
最新刊期
2020 年 第 25 卷 第 12 期
-
 摘要:显著性检测一直是计算机视觉领域的关键问题,在视觉跟踪、图像压缩和目标识别等方面有着非常重要的应用。基于传统RGB图像和RGB-D(RGB depth)图像的显著性检测易受复杂背景、光照、遮挡等因素影响,在复杂场景的检测精度较低,鲁棒的显著性检测仍存在很大挑战。随着光场成像技术的发展,人们开始从新的途径解决显著性检测问题。光场数据记录着空间光线位置信息和方向信息,隐含场景的几何结构,能为显著性检测提供可靠的背景、深度等先验信息。因此,利用光场数据进行显著性检测得到了广泛关注,成为研究热点。尽管基于光场数据的显著性检测算法陆续出现,但是缺少对该问题的深刻理解以及研究进展的全面综述。本文系统地综述了基于光场数据的显著性检测研究现状,并进行深入探讨和展望。对光场理论以及用于光场显著性检测的公共数据集进行介绍;系统地介绍了光场显著性检测领域的算法模型和最新进展,从人工设计光场特征、稀疏编码特征和深度学习特征等方面进行全面阐述及分析;通过4个公共光场显著性数据集上的实验数据对不同方法的优缺点进行比较和分析,并结合实际应用指出当前研究的局限性与发展趋势。关键词:显著性检测;光场相机;光场特征;稀疏编码;深度学习74|83|4更新时间:2024-05-07
摘要:显著性检测一直是计算机视觉领域的关键问题,在视觉跟踪、图像压缩和目标识别等方面有着非常重要的应用。基于传统RGB图像和RGB-D(RGB depth)图像的显著性检测易受复杂背景、光照、遮挡等因素影响,在复杂场景的检测精度较低,鲁棒的显著性检测仍存在很大挑战。随着光场成像技术的发展,人们开始从新的途径解决显著性检测问题。光场数据记录着空间光线位置信息和方向信息,隐含场景的几何结构,能为显著性检测提供可靠的背景、深度等先验信息。因此,利用光场数据进行显著性检测得到了广泛关注,成为研究热点。尽管基于光场数据的显著性检测算法陆续出现,但是缺少对该问题的深刻理解以及研究进展的全面综述。本文系统地综述了基于光场数据的显著性检测研究现状,并进行深入探讨和展望。对光场理论以及用于光场显著性检测的公共数据集进行介绍;系统地介绍了光场显著性检测领域的算法模型和最新进展,从人工设计光场特征、稀疏编码特征和深度学习特征等方面进行全面阐述及分析;通过4个公共光场显著性数据集上的实验数据对不同方法的优缺点进行比较和分析,并结合实际应用指出当前研究的局限性与发展趋势。关键词:显著性检测;光场相机;光场特征;稀疏编码;深度学习74|83|4更新时间:2024-05-07
综述

-
 摘要:目的雨天户外采集的图像常常因为雨线覆盖图像信息产生色变和模糊现象。为了提高雨天图像的质量,本文提出一种基于自适应选择卷积网络深度学习的单幅图像去雨算法。方法针对雨图中背景误判和雨痕残留问题,加入网络训练的雨线修正系数(refine factor,RF),改进现有雨图模型,更精确地描述雨图中各像素受到雨线的影响。构建选择卷积网络(selective kernel network,SK Net),自适应地选择不同卷积核对应维度的信息,进一步学习、融合不同卷积核的信息,提高网络的表达力,最后构建包含SK Net、refine factor net和residual net子网络的自适应卷积残差修正网络(selective kernel convolution using a residual refine factor,SKRF),直接学习雨线图和残差修正系数(RF),减少映射区间,减少背景误判。结果实验通过设计的SKRF网络,在公开的Rain12测试集上进行去雨实验,取得了比现有方法更高的精确度,峰值信噪比(peak signal to noise ratio,PSNR)达到34.62 dB,结构相似性(structural similarity,SSIM)达到0.970 6。表明SKRF网络对单幅图像去雨效果有明显优势。结论单幅图像去雨SKRF算法为雨图模型中的雨线图提供一个额外的修正残差系数,以降低学习映射区间,自适应选择卷积网络模型提升雨图模型的表达力和兼容性。关键词:单幅图像去雨;深度学习;选择卷积网络;修正系数;残差学习40|23|4更新时间:2024-05-07
摘要:目的雨天户外采集的图像常常因为雨线覆盖图像信息产生色变和模糊现象。为了提高雨天图像的质量,本文提出一种基于自适应选择卷积网络深度学习的单幅图像去雨算法。方法针对雨图中背景误判和雨痕残留问题,加入网络训练的雨线修正系数(refine factor,RF),改进现有雨图模型,更精确地描述雨图中各像素受到雨线的影响。构建选择卷积网络(selective kernel network,SK Net),自适应地选择不同卷积核对应维度的信息,进一步学习、融合不同卷积核的信息,提高网络的表达力,最后构建包含SK Net、refine factor net和residual net子网络的自适应卷积残差修正网络(selective kernel convolution using a residual refine factor,SKRF),直接学习雨线图和残差修正系数(RF),减少映射区间,减少背景误判。结果实验通过设计的SKRF网络,在公开的Rain12测试集上进行去雨实验,取得了比现有方法更高的精确度,峰值信噪比(peak signal to noise ratio,PSNR)达到34.62 dB,结构相似性(structural similarity,SSIM)达到0.970 6。表明SKRF网络对单幅图像去雨效果有明显优势。结论单幅图像去雨SKRF算法为雨图模型中的雨线图提供一个额外的修正残差系数,以降低学习映射区间,自适应选择卷积网络模型提升雨图模型的表达力和兼容性。关键词:单幅图像去雨;深度学习;选择卷积网络;修正系数;残差学习40|23|4更新时间:2024-05-07 -
 摘要:目的随机脉冲噪声(random-valued impulse noise,RVIN)检测器将局部图像统计值(local image statistics,LIS)作为图块中心像素点是否为噪声的判断依据,但LIS的描述能力较弱,在不同程度上制约了RVIN检测器的检测正确率,影响了后续开关型降噪模块的修复效果。为此,提出了一种基于局部特定空间关系统计特征的RVIN噪声检测器。方法以局部中心像素点的8个邻域像素对数差值排序值(rank-ordered logarithmic difference,ROLD)并结合1个最小方向对数差值(minimum orientation logarithmic difference,MOLD)共9个反映局部特定空间关系的LIS统计值构成描述中心像素点是否为RVIN的噪声感知特征矢量,并通过在大量样本图块数据上提取的RVIN噪声感知特征矢量及其对应的噪声标签作为训练对(training pairs),训练获得一个基于多层感知网络(multi-layer perception,MLP)的RVIN噪声检测器。结果对比实验从检测正确率和实际应用效果2个方面检验所提出的RVIN检测器的有效性,分别在10幅常用图像和50幅BSD(Berkeley segmentation data)纹理图像上进行测试,并与经典的脉冲噪声降噪算法中包含的噪声检测器以及MLPNNC(MLP neural network classifier)噪声检测器相比较,以漏检数、误检数和错检总数作为评价噪声检测正确率的指标。在常用图像集上本文所提RVIN检测器的漏检数和误检数较为平衡,在错检总数上排名处于所有对比算法中的前2名,为后续的降噪模块打下了很好的基础。在BSD纹理图像集上,将本文提出的RVIN检测器和GIRAF(generic iteratively reweighted annihilating filter)算法组合构成一种RVIN噪声降噪算法(proposed-GIRAF),proposed-GIRAF算法在50幅BSD图像上的峰值信噪比(peak signal-to-noise ratio,PSNR)均值在各个噪声比例下均取得了最优结果,与排名第2的对比算法相比,提升了0.471.96 dB。实验数据表明,所提出的RVIN噪声检测器的检测正确率优于现有的检测器,与修复算法联用后即可获得一种降噪效果更佳的开关型RVIN降噪算法。结论本文提出的RVIN噪声检测器在各个噪声比例下具有鲁棒的预测准确性,配合GIRAF算法使用后,与经典的RVIN降噪算法相比,降噪效果最佳,具有很强的实用性。关键词:图像降噪;随机脉冲噪声;局部空间结构关系;8邻域对数差值排序值;最小方向对数差值;多层感知网络;检测正确率29|22|0更新时间:2024-05-07
摘要:目的随机脉冲噪声(random-valued impulse noise,RVIN)检测器将局部图像统计值(local image statistics,LIS)作为图块中心像素点是否为噪声的判断依据,但LIS的描述能力较弱,在不同程度上制约了RVIN检测器的检测正确率,影响了后续开关型降噪模块的修复效果。为此,提出了一种基于局部特定空间关系统计特征的RVIN噪声检测器。方法以局部中心像素点的8个邻域像素对数差值排序值(rank-ordered logarithmic difference,ROLD)并结合1个最小方向对数差值(minimum orientation logarithmic difference,MOLD)共9个反映局部特定空间关系的LIS统计值构成描述中心像素点是否为RVIN的噪声感知特征矢量,并通过在大量样本图块数据上提取的RVIN噪声感知特征矢量及其对应的噪声标签作为训练对(training pairs),训练获得一个基于多层感知网络(multi-layer perception,MLP)的RVIN噪声检测器。结果对比实验从检测正确率和实际应用效果2个方面检验所提出的RVIN检测器的有效性,分别在10幅常用图像和50幅BSD(Berkeley segmentation data)纹理图像上进行测试,并与经典的脉冲噪声降噪算法中包含的噪声检测器以及MLPNNC(MLP neural network classifier)噪声检测器相比较,以漏检数、误检数和错检总数作为评价噪声检测正确率的指标。在常用图像集上本文所提RVIN检测器的漏检数和误检数较为平衡,在错检总数上排名处于所有对比算法中的前2名,为后续的降噪模块打下了很好的基础。在BSD纹理图像集上,将本文提出的RVIN检测器和GIRAF(generic iteratively reweighted annihilating filter)算法组合构成一种RVIN噪声降噪算法(proposed-GIRAF),proposed-GIRAF算法在50幅BSD图像上的峰值信噪比(peak signal-to-noise ratio,PSNR)均值在各个噪声比例下均取得了最优结果,与排名第2的对比算法相比,提升了0.471.96 dB。实验数据表明,所提出的RVIN噪声检测器的检测正确率优于现有的检测器,与修复算法联用后即可获得一种降噪效果更佳的开关型RVIN降噪算法。结论本文提出的RVIN噪声检测器在各个噪声比例下具有鲁棒的预测准确性,配合GIRAF算法使用后,与经典的RVIN降噪算法相比,降噪效果最佳,具有很强的实用性。关键词:图像降噪;随机脉冲噪声;局部空间结构关系;8邻域对数差值排序值;最小方向对数差值;多层感知网络;检测正确率29|22|0更新时间:2024-05-07 -
 摘要:目的图像修复是计算机视觉领域的研究热点之一。基于深度学习的图像修复方法取得了一定成绩,但在处理全局与局部属性联系密切的图像时难以获得理想效果,尤其在修复较大面积图像缺损时,结果的语义合理性、结构连贯性和细节准确性均有待提高。针对上述问题,提出一种基于全卷积网络,结合生成式对抗网络思想的图像修复模型。方法基于全卷积神经网络,结合跳跃连接、扩张卷积等方法,提出一种新颖的图像修复网络作为生成器修复缺损图像;引入结构相似性(structural similarity,SSIM)作为图像修复的重构损失,从人眼视觉系统的角度监督指导模型学习,提高图像修复效果;使用改进后的全局和局部上下文判别网络作为双路判别器,对修复结果进行真伪判别,同时,结合对抗式损失,提出一种联合损失用于监督模型的训练,使修复区域内容真实自然且与整幅图像具有属性一致性。结果为验证本文图像修复模型的有效性,在CelebA-HQ数据集上,以主观感受和客观指标为依据,与目前主流的图像修复算法进行图像修复效果对比。结果表明,本文方法在修复结果的语义合理性、结构连贯性以及细节准确性等方面均取得了进步,峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性的均值分别达到31.30 dB和90.58%。结论本文提出的图像修复模型对图像高级语义有更好的理解,对上下文信息和细节信息把握更精准,能取得更符合人眼视觉感受的图像修复结果。关键词:图像修复;全卷积神经网络;扩张卷积;跳跃连接;对抗式损失94|146|4更新时间:2024-05-07
摘要:目的图像修复是计算机视觉领域的研究热点之一。基于深度学习的图像修复方法取得了一定成绩,但在处理全局与局部属性联系密切的图像时难以获得理想效果,尤其在修复较大面积图像缺损时,结果的语义合理性、结构连贯性和细节准确性均有待提高。针对上述问题,提出一种基于全卷积网络,结合生成式对抗网络思想的图像修复模型。方法基于全卷积神经网络,结合跳跃连接、扩张卷积等方法,提出一种新颖的图像修复网络作为生成器修复缺损图像;引入结构相似性(structural similarity,SSIM)作为图像修复的重构损失,从人眼视觉系统的角度监督指导模型学习,提高图像修复效果;使用改进后的全局和局部上下文判别网络作为双路判别器,对修复结果进行真伪判别,同时,结合对抗式损失,提出一种联合损失用于监督模型的训练,使修复区域内容真实自然且与整幅图像具有属性一致性。结果为验证本文图像修复模型的有效性,在CelebA-HQ数据集上,以主观感受和客观指标为依据,与目前主流的图像修复算法进行图像修复效果对比。结果表明,本文方法在修复结果的语义合理性、结构连贯性以及细节准确性等方面均取得了进步,峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性的均值分别达到31.30 dB和90.58%。结论本文提出的图像修复模型对图像高级语义有更好的理解,对上下文信息和细节信息把握更精准,能取得更符合人眼视觉感受的图像修复结果。关键词:图像修复;全卷积神经网络;扩张卷积;跳跃连接;对抗式损失94|146|4更新时间:2024-05-07
图像处理和编码
-
 摘要:目的视频中的人体行为识别技术对智能安防、人机协作和助老助残等领域的智能化起着积极的促进作用,具有广泛的应用前景。但是,现有的识别方法在人体行为时空特征的有效利用方面仍存在问题,识别准确率仍有待提高。为此,本文提出一种在空间域使用深度学习网络提取人体行为关键语义信息并在时间域串联分析从而准确识别视频中人体行为的方法。方法根据视频图像内容,剔除人体行为重复及冗余信息,提取最能表达人体行为变化的关键帧。设计并构造深度学习网络,对图像语义信息进行分析,提取表达重要语义信息的图像关键语义区域,有效描述人体行为的空间信息。使用孪生神经网络计算视频帧间关键语义区域的相关性,将语义信息相似的区域串联为关键语义区域链,将关键语义区域链的深度学习特征计算并融合为表达视频中人体行为的特征,训练分类器实现人体行为识别。结果使用具有挑战性的人体行为识别数据集UCF(University of Central Florida)50对本文方法进行验证,得到的人体行为识别准确率为94.3%,与现有方法相比有显著提高。有效性验证实验表明,本文提出的视频中关键语义区域计算和帧间关键语义区域相关性计算方法能够有效提高人体行为识别的准确率。结论实验结果表明,本文提出的人体行为识别方法能够有效利用视频中人体行为的时空信息,显著提高人体行为识别准确率。关键词:人机交互;深度学习网络;人体行为关键语义信息;人体行为识别;视频关键帧33|26|1更新时间:2024-05-07
摘要:目的视频中的人体行为识别技术对智能安防、人机协作和助老助残等领域的智能化起着积极的促进作用,具有广泛的应用前景。但是,现有的识别方法在人体行为时空特征的有效利用方面仍存在问题,识别准确率仍有待提高。为此,本文提出一种在空间域使用深度学习网络提取人体行为关键语义信息并在时间域串联分析从而准确识别视频中人体行为的方法。方法根据视频图像内容,剔除人体行为重复及冗余信息,提取最能表达人体行为变化的关键帧。设计并构造深度学习网络,对图像语义信息进行分析,提取表达重要语义信息的图像关键语义区域,有效描述人体行为的空间信息。使用孪生神经网络计算视频帧间关键语义区域的相关性,将语义信息相似的区域串联为关键语义区域链,将关键语义区域链的深度学习特征计算并融合为表达视频中人体行为的特征,训练分类器实现人体行为识别。结果使用具有挑战性的人体行为识别数据集UCF(University of Central Florida)50对本文方法进行验证,得到的人体行为识别准确率为94.3%,与现有方法相比有显著提高。有效性验证实验表明,本文提出的视频中关键语义区域计算和帧间关键语义区域相关性计算方法能够有效提高人体行为识别的准确率。结论实验结果表明,本文提出的人体行为识别方法能够有效利用视频中人体行为的时空信息,显著提高人体行为识别准确率。关键词:人机交互;深度学习网络;人体行为关键语义信息;人体行为识别;视频关键帧33|26|1更新时间:2024-05-07 -
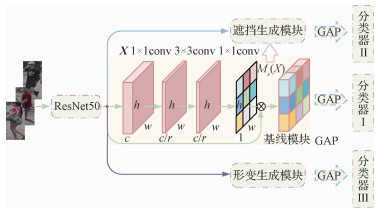 摘要:目的姿态变化和遮挡导致行人表现出明显差异,给行人再识别带来了巨大挑战。针对以上问题,本文提出一种融合形变与遮挡机制的行人再识别算法。方法为了模拟行人姿态的变化,在基础网络输出的特征图上采用卷积的形式为特征图的每个位置学习两个偏移量,偏移量包括水平和垂直两个方向,后续的卷积操作通过考虑每个位置的偏移量提取形变的特征,从而提高网络应对行人姿态改变时的能力;为了解决遮挡问题,本文通过擦除空间注意力高响应对应的特征区域而仅保留低响应特征区域,模拟行人遮挡样本,进一步改善网络应对遮挡样本的能力。在测试阶段,将两种方法提取的特征与基础网络特征级联,保证特征描述子的鲁棒性。结果本文方法在行人再识别领域3个公开大尺度数据集Market-1501、DukeMTMC-reID和CUHK03(包括detected和labeled)上进行评估,首位命中率Rank-1分别达到89.52%、81.96%、48.79%和50.29%,平均精度均值(mean average precision,mAP)分别达到73.98%、64.45%、43.77%和45.58%。结论本文提出的融合形变与遮挡机制的行人再识别算法可以学习到鉴别能力更强的行人再识别模型,从而提取更加具有区分性的行人特征,尤其是针对复杂场景,在发生行人姿态改变及遮挡时仍能保持较高的识别准确率。关键词:行人再识别;形变;遮挡;空间注意力机制;鲁棒性117|121|7更新时间:2024-05-07
摘要:目的姿态变化和遮挡导致行人表现出明显差异,给行人再识别带来了巨大挑战。针对以上问题,本文提出一种融合形变与遮挡机制的行人再识别算法。方法为了模拟行人姿态的变化,在基础网络输出的特征图上采用卷积的形式为特征图的每个位置学习两个偏移量,偏移量包括水平和垂直两个方向,后续的卷积操作通过考虑每个位置的偏移量提取形变的特征,从而提高网络应对行人姿态改变时的能力;为了解决遮挡问题,本文通过擦除空间注意力高响应对应的特征区域而仅保留低响应特征区域,模拟行人遮挡样本,进一步改善网络应对遮挡样本的能力。在测试阶段,将两种方法提取的特征与基础网络特征级联,保证特征描述子的鲁棒性。结果本文方法在行人再识别领域3个公开大尺度数据集Market-1501、DukeMTMC-reID和CUHK03(包括detected和labeled)上进行评估,首位命中率Rank-1分别达到89.52%、81.96%、48.79%和50.29%,平均精度均值(mean average precision,mAP)分别达到73.98%、64.45%、43.77%和45.58%。结论本文提出的融合形变与遮挡机制的行人再识别算法可以学习到鉴别能力更强的行人再识别模型,从而提取更加具有区分性的行人特征,尤其是针对复杂场景,在发生行人姿态改变及遮挡时仍能保持较高的识别准确率。关键词:行人再识别;形变;遮挡;空间注意力机制;鲁棒性117|121|7更新时间:2024-05-07 -
 摘要:目的视频行为识别和理解是智能监控、人机交互和虚拟现实等诸多应用中的一项基础技术,由于视频时空结构的复杂性,以及视频内容的多样性,当前行为识别仍面临如何高效提取视频的时域表示、如何高效提取视频特征并在时间轴上建模的难点问题。针对这些难点,提出了一种多特征融合的行为识别模型。方法首先,提取视频中高频信息和低频信息,采用本文提出的两帧融合算法和三帧融合算法压缩原始数据,保留原始视频绝大多数信息,增强原始数据集,更好地表达原始行为信息。其次,设计双路特征提取网络,一路将融合数据正向输入网络提取细节特征,另一路将融合数据逆向输入网络提取整体特征,接着将两路特征加权融合,每一路特征提取网络均使用通用视频描述符——3D ConvNets(3D convolutional neural networks)结构。然后,采用BiConvLSTM(bidirectional convolutional long short-term memory network)网络对融合特征进一步提取局部信息并在时间轴上建模,解决视频序列中某些行为间隔相对较长的问题。最后,利用Softmax最大化似然函数分类行为动作。结果为了验证本文算法的有效性,在公开的行为识别数据集UCF101和HMDB51上,采用5折交叉验证的方式进行整体测试与分析,然后针对每类行为动作进行比较统计。结果表明,本文算法在两个验证集上的平均准确率分别为96.47%和80.03%。结论通过与目前主流行为识别模型比较,本文提出的多特征模型获得了最高的识别精度,具有通用、紧凑、简单和高效的特点。关键词:行为识别;双路特征提取网络;3维卷积神经网络;双向卷积长短期记忆网络;加权融合;高频特征;低频特征55|50|5更新时间:2024-05-07
摘要:目的视频行为识别和理解是智能监控、人机交互和虚拟现实等诸多应用中的一项基础技术,由于视频时空结构的复杂性,以及视频内容的多样性,当前行为识别仍面临如何高效提取视频的时域表示、如何高效提取视频特征并在时间轴上建模的难点问题。针对这些难点,提出了一种多特征融合的行为识别模型。方法首先,提取视频中高频信息和低频信息,采用本文提出的两帧融合算法和三帧融合算法压缩原始数据,保留原始视频绝大多数信息,增强原始数据集,更好地表达原始行为信息。其次,设计双路特征提取网络,一路将融合数据正向输入网络提取细节特征,另一路将融合数据逆向输入网络提取整体特征,接着将两路特征加权融合,每一路特征提取网络均使用通用视频描述符——3D ConvNets(3D convolutional neural networks)结构。然后,采用BiConvLSTM(bidirectional convolutional long short-term memory network)网络对融合特征进一步提取局部信息并在时间轴上建模,解决视频序列中某些行为间隔相对较长的问题。最后,利用Softmax最大化似然函数分类行为动作。结果为了验证本文算法的有效性,在公开的行为识别数据集UCF101和HMDB51上,采用5折交叉验证的方式进行整体测试与分析,然后针对每类行为动作进行比较统计。结果表明,本文算法在两个验证集上的平均准确率分别为96.47%和80.03%。结论通过与目前主流行为识别模型比较,本文提出的多特征模型获得了最高的识别精度,具有通用、紧凑、简单和高效的特点。关键词:行为识别;双路特征提取网络;3维卷积神经网络;双向卷积长短期记忆网络;加权融合;高频特征;低频特征55|50|5更新时间:2024-05-07 -
 摘要:目的相对于其他生物特征识别技术,人脸识别具有非接触、不易察觉和易于推广等特点,在公共安全和日常生活中得到广泛应用。在移动互联网时代,云端人脸识别可以有效地提高识别精度,但是需要将大量的人脸数据上传到第三方服务器。由于人的面部特征是唯一的,一旦数据库泄露就会面临模板攻击和假冒攻击等安全威胁。为了保证人脸识别系统的安全性并提高其识别率,本文提出一种融合人脸结构特征的可撤销人脸识别算法。方法首先,对原始人脸图像提取结构特征作为虚部分量,与原始人脸图像联合构建复数矩阵并通过随机二值矩阵进行置乱操作。然后,使用2维主成分分析方法将置乱的复数矩阵映射到新的特征空间。最后,采用基于曼哈顿距离的最近邻分类器计算识别率。结果在4个不同人脸数据库上的实验结果表明,原始人脸图像和结构特征图像经过随机二值矩阵置乱后,人眼无法察觉出有用的信息且可以重新生成,而且融合方差特征后,在GT(Georgia Tech)、NIR(Near Infrared)、VIS(Visible Light)和YMU(YouTuBe Makeup)人脸数据库上,平均人脸识别率分别提高了4.9%、2.25%、2.25%和1.98%,且平均测试时间均在1.0 ms之内,表明该算法实时性强,能够满足实际应用场景的需求。结论本文算法可在不影响识别率的情况下保证系统的安全性,满足可撤销性。同时,融合结构特征丰富了人脸信息的表征,提高了人脸识别系统的识别率。关键词:可撤销人脸识别;随机二值矩阵;2维主成分分析;人脸结构特征;复数矩阵18|19|1更新时间:2024-05-07
摘要:目的相对于其他生物特征识别技术,人脸识别具有非接触、不易察觉和易于推广等特点,在公共安全和日常生活中得到广泛应用。在移动互联网时代,云端人脸识别可以有效地提高识别精度,但是需要将大量的人脸数据上传到第三方服务器。由于人的面部特征是唯一的,一旦数据库泄露就会面临模板攻击和假冒攻击等安全威胁。为了保证人脸识别系统的安全性并提高其识别率,本文提出一种融合人脸结构特征的可撤销人脸识别算法。方法首先,对原始人脸图像提取结构特征作为虚部分量,与原始人脸图像联合构建复数矩阵并通过随机二值矩阵进行置乱操作。然后,使用2维主成分分析方法将置乱的复数矩阵映射到新的特征空间。最后,采用基于曼哈顿距离的最近邻分类器计算识别率。结果在4个不同人脸数据库上的实验结果表明,原始人脸图像和结构特征图像经过随机二值矩阵置乱后,人眼无法察觉出有用的信息且可以重新生成,而且融合方差特征后,在GT(Georgia Tech)、NIR(Near Infrared)、VIS(Visible Light)和YMU(YouTuBe Makeup)人脸数据库上,平均人脸识别率分别提高了4.9%、2.25%、2.25%和1.98%,且平均测试时间均在1.0 ms之内,表明该算法实时性强,能够满足实际应用场景的需求。结论本文算法可在不影响识别率的情况下保证系统的安全性,满足可撤销性。同时,融合结构特征丰富了人脸信息的表征,提高了人脸识别系统的识别率。关键词:可撤销人脸识别;随机二值矩阵;2维主成分分析;人脸结构特征;复数矩阵18|19|1更新时间:2024-05-07 -
 摘要:目的使用深度孪生网络解决图像协同分割问题,显著提高了图像分割精度。然而,深度孪生网络需要巨大的计算量,使其应用受到限制。为此,提出一种融合二值化注意力机制与知识蒸馏的孪生网络压缩方法,旨在获取计算量小且分割精度高的孪生网络。方法首先提出一种二值化注意力机制,将其运用到孪生网络中,抽取大网络中的重要知识,再根据重要知识的维度重构原大网络,获取孪生小网络结构。然后基于一种改进的知识蒸馏方法将大网络中的知识迁移到小网络中,迁移过程中先后用大网络的中间层重要知识和真实标签分别指导小网络训练,以获取目标孪生小网络的权值。结果实验结果表明,本文方法可将原孪生网络的规模压缩为原来的1/3.3,显著减小网络计算量,且分割结果接近于现有协同分割方法的最好结果。在MLMR-COS数据集上,压缩后的小网络分割精度略高于大网络,平均Jaccard系数提升了0.07%;在Internet数据集上,小网络分割结果的平均Jaccard系数比传统图像分割方法的最好结果高5%,且达到现有深度协同分割方法的最好效果;对于图像相对复杂的iCoseg数据集,压缩后的小网络分割精度相比于传统图像分割方法和深度协同分割方法的最好效果仅略有下降。结论本文提出的孪生网络压缩方法显著减小了网络计算量和参数量,分割效果接近现有协同分割方法的最好结果。关键词:孪生网络;网络压缩;知识蒸馏;注意力机制;图像协同分割47|29|2更新时间:2024-05-07
摘要:目的使用深度孪生网络解决图像协同分割问题,显著提高了图像分割精度。然而,深度孪生网络需要巨大的计算量,使其应用受到限制。为此,提出一种融合二值化注意力机制与知识蒸馏的孪生网络压缩方法,旨在获取计算量小且分割精度高的孪生网络。方法首先提出一种二值化注意力机制,将其运用到孪生网络中,抽取大网络中的重要知识,再根据重要知识的维度重构原大网络,获取孪生小网络结构。然后基于一种改进的知识蒸馏方法将大网络中的知识迁移到小网络中,迁移过程中先后用大网络的中间层重要知识和真实标签分别指导小网络训练,以获取目标孪生小网络的权值。结果实验结果表明,本文方法可将原孪生网络的规模压缩为原来的1/3.3,显著减小网络计算量,且分割结果接近于现有协同分割方法的最好结果。在MLMR-COS数据集上,压缩后的小网络分割精度略高于大网络,平均Jaccard系数提升了0.07%;在Internet数据集上,小网络分割结果的平均Jaccard系数比传统图像分割方法的最好结果高5%,且达到现有深度协同分割方法的最好效果;对于图像相对复杂的iCoseg数据集,压缩后的小网络分割精度相比于传统图像分割方法和深度协同分割方法的最好效果仅略有下降。结论本文提出的孪生网络压缩方法显著减小了网络计算量和参数量,分割效果接近现有协同分割方法的最好结果。关键词:孪生网络;网络压缩;知识蒸馏;注意力机制;图像协同分割47|29|2更新时间:2024-05-07 -
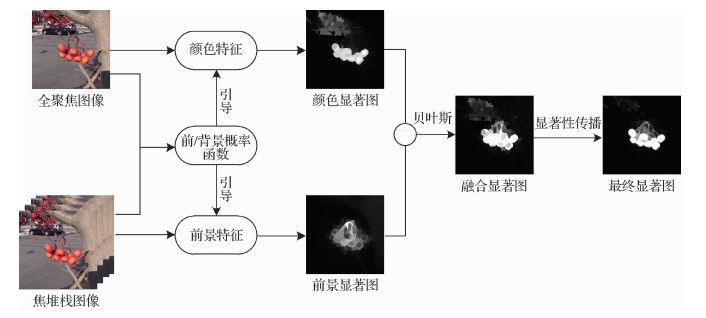 摘要:目的图像显著性检测方法对前景与背景颜色、纹理相似或背景杂乱的场景,存在背景难抑制、检测对象不完整、边缘模糊以及方块效应等问题。光场图像具有重聚焦能力,能提供聚焦度线索,有效区分图像前景和背景区域,从而提高显著性检测的精度。因此,提出一种基于聚焦度和传播机制的光场图像显著性检测方法。方法使用高斯滤波器对焦堆栈图像的聚焦度信息进行衡量,确定前景图像和背景图像。利用背景图像的聚焦度信息和空间位置构建前/背景概率函数,并引导光场图像特征进行显著性检测,以提高显著图的准确率。另外,充分利用邻近超像素的空间一致性,采用基于K近邻法(K-nearest neighbor,K-NN)的图模型显著性传播机制进一步优化显著图,均匀地突出整个显著区域,从而得到更加精确的显著图。结果在光场图像基准数据集上进行显著性检测实验,对比3种主流的传统光场图像显著性检测方法及两种深度学习方法,本文方法生成的显著图可以有效抑制背景区域,均匀地突出整个显著对象,边缘也更加清晰,更符合人眼视觉感知。查准率达到85.16%,高于对比方法,F度量(F-measure)和平均绝对误差(mean absolute error,MAE)分别为72.79%和13.49%,优于传统的光场图像显著性检测方法。结论本文基于聚焦度和传播机制提出的光场图像显著性模型,在前/背景相似或杂乱背景的场景中可以均匀地突出显著区域,更好地抑制背景区域。关键词:显著性检测;光场图像;聚焦度;前/背景概率函数;传播机制;空间一致性26|24|5更新时间:2024-05-07
摘要:目的图像显著性检测方法对前景与背景颜色、纹理相似或背景杂乱的场景,存在背景难抑制、检测对象不完整、边缘模糊以及方块效应等问题。光场图像具有重聚焦能力,能提供聚焦度线索,有效区分图像前景和背景区域,从而提高显著性检测的精度。因此,提出一种基于聚焦度和传播机制的光场图像显著性检测方法。方法使用高斯滤波器对焦堆栈图像的聚焦度信息进行衡量,确定前景图像和背景图像。利用背景图像的聚焦度信息和空间位置构建前/背景概率函数,并引导光场图像特征进行显著性检测,以提高显著图的准确率。另外,充分利用邻近超像素的空间一致性,采用基于K近邻法(K-nearest neighbor,K-NN)的图模型显著性传播机制进一步优化显著图,均匀地突出整个显著区域,从而得到更加精确的显著图。结果在光场图像基准数据集上进行显著性检测实验,对比3种主流的传统光场图像显著性检测方法及两种深度学习方法,本文方法生成的显著图可以有效抑制背景区域,均匀地突出整个显著对象,边缘也更加清晰,更符合人眼视觉感知。查准率达到85.16%,高于对比方法,F度量(F-measure)和平均绝对误差(mean absolute error,MAE)分别为72.79%和13.49%,优于传统的光场图像显著性检测方法。结论本文基于聚焦度和传播机制提出的光场图像显著性模型,在前/背景相似或杂乱背景的场景中可以均匀地突出显著区域,更好地抑制背景区域。关键词:显著性检测;光场图像;聚焦度;前/背景概率函数;传播机制;空间一致性26|24|5更新时间:2024-05-07
图像分析和识别
-
 摘要:目的模式识别中,通常使用大量标注数据和有效的机器学习算法训练分类器应对不确定性问题。然而,这一过程缺乏知识表征和可解释性。认知心理学和实验心理学的研究表明,人类往往不使用代价如此巨大的机制,而是使用表征、归纳、推理、解释和约束传播等与符号主义人工智能方法类似的手段来应对物体识别中的不确定性并提供可解释性。因此本文旨在从传统的符号计算出发,利用骨架拓扑结构表征提供一种可解释性的思路。方法以骨架树为基本手段来形成物体拓扑结构特征和几何特征的形式化表征,并基于泛化框架对少量同类表征进行知识抽取来形成关于物体类别的知识概括显式化表征。结果在形成物体类别的概括表征实验中,通过路径重建直观展示了同类属物体上得到的最一般表征的几何物理意义。在可解释性验证实验中,通过跨数据的拓扑应用展示了新测试样本相对于概括表征的特定差异,表明该表征具有良好的可解释性。最后在形状补全的不确定性推理实验中,不仅可以得到识别结论,而且清晰展示了识别背后做出的判断依据,进一步验证了该表征的可解释性。结论实验表明一般化的形式表征能够应对尺寸、颜色和形状等不确定性问题,本文方法避免了基于纹理特征所带来的不确定性,适用于任意基于基元的表征方式,具有更好的鲁棒性、普适性和可解释性,计算代价更小。关键词:视觉任务;骨架;不确定性;拓扑知识表征;可解释性41|22|0更新时间:2024-05-07
摘要:目的模式识别中,通常使用大量标注数据和有效的机器学习算法训练分类器应对不确定性问题。然而,这一过程缺乏知识表征和可解释性。认知心理学和实验心理学的研究表明,人类往往不使用代价如此巨大的机制,而是使用表征、归纳、推理、解释和约束传播等与符号主义人工智能方法类似的手段来应对物体识别中的不确定性并提供可解释性。因此本文旨在从传统的符号计算出发,利用骨架拓扑结构表征提供一种可解释性的思路。方法以骨架树为基本手段来形成物体拓扑结构特征和几何特征的形式化表征,并基于泛化框架对少量同类表征进行知识抽取来形成关于物体类别的知识概括显式化表征。结果在形成物体类别的概括表征实验中,通过路径重建直观展示了同类属物体上得到的最一般表征的几何物理意义。在可解释性验证实验中,通过跨数据的拓扑应用展示了新测试样本相对于概括表征的特定差异,表明该表征具有良好的可解释性。最后在形状补全的不确定性推理实验中,不仅可以得到识别结论,而且清晰展示了识别背后做出的判断依据,进一步验证了该表征的可解释性。结论实验表明一般化的形式表征能够应对尺寸、颜色和形状等不确定性问题,本文方法避免了基于纹理特征所带来的不确定性,适用于任意基于基元的表征方式,具有更好的鲁棒性、普适性和可解释性,计算代价更小。关键词:视觉任务;骨架;不确定性;拓扑知识表征;可解释性41|22|0更新时间:2024-05-07 -
 摘要:目的针对传统非刚性3维模型的对应关系计算方法需要模型间真实对应关系监督的缺点,提出一种自监督深度残差函数映射网络(self-supervised deep residual functional maps network,SSDRFMN)。方法首先将局部坐标系与直方图结合以计算3维模型的特征描述符,即方向直方图签名(signature of histograms of orientations,SHOT)描述符;其次将源模型与目标模型的SHOT描述符输入SSDRFMN,利用深度函数映射(deep functional maps,DFM)层计算两个模型间的函数映射矩阵,并通过模糊对应层将函数映射关系转换为点到点的对应关系;最后利用自监督损失函数计算模型间的测地距离误差,对计算出的对应关系进行评估。结果实验结果表明,在MPI-FAUST数据集上,本文算法相比于有监督的深度函数映射(supervised deep functional maps,SDFM)算法,人体模型对应关系的测地误差减小了1.45;相比于频谱上采样(spectral upsampling,SU)算法减小了1.67。在TOSCA数据集上,本文算法相比于SDFM算法,狗、猫和狼等模型的对应关系的测地误差分别减小了3.13、0.98和1.89;相比于SU算法分别减小了2.81、2.22和1.11,并有效克服了已有深度函数映射方法需要模型间的真实对应关系来监督的缺点,使得该方法可以适用于不同的数据集,可扩展性大幅增强。结论本文通过自监督深度残差函数映射网络训练模型的方向直方图签名描述符,提升了模型对应关系的准确率。本文方法可以适应于不同的数据集,相比传统方法,普适性较好。关键词:非刚性3维模型;模型对应关系;深度函数映射;模糊对应;自监督损失函数;测地误差33|18|0更新时间:2024-05-07
摘要:目的针对传统非刚性3维模型的对应关系计算方法需要模型间真实对应关系监督的缺点,提出一种自监督深度残差函数映射网络(self-supervised deep residual functional maps network,SSDRFMN)。方法首先将局部坐标系与直方图结合以计算3维模型的特征描述符,即方向直方图签名(signature of histograms of orientations,SHOT)描述符;其次将源模型与目标模型的SHOT描述符输入SSDRFMN,利用深度函数映射(deep functional maps,DFM)层计算两个模型间的函数映射矩阵,并通过模糊对应层将函数映射关系转换为点到点的对应关系;最后利用自监督损失函数计算模型间的测地距离误差,对计算出的对应关系进行评估。结果实验结果表明,在MPI-FAUST数据集上,本文算法相比于有监督的深度函数映射(supervised deep functional maps,SDFM)算法,人体模型对应关系的测地误差减小了1.45;相比于频谱上采样(spectral upsampling,SU)算法减小了1.67。在TOSCA数据集上,本文算法相比于SDFM算法,狗、猫和狼等模型的对应关系的测地误差分别减小了3.13、0.98和1.89;相比于SU算法分别减小了2.81、2.22和1.11,并有效克服了已有深度函数映射方法需要模型间的真实对应关系来监督的缺点,使得该方法可以适用于不同的数据集,可扩展性大幅增强。结论本文通过自监督深度残差函数映射网络训练模型的方向直方图签名描述符,提升了模型对应关系的准确率。本文方法可以适应于不同的数据集,相比传统方法,普适性较好。关键词:非刚性3维模型;模型对应关系;深度函数映射;模糊对应;自监督损失函数;测地误差33|18|0更新时间:2024-05-07 -
 摘要:目的在自动化和智能化的现代生产制造过程中,视频异常事件检测技术扮演着越来越重要的角色,但由于实际生产制造中异常事件的复杂性及无关生产背景的干扰,使其成为一项非常具有挑战性的任务。很多传统方法采用手工设计的低级特征对视频的局部区域进行特征提取,然而此特征很难同时表示运动与外观特征。此外,一些基于深度学习的视频异常事件检测方法直接通过自编码器的重构误差大小来判定测试样本是否为正常或异常事件,然而实际情况往往会出现一些原本为异常的测试样本经过自编码得到的重构误差也小于设定阈值,从而将其错误地判定为正常事件,出现异常事件漏检的情形。针对此不足,本文提出一种融合自编码器和one-class支持向量机(support vector machine,SVM)的异常事件检测模型。方法通过高斯混合模型(Gaussian mixture model,GMM)提取固定大小的时空兴趣块(region of interest,ROI);通过预训练的3维卷积神经网络(3D convolutional neural network,C3D)对ROI进行高层次的特征提取;利用提取的高维特征训练一个堆叠的降噪自编码器,通过比较重构误差与设定阈值的大小,将测试样本判定为正常、异常和可疑3种情况之一;对自编码器降维后的特征训练一个one-class SVM模型,用于对可疑测试样本进行二次检测,进一步排除异常事件。结果本文对实际生产制造环境下的机器人工作场景进行实验,采用AUC(area under ROC)和等错误率(equal error rate,EER)两个常用指标进行评估。在设定合适的误差阈值时,结果显示受试者工作特征(receiver operating characteristic,ROC)曲线下AUC达到91.7%,EER为13.8%。同时,在公共数据特征集USCD(University of California,San Diego)Ped1和USCD Ped2上进行了模型评估,并与一些常用方法进行了比较,在USCD Ped1数据集中,相比于性能第2的方法,AUC在帧级别和像素级别分别提高了2.6%和22.3%;在USCD Ped2数据集中,相比于性能第2的方法,AUC在帧级别提高了6.7%,从而验证了所提检测方法的有效性与准确性。结论本文提出的视频异常事件检测模型,结合了传统模型与深度学习模型,使视频异常事件检测结果更加准确。关键词:视频异常事件检测;时空兴趣块;3维卷积神经网络;降噪自编码器;one-class支持向量机40|51|6更新时间:2024-05-07
摘要:目的在自动化和智能化的现代生产制造过程中,视频异常事件检测技术扮演着越来越重要的角色,但由于实际生产制造中异常事件的复杂性及无关生产背景的干扰,使其成为一项非常具有挑战性的任务。很多传统方法采用手工设计的低级特征对视频的局部区域进行特征提取,然而此特征很难同时表示运动与外观特征。此外,一些基于深度学习的视频异常事件检测方法直接通过自编码器的重构误差大小来判定测试样本是否为正常或异常事件,然而实际情况往往会出现一些原本为异常的测试样本经过自编码得到的重构误差也小于设定阈值,从而将其错误地判定为正常事件,出现异常事件漏检的情形。针对此不足,本文提出一种融合自编码器和one-class支持向量机(support vector machine,SVM)的异常事件检测模型。方法通过高斯混合模型(Gaussian mixture model,GMM)提取固定大小的时空兴趣块(region of interest,ROI);通过预训练的3维卷积神经网络(3D convolutional neural network,C3D)对ROI进行高层次的特征提取;利用提取的高维特征训练一个堆叠的降噪自编码器,通过比较重构误差与设定阈值的大小,将测试样本判定为正常、异常和可疑3种情况之一;对自编码器降维后的特征训练一个one-class SVM模型,用于对可疑测试样本进行二次检测,进一步排除异常事件。结果本文对实际生产制造环境下的机器人工作场景进行实验,采用AUC(area under ROC)和等错误率(equal error rate,EER)两个常用指标进行评估。在设定合适的误差阈值时,结果显示受试者工作特征(receiver operating characteristic,ROC)曲线下AUC达到91.7%,EER为13.8%。同时,在公共数据特征集USCD(University of California,San Diego)Ped1和USCD Ped2上进行了模型评估,并与一些常用方法进行了比较,在USCD Ped1数据集中,相比于性能第2的方法,AUC在帧级别和像素级别分别提高了2.6%和22.3%;在USCD Ped2数据集中,相比于性能第2的方法,AUC在帧级别提高了6.7%,从而验证了所提检测方法的有效性与准确性。结论本文提出的视频异常事件检测模型,结合了传统模型与深度学习模型,使视频异常事件检测结果更加准确。关键词:视频异常事件检测;时空兴趣块;3维卷积神经网络;降噪自编码器;one-class支持向量机40|51|6更新时间:2024-05-07 -
 摘要:目的光场相机一次成像可以同时获取场景中光线的空间和角度信息,为深度估计提供了条件。然而,光场图像场景中出现高光现象使得深度估计变得困难。为了提高算法处理高光问题的可靠性,本文提出了一种基于光场图像多视角上下文信息的抗高光深度估计方法。方法本文利用光场子孔径图像的多视角特性,创建多视角输入支路,获取不同视角下图像的特征信息;利用空洞卷积增大网络感受野,获取更大范围的图像上下文信息,通过同一深度平面未发生高光的区域的深度信息,进而恢复高光区域深度信息。同时,本文设计了一种新型的多尺度特征融合方法,串联多膨胀率空洞卷积特征与多卷积核普通卷积特征,进一步提高了估计结果的精度和平滑度。结果实验在3个数据集上与最新的4种方法进行了比较。实验结果表明,本文方法整体深度估计性能较好,在4D light field benchmark合成数据集上,相比于性能第2的模型,均方误差(mean square error,MSE)降低了20.24%,坏像素率(bad pixel,BP)降低了2.62%,峰值信噪比(peak signal-to-noise ratio,PSNR)提高了4.96%。同时,通过对CVIA(computer vision and image analysis)Konstanz specular dataset合成数据集和Lytro Illum拍摄的真实场景数据集的定性分析,验证了本文算法的有效性和可靠性。消融实验结果表明多尺度特征融合方法改善了深度估计在高光区域的效果。结论本文提出的深度估计模型能够有效估计图像深度信息。特别地,高光区域深度信息恢复精度高、物体边缘区域平滑,能够较好地保存图像细节信息。关键词:深度估计;光场;抗高光;上下文信息;卷积神经网络56|19|2更新时间:2024-05-07
摘要:目的光场相机一次成像可以同时获取场景中光线的空间和角度信息,为深度估计提供了条件。然而,光场图像场景中出现高光现象使得深度估计变得困难。为了提高算法处理高光问题的可靠性,本文提出了一种基于光场图像多视角上下文信息的抗高光深度估计方法。方法本文利用光场子孔径图像的多视角特性,创建多视角输入支路,获取不同视角下图像的特征信息;利用空洞卷积增大网络感受野,获取更大范围的图像上下文信息,通过同一深度平面未发生高光的区域的深度信息,进而恢复高光区域深度信息。同时,本文设计了一种新型的多尺度特征融合方法,串联多膨胀率空洞卷积特征与多卷积核普通卷积特征,进一步提高了估计结果的精度和平滑度。结果实验在3个数据集上与最新的4种方法进行了比较。实验结果表明,本文方法整体深度估计性能较好,在4D light field benchmark合成数据集上,相比于性能第2的模型,均方误差(mean square error,MSE)降低了20.24%,坏像素率(bad pixel,BP)降低了2.62%,峰值信噪比(peak signal-to-noise ratio,PSNR)提高了4.96%。同时,通过对CVIA(computer vision and image analysis)Konstanz specular dataset合成数据集和Lytro Illum拍摄的真实场景数据集的定性分析,验证了本文算法的有效性和可靠性。消融实验结果表明多尺度特征融合方法改善了深度估计在高光区域的效果。结论本文提出的深度估计模型能够有效估计图像深度信息。特别地,高光区域深度信息恢复精度高、物体边缘区域平滑,能够较好地保存图像细节信息。关键词:深度估计;光场;抗高光;上下文信息;卷积神经网络56|19|2更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的数字浅浮雕是在平面载体上塑造高低起伏形象的一种造型艺术,具有独特的结构及视觉效果,应用场景极为广泛。为了增加数字浮雕设计的多样性,实现浮雕的风格化应用,提出一种基于高度图的浅浮雕模型生成方法。方法引入掩模理论,利用掩模操作对待处理的图像进行处理,融合图像处理技术,控制所要生成浮雕不同部位的高度,得到控制浮雕生成效果的高度图,借鉴已有的浅浮雕模型生成方法,利用基于高斯混合模型的滚动引导法向滤波(Gaussian mixture model based rolling guidance normal filtering,GRNF)进行法向分解,基于SfG(surface from gradients)的局部调整和全局重建的方法进行曲面重建,采用拉普拉斯算子及双边滤波器进行去噪平滑处理,最终生成不同高度风格的浅浮雕模型。结果实验结果表明,本文方法能够生成带有不同视觉效果的浅浮雕模型,通过对细节特征及结构特征相关参数的调整,均能够生成轮廓清晰、细节丰富的浅浮雕模型。结论本文提出的基于高度图的浅浮雕模型生成方法能够为浅浮雕的多样化设计提供新的思路和方法,在家居装饰行业中有重要的应用价值。关键词:浅浮雕;法向分解;几何重建;高度图;掩模理论32|18|1更新时间:2024-05-07
摘要:目的数字浅浮雕是在平面载体上塑造高低起伏形象的一种造型艺术,具有独特的结构及视觉效果,应用场景极为广泛。为了增加数字浮雕设计的多样性,实现浮雕的风格化应用,提出一种基于高度图的浅浮雕模型生成方法。方法引入掩模理论,利用掩模操作对待处理的图像进行处理,融合图像处理技术,控制所要生成浮雕不同部位的高度,得到控制浮雕生成效果的高度图,借鉴已有的浅浮雕模型生成方法,利用基于高斯混合模型的滚动引导法向滤波(Gaussian mixture model based rolling guidance normal filtering,GRNF)进行法向分解,基于SfG(surface from gradients)的局部调整和全局重建的方法进行曲面重建,采用拉普拉斯算子及双边滤波器进行去噪平滑处理,最终生成不同高度风格的浅浮雕模型。结果实验结果表明,本文方法能够生成带有不同视觉效果的浅浮雕模型,通过对细节特征及结构特征相关参数的调整,均能够生成轮廓清晰、细节丰富的浅浮雕模型。结论本文提出的基于高度图的浅浮雕模型生成方法能够为浅浮雕的多样化设计提供新的思路和方法,在家居装饰行业中有重要的应用价值。关键词:浅浮雕;法向分解;几何重建;高度图;掩模理论32|18|1更新时间:2024-05-07
计算机图形学
-
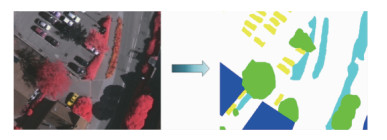 摘要:目的遥感图像语义分割是根据土地覆盖类型对图像中每个像素进行分类,是遥感图像处理领域的一个重要研究方向。由于遥感图像包含的地物尺度差别大、地物边界复杂等原因,准确提取遥感图像特征具有一定难度,使得精确分割遥感图像比较困难。卷积神经网络因其自主分层提取图像特征的特点逐步成为图像处理领域的主流算法,本文将基于残差密集空间金字塔的卷积神经网络应用于城市地区遥感图像分割,以提升高分辨率城市地区遥感影像语义分割的精度。方法模型将带孔卷积引入残差网络,代替网络中的下采样操作,在扩大特征图感受野的同时能够保持特征图尺寸不变;模型基于密集连接机制级联空间金字塔结构各分支,每个分支的输出都有更加密集的感受野信息;模型利用跳线连接跨层融合网络特征,结合网络中的高层语义特征和低层纹理特征恢复空间信息。结果基于ISPRS(International Society for Photogrammetry and Remote Sensing)Vaihingen地区遥感数据集展开充分的实验研究,实验结果表明,本文模型在6种不同的地物分类上的平均交并比和平均F1值分别达到69.88%和81.39%,性能在数学指标和视觉效果上均优于SegNet、pix2pix、Res-shuffling-Net以及SDFCN(symmetrical dense-shortcut fully convolutional network)算法。结论将密集连接改进空间金字塔池化网络应用于高分辨率遥感图像语义分割,该模型利用了遥感图像不同尺度下的特征、高层语义信息和低层纹理信息,有效提升了城市地区遥感图像分割精度。关键词:语义分割;遥感影像;多尺度;残差卷积网络;密集连接41|44|2更新时间:2024-05-07
摘要:目的遥感图像语义分割是根据土地覆盖类型对图像中每个像素进行分类,是遥感图像处理领域的一个重要研究方向。由于遥感图像包含的地物尺度差别大、地物边界复杂等原因,准确提取遥感图像特征具有一定难度,使得精确分割遥感图像比较困难。卷积神经网络因其自主分层提取图像特征的特点逐步成为图像处理领域的主流算法,本文将基于残差密集空间金字塔的卷积神经网络应用于城市地区遥感图像分割,以提升高分辨率城市地区遥感影像语义分割的精度。方法模型将带孔卷积引入残差网络,代替网络中的下采样操作,在扩大特征图感受野的同时能够保持特征图尺寸不变;模型基于密集连接机制级联空间金字塔结构各分支,每个分支的输出都有更加密集的感受野信息;模型利用跳线连接跨层融合网络特征,结合网络中的高层语义特征和低层纹理特征恢复空间信息。结果基于ISPRS(International Society for Photogrammetry and Remote Sensing)Vaihingen地区遥感数据集展开充分的实验研究,实验结果表明,本文模型在6种不同的地物分类上的平均交并比和平均F1值分别达到69.88%和81.39%,性能在数学指标和视觉效果上均优于SegNet、pix2pix、Res-shuffling-Net以及SDFCN(symmetrical dense-shortcut fully convolutional network)算法。结论将密集连接改进空间金字塔池化网络应用于高分辨率遥感图像语义分割,该模型利用了遥感图像不同尺度下的特征、高层语义信息和低层纹理信息,有效提升了城市地区遥感图像分割精度。关键词:语义分割;遥感影像;多尺度;残差卷积网络;密集连接41|44|2更新时间:2024-05-07 -
 摘要:目的高分辨率遥感图像检索中,单一特征难以准确描述遥感图像的复杂信息。为了充分利用不同卷积神经网络(convolutional neural networks,CNN)的学习参数来提高遥感图像的特征表达,提出一种基于判别相关分析的方法融合不同CNN的高层特征。方法将高层特征作为特殊的卷积层特征处理,为了更好地保留图像的原始空间信息,在图像的原始输入尺寸下提取不同高层特征,再对高层特征进行最大池化来获得显著特征;计算高层特征的类间散布矩阵,结合判别相关分析来增强同类特征的联系,并突出不同类特征之间的差异,从而提高特征的判别力;选择串联与相加两种方法来对不同特征进行融合,用所得融合特征来检索高分辨率遥感图像。结果在UC-Merced、RSSCN7和WHU-RS19数据集上的实验表明,与单一高层特征相比,绝大多数融合特征的检索准确率和检索时间都得到有效改进。其中,在3个数据集上的平均精确率均值(mean average precision,mAP)分别提高了10.4% 14.1%、5.7% 9.9%和5.9% 17.6%。以检索能力接近的特征进行融合时,性能提升更明显。在UC-Merced数据集上,融合特征的平均归一化修改检索等级(average normalized modified retrieval rank,ANMRR)和mAP达到13.21%和84.06%,与几种较新的遥感图像检索方法相比有一定优势。结论本文提出的基于判别相关分析的特征融合方法有效结合了不同CNN高层特征的显著信息,在降低特征冗余性的同时,提升了特征的表达能力,从而提高了遥感图像的检索性能。关键词:遥感图像检索;卷积神经网络;高层特征融合;判别相关分析;最大池化55|108|4更新时间:2024-05-07
摘要:目的高分辨率遥感图像检索中,单一特征难以准确描述遥感图像的复杂信息。为了充分利用不同卷积神经网络(convolutional neural networks,CNN)的学习参数来提高遥感图像的特征表达,提出一种基于判别相关分析的方法融合不同CNN的高层特征。方法将高层特征作为特殊的卷积层特征处理,为了更好地保留图像的原始空间信息,在图像的原始输入尺寸下提取不同高层特征,再对高层特征进行最大池化来获得显著特征;计算高层特征的类间散布矩阵,结合判别相关分析来增强同类特征的联系,并突出不同类特征之间的差异,从而提高特征的判别力;选择串联与相加两种方法来对不同特征进行融合,用所得融合特征来检索高分辨率遥感图像。结果在UC-Merced、RSSCN7和WHU-RS19数据集上的实验表明,与单一高层特征相比,绝大多数融合特征的检索准确率和检索时间都得到有效改进。其中,在3个数据集上的平均精确率均值(mean average precision,mAP)分别提高了10.4% 14.1%、5.7% 9.9%和5.9% 17.6%。以检索能力接近的特征进行融合时,性能提升更明显。在UC-Merced数据集上,融合特征的平均归一化修改检索等级(average normalized modified retrieval rank,ANMRR)和mAP达到13.21%和84.06%,与几种较新的遥感图像检索方法相比有一定优势。结论本文提出的基于判别相关分析的特征融合方法有效结合了不同CNN高层特征的显著信息,在降低特征冗余性的同时,提升了特征的表达能力,从而提高了遥感图像的检索性能。关键词:遥感图像检索;卷积神经网络;高层特征融合;判别相关分析;最大池化55|108|4更新时间:2024-05-07 -
 摘要:目的城镇建成区是城镇研究重要的基础信息,也是实施区域规划、落实城镇功能空间布局的前提。但是遥感影像中城镇建成区的环境复杂,同时不同城镇建成区在坐落位置、发展规模等方面存在许多差异,导致其信息提取存在一定困难。方法本文基于面向图像语义分割的深度卷积神经网络,使用针对特征图的强化模块和通道域的注意力模块,对原始DeepLab网络进行改进,并通过滑动窗口预测、全连接条件随机场处理方法,更准确地实现城镇建成区提取。同时,针对使用深度学习算法容易出现过拟合和鲁棒性不强的问题,采用数据扩充增强技术进一步提升模型能力。结果实验数据是三亚和海口部分地区的高分二号遥感影像。结果表明,本文方法的正确率高于93%,Kappa系数大于0.837,可以有效地提取出大尺度高分辨率遥感影像中的城镇建成区,且提取结果最为接近实际情况。结论针对高分辨率遥感卫星影像中城镇建成区的光谱信息多样化、纹理结构复杂化等特点,本文算法能在特征提取网络中获取更多特征信息。本文使用改进的深度学习方法,提出两种处理方法,显著提高了模型的精度,在实际大幅遥感影像的使用中表现优秀,具有重要的实用价值和广阔的应用前景。关键词:卷积神经网络;注意力机制;遥感图像;城镇建成区;信息提取41|20|3更新时间:2024-05-07
摘要:目的城镇建成区是城镇研究重要的基础信息,也是实施区域规划、落实城镇功能空间布局的前提。但是遥感影像中城镇建成区的环境复杂,同时不同城镇建成区在坐落位置、发展规模等方面存在许多差异,导致其信息提取存在一定困难。方法本文基于面向图像语义分割的深度卷积神经网络,使用针对特征图的强化模块和通道域的注意力模块,对原始DeepLab网络进行改进,并通过滑动窗口预测、全连接条件随机场处理方法,更准确地实现城镇建成区提取。同时,针对使用深度学习算法容易出现过拟合和鲁棒性不强的问题,采用数据扩充增强技术进一步提升模型能力。结果实验数据是三亚和海口部分地区的高分二号遥感影像。结果表明,本文方法的正确率高于93%,Kappa系数大于0.837,可以有效地提取出大尺度高分辨率遥感影像中的城镇建成区,且提取结果最为接近实际情况。结论针对高分辨率遥感卫星影像中城镇建成区的光谱信息多样化、纹理结构复杂化等特点,本文算法能在特征提取网络中获取更多特征信息。本文使用改进的深度学习方法,提出两种处理方法,显著提高了模型的精度,在实际大幅遥感影像的使用中表现优秀,具有重要的实用价值和广阔的应用前景。关键词:卷积神经网络;注意力机制;遥感图像;城镇建成区;信息提取41|20|3更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0