
最新刊期
2019 年 第 24 卷 第 5 期
-
 摘要:目的本文是关于中国图像工程的年度文献系列综述之二十四。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,对2018年度图像工程相关文献进行了统计和分析。方法从国内15种有关图像工程重要中文期刊在2018年发行的共148期上所发表的2 863篇学术研究和技术应用文献中,选取出747篇属于图像工程领域的文献,并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前13年相同),并在此基础上分别进行各期刊各类文献的统计和分析。结果根据对2018年统计数据的分析可看出:图像分析方向当前得到了最多的关注,其中目标检测和识别、图像分割和边缘检测、目标特性的提取分析都是关注的焦点。遥感、雷达、测绘等领域的图像技术研究和应用都最为活跃。结论中国图像工程在2018年的研究深度和广度还在提高和扩大,仍保持了快速发展的势头。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学160|183|0更新时间:2024-05-08
摘要:目的本文是关于中国图像工程的年度文献系列综述之二十四。为了使国内广大从事图像工程研究和图像技术应用的科技人员能够较全面地了解国内图像工程研究和发展的现状,能够有针对性地查询有关文献,且向期刊编者和作者提供有用的参考,对2018年度图像工程相关文献进行了统计和分析。方法从国内15种有关图像工程重要中文期刊在2018年发行的共148期上所发表的2 863篇学术研究和技术应用文献中,选取出747篇属于图像工程领域的文献,并根据各文献的主要内容将其分别归入图像处理、图像分析、图像理解、技术应用和综述评论5个大类,然后进一步分入23个专业小类(与前13年相同),并在此基础上分别进行各期刊各类文献的统计和分析。结果根据对2018年统计数据的分析可看出:图像分析方向当前得到了最多的关注,其中目标检测和识别、图像分割和边缘检测、目标特性的提取分析都是关注的焦点。遥感、雷达、测绘等领域的图像技术研究和应用都最为活跃。结论中国图像工程在2018年的研究深度和广度还在提高和扩大,仍保持了快速发展的势头。关键词:图像工程;图像处理;图像分析;图像理解;技术应用;文献综述;文献统计;文献分类;文献计量学160|183|0更新时间:2024-05-08 -
 摘要:目的图像匹配作为计算机视觉的核心任务,是后续高级图像处理的关键,如目标识别、图像拼接、3维重建、视觉定位、场景深度计算等。本文从局部不变特征点、直线、区域匹配3个方面对图像匹配方法予以综述。方法局部不变特征点匹配在图像匹配领域发展中最早出现,对这类方法中经典的算法本文仅予以简述,对于近年来新出现的方法予以重点介绍,尤其是基于深度学习的匹配方法,包括时间不变特征检测器(TILDE)、Quad-networks、深度卷积特征点描述符(DeepDesc)、基于学习的不变特征变换(LIFT)等。由于外点剔除类方法常用于提高局部不变点特征匹配的准确率,因此也对这类方法予以介绍,包括用于全局运动建模的双边函数(BF)、基于网格的运动统计(GMS)、向量场一致性估计(VFC)等。与局部不变特征点相比,线包含更多场景和对象的结构信息,更适用于具有重复纹理信息的像对匹配中,线匹配的研究需要克服包括端点位置不准确、线段外观不明显、线段碎片等问题,解决这类问题的方法有线带描述符(LBD)、基于上下文和表面的线匹配(CA)、基于点对应的线匹配(LP)、共面线点投影不变量法等,本文从问题解决过程的角度对这类方法予以介绍。区域匹配从区域特征提取与匹配、模板匹配两个角度对这类算法予以介绍,典型的区域特征提取与匹配方法包括最大稳定极值区域(MSER)、基于树的莫尔斯区域(TBMR),模板匹配包括快速仿射模板匹配(FAsT-Match)、彩色图像的快速仿射模板匹配(CFAST-Match)、具有变形和多样性的相似性度量(DDIS)、遮挡感知模板匹配(OATM),以及深度学习类的方法MatchNet、L2-Net、PN-Net、DeepCD等。结果本文从局部不变特征点、直线、区域3个方面对图像匹配方法进行总结对比,包括特征匹配方法中影响因素的比较、基于深度学习类匹配方法的比较等,给出这类方法对应的论文及代码下载地址,并对未来的研究方向予以展望。结论图像匹配是计算机视觉领域后续高级处理的基础,目前在宽基线匹配、实时匹配方面仍需进一步深入研究。关键词:图像匹配;局部不变特征匹配;直线匹配;区域匹配;语义匹配;深度学习277|178|0更新时间:2024-05-08
摘要:目的图像匹配作为计算机视觉的核心任务,是后续高级图像处理的关键,如目标识别、图像拼接、3维重建、视觉定位、场景深度计算等。本文从局部不变特征点、直线、区域匹配3个方面对图像匹配方法予以综述。方法局部不变特征点匹配在图像匹配领域发展中最早出现,对这类方法中经典的算法本文仅予以简述,对于近年来新出现的方法予以重点介绍,尤其是基于深度学习的匹配方法,包括时间不变特征检测器(TILDE)、Quad-networks、深度卷积特征点描述符(DeepDesc)、基于学习的不变特征变换(LIFT)等。由于外点剔除类方法常用于提高局部不变点特征匹配的准确率,因此也对这类方法予以介绍,包括用于全局运动建模的双边函数(BF)、基于网格的运动统计(GMS)、向量场一致性估计(VFC)等。与局部不变特征点相比,线包含更多场景和对象的结构信息,更适用于具有重复纹理信息的像对匹配中,线匹配的研究需要克服包括端点位置不准确、线段外观不明显、线段碎片等问题,解决这类问题的方法有线带描述符(LBD)、基于上下文和表面的线匹配(CA)、基于点对应的线匹配(LP)、共面线点投影不变量法等,本文从问题解决过程的角度对这类方法予以介绍。区域匹配从区域特征提取与匹配、模板匹配两个角度对这类算法予以介绍,典型的区域特征提取与匹配方法包括最大稳定极值区域(MSER)、基于树的莫尔斯区域(TBMR),模板匹配包括快速仿射模板匹配(FAsT-Match)、彩色图像的快速仿射模板匹配(CFAST-Match)、具有变形和多样性的相似性度量(DDIS)、遮挡感知模板匹配(OATM),以及深度学习类的方法MatchNet、L2-Net、PN-Net、DeepCD等。结果本文从局部不变特征点、直线、区域3个方面对图像匹配方法进行总结对比,包括特征匹配方法中影响因素的比较、基于深度学习类匹配方法的比较等,给出这类方法对应的论文及代码下载地址,并对未来的研究方向予以展望。结论图像匹配是计算机视觉领域后续高级处理的基础,目前在宽基线匹配、实时匹配方面仍需进一步深入研究。关键词:图像匹配;局部不变特征匹配;直线匹配;区域匹配;语义匹配;深度学习277|178|0更新时间:2024-05-08
综述

-
 摘要:目的TV(total variation)模型在图像修复时易导致图像中具有弱导数性质的纹理和边缘细节等信息变得模糊,为了克服该缺陷,分数阶微分被引入到TV模型中,但传统的分数阶TV模型对弱边缘和弱纹理等细节信息的保持仍不够理想,并且没有充分利用图像已知区域的先验信息,修复精度仍有待提高。方法针对该问题,提出结合纹理结构信息和分数阶TV模型的图像修复算法。改进的模型在分数阶TV模型求解时,在梯度计算过程中增加了一个极小值,克服了正则项和数据项在零点处的不可微,从而增加了模型的稳定性。再则改进的模型根据图像已知区域的先验信息确定待修复区域的纹理方向,从而更好地保持了图像中的纹理细节和弱边缘信息。结果将本文算法与3种修复效果较好的算法进行对比,采用客观评价指标:均方差(MSE)、峰值信噪比(PSNR)和差值图像进行评价,实验结果表明本文算法在不同的纹理图像修复中均取得较好的效果,如对标准图像库中的Barbara和Lena图像以及岩石图像进行修复后,与原始TV模型相比,它们的峰值信噪比分别提高5.94%、8.07%和3.85%,灰度均方差分别降低48.66%、65.89%和35%;与分数阶TV模型相比,它们的峰值信噪比分别提高4.17%、8.59%和1.81%,灰度均方差分别降低37.90%、68.00%和18.68%。结论提出的模型相对于原始的TV模型和分数阶TV模型,均能有效地提高图像修复的精度,适合于包含较多弱纹理和弱边缘信息的图像修复,该模型是TV模型的重要延伸和推广。关键词:图像修复;分数阶微分;弱纹理;TV模型;边缘细节28|30|0更新时间:2024-05-08
摘要:目的TV(total variation)模型在图像修复时易导致图像中具有弱导数性质的纹理和边缘细节等信息变得模糊,为了克服该缺陷,分数阶微分被引入到TV模型中,但传统的分数阶TV模型对弱边缘和弱纹理等细节信息的保持仍不够理想,并且没有充分利用图像已知区域的先验信息,修复精度仍有待提高。方法针对该问题,提出结合纹理结构信息和分数阶TV模型的图像修复算法。改进的模型在分数阶TV模型求解时,在梯度计算过程中增加了一个极小值,克服了正则项和数据项在零点处的不可微,从而增加了模型的稳定性。再则改进的模型根据图像已知区域的先验信息确定待修复区域的纹理方向,从而更好地保持了图像中的纹理细节和弱边缘信息。结果将本文算法与3种修复效果较好的算法进行对比,采用客观评价指标:均方差(MSE)、峰值信噪比(PSNR)和差值图像进行评价,实验结果表明本文算法在不同的纹理图像修复中均取得较好的效果,如对标准图像库中的Barbara和Lena图像以及岩石图像进行修复后,与原始TV模型相比,它们的峰值信噪比分别提高5.94%、8.07%和3.85%,灰度均方差分别降低48.66%、65.89%和35%;与分数阶TV模型相比,它们的峰值信噪比分别提高4.17%、8.59%和1.81%,灰度均方差分别降低37.90%、68.00%和18.68%。结论提出的模型相对于原始的TV模型和分数阶TV模型,均能有效地提高图像修复的精度,适合于包含较多弱纹理和弱边缘信息的图像修复,该模型是TV模型的重要延伸和推广。关键词:图像修复;分数阶微分;弱纹理;TV模型;边缘细节28|30|0更新时间:2024-05-08 -
 摘要:目的为了能在光照变化、动态背景干扰这一类复杂场景中实时、准确地分割出运动前景,针对传统的基于颜色特征和基于像素的方法的不足,提出一种在颜色属性空间进行区域直方图建模的运动目标检测方法。方法首先将RGB颜色空间映射到更为稳健的低维颜色属性空间,以颜色属性为特征在像素的局部范围内建立直方图,同时记录直方图每一个分区中像素的空间信息,使用K个空间直方图构成每个像素的背景模型,每个直方图根据其匹配度赋予不同的权重。降维的颜色属性提高了模型的鲁棒性和检测的时效性,空间直方图引入的位置信息提高了背景模型的准确性。然后通过学习率αb和αω来控制各模型直方图及其权重的更新,以提高模型的适应性。在标准测试数据集的所有视频序列中进行了实验,通过分析综合性能指标(F1)及平均假阳性(FN)曲线,确定了算法中涉及参数的合理取值范围。结果对实验结果定性和定量的分析表明,本文方法能够得到良好的前景检测效果,尤其在多模态场景和光线变化的复杂场景中能显著提高检测性能。各类场景的平均综合性能指标(average F1)相比性能突出的方法ViBe、LOBSTER(local binary similarity segmenter)和DECOLOR(detecting contiguous outliers in the low-rank representation)分别提高了0.65%、3.86%和3.9%,并通过GPU并行加速实现运动目标的实时检测。结论在复杂视频环境下的运动目标检测中,相比已有方法,本文方法能够更为准确地分割出运动前景,是一种实时、有效的检测方法,具有一定的实用价值。关键词:计算机视觉;智能视频分析;运动检测;背景建模;颜色属性;空间直方图21|25|0更新时间:2024-05-08
摘要:目的为了能在光照变化、动态背景干扰这一类复杂场景中实时、准确地分割出运动前景,针对传统的基于颜色特征和基于像素的方法的不足,提出一种在颜色属性空间进行区域直方图建模的运动目标检测方法。方法首先将RGB颜色空间映射到更为稳健的低维颜色属性空间,以颜色属性为特征在像素的局部范围内建立直方图,同时记录直方图每一个分区中像素的空间信息,使用K个空间直方图构成每个像素的背景模型,每个直方图根据其匹配度赋予不同的权重。降维的颜色属性提高了模型的鲁棒性和检测的时效性,空间直方图引入的位置信息提高了背景模型的准确性。然后通过学习率αb和αω来控制各模型直方图及其权重的更新,以提高模型的适应性。在标准测试数据集的所有视频序列中进行了实验,通过分析综合性能指标(F1)及平均假阳性(FN)曲线,确定了算法中涉及参数的合理取值范围。结果对实验结果定性和定量的分析表明,本文方法能够得到良好的前景检测效果,尤其在多模态场景和光线变化的复杂场景中能显著提高检测性能。各类场景的平均综合性能指标(average F1)相比性能突出的方法ViBe、LOBSTER(local binary similarity segmenter)和DECOLOR(detecting contiguous outliers in the low-rank representation)分别提高了0.65%、3.86%和3.9%,并通过GPU并行加速实现运动目标的实时检测。结论在复杂视频环境下的运动目标检测中,相比已有方法,本文方法能够更为准确地分割出运动前景,是一种实时、有效的检测方法,具有一定的实用价值。关键词:计算机视觉;智能视频分析;运动检测;背景建模;颜色属性;空间直方图21|25|0更新时间:2024-05-08 -
 摘要:目的未来视频编码(FVC)是在高效视频编码标准(HEVC)的基础上提出的新一代编码技术,复杂度极高。针对现有的基于HEVC的快速编码方法不适用于FVC中的四叉树加二叉树编码结构或节省时间有限的问题,提出了一种结合随机森林的FVC帧内编码单元(CU)快速划分算法。方法针对FVC中的四叉树加二叉树结构进行优化。首先,提取视频编码过程中的各CU的图像纹理特征和划分结果;然后,分别使用各划分深度下的纹理特征和划分结果进行在线训练,建立多个随机森林模型,不同深度的CU对应不同的模型;最后,使用模型对视频其余帧的CU进行划分结果预测,从而减少了划分模式遍历和率失真代价计算的次数,节省了编码时间。结果实验结果表明,与原始平台算法相比,本文算法能够节省44.1%的时间,在相同峰值信噪比的情况下,比特率仅上升2.6%;与当前先进的方法相比,能进一步节省20%以上的时间。结论通过提取图像的纹理特征,建立随机森林模型,对CU划分结果进行预测,在保证编码率失真性能的前提下,有效地降低了FVC的帧内CU划分复杂度。关键词:视频编码;未来视频编码;帧内快速编码;机器学习;随机森林20|70|0更新时间:2024-05-08
摘要:目的未来视频编码(FVC)是在高效视频编码标准(HEVC)的基础上提出的新一代编码技术,复杂度极高。针对现有的基于HEVC的快速编码方法不适用于FVC中的四叉树加二叉树编码结构或节省时间有限的问题,提出了一种结合随机森林的FVC帧内编码单元(CU)快速划分算法。方法针对FVC中的四叉树加二叉树结构进行优化。首先,提取视频编码过程中的各CU的图像纹理特征和划分结果;然后,分别使用各划分深度下的纹理特征和划分结果进行在线训练,建立多个随机森林模型,不同深度的CU对应不同的模型;最后,使用模型对视频其余帧的CU进行划分结果预测,从而减少了划分模式遍历和率失真代价计算的次数,节省了编码时间。结果实验结果表明,与原始平台算法相比,本文算法能够节省44.1%的时间,在相同峰值信噪比的情况下,比特率仅上升2.6%;与当前先进的方法相比,能进一步节省20%以上的时间。结论通过提取图像的纹理特征,建立随机森林模型,对CU划分结果进行预测,在保证编码率失真性能的前提下,有效地降低了FVC的帧内CU划分复杂度。关键词:视频编码;未来视频编码;帧内快速编码;机器学习;随机森林20|70|0更新时间:2024-05-08
图像处理和编码
-
 摘要:目的在视频监控和人群模式行为理解的重要应用中,识别分割场景中的集体行为仍然是一个极具挑战性的问题。在这项研究中,提出一种基于流形密度的集体聚类算法,能够识别具有任意形状和不同密度条件下的集体行为的局部和全局模式。方法受群体运动行为的流形拓扑结构启发,首先提出一种新的流形距离度量方式用于挖掘群体运动的深层行为模式。进一步定义了集体聚集密度的概念,并通过基于聚集密度的聚类算法识别具有局部一致性行为的群组,这种策略更适用于识别具有任意形状的聚类。同时考虑到子群组之间的复杂交互作用,引入层次聚集合并算法得到全局集体行为模式,可以有效地表征全局一致性关系。结果针对不同情况下的复杂场景,本文算法在集体视频监控数据集下的实验结果表明了其有效性和鲁棒性,相比于传统的聚类方法和标准经典算法,以平均误差(AD)和方差(VAR)作为评价指标来评价算法性能,本文方法将识别分割聚集行为群组的误差率结果控制在了0.81和0.99以内,相比许多经典方法有较大提升。同时在具有复杂流形结构及任意密度条件下的人群场景中能够取得精确有效的识别结果,解决了经典方法在该特殊场景下存在的缺点。结论本文针对已有方法在流形结构场景识别集体行为流向缺乏精确性和稳定性的描述和分析这一问题,提出了基于流形密度的群组聚集聚类识别算法,在多个复杂真实视频数据集中进行实验,证明了所提方法的有效性,并相比于已有方法具有更高的识别精度。关键词:聚集行为;密度峰值聚类;聚集流形;聚集性;行为一致性22|10|0更新时间:2024-05-08
摘要:目的在视频监控和人群模式行为理解的重要应用中,识别分割场景中的集体行为仍然是一个极具挑战性的问题。在这项研究中,提出一种基于流形密度的集体聚类算法,能够识别具有任意形状和不同密度条件下的集体行为的局部和全局模式。方法受群体运动行为的流形拓扑结构启发,首先提出一种新的流形距离度量方式用于挖掘群体运动的深层行为模式。进一步定义了集体聚集密度的概念,并通过基于聚集密度的聚类算法识别具有局部一致性行为的群组,这种策略更适用于识别具有任意形状的聚类。同时考虑到子群组之间的复杂交互作用,引入层次聚集合并算法得到全局集体行为模式,可以有效地表征全局一致性关系。结果针对不同情况下的复杂场景,本文算法在集体视频监控数据集下的实验结果表明了其有效性和鲁棒性,相比于传统的聚类方法和标准经典算法,以平均误差(AD)和方差(VAR)作为评价指标来评价算法性能,本文方法将识别分割聚集行为群组的误差率结果控制在了0.81和0.99以内,相比许多经典方法有较大提升。同时在具有复杂流形结构及任意密度条件下的人群场景中能够取得精确有效的识别结果,解决了经典方法在该特殊场景下存在的缺点。结论本文针对已有方法在流形结构场景识别集体行为流向缺乏精确性和稳定性的描述和分析这一问题,提出了基于流形密度的群组聚集聚类识别算法,在多个复杂真实视频数据集中进行实验,证明了所提方法的有效性,并相比于已有方法具有更高的识别精度。关键词:聚集行为;密度峰值聚类;聚集流形;聚集性;行为一致性22|10|0更新时间:2024-05-08 -
 摘要:目的近年来,随着人脸识别认证技术的发展及逐渐普及,大量人脸照片存放在第三方服务器上的现象十分普遍,如何对人脸进行隐私保护这个问题变得十分突出。方法首先对人脸图像进行预处理,然后采用Arnold变换对人脸关键部位进行分块随机置乱,并将置乱结果图输入到深度卷积神经网络中。为了解决人脸照片在分块置乱时由于本身拍照角度的原因导致的分块不均等因素,在预处理时根据人眼进行特性点定位,再据此进行对齐处理,使得预处理后的照片人眼处于同一水平线。针对人脸隐私保护及加扰置乱后图像的识别,本文提出了基于分块随机加扰的深度卷积神经网络模型。不包含附加层,该模型网络结构由4个卷积层、3个池化层、1个全连接层和1个softmax回归层组成。服务器端通过深度神经网络模型直接对置乱后人脸图像进行验证识别。结果该算法使服务器端全程不存储原始人脸模板,实现了对原始人脸图像的有效加扰保护。实验采用该T深度卷积神经网络对处理过后的ORL人脸库进行识别,最终识别准确率达到97.62%。同时通过多组对比实验,验证了本文方法的有效性。结论与其他文献中手工提取特征并利用决策树和随机森林进行训练识别的方法相比,本文方法减少了人工提取特征的工作量,且具有高识别率。关键词:人脸识别认证;卷积神经网络;Arnold变换;人脸对齐;人脸隐私保护22|9|0更新时间:2024-05-08
摘要:目的近年来,随着人脸识别认证技术的发展及逐渐普及,大量人脸照片存放在第三方服务器上的现象十分普遍,如何对人脸进行隐私保护这个问题变得十分突出。方法首先对人脸图像进行预处理,然后采用Arnold变换对人脸关键部位进行分块随机置乱,并将置乱结果图输入到深度卷积神经网络中。为了解决人脸照片在分块置乱时由于本身拍照角度的原因导致的分块不均等因素,在预处理时根据人眼进行特性点定位,再据此进行对齐处理,使得预处理后的照片人眼处于同一水平线。针对人脸隐私保护及加扰置乱后图像的识别,本文提出了基于分块随机加扰的深度卷积神经网络模型。不包含附加层,该模型网络结构由4个卷积层、3个池化层、1个全连接层和1个softmax回归层组成。服务器端通过深度神经网络模型直接对置乱后人脸图像进行验证识别。结果该算法使服务器端全程不存储原始人脸模板,实现了对原始人脸图像的有效加扰保护。实验采用该T深度卷积神经网络对处理过后的ORL人脸库进行识别,最终识别准确率达到97.62%。同时通过多组对比实验,验证了本文方法的有效性。结论与其他文献中手工提取特征并利用决策树和随机森林进行训练识别的方法相比,本文方法减少了人工提取特征的工作量,且具有高识别率。关键词:人脸识别认证;卷积神经网络;Arnold变换;人脸对齐;人脸隐私保护22|9|0更新时间:2024-05-08 -
 摘要:目的相较于传统表情,自发表情更能揭示一个人的真实情感,在国家安防、医疗等领域有巨大的应用潜力。由于自发表情具有诱导困难、样本难以采集等特殊性,因此数据样本较少。为判别自发表情的种类,结合在越来越多的场景得到广泛应用的神经网络学习方法,提出基于深度迁移网络的表情种类判别方法。方法为保留原始自发表情图片的特征,即使在小数据样本上也不使用数据增强技术,并将光流特征3维图像作为对比样本。将样本置入不同的迁移网络模型中进行训练,然后将经过训练的同结构的网络组合成同构网络并输出结果,从而实现自发表情种类的判别。结果实验结果表明本文方法在不同数据库上均表现出优异的自发表情分类判别特性。在开放的自发表情数据库CASME、CASMEⅡ和CAS(ME)2上的测试平均准确率分别达到了94.3%、97.3%和97.2%,比目前最好测试结果高7%。结论本文将迁移学习方法应用于自发表情种类的判别,并对不同网络模型以及不同种类的样本进行比较,取得了目前最优的自发表情种类判别的平均准确率。关键词:自发表情;迁移学习;分类;神经网络;同构网络15|9|0更新时间:2024-05-08
摘要:目的相较于传统表情,自发表情更能揭示一个人的真实情感,在国家安防、医疗等领域有巨大的应用潜力。由于自发表情具有诱导困难、样本难以采集等特殊性,因此数据样本较少。为判别自发表情的种类,结合在越来越多的场景得到广泛应用的神经网络学习方法,提出基于深度迁移网络的表情种类判别方法。方法为保留原始自发表情图片的特征,即使在小数据样本上也不使用数据增强技术,并将光流特征3维图像作为对比样本。将样本置入不同的迁移网络模型中进行训练,然后将经过训练的同结构的网络组合成同构网络并输出结果,从而实现自发表情种类的判别。结果实验结果表明本文方法在不同数据库上均表现出优异的自发表情分类判别特性。在开放的自发表情数据库CASME、CASMEⅡ和CAS(ME)2上的测试平均准确率分别达到了94.3%、97.3%和97.2%,比目前最好测试结果高7%。结论本文将迁移学习方法应用于自发表情种类的判别,并对不同网络模型以及不同种类的样本进行比较,取得了目前最优的自发表情种类判别的平均准确率。关键词:自发表情;迁移学习;分类;神经网络;同构网络15|9|0更新时间:2024-05-08 -
 摘要:目的针对花卉图像标注样本缺乏、标注成本高、传统基于深度学习的细粒度图像分类方法无法较好地定位花卉目标区域等问题,提出一种基于选择性深度卷积特征融合的无监督花卉图像分类方法。方法构建基于选择性深度卷积特征融合的花卉图像分类网络。首先运用保持长宽比的尺寸归一化方法对花卉图像进行预处理,使得图像的尺寸相同,且目标不变形、不丢失图像细节信息;之后运用由ImageNet预训练好的深度卷积神经网络VGG-16模型对预处理的花卉图像进行特征学习,根据特征图的响应值分布选取有效的深度卷积特征,并将多层深度卷积特征进行融合;最后运用softmax分类层进行分类。结果在Oxford 102 Flowers数据集上做了对比实验,将本文方法与传统的基于深度学习模型的花卉图像分类方法进行对比,本文方法的分类准确率达85.55%,较深度学习模型Xception高27.67%。结论提出了基于选择性卷积特征融合的花卉图像分类方法,该方法采用无监督的方式定位花卉图像中的显著区域,去除了背景和噪声部分对花卉目标的干扰,提高了花卉图像分类的准确率,适用于处理缺乏带标注的样本时的花卉图像分类问题。关键词:花卉分类;深度学习;显著区域;特征选取;特征融合22|49|0更新时间:2024-05-08
摘要:目的针对花卉图像标注样本缺乏、标注成本高、传统基于深度学习的细粒度图像分类方法无法较好地定位花卉目标区域等问题,提出一种基于选择性深度卷积特征融合的无监督花卉图像分类方法。方法构建基于选择性深度卷积特征融合的花卉图像分类网络。首先运用保持长宽比的尺寸归一化方法对花卉图像进行预处理,使得图像的尺寸相同,且目标不变形、不丢失图像细节信息;之后运用由ImageNet预训练好的深度卷积神经网络VGG-16模型对预处理的花卉图像进行特征学习,根据特征图的响应值分布选取有效的深度卷积特征,并将多层深度卷积特征进行融合;最后运用softmax分类层进行分类。结果在Oxford 102 Flowers数据集上做了对比实验,将本文方法与传统的基于深度学习模型的花卉图像分类方法进行对比,本文方法的分类准确率达85.55%,较深度学习模型Xception高27.67%。结论提出了基于选择性卷积特征融合的花卉图像分类方法,该方法采用无监督的方式定位花卉图像中的显著区域,去除了背景和噪声部分对花卉目标的干扰,提高了花卉图像分类的准确率,适用于处理缺乏带标注的样本时的花卉图像分类问题。关键词:花卉分类;深度学习;显著区域;特征选取;特征融合22|49|0更新时间:2024-05-08 -
 摘要:目的目前垃圾主要采用名称检索的方式开展分类,这类方法通常基于事先设定的数据分类,很难有效包含现有所有的垃圾,更难应对未来持续增多的垃圾,针对上述问题,面向生活垃圾,提出一种基于自我训练的长效垃圾分类方法。方法首先,采用Bagging将两类分类能力和训练机制不同的基分类器:K近邻分类器和支持向量机,根据它们各自独立的投票和权重进行有机组合,提出了一种新颖的集成分类器对生活垃圾进行分类;其次,基于直观的图像交互反馈,动态地更新分类器相应分类结果的置信度和基于云的训练样本集,提升后续分类的准确性和方法本身的自学习能力。结果使用包含233条生活垃圾的训练样本集对原型系统进行训练,并使用151条垃圾样例进行测试,实验表明本文提出的集成分类器对生活垃圾的分类准确性可以达到95%左右。通过逐步提高训练样本集中错误样本的比例(≤ 30%)并重新训练集成分类器,再采用上述151条样例共开展了150次分类测试。相应的平均准确率分析表明,本文的集成分类器具有较高且较为稳定的分类准确率(≥ 93%)。此外,在上述实验中加入反馈机制后,平均准确率分析表明,该机制能有效地减轻错误样本对本文集成分类器准确率衰减带来的影响。结论本文方法对生活垃圾分类具有较高的分类准确率、鲁棒性且具有良好的长效性。关键词:垃圾分类;自我训练;集成分类器;Bagging;长效分类19|102|0更新时间:2024-05-08
摘要:目的目前垃圾主要采用名称检索的方式开展分类,这类方法通常基于事先设定的数据分类,很难有效包含现有所有的垃圾,更难应对未来持续增多的垃圾,针对上述问题,面向生活垃圾,提出一种基于自我训练的长效垃圾分类方法。方法首先,采用Bagging将两类分类能力和训练机制不同的基分类器:K近邻分类器和支持向量机,根据它们各自独立的投票和权重进行有机组合,提出了一种新颖的集成分类器对生活垃圾进行分类;其次,基于直观的图像交互反馈,动态地更新分类器相应分类结果的置信度和基于云的训练样本集,提升后续分类的准确性和方法本身的自学习能力。结果使用包含233条生活垃圾的训练样本集对原型系统进行训练,并使用151条垃圾样例进行测试,实验表明本文提出的集成分类器对生活垃圾的分类准确性可以达到95%左右。通过逐步提高训练样本集中错误样本的比例(≤ 30%)并重新训练集成分类器,再采用上述151条样例共开展了150次分类测试。相应的平均准确率分析表明,本文的集成分类器具有较高且较为稳定的分类准确率(≥ 93%)。此外,在上述实验中加入反馈机制后,平均准确率分析表明,该机制能有效地减轻错误样本对本文集成分类器准确率衰减带来的影响。结论本文方法对生活垃圾分类具有较高的分类准确率、鲁棒性且具有良好的长效性。关键词:垃圾分类;自我训练;集成分类器;Bagging;长效分类19|102|0更新时间:2024-05-08 -
 摘要:目的符合用户视觉特性的3维图像体验质量评价方法有助于准确、客观地体现用户观看3D图像或视频时的视觉感知体验,从而给优化3维内容提供一定的思路。现有的评价方法仅从图像失真、深度感知和视觉舒适度中的一个维度或两个维度出发对立体图像进行评价,评价结果的准确性有待进一步提升。为了更加全面和准确地评价3D图像的视觉感知体验,提出了一种用户多维感知的3D图像体验质量评价算法。方法首先对左右图像的差异图像和融合图像提取自然场景统计参数表示失真特征;然后对深度图像提取敏感区域,对敏感区域绘制失真前后深度变换直方图,统计深度变化情况以及利用尺度不变特征变换(SIFT)关键点匹配算法计算匹配点数目,两者共同表示深度感知特征;接下来对视觉显著区域提取视差均值、幅值表示舒适度特征;最后综合考虑图像失真、深度感知和视觉舒适度3个维度特征,将3个维度特征归一化后联合成体验质量特征向量,采用支持向量回归(SVR)训练评价模型,并得到最终的体验质量得分。结果在LIVE和Waterloo IVC数据库上的实验结果表明,所提出的方法与人们的主观感知的相关性达到了0.942和0.858。结论该方法充分利用了立体图像的特性,评价结果优于比较的几种经典算法,所构建模型的评价结果与用户的主观体验有更好的一致性。关键词:质量评价;失真;深度感;视觉疲劳;用户体验19|22|0更新时间:2024-05-08
摘要:目的符合用户视觉特性的3维图像体验质量评价方法有助于准确、客观地体现用户观看3D图像或视频时的视觉感知体验,从而给优化3维内容提供一定的思路。现有的评价方法仅从图像失真、深度感知和视觉舒适度中的一个维度或两个维度出发对立体图像进行评价,评价结果的准确性有待进一步提升。为了更加全面和准确地评价3D图像的视觉感知体验,提出了一种用户多维感知的3D图像体验质量评价算法。方法首先对左右图像的差异图像和融合图像提取自然场景统计参数表示失真特征;然后对深度图像提取敏感区域,对敏感区域绘制失真前后深度变换直方图,统计深度变化情况以及利用尺度不变特征变换(SIFT)关键点匹配算法计算匹配点数目,两者共同表示深度感知特征;接下来对视觉显著区域提取视差均值、幅值表示舒适度特征;最后综合考虑图像失真、深度感知和视觉舒适度3个维度特征,将3个维度特征归一化后联合成体验质量特征向量,采用支持向量回归(SVR)训练评价模型,并得到最终的体验质量得分。结果在LIVE和Waterloo IVC数据库上的实验结果表明,所提出的方法与人们的主观感知的相关性达到了0.942和0.858。结论该方法充分利用了立体图像的特性,评价结果优于比较的几种经典算法,所构建模型的评价结果与用户的主观体验有更好的一致性。关键词:质量评价;失真;深度感;视觉疲劳;用户体验19|22|0更新时间:2024-05-08
图像分析和识别
-
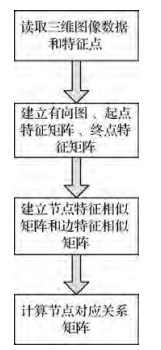 摘要:目的现有的图匹配算法大多应用于二维图像,对三维图像的特征点匹配存在匹配准确率低和计算速度慢等问题。为解决这些问题,本文将分解图匹配算法扩展应用在了三维图像上。方法首先将需要匹配的两个三维图像的特征点作为图的节点集;再通过Delaunay三角剖分算法,将三维特征点相连,则相连得到的边就作为图的边集,从而建立有向图;然后,根据三维图像的特征点构建相应的三维有向图及其邻接矩阵;再根据有向图中的节点特征和边特征分别构建节点特征相似矩阵和边特征相似矩阵;最后根据这两个特征矩阵将节点匹配问题转化为求极值问题并求解。结果实验表明,在手工选取特征点的情况下,本文算法对相同三维图像的特征点匹配有97.56%的平均准确率;对不同三维图像特征点匹配有76.39%的平均准确率;在三维图像有旋转的情况下,有90%以上的平均准确率;在特征点部分缺失的情况下,平均匹配准确率也能达到80%。在通过三维尺度不变特征变换(SIFT)算法得到特征点的情况下,本文算法对9个三维模型的特征点的平均匹配准确率为98.78%。结论本文提出的基于图论的三维图像特征点匹配算法,经实验结果验证,可以取得较好的匹配效果。关键词:图匹配;三维图像处理;图论;路径跟踪算法;人工智能25|54|0更新时间:2024-05-08
摘要:目的现有的图匹配算法大多应用于二维图像,对三维图像的特征点匹配存在匹配准确率低和计算速度慢等问题。为解决这些问题,本文将分解图匹配算法扩展应用在了三维图像上。方法首先将需要匹配的两个三维图像的特征点作为图的节点集;再通过Delaunay三角剖分算法,将三维特征点相连,则相连得到的边就作为图的边集,从而建立有向图;然后,根据三维图像的特征点构建相应的三维有向图及其邻接矩阵;再根据有向图中的节点特征和边特征分别构建节点特征相似矩阵和边特征相似矩阵;最后根据这两个特征矩阵将节点匹配问题转化为求极值问题并求解。结果实验表明,在手工选取特征点的情况下,本文算法对相同三维图像的特征点匹配有97.56%的平均准确率;对不同三维图像特征点匹配有76.39%的平均准确率;在三维图像有旋转的情况下,有90%以上的平均准确率;在特征点部分缺失的情况下,平均匹配准确率也能达到80%。在通过三维尺度不变特征变换(SIFT)算法得到特征点的情况下,本文算法对9个三维模型的特征点的平均匹配准确率为98.78%。结论本文提出的基于图论的三维图像特征点匹配算法,经实验结果验证,可以取得较好的匹配效果。关键词:图匹配;三维图像处理;图论;路径跟踪算法;人工智能25|54|0更新时间:2024-05-08 -
 摘要:目的轮廓是对图像目标的一种稀疏表达方式,从图像中提取出有效物体轮廓可以更好地完成后续的视觉认知任务,所以轮廓检测在计算机视觉领域具有较好的应用。本文考虑到初级视通路中视觉信息传递和处理流程中的特点,提出了一种基于初级视通路计算模型的轮廓检测方法。方法在视网膜神经节环节,提出一种体现方向选择特性的经典感受野(CRF)改进模型,利用多尺度特征融合策略来模拟视网膜神经节细胞对图像目标的初级轮廓响应;在视网膜神经节到神经节-外膝体(LGN)的视通路中,提出一种反映视觉信息时空尺度特征的时空编码机制,模拟神经节-外膝体通路对初级轮廓响应的去冗余处理;利用非下采样轮廓波变换和Gabor变换协同作用,模拟非经典感受野(NCRF)的侧向抑制特性。最后利用初级视皮层对整体轮廓的前馈机制,实现对轮廓局部细节信息的完整性融合。结果选择将RuG40图库的所有图像作为测试集合进行模型性能测试,对检测结果进行非极大值抑制和阈值处理,最终将得到的二值轮廓图与基准图比较,整个数据集和单张图的最优平均P指标分别为0.49和0.56。对于单个图像最优参数条件下的检测结果均值,将本文方法与非经典感受野抑制模型(ISO)和多特征外周抑制模型(MCI)比较,较两者分别提高了19.1%和7.7%。结果表明本文方法能有效突出主体轮廓并抑制纹理背景。结论面向图像处理应用的初级视通路计算模型,将为后续图像理解和分析提供一种新的思路。关键词:轮廓检测;视觉机制;多尺度特征融合;侧向抑制性质;时空编码19|10|0更新时间:2024-05-08
摘要:目的轮廓是对图像目标的一种稀疏表达方式,从图像中提取出有效物体轮廓可以更好地完成后续的视觉认知任务,所以轮廓检测在计算机视觉领域具有较好的应用。本文考虑到初级视通路中视觉信息传递和处理流程中的特点,提出了一种基于初级视通路计算模型的轮廓检测方法。方法在视网膜神经节环节,提出一种体现方向选择特性的经典感受野(CRF)改进模型,利用多尺度特征融合策略来模拟视网膜神经节细胞对图像目标的初级轮廓响应;在视网膜神经节到神经节-外膝体(LGN)的视通路中,提出一种反映视觉信息时空尺度特征的时空编码机制,模拟神经节-外膝体通路对初级轮廓响应的去冗余处理;利用非下采样轮廓波变换和Gabor变换协同作用,模拟非经典感受野(NCRF)的侧向抑制特性。最后利用初级视皮层对整体轮廓的前馈机制,实现对轮廓局部细节信息的完整性融合。结果选择将RuG40图库的所有图像作为测试集合进行模型性能测试,对检测结果进行非极大值抑制和阈值处理,最终将得到的二值轮廓图与基准图比较,整个数据集和单张图的最优平均P指标分别为0.49和0.56。对于单个图像最优参数条件下的检测结果均值,将本文方法与非经典感受野抑制模型(ISO)和多特征外周抑制模型(MCI)比较,较两者分别提高了19.1%和7.7%。结果表明本文方法能有效突出主体轮廓并抑制纹理背景。结论面向图像处理应用的初级视通路计算模型,将为后续图像理解和分析提供一种新的思路。关键词:轮廓检测;视觉机制;多尺度特征融合;侧向抑制性质;时空编码19|10|0更新时间:2024-05-08
图像理解和计算机视觉
-
 摘要:目的对于大数据挖掘,可视分析是一种非常重要的研究手段,有助于快速、直观地理解分析大数据蕴含的价值信息。但因其海量、时空、高维等特征,大数据可视化存在内存消耗大、渲染延迟高、可视效果差等问题。针对上述问题,以海量时空点数据为例,采用预处理可视化方案,设计并实现了一套高可扩展的分布式可视分析框架。 方法借鉴瓦片金字塔模型提出一种多维度聚合金字塔模型(MAP),将瓦片金字塔的2D空间层级聚合扩展到时间/空间/属性多维度,同时支持时间、空间、属性的多维层级聚合。进而以Spark集群作为并行预处理工具,以HBase分布式数据库持久化存储MAP模型数据,实现了一套开源的分布式可视化框架(MAP-Vis)。 结果以纽约出租车数据集为例,本研究实验证明能够支持时间/空间/属性多尺度、多维度联动的交互式可视化,同时具有高可扩展的预处理能力和存储能力。结论 在分布式处理能力支持下,系统能实现亚秒级的查询响应,达到良好的交互式可视化效果,证明MAP-Vis是一种有效的大数据交互式可视化方案。关键词:大数据;多维;层级聚合;分布式数据库;可视分析25|12|0更新时间:2024-05-08
摘要:目的对于大数据挖掘,可视分析是一种非常重要的研究手段,有助于快速、直观地理解分析大数据蕴含的价值信息。但因其海量、时空、高维等特征,大数据可视化存在内存消耗大、渲染延迟高、可视效果差等问题。针对上述问题,以海量时空点数据为例,采用预处理可视化方案,设计并实现了一套高可扩展的分布式可视分析框架。 方法借鉴瓦片金字塔模型提出一种多维度聚合金字塔模型(MAP),将瓦片金字塔的2D空间层级聚合扩展到时间/空间/属性多维度,同时支持时间、空间、属性的多维层级聚合。进而以Spark集群作为并行预处理工具,以HBase分布式数据库持久化存储MAP模型数据,实现了一套开源的分布式可视化框架(MAP-Vis)。 结果以纽约出租车数据集为例,本研究实验证明能够支持时间/空间/属性多尺度、多维度联动的交互式可视化,同时具有高可扩展的预处理能力和存储能力。结论 在分布式处理能力支持下,系统能实现亚秒级的查询响应,达到良好的交互式可视化效果,证明MAP-Vis是一种有效的大数据交互式可视化方案。关键词:大数据;多维;层级聚合;分布式数据库;可视分析25|12|0更新时间:2024-05-08
计算机图形学
-
 摘要:目的医学图像的像素级标注工作需要耗费大量的人力。针对这一问题,本文以医学图像中典型的眼底图像视盘分割为例,提出了一种带尺寸约束的弱监督眼底图像视盘分割算法。方法对传统卷积神经网络框架进行改进,根据视盘的结构特点设计新的卷积融合层,能够更好地提升分割性能。为了进一步提高视盘分割精度,本文对卷积神经网络的输出进行了尺寸约束,同时用一种新的损失函数对尺寸约束进行优化,所提的损失公式可以用标准随机梯度下降方法来优化。结果在RIM-ONE视盘数据集上展开实验,并与经典的全监督视盘分割方法进行比较。实验结果表明,本文算法在只使用图像级标签的情况下,平均准确识别率(mAcc)、平均精度(mPre)和平均交并比(mIoU)分别能达到0.852、0.831、0.827。结论本文算法不需要专家进行像素级标注就能够实现视盘的准确分割,只使用图像级标注就能够得到像素级标注的分割精度。缓解了医学图像中像素级标注难度大的问题。关键词:弱监督学习;视盘分割;尺寸约束;卷积神经网络;眼底图像21|10|0更新时间:2024-05-08
摘要:目的医学图像的像素级标注工作需要耗费大量的人力。针对这一问题,本文以医学图像中典型的眼底图像视盘分割为例,提出了一种带尺寸约束的弱监督眼底图像视盘分割算法。方法对传统卷积神经网络框架进行改进,根据视盘的结构特点设计新的卷积融合层,能够更好地提升分割性能。为了进一步提高视盘分割精度,本文对卷积神经网络的输出进行了尺寸约束,同时用一种新的损失函数对尺寸约束进行优化,所提的损失公式可以用标准随机梯度下降方法来优化。结果在RIM-ONE视盘数据集上展开实验,并与经典的全监督视盘分割方法进行比较。实验结果表明,本文算法在只使用图像级标签的情况下,平均准确识别率(mAcc)、平均精度(mPre)和平均交并比(mIoU)分别能达到0.852、0.831、0.827。结论本文算法不需要专家进行像素级标注就能够实现视盘的准确分割,只使用图像级标注就能够得到像素级标注的分割精度。缓解了医学图像中像素级标注难度大的问题。关键词:弱监督学习;视盘分割;尺寸约束;卷积神经网络;眼底图像21|10|0更新时间:2024-05-08
医学图像处理
-
 摘要:目的云覆盖着地球上空大部分区域,在地球水循环、地气系统能量平衡和辐射传输过程中有着重要的作用,同时云也是天气气候中最重要、最活跃的因子之一;此外,云覆盖地表信息,导致影像配准、融合等处理过程的很多问题,所以云检测十分重要。方法基于2015年发射的深空气候观测台(DSCOVR)卫星搭载的地球彩色成像相机(EPIC)数据,针对EPIC数据波段范围较广和影像数据是半球尺度的特点,以云指数法作为基础,提出一种新的面向半球尺度数据的云检测方法。首先,分析EPIC数据各个波段的波段特征,尤其是紫光波段,然后根据云在不同波段的反射特性,以指数的形式完成波段组合进行云检测,再与SVM(support vector machine)云检测法和可见光云检测法进行比较,最后利用EPIC L2产品对所获得的云分布图和统计云量值进行结果验证,以正确率、漏检率、误检率和Kappa系数作为参考标准完成精度评定。结果实际EPIC夏季(2017年7月)和冬季(2017年1月)数据的实验结果表明,本文方法的正确率均高于91%,Kappa系数大于0.9;其他方法的正确率均低于89%,且Kappa系数在0.8左右,均小于0.9。所以本文能够有效地检测到薄云(即使在冬季),且云量和云的分布都最为接近实际。结论在EPIC影像的云检测过程中,本文方法从云分布图和云量结果两个方面都优于可见光云检测法和SVM云检测法,经EPIC L2产品验证,本文方法有效、可靠,且能够快速获得半球范围内云的分布情况,有助于对全球云的动态研究和自然天气预测。关键词:半球尺度;DISCOVR EPIC;云检测;云指数法;云量;云分布16|10|0更新时间:2024-05-08
摘要:目的云覆盖着地球上空大部分区域,在地球水循环、地气系统能量平衡和辐射传输过程中有着重要的作用,同时云也是天气气候中最重要、最活跃的因子之一;此外,云覆盖地表信息,导致影像配准、融合等处理过程的很多问题,所以云检测十分重要。方法基于2015年发射的深空气候观测台(DSCOVR)卫星搭载的地球彩色成像相机(EPIC)数据,针对EPIC数据波段范围较广和影像数据是半球尺度的特点,以云指数法作为基础,提出一种新的面向半球尺度数据的云检测方法。首先,分析EPIC数据各个波段的波段特征,尤其是紫光波段,然后根据云在不同波段的反射特性,以指数的形式完成波段组合进行云检测,再与SVM(support vector machine)云检测法和可见光云检测法进行比较,最后利用EPIC L2产品对所获得的云分布图和统计云量值进行结果验证,以正确率、漏检率、误检率和Kappa系数作为参考标准完成精度评定。结果实际EPIC夏季(2017年7月)和冬季(2017年1月)数据的实验结果表明,本文方法的正确率均高于91%,Kappa系数大于0.9;其他方法的正确率均低于89%,且Kappa系数在0.8左右,均小于0.9。所以本文能够有效地检测到薄云(即使在冬季),且云量和云的分布都最为接近实际。结论在EPIC影像的云检测过程中,本文方法从云分布图和云量结果两个方面都优于可见光云检测法和SVM云检测法,经EPIC L2产品验证,本文方法有效、可靠,且能够快速获得半球范围内云的分布情况,有助于对全球云的动态研究和自然天气预测。关键词:半球尺度;DISCOVR EPIC;云检测;云指数法;云量;云分布16|10|0更新时间:2024-05-08
遥感图像处理
其他
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0