
最新刊期
2021 年 第 26 卷 第 10 期
-
 摘要:图像分类是计算机视觉中的一项重要任务,传统的图像分类方法具有一定的局限性。随着人工智能技术的发展,深度学习技术越来越成熟,利用深度卷积神经网络对图像进行分类成为研究热点,图像分类的深度卷积神经网络结构越来越多样,其性能远远好于传统的图像分类方法。本文立足于图像分类的深度卷积神经网络模型结构,根据模型发展和模型优化的历程,将深度卷积神经网络分为经典深度卷积神经网络模型、注意力机制深度卷积神经网络模型、轻量级深度卷积神经网络模型和神经网络架构搜索模型等4类,并对各类深度卷积神经网络模型结构的构造方法和特点进行了全面综述,对各类分类模型的性能进行了对比与分析。虽然深度卷积神经网络模型的结构设计越来越精妙,模型优化的方法越来越强大,图像分类准确率在不断刷新的同时,模型的参数量也在逐渐降低,训练和推理速度不断加快。然而深度卷积神经网络模型仍有一定的局限性,本文给出了存在的问题和未来可能的研究方向,即深度卷积神经网络模型主要以有监督学习方式进行图像分类,受到数据集质量和规模的限制,无监督式学习和半监督学习方式的深度卷积神经网络模型将是未来的重点研究方向之一;深度卷积神经网络模型的速度和资源消耗仍不尽人意,应用于移动式设备具有一定的挑战性;模型的优化方法以及衡量模型优劣的度量方法有待深入研究;人工设计深度卷积神经网络结构耗时耗力,神经架构搜索方法将是未来深度卷积神经网络模型设计的发展方向。关键词:深度学习;图像分类(IC);深度卷积神经网络(DCNN);模型结构;模型优化429|291|35更新时间:2024-05-07
摘要:图像分类是计算机视觉中的一项重要任务,传统的图像分类方法具有一定的局限性。随着人工智能技术的发展,深度学习技术越来越成熟,利用深度卷积神经网络对图像进行分类成为研究热点,图像分类的深度卷积神经网络结构越来越多样,其性能远远好于传统的图像分类方法。本文立足于图像分类的深度卷积神经网络模型结构,根据模型发展和模型优化的历程,将深度卷积神经网络分为经典深度卷积神经网络模型、注意力机制深度卷积神经网络模型、轻量级深度卷积神经网络模型和神经网络架构搜索模型等4类,并对各类深度卷积神经网络模型结构的构造方法和特点进行了全面综述,对各类分类模型的性能进行了对比与分析。虽然深度卷积神经网络模型的结构设计越来越精妙,模型优化的方法越来越强大,图像分类准确率在不断刷新的同时,模型的参数量也在逐渐降低,训练和推理速度不断加快。然而深度卷积神经网络模型仍有一定的局限性,本文给出了存在的问题和未来可能的研究方向,即深度卷积神经网络模型主要以有监督学习方式进行图像分类,受到数据集质量和规模的限制,无监督式学习和半监督学习方式的深度卷积神经网络模型将是未来的重点研究方向之一;深度卷积神经网络模型的速度和资源消耗仍不尽人意,应用于移动式设备具有一定的挑战性;模型的优化方法以及衡量模型优劣的度量方法有待深入研究;人工设计深度卷积神经网络结构耗时耗力,神经架构搜索方法将是未来深度卷积神经网络模型设计的发展方向。关键词:深度学习;图像分类(IC);深度卷积神经网络(DCNN);模型结构;模型优化429|291|35更新时间:2024-05-07 -
 摘要:本文是对至今已连续发表25年的中国图像工程年度文献综述系列的概括回顾。近25年来,为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解图像工程研究和发展的现状,能够有针对性地查询有关文献,并向期刊编者和作者提供有用的参考,笔者每年都对上一年度图像工程的相关文献进行统计和分析。25年间,该综述系列从国内15种有关图像工程重要期刊所发行的共2 964期上所发表的65 040篇学术研究和技术应用文献中,选取出15 856篇属于图像工程领域的文献,并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类,并在此基础上分别进行各期刊各类文献的统计和分析。此次回顾,除汇总了25年的统计分类情况,还着重对一些主要的研究方向进行了分析和讨论。这样,不仅可从中了解最近四分之一个世纪图像工程相关文献的发表情况,还可以提供全面和可信的各研究方向发展趋势的信息。关键词:图像工程(IE);图像处理(IP);图像分析(IA);图像理解(IU);技术应用(TA);文献综述;文献分类;文献计量学54|88|3更新时间:2024-05-07
摘要:本文是对至今已连续发表25年的中国图像工程年度文献综述系列的概括回顾。近25年来,为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解图像工程研究和发展的现状,能够有针对性地查询有关文献,并向期刊编者和作者提供有用的参考,笔者每年都对上一年度图像工程的相关文献进行统计和分析。25年间,该综述系列从国内15种有关图像工程重要期刊所发行的共2 964期上所发表的65 040篇学术研究和技术应用文献中,选取出15 856篇属于图像工程领域的文献,并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类,并在此基础上分别进行各期刊各类文献的统计和分析。此次回顾,除汇总了25年的统计分类情况,还着重对一些主要的研究方向进行了分析和讨论。这样,不仅可从中了解最近四分之一个世纪图像工程相关文献的发表情况,还可以提供全面和可信的各研究方向发展趋势的信息。关键词:图像工程(IE);图像处理(IP);图像分析(IA);图像理解(IU);技术应用(TA);文献综述;文献分类;文献计量学54|88|3更新时间:2024-05-07
综述

-
 摘要:目的基于光学遥感图像的舰船目标识别研究广受关注,但是目前公开的光学遥感图像舰船目标识别数据集存在规模小、目标类别少等问题,难以训练出具有较高舰船识别精度的深度学习模型。为此,本文面向基于深度学习的舰船目标精细识别任务研究需求,搜集公开的包含舰船目标的高分辨率谷歌地球和GF-2卫星水面场景遥感图像,构建了一个高分辨率光学遥感图像舰船目标精细识别数据集(fine-grained ship collection-23,FGSC-23)。方法将图像中的舰船目标裁剪出来,制作舰船样本切片,人工对目标类别进行标注,并在每个切片中增加舰船长宽比和分布方向两类属性标签,最终形成包含23个类别、4 052个实例的舰船目标识别数据集。结果按1:4比例将数据集中各类别图像随机划分为测试集和训练集,并展开验证实验。实验结果表明,在通用识别模型识别效果验证中,VGG16(Visual Geometry Group 16-layer net)、ResNet50、Inception-v3、DenseNet121、MobileNet和Xception等经典卷积神经网络(convolutional neural network,CNN)模型的整体测试精度分别为79.88%、81.33%、83.88%、84.00%、84.24%和87.76%;在舰船目标精细识别的模型效果验证中,以VGG16和ResNet50模型为基准网络,改进模型在测试集上的整体测试精度分别为93.58%和93.09%。结论构建的FGSC-23数据集能够满足舰船目标识别算法的验证任务。关键词:光学遥感图像;舰船目标;精细识别;数据集;深度学习546|312|3更新时间:2024-05-07
摘要:目的基于光学遥感图像的舰船目标识别研究广受关注,但是目前公开的光学遥感图像舰船目标识别数据集存在规模小、目标类别少等问题,难以训练出具有较高舰船识别精度的深度学习模型。为此,本文面向基于深度学习的舰船目标精细识别任务研究需求,搜集公开的包含舰船目标的高分辨率谷歌地球和GF-2卫星水面场景遥感图像,构建了一个高分辨率光学遥感图像舰船目标精细识别数据集(fine-grained ship collection-23,FGSC-23)。方法将图像中的舰船目标裁剪出来,制作舰船样本切片,人工对目标类别进行标注,并在每个切片中增加舰船长宽比和分布方向两类属性标签,最终形成包含23个类别、4 052个实例的舰船目标识别数据集。结果按1:4比例将数据集中各类别图像随机划分为测试集和训练集,并展开验证实验。实验结果表明,在通用识别模型识别效果验证中,VGG16(Visual Geometry Group 16-layer net)、ResNet50、Inception-v3、DenseNet121、MobileNet和Xception等经典卷积神经网络(convolutional neural network,CNN)模型的整体测试精度分别为79.88%、81.33%、83.88%、84.00%、84.24%和87.76%;在舰船目标精细识别的模型效果验证中,以VGG16和ResNet50模型为基准网络,改进模型在测试集上的整体测试精度分别为93.58%和93.09%。结论构建的FGSC-23数据集能够满足舰船目标识别算法的验证任务。关键词:光学遥感图像;舰船目标;精细识别;数据集;深度学习546|312|3更新时间:2024-05-07
数据集论文
-
 摘要:目的针对现有图像转换方法的深度学习模型中生成式网络(generator network)结构单一化问题,改进了条件生成式对抗网络(conditional generative adversarial network,CGAN)的结构,提出了一种融合残差网络(ResNet)和稠密网络(DenseNet)两种不同结构的并行生成器网络模型。方法构建残差、稠密生成器分支网络模型,输入红外图像,分别经过残差、稠密生成器分支网络各自生成可见光转换图像,并提出一种基于图像分割的线性插值算法,将各生成器分支网络的转换图像进行融合,获取最终的可见光转换图像;为防止小样本条件下的训练过程中出现过拟合,在判别器网络结构中插入dropout层;设计最优阈值分割目标函数,在并行生成器网络训练过程中获取最优融合参数。结果在公共红外-可见光数据集上测试,相较于现有图像转换深度学习模型Pix2Pix和CycleGAN等,本文方法在性能指标均方误差(mean square error,MSE)和结构相似性(structural similarity index,SSIM)上均取得显著提高。结论并行生成器网络模型有效融合了各分支网络结构的优点,图像转换结果更加准确真实。关键词:模态转换;残差网络;稠密网络;线性插值融合;并行生成器网络81|107|5更新时间:2024-05-07
摘要:目的针对现有图像转换方法的深度学习模型中生成式网络(generator network)结构单一化问题,改进了条件生成式对抗网络(conditional generative adversarial network,CGAN)的结构,提出了一种融合残差网络(ResNet)和稠密网络(DenseNet)两种不同结构的并行生成器网络模型。方法构建残差、稠密生成器分支网络模型,输入红外图像,分别经过残差、稠密生成器分支网络各自生成可见光转换图像,并提出一种基于图像分割的线性插值算法,将各生成器分支网络的转换图像进行融合,获取最终的可见光转换图像;为防止小样本条件下的训练过程中出现过拟合,在判别器网络结构中插入dropout层;设计最优阈值分割目标函数,在并行生成器网络训练过程中获取最优融合参数。结果在公共红外-可见光数据集上测试,相较于现有图像转换深度学习模型Pix2Pix和CycleGAN等,本文方法在性能指标均方误差(mean square error,MSE)和结构相似性(structural similarity index,SSIM)上均取得显著提高。结论并行生成器网络模型有效融合了各分支网络结构的优点,图像转换结果更加准确真实。关键词:模态转换;残差网络;稠密网络;线性插值融合;并行生成器网络81|107|5更新时间:2024-05-07
图像处理和编码
-
 摘要:目的现有的足迹研究主要针对赤足和穿袜足迹,取得了较高的识别精度,但需要进行脱鞋配合;而单枚穿鞋足迹由于受到鞋底花纹的影响,识别精度低,主要用于检索。由于穿鞋足迹序列不仅包含人足的结构特征还包含人行走的运动特征,将其用于人身识别会比基于单枚穿鞋足迹的识别精度高。基于此,本文对基于穿鞋足迹序列的身份识别方法进行了研究,提出了穿鞋足迹序列的足迹能量图组表达与识别算法。方法构建反映人足结构和走路行为特性的足迹能量图组来表达足迹序列,从而进行身份识别。足迹能量图组由步态能量图、步幅能量图和步宽能量图构成。步态能量图反映的是足底各个部位与承痕体相互作用形成的效果以及脚的解剖结构特征;步幅能量图和步宽能量图反映的是行走过程中双脚的空间搭配关系以及运动特征,体现人的行为信息。足迹序列之间的匹配得分由各能量图之间的相似度加权计算,其中加权系数采用铰链损失函数训练而得,各能量图之间的相似度采用归一化互相关函数计算而得。将匹配得分最高的足迹序列对应的标签作为最终的识别结果。结果根据采集方式、鞋的新旧程度和鞋底花纹种类构建了3个数据集,分别为采用光学成像仪采集的穿日常鞋的穿鞋足迹序列数据集MUSSRO-SR、采用光学成像仪采集的穿同花纹新鞋的穿鞋足迹序列数据集MUSSRO-SS和采用墨拓扫描方式采集的穿新鞋的穿鞋足迹序列数据集MUSSRS-SS。分别在上述3个数据集上进行了识别模式和验证模式实验,识别率分别达到100%、97.65%和83%,等错误率分别为0.36%、1.17%和6.99%。结论在3种类型不同的数据集上的实验结果表明,本文提出的足迹能量图组能够实现对穿鞋足迹序列的有效表达,并实际验证了基于穿鞋足迹序列的身份识别的可行性。关键词:身份识别;穿鞋足迹序列识别;足迹能量图组(SEMS);步态能量图(TEM);步幅能量图(SEM);步宽能量图(SWEM)76|48|1更新时间:2024-05-07
摘要:目的现有的足迹研究主要针对赤足和穿袜足迹,取得了较高的识别精度,但需要进行脱鞋配合;而单枚穿鞋足迹由于受到鞋底花纹的影响,识别精度低,主要用于检索。由于穿鞋足迹序列不仅包含人足的结构特征还包含人行走的运动特征,将其用于人身识别会比基于单枚穿鞋足迹的识别精度高。基于此,本文对基于穿鞋足迹序列的身份识别方法进行了研究,提出了穿鞋足迹序列的足迹能量图组表达与识别算法。方法构建反映人足结构和走路行为特性的足迹能量图组来表达足迹序列,从而进行身份识别。足迹能量图组由步态能量图、步幅能量图和步宽能量图构成。步态能量图反映的是足底各个部位与承痕体相互作用形成的效果以及脚的解剖结构特征;步幅能量图和步宽能量图反映的是行走过程中双脚的空间搭配关系以及运动特征,体现人的行为信息。足迹序列之间的匹配得分由各能量图之间的相似度加权计算,其中加权系数采用铰链损失函数训练而得,各能量图之间的相似度采用归一化互相关函数计算而得。将匹配得分最高的足迹序列对应的标签作为最终的识别结果。结果根据采集方式、鞋的新旧程度和鞋底花纹种类构建了3个数据集,分别为采用光学成像仪采集的穿日常鞋的穿鞋足迹序列数据集MUSSRO-SR、采用光学成像仪采集的穿同花纹新鞋的穿鞋足迹序列数据集MUSSRO-SS和采用墨拓扫描方式采集的穿新鞋的穿鞋足迹序列数据集MUSSRS-SS。分别在上述3个数据集上进行了识别模式和验证模式实验,识别率分别达到100%、97.65%和83%,等错误率分别为0.36%、1.17%和6.99%。结论在3种类型不同的数据集上的实验结果表明,本文提出的足迹能量图组能够实现对穿鞋足迹序列的有效表达,并实际验证了基于穿鞋足迹序列的身份识别的可行性。关键词:身份识别;穿鞋足迹序列识别;足迹能量图组(SEMS);步态能量图(TEM);步幅能量图(SEM);步宽能量图(SWEM)76|48|1更新时间:2024-05-07 -
 摘要:目的从大量数据中学习时空目标模型对于半监督视频目标分割任务至关重要,现有方法主要依赖第1帧的参考掩膜(通过光流或先前的掩膜进行辅助)估计目标分割掩膜。但由于这些模型在对空间和时域建模方面的局限性,在快速的外观变化或遮挡下很容易失效。因此,提出一种时空部件图卷积网络模型生成鲁棒的时空目标特征。方法首先,使用孪生编码模型,该模型包括两个分支:一个分支输入历史帧和掩膜捕获序列的动态特征,另一个分支输入当前帧图像和前一帧的分割掩膜。其次,构建时空部件图,使用图卷积网络学习时空特征,增强目标的外观和运动模型,并引入通道注意模块,将鲁棒的时空目标模型输出到解码模块。最后,结合相邻阶段的多尺度图像特征,从时空信息中分割出目标。结果在DAVIS(densely annotated video segmentation)-2016和DAVIS-2017两个数据集上与最新的12种方法进行比较,在DAVIS-2016数据集上获得了良好性能,Jacccard相似度平均值(Jaccard similarity-mean,J-M)和F度量平均值(F measure-mean,F-M)得分达到了85.3%,比性能最高的对比方法提高了1.7%;在DAVIS-2017数据集上,J-M和F-M得分达到了68.6%,比性能最高的对比方法提高了1.2%。同时,在DAVIS-2016数据集上,进行了网络输入与后处理的对比实验,结果证明本文方法改善了多帧时空特征的效果。结论本文方法不需要在线微调和后处理,时空部件图模型可缓解因目标外观变化导致的视觉目标漂移问题,同时平滑精细模块增加了目标边缘细节信息,提高了视频目标分割的性能。关键词:视频目标分割(VOS);图卷积网络;时空特征;注意机制;深度神经网络77|152|2更新时间:2024-05-07
摘要:目的从大量数据中学习时空目标模型对于半监督视频目标分割任务至关重要,现有方法主要依赖第1帧的参考掩膜(通过光流或先前的掩膜进行辅助)估计目标分割掩膜。但由于这些模型在对空间和时域建模方面的局限性,在快速的外观变化或遮挡下很容易失效。因此,提出一种时空部件图卷积网络模型生成鲁棒的时空目标特征。方法首先,使用孪生编码模型,该模型包括两个分支:一个分支输入历史帧和掩膜捕获序列的动态特征,另一个分支输入当前帧图像和前一帧的分割掩膜。其次,构建时空部件图,使用图卷积网络学习时空特征,增强目标的外观和运动模型,并引入通道注意模块,将鲁棒的时空目标模型输出到解码模块。最后,结合相邻阶段的多尺度图像特征,从时空信息中分割出目标。结果在DAVIS(densely annotated video segmentation)-2016和DAVIS-2017两个数据集上与最新的12种方法进行比较,在DAVIS-2016数据集上获得了良好性能,Jacccard相似度平均值(Jaccard similarity-mean,J-M)和F度量平均值(F measure-mean,F-M)得分达到了85.3%,比性能最高的对比方法提高了1.7%;在DAVIS-2017数据集上,J-M和F-M得分达到了68.6%,比性能最高的对比方法提高了1.2%。同时,在DAVIS-2016数据集上,进行了网络输入与后处理的对比实验,结果证明本文方法改善了多帧时空特征的效果。结论本文方法不需要在线微调和后处理,时空部件图模型可缓解因目标外观变化导致的视觉目标漂移问题,同时平滑精细模块增加了目标边缘细节信息,提高了视频目标分割的性能。关键词:视频目标分割(VOS);图卷积网络;时空特征;注意机制;深度神经网络77|152|2更新时间:2024-05-07 -
 摘要:目的显著性目标检测是机器视觉应用的基础,然而目前很多方法在显著性物体与背景相似、低光照等一些复杂场景得到的效果并不理想。为了提升显著性检测的性能,提出一种多支路协同的RGB-T(thermal)图像显著性目标检测方法。方法将模型主体设计为两条主干网络和三条解码支路。主干网络用于提取RGB图像和Thermal图像的特征表示,解码支路则分别对RGB特征、Thermal特征以及两者的融合特征以协同互补的方式预测图像中的显著性物体。在特征提取的主干网络中,通过特征增强模块实现多模图像的融合互补,同时采用适当修正的金字塔池化模块,从深层次特征中获取全局语义信息。在解码过程中,利用通道注意力机制进一步区分卷积神经网络(convolutional neural networks,CNN)生成的特征在不同通道之间对应的语义信息差异。结果在VT821和VT1000两个数据集上进行测试,本文方法的最大F-measure值分别为0.843 7和0.880 5,平均绝对误差(mean absolute error,MAE)值分别为0.039 4和0.032 2,相较于对比方法,提升了整体检测性能。结论通过对比实验表明,本文提出的方法提高了显著性检测的稳定性,在一些低光照场景取得了更好效果。关键词:RGB-T显著性目标检测;多模图像融合;多支路协同预测;通道注意力机制;金字塔池化模块(PPM)116|1161|5更新时间:2024-05-07
摘要:目的显著性目标检测是机器视觉应用的基础,然而目前很多方法在显著性物体与背景相似、低光照等一些复杂场景得到的效果并不理想。为了提升显著性检测的性能,提出一种多支路协同的RGB-T(thermal)图像显著性目标检测方法。方法将模型主体设计为两条主干网络和三条解码支路。主干网络用于提取RGB图像和Thermal图像的特征表示,解码支路则分别对RGB特征、Thermal特征以及两者的融合特征以协同互补的方式预测图像中的显著性物体。在特征提取的主干网络中,通过特征增强模块实现多模图像的融合互补,同时采用适当修正的金字塔池化模块,从深层次特征中获取全局语义信息。在解码过程中,利用通道注意力机制进一步区分卷积神经网络(convolutional neural networks,CNN)生成的特征在不同通道之间对应的语义信息差异。结果在VT821和VT1000两个数据集上进行测试,本文方法的最大F-measure值分别为0.843 7和0.880 5,平均绝对误差(mean absolute error,MAE)值分别为0.039 4和0.032 2,相较于对比方法,提升了整体检测性能。结论通过对比实验表明,本文提出的方法提高了显著性检测的稳定性,在一些低光照场景取得了更好效果。关键词:RGB-T显著性目标检测;多模图像融合;多支路协同预测;通道注意力机制;金字塔池化模块(PPM)116|1161|5更新时间:2024-05-07 -
 摘要:目的为了有效解决传统行人检测算法在分辨率低、行人尺寸较小等情境下检测精度低的问题,将基于区域全卷积网络(region-based fully convolutional networks,R-FCN)的目标检测算法引入到行人检测中,提出一种改进R-FCN模型的小尺度行人检测算法。方法为了使特征提取更加准确,在ResNet-101的conv5阶段中嵌入可变形卷积层,扩大特征图的感受野;为提高小尺寸行人检测精度,在ResNet-101中增加另一条检测路径,对不同尺寸大小的特征图进行感兴趣区域池化;为解决小尺寸行人检测中的误检问题,利用自举策略的非极大值抑制算法代替传统的非极大值抑制算法。结果在基准数据集Caltech上进行评估,实验表明,改进的R-FCN算法与具有代表性的单阶段检测器(single shot multiBox detector,SSD)算法和两阶段检测器中的Faster R-CNN(region convolutional neural network)算法相比,检测精度分别提高了3.29%和2.78%;在相同ResNet-101基础网络下,检测精度比原始R-FCN算法提高了12.10%。结论本文提出的改进R-FCN模型,使小尺寸行人检测精度更加准确。相比原始模型,改进的R-FCN模型对行人检测的精确率和召回率有更好的平衡能力,在保证精确率的同时,具有更大的召回率。关键词:行人检测;区域全卷积网络(R-FCN);可变形卷积;多路径;非极大值抑制(NMS);Caltech数据集147|157|3更新时间:2024-05-07
摘要:目的为了有效解决传统行人检测算法在分辨率低、行人尺寸较小等情境下检测精度低的问题,将基于区域全卷积网络(region-based fully convolutional networks,R-FCN)的目标检测算法引入到行人检测中,提出一种改进R-FCN模型的小尺度行人检测算法。方法为了使特征提取更加准确,在ResNet-101的conv5阶段中嵌入可变形卷积层,扩大特征图的感受野;为提高小尺寸行人检测精度,在ResNet-101中增加另一条检测路径,对不同尺寸大小的特征图进行感兴趣区域池化;为解决小尺寸行人检测中的误检问题,利用自举策略的非极大值抑制算法代替传统的非极大值抑制算法。结果在基准数据集Caltech上进行评估,实验表明,改进的R-FCN算法与具有代表性的单阶段检测器(single shot multiBox detector,SSD)算法和两阶段检测器中的Faster R-CNN(region convolutional neural network)算法相比,检测精度分别提高了3.29%和2.78%;在相同ResNet-101基础网络下,检测精度比原始R-FCN算法提高了12.10%。结论本文提出的改进R-FCN模型,使小尺寸行人检测精度更加准确。相比原始模型,改进的R-FCN模型对行人检测的精确率和召回率有更好的平衡能力,在保证精确率的同时,具有更大的召回率。关键词:行人检测;区域全卷积网络(R-FCN);可变形卷积;多路径;非极大值抑制(NMS);Caltech数据集147|157|3更新时间:2024-05-07 -
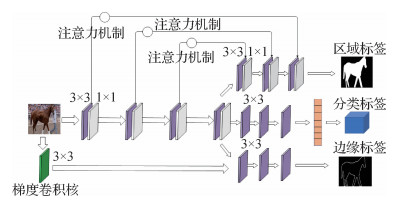 摘要:目的针对已有图像拼接篡改检测方法中存在的真伪判断分类精度不高、拼接篡改区域定位不准确问题,本文设计了一种篡改边缘两侧和篡改区域内外不一致性引导下的重点关注篡改区域与篡改边缘的图像拼接篡改检测卷积神经网络。方法图像内容在篡改过程中,拼接物体的边缘都会留下篡改痕迹,这是图像拼接篡改检测的重要线索。因此,本文设计了一条篡改边缘提取分支,通过学习拼接物体边缘两侧的不一致性,重点提取拼接篡改区域的边缘轮廓。考虑到篡改边缘像素点过少会导致网络难以收敛,提出一个边缘加粗策略,形成一个边缘加粗的"甜甜圈",使得篡改边缘提取结果更具完整性。在不同图像采集过程中,所用相机设备和光线条件等因素不同,导致每幅图像包含的信息也不尽相同。对此,设计了一条篡改区域定位分支,重点学习来自不同图像拼接区域与周围区域之间不一致性的差异化特征,并将注意力机制引入图像拼接篡改检测的篡改区域定位分支,进一步提高对拼接篡改区域的学习关注程度。面向真伪判断设计了一条图像是否经过拼接篡改的二分类网络分支,不但可以快速有效地给出输入图像是否为篡改图像的判断结果,而且可以与上述两条分支的输出结果一起提供给用户,由用户结合视觉语义信息进行综合判断。结果本文算法与已有的4个代表性方法在4个专业数据集上进行算法实验和性能比较。在真伪判断分类的精确度方面,在Dresden、COCO(common objects in context)、RAISE(a raw images dataset for digital image forensics)和IFS-TC(information forensics and security technical committee)数据集上分别提高了8.3%、4.6%、1.0%和1.0%;在篡改区域定位的准确度方面,F1评分与重叠度IOU(intersection over union)指标较已有方法分别提升了9.4%和8.6%。结论本文算法将真伪判别分类、篡改区域定位和篡改边缘提取融合在一起,互相促进,较大提升了各分支任务的性能表现,在图像拼接篡改检测方面取得了优于已有方法的效果,为数字图像取证技术领域的研究工作拓展了思路。关键词:图像拼接篡改检测;卷积神经网络(CNN);篡改区域定位;篡改边缘提取;真伪判别分类188|162|5更新时间:2024-05-07
摘要:目的针对已有图像拼接篡改检测方法中存在的真伪判断分类精度不高、拼接篡改区域定位不准确问题,本文设计了一种篡改边缘两侧和篡改区域内外不一致性引导下的重点关注篡改区域与篡改边缘的图像拼接篡改检测卷积神经网络。方法图像内容在篡改过程中,拼接物体的边缘都会留下篡改痕迹,这是图像拼接篡改检测的重要线索。因此,本文设计了一条篡改边缘提取分支,通过学习拼接物体边缘两侧的不一致性,重点提取拼接篡改区域的边缘轮廓。考虑到篡改边缘像素点过少会导致网络难以收敛,提出一个边缘加粗策略,形成一个边缘加粗的"甜甜圈",使得篡改边缘提取结果更具完整性。在不同图像采集过程中,所用相机设备和光线条件等因素不同,导致每幅图像包含的信息也不尽相同。对此,设计了一条篡改区域定位分支,重点学习来自不同图像拼接区域与周围区域之间不一致性的差异化特征,并将注意力机制引入图像拼接篡改检测的篡改区域定位分支,进一步提高对拼接篡改区域的学习关注程度。面向真伪判断设计了一条图像是否经过拼接篡改的二分类网络分支,不但可以快速有效地给出输入图像是否为篡改图像的判断结果,而且可以与上述两条分支的输出结果一起提供给用户,由用户结合视觉语义信息进行综合判断。结果本文算法与已有的4个代表性方法在4个专业数据集上进行算法实验和性能比较。在真伪判断分类的精确度方面,在Dresden、COCO(common objects in context)、RAISE(a raw images dataset for digital image forensics)和IFS-TC(information forensics and security technical committee)数据集上分别提高了8.3%、4.6%、1.0%和1.0%;在篡改区域定位的准确度方面,F1评分与重叠度IOU(intersection over union)指标较已有方法分别提升了9.4%和8.6%。结论本文算法将真伪判别分类、篡改区域定位和篡改边缘提取融合在一起,互相促进,较大提升了各分支任务的性能表现,在图像拼接篡改检测方面取得了优于已有方法的效果,为数字图像取证技术领域的研究工作拓展了思路。关键词:图像拼接篡改检测;卷积神经网络(CNN);篡改区域定位;篡改边缘提取;真伪判别分类188|162|5更新时间:2024-05-07
图像分析和识别
-
 摘要:目的针对红外与可见光图像融合时易产生边缘细节信息丢失、融合结果有光晕伪影等问题,同时为充分获取多源图像的重要特征,将各向异性导向滤波和相位一致性结合,提出一种红外与可见光图像融合算法。方法首先,采用各向异性导向滤波从源图像获得包含大尺度变化的基础图和包含小尺度细节的系列细节图;其次,利用相位一致性和高斯滤波计算显著图,进而通过对比像素显著性得到初始权重二值图,再利用各向异性导向滤波优化权重图,达到去除噪声和抑制光晕伪影;最后,通过图像重构得到融合结果。结果从主客观两个方面,将所提方法与卷积神经网络(convolutional neural network,CNN)、双树复小波变换(dual-tree complex wavelet transform,DTCWT)、导向滤波(guided filtering,GFF)和各向异性扩散(anisotropic diffusion,ADF)等4种经典红外与可见光融合方法在TNO公开数据集上进行实验对比。主观分析上,所提算法结果在边缘细节、背景保存和目标完整度等方面均优于其他4种方法;客观分析上,选取互信息(mutual information,MI)、边缘信息保持度(degree of edge information,QAB/F)、熵(entropy,EN)和基于梯度的特征互信息(gradient based feature mutual information,FMI_gradient)等4种图像质量评价指数进行综合评价。相较于其他4种方法,本文算法的各项指标均有一定幅度的提高,MI平均值较GFF提高了21.67%,QAB/F平均值较CNN提高了20.21%,EN平均值较CNN提高了5.69%,FMI_gradient平均值较GFF提高了3.14%。结论本文基于各向异性导向滤波融合算法可解决原始导向滤波存在的细节"光晕"问题,有效抑制融合结果中伪影的产生,同时具有尺度感知特性,能更好保留源图像的边缘细节信息和背景信息,提高了融合结果的准确性。关键词:图像融合;多尺度分解(MSD);边缘保持滤波;各向异性导向滤波(AnisGF);相位一致性(PC)87|44|11更新时间:2024-05-07
摘要:目的针对红外与可见光图像融合时易产生边缘细节信息丢失、融合结果有光晕伪影等问题,同时为充分获取多源图像的重要特征,将各向异性导向滤波和相位一致性结合,提出一种红外与可见光图像融合算法。方法首先,采用各向异性导向滤波从源图像获得包含大尺度变化的基础图和包含小尺度细节的系列细节图;其次,利用相位一致性和高斯滤波计算显著图,进而通过对比像素显著性得到初始权重二值图,再利用各向异性导向滤波优化权重图,达到去除噪声和抑制光晕伪影;最后,通过图像重构得到融合结果。结果从主客观两个方面,将所提方法与卷积神经网络(convolutional neural network,CNN)、双树复小波变换(dual-tree complex wavelet transform,DTCWT)、导向滤波(guided filtering,GFF)和各向异性扩散(anisotropic diffusion,ADF)等4种经典红外与可见光融合方法在TNO公开数据集上进行实验对比。主观分析上,所提算法结果在边缘细节、背景保存和目标完整度等方面均优于其他4种方法;客观分析上,选取互信息(mutual information,MI)、边缘信息保持度(degree of edge information,QAB/F)、熵(entropy,EN)和基于梯度的特征互信息(gradient based feature mutual information,FMI_gradient)等4种图像质量评价指数进行综合评价。相较于其他4种方法,本文算法的各项指标均有一定幅度的提高,MI平均值较GFF提高了21.67%,QAB/F平均值较CNN提高了20.21%,EN平均值较CNN提高了5.69%,FMI_gradient平均值较GFF提高了3.14%。结论本文基于各向异性导向滤波融合算法可解决原始导向滤波存在的细节"光晕"问题,有效抑制融合结果中伪影的产生,同时具有尺度感知特性,能更好保留源图像的边缘细节信息和背景信息,提高了融合结果的准确性。关键词:图像融合;多尺度分解(MSD);边缘保持滤波;各向异性导向滤波(AnisGF);相位一致性(PC)87|44|11更新时间:2024-05-07 -
 摘要:目的针对图像融合中信息量不够丰富和边缘细节模糊问题,结合多尺度分析、稀疏表示和显著性特征等图像表示方法,提出一种卷积稀疏与细节显著图解析的图像融合方法。方法首先构造一种自适应样本集,训练出契合度更高的字典滤波器组。然后将待融合图像进行多尺度分析得到高低频子图,对低频子图进行卷积稀疏表示,通过权重分析构建一种加权融合规则,得到信息量更加丰富的低频子图;对高频子图构造细节显著图,进行相似性分析,建立一种高频融合规则,得到边缘细节更加凸显的高频子图。最后进行相应逆变换得到最终图像。结果实验在随机挑选的3组灰度图像集和4组彩色图像集上进行,与具有代表性的7种融合方法进行效果对比。结果表明,本文方法的视觉效果明显较优,平均梯度上依次平均提高39.3%、32.1%、34.7%、28.3%、35.8%、28%、30.4%;在信息熵上依次平均提高6.2%、4.5%、1.9%、0.4%、1.5%、2.4%、2.9%;在空间频率上依次平均提高31.8%、25.8%、29.7%、22.2%、28.6%、22.9%、25.3%;在边缘强度上依次平均提高39.5%、32.1%、35.1%、28.8%、36.6%、28.7%、31.3%。结论本文方法在一定程度上解决了信息量不足的问题,较好地解决了图像边缘细节模糊的问题,使图像中奇异性更加明显的内容被保留下来。关键词:多尺度分析;自适应样本集;卷积稀疏;细节显著图;图像融合82|277|2更新时间:2024-05-07
摘要:目的针对图像融合中信息量不够丰富和边缘细节模糊问题,结合多尺度分析、稀疏表示和显著性特征等图像表示方法,提出一种卷积稀疏与细节显著图解析的图像融合方法。方法首先构造一种自适应样本集,训练出契合度更高的字典滤波器组。然后将待融合图像进行多尺度分析得到高低频子图,对低频子图进行卷积稀疏表示,通过权重分析构建一种加权融合规则,得到信息量更加丰富的低频子图;对高频子图构造细节显著图,进行相似性分析,建立一种高频融合规则,得到边缘细节更加凸显的高频子图。最后进行相应逆变换得到最终图像。结果实验在随机挑选的3组灰度图像集和4组彩色图像集上进行,与具有代表性的7种融合方法进行效果对比。结果表明,本文方法的视觉效果明显较优,平均梯度上依次平均提高39.3%、32.1%、34.7%、28.3%、35.8%、28%、30.4%;在信息熵上依次平均提高6.2%、4.5%、1.9%、0.4%、1.5%、2.4%、2.9%;在空间频率上依次平均提高31.8%、25.8%、29.7%、22.2%、28.6%、22.9%、25.3%;在边缘强度上依次平均提高39.5%、32.1%、35.1%、28.8%、36.6%、28.7%、31.3%。结论本文方法在一定程度上解决了信息量不足的问题,较好地解决了图像边缘细节模糊的问题,使图像中奇异性更加明显的内容被保留下来。关键词:多尺度分析;自适应样本集;卷积稀疏;细节显著图;图像融合82|277|2更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的对于满足低阶连续的链接Bézier曲线,提高曲线之间的连续性以达到平滑的目的,需要对曲线的控制顶点进行相应调整。因此,可根据具体的目标对需要调整的控制顶点进行优化选取,使得平滑后的链接曲线满足相应的要求。针对这一问题,给出了3种目标下优化调整控制顶点的方法。方法首先对讨论的问题进行描述,分别指出链接Bézier曲线从C0连续平滑为C1连续和从C1连续平滑为C2连续两种情形需调整的控制顶点;然后分别给出两种情形下,以新旧控制顶点距离极小为目标、曲线内能极小为目标、新旧控制顶点距离与曲线内能同时极小为目标,对链接Bézier曲线进行平滑的方法,最后对3种极小化方法进行对比,并指出了不同方法的适用场合。结果数值算例表明,距离极小化方法调整后的控制顶点偏离原控制顶点的距离相对较小,适合于控制顶点取自于实物时的应用场合;内能极小化方法获得的链接曲线内能相对较小,适合于要求曲线能量尽可能小的应用场合;距离与内能同时极小化方法兼顾了新旧控制顶点的距离和链接曲线的内能,适合于对两个目标都有要求的应用场合。结论提出的方法为链接Bézier曲线的平滑提供了3种有效手段,且易于实现,对其他类型链接曲线的平滑具有参考价值。关键词:Bezier曲线;链接;平滑;控制顶点优化;距离极小;内能极小61|23|0更新时间:2024-05-07
摘要:目的对于满足低阶连续的链接Bézier曲线,提高曲线之间的连续性以达到平滑的目的,需要对曲线的控制顶点进行相应调整。因此,可根据具体的目标对需要调整的控制顶点进行优化选取,使得平滑后的链接曲线满足相应的要求。针对这一问题,给出了3种目标下优化调整控制顶点的方法。方法首先对讨论的问题进行描述,分别指出链接Bézier曲线从C0连续平滑为C1连续和从C1连续平滑为C2连续两种情形需调整的控制顶点;然后分别给出两种情形下,以新旧控制顶点距离极小为目标、曲线内能极小为目标、新旧控制顶点距离与曲线内能同时极小为目标,对链接Bézier曲线进行平滑的方法,最后对3种极小化方法进行对比,并指出了不同方法的适用场合。结果数值算例表明,距离极小化方法调整后的控制顶点偏离原控制顶点的距离相对较小,适合于控制顶点取自于实物时的应用场合;内能极小化方法获得的链接曲线内能相对较小,适合于要求曲线能量尽可能小的应用场合;距离与内能同时极小化方法兼顾了新旧控制顶点的距离和链接曲线的内能,适合于对两个目标都有要求的应用场合。结论提出的方法为链接Bézier曲线的平滑提供了3种有效手段,且易于实现,对其他类型链接曲线的平滑具有参考价值。关键词:Bezier曲线;链接;平滑;控制顶点优化;距离极小;内能极小61|23|0更新时间:2024-05-07
计算机图形学
-
 摘要:目的在视频前景检测中,像素级的背景减除法检测结果轮廓清晰,灵活性高。然而,基于样本一致性的像素级分类方法不能有效利用像素信息,遇到颜色伪装和出现静止前景等复杂情形时无法有效检测前景。为解决这一问题,提出一种基于置信度加权融合和视觉注意的前景检测方法。方法通过加权融合样本的颜色置信度和纹理置信度之和判断前景,进行自适应更新样本的置信度和权值;通过划分子序列结合颜色显著性和纹理差异度构建视觉注意机制判定静止前景目标,使用更新置信度最小样本的策略保持背景模型的动态更新。结果本文方法在CDW 2014(change detection workshops 2014)和SBM-RGBD(scene background modeling red-green-blue-depth)数据集上进行检测,相较于5种主流算法,本文算法的查全率和精度相较于次好算法分别提高2.66%和1.48%,综合性能最优。结论本文算法提高了在颜色伪装和存在静止前景等复杂情形下前景检测的精度和召回率,在公开数据集上得到更好的检测效果。可将其应用于存在颜色伪装和静止前景等复杂情形的视频监控中。关键词:目标检测;前景检测;置信度;颜色伪装;视觉注意;静态前景91|136|0更新时间:2024-05-07
摘要:目的在视频前景检测中,像素级的背景减除法检测结果轮廓清晰,灵活性高。然而,基于样本一致性的像素级分类方法不能有效利用像素信息,遇到颜色伪装和出现静止前景等复杂情形时无法有效检测前景。为解决这一问题,提出一种基于置信度加权融合和视觉注意的前景检测方法。方法通过加权融合样本的颜色置信度和纹理置信度之和判断前景,进行自适应更新样本的置信度和权值;通过划分子序列结合颜色显著性和纹理差异度构建视觉注意机制判定静止前景目标,使用更新置信度最小样本的策略保持背景模型的动态更新。结果本文方法在CDW 2014(change detection workshops 2014)和SBM-RGBD(scene background modeling red-green-blue-depth)数据集上进行检测,相较于5种主流算法,本文算法的查全率和精度相较于次好算法分别提高2.66%和1.48%,综合性能最优。结论本文算法提高了在颜色伪装和存在静止前景等复杂情形下前景检测的精度和召回率,在公开数据集上得到更好的检测效果。可将其应用于存在颜色伪装和静止前景等复杂情形的视频监控中。关键词:目标检测;前景检测;置信度;颜色伪装;视觉注意;静态前景91|136|0更新时间:2024-05-07 -
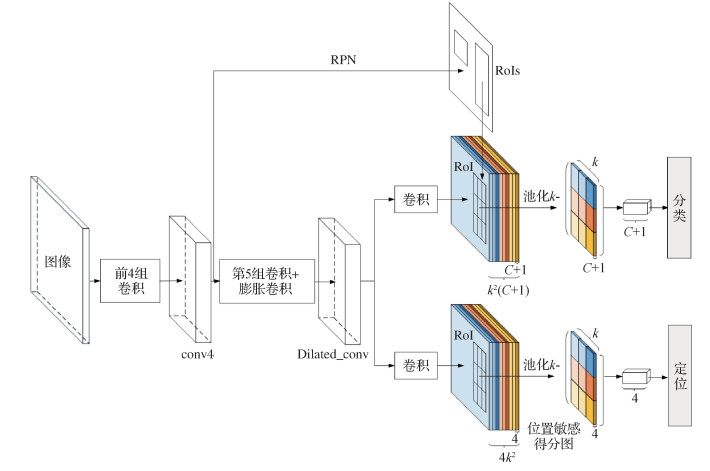 摘要:目的卷积神经网络广泛应用于目标检测中,视频目标检测的任务是在序列图像中对运动目标进行分类和定位。现有的大部分视频目标检测方法在静态图像目标检测器的基础上,利用视频特有的时间相关性来解决运动目标遮挡、模糊等现象导致的漏检和误检问题。方法本文提出一种双光流网络指导的视频目标检测模型,在两阶段目标检测的框架下,对于不同间距的近邻帧,利用两种不同的光流网络估计光流场进行多帧图像特征融合,对于与当前帧间距较小的近邻帧,利用小位移运动估计的光流网络估计光流场,对于间距较大的近邻帧,利用大位移运动估计的光流网络估计光流场,并在光流的指导下融合多个近邻帧的特征来补偿当前帧的特征。结果实验结果表明,本文模型的mAP(mean average precision)为76.4%,相比于TCN(temporal convolutional networks)模型、TPN+LSTM(tubelet proposal network and long short term memory network)模型、D(&T loss)模型和FGFA(flow-guided feature aggregation)模型分别提高了28.9%、8.0%、0.6%和0.2%。结论本文模型利用视频特有的时间相关性,通过双光流网络能够准确地从近邻帧补偿当前帧的特征,提高了视频目标检测的准确率,较好地解决了视频目标检测中目标漏检和误检的问题。关键词:目标检测;卷积神经网络(CNN);运动估计;运动补偿;光流网络;特征融合165|118|1更新时间:2024-05-07
摘要:目的卷积神经网络广泛应用于目标检测中,视频目标检测的任务是在序列图像中对运动目标进行分类和定位。现有的大部分视频目标检测方法在静态图像目标检测器的基础上,利用视频特有的时间相关性来解决运动目标遮挡、模糊等现象导致的漏检和误检问题。方法本文提出一种双光流网络指导的视频目标检测模型,在两阶段目标检测的框架下,对于不同间距的近邻帧,利用两种不同的光流网络估计光流场进行多帧图像特征融合,对于与当前帧间距较小的近邻帧,利用小位移运动估计的光流网络估计光流场,对于间距较大的近邻帧,利用大位移运动估计的光流网络估计光流场,并在光流的指导下融合多个近邻帧的特征来补偿当前帧的特征。结果实验结果表明,本文模型的mAP(mean average precision)为76.4%,相比于TCN(temporal convolutional networks)模型、TPN+LSTM(tubelet proposal network and long short term memory network)模型、D(&T loss)模型和FGFA(flow-guided feature aggregation)模型分别提高了28.9%、8.0%、0.6%和0.2%。结论本文模型利用视频特有的时间相关性,通过双光流网络能够准确地从近邻帧补偿当前帧的特征,提高了视频目标检测的准确率,较好地解决了视频目标检测中目标漏检和误检的问题。关键词:目标检测;卷积神经网络(CNN);运动估计;运动补偿;光流网络;特征融合165|118|1更新时间:2024-05-07 -
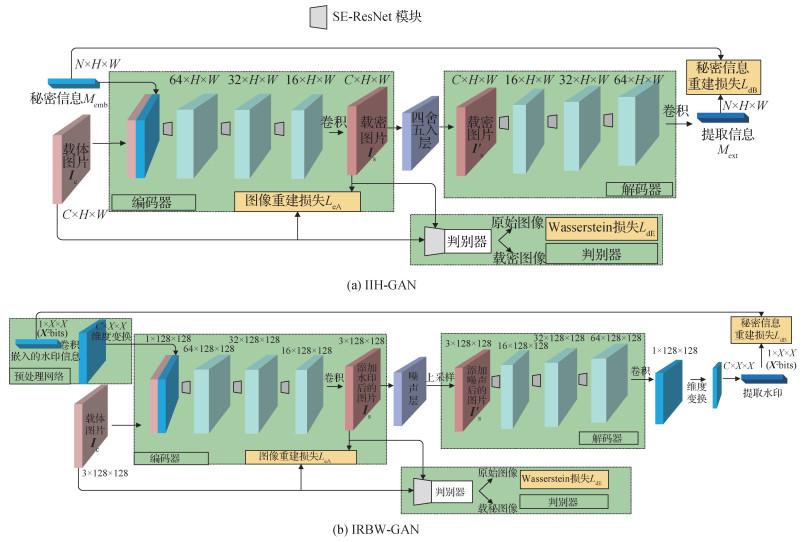 摘要:目的图像信息隐藏包括图像隐写术和图像水印技术两个分支。隐写术是一种将秘密信息隐藏在载体中的技术,目的是为了实现隐秘通信,其主要评价指标是抵御隐写分析的能力。水印技术与隐写术原理类似,但其是通过把水印信息嵌入到载体中以达到保护知识产权的作用,追求的是防止水印被破坏而尽可能地提高水印信息的鲁棒性。研究者们试图利用生成对抗网络(generative adversarial networks,GANs)进行自动化的隐写算法以及鲁棒水印算法的设计,但所设计的算法在信息提取准确率、嵌入容量和隐写安全性或水印鲁棒性、水印图像质量等方面存在不足。方法本文提出了基于生成对抗网络的新型端到端隐写模型(image information hiding-GAN,IIH-GAN)和鲁棒盲水印模型(image robust blind watermark-GAN,IRBW-GAN),分别用于图像隐写术和图像鲁棒盲水印。网络模型中使用了更有效的编码器和解码器结构SE-ResNet(squeeze and excitation ResNet),该模块根据通道之间的相互依赖性来自适应地重新校准通道方式的特征响应。结果实验结果表明隐写模型IIH-GAN相对其他方法在性能方面具有较大改善,当已知训练好的隐写分析模型的内部参数时,将对抗样本加入到IIH-GAN的训练过程,最终可以使隐写分析模型的检测准确率从97.43%降低至49.29%。该隐写模型还可以在256×256像素的图像上做到高达1 bit/像素(bits-per-pixel)的相对嵌入容量;IRBW-GAN水印模型在提升水印嵌入容量的同时显著提升了水印图像质量以及水印提取正确率,在JEPG压缩的攻击下较对比方法提取准确率提高了约20%。结论本文所提IIH-GAN和IRBW-GAN模型在图像隐写和图像水印领域分别实现了领先于对比模型的性能。关键词:图像信息隐藏;图像隐写术;生成对抗网络(GANs);对抗样本;鲁棒盲水印245|211|6更新时间:2024-05-07
摘要:目的图像信息隐藏包括图像隐写术和图像水印技术两个分支。隐写术是一种将秘密信息隐藏在载体中的技术,目的是为了实现隐秘通信,其主要评价指标是抵御隐写分析的能力。水印技术与隐写术原理类似,但其是通过把水印信息嵌入到载体中以达到保护知识产权的作用,追求的是防止水印被破坏而尽可能地提高水印信息的鲁棒性。研究者们试图利用生成对抗网络(generative adversarial networks,GANs)进行自动化的隐写算法以及鲁棒水印算法的设计,但所设计的算法在信息提取准确率、嵌入容量和隐写安全性或水印鲁棒性、水印图像质量等方面存在不足。方法本文提出了基于生成对抗网络的新型端到端隐写模型(image information hiding-GAN,IIH-GAN)和鲁棒盲水印模型(image robust blind watermark-GAN,IRBW-GAN),分别用于图像隐写术和图像鲁棒盲水印。网络模型中使用了更有效的编码器和解码器结构SE-ResNet(squeeze and excitation ResNet),该模块根据通道之间的相互依赖性来自适应地重新校准通道方式的特征响应。结果实验结果表明隐写模型IIH-GAN相对其他方法在性能方面具有较大改善,当已知训练好的隐写分析模型的内部参数时,将对抗样本加入到IIH-GAN的训练过程,最终可以使隐写分析模型的检测准确率从97.43%降低至49.29%。该隐写模型还可以在256×256像素的图像上做到高达1 bit/像素(bits-per-pixel)的相对嵌入容量;IRBW-GAN水印模型在提升水印嵌入容量的同时显著提升了水印图像质量以及水印提取正确率,在JEPG压缩的攻击下较对比方法提取准确率提高了约20%。结论本文所提IIH-GAN和IRBW-GAN模型在图像隐写和图像水印领域分别实现了领先于对比模型的性能。关键词:图像信息隐藏;图像隐写术;生成对抗网络(GANs);对抗样本;鲁棒盲水印245|211|6更新时间:2024-05-07 -
 摘要:目的前景分割是图像理解领域中的重要任务,在无监督条件下,由于不同图像、不同实例往往具有多变的表达形式,这使得基于固定规则、单一类型特征的方法很难保证稳定的分割性能。针对这一问题,本文提出了一种基于语义-表观特征融合的无监督前景分割方法(semantic apparent feature fusion,SAFF)。方法基于语义特征能够对前景物体关键区域产生精准的响应,但往往产生的前景分割结果只关注于关键区域,缺乏物体的完整表达;而以显著性、边缘为代表的表观特征则提供了更丰富的细节表达信息,但基于表观规则无法应对不同的实例和图像成像模式。为了融合表观特征和语义特征优势,研究建立了融合语义、表观信息的一元区域特征和二元上下文特征编码的方法,实现了对两种特征表达的全面描述。接着,设计了一种图内自适应参数学习的方法,用于计算最适合的特征权重,并生成前景置信分数图。进一步地,使用分割网络来学习不同实例间前景的共性特征。结果通过融合语义和表观特征并采用图像间共性语义学习的方法,本文方法在PASCAL VOC(pattern analysis,statistical modelling and computational learning visual object classes)2012训练集和验证集上取得了显著超过类别激活映射(class activation mapping,CAM)和判别性区域特征融合方法(discriminative regional feature integration,DRFI)的前景分割性能,在F测度指标上分别提升了3.5%和3.4%。结论本文方法可以将任意一种语义特征和表观特征前景计算模块作为基础单元,实现对两种策略的融合优化,取得了更优的前景分割性能。关键词:计算机视觉;前景分割;无监督学习;语义—表观特征融合;自然场景图像;PASCAL VOC数据集;自适应加权114|123|0更新时间:2024-05-07
摘要:目的前景分割是图像理解领域中的重要任务,在无监督条件下,由于不同图像、不同实例往往具有多变的表达形式,这使得基于固定规则、单一类型特征的方法很难保证稳定的分割性能。针对这一问题,本文提出了一种基于语义-表观特征融合的无监督前景分割方法(semantic apparent feature fusion,SAFF)。方法基于语义特征能够对前景物体关键区域产生精准的响应,但往往产生的前景分割结果只关注于关键区域,缺乏物体的完整表达;而以显著性、边缘为代表的表观特征则提供了更丰富的细节表达信息,但基于表观规则无法应对不同的实例和图像成像模式。为了融合表观特征和语义特征优势,研究建立了融合语义、表观信息的一元区域特征和二元上下文特征编码的方法,实现了对两种特征表达的全面描述。接着,设计了一种图内自适应参数学习的方法,用于计算最适合的特征权重,并生成前景置信分数图。进一步地,使用分割网络来学习不同实例间前景的共性特征。结果通过融合语义和表观特征并采用图像间共性语义学习的方法,本文方法在PASCAL VOC(pattern analysis,statistical modelling and computational learning visual object classes)2012训练集和验证集上取得了显著超过类别激活映射(class activation mapping,CAM)和判别性区域特征融合方法(discriminative regional feature integration,DRFI)的前景分割性能,在F测度指标上分别提升了3.5%和3.4%。结论本文方法可以将任意一种语义特征和表观特征前景计算模块作为基础单元,实现对两种策略的融合优化,取得了更优的前景分割性能。关键词:计算机视觉;前景分割;无监督学习;语义—表观特征融合;自然场景图像;PASCAL VOC数据集;自适应加权114|123|0更新时间:2024-05-07 -
 摘要:目的激光雷达采集的室外场景点云数据规模庞大且包含丰富的空间结构细节信息,但是目前多数点云分割方法并不能很好地平衡结构细节信息的提取和计算量之间的关系。一些方法将点云变换到多视图或体素化网格等稠密表示形式进行处理,虽然极大地减少了计算量,但却忽略了由激光雷达成像特点以及点云变换引起的信息丢失和遮挡问题,导致分割性能降低,尤其是在小样本数据以及行人和骑行者等小物体场景中。针对投影过程中的空间细节信息丢失问题,根据人类观察机制提出了一种场景视点偏移方法,以改善三维(3D)激光雷达点云分割结果。方法利用球面投影将3D点云转换为2维(2D)球面正视图(spherical front view,SFV)。水平移动SFV的原始视点以生成多视点序列,解决点云变换引起的信息丢失和遮挡的问题。考虑到多视图序列中的冗余,利用卷积神经网络(convolutional neural networks,CNN)构建场景视点偏移预测模块来预测最佳场景视点偏移。结果添加场景视点偏移模块后,在小样本数据集中,行人和骑行者分割结果改善相对明显,行人和骑行者(不同偏移距离下)的交叉比相较于原方法最高提升6.5%和15.5%。添加场景视点偏移模块和偏移预测模块后,各类别的交叉比提高1.6% 3%。在公用数据集KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute)上与其他算法相比,行人和骑行者的分割结果取得了较大提升,其中行人交叉比最高提升9.1%。结论本文提出的结合人类观察机制和激光雷达点云成像特点的场景视点偏移与偏移预测方法易于适配不同的点云分割方法,使得点云分割结果更加准确。关键词:点云分割;球面正视图(SFV);场景视点偏移;场景视点偏移预测;卷积神经网络(CNN)65|145|5更新时间:2024-05-07
摘要:目的激光雷达采集的室外场景点云数据规模庞大且包含丰富的空间结构细节信息,但是目前多数点云分割方法并不能很好地平衡结构细节信息的提取和计算量之间的关系。一些方法将点云变换到多视图或体素化网格等稠密表示形式进行处理,虽然极大地减少了计算量,但却忽略了由激光雷达成像特点以及点云变换引起的信息丢失和遮挡问题,导致分割性能降低,尤其是在小样本数据以及行人和骑行者等小物体场景中。针对投影过程中的空间细节信息丢失问题,根据人类观察机制提出了一种场景视点偏移方法,以改善三维(3D)激光雷达点云分割结果。方法利用球面投影将3D点云转换为2维(2D)球面正视图(spherical front view,SFV)。水平移动SFV的原始视点以生成多视点序列,解决点云变换引起的信息丢失和遮挡的问题。考虑到多视图序列中的冗余,利用卷积神经网络(convolutional neural networks,CNN)构建场景视点偏移预测模块来预测最佳场景视点偏移。结果添加场景视点偏移模块后,在小样本数据集中,行人和骑行者分割结果改善相对明显,行人和骑行者(不同偏移距离下)的交叉比相较于原方法最高提升6.5%和15.5%。添加场景视点偏移模块和偏移预测模块后,各类别的交叉比提高1.6% 3%。在公用数据集KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute)上与其他算法相比,行人和骑行者的分割结果取得了较大提升,其中行人交叉比最高提升9.1%。结论本文提出的结合人类观察机制和激光雷达点云成像特点的场景视点偏移与偏移预测方法易于适配不同的点云分割方法,使得点云分割结果更加准确。关键词:点云分割;球面正视图(SFV);场景视点偏移;场景视点偏移预测;卷积神经网络(CNN)65|145|5更新时间:2024-05-07 -
 摘要:目的SLAM(simultaneous localization and mapping)是移动机器人在未知环境进行探索、感知和导航的关键技术。激光SLAM测量精确,便于机器人导航和路径规划,但缺乏语义信息。而视觉SLAM的图像能提供丰富的语义信息,特征区分度更高,但其构建的地图不能直接用于路径规划和导航。为了实现移动机器人构建语义地图并在地图上进行路径规划,本文提出一种语义栅格建图方法。方法建立可同步获取激光和语义数据的激光-相机系统,将采集的激光分割数据与目标检测算法获得的物体包围盒进行匹配,得到各物体对应的语义激光分割数据。将连续多帧语义激光分割数据同步融入占据栅格地图。对具有不同语义类别的栅格进行聚类,得到标注物体类别和轮廓的语义栅格地图。此外,针对语义栅格地图发布导航任务,利用路径搜索算法进行路径规划,并对其进行改进。结果在实验室走廊和办公室分别进行了语义栅格建图的实验,并与原始栅格地图进行了比较。在语义栅格地图的基础上进行了路径规划,并采用了语义赋权算法对易移动物体的路径进行对比。结论多种环境下的实验表明本文方法能获得与真实环境一致性较高、标注环境中物体类别和轮廓的语义栅格地图,且实验硬件结构简单、成本低、性能良好,适用于智能化机器人的导航和路径规划。目的SLAM(simultaneous localization and mapping)是移动机器人在未知环境进行探索、感知和导航的关键技术。激光SLAM测量精确,便于机器人导航和路径规划,但缺乏语义信息。而视觉SLAM的图像能提供丰富的语义信息,特征区分度更高,但其构建的地图不能直接用于路径规划和导航。为了实现移动机器人构建语义地图并在地图上进行路径规划,本文提出一种语义栅格建图方法。方法建立可同步获取激光和语义数据的激光-相机系统,将采集的激光分割数据与目标检测算法获得的物体包围盒进行匹配,得到各物体对应的语义激光分割数据。将连续多帧语义激光分割数据同步融入占据栅格地图。对具有不同语义类别的栅格进行聚类,得到标注物体类别和轮廓的语义栅格地图。此外,针对语义栅格地图发布导航任务,利用路径搜索算法进行路径规划,并对其进行改进。结果在实验室走廊和办公室分别进行了语义栅格建图的实验,并与原始栅格地图进行了比较。在语义栅格地图的基础上进行了路径规划,并采用了语义赋权算法对易移动物体的路径进行对比。结论多种环境下的实验表明本文方法能获得与真实环境一致性较高、标注环境中物体类别和轮廓的语义栅格地图,且实验硬件结构简单、成本低、性能良好,适用于智能化机器人的导航和路径规划。关键词:智能机器人;语义栅格地图;激光SLAM;目标检测;路径规划260|527|0更新时间:2024-05-07
摘要:目的SLAM(simultaneous localization and mapping)是移动机器人在未知环境进行探索、感知和导航的关键技术。激光SLAM测量精确,便于机器人导航和路径规划,但缺乏语义信息。而视觉SLAM的图像能提供丰富的语义信息,特征区分度更高,但其构建的地图不能直接用于路径规划和导航。为了实现移动机器人构建语义地图并在地图上进行路径规划,本文提出一种语义栅格建图方法。方法建立可同步获取激光和语义数据的激光-相机系统,将采集的激光分割数据与目标检测算法获得的物体包围盒进行匹配,得到各物体对应的语义激光分割数据。将连续多帧语义激光分割数据同步融入占据栅格地图。对具有不同语义类别的栅格进行聚类,得到标注物体类别和轮廓的语义栅格地图。此外,针对语义栅格地图发布导航任务,利用路径搜索算法进行路径规划,并对其进行改进。结果在实验室走廊和办公室分别进行了语义栅格建图的实验,并与原始栅格地图进行了比较。在语义栅格地图的基础上进行了路径规划,并采用了语义赋权算法对易移动物体的路径进行对比。结论多种环境下的实验表明本文方法能获得与真实环境一致性较高、标注环境中物体类别和轮廓的语义栅格地图,且实验硬件结构简单、成本低、性能良好,适用于智能化机器人的导航和路径规划。目的SLAM(simultaneous localization and mapping)是移动机器人在未知环境进行探索、感知和导航的关键技术。激光SLAM测量精确,便于机器人导航和路径规划,但缺乏语义信息。而视觉SLAM的图像能提供丰富的语义信息,特征区分度更高,但其构建的地图不能直接用于路径规划和导航。为了实现移动机器人构建语义地图并在地图上进行路径规划,本文提出一种语义栅格建图方法。方法建立可同步获取激光和语义数据的激光-相机系统,将采集的激光分割数据与目标检测算法获得的物体包围盒进行匹配,得到各物体对应的语义激光分割数据。将连续多帧语义激光分割数据同步融入占据栅格地图。对具有不同语义类别的栅格进行聚类,得到标注物体类别和轮廓的语义栅格地图。此外,针对语义栅格地图发布导航任务,利用路径搜索算法进行路径规划,并对其进行改进。结果在实验室走廊和办公室分别进行了语义栅格建图的实验,并与原始栅格地图进行了比较。在语义栅格地图的基础上进行了路径规划,并采用了语义赋权算法对易移动物体的路径进行对比。结论多种环境下的实验表明本文方法能获得与真实环境一致性较高、标注环境中物体类别和轮廓的语义栅格地图,且实验硬件结构简单、成本低、性能良好,适用于智能化机器人的导航和路径规划。关键词:智能机器人;语义栅格地图;激光SLAM;目标检测;路径规划260|527|0更新时间:2024-05-07 -
 摘要:目的随着图像检索所依赖的特征愈发精细化,在提高检索精度的同时,也不可避免地产生众多非相关和冗余的特征。针对在大规模图像检索和分类中高维度特征所带来的时间和空间挑战,从减少特征数量这一简单思路出发,提出了一种有效的连通图特征点选择方法,探寻图像检索精度和特征选择间的平衡。方法基于词袋模型(bag of words,BOW)的图像检索机制,结合最近邻单词交叉核、特征距离和特征尺度等属性,构建包含若干个连通分支和平凡图的像素级特征分离图,利用子图特征点的逆文本频率修正边权值,从各连通分量的节点数量和孤立点最近邻单词相关性两个方面开展特征选择,将问题转化为在保证图像匹配精度情况下,最小化特征分离图的阶。结果实验采用Oxford和Paris公开数据集,在特征存储容量、时间复杂度集和检索精度等方面进行评估,并对不同特征抽取和选择方法进行了对比。实验结果表明选择后的特征数量和存储容量有效约简50%以上;100 k词典的KD-Tree查询时间减少近58%;相对于其他编码方法和全连接层特征,Oxford数据集检索精度平均提升近7.5%;Paris数据集中检索精度平均高于其他编码方法4%,但检索效果不如全连接层特征。大量实验表明了大连通域的冗余性和孤立点的可选择性。结论通过构建特征分离图,摒弃大连通域的冗余特征点,保留具有最近邻单词相关性的孤立特征点,最终形成图像的精简特征点集。整体检索效果稳定,其检索精度基本与原始特征点集持平,且部分类别效果优于原始特征和其他方法。同时,选择后特征的重用性好,方便进一步聚合集成。关键词:词袋模型(BOW);特征选择;图像检索;连通分量;聚合特征58|46|0更新时间:2024-05-07
摘要:目的随着图像检索所依赖的特征愈发精细化,在提高检索精度的同时,也不可避免地产生众多非相关和冗余的特征。针对在大规模图像检索和分类中高维度特征所带来的时间和空间挑战,从减少特征数量这一简单思路出发,提出了一种有效的连通图特征点选择方法,探寻图像检索精度和特征选择间的平衡。方法基于词袋模型(bag of words,BOW)的图像检索机制,结合最近邻单词交叉核、特征距离和特征尺度等属性,构建包含若干个连通分支和平凡图的像素级特征分离图,利用子图特征点的逆文本频率修正边权值,从各连通分量的节点数量和孤立点最近邻单词相关性两个方面开展特征选择,将问题转化为在保证图像匹配精度情况下,最小化特征分离图的阶。结果实验采用Oxford和Paris公开数据集,在特征存储容量、时间复杂度集和检索精度等方面进行评估,并对不同特征抽取和选择方法进行了对比。实验结果表明选择后的特征数量和存储容量有效约简50%以上;100 k词典的KD-Tree查询时间减少近58%;相对于其他编码方法和全连接层特征,Oxford数据集检索精度平均提升近7.5%;Paris数据集中检索精度平均高于其他编码方法4%,但检索效果不如全连接层特征。大量实验表明了大连通域的冗余性和孤立点的可选择性。结论通过构建特征分离图,摒弃大连通域的冗余特征点,保留具有最近邻单词相关性的孤立特征点,最终形成图像的精简特征点集。整体检索效果稳定,其检索精度基本与原始特征点集持平,且部分类别效果优于原始特征和其他方法。同时,选择后特征的重用性好,方便进一步聚合集成。关键词:词袋模型(BOW);特征选择;图像检索;连通分量;聚合特征58|46|0更新时间:2024-05-07
NCIG 2020
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0