
最新刊期
2019 年 第 24 卷 第 3 期
- 摘要:目的为完善图像加密的理论及算法体系,并为图像加密实践提供性质优良的可行方案。基于Henon映射,构造了一类广义混沌映射:H-S(Henon Sine)映射,并以H-S混沌映射、矩阵非线性变换、矩阵点运算和取整运算为工具,运用序列重排和灰度变换技术设计了一种图像混合加密算法。方法首先,将第1混沌密钥矩阵与像素矩阵进行非线性变换,通过对变换结果的随机排序,给出原始图像的置乱加密方法;其次,在置乱图像和第2混沌密钥矩阵之间实施与第1阶段参数不同的变换并应用取整运算实现灰度加密。再次,通过逆运算和逆变换实现图像解密。结果由于混沌密钥、非线性运算和随机因素的联合作用,加密算法具有1次1密的特征,因而具有完备的抗攻击性能;同时算法结构简单、计算复杂度低而便于程序实现;算法规避了常用混沌加密对映射的可逆性要求,对任意大小的矩形图像都有效,具有广泛的适用性。结论加解密仿真实验验证了算法的可行性和有效性,针对加密时间、图像灰度曲面、图像信息熵、加解密图像的相关性和相似性、密钥敏感性、差分攻击等展开全面的加密性能分析,佐证了加密方案的安全性和鲁棒性。同其他类型的置乱加密算法的比对佐证了算法的优越性。本文算法为任意大小的矩形灰度图像加密提供了参考方案,此方案经过适当调整即可应用于矩形彩色图像加密。关键词:混合加密;混沌映射;矩阵点运算;非线性变换;序列重排0|28|2更新时间:2024-05-07
-
 摘要:目的近年来,随着数字摄影技术的飞速发展,图像增强技术越来越受到重视。图像构图作为图像增强中影响美学的重要因素,一直都是研究的热点。为此,从立体图像布局调整出发,提出一种基于Delaunay网格形变的立体图像内容重组方法。方法首先将待重组的一对立体图像记为源图像,将用于重组规则确定的一幅图像记为参考图像;然后对源图像需要调整的目标、特征线和其他区域进行取点操作,建立Delaunay网格。将源图像的左图与参考图像进行模板匹配操作,得到源图像与参考图像在结构布局上的对应关系;最后利用网格形变的特性,移动和缩放目标对象,并对立体图像的深度进行自适应调整。结果针对目标对象的移动、缩放和特征线调整几方面进行优化。当只涉及目标对象的移动或特征线调整时,立体图像视差保持不变;当目标对象缩放时,立体图像中目标对象的视差按照缩放比例变化而背景视差保持不变。实验结果表明,重组后的立体图像构图与参考图像一致且深度能自适应调整。与最新方法比较,本文方法在目标对象分割精度和图像语义保持方面具有优势。结论根据网格形变相关理论,构建图像质量、布局匹配和视差适应3种能量项,实现了立体图像的内容重组。与现有需要提取和粘贴目标对象的重组方法不同,本文方法对目标对象的分割精度要求不高,不需要图像修复和混合技术,重组后的立体图像没有伪影和语义错误出现。用户可以通过参考图像来引导立体图像的布局调整,达到期望的图像增强效果。关键词:立体图像编辑;立体图像布局;Delaunay网格形变;深度自适应;优化12|4|1更新时间:2024-05-07
摘要:目的近年来,随着数字摄影技术的飞速发展,图像增强技术越来越受到重视。图像构图作为图像增强中影响美学的重要因素,一直都是研究的热点。为此,从立体图像布局调整出发,提出一种基于Delaunay网格形变的立体图像内容重组方法。方法首先将待重组的一对立体图像记为源图像,将用于重组规则确定的一幅图像记为参考图像;然后对源图像需要调整的目标、特征线和其他区域进行取点操作,建立Delaunay网格。将源图像的左图与参考图像进行模板匹配操作,得到源图像与参考图像在结构布局上的对应关系;最后利用网格形变的特性,移动和缩放目标对象,并对立体图像的深度进行自适应调整。结果针对目标对象的移动、缩放和特征线调整几方面进行优化。当只涉及目标对象的移动或特征线调整时,立体图像视差保持不变;当目标对象缩放时,立体图像中目标对象的视差按照缩放比例变化而背景视差保持不变。实验结果表明,重组后的立体图像构图与参考图像一致且深度能自适应调整。与最新方法比较,本文方法在目标对象分割精度和图像语义保持方面具有优势。结论根据网格形变相关理论,构建图像质量、布局匹配和视差适应3种能量项,实现了立体图像的内容重组。与现有需要提取和粘贴目标对象的重组方法不同,本文方法对目标对象的分割精度要求不高,不需要图像修复和混合技术,重组后的立体图像没有伪影和语义错误出现。用户可以通过参考图像来引导立体图像的布局调整,达到期望的图像增强效果。关键词:立体图像编辑;立体图像布局;Delaunay网格形变;深度自适应;优化12|4|1更新时间:2024-05-07 -
 摘要:目的医学影像获取和视频监控过程中会出现一些恶劣环境,导致图像有许多强噪声斑点,质量较差。在处理强噪声图像时,传统的基于变分模型的算法,因需要计算高阶偏微分方程,计算复杂且收敛较慢;而隐式使用图像曲率信息的曲率滤波模型,在处理强噪声图像时,又存在去噪不完全的缺陷。为了克服这些缺陷,在保持图像边缘和细节特征的同时去除图像的强噪声,实现快速去噪,提出了一种改进的曲率滤波算法。方法本文算法在隐式计算曲率时,通过半窗三角切平面和最小三角切平面的组合,用投影算子代替传统曲率滤波的最小三角切平面投影算子,并根据强噪声图像存在强噪声斑点的特征,修正正则能量函数,增添局部方差的正则能量,使得正则项的约束更加合理,提高了算法的去噪性能,从而达到增强去噪能力和保护图像边缘与细节的目的。结果针对多种不同强度的混合噪声图像对本文算法性能进行测试,并与传统的基于变分法的去噪算法(ROF)和曲率滤波去噪等算法进行去噪效果对比,同时使用峰值信噪比(PSNR)和结构相似性(SSIM)作为滤波算法性能的客观评价指标。本文算法在对强噪声图像去噪处理时,能够有效地保持图像的边缘和细节特征,具备较好的PSNR和SSIM,在PSNR上比ROF模型和曲率滤波算法分别平均提高1.67 dB和2.93 dB,SSIM分别平均提高0.29和0.26。由于采用了隐式计算图像曲率,算法的处理速度与曲率滤波算法相近。结论根据强噪声图像噪声特征对曲率滤波算法进行优化,改进投影算子和能量函数正则项,使得曲率滤波算法能够更好地适用于强噪声图像,实验结果表明,该方法与传统的变分法相比,对强噪声图像去噪效果显著。关键词:图像去噪;曲率滤波;强噪声;高斯曲率;变分模型18|5|4更新时间:2024-05-07
摘要:目的医学影像获取和视频监控过程中会出现一些恶劣环境,导致图像有许多强噪声斑点,质量较差。在处理强噪声图像时,传统的基于变分模型的算法,因需要计算高阶偏微分方程,计算复杂且收敛较慢;而隐式使用图像曲率信息的曲率滤波模型,在处理强噪声图像时,又存在去噪不完全的缺陷。为了克服这些缺陷,在保持图像边缘和细节特征的同时去除图像的强噪声,实现快速去噪,提出了一种改进的曲率滤波算法。方法本文算法在隐式计算曲率时,通过半窗三角切平面和最小三角切平面的组合,用投影算子代替传统曲率滤波的最小三角切平面投影算子,并根据强噪声图像存在强噪声斑点的特征,修正正则能量函数,增添局部方差的正则能量,使得正则项的约束更加合理,提高了算法的去噪性能,从而达到增强去噪能力和保护图像边缘与细节的目的。结果针对多种不同强度的混合噪声图像对本文算法性能进行测试,并与传统的基于变分法的去噪算法(ROF)和曲率滤波去噪等算法进行去噪效果对比,同时使用峰值信噪比(PSNR)和结构相似性(SSIM)作为滤波算法性能的客观评价指标。本文算法在对强噪声图像去噪处理时,能够有效地保持图像的边缘和细节特征,具备较好的PSNR和SSIM,在PSNR上比ROF模型和曲率滤波算法分别平均提高1.67 dB和2.93 dB,SSIM分别平均提高0.29和0.26。由于采用了隐式计算图像曲率,算法的处理速度与曲率滤波算法相近。结论根据强噪声图像噪声特征对曲率滤波算法进行优化,改进投影算子和能量函数正则项,使得曲率滤波算法能够更好地适用于强噪声图像,实验结果表明,该方法与传统的变分法相比,对强噪声图像去噪效果显著。关键词:图像去噪;曲率滤波;强噪声;高斯曲率;变分模型18|5|4更新时间:2024-05-07 -
 摘要:目的多假设预测是视频压缩感知多假设预测残差重构算法的关键技术之一,现有的视频压缩感知多假设预测算法中预测分块固定,这种方法存在两点不足:1)对于视频帧中运动形式复杂的图像块预测效果不佳;2)对于运动平缓区域,相邻图像块的运动矢量非常相近,每块单独通过运动估计寻找最佳匹配块,导致算法复杂度较大。针对这些问题,提出了分级多假设预测思路(Hi-MH),即对运动复杂程度不同的区域采取不同的块匹配预测方法。方法对于平缓运动区域的图像块,利用邻域图像块的运动矢量预测当前块的运动矢量,从而降低运动估计的算法复杂度;对于运动较复杂的图像块,用更小的块寻找最佳匹配;对于运动特别复杂的图像块利用自回归模型对单个像素点进行预测,提高预测精度。结果Hi-MH算法与现有的快速搜索预测算法相比,每帧预测时间至少缩短了1.4 s,与现有最优的视频压缩感知重构算法相比,对于运动较为复杂的视频序列,峰值信噪比(PSNR)提升幅度达到1 dB。结论Hi-MH算法对于运动形式简单的视频序列或区域降低了计算复杂度,对于运动形式较为复杂的视频序列或区域提高了预测精度。关键词:视频压缩感知;多假设预测;块匹配;运动估计;自回归53|49|0更新时间:2024-05-07
摘要:目的多假设预测是视频压缩感知多假设预测残差重构算法的关键技术之一,现有的视频压缩感知多假设预测算法中预测分块固定,这种方法存在两点不足:1)对于视频帧中运动形式复杂的图像块预测效果不佳;2)对于运动平缓区域,相邻图像块的运动矢量非常相近,每块单独通过运动估计寻找最佳匹配块,导致算法复杂度较大。针对这些问题,提出了分级多假设预测思路(Hi-MH),即对运动复杂程度不同的区域采取不同的块匹配预测方法。方法对于平缓运动区域的图像块,利用邻域图像块的运动矢量预测当前块的运动矢量,从而降低运动估计的算法复杂度;对于运动较复杂的图像块,用更小的块寻找最佳匹配;对于运动特别复杂的图像块利用自回归模型对单个像素点进行预测,提高预测精度。结果Hi-MH算法与现有的快速搜索预测算法相比,每帧预测时间至少缩短了1.4 s,与现有最优的视频压缩感知重构算法相比,对于运动较为复杂的视频序列,峰值信噪比(PSNR)提升幅度达到1 dB。结论Hi-MH算法对于运动形式简单的视频序列或区域降低了计算复杂度,对于运动形式较为复杂的视频序列或区域提高了预测精度。关键词:视频压缩感知;多假设预测;块匹配;运动估计;自回归53|49|0更新时间:2024-05-07
图像处理和编码

-
 摘要:目的图像协同分割技术是通过多幅参考图像以实现前景目标与背景区域的分离,并已被广泛应用于图像分类和目标识别等领域中。不过,现有多数的图像协同分割算法只适用于背景变化较大且前景几乎不变的环境。为此,提出一种新的无监督协同分割算法。方法本文方法是无监督式的,在分级图像分割的基础上通过渐进式优化框架分别实现前景和背景模型的更新估计,同时结合图像内部和不同图像之间的分级区域相似度关联进一步增强上述模型估计的鲁棒性。该无监督的方法不需要进行预先样本学习,能够同时处理两幅或多幅图像且适用于同时存在多个前景目标的情况,并且能够较好地适应前景物体类的变化。结果通过基于iCoseg和MSRC图像集的实验证明,该算法无需图像间具有显著的前景和背景差异这一约束,与现有的经典方法相比更适用于前景变化剧烈以及同时存在多个前景目标等更为一般化的图像场景中。结论该方法通过对分级图像分割得到的超像素外观分布分别进行递归式估计来实现前景和背景的有效区分,并同时融合了图像内部以及不同图像区域之间的区域关联性来增加图像前景和背景分布估计的一致性。实验表明当前景变化显著时本文方法相比于现有方法具有更为鲁棒的表现。关键词:图像协同分割;分级图像分割;渐进式前景估计;分级区域关联;归一化割13|4|0更新时间:2024-05-07
摘要:目的图像协同分割技术是通过多幅参考图像以实现前景目标与背景区域的分离,并已被广泛应用于图像分类和目标识别等领域中。不过,现有多数的图像协同分割算法只适用于背景变化较大且前景几乎不变的环境。为此,提出一种新的无监督协同分割算法。方法本文方法是无监督式的,在分级图像分割的基础上通过渐进式优化框架分别实现前景和背景模型的更新估计,同时结合图像内部和不同图像之间的分级区域相似度关联进一步增强上述模型估计的鲁棒性。该无监督的方法不需要进行预先样本学习,能够同时处理两幅或多幅图像且适用于同时存在多个前景目标的情况,并且能够较好地适应前景物体类的变化。结果通过基于iCoseg和MSRC图像集的实验证明,该算法无需图像间具有显著的前景和背景差异这一约束,与现有的经典方法相比更适用于前景变化剧烈以及同时存在多个前景目标等更为一般化的图像场景中。结论该方法通过对分级图像分割得到的超像素外观分布分别进行递归式估计来实现前景和背景的有效区分,并同时融合了图像内部以及不同图像区域之间的区域关联性来增加图像前景和背景分布估计的一致性。实验表明当前景变化显著时本文方法相比于现有方法具有更为鲁棒的表现。关键词:图像协同分割;分级图像分割;渐进式前景估计;分级区域关联;归一化割13|4|0更新时间:2024-05-07 -
 摘要:目的近年来,由于局部图像描述符在大的视角与光度变化、噪声、局部遮挡等方面具有良好性能,已成功应用于图像搜索、机器人导航、图像分类、视频行为识别等各种计算机视觉研究领域。方法提出了一种新的用于图像区域描述的局部特征:局部灰度极值模式(LIEP)。在离一个像素点半径不同的两个同心圆上分别均匀抽样相同点数的采样点,不同同心圆上采样点与中心像素点之间的夹角相互内插,分别独立计算每个同心圆上采样点的最大和最小灰度模式。计算半径小的同心圆上的最大灰度模式和半径大的同心圆上的最小灰度模式的2维联合分布,得到一种极值模式。再计算半径小的同心圆上的最小灰度模式和半径大的同心圆上的最大灰度模式的2维联合分布,得到另一种极值模式。最后对这2种极值模式进行级联,得到LIEP。相对于局部灰度序模式和局部二进制模式,LIEP在图像光度和几何变化下更稳定,抗噪声性能更强,出现模式错误的概率更小。LIEP在局部旋转不变坐标系统下计算,采用多支撑域和图像块全局灰度序空间汇聚方法得到一种新的局部图像描述符:LIEP空间分布直方图(LIEPH)。LIEPH描述符具有单调光照不变性和在不计算图像块主方向条件下保持旋转不变性。结果在标准图像匹配数据库上的实验表明:LIEPH的查全率-查错率曲线都位于最上方,匹配性能大大优于单支撑域描述符SIFT(scale invariant feature transform)、CS-LBP(center-symmetric local binary pattern)、LIOP(local intensity order pattern)、HRI-CSLTP(histogram of relative intensities and center-symmetric local ternary patterns)、EOD(exact order based descriptor)及多支撑域描述符MRRID(multisupport region rotation and intensity monotonic imariant descriptor)。在大的图像几何畸变下,LIEPH更能展现优越的匹配性能。在对描述符进行定量分析的实验中,当查错率(1-precision)取固定值0.4时,LIEPH描述符的查全率(recall)值在各种图像畸变下都是最大的。在标准图像匹配数据库上添加高斯和椒盐噪声的实验中,LIEPH的匹配性能远远优于MRRID。LIEPH算法的复杂度更低,计算时间接近MRRID的1/2。结论LIEPH对局部图像区域的纹理统计特性具有很高的描述能力,在辨别性、鲁棒性和抗噪声方面的优越性能使其可以应用于复杂条件下的图像区域描述和匹配场合。关键词:局部图像描述符;局部灰度序模式;局部二进制模式;局部灰度极值模式;图像匹配14|5|0更新时间:2024-05-07
摘要:目的近年来,由于局部图像描述符在大的视角与光度变化、噪声、局部遮挡等方面具有良好性能,已成功应用于图像搜索、机器人导航、图像分类、视频行为识别等各种计算机视觉研究领域。方法提出了一种新的用于图像区域描述的局部特征:局部灰度极值模式(LIEP)。在离一个像素点半径不同的两个同心圆上分别均匀抽样相同点数的采样点,不同同心圆上采样点与中心像素点之间的夹角相互内插,分别独立计算每个同心圆上采样点的最大和最小灰度模式。计算半径小的同心圆上的最大灰度模式和半径大的同心圆上的最小灰度模式的2维联合分布,得到一种极值模式。再计算半径小的同心圆上的最小灰度模式和半径大的同心圆上的最大灰度模式的2维联合分布,得到另一种极值模式。最后对这2种极值模式进行级联,得到LIEP。相对于局部灰度序模式和局部二进制模式,LIEP在图像光度和几何变化下更稳定,抗噪声性能更强,出现模式错误的概率更小。LIEP在局部旋转不变坐标系统下计算,采用多支撑域和图像块全局灰度序空间汇聚方法得到一种新的局部图像描述符:LIEP空间分布直方图(LIEPH)。LIEPH描述符具有单调光照不变性和在不计算图像块主方向条件下保持旋转不变性。结果在标准图像匹配数据库上的实验表明:LIEPH的查全率-查错率曲线都位于最上方,匹配性能大大优于单支撑域描述符SIFT(scale invariant feature transform)、CS-LBP(center-symmetric local binary pattern)、LIOP(local intensity order pattern)、HRI-CSLTP(histogram of relative intensities and center-symmetric local ternary patterns)、EOD(exact order based descriptor)及多支撑域描述符MRRID(multisupport region rotation and intensity monotonic imariant descriptor)。在大的图像几何畸变下,LIEPH更能展现优越的匹配性能。在对描述符进行定量分析的实验中,当查错率(1-precision)取固定值0.4时,LIEPH描述符的查全率(recall)值在各种图像畸变下都是最大的。在标准图像匹配数据库上添加高斯和椒盐噪声的实验中,LIEPH的匹配性能远远优于MRRID。LIEPH算法的复杂度更低,计算时间接近MRRID的1/2。结论LIEPH对局部图像区域的纹理统计特性具有很高的描述能力,在辨别性、鲁棒性和抗噪声方面的优越性能使其可以应用于复杂条件下的图像区域描述和匹配场合。关键词:局部图像描述符;局部灰度序模式;局部二进制模式;局部灰度极值模式;图像匹配14|5|0更新时间:2024-05-07 -
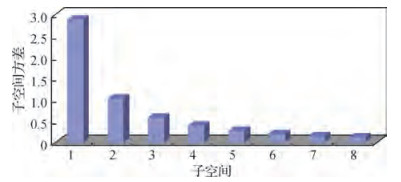 摘要:目的基于哈希编码的检索方法是图像检索领域中的经典方法。其原理是将原始空间中相似的图片经哈希函数投影、量化后,在汉明空间中得到相近的哈希码。此类方法一般包括两个过程:投影和量化。投影过程大多采用主成分分析法对原始数据进行降维,但不同方法的量化过程差异较大。对于信息量不均衡的数据,传统的图像哈希检索方法采用等长固定编码位数量化的方式,导致出现低编码效率和低量化精度等问题。为此,本文提出基于哈夫曼编码的乘积量化方法。方法首先,利用乘积量化法对降维后的数据进行量化,以便较好地保持数据在原始空间中的分布情况。然后,采用子空间方差作为衡量信息量的标准,并以此作为编码位数分配的依据。最后,借助于哈夫曼树,给方差大的子空间分配更多的编码位数。结果在常用公开数据集MNIST、NUS-WIDE和22K LabelMe上进行实验验证,与原始的乘积量化方法相比,所提出方法能平均降低49%的量化误差,并提高19%的平均准确率。在数据集MNIST上,与同类方法的变换编码方法(TC)进行对比,比较了从32 bit到256 bit编码时的训练时间,本文方法的训练时间能够平均缩短22.5 s。结论本文提出了一种基于多位编码乘积量化的哈希方法,该方法提高了哈希编码的效率和量化精度,在平均准确率、召回率等性能上优于其他同类算法,可以有效地应用到图像检索相关领域。关键词:哈希;图像检索;近似最近邻搜索;乘积量化;比特分配;编码效率15|4|3更新时间:2024-05-07
摘要:目的基于哈希编码的检索方法是图像检索领域中的经典方法。其原理是将原始空间中相似的图片经哈希函数投影、量化后,在汉明空间中得到相近的哈希码。此类方法一般包括两个过程:投影和量化。投影过程大多采用主成分分析法对原始数据进行降维,但不同方法的量化过程差异较大。对于信息量不均衡的数据,传统的图像哈希检索方法采用等长固定编码位数量化的方式,导致出现低编码效率和低量化精度等问题。为此,本文提出基于哈夫曼编码的乘积量化方法。方法首先,利用乘积量化法对降维后的数据进行量化,以便较好地保持数据在原始空间中的分布情况。然后,采用子空间方差作为衡量信息量的标准,并以此作为编码位数分配的依据。最后,借助于哈夫曼树,给方差大的子空间分配更多的编码位数。结果在常用公开数据集MNIST、NUS-WIDE和22K LabelMe上进行实验验证,与原始的乘积量化方法相比,所提出方法能平均降低49%的量化误差,并提高19%的平均准确率。在数据集MNIST上,与同类方法的变换编码方法(TC)进行对比,比较了从32 bit到256 bit编码时的训练时间,本文方法的训练时间能够平均缩短22.5 s。结论本文提出了一种基于多位编码乘积量化的哈希方法,该方法提高了哈希编码的效率和量化精度,在平均准确率、召回率等性能上优于其他同类算法,可以有效地应用到图像检索相关领域。关键词:哈希;图像检索;近似最近邻搜索;乘积量化;比特分配;编码效率15|4|3更新时间:2024-05-07 -
 摘要:目的使用运动历史点云(MHPC)进行人体行为识别的方法,由于点云数据量大,在提取特征时运算复杂度很高。而使用深度运动图(DMM)进行人体行为识别的方法,提取特征简单,但是包含的动作信息不全面,限制了人体行为识别精度的上限。针对上述问题,提出了一种多视角深度运动图的人体行为识别算法。方法首先采用深度图序列生成MHPC对动作进行表示,接着将MHPC旋转特定角度补充更多视角下的动作信息;然后将原始和旋转后MHPC投影到笛卡儿坐标平面,生成多视角深度运动图,并对其提取方向梯度直方图,采用串联融合生成特征向量;最后使用支持向量机对特征向量进行分类识别,在MSR Action3D和自建数据库上对算法进行验证。结果MSR Action3D数据库有2种实验设置,采用实验设置1时,算法识别率为96.8%,比APS_PHOG(axonometric projections and PHOG feature)算法高2.5%,比DMM算法高1.9%,比DMM_CRC(depth motion maps and collaborative representation classifier)算法高1.1%。采用实验设置2时,算法识别率为93.82%,比DMM算法高5.09%,比HON4D(histogram of oriented 4D surface normal)算法高4.93%。在自建数据库上该算法识别率达到97.98%,比MHPC算法高3.98%。结论实验结果表明,多视角深度运动图不但解决了MHPC提取特征复杂的问题,而且使DMM包含了更多视角下的动作信息,有效提高了人体行为识别的精度。关键词:人体行为识别;深度图像;深度运动图;多视角深度运动图;运动历史点云;方向梯度直方图;支持向量机36|91|2更新时间:2024-05-07
摘要:目的使用运动历史点云(MHPC)进行人体行为识别的方法,由于点云数据量大,在提取特征时运算复杂度很高。而使用深度运动图(DMM)进行人体行为识别的方法,提取特征简单,但是包含的动作信息不全面,限制了人体行为识别精度的上限。针对上述问题,提出了一种多视角深度运动图的人体行为识别算法。方法首先采用深度图序列生成MHPC对动作进行表示,接着将MHPC旋转特定角度补充更多视角下的动作信息;然后将原始和旋转后MHPC投影到笛卡儿坐标平面,生成多视角深度运动图,并对其提取方向梯度直方图,采用串联融合生成特征向量;最后使用支持向量机对特征向量进行分类识别,在MSR Action3D和自建数据库上对算法进行验证。结果MSR Action3D数据库有2种实验设置,采用实验设置1时,算法识别率为96.8%,比APS_PHOG(axonometric projections and PHOG feature)算法高2.5%,比DMM算法高1.9%,比DMM_CRC(depth motion maps and collaborative representation classifier)算法高1.1%。采用实验设置2时,算法识别率为93.82%,比DMM算法高5.09%,比HON4D(histogram of oriented 4D surface normal)算法高4.93%。在自建数据库上该算法识别率达到97.98%,比MHPC算法高3.98%。结论实验结果表明,多视角深度运动图不但解决了MHPC提取特征复杂的问题,而且使DMM包含了更多视角下的动作信息,有效提高了人体行为识别的精度。关键词:人体行为识别;深度图像;深度运动图;多视角深度运动图;运动历史点云;方向梯度直方图;支持向量机36|91|2更新时间:2024-05-07
图像分析和识别
-
 摘要:目的近几年应用在单幅图像超分辨率重建上的深度学习算法都是使用单种尺度的卷积核提取低分辨率图像的特征信息,这样很容易造成细节信息的遗漏。另外,为了获得更好的图像超分辨率重建效果,网络模型也不断被加深,伴随而来的梯度消失问题会使得训练时间延长,难度加大。针对当前存在的超分辨率重建中的问题,本文结合GoogleNet思想、残差网络思想和密集型卷积网络思想,提出一种多尺度密集残差网络模型。方法本文使用3种不同尺度卷积核对输入的低分辨率图像进行卷积处理,采集不同卷积核下的底层特征,这样可以较多地提取低分辨率图像中的细节信息,有利于图像恢复。再将采集的特征信息输入残差块中,每个残差块都包含了多个由卷积层和激活层构成的特征提取单元。另外,每个特征提取单元的输出都会通过短路径连接到下一个特征提取单元。短路径连接可以有效地缓解梯度消失现象,加强特征传播,促进特征再利用。接下来,融合3种卷积核提取的特征信息,经过降维处理后与3×3像素的卷积核提取的特征信息相加形成全局残差学习。最后经过重建层,得到清晰的高分辨率图像。整个训练过程中,一幅输入的低分辨率图像对应着一幅高分辨率图像标签,这种端到端的学习方法使得训练更加迅速。结果本文使用两个客观评价标准PSNR(peak signal-to-noise ratio)和SSIM(structural similarity index)对实验的效果图进行测试,并与其他主流的方法进行对比。最终的结果显示,本文算法在Set5等多个测试数据集中的表现相比于插值法和SRCNN算法,在放大3倍时效果提升约3.4 dB和1.1 dB,在放大4倍时提升约3.5 dB和1.4 dB。结论实验数据以及效果图证明本文算法能够较好地恢复低分辨率图像的边缘和纹理信息。关键词:单幅图像超分辨率;多尺度卷积核;残差网络;密集型卷积网络;特征提取单元12|4|11更新时间:2024-05-07
摘要:目的近几年应用在单幅图像超分辨率重建上的深度学习算法都是使用单种尺度的卷积核提取低分辨率图像的特征信息,这样很容易造成细节信息的遗漏。另外,为了获得更好的图像超分辨率重建效果,网络模型也不断被加深,伴随而来的梯度消失问题会使得训练时间延长,难度加大。针对当前存在的超分辨率重建中的问题,本文结合GoogleNet思想、残差网络思想和密集型卷积网络思想,提出一种多尺度密集残差网络模型。方法本文使用3种不同尺度卷积核对输入的低分辨率图像进行卷积处理,采集不同卷积核下的底层特征,这样可以较多地提取低分辨率图像中的细节信息,有利于图像恢复。再将采集的特征信息输入残差块中,每个残差块都包含了多个由卷积层和激活层构成的特征提取单元。另外,每个特征提取单元的输出都会通过短路径连接到下一个特征提取单元。短路径连接可以有效地缓解梯度消失现象,加强特征传播,促进特征再利用。接下来,融合3种卷积核提取的特征信息,经过降维处理后与3×3像素的卷积核提取的特征信息相加形成全局残差学习。最后经过重建层,得到清晰的高分辨率图像。整个训练过程中,一幅输入的低分辨率图像对应着一幅高分辨率图像标签,这种端到端的学习方法使得训练更加迅速。结果本文使用两个客观评价标准PSNR(peak signal-to-noise ratio)和SSIM(structural similarity index)对实验的效果图进行测试,并与其他主流的方法进行对比。最终的结果显示,本文算法在Set5等多个测试数据集中的表现相比于插值法和SRCNN算法,在放大3倍时效果提升约3.4 dB和1.1 dB,在放大4倍时提升约3.5 dB和1.4 dB。结论实验数据以及效果图证明本文算法能够较好地恢复低分辨率图像的边缘和纹理信息。关键词:单幅图像超分辨率;多尺度卷积核;残差网络;密集型卷积网络;特征提取单元12|4|11更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的针对基于内容的图像检索存在低层视觉特征与用户对图像理解的高层语义不一致、图像检索的精度较低以及传统的分类方法准确度低等问题,提出一种基于卷积神经网络和相关反馈支持向量机的遥感图像检索方法。方法通过对比度受限直方图均衡化算法对遥感图像进行预处理,限制遥感图像噪声的放大,采用自学习能力良好的卷积神经网络对遥感图像进行多层神经网络的监督学习提取丰富的图像特征,并将支持向量机作为基分类器,根据测试样本数据到分类超平面的距离进行排序得到检索结果,最后采用相关反馈策略对检索结果进行重新调整。结果在UC Merced Land-Use遥感图像数据集上进行图像检索实验,在mAP(mean average precision)精度指标上,当检索返回图像数为100时,本文方法比LSH(locality sensitive Hashing)方法提高了29.4%,比DSH(density sensitive Hashing)方法提高了37.2%,比EMR(efficient manifold ranking)方法提高了68.8%,比未添加反馈和训练集筛选的SVM(support vector machine)方法提高了3.5%,对于平均检索速度,本文方法比对比方法中mAP精度最高的方法提高了4倍,针对复杂的遥感图像数据,本文方法的检索效果较其他方法表现出色。结论本文提出了一种以距离评价标准为核心的反馈策略,以提高检索精度,并采用多距离结合的Top-k排序方法合理筛选训练集,以提高检索速度,本文方法可以广泛应用于人脸识别和目标跟踪等领域,对提升检索性能具有重要意义。关键词:遥感图像检索;卷积神经网络;反馈;支持向量机;对比度受限直方图均衡化;Top-k排序15|34|4更新时间:2024-05-07
摘要:目的针对基于内容的图像检索存在低层视觉特征与用户对图像理解的高层语义不一致、图像检索的精度较低以及传统的分类方法准确度低等问题,提出一种基于卷积神经网络和相关反馈支持向量机的遥感图像检索方法。方法通过对比度受限直方图均衡化算法对遥感图像进行预处理,限制遥感图像噪声的放大,采用自学习能力良好的卷积神经网络对遥感图像进行多层神经网络的监督学习提取丰富的图像特征,并将支持向量机作为基分类器,根据测试样本数据到分类超平面的距离进行排序得到检索结果,最后采用相关反馈策略对检索结果进行重新调整。结果在UC Merced Land-Use遥感图像数据集上进行图像检索实验,在mAP(mean average precision)精度指标上,当检索返回图像数为100时,本文方法比LSH(locality sensitive Hashing)方法提高了29.4%,比DSH(density sensitive Hashing)方法提高了37.2%,比EMR(efficient manifold ranking)方法提高了68.8%,比未添加反馈和训练集筛选的SVM(support vector machine)方法提高了3.5%,对于平均检索速度,本文方法比对比方法中mAP精度最高的方法提高了4倍,针对复杂的遥感图像数据,本文方法的检索效果较其他方法表现出色。结论本文提出了一种以距离评价标准为核心的反馈策略,以提高检索精度,并采用多距离结合的Top-k排序方法合理筛选训练集,以提高检索速度,本文方法可以广泛应用于人脸识别和目标跟踪等领域,对提升检索性能具有重要意义。关键词:遥感图像检索;卷积神经网络;反馈;支持向量机;对比度受限直方图均衡化;Top-k排序15|34|4更新时间:2024-05-07 -
 摘要:目的全色图像的空间细节信息增强和多光谱图像的光谱信息保持通常是相互矛盾的,如何能够在这对矛盾中实现最佳融合效果一直以来都是遥感图像融合领域的研究热点与难点。为了有效结合光谱信息与空间细节信息,进一步改善多光谱与全色图像的融合质量,提出一种形态学滤波和改进脉冲耦合神经网络(PCNN)的非下采样剪切波变换(NSST)域多光谱与全色图像融合方法。方法该方法首先分别对多光谱和全色图像进行非下采样剪切波变换;对二者的低频分量采用形态学滤波和高通调制框架(HPM)进行融合,将全色图像低频子带的细节信息注入到多光谱图像低频子带中得到融合后的低频子带;对二者的高频分量则采用改进脉冲耦合神经网络的方法进行融合,进一步增强融合图像中的空间细节信息;最后通过NSST逆变换得到融合图像。结果仿真实验表明,本文方法得到的融合图像细节信息清晰且光谱保真度高,视觉效果上优势明显,且各项评价指标与其他方法相比整体上较优。相比于5种方法中3组融合结果各指标平均值中的最优值,清晰度和空间频率分别比NSCT-PCNN方法提高0.5%和1.0%,光谱扭曲度比NSST-PCNN方法降低4.2%,相关系数比NSST-PCNN方法提高1.4%,信息熵仅比NSST-PCNN方法低0.08%。相关系数和光谱扭曲度两项指标的评价结果表明本文方法相比于其他5种方法能够更好地保持光谱信息,清晰度和空间频率两项指标的评价结果则展示了本文方法具有优于其他对比方法的空间细节注入能力,信息熵指标虽不是最优值,但与最优值非常接近。结论分析视觉效果及各项客观评价指标可以看出,本文方法在提高融合图像空间分辨率的同时,很好地保持了光谱信息。综合来看,本文方法在主观与客观方面均具有优于亮度色调饱和度(IHS)法、主成分分析(PCA)法、基于非负矩阵分解(CNMF)、基于非下采样轮廓波变换和脉冲耦合神经网络(NSCT-PCNN)以及基于非下采样剪切波变换和脉冲耦合神经网络(NSST-PCNN)5种经典及现有流行方法的融合效果。关键词:多光谱与全色图像融合;非下采样剪切波变换;形态学滤波;高通调制;脉冲耦合神经网络14|24|13更新时间:2024-05-07
摘要:目的全色图像的空间细节信息增强和多光谱图像的光谱信息保持通常是相互矛盾的,如何能够在这对矛盾中实现最佳融合效果一直以来都是遥感图像融合领域的研究热点与难点。为了有效结合光谱信息与空间细节信息,进一步改善多光谱与全色图像的融合质量,提出一种形态学滤波和改进脉冲耦合神经网络(PCNN)的非下采样剪切波变换(NSST)域多光谱与全色图像融合方法。方法该方法首先分别对多光谱和全色图像进行非下采样剪切波变换;对二者的低频分量采用形态学滤波和高通调制框架(HPM)进行融合,将全色图像低频子带的细节信息注入到多光谱图像低频子带中得到融合后的低频子带;对二者的高频分量则采用改进脉冲耦合神经网络的方法进行融合,进一步增强融合图像中的空间细节信息;最后通过NSST逆变换得到融合图像。结果仿真实验表明,本文方法得到的融合图像细节信息清晰且光谱保真度高,视觉效果上优势明显,且各项评价指标与其他方法相比整体上较优。相比于5种方法中3组融合结果各指标平均值中的最优值,清晰度和空间频率分别比NSCT-PCNN方法提高0.5%和1.0%,光谱扭曲度比NSST-PCNN方法降低4.2%,相关系数比NSST-PCNN方法提高1.4%,信息熵仅比NSST-PCNN方法低0.08%。相关系数和光谱扭曲度两项指标的评价结果表明本文方法相比于其他5种方法能够更好地保持光谱信息,清晰度和空间频率两项指标的评价结果则展示了本文方法具有优于其他对比方法的空间细节注入能力,信息熵指标虽不是最优值,但与最优值非常接近。结论分析视觉效果及各项客观评价指标可以看出,本文方法在提高融合图像空间分辨率的同时,很好地保持了光谱信息。综合来看,本文方法在主观与客观方面均具有优于亮度色调饱和度(IHS)法、主成分分析(PCA)法、基于非负矩阵分解(CNMF)、基于非下采样轮廓波变换和脉冲耦合神经网络(NSCT-PCNN)以及基于非下采样剪切波变换和脉冲耦合神经网络(NSST-PCNN)5种经典及现有流行方法的融合效果。关键词:多光谱与全色图像融合;非下采样剪切波变换;形态学滤波;高通调制;脉冲耦合神经网络14|24|13更新时间:2024-05-07
遥感图像处理
-
 摘要:目的图像修复是计算机视觉领域研究的一项重要内容,其目的是根据图像中已知内容来自动地恢复丢失的内容,在图像编辑、影视特技制作、虚拟现实及数字文化遗产保护等领域都具有广泛的应用价值。而近年来,随着深度学习在学术界和工业界的广泛研究,其在图像语义提取、特征表示、图像生成等方面的应用优势日益突出,使得基于深度学习的图像修复方法的研究成为了国内外一个研究热点,得到了越来越多的关注。为了使更多研究者对基于深度学习的图像修复理论及其发展进行探索,本文对该领域研究现状进行综述。方法首先对基于深度学习图像修复方法提出的理论依据进行分析;然后对其中涉及的关键技术进行研究;总结了近年来基于深度学习的主要图像修复方法,并依据修复网络的结构对现有方法进行了分类,即分为基于卷积自编码网络结构的图像修复方法、基于生成式对抗网络结构的图像修复方法和基于循环神经网络结构的图像修复方法。结果在基于深度学习的图像修复方法中,深度学习网络的设计和训练过程中的损失函数的选择是其重要的内容,各类方法各有优缺点和其适用范围,如何提高修复结果语义的合理性、结构及细节的正确性,一直是研究者们努力的方向,基于此目的,本文通过实验分析总结了各类方法的主要特点、存在的问题、对训练样本的要求、主要应用领域及参考代码。结论基于深度学习图像修复领域的研究已经取得了一些显著进展,但目前深度学习在图像修复中的应用仍处于起步阶段,主要研究的内容也仅仅是利用待修复图像本身的图像内容信息,因此基于深度学习的图像修复仍是一个极具挑战的课题。如何设计具有普适性的修复网络,提高修复结果的准确性,还需要更加深入的研究。关键词:图像修复;深度学习;卷积神经网络;生成式对抗网络;循环神经网络;深度卷积自编码器网络45|7|21更新时间:2024-05-07
摘要:目的图像修复是计算机视觉领域研究的一项重要内容,其目的是根据图像中已知内容来自动地恢复丢失的内容,在图像编辑、影视特技制作、虚拟现实及数字文化遗产保护等领域都具有广泛的应用价值。而近年来,随着深度学习在学术界和工业界的广泛研究,其在图像语义提取、特征表示、图像生成等方面的应用优势日益突出,使得基于深度学习的图像修复方法的研究成为了国内外一个研究热点,得到了越来越多的关注。为了使更多研究者对基于深度学习的图像修复理论及其发展进行探索,本文对该领域研究现状进行综述。方法首先对基于深度学习图像修复方法提出的理论依据进行分析;然后对其中涉及的关键技术进行研究;总结了近年来基于深度学习的主要图像修复方法,并依据修复网络的结构对现有方法进行了分类,即分为基于卷积自编码网络结构的图像修复方法、基于生成式对抗网络结构的图像修复方法和基于循环神经网络结构的图像修复方法。结果在基于深度学习的图像修复方法中,深度学习网络的设计和训练过程中的损失函数的选择是其重要的内容,各类方法各有优缺点和其适用范围,如何提高修复结果语义的合理性、结构及细节的正确性,一直是研究者们努力的方向,基于此目的,本文通过实验分析总结了各类方法的主要特点、存在的问题、对训练样本的要求、主要应用领域及参考代码。结论基于深度学习图像修复领域的研究已经取得了一些显著进展,但目前深度学习在图像修复中的应用仍处于起步阶段,主要研究的内容也仅仅是利用待修复图像本身的图像内容信息,因此基于深度学习的图像修复仍是一个极具挑战的课题。如何设计具有普适性的修复网络,提高修复结果的准确性,还需要更加深入的研究。关键词:图像修复;深度学习;卷积神经网络;生成式对抗网络;循环神经网络;深度卷积自编码器网络45|7|21更新时间:2024-05-07 -
 摘要:目的基于全卷积神经网络的图像语义分割研究已成为该领域的主流研究方向。然而,在该网络框架中由于特征图的多次下采样使得图像分辨率逐渐下降,致使小目标丢失,边缘粗糙,语义分割结果较差。为解决或缓解该问题,提出一种基于特征图切分的图像语义分割方法。方法本文方法主要包含中间层特征图切分与相对应的特征提取两部分操作。特征图切分模块主要针对中间层特征图,将其切分成若干等份,同时将每一份上采样至原特征图大小,使每个切分区域的分辨率增大;然后,各个切分特征图通过参数共享的特征提取模块,该模块中的多尺度卷积与注意力机制,有效利用各切块的上下文信息与判别信息,使其更关注局部区域的小目标物体,提高小目标物体的判别力。进一步,再将提取的特征与网络原输出相融合,从而能够更高效地进行中间层特征复用,对小目标识别定位、分割边缘精细化以及网络语义判别力有明显改善。结果在两个城市道路数据集CamVid以及GATECH上进行验证实验,论证本文方法的有效性。在CamVid数据集上平均交并比达到66.3%,在GATECH上平均交并比达到52.6%。结论基于特征图切分的图像分割方法,更好地利用了图像的空间区域分布信息,增强了网络对于不同空间位置的语义类别判定能力以及小目标物体的关注度,提供更有效的上下文信息和全局信息,提高了网络对于小目标物体的判别能力,改善了网络整体分割性能。关键词:深度学习;全卷积神经网络;语义分割;场景解析;特征切分;多尺度;特征复用19|5|4更新时间:2024-05-07
摘要:目的基于全卷积神经网络的图像语义分割研究已成为该领域的主流研究方向。然而,在该网络框架中由于特征图的多次下采样使得图像分辨率逐渐下降,致使小目标丢失,边缘粗糙,语义分割结果较差。为解决或缓解该问题,提出一种基于特征图切分的图像语义分割方法。方法本文方法主要包含中间层特征图切分与相对应的特征提取两部分操作。特征图切分模块主要针对中间层特征图,将其切分成若干等份,同时将每一份上采样至原特征图大小,使每个切分区域的分辨率增大;然后,各个切分特征图通过参数共享的特征提取模块,该模块中的多尺度卷积与注意力机制,有效利用各切块的上下文信息与判别信息,使其更关注局部区域的小目标物体,提高小目标物体的判别力。进一步,再将提取的特征与网络原输出相融合,从而能够更高效地进行中间层特征复用,对小目标识别定位、分割边缘精细化以及网络语义判别力有明显改善。结果在两个城市道路数据集CamVid以及GATECH上进行验证实验,论证本文方法的有效性。在CamVid数据集上平均交并比达到66.3%,在GATECH上平均交并比达到52.6%。结论基于特征图切分的图像分割方法,更好地利用了图像的空间区域分布信息,增强了网络对于不同空间位置的语义类别判定能力以及小目标物体的关注度,提供更有效的上下文信息和全局信息,提高了网络对于小目标物体的判别能力,改善了网络整体分割性能。关键词:深度学习;全卷积神经网络;语义分割;场景解析;特征切分;多尺度;特征复用19|5|4更新时间:2024-05-07 -
 摘要:目的目前主流物体检测算法需要预先划定默认框,通过对默认框的筛选剔除得到物体框。为了保证足够的召回率,就必须要预设足够密集和多尺度的默认框,这就导致了图像中各个区域被重复检测,造成了极大的计算浪费。提出一种不需要划定默认框,实现完全端到端深度学习语义分割及物体检测的多任务深度学习模型(FCDN),使得检测模型能够在保证精度的同时提高检测速度。方法首先分析了被检测物体数量不可预知是目前主流物体检测算法需要预先划定默认框的原因,由于目前深度学习物体检测算法都是由图像分类模型拓展而来,被检测数量的无法预知导致无法设置检测模型的输出,为了保证召回率,必须要对足够密集和多尺度的默认框进行分类识别;物体检测任务需要物体的类别信息以实现对不同类物体的识别,也需要物体的边界信息以实现对各个物体的区分、定位;语义分割提取了丰富的物体类别信息,可以根据语义分割图识别物体的种类,同时采用语义分割的思想,设计模块提取图像中物体的边界关键点,结合语义分割图和边界关键点分布图,从而完成物体的识别和定位。结果为了验证基于语义分割思想的物体检测方法的可行性,训练模型并在VOC(visual object classes)2007 test数据集上进行测试,与目前主流物体检测算法进行性能对比,结果表明,利用新模型可以同时实现语义分割和物体检测任务,在训练样本相同的条件下训练后,其物体检测精度优于经典的物体检测模型;在算法的运行速度上,相比于FCN,减少了8 ms,比较接近于YOLO(you only look once)等快速检测算法。结论本文提出了一种新的物体检测思路,不再以图像分类为检测基础,不需要对预设的密集且多尺度的默认框进行分类识别;实验结果表明充分利用语义分割提取的丰富信息,根据语义分割图和边界关键点完成物体检测的方法是可行的,该方法避免了对图像的重复检测和计算浪费;同时通过减少语义分割预测的像素点数量来提高检测效率,并通过实验验证简化后的语义分割结果仍足够进行物体检测任务。关键词:深度学习;物体检测;语义分割;边界关键点;多任务学习;迁移学习;默认框24|29|4更新时间:2024-05-07
摘要:目的目前主流物体检测算法需要预先划定默认框,通过对默认框的筛选剔除得到物体框。为了保证足够的召回率,就必须要预设足够密集和多尺度的默认框,这就导致了图像中各个区域被重复检测,造成了极大的计算浪费。提出一种不需要划定默认框,实现完全端到端深度学习语义分割及物体检测的多任务深度学习模型(FCDN),使得检测模型能够在保证精度的同时提高检测速度。方法首先分析了被检测物体数量不可预知是目前主流物体检测算法需要预先划定默认框的原因,由于目前深度学习物体检测算法都是由图像分类模型拓展而来,被检测数量的无法预知导致无法设置检测模型的输出,为了保证召回率,必须要对足够密集和多尺度的默认框进行分类识别;物体检测任务需要物体的类别信息以实现对不同类物体的识别,也需要物体的边界信息以实现对各个物体的区分、定位;语义分割提取了丰富的物体类别信息,可以根据语义分割图识别物体的种类,同时采用语义分割的思想,设计模块提取图像中物体的边界关键点,结合语义分割图和边界关键点分布图,从而完成物体的识别和定位。结果为了验证基于语义分割思想的物体检测方法的可行性,训练模型并在VOC(visual object classes)2007 test数据集上进行测试,与目前主流物体检测算法进行性能对比,结果表明,利用新模型可以同时实现语义分割和物体检测任务,在训练样本相同的条件下训练后,其物体检测精度优于经典的物体检测模型;在算法的运行速度上,相比于FCN,减少了8 ms,比较接近于YOLO(you only look once)等快速检测算法。结论本文提出了一种新的物体检测思路,不再以图像分类为检测基础,不需要对预设的密集且多尺度的默认框进行分类识别;实验结果表明充分利用语义分割提取的丰富信息,根据语义分割图和边界关键点完成物体检测的方法是可行的,该方法避免了对图像的重复检测和计算浪费;同时通过减少语义分割预测的像素点数量来提高检测效率,并通过实验验证简化后的语义分割结果仍足够进行物体检测任务。关键词:深度学习;物体检测;语义分割;边界关键点;多任务学习;迁移学习;默认框24|29|4更新时间:2024-05-07 -
 摘要:目的人群密度估计任务是通过对人群特征的提取和分析,估算出密度分布情况和人群计数结果。现有技术运用的CNN网络中的下采样操作会丢失部分人群信息,且平均融合方式会使多尺度效应平均化,该策略并不一定能得到准确的估计结果。为了解决上述问题,提出一种新的基于对抗式扩张卷积的多尺度人群密度估计模型。方法利用扩张卷积在不损失分辨率的情况下对输入图像进行特征提取,且不同的扩张系数可以聚集多尺度上下文信息。最后通过对抗式损失函数将网络中提取的不同尺度的特征信息以合作式的方式融合,得到准确的密度估计结果。结果在4个主要的人群计数数据集上进行对比实验。在测试阶段,将测试图像输入训练好的生成器网络,输出预测密度图;将密度图积分求和得到总人数,并以平均绝对误差(MAE)和均方误差(MSE)作为评价指标进行结果对比。其中,在ShanghaiTech数据集上Part_A的MAE和MSE分别降至60.5和109.7,Part_B的MAE和MSE分别降至10.2和15.3,提升效果明显。结论本文提出了一种新的基于对抗式扩张卷积的多尺度人群密度估计模型。实验结果表明,在人群分布差异较大的场景中构建的算法模型有较好的自适应性,能根据不同的场景提取特征估算密度分布,并对人群进行准确计数。关键词:人群密度估计;多尺度;对抗式损失;扩张卷积;计算机视觉;人群安全13|4|1更新时间:2024-05-07
摘要:目的人群密度估计任务是通过对人群特征的提取和分析,估算出密度分布情况和人群计数结果。现有技术运用的CNN网络中的下采样操作会丢失部分人群信息,且平均融合方式会使多尺度效应平均化,该策略并不一定能得到准确的估计结果。为了解决上述问题,提出一种新的基于对抗式扩张卷积的多尺度人群密度估计模型。方法利用扩张卷积在不损失分辨率的情况下对输入图像进行特征提取,且不同的扩张系数可以聚集多尺度上下文信息。最后通过对抗式损失函数将网络中提取的不同尺度的特征信息以合作式的方式融合,得到准确的密度估计结果。结果在4个主要的人群计数数据集上进行对比实验。在测试阶段,将测试图像输入训练好的生成器网络,输出预测密度图;将密度图积分求和得到总人数,并以平均绝对误差(MAE)和均方误差(MSE)作为评价指标进行结果对比。其中,在ShanghaiTech数据集上Part_A的MAE和MSE分别降至60.5和109.7,Part_B的MAE和MSE分别降至10.2和15.3,提升效果明显。结论本文提出了一种新的基于对抗式扩张卷积的多尺度人群密度估计模型。实验结果表明,在人群分布差异较大的场景中构建的算法模型有较好的自适应性,能根据不同的场景提取特征估算密度分布,并对人群进行准确计数。关键词:人群密度估计;多尺度;对抗式损失;扩张卷积;计算机视觉;人群安全13|4|1更新时间:2024-05-07
ChinaMM 2018
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0