
最新刊期
2020 年 第 25 卷 第 4 期
-
 摘要:目标检测的任务是从图像中精确且高效地识别、定位出大量预定义类别的物体实例。随着深度学习的广泛应用,目标检测的精确度和效率都得到了较大提升,但基于深度学习的目标检测仍面临改进与优化主流目标检测算法的性能、提高小目标物体检测精度、实现多类别物体检测、轻量化检测模型等关键技术的挑战。针对上述挑战,本文在广泛文献调研的基础上,从双阶段、单阶段目标检测算法的改进与结合的角度分析了改进与优化主流目标检测算法的方法,从骨干网络、增加视觉感受野、特征融合、级联卷积神经网络和模型的训练方式的角度分析了提升小目标检测精度的方法,从训练方式和网络结构的角度分析了用于多类别物体检测的方法,从网络结构的角度分析了用于轻量化检测模型的方法。此外,对目标检测的通用数据集进行了详细介绍,从4个方面对该领域代表性算法的性能表现进行了对比分析,对目标检测中待解决的问题与未来研究方向做出预测和展望。目标检测研究是计算机视觉和模式识别中备受青睐的热点,仍然有更多高精度和高效的算法相继提出,未来将朝着更多的研究方向发展。关键词:目标检测;深度学习;小目标;多类别;轻量化404|245|85更新时间:2024-05-07
摘要:目标检测的任务是从图像中精确且高效地识别、定位出大量预定义类别的物体实例。随着深度学习的广泛应用,目标检测的精确度和效率都得到了较大提升,但基于深度学习的目标检测仍面临改进与优化主流目标检测算法的性能、提高小目标物体检测精度、实现多类别物体检测、轻量化检测模型等关键技术的挑战。针对上述挑战,本文在广泛文献调研的基础上,从双阶段、单阶段目标检测算法的改进与结合的角度分析了改进与优化主流目标检测算法的方法,从骨干网络、增加视觉感受野、特征融合、级联卷积神经网络和模型的训练方式的角度分析了提升小目标检测精度的方法,从训练方式和网络结构的角度分析了用于多类别物体检测的方法,从网络结构的角度分析了用于轻量化检测模型的方法。此外,对目标检测的通用数据集进行了详细介绍,从4个方面对该领域代表性算法的性能表现进行了对比分析,对目标检测中待解决的问题与未来研究方向做出预测和展望。目标检测研究是计算机视觉和模式识别中备受青睐的热点,仍然有更多高精度和高效的算法相继提出,未来将朝着更多的研究方向发展。关键词:目标检测;深度学习;小目标;多类别;轻量化404|245|85更新时间:2024-05-07
综述

-
 摘要:目的人脸图像蕴含着丰富的个人敏感信息,直接发布可能会造成个人隐私泄露。为了保护人脸图像中的隐私信息,提出3种基于矩阵分解与差分隐私技术相结合的人脸图像发布算法,即LRA(low rank-based private facial image release algorithm)、SRA(SVD-based private facial image release algorithm)和ESRA(enhanced SVD-based private facial image release algorithm)。方法为了减少拉普拉斯机制带来的噪音误差,3种算法均将人脸图像作为实数域2维矩阵,充分利用矩阵低秩分解与奇异值分解技术压缩图像。在SRA和ESRA算法中,如何选择矩阵压缩参数r会直接制约由拉普拉斯机制引起的噪音误差以及由矩阵压缩导致的重构误差。SRA算法利用启发式设置参数r,然而r值增大导致过大的噪音误差,r值减小导致过大的重构误差。为了有效均衡这两种误差,ESRA算法引入一种基于指数机制的挑选参数r的方法,能够在不同的分解矩阵中挑选合理的矩阵尺寸来压缩人脸图像,然后利用拉普拉斯机制对挑选的矩阵添加相应的噪音,进而使整个处理过程满足ε-差分隐私。结果基于6种真实人脸图像数据集,采用支持向量机(support vector machine,SVM)分类技术与信息熵验证6种算法的正确性。从算法的准确率、召回率、F1-Score,以及信息熵度量结果显示,提出的LRA、SRA与ESRA算法均优于LAP(Laplace-based facial image protection)、LRM(low-rank mechanism)以及MM(matrix mechanism)算法,其中ESRA算法在Faces95数据集上的准确率和F1-Score分别是LRA、LRM和MM算法的40倍、20倍和1倍多。相对于其他5种算法,ESRA算法对数据集大的变化相对稳定,可用性最好。结论本文算法能够实现满足ε-差分隐私的敏感人脸图像发布,具有较好的可用性与鲁棒性,并且为灰度人脸图像的隐私保护提供了新的指导方法与思路,能有效用于社交平台和医疗系统等领域。关键词:人脸图像;隐私保护;差分隐私;矩阵分解;低秩分解;奇异值分解77|109|3更新时间:2024-05-07
摘要:目的人脸图像蕴含着丰富的个人敏感信息,直接发布可能会造成个人隐私泄露。为了保护人脸图像中的隐私信息,提出3种基于矩阵分解与差分隐私技术相结合的人脸图像发布算法,即LRA(low rank-based private facial image release algorithm)、SRA(SVD-based private facial image release algorithm)和ESRA(enhanced SVD-based private facial image release algorithm)。方法为了减少拉普拉斯机制带来的噪音误差,3种算法均将人脸图像作为实数域2维矩阵,充分利用矩阵低秩分解与奇异值分解技术压缩图像。在SRA和ESRA算法中,如何选择矩阵压缩参数r会直接制约由拉普拉斯机制引起的噪音误差以及由矩阵压缩导致的重构误差。SRA算法利用启发式设置参数r,然而r值增大导致过大的噪音误差,r值减小导致过大的重构误差。为了有效均衡这两种误差,ESRA算法引入一种基于指数机制的挑选参数r的方法,能够在不同的分解矩阵中挑选合理的矩阵尺寸来压缩人脸图像,然后利用拉普拉斯机制对挑选的矩阵添加相应的噪音,进而使整个处理过程满足ε-差分隐私。结果基于6种真实人脸图像数据集,采用支持向量机(support vector machine,SVM)分类技术与信息熵验证6种算法的正确性。从算法的准确率、召回率、F1-Score,以及信息熵度量结果显示,提出的LRA、SRA与ESRA算法均优于LAP(Laplace-based facial image protection)、LRM(low-rank mechanism)以及MM(matrix mechanism)算法,其中ESRA算法在Faces95数据集上的准确率和F1-Score分别是LRA、LRM和MM算法的40倍、20倍和1倍多。相对于其他5种算法,ESRA算法对数据集大的变化相对稳定,可用性最好。结论本文算法能够实现满足ε-差分隐私的敏感人脸图像发布,具有较好的可用性与鲁棒性,并且为灰度人脸图像的隐私保护提供了新的指导方法与思路,能有效用于社交平台和医疗系统等领域。关键词:人脸图像;隐私保护;差分隐私;矩阵分解;低秩分解;奇异值分解77|109|3更新时间:2024-05-07
图像处理和编码
-
 摘要:目的图像的变化检测是视觉领域的一个重要问题,传统的变化检测对光照变化、相机位姿差异过于敏感,使得在真实场景中检测结果较差。鉴于卷积神经网络(convolutional neural networks,CNN)可以提取图像中的深度语义特征,提出一种基于多尺度深度特征融合的变化检测模型,通过提取并融合图像的高级语义特征来克服检测噪音。方法使用VGG(visual geometry group)16作为网络的基本模型,采用孪生网络结构,分别从参考图像和查询图像中提取不同网络层的深度特征。将两幅图像对应网络层的深度特征拼接后送入一个编码层,通过编码层逐步将高层与低层网络特征进行多尺度融合,充分结合高层的语义和低层的纹理特征,检测出准确的变化区域。使用卷积层对每一个编码层的特征进行运算产生对应尺度的预测结果。将不同尺度的预测结果融合得到进一步细化的检测结果。结果与SC_SOBS(SC-self-organizing background subtraction)、SuBSENSE(self-balanced sensitivity segmenter)、FGCD(fine-grained change detection)和全卷积网络(fully convolutional network,FCN)4种检测方法进行对比。与性能第2的模型FCN相比,本文方法在VL_CMU_CD(visual localization of Carnegie Mellon University for change detection)数据集中,综合评价指标F1值和精度值分别提高了12.2%和24.4%;在PCD(panoramic change detection)数据集中,F1值和精度值分别提高了2.1%和17.7%;在CDnet(change detection net)数据集中,F1值和精度值分别提高了8.5%和5.8%。结论本文提出的基于多尺度深度特征融合的变化检测方法,利用卷积神经网络的不同网络层特征,有效克服了光照和相机位姿差异,在不同数据集上均能得到较为鲁棒的变化检测结果。关键词:变化检测;特征融合;多尺度;孪生网络;深度学习51|30|6更新时间:2024-05-07
摘要:目的图像的变化检测是视觉领域的一个重要问题,传统的变化检测对光照变化、相机位姿差异过于敏感,使得在真实场景中检测结果较差。鉴于卷积神经网络(convolutional neural networks,CNN)可以提取图像中的深度语义特征,提出一种基于多尺度深度特征融合的变化检测模型,通过提取并融合图像的高级语义特征来克服检测噪音。方法使用VGG(visual geometry group)16作为网络的基本模型,采用孪生网络结构,分别从参考图像和查询图像中提取不同网络层的深度特征。将两幅图像对应网络层的深度特征拼接后送入一个编码层,通过编码层逐步将高层与低层网络特征进行多尺度融合,充分结合高层的语义和低层的纹理特征,检测出准确的变化区域。使用卷积层对每一个编码层的特征进行运算产生对应尺度的预测结果。将不同尺度的预测结果融合得到进一步细化的检测结果。结果与SC_SOBS(SC-self-organizing background subtraction)、SuBSENSE(self-balanced sensitivity segmenter)、FGCD(fine-grained change detection)和全卷积网络(fully convolutional network,FCN)4种检测方法进行对比。与性能第2的模型FCN相比,本文方法在VL_CMU_CD(visual localization of Carnegie Mellon University for change detection)数据集中,综合评价指标F1值和精度值分别提高了12.2%和24.4%;在PCD(panoramic change detection)数据集中,F1值和精度值分别提高了2.1%和17.7%;在CDnet(change detection net)数据集中,F1值和精度值分别提高了8.5%和5.8%。结论本文提出的基于多尺度深度特征融合的变化检测方法,利用卷积神经网络的不同网络层特征,有效克服了光照和相机位姿差异,在不同数据集上均能得到较为鲁棒的变化检测结果。关键词:变化检测;特征融合;多尺度;孪生网络;深度学习51|30|6更新时间:2024-05-07 -
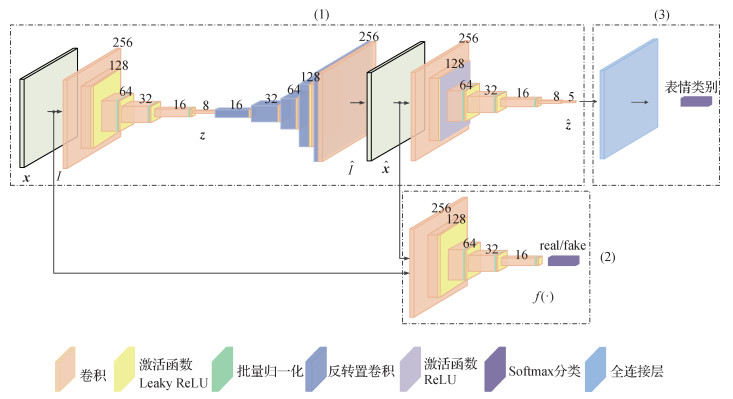 摘要:目的为解决真实环境中由类内差距引起的面部表情识别率低及室内外复杂环境对类内差距较大的面部表情识别难度大等问题,提出一种利用生成对抗网络(generative adversarial network,GAN)识别面部表情的方法。方法在GAN生成对抗的思想下,构建一种IC-GAN(intra-class gap GAN)网络结构,使用卷积组建编码器、解码器对自制混合表情图像进行更深层次的特征提取,使用基于动量的Adam(adaptive moment estimation)优化算法进行网络权重更新,重点针对真实环境面部表情识别过程中的类内差距较大的表情进行识别,使其更好地适应类内差异较大的任务。结果基于Pytorch环境,在自制的面部表情数据集上进行训练,在面部表情验证集上进行测试,并与深度置信网络(deep belief network,DBN)和GoogLeNet网络进行对比实验,最终IC-GAN网络的识别结果比DBN网络和GoogLeNet网络分别提高11%和8.3%。结论实验验证了IC-GAN在类内差距较大的面部表情识别中的精度,降低了面部表情在类内差距较大情况下的误识率,提高了系统鲁棒性,为面部表情的生成工作打下了坚实的基础。关键词:深度学习;生成对抗网络;IC-GAN(intra-class gap GAN);面部表情识别50|80|1更新时间:2024-05-07
摘要:目的为解决真实环境中由类内差距引起的面部表情识别率低及室内外复杂环境对类内差距较大的面部表情识别难度大等问题,提出一种利用生成对抗网络(generative adversarial network,GAN)识别面部表情的方法。方法在GAN生成对抗的思想下,构建一种IC-GAN(intra-class gap GAN)网络结构,使用卷积组建编码器、解码器对自制混合表情图像进行更深层次的特征提取,使用基于动量的Adam(adaptive moment estimation)优化算法进行网络权重更新,重点针对真实环境面部表情识别过程中的类内差距较大的表情进行识别,使其更好地适应类内差异较大的任务。结果基于Pytorch环境,在自制的面部表情数据集上进行训练,在面部表情验证集上进行测试,并与深度置信网络(deep belief network,DBN)和GoogLeNet网络进行对比实验,最终IC-GAN网络的识别结果比DBN网络和GoogLeNet网络分别提高11%和8.3%。结论实验验证了IC-GAN在类内差距较大的面部表情识别中的精度,降低了面部表情在类内差距较大情况下的误识率,提高了系统鲁棒性,为面部表情的生成工作打下了坚实的基础。关键词:深度学习;生成对抗网络;IC-GAN(intra-class gap GAN);面部表情识别50|80|1更新时间:2024-05-07 -
 摘要:目的维吾尔文属于黏着性语言,其组成方式是在词干上添加词缀来实现不同的语义,在添加词缀的过程中词干的尾部会发生一定的形态变化,而且词干添加词缀的时候也可能会发生弱化、脱落、增音等音变现象导致进一步的形态变化,所以利用目前的图像文字检索(word spotting)技术只能检索到某一具体的维吾尔文词汇,却不能以某一词干为检索词,检索出其对应的带后缀的词语。为此,提出了基于映射关系的带后缀印刷体维吾尔文词语检索技术。方法首先利用局部特征对维吾尔文词图像进行特征提取,其次将获得的特征用快速最近邻搜索(fast library for approximate nearest neighbors,FLANN)双向匹配来获得特征匹配集,最后将特征匹配集进行单应性变换和透视变换到待检索维吾尔文词图像上,把特征匹配集转化为空间关系,经过映射匹配对特征匹配集的空间关系进行后缀词检索,从而实现印刷体维吾尔文图像带后缀词检索的需求。结果实验数据选取190幅维吾尔文印刷体文本图像中的17 648幅切割词图像,并对其中30幅词图像的167幅后缀词图像进行后缀检索,采用不同的局部特征算法进行后缀检索对比,结果表明,尺度不变特征变换(scale-invariant feature transform,SIFT)算法的后缀检索效果优于SURF(speeded up robust features)算法,精确率和召回率分别达到了94.23%和88.02%,在印刷体文档图像中,可以高效地检索到词干组成的后缀词,能够满足用户的不同检索需求,具有普适性。在弱化、脱落、增音和多种音变同时出现以及词干尾部发生变化的不同情况下进行后缀检索对比实验,实验结果表明在弱化和词干尾部变化而导致的形态变化中,检索效率最佳。结论本文提出的基于映射关系进行后缀词图像检索的方法,是第一次对维吾尔文带后缀词检索方式的一种实现,利用匹配集之间的空间关系,对维吾尔文带后缀词图像实现了高效检索的目的。关键词:维吾尔文;带后缀词检索;局部特征;单应矩阵;透视变换20|24|0更新时间:2024-05-07
摘要:目的维吾尔文属于黏着性语言,其组成方式是在词干上添加词缀来实现不同的语义,在添加词缀的过程中词干的尾部会发生一定的形态变化,而且词干添加词缀的时候也可能会发生弱化、脱落、增音等音变现象导致进一步的形态变化,所以利用目前的图像文字检索(word spotting)技术只能检索到某一具体的维吾尔文词汇,却不能以某一词干为检索词,检索出其对应的带后缀的词语。为此,提出了基于映射关系的带后缀印刷体维吾尔文词语检索技术。方法首先利用局部特征对维吾尔文词图像进行特征提取,其次将获得的特征用快速最近邻搜索(fast library for approximate nearest neighbors,FLANN)双向匹配来获得特征匹配集,最后将特征匹配集进行单应性变换和透视变换到待检索维吾尔文词图像上,把特征匹配集转化为空间关系,经过映射匹配对特征匹配集的空间关系进行后缀词检索,从而实现印刷体维吾尔文图像带后缀词检索的需求。结果实验数据选取190幅维吾尔文印刷体文本图像中的17 648幅切割词图像,并对其中30幅词图像的167幅后缀词图像进行后缀检索,采用不同的局部特征算法进行后缀检索对比,结果表明,尺度不变特征变换(scale-invariant feature transform,SIFT)算法的后缀检索效果优于SURF(speeded up robust features)算法,精确率和召回率分别达到了94.23%和88.02%,在印刷体文档图像中,可以高效地检索到词干组成的后缀词,能够满足用户的不同检索需求,具有普适性。在弱化、脱落、增音和多种音变同时出现以及词干尾部发生变化的不同情况下进行后缀检索对比实验,实验结果表明在弱化和词干尾部变化而导致的形态变化中,检索效率最佳。结论本文提出的基于映射关系进行后缀词图像检索的方法,是第一次对维吾尔文带后缀词检索方式的一种实现,利用匹配集之间的空间关系,对维吾尔文带后缀词图像实现了高效检索的目的。关键词:维吾尔文;带后缀词检索;局部特征;单应矩阵;透视变换20|24|0更新时间:2024-05-07 -
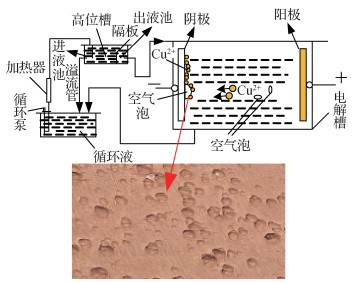 摘要:目的铜电解过程中常因电解液溶解气体过饱阻止铜离子析出而在铜板表面形成凸起,常由操作员目视对铜板表面质量进行鉴别以决定归类,针对人工判别电解阴极铜板表面质量准确度和效率都较低的问题,提出一种结合混沌鸟群算法的铜板表面凸起智能识别方法。方法为增强算法的全局搜索能力,引入鸟群算法;选取鸟群劣质个体交替进行混和动态步长位置更新增加种群多样性以免陷入局部最优;对铜板表面缺陷进行分析,提出基点生长法并结合形态学开操作消除铜板图像纹理以提高算法对凸起面积计算的准确性。将最佳熵阈值确定法(Kapur-Sahoo-Wong,KSW)作为鸟群算法的适应度函数对铜板图像进行阈值分割,通过统计分割图像凸起像素点个数,得到实际凸起面积占比以决定铜板是否合格。结果将本文算法与遗传算法(genetic algorithm,GA)、鸡群算法(chicken swarm optimization,CSO)、萤火虫算法(glowworm swarm optimization,GSO)及鸟群算法(bird swarm algorithm,BSA)4种算法分别在时间、适应度值和结构相似度(structural similarity index measurement,SSIM)3个指标下分析对比,实验结果表明,本文算法适应度值可提高0.0030.701,SSIM值可提高0.0750.169。结论本文方法能有效检测铜板表面凸起面积占比并对其进行合格品、次品分类。关键词:铜板缺陷;阈值分割;鸟群算法;混沌理论;基点生长法;KSW熵法56|70|1更新时间:2024-05-07
摘要:目的铜电解过程中常因电解液溶解气体过饱阻止铜离子析出而在铜板表面形成凸起,常由操作员目视对铜板表面质量进行鉴别以决定归类,针对人工判别电解阴极铜板表面质量准确度和效率都较低的问题,提出一种结合混沌鸟群算法的铜板表面凸起智能识别方法。方法为增强算法的全局搜索能力,引入鸟群算法;选取鸟群劣质个体交替进行混和动态步长位置更新增加种群多样性以免陷入局部最优;对铜板表面缺陷进行分析,提出基点生长法并结合形态学开操作消除铜板图像纹理以提高算法对凸起面积计算的准确性。将最佳熵阈值确定法(Kapur-Sahoo-Wong,KSW)作为鸟群算法的适应度函数对铜板图像进行阈值分割,通过统计分割图像凸起像素点个数,得到实际凸起面积占比以决定铜板是否合格。结果将本文算法与遗传算法(genetic algorithm,GA)、鸡群算法(chicken swarm optimization,CSO)、萤火虫算法(glowworm swarm optimization,GSO)及鸟群算法(bird swarm algorithm,BSA)4种算法分别在时间、适应度值和结构相似度(structural similarity index measurement,SSIM)3个指标下分析对比,实验结果表明,本文算法适应度值可提高0.0030.701,SSIM值可提高0.0750.169。结论本文方法能有效检测铜板表面凸起面积占比并对其进行合格品、次品分类。关键词:铜板缺陷;阈值分割;鸟群算法;混沌理论;基点生长法;KSW熵法56|70|1更新时间:2024-05-07 -
 摘要:目的复杂场景下目标频繁且长时间的遮挡、跟踪目标外观相似引起身份转换等问题给多目标跟踪带来许多挑战。针对多目标跟踪在复杂场景中因长时间遮挡引起身份转换和轨迹分段的问题,提出一种基于自适应在线判别外观学习的分层关联多目标跟踪算法。方法利用轨迹置信度将多目标跟踪分为局部关联和全局关联两个层次。在局部关联中,置信度高的可靠轨迹利用外观、位置-大小相似度与当前帧检测点进行关联;在全局关联中,置信度低的不可靠轨迹引入运动模型和有效关联范围进一步关联分段的轨迹。在提取目标外观特征时引入增量线性可判别分析方法以解决身份转换问题,依据新增样本与目标样本均值的外观特征差异自适应地更新目标外观模型。结果在公开数据集2D MOT2015中的PETS09-S2L1、TUD-Stadmitte、Town-Center 3个数据集中与当前10种多目标跟踪算法进行比较,该方法对各个数据集身份转换和轨迹分段都有减少,其中在Town-Center数据集中,身份转换减少了60个,轨迹分段减少了84个,跟踪准确度提高了5.2%以上。结论本文多目标跟踪方法,能够在复杂场景中稳定有效地实现多目标跟踪,减少轨迹分段现象,其中引入的在线线性可判别外观学习对遮挡产生的身份转换具有良好的解决效果。关键词:多目标跟踪;局部关联;全局关联;轨迹置信度;增量线性可判别分析45|218|6更新时间:2024-05-07
摘要:目的复杂场景下目标频繁且长时间的遮挡、跟踪目标外观相似引起身份转换等问题给多目标跟踪带来许多挑战。针对多目标跟踪在复杂场景中因长时间遮挡引起身份转换和轨迹分段的问题,提出一种基于自适应在线判别外观学习的分层关联多目标跟踪算法。方法利用轨迹置信度将多目标跟踪分为局部关联和全局关联两个层次。在局部关联中,置信度高的可靠轨迹利用外观、位置-大小相似度与当前帧检测点进行关联;在全局关联中,置信度低的不可靠轨迹引入运动模型和有效关联范围进一步关联分段的轨迹。在提取目标外观特征时引入增量线性可判别分析方法以解决身份转换问题,依据新增样本与目标样本均值的外观特征差异自适应地更新目标外观模型。结果在公开数据集2D MOT2015中的PETS09-S2L1、TUD-Stadmitte、Town-Center 3个数据集中与当前10种多目标跟踪算法进行比较,该方法对各个数据集身份转换和轨迹分段都有减少,其中在Town-Center数据集中,身份转换减少了60个,轨迹分段减少了84个,跟踪准确度提高了5.2%以上。结论本文多目标跟踪方法,能够在复杂场景中稳定有效地实现多目标跟踪,减少轨迹分段现象,其中引入的在线线性可判别外观学习对遮挡产生的身份转换具有良好的解决效果。关键词:多目标跟踪;局部关联;全局关联;轨迹置信度;增量线性可判别分析45|218|6更新时间:2024-05-07
图像分析和识别
-
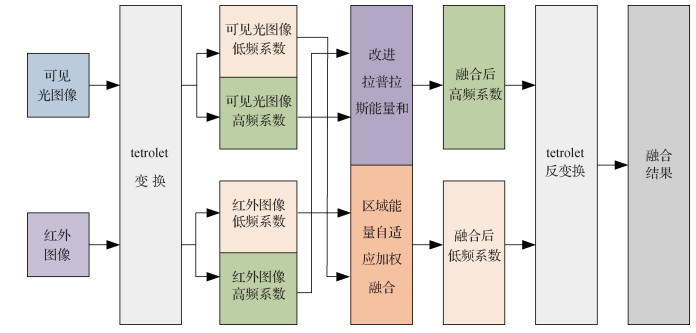 摘要:目的红外与可见光图像融合算法大部分可以达到认知场景的目的,但是无法对场景中的细节特征进行更加细致的刻画。为进一步提高场景辨识度,提出一种基于tetrolet变换的多尺度几何变换图像融合算法。方法首先,将红外与可见光图像映射到tetrolet变换域,并将二者分解为低频系数和高频系数。然后,对低频系数,将区域能量理论与传统的加权法相结合,利用区域能量的多变性和区域像素的相关性,自适应地选择加权系数进行融合;对高频系数,利用改进的多方向拉普拉斯算子方法计算拉普拉斯能量和,再引入区域平滑度为阈值设定高频系数融合规则。最后,将融合所得新的低频和高频系数进行图像重建得到融合结果。结果在kaptein、street和road等3组红外与可见光图像上,与轮廓波变换(contourlet transformation,CL)、离散小波变换(discrete wavelet transformation,DWT)和非下采样轮廓波变换(nonsubsampled contourlet transformation,NSCT)等3种方法的融合结果进行比较,主观评判上,本文算法融合结果在背景、目标物以及细节体现方面均优于其他3种方法;客观指标上,本文算法相较于其他3种方法,运行时间较NSCT方法提升了0.37 s,平均梯度(average gradient,AvG)值和空间频率(spatial frequency,SF)值均有大幅提高,提高幅度最大为5.42和2.75,峰值信噪比(peak signal to noise ratio,PSNR)值、信息熵(information entropy,IE)值和结构相似性(structural similarity index,SSIM)值分别提高0.25、0.12和0.19。结论本文提出的红外与可见光图像融合算法改善了融合图像的细节刻画,使观察者对场景的理解能力有所提升。关键词:图像融合;tetrolet变换;区域能量自适应;拉普拉斯算子;拉普拉斯能量和37|22|10更新时间:2024-05-07
摘要:目的红外与可见光图像融合算法大部分可以达到认知场景的目的,但是无法对场景中的细节特征进行更加细致的刻画。为进一步提高场景辨识度,提出一种基于tetrolet变换的多尺度几何变换图像融合算法。方法首先,将红外与可见光图像映射到tetrolet变换域,并将二者分解为低频系数和高频系数。然后,对低频系数,将区域能量理论与传统的加权法相结合,利用区域能量的多变性和区域像素的相关性,自适应地选择加权系数进行融合;对高频系数,利用改进的多方向拉普拉斯算子方法计算拉普拉斯能量和,再引入区域平滑度为阈值设定高频系数融合规则。最后,将融合所得新的低频和高频系数进行图像重建得到融合结果。结果在kaptein、street和road等3组红外与可见光图像上,与轮廓波变换(contourlet transformation,CL)、离散小波变换(discrete wavelet transformation,DWT)和非下采样轮廓波变换(nonsubsampled contourlet transformation,NSCT)等3种方法的融合结果进行比较,主观评判上,本文算法融合结果在背景、目标物以及细节体现方面均优于其他3种方法;客观指标上,本文算法相较于其他3种方法,运行时间较NSCT方法提升了0.37 s,平均梯度(average gradient,AvG)值和空间频率(spatial frequency,SF)值均有大幅提高,提高幅度最大为5.42和2.75,峰值信噪比(peak signal to noise ratio,PSNR)值、信息熵(information entropy,IE)值和结构相似性(structural similarity index,SSIM)值分别提高0.25、0.12和0.19。结论本文提出的红外与可见光图像融合算法改善了融合图像的细节刻画,使观察者对场景的理解能力有所提升。关键词:图像融合;tetrolet变换;区域能量自适应;拉普拉斯算子;拉普拉斯能量和37|22|10更新时间:2024-05-07 -
 摘要:目的跨年龄素描-照片转换旨在根据面部素描图像合成同一人物不同年龄阶段的面部照片图像。该任务在公共安全和数字娱乐等领域具有广泛的应用价值,然而由于配对样本难以收集和人脸老化机制复杂等原因,目前研究较少。针对此情况,提出一种基于双重对偶生成对抗网络(double dual generative adversarial networks,D-DualGANs)的跨年龄素描-照片转换方法。方法该网络通过设置4个生成器和4个判别器,以对抗训练的方式,分别学习素描到照片、源年龄组到目标年龄组的正向及反向映射。使素描图像与照片图像的生成过程相结合,老化图像与退龄图像的生成过程相结合,分别实现图像风格属性和年龄属性上的对偶。并增加重构身份损失和完全重构损失以约束图像生成。最终使输入的来自不同年龄组的素描图像和照片图像,分别转换成对方年龄组下的照片和素描。结果为香港中文大学面部素描数据集(Chinese University of Hong Kong(CUHK)face sketch database,CUFS)和香港中文大学面部素描人脸识别技术数据集(CUHK face sketch face recognition technology database,CUFSF)的图像制作对应的年龄标签,并依据标签将图像分成3个年龄组,共训练6个D-DualGANs模型以实现3个年龄组图像之间的两两转换。同非端到端的方法相比,本文方法生成图像的变形和噪声更小,且年龄平均绝对误差(mean absolute error,MAE)更低,与原图像相似度的投票对比表明11~30素描与31~50照片的转换效果最好。结论双重对偶生成对抗网络可以同时转换输入图像的年龄和风格属性,且生成的图像有效保留了原图像的身份特征,有效解决了图像跨风格且跨年龄的转换问题。关键词:生成对抗网络;图像转换;人脸老化;异质图像合成;人脸素描合成71|172|2更新时间:2024-05-07
摘要:目的跨年龄素描-照片转换旨在根据面部素描图像合成同一人物不同年龄阶段的面部照片图像。该任务在公共安全和数字娱乐等领域具有广泛的应用价值,然而由于配对样本难以收集和人脸老化机制复杂等原因,目前研究较少。针对此情况,提出一种基于双重对偶生成对抗网络(double dual generative adversarial networks,D-DualGANs)的跨年龄素描-照片转换方法。方法该网络通过设置4个生成器和4个判别器,以对抗训练的方式,分别学习素描到照片、源年龄组到目标年龄组的正向及反向映射。使素描图像与照片图像的生成过程相结合,老化图像与退龄图像的生成过程相结合,分别实现图像风格属性和年龄属性上的对偶。并增加重构身份损失和完全重构损失以约束图像生成。最终使输入的来自不同年龄组的素描图像和照片图像,分别转换成对方年龄组下的照片和素描。结果为香港中文大学面部素描数据集(Chinese University of Hong Kong(CUHK)face sketch database,CUFS)和香港中文大学面部素描人脸识别技术数据集(CUHK face sketch face recognition technology database,CUFSF)的图像制作对应的年龄标签,并依据标签将图像分成3个年龄组,共训练6个D-DualGANs模型以实现3个年龄组图像之间的两两转换。同非端到端的方法相比,本文方法生成图像的变形和噪声更小,且年龄平均绝对误差(mean absolute error,MAE)更低,与原图像相似度的投票对比表明11~30素描与31~50照片的转换效果最好。结论双重对偶生成对抗网络可以同时转换输入图像的年龄和风格属性,且生成的图像有效保留了原图像的身份特征,有效解决了图像跨风格且跨年龄的转换问题。关键词:生成对抗网络;图像转换;人脸老化;异质图像合成;人脸素描合成71|172|2更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的针对图像合成配准算法中鲁棒性差及合成图像特征信息不足导致配准精度不高的问题,提出了基于残差密集相对平均条件生成对抗网络(residual dense-relativistic average conditional generative adversarial network,RD-RaCGAN)的多模态脑部图像配准方法。方法相对平均生成对抗网络中的相对平均鉴别器能够增强模型稳定性,条件生成对抗网络加入条件变量能提高生成数据质量,结合两种网络特点,利用残差密集块充分提取深层网络特征的能力,构建RD-RaCGAN合成模型。然后,待配准的参考CT(computed tomography)和浮动MR(magnetic resonance)图像通过已训练好的RD-RaCGAN合成模型双向合成对应的参考MR和浮动CT图像。采用区域自适应配准算法,从参考CT和浮动CT图像中选取骨骼信息的关键点,从浮动MR和参考MR图像中选取软组织信息的关键点,通过提取的关键点指导形变场的估计。从浮动CT图像到参考CT图像估计一个形变场。类似地,从浮动MR图像到参考MR图像估计一个形变场。另外,采用分层对称的思想进一步优化两个形变场,当两个形变场之间的差异达到最小时,将两个形变场融合得到最终的形变场,并将形变场作用于浮动图像完成配准。结果实验结果表明,与其他6种图像合成方法相比,本文模型合成的目标图像在视觉效果和客观评价指标上均优于其他方法。对比Powell优化的MI(mutual information)法、ANTs-SyN(advanced normalization toolbox-symmetric normalization)、D.Demons(diffeomorphic demons)、Cue-Aware Net(cue-aware deep regression network)和I-SI(intensity and spatial information)的图像配准方法,归一化互信息分别提高了43.71%、12.87%、10.59%、0.47%、5.59%,均方根误差均值分别下降了39.80%、38.67%、15.68%、4.38%、2.61%。结论本文提出的多模态脑部图像配准方法具有很强的鲁棒性,能够稳定、准确地完成图像配准任务。关键词:医学图像配准;图像合成;相对平均生成对抗网络;残差密集块;最小二乘;条件生成对抗网络(CGAN)79|87|3更新时间:2024-05-07
摘要:目的针对图像合成配准算法中鲁棒性差及合成图像特征信息不足导致配准精度不高的问题,提出了基于残差密集相对平均条件生成对抗网络(residual dense-relativistic average conditional generative adversarial network,RD-RaCGAN)的多模态脑部图像配准方法。方法相对平均生成对抗网络中的相对平均鉴别器能够增强模型稳定性,条件生成对抗网络加入条件变量能提高生成数据质量,结合两种网络特点,利用残差密集块充分提取深层网络特征的能力,构建RD-RaCGAN合成模型。然后,待配准的参考CT(computed tomography)和浮动MR(magnetic resonance)图像通过已训练好的RD-RaCGAN合成模型双向合成对应的参考MR和浮动CT图像。采用区域自适应配准算法,从参考CT和浮动CT图像中选取骨骼信息的关键点,从浮动MR和参考MR图像中选取软组织信息的关键点,通过提取的关键点指导形变场的估计。从浮动CT图像到参考CT图像估计一个形变场。类似地,从浮动MR图像到参考MR图像估计一个形变场。另外,采用分层对称的思想进一步优化两个形变场,当两个形变场之间的差异达到最小时,将两个形变场融合得到最终的形变场,并将形变场作用于浮动图像完成配准。结果实验结果表明,与其他6种图像合成方法相比,本文模型合成的目标图像在视觉效果和客观评价指标上均优于其他方法。对比Powell优化的MI(mutual information)法、ANTs-SyN(advanced normalization toolbox-symmetric normalization)、D.Demons(diffeomorphic demons)、Cue-Aware Net(cue-aware deep regression network)和I-SI(intensity and spatial information)的图像配准方法,归一化互信息分别提高了43.71%、12.87%、10.59%、0.47%、5.59%,均方根误差均值分别下降了39.80%、38.67%、15.68%、4.38%、2.61%。结论本文提出的多模态脑部图像配准方法具有很强的鲁棒性,能够稳定、准确地完成图像配准任务。关键词:医学图像配准;图像合成;相对平均生成对抗网络;残差密集块;最小二乘;条件生成对抗网络(CGAN)79|87|3更新时间:2024-05-07 -
 摘要:目的肺区分割是肺癌计算机辅助诊断系统的首要步骤。主动形状模型(active shape model,ASM)能根据训练集获得肺区形状模型,再结合待分割肺区影像自身的局部特征,进行测试影像的分割。由于主成分分析(principal component analysis,PCA)仅能去除服从高斯分布的噪声,不能处理其他类型的噪声,所以当训练集含有非高斯类型的噪声样本时,采用基于PCA的ASM无法训练出正确的形状模型,使得肺区分割不能得到正确的结果。而低秩(low rank,LR)理论的鲁棒主成分分析(robust principal component analysis,RPCA)能去除各种类型的噪声,基于此,本文提出一种将RPCA与ASM相结合的方法。方法首先对训练样本集标记点矩阵进行低秩分解,去除噪声样本对训练出的形状模型的影响。然后在ASM训练局部梯度模型时,用判断训练样本轮廓上的标记点曲率直方图的相似度来去除噪声样本。结果在训练集含噪声样本时,将基于RPCA的ASM与传统ASM(即基于PCA的ASM)分别生成的形状模型进行对比,发现基于RPCA的ASM生成的形状模型与训练集无噪声样本时传统ASM生成的形状模型更相符。在训练集含噪声样本的情况下,基于RPCA的ASM方法分割EMPIRE10数据集中的22个肺影像,与金标准的重叠度为94.5%,而基于PCA的ASM方法分割准确率仅为69.5%。结论实验结果表明,在训练样本集中有噪声样本的情况下,基于RPCA的ASM分割能得到比基于PCA的ASM更好的分割效果。关键词:低秩;主动形状模型;鲁棒主成分分析;肺区分割;噪声样本11|4|0更新时间:2024-05-07
摘要:目的肺区分割是肺癌计算机辅助诊断系统的首要步骤。主动形状模型(active shape model,ASM)能根据训练集获得肺区形状模型,再结合待分割肺区影像自身的局部特征,进行测试影像的分割。由于主成分分析(principal component analysis,PCA)仅能去除服从高斯分布的噪声,不能处理其他类型的噪声,所以当训练集含有非高斯类型的噪声样本时,采用基于PCA的ASM无法训练出正确的形状模型,使得肺区分割不能得到正确的结果。而低秩(low rank,LR)理论的鲁棒主成分分析(robust principal component analysis,RPCA)能去除各种类型的噪声,基于此,本文提出一种将RPCA与ASM相结合的方法。方法首先对训练样本集标记点矩阵进行低秩分解,去除噪声样本对训练出的形状模型的影响。然后在ASM训练局部梯度模型时,用判断训练样本轮廓上的标记点曲率直方图的相似度来去除噪声样本。结果在训练集含噪声样本时,将基于RPCA的ASM与传统ASM(即基于PCA的ASM)分别生成的形状模型进行对比,发现基于RPCA的ASM生成的形状模型与训练集无噪声样本时传统ASM生成的形状模型更相符。在训练集含噪声样本的情况下,基于RPCA的ASM方法分割EMPIRE10数据集中的22个肺影像,与金标准的重叠度为94.5%,而基于PCA的ASM方法分割准确率仅为69.5%。结论实验结果表明,在训练样本集中有噪声样本的情况下,基于RPCA的ASM分割能得到比基于PCA的ASM更好的分割效果。关键词:低秩;主动形状模型;鲁棒主成分分析;肺区分割;噪声样本11|4|0更新时间:2024-05-07
医学图像处理
-
 摘要:目的海岛作为一项特殊资源,在海洋开发和利用方面发挥着重要的作用;遥感作为一种非接触式远距离探测手段,为海岛研究提供了重要的数据来源;而深度学习因其对图像特征的提取能力和对复杂问题的拟合能力广泛应用于各个领域。本文结合深度学习的计算优势,兼顾遥感影像的波段数量多和覆盖范围大的特征,以海岛岸线的快速分割为目的,提出了一种改进的海岛岸线遥感影像分割模型。方法该分割模型包括3方面:1)针对遥感影像的多波段特征,提出基于最佳指数的遥感影像波段组合选择,将选择后的波段组合作为海岛岸线分割模型的输入数据;2)针对遥感影像大范围覆盖的特征,提出基于Deeplab神经网络结构的海岛岸线粗分割,将粗分割结果作为海岛岸线优化的初始边界;3)利用全连接条件随机场优化海岛岸线,实现海岛岸线的细分割提取。结果以大小不等的4个海岛的岸线提取为例,分别采用改进的海岛岸线分割模型、全卷积神经网络模型(fully convolutional networks,FCN)、Deeplab模型和目视解译法从遥感影像数据中分割海岛岸线。同时,引入平均交并比(mean intersection over union,MIoU)和相对误差,对各模型分割的海岛岸线结果进行精度比较。结果表明,本文改进的海岛岸线分割模型克服了FCN模型海岛岸线的不连续性问题,降低了海岛岸线的误分割现象;从MIoU值的比较可以看出,本文改进模型与目视解译的海岛岸线结果具有更高的吻合度,较FCN模型提高了17.7%,较Deeplab模型提高了5.2%;从海岸岸线的周长和面积的相对误差可以看出,本文改进模型的相对误差均低于FCN模型和Deeplab模型。结论本文改进模型包含了面向遥感影像的波段选择、利用神经网络训练的海岛岸线粗分割和基于全连接条件随机场的海岛岸线优化,在保证岸线连续性的前提下,提高了海岛岸线的分割精度。关键词:海岛岸线;图像分割;深度学习;最佳指数;Deeplab神经网络;全连接条件随机场83|5|4更新时间:2024-05-07
摘要:目的海岛作为一项特殊资源,在海洋开发和利用方面发挥着重要的作用;遥感作为一种非接触式远距离探测手段,为海岛研究提供了重要的数据来源;而深度学习因其对图像特征的提取能力和对复杂问题的拟合能力广泛应用于各个领域。本文结合深度学习的计算优势,兼顾遥感影像的波段数量多和覆盖范围大的特征,以海岛岸线的快速分割为目的,提出了一种改进的海岛岸线遥感影像分割模型。方法该分割模型包括3方面:1)针对遥感影像的多波段特征,提出基于最佳指数的遥感影像波段组合选择,将选择后的波段组合作为海岛岸线分割模型的输入数据;2)针对遥感影像大范围覆盖的特征,提出基于Deeplab神经网络结构的海岛岸线粗分割,将粗分割结果作为海岛岸线优化的初始边界;3)利用全连接条件随机场优化海岛岸线,实现海岛岸线的细分割提取。结果以大小不等的4个海岛的岸线提取为例,分别采用改进的海岛岸线分割模型、全卷积神经网络模型(fully convolutional networks,FCN)、Deeplab模型和目视解译法从遥感影像数据中分割海岛岸线。同时,引入平均交并比(mean intersection over union,MIoU)和相对误差,对各模型分割的海岛岸线结果进行精度比较。结果表明,本文改进的海岛岸线分割模型克服了FCN模型海岛岸线的不连续性问题,降低了海岛岸线的误分割现象;从MIoU值的比较可以看出,本文改进模型与目视解译的海岛岸线结果具有更高的吻合度,较FCN模型提高了17.7%,较Deeplab模型提高了5.2%;从海岸岸线的周长和面积的相对误差可以看出,本文改进模型的相对误差均低于FCN模型和Deeplab模型。结论本文改进模型包含了面向遥感影像的波段选择、利用神经网络训练的海岛岸线粗分割和基于全连接条件随机场的海岛岸线优化,在保证岸线连续性的前提下,提高了海岛岸线的分割精度。关键词:海岛岸线;图像分割;深度学习;最佳指数;Deeplab神经网络;全连接条件随机场83|5|4更新时间:2024-05-07 -
 摘要:目的时空分辨率较高的土壤湿度数据对于生产实践和科学研究具有重要意义。以国产的风云气象卫星为数据源,利用卷积神经网络自主学习输入变量间深层关联的优势,获取高质量土壤湿度数据,为科学研究和生产实践服务。方法首先构建了一个土壤湿度提取卷积神经网络(soil moisture convolutional neural network,SMCNN),SMCNN由温度子网络和土壤湿度子网络构成,每个子网络均包含特征提取器和编码器。特征提取器用于为每个像素生成一个特征向量,其中温度子网络的特征提取器由11个卷积层组成,湿度子网络的特征提取器由9个卷积层组成,卷积层均使用1×1的卷积核。编码器用于将提取到的特征拟合为目标变量。两个子网络均使用平均方差作为损失函数。使用随机梯度下降算法对模型进行训练,最后利用训练好的模型提取区域土壤湿度数据。结果选择宁夏回族自治区为实验区,利用获取的2016-2019年风云3D影像和相应地面站点数据作为实验数据,选择线性回归模型、BP(back propagation)神经网络模型作为对比模型开展数据实验,选择均方根误差作为评价指标。实验结果表明,SMCNN的均方根误差为0.006 7,优于对比模型,SMCNN模型在从风云影像中提取土壤湿度方面具有优势。结论本文利用卷积神经网络分别构建用于反演地表温度和土壤湿度的子网络,再组成一个完整的土壤湿度反演网络结构,从风云3D数据中获取数值精度、时空分辨率均较高的土壤湿度数据,满足了科学研究和生产实践对大范围高精度土壤湿度数据的需求。关键词:深度学习;卷积神经网络;风云3D;数据拟合;土壤湿度;宁夏回族自治区11|4|3更新时间:2024-05-07
摘要:目的时空分辨率较高的土壤湿度数据对于生产实践和科学研究具有重要意义。以国产的风云气象卫星为数据源,利用卷积神经网络自主学习输入变量间深层关联的优势,获取高质量土壤湿度数据,为科学研究和生产实践服务。方法首先构建了一个土壤湿度提取卷积神经网络(soil moisture convolutional neural network,SMCNN),SMCNN由温度子网络和土壤湿度子网络构成,每个子网络均包含特征提取器和编码器。特征提取器用于为每个像素生成一个特征向量,其中温度子网络的特征提取器由11个卷积层组成,湿度子网络的特征提取器由9个卷积层组成,卷积层均使用1×1的卷积核。编码器用于将提取到的特征拟合为目标变量。两个子网络均使用平均方差作为损失函数。使用随机梯度下降算法对模型进行训练,最后利用训练好的模型提取区域土壤湿度数据。结果选择宁夏回族自治区为实验区,利用获取的2016-2019年风云3D影像和相应地面站点数据作为实验数据,选择线性回归模型、BP(back propagation)神经网络模型作为对比模型开展数据实验,选择均方根误差作为评价指标。实验结果表明,SMCNN的均方根误差为0.006 7,优于对比模型,SMCNN模型在从风云影像中提取土壤湿度方面具有优势。结论本文利用卷积神经网络分别构建用于反演地表温度和土壤湿度的子网络,再组成一个完整的土壤湿度反演网络结构,从风云3D数据中获取数值精度、时空分辨率均较高的土壤湿度数据,满足了科学研究和生产实践对大范围高精度土壤湿度数据的需求。关键词:深度学习;卷积神经网络;风云3D;数据拟合;土壤湿度;宁夏回族自治区11|4|3更新时间:2024-05-07 -
 摘要:目的遥感卫星幅宽较大,成像区域内的薄云和雾很难区分,云雾降低了遥感影像的解译精度和对目标地物判别的准确性。传统的云雾去除方法是通过调整图像的对比度和饱和度来提高重建图像的质量,对不均匀分布云雾的适应性不强。为此,本文以"高分二号"(GF-2)遥感数据为例,提出一种结合高斯曲率滤波的雾度图(haze thickness map,HTM)求解算法。方法采用遥感影像的红波段进行HTM求解,首先通过不重叠的滑动窗口对整幅图像取暗像素,得到HTM估计值,利用高斯曲率滤波对其进行平滑,减少噪声干扰,保持地物边缘特征,并通过插值运算恢复到原图尺寸;然后利用改进的2维最大熵自动确定分割阈值,提取HTM中白色区域并抑制,对边缘处的像素值进行校正;最后通过HTM结果恢复出清晰影像。结果由目视判读结合评价指标进行评价,将改进的暗原色先验法、传统的HTM算法与本文改进的方法在不同地区含云雾的遥感影像上进行对比实验。本文改进方法所得结果与传统方法相比,灰度均值降低约34.96%,平均梯度提升约18.48%,信噪比提升约34.77%,对比度提升约39.41%,对于不均匀遮挡的云雾去除具有较好效果。结论改进的方法能够去除云雾干扰,有效改善影像数据的视觉效果,同时能够保留大量的细节信息,较传统方法更优。关键词:遥感影像;高斯曲率滤波;不均匀云雾去除;2维最大熵;高分二号12|4|1更新时间:2024-05-07
摘要:目的遥感卫星幅宽较大,成像区域内的薄云和雾很难区分,云雾降低了遥感影像的解译精度和对目标地物判别的准确性。传统的云雾去除方法是通过调整图像的对比度和饱和度来提高重建图像的质量,对不均匀分布云雾的适应性不强。为此,本文以"高分二号"(GF-2)遥感数据为例,提出一种结合高斯曲率滤波的雾度图(haze thickness map,HTM)求解算法。方法采用遥感影像的红波段进行HTM求解,首先通过不重叠的滑动窗口对整幅图像取暗像素,得到HTM估计值,利用高斯曲率滤波对其进行平滑,减少噪声干扰,保持地物边缘特征,并通过插值运算恢复到原图尺寸;然后利用改进的2维最大熵自动确定分割阈值,提取HTM中白色区域并抑制,对边缘处的像素值进行校正;最后通过HTM结果恢复出清晰影像。结果由目视判读结合评价指标进行评价,将改进的暗原色先验法、传统的HTM算法与本文改进的方法在不同地区含云雾的遥感影像上进行对比实验。本文改进方法所得结果与传统方法相比,灰度均值降低约34.96%,平均梯度提升约18.48%,信噪比提升约34.77%,对比度提升约39.41%,对于不均匀遮挡的云雾去除具有较好效果。结论改进的方法能够去除云雾干扰,有效改善影像数据的视觉效果,同时能够保留大量的细节信息,较传统方法更优。关键词:遥感影像;高斯曲率滤波;不均匀云雾去除;2维最大熵;高分二号12|4|1更新时间:2024-05-07
遥感图像处理
-
 摘要:目的基于非负矩阵分解的高光谱图像无监督解混算法普遍存在着目标函数对噪声敏感、在低信噪比条件下端元提取和丰度估计性能不佳的缺点。因此,提出一种基于稳健非负矩阵分解的高光谱图像混合像元分解算法。方法首先在传统基于非负矩阵分解的解混算法基础上,对目标函数加以改进,用更加稳健的L1范数作为重建误差项,提高算法对噪声的适应能力,得到新的无监督解混目标函数。针对新目标函数的非凸特性,利用梯度下降法对端元矩阵和丰度矩阵交替迭代求解,进而完成优化求解,得到端元和丰度估计值。结果分别利用模拟和真实高光谱数据,对算法性能进行定性和定量分析。在模拟数据集中,将本文算法与具有代表性的5种无监督解混算法进行比较,相比于对比算法中最优者,本文算法在典型信噪比20 dB下,光谱角距离(spectral angle distance,SAD)增大了10.5%,信号重构误差(signal to reconstruction error,SRE)减小了9.3%;在真实数据集中,利用光谱库中的地物光谱特征验证本文算法端元提取质量,并利用真实地物分布定性分析丰度估计结果。结论提出的基于稳健非负矩阵分解的高光谱无监督解混算法,在低信噪比条件下,能够获得较好的端元提取和丰度估计精度,解混效果更好。关键词:非负矩阵分解;无监督混合像元分解;端元提取;丰度估计;高光谱图像13|4|2更新时间:2024-05-07
摘要:目的基于非负矩阵分解的高光谱图像无监督解混算法普遍存在着目标函数对噪声敏感、在低信噪比条件下端元提取和丰度估计性能不佳的缺点。因此,提出一种基于稳健非负矩阵分解的高光谱图像混合像元分解算法。方法首先在传统基于非负矩阵分解的解混算法基础上,对目标函数加以改进,用更加稳健的L1范数作为重建误差项,提高算法对噪声的适应能力,得到新的无监督解混目标函数。针对新目标函数的非凸特性,利用梯度下降法对端元矩阵和丰度矩阵交替迭代求解,进而完成优化求解,得到端元和丰度估计值。结果分别利用模拟和真实高光谱数据,对算法性能进行定性和定量分析。在模拟数据集中,将本文算法与具有代表性的5种无监督解混算法进行比较,相比于对比算法中最优者,本文算法在典型信噪比20 dB下,光谱角距离(spectral angle distance,SAD)增大了10.5%,信号重构误差(signal to reconstruction error,SRE)减小了9.3%;在真实数据集中,利用光谱库中的地物光谱特征验证本文算法端元提取质量,并利用真实地物分布定性分析丰度估计结果。结论提出的基于稳健非负矩阵分解的高光谱无监督解混算法,在低信噪比条件下,能够获得较好的端元提取和丰度估计精度,解混效果更好。关键词:非负矩阵分解;无监督混合像元分解;端元提取;丰度估计;高光谱图像13|4|2更新时间:2024-05-07 -
 摘要:目的人脸关键点检测和人脸表情识别两个任务紧密相关。已有对两者结合的工作均是两个任务的直接耦合, 忽略了其内在联系。针对这一问题, 提出了一个多任务的深度框架, 借助关键点特征识别人脸表情。方法参考inception结构设计了一个深度网络, 同时检测关键点并且识别人脸表情, 网络在两个任务的监督下, 更加关注关键点附近的信息, 使得五官周围的特征获得较大响应值。为进一步减小人脸其他区域的噪声对表情识别的影响, 利用检测到的关键点生成一张位置注意图, 进一步增加五官周围特征的权重, 减小人脸边缘区域的特征响应值。复杂表情引起人脸部分区域的形变, 增加了关键点检测的难度, 为缓解这一问题, 引入了中间监督层, 在第1级检测关键点的网络中增加较小权重的表情识别任务, 一方面, 提高复杂表情样本的关键点检测结果, 另一方面, 使得网络提取更多表情相关的特征。结果在3个公开数据集:CK+(Cohn-Kanade dataset), Oulu(Oulu-CASIA NIR & VIS facial expression database)和MMI(MMI facial expression database)上与经典方法进行比较, 本文方法在CK+数据集上的识别准确率取得了最高值, 在Oulu和MMI数据集上的识别准确率比目前识别率最高的方法分别提升了0.14%和0.54%。结论实验结果表明了引入关键点信息的有效性:多任务的卷积神经网络表情识别准确率高于单任务的传统卷积神经网络。同时, 引入注意力模型也提升了多任务网络中表情的识别率。关键词:人脸表情识别;关键点检测;多任务;注意力模型;中间监督13|4|4更新时间:2024-05-07
摘要:目的人脸关键点检测和人脸表情识别两个任务紧密相关。已有对两者结合的工作均是两个任务的直接耦合, 忽略了其内在联系。针对这一问题, 提出了一个多任务的深度框架, 借助关键点特征识别人脸表情。方法参考inception结构设计了一个深度网络, 同时检测关键点并且识别人脸表情, 网络在两个任务的监督下, 更加关注关键点附近的信息, 使得五官周围的特征获得较大响应值。为进一步减小人脸其他区域的噪声对表情识别的影响, 利用检测到的关键点生成一张位置注意图, 进一步增加五官周围特征的权重, 减小人脸边缘区域的特征响应值。复杂表情引起人脸部分区域的形变, 增加了关键点检测的难度, 为缓解这一问题, 引入了中间监督层, 在第1级检测关键点的网络中增加较小权重的表情识别任务, 一方面, 提高复杂表情样本的关键点检测结果, 另一方面, 使得网络提取更多表情相关的特征。结果在3个公开数据集:CK+(Cohn-Kanade dataset), Oulu(Oulu-CASIA NIR & VIS facial expression database)和MMI(MMI facial expression database)上与经典方法进行比较, 本文方法在CK+数据集上的识别准确率取得了最高值, 在Oulu和MMI数据集上的识别准确率比目前识别率最高的方法分别提升了0.14%和0.54%。结论实验结果表明了引入关键点信息的有效性:多任务的卷积神经网络表情识别准确率高于单任务的传统卷积神经网络。同时, 引入注意力模型也提升了多任务网络中表情的识别率。关键词:人脸表情识别;关键点检测;多任务;注意力模型;中间监督13|4|4更新时间:2024-05-07 -
 摘要:目的水平集模型是图像分割中的一种先进方法,在陆地环境图像分割中展现出较好效果。特征融合策略被广泛引入到该模型框架,以拉伸目标-背景对比度,进而提高对高噪声、杂乱纹理等多类复杂图像的处理性能。然而,在水下环境中,由于水体高散射、强衰减等多因素的共同作用,使得现有图像特征及水平集模型难以适用于对水下图像的分割任务,分割结果与目标形态间存在较大差异。鉴于此,提出一种适用于水下图像分割的区域-边缘水平集模型,以提高水下图像目标分割的准确性。方法综合应用图像的区域特征及边缘特征对水下目标进行辨识。对于区域特征,引入水下图像显著性特征;对于边缘特征,创新性地提出了一种基于深度信息的边缘特征提取方法。所提方法在融合区域级和边缘级特征的基础上,引入距离正则项对水平集函数进行规范,以增强水平集函数演化的稳定性。结果基于YouTube和Bubblevision的水下数据集的实验结果表明,所提方法不仅对高散射强衰减的低对比度水下图像实现较好的分割效果,同时对处理强背景噪声图像也有较好的鲁棒性,与水平集分割方法(local pre-fitting,LPF)相比,分割精确度至少提高11.5%,与显著性检测方法(hierarchical co-salient detection via color names,HCN)相比,精确度提高6.7%左右。结论实验表明区域-边缘特征融合以及其基础上的水平集模型能够较好地克服水下图像分割中的部分难点,所提方法能够较好分割水下目标区域并拟合目标轮廓,与现有方法对比获得了较好的分割结果。关键词:水下图像分割;水平集;深度信息;边缘特征;图像显著性24|4|2更新时间:2024-05-07
摘要:目的水平集模型是图像分割中的一种先进方法,在陆地环境图像分割中展现出较好效果。特征融合策略被广泛引入到该模型框架,以拉伸目标-背景对比度,进而提高对高噪声、杂乱纹理等多类复杂图像的处理性能。然而,在水下环境中,由于水体高散射、强衰减等多因素的共同作用,使得现有图像特征及水平集模型难以适用于对水下图像的分割任务,分割结果与目标形态间存在较大差异。鉴于此,提出一种适用于水下图像分割的区域-边缘水平集模型,以提高水下图像目标分割的准确性。方法综合应用图像的区域特征及边缘特征对水下目标进行辨识。对于区域特征,引入水下图像显著性特征;对于边缘特征,创新性地提出了一种基于深度信息的边缘特征提取方法。所提方法在融合区域级和边缘级特征的基础上,引入距离正则项对水平集函数进行规范,以增强水平集函数演化的稳定性。结果基于YouTube和Bubblevision的水下数据集的实验结果表明,所提方法不仅对高散射强衰减的低对比度水下图像实现较好的分割效果,同时对处理强背景噪声图像也有较好的鲁棒性,与水平集分割方法(local pre-fitting,LPF)相比,分割精确度至少提高11.5%,与显著性检测方法(hierarchical co-salient detection via color names,HCN)相比,精确度提高6.7%左右。结论实验表明区域-边缘特征融合以及其基础上的水平集模型能够较好地克服水下图像分割中的部分难点,所提方法能够较好分割水下目标区域并拟合目标轮廓,与现有方法对比获得了较好的分割结果。关键词:水下图像分割;水平集;深度信息;边缘特征;图像显著性24|4|2更新时间:2024-05-07 -
 摘要:目的利用深度图序列进行人体行为识别是机器视觉和人工智能中的一个重要研究领域,现有研究中存在深度图序列冗余信息过多以及生成的特征图中时序信息缺失等问题。针对深度图序列中冗余信息过多的问题,提出一种关键帧算法,该算法提高了人体行为识别算法的运算效率;针对时序信息缺失的问题,提出了一种新的深度图序列特征表示方法,即深度时空能量图(depth spatial-temporal energy map,DSTEM),该算法突出了人体行为特征的时序性。方法关键帧算法根据差分图像序列的冗余系数剔除深度图序列的冗余帧,得到足以表述人体行为的关键帧序列。DSTEM算法根据人体外形及运动特点建立能量场,获得人体能量信息,再将能量信息投影到3个正交轴获得DSTEM。结果在MSR_Action3D数据集上的实验结果表明,关键帧算法减少冗余量,各算法在关键帧算法处理后运算效率提高了20% 30%。对DSTEM提取的方向梯度直方图(histogram of oriented gradient,HOG)特征,不仅在只有正序行为的数据库上识别准确率达到95.54%,而且在同时具有正序和反序行为的数据库上也能保持82.14%的识别准确率。结论关键帧算法减少了深度图序列中的冗余信息,提高了特征图提取速率;DSTEM不仅保留了经过能量场突出的人体行为的空间信息,而且完整地记录了人体行为的时序信息,在带有时序信息的行为数据上依然保持较高的识别准确率。关键词:行为识别;深度图序列;时序信息;深度时空能量图;关键帧22|8|2更新时间:2024-05-07
摘要:目的利用深度图序列进行人体行为识别是机器视觉和人工智能中的一个重要研究领域,现有研究中存在深度图序列冗余信息过多以及生成的特征图中时序信息缺失等问题。针对深度图序列中冗余信息过多的问题,提出一种关键帧算法,该算法提高了人体行为识别算法的运算效率;针对时序信息缺失的问题,提出了一种新的深度图序列特征表示方法,即深度时空能量图(depth spatial-temporal energy map,DSTEM),该算法突出了人体行为特征的时序性。方法关键帧算法根据差分图像序列的冗余系数剔除深度图序列的冗余帧,得到足以表述人体行为的关键帧序列。DSTEM算法根据人体外形及运动特点建立能量场,获得人体能量信息,再将能量信息投影到3个正交轴获得DSTEM。结果在MSR_Action3D数据集上的实验结果表明,关键帧算法减少冗余量,各算法在关键帧算法处理后运算效率提高了20% 30%。对DSTEM提取的方向梯度直方图(histogram of oriented gradient,HOG)特征,不仅在只有正序行为的数据库上识别准确率达到95.54%,而且在同时具有正序和反序行为的数据库上也能保持82.14%的识别准确率。结论关键帧算法减少了深度图序列中的冗余信息,提高了特征图提取速率;DSTEM不仅保留了经过能量场突出的人体行为的空间信息,而且完整地记录了人体行为的时序信息,在带有时序信息的行为数据上依然保持较高的识别准确率。关键词:行为识别;深度图序列;时序信息;深度时空能量图;关键帧22|8|2更新时间:2024-05-07
ChinaMM 2019会议专栏
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0