
最新刊期
2019 年 第 24 卷 第 9 期
- 摘要:城市视频实景地图兼具地图立体空间、视频时间4维度层面信息统一表达能力,对于我国城市立体监控系统构建、互联网地图产品发展,以及未来实景3维中国建设战略实施具有重要意义和应用价值。为引起更多研究者进行探索,对城市视频实景地图构建方法、技术及其应用前景进行讨论。从增强虚拟环境技术(AVE)角度出发,对融合全景视频与地理3维模型构建城市视频实景地图涉及的全景摄像机标定、全景视频空间配准及视频纹理映射、实时渲染系列技术、方法进行了梳理。经过分析得出:1)适合传统“针孔”模型的摄像机标定、影像空间配准理论和方法,需根据全景摄像机球面投影模型进行拓展;2)适合静态纹理的大规模3D场景渲染LOD(levels of detail)技术和策略,需结合视频传输带宽限制、高帧率特点进行技术创新。城市视频实景地图构建是一项值得重视的崭新课题,将有力促进互联网、人工智能前沿技术发展,有望给相关行业带来万亿级市场机遇。关键词:视频实景地图;3维地图;虚拟现实;全景摄像机标定;视频空间配准;视频纹理映射;实时渲染63|64|4更新时间:2024-05-07
学者观点

-
 摘要:光学遥感影像经常受到云或霾影响,而在多数情况下极少能获取辅助数据用于遥感影像去霾;因此单幅光学遥感影像的图像处理去霾算法成为遥感影像预处理的重要技术。目前,不同研究者设计了多种算法,但是缺乏系统性的总结与对比分析,本文旨在系统性地总结单幅遥感影像去霾算法的研究进展,并提供典型算法的基本原理、优缺点及适用场景。采用文献综合分析方法从霾条件影像成像模型、基础原理和结果评价3方面对当前的去霾算法进行归类总结和原理剖析,然后结合具体应用场景分析算法的适用范围和存在问题,并提出可行的解决方案。常见的去霾算法大体可归纳为暗目标减法、滤波法、暗通道先验法和经验变换法4类,这些算法采用的霾条件影像成像模型包括加法模型、霾传输衰减模型和照明—反射模型等;在算法的评估中,常用的手段有主观分析方法、影像光谱特征分析方法以及图像质量指标评估法等。现有算法并不能适用于所有的场景或图像,存在模型参数难以自适应调整、模型对特殊地物类型敏感、处理结果失真严重等问题;算法的评价主要采用主观对比分析方法,根据应用需求构建客观指标成为目前的热点方向。关键词:遥感影像去霾;暗目标减法;暗通道先验;霾传输衰减;图像质量评价;霾优化变换;小波分解95|120|1更新时间:2024-05-07
摘要:光学遥感影像经常受到云或霾影响,而在多数情况下极少能获取辅助数据用于遥感影像去霾;因此单幅光学遥感影像的图像处理去霾算法成为遥感影像预处理的重要技术。目前,不同研究者设计了多种算法,但是缺乏系统性的总结与对比分析,本文旨在系统性地总结单幅遥感影像去霾算法的研究进展,并提供典型算法的基本原理、优缺点及适用场景。采用文献综合分析方法从霾条件影像成像模型、基础原理和结果评价3方面对当前的去霾算法进行归类总结和原理剖析,然后结合具体应用场景分析算法的适用范围和存在问题,并提出可行的解决方案。常见的去霾算法大体可归纳为暗目标减法、滤波法、暗通道先验法和经验变换法4类,这些算法采用的霾条件影像成像模型包括加法模型、霾传输衰减模型和照明—反射模型等;在算法的评估中,常用的手段有主观分析方法、影像光谱特征分析方法以及图像质量指标评估法等。现有算法并不能适用于所有的场景或图像,存在模型参数难以自适应调整、模型对特殊地物类型敏感、处理结果失真严重等问题;算法的评价主要采用主观对比分析方法,根据应用需求构建客观指标成为目前的热点方向。关键词:遥感影像去霾;暗目标减法;暗通道先验;霾传输衰减;图像质量评价;霾优化变换;小波分解95|120|1更新时间:2024-05-07
综述
-
 摘要:目的弥散加权成像(DWI)作为一种新型医学影像成像技术,已逐渐成为诊断心脏、大脑、肾脏、肝脏等器官中的神经、纤维组织病变的重要方法和手段。与传统的核磁共振(MRI)成像相比,通过使用不同的扩散方向矢量,在不同的扩散参数下,DWI图像呈现的灰度信息也有所不同。目前尚无相关文献提出针对DWI图像版权信息进行有效保护的相关研究。方法为有效保护病人的DWI图像版权信息,提出一种基于DWI图像的整数小波变换域(IWT)统计直方图的鲁棒水印算法。该算法首先通过最大类间方差分割算法和面积控制阈值获取指定断层中带有弥散梯度方向图像的前景区域,作为待嵌入区域。对待嵌入区域使用整数小波变换获取低频子带系数,利用固定步长对低频子带系数进行统计,生成统计直方图,对统计直方图相邻簇的比值关系进行修改用于水印嵌入;最后提出DWI表观系数与弥散张量成像(DTI)中弥散张量值的可逆关系构建可逆密钥,利用该密钥将嵌入水印后的DWI图像再次加密,从而有效保护DWI图像的版权信息。结果实验结果表明该算法引入的水印信息对DWI图像中的纤维参数改变量极小。在纤维方向和平均弥散程度改变个数上,本文算法与文献方法相比,分别降低了100多个和30多个;在可视质量上,本文算法提高约8 dB。在高斯噪声、小角度旋转等攻击中,本文算法能够提供较高的提取水印准确率。结论本文算法对医生诊断的影响在可接受的范围内,且在感兴趣区域遭受各种常见攻击时,具有较高的安全性和鲁棒性。关键词:弥散加权成像;直方图;固定步长统计;比值关系;鲁棒水印24|46|6更新时间:2024-05-07
摘要:目的弥散加权成像(DWI)作为一种新型医学影像成像技术,已逐渐成为诊断心脏、大脑、肾脏、肝脏等器官中的神经、纤维组织病变的重要方法和手段。与传统的核磁共振(MRI)成像相比,通过使用不同的扩散方向矢量,在不同的扩散参数下,DWI图像呈现的灰度信息也有所不同。目前尚无相关文献提出针对DWI图像版权信息进行有效保护的相关研究。方法为有效保护病人的DWI图像版权信息,提出一种基于DWI图像的整数小波变换域(IWT)统计直方图的鲁棒水印算法。该算法首先通过最大类间方差分割算法和面积控制阈值获取指定断层中带有弥散梯度方向图像的前景区域,作为待嵌入区域。对待嵌入区域使用整数小波变换获取低频子带系数,利用固定步长对低频子带系数进行统计,生成统计直方图,对统计直方图相邻簇的比值关系进行修改用于水印嵌入;最后提出DWI表观系数与弥散张量成像(DTI)中弥散张量值的可逆关系构建可逆密钥,利用该密钥将嵌入水印后的DWI图像再次加密,从而有效保护DWI图像的版权信息。结果实验结果表明该算法引入的水印信息对DWI图像中的纤维参数改变量极小。在纤维方向和平均弥散程度改变个数上,本文算法与文献方法相比,分别降低了100多个和30多个;在可视质量上,本文算法提高约8 dB。在高斯噪声、小角度旋转等攻击中,本文算法能够提供较高的提取水印准确率。结论本文算法对医生诊断的影响在可接受的范围内,且在感兴趣区域遭受各种常见攻击时,具有较高的安全性和鲁棒性。关键词:弥散加权成像;直方图;固定步长统计;比值关系;鲁棒水印24|46|6更新时间:2024-05-07
图像处理和编码
-
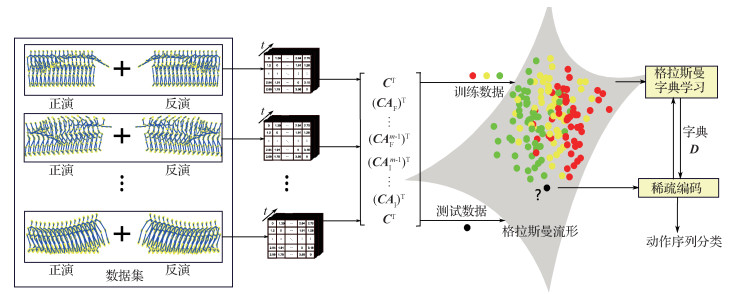 摘要:目的人体行为识别在视频监控、环境辅助生活、人机交互和智能驾驶等领域展现出了极其广泛的应用前景。由于目标物体遮挡、视频背景阴影、光照变化、视角变化、多尺度变化、人的衣服和外观变化等问题,使得对视频的处理与分析变得非常困难。为此,本文利用时间序列正反演构造基于张量的线性动态模型,估计模型的参数作为动作序列描述符,构造更加完备的观测矩阵。方法首先从深度图像提取人体关节点,建立张量形式的人体骨骼正反向序列。然后利用基于张量的线性动态系统和Tucker分解学习参数元组(AF,AI,C),其中C表示人体骨架信息的空间信息,AF和AI分别描述正向和反向时间序列的动态性。通过参数元组构造观测矩阵,一个动作就可以表示为观测矩阵的子空间,对应着格拉斯曼流形上的一点。最后通过在格拉斯曼流形上进行字典学习和稀疏编码完成动作识别。结果实验结果表明,在MSR-Action 3D数据集上,该算法比Eigenjoints算法高13.55%,比局部切从支持向量机(LTBSVM)算法高2.79%,比基于张量的线性动态系统(tLDS)算法高1%。在UT-Kinect数据集上,该算法的行为识别率比LTBSVM算法高5.8%,比tLDS算法高1.3%。结论通过大量实验评估,验证了基于时间序列正反演构造出来的tLDS模型很好地解决了上述问题,提高了人体动作识别率。关键词:时间序列正反演;人体行为识别;人体骨架;线性动态系统;格拉斯曼流形29|46|0更新时间:2024-05-07
摘要:目的人体行为识别在视频监控、环境辅助生活、人机交互和智能驾驶等领域展现出了极其广泛的应用前景。由于目标物体遮挡、视频背景阴影、光照变化、视角变化、多尺度变化、人的衣服和外观变化等问题,使得对视频的处理与分析变得非常困难。为此,本文利用时间序列正反演构造基于张量的线性动态模型,估计模型的参数作为动作序列描述符,构造更加完备的观测矩阵。方法首先从深度图像提取人体关节点,建立张量形式的人体骨骼正反向序列。然后利用基于张量的线性动态系统和Tucker分解学习参数元组(AF,AI,C),其中C表示人体骨架信息的空间信息,AF和AI分别描述正向和反向时间序列的动态性。通过参数元组构造观测矩阵,一个动作就可以表示为观测矩阵的子空间,对应着格拉斯曼流形上的一点。最后通过在格拉斯曼流形上进行字典学习和稀疏编码完成动作识别。结果实验结果表明,在MSR-Action 3D数据集上,该算法比Eigenjoints算法高13.55%,比局部切从支持向量机(LTBSVM)算法高2.79%,比基于张量的线性动态系统(tLDS)算法高1%。在UT-Kinect数据集上,该算法的行为识别率比LTBSVM算法高5.8%,比tLDS算法高1.3%。结论通过大量实验评估,验证了基于时间序列正反演构造出来的tLDS模型很好地解决了上述问题,提高了人体动作识别率。关键词:时间序列正反演;人体行为识别;人体骨架;线性动态系统;格拉斯曼流形29|46|0更新时间:2024-05-07 -
 摘要:目的车标是车辆的显著性特征,通过车标的分类与识别可以极大缩小车辆型号识别的范围,是车辆品牌和型号识别中的重要环节。基于特征描述子的车标识别算法存在如下缺点:一方面,算法提取的特征数量有限,不能全面描述车标的特征;另一方面,提取的特征过于冗杂,维度高,需要大量的计算时间。为了提取更加丰富的车标特征,提高识别效率,提出一种增强边缘梯度特征局部量化策略驱动下的车标识别方法。方法首先提取车标图像的增强边缘特征,即根据不同的梯度方向提取梯度信息,生成梯度大小矩阵,并采用LTP(local ternary patterns)算子在梯度大小矩阵上进一步进行特征提取,然后采用特征码本对提取的特征进行量化操作,在确保车标特征描述能力的同时,精简了特征数目,缩短了局部向量的长度,最后采用WPCA(whitened principal component analysis)进行特征降维操作,并基于CRC(collaborative representation based classification)分类器进行车标的识别。结果基于本文算法提取的车标特征向量,能够很好地描述车标图像的特征,在HFUT-VL1车标数据集上取得了97.85%的识别率(平均每类训练样本为10张),且在识别难度较大的XMU车标数据集上也能取得90%以上的识别率(平均每类训练样本为100张),与其他识别算法相比,识别率有明显提高,且具有更强的鲁棒性。结论增强边缘梯度特征局部量化策略驱动下的车标识别算法提取的特征信息能够有效地描述车标,具有很高的识别率和很强的鲁棒性,大大降低了特征向量的维度,提高了识别效率。关键词:车标识别;梯度特征;多梯度方向;增强边缘梯度特征;局部量化45|195|1更新时间:2024-05-07
摘要:目的车标是车辆的显著性特征,通过车标的分类与识别可以极大缩小车辆型号识别的范围,是车辆品牌和型号识别中的重要环节。基于特征描述子的车标识别算法存在如下缺点:一方面,算法提取的特征数量有限,不能全面描述车标的特征;另一方面,提取的特征过于冗杂,维度高,需要大量的计算时间。为了提取更加丰富的车标特征,提高识别效率,提出一种增强边缘梯度特征局部量化策略驱动下的车标识别方法。方法首先提取车标图像的增强边缘特征,即根据不同的梯度方向提取梯度信息,生成梯度大小矩阵,并采用LTP(local ternary patterns)算子在梯度大小矩阵上进一步进行特征提取,然后采用特征码本对提取的特征进行量化操作,在确保车标特征描述能力的同时,精简了特征数目,缩短了局部向量的长度,最后采用WPCA(whitened principal component analysis)进行特征降维操作,并基于CRC(collaborative representation based classification)分类器进行车标的识别。结果基于本文算法提取的车标特征向量,能够很好地描述车标图像的特征,在HFUT-VL1车标数据集上取得了97.85%的识别率(平均每类训练样本为10张),且在识别难度较大的XMU车标数据集上也能取得90%以上的识别率(平均每类训练样本为100张),与其他识别算法相比,识别率有明显提高,且具有更强的鲁棒性。结论增强边缘梯度特征局部量化策略驱动下的车标识别算法提取的特征信息能够有效地描述车标,具有很高的识别率和很强的鲁棒性,大大降低了特征向量的维度,提高了识别效率。关键词:车标识别;梯度特征;多梯度方向;增强边缘梯度特征;局部量化45|195|1更新时间:2024-05-07 -
 摘要:目的硬币上的发行年份是判别硬币外观质量的一个重要信息,为了对流通中的欧元硬币进行准确清分,有必要对欧元硬币上的发行年份进行检测与识别。但由于欧元硬币年份数字位姿的不确定性、尺寸的非归一化、其他文字符号的干扰、数字排列方式的多样性使得利用计算机视觉算法实现欧元硬币年份的自动检测、识别与判读存在较大困难。本文针对欧元硬币年份检测与识别的特殊性,提出基于Faster-RCNN(faster-region convolutional neural network)模型的数字检测方法,以及基于聚类算法和先验规则的年份排序算法。方法首先对训练数据进行增量化处理,例如旋转、缩放等方式极大地扩充训练样本的规模;然后重新训练Faster-RCNN网络模型,使其能够适应硬币中数字的各种位姿和尺寸变化;进而利用$K$-means聚类算法将获得的数字候选框聚成4类,选取每类中置信度最大的候选框;最后根据预先确定的不同国别硬币的年份排列方式,通过适当的排序算法即可得到正确的年份信息。结果在自建的实验平台上对欧盟中的12个国家的5种较大币值的硬币进行采样获得4 429幅图像,按1 :1比例划分为训练样本和测试样本。实验表明,本文方法的年份检测识别准确率达到89.62%,计算耗时约215 ms,基本满足准确性和实时性要求。结论本文算法具备实时、鲁棒、高精度的良好性能,具有较高的实际应用价值。关键词:目标检测;数字检测;年份排序;欧元硬币;Faster-RCNN;$K$-means聚类12|4|0更新时间:2024-05-07
摘要:目的硬币上的发行年份是判别硬币外观质量的一个重要信息,为了对流通中的欧元硬币进行准确清分,有必要对欧元硬币上的发行年份进行检测与识别。但由于欧元硬币年份数字位姿的不确定性、尺寸的非归一化、其他文字符号的干扰、数字排列方式的多样性使得利用计算机视觉算法实现欧元硬币年份的自动检测、识别与判读存在较大困难。本文针对欧元硬币年份检测与识别的特殊性,提出基于Faster-RCNN(faster-region convolutional neural network)模型的数字检测方法,以及基于聚类算法和先验规则的年份排序算法。方法首先对训练数据进行增量化处理,例如旋转、缩放等方式极大地扩充训练样本的规模;然后重新训练Faster-RCNN网络模型,使其能够适应硬币中数字的各种位姿和尺寸变化;进而利用$K$-means聚类算法将获得的数字候选框聚成4类,选取每类中置信度最大的候选框;最后根据预先确定的不同国别硬币的年份排列方式,通过适当的排序算法即可得到正确的年份信息。结果在自建的实验平台上对欧盟中的12个国家的5种较大币值的硬币进行采样获得4 429幅图像,按1 :1比例划分为训练样本和测试样本。实验表明,本文方法的年份检测识别准确率达到89.62%,计算耗时约215 ms,基本满足准确性和实时性要求。结论本文算法具备实时、鲁棒、高精度的良好性能,具有较高的实际应用价值。关键词:目标检测;数字检测;年份排序;欧元硬币;Faster-RCNN;$K$-means聚类12|4|0更新时间:2024-05-07 -
 摘要:目的行人检测是计算机视觉领域中的重点研究问题。经典的可变形部件模型(DPM)算法在行人检测领域素有高检测精度的优点,但由于在构建特征金字塔前处理过多召回率低的候选区域,导致计算速度偏慢,严重影响系统的实时性。针对该问题,本文对模型中选取候选检测区域的流程进行了改进,提出一种结合网格密度聚类算法和选择性搜索算法的行人检测候选对象生成方法来改进DPM模型。方法首先使用三帧差法和高斯混合模型收集固定数量的运动物体坐标点,然后结合基于网格密度的聚类算法构建网格坐标模型,生成目标频繁运动区域,同时进行动态掩层处理。随后引入改进的选择性搜索算法,结合支持向量机(SVM)训练得到的行人轮廓宽高比,提取该区域中高置信度的行人候选检测窗口,从而排除大量冗余的区域假设,完成对候选行人检测区域的精筛选,最后融合至DPM算法进行行人检测。结果所提方法在PETS 2009 Bench-mark数据集上进行检测,实验结果表明,该方法对复杂背景下的检测有较强的稳定性,与传统DPM模型相比,精度提高了1.71%、平均对数漏检率降低2.2%、检测速度提高为3.7倍左右。结论本文提出一种基于网格密度聚类的行人检测候选域生成算法,能够有效表达行人信息,与其他行人检测算法相比,有更好的精度和更快的速度,在检测率、检测时间方面均有提高,能够实现有效、快速的行人检测,具有实际意义。关键词:可变形部件模型;网格密度;选择性搜索;行人检测;候选窗口15|4|0更新时间:2024-05-07
摘要:目的行人检测是计算机视觉领域中的重点研究问题。经典的可变形部件模型(DPM)算法在行人检测领域素有高检测精度的优点,但由于在构建特征金字塔前处理过多召回率低的候选区域,导致计算速度偏慢,严重影响系统的实时性。针对该问题,本文对模型中选取候选检测区域的流程进行了改进,提出一种结合网格密度聚类算法和选择性搜索算法的行人检测候选对象生成方法来改进DPM模型。方法首先使用三帧差法和高斯混合模型收集固定数量的运动物体坐标点,然后结合基于网格密度的聚类算法构建网格坐标模型,生成目标频繁运动区域,同时进行动态掩层处理。随后引入改进的选择性搜索算法,结合支持向量机(SVM)训练得到的行人轮廓宽高比,提取该区域中高置信度的行人候选检测窗口,从而排除大量冗余的区域假设,完成对候选行人检测区域的精筛选,最后融合至DPM算法进行行人检测。结果所提方法在PETS 2009 Bench-mark数据集上进行检测,实验结果表明,该方法对复杂背景下的检测有较强的稳定性,与传统DPM模型相比,精度提高了1.71%、平均对数漏检率降低2.2%、检测速度提高为3.7倍左右。结论本文提出一种基于网格密度聚类的行人检测候选域生成算法,能够有效表达行人信息,与其他行人检测算法相比,有更好的精度和更快的速度,在检测率、检测时间方面均有提高,能够实现有效、快速的行人检测,具有实际意义。关键词:可变形部件模型;网格密度;选择性搜索;行人检测;候选窗口15|4|0更新时间:2024-05-07 -
 摘要:目的显著性目标检测算法主要分为基于低级特征的传统方法和基于深度学习的新方法,传统方法难以捕获对象的高级语义信息,基于深度学习的新方法能捕获高级语义信息却忽略了边缘特征。为了充分发挥两种方法的优势,基于将二者结合的思路,本文利用稀疏能使得显著性对象指向性凝聚的优势,提出了一种基于稀疏自编码和显著性结果优化的方法。方法对VGG(visual geometry group)网络第4个池化层的特征图进行稀疏自编码处理,得到5张稀疏显著性特征图,再与传统方法得到的显著图一起输入卷积神经网络进行显著性结果优化。结果使用DRFI(discriminative regional feature integration)、HDCT(high dimensional color transform)、RRWR(regularized random walks ranking)和CGVS(contour-guided visual search)等传统方法在DUT-OMRON、ECSSD、HKU-IS和MSRA等公开数据集上进行实验,表明本文算法有效改善了显著性对象的F值和MAE(mean absolute error)值。在F值提高方面,优化后的DRFI方法提升最高,在HKU-IS数据集上提高了24.53%。在MAE值降低方面,CGVS方法降低最少,在ECSSD数据集上降低了12.78%,降低最多的接近50%。而且本模型结构简单,参数少,计算效率高,训练时间约5 h,图像的平均测试时间约为3 s,有很强的实际应用性。结论本文提出了一种显著性结果优化算法,实验结果表明算法有效改善了显著性对象F值和MAE值,在对显著性对象检测要求越来越准确的对象识别等任务中有较好的适应性和应用性前景。关键词:显著性检测;VGG;稀疏自编码;图像融合;卷积神经网络13|4|0更新时间:2024-05-07
摘要:目的显著性目标检测算法主要分为基于低级特征的传统方法和基于深度学习的新方法,传统方法难以捕获对象的高级语义信息,基于深度学习的新方法能捕获高级语义信息却忽略了边缘特征。为了充分发挥两种方法的优势,基于将二者结合的思路,本文利用稀疏能使得显著性对象指向性凝聚的优势,提出了一种基于稀疏自编码和显著性结果优化的方法。方法对VGG(visual geometry group)网络第4个池化层的特征图进行稀疏自编码处理,得到5张稀疏显著性特征图,再与传统方法得到的显著图一起输入卷积神经网络进行显著性结果优化。结果使用DRFI(discriminative regional feature integration)、HDCT(high dimensional color transform)、RRWR(regularized random walks ranking)和CGVS(contour-guided visual search)等传统方法在DUT-OMRON、ECSSD、HKU-IS和MSRA等公开数据集上进行实验,表明本文算法有效改善了显著性对象的F值和MAE(mean absolute error)值。在F值提高方面,优化后的DRFI方法提升最高,在HKU-IS数据集上提高了24.53%。在MAE值降低方面,CGVS方法降低最少,在ECSSD数据集上降低了12.78%,降低最多的接近50%。而且本模型结构简单,参数少,计算效率高,训练时间约5 h,图像的平均测试时间约为3 s,有很强的实际应用性。结论本文提出了一种显著性结果优化算法,实验结果表明算法有效改善了显著性对象F值和MAE值,在对显著性对象检测要求越来越准确的对象识别等任务中有较好的适应性和应用性前景。关键词:显著性检测;VGG;稀疏自编码;图像融合;卷积神经网络13|4|0更新时间:2024-05-07 -
 摘要:目的高填方渠段渗漏监测技术是南水北调工程安全监测的关键技术之一。针对目前高填方渠道渗漏检测易受环境干扰导致判断结果不准确的问题,设计了基于Gabor-SVM(support vector machine)的南水北调中线工程高填方渠道水泥坡面破损识别模型。方法首先对高填方渠道水泥渠面图像进行预处理;然后研究Gabor小波的多方向/尺度选择特性,对提取的水泥坡面图像特征进行分析,寻找最佳尺度/方向参数组;最后根据训练好的样本特征,用SVM进行水泥坡面破损等级的分类处理,将破损类别划分为正常、裂缝、孔洞及破碎4种。在相同环境下,将Gabor-SVM与直方图-SVM、灰度共生矩阵-SVM、Canny边缘检测算法-SVM的破损识别进行比较分析。结果基于Gabor-SVM的水泥面破损识别方法在小波取6/12参数时,整体识别结果最佳,其中正常、裂缝、孔洞、破碎的识别率分别为98%、63%、88%、90%,平均识别率约为85%,相比其他几种方法的平均识别率(约50%),Gabor-SVM方法具有更好的识别能力。结论基于Gabor-SVM的水泥渠面破损识别模型有一定的识别效果,但对裂缝类别的高填方水泥坡面识别效果不理想,还需要进一步深入研究,以期为查找南水北调高填方渠道渗漏隐患提供技术支持。关键词:南水北调中线工程;多尺度/方向特征提取;破损识别;Gabor小波;SVM分类11|4|0更新时间:2024-05-07
摘要:目的高填方渠段渗漏监测技术是南水北调工程安全监测的关键技术之一。针对目前高填方渠道渗漏检测易受环境干扰导致判断结果不准确的问题,设计了基于Gabor-SVM(support vector machine)的南水北调中线工程高填方渠道水泥坡面破损识别模型。方法首先对高填方渠道水泥渠面图像进行预处理;然后研究Gabor小波的多方向/尺度选择特性,对提取的水泥坡面图像特征进行分析,寻找最佳尺度/方向参数组;最后根据训练好的样本特征,用SVM进行水泥坡面破损等级的分类处理,将破损类别划分为正常、裂缝、孔洞及破碎4种。在相同环境下,将Gabor-SVM与直方图-SVM、灰度共生矩阵-SVM、Canny边缘检测算法-SVM的破损识别进行比较分析。结果基于Gabor-SVM的水泥面破损识别方法在小波取6/12参数时,整体识别结果最佳,其中正常、裂缝、孔洞、破碎的识别率分别为98%、63%、88%、90%,平均识别率约为85%,相比其他几种方法的平均识别率(约50%),Gabor-SVM方法具有更好的识别能力。结论基于Gabor-SVM的水泥渠面破损识别模型有一定的识别效果,但对裂缝类别的高填方水泥坡面识别效果不理想,还需要进一步深入研究,以期为查找南水北调高填方渠道渗漏隐患提供技术支持。关键词:南水北调中线工程;多尺度/方向特征提取;破损识别;Gabor小波;SVM分类11|4|0更新时间:2024-05-07 -
 摘要:目的小样本学习任务旨在仅提供少量有标签样本的情况下完成对测试样本的正确分类。基于度量学习的小样本学习方法通过将样本映射到嵌入空间,计算距离得到相似性度量以预测类别,但未能从类内多个支持向量中归纳出具有代表性的特征以表征类概念,限制了分类准确率的进一步提高。针对该问题,本文提出代表特征网络,分类效果提升显著。方法代表特征网络通过类代表特征的度量学习策略,利用类中支持向量集学习得到的代表特征有效地表达类概念,实现对测试样本的正确分类。具体地说,代表特征网络包含两个模块,首先通过嵌入模块提取抽象层次高的嵌入向量,然后堆叠嵌入向量经过代表特征模块得到各个类代表特征。随后通过计算测试样本嵌入向量与各类代表特征的距离以预测类别,最后使用提出的混合损失函数计算损失以拉大嵌入空间中相互类别间距减少相似类别错分情况。结果经过广泛实验,在Omniglot、miniImageNet和Cifar100数据集上都验证了本文模型不仅可以获得目前已知最好的分类准确率,而且能够保持较高的训练效率。结论代表特征网络可以从类中多个支持向量有效地归纳出代表特征用于对测试样本的分类,对比直接使用支持向量进行分类具有更好的鲁棒性,进一步提高了小样本条件下的分类准确率。关键词:小样本学习;度量学习;代表特征网络;混合损失函数;微调25|243|2更新时间:2024-05-07
摘要:目的小样本学习任务旨在仅提供少量有标签样本的情况下完成对测试样本的正确分类。基于度量学习的小样本学习方法通过将样本映射到嵌入空间,计算距离得到相似性度量以预测类别,但未能从类内多个支持向量中归纳出具有代表性的特征以表征类概念,限制了分类准确率的进一步提高。针对该问题,本文提出代表特征网络,分类效果提升显著。方法代表特征网络通过类代表特征的度量学习策略,利用类中支持向量集学习得到的代表特征有效地表达类概念,实现对测试样本的正确分类。具体地说,代表特征网络包含两个模块,首先通过嵌入模块提取抽象层次高的嵌入向量,然后堆叠嵌入向量经过代表特征模块得到各个类代表特征。随后通过计算测试样本嵌入向量与各类代表特征的距离以预测类别,最后使用提出的混合损失函数计算损失以拉大嵌入空间中相互类别间距减少相似类别错分情况。结果经过广泛实验,在Omniglot、miniImageNet和Cifar100数据集上都验证了本文模型不仅可以获得目前已知最好的分类准确率,而且能够保持较高的训练效率。结论代表特征网络可以从类中多个支持向量有效地归纳出代表特征用于对测试样本的分类,对比直接使用支持向量进行分类具有更好的鲁棒性,进一步提高了小样本条件下的分类准确率。关键词:小样本学习;度量学习;代表特征网络;混合损失函数;微调25|243|2更新时间:2024-05-07 -
 摘要:目的目前深度神经网络已成功应用于众多机器学习任务,并展现出惊人的性能提升效果。然而传统的深度网络和机器学习算法都假定训练数据和测试数据服从的是同一分布,而这种假设在实际应用中往往是不成立的。如果训练数据和测试数据的分布差异很大,那么由传统机器学习算法训练出来的分类器的性能将会大大降低。为了解决此类问题,提出了一种基于多层校正的无监督领域自适应方法。方法首先利用多层校正来调整现有的深度网络,利用加法叠加来完美对齐源域和目标域的数据表示;然后采用多层权值最大均值差异来适应目标域,增加网络的表示能力;最后提取学习获得的域不变特征来进行分类,得到目标图像的识别效果。结果本文算法在Office-31图像数据集等4个数字数据集上分别进行了测试实验,以对比不同算法在图像识别和分类方面的性能差异,并进行准确度测量。测试结果显示,与同领域算法相比,本文算法在准确率上至少提高了5%,在应对照明变化、复杂背景和图像质量不佳等干扰情况时,亦能获得较好的分类效果,体现出更强的鲁棒性。结论在领域自适应相关数据集上的实验结果表明,本文方法具备一定的泛化能力,可以实现较高的分类性能,并且优于其他现有的无监督领域自适应方法。关键词:领域自适应;域不变特征;多层校正;图像识别;迁移学习50|5|0更新时间:2024-05-07
摘要:目的目前深度神经网络已成功应用于众多机器学习任务,并展现出惊人的性能提升效果。然而传统的深度网络和机器学习算法都假定训练数据和测试数据服从的是同一分布,而这种假设在实际应用中往往是不成立的。如果训练数据和测试数据的分布差异很大,那么由传统机器学习算法训练出来的分类器的性能将会大大降低。为了解决此类问题,提出了一种基于多层校正的无监督领域自适应方法。方法首先利用多层校正来调整现有的深度网络,利用加法叠加来完美对齐源域和目标域的数据表示;然后采用多层权值最大均值差异来适应目标域,增加网络的表示能力;最后提取学习获得的域不变特征来进行分类,得到目标图像的识别效果。结果本文算法在Office-31图像数据集等4个数字数据集上分别进行了测试实验,以对比不同算法在图像识别和分类方面的性能差异,并进行准确度测量。测试结果显示,与同领域算法相比,本文算法在准确率上至少提高了5%,在应对照明变化、复杂背景和图像质量不佳等干扰情况时,亦能获得较好的分类效果,体现出更强的鲁棒性。结论在领域自适应相关数据集上的实验结果表明,本文方法具备一定的泛化能力,可以实现较高的分类性能,并且优于其他现有的无监督领域自适应方法。关键词:领域自适应;域不变特征;多层校正;图像识别;迁移学习50|5|0更新时间:2024-05-07
图像分析和识别
-
 摘要:目的 双目测距对水面无人艇自主避障以及视觉侦察具有重要意义,但视觉传感器成像易受光照环境及运动模糊等因素的影响,基于经典Census变换的立体匹配代价计算方法耗时长,且视差获取精度差,影响测距精度。为了提高测距精度并保证算法运行速度,提出一种用于双目测距的快速立体匹配算法。方法 基于传统Census变换,提出一种新的比特串生成方法,在匹配点正方形支持窗口的各边等距各选3个像素点,共选出8个像素点,这8个像素点两两比较生成一个字节的比特串。将左右视场中的匹配点与待匹配点的比特串进行异或,得到两点的汉明距离,在各汉明距离中找到距离最小的像素点作为匹配像素点,两像素点的横坐标差为视差。本文采用区域视差计算的方法,在左右视场确定同一目标区域后进行视差提取和滤波,利用平均视差计算目标的距离。结果 本文算法与基于传统Census变换的立体匹配视差获取方法相比,在运算速度方面优势明显,时间稳定在0.4 s左右,用时仅为传统Census变换算法的1/5。在Middlebury数据集中的图像对teddy和cones上进行的算法运行时间对比实验中,本文基于Census变换改进的算法比已有的基于Census变换的匹配算法在运行时间上快了近20 s。在实际双目测距实验中,采用本文算法在1019 m范围内测距误差在5%以内,根据无人艇的运动特点和避障要求,通过分析可知该算法的测距精度可以满足低速无人艇的避障需求。结论 本文给出的基于改进Census变换的匹配算法在立体匹配速度上有大幅提高,提取目标视差用于测距,实际测距结果表明,本文算法能够满足水面无人艇的视觉避障要求。关键词:测距;双目视觉;改进Census变换;立体匹配;区域视差提取15|19|3更新时间:2024-05-07
摘要:目的 双目测距对水面无人艇自主避障以及视觉侦察具有重要意义,但视觉传感器成像易受光照环境及运动模糊等因素的影响,基于经典Census变换的立体匹配代价计算方法耗时长,且视差获取精度差,影响测距精度。为了提高测距精度并保证算法运行速度,提出一种用于双目测距的快速立体匹配算法。方法 基于传统Census变换,提出一种新的比特串生成方法,在匹配点正方形支持窗口的各边等距各选3个像素点,共选出8个像素点,这8个像素点两两比较生成一个字节的比特串。将左右视场中的匹配点与待匹配点的比特串进行异或,得到两点的汉明距离,在各汉明距离中找到距离最小的像素点作为匹配像素点,两像素点的横坐标差为视差。本文采用区域视差计算的方法,在左右视场确定同一目标区域后进行视差提取和滤波,利用平均视差计算目标的距离。结果 本文算法与基于传统Census变换的立体匹配视差获取方法相比,在运算速度方面优势明显,时间稳定在0.4 s左右,用时仅为传统Census变换算法的1/5。在Middlebury数据集中的图像对teddy和cones上进行的算法运行时间对比实验中,本文基于Census变换改进的算法比已有的基于Census变换的匹配算法在运行时间上快了近20 s。在实际双目测距实验中,采用本文算法在1019 m范围内测距误差在5%以内,根据无人艇的运动特点和避障要求,通过分析可知该算法的测距精度可以满足低速无人艇的避障需求。结论 本文给出的基于改进Census变换的匹配算法在立体匹配速度上有大幅提高,提取目标视差用于测距,实际测距结果表明,本文算法能够满足水面无人艇的视觉避障要求。关键词:测距;双目视觉;改进Census变换;立体匹配;区域视差提取15|19|3更新时间:2024-05-07 -
 摘要:目的 研究表明,图像的恰可察觉失真(JND)阈值主要与视觉系统的亮度适应性、对比度掩模、模块掩模以及图像结构等因素有关。为了更好地研究图像结构对JND阈值的影响,提出一种基于稀疏表示的结构信息和非结构信息分离模型,并应用于自然图像的JND阈值估计,使JND阈值模型与人眼视觉系统具有更好的一致性。方法 首先通过K-均值奇异值分解算法(K-SVD)得到过完备视觉字典。然后利用该过完备字典对输入的自然图像进行稀疏表示和重建,得到该图像对应的结构层和非结构层。针对结构层和非结构层,进一步设计基于亮度适应性与对比度掩模的结构层JND估计模型和基于亮度对比度与信息不确定度的非结构层JND估计模型。最后利用一个能够刻画掩模效应的非线性可加模型对以上两个分量的JND估计模型进行融合。结果 本文提出的JND估计模型利用稀疏表示将自然图像的结构/非结构信息进行分离,然后采用符合各自分量特点的JND模型进行计算,与视觉感知机理高度一致。实验结果表明,本文JND模型能够有效地预测自然图像的JND阈值,受污染图的峰值信噪比(PSNR)值比其他3个JND对比模型值高出35 dB。结论 与现有模型相比,该模型与人眼主观视觉感知具有更好的一致性,更能有效地预测自然图像的JND阈值。关键词:恰可察觉失真;稀疏表示;人眼视觉系统;结构信息;非结构信息12|4|1更新时间:2024-05-07
摘要:目的 研究表明,图像的恰可察觉失真(JND)阈值主要与视觉系统的亮度适应性、对比度掩模、模块掩模以及图像结构等因素有关。为了更好地研究图像结构对JND阈值的影响,提出一种基于稀疏表示的结构信息和非结构信息分离模型,并应用于自然图像的JND阈值估计,使JND阈值模型与人眼视觉系统具有更好的一致性。方法 首先通过K-均值奇异值分解算法(K-SVD)得到过完备视觉字典。然后利用该过完备字典对输入的自然图像进行稀疏表示和重建,得到该图像对应的结构层和非结构层。针对结构层和非结构层,进一步设计基于亮度适应性与对比度掩模的结构层JND估计模型和基于亮度对比度与信息不确定度的非结构层JND估计模型。最后利用一个能够刻画掩模效应的非线性可加模型对以上两个分量的JND估计模型进行融合。结果 本文提出的JND估计模型利用稀疏表示将自然图像的结构/非结构信息进行分离,然后采用符合各自分量特点的JND模型进行计算,与视觉感知机理高度一致。实验结果表明,本文JND模型能够有效地预测自然图像的JND阈值,受污染图的峰值信噪比(PSNR)值比其他3个JND对比模型值高出35 dB。结论 与现有模型相比,该模型与人眼主观视觉感知具有更好的一致性,更能有效地预测自然图像的JND阈值。关键词:恰可察觉失真;稀疏表示;人眼视觉系统;结构信息;非结构信息12|4|1更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的 建立行为可信的虚拟角色能够使严肃游戏更加有趣,提升用户使用的体验感。尽管严肃游戏的图形渲染技术已经日趋成熟,但现有的虚拟角色行为表现方式多采用确定性模型,很难反映虚拟角色行为表现的多样性。方法 本文构建了符合辅助社交训练的严肃游戏剧情,采用智能体来描述虚拟角色,赋予虚拟角色视觉、听觉双通道感知。基于马斯洛动机理论,采用食物、休息、交流和安全等动机来描述情绪的产生,利用大五(OCEAN)个性模型来描述虚拟角色的不同个性差别。用外部刺激和内部动机需求来计算情绪强度,利用行为树描述虚拟角色的行为。运用正态云模型处理虚拟角色行为表现的不确定性,并以行走方向、社交距离、交流时身体朝向3个典型的行为表现给出了具体处理方法。结果 在所实现的游戏原型系统中,对于虚拟角色的自主行为和行为表现的不确定性进行了用户体验测试。结果表明,在场景探索任务中,虚拟角色的自主行为模型能减少用户探索场景所耗费的时间,并且可以促进用户与虚拟角色交流;在行为表现测试中,本文模型的自然性评价要高于确定性模型。结论 本文虚拟角色行为模型在一定程度上可提升用户的体验感,有望为建立行为可信的虚拟角色提供一种新的途径。关键词:严肃游戏;虚拟角色;辅助社交;云模型;行为表现;不确定性44|4|1更新时间:2024-05-07
摘要:目的 建立行为可信的虚拟角色能够使严肃游戏更加有趣,提升用户使用的体验感。尽管严肃游戏的图形渲染技术已经日趋成熟,但现有的虚拟角色行为表现方式多采用确定性模型,很难反映虚拟角色行为表现的多样性。方法 本文构建了符合辅助社交训练的严肃游戏剧情,采用智能体来描述虚拟角色,赋予虚拟角色视觉、听觉双通道感知。基于马斯洛动机理论,采用食物、休息、交流和安全等动机来描述情绪的产生,利用大五(OCEAN)个性模型来描述虚拟角色的不同个性差别。用外部刺激和内部动机需求来计算情绪强度,利用行为树描述虚拟角色的行为。运用正态云模型处理虚拟角色行为表现的不确定性,并以行走方向、社交距离、交流时身体朝向3个典型的行为表现给出了具体处理方法。结果 在所实现的游戏原型系统中,对于虚拟角色的自主行为和行为表现的不确定性进行了用户体验测试。结果表明,在场景探索任务中,虚拟角色的自主行为模型能减少用户探索场景所耗费的时间,并且可以促进用户与虚拟角色交流;在行为表现测试中,本文模型的自然性评价要高于确定性模型。结论 本文虚拟角色行为模型在一定程度上可提升用户的体验感,有望为建立行为可信的虚拟角色提供一种新的途径。关键词:严肃游戏;虚拟角色;辅助社交;云模型;行为表现;不确定性44|4|1更新时间:2024-05-07
虚拟现实和增强现实
-
 摘要:目的 视网膜血管健康状况的自动分析对糖尿病、心脑血管疾病以及多种眼科疾病的快速无创诊断具有重要参考价值。视网膜图像中血管网络结构复杂且图像背景亮度不均使得血管区域的准确自动提取具有较大难度。本文通过使用具有对称全卷积结构的U-net深度神经网络实现视网膜血管的高精度分割。方法 基于U-net网络中的层次化对称结构和Dense-net网络中的稠密连接方式,提出一种改进的适用于视网膜血管精准提取的深度神经网络模型。首先使用白化预处理技术弱化原始彩色眼底图像中的亮度不均,增强图像中血管区域的对比度;接着对数据集进行随机旋转、Gamma变换操作实现数据增广;然后将每一幅图像随机分割成若干较小的图块,用于减小模型参数规模,降低训练难度。结果 使用多种性能指标对训练后的模型进行综合评定,模型在DRIVE数据集上的灵敏度、特异性、准确率和AUC(area under the curve)分别达到0.740 9、0.992 9、0.970 7和0.917 1。所提算法与目前主流方法进行了全面比较,结果显示本文算法各项性能指标均表现良好。结论 本文针对视网膜图像中血管区域高精度自动提取难度大的问题,提出了一种具有稠密连接方式的对称全卷积神经网络改进模型。结果表明该模型在视网膜血管分割中能够达到良好效果,具有较好的研究及应用价值。关键词:视网膜血管分割;深度学习;全卷积神经网络;U-Net;Dense-net25|67|6更新时间:2024-05-07
摘要:目的 视网膜血管健康状况的自动分析对糖尿病、心脑血管疾病以及多种眼科疾病的快速无创诊断具有重要参考价值。视网膜图像中血管网络结构复杂且图像背景亮度不均使得血管区域的准确自动提取具有较大难度。本文通过使用具有对称全卷积结构的U-net深度神经网络实现视网膜血管的高精度分割。方法 基于U-net网络中的层次化对称结构和Dense-net网络中的稠密连接方式,提出一种改进的适用于视网膜血管精准提取的深度神经网络模型。首先使用白化预处理技术弱化原始彩色眼底图像中的亮度不均,增强图像中血管区域的对比度;接着对数据集进行随机旋转、Gamma变换操作实现数据增广;然后将每一幅图像随机分割成若干较小的图块,用于减小模型参数规模,降低训练难度。结果 使用多种性能指标对训练后的模型进行综合评定,模型在DRIVE数据集上的灵敏度、特异性、准确率和AUC(area under the curve)分别达到0.740 9、0.992 9、0.970 7和0.917 1。所提算法与目前主流方法进行了全面比较,结果显示本文算法各项性能指标均表现良好。结论 本文针对视网膜图像中血管区域高精度自动提取难度大的问题,提出了一种具有稠密连接方式的对称全卷积神经网络改进模型。结果表明该模型在视网膜血管分割中能够达到良好效果,具有较好的研究及应用价值。关键词:视网膜血管分割;深度学习;全卷积神经网络;U-Net;Dense-net25|67|6更新时间:2024-05-07 -
 摘要:目的 由MRI(magnetic resonance imaging)得到的影像具有分辨率高、软组织对比好等优点,使得医生能更精确地获得需要的信息,精确的前列腺MRI分割是计算机辅助检测和诊断算法的必要预处理阶段。因此临床上需要一种自动或半自动的前列腺分割算法,为各种各样的临床应用提供具有鲁棒性、高质量的结果。提出一种多尺度判别条件生成对抗网络对前列腺MRI图像进行自动分割以满足临床实践的需求。方法 提出的分割方法是基于条件生成对抗网络,由生成器和判别器两部分组成。生成器由类似U-Net的卷积神经网络组成,根据输入的MRI生成前列腺区域的掩膜;判别器是一个多尺度判别器,同一网络结构,输入图像尺寸不同的两个判别器。为了训练稳定,本文方法使用了特征匹配损失。在网络训练过程中使用对抗训练机制迭代地优化生成器和判别器,直至判别器和生成器同时收敛为止。训练好的生成器即可完成前列腺MRI分割。结果 实验数据来自PROMISE12前列腺分割比赛和安徽医科大学第一附属医院,以Dice相似性系数和Hausdorff距离作为评价指标,本文算法的Dice相似性系数为88.9%,Hausdorff距离为5.3 mm,与U-Net、DSCNN(deeply-supervised convolutional neured network)等方法相比,本文算法分割更准确,鲁棒性更高。在测试阶段,每幅图像仅需不到1 s的时间即可完成分割,超出了专门医生的分割速度。结论 提出了一种多尺度判别条件生成对抗网络来分割前列腺,从定量和定性分析可以看出本文算法的有效性,能够准确地对前列腺进行分割,达到了实时分割要求,符合临床诊断和治疗需求。关键词:MRI;前列腺分割;生成对抗网络;生成器;判别器25|27|1更新时间:2024-05-07
摘要:目的 由MRI(magnetic resonance imaging)得到的影像具有分辨率高、软组织对比好等优点,使得医生能更精确地获得需要的信息,精确的前列腺MRI分割是计算机辅助检测和诊断算法的必要预处理阶段。因此临床上需要一种自动或半自动的前列腺分割算法,为各种各样的临床应用提供具有鲁棒性、高质量的结果。提出一种多尺度判别条件生成对抗网络对前列腺MRI图像进行自动分割以满足临床实践的需求。方法 提出的分割方法是基于条件生成对抗网络,由生成器和判别器两部分组成。生成器由类似U-Net的卷积神经网络组成,根据输入的MRI生成前列腺区域的掩膜;判别器是一个多尺度判别器,同一网络结构,输入图像尺寸不同的两个判别器。为了训练稳定,本文方法使用了特征匹配损失。在网络训练过程中使用对抗训练机制迭代地优化生成器和判别器,直至判别器和生成器同时收敛为止。训练好的生成器即可完成前列腺MRI分割。结果 实验数据来自PROMISE12前列腺分割比赛和安徽医科大学第一附属医院,以Dice相似性系数和Hausdorff距离作为评价指标,本文算法的Dice相似性系数为88.9%,Hausdorff距离为5.3 mm,与U-Net、DSCNN(deeply-supervised convolutional neured network)等方法相比,本文算法分割更准确,鲁棒性更高。在测试阶段,每幅图像仅需不到1 s的时间即可完成分割,超出了专门医生的分割速度。结论 提出了一种多尺度判别条件生成对抗网络来分割前列腺,从定量和定性分析可以看出本文算法的有效性,能够准确地对前列腺进行分割,达到了实时分割要求,符合临床诊断和治疗需求。关键词:MRI;前列腺分割;生成对抗网络;生成器;判别器25|27|1更新时间:2024-05-07 -
 摘要:目的针对基于稀疏编码的医学图像融合方法存在的细节保存能力不足的问题,提出了一种基于卷积稀疏表示双重字典学习与自适应脉冲耦合神经网络(PCNN)的多模态医学图像融合方法。方法首先通过已配准的训练图像去学习卷积稀疏与卷积低秩子字典,在两个字典下使用交替方向乘子法(ADMM)求得其卷积稀疏表示系数与卷积低秩表示系数,通过与对应的字典重构得到卷积稀疏与卷积低秩分量;然后利用改进的的拉普拉斯能量和(NSML)以及空间频率和(NMSF)去激励PCNN分别对卷积稀疏与卷积低秩分量进行融合;最后将融合后的卷积稀疏与卷积低秩分量进行组合得到最终的融合图像。结果对灰度图像与彩色图像进行实验仿真并与其他融合方法进行比较,实验结果表明,所提出的融合方法在客观评估和视觉质量方面明显优于对比的6种方法,在4种指标上都有最优的表现;与6种多模态图像融合方法相比,3组实验平均标准差分别提高了7%、10%、5.2%;平均互信息分别提高了33.4%、10.9%、11.3%;平均空间频率分别提高了8.2%、9.6%、5.6%;平均边缘评价因子分别提高了16.9%、20.7%、21.6%。结论与其他稀疏表示方法相比,有效提高了多模态医学图像融合的质量,更好地保留了源图像的细节信息,使融合图像的信息更加丰富,符合人眼的视觉特性,有效地辅助医生进行疾病诊断。关键词:医学图像融合;双重字典学习;卷积稀疏;卷积低秩;脉冲耦合神经网络14|8|4更新时间:2024-05-07
摘要:目的针对基于稀疏编码的医学图像融合方法存在的细节保存能力不足的问题,提出了一种基于卷积稀疏表示双重字典学习与自适应脉冲耦合神经网络(PCNN)的多模态医学图像融合方法。方法首先通过已配准的训练图像去学习卷积稀疏与卷积低秩子字典,在两个字典下使用交替方向乘子法(ADMM)求得其卷积稀疏表示系数与卷积低秩表示系数,通过与对应的字典重构得到卷积稀疏与卷积低秩分量;然后利用改进的的拉普拉斯能量和(NSML)以及空间频率和(NMSF)去激励PCNN分别对卷积稀疏与卷积低秩分量进行融合;最后将融合后的卷积稀疏与卷积低秩分量进行组合得到最终的融合图像。结果对灰度图像与彩色图像进行实验仿真并与其他融合方法进行比较,实验结果表明,所提出的融合方法在客观评估和视觉质量方面明显优于对比的6种方法,在4种指标上都有最优的表现;与6种多模态图像融合方法相比,3组实验平均标准差分别提高了7%、10%、5.2%;平均互信息分别提高了33.4%、10.9%、11.3%;平均空间频率分别提高了8.2%、9.6%、5.6%;平均边缘评价因子分别提高了16.9%、20.7%、21.6%。结论与其他稀疏表示方法相比,有效提高了多模态医学图像融合的质量,更好地保留了源图像的细节信息,使融合图像的信息更加丰富,符合人眼的视觉特性,有效地辅助医生进行疾病诊断。关键词:医学图像融合;双重字典学习;卷积稀疏;卷积低秩;脉冲耦合神经网络14|8|4更新时间:2024-05-07
医学图像处理
-
 摘要:目的为了解决基于卷积神经网络的算法对高光谱图像小样本分类精度较低、模型结构复杂和计算量大的问题,提出了一种变维卷积神经网络。方法变维卷积神经网络对高光谱分类过程可根据内部特征图维度的变化分为空—谱信息融合、降维、混合特征提取与空—谱联合分类的过程。这种变维结构通过改变特征映射的维度,简化了网络结构并减少了计算量,并通过对空—谱信息的充分提取提高了卷积神经网络对小样本高光谱图像分类的精度。结果实验分为变维卷积神经网络的性能分析实验与分类性能对比实验,所用的数据集为Indian Pines和Pavia University Scene数据集。通过实验可知,变维卷积神经网络对高光谱小样本可取得较高的分类精度,在Indian Pines和Pavia University Scene数据集上的总体分类精度分别为87.87%和98.18%,与其他分类算法对比有较明显的性能优势。结论实验结果表明,合理的参数优化可有效提高变维卷积神经网络的分类精度,这种变维模型可较大程度提高对高光谱图像中小样本数据的分类性能,并可进一步推广到其他与高光谱图像相关的深度学习分类模型中。关键词:卷积神经网络;高光谱图像;小样本数据;变维特征提取;空-谱联合分类12|4|2更新时间:2024-05-07
摘要:目的为了解决基于卷积神经网络的算法对高光谱图像小样本分类精度较低、模型结构复杂和计算量大的问题,提出了一种变维卷积神经网络。方法变维卷积神经网络对高光谱分类过程可根据内部特征图维度的变化分为空—谱信息融合、降维、混合特征提取与空—谱联合分类的过程。这种变维结构通过改变特征映射的维度,简化了网络结构并减少了计算量,并通过对空—谱信息的充分提取提高了卷积神经网络对小样本高光谱图像分类的精度。结果实验分为变维卷积神经网络的性能分析实验与分类性能对比实验,所用的数据集为Indian Pines和Pavia University Scene数据集。通过实验可知,变维卷积神经网络对高光谱小样本可取得较高的分类精度,在Indian Pines和Pavia University Scene数据集上的总体分类精度分别为87.87%和98.18%,与其他分类算法对比有较明显的性能优势。结论实验结果表明,合理的参数优化可有效提高变维卷积神经网络的分类精度,这种变维模型可较大程度提高对高光谱图像中小样本数据的分类性能,并可进一步推广到其他与高光谱图像相关的深度学习分类模型中。关键词:卷积神经网络;高光谱图像;小样本数据;变维特征提取;空-谱联合分类12|4|2更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0