
最新刊期
2021 年 第 26 卷 第 3 期
-
 摘要:医学大数据主要包括电子健康档案数据(electronic health record,EHR)、医学影像数据和基因信息数据等,其中医学影像数据占现阶段医学数据的绝大部分。如何将医学大数据应用于临床实践?这是计算机科学研究人员非常关注的问题,医学人工智能提供了一个很好的答案。通过结合医学图像大数据分析方向截至2020年的最新研究进展,以及医学图像大数据分析领域最近的工作,梳理了当前在医学图像领域以核磁共振影像、超声影像、病理和电信号为代表的4个子领域以及部分其他方向使用深度学习进行图像分析的方法理论和主要流程,对不同算法进行结果评价。本文分析了现有算法的优缺点以及医学影像领域的重难点,介绍了智能成像和深度学习在大数据分析以及疾病早期诊断领域的应用,同时展望了本领域未来的发展热点。深度学习在医学影像领域发展迅速,发展前景广阔,对疾病的早期诊断有重要作用,能有效提高医生工作效率并减轻负担,具有重要的理论研究和实际应用价值。关键词:深度学习;目标分割;磁共振图像(MRI);病理;超声;综述199|301|11更新时间:2024-05-07
摘要:医学大数据主要包括电子健康档案数据(electronic health record,EHR)、医学影像数据和基因信息数据等,其中医学影像数据占现阶段医学数据的绝大部分。如何将医学大数据应用于临床实践?这是计算机科学研究人员非常关注的问题,医学人工智能提供了一个很好的答案。通过结合医学图像大数据分析方向截至2020年的最新研究进展,以及医学图像大数据分析领域最近的工作,梳理了当前在医学图像领域以核磁共振影像、超声影像、病理和电信号为代表的4个子领域以及部分其他方向使用深度学习进行图像分析的方法理论和主要流程,对不同算法进行结果评价。本文分析了现有算法的优缺点以及医学影像领域的重难点,介绍了智能成像和深度学习在大数据分析以及疾病早期诊断领域的应用,同时展望了本领域未来的发展热点。深度学习在医学影像领域发展迅速,发展前景广阔,对疾病的早期诊断有重要作用,能有效提高医生工作效率并减轻负担,具有重要的理论研究和实际应用价值。关键词:深度学习;目标分割;磁共振图像(MRI);病理;超声;综述199|301|11更新时间:2024-05-07
学者观点

-
 摘要:数据作为深度学习的驱动力,对于模型的训练至关重要。充足的训练数据不仅可以缓解模型在训练时的过拟合问题,而且可以进一步扩大参数搜索空间,帮助模型进一步朝着全局最优解优化。然而,在许多领域或任务中,获取到充足训练样本的难度和代价非常高。因此,数据增广成为一种常用的增加训练样本的手段。本文对目前深度学习中的图像数据增广方法进行研究综述,梳理了目前深度学习领域为缓解模型过拟合问题而提出的各类数据增广方法,按照方法本质原理的不同,将其分为单数据变形、多数据混合、学习数据分布和学习增广策略等4类方法,并以图像数据为主要研究对象,对各类算法进一步按照核心思想进行细分,并对方法的原理、适用场景和优缺点进行比较和分析,帮助研究者根据数据的特点选用合适的数据增广方法,为后续国内外研究者应用和发展研究数据增广方法提供基础。针对图像的数据增广方法,单数据变形方法主要可以分为几何变换、色域变换、清晰度变换、噪声注入和局部擦除等5种;多数据混合可按照图像维度的混合和特征空间下的混合进行划分;学习数据分布的方法主要基于生成对抗网络和图像风格迁移的应用进行划分;学习增广策略的典型方法则可以按照基于元学习和基于强化学习进行分类。目前,数据增广已然成为推进深度学习在各领域应用的一项重要技术,可以很有效地缓解训练数据不足带来的深度学习模型过拟合的问题,进一步提高模型的精度。在实际应用中可根据数据和任务的特点选择和组合最合适的方法,形成一套有效的数据增广方案,进而为深度学习方法的应用提供更强的动力。在未来,根据数据和任务基于强化学习探索最优的组合策略,基于元学习自适应地学习最优数据变形和混合方式,基于生成对抗网络进一步拟合真实数据分布以采样高质量的未知数据,基于风格迁移探索多模态数据互相转换的应用,这些研究方向十分值得探索并且具有广阔的发展前景。关键词:深度学习;过拟合;数据增广;图像变换;生成对抗网络;元学习;强化学习578|592|18更新时间:2024-05-07
摘要:数据作为深度学习的驱动力,对于模型的训练至关重要。充足的训练数据不仅可以缓解模型在训练时的过拟合问题,而且可以进一步扩大参数搜索空间,帮助模型进一步朝着全局最优解优化。然而,在许多领域或任务中,获取到充足训练样本的难度和代价非常高。因此,数据增广成为一种常用的增加训练样本的手段。本文对目前深度学习中的图像数据增广方法进行研究综述,梳理了目前深度学习领域为缓解模型过拟合问题而提出的各类数据增广方法,按照方法本质原理的不同,将其分为单数据变形、多数据混合、学习数据分布和学习增广策略等4类方法,并以图像数据为主要研究对象,对各类算法进一步按照核心思想进行细分,并对方法的原理、适用场景和优缺点进行比较和分析,帮助研究者根据数据的特点选用合适的数据增广方法,为后续国内外研究者应用和发展研究数据增广方法提供基础。针对图像的数据增广方法,单数据变形方法主要可以分为几何变换、色域变换、清晰度变换、噪声注入和局部擦除等5种;多数据混合可按照图像维度的混合和特征空间下的混合进行划分;学习数据分布的方法主要基于生成对抗网络和图像风格迁移的应用进行划分;学习增广策略的典型方法则可以按照基于元学习和基于强化学习进行分类。目前,数据增广已然成为推进深度学习在各领域应用的一项重要技术,可以很有效地缓解训练数据不足带来的深度学习模型过拟合的问题,进一步提高模型的精度。在实际应用中可根据数据和任务的特点选择和组合最合适的方法,形成一套有效的数据增广方案,进而为深度学习方法的应用提供更强的动力。在未来,根据数据和任务基于强化学习探索最优的组合策略,基于元学习自适应地学习最优数据变形和混合方式,基于生成对抗网络进一步拟合真实数据分布以采样高质量的未知数据,基于风格迁移探索多模态数据互相转换的应用,这些研究方向十分值得探索并且具有广阔的发展前景。关键词:深度学习;过拟合;数据增广;图像变换;生成对抗网络;元学习;强化学习578|592|18更新时间:2024-05-07
综述
-
 摘要:目的双目测距和单目测距是目前常用的两种基于光学传感器的测距方法,双目测距需要相机标定和图像配准,计算量大且测量范围有限,而单目测距减少了对设备和场地的要求,加快了计算时间。为了解决现有的单目测距方法存在精度低、鲁棒性差等缺点,本文提出了一种基于单模糊图像和B样条小波变换的自适应距离测量方法。方法引入拉普拉斯算子量化评估图像模糊程度,并根据模糊程度值自动定位阶跃边缘;利用B样条小波变换代替高斯滤波器主动模糊化目标图像,并通过分析图像模糊程度、模糊次数以及测量误差之间的关系模型,自适应地计算不同景物图像的最优模糊次数;根据最优模糊图像中阶跃边缘两侧模糊程度变化求解目标边缘和相机之间的相对距离。结果本文方法与基于高斯模糊图像的距离测量方法相比精度更高,平均相对误差降低5%。使用不同模糊次数对同样的图像进行距离测量时,本文算法能够自适应选取最优模糊次数,保证所测量距离的精度更高。结论本文提出的单视觉测距方法,综合了传统的方法和B样条小波的优点,测距结果更准确,自适应性和鲁棒性更高。关键词:单目视觉;距离测量;B样条小波;拉普拉斯算子;模糊程度评估56|158|2更新时间:2024-05-07
摘要:目的双目测距和单目测距是目前常用的两种基于光学传感器的测距方法,双目测距需要相机标定和图像配准,计算量大且测量范围有限,而单目测距减少了对设备和场地的要求,加快了计算时间。为了解决现有的单目测距方法存在精度低、鲁棒性差等缺点,本文提出了一种基于单模糊图像和B样条小波变换的自适应距离测量方法。方法引入拉普拉斯算子量化评估图像模糊程度,并根据模糊程度值自动定位阶跃边缘;利用B样条小波变换代替高斯滤波器主动模糊化目标图像,并通过分析图像模糊程度、模糊次数以及测量误差之间的关系模型,自适应地计算不同景物图像的最优模糊次数;根据最优模糊图像中阶跃边缘两侧模糊程度变化求解目标边缘和相机之间的相对距离。结果本文方法与基于高斯模糊图像的距离测量方法相比精度更高,平均相对误差降低5%。使用不同模糊次数对同样的图像进行距离测量时,本文算法能够自适应选取最优模糊次数,保证所测量距离的精度更高。结论本文提出的单视觉测距方法,综合了传统的方法和B样条小波的优点,测距结果更准确,自适应性和鲁棒性更高。关键词:单目视觉;距离测量;B样条小波;拉普拉斯算子;模糊程度评估56|158|2更新时间:2024-05-07
图像处理和编码
-
 摘要:目的表观模型对视觉目标跟踪的性能起着决定性的作用。基于网络调制的跟踪算法通过构建高效的子网络学习参考帧目标的表观信息,以用于测试帧目标的鲁棒匹配,在多个目标跟踪数据集上表现优异。但是,这类跟踪算法忽视了高阶信息对鲁棒建模物体表观的重要作用,致使在物体表观发生大尺度变化时易产生跟踪漂移。为此本文提出全局上下文信息增强的二阶池化调制子网络,以学习高阶特征提升跟踪器的性能。方法首先,利用卷积神经网络(convolutional neural networks,CNN)提取参考帧和测试帧的特征;然后,对提取的特征采用不同方向的长短时记忆网络(long shot-term memory networks,LSTM)捕获每个像素的全局上下文信息,再经过二阶池化网络提取高阶信息;最后,通过调制机制引导测试帧学习最优交并比预测。同时,为提升跟踪器的稳定性,在线跟踪通过指数加权平均自适应更新物体表观特征。结果实验结果表明,在OTB100(object tracking benchmark)数据集上,本文方法的成功率为67.9%,超越跟踪器ATOM(accurate tracking by overlap maximization)1.5%;在VOT(visual object tracking)2018数据集上平均期望重叠率(expected average overlap,EAO)为0.44,超越ATOM 4%。结论本文通过构建全局上下文信息增强的二阶池化调制子网络来学习高效的表观模型,使跟踪器达到目前领先的性能。关键词:视觉目标跟踪(VOT);卷积神经网络(CNN);网络调制;上下文信息;注意力机制68|110|1更新时间:2024-05-07
摘要:目的表观模型对视觉目标跟踪的性能起着决定性的作用。基于网络调制的跟踪算法通过构建高效的子网络学习参考帧目标的表观信息,以用于测试帧目标的鲁棒匹配,在多个目标跟踪数据集上表现优异。但是,这类跟踪算法忽视了高阶信息对鲁棒建模物体表观的重要作用,致使在物体表观发生大尺度变化时易产生跟踪漂移。为此本文提出全局上下文信息增强的二阶池化调制子网络,以学习高阶特征提升跟踪器的性能。方法首先,利用卷积神经网络(convolutional neural networks,CNN)提取参考帧和测试帧的特征;然后,对提取的特征采用不同方向的长短时记忆网络(long shot-term memory networks,LSTM)捕获每个像素的全局上下文信息,再经过二阶池化网络提取高阶信息;最后,通过调制机制引导测试帧学习最优交并比预测。同时,为提升跟踪器的稳定性,在线跟踪通过指数加权平均自适应更新物体表观特征。结果实验结果表明,在OTB100(object tracking benchmark)数据集上,本文方法的成功率为67.9%,超越跟踪器ATOM(accurate tracking by overlap maximization)1.5%;在VOT(visual object tracking)2018数据集上平均期望重叠率(expected average overlap,EAO)为0.44,超越ATOM 4%。结论本文通过构建全局上下文信息增强的二阶池化调制子网络来学习高效的表观模型,使跟踪器达到目前领先的性能。关键词:视觉目标跟踪(VOT);卷积神经网络(CNN);网络调制;上下文信息;注意力机制68|110|1更新时间:2024-05-07 -
 摘要:目的针对相关滤波跟踪算法,目标与周围背景进行等值权重训练滤波器导致目标与背景信息相似时,易出现目标漂移问题,本文提出一种基于背景与方向感知的相关滤波跟踪算法。方法将目标周围的背景信息学习到滤波器中,利用卡尔曼滤波预测目标的运动状态和运动方向,提取目标运动方向上的背景信息,将目标运动方向上与非运动方向上的背景信息进行滤波器训练,保证分配给目标运动方向上背景信息的训练权重高于非运动方向上的权重,增加滤波器对目标和背景信息的分辨能力,采用线性插值法得到最大响应值,用于确定目标位置;构造辅助因子g,利用增广拉格朗日乘子法(augmented Lagrange method,ALM)将约束项放到优化函数里,采用交替求解算法(alternating direction method of multipliers,ADMM)将求解目标问题转化为求滤波器和辅助因子的最优解,降低计算复杂度;采用多分辨率搜索方法来估计目标变换的尺度。结果在数据集OTB50(object tracking benchmark)和OTB100上的平均精确率和平均成功率分别为0.804和0.748,相比BACF(background-aware correlation filters)算法分别提高了7%和16%;在数据集LaSOT上本文算法精确率为0.329,相比BACF(0.239)的精确率得分,更能体现本文算法的鲁棒性。结论与其他主流算法相比,本文算法在运动模糊、背景杂乱和形变等复杂条件下跟踪效果更加鲁棒。关键词:计算机视觉;目标跟踪;相关滤波;背景感知;卡尔曼滤波;交替求解算法(ADMM)121|222|5更新时间:2024-05-07
摘要:目的针对相关滤波跟踪算法,目标与周围背景进行等值权重训练滤波器导致目标与背景信息相似时,易出现目标漂移问题,本文提出一种基于背景与方向感知的相关滤波跟踪算法。方法将目标周围的背景信息学习到滤波器中,利用卡尔曼滤波预测目标的运动状态和运动方向,提取目标运动方向上的背景信息,将目标运动方向上与非运动方向上的背景信息进行滤波器训练,保证分配给目标运动方向上背景信息的训练权重高于非运动方向上的权重,增加滤波器对目标和背景信息的分辨能力,采用线性插值法得到最大响应值,用于确定目标位置;构造辅助因子g,利用增广拉格朗日乘子法(augmented Lagrange method,ALM)将约束项放到优化函数里,采用交替求解算法(alternating direction method of multipliers,ADMM)将求解目标问题转化为求滤波器和辅助因子的最优解,降低计算复杂度;采用多分辨率搜索方法来估计目标变换的尺度。结果在数据集OTB50(object tracking benchmark)和OTB100上的平均精确率和平均成功率分别为0.804和0.748,相比BACF(background-aware correlation filters)算法分别提高了7%和16%;在数据集LaSOT上本文算法精确率为0.329,相比BACF(0.239)的精确率得分,更能体现本文算法的鲁棒性。结论与其他主流算法相比,本文算法在运动模糊、背景杂乱和形变等复杂条件下跟踪效果更加鲁棒。关键词:计算机视觉;目标跟踪;相关滤波;背景感知;卡尔曼滤波;交替求解算法(ADMM)121|222|5更新时间:2024-05-07 -
 摘要:目的视频目标检测旨在序列图像中定位运动目标,并为各个目标分配指定的类别标签。视频目标检测存在目标模糊和多目标遮挡等问题,现有的大部分视频目标检测方法是在静态图像目标检测的基础上,通过考虑时空一致性来提高运动目标检测的准确率,但由于运动目标存在遮挡、模糊等现象,目前视频目标检测的鲁棒性不高。为此,本文提出了一种单阶段多框检测(single shot multibox detector,SSD)与时空特征融合的视频目标检测模型。方法在单阶段目标检测的SSD模型框架下,利用光流网络估计当前帧与近邻帧之间的光流场,结合多个近邻帧的特征对当前帧的特征进行运动补偿,并利用特征金字塔网络提取多尺度特征用于检测不同尺寸的目标,最后通过高低层特征融合增强低层特征的语义信息。结果实验结果表明,本文模型在ImageNet VID(Imagelvet for video object detetion)数据集上的mAP(mean average precision)为72.0%,相对于TCN(temporal convolutional networks)模型、TPN+LSTM(tubelet proposal network and long short term memory network)模型和SSD+孪生网络模型,分别提高了24.5%、3.6%和2.5%,在不同结构网络模型上的分离实验进一步验证了本文模型的有效性。结论本文模型利用视频特有的时间相关性和空间相关性,通过时空特征融合提高了视频目标检测的准确率,较好地解决了视频目标检测中目标漏检和误检的问题。关键词:目标检测;单阶段多框检测;特征融合;光流;特征金字塔网络98|212|7更新时间:2024-05-07
摘要:目的视频目标检测旨在序列图像中定位运动目标,并为各个目标分配指定的类别标签。视频目标检测存在目标模糊和多目标遮挡等问题,现有的大部分视频目标检测方法是在静态图像目标检测的基础上,通过考虑时空一致性来提高运动目标检测的准确率,但由于运动目标存在遮挡、模糊等现象,目前视频目标检测的鲁棒性不高。为此,本文提出了一种单阶段多框检测(single shot multibox detector,SSD)与时空特征融合的视频目标检测模型。方法在单阶段目标检测的SSD模型框架下,利用光流网络估计当前帧与近邻帧之间的光流场,结合多个近邻帧的特征对当前帧的特征进行运动补偿,并利用特征金字塔网络提取多尺度特征用于检测不同尺寸的目标,最后通过高低层特征融合增强低层特征的语义信息。结果实验结果表明,本文模型在ImageNet VID(Imagelvet for video object detetion)数据集上的mAP(mean average precision)为72.0%,相对于TCN(temporal convolutional networks)模型、TPN+LSTM(tubelet proposal network and long short term memory network)模型和SSD+孪生网络模型,分别提高了24.5%、3.6%和2.5%,在不同结构网络模型上的分离实验进一步验证了本文模型的有效性。结论本文模型利用视频特有的时间相关性和空间相关性,通过时空特征融合提高了视频目标检测的准确率,较好地解决了视频目标检测中目标漏检和误检的问题。关键词:目标检测;单阶段多框检测;特征融合;光流;特征金字塔网络98|212|7更新时间:2024-05-07 -
 摘要:目的随着智能交通领域车牌应用需求的升级,以及车牌图像复杂性的提高,自然场景下的车牌识别面临挑战。为应对自然场景下车牌的不规则变形问题,充分考虑车牌的形状特征,提出了一种自然场景下的变形车牌检测模型DLPD-Net(distorted license plate detection network)。方法该模型首次将免锚框目标检测方法应用于车牌检测任务中,不再使用锚框获取车牌候选区域,而是基于车牌热力值图与偏移值图来预测车牌中心;然后基于仿射变换寻找车牌角点位置,将变形车牌校正为接近于正面视角的平面矩形,从而实现在各种自然场景下变形车牌的检测。结果一方面,基于数据集CD-HARD评估DLPD-Net检测算法的性能;另一方面,基于数据集AOLP(the application-oriented license plate database)和CD-HARD评估基于DLPD-Net的车牌识别系统的有效性。实验结果表明,DLPD-Net具有更好的变形车牌检测性能,能够提升车牌识别系统的识别准确率,在数据集CD-HARD上识别准确率为79.4%,高出其他方法4.4% 12.1%,平均处理时间为237 ms。在数据集AOLP上取得了96.6%的识别准确率,未使用扩充数据集的情况下识别准确率达到了94.9%,高出其他方法1.6% 25.2%,平均处理时间为185 ms。结论本文提出的自然场景下的变形车牌检测模型DLPD-Net,能够实现在多种变形条件下的车牌检测,鲁棒性强,对遮挡、污垢和图像模糊等复杂自然环境下的车牌检测具有良好检测效果,同时,基于该检测模型的车牌识别系统在非受限的自然场景下具有更高的实用性。关键词:自动车牌识别(ALPR);深度学习;车牌检测;车牌校正;字符识别82|125|1更新时间:2024-05-07
摘要:目的随着智能交通领域车牌应用需求的升级,以及车牌图像复杂性的提高,自然场景下的车牌识别面临挑战。为应对自然场景下车牌的不规则变形问题,充分考虑车牌的形状特征,提出了一种自然场景下的变形车牌检测模型DLPD-Net(distorted license plate detection network)。方法该模型首次将免锚框目标检测方法应用于车牌检测任务中,不再使用锚框获取车牌候选区域,而是基于车牌热力值图与偏移值图来预测车牌中心;然后基于仿射变换寻找车牌角点位置,将变形车牌校正为接近于正面视角的平面矩形,从而实现在各种自然场景下变形车牌的检测。结果一方面,基于数据集CD-HARD评估DLPD-Net检测算法的性能;另一方面,基于数据集AOLP(the application-oriented license plate database)和CD-HARD评估基于DLPD-Net的车牌识别系统的有效性。实验结果表明,DLPD-Net具有更好的变形车牌检测性能,能够提升车牌识别系统的识别准确率,在数据集CD-HARD上识别准确率为79.4%,高出其他方法4.4% 12.1%,平均处理时间为237 ms。在数据集AOLP上取得了96.6%的识别准确率,未使用扩充数据集的情况下识别准确率达到了94.9%,高出其他方法1.6% 25.2%,平均处理时间为185 ms。结论本文提出的自然场景下的变形车牌检测模型DLPD-Net,能够实现在多种变形条件下的车牌检测,鲁棒性强,对遮挡、污垢和图像模糊等复杂自然环境下的车牌检测具有良好检测效果,同时,基于该检测模型的车牌识别系统在非受限的自然场景下具有更高的实用性。关键词:自动车牌识别(ALPR);深度学习;车牌检测;车牌校正;字符识别82|125|1更新时间:2024-05-07 -
 摘要:目的传统以先验知识为基础的去雾算法,如最大化饱和度、暗通道等,在某些特定场景下效果非常不稳定,会出现色彩扭曲和光晕等现象。由于标注好的训练数据严重不足、特征的冗余性等原因,传统基于学习的去雾算法容易导致模型过拟合。为克服这些问题,本文提出一种基于两阶段特征提取的场景透射率回归去雾方法。方法在第1阶段,提取图像在颜色空间上的饱和度、最小通道、最大通道以及灰度图的盖博响应等43维特征作为初始雾的特征,并在提取的特征图像局部窗口内,进一步提取最小值、最大值、均值、方差、偏度、峰度、高斯均值等7维特征。在第2阶段,将提取的43×7=301个维度特征组成表征雾的二阶段特征向量。最后采用支持向量机进行训练,得到雾的特征向量和场景透射率的回归模型。结果实验结果表明,本文算法取得了非常好的去雾效果。平均梯度值为4.475,高于所有对比算法;峰值信噪比为18.150 dB,仅次于多尺度卷积神经网络去雾算法;结构相似性为0.867,处于较高水平;去雾后的亮度和对比度,也均排于前列。本文算法的去雾测试性能接近甚至超过了已有的基于深度学习的去雾算法,表明本文提出的两阶段特征能够很好地对雾进行表征,实现了小样本学习的高效去雾。结论本文通过两阶段的特征提取策略,极大提升了算法的鲁棒性,仅需要极少量样本就能训练得到性能很好的去雾模型,具有很好的泛化性能。关键词:图像去雾;图像增强;特征提取;支持向量机(SVM);机器学习108|276|4更新时间:2024-05-07
摘要:目的传统以先验知识为基础的去雾算法,如最大化饱和度、暗通道等,在某些特定场景下效果非常不稳定,会出现色彩扭曲和光晕等现象。由于标注好的训练数据严重不足、特征的冗余性等原因,传统基于学习的去雾算法容易导致模型过拟合。为克服这些问题,本文提出一种基于两阶段特征提取的场景透射率回归去雾方法。方法在第1阶段,提取图像在颜色空间上的饱和度、最小通道、最大通道以及灰度图的盖博响应等43维特征作为初始雾的特征,并在提取的特征图像局部窗口内,进一步提取最小值、最大值、均值、方差、偏度、峰度、高斯均值等7维特征。在第2阶段,将提取的43×7=301个维度特征组成表征雾的二阶段特征向量。最后采用支持向量机进行训练,得到雾的特征向量和场景透射率的回归模型。结果实验结果表明,本文算法取得了非常好的去雾效果。平均梯度值为4.475,高于所有对比算法;峰值信噪比为18.150 dB,仅次于多尺度卷积神经网络去雾算法;结构相似性为0.867,处于较高水平;去雾后的亮度和对比度,也均排于前列。本文算法的去雾测试性能接近甚至超过了已有的基于深度学习的去雾算法,表明本文提出的两阶段特征能够很好地对雾进行表征,实现了小样本学习的高效去雾。结论本文通过两阶段的特征提取策略,极大提升了算法的鲁棒性,仅需要极少量样本就能训练得到性能很好的去雾模型,具有很好的泛化性能。关键词:图像去雾;图像增强;特征提取;支持向量机(SVM);机器学习108|276|4更新时间:2024-05-07
图像分析和识别
-
 摘要:目的散焦模糊检测致力于区分图像中的清晰与模糊像素,广泛应用于诸多领域,是计算机视觉中的重要研究方向。待检测图像含复杂场景时,现有的散焦模糊检测方法存在精度不够高、检测结果边界不完整等问题。本文提出一种由粗到精的多尺度散焦模糊检测网络,通过融合不同尺度下图像的多层卷积特征提高散焦模糊的检测精度。方法将图像缩放至不同尺度,使用卷积神经网络从每个尺度下的图像中提取多层卷积特征,并使用卷积层融合不同尺度图像对应层的特征;使用卷积长短时记忆(convolutional long-short term memory,Conv-LSTM)层自顶向下地整合不同尺度的模糊特征,同时生成对应尺度的模糊检测图,以这种方式将深层的语义信息逐步传递至浅层网络;在此过程中,将深浅层特征联合,利用浅层特征细化深一层的模糊检测结果;使用卷积层将多尺度检测结果融合得到最终结果。本文在网络训练过程中使用了多层监督策略确保每个Conv-LSTM层都能达到最优。结果在DUT(Dalian University of Technology)和CUHK(The Chinese University of Hong Kong)两个公共的模糊检测数据集上进行训练和测试,对比了包括当前最好的模糊检测算法BTBCRL(bottom-top-bottom network with cascaded defocus blur detection map residual learning),DeFusionNet(defocus blur detection network via recurrently fusing and refining multi-scale deep features)和DHDE(multi-scale deep and hand-crafted features for defocus estimation)等10种算法。实验结果表明:在DUT数据集上,本文模型相比于DeFusionNet模型,MAE(mean absolute error)值降低了38.8%,F0.3值提高了5.4%;在CUHK数据集上,相比于LBP(local binary pattern)算法,MAE值降低了36.7%,F0.3值提高了9.7%。通过实验对比,充分验证了本文提出的散焦模糊检测模型的有效性。结论本文提出的由粗到精的多尺度散焦模糊检测方法,通过融合不同尺度图像的特征,以及使用卷积长短时记忆层自顶向下地整合深层的语义信息和浅层的细节信息,使得模型在不同的图像场景中能得到更加准确的散焦模糊检测结果。关键词:散焦模糊检测(DBD);多尺度特征;卷积长短时记忆(Conv-LSTM);由粗到精;多层监督77|50|1更新时间:2024-05-07
摘要:目的散焦模糊检测致力于区分图像中的清晰与模糊像素,广泛应用于诸多领域,是计算机视觉中的重要研究方向。待检测图像含复杂场景时,现有的散焦模糊检测方法存在精度不够高、检测结果边界不完整等问题。本文提出一种由粗到精的多尺度散焦模糊检测网络,通过融合不同尺度下图像的多层卷积特征提高散焦模糊的检测精度。方法将图像缩放至不同尺度,使用卷积神经网络从每个尺度下的图像中提取多层卷积特征,并使用卷积层融合不同尺度图像对应层的特征;使用卷积长短时记忆(convolutional long-short term memory,Conv-LSTM)层自顶向下地整合不同尺度的模糊特征,同时生成对应尺度的模糊检测图,以这种方式将深层的语义信息逐步传递至浅层网络;在此过程中,将深浅层特征联合,利用浅层特征细化深一层的模糊检测结果;使用卷积层将多尺度检测结果融合得到最终结果。本文在网络训练过程中使用了多层监督策略确保每个Conv-LSTM层都能达到最优。结果在DUT(Dalian University of Technology)和CUHK(The Chinese University of Hong Kong)两个公共的模糊检测数据集上进行训练和测试,对比了包括当前最好的模糊检测算法BTBCRL(bottom-top-bottom network with cascaded defocus blur detection map residual learning),DeFusionNet(defocus blur detection network via recurrently fusing and refining multi-scale deep features)和DHDE(multi-scale deep and hand-crafted features for defocus estimation)等10种算法。实验结果表明:在DUT数据集上,本文模型相比于DeFusionNet模型,MAE(mean absolute error)值降低了38.8%,F0.3值提高了5.4%;在CUHK数据集上,相比于LBP(local binary pattern)算法,MAE值降低了36.7%,F0.3值提高了9.7%。通过实验对比,充分验证了本文提出的散焦模糊检测模型的有效性。结论本文提出的由粗到精的多尺度散焦模糊检测方法,通过融合不同尺度图像的特征,以及使用卷积长短时记忆层自顶向下地整合深层的语义信息和浅层的细节信息,使得模型在不同的图像场景中能得到更加准确的散焦模糊检测结果。关键词:散焦模糊检测(DBD);多尺度特征;卷积长短时记忆(Conv-LSTM);由粗到精;多层监督77|50|1更新时间:2024-05-07 -
 摘要:目的生成式对抗网络(generative adversarial network,GAN)是一种无监督生成模型,通过生成模型和判别模型的博弈学习生成图像。GAN的生成模型是逐级直接生成图像,下级网络无法得知上级网络学习的特征,以至于生成的图像多样性不够丰富。另外,随着网络层数的增加,参数变多,反向传播变得困难,出现训练不稳定和梯度消失等问题。针对上述问题,基于残差网络(residual network,ResNet)和组标准化(group normalization,GN),提出了一种残差生成式对抗网络(residual generative adversarial networks,Re-GAN)。方法Re-GAN在生成模型中构建深度残差网络模块,通过跳连接的方式融合上级网络学习的特征,增强生成图像的多样性和质量,改善反向传播过程,增强生成式对抗网络的训练稳定性,缓解梯度消失。随后采用组标准化(GN)来适应不同批次的学习,使训练过程更加稳定。结果在Cifar10、CelebA和LSUN数据集上对算法的性能进行测试。Re-GAN的IS(inception score)均值在批次为64时,比DCGAN(deep convolutional GAN)和WGAN(Wasserstein-GAN)分别提高了5%和30%,在批次为4时,比DCGAN和WGAN分别提高了0.2%和13%,表明无论批次大小,Re-GAN生成图像具有很好的多样性。Re-GAN的FID(Fréchet inception distance)在批次为64时比DCGAN和WGAN分别降低了18%和11%,在批次为4时比DCGAN和WGAN分别降低了4%和10%,表明Re-GAN生成图像的质量更好。同时,Re-GAN缓解了训练过程中出现的训练不稳定和梯度消失等问题。结论实验结果表明,在图像生成方面,Re-GAN的生成图像质量高、多样性强;在网络训练方面,Re-GAN在不同批次下的训练具有更好的兼容性,使训练过程更加稳定,梯度消失得到缓解。关键词:图像生成;深度学习;卷积神经网络;生成式对抗网络;残差网络;组标准化252|308|5更新时间:2024-05-07
摘要:目的生成式对抗网络(generative adversarial network,GAN)是一种无监督生成模型,通过生成模型和判别模型的博弈学习生成图像。GAN的生成模型是逐级直接生成图像,下级网络无法得知上级网络学习的特征,以至于生成的图像多样性不够丰富。另外,随着网络层数的增加,参数变多,反向传播变得困难,出现训练不稳定和梯度消失等问题。针对上述问题,基于残差网络(residual network,ResNet)和组标准化(group normalization,GN),提出了一种残差生成式对抗网络(residual generative adversarial networks,Re-GAN)。方法Re-GAN在生成模型中构建深度残差网络模块,通过跳连接的方式融合上级网络学习的特征,增强生成图像的多样性和质量,改善反向传播过程,增强生成式对抗网络的训练稳定性,缓解梯度消失。随后采用组标准化(GN)来适应不同批次的学习,使训练过程更加稳定。结果在Cifar10、CelebA和LSUN数据集上对算法的性能进行测试。Re-GAN的IS(inception score)均值在批次为64时,比DCGAN(deep convolutional GAN)和WGAN(Wasserstein-GAN)分别提高了5%和30%,在批次为4时,比DCGAN和WGAN分别提高了0.2%和13%,表明无论批次大小,Re-GAN生成图像具有很好的多样性。Re-GAN的FID(Fréchet inception distance)在批次为64时比DCGAN和WGAN分别降低了18%和11%,在批次为4时比DCGAN和WGAN分别降低了4%和10%,表明Re-GAN生成图像的质量更好。同时,Re-GAN缓解了训练过程中出现的训练不稳定和梯度消失等问题。结论实验结果表明,在图像生成方面,Re-GAN的生成图像质量高、多样性强;在网络训练方面,Re-GAN在不同批次下的训练具有更好的兼容性,使训练过程更加稳定,梯度消失得到缓解。关键词:图像生成;深度学习;卷积神经网络;生成式对抗网络;残差网络;组标准化252|308|5更新时间:2024-05-07 -
 摘要:目的基于神经网络的图像超分辨率重建技术主要是通过单一网络非线性映射学习得到高低分辨率之间特征信息关系来进行重建,在此过程中较浅网络的图像特征信息很容易丢失,加深网络深度又会增加网络训练时间和训练难度。针对此过程出现的训练时间长、重建结果细节信息较模糊等问题,提出一种多通道递归残差学习机制,以提高网络训练效率和图像重建质量。方法设计一种多通道递归残差网络模型,该模型首先利用递归方法将残差网络块进行复用,形成32层递归网络,来减少网络参数、增加网络深度,以加速网络收敛并获取更丰富的特征信息。然后采集不同卷积核下的特征信息,输入到各通道对应的递归残差网络后再一起输入到共用的重建网络中,提高对细节信息的重建能力。最后引入一种交叉学习机制,将通道1、2、3两两排列组合交叉相连,进一步加速不同通道特征信息融合、促进参数传递、提高网络重建性能。结果本文模型使用DIV2K(DIVerse 2K)数据集进行训练,在Set5、Set14、BSD100和Urban100数据集上进行测试,并与Bicubic、SRCNN(super-resolution convolutional neural network)、VDSR(super-resolution using very deep convolutional network)、LapSRN(deep Laplacian pyramid networks for fast and accurate super-resolution)和EDSR_baseline(enhanced deep residual networks for single image super-resolution_baseline)等方法的实验结果进行对比,结果显示前者获取细节特征信息能力提高,图像有了更清晰丰富的细节信息;客观数据方面,本文算法的数据有明显的提升,尤其在细节信息较多的Urban100数据集中PSNR(peak signal-to-noise ratio)平均分别提升了3.87 dB、1.93 dB、1.00 dB、1.12 dB和0.48 dB,网络训练效率相较非递归残差网络提升30%。结论本文模型可获得更好的视觉效果和客观质量评价,而且相较非递归残差网络训练过程耗时更短,可用于复杂场景下图像的超分辨率重建。关键词:超分辨重建;多通道;递归;交叉;残差网络模型114|476|25更新时间:2024-05-07
摘要:目的基于神经网络的图像超分辨率重建技术主要是通过单一网络非线性映射学习得到高低分辨率之间特征信息关系来进行重建,在此过程中较浅网络的图像特征信息很容易丢失,加深网络深度又会增加网络训练时间和训练难度。针对此过程出现的训练时间长、重建结果细节信息较模糊等问题,提出一种多通道递归残差学习机制,以提高网络训练效率和图像重建质量。方法设计一种多通道递归残差网络模型,该模型首先利用递归方法将残差网络块进行复用,形成32层递归网络,来减少网络参数、增加网络深度,以加速网络收敛并获取更丰富的特征信息。然后采集不同卷积核下的特征信息,输入到各通道对应的递归残差网络后再一起输入到共用的重建网络中,提高对细节信息的重建能力。最后引入一种交叉学习机制,将通道1、2、3两两排列组合交叉相连,进一步加速不同通道特征信息融合、促进参数传递、提高网络重建性能。结果本文模型使用DIV2K(DIVerse 2K)数据集进行训练,在Set5、Set14、BSD100和Urban100数据集上进行测试,并与Bicubic、SRCNN(super-resolution convolutional neural network)、VDSR(super-resolution using very deep convolutional network)、LapSRN(deep Laplacian pyramid networks for fast and accurate super-resolution)和EDSR_baseline(enhanced deep residual networks for single image super-resolution_baseline)等方法的实验结果进行对比,结果显示前者获取细节特征信息能力提高,图像有了更清晰丰富的细节信息;客观数据方面,本文算法的数据有明显的提升,尤其在细节信息较多的Urban100数据集中PSNR(peak signal-to-noise ratio)平均分别提升了3.87 dB、1.93 dB、1.00 dB、1.12 dB和0.48 dB,网络训练效率相较非递归残差网络提升30%。结论本文模型可获得更好的视觉效果和客观质量评价,而且相较非递归残差网络训练过程耗时更短,可用于复杂场景下图像的超分辨率重建。关键词:超分辨重建;多通道;递归;交叉;残差网络模型114|476|25更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的降水是影响全球气候变化和系统环境的重要因素,面向降水数据开展时空关联分析,对于区域气候特征探索及异常情况监测具有重要的意义。然而,降水时空关联特征的分析是一个复杂且耗时的过程,与气象站点的空间分布以及降水的时间序列密切相关。本文综合考虑降水的时空变化特征,研究和设计面向降水数据时空关联特征分析的可视化系统工具。方法利用地图和矩阵图呈现降水数据的空间分布和周期变化特征,设计径向盒须图对降水数据的时空变化异常特征进行捕获;通过局部Moran's I指数的计算和热力图的呈现表达降水的空间相关性,支持用户交互式地探索空间相关性的时序变化特征;利用普通克里金插值模型获得降水空间插值图,并对插值结果的准确性进行可视化评估。结果以中国安徽省1971-2014年气象观测站长时间序列月降水数据集为例进行分析,实验结果证明本研究可视化交互系统能够直观高效地探索区域降水长时间序列时空变化特征和极端降水情况;有效探究区域降水空间分布模式、不同站点降水信息间空间依赖性和异质性,并快速发现降水奇异点;分析区域不同时间尺度降水气候特征空间变化。结论系统工具集成便捷的交互模式,支持用户探索式地分析降水数据的时空关联特征,进而有效地探究区域气候变化规律和特征分布关系。基于真实降水数据的实验结果以及降水领域专家的反馈,进一步验证了本文系统工具的有效性和实用性。关键词:降水;时空关联特征;周期变化特征;Moran's I指数;普通克里金插值125|140|0更新时间:2024-05-07
摘要:目的降水是影响全球气候变化和系统环境的重要因素,面向降水数据开展时空关联分析,对于区域气候特征探索及异常情况监测具有重要的意义。然而,降水时空关联特征的分析是一个复杂且耗时的过程,与气象站点的空间分布以及降水的时间序列密切相关。本文综合考虑降水的时空变化特征,研究和设计面向降水数据时空关联特征分析的可视化系统工具。方法利用地图和矩阵图呈现降水数据的空间分布和周期变化特征,设计径向盒须图对降水数据的时空变化异常特征进行捕获;通过局部Moran's I指数的计算和热力图的呈现表达降水的空间相关性,支持用户交互式地探索空间相关性的时序变化特征;利用普通克里金插值模型获得降水空间插值图,并对插值结果的准确性进行可视化评估。结果以中国安徽省1971-2014年气象观测站长时间序列月降水数据集为例进行分析,实验结果证明本研究可视化交互系统能够直观高效地探索区域降水长时间序列时空变化特征和极端降水情况;有效探究区域降水空间分布模式、不同站点降水信息间空间依赖性和异质性,并快速发现降水奇异点;分析区域不同时间尺度降水气候特征空间变化。结论系统工具集成便捷的交互模式,支持用户探索式地分析降水数据的时空关联特征,进而有效地探究区域气候变化规律和特征分布关系。基于真实降水数据的实验结果以及降水领域专家的反馈,进一步验证了本文系统工具的有效性和实用性。关键词:降水;时空关联特征;周期变化特征;Moran's I指数;普通克里金插值125|140|0更新时间:2024-05-07
计算机图形学
-
 摘要:目的乳腺癌是常见的高发病率肿瘤疾病,早期确诊是预防乳腺癌的关键。为获得肿瘤准确的边缘和形状信息,提高乳腺肿瘤诊断的准确性,本文提出了一种结合残差路径及密集连接的乳腺超声肿瘤分割方法。方法基于经典的深度学习分割模型U-Net,添加残差路径,减少编码器和解码器特征映射之间的差异。在此基础上,在特征输入层到解码器最后一步之间引入密集块,通过密集块组成从输入特征映射到解码最后一层的新连接,减少输入特征图与解码特征图之间的差距,减少特征损失并保存更有效信息。结果将本文模型与经典的U-Net模型、引入残差路径的U-Net(U-Net with Res paths)模型在上海新华医院崇明分院乳腺肿瘤超声数据集上进行10-fold交叉验证实验。本文模型的真阳率(true positive,TP)、杰卡德相似系数(Jaccard similarity,JS)和骰子系数(Dice coefficients,DC)分别为0.870 7、0.803 7和0.882 4,相比U-Net模型分别提高了1.08%、2.14%和2.01%;假阳率(false positive,FP)和豪斯多夫距离(Hausdorff distance,HD)分别为0.104 0和22.311 4,相比U-Net模型分别下降了1.68%和1.410 2。在54幅图像的测试集中,评价指标JS > 0.75的肿瘤图像数量的总平均数为42.1,最大值为46。对比实验结果表明,提出的算法有效改善了分割结果,提高了分割的准确性。结论本文提出的基于U-Net结构并结合残差路径与新的连接的分割模型,改善了乳腺超声肿瘤图像分割的精确度。关键词:肿瘤分割;乳腺超声;卷积网络;残差路径;密集块48|163|0更新时间:2024-05-07
摘要:目的乳腺癌是常见的高发病率肿瘤疾病,早期确诊是预防乳腺癌的关键。为获得肿瘤准确的边缘和形状信息,提高乳腺肿瘤诊断的准确性,本文提出了一种结合残差路径及密集连接的乳腺超声肿瘤分割方法。方法基于经典的深度学习分割模型U-Net,添加残差路径,减少编码器和解码器特征映射之间的差异。在此基础上,在特征输入层到解码器最后一步之间引入密集块,通过密集块组成从输入特征映射到解码最后一层的新连接,减少输入特征图与解码特征图之间的差距,减少特征损失并保存更有效信息。结果将本文模型与经典的U-Net模型、引入残差路径的U-Net(U-Net with Res paths)模型在上海新华医院崇明分院乳腺肿瘤超声数据集上进行10-fold交叉验证实验。本文模型的真阳率(true positive,TP)、杰卡德相似系数(Jaccard similarity,JS)和骰子系数(Dice coefficients,DC)分别为0.870 7、0.803 7和0.882 4,相比U-Net模型分别提高了1.08%、2.14%和2.01%;假阳率(false positive,FP)和豪斯多夫距离(Hausdorff distance,HD)分别为0.104 0和22.311 4,相比U-Net模型分别下降了1.68%和1.410 2。在54幅图像的测试集中,评价指标JS > 0.75的肿瘤图像数量的总平均数为42.1,最大值为46。对比实验结果表明,提出的算法有效改善了分割结果,提高了分割的准确性。结论本文提出的基于U-Net结构并结合残差路径与新的连接的分割模型,改善了乳腺超声肿瘤图像分割的精确度。关键词:肿瘤分割;乳腺超声;卷积网络;残差路径;密集块48|163|0更新时间:2024-05-07
医学图像处理
-
 摘要:目的航空遥感图像中多为尺寸小、方向错乱和背景复杂的目标。传统的目标检测算法由于模型的特征提取网络对输入图像进行多次下采样,分辨率大幅降低,容易造成目标特征信息丢失,而且不同尺度的特征图未能有效融合,检测目标之间存在的相似特征不能有效关联,不仅时间复杂度高,而且提取的特征信息不足,导致目标漏检率和误检率偏高。为了提升算法对航空遥感图像目标的检测准确率,本文提出一种基于并行高分辨率结构结合长短期记忆网络(long short-term memory,LSTM)的目标检测算法。方法首先,构建并行高分辨率网络结构,由高分辨率子网络作为第1阶段,分辨率从高到低逐步增加子网络,将多个子网并行连接,构建子网时对不同分辨率的特征图反复融合,以增强目标特征表达;其次,对各个子网提取的特征图进行双线性插值上采样,并拼接通道特征;最后,使用双向LSTM整合通道特征信息,完成多尺度检测。结果将本文提出的检测算法在COCO(common objects in context)2017数据集、KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)车辆检测和UCAS-AOD(University of Chinese Academy of Sciences-Aerial Object Detection)航空遥感数据集上进行实验验证,平均检测准确率(mean average precision,mAP)分别为41.6%、69.4%和69.3%。在COCO 2017、KITTI和VCAS-AOD数据集上,本文算法与SSD513算法相比,平均检测准确率分别提升10.46%、7.3%、8.8%。结论本文方法有效提高了航空遥感图像中目标的平均检测准确率。关键词:航空遥感图像;机器视觉;小目标检测;并行高分辨率网络;长短期记忆网络;COCO数据集;UCAS-AOD数据集232|204|12更新时间:2024-05-07
摘要:目的航空遥感图像中多为尺寸小、方向错乱和背景复杂的目标。传统的目标检测算法由于模型的特征提取网络对输入图像进行多次下采样,分辨率大幅降低,容易造成目标特征信息丢失,而且不同尺度的特征图未能有效融合,检测目标之间存在的相似特征不能有效关联,不仅时间复杂度高,而且提取的特征信息不足,导致目标漏检率和误检率偏高。为了提升算法对航空遥感图像目标的检测准确率,本文提出一种基于并行高分辨率结构结合长短期记忆网络(long short-term memory,LSTM)的目标检测算法。方法首先,构建并行高分辨率网络结构,由高分辨率子网络作为第1阶段,分辨率从高到低逐步增加子网络,将多个子网并行连接,构建子网时对不同分辨率的特征图反复融合,以增强目标特征表达;其次,对各个子网提取的特征图进行双线性插值上采样,并拼接通道特征;最后,使用双向LSTM整合通道特征信息,完成多尺度检测。结果将本文提出的检测算法在COCO(common objects in context)2017数据集、KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)车辆检测和UCAS-AOD(University of Chinese Academy of Sciences-Aerial Object Detection)航空遥感数据集上进行实验验证,平均检测准确率(mean average precision,mAP)分别为41.6%、69.4%和69.3%。在COCO 2017、KITTI和VCAS-AOD数据集上,本文算法与SSD513算法相比,平均检测准确率分别提升10.46%、7.3%、8.8%。结论本文方法有效提高了航空遥感图像中目标的平均检测准确率。关键词:航空遥感图像;机器视觉;小目标检测;并行高分辨率网络;长短期记忆网络;COCO数据集;UCAS-AOD数据集232|204|12更新时间:2024-05-07 -
 摘要:目的遥感图像上任意方向舰船目标的检测,是给出舰船在图像上的最小外切矩形边界框。基于双阶段深度网络的任意方向舰船检测算法速度较慢;基于单阶段深度网络的任意方向舰船检测算法速度较快,但由于舰船具有较大长宽比的形态特点,导致虚警率较高。为了降低单阶段目标检测的虚警率,进一步提升检测速度,针对舰船目标的形态特点,提出了基于密集子区域切割的快速检测算法。方法沿长轴方向,将舰船整体密集切割为若干个包含在正方形标注框内的局部子区域,确保标注框内最佳的子区域面积有效占比,保证核心检测网络的泛化能力;以子区域为检测目标,训练核心网络,在训练过程对重叠子区域进行整合;基于子图分割将检测得到的子区域进行合并,进而估计方向角度等关键舰船目标参数。其中采用子区域合并后处理替代了非极大值抑制后处理,保证了检测速度。结果在HRSC2016(high resolution ship collections)实测数据集上,与最新的改进YOLOv3(you only look once)、RRCNN (rotated region convolutional neural network)、RRPN (rotation region proposal networks)、R-DFPN-3(rotation dense feature pyramid network)和R-DFPN-4等5种算法进行了比较,相较于检测精度最高的R-DFPN-4对照算法,本文算法的mAP (mean average precision)(IOU (inter section over union)=0.5)值提高了1.9%,平均耗时降低了57.9%;相较于检测速度最快的改进YOLOv3对照算法,本文算法的mAP (IOU=0.5)值提高了3.6%,平均耗时降低了31.4%。结论本文所提出的任意方向舰船检测算法,结合了舰船目标的形态特点,在检测精度与检测速度均优于当前主流任意方向舰船检测算法,检测速度有明显提升。关键词:任意方向舰船检测;密集子区域切割;子图分割;子区域合并;快速检测58|73|1更新时间:2024-05-07
摘要:目的遥感图像上任意方向舰船目标的检测,是给出舰船在图像上的最小外切矩形边界框。基于双阶段深度网络的任意方向舰船检测算法速度较慢;基于单阶段深度网络的任意方向舰船检测算法速度较快,但由于舰船具有较大长宽比的形态特点,导致虚警率较高。为了降低单阶段目标检测的虚警率,进一步提升检测速度,针对舰船目标的形态特点,提出了基于密集子区域切割的快速检测算法。方法沿长轴方向,将舰船整体密集切割为若干个包含在正方形标注框内的局部子区域,确保标注框内最佳的子区域面积有效占比,保证核心检测网络的泛化能力;以子区域为检测目标,训练核心网络,在训练过程对重叠子区域进行整合;基于子图分割将检测得到的子区域进行合并,进而估计方向角度等关键舰船目标参数。其中采用子区域合并后处理替代了非极大值抑制后处理,保证了检测速度。结果在HRSC2016(high resolution ship collections)实测数据集上,与最新的改进YOLOv3(you only look once)、RRCNN (rotated region convolutional neural network)、RRPN (rotation region proposal networks)、R-DFPN-3(rotation dense feature pyramid network)和R-DFPN-4等5种算法进行了比较,相较于检测精度最高的R-DFPN-4对照算法,本文算法的mAP (mean average precision)(IOU (inter section over union)=0.5)值提高了1.9%,平均耗时降低了57.9%;相较于检测速度最快的改进YOLOv3对照算法,本文算法的mAP (IOU=0.5)值提高了3.6%,平均耗时降低了31.4%。结论本文所提出的任意方向舰船检测算法,结合了舰船目标的形态特点,在检测精度与检测速度均优于当前主流任意方向舰船检测算法,检测速度有明显提升。关键词:任意方向舰船检测;密集子区域切割;子图分割;子区域合并;快速检测58|73|1更新时间:2024-05-07 -
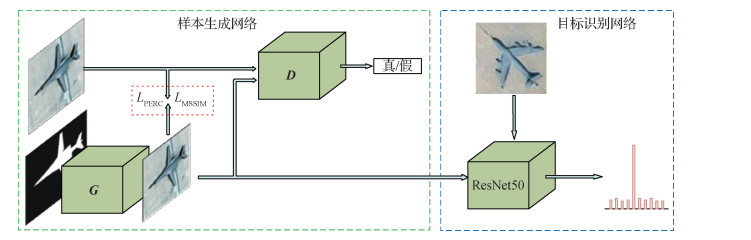 摘要:目的基于深度学习的飞机目标识别方法在遥感图像解译领域取得了很大进步,但其泛化能力依赖于大规模数据集。条件生成对抗网络(conditional generative adversarial network,CGAN)可用于产生逼真的生成样本以扩充真实数据集,但对复杂遥感场景的建模能力有限,生成样本质量低。针对这些问题,提出了一种结合CGAN样本生成的飞机识别框架。方法改进条件生成对抗网络,利用感知损失提高生成器对遥感图像的建模能力,提出了基于掩膜的结构相似性(structural similarity,SSIM)度量损失函数(masked-SSIM loss)以提高生成样本中飞机区域的图像质量,该损失函数与飞机的掩膜相结合以保证只作用于图像中的飞机区域而不影响背景区域。选取一个基于残差网络的识别模型,与改进后的生成模型结合,构成飞机识别框架,训练过程中利用生成样本代替真实的卫星图像,降低了对实际卫星数据规模的需求。结果采用生成样本与真实样本训练的识别模型在真实样本上的进行实验,前者的准确率比后者低0.33%;对于生成模型,在加入感知损失后,生成样本的峰值信噪比(peak signal to noise ratio,PSNR)提高了0.79 dB,SSIM提高了0.094;在加入基于掩膜的结构相似性度量损失函数后,生成样本的PSNR提高了0.09 dB,SSIM提高了0.252。结论本文提出的基于样本生成的飞机识别框架生成了质量更高的样本,这些样本可以替代真实样本对识别模型进行训练,有效地解决了飞机识别任务中的样本不足问题。关键词:深度学习;卷积神经网络;生成对抗网络;光学遥感图像;目标识别113|148|2更新时间:2024-05-07
摘要:目的基于深度学习的飞机目标识别方法在遥感图像解译领域取得了很大进步,但其泛化能力依赖于大规模数据集。条件生成对抗网络(conditional generative adversarial network,CGAN)可用于产生逼真的生成样本以扩充真实数据集,但对复杂遥感场景的建模能力有限,生成样本质量低。针对这些问题,提出了一种结合CGAN样本生成的飞机识别框架。方法改进条件生成对抗网络,利用感知损失提高生成器对遥感图像的建模能力,提出了基于掩膜的结构相似性(structural similarity,SSIM)度量损失函数(masked-SSIM loss)以提高生成样本中飞机区域的图像质量,该损失函数与飞机的掩膜相结合以保证只作用于图像中的飞机区域而不影响背景区域。选取一个基于残差网络的识别模型,与改进后的生成模型结合,构成飞机识别框架,训练过程中利用生成样本代替真实的卫星图像,降低了对实际卫星数据规模的需求。结果采用生成样本与真实样本训练的识别模型在真实样本上的进行实验,前者的准确率比后者低0.33%;对于生成模型,在加入感知损失后,生成样本的峰值信噪比(peak signal to noise ratio,PSNR)提高了0.79 dB,SSIM提高了0.094;在加入基于掩膜的结构相似性度量损失函数后,生成样本的PSNR提高了0.09 dB,SSIM提高了0.252。结论本文提出的基于样本生成的飞机识别框架生成了质量更高的样本,这些样本可以替代真实样本对识别模型进行训练,有效地解决了飞机识别任务中的样本不足问题。关键词:深度学习;卷积神经网络;生成对抗网络;光学遥感图像;目标识别113|148|2更新时间:2024-05-07 -
 摘要:目的针对高分辨率遥感影像语义分割中普遍存在的分割精度不高、目标边界模糊等问题,提出一种综合利用边界信息和网络多尺度特征的边缘损失增强语义分割方法。方法对单幅高分辨率遥感影像,首先通过对VGG-16(visual geometry group 16-layer net)网络引入侧边输出结构,提取到图像丰富的特征细节;然后使用深度监督的短连接结构将从深层到浅层的侧边输出组合起来,实现多层次和多尺度特征融合;最后添加边缘损失增强结构,用以获得较为清晰的目标边界,提高分割结果的准确性和完整性。结果为了验证所提方法的有效性,选取中国北方种植大棚遥感影像和Google Earth上的光伏板组件遥感影像进行人工标注,并制作实验数据集。在这两个数据集上,将所提方法与几种常用的语义分割方法进行对比实验。实验结果表明,所提方法的精度在召回率为00.9之间时均在0.8以上,在2个数据集上的平均绝对误差分别为0.079 1和0.036 2。同时,通过消融实验分析了各个功能模块对最终结果的贡献。结论与当前先进方法相比,本文提出的边缘损失增强地物分割方法能够更加精确地从遥感影像的复杂背景中提取目标区域,使分割时提取到的目标拥有更加清晰的边缘。关键词:高分辨率遥感影像;卷积神经网络;语义分割;多特征融合;边缘损失增强网络;平均绝对误差84|286|2更新时间:2024-05-07
摘要:目的针对高分辨率遥感影像语义分割中普遍存在的分割精度不高、目标边界模糊等问题,提出一种综合利用边界信息和网络多尺度特征的边缘损失增强语义分割方法。方法对单幅高分辨率遥感影像,首先通过对VGG-16(visual geometry group 16-layer net)网络引入侧边输出结构,提取到图像丰富的特征细节;然后使用深度监督的短连接结构将从深层到浅层的侧边输出组合起来,实现多层次和多尺度特征融合;最后添加边缘损失增强结构,用以获得较为清晰的目标边界,提高分割结果的准确性和完整性。结果为了验证所提方法的有效性,选取中国北方种植大棚遥感影像和Google Earth上的光伏板组件遥感影像进行人工标注,并制作实验数据集。在这两个数据集上,将所提方法与几种常用的语义分割方法进行对比实验。实验结果表明,所提方法的精度在召回率为00.9之间时均在0.8以上,在2个数据集上的平均绝对误差分别为0.079 1和0.036 2。同时,通过消融实验分析了各个功能模块对最终结果的贡献。结论与当前先进方法相比,本文提出的边缘损失增强地物分割方法能够更加精确地从遥感影像的复杂背景中提取目标区域,使分割时提取到的目标拥有更加清晰的边缘。关键词:高分辨率遥感影像;卷积神经网络;语义分割;多特征融合;边缘损失增强网络;平均绝对误差84|286|2更新时间:2024-05-07 -
 摘要:目的遥感图像建筑物分割是图像处理中的一项重要应用,卷积神经网络在遥感图像建筑物分割中展现出优秀性能,但仍存在建筑物漏分、错分,尤其是小建筑物漏分以及建筑物边缘不平滑等问题。针对上述问题,本文提出一种含多级通道注意力机制的条件生成对抗网络(conditional generative adversarial network,CGAN)模型Ra-CGAN,用于分割遥感图像建筑物。方法首先构建一个具有多级通道注意力机制的生成模型G,通过融合包含注意力机制的深层语义与浅层细节信息,使网络提取丰富的上下文信息,更好地应对建筑物的尺度变化,改善小建筑物漏分问题。其次,构建一个判别网络D,通过矫正真实标签图与生成模型生成的分割图之间的差异来改善分割结果。最后,通过带有条件约束的G和D之间的对抗训练,学习高阶数据分布特征,使建筑物空间连续性更强,提升分割结果的边界准确性及平滑性。结果在WHU Building Dataset和Satellite Dataset II数据集上进行实验,并与优秀方法对比。在WHU数据集中,分割性能相对于未加入通道注意力机制和对抗训练的模型明显提高,且在复杂建筑物的空间连续性、小建筑物完整性以及建筑物边缘准确和平滑性上表现更好;相比性能第2的模型,交并比(intersection over union,IOU)值提高了1.1%,F1-score提高了1.1%。在Satellite数据集中,相比其他模型,准确率更高,尤其是在数据样本不充足的条件下,得益于生成对抗训练,分割效果得到了大幅提升;相比性能第2的模型,IOU值提高了1.7%,F1-score提高了1.6%。结论本文提出的含多级通道注意力机制的CGAN遥感图像建筑物分割模型,综合了多级通道注意力机制生成模型与条件生成对抗网络的优点,在不同数据集上均获得了更精确的遥感图像建筑物分割结果。关键词:深度卷积神经网络;遥感图像分割;条件生成对抗网络(CGAN);注意力机制;多尺度特征融合97|172|6更新时间:2024-05-07
摘要:目的遥感图像建筑物分割是图像处理中的一项重要应用,卷积神经网络在遥感图像建筑物分割中展现出优秀性能,但仍存在建筑物漏分、错分,尤其是小建筑物漏分以及建筑物边缘不平滑等问题。针对上述问题,本文提出一种含多级通道注意力机制的条件生成对抗网络(conditional generative adversarial network,CGAN)模型Ra-CGAN,用于分割遥感图像建筑物。方法首先构建一个具有多级通道注意力机制的生成模型G,通过融合包含注意力机制的深层语义与浅层细节信息,使网络提取丰富的上下文信息,更好地应对建筑物的尺度变化,改善小建筑物漏分问题。其次,构建一个判别网络D,通过矫正真实标签图与生成模型生成的分割图之间的差异来改善分割结果。最后,通过带有条件约束的G和D之间的对抗训练,学习高阶数据分布特征,使建筑物空间连续性更强,提升分割结果的边界准确性及平滑性。结果在WHU Building Dataset和Satellite Dataset II数据集上进行实验,并与优秀方法对比。在WHU数据集中,分割性能相对于未加入通道注意力机制和对抗训练的模型明显提高,且在复杂建筑物的空间连续性、小建筑物完整性以及建筑物边缘准确和平滑性上表现更好;相比性能第2的模型,交并比(intersection over union,IOU)值提高了1.1%,F1-score提高了1.1%。在Satellite数据集中,相比其他模型,准确率更高,尤其是在数据样本不充足的条件下,得益于生成对抗训练,分割效果得到了大幅提升;相比性能第2的模型,IOU值提高了1.7%,F1-score提高了1.6%。结论本文提出的含多级通道注意力机制的CGAN遥感图像建筑物分割模型,综合了多级通道注意力机制生成模型与条件生成对抗网络的优点,在不同数据集上均获得了更精确的遥感图像建筑物分割结果。关键词:深度卷积神经网络;遥感图像分割;条件生成对抗网络(CGAN);注意力机制;多尺度特征融合97|172|6更新时间:2024-05-07 -
 摘要:目的高分2号卫星(GF-2)是首颗民用高空间分辨率光学卫星,具有亚米级高空间分辨率与宽覆盖结合的显著特点,为城市绿地信息提取等多领域提供了重要的数据支撑。本文利用GF-2卫星多光谱遥感影像,将一种改进的U-Net卷积神经网络首次应用于城市绿地分类,提出一种面向高分遥感影像的城市绿地自动分类提取技术。方法先针对小样本训练集容易产生的过拟合问题对U-Net网络进行改进,添加批标准化(batch normalization,BN)和dropout层获得U-Net+模型;再采用随机裁剪和随机数据增强的方式扩充数据集,使得在充分利用影像信息的同时保证样本随机性,增强模型稳定性。结果将U-Net+模型与最大似然法(maximum likelihood estimation,MLE)、神经网络(neural networks,NNs)和支持向量机(support vector machine,SVM)3种传统分类方法以及U-Net、SegNet和DeepLabv3+这3种深度学习语义分割模型进行分类结果精度对比。改进后的U-Net+模型能有效防止过拟合,模型总体分类精度比改进前提高了1.06%。基于改进的U-Net+模型的城市绿地总体分类精度为92.73%,平均F1分数为91.85%。各分类方法按照总体分类精度从大到小依次为U-Net+(92.73%)、U-Net (91.67%)、SegNet (88.98%)、DeepLabv3+(87.41%)、SVM (81.32%)、NNs (79.92%)和MLE (77.21%)。深度学习城市绿地分类方法能充分挖掘数据的光谱、纹理及潜在特征信息,有效降低分类过程中产生的"椒盐噪声",具有较好的样本容错能力,比传统遥感分类方法更适用于城市绿地信息提取。结论改进后的U-Net+卷积神经网络模型能够有效提升高分遥感影像城市绿地自动分类提取精度,为城市绿地分类提供了一种新的智能解译方法。关键词:城市绿地;卷积神经网络;U-Net;高分遥感;语义分割285|211|18更新时间:2024-05-07
摘要:目的高分2号卫星(GF-2)是首颗民用高空间分辨率光学卫星,具有亚米级高空间分辨率与宽覆盖结合的显著特点,为城市绿地信息提取等多领域提供了重要的数据支撑。本文利用GF-2卫星多光谱遥感影像,将一种改进的U-Net卷积神经网络首次应用于城市绿地分类,提出一种面向高分遥感影像的城市绿地自动分类提取技术。方法先针对小样本训练集容易产生的过拟合问题对U-Net网络进行改进,添加批标准化(batch normalization,BN)和dropout层获得U-Net+模型;再采用随机裁剪和随机数据增强的方式扩充数据集,使得在充分利用影像信息的同时保证样本随机性,增强模型稳定性。结果将U-Net+模型与最大似然法(maximum likelihood estimation,MLE)、神经网络(neural networks,NNs)和支持向量机(support vector machine,SVM)3种传统分类方法以及U-Net、SegNet和DeepLabv3+这3种深度学习语义分割模型进行分类结果精度对比。改进后的U-Net+模型能有效防止过拟合,模型总体分类精度比改进前提高了1.06%。基于改进的U-Net+模型的城市绿地总体分类精度为92.73%,平均F1分数为91.85%。各分类方法按照总体分类精度从大到小依次为U-Net+(92.73%)、U-Net (91.67%)、SegNet (88.98%)、DeepLabv3+(87.41%)、SVM (81.32%)、NNs (79.92%)和MLE (77.21%)。深度学习城市绿地分类方法能充分挖掘数据的光谱、纹理及潜在特征信息,有效降低分类过程中产生的"椒盐噪声",具有较好的样本容错能力,比传统遥感分类方法更适用于城市绿地信息提取。结论改进后的U-Net+卷积神经网络模型能够有效提升高分遥感影像城市绿地自动分类提取精度,为城市绿地分类提供了一种新的智能解译方法。关键词:城市绿地;卷积神经网络;U-Net;高分遥感;语义分割285|211|18更新时间:2024-05-07 -
 摘要:目的卫星遥感技术在硬件方面的局限导致获取的遥感图像在时间与空间分辨率之间存在矛盾,而时空融合提供了一种高效、低成本的方式来融合具有时空互补性的两类遥感图像数据(典型代表是Landsat和MODIS (moderate-resolution imaging spectroradiometer)图像),生成同时具有高时空分辨率的融合数据,解决该问题。方法提出了一种基于条件生成对抗网络的时空融合方法,可高效处理实际应用中的大量遥感数据。与现有的学习模型相比,该模型具有以下优点:1)通过学习一个非线性映射关系来显式地关联MODIS图像和Landsat图像;2)自动学习有效的图像特征;3)将特征提取、非线性映射和图像重建统一到一个框架下进行优化。在训练阶段,使用条件生成对抗网络建立降采样Landsat和MODIS图像之间的非线性映射,然后在原始Landsat和降采样Landsat之间训练多尺度超分条件生成对抗网络。预测过程包含两层:每层均包括基于条件生成对抗网络的预测和融合模型。分别实现从MODIS到降采样Landsat数据之间的非线性映射以及降采样Landsat与原始Landsat之间的超分辨率首建。结果在基准数据集CIA (coleam bally irrigation area)和LGC (lower Gwydir catchment)上的结果表明,条件生成对抗网络的方法在4种评测指标上均达到领先结果,例如在CIA数据集上,RMSE (root mean squared error)、SAM (spectral angle mapper)、SSIM (structural similarity)和ERGAS (erreur relative global adimensionnelle desynthese)分别平均提高了0.001、0.15、0.008和0.065;在LGC数据集上分别平均提高了0.001 2、0.7、0.018和0.008 9。明显优于现有基于稀疏表示的方法与基于卷积神经网络的方法。结论本文提出的条件生成对抗融合模型,能够充分学习Landsat和MODIS图像之间复杂的非线性映射,产生更加准确的融合结果。关键词:时空融合;深度学习;条件生成对抗网络(CGAN);拉普拉斯金字塔;遥感图像处理62|44|3更新时间:2024-05-07
摘要:目的卫星遥感技术在硬件方面的局限导致获取的遥感图像在时间与空间分辨率之间存在矛盾,而时空融合提供了一种高效、低成本的方式来融合具有时空互补性的两类遥感图像数据(典型代表是Landsat和MODIS (moderate-resolution imaging spectroradiometer)图像),生成同时具有高时空分辨率的融合数据,解决该问题。方法提出了一种基于条件生成对抗网络的时空融合方法,可高效处理实际应用中的大量遥感数据。与现有的学习模型相比,该模型具有以下优点:1)通过学习一个非线性映射关系来显式地关联MODIS图像和Landsat图像;2)自动学习有效的图像特征;3)将特征提取、非线性映射和图像重建统一到一个框架下进行优化。在训练阶段,使用条件生成对抗网络建立降采样Landsat和MODIS图像之间的非线性映射,然后在原始Landsat和降采样Landsat之间训练多尺度超分条件生成对抗网络。预测过程包含两层:每层均包括基于条件生成对抗网络的预测和融合模型。分别实现从MODIS到降采样Landsat数据之间的非线性映射以及降采样Landsat与原始Landsat之间的超分辨率首建。结果在基准数据集CIA (coleam bally irrigation area)和LGC (lower Gwydir catchment)上的结果表明,条件生成对抗网络的方法在4种评测指标上均达到领先结果,例如在CIA数据集上,RMSE (root mean squared error)、SAM (spectral angle mapper)、SSIM (structural similarity)和ERGAS (erreur relative global adimensionnelle desynthese)分别平均提高了0.001、0.15、0.008和0.065;在LGC数据集上分别平均提高了0.001 2、0.7、0.018和0.008 9。明显优于现有基于稀疏表示的方法与基于卷积神经网络的方法。结论本文提出的条件生成对抗融合模型,能够充分学习Landsat和MODIS图像之间复杂的非线性映射,产生更加准确的融合结果。关键词:时空融合;深度学习;条件生成对抗网络(CGAN);拉普拉斯金字塔;遥感图像处理62|44|3更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0