
最新刊期
2020 年 第 25 卷 第 7 期
-
 摘要:非真实感绘制技术(non-photorealistic rendering,NPR)主要用于模拟艺术风格、表现艺术特质和传达用户情感等,是计算机图形学的重要组成部分,其研究对象逐渐丰富,研究方法不断创新。本文从基于图像建模的绘制方法、基于深度学习的绘制方法、中国特有艺术作品的数字化模拟、非真实感情感特征识别以及非真实感视频场景绘制等5个方面概述目前研究进展,然后从扩展非真实感研究对象、增强视频绘制帧间连贯性、提取艺术风格情感特征以及评价非真实感绘制结果等4个角度讨论需要进一步研究的问题。针对需要深入研究的问题,指出提高算法的通用性和绘制效率,以及提高深度学习网络的泛化性,有助于扩展研究对象,模拟艺术风格的多样性,同时减小视频场景的帧间跳变;对艺术风格作品具有的情感特征、内在机理特征进行模拟,有助于提高绘制结果与艺术风格图像的相似度;结合主观和客观评价模型,可以更准确地对绘制结果进行评价,同时有利于优化网络模型参数,提高绘制效率。非真实感绘制在计算机视觉、文化遗产保护等领域具有重要的应用前景,但其研究对象、绘制算法、绘制效率仍然存在很多亟待解决的问题,随着硬件设备的不断改进,综合运用学科交叉知识、扩展应用领域将进一步推动非真实感绘制技术的发展。关键词:非真实感绘制;图像建模;数字化模拟;情感识别;评价标准82|84|4更新时间:2024-05-07
摘要:非真实感绘制技术(non-photorealistic rendering,NPR)主要用于模拟艺术风格、表现艺术特质和传达用户情感等,是计算机图形学的重要组成部分,其研究对象逐渐丰富,研究方法不断创新。本文从基于图像建模的绘制方法、基于深度学习的绘制方法、中国特有艺术作品的数字化模拟、非真实感情感特征识别以及非真实感视频场景绘制等5个方面概述目前研究进展,然后从扩展非真实感研究对象、增强视频绘制帧间连贯性、提取艺术风格情感特征以及评价非真实感绘制结果等4个角度讨论需要进一步研究的问题。针对需要深入研究的问题,指出提高算法的通用性和绘制效率,以及提高深度学习网络的泛化性,有助于扩展研究对象,模拟艺术风格的多样性,同时减小视频场景的帧间跳变;对艺术风格作品具有的情感特征、内在机理特征进行模拟,有助于提高绘制结果与艺术风格图像的相似度;结合主观和客观评价模型,可以更准确地对绘制结果进行评价,同时有利于优化网络模型参数,提高绘制效率。非真实感绘制在计算机视觉、文化遗产保护等领域具有重要的应用前景,但其研究对象、绘制算法、绘制效率仍然存在很多亟待解决的问题,随着硬件设备的不断改进,综合运用学科交叉知识、扩展应用领域将进一步推动非真实感绘制技术的发展。关键词:非真实感绘制;图像建模;数字化模拟;情感识别;评价标准82|84|4更新时间:2024-05-07
学者观点

-
 摘要:随着网络上图像和视频数据的快速增长,传统图像检索方法已难以高效处理海量数据。在面向大规模图像检索时,特征哈希与深度学习结合的深度哈希技术已成为发展趋势,为全面认识和理解深度哈希图像检索方法,本文对其进行梳理和综述。根据是否使用标签信息将深度哈希方法分为无监督、半监督和监督深度哈希方法,根据无监督和半监督深度哈希方法的主要研究点进一步分为基于卷积神经网络(convolutional neural networks,CNN)和基于生成对抗网络(generative adversarial networks,GAN)的无监督/半监督深度哈希方法,根据数据标签信息差异将监督深度哈希方法进一步分为基于三元组和基于成对监督信息的深度哈希方法,根据各种方法使用损失函数的不同对每类方法中一些经典方法的原理及特性进行介绍,对各种方法的优缺点进行分析。通过分析和比较各种深度哈希方法在CIFAR-10和NUS-WIDE数据集上的检索性能,以及深度哈希算法在西安邮电大学图像与信息处理研究所(Center for Image and Information Processing,CⅡP)自建的两个特色数据库上的测试结果,对基于深度哈希的检索技术进行总结,分析了深度哈希的检索技术未来的发展前景。监督深度哈希的图像检索方法虽然取得了较高的检索精度。但由于监督深度哈希方法高度依赖数据标签,无监督深度哈希技术更加受到关注。基于深度哈希技术进行图像检索是实现大规模图像数据高效检索的有效方法,但存在亟待攻克的技术难点。针对实际应用需求,关于无监督深度哈希算法的研究仍需要更多关注。关键词:图像检索;无监督;监督;深度学习;哈希;深度哈希223|129|11更新时间:2024-05-07
摘要:随着网络上图像和视频数据的快速增长,传统图像检索方法已难以高效处理海量数据。在面向大规模图像检索时,特征哈希与深度学习结合的深度哈希技术已成为发展趋势,为全面认识和理解深度哈希图像检索方法,本文对其进行梳理和综述。根据是否使用标签信息将深度哈希方法分为无监督、半监督和监督深度哈希方法,根据无监督和半监督深度哈希方法的主要研究点进一步分为基于卷积神经网络(convolutional neural networks,CNN)和基于生成对抗网络(generative adversarial networks,GAN)的无监督/半监督深度哈希方法,根据数据标签信息差异将监督深度哈希方法进一步分为基于三元组和基于成对监督信息的深度哈希方法,根据各种方法使用损失函数的不同对每类方法中一些经典方法的原理及特性进行介绍,对各种方法的优缺点进行分析。通过分析和比较各种深度哈希方法在CIFAR-10和NUS-WIDE数据集上的检索性能,以及深度哈希算法在西安邮电大学图像与信息处理研究所(Center for Image and Information Processing,CⅡP)自建的两个特色数据库上的测试结果,对基于深度哈希的检索技术进行总结,分析了深度哈希的检索技术未来的发展前景。监督深度哈希的图像检索方法虽然取得了较高的检索精度。但由于监督深度哈希方法高度依赖数据标签,无监督深度哈希技术更加受到关注。基于深度哈希技术进行图像检索是实现大规模图像数据高效检索的有效方法,但存在亟待攻克的技术难点。针对实际应用需求,关于无监督深度哈希算法的研究仍需要更多关注。关键词:图像检索;无监督;监督;深度学习;哈希;深度哈希223|129|11更新时间:2024-05-07 -
 摘要:严肃游戏是计算机游戏一个新的发展方向,可以提供形象互动的模拟教学环境,已经广泛应用于科学教育、康复医疗、应急管理、军事训练等领域。虚拟角色是严肃游戏中模拟具有生命特征的图形实体,行为可信的虚拟角色能够提升用户使用严肃游戏的体验感。严肃游戏中的图形渲染技术已经逐步成熟,而虚拟角色行为建模的研究尚在初级阶段。可信的虚拟角色必须能够具有感知、情绪和行为能力。本文分别从游戏剧情与行为、行为建模方法、行为学习和行为建模评价等4个方面来分析虚拟角色行为建模研究。分析了有限状态机和行为树的特点,讨论了虚拟角色的行为学习方法。指出了强化学习的关键要素,探讨了深度强化学习的应用途径。综合已有研究,归纳了虚拟角色行为框架,该框架主要包括感觉输入、知觉分析、行为决策和动作4大模块。从情感计算的融入、游戏剧情和场景设计、智能手机平台和多通道交互4个角度讨论需要进一步研究的问题。虚拟角色的行为建模需要综合地考虑游戏剧情、机器学习和人机交互技术,构建具有自主感知、情绪、行为、学习能力、多通道交互的虚拟角色能够极大地提升严肃游戏的感染力,更好地体现寓教于乐。关键词:严肃游戏;虚拟角色;行为建模;情感建模;行为学习40|37|2更新时间:2024-05-07
摘要:严肃游戏是计算机游戏一个新的发展方向,可以提供形象互动的模拟教学环境,已经广泛应用于科学教育、康复医疗、应急管理、军事训练等领域。虚拟角色是严肃游戏中模拟具有生命特征的图形实体,行为可信的虚拟角色能够提升用户使用严肃游戏的体验感。严肃游戏中的图形渲染技术已经逐步成熟,而虚拟角色行为建模的研究尚在初级阶段。可信的虚拟角色必须能够具有感知、情绪和行为能力。本文分别从游戏剧情与行为、行为建模方法、行为学习和行为建模评价等4个方面来分析虚拟角色行为建模研究。分析了有限状态机和行为树的特点,讨论了虚拟角色的行为学习方法。指出了强化学习的关键要素,探讨了深度强化学习的应用途径。综合已有研究,归纳了虚拟角色行为框架,该框架主要包括感觉输入、知觉分析、行为决策和动作4大模块。从情感计算的融入、游戏剧情和场景设计、智能手机平台和多通道交互4个角度讨论需要进一步研究的问题。虚拟角色的行为建模需要综合地考虑游戏剧情、机器学习和人机交互技术,构建具有自主感知、情绪、行为、学习能力、多通道交互的虚拟角色能够极大地提升严肃游戏的感染力,更好地体现寓教于乐。关键词:严肃游戏;虚拟角色;行为建模;情感建模;行为学习40|37|2更新时间:2024-05-07 -
 摘要:计算机视觉在智能制造工业检测中发挥着检测识别和定位分析的重要作用,为提高工业检测的检测速率和准确率以及智能自动化程度做出了巨大的贡献。然而计算机视觉在应用过程中一直存在技术应用难点,其中3大瓶颈问题是:计算机视觉应用易受光照影响、样本数据难以支持深度学习、先验知识难以加入演化算法。这些瓶颈问题使得计算机视觉在智能制造中的应用无法发挥最佳效能。因此,需要系统地加以分析和解决。本文总结了智能制造和计算机视觉的概念及其重要性,分析了计算机视觉在智能制造工业检测领域的发展现状和需求。针对计算机视觉应用存在的3大瓶颈问题总结分析了问题现状和已有解决方法。经过深入分析发现:针对受光照影响大的问题,可以通过算法和图像采集两个环节解决;针对样本数据难以支持深度学习的问题,可以通过小样本数据处理算法和样本数量分布平衡方法解决;针对先验知识难以加入演化算法的问题,可以通过机器学习和强化学习解决。上述解决方案中的方法不尽相同,各有优劣,需要结合智能制造中具体应用研究和改进。关键词:智能制造;计算机视觉;光照均匀控制;样本数据增广;先验知识应用119|164|2更新时间:2024-05-07
摘要:计算机视觉在智能制造工业检测中发挥着检测识别和定位分析的重要作用,为提高工业检测的检测速率和准确率以及智能自动化程度做出了巨大的贡献。然而计算机视觉在应用过程中一直存在技术应用难点,其中3大瓶颈问题是:计算机视觉应用易受光照影响、样本数据难以支持深度学习、先验知识难以加入演化算法。这些瓶颈问题使得计算机视觉在智能制造中的应用无法发挥最佳效能。因此,需要系统地加以分析和解决。本文总结了智能制造和计算机视觉的概念及其重要性,分析了计算机视觉在智能制造工业检测领域的发展现状和需求。针对计算机视觉应用存在的3大瓶颈问题总结分析了问题现状和已有解决方法。经过深入分析发现:针对受光照影响大的问题,可以通过算法和图像采集两个环节解决;针对样本数据难以支持深度学习的问题,可以通过小样本数据处理算法和样本数量分布平衡方法解决;针对先验知识难以加入演化算法的问题,可以通过机器学习和强化学习解决。上述解决方案中的方法不尽相同,各有优劣,需要结合智能制造中具体应用研究和改进。关键词:智能制造;计算机视觉;光照均匀控制;样本数据增广;先验知识应用119|164|2更新时间:2024-05-07
综述
-
 摘要:目的利用深度卷积神经网络(deep convolutional neural network,DCNN)构建的非开关型随机脉冲噪声(random-valued impulse noise,RVIN)降噪模型在降噪效果和执行效率上均比主流的开关型RVIN降噪算法更有优势,但在实际应用中,这类基于训练(数据驱动)的降噪模型,其性能却受制于能否对待降噪图像受噪声干扰的严重程度进行准确的测定(即存在数据依赖问题)。为此,提出了一种基于浅层卷积神经网络的快速RVIN噪声比例预测(noise ratio estimation,NRE)模型。方法该预测模型的主要任务是检测待降噪图像中的噪声比例值并将其作为反映图像受噪声干扰严重程度的指标,依据NRE预测模型的检测结果可以自适应调用相应预先训练好的特定区间DCNN降噪模型,从而快速且高质量地完成图像降噪任务。结果分别在10幅常用图像和50幅纹理图像两个测试集上进行测试,并与现有的主流RVIN降噪算法中的检测模块进行对比。在常用图像测试集上,本文所提出的NRE预测模型的预测准确性最高。相比于噪声比例预测精度排名第2的算法,NRE预测模型在噪声比例预测值均方根误差上低0.6% 2.4%。在50幅纹理图像测试集上,NRE模型的均方根误差波动范围最小,表明其稳定性最好。通过在1幅大小为512×512像素图像上的总体平均执行时间来比较各个算法执行效率的优劣,NRE模型执行时间仅为0.02 s。实验数据表明:所提出的NRE预测模型在受各种不同噪声比例干扰的自然图像上均可以快速而稳定地测定图像中受RVIN噪声干扰的严重程度,非盲的DCNN降噪模型与其联用后即可无缝地转化为盲降噪算法。结论本文RVIN噪声比例预测模型在各个噪声比例下具有鲁棒的预测准确性,与基于DCNN的非开关型RVIN深度降噪模型配合使用后能妥善解决DCNN网络模型固有的数据依赖问题。关键词:随机脉冲噪声;噪声比例估计;浅层卷积神经网络;非逐点模式;执行效率;盲降噪43|55|0更新时间:2024-05-07
摘要:目的利用深度卷积神经网络(deep convolutional neural network,DCNN)构建的非开关型随机脉冲噪声(random-valued impulse noise,RVIN)降噪模型在降噪效果和执行效率上均比主流的开关型RVIN降噪算法更有优势,但在实际应用中,这类基于训练(数据驱动)的降噪模型,其性能却受制于能否对待降噪图像受噪声干扰的严重程度进行准确的测定(即存在数据依赖问题)。为此,提出了一种基于浅层卷积神经网络的快速RVIN噪声比例预测(noise ratio estimation,NRE)模型。方法该预测模型的主要任务是检测待降噪图像中的噪声比例值并将其作为反映图像受噪声干扰严重程度的指标,依据NRE预测模型的检测结果可以自适应调用相应预先训练好的特定区间DCNN降噪模型,从而快速且高质量地完成图像降噪任务。结果分别在10幅常用图像和50幅纹理图像两个测试集上进行测试,并与现有的主流RVIN降噪算法中的检测模块进行对比。在常用图像测试集上,本文所提出的NRE预测模型的预测准确性最高。相比于噪声比例预测精度排名第2的算法,NRE预测模型在噪声比例预测值均方根误差上低0.6% 2.4%。在50幅纹理图像测试集上,NRE模型的均方根误差波动范围最小,表明其稳定性最好。通过在1幅大小为512×512像素图像上的总体平均执行时间来比较各个算法执行效率的优劣,NRE模型执行时间仅为0.02 s。实验数据表明:所提出的NRE预测模型在受各种不同噪声比例干扰的自然图像上均可以快速而稳定地测定图像中受RVIN噪声干扰的严重程度,非盲的DCNN降噪模型与其联用后即可无缝地转化为盲降噪算法。结论本文RVIN噪声比例预测模型在各个噪声比例下具有鲁棒的预测准确性,与基于DCNN的非开关型RVIN深度降噪模型配合使用后能妥善解决DCNN网络模型固有的数据依赖问题。关键词:随机脉冲噪声;噪声比例估计;浅层卷积神经网络;非逐点模式;执行效率;盲降噪43|55|0更新时间:2024-05-07 -
 摘要:目的图像复原是基于物理模型提高退化图像质量的一种客观方法,复原图像无失真且细节丰富。烧结机尾断面火焰图像可以反映料层的烧结状态,对烧结矿质量的检测起到至关重要的作用。由于烧结机尾环境恶劣,存在大量的烟气、粉尘以及亮度不均等干扰因素,导致相机采集到的烧结断面火焰图像存在退化现象。为消除这些影响,本文建立了烧结断面火焰图像退化模型,提出了有效的烧结断面火焰图像复原算法。方法基于大气散射模型,采用一级多散射方法对烟尘多次散射过程进行简化,建立烧结断面火焰图像退化模型,依据Retinex理论,将场景成像分解为环境光照射分量与反射率的乘积,明确复原图像所求参数。1)求取原始图像亮度,利用Retinex理论分解原始图像,使用双边滤波来调整亮度图像,采用Sigmoid函数对反射图像进行增强,得到亮度平衡后新的烧结断面火焰图像;2)利用暗通道原理估计环境光值,结合引导滤波细化图像透射率分布;3)采用容差机制改进火焰区域的透射率,得到复原图像。结果使用本文方法对单幅图像进行复原并与其他4种方法进行主客观评价,结果表明本文得到的复原图像亮度均衡,火焰区域细节清晰并且与烧结料层区别明显,在保持较高图像对比度的同时,图像信息熵和峰值信噪比分别为17.532 bit与22.127 dB,相比其他算法明显提高。结论本文研究了烧结断面火焰图像的退化模型,提出有效的复原算法,实现了Retinex理论与暗通道原理的有机结合,复原图像质量较高,为烧结火焰特征准确提取打下基础。关键词:图像复原;Retinex;暗通道先验;火焰图像;烧结机126|84|0更新时间:2024-05-07
摘要:目的图像复原是基于物理模型提高退化图像质量的一种客观方法,复原图像无失真且细节丰富。烧结机尾断面火焰图像可以反映料层的烧结状态,对烧结矿质量的检测起到至关重要的作用。由于烧结机尾环境恶劣,存在大量的烟气、粉尘以及亮度不均等干扰因素,导致相机采集到的烧结断面火焰图像存在退化现象。为消除这些影响,本文建立了烧结断面火焰图像退化模型,提出了有效的烧结断面火焰图像复原算法。方法基于大气散射模型,采用一级多散射方法对烟尘多次散射过程进行简化,建立烧结断面火焰图像退化模型,依据Retinex理论,将场景成像分解为环境光照射分量与反射率的乘积,明确复原图像所求参数。1)求取原始图像亮度,利用Retinex理论分解原始图像,使用双边滤波来调整亮度图像,采用Sigmoid函数对反射图像进行增强,得到亮度平衡后新的烧结断面火焰图像;2)利用暗通道原理估计环境光值,结合引导滤波细化图像透射率分布;3)采用容差机制改进火焰区域的透射率,得到复原图像。结果使用本文方法对单幅图像进行复原并与其他4种方法进行主客观评价,结果表明本文得到的复原图像亮度均衡,火焰区域细节清晰并且与烧结料层区别明显,在保持较高图像对比度的同时,图像信息熵和峰值信噪比分别为17.532 bit与22.127 dB,相比其他算法明显提高。结论本文研究了烧结断面火焰图像的退化模型,提出有效的复原算法,实现了Retinex理论与暗通道原理的有机结合,复原图像质量较高,为烧结火焰特征准确提取打下基础。关键词:图像复原;Retinex;暗通道先验;火焰图像;烧结机126|84|0更新时间:2024-05-07 -
 摘要:目的随着互联网通信和多媒体技术的快速发展,单幅图像加密技术难以满足日益增长的数据传输需求。为提高图像加密系统的传输效率,同时保证安全性和鲁棒性,本文构建一种基于gyrator变换和多分辨率奇异值分解(multi-resolution singular value decomposition,MRSVD)的多图像加密算法。方法首先,将明文图像每两幅组合为复数矩阵,利用改进的logistic映射生成混沌相位掩模,对复数矩阵进行gyrator域的双随机相位编码。其次,将变换后矩阵的实部分量和虚部分量组合为实数矩阵并进行多分辨率奇异值分解。最后,使用正交系数矩阵对多分辨率奇异值分解的结果进行线性组合得到密文图像。结果实验结果表明,使用本文算法得到的解密图像的峰值信噪比大于300 dB,解密图像质量相较于对比算法的解密图像质量更好;密钥发生微小改变前后密文相关系数(correlation coefficient,CC)远小于0.20,明文像素值发生微小变化时像素变化率(number of pixels change rate,NPCR)与归一化平均变化强度(unified average changing intensity,UACI)分别约为0.999 0和0.333 7;密钥空间大小为5.616 9×1060,可以抵御蛮力攻击;当密文图像受到一定强度的高斯白噪声和剪切攻击时,本文算法能够较好地恢复明文图像。结论所提出的多图像加密算法在高质量恢复明文图像的同时具有较高的安全性和较强的鲁棒性,可以应用于图像的内容保护与安全传输。关键词:多图像加密;gyrator变换;多分辨率奇异值分解;改进的logistic映射;双随机相位编码42|71|1更新时间:2024-05-07
摘要:目的随着互联网通信和多媒体技术的快速发展,单幅图像加密技术难以满足日益增长的数据传输需求。为提高图像加密系统的传输效率,同时保证安全性和鲁棒性,本文构建一种基于gyrator变换和多分辨率奇异值分解(multi-resolution singular value decomposition,MRSVD)的多图像加密算法。方法首先,将明文图像每两幅组合为复数矩阵,利用改进的logistic映射生成混沌相位掩模,对复数矩阵进行gyrator域的双随机相位编码。其次,将变换后矩阵的实部分量和虚部分量组合为实数矩阵并进行多分辨率奇异值分解。最后,使用正交系数矩阵对多分辨率奇异值分解的结果进行线性组合得到密文图像。结果实验结果表明,使用本文算法得到的解密图像的峰值信噪比大于300 dB,解密图像质量相较于对比算法的解密图像质量更好;密钥发生微小改变前后密文相关系数(correlation coefficient,CC)远小于0.20,明文像素值发生微小变化时像素变化率(number of pixels change rate,NPCR)与归一化平均变化强度(unified average changing intensity,UACI)分别约为0.999 0和0.333 7;密钥空间大小为5.616 9×1060,可以抵御蛮力攻击;当密文图像受到一定强度的高斯白噪声和剪切攻击时,本文算法能够较好地恢复明文图像。结论所提出的多图像加密算法在高质量恢复明文图像的同时具有较高的安全性和较强的鲁棒性,可以应用于图像的内容保护与安全传输。关键词:多图像加密;gyrator变换;多分辨率奇异值分解;改进的logistic映射;双随机相位编码42|71|1更新时间:2024-05-07 -
 摘要:目的为提高水下获取的结构物表面缺陷图像的对比度和清晰度,便于缺陷区域的分割、提取和识别工作,提出了一种基于改进的湍流模型和引导滤波平滑的retinex的图像增强方法。方法将光照不均的水下图像转换到Lab空间,对亮度空间进行自适应直方图均衡的匀光处理,根据暗通道先验理论估算匀光图像的透射率,结合大气湍流通用模型模拟退化图像,通过调整透射率系数获得退化图像。采用维纳滤波过滤图像噪声,将滤波后的图像作为导向图,利用导向滤波细化获得边缘保持的图像。根据3σ准则对3通道多尺度retinex(multi-scale retinex,MSR)的反射分量进行色彩矫正,获取最终增强后的水下结构物表面缺陷图像。结果选取多组在不同湍流环境下采集的图像为研究对象,采用本文提出的方法进行实验,并与经典的暗通道算法、直方图均衡算法以及单尺度retinex算法对比,使用信噪比、信息熵、标准差和平均梯度等指标进行评估。实验结果表明,本文方法的信息熵、标准差相较直方图均衡算法和单尺度retinex分别提高了11.7%和25.6%,分割准确率上升了3.1%。从主观效果上看,本文算法图像细节更为丰富,视觉效果自然。结论本文算法改善了退化模型的自适应问题,在信息熵、标准差、平均梯度等综合指标上均有优异表现,与暗通道先验方法相比,信噪比、平均梯度大幅提升,同时实现了缺陷的边缘保持效果,为下阶段的图像处理提供了良好的信息源。关键词:水下图像增强;湍流模型;透射率;维纳滤波;多尺度retinex;色彩校正122|145|4更新时间:2024-05-07
摘要:目的为提高水下获取的结构物表面缺陷图像的对比度和清晰度,便于缺陷区域的分割、提取和识别工作,提出了一种基于改进的湍流模型和引导滤波平滑的retinex的图像增强方法。方法将光照不均的水下图像转换到Lab空间,对亮度空间进行自适应直方图均衡的匀光处理,根据暗通道先验理论估算匀光图像的透射率,结合大气湍流通用模型模拟退化图像,通过调整透射率系数获得退化图像。采用维纳滤波过滤图像噪声,将滤波后的图像作为导向图,利用导向滤波细化获得边缘保持的图像。根据3σ准则对3通道多尺度retinex(multi-scale retinex,MSR)的反射分量进行色彩矫正,获取最终增强后的水下结构物表面缺陷图像。结果选取多组在不同湍流环境下采集的图像为研究对象,采用本文提出的方法进行实验,并与经典的暗通道算法、直方图均衡算法以及单尺度retinex算法对比,使用信噪比、信息熵、标准差和平均梯度等指标进行评估。实验结果表明,本文方法的信息熵、标准差相较直方图均衡算法和单尺度retinex分别提高了11.7%和25.6%,分割准确率上升了3.1%。从主观效果上看,本文算法图像细节更为丰富,视觉效果自然。结论本文算法改善了退化模型的自适应问题,在信息熵、标准差、平均梯度等综合指标上均有优异表现,与暗通道先验方法相比,信噪比、平均梯度大幅提升,同时实现了缺陷的边缘保持效果,为下阶段的图像处理提供了良好的信息源。关键词:水下图像增强;湍流模型;透射率;维纳滤波;多尺度retinex;色彩校正122|145|4更新时间:2024-05-07
图像处理和编码
-
 摘要:目的行人再识别是指在一个或者多个相机拍摄的图像或视频中实现行人匹配的技术,广泛用于图像检索、智能安保等领域。按照相机种类和拍摄视角的不同,行人再识别算法可主要分为基于侧视角彩色相机的行人再识别算法和基于俯视角深度相机的行人再识别算法。在侧视角彩色相机场景中,行人身体的大部分表观信息可见;而在俯视角深度相机场景中,仅行人头部和肩部的结构信息可见。现有的多数算法主要针对侧视角彩色相机场景,只有少数算法可以直接应用于俯视角深度相机场景中,尤其是低分辨率场景,如公交车的车载飞行时间(time of flight,TOF)相机拍摄的视频。因此针对俯视角深度相机场景,本文提出了一种基于俯视深度头肩序列的行人再识别算法,以期提高低分辨率场景下的行人再识别精度。方法对俯视深度头肩序列进行头部区域检测和卡尔曼滤波器跟踪,获取行人的头部图像序列,构建头部深度能量图组(head depth energy map group,HeDEMaG),并据此提取深度特征、面积特征、投影特征、傅里叶描述子和方向梯度直方图(histogram of oriented gradient,HOG)特征。计算行人之间头部深度能量图组的各特征之间的相似度,再利用经过模型学习所获得的权重系数对各特征相似度进行加权融合,从而得到相似度总分,将最大相似度对应的行人标签作为识别结果,实现行人再识别。结果本文算法在公开的室内单人场景TVPR(top view person re-identification)数据集、自建的室内多人场景TDPI-L(top-view depth based person identification for laboratory scenarios)数据集和公交车实际场景TDPI-B(top-view depth based person identification for bus scenarios)数据集上进行了测试,使用首位匹配率(rank-1)、前5位匹配率(rank-5)、宏F1值(macro-F1)、累计匹配曲线(cumulative match characteristic,CMC)和平均耗时等5个指标来衡量算法性能。其中,rank-1、rank-5和macro-F1分别达到61%、68%和67%以上,相比于典型算法至少提高了11%。结论本文构建了表达行人结构与行为特征的头部深度能量图组,实现了适合低分辨率行人的多特征表达;提出了基于权重学习的相似度融合,提高了识别精度,在室内单人、室内多人和公交车实际场景数据集中均取得了较好的效果。关键词:深度相机;俯视深度头肩序列;头部深度能量图组;相似度权重学习;行人再识别83|113|1更新时间:2024-05-07
摘要:目的行人再识别是指在一个或者多个相机拍摄的图像或视频中实现行人匹配的技术,广泛用于图像检索、智能安保等领域。按照相机种类和拍摄视角的不同,行人再识别算法可主要分为基于侧视角彩色相机的行人再识别算法和基于俯视角深度相机的行人再识别算法。在侧视角彩色相机场景中,行人身体的大部分表观信息可见;而在俯视角深度相机场景中,仅行人头部和肩部的结构信息可见。现有的多数算法主要针对侧视角彩色相机场景,只有少数算法可以直接应用于俯视角深度相机场景中,尤其是低分辨率场景,如公交车的车载飞行时间(time of flight,TOF)相机拍摄的视频。因此针对俯视角深度相机场景,本文提出了一种基于俯视深度头肩序列的行人再识别算法,以期提高低分辨率场景下的行人再识别精度。方法对俯视深度头肩序列进行头部区域检测和卡尔曼滤波器跟踪,获取行人的头部图像序列,构建头部深度能量图组(head depth energy map group,HeDEMaG),并据此提取深度特征、面积特征、投影特征、傅里叶描述子和方向梯度直方图(histogram of oriented gradient,HOG)特征。计算行人之间头部深度能量图组的各特征之间的相似度,再利用经过模型学习所获得的权重系数对各特征相似度进行加权融合,从而得到相似度总分,将最大相似度对应的行人标签作为识别结果,实现行人再识别。结果本文算法在公开的室内单人场景TVPR(top view person re-identification)数据集、自建的室内多人场景TDPI-L(top-view depth based person identification for laboratory scenarios)数据集和公交车实际场景TDPI-B(top-view depth based person identification for bus scenarios)数据集上进行了测试,使用首位匹配率(rank-1)、前5位匹配率(rank-5)、宏F1值(macro-F1)、累计匹配曲线(cumulative match characteristic,CMC)和平均耗时等5个指标来衡量算法性能。其中,rank-1、rank-5和macro-F1分别达到61%、68%和67%以上,相比于典型算法至少提高了11%。结论本文构建了表达行人结构与行为特征的头部深度能量图组,实现了适合低分辨率行人的多特征表达;提出了基于权重学习的相似度融合,提高了识别精度,在室内单人、室内多人和公交车实际场景数据集中均取得了较好的效果。关键词:深度相机;俯视深度头肩序列;头部深度能量图组;相似度权重学习;行人再识别83|113|1更新时间:2024-05-07 -
 摘要:目的人脸识别技术在很多领域起着重要作用,但大量的欺诈攻击对人脸识别产生了威胁,比如打印攻击和重放攻击。传统的活体检测方法是以手工方式提取特征且缺乏对时间维度的考虑,导致检测效果不佳。针对以上问题,提出一种结合混合池化的双流活体检测网络。方法对数据集提取光流图像并进行面部检测,得到双流网络的两个输入;在双流网络末端加入空间金字塔和全局平均混合池化,利用全连接层对池化后的特征进行分类并进行分数层面的融合;对空间流网络和时间流网络进行融合得到一个最优结果,同时考虑了不同颜色空间对检测性能的影响。结果在CASIA-FASD(CASIA face anti-spoofing database)和replay-attack两个数据集上做了多组对比实验,在CASIA-FASD数据集上,等错误率(equal error rate,EER)为1.701%;在replay-attack数据集上,等错误率和半错误率(half total error rate,HTER)分别为0.091%和0.082%。结论结合混合池化的双流活体检测网络充分考虑时间维度,提出的空间金字塔和全局平均混合池化策略能有效地利用特征。针对包含多种攻击类型、图像质量差异较大的数据集,本文提出的网络模型均能取得较低的错误率。关键词:活体检测;卷积神经网络;双流网络;光流法;空间金字塔池化;全局平均池化30|19|6更新时间:2024-05-07
摘要:目的人脸识别技术在很多领域起着重要作用,但大量的欺诈攻击对人脸识别产生了威胁,比如打印攻击和重放攻击。传统的活体检测方法是以手工方式提取特征且缺乏对时间维度的考虑,导致检测效果不佳。针对以上问题,提出一种结合混合池化的双流活体检测网络。方法对数据集提取光流图像并进行面部检测,得到双流网络的两个输入;在双流网络末端加入空间金字塔和全局平均混合池化,利用全连接层对池化后的特征进行分类并进行分数层面的融合;对空间流网络和时间流网络进行融合得到一个最优结果,同时考虑了不同颜色空间对检测性能的影响。结果在CASIA-FASD(CASIA face anti-spoofing database)和replay-attack两个数据集上做了多组对比实验,在CASIA-FASD数据集上,等错误率(equal error rate,EER)为1.701%;在replay-attack数据集上,等错误率和半错误率(half total error rate,HTER)分别为0.091%和0.082%。结论结合混合池化的双流活体检测网络充分考虑时间维度,提出的空间金字塔和全局平均混合池化策略能有效地利用特征。针对包含多种攻击类型、图像质量差异较大的数据集,本文提出的网络模型均能取得较低的错误率。关键词:活体检测;卷积神经网络;双流网络;光流法;空间金字塔池化;全局平均池化30|19|6更新时间:2024-05-07 -
 摘要:目的虹膜作为一种具有高稳定性与区分性的生物特征,使得虹膜识别在应用场景中十分普及,但很多虹膜识别系统在抵御各类演示攻击时无法保证十足的可靠性,导致虹膜识别在高级安全场景中的应用受限,使得虹膜活体检测成为生物识别技术中亟需解决的问题之一。现有的区分真实与假体虹膜最先进的算法主要依靠在原始灰度空间中提取的虹膜纹理深度特征,但这类特征差异不明显,只能辨别单源假体虹膜。为此,提出一种基于增强型灰度图像空间的虹膜活体检测方法。方法利用残差网络(ResNet)将原始虹膜图像映射到可分离的灰度图像空间,使真假虹膜特征具有明显的判别性;用预训练LightCNN(light convolational neural networks)-4网络提取新空间中的虹膜纹理特征;设计三元组损失函数与softmax损失函数训练模型实现二分类任务。结果在两个单源假虹膜数据库上采用闭集检测方式分别取得100%和99.75%的准确率;在多源假虹膜数据库上采用开集检测方式分别取得98.94%和99.06%的准确率。结论本文方法通过空间映射的方式增强真假虹膜纹理之间清晰度的差异,设计三元组损失函数与softmax损失函数训练模型,既增加正负样本集之间的距离差,又提升模型收敛速度。实验结果表明,基于图像空间的分析与变换可有效解决真实虹膜与各类假体虹膜在原始灰度空间中不易区分的问题,并且使网络能够准确检测未知类型的假体虹膜样本,实现虹膜活体检测的最新性能,进一步提升了虹膜活体检测方法的泛化性。关键词:虹膜活体检测;增强型灰度空间;三元组网络;特征差异;泛化性36|56|6更新时间:2024-05-07
摘要:目的虹膜作为一种具有高稳定性与区分性的生物特征,使得虹膜识别在应用场景中十分普及,但很多虹膜识别系统在抵御各类演示攻击时无法保证十足的可靠性,导致虹膜识别在高级安全场景中的应用受限,使得虹膜活体检测成为生物识别技术中亟需解决的问题之一。现有的区分真实与假体虹膜最先进的算法主要依靠在原始灰度空间中提取的虹膜纹理深度特征,但这类特征差异不明显,只能辨别单源假体虹膜。为此,提出一种基于增强型灰度图像空间的虹膜活体检测方法。方法利用残差网络(ResNet)将原始虹膜图像映射到可分离的灰度图像空间,使真假虹膜特征具有明显的判别性;用预训练LightCNN(light convolational neural networks)-4网络提取新空间中的虹膜纹理特征;设计三元组损失函数与softmax损失函数训练模型实现二分类任务。结果在两个单源假虹膜数据库上采用闭集检测方式分别取得100%和99.75%的准确率;在多源假虹膜数据库上采用开集检测方式分别取得98.94%和99.06%的准确率。结论本文方法通过空间映射的方式增强真假虹膜纹理之间清晰度的差异,设计三元组损失函数与softmax损失函数训练模型,既增加正负样本集之间的距离差,又提升模型收敛速度。实验结果表明,基于图像空间的分析与变换可有效解决真实虹膜与各类假体虹膜在原始灰度空间中不易区分的问题,并且使网络能够准确检测未知类型的假体虹膜样本,实现虹膜活体检测的最新性能,进一步提升了虹膜活体检测方法的泛化性。关键词:虹膜活体检测;增强型灰度空间;三元组网络;特征差异;泛化性36|56|6更新时间:2024-05-07 -
 摘要:目的线状目标的检测具有非常广泛的应用领域,如车道线、道路及裂缝的检测等,而裂缝是其中最难检测的线状目标。为避免直接提取线状目标时图像分割难的问题,以裂缝和车道线为例,提出了一种新的跟踪线状目标中线的算法。方法对图像进行高斯平滑,用一种新的分数阶微分模板增强图像中的模糊及微细线状目标;基于Steger算法提出一种提取线状目标中心线特征点的算法,避免了提取整体目标的困难;根据水动力学思想将裂隙看成溪流,通过最大熵阈值处理后,先进行特征点的连接,再基于线段之间的距离及夹角进行线段之间的连接(溪流之间的融合)。结果对300幅裂缝图像及4种类别的其他线状目标图像进行试验,并与距离变换、最大熵阈值法+细线化Otsu阈值分割+细线化、谷底边界检测等类似算法进行比较分析,本文算法检测出的线状目标的连续性好、漏检(大间隙少)和误检(毛刺及多余线段少)率均较低。结论本文算法能够在复杂的线状目标图像中准确快速地提取目标的中心线,一定程度上改善了复杂线状目标图像分割难的问题。关键词:线状目标;裂缝;分数阶微分;Steger;水动力学30|32|1更新时间:2024-05-07
摘要:目的线状目标的检测具有非常广泛的应用领域,如车道线、道路及裂缝的检测等,而裂缝是其中最难检测的线状目标。为避免直接提取线状目标时图像分割难的问题,以裂缝和车道线为例,提出了一种新的跟踪线状目标中线的算法。方法对图像进行高斯平滑,用一种新的分数阶微分模板增强图像中的模糊及微细线状目标;基于Steger算法提出一种提取线状目标中心线特征点的算法,避免了提取整体目标的困难;根据水动力学思想将裂隙看成溪流,通过最大熵阈值处理后,先进行特征点的连接,再基于线段之间的距离及夹角进行线段之间的连接(溪流之间的融合)。结果对300幅裂缝图像及4种类别的其他线状目标图像进行试验,并与距离变换、最大熵阈值法+细线化Otsu阈值分割+细线化、谷底边界检测等类似算法进行比较分析,本文算法检测出的线状目标的连续性好、漏检(大间隙少)和误检(毛刺及多余线段少)率均较低。结论本文算法能够在复杂的线状目标图像中准确快速地提取目标的中心线,一定程度上改善了复杂线状目标图像分割难的问题。关键词:线状目标;裂缝;分数阶微分;Steger;水动力学30|32|1更新时间:2024-05-07 -
 摘要:目的时序动作检测(temporal action detection)作为计算机视觉领域的一个热点课题,其目的是检测视频中动作发生的具体区间,并确定动作的类别。这一课题在现实生活中具有深远的实际意义。如何在长视频中快速定位且实现时序动作检测仍然面临挑战。为此,本文致力于定位并优化动作发生时域的候选集,提出了时域候选区域优化的时序动作检测方法TPO(temporal proposal optimization)。方法采用卷积神经网络(convolutional neural network,CNN)和双向长短期记忆网络(bidirectional long short term memory,BLSTM)来捕捉视频的局部时序关联性和全局时序信息;并引入联级时序分类优化(connectionist temporal classification,CTC)方法,评估每个时序位置的边界概率和动作概率得分;最后,融合两者的概率得分曲线,优化时域候选区域候选并排序,最终实现时序上的动作检测。结果在ActivityNet v1.3数据集上进行实验验证,TPO在各评价指标,如一定时域候选数量下的平均召回率AR@100(average recall@100),曲线下的面积AUC(area under a curve)和平均均值平均精度mAP(mean average precision)上分别达到74.66、66.32、30.5,而各阈值下的均值平均精度mAP@IoU(mAP@intersection over union)在阈值为0.75和0.95时也分别达到了30.73和8.22,与SSN(structured segment network)、TCN(temporal context network)、Prop-SSAD(single shot action detector for proposal)、CTAP(complementary temporal action proposal)和BSN(boundary sensitive network)等方法相比,TPO的所有性能指标均有提高。结论本文提出的模型兼顾了视频的全局时序信息和局部时序信息,使得预测的动作候选区域边界更为准确和灵活,同时也验证了候选区域的准确性能够有效提高时序动作检测的精确度。关键词:时序动作检测;时域候选区域;动作概率得分;级联时序分类;卷积神经网络;双向长短期记忆网络27|16|3更新时间:2024-05-07
摘要:目的时序动作检测(temporal action detection)作为计算机视觉领域的一个热点课题,其目的是检测视频中动作发生的具体区间,并确定动作的类别。这一课题在现实生活中具有深远的实际意义。如何在长视频中快速定位且实现时序动作检测仍然面临挑战。为此,本文致力于定位并优化动作发生时域的候选集,提出了时域候选区域优化的时序动作检测方法TPO(temporal proposal optimization)。方法采用卷积神经网络(convolutional neural network,CNN)和双向长短期记忆网络(bidirectional long short term memory,BLSTM)来捕捉视频的局部时序关联性和全局时序信息;并引入联级时序分类优化(connectionist temporal classification,CTC)方法,评估每个时序位置的边界概率和动作概率得分;最后,融合两者的概率得分曲线,优化时域候选区域候选并排序,最终实现时序上的动作检测。结果在ActivityNet v1.3数据集上进行实验验证,TPO在各评价指标,如一定时域候选数量下的平均召回率AR@100(average recall@100),曲线下的面积AUC(area under a curve)和平均均值平均精度mAP(mean average precision)上分别达到74.66、66.32、30.5,而各阈值下的均值平均精度mAP@IoU(mAP@intersection over union)在阈值为0.75和0.95时也分别达到了30.73和8.22,与SSN(structured segment network)、TCN(temporal context network)、Prop-SSAD(single shot action detector for proposal)、CTAP(complementary temporal action proposal)和BSN(boundary sensitive network)等方法相比,TPO的所有性能指标均有提高。结论本文提出的模型兼顾了视频的全局时序信息和局部时序信息,使得预测的动作候选区域边界更为准确和灵活,同时也验证了候选区域的准确性能够有效提高时序动作检测的精确度。关键词:时序动作检测;时域候选区域;动作概率得分;级联时序分类;卷积神经网络;双向长短期记忆网络27|16|3更新时间:2024-05-07
图像分析和识别
-
 摘要:目的目前已有的人体姿态跟踪算法的跟踪精度仍有待提高,特别是对灵活运动的手臂部位的跟踪。为提高人体姿态的跟踪精度,本文首次提出一种将视觉时空信息与深度学习网络相结合的人体姿态跟踪方法。方法在人体姿态跟踪过程中,利用视频时间信息计算出人体目标区域的运动信息,使用运动信息对人体部位姿态模型在帧间传递;考虑到基于图像空间特征的方法对形态较为固定的人体部位如躯干和头部能够较好地检测,而对手臂的检测效果较差,构造并训练一种轻量级的深度学习网络,用于生成人体手臂部位的附加候选样本;利用深度学习网络生成手臂特征一致性概率图,与视频空间信息结合计算得到最优部位姿态,并将各部位重组为完整人体姿态跟踪结果。结果使用两个具有挑战性的人体姿态跟踪数据集VideoPose2.0和YouTubePose对本文算法进行验证,得到的手臂关节点平均跟踪精度分别为81.4%和84.5%,与现有方法相比有明显提高;此外,通过在VideoPose2.0数据集上的实验,验证了本文提出的对下臂附加采样的算法和手臂特征一致性计算的算法能够有效提高人体姿态关节点的跟踪精度。结论提出的结合时空信息与深度学习网络的人体姿态跟踪方法能够有效提高人体姿态跟踪的精度,特别是对灵活运动的人体姿态下臂关节点的跟踪精度有显著提高。关键词:人体姿态跟踪;视觉目标跟踪;人机交互;深度学习网络;关节点概率图47|56|2更新时间:2024-05-07
摘要:目的目前已有的人体姿态跟踪算法的跟踪精度仍有待提高,特别是对灵活运动的手臂部位的跟踪。为提高人体姿态的跟踪精度,本文首次提出一种将视觉时空信息与深度学习网络相结合的人体姿态跟踪方法。方法在人体姿态跟踪过程中,利用视频时间信息计算出人体目标区域的运动信息,使用运动信息对人体部位姿态模型在帧间传递;考虑到基于图像空间特征的方法对形态较为固定的人体部位如躯干和头部能够较好地检测,而对手臂的检测效果较差,构造并训练一种轻量级的深度学习网络,用于生成人体手臂部位的附加候选样本;利用深度学习网络生成手臂特征一致性概率图,与视频空间信息结合计算得到最优部位姿态,并将各部位重组为完整人体姿态跟踪结果。结果使用两个具有挑战性的人体姿态跟踪数据集VideoPose2.0和YouTubePose对本文算法进行验证,得到的手臂关节点平均跟踪精度分别为81.4%和84.5%,与现有方法相比有明显提高;此外,通过在VideoPose2.0数据集上的实验,验证了本文提出的对下臂附加采样的算法和手臂特征一致性计算的算法能够有效提高人体姿态关节点的跟踪精度。结论提出的结合时空信息与深度学习网络的人体姿态跟踪方法能够有效提高人体姿态跟踪的精度,特别是对灵活运动的人体姿态下臂关节点的跟踪精度有显著提高。关键词:人体姿态跟踪;视觉目标跟踪;人机交互;深度学习网络;关节点概率图47|56|2更新时间:2024-05-07
图像理解和计算机视觉
-
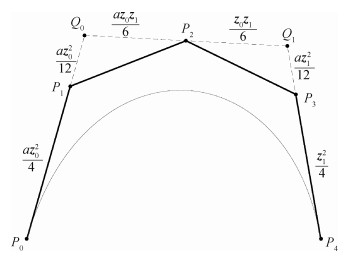 摘要:目的PH(Pythagorean hodograph)曲线由于具备有理等距曲线、弧长可精确计算等优良的几何性质,广泛应用于数控加工和路径规划等方面。曲线插值是曲线构造的主要手段之一,虽然对PH曲线的Hermite插值方法进行了广泛研究,但插值给定数据点的构造方法仍有待突破,为推广四次PH曲线的应用范围,提出了一种新的四次PH曲线的3点插值问题解决方法。方法从四次PH曲线的代数充分必要条件出发,在该曲线的Bézier控制多边形中引入辅助控制顶点,指出其中实参数的几何意义,该实参数可作为形状调节因子对构造曲线进行交互。对给定的3个平面型值点进行参数化确定相应的参数值;通过对四次PH曲线一阶导数积分得到曲线的显式表达,其中包含一个待定复常量,将给定的约束点代入曲线的显式表达式得到关于待定复常量的一元二次复方程,求解该复方程并反求Bézier控制顶点得到符合约束条件的四次PH曲线。结果实验对通过构造插值给定数据点的四次PH曲线进行比较,当形状调节因此改变时,曲线形状可进行有效交互。每次交互得到两条四次PH曲线,通过弧长、弯曲能量、绝对旋转数的计算得到最优曲线,并构造得到PH曲线的等距线。结论本文方法给定的形状调节参数具有明确的代数意义和几何意义,本文方法易于实现,可有效进行交互。关键词:计算机辅助设计;Bezier曲线;控制多边形;等距曲线;四次PH曲线;插值48|62|0更新时间:2024-05-07
摘要:目的PH(Pythagorean hodograph)曲线由于具备有理等距曲线、弧长可精确计算等优良的几何性质,广泛应用于数控加工和路径规划等方面。曲线插值是曲线构造的主要手段之一,虽然对PH曲线的Hermite插值方法进行了广泛研究,但插值给定数据点的构造方法仍有待突破,为推广四次PH曲线的应用范围,提出了一种新的四次PH曲线的3点插值问题解决方法。方法从四次PH曲线的代数充分必要条件出发,在该曲线的Bézier控制多边形中引入辅助控制顶点,指出其中实参数的几何意义,该实参数可作为形状调节因子对构造曲线进行交互。对给定的3个平面型值点进行参数化确定相应的参数值;通过对四次PH曲线一阶导数积分得到曲线的显式表达,其中包含一个待定复常量,将给定的约束点代入曲线的显式表达式得到关于待定复常量的一元二次复方程,求解该复方程并反求Bézier控制顶点得到符合约束条件的四次PH曲线。结果实验对通过构造插值给定数据点的四次PH曲线进行比较,当形状调节因此改变时,曲线形状可进行有效交互。每次交互得到两条四次PH曲线,通过弧长、弯曲能量、绝对旋转数的计算得到最优曲线,并构造得到PH曲线的等距线。结论本文方法给定的形状调节参数具有明确的代数意义和几何意义,本文方法易于实现,可有效进行交互。关键词:计算机辅助设计;Bezier曲线;控制多边形;等距曲线;四次PH曲线;插值48|62|0更新时间:2024-05-07
计算机图形学
-
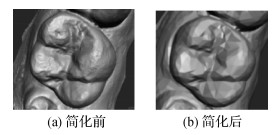 摘要:目的选取牙齿种子点是计算机正畸中常用牙齿分割方法的关键步骤。目前业内大部分牙齿正畸软件都采用需要交互标记的分割方法,通过人机交互在3维牙颌模型上选取每一颗牙齿的种子点,效率较低。针对这一问题,提出基于特征导向的图卷积网络(feature-steered graph convolutional network,FeaStNet)牙齿种子点自动选取方法。方法通过分析每个牙齿类型的种子点位置和最终分割效果,设立统一的规则,建立了牙颌模型的种子点数据集;利用特征导向的图卷积构建了新的多尺度网络结构,用于识别3维牙颌模型上的特征信息,为了更好地拟合牙齿特征,加深网络模型的深度;再通过训练调整参数和多尺度网络结构,寻找特定的种子点,使用均值平方差损失函数对模型进行评估,以提高预测模型的精确度;把网络寻找出的特征点作为基础点,在牙颌模型上找出与基础点距离最近的点作为种子点,如果种子点位置准确,则根据种子点将牙齿与牙龈分割开。对于种子点位置不准确的结果,通过人工操作修正种子点位置,再进行分割。结果实验在自建的数据集中测试,其中种子点全部准确的牙颌占88%,其余情况下只需要调整部分不准确种子点的位置。该方法简单快速,与现有方法相比,需要较少的人工干预,提高了工作效率。结论提出的种子点自动选取方法,能够自动选取牙齿种子点,解决牙齿分割中需要进行交互标记的问题,基本实现了牙齿分割的自动化,适用于各类畸形牙患者模型的牙齿分割。关键词:口腔正畸;牙齿分割;特征导向的图卷积;牙齿种子点;3维牙齿模型57|55|2更新时间:2024-05-07
摘要:目的选取牙齿种子点是计算机正畸中常用牙齿分割方法的关键步骤。目前业内大部分牙齿正畸软件都采用需要交互标记的分割方法,通过人机交互在3维牙颌模型上选取每一颗牙齿的种子点,效率较低。针对这一问题,提出基于特征导向的图卷积网络(feature-steered graph convolutional network,FeaStNet)牙齿种子点自动选取方法。方法通过分析每个牙齿类型的种子点位置和最终分割效果,设立统一的规则,建立了牙颌模型的种子点数据集;利用特征导向的图卷积构建了新的多尺度网络结构,用于识别3维牙颌模型上的特征信息,为了更好地拟合牙齿特征,加深网络模型的深度;再通过训练调整参数和多尺度网络结构,寻找特定的种子点,使用均值平方差损失函数对模型进行评估,以提高预测模型的精确度;把网络寻找出的特征点作为基础点,在牙颌模型上找出与基础点距离最近的点作为种子点,如果种子点位置准确,则根据种子点将牙齿与牙龈分割开。对于种子点位置不准确的结果,通过人工操作修正种子点位置,再进行分割。结果实验在自建的数据集中测试,其中种子点全部准确的牙颌占88%,其余情况下只需要调整部分不准确种子点的位置。该方法简单快速,与现有方法相比,需要较少的人工干预,提高了工作效率。结论提出的种子点自动选取方法,能够自动选取牙齿种子点,解决牙齿分割中需要进行交互标记的问题,基本实现了牙齿分割的自动化,适用于各类畸形牙患者模型的牙齿分割。关键词:口腔正畸;牙齿分割;特征导向的图卷积;牙齿种子点;3维牙齿模型57|55|2更新时间:2024-05-07 -
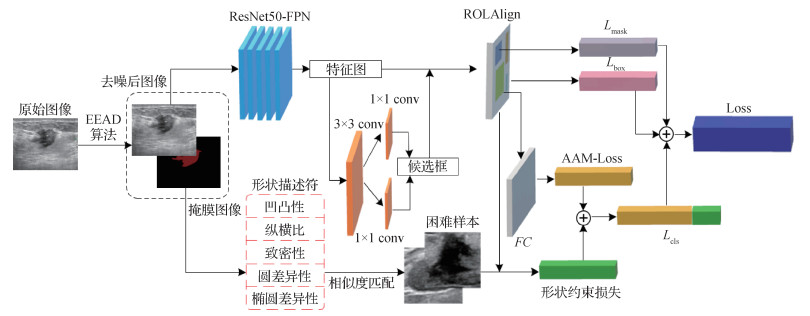 摘要:目的超声诊断常作为乳腺肿瘤首选的影像学检查和术前评估方法,但存在良恶性结节的图像表现重叠、诊断严重依赖医生经验,以及需要较多人机交互等问题。为减少误诊和不必要的穿刺活检率,以及提高诊断自动化程度,本文提出一种端到端的模型,实现结节区域自动提取及良恶性鉴别。方法就超声图像散斑噪声问题使用基于边缘增强的各向异性扩散去噪模型(edge enhanced anisotropic diffusion,EEAD)实现数据预处理,之后针对结节良恶性特征提出一个改进的损失函数以增强鉴别性能,通过形状描述符组合挖掘因形状与其他类别相似从而易导致错判的困难样本,为使该部分困难样本具有更好的区分性,应用改进的损失函数,并在此基础上构建困难样本形状约束损失项,用来调整形状相似但类别不同样本间的特征映射。结果为验证算法的有效性,构建了一个包含1 805幅图像的乳腺超声数据集,在该数据集上具有5年资历医生的平均判断准确率为85.3%,而本文方法在该数据集上分类正确率为92.58%,敏感性为90.44%,特异性为93.72%,AUC(area under curve)为0.946,均优于对比算法;相对传统Softmax损失函数,各评价指标提高了5% 12%。结论本文提出了一个端到端的乳腺超声图像分类方法,实用性强;通过将医学知识融合到优化模型,增加的困难样本形状约束损失项可提高乳腺肿瘤良恶性诊断的准确性和鲁棒性,各项评价指标均高于超声科医生,具有临床应用价值。关键词:乳腺超声图像;乳腺结节分类;深度学习;损失函数;计算机辅助诊断;困难样本39|26|3更新时间:2024-05-07
摘要:目的超声诊断常作为乳腺肿瘤首选的影像学检查和术前评估方法,但存在良恶性结节的图像表现重叠、诊断严重依赖医生经验,以及需要较多人机交互等问题。为减少误诊和不必要的穿刺活检率,以及提高诊断自动化程度,本文提出一种端到端的模型,实现结节区域自动提取及良恶性鉴别。方法就超声图像散斑噪声问题使用基于边缘增强的各向异性扩散去噪模型(edge enhanced anisotropic diffusion,EEAD)实现数据预处理,之后针对结节良恶性特征提出一个改进的损失函数以增强鉴别性能,通过形状描述符组合挖掘因形状与其他类别相似从而易导致错判的困难样本,为使该部分困难样本具有更好的区分性,应用改进的损失函数,并在此基础上构建困难样本形状约束损失项,用来调整形状相似但类别不同样本间的特征映射。结果为验证算法的有效性,构建了一个包含1 805幅图像的乳腺超声数据集,在该数据集上具有5年资历医生的平均判断准确率为85.3%,而本文方法在该数据集上分类正确率为92.58%,敏感性为90.44%,特异性为93.72%,AUC(area under curve)为0.946,均优于对比算法;相对传统Softmax损失函数,各评价指标提高了5% 12%。结论本文提出了一个端到端的乳腺超声图像分类方法,实用性强;通过将医学知识融合到优化模型,增加的困难样本形状约束损失项可提高乳腺肿瘤良恶性诊断的准确性和鲁棒性,各项评价指标均高于超声科医生,具有临床应用价值。关键词:乳腺超声图像;乳腺结节分类;深度学习;损失函数;计算机辅助诊断;困难样本39|26|3更新时间:2024-05-07
医学图像处理
-
 摘要:目的传统的道路提取方法自动化程度不高,无法满足快速获取道路信息的需求。使用深度学习的道路提取方法多关注精度的提升,网络冗余度较高。而迁移学习通过将知识从源领域迁移到目标领域,可以快速完成目标学习任务。因此,本文利用高分辨率卫星快视数据快速获取的特性,构建了一种基于迁移学习的道路快速提取深度神经网络。方法采用基于预训练网络的迁移学习方法,可以将本文整个道路提取过程分为两个阶段:首先在开源大型数据库ImageNet上训练源网络,保存此阶段最优模型;第2阶段迁移预训练保存的模型至目标网络,利用预训练保存的权重参数指导目标网络继续训练,此时快视数据作为输入,只做目标任务的定向微调,从而加速网络训练。总体来说,前期预训练是一个抽取通用特征参数的过程,目标训练是针对道路提取任务特化的过程。结果本文构建的基于迁移学习的快速道路提取网络,迁移预训练模型与不迁移相比验证精度提升6.0%,单幅尺寸为256×256像素的数据测试时间减少49.4%。快视数据测试集平均精度可达88.3%。截取一轨中7 304×6 980像素位于天津滨海新区的快视数据,可在54 s内完成道路提取。与其他迁移模型对比,本文方法在快速预测道路的同时且能达到较高的准确率。结论实验结果表明,本文针对高分卫星快视数据,提出的利用预训练模型初始化网络能有效利用权重参数,使模型趋于轻量化,使得精度提升的同时也加快了提取速度,能够实现道路信息快速精准获取。关键词:高分辨率卫星;快视数据;道路快速提取;迁移学习;微调32|78|1更新时间:2024-05-07
摘要:目的传统的道路提取方法自动化程度不高,无法满足快速获取道路信息的需求。使用深度学习的道路提取方法多关注精度的提升,网络冗余度较高。而迁移学习通过将知识从源领域迁移到目标领域,可以快速完成目标学习任务。因此,本文利用高分辨率卫星快视数据快速获取的特性,构建了一种基于迁移学习的道路快速提取深度神经网络。方法采用基于预训练网络的迁移学习方法,可以将本文整个道路提取过程分为两个阶段:首先在开源大型数据库ImageNet上训练源网络,保存此阶段最优模型;第2阶段迁移预训练保存的模型至目标网络,利用预训练保存的权重参数指导目标网络继续训练,此时快视数据作为输入,只做目标任务的定向微调,从而加速网络训练。总体来说,前期预训练是一个抽取通用特征参数的过程,目标训练是针对道路提取任务特化的过程。结果本文构建的基于迁移学习的快速道路提取网络,迁移预训练模型与不迁移相比验证精度提升6.0%,单幅尺寸为256×256像素的数据测试时间减少49.4%。快视数据测试集平均精度可达88.3%。截取一轨中7 304×6 980像素位于天津滨海新区的快视数据,可在54 s内完成道路提取。与其他迁移模型对比,本文方法在快速预测道路的同时且能达到较高的准确率。结论实验结果表明,本文针对高分卫星快视数据,提出的利用预训练模型初始化网络能有效利用权重参数,使模型趋于轻量化,使得精度提升的同时也加快了提取速度,能够实现道路信息快速精准获取。关键词:高分辨率卫星;快视数据;道路快速提取;迁移学习;微调32|78|1更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0