限性,有效利用多模态帖子信息并联合多种编码策略构建每个新闻事件的表示,本文提出一种新颖的基于多模态多层次事件网络的社交媒体谣言检测方法。方法通过一个多模态的帖子嵌入层,同时利用文本内容和视觉内容;将多模态的帖子嵌入向量送入多层次事件编码网络,联合使用多种编码策略,以由粗到细的方式描述事件特征。结果在Twitter和Pheme数据集上的大量实验表明,本文提出的多模态多层次事件网络模型比现有的SVM-TS(support vector machine—time structure)、CNN(convolutional neural network)、GRU(gated recurrent unit)、CallAtRumors和MKEMN(multimodal knowledge-aware event memory network)等方法在准确率上提升了4 %以上。结论本文提出的谣言检测模型,对每个事件的全局、时间和局部信息进行建模,提升了谣言检测的性能。关键词:多模态;谣言检测;社交媒体;多层次编码策略;事件网络122|201|1更新时间:2024-05-07
摘要:目的自动检测谣言至关重要,目前已有多种谣言检测方法,但存在以下两点局限:1)只考虑文本内容,忽略了可用于判断谣言的辅助多模态信息;2)只关注时间序列模型捕捉谣言事件的时间特征,没有很好地研究事件的局部信息和全局信息。为了克服这些局限性,有效利用多模态帖子信息并联合多种编码策略构建每个新闻事件的表示,本文提出一种新颖的基于多模态多层次事件网络的社交媒体谣言检测方法。方法通过一个多模态的帖子嵌入层,同时利用文本内容和视觉内容;将多模态的帖子嵌入向量送入多层次事件编码网络,联合使用多种编码策略,以由粗到细的方式描述事件特征。结果在Twitter和Pheme数据集上的大量实验表明,本文提出的多模态多层次事件网络模型比现有的SVM-TS(support vector machine—time structure)、CNN(convolutional neural network)、GRU(gated recurrent unit)、CallAtRumors和MKEMN(multimodal knowledge-aware event memory network)等方法在准确率上提升了4 %以上。结论本文提出的谣言检测模型,对每个事件的全局、时间和局部信息进行建模,提升了谣言检测的性能。关键词:多模态;谣言检测;社交媒体;多层次编码策略;事件网络122|201|1更新时间:2024-05-07 -
 摘要:目的在人体行为识别算法的研究领域,通过视频特征实现零样本识别的研究越来越多。但是,目前大部分研究是基于单模态数据展开的,关于多模态融合的研究还较少。为了研究多种模态数据对零样本人体动作识别的影响,本文提出了一种基于多模态融合的零样本人体动作识别(zero-shot human action recognition framework based on multimodel fusion,ZSAR-MF)框架。方法本文框架主要由传感器特征提取模块、分类模块和视频特征提取模块组成。具体来说,传感器特征提取模块使用卷积神经网络(convolutional neural network,CNN)提取心率和加速度特征;分类模块利用所有概念(传感器特征、动作和对象名称)的词向量生成动作类别分类器;视频特征提取模块将每个动作的属性、对象分数和传感器特征映射到属性—特征空间中,最后使用分类模块生成的分类器对每个动作的属性和传感器特征进行评估。结果本文实验在Stanford-ECM数据集上展开,对比结果表明本文ZSAR-MF模型比基于单模态数据的零样本识别模型在识别准确率上提高了4 %左右。结论本文所提出的基于多模态融合的零样本人体动作识别框架,有效地融合了传感器特征和视频特征,并显著提高了零样本人体动作识别的准确率。关键词:零样本;多模态融合;动作识别;传感器数据;视频特征193|195|3更新时间:2024-05-07
摘要:目的在人体行为识别算法的研究领域,通过视频特征实现零样本识别的研究越来越多。但是,目前大部分研究是基于单模态数据展开的,关于多模态融合的研究还较少。为了研究多种模态数据对零样本人体动作识别的影响,本文提出了一种基于多模态融合的零样本人体动作识别(zero-shot human action recognition framework based on multimodel fusion,ZSAR-MF)框架。方法本文框架主要由传感器特征提取模块、分类模块和视频特征提取模块组成。具体来说,传感器特征提取模块使用卷积神经网络(convolutional neural network,CNN)提取心率和加速度特征;分类模块利用所有概念(传感器特征、动作和对象名称)的词向量生成动作类别分类器;视频特征提取模块将每个动作的属性、对象分数和传感器特征映射到属性—特征空间中,最后使用分类模块生成的分类器对每个动作的属性和传感器特征进行评估。结果本文实验在Stanford-ECM数据集上展开,对比结果表明本文ZSAR-MF模型比基于单模态数据的零样本识别模型在识别准确率上提高了4 %左右。结论本文所提出的基于多模态融合的零样本人体动作识别框架,有效地融合了传感器特征和视频特征,并显著提高了零样本人体动作识别的准确率。关键词:零样本;多模态融合;动作识别;传感器数据;视频特征193|195|3更新时间:2024-05-07 -
 摘要:目的足球比赛视频中的球员跟踪算法为足球赛事分析提供基础的数据支持。但足球比赛中球员跟踪存在极大的挑战:球员进攻、防守和争夺球权时,目标球员可能产生快速移动、严重遮挡和周围出现若干名干扰球员的情况,目前仍没有一种能够完美解决足球比赛中球员跟踪问题的算法。因此如何解决足球场景中的困难,提升球员跟踪的准确度,成为当前研究的热点问题。方法本文在分析足球比赛视频中球员目标特点的基础上,通过融合干扰项感知的颜色模型和目标感知的深度模型,提出并设计了一种球员感知的跟踪算法。干扰项感知的颜色模型分别提取目标、背景和干扰项的颜色直方图,利用贝叶斯公式得到搜索区域中每个像素点属于目标的似然概率。目标感知的深度模型利用孪生网络计算搜索区域与目标的相似度。针对跟踪漂移问题,使用全局跟踪器和局部跟踪器分别跟踪目标整体和目标上半身,并且在两个跟踪器的跟踪结果出现较大差异的时候分析跟踪器有效性并进行定位修正。结果在公共的足球数据集上将本文算法与10个其他跟踪算法进行对比实验,同时对于文本算法进行了局部跟踪器的消融实验。实验结果表明,球员感知跟踪算法的平均有效重叠率达到了0.560 3,在存在同队球员和异队球员干扰的情况下,本文算法比排名第2的算法的有效重叠率分别高出3.7%和6.6%,明显优于其他算法,但是由于引入了干扰项感知的颜色模型、目标感知的深度模型以及局部跟踪器等模块增加了算法的时间复杂度,导致本文算法跟踪速度较慢。结论本文总结了跟踪算法的整体流程并分析了实验结果,认为干扰项感知、目标感知和局部跟踪这3个策略在足球场景中的球员跟踪问题中起到了重要的作用,为未来在足球球员跟踪领域研究的继续深入提供了参考依据。关键词:计算机视觉;图像处理;目标跟踪;足球球员跟踪;干扰项感知;目标感知;局部跟踪176|271|0更新时间:2024-05-07
摘要:目的足球比赛视频中的球员跟踪算法为足球赛事分析提供基础的数据支持。但足球比赛中球员跟踪存在极大的挑战:球员进攻、防守和争夺球权时,目标球员可能产生快速移动、严重遮挡和周围出现若干名干扰球员的情况,目前仍没有一种能够完美解决足球比赛中球员跟踪问题的算法。因此如何解决足球场景中的困难,提升球员跟踪的准确度,成为当前研究的热点问题。方法本文在分析足球比赛视频中球员目标特点的基础上,通过融合干扰项感知的颜色模型和目标感知的深度模型,提出并设计了一种球员感知的跟踪算法。干扰项感知的颜色模型分别提取目标、背景和干扰项的颜色直方图,利用贝叶斯公式得到搜索区域中每个像素点属于目标的似然概率。目标感知的深度模型利用孪生网络计算搜索区域与目标的相似度。针对跟踪漂移问题,使用全局跟踪器和局部跟踪器分别跟踪目标整体和目标上半身,并且在两个跟踪器的跟踪结果出现较大差异的时候分析跟踪器有效性并进行定位修正。结果在公共的足球数据集上将本文算法与10个其他跟踪算法进行对比实验,同时对于文本算法进行了局部跟踪器的消融实验。实验结果表明,球员感知跟踪算法的平均有效重叠率达到了0.560 3,在存在同队球员和异队球员干扰的情况下,本文算法比排名第2的算法的有效重叠率分别高出3.7%和6.6%,明显优于其他算法,但是由于引入了干扰项感知的颜色模型、目标感知的深度模型以及局部跟踪器等模块增加了算法的时间复杂度,导致本文算法跟踪速度较慢。结论本文总结了跟踪算法的整体流程并分析了实验结果,认为干扰项感知、目标感知和局部跟踪这3个策略在足球场景中的球员跟踪问题中起到了重要的作用,为未来在足球球员跟踪领域研究的继续深入提供了参考依据。关键词:计算机视觉;图像处理;目标跟踪;足球球员跟踪;干扰项感知;目标感知;局部跟踪176|271|0更新时间:2024-05-07 -
 摘要:目的多人交互行为的识别在现实生活中有着广泛应用。现有的关于人类活动分析的研究主要集中在对单人简单行为的视频片段进行分类,而对于理解具有多人之间关系的复杂人类活动的问题还没有得到充分的解决。方法针对多人交互动作中两人肢体行为的特点,本文提出基于骨架的时空建模方法,将时空建模特征输入到广义图卷积中进行特征学习,通过谱图卷积的高阶快速切比雪夫多项式进行逼近。同时对骨架之间的交互信息进行设计,通过捕获这种额外的交互信息增加动作识别的准确性。为增强时域信息的提取,创新性地将切片循环神经网络(recurrent neural network,RNN)应用于视频动作识别,以捕获整个动作序列依赖性信息。结果本文在UT-Interaction数据集和SBU数据集上对本文算法进行评估,在UT-Interaction数据集中,与H-LSTCM(hierarchical long short-term concurrent memory)等算法进行了比较,相较于次好算法提高了0.7%,在SBU数据集中,相较于GCNConv(semi-supervised classification with graph convolutional networks)、RotClips+MTCNN(rotating cliips+multi-task convolutional neural netowrk)、SGC(simplifying graph convolutional)等算法分别提升了5.2%、1.03%、1.2%。同时也在SBU数据集中进行了融合实验,分别验证了不同连接与切片RNN的有效性。结论本文提出的融合时空图卷积的交互识别方法,对于交互类动作的识别具有较高的准确率,普遍适用于对象之间产生互动的行为识别。关键词:动作识别;交互信息;时空建模;图卷积;切片循环神经网络(RNN)140|152|4更新时间:2024-05-07
摘要:目的多人交互行为的识别在现实生活中有着广泛应用。现有的关于人类活动分析的研究主要集中在对单人简单行为的视频片段进行分类,而对于理解具有多人之间关系的复杂人类活动的问题还没有得到充分的解决。方法针对多人交互动作中两人肢体行为的特点,本文提出基于骨架的时空建模方法,将时空建模特征输入到广义图卷积中进行特征学习,通过谱图卷积的高阶快速切比雪夫多项式进行逼近。同时对骨架之间的交互信息进行设计,通过捕获这种额外的交互信息增加动作识别的准确性。为增强时域信息的提取,创新性地将切片循环神经网络(recurrent neural network,RNN)应用于视频动作识别,以捕获整个动作序列依赖性信息。结果本文在UT-Interaction数据集和SBU数据集上对本文算法进行评估,在UT-Interaction数据集中,与H-LSTCM(hierarchical long short-term concurrent memory)等算法进行了比较,相较于次好算法提高了0.7%,在SBU数据集中,相较于GCNConv(semi-supervised classification with graph convolutional networks)、RotClips+MTCNN(rotating cliips+multi-task convolutional neural netowrk)、SGC(simplifying graph convolutional)等算法分别提升了5.2%、1.03%、1.2%。同时也在SBU数据集中进行了融合实验,分别验证了不同连接与切片RNN的有效性。结论本文提出的融合时空图卷积的交互识别方法,对于交互类动作的识别具有较高的准确率,普遍适用于对象之间产生互动的行为识别。关键词:动作识别;交互信息;时空建模;图卷积;切片循环神经网络(RNN)140|152|4更新时间:2024-05-07 -
 摘要:目的随着移动互联网和人工智能的蓬勃发展,海量的视频数据不断产生,如何对这些视频数据进行处理分析是研究人员面临的一个挑战性问题。视频中的物体由于拍摄角度、快速运动和部分遮挡等原因常常表现得模糊和多样,与普通图像数据集的质量存在不小差距,这使得对视频数据的实例分割难度较大。目前的视频实例分割框架大多依靠图像检测方法直接处理单帧图像,通过关联匹配组成同一目标的掩膜序列,缺少对视频困难场景的特定处理,忽略对视频时序信息的利用。方法本文设计了一种基于时序特征融合的多任务学习视频实例分割模型。针对普通视频图像质量较差的问题,本模型结合特征金字塔和缩放点积注意力机制,在时间上把其他帧检测到的目标特征加权聚合到当前图像特征上,强化了候选目标的特征响应,抑制背景信息,然后通过融合多尺度特征丰富了图像的空间语义信息。同时,在分割网络模块增加点预测网络,提升了分割准确度,通过多任务学习的方式实现端到端的视频物体同时检测、分割和关联跟踪。结果在YouTube-VIS验证集上的实验表明,与现有方法比较,本文方法在视频实例分割任务上平均精度均值提高了2%左右。对比实验结果证明提出的时序特征融合模块改善了视频分割的效果。结论针对当前视频实例分割工作存在的忽略对视频时序上下文信息的利用,缺少对视频困难场景进行处理的问题,本文提出融合时序特征的多任务学习视频实例分割模型,提升对视频中物体的分割效果。关键词:计算机视觉;实例分割;视频实例分割;缩放点积注意力;多尺度融合196|174|1更新时间:2024-05-07
摘要:目的随着移动互联网和人工智能的蓬勃发展,海量的视频数据不断产生,如何对这些视频数据进行处理分析是研究人员面临的一个挑战性问题。视频中的物体由于拍摄角度、快速运动和部分遮挡等原因常常表现得模糊和多样,与普通图像数据集的质量存在不小差距,这使得对视频数据的实例分割难度较大。目前的视频实例分割框架大多依靠图像检测方法直接处理单帧图像,通过关联匹配组成同一目标的掩膜序列,缺少对视频困难场景的特定处理,忽略对视频时序信息的利用。方法本文设计了一种基于时序特征融合的多任务学习视频实例分割模型。针对普通视频图像质量较差的问题,本模型结合特征金字塔和缩放点积注意力机制,在时间上把其他帧检测到的目标特征加权聚合到当前图像特征上,强化了候选目标的特征响应,抑制背景信息,然后通过融合多尺度特征丰富了图像的空间语义信息。同时,在分割网络模块增加点预测网络,提升了分割准确度,通过多任务学习的方式实现端到端的视频物体同时检测、分割和关联跟踪。结果在YouTube-VIS验证集上的实验表明,与现有方法比较,本文方法在视频实例分割任务上平均精度均值提高了2%左右。对比实验结果证明提出的时序特征融合模块改善了视频分割的效果。结论针对当前视频实例分割工作存在的忽略对视频时序上下文信息的利用,缺少对视频困难场景进行处理的问题,本文提出融合时序特征的多任务学习视频实例分割模型,提升对视频中物体的分割效果。关键词:计算机视觉;实例分割;视频实例分割;缩放点积注意力;多尺度融合196|174|1更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的肝脏肿瘤是人体最具侵袭性的恶性肿瘤之一,传统的肿瘤诊断依靠观察患者的CT(computed tomography)图像,工作量大时易造成疲劳,难免会产生误诊,为此使用计算机辅助的方法进行诊断,但现有的深度学习方法中存在肿瘤分类准确率低、网络的特征表达能力和特征提取能力较弱等问题。对此,本文设计了一种多尺度深度特征提取的分类网络模型。方法首先在原始CT图像中选取感兴趣区域,然后根据CT图像的头文件进行像素值转换,并进行数据增强来扩充构建数据集,最后将处理后的数据输入到本文提出的分类网络模型中输出分类结果。该网络通过多尺度特征提取模块来提取图像的多尺度特征并增加网络的感受野,使用深度特征提取模块降低背景噪声信息,并着重关注病灶区域有效特征,通过集成并行的空洞卷积使得尺度多元化,并将普通卷积用八度卷积替换来减少参数量,提升分类性能,最终实现了对肝脏肿瘤的精确分类。结果本文模型达到了87.74%的最高准确率,比原始模型提升了9.92%;与现有主流分类网络进行比较,多项评价指标占优,达到了86.04%的召回率,87%的精准率,86.42%的F1分数;此外,通过消融实验进一步验证了所提方法的有效性。结论本文方法可以较为准确地对肝脏肿瘤进行分类,将此方法结合到专业的医疗软件当中去,能够为医生早期的诊断和治疗提供可靠依据。关键词:深度学习;肝脏肿瘤分类;多尺度特征;特征提取;空洞卷积66|159|1更新时间:2024-05-07
摘要:目的肝脏肿瘤是人体最具侵袭性的恶性肿瘤之一,传统的肿瘤诊断依靠观察患者的CT(computed tomography)图像,工作量大时易造成疲劳,难免会产生误诊,为此使用计算机辅助的方法进行诊断,但现有的深度学习方法中存在肿瘤分类准确率低、网络的特征表达能力和特征提取能力较弱等问题。对此,本文设计了一种多尺度深度特征提取的分类网络模型。方法首先在原始CT图像中选取感兴趣区域,然后根据CT图像的头文件进行像素值转换,并进行数据增强来扩充构建数据集,最后将处理后的数据输入到本文提出的分类网络模型中输出分类结果。该网络通过多尺度特征提取模块来提取图像的多尺度特征并增加网络的感受野,使用深度特征提取模块降低背景噪声信息,并着重关注病灶区域有效特征,通过集成并行的空洞卷积使得尺度多元化,并将普通卷积用八度卷积替换来减少参数量,提升分类性能,最终实现了对肝脏肿瘤的精确分类。结果本文模型达到了87.74%的最高准确率,比原始模型提升了9.92%;与现有主流分类网络进行比较,多项评价指标占优,达到了86.04%的召回率,87%的精准率,86.42%的F1分数;此外,通过消融实验进一步验证了所提方法的有效性。结论本文方法可以较为准确地对肝脏肿瘤进行分类,将此方法结合到专业的医疗软件当中去,能够为医生早期的诊断和治疗提供可靠依据。关键词:深度学习;肝脏肿瘤分类;多尺度特征;特征提取;空洞卷积66|159|1更新时间:2024-05-07 -
 摘要:目的肺结节是肺癌的早期存在形式。低剂量CT(computed tomogragphy)扫描作为肺癌筛查的重要检查手段,已经大规模应用于健康体检,但巨大的CT数据带来了大量工作,随着人工智能技术的快速发展,基于深度学习的计算机辅助肺结节检测引起了关注。由于肺结节尺寸差别较大,在多个尺度上表示特征对结节检测任务至关重要。针对结节尺寸差别较大导致的结节检测困难问题,提出一种基于深度卷积神经网络的胸部CT序列图像3D多尺度肺结节检测方法。方法包括两阶段:1)尽可能提高敏感度的结节初检网络;2)尽可能减少假阳性结节数量的假阳性降低网络。在结节初检网络中,以组合了压缩激励单元的Res2Net网络为骨干结构,使同一层卷积具有多种感受野,提取肺结节的多尺度特征信息,并使用引入了上下文增强模块和空间注意力模块的区域推荐网络结构,确定候选区域;在由Res2Net网络模块和压缩激励单元组成的假阳性降低网络中对候选结节进一步分类,以降低假阳性,获得最终结果。结果在公共数据集LUNA16(lung nodule analysis 16)上进行实验,实验结果表明,对于结节初检网络阶段,当平均每例假阳性个数为22时,敏感度可达到0.983,相比基准ResNet + FPN(feature pyramid network)方法,平均敏感度和最高敏感度分别提高了2.6%和0.8%;对于整个3D多尺度肺结节检测网络,当平均每例假阳性个数为1时,敏感度为0.924。结论与现有主流方案相比,该检测方法不但提高了肺结节检测的敏感度,还有效地控制了假阳性,取得了更优的性能。关键词:肺结节检测;卷积神经网络(CNN);多尺度;区域推荐网络;上下文增强;空间注意力;假阳性降低85|170|3更新时间:2024-05-07
摘要:目的肺结节是肺癌的早期存在形式。低剂量CT(computed tomogragphy)扫描作为肺癌筛查的重要检查手段,已经大规模应用于健康体检,但巨大的CT数据带来了大量工作,随着人工智能技术的快速发展,基于深度学习的计算机辅助肺结节检测引起了关注。由于肺结节尺寸差别较大,在多个尺度上表示特征对结节检测任务至关重要。针对结节尺寸差别较大导致的结节检测困难问题,提出一种基于深度卷积神经网络的胸部CT序列图像3D多尺度肺结节检测方法。方法包括两阶段:1)尽可能提高敏感度的结节初检网络;2)尽可能减少假阳性结节数量的假阳性降低网络。在结节初检网络中,以组合了压缩激励单元的Res2Net网络为骨干结构,使同一层卷积具有多种感受野,提取肺结节的多尺度特征信息,并使用引入了上下文增强模块和空间注意力模块的区域推荐网络结构,确定候选区域;在由Res2Net网络模块和压缩激励单元组成的假阳性降低网络中对候选结节进一步分类,以降低假阳性,获得最终结果。结果在公共数据集LUNA16(lung nodule analysis 16)上进行实验,实验结果表明,对于结节初检网络阶段,当平均每例假阳性个数为22时,敏感度可达到0.983,相比基准ResNet + FPN(feature pyramid network)方法,平均敏感度和最高敏感度分别提高了2.6%和0.8%;对于整个3D多尺度肺结节检测网络,当平均每例假阳性个数为1时,敏感度为0.924。结论与现有主流方案相比,该检测方法不但提高了肺结节检测的敏感度,还有效地控制了假阳性,取得了更优的性能。关键词:肺结节检测;卷积神经网络(CNN);多尺度;区域推荐网络;上下文增强;空间注意力;假阳性降低85|170|3更新时间:2024-05-07 -
 摘要:目的糖尿病性视网膜病变(diabetic retinopathy,DR)是一种常见的致盲性视网膜疾病,需要患者在早期就能够被诊断并接受治疗,否则将会造成永久性的视力丧失。能否检测到视网膜图像中的微小病变如微血管瘤,是糖尿病性视网膜病变分级的关键。然而这些病变过于细小导致使用一般方法难以正确地辨别。为了解决这一问题,本文提出了一种基于多通道注意力选择机制的细粒度分级方法(fine-grained grading method based on multi-channel attention selection,FGMAS)用于糖尿病性视网膜病变的分级。方法该方法结合了细粒度分类方法和多通道注意力选择机制,通过获取局部特征提升分级的准确度。此外考虑到每一层通道特征信息量与分类置信度的关系,本文引入了排序损失以优化每一层通道的信息量,用于获取更加具有信息量的局部区域。结果使用两个公开的视网膜数据集(Kaggle和Messidor)来评估提出的细粒度分级方法和多通道注意力选择机制的有效性。实验结果表明:FGMAS在Kaggle数据集上进行的五级分类任务中相较于现有方法,在平均准确度(average of classification accuracy,ACA)上取得了3.4%10.4%的提升。尤其是对于病变点最小的1级病变,准确率提升了11%18.9%。此外,本文使用FGMAS在Messidor数据集上进行二分类任务。在推荐转诊/不推荐转诊分类上FGMAS得到的准确度(accuracy,Acc)为0.912,比现有方法提升了0.1%1.9%,同时AUC(area under the curve)为0.962,比现有方法提升了0.5%9.9%;在正常/不正常分类上FGMAS得到的准确度为0.909,比现有方法提升了2.9%8.8%,AUC为0.950,比现有方法提升了0.4%8.9%。实验结果表明,本文方法在五分类和二分类上均优于现有方法。结论本文所提细粒度分级模型,综合了细粒度提取局部区域的思路以及多通道注意力选择机制,可以获得较为准确的分级结果。关键词:糖尿病性视网膜病变(DR);病变分级;细粒度分级;深度学习;多通道注意力选择机制;局部特征提取89|71|3更新时间:2024-05-07
摘要:目的糖尿病性视网膜病变(diabetic retinopathy,DR)是一种常见的致盲性视网膜疾病,需要患者在早期就能够被诊断并接受治疗,否则将会造成永久性的视力丧失。能否检测到视网膜图像中的微小病变如微血管瘤,是糖尿病性视网膜病变分级的关键。然而这些病变过于细小导致使用一般方法难以正确地辨别。为了解决这一问题,本文提出了一种基于多通道注意力选择机制的细粒度分级方法(fine-grained grading method based on multi-channel attention selection,FGMAS)用于糖尿病性视网膜病变的分级。方法该方法结合了细粒度分类方法和多通道注意力选择机制,通过获取局部特征提升分级的准确度。此外考虑到每一层通道特征信息量与分类置信度的关系,本文引入了排序损失以优化每一层通道的信息量,用于获取更加具有信息量的局部区域。结果使用两个公开的视网膜数据集(Kaggle和Messidor)来评估提出的细粒度分级方法和多通道注意力选择机制的有效性。实验结果表明:FGMAS在Kaggle数据集上进行的五级分类任务中相较于现有方法,在平均准确度(average of classification accuracy,ACA)上取得了3.4%10.4%的提升。尤其是对于病变点最小的1级病变,准确率提升了11%18.9%。此外,本文使用FGMAS在Messidor数据集上进行二分类任务。在推荐转诊/不推荐转诊分类上FGMAS得到的准确度(accuracy,Acc)为0.912,比现有方法提升了0.1%1.9%,同时AUC(area under the curve)为0.962,比现有方法提升了0.5%9.9%;在正常/不正常分类上FGMAS得到的准确度为0.909,比现有方法提升了2.9%8.8%,AUC为0.950,比现有方法提升了0.4%8.9%。实验结果表明,本文方法在五分类和二分类上均优于现有方法。结论本文所提细粒度分级模型,综合了细粒度提取局部区域的思路以及多通道注意力选择机制,可以获得较为准确的分级结果。关键词:糖尿病性视网膜病变(DR);病变分级;细粒度分级;深度学习;多通道注意力选择机制;局部特征提取89|71|3更新时间:2024-05-07
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0