
最新刊期
2020 年 第 25 卷 第 6 期
-
 摘要:在计算机视觉领域中,语义分割是场景解析和行为识别的关键任务,基于深度卷积神经网络的图像语义分割方法已经取得突破性进展。语义分割的任务是对图像中的每一个像素分配所属的类别标签,属于像素级的图像理解。目标检测仅定位目标的边界框,而语义分割需要分割出图像中的目标。本文首先分析和描述了语义分割领域存在的困难和挑战,介绍了语义分割算法性能评价的常用数据集和客观评测指标。然后,归纳和总结了现阶段主流的基于深度卷积神经网络的图像语义分割方法的国内外研究现状,依据网络训练是否需要像素级的标注图像,将现有方法分为基于监督学习的语义分割和基于弱监督学习的语义分割两类,详细阐述并分析这两类方法各自的优势和不足。本文在PASCAL VOC(pattern analysis,statistical modelling and computational learning visual object classes)2012数据集上比较了部分监督学习和弱监督学习的语义分割模型,并给出了监督学习模型和弱监督学习模型中的最优方法,以及对应的MIoU(mean intersection-over-union)。最后,指出了图像语义分割领域未来可能的热点方向。关键词:语义分割;卷积神经网络;监督学习;弱监督学习68|109|22更新时间:2024-05-07
摘要:在计算机视觉领域中,语义分割是场景解析和行为识别的关键任务,基于深度卷积神经网络的图像语义分割方法已经取得突破性进展。语义分割的任务是对图像中的每一个像素分配所属的类别标签,属于像素级的图像理解。目标检测仅定位目标的边界框,而语义分割需要分割出图像中的目标。本文首先分析和描述了语义分割领域存在的困难和挑战,介绍了语义分割算法性能评价的常用数据集和客观评测指标。然后,归纳和总结了现阶段主流的基于深度卷积神经网络的图像语义分割方法的国内外研究现状,依据网络训练是否需要像素级的标注图像,将现有方法分为基于监督学习的语义分割和基于弱监督学习的语义分割两类,详细阐述并分析这两类方法各自的优势和不足。本文在PASCAL VOC(pattern analysis,statistical modelling and computational learning visual object classes)2012数据集上比较了部分监督学习和弱监督学习的语义分割模型,并给出了监督学习模型和弱监督学习模型中的最优方法,以及对应的MIoU(mean intersection-over-union)。最后,指出了图像语义分割领域未来可能的热点方向。关键词:语义分割;卷积神经网络;监督学习;弱监督学习68|109|22更新时间:2024-05-07
综述

-
 摘要:目的基于数字水印技术的音乐作品版权保护是学术界的研究热点之一,多数数字音频水印方案仅仅能够对抗简单的常规信号处理,无法有效抵抗破坏性较强的一般性去同步攻击。为此,提出了一种基于稳健局部特征的非下采样小波域数字水印算法。方法利用非下采样小波域平滑梯度检测算子从载体音频中提取稳定的音频特征点,结合数字音频样本响应确定局部特征音频段,采用量化调制策略将数字水印信号重复嵌入局部特征音频段中。结果选取4段典型的采样频率为44.1 kHz、量化精度为16 bit、长度为15 s的单声道数字音频信号作为原始载体进行测试,并与经典算法在不可感知性和鲁棒性两方面进行对比。结果表明,本文算法在含水印音频与原始载体音频间的信噪比平均提升了5.7 dB,同时常规攻击和去同步攻击下的平均检测率分别保持在0.925和0.913,高于大多数传统算法,表明了本文算法具有较好的不可感知性。在常规信号处理(MP3压缩、重新量化、重新采样等)和去同步攻击(幅度缩放、随机剪切、音调伸缩、DA/AD转换、抖动等)方面均具有较好的鲁棒性。结论本文利用描述能力强且性能稳定的平滑梯度刻画局部数字音频性质,提出一种基于平滑梯度的非下采样小波域音频特征点提取方法,有效解决了音频特征点稳定性差且分布极不均匀的缺点,提高了数字音频水印对音调伸缩、随机剪切、抖动等攻击的抵抗能力。关键词:音频水印;去同步攻击;特征点;平滑梯度;非下采样小波变换34|24|1更新时间:2024-05-07
摘要:目的基于数字水印技术的音乐作品版权保护是学术界的研究热点之一,多数数字音频水印方案仅仅能够对抗简单的常规信号处理,无法有效抵抗破坏性较强的一般性去同步攻击。为此,提出了一种基于稳健局部特征的非下采样小波域数字水印算法。方法利用非下采样小波域平滑梯度检测算子从载体音频中提取稳定的音频特征点,结合数字音频样本响应确定局部特征音频段,采用量化调制策略将数字水印信号重复嵌入局部特征音频段中。结果选取4段典型的采样频率为44.1 kHz、量化精度为16 bit、长度为15 s的单声道数字音频信号作为原始载体进行测试,并与经典算法在不可感知性和鲁棒性两方面进行对比。结果表明,本文算法在含水印音频与原始载体音频间的信噪比平均提升了5.7 dB,同时常规攻击和去同步攻击下的平均检测率分别保持在0.925和0.913,高于大多数传统算法,表明了本文算法具有较好的不可感知性。在常规信号处理(MP3压缩、重新量化、重新采样等)和去同步攻击(幅度缩放、随机剪切、音调伸缩、DA/AD转换、抖动等)方面均具有较好的鲁棒性。结论本文利用描述能力强且性能稳定的平滑梯度刻画局部数字音频性质,提出一种基于平滑梯度的非下采样小波域音频特征点提取方法,有效解决了音频特征点稳定性差且分布极不均匀的缺点,提高了数字音频水印对音调伸缩、随机剪切、抖动等攻击的抵抗能力。关键词:音频水印;去同步攻击;特征点;平滑梯度;非下采样小波变换34|24|1更新时间:2024-05-07
图像处理和编码
-
 摘要:目的显著性检测算法大多使用背景先验提高算法性能,但传统模型只是简单地将图像四周的边缘区域作为背景区域,导致结果在显著性物体触及到图像边界的情况下产生误检测。为更准确地应用背景先验,提出一种融合背景块再选取过程的显著性检测方法。方法利用背景先验、中心先验和颜色分布特征获得种子向量并构建扩散矩阵,经扩散方法得到初步显著图,并以此为输入再经扩散方法得到二层显著图。依据Fisher准则的思想以二层显著图为基础创建背景块再选取过程,将选取的背景块组成背景向量并构建扩散矩阵,经扩散方法得到背景显著图。将背景显著图与二层显著图进行非线性融合获得最终显著图。结果在5个通用数据集上将本文算法与6种算法进行实验对比。本文算法在MSRA10K(Microsoft Research Asia 10K)数据集上,平均绝对误差(mean absolute error,MAE)取得了最小值,与基于多特征扩散方法的显著性物体检测算法(salient object detection via multi-feature diffusion-based method,LMH)相比,F值提升了0.84%,MAE降低了1.9%;在数据集ECSSD(extended complex scene saliency dataset)上,MAE取得了次优值,F值取得了最优值,与LMH算法相比,F值提升了1.33%;在SED2(segmentation evaluation database 2)数据集上,MAE与F值均取得了次优值,与LMH算法相比,F值提升了0.7%,MAE降低了0.93%。本文算法检测结果在主观对比中均优于LMH算法,表现为检测所得的显著性物体更加完整,置信度更高,在客观对比中,查全率均优于LMH算法。结论提出的显著性检测模型能更好地应用背景先验,使主客观检测结果有更好提升。关键词:显著性检测;背景先验;背景块再选取;Fisher准则;扩散方法19|25|1更新时间:2024-05-07
摘要:目的显著性检测算法大多使用背景先验提高算法性能,但传统模型只是简单地将图像四周的边缘区域作为背景区域,导致结果在显著性物体触及到图像边界的情况下产生误检测。为更准确地应用背景先验,提出一种融合背景块再选取过程的显著性检测方法。方法利用背景先验、中心先验和颜色分布特征获得种子向量并构建扩散矩阵,经扩散方法得到初步显著图,并以此为输入再经扩散方法得到二层显著图。依据Fisher准则的思想以二层显著图为基础创建背景块再选取过程,将选取的背景块组成背景向量并构建扩散矩阵,经扩散方法得到背景显著图。将背景显著图与二层显著图进行非线性融合获得最终显著图。结果在5个通用数据集上将本文算法与6种算法进行实验对比。本文算法在MSRA10K(Microsoft Research Asia 10K)数据集上,平均绝对误差(mean absolute error,MAE)取得了最小值,与基于多特征扩散方法的显著性物体检测算法(salient object detection via multi-feature diffusion-based method,LMH)相比,F值提升了0.84%,MAE降低了1.9%;在数据集ECSSD(extended complex scene saliency dataset)上,MAE取得了次优值,F值取得了最优值,与LMH算法相比,F值提升了1.33%;在SED2(segmentation evaluation database 2)数据集上,MAE与F值均取得了次优值,与LMH算法相比,F值提升了0.7%,MAE降低了0.93%。本文算法检测结果在主观对比中均优于LMH算法,表现为检测所得的显著性物体更加完整,置信度更高,在客观对比中,查全率均优于LMH算法。结论提出的显著性检测模型能更好地应用背景先验,使主客观检测结果有更好提升。关键词:显著性检测;背景先验;背景块再选取;Fisher准则;扩散方法19|25|1更新时间:2024-05-07 -
 摘要:目的传统显著性检测模型大多利用手工选择的中低层特征和先验信息进行物体检测,其准确率和召回率较低,随着深度卷积神经网络的兴起,显著性检测得以快速发展。然而,现有显著性方法仍存在共性缺点,难以在复杂图像中均匀地突显整个物体的明确边界和内部区域,主要原因是缺乏足够且丰富的特征用于检测。方法在VGG(visual geometry group)模型的基础上进行改进,去掉最后的全连接层,采用跳层连接的方式用于像素级别的显著性预测,可以有效结合来自卷积神经网络不同卷积层的多尺度信息。此外,它能够在数据驱动的框架中结合高级语义信息和低层细节信息。为了有效地保留物体边界和内部区域的统一,采用全连接的条件随机场(conditional random field,CRF)模型对得到的显著性特征图进行调整。结果本文在6个广泛使用的公开数据集DUT-OMRON(Dalian University of Technology and OMRON Corporation)、ECSSD(extended complex scene saliency dataset)、SED2(segmentation evalution database 2)、HKU、PASCAL-S和SOD(salient objects dataset)上进行了测试,并就准确率—召回率(precision-recall,PR)曲线、F测度值(F-measure)、最大F测度值、加权F测度值和均方误差(mean absolute error,MAE)等性能评估指标与14种最先进且具有代表性的方法进行比较。结果显示,本文方法在6个数据集上的F测度值分别为0.696、0.876、0.797、0.868、0.772和0.785;最大F测度值分别为0.747、0.899、0.859、0.889、0.814和0.833;加权F测度值分别为0.656、0.854、0.772、0.844、0.732和0.762;MAE值分别为0.074、0.061、0.093、0.049、0.099和0.124。无论是前景和背景颜色相似的图像集,还是多物体的复杂图像集,本文方法的各项性能均接近最新研究成果,且优于大多数具有代表性的方法。结论本文方法对各种场景的图像显著性检测都具有较强的鲁棒性,同时可以使显著性物体的边界和内部区域更均匀,检测结果更准确。关键词:显著性物体检测;显著性;卷积神经网络;多尺度特征;数据驱动24|27|4更新时间:2024-05-07
摘要:目的传统显著性检测模型大多利用手工选择的中低层特征和先验信息进行物体检测,其准确率和召回率较低,随着深度卷积神经网络的兴起,显著性检测得以快速发展。然而,现有显著性方法仍存在共性缺点,难以在复杂图像中均匀地突显整个物体的明确边界和内部区域,主要原因是缺乏足够且丰富的特征用于检测。方法在VGG(visual geometry group)模型的基础上进行改进,去掉最后的全连接层,采用跳层连接的方式用于像素级别的显著性预测,可以有效结合来自卷积神经网络不同卷积层的多尺度信息。此外,它能够在数据驱动的框架中结合高级语义信息和低层细节信息。为了有效地保留物体边界和内部区域的统一,采用全连接的条件随机场(conditional random field,CRF)模型对得到的显著性特征图进行调整。结果本文在6个广泛使用的公开数据集DUT-OMRON(Dalian University of Technology and OMRON Corporation)、ECSSD(extended complex scene saliency dataset)、SED2(segmentation evalution database 2)、HKU、PASCAL-S和SOD(salient objects dataset)上进行了测试,并就准确率—召回率(precision-recall,PR)曲线、F测度值(F-measure)、最大F测度值、加权F测度值和均方误差(mean absolute error,MAE)等性能评估指标与14种最先进且具有代表性的方法进行比较。结果显示,本文方法在6个数据集上的F测度值分别为0.696、0.876、0.797、0.868、0.772和0.785;最大F测度值分别为0.747、0.899、0.859、0.889、0.814和0.833;加权F测度值分别为0.656、0.854、0.772、0.844、0.732和0.762;MAE值分别为0.074、0.061、0.093、0.049、0.099和0.124。无论是前景和背景颜色相似的图像集,还是多物体的复杂图像集,本文方法的各项性能均接近最新研究成果,且优于大多数具有代表性的方法。结论本文方法对各种场景的图像显著性检测都具有较强的鲁棒性,同时可以使显著性物体的边界和内部区域更均匀,检测结果更准确。关键词:显著性物体检测;显著性;卷积神经网络;多尺度特征;数据驱动24|27|4更新时间:2024-05-07 -
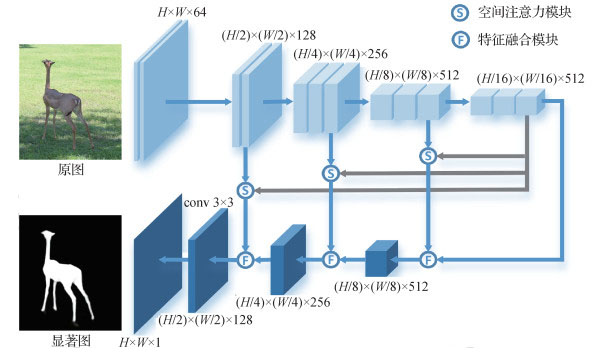 摘要:目的多层特征对于显著性检测具有重要作用,多层特征的提取和融合是显著性检测研究的重要方向之一。针对现有的多层特征提取中忽略了特征融合与传递、对背景干扰信息敏感等问题,本文基于特征金字塔网络和注意力机制提出一种结合空间注意力的多层特征融合显著性检测模型,该模型用简单的网络结构较好地实现了多层特征的融合与传递。方法为了提高特征融合质量,设计了多层次的特征融合模块,通过不同尺度的池化和卷积优化高层特征和低层特征的融合与传递过程。为了减少低层特征中的背景等噪声干扰,设计了空间注意力模块,利用不同尺度的池化和卷积从高层特征获得空间注意力图,通过注意力图为低层特征补充全局语义信息,突出低层特征的前景并抑制背景干扰。结果本文在DUTS,DUT-OMRON(Dalian University of Technology and OMRON Corporation),HKU-IS和ECSSD(extended complex scene saliency dataset)4个公开数据集上对比了9种相关的主流显著性检测方法,在DUTS-test数据集中相对于性能第2的模型,本文方法的最大F值(MaxF)提高了1.04%,平均绝对误差(mean absolute error,MAE)下降了4.35%,准确率—召回率(precision-recall,PR)曲线、结构性度量(S-measure)等评价指标也均优于对比方法,得到的显著图更接近真值图,同时模型也有着不错的速度表现。结论本文用简单的网络结构较好地实现了多层次特征的融合,特征融合模块提高了特征融合与传递质量,空间注意力模块实现了有效的特征选择,突出了显著区域、减少了背景噪声的干扰。大量的实验表明了模型的综合性能以及各个模块的有效性。关键词:显著性检测;深度学习;特征金字塔;特征融合;空间注意力34|24|4更新时间:2024-05-07
摘要:目的多层特征对于显著性检测具有重要作用,多层特征的提取和融合是显著性检测研究的重要方向之一。针对现有的多层特征提取中忽略了特征融合与传递、对背景干扰信息敏感等问题,本文基于特征金字塔网络和注意力机制提出一种结合空间注意力的多层特征融合显著性检测模型,该模型用简单的网络结构较好地实现了多层特征的融合与传递。方法为了提高特征融合质量,设计了多层次的特征融合模块,通过不同尺度的池化和卷积优化高层特征和低层特征的融合与传递过程。为了减少低层特征中的背景等噪声干扰,设计了空间注意力模块,利用不同尺度的池化和卷积从高层特征获得空间注意力图,通过注意力图为低层特征补充全局语义信息,突出低层特征的前景并抑制背景干扰。结果本文在DUTS,DUT-OMRON(Dalian University of Technology and OMRON Corporation),HKU-IS和ECSSD(extended complex scene saliency dataset)4个公开数据集上对比了9种相关的主流显著性检测方法,在DUTS-test数据集中相对于性能第2的模型,本文方法的最大F值(MaxF)提高了1.04%,平均绝对误差(mean absolute error,MAE)下降了4.35%,准确率—召回率(precision-recall,PR)曲线、结构性度量(S-measure)等评价指标也均优于对比方法,得到的显著图更接近真值图,同时模型也有着不错的速度表现。结论本文用简单的网络结构较好地实现了多层次特征的融合,特征融合模块提高了特征融合与传递质量,空间注意力模块实现了有效的特征选择,突出了显著区域、减少了背景噪声的干扰。大量的实验表明了模型的综合性能以及各个模块的有效性。关键词:显著性检测;深度学习;特征金字塔;特征融合;空间注意力34|24|4更新时间:2024-05-07 -
 摘要:目的低秩稀疏学习目标跟踪算法在目标快速运动和严重遮挡等情况下容易出现跟踪漂移现象,为此提出一种变分调整约束下的反向低秩稀疏学习目标跟踪算法。方法采用核范数凸近似低秩约束描述候选粒子间的时域相关性,去除不相关粒子,适应目标外观变化。通过反向稀疏表示描述目标表观,用候选粒子稀疏表示目标模板,减少在线跟踪中L1优化问题的数目,提高跟踪效率。在有界变差空间利用变分调整对稀疏系数差分建模,约束目标表观在相邻帧间具有较小变化,但允许连续帧间差异存在跳跃不连续性,以适应目标快速运动。结果实验利用OTB(object tracking benchmark)数据集中的4组涵盖了严重遮挡、快速运动、光照和尺度变化等挑战因素的标准视频序列进行测试,定性和定量对比了本文算法与5种热点算法的跟踪效果。定性分析基于视频序列的主要挑战因素进行比较,定量分析通过中心点位置误差(central pixel error,CPE)比较跟踪算法的精度。与CNT(convolutional networks training)、SCM(sparse collaborative model)、IST(inverse sparse tracker)、DDL(discriminative dictionary learning)和LLR(locally low-rank representation)算法相比,平均CPE值分别提高了2.80、4.16、13.37、35.94和41.59。实验结果表明,本文算法达到了较高的跟踪精度,对上述挑战因素更具鲁棒性。结论本文提出的跟踪算法,综合了低秩稀疏学习和变分优化调整的优势,在复杂场景下具有较高的跟踪精度,特别是对严重遮挡和快速运动情况的有效跟踪更具鲁棒性。关键词:目标跟踪;变分法;稀疏表示;低秩约束;粒子滤波50|46|1更新时间:2024-05-07
摘要:目的低秩稀疏学习目标跟踪算法在目标快速运动和严重遮挡等情况下容易出现跟踪漂移现象,为此提出一种变分调整约束下的反向低秩稀疏学习目标跟踪算法。方法采用核范数凸近似低秩约束描述候选粒子间的时域相关性,去除不相关粒子,适应目标外观变化。通过反向稀疏表示描述目标表观,用候选粒子稀疏表示目标模板,减少在线跟踪中L1优化问题的数目,提高跟踪效率。在有界变差空间利用变分调整对稀疏系数差分建模,约束目标表观在相邻帧间具有较小变化,但允许连续帧间差异存在跳跃不连续性,以适应目标快速运动。结果实验利用OTB(object tracking benchmark)数据集中的4组涵盖了严重遮挡、快速运动、光照和尺度变化等挑战因素的标准视频序列进行测试,定性和定量对比了本文算法与5种热点算法的跟踪效果。定性分析基于视频序列的主要挑战因素进行比较,定量分析通过中心点位置误差(central pixel error,CPE)比较跟踪算法的精度。与CNT(convolutional networks training)、SCM(sparse collaborative model)、IST(inverse sparse tracker)、DDL(discriminative dictionary learning)和LLR(locally low-rank representation)算法相比,平均CPE值分别提高了2.80、4.16、13.37、35.94和41.59。实验结果表明,本文算法达到了较高的跟踪精度,对上述挑战因素更具鲁棒性。结论本文提出的跟踪算法,综合了低秩稀疏学习和变分优化调整的优势,在复杂场景下具有较高的跟踪精度,特别是对严重遮挡和快速运动情况的有效跟踪更具鲁棒性。关键词:目标跟踪;变分法;稀疏表示;低秩约束;粒子滤波50|46|1更新时间:2024-05-07 -
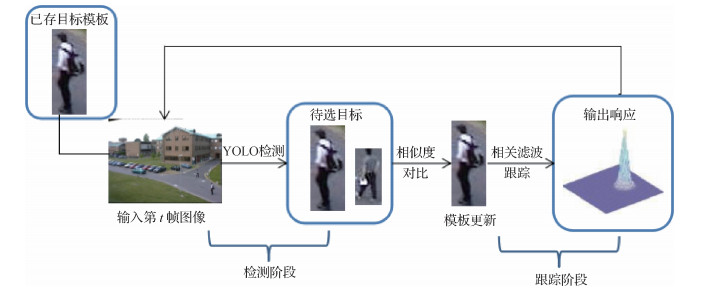 摘要:目的尺度突变是目标跟踪中一项极具挑战性的任务,短时间内目标的尺度发生突变会导致跟踪要素丢失,使得跟踪误差积累导致跟踪漂移,为了更好地解决这一问题,提出了一种先检测后跟踪的自适应尺度突变的跟踪算法(kernelized correlation filter_you only look once,KCF_YOLO)。方法在跟踪的训练阶段使用相关滤波跟踪器实现快速跟踪,在检测阶段使用YOLO(you only look once)V3神经网络,并设计了自适应的模板更新策略,采用将检测到的物体的相似度与目标模板的颜色特征和图像指纹特征融合后的相似度进行对比的方法,判断目标是否发生遮挡,据此决定是否在当前帧更新目标模板。结果为证明本文方法的有效性在OTB(object tracking benchmark)2015数据集中具有尺度突变代表性的11个视频序列上进行试验,试验视频序列目标尺度变化为0.19.2倍,结果表明本文方法平均跟踪精度为0.955,平均跟踪速度为36帧/s,与经典尺度自适应跟踪算法比较,精度平均提高31.74%。结论本文使用相关滤波和神经网络在目标跟踪过程中先检测后跟踪的思想,提高了算法对目标跟踪过程中尺度突变情况的适应能力,实验结果验证了加入检测策略对后续目标尺度发生突变导致跟踪漂移的情况起到了很好的纠正作用,以及自适应模板更新策略的有效性。关键词:目标跟踪;相关滤波;神经网络检测;尺度突变;尺度自适应33|33|2更新时间:2024-05-07
摘要:目的尺度突变是目标跟踪中一项极具挑战性的任务,短时间内目标的尺度发生突变会导致跟踪要素丢失,使得跟踪误差积累导致跟踪漂移,为了更好地解决这一问题,提出了一种先检测后跟踪的自适应尺度突变的跟踪算法(kernelized correlation filter_you only look once,KCF_YOLO)。方法在跟踪的训练阶段使用相关滤波跟踪器实现快速跟踪,在检测阶段使用YOLO(you only look once)V3神经网络,并设计了自适应的模板更新策略,采用将检测到的物体的相似度与目标模板的颜色特征和图像指纹特征融合后的相似度进行对比的方法,判断目标是否发生遮挡,据此决定是否在当前帧更新目标模板。结果为证明本文方法的有效性在OTB(object tracking benchmark)2015数据集中具有尺度突变代表性的11个视频序列上进行试验,试验视频序列目标尺度变化为0.19.2倍,结果表明本文方法平均跟踪精度为0.955,平均跟踪速度为36帧/s,与经典尺度自适应跟踪算法比较,精度平均提高31.74%。结论本文使用相关滤波和神经网络在目标跟踪过程中先检测后跟踪的思想,提高了算法对目标跟踪过程中尺度突变情况的适应能力,实验结果验证了加入检测策略对后续目标尺度发生突变导致跟踪漂移的情况起到了很好的纠正作用,以及自适应模板更新策略的有效性。关键词:目标跟踪;相关滤波;神经网络检测;尺度突变;尺度自适应33|33|2更新时间:2024-05-07 -
 摘要:目的针对现实场景中跟踪目标背景复杂、光照变化、快速运动、旋转等问题,提出自适应多特征融合的相关滤波跟踪算法。方法提取目标的HOG(histogram of oriented gradients)特征和利用卷积神经网络提取高、低层卷积特征,借助一种自适应阈值分割方法评估每种特征的有效性,得到特征融合的权重比。根据权重系数融合每种特征的响应图,并据此得到目标的新估计位置,利用尺度相关滤波器计算目标尺度,得到目标尺度完成跟踪。结果在OTB(object tracking benchmark)-2013公开数据集上进行实验,在对多特征融合进行分析的基础上,测试了本文算法在11种不同属性下的跟踪性能,并与当前流行的7种算法进行对比分析。结果表明,本文算法的成功率和精确度均排名第1,相较于基准算法DSST (discriminative scale space tracking)跟踪精确度提高了4%,成功率提高了6%。在复杂场景下比其他主流算法更具有鲁棒性。结论本文算法以DSST相关滤波跟踪器为基准算法,借助自适应阈值分割方法评估每种特征的有效性,自适应融合两层卷积特征和HOG特征,使得判别性越强的单一特征融合权重越大,较好表达了目标的外观模型,在背景复杂、目标消失、光照变化、快速运动、旋转等场景下表现出较强的跟踪准确性。关键词:目标跟踪;卷积特征;相关滤波器;特征融合;自适应阈值分割45|68|6更新时间:2024-05-07
摘要:目的针对现实场景中跟踪目标背景复杂、光照变化、快速运动、旋转等问题,提出自适应多特征融合的相关滤波跟踪算法。方法提取目标的HOG(histogram of oriented gradients)特征和利用卷积神经网络提取高、低层卷积特征,借助一种自适应阈值分割方法评估每种特征的有效性,得到特征融合的权重比。根据权重系数融合每种特征的响应图,并据此得到目标的新估计位置,利用尺度相关滤波器计算目标尺度,得到目标尺度完成跟踪。结果在OTB(object tracking benchmark)-2013公开数据集上进行实验,在对多特征融合进行分析的基础上,测试了本文算法在11种不同属性下的跟踪性能,并与当前流行的7种算法进行对比分析。结果表明,本文算法的成功率和精确度均排名第1,相较于基准算法DSST (discriminative scale space tracking)跟踪精确度提高了4%,成功率提高了6%。在复杂场景下比其他主流算法更具有鲁棒性。结论本文算法以DSST相关滤波跟踪器为基准算法,借助自适应阈值分割方法评估每种特征的有效性,自适应融合两层卷积特征和HOG特征,使得判别性越强的单一特征融合权重越大,较好表达了目标的外观模型,在背景复杂、目标消失、光照变化、快速运动、旋转等场景下表现出较强的跟踪准确性。关键词:目标跟踪;卷积特征;相关滤波器;特征融合;自适应阈值分割45|68|6更新时间:2024-05-07 -
 摘要:目的雷达辐射源识别是指先提取雷达辐射源信号特征,再将特征输入分类器进行识别。随着电子科技水平的提高,各种干扰技术应用于雷达辐射源信号中,使得信号个体特征差异越来越不明显,仅靠传统的模板匹配、分类器设计、决策匹配等辐射源识别技术难以提取信号可辨性特征。针对这一问题,利用深度学习良好的数据解析能力,提出了一种基于卷积神经网络的辐射源识别方法。方法根据雷达辐射源信号的特点,对未知辐射源信号提取频域、功率谱、信号包络、模糊函数代表性切片等传统域特征,从中获得有效的训练样本特征集合,利用卷积神经网络自动获取训练样本深层个体特征得到辐射源识别模型,将其用于所有测试样本中,获得辐射源识别结果。结果在不同域特征下对卷积神经网络的识别性能进行测试实验,并将本文方法与基于机器学习和基于深度强化学习的深度Q网络模型(depth Q network,DQN)识别算法进行对比,结果表明,当卷积神经网络的输入为频域特征时,本文方法的识别准确率达100%,相比支持向量机(support vector machine,SVM)提高了0.9%,当输入为模糊函数切片特征和频域时,本文方法的平均识别准确率与SVM模型、极限学习机(extreme learning machine,ELM)分类器和DQN算法相比,分别提高了16.13%、1.87%和0.15%。结论实验结果表明本文方法能有效提高雷达辐射源信号的识别准确率。关键词:深度学习;雷达辐射源识别;卷积神经网络(CNN);识别准确率;频域特征;模糊函数切片34|31|1更新时间:2024-05-07
摘要:目的雷达辐射源识别是指先提取雷达辐射源信号特征,再将特征输入分类器进行识别。随着电子科技水平的提高,各种干扰技术应用于雷达辐射源信号中,使得信号个体特征差异越来越不明显,仅靠传统的模板匹配、分类器设计、决策匹配等辐射源识别技术难以提取信号可辨性特征。针对这一问题,利用深度学习良好的数据解析能力,提出了一种基于卷积神经网络的辐射源识别方法。方法根据雷达辐射源信号的特点,对未知辐射源信号提取频域、功率谱、信号包络、模糊函数代表性切片等传统域特征,从中获得有效的训练样本特征集合,利用卷积神经网络自动获取训练样本深层个体特征得到辐射源识别模型,将其用于所有测试样本中,获得辐射源识别结果。结果在不同域特征下对卷积神经网络的识别性能进行测试实验,并将本文方法与基于机器学习和基于深度强化学习的深度Q网络模型(depth Q network,DQN)识别算法进行对比,结果表明,当卷积神经网络的输入为频域特征时,本文方法的识别准确率达100%,相比支持向量机(support vector machine,SVM)提高了0.9%,当输入为模糊函数切片特征和频域时,本文方法的平均识别准确率与SVM模型、极限学习机(extreme learning machine,ELM)分类器和DQN算法相比,分别提高了16.13%、1.87%和0.15%。结论实验结果表明本文方法能有效提高雷达辐射源信号的识别准确率。关键词:深度学习;雷达辐射源识别;卷积神经网络(CNN);识别准确率;频域特征;模糊函数切片34|31|1更新时间:2024-05-07 -
 摘要:目的针对不同视点下具有视差的待拼接图像中,特征点筛选存在漏检率高和配准精度低的问题,提出了一种基于特征点平面相似性聚类的图像拼接算法。方法根据相同平面特征点符合同一变换的特点,计算特征点间的相似性度量,利用凝聚层次聚类把特征点划分为不同平面,筛选误匹配点。将图像划分为相等大小的网格,利用特征点与网格平面信息计算每个特征点的权重,通过带权重线性变换计算网格的局部单应变换矩阵。最后利用多频率融合方法融合配准图像。结果在20个不同场景图像数据上进行特征点筛选比较实验,随机抽样一致性(random sample consensus,RANSAC)算法的平均误筛选个数为30,平均误匹配个数为8,而本文方法的平均误筛选个数为3,平均误匹配个数为2。对20个不同场景的多视角图像,本文方法与AutoStitch(automatic stitching)、APAP(as projective as possible)和AANAP(adaptive as-natural-as-possible)等3种算法进行了图像拼接比较实验,本文算法相比性能第2的算法,峰值信噪比(peak signal to noise ratio,PSNR)平均提高了8.7%,结构相似性(structural similarity,SSIM)平均提高了9.6%。结论由本文提出的基于特征点平面相似性聚类的图像拼接算法处理后的图像保留了更多的特征点,因此提高了配准精度,能够取得更好的拼接效果。关键词:图像拼接;图像配准;层次聚类;视差图像;局部单应变换;特征点匹配30|26|0更新时间:2024-05-07
摘要:目的针对不同视点下具有视差的待拼接图像中,特征点筛选存在漏检率高和配准精度低的问题,提出了一种基于特征点平面相似性聚类的图像拼接算法。方法根据相同平面特征点符合同一变换的特点,计算特征点间的相似性度量,利用凝聚层次聚类把特征点划分为不同平面,筛选误匹配点。将图像划分为相等大小的网格,利用特征点与网格平面信息计算每个特征点的权重,通过带权重线性变换计算网格的局部单应变换矩阵。最后利用多频率融合方法融合配准图像。结果在20个不同场景图像数据上进行特征点筛选比较实验,随机抽样一致性(random sample consensus,RANSAC)算法的平均误筛选个数为30,平均误匹配个数为8,而本文方法的平均误筛选个数为3,平均误匹配个数为2。对20个不同场景的多视角图像,本文方法与AutoStitch(automatic stitching)、APAP(as projective as possible)和AANAP(adaptive as-natural-as-possible)等3种算法进行了图像拼接比较实验,本文算法相比性能第2的算法,峰值信噪比(peak signal to noise ratio,PSNR)平均提高了8.7%,结构相似性(structural similarity,SSIM)平均提高了9.6%。结论由本文提出的基于特征点平面相似性聚类的图像拼接算法处理后的图像保留了更多的特征点,因此提高了配准精度,能够取得更好的拼接效果。关键词:图像拼接;图像配准;层次聚类;视差图像;局部单应变换;特征点匹配30|26|0更新时间:2024-05-07 -
 摘要:目的传统图像语义分割需要的像素级标注数据难以大量获取,图像语义分割的弱监督学习是当前的重要研究方向。弱监督学习是指使用弱标注样本完成监督学习,弱标注比像素级标注的标注速度快、标注方式简单,包括散点、边界框、涂鸦等标注方式。方法针对现有方法对多层特征利用不充分的问题,提出了一种基于动态掩膜生成的弱监督语义分割方法。该方法以边界框作为初始前景分割轮廓,使用迭代方式通过卷积神经网络(convolutional neural network,CNN)多层特征获取前景目标的边缘信息,根据边缘信息生成掩膜。迭代的过程中首先使用高层特征对前景目标的大体形状和位置做出估计,得到粗略的物体分割掩膜。然后根据已获得的粗略掩膜,逐层使用CNN特征对掩膜进行更新。结果在Pascal VOC(visual object classes) 2012数据集上取得了78.06%的分割精度,相比于边界框监督、弱—半监督、掩膜排序和实例剪切方法,分别提高了14.71%、4.04%、3.10%和0.92%。结论该方法能够利用高层语义特征,减少分割掩膜中语义级别的错误,同时使用底层特征对掩膜进行更新,可以提高分割边缘的准确性。关键词:语义分割;弱监督学习;高斯混合模型;全卷积网络;特征融合36|18|3更新时间:2024-05-07
摘要:目的传统图像语义分割需要的像素级标注数据难以大量获取,图像语义分割的弱监督学习是当前的重要研究方向。弱监督学习是指使用弱标注样本完成监督学习,弱标注比像素级标注的标注速度快、标注方式简单,包括散点、边界框、涂鸦等标注方式。方法针对现有方法对多层特征利用不充分的问题,提出了一种基于动态掩膜生成的弱监督语义分割方法。该方法以边界框作为初始前景分割轮廓,使用迭代方式通过卷积神经网络(convolutional neural network,CNN)多层特征获取前景目标的边缘信息,根据边缘信息生成掩膜。迭代的过程中首先使用高层特征对前景目标的大体形状和位置做出估计,得到粗略的物体分割掩膜。然后根据已获得的粗略掩膜,逐层使用CNN特征对掩膜进行更新。结果在Pascal VOC(visual object classes) 2012数据集上取得了78.06%的分割精度,相比于边界框监督、弱—半监督、掩膜排序和实例剪切方法,分别提高了14.71%、4.04%、3.10%和0.92%。结论该方法能够利用高层语义特征,减少分割掩膜中语义级别的错误,同时使用底层特征对掩膜进行更新,可以提高分割边缘的准确性。关键词:语义分割;弱监督学习;高斯混合模型;全卷积网络;特征融合36|18|3更新时间:2024-05-07 -
 摘要:目的深度网络用于3维点云数据的分类分割任务时,精度与模型在全局和局部特征上的描述能力密切相关。现有的特征提取网络,往往将全局特征和不同尺度下的局部特征相结合,忽略了点与点之间的结构信息和位置关系。为此,通过在分类分割模型中引入图卷积神经网络(graph convolution neural network,GCN)和改进池化层函数,增强局部特征表征能力和获取更丰富的全局特征,改善模型对点云数据的分类分割性能。方法GCN模块通过K近邻算法构造图结构,利用相邻点对的边缘卷积获取局部特征,在深度网络模型中动态扩展GCN使模型获得完备的局部特征。在池化层,通过选择差异性的池化函数,联合提取多个全局特征并进行综合,保证模型在数据抖动时的鲁棒性。结果在ModelNet40、ShapeNet和S3DIS(stanford large-scale 3D indoor semantics)数据集上进行分类、部分分割以及语义场景分割实验,验证模型的分类分割性能。与PointNet相比,在ModelNet40分类实验中,整体精度和平均分类精度分别提升4%和3.7%;在ShapeNet部分分割数据集和S3DIS室内场景数据集中,平均交并比(mean intersection-over-union,mIoU)分别高1.4%和9.8%。采用不同的池化函数测试结果表明,本文提出的差异性池化函数与PointNet提出的池化函数相比,平均分类精度提升了0.9%,有效改善了模型性能。结论本文改进的网络模型可以有效获取点云数据中的全局和局部特征,实现更优的分类和分割效果。关键词:点云;深度学习;图卷积神经网络(GCN);差异性池化函数;分类分割;联合特征22|22|4更新时间:2024-05-07
摘要:目的深度网络用于3维点云数据的分类分割任务时,精度与模型在全局和局部特征上的描述能力密切相关。现有的特征提取网络,往往将全局特征和不同尺度下的局部特征相结合,忽略了点与点之间的结构信息和位置关系。为此,通过在分类分割模型中引入图卷积神经网络(graph convolution neural network,GCN)和改进池化层函数,增强局部特征表征能力和获取更丰富的全局特征,改善模型对点云数据的分类分割性能。方法GCN模块通过K近邻算法构造图结构,利用相邻点对的边缘卷积获取局部特征,在深度网络模型中动态扩展GCN使模型获得完备的局部特征。在池化层,通过选择差异性的池化函数,联合提取多个全局特征并进行综合,保证模型在数据抖动时的鲁棒性。结果在ModelNet40、ShapeNet和S3DIS(stanford large-scale 3D indoor semantics)数据集上进行分类、部分分割以及语义场景分割实验,验证模型的分类分割性能。与PointNet相比,在ModelNet40分类实验中,整体精度和平均分类精度分别提升4%和3.7%;在ShapeNet部分分割数据集和S3DIS室内场景数据集中,平均交并比(mean intersection-over-union,mIoU)分别高1.4%和9.8%。采用不同的池化函数测试结果表明,本文提出的差异性池化函数与PointNet提出的池化函数相比,平均分类精度提升了0.9%,有效改善了模型性能。结论本文改进的网络模型可以有效获取点云数据中的全局和局部特征,实现更优的分类和分割效果。关键词:点云;深度学习;图卷积神经网络(GCN);差异性池化函数;分类分割;联合特征22|22|4更新时间:2024-05-07
图像分析和识别
-
 摘要:目的基于相关滤波和孪生神经网络的两类判别式目标跟踪方法研究已取得了较大进展,但后者计算量过大,完全依赖GPU(graphics processing unit)加速运算。传统相关滤波方法由于滤波模型采用固定更新间隔,难以兼顾快速变化目标和一般目标。针对这一问题,提出一种基于目标外观状态分析的动态模型更新算法,优化计算负载并提高跟踪精度,兼顾缓变目标的鲁棒跟踪和快速变化目标的精确跟踪。方法通过帧间信息计算并提取目标区域图像的光流直方图特征,利用支持向量机进行分类从而判断目标是否处于外观变化状态,随后根据目标类别和目标区域图像的光流主分量幅值动态设置合适的相关滤波器更新间隔。通过在首帧进行前背景分离运算,进一步增强对目标外观表征的学习,提高跟踪精度。结果在OTB100(object tracking benchmark with 100 sequences)基准数据集上与其他6种快速跟踪算法进行对比实验,本文算法的精准度和成功率分别为86.4%和64.9%,分别比第2名ECO-HC(efficient convolution operators using hand-crafted features)算法高出1.4%和0.9%。在平面内旋转、遮挡、部分超出视野和光照变化这些极具挑战性的复杂环境下,精准度分别比第2名高出3.0%、4.4%、5.2%和6.0%,成功率高出1.9%、3.1%、4.9%和4.0%。本文算法在CPU(central processing unit)上的运行速度为32.15帧/s,满足跟踪问题实时性的要求。结论本文的自适应模型更新算法在优化计算负载的同时取得了更好的跟踪精度,适合于工程部署与应用。关键词:目标跟踪;相关滤波;光流;外观状态分析;自适应模型更新25|19|1更新时间:2024-05-07
摘要:目的基于相关滤波和孪生神经网络的两类判别式目标跟踪方法研究已取得了较大进展,但后者计算量过大,完全依赖GPU(graphics processing unit)加速运算。传统相关滤波方法由于滤波模型采用固定更新间隔,难以兼顾快速变化目标和一般目标。针对这一问题,提出一种基于目标外观状态分析的动态模型更新算法,优化计算负载并提高跟踪精度,兼顾缓变目标的鲁棒跟踪和快速变化目标的精确跟踪。方法通过帧间信息计算并提取目标区域图像的光流直方图特征,利用支持向量机进行分类从而判断目标是否处于外观变化状态,随后根据目标类别和目标区域图像的光流主分量幅值动态设置合适的相关滤波器更新间隔。通过在首帧进行前背景分离运算,进一步增强对目标外观表征的学习,提高跟踪精度。结果在OTB100(object tracking benchmark with 100 sequences)基准数据集上与其他6种快速跟踪算法进行对比实验,本文算法的精准度和成功率分别为86.4%和64.9%,分别比第2名ECO-HC(efficient convolution operators using hand-crafted features)算法高出1.4%和0.9%。在平面内旋转、遮挡、部分超出视野和光照变化这些极具挑战性的复杂环境下,精准度分别比第2名高出3.0%、4.4%、5.2%和6.0%,成功率高出1.9%、3.1%、4.9%和4.0%。本文算法在CPU(central processing unit)上的运行速度为32.15帧/s,满足跟踪问题实时性的要求。结论本文的自适应模型更新算法在优化计算负载的同时取得了更好的跟踪精度,适合于工程部署与应用。关键词:目标跟踪;相关滤波;光流;外观状态分析;自适应模型更新25|19|1更新时间:2024-05-07 -
 摘要:目的通过深度学习卷积神经网络进行3维目标检测的方法已取得巨大进展,但卷积神经网络提取的特征既缺乏不同区域特征的依赖关系,也缺乏不同通道特征的依赖关系,同时难以保证在无损空间分辨率的情况下扩大感受野。针对以上不足,提出了一种结合混合域注意力与空洞卷积的3维目标检测方法。方法在输入层融入空间域注意力机制,变换输入信息的空间位置,保留需重点关注的区域特征;在网络中融入通道域注意力机制,提取特征的通道权重,获取关键通道特征;通过融合空间域与通道域注意力机制,对特征进行混合空间与通道的混合注意。在特征提取器的输出层融入结合空洞卷积与通道注意力机制的网络层,在不损失空间分辨率的情况下扩大感受野,根据不同感受野提取特征的通道权重后进行融合,得到全局感受野的关键通道特征;引入特征金字塔结构构建特征提取器,提取高分辨率的特征图,大幅提升网络的检测性能。运用基于二阶段的区域生成网络,回归定位更准确的3维目标框。结果KITTI(A project of Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)数据集中的实验结果表明,在物体被遮挡的程度由轻到高时,对测试集中的car类别,3维目标检测框的平均精度AP3D值分别为83.45%、74.29%、67.92%,鸟瞰视角2维目标检测框的平均精度APBEV值分别为89.61%、87.05%、79.69%;对pedestrian和cyclist类别,AP3D和APBEV值同样比其他方法的检测结果有一定优势。结论本文提出的3维目标检测网络,一定程度上解决了3维检测任务中卷积神经网络提取的特征缺乏视觉注意力的问题,从而使3维目标检测更有效地运用于室外自动驾驶。关键词:3维目标检测;注意力机制;空洞卷积;感受野;金字塔网络;卷积神经网络(CNN)23|17|3更新时间:2024-05-07
摘要:目的通过深度学习卷积神经网络进行3维目标检测的方法已取得巨大进展,但卷积神经网络提取的特征既缺乏不同区域特征的依赖关系,也缺乏不同通道特征的依赖关系,同时难以保证在无损空间分辨率的情况下扩大感受野。针对以上不足,提出了一种结合混合域注意力与空洞卷积的3维目标检测方法。方法在输入层融入空间域注意力机制,变换输入信息的空间位置,保留需重点关注的区域特征;在网络中融入通道域注意力机制,提取特征的通道权重,获取关键通道特征;通过融合空间域与通道域注意力机制,对特征进行混合空间与通道的混合注意。在特征提取器的输出层融入结合空洞卷积与通道注意力机制的网络层,在不损失空间分辨率的情况下扩大感受野,根据不同感受野提取特征的通道权重后进行融合,得到全局感受野的关键通道特征;引入特征金字塔结构构建特征提取器,提取高分辨率的特征图,大幅提升网络的检测性能。运用基于二阶段的区域生成网络,回归定位更准确的3维目标框。结果KITTI(A project of Karlsruhe Institute of Technology and Toyota Technological Institute at Chicago)数据集中的实验结果表明,在物体被遮挡的程度由轻到高时,对测试集中的car类别,3维目标检测框的平均精度AP3D值分别为83.45%、74.29%、67.92%,鸟瞰视角2维目标检测框的平均精度APBEV值分别为89.61%、87.05%、79.69%;对pedestrian和cyclist类别,AP3D和APBEV值同样比其他方法的检测结果有一定优势。结论本文提出的3维目标检测网络,一定程度上解决了3维检测任务中卷积神经网络提取的特征缺乏视觉注意力的问题,从而使3维目标检测更有效地运用于室外自动驾驶。关键词:3维目标检测;注意力机制;空洞卷积;感受野;金字塔网络;卷积神经网络(CNN)23|17|3更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的基于物理的烟雾模拟是计算机图形学的重要组成部分,渲染具有细小结构的高分辨率烟雾,需要大量的计算资源和高精度的数值求解方法。针对目前高精度湍流烟雾模拟速度慢,仿真困难的现状,提出了基于字典神经网络的方法,能够快速合成湍流烟雾,使得合成的结果增加细节的同时,保持高分辨率烟雾结果的重要结构信息。方法使用高精度的数值仿真求解方法获得高分辨率和低分辨率的湍流烟雾数据,通过采集速度场局部块及相应的空间位置信息和时间特征生成数据集,设计字典神经网络的网络架构,训练烟雾高频成分字典预测器,在GPU(graphic processing unit)上实现并行化,快速合成高分辨率的湍流烟雾结果。结果实验表明,基于字典神经网络的方法能够在非常低分辨率的烟雾数据下合成空间和时间上连续的高分辨率湍流烟雾结果,效率比通过在GPU平台上直接仿真得到高分辨率湍流烟雾的结果快了一个数量级,且合成的烟雾结果与数值仿真方法得到的高分辨率湍流烟雾结果足够接近。结论本文方法解决了烟雾的上采样问题,能够从非常低分辨率的烟雾仿真结果,通过设计基于字典神经网络结构以及特征描述符编码烟雾速度场的局部和全局信息,快速合成高分辨率湍流烟雾结果,且保持高精度烟雾的细节,与数值仿真方法的对比表明了本文方法的有效性。关键词:烟雾模拟;神经网络;粒子系统;计算机动画;字典学习20|18|0更新时间:2024-05-07
摘要:目的基于物理的烟雾模拟是计算机图形学的重要组成部分,渲染具有细小结构的高分辨率烟雾,需要大量的计算资源和高精度的数值求解方法。针对目前高精度湍流烟雾模拟速度慢,仿真困难的现状,提出了基于字典神经网络的方法,能够快速合成湍流烟雾,使得合成的结果增加细节的同时,保持高分辨率烟雾结果的重要结构信息。方法使用高精度的数值仿真求解方法获得高分辨率和低分辨率的湍流烟雾数据,通过采集速度场局部块及相应的空间位置信息和时间特征生成数据集,设计字典神经网络的网络架构,训练烟雾高频成分字典预测器,在GPU(graphic processing unit)上实现并行化,快速合成高分辨率的湍流烟雾结果。结果实验表明,基于字典神经网络的方法能够在非常低分辨率的烟雾数据下合成空间和时间上连续的高分辨率湍流烟雾结果,效率比通过在GPU平台上直接仿真得到高分辨率湍流烟雾的结果快了一个数量级,且合成的烟雾结果与数值仿真方法得到的高分辨率湍流烟雾结果足够接近。结论本文方法解决了烟雾的上采样问题,能够从非常低分辨率的烟雾仿真结果,通过设计基于字典神经网络结构以及特征描述符编码烟雾速度场的局部和全局信息,快速合成高分辨率湍流烟雾结果,且保持高精度烟雾的细节,与数值仿真方法的对比表明了本文方法的有效性。关键词:烟雾模拟;神经网络;粒子系统;计算机动画;字典学习20|18|0更新时间:2024-05-07 -
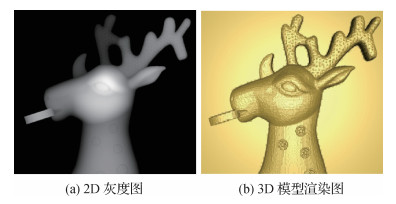 摘要:目的针对低质量浅浮雕表面的噪声现象,提出一种二次联合局部自适应稀疏表示和非局部低秩矩阵近似的浅浮雕优化算法。方法本文方法分两个阶段。第1阶段,将浅浮雕灰度图划分成大小相同的数据块,提取边界块并进行去噪,分别对数据块进行稀疏表示和低秩近似处理。一方面,通过字典学习获得过完备字典和稀疏编码;另一方面,利用K均值聚类算法(K-means)将事先构建的外部字典库划分成k类,从k个簇中心匹配每个数据块的相似块并组成相似矩阵,依次进行低秩近似和特征增强处理。最后通过最小二乘法求解,重建并聚合新建数据块以得到新的高度场。第2阶段与第1阶段的结构相似,主要区别在于改用重建高度场的非局部自身相似性来实现块匹配。结果在不同图像压缩率下(70%,50%,30%),对比本文方法与BM3D(block-matching and 3D filtering)、WNNM(weighted nuclear norm minimization)、STROLLR(sparsifying transform learning and low-rank)、TWSC(trilateral weighted sparse coding)4个平滑降噪方法的浅浮雕重建结果,发现BM3D和STROLLR方法的特征保持虽好,但平滑效果较差,WNNM方法出现模型破损现象,TWSC方法的平滑效果比BM3D和STROLLR方法更好,但特征也同时被光顺化。阴影恢复形状法(shape from shading,SFS)是一种基于图像的3D建模法,但是其重建结果比较粗糙。相比之下,本文方法生成的浅浮雕模型更加清晰直观,在浅浮雕的特征增强和平滑去噪方面都展现出更好的性能。结论本文综合数据块的局部稀疏性和数据块之间的非局部相似性对粗糙的浅浮雕模型进行二次高度场重建。本文方法有效改善了现有浅浮雕模型的质量,提高了模型的整体视觉效果,为浅浮雕的优化提供了新方法。关键词:浅浮雕;平滑去噪;稀疏表示;块匹配;低秩矩阵近似36|40|1更新时间:2024-05-07
摘要:目的针对低质量浅浮雕表面的噪声现象,提出一种二次联合局部自适应稀疏表示和非局部低秩矩阵近似的浅浮雕优化算法。方法本文方法分两个阶段。第1阶段,将浅浮雕灰度图划分成大小相同的数据块,提取边界块并进行去噪,分别对数据块进行稀疏表示和低秩近似处理。一方面,通过字典学习获得过完备字典和稀疏编码;另一方面,利用K均值聚类算法(K-means)将事先构建的外部字典库划分成k类,从k个簇中心匹配每个数据块的相似块并组成相似矩阵,依次进行低秩近似和特征增强处理。最后通过最小二乘法求解,重建并聚合新建数据块以得到新的高度场。第2阶段与第1阶段的结构相似,主要区别在于改用重建高度场的非局部自身相似性来实现块匹配。结果在不同图像压缩率下(70%,50%,30%),对比本文方法与BM3D(block-matching and 3D filtering)、WNNM(weighted nuclear norm minimization)、STROLLR(sparsifying transform learning and low-rank)、TWSC(trilateral weighted sparse coding)4个平滑降噪方法的浅浮雕重建结果,发现BM3D和STROLLR方法的特征保持虽好,但平滑效果较差,WNNM方法出现模型破损现象,TWSC方法的平滑效果比BM3D和STROLLR方法更好,但特征也同时被光顺化。阴影恢复形状法(shape from shading,SFS)是一种基于图像的3D建模法,但是其重建结果比较粗糙。相比之下,本文方法生成的浅浮雕模型更加清晰直观,在浅浮雕的特征增强和平滑去噪方面都展现出更好的性能。结论本文综合数据块的局部稀疏性和数据块之间的非局部相似性对粗糙的浅浮雕模型进行二次高度场重建。本文方法有效改善了现有浅浮雕模型的质量,提高了模型的整体视觉效果,为浅浮雕的优化提供了新方法。关键词:浅浮雕;平滑去噪;稀疏表示;块匹配;低秩矩阵近似36|40|1更新时间:2024-05-07
计算机图形学
-
 摘要:目的青光眼是一种可导致视力严重减弱甚至失明的高发眼部疾病。在眼底图像中,视杯和视盘的检测是青光眼临床诊断的重要步骤之一。然而,眼底图像普遍是灰度不均匀的,眼底结构复杂,不同结构之间的灰度重叠较多,受到血管和病变的干扰较为严重。这些都给视盘与视杯的分割带来很大挑战。因此,为了更准确地提取眼底图像中的视杯和视盘区域,提出一种基于双层水平集描述的眼底图像视杯视盘分割方法。方法通过水平集函数的不同层级分别表示视杯轮廓和视盘轮廓,依据视杯与视盘间的位置关系建立距离约束,应用图像的局部信息驱动活动轮廓演化,克服图像的灰度不均匀性。根据视杯与视盘的几何形状特征,引入视杯与视盘形状的先验信息约束活动轮廓的演化,从而实现视杯与视盘的准确分割。结果本文使用印度Aravind眼科医院提供的具有视杯和视盘真实轮廓注释的CDRISHTI-GS1数据集对本文方法进行实验验证。该数据集主要用来验证视杯及视盘分割方法的鲁棒性和有效性。本文方法在数据集上对视杯和视盘区域进行分割,取得了67.52%的视杯平均重叠率,81.04%的视盘平均重叠率,0.719的视杯F1分数和0.845的视盘F1分数,结果优于基于COSFIRE(combination of shifted filter responses)滤波模型的视杯视盘分割方法、基于先验形状约束的多相Chan-Vese(C-V)模型和基于聚类融合的水平集方法。结论实验结果表明,本文方法能够有效克服眼底图像灰度不均匀、血管及病变区域的干扰等影响,更为准确地提取视杯与视盘区域。关键词:眼底图像;双层水平集方法;视杯分割;视盘分割;形状先验约束51|57|3更新时间:2024-05-07
摘要:目的青光眼是一种可导致视力严重减弱甚至失明的高发眼部疾病。在眼底图像中,视杯和视盘的检测是青光眼临床诊断的重要步骤之一。然而,眼底图像普遍是灰度不均匀的,眼底结构复杂,不同结构之间的灰度重叠较多,受到血管和病变的干扰较为严重。这些都给视盘与视杯的分割带来很大挑战。因此,为了更准确地提取眼底图像中的视杯和视盘区域,提出一种基于双层水平集描述的眼底图像视杯视盘分割方法。方法通过水平集函数的不同层级分别表示视杯轮廓和视盘轮廓,依据视杯与视盘间的位置关系建立距离约束,应用图像的局部信息驱动活动轮廓演化,克服图像的灰度不均匀性。根据视杯与视盘的几何形状特征,引入视杯与视盘形状的先验信息约束活动轮廓的演化,从而实现视杯与视盘的准确分割。结果本文使用印度Aravind眼科医院提供的具有视杯和视盘真实轮廓注释的CDRISHTI-GS1数据集对本文方法进行实验验证。该数据集主要用来验证视杯及视盘分割方法的鲁棒性和有效性。本文方法在数据集上对视杯和视盘区域进行分割,取得了67.52%的视杯平均重叠率,81.04%的视盘平均重叠率,0.719的视杯F1分数和0.845的视盘F1分数,结果优于基于COSFIRE(combination of shifted filter responses)滤波模型的视杯视盘分割方法、基于先验形状约束的多相Chan-Vese(C-V)模型和基于聚类融合的水平集方法。结论实验结果表明,本文方法能够有效克服眼底图像灰度不均匀、血管及病变区域的干扰等影响,更为准确地提取视杯与视盘区域。关键词:眼底图像;双层水平集方法;视杯分割;视盘分割;形状先验约束51|57|3更新时间:2024-05-07
医学图像处理
-
 摘要:目的随着遥感影像空间分辨率的提升,相同地物的空间纹理表现形式差异变大,地物特征更加复杂多样,传统的变化检测方法已很难满足需求。为提高高分辨率遥感影像的变化检测精度,尤其对相同地物中纹理差异较大的区域做出有效判别,提出结合深度学习和超像元分割的高分辨率遥感影像变化检测方法。方法将有限带标签数据分割成切片作训练样本,按照样本形式设计一个多切片尺度特征融合网络并对其训练,获得测试图像的初步变化检测结果;利用超像元分割算法将测试图像分割成许多无重叠的同质性区域,并将分割结果与前述检测结果叠合,得到带分割标记的变化检测结果;用举手表决算法统计带分割标记的变化检测结果中超像元的变化状况,得到最终变化检测结果。结果在变化检测实验结果中,本文提出的多切片尺度特征融合卷积网络模型在广东数据集和香港数据集上,优于单一切片尺度下卷积神经网络模型,并且结合超像元的多切片尺度特征融合卷积网络模型得到的Kappa系数分别达到80%和82%,比相应的非超像元算法分别提高了6%和8%,在两个测试集上表现均优于长短时记忆网络、深度置信网络等对比算法。结论本文提出的卷积神经网络变化检测方法可以充分学习切片的空间信息和其他有效特征,避免过拟合现象;多层尺度切片特征融合的方法优于单一切片尺度训练神经网络的方法;结合深度学习和超像元分割算法,检测单元实现了由切片到超像元的转变,能对同物异谱的区域做出有效判决,有利于提升变化检测精度。关键词:高分辨率遥感影像;变化检测;深度学习;超像元;多切片尺度特征融合56|35|9更新时间:2024-05-07
摘要:目的随着遥感影像空间分辨率的提升,相同地物的空间纹理表现形式差异变大,地物特征更加复杂多样,传统的变化检测方法已很难满足需求。为提高高分辨率遥感影像的变化检测精度,尤其对相同地物中纹理差异较大的区域做出有效判别,提出结合深度学习和超像元分割的高分辨率遥感影像变化检测方法。方法将有限带标签数据分割成切片作训练样本,按照样本形式设计一个多切片尺度特征融合网络并对其训练,获得测试图像的初步变化检测结果;利用超像元分割算法将测试图像分割成许多无重叠的同质性区域,并将分割结果与前述检测结果叠合,得到带分割标记的变化检测结果;用举手表决算法统计带分割标记的变化检测结果中超像元的变化状况,得到最终变化检测结果。结果在变化检测实验结果中,本文提出的多切片尺度特征融合卷积网络模型在广东数据集和香港数据集上,优于单一切片尺度下卷积神经网络模型,并且结合超像元的多切片尺度特征融合卷积网络模型得到的Kappa系数分别达到80%和82%,比相应的非超像元算法分别提高了6%和8%,在两个测试集上表现均优于长短时记忆网络、深度置信网络等对比算法。结论本文提出的卷积神经网络变化检测方法可以充分学习切片的空间信息和其他有效特征,避免过拟合现象;多层尺度切片特征融合的方法优于单一切片尺度训练神经网络的方法;结合深度学习和超像元分割算法,检测单元实现了由切片到超像元的转变,能对同物异谱的区域做出有效判决,有利于提升变化检测精度。关键词:高分辨率遥感影像;变化检测;深度学习;超像元;多切片尺度特征融合56|35|9更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0