
最新刊期
2020 年 第 25 卷 第 8 期
-
 摘要:神经纤维跟踪通过整合纤维局部结构方向信息,可以描绘出具有解剖学意义的空间纤维结构,是扩散磁共振成像的关键步骤,对临床医学与神经科学等有着重大意义。然而,大量的研究和临床应用表明,目前的神经纤维跟踪算法重构出了大量虚假纤维而备受质疑。为了给研究者和临床医生选择神经纤维跟踪算法提供依据,本文深入分析了当前的主要跟踪算法并进行定量评估与定性比较。从确定型、概率型和全局优化等方法详细介绍各典型跟踪算法;利用Fibercup和国际医学磁共振学会(International Society for Magnetic Resonance in Medicine,ISMRM)2015挑战数据进行实验,定量对比9种常用算法的优缺点,并分析了这些算法在实际临床数据的成像结果及其面临的挑战;结合实验结果与算法理论分析各算法的内在联系与区别。不同跟踪算法在效果上有着较大的差异,确定型算法在描绘主要纤维结构上更为明显,概率型算法描绘的纤维分布更为全面,全局优化算法的纤维轨迹更符合全局数据而避免了误差累积问题。纤维跟踪对于分析人脑神经纤维连接具有很高的研究价值和应用价值。不同类型的算法有着各自的优缺点,目前并没有一种跟踪算法可以摒弃其他算法缺点而结合所有优点。另外目前纤维跟踪算法的结果与实际情况均有着一定差距,如何描绘出更为精确的纤维轨迹仍是一个具有挑战性的问题。关键词:扩散磁共振成像(dMRI);各向异性;白质纤维跟踪(WMT);贝叶斯;全局优化;国际医学磁共振学会(ISMRM)2015挑战数据20|38|3更新时间:2024-05-07
摘要:神经纤维跟踪通过整合纤维局部结构方向信息,可以描绘出具有解剖学意义的空间纤维结构,是扩散磁共振成像的关键步骤,对临床医学与神经科学等有着重大意义。然而,大量的研究和临床应用表明,目前的神经纤维跟踪算法重构出了大量虚假纤维而备受质疑。为了给研究者和临床医生选择神经纤维跟踪算法提供依据,本文深入分析了当前的主要跟踪算法并进行定量评估与定性比较。从确定型、概率型和全局优化等方法详细介绍各典型跟踪算法;利用Fibercup和国际医学磁共振学会(International Society for Magnetic Resonance in Medicine,ISMRM)2015挑战数据进行实验,定量对比9种常用算法的优缺点,并分析了这些算法在实际临床数据的成像结果及其面临的挑战;结合实验结果与算法理论分析各算法的内在联系与区别。不同跟踪算法在效果上有着较大的差异,确定型算法在描绘主要纤维结构上更为明显,概率型算法描绘的纤维分布更为全面,全局优化算法的纤维轨迹更符合全局数据而避免了误差累积问题。纤维跟踪对于分析人脑神经纤维连接具有很高的研究价值和应用价值。不同类型的算法有着各自的优缺点,目前并没有一种跟踪算法可以摒弃其他算法缺点而结合所有优点。另外目前纤维跟踪算法的结果与实际情况均有着一定差距,如何描绘出更为精确的纤维轨迹仍是一个具有挑战性的问题。关键词:扩散磁共振成像(dMRI);各向异性;白质纤维跟踪(WMT);贝叶斯;全局优化;国际医学磁共振学会(ISMRM)2015挑战数据20|38|3更新时间:2024-05-07 -
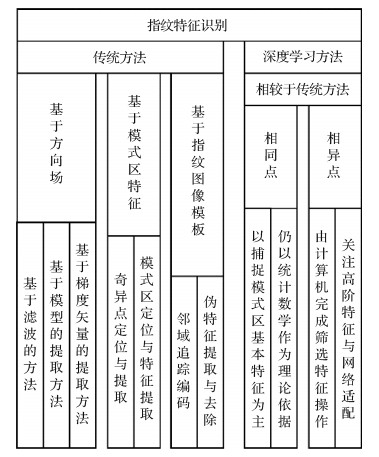 摘要:生物特征识别是身份认证的重要手段,特征提取技术在其中扮演了关键角色,直接影响识别的结果。随着特征提取技术日趋成熟,学者们逐渐将目光投向了生物特征间的相关性问题。本文以单模态和多模态生物识别中的特征提取方法为研究对象,回顾了人脸与指纹的特征提取方法,分析了基于经验知识的特征分类提取方法以及基于深度学习的计算机逻辑采样提取方法,并从图像处理的角度对单模态与多模态方法进行对比。以当前多模态生物特征提取方法和DNA表达过程为引,提出了不同模态的生物特征之间存在相关性的猜想,以及对这一猜想进行建模的思路。在多模态生物特征提取的基础上,对今后可能有进展的各生物特征之间的相关性建模进行了展望。关键词:生物特征提取;指纹;人脸;多模态;相关性53|161|2更新时间:2024-05-07
摘要:生物特征识别是身份认证的重要手段,特征提取技术在其中扮演了关键角色,直接影响识别的结果。随着特征提取技术日趋成熟,学者们逐渐将目光投向了生物特征间的相关性问题。本文以单模态和多模态生物识别中的特征提取方法为研究对象,回顾了人脸与指纹的特征提取方法,分析了基于经验知识的特征分类提取方法以及基于深度学习的计算机逻辑采样提取方法,并从图像处理的角度对单模态与多模态方法进行对比。以当前多模态生物特征提取方法和DNA表达过程为引,提出了不同模态的生物特征之间存在相关性的猜想,以及对这一猜想进行建模的思路。在多模态生物特征提取的基础上,对今后可能有进展的各生物特征之间的相关性建模进行了展望。关键词:生物特征提取;指纹;人脸;多模态;相关性53|161|2更新时间:2024-05-07
综述

-
 摘要:目的运用视觉和机器学习方法对步态进行研究已成为当前热点,但多集中在身份识别领域。本文从不同的视角对其进行研究,探讨一种基于点云数据和人体语义特征模型的异常步态3维人体建模和可变视角识别方法。方法运用非刚性变形和蒙皮方法,构建基于形体和姿态语义特征的参数化3维人体模型;以红外结构光传感器获取的人体异常步态点云数据为观测目标,构建其对应形体和姿态特征的3维人体模型。通过ConvGRU(convolution gated necurrent unit)卷积循环神经网络来提取其投影深度图像的时空特征,并将样本划分为正样本、负样本和自身样本三元组,对异常步态分类器进行训练,以提高分类器对细小差异的鉴别能力。同时对异常步态数据获取难度大和训练视角少的问题,提出了一种基于形体、姿态和视角变换的训练样本扩充方法,以提高模型在面对视角变化时的泛化能力。结果使用CSU(Central South University)3维异常步态数据库和DHA(depth-included human action video)深度人体行为数据库进行实验,并对比了不同异常步态或行为识别方法的效果。结果表明,本文方法在CSU异常步态库实验中,0°、45°和90°视角下对异常步态的综合检测识别率达到了96.6%,特别是在90°到0°交叉和变换视角实验中,比使用DMHI(difference motion history image)和DMM-CNN(depth motion map-convolutional neural network)等步态动作特征要高出25%以上。在DHA深度人体运动数据库实验中,本文方法识别率接近98%,比DMM等相关算法高出2%~3%。结论提出的3维异常步态识别方法综合了3维人体先验知识、循环卷积网络的时空特性和虚拟视角样本合成方法的优点,不仅能提高异常步态在面对视角变换时的识别准确性,同时也为3维异常步态检测和识别提供一种新思路。关键词:机器视觉;人体识别;异常步态3维建模;虚拟样本合成;卷积循环神经网络28|18|0更新时间:2024-05-07
摘要:目的运用视觉和机器学习方法对步态进行研究已成为当前热点,但多集中在身份识别领域。本文从不同的视角对其进行研究,探讨一种基于点云数据和人体语义特征模型的异常步态3维人体建模和可变视角识别方法。方法运用非刚性变形和蒙皮方法,构建基于形体和姿态语义特征的参数化3维人体模型;以红外结构光传感器获取的人体异常步态点云数据为观测目标,构建其对应形体和姿态特征的3维人体模型。通过ConvGRU(convolution gated necurrent unit)卷积循环神经网络来提取其投影深度图像的时空特征,并将样本划分为正样本、负样本和自身样本三元组,对异常步态分类器进行训练,以提高分类器对细小差异的鉴别能力。同时对异常步态数据获取难度大和训练视角少的问题,提出了一种基于形体、姿态和视角变换的训练样本扩充方法,以提高模型在面对视角变化时的泛化能力。结果使用CSU(Central South University)3维异常步态数据库和DHA(depth-included human action video)深度人体行为数据库进行实验,并对比了不同异常步态或行为识别方法的效果。结果表明,本文方法在CSU异常步态库实验中,0°、45°和90°视角下对异常步态的综合检测识别率达到了96.6%,特别是在90°到0°交叉和变换视角实验中,比使用DMHI(difference motion history image)和DMM-CNN(depth motion map-convolutional neural network)等步态动作特征要高出25%以上。在DHA深度人体运动数据库实验中,本文方法识别率接近98%,比DMM等相关算法高出2%~3%。结论提出的3维异常步态识别方法综合了3维人体先验知识、循环卷积网络的时空特性和虚拟视角样本合成方法的优点,不仅能提高异常步态在面对视角变换时的识别准确性,同时也为3维异常步态检测和识别提供一种新思路。关键词:机器视觉;人体识别;异常步态3维建模;虚拟样本合成;卷积循环神经网络28|18|0更新时间:2024-05-07 -
 摘要:目的点态卷积网络用于点云分类分割任务时,由于点态卷积算子可直接处理点云数据,逐点提取局部特征向量,解决了结构化点云带来的维度剧增和信息丢失等问题。但是为了保持点云数据结构的一致性,点态卷积算子及卷积网络模型本身并不具有描述点云全局特征的结构,因此,对点态卷积网络模型进行扩展,扩展后的模型具有的全局特征是保证分类分割准确性的重要依据。方法构造中心点放射模型来描述点云逐点相对于全局的几何约束关系,将其引入到点态卷积网络的特征拼接环节扩展特征向量,从而为点态卷积网络构建完善的局部—全局特征描述,用于点云数据的分类分割任务。首先,将点云视为由中心点以一定方向和距离放射到物体表面的点的集合,由中心点指向点云各点的放射矢量,其矢量大小确定了各点所存在的曲面和对于中心点的紧密程度,矢量方向描述了各点对于中心点的包围方向及存在的射线。进而由点云中的坐标信息得到点云的中心点,逐点计算放射矢量构造中心点放射模型,用以描述点云的全局特征。然后,利用点云数据的坐标信息来检索点的属性,确定卷积中参与特定点卷积运算的邻域,点态卷积算子遍历点云各点,输出逐点局部特征,进一步经多层点态卷积操作得到不同深度上的局部特征描述。最后,将中心点放射模型的全局特征和点态卷积的局部特征拼接,完成特征扩展,得到点态卷积网络的扩展模型。拼接后的局部—全局特征输入全连接层用于类标签预测,输入点态卷积层用于逐点标签预测。结果在ModelNet40和S3DIS(Stanford large-scale 3D indoor spaces dataset)数据集上分别进行实验,验证模型的分类分割性能。在ModelNet40的分类实验中,与点态卷积网络相比,扩展后的网络模型在整体分类精度和类属分类精度上分别提高1.8%和3.5%,在S3DIS数据集的分割实验中,扩展后的点态卷积网络模型整体分割精度和,类属分割精度分别提高0.7%和2.2%。结论引入的中心点放射模型可以有效获取点云数据的全局特征,扩展后的点态卷积网络模型实现了更优的分类和分割效果。关键词:点云;点态卷积;中心点放射模型;分类;分割;特征扩展67|31|3更新时间:2024-05-07
摘要:目的点态卷积网络用于点云分类分割任务时,由于点态卷积算子可直接处理点云数据,逐点提取局部特征向量,解决了结构化点云带来的维度剧增和信息丢失等问题。但是为了保持点云数据结构的一致性,点态卷积算子及卷积网络模型本身并不具有描述点云全局特征的结构,因此,对点态卷积网络模型进行扩展,扩展后的模型具有的全局特征是保证分类分割准确性的重要依据。方法构造中心点放射模型来描述点云逐点相对于全局的几何约束关系,将其引入到点态卷积网络的特征拼接环节扩展特征向量,从而为点态卷积网络构建完善的局部—全局特征描述,用于点云数据的分类分割任务。首先,将点云视为由中心点以一定方向和距离放射到物体表面的点的集合,由中心点指向点云各点的放射矢量,其矢量大小确定了各点所存在的曲面和对于中心点的紧密程度,矢量方向描述了各点对于中心点的包围方向及存在的射线。进而由点云中的坐标信息得到点云的中心点,逐点计算放射矢量构造中心点放射模型,用以描述点云的全局特征。然后,利用点云数据的坐标信息来检索点的属性,确定卷积中参与特定点卷积运算的邻域,点态卷积算子遍历点云各点,输出逐点局部特征,进一步经多层点态卷积操作得到不同深度上的局部特征描述。最后,将中心点放射模型的全局特征和点态卷积的局部特征拼接,完成特征扩展,得到点态卷积网络的扩展模型。拼接后的局部—全局特征输入全连接层用于类标签预测,输入点态卷积层用于逐点标签预测。结果在ModelNet40和S3DIS(Stanford large-scale 3D indoor spaces dataset)数据集上分别进行实验,验证模型的分类分割性能。在ModelNet40的分类实验中,与点态卷积网络相比,扩展后的网络模型在整体分类精度和类属分类精度上分别提高1.8%和3.5%,在S3DIS数据集的分割实验中,扩展后的点态卷积网络模型整体分割精度和,类属分割精度分别提高0.7%和2.2%。结论引入的中心点放射模型可以有效获取点云数据的全局特征,扩展后的点态卷积网络模型实现了更优的分类和分割效果。关键词:点云;点态卷积;中心点放射模型;分类;分割;特征扩展67|31|3更新时间:2024-05-07 -
 摘要:目的视频目标分割是计算机视觉领域的一个重要方向,已有的一些方法在面对目标形状不规则、帧间运动存在干扰信息和运动速度过快等情况时,显得无能为力。针对以上不足,提出基于特征一致性的分割算法。方法本文分割算法框架是基于马尔可夫随机场(Markov random field,MRF)的图论方法。使用高斯混合模型,对预先给定的已标记区域分别进行颜色特征的建模,获得分割的数据项。结合颜色、光流方向等多种特征,建立时空平滑项。在此基础之上,加入基于特征一致性的能量约束项,以增强分割结果的外观一致性。这项添加的能量本身属于一种高阶能量约束,会显著增加能量优化的计算复杂度。为此,添加辅助结点,以解决能量的优化问题,从而提高算法速度。结果在DAVIS_2016(densely annotated video segmentation)数据集上对该算法进行评估与测试,并与最新的基于图论的方法进行对比分析,对比算法主要有HVS(efficient hierarchical graph-based video segmentation)、NLC(video segmentation by non-local consensus voting)、BVS(bilateral space video segmentation)和OFL(video segmentation via object flow)。本文算法的分割结果精度排在第2,比OFL算法略低1.6%;在算法的运行速度方面,本文算法领先于对比方法,尤其是OFL算法的近6倍。结论所提出的分割算法在MRF框架的基础之上融合了特征一致性的约束,在不增加额外计算复杂度的前提下,提高了分割精度,提升了算法运行速度。关键词:视频目标分割;特征一致性;马尔可夫随机场(MRF);辅助结点;能量优化30|30|3更新时间:2024-05-07
摘要:目的视频目标分割是计算机视觉领域的一个重要方向,已有的一些方法在面对目标形状不规则、帧间运动存在干扰信息和运动速度过快等情况时,显得无能为力。针对以上不足,提出基于特征一致性的分割算法。方法本文分割算法框架是基于马尔可夫随机场(Markov random field,MRF)的图论方法。使用高斯混合模型,对预先给定的已标记区域分别进行颜色特征的建模,获得分割的数据项。结合颜色、光流方向等多种特征,建立时空平滑项。在此基础之上,加入基于特征一致性的能量约束项,以增强分割结果的外观一致性。这项添加的能量本身属于一种高阶能量约束,会显著增加能量优化的计算复杂度。为此,添加辅助结点,以解决能量的优化问题,从而提高算法速度。结果在DAVIS_2016(densely annotated video segmentation)数据集上对该算法进行评估与测试,并与最新的基于图论的方法进行对比分析,对比算法主要有HVS(efficient hierarchical graph-based video segmentation)、NLC(video segmentation by non-local consensus voting)、BVS(bilateral space video segmentation)和OFL(video segmentation via object flow)。本文算法的分割结果精度排在第2,比OFL算法略低1.6%;在算法的运行速度方面,本文算法领先于对比方法,尤其是OFL算法的近6倍。结论所提出的分割算法在MRF框架的基础之上融合了特征一致性的约束,在不增加额外计算复杂度的前提下,提高了分割精度,提升了算法运行速度。关键词:视频目标分割;特征一致性;马尔可夫随机场(MRF);辅助结点;能量优化30|30|3更新时间:2024-05-07 -
 摘要:目的地标识别是图像和视觉领域一个应用问题,针对地标识别中全局特征对视角变化敏感和局部特征对光线变化敏感等单一特征所存在的问题,提出一种基于增量角度域损失(additive angular margin loss,ArcFace损失)并对多种特征进行融合的弱监督地标识别模型。方法使用图像检索取Top-1的方法来完成识别任务。首先证明了ArcFace损失参数选取的范围,并于模型训练时使用该范围作为参数选取的依据,接着使用一种有效融合局部特征与全局特征的方法来获取图像特征以用于检索。其中,模型训练过程分为两步,第1步是在谷歌地标数据集上使用ArcFace损失函数微调ImageNet预训练模型权重,第2步是增加注意力机制并训练注意力网络。推理过程分为3个部分:抽取全局特征、获取局部特征和特征融合。具体而言,对输入的查询图像,首先从微调卷积神经网络的特征嵌入层提取全局特征;然后在网络中间层使用注意力机制提取局部特征;最后将两种特征向量横向拼接并用图像检索的方法给出数据库中与当前查询图像最相似的结果。结果实验结果表明,在巴黎、牛津建筑数据集上,特征融合方法可以使浅层网络达到深层预训练网络的效果,融合特征相比于全局特征(mean average precision,mAP)值提升约1%。实验还表明在神经网络嵌入特征上无需再加入特征白化过程。最后在城市级街景图像中本文模型也取得了较为满意的效果。结论本模型使用ArcFace损失进行训练且使多种特征相似性结果进行有效互补,提升了模型在实际应用场景中的抗干扰能力。关键词:地标识别;增量角度域损失函数;注意力机制;多特征融合;卷积神经网络(CNN)31|17|2更新时间:2024-05-07
摘要:目的地标识别是图像和视觉领域一个应用问题,针对地标识别中全局特征对视角变化敏感和局部特征对光线变化敏感等单一特征所存在的问题,提出一种基于增量角度域损失(additive angular margin loss,ArcFace损失)并对多种特征进行融合的弱监督地标识别模型。方法使用图像检索取Top-1的方法来完成识别任务。首先证明了ArcFace损失参数选取的范围,并于模型训练时使用该范围作为参数选取的依据,接着使用一种有效融合局部特征与全局特征的方法来获取图像特征以用于检索。其中,模型训练过程分为两步,第1步是在谷歌地标数据集上使用ArcFace损失函数微调ImageNet预训练模型权重,第2步是增加注意力机制并训练注意力网络。推理过程分为3个部分:抽取全局特征、获取局部特征和特征融合。具体而言,对输入的查询图像,首先从微调卷积神经网络的特征嵌入层提取全局特征;然后在网络中间层使用注意力机制提取局部特征;最后将两种特征向量横向拼接并用图像检索的方法给出数据库中与当前查询图像最相似的结果。结果实验结果表明,在巴黎、牛津建筑数据集上,特征融合方法可以使浅层网络达到深层预训练网络的效果,融合特征相比于全局特征(mean average precision,mAP)值提升约1%。实验还表明在神经网络嵌入特征上无需再加入特征白化过程。最后在城市级街景图像中本文模型也取得了较为满意的效果。结论本模型使用ArcFace损失进行训练且使多种特征相似性结果进行有效互补,提升了模型在实际应用场景中的抗干扰能力。关键词:地标识别;增量角度域损失函数;注意力机制;多特征融合;卷积神经网络(CNN)31|17|2更新时间:2024-05-07 -
 摘要:目的细粒度图像检索是当前细粒度图像分析和视觉领域的热点问题。以鞋类图像为例,传统方法仅提取其粗粒度特征且缺少关键的语义属性,难以区分部件间的细微差异,不能有效用于细粒度检索。针对鞋类图像检索大多基于简单款式导致检索效率不高的问题,提出一种结合部件检测和语义网络的细粒度鞋类图像检索方法。方法结合标注后的鞋类图像训练集对输入的待检鞋类图像进行部件检测;基于部件检测后的鞋类图像和定义的语义属性训练语义网络,以提取待检图像和训练图像的特征向量,并采用主成分分析进行降维;通过对鞋类图像训练集中每个候选图像与待检图像间的特征向量进行度量学习,按其匹配度高低顺序输出检索结果。结果实验在UT-Zap50K数据集上与目前检索效果较好的4种方法进行比较,检索精度提高近6%。同时,与同任务的SHOE-CNN(semantic hierarchy of attribute convolutional neural network)检索方法比较,本文具有更高的检索准确率。结论针对传统图像特征缺少细微的视觉描述导致鞋类图像检索准确率低的问题,提出一种细粒度鞋类图像检索方法,既提高了鞋类图像检索的精度和准确率,又能较好地满足实际应用需求。关键词:细粒度图像检索;鞋类图像;部件检测;语义网络;特征向量;度量学习56|79|3更新时间:2024-05-07
摘要:目的细粒度图像检索是当前细粒度图像分析和视觉领域的热点问题。以鞋类图像为例,传统方法仅提取其粗粒度特征且缺少关键的语义属性,难以区分部件间的细微差异,不能有效用于细粒度检索。针对鞋类图像检索大多基于简单款式导致检索效率不高的问题,提出一种结合部件检测和语义网络的细粒度鞋类图像检索方法。方法结合标注后的鞋类图像训练集对输入的待检鞋类图像进行部件检测;基于部件检测后的鞋类图像和定义的语义属性训练语义网络,以提取待检图像和训练图像的特征向量,并采用主成分分析进行降维;通过对鞋类图像训练集中每个候选图像与待检图像间的特征向量进行度量学习,按其匹配度高低顺序输出检索结果。结果实验在UT-Zap50K数据集上与目前检索效果较好的4种方法进行比较,检索精度提高近6%。同时,与同任务的SHOE-CNN(semantic hierarchy of attribute convolutional neural network)检索方法比较,本文具有更高的检索准确率。结论针对传统图像特征缺少细微的视觉描述导致鞋类图像检索准确率低的问题,提出一种细粒度鞋类图像检索方法,既提高了鞋类图像检索的精度和准确率,又能较好地满足实际应用需求。关键词:细粒度图像检索;鞋类图像;部件检测;语义网络;特征向量;度量学习56|79|3更新时间:2024-05-07
图像分析和识别
-
 摘要:目的目前文本到图像的生成模型仅在具有单个对象的图像数据集上表现良好,当一幅图像涉及多个对象和关系时,生成的图像就会变得混乱。已有的解决方案是将文本描述转换为更能表示图像中场景关系的场景图结构,然后利用场景图生成图像,但是现有的场景图到图像的生成模型最终生成的图像不够清晰,对象细节不足。为此,提出一种基于图注意力网络的场景图到图像的生成模型,生成更高质量的图像。方法模型由提取场景图特征的图注意力网络、合成场景布局的对象布局网络、将场景布局转换为生成图像的级联细化网络以及提高生成图像质量的鉴别器网络组成。图注意力网络将得到的具有更强表达能力的输出对象特征向量传递给改进的对象布局网络,合成更接近真实标签的场景布局。同时,提出使用特征匹配的方式计算图像损失,使得最终生成图像与真实图像在语义上更加相似。结果通过在包含多个对象的COCO-Stuff图像数据集中训练模型生成64×64像素的图像,本文模型可以生成包含多个对象和关系的复杂场景图像,且生成图像的Inception Score为7.8左右,与原有的场景图到图像生成模型相比提高了0.5。结论本文提出的基于图注意力网络的场景图到图像生成模型不仅可以生成包含多个对象和关系的复杂场景图像,而且生成图像质量更高,细节更清晰。关键词:场景图生成图像;图注意力网络;场景布局;特征匹配;级联细化网络43|27|3更新时间:2024-05-07
摘要:目的目前文本到图像的生成模型仅在具有单个对象的图像数据集上表现良好,当一幅图像涉及多个对象和关系时,生成的图像就会变得混乱。已有的解决方案是将文本描述转换为更能表示图像中场景关系的场景图结构,然后利用场景图生成图像,但是现有的场景图到图像的生成模型最终生成的图像不够清晰,对象细节不足。为此,提出一种基于图注意力网络的场景图到图像的生成模型,生成更高质量的图像。方法模型由提取场景图特征的图注意力网络、合成场景布局的对象布局网络、将场景布局转换为生成图像的级联细化网络以及提高生成图像质量的鉴别器网络组成。图注意力网络将得到的具有更强表达能力的输出对象特征向量传递给改进的对象布局网络,合成更接近真实标签的场景布局。同时,提出使用特征匹配的方式计算图像损失,使得最终生成图像与真实图像在语义上更加相似。结果通过在包含多个对象的COCO-Stuff图像数据集中训练模型生成64×64像素的图像,本文模型可以生成包含多个对象和关系的复杂场景图像,且生成图像的Inception Score为7.8左右,与原有的场景图到图像生成模型相比提高了0.5。结论本文提出的基于图注意力网络的场景图到图像生成模型不仅可以生成包含多个对象和关系的复杂场景图像,而且生成图像质量更高,细节更清晰。关键词:场景图生成图像;图注意力网络;场景布局;特征匹配;级联细化网络43|27|3更新时间:2024-05-07 -
 摘要:目的图像描述结果的准确合理性体现在模型对信息处理的两个方面,即视觉模块对特征信息提取的丰富程度和语言模块对描述复杂场景句子的处理能力。然而现有图像描述模型仅使用一个编码器对图像进行特征提取,容易造成特征信息丢失,进而无法全面理解输入图像的语义。运用RNN(recurrent neural network)或LSTM(long short-term memory)在对句子建模时容易忽略句子的基本层次结构,且对长序列单词的学习效果不佳。针对上述问题,提出一种跨层多模型特征融合与因果卷积解码的图像描述模型。方法在视觉特征提取模块,对单个模型添加低层到高层的跨层特征融合结构,实现语义特征和细节特征之间的信息互补,训练出多个编码器对图像进行特征提取,在充分描述和表征图像语义方面起到补充作用。在语言模块中使用因果卷积对描述复杂场景的长序列单词进行建模处理,得到一组单词特征。使用attention机制将图像特征和单词特征进行连接匹配,用于学习文本信息与图像不同区域之间的相关性,最终通过预测模块结合Softmax函数得到单词的最终预测概率。结果在MS COCO(Microsoft common objects in context)和Flickr30k两个数据集上使用不同评估方法对模型进行验证,实验结果表明本文提出的模型性能较好。反映生成单词准确率的BLEU(bilingual evaluation understudy)-1指标值高达72.1%,且在其他多个评估指标上优于其他主流对比方法,如B-4指标超过性能优越的Hard-ATT(“Hard” attention)方法6.0%,B-1和CIDEr(consensus-based image description evaluation)指标分别超过emb-g(embedding guidance)LSTM方法5.1%和13.3%,与同样使用CNN(convolutional neural network)+CNN策略的ConvCap(convdntioral captioning)方法相比,在B-1指标上本文模型提升了0.3%。结论本文设计的模型能够有效提取和保存复杂背景图像中的语义信息,且具有处理长序列单词的能力,对图像内容的描述更准确、信息表达更丰富。关键词:图像描述;跨层特征融合;卷积解码;因果卷积;attention机制47|28|3更新时间:2024-05-07
摘要:目的图像描述结果的准确合理性体现在模型对信息处理的两个方面,即视觉模块对特征信息提取的丰富程度和语言模块对描述复杂场景句子的处理能力。然而现有图像描述模型仅使用一个编码器对图像进行特征提取,容易造成特征信息丢失,进而无法全面理解输入图像的语义。运用RNN(recurrent neural network)或LSTM(long short-term memory)在对句子建模时容易忽略句子的基本层次结构,且对长序列单词的学习效果不佳。针对上述问题,提出一种跨层多模型特征融合与因果卷积解码的图像描述模型。方法在视觉特征提取模块,对单个模型添加低层到高层的跨层特征融合结构,实现语义特征和细节特征之间的信息互补,训练出多个编码器对图像进行特征提取,在充分描述和表征图像语义方面起到补充作用。在语言模块中使用因果卷积对描述复杂场景的长序列单词进行建模处理,得到一组单词特征。使用attention机制将图像特征和单词特征进行连接匹配,用于学习文本信息与图像不同区域之间的相关性,最终通过预测模块结合Softmax函数得到单词的最终预测概率。结果在MS COCO(Microsoft common objects in context)和Flickr30k两个数据集上使用不同评估方法对模型进行验证,实验结果表明本文提出的模型性能较好。反映生成单词准确率的BLEU(bilingual evaluation understudy)-1指标值高达72.1%,且在其他多个评估指标上优于其他主流对比方法,如B-4指标超过性能优越的Hard-ATT(“Hard” attention)方法6.0%,B-1和CIDEr(consensus-based image description evaluation)指标分别超过emb-g(embedding guidance)LSTM方法5.1%和13.3%,与同样使用CNN(convolutional neural network)+CNN策略的ConvCap(convdntioral captioning)方法相比,在B-1指标上本文模型提升了0.3%。结论本文设计的模型能够有效提取和保存复杂背景图像中的语义信息,且具有处理长序列单词的能力,对图像内容的描述更准确、信息表达更丰富。关键词:图像描述;跨层特征融合;卷积解码;因果卷积;attention机制47|28|3更新时间:2024-05-07 -
 摘要:目的针对基于Haar-like特征的Adaboost人脸检测算法,在应用于视频流时训练的时间较长,以及检测效率较低的问题,提出了一种基于区间阈值的Adaboost人脸检测算法。方法通过运行传统的Adaboost算法对人脸图像Haar-like特征值进行提取分析后,对人脸样本与非人脸样本特征值进行比较,发现在某一特定的特征值区间内,人脸和非人脸区域能够得到准确区分,根据此特性,进行分类器的选择,在简化弱分类器计算步骤的同时,降低训练时间,提高对人脸的识别能力。除此之外,弱分类器的增强通过Adaboost算法的放大使得强分类器分类精度提高,与级联结构的配合使用也提升了最终模型检测人脸的准确率。结果利用MIT(Massachusetts Institute of Technology)标准人脸库对改进Adaboost算法的性能进行验证,通过实验验证结果可知,改进后的Adaboost人脸检测算法训练速度提升为原来的1.44倍,检测率上升到94.93%,虚警率下降到6.03%。并且将改进算法在ORL(Olivetti Research Laboratory)、FERET(face recognition technology)以及CMU Multi-PIE(the CMU Multi-PIE face database)这3种标准人脸库中,分别与SVM(support vector machine)、DL(deep learning)、CNN(convolutional neural networks)以及肤色模型等4种算法进行了人脸检测对比实验,实验结果显示,改进后的Adaboost算法在进行人脸检测时,检测率提升了2.66%,训练所需时间减少至624.45 s,检测效果明显提升。结论提出的基于区间阈值的Adaboost人脸检测算法,在分类器的训练和人脸检测方面都比传统的Adaboost算法性能更高,能够更好地满足人员较密集处(如球场等地)对多人脸同时检测的实际需求。关键词:人脸检测;Adaboost算法;统计分析;Haar-like特征;区间阈值22|42|2更新时间:2024-05-07
摘要:目的针对基于Haar-like特征的Adaboost人脸检测算法,在应用于视频流时训练的时间较长,以及检测效率较低的问题,提出了一种基于区间阈值的Adaboost人脸检测算法。方法通过运行传统的Adaboost算法对人脸图像Haar-like特征值进行提取分析后,对人脸样本与非人脸样本特征值进行比较,发现在某一特定的特征值区间内,人脸和非人脸区域能够得到准确区分,根据此特性,进行分类器的选择,在简化弱分类器计算步骤的同时,降低训练时间,提高对人脸的识别能力。除此之外,弱分类器的增强通过Adaboost算法的放大使得强分类器分类精度提高,与级联结构的配合使用也提升了最终模型检测人脸的准确率。结果利用MIT(Massachusetts Institute of Technology)标准人脸库对改进Adaboost算法的性能进行验证,通过实验验证结果可知,改进后的Adaboost人脸检测算法训练速度提升为原来的1.44倍,检测率上升到94.93%,虚警率下降到6.03%。并且将改进算法在ORL(Olivetti Research Laboratory)、FERET(face recognition technology)以及CMU Multi-PIE(the CMU Multi-PIE face database)这3种标准人脸库中,分别与SVM(support vector machine)、DL(deep learning)、CNN(convolutional neural networks)以及肤色模型等4种算法进行了人脸检测对比实验,实验结果显示,改进后的Adaboost算法在进行人脸检测时,检测率提升了2.66%,训练所需时间减少至624.45 s,检测效果明显提升。结论提出的基于区间阈值的Adaboost人脸检测算法,在分类器的训练和人脸检测方面都比传统的Adaboost算法性能更高,能够更好地满足人员较密集处(如球场等地)对多人脸同时检测的实际需求。关键词:人脸检测;Adaboost算法;统计分析;Haar-like特征;区间阈值22|42|2更新时间:2024-05-07 -
 摘要:目的针对现有语义分割算法存在的因池化操作造成分辨率降低导致的分割结果变差、忽视特征图不同通道和位置特征的区别以及特征图融合时方法简单,没有考虑到不同感受视野特征区别等问题,设计了一种基于膨胀卷积和注意力机制的语义分割算法。方法主要包括两条路径:空间信息路径使用膨胀卷积,采用较小的下采样倍数以保持图像的分辨率,获得图像的细节信息;语义信息路径使用ResNet(residual network)采集特征以获得较大的感受视野,引入注意力机制模块为特征图的不同部分分配权重,使得精度损失降低。设计特征融合模块为两条路径获得的不同感受视野的特征图分配权重,并将其融合到一起,得到最后的分割结果。结果为证实结果的有效性,在Camvid和Cityscapes数据集上进行验证,使用平均交并比(mean intersection over union,MIoU)和精确度(precision)作为度量标准。结果显示,在Camvid数据集上,MIoU和精确度分别为69.47%和92.32%,比性能第2的模型分别提高了1.3%和3.09%。在Cityscapes数据集上,MIoU和精确度分别为78.48%和93.83%,比性能第2的模型分别提高了1.16%和3.60%。结论本文采用膨胀卷积和注意力机制模块,在保证感受视野并且提高分辨率的同时,弥补了下采样带来的精度损失,能够更好地指导模型学习,且提出的特征融合模块可以更好地融合不同感受视野的特征。关键词:语义分割;卷积神经网络;感受视野;膨胀卷积;注意力机制;特征融合30|29|7更新时间:2024-05-07
摘要:目的针对现有语义分割算法存在的因池化操作造成分辨率降低导致的分割结果变差、忽视特征图不同通道和位置特征的区别以及特征图融合时方法简单,没有考虑到不同感受视野特征区别等问题,设计了一种基于膨胀卷积和注意力机制的语义分割算法。方法主要包括两条路径:空间信息路径使用膨胀卷积,采用较小的下采样倍数以保持图像的分辨率,获得图像的细节信息;语义信息路径使用ResNet(residual network)采集特征以获得较大的感受视野,引入注意力机制模块为特征图的不同部分分配权重,使得精度损失降低。设计特征融合模块为两条路径获得的不同感受视野的特征图分配权重,并将其融合到一起,得到最后的分割结果。结果为证实结果的有效性,在Camvid和Cityscapes数据集上进行验证,使用平均交并比(mean intersection over union,MIoU)和精确度(precision)作为度量标准。结果显示,在Camvid数据集上,MIoU和精确度分别为69.47%和92.32%,比性能第2的模型分别提高了1.3%和3.09%。在Cityscapes数据集上,MIoU和精确度分别为78.48%和93.83%,比性能第2的模型分别提高了1.16%和3.60%。结论本文采用膨胀卷积和注意力机制模块,在保证感受视野并且提高分辨率的同时,弥补了下采样带来的精度损失,能够更好地指导模型学习,且提出的特征融合模块可以更好地融合不同感受视野的特征。关键词:语义分割;卷积神经网络;感受视野;膨胀卷积;注意力机制;特征融合30|29|7更新时间:2024-05-07 -
 摘要:目的基于深度学习的多聚焦图像融合方法主要是利用卷积神经网络(convolutional neural network,CNN)将像素分类为聚焦与散焦。监督学习过程常使用人造数据集,标签数据的精确度直接影响了分类精确度,从而影响后续手工设计融合规则的准确度与全聚焦图像的融合效果。为了使融合网络可以自适应地调整融合规则,提出了一种基于自学习融合规则的多聚焦图像融合算法。方法采用自编码网络架构,提取特征,同时学习融合规则和重构规则,以实现无监督的端到端融合网络;将多聚焦图像的初始决策图作为先验输入,学习图像丰富的细节信息;在损失函数中加入局部策略,包含结构相似度(structural similarity index measure,SSIM)和均方误差(mean squared error,MSE),以确保更加准确地还原图像。结果在Lytro等公开数据集上从主观和客观角度对本文模型进行评价,以验证融合算法设计的合理性。从主观评价来看,模型不仅可以较好地融合聚焦区域,有效避免融合图像中出现伪影,而且能够保留足够的细节信息,视觉效果自然清晰;从客观评价来看,通过将模型融合的图像与其他主流多聚焦图像融合算法的融合图像进行量化比较,在熵、Qw、相关系数和视觉信息保真度上的平均精度均为最优,分别为7.457 4,0.917 7,0.978 8和0.890 8。结论提出了一种用于多聚焦图像的融合算法,不仅能够对融合规则进行自学习、调整,并且融合图像效果可与现有方法媲美,有助于进一步理解基于深度学习的多聚焦图像融合机制。关键词:多聚焦图像融合;自编码;自学习;端到端;结构相似度24|30|2更新时间:2024-05-07
摘要:目的基于深度学习的多聚焦图像融合方法主要是利用卷积神经网络(convolutional neural network,CNN)将像素分类为聚焦与散焦。监督学习过程常使用人造数据集,标签数据的精确度直接影响了分类精确度,从而影响后续手工设计融合规则的准确度与全聚焦图像的融合效果。为了使融合网络可以自适应地调整融合规则,提出了一种基于自学习融合规则的多聚焦图像融合算法。方法采用自编码网络架构,提取特征,同时学习融合规则和重构规则,以实现无监督的端到端融合网络;将多聚焦图像的初始决策图作为先验输入,学习图像丰富的细节信息;在损失函数中加入局部策略,包含结构相似度(structural similarity index measure,SSIM)和均方误差(mean squared error,MSE),以确保更加准确地还原图像。结果在Lytro等公开数据集上从主观和客观角度对本文模型进行评价,以验证融合算法设计的合理性。从主观评价来看,模型不仅可以较好地融合聚焦区域,有效避免融合图像中出现伪影,而且能够保留足够的细节信息,视觉效果自然清晰;从客观评价来看,通过将模型融合的图像与其他主流多聚焦图像融合算法的融合图像进行量化比较,在熵、Qw、相关系数和视觉信息保真度上的平均精度均为最优,分别为7.457 4,0.917 7,0.978 8和0.890 8。结论提出了一种用于多聚焦图像的融合算法,不仅能够对融合规则进行自学习、调整,并且融合图像效果可与现有方法媲美,有助于进一步理解基于深度学习的多聚焦图像融合机制。关键词:多聚焦图像融合;自编码;自学习;端到端;结构相似度24|30|2更新时间:2024-05-07 -
 摘要:目的基于视觉的前车防碰撞预警技术是汽车主动安全领域的一个重要研究方向,其中对前车进行快速准确检测并建立稳定可靠的安全距离模型是该技术亟待解决的两个难点。为此,本文提出车路视觉协同的高速公路防碰撞预警算法。方法将通过图像处理技术检测出来的视频图像中的车道线和自车的行驶速度作为输入,运用安全区实时计算算法构建安全距离模型,在当前车辆前方形成一块预警安全区域。采用深度神经网络YOLOv3(you only look once v3)对前车进行实时检测,得到车辆的位置信息。根据图像中前车的位置和构建的安全距离模型,对可能发生的追尾碰撞事故进行预测。结果实验结果表明,重新训练的YOLOv3算法车辆检测准确率为98.04%,提出算法与马自达CX-4的FOW(forward obstruction warning)前方碰撞预警系统相比,能够侧向和前向预警,并提前0.8 s发出警报。结论本文方法与传统的车载超声波、雷达或激光测距的防碰撞预警方法相比,具有较强的适用性和稳定性,预警准确率高,可以帮助提高司机在高速公路上的行车安全性。关键词:前防碰撞预警;安全距离模型;车道线检测;车辆实时检测;YOLOv323|35|3更新时间:2024-05-07
摘要:目的基于视觉的前车防碰撞预警技术是汽车主动安全领域的一个重要研究方向,其中对前车进行快速准确检测并建立稳定可靠的安全距离模型是该技术亟待解决的两个难点。为此,本文提出车路视觉协同的高速公路防碰撞预警算法。方法将通过图像处理技术检测出来的视频图像中的车道线和自车的行驶速度作为输入,运用安全区实时计算算法构建安全距离模型,在当前车辆前方形成一块预警安全区域。采用深度神经网络YOLOv3(you only look once v3)对前车进行实时检测,得到车辆的位置信息。根据图像中前车的位置和构建的安全距离模型,对可能发生的追尾碰撞事故进行预测。结果实验结果表明,重新训练的YOLOv3算法车辆检测准确率为98.04%,提出算法与马自达CX-4的FOW(forward obstruction warning)前方碰撞预警系统相比,能够侧向和前向预警,并提前0.8 s发出警报。结论本文方法与传统的车载超声波、雷达或激光测距的防碰撞预警方法相比,具有较强的适用性和稳定性,预警准确率高,可以帮助提高司机在高速公路上的行车安全性。关键词:前防碰撞预警;安全距离模型;车道线检测;车辆实时检测;YOLOv323|35|3更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的针对多通路Metropolis光照传播(multiplexed Metropolis light transport,MMLT)算法在亮度不均匀区域接受概率低、采样数量与光照分布不对称以及亮度均匀区域样本流动性差的问题,提出一种兼顾整体和局部处理的融合突变策略。方法整体上,以方差动态度量像素平面亮度均匀度,并自适应调整采样步长,记录每个像素位置的采样数量,当采样进行到当前采样像素的样本数量达到阈值,且当前样本是马尔可夫链起始样本或大突变后首个样本时,以方差度量当前采样像素及其8邻域范围内亮度均匀程度,并以方差的计算结果调整当前马尔可夫链的采样步长。若当前采样像素的样本数量达到阈值,且当前样本是马尔可夫链小突变时,则兼顾采样数量和光照强度计算当前像素8邻域内的采样权重。结果实验将改进算法和MMLT算法在不同光照和材质的场景下进行对比,改进算法在保证高光区域渲染效果外,使亮度不均匀区域的渲染结果更加细腻,亮度均匀区域样本更为分散。结论本文提出以方差动态度量图像亮度均匀度,自适应调整采样步长与加强高光区域采样相结合的融合突变策略,可以使样本在亮度不均匀区域聚集进行精细采样,在亮度变化剧烈处改善局部采样数量与光照分布不对称现象,在亮度均匀区域增强样本的遍历性。关键词:融合突变策略;多通路Metropolis;采样步长;接受概率;方差;亮度均匀度16|21|0更新时间:2024-05-07
摘要:目的针对多通路Metropolis光照传播(multiplexed Metropolis light transport,MMLT)算法在亮度不均匀区域接受概率低、采样数量与光照分布不对称以及亮度均匀区域样本流动性差的问题,提出一种兼顾整体和局部处理的融合突变策略。方法整体上,以方差动态度量像素平面亮度均匀度,并自适应调整采样步长,记录每个像素位置的采样数量,当采样进行到当前采样像素的样本数量达到阈值,且当前样本是马尔可夫链起始样本或大突变后首个样本时,以方差度量当前采样像素及其8邻域范围内亮度均匀程度,并以方差的计算结果调整当前马尔可夫链的采样步长。若当前采样像素的样本数量达到阈值,且当前样本是马尔可夫链小突变时,则兼顾采样数量和光照强度计算当前像素8邻域内的采样权重。结果实验将改进算法和MMLT算法在不同光照和材质的场景下进行对比,改进算法在保证高光区域渲染效果外,使亮度不均匀区域的渲染结果更加细腻,亮度均匀区域样本更为分散。结论本文提出以方差动态度量图像亮度均匀度,自适应调整采样步长与加强高光区域采样相结合的融合突变策略,可以使样本在亮度不均匀区域聚集进行精细采样,在亮度变化剧烈处改善局部采样数量与光照分布不对称现象,在亮度均匀区域增强样本的遍历性。关键词:融合突变策略;多通路Metropolis;采样步长;接受概率;方差;亮度均匀度16|21|0更新时间:2024-05-07 -
 摘要:目的为了解决自碰撞检测剔除率低和检测速度慢的问题,提出一种AABB(aixe align bounding box)—圆形包围盒树结构和具有二分类功能的深度神经网络(deep neural network,DNN)加速包围盒相交检测的方法。方法对变形体构建AABB—圆形包围盒树,即对内部节点构建AABB包围盒,对叶子节点构建圆形包围盒。根据AABB—圆形包围盒生成包围盒测试树(bounding volume test tree,BVTT),采用深度神经网络优化BVTT的包围盒相交测试和法向锥测试,输出碰撞三角形对。结果在确定最优隐含层数和每层最优节点数保证深度神经网络达到最佳准确率的情况下,实验结果表明,在没有自碰撞的情况下,本文方法与AABB-OBB方法、经典包围盒方法耗时相同,但在自碰撞足够多的模拟场景中,融合深度神经网络的AABB-圆形包围盒方法比AABB-OBB(oriented bounding box)方法和经典的包围盒方法速度更快,整体耗时缩短了21%~37%。同时,对5种方法的更新率、检测效率和图元相交测试时间进行实验对比,发现本文方法比AABB-OBB方法和经典的方法具有更好的贴合性和更快的相交测试速度。结论本文方法相对于AABB-OBB方法、经典包围盒方法的测试速度更快,不仅提高了自碰撞检测高层剔除率,同时降低了模拟整体耗时,更适用于实时变形体自碰撞检测领域。关键词:自碰撞检测;混合层次包围盒;圆形包围盒;深度神经网络;图元相交测试20|20|6更新时间:2024-05-07
摘要:目的为了解决自碰撞检测剔除率低和检测速度慢的问题,提出一种AABB(aixe align bounding box)—圆形包围盒树结构和具有二分类功能的深度神经网络(deep neural network,DNN)加速包围盒相交检测的方法。方法对变形体构建AABB—圆形包围盒树,即对内部节点构建AABB包围盒,对叶子节点构建圆形包围盒。根据AABB—圆形包围盒生成包围盒测试树(bounding volume test tree,BVTT),采用深度神经网络优化BVTT的包围盒相交测试和法向锥测试,输出碰撞三角形对。结果在确定最优隐含层数和每层最优节点数保证深度神经网络达到最佳准确率的情况下,实验结果表明,在没有自碰撞的情况下,本文方法与AABB-OBB方法、经典包围盒方法耗时相同,但在自碰撞足够多的模拟场景中,融合深度神经网络的AABB-圆形包围盒方法比AABB-OBB(oriented bounding box)方法和经典的包围盒方法速度更快,整体耗时缩短了21%~37%。同时,对5种方法的更新率、检测效率和图元相交测试时间进行实验对比,发现本文方法比AABB-OBB方法和经典的方法具有更好的贴合性和更快的相交测试速度。结论本文方法相对于AABB-OBB方法、经典包围盒方法的测试速度更快,不仅提高了自碰撞检测高层剔除率,同时降低了模拟整体耗时,更适用于实时变形体自碰撞检测领域。关键词:自碰撞检测;混合层次包围盒;圆形包围盒;深度神经网络;图元相交测试20|20|6更新时间:2024-05-07
计算机图形学
-
 摘要:目的长期感染溃疡性结肠炎(ulcerative colitis,UC)的患者罹患结肠癌的风险显著提升,因此早期进行结肠镜检测十分必要,但内窥镜图像数量巨大且伴有噪声干扰,需要找到精确的图像特征,为医师提供计算机辅助诊断。为解决UC图像与正常肠道图像的分类问题,提出了一种基于压缩感知和空间金字塔池化结合的图像特征提取方法。方法使用块递归最小二乘(block recursive least squares,BRLS)进行初始字典训练。提出基于先验知识进行观测矩阵与稀疏字典的交替优化算法,并利用压缩感知框架获得图像的稀疏表示,该框架改善了原来基于稀疏编码的图像分类方法无法精确表示图像的问题,然后结合最大空间金字塔池化方法提取压缩感知空间金字塔池化(compressed sensing spatial pyramid pooling,CSSPP)图像特征,由于压缩感知的引入,获得的图像特征比稀疏编码更加丰富和精确。最后使用线性核支持向量机(support vector machine,SVM)进行图像分类。结果对Kvasir数据集中的2 000幅真实肠道图像的分类结果表明,该特征的准确率比特征袋(bag of features,BoF)、稀疏编码空间金字塔匹配(sparse coding spatial pyramid matching,SCSPM)和局部约束线性编码(locality-constrained linear coding,LLC)分别提升了12.35%、3.99%和2.27%。结论本文提出的溃疡性结肠炎辅助诊断模型,综合了压缩感知和空间金字塔池化的优点,获得了较对比方法更加精确的识别感染图像检测结果。关键词:溃疡性结肠炎;计算机辅助诊断;压缩感知;交替优化;空间金字塔池化25|38|1更新时间:2024-05-07
摘要:目的长期感染溃疡性结肠炎(ulcerative colitis,UC)的患者罹患结肠癌的风险显著提升,因此早期进行结肠镜检测十分必要,但内窥镜图像数量巨大且伴有噪声干扰,需要找到精确的图像特征,为医师提供计算机辅助诊断。为解决UC图像与正常肠道图像的分类问题,提出了一种基于压缩感知和空间金字塔池化结合的图像特征提取方法。方法使用块递归最小二乘(block recursive least squares,BRLS)进行初始字典训练。提出基于先验知识进行观测矩阵与稀疏字典的交替优化算法,并利用压缩感知框架获得图像的稀疏表示,该框架改善了原来基于稀疏编码的图像分类方法无法精确表示图像的问题,然后结合最大空间金字塔池化方法提取压缩感知空间金字塔池化(compressed sensing spatial pyramid pooling,CSSPP)图像特征,由于压缩感知的引入,获得的图像特征比稀疏编码更加丰富和精确。最后使用线性核支持向量机(support vector machine,SVM)进行图像分类。结果对Kvasir数据集中的2 000幅真实肠道图像的分类结果表明,该特征的准确率比特征袋(bag of features,BoF)、稀疏编码空间金字塔匹配(sparse coding spatial pyramid matching,SCSPM)和局部约束线性编码(locality-constrained linear coding,LLC)分别提升了12.35%、3.99%和2.27%。结论本文提出的溃疡性结肠炎辅助诊断模型,综合了压缩感知和空间金字塔池化的优点,获得了较对比方法更加精确的识别感染图像检测结果。关键词:溃疡性结肠炎;计算机辅助诊断;压缩感知;交替优化;空间金字塔池化25|38|1更新时间:2024-05-07 -
 摘要:目的肝肿瘤分类计算机辅助诊断技术在临床医学中具有重要意义,但样本缺乏、标注成本高及肝脏图像的敏感性等原因,限制了深度学习的分类潜能,使得肝肿瘤分类依然是医学图像处理领域中具有挑战性的任务。针对上述问题,本文提出了一种结合特征重用和注意力机制的肝肿瘤自动分类方法。方法利用特征重用模块对计算机断层扫描(computed tomography,CT)图像进行伪自然图像的预处理,复制经Hounsfield处理后的原通道信息,并通过数据增强扩充现有数据;引入基于注意力机制的特征提取模块,从全局和局部两个方面分别对原始数据进行加权处理,充分挖掘现有样本的高维语义特征;通过迁移学习的训练策略训练提出的网络模型,并使用Softmax分类器实现肝肿瘤的精准分类。结果在120个病人的514幅CT扫描切片上进行了综合实验。与基准方法相比,本文方法平均分类准确率为87.78%,提高了9.73%;与肝肿瘤分类算法相比,本文算法针对转移性肝腺癌、血管瘤、肝细胞癌及正常肝组织的分类召回率分别达到79.47%、79.67%、85.73%和98.31%;与主流分类模型相比,本文模型在多种评价指标中均表现优异,平均准确率、召回率、精确率、F1-score及AUC(area under ROC curve)分别为87.78%、84.43%、84.59%、84.44%和97.50%。消融实验表明了本文设计的有效性。结论本文方法能提高肝脏肿瘤的分类结果,可为临床诊断提供依据。关键词:深度学习;肝肿瘤分类;注意力机制;特征重用;特征提取42|81|0更新时间:2024-05-07
摘要:目的肝肿瘤分类计算机辅助诊断技术在临床医学中具有重要意义,但样本缺乏、标注成本高及肝脏图像的敏感性等原因,限制了深度学习的分类潜能,使得肝肿瘤分类依然是医学图像处理领域中具有挑战性的任务。针对上述问题,本文提出了一种结合特征重用和注意力机制的肝肿瘤自动分类方法。方法利用特征重用模块对计算机断层扫描(computed tomography,CT)图像进行伪自然图像的预处理,复制经Hounsfield处理后的原通道信息,并通过数据增强扩充现有数据;引入基于注意力机制的特征提取模块,从全局和局部两个方面分别对原始数据进行加权处理,充分挖掘现有样本的高维语义特征;通过迁移学习的训练策略训练提出的网络模型,并使用Softmax分类器实现肝肿瘤的精准分类。结果在120个病人的514幅CT扫描切片上进行了综合实验。与基准方法相比,本文方法平均分类准确率为87.78%,提高了9.73%;与肝肿瘤分类算法相比,本文算法针对转移性肝腺癌、血管瘤、肝细胞癌及正常肝组织的分类召回率分别达到79.47%、79.67%、85.73%和98.31%;与主流分类模型相比,本文模型在多种评价指标中均表现优异,平均准确率、召回率、精确率、F1-score及AUC(area under ROC curve)分别为87.78%、84.43%、84.59%、84.44%和97.50%。消融实验表明了本文设计的有效性。结论本文方法能提高肝脏肿瘤的分类结果,可为临床诊断提供依据。关键词:深度学习;肝肿瘤分类;注意力机制;特征重用;特征提取42|81|0更新时间:2024-05-07 -
 摘要:目的糖尿病视网膜病变(diabetic retinopathy,DR)是一种病发率和致盲率都很高的糖尿病并发症。临床中,由于视网膜图像不同等级之间差异性小以及临床医生经验的不同,会出现误诊、漏诊等情况,目前基于人工DR的诊断分类性能差且耗时费力。基于此,本文提出一种融合注意力机制(attention mechanism)和高效率网络(high-efficiency network,EfficientNet)的DR影像自动分类识别方法,以此达到对病变类型的精确诊断。方法针对实验中DR数据集存在的问题,进行剔除、去噪、扩增和归一化等处理;利用EfficientNet进行特征提取,采用迁移学习的策略用DR的数据集对EfficientNet进行学习与训练,提取深度特征。为了解决病变之间差异小的问题,防止网络对糖尿病视网膜图像的特征学习时出现错分等情况,在EfficientNet输出结果上加入注意力机制;根据网络提取的特征在深度分类器中进行分类,将视网膜图像按等级进行五分类。结果本文方法的分类精度、敏感性、特异性和二次加权(kappa)值分别为97.2%、95.6%、98.7%和0.84,具有较好的分类性能及鲁棒性。结论基于融合注意力机制的高效率网络(attention EfficientNet,A-EfficientNet)的DR分类算法有效地提高了DR筛查效率,解决了人工分类的手动提取特征的局限性,在临床上对医生诊断起到了辅助作用,能更有效地防治此类恶性眼疾造成严重视力损伤、甚至失明。关键词:糖尿病视网膜病变分类;高效率网络;注意力机制;深度学习;迁移学习;深度特征61|62|1更新时间:2024-05-07
摘要:目的糖尿病视网膜病变(diabetic retinopathy,DR)是一种病发率和致盲率都很高的糖尿病并发症。临床中,由于视网膜图像不同等级之间差异性小以及临床医生经验的不同,会出现误诊、漏诊等情况,目前基于人工DR的诊断分类性能差且耗时费力。基于此,本文提出一种融合注意力机制(attention mechanism)和高效率网络(high-efficiency network,EfficientNet)的DR影像自动分类识别方法,以此达到对病变类型的精确诊断。方法针对实验中DR数据集存在的问题,进行剔除、去噪、扩增和归一化等处理;利用EfficientNet进行特征提取,采用迁移学习的策略用DR的数据集对EfficientNet进行学习与训练,提取深度特征。为了解决病变之间差异小的问题,防止网络对糖尿病视网膜图像的特征学习时出现错分等情况,在EfficientNet输出结果上加入注意力机制;根据网络提取的特征在深度分类器中进行分类,将视网膜图像按等级进行五分类。结果本文方法的分类精度、敏感性、特异性和二次加权(kappa)值分别为97.2%、95.6%、98.7%和0.84,具有较好的分类性能及鲁棒性。结论基于融合注意力机制的高效率网络(attention EfficientNet,A-EfficientNet)的DR分类算法有效地提高了DR筛查效率,解决了人工分类的手动提取特征的局限性,在临床上对医生诊断起到了辅助作用,能更有效地防治此类恶性眼疾造成严重视力损伤、甚至失明。关键词:糖尿病视网膜病变分类;高效率网络;注意力机制;深度学习;迁移学习;深度特征61|62|1更新时间:2024-05-07
医学图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0