
最新刊期
2020 年 第 25 卷 第 2 期
-
 摘要:磁共振成像(MRI)作为一种典型的非侵入式成像技术,可产生高质量的无损伤和无颅骨伪影的脑影像,为脑肿瘤的诊断和治疗提供更为全面的信息,是脑肿瘤诊疗的主要技术手段。MRI脑肿瘤自动分割利用计算机技术从多模态脑影像中自动将肿瘤区(坏死区、水肿区、非增强肿瘤区和增强肿瘤区)和正常组织区进行分割和标注,对于辅助脑肿瘤的诊疗具有重要作用。本文对MRI脑肿瘤图像分割的深度学习方法进行了总结与分析,给出了各类方法的基本思想、网络架构形式、代表性改进方案以及优缺点总结等,并给出了部分典型方法在BraTS(multimodal brain tumor segmentation)数据集上的性能表现与分析结果。通过对该领域研究方法进行综述,对现有基于深度学习的MRI脑肿瘤分割研究方法进行了梳理,作为新的发展方向,MRI脑肿瘤图像分割的深度学习方法较传统方法已取得明显的性能提升,已成为领域主流方法并持续展现出良好的发展前景,有助于进一步推动MRI脑肿瘤分割在临床诊疗上的应用。关键词:磁共振成像;脑肿瘤;人工神经网络;深度学习;分割114|274|18更新时间:2024-05-07
摘要:磁共振成像(MRI)作为一种典型的非侵入式成像技术,可产生高质量的无损伤和无颅骨伪影的脑影像,为脑肿瘤的诊断和治疗提供更为全面的信息,是脑肿瘤诊疗的主要技术手段。MRI脑肿瘤自动分割利用计算机技术从多模态脑影像中自动将肿瘤区(坏死区、水肿区、非增强肿瘤区和增强肿瘤区)和正常组织区进行分割和标注,对于辅助脑肿瘤的诊疗具有重要作用。本文对MRI脑肿瘤图像分割的深度学习方法进行了总结与分析,给出了各类方法的基本思想、网络架构形式、代表性改进方案以及优缺点总结等,并给出了部分典型方法在BraTS(multimodal brain tumor segmentation)数据集上的性能表现与分析结果。通过对该领域研究方法进行综述,对现有基于深度学习的MRI脑肿瘤分割研究方法进行了梳理,作为新的发展方向,MRI脑肿瘤图像分割的深度学习方法较传统方法已取得明显的性能提升,已成为领域主流方法并持续展现出良好的发展前景,有助于进一步推动MRI脑肿瘤分割在临床诊疗上的应用。关键词:磁共振成像;脑肿瘤;人工神经网络;深度学习;分割114|274|18更新时间:2024-05-07
综述

-
 摘要:目的人脸超分辨率重建是特定应用领域的超分辨率问题,为了充分利用面部先验知识,提出一种基于多任务联合学习的深度人脸超分辨率重建算法。方法首先使用残差学习和对称式跨层连接网络提取低分辨率人脸的多层次特征,根据不同任务的学习难易程度设置损失权重和损失阈值,对网络进行多属性联合学习训练。然后使用感知损失函数衡量HR(high-resolution)图像与SR(super-resolution)图像在语义层面的差距,并论证感知损失在提高人脸语义信息重建效果方面的有效性。最后对人脸属性数据集进行增强,在此基础上进行联合多任务学习,以获得视觉感知效果更加真实的超分辨率结果。结果使用峰值信噪比(PSNR)和结构相似度(SSIM)两个客观评价标准对实验结果进行评价,并与其他主流方法进行对比。实验结果显示,在人脸属性数据集(CelebA)上,在放大8倍时,与通用超分辨率MemNet(persistent memory network)算法和人脸超分辨率FSRNet(end-to-end learning face super-resolution network)算法相比,本文算法的PSNR分别提升约2.15 dB和1.2 dB。结论实验数据与效果图表明本文算法可以更好地利用人脸先验知识,产生在视觉感知上更加真实和清晰的人脸边缘和纹理细节。关键词:多任务联合学习;图像修复;深度学习;超分辨率;感知损失58|99|4更新时间:2024-05-07
摘要:目的人脸超分辨率重建是特定应用领域的超分辨率问题,为了充分利用面部先验知识,提出一种基于多任务联合学习的深度人脸超分辨率重建算法。方法首先使用残差学习和对称式跨层连接网络提取低分辨率人脸的多层次特征,根据不同任务的学习难易程度设置损失权重和损失阈值,对网络进行多属性联合学习训练。然后使用感知损失函数衡量HR(high-resolution)图像与SR(super-resolution)图像在语义层面的差距,并论证感知损失在提高人脸语义信息重建效果方面的有效性。最后对人脸属性数据集进行增强,在此基础上进行联合多任务学习,以获得视觉感知效果更加真实的超分辨率结果。结果使用峰值信噪比(PSNR)和结构相似度(SSIM)两个客观评价标准对实验结果进行评价,并与其他主流方法进行对比。实验结果显示,在人脸属性数据集(CelebA)上,在放大8倍时,与通用超分辨率MemNet(persistent memory network)算法和人脸超分辨率FSRNet(end-to-end learning face super-resolution network)算法相比,本文算法的PSNR分别提升约2.15 dB和1.2 dB。结论实验数据与效果图表明本文算法可以更好地利用人脸先验知识,产生在视觉感知上更加真实和清晰的人脸边缘和纹理细节。关键词:多任务联合学习;图像修复;深度学习;超分辨率;感知损失58|99|4更新时间:2024-05-07 -
 摘要:目的图像的风格迁移是近年来机器视觉领域的研究热点之一。针对传统基于卷积神经网络(CNN)的图像风格迁移方法得到的结果图像存在风格纹理不均匀、噪声增强及迭代时间长等问题,本文在CNN框架下提出了一种基于相关对齐的总变分图像风格迁移新模型。方法在详细地分析了传统风格迁移方法的基础上,新模型引入了基于相关对齐的风格纹理提取方法,通过最小化损失函数,使得风格信息更加均匀地分布在结果图像中。通过分析比较CNN分解图像后不同卷积层的重构结果,提出了新的卷积层选择策略,以有效地提高风格迁移模型的效率。新模型引入了经典的总变分正则,以有效地抑制风格迁移过程中产生的噪声,使结果图像具有更好的视觉效果。结果仿真实验结果说明,相对于传统方法,本文方法得到的结果图像在风格纹理和内容信息上均有更好的表现,即在风格纹理更加均匀细腻的基础上较好地保留了内容图像的信息。另外,新模型可以有效地抑制风格迁移过程中产生的噪声,且具有更高的运行效率(新模型比传统模型迭代时间减少了约30%)。结论与传统方法相比,本文方法得到的结果图像在视觉效果方面有更好的表现,且其效率明显优于传统的风格迁移模型。关键词:相关对齐;总变分;风格迁移;机器视觉;卷积神经网络31|33|7更新时间:2024-05-07
摘要:目的图像的风格迁移是近年来机器视觉领域的研究热点之一。针对传统基于卷积神经网络(CNN)的图像风格迁移方法得到的结果图像存在风格纹理不均匀、噪声增强及迭代时间长等问题,本文在CNN框架下提出了一种基于相关对齐的总变分图像风格迁移新模型。方法在详细地分析了传统风格迁移方法的基础上,新模型引入了基于相关对齐的风格纹理提取方法,通过最小化损失函数,使得风格信息更加均匀地分布在结果图像中。通过分析比较CNN分解图像后不同卷积层的重构结果,提出了新的卷积层选择策略,以有效地提高风格迁移模型的效率。新模型引入了经典的总变分正则,以有效地抑制风格迁移过程中产生的噪声,使结果图像具有更好的视觉效果。结果仿真实验结果说明,相对于传统方法,本文方法得到的结果图像在风格纹理和内容信息上均有更好的表现,即在风格纹理更加均匀细腻的基础上较好地保留了内容图像的信息。另外,新模型可以有效地抑制风格迁移过程中产生的噪声,且具有更高的运行效率(新模型比传统模型迭代时间减少了约30%)。结论与传统方法相比,本文方法得到的结果图像在视觉效果方面有更好的表现,且其效率明显优于传统的风格迁移模型。关键词:相关对齐;总变分;风格迁移;机器视觉;卷积神经网络31|33|7更新时间:2024-05-07 -
 摘要:目的语义分割是计算机视觉中一项具有挑战性的任务,其核心是为图像中的每个像素分配相应的语义类别标签。然而,在语义分割任务中,缺乏丰富的多尺度信息和足够的空间信息会严重影响图像分割结果。为进一步提升图像分割效果,从提取丰富的多尺度信息和充分的空间信息出发,本文提出了一种基于编码-解码结构的语义分割模型。方法运用ResNet-101网络作为模型的骨架提取特征图,在骨架末端附加一个多尺度信息融合模块,用于在网络深层提取区分力强且多尺度信息丰富的特征图。并且,在网络浅层引入空间信息捕获模块来提取丰富的空间信息。由空间信息捕获模块捕获的带有丰富空间信息的特征图和由多尺度信息融合模块提取的区分力强且多尺度信息丰富的特征图将融合为一个新的信息丰富的特征图集合,经过多核卷积块细化之后,最终运用数据依赖的上采样(DUpsampling)操作得到图像分割结果。结果此模型在2个公开数据集(Cityscapes数据集和PASCAL VOC 2012数据集)上进行了大量实验,验证了所设计的每个模块及整个模型的有效性。新模型与最新的10种方法进行了比较,在Cityscapes数据集中,相比于RefineNet模型、DeepLabv2-CRF模型和LRR(Laplacian reconstruction and refinement)模型,平均交并比(mIoU)值分别提高了0.52%、3.72%和4.42%;在PASCAL VOC 2012数据集中,相比于Piecewise模型、DPN(deep parsing network)模型和GCRF(Gaussion conditional random field network)模型,mIoU值分别提高了6.23%、7.43%和8.33%。结论本文语义分割模型,提取了更加丰富的多尺度信息和空间信息,使得分割结果更加准确。此模型可应用于医学图像分析、自动驾驶、无人机等领域。关键词:语义分割;克罗内克卷积;多尺度信息;空间信息;注意力机制;编码—解码结构;Cityscapes数据集;PASCAL VOC 2012数据集53|73|5更新时间:2024-05-07
摘要:目的语义分割是计算机视觉中一项具有挑战性的任务,其核心是为图像中的每个像素分配相应的语义类别标签。然而,在语义分割任务中,缺乏丰富的多尺度信息和足够的空间信息会严重影响图像分割结果。为进一步提升图像分割效果,从提取丰富的多尺度信息和充分的空间信息出发,本文提出了一种基于编码-解码结构的语义分割模型。方法运用ResNet-101网络作为模型的骨架提取特征图,在骨架末端附加一个多尺度信息融合模块,用于在网络深层提取区分力强且多尺度信息丰富的特征图。并且,在网络浅层引入空间信息捕获模块来提取丰富的空间信息。由空间信息捕获模块捕获的带有丰富空间信息的特征图和由多尺度信息融合模块提取的区分力强且多尺度信息丰富的特征图将融合为一个新的信息丰富的特征图集合,经过多核卷积块细化之后,最终运用数据依赖的上采样(DUpsampling)操作得到图像分割结果。结果此模型在2个公开数据集(Cityscapes数据集和PASCAL VOC 2012数据集)上进行了大量实验,验证了所设计的每个模块及整个模型的有效性。新模型与最新的10种方法进行了比较,在Cityscapes数据集中,相比于RefineNet模型、DeepLabv2-CRF模型和LRR(Laplacian reconstruction and refinement)模型,平均交并比(mIoU)值分别提高了0.52%、3.72%和4.42%;在PASCAL VOC 2012数据集中,相比于Piecewise模型、DPN(deep parsing network)模型和GCRF(Gaussion conditional random field network)模型,mIoU值分别提高了6.23%、7.43%和8.33%。结论本文语义分割模型,提取了更加丰富的多尺度信息和空间信息,使得分割结果更加准确。此模型可应用于医学图像分析、自动驾驶、无人机等领域。关键词:语义分割;克罗内克卷积;多尺度信息;空间信息;注意力机制;编码—解码结构;Cityscapes数据集;PASCAL VOC 2012数据集53|73|5更新时间:2024-05-07
图像处理和编码
-
 摘要:目的基于超像素分割的显著物体检测模型在很多公开数据集上表现优异,但在实际场景应用时,超像素分割的数量和大小难以自适应图像和目标大小的变化,从而使性能下降,且分割过多会耗时过大。为解决这一问题,本文提出基于布尔图和灰度稀缺性的小目标显著性检测方法。方法利用布尔图的思想,提取图像中较为突出的闭合区域,根据闭合区域的大小赋予其显著值,形成一幅显著图;利用灰度稀缺性,为图像中的稀缺灰度值赋予高显著值,抑制烟雾、云、光照渐晕等渐变背景,生成另一幅显著图;将两幅显著图融合,得到具有全分辨率、目标突出且轮廓清晰的显著图。结果在3个数据集上与14种显著性模型进行对比,本文算法生成的显著图能有效抑制背景,并检测出多个小目标。其中,在复杂背景数据集上,本文算法具有最高的F值(F-measure)和最小的MAE(mean absolute error)值,AUC(area under ROC curve)值仅次于DRFI(discriminative regional feature integration)和ASNet(attentive saliency network)模型,AUC和F-measure值比BMS(Boolean map based saliency)模型分别提高了1.9%和6.9%,MAE值降低了1.8%;在SO200数据集上,本文算法的F-measure值最高,MAE值仅次于ASNet,F-measure值比BMS模型提高了3.8%,MAE值降低了2%;在SED2数据集上,本文算法也优于6种传统模型。在运行时间方面,本文算法具有明显优势,处理400×300像素的图像时,帧频可达12帧/s。结论本文算法具有良好的适应性和鲁棒性,对于复杂背景下的小目标具有良好的显著性检测效果。关键词:显著物体检测;布尔图;灰度稀缺性;小目标;复杂背景44|15|3更新时间:2024-05-07
摘要:目的基于超像素分割的显著物体检测模型在很多公开数据集上表现优异,但在实际场景应用时,超像素分割的数量和大小难以自适应图像和目标大小的变化,从而使性能下降,且分割过多会耗时过大。为解决这一问题,本文提出基于布尔图和灰度稀缺性的小目标显著性检测方法。方法利用布尔图的思想,提取图像中较为突出的闭合区域,根据闭合区域的大小赋予其显著值,形成一幅显著图;利用灰度稀缺性,为图像中的稀缺灰度值赋予高显著值,抑制烟雾、云、光照渐晕等渐变背景,生成另一幅显著图;将两幅显著图融合,得到具有全分辨率、目标突出且轮廓清晰的显著图。结果在3个数据集上与14种显著性模型进行对比,本文算法生成的显著图能有效抑制背景,并检测出多个小目标。其中,在复杂背景数据集上,本文算法具有最高的F值(F-measure)和最小的MAE(mean absolute error)值,AUC(area under ROC curve)值仅次于DRFI(discriminative regional feature integration)和ASNet(attentive saliency network)模型,AUC和F-measure值比BMS(Boolean map based saliency)模型分别提高了1.9%和6.9%,MAE值降低了1.8%;在SO200数据集上,本文算法的F-measure值最高,MAE值仅次于ASNet,F-measure值比BMS模型提高了3.8%,MAE值降低了2%;在SED2数据集上,本文算法也优于6种传统模型。在运行时间方面,本文算法具有明显优势,处理400×300像素的图像时,帧频可达12帧/s。结论本文算法具有良好的适应性和鲁棒性,对于复杂背景下的小目标具有良好的显著性检测效果。关键词:显著物体检测;布尔图;灰度稀缺性;小目标;复杂背景44|15|3更新时间:2024-05-07 -
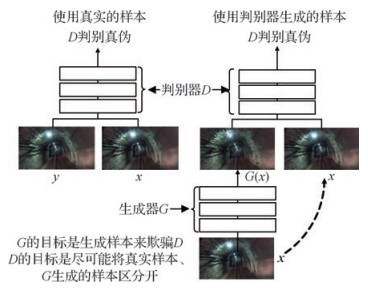 摘要:目的传统的轨道检测算法受环境干扰因素大导致检测效率低,基于卷积神经网络(CNN)算法的轨道检测结果缺乏对于对象的细腻、独特刻画且过多依赖可视化后处理技术,因此本文提出一种结合多尺度信息的条件生成对抗网络(CGAN)轨道线检测算法。方法在生成器网络中采用多粒度结构将生成器分解为全局和局部两个部分;在判别器网络中采用多尺度共享卷积结构,进一步监督生成器的训练;引入蒙特卡罗搜索技术通过对生成器的中间状态进行搜索,并将结果再送入到判别器中进行对比。结果在井下巷道场景测试集中,本文方法取得了82.43%像素精度和0.621 8的平均交并比,并且对轨道的检测可以达到95.01%的准确率;与现有的语义分割的算法相比,表现出了优越性。结论本文方法能够有效应用于井下复杂环境,一定程度上解决了传统的图像处理算法和卷积神经网络算法存在的问题,从而有效服务于井下自动驾驶。关键词:轨道检测;条件生成对抗网络;多尺度信息;蒙特卡洛搜索;井下自动驾驶19|18|2更新时间:2024-05-07
摘要:目的传统的轨道检测算法受环境干扰因素大导致检测效率低,基于卷积神经网络(CNN)算法的轨道检测结果缺乏对于对象的细腻、独特刻画且过多依赖可视化后处理技术,因此本文提出一种结合多尺度信息的条件生成对抗网络(CGAN)轨道线检测算法。方法在生成器网络中采用多粒度结构将生成器分解为全局和局部两个部分;在判别器网络中采用多尺度共享卷积结构,进一步监督生成器的训练;引入蒙特卡罗搜索技术通过对生成器的中间状态进行搜索,并将结果再送入到判别器中进行对比。结果在井下巷道场景测试集中,本文方法取得了82.43%像素精度和0.621 8的平均交并比,并且对轨道的检测可以达到95.01%的准确率;与现有的语义分割的算法相比,表现出了优越性。结论本文方法能够有效应用于井下复杂环境,一定程度上解决了传统的图像处理算法和卷积神经网络算法存在的问题,从而有效服务于井下自动驾驶。关键词:轨道检测;条件生成对抗网络;多尺度信息;蒙特卡洛搜索;井下自动驾驶19|18|2更新时间:2024-05-07 -
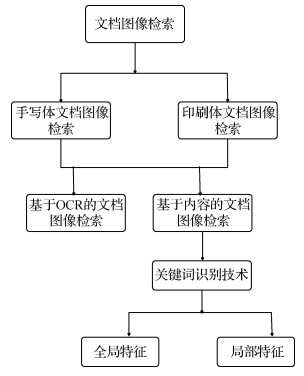 摘要:目的文档图像检索过程中,传统的光学字符识别(OCR)技术因易受文档图像质量和字体等相关因素的影响,难以达到有效检索的目的。关键词识别技术作为OCR技术的替代方案,不需经过繁琐的OCR识别,可直接对关键词进行检索。本文针对Harris算法聚簇现象严重和运算速度慢等问题,在关键词识别技术的框架下提出了改进Harris的图像匹配算法。方法基于Fast进行特征点检测,利用Harris进行特征描述,并采用非极大值抑制的方法,最后利用暴力匹配中的汉明距离进行特征的相似性度量,输出最终的匹配结果。结果实验结果表明本文算法在特征提取上的时间为0.101 s,相对于原始Harris算法的0.664 s和SIFT算法的1.066 s,实时性方面有了明显提高,改善了原始算法的聚簇现象,并且在无噪声的情况下,准确率达到98%,高于Sift算法的90%,召回率达到87.5%,而且在固定均值,不断提高方差的高斯噪声条件下,与Sift算法相比,准确率也高于后者,取得了较好的实验效果。结论本文提出的方法满足了快速、精确的查找需求,在印刷体图像的文档图像检索中有效提高了检索率,具有较好的实验效果。关键词:Fast+Harris;特征提取;暴力匹配;角点检测;关键词识别技术;印刷体文档图像21|23|1更新时间:2024-05-07
摘要:目的文档图像检索过程中,传统的光学字符识别(OCR)技术因易受文档图像质量和字体等相关因素的影响,难以达到有效检索的目的。关键词识别技术作为OCR技术的替代方案,不需经过繁琐的OCR识别,可直接对关键词进行检索。本文针对Harris算法聚簇现象严重和运算速度慢等问题,在关键词识别技术的框架下提出了改进Harris的图像匹配算法。方法基于Fast进行特征点检测,利用Harris进行特征描述,并采用非极大值抑制的方法,最后利用暴力匹配中的汉明距离进行特征的相似性度量,输出最终的匹配结果。结果实验结果表明本文算法在特征提取上的时间为0.101 s,相对于原始Harris算法的0.664 s和SIFT算法的1.066 s,实时性方面有了明显提高,改善了原始算法的聚簇现象,并且在无噪声的情况下,准确率达到98%,高于Sift算法的90%,召回率达到87.5%,而且在固定均值,不断提高方差的高斯噪声条件下,与Sift算法相比,准确率也高于后者,取得了较好的实验效果。结论本文提出的方法满足了快速、精确的查找需求,在印刷体图像的文档图像检索中有效提高了检索率,具有较好的实验效果。关键词:Fast+Harris;特征提取;暴力匹配;角点检测;关键词识别技术;印刷体文档图像21|23|1更新时间:2024-05-07 -
 摘要:目的图像因各种因素的影响存在一定程度的噪声,而噪声会在图像分割时影响待分割目标的边缘识别,导致分割结果难以达到理想状态。针对以上问题,在距离规则化水平集(DRLSE)演化模型的基础上,提出一种将各向异性扩散散度场信息融合到DRLSE模型中的新模型。方法将水平集函数初始化为分段常数表达式,设定演化方程中的参数和水平集函数演化过程中的迭代时间步长Δ
摘要:目的图像因各种因素的影响存在一定程度的噪声,而噪声会在图像分割时影响待分割目标的边缘识别,导致分割结果难以达到理想状态。针对以上问题,在距离规则化水平集(DRLSE)演化模型的基础上,提出一种将各向异性扩散散度场信息融合到DRLSE模型中的新模型。方法将水平集函数初始化为分段常数表达式,设定演化方程中的参数和水平集函数演化过程中的迭代时间步长Δ$t$ $α$ $α$ $I$ 关键词:图像分割;噪声;边缘识别;水平集;各向异性扩散40|53|0更新时间:2024-05-07 -
 摘要:目的在文档图像版面分析上,主流的深度学习方法克服了传统方法的缺点,能够同时实现文档版面的区域定位与分类,但大多需要复杂的预处理过程,模型结构复杂。此外,文档图像数据不足的问题导致文档图像版面分析无法在通用的深度学习模型上取得较好的性能。针对上述问题,提出一种多特征融合卷积神经网络的深度学习方法。方法首先,采用不同大小的卷积核并行对输入图像进行特征提取,接着将卷积后的特征图进行融合,组成特征融合模块;然后选取DeeplabV3中的串并行空间金字塔策略,并添加图像级特征对提取的特征图进一步优化;最后通过双线性插值法对图像进行恢复,完成文档版面目标,即插图、表格、公式的定位与识别任务。结果本文采用mIOU(mean intersection over union)以及PA(pixel accuracy)两个指标作为评价标准,在ICDAR 2017 POD文档版面目标检测数据集上的实验表明,提出算法在mIOU与PA上分别达到87.26%和98.10%。对比FCN(fully convolutional networks),提出算法在mIOU与PA上分别提升约14.66%和2.22%,并且提出的特征融合模块对模型在mIOU与PA上分别有1.45%与0.22%的提升。结论本文算法在一个网络框架下同时实现了文档版面多种目标的定位与识别,在训练上并不需要对图像做复杂的预处理,模型结构简单。实验数据表明本文算法在训练数据较少的情况下能够取得较好的识别效果,优于FCN和DeeplabV3方法。关键词:文档图像处理;版面分析;目标检测;深度学习;语义分割54|36|5更新时间:2024-05-07
摘要:目的在文档图像版面分析上,主流的深度学习方法克服了传统方法的缺点,能够同时实现文档版面的区域定位与分类,但大多需要复杂的预处理过程,模型结构复杂。此外,文档图像数据不足的问题导致文档图像版面分析无法在通用的深度学习模型上取得较好的性能。针对上述问题,提出一种多特征融合卷积神经网络的深度学习方法。方法首先,采用不同大小的卷积核并行对输入图像进行特征提取,接着将卷积后的特征图进行融合,组成特征融合模块;然后选取DeeplabV3中的串并行空间金字塔策略,并添加图像级特征对提取的特征图进一步优化;最后通过双线性插值法对图像进行恢复,完成文档版面目标,即插图、表格、公式的定位与识别任务。结果本文采用mIOU(mean intersection over union)以及PA(pixel accuracy)两个指标作为评价标准,在ICDAR 2017 POD文档版面目标检测数据集上的实验表明,提出算法在mIOU与PA上分别达到87.26%和98.10%。对比FCN(fully convolutional networks),提出算法在mIOU与PA上分别提升约14.66%和2.22%,并且提出的特征融合模块对模型在mIOU与PA上分别有1.45%与0.22%的提升。结论本文算法在一个网络框架下同时实现了文档版面多种目标的定位与识别,在训练上并不需要对图像做复杂的预处理,模型结构简单。实验数据表明本文算法在训练数据较少的情况下能够取得较好的识别效果,优于FCN和DeeplabV3方法。关键词:文档图像处理;版面分析;目标检测;深度学习;语义分割54|36|5更新时间:2024-05-07 -
 摘要:目的图像的显著性目标检测是计算机视觉领域的重要研究课题。针对现有显著性目标检测结果存在的纹理细节刻画不明显和边缘轮廓显示不完整的问题,提出一种融合多特征与先验信息的显著性目标检测方法,该方法能够高效而全面地获取图像中的显著性区域。方法首先,提取图像感兴趣的点集,计算全局对比度图,利用贝叶斯方法融合凸包和全局对比度图获得对比度特征图。通过多尺度下的颜色直方图得到颜色空间图,根据信息熵定理计算最小信息熵,并将该尺度下的颜色空间图作为颜色特征图。通过反锐化掩模方法提高图像清晰度,利用局部二值算子(LBP)获得纹理特征图。然后,通过图形正则化(GR)和流行排序(MR)算法得到中心先验图和边缘先验图。最后,利用元胞自动机融合对比度特征图、颜色特征图、纹理特征图、中心先验图和边缘先验图获得初级显著图,再通过快速引导滤波器优化处理得到最终显著图。结果在2个公开的数据集MSRA10K和ECSSD上验证本文算法并与12种具有开源代码的流行算法进行比较,实验结果表明,本文算法在准确率-召回率(PR)曲线、受试者工作特征(ROC)曲线、综合评价指标(F-measure)、平均绝对误差(MAE)和结构化度量指标(S-measure)等方面有显著提升,整体性能优于对比算法。结论本文算法充分利用了图像的对比度特征、颜色特征、纹理特征,采用中心先验和边缘先验算法,在全面提取显著性区域的同时,能够较好地保留图像的纹理信息和细节信息,使得边缘轮廓更加完整,满足人眼的层次要求和细节要求,并具有一定的适用性。关键词:显著性目标检测;多特征;先验信息;元胞自动机;快速引导滤波器22|12|3更新时间:2024-05-07
摘要:目的图像的显著性目标检测是计算机视觉领域的重要研究课题。针对现有显著性目标检测结果存在的纹理细节刻画不明显和边缘轮廓显示不完整的问题,提出一种融合多特征与先验信息的显著性目标检测方法,该方法能够高效而全面地获取图像中的显著性区域。方法首先,提取图像感兴趣的点集,计算全局对比度图,利用贝叶斯方法融合凸包和全局对比度图获得对比度特征图。通过多尺度下的颜色直方图得到颜色空间图,根据信息熵定理计算最小信息熵,并将该尺度下的颜色空间图作为颜色特征图。通过反锐化掩模方法提高图像清晰度,利用局部二值算子(LBP)获得纹理特征图。然后,通过图形正则化(GR)和流行排序(MR)算法得到中心先验图和边缘先验图。最后,利用元胞自动机融合对比度特征图、颜色特征图、纹理特征图、中心先验图和边缘先验图获得初级显著图,再通过快速引导滤波器优化处理得到最终显著图。结果在2个公开的数据集MSRA10K和ECSSD上验证本文算法并与12种具有开源代码的流行算法进行比较,实验结果表明,本文算法在准确率-召回率(PR)曲线、受试者工作特征(ROC)曲线、综合评价指标(F-measure)、平均绝对误差(MAE)和结构化度量指标(S-measure)等方面有显著提升,整体性能优于对比算法。结论本文算法充分利用了图像的对比度特征、颜色特征、纹理特征,采用中心先验和边缘先验算法,在全面提取显著性区域的同时,能够较好地保留图像的纹理信息和细节信息,使得边缘轮廓更加完整,满足人眼的层次要求和细节要求,并具有一定的适用性。关键词:显著性目标检测;多特征;先验信息;元胞自动机;快速引导滤波器22|12|3更新时间:2024-05-07
图像分析和识别
-
 摘要:目的图像字幕生成是一个涉及计算机视觉和自然语言处理的热门研究领域,其目的是生成可以准确表达图片内容的句子。在已经提出的方法中,生成的句子存在描述不准确、缺乏连贯性的问题。为此,提出一种基于编码器-解码器框架和生成式对抗网络的融合训练新方法。通过对生成字幕整体和局部分别进行优化,提高生成句子的准确性和连贯性。方法使用卷积神经网络作为编码器提取图像特征,并将得到的特征和图像对应的真实描述共同作为解码器的输入。使用长短时记忆网络作为解码器进行图像字幕生成。在字幕生成的每个时刻,分别使用真实描述和前一时刻生成的字幕作为下一时刻的输入,同时生成两组字幕。计算使用真实描述生成的字幕和真实描述本身之间的相似性,以及使用前一时刻的输出生成的字幕通过判别器得到的分数。将二者组合成一个新的融合优化函数指导生成器的训练。结果在CUB-200数据集上,与未使用约束器的方法相比,本文方法在BLEU-4、BLEU-3、BLEI-2、BLEU-1、ROUGE-L和METEOR等6个评价指标上的得分分别提升了0.8%、1.2%、1.6%、0.9%、1.8%和1.0%。在Oxford-102数据集上,与未使用约束器的方法相比,本文方法在CIDEr、BLEU-4、BLEU-3、BLEU-2、BLEU-1、ROUGE-L和METEOR等7个评价指标上的得分分别提升了3.8%、1.5%、1.7%、1.4%、1.5%、0.5%和0.1%。在MSCOCO数据集上,本文方法在BLEU-2和BLEU-3两项评价指标上取得了最优值,分别为50.4%和36.8%。结论本文方法将图像字幕中单词前后的使用关系纳入考虑范围,并使用约束器对字幕局部信息进行优化,有效解决了之前方法生成的字幕准确度和连贯度不高的问题,可以很好地用于图像理解和图像字幕生成。关键词:图像字幕生成;约束学习;强化学习;生成式对抗网络;融合训练22|20|2更新时间:2024-05-07
摘要:目的图像字幕生成是一个涉及计算机视觉和自然语言处理的热门研究领域,其目的是生成可以准确表达图片内容的句子。在已经提出的方法中,生成的句子存在描述不准确、缺乏连贯性的问题。为此,提出一种基于编码器-解码器框架和生成式对抗网络的融合训练新方法。通过对生成字幕整体和局部分别进行优化,提高生成句子的准确性和连贯性。方法使用卷积神经网络作为编码器提取图像特征,并将得到的特征和图像对应的真实描述共同作为解码器的输入。使用长短时记忆网络作为解码器进行图像字幕生成。在字幕生成的每个时刻,分别使用真实描述和前一时刻生成的字幕作为下一时刻的输入,同时生成两组字幕。计算使用真实描述生成的字幕和真实描述本身之间的相似性,以及使用前一时刻的输出生成的字幕通过判别器得到的分数。将二者组合成一个新的融合优化函数指导生成器的训练。结果在CUB-200数据集上,与未使用约束器的方法相比,本文方法在BLEU-4、BLEU-3、BLEI-2、BLEU-1、ROUGE-L和METEOR等6个评价指标上的得分分别提升了0.8%、1.2%、1.6%、0.9%、1.8%和1.0%。在Oxford-102数据集上,与未使用约束器的方法相比,本文方法在CIDEr、BLEU-4、BLEU-3、BLEU-2、BLEU-1、ROUGE-L和METEOR等7个评价指标上的得分分别提升了3.8%、1.5%、1.7%、1.4%、1.5%、0.5%和0.1%。在MSCOCO数据集上,本文方法在BLEU-2和BLEU-3两项评价指标上取得了最优值,分别为50.4%和36.8%。结论本文方法将图像字幕中单词前后的使用关系纳入考虑范围,并使用约束器对字幕局部信息进行优化,有效解决了之前方法生成的字幕准确度和连贯度不高的问题,可以很好地用于图像理解和图像字幕生成。关键词:图像字幕生成;约束学习;强化学习;生成式对抗网络;融合训练22|20|2更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的针对现有刺绣模拟算法中针线感不强、针线轨迹方向单一等问题, 提出了一种基于多尺度双通道卷积神经网络的刺绣模拟算法。方法1) 搭建多尺度双通道网络, 选取一幅刺绣艺术作品作为风格图像, 将MSCOCO(microsoft common objects in context)数据集作为训练集, 输入网络得到VGG(visual geometry group)网络损失和拉普拉斯损失; 2)将总损失值传回到网络, 通过梯度下降法更新网络参数, 并且重复更新参数直到指定的训练次数完成网络训练; 3)选取一幅目标图像作为刺绣模拟的内容图像, 输入训练完成的网络, 获得具有刺绣艺术风格的结果图像; 4)使用掩模图像将得到的结果图像与绣布图像进行图像融合, 即完成目标图像的刺绣模拟。结果本文算法能产生明显的针线感和多方向的针线轨迹, 增强了刺绣模拟绘制艺术作品的表现力。结论本文将输入图像经过多尺度双通道卷积神经网络进行前向传播, 并使用VGG19、VGG16和拉普拉斯模块作为损失网络进行刺绣模拟。实验结果表明, 与现有卷积神经网络风格模拟算法对比, 本文提出的网络能够学习到刺绣艺术风格图像的针线特征, 得到的图像贴近真实刺绣艺术作品。关键词:刺绣模拟;卷积神经网络;多尺度双通道;VGG网络损失;拉普拉斯损失13|4|1更新时间:2024-05-07
摘要:目的针对现有刺绣模拟算法中针线感不强、针线轨迹方向单一等问题, 提出了一种基于多尺度双通道卷积神经网络的刺绣模拟算法。方法1) 搭建多尺度双通道网络, 选取一幅刺绣艺术作品作为风格图像, 将MSCOCO(microsoft common objects in context)数据集作为训练集, 输入网络得到VGG(visual geometry group)网络损失和拉普拉斯损失; 2)将总损失值传回到网络, 通过梯度下降法更新网络参数, 并且重复更新参数直到指定的训练次数完成网络训练; 3)选取一幅目标图像作为刺绣模拟的内容图像, 输入训练完成的网络, 获得具有刺绣艺术风格的结果图像; 4)使用掩模图像将得到的结果图像与绣布图像进行图像融合, 即完成目标图像的刺绣模拟。结果本文算法能产生明显的针线感和多方向的针线轨迹, 增强了刺绣模拟绘制艺术作品的表现力。结论本文将输入图像经过多尺度双通道卷积神经网络进行前向传播, 并使用VGG19、VGG16和拉普拉斯模块作为损失网络进行刺绣模拟。实验结果表明, 与现有卷积神经网络风格模拟算法对比, 本文提出的网络能够学习到刺绣艺术风格图像的针线特征, 得到的图像贴近真实刺绣艺术作品。关键词:刺绣模拟;卷积神经网络;多尺度双通道;VGG网络损失;拉普拉斯损失13|4|1更新时间:2024-05-07
计算机图形学
-
 摘要:目的采用不同染色方法获得的周围神经标本经过MicroCT扫描后, 会获得不同效果的神经断层扫描图像。本文针对饱和氯化钙染色、无染色方法获得的两种周围神经MicroCT图像, 提出一种通用的方法, 实现不同染色方法获得的周围神经MicroCT图像在统一架构下的神经束轮廓获取。方法首先设计通用方法架构, 构建图像数据集, 完成图像标注、分组等关键性的准备环节。然后将迁移学习算法与蒙皮区域卷积神经网络(mask R-CNN)算法结合起来, 设计通用方法中的识别模型。最后设计多组实验, 采用不同分组的图像数据集对通用方法进行训练、测试, 以验证通用方法的效果。结果通用方法对不同分组的图像数据集的神经束轮廓获取准确率均超过95%, 交并比均在86%以上, 检测时间均小于0.06 s。此外, 对于神经束轮廓信息较复杂的图像数据集, 迁移学习结合mask R-CNN的识别模型与纯mask R-CNN的识别模型相比较, 准确率和交并比分别提高了5.5% 9.8%和2.4% 3.2%。结论实验结果表明, 针对不同染色方法获得的周围神经MicroCT图像, 采用本文方法可以准确、快速、全自动获取得到神经束轮廓。此外, 经过迁移后的mask R-CNN能显著提高神经束轮廓获取的准确性和鲁棒性。关键词:周围神经;神经束;轮廓获取;迁移学习;蒙皮区域卷积神经网络;MicroCT图像12|4|1更新时间:2024-05-07
摘要:目的采用不同染色方法获得的周围神经标本经过MicroCT扫描后, 会获得不同效果的神经断层扫描图像。本文针对饱和氯化钙染色、无染色方法获得的两种周围神经MicroCT图像, 提出一种通用的方法, 实现不同染色方法获得的周围神经MicroCT图像在统一架构下的神经束轮廓获取。方法首先设计通用方法架构, 构建图像数据集, 完成图像标注、分组等关键性的准备环节。然后将迁移学习算法与蒙皮区域卷积神经网络(mask R-CNN)算法结合起来, 设计通用方法中的识别模型。最后设计多组实验, 采用不同分组的图像数据集对通用方法进行训练、测试, 以验证通用方法的效果。结果通用方法对不同分组的图像数据集的神经束轮廓获取准确率均超过95%, 交并比均在86%以上, 检测时间均小于0.06 s。此外, 对于神经束轮廓信息较复杂的图像数据集, 迁移学习结合mask R-CNN的识别模型与纯mask R-CNN的识别模型相比较, 准确率和交并比分别提高了5.5% 9.8%和2.4% 3.2%。结论实验结果表明, 针对不同染色方法获得的周围神经MicroCT图像, 采用本文方法可以准确、快速、全自动获取得到神经束轮廓。此外, 经过迁移后的mask R-CNN能显著提高神经束轮廓获取的准确性和鲁棒性。关键词:周围神经;神经束;轮廓获取;迁移学习;蒙皮区域卷积神经网络;MicroCT图像12|4|1更新时间:2024-05-07 -
 摘要:目的超声胎儿头部边缘检测是胎儿头围测量的关键步骤,因胎儿头部超声图像边界模糊、超声声影造成图像中胎儿颅骨部分缺失、羊水及子宫壁形成与胎儿头部纹理及灰度相似的结构等因素干扰,给超声胎儿头部边缘检测及头围测量带来一定的难度。本文提出一种基于端到端的神经网络超声图像分割方法,用于胎儿头部边缘检测。方法以UNet++神经网络结构为基础,结合UNet++最后一层特征,构成融合型UNet++网络。训练过程中,为缓解模型训练过拟合问题,在每一卷积层后接一个空间dropout层。具体思路是通过融合型UNet++深度神经网络提取超声胎儿头部图像特征,通过胎儿头部区域概率图预测,输出胎儿头部语义分割的感兴趣区域。进一步获取胎儿的头部边缘关键点信息,并采用边缘曲线拟合方法拟合边缘,最终测量出胎儿头围大小。结果针对现有2维超声胎儿头围自动测量公开数据集HC18,以Dice系数、Hausdorff距离(HD)、头围绝对差值(AD)等指标评估本文模型性能,结果Dice系数为98.06%,HD距离为1.21±0.69 mm,头围测量AD为1.84±1.73 mm。在妊娠中期测试数据中,Dice系数为98.24%,HD距离为1.15±0.59 mm,头围测量AD为1.76±1.55 mm。在生物医学图像分析平台Grand Challenge上HC18数据集已提交结果中,融合型UNet++的Dice系数排在第3名,HD排在第2名,AD排在第10名。结论与经典超声胎儿头围测量方法及已有的机器学习方法应用研究相比,融合型UNet++能有效克服超声边界模糊、边缘缺失等干扰,精准分割出胎儿头部感兴趣区域,获取边缘关键点信息。与现有神经网络框架相比,融合型UNet++能充分利用上下文相关信息与局部定位功能,在妊娠中期的头围测量中,本文方法明显优于其他方法。关键词:医学图像分割;UNet++;胎儿头部边缘检测;胎儿头围测量;深度学习;超声图像19|8|5更新时间:2024-05-07
摘要:目的超声胎儿头部边缘检测是胎儿头围测量的关键步骤,因胎儿头部超声图像边界模糊、超声声影造成图像中胎儿颅骨部分缺失、羊水及子宫壁形成与胎儿头部纹理及灰度相似的结构等因素干扰,给超声胎儿头部边缘检测及头围测量带来一定的难度。本文提出一种基于端到端的神经网络超声图像分割方法,用于胎儿头部边缘检测。方法以UNet++神经网络结构为基础,结合UNet++最后一层特征,构成融合型UNet++网络。训练过程中,为缓解模型训练过拟合问题,在每一卷积层后接一个空间dropout层。具体思路是通过融合型UNet++深度神经网络提取超声胎儿头部图像特征,通过胎儿头部区域概率图预测,输出胎儿头部语义分割的感兴趣区域。进一步获取胎儿的头部边缘关键点信息,并采用边缘曲线拟合方法拟合边缘,最终测量出胎儿头围大小。结果针对现有2维超声胎儿头围自动测量公开数据集HC18,以Dice系数、Hausdorff距离(HD)、头围绝对差值(AD)等指标评估本文模型性能,结果Dice系数为98.06%,HD距离为1.21±0.69 mm,头围测量AD为1.84±1.73 mm。在妊娠中期测试数据中,Dice系数为98.24%,HD距离为1.15±0.59 mm,头围测量AD为1.76±1.55 mm。在生物医学图像分析平台Grand Challenge上HC18数据集已提交结果中,融合型UNet++的Dice系数排在第3名,HD排在第2名,AD排在第10名。结论与经典超声胎儿头围测量方法及已有的机器学习方法应用研究相比,融合型UNet++能有效克服超声边界模糊、边缘缺失等干扰,精准分割出胎儿头部感兴趣区域,获取边缘关键点信息。与现有神经网络框架相比,融合型UNet++能充分利用上下文相关信息与局部定位功能,在妊娠中期的头围测量中,本文方法明显优于其他方法。关键词:医学图像分割;UNet++;胎儿头部边缘检测;胎儿头围测量;深度学习;超声图像19|8|5更新时间:2024-05-07 -
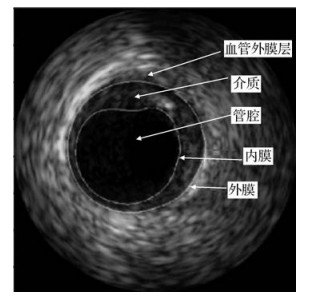 摘要:目的血管内超声(IVUS)图像动脉壁边界分割不仅对血管壁和斑块特征的定量分析至关重要,而且对血管弹性定性分析和重建动脉3维模型也是必需的。针对IVUS图像传统分割方法建模复杂、运算量大且需分别设计算法串行提取内膜和外膜的缺点,本文提出基于极值区域检测的IVUS图像并行分割方法。方法本文方法包含极值区域检测、极值区域筛选以及轮廓拟合3部分。对单帧IVUS图像提取极值区域,经面积筛选后得到候选区域,并将区域的局部二值模式(LBP)特征、灰度差异和边缘周长的乘积作为筛选矢量在候选区域中提取代表管腔和介质的两个极值区域,并进行轮廓的椭圆拟合化,完成分割。结果在包含326幅20 MHz的IVUS(intravascular ultrasound)B模式图像的标准公开数据集上,定性展示极值区域轮廓和椭圆拟合轮廓,并与专家手动绘制的结果进行对比;然后使用DC(dice coefficient)、JI(jaccard index)、PAD(percentage of area difference)指标以及HD(hausdorff distance)对本文算法做鲁棒性测试和泛化测试,实验中内膜各指标值分别为0.94±0.02,0.90±0.04,0.05±0.05,0.28±0.14 mm,外膜各指标值分别为0.91±0.07,0.87±0.11,0.11±0.11,0.41±0.31 mm,与相关文献的定量对比实验结果表明本文算法提取的内外膜性能均有所提高。此外,本文方法在临床数据集上的测试效果也很好,与专家手动描绘十分接近。结论结合极值区域检测的IVUS图像并行分割,算法在精度和鲁棒性方面均得到了改善。关键词:IVUS图像;内外膜分割;边缘检测;极值区域;轮廓拟合24|4|1更新时间:2024-05-07
摘要:目的血管内超声(IVUS)图像动脉壁边界分割不仅对血管壁和斑块特征的定量分析至关重要,而且对血管弹性定性分析和重建动脉3维模型也是必需的。针对IVUS图像传统分割方法建模复杂、运算量大且需分别设计算法串行提取内膜和外膜的缺点,本文提出基于极值区域检测的IVUS图像并行分割方法。方法本文方法包含极值区域检测、极值区域筛选以及轮廓拟合3部分。对单帧IVUS图像提取极值区域,经面积筛选后得到候选区域,并将区域的局部二值模式(LBP)特征、灰度差异和边缘周长的乘积作为筛选矢量在候选区域中提取代表管腔和介质的两个极值区域,并进行轮廓的椭圆拟合化,完成分割。结果在包含326幅20 MHz的IVUS(intravascular ultrasound)B模式图像的标准公开数据集上,定性展示极值区域轮廓和椭圆拟合轮廓,并与专家手动绘制的结果进行对比;然后使用DC(dice coefficient)、JI(jaccard index)、PAD(percentage of area difference)指标以及HD(hausdorff distance)对本文算法做鲁棒性测试和泛化测试,实验中内膜各指标值分别为0.94±0.02,0.90±0.04,0.05±0.05,0.28±0.14 mm,外膜各指标值分别为0.91±0.07,0.87±0.11,0.11±0.11,0.41±0.31 mm,与相关文献的定量对比实验结果表明本文算法提取的内外膜性能均有所提高。此外,本文方法在临床数据集上的测试效果也很好,与专家手动描绘十分接近。结论结合极值区域检测的IVUS图像并行分割,算法在精度和鲁棒性方面均得到了改善。关键词:IVUS图像;内外膜分割;边缘检测;极值区域;轮廓拟合24|4|1更新时间:2024-05-07
医学图像处理
-
 摘要:目的西北太平洋是我国远洋渔船从事大规模商业性捕捞的重要作业海域,也是中尺度涡的活跃区域,因此中尺度涡的提取方法研究对渔场分析有十分重要的意义。传统的研究方法多依赖栅格数据进行涡旋提取,并用标准圆形来拟合涡旋,难以提取涡旋的多核结构,本研究对此进行了改进。方法利用海表面高度异常数据,充分考虑海洋涡旋形状多样性以及矢量数据结构的优点,结合过去研究中的涡旋约束条件,基于无阈值的闭合等值线法,确定涡旋边界和中心,实现对西北太平洋黑潮延伸区的不规则矢量涡旋的提取。结果由于原始的海表面高度异常栅格数据图最接近海洋中涡旋实际存在的形状和位置,因此分别以1997年6月1日、2000年6月1日、2003年6月1日、2006年6月1日、2009年6月1日、2015年6月1日的涡旋提取结果为例与同一时间同一研究区域内原始海表面高度异常数据栅格图以及传统研究方法中标准圆形的涡旋提取结果进行比较。选取1994年6月1日的提取结果为例,同等比例放大同一位置涡旋,计算重叠率,重叠率的最大值为89%,最小值为22%,平均重叠率为65%。结果表明,本文的提取结果更接近海洋中涡旋的实际形状和位置,且精度更高。结论本文基于海洋卫星高度计的涡旋提取方法,充分考虑了海洋涡旋形状不规则的特点,综合了矢量数据结构的优点,更符合海洋中涡旋的实际形状和位置,比传统方法得到的结果具有更高的准确性和易用性,适用于涡旋与渔场关系的研究。关键词:海洋涡旋;海洋卫星高度计;不规则矢量;矢量数据结构12|4|0更新时间:2024-05-07
摘要:目的西北太平洋是我国远洋渔船从事大规模商业性捕捞的重要作业海域,也是中尺度涡的活跃区域,因此中尺度涡的提取方法研究对渔场分析有十分重要的意义。传统的研究方法多依赖栅格数据进行涡旋提取,并用标准圆形来拟合涡旋,难以提取涡旋的多核结构,本研究对此进行了改进。方法利用海表面高度异常数据,充分考虑海洋涡旋形状多样性以及矢量数据结构的优点,结合过去研究中的涡旋约束条件,基于无阈值的闭合等值线法,确定涡旋边界和中心,实现对西北太平洋黑潮延伸区的不规则矢量涡旋的提取。结果由于原始的海表面高度异常栅格数据图最接近海洋中涡旋实际存在的形状和位置,因此分别以1997年6月1日、2000年6月1日、2003年6月1日、2006年6月1日、2009年6月1日、2015年6月1日的涡旋提取结果为例与同一时间同一研究区域内原始海表面高度异常数据栅格图以及传统研究方法中标准圆形的涡旋提取结果进行比较。选取1994年6月1日的提取结果为例,同等比例放大同一位置涡旋,计算重叠率,重叠率的最大值为89%,最小值为22%,平均重叠率为65%。结果表明,本文的提取结果更接近海洋中涡旋的实际形状和位置,且精度更高。结论本文基于海洋卫星高度计的涡旋提取方法,充分考虑了海洋涡旋形状不规则的特点,综合了矢量数据结构的优点,更符合海洋中涡旋的实际形状和位置,比传统方法得到的结果具有更高的准确性和易用性,适用于涡旋与渔场关系的研究。关键词:海洋涡旋;海洋卫星高度计;不规则矢量;矢量数据结构12|4|0更新时间:2024-05-07 -
 摘要:目的合成孔径雷达(SAR)图像中像素强度统计分布呈现出复杂的特性,而传统混合模型难以建模非对称、重尾或多峰等特性的分布。为了准确建模SAR图像统计分布并得到高精度分割结果,本文提出一种利用空间约束层次加权Gamma混合模型(HWGaMM)的SAR图像分割算法。方法采用Gamma分布的加权和定义混合组份;考虑到同质区域内像素强度的差异性和异质区域间像素强度的相似性,采用混合组份加权和定义HWGaMM结构。采用马尔可夫随机场(MRF)建模像素空间位置关系,利用中心像素及其邻域像素的后验概率定义混合权重以将像素邻域关系引入HWGaMM,构建空间约束HWGaMM,以降低SAR图像内固有斑点噪声的影响。提出算法结合M-H(Metropolis-Hastings)和期望最大化算法(EM)求解模型参数,以实现快速SAR图像分割。该求解方法避免了M-H算法效率低的缺陷,同时克服了EM算法难以求解Gamma分布中形状参数的问题。结果采用3种传统混合模型分割算法作为对比算法进行分割实验。拟合直方图结果表明本文算法具有准确建模复杂统计分布的能力。在分割精度上,本文算法比基于高斯混合模型(GMM)、Gamma分布和Gamma混合模型(GaMM)分割算法分别提高33%,29%和9%。在分割时间上,本文算法虽然比GMM算法多64 s,但与基于Gamma分布和GaMM算法相比较分别快600 s和420 s。因此,本文算法比传统M-H算法的分割效率有很大的提高。结论提出一种空间约束HWGaMM的SAR图像分割算法,实验结果表明提出的HWGaMM算法具有准确建模复杂统计分布的能力,且具有较高的精度和效率。关键词:SAR图像分割;层次化加权Gamma混合模型;马尔可夫随机场;期望最大化法;M-H算法13|5|1更新时间:2024-05-07
摘要:目的合成孔径雷达(SAR)图像中像素强度统计分布呈现出复杂的特性,而传统混合模型难以建模非对称、重尾或多峰等特性的分布。为了准确建模SAR图像统计分布并得到高精度分割结果,本文提出一种利用空间约束层次加权Gamma混合模型(HWGaMM)的SAR图像分割算法。方法采用Gamma分布的加权和定义混合组份;考虑到同质区域内像素强度的差异性和异质区域间像素强度的相似性,采用混合组份加权和定义HWGaMM结构。采用马尔可夫随机场(MRF)建模像素空间位置关系,利用中心像素及其邻域像素的后验概率定义混合权重以将像素邻域关系引入HWGaMM,构建空间约束HWGaMM,以降低SAR图像内固有斑点噪声的影响。提出算法结合M-H(Metropolis-Hastings)和期望最大化算法(EM)求解模型参数,以实现快速SAR图像分割。该求解方法避免了M-H算法效率低的缺陷,同时克服了EM算法难以求解Gamma分布中形状参数的问题。结果采用3种传统混合模型分割算法作为对比算法进行分割实验。拟合直方图结果表明本文算法具有准确建模复杂统计分布的能力。在分割精度上,本文算法比基于高斯混合模型(GMM)、Gamma分布和Gamma混合模型(GaMM)分割算法分别提高33%,29%和9%。在分割时间上,本文算法虽然比GMM算法多64 s,但与基于Gamma分布和GaMM算法相比较分别快600 s和420 s。因此,本文算法比传统M-H算法的分割效率有很大的提高。结论提出一种空间约束HWGaMM的SAR图像分割算法,实验结果表明提出的HWGaMM算法具有准确建模复杂统计分布的能力,且具有较高的精度和效率。关键词:SAR图像分割;层次化加权Gamma混合模型;马尔可夫随机场;期望最大化法;M-H算法13|5|1更新时间:2024-05-07
遥感图像处理
-
 摘要:目的随着城市交通拥堵问题的日益严重,建立有效的道路拥堵可视化系统,对智慧城市建设起着重要作用。针对目前基于车辆密度分析法、车速判定法、行驶时间判定法等模式单一,可信度低的问题,提出了一种基于DBSCAN+(density-based spatial clustering of applications with noise plus)的道路拥堵识别可视化方法。方法引入分块并行计算,相较于传统密度算法,可以适应大规模轨迹数据,并行降维聚类速度快。对结果中缓行区类簇判别路段起始点和终止点,通过曲线拟合和拓扑网络纠偏算法,将类簇中轨迹样本点所表征的路段通过地图匹配算法匹配在电子地图中,并结合各类簇中浮动车平均行驶速度判别道路拥堵程度,以颜色深浅程度进行区分可视化。结果实验结果表明,DBSCAN+算法相较现有改进的DBSCAN算法时间复杂度具有优势,由指数降为线性,可适应海量轨迹点。相较主流地图产品,利用城市出租车车载OBD(on board diagnostics)数据进行城区道路拥堵识别,提取非畅通路段总检出长度相较最优产品提高28.9%,拥堵识别命中率高达91%,较主流产品城区拥堵识别平均命中率提高15%。结论在城市路网中,基于DBSCAN+密度聚类和缓行区平均移动速度的多表征道路拥堵识别算法与主流地图产品相比,对拥堵识别率、通勤程度划分更具代表性,可信度更高,可以为道路拥堵识别的实时性提供保障。关键词:并行聚类;拥堵识别;轨迹大数据;智慧城市;可视化13|5|2更新时间:2024-05-07
摘要:目的随着城市交通拥堵问题的日益严重,建立有效的道路拥堵可视化系统,对智慧城市建设起着重要作用。针对目前基于车辆密度分析法、车速判定法、行驶时间判定法等模式单一,可信度低的问题,提出了一种基于DBSCAN+(density-based spatial clustering of applications with noise plus)的道路拥堵识别可视化方法。方法引入分块并行计算,相较于传统密度算法,可以适应大规模轨迹数据,并行降维聚类速度快。对结果中缓行区类簇判别路段起始点和终止点,通过曲线拟合和拓扑网络纠偏算法,将类簇中轨迹样本点所表征的路段通过地图匹配算法匹配在电子地图中,并结合各类簇中浮动车平均行驶速度判别道路拥堵程度,以颜色深浅程度进行区分可视化。结果实验结果表明,DBSCAN+算法相较现有改进的DBSCAN算法时间复杂度具有优势,由指数降为线性,可适应海量轨迹点。相较主流地图产品,利用城市出租车车载OBD(on board diagnostics)数据进行城区道路拥堵识别,提取非畅通路段总检出长度相较最优产品提高28.9%,拥堵识别命中率高达91%,较主流产品城区拥堵识别平均命中率提高15%。结论在城市路网中,基于DBSCAN+密度聚类和缓行区平均移动速度的多表征道路拥堵识别算法与主流地图产品相比,对拥堵识别率、通勤程度划分更具代表性,可信度更高,可以为道路拥堵识别的实时性提供保障。关键词:并行聚类;拥堵识别;轨迹大数据;智慧城市;可视化13|5|2更新时间:2024-05-07
地理信息技术
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0