
最新刊期
2020 年 第 25 卷 第 9 期
-
 摘要:随着航空航天、遥感和通信等技术的快速发展,5G等高效通信技术的革新,遥感边缘智能(edge intelligence)成为当下备受关注的研究课题。遥感边缘智能技术通过将遥感数据处理与分析技术前置实现,在近数据源的位置进行高效地遥感信息分析和决策,在卫星在轨处理解译、无人机动态实时跟踪、大规模城市环境重建和无人驾驶识别规划等应用场景中起着至关重要的作用。本文对边缘智能在遥感数据解译中的研究现状进行了归纳总结,介绍了目前遥感智能算法模型在边缘设备进行部署应用中面临的主要问题,即数据样本的限制、计算资源的限制以及灾难性遗忘问题等。针对问题具体阐述了解决思路和主要技术途径,包括小样本情况下的泛化学习方法,详细介绍了样本生成和知识复用两种解决思路;轻量化模型的设计与训练,分析了模型剪枝和量化等方法以及基于知识蒸馏的训练框架;面向多任务的持续学习方法,对比了样本数据重现和模型结构扩展两种原理。同时,还结合了典型的遥感边缘智能应用,对代表性算法的优势和不足进行了深层剖析。最后介绍了遥感边缘智能面临的挑战,以及未来技术的主要发展方向。关键词:遥感数据;边缘智能;小样本学习;模型轻量化;持续学习89|77|5更新时间:2024-05-07
摘要:随着航空航天、遥感和通信等技术的快速发展,5G等高效通信技术的革新,遥感边缘智能(edge intelligence)成为当下备受关注的研究课题。遥感边缘智能技术通过将遥感数据处理与分析技术前置实现,在近数据源的位置进行高效地遥感信息分析和决策,在卫星在轨处理解译、无人机动态实时跟踪、大规模城市环境重建和无人驾驶识别规划等应用场景中起着至关重要的作用。本文对边缘智能在遥感数据解译中的研究现状进行了归纳总结,介绍了目前遥感智能算法模型在边缘设备进行部署应用中面临的主要问题,即数据样本的限制、计算资源的限制以及灾难性遗忘问题等。针对问题具体阐述了解决思路和主要技术途径,包括小样本情况下的泛化学习方法,详细介绍了样本生成和知识复用两种解决思路;轻量化模型的设计与训练,分析了模型剪枝和量化等方法以及基于知识蒸馏的训练框架;面向多任务的持续学习方法,对比了样本数据重现和模型结构扩展两种原理。同时,还结合了典型的遥感边缘智能应用,对代表性算法的优势和不足进行了深层剖析。最后介绍了遥感边缘智能面临的挑战,以及未来技术的主要发展方向。关键词:遥感数据;边缘智能;小样本学习;模型轻量化;持续学习89|77|5更新时间:2024-05-07
学者观点

-
 摘要:红外探测技术具有不受环境等因素干扰的优势,在红外制导、预警等军事领域的应用日益广泛。随着对红外弱小目标检测技术的研究越来越深入,相应的检测方法越来越多样。本文通过对红外弱小目标图像中目标与背景的特性以及红外弱小目标检测技术难点问题进行分析,根据当前是否利用帧间相关信息,分别从基于单帧红外图像和基于红外序列两个角度,选取了相应的红外弱小目标算法进行对比,对其中典型算法的原理、流程以及特点等进行了详细综述,并对每类检测算法的性能进行了比较。针对红外弱小目标图像信噪比低的特点,对红外弱小目标检测算法的难点问题进行分析,给出了目前各种算法的解决方法和不足,探讨红外弱小目标检测算法的发展方向,即研究计算量小、性能优、鲁棒性强、实时性好和便于硬件实现的算法。关键词:红外图像;红外序列;红外弱小目标;低秩稀疏表示;小目标检测442|412|20更新时间:2024-05-07
摘要:红外探测技术具有不受环境等因素干扰的优势,在红外制导、预警等军事领域的应用日益广泛。随着对红外弱小目标检测技术的研究越来越深入,相应的检测方法越来越多样。本文通过对红外弱小目标图像中目标与背景的特性以及红外弱小目标检测技术难点问题进行分析,根据当前是否利用帧间相关信息,分别从基于单帧红外图像和基于红外序列两个角度,选取了相应的红外弱小目标算法进行对比,对其中典型算法的原理、流程以及特点等进行了详细综述,并对每类检测算法的性能进行了比较。针对红外弱小目标图像信噪比低的特点,对红外弱小目标检测算法的难点问题进行分析,给出了目前各种算法的解决方法和不足,探讨红外弱小目标检测算法的发展方向,即研究计算量小、性能优、鲁棒性强、实时性好和便于硬件实现的算法。关键词:红外图像;红外序列;红外弱小目标;低秩稀疏表示;小目标检测442|412|20更新时间:2024-05-07 -
 摘要:目标检测试图用给定的标签标记自然图像中出现的对象实例,已经广泛用于自动驾驶、监控安防等领域。随着深度学习技术的普及,基于卷积神经网络的通用目标检测框架获得了远好于其他方法的目标检测结果。然而,由于卷积神经网络的特性限制,通用目标检测依然面临尺度、光照和遮挡等许多问题的挑战。本文的目的是对卷积神经网络架构中针对尺度的目标检测策略进行全面综述。首先,介绍通用目标检测的发展概况及使用的主要数据集,包括通用目标检测框架的两种类别及发展,详述基于候选区域的两阶段目标检测算法的沿革和结构层面的创新,以及基于一次回归的目标检测算法的3个不同的流派。其次,对针对检测问题中影响效果的尺度问题的优化思路进行简单分类,包括多特征融合策略、针对感受野的卷积变形和训练策略的设计等。最后,给出了各个不同检测框架在通用数据集上对不同尺寸目标的检测准确度,以及未来可能的针对尺度变换的发展方向。关键词:图像语义理解;通用目标检测;卷积神经网络;尺度变换;小目标检测23|42|1更新时间:2024-05-07
摘要:目标检测试图用给定的标签标记自然图像中出现的对象实例,已经广泛用于自动驾驶、监控安防等领域。随着深度学习技术的普及,基于卷积神经网络的通用目标检测框架获得了远好于其他方法的目标检测结果。然而,由于卷积神经网络的特性限制,通用目标检测依然面临尺度、光照和遮挡等许多问题的挑战。本文的目的是对卷积神经网络架构中针对尺度的目标检测策略进行全面综述。首先,介绍通用目标检测的发展概况及使用的主要数据集,包括通用目标检测框架的两种类别及发展,详述基于候选区域的两阶段目标检测算法的沿革和结构层面的创新,以及基于一次回归的目标检测算法的3个不同的流派。其次,对针对检测问题中影响效果的尺度问题的优化思路进行简单分类,包括多特征融合策略、针对感受野的卷积变形和训练策略的设计等。最后,给出了各个不同检测框架在通用数据集上对不同尺寸目标的检测准确度,以及未来可能的针对尺度变换的发展方向。关键词:图像语义理解;通用目标检测;卷积神经网络;尺度变换;小目标检测23|42|1更新时间:2024-05-07
综述
-
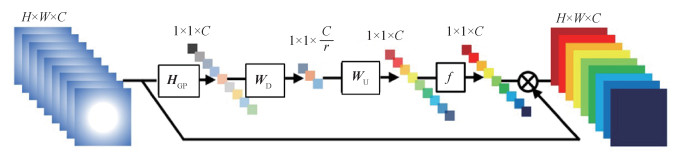 摘要:目的深层卷积神经网络在单幅图像超分辨率任务中取得了巨大成功。从3个卷积层的超分辨率重建卷积神经网络(super-resolution convolutional neural network,SRCNN)到超过300层的残差注意力网络(residual channel attention network,RCAN),网络的深度和整体性能有了显著提高。然而,尽管深层网络方法提高了重建图像的质量,但因计算量大、实时性差等问题并不适合真实场景。针对该问题,本文提出轻量级的层次特征融合空间注意力网络来快速重建图像的高频细节。方法网络由浅层特征提取层、分层特征融合层、上采样层和重建层组成。浅层特征提取层使用1个卷积层提取浅层特征,并对特征通道进行扩充;分层特征融合层由局部特征融合和全局特征融合组成,整个网络包含9个残差注意力块(residual attention block,RAB),每3个构成一个残差注意力组,分别在组内和组间进行局部特征融合和全局特征融合。在每个残差注意力块内部,首先使用卷积层提取特征,再使用空间注意力模块对特征图的不同空间位置分配不同的权重,提高高频区域特征的注意力,以快速恢复高频细节信息;上采样层使用亚像素卷积对特征图进行上采样,将特征图放大到目标图像的尺寸;重建层使用1个卷积层进行重建,得到重建后的高分辨率图像。结果在Set5、Set14、BSD(Berkeley segmentation dataset)100、Urban100和Manga109测试数据集上进行测试。当放大因子为4时,峰值信噪比分别为31.98 dB、28.40 dB、27.45 dB、25.77 dB和29.37 dB。本文算法比其他同等规模的网络在测试结果上有明显提升。结论本文提出的多层特征融合注意力网络,通过结合空间注意力模块和分层特征融合结构的优势,可以快速恢复图像的高频细节并且具有较小的计算复杂度。关键词:超分辨率重建;卷积神经网络;分层特征融合;残差学习;注意力机制211|144|11更新时间:2024-05-07
摘要:目的深层卷积神经网络在单幅图像超分辨率任务中取得了巨大成功。从3个卷积层的超分辨率重建卷积神经网络(super-resolution convolutional neural network,SRCNN)到超过300层的残差注意力网络(residual channel attention network,RCAN),网络的深度和整体性能有了显著提高。然而,尽管深层网络方法提高了重建图像的质量,但因计算量大、实时性差等问题并不适合真实场景。针对该问题,本文提出轻量级的层次特征融合空间注意力网络来快速重建图像的高频细节。方法网络由浅层特征提取层、分层特征融合层、上采样层和重建层组成。浅层特征提取层使用1个卷积层提取浅层特征,并对特征通道进行扩充;分层特征融合层由局部特征融合和全局特征融合组成,整个网络包含9个残差注意力块(residual attention block,RAB),每3个构成一个残差注意力组,分别在组内和组间进行局部特征融合和全局特征融合。在每个残差注意力块内部,首先使用卷积层提取特征,再使用空间注意力模块对特征图的不同空间位置分配不同的权重,提高高频区域特征的注意力,以快速恢复高频细节信息;上采样层使用亚像素卷积对特征图进行上采样,将特征图放大到目标图像的尺寸;重建层使用1个卷积层进行重建,得到重建后的高分辨率图像。结果在Set5、Set14、BSD(Berkeley segmentation dataset)100、Urban100和Manga109测试数据集上进行测试。当放大因子为4时,峰值信噪比分别为31.98 dB、28.40 dB、27.45 dB、25.77 dB和29.37 dB。本文算法比其他同等规模的网络在测试结果上有明显提升。结论本文提出的多层特征融合注意力网络,通过结合空间注意力模块和分层特征融合结构的优势,可以快速恢复图像的高频细节并且具有较小的计算复杂度。关键词:超分辨率重建;卷积神经网络;分层特征融合;残差学习;注意力机制211|144|11更新时间:2024-05-07 -
 摘要:目的视频质量评价是视频技术研究的关键之一。水下环境比其他自然环境更加复杂,自然光在深水中被完全吸收,拍摄所用的人工光源在水中传播时会发生光吸收、色散和散射等情况,同时受水体浑浊度和拍摄设备等影响,导致水下视频具有高度的空间弱可视性和时间不稳定性,常规视频质量评价方法无法对水下视频进行准确、有效的评价。本文考虑水下视频特性,提出一种适用小样本的结合空域统计特性与编码的水下视频质量评价方法。方法基于水下视频成像特性,建立新的水下视频数据库,设计主观质量评价方法对所有视频进行15分质量标注。从水下视频中提取视频帧图像,针对空间域计算图像失真统计特性,然后结合视频编码参数,通过训练线性模型权重系数完成水下视频的质量评价。结果实验表明,与几种主流的质量评价方法相比,本文水下视频质量评价方法与人类视觉感知的相关性最高,模型评价结果与主观质量评价结果的皮尔森线性相关系数PCC(Pearson's correlation coefficient)为0.840 8,斯皮尔曼等级秩序相关系数SROCC(Spearman's rank order correlation coefficient)为0.832 2。通过比较各方法评价结果与真实值的均方误差(mean square error,MSE),本文方法MSE值最小,为0.113 1,说明本文的质量评价结果更加稳定。结论本文通过空间域单帧图像自然场景统计特性和视频编码参数融合的方式,提出的无参考水下视频质量评价方法,能够很好地运用小样本水下视频数据集建立与人类视觉感知高度相关的评价模型,为水下视频做出更准确的质量评价。关键词:视频质量评价;客观质量评价模型;水下视频;自然场景统计;编码参数55|130|4更新时间:2024-05-07
摘要:目的视频质量评价是视频技术研究的关键之一。水下环境比其他自然环境更加复杂,自然光在深水中被完全吸收,拍摄所用的人工光源在水中传播时会发生光吸收、色散和散射等情况,同时受水体浑浊度和拍摄设备等影响,导致水下视频具有高度的空间弱可视性和时间不稳定性,常规视频质量评价方法无法对水下视频进行准确、有效的评价。本文考虑水下视频特性,提出一种适用小样本的结合空域统计特性与编码的水下视频质量评价方法。方法基于水下视频成像特性,建立新的水下视频数据库,设计主观质量评价方法对所有视频进行15分质量标注。从水下视频中提取视频帧图像,针对空间域计算图像失真统计特性,然后结合视频编码参数,通过训练线性模型权重系数完成水下视频的质量评价。结果实验表明,与几种主流的质量评价方法相比,本文水下视频质量评价方法与人类视觉感知的相关性最高,模型评价结果与主观质量评价结果的皮尔森线性相关系数PCC(Pearson's correlation coefficient)为0.840 8,斯皮尔曼等级秩序相关系数SROCC(Spearman's rank order correlation coefficient)为0.832 2。通过比较各方法评价结果与真实值的均方误差(mean square error,MSE),本文方法MSE值最小,为0.113 1,说明本文的质量评价结果更加稳定。结论本文通过空间域单帧图像自然场景统计特性和视频编码参数融合的方式,提出的无参考水下视频质量评价方法,能够很好地运用小样本水下视频数据集建立与人类视觉感知高度相关的评价模型,为水下视频做出更准确的质量评价。关键词:视频质量评价;客观质量评价模型;水下视频;自然场景统计;编码参数55|130|4更新时间:2024-05-07
图像处理和编码
-
 摘要:目的织物识别是提高纺织业竞争力的重要计算机辅助技术。与通用图像相比,织物图像通常只在纹理和形状特征方面呈现细微差异。目前常见的织物识别算法仅考虑图像特征,未结合织物面料的视觉和触觉特征,不能反映出织物本身面料属性,导致识别准确率较低。本文以常见服用织物为例,针对目前常见织物面料识别准确率不高的问题,提出一种结合面料属性和触觉感测的织物图像识别算法。方法针对输入的织物样本,建立织物图像的几何测量方法,量化分析影响织物面料属性的3个关键因素,即恢复性、拉伸性和弯曲性,并进行面料属性的参数化建模,得到面料属性的几何度量。通过传感器设置对织物进行触感测量,采用卷积神经网络(convolutional neural network,CNN)提取测量后的织物触感图像的底层特征。将面料属性几何度量与提取的底层特征进行匹配,通过CNN训练得到织物面料识别模型,学习织物面料属性的不同参数,实现织物面料的识别并输出识别结果。结果在构建的常见服用织物样本上验证了本文方法,与同任务的方法比较,本文方法识别率更高,平均识别率达到89.5%。结论提出了一种基于面料属性和触觉感测的织物图像识别方法,能准确识别常用的服装织物面料,有效提高了织物识别的准确率,能较好地满足实际应用需求。关键词:织物识别;面料属性;触觉感测;卷积神经网络;参数学习16|14|0更新时间:2024-05-07
摘要:目的织物识别是提高纺织业竞争力的重要计算机辅助技术。与通用图像相比,织物图像通常只在纹理和形状特征方面呈现细微差异。目前常见的织物识别算法仅考虑图像特征,未结合织物面料的视觉和触觉特征,不能反映出织物本身面料属性,导致识别准确率较低。本文以常见服用织物为例,针对目前常见织物面料识别准确率不高的问题,提出一种结合面料属性和触觉感测的织物图像识别算法。方法针对输入的织物样本,建立织物图像的几何测量方法,量化分析影响织物面料属性的3个关键因素,即恢复性、拉伸性和弯曲性,并进行面料属性的参数化建模,得到面料属性的几何度量。通过传感器设置对织物进行触感测量,采用卷积神经网络(convolutional neural network,CNN)提取测量后的织物触感图像的底层特征。将面料属性几何度量与提取的底层特征进行匹配,通过CNN训练得到织物面料识别模型,学习织物面料属性的不同参数,实现织物面料的识别并输出识别结果。结果在构建的常见服用织物样本上验证了本文方法,与同任务的方法比较,本文方法识别率更高,平均识别率达到89.5%。结论提出了一种基于面料属性和触觉感测的织物图像识别方法,能准确识别常用的服装织物面料,有效提高了织物识别的准确率,能较好地满足实际应用需求。关键词:织物识别;面料属性;触觉感测;卷积神经网络;参数学习16|14|0更新时间:2024-05-07 -
 摘要:目的模糊车牌识别是车牌识别领域的难题,针对模糊车牌图像收集困难、车牌识别算法模型太大、不适用于移动或嵌入式设备等不足,本文提出了一种轻量级的模糊车牌识别方法,使用深度卷积生成对抗网络生成模糊车牌图像,用于解决现实场景中模糊车牌难以收集的问题,在提升算法识别准确性的同时提升了部署泛化能力。方法该算法主要包含两部分,即基于优化卷积生成对抗网络的模糊车牌图像生成和基于深度可分离卷积网络与双向长短时记忆(long short-term memory,LSTM)的轻量级车牌识别。首先,使用Wasserstein距离优化卷积生成对抗网络的损失函数,提高生成车牌图像的多样性和稳定性;其次,在卷积循环神经网络的基础上,结合深度可分离卷积设计了一个轻量级的车牌识别模型,深度可分离卷积网络在减少识别算法计算量的同时,能对训练样本进行有效的特征学习,将特征图转换为特征序列后输入到双向LSTM网络中,进行序列学习与标注。结果实验表明,增加生成对抗网络生成的车牌图像,能有效提高本文算法、传统车牌识别和基于深度学习的车牌识别方法的识别率,为进一步提高各类算法的识别率提供了一种可行方案。结合深度可分离卷积的轻量级车牌识别模型,识别率与基于标准循环卷积神经网络(convolutional recurrent neural network,CRNN)的车牌识别方法经本文生成图像提高后的识别率相当,但在模型的大小和识别速度上都优于标准的CRNN模型,本文算法的模型大小为45 MB,识别速度为12.5帧/s,标准CRNN模型大小是82 MB,识别速度只有7帧/s。结论使用生成对抗网络生成图像,可有效解决模糊车牌图像样本不足的问题;结合深度可分离卷积的轻量级车牌识别模型,具有良好的识别准确性和较好的部署泛化能力。关键词:模糊车牌识别;深度学习;生成对抗网络(GAN);深度可分离卷积;循环神经网络(CRNN)35|22|2更新时间:2024-05-07
摘要:目的模糊车牌识别是车牌识别领域的难题,针对模糊车牌图像收集困难、车牌识别算法模型太大、不适用于移动或嵌入式设备等不足,本文提出了一种轻量级的模糊车牌识别方法,使用深度卷积生成对抗网络生成模糊车牌图像,用于解决现实场景中模糊车牌难以收集的问题,在提升算法识别准确性的同时提升了部署泛化能力。方法该算法主要包含两部分,即基于优化卷积生成对抗网络的模糊车牌图像生成和基于深度可分离卷积网络与双向长短时记忆(long short-term memory,LSTM)的轻量级车牌识别。首先,使用Wasserstein距离优化卷积生成对抗网络的损失函数,提高生成车牌图像的多样性和稳定性;其次,在卷积循环神经网络的基础上,结合深度可分离卷积设计了一个轻量级的车牌识别模型,深度可分离卷积网络在减少识别算法计算量的同时,能对训练样本进行有效的特征学习,将特征图转换为特征序列后输入到双向LSTM网络中,进行序列学习与标注。结果实验表明,增加生成对抗网络生成的车牌图像,能有效提高本文算法、传统车牌识别和基于深度学习的车牌识别方法的识别率,为进一步提高各类算法的识别率提供了一种可行方案。结合深度可分离卷积的轻量级车牌识别模型,识别率与基于标准循环卷积神经网络(convolutional recurrent neural network,CRNN)的车牌识别方法经本文生成图像提高后的识别率相当,但在模型的大小和识别速度上都优于标准的CRNN模型,本文算法的模型大小为45 MB,识别速度为12.5帧/s,标准CRNN模型大小是82 MB,识别速度只有7帧/s。结论使用生成对抗网络生成图像,可有效解决模糊车牌图像样本不足的问题;结合深度可分离卷积的轻量级车牌识别模型,具有良好的识别准确性和较好的部署泛化能力。关键词:模糊车牌识别;深度学习;生成对抗网络(GAN);深度可分离卷积;循环神经网络(CRNN)35|22|2更新时间:2024-05-07 -
 摘要:目的度量学习是机器学习与图像处理中依赖于任务的基础研究问题。由于实际应用背景复杂,在大量不可避免的噪声环境下,度量学习方法的性能受到一定影响。为了降低噪声影响,现有方法常用L1距离取代L2距离,这种方式可以同时减小相似样本和不相似样本的损失尺度,却忽略了噪声对类内和类间样本的不同影响。为此,本文提出了一种非贪婪的鲁棒性度量学习算法——基于L2/L1损失的边缘费歇尔分析(marginal Fisher analysis based on L2/L1 loss,MFA-L2/L1),采用更具判别性的损失,可提升噪声环境下的识别性能。方法在边缘费歇尔分析(marginal Fisher analysis,MFA)方法的基础上,所提模型采用L2距离刻画相似样本损失、L1距离刻画不相似样本损失,同时加大对两类样本的惩罚程度以提升方法的判别性。首先,针对模型非凸带来的求解困难,将目标函数转为迭代两个凸函数之差便于求解;然后,受DCA(difference of convex functions algorithm)思想启发,推导出非贪婪的迭代求解算法,求得最终度量矩阵;最后,算法的理论证明保证了迭代算法的收敛性。结果在5个UCI(University of California Irrine)数据集和7个人脸数据集上进行对比实验:1)在不同程度噪声的5个UCI数据集上,MFA-L2/L1算法最优,且具有较好的抗噪性,尤其在30%噪声程度的Seeds和Wine数据集上,与次优方法LDA-NgL1(non-greedy L1-norm linear discriminant analysis))相比,MFA-L2/L1的准确率高出9%;2)在不同维度的AR和FEI人脸数据集上的实验,验证了模型采用L1损失、采用L2损失提升了模型的判别性;3)在Senthil、Yale、ORL、Caltech和UMIST人脸数据集的仿真实验中,MFA-L2/L1算法呈现出较强鲁棒性,性能排名第1。结论本文提出了一种基于L2/L1损失的鲁棒性度量学习模型,并推导了一种便捷有效的非贪婪式求解算法,进行了算法收敛性的理论分析。在不同数据集的不同噪声情况下的实验结果表明,所提算法具有较好的识别率和鲁棒性。关键词:距离度量学习;鲁棒性;非贪婪算法;边缘费歇尔分析(MFA);分类识别;L2/L1损失34|100|0更新时间:2024-05-07
摘要:目的度量学习是机器学习与图像处理中依赖于任务的基础研究问题。由于实际应用背景复杂,在大量不可避免的噪声环境下,度量学习方法的性能受到一定影响。为了降低噪声影响,现有方法常用L1距离取代L2距离,这种方式可以同时减小相似样本和不相似样本的损失尺度,却忽略了噪声对类内和类间样本的不同影响。为此,本文提出了一种非贪婪的鲁棒性度量学习算法——基于L2/L1损失的边缘费歇尔分析(marginal Fisher analysis based on L2/L1 loss,MFA-L2/L1),采用更具判别性的损失,可提升噪声环境下的识别性能。方法在边缘费歇尔分析(marginal Fisher analysis,MFA)方法的基础上,所提模型采用L2距离刻画相似样本损失、L1距离刻画不相似样本损失,同时加大对两类样本的惩罚程度以提升方法的判别性。首先,针对模型非凸带来的求解困难,将目标函数转为迭代两个凸函数之差便于求解;然后,受DCA(difference of convex functions algorithm)思想启发,推导出非贪婪的迭代求解算法,求得最终度量矩阵;最后,算法的理论证明保证了迭代算法的收敛性。结果在5个UCI(University of California Irrine)数据集和7个人脸数据集上进行对比实验:1)在不同程度噪声的5个UCI数据集上,MFA-L2/L1算法最优,且具有较好的抗噪性,尤其在30%噪声程度的Seeds和Wine数据集上,与次优方法LDA-NgL1(non-greedy L1-norm linear discriminant analysis))相比,MFA-L2/L1的准确率高出9%;2)在不同维度的AR和FEI人脸数据集上的实验,验证了模型采用L1损失、采用L2损失提升了模型的判别性;3)在Senthil、Yale、ORL、Caltech和UMIST人脸数据集的仿真实验中,MFA-L2/L1算法呈现出较强鲁棒性,性能排名第1。结论本文提出了一种基于L2/L1损失的鲁棒性度量学习模型,并推导了一种便捷有效的非贪婪式求解算法,进行了算法收敛性的理论分析。在不同数据集的不同噪声情况下的实验结果表明,所提算法具有较好的识别率和鲁棒性。关键词:距离度量学习;鲁棒性;非贪婪算法;边缘费歇尔分析(MFA);分类识别;L2/L1损失34|100|0更新时间:2024-05-07 -
 摘要:目的显著性检测领域的研究重点和难点是检测具有复杂结构信息的显著物体。传统的基于图像块的检测算法,主要根据相对规则的图像块进行检测,计算过程中不能充分利用图像不规则的结构和纹理的信息,对算法精度产生影响。针对上述问题,本文提出一种基于不规则像素簇的显著性检测算法。方法根据像素点的颜色信息量化颜色空间,同时寻找图像的颜色中心,将每个像素的颜色替代为最近的颜色中心的颜色。然后根据相同颜色标签的连通域形成不规则像素簇,并以连通域的中心为该簇的位置中心,以该连通域对应颜色中心的颜色为该簇整体的颜色。通过像素簇的全局对比度得到对比度先验图,利用目标粗定位法估计显著目标的中心,计算图像的中心先验图。然后将对比度先验图与中心先验图结合得到初始显著图。为了使显著图更加均匀地突出显著目标,利用图模型及形态学变化改善初始显著图效果。结果将本文算法与5种公认表现最好的算法进行对比,并通过5组图像进行验证,采用客观评价指标精确率—召回率(precision-recall,PR)曲线以及精确率和召回率的调和平均数F-measure进行评价,结果表明本文算法在PR曲线上较其他算法表现良好,在F-measure方面相比其他5种算法均有00.3的提升,且有更佳的视觉效果。结论本文通过更合理地对像素簇进行划分,并对目标物体进行粗定位,更好地考虑了图像的结构和纹理特征,在显著性检测中有较好的检测效果,普适性强。关键词:显著性检测;不规则块;颜色空间量化;全局对比度;中心先验73|111|1更新时间:2024-05-07
摘要:目的显著性检测领域的研究重点和难点是检测具有复杂结构信息的显著物体。传统的基于图像块的检测算法,主要根据相对规则的图像块进行检测,计算过程中不能充分利用图像不规则的结构和纹理的信息,对算法精度产生影响。针对上述问题,本文提出一种基于不规则像素簇的显著性检测算法。方法根据像素点的颜色信息量化颜色空间,同时寻找图像的颜色中心,将每个像素的颜色替代为最近的颜色中心的颜色。然后根据相同颜色标签的连通域形成不规则像素簇,并以连通域的中心为该簇的位置中心,以该连通域对应颜色中心的颜色为该簇整体的颜色。通过像素簇的全局对比度得到对比度先验图,利用目标粗定位法估计显著目标的中心,计算图像的中心先验图。然后将对比度先验图与中心先验图结合得到初始显著图。为了使显著图更加均匀地突出显著目标,利用图模型及形态学变化改善初始显著图效果。结果将本文算法与5种公认表现最好的算法进行对比,并通过5组图像进行验证,采用客观评价指标精确率—召回率(precision-recall,PR)曲线以及精确率和召回率的调和平均数F-measure进行评价,结果表明本文算法在PR曲线上较其他算法表现良好,在F-measure方面相比其他5种算法均有00.3的提升,且有更佳的视觉效果。结论本文通过更合理地对像素簇进行划分,并对目标物体进行粗定位,更好地考虑了图像的结构和纹理特征,在显著性检测中有较好的检测效果,普适性强。关键词:显著性检测;不规则块;颜色空间量化;全局对比度;中心先验73|111|1更新时间:2024-05-07 -
 摘要:目的尺度集模型是一种有效的影像多尺度分割模型,但数据结构复杂、构建效率低下且冗余尺度较多。针对这些问题,提出了一种由全局区域相异度阈值驱动构建稀疏尺度集模型的方法。方法本文方法改变了尺度集模型构建的驱动方式,通过重复进行增大全局区域相异度阈值以及合并所有小于当前全局区域相异度阈值的邻接区域这2个步骤完成尺度集的构建。同时,将依次出现的全局区域相异度阈值与从小到大的抽象尺度对应,采用深度优先搜索在区域邻接图中快速搜索满足条件的邻接区域,采用三次指数平滑法预测下一尺度的全局区域相异度阈值,采用基于局部方差和莫兰指数的尺度属性分析消除冗余的欠分割尺度。结果与传统尺度集相比,稀疏尺度集极大地简化了底层数据结构,通过调节模型核心参数可以有效消除冗余尺度。保守参数设置下,稀疏尺度集的构建速度提高至传统尺度集的3.11倍,且二者区域合并质量无明显差别。结论本文提出的稀疏尺度集模型能够在不引起合并质量下降的前提下大幅度提高模型构建速度,将具有更加广泛与灵活的应用。关键词:尺度集模型;多尺度分割;区域合并;尺度属性分析;面向对象影像分析50|184|1更新时间:2024-05-07
摘要:目的尺度集模型是一种有效的影像多尺度分割模型,但数据结构复杂、构建效率低下且冗余尺度较多。针对这些问题,提出了一种由全局区域相异度阈值驱动构建稀疏尺度集模型的方法。方法本文方法改变了尺度集模型构建的驱动方式,通过重复进行增大全局区域相异度阈值以及合并所有小于当前全局区域相异度阈值的邻接区域这2个步骤完成尺度集的构建。同时,将依次出现的全局区域相异度阈值与从小到大的抽象尺度对应,采用深度优先搜索在区域邻接图中快速搜索满足条件的邻接区域,采用三次指数平滑法预测下一尺度的全局区域相异度阈值,采用基于局部方差和莫兰指数的尺度属性分析消除冗余的欠分割尺度。结果与传统尺度集相比,稀疏尺度集极大地简化了底层数据结构,通过调节模型核心参数可以有效消除冗余尺度。保守参数设置下,稀疏尺度集的构建速度提高至传统尺度集的3.11倍,且二者区域合并质量无明显差别。结论本文提出的稀疏尺度集模型能够在不引起合并质量下降的前提下大幅度提高模型构建速度,将具有更加广泛与灵活的应用。关键词:尺度集模型;多尺度分割;区域合并;尺度属性分析;面向对象影像分析50|184|1更新时间:2024-05-07
图像分析和识别
-
 摘要:目的视觉里程计(visual odometry,VO)仅需要普通相机即可实现精度可观的自主定位,已经成为计算机视觉和机器人领域的研究热点,但是当前研究及应用大多基于场景为静态的假设,即场景中只有相机运动这一个运动模型,无法处理多个运动模型,因此本文提出一种基于分裂合并运动分割的多运动视觉里程计方法,获得场景中除相机运动外多个运动目标的运动状态。方法基于传统的视觉里程计框架,引入多模型拟合的方法分割出动态场景中的多个运动模型,采用RANSAC(random sample consensus)方法估计出多个运动模型的运动参数实例;接着将相机运动信息以及各个运动目标的运动信息转换到统一的坐标系中,获得相机的视觉里程计结果,以及场景中各个运动目标对应各个时刻的位姿信息;最后采用局部窗口光束法平差直接对相机的姿态以及计算出来的相机相对于各个运动目标的姿态进行校正,利用相机运动模型的内点和各个时刻获得的相机相对于运动目标的运动参数,对多个运动模型的轨迹进行优化。结果本文所构建的连续帧运动分割方法能够达到较好的分割结果,具有较好的鲁棒性,连续帧的分割精度均能达到近100%,充分保证后续估计各个运动模型参数的准确性。本文方法不仅能够有效估计出相机的位姿,还能估计出场景中存在的显著移动目标的位姿,在各个分段路径中相机自定位与移动目标的定位结果位置平均误差均小于6%。结论本文方法能够同时分割出动态场景中的相机自身运动模型和不同运动的动态物体运动模型,进而同时估计出相机和各个动态物体的绝对运动轨迹,构建出多运动视觉里程计过程。关键词:多运动视觉里程计;多模型拟合;运动分割;量化残差偏好;交替采样与聚类59|103|0更新时间:2024-05-07
摘要:目的视觉里程计(visual odometry,VO)仅需要普通相机即可实现精度可观的自主定位,已经成为计算机视觉和机器人领域的研究热点,但是当前研究及应用大多基于场景为静态的假设,即场景中只有相机运动这一个运动模型,无法处理多个运动模型,因此本文提出一种基于分裂合并运动分割的多运动视觉里程计方法,获得场景中除相机运动外多个运动目标的运动状态。方法基于传统的视觉里程计框架,引入多模型拟合的方法分割出动态场景中的多个运动模型,采用RANSAC(random sample consensus)方法估计出多个运动模型的运动参数实例;接着将相机运动信息以及各个运动目标的运动信息转换到统一的坐标系中,获得相机的视觉里程计结果,以及场景中各个运动目标对应各个时刻的位姿信息;最后采用局部窗口光束法平差直接对相机的姿态以及计算出来的相机相对于各个运动目标的姿态进行校正,利用相机运动模型的内点和各个时刻获得的相机相对于运动目标的运动参数,对多个运动模型的轨迹进行优化。结果本文所构建的连续帧运动分割方法能够达到较好的分割结果,具有较好的鲁棒性,连续帧的分割精度均能达到近100%,充分保证后续估计各个运动模型参数的准确性。本文方法不仅能够有效估计出相机的位姿,还能估计出场景中存在的显著移动目标的位姿,在各个分段路径中相机自定位与移动目标的定位结果位置平均误差均小于6%。结论本文方法能够同时分割出动态场景中的相机自身运动模型和不同运动的动态物体运动模型,进而同时估计出相机和各个动态物体的绝对运动轨迹,构建出多运动视觉里程计过程。关键词:多运动视觉里程计;多模型拟合;运动分割;量化残差偏好;交替采样与聚类59|103|0更新时间:2024-05-07 -
 摘要:目的多行人跟踪一直是计算机视觉领域最具挑战性的任务之一,然而受相机移动、行人频繁遮挡和碰撞影响导致第一人称视频中行人跟踪存在效率和精度不高的问题。对此,本文提出一种基于社会力模型优化的第一人称视角下的多行人跟踪算法。方法采用基于目标检测的跟踪算法,将跟踪问题简化为检测到的目标匹配问题,并且在初步跟踪之后进行社会力优化,有效解决频繁遮挡和碰撞行为导致的错误跟踪问题。首先,采用特征提取策略和宽高比重新设置的单步多框检测器(single shot multi-box detector,SSD),对输入的第一人称视频序列进行检测,并基于卷积神经网络(convolutional neural network,CNN)模型提取行人的表观特征,通过计算行人特征相似度获得初步的行人跟踪结果;然后,进行跟踪结果的社会力优化,一是定义行人分组行为,对每个行人跟踪目标进行分组计算,并通过添加分组标识,实现同组行人在遮挡的情况下的准确跟踪;二是通过定义的行人领域,对行人分组进行排斥计算,实现避免碰撞后的准确跟踪。结果在公用数据集ETH(eidgenössische technische hochschule)、MOT16(multi-object tracking 16)和ADL(adelaide)的6个第一人称视频序列上与其他跟踪算法进行对比实验,本文算法的运行速度达到准实时的20.8帧/s,同时相比其他准实时算法,本文算法的整体跟踪性能MOTA(multiple object tracking accuracy)提高了2.5%。结论提出的第一人称视频中社会力优化的多行人跟踪算法,既能准确地在第一人称场景中跟踪多个行人,又能较好地满足实际应用需求。关键词:第一人称视频;多行人跟踪;社会力优化;碰撞避免;分组行为37|21|0更新时间:2024-05-07
摘要:目的多行人跟踪一直是计算机视觉领域最具挑战性的任务之一,然而受相机移动、行人频繁遮挡和碰撞影响导致第一人称视频中行人跟踪存在效率和精度不高的问题。对此,本文提出一种基于社会力模型优化的第一人称视角下的多行人跟踪算法。方法采用基于目标检测的跟踪算法,将跟踪问题简化为检测到的目标匹配问题,并且在初步跟踪之后进行社会力优化,有效解决频繁遮挡和碰撞行为导致的错误跟踪问题。首先,采用特征提取策略和宽高比重新设置的单步多框检测器(single shot multi-box detector,SSD),对输入的第一人称视频序列进行检测,并基于卷积神经网络(convolutional neural network,CNN)模型提取行人的表观特征,通过计算行人特征相似度获得初步的行人跟踪结果;然后,进行跟踪结果的社会力优化,一是定义行人分组行为,对每个行人跟踪目标进行分组计算,并通过添加分组标识,实现同组行人在遮挡的情况下的准确跟踪;二是通过定义的行人领域,对行人分组进行排斥计算,实现避免碰撞后的准确跟踪。结果在公用数据集ETH(eidgenössische technische hochschule)、MOT16(multi-object tracking 16)和ADL(adelaide)的6个第一人称视频序列上与其他跟踪算法进行对比实验,本文算法的运行速度达到准实时的20.8帧/s,同时相比其他准实时算法,本文算法的整体跟踪性能MOTA(multiple object tracking accuracy)提高了2.5%。结论提出的第一人称视频中社会力优化的多行人跟踪算法,既能准确地在第一人称场景中跟踪多个行人,又能较好地满足实际应用需求。关键词:第一人称视频;多行人跟踪;社会力优化;碰撞避免;分组行为37|21|0更新时间:2024-05-07 -
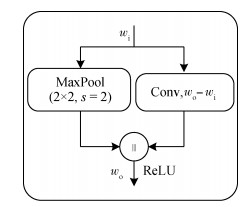 摘要:目的为解决实时车辆驾驶中因物体遮挡、光照变化和阴影干扰等多场景环境影响造成的车道线检测实时性和准确性不佳的问题,提出一种引入辅助损失的车道线检测模型。方法该模型改进了有效的残差分解网络(effcient residual factorized network,ERFNet),在ERFNet的编码器之后加入车道预测分支和辅助训练分支,使得解码阶段与车道预测分支、辅助训练分支并列,并且在辅助训练分支的卷积层之后,利用双线性插值来匹配输入图像的分辨率,从而对4条车道线和图像背景进行分类。通过计算辅助损失,将辅助损失以一定的权重协同语义分割损失、车道预测损失进行反向传播,较好地解决了梯度消失问题。语义分割得到每条车道线的概率分布图,分别在每条车道线的概率分布图上按行找出概率大于特定阈值的最大点的坐标,并按一定规则选取相应的坐标点,形成拟合的车道线。结果经过在CULane公共数据集上实验测试,模型在正常场景的F1指标为91.85%,与空间卷积神经网络(spatial convolutional neural network,SCNN)模型相比,提高了1.25%,比其他场景分别提高了1%~7%;9种场景的F1平均值为73.76%,比目前最好的残差网络——101-自注意力蒸馏(ResNet-101-self attention distillation,R-101-SAD)模型(71.80%)高出1.96%。在单个GPU上测试,每幅图像的平均运行时间缩短至原来的1/13,模型的参数量减少至原来的1/10。与平均运行时间最短的车道线检测模型ENet——自注意力蒸馏(ENet-self attention distillation,ENet-SAD)相比,单幅图像的平均运行时间减短了2.3 ms。结论在物体遮挡、光照变化、阴影干扰等多种复杂场景下,对于实时驾驶车辆而言,本文模型具有准确性高和实时性好等特点。关键词:多场景车道线检测;语义分割网络;辅助损失;梯度消失;CULane数据集43|22|1更新时间:2024-05-07
摘要:目的为解决实时车辆驾驶中因物体遮挡、光照变化和阴影干扰等多场景环境影响造成的车道线检测实时性和准确性不佳的问题,提出一种引入辅助损失的车道线检测模型。方法该模型改进了有效的残差分解网络(effcient residual factorized network,ERFNet),在ERFNet的编码器之后加入车道预测分支和辅助训练分支,使得解码阶段与车道预测分支、辅助训练分支并列,并且在辅助训练分支的卷积层之后,利用双线性插值来匹配输入图像的分辨率,从而对4条车道线和图像背景进行分类。通过计算辅助损失,将辅助损失以一定的权重协同语义分割损失、车道预测损失进行反向传播,较好地解决了梯度消失问题。语义分割得到每条车道线的概率分布图,分别在每条车道线的概率分布图上按行找出概率大于特定阈值的最大点的坐标,并按一定规则选取相应的坐标点,形成拟合的车道线。结果经过在CULane公共数据集上实验测试,模型在正常场景的F1指标为91.85%,与空间卷积神经网络(spatial convolutional neural network,SCNN)模型相比,提高了1.25%,比其他场景分别提高了1%~7%;9种场景的F1平均值为73.76%,比目前最好的残差网络——101-自注意力蒸馏(ResNet-101-self attention distillation,R-101-SAD)模型(71.80%)高出1.96%。在单个GPU上测试,每幅图像的平均运行时间缩短至原来的1/13,模型的参数量减少至原来的1/10。与平均运行时间最短的车道线检测模型ENet——自注意力蒸馏(ENet-self attention distillation,ENet-SAD)相比,单幅图像的平均运行时间减短了2.3 ms。结论在物体遮挡、光照变化、阴影干扰等多种复杂场景下,对于实时驾驶车辆而言,本文模型具有准确性高和实时性好等特点。关键词:多场景车道线检测;语义分割网络;辅助损失;梯度消失;CULane数据集43|22|1更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的计盒法是一种计算二值图像分形维数的常用方法,传统方法如BCM(box-counting method)对无旋转的图像结构具有较理想的计算结果,但是对具有旋转的图像结构的拟合结果偏差较大,导致同一物体在不同旋转角度下的图像的计算结果存在较大差异。为了减小图像旋转对盒维数的影响,本文提出了一种计算二值位图分形维数的新方法——旋转骨架法。方法将二值图像提取骨架,使位图转换为矢量图,利用遗传算法计算图像中物体的最小包容矩形和旋转角度,然后将矢量图进行旋转使其变为一个无旋转的图形,接下来采用多尺度的盒子覆盖矢量图形得到多个拟合点,最后按最小二乘法对拟合点进行拟合得到盒维数。与BCM方法相比,其核心工作与关键改进为骨架的提取、最小包容体的计算、矢量图的分形维数计算等过程。结果对3种类型的图像进行了分析,在自相似的分形图像中,相比BCM方法,3幅图的平均误差分别降低了0.725 2%、3.060 5%和2.298 5%,变化幅度分别降低了0.057 3、0.088 3和0.085 9;在文字扫描图像中,相比BCM方法,变化幅度降低了0.012 75,平均拟合误差降低了0.001 28;在植物图像中,与BCM方法相比,分形维数的变化幅度降低了0.017 04,平均拟合误差降低了0.000 5。结论该方法充分利用了位图易旋转、无厚度的特点,减小了图像旋转对盒维数的影响,评价结果优于BCM方法。关键词:分形维数;计盒法;旋转骨架法;矢量图;二值图像23|37|0更新时间:2024-05-07
摘要:目的计盒法是一种计算二值图像分形维数的常用方法,传统方法如BCM(box-counting method)对无旋转的图像结构具有较理想的计算结果,但是对具有旋转的图像结构的拟合结果偏差较大,导致同一物体在不同旋转角度下的图像的计算结果存在较大差异。为了减小图像旋转对盒维数的影响,本文提出了一种计算二值位图分形维数的新方法——旋转骨架法。方法将二值图像提取骨架,使位图转换为矢量图,利用遗传算法计算图像中物体的最小包容矩形和旋转角度,然后将矢量图进行旋转使其变为一个无旋转的图形,接下来采用多尺度的盒子覆盖矢量图形得到多个拟合点,最后按最小二乘法对拟合点进行拟合得到盒维数。与BCM方法相比,其核心工作与关键改进为骨架的提取、最小包容体的计算、矢量图的分形维数计算等过程。结果对3种类型的图像进行了分析,在自相似的分形图像中,相比BCM方法,3幅图的平均误差分别降低了0.725 2%、3.060 5%和2.298 5%,变化幅度分别降低了0.057 3、0.088 3和0.085 9;在文字扫描图像中,相比BCM方法,变化幅度降低了0.012 75,平均拟合误差降低了0.001 28;在植物图像中,与BCM方法相比,分形维数的变化幅度降低了0.017 04,平均拟合误差降低了0.000 5。结论该方法充分利用了位图易旋转、无厚度的特点,减小了图像旋转对盒维数的影响,评价结果优于BCM方法。关键词:分形维数;计盒法;旋转骨架法;矢量图;二值图像23|37|0更新时间:2024-05-07 -
 摘要:目的分形几何学的理论研究与应用实践方兴未艾,在分形的计算机生成领域,传统方法是在空间域中,通过对生成元的迭代操作而形成。为了扩展分形的生成方法,本文将频谱分析引入到分形几何中。方法正交函数系是频谱分析的核心问题之一。考虑到分形曲线是一类连续而不光滑的折线型信号,通常的三角函数(Fourier变换)、连续小波变换仅适用于光滑的对象,否则会出现所谓“Gibbs现象”;另一方面,以V-系统为代表的正交分段多项式函数系适用于表达包含间断性的对象,否则会出现信息冗余。因此,通常的正交函数系均不适合分形的频谱表达与分析。针对分形曲线的特点,本文将其视为一次样条函数,通过引入一类正交样条函数系-Franklin函数系,实现了对分形曲线的有限项精确正交表达,得到Franklin频谱,从而完成分形的时频变换。然后,对Franklin频谱系数在不同尺度上进行修改。最后,通过正交重构得到新的分形。结果对比实验验证了Franklin函数系在分形曲线频域表达方面的优越之处,它既能通过最小项数实现分形的正交表达,而且不会出现Gibbs现象。本文以von Koch曲线、Sierpinski square曲线和Hilbert曲线这3个经典分形为例,通过对Franklin谱在不同尺度上的自由调节,能够方便地生成大量形态各异的新的分形曲线。结论Franklin谱不仅能够实现对分形曲线的有限精确重构,而且还能在不同尺度上刻画分形的形态特征。基于Franklin频谱调节实现的分形生成方法,只要修改频谱就可以得到大量的新型分形曲线,而且这些分形的样式千变万化,几乎不可预测,这种分形生成方式为分形设计带来了巨大的自由空间,为分形的生成提供了新的思路与方案。关键词:分形曲线;正交函数系;Franklin函数;频谱分析;多分辨率24|24|1更新时间:2024-05-07
摘要:目的分形几何学的理论研究与应用实践方兴未艾,在分形的计算机生成领域,传统方法是在空间域中,通过对生成元的迭代操作而形成。为了扩展分形的生成方法,本文将频谱分析引入到分形几何中。方法正交函数系是频谱分析的核心问题之一。考虑到分形曲线是一类连续而不光滑的折线型信号,通常的三角函数(Fourier变换)、连续小波变换仅适用于光滑的对象,否则会出现所谓“Gibbs现象”;另一方面,以V-系统为代表的正交分段多项式函数系适用于表达包含间断性的对象,否则会出现信息冗余。因此,通常的正交函数系均不适合分形的频谱表达与分析。针对分形曲线的特点,本文将其视为一次样条函数,通过引入一类正交样条函数系-Franklin函数系,实现了对分形曲线的有限项精确正交表达,得到Franklin频谱,从而完成分形的时频变换。然后,对Franklin频谱系数在不同尺度上进行修改。最后,通过正交重构得到新的分形。结果对比实验验证了Franklin函数系在分形曲线频域表达方面的优越之处,它既能通过最小项数实现分形的正交表达,而且不会出现Gibbs现象。本文以von Koch曲线、Sierpinski square曲线和Hilbert曲线这3个经典分形为例,通过对Franklin谱在不同尺度上的自由调节,能够方便地生成大量形态各异的新的分形曲线。结论Franklin谱不仅能够实现对分形曲线的有限精确重构,而且还能在不同尺度上刻画分形的形态特征。基于Franklin频谱调节实现的分形生成方法,只要修改频谱就可以得到大量的新型分形曲线,而且这些分形的样式千变万化,几乎不可预测,这种分形生成方式为分形设计带来了巨大的自由空间,为分形的生成提供了新的思路与方案。关键词:分形曲线;正交函数系;Franklin函数;频谱分析;多分辨率24|24|1更新时间:2024-05-07
计算机图形学
-
 摘要:目的青光眼和病理性近视等会对人的视力造成不可逆的损害,早期的眼科疾病诊断能够大大降低发病率。由于眼底图像的复杂性,视盘分割很容易受到血管和病变等区域的影响,导致传统方法不能精确地分割出视盘。针对这一问题,提出了一种基于深度学习的视盘分割方法RA-UNet(residual attention UNet),提高了视盘分割精度,实现了自动、端到端的分割。方法在原始UNet基础上进行了改进。使用融合注意力机制的ResNet34作为下采样层来增强图像特征提取能力,加载预训练权重,有助于解决训练样本少导致的过拟合问题。注意力机制可以引入全局上下文信息,增强有用特征并抑制无用特征响应。修改UNet的上采样层,降低模型参数量,帮助模型训练。对网络输出的分割图进行后处理,消除错误样本。同时,使用DiceLoss损失函数替代普通的交叉熵损失函数来优化网络参数。结果在4个数据集上分别与其他方法进行比较,在RIM-ONE(retinal image database for optic nerve evaluation)-R1数据集中,F分数和重叠率分别为0.957 4和0.918 2,比UNet分别提高了2.89%和5.17%;在RIM-ONE-R3数据集中,F分数和重叠率分别为0.969和0.939 8,比UNet分别提高了1.5%和2.78%;在Drishti-GS1数据集中,F分数和重叠率分别为0.966 2和0.934 5,比UNet分别提高了1.65%和3.04%;在iChallenge-PM病理性近视挑战赛数据集中,F分数和重叠率分别为0.942 4和0.891 1,分别比UNet提高了3.59%和6.22%。同时还在RIM-ONE-R1和Drishti-GS1中进行了消融实验,验证了改进算法中各个模块均有助于提升视盘分割效果。结论提出的RA-UNet,提升了视盘分割精度,对有病变区域的图像也有良好的视盘分割性能,同时具有良好的泛化性能。关键词:青光眼;UNet;深度学习;视盘分割;预训练;注意力机制;DiceLoss107|69|10更新时间:2024-05-07
摘要:目的青光眼和病理性近视等会对人的视力造成不可逆的损害,早期的眼科疾病诊断能够大大降低发病率。由于眼底图像的复杂性,视盘分割很容易受到血管和病变等区域的影响,导致传统方法不能精确地分割出视盘。针对这一问题,提出了一种基于深度学习的视盘分割方法RA-UNet(residual attention UNet),提高了视盘分割精度,实现了自动、端到端的分割。方法在原始UNet基础上进行了改进。使用融合注意力机制的ResNet34作为下采样层来增强图像特征提取能力,加载预训练权重,有助于解决训练样本少导致的过拟合问题。注意力机制可以引入全局上下文信息,增强有用特征并抑制无用特征响应。修改UNet的上采样层,降低模型参数量,帮助模型训练。对网络输出的分割图进行后处理,消除错误样本。同时,使用DiceLoss损失函数替代普通的交叉熵损失函数来优化网络参数。结果在4个数据集上分别与其他方法进行比较,在RIM-ONE(retinal image database for optic nerve evaluation)-R1数据集中,F分数和重叠率分别为0.957 4和0.918 2,比UNet分别提高了2.89%和5.17%;在RIM-ONE-R3数据集中,F分数和重叠率分别为0.969和0.939 8,比UNet分别提高了1.5%和2.78%;在Drishti-GS1数据集中,F分数和重叠率分别为0.966 2和0.934 5,比UNet分别提高了1.65%和3.04%;在iChallenge-PM病理性近视挑战赛数据集中,F分数和重叠率分别为0.942 4和0.891 1,分别比UNet提高了3.59%和6.22%。同时还在RIM-ONE-R1和Drishti-GS1中进行了消融实验,验证了改进算法中各个模块均有助于提升视盘分割效果。结论提出的RA-UNet,提升了视盘分割精度,对有病变区域的图像也有良好的视盘分割性能,同时具有良好的泛化性能。关键词:青光眼;UNet;深度学习;视盘分割;预训练;注意力机制;DiceLoss107|69|10更新时间:2024-05-07 -
 摘要:目的超声图像是临床医学中应用最广泛的医学图像之一,但左心室超声图像一般具有强噪声、弱边缘和组织结构复杂等问题,其图像分割难度较大。临床上需要一种效率高、质量好的超声图像左心室分割算法。本文提出一种基于深层聚合残差密集网络(deep layer aggregation for residual dense network,DLA-RDNet)的超声图像左心室分割算法。方法对获取的超声图像进行形态学操作,定位目标区域,得到目标图像。构建残差密集网络(residual dense network,RDNet)用于提取图像特征,并将RDNet得到的层次信息通过深层聚合(deep layer aggregation,DLA)的方式紧密融合到一起,得到分割网络DLA-RDNet,用于实现对超声图像左心室的精确分割。通过深监督(deep supervision,DS)方式为网络剪枝,简化网络结构,提升网络运行速度。结果数据测试集的实验结果表明,所提算法平均准确率为95.68%,平均交并比为97.13%,平均相似性系数为97.15%,平均垂直距离为0.31 mm,分割轮廓合格率为99.32%。与6种分割算法相比,所提算法的分割精度更高。在测试阶段,每幅图像仅需不到1 s的时间即可完成分割,远远超出了专业医生的分割速度。结论提出了一种深层聚合残差密集神经网络对超声图像左心室进行分割,通过主、客观对比实验表明本文算法的有效性,能够较对比方法更实时准确地对超声图像左心室进行分割,符合临床医学中超声图像左心室分割的需求。关键词:超声图像;左心室分割;深层聚合;残差密集网络;网络剪枝39|84|4更新时间:2024-05-07
摘要:目的超声图像是临床医学中应用最广泛的医学图像之一,但左心室超声图像一般具有强噪声、弱边缘和组织结构复杂等问题,其图像分割难度较大。临床上需要一种效率高、质量好的超声图像左心室分割算法。本文提出一种基于深层聚合残差密集网络(deep layer aggregation for residual dense network,DLA-RDNet)的超声图像左心室分割算法。方法对获取的超声图像进行形态学操作,定位目标区域,得到目标图像。构建残差密集网络(residual dense network,RDNet)用于提取图像特征,并将RDNet得到的层次信息通过深层聚合(deep layer aggregation,DLA)的方式紧密融合到一起,得到分割网络DLA-RDNet,用于实现对超声图像左心室的精确分割。通过深监督(deep supervision,DS)方式为网络剪枝,简化网络结构,提升网络运行速度。结果数据测试集的实验结果表明,所提算法平均准确率为95.68%,平均交并比为97.13%,平均相似性系数为97.15%,平均垂直距离为0.31 mm,分割轮廓合格率为99.32%。与6种分割算法相比,所提算法的分割精度更高。在测试阶段,每幅图像仅需不到1 s的时间即可完成分割,远远超出了专业医生的分割速度。结论提出了一种深层聚合残差密集神经网络对超声图像左心室进行分割,通过主、客观对比实验表明本文算法的有效性,能够较对比方法更实时准确地对超声图像左心室进行分割,符合临床医学中超声图像左心室分割的需求。关键词:超声图像;左心室分割;深层聚合;残差密集网络;网络剪枝39|84|4更新时间:2024-05-07
医学图像处理
-
 摘要:目的利用合成孔径雷达(synthetic aperture radar,SAR)图像进行舰船目标检测是实施海洋监视的重要手段。基于深度学习的目标检测模型在自然图像目标检测任务中取得了巨大成功,但由于自然图像与SAR图像的差异,不能将其直接迁移到SAR图像目标检测中。针对SAR图像目标检测实际应用中对速度和精度的需求,借鉴经典的单阶段目标检测模型(single shot detector,SSD)框架,提出一种基于特征优化的轻量化SAR图像舰船目标检测网络。方法改进模型并精简网络结构,提出一种数据驱动的目标分布聚类算法,学习SAR数据集的目标尺度、长宽比分布特性,用于网络参数设定;对卷积神经网络(convolutional neural network,CNN)提取的特征进行优化,提出一种双向高低层特征融合机制,将高层特征的语义信息通过语义聚合模块加成到低层特征中,在低层特征中提取特征平均图,处理后作为高层特征的注意力权重图对高层特征进行逐像素加权,将低层特征丰富的空间信息融入到高层特征中。结果利用公开的SAR舰船目标检测数据集(SAR ship detection dataset,SSDD)进行实验,与原始的SSD模型相比,轻量化结构设计在不损失检测精度的前提下,样本测试时间仅为SSD的65%;双向特征融合机制将平均精确度(average precision,AP)值由77.93%提升至80.13%,训练和测试时间分别为SSD的64.1%和72.6%;与公开的基于深度学习的SAR舰船目标检测方法相比,本文方法在速度和精度上都取得了最佳性能,AP值较精度次优模型提升了1.23%,训练和测试时间较精度次优模型分别提升了559.34 ms和175.35 ms。结论实验充分验证了本文所提模型的有效性,本文模型兼具检测速度与精度优势,具有很强的实用性。关键词:合成孔径雷达图像;舰船目标检测;聚类;特征融合;注意力机制27|38|9更新时间:2024-05-07
摘要:目的利用合成孔径雷达(synthetic aperture radar,SAR)图像进行舰船目标检测是实施海洋监视的重要手段。基于深度学习的目标检测模型在自然图像目标检测任务中取得了巨大成功,但由于自然图像与SAR图像的差异,不能将其直接迁移到SAR图像目标检测中。针对SAR图像目标检测实际应用中对速度和精度的需求,借鉴经典的单阶段目标检测模型(single shot detector,SSD)框架,提出一种基于特征优化的轻量化SAR图像舰船目标检测网络。方法改进模型并精简网络结构,提出一种数据驱动的目标分布聚类算法,学习SAR数据集的目标尺度、长宽比分布特性,用于网络参数设定;对卷积神经网络(convolutional neural network,CNN)提取的特征进行优化,提出一种双向高低层特征融合机制,将高层特征的语义信息通过语义聚合模块加成到低层特征中,在低层特征中提取特征平均图,处理后作为高层特征的注意力权重图对高层特征进行逐像素加权,将低层特征丰富的空间信息融入到高层特征中。结果利用公开的SAR舰船目标检测数据集(SAR ship detection dataset,SSDD)进行实验,与原始的SSD模型相比,轻量化结构设计在不损失检测精度的前提下,样本测试时间仅为SSD的65%;双向特征融合机制将平均精确度(average precision,AP)值由77.93%提升至80.13%,训练和测试时间分别为SSD的64.1%和72.6%;与公开的基于深度学习的SAR舰船目标检测方法相比,本文方法在速度和精度上都取得了最佳性能,AP值较精度次优模型提升了1.23%,训练和测试时间较精度次优模型分别提升了559.34 ms和175.35 ms。结论实验充分验证了本文所提模型的有效性,本文模型兼具检测速度与精度优势,具有很强的实用性。关键词:合成孔径雷达图像;舰船目标检测;聚类;特征融合;注意力机制27|38|9更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0