
最新刊期
2020 年 第 25 卷 第 3 期
-
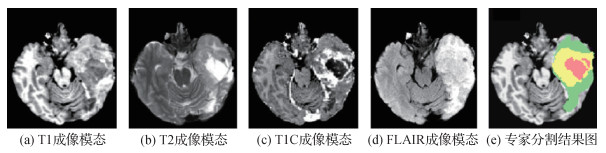 摘要:脑肿瘤分割是医学图像处理中的一项重要内容,其目的是辅助医生做出准确的诊断和治疗,在临床脑部医学领域具有重要的实用价值。核磁共振成像(MRI)是临床医生研究脑部组织结构的主要影像学工具,为了使更多研究者对MRI脑肿瘤图像分割理论及其发展进行探索,本文对该领域研究现状进行综述。首先总结了用于MRI脑肿瘤图像分割的方法,并对现有方法进行了分类,即分为监督分割和非监督分割;然后重点综述了基于深度学习的脑肿瘤分割方法,在研究其关键技术基础上归纳了优化策略;最后介绍了脑肿瘤分割(BraTS)挑战,并结合挑战中所用方法展望了脑肿瘤分割领域未来的发展趋势。MRI脑肿瘤图像分割领域的研究已经取得了一些显著进展,尤其是深度学习的发展为该领域的研究提供了新的思路。但由于脑肿瘤在大小、形状和位置方面的高度变化,以及脑肿瘤图像数据有限且类别不平衡等问题,使得脑肿瘤图像分割仍是一个极具挑战的课题。由于分割过程缺乏可解释性和透明性,如何将全自动分割方法应用于临床试验,还需要进行深入研究。关键词:脑肿瘤图像分割;核磁共振成像(MRI);监督分割;非监督分割;深度学习304|285|11更新时间:2024-05-07
摘要:脑肿瘤分割是医学图像处理中的一项重要内容,其目的是辅助医生做出准确的诊断和治疗,在临床脑部医学领域具有重要的实用价值。核磁共振成像(MRI)是临床医生研究脑部组织结构的主要影像学工具,为了使更多研究者对MRI脑肿瘤图像分割理论及其发展进行探索,本文对该领域研究现状进行综述。首先总结了用于MRI脑肿瘤图像分割的方法,并对现有方法进行了分类,即分为监督分割和非监督分割;然后重点综述了基于深度学习的脑肿瘤分割方法,在研究其关键技术基础上归纳了优化策略;最后介绍了脑肿瘤分割(BraTS)挑战,并结合挑战中所用方法展望了脑肿瘤分割领域未来的发展趋势。MRI脑肿瘤图像分割领域的研究已经取得了一些显著进展,尤其是深度学习的发展为该领域的研究提供了新的思路。但由于脑肿瘤在大小、形状和位置方面的高度变化,以及脑肿瘤图像数据有限且类别不平衡等问题,使得脑肿瘤图像分割仍是一个极具挑战的课题。由于分割过程缺乏可解释性和透明性,如何将全自动分割方法应用于临床试验,还需要进行深入研究。关键词:脑肿瘤图像分割;核磁共振成像(MRI);监督分割;非监督分割;深度学习304|285|11更新时间:2024-05-07
学者观点

-
 摘要:目的针对传统Retinex算法存在的泛灰、光晕、边界突出以及高曝光区域细节增强不明显的现象,将Retinex和多聚焦融合的思想融合在一起,提出一种基于Retinex的改进双边滤波的多聚焦融合算法。方法首先根据图像情况在像素级层次将反射图像分解为最优亮暗区域两部分,然后利用线性积分变换和邻近像素最优推荐算法,将原始图像与最优亮区域多聚焦融合得到图像
摘要:目的针对传统Retinex算法存在的泛灰、光晕、边界突出以及高曝光区域细节增强不明显的现象,将Retinex和多聚焦融合的思想融合在一起,提出一种基于Retinex的改进双边滤波的多聚焦融合算法。方法首先根据图像情况在像素级层次将反射图像分解为最优亮暗区域两部分,然后利用线性积分变换和邻近像素最优推荐算法,将原始图像与最优亮区域多聚焦融合得到图像T ,再将图像T 与最优暗区域重复以上步骤得到图像S ,最后利用引导滤波进行边界修复得到最终图像。结果选择两组图像girl和boat进行实验,与SSR(single scale Retinex)、BSSR(Retinex algorithm based on bilateral filtering)、BIFT(Retinex image enhancement algorithm based on image fusion technology)和RVRG(Retinex variational model based on relative gradient regularization and its application)4种方法进行对比,本文方法在方差和信息熵两方面表现出明显优势。在均值方面,比BIFT和RVRG分别平均提高16.37和20.90;在方差方面,比BIFT和RVRG分别平均提高1.25和4.42;在信息熵方面,比BIFT和RVRG分别平均提高0.1和0.17;在平均梯度方面,比BIFT和RVRG分别平均提高1.21和0.42。对比BIFT和RVRG的实验数据,证明了本文方法的有效性。结论实验结果表明,相比较其他图像增强算法,本文算法能更有效抑制图像的泛灰、光晕和边界突出现象,图像细节增强效果特别显著。关键词:Retinex算法;引导滤波;最优亮暗区域;邻近像素最优推荐算法;改进双边滤波56|471|3更新时间:2024-05-07 -
 摘要:目的现实中的纹理往往具有类型多样、形态多变、结构复杂等特点,直接影响到纹理图像分割的准确性。传统的无监督纹理图像分割算法具有一定的局限性,不能很好地提取稳定的纹理特征。本文提出了基于Gabor滤波器和改进的LTP(local ternary pattern)算子的针对复杂纹理图像的纹理特征提取算法。方法利用Gabor滤波器和扩展LTP算子分别提取相同或相似纹理模式的纹理特征和纹理的差异性特征,并将这些特征融入到水平集框架中对纹理图像进行分割。结果通过实验表明,对纹理方向及尺度变化较大的图像、复杂背景下的纹理图像以及弱纹理模式的图像,本文方法整体分割结果明显优于传统的Gabor滤波器、结构张量、拓展结构张量、局部相似度因子等纹理分割方法得到的结果。同时,将本文方法与基于LTP的方法进行对比,分割结果依然更优。在量化指标方面,将本文方法与各种无监督的纹理分割方法就分割准确度进行对比,结果表明,在典型的纹理图像上,本文方法准确度达到97%以上,高于其他方法的分割准确度。结论提出了一种结合Gabor滤波器和扩展LTP算子的无监督多特征的纹理图像分割方法,能够较好地提取相似纹理模式的特征和纹理的差异性特征,且这些纹理特征可以很好地融合到水平集框架中,对真实世界复杂纹理图像能够得到良好的分割效果。关键词:纹理图像分割;Gabor滤波器;扩展LTP(local ternary pattern)算子;无监督43|131|1更新时间:2024-05-07
摘要:目的现实中的纹理往往具有类型多样、形态多变、结构复杂等特点,直接影响到纹理图像分割的准确性。传统的无监督纹理图像分割算法具有一定的局限性,不能很好地提取稳定的纹理特征。本文提出了基于Gabor滤波器和改进的LTP(local ternary pattern)算子的针对复杂纹理图像的纹理特征提取算法。方法利用Gabor滤波器和扩展LTP算子分别提取相同或相似纹理模式的纹理特征和纹理的差异性特征,并将这些特征融入到水平集框架中对纹理图像进行分割。结果通过实验表明,对纹理方向及尺度变化较大的图像、复杂背景下的纹理图像以及弱纹理模式的图像,本文方法整体分割结果明显优于传统的Gabor滤波器、结构张量、拓展结构张量、局部相似度因子等纹理分割方法得到的结果。同时,将本文方法与基于LTP的方法进行对比,分割结果依然更优。在量化指标方面,将本文方法与各种无监督的纹理分割方法就分割准确度进行对比,结果表明,在典型的纹理图像上,本文方法准确度达到97%以上,高于其他方法的分割准确度。结论提出了一种结合Gabor滤波器和扩展LTP算子的无监督多特征的纹理图像分割方法,能够较好地提取相似纹理模式的特征和纹理的差异性特征,且这些纹理特征可以很好地融合到水平集框架中,对真实世界复杂纹理图像能够得到良好的分割效果。关键词:纹理图像分割;Gabor滤波器;扩展LTP(local ternary pattern)算子;无监督43|131|1更新时间:2024-05-07
图像处理和编码
-
 摘要:目的2D姿态估计的误差是导致3D人体姿态估计产生误差的主要原因,如何在2D误差或噪声干扰下从2D姿态映射到最优、最合理的3D姿态,是提高3D人体姿态估计的关键。本文提出了一种稀疏表示与深度模型联合的3D姿态估计方法,以将3D姿态空间几何先验与时间信息相结合,达到提高3D姿态估计精度的目的。方法利用融合稀疏表示的3D可变形状模型得到单帧图像可靠的3D初始值。构建多通道长短时记忆MLSTM(multi-channel long short term memory)降噪编/解码器,将获得的单帧3D初始值以时间序列形式输入到其中,利用MLSTM降噪编/解码器学习相邻帧之间人物姿态的时间依赖关系,并施加时间平滑约束,得到最终优化的3D姿态。结果在Human3.6M数据集上进行了对比实验。对于两种输入数据:数据集给出的2D坐标和通过卷积神经网络获得的2D估计坐标,相比于单帧估计,通过MLSTM降噪编/解码器优化后的视频序列平均重构误差分别下降了12.6%,13%;相比于现有的基于视频的稀疏模型方法,本文方法对视频的平均重构误差下降了6.4%,9.1%。对于2D估计坐标数据,相比于现有的深度模型方法,本文方法对视频的平均重构误差下降了12.8%。结论本文提出的基于时间信息的MLSTM降噪编/解码器与稀疏模型相结合,有效利用了3D姿态先验知识,视频帧间人物姿态连续变化的时间和空间依赖性,一定程度上提高了单目视频3D姿态估计的精度。关键词:姿态估计;3D人体姿态;稀疏表示;LSTM(long short term memory);残差连接69|59|1更新时间:2024-05-07
摘要:目的2D姿态估计的误差是导致3D人体姿态估计产生误差的主要原因,如何在2D误差或噪声干扰下从2D姿态映射到最优、最合理的3D姿态,是提高3D人体姿态估计的关键。本文提出了一种稀疏表示与深度模型联合的3D姿态估计方法,以将3D姿态空间几何先验与时间信息相结合,达到提高3D姿态估计精度的目的。方法利用融合稀疏表示的3D可变形状模型得到单帧图像可靠的3D初始值。构建多通道长短时记忆MLSTM(multi-channel long short term memory)降噪编/解码器,将获得的单帧3D初始值以时间序列形式输入到其中,利用MLSTM降噪编/解码器学习相邻帧之间人物姿态的时间依赖关系,并施加时间平滑约束,得到最终优化的3D姿态。结果在Human3.6M数据集上进行了对比实验。对于两种输入数据:数据集给出的2D坐标和通过卷积神经网络获得的2D估计坐标,相比于单帧估计,通过MLSTM降噪编/解码器优化后的视频序列平均重构误差分别下降了12.6%,13%;相比于现有的基于视频的稀疏模型方法,本文方法对视频的平均重构误差下降了6.4%,9.1%。对于2D估计坐标数据,相比于现有的深度模型方法,本文方法对视频的平均重构误差下降了12.8%。结论本文提出的基于时间信息的MLSTM降噪编/解码器与稀疏模型相结合,有效利用了3D姿态先验知识,视频帧间人物姿态连续变化的时间和空间依赖性,一定程度上提高了单目视频3D姿态估计的精度。关键词:姿态估计;3D人体姿态;稀疏表示;LSTM(long short term memory);残差连接69|59|1更新时间:2024-05-07 -
 摘要:目的传统的单目视觉深度测量方法具有设备简单、价格低廉、运算速度快等优点,但需要对相机进行复杂标定,并且只在特定的场景条件下适用。为此,提出基于运动视差线索的物体深度测量方法,从图像中提取特征点,利用特征点与图像深度的关系得到测量结果。方法对两幅图像进行分割,获取被测量物体所在区域;然后采用本文提出的改进的尺度不变特征变换SIFT(scale-invariant feature transtorm)算法对两幅图像进行匹配,结合图像匹配和图像分割的结果获取被测量物体的匹配结果;用Graham扫描法求得匹配后特征点的凸包,获取凸包上最长线段的长度;最后利用相机成像的基本原理和三角几何知识求出图像深度。结果实验结果表明,本文方法在测量精度和实时性两方面都有所提升。当图像中的物体不被遮挡时,实际距离与测量距离之间的误差为2.60%,测量距离的时间消耗为1.577 s;当图像中的物体存在部分遮挡时,该方法也获得了较好的测量结果,实际距离与测量距离之间的误差为3.19%,测量距离所需时间为1.689 s。结论利用两幅图像上的特征点来估计图像深度,对图像中物体存在部分遮挡情况具有良好的鲁棒性,同时避免了复杂的摄像机标定过程,具有实际应用价值。关键词:图像深度;单目视觉;运动视差;改进的尺度不变特征变换算法;Graham扫描法20|44|1更新时间:2024-05-07
摘要:目的传统的单目视觉深度测量方法具有设备简单、价格低廉、运算速度快等优点,但需要对相机进行复杂标定,并且只在特定的场景条件下适用。为此,提出基于运动视差线索的物体深度测量方法,从图像中提取特征点,利用特征点与图像深度的关系得到测量结果。方法对两幅图像进行分割,获取被测量物体所在区域;然后采用本文提出的改进的尺度不变特征变换SIFT(scale-invariant feature transtorm)算法对两幅图像进行匹配,结合图像匹配和图像分割的结果获取被测量物体的匹配结果;用Graham扫描法求得匹配后特征点的凸包,获取凸包上最长线段的长度;最后利用相机成像的基本原理和三角几何知识求出图像深度。结果实验结果表明,本文方法在测量精度和实时性两方面都有所提升。当图像中的物体不被遮挡时,实际距离与测量距离之间的误差为2.60%,测量距离的时间消耗为1.577 s;当图像中的物体存在部分遮挡时,该方法也获得了较好的测量结果,实际距离与测量距离之间的误差为3.19%,测量距离所需时间为1.689 s。结论利用两幅图像上的特征点来估计图像深度,对图像中物体存在部分遮挡情况具有良好的鲁棒性,同时避免了复杂的摄像机标定过程,具有实际应用价值。关键词:图像深度;单目视觉;运动视差;改进的尺度不变特征变换算法;Graham扫描法20|44|1更新时间:2024-05-07 -
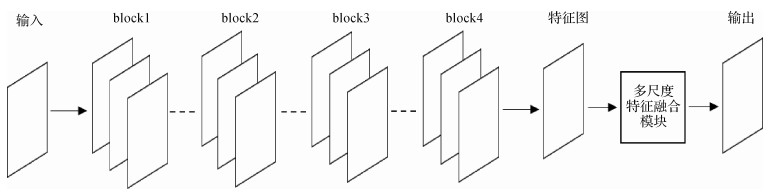 摘要:目的目标语义特征提取效果直接影响图像语义分割的精度,传统的单尺度特征提取方法对目标的语义分割精度较低,为此,提出一种基于多尺度特征融合的工件目标语义分割方法,利用卷积神经网络提取目标的多尺度局部特征语义信息,并将不同尺度的语义信息进行像素融合,使神经网络充分捕获图像中的上下文信息,获得更好的特征表示,有效实现工件目标的语义分割。方法使用常用的多类工件图像定义视觉任务,利用残差网络模块获得目标的单尺度语义特征图,再结合本文提出的多尺度特征提取方式获得不同尺度的局部特征语义信息,通过信息融合获得目标分割图。使用上述方法经多次迭代训练后得到与视觉任务相关的工件目标分割模型,并对训练权重与超参数进行保存。结果将本文方法和传统的单尺度特征提取方法做定性和定量的测试实验,结果表明,获得的分割网络模型对测试集中的目标都具有较精确的分割能力,与单尺度特征提取方法相比,本文方法的平均交并比mIOU(mean intersection over union)指标在验证集上训练精度提高了4.52%,在测试集上分割精度提高了4.84%。当测试样本中包含的目标种类较少且目标边缘清晰时,本文方法能够得到更精准的分割结果。结论本文提出的语义分割方法,通过多尺度特征融合的方式增强了神经网络模型对目标特征的提取能力,使训练得到的分割网络模型比传统的单尺度特征提取方式在测试集上具有更优秀的性能,从而验证了所提出方法的有效性。关键词:残差网络;语义分割;多尺度特征;深度学习;视觉任务31|47|4更新时间:2024-05-07
摘要:目的目标语义特征提取效果直接影响图像语义分割的精度,传统的单尺度特征提取方法对目标的语义分割精度较低,为此,提出一种基于多尺度特征融合的工件目标语义分割方法,利用卷积神经网络提取目标的多尺度局部特征语义信息,并将不同尺度的语义信息进行像素融合,使神经网络充分捕获图像中的上下文信息,获得更好的特征表示,有效实现工件目标的语义分割。方法使用常用的多类工件图像定义视觉任务,利用残差网络模块获得目标的单尺度语义特征图,再结合本文提出的多尺度特征提取方式获得不同尺度的局部特征语义信息,通过信息融合获得目标分割图。使用上述方法经多次迭代训练后得到与视觉任务相关的工件目标分割模型,并对训练权重与超参数进行保存。结果将本文方法和传统的单尺度特征提取方法做定性和定量的测试实验,结果表明,获得的分割网络模型对测试集中的目标都具有较精确的分割能力,与单尺度特征提取方法相比,本文方法的平均交并比mIOU(mean intersection over union)指标在验证集上训练精度提高了4.52%,在测试集上分割精度提高了4.84%。当测试样本中包含的目标种类较少且目标边缘清晰时,本文方法能够得到更精准的分割结果。结论本文提出的语义分割方法,通过多尺度特征融合的方式增强了神经网络模型对目标特征的提取能力,使训练得到的分割网络模型比传统的单尺度特征提取方式在测试集上具有更优秀的性能,从而验证了所提出方法的有效性。关键词:残差网络;语义分割;多尺度特征;深度学习;视觉任务31|47|4更新时间:2024-05-07 -
 摘要:目的针对密集连接卷积神经网络(DenseNet)没有充分考虑通道特征相关性以及层间特征相关性的缺点,本文结合软注意力机制提出了端到端双通道特征重标定密集连接卷积神经网络。方法提出的网络同时实现了DenseNet网络的通道特征重标定与层间特征重标定。给出了DenseNet网络通道特征重标定与层间特征重标定方法;构建了端到端双通道特征重标定密集连接卷积神经网络,该网络每个卷积层的输出特征图经过两个通道分别完成通道特征重标定以及层间特征重标定,再进行两种重标定后特征图的融合。结果为了验证本文方法在不同图像分类数据集上的有效性和适应性,在图像分类数据集CIFAR-10/100以及人脸年龄数据集MORPH、Adience上进行了实验,提高了图像分类准确率,并分析了模型的参数量、训练及测试时长,验证了本文方法的实用性。与DenseNet网络相比,40层及64层双通道特征重标定密集连接卷积神经网络DFR-DenseNet(dual feature reweight DenseNet),在CIFAR-10数据集上,参数量仅分别增加1.87%、1.23%,错误率分别降低了12%、9.11%,在CIFAR-100数据集上,错误率分别降低了5.56%、5.41%;与121层DFR-DenseNet网络相比,在MORPH数据集上,平均绝对误差(MAE)值降低了7.33%,在Adience数据集上,年龄组估计准确率提高了2%;与多级特征重标定密集连接卷积神经网络MFR-DenseNet(multiple feature reweight DenseNet)相比,DFR-DenseNet网络参数量减少了一半,测试耗时约缩短为MFR-DenseNet的61%。结论实验结果表明本文端到端双通道特征重标定密集连接卷积神经网络能够增强网络的学习能力,提高图像分类的准确率,并对不同图像分类数据集具有一定的适应性、实用性。关键词:双通道特征重标定密集连接卷积神经网络;通道特征重标定;层间特征重标定;图像分类;端到端35|63|5更新时间:2024-05-07
摘要:目的针对密集连接卷积神经网络(DenseNet)没有充分考虑通道特征相关性以及层间特征相关性的缺点,本文结合软注意力机制提出了端到端双通道特征重标定密集连接卷积神经网络。方法提出的网络同时实现了DenseNet网络的通道特征重标定与层间特征重标定。给出了DenseNet网络通道特征重标定与层间特征重标定方法;构建了端到端双通道特征重标定密集连接卷积神经网络,该网络每个卷积层的输出特征图经过两个通道分别完成通道特征重标定以及层间特征重标定,再进行两种重标定后特征图的融合。结果为了验证本文方法在不同图像分类数据集上的有效性和适应性,在图像分类数据集CIFAR-10/100以及人脸年龄数据集MORPH、Adience上进行了实验,提高了图像分类准确率,并分析了模型的参数量、训练及测试时长,验证了本文方法的实用性。与DenseNet网络相比,40层及64层双通道特征重标定密集连接卷积神经网络DFR-DenseNet(dual feature reweight DenseNet),在CIFAR-10数据集上,参数量仅分别增加1.87%、1.23%,错误率分别降低了12%、9.11%,在CIFAR-100数据集上,错误率分别降低了5.56%、5.41%;与121层DFR-DenseNet网络相比,在MORPH数据集上,平均绝对误差(MAE)值降低了7.33%,在Adience数据集上,年龄组估计准确率提高了2%;与多级特征重标定密集连接卷积神经网络MFR-DenseNet(multiple feature reweight DenseNet)相比,DFR-DenseNet网络参数量减少了一半,测试耗时约缩短为MFR-DenseNet的61%。结论实验结果表明本文端到端双通道特征重标定密集连接卷积神经网络能够增强网络的学习能力,提高图像分类的准确率,并对不同图像分类数据集具有一定的适应性、实用性。关键词:双通道特征重标定密集连接卷积神经网络;通道特征重标定;层间特征重标定;图像分类;端到端35|63|5更新时间:2024-05-07 -
 摘要:目的在机器视觉的蚕茧分选研究中,完整的表面图像有利于提高蚕茧的识别准确度。由于蚕茧的形状呈长椭圆形,其在成像面上的投影存在信息压缩,需对其图像展开后才能进行拼接,因此提出了一种基于等效阶梯柱面模型的蚕茧表面图像展开方法。方法对采集到的蚕茧图像预处理后进行椭圆拟合,根据拟合结果建立蚕茧的数学模型,基于微积分化曲为直的思想,将蚕茧模型转化为等效阶梯柱面模型,建立相应的坐标系,推导出阶梯柱面模型展开图与原图的像素坐标映射关系,进而实现蚕茧表面图像的展开。结果对比本文方法与采用蚕茧最大半径值的柱面展开方法对阶梯柱面模型表面图像的展开结果,评价两种展开方法方格左上角的坐标值与理论值之间的平均绝对误差,本文方法为1.66像素,对比方法为3.06像素。说明本文方法得到的坐标值与理论值的拟合程度更高,绝对误差范围和平均误差值更小。此外,对展开的蚕茧表面图像进行重复部分拼接实验,拼接后图像重叠处及重叠区域边缘的蚕茧表面纹理连续性保持良好。结论等效阶梯柱面展开方法可以有效的实现蚕茧表面图像展开,还原其表面原始信息,为后续蚕茧表面图像完整拼接提供良好的技术支撑。关键词:蚕茧分选;图像处理;柱面展开;阶梯柱面模型;数学建模40|62|6更新时间:2024-05-07
摘要:目的在机器视觉的蚕茧分选研究中,完整的表面图像有利于提高蚕茧的识别准确度。由于蚕茧的形状呈长椭圆形,其在成像面上的投影存在信息压缩,需对其图像展开后才能进行拼接,因此提出了一种基于等效阶梯柱面模型的蚕茧表面图像展开方法。方法对采集到的蚕茧图像预处理后进行椭圆拟合,根据拟合结果建立蚕茧的数学模型,基于微积分化曲为直的思想,将蚕茧模型转化为等效阶梯柱面模型,建立相应的坐标系,推导出阶梯柱面模型展开图与原图的像素坐标映射关系,进而实现蚕茧表面图像的展开。结果对比本文方法与采用蚕茧最大半径值的柱面展开方法对阶梯柱面模型表面图像的展开结果,评价两种展开方法方格左上角的坐标值与理论值之间的平均绝对误差,本文方法为1.66像素,对比方法为3.06像素。说明本文方法得到的坐标值与理论值的拟合程度更高,绝对误差范围和平均误差值更小。此外,对展开的蚕茧表面图像进行重复部分拼接实验,拼接后图像重叠处及重叠区域边缘的蚕茧表面纹理连续性保持良好。结论等效阶梯柱面展开方法可以有效的实现蚕茧表面图像展开,还原其表面原始信息,为后续蚕茧表面图像完整拼接提供良好的技术支撑。关键词:蚕茧分选;图像处理;柱面展开;阶梯柱面模型;数学建模40|62|6更新时间:2024-05-07
图像分析和识别
-
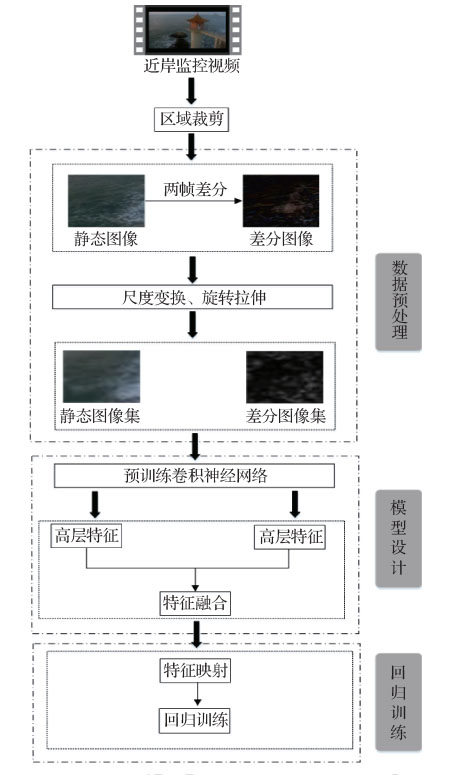 摘要:目的目前基于视觉信息的海浪要素检测方法分为基于立体视觉和基于视频/图像特征的检测方法,前者对浪高的解析不稳定、模型复杂、鲁棒性较差、不能很好地满足实际应用的需求,后者主要检测海浪的运动方向和浪高等级,无法获取精确的浪高值,其中基于图像特征的检测受限于先验知识,检测稳定性较差。为此,本文结合深度学习的特征学习机制,提出了一种面向近岸海浪视频的浪高自动检测方法。方法从近岸海浪监控视频中提取视频帧图像,计算相邻两帧差分获取差分图像,通过数据预处理对静态图像集和差分图像集进行数据扩充;针对两类图像集分别设计多层局部感知卷积神经网络NIN(network in network)结构并预训练网络模型;分别用预训练的网络模型提取静态图像和差分图像的高层特征来表达空间和时间维度的信息,并融合两类特征;通过预训练支持向量回归SVR(support vactor regerssion)模型完成浪高的自动检测。结果实验结果表明,本文近岸海浪视频浪高检测方法在浪高检测上的平均绝对误差为0.109 5 m,平均相对误差为7.39%;从不同绝对误差范围内的测试集精度上可以看出,基于时间和空间信息融合的回归模型精度变化更加平稳,基于空间信息的NIN模型的精度变化幅度较大,因此本文方法有较好的检测稳定性。结论通过预训练卷积神经网络提取近岸视频图像时间和空间信息融合的方式,有效弥补了人工设计特征的不完备性,对近岸视频的浪高检测具有较强的鲁棒性,在业务化检测需求范围内(浪高平均相对误差≤ 20%)有着较好的实用性。关键词:浪高检测;近岸海浪视频;深度学习;多层局部感知卷积神经网络;特征提取45|74|2更新时间:2024-05-07
摘要:目的目前基于视觉信息的海浪要素检测方法分为基于立体视觉和基于视频/图像特征的检测方法,前者对浪高的解析不稳定、模型复杂、鲁棒性较差、不能很好地满足实际应用的需求,后者主要检测海浪的运动方向和浪高等级,无法获取精确的浪高值,其中基于图像特征的检测受限于先验知识,检测稳定性较差。为此,本文结合深度学习的特征学习机制,提出了一种面向近岸海浪视频的浪高自动检测方法。方法从近岸海浪监控视频中提取视频帧图像,计算相邻两帧差分获取差分图像,通过数据预处理对静态图像集和差分图像集进行数据扩充;针对两类图像集分别设计多层局部感知卷积神经网络NIN(network in network)结构并预训练网络模型;分别用预训练的网络模型提取静态图像和差分图像的高层特征来表达空间和时间维度的信息,并融合两类特征;通过预训练支持向量回归SVR(support vactor regerssion)模型完成浪高的自动检测。结果实验结果表明,本文近岸海浪视频浪高检测方法在浪高检测上的平均绝对误差为0.109 5 m,平均相对误差为7.39%;从不同绝对误差范围内的测试集精度上可以看出,基于时间和空间信息融合的回归模型精度变化更加平稳,基于空间信息的NIN模型的精度变化幅度较大,因此本文方法有较好的检测稳定性。结论通过预训练卷积神经网络提取近岸视频图像时间和空间信息融合的方式,有效弥补了人工设计特征的不完备性,对近岸视频的浪高检测具有较强的鲁棒性,在业务化检测需求范围内(浪高平均相对误差≤ 20%)有着较好的实用性。关键词:浪高检测;近岸海浪视频;深度学习;多层局部感知卷积神经网络;特征提取45|74|2更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的针对农业机械化、信息化和智能化发展对棉花长势快速监测与评估提出的需求,提出一种新的技术途径,依据低空无人机UAV(unmanned aerial vehicle)遥感技术为苗期棉花株数快速估算和长势等级分类。方法基于高分辨率无人机多光谱遥感影像,利用光谱信息、空间位置及数学形态学信息,结合田间调查数据,引入Hough变换等数学形态学方法实现田间棉苗垄中心线的提取,利用支持向量机回归方法构建具有较好稳健性的棉株估算模型,并依据株数估算结果进一步实现了保苗率、壮苗率计算和整体长势等级分类。结果以田间实地测量得到的样方数据为参考,对模型棉株估算精度评估的结果显示:支持向量机回归模型得到的株数估算精度更高,优于对比模型,估算值与观测值之间的确定系数R2为0.945 6,均方根误差为0.510 7。以株数为指标评估得到的整体长势空间分布与地面样方调查情况一致,实验田块里弱、壮、旺苗的比例分别为14.50%、83.37%、2.13%,表明研究区棉田出苗整齐度较差,整体长势偏弱。结论本文建立的棉苗株数与数学形态特征的回归模型能有效识别棉苗株数并进行整体长势等级分类,可为精准田间管理提供依据,为无人机在农业中的应用提供参考。关键词:无人机;多光谱遥感;支持向量机回归;棉苗株数;长势等级;石河子19|6|4更新时间:2024-05-07
摘要:目的针对农业机械化、信息化和智能化发展对棉花长势快速监测与评估提出的需求,提出一种新的技术途径,依据低空无人机UAV(unmanned aerial vehicle)遥感技术为苗期棉花株数快速估算和长势等级分类。方法基于高分辨率无人机多光谱遥感影像,利用光谱信息、空间位置及数学形态学信息,结合田间调查数据,引入Hough变换等数学形态学方法实现田间棉苗垄中心线的提取,利用支持向量机回归方法构建具有较好稳健性的棉株估算模型,并依据株数估算结果进一步实现了保苗率、壮苗率计算和整体长势等级分类。结果以田间实地测量得到的样方数据为参考,对模型棉株估算精度评估的结果显示:支持向量机回归模型得到的株数估算精度更高,优于对比模型,估算值与观测值之间的确定系数R2为0.945 6,均方根误差为0.510 7。以株数为指标评估得到的整体长势空间分布与地面样方调查情况一致,实验田块里弱、壮、旺苗的比例分别为14.50%、83.37%、2.13%,表明研究区棉田出苗整齐度较差,整体长势偏弱。结论本文建立的棉苗株数与数学形态特征的回归模型能有效识别棉苗株数并进行整体长势等级分类,可为精准田间管理提供依据,为无人机在农业中的应用提供参考。关键词:无人机;多光谱遥感;支持向量机回归;棉苗株数;长势等级;石河子19|6|4更新时间:2024-05-07 -
 摘要:目的遥感影像地物提取是遥感领域的研究热点。由于背景和地物类型复杂多样,单纯利用传统方法很难对地物类别进行准确区分和判断,因而常常造成误提取和漏提取。目前基于卷积神经网络CNN(convolutional neural network)的方法进行地物提取的效果普遍优于传统方法,但需要大量的时间进行训练,甚至可能出现收敛慢或网络不收敛的情况。为此,基于多视觉信息特征的互补原理,提出了一种双视觉全卷积网络结构。方法该网络利用VGG(visual geometry group)16和AlexNet分别提取局部和全局视觉特征,并经过融合网络对两种特征进行处理,以充分利用其包含的互补信息。同时,将局部特征提取网络作为主网络,减少计算复杂度,将全局特征提取网络作为辅助网络,提高预测置信度,加快收敛,减少训练时间。结果选取公开的建筑物数据集和道路数据集进行实验,并与二分类性能优异的U-Net网络和轻量型Mnih网络进行对比。实验结果表明,本文提出的双视觉全卷积网络的平均收敛时间仅为U-Net网络的15.46%;提取精度与U-Net相当,远高于Mnih;在95%的置信水平上,该网络的置信区间明显优于U-Net。结论本文提出的双视觉全卷积网络,融合了影像中地物的局部细节特征和全局特征,能保持较高的提取精度和置信度,且更易训练和收敛,为后续遥感影像地物提取与神经网络的设计提供了参考方向。关键词:遥感;地物提取;全卷积网络;双视觉;局部信息;全局信息13|5|1更新时间:2024-05-07
摘要:目的遥感影像地物提取是遥感领域的研究热点。由于背景和地物类型复杂多样,单纯利用传统方法很难对地物类别进行准确区分和判断,因而常常造成误提取和漏提取。目前基于卷积神经网络CNN(convolutional neural network)的方法进行地物提取的效果普遍优于传统方法,但需要大量的时间进行训练,甚至可能出现收敛慢或网络不收敛的情况。为此,基于多视觉信息特征的互补原理,提出了一种双视觉全卷积网络结构。方法该网络利用VGG(visual geometry group)16和AlexNet分别提取局部和全局视觉特征,并经过融合网络对两种特征进行处理,以充分利用其包含的互补信息。同时,将局部特征提取网络作为主网络,减少计算复杂度,将全局特征提取网络作为辅助网络,提高预测置信度,加快收敛,减少训练时间。结果选取公开的建筑物数据集和道路数据集进行实验,并与二分类性能优异的U-Net网络和轻量型Mnih网络进行对比。实验结果表明,本文提出的双视觉全卷积网络的平均收敛时间仅为U-Net网络的15.46%;提取精度与U-Net相当,远高于Mnih;在95%的置信水平上,该网络的置信区间明显优于U-Net。结论本文提出的双视觉全卷积网络,融合了影像中地物的局部细节特征和全局特征,能保持较高的提取精度和置信度,且更易训练和收敛,为后续遥感影像地物提取与神经网络的设计提供了参考方向。关键词:遥感;地物提取;全卷积网络;双视觉;局部信息;全局信息13|5|1更新时间:2024-05-07
遥感图像处理
-
 摘要:目的遥感图像融合是将一幅高空间分辨率的全色图像和对应场景的低空间分辨率的多光谱图像,融合成一幅在光谱和空间两方面都具有高分辨率的多光谱图像。为了使融合结果在保持较高空间分辨率的同时减轻光谱失真现象,提出了自适应的权重注入机制,并针对上采样图像降质使先验信息变得不精确的问题,提出了通道梯度约束和光谱关系校正约束。方法使用变分法处理遥感图像融合问题。考虑传感器的物理特性,使用自适应的权重注入机制向多光谱图像各波段注入不同的空间信息,以处理多光谱图像波段间的差异,避免向多光谱图像中注入过多的空间信息导致光谱失真。考虑到上采样的图像是降质的,采用局部光谱一致性约束和通道梯度约束作为先验信息的约束,基于图像退化模型,使用光谱关系校正约束更精确地保持融合结果的波段间关系。结果在Geoeye和Pleiades卫星数据上同6种表现优异的算法进行对比实验,本文提出的模型在2个卫星数据上除了相关系数CC(correlation coefficient)和光谱角映射SAM(spectral angle mapper)评价指标表现不够稳定,偶尔为次优值外,在相对全局误差ERGAS(erreur relative globale adimensionnelle de synthèse)、峰值信噪比PSNR(peak signal-to-noise ratio)、相对平均光谱误差RASE(relative average spectral error)、均方根误差RMSE(root mean squared error)、光谱信息散度SID(spectral information divergence)等评价指标上均为最优值。结论本文模型与对比算法相比,在空间分辨率提升和光谱保持方面都取得了良好效果。关键词:遥感图像融合;多光谱图像;变分法;自适应权重;通道梯度约束;光谱关系校正约束24|20|3更新时间:2024-05-07
摘要:目的遥感图像融合是将一幅高空间分辨率的全色图像和对应场景的低空间分辨率的多光谱图像,融合成一幅在光谱和空间两方面都具有高分辨率的多光谱图像。为了使融合结果在保持较高空间分辨率的同时减轻光谱失真现象,提出了自适应的权重注入机制,并针对上采样图像降质使先验信息变得不精确的问题,提出了通道梯度约束和光谱关系校正约束。方法使用变分法处理遥感图像融合问题。考虑传感器的物理特性,使用自适应的权重注入机制向多光谱图像各波段注入不同的空间信息,以处理多光谱图像波段间的差异,避免向多光谱图像中注入过多的空间信息导致光谱失真。考虑到上采样的图像是降质的,采用局部光谱一致性约束和通道梯度约束作为先验信息的约束,基于图像退化模型,使用光谱关系校正约束更精确地保持融合结果的波段间关系。结果在Geoeye和Pleiades卫星数据上同6种表现优异的算法进行对比实验,本文提出的模型在2个卫星数据上除了相关系数CC(correlation coefficient)和光谱角映射SAM(spectral angle mapper)评价指标表现不够稳定,偶尔为次优值外,在相对全局误差ERGAS(erreur relative globale adimensionnelle de synthèse)、峰值信噪比PSNR(peak signal-to-noise ratio)、相对平均光谱误差RASE(relative average spectral error)、均方根误差RMSE(root mean squared error)、光谱信息散度SID(spectral information divergence)等评价指标上均为最优值。结论本文模型与对比算法相比,在空间分辨率提升和光谱保持方面都取得了良好效果。关键词:遥感图像融合;多光谱图像;变分法;自适应权重;通道梯度约束;光谱关系校正约束24|20|3更新时间:2024-05-07 -
 摘要:目的在栅格地理数据的使用过程中,为防止数据被破坏或被篡改,需要加强对数据完整性的检验;为防止数据被恶意传播,需要加强对数据版权信息的保护。双重水印技术可以同时完成这两项任务。方法利用基于异或的(2,2)-视觉密码方案VCS(visual cryptography scheme)和离散小波变换DWT(discrete wavelet transform),对数字栅格地理数据嵌入双重水印,使用半脆弱性水印作为第1重水印进行完整性检验,水印信息依据DWT变换后高频系数中水平分量之间的大小关系嵌入;使用零水印作为第2重水印进行版权保护,提取DWT变换后经低频子带奇异值分解的特征值生成特征份,利用基于异或的(2,2)-VCS,根据特征份和水印信息生成版权份。结果为验证算法的有效性,对具体的栅格地理数据进行实验分析。结果表明,本文算法中第1重水印能够正确区分偶然攻击和恶意破坏,对含水印的栅格地理数据进行质量因子为90、80、70、60、50的JPEG压缩后,提取出完整性水印的归一化相关系数NC(normalized correlation)值分别是1、0.996、0.987、0.9513、0.949,在定位裁剪攻击时,能准确地定位到篡改的位置,对于定位替换攻击时,能定位到篡改的大致位置;第2重水印具有良好的视觉效果和较强的鲁棒性,对含水印的栅格地理数据进行滤波攻击、JPEG压缩、裁剪攻击、缩放攻击等性能测试,提取出版权水印的NC值优于其他方案。结论论文基于异或的(2,2)-VCS和DWT提出的栅格地理数据双重水印算法,在实现数据完整性检验的同时达到了版权保护的目的。关键词:栅格地理数据;视觉密码;离散小波变换;数字水印;完整性检验;版权保护69|4|1更新时间:2024-05-07
摘要:目的在栅格地理数据的使用过程中,为防止数据被破坏或被篡改,需要加强对数据完整性的检验;为防止数据被恶意传播,需要加强对数据版权信息的保护。双重水印技术可以同时完成这两项任务。方法利用基于异或的(2,2)-视觉密码方案VCS(visual cryptography scheme)和离散小波变换DWT(discrete wavelet transform),对数字栅格地理数据嵌入双重水印,使用半脆弱性水印作为第1重水印进行完整性检验,水印信息依据DWT变换后高频系数中水平分量之间的大小关系嵌入;使用零水印作为第2重水印进行版权保护,提取DWT变换后经低频子带奇异值分解的特征值生成特征份,利用基于异或的(2,2)-VCS,根据特征份和水印信息生成版权份。结果为验证算法的有效性,对具体的栅格地理数据进行实验分析。结果表明,本文算法中第1重水印能够正确区分偶然攻击和恶意破坏,对含水印的栅格地理数据进行质量因子为90、80、70、60、50的JPEG压缩后,提取出完整性水印的归一化相关系数NC(normalized correlation)值分别是1、0.996、0.987、0.9513、0.949,在定位裁剪攻击时,能准确地定位到篡改的位置,对于定位替换攻击时,能定位到篡改的大致位置;第2重水印具有良好的视觉效果和较强的鲁棒性,对含水印的栅格地理数据进行滤波攻击、JPEG压缩、裁剪攻击、缩放攻击等性能测试,提取出版权水印的NC值优于其他方案。结论论文基于异或的(2,2)-VCS和DWT提出的栅格地理数据双重水印算法,在实现数据完整性检验的同时达到了版权保护的目的。关键词:栅格地理数据;视觉密码;离散小波变换;数字水印;完整性检验;版权保护69|4|1更新时间:2024-05-07 -
 摘要:目的在高光谱地物分类中,混合像元在两个方面给单标签分类带来了负面影响:单类地物在混入异类地物后,其光谱特征会发生改变,失去独特性,使类内差异变大;多类地物在混合比例加深的情况下,光谱曲线会互相趋近,使类间差异变小。为了解决这一问题,本文将多标签技术运用在高光谱分类中。方法基于高光谱特性,本文将欧氏距离与光谱角有机结合运用到基于类属属性的多标签学习LIFT(multi-label learning with label specific features)算法的类属属性构建中,形成了适合高光谱多标签的方法。基于标签地位的不相等,本文为多标签数据标注丰度最大标签,并在K最近邻KNN(k-nearest neighbor)算法中为丰度最大的标签设置比其余标签更大的权重,完成对最大丰度标签的分类。结果在多标签分类与单标签分类的比较中,多标签表现更优,且多标签在precision指标上表现良好,高于单标签0.5% 1.5%。在与其余4种多标签方法的比较中,本文多标签方法在2个数据集上表现最优,在剩余1个数据集上表现次优。在最大丰度标签的分类上,本文方法表现优于单标签分类,在数据集Jasper Ridge上的总体分类精度提高0.2%,混合像元分类精度提高0.5%。结论多标签分类技术应用在高光谱地物分类上是可行的,可以提升分类效果。本文方法根据高光谱数据的特性对LIFT方法进行了改造,在高光谱多标签分类上表现优异。高光谱地物的多标签分类中,每个像元多个标签的地位不同,在分类中可以通过设置不同权重体现该性质,提升分类精度。关键词:遥感;高光谱分类;多标签分类;基于类属属性的多标签学习LIFT;类属属性;光谱相似度21|5|2更新时间:2024-05-07
摘要:目的在高光谱地物分类中,混合像元在两个方面给单标签分类带来了负面影响:单类地物在混入异类地物后,其光谱特征会发生改变,失去独特性,使类内差异变大;多类地物在混合比例加深的情况下,光谱曲线会互相趋近,使类间差异变小。为了解决这一问题,本文将多标签技术运用在高光谱分类中。方法基于高光谱特性,本文将欧氏距离与光谱角有机结合运用到基于类属属性的多标签学习LIFT(multi-label learning with label specific features)算法的类属属性构建中,形成了适合高光谱多标签的方法。基于标签地位的不相等,本文为多标签数据标注丰度最大标签,并在K最近邻KNN(k-nearest neighbor)算法中为丰度最大的标签设置比其余标签更大的权重,完成对最大丰度标签的分类。结果在多标签分类与单标签分类的比较中,多标签表现更优,且多标签在precision指标上表现良好,高于单标签0.5% 1.5%。在与其余4种多标签方法的比较中,本文多标签方法在2个数据集上表现最优,在剩余1个数据集上表现次优。在最大丰度标签的分类上,本文方法表现优于单标签分类,在数据集Jasper Ridge上的总体分类精度提高0.2%,混合像元分类精度提高0.5%。结论多标签分类技术应用在高光谱地物分类上是可行的,可以提升分类效果。本文方法根据高光谱数据的特性对LIFT方法进行了改造,在高光谱多标签分类上表现优异。高光谱地物的多标签分类中,每个像元多个标签的地位不同,在分类中可以通过设置不同权重体现该性质,提升分类精度。关键词:遥感;高光谱分类;多标签分类;基于类属属性的多标签学习LIFT;类属属性;光谱相似度21|5|2更新时间:2024-05-07 -
 摘要:目的时空融合是解决当前传感器无法兼顾遥感图像的空间分辨率和时间分辨率的有效方法。在只有一对精细-粗略图像作为先验的条件下,当前的时空融合算法在预测地物变化时并不能取得令人满意的结果。针对这个问题,本文提出一种基于线性模型的遥感图像时空融合算法。方法使用线性关系表示图像间的时间模型,并假设时间模型与传感器无关。通过分析图像时间变化的客观规律,对模型进行全局和局部约束。此外引入一种多时相的相似像素搜寻策略,更灵活地选取相似像素,消除了传统算法存在的模块效应。结果在两个数据集上与STARFM(spatial and temporal adaptive reflectance fusion model)算法和FSDAF(flexible spatiotemporal data fusion)算法进行比较,实验结果表明,在主要发生物候变化的第1个数据集,本文方法的相关系数CC(correlation coefficient)分别提升了0.25%和0.28%,峰值信噪比PSNR(peak signal-to-noise ratio)分别提升了0.153 1 dB和1.379 dB,均方根误差RMSE(root mean squared error)分别降低了0.05%和0.69%,结构相似性SSIM(structural similarity)分别提升了0.79%和2.3%。在发生剧烈地物变化的第2个数据集,本文方法的相关系数分别提升了6.64%和3.26%,峰值信噪比分别提升了2.086 0 dB和2.510 7 dB,均方根误差分别降低了1.45%和2.08%,结构相似性分别提升了11.76%和11.2%。结论本文方法根据时间变化的特点,对时间模型进行优化,同时采用更加灵活的相似像素搜寻策略,收到了很好的效果,提升了融合结果的准确性。关键词:遥感图像;时空融合;线性模型;权重函数;参数估计15|0|3更新时间:2024-05-07
摘要:目的时空融合是解决当前传感器无法兼顾遥感图像的空间分辨率和时间分辨率的有效方法。在只有一对精细-粗略图像作为先验的条件下,当前的时空融合算法在预测地物变化时并不能取得令人满意的结果。针对这个问题,本文提出一种基于线性模型的遥感图像时空融合算法。方法使用线性关系表示图像间的时间模型,并假设时间模型与传感器无关。通过分析图像时间变化的客观规律,对模型进行全局和局部约束。此外引入一种多时相的相似像素搜寻策略,更灵活地选取相似像素,消除了传统算法存在的模块效应。结果在两个数据集上与STARFM(spatial and temporal adaptive reflectance fusion model)算法和FSDAF(flexible spatiotemporal data fusion)算法进行比较,实验结果表明,在主要发生物候变化的第1个数据集,本文方法的相关系数CC(correlation coefficient)分别提升了0.25%和0.28%,峰值信噪比PSNR(peak signal-to-noise ratio)分别提升了0.153 1 dB和1.379 dB,均方根误差RMSE(root mean squared error)分别降低了0.05%和0.69%,结构相似性SSIM(structural similarity)分别提升了0.79%和2.3%。在发生剧烈地物变化的第2个数据集,本文方法的相关系数分别提升了6.64%和3.26%,峰值信噪比分别提升了2.086 0 dB和2.510 7 dB,均方根误差分别降低了1.45%和2.08%,结构相似性分别提升了11.76%和11.2%。结论本文方法根据时间变化的特点,对时间模型进行优化,同时采用更加灵活的相似像素搜寻策略,收到了很好的效果,提升了融合结果的准确性。关键词:遥感图像;时空融合;线性模型;权重函数;参数估计15|0|3更新时间:2024-05-07 -
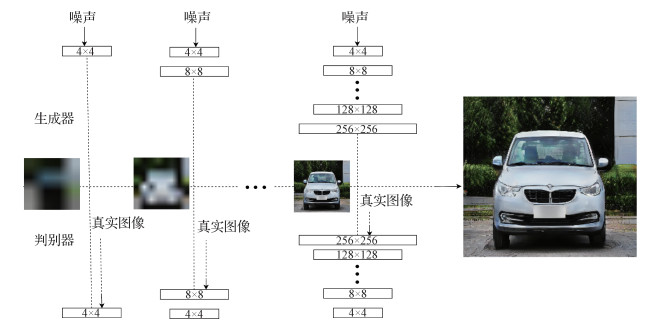 摘要:目的车型识别在智能交通、智慧安防、自动驾驶等领域具有十分重要的应用前景。而车型识别中,带标签车型数据的数量是影响车型识别的重要因素。本文以"增强数据"为核心,结合PGGAN(progressive growing of GANs)和Attention机制,提出一种基于对抗网络生成数据再分类的网络模型AT-PGGAN(attention-progressive growing of GANs),采用模型生成带标签车型图像的数量,从而提高车型识别准确率。方法该模型由生成网络和分类网络组成,利用生成网络对训练数据进行增强扩充,利用注意力机制和标签重嵌入方法对生成网络进行优化使其生成图像细节更加完善,提出标签重标定的方法重新确定生成图像的标签数据,并对生成图像进行相应的筛选。使用扩充的图像加上原有数据集的图像作为输入训练分类网络。结果本文模型能够很好地扩充已有的车辆图像,在公开数据集StanfordCars上,其识别准确率相比未使用AT-PGGAN模型进行数据扩充的分类网络均有1%以上的提升,在CompCars上与其他网络进行对比,本文方法在同等条件下最高准确率达到96.6%,高于对比方法。实验结果表明该方法能有效提高车辆精细识别的准确率。结论将生成对抗网络用于对数据的扩充增强,生成图像能够很好地模拟原图像数据,对原图像数据具有正则的作用,图像数据可以使图像的细粒度识别准确率获得一定的提升,具有较大的应用前景。关键词:细粒度识别;车型识别;生成对抗网络;注意力机制;半监督学习26|4|1更新时间:2024-05-07
摘要:目的车型识别在智能交通、智慧安防、自动驾驶等领域具有十分重要的应用前景。而车型识别中,带标签车型数据的数量是影响车型识别的重要因素。本文以"增强数据"为核心,结合PGGAN(progressive growing of GANs)和Attention机制,提出一种基于对抗网络生成数据再分类的网络模型AT-PGGAN(attention-progressive growing of GANs),采用模型生成带标签车型图像的数量,从而提高车型识别准确率。方法该模型由生成网络和分类网络组成,利用生成网络对训练数据进行增强扩充,利用注意力机制和标签重嵌入方法对生成网络进行优化使其生成图像细节更加完善,提出标签重标定的方法重新确定生成图像的标签数据,并对生成图像进行相应的筛选。使用扩充的图像加上原有数据集的图像作为输入训练分类网络。结果本文模型能够很好地扩充已有的车辆图像,在公开数据集StanfordCars上,其识别准确率相比未使用AT-PGGAN模型进行数据扩充的分类网络均有1%以上的提升,在CompCars上与其他网络进行对比,本文方法在同等条件下最高准确率达到96.6%,高于对比方法。实验结果表明该方法能有效提高车辆精细识别的准确率。结论将生成对抗网络用于对数据的扩充增强,生成图像能够很好地模拟原图像数据,对原图像数据具有正则的作用,图像数据可以使图像的细粒度识别准确率获得一定的提升,具有较大的应用前景。关键词:细粒度识别;车型识别;生成对抗网络;注意力机制;半监督学习26|4|1更新时间:2024-05-07 -
 摘要:目的现有的车标识别方法尽管取得了不错的识别效果,但最终的识别率容易遇到瓶颈,很难得到提升。车标识别是智能交通系统中至关重要的一部分,识别率的微小提升也能带来巨大的社会价值。通过挖掘与分析车标识别中潜在的问题和难点,发现未能得到正确分类的图像大部分为模糊车标图像。针对车标图像中存在的成像模糊等情况,本文提出一种基于抗模糊特征提取的车标识别方法。方法构建车标图像金字塔模型,分别提取图像的抗纹理模糊特征和抗边缘模糊特征。抗纹理模糊特征的提取使用局部量化的LPQ(local phase quantization)模式,可以增强原始特征的鲁棒性,抗边缘模糊特征的提取基于局部块弱梯度消除的HOG(histogram of oriented gradient)特征提取方法,可以在描述车标图像边缘梯度信息的同时,提升特征的抗模糊能力。最后利用CCA(canonical correlation analysis)方法进行两种抗模糊特征的融合并用于后续的降维与分类。结果本文方法在多个数据集上均取得了很好的识别效果,在20幅训练样本下,本文方法在公开车标数据集HFUT-VL(vehicle logo dataset from Hefei University of Technology)上取得了99.04%的识别率,在本文构建的模糊车标数据集BVL(blurring vehicle logo dataset)上也取得了97.19%的识别率。而在难度较大的XMU(Xiamen University vehicle logo dataset)上,本文方法在100幅训练样本下也达到了96.87%的识别率,识别效果高于一些具有较好表现的车标识别方法,表现出很强的鲁棒性和抗模糊性。结论本文方法提高了对成像质量欠缺的车标图像的识别能力,从而提升了整体识别效果,更符合实际应用中车标识别的需求。关键词:车标识别;梯度特征;抗模糊特征;局部量化;图像金字塔12|4|1更新时间:2024-05-07
摘要:目的现有的车标识别方法尽管取得了不错的识别效果,但最终的识别率容易遇到瓶颈,很难得到提升。车标识别是智能交通系统中至关重要的一部分,识别率的微小提升也能带来巨大的社会价值。通过挖掘与分析车标识别中潜在的问题和难点,发现未能得到正确分类的图像大部分为模糊车标图像。针对车标图像中存在的成像模糊等情况,本文提出一种基于抗模糊特征提取的车标识别方法。方法构建车标图像金字塔模型,分别提取图像的抗纹理模糊特征和抗边缘模糊特征。抗纹理模糊特征的提取使用局部量化的LPQ(local phase quantization)模式,可以增强原始特征的鲁棒性,抗边缘模糊特征的提取基于局部块弱梯度消除的HOG(histogram of oriented gradient)特征提取方法,可以在描述车标图像边缘梯度信息的同时,提升特征的抗模糊能力。最后利用CCA(canonical correlation analysis)方法进行两种抗模糊特征的融合并用于后续的降维与分类。结果本文方法在多个数据集上均取得了很好的识别效果,在20幅训练样本下,本文方法在公开车标数据集HFUT-VL(vehicle logo dataset from Hefei University of Technology)上取得了99.04%的识别率,在本文构建的模糊车标数据集BVL(blurring vehicle logo dataset)上也取得了97.19%的识别率。而在难度较大的XMU(Xiamen University vehicle logo dataset)上,本文方法在100幅训练样本下也达到了96.87%的识别率,识别效果高于一些具有较好表现的车标识别方法,表现出很强的鲁棒性和抗模糊性。结论本文方法提高了对成像质量欠缺的车标图像的识别能力,从而提升了整体识别效果,更符合实际应用中车标识别的需求。关键词:车标识别;梯度特征;抗模糊特征;局部量化;图像金字塔12|4|1更新时间:2024-05-07 -
 摘要:目的随着人脸识别系统应用的日益广泛,提高身份认证的安全性,提升人脸活体检测的有效性已经成为迫切需要解决的问题。针对活体检测中真实用户的照片存在的人脸欺骗问题,提出一种新的解决照片攻击的人脸活体检测算法。方法利用局部二值模式LBP(local binary pattern)、TV-L1(total variation regularization and the robust L1 norm)光流法、光学应变和深度网络实现的人脸活体检测方法。对原始数据进行预处理得到LBP特征图;对LBP特征图提取光流信息,提高对噪声适应的鲁棒性;计算光流的导数得到图像的光学应变图,以表征相邻两帧之间的微纹理性质的微小移动量;通过卷积神经网络模型(CNN)将每个应变图编码成特征向量,最终将特征向量传递给长短期记忆LSTM(long short term memory)模型进行分类,实现真假人脸的判别。结果实验在两个公开的人脸活体检测数据库上进行,并将本文算法与具有代表性的活体检测算法进行对比。在南京航空航天大学(NUAA)人脸活体检测数据库中,算法精度达到99.79%;在Replay-attack数据库中,算法精度达到98.2%,对比实验的结果证明本文算法对照片攻击的识别更加准确。结论本文提出的针对照片攻击的人脸活体检测算法,融合光学应变图像和深度学习模型的优点,使得人脸活体检测更加准确。关键词:人脸活体检测;局部二值模式;TV-L1光流法;光学应变;长短期记忆模型14|4|3更新时间:2024-05-07
摘要:目的随着人脸识别系统应用的日益广泛,提高身份认证的安全性,提升人脸活体检测的有效性已经成为迫切需要解决的问题。针对活体检测中真实用户的照片存在的人脸欺骗问题,提出一种新的解决照片攻击的人脸活体检测算法。方法利用局部二值模式LBP(local binary pattern)、TV-L1(total variation regularization and the robust L1 norm)光流法、光学应变和深度网络实现的人脸活体检测方法。对原始数据进行预处理得到LBP特征图;对LBP特征图提取光流信息,提高对噪声适应的鲁棒性;计算光流的导数得到图像的光学应变图,以表征相邻两帧之间的微纹理性质的微小移动量;通过卷积神经网络模型(CNN)将每个应变图编码成特征向量,最终将特征向量传递给长短期记忆LSTM(long short term memory)模型进行分类,实现真假人脸的判别。结果实验在两个公开的人脸活体检测数据库上进行,并将本文算法与具有代表性的活体检测算法进行对比。在南京航空航天大学(NUAA)人脸活体检测数据库中,算法精度达到99.79%;在Replay-attack数据库中,算法精度达到98.2%,对比实验的结果证明本文算法对照片攻击的识别更加准确。结论本文提出的针对照片攻击的人脸活体检测算法,融合光学应变图像和深度学习模型的优点,使得人脸活体检测更加准确。关键词:人脸活体检测;局部二值模式;TV-L1光流法;光学应变;长短期记忆模型14|4|3更新时间:2024-05-07
CACIS 2019会议专栏
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0