
最新刊期
2019 年 第 24 卷 第 4 期
-
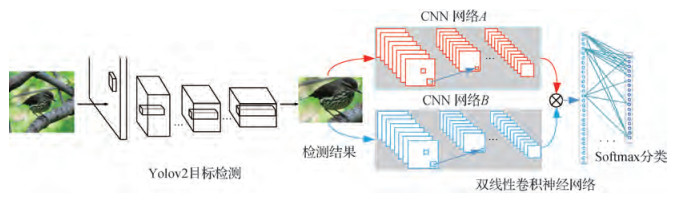 摘要:目的细粒度图像分类是指对一个大类别进行更细致的子类划分,如区分鸟的种类、车的品牌款式、狗的品种等。针对细粒度图像分类中的无关信息太多和背景干扰问题,本文利用深度卷积网络构建了细粒度图像聚焦—识别的联合学习框架,通过去除背景、突出待识别目标、自动定位有区分度的区域,从而提高细粒度图像分类识别率。方法首先基于Yolov2(youonly look once v2)的网络快速检测出目标物体,消除背景干扰和无关信息对分类结果的影响,实现聚焦判别性区域,之后将检测到的物体(即Yolov2的输出)输入双线性卷积神经网络进行训练和分类。此网络框架可以实现端到端的训练,且只依赖于类别标注信息,而无需借助其他的人工标注信息。结果在细粒度图像库CUB-200-2011、Cars196和Aircrafts100上进行实验验证,本文模型的分类精度分别达到84.5%、92%和88.4%,与同类型分类算法得到的最高分类精度相比,准确度分别提升了0.4%、0.7%和3.9%,比使用两个相同D(dence)-Net网络的方法分别高出0.5%、1.4%和4.5%。结论使用聚焦—识别深度学习框架提取有区分度的区域对细粒度图像分类有积极作用,能够滤除大部分对细粒度图像分类没有贡献的区域,使得网络能够学习到更多有利于细粒度图像分类的特征,从而降低背景干扰对分类结果的影响,提高模型的识别率。关键词:细粒度图像分类;目标检测;双线性卷积神经网络;聚焦—识别框架;区分度59|81|4更新时间:2024-05-07
摘要:目的细粒度图像分类是指对一个大类别进行更细致的子类划分,如区分鸟的种类、车的品牌款式、狗的品种等。针对细粒度图像分类中的无关信息太多和背景干扰问题,本文利用深度卷积网络构建了细粒度图像聚焦—识别的联合学习框架,通过去除背景、突出待识别目标、自动定位有区分度的区域,从而提高细粒度图像分类识别率。方法首先基于Yolov2(youonly look once v2)的网络快速检测出目标物体,消除背景干扰和无关信息对分类结果的影响,实现聚焦判别性区域,之后将检测到的物体(即Yolov2的输出)输入双线性卷积神经网络进行训练和分类。此网络框架可以实现端到端的训练,且只依赖于类别标注信息,而无需借助其他的人工标注信息。结果在细粒度图像库CUB-200-2011、Cars196和Aircrafts100上进行实验验证,本文模型的分类精度分别达到84.5%、92%和88.4%,与同类型分类算法得到的最高分类精度相比,准确度分别提升了0.4%、0.7%和3.9%,比使用两个相同D(dence)-Net网络的方法分别高出0.5%、1.4%和4.5%。结论使用聚焦—识别深度学习框架提取有区分度的区域对细粒度图像分类有积极作用,能够滤除大部分对细粒度图像分类没有贡献的区域,使得网络能够学习到更多有利于细粒度图像分类的特征,从而降低背景干扰对分类结果的影响,提高模型的识别率。关键词:细粒度图像分类;目标检测;双线性卷积神经网络;聚焦—识别框架;区分度59|81|4更新时间:2024-05-07 -
 摘要:目的传统的稀疏表示分类方法运用高维数据提升算法的稀疏分类能力,早已引起了广泛关注,但其忽视了测试样本与训练样本间的信息冗余,导致了不确定性的决策分类问题。为此,本文提出一种基于卷积神经网络和PCA约束优化模型的稀疏表示分类方法(EPCNN-SRC)。方法首先通过深度卷积神经网络计算,在输出层提取对应的特征图像,用以表征原始样本的鲁棒人脸特征。然后在此特征基础上,构建一个PCA(principal component analysis)约束优化模型来线性表示测试样本,计算对应的PCA系数。最后使用稀疏表示分类算法重构测试样本与每类训练样本的PCA系数来完成分类。结果本文设计的分类模型与一些典型的稀疏分类方法相比,取得了更好的分类性能,在AR、FERET、FRGC和LFW人脸数据库上的实验结果显示,当每类仅有一个训练样本时,EPCNN-SRC算法的识别率分别达到96.92%、96.15%、86.94%和42.44%,均高于传统的表示分类方法,充分验证了本文算法的有效性。同时,本文方法不仅提升了对测试样本稀疏表示的鲁棒性,而且在保证识别率的基础上,有效降低了算法的时间复杂度,在FERET数据库上的运行时间为4.92 s,均低于一些传统方法的运行时间。结论基于卷积神经网络和PCA约束优化模型的稀疏表示分类方法,将深度学习特征与PCA方法相结合,不仅具有较好的识别准确度,而且对稀疏分类也具有很好的鲁棒性,尤其在小样本问题上优势显著。关键词:稀疏表示;卷积神经网络;特征降维;主成分约束优化;人脸识别38|125|0更新时间:2024-05-07
摘要:目的传统的稀疏表示分类方法运用高维数据提升算法的稀疏分类能力,早已引起了广泛关注,但其忽视了测试样本与训练样本间的信息冗余,导致了不确定性的决策分类问题。为此,本文提出一种基于卷积神经网络和PCA约束优化模型的稀疏表示分类方法(EPCNN-SRC)。方法首先通过深度卷积神经网络计算,在输出层提取对应的特征图像,用以表征原始样本的鲁棒人脸特征。然后在此特征基础上,构建一个PCA(principal component analysis)约束优化模型来线性表示测试样本,计算对应的PCA系数。最后使用稀疏表示分类算法重构测试样本与每类训练样本的PCA系数来完成分类。结果本文设计的分类模型与一些典型的稀疏分类方法相比,取得了更好的分类性能,在AR、FERET、FRGC和LFW人脸数据库上的实验结果显示,当每类仅有一个训练样本时,EPCNN-SRC算法的识别率分别达到96.92%、96.15%、86.94%和42.44%,均高于传统的表示分类方法,充分验证了本文算法的有效性。同时,本文方法不仅提升了对测试样本稀疏表示的鲁棒性,而且在保证识别率的基础上,有效降低了算法的时间复杂度,在FERET数据库上的运行时间为4.92 s,均低于一些传统方法的运行时间。结论基于卷积神经网络和PCA约束优化模型的稀疏表示分类方法,将深度学习特征与PCA方法相结合,不仅具有较好的识别准确度,而且对稀疏分类也具有很好的鲁棒性,尤其在小样本问题上优势显著。关键词:稀疏表示;卷积神经网络;特征降维;主成分约束优化;人脸识别38|125|0更新时间:2024-05-07 -
 摘要:目的由于摄像机视角和成像质量的差异,造成行人姿态变化、图像分辨率变化和光照变化等问题的出现,从而导致同一行人在不同监控视频中的外观区别很大,给行人再识别带来很大挑战。为提高行人再识别的识别率,针对行人姿态变化问题,提出一种区域块分割和融合的行人再识别算法。方法首先根据人体结构分布,将行人图像划分为3个局部区域。然后根据各区域在识别过程中的作用不同,将GOG(Gaussian of Gaussian)特征、LOMO(local maximal occurrence)特征和KCCA(Kernel canonical correlation analysis)特征的不同组合作为各区域特征。接着通过距离测度算法学习对应区域之间的相似度,并通过干扰块剔除算法消除图像中出现的无效干扰块,融合有效区域块的相似度。最后将行人图像对的全局相似度和各局部区域相似度进行融合,实现行人再识别。结果在4个基准数据集VIPeR、GRID、PRID450S和CUHK01上进行了大量实验,其中Rank1(排名第1的搜索结果即为待查询人的比例)分别为62.85%、30.56%、71.82%和79.03%,Rank5分别为86.17%、51.20%、91.16%和93.60%,识别率均有显著提高,具有实际应用价值。结论提出的区域块分割和融合方法,能够去除图像中的无用信息和干扰信息,同时保留行人的有效信息并高效利用。该方法在一定程度上能够解决行人姿态变化带来的外观差异问题,大幅度地提升识别率。关键词:行人再识别;人体结构信息;区域块分割;干扰块剔除;区域块融合20|49|2更新时间:2024-05-07
摘要:目的由于摄像机视角和成像质量的差异,造成行人姿态变化、图像分辨率变化和光照变化等问题的出现,从而导致同一行人在不同监控视频中的外观区别很大,给行人再识别带来很大挑战。为提高行人再识别的识别率,针对行人姿态变化问题,提出一种区域块分割和融合的行人再识别算法。方法首先根据人体结构分布,将行人图像划分为3个局部区域。然后根据各区域在识别过程中的作用不同,将GOG(Gaussian of Gaussian)特征、LOMO(local maximal occurrence)特征和KCCA(Kernel canonical correlation analysis)特征的不同组合作为各区域特征。接着通过距离测度算法学习对应区域之间的相似度,并通过干扰块剔除算法消除图像中出现的无效干扰块,融合有效区域块的相似度。最后将行人图像对的全局相似度和各局部区域相似度进行融合,实现行人再识别。结果在4个基准数据集VIPeR、GRID、PRID450S和CUHK01上进行了大量实验,其中Rank1(排名第1的搜索结果即为待查询人的比例)分别为62.85%、30.56%、71.82%和79.03%,Rank5分别为86.17%、51.20%、91.16%和93.60%,识别率均有显著提高,具有实际应用价值。结论提出的区域块分割和融合方法,能够去除图像中的无用信息和干扰信息,同时保留行人的有效信息并高效利用。该方法在一定程度上能够解决行人姿态变化带来的外观差异问题,大幅度地提升识别率。关键词:行人再识别;人体结构信息;区域块分割;干扰块剔除;区域块融合20|49|2更新时间:2024-05-07 -
 摘要:目的头肩检测由于抗遮挡能力强、计算需求低,常用于复杂场景中的人体检测。针对嵌入式头肩检测中常用的运动检测和手工模型匹配方法检测精度较低、对不同姿态和人体外观适应性较差的问题,提出了使用聚合通道特征的嵌入式实时人体头肩检测方法。方法首先分析多种行人检测与人体姿态数据集,从中生成多姿态、多视角的人体头肩样本集;然后基于图像的聚合通道特征,使用AdaBoost算法通过多个阶段的训练,得到基于增强决策树的头肩图像分类器;接下来,在快速特征金字塔算法的基础上,针对ARM-Linux平台,利用多核并行和单指令多数据流技术,加速图像特征金字塔的计算;最后,进行多线程的滑动窗口检测,利用头肩图像分类器识别每个检测窗口,并通过非极大值抑制(NMS)算法优化检测结果。结果重新标注了INRIA验证数据集中的头肩样本,采用本文训练得到的头肩图像分类器进行检测,通过样本漏检率、每图片平均误检率以及ROC(receiver operating characteristic)曲线评估检测效果。对INRIA数据集中高度≥50像素的头肩目标的对数平均漏检率为16.61%。此外,采集了不同场景中多种姿态、视角下的头肩图像,以验证分类器的适应性,结果表明该分类器能够良好检测多姿态、多视角、受遮挡以及不同光照情况下的头肩目标。但由于检测器感受野局限于头肩区域,对少量疑似头肩样本的图像区域存在误检测。在嵌入式平台(树莓派3B)中,经过优化的头肩检测程序,对640×480像素分辨率的图像,特征计算耗时约213 ms;对单个包含正样本的检测窗口,分类耗时约2 ms。整体检测效率能够满足视频流实时检测的需求。结论本文基于聚合通道特征进行人体头肩检测,采用种类丰富、标注准确的头肩训练样本,使用AdaBoost算法学习头肩图像的聚合通道特征,得到的头肩图像分类器适应性强,硬件性能要求低,能够良好检测多视角、多姿态的人体头肩图像,并具备在嵌入式平台上实时检测视频流的能力,应用场景广泛。关键词:行人检测;头肩检测;嵌入式;聚合通道特征;AdaBoost;机器学习27|56|0更新时间:2024-05-07
摘要:目的头肩检测由于抗遮挡能力强、计算需求低,常用于复杂场景中的人体检测。针对嵌入式头肩检测中常用的运动检测和手工模型匹配方法检测精度较低、对不同姿态和人体外观适应性较差的问题,提出了使用聚合通道特征的嵌入式实时人体头肩检测方法。方法首先分析多种行人检测与人体姿态数据集,从中生成多姿态、多视角的人体头肩样本集;然后基于图像的聚合通道特征,使用AdaBoost算法通过多个阶段的训练,得到基于增强决策树的头肩图像分类器;接下来,在快速特征金字塔算法的基础上,针对ARM-Linux平台,利用多核并行和单指令多数据流技术,加速图像特征金字塔的计算;最后,进行多线程的滑动窗口检测,利用头肩图像分类器识别每个检测窗口,并通过非极大值抑制(NMS)算法优化检测结果。结果重新标注了INRIA验证数据集中的头肩样本,采用本文训练得到的头肩图像分类器进行检测,通过样本漏检率、每图片平均误检率以及ROC(receiver operating characteristic)曲线评估检测效果。对INRIA数据集中高度≥50像素的头肩目标的对数平均漏检率为16.61%。此外,采集了不同场景中多种姿态、视角下的头肩图像,以验证分类器的适应性,结果表明该分类器能够良好检测多姿态、多视角、受遮挡以及不同光照情况下的头肩目标。但由于检测器感受野局限于头肩区域,对少量疑似头肩样本的图像区域存在误检测。在嵌入式平台(树莓派3B)中,经过优化的头肩检测程序,对640×480像素分辨率的图像,特征计算耗时约213 ms;对单个包含正样本的检测窗口,分类耗时约2 ms。整体检测效率能够满足视频流实时检测的需求。结论本文基于聚合通道特征进行人体头肩检测,采用种类丰富、标注准确的头肩训练样本,使用AdaBoost算法学习头肩图像的聚合通道特征,得到的头肩图像分类器适应性强,硬件性能要求低,能够良好检测多视角、多姿态的人体头肩图像,并具备在嵌入式平台上实时检测视频流的能力,应用场景广泛。关键词:行人检测;头肩检测;嵌入式;聚合通道特征;AdaBoost;机器学习27|56|0更新时间:2024-05-07 -
 摘要:目的传统的相关滤波跟踪算法采用对跟踪目标(唯一准确正样本)循环移位获取负样本,在整个学习过程中没有对真正的背景信息进行建模,因此当目标与背景信息极其相似时容易漂移。大多数跟踪算法为了提高跟踪性能,在时间序列上收集了大量的训练样本而导致计算复杂度的增加。采用模型在线更新策略,由于未考虑时间一致性,使得学习到的滤波器可能偏向背景而发生漂移。为了改善以上问题,本文在背景感知相关滤波(BACF)跟踪算法的基础上,加入时间感知,构建了一个带等式限制的相关滤波目标函数,称为背景与时间感知相关滤波(BTCF)视觉跟踪。该算法不但获取了真正的负样本作为训练集,而且仅用当前帧信息无需模型在线更新策略就能学习到具有较强判别力的相关滤波器。方法首先将带等式限制的相关滤波目标函数转化为无约束的增广拉格朗日乘子公式,然后采用交替方向乘子方法(ADMM)转化为两个具有闭式解的子问题迭代求最优解。结果采用OTB2015数据库中的OPE(one pass evaluation)评价准则,以成功率曲线图线下面积(AUC)和中心点位置误差为评判标准,在OTB2015公开数据库上与10个比较优秀的视觉跟踪算法进行对比实验。结果显示,100个视频序列和11个视频属性的成功率及对应的AUC和中心位置误差均明显优于其他基于相关滤波的视觉跟踪算法,说明本文算法具有良好的跟踪效果。本文的BTCF算法仅采用HOG纯手工特征,在OTB2015数据库上AUC较BACF算法提高了1.3%;由于颜色与边缘特征具有互补特性,本文融合CN(color names)特征后,在OTB2015数据库上,AUC较BACF算法提高了4.2%,采用纯手工特征跟踪性能AUC达到0.663,跟踪速度达到25.4帧/
摘要:目的传统的相关滤波跟踪算法采用对跟踪目标(唯一准确正样本)循环移位获取负样本,在整个学习过程中没有对真正的背景信息进行建模,因此当目标与背景信息极其相似时容易漂移。大多数跟踪算法为了提高跟踪性能,在时间序列上收集了大量的训练样本而导致计算复杂度的增加。采用模型在线更新策略,由于未考虑时间一致性,使得学习到的滤波器可能偏向背景而发生漂移。为了改善以上问题,本文在背景感知相关滤波(BACF)跟踪算法的基础上,加入时间感知,构建了一个带等式限制的相关滤波目标函数,称为背景与时间感知相关滤波(BTCF)视觉跟踪。该算法不但获取了真正的负样本作为训练集,而且仅用当前帧信息无需模型在线更新策略就能学习到具有较强判别力的相关滤波器。方法首先将带等式限制的相关滤波目标函数转化为无约束的增广拉格朗日乘子公式,然后采用交替方向乘子方法(ADMM)转化为两个具有闭式解的子问题迭代求最优解。结果采用OTB2015数据库中的OPE(one pass evaluation)评价准则,以成功率曲线图线下面积(AUC)和中心点位置误差为评判标准,在OTB2015公开数据库上与10个比较优秀的视觉跟踪算法进行对比实验。结果显示,100个视频序列和11个视频属性的成功率及对应的AUC和中心位置误差均明显优于其他基于相关滤波的视觉跟踪算法,说明本文算法具有良好的跟踪效果。本文的BTCF算法仅采用HOG纯手工特征,在OTB2015数据库上AUC较BACF算法提高了1.3%;由于颜色与边缘特征具有互补特性,本文融合CN(color names)特征后,在OTB2015数据库上,AUC较BACF算法提高了4.2%,采用纯手工特征跟踪性能AUC达到0.663,跟踪速度达到25.4帧/${\rm{s}}$ 关键词:视觉跟踪;相关滤波;背景感知;时间感知;正则化;交替方向乘子法17|6|7更新时间:2024-05-07 -
 摘要:目的水泥厂作为重要的污染源企业需要对其进行统计和监管,近几年随着卫星遥感技术的发展和遥感影像分辨率的提高,使得基于卫星影像进行水泥厂目标检测成为可能。但是由于遥感图像中建筑目标的环境复杂多变,同时各个水泥厂在生产规模、设备构成、厂区结构、坐落方位上存在较大差异,图像表观上的形态各异和复杂环境干扰使得传统图像识别方法难以设计和提取有效特征。鉴于深度学习在视觉目标检测领域的成功应用,本文将研究应用深度卷积神经网络方法,实现在卫星图像上识别与定位水泥厂目标,为环保部门提供一种高效便捷的水泥厂目标检测和统计方法。方法基于面向目标检测与定位的Faster R-CNN深度学习框架,以准确检测与定位水泥厂区域为目的,以京津冀地区的水泥厂位置作为训练和测试数据集,选用3种结构不同的提取特征卷积神经网络模型进行了对比实验。并针对小样本训练容易出现的过拟合和误检问题,采用图像去雾预处理、数据扩充、引入负样本等技术进一步提升模型能力。结果测试集实验结果表明ResNet特征提取网络效果最好,准确率达到74%。为了进一步提高检出率并降低误检率,引入3种模型能力提升方法,在扩充检测数据集中的检出率达到94%,误检率降低到14%;在全球水泥厂数据集中的图像检出率达到96%,万幅随机图像的误检数量为30幅(0.3%)。对上海地区的卫星图像进行扫描检测,结果检测出11个已登记的水泥厂(共登记16个),另外还检测出17个未登记的水泥厂。结论对于卫星地图上水泥厂这种具有特殊建筑构造但也存在厂区几何形状各异、所处地理环境复杂、随季节性变化等特点,本文提出的基于深度卷积网络的卫星图像水泥厂检测方法,能够自动学习提取有效的图像特征并对目标进行准确检测。针对小样本训练问题,引入3种方法显著提高了模型的检测精度。在模型泛化能力测试中,经过优化后的模型在水泥厂建筑目标检测任务中表现良好,具有重要的应用价值。关键词:高分辨率卫星图像;目标检测;卷积神经网络;深度学习;模型优化25|4|4更新时间:2024-05-07
摘要:目的水泥厂作为重要的污染源企业需要对其进行统计和监管,近几年随着卫星遥感技术的发展和遥感影像分辨率的提高,使得基于卫星影像进行水泥厂目标检测成为可能。但是由于遥感图像中建筑目标的环境复杂多变,同时各个水泥厂在生产规模、设备构成、厂区结构、坐落方位上存在较大差异,图像表观上的形态各异和复杂环境干扰使得传统图像识别方法难以设计和提取有效特征。鉴于深度学习在视觉目标检测领域的成功应用,本文将研究应用深度卷积神经网络方法,实现在卫星图像上识别与定位水泥厂目标,为环保部门提供一种高效便捷的水泥厂目标检测和统计方法。方法基于面向目标检测与定位的Faster R-CNN深度学习框架,以准确检测与定位水泥厂区域为目的,以京津冀地区的水泥厂位置作为训练和测试数据集,选用3种结构不同的提取特征卷积神经网络模型进行了对比实验。并针对小样本训练容易出现的过拟合和误检问题,采用图像去雾预处理、数据扩充、引入负样本等技术进一步提升模型能力。结果测试集实验结果表明ResNet特征提取网络效果最好,准确率达到74%。为了进一步提高检出率并降低误检率,引入3种模型能力提升方法,在扩充检测数据集中的检出率达到94%,误检率降低到14%;在全球水泥厂数据集中的图像检出率达到96%,万幅随机图像的误检数量为30幅(0.3%)。对上海地区的卫星图像进行扫描检测,结果检测出11个已登记的水泥厂(共登记16个),另外还检测出17个未登记的水泥厂。结论对于卫星地图上水泥厂这种具有特殊建筑构造但也存在厂区几何形状各异、所处地理环境复杂、随季节性变化等特点,本文提出的基于深度卷积网络的卫星图像水泥厂检测方法,能够自动学习提取有效的图像特征并对目标进行准确检测。针对小样本训练问题,引入3种方法显著提高了模型的检测精度。在模型泛化能力测试中,经过优化后的模型在水泥厂建筑目标检测任务中表现良好,具有重要的应用价值。关键词:高分辨率卫星图像;目标检测;卷积神经网络;深度学习;模型优化25|4|4更新时间:2024-05-07 -
 摘要:目的少数民族服装色彩及样式种类繁多等因素导致少数民族服装图像识别率较低。以云南少数民族服装为例,提出一种结合人体检测和多任务学习的少数民族服装识别方法。方法首先通过
摘要:目的少数民族服装色彩及样式种类繁多等因素导致少数民族服装图像识别率较低。以云南少数民族服装为例,提出一种结合人体检测和多任务学习的少数民族服装识别方法。方法首先通过$k$ 关键词:少数民族服装;图像识别;人体检测;语义属性;多任务学习13|4|8更新时间:2024-05-07 -
 摘要:目的便捷的商品检索是用户网络购物体验良好的关键环节。由于电商对商品描述方式的规范性要求以及用户对商品属性理解差异等问题,基于关键词的检索方法在商品检索的应用并不理想。近年来,以图搜图的检索方式在各大电商平台上得到越来越多的应用,但检索结果往往不尽如人意。为此,提出了一种新的检索思路,从商品外观设计特征出发,将人们对商品的认知模式引入到商品图片的检索过程,从而获得更符合人们预期的检索结果。方法以时尚女包商品为例,在分析设计师的设计规范的基础上,将外观设计特征分解为形状特征、颜色特征和设计元素特征。利用深度卷积神经网络建模、提取特征,并使用哈希方法和Top3类内检索算法加快检索速度。结果利用建立的商品数据集构建3个对应的特征模型,并进行分类识别和图像检索实验。结果表明,各个模型Top1的识别准确率均小于95%,而Top3的识别准确率均在98.5%以上;商品检索速度加快了将近3.5倍。实验及用户调查结果表明,本文提出的检索方法与淘宝、百度图片等基于图像的检索工具相比,检索结果更为多样,与原图像相似度更高。结论本文提出的从商品外观设计规范出发、与人的认知模式相结合的商品检索方法,更能满足用户的检索意图,可用于时尚女包商品检索,对基于图像的其他商品的检索方法的研究具有借鉴意义。关键词:认知;设计规范;网络购物;图像检索;深度卷积神经网络;哈希方法13|4|0更新时间:2024-05-07
摘要:目的便捷的商品检索是用户网络购物体验良好的关键环节。由于电商对商品描述方式的规范性要求以及用户对商品属性理解差异等问题,基于关键词的检索方法在商品检索的应用并不理想。近年来,以图搜图的检索方式在各大电商平台上得到越来越多的应用,但检索结果往往不尽如人意。为此,提出了一种新的检索思路,从商品外观设计特征出发,将人们对商品的认知模式引入到商品图片的检索过程,从而获得更符合人们预期的检索结果。方法以时尚女包商品为例,在分析设计师的设计规范的基础上,将外观设计特征分解为形状特征、颜色特征和设计元素特征。利用深度卷积神经网络建模、提取特征,并使用哈希方法和Top3类内检索算法加快检索速度。结果利用建立的商品数据集构建3个对应的特征模型,并进行分类识别和图像检索实验。结果表明,各个模型Top1的识别准确率均小于95%,而Top3的识别准确率均在98.5%以上;商品检索速度加快了将近3.5倍。实验及用户调查结果表明,本文提出的检索方法与淘宝、百度图片等基于图像的检索工具相比,检索结果更为多样,与原图像相似度更高。结论本文提出的从商品外观设计规范出发、与人的认知模式相结合的商品检索方法,更能满足用户的检索意图,可用于时尚女包商品检索,对基于图像的其他商品的检索方法的研究具有借鉴意义。关键词:认知;设计规范;网络购物;图像检索;深度卷积神经网络;哈希方法13|4|0更新时间:2024-05-07 -
 摘要:目的随着自动驾驶技术不断引入生活,机器视觉中道路场景分割算法的研究已至关重要。传统方法中大多数研究者使用机器学习方法对阈值分割,而近年来深度学习的引入,使得卷积神经网络被广泛应用于该领域。方法针对传统阈值分割方法难以有效提取多场景下道路图像阈值的问题和直接用深度神经网络来训练数据导致过分割严重的问题,本文提出了结合KSW(key seat wiper)和全卷积神经网络(FCNN)的道路场景分割方法,该方法结合了KSW熵法及遗传算法,利用深度学习在不同场景下的特征提取,并将其运用到无人驾驶技术的道路分割中。首先对道路场景测试集利用KSW熵法及遗传算法得到训练集,然后导入到全卷积神经网络中进行训练得到有效训练模型,最后通过训练模型实现对任意一幅道路场景图分割。结果实验结果表明,在KITTI数据集中进行测试,天空和树木的分割精度分别达到91.3%和94.3%,道路、车辆、行人的分割精度提高了2%左右。从分割结果中明显看出,道路图像中的积水、泥潭、树木等信息存在的过分割现象有良好的改观。结论相比传统机器学习道路场景分割方法,本文方法在一定程度上提高了分割精度。对比深度学习直接应用于道路场景分割的方法,本文方法在一定程度上避免了过分割现象,提高了模型的鲁棒性。综上所述,本文提出的结合KSW和FCNN的道路场景分割算法有广泛的研究前景,有望应用于医学图像和遥感图像的处理中。关键词:图像分割;道路分割;全卷积神经网络;深度学习;遗传算法30|39|1更新时间:2024-05-07
摘要:目的随着自动驾驶技术不断引入生活,机器视觉中道路场景分割算法的研究已至关重要。传统方法中大多数研究者使用机器学习方法对阈值分割,而近年来深度学习的引入,使得卷积神经网络被广泛应用于该领域。方法针对传统阈值分割方法难以有效提取多场景下道路图像阈值的问题和直接用深度神经网络来训练数据导致过分割严重的问题,本文提出了结合KSW(key seat wiper)和全卷积神经网络(FCNN)的道路场景分割方法,该方法结合了KSW熵法及遗传算法,利用深度学习在不同场景下的特征提取,并将其运用到无人驾驶技术的道路分割中。首先对道路场景测试集利用KSW熵法及遗传算法得到训练集,然后导入到全卷积神经网络中进行训练得到有效训练模型,最后通过训练模型实现对任意一幅道路场景图分割。结果实验结果表明,在KITTI数据集中进行测试,天空和树木的分割精度分别达到91.3%和94.3%,道路、车辆、行人的分割精度提高了2%左右。从分割结果中明显看出,道路图像中的积水、泥潭、树木等信息存在的过分割现象有良好的改观。结论相比传统机器学习道路场景分割方法,本文方法在一定程度上提高了分割精度。对比深度学习直接应用于道路场景分割的方法,本文方法在一定程度上避免了过分割现象,提高了模型的鲁棒性。综上所述,本文提出的结合KSW和FCNN的道路场景分割算法有广泛的研究前景,有望应用于医学图像和遥感图像的处理中。关键词:图像分割;道路分割;全卷积神经网络;深度学习;遗传算法30|39|1更新时间:2024-05-07
图像分析和识别

-
 摘要:目的近年来关于人脸老化/去龄化的研究在深度学习的推动下取得了飞速发展,2017年提出的条件对抗自编码器(CAAE)人脸老化/去龄化模型生成的人脸不仅可信度高,而且更贴近目标年龄。然而在人脸老化/去龄化过程中仍存在生成图像分辨率低、人工鬼影噪声严重(生成人脸器官扭曲)等问题。为此,在CAAE的基础上,提出一个人脸老化/去龄化的高质量图像生成模型(HQGM)。方法用边界平衡对抗生成网络(BEGAN)替换CAAE中的对抗生成网络(GAN)。BEGAN在人脸图像生成上不仅分辨率更高而且具有更好的视觉效果。在此基础上,添加两个提高生成图像质量的损失函数:图像梯度差损失函数和人脸特征损失函数。图像梯度差损失函数通过缩小生成图像和真实图像的图像梯度,使生成图像具有更多轮廓等高频信息;人脸特征损失函数将生成图像和真实图像分别输入到配置预训练参数的VGG-FACE网络模型中,输出各自的特征图。通过缩小两幅特征图的对应点差值,使生成图像具有更多真实图像的人脸特征信息。结果实验使用UTKface、FGnet和Morph数据集,经过训练,每幅测试图像分别生成10幅不同年龄的图像。与CAAE相比,HQGM可以有效去除人工鬼影噪声,峰值信噪比高3.2 dB,结构相似性高0.06,提升显著。结论HQGM可以生成具有丰富纹理信息和人脸特征信息的人脸老化/去龄化图像。关键词:人脸老化/去龄化;深度学习;边界平衡对抗生成网络;人脸特征;纹理;VGG-FACE网络27|202|4更新时间:2024-05-07
摘要:目的近年来关于人脸老化/去龄化的研究在深度学习的推动下取得了飞速发展,2017年提出的条件对抗自编码器(CAAE)人脸老化/去龄化模型生成的人脸不仅可信度高,而且更贴近目标年龄。然而在人脸老化/去龄化过程中仍存在生成图像分辨率低、人工鬼影噪声严重(生成人脸器官扭曲)等问题。为此,在CAAE的基础上,提出一个人脸老化/去龄化的高质量图像生成模型(HQGM)。方法用边界平衡对抗生成网络(BEGAN)替换CAAE中的对抗生成网络(GAN)。BEGAN在人脸图像生成上不仅分辨率更高而且具有更好的视觉效果。在此基础上,添加两个提高生成图像质量的损失函数:图像梯度差损失函数和人脸特征损失函数。图像梯度差损失函数通过缩小生成图像和真实图像的图像梯度,使生成图像具有更多轮廓等高频信息;人脸特征损失函数将生成图像和真实图像分别输入到配置预训练参数的VGG-FACE网络模型中,输出各自的特征图。通过缩小两幅特征图的对应点差值,使生成图像具有更多真实图像的人脸特征信息。结果实验使用UTKface、FGnet和Morph数据集,经过训练,每幅测试图像分别生成10幅不同年龄的图像。与CAAE相比,HQGM可以有效去除人工鬼影噪声,峰值信噪比高3.2 dB,结构相似性高0.06,提升显著。结论HQGM可以生成具有丰富纹理信息和人脸特征信息的人脸老化/去龄化图像。关键词:人脸老化/去龄化;深度学习;边界平衡对抗生成网络;人脸特征;纹理;VGG-FACE网络27|202|4更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的基于视觉的3维场景重建技术已在机器人导航、航拍地图构建和增强现实等领域得到广泛应用。不过,当相机出现较大运动时则会使得传统基于窄基线约束的3维重建方法无法正常工作。方法针对宽基线环境,提出了一种融合高层语义先验的3维场景重建算法。该方法在马尔可夫随机场(MRF)模型的基础上,结合超像素的外观、共线性、共面性和深度等多种特征对不同视角图像中各个超像素的3维位置和朝向进行推理,从而实现宽基线条件下的初始3维重建。与此同时,还以递归的方式利用高层语义先验对相似深度超像素实现合并,进而对场景深度和3维模型进行渐进式优化。结果实验结果表明,本文方法在多种不同的宽基线环境,尤其是相机运动较为剧烈的情况下,依然能够取得比传统方法更为稳定而精确的深度估计和3维场景重建效果。结论本文展示了在宽基线条件下如何将多元图像特征与基于三角化的几何特征相结合以构建出精确的3维场景模型。本文方法采用MRF模型对不同视角图像中超像素的3维位置和朝向进行同时推理,并结合高层语义先验对3维重建的过程提供指导。与此同时,还使用了一种递归式框架以实现场景深度的渐进式优化。实验结果表明,本文方法在不同的宽基线环境下均能够获得比传统方法更接近真实描述的3维场景模型。关键词:宽基线匹配;致密3维场景重建;高层语义先验;超像素合并;渐进式优化13|4|2更新时间:2024-05-07
摘要:目的基于视觉的3维场景重建技术已在机器人导航、航拍地图构建和增强现实等领域得到广泛应用。不过,当相机出现较大运动时则会使得传统基于窄基线约束的3维重建方法无法正常工作。方法针对宽基线环境,提出了一种融合高层语义先验的3维场景重建算法。该方法在马尔可夫随机场(MRF)模型的基础上,结合超像素的外观、共线性、共面性和深度等多种特征对不同视角图像中各个超像素的3维位置和朝向进行推理,从而实现宽基线条件下的初始3维重建。与此同时,还以递归的方式利用高层语义先验对相似深度超像素实现合并,进而对场景深度和3维模型进行渐进式优化。结果实验结果表明,本文方法在多种不同的宽基线环境,尤其是相机运动较为剧烈的情况下,依然能够取得比传统方法更为稳定而精确的深度估计和3维场景重建效果。结论本文展示了在宽基线条件下如何将多元图像特征与基于三角化的几何特征相结合以构建出精确的3维场景模型。本文方法采用MRF模型对不同视角图像中超像素的3维位置和朝向进行同时推理,并结合高层语义先验对3维重建的过程提供指导。与此同时,还使用了一种递归式框架以实现场景深度的渐进式优化。实验结果表明,本文方法在不同的宽基线环境下均能够获得比传统方法更接近真实描述的3维场景模型。关键词:宽基线匹配;致密3维场景重建;高层语义先验;超像素合并;渐进式优化13|4|2更新时间:2024-05-07 -
 摘要:目的为了使构造的曲线拥有传统Bézier曲线的良好性质,同时还具备形状可调性、逼近性、保形性以及实用性。方法首先在拟扩展切比雪夫空间的框架下,构造了一类具有全正性的拟三次三角Bernstein基函数,并给出了该基函数的性质;基于此基函数,构造了相应的拟三次三角Bézier曲线,分析了其曲线的性质,得到了生成曲线的割角算法以及C1,C2光滑拼接条件,同时还提出了一种估计曲线逼近控制多边形程度的三角Bernstein算子;接着在拟三次三角Bernstein基函数的基础上提出一种三角域上带3个指数参数的拟三次三角Bernstein-Bézier基,基于此基生成了一种三角域上的拟三次三角Bernstein-Bézier曲面,该曲面可以构建边界为椭圆弧、抛物线弧以及圆弧的曲面,此外,还提出一种实用的de-Casteljau-type算法,同时还给出了连接两个曲面的G1连续条件。结果实验表明,本文在拟扩展切比雪夫空间中构造的具有全正性的曲线曲面,能够灵活地进行形状调整,而且具有良好的逼近性以及适用性。结论本文在拟扩展切比雪夫空间的框架下构造了一类具有全正性的基函数,并以此基函数进行曲线曲面构造。实验表明本文构造的曲线具备传统三次Bézier曲线的所有优良性质,而且具有灵活的形状可调性。随着参数的增大,所生成的曲线能够更加逼近控制多边形,模拟控制多边形的行为。此外,本文在三角域上构造的曲面能够生成边界为椭圆弧的曲面。综上,本文提出的基函数满足几何工业的需要,是一种实用的方法。关键词:拟扩展切比雪夫空间;全正性;割角算法;三角域曲面;de-Casteljau-tpye算法13|4|1更新时间:2024-05-07
摘要:目的为了使构造的曲线拥有传统Bézier曲线的良好性质,同时还具备形状可调性、逼近性、保形性以及实用性。方法首先在拟扩展切比雪夫空间的框架下,构造了一类具有全正性的拟三次三角Bernstein基函数,并给出了该基函数的性质;基于此基函数,构造了相应的拟三次三角Bézier曲线,分析了其曲线的性质,得到了生成曲线的割角算法以及C1,C2光滑拼接条件,同时还提出了一种估计曲线逼近控制多边形程度的三角Bernstein算子;接着在拟三次三角Bernstein基函数的基础上提出一种三角域上带3个指数参数的拟三次三角Bernstein-Bézier基,基于此基生成了一种三角域上的拟三次三角Bernstein-Bézier曲面,该曲面可以构建边界为椭圆弧、抛物线弧以及圆弧的曲面,此外,还提出一种实用的de-Casteljau-type算法,同时还给出了连接两个曲面的G1连续条件。结果实验表明,本文在拟扩展切比雪夫空间中构造的具有全正性的曲线曲面,能够灵活地进行形状调整,而且具有良好的逼近性以及适用性。结论本文在拟扩展切比雪夫空间的框架下构造了一类具有全正性的基函数,并以此基函数进行曲线曲面构造。实验表明本文构造的曲线具备传统三次Bézier曲线的所有优良性质,而且具有灵活的形状可调性。随着参数的增大,所生成的曲线能够更加逼近控制多边形,模拟控制多边形的行为。此外,本文在三角域上构造的曲面能够生成边界为椭圆弧的曲面。综上,本文提出的基函数满足几何工业的需要,是一种实用的方法。关键词:拟扩展切比雪夫空间;全正性;割角算法;三角域曲面;de-Casteljau-tpye算法13|4|1更新时间:2024-05-07
计算机图形学
-
 摘要:目的高光谱图像波段数目巨大,导致在解译及分类过程中出现“维数灾难”的现象。针对该问题,在K-means聚类算法基础上,考虑各个波段对不同聚类的重要程度,同时顾及类间信息,提出一种基于熵加权K-means全局信息聚类的高光谱图像分类算法。方法首先,引入波段权重,用来刻画各个波段对不同聚类的重要程度,并定义熵信息测度表达该权重。其次,为避免局部最优聚类,引入类间距离测度实现全局最优聚类。最后,将上述两类测度引入K-means聚类目标函数,通过最小化目标函数得到最优分类结果。结果为了验证提出的高光谱图像分类方法的有效性,对Salinas高光谱图像和Pavia University高光谱图像标准图中的地物类别根据其光谱反射率差异程度进行合并,将合并后的标准图作为新的标准分类图。分别采用本文算法和传统K-means算法对Salinas高光谱图像和Pavia University高光谱图像进行实验,并定性、定量地评价和分析了实验结果。对于图像中合并后的地物类别,光谱反射率差异程度大,从视觉上看,本文算法较传统K-means算法有更好的分类结果;从分类精度看,本文算法的总精度分别为92.20%和82.96%,K-means算法的总精度分别为83.39%和67.06%,较K-means算法增长8.81%和15.9%。结论提出一种基于熵加权K-means全局信息聚类的高光谱图像分类算法,实验结果表明,本文算法对高光谱图像中具有不同光谱反射率差异程度的各类地物目标均能取得很好的分类结果。关键词:波段加权;信息熵;类间信息;K-means;高光谱图像;分类13|5|6更新时间:2024-05-07
摘要:目的高光谱图像波段数目巨大,导致在解译及分类过程中出现“维数灾难”的现象。针对该问题,在K-means聚类算法基础上,考虑各个波段对不同聚类的重要程度,同时顾及类间信息,提出一种基于熵加权K-means全局信息聚类的高光谱图像分类算法。方法首先,引入波段权重,用来刻画各个波段对不同聚类的重要程度,并定义熵信息测度表达该权重。其次,为避免局部最优聚类,引入类间距离测度实现全局最优聚类。最后,将上述两类测度引入K-means聚类目标函数,通过最小化目标函数得到最优分类结果。结果为了验证提出的高光谱图像分类方法的有效性,对Salinas高光谱图像和Pavia University高光谱图像标准图中的地物类别根据其光谱反射率差异程度进行合并,将合并后的标准图作为新的标准分类图。分别采用本文算法和传统K-means算法对Salinas高光谱图像和Pavia University高光谱图像进行实验,并定性、定量地评价和分析了实验结果。对于图像中合并后的地物类别,光谱反射率差异程度大,从视觉上看,本文算法较传统K-means算法有更好的分类结果;从分类精度看,本文算法的总精度分别为92.20%和82.96%,K-means算法的总精度分别为83.39%和67.06%,较K-means算法增长8.81%和15.9%。结论提出一种基于熵加权K-means全局信息聚类的高光谱图像分类算法,实验结果表明,本文算法对高光谱图像中具有不同光谱反射率差异程度的各类地物目标均能取得很好的分类结果。关键词:波段加权;信息熵;类间信息;K-means;高光谱图像;分类13|5|6更新时间:2024-05-07 -
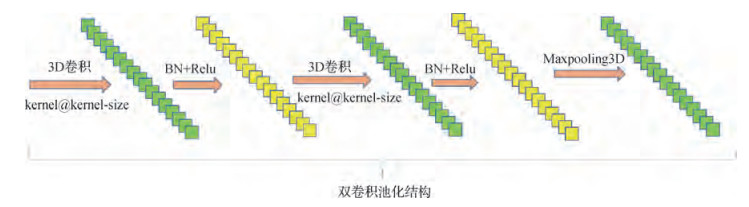 摘要:目的高光谱遥感影像数据包含丰富的空间和光谱信息,但由于信号的高维特性、信息冗余、多种不确定性和地表覆盖的同物异谱及同谱异物现象,导致高光谱数据结构呈高度非线性。3D-CNN(3D convolutional neural network)能够利用高光谱遥感影像数据立方体的特性,实现光谱和空间信息融合,提取影像分类中重要的有判别力的特征。为此,提出了基于双卷积池化结构的3D-CNN高光谱遥感影像分类方法。方法双卷积池化结构包括两个卷积层、两个BN(batch normalization)层和一个池化层,既考虑到高光谱遥感影像标签数据缺乏的问题,也考虑到高光谱影像高维特性和模型深度之间的平衡问题,模型充分利用空谱联合提供的语义信息,有利于提取小样本和高维特性的高光谱影像特征。基于双卷积池化结构的3D-CNN网络将没有经过特征处理的3D遥感影像作为输入数据,产生的深度学习分类器模型以端到端的方式训练,不需要做复杂的预处理,此外模型使用了BN和Dropout等正则化策略以避免过拟合现象。结果实验对比了SVM(support vector machine)、SAE(stack autoencoder)以及目前主流的CNN方法,该模型在Indian Pines和Pavia University数据集上最高分别取得了99.65%和99.82%的总体分类精度,有效提高了高光谱遥感影像地物分类精度。结论讨论了双卷积池化结构的数目、正则化策略、高光谱首层卷积的光谱采样步长、卷积核大小、相邻像素块大小和学习率等6个因素对实验结果的影响,本文提出的双卷积池化结构可以根据数据集特点进行组合复用,与其他深度学习模型相比,需要更少的参数,计算效率更高。关键词:3D-CNN;双卷积池化结构;空谱联合特征;高光谱影像分类;正则化策略17|4|13更新时间:2024-05-07
摘要:目的高光谱遥感影像数据包含丰富的空间和光谱信息,但由于信号的高维特性、信息冗余、多种不确定性和地表覆盖的同物异谱及同谱异物现象,导致高光谱数据结构呈高度非线性。3D-CNN(3D convolutional neural network)能够利用高光谱遥感影像数据立方体的特性,实现光谱和空间信息融合,提取影像分类中重要的有判别力的特征。为此,提出了基于双卷积池化结构的3D-CNN高光谱遥感影像分类方法。方法双卷积池化结构包括两个卷积层、两个BN(batch normalization)层和一个池化层,既考虑到高光谱遥感影像标签数据缺乏的问题,也考虑到高光谱影像高维特性和模型深度之间的平衡问题,模型充分利用空谱联合提供的语义信息,有利于提取小样本和高维特性的高光谱影像特征。基于双卷积池化结构的3D-CNN网络将没有经过特征处理的3D遥感影像作为输入数据,产生的深度学习分类器模型以端到端的方式训练,不需要做复杂的预处理,此外模型使用了BN和Dropout等正则化策略以避免过拟合现象。结果实验对比了SVM(support vector machine)、SAE(stack autoencoder)以及目前主流的CNN方法,该模型在Indian Pines和Pavia University数据集上最高分别取得了99.65%和99.82%的总体分类精度,有效提高了高光谱遥感影像地物分类精度。结论讨论了双卷积池化结构的数目、正则化策略、高光谱首层卷积的光谱采样步长、卷积核大小、相邻像素块大小和学习率等6个因素对实验结果的影响,本文提出的双卷积池化结构可以根据数据集特点进行组合复用,与其他深度学习模型相比,需要更少的参数,计算效率更高。关键词:3D-CNN;双卷积池化结构;空谱联合特征;高光谱影像分类;正则化策略17|4|13更新时间:2024-05-07 -
 摘要:目的哈希检索旨在将海量数据空间中的高维数据映射为紧凑的二进制哈希码,并通过位运算和异或运算快速计算任意两个二进制哈希码之间的汉明距离,从而能够在保持相似性的条件下,有效实现对大数据保持相似性的检索。但是,遥感影像数据除了具有影像特征之外,还具有丰富的语义信息,传统哈希提取影像特征并生成哈希码的方法不能有效利用遥感影像包含的语义信息,从而限制了遥感影像检索的精度。针对遥感影像中的语义信息,提出了一种基于深度语义哈希的遥感影像检索方法。方法首先在具有多语义标签的遥感影像数据训练集的基础上,利用两个不同配置参数的深度卷积网络分别提取遥感影像的影像特征和语义特征,然后利用后向传播算法针对提取的两类特征学习出深度网络中的各项参数并生成遥感影像的二进制哈希码。生成的二进制哈希码之间能够有效保持原始高维遥感影像的相似性。结果在高分二号与谷歌地球遥感影像数据集、CIFAR-10数据集及FLICKR-25K数据集上进行实验,并与多种方法进行比较和分析。当编码位数为64时,相对于DPSH(deep supervised Hashing with pairwise labels)方法,在高分二号与谷歌地球遥感影像数据集、CIFAR-10数据集、FLICKR-25K数据集上,mAP(mean average precision)指标分别提高了约2%、6%7%、0.6%。结论本文提出的端对端的深度学习框架,对于带有一个或多个语义标签的遥感影像,能够利用语义特征有效提高对数据集的检索性能。关键词:哈希;影像检索;深度学习;语义挖掘;遥感22|5|0更新时间:2024-05-07
摘要:目的哈希检索旨在将海量数据空间中的高维数据映射为紧凑的二进制哈希码,并通过位运算和异或运算快速计算任意两个二进制哈希码之间的汉明距离,从而能够在保持相似性的条件下,有效实现对大数据保持相似性的检索。但是,遥感影像数据除了具有影像特征之外,还具有丰富的语义信息,传统哈希提取影像特征并生成哈希码的方法不能有效利用遥感影像包含的语义信息,从而限制了遥感影像检索的精度。针对遥感影像中的语义信息,提出了一种基于深度语义哈希的遥感影像检索方法。方法首先在具有多语义标签的遥感影像数据训练集的基础上,利用两个不同配置参数的深度卷积网络分别提取遥感影像的影像特征和语义特征,然后利用后向传播算法针对提取的两类特征学习出深度网络中的各项参数并生成遥感影像的二进制哈希码。生成的二进制哈希码之间能够有效保持原始高维遥感影像的相似性。结果在高分二号与谷歌地球遥感影像数据集、CIFAR-10数据集及FLICKR-25K数据集上进行实验,并与多种方法进行比较和分析。当编码位数为64时,相对于DPSH(deep supervised Hashing with pairwise labels)方法,在高分二号与谷歌地球遥感影像数据集、CIFAR-10数据集、FLICKR-25K数据集上,mAP(mean average precision)指标分别提高了约2%、6%7%、0.6%。结论本文提出的端对端的深度学习框架,对于带有一个或多个语义标签的遥感影像,能够利用语义特征有效提高对数据集的检索性能。关键词:哈希;影像检索;深度学习;语义挖掘;遥感22|5|0更新时间:2024-05-07
遥感图像处理
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0