
最新刊期
2020 年 第 25 卷 第 5 期
- 摘要:多源空—谱遥感图像融合方法作为两路不完全观测多通道数据的计算重构反问题,其挑战在于补充信息不足、模糊和噪声等引起的病态性,现有方法在互补特征保持的分辨率增强方面仍有很大的改进空间。为了推动遥感图像融合技术的发展,本文系统概述目前融合建模的代表性方法,包括成分替代、多分辨率分析、变量回归、贝叶斯、变分和模型与数据混合驱动等方法体系及其存在问题。从贝叶斯融合建模的角度,分析了互补特征保真和图像先验在优化融合中的关键作用和建模机理,并综述了目前若干图像先验建模的新趋势,包括:分数阶正则化、非局部正则化、结构化稀疏表示、矩阵低秩至张量低秩表示、解析先验与深度先验的复合等。本文对各领域面临的主要挑战和可能的研究方向进行了概述和讨论,指出解析模型和数据混合驱动将是图像融合的重要发展方向,并需要结合成像退化机理、数据紧致表示和高效计算等问题,突破现有模型优化融合的技术瓶颈,进一步发展更优良的光谱信息保真和更低算法复杂度的融合方法。同时,为了解决大数据问题,有必要在Hadoop和SPARK等大数据平台上进行高性能计算,以更有利于多源数据融合算法的加速实现。关键词:图像融合;全色锐化;反问题;正则化;模型优化;数据驱动;深度学习39|31|11更新时间:2024-05-08
学者观点

-
 摘要:本文是关于中国图像工程的年度文献综述系列之二十五。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够更全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,对2019年度图像工程相关文献进行了统计和分析。从国内15种图像工程相关重要中文期刊在2019年发行的共148期上所发表的2 854篇学术研究和技术应用文献中,选取出761篇属于图像工程领域的文献,并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前14年相同),并在此基础上分别进行各期刊各类文献的统计和分析。另外,还将这25年从这15种期刊的共2 964期上所发表的65 040篇学术研究和技术应用文献中所选取出的15 856篇属于图像工程领域的文献分成5个五年的阶段,分别对5个阶段的图像工程文献的选取情况以及各大类和各小类图像工程文献的数量进行了综合统计和对比分析。根据对2019年统计数据的分析可看出:图像分析方向当前得到了最多的关注,其中目标检测和识别、图像分割和边缘检测、目标特性的提取分析都是关注的焦点。遥感、雷达、测绘等领域的图像技术研究和应用最为活跃。根据对25年统计数据的比较可看出:图像处理、图像分析、图像理解和技术应用4个大类中都有一些小类的文献数量保持领先,但也有一些小类的文献数量逐步减少,反映了不同研究方向这些年来的变化情况。中国图像工程在2019年的研究深度和广度还在提高和扩大,仍保持了快速发展的势头。综合25年的统计数据为读者提供了更全面和更可信的各研究方向发展趋势信息。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学67|54|5更新时间:2024-05-08
摘要:本文是关于中国图像工程的年度文献综述系列之二十五。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够更全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,对2019年度图像工程相关文献进行了统计和分析。从国内15种图像工程相关重要中文期刊在2019年发行的共148期上所发表的2 854篇学术研究和技术应用文献中,选取出761篇属于图像工程领域的文献,并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前14年相同),并在此基础上分别进行各期刊各类文献的统计和分析。另外,还将这25年从这15种期刊的共2 964期上所发表的65 040篇学术研究和技术应用文献中所选取出的15 856篇属于图像工程领域的文献分成5个五年的阶段,分别对5个阶段的图像工程文献的选取情况以及各大类和各小类图像工程文献的数量进行了综合统计和对比分析。根据对2019年统计数据的分析可看出:图像分析方向当前得到了最多的关注,其中目标检测和识别、图像分割和边缘检测、目标特性的提取分析都是关注的焦点。遥感、雷达、测绘等领域的图像技术研究和应用最为活跃。根据对25年统计数据的比较可看出:图像处理、图像分析、图像理解和技术应用4个大类中都有一些小类的文献数量保持领先,但也有一些小类的文献数量逐步减少,反映了不同研究方向这些年来的变化情况。中国图像工程在2019年的研究深度和广度还在提高和扩大,仍保持了快速发展的势头。综合25年的统计数据为读者提供了更全面和更可信的各研究方向发展趋势信息。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学67|54|5更新时间:2024-05-08
综述
-
 摘要:目的视频重压缩是视频取证技术的重要辅助性手段。目前,不同编码参数进行压缩的高效视频编码(high efficiency video coding,HEVC)视频重压缩检测已经取得较高的准确度,而在前后采用相同编码参数压缩过程中,HEVC视频重压缩操作的痕迹非常小,检测难度大。为此,提出了在相同编码参数下基于视频质量下降机制的视频重压缩检测算法。方法在经过多次相同编码参数压缩后,可以观察到视频的质量趋于不变,利用视频质量下降程度可以区分单压缩视频和重压缩视频。本文提出I帧预测单元模式(intra-coded picture prediction unit mode,IPUM)和P帧预测单元模式(predicted picture prediction unit mode,PPUM)两类视频特征,即分别从I帧和P帧中的亮度分量(Y)提取预测单元(prediction unit,PU)的模式。从待测视频中提取IPUM和PPUM特征,将HEVC视频以相同的编码参数压缩3次,每次提取上述特征。由于I帧、P帧中不同尺寸的PU数量相差较大,应选取数量较多的PU作为统计特征。统计平均每一I帧、P帧在相同位置第n次压缩和第n+1次压缩不同的PU模式,构成6维特征集送入支持向量机(support vector machine,SVM)进行分类。结果本文方法在CIF(common intermediate format)数据集、720p数据集、1 080p数据集的平均检测准确度分别为95.45%,94.8%,95.53%。在不同的图像组(group of pictures,GOP)和帧删除的情况下均具有较好的表现。结论本文方法利用在相同位置连续两次压缩不同的PU模式数来揭示视频质量下降的规律,具有较高的准确度,且在不同情况下均有较好表现。关键词:视频取证;视频重压缩;高效视频编码;相同编码参数;质量下降;预测单元79|117|1更新时间:2024-05-08
摘要:目的视频重压缩是视频取证技术的重要辅助性手段。目前,不同编码参数进行压缩的高效视频编码(high efficiency video coding,HEVC)视频重压缩检测已经取得较高的准确度,而在前后采用相同编码参数压缩过程中,HEVC视频重压缩操作的痕迹非常小,检测难度大。为此,提出了在相同编码参数下基于视频质量下降机制的视频重压缩检测算法。方法在经过多次相同编码参数压缩后,可以观察到视频的质量趋于不变,利用视频质量下降程度可以区分单压缩视频和重压缩视频。本文提出I帧预测单元模式(intra-coded picture prediction unit mode,IPUM)和P帧预测单元模式(predicted picture prediction unit mode,PPUM)两类视频特征,即分别从I帧和P帧中的亮度分量(Y)提取预测单元(prediction unit,PU)的模式。从待测视频中提取IPUM和PPUM特征,将HEVC视频以相同的编码参数压缩3次,每次提取上述特征。由于I帧、P帧中不同尺寸的PU数量相差较大,应选取数量较多的PU作为统计特征。统计平均每一I帧、P帧在相同位置第n次压缩和第n+1次压缩不同的PU模式,构成6维特征集送入支持向量机(support vector machine,SVM)进行分类。结果本文方法在CIF(common intermediate format)数据集、720p数据集、1 080p数据集的平均检测准确度分别为95.45%,94.8%,95.53%。在不同的图像组(group of pictures,GOP)和帧删除的情况下均具有较好的表现。结论本文方法利用在相同位置连续两次压缩不同的PU模式数来揭示视频质量下降的规律,具有较高的准确度,且在不同情况下均有较好表现。关键词:视频取证;视频重压缩;高效视频编码;相同编码参数;质量下降;预测单元79|117|1更新时间:2024-05-08 -
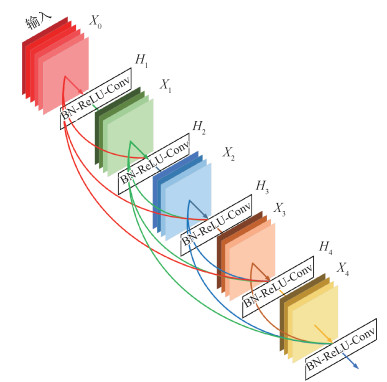 摘要:目的非均匀盲去运动模糊是图像处理和计算机视觉中的基础课题之一。传统去模糊算法有处理模糊种类单一、耗费时间两大缺点,且一直未能有效解决。随着神经网络在图像生成领域的出色表现,本文把去运动模糊视为图像生成的一种特殊问题,提出一种基于神经网络的快速去模糊方法。方法首先,将图像分类方向表现优异的密集连接卷积网络(dense connected convolutional network,DenseNets)应用到去模糊领域,该网络能充分利用中间层的有用信息。在损失函数方面,采用更符合去模糊目的的感知损失(perceptual loss),保证生成图像和清晰图像在内容上的一致性。采用生成对抗网络(generative adversarial network,GAN),使生成的图像在感官上与清晰图像更加接近。结果通过测试生成图像相对于清晰图像的峰值信噪比(peak signal to noise ratio,PSNR),结构相似性(structural similarity,SSIM)和复原时间来评价算法性能的优劣。相比DeblurGAN(blind motion deblurring using conditional adversarial networks),本文算法在GOPRO测试集上的平均PSNR提高了0.91,复原时间缩短了0.32 s,能成功恢复出因运动模糊而丢失的细节信息。在Kohler数据集上的性能也优于当前主流算法,能够处理不同的模糊核,鲁棒性强。结论本文算法网络结构简单,复原效果好,生成图像的速度也明显快于其他方法。同时,该算法鲁棒性强,适合处理各种因运动模糊而导致的图像退化问题。关键词:运动模糊;盲去模糊;生成对抗网络(GAN);密集连接卷积网络(DenseNets);感知损失;全卷积网络(FCN)70|94|9更新时间:2024-05-08
摘要:目的非均匀盲去运动模糊是图像处理和计算机视觉中的基础课题之一。传统去模糊算法有处理模糊种类单一、耗费时间两大缺点,且一直未能有效解决。随着神经网络在图像生成领域的出色表现,本文把去运动模糊视为图像生成的一种特殊问题,提出一种基于神经网络的快速去模糊方法。方法首先,将图像分类方向表现优异的密集连接卷积网络(dense connected convolutional network,DenseNets)应用到去模糊领域,该网络能充分利用中间层的有用信息。在损失函数方面,采用更符合去模糊目的的感知损失(perceptual loss),保证生成图像和清晰图像在内容上的一致性。采用生成对抗网络(generative adversarial network,GAN),使生成的图像在感官上与清晰图像更加接近。结果通过测试生成图像相对于清晰图像的峰值信噪比(peak signal to noise ratio,PSNR),结构相似性(structural similarity,SSIM)和复原时间来评价算法性能的优劣。相比DeblurGAN(blind motion deblurring using conditional adversarial networks),本文算法在GOPRO测试集上的平均PSNR提高了0.91,复原时间缩短了0.32 s,能成功恢复出因运动模糊而丢失的细节信息。在Kohler数据集上的性能也优于当前主流算法,能够处理不同的模糊核,鲁棒性强。结论本文算法网络结构简单,复原效果好,生成图像的速度也明显快于其他方法。同时,该算法鲁棒性强,适合处理各种因运动模糊而导致的图像退化问题。关键词:运动模糊;盲去模糊;生成对抗网络(GAN);密集连接卷积网络(DenseNets);感知损失;全卷积网络(FCN)70|94|9更新时间:2024-05-08 -
 摘要:目的为提取可充分表达图像语义信息的图像特征,减少哈希检索中的投影误差,并生成更紧致的二值哈希码,提出一种基于密集网络和改进的监督核哈希方法。方法用训练优化好的密集网络提取图像的高层语义特征;先对提取到的图像特征进行核主成分分析投影,充分挖掘图像特征中隐含的非线性信息,以减少投影误差,再利用监督核哈希方法对图像特征进行监督学习,将特征映射到汉明空间,生成更紧致的二值哈希码。结果为验证提出方法的有效性、可拓展性以及高效性,在Paris6K和LUNA16(lung nodule analysis 16)数据集上与其他6种常用哈希方法相比,所提方法在不同哈希码长下的平均检索精度均较高,且在哈希码长为64 bit时,平均检索精度达到最高,分别为89.2%和92.9%;与基于卷积神经网络的哈希算法(convolution neural network Hashing,CNNH)方法相比,所提方法的时间复杂度有所降低。结论提出一种基于密集网络和改进的监督核哈希方法,提高了图像特征的表达能力和投影精度,具有较好的检索性能和较低的时间复杂度;且所提方法的可拓展性也较好,不仅能够有效应用到彩色图像检索领域,也可以应用在医学灰度图像检索领域。关键词:密集卷积网络(DenseNet);监督核哈希;图像特征;投影误差;核主成分分析24|19|0更新时间:2024-05-08
摘要:目的为提取可充分表达图像语义信息的图像特征,减少哈希检索中的投影误差,并生成更紧致的二值哈希码,提出一种基于密集网络和改进的监督核哈希方法。方法用训练优化好的密集网络提取图像的高层语义特征;先对提取到的图像特征进行核主成分分析投影,充分挖掘图像特征中隐含的非线性信息,以减少投影误差,再利用监督核哈希方法对图像特征进行监督学习,将特征映射到汉明空间,生成更紧致的二值哈希码。结果为验证提出方法的有效性、可拓展性以及高效性,在Paris6K和LUNA16(lung nodule analysis 16)数据集上与其他6种常用哈希方法相比,所提方法在不同哈希码长下的平均检索精度均较高,且在哈希码长为64 bit时,平均检索精度达到最高,分别为89.2%和92.9%;与基于卷积神经网络的哈希算法(convolution neural network Hashing,CNNH)方法相比,所提方法的时间复杂度有所降低。结论提出一种基于密集网络和改进的监督核哈希方法,提高了图像特征的表达能力和投影精度,具有较好的检索性能和较低的时间复杂度;且所提方法的可拓展性也较好,不仅能够有效应用到彩色图像检索领域,也可以应用在医学灰度图像检索领域。关键词:密集卷积网络(DenseNet);监督核哈希;图像特征;投影误差;核主成分分析24|19|0更新时间:2024-05-08
图像处理和编码
-
 摘要:目的域自适应分割网(AdaptSegNet)在城市场景语义分割中可获得较好的效果,但是该方法直接采用存在较大域差异(domain gap)的源域数据集GTA(grand theft auto)5与目标域数据集Cityscapes进行对抗训练,并且在网络的不同特征层间的对抗学习中使用固定的学习率,所以分割精度仍有待提高。针对上述问题,提出了一种新的域自适应的城市场景语义分割方法。方法采用SG-GAN(semantic-aware grad-generative adversarial network(GAN))方法对虚拟数据集GTA5进行预处理,生成新的数据集SG-GTA5,其在灰度、结构以及边缘等信息上都更加接近现实场景Cityscapes,并用新生成的数据集代替原来的GTA5数据集作为网络的输入。针对AdaptSegNet加入的固定学习率问题,在网络的不同特征层引入自适应的学习率进行对抗学习,通过该学习率自适应地调整不同特征层的损失值,达到动态更新网络参数的目标。同时,在对抗网络的判别器中增加一层卷积层,以增强网络的判别能力。结果在真实场景数据集Cityscapes上进行验证,并与相关的域自适应分割模型进行对比,结果表明:提出的网络模型能更好地分割出城市交通场景中较复杂的物体,对于sidewalk、wall、pole、car、sky的平均交并比(mean intersection over union,mIoU)分别提高了9.6%、5.9%、4.9%、5.5%、4.8%。结论提出方法降低了源域和目标域数据集之间的域差异,减少了训练过程中的对抗损失值,规避了网络在反向传播训练过程中出现的梯度爆炸问题,从而有效地提高了网络模型的分割精度;同时提出基于该自适应的学习率进一步提升模型的分割性能;在模型的判别器网络中新添加一个卷积层,能学习到图像的更多高层语义信息,有效地缓解了类漂移的问题。关键词:城市场景;语义分割;生成对抗网络;域自适应;自适应学习率36|34|4更新时间:2024-05-08
摘要:目的域自适应分割网(AdaptSegNet)在城市场景语义分割中可获得较好的效果,但是该方法直接采用存在较大域差异(domain gap)的源域数据集GTA(grand theft auto)5与目标域数据集Cityscapes进行对抗训练,并且在网络的不同特征层间的对抗学习中使用固定的学习率,所以分割精度仍有待提高。针对上述问题,提出了一种新的域自适应的城市场景语义分割方法。方法采用SG-GAN(semantic-aware grad-generative adversarial network(GAN))方法对虚拟数据集GTA5进行预处理,生成新的数据集SG-GTA5,其在灰度、结构以及边缘等信息上都更加接近现实场景Cityscapes,并用新生成的数据集代替原来的GTA5数据集作为网络的输入。针对AdaptSegNet加入的固定学习率问题,在网络的不同特征层引入自适应的学习率进行对抗学习,通过该学习率自适应地调整不同特征层的损失值,达到动态更新网络参数的目标。同时,在对抗网络的判别器中增加一层卷积层,以增强网络的判别能力。结果在真实场景数据集Cityscapes上进行验证,并与相关的域自适应分割模型进行对比,结果表明:提出的网络模型能更好地分割出城市交通场景中较复杂的物体,对于sidewalk、wall、pole、car、sky的平均交并比(mean intersection over union,mIoU)分别提高了9.6%、5.9%、4.9%、5.5%、4.8%。结论提出方法降低了源域和目标域数据集之间的域差异,减少了训练过程中的对抗损失值,规避了网络在反向传播训练过程中出现的梯度爆炸问题,从而有效地提高了网络模型的分割精度;同时提出基于该自适应的学习率进一步提升模型的分割性能;在模型的判别器网络中新添加一个卷积层,能学习到图像的更多高层语义信息,有效地缓解了类漂移的问题。关键词:城市场景;语义分割;生成对抗网络;域自适应;自适应学习率36|34|4更新时间:2024-05-08 -
 摘要:目的多相图像分割是图像处理与分析的重要问题,变分图像分割的Vese-Chan模型是多相图像分割的基本模型,由于该模型使用较少的标签函数构造区域划分的特征函数,具有求解规模小的优点。图割(graph cut,GC)算法可将上述能量泛函的极值问题转化为最小割/最大流问题求解,大大提高了计算效率。连续最大流(continuous max-flow,CMF)方法是经典GC算法的连续化表达,不仅具备GC算法的高效性,且克服了经典GC算法由于离散导致的精度下降问题。本文提出基于凸松弛的多相图像分割Vese-Chan模型的连续最大流方法。方法根据划分区域编号的二进制表示构造两类特征函数,将多相图像分割转化为多个交替优化的两相图像分割问题。引入对偶变量将Vese-Chan模型转化为与最小割问题相对应的连续最大流问题,并引入Lagrange乘子设计交替方向乘子方法(alternating direction method of multipliers,ADMM),将能量泛函的优化问题转化为一系列简单的子优化问题。结果对灰度图像和彩色图像进行数值实验,从分割效果看,本文方法对于医学图像、遥感图像等复杂图像的分割效果更加精确,对分割对象和背景更好地分离;从分割效率看,本文方法减少了迭代次数和运算时间。在使用2个标签函数的分割实验中,本文方法运算时间加速比分别为6.35%、10.75%、12.39%和7.83%;在使用3个标签函数的分割实验中,运算时间加速比分别为12.32%、15.45%和14.04%;在使用4个标签函数的分割实验中,运算时间加速比分别为16.69%和20.07%。结论本文提出的多相图像分割Vese-Chan模型的连续最大流方法优化了分割效果,减少了迭代次数,从而提高了计算效率。关键词:多相图像分割;Vese-Chan模型;凸松弛;连续最大流方法;交替方向乘子方法17|15|0更新时间:2024-05-08
摘要:目的多相图像分割是图像处理与分析的重要问题,变分图像分割的Vese-Chan模型是多相图像分割的基本模型,由于该模型使用较少的标签函数构造区域划分的特征函数,具有求解规模小的优点。图割(graph cut,GC)算法可将上述能量泛函的极值问题转化为最小割/最大流问题求解,大大提高了计算效率。连续最大流(continuous max-flow,CMF)方法是经典GC算法的连续化表达,不仅具备GC算法的高效性,且克服了经典GC算法由于离散导致的精度下降问题。本文提出基于凸松弛的多相图像分割Vese-Chan模型的连续最大流方法。方法根据划分区域编号的二进制表示构造两类特征函数,将多相图像分割转化为多个交替优化的两相图像分割问题。引入对偶变量将Vese-Chan模型转化为与最小割问题相对应的连续最大流问题,并引入Lagrange乘子设计交替方向乘子方法(alternating direction method of multipliers,ADMM),将能量泛函的优化问题转化为一系列简单的子优化问题。结果对灰度图像和彩色图像进行数值实验,从分割效果看,本文方法对于医学图像、遥感图像等复杂图像的分割效果更加精确,对分割对象和背景更好地分离;从分割效率看,本文方法减少了迭代次数和运算时间。在使用2个标签函数的分割实验中,本文方法运算时间加速比分别为6.35%、10.75%、12.39%和7.83%;在使用3个标签函数的分割实验中,运算时间加速比分别为12.32%、15.45%和14.04%;在使用4个标签函数的分割实验中,运算时间加速比分别为16.69%和20.07%。结论本文提出的多相图像分割Vese-Chan模型的连续最大流方法优化了分割效果,减少了迭代次数,从而提高了计算效率。关键词:多相图像分割;Vese-Chan模型;凸松弛;连续最大流方法;交替方向乘子方法17|15|0更新时间:2024-05-08 -
 摘要:目的在行人再识别中,经常出现由于行人身体部位被遮挡和行人图像对之间不对齐而导致误判的情况。利用人体固有结构的特性,关注具有显著性特征的行人部件,忽略带有干扰信息的其他部件,有利于判断不同摄像头拍摄的行人对是否为同一人。因此,提出了基于注意力机制和多属性分类的行人再识别方法。方法在训练阶段,利用改进的ResNet50网络作为基本框架提取特征,随后传递给全局分支和局部分支。在全局分支中,将该特征作为全局特征进行身份和全局属性分类;在局部分支中,按信道展开特征,获取每层响应值最高的点,聚合这些点,分成4个行人部件,计算每个行人部件上显著性特征的权重,并乘以初始特征得到每个部件的总特征。最后将这4个部件的总特征都进行身份和对应属性的分类。在测试阶段,将通过网络提取的部位特征和全局特征串联起来,计算行人间的相似度,从而判断是否为同一人。结果本文方法引入了Market-1501_attribute和DukeMTMC-attribute数据集中的属性信息,并在Market-1501和DukeMTMC-reid数据集上进行测试,其中rank-1分别达到90.67%和80.2%,mAP分别达到76.65%和62.14%;使用re-ranking算法后,rank-1分别达到92.4%和84.15%,mAP分别达到87.5%和78.41%,相比近年来具有代表性的其他方法,识别率有了极大提升。结论本文方法通过学习行人属性能更快地聚集行人部件的注意力,而注意力机制又能更好地学习行人部位的显著性特征,从而有效解决了行人被遮挡和不对齐的问题,提高了行人再识别的准确率。关键词:行人再识别;全局特征;局部特征;行人部件;注意力机制;属性信息32|37|9更新时间:2024-05-08
摘要:目的在行人再识别中,经常出现由于行人身体部位被遮挡和行人图像对之间不对齐而导致误判的情况。利用人体固有结构的特性,关注具有显著性特征的行人部件,忽略带有干扰信息的其他部件,有利于判断不同摄像头拍摄的行人对是否为同一人。因此,提出了基于注意力机制和多属性分类的行人再识别方法。方法在训练阶段,利用改进的ResNet50网络作为基本框架提取特征,随后传递给全局分支和局部分支。在全局分支中,将该特征作为全局特征进行身份和全局属性分类;在局部分支中,按信道展开特征,获取每层响应值最高的点,聚合这些点,分成4个行人部件,计算每个行人部件上显著性特征的权重,并乘以初始特征得到每个部件的总特征。最后将这4个部件的总特征都进行身份和对应属性的分类。在测试阶段,将通过网络提取的部位特征和全局特征串联起来,计算行人间的相似度,从而判断是否为同一人。结果本文方法引入了Market-1501_attribute和DukeMTMC-attribute数据集中的属性信息,并在Market-1501和DukeMTMC-reid数据集上进行测试,其中rank-1分别达到90.67%和80.2%,mAP分别达到76.65%和62.14%;使用re-ranking算法后,rank-1分别达到92.4%和84.15%,mAP分别达到87.5%和78.41%,相比近年来具有代表性的其他方法,识别率有了极大提升。结论本文方法通过学习行人属性能更快地聚集行人部件的注意力,而注意力机制又能更好地学习行人部位的显著性特征,从而有效解决了行人被遮挡和不对齐的问题,提高了行人再识别的准确率。关键词:行人再识别;全局特征;局部特征;行人部件;注意力机制;属性信息32|37|9更新时间:2024-05-08 -
 摘要:目的行人再识别是实现跨摄像头识别同一行人的关键技术,面临外观、光照、姿态、背景等问题,其中区别行人个体差异的核心是行人整体和局部特征的表征。为了高效地表征行人,提出一种多分辨率特征注意力融合的行人再识别方法。方法借助注意力机制,基于主干网络HRNet(high-resolution network),通过交错卷积构建4个不同的分支来抽取多分辨率行人图像特征,既对行人不同粒度特征进行抽取,也对不同分支特征进行交互,对行人进行高效的特征表示。结果在Market1501、CUHK03以及DukeMTMC-ReID这3个数据集上验证了所提方法的有效性,rank1分别达到95.3%、72.8%、90.5%,mAP(mean average precision)分别达到89.2%、70.4%、81.5%。在Market1501与DukeMTMC-ReID两个数据集上实验结果超越了当前最好表现。结论本文方法着重提升网络提取特征的能力,得到强有力的特征表示,可用于行人再识别、图像分类和目标检测等与特征提取相关的计算机视觉任务,显著提升行人再识别的准确性。关键词:HRNet;交错卷积;注意力机制;多分辨率特征表示;特征融合;行人再识别65|66|7更新时间:2024-05-08
摘要:目的行人再识别是实现跨摄像头识别同一行人的关键技术,面临外观、光照、姿态、背景等问题,其中区别行人个体差异的核心是行人整体和局部特征的表征。为了高效地表征行人,提出一种多分辨率特征注意力融合的行人再识别方法。方法借助注意力机制,基于主干网络HRNet(high-resolution network),通过交错卷积构建4个不同的分支来抽取多分辨率行人图像特征,既对行人不同粒度特征进行抽取,也对不同分支特征进行交互,对行人进行高效的特征表示。结果在Market1501、CUHK03以及DukeMTMC-ReID这3个数据集上验证了所提方法的有效性,rank1分别达到95.3%、72.8%、90.5%,mAP(mean average precision)分别达到89.2%、70.4%、81.5%。在Market1501与DukeMTMC-ReID两个数据集上实验结果超越了当前最好表现。结论本文方法着重提升网络提取特征的能力,得到强有力的特征表示,可用于行人再识别、图像分类和目标检测等与特征提取相关的计算机视觉任务,显著提升行人再识别的准确性。关键词:HRNet;交错卷积;注意力机制;多分辨率特征表示;特征融合;行人再识别65|66|7更新时间:2024-05-08 -
 摘要:目的电线预警对于直升机和无人飞行器的低空飞行安全至关重要,利用可见光和红外图像识别电线是一个有效途径。传统识别方法需要人工设计的滤波器提取电线的局部特征,再使用Hough变换等方法找出直线,支持向量机和随机森林等机器学习方法仅给出图像中有无电线的识别结果。本文提出一种基于全卷积网络的电线识别方法,能在自动学习特征提取器的同时得到电线的具体位置等信息。方法首先利用复杂背景生成大量包含电线图像和像素标签的成对仿真数据;然后改进U-Net网络结构以适应电线识别任务,使用仿真数据进行网络训练。由于图像中电线所占的像素很少,因此采用聚焦损失函数以平衡大量负样本的影响。结果在一个同时包含红外图像和可见光图像各4 000幅的电力巡线数据集上,与VGG(visual geometry group)16等多种特征的随机森林方法相比,本文方法的电线识别率达到了99%以上,而虚警率不到2%;同时,本文方法输出的像素分割结果中,电线基本都能被识别出来。结论本文提出的全卷积网络电线识别方法能够提取电线的光学图像特征,而且与传统机器学习方法相比能将电线从场景中精确提取出来,使得识别结果更加有判断的依据。关键词:全卷积网络(FCN);电线识别;低空飞行安全;仿真数据;多源图像57|154|5更新时间:2024-05-08
摘要:目的电线预警对于直升机和无人飞行器的低空飞行安全至关重要,利用可见光和红外图像识别电线是一个有效途径。传统识别方法需要人工设计的滤波器提取电线的局部特征,再使用Hough变换等方法找出直线,支持向量机和随机森林等机器学习方法仅给出图像中有无电线的识别结果。本文提出一种基于全卷积网络的电线识别方法,能在自动学习特征提取器的同时得到电线的具体位置等信息。方法首先利用复杂背景生成大量包含电线图像和像素标签的成对仿真数据;然后改进U-Net网络结构以适应电线识别任务,使用仿真数据进行网络训练。由于图像中电线所占的像素很少,因此采用聚焦损失函数以平衡大量负样本的影响。结果在一个同时包含红外图像和可见光图像各4 000幅的电力巡线数据集上,与VGG(visual geometry group)16等多种特征的随机森林方法相比,本文方法的电线识别率达到了99%以上,而虚警率不到2%;同时,本文方法输出的像素分割结果中,电线基本都能被识别出来。结论本文提出的全卷积网络电线识别方法能够提取电线的光学图像特征,而且与传统机器学习方法相比能将电线从场景中精确提取出来,使得识别结果更加有判断的依据。关键词:全卷积网络(FCN);电线识别;低空飞行安全;仿真数据;多源图像57|154|5更新时间:2024-05-08 -
 摘要:目的为了充分提取版画、中国画、油画、水彩画和水粉画等艺术图像的整体风格和局部细节特征,实现计算机自动分类检索艺术图像的需求,提出通过双核压缩激活模块(double kernel squeeze-and-excitation,DKSE)和深度可分离卷积搭建卷积神经网络对艺术图像进行分类。方法根据SKNet(selective kernel networks)自适应调节感受野提取图像整体与细节特征的结构特点和SENet(squeeze-and-excitation networks)增强通道特征的特点构建DKSE模块,利用DKSE模块分支上的卷积核提取输入图像的整体特征与局部细节特征;将分支上的特征图进行特征融合,并对融合后的特征图进行特征压缩和激活处理;将处理后的特征加权映射到不同分支的特征图上并进行特征融合;通过DKSE模块与深度可分离卷积搭建卷积神经网络对艺术图像进行分类。结果使用本文网络模型对有无数据增强(5类艺术图像数据增强后共25 634幅)处理的数据分类,数据增强后的分类准确率比未增强处理的准确率高9.21%。将本文方法与其他网络模型和传统分类方法相比,本文方法的分类准确率达到86.55%,比传统分类方法高26.35%。当DKSE模块分支上的卷积核为1×1和5×5,且放在本文网络模型第3个深度可分离卷积后,分类准确率达到87.58%。结论DKSE模块可以有效提高模型分类性能,充分提取艺术图像的整体与局部细节特征,比传统网络模型具有更好的分类准确率。关键词:艺术图像分类;深度可分离卷积;卷积神经网络;整体特征;局部细节特征40|19|3更新时间:2024-05-08
摘要:目的为了充分提取版画、中国画、油画、水彩画和水粉画等艺术图像的整体风格和局部细节特征,实现计算机自动分类检索艺术图像的需求,提出通过双核压缩激活模块(double kernel squeeze-and-excitation,DKSE)和深度可分离卷积搭建卷积神经网络对艺术图像进行分类。方法根据SKNet(selective kernel networks)自适应调节感受野提取图像整体与细节特征的结构特点和SENet(squeeze-and-excitation networks)增强通道特征的特点构建DKSE模块,利用DKSE模块分支上的卷积核提取输入图像的整体特征与局部细节特征;将分支上的特征图进行特征融合,并对融合后的特征图进行特征压缩和激活处理;将处理后的特征加权映射到不同分支的特征图上并进行特征融合;通过DKSE模块与深度可分离卷积搭建卷积神经网络对艺术图像进行分类。结果使用本文网络模型对有无数据增强(5类艺术图像数据增强后共25 634幅)处理的数据分类,数据增强后的分类准确率比未增强处理的准确率高9.21%。将本文方法与其他网络模型和传统分类方法相比,本文方法的分类准确率达到86.55%,比传统分类方法高26.35%。当DKSE模块分支上的卷积核为1×1和5×5,且放在本文网络模型第3个深度可分离卷积后,分类准确率达到87.58%。结论DKSE模块可以有效提高模型分类性能,充分提取艺术图像的整体与局部细节特征,比传统网络模型具有更好的分类准确率。关键词:艺术图像分类;深度可分离卷积;卷积神经网络;整体特征;局部细节特征40|19|3更新时间:2024-05-08
图像分析和识别
-
 摘要:目的针对现今主流one-stage网络框架在检测高帧率视频中的复杂目标场景时,无法兼顾检测精度和检测效率的问题,本文改进one-stage网络架构,并使用光流跟踪特征图,提出一种高效检测复杂场景的快速金字塔网络(snap pyramid network,SPNet)。方法调查特征提取网络以及金字塔网络内部,实现特征矩阵及卷积结构完全可视化,找到one-stage网络模型有效提升检测小目标以及密集目标的关键因素;构建复杂场景检测网络SPNet,由骨干网络(MainNet)内置子网络跟踪器(TrackNet)。在MainNet部分,设计特征权重控制(feature weight control,FWC)模块,改进基本单元(basic block),并设计MainNet的核心网络(BackBone)与特征金字塔网络(feature pyramid network,FPN)架构结合的多尺度金字塔结构,有效提升视频关键帧中存在的小而密集目标的检测精度和鲁棒性;在TrackNet部分,内置光流跟踪器到BackBone,使用高精度的光流矢量映射BackBone卷积出的特征图,代替传统的特征全卷积网络架构,有效提升检测效率。结果SPNet能够兼顾小目标、密集目标的检测性能,在目标检测数据集MS COCO(Microsoft common objects in context)和PASCAL VOC上的平均精度为52.8%和75.96%,在MS COCO上的小目标平均精度为13.9%;在目标跟踪数据集VOT(visual object tracking)上的平均精度为42.1%,检测速度提高到5070帧/s。结论本文快速金字塔结构目标检测框架,重构了one-stage检测网络的结构,利用光流充分复用卷积特征信息,侧重于复杂场景的检测能力与视频流的检测效率,实现了精度与速度的良好平衡。关键词:计算机视觉;深度学习;复杂目标检测;one-stage网络;光流法84|181|0更新时间:2024-05-08
摘要:目的针对现今主流one-stage网络框架在检测高帧率视频中的复杂目标场景时,无法兼顾检测精度和检测效率的问题,本文改进one-stage网络架构,并使用光流跟踪特征图,提出一种高效检测复杂场景的快速金字塔网络(snap pyramid network,SPNet)。方法调查特征提取网络以及金字塔网络内部,实现特征矩阵及卷积结构完全可视化,找到one-stage网络模型有效提升检测小目标以及密集目标的关键因素;构建复杂场景检测网络SPNet,由骨干网络(MainNet)内置子网络跟踪器(TrackNet)。在MainNet部分,设计特征权重控制(feature weight control,FWC)模块,改进基本单元(basic block),并设计MainNet的核心网络(BackBone)与特征金字塔网络(feature pyramid network,FPN)架构结合的多尺度金字塔结构,有效提升视频关键帧中存在的小而密集目标的检测精度和鲁棒性;在TrackNet部分,内置光流跟踪器到BackBone,使用高精度的光流矢量映射BackBone卷积出的特征图,代替传统的特征全卷积网络架构,有效提升检测效率。结果SPNet能够兼顾小目标、密集目标的检测性能,在目标检测数据集MS COCO(Microsoft common objects in context)和PASCAL VOC上的平均精度为52.8%和75.96%,在MS COCO上的小目标平均精度为13.9%;在目标跟踪数据集VOT(visual object tracking)上的平均精度为42.1%,检测速度提高到5070帧/s。结论本文快速金字塔结构目标检测框架,重构了one-stage检测网络的结构,利用光流充分复用卷积特征信息,侧重于复杂场景的检测能力与视频流的检测效率,实现了精度与速度的良好平衡。关键词:计算机视觉;深度学习;复杂目标检测;one-stage网络;光流法84|181|0更新时间:2024-05-08 -
 摘要:目的现有大多数视觉问答模型均采用自上而下的视觉注意力机制,对图像内容无加权统一处理,无法更好地表征图像信息,且因为缺乏长期记忆模块,无法对信息进行长时间记忆存储,在推理答案过程中会造成有效信息丢失,从而预测出错误答案。为此,提出一种结合自底向上注意力机制和记忆网络的视觉问答模型,通过增强对图像内容的表示和记忆,提高视觉问答的准确率。方法预训练一个目标检测模型提取图像中的目标和显著性区域作为图像特征,联合问题表示输入到记忆网络,记忆网络根据问题检索输入图像特征中的有用信息,并结合输入图像信息和问题表示进行多次迭代、更新,以生成最终的信息表示,最后融合记忆网络记忆的最终信息和问题表示,推测出正确答案。结果在公开的大规模数据集VQA(visual question answering)v2.0上与现有主流算法进行比较实验和消融实验,结果表明,提出的模型在视觉问答任务中的准确率有显著提升,总体准确率为64.0%。与MCB(multimodal compact bilinear)算法相比,总体准确率提升了1.7%;与性能较好的VQA machine算法相比,总体准确率提升了1%,其中回答是/否、计数和其他类型问题的准确率分别提升了1.1%、3.4%和0.6%。整体性能优于其他对比算法,验证了提出算法的有效性。结论本文提出的结合自底向上注意力机制和记忆网络的视觉问答模型,更符合人类的视觉注意力机制,并且在推理答案的过程中减少了信息丢失,有效提升了视觉问答的准确率。关键词:视觉问答;自底向上;注意力机制;记忆网络;多模态融合;多分类23|31|7更新时间:2024-05-08
摘要:目的现有大多数视觉问答模型均采用自上而下的视觉注意力机制,对图像内容无加权统一处理,无法更好地表征图像信息,且因为缺乏长期记忆模块,无法对信息进行长时间记忆存储,在推理答案过程中会造成有效信息丢失,从而预测出错误答案。为此,提出一种结合自底向上注意力机制和记忆网络的视觉问答模型,通过增强对图像内容的表示和记忆,提高视觉问答的准确率。方法预训练一个目标检测模型提取图像中的目标和显著性区域作为图像特征,联合问题表示输入到记忆网络,记忆网络根据问题检索输入图像特征中的有用信息,并结合输入图像信息和问题表示进行多次迭代、更新,以生成最终的信息表示,最后融合记忆网络记忆的最终信息和问题表示,推测出正确答案。结果在公开的大规模数据集VQA(visual question answering)v2.0上与现有主流算法进行比较实验和消融实验,结果表明,提出的模型在视觉问答任务中的准确率有显著提升,总体准确率为64.0%。与MCB(multimodal compact bilinear)算法相比,总体准确率提升了1.7%;与性能较好的VQA machine算法相比,总体准确率提升了1%,其中回答是/否、计数和其他类型问题的准确率分别提升了1.1%、3.4%和0.6%。整体性能优于其他对比算法,验证了提出算法的有效性。结论本文提出的结合自底向上注意力机制和记忆网络的视觉问答模型,更符合人类的视觉注意力机制,并且在推理答案的过程中减少了信息丢失,有效提升了视觉问答的准确率。关键词:视觉问答;自底向上;注意力机制;记忆网络;多模态融合;多分类23|31|7更新时间:2024-05-08 -
 摘要:目的为解决小重叠度、大视角影像自然拼接问题,提出一种统筹图像变换和缝合线生成过程的影像拼接新方法。方法主要包括两部分:1)将单应性映射引入到薄板样条变换(thin plate spline,TPS)并建立二次图像变换模型,在同一变换框架下进行全局单应性透视变换及基于径向基函数的局部映射调整,实现拼接影像透视特性良好保持与减少局部变形,且有效满足缝合线控制点无误差配准计算需要;2)根据控制点像素配准精度优于非控制点像素配准精度,对基准影像控制点集进行三角构网,并从中搜索初始缝合线,结合二次配准模型参数和动态规划匹配过程,获得控制点更密集且配准误差总体最小的最终缝合线,有效抑制图像融合时鬼影现象的产生,且计算实现上更简单。结果对两组标准影像进行拼接测试,并与3种方法(双单应性变换(dual-homography warping,DHW)、平滑变化的仿射拼接(smoothly varying affine stitching,SVA)、尽可能投影(as-projective-as-possible,APAP)的移动直接线性变换拼接(image stitching with moving direct linenr transform(DLT))对比,本文方法拼接影像局部变形失真最小、匹配控制点配准精度最高:在railtracks影像训练集(trarning set,TR)、测试集(test set)上分别为0和2.27;在temple影像训练集TR、测试集TE上分别为0和1.46;不同场景多路采集视频影像拼接透视特性保持良好,视觉效果自然。结论本文方法影像拼接时无先验知识要求、参数可线性求解,整体视觉效果流畅、重叠区域与非重叠区域过渡平滑,具有较好的应用价值。关键词:图像拼接;图像变换;图像融合;缝合线生成;全景影像;薄板样条变换47|44|3更新时间:2024-05-08
摘要:目的为解决小重叠度、大视角影像自然拼接问题,提出一种统筹图像变换和缝合线生成过程的影像拼接新方法。方法主要包括两部分:1)将单应性映射引入到薄板样条变换(thin plate spline,TPS)并建立二次图像变换模型,在同一变换框架下进行全局单应性透视变换及基于径向基函数的局部映射调整,实现拼接影像透视特性良好保持与减少局部变形,且有效满足缝合线控制点无误差配准计算需要;2)根据控制点像素配准精度优于非控制点像素配准精度,对基准影像控制点集进行三角构网,并从中搜索初始缝合线,结合二次配准模型参数和动态规划匹配过程,获得控制点更密集且配准误差总体最小的最终缝合线,有效抑制图像融合时鬼影现象的产生,且计算实现上更简单。结果对两组标准影像进行拼接测试,并与3种方法(双单应性变换(dual-homography warping,DHW)、平滑变化的仿射拼接(smoothly varying affine stitching,SVA)、尽可能投影(as-projective-as-possible,APAP)的移动直接线性变换拼接(image stitching with moving direct linenr transform(DLT))对比,本文方法拼接影像局部变形失真最小、匹配控制点配准精度最高:在railtracks影像训练集(trarning set,TR)、测试集(test set)上分别为0和2.27;在temple影像训练集TR、测试集TE上分别为0和1.46;不同场景多路采集视频影像拼接透视特性保持良好,视觉效果自然。结论本文方法影像拼接时无先验知识要求、参数可线性求解,整体视觉效果流畅、重叠区域与非重叠区域过渡平滑,具有较好的应用价值。关键词:图像拼接;图像变换;图像融合;缝合线生成;全景影像;薄板样条变换47|44|3更新时间:2024-05-08
图像理解和计算机视觉
-
 摘要:目的基于控制单元的形状编辑效果受各个控制单元对应权重的影响,而计算闭合形式的控制点权重方法难以有效地处理控制骨骼权重。针对3维空间的控制骨骼提出了一种虚拟控制单元插入算法和骨骼关节点标架变换方法,以保持骨骼控制区域的形状,从而得到过渡平滑、形状保持的良好编辑效果。方法选择
摘要:目的基于控制单元的形状编辑效果受各个控制单元对应权重的影响,而计算闭合形式的控制点权重方法难以有效地处理控制骨骼权重。针对3维空间的控制骨骼提出了一种虚拟控制单元插入算法和骨骼关节点标架变换方法,以保持骨骼控制区域的形状,从而得到过渡平滑、形状保持的良好编辑效果。方法选择${C^2}$ 关键词:线性混合;平滑处理;区域分解;并行计算;网格变形32|24|0更新时间:2024-05-08
计算机图形学
-
 摘要:目的肌骨超声宽景图像易出现解剖结构错位、断裂等现象,其成像算法中的特征检测影响宽景图像的质量,也是超声图像配准、分析等算法的关键步骤,但目前仍未有相关研究明确指出适合提取肌骨超声图像特征点的算法。本文利用结合SIFT(scale invariant feature transform)描述子的FAST(features from accelerated segment test)算法以及SIFT、SURF(speeded-up robust features)、ORB(oriented FAST and rotated binary robust independent elementary features(BRIEF))算法对肌骨超声图像序列进行图像拼接,并对各算法的性能进行比较评估,为肌骨超声图像配准、宽景成像提供可参考的特征检测解决方案。方法采集5组正常股四头肌的超声图像序列,每组再采样10幅图像。利用经典的图像拼接算法进行肌骨图像的特征检测以及图像拼接。分别利用上述4种算法提取肌骨超声图像的特征点;对特征点进行特征匹配,估算出图像间的形变矩阵;对所有待拼接的图像进行坐标变换以及融合处理,得到拼接全景图,并在特征检测性能、特征匹配性能、图像配准性能以及拼接效果等方面对4种算法进行评估比较。结果实验结果表明,与SIFT、SURF、ORB算法相比,FAST-SIFT算法所提取的特征点分布更均匀,可以检测到大部分肌纤维的端点,且特征点检测时间最短,约4 ms,其平均匹配对数最多,是其他特征检测算法的25倍,其互信息和归一化互相关系数均值分别为1.016和0.748,均高于其他3种特征检测算法,表明其图像配准精度更高。且FAST-SIFT算法的图像拼接效果更好,没有明显的解剖结构错位、断裂、拼接不连贯等现象。结论与SIFT、SURF、ORB算法相比,FAST-SIFT算法是更适合提取肌骨超声图像特征点的特征检测算法,在图像配准精度等方面都具有一定的优势。关键词:肌骨超声图像;特征检测;特征匹配;图像配准;图像拼接38|41|1更新时间:2024-05-08
摘要:目的肌骨超声宽景图像易出现解剖结构错位、断裂等现象,其成像算法中的特征检测影响宽景图像的质量,也是超声图像配准、分析等算法的关键步骤,但目前仍未有相关研究明确指出适合提取肌骨超声图像特征点的算法。本文利用结合SIFT(scale invariant feature transform)描述子的FAST(features from accelerated segment test)算法以及SIFT、SURF(speeded-up robust features)、ORB(oriented FAST and rotated binary robust independent elementary features(BRIEF))算法对肌骨超声图像序列进行图像拼接,并对各算法的性能进行比较评估,为肌骨超声图像配准、宽景成像提供可参考的特征检测解决方案。方法采集5组正常股四头肌的超声图像序列,每组再采样10幅图像。利用经典的图像拼接算法进行肌骨图像的特征检测以及图像拼接。分别利用上述4种算法提取肌骨超声图像的特征点;对特征点进行特征匹配,估算出图像间的形变矩阵;对所有待拼接的图像进行坐标变换以及融合处理,得到拼接全景图,并在特征检测性能、特征匹配性能、图像配准性能以及拼接效果等方面对4种算法进行评估比较。结果实验结果表明,与SIFT、SURF、ORB算法相比,FAST-SIFT算法所提取的特征点分布更均匀,可以检测到大部分肌纤维的端点,且特征点检测时间最短,约4 ms,其平均匹配对数最多,是其他特征检测算法的25倍,其互信息和归一化互相关系数均值分别为1.016和0.748,均高于其他3种特征检测算法,表明其图像配准精度更高。且FAST-SIFT算法的图像拼接效果更好,没有明显的解剖结构错位、断裂、拼接不连贯等现象。结论与SIFT、SURF、ORB算法相比,FAST-SIFT算法是更适合提取肌骨超声图像特征点的特征检测算法,在图像配准精度等方面都具有一定的优势。关键词:肌骨超声图像;特征检测;特征匹配;图像配准;图像拼接38|41|1更新时间:2024-05-08
医学图像处理
-
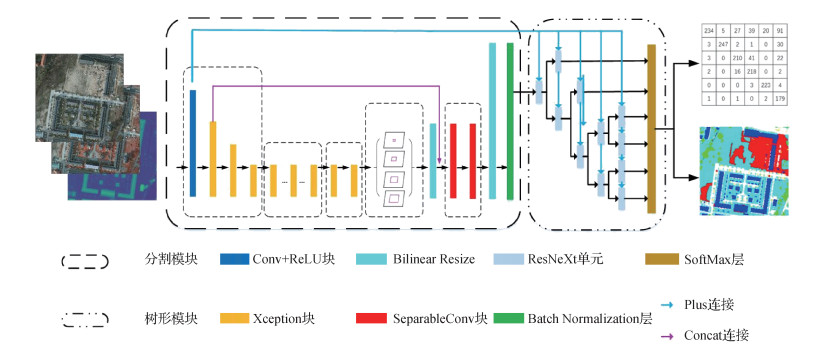 摘要:目的高分辨率遥感图像通常包含复杂的语义信息与易混淆的目标,对其语义分割是一项重要且具有挑战性的任务。基于DeepLab V3+网络结构,结合树形神经网络结构模块,设计出一种针对高分辨率遥感图像的语义分割网络。方法提出的网络结构不仅对DeepLab V3+做出了修改,使其适用于多尺度、多模态的数据,而且在其后添加连接树形神经网络结构模块。树形结构通过建立混淆矩阵、提取混淆图、构建图分割,能够对易混淆的像素更好地区分,得到更准确的分割结果。结果在国际摄影测量及遥感探测学会(International Society for Photogrammetry and Remote Sensing,ISPRS)提供的两个不同城市的遥感影像集上分别进行了实验,模型在整体准确率(overall accuracy,OA)这一项表现最好,在Vaihingen和Potsdam数据集上分别达到了90.4%和90.7%,其整体分割准确率较其基准结果有10.3%和17.4%的提升,对比ISPRS官方网站上的3种先进方法也有显著提升。结论提出结合DeepLab V3+和树形结构的卷积神经网络,有效提升了高分辨率遥感图像语义分割整体精度,其中易混淆类别数据的分割准确率显著提高。在包含复杂语义信息的高分辨率遥感图像中,由于易混淆类别之间的像素分割错误减少,使用了树形结构的网络模型的整体分割准确率也有较大提升。关键词:卷积神经网络;遥感图像;语义分割;树形结构;Deeplab v3+79|62|5更新时间:2024-05-08
摘要:目的高分辨率遥感图像通常包含复杂的语义信息与易混淆的目标,对其语义分割是一项重要且具有挑战性的任务。基于DeepLab V3+网络结构,结合树形神经网络结构模块,设计出一种针对高分辨率遥感图像的语义分割网络。方法提出的网络结构不仅对DeepLab V3+做出了修改,使其适用于多尺度、多模态的数据,而且在其后添加连接树形神经网络结构模块。树形结构通过建立混淆矩阵、提取混淆图、构建图分割,能够对易混淆的像素更好地区分,得到更准确的分割结果。结果在国际摄影测量及遥感探测学会(International Society for Photogrammetry and Remote Sensing,ISPRS)提供的两个不同城市的遥感影像集上分别进行了实验,模型在整体准确率(overall accuracy,OA)这一项表现最好,在Vaihingen和Potsdam数据集上分别达到了90.4%和90.7%,其整体分割准确率较其基准结果有10.3%和17.4%的提升,对比ISPRS官方网站上的3种先进方法也有显著提升。结论提出结合DeepLab V3+和树形结构的卷积神经网络,有效提升了高分辨率遥感图像语义分割整体精度,其中易混淆类别数据的分割准确率显著提高。在包含复杂语义信息的高分辨率遥感图像中,由于易混淆类别之间的像素分割错误减少,使用了树形结构的网络模型的整体分割准确率也有较大提升。关键词:卷积神经网络;遥感图像;语义分割;树形结构;Deeplab v3+79|62|5更新时间:2024-05-08 -
 摘要:目的高光谱图像具有高维度的光谱结构,而且邻近波段之间往往存在大量冗余信息,导致在随机样本选择策略和图像分类过程中出现选择波段算法复杂度较高和不适合小样本的现象。针对该问题,在集成学习算法的基础上,考虑不同波段在高光谱图像分类过程中的作用不同,提出一种融合累积变异比和超限学习机的高光谱图像分类算法。方法定义波段的累积变异比函数来确定各波段在分类算法的贡献程度。基于累积变异比函数剔除低效波段,并结合空谱特征进行平均分组加权随机选择策略进行数据降维。为了进一步提高算法的泛化能力,对降维后提取的空谱特征进行多次样本重采样,训练得到多个超限学习机弱分类器,再将多个弱分类器的结果通过投票表决法得到最后的分类结果。结果实验使用Indian Pines、Pavia University scene和Salinas这3种典型的高光谱图像作为实验标准数据集,采用支持向量机(support vector machine,SVM),超限学习机(extreme learning machine,ELM),基于二进制多层Gabor超限学习机(ELM with Gabor,GELM),核函数超限学习机(ELM with kernel,KELM),GELM-CK(GELM with composite kernel),KELM-CK(KELM with composite kernel)和SS-EELM(spatial-spectral and ensemble ELM)为标准检测算法验证本文算法的有效性,在样本比例较小的实验中,本文算法的总体分类精度在3种数据集中分别为98.0%、98.9%和97.9%,比其他算法平均分别高出9.6%和4.7%和4.1%。本文算法耗时在3种数据集中分别为15.2 s、60.4 s和169.4 s。在同类目标空谱特性差异较大的情况下,相比于分类精度较高的KELM-CK和SS-EELM算法减少了算法耗时,提高了总体分类精度;在同类目标空谱特性相近的情况下,相比于其他算法,样本数量的增加对本文算法的耗时影响较小。结论本文算法通过波段的累积变异比函数优化了平均分组波段选择策略,针对各类地物目标分布较广泛并且同类目标空谱特性差异较大的高光谱数据集,能够有效提取特征光谱维度的差异性,确定参数较少,总体分类效果较好。关键词:高光谱图像;超限学习机;累积变异比;投票表决;分类15|15|2更新时间:2024-05-08
摘要:目的高光谱图像具有高维度的光谱结构,而且邻近波段之间往往存在大量冗余信息,导致在随机样本选择策略和图像分类过程中出现选择波段算法复杂度较高和不适合小样本的现象。针对该问题,在集成学习算法的基础上,考虑不同波段在高光谱图像分类过程中的作用不同,提出一种融合累积变异比和超限学习机的高光谱图像分类算法。方法定义波段的累积变异比函数来确定各波段在分类算法的贡献程度。基于累积变异比函数剔除低效波段,并结合空谱特征进行平均分组加权随机选择策略进行数据降维。为了进一步提高算法的泛化能力,对降维后提取的空谱特征进行多次样本重采样,训练得到多个超限学习机弱分类器,再将多个弱分类器的结果通过投票表决法得到最后的分类结果。结果实验使用Indian Pines、Pavia University scene和Salinas这3种典型的高光谱图像作为实验标准数据集,采用支持向量机(support vector machine,SVM),超限学习机(extreme learning machine,ELM),基于二进制多层Gabor超限学习机(ELM with Gabor,GELM),核函数超限学习机(ELM with kernel,KELM),GELM-CK(GELM with composite kernel),KELM-CK(KELM with composite kernel)和SS-EELM(spatial-spectral and ensemble ELM)为标准检测算法验证本文算法的有效性,在样本比例较小的实验中,本文算法的总体分类精度在3种数据集中分别为98.0%、98.9%和97.9%,比其他算法平均分别高出9.6%和4.7%和4.1%。本文算法耗时在3种数据集中分别为15.2 s、60.4 s和169.4 s。在同类目标空谱特性差异较大的情况下,相比于分类精度较高的KELM-CK和SS-EELM算法减少了算法耗时,提高了总体分类精度;在同类目标空谱特性相近的情况下,相比于其他算法,样本数量的增加对本文算法的耗时影响较小。结论本文算法通过波段的累积变异比函数优化了平均分组波段选择策略,针对各类地物目标分布较广泛并且同类目标空谱特性差异较大的高光谱数据集,能够有效提取特征光谱维度的差异性,确定参数较少,总体分类效果较好。关键词:高光谱图像;超限学习机;累积变异比;投票表决;分类15|15|2更新时间:2024-05-08
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0