
最新刊期
2019 年 第 24 卷 第 2 期
-
 摘要:目的服装检索对于在线服装的推广和销售有着重要的作用。而目前的服装检索算法无法准确地检索出非文本描述的服装。特别是对于跨场景的多标签服装图片,服装检索算法的准确率还有待提升。本文针对跨场景多标签服装图片的差异性较大以及卷积神经网络输出特征维度过高的问题,提出了深度多标签解析和哈希的服装检索算法。方法该方法首先在FCN(fully convolutional network)的基础上加入条件随机场,对FCN的结果进行后处理,搭建了FCN粗分割加CRFs(conditional random fields)精分割的端到端的网络结构,实现了像素级别的语义识别。其次,针对跨场景服装检索的特点,我们调整了CCP(Clothing Co-Parsing)数据集,并构建了Consumer-to-Shop数据集。针对检索过程中容易出现的语义漂移现象,使用多任务学习网络分别训练了衣物分类模型和衣物相似度模型。结果我们首先在Consumer-to-Shop数据集上进行了服装解析的对比实验,实验结果表明在添加了CRFs作为后处理之后,服装解析的效果有了明显提升。然后与3种主流检索算法进行了对比,结果显示,本文方法在使用哈希特征的条件下,也可以取得较好的检索效果。在top-5正确率上比WTBI(where to buy it)高出1.31%,比DARN(dual attribute-aware ranking network)高出0.21%。结论针对服装检索的跨场景效果差、检索效率低的问题,本文提出了一种基于像素级别语义分割和哈希编码的快速多目标服装检索方法。与其他检索方法相比,本文在多目标、多标签服装检索场景有一定的优势,并且在保持了一定检索效果的前提下,有效地降低了存储空间,提高了检索效率。关键词:服装检索;全卷积网络;哈希映射;多标签解析;多任务学习20|61|3更新时间:2024-05-07
摘要:目的服装检索对于在线服装的推广和销售有着重要的作用。而目前的服装检索算法无法准确地检索出非文本描述的服装。特别是对于跨场景的多标签服装图片,服装检索算法的准确率还有待提升。本文针对跨场景多标签服装图片的差异性较大以及卷积神经网络输出特征维度过高的问题,提出了深度多标签解析和哈希的服装检索算法。方法该方法首先在FCN(fully convolutional network)的基础上加入条件随机场,对FCN的结果进行后处理,搭建了FCN粗分割加CRFs(conditional random fields)精分割的端到端的网络结构,实现了像素级别的语义识别。其次,针对跨场景服装检索的特点,我们调整了CCP(Clothing Co-Parsing)数据集,并构建了Consumer-to-Shop数据集。针对检索过程中容易出现的语义漂移现象,使用多任务学习网络分别训练了衣物分类模型和衣物相似度模型。结果我们首先在Consumer-to-Shop数据集上进行了服装解析的对比实验,实验结果表明在添加了CRFs作为后处理之后,服装解析的效果有了明显提升。然后与3种主流检索算法进行了对比,结果显示,本文方法在使用哈希特征的条件下,也可以取得较好的检索效果。在top-5正确率上比WTBI(where to buy it)高出1.31%,比DARN(dual attribute-aware ranking network)高出0.21%。结论针对服装检索的跨场景效果差、检索效率低的问题,本文提出了一种基于像素级别语义分割和哈希编码的快速多目标服装检索方法。与其他检索方法相比,本文在多目标、多标签服装检索场景有一定的优势,并且在保持了一定检索效果的前提下,有效地降低了存储空间,提高了检索效率。关键词:服装检索;全卷积网络;哈希映射;多标签解析;多任务学习20|61|3更新时间:2024-05-07 -
 摘要:目的图像去雾是降低雾、霾、沙等低能见度成像环境对图像的退化影响,提高图像信息获取质量的过程。为了消除先验盲区,同时进一步提高去雾图像边缘细节的清晰度,提出一种混合先验与加权引导滤波的图像去雾算法。方法首先改进大气光值估计方法,提高大气光值估计的准确性。然后利用混合先验理论求取双约束区域的大气透射率,一定程度上消除了先验盲区,提高了去雾算法的鲁棒性。最后利用加权引导滤波算法优化透射率图,提高了图像边缘细节的清晰度。结果本文以通用去雾测试图像和小型无人机拍摄的雾天图像作为实验对象,通过对比分析4种组合步骤算法的复原效果,验证本文各步骤改进方法的合理性与整体算法的优越性。实验结果表明:混合先验理论改善了暗原色先验在明亮区域的失真现象和颜色衰减先验对浓雾处理上的不足,取得了较好的视觉效果;加权引导滤波改善了图像边缘模糊的现象,使复原后的图像边缘细节更加清晰;相较传统算法,本文算法视觉效果更好,去雾图像边缘细节更加明显,综合评价指标均值提升幅度较大。结论针对有雾图像复原,通过理论分析和实验验证,说明了本文各步骤的改进具有一定的优越性,所提的算法具有较强的鲁棒性。关键词:图像去雾;混合先验;双约束区域;引导滤波;大气光值22|5|6更新时间:2024-05-07
摘要:目的图像去雾是降低雾、霾、沙等低能见度成像环境对图像的退化影响,提高图像信息获取质量的过程。为了消除先验盲区,同时进一步提高去雾图像边缘细节的清晰度,提出一种混合先验与加权引导滤波的图像去雾算法。方法首先改进大气光值估计方法,提高大气光值估计的准确性。然后利用混合先验理论求取双约束区域的大气透射率,一定程度上消除了先验盲区,提高了去雾算法的鲁棒性。最后利用加权引导滤波算法优化透射率图,提高了图像边缘细节的清晰度。结果本文以通用去雾测试图像和小型无人机拍摄的雾天图像作为实验对象,通过对比分析4种组合步骤算法的复原效果,验证本文各步骤改进方法的合理性与整体算法的优越性。实验结果表明:混合先验理论改善了暗原色先验在明亮区域的失真现象和颜色衰减先验对浓雾处理上的不足,取得了较好的视觉效果;加权引导滤波改善了图像边缘模糊的现象,使复原后的图像边缘细节更加清晰;相较传统算法,本文算法视觉效果更好,去雾图像边缘细节更加明显,综合评价指标均值提升幅度较大。结论针对有雾图像复原,通过理论分析和实验验证,说明了本文各步骤的改进具有一定的优越性,所提的算法具有较强的鲁棒性。关键词:图像去雾;混合先验;双约束区域;引导滤波;大气光值22|5|6更新时间:2024-05-07 -
 摘要:目的图像的梯度分布被广泛应用在自然图像去模糊中,但研究结果显示先前的梯度参数估计方法不能很好地适应图像局部纹理变化。为此根据图像分块平稳的特点提出一种采用局部自适应梯度稀疏模型的图像去模糊模型。方法该模型采用广义高斯分布(GGD)来描述图像不同区域的梯度分布,在最大后验概率框架下建立自适应梯度稀疏模型,然后采用变量分裂交替优化算法来求解模型中的最小化问题。在GGD参数估计中,先对模糊图像进行预处理,并将预处理后的图像分成纹理区和平滑区,仅对纹理区采用全局收敛算法进行GGD参数估计,而对平滑区设置固定参数值。结果本文算法与近年来常用的去模糊去噪算法在不同类型的自然图像上进行了对比。实验结果表明,本文的参数估计法能精确地表达图像局部纹理变化,当在低噪声(加1%噪声),分别加入模糊核1和2的条件下,经本文算法去除模糊和噪声后的图像相较对比算法能分别提高信噪比值0.04~2.96 dB和0.14~3.19 dB;在高噪声(加4%噪声)不同模糊核下,能分别提高0.19~4.50 dB和0.20~3.63 dB,同时本文算法相比2017年Pan等人提出的算法(加2%噪声)能提升0.15~0.36 dB。此外,本文算法在主观视觉上能获得更清晰的纹理和边缘结构信息。结论本文算法在主客观评价上都表现出了良好的去模糊性能,可应用在自然图像和低照明图像等的去模糊领域。关键词:图像去模糊;自适应梯度稀疏;统计先验;分布参数估计;图像反卷积27|49|1更新时间:2024-05-07
摘要:目的图像的梯度分布被广泛应用在自然图像去模糊中,但研究结果显示先前的梯度参数估计方法不能很好地适应图像局部纹理变化。为此根据图像分块平稳的特点提出一种采用局部自适应梯度稀疏模型的图像去模糊模型。方法该模型采用广义高斯分布(GGD)来描述图像不同区域的梯度分布,在最大后验概率框架下建立自适应梯度稀疏模型,然后采用变量分裂交替优化算法来求解模型中的最小化问题。在GGD参数估计中,先对模糊图像进行预处理,并将预处理后的图像分成纹理区和平滑区,仅对纹理区采用全局收敛算法进行GGD参数估计,而对平滑区设置固定参数值。结果本文算法与近年来常用的去模糊去噪算法在不同类型的自然图像上进行了对比。实验结果表明,本文的参数估计法能精确地表达图像局部纹理变化,当在低噪声(加1%噪声),分别加入模糊核1和2的条件下,经本文算法去除模糊和噪声后的图像相较对比算法能分别提高信噪比值0.04~2.96 dB和0.14~3.19 dB;在高噪声(加4%噪声)不同模糊核下,能分别提高0.19~4.50 dB和0.20~3.63 dB,同时本文算法相比2017年Pan等人提出的算法(加2%噪声)能提升0.15~0.36 dB。此外,本文算法在主观视觉上能获得更清晰的纹理和边缘结构信息。结论本文算法在主客观评价上都表现出了良好的去模糊性能,可应用在自然图像和低照明图像等的去模糊领域。关键词:图像去模糊;自适应梯度稀疏;统计先验;分布参数估计;图像反卷积27|49|1更新时间:2024-05-07 -
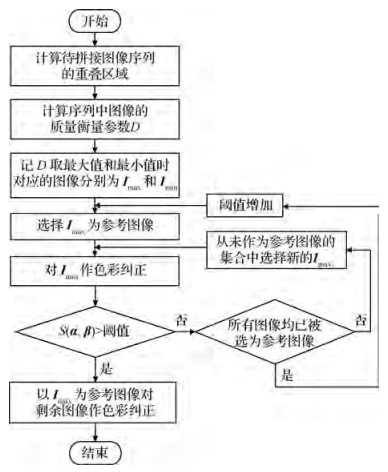 摘要:目的色彩纠正和图像融合是生成高质量全景场景图像的关键技术。色彩纠正中参考图像的选择以及图像融合算法,决定着所生成全景图像的质量和速度。现有方法在确定一幅图像是否适合作为参考图像时,需要遍历所有其他图像,计算其作为参考图像进行色彩纠正的效果,复杂度高,速度慢;在图像融合时存在融合质量与融合速度之间的矛盾。因此,如何快速生成高质量的全景图像就成为全景场景再现的主要诉求。为此本文提出优化的参考图像自动选择的色彩纠正方法和基于重叠区域划分的分区融合方法。方法针对参考图像选择算法复杂度高的问题,根据图像质量与稳定性通常呈反比关系的事实,采用贪婪策略,选择质量最差的图像在色彩纠正前后的相似度,作为是否选择当前图像作为参考图像的评价指标,在保证参考图像满足色彩纠正需求的前提下,大幅降低计算复杂度。针对融合质量与融合速度之间的矛盾,提出分区融合:将重叠区域划分为接缝区域和非接缝区域,利用泊松融合的接缝不可见性和线性融合实现速度快的特性分别对接缝区域和非接缝区域进行融合,既保证融合的质量,又加快融合速度。在此基础上,加入简单点光源,解决上述过程产生的光线一致性问题,进一步提高图像质量。结果采用主观和客观相结合的方法对结果进行评估。主观方面,本文算法生成的全景图像色彩基本实现平滑过渡且图像原始信息保留完整。客观方面,色彩纠正前后图像的结构相似度(SSIM)控制在0.85~0.99之间,时间复杂度由原来的O(
摘要:目的色彩纠正和图像融合是生成高质量全景场景图像的关键技术。色彩纠正中参考图像的选择以及图像融合算法,决定着所生成全景图像的质量和速度。现有方法在确定一幅图像是否适合作为参考图像时,需要遍历所有其他图像,计算其作为参考图像进行色彩纠正的效果,复杂度高,速度慢;在图像融合时存在融合质量与融合速度之间的矛盾。因此,如何快速生成高质量的全景图像就成为全景场景再现的主要诉求。为此本文提出优化的参考图像自动选择的色彩纠正方法和基于重叠区域划分的分区融合方法。方法针对参考图像选择算法复杂度高的问题,根据图像质量与稳定性通常呈反比关系的事实,采用贪婪策略,选择质量最差的图像在色彩纠正前后的相似度,作为是否选择当前图像作为参考图像的评价指标,在保证参考图像满足色彩纠正需求的前提下,大幅降低计算复杂度。针对融合质量与融合速度之间的矛盾,提出分区融合:将重叠区域划分为接缝区域和非接缝区域,利用泊松融合的接缝不可见性和线性融合实现速度快的特性分别对接缝区域和非接缝区域进行融合,既保证融合的质量,又加快融合速度。在此基础上,加入简单点光源,解决上述过程产生的光线一致性问题,进一步提高图像质量。结果采用主观和客观相结合的方法对结果进行评估。主观方面,本文算法生成的全景图像色彩基本实现平滑过渡且图像原始信息保留完整。客观方面,色彩纠正前后图像的结构相似度(SSIM)控制在0.85~0.99之间,时间复杂度由原来的O(${n^2}$ $n$ 关键词:全景场景再现;参考图像;色彩纠正;图像融合;区域划分;局部光源11|6|0更新时间:2024-05-07
图像处理和编码

-
 摘要:目的传统人脸检测方法因人脸多姿态变化和人脸面部特征不完整等问题,导致检测效果不佳。为解决上述问题,提出一种两层级联卷积神经网络(TC_CNN)人脸检测方法。方法首先,构建两层卷积神经网络模型,利用前端卷积神经网络模型对人脸图像进行特征粗略提取,再利用最大值池化方法对粗提取得到的人脸特征进行降维操作,输出多个疑似人脸窗口;其次,将前端粗提取得到的人脸窗口作为后端卷积神经网络模型的输入进行特征精细提取,并通过池化操作得到新的特征图;最后,通过全连接层判别输出最佳检测窗口,完成人脸检测全过程。结果实验选取FDDB人脸检测数据集中包含人脸多姿态变化以及人脸面部特征信息不完整等情况的图像进行测试,TC_CNN方法人脸检测率达到96.39%,误检率低至3.78%,相比当前流行方法在保证算法效率的同时检测率均有提高。结论两层级联卷积神经网络人脸检测方法能够在人脸多姿态变化和面部特征信息不完整等情况下实现精准检测,保证较高的检测率,有效降低误检率,方法具有较好的鲁棒性和泛化能力。关键词:人脸检测;卷积神经网络;十折交叉验证;两层级联卷积神经网络;最大值池化19|35|3更新时间:2024-05-07
摘要:目的传统人脸检测方法因人脸多姿态变化和人脸面部特征不完整等问题,导致检测效果不佳。为解决上述问题,提出一种两层级联卷积神经网络(TC_CNN)人脸检测方法。方法首先,构建两层卷积神经网络模型,利用前端卷积神经网络模型对人脸图像进行特征粗略提取,再利用最大值池化方法对粗提取得到的人脸特征进行降维操作,输出多个疑似人脸窗口;其次,将前端粗提取得到的人脸窗口作为后端卷积神经网络模型的输入进行特征精细提取,并通过池化操作得到新的特征图;最后,通过全连接层判别输出最佳检测窗口,完成人脸检测全过程。结果实验选取FDDB人脸检测数据集中包含人脸多姿态变化以及人脸面部特征信息不完整等情况的图像进行测试,TC_CNN方法人脸检测率达到96.39%,误检率低至3.78%,相比当前流行方法在保证算法效率的同时检测率均有提高。结论两层级联卷积神经网络人脸检测方法能够在人脸多姿态变化和面部特征信息不完整等情况下实现精准检测,保证较高的检测率,有效降低误检率,方法具有较好的鲁棒性和泛化能力。关键词:人脸检测;卷积神经网络;十折交叉验证;两层级联卷积神经网络;最大值池化19|35|3更新时间:2024-05-07 -
 摘要:目的人脸2维图像反映出来的纹理并非是3维人脸曲面真实的纹理,并且受光照和妆容的影响很大,因此探索3维局部纹理特征对于人脸识别任务有着重要的意义。为此详细分析了一种新颖的3维局部纹理特征mesh-LBP对于人脸纹理的描述能力。方法首先,在特征提取和识别任务之前,进行一系列的预处理:人脸分割、离群点移除和孔洞填补;接着,在预处理后的人脸曲面上,提取原始mesh-LBP特征,以及基于阈值化策略的3种改进特征:mesh-tLBP、mesh-MBP和mesh-LTP;然后,对于上述提取的4种特征,采用不同的统计方法,包括整体直方图、局部分块直方图和整体编码图像,用做人脸纹理的特征描述。最后,针对CASIA3D数据集中不同表情和姿态变化的人脸,采用余弦相似度进行人脸的识别任务。结果通过对比人脸曲面和普通物体曲面的纹理特征,发现人脸纹理完全不同于普通纹理,不规则并且难以描述;通过对比mesh-LBP两种变体,发现mesh-LBP(
摘要:目的人脸2维图像反映出来的纹理并非是3维人脸曲面真实的纹理,并且受光照和妆容的影响很大,因此探索3维局部纹理特征对于人脸识别任务有着重要的意义。为此详细分析了一种新颖的3维局部纹理特征mesh-LBP对于人脸纹理的描述能力。方法首先,在特征提取和识别任务之前,进行一系列的预处理:人脸分割、离群点移除和孔洞填补;接着,在预处理后的人脸曲面上,提取原始mesh-LBP特征,以及基于阈值化策略的3种改进特征:mesh-tLBP、mesh-MBP和mesh-LTP;然后,对于上述提取的4种特征,采用不同的统计方法,包括整体直方图、局部分块直方图和整体编码图像,用做人脸纹理的特征描述。最后,针对CASIA3D数据集中不同表情和姿态变化的人脸,采用余弦相似度进行人脸的识别任务。结果通过对比人脸曲面和普通物体曲面的纹理特征,发现人脸纹理完全不同于普通纹理,不规则并且难以描述;通过对比mesh-LBP两种变体,发现mesh-LBP($α_1$ $α_2$ 关键词:3维纹理;mesh-LBP;阈值化策略;统计方法;3维人脸识别11|4|1更新时间:2024-05-07 -
 摘要:目的表情识别在商业、安全、医学等领域有着广泛的应用前景,能够快速准确地识别出面部表情对其研究与应用具有重要意义。传统的机器学习方法需要手工提取特征且准确率难以保证。近年来,卷积神经网络因其良好的自学习和泛化能力得到广泛应用,但还存在表情特征提取困难、网络训练时间过长等问题,针对以上问题,提出一种基于并行卷积神经网络的表情识别方法。方法首先对面部表情图像进行人脸定位、灰度统一以及角度调整等预处理,去除了复杂的背景、光照、角度等影响,得到了精确的人脸部分。然后针对表情图像设计一个具有两个并行卷积池化单元的卷积神经网络,可以提取细微的表情部分。该并行结构具有3个不同的通道,分别提取不同的图像特征并进行融合,最后送入SoftMax层进行分类。结果实验使用提出的并行卷积神经网络在CK+、FER2013两个表情数据集上进行了10倍交叉验证,最终的结果取10次验证的平均值,在CK+及FER2013上取得了94.03%与65.6%的准确率。迭代一次的时间分别为0.185 s和0.101 s。结论为卷积神经网络的设计提供了一种新思路,可以在控制深度的同时扩展广度,提取更多的表情特征。实验结果表明,针对数量、分辨率、大小等差异较大的表情数据集,该网络模型均能够获得较高的识别率并缩短训练时间。关键词:表情识别;深度学习;卷积神经网络;并行处理;图像分类21|70|21更新时间:2024-05-07
摘要:目的表情识别在商业、安全、医学等领域有着广泛的应用前景,能够快速准确地识别出面部表情对其研究与应用具有重要意义。传统的机器学习方法需要手工提取特征且准确率难以保证。近年来,卷积神经网络因其良好的自学习和泛化能力得到广泛应用,但还存在表情特征提取困难、网络训练时间过长等问题,针对以上问题,提出一种基于并行卷积神经网络的表情识别方法。方法首先对面部表情图像进行人脸定位、灰度统一以及角度调整等预处理,去除了复杂的背景、光照、角度等影响,得到了精确的人脸部分。然后针对表情图像设计一个具有两个并行卷积池化单元的卷积神经网络,可以提取细微的表情部分。该并行结构具有3个不同的通道,分别提取不同的图像特征并进行融合,最后送入SoftMax层进行分类。结果实验使用提出的并行卷积神经网络在CK+、FER2013两个表情数据集上进行了10倍交叉验证,最终的结果取10次验证的平均值,在CK+及FER2013上取得了94.03%与65.6%的准确率。迭代一次的时间分别为0.185 s和0.101 s。结论为卷积神经网络的设计提供了一种新思路,可以在控制深度的同时扩展广度,提取更多的表情特征。实验结果表明,针对数量、分辨率、大小等差异较大的表情数据集,该网络模型均能够获得较高的识别率并缩短训练时间。关键词:表情识别;深度学习;卷积神经网络;并行处理;图像分类21|70|21更新时间:2024-05-07 -
 摘要:目的针对直线描述子匹配算法缺乏有效的几何约束,且易受弱纹理、尺度变化的影响,提出一种结合多重约束条件的LBD描述子的直线段匹配算法(LBDs)。方法该算法以LSD算法提取的直线段作为匹配基元,利用SIFT匹配得到的同名点构建同名三角网约束确定候选直线;参考影像上以目标直线段为中心轴建立该直线段的矩形支撑域;根据目标直线段端点及其支撑域四角点在搜索影像上的核线约束建立候选直线段的对应支撑域;利用仿射变换统一目标直线段及候选直线段支撑域的大小;将直线段支撑域分解为大小相等的条形带,通过计算每个条形带的描述符得到该直线段的描述子,依次完成目标直线段与候选直线段LBD描述子的构建;分别计算目标直线段与每个候选直线段描述子向量间的欧氏距离,将满足最近邻距离比准则的候选直线段作为匹配结果;最后选取角度约束对匹配结果检核,确定同名直线。结果实验选取网上公开的3组分别存在角度、旋转、尺度变换的近景影像对作为实验数据,采用LBDs分别对其进行直线段匹配实验,并与其他直线段匹配算法进行对比分析,实验结果表明,LBDs获取同名直线数目约为其他算法的1.061.41倍,匹配正确率也提高了2.411.6个百分点,从匹配效率上来看,LBDs更为耗时,但兼顾该算法匹配获得同名直线数目、匹配正确率及运行时间,LBDs的鲁棒性更强,匹配结果的准确性与可靠性较高。结论结合多重约束条件构建的LBD描述子对于存在角度、旋转和尺度变化的影像进行直线匹配过程中具有稳定性。关键词:多重约束;LBD描述子;直线匹配;最近邻距离比;角度约束11|4|3更新时间:2024-05-07
摘要:目的针对直线描述子匹配算法缺乏有效的几何约束,且易受弱纹理、尺度变化的影响,提出一种结合多重约束条件的LBD描述子的直线段匹配算法(LBDs)。方法该算法以LSD算法提取的直线段作为匹配基元,利用SIFT匹配得到的同名点构建同名三角网约束确定候选直线;参考影像上以目标直线段为中心轴建立该直线段的矩形支撑域;根据目标直线段端点及其支撑域四角点在搜索影像上的核线约束建立候选直线段的对应支撑域;利用仿射变换统一目标直线段及候选直线段支撑域的大小;将直线段支撑域分解为大小相等的条形带,通过计算每个条形带的描述符得到该直线段的描述子,依次完成目标直线段与候选直线段LBD描述子的构建;分别计算目标直线段与每个候选直线段描述子向量间的欧氏距离,将满足最近邻距离比准则的候选直线段作为匹配结果;最后选取角度约束对匹配结果检核,确定同名直线。结果实验选取网上公开的3组分别存在角度、旋转、尺度变换的近景影像对作为实验数据,采用LBDs分别对其进行直线段匹配实验,并与其他直线段匹配算法进行对比分析,实验结果表明,LBDs获取同名直线数目约为其他算法的1.061.41倍,匹配正确率也提高了2.411.6个百分点,从匹配效率上来看,LBDs更为耗时,但兼顾该算法匹配获得同名直线数目、匹配正确率及运行时间,LBDs的鲁棒性更强,匹配结果的准确性与可靠性较高。结论结合多重约束条件构建的LBD描述子对于存在角度、旋转和尺度变化的影像进行直线匹配过程中具有稳定性。关键词:多重约束;LBD描述子;直线匹配;最近邻距离比;角度约束11|4|3更新时间:2024-05-07
图像分析和识别
-
 摘要:目的点云目标识别流程分为离线与在线阶段。离线阶段基于待识别目标的CAD模型构建一个模型库,在线基于近邻查找完成识别。本文针对离线阶段,提出一种新的模型库构建方法。方法首先将CAD模型置于一个二十面体中心,使用多个虚拟相机获取CAD模型在不同视角下的点云;然后将每个不同视角下的点云进行主成分分析并基于主成分分析的结果从多个选定的方向将点云切分为多个子部分,这些子部分包含点云的全局及局部信息;接着对每个子部分使用聚类算法获取其最大聚类,去除离群点;最后结合多种方式删减一些冗余聚类,减小模型库规模。结果在多个公开数据集上使用多种点云描述子进行对比实验,识别结果表明,相对于传统的模型库构建方法,基于本文方法进行识别正确率更高,在某些点云描述子上的识别正确率提升达到10%以上。结论通过将CAD模型在不同视角下点云的全局与局部信息都加入模型库中,本文提出的模型库构建方法可有效提高点云目标识别正确率,改善了场景目标发生遮挡时,近邻查找识别精度不高的问题。关键词:点云目标识别;离线阶段;模型库构建;点云特征提取;全局与局部35|8|3更新时间:2024-05-07
摘要:目的点云目标识别流程分为离线与在线阶段。离线阶段基于待识别目标的CAD模型构建一个模型库,在线基于近邻查找完成识别。本文针对离线阶段,提出一种新的模型库构建方法。方法首先将CAD模型置于一个二十面体中心,使用多个虚拟相机获取CAD模型在不同视角下的点云;然后将每个不同视角下的点云进行主成分分析并基于主成分分析的结果从多个选定的方向将点云切分为多个子部分,这些子部分包含点云的全局及局部信息;接着对每个子部分使用聚类算法获取其最大聚类,去除离群点;最后结合多种方式删减一些冗余聚类,减小模型库规模。结果在多个公开数据集上使用多种点云描述子进行对比实验,识别结果表明,相对于传统的模型库构建方法,基于本文方法进行识别正确率更高,在某些点云描述子上的识别正确率提升达到10%以上。结论通过将CAD模型在不同视角下点云的全局与局部信息都加入模型库中,本文提出的模型库构建方法可有效提高点云目标识别正确率,改善了场景目标发生遮挡时,近邻查找识别精度不高的问题。关键词:点云目标识别;离线阶段;模型库构建;点云特征提取;全局与局部35|8|3更新时间:2024-05-07
图像理解和计算机视觉
-
 摘要:目的深度学习已经大量应用于合成孔径宽达(SAR)图像目标识别领域,但大多数工作是基于MSTAR数据集的标准操作条件展开研究。当将深度学习应用于同类含变体目标时,例如T72子类,由于目标间差异小,所以仍存在着较大的挑战。本文从极大限度地保留SAR图像输入特征出发,设计一种适用于SAR变体目标识别的深度卷积神经网络结构。方法设计网络主要由多尺度空间特征提取模块和DenseNet中的稠密块、转移层构成。多尺度特征提取模块置于网络底层,通过使用尺寸分别为1×1、3×3、5×5、7×7、9×9的卷积核,提取丰富空间特征的同时保留输入图像信息。为使输入图像信息更加有效地向后传递,基于DenseNet中的稠密块和转移层进行后续网络层设计。在对训练样本进行样本扩充基础上,分析了输入图像分辨率及目标存在平移和不同噪声水平等情况对模型识别精度的影响,与用于SAR图像目标识别的深度模型识别精度在标准操作条件下进行了对比分析。结果实验结果表明,对T72 8类变体目标进行分类,设计的模型能够取得95.48%的识别精度,在存在目标平移和不同噪声水平情况下,平均识别精度分别达到了94.61%和86.36%。对10类目标(包括不含变体和含变体情况)在进行数据增强的情况下进行模型训练与测试,分别达到了99.38%和98.81%的识别精度,略优于其他对比模型结构识别精度。结论提出的模型可以充分利用输入图像以及各卷积层输出的特征,学习目标图像的细节差异,不仅适用于SAR图像变体目标的识别任务,同时在标准操作条件下的识别任务也取得了较高的识别结果。关键词:SAR目标识别;变体目标;深度学习;多尺度特征;DenseNet37|47|2更新时间:2024-05-07
摘要:目的深度学习已经大量应用于合成孔径宽达(SAR)图像目标识别领域,但大多数工作是基于MSTAR数据集的标准操作条件展开研究。当将深度学习应用于同类含变体目标时,例如T72子类,由于目标间差异小,所以仍存在着较大的挑战。本文从极大限度地保留SAR图像输入特征出发,设计一种适用于SAR变体目标识别的深度卷积神经网络结构。方法设计网络主要由多尺度空间特征提取模块和DenseNet中的稠密块、转移层构成。多尺度特征提取模块置于网络底层,通过使用尺寸分别为1×1、3×3、5×5、7×7、9×9的卷积核,提取丰富空间特征的同时保留输入图像信息。为使输入图像信息更加有效地向后传递,基于DenseNet中的稠密块和转移层进行后续网络层设计。在对训练样本进行样本扩充基础上,分析了输入图像分辨率及目标存在平移和不同噪声水平等情况对模型识别精度的影响,与用于SAR图像目标识别的深度模型识别精度在标准操作条件下进行了对比分析。结果实验结果表明,对T72 8类变体目标进行分类,设计的模型能够取得95.48%的识别精度,在存在目标平移和不同噪声水平情况下,平均识别精度分别达到了94.61%和86.36%。对10类目标(包括不含变体和含变体情况)在进行数据增强的情况下进行模型训练与测试,分别达到了99.38%和98.81%的识别精度,略优于其他对比模型结构识别精度。结论提出的模型可以充分利用输入图像以及各卷积层输出的特征,学习目标图像的细节差异,不仅适用于SAR图像变体目标的识别任务,同时在标准操作条件下的识别任务也取得了较高的识别结果。关键词:SAR目标识别;变体目标;深度学习;多尺度特征;DenseNet37|47|2更新时间:2024-05-07
遥感图像处理
-
 摘要:目的通过烟雾检测能够实现早期火灾预警,但烟雾的形状、色彩等属性对环境的变化敏感,使得烟雾特征容易缺乏辨别力与鲁棒性,最终导致图像烟雾识别、检测的误报率与错误率较高。为解决以上问题,提出一种基于Gabor滤波的层级结构,可视为Gabor网络。方法首先,构建一个Gabor卷积单元,包括基于Gabor的多尺度、多方向局部响应提取和跨通道响应浓缩;然后,将Gabor卷积单元输出的浓缩响应图进行跨通道编码并统计出直方图特征,以上Gabor卷积单元与编码层构成了一个Gabor基础层,用于提取多尺度、多方向的基础特征,对基础层引入最大响应索引编码和全局优化能生成扩展特征;最后,将基础和扩展特征首尾相连形成完整烟雾特征,通过堆叠上述Gabor基础层能形成一个前馈网络结构,将每一层特征首尾相连即可获得烟雾的多层级特征。结果实验结果表明,此Gabor网络泛化性能好,所提烟雾特征的辨别力在对比实验中综合排名第一,所提纹理特征的辨别力在两个纹理数据集上分别排名第一与第二。结论所提Gabor网络能够实现多尺度、多方向的多层级纹理特征表达,既能提高烟雾识别的综合效果,也可提高纹理分类的准确率。未来可进一步研究如何降低特征的冗余度,探索不同层特征之间的关系并加以利用,以期在视频烟雾实时识别中得到实际应用。关键词:烟雾识别;纹理分类;特征提取;Gabor滤波;层级结构13|6|10更新时间:2024-05-07
摘要:目的通过烟雾检测能够实现早期火灾预警,但烟雾的形状、色彩等属性对环境的变化敏感,使得烟雾特征容易缺乏辨别力与鲁棒性,最终导致图像烟雾识别、检测的误报率与错误率较高。为解决以上问题,提出一种基于Gabor滤波的层级结构,可视为Gabor网络。方法首先,构建一个Gabor卷积单元,包括基于Gabor的多尺度、多方向局部响应提取和跨通道响应浓缩;然后,将Gabor卷积单元输出的浓缩响应图进行跨通道编码并统计出直方图特征,以上Gabor卷积单元与编码层构成了一个Gabor基础层,用于提取多尺度、多方向的基础特征,对基础层引入最大响应索引编码和全局优化能生成扩展特征;最后,将基础和扩展特征首尾相连形成完整烟雾特征,通过堆叠上述Gabor基础层能形成一个前馈网络结构,将每一层特征首尾相连即可获得烟雾的多层级特征。结果实验结果表明,此Gabor网络泛化性能好,所提烟雾特征的辨别力在对比实验中综合排名第一,所提纹理特征的辨别力在两个纹理数据集上分别排名第一与第二。结论所提Gabor网络能够实现多尺度、多方向的多层级纹理特征表达,既能提高烟雾识别的综合效果,也可提高纹理分类的准确率。未来可进一步研究如何降低特征的冗余度,探索不同层特征之间的关系并加以利用,以期在视频烟雾实时识别中得到实际应用。关键词:烟雾识别;纹理分类;特征提取;Gabor滤波;层级结构13|6|10更新时间:2024-05-07 -
 摘要:目的为了进一步提高智能监控场景下行为识别的准确率和时间效率,提出了一种基于YOLO(you only look once:unified,real-time object detection)并结合LSTM(long short-term memory)和CNN(convolutional neural network)的人体行为识别算法LC-YOLO(LSTM and CNN based on YOLO)。方法利用YOLO目标检测的实时性,首先对监控视频中的特定行为进行即时检测,获取目标大小、位置等信息后进行深度特征提取;然后,去除图像中无关区域的噪声数据;最后,结合LSTM建模处理时间序列,对监控视频中的行为动作序列做出最终的行为判别。结果在公开行为识别数据集KTH和MSR中的实验表明,各行为平均识别率达到了96.6%,平均识别速度达到215 ms,本文方法在智能监控的行为识别上具有较好效果。结论提出了一种行为识别算法,实验结果表明算法有效提高了行为识别的实时性和准确率,在实时性要求较高和场景复杂的智能监控中有较好的适应性和广泛的应用前景。关键词:行为识别;目标检测;深度学习;卷积神经网络;循环神经网络50|87|11更新时间:2024-05-07
摘要:目的为了进一步提高智能监控场景下行为识别的准确率和时间效率,提出了一种基于YOLO(you only look once:unified,real-time object detection)并结合LSTM(long short-term memory)和CNN(convolutional neural network)的人体行为识别算法LC-YOLO(LSTM and CNN based on YOLO)。方法利用YOLO目标检测的实时性,首先对监控视频中的特定行为进行即时检测,获取目标大小、位置等信息后进行深度特征提取;然后,去除图像中无关区域的噪声数据;最后,结合LSTM建模处理时间序列,对监控视频中的行为动作序列做出最终的行为判别。结果在公开行为识别数据集KTH和MSR中的实验表明,各行为平均识别率达到了96.6%,平均识别速度达到215 ms,本文方法在智能监控的行为识别上具有较好效果。结论提出了一种行为识别算法,实验结果表明算法有效提高了行为识别的实时性和准确率,在实时性要求较高和场景复杂的智能监控中有较好的适应性和广泛的应用前景。关键词:行为识别;目标检测;深度学习;卷积神经网络;循环神经网络50|87|11更新时间:2024-05-07 -
 摘要:目的目标跟踪是计算机视觉领域重点研究方向之一,在智能交通、人机交互等方面有着广泛应用。尽管目前基于相关滤波的方法由于其高效、鲁棒在该领域取得了显著进展,但特征的选择和表示一直是追踪过程中建立目标外观时的首要考虑因素。为了提高外观模型的鲁棒性,越来越多的跟踪器中引入梯度特征、颜色特征或其他组合特征代替原始灰度单一特征,但是该类方法没有结合特征本身考虑不同特征在模型中所占的比重。方法本文重点研究特征的选取以及融合方式,通过引入权重向量对特征进行融合,设计了基于加权多特征外观模型的追踪器。根据特征的计算方式,构造了一项二元一次方程,将权重向量的求解转化为确定特征的比例系数,结合特征本身的维度信息,得到方程的有限组整数解集,最后通过实验确定最终的比例系数,并将其归一化得到权重向量,进而构建一种新的加权混合特征模型对目标外观建模。结果采用OTB-100中的100个视频序列,将本文算法与其他7种主流算法,包括5种相关滤波类方法,以精确度、平均中心误差、实时性为评价指标进行了对比实验分析。在保证实时性的同时,本文算法在Basketball、DragonBaby、Panda、Lemming等多个数据集上均表现出了更好的追踪结果。在100个视频集上的平均结果与基于多特征融合的尺度自适应跟踪器相比,精确度提高了1.2%。结论本文基于相关滤波的追踪框架在进行目标的外观描述时引入权重向量,进而提出了加权多特征融合追踪器,使得在复杂动态场景下追踪长度更长,提高了算法的鲁棒性。关键词:相关滤波;外观描述;特征融合;加权特征;实时追踪15|6|1更新时间:2024-05-07
摘要:目的目标跟踪是计算机视觉领域重点研究方向之一,在智能交通、人机交互等方面有着广泛应用。尽管目前基于相关滤波的方法由于其高效、鲁棒在该领域取得了显著进展,但特征的选择和表示一直是追踪过程中建立目标外观时的首要考虑因素。为了提高外观模型的鲁棒性,越来越多的跟踪器中引入梯度特征、颜色特征或其他组合特征代替原始灰度单一特征,但是该类方法没有结合特征本身考虑不同特征在模型中所占的比重。方法本文重点研究特征的选取以及融合方式,通过引入权重向量对特征进行融合,设计了基于加权多特征外观模型的追踪器。根据特征的计算方式,构造了一项二元一次方程,将权重向量的求解转化为确定特征的比例系数,结合特征本身的维度信息,得到方程的有限组整数解集,最后通过实验确定最终的比例系数,并将其归一化得到权重向量,进而构建一种新的加权混合特征模型对目标外观建模。结果采用OTB-100中的100个视频序列,将本文算法与其他7种主流算法,包括5种相关滤波类方法,以精确度、平均中心误差、实时性为评价指标进行了对比实验分析。在保证实时性的同时,本文算法在Basketball、DragonBaby、Panda、Lemming等多个数据集上均表现出了更好的追踪结果。在100个视频集上的平均结果与基于多特征融合的尺度自适应跟踪器相比,精确度提高了1.2%。结论本文基于相关滤波的追踪框架在进行目标的外观描述时引入权重向量,进而提出了加权多特征融合追踪器,使得在复杂动态场景下追踪长度更长,提高了算法的鲁棒性。关键词:相关滤波;外观描述;特征融合;加权特征;实时追踪15|6|1更新时间:2024-05-07 -
 摘要:目的近年来,卷积神经网络在解决图像超分辨率的问题上取得了巨大成功,不同结构的网络模型相继被提出。通过学习,这些网络模型对输入图像的特征进行抽象、组合,进而建立了从低分辨率的输入图像到高分辨率的目标图像的有效非线性映射。在该过程中,无论是图像的低阶像素级特征,还是高阶各层抽象特征,都对像素间相关性的挖掘起了重要作用,影响着目标高分辨图像的性能。而目前典型的超分辨率网络模型,如SRCNN(super-resolution convolutional neural network)、VDSR(very deep convolutional networks for super-resolution)、LapSRN(Laplacian pyramid super-resolution networks)等,都未充分利用这些多层次的特征。方法提出一种充分融合网络多阶特征的图像超分辨率算法:该模型基于递归神经网络,由相同的单元串联构成,单元间参数共享;在每个单元内部,从低阶到高阶的逐级特征被级联、融合,以获得更丰富的信息来强化网络的学习能力;在训练中,采用基于残差的策略,单元内使用局部残差学习,整体网络使用全局残差学习,以加快训练速度。结果所提出的网络模型在通用4个测试集上,针对分辨率放大2倍、3倍、4倍的情况,与深层超分辨率网络VDSR相比,平均分别能够获得0.24 dB、0.23 dB、0.19 dB的增益。结论实验结果表明,所提出的递归式多阶特征融合图像超分辨率算法,有效提升了性能,特别是在细节非常丰富的Urban100数据集上,该算法对细节的处理效果尤为明显,图像的客观质量与主观质量都得到显著改善。关键词:图像超分辨率;卷积神经网络;特征融合;递归神经网络;残差学习17|4|6更新时间:2024-05-07
摘要:目的近年来,卷积神经网络在解决图像超分辨率的问题上取得了巨大成功,不同结构的网络模型相继被提出。通过学习,这些网络模型对输入图像的特征进行抽象、组合,进而建立了从低分辨率的输入图像到高分辨率的目标图像的有效非线性映射。在该过程中,无论是图像的低阶像素级特征,还是高阶各层抽象特征,都对像素间相关性的挖掘起了重要作用,影响着目标高分辨图像的性能。而目前典型的超分辨率网络模型,如SRCNN(super-resolution convolutional neural network)、VDSR(very deep convolutional networks for super-resolution)、LapSRN(Laplacian pyramid super-resolution networks)等,都未充分利用这些多层次的特征。方法提出一种充分融合网络多阶特征的图像超分辨率算法:该模型基于递归神经网络,由相同的单元串联构成,单元间参数共享;在每个单元内部,从低阶到高阶的逐级特征被级联、融合,以获得更丰富的信息来强化网络的学习能力;在训练中,采用基于残差的策略,单元内使用局部残差学习,整体网络使用全局残差学习,以加快训练速度。结果所提出的网络模型在通用4个测试集上,针对分辨率放大2倍、3倍、4倍的情况,与深层超分辨率网络VDSR相比,平均分别能够获得0.24 dB、0.23 dB、0.19 dB的增益。结论实验结果表明,所提出的递归式多阶特征融合图像超分辨率算法,有效提升了性能,特别是在细节非常丰富的Urban100数据集上,该算法对细节的处理效果尤为明显,图像的客观质量与主观质量都得到显著改善。关键词:图像超分辨率;卷积神经网络;特征融合;递归神经网络;残差学习17|4|6更新时间:2024-05-07 -
 摘要:目的决策系统是无人驾驶技术的核心研究之一。已有决策系统存在逻辑不合理、计算效率低、应用场景局限等问题,因此提出一种动态环境下无人驾驶路径决策仿真。方法首先,基于规则模型构建适于无人驾驶决策系统的交通有限状态机;其次,针对交通动态特征,提出基于统计模型的动态目标路径算法计算状态迁移风险;最后,将交通状态机和动态目标路径算法有机结合,设计出一种基于有限状态机的无人驾驶动态目标路径模型,适用于交叉口冲突避免和三车道换道行为。将全速度差连续跟驰模型运用到换道规则中,并基于冲突时间提出动态临界跟车距离。结果为验证模型的有效性和高效性,对交通环境进行虚拟现实建模,模拟交叉口通行和三车道换道行为,分析文中模型对车流量和换道率的影响。实验结果显示,在交叉口通行时,自主车辆不仅可以检测冲突还可以根据风险评估结果执行安全合理的决策。三车道换道时,自主车辆既可以实现紧急让道,也可以通过执行换道达成自身驾驶期望。通过将实测数据和其他两种方法对比,当车流密度在0.20.5时,本文模型的平均速度最高分别提高32 km/h和22 km/h。当车流密度不超过0.65时,本文模型的换道成功率最高分别提升37%和25%。结论实验结果说明本文方法不仅可以在动态城区环境下提高决策安全性和正确性,还可以提高车流量饱和度,缓解交通堵塞。关键词:风险系数;换道行为;冲突避免;无人驾驶技术;全速度差连续跟驰模型11|4|0更新时间:2024-05-07
摘要:目的决策系统是无人驾驶技术的核心研究之一。已有决策系统存在逻辑不合理、计算效率低、应用场景局限等问题,因此提出一种动态环境下无人驾驶路径决策仿真。方法首先,基于规则模型构建适于无人驾驶决策系统的交通有限状态机;其次,针对交通动态特征,提出基于统计模型的动态目标路径算法计算状态迁移风险;最后,将交通状态机和动态目标路径算法有机结合,设计出一种基于有限状态机的无人驾驶动态目标路径模型,适用于交叉口冲突避免和三车道换道行为。将全速度差连续跟驰模型运用到换道规则中,并基于冲突时间提出动态临界跟车距离。结果为验证模型的有效性和高效性,对交通环境进行虚拟现实建模,模拟交叉口通行和三车道换道行为,分析文中模型对车流量和换道率的影响。实验结果显示,在交叉口通行时,自主车辆不仅可以检测冲突还可以根据风险评估结果执行安全合理的决策。三车道换道时,自主车辆既可以实现紧急让道,也可以通过执行换道达成自身驾驶期望。通过将实测数据和其他两种方法对比,当车流密度在0.20.5时,本文模型的平均速度最高分别提高32 km/h和22 km/h。当车流密度不超过0.65时,本文模型的换道成功率最高分别提升37%和25%。结论实验结果说明本文方法不仅可以在动态城区环境下提高决策安全性和正确性,还可以提高车流量饱和度,缓解交通堵塞。关键词:风险系数;换道行为;冲突避免;无人驾驶技术;全速度差连续跟驰模型11|4|0更新时间:2024-05-07
ChinaMM 2018
- 地址:北京市海淀区北四环西路19号中科院电子所主楼223室 邮编:100190
- 联系电话:010-58887035/58887030/58887418 Email:jig@aircas.ac.cn
- 技术支持由北京北大方正电子有限公司提供 京ICP备05080539号-4
 京公网安备11010802024621
京公网安备11010802024621 - 本系统建议在Chrome、 IE9+ 以上版本浏览器阅读本站内容,360浏览器请切换至极速模式
- Cookies帮助我们提供服务并提供个性化体验。使用本网站,即表示您同意我们使用Cookies

0