
最新刊期
2021 年 第 26 卷 第 12 期
-
 摘要:深度视觉生成是计算机视觉领域的热门方向,旨在使计算机能够根据输入数据自动生成预期的视觉内容。深度视觉生成使用人工智能技术赋能相关产业,推动产业自动化、智能化改革与转型。生成对抗网络(generative adversarial networks,GANs)是深度视觉生成的有效工具,近年来受到极大关注,成为快速发展的研究方向。GANs能够接收多种模态的输入数据,包括噪声、图像、文本和视频,以对抗博弈的模式进行图像生成和视频生成,已成功应用于多项视觉生成任务。利用GANs实现真实的、多样化和可控的视觉生成具有重要的研究意义。本文对近年来深度对抗视觉生成的相关工作进行综述。首先介绍深度视觉生成背景及典型生成模型,然后根据深度对抗视觉生成的主流任务概述相关算法,总结深度对抗视觉生成目前面临的痛点问题,在此基础上分析深度对抗视觉生成的未来发展趋势。关键词:深度学习;视觉生成;生成对抗网络(GANs);图像生成;视频生成;3维深度图像生成;风格迁移;可控生成209|179|1更新时间:2024-05-07
摘要:深度视觉生成是计算机视觉领域的热门方向,旨在使计算机能够根据输入数据自动生成预期的视觉内容。深度视觉生成使用人工智能技术赋能相关产业,推动产业自动化、智能化改革与转型。生成对抗网络(generative adversarial networks,GANs)是深度视觉生成的有效工具,近年来受到极大关注,成为快速发展的研究方向。GANs能够接收多种模态的输入数据,包括噪声、图像、文本和视频,以对抗博弈的模式进行图像生成和视频生成,已成功应用于多项视觉生成任务。利用GANs实现真实的、多样化和可控的视觉生成具有重要的研究意义。本文对近年来深度对抗视觉生成的相关工作进行综述。首先介绍深度视觉生成背景及典型生成模型,然后根据深度对抗视觉生成的主流任务概述相关算法,总结深度对抗视觉生成目前面临的痛点问题,在此基础上分析深度对抗视觉生成的未来发展趋势。关键词:深度学习;视觉生成;生成对抗网络(GANs);图像生成;视频生成;3维深度图像生成;风格迁移;可控生成209|179|1更新时间:2024-05-07 -
 摘要:机器的情感是通过融入具有情感能力的智能体实现的,虽然目前在人机交互领域已经有大量研究成果,但有关智能体情感计算方面的研究尚处起步阶段,深入开展这项研究对推动人机交互领域的发展具有重要的科学和应用价值。本文通过检索Scopus数据库选择有代表性的文献,重点关注情感在智能体和用户之间的双向流动,分别从智能体对用户的情绪感知和对用户情绪调节的角度开展分析总结。首先梳理了用户情绪的识别方法,即通过用户的表情、语音、姿态、生理信号和文本信息等多通道信息分析用户的情绪状态,归纳了情绪识别中的一些机器学习方法。其次从用户体验角度分析具有情绪表现力的智能体对用户的影响,总结了智能体的情绪生成和表现技术,指出智能体除了通过表情之外,还可以通过注视、姿态、头部运动和手势等非言语动作来表现情绪。并且梳理了典型的智能体情绪架构,举例说明了强化学习在智能体情绪设计中的作用。同时为了验证模型的准确性,比较了已有的情感评估手段和评价指标。最后指出智能体情感计算急需解决的问题。通过对现有研究的总结,智能体情感计算研究是一个很有前景的研究方向,希望本文能够为深入开展相关研究提供借鉴。关键词:人机交互;智能体;情感计算;情绪;感知;表现312|444|2更新时间:2024-05-07
摘要:机器的情感是通过融入具有情感能力的智能体实现的,虽然目前在人机交互领域已经有大量研究成果,但有关智能体情感计算方面的研究尚处起步阶段,深入开展这项研究对推动人机交互领域的发展具有重要的科学和应用价值。本文通过检索Scopus数据库选择有代表性的文献,重点关注情感在智能体和用户之间的双向流动,分别从智能体对用户的情绪感知和对用户情绪调节的角度开展分析总结。首先梳理了用户情绪的识别方法,即通过用户的表情、语音、姿态、生理信号和文本信息等多通道信息分析用户的情绪状态,归纳了情绪识别中的一些机器学习方法。其次从用户体验角度分析具有情绪表现力的智能体对用户的影响,总结了智能体的情绪生成和表现技术,指出智能体除了通过表情之外,还可以通过注视、姿态、头部运动和手势等非言语动作来表现情绪。并且梳理了典型的智能体情绪架构,举例说明了强化学习在智能体情绪设计中的作用。同时为了验证模型的准确性,比较了已有的情感评估手段和评价指标。最后指出智能体情感计算急需解决的问题。通过对现有研究的总结,智能体情感计算研究是一个很有前景的研究方向,希望本文能够为深入开展相关研究提供借鉴。关键词:人机交互;智能体;情感计算;情绪;感知;表现312|444|2更新时间:2024-05-07 -
 摘要:视觉环境感知在自动驾驶汽车发展中起着关键作用,在智能后视镜、倒车雷达、360°全景、行车记录仪、碰撞预警、红绿灯识别、车道偏移、并线辅助和自动泊车等领域也有着广泛运用。传统的环境信息获取方式是窄角针孔摄像头,视野有限有盲区,解决这个问题的方法是环境信息感知使用鱼眼镜头,广角视图能够提供整个180°的半球视图,理论上仅需两个摄像头即可覆盖360°,为视觉感知提供更多信息。处理环视图像目前主要有两种途径:一是对图像先纠正,去失真,缺点是图像去失真会损害图像质量,并导致信息丢失;二是直接对形变的鱼眼图像进行建模,但目前还没有效果比较好的建模方法。此外,环视鱼眼图像数据集的缺乏也是制约相关研究的一大难题。针对上述挑战,本文总结了环视鱼眼图像的相关研究,包括环视鱼眼图像的校正处理、环视鱼眼图像中的目标检测、环视鱼眼图像中的语义分割、伪环视鱼眼图像数据集生成方法和其他鱼眼图像建模方法等,结合自动驾驶汽车的环境感知应用背景,分析了这些模型的效率和这些处理方法的优劣,并对目前公开的环视鱼眼图像通用数据集进行了详细介绍,对环视鱼眼图像中待解决的问题与未来研究方向做出预测和展望。关键词:自动驾驶;环视鱼眼图像;图像校正;目标检测;语义分割;鱼眼图像数据集;研究综述135|426|0更新时间:2024-05-07
摘要:视觉环境感知在自动驾驶汽车发展中起着关键作用,在智能后视镜、倒车雷达、360°全景、行车记录仪、碰撞预警、红绿灯识别、车道偏移、并线辅助和自动泊车等领域也有着广泛运用。传统的环境信息获取方式是窄角针孔摄像头,视野有限有盲区,解决这个问题的方法是环境信息感知使用鱼眼镜头,广角视图能够提供整个180°的半球视图,理论上仅需两个摄像头即可覆盖360°,为视觉感知提供更多信息。处理环视图像目前主要有两种途径:一是对图像先纠正,去失真,缺点是图像去失真会损害图像质量,并导致信息丢失;二是直接对形变的鱼眼图像进行建模,但目前还没有效果比较好的建模方法。此外,环视鱼眼图像数据集的缺乏也是制约相关研究的一大难题。针对上述挑战,本文总结了环视鱼眼图像的相关研究,包括环视鱼眼图像的校正处理、环视鱼眼图像中的目标检测、环视鱼眼图像中的语义分割、伪环视鱼眼图像数据集生成方法和其他鱼眼图像建模方法等,结合自动驾驶汽车的环境感知应用背景,分析了这些模型的效率和这些处理方法的优劣,并对目前公开的环视鱼眼图像通用数据集进行了详细介绍,对环视鱼眼图像中待解决的问题与未来研究方向做出预测和展望。关键词:自动驾驶;环视鱼眼图像;图像校正;目标检测;语义分割;鱼眼图像数据集;研究综述135|426|0更新时间:2024-05-07
综述

-
 摘要:目的 多曝光图像融合(multi-exposure fusion,MEF)是利用一组不同曝光度的低动态范围(low dynamic range,LDR)图像进行合成,得到类似高动态范围(high dynamic range,HDR)图像视觉效果图像的过程。传统多曝光图像融合在一定程度上存在图像细节信息受损、边界不清晰以及部分色彩失真等问题。为了充分综合待融合图像的有效信息,提出了一种基于图像分解和色彩先验的双尺度多曝光图像融合方法。 方法 使用快速导向滤波进行图像分解,分离出细节层对其进行增强处理,保留更多的细节信息,同时减少融合图像的光晕伪影;根据色彩先验,利用亮度和饱和度之差判断图像曝光程度,并联合亮度与饱和度之差以及图像对比度计算多曝光图像融合权重,同时保障融合图像的亮度和对比度;利用导向滤波对权重图进行优化,抑制噪声,增加像素之间的相关性,提升融合图像的视觉效果。 结果 在24组多曝光图像序列上进行实验,从主观评价角度来看,该融合方法能够提升图像整体对比度及色彩饱和度,并兼顾过曝光区域和欠曝光区域的细节提升。从客观评价标准分析,采用两种不同的多曝光图像序列融合结果的质量评估算法,评价结果显示融合性能均有所提高,对应的指标均值分别为0.982和0.970。与其他对比算法的数据结果比较,在两种不同的结构相似性指标上均有所提升,平均提升分别为1.2%和1.1%。 结论 通过主观和客观评价,证实了所提方法在图像对比度、色彩饱和度以及细节信息保留的处理效果十分显著,具有良好的融合性能。关键词:多曝光图像融合(MEF);高动态范围成像;导向滤波;快速导向滤波;色彩先验63|134|1更新时间:2024-05-07
摘要:目的 多曝光图像融合(multi-exposure fusion,MEF)是利用一组不同曝光度的低动态范围(low dynamic range,LDR)图像进行合成,得到类似高动态范围(high dynamic range,HDR)图像视觉效果图像的过程。传统多曝光图像融合在一定程度上存在图像细节信息受损、边界不清晰以及部分色彩失真等问题。为了充分综合待融合图像的有效信息,提出了一种基于图像分解和色彩先验的双尺度多曝光图像融合方法。 方法 使用快速导向滤波进行图像分解,分离出细节层对其进行增强处理,保留更多的细节信息,同时减少融合图像的光晕伪影;根据色彩先验,利用亮度和饱和度之差判断图像曝光程度,并联合亮度与饱和度之差以及图像对比度计算多曝光图像融合权重,同时保障融合图像的亮度和对比度;利用导向滤波对权重图进行优化,抑制噪声,增加像素之间的相关性,提升融合图像的视觉效果。 结果 在24组多曝光图像序列上进行实验,从主观评价角度来看,该融合方法能够提升图像整体对比度及色彩饱和度,并兼顾过曝光区域和欠曝光区域的细节提升。从客观评价标准分析,采用两种不同的多曝光图像序列融合结果的质量评估算法,评价结果显示融合性能均有所提高,对应的指标均值分别为0.982和0.970。与其他对比算法的数据结果比较,在两种不同的结构相似性指标上均有所提升,平均提升分别为1.2%和1.1%。 结论 通过主观和客观评价,证实了所提方法在图像对比度、色彩饱和度以及细节信息保留的处理效果十分显著,具有良好的融合性能。关键词:多曝光图像融合(MEF);高动态范围成像;导向滤波;快速导向滤波;色彩先验63|134|1更新时间:2024-05-07 -
 摘要:目的 针对图像融合中存在的目标信息减弱、背景细节不清晰、边缘模糊和融合效率低等不足,为了充分利用源图像的有用特征,将双尺度分解与基于视觉显著性的融合权重的思想融合在一起,提出了一种基于显著性分析和空间一致性的双尺度图像融合方法。 方法 利用均值滤波器对源图像进行双尺度分解,先后得到源图像的基层图像信息和细节层图像信息;对基层图像基于加权平均规则融合,对细节层图像先基于显著性分析得到初始权重图,再利用引导滤波优化得到的最终权重图指导加权;通过双尺度重建得到融合图像。 结果 根据传统方法与深度学习的不同特点,在TNO等公开数据集上从主观和客观两方面对所提方法进行评价。从主观分析来看,本文方法可以有效提取和融合源图像中的重要信息,得到融合质量高、视觉效果自然清晰的图像。从客观评价来看,实验验证了本文方法在提升融合效果上的有效性。与各种融合结果进行量化比较,在平均梯度、边缘强度、空间频率、特征互信息和交叉熵上的平均精度均为最优;与深度学习方法相比,熵、平均梯度、边缘强度、空间频率、特征互信息和交叉熵等指标均值分别提升了6.87%、91.28%、91.45%、85.10%、0.18%和45.45%。 结论 实验结果表明,所提方法不仅在目标、背景细节和边缘等信息的增强效果显著,而且能快速有效地利用源图像的有用特征。关键词:红外图像;可见光图像;显著性分析;空间一致性;双尺度分解;图像融合71|158|9更新时间:2024-05-07
摘要:目的 针对图像融合中存在的目标信息减弱、背景细节不清晰、边缘模糊和融合效率低等不足,为了充分利用源图像的有用特征,将双尺度分解与基于视觉显著性的融合权重的思想融合在一起,提出了一种基于显著性分析和空间一致性的双尺度图像融合方法。 方法 利用均值滤波器对源图像进行双尺度分解,先后得到源图像的基层图像信息和细节层图像信息;对基层图像基于加权平均规则融合,对细节层图像先基于显著性分析得到初始权重图,再利用引导滤波优化得到的最终权重图指导加权;通过双尺度重建得到融合图像。 结果 根据传统方法与深度学习的不同特点,在TNO等公开数据集上从主观和客观两方面对所提方法进行评价。从主观分析来看,本文方法可以有效提取和融合源图像中的重要信息,得到融合质量高、视觉效果自然清晰的图像。从客观评价来看,实验验证了本文方法在提升融合效果上的有效性。与各种融合结果进行量化比较,在平均梯度、边缘强度、空间频率、特征互信息和交叉熵上的平均精度均为最优;与深度学习方法相比,熵、平均梯度、边缘强度、空间频率、特征互信息和交叉熵等指标均值分别提升了6.87%、91.28%、91.45%、85.10%、0.18%和45.45%。 结论 实验结果表明,所提方法不仅在目标、背景细节和边缘等信息的增强效果显著,而且能快速有效地利用源图像的有用特征。关键词:红外图像;可见光图像;显著性分析;空间一致性;双尺度分解;图像融合71|158|9更新时间:2024-05-07 -
 摘要:目的 深度卷积网络在图像超分辨率重建领域具有优异性能,越来越多的方法趋向于更深、更宽的网络设计。然而,复杂的网络结构对计算资源的要求也越来越高。随着智能边缘设备(如智能手机)的流行,高效能的超分重建算法有着巨大的实际应用场景。因此,本文提出一种极轻量的高效超分网络,通过循环特征选择单元和参数共享机制,不仅大幅降低了参数量和浮点运算次数(floating point operations,FLOPs),而且具有优异的重建性能。 方法本文网络由浅层特征提取、深层特征提取和上采样重建3部分构成。浅层特征提取模块包含一个卷积层,产生的特征循环经过一个带有高效通道注意力模块的特征选择单元进行非线性映射提取出深层特征。该特征选择单元含有多个卷积层的特征增强模块,通过保留每个卷积层的部分特征并在模块末端融合增强层次信息。通过高效通道注意力模块重新调整各通道的特征。借助循环机制(循环6次)可以有效提升性能且大幅减少参数量。上采样重建通过参数共享的上采样模块同时将浅层与深层特征进放大、融合得到高分辨率图像。 结果与先进的轻量级网络进行对比,本文网络极大减少了参数量和FLOPs,在Set5、Set14、B100、Urban100和Manga109等基准测试数据集上进行定量评估,在图像质量指标峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)上也获得了更好的结果。 结论本文通过循环的特征选择单元有效挖掘出图像的高频信息,并通过参数共享机制极大减少了参数量,实现了轻量的高质量超分重建。关键词:图像超分辨率;轻量网络;递归机制;参数共享;特征增强;高效通道注意力63|26|1更新时间:2024-05-07
摘要:目的 深度卷积网络在图像超分辨率重建领域具有优异性能,越来越多的方法趋向于更深、更宽的网络设计。然而,复杂的网络结构对计算资源的要求也越来越高。随着智能边缘设备(如智能手机)的流行,高效能的超分重建算法有着巨大的实际应用场景。因此,本文提出一种极轻量的高效超分网络,通过循环特征选择单元和参数共享机制,不仅大幅降低了参数量和浮点运算次数(floating point operations,FLOPs),而且具有优异的重建性能。 方法本文网络由浅层特征提取、深层特征提取和上采样重建3部分构成。浅层特征提取模块包含一个卷积层,产生的特征循环经过一个带有高效通道注意力模块的特征选择单元进行非线性映射提取出深层特征。该特征选择单元含有多个卷积层的特征增强模块,通过保留每个卷积层的部分特征并在模块末端融合增强层次信息。通过高效通道注意力模块重新调整各通道的特征。借助循环机制(循环6次)可以有效提升性能且大幅减少参数量。上采样重建通过参数共享的上采样模块同时将浅层与深层特征进放大、融合得到高分辨率图像。 结果与先进的轻量级网络进行对比,本文网络极大减少了参数量和FLOPs,在Set5、Set14、B100、Urban100和Manga109等基准测试数据集上进行定量评估,在图像质量指标峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)上也获得了更好的结果。 结论本文通过循环的特征选择单元有效挖掘出图像的高频信息,并通过参数共享机制极大减少了参数量,实现了轻量的高质量超分重建。关键词:图像超分辨率;轻量网络;递归机制;参数共享;特征增强;高效通道注意力63|26|1更新时间:2024-05-07 -
 摘要:目的 通道注意力机制在图像超分辨率中已经得到了广泛应用,但是当前多数算法只能在通道层面选择感兴趣的特征图而忽略了空间层面的信息,使得特征图中局部空间层面上的信息不能合理利用。针对此问题,提出了区域级通道注意力下的图像超分辨率算法。 方法设计了非局部残差密集网络作为网络的主体结构,包括非局部模块和残差密集注意力模块。非局部模块提取非局部相似信息并传到后续网络中,残差密集注意力模块在残差密集块结构的基础上添加了区域级通道注意力机制,可以给不同空间区域上的通道分配不同的注意力,使空间上的信息也能得到充分利用。同时针对当前普遍使用的L1和L2损失函数容易造成生成结果平滑的问题,提出了高频关注损失,该损失函数提高了图像高频细节位置上损失的权重,从而在后期微调过程中使网络更好地关注到图像的高频细节部分。 结果在4个标准测试集Set5、Set14、BSD100(Berkeley segmentation dataset)和Urban100上进行4倍放大实验,相比较于插值方法和SRCNN(image super-resolution using deep convolutional networks)算法,本文方法的PSNR(peak signal to noise ratio)均值分别提升约3.15 dB和1.58 dB。 结论区域级通道注意力下的图像超分辨率算法通过使用区域级通道注意力机制自适应调整网络对不同空间区域上通道的关注程度,同时结合高频关注损失加强对图像高频细节部分的关注程度,使生成的高分辨率图像具有更好的视觉效果。关键词:深度学习;卷积神经网络(CNN);超分辨率;注意力机制;非局部神经网络159|255|4更新时间:2024-05-07
摘要:目的 通道注意力机制在图像超分辨率中已经得到了广泛应用,但是当前多数算法只能在通道层面选择感兴趣的特征图而忽略了空间层面的信息,使得特征图中局部空间层面上的信息不能合理利用。针对此问题,提出了区域级通道注意力下的图像超分辨率算法。 方法设计了非局部残差密集网络作为网络的主体结构,包括非局部模块和残差密集注意力模块。非局部模块提取非局部相似信息并传到后续网络中,残差密集注意力模块在残差密集块结构的基础上添加了区域级通道注意力机制,可以给不同空间区域上的通道分配不同的注意力,使空间上的信息也能得到充分利用。同时针对当前普遍使用的L1和L2损失函数容易造成生成结果平滑的问题,提出了高频关注损失,该损失函数提高了图像高频细节位置上损失的权重,从而在后期微调过程中使网络更好地关注到图像的高频细节部分。 结果在4个标准测试集Set5、Set14、BSD100(Berkeley segmentation dataset)和Urban100上进行4倍放大实验,相比较于插值方法和SRCNN(image super-resolution using deep convolutional networks)算法,本文方法的PSNR(peak signal to noise ratio)均值分别提升约3.15 dB和1.58 dB。 结论区域级通道注意力下的图像超分辨率算法通过使用区域级通道注意力机制自适应调整网络对不同空间区域上通道的关注程度,同时结合高频关注损失加强对图像高频细节部分的关注程度,使生成的高分辨率图像具有更好的视觉效果。关键词:深度学习;卷积神经网络(CNN);超分辨率;注意力机制;非局部神经网络159|255|4更新时间:2024-05-07
图像处理和编码
-
 摘要:目的在点云场景中,语义分割对场景理解来说是至关重要的视觉任务。由于图像是结构化的,而点云是非结构化的,点云上的卷积通常比图像上的卷积更加困难,会消耗更多的计算和内存资源。在这种情况下,大尺度场景的分割往往需要分块进行,导致效率不足并且无法捕捉足够的场景信息。为了解决这个问题,本文设计了一种计算高效且内存高效的网络结构,可以用于端到端的大尺度场景语义分割。方法结合空间深度卷积和残差结构设计空间深度残差(spatial depthwise residual,SDR)块,其具有高效的计算效率和内存效率,并且可以有效地从点云中学习到几何特征。另外,设计一种扩张特征整合(dilated feature aggregation,DFA)模块,可以有效地增加感受野而仅增加少量的计算量。结合SDR块和DFA模块,本文构建SDRNet(spatial depthwise residual network),这是一种encoder-decoder深度网络结构,可以用于大尺度点云场景语义分割。同时,针对空间卷积核输入数据的分布不利于训练问题,提出层级标准化来减小参数学习的难度。特别地,针对稀疏雷达点云的旋转不变性,提出一种特殊的SDR块,可以消除雷达数据绕Z轴旋转的影响,显著提高网络处理激光雷达点云时的性能。结果在S3DIS(stanford large-scale 3D indoor space)和SemanticKITTI(Karlsruhe Institute of Technology and Toyota Technological Institute)数据集上对提出的方法进行测试,并分析点数与帧率的关系。本文方法在S3DIS数据集上的平均交并比(mean intersection over union,mIoU)为71.7%,在SemanticKITTI上的mIoU在线单次扫描评估中达到59.1%。结论实验结果表明,本文提出的SDRNet能够直接在大尺度场景下进行语义分割。在S3DIS和SemanticKITTI数据集上的实验结果证明本文方法在精度上有较好表现。通过分析点数量与帧率之间的关系,得到的数据表明本文提出的SDRNet能保持较高精度和较快的推理速率。关键词:深度学习;语义分割;标准化;点云;残差神经网络;感受野63|178|3更新时间:2024-05-07
摘要:目的在点云场景中,语义分割对场景理解来说是至关重要的视觉任务。由于图像是结构化的,而点云是非结构化的,点云上的卷积通常比图像上的卷积更加困难,会消耗更多的计算和内存资源。在这种情况下,大尺度场景的分割往往需要分块进行,导致效率不足并且无法捕捉足够的场景信息。为了解决这个问题,本文设计了一种计算高效且内存高效的网络结构,可以用于端到端的大尺度场景语义分割。方法结合空间深度卷积和残差结构设计空间深度残差(spatial depthwise residual,SDR)块,其具有高效的计算效率和内存效率,并且可以有效地从点云中学习到几何特征。另外,设计一种扩张特征整合(dilated feature aggregation,DFA)模块,可以有效地增加感受野而仅增加少量的计算量。结合SDR块和DFA模块,本文构建SDRNet(spatial depthwise residual network),这是一种encoder-decoder深度网络结构,可以用于大尺度点云场景语义分割。同时,针对空间卷积核输入数据的分布不利于训练问题,提出层级标准化来减小参数学习的难度。特别地,针对稀疏雷达点云的旋转不变性,提出一种特殊的SDR块,可以消除雷达数据绕Z轴旋转的影响,显著提高网络处理激光雷达点云时的性能。结果在S3DIS(stanford large-scale 3D indoor space)和SemanticKITTI(Karlsruhe Institute of Technology and Toyota Technological Institute)数据集上对提出的方法进行测试,并分析点数与帧率的关系。本文方法在S3DIS数据集上的平均交并比(mean intersection over union,mIoU)为71.7%,在SemanticKITTI上的mIoU在线单次扫描评估中达到59.1%。结论实验结果表明,本文提出的SDRNet能够直接在大尺度场景下进行语义分割。在S3DIS和SemanticKITTI数据集上的实验结果证明本文方法在精度上有较好表现。通过分析点数量与帧率之间的关系,得到的数据表明本文提出的SDRNet能保持较高精度和较快的推理速率。关键词:深度学习;语义分割;标准化;点云;残差神经网络;感受野63|178|3更新时间:2024-05-07 -
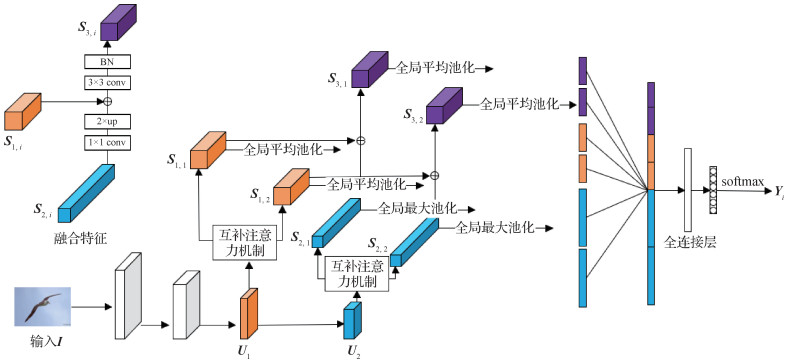 摘要:目的由于分类对象具有细微类间差异和较大类内变化的特点,细粒度分类一直是一个具有挑战性的任务。绝大多数方法利用注意力机制学习目标中显著的局部特征。然而,传统的注意力机制往往只关注了目标最显著的局部特征,同时抑制其他区域的次级显著信息,但是这些抑制的信息中通常也含有目标的有效特征。为了充分提取目标中的有效显著特征,本文提出了一种简单而有效的互补注意力机制。方法基于SE(squeeze-and-excitation)注意力机制,提出了一种新的注意力机制,称为互补注意力机制(complemented SE,CSE)。既从原始特征中提取主要的显著局部特征,也从抑制的剩余通道信息中提取次级显著特征,这些特征之间具有互补性,通过融合这些特征可以得到更加高效的特征表示。结果在CUB-Birds(Caltech-UCSD Birds-200- 2011)、Stanford Dogs、Stanford Cars和FGVC-Aircraft(fine-grained visual classification of aircraft)4个细粒度数据集上对所提方法进行验证,以ResNet50为主干网络,在测试集上的分类精度分别达到了87.9%、89.1%、93.9%和92.4%。实验结果表明,所提方法在CUB-Birds和Stanford Dogs两个数据集上超越了当前表现最好的方法,在Stanford Cars和FGVC-Aircraft数据集的表现也接近当前主流方法。结论本文方法着重提升注意力机制提取特征的能力,得到高效的目标特征表示,可用于细粒度图像分类和特征提取相关的计算机视觉任务。关键词:细粒度;注意力机制;图像分类;特征提取;特征表示173|225|2更新时间:2024-05-07
摘要:目的由于分类对象具有细微类间差异和较大类内变化的特点,细粒度分类一直是一个具有挑战性的任务。绝大多数方法利用注意力机制学习目标中显著的局部特征。然而,传统的注意力机制往往只关注了目标最显著的局部特征,同时抑制其他区域的次级显著信息,但是这些抑制的信息中通常也含有目标的有效特征。为了充分提取目标中的有效显著特征,本文提出了一种简单而有效的互补注意力机制。方法基于SE(squeeze-and-excitation)注意力机制,提出了一种新的注意力机制,称为互补注意力机制(complemented SE,CSE)。既从原始特征中提取主要的显著局部特征,也从抑制的剩余通道信息中提取次级显著特征,这些特征之间具有互补性,通过融合这些特征可以得到更加高效的特征表示。结果在CUB-Birds(Caltech-UCSD Birds-200- 2011)、Stanford Dogs、Stanford Cars和FGVC-Aircraft(fine-grained visual classification of aircraft)4个细粒度数据集上对所提方法进行验证,以ResNet50为主干网络,在测试集上的分类精度分别达到了87.9%、89.1%、93.9%和92.4%。实验结果表明,所提方法在CUB-Birds和Stanford Dogs两个数据集上超越了当前表现最好的方法,在Stanford Cars和FGVC-Aircraft数据集的表现也接近当前主流方法。结论本文方法着重提升注意力机制提取特征的能力,得到高效的目标特征表示,可用于细粒度图像分类和特征提取相关的计算机视觉任务。关键词:细粒度;注意力机制;图像分类;特征提取;特征表示173|225|2更新时间:2024-05-07 -
 摘要:目的高光谱人脸数据具有丰富的鉴别信息。最优谱带选择和谱内间特征表示是高光谱人脸识别的关键。基于高光谱波段范围为4001 090 nm和采样间隔为10 nm的高光谱成像人脸数据,本文提出一种分块谱带选择和VGG(Visual Geometry Group)网络的高光谱人脸识别方法。方法为了优化适合人脸识别的谱带组合,基于人脸关键点,提出分块局部二值模式(local binary pattern,LBP)特征的AdaBoost支持向量机(support vector machine,SVM)谱带选择方法。基于卷积神经网络结构建立一个面向高光谱人脸特点的深度网络(VGG12),提取谱带内特征。融合不同谱带的深度特征,利用三层堆栈自编码器(stack auto-encoder,SAE)抽取谱间特征。对提取的谱间和谱内特征,采用最近邻分类器完成最后的识别。结果为了验证提出方法的有效性,在公开的高光谱人脸数据集UWA-HSFD(University of Western Australia hyperspectral face database)和PolyU-HSFD(Hong Kong Polytechnic University hyperspectral face database)上进行对比试验。结果显示,基于分块LBP特征的谱带选择算法优于传统基于整幅图像像素的方法,提出的VGG12网络相比已有深度学习网络,仅保留少量(68个)谱带,在两个数据集上都取得了最高的识别率(96.8%和97.2%),表明传统可见光人脸深度网络并不适合高光谱人脸识别。结论实验结果表明,高光谱数据用于人脸识别中,谱带选择与深度学习结合是有效的,本文方法联合有监督深度网络(VGG12)和无监督学习网络(SAE)挖掘谱内和谱间鉴别特征,在降低深度网络训练复杂度的同时取得了较其他深度网络更好的识别性能。关键词:高光谱人脸识别;局部二值模式(LBP);VGG网络;谱带选择;AdaBoost SVM82|204|0更新时间:2024-05-07
摘要:目的高光谱人脸数据具有丰富的鉴别信息。最优谱带选择和谱内间特征表示是高光谱人脸识别的关键。基于高光谱波段范围为4001 090 nm和采样间隔为10 nm的高光谱成像人脸数据,本文提出一种分块谱带选择和VGG(Visual Geometry Group)网络的高光谱人脸识别方法。方法为了优化适合人脸识别的谱带组合,基于人脸关键点,提出分块局部二值模式(local binary pattern,LBP)特征的AdaBoost支持向量机(support vector machine,SVM)谱带选择方法。基于卷积神经网络结构建立一个面向高光谱人脸特点的深度网络(VGG12),提取谱带内特征。融合不同谱带的深度特征,利用三层堆栈自编码器(stack auto-encoder,SAE)抽取谱间特征。对提取的谱间和谱内特征,采用最近邻分类器完成最后的识别。结果为了验证提出方法的有效性,在公开的高光谱人脸数据集UWA-HSFD(University of Western Australia hyperspectral face database)和PolyU-HSFD(Hong Kong Polytechnic University hyperspectral face database)上进行对比试验。结果显示,基于分块LBP特征的谱带选择算法优于传统基于整幅图像像素的方法,提出的VGG12网络相比已有深度学习网络,仅保留少量(68个)谱带,在两个数据集上都取得了最高的识别率(96.8%和97.2%),表明传统可见光人脸深度网络并不适合高光谱人脸识别。结论实验结果表明,高光谱数据用于人脸识别中,谱带选择与深度学习结合是有效的,本文方法联合有监督深度网络(VGG12)和无监督学习网络(SAE)挖掘谱内和谱间鉴别特征,在降低深度网络训练复杂度的同时取得了较其他深度网络更好的识别性能。关键词:高光谱人脸识别;局部二值模式(LBP);VGG网络;谱带选择;AdaBoost SVM82|204|0更新时间:2024-05-07 -
 摘要:目的人体骨架的动态变化对于动作识别具有重要意义。从关节轨迹的角度出发,部分对动作类别判定具有价值的关节轨迹传达了最重要的信息。在同一动作的每次尝试中,相应关节的轨迹一般具有相似的基本形状,但其具体形式会受到一定的畸变影响。基于对畸变因素的分析,将人体运动中关节轨迹的常见变换建模为时空双仿射变换。方法首先用一个统一的表达式以内外变换的形式将时空双仿射变换进行描述。基于变换前后轨迹曲线的微分关系推导设计了双仿射微分不变量,用于描述关节轨迹的局部属性。基于微分不变量和关节坐标在数据结构上的同构特点,提出了一种通道增强方法,使用微分不变量将输入数据沿通道维度扩展后,输入神经网络进行训练与评估,用于提高神经网络的泛化能力。结果实验在两个大型动作识别数据集NTU(Nanyang Technological University)RGB+D(NTU 60)和NTU RGB+D 120(NTU 120)上与若干最新方法及两种基线方法进行比较,在两种实验设置(跨参与者识别与跨视角识别)中均取得了明显的改进结果。相比于使用原始数据的时空图神经卷积网络(spatio-temporal graph convolutional networks,ST-GCN),在NTU 60数据集中,跨参与者与跨视角的识别准确率分别提高了1.9%和3.0%;在NTU 120数据集中,跨参与者与跨环境的识别准确率分别提高了5.6%和4.5%。同时对比于数据增强,基于不变特征的通道增强方法在两种实验设置下都能有明显改善,更为有效地提升了网络的泛化能力。结论本文提出的不变特征与通道增强,直观有效地综合了传统特征和深度学习的优点,有效提高了骨架动作识别的准确性,改善了神经网络的泛化能力。关键词:运动分析;骨架动作识别;时空双仿射变换;微分不变量;通道增强;泛化能力93|220|1更新时间:2024-05-07
摘要:目的人体骨架的动态变化对于动作识别具有重要意义。从关节轨迹的角度出发,部分对动作类别判定具有价值的关节轨迹传达了最重要的信息。在同一动作的每次尝试中,相应关节的轨迹一般具有相似的基本形状,但其具体形式会受到一定的畸变影响。基于对畸变因素的分析,将人体运动中关节轨迹的常见变换建模为时空双仿射变换。方法首先用一个统一的表达式以内外变换的形式将时空双仿射变换进行描述。基于变换前后轨迹曲线的微分关系推导设计了双仿射微分不变量,用于描述关节轨迹的局部属性。基于微分不变量和关节坐标在数据结构上的同构特点,提出了一种通道增强方法,使用微分不变量将输入数据沿通道维度扩展后,输入神经网络进行训练与评估,用于提高神经网络的泛化能力。结果实验在两个大型动作识别数据集NTU(Nanyang Technological University)RGB+D(NTU 60)和NTU RGB+D 120(NTU 120)上与若干最新方法及两种基线方法进行比较,在两种实验设置(跨参与者识别与跨视角识别)中均取得了明显的改进结果。相比于使用原始数据的时空图神经卷积网络(spatio-temporal graph convolutional networks,ST-GCN),在NTU 60数据集中,跨参与者与跨视角的识别准确率分别提高了1.9%和3.0%;在NTU 120数据集中,跨参与者与跨环境的识别准确率分别提高了5.6%和4.5%。同时对比于数据增强,基于不变特征的通道增强方法在两种实验设置下都能有明显改善,更为有效地提升了网络的泛化能力。结论本文提出的不变特征与通道增强,直观有效地综合了传统特征和深度学习的优点,有效提高了骨架动作识别的准确性,改善了神经网络的泛化能力。关键词:运动分析;骨架动作识别;时空双仿射变换;微分不变量;通道增强;泛化能力93|220|1更新时间:2024-05-07 -
 摘要:目的现有显著性检测方法大多只关注显著目标的中心信息,使得算法只能得到中心清晰、边缘模糊的显著目标,丢失了一些重要的边界信息,而使用核范数约束进行低秩矩阵恢复,运算过程冗余。为解决以上问题,本文提出一种无监督迭代重加权最小二乘低秩恢复算法,用于图像视觉显著性检测。方法将图像分为细中粗3种尺度的分割,从细粒度和粗粒度先验的融合中得到分割先验信息;将融合后的分割先验信息通过迭代重加权最小二乘法求解平滑低秩矩阵恢复,生成粗略显著图;使用中粒度分割先验对粗略显著图进行平滑,生成最终的视觉显著图。结果实验在MSRA10K(Microsoft Research Asia 10K)、SOD(salient object detection dataset)和ECSSD(extended complex scene saliency dataset)数据集上进行测试,并与现有的11种算法进行对比。结果表明,本文算法可生成边界清晰的显著图。在MSRA10K数据集上,本文算法实现了最高的AUC(area under ROC(receiver operating characteristic)curve)和F-measure值,MAE(mean absolute error)值仅次于SMD(structured matrix decomposition)算法和RBD(robust back ground detection)算法,AUC和F-measure值比次优算法RPCA(robust principal component analysis)分别提高了3.9%和12.3%;在SOD数据集上,综合AUC、F-measure和MAE值来看,本文算法优于除SMD算法以外的其他算法,AUC值仅次于SMD算法、SC(smoothness constraint)算法和GBVS(graph-based visual salieney)算法,F-measure值低于最优算法SMD 2.6%;在ECSSD数据集上,本文算法实现了最高的F-measure值75.5%,AUC值略低于最优算法SC 1%,MAE值略低于最优算法HCNs(hierarchical co-salient object detection via color names)2%。结论实验结果表明,本文算法能从前景复杂或背景复杂的显著图像中更准确地检测出边界清晰的显著目标。关键词:显著目标检测;多尺度分割先验;低秩恢复;迭代重加权最小二乘法;前景复杂;背景复杂68|164|0更新时间:2024-05-07
摘要:目的现有显著性检测方法大多只关注显著目标的中心信息,使得算法只能得到中心清晰、边缘模糊的显著目标,丢失了一些重要的边界信息,而使用核范数约束进行低秩矩阵恢复,运算过程冗余。为解决以上问题,本文提出一种无监督迭代重加权最小二乘低秩恢复算法,用于图像视觉显著性检测。方法将图像分为细中粗3种尺度的分割,从细粒度和粗粒度先验的融合中得到分割先验信息;将融合后的分割先验信息通过迭代重加权最小二乘法求解平滑低秩矩阵恢复,生成粗略显著图;使用中粒度分割先验对粗略显著图进行平滑,生成最终的视觉显著图。结果实验在MSRA10K(Microsoft Research Asia 10K)、SOD(salient object detection dataset)和ECSSD(extended complex scene saliency dataset)数据集上进行测试,并与现有的11种算法进行对比。结果表明,本文算法可生成边界清晰的显著图。在MSRA10K数据集上,本文算法实现了最高的AUC(area under ROC(receiver operating characteristic)curve)和F-measure值,MAE(mean absolute error)值仅次于SMD(structured matrix decomposition)算法和RBD(robust back ground detection)算法,AUC和F-measure值比次优算法RPCA(robust principal component analysis)分别提高了3.9%和12.3%;在SOD数据集上,综合AUC、F-measure和MAE值来看,本文算法优于除SMD算法以外的其他算法,AUC值仅次于SMD算法、SC(smoothness constraint)算法和GBVS(graph-based visual salieney)算法,F-measure值低于最优算法SMD 2.6%;在ECSSD数据集上,本文算法实现了最高的F-measure值75.5%,AUC值略低于最优算法SC 1%,MAE值略低于最优算法HCNs(hierarchical co-salient object detection via color names)2%。结论实验结果表明,本文算法能从前景复杂或背景复杂的显著图像中更准确地检测出边界清晰的显著目标。关键词:显著目标检测;多尺度分割先验;低秩恢复;迭代重加权最小二乘法;前景复杂;背景复杂68|164|0更新时间:2024-05-07 -
 摘要:目的在施工现场,安全帽是最为常见和实用的个人防护用具,能够有效防止和减轻意外带来的头部伤害。但在施工现场的安全帽佩戴检测任务中,经常出现难以检测到小目标,或因为复杂多变的环境因素导致检测准确率降低等情况。针对这些问题,提出一种融合环境特征与改进YOLOv4(you only look once version 4)的安全帽佩戴检测方法。方法为补充卷积池化等过程中丢失的特征,在保证YOLOv4得到的3种不同大小的输出特征图与原图经过特征提取得到的特征图感受野一致的情况下,将两者相加,融合高低层特征,捕捉更多细节信息;对融合后的特征图采用3×3卷积操作,以减小特征图融合后的混叠效应,保证特征稳定性;为适应施工现场的各种环境,利用多种数据增强方式进行环境模拟,并采用对抗训练方法增强模型的泛化能力和鲁棒性。结果提出的改进YOLOv4方法在开源安全帽佩戴检测数据集(safety helmet wearing dataset,SHWD)上进行测试,平均精度均值(mean average precision,mAP)达到91.55%,较当前流行的几种目标检测算法性能有所提升,其中相比于YOLOv4,mAP提高了5.2%。此外,改进YOLOv4方法在融合环境特征进行数据增强后,mAP提高了4.27%,在各种真实环境条件下进行测试时都有较稳定的表现。结论提出的融合环境特征与改进YOLOv4的安全帽佩戴检测方法,以改进模型和数据增强的方式提升模型准确率、泛化能力和鲁棒性,为安全帽佩戴检测提供了有效保障。关键词:安全帽佩戴检测;特征图融合;数据增强;对抗样本;YOLOv4105|95|9更新时间:2024-05-07
摘要:目的在施工现场,安全帽是最为常见和实用的个人防护用具,能够有效防止和减轻意外带来的头部伤害。但在施工现场的安全帽佩戴检测任务中,经常出现难以检测到小目标,或因为复杂多变的环境因素导致检测准确率降低等情况。针对这些问题,提出一种融合环境特征与改进YOLOv4(you only look once version 4)的安全帽佩戴检测方法。方法为补充卷积池化等过程中丢失的特征,在保证YOLOv4得到的3种不同大小的输出特征图与原图经过特征提取得到的特征图感受野一致的情况下,将两者相加,融合高低层特征,捕捉更多细节信息;对融合后的特征图采用3×3卷积操作,以减小特征图融合后的混叠效应,保证特征稳定性;为适应施工现场的各种环境,利用多种数据增强方式进行环境模拟,并采用对抗训练方法增强模型的泛化能力和鲁棒性。结果提出的改进YOLOv4方法在开源安全帽佩戴检测数据集(safety helmet wearing dataset,SHWD)上进行测试,平均精度均值(mean average precision,mAP)达到91.55%,较当前流行的几种目标检测算法性能有所提升,其中相比于YOLOv4,mAP提高了5.2%。此外,改进YOLOv4方法在融合环境特征进行数据增强后,mAP提高了4.27%,在各种真实环境条件下进行测试时都有较稳定的表现。结论提出的融合环境特征与改进YOLOv4的安全帽佩戴检测方法,以改进模型和数据增强的方式提升模型准确率、泛化能力和鲁棒性,为安全帽佩戴检测提供了有效保障。关键词:安全帽佩戴检测;特征图融合;数据增强;对抗样本;YOLOv4105|95|9更新时间:2024-05-07
图像分析和识别
-
 摘要:目的3维人体重建的目标在于建立真实可靠的3维人体模型。但目前基于SMPL(skinned multi-person linear model)模型重建3维人体的实验和一些公开数据集中,常常会出现预测的姿势角度值不符合真实人体关节角度规则的现象。针对这一问题,本文提出设置关节旋转角值域,使得重建的结果真实性更强、更符合人体关节机械结构。方法根据人体关节的联接结构将各个关节的运动进行划分。根据划分结果计算关节运动自由度,并结合实际情况提出基于SMPL模型的关节旋转值域。提出一个简单的重建方法来验证值域分析的正确性。结果使用3维人体数据集UP-3D进行相关实验,并对比以往直接根据学习结果生成重建模型的数据。在使用轴角作为损失参数的情况下,重建精度提高显著,平均误差降低15.1%。在使用所有损失函数后,平均误差比直接根据预测值生成重建模型的两段式重建方法降低7.0%。重建结果与UP-3D数据集进行真实性对比有显著的关节联动性效果。结论本文提出的关节旋转角值域设置对基于SMPL模型进行3维人体重建的方法在进行关节点旋转角回归的过程中起到了很大作用,重建的模型也更符合人体关节运动联动性。关键词:SMPL模型;3维人体重建;关节角度;重建真实性;关节运动联动性85|1205|1更新时间:2024-05-07
摘要:目的3维人体重建的目标在于建立真实可靠的3维人体模型。但目前基于SMPL(skinned multi-person linear model)模型重建3维人体的实验和一些公开数据集中,常常会出现预测的姿势角度值不符合真实人体关节角度规则的现象。针对这一问题,本文提出设置关节旋转角值域,使得重建的结果真实性更强、更符合人体关节机械结构。方法根据人体关节的联接结构将各个关节的运动进行划分。根据划分结果计算关节运动自由度,并结合实际情况提出基于SMPL模型的关节旋转值域。提出一个简单的重建方法来验证值域分析的正确性。结果使用3维人体数据集UP-3D进行相关实验,并对比以往直接根据学习结果生成重建模型的数据。在使用轴角作为损失参数的情况下,重建精度提高显著,平均误差降低15.1%。在使用所有损失函数后,平均误差比直接根据预测值生成重建模型的两段式重建方法降低7.0%。重建结果与UP-3D数据集进行真实性对比有显著的关节联动性效果。结论本文提出的关节旋转角值域设置对基于SMPL模型进行3维人体重建的方法在进行关节点旋转角回归的过程中起到了很大作用,重建的模型也更符合人体关节运动联动性。关键词:SMPL模型;3维人体重建;关节角度;重建真实性;关节运动联动性85|1205|1更新时间:2024-05-07 -
 摘要:目的符合曼哈顿假设的结构化场景简称曼哈顿世界,具有丰富的场景结构特征。消失点作为直线的潜在观测,是一种全局信息,可以显式地体现载体坐标系与世界坐标系之间的姿态关系。为更加准确地估计消失点,本文针对单目图像,同时考虑实时性和准确性,提出了具有更高精度的基于非线性优化的消失点估计算法。方法分析目前性能最优的基于随机采样一致性(random sample consistency,RANSAC)的消失点估计方法,通过对直线单参数化、利用正交性约束生成候选假设以及RANSAC过程的重点分析与改进,更加快速准确地得到消失点估计,为后续优化提供初值。利用直线分类时计算的误差度量构建最小二乘优化模型,采用非线性优化方法迭代求解,并采用鲁棒核函数保证迭代的精确性和结果的最优性。结果通过仿真实验和基于公共数据集的实验对本文提出算法与目前性能最优算法进行比较。仿真实验中,相比于RCM(R3_CM1)及RCMI(R3_CM1_Iter),本文算法结果在轴角形式下的角度偏差减小了24.6%;有先验信息约束时,角度偏差降低一个数量级,仅为0.06°,精度大幅提高。在YUD(York urban city databbase)数据集中,本文算法相较于RCM和RCMI,角度偏差分别减小了27.2%和23.8%,并且80%的消失点估计结果角度偏差小于1.5°,性能明显提升且更具稳定性。此外,本文算法在仿真实验对每一图像帧的平均优化耗时为0.008 s,可保证整体的实时性。结论本文提出的消失点估计算法,对基于RANSAC的方法进行了改进,在不影响实时性的基础上,估计结果更加准确、鲁棒,并且更具稳定性。关键词:曼哈顿世界;消失点(VP);随机采样一致性(RANSAC);非线性优化;误差度量63|130|2更新时间:2024-05-07
摘要:目的符合曼哈顿假设的结构化场景简称曼哈顿世界,具有丰富的场景结构特征。消失点作为直线的潜在观测,是一种全局信息,可以显式地体现载体坐标系与世界坐标系之间的姿态关系。为更加准确地估计消失点,本文针对单目图像,同时考虑实时性和准确性,提出了具有更高精度的基于非线性优化的消失点估计算法。方法分析目前性能最优的基于随机采样一致性(random sample consistency,RANSAC)的消失点估计方法,通过对直线单参数化、利用正交性约束生成候选假设以及RANSAC过程的重点分析与改进,更加快速准确地得到消失点估计,为后续优化提供初值。利用直线分类时计算的误差度量构建最小二乘优化模型,采用非线性优化方法迭代求解,并采用鲁棒核函数保证迭代的精确性和结果的最优性。结果通过仿真实验和基于公共数据集的实验对本文提出算法与目前性能最优算法进行比较。仿真实验中,相比于RCM(R3_CM1)及RCMI(R3_CM1_Iter),本文算法结果在轴角形式下的角度偏差减小了24.6%;有先验信息约束时,角度偏差降低一个数量级,仅为0.06°,精度大幅提高。在YUD(York urban city databbase)数据集中,本文算法相较于RCM和RCMI,角度偏差分别减小了27.2%和23.8%,并且80%的消失点估计结果角度偏差小于1.5°,性能明显提升且更具稳定性。此外,本文算法在仿真实验对每一图像帧的平均优化耗时为0.008 s,可保证整体的实时性。结论本文提出的消失点估计算法,对基于RANSAC的方法进行了改进,在不影响实时性的基础上,估计结果更加准确、鲁棒,并且更具稳定性。关键词:曼哈顿世界;消失点(VP);随机采样一致性(RANSAC);非线性优化;误差度量63|130|2更新时间:2024-05-07 -
 摘要:目的行人感知是自动驾驶中必不可少的一项内容,是行车安全的保障。传统激光雷达和单目视觉组合的行人感知模式,设备硬件成本高且多源数据匹配易导致误差产生。对此,本文结合双目机器视觉技术与深度学习图像识别技术,实现对公共路权环境下路侧行人的自动感知与精准定位。方法利用双目道路智能感知系统采集道路前景图像构建4种交通环境下的行人识别模型训练库;采用RetinaNet深度学习模型进行目标行人自动识别;通过半全局块匹配(semi-global block matching,SGBM)算法实现行人道路前景图像对的视差值计算;通过计算得出的视差图分别统计U-V方向的视差值,提出结合行人识别模型和U-V视差的测距算法,实现目标行人的坐标定位。结果实验统计2.5 km连续测试路段的行人识别结果,对比人工统计结果,本文算法的召回率为96.27%。与YOLOv3(you only look once)和Tiny-YOLOv3方法在4种交通路况下进行比较,平均F值为96.42%,比YOLOv3和Tiny-YOLOv3分别提高0.9%和3.03%;同时,实验利用标定块在室内分别拍摄3 m、4 m和5 m不同距离的20对双目图像,验证测距算法,计算标准偏差皆小于0.01。结论本文提出的结合RetinaNet目标识别模型与改进U-V视差算法能够实现对道路行人的检测,可以为自动驾驶的安全保障提供技术支持,具有一定的应用价值。关键词:行人检测;深度学习;RetinaNet;半全局块匹配(SGBM)算法;U-V视差算法123|126|6更新时间:2024-05-07
摘要:目的行人感知是自动驾驶中必不可少的一项内容,是行车安全的保障。传统激光雷达和单目视觉组合的行人感知模式,设备硬件成本高且多源数据匹配易导致误差产生。对此,本文结合双目机器视觉技术与深度学习图像识别技术,实现对公共路权环境下路侧行人的自动感知与精准定位。方法利用双目道路智能感知系统采集道路前景图像构建4种交通环境下的行人识别模型训练库;采用RetinaNet深度学习模型进行目标行人自动识别;通过半全局块匹配(semi-global block matching,SGBM)算法实现行人道路前景图像对的视差值计算;通过计算得出的视差图分别统计U-V方向的视差值,提出结合行人识别模型和U-V视差的测距算法,实现目标行人的坐标定位。结果实验统计2.5 km连续测试路段的行人识别结果,对比人工统计结果,本文算法的召回率为96.27%。与YOLOv3(you only look once)和Tiny-YOLOv3方法在4种交通路况下进行比较,平均F值为96.42%,比YOLOv3和Tiny-YOLOv3分别提高0.9%和3.03%;同时,实验利用标定块在室内分别拍摄3 m、4 m和5 m不同距离的20对双目图像,验证测距算法,计算标准偏差皆小于0.01。结论本文提出的结合RetinaNet目标识别模型与改进U-V视差算法能够实现对道路行人的检测,可以为自动驾驶的安全保障提供技术支持,具有一定的应用价值。关键词:行人检测;深度学习;RetinaNet;半全局块匹配(SGBM)算法;U-V视差算法123|126|6更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的浮动顶油罐是遥感图像中具有圆形特征的典型人造目标,其高精度定位与参数提取问题是一类代表性的应用问题,针对该问题,传统的基于圆形特征的变换域提取方法鲁棒性差,参数选择需要不断手动调整;基于深度学习的方法利用对已有标注图像的训练求解网络参数,提高了自动化程度,但对于圆形目标而言,覆盖圆周需要较大的感受野,这对应较大的网络结构,随之带来细节信息缺失或参数量、运算量增大的问题。本文针对油罐的定位与参数提取问题,将传统特征提取与深度学习结合,提出了一种计算量小、精度高的方法。方法基于快速径向对称变换(fast radial symmetry transform,FRST)后的变换域数据及原始数据构建了卷积神经网络(convolutional neural networks,CNN),给出了训练过程及参数选择,有效地将圆形特征的先验引入深度学习过程,计算复杂度低,用较少层的网络实现了高精度的定位。结果基于SkySat数据的实验表明,该方法比单纯基于深度学习的方法在相同网络量级上精度得到了有效提高,预测误差平均降低了17.42%,且随着网络深度的增加,精度仍有明显提高,在较浅层次网络中,预测误差平均降低了19.19%,在较深层次网络中,预测误差平均降低了15.66%。结论本文针对油罐遥感图像定位与参数提取问题,提出了一种基于变换域特征结合深度学习的方法,有效降低了计算量,提升了精度和稳定性。本文方法适用于油罐等圆形或类圆形目标的精确定位和参数提取。关键词:遥感图像;油罐;定位;参数提取;深度学习;快速径向对称变换(FRST)94|219|2更新时间:2024-05-07
摘要:目的浮动顶油罐是遥感图像中具有圆形特征的典型人造目标,其高精度定位与参数提取问题是一类代表性的应用问题,针对该问题,传统的基于圆形特征的变换域提取方法鲁棒性差,参数选择需要不断手动调整;基于深度学习的方法利用对已有标注图像的训练求解网络参数,提高了自动化程度,但对于圆形目标而言,覆盖圆周需要较大的感受野,这对应较大的网络结构,随之带来细节信息缺失或参数量、运算量增大的问题。本文针对油罐的定位与参数提取问题,将传统特征提取与深度学习结合,提出了一种计算量小、精度高的方法。方法基于快速径向对称变换(fast radial symmetry transform,FRST)后的变换域数据及原始数据构建了卷积神经网络(convolutional neural networks,CNN),给出了训练过程及参数选择,有效地将圆形特征的先验引入深度学习过程,计算复杂度低,用较少层的网络实现了高精度的定位。结果基于SkySat数据的实验表明,该方法比单纯基于深度学习的方法在相同网络量级上精度得到了有效提高,预测误差平均降低了17.42%,且随着网络深度的增加,精度仍有明显提高,在较浅层次网络中,预测误差平均降低了19.19%,在较深层次网络中,预测误差平均降低了15.66%。结论本文针对油罐遥感图像定位与参数提取问题,提出了一种基于变换域特征结合深度学习的方法,有效降低了计算量,提升了精度和稳定性。本文方法适用于油罐等圆形或类圆形目标的精确定位和参数提取。关键词:遥感图像;油罐;定位;参数提取;深度学习;快速径向对称变换(FRST)94|219|2更新时间:2024-05-07 -
 摘要:目的遥感图像配准是对多组图像进行匹配和叠加的过程。该技术在地物检测、航空图像分类和卫星图像融合等方面发挥着重要作用,主要有传统方法和基于深度学习的方法。其中,传统遥感图像配准算法在进行配准时会耗费大量人力,并且运行时间过长。而基于深度学习的遥感图像配准算法虽然减少了人工成本,提高了模型自适应学习的能力,但是算法的配准精度和运行时间仍有待提高。针对基于深度学习的配准算法存在的问题,本文提出了参数合成的空间变换网络对遥感图像进行双向一致性配准。方法通过增加空间变换网络的深度、合成网络内部的参数对空间变换模型进行改进,并将改进后的模型作为特征提取部分的骨干网络,有效地提高网络的鲁棒性。同时,将单向配准方法改为双向配准方法,进行双向的特征匹配和特征回归,保证配准方向的一致性。然后将回归得到的双向参数加权合成,提高模型的可靠性和准确性。结果将本文实验结果与两种经典的传统方法SIFT(scale-invariant feature transform)、SURF(speeded up robust features)对比,同时与近3年提出的CNNGeo(convolutional neural network architecture for geometric matching)、CNN-Registration(multi-temporal remote sensing image registration)和RMNet(robust matching network)3种最新的方法对比,配准结果表明本文方法不仅在定性的视觉效果上较为优异,而且在定量的评估指标上也有不错的效果。在Aerial Image Dataset数据集上,本文使用"关键点正确评估比例"与以上5种方法对比,精度分别提高了36.2%、75.9%、53.6%、29.9%和1.7%;配准时间分别降低了9.24 s、7.16 s、48.29 s、1.06 s和4.06 s。结论本文所提出的配准方法适用于时间差异变化(多时相)、视角差异(多视角)与拍摄传感器不同(多模态)的3种类型的遥感图像配准应用。在这3种类型的配准应用下,本文算法具有较高的配准精度和配准效率。关键词:图像处理;遥感图像配准;空间变换网络(STN);参数合成;双向一致性60|227|3更新时间:2024-05-07
摘要:目的遥感图像配准是对多组图像进行匹配和叠加的过程。该技术在地物检测、航空图像分类和卫星图像融合等方面发挥着重要作用,主要有传统方法和基于深度学习的方法。其中,传统遥感图像配准算法在进行配准时会耗费大量人力,并且运行时间过长。而基于深度学习的遥感图像配准算法虽然减少了人工成本,提高了模型自适应学习的能力,但是算法的配准精度和运行时间仍有待提高。针对基于深度学习的配准算法存在的问题,本文提出了参数合成的空间变换网络对遥感图像进行双向一致性配准。方法通过增加空间变换网络的深度、合成网络内部的参数对空间变换模型进行改进,并将改进后的模型作为特征提取部分的骨干网络,有效地提高网络的鲁棒性。同时,将单向配准方法改为双向配准方法,进行双向的特征匹配和特征回归,保证配准方向的一致性。然后将回归得到的双向参数加权合成,提高模型的可靠性和准确性。结果将本文实验结果与两种经典的传统方法SIFT(scale-invariant feature transform)、SURF(speeded up robust features)对比,同时与近3年提出的CNNGeo(convolutional neural network architecture for geometric matching)、CNN-Registration(multi-temporal remote sensing image registration)和RMNet(robust matching network)3种最新的方法对比,配准结果表明本文方法不仅在定性的视觉效果上较为优异,而且在定量的评估指标上也有不错的效果。在Aerial Image Dataset数据集上,本文使用"关键点正确评估比例"与以上5种方法对比,精度分别提高了36.2%、75.9%、53.6%、29.9%和1.7%;配准时间分别降低了9.24 s、7.16 s、48.29 s、1.06 s和4.06 s。结论本文所提出的配准方法适用于时间差异变化(多时相)、视角差异(多视角)与拍摄传感器不同(多模态)的3种类型的遥感图像配准应用。在这3种类型的配准应用下,本文算法具有较高的配准精度和配准效率。关键词:图像处理;遥感图像配准;空间变换网络(STN);参数合成;双向一致性60|227|3更新时间:2024-05-07 -
 摘要:目的海洋锋的高效检测对海洋生态环境变化、渔业资源评估、渔情预报及台风路径预测等具有重要意义。海洋锋具有边界信息不明显且多变的弱边缘性,传统基于梯度阈值法及边缘检测的海洋锋检测方法,存在阈值选择不固定、判定指标不一致导致检测精度较低的问题。针对上述问题,基于Mask R-CNN(region convolutional neural network)提出一种改进的海洋锋自动检测方法。方法兼顾考虑海洋锋的小数据量及弱边缘性,首先对数据扩增,并基于不同算法对海表温度(sea surface temperatures,SST)遥感影像进行增强;其次,基于迁移学习的思想采用COCO(common objects in context)数据集对网络模型进行初始化;同时,对Mask R-CNN中残差神经网络(residual neural network,ResNet)和特征金字塔模型(feature pyramid network,FPN)分别进行改进,在充分利用低层特征高分辨率和高层特征的高语义信息的基础上,对多个尺度的融合特征图分别进行目标预测,提升海洋锋的检测精度。结果为验证本文方法的有效性,从训练数据和实验模型上分别设计多组对比实验。实验结果表明,相比常用的Mask R-CNN和YOLOv3(you only look once)神经网络,本文方法对SST梯度影像数据集上的海洋锋检测效果最好,海洋锋的定位准确率(intersection over union,IoU)及检测平均精度均值(mean average precision,mAP)达0.85以上。此外,通过对比分析实验结果发现,本文方法对强海洋锋的检测效果明显优于弱海洋锋。结论本文根据专家经验设立合理的海洋锋检测标准,更好地考虑了海洋锋的弱边缘性。通过设计多组对比实验,验证了本文方法对海洋锋的高精度检测效果。关键词:深度学习;Mask R-CNN;弱边缘性;图像增强;海洋锋检测88|39|2更新时间:2024-05-07
摘要:目的海洋锋的高效检测对海洋生态环境变化、渔业资源评估、渔情预报及台风路径预测等具有重要意义。海洋锋具有边界信息不明显且多变的弱边缘性,传统基于梯度阈值法及边缘检测的海洋锋检测方法,存在阈值选择不固定、判定指标不一致导致检测精度较低的问题。针对上述问题,基于Mask R-CNN(region convolutional neural network)提出一种改进的海洋锋自动检测方法。方法兼顾考虑海洋锋的小数据量及弱边缘性,首先对数据扩增,并基于不同算法对海表温度(sea surface temperatures,SST)遥感影像进行增强;其次,基于迁移学习的思想采用COCO(common objects in context)数据集对网络模型进行初始化;同时,对Mask R-CNN中残差神经网络(residual neural network,ResNet)和特征金字塔模型(feature pyramid network,FPN)分别进行改进,在充分利用低层特征高分辨率和高层特征的高语义信息的基础上,对多个尺度的融合特征图分别进行目标预测,提升海洋锋的检测精度。结果为验证本文方法的有效性,从训练数据和实验模型上分别设计多组对比实验。实验结果表明,相比常用的Mask R-CNN和YOLOv3(you only look once)神经网络,本文方法对SST梯度影像数据集上的海洋锋检测效果最好,海洋锋的定位准确率(intersection over union,IoU)及检测平均精度均值(mean average precision,mAP)达0.85以上。此外,通过对比分析实验结果发现,本文方法对强海洋锋的检测效果明显优于弱海洋锋。结论本文根据专家经验设立合理的海洋锋检测标准,更好地考虑了海洋锋的弱边缘性。通过设计多组对比实验,验证了本文方法对海洋锋的高精度检测效果。关键词:深度学习;Mask R-CNN;弱边缘性;图像增强;海洋锋检测88|39|2更新时间:2024-05-07 -
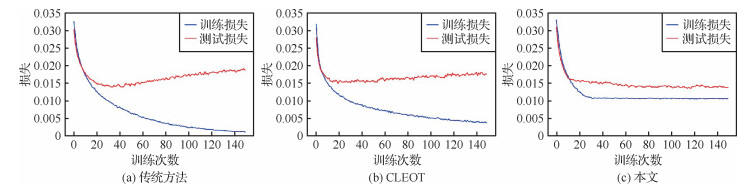 摘要:目的基于深度神经网络的遥感图像处理方法在训练过程中往往需要大量准确标注的数据,一旦标注数据中存在标签噪声,将导致深度神经网络性能显著降低。为了解决噪声造成的性能下降问题,提出了一种噪声鲁棒的轻量级深度遥感场景图像分类检索方法,能够同时完成分类和哈希检索任务,有效提高深度神经网络在有标签噪声遥感数据上的分类和哈希检索性能。方法选取轻量级神经网络作为骨干网,而后设计能够同时完成分类和哈希检索任务的双分支结构,最后通过设置损失基准的正则化方法,有效减轻模型对噪声的过拟合,得到噪声鲁棒的分类检索模型。结果本文在两个公开遥感场景数据集上进行分类测试,并与8种方法进行比较。本文方法在AID(aerial image datasets)数据集上,所有噪声比例下的分类精度比次优方法平均高出7.8%,在NWPU-RESISC45(benchmark created by Northwestern Polytechnical University for remote sensing image scene classification covering 45 scene classes)数据集上,分类精度比次优方法平均高出8.1%。在效率方面,本文方法的推理速度比CLEOT(classification loss with entropic optimal transport)方法提升了2.8倍,而计算量和参数量均不超过CLEOT方法的5%。在遥感图像哈希检索任务中,在AID数据集上,本文方法的平均精度均值(mean average precision,mAP)在3种不同哈希比特下比MiLaN(metric-learning based deep hashing network)方法平均提高了5.9%。结论本文方法可以同时完成遥感图像分类和哈希检索任务,在保持模型轻量高效的情况下,有效提升了深度神经网络在有标签噪声遥感数据上的鲁棒性。关键词:标签噪声;鲁棒学习;图像分类;图像检索;哈希学习;轻量级网络580|267|0更新时间:2024-05-07
摘要:目的基于深度神经网络的遥感图像处理方法在训练过程中往往需要大量准确标注的数据,一旦标注数据中存在标签噪声,将导致深度神经网络性能显著降低。为了解决噪声造成的性能下降问题,提出了一种噪声鲁棒的轻量级深度遥感场景图像分类检索方法,能够同时完成分类和哈希检索任务,有效提高深度神经网络在有标签噪声遥感数据上的分类和哈希检索性能。方法选取轻量级神经网络作为骨干网,而后设计能够同时完成分类和哈希检索任务的双分支结构,最后通过设置损失基准的正则化方法,有效减轻模型对噪声的过拟合,得到噪声鲁棒的分类检索模型。结果本文在两个公开遥感场景数据集上进行分类测试,并与8种方法进行比较。本文方法在AID(aerial image datasets)数据集上,所有噪声比例下的分类精度比次优方法平均高出7.8%,在NWPU-RESISC45(benchmark created by Northwestern Polytechnical University for remote sensing image scene classification covering 45 scene classes)数据集上,分类精度比次优方法平均高出8.1%。在效率方面,本文方法的推理速度比CLEOT(classification loss with entropic optimal transport)方法提升了2.8倍,而计算量和参数量均不超过CLEOT方法的5%。在遥感图像哈希检索任务中,在AID数据集上,本文方法的平均精度均值(mean average precision,mAP)在3种不同哈希比特下比MiLaN(metric-learning based deep hashing network)方法平均提高了5.9%。结论本文方法可以同时完成遥感图像分类和哈希检索任务,在保持模型轻量高效的情况下,有效提升了深度神经网络在有标签噪声遥感数据上的鲁棒性。关键词:标签噪声;鲁棒学习;图像分类;图像检索;哈希学习;轻量级网络580|267|0更新时间:2024-05-07 -
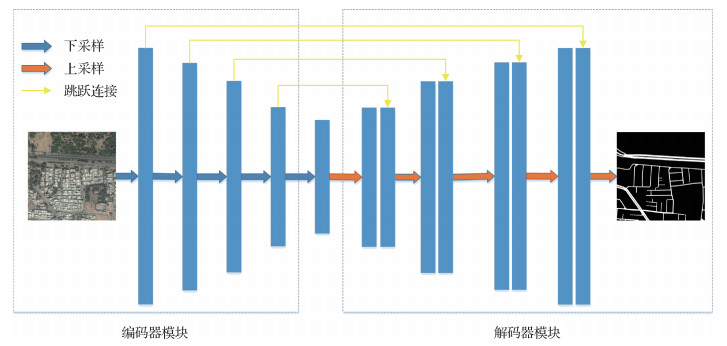 摘要:目的遥感图像道路提取在城市规划、交通管理、车辆导航和地图更新等领域中发挥了重要作用,但遥感图像受光照、噪声和遮挡等因素以及识别过程中大量相似的非道路目标干扰,导致提取高质量的遥感图像道路有很大难度。为此,提出一种结合上下文信息和注意力机制的U-Net型道路分割网络。方法使用Resnet-34预训练网络作为编码器实现特征提取,通过上下文信息提取模块对图像的上下文信息进行整合,确保对道路的几何拓扑结构特征的提取;使用注意力机制对跳跃连接传递的特征进行权重调整,提升网络对于道路边缘区域的分割效果。结果在公共数据集Deep Globe道路提取数据集上对模型进行测试,召回率和交并比指标分别达到0.847 2和0.691 5。与主流方法U-Net和CE-Net(context encoder network)等进行比较,实验结果表明本文方法在性能上表现良好,能有效提高道路分割的精确度。结论本文针对遥感图像道路提取中道路结构不完整和道路边缘区域不清晰问题,提出一种结合上下文信息和注意力机制的遥感道路提取模型。实验结果表明该网络在遥感图像道路提取上达到良好效果,具有较高的研究和应用价值。关键词:U-Net;深度学习;遥感图像;道路提取;残差网络;注意力机制204|1839|5更新时间:2024-05-07
摘要:目的遥感图像道路提取在城市规划、交通管理、车辆导航和地图更新等领域中发挥了重要作用,但遥感图像受光照、噪声和遮挡等因素以及识别过程中大量相似的非道路目标干扰,导致提取高质量的遥感图像道路有很大难度。为此,提出一种结合上下文信息和注意力机制的U-Net型道路分割网络。方法使用Resnet-34预训练网络作为编码器实现特征提取,通过上下文信息提取模块对图像的上下文信息进行整合,确保对道路的几何拓扑结构特征的提取;使用注意力机制对跳跃连接传递的特征进行权重调整,提升网络对于道路边缘区域的分割效果。结果在公共数据集Deep Globe道路提取数据集上对模型进行测试,召回率和交并比指标分别达到0.847 2和0.691 5。与主流方法U-Net和CE-Net(context encoder network)等进行比较,实验结果表明本文方法在性能上表现良好,能有效提高道路分割的精确度。结论本文针对遥感图像道路提取中道路结构不完整和道路边缘区域不清晰问题,提出一种结合上下文信息和注意力机制的遥感道路提取模型。实验结果表明该网络在遥感图像道路提取上达到良好效果,具有较高的研究和应用价值。关键词:U-Net;深度学习;遥感图像;道路提取;残差网络;注意力机制204|1839|5更新时间:2024-05-07 -
 摘要:目的深度语义分割网络的优良性能高度依赖于大规模和高质量的像素级标签数据。在现实任务中,收集大规模、高质量的像素级水体标签数据将耗费大量人力物力。为了减少标注工作量,本文提出使用已有的公开水体覆盖产品来创建遥感影像对应的水体标签,然而已有的公开水体覆盖产品的空间分辨率低且存在一定错误。对此,提出采用弱监督深度学习方法训练深度语义分割网络。方法在训练阶段,将原始数据集划分为多个互不重叠的子数据集,分别训练深度语义分割网络,并将训练得到的多个深度语义分割网络协同更新标签,然后利用更新后的标签重复前述过程,重新训练深度语义分割网络,多次迭代后可以获得好的深度语义分割网络。在测试阶段,多源遥感影像经多个代表不同视角的深度语义分割网络分别预测,然后投票产生最后的水体检测结果。结果为了验证本文方法的有效性,基于原始多源遥感影像数据创建了一个面向水体检测的多源遥感影像数据集,并与基于传统的水体指数阈值分割法和基于低质量水体标签直接学习的深度语义分割网络进行比较,交并比(intersection-over-union,IoU)分别提升了5.5%和7.2%。结论实验结果表明,本文方法具有收敛性,并且光学影像和合成孔径雷达(synthetic aperture radar,SAR)影像的融合有助于提高水体检测性能。在使用分辨率低、噪声多的水体标签进行训练的情况下,训练所得多视角模型的水体检测精度明显优于基于传统的水体指数阈值分割法和基于低质量水体标签直接学习的深度语义分割网络。关键词:水体检测;多源遥感影像;低分辨率噪声标签;弱监督深度语义分割网络110|176|7更新时间:2024-05-07
摘要:目的深度语义分割网络的优良性能高度依赖于大规模和高质量的像素级标签数据。在现实任务中,收集大规模、高质量的像素级水体标签数据将耗费大量人力物力。为了减少标注工作量,本文提出使用已有的公开水体覆盖产品来创建遥感影像对应的水体标签,然而已有的公开水体覆盖产品的空间分辨率低且存在一定错误。对此,提出采用弱监督深度学习方法训练深度语义分割网络。方法在训练阶段,将原始数据集划分为多个互不重叠的子数据集,分别训练深度语义分割网络,并将训练得到的多个深度语义分割网络协同更新标签,然后利用更新后的标签重复前述过程,重新训练深度语义分割网络,多次迭代后可以获得好的深度语义分割网络。在测试阶段,多源遥感影像经多个代表不同视角的深度语义分割网络分别预测,然后投票产生最后的水体检测结果。结果为了验证本文方法的有效性,基于原始多源遥感影像数据创建了一个面向水体检测的多源遥感影像数据集,并与基于传统的水体指数阈值分割法和基于低质量水体标签直接学习的深度语义分割网络进行比较,交并比(intersection-over-union,IoU)分别提升了5.5%和7.2%。结论实验结果表明,本文方法具有收敛性,并且光学影像和合成孔径雷达(synthetic aperture radar,SAR)影像的融合有助于提高水体检测性能。在使用分辨率低、噪声多的水体标签进行训练的情况下,训练所得多视角模型的水体检测精度明显优于基于传统的水体指数阈值分割法和基于低质量水体标签直接学习的深度语义分割网络。关键词:水体检测;多源遥感影像;低分辨率噪声标签;弱监督深度语义分割网络110|176|7更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0